
problem_id
stringlengths 18
22
| source
stringclasses 1
value | task_type
stringclasses 1
value | in_source_id
stringlengths 13
58
| prompt
stringlengths 1.71k
18.9k
| golden_diff
stringlengths 145
5.13k
| verification_info
stringlengths 465
23.6k
| num_tokens_prompt
int64 556
4.1k
| num_tokens_diff
int64 47
1.02k
|
|---|---|---|---|---|---|---|---|---|
gh_patches_debug_27046
|
rasdani/github-patches
|
git_diff
|
CTFd__CTFd-410
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Move plugin focused functions to the plugins folder
`override_template`
`register_plugin_script`
`register_plugin_stylesheet`
These should move to the plugins directory.
</issue>
<code>
[start of CTFd/plugins/__init__.py]
1 import glob
2 import importlib
3 import os
4
5 from flask.helpers import safe_join
6 from flask import send_file, send_from_directory, abort
7 from CTFd.utils import admins_only as admins_only_wrapper
8
9
10 def register_plugin_assets_directory(app, base_path, admins_only=False):
11 """
12 Registers a directory to serve assets
13
14 :param app: A CTFd application
15 :param string base_path: The path to the directory
16 :param boolean admins_only: Whether or not the assets served out of the directory should be accessible to the public
17 :return:
18 """
19 base_path = base_path.strip('/')
20
21 def assets_handler(path):
22 return send_from_directory(base_path, path)
23
24 if admins_only:
25 asset_handler = admins_only_wrapper(assets_handler)
26
27 rule = '/' + base_path + '/<path:path>'
28 app.add_url_rule(rule=rule, endpoint=base_path, view_func=assets_handler)
29
30
31 def register_plugin_asset(app, asset_path, admins_only=False):
32 """
33 Registers an file path to be served by CTFd
34
35 :param app: A CTFd application
36 :param string asset_path: The path to the asset file
37 :param boolean admins_only: Whether or not this file should be accessible to the public
38 :return:
39 """
40 asset_path = asset_path.strip('/')
41
42 def asset_handler():
43 return send_file(asset_path)
44
45 if admins_only:
46 asset_handler = admins_only_wrapper(asset_handler)
47 rule = '/' + asset_path
48 app.add_url_rule(rule=rule, endpoint=asset_path, view_func=asset_handler)
49
50
51 def init_plugins(app):
52 """
53 Searches for the load function in modules in the CTFd/plugins folder. This function is called with the current CTFd
54 app as a parameter. This allows CTFd plugins to modify CTFd's behavior.
55
56 :param app: A CTFd application
57 :return:
58 """
59 modules = glob.glob(os.path.dirname(__file__) + "/*")
60 blacklist = {'__pycache__'}
61 for module in modules:
62 module_name = os.path.basename(module)
63 if os.path.isdir(module) and module_name not in blacklist:
64 module = '.' + module_name
65 module = importlib.import_module(module, package='CTFd.plugins')
66 module.load(app)
67 print(" * Loaded module, %s" % module)
68
[end of CTFd/plugins/__init__.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/CTFd/plugins/__init__.py b/CTFd/plugins/__init__.py
--- a/CTFd/plugins/__init__.py
+++ b/CTFd/plugins/__init__.py
@@ -3,8 +3,13 @@
import os
from flask.helpers import safe_join
-from flask import send_file, send_from_directory, abort
-from CTFd.utils import admins_only as admins_only_wrapper
+from flask import current_app as app, send_file, send_from_directory, abort
+from CTFd.utils import (
+ admins_only as admins_only_wrapper,
+ override_template as utils_override_template,
+ register_plugin_script as utils_register_plugin_script,
+ register_plugin_stylesheet as utils_register_plugin_stylesheet
+)
def register_plugin_assets_directory(app, base_path, admins_only=False):
@@ -48,6 +53,29 @@
app.add_url_rule(rule=rule, endpoint=asset_path, view_func=asset_handler)
+def override_template(*args, **kwargs):
+ """
+ Overrides a template with the provided html content.
+
+ e.g. override_template('scoreboard.html', '<h1>scores</h1>')
+ """
+ utils_override_template(*args, **kwargs)
+
+
+def register_plugin_script(*args, **kwargs):
+ """
+ Adds a given script to the base.html template which all pages inherit from
+ """
+ utils_register_plugin_script(*args, **kwargs)
+
+
+def register_plugin_stylesheet(*args, **kwargs):
+ """
+ Adds a given stylesheet to the base.html template which all pages inherit from.
+ """
+ utils_register_plugin_stylesheet(*args, **kwargs)
+
+
def init_plugins(app):
"""
Searches for the load function in modules in the CTFd/plugins folder. This function is called with the current CTFd
|
{"golden_diff": "diff --git a/CTFd/plugins/__init__.py b/CTFd/plugins/__init__.py\n--- a/CTFd/plugins/__init__.py\n+++ b/CTFd/plugins/__init__.py\n@@ -3,8 +3,13 @@\n import os\n \n from flask.helpers import safe_join\n-from flask import send_file, send_from_directory, abort\n-from CTFd.utils import admins_only as admins_only_wrapper\n+from flask import current_app as app, send_file, send_from_directory, abort\n+from CTFd.utils import (\n+ admins_only as admins_only_wrapper,\n+ override_template as utils_override_template,\n+ register_plugin_script as utils_register_plugin_script,\n+ register_plugin_stylesheet as utils_register_plugin_stylesheet\n+)\n \n \n def register_plugin_assets_directory(app, base_path, admins_only=False):\n@@ -48,6 +53,29 @@\n app.add_url_rule(rule=rule, endpoint=asset_path, view_func=asset_handler)\n \n \n+def override_template(*args, **kwargs):\n+ \"\"\"\n+ Overrides a template with the provided html content.\n+\n+ e.g. override_template('scoreboard.html', '<h1>scores</h1>')\n+ \"\"\"\n+ utils_override_template(*args, **kwargs)\n+\n+\n+def register_plugin_script(*args, **kwargs):\n+ \"\"\"\n+ Adds a given script to the base.html template which all pages inherit from\n+ \"\"\"\n+ utils_register_plugin_script(*args, **kwargs)\n+\n+\n+def register_plugin_stylesheet(*args, **kwargs):\n+ \"\"\"\n+ Adds a given stylesheet to the base.html template which all pages inherit from.\n+ \"\"\"\n+ utils_register_plugin_stylesheet(*args, **kwargs)\n+\n+\n def init_plugins(app):\n \"\"\"\n Searches for the load function in modules in the CTFd/plugins folder. This function is called with the current CTFd\n", "issue": "Move plugin focused functions to the plugins folder\n`override_template`\r\n`register_plugin_script`\r\n`register_plugin_stylesheet`\r\n\r\nThese should move to the plugins directory.\n", "before_files": [{"content": "import glob\nimport importlib\nimport os\n\nfrom flask.helpers import safe_join\nfrom flask import send_file, send_from_directory, abort\nfrom CTFd.utils import admins_only as admins_only_wrapper\n\n\ndef register_plugin_assets_directory(app, base_path, admins_only=False):\n \"\"\"\n Registers a directory to serve assets\n\n :param app: A CTFd application\n :param string base_path: The path to the directory\n :param boolean admins_only: Whether or not the assets served out of the directory should be accessible to the public\n :return:\n \"\"\"\n base_path = base_path.strip('/')\n\n def assets_handler(path):\n return send_from_directory(base_path, path)\n\n if admins_only:\n asset_handler = admins_only_wrapper(assets_handler)\n\n rule = '/' + base_path + '/<path:path>'\n app.add_url_rule(rule=rule, endpoint=base_path, view_func=assets_handler)\n\n\ndef register_plugin_asset(app, asset_path, admins_only=False):\n \"\"\"\n Registers an file path to be served by CTFd\n\n :param app: A CTFd application\n :param string asset_path: The path to the asset file\n :param boolean admins_only: Whether or not this file should be accessible to the public\n :return:\n \"\"\"\n asset_path = asset_path.strip('/')\n\n def asset_handler():\n return send_file(asset_path)\n\n if admins_only:\n asset_handler = admins_only_wrapper(asset_handler)\n rule = '/' + asset_path\n app.add_url_rule(rule=rule, endpoint=asset_path, view_func=asset_handler)\n\n\ndef init_plugins(app):\n \"\"\"\n Searches for the load function in modules in the CTFd/plugins folder. This function is called with the current CTFd\n app as a parameter. This allows CTFd plugins to modify CTFd's behavior.\n\n :param app: A CTFd application\n :return:\n \"\"\"\n modules = glob.glob(os.path.dirname(__file__) + \"/*\")\n blacklist = {'__pycache__'}\n for module in modules:\n module_name = os.path.basename(module)\n if os.path.isdir(module) and module_name not in blacklist:\n module = '.' + module_name\n module = importlib.import_module(module, package='CTFd.plugins')\n module.load(app)\n print(\" * Loaded module, %s\" % module)\n", "path": "CTFd/plugins/__init__.py"}]}
| 1,214 | 399 |
gh_patches_debug_33168
|
rasdani/github-patches
|
git_diff
|
tensorflow__addons-2265
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Drop GELU for 0.13 release
https://www.tensorflow.org/api_docs/python/tf/keras/activations/gelu will be available in TF2.4. Deprecation warning is already set for our upcming 0.12 release
</issue>
<code>
[start of tensorflow_addons/activations/gelu.py]
1 # Copyright 2019 The TensorFlow Authors. All Rights Reserved.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14 # ==============================================================================
15
16 import tensorflow as tf
17 import math
18 import warnings
19
20 from tensorflow_addons.utils import types
21
22
23 @tf.keras.utils.register_keras_serializable(package="Addons")
24 def gelu(x: types.TensorLike, approximate: bool = True) -> tf.Tensor:
25 r"""Gaussian Error Linear Unit.
26
27 Computes gaussian error linear:
28
29 $$
30 \mathrm{gelu}(x) = x \Phi(x),
31 $$
32
33 where
34
35 $$
36 \Phi(x) = \frac{1}{2} \left[ 1 + \mathrm{erf}(\frac{x}{\sqrt{2}}) \right]$
37 $$
38
39 when `approximate` is `False`; or
40
41 $$
42 \Phi(x) = \frac{x}{2} \left[ 1 + \tanh(\sqrt{\frac{2}{\pi}} \cdot (x + 0.044715 \cdot x^3)) \right]
43 $$
44
45 when `approximate` is `True`.
46
47 See [Gaussian Error Linear Units (GELUs)](https://arxiv.org/abs/1606.08415)
48 and [BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding](https://arxiv.org/abs/1810.04805).
49
50 Usage:
51
52 >>> tfa.options.TF_ADDONS_PY_OPS = True
53 >>> x = tf.constant([-1.0, 0.0, 1.0])
54 >>> tfa.activations.gelu(x, approximate=False)
55 <tf.Tensor: shape=(3,), dtype=float32, numpy=array([-0.15865529, 0. , 0.8413447 ], dtype=float32)>
56 >>> tfa.activations.gelu(x, approximate=True)
57 <tf.Tensor: shape=(3,), dtype=float32, numpy=array([-0.158808, 0. , 0.841192], dtype=float32)>
58
59 Args:
60 x: A `Tensor`. Must be one of the following types:
61 `float16`, `float32`, `float64`.
62 approximate: bool, whether to enable approximation.
63 Returns:
64 A `Tensor`. Has the same type as `x`.
65 """
66 warnings.warn(
67 "gelu activation has been migrated to core TensorFlow, "
68 "and will be deprecated in Addons 0.13.",
69 DeprecationWarning,
70 )
71
72 x = tf.convert_to_tensor(x)
73
74 return _gelu_py(x, approximate)
75
76
77 def _gelu_py(x: types.TensorLike, approximate: bool = True) -> tf.Tensor:
78 x = tf.convert_to_tensor(x)
79 if approximate:
80 pi = tf.cast(math.pi, x.dtype)
81 coeff = tf.cast(0.044715, x.dtype)
82 return 0.5 * x * (1.0 + tf.tanh(tf.sqrt(2.0 / pi) * (x + coeff * tf.pow(x, 3))))
83 else:
84 return 0.5 * x * (1.0 + tf.math.erf(x / tf.cast(tf.sqrt(2.0), x.dtype)))
85
[end of tensorflow_addons/activations/gelu.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/tensorflow_addons/activations/gelu.py b/tensorflow_addons/activations/gelu.py
--- a/tensorflow_addons/activations/gelu.py
+++ b/tensorflow_addons/activations/gelu.py
@@ -18,6 +18,7 @@
import warnings
from tensorflow_addons.utils import types
+from distutils.version import LooseVersion
@tf.keras.utils.register_keras_serializable(package="Addons")
@@ -47,6 +48,9 @@
See [Gaussian Error Linear Units (GELUs)](https://arxiv.org/abs/1606.08415)
and [BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding](https://arxiv.org/abs/1810.04805).
+ Note that `approximate` will default to `False` from TensorFlow version 2.4 onwards.
+ Consider using `tf.nn.gelu` instead.
+
Usage:
>>> tfa.options.TF_ADDONS_PY_OPS = True
@@ -54,7 +58,7 @@
>>> tfa.activations.gelu(x, approximate=False)
<tf.Tensor: shape=(3,), dtype=float32, numpy=array([-0.15865529, 0. , 0.8413447 ], dtype=float32)>
>>> tfa.activations.gelu(x, approximate=True)
- <tf.Tensor: shape=(3,), dtype=float32, numpy=array([-0.158808, 0. , 0.841192], dtype=float32)>
+ <tf.Tensor: shape=(3,), dtype=float32, numpy=array([-0.15880796, 0. , 0.841192 ], dtype=float32)>
Args:
x: A `Tensor`. Must be one of the following types:
@@ -71,7 +75,15 @@
x = tf.convert_to_tensor(x)
- return _gelu_py(x, approximate)
+ if LooseVersion(tf.__version__) >= "2.4":
+ gelu_op = tf.nn.gelu
+ warnings.warn(
+ "Default value of `approximate` is changed from `True` to `False`"
+ )
+ else:
+ gelu_op = _gelu_py
+
+ return gelu_op(x, approximate)
def _gelu_py(x: types.TensorLike, approximate: bool = True) -> tf.Tensor:
|
{"golden_diff": "diff --git a/tensorflow_addons/activations/gelu.py b/tensorflow_addons/activations/gelu.py\n--- a/tensorflow_addons/activations/gelu.py\n+++ b/tensorflow_addons/activations/gelu.py\n@@ -18,6 +18,7 @@\n import warnings\n \n from tensorflow_addons.utils import types\n+from distutils.version import LooseVersion\n \n \n @tf.keras.utils.register_keras_serializable(package=\"Addons\")\n@@ -47,6 +48,9 @@\n See [Gaussian Error Linear Units (GELUs)](https://arxiv.org/abs/1606.08415)\n and [BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding](https://arxiv.org/abs/1810.04805).\n \n+ Note that `approximate` will default to `False` from TensorFlow version 2.4 onwards.\n+ Consider using `tf.nn.gelu` instead.\n+\n Usage:\n \n >>> tfa.options.TF_ADDONS_PY_OPS = True\n@@ -54,7 +58,7 @@\n >>> tfa.activations.gelu(x, approximate=False)\n <tf.Tensor: shape=(3,), dtype=float32, numpy=array([-0.15865529, 0. , 0.8413447 ], dtype=float32)>\n >>> tfa.activations.gelu(x, approximate=True)\n- <tf.Tensor: shape=(3,), dtype=float32, numpy=array([-0.158808, 0. , 0.841192], dtype=float32)>\n+ <tf.Tensor: shape=(3,), dtype=float32, numpy=array([-0.15880796, 0. , 0.841192 ], dtype=float32)>\n \n Args:\n x: A `Tensor`. Must be one of the following types:\n@@ -71,7 +75,15 @@\n \n x = tf.convert_to_tensor(x)\n \n- return _gelu_py(x, approximate)\n+ if LooseVersion(tf.__version__) >= \"2.4\":\n+ gelu_op = tf.nn.gelu\n+ warnings.warn(\n+ \"Default value of `approximate` is changed from `True` to `False`\"\n+ )\n+ else:\n+ gelu_op = _gelu_py\n+\n+ return gelu_op(x, approximate)\n \n \n def _gelu_py(x: types.TensorLike, approximate: bool = True) -> tf.Tensor:\n", "issue": "Drop GELU for 0.13 release\nhttps://www.tensorflow.org/api_docs/python/tf/keras/activations/gelu will be available in TF2.4. Deprecation warning is already set for our upcming 0.12 release\n", "before_files": [{"content": "# Copyright 2019 The TensorFlow Authors. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n# ==============================================================================\n\nimport tensorflow as tf\nimport math\nimport warnings\n\nfrom tensorflow_addons.utils import types\n\n\[email protected]_keras_serializable(package=\"Addons\")\ndef gelu(x: types.TensorLike, approximate: bool = True) -> tf.Tensor:\n r\"\"\"Gaussian Error Linear Unit.\n\n Computes gaussian error linear:\n\n $$\n \\mathrm{gelu}(x) = x \\Phi(x),\n $$\n\n where\n\n $$\n \\Phi(x) = \\frac{1}{2} \\left[ 1 + \\mathrm{erf}(\\frac{x}{\\sqrt{2}}) \\right]$\n $$\n\n when `approximate` is `False`; or\n\n $$\n \\Phi(x) = \\frac{x}{2} \\left[ 1 + \\tanh(\\sqrt{\\frac{2}{\\pi}} \\cdot (x + 0.044715 \\cdot x^3)) \\right]\n $$\n\n when `approximate` is `True`.\n\n See [Gaussian Error Linear Units (GELUs)](https://arxiv.org/abs/1606.08415)\n and [BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding](https://arxiv.org/abs/1810.04805).\n\n Usage:\n\n >>> tfa.options.TF_ADDONS_PY_OPS = True\n >>> x = tf.constant([-1.0, 0.0, 1.0])\n >>> tfa.activations.gelu(x, approximate=False)\n <tf.Tensor: shape=(3,), dtype=float32, numpy=array([-0.15865529, 0. , 0.8413447 ], dtype=float32)>\n >>> tfa.activations.gelu(x, approximate=True)\n <tf.Tensor: shape=(3,), dtype=float32, numpy=array([-0.158808, 0. , 0.841192], dtype=float32)>\n\n Args:\n x: A `Tensor`. Must be one of the following types:\n `float16`, `float32`, `float64`.\n approximate: bool, whether to enable approximation.\n Returns:\n A `Tensor`. Has the same type as `x`.\n \"\"\"\n warnings.warn(\n \"gelu activation has been migrated to core TensorFlow, \"\n \"and will be deprecated in Addons 0.13.\",\n DeprecationWarning,\n )\n\n x = tf.convert_to_tensor(x)\n\n return _gelu_py(x, approximate)\n\n\ndef _gelu_py(x: types.TensorLike, approximate: bool = True) -> tf.Tensor:\n x = tf.convert_to_tensor(x)\n if approximate:\n pi = tf.cast(math.pi, x.dtype)\n coeff = tf.cast(0.044715, x.dtype)\n return 0.5 * x * (1.0 + tf.tanh(tf.sqrt(2.0 / pi) * (x + coeff * tf.pow(x, 3))))\n else:\n return 0.5 * x * (1.0 + tf.math.erf(x / tf.cast(tf.sqrt(2.0), x.dtype)))\n", "path": "tensorflow_addons/activations/gelu.py"}]}
| 1,628 | 586 |
gh_patches_debug_5095
|
rasdani/github-patches
|
git_diff
|
kivy__kivy-3104
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Issues with popup on py3
When running the following code in py3 on windows I get the following error:
``` py
from kivy.uix.widget import Widget
from kivy.uix.popup import Popup
w1 = Widget()
w2 = Widget()
p1 = Popup(content=w1)
p2 = Popup(content=w2)
```
```
Traceback (most recent call last):
File "playground8.py", line 7, in <module>
p2 = Popup(content=w2)
File "C:\Users\Matthew Einhorn\Desktop\Kivy-1.8.0-py3.3-win32\kivy\kivy\uix\modalview.py", line 152, in __init__
super(ModalView, self).__init__(**kwargs)
File "C:\Users\Matthew Einhorn\Desktop\Kivy-1.8.0-py3.3-win32\kivy\kivy\uix\anchorlayout.py", line 68, in __init__
super(AnchorLayout, self).__init__(**kwargs)
File "C:\Users\Matthew Einhorn\Desktop\Kivy-1.8.0-py3.3-win32\kivy\kivy\uix\layout.py", line 66, in __init__
super(Layout, self).__init__(**kwargs)
File "C:\Users\Matthew Einhorn\Desktop\Kivy-1.8.0-py3.3-win32\kivy\kivy\uix\widget.py", line 261, in __init__
super(Widget, self).__init__(**kwargs)
File "kivy\_event.pyx", line 271, in kivy._event.EventDispatcher.__init__ (kivy\_event.c:4933)
File "kivy\properties.pyx", line 397, in kivy.properties.Property.__set__ (kivy\properties.c:4680)
File "kivy\properties.pyx", line 429, in kivy.properties.Property.set (kivy\properties.c:5203)
File "kivy\properties.pyx", line 480, in kivy.properties.Property.dispatch (kivy\properties.c:5779)
File "kivy\_event.pyx", line 1168, in kivy._event.EventObservers.dispatch (kivy\_event.c:12154)
File "kivy\_event.pyx", line 1074, in kivy._event.EventObservers._dispatch (kivy\_event.c:11451)
File "C:\Users\Matthew Einhorn\Desktop\Kivy-1.8.0-py3.3-win32\kivy\kivy\uix\popup.py", line 188, in on_content
if not hasattr(value, 'popup'):
File "kivy\properties.pyx", line 402, in kivy.properties.Property.__get__ (kivy\properties.c:4776)
File "kivy\properties.pyx", line 435, in kivy.properties.Property.get (kivy\properties.c:5416)
KeyError: 'popup'
```
The reason is because of https://github.com/kivy/kivy/blob/master/kivy/uix/popup.py#L188. Both Widgets are created first. Then upon creation of first Popup its `on_content` is executed and a property in that widget as well in Widget class is created. However, it's only initialized for w1, w2 `__storage` has not been initialized for w2. So when hasattr is called on widget 2 and in python 3 it causes obj.__storage['popup']` to be executed from get, because storage has not been initialized for 'popup' in this widget it crashes.
The question is, why does the Popup code do this `create_property` stuff?
</issue>
<code>
[start of kivy/uix/popup.py]
1 '''
2 Popup
3 =====
4
5 .. versionadded:: 1.0.7
6
7 .. image:: images/popup.jpg
8 :align: right
9
10 The :class:`Popup` widget is used to create modal popups. By default, the popup
11 will cover the whole "parent" window. When you are creating a popup, you
12 must at least set a :attr:`Popup.title` and :attr:`Popup.content`.
13
14 Remember that the default size of a Widget is size_hint=(1, 1). If you don't
15 want your popup to be fullscreen, either use size hints with values less than 1
16 (for instance size_hint=(.8, .8)) or deactivate the size_hint and use
17 fixed size attributes.
18
19
20 .. versionchanged:: 1.4.0
21 The :class:`Popup` class now inherits from
22 :class:`~kivy.uix.modalview.ModalView`. The :class:`Popup` offers a default
23 layout with a title and a separation bar.
24
25 Examples
26 --------
27
28 Example of a simple 400x400 Hello world popup::
29
30 popup = Popup(title='Test popup',
31 content=Label(text='Hello world'),
32 size_hint=(None, None), size=(400, 400))
33
34 By default, any click outside the popup will dismiss/close it. If you don't
35 want that, you can set
36 :attr:`~kivy.uix.modalview.ModalView.auto_dismiss` to False::
37
38 popup = Popup(title='Test popup', content=Label(text='Hello world'),
39 auto_dismiss=False)
40 popup.open()
41
42 To manually dismiss/close the popup, use
43 :attr:`~kivy.uix.modalview.ModalView.dismiss`::
44
45 popup.dismiss()
46
47 Both :meth:`~kivy.uix.modalview.ModalView.open` and
48 :meth:`~kivy.uix.modalview.ModalView.dismiss` are bindable. That means you
49 can directly bind the function to an action, e.g. to a button's on_press::
50
51 # create content and add to the popup
52 content = Button(text='Close me!')
53 popup = Popup(content=content, auto_dismiss=False)
54
55 # bind the on_press event of the button to the dismiss function
56 content.bind(on_press=popup.dismiss)
57
58 # open the popup
59 popup.open()
60
61
62 Popup Events
63 ------------
64
65 There are two events available: `on_open` which is raised when the popup is
66 opening, and `on_dismiss` which is raised when the popup is closed.
67 For `on_dismiss`, you can prevent the
68 popup from closing by explictly returning True from your callback::
69
70 def my_callback(instance):
71 print('Popup', instance, 'is being dismissed but is prevented!')
72 return True
73 popup = Popup(content=Label(text='Hello world'))
74 popup.bind(on_dismiss=my_callback)
75 popup.open()
76
77 '''
78
79 __all__ = ('Popup', 'PopupException')
80
81 from kivy.uix.modalview import ModalView
82 from kivy.properties import (StringProperty, ObjectProperty, OptionProperty,
83 NumericProperty, ListProperty)
84
85
86 class PopupException(Exception):
87 '''Popup exception, fired when multiple content widgets are added to the
88 popup.
89
90 .. versionadded:: 1.4.0
91 '''
92
93
94 class Popup(ModalView):
95 '''Popup class. See module documentation for more information.
96
97 :Events:
98 `on_open`:
99 Fired when the Popup is opened.
100 `on_dismiss`:
101 Fired when the Popup is closed. If the callback returns True, the
102 dismiss will be canceled.
103 '''
104
105 title = StringProperty('No title')
106 '''String that represents the title of the popup.
107
108 :attr:`title` is a :class:`~kivy.properties.StringProperty` and defaults to
109 'No title'.
110 '''
111
112 title_size = NumericProperty('14sp')
113 '''Represents the font size of the popup title.
114
115 .. versionadded:: 1.6.0
116
117 :attr:`title_size` is a :class:`~kivy.properties.NumericProperty` and
118 defaults to '14sp'.
119 '''
120
121 title_align = OptionProperty('left',
122 options=['left', 'center', 'right', 'justify'])
123 '''Horizontal alignment of the title.
124
125 .. versionadded:: 1.9.0
126
127 :attr:`title_align` is a :class:`~kivy.properties.OptionProperty` and
128 defaults to 'left'. Available options are left, middle, right and justify.
129 '''
130
131 title_font = StringProperty('DroidSans')
132 '''Font used to render the title text.
133
134 .. versionadded:: 1.9.0
135
136 :attr:`title_font` is a :class:`~kivy.properties.StringProperty` and
137 defaults to 'DroidSans'.
138 '''
139
140 content = ObjectProperty(None)
141 '''Content of the popup that is displayed just under the title.
142
143 :attr:`content` is an :class:`~kivy.properties.ObjectProperty` and defaults
144 to None.
145 '''
146
147 title_color = ListProperty([1, 1, 1, 1])
148 '''Color used by the Title.
149
150 .. versionadded:: 1.8.0
151
152 :attr:`title_color` is a :class:`~kivy.properties.ListProperty` and
153 defaults to [1, 1, 1, 1].
154 '''
155
156 separator_color = ListProperty([47 / 255., 167 / 255., 212 / 255., 1.])
157 '''Color used by the separator between title and content.
158
159 .. versionadded:: 1.1.0
160
161 :attr:`separator_color` is a :class:`~kivy.properties.ListProperty` and
162 defaults to [47 / 255., 167 / 255., 212 / 255., 1.]
163 '''
164
165 separator_height = NumericProperty('2dp')
166 '''Height of the separator.
167
168 .. versionadded:: 1.1.0
169
170 :attr:`separator_height` is a :class:`~kivy.properties.NumericProperty` and
171 defaults to 2dp.
172 '''
173
174 # Internal properties used for graphical representation.
175
176 _container = ObjectProperty(None)
177
178 def add_widget(self, widget):
179 if self._container:
180 if self.content:
181 raise PopupException(
182 'Popup can have only one widget as content')
183 self.content = widget
184 else:
185 super(Popup, self).add_widget(widget)
186
187 def on_content(self, instance, value):
188 if not hasattr(value, 'popup'):
189 value.create_property('popup')
190 value.popup = self
191 if self._container:
192 self._container.clear_widgets()
193 self._container.add_widget(value)
194
195 def on__container(self, instance, value):
196 if value is None or self.content is None:
197 return
198 self._container.clear_widgets()
199 self._container.add_widget(self.content)
200
201 def on_touch_down(self, touch):
202 if self.disabled and self.collide_point(*touch.pos):
203 return True
204 return super(Popup, self).on_touch_down(touch)
205
206
207 if __name__ == '__main__':
208 from kivy.base import runTouchApp
209 from kivy.uix.button import Button
210 from kivy.uix.label import Label
211 from kivy.uix.gridlayout import GridLayout
212 from kivy.core.window import Window
213
214 # add popup
215 content = GridLayout(cols=1)
216 content_cancel = Button(text='Cancel', size_hint_y=None, height=40)
217 content.add_widget(Label(text='This is a hello world'))
218 content.add_widget(content_cancel)
219 popup = Popup(title='Test popup',
220 size_hint=(None, None), size=(256, 256),
221 content=content, disabled=True)
222 content_cancel.bind(on_release=popup.dismiss)
223
224 layout = GridLayout(cols=3)
225 for x in range(9):
226 btn = Button(text=str(x))
227 btn.bind(on_release=popup.open)
228 layout.add_widget(btn)
229
230 Window.add_widget(layout)
231
232 popup.open()
233
234 runTouchApp()
235
[end of kivy/uix/popup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/kivy/uix/popup.py b/kivy/uix/popup.py
--- a/kivy/uix/popup.py
+++ b/kivy/uix/popup.py
@@ -185,9 +185,6 @@
super(Popup, self).add_widget(widget)
def on_content(self, instance, value):
- if not hasattr(value, 'popup'):
- value.create_property('popup')
- value.popup = self
if self._container:
self._container.clear_widgets()
self._container.add_widget(value)
|
{"golden_diff": "diff --git a/kivy/uix/popup.py b/kivy/uix/popup.py\n--- a/kivy/uix/popup.py\n+++ b/kivy/uix/popup.py\n@@ -185,9 +185,6 @@\n super(Popup, self).add_widget(widget)\n \n def on_content(self, instance, value):\n- if not hasattr(value, 'popup'):\n- value.create_property('popup')\n- value.popup = self\n if self._container:\n self._container.clear_widgets()\n self._container.add_widget(value)\n", "issue": "Issues with popup on py3\nWhen running the following code in py3 on windows I get the following error:\n\n``` py\nfrom kivy.uix.widget import Widget\nfrom kivy.uix.popup import Popup\n\nw1 = Widget()\nw2 = Widget()\np1 = Popup(content=w1)\np2 = Popup(content=w2)\n```\n\n```\n Traceback (most recent call last):\n File \"playground8.py\", line 7, in <module>\n p2 = Popup(content=w2)\n File \"C:\\Users\\Matthew Einhorn\\Desktop\\Kivy-1.8.0-py3.3-win32\\kivy\\kivy\\uix\\modalview.py\", line 152, in __init__\n super(ModalView, self).__init__(**kwargs)\n File \"C:\\Users\\Matthew Einhorn\\Desktop\\Kivy-1.8.0-py3.3-win32\\kivy\\kivy\\uix\\anchorlayout.py\", line 68, in __init__\n super(AnchorLayout, self).__init__(**kwargs)\n File \"C:\\Users\\Matthew Einhorn\\Desktop\\Kivy-1.8.0-py3.3-win32\\kivy\\kivy\\uix\\layout.py\", line 66, in __init__\n super(Layout, self).__init__(**kwargs)\n File \"C:\\Users\\Matthew Einhorn\\Desktop\\Kivy-1.8.0-py3.3-win32\\kivy\\kivy\\uix\\widget.py\", line 261, in __init__\n super(Widget, self).__init__(**kwargs)\n File \"kivy\\_event.pyx\", line 271, in kivy._event.EventDispatcher.__init__ (kivy\\_event.c:4933)\n File \"kivy\\properties.pyx\", line 397, in kivy.properties.Property.__set__ (kivy\\properties.c:4680)\n File \"kivy\\properties.pyx\", line 429, in kivy.properties.Property.set (kivy\\properties.c:5203)\n File \"kivy\\properties.pyx\", line 480, in kivy.properties.Property.dispatch (kivy\\properties.c:5779)\n File \"kivy\\_event.pyx\", line 1168, in kivy._event.EventObservers.dispatch (kivy\\_event.c:12154)\n File \"kivy\\_event.pyx\", line 1074, in kivy._event.EventObservers._dispatch (kivy\\_event.c:11451)\n File \"C:\\Users\\Matthew Einhorn\\Desktop\\Kivy-1.8.0-py3.3-win32\\kivy\\kivy\\uix\\popup.py\", line 188, in on_content\n if not hasattr(value, 'popup'):\n File \"kivy\\properties.pyx\", line 402, in kivy.properties.Property.__get__ (kivy\\properties.c:4776)\n File \"kivy\\properties.pyx\", line 435, in kivy.properties.Property.get (kivy\\properties.c:5416)\n KeyError: 'popup'\n```\n\nThe reason is because of https://github.com/kivy/kivy/blob/master/kivy/uix/popup.py#L188. Both Widgets are created first. Then upon creation of first Popup its `on_content` is executed and a property in that widget as well in Widget class is created. However, it's only initialized for w1, w2 `__storage` has not been initialized for w2. So when hasattr is called on widget 2 and in python 3 it causes obj.__storage['popup']` to be executed from get, because storage has not been initialized for 'popup' in this widget it crashes.\n\nThe question is, why does the Popup code do this `create_property` stuff?\n\n", "before_files": [{"content": "'''\nPopup\n=====\n\n.. versionadded:: 1.0.7\n\n.. image:: images/popup.jpg\n :align: right\n\nThe :class:`Popup` widget is used to create modal popups. By default, the popup\nwill cover the whole \"parent\" window. When you are creating a popup, you\nmust at least set a :attr:`Popup.title` and :attr:`Popup.content`.\n\nRemember that the default size of a Widget is size_hint=(1, 1). If you don't\nwant your popup to be fullscreen, either use size hints with values less than 1\n(for instance size_hint=(.8, .8)) or deactivate the size_hint and use\nfixed size attributes.\n\n\n.. versionchanged:: 1.4.0\n The :class:`Popup` class now inherits from\n :class:`~kivy.uix.modalview.ModalView`. The :class:`Popup` offers a default\n layout with a title and a separation bar.\n\nExamples\n--------\n\nExample of a simple 400x400 Hello world popup::\n\n popup = Popup(title='Test popup',\n content=Label(text='Hello world'),\n size_hint=(None, None), size=(400, 400))\n\nBy default, any click outside the popup will dismiss/close it. If you don't\nwant that, you can set\n:attr:`~kivy.uix.modalview.ModalView.auto_dismiss` to False::\n\n popup = Popup(title='Test popup', content=Label(text='Hello world'),\n auto_dismiss=False)\n popup.open()\n\nTo manually dismiss/close the popup, use\n:attr:`~kivy.uix.modalview.ModalView.dismiss`::\n\n popup.dismiss()\n\nBoth :meth:`~kivy.uix.modalview.ModalView.open` and\n:meth:`~kivy.uix.modalview.ModalView.dismiss` are bindable. That means you\ncan directly bind the function to an action, e.g. to a button's on_press::\n\n # create content and add to the popup\n content = Button(text='Close me!')\n popup = Popup(content=content, auto_dismiss=False)\n\n # bind the on_press event of the button to the dismiss function\n content.bind(on_press=popup.dismiss)\n\n # open the popup\n popup.open()\n\n\nPopup Events\n------------\n\nThere are two events available: `on_open` which is raised when the popup is\nopening, and `on_dismiss` which is raised when the popup is closed.\nFor `on_dismiss`, you can prevent the\npopup from closing by explictly returning True from your callback::\n\n def my_callback(instance):\n print('Popup', instance, 'is being dismissed but is prevented!')\n return True\n popup = Popup(content=Label(text='Hello world'))\n popup.bind(on_dismiss=my_callback)\n popup.open()\n\n'''\n\n__all__ = ('Popup', 'PopupException')\n\nfrom kivy.uix.modalview import ModalView\nfrom kivy.properties import (StringProperty, ObjectProperty, OptionProperty,\n NumericProperty, ListProperty)\n\n\nclass PopupException(Exception):\n '''Popup exception, fired when multiple content widgets are added to the\n popup.\n\n .. versionadded:: 1.4.0\n '''\n\n\nclass Popup(ModalView):\n '''Popup class. See module documentation for more information.\n\n :Events:\n `on_open`:\n Fired when the Popup is opened.\n `on_dismiss`:\n Fired when the Popup is closed. If the callback returns True, the\n dismiss will be canceled.\n '''\n\n title = StringProperty('No title')\n '''String that represents the title of the popup.\n\n :attr:`title` is a :class:`~kivy.properties.StringProperty` and defaults to\n 'No title'.\n '''\n\n title_size = NumericProperty('14sp')\n '''Represents the font size of the popup title.\n\n .. versionadded:: 1.6.0\n\n :attr:`title_size` is a :class:`~kivy.properties.NumericProperty` and\n defaults to '14sp'.\n '''\n\n title_align = OptionProperty('left',\n options=['left', 'center', 'right', 'justify'])\n '''Horizontal alignment of the title.\n\n .. versionadded:: 1.9.0\n\n :attr:`title_align` is a :class:`~kivy.properties.OptionProperty` and\n defaults to 'left'. Available options are left, middle, right and justify.\n '''\n\n title_font = StringProperty('DroidSans')\n '''Font used to render the title text.\n\n .. versionadded:: 1.9.0\n\n :attr:`title_font` is a :class:`~kivy.properties.StringProperty` and\n defaults to 'DroidSans'.\n '''\n\n content = ObjectProperty(None)\n '''Content of the popup that is displayed just under the title.\n\n :attr:`content` is an :class:`~kivy.properties.ObjectProperty` and defaults\n to None.\n '''\n\n title_color = ListProperty([1, 1, 1, 1])\n '''Color used by the Title.\n\n .. versionadded:: 1.8.0\n\n :attr:`title_color` is a :class:`~kivy.properties.ListProperty` and\n defaults to [1, 1, 1, 1].\n '''\n\n separator_color = ListProperty([47 / 255., 167 / 255., 212 / 255., 1.])\n '''Color used by the separator between title and content.\n\n .. versionadded:: 1.1.0\n\n :attr:`separator_color` is a :class:`~kivy.properties.ListProperty` and\n defaults to [47 / 255., 167 / 255., 212 / 255., 1.]\n '''\n\n separator_height = NumericProperty('2dp')\n '''Height of the separator.\n\n .. versionadded:: 1.1.0\n\n :attr:`separator_height` is a :class:`~kivy.properties.NumericProperty` and\n defaults to 2dp.\n '''\n\n # Internal properties used for graphical representation.\n\n _container = ObjectProperty(None)\n\n def add_widget(self, widget):\n if self._container:\n if self.content:\n raise PopupException(\n 'Popup can have only one widget as content')\n self.content = widget\n else:\n super(Popup, self).add_widget(widget)\n\n def on_content(self, instance, value):\n if not hasattr(value, 'popup'):\n value.create_property('popup')\n value.popup = self\n if self._container:\n self._container.clear_widgets()\n self._container.add_widget(value)\n\n def on__container(self, instance, value):\n if value is None or self.content is None:\n return\n self._container.clear_widgets()\n self._container.add_widget(self.content)\n\n def on_touch_down(self, touch):\n if self.disabled and self.collide_point(*touch.pos):\n return True\n return super(Popup, self).on_touch_down(touch)\n\n\nif __name__ == '__main__':\n from kivy.base import runTouchApp\n from kivy.uix.button import Button\n from kivy.uix.label import Label\n from kivy.uix.gridlayout import GridLayout\n from kivy.core.window import Window\n\n # add popup\n content = GridLayout(cols=1)\n content_cancel = Button(text='Cancel', size_hint_y=None, height=40)\n content.add_widget(Label(text='This is a hello world'))\n content.add_widget(content_cancel)\n popup = Popup(title='Test popup',\n size_hint=(None, None), size=(256, 256),\n content=content, disabled=True)\n content_cancel.bind(on_release=popup.dismiss)\n\n layout = GridLayout(cols=3)\n for x in range(9):\n btn = Button(text=str(x))\n btn.bind(on_release=popup.open)\n layout.add_widget(btn)\n\n Window.add_widget(layout)\n\n popup.open()\n\n runTouchApp()\n", "path": "kivy/uix/popup.py"}]}
| 3,785 | 122 |
gh_patches_debug_60845
|
rasdani/github-patches
|
git_diff
|
uclapi__uclapi-226
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
timetable/data/departments endpoint returns 500 error
The timetable/data/departments endpoint is currently returning a 500 error on any request.
I know it's not a documented endpoint, but it would be nice if it worked :)
It looks to me like the problem is line 85 below - `rate_limiting_data` is being passed as an argument to `append`.
https://github.com/uclapi/uclapi/blob/cfd6753ae3d979bbe53573dad68babc2de19e04d/backend/uclapi/timetable/views.py#L82-L85
Removing that and replacing with this:
```python
depts["departments"].append({
"department_id": dept.deptid,
"name": dept.name})
```
should fix it, though I don't have the whole API setup installed, so I can't be sure.
</issue>
<code>
[start of backend/uclapi/timetable/views.py]
1 from django.conf import settings
2
3 from rest_framework.decorators import api_view
4
5 from common.helpers import PrettyJsonResponse as JsonResponse
6
7 from .models import Lock, Course, Depts, ModuleA, ModuleB
8
9 from .app_helpers import get_student_timetable, get_custom_timetable
10
11 from common.decorators import uclapi_protected_endpoint
12
13 _SETID = settings.ROOMBOOKINGS_SETID
14
15
16 @api_view(["GET"])
17 @uclapi_protected_endpoint(personal_data=True, required_scopes=['timetable'])
18 def get_personal_timetable(request, *args, **kwargs):
19 token = kwargs['token']
20 user = token.user
21 try:
22 date_filter = request.GET["date_filter"]
23 timetable = get_student_timetable(user.employee_id, date_filter)
24 except KeyError:
25 timetable = get_student_timetable(user.employee_id)
26
27 response = {
28 "ok": True,
29 "timetable": timetable
30 }
31 return JsonResponse(response, rate_limiting_data=kwargs)
32
33
34 @api_view(["GET"])
35 @uclapi_protected_endpoint()
36 def get_modules_timetable(request, *args, **kwargs):
37 module_ids = request.GET.get("modules")
38 if module_ids is None:
39 return JsonResponse({
40 "ok": False,
41 "error": "No module IDs provided."
42 }, rate_limiting_data=kwargs)
43
44 try:
45 modules = module_ids.split(',')
46 except ValueError:
47 return JsonResponse({
48 "ok": False,
49 "error": "Invalid module IDs provided."
50 }, rate_limiting_data=kwargs)
51
52 try:
53 date_filter = request.GET["date_filter"]
54 custom_timetable = get_custom_timetable(modules, date_filter)
55 except KeyError:
56 custom_timetable = get_custom_timetable(modules)
57
58 if custom_timetable:
59 response_json = {
60 "ok": True,
61 "timetable": custom_timetable
62 }
63 return JsonResponse(response_json, rate_limiting_data=kwargs)
64 else:
65 response_json = {
66 "ok": False,
67 "error": "One or more invalid Module IDs supplied."
68 }
69 response = JsonResponse(response_json, rate_limiting_data=kwargs)
70 response.status_code = 400
71 return response
72
73
74 @api_view(["GET"])
75 @uclapi_protected_endpoint()
76 def get_departments(request, *args, **kwargs):
77 """
78 Returns all departments at UCL
79 """
80 depts = {"ok": True, "departments": []}
81 for dept in Depts.objects.all():
82 depts["departments"].append({
83 "department_id": dept.deptid,
84 "name": dept.name
85 }, rate_limiting_data=kwargs)
86 return JsonResponse(depts, rate_limiting_data=kwargs)
87
88
89 @api_view(["GET"])
90 @uclapi_protected_endpoint()
91 def get_department_courses(request, *args, **kwargs):
92 """
93 Returns all the courses in UCL with relevant ID
94 """
95 try:
96 department_id = request.GET["department"]
97 except KeyError:
98 response = JsonResponse({
99 "ok": False,
100 "error": "Supply a Department ID using the department parameter."
101 }, rate_limiting_data=kwargs)
102 response.status_code = 400
103 return response
104
105 courses = {"ok": True, "courses": []}
106 for course in Course.objects.filter(owner=department_id, setid=_SETID):
107 courses["courses"].append({
108 "course_name": course.name,
109 "course_id": course.courseid,
110 "years": course.numyears
111 })
112 return JsonResponse(courses, rate_limiting_data=kwargs)
113
114
115 @api_view(["GET"])
116 @uclapi_protected_endpoint()
117 def get_department_modules(request, *args, **kwargs):
118 """
119 Returns all modules taught by a particular department.
120 """
121 try:
122 department_id = request.GET["department"]
123 except KeyError:
124 response = JsonResponse({
125 "ok": False,
126 "error": "Supply a Department ID using the department parameter."
127 }, rate_limiting_data=kwargs)
128 response.status_code = 400
129 return response
130
131 modules = {"ok": True, "modules": []}
132 lock = Lock.objects.all()[0]
133 m = ModuleA if lock.a else ModuleB
134 for module in m.objects.filter(owner=department_id, setid=_SETID):
135 modules["modules"].append({
136 "module_id": module.moduleid,
137 "name": module.name,
138 "module_code": module.linkcode,
139 "class_size": module.csize
140 })
141
142 return JsonResponse(modules, rate_limiting_data=kwargs)
143
[end of backend/uclapi/timetable/views.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/backend/uclapi/timetable/views.py b/backend/uclapi/timetable/views.py
--- a/backend/uclapi/timetable/views.py
+++ b/backend/uclapi/timetable/views.py
@@ -82,7 +82,7 @@
depts["departments"].append({
"department_id": dept.deptid,
"name": dept.name
- }, rate_limiting_data=kwargs)
+ })
return JsonResponse(depts, rate_limiting_data=kwargs)
|
{"golden_diff": "diff --git a/backend/uclapi/timetable/views.py b/backend/uclapi/timetable/views.py\n--- a/backend/uclapi/timetable/views.py\n+++ b/backend/uclapi/timetable/views.py\n@@ -82,7 +82,7 @@\n depts[\"departments\"].append({\n \"department_id\": dept.deptid,\n \"name\": dept.name\n- }, rate_limiting_data=kwargs)\n+ })\n return JsonResponse(depts, rate_limiting_data=kwargs)\n", "issue": "timetable/data/departments endpoint returns 500 error\nThe timetable/data/departments endpoint is currently returning a 500 error on any request.\r\n\r\nI know it's not a documented endpoint, but it would be nice if it worked :)\r\n\r\nIt looks to me like the problem is line 85 below - `rate_limiting_data` is being passed as an argument to `append`. \r\n\r\nhttps://github.com/uclapi/uclapi/blob/cfd6753ae3d979bbe53573dad68babc2de19e04d/backend/uclapi/timetable/views.py#L82-L85\r\n\r\nRemoving that and replacing with this:\r\n```python\r\ndepts[\"departments\"].append({ \r\n\"department_id\": dept.deptid, \r\n\"name\": dept.name}) \r\n```\r\nshould fix it, though I don't have the whole API setup installed, so I can't be sure.\n", "before_files": [{"content": "from django.conf import settings\n\nfrom rest_framework.decorators import api_view\n\nfrom common.helpers import PrettyJsonResponse as JsonResponse\n\nfrom .models import Lock, Course, Depts, ModuleA, ModuleB\n\nfrom .app_helpers import get_student_timetable, get_custom_timetable\n\nfrom common.decorators import uclapi_protected_endpoint\n\n_SETID = settings.ROOMBOOKINGS_SETID\n\n\n@api_view([\"GET\"])\n@uclapi_protected_endpoint(personal_data=True, required_scopes=['timetable'])\ndef get_personal_timetable(request, *args, **kwargs):\n token = kwargs['token']\n user = token.user\n try:\n date_filter = request.GET[\"date_filter\"]\n timetable = get_student_timetable(user.employee_id, date_filter)\n except KeyError:\n timetable = get_student_timetable(user.employee_id)\n\n response = {\n \"ok\": True,\n \"timetable\": timetable\n }\n return JsonResponse(response, rate_limiting_data=kwargs)\n\n\n@api_view([\"GET\"])\n@uclapi_protected_endpoint()\ndef get_modules_timetable(request, *args, **kwargs):\n module_ids = request.GET.get(\"modules\")\n if module_ids is None:\n return JsonResponse({\n \"ok\": False,\n \"error\": \"No module IDs provided.\"\n }, rate_limiting_data=kwargs)\n\n try:\n modules = module_ids.split(',')\n except ValueError:\n return JsonResponse({\n \"ok\": False,\n \"error\": \"Invalid module IDs provided.\"\n }, rate_limiting_data=kwargs)\n\n try:\n date_filter = request.GET[\"date_filter\"]\n custom_timetable = get_custom_timetable(modules, date_filter)\n except KeyError:\n custom_timetable = get_custom_timetable(modules)\n\n if custom_timetable:\n response_json = {\n \"ok\": True,\n \"timetable\": custom_timetable\n }\n return JsonResponse(response_json, rate_limiting_data=kwargs)\n else:\n response_json = {\n \"ok\": False,\n \"error\": \"One or more invalid Module IDs supplied.\"\n }\n response = JsonResponse(response_json, rate_limiting_data=kwargs)\n response.status_code = 400\n return response\n\n\n@api_view([\"GET\"])\n@uclapi_protected_endpoint()\ndef get_departments(request, *args, **kwargs):\n \"\"\"\n Returns all departments at UCL\n \"\"\"\n depts = {\"ok\": True, \"departments\": []}\n for dept in Depts.objects.all():\n depts[\"departments\"].append({\n \"department_id\": dept.deptid,\n \"name\": dept.name\n }, rate_limiting_data=kwargs)\n return JsonResponse(depts, rate_limiting_data=kwargs)\n\n\n@api_view([\"GET\"])\n@uclapi_protected_endpoint()\ndef get_department_courses(request, *args, **kwargs):\n \"\"\"\n Returns all the courses in UCL with relevant ID\n \"\"\"\n try:\n department_id = request.GET[\"department\"]\n except KeyError:\n response = JsonResponse({\n \"ok\": False,\n \"error\": \"Supply a Department ID using the department parameter.\"\n }, rate_limiting_data=kwargs)\n response.status_code = 400\n return response\n\n courses = {\"ok\": True, \"courses\": []}\n for course in Course.objects.filter(owner=department_id, setid=_SETID):\n courses[\"courses\"].append({\n \"course_name\": course.name,\n \"course_id\": course.courseid,\n \"years\": course.numyears\n })\n return JsonResponse(courses, rate_limiting_data=kwargs)\n\n\n@api_view([\"GET\"])\n@uclapi_protected_endpoint()\ndef get_department_modules(request, *args, **kwargs):\n \"\"\"\n Returns all modules taught by a particular department.\n \"\"\"\n try:\n department_id = request.GET[\"department\"]\n except KeyError:\n response = JsonResponse({\n \"ok\": False,\n \"error\": \"Supply a Department ID using the department parameter.\"\n }, rate_limiting_data=kwargs)\n response.status_code = 400\n return response\n\n modules = {\"ok\": True, \"modules\": []}\n lock = Lock.objects.all()[0]\n m = ModuleA if lock.a else ModuleB\n for module in m.objects.filter(owner=department_id, setid=_SETID):\n modules[\"modules\"].append({\n \"module_id\": module.moduleid,\n \"name\": module.name,\n \"module_code\": module.linkcode,\n \"class_size\": module.csize\n })\n\n return JsonResponse(modules, rate_limiting_data=kwargs)\n", "path": "backend/uclapi/timetable/views.py"}]}
| 2,053 | 111 |
gh_patches_debug_21817
|
rasdani/github-patches
|
git_diff
|
pantsbuild__pants-18258
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
`shfmt` assumes downloaded executable will be named `shfmt_{version}_{platform}`, and breaks if it isn't
**Describe the bug**
To reduce network transfer & flakiness during CI, we've pre-cached all the "external" tools used by Pants in our executor container. As part of this I've overridden the `url_template` for each tool to use a `file://` URL. The URL-paths I ended up using in the image were "simplified" from the defaults - for example, I have:
```toml
[shfmt]
url_template = "file:///opt/pants-tools/shfmt/{version}/shfmt"
```
When CI runs with this config, it fails with:
```
Error launching process: Os { code: 2, kind: NotFound, message: "No such file or directory" }
```
I `ssh`'d into one of the executors that hit this failure, and looked inside the failing sandbox. There I saw:
1. The `shfmt` binary _was_ in the sandbox, and runnable
2. According to `__run.sh`, Pants was trying to invoke `./shfmt_v3.2.4_linux_amd64` instead of plain `./shfmt`
I believe this is happening because the `shfmt` subsystem defines `generate_exe` to hard-code the same naming pattern as is used in the default `url_pattern`: https://github.com/pantsbuild/pants/blob/ac9e27b142b14f079089522c1175a9e380291100/src/python/pants/backend/shell/lint/shfmt/subsystem.py#L56-L58
I think things would operate as expected if we deleted that `generate_exe` override, since the `shfmt` download is the executable itself.
**Pants version**
2.15.0rc4
**OS**
Observed on Linux
**Additional info**
https://app.toolchain.com/organizations/color/repos/color/builds/pants_run_2023_02_15_12_48_26_897_660d20c55cc041fbb63374c79a4402b0/
</issue>
<code>
[start of src/python/pants/backend/shell/lint/shfmt/subsystem.py]
1 # Copyright 2021 Pants project contributors (see CONTRIBUTORS.md).
2 # Licensed under the Apache License, Version 2.0 (see LICENSE).
3
4 from __future__ import annotations
5
6 import os.path
7 from typing import Iterable
8
9 from pants.core.util_rules.config_files import ConfigFilesRequest
10 from pants.core.util_rules.external_tool import TemplatedExternalTool
11 from pants.engine.platform import Platform
12 from pants.option.option_types import ArgsListOption, BoolOption, SkipOption
13 from pants.util.strutil import softwrap
14
15
16 class Shfmt(TemplatedExternalTool):
17 options_scope = "shfmt"
18 name = "shfmt"
19 help = "An autoformatter for shell scripts (https://github.com/mvdan/sh)."
20
21 default_version = "v3.6.0"
22 default_known_versions = [
23 "v3.2.4|macos_arm64 |e70fc42e69debe3e400347d4f918630cdf4bf2537277d672bbc43490387508ec|2998546",
24 "v3.2.4|macos_x86_64|43a0461a1b54070ddc04fbbf1b78f7861ee39a65a61f5466d15a39c4aba4f917|2980208",
25 "v3.2.4|linux_arm64 |6474d9cc08a1c9fe2ef4be7a004951998e3067d46cf55a011ddd5ff7bfab3de6|2752512",
26 "v3.2.4|linux_x86_64|3f5a47f8fec27fae3e06d611559a2063f5d27e4b9501171dde9959b8c60a3538|2797568",
27 "v3.6.0|macos_arm64 |633f242246ee0a866c5f5df25cbf61b6af0d5e143555aca32950059cf13d91e0|3065202",
28 "v3.6.0|macos_x86_64|b8c9c025b498e2816b62f0b717f6032e9ab49e725a45b8205f52f66318f17185|3047552",
29 "v3.6.0|linux_arm64 |fb1cf0af3dbe9aac7d98e38e3c7426765208ecfe23cb2da51037bb234776fd70|2818048",
30 "v3.6.0|linux_x86_64|5741a02a641de7e56b8da170e71a97e58050d66a3cf485fb268d6a5a8bb74afb|2850816",
31 ]
32
33 default_url_template = (
34 "https://github.com/mvdan/sh/releases/download/{version}/shfmt_{version}_{platform}"
35 )
36 default_url_platform_mapping = {
37 "macos_arm64": "darwin_arm64",
38 "macos_x86_64": "darwin_amd64",
39 "linux_arm64": "linux_arm64",
40 "linux_x86_64": "linux_amd64",
41 }
42
43 skip = SkipOption("fmt", "lint")
44 args = ArgsListOption(example="-i 2")
45 config_discovery = BoolOption(
46 default=True,
47 advanced=True,
48 help=softwrap(
49 """
50 If true, Pants will include all relevant `.editorconfig` files during runs.
51 See https://editorconfig.org.
52 """
53 ),
54 )
55
56 def generate_exe(self, plat: Platform) -> str:
57 plat_str = self.default_url_platform_mapping[plat.value]
58 return f"./shfmt_{self.version}_{plat_str}"
59
60 def config_request(self, dirs: Iterable[str]) -> ConfigFilesRequest:
61 # Refer to https://editorconfig.org/#file-location for how config files are discovered.
62 candidates = (os.path.join(d, ".editorconfig") for d in ("", *dirs))
63 return ConfigFilesRequest(
64 discovery=self.config_discovery,
65 check_content={fp: b"[*.sh]" for fp in candidates},
66 )
67
[end of src/python/pants/backend/shell/lint/shfmt/subsystem.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/python/pants/backend/shell/lint/shfmt/subsystem.py b/src/python/pants/backend/shell/lint/shfmt/subsystem.py
--- a/src/python/pants/backend/shell/lint/shfmt/subsystem.py
+++ b/src/python/pants/backend/shell/lint/shfmt/subsystem.py
@@ -8,7 +8,6 @@
from pants.core.util_rules.config_files import ConfigFilesRequest
from pants.core.util_rules.external_tool import TemplatedExternalTool
-from pants.engine.platform import Platform
from pants.option.option_types import ArgsListOption, BoolOption, SkipOption
from pants.util.strutil import softwrap
@@ -53,10 +52,6 @@
),
)
- def generate_exe(self, plat: Platform) -> str:
- plat_str = self.default_url_platform_mapping[plat.value]
- return f"./shfmt_{self.version}_{plat_str}"
-
def config_request(self, dirs: Iterable[str]) -> ConfigFilesRequest:
# Refer to https://editorconfig.org/#file-location for how config files are discovered.
candidates = (os.path.join(d, ".editorconfig") for d in ("", *dirs))
|
{"golden_diff": "diff --git a/src/python/pants/backend/shell/lint/shfmt/subsystem.py b/src/python/pants/backend/shell/lint/shfmt/subsystem.py\n--- a/src/python/pants/backend/shell/lint/shfmt/subsystem.py\n+++ b/src/python/pants/backend/shell/lint/shfmt/subsystem.py\n@@ -8,7 +8,6 @@\n \n from pants.core.util_rules.config_files import ConfigFilesRequest\n from pants.core.util_rules.external_tool import TemplatedExternalTool\n-from pants.engine.platform import Platform\n from pants.option.option_types import ArgsListOption, BoolOption, SkipOption\n from pants.util.strutil import softwrap\n \n@@ -53,10 +52,6 @@\n ),\n )\n \n- def generate_exe(self, plat: Platform) -> str:\n- plat_str = self.default_url_platform_mapping[plat.value]\n- return f\"./shfmt_{self.version}_{plat_str}\"\n-\n def config_request(self, dirs: Iterable[str]) -> ConfigFilesRequest:\n # Refer to https://editorconfig.org/#file-location for how config files are discovered.\n candidates = (os.path.join(d, \".editorconfig\") for d in (\"\", *dirs))\n", "issue": "`shfmt` assumes downloaded executable will be named `shfmt_{version}_{platform}`, and breaks if it isn't\n**Describe the bug**\r\n\r\nTo reduce network transfer & flakiness during CI, we've pre-cached all the \"external\" tools used by Pants in our executor container. As part of this I've overridden the `url_template` for each tool to use a `file://` URL. The URL-paths I ended up using in the image were \"simplified\" from the defaults - for example, I have:\r\n```toml\r\n[shfmt]\r\nurl_template = \"file:///opt/pants-tools/shfmt/{version}/shfmt\"\r\n```\r\n\r\nWhen CI runs with this config, it fails with:\r\n```\r\nError launching process: Os { code: 2, kind: NotFound, message: \"No such file or directory\" }\r\n```\r\n\r\nI `ssh`'d into one of the executors that hit this failure, and looked inside the failing sandbox. There I saw:\r\n1. The `shfmt` binary _was_ in the sandbox, and runnable\r\n2. According to `__run.sh`, Pants was trying to invoke `./shfmt_v3.2.4_linux_amd64` instead of plain `./shfmt`\r\n\r\nI believe this is happening because the `shfmt` subsystem defines `generate_exe` to hard-code the same naming pattern as is used in the default `url_pattern`: https://github.com/pantsbuild/pants/blob/ac9e27b142b14f079089522c1175a9e380291100/src/python/pants/backend/shell/lint/shfmt/subsystem.py#L56-L58\r\n\r\nI think things would operate as expected if we deleted that `generate_exe` override, since the `shfmt` download is the executable itself.\r\n\r\n**Pants version**\r\n\r\n2.15.0rc4\r\n\r\n**OS**\r\n\r\nObserved on Linux\r\n\r\n**Additional info**\r\n\r\nhttps://app.toolchain.com/organizations/color/repos/color/builds/pants_run_2023_02_15_12_48_26_897_660d20c55cc041fbb63374c79a4402b0/\r\n\n", "before_files": [{"content": "# Copyright 2021 Pants project contributors (see CONTRIBUTORS.md).\n# Licensed under the Apache License, Version 2.0 (see LICENSE).\n\nfrom __future__ import annotations\n\nimport os.path\nfrom typing import Iterable\n\nfrom pants.core.util_rules.config_files import ConfigFilesRequest\nfrom pants.core.util_rules.external_tool import TemplatedExternalTool\nfrom pants.engine.platform import Platform\nfrom pants.option.option_types import ArgsListOption, BoolOption, SkipOption\nfrom pants.util.strutil import softwrap\n\n\nclass Shfmt(TemplatedExternalTool):\n options_scope = \"shfmt\"\n name = \"shfmt\"\n help = \"An autoformatter for shell scripts (https://github.com/mvdan/sh).\"\n\n default_version = \"v3.6.0\"\n default_known_versions = [\n \"v3.2.4|macos_arm64 |e70fc42e69debe3e400347d4f918630cdf4bf2537277d672bbc43490387508ec|2998546\",\n \"v3.2.4|macos_x86_64|43a0461a1b54070ddc04fbbf1b78f7861ee39a65a61f5466d15a39c4aba4f917|2980208\",\n \"v3.2.4|linux_arm64 |6474d9cc08a1c9fe2ef4be7a004951998e3067d46cf55a011ddd5ff7bfab3de6|2752512\",\n \"v3.2.4|linux_x86_64|3f5a47f8fec27fae3e06d611559a2063f5d27e4b9501171dde9959b8c60a3538|2797568\",\n \"v3.6.0|macos_arm64 |633f242246ee0a866c5f5df25cbf61b6af0d5e143555aca32950059cf13d91e0|3065202\",\n \"v3.6.0|macos_x86_64|b8c9c025b498e2816b62f0b717f6032e9ab49e725a45b8205f52f66318f17185|3047552\",\n \"v3.6.0|linux_arm64 |fb1cf0af3dbe9aac7d98e38e3c7426765208ecfe23cb2da51037bb234776fd70|2818048\",\n \"v3.6.0|linux_x86_64|5741a02a641de7e56b8da170e71a97e58050d66a3cf485fb268d6a5a8bb74afb|2850816\",\n ]\n\n default_url_template = (\n \"https://github.com/mvdan/sh/releases/download/{version}/shfmt_{version}_{platform}\"\n )\n default_url_platform_mapping = {\n \"macos_arm64\": \"darwin_arm64\",\n \"macos_x86_64\": \"darwin_amd64\",\n \"linux_arm64\": \"linux_arm64\",\n \"linux_x86_64\": \"linux_amd64\",\n }\n\n skip = SkipOption(\"fmt\", \"lint\")\n args = ArgsListOption(example=\"-i 2\")\n config_discovery = BoolOption(\n default=True,\n advanced=True,\n help=softwrap(\n \"\"\"\n If true, Pants will include all relevant `.editorconfig` files during runs.\n See https://editorconfig.org.\n \"\"\"\n ),\n )\n\n def generate_exe(self, plat: Platform) -> str:\n plat_str = self.default_url_platform_mapping[plat.value]\n return f\"./shfmt_{self.version}_{plat_str}\"\n\n def config_request(self, dirs: Iterable[str]) -> ConfigFilesRequest:\n # Refer to https://editorconfig.org/#file-location for how config files are discovered.\n candidates = (os.path.join(d, \".editorconfig\") for d in (\"\", *dirs))\n return ConfigFilesRequest(\n discovery=self.config_discovery,\n check_content={fp: b\"[*.sh]\" for fp in candidates},\n )\n", "path": "src/python/pants/backend/shell/lint/shfmt/subsystem.py"}]}
| 2,317 | 253 |
gh_patches_debug_3045
|
rasdani/github-patches
|
git_diff
|
ethereum__web3.py-1095
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Dissallow python 3.5.1
### What was wrong?
It looks like `typing.NewType` may not be available in python 3.5.1
https://github.com/ethereum/web3.py/issues/1091
### How can it be fixed?
Check what version `NewType` was added and restrict our python versions as declared in `setup.py` to be `>=` that version
</issue>
<code>
[start of setup.py]
1 #!/usr/bin/env python
2 # -*- coding: utf-8 -*-
3 from setuptools import (
4 find_packages,
5 setup,
6 )
7
8 extras_require = {
9 'tester': [
10 "eth-tester[py-evm]==0.1.0-beta.32",
11 "py-geth>=2.0.1,<3.0.0",
12 ],
13 'testrpc': ["eth-testrpc>=1.3.3,<2.0.0"],
14 'linter': [
15 "flake8==3.4.1",
16 "isort>=4.2.15,<5",
17 ],
18 'docs': [
19 "mock",
20 "sphinx-better-theme>=0.1.4",
21 "click>=5.1",
22 "configparser==3.5.0",
23 "contextlib2>=0.5.4",
24 #"eth-testrpc>=0.8.0",
25 #"ethereum-tester-client>=1.1.0",
26 "ethtoken",
27 "py-geth>=1.4.0",
28 "py-solc>=0.4.0",
29 "pytest>=2.7.2",
30 "sphinx",
31 "sphinx_rtd_theme>=0.1.9",
32 "toposort>=1.4",
33 "urllib3",
34 "web3>=2.1.0",
35 "wheel"
36 ],
37 'dev': [
38 "bumpversion",
39 "flaky>=3.3.0",
40 "hypothesis>=3.31.2",
41 "pytest>=3.5.0,<4",
42 "pytest-mock==1.*",
43 "pytest-pythonpath>=0.3",
44 "pytest-watch==4.*",
45 "pytest-xdist==1.*",
46 "setuptools>=36.2.0",
47 "tox>=1.8.0",
48 "tqdm",
49 "when-changed"
50 ]
51 }
52
53 extras_require['dev'] = (
54 extras_require['tester'] +
55 extras_require['linter'] +
56 extras_require['docs'] +
57 extras_require['dev']
58 )
59
60 setup(
61 name='web3',
62 # *IMPORTANT*: Don't manually change the version here. Use the 'bumpversion' utility.
63 version='4.7.1',
64 description="""Web3.py""",
65 long_description_markdown_filename='README.md',
66 author='Piper Merriam',
67 author_email='[email protected]',
68 url='https://github.com/ethereum/web3.py',
69 include_package_data=True,
70 install_requires=[
71 "toolz>=0.9.0,<1.0.0;implementation_name=='pypy'",
72 "cytoolz>=0.9.0,<1.0.0;implementation_name=='cpython'",
73 "eth-abi>=1.2.0,<2.0.0",
74 "eth-account>=0.2.1,<0.4.0",
75 "eth-utils>=1.0.1,<2.0.0",
76 "hexbytes>=0.1.0,<1.0.0",
77 "lru-dict>=1.1.6,<2.0.0",
78 "eth-hash[pycryptodome]>=0.2.0,<1.0.0",
79 "requests>=2.16.0,<3.0.0",
80 "websockets>=6.0.0,<7.0.0",
81 "pypiwin32>=223;platform_system=='Windows'",
82 ],
83 setup_requires=['setuptools-markdown'],
84 python_requires='>=3.5, <4',
85 extras_require=extras_require,
86 py_modules=['web3', 'ens'],
87 license="MIT",
88 zip_safe=False,
89 keywords='ethereum',
90 packages=find_packages(exclude=["tests", "tests.*"]),
91 classifiers=[
92 'Development Status :: 5 - Production/Stable',
93 'Intended Audience :: Developers',
94 'License :: OSI Approved :: MIT License',
95 'Natural Language :: English',
96 'Programming Language :: Python :: 3',
97 'Programming Language :: Python :: 3.5',
98 'Programming Language :: Python :: 3.6',
99 ],
100 )
101
[end of setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -81,7 +81,7 @@
"pypiwin32>=223;platform_system=='Windows'",
],
setup_requires=['setuptools-markdown'],
- python_requires='>=3.5, <4',
+ python_requires='>=3.5.2, <4',
extras_require=extras_require,
py_modules=['web3', 'ens'],
license="MIT",
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -81,7 +81,7 @@\n \"pypiwin32>=223;platform_system=='Windows'\",\n ],\n setup_requires=['setuptools-markdown'],\n- python_requires='>=3.5, <4',\n+ python_requires='>=3.5.2, <4',\n extras_require=extras_require,\n py_modules=['web3', 'ens'],\n license=\"MIT\",\n", "issue": "Dissallow python 3.5.1\n### What was wrong?\r\n\r\nIt looks like `typing.NewType` may not be available in python 3.5.1\r\n\r\nhttps://github.com/ethereum/web3.py/issues/1091\r\n\r\n### How can it be fixed?\r\n\r\nCheck what version `NewType` was added and restrict our python versions as declared in `setup.py` to be `>=` that version\n", "before_files": [{"content": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\nfrom setuptools import (\n find_packages,\n setup,\n)\n\nextras_require = {\n 'tester': [\n \"eth-tester[py-evm]==0.1.0-beta.32\",\n \"py-geth>=2.0.1,<3.0.0\",\n ],\n 'testrpc': [\"eth-testrpc>=1.3.3,<2.0.0\"],\n 'linter': [\n \"flake8==3.4.1\",\n \"isort>=4.2.15,<5\",\n ],\n 'docs': [\n \"mock\",\n \"sphinx-better-theme>=0.1.4\",\n \"click>=5.1\",\n \"configparser==3.5.0\",\n \"contextlib2>=0.5.4\",\n #\"eth-testrpc>=0.8.0\",\n #\"ethereum-tester-client>=1.1.0\",\n \"ethtoken\",\n \"py-geth>=1.4.0\",\n \"py-solc>=0.4.0\",\n \"pytest>=2.7.2\",\n \"sphinx\",\n \"sphinx_rtd_theme>=0.1.9\",\n \"toposort>=1.4\",\n \"urllib3\",\n \"web3>=2.1.0\",\n \"wheel\"\n ],\n 'dev': [\n \"bumpversion\",\n \"flaky>=3.3.0\",\n \"hypothesis>=3.31.2\",\n \"pytest>=3.5.0,<4\",\n \"pytest-mock==1.*\",\n \"pytest-pythonpath>=0.3\",\n \"pytest-watch==4.*\",\n \"pytest-xdist==1.*\",\n \"setuptools>=36.2.0\",\n \"tox>=1.8.0\",\n \"tqdm\",\n \"when-changed\"\n ]\n}\n\nextras_require['dev'] = (\n extras_require['tester'] +\n extras_require['linter'] +\n extras_require['docs'] +\n extras_require['dev']\n)\n\nsetup(\n name='web3',\n # *IMPORTANT*: Don't manually change the version here. Use the 'bumpversion' utility.\n version='4.7.1',\n description=\"\"\"Web3.py\"\"\",\n long_description_markdown_filename='README.md',\n author='Piper Merriam',\n author_email='[email protected]',\n url='https://github.com/ethereum/web3.py',\n include_package_data=True,\n install_requires=[\n \"toolz>=0.9.0,<1.0.0;implementation_name=='pypy'\",\n \"cytoolz>=0.9.0,<1.0.0;implementation_name=='cpython'\",\n \"eth-abi>=1.2.0,<2.0.0\",\n \"eth-account>=0.2.1,<0.4.0\",\n \"eth-utils>=1.0.1,<2.0.0\",\n \"hexbytes>=0.1.0,<1.0.0\",\n \"lru-dict>=1.1.6,<2.0.0\",\n \"eth-hash[pycryptodome]>=0.2.0,<1.0.0\",\n \"requests>=2.16.0,<3.0.0\",\n \"websockets>=6.0.0,<7.0.0\",\n \"pypiwin32>=223;platform_system=='Windows'\",\n ],\n setup_requires=['setuptools-markdown'],\n python_requires='>=3.5, <4',\n extras_require=extras_require,\n py_modules=['web3', 'ens'],\n license=\"MIT\",\n zip_safe=False,\n keywords='ethereum',\n packages=find_packages(exclude=[\"tests\", \"tests.*\"]),\n classifiers=[\n 'Development Status :: 5 - Production/Stable',\n 'Intended Audience :: Developers',\n 'License :: OSI Approved :: MIT License',\n 'Natural Language :: English',\n 'Programming Language :: Python :: 3',\n 'Programming Language :: Python :: 3.5',\n 'Programming Language :: Python :: 3.6',\n ],\n)\n", "path": "setup.py"}]}
| 1,731 | 110 |
gh_patches_debug_1632
|
rasdani/github-patches
|
git_diff
|
ansible__ansible-modules-extras-1291
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
pam_limits - documentation is not updated
`limit_type` choices are `hard`, `soft` in the [documentation](http://docs.ansible.com/ansible/pam_limits_module.html) but in the [code](https://github.com/ansible/ansible-modules-extras/blob/devel/system/pam_limits.py#L95) `-` is supported.
pam_limits - documentation is not updated
`limit_type` choices are `hard`, `soft` in the [documentation](http://docs.ansible.com/ansible/pam_limits_module.html) but in the [code](https://github.com/ansible/ansible-modules-extras/blob/devel/system/pam_limits.py#L95) `-` is supported.
</issue>
<code>
[start of system/pam_limits.py]
1 #!/usr/bin/python
2 # -*- coding: utf-8 -*-
3
4 # (c) 2014, Sebastien Rohaut <[email protected]>
5 #
6 # This file is part of Ansible
7 #
8 # Ansible is free software: you can redistribute it and/or modify
9 # it under the terms of the GNU General Public License as published by
10 # the Free Software Foundation, either version 3 of the License, or
11 # (at your option) any later version.
12 #
13 # Ansible is distributed in the hope that it will be useful,
14 # but WITHOUT ANY WARRANTY; without even the implied warranty of
15 # MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
16 # GNU General Public License for more details.
17 #
18 # You should have received a copy of the GNU General Public License
19 # along with Ansible. If not, see <http://www.gnu.org/licenses/>.
20
21 import os
22 import os.path
23 import shutil
24 import re
25
26 DOCUMENTATION = '''
27 ---
28 module: pam_limits
29 version_added: "2.0"
30 short_description: Modify Linux PAM limits
31 description:
32 - The M(pam_limits) module modify PAM limits, default in /etc/security/limits.conf.
33 For the full documentation, see man limits.conf(5).
34 options:
35 domain:
36 description:
37 - A username, @groupname, wildcard, uid/gid range.
38 required: true
39 limit_type:
40 description:
41 - Limit type, see C(man limits) for an explanation
42 required: true
43 choices: [ "hard", "soft" ]
44 limit_item:
45 description:
46 - The limit to be set
47 required: true
48 choices: [ "core", "data", "fsize", "memlock", "nofile", "rss", "stack", "cpu", "nproc", "as", "maxlogins", "maxsyslogins", "priority", "locks", "sigpending", "msgqueue", "nice", "rtprio", "chroot" ]
49 value:
50 description:
51 - The value of the limit.
52 required: true
53 backup:
54 description:
55 - Create a backup file including the timestamp information so you can get
56 the original file back if you somehow clobbered it incorrectly.
57 required: false
58 choices: [ "yes", "no" ]
59 default: "no"
60 use_min:
61 description:
62 - If set to C(yes), the minimal value will be used or conserved.
63 If the specified value is inferior to the value in the file, file content is replaced with the new value,
64 else content is not modified.
65 required: false
66 choices: [ "yes", "no" ]
67 default: "no"
68 use_max:
69 description:
70 - If set to C(yes), the maximal value will be used or conserved.
71 If the specified value is superior to the value in the file, file content is replaced with the new value,
72 else content is not modified.
73 required: false
74 choices: [ "yes", "no" ]
75 default: "no"
76 dest:
77 description:
78 - Modify the limits.conf path.
79 required: false
80 default: "/etc/security/limits.conf"
81 '''
82
83 EXAMPLES = '''
84 # Add or modify limits for the user joe
85 - pam_limits: domain=joe limit_type=soft limit_item=nofile value=64000
86
87 # Add or modify limits for the user joe. Keep or set the maximal value
88 - pam_limits: domain=joe limit_type=soft limit_item=nofile value=1000000
89 '''
90
91 def main():
92
93 pam_items = [ 'core', 'data', 'fsize', 'memlock', 'nofile', 'rss', 'stack', 'cpu', 'nproc', 'as', 'maxlogins', 'maxsyslogins', 'priority', 'locks', 'sigpending', 'msgqueue', 'nice', 'rtprio', 'chroot' ]
94
95 pam_types = [ 'soft', 'hard', '-' ]
96
97 limits_conf = '/etc/security/limits.conf'
98
99 module = AnsibleModule(
100 # not checking because of daisy chain to file module
101 argument_spec = dict(
102 domain = dict(required=True, type='str'),
103 limit_type = dict(required=True, type='str', choices=pam_types),
104 limit_item = dict(required=True, type='str', choices=pam_items),
105 value = dict(required=True, type='str'),
106 use_max = dict(default=False, type='bool'),
107 use_min = dict(default=False, type='bool'),
108 backup = dict(default=False, type='bool'),
109 dest = dict(default=limits_conf, type='str'),
110 comment = dict(required=False, default='', type='str')
111 )
112 )
113
114 domain = module.params['domain']
115 limit_type = module.params['limit_type']
116 limit_item = module.params['limit_item']
117 value = module.params['value']
118 use_max = module.params['use_max']
119 use_min = module.params['use_min']
120 backup = module.params['backup']
121 limits_conf = module.params['dest']
122 new_comment = module.params['comment']
123
124 changed = False
125
126 if os.path.isfile(limits_conf):
127 if not os.access(limits_conf, os.W_OK):
128 module.fail_json(msg="%s is not writable. Use sudo" % (limits_conf) )
129 else:
130 module.fail_json(msg="%s is not visible (check presence, access rights, use sudo)" % (limits_conf) )
131
132 if use_max and use_min:
133 module.fail_json(msg="Cannot use use_min and use_max at the same time." )
134
135 if not (value in ['unlimited', 'infinity', '-1'] or value.isdigit()):
136 module.fail_json(msg="Argument 'value' can be one of 'unlimited', 'infinity', '-1' or positive number. Refer to manual pages for more details.")
137
138 # Backup
139 if backup:
140 backup_file = module.backup_local(limits_conf)
141
142 space_pattern = re.compile(r'\s+')
143
144 message = ''
145 f = open (limits_conf, 'r')
146 # Tempfile
147 nf = tempfile.NamedTemporaryFile(delete = False)
148
149 found = False
150 new_value = value
151
152 for line in f:
153
154 if line.startswith('#'):
155 nf.write(line)
156 continue
157
158 newline = re.sub(space_pattern, ' ', line).strip()
159 if not newline:
160 nf.write(line)
161 continue
162
163 # Remove comment in line
164 newline = newline.split('#',1)[0]
165 try:
166 old_comment = line.split('#',1)[1]
167 except:
168 old_comment = ''
169
170 newline = newline.rstrip()
171
172 if not new_comment:
173 new_comment = old_comment
174
175 if new_comment:
176 new_comment = "\t#"+new_comment
177
178 line_fields = newline.split(' ')
179
180 if len(line_fields) != 4:
181 nf.write(line)
182 continue
183
184 line_domain = line_fields[0]
185 line_type = line_fields[1]
186 line_item = line_fields[2]
187 actual_value = line_fields[3]
188
189 if not (actual_value in ['unlimited', 'infinity', '-1'] or actual_value.isdigit()):
190 module.fail_json(msg="Invalid configuration of '%s'. Current value of %s is unsupported." % (limits_conf, line_item))
191
192 # Found the line
193 if line_domain == domain and line_type == limit_type and line_item == limit_item:
194 found = True
195 if value == actual_value:
196 message = line
197 nf.write(line)
198 continue
199
200 actual_value_unlimited = actual_value in ['unlimited', 'infinity', '-1']
201 value_unlimited = value in ['unlimited', 'infinity', '-1']
202
203 if use_max:
204 if value.isdigit() and actual_value.isdigit():
205 new_value = max(int(value), int(actual_value))
206 elif actual_value_unlimited:
207 new_value = actual_value
208 else:
209 new_value = value
210
211 if use_min:
212 if value.isdigit() and actual_value.isdigit():
213 new_value = min(int(value), int(actual_value))
214 elif value_unlimited:
215 new_value = actual_value
216 else:
217 new_value = value
218
219 # Change line only if value has changed
220 if new_value != actual_value:
221 changed = True
222 new_limit = domain + "\t" + limit_type + "\t" + limit_item + "\t" + str(new_value) + new_comment + "\n"
223 message = new_limit
224 nf.write(new_limit)
225 else:
226 message = line
227 nf.write(line)
228 else:
229 nf.write(line)
230
231 if not found:
232 changed = True
233 new_limit = domain + "\t" + limit_type + "\t" + limit_item + "\t" + str(new_value) + new_comment + "\n"
234 message = new_limit
235 nf.write(new_limit)
236
237 f.close()
238 nf.close()
239
240 # Copy tempfile to newfile
241 module.atomic_move(nf.name, f.name)
242
243 res_args = dict(
244 changed = changed, msg = message
245 )
246
247 if backup:
248 res_args['backup_file'] = backup_file
249
250 module.exit_json(**res_args)
251
252
253 # import module snippets
254 from ansible.module_utils.basic import *
255 main()
256
[end of system/pam_limits.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/system/pam_limits.py b/system/pam_limits.py
--- a/system/pam_limits.py
+++ b/system/pam_limits.py
@@ -40,7 +40,7 @@
description:
- Limit type, see C(man limits) for an explanation
required: true
- choices: [ "hard", "soft" ]
+ choices: [ "hard", "soft", "-" ]
limit_item:
description:
- The limit to be set
|
{"golden_diff": "diff --git a/system/pam_limits.py b/system/pam_limits.py\n--- a/system/pam_limits.py\n+++ b/system/pam_limits.py\n@@ -40,7 +40,7 @@\n description:\n - Limit type, see C(man limits) for an explanation\n required: true\n- choices: [ \"hard\", \"soft\" ]\n+ choices: [ \"hard\", \"soft\", \"-\" ]\n limit_item:\n description:\n - The limit to be set\n", "issue": "pam_limits - documentation is not updated \n`limit_type` choices are `hard`, `soft` in the [documentation](http://docs.ansible.com/ansible/pam_limits_module.html) but in the [code](https://github.com/ansible/ansible-modules-extras/blob/devel/system/pam_limits.py#L95) `-` is supported.\n\npam_limits - documentation is not updated \n`limit_type` choices are `hard`, `soft` in the [documentation](http://docs.ansible.com/ansible/pam_limits_module.html) but in the [code](https://github.com/ansible/ansible-modules-extras/blob/devel/system/pam_limits.py#L95) `-` is supported.\n\n", "before_files": [{"content": "#!/usr/bin/python\n# -*- coding: utf-8 -*-\n\n# (c) 2014, Sebastien Rohaut <[email protected]>\n#\n# This file is part of Ansible\n#\n# Ansible is free software: you can redistribute it and/or modify\n# it under the terms of the GNU General Public License as published by\n# the Free Software Foundation, either version 3 of the License, or\n# (at your option) any later version.\n#\n# Ansible is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License\n# along with Ansible. If not, see <http://www.gnu.org/licenses/>.\n\nimport os\nimport os.path\nimport shutil\nimport re\n\nDOCUMENTATION = '''\n---\nmodule: pam_limits\nversion_added: \"2.0\"\nshort_description: Modify Linux PAM limits\ndescription:\n - The M(pam_limits) module modify PAM limits, default in /etc/security/limits.conf.\n For the full documentation, see man limits.conf(5).\noptions:\n domain:\n description:\n - A username, @groupname, wildcard, uid/gid range.\n required: true\n limit_type:\n description:\n - Limit type, see C(man limits) for an explanation\n required: true\n choices: [ \"hard\", \"soft\" ]\n limit_item:\n description:\n - The limit to be set\n required: true\n choices: [ \"core\", \"data\", \"fsize\", \"memlock\", \"nofile\", \"rss\", \"stack\", \"cpu\", \"nproc\", \"as\", \"maxlogins\", \"maxsyslogins\", \"priority\", \"locks\", \"sigpending\", \"msgqueue\", \"nice\", \"rtprio\", \"chroot\" ]\n value:\n description:\n - The value of the limit.\n required: true\n backup:\n description:\n - Create a backup file including the timestamp information so you can get\n the original file back if you somehow clobbered it incorrectly.\n required: false\n choices: [ \"yes\", \"no\" ]\n default: \"no\"\n use_min:\n description:\n - If set to C(yes), the minimal value will be used or conserved.\n If the specified value is inferior to the value in the file, file content is replaced with the new value,\n else content is not modified.\n required: false\n choices: [ \"yes\", \"no\" ]\n default: \"no\"\n use_max:\n description:\n - If set to C(yes), the maximal value will be used or conserved.\n If the specified value is superior to the value in the file, file content is replaced with the new value,\n else content is not modified.\n required: false\n choices: [ \"yes\", \"no\" ]\n default: \"no\"\n dest:\n description:\n - Modify the limits.conf path.\n required: false\n default: \"/etc/security/limits.conf\"\n'''\n\nEXAMPLES = '''\n# Add or modify limits for the user joe\n- pam_limits: domain=joe limit_type=soft limit_item=nofile value=64000\n\n# Add or modify limits for the user joe. Keep or set the maximal value\n- pam_limits: domain=joe limit_type=soft limit_item=nofile value=1000000\n'''\n\ndef main():\n\n pam_items = [ 'core', 'data', 'fsize', 'memlock', 'nofile', 'rss', 'stack', 'cpu', 'nproc', 'as', 'maxlogins', 'maxsyslogins', 'priority', 'locks', 'sigpending', 'msgqueue', 'nice', 'rtprio', 'chroot' ]\n\n pam_types = [ 'soft', 'hard', '-' ]\n\n limits_conf = '/etc/security/limits.conf'\n\n module = AnsibleModule(\n # not checking because of daisy chain to file module\n argument_spec = dict(\n domain = dict(required=True, type='str'),\n limit_type = dict(required=True, type='str', choices=pam_types),\n limit_item = dict(required=True, type='str', choices=pam_items),\n value = dict(required=True, type='str'),\n use_max = dict(default=False, type='bool'),\n use_min = dict(default=False, type='bool'),\n backup = dict(default=False, type='bool'),\n dest = dict(default=limits_conf, type='str'),\n comment = dict(required=False, default='', type='str')\n )\n )\n\n domain = module.params['domain']\n limit_type = module.params['limit_type']\n limit_item = module.params['limit_item']\n value = module.params['value']\n use_max = module.params['use_max']\n use_min = module.params['use_min']\n backup = module.params['backup']\n limits_conf = module.params['dest']\n new_comment = module.params['comment']\n\n changed = False\n\n if os.path.isfile(limits_conf):\n if not os.access(limits_conf, os.W_OK):\n module.fail_json(msg=\"%s is not writable. Use sudo\" % (limits_conf) )\n else:\n module.fail_json(msg=\"%s is not visible (check presence, access rights, use sudo)\" % (limits_conf) )\n\n if use_max and use_min:\n module.fail_json(msg=\"Cannot use use_min and use_max at the same time.\" )\n\n if not (value in ['unlimited', 'infinity', '-1'] or value.isdigit()):\n module.fail_json(msg=\"Argument 'value' can be one of 'unlimited', 'infinity', '-1' or positive number. Refer to manual pages for more details.\")\n\n # Backup\n if backup:\n backup_file = module.backup_local(limits_conf)\n\n space_pattern = re.compile(r'\\s+')\n\n message = ''\n f = open (limits_conf, 'r')\n # Tempfile\n nf = tempfile.NamedTemporaryFile(delete = False)\n\n found = False\n new_value = value\n\n for line in f:\n\n if line.startswith('#'):\n nf.write(line)\n continue\n\n newline = re.sub(space_pattern, ' ', line).strip()\n if not newline:\n nf.write(line)\n continue\n\n # Remove comment in line\n newline = newline.split('#',1)[0]\n try:\n old_comment = line.split('#',1)[1]\n except:\n old_comment = ''\n\n newline = newline.rstrip()\n\n if not new_comment:\n new_comment = old_comment\n\n if new_comment:\n new_comment = \"\\t#\"+new_comment\n\n line_fields = newline.split(' ')\n\n if len(line_fields) != 4:\n nf.write(line)\n continue\n\n line_domain = line_fields[0]\n line_type = line_fields[1]\n line_item = line_fields[2]\n actual_value = line_fields[3]\n\n if not (actual_value in ['unlimited', 'infinity', '-1'] or actual_value.isdigit()):\n module.fail_json(msg=\"Invalid configuration of '%s'. Current value of %s is unsupported.\" % (limits_conf, line_item))\n\n # Found the line\n if line_domain == domain and line_type == limit_type and line_item == limit_item:\n found = True\n if value == actual_value:\n message = line\n nf.write(line)\n continue\n\n actual_value_unlimited = actual_value in ['unlimited', 'infinity', '-1']\n value_unlimited = value in ['unlimited', 'infinity', '-1']\n\n if use_max:\n if value.isdigit() and actual_value.isdigit():\n new_value = max(int(value), int(actual_value))\n elif actual_value_unlimited:\n new_value = actual_value\n else:\n new_value = value\n\n if use_min:\n if value.isdigit() and actual_value.isdigit():\n new_value = min(int(value), int(actual_value))\n elif value_unlimited:\n new_value = actual_value\n else:\n new_value = value\n\n # Change line only if value has changed\n if new_value != actual_value:\n changed = True\n new_limit = domain + \"\\t\" + limit_type + \"\\t\" + limit_item + \"\\t\" + str(new_value) + new_comment + \"\\n\"\n message = new_limit\n nf.write(new_limit)\n else:\n message = line\n nf.write(line)\n else:\n nf.write(line)\n\n if not found:\n changed = True\n new_limit = domain + \"\\t\" + limit_type + \"\\t\" + limit_item + \"\\t\" + str(new_value) + new_comment + \"\\n\"\n message = new_limit\n nf.write(new_limit)\n\n f.close()\n nf.close()\n\n # Copy tempfile to newfile\n module.atomic_move(nf.name, f.name)\n\n res_args = dict(\n changed = changed, msg = message\n )\n\n if backup:\n res_args['backup_file'] = backup_file\n\n module.exit_json(**res_args)\n\n\n# import module snippets\nfrom ansible.module_utils.basic import *\nmain()\n", "path": "system/pam_limits.py"}]}
| 3,401 | 106 |
gh_patches_debug_22163
|
rasdani/github-patches
|
git_diff
|
learningequality__kolibri-5797
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
add support for OIDC in account creation flow
### Observed behavior
currently SSO works for sign in but not account creation
### Expected behavior
the 'next' parameter needs to be passed from the sign in page to the account creation page and handled there
### User-facing consequences
The following flow is not supported:
> 1. User comes to SCE portal and click on login for one server, system would redirect to Kolibri portal.
> 2. On Kolibri portal, user decides to not login but register and clicks on register.
> 3. After registration, user is redirecting to Kolibri portal instead of returning back to SCE portal.
### Context
0.12.5
</issue>
<code>
[start of kolibri/core/theme_hook.py]
1 from __future__ import absolute_import
2 from __future__ import print_function
3 from __future__ import unicode_literals
4
5 import logging
6
7 from kolibri.plugins import hooks
8 import kolibri
9 from django.utils.six.moves.urllib import parse
10 from django.conf import settings
11 import os
12
13 logger = logging.getLogger(__name__)
14
15
16 # Important for cache busting
17 THEME_NAME = "themeName"
18 THEME_VERSION = "themeVersion"
19
20 # These constants are used by theme.js and the $theme mixin on the front-end
21 TOKEN_MAPPING = "tokenMapping"
22 BRAND_COLORS = "brandColors"
23 PRIMARY = "primary"
24 SECONDARY = "secondary"
25 COLOR_V50 = "v_50"
26 COLOR_V100 = "v_100"
27 COLOR_V200 = "v_200"
28 COLOR_V300 = "v_300"
29 COLOR_V400 = "v_400"
30 COLOR_V500 = "v_500"
31 COLOR_V600 = "v_600"
32 COLOR_V700 = "v_700"
33 COLOR_V800 = "v_800"
34 COLOR_V900 = "v_900"
35 SIGN_IN = "signIn"
36 SIDE_NAV = "sideNav"
37 APP_BAR = "appBar"
38 BACKGROUND = "background"
39 TITLE = "title"
40 TITLE_STYLE = "titleStyle"
41 TOP_LOGO = "topLogo"
42 IMG_SRC = "src"
43 IMG_STYLE = "style"
44 IMG_ALT = "alt"
45 SHOW_K_FOOTER_LOGO = "showKolibriFooterLogo"
46
47 # This is the image file name that will be used when customizing the sign-in background
48 # image using the 'kolibri manage background' command. It does not attempt to use a file
49 # extension (like .jpg) because we don't know if it's a JPG, SVG, PNG, etc...
50 DEFAULT_BG_IMAGE_FILE = "background_image"
51 DEFAULT_BG_MD5_FILE = "background_image_md5"
52
53
54 def _isSet(theme, keys):
55 """
56 Given a theme dict, recursively check that all the keys are populated
57 and that the associated value is truthy
58 """
59 obj = theme
60 for key in keys:
61 if not obj or key not in obj:
62 return False
63 obj = obj[key]
64 return bool(obj)
65
66
67 def _validateMetadata(theme):
68 if THEME_NAME not in theme:
69 logger.error("a theme name must be set")
70 if THEME_VERSION not in theme:
71 logger.error("a theme version must be set")
72
73
74 def _validateBrandColors(theme):
75 if BRAND_COLORS not in theme:
76 logger.error("brand colors not defined by theme")
77 return
78
79 required_colors = [PRIMARY, SECONDARY]
80 color_names = [
81 COLOR_V50,
82 COLOR_V100,
83 COLOR_V200,
84 COLOR_V300,
85 COLOR_V400,
86 COLOR_V500,
87 COLOR_V600,
88 COLOR_V700,
89 COLOR_V800,
90 COLOR_V900,
91 ]
92 for color in required_colors:
93 if color not in theme[BRAND_COLORS]:
94 logger.error("'{}' not defined by theme".format(color))
95 for name in color_names:
96 if name not in theme[BRAND_COLORS][color]:
97 logger.error("{} '{}' not defined by theme".format(color, name))
98
99
100 def _initFields(theme):
101 """
102 set up top-level dicts if they don't exist
103 """
104 if SIGN_IN not in theme:
105 theme[SIGN_IN] = {}
106 if TOKEN_MAPPING not in theme:
107 theme[TOKEN_MAPPING] = {}
108 if SIDE_NAV not in theme:
109 theme[SIDE_NAV] = {}
110 if APP_BAR not in theme:
111 theme[APP_BAR] = {}
112
113
114 class ThemeHook(hooks.KolibriHook):
115 """
116 A hook to allow custom theming of Kolibri
117 Use this tool to help generate your brand colors: https://materialpalettes.com/
118 """
119
120 class Meta:
121 abstract = True
122
123 @property
124 @hooks.only_one_registered
125 def cacheKey(self):
126 theme = list(self.registered_hooks)[0].theme
127 return parse.quote(
128 "{}-{}-{}".format(
129 kolibri.__version__, theme[THEME_NAME], theme[THEME_VERSION]
130 )
131 )
132
133 @property
134 @hooks.only_one_registered
135 def theme(self):
136 theme = list(self.registered_hooks)[0].theme
137
138 # some validation and initialization
139 _initFields(theme)
140 _validateMetadata(theme)
141 _validateBrandColors(theme)
142
143 # set up cache busting
144 bust = "?" + self.cacheKey
145 if _isSet(theme, [SIGN_IN, BACKGROUND]):
146 theme[SIGN_IN][BACKGROUND] += bust
147 if _isSet(theme, [SIGN_IN, TOP_LOGO, IMG_SRC]):
148 theme[SIGN_IN][TOP_LOGO][IMG_SRC] += bust
149 if _isSet(theme, [SIDE_NAV, TOP_LOGO, IMG_SRC]):
150 theme[SIDE_NAV][TOP_LOGO][IMG_SRC] += bust
151 if _isSet(theme, [APP_BAR, TOP_LOGO, IMG_SRC]):
152 theme[APP_BAR][TOP_LOGO][IMG_SRC] += bust
153
154 # if a background image has been locally set using the `manage background` command, use it
155 bg_img = os.path.join(settings.MEDIA_ROOT, DEFAULT_BG_IMAGE_FILE)
156 if os.path.exists(bg_img):
157 theme[SIGN_IN][BACKGROUND] = parse.urljoin(
158 settings.MEDIA_URL, DEFAULT_BG_IMAGE_FILE
159 )
160 # add cache busting
161 md5_file = os.path.join(settings.MEDIA_ROOT, DEFAULT_BG_MD5_FILE)
162 if os.path.exists(md5_file):
163 with open(md5_file) as f:
164 theme[SIGN_IN][BACKGROUND] += "?{}".format(f.read())
165
166 return theme
167
[end of kolibri/core/theme_hook.py]
[start of kolibri/plugins/default_theme/kolibri_plugin.py]
1 from __future__ import absolute_import
2 from __future__ import print_function
3 from __future__ import unicode_literals
4
5 from django.contrib.staticfiles.templatetags.staticfiles import static
6
7 from kolibri.plugins.base import KolibriPluginBase
8
9 from kolibri.core import theme_hook
10
11
12 class DefaultThemePlugin(KolibriPluginBase):
13 pass
14
15
16 class DefaultThemeHook(theme_hook.ThemeHook):
17 @property
18 def theme(self):
19 return {
20 # metadata
21 theme_hook.THEME_NAME: "Default theme",
22 theme_hook.THEME_VERSION: 1, # increment when changes are made
23 # specify primary and secondary brand colors
24 theme_hook.BRAND_COLORS: {
25 theme_hook.PRIMARY: {
26 theme_hook.COLOR_V50: "#f0e7ed",
27 theme_hook.COLOR_V100: "#dbc3d4",
28 theme_hook.COLOR_V200: "#c59db9",
29 theme_hook.COLOR_V300: "#ac799d",
30 theme_hook.COLOR_V400: "#996189",
31 theme_hook.COLOR_V500: "#874e77",
32 theme_hook.COLOR_V600: "#7c4870",
33 theme_hook.COLOR_V700: "#6e4167",
34 theme_hook.COLOR_V800: "#5f3b5c",
35 theme_hook.COLOR_V900: "#4b2e4d",
36 },
37 theme_hook.SECONDARY: {
38 theme_hook.COLOR_V50: "#e3f0ed",
39 theme_hook.COLOR_V100: "#badbd2",
40 theme_hook.COLOR_V200: "#8dc5b6",
41 theme_hook.COLOR_V300: "#62af9a",
42 theme_hook.COLOR_V400: "#479e86",
43 theme_hook.COLOR_V500: "#368d74",
44 theme_hook.COLOR_V600: "#328168",
45 theme_hook.COLOR_V700: "#2c715a",
46 theme_hook.COLOR_V800: "#26614d",
47 theme_hook.COLOR_V900: "#1b4634",
48 },
49 },
50 # sign-in page config
51 theme_hook.SIGN_IN: {
52 theme_hook.BACKGROUND: static("background.jpg"),
53 theme_hook.TITLE: None, # use default: "Kolibri"
54 theme_hook.TOP_LOGO: {
55 theme_hook.IMG_SRC: None, # use default Kolibri bird
56 theme_hook.IMG_STYLE: "padding-left: 64px; padding-right: 64px; margin-bottom: 8px; margin-top: 8px",
57 theme_hook.IMG_ALT: None,
58 },
59 theme_hook.SHOW_K_FOOTER_LOGO: False,
60 },
61 # side-nav config
62 theme_hook.SIDE_NAV: {theme_hook.SHOW_K_FOOTER_LOGO: True},
63 # app bar config
64 theme_hook.APP_BAR: {theme_hook.TOP_LOGO: None},
65 }
66
[end of kolibri/plugins/default_theme/kolibri_plugin.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/kolibri/core/theme_hook.py b/kolibri/core/theme_hook.py
--- a/kolibri/core/theme_hook.py
+++ b/kolibri/core/theme_hook.py
@@ -42,7 +42,10 @@
IMG_SRC = "src"
IMG_STYLE = "style"
IMG_ALT = "alt"
+SHOW_TITLE = "showTitle"
SHOW_K_FOOTER_LOGO = "showKolibriFooterLogo"
+SHOW_POWERED_BY = "showPoweredBy"
+POWERED_BY_STYLE = "poweredByStyle"
# This is the image file name that will be used when customizing the sign-in background
# image using the 'kolibri manage background' command. It does not attempt to use a file
diff --git a/kolibri/plugins/default_theme/kolibri_plugin.py b/kolibri/plugins/default_theme/kolibri_plugin.py
--- a/kolibri/plugins/default_theme/kolibri_plugin.py
+++ b/kolibri/plugins/default_theme/kolibri_plugin.py
@@ -56,6 +56,8 @@
theme_hook.IMG_STYLE: "padding-left: 64px; padding-right: 64px; margin-bottom: 8px; margin-top: 8px",
theme_hook.IMG_ALT: None,
},
+ theme_hook.SHOW_POWERED_BY: False,
+ theme_hook.SHOW_TITLE: True,
theme_hook.SHOW_K_FOOTER_LOGO: False,
},
# side-nav config
|
{"golden_diff": "diff --git a/kolibri/core/theme_hook.py b/kolibri/core/theme_hook.py\n--- a/kolibri/core/theme_hook.py\n+++ b/kolibri/core/theme_hook.py\n@@ -42,7 +42,10 @@\n IMG_SRC = \"src\"\n IMG_STYLE = \"style\"\n IMG_ALT = \"alt\"\n+SHOW_TITLE = \"showTitle\"\n SHOW_K_FOOTER_LOGO = \"showKolibriFooterLogo\"\n+SHOW_POWERED_BY = \"showPoweredBy\"\n+POWERED_BY_STYLE = \"poweredByStyle\"\n \n # This is the image file name that will be used when customizing the sign-in background\n # image using the 'kolibri manage background' command. It does not attempt to use a file\ndiff --git a/kolibri/plugins/default_theme/kolibri_plugin.py b/kolibri/plugins/default_theme/kolibri_plugin.py\n--- a/kolibri/plugins/default_theme/kolibri_plugin.py\n+++ b/kolibri/plugins/default_theme/kolibri_plugin.py\n@@ -56,6 +56,8 @@\n theme_hook.IMG_STYLE: \"padding-left: 64px; padding-right: 64px; margin-bottom: 8px; margin-top: 8px\",\n theme_hook.IMG_ALT: None,\n },\n+ theme_hook.SHOW_POWERED_BY: False,\n+ theme_hook.SHOW_TITLE: True,\n theme_hook.SHOW_K_FOOTER_LOGO: False,\n },\n # side-nav config\n", "issue": "add support for OIDC in account creation flow\n\r\n### Observed behavior\r\n\r\ncurrently SSO works for sign in but not account creation\r\n\r\n### Expected behavior\r\n\r\nthe 'next' parameter needs to be passed from the sign in page to the account creation page and handled there\r\n\r\n### User-facing consequences\r\n\r\nThe following flow is not supported:\r\n\r\n> 1. User comes to SCE portal and click on login for one server, system would redirect to Kolibri portal.\r\n> 2. On Kolibri portal, user decides to not login but register and clicks on register.\r\n> 3. After registration, user is redirecting to Kolibri portal instead of returning back to SCE portal.\r\n\r\n\r\n\r\n### Context\r\n\r\n0.12.5\n", "before_files": [{"content": "from __future__ import absolute_import\nfrom __future__ import print_function\nfrom __future__ import unicode_literals\n\nimport logging\n\nfrom kolibri.plugins import hooks\nimport kolibri\nfrom django.utils.six.moves.urllib import parse\nfrom django.conf import settings\nimport os\n\nlogger = logging.getLogger(__name__)\n\n\n# Important for cache busting\nTHEME_NAME = \"themeName\"\nTHEME_VERSION = \"themeVersion\"\n\n# These constants are used by theme.js and the $theme mixin on the front-end\nTOKEN_MAPPING = \"tokenMapping\"\nBRAND_COLORS = \"brandColors\"\nPRIMARY = \"primary\"\nSECONDARY = \"secondary\"\nCOLOR_V50 = \"v_50\"\nCOLOR_V100 = \"v_100\"\nCOLOR_V200 = \"v_200\"\nCOLOR_V300 = \"v_300\"\nCOLOR_V400 = \"v_400\"\nCOLOR_V500 = \"v_500\"\nCOLOR_V600 = \"v_600\"\nCOLOR_V700 = \"v_700\"\nCOLOR_V800 = \"v_800\"\nCOLOR_V900 = \"v_900\"\nSIGN_IN = \"signIn\"\nSIDE_NAV = \"sideNav\"\nAPP_BAR = \"appBar\"\nBACKGROUND = \"background\"\nTITLE = \"title\"\nTITLE_STYLE = \"titleStyle\"\nTOP_LOGO = \"topLogo\"\nIMG_SRC = \"src\"\nIMG_STYLE = \"style\"\nIMG_ALT = \"alt\"\nSHOW_K_FOOTER_LOGO = \"showKolibriFooterLogo\"\n\n# This is the image file name that will be used when customizing the sign-in background\n# image using the 'kolibri manage background' command. It does not attempt to use a file\n# extension (like .jpg) because we don't know if it's a JPG, SVG, PNG, etc...\nDEFAULT_BG_IMAGE_FILE = \"background_image\"\nDEFAULT_BG_MD5_FILE = \"background_image_md5\"\n\n\ndef _isSet(theme, keys):\n \"\"\"\n Given a theme dict, recursively check that all the keys are populated\n and that the associated value is truthy\n \"\"\"\n obj = theme\n for key in keys:\n if not obj or key not in obj:\n return False\n obj = obj[key]\n return bool(obj)\n\n\ndef _validateMetadata(theme):\n if THEME_NAME not in theme:\n logger.error(\"a theme name must be set\")\n if THEME_VERSION not in theme:\n logger.error(\"a theme version must be set\")\n\n\ndef _validateBrandColors(theme):\n if BRAND_COLORS not in theme:\n logger.error(\"brand colors not defined by theme\")\n return\n\n required_colors = [PRIMARY, SECONDARY]\n color_names = [\n COLOR_V50,\n COLOR_V100,\n COLOR_V200,\n COLOR_V300,\n COLOR_V400,\n COLOR_V500,\n COLOR_V600,\n COLOR_V700,\n COLOR_V800,\n COLOR_V900,\n ]\n for color in required_colors:\n if color not in theme[BRAND_COLORS]:\n logger.error(\"'{}' not defined by theme\".format(color))\n for name in color_names:\n if name not in theme[BRAND_COLORS][color]:\n logger.error(\"{} '{}' not defined by theme\".format(color, name))\n\n\ndef _initFields(theme):\n \"\"\"\n set up top-level dicts if they don't exist\n \"\"\"\n if SIGN_IN not in theme:\n theme[SIGN_IN] = {}\n if TOKEN_MAPPING not in theme:\n theme[TOKEN_MAPPING] = {}\n if SIDE_NAV not in theme:\n theme[SIDE_NAV] = {}\n if APP_BAR not in theme:\n theme[APP_BAR] = {}\n\n\nclass ThemeHook(hooks.KolibriHook):\n \"\"\"\n A hook to allow custom theming of Kolibri\n Use this tool to help generate your brand colors: https://materialpalettes.com/\n \"\"\"\n\n class Meta:\n abstract = True\n\n @property\n @hooks.only_one_registered\n def cacheKey(self):\n theme = list(self.registered_hooks)[0].theme\n return parse.quote(\n \"{}-{}-{}\".format(\n kolibri.__version__, theme[THEME_NAME], theme[THEME_VERSION]\n )\n )\n\n @property\n @hooks.only_one_registered\n def theme(self):\n theme = list(self.registered_hooks)[0].theme\n\n # some validation and initialization\n _initFields(theme)\n _validateMetadata(theme)\n _validateBrandColors(theme)\n\n # set up cache busting\n bust = \"?\" + self.cacheKey\n if _isSet(theme, [SIGN_IN, BACKGROUND]):\n theme[SIGN_IN][BACKGROUND] += bust\n if _isSet(theme, [SIGN_IN, TOP_LOGO, IMG_SRC]):\n theme[SIGN_IN][TOP_LOGO][IMG_SRC] += bust\n if _isSet(theme, [SIDE_NAV, TOP_LOGO, IMG_SRC]):\n theme[SIDE_NAV][TOP_LOGO][IMG_SRC] += bust\n if _isSet(theme, [APP_BAR, TOP_LOGO, IMG_SRC]):\n theme[APP_BAR][TOP_LOGO][IMG_SRC] += bust\n\n # if a background image has been locally set using the `manage background` command, use it\n bg_img = os.path.join(settings.MEDIA_ROOT, DEFAULT_BG_IMAGE_FILE)\n if os.path.exists(bg_img):\n theme[SIGN_IN][BACKGROUND] = parse.urljoin(\n settings.MEDIA_URL, DEFAULT_BG_IMAGE_FILE\n )\n # add cache busting\n md5_file = os.path.join(settings.MEDIA_ROOT, DEFAULT_BG_MD5_FILE)\n if os.path.exists(md5_file):\n with open(md5_file) as f:\n theme[SIGN_IN][BACKGROUND] += \"?{}\".format(f.read())\n\n return theme\n", "path": "kolibri/core/theme_hook.py"}, {"content": "from __future__ import absolute_import\nfrom __future__ import print_function\nfrom __future__ import unicode_literals\n\nfrom django.contrib.staticfiles.templatetags.staticfiles import static\n\nfrom kolibri.plugins.base import KolibriPluginBase\n\nfrom kolibri.core import theme_hook\n\n\nclass DefaultThemePlugin(KolibriPluginBase):\n pass\n\n\nclass DefaultThemeHook(theme_hook.ThemeHook):\n @property\n def theme(self):\n return {\n # metadata\n theme_hook.THEME_NAME: \"Default theme\",\n theme_hook.THEME_VERSION: 1, # increment when changes are made\n # specify primary and secondary brand colors\n theme_hook.BRAND_COLORS: {\n theme_hook.PRIMARY: {\n theme_hook.COLOR_V50: \"#f0e7ed\",\n theme_hook.COLOR_V100: \"#dbc3d4\",\n theme_hook.COLOR_V200: \"#c59db9\",\n theme_hook.COLOR_V300: \"#ac799d\",\n theme_hook.COLOR_V400: \"#996189\",\n theme_hook.COLOR_V500: \"#874e77\",\n theme_hook.COLOR_V600: \"#7c4870\",\n theme_hook.COLOR_V700: \"#6e4167\",\n theme_hook.COLOR_V800: \"#5f3b5c\",\n theme_hook.COLOR_V900: \"#4b2e4d\",\n },\n theme_hook.SECONDARY: {\n theme_hook.COLOR_V50: \"#e3f0ed\",\n theme_hook.COLOR_V100: \"#badbd2\",\n theme_hook.COLOR_V200: \"#8dc5b6\",\n theme_hook.COLOR_V300: \"#62af9a\",\n theme_hook.COLOR_V400: \"#479e86\",\n theme_hook.COLOR_V500: \"#368d74\",\n theme_hook.COLOR_V600: \"#328168\",\n theme_hook.COLOR_V700: \"#2c715a\",\n theme_hook.COLOR_V800: \"#26614d\",\n theme_hook.COLOR_V900: \"#1b4634\",\n },\n },\n # sign-in page config\n theme_hook.SIGN_IN: {\n theme_hook.BACKGROUND: static(\"background.jpg\"),\n theme_hook.TITLE: None, # use default: \"Kolibri\"\n theme_hook.TOP_LOGO: {\n theme_hook.IMG_SRC: None, # use default Kolibri bird\n theme_hook.IMG_STYLE: \"padding-left: 64px; padding-right: 64px; margin-bottom: 8px; margin-top: 8px\",\n theme_hook.IMG_ALT: None,\n },\n theme_hook.SHOW_K_FOOTER_LOGO: False,\n },\n # side-nav config\n theme_hook.SIDE_NAV: {theme_hook.SHOW_K_FOOTER_LOGO: True},\n # app bar config\n theme_hook.APP_BAR: {theme_hook.TOP_LOGO: None},\n }\n", "path": "kolibri/plugins/default_theme/kolibri_plugin.py"}]}
| 3,188 | 319 |
gh_patches_debug_66259
|
rasdani/github-patches
|
git_diff
|
qtile__qtile-1432
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
docs: Missing deps when building widget docs gives "alias to ImportErrorWidget"
See http://docs.qtile.org/en/latest/manual/ref/widgets.html#memory for example.
I guess the widget dependencies are not installed while building the docs, resulting in Sphinx telling the widget is an alias to `libqtile.widget.import_error.make_error.<locals>.ImportErrorWidget`.
EDIT: okay I see where the deps are listed: in `docs/conf.py`. Indeed `mpd` is present but `psutil` is not, so the `Memory` widget's docs do not build.
</issue>
<code>
[start of docs/conf.py]
1 # -*- coding: utf-8 -*-
2 #
3 # Qtile documentation build configuration file, created by
4 # sphinx-quickstart on Sat Feb 11 15:20:21 2012.
5 #
6 # This file is execfile()d with the current directory set to its containing dir.
7 #
8 # Note that not all possible configuration values are present in this
9 # autogenerated file.
10 #
11 # All configuration values have a default; values that are commented out
12 # serve to show the default.
13
14 import os
15 import sys
16 from unittest.mock import MagicMock
17
18
19 class Mock(MagicMock):
20 # xcbq does a dir() on objects and pull stuff out of them and tries to sort
21 # the result. MagicMock has a bunch of stuff that can't be sorted, so let's
22 # like about dir().
23 def __dir__(self):
24 return []
25
26 MOCK_MODULES = [
27 'libqtile._ffi_pango',
28 'libqtile.core._ffi_xcursors',
29 'cairocffi',
30 'cairocffi.pixbuf',
31 'cffi',
32 'dateutil',
33 'dateutil.parser',
34 'dbus',
35 'dbus.mainloop.glib',
36 'iwlib',
37 'keyring',
38 'mpd',
39 'trollius',
40 'xcffib',
41 'xcffib.randr',
42 'xcffib.xfixes',
43 'xcffib.xinerama',
44 'xcffib.xproto',
45 'xdg.IconTheme',
46 ]
47 sys.modules.update((mod_name, Mock()) for mod_name in MOCK_MODULES)
48
49 # If extensions (or modules to document with autodoc) are in another directory,
50 # add these directories to sys.path here. If the directory is relative to the
51 # documentation root, use os.path.abspath to make it absolute, like shown here.
52 sys.path.insert(0, os.path.abspath('.'))
53 sys.path.insert(0, os.path.abspath('../'))
54
55 # -- General configuration -----------------------------------------------------
56
57 # If your documentation needs a minimal Sphinx version, state it here.
58 #needs_sphinx = '1.0'
59
60 # Add any Sphinx extension module names here, as strings. They can be extensions
61 # coming with Sphinx (named 'sphinx.ext.*') or your custom ones.
62 extensions = [
63 'sphinx.ext.autodoc',
64 'sphinx.ext.autosummary',
65 'sphinx.ext.coverage',
66 'sphinx.ext.graphviz',
67 'sphinx.ext.todo',
68 'sphinx.ext.viewcode',
69 'sphinxcontrib.seqdiag',
70 'sphinx_qtile',
71 'numpydoc',
72 ]
73
74 numpydoc_show_class_members = False
75
76 # Add any paths that contain templates here, relative to this directory.
77 templates_path = []
78
79 # The suffix of source filenames.
80 source_suffix = '.rst'
81
82 # The encoding of source files.
83 #source_encoding = 'utf-8-sig'
84
85 # The master toctree document.
86 master_doc = 'index'
87
88 # General information about the project.
89 project = u'Qtile'
90 copyright = u'2008-2019, Aldo Cortesi and contributers'
91
92 # The version info for the project you're documenting, acts as replacement for
93 # |version| and |release|, also used in various other places throughout the
94 # built documents.
95 #
96 # The short X.Y version.
97 version = '0.14.2'
98 # The full version, including alpha/beta/rc tags.
99 release = version
100
101 # The language for content autogenerated by Sphinx. Refer to documentation
102 # for a list of supported languages.
103 #language = None
104
105 # There are two options for replacing |today|: either, you set today to some
106 # non-false value, then it is used:
107 #today = ''
108 # Else, today_fmt is used as the format for a strftime call.
109 #today_fmt = '%B %d, %Y'
110
111 # List of patterns, relative to source directory, that match files and
112 # directories to ignore when looking for source files.
113 exclude_patterns = ['_build', 'man']
114
115 # The reST default role (used for this markup: `text`) to use for all documents.
116 #default_role = None
117
118 # If true, '()' will be appended to :func: etc. cross-reference text.
119 #add_function_parentheses = True
120
121 # If true, the current module name will be prepended to all description
122 # unit titles (such as .. function::).
123 #add_module_names = True
124
125 # If true, sectionauthor and moduleauthor directives will be shown in the
126 # output. They are ignored by default.
127 #show_authors = False
128
129 # The name of the Pygments (syntax highlighting) style to use.
130 pygments_style = 'sphinx'
131
132 # A list of ignored prefixes for module index sorting.
133 #modindex_common_prefix = []
134
135 # If true, `todo` and `todoList` produce output, else they produce nothing.
136 todo_include_todos = True
137
138
139 # -- Options for HTML output --------fautod-------------------------------------------
140
141 # The theme to use for HTML and HTML Help pages. See the documentation for
142 # a list of builtin themes.
143 #html_theme = 'default'
144
145 # Theme options are theme-specific and customize the look and feel of a theme
146 # further. For a list of options available for each theme, see the
147 # documentation.
148 #html_theme_options = {}
149
150 # Add any paths that contain custom themes here, relative to this directory.
151 #html_theme_path = []
152
153 # The name for this set of Sphinx documents. If None, it defaults to
154 # "<project> v<release> documentation".
155 #html_title = None
156
157 # A shorter title for the navigation bar. Default is the same as html_title.
158 #html_short_title = None
159
160 # The name of an image file (relative to this directory) to place at the top
161 # of the sidebar.
162 #html_logo = None
163
164 # The name of an image file (within the static path) to use as favicon of the
165 # docs. This file should be a Windows icon file (.ico) being 16x16 or 32x32
166 # pixels large.
167 html_favicon = '_static/favicon.ico'
168
169 # Add any paths that contain custom static files (such as style sheets) here,
170 # relative to this directory. They are copied after the builtin static files,
171 # so a file named "default.css" will overwrite the builtin "default.css".
172 html_static_path = ['_static']
173
174 # If not '', a 'Last updated on:' timestamp is inserted at every page bottom,
175 # using the given strftime format.
176 #html_last_updated_fmt = '%b %d, %Y'
177
178 # If true, SmartyPants will be used to convert quotes and dashes to
179 # typographically correct entities.
180 #html_use_smartypants = True
181
182 # Custom sidebar templates, maps document names to template names.
183 #html_sidebars = {}
184
185 # Additional templates that should be rendered to pages, maps page names to
186 # template names.
187 #html_additional_pages = {'index': 'index.html'}
188
189 # If false, no module index is generated.
190 #html_domain_indices = True
191
192 # If false, no index is generated.
193 html_use_index = True
194
195 # If true, the index is split into individual pages for each letter.
196 #html_split_index = False
197
198 # If true, links to the reST sources are added to the pages.
199 #html_show_sourcelink = True
200
201 # If true, "Created using Sphinx" is shown in the HTML footer. Default is True.
202 #html_show_sphinx = True
203
204 # If true, "(C) Copyright ..." is shown in the HTML footer. Default is True.
205 #html_show_copyright = True
206
207 # If true, an OpenSearch description file will be output, and all pages will
208 # contain a <link> tag referring to it. The value of this option must be the
209 # base URL from which the finished HTML is served.
210 #html_use_opensearch = ''
211
212 # This is the file name suffix for HTML files (e.g. ".xhtml").
213 #html_file_suffix = None
214
215 # Output file base name for HTML help builder.
216 htmlhelp_basename = 'Qtiledoc'
217
218
219 # -- Options for LaTeX output --------------------------------------------------
220
221 latex_elements = {
222 # The paper size ('letterpaper' or 'a4paper').
223 #'papersize': 'letterpaper',
224
225 # The font size ('10pt', '11pt' or '12pt').
226 #'pointsize': '10pt',
227
228 # Additional stuff for the LaTeX preamble.
229 #'preamble': '',
230 }
231
232 # Grouping the document tree into LaTeX files. List of tuples
233 # (source start file, target name, title, author, documentclass [howto/manual]).
234 latex_documents = [
235 ('index', 'Qtile.tex', u'Qtile Documentation',
236 u'Aldo Cortesi', 'manual'),
237 ]
238
239 # The name of an image file (relative to this directory) to place at the top of
240 # the title page.
241 #latex_logo = None
242
243 # For "manual" documents, if this is true, then toplevel headings are parts,
244 # not chapters.
245 #latex_use_parts = False
246
247 # If true, show page references after internal links.
248 #latex_show_pagerefs = False
249
250 # If true, show URL addresses after external links.
251 #latex_show_urls = False
252
253 # Documents to append as an appendix to all manuals.
254 #latex_appendices = []
255
256 # If false, no module index is generated.
257 #latex_domain_indices = True
258
259
260 # -- Options for manual page output --------------------------------------------
261
262 # One entry per manual page. List of tuples
263 # (source start file, name, description, authors, manual section).
264 man_pages = [
265 ('man/qtile', 'qtile', u'Qtile Documentation',
266 [u'Tycho Andersen'], 1),
267 ('man/qshell', 'qshell', u'Qtile Documentation',
268 [u'Tycho Andersen'], 1),
269 ]
270
271 # If true, show URL addresses after external links.
272 #man_show_urls = False
273
274
275 # -- Options for Texinfo output ------------------------------------------------
276
277 # Grouping the document tree into Texinfo files. List of tuples
278 # (source start file, target name, title, author,
279 # dir menu entry, description, category)
280 texinfo_documents = [
281 ('index', 'Qtile', u'Qtile Documentation',
282 u'Aldo Cortesi', 'Qtile', 'A hackable tiling window manager.',
283 'Miscellaneous'),
284 ]
285
286 # Documents to append as an appendix to all manuals.
287 #texinfo_appendices = []
288
289 # If false, no module index is generated.
290 #texinfo_domain_indices = True
291
292 # How to display URL addresses: 'footnote', 'no', or 'inline'.
293 #texinfo_show_urls = 'footnote'
294
295 # only import and set the theme if we're building docs locally
296 if not os.environ.get('READTHEDOCS'):
297 import sphinx_rtd_theme
298 html_theme = 'sphinx_rtd_theme'
299 html_theme_path = [sphinx_rtd_theme.get_html_theme_path()]
300
301
302 graphviz_dot_args = ['-Lg']
303
304 # A workaround for the responsive tables always having annoying scrollbars.
305 def setup(app):
306 app.add_stylesheet("no_scrollbars.css")
307
[end of docs/conf.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/docs/conf.py b/docs/conf.py
--- a/docs/conf.py
+++ b/docs/conf.py
@@ -36,6 +36,7 @@
'iwlib',
'keyring',
'mpd',
+ 'psutil',
'trollius',
'xcffib',
'xcffib.randr',
|
{"golden_diff": "diff --git a/docs/conf.py b/docs/conf.py\n--- a/docs/conf.py\n+++ b/docs/conf.py\n@@ -36,6 +36,7 @@\n 'iwlib',\n 'keyring',\n 'mpd',\n+ 'psutil',\n 'trollius',\n 'xcffib',\n 'xcffib.randr',\n", "issue": "docs: Missing deps when building widget docs gives \"alias to ImportErrorWidget\"\nSee http://docs.qtile.org/en/latest/manual/ref/widgets.html#memory for example.\r\n\r\nI guess the widget dependencies are not installed while building the docs, resulting in Sphinx telling the widget is an alias to `libqtile.widget.import_error.make_error.<locals>.ImportErrorWidget`.\r\n\r\nEDIT: okay I see where the deps are listed: in `docs/conf.py`. Indeed `mpd` is present but `psutil` is not, so the `Memory` widget's docs do not build.\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n#\n# Qtile documentation build configuration file, created by\n# sphinx-quickstart on Sat Feb 11 15:20:21 2012.\n#\n# This file is execfile()d with the current directory set to its containing dir.\n#\n# Note that not all possible configuration values are present in this\n# autogenerated file.\n#\n# All configuration values have a default; values that are commented out\n# serve to show the default.\n\nimport os\nimport sys\nfrom unittest.mock import MagicMock\n\n\nclass Mock(MagicMock):\n # xcbq does a dir() on objects and pull stuff out of them and tries to sort\n # the result. MagicMock has a bunch of stuff that can't be sorted, so let's\n # like about dir().\n def __dir__(self):\n return []\n\nMOCK_MODULES = [\n 'libqtile._ffi_pango',\n 'libqtile.core._ffi_xcursors',\n 'cairocffi',\n 'cairocffi.pixbuf',\n 'cffi',\n 'dateutil',\n 'dateutil.parser',\n 'dbus',\n 'dbus.mainloop.glib',\n 'iwlib',\n 'keyring',\n 'mpd',\n 'trollius',\n 'xcffib',\n 'xcffib.randr',\n 'xcffib.xfixes',\n 'xcffib.xinerama',\n 'xcffib.xproto',\n 'xdg.IconTheme',\n]\nsys.modules.update((mod_name, Mock()) for mod_name in MOCK_MODULES)\n\n# If extensions (or modules to document with autodoc) are in another directory,\n# add these directories to sys.path here. If the directory is relative to the\n# documentation root, use os.path.abspath to make it absolute, like shown here.\nsys.path.insert(0, os.path.abspath('.'))\nsys.path.insert(0, os.path.abspath('../'))\n\n# -- General configuration -----------------------------------------------------\n\n# If your documentation needs a minimal Sphinx version, state it here.\n#needs_sphinx = '1.0'\n\n# Add any Sphinx extension module names here, as strings. They can be extensions\n# coming with Sphinx (named 'sphinx.ext.*') or your custom ones.\nextensions = [\n 'sphinx.ext.autodoc',\n 'sphinx.ext.autosummary',\n 'sphinx.ext.coverage',\n 'sphinx.ext.graphviz',\n 'sphinx.ext.todo',\n 'sphinx.ext.viewcode',\n 'sphinxcontrib.seqdiag',\n 'sphinx_qtile',\n 'numpydoc',\n]\n\nnumpydoc_show_class_members = False\n\n# Add any paths that contain templates here, relative to this directory.\ntemplates_path = []\n\n# The suffix of source filenames.\nsource_suffix = '.rst'\n\n# The encoding of source files.\n#source_encoding = 'utf-8-sig'\n\n# The master toctree document.\nmaster_doc = 'index'\n\n# General information about the project.\nproject = u'Qtile'\ncopyright = u'2008-2019, Aldo Cortesi and contributers'\n\n# The version info for the project you're documenting, acts as replacement for\n# |version| and |release|, also used in various other places throughout the\n# built documents.\n#\n# The short X.Y version.\nversion = '0.14.2'\n# The full version, including alpha/beta/rc tags.\nrelease = version\n\n# The language for content autogenerated by Sphinx. Refer to documentation\n# for a list of supported languages.\n#language = None\n\n# There are two options for replacing |today|: either, you set today to some\n# non-false value, then it is used:\n#today = ''\n# Else, today_fmt is used as the format for a strftime call.\n#today_fmt = '%B %d, %Y'\n\n# List of patterns, relative to source directory, that match files and\n# directories to ignore when looking for source files.\nexclude_patterns = ['_build', 'man']\n\n# The reST default role (used for this markup: `text`) to use for all documents.\n#default_role = None\n\n# If true, '()' will be appended to :func: etc. cross-reference text.\n#add_function_parentheses = True\n\n# If true, the current module name will be prepended to all description\n# unit titles (such as .. function::).\n#add_module_names = True\n\n# If true, sectionauthor and moduleauthor directives will be shown in the\n# output. They are ignored by default.\n#show_authors = False\n\n# The name of the Pygments (syntax highlighting) style to use.\npygments_style = 'sphinx'\n\n# A list of ignored prefixes for module index sorting.\n#modindex_common_prefix = []\n\n# If true, `todo` and `todoList` produce output, else they produce nothing.\ntodo_include_todos = True\n\n\n# -- Options for HTML output --------fautod-------------------------------------------\n\n# The theme to use for HTML and HTML Help pages. See the documentation for\n# a list of builtin themes.\n#html_theme = 'default'\n\n# Theme options are theme-specific and customize the look and feel of a theme\n# further. For a list of options available for each theme, see the\n# documentation.\n#html_theme_options = {}\n\n# Add any paths that contain custom themes here, relative to this directory.\n#html_theme_path = []\n\n# The name for this set of Sphinx documents. If None, it defaults to\n# \"<project> v<release> documentation\".\n#html_title = None\n\n# A shorter title for the navigation bar. Default is the same as html_title.\n#html_short_title = None\n\n# The name of an image file (relative to this directory) to place at the top\n# of the sidebar.\n#html_logo = None\n\n# The name of an image file (within the static path) to use as favicon of the\n# docs. This file should be a Windows icon file (.ico) being 16x16 or 32x32\n# pixels large.\nhtml_favicon = '_static/favicon.ico'\n\n# Add any paths that contain custom static files (such as style sheets) here,\n# relative to this directory. They are copied after the builtin static files,\n# so a file named \"default.css\" will overwrite the builtin \"default.css\".\nhtml_static_path = ['_static']\n\n# If not '', a 'Last updated on:' timestamp is inserted at every page bottom,\n# using the given strftime format.\n#html_last_updated_fmt = '%b %d, %Y'\n\n# If true, SmartyPants will be used to convert quotes and dashes to\n# typographically correct entities.\n#html_use_smartypants = True\n\n# Custom sidebar templates, maps document names to template names.\n#html_sidebars = {}\n\n# Additional templates that should be rendered to pages, maps page names to\n# template names.\n#html_additional_pages = {'index': 'index.html'}\n\n# If false, no module index is generated.\n#html_domain_indices = True\n\n# If false, no index is generated.\nhtml_use_index = True\n\n# If true, the index is split into individual pages for each letter.\n#html_split_index = False\n\n# If true, links to the reST sources are added to the pages.\n#html_show_sourcelink = True\n\n# If true, \"Created using Sphinx\" is shown in the HTML footer. Default is True.\n#html_show_sphinx = True\n\n# If true, \"(C) Copyright ...\" is shown in the HTML footer. Default is True.\n#html_show_copyright = True\n\n# If true, an OpenSearch description file will be output, and all pages will\n# contain a <link> tag referring to it. The value of this option must be the\n# base URL from which the finished HTML is served.\n#html_use_opensearch = ''\n\n# This is the file name suffix for HTML files (e.g. \".xhtml\").\n#html_file_suffix = None\n\n# Output file base name for HTML help builder.\nhtmlhelp_basename = 'Qtiledoc'\n\n\n# -- Options for LaTeX output --------------------------------------------------\n\nlatex_elements = {\n# The paper size ('letterpaper' or 'a4paper').\n#'papersize': 'letterpaper',\n\n# The font size ('10pt', '11pt' or '12pt').\n#'pointsize': '10pt',\n\n# Additional stuff for the LaTeX preamble.\n#'preamble': '',\n}\n\n# Grouping the document tree into LaTeX files. List of tuples\n# (source start file, target name, title, author, documentclass [howto/manual]).\nlatex_documents = [\n ('index', 'Qtile.tex', u'Qtile Documentation',\n u'Aldo Cortesi', 'manual'),\n]\n\n# The name of an image file (relative to this directory) to place at the top of\n# the title page.\n#latex_logo = None\n\n# For \"manual\" documents, if this is true, then toplevel headings are parts,\n# not chapters.\n#latex_use_parts = False\n\n# If true, show page references after internal links.\n#latex_show_pagerefs = False\n\n# If true, show URL addresses after external links.\n#latex_show_urls = False\n\n# Documents to append as an appendix to all manuals.\n#latex_appendices = []\n\n# If false, no module index is generated.\n#latex_domain_indices = True\n\n\n# -- Options for manual page output --------------------------------------------\n\n# One entry per manual page. List of tuples\n# (source start file, name, description, authors, manual section).\nman_pages = [\n ('man/qtile', 'qtile', u'Qtile Documentation',\n [u'Tycho Andersen'], 1),\n ('man/qshell', 'qshell', u'Qtile Documentation',\n [u'Tycho Andersen'], 1),\n]\n\n# If true, show URL addresses after external links.\n#man_show_urls = False\n\n\n# -- Options for Texinfo output ------------------------------------------------\n\n# Grouping the document tree into Texinfo files. List of tuples\n# (source start file, target name, title, author,\n# dir menu entry, description, category)\ntexinfo_documents = [\n ('index', 'Qtile', u'Qtile Documentation',\n u'Aldo Cortesi', 'Qtile', 'A hackable tiling window manager.',\n 'Miscellaneous'),\n]\n\n# Documents to append as an appendix to all manuals.\n#texinfo_appendices = []\n\n# If false, no module index is generated.\n#texinfo_domain_indices = True\n\n# How to display URL addresses: 'footnote', 'no', or 'inline'.\n#texinfo_show_urls = 'footnote'\n\n# only import and set the theme if we're building docs locally\nif not os.environ.get('READTHEDOCS'):\n import sphinx_rtd_theme\n html_theme = 'sphinx_rtd_theme'\n html_theme_path = [sphinx_rtd_theme.get_html_theme_path()]\n\n\ngraphviz_dot_args = ['-Lg']\n\n# A workaround for the responsive tables always having annoying scrollbars.\ndef setup(app):\n app.add_stylesheet(\"no_scrollbars.css\")\n", "path": "docs/conf.py"}]}
| 3,885 | 77 |
gh_patches_debug_42121
|
rasdani/github-patches
|
git_diff
|
MongoEngine__mongoengine-1871
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Flaky test in test suite makes CI randomly failing due to query_counter context manager
The test `def test_no_cached_queryset(self):` Is failing from time to time which is not handy as it makes the CI failing for unrelated reasons in PRs (e.g: #1766). https://github.com/MongoEngine/mongoengine/blob/42bbe6392729ee12ee4461452ac3614814933dcd/tests/queryset/queryset.py#L4709-L4719
The issue occurs because the query_counter() context was catching queries that aren't related to this particular test.
I managed to reproduce the issue after adding some debugging code and running travis in my fork (https://travis-ci.com/bagerard/mongoengine/jobs/143421029). The additional query being counted is actually a 'killcursors' query, probably being issued after the garbage collector closes another pymongo cursors.
The query_counter context manager is very handy for debugging but since it is not only counting the queries being issued within the context (other threads or processes can pollute it), it is not very robust.
I'll push a PR that makes the query_counter context ignoring 'killcursors' queries to fix this (and add a parameter `ignore_query` to the query_counter to let users customize the behavior if needed). Let me know if you have other ideas
</issue>
<code>
[start of mongoengine/context_managers.py]
1 from contextlib import contextmanager
2 from pymongo.write_concern import WriteConcern
3 from mongoengine.common import _import_class
4 from mongoengine.connection import DEFAULT_CONNECTION_NAME, get_db
5
6
7 __all__ = ('switch_db', 'switch_collection', 'no_dereference',
8 'no_sub_classes', 'query_counter', 'set_write_concern')
9
10
11 class switch_db(object):
12 """switch_db alias context manager.
13
14 Example ::
15
16 # Register connections
17 register_connection('default', 'mongoenginetest')
18 register_connection('testdb-1', 'mongoenginetest2')
19
20 class Group(Document):
21 name = StringField()
22
23 Group(name='test').save() # Saves in the default db
24
25 with switch_db(Group, 'testdb-1') as Group:
26 Group(name='hello testdb!').save() # Saves in testdb-1
27 """
28
29 def __init__(self, cls, db_alias):
30 """Construct the switch_db context manager
31
32 :param cls: the class to change the registered db
33 :param db_alias: the name of the specific database to use
34 """
35 self.cls = cls
36 self.collection = cls._get_collection()
37 self.db_alias = db_alias
38 self.ori_db_alias = cls._meta.get('db_alias', DEFAULT_CONNECTION_NAME)
39
40 def __enter__(self):
41 """Change the db_alias and clear the cached collection."""
42 self.cls._meta['db_alias'] = self.db_alias
43 self.cls._collection = None
44 return self.cls
45
46 def __exit__(self, t, value, traceback):
47 """Reset the db_alias and collection."""
48 self.cls._meta['db_alias'] = self.ori_db_alias
49 self.cls._collection = self.collection
50
51
52 class switch_collection(object):
53 """switch_collection alias context manager.
54
55 Example ::
56
57 class Group(Document):
58 name = StringField()
59
60 Group(name='test').save() # Saves in the default db
61
62 with switch_collection(Group, 'group1') as Group:
63 Group(name='hello testdb!').save() # Saves in group1 collection
64 """
65
66 def __init__(self, cls, collection_name):
67 """Construct the switch_collection context manager.
68
69 :param cls: the class to change the registered db
70 :param collection_name: the name of the collection to use
71 """
72 self.cls = cls
73 self.ori_collection = cls._get_collection()
74 self.ori_get_collection_name = cls._get_collection_name
75 self.collection_name = collection_name
76
77 def __enter__(self):
78 """Change the _get_collection_name and clear the cached collection."""
79
80 @classmethod
81 def _get_collection_name(cls):
82 return self.collection_name
83
84 self.cls._get_collection_name = _get_collection_name
85 self.cls._collection = None
86 return self.cls
87
88 def __exit__(self, t, value, traceback):
89 """Reset the collection."""
90 self.cls._collection = self.ori_collection
91 self.cls._get_collection_name = self.ori_get_collection_name
92
93
94 class no_dereference(object):
95 """no_dereference context manager.
96
97 Turns off all dereferencing in Documents for the duration of the context
98 manager::
99
100 with no_dereference(Group) as Group:
101 Group.objects.find()
102 """
103
104 def __init__(self, cls):
105 """Construct the no_dereference context manager.
106
107 :param cls: the class to turn dereferencing off on
108 """
109 self.cls = cls
110
111 ReferenceField = _import_class('ReferenceField')
112 GenericReferenceField = _import_class('GenericReferenceField')
113 ComplexBaseField = _import_class('ComplexBaseField')
114
115 self.deref_fields = [k for k, v in self.cls._fields.iteritems()
116 if isinstance(v, (ReferenceField,
117 GenericReferenceField,
118 ComplexBaseField))]
119
120 def __enter__(self):
121 """Change the objects default and _auto_dereference values."""
122 for field in self.deref_fields:
123 self.cls._fields[field]._auto_dereference = False
124 return self.cls
125
126 def __exit__(self, t, value, traceback):
127 """Reset the default and _auto_dereference values."""
128 for field in self.deref_fields:
129 self.cls._fields[field]._auto_dereference = True
130 return self.cls
131
132
133 class no_sub_classes(object):
134 """no_sub_classes context manager.
135
136 Only returns instances of this class and no sub (inherited) classes::
137
138 with no_sub_classes(Group) as Group:
139 Group.objects.find()
140 """
141
142 def __init__(self, cls):
143 """Construct the no_sub_classes context manager.
144
145 :param cls: the class to turn querying sub classes on
146 """
147 self.cls = cls
148 self.cls_initial_subclasses = None
149
150 def __enter__(self):
151 """Change the objects default and _auto_dereference values."""
152 self.cls_initial_subclasses = self.cls._subclasses
153 self.cls._subclasses = (self.cls._class_name,)
154 return self.cls
155
156 def __exit__(self, t, value, traceback):
157 """Reset the default and _auto_dereference values."""
158 self.cls._subclasses = self.cls_initial_subclasses
159
160
161 class query_counter(object):
162 """Query_counter context manager to get the number of queries."""
163
164 def __init__(self):
165 """Construct the query_counter."""
166 self.counter = 0
167 self.db = get_db()
168
169 def __enter__(self):
170 """On every with block we need to drop the profile collection."""
171 self.db.set_profiling_level(0)
172 self.db.system.profile.drop()
173 self.db.set_profiling_level(2)
174 return self
175
176 def __exit__(self, t, value, traceback):
177 """Reset the profiling level."""
178 self.db.set_profiling_level(0)
179
180 def __eq__(self, value):
181 """== Compare querycounter."""
182 counter = self._get_count()
183 return value == counter
184
185 def __ne__(self, value):
186 """!= Compare querycounter."""
187 return not self.__eq__(value)
188
189 def __lt__(self, value):
190 """< Compare querycounter."""
191 return self._get_count() < value
192
193 def __le__(self, value):
194 """<= Compare querycounter."""
195 return self._get_count() <= value
196
197 def __gt__(self, value):
198 """> Compare querycounter."""
199 return self._get_count() > value
200
201 def __ge__(self, value):
202 """>= Compare querycounter."""
203 return self._get_count() >= value
204
205 def __int__(self):
206 """int representation."""
207 return self._get_count()
208
209 def __repr__(self):
210 """repr query_counter as the number of queries."""
211 return u"%s" % self._get_count()
212
213 def _get_count(self):
214 """Get the number of queries."""
215 ignore_query = {'ns': {'$ne': '%s.system.indexes' % self.db.name}}
216 count = self.db.system.profile.find(ignore_query).count() - self.counter
217 self.counter += 1 # Account for the query we just fired
218 return count
219
220
221 @contextmanager
222 def set_write_concern(collection, write_concerns):
223 combined_concerns = dict(collection.write_concern.document.items())
224 combined_concerns.update(write_concerns)
225 yield collection.with_options(write_concern=WriteConcern(**combined_concerns))
226
[end of mongoengine/context_managers.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/mongoengine/context_managers.py b/mongoengine/context_managers.py
--- a/mongoengine/context_managers.py
+++ b/mongoengine/context_managers.py
@@ -159,51 +159,69 @@
class query_counter(object):
- """Query_counter context manager to get the number of queries."""
+ """Query_counter context manager to get the number of queries.
+ This works by updating the `profiling_level` of the database so that all queries get logged,
+ resetting the db.system.profile collection at the beginnig of the context and counting the new entries.
+
+ This was designed for debugging purpose. In fact it is a global counter so queries issued by other threads/processes
+ can interfere with it
+
+ Be aware that:
+ - Iterating over large amount of documents (>101) makes pymongo issue `getmore` queries to fetch the next batch of
+ documents (https://docs.mongodb.com/manual/tutorial/iterate-a-cursor/#cursor-batches)
+ - Some queries are ignored by default by the counter (killcursors, db.system.indexes)
+ """
def __init__(self):
- """Construct the query_counter."""
- self.counter = 0
+ """Construct the query_counter
+ """
self.db = get_db()
-
- def __enter__(self):
- """On every with block we need to drop the profile collection."""
+ self.initial_profiling_level = None
+ self._ctx_query_counter = 0 # number of queries issued by the context
+
+ self._ignored_query = {
+ 'ns':
+ {'$ne': '%s.system.indexes' % self.db.name},
+ 'op':
+ {'$ne': 'killcursors'}
+ }
+
+ def _turn_on_profiling(self):
+ self.initial_profiling_level = self.db.profiling_level()
self.db.set_profiling_level(0)
self.db.system.profile.drop()
self.db.set_profiling_level(2)
+
+ def _resets_profiling(self):
+ self.db.set_profiling_level(self.initial_profiling_level)
+
+ def __enter__(self):
+ self._turn_on_profiling()
return self
def __exit__(self, t, value, traceback):
- """Reset the profiling level."""
- self.db.set_profiling_level(0)
+ self._resets_profiling()
def __eq__(self, value):
- """== Compare querycounter."""
counter = self._get_count()
return value == counter
def __ne__(self, value):
- """!= Compare querycounter."""
return not self.__eq__(value)
def __lt__(self, value):
- """< Compare querycounter."""
return self._get_count() < value
def __le__(self, value):
- """<= Compare querycounter."""
return self._get_count() <= value
def __gt__(self, value):
- """> Compare querycounter."""
return self._get_count() > value
def __ge__(self, value):
- """>= Compare querycounter."""
return self._get_count() >= value
def __int__(self):
- """int representation."""
return self._get_count()
def __repr__(self):
@@ -211,10 +229,12 @@
return u"%s" % self._get_count()
def _get_count(self):
- """Get the number of queries."""
- ignore_query = {'ns': {'$ne': '%s.system.indexes' % self.db.name}}
- count = self.db.system.profile.find(ignore_query).count() - self.counter
- self.counter += 1 # Account for the query we just fired
+ """Get the number of queries by counting the current number of entries in db.system.profile
+ and substracting the queries issued by this context. In fact everytime this is called, 1 query is
+ issued so we need to balance that
+ """
+ count = self.db.system.profile.find(self._ignored_query).count() - self._ctx_query_counter
+ self._ctx_query_counter += 1 # Account for the query we just issued to gather the information
return count
|
{"golden_diff": "diff --git a/mongoengine/context_managers.py b/mongoengine/context_managers.py\n--- a/mongoengine/context_managers.py\n+++ b/mongoengine/context_managers.py\n@@ -159,51 +159,69 @@\n \n \n class query_counter(object):\n- \"\"\"Query_counter context manager to get the number of queries.\"\"\"\n+ \"\"\"Query_counter context manager to get the number of queries.\n+ This works by updating the `profiling_level` of the database so that all queries get logged,\n+ resetting the db.system.profile collection at the beginnig of the context and counting the new entries.\n+\n+ This was designed for debugging purpose. In fact it is a global counter so queries issued by other threads/processes\n+ can interfere with it\n+\n+ Be aware that:\n+ - Iterating over large amount of documents (>101) makes pymongo issue `getmore` queries to fetch the next batch of\n+ documents (https://docs.mongodb.com/manual/tutorial/iterate-a-cursor/#cursor-batches)\n+ - Some queries are ignored by default by the counter (killcursors, db.system.indexes)\n+ \"\"\"\n \n def __init__(self):\n- \"\"\"Construct the query_counter.\"\"\"\n- self.counter = 0\n+ \"\"\"Construct the query_counter\n+ \"\"\"\n self.db = get_db()\n-\n- def __enter__(self):\n- \"\"\"On every with block we need to drop the profile collection.\"\"\"\n+ self.initial_profiling_level = None\n+ self._ctx_query_counter = 0 # number of queries issued by the context\n+\n+ self._ignored_query = {\n+ 'ns':\n+ {'$ne': '%s.system.indexes' % self.db.name},\n+ 'op':\n+ {'$ne': 'killcursors'}\n+ }\n+\n+ def _turn_on_profiling(self):\n+ self.initial_profiling_level = self.db.profiling_level()\n self.db.set_profiling_level(0)\n self.db.system.profile.drop()\n self.db.set_profiling_level(2)\n+\n+ def _resets_profiling(self):\n+ self.db.set_profiling_level(self.initial_profiling_level)\n+\n+ def __enter__(self):\n+ self._turn_on_profiling()\n return self\n \n def __exit__(self, t, value, traceback):\n- \"\"\"Reset the profiling level.\"\"\"\n- self.db.set_profiling_level(0)\n+ self._resets_profiling()\n \n def __eq__(self, value):\n- \"\"\"== Compare querycounter.\"\"\"\n counter = self._get_count()\n return value == counter\n \n def __ne__(self, value):\n- \"\"\"!= Compare querycounter.\"\"\"\n return not self.__eq__(value)\n \n def __lt__(self, value):\n- \"\"\"< Compare querycounter.\"\"\"\n return self._get_count() < value\n \n def __le__(self, value):\n- \"\"\"<= Compare querycounter.\"\"\"\n return self._get_count() <= value\n \n def __gt__(self, value):\n- \"\"\"> Compare querycounter.\"\"\"\n return self._get_count() > value\n \n def __ge__(self, value):\n- \"\"\">= Compare querycounter.\"\"\"\n return self._get_count() >= value\n \n def __int__(self):\n- \"\"\"int representation.\"\"\"\n return self._get_count()\n \n def __repr__(self):\n@@ -211,10 +229,12 @@\n return u\"%s\" % self._get_count()\n \n def _get_count(self):\n- \"\"\"Get the number of queries.\"\"\"\n- ignore_query = {'ns': {'$ne': '%s.system.indexes' % self.db.name}}\n- count = self.db.system.profile.find(ignore_query).count() - self.counter\n- self.counter += 1 # Account for the query we just fired\n+ \"\"\"Get the number of queries by counting the current number of entries in db.system.profile\n+ and substracting the queries issued by this context. In fact everytime this is called, 1 query is\n+ issued so we need to balance that\n+ \"\"\"\n+ count = self.db.system.profile.find(self._ignored_query).count() - self._ctx_query_counter\n+ self._ctx_query_counter += 1 # Account for the query we just issued to gather the information\n return count\n", "issue": "Flaky test in test suite makes CI randomly failing due to query_counter context manager\nThe test `def test_no_cached_queryset(self):` Is failing from time to time which is not handy as it makes the CI failing for unrelated reasons in PRs (e.g: #1766). https://github.com/MongoEngine/mongoengine/blob/42bbe6392729ee12ee4461452ac3614814933dcd/tests/queryset/queryset.py#L4709-L4719\r\n\r\nThe issue occurs because the query_counter() context was catching queries that aren't related to this particular test.\r\n\r\nI managed to reproduce the issue after adding some debugging code and running travis in my fork (https://travis-ci.com/bagerard/mongoengine/jobs/143421029). The additional query being counted is actually a 'killcursors' query, probably being issued after the garbage collector closes another pymongo cursors.\r\n\r\nThe query_counter context manager is very handy for debugging but since it is not only counting the queries being issued within the context (other threads or processes can pollute it), it is not very robust.\r\n\r\nI'll push a PR that makes the query_counter context ignoring 'killcursors' queries to fix this (and add a parameter `ignore_query` to the query_counter to let users customize the behavior if needed). Let me know if you have other ideas\n", "before_files": [{"content": "from contextlib import contextmanager\nfrom pymongo.write_concern import WriteConcern\nfrom mongoengine.common import _import_class\nfrom mongoengine.connection import DEFAULT_CONNECTION_NAME, get_db\n\n\n__all__ = ('switch_db', 'switch_collection', 'no_dereference',\n 'no_sub_classes', 'query_counter', 'set_write_concern')\n\n\nclass switch_db(object):\n \"\"\"switch_db alias context manager.\n\n Example ::\n\n # Register connections\n register_connection('default', 'mongoenginetest')\n register_connection('testdb-1', 'mongoenginetest2')\n\n class Group(Document):\n name = StringField()\n\n Group(name='test').save() # Saves in the default db\n\n with switch_db(Group, 'testdb-1') as Group:\n Group(name='hello testdb!').save() # Saves in testdb-1\n \"\"\"\n\n def __init__(self, cls, db_alias):\n \"\"\"Construct the switch_db context manager\n\n :param cls: the class to change the registered db\n :param db_alias: the name of the specific database to use\n \"\"\"\n self.cls = cls\n self.collection = cls._get_collection()\n self.db_alias = db_alias\n self.ori_db_alias = cls._meta.get('db_alias', DEFAULT_CONNECTION_NAME)\n\n def __enter__(self):\n \"\"\"Change the db_alias and clear the cached collection.\"\"\"\n self.cls._meta['db_alias'] = self.db_alias\n self.cls._collection = None\n return self.cls\n\n def __exit__(self, t, value, traceback):\n \"\"\"Reset the db_alias and collection.\"\"\"\n self.cls._meta['db_alias'] = self.ori_db_alias\n self.cls._collection = self.collection\n\n\nclass switch_collection(object):\n \"\"\"switch_collection alias context manager.\n\n Example ::\n\n class Group(Document):\n name = StringField()\n\n Group(name='test').save() # Saves in the default db\n\n with switch_collection(Group, 'group1') as Group:\n Group(name='hello testdb!').save() # Saves in group1 collection\n \"\"\"\n\n def __init__(self, cls, collection_name):\n \"\"\"Construct the switch_collection context manager.\n\n :param cls: the class to change the registered db\n :param collection_name: the name of the collection to use\n \"\"\"\n self.cls = cls\n self.ori_collection = cls._get_collection()\n self.ori_get_collection_name = cls._get_collection_name\n self.collection_name = collection_name\n\n def __enter__(self):\n \"\"\"Change the _get_collection_name and clear the cached collection.\"\"\"\n\n @classmethod\n def _get_collection_name(cls):\n return self.collection_name\n\n self.cls._get_collection_name = _get_collection_name\n self.cls._collection = None\n return self.cls\n\n def __exit__(self, t, value, traceback):\n \"\"\"Reset the collection.\"\"\"\n self.cls._collection = self.ori_collection\n self.cls._get_collection_name = self.ori_get_collection_name\n\n\nclass no_dereference(object):\n \"\"\"no_dereference context manager.\n\n Turns off all dereferencing in Documents for the duration of the context\n manager::\n\n with no_dereference(Group) as Group:\n Group.objects.find()\n \"\"\"\n\n def __init__(self, cls):\n \"\"\"Construct the no_dereference context manager.\n\n :param cls: the class to turn dereferencing off on\n \"\"\"\n self.cls = cls\n\n ReferenceField = _import_class('ReferenceField')\n GenericReferenceField = _import_class('GenericReferenceField')\n ComplexBaseField = _import_class('ComplexBaseField')\n\n self.deref_fields = [k for k, v in self.cls._fields.iteritems()\n if isinstance(v, (ReferenceField,\n GenericReferenceField,\n ComplexBaseField))]\n\n def __enter__(self):\n \"\"\"Change the objects default and _auto_dereference values.\"\"\"\n for field in self.deref_fields:\n self.cls._fields[field]._auto_dereference = False\n return self.cls\n\n def __exit__(self, t, value, traceback):\n \"\"\"Reset the default and _auto_dereference values.\"\"\"\n for field in self.deref_fields:\n self.cls._fields[field]._auto_dereference = True\n return self.cls\n\n\nclass no_sub_classes(object):\n \"\"\"no_sub_classes context manager.\n\n Only returns instances of this class and no sub (inherited) classes::\n\n with no_sub_classes(Group) as Group:\n Group.objects.find()\n \"\"\"\n\n def __init__(self, cls):\n \"\"\"Construct the no_sub_classes context manager.\n\n :param cls: the class to turn querying sub classes on\n \"\"\"\n self.cls = cls\n self.cls_initial_subclasses = None\n\n def __enter__(self):\n \"\"\"Change the objects default and _auto_dereference values.\"\"\"\n self.cls_initial_subclasses = self.cls._subclasses\n self.cls._subclasses = (self.cls._class_name,)\n return self.cls\n\n def __exit__(self, t, value, traceback):\n \"\"\"Reset the default and _auto_dereference values.\"\"\"\n self.cls._subclasses = self.cls_initial_subclasses\n\n\nclass query_counter(object):\n \"\"\"Query_counter context manager to get the number of queries.\"\"\"\n\n def __init__(self):\n \"\"\"Construct the query_counter.\"\"\"\n self.counter = 0\n self.db = get_db()\n\n def __enter__(self):\n \"\"\"On every with block we need to drop the profile collection.\"\"\"\n self.db.set_profiling_level(0)\n self.db.system.profile.drop()\n self.db.set_profiling_level(2)\n return self\n\n def __exit__(self, t, value, traceback):\n \"\"\"Reset the profiling level.\"\"\"\n self.db.set_profiling_level(0)\n\n def __eq__(self, value):\n \"\"\"== Compare querycounter.\"\"\"\n counter = self._get_count()\n return value == counter\n\n def __ne__(self, value):\n \"\"\"!= Compare querycounter.\"\"\"\n return not self.__eq__(value)\n\n def __lt__(self, value):\n \"\"\"< Compare querycounter.\"\"\"\n return self._get_count() < value\n\n def __le__(self, value):\n \"\"\"<= Compare querycounter.\"\"\"\n return self._get_count() <= value\n\n def __gt__(self, value):\n \"\"\"> Compare querycounter.\"\"\"\n return self._get_count() > value\n\n def __ge__(self, value):\n \"\"\">= Compare querycounter.\"\"\"\n return self._get_count() >= value\n\n def __int__(self):\n \"\"\"int representation.\"\"\"\n return self._get_count()\n\n def __repr__(self):\n \"\"\"repr query_counter as the number of queries.\"\"\"\n return u\"%s\" % self._get_count()\n\n def _get_count(self):\n \"\"\"Get the number of queries.\"\"\"\n ignore_query = {'ns': {'$ne': '%s.system.indexes' % self.db.name}}\n count = self.db.system.profile.find(ignore_query).count() - self.counter\n self.counter += 1 # Account for the query we just fired\n return count\n\n\n@contextmanager\ndef set_write_concern(collection, write_concerns):\n combined_concerns = dict(collection.write_concern.document.items())\n combined_concerns.update(write_concerns)\n yield collection.with_options(write_concern=WriteConcern(**combined_concerns))\n", "path": "mongoengine/context_managers.py"}]}
| 3,051 | 944 |
gh_patches_debug_25412
|
rasdani/github-patches
|
git_diff
|
keras-team__keras-18926
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Implement `binomial` and `beta` distribution functions in `keras.random`
Following up on the issue https://github.com/keras-team/keras/issues/18918
- Implement `binomial` and `beta` distribution functions in all backends currently supported by Keras namely TensorFlow, Jax, PyTorch and Numpy.
- Add unit tests for each of these functions
Importantly,
As tensorflow doesn't offer a built-in method for beta function so I've implemented a workaround using a statistical formula to use gamma distributed random variables to derive beta distributed random variable.
Specifically, $U(a, b) = X(a) / (X(a) + Y(b))$ where $U(a,b)$ is the beta distributed random variable using parameters $a$ and $b$ and $X(a)$ and $Y(b)$ are gamma-distributed random variables using parameter $a$ and $b$ respectively.
</issue>
<code>
[start of keras/backend/torch/random.py]
1 import torch
2 import torch._dynamo as dynamo
3 import torch.nn.functional as tnn
4
5 from keras.backend.config import floatx
6 from keras.backend.torch.core import convert_to_tensor
7 from keras.backend.torch.core import get_device
8 from keras.backend.torch.core import to_torch_dtype
9 from keras.random.seed_generator import SeedGenerator
10 from keras.random.seed_generator import draw_seed
11 from keras.random.seed_generator import make_default_seed
12
13
14 # torch.Generator not supported with dynamo
15 # see: https://github.com/pytorch/pytorch/issues/88576
16 @dynamo.disable()
17 def torch_seed_generator(seed):
18 first_seed, second_seed = draw_seed(seed)
19 device = get_device()
20 if device == "meta":
21 # Generator is not supported by the meta device.
22 return None
23 generator = torch.Generator(device=get_device())
24 generator.manual_seed(int(first_seed + second_seed))
25 return generator
26
27
28 def normal(shape, mean=0.0, stddev=1.0, dtype=None, seed=None):
29 dtype = dtype or floatx()
30 dtype = to_torch_dtype(dtype)
31 # Do not use generator during symbolic execution.
32 if get_device() == "meta":
33 return torch.normal(
34 mean, stddev, size=shape, dtype=dtype, device=get_device()
35 )
36 generator = torch_seed_generator(seed)
37 return torch.normal(
38 mean,
39 stddev,
40 size=shape,
41 generator=generator,
42 dtype=dtype,
43 device=get_device(),
44 )
45
46
47 def categorical(logits, num_samples, dtype="int32", seed=None):
48 logits = convert_to_tensor(logits)
49 dtype = to_torch_dtype(dtype)
50 probs = torch.softmax(logits, dim=-1)
51 # Do not use generator during symbolic execution.
52 if get_device() == "meta":
53 return torch.multinomial(
54 probs,
55 num_samples,
56 replacement=True,
57 ).type(dtype)
58 generator = torch_seed_generator(seed)
59 return torch.multinomial(
60 probs,
61 num_samples,
62 replacement=True,
63 generator=generator,
64 ).type(dtype)
65
66
67 def uniform(shape, minval=0.0, maxval=1.0, dtype=None, seed=None):
68 dtype = dtype or floatx()
69 dtype = to_torch_dtype(dtype)
70 requested_shape = shape
71 if len(requested_shape) == 0:
72 shape = (1,)
73 # Do not use generator during symbolic execution.
74 if get_device() == "meta":
75 rand_tensor = torch.rand(size=shape, dtype=dtype, device=get_device())
76 else:
77 generator = torch_seed_generator(seed)
78 rand_tensor = torch.rand(
79 size=shape, generator=generator, dtype=dtype, device=get_device()
80 )
81
82 output = (maxval - minval) * rand_tensor + minval
83
84 if len(requested_shape) == 0:
85 return output[0]
86 return output
87
88
89 def randint(shape, minval, maxval, dtype="int32", seed=None):
90 dtype = to_torch_dtype(dtype)
91 # Do not use generator during symbolic execution.
92 if get_device() == "meta":
93 return torch.randint(
94 low=minval,
95 high=maxval,
96 size=shape,
97 dtype=dtype,
98 device=get_device(),
99 )
100 generator = torch_seed_generator(seed)
101 return torch.randint(
102 low=minval,
103 high=maxval,
104 size=shape,
105 generator=generator,
106 dtype=dtype,
107 device=get_device(),
108 )
109
110
111 def truncated_normal(shape, mean=0.0, stddev=1.0, dtype=None, seed=None):
112 # Take a larger standard normal dist, discard values outside 2 * stddev
113 # Offset by mean and stddev
114 x = normal(tuple(shape) + (4,), mean=0, stddev=1, dtype=dtype, seed=seed)
115 valid = (x > -2) & (x < 2)
116 indexes = valid.max(-1, keepdim=True)[1]
117 trunc_x = torch.empty(shape, device=get_device())
118 trunc_x.data.copy_(x.gather(-1, indexes).squeeze(-1))
119 trunc_x.data.mul_(stddev).add_(mean)
120 return trunc_x
121
122
123 def _get_concrete_noise_shape(inputs, noise_shape):
124 if noise_shape is None:
125 return inputs.shape
126
127 concrete_inputs_shape = inputs.shape
128 concrete_noise_shape = []
129 for i, value in enumerate(noise_shape):
130 concrete_noise_shape.append(
131 concrete_inputs_shape[i] if value is None else value
132 )
133 return concrete_noise_shape
134
135
136 def dropout(inputs, rate, noise_shape=None, seed=None):
137 if (
138 seed is not None
139 and not (isinstance(seed, SeedGenerator) and seed._initial_seed is None)
140 or noise_shape is not None
141 ):
142 keep_prob = 1.0 - rate
143 noise_shape = _get_concrete_noise_shape(inputs, noise_shape)
144 keep_prob_matrix = torch.full(
145 noise_shape, keep_prob, device=get_device()
146 )
147 generator = torch_seed_generator(seed)
148
149 # Do not use generator during symbolic execution.
150 if get_device() == "meta":
151 mask = torch.bernoulli(keep_prob_matrix)
152 else:
153 mask = torch.bernoulli(keep_prob_matrix, generator=generator)
154
155 mask = mask.bool()
156 mask = torch.broadcast_to(mask, inputs.shape)
157 return torch.where(
158 mask,
159 inputs / keep_prob,
160 torch.zeros_like(inputs, dtype=inputs.dtype),
161 )
162 # Fast path, unseeded (since torch doesn't support seeding dropout!!!!)
163 # Using the above implementation is possible, but much slower.
164 return torch.nn.functional.dropout(
165 inputs, p=rate, training=True, inplace=False
166 )
167
168
169 def shuffle(x, axis=0, seed=None):
170 # Ref: https://github.com/pytorch/pytorch/issues/71409
171 x = convert_to_tensor(x)
172
173 # Get permutation indices
174 # Do not use generator during symbolic execution.
175 if get_device() == "meta":
176 row_perm = torch.rand(x.shape[: axis + 1], device=get_device()).argsort(
177 axis
178 )
179 else:
180 generator = torch_seed_generator(seed)
181 row_perm = torch.rand(
182 x.shape[: axis + 1], generator=generator, device=get_device()
183 ).argsort(axis)
184 for _ in range(x.ndim - axis - 1):
185 row_perm.unsqueeze_(-1)
186
187 # Reformat this for the gather operation
188 row_perm = row_perm.repeat(
189 *[1 for _ in range(axis + 1)], *(x.shape[axis + 1 :])
190 )
191 return x.gather(axis, row_perm)
192
193
194 def gamma(shape, alpha, dtype=None, seed=None):
195 dtype = dtype or floatx()
196 dtype = to_torch_dtype(dtype)
197 alpha = torch.ones(shape) * torch.tensor(alpha)
198 beta = torch.ones(shape)
199 prev_rng_state = torch.random.get_rng_state()
200 first_seed, second_seed = draw_seed(seed)
201 torch.manual_seed(first_seed + second_seed)
202 gamma_distribution = torch.distributions.gamma.Gamma(alpha, beta)
203 sample = gamma_distribution.sample().type(dtype)
204 torch.random.set_rng_state(prev_rng_state)
205 return sample
206
207
208 def binomial(shape, counts, probabilities, dtype=None, seed=None):
209 dtype = dtype or floatx()
210 dtype = to_torch_dtype(dtype)
211 counts = torch.ones(shape) * convert_to_tensor(counts)
212 probabilities = torch.ones(shape) * convert_to_tensor(probabilities)
213 prev_rng_state = torch.random.get_rng_state()
214 first_seed, second_seed = draw_seed(seed)
215 torch.manual_seed(first_seed + second_seed)
216 binomial_distribution = torch.distributions.binomial.Binomial(
217 total_count=counts, probs=probabilities
218 )
219 sample = binomial_distribution.sample().type(dtype)
220 torch.random.set_rng_state(prev_rng_state)
221 return sample
222
223
224 def beta(shape, alpha, beta, dtype=None, seed=None):
225 dtype = dtype or floatx()
226 dtype = to_torch_dtype(dtype)
227 alpha = torch.ones(shape) * convert_to_tensor(alpha)
228 beta = torch.ones(shape) * convert_to_tensor(beta)
229 prev_rng_state = torch.random.get_rng_state()
230 first_seed, second_seed = draw_seed(seed)
231 torch.manual_seed(first_seed + second_seed)
232 beta_distribution = torch.distributions.beta.Beta(
233 concentration1=alpha, concentration0=beta
234 )
235 sample = beta_distribution.sample().type(dtype)
236 torch.random.set_rng_state(prev_rng_state)
237 return sample
238
[end of keras/backend/torch/random.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/keras/backend/torch/random.py b/keras/backend/torch/random.py
--- a/keras/backend/torch/random.py
+++ b/keras/backend/torch/random.py
@@ -208,8 +208,8 @@
def binomial(shape, counts, probabilities, dtype=None, seed=None):
dtype = dtype or floatx()
dtype = to_torch_dtype(dtype)
- counts = torch.ones(shape) * convert_to_tensor(counts)
- probabilities = torch.ones(shape) * convert_to_tensor(probabilities)
+ counts = torch.broadcast_to(convert_to_tensor(counts), shape)
+ probabilities = torch.broadcast_to(convert_to_tensor(probabilities), shape)
prev_rng_state = torch.random.get_rng_state()
first_seed, second_seed = draw_seed(seed)
torch.manual_seed(first_seed + second_seed)
@@ -224,8 +224,8 @@
def beta(shape, alpha, beta, dtype=None, seed=None):
dtype = dtype or floatx()
dtype = to_torch_dtype(dtype)
- alpha = torch.ones(shape) * convert_to_tensor(alpha)
- beta = torch.ones(shape) * convert_to_tensor(beta)
+ alpha = torch.broadcast_to(convert_to_tensor(alpha), shape)
+ beta = torch.broadcast_to(convert_to_tensor(beta), shape)
prev_rng_state = torch.random.get_rng_state()
first_seed, second_seed = draw_seed(seed)
torch.manual_seed(first_seed + second_seed)
|
{"golden_diff": "diff --git a/keras/backend/torch/random.py b/keras/backend/torch/random.py\n--- a/keras/backend/torch/random.py\n+++ b/keras/backend/torch/random.py\n@@ -208,8 +208,8 @@\n def binomial(shape, counts, probabilities, dtype=None, seed=None):\n dtype = dtype or floatx()\n dtype = to_torch_dtype(dtype)\n- counts = torch.ones(shape) * convert_to_tensor(counts)\n- probabilities = torch.ones(shape) * convert_to_tensor(probabilities)\n+ counts = torch.broadcast_to(convert_to_tensor(counts), shape)\n+ probabilities = torch.broadcast_to(convert_to_tensor(probabilities), shape)\n prev_rng_state = torch.random.get_rng_state()\n first_seed, second_seed = draw_seed(seed)\n torch.manual_seed(first_seed + second_seed)\n@@ -224,8 +224,8 @@\n def beta(shape, alpha, beta, dtype=None, seed=None):\n dtype = dtype or floatx()\n dtype = to_torch_dtype(dtype)\n- alpha = torch.ones(shape) * convert_to_tensor(alpha)\n- beta = torch.ones(shape) * convert_to_tensor(beta)\n+ alpha = torch.broadcast_to(convert_to_tensor(alpha), shape)\n+ beta = torch.broadcast_to(convert_to_tensor(beta), shape)\n prev_rng_state = torch.random.get_rng_state()\n first_seed, second_seed = draw_seed(seed)\n torch.manual_seed(first_seed + second_seed)\n", "issue": "Implement `binomial` and `beta` distribution functions in `keras.random`\nFollowing up on the issue https://github.com/keras-team/keras/issues/18918\r\n\r\n- Implement `binomial` and `beta` distribution functions in all backends currently supported by Keras namely TensorFlow, Jax, PyTorch and Numpy.\r\n- Add unit tests for each of these functions\r\n\r\nImportantly,\r\nAs tensorflow doesn't offer a built-in method for beta function so I've implemented a workaround using a statistical formula to use gamma distributed random variables to derive beta distributed random variable.\r\nSpecifically, $U(a, b) = X(a) / (X(a) + Y(b))$ where $U(a,b)$ is the beta distributed random variable using parameters $a$ and $b$ and $X(a)$ and $Y(b)$ are gamma-distributed random variables using parameter $a$ and $b$ respectively.\n", "before_files": [{"content": "import torch\nimport torch._dynamo as dynamo\nimport torch.nn.functional as tnn\n\nfrom keras.backend.config import floatx\nfrom keras.backend.torch.core import convert_to_tensor\nfrom keras.backend.torch.core import get_device\nfrom keras.backend.torch.core import to_torch_dtype\nfrom keras.random.seed_generator import SeedGenerator\nfrom keras.random.seed_generator import draw_seed\nfrom keras.random.seed_generator import make_default_seed\n\n\n# torch.Generator not supported with dynamo\n# see: https://github.com/pytorch/pytorch/issues/88576\[email protected]()\ndef torch_seed_generator(seed):\n first_seed, second_seed = draw_seed(seed)\n device = get_device()\n if device == \"meta\":\n # Generator is not supported by the meta device.\n return None\n generator = torch.Generator(device=get_device())\n generator.manual_seed(int(first_seed + second_seed))\n return generator\n\n\ndef normal(shape, mean=0.0, stddev=1.0, dtype=None, seed=None):\n dtype = dtype or floatx()\n dtype = to_torch_dtype(dtype)\n # Do not use generator during symbolic execution.\n if get_device() == \"meta\":\n return torch.normal(\n mean, stddev, size=shape, dtype=dtype, device=get_device()\n )\n generator = torch_seed_generator(seed)\n return torch.normal(\n mean,\n stddev,\n size=shape,\n generator=generator,\n dtype=dtype,\n device=get_device(),\n )\n\n\ndef categorical(logits, num_samples, dtype=\"int32\", seed=None):\n logits = convert_to_tensor(logits)\n dtype = to_torch_dtype(dtype)\n probs = torch.softmax(logits, dim=-1)\n # Do not use generator during symbolic execution.\n if get_device() == \"meta\":\n return torch.multinomial(\n probs,\n num_samples,\n replacement=True,\n ).type(dtype)\n generator = torch_seed_generator(seed)\n return torch.multinomial(\n probs,\n num_samples,\n replacement=True,\n generator=generator,\n ).type(dtype)\n\n\ndef uniform(shape, minval=0.0, maxval=1.0, dtype=None, seed=None):\n dtype = dtype or floatx()\n dtype = to_torch_dtype(dtype)\n requested_shape = shape\n if len(requested_shape) == 0:\n shape = (1,)\n # Do not use generator during symbolic execution.\n if get_device() == \"meta\":\n rand_tensor = torch.rand(size=shape, dtype=dtype, device=get_device())\n else:\n generator = torch_seed_generator(seed)\n rand_tensor = torch.rand(\n size=shape, generator=generator, dtype=dtype, device=get_device()\n )\n\n output = (maxval - minval) * rand_tensor + minval\n\n if len(requested_shape) == 0:\n return output[0]\n return output\n\n\ndef randint(shape, minval, maxval, dtype=\"int32\", seed=None):\n dtype = to_torch_dtype(dtype)\n # Do not use generator during symbolic execution.\n if get_device() == \"meta\":\n return torch.randint(\n low=minval,\n high=maxval,\n size=shape,\n dtype=dtype,\n device=get_device(),\n )\n generator = torch_seed_generator(seed)\n return torch.randint(\n low=minval,\n high=maxval,\n size=shape,\n generator=generator,\n dtype=dtype,\n device=get_device(),\n )\n\n\ndef truncated_normal(shape, mean=0.0, stddev=1.0, dtype=None, seed=None):\n # Take a larger standard normal dist, discard values outside 2 * stddev\n # Offset by mean and stddev\n x = normal(tuple(shape) + (4,), mean=0, stddev=1, dtype=dtype, seed=seed)\n valid = (x > -2) & (x < 2)\n indexes = valid.max(-1, keepdim=True)[1]\n trunc_x = torch.empty(shape, device=get_device())\n trunc_x.data.copy_(x.gather(-1, indexes).squeeze(-1))\n trunc_x.data.mul_(stddev).add_(mean)\n return trunc_x\n\n\ndef _get_concrete_noise_shape(inputs, noise_shape):\n if noise_shape is None:\n return inputs.shape\n\n concrete_inputs_shape = inputs.shape\n concrete_noise_shape = []\n for i, value in enumerate(noise_shape):\n concrete_noise_shape.append(\n concrete_inputs_shape[i] if value is None else value\n )\n return concrete_noise_shape\n\n\ndef dropout(inputs, rate, noise_shape=None, seed=None):\n if (\n seed is not None\n and not (isinstance(seed, SeedGenerator) and seed._initial_seed is None)\n or noise_shape is not None\n ):\n keep_prob = 1.0 - rate\n noise_shape = _get_concrete_noise_shape(inputs, noise_shape)\n keep_prob_matrix = torch.full(\n noise_shape, keep_prob, device=get_device()\n )\n generator = torch_seed_generator(seed)\n\n # Do not use generator during symbolic execution.\n if get_device() == \"meta\":\n mask = torch.bernoulli(keep_prob_matrix)\n else:\n mask = torch.bernoulli(keep_prob_matrix, generator=generator)\n\n mask = mask.bool()\n mask = torch.broadcast_to(mask, inputs.shape)\n return torch.where(\n mask,\n inputs / keep_prob,\n torch.zeros_like(inputs, dtype=inputs.dtype),\n )\n # Fast path, unseeded (since torch doesn't support seeding dropout!!!!)\n # Using the above implementation is possible, but much slower.\n return torch.nn.functional.dropout(\n inputs, p=rate, training=True, inplace=False\n )\n\n\ndef shuffle(x, axis=0, seed=None):\n # Ref: https://github.com/pytorch/pytorch/issues/71409\n x = convert_to_tensor(x)\n\n # Get permutation indices\n # Do not use generator during symbolic execution.\n if get_device() == \"meta\":\n row_perm = torch.rand(x.shape[: axis + 1], device=get_device()).argsort(\n axis\n )\n else:\n generator = torch_seed_generator(seed)\n row_perm = torch.rand(\n x.shape[: axis + 1], generator=generator, device=get_device()\n ).argsort(axis)\n for _ in range(x.ndim - axis - 1):\n row_perm.unsqueeze_(-1)\n\n # Reformat this for the gather operation\n row_perm = row_perm.repeat(\n *[1 for _ in range(axis + 1)], *(x.shape[axis + 1 :])\n )\n return x.gather(axis, row_perm)\n\n\ndef gamma(shape, alpha, dtype=None, seed=None):\n dtype = dtype or floatx()\n dtype = to_torch_dtype(dtype)\n alpha = torch.ones(shape) * torch.tensor(alpha)\n beta = torch.ones(shape)\n prev_rng_state = torch.random.get_rng_state()\n first_seed, second_seed = draw_seed(seed)\n torch.manual_seed(first_seed + second_seed)\n gamma_distribution = torch.distributions.gamma.Gamma(alpha, beta)\n sample = gamma_distribution.sample().type(dtype)\n torch.random.set_rng_state(prev_rng_state)\n return sample\n\n\ndef binomial(shape, counts, probabilities, dtype=None, seed=None):\n dtype = dtype or floatx()\n dtype = to_torch_dtype(dtype)\n counts = torch.ones(shape) * convert_to_tensor(counts)\n probabilities = torch.ones(shape) * convert_to_tensor(probabilities)\n prev_rng_state = torch.random.get_rng_state()\n first_seed, second_seed = draw_seed(seed)\n torch.manual_seed(first_seed + second_seed)\n binomial_distribution = torch.distributions.binomial.Binomial(\n total_count=counts, probs=probabilities\n )\n sample = binomial_distribution.sample().type(dtype)\n torch.random.set_rng_state(prev_rng_state)\n return sample\n\n\ndef beta(shape, alpha, beta, dtype=None, seed=None):\n dtype = dtype or floatx()\n dtype = to_torch_dtype(dtype)\n alpha = torch.ones(shape) * convert_to_tensor(alpha)\n beta = torch.ones(shape) * convert_to_tensor(beta)\n prev_rng_state = torch.random.get_rng_state()\n first_seed, second_seed = draw_seed(seed)\n torch.manual_seed(first_seed + second_seed)\n beta_distribution = torch.distributions.beta.Beta(\n concentration1=alpha, concentration0=beta\n )\n sample = beta_distribution.sample().type(dtype)\n torch.random.set_rng_state(prev_rng_state)\n return sample\n", "path": "keras/backend/torch/random.py"}]}
| 3,193 | 315 |
gh_patches_debug_29233
|
rasdani/github-patches
|
git_diff
|
spack__spack-5268
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Spack provides wrong path for include library
I am trying to setup my own package for Spack using a very simple C++ program:
```
// in test.cpp
#include <iostream>
#include <armadillo>
using namespace std;
using namespace arma;
int main()
{
mat A = randu<mat>(4,5);
mat B = randu<mat>(4,5);
cout << A*B.t() << endl;
return 0;
}
```
The program depends on the library Armadillo. I compile the program using CMake; here is my CMakeLists.txt file:
```
project(test)
# -----------------------------------------------------------------------------
# Require CMake 2.8.
cmake_minimum_required(VERSION 2.8)
# -----------------------------------------------------------------------------
# CMake policies.
# VERSION not allowed in project() unless CMP0048 is set to NEW.
cmake_policy(SET CMP0048 NEW)
# Allow creating targets with reserved names
# or which do not match the validity pattern.
cmake_policy(SET CMP0037 OLD)
# -----------------------------------------------------------------------------
find_package(Armadillo)
if(ARMADILLO_FOUND)
list(APPEND OLIVE_DEFINITIONS "-DHAVE_ARMA")
list(APPEND OLIVE_INCLUDE_DIRS "${ARMADILLO_INCLUDE_DIRS}")
else()
MESSAGE(FATAL_ERROR "A library with Armadillo API is not found.")
endif()
# -----------------------------------------------------------------------------
find_package(BLAS REQUIRED)
find_package(LAPACK REQUIRED)
if(LAPACK_FOUND)
list(APPEND OLIVE_LIBRARIES ${LAPACK_LIBRARIES})
else()
MESSAGE(FATAL_ERROR "A library with LAPACK API is not found.")
endif()
# -----------------------------------------------------------------------------
# Preprocessor definitions.
foreach(OLIVE_DEFINITION ${OLIVE_DEFINITIONS})
add_definitions(${OLIVE_DEFINITION})
endforeach()
# Include directories.
foreach(OLIVE_INCLUDE_DIR ${OLIVE_INCLUDE_DIRS})
include_directories(${OLIVE_INCLUDE_DIR})
endforeach()
# Linker directories.
foreach(OLIVE_LIBRARY_DIR ${OLIVE_LIBRARY_DIRS})
link_directories(${OLIVE_LIBRARY_DIR})
endforeach()
# Executable.
add_executable (test test.cpp)
target_link_libraries(test ${OLIVE_LIBRARIES})
```
Then I create a package using the `spack create` command:
```
from spack import *
class Olive(CMakePackage):
homepage = "http://www.example.com"
url = "file:///home/chvillanuevap/Workspace/olive-1.0.0.tar.gz"
version('1.0.0', '4d594401468e9a7766c2c2e0f1c0c4e2')
depends_on('cmake', type='build')
depends_on('armadillo')
def cmake_args(self):
args = []
return args
```
When I run `spack install olive`, I get the following error:
```
Building CXX object CMakeFiles/test.dir/test.cpp.o
/home/chvillanuevap/Workspace/spack/lib/spack/env/gcc/g++ -DHAVE_ARMA -I/home/chvillanuevap/Workspace/spack/opt/spack/linux-ubuntu16-x86_64/gcc-5.4.0/armadillo-7.500.0-k7fwnukwvvyzgfxhyhhwwxjhaohmdmit/include -O2 -g -DNDEBUG -o CMakeFiles/test.dir/test.cpp.o -c /home/chvillanuevap/Workspace/spack/var/spack/stage/olive-1.0.0-io6llpqdxqohx457argmnsjqtq4fpmhr/olive/test.cpp
In file included from /home/chvillanuevap/Workspace/spack/opt/spack/linux-ubuntu16-x86_64/gcc-5.4.0/armadillo-7.500.0-k7fwnukwvvyzgfxhyhhwwxjhaohmdmit/include/armadillo:83:0,
from /home/chvillanuevap/Workspace/spack/var/spack/stage/olive-1.0.0-io6llpqdxqohx457argmnsjqtq4fpmhr/olive/test.cpp:2:
/home/chvillanuevap/Workspace/spack/opt/spack/linux-ubuntu16-x86_64/gcc-5.4.0/armadillo-7.500.0-k7fwnukwvvyzgfxhyhhwwxjhaohmdmit/include/armadillo_bits/include_superlu.hpp:91:53: fatal error: /home/chvillanuevap/Workspace/spack/opt/spack/1-ubuntu16-x86_64/gcc-5.4.0/superlu-5.2.1-lrqbalx6k6q6btuxmszymj7p5dal65d2/include/supermatrix.h: No such file or directory
```
Notice how the path for SuperLU (a dependency of Armadillo) says `1-ubuntu16-x86_64` for the architecture instead of the correct `linux-ubuntu16-x86_64`. Why does this happen?
</issue>
<code>
[start of var/spack/repos/builtin/packages/armadillo/package.py]
1 ##############################################################################
2 # Copyright (c) 2013-2016, Lawrence Livermore National Security, LLC.
3 # Produced at the Lawrence Livermore National Laboratory.
4 #
5 # This file is part of Spack.
6 # Created by Todd Gamblin, [email protected], All rights reserved.
7 # LLNL-CODE-647188
8 #
9 # For details, see https://github.com/llnl/spack
10 # Please also see the NOTICE and LICENSE files for our notice and the LGPL.
11 #
12 # This program is free software; you can redistribute it and/or modify
13 # it under the terms of the GNU Lesser General Public License (as
14 # published by the Free Software Foundation) version 2.1, February 1999.
15 #
16 # This program is distributed in the hope that it will be useful, but
17 # WITHOUT ANY WARRANTY; without even the IMPLIED WARRANTY OF
18 # MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the terms and
19 # conditions of the GNU Lesser General Public License for more details.
20 #
21 # You should have received a copy of the GNU Lesser General Public
22 # License along with this program; if not, write to the Free Software
23 # Foundation, Inc., 59 Temple Place, Suite 330, Boston, MA 02111-1307 USA
24 ##############################################################################
25 from spack import *
26
27
28 class Armadillo(CMakePackage):
29 """Armadillo is a high quality linear algebra library (matrix maths)
30 for the C++ language, aiming towards a good balance between speed and
31 ease of use."""
32
33 homepage = "http://arma.sourceforge.net/"
34 url = "http://sourceforge.net/projects/arma/files/armadillo-7.200.1.tar.xz"
35
36 version('7.900.1', '5ef71763bd429a3d481499878351f3be')
37 version('7.500.0', '7d316fdf3c3c7ea92b64704180ae315d')
38 version('7.200.2', 'b21585372d67a8876117fd515d8cf0a2')
39 version('7.200.1', 'ed86d6df0058979e107502e1fe3e469e')
40
41 variant('hdf5', default=False, description='Include HDF5 support')
42
43 depends_on('[email protected]:', type='build')
44 depends_on('arpack-ng') # old arpack causes undefined symbols
45 depends_on('blas')
46 depends_on('lapack')
47 depends_on('[email protected]:')
48 depends_on('hdf5', when='+hdf5')
49
50 def cmake_args(self):
51 spec = self.spec
52
53 arpack = find_libraries('libarpack', root=spec[
54 'arpack-ng'].prefix.lib, shared=True)
55 superlu = find_libraries('libsuperlu', root=spec[
56 'superlu'].prefix, shared=False, recurse=True)
57 return [
58 # ARPACK support
59 '-DARPACK_LIBRARY={0}'.format(arpack.joined()),
60 # BLAS support
61 '-DBLAS_LIBRARY={0}'.format(spec['blas'].libs.joined()),
62 # LAPACK support
63 '-DLAPACK_LIBRARY={0}'.format(spec['lapack'].libs.joined()),
64 # SuperLU support
65 '-DSuperLU_INCLUDE_DIR={0}'.format(spec['superlu'].prefix.include),
66 '-DSuperLU_LIBRARY={0}'.format(superlu.joined()),
67 # HDF5 support
68 '-DDETECT_HDF5={0}'.format('ON' if '+hdf5' in spec else 'OFF')
69 ]
70
[end of var/spack/repos/builtin/packages/armadillo/package.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/var/spack/repos/builtin/packages/armadillo/package.py b/var/spack/repos/builtin/packages/armadillo/package.py
--- a/var/spack/repos/builtin/packages/armadillo/package.py
+++ b/var/spack/repos/builtin/packages/armadillo/package.py
@@ -33,6 +33,9 @@
homepage = "http://arma.sourceforge.net/"
url = "http://sourceforge.net/projects/arma/files/armadillo-7.200.1.tar.xz"
+ version('8.100.1', 'd9762d6f097e0451d0cfadfbda295e7c')
+ version('7.950.1', 'c06eb38b12cae49cab0ce05f96147147')
+ # NOTE: v7.900.1 download url seems broken is no v7.950.1?
version('7.900.1', '5ef71763bd429a3d481499878351f3be')
version('7.500.0', '7d316fdf3c3c7ea92b64704180ae315d')
version('7.200.2', 'b21585372d67a8876117fd515d8cf0a2')
@@ -47,11 +50,17 @@
depends_on('[email protected]:')
depends_on('hdf5', when='+hdf5')
+ # Adds an `#undef linux` to prevent preprocessor expansion of include
+ # directories with `linux` in them getting transformed into a 1.
+ # E.g. `/path/linux-x86_64/dir` -> `/path/1-x86_64/dir` if/when a linux
+ # platform's compiler is adding `#define linux 1`.
+ patch('undef_linux.patch', when='platform=linux')
+
def cmake_args(self):
spec = self.spec
arpack = find_libraries('libarpack', root=spec[
- 'arpack-ng'].prefix.lib, shared=True)
+ 'arpack-ng'].prefix.lib64, shared=True)
superlu = find_libraries('libsuperlu', root=spec[
'superlu'].prefix, shared=False, recurse=True)
return [
|
{"golden_diff": "diff --git a/var/spack/repos/builtin/packages/armadillo/package.py b/var/spack/repos/builtin/packages/armadillo/package.py\n--- a/var/spack/repos/builtin/packages/armadillo/package.py\n+++ b/var/spack/repos/builtin/packages/armadillo/package.py\n@@ -33,6 +33,9 @@\n homepage = \"http://arma.sourceforge.net/\"\n url = \"http://sourceforge.net/projects/arma/files/armadillo-7.200.1.tar.xz\"\n \n+ version('8.100.1', 'd9762d6f097e0451d0cfadfbda295e7c')\n+ version('7.950.1', 'c06eb38b12cae49cab0ce05f96147147')\n+ # NOTE: v7.900.1 download url seems broken is no v7.950.1?\n version('7.900.1', '5ef71763bd429a3d481499878351f3be')\n version('7.500.0', '7d316fdf3c3c7ea92b64704180ae315d')\n version('7.200.2', 'b21585372d67a8876117fd515d8cf0a2')\n@@ -47,11 +50,17 @@\n depends_on('[email protected]:')\n depends_on('hdf5', when='+hdf5')\n \n+ # Adds an `#undef linux` to prevent preprocessor expansion of include\n+ # directories with `linux` in them getting transformed into a 1.\n+ # E.g. `/path/linux-x86_64/dir` -> `/path/1-x86_64/dir` if/when a linux\n+ # platform's compiler is adding `#define linux 1`.\n+ patch('undef_linux.patch', when='platform=linux')\n+\n def cmake_args(self):\n spec = self.spec\n \n arpack = find_libraries('libarpack', root=spec[\n- 'arpack-ng'].prefix.lib, shared=True)\n+ 'arpack-ng'].prefix.lib64, shared=True)\n superlu = find_libraries('libsuperlu', root=spec[\n 'superlu'].prefix, shared=False, recurse=True)\n return [\n", "issue": "Spack provides wrong path for include library\nI am trying to setup my own package for Spack using a very simple C++ program:\r\n\r\n```\r\n// in test.cpp\r\n#include <iostream>\r\n#include <armadillo>\r\n\r\nusing namespace std;\r\nusing namespace arma;\r\n\r\nint main()\r\n{\r\n\tmat A = randu<mat>(4,5);\r\n\tmat B = randu<mat>(4,5);\r\n\r\n\tcout << A*B.t() << endl;\r\n\r\n\treturn 0;\r\n}\r\n```\r\n\r\nThe program depends on the library Armadillo. I compile the program using CMake; here is my CMakeLists.txt file:\r\n\r\n```\r\nproject(test)\r\n\r\n# -----------------------------------------------------------------------------\r\n\r\n# Require CMake 2.8.\r\ncmake_minimum_required(VERSION 2.8)\r\n\r\n# -----------------------------------------------------------------------------\r\n# CMake policies.\r\n\r\n# VERSION not allowed in project() unless CMP0048 is set to NEW.\r\ncmake_policy(SET CMP0048 NEW)\r\n\r\n# Allow creating targets with reserved names\r\n# or which do not match the validity pattern.\r\ncmake_policy(SET CMP0037 OLD)\r\n\r\n# -----------------------------------------------------------------------------\r\n\r\nfind_package(Armadillo)\r\n\r\nif(ARMADILLO_FOUND)\r\n list(APPEND OLIVE_DEFINITIONS \"-DHAVE_ARMA\")\r\n list(APPEND OLIVE_INCLUDE_DIRS \"${ARMADILLO_INCLUDE_DIRS}\")\r\nelse()\r\n MESSAGE(FATAL_ERROR \"A library with Armadillo API is not found.\")\r\nendif()\r\n\r\n# ----------------------------------------------------------------------------- \r\n\r\nfind_package(BLAS REQUIRED)\r\n\r\nfind_package(LAPACK REQUIRED)\r\n\r\nif(LAPACK_FOUND)\r\n list(APPEND OLIVE_LIBRARIES ${LAPACK_LIBRARIES})\r\nelse()\r\n MESSAGE(FATAL_ERROR \"A library with LAPACK API is not found.\")\r\nendif()\r\n \r\n# ----------------------------------------------------------------------------- \r\n\r\n# Preprocessor definitions.\r\nforeach(OLIVE_DEFINITION ${OLIVE_DEFINITIONS})\r\n add_definitions(${OLIVE_DEFINITION})\r\nendforeach()\r\n\r\n# Include directories.\r\nforeach(OLIVE_INCLUDE_DIR ${OLIVE_INCLUDE_DIRS})\r\n include_directories(${OLIVE_INCLUDE_DIR})\r\nendforeach()\r\n\r\n# Linker directories.\r\nforeach(OLIVE_LIBRARY_DIR ${OLIVE_LIBRARY_DIRS})\r\n link_directories(${OLIVE_LIBRARY_DIR})\r\nendforeach()\r\n\r\n# Executable.\r\nadd_executable (test test.cpp)\r\ntarget_link_libraries(test ${OLIVE_LIBRARIES})\r\n```\r\n\r\nThen I create a package using the `spack create` command:\r\n\r\n```\r\nfrom spack import *\r\n\r\nclass Olive(CMakePackage):\r\n\r\n homepage = \"http://www.example.com\"\r\n url = \"file:///home/chvillanuevap/Workspace/olive-1.0.0.tar.gz\"\r\n\r\n version('1.0.0', '4d594401468e9a7766c2c2e0f1c0c4e2')\r\n\r\n depends_on('cmake', type='build')\r\n depends_on('armadillo')\r\n\r\n def cmake_args(self):\r\n args = []\r\n return args\r\n```\r\n\r\nWhen I run `spack install olive`, I get the following error:\r\n\r\n```\r\nBuilding CXX object CMakeFiles/test.dir/test.cpp.o\r\n/home/chvillanuevap/Workspace/spack/lib/spack/env/gcc/g++ -DHAVE_ARMA -I/home/chvillanuevap/Workspace/spack/opt/spack/linux-ubuntu16-x86_64/gcc-5.4.0/armadillo-7.500.0-k7fwnukwvvyzgfxhyhhwwxjhaohmdmit/include -O2 -g -DNDEBUG -o CMakeFiles/test.dir/test.cpp.o -c /home/chvillanuevap/Workspace/spack/var/spack/stage/olive-1.0.0-io6llpqdxqohx457argmnsjqtq4fpmhr/olive/test.cpp\r\nIn file included from /home/chvillanuevap/Workspace/spack/opt/spack/linux-ubuntu16-x86_64/gcc-5.4.0/armadillo-7.500.0-k7fwnukwvvyzgfxhyhhwwxjhaohmdmit/include/armadillo:83:0,\r\n from /home/chvillanuevap/Workspace/spack/var/spack/stage/olive-1.0.0-io6llpqdxqohx457argmnsjqtq4fpmhr/olive/test.cpp:2:\r\n/home/chvillanuevap/Workspace/spack/opt/spack/linux-ubuntu16-x86_64/gcc-5.4.0/armadillo-7.500.0-k7fwnukwvvyzgfxhyhhwwxjhaohmdmit/include/armadillo_bits/include_superlu.hpp:91:53: fatal error: /home/chvillanuevap/Workspace/spack/opt/spack/1-ubuntu16-x86_64/gcc-5.4.0/superlu-5.2.1-lrqbalx6k6q6btuxmszymj7p5dal65d2/include/supermatrix.h: No such file or directory\r\n```\r\n\r\nNotice how the path for SuperLU (a dependency of Armadillo) says `1-ubuntu16-x86_64` for the architecture instead of the correct `linux-ubuntu16-x86_64`. Why does this happen?\n", "before_files": [{"content": "##############################################################################\n# Copyright (c) 2013-2016, Lawrence Livermore National Security, LLC.\n# Produced at the Lawrence Livermore National Laboratory.\n#\n# This file is part of Spack.\n# Created by Todd Gamblin, [email protected], All rights reserved.\n# LLNL-CODE-647188\n#\n# For details, see https://github.com/llnl/spack\n# Please also see the NOTICE and LICENSE files for our notice and the LGPL.\n#\n# This program is free software; you can redistribute it and/or modify\n# it under the terms of the GNU Lesser General Public License (as\n# published by the Free Software Foundation) version 2.1, February 1999.\n#\n# This program is distributed in the hope that it will be useful, but\n# WITHOUT ANY WARRANTY; without even the IMPLIED WARRANTY OF\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the terms and\n# conditions of the GNU Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this program; if not, write to the Free Software\n# Foundation, Inc., 59 Temple Place, Suite 330, Boston, MA 02111-1307 USA\n##############################################################################\nfrom spack import *\n\n\nclass Armadillo(CMakePackage):\n \"\"\"Armadillo is a high quality linear algebra library (matrix maths)\n for the C++ language, aiming towards a good balance between speed and\n ease of use.\"\"\"\n\n homepage = \"http://arma.sourceforge.net/\"\n url = \"http://sourceforge.net/projects/arma/files/armadillo-7.200.1.tar.xz\"\n\n version('7.900.1', '5ef71763bd429a3d481499878351f3be')\n version('7.500.0', '7d316fdf3c3c7ea92b64704180ae315d')\n version('7.200.2', 'b21585372d67a8876117fd515d8cf0a2')\n version('7.200.1', 'ed86d6df0058979e107502e1fe3e469e')\n\n variant('hdf5', default=False, description='Include HDF5 support')\n\n depends_on('[email protected]:', type='build')\n depends_on('arpack-ng') # old arpack causes undefined symbols\n depends_on('blas')\n depends_on('lapack')\n depends_on('[email protected]:')\n depends_on('hdf5', when='+hdf5')\n\n def cmake_args(self):\n spec = self.spec\n\n arpack = find_libraries('libarpack', root=spec[\n 'arpack-ng'].prefix.lib, shared=True)\n superlu = find_libraries('libsuperlu', root=spec[\n 'superlu'].prefix, shared=False, recurse=True)\n return [\n # ARPACK support\n '-DARPACK_LIBRARY={0}'.format(arpack.joined()),\n # BLAS support\n '-DBLAS_LIBRARY={0}'.format(spec['blas'].libs.joined()),\n # LAPACK support\n '-DLAPACK_LIBRARY={0}'.format(spec['lapack'].libs.joined()),\n # SuperLU support\n '-DSuperLU_INCLUDE_DIR={0}'.format(spec['superlu'].prefix.include),\n '-DSuperLU_LIBRARY={0}'.format(superlu.joined()),\n # HDF5 support\n '-DDETECT_HDF5={0}'.format('ON' if '+hdf5' in spec else 'OFF')\n ]\n", "path": "var/spack/repos/builtin/packages/armadillo/package.py"}]}
| 2,696 | 576 |
gh_patches_debug_6538
|
rasdani/github-patches
|
git_diff
|
microsoft__torchgeo-91
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Samplers don't work in parallel
When I try to use RandomGeoSampler with `num_workers` >= 1, I get the following error:
```
Traceback (most recent call last):
File "/anaconda/envs/azureml_py38/lib/python3.9/multiprocessing/process.py", line 315, in _bootstrap
self.run()
File "/anaconda/envs/azureml_py38/lib/python3.9/multiprocessing/process.py", line 108, in run
self._target(*self._args, **self._kwargs)
File "/anaconda/envs/azureml_py38/lib/python3.9/site-packages/torch/utils/data/_utils/worker.py", line 260, in _worker_loop
r = index_queue.get(timeout=MP_STATUS_CHECK_INTERVAL)
File "/anaconda/envs/azureml_py38/lib/python3.9/multiprocessing/queues.py", line 122, in get
return _ForkingPickler.loads(res)
TypeError: __new__() missing 5 required positional arguments: 'maxx', 'miny', 'maxy', 'mint', and 'maxt'
```
</issue>
<code>
[start of torchgeo/datasets/utils.py]
1 """Common dataset utilities."""
2
3 import bz2
4 import contextlib
5 import gzip
6 import lzma
7 import os
8 import tarfile
9 import zipfile
10 from typing import Any, Dict, Iterator, List, Optional, Tuple, Union
11
12 import torch
13 from torch import Tensor
14 from torchvision.datasets.utils import check_integrity, download_url
15
16 __all__ = (
17 "check_integrity",
18 "download_url",
19 "download_and_extract_archive",
20 "extract_archive",
21 "BoundingBox",
22 "working_dir",
23 "collate_dict",
24 )
25
26
27 class _rarfile:
28 class RarFile:
29 def __init__(self, *args: Any, **kwargs: Any) -> None:
30 self.args = args
31 self.kwargs = kwargs
32
33 def __enter__(self) -> Any:
34 try:
35 import rarfile
36 except ImportError:
37 raise ImportError(
38 "rarfile is not installed and is required to extract this dataset"
39 )
40
41 # TODO: catch exception for when rarfile is installed but not
42 # unrar/unar/bsdtar
43 return rarfile.RarFile(*self.args, **self.kwargs)
44
45 def __exit__(self, exc_type: None, exc_value: None, traceback: None) -> None:
46 pass
47
48
49 def extract_archive(src: str, dst: Optional[str] = None) -> None:
50 """Extract an archive.
51
52 Args:
53 src: file to be extracted
54 dst: directory to extract to (defaults to dirname of ``src``)
55
56 Raises:
57 RuntimeError: if src file has unknown archival/compression scheme
58 """
59 if dst is None:
60 dst = os.path.dirname(src)
61
62 suffix_and_extractor: List[Tuple[Union[str, Tuple[str, ...]], Any]] = [
63 (".rar", _rarfile.RarFile),
64 (
65 (".tar", ".tar.gz", ".tar.bz2", ".tar.xz", ".tgz", ".tbz2", ".tbz", ".txz"),
66 tarfile.open,
67 ),
68 (".zip", zipfile.ZipFile),
69 ]
70
71 for suffix, extractor in suffix_and_extractor:
72 if src.endswith(suffix):
73 with extractor(src, "r") as f:
74 f.extractall(dst)
75 return
76
77 suffix_and_decompressor: List[Tuple[str, Any]] = [
78 (".bz2", bz2.open),
79 (".gz", gzip.open),
80 (".xz", lzma.open),
81 ]
82
83 for suffix, decompressor in suffix_and_decompressor:
84 if src.endswith(suffix):
85 dst = os.path.join(dst, os.path.basename(src).replace(suffix, ""))
86 with decompressor(src, "rb") as sf, open(dst, "wb") as df:
87 df.write(sf.read())
88 return
89
90 raise RuntimeError("src file has unknown archival/compression scheme")
91
92
93 def download_and_extract_archive(
94 url: str,
95 download_root: str,
96 extract_root: Optional[str] = None,
97 filename: Optional[str] = None,
98 md5: Optional[str] = None,
99 ) -> None:
100 """Download and extract an archive.
101
102 Args:
103 url: URL to download
104 download_root: directory to download to
105 extract_root: directory to extract to (defaults to ``download_root``)
106 filename: download filename (defaults to basename of ``url``)
107 md5: checksum for download verification
108 """
109 download_root = os.path.expanduser(download_root)
110 if extract_root is None:
111 extract_root = download_root
112 if not filename:
113 filename = os.path.basename(url)
114
115 download_url(url, download_root, filename, md5)
116
117 archive = os.path.join(download_root, filename)
118 print("Extracting {} to {}".format(archive, extract_root))
119 extract_archive(archive, extract_root)
120
121
122 def download_radiant_mlhub(
123 dataset_id: str, download_root: str, api_key: Optional[str] = None
124 ) -> None:
125 """Download a dataset from Radiant Earth.
126
127 Args:
128 dataset_id: the ID of the dataset to fetch
129 download_root: directory to download to
130 api_key: the API key to use for all requests from the session. Can also be
131 passed in via the ``MLHUB_API_KEY`` environment variable, or configured in
132 ``~/.mlhub/profiles``.
133 """
134 try:
135 import radiant_mlhub
136 except ImportError:
137 raise ImportError(
138 "radiant_mlhub is not installed and is required to download this dataset"
139 )
140
141 dataset = radiant_mlhub.Dataset.fetch(dataset_id, api_key=api_key)
142 dataset.download(output_dir=download_root, api_key=api_key)
143
144
145 class BoundingBox(Tuple[float, float, float, float, float, float]):
146 """Data class for indexing spatiotemporal data.
147
148 Attributes:
149 minx (float): western boundary
150 maxx (float): eastern boundary
151 miny (float): southern boundary
152 maxy (float): northern boundary
153 mint (float): earliest boundary
154 maxt (float): latest boundary
155 """
156
157 def __new__(
158 cls,
159 minx: float,
160 maxx: float,
161 miny: float,
162 maxy: float,
163 mint: float,
164 maxt: float,
165 ) -> "BoundingBox":
166 """Create a new instance of BoundingBox.
167
168 Args:
169 minx: western boundary
170 maxx: eastern boundary
171 miny: southern boundary
172 maxy: northern boundary
173 mint: earliest boundary
174 maxt: latest boundary
175
176 Raises:
177 ValueError: if bounding box is invalid
178 (minx > maxx, miny > maxy, or mint > maxt)
179 """
180 if minx > maxx:
181 raise ValueError(f"Bounding box is invalid: 'minx={minx}' > 'maxx={maxx}'")
182 if miny > maxy:
183 raise ValueError(f"Bounding box is invalid: 'miny={miny}' > 'maxy={maxy}'")
184 if mint > maxt:
185 raise ValueError(f"Bounding box is invalid: 'mint={mint}' > 'maxt={maxt}'")
186
187 # Using super() doesn't work with mypy, see:
188 # https://stackoverflow.com/q/60611012/5828163
189 return tuple.__new__(cls, [minx, maxx, miny, maxy, mint, maxt])
190
191 def __init__(
192 self,
193 minx: float,
194 maxx: float,
195 miny: float,
196 maxy: float,
197 mint: float,
198 maxt: float,
199 ) -> None:
200 """Initialize a new instance of BoundingBox.
201
202 Args:
203 minx: western boundary
204 maxx: eastern boundary
205 miny: southern boundary
206 maxy: northern boundary
207 mint: earliest boundary
208 maxt: latest boundary
209 """
210 self.minx = minx
211 self.maxx = maxx
212 self.miny = miny
213 self.maxy = maxy
214 self.mint = mint
215 self.maxt = maxt
216
217 def __repr__(self) -> str:
218 """Return the formal string representation of the object.
219
220 Returns:
221 formal string representation
222 """
223 return (
224 f"{self.__class__.__name__}(minx={self.minx}, maxx={self.maxx}, "
225 f"miny={self.miny}, maxy={self.maxy}, mint={self.mint}, maxt={self.maxt})"
226 )
227
228 def intersects(self, other: "BoundingBox") -> bool:
229 """Whether or not two bounding boxes intersect.
230
231 Args:
232 other: another bounding box
233
234 Returns:
235 True if bounding boxes intersect, else False
236 """
237 return (
238 self.minx <= other.maxx
239 and self.maxx >= other.minx
240 and self.miny <= other.maxy
241 and self.maxy >= other.miny
242 and self.mint <= other.maxt
243 and self.maxt >= other.mint
244 )
245
246
247 @contextlib.contextmanager
248 def working_dir(dirname: str, create: bool = False) -> Iterator[None]:
249 """Context manager for changing directories.
250
251 Args:
252 dirname: directory to temporarily change to
253 create: if True, create the destination directory
254 """
255 if create:
256 os.makedirs(dirname, exist_ok=True)
257
258 cwd = os.getcwd()
259 os.chdir(dirname)
260
261 try:
262 yield
263 finally:
264 os.chdir(cwd)
265
266
267 def collate_dict(samples: List[Dict[str, Any]]) -> Dict[str, Any]:
268 """Merge a list of samples to form a mini-batch of Tensors.
269
270 Args:
271 samples: list of samples
272
273 Returns:
274 a single sample
275 """
276 collated = {}
277 for key, value in samples[0].items():
278 if isinstance(value, Tensor):
279 collated[key] = torch.stack([sample[key] for sample in samples])
280 else:
281 collated[key] = [
282 sample[key] for sample in samples
283 ] # type: ignore[assignment]
284 return collated
285
[end of torchgeo/datasets/utils.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/torchgeo/datasets/utils.py b/torchgeo/datasets/utils.py
--- a/torchgeo/datasets/utils.py
+++ b/torchgeo/datasets/utils.py
@@ -214,6 +214,14 @@
self.mint = mint
self.maxt = maxt
+ def __getnewargs__(self) -> Tuple[float, float, float, float, float, float]:
+ """Values passed to the ``__new__()`` method upon unpickling.
+
+ Returns:
+ tuple of bounds
+ """
+ return self.minx, self.maxx, self.miny, self.maxy, self.mint, self.maxt
+
def __repr__(self) -> str:
"""Return the formal string representation of the object.
|
{"golden_diff": "diff --git a/torchgeo/datasets/utils.py b/torchgeo/datasets/utils.py\n--- a/torchgeo/datasets/utils.py\n+++ b/torchgeo/datasets/utils.py\n@@ -214,6 +214,14 @@\n self.mint = mint\n self.maxt = maxt\n \n+ def __getnewargs__(self) -> Tuple[float, float, float, float, float, float]:\n+ \"\"\"Values passed to the ``__new__()`` method upon unpickling.\n+\n+ Returns:\n+ tuple of bounds\n+ \"\"\"\n+ return self.minx, self.maxx, self.miny, self.maxy, self.mint, self.maxt\n+\n def __repr__(self) -> str:\n \"\"\"Return the formal string representation of the object.\n", "issue": "Samplers don't work in parallel\nWhen I try to use RandomGeoSampler with `num_workers` >= 1, I get the following error:\r\n```\r\nTraceback (most recent call last):\r\n File \"/anaconda/envs/azureml_py38/lib/python3.9/multiprocessing/process.py\", line 315, in _bootstrap\r\n self.run()\r\n File \"/anaconda/envs/azureml_py38/lib/python3.9/multiprocessing/process.py\", line 108, in run\r\n self._target(*self._args, **self._kwargs)\r\n File \"/anaconda/envs/azureml_py38/lib/python3.9/site-packages/torch/utils/data/_utils/worker.py\", line 260, in _worker_loop\r\n r = index_queue.get(timeout=MP_STATUS_CHECK_INTERVAL)\r\n File \"/anaconda/envs/azureml_py38/lib/python3.9/multiprocessing/queues.py\", line 122, in get\r\n return _ForkingPickler.loads(res)\r\nTypeError: __new__() missing 5 required positional arguments: 'maxx', 'miny', 'maxy', 'mint', and 'maxt'\r\n```\n", "before_files": [{"content": "\"\"\"Common dataset utilities.\"\"\"\n\nimport bz2\nimport contextlib\nimport gzip\nimport lzma\nimport os\nimport tarfile\nimport zipfile\nfrom typing import Any, Dict, Iterator, List, Optional, Tuple, Union\n\nimport torch\nfrom torch import Tensor\nfrom torchvision.datasets.utils import check_integrity, download_url\n\n__all__ = (\n \"check_integrity\",\n \"download_url\",\n \"download_and_extract_archive\",\n \"extract_archive\",\n \"BoundingBox\",\n \"working_dir\",\n \"collate_dict\",\n)\n\n\nclass _rarfile:\n class RarFile:\n def __init__(self, *args: Any, **kwargs: Any) -> None:\n self.args = args\n self.kwargs = kwargs\n\n def __enter__(self) -> Any:\n try:\n import rarfile\n except ImportError:\n raise ImportError(\n \"rarfile is not installed and is required to extract this dataset\"\n )\n\n # TODO: catch exception for when rarfile is installed but not\n # unrar/unar/bsdtar\n return rarfile.RarFile(*self.args, **self.kwargs)\n\n def __exit__(self, exc_type: None, exc_value: None, traceback: None) -> None:\n pass\n\n\ndef extract_archive(src: str, dst: Optional[str] = None) -> None:\n \"\"\"Extract an archive.\n\n Args:\n src: file to be extracted\n dst: directory to extract to (defaults to dirname of ``src``)\n\n Raises:\n RuntimeError: if src file has unknown archival/compression scheme\n \"\"\"\n if dst is None:\n dst = os.path.dirname(src)\n\n suffix_and_extractor: List[Tuple[Union[str, Tuple[str, ...]], Any]] = [\n (\".rar\", _rarfile.RarFile),\n (\n (\".tar\", \".tar.gz\", \".tar.bz2\", \".tar.xz\", \".tgz\", \".tbz2\", \".tbz\", \".txz\"),\n tarfile.open,\n ),\n (\".zip\", zipfile.ZipFile),\n ]\n\n for suffix, extractor in suffix_and_extractor:\n if src.endswith(suffix):\n with extractor(src, \"r\") as f:\n f.extractall(dst)\n return\n\n suffix_and_decompressor: List[Tuple[str, Any]] = [\n (\".bz2\", bz2.open),\n (\".gz\", gzip.open),\n (\".xz\", lzma.open),\n ]\n\n for suffix, decompressor in suffix_and_decompressor:\n if src.endswith(suffix):\n dst = os.path.join(dst, os.path.basename(src).replace(suffix, \"\"))\n with decompressor(src, \"rb\") as sf, open(dst, \"wb\") as df:\n df.write(sf.read())\n return\n\n raise RuntimeError(\"src file has unknown archival/compression scheme\")\n\n\ndef download_and_extract_archive(\n url: str,\n download_root: str,\n extract_root: Optional[str] = None,\n filename: Optional[str] = None,\n md5: Optional[str] = None,\n) -> None:\n \"\"\"Download and extract an archive.\n\n Args:\n url: URL to download\n download_root: directory to download to\n extract_root: directory to extract to (defaults to ``download_root``)\n filename: download filename (defaults to basename of ``url``)\n md5: checksum for download verification\n \"\"\"\n download_root = os.path.expanduser(download_root)\n if extract_root is None:\n extract_root = download_root\n if not filename:\n filename = os.path.basename(url)\n\n download_url(url, download_root, filename, md5)\n\n archive = os.path.join(download_root, filename)\n print(\"Extracting {} to {}\".format(archive, extract_root))\n extract_archive(archive, extract_root)\n\n\ndef download_radiant_mlhub(\n dataset_id: str, download_root: str, api_key: Optional[str] = None\n) -> None:\n \"\"\"Download a dataset from Radiant Earth.\n\n Args:\n dataset_id: the ID of the dataset to fetch\n download_root: directory to download to\n api_key: the API key to use for all requests from the session. Can also be\n passed in via the ``MLHUB_API_KEY`` environment variable, or configured in\n ``~/.mlhub/profiles``.\n \"\"\"\n try:\n import radiant_mlhub\n except ImportError:\n raise ImportError(\n \"radiant_mlhub is not installed and is required to download this dataset\"\n )\n\n dataset = radiant_mlhub.Dataset.fetch(dataset_id, api_key=api_key)\n dataset.download(output_dir=download_root, api_key=api_key)\n\n\nclass BoundingBox(Tuple[float, float, float, float, float, float]):\n \"\"\"Data class for indexing spatiotemporal data.\n\n Attributes:\n minx (float): western boundary\n maxx (float): eastern boundary\n miny (float): southern boundary\n maxy (float): northern boundary\n mint (float): earliest boundary\n maxt (float): latest boundary\n \"\"\"\n\n def __new__(\n cls,\n minx: float,\n maxx: float,\n miny: float,\n maxy: float,\n mint: float,\n maxt: float,\n ) -> \"BoundingBox\":\n \"\"\"Create a new instance of BoundingBox.\n\n Args:\n minx: western boundary\n maxx: eastern boundary\n miny: southern boundary\n maxy: northern boundary\n mint: earliest boundary\n maxt: latest boundary\n\n Raises:\n ValueError: if bounding box is invalid\n (minx > maxx, miny > maxy, or mint > maxt)\n \"\"\"\n if minx > maxx:\n raise ValueError(f\"Bounding box is invalid: 'minx={minx}' > 'maxx={maxx}'\")\n if miny > maxy:\n raise ValueError(f\"Bounding box is invalid: 'miny={miny}' > 'maxy={maxy}'\")\n if mint > maxt:\n raise ValueError(f\"Bounding box is invalid: 'mint={mint}' > 'maxt={maxt}'\")\n\n # Using super() doesn't work with mypy, see:\n # https://stackoverflow.com/q/60611012/5828163\n return tuple.__new__(cls, [minx, maxx, miny, maxy, mint, maxt])\n\n def __init__(\n self,\n minx: float,\n maxx: float,\n miny: float,\n maxy: float,\n mint: float,\n maxt: float,\n ) -> None:\n \"\"\"Initialize a new instance of BoundingBox.\n\n Args:\n minx: western boundary\n maxx: eastern boundary\n miny: southern boundary\n maxy: northern boundary\n mint: earliest boundary\n maxt: latest boundary\n \"\"\"\n self.minx = minx\n self.maxx = maxx\n self.miny = miny\n self.maxy = maxy\n self.mint = mint\n self.maxt = maxt\n\n def __repr__(self) -> str:\n \"\"\"Return the formal string representation of the object.\n\n Returns:\n formal string representation\n \"\"\"\n return (\n f\"{self.__class__.__name__}(minx={self.minx}, maxx={self.maxx}, \"\n f\"miny={self.miny}, maxy={self.maxy}, mint={self.mint}, maxt={self.maxt})\"\n )\n\n def intersects(self, other: \"BoundingBox\") -> bool:\n \"\"\"Whether or not two bounding boxes intersect.\n\n Args:\n other: another bounding box\n\n Returns:\n True if bounding boxes intersect, else False\n \"\"\"\n return (\n self.minx <= other.maxx\n and self.maxx >= other.minx\n and self.miny <= other.maxy\n and self.maxy >= other.miny\n and self.mint <= other.maxt\n and self.maxt >= other.mint\n )\n\n\[email protected]\ndef working_dir(dirname: str, create: bool = False) -> Iterator[None]:\n \"\"\"Context manager for changing directories.\n\n Args:\n dirname: directory to temporarily change to\n create: if True, create the destination directory\n \"\"\"\n if create:\n os.makedirs(dirname, exist_ok=True)\n\n cwd = os.getcwd()\n os.chdir(dirname)\n\n try:\n yield\n finally:\n os.chdir(cwd)\n\n\ndef collate_dict(samples: List[Dict[str, Any]]) -> Dict[str, Any]:\n \"\"\"Merge a list of samples to form a mini-batch of Tensors.\n\n Args:\n samples: list of samples\n\n Returns:\n a single sample\n \"\"\"\n collated = {}\n for key, value in samples[0].items():\n if isinstance(value, Tensor):\n collated[key] = torch.stack([sample[key] for sample in samples])\n else:\n collated[key] = [\n sample[key] for sample in samples\n ] # type: ignore[assignment]\n return collated\n", "path": "torchgeo/datasets/utils.py"}]}
| 3,537 | 175 |
gh_patches_debug_5688
|
rasdani/github-patches
|
git_diff
|
facebookresearch__CompilerGym-735
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Running autotuning fails with `Primary config directory not found.`
## 🐛 Bug
When I tried running the auto tuning script, I get an error saying `Primary config directory not found`. See details below.
## To Reproduce
Steps to reproduce the behavior:
1. Run `make install` from base directory to install from source
2. Run `python setup.py install` from `examples/` to install scripts.
3. Run the following command to run the script
```
HYDRA_FULL_ERROR=1 python -m llvm_autotuning.tune -m \
experiment=my-exp \
outputs=/tmp/logs \
executor.cpus=32 \
num_replicas=1 \
autotuner=nevergrad \
autotuner.optimization_target=runtime \
autotuner.search_time_seconds=600
```
The full error message is:
```
Traceback (most recent call last):
File "/Users/qingweilan/miniconda3/envs/compiler_gym/lib/python3.8/runpy.py", line 194, in _run_module_as_main
return _run_code(code, main_globals, None,
File "/Users/qingweilan/miniconda3/envs/compiler_gym/lib/python3.8/runpy.py", line 87, in _run_code
exec(code, run_globals)
File "/Users/qingweilan/miniconda3/envs/compiler_gym/lib/python3.8/site-packages/compiler_gym_examples-0.2.4-py3.8.egg/llvm_autotuning/tune.py", line 37, in <module>
main()
File "/Users/qingweilan/miniconda3/envs/compiler_gym/lib/python3.8/site-packages/hydra/main.py", line 49, in decorated_main
_run_hydra(
File "/Users/qingweilan/miniconda3/envs/compiler_gym/lib/python3.8/site-packages/hydra/_internal/utils.py", line 375, in _run_hydra
run_and_report(
File "/Users/qingweilan/miniconda3/envs/compiler_gym/lib/python3.8/site-packages/hydra/_internal/utils.py", line 214, in run_and_report
raise ex
File "/Users/qingweilan/miniconda3/envs/compiler_gym/lib/python3.8/site-packages/hydra/_internal/utils.py", line 211, in run_and_report
return func()
File "/Users/qingweilan/miniconda3/envs/compiler_gym/lib/python3.8/site-packages/hydra/_internal/utils.py", line 376, in <lambda>
lambda: hydra.multirun(
File "/Users/qingweilan/miniconda3/envs/compiler_gym/lib/python3.8/site-packages/hydra/_internal/hydra.py", line 121, in multirun
cfg = self.compose_config(
File "/Users/qingweilan/miniconda3/envs/compiler_gym/lib/python3.8/site-packages/hydra/_internal/hydra.py", line 564, in compose_config
cfg = self.config_loader.load_configuration(
File "/Users/qingweilan/miniconda3/envs/compiler_gym/lib/python3.8/site-packages/hydra/_internal/config_loader_impl.py", line 146, in load_configuration
return self._load_configuration_impl(
File "/Users/qingweilan/miniconda3/envs/compiler_gym/lib/python3.8/site-packages/hydra/_internal/config_loader_impl.py", line 227, in _load_configuration_impl
self.ensure_main_config_source_available()
File "/Users/qingweilan/miniconda3/envs/compiler_gym/lib/python3.8/site-packages/hydra/_internal/config_loader_impl.py", line 134, in ensure_main_config_source_available
self._missing_config_error(
File "/Users/qingweilan/miniconda3/envs/compiler_gym/lib/python3.8/site-packages/hydra/_internal/config_loader_impl.py", line 108, in _missing_config_error
raise MissingConfigException(
hydra.errors.MissingConfigException: Primary config directory not found.
Check that the config directory '/Users/qingweilan/miniconda3/envs/compiler_gym/lib/python3.8/site-packages/compiler_gym_examples-0.2.4-py3.8.egg/llvm_autotuning/config' exists and readable
```
## Expected behavior
The script shouldn't fail.
## Environment
Please fill in this checklist:
- CompilerGym: latest development branch
- How you installed CompilerGym (pip, source): source
- OS: MacOS
- Python version: 3.7
- Build command you used (if compiling from source): make install
- GCC/clang version (if compiling from source):
- Versions of any other relevant libraries:
You may use the
[environment collection script](https://raw.githubusercontent.com/facebookresearch/CompilerGym/stable/build_tools/collect_env.py)
to generate most of this information. You can get the script and run it with:
```sh
wget https://raw.githubusercontent.com/facebookresearch/CompilerGym/stable/build_tools/collect_env.py
# For security purposes, please check the contents of collect_env.py before running it.
python collect_env.py
```
</issue>
<code>
[start of examples/setup.py]
1 #!/usr/bin/env python3
2 #
3 # Copyright (c) Facebook, Inc. and its affiliates.
4 #
5 # This source code is licensed under the MIT license found in the
6 # LICENSE file in the root directory of this source tree.
7
8 import distutils.util
9
10 import setuptools
11
12 with open("../VERSION") as f:
13 version = f.read().strip()
14 with open("requirements.txt") as f:
15 requirements = [ln.split("#")[0].rstrip() for ln in f.readlines()]
16 with open("../tests/requirements.txt") as f:
17 requirements += [ln.split("#")[0].rstrip() for ln in f.readlines()]
18
19 setuptools.setup(
20 name="compiler_gym_examples",
21 version=version,
22 description="Example code for CompilerGym",
23 author="Facebook AI Research",
24 url="https://github.com/facebookresearch/CompilerGym",
25 license="MIT",
26 install_requires=requirements,
27 packages=[
28 "llvm_autotuning",
29 "llvm_autotuning.autotuners",
30 "llvm_rl",
31 "llvm_rl.model",
32 ],
33 package_data={
34 "llvm_rl": [
35 "config/*.yaml",
36 "config/**/*.yaml",
37 ]
38 },
39 python_requires=">=3.8",
40 platforms=[distutils.util.get_platform()],
41 zip_safe=False,
42 )
43
[end of examples/setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/examples/setup.py b/examples/setup.py
--- a/examples/setup.py
+++ b/examples/setup.py
@@ -31,10 +31,14 @@
"llvm_rl.model",
],
package_data={
+ "llvm_autotuning": [
+ "config/*.yaml",
+ "config/**/*.yaml",
+ ],
"llvm_rl": [
"config/*.yaml",
"config/**/*.yaml",
- ]
+ ],
},
python_requires=">=3.8",
platforms=[distutils.util.get_platform()],
|
{"golden_diff": "diff --git a/examples/setup.py b/examples/setup.py\n--- a/examples/setup.py\n+++ b/examples/setup.py\n@@ -31,10 +31,14 @@\n \"llvm_rl.model\",\n ],\n package_data={\n+ \"llvm_autotuning\": [\n+ \"config/*.yaml\",\n+ \"config/**/*.yaml\",\n+ ],\n \"llvm_rl\": [\n \"config/*.yaml\",\n \"config/**/*.yaml\",\n- ]\n+ ],\n },\n python_requires=\">=3.8\",\n platforms=[distutils.util.get_platform()],\n", "issue": "Running autotuning fails with `Primary config directory not found.`\n## \ud83d\udc1b Bug\r\n\r\nWhen I tried running the auto tuning script, I get an error saying `Primary config directory not found`. See details below.\r\n\r\n## To Reproduce\r\n\r\nSteps to reproduce the behavior:\r\n\r\n1. Run `make install` from base directory to install from source\r\n2. Run `python setup.py install` from `examples/` to install scripts.\r\n3. Run the following command to run the script\r\n\r\n```\r\nHYDRA_FULL_ERROR=1 python -m llvm_autotuning.tune -m \\\r\n experiment=my-exp \\\r\n outputs=/tmp/logs \\\r\n executor.cpus=32 \\\r\n num_replicas=1 \\\r\n autotuner=nevergrad \\\r\n autotuner.optimization_target=runtime \\ \r\n autotuner.search_time_seconds=600\r\n```\r\n\r\nThe full error message is:\r\n\r\n```\r\nTraceback (most recent call last):\r\n File \"/Users/qingweilan/miniconda3/envs/compiler_gym/lib/python3.8/runpy.py\", line 194, in _run_module_as_main\r\n return _run_code(code, main_globals, None,\r\n File \"/Users/qingweilan/miniconda3/envs/compiler_gym/lib/python3.8/runpy.py\", line 87, in _run_code\r\n exec(code, run_globals)\r\n File \"/Users/qingweilan/miniconda3/envs/compiler_gym/lib/python3.8/site-packages/compiler_gym_examples-0.2.4-py3.8.egg/llvm_autotuning/tune.py\", line 37, in <module>\r\n main()\r\n File \"/Users/qingweilan/miniconda3/envs/compiler_gym/lib/python3.8/site-packages/hydra/main.py\", line 49, in decorated_main\r\n _run_hydra(\r\n File \"/Users/qingweilan/miniconda3/envs/compiler_gym/lib/python3.8/site-packages/hydra/_internal/utils.py\", line 375, in _run_hydra\r\n run_and_report(\r\n File \"/Users/qingweilan/miniconda3/envs/compiler_gym/lib/python3.8/site-packages/hydra/_internal/utils.py\", line 214, in run_and_report\r\n raise ex\r\n File \"/Users/qingweilan/miniconda3/envs/compiler_gym/lib/python3.8/site-packages/hydra/_internal/utils.py\", line 211, in run_and_report\r\n return func()\r\n File \"/Users/qingweilan/miniconda3/envs/compiler_gym/lib/python3.8/site-packages/hydra/_internal/utils.py\", line 376, in <lambda>\r\n lambda: hydra.multirun(\r\n File \"/Users/qingweilan/miniconda3/envs/compiler_gym/lib/python3.8/site-packages/hydra/_internal/hydra.py\", line 121, in multirun\r\n cfg = self.compose_config(\r\n File \"/Users/qingweilan/miniconda3/envs/compiler_gym/lib/python3.8/site-packages/hydra/_internal/hydra.py\", line 564, in compose_config\r\n cfg = self.config_loader.load_configuration(\r\n File \"/Users/qingweilan/miniconda3/envs/compiler_gym/lib/python3.8/site-packages/hydra/_internal/config_loader_impl.py\", line 146, in load_configuration\r\n return self._load_configuration_impl(\r\n File \"/Users/qingweilan/miniconda3/envs/compiler_gym/lib/python3.8/site-packages/hydra/_internal/config_loader_impl.py\", line 227, in _load_configuration_impl\r\n self.ensure_main_config_source_available()\r\n File \"/Users/qingweilan/miniconda3/envs/compiler_gym/lib/python3.8/site-packages/hydra/_internal/config_loader_impl.py\", line 134, in ensure_main_config_source_available\r\n self._missing_config_error(\r\n File \"/Users/qingweilan/miniconda3/envs/compiler_gym/lib/python3.8/site-packages/hydra/_internal/config_loader_impl.py\", line 108, in _missing_config_error\r\n raise MissingConfigException(\r\nhydra.errors.MissingConfigException: Primary config directory not found.\r\nCheck that the config directory '/Users/qingweilan/miniconda3/envs/compiler_gym/lib/python3.8/site-packages/compiler_gym_examples-0.2.4-py3.8.egg/llvm_autotuning/config' exists and readable\r\n```\r\n\r\n## Expected behavior\r\n\r\nThe script shouldn't fail.\r\n\r\n## Environment\r\n\r\nPlease fill in this checklist:\r\n\r\n- CompilerGym: latest development branch\r\n- How you installed CompilerGym (pip, source): source\r\n- OS: MacOS\r\n- Python version: 3.7\r\n- Build command you used (if compiling from source): make install\r\n- GCC/clang version (if compiling from source):\r\n- Versions of any other relevant libraries:\r\n\r\nYou may use the\r\n[environment collection script](https://raw.githubusercontent.com/facebookresearch/CompilerGym/stable/build_tools/collect_env.py)\r\nto generate most of this information. You can get the script and run it with:\r\n\r\n```sh\r\nwget https://raw.githubusercontent.com/facebookresearch/CompilerGym/stable/build_tools/collect_env.py\r\n# For security purposes, please check the contents of collect_env.py before running it.\r\npython collect_env.py\r\n```\r\n\n", "before_files": [{"content": "#!/usr/bin/env python3\n#\n# Copyright (c) Facebook, Inc. and its affiliates.\n#\n# This source code is licensed under the MIT license found in the\n# LICENSE file in the root directory of this source tree.\n\nimport distutils.util\n\nimport setuptools\n\nwith open(\"../VERSION\") as f:\n version = f.read().strip()\nwith open(\"requirements.txt\") as f:\n requirements = [ln.split(\"#\")[0].rstrip() for ln in f.readlines()]\nwith open(\"../tests/requirements.txt\") as f:\n requirements += [ln.split(\"#\")[0].rstrip() for ln in f.readlines()]\n\nsetuptools.setup(\n name=\"compiler_gym_examples\",\n version=version,\n description=\"Example code for CompilerGym\",\n author=\"Facebook AI Research\",\n url=\"https://github.com/facebookresearch/CompilerGym\",\n license=\"MIT\",\n install_requires=requirements,\n packages=[\n \"llvm_autotuning\",\n \"llvm_autotuning.autotuners\",\n \"llvm_rl\",\n \"llvm_rl.model\",\n ],\n package_data={\n \"llvm_rl\": [\n \"config/*.yaml\",\n \"config/**/*.yaml\",\n ]\n },\n python_requires=\">=3.8\",\n platforms=[distutils.util.get_platform()],\n zip_safe=False,\n)\n", "path": "examples/setup.py"}]}
| 2,049 | 120 |
gh_patches_debug_16686
|
rasdani/github-patches
|
git_diff
|
open-mmlab__mmcv-1138
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
SyncBatchNorm breaks after PyTorch 1.9.0
**Describe the Issue**
`torch.nn.SyncBatchNorm` has been updated since PyTorch 1.9.0 and `_specify_ddp_gpu_num()` is no longer available, breaking the following code snippet: https://github.com/open-mmlab/mmcv/blob/eb08835fa246ea81263eb25fbe2caa54ef11271c/mmcv/utils/parrots_wrapper.py#L83-L87
More details: https://github.com/open-mmlab/mmocr/issues/325
</issue>
<code>
[start of mmcv/utils/parrots_wrapper.py]
1 from functools import partial
2
3 import torch
4
5 TORCH_VERSION = torch.__version__
6
7
8 def _get_cuda_home():
9 if TORCH_VERSION == 'parrots':
10 from parrots.utils.build_extension import CUDA_HOME
11 else:
12 from torch.utils.cpp_extension import CUDA_HOME
13 return CUDA_HOME
14
15
16 def get_build_config():
17 if TORCH_VERSION == 'parrots':
18 from parrots.config import get_build_info
19 return get_build_info()
20 else:
21 return torch.__config__.show()
22
23
24 def _get_conv():
25 if TORCH_VERSION == 'parrots':
26 from parrots.nn.modules.conv import _ConvNd, _ConvTransposeMixin
27 else:
28 from torch.nn.modules.conv import _ConvNd, _ConvTransposeMixin
29 return _ConvNd, _ConvTransposeMixin
30
31
32 def _get_dataloader():
33 if TORCH_VERSION == 'parrots':
34 from torch.utils.data import DataLoader, PoolDataLoader
35 else:
36 from torch.utils.data import DataLoader
37 PoolDataLoader = DataLoader
38 return DataLoader, PoolDataLoader
39
40
41 def _get_extension():
42 if TORCH_VERSION == 'parrots':
43 from parrots.utils.build_extension import BuildExtension, Extension
44 CppExtension = partial(Extension, cuda=False)
45 CUDAExtension = partial(Extension, cuda=True)
46 else:
47 from torch.utils.cpp_extension import (BuildExtension, CppExtension,
48 CUDAExtension)
49 return BuildExtension, CppExtension, CUDAExtension
50
51
52 def _get_pool():
53 if TORCH_VERSION == 'parrots':
54 from parrots.nn.modules.pool import (_AdaptiveAvgPoolNd,
55 _AdaptiveMaxPoolNd, _AvgPoolNd,
56 _MaxPoolNd)
57 else:
58 from torch.nn.modules.pooling import (_AdaptiveAvgPoolNd,
59 _AdaptiveMaxPoolNd, _AvgPoolNd,
60 _MaxPoolNd)
61 return _AdaptiveAvgPoolNd, _AdaptiveMaxPoolNd, _AvgPoolNd, _MaxPoolNd
62
63
64 def _get_norm():
65 if TORCH_VERSION == 'parrots':
66 from parrots.nn.modules.batchnorm import _BatchNorm, _InstanceNorm
67 SyncBatchNorm_ = torch.nn.SyncBatchNorm2d
68 else:
69 from torch.nn.modules.instancenorm import _InstanceNorm
70 from torch.nn.modules.batchnorm import _BatchNorm
71 SyncBatchNorm_ = torch.nn.SyncBatchNorm
72 return _BatchNorm, _InstanceNorm, SyncBatchNorm_
73
74
75 CUDA_HOME = _get_cuda_home()
76 _ConvNd, _ConvTransposeMixin = _get_conv()
77 DataLoader, PoolDataLoader = _get_dataloader()
78 BuildExtension, CppExtension, CUDAExtension = _get_extension()
79 _BatchNorm, _InstanceNorm, SyncBatchNorm_ = _get_norm()
80 _AdaptiveAvgPoolNd, _AdaptiveMaxPoolNd, _AvgPoolNd, _MaxPoolNd = _get_pool()
81
82
83 class SyncBatchNorm(SyncBatchNorm_):
84
85 def _specify_ddp_gpu_num(self, gpu_size):
86 if TORCH_VERSION != 'parrots':
87 super()._specify_ddp_gpu_num(gpu_size)
88
89 def _check_input_dim(self, input):
90 if TORCH_VERSION == 'parrots':
91 if input.dim() < 2:
92 raise ValueError(
93 f'expected at least 2D input (got {input.dim()}D input)')
94 else:
95 super()._check_input_dim(input)
96
[end of mmcv/utils/parrots_wrapper.py]
[start of mmcv/cnn/bricks/norm.py]
1 import inspect
2
3 import torch.nn as nn
4
5 from mmcv.utils import is_tuple_of
6 from mmcv.utils.parrots_wrapper import SyncBatchNorm, _BatchNorm, _InstanceNorm
7 from .registry import NORM_LAYERS
8
9 NORM_LAYERS.register_module('BN', module=nn.BatchNorm2d)
10 NORM_LAYERS.register_module('BN1d', module=nn.BatchNorm1d)
11 NORM_LAYERS.register_module('BN2d', module=nn.BatchNorm2d)
12 NORM_LAYERS.register_module('BN3d', module=nn.BatchNorm3d)
13 NORM_LAYERS.register_module('SyncBN', module=SyncBatchNorm)
14 NORM_LAYERS.register_module('GN', module=nn.GroupNorm)
15 NORM_LAYERS.register_module('LN', module=nn.LayerNorm)
16 NORM_LAYERS.register_module('IN', module=nn.InstanceNorm2d)
17 NORM_LAYERS.register_module('IN1d', module=nn.InstanceNorm1d)
18 NORM_LAYERS.register_module('IN2d', module=nn.InstanceNorm2d)
19 NORM_LAYERS.register_module('IN3d', module=nn.InstanceNorm3d)
20
21
22 def infer_abbr(class_type):
23 """Infer abbreviation from the class name.
24
25 When we build a norm layer with `build_norm_layer()`, we want to preserve
26 the norm type in variable names, e.g, self.bn1, self.gn. This method will
27 infer the abbreviation to map class types to abbreviations.
28
29 Rule 1: If the class has the property "_abbr_", return the property.
30 Rule 2: If the parent class is _BatchNorm, GroupNorm, LayerNorm or
31 InstanceNorm, the abbreviation of this layer will be "bn", "gn", "ln" and
32 "in" respectively.
33 Rule 3: If the class name contains "batch", "group", "layer" or "instance",
34 the abbreviation of this layer will be "bn", "gn", "ln" and "in"
35 respectively.
36 Rule 4: Otherwise, the abbreviation falls back to "norm".
37
38 Args:
39 class_type (type): The norm layer type.
40
41 Returns:
42 str: The inferred abbreviation.
43 """
44 if not inspect.isclass(class_type):
45 raise TypeError(
46 f'class_type must be a type, but got {type(class_type)}')
47 if hasattr(class_type, '_abbr_'):
48 return class_type._abbr_
49 if issubclass(class_type, _InstanceNorm): # IN is a subclass of BN
50 return 'in'
51 elif issubclass(class_type, _BatchNorm):
52 return 'bn'
53 elif issubclass(class_type, nn.GroupNorm):
54 return 'gn'
55 elif issubclass(class_type, nn.LayerNorm):
56 return 'ln'
57 else:
58 class_name = class_type.__name__.lower()
59 if 'batch' in class_name:
60 return 'bn'
61 elif 'group' in class_name:
62 return 'gn'
63 elif 'layer' in class_name:
64 return 'ln'
65 elif 'instance' in class_name:
66 return 'in'
67 else:
68 return 'norm_layer'
69
70
71 def build_norm_layer(cfg, num_features, postfix=''):
72 """Build normalization layer.
73
74 Args:
75 cfg (dict): The norm layer config, which should contain:
76
77 - type (str): Layer type.
78 - layer args: Args needed to instantiate a norm layer.
79 - requires_grad (bool, optional): Whether stop gradient updates.
80 num_features (int): Number of input channels.
81 postfix (int | str): The postfix to be appended into norm abbreviation
82 to create named layer.
83
84 Returns:
85 (str, nn.Module): The first element is the layer name consisting of
86 abbreviation and postfix, e.g., bn1, gn. The second element is the
87 created norm layer.
88 """
89 if not isinstance(cfg, dict):
90 raise TypeError('cfg must be a dict')
91 if 'type' not in cfg:
92 raise KeyError('the cfg dict must contain the key "type"')
93 cfg_ = cfg.copy()
94
95 layer_type = cfg_.pop('type')
96 if layer_type not in NORM_LAYERS:
97 raise KeyError(f'Unrecognized norm type {layer_type}')
98
99 norm_layer = NORM_LAYERS.get(layer_type)
100 abbr = infer_abbr(norm_layer)
101
102 assert isinstance(postfix, (int, str))
103 name = abbr + str(postfix)
104
105 requires_grad = cfg_.pop('requires_grad', True)
106 cfg_.setdefault('eps', 1e-5)
107 if layer_type != 'GN':
108 layer = norm_layer(num_features, **cfg_)
109 if layer_type == 'SyncBN':
110 layer._specify_ddp_gpu_num(1)
111 else:
112 assert 'num_groups' in cfg_
113 layer = norm_layer(num_channels=num_features, **cfg_)
114
115 for param in layer.parameters():
116 param.requires_grad = requires_grad
117
118 return name, layer
119
120
121 def is_norm(layer, exclude=None):
122 """Check if a layer is a normalization layer.
123
124 Args:
125 layer (nn.Module): The layer to be checked.
126 exclude (type | tuple[type]): Types to be excluded.
127
128 Returns:
129 bool: Whether the layer is a norm layer.
130 """
131 if exclude is not None:
132 if not isinstance(exclude, tuple):
133 exclude = (exclude, )
134 if not is_tuple_of(exclude, type):
135 raise TypeError(
136 f'"exclude" must be either None or type or a tuple of types, '
137 f'but got {type(exclude)}: {exclude}')
138
139 if exclude and isinstance(layer, exclude):
140 return False
141
142 all_norm_bases = (_BatchNorm, _InstanceNorm, nn.GroupNorm, nn.LayerNorm)
143 return isinstance(layer, all_norm_bases)
144
[end of mmcv/cnn/bricks/norm.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/mmcv/cnn/bricks/norm.py b/mmcv/cnn/bricks/norm.py
--- a/mmcv/cnn/bricks/norm.py
+++ b/mmcv/cnn/bricks/norm.py
@@ -106,7 +106,7 @@
cfg_.setdefault('eps', 1e-5)
if layer_type != 'GN':
layer = norm_layer(num_features, **cfg_)
- if layer_type == 'SyncBN':
+ if layer_type == 'SyncBN' and hasattr(layer, '_specify_ddp_gpu_num'):
layer._specify_ddp_gpu_num(1)
else:
assert 'num_groups' in cfg_
diff --git a/mmcv/utils/parrots_wrapper.py b/mmcv/utils/parrots_wrapper.py
--- a/mmcv/utils/parrots_wrapper.py
+++ b/mmcv/utils/parrots_wrapper.py
@@ -82,10 +82,6 @@
class SyncBatchNorm(SyncBatchNorm_):
- def _specify_ddp_gpu_num(self, gpu_size):
- if TORCH_VERSION != 'parrots':
- super()._specify_ddp_gpu_num(gpu_size)
-
def _check_input_dim(self, input):
if TORCH_VERSION == 'parrots':
if input.dim() < 2:
|
{"golden_diff": "diff --git a/mmcv/cnn/bricks/norm.py b/mmcv/cnn/bricks/norm.py\n--- a/mmcv/cnn/bricks/norm.py\n+++ b/mmcv/cnn/bricks/norm.py\n@@ -106,7 +106,7 @@\n cfg_.setdefault('eps', 1e-5)\n if layer_type != 'GN':\n layer = norm_layer(num_features, **cfg_)\n- if layer_type == 'SyncBN':\n+ if layer_type == 'SyncBN' and hasattr(layer, '_specify_ddp_gpu_num'):\n layer._specify_ddp_gpu_num(1)\n else:\n assert 'num_groups' in cfg_\ndiff --git a/mmcv/utils/parrots_wrapper.py b/mmcv/utils/parrots_wrapper.py\n--- a/mmcv/utils/parrots_wrapper.py\n+++ b/mmcv/utils/parrots_wrapper.py\n@@ -82,10 +82,6 @@\n \n class SyncBatchNorm(SyncBatchNorm_):\n \n- def _specify_ddp_gpu_num(self, gpu_size):\n- if TORCH_VERSION != 'parrots':\n- super()._specify_ddp_gpu_num(gpu_size)\n-\n def _check_input_dim(self, input):\n if TORCH_VERSION == 'parrots':\n if input.dim() < 2:\n", "issue": "SyncBatchNorm breaks after PyTorch 1.9.0\n**Describe the Issue**\r\n`torch.nn.SyncBatchNorm` has been updated since PyTorch 1.9.0 and `_specify_ddp_gpu_num()` is no longer available, breaking the following code snippet: https://github.com/open-mmlab/mmcv/blob/eb08835fa246ea81263eb25fbe2caa54ef11271c/mmcv/utils/parrots_wrapper.py#L83-L87\r\n\r\nMore details: https://github.com/open-mmlab/mmocr/issues/325\n", "before_files": [{"content": "from functools import partial\n\nimport torch\n\nTORCH_VERSION = torch.__version__\n\n\ndef _get_cuda_home():\n if TORCH_VERSION == 'parrots':\n from parrots.utils.build_extension import CUDA_HOME\n else:\n from torch.utils.cpp_extension import CUDA_HOME\n return CUDA_HOME\n\n\ndef get_build_config():\n if TORCH_VERSION == 'parrots':\n from parrots.config import get_build_info\n return get_build_info()\n else:\n return torch.__config__.show()\n\n\ndef _get_conv():\n if TORCH_VERSION == 'parrots':\n from parrots.nn.modules.conv import _ConvNd, _ConvTransposeMixin\n else:\n from torch.nn.modules.conv import _ConvNd, _ConvTransposeMixin\n return _ConvNd, _ConvTransposeMixin\n\n\ndef _get_dataloader():\n if TORCH_VERSION == 'parrots':\n from torch.utils.data import DataLoader, PoolDataLoader\n else:\n from torch.utils.data import DataLoader\n PoolDataLoader = DataLoader\n return DataLoader, PoolDataLoader\n\n\ndef _get_extension():\n if TORCH_VERSION == 'parrots':\n from parrots.utils.build_extension import BuildExtension, Extension\n CppExtension = partial(Extension, cuda=False)\n CUDAExtension = partial(Extension, cuda=True)\n else:\n from torch.utils.cpp_extension import (BuildExtension, CppExtension,\n CUDAExtension)\n return BuildExtension, CppExtension, CUDAExtension\n\n\ndef _get_pool():\n if TORCH_VERSION == 'parrots':\n from parrots.nn.modules.pool import (_AdaptiveAvgPoolNd,\n _AdaptiveMaxPoolNd, _AvgPoolNd,\n _MaxPoolNd)\n else:\n from torch.nn.modules.pooling import (_AdaptiveAvgPoolNd,\n _AdaptiveMaxPoolNd, _AvgPoolNd,\n _MaxPoolNd)\n return _AdaptiveAvgPoolNd, _AdaptiveMaxPoolNd, _AvgPoolNd, _MaxPoolNd\n\n\ndef _get_norm():\n if TORCH_VERSION == 'parrots':\n from parrots.nn.modules.batchnorm import _BatchNorm, _InstanceNorm\n SyncBatchNorm_ = torch.nn.SyncBatchNorm2d\n else:\n from torch.nn.modules.instancenorm import _InstanceNorm\n from torch.nn.modules.batchnorm import _BatchNorm\n SyncBatchNorm_ = torch.nn.SyncBatchNorm\n return _BatchNorm, _InstanceNorm, SyncBatchNorm_\n\n\nCUDA_HOME = _get_cuda_home()\n_ConvNd, _ConvTransposeMixin = _get_conv()\nDataLoader, PoolDataLoader = _get_dataloader()\nBuildExtension, CppExtension, CUDAExtension = _get_extension()\n_BatchNorm, _InstanceNorm, SyncBatchNorm_ = _get_norm()\n_AdaptiveAvgPoolNd, _AdaptiveMaxPoolNd, _AvgPoolNd, _MaxPoolNd = _get_pool()\n\n\nclass SyncBatchNorm(SyncBatchNorm_):\n\n def _specify_ddp_gpu_num(self, gpu_size):\n if TORCH_VERSION != 'parrots':\n super()._specify_ddp_gpu_num(gpu_size)\n\n def _check_input_dim(self, input):\n if TORCH_VERSION == 'parrots':\n if input.dim() < 2:\n raise ValueError(\n f'expected at least 2D input (got {input.dim()}D input)')\n else:\n super()._check_input_dim(input)\n", "path": "mmcv/utils/parrots_wrapper.py"}, {"content": "import inspect\n\nimport torch.nn as nn\n\nfrom mmcv.utils import is_tuple_of\nfrom mmcv.utils.parrots_wrapper import SyncBatchNorm, _BatchNorm, _InstanceNorm\nfrom .registry import NORM_LAYERS\n\nNORM_LAYERS.register_module('BN', module=nn.BatchNorm2d)\nNORM_LAYERS.register_module('BN1d', module=nn.BatchNorm1d)\nNORM_LAYERS.register_module('BN2d', module=nn.BatchNorm2d)\nNORM_LAYERS.register_module('BN3d', module=nn.BatchNorm3d)\nNORM_LAYERS.register_module('SyncBN', module=SyncBatchNorm)\nNORM_LAYERS.register_module('GN', module=nn.GroupNorm)\nNORM_LAYERS.register_module('LN', module=nn.LayerNorm)\nNORM_LAYERS.register_module('IN', module=nn.InstanceNorm2d)\nNORM_LAYERS.register_module('IN1d', module=nn.InstanceNorm1d)\nNORM_LAYERS.register_module('IN2d', module=nn.InstanceNorm2d)\nNORM_LAYERS.register_module('IN3d', module=nn.InstanceNorm3d)\n\n\ndef infer_abbr(class_type):\n \"\"\"Infer abbreviation from the class name.\n\n When we build a norm layer with `build_norm_layer()`, we want to preserve\n the norm type in variable names, e.g, self.bn1, self.gn. This method will\n infer the abbreviation to map class types to abbreviations.\n\n Rule 1: If the class has the property \"_abbr_\", return the property.\n Rule 2: If the parent class is _BatchNorm, GroupNorm, LayerNorm or\n InstanceNorm, the abbreviation of this layer will be \"bn\", \"gn\", \"ln\" and\n \"in\" respectively.\n Rule 3: If the class name contains \"batch\", \"group\", \"layer\" or \"instance\",\n the abbreviation of this layer will be \"bn\", \"gn\", \"ln\" and \"in\"\n respectively.\n Rule 4: Otherwise, the abbreviation falls back to \"norm\".\n\n Args:\n class_type (type): The norm layer type.\n\n Returns:\n str: The inferred abbreviation.\n \"\"\"\n if not inspect.isclass(class_type):\n raise TypeError(\n f'class_type must be a type, but got {type(class_type)}')\n if hasattr(class_type, '_abbr_'):\n return class_type._abbr_\n if issubclass(class_type, _InstanceNorm): # IN is a subclass of BN\n return 'in'\n elif issubclass(class_type, _BatchNorm):\n return 'bn'\n elif issubclass(class_type, nn.GroupNorm):\n return 'gn'\n elif issubclass(class_type, nn.LayerNorm):\n return 'ln'\n else:\n class_name = class_type.__name__.lower()\n if 'batch' in class_name:\n return 'bn'\n elif 'group' in class_name:\n return 'gn'\n elif 'layer' in class_name:\n return 'ln'\n elif 'instance' in class_name:\n return 'in'\n else:\n return 'norm_layer'\n\n\ndef build_norm_layer(cfg, num_features, postfix=''):\n \"\"\"Build normalization layer.\n\n Args:\n cfg (dict): The norm layer config, which should contain:\n\n - type (str): Layer type.\n - layer args: Args needed to instantiate a norm layer.\n - requires_grad (bool, optional): Whether stop gradient updates.\n num_features (int): Number of input channels.\n postfix (int | str): The postfix to be appended into norm abbreviation\n to create named layer.\n\n Returns:\n (str, nn.Module): The first element is the layer name consisting of\n abbreviation and postfix, e.g., bn1, gn. The second element is the\n created norm layer.\n \"\"\"\n if not isinstance(cfg, dict):\n raise TypeError('cfg must be a dict')\n if 'type' not in cfg:\n raise KeyError('the cfg dict must contain the key \"type\"')\n cfg_ = cfg.copy()\n\n layer_type = cfg_.pop('type')\n if layer_type not in NORM_LAYERS:\n raise KeyError(f'Unrecognized norm type {layer_type}')\n\n norm_layer = NORM_LAYERS.get(layer_type)\n abbr = infer_abbr(norm_layer)\n\n assert isinstance(postfix, (int, str))\n name = abbr + str(postfix)\n\n requires_grad = cfg_.pop('requires_grad', True)\n cfg_.setdefault('eps', 1e-5)\n if layer_type != 'GN':\n layer = norm_layer(num_features, **cfg_)\n if layer_type == 'SyncBN':\n layer._specify_ddp_gpu_num(1)\n else:\n assert 'num_groups' in cfg_\n layer = norm_layer(num_channels=num_features, **cfg_)\n\n for param in layer.parameters():\n param.requires_grad = requires_grad\n\n return name, layer\n\n\ndef is_norm(layer, exclude=None):\n \"\"\"Check if a layer is a normalization layer.\n\n Args:\n layer (nn.Module): The layer to be checked.\n exclude (type | tuple[type]): Types to be excluded.\n\n Returns:\n bool: Whether the layer is a norm layer.\n \"\"\"\n if exclude is not None:\n if not isinstance(exclude, tuple):\n exclude = (exclude, )\n if not is_tuple_of(exclude, type):\n raise TypeError(\n f'\"exclude\" must be either None or type or a tuple of types, '\n f'but got {type(exclude)}: {exclude}')\n\n if exclude and isinstance(layer, exclude):\n return False\n\n all_norm_bases = (_BatchNorm, _InstanceNorm, nn.GroupNorm, nn.LayerNorm)\n return isinstance(layer, all_norm_bases)\n", "path": "mmcv/cnn/bricks/norm.py"}]}
| 3,221 | 302 |
gh_patches_debug_35789
|
rasdani/github-patches
|
git_diff
|
saulpw__visidata-1188
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[save-selected] default save filename is not valid
**Small description**
When doing a `save-selected` the default sheet name is invalid, see the screenshot below
**Expected result**
For the suggested file name to be valid and useable. Maybe something like '`sheet1_sheet2_.csv`'.
**Actual result with screenshot**
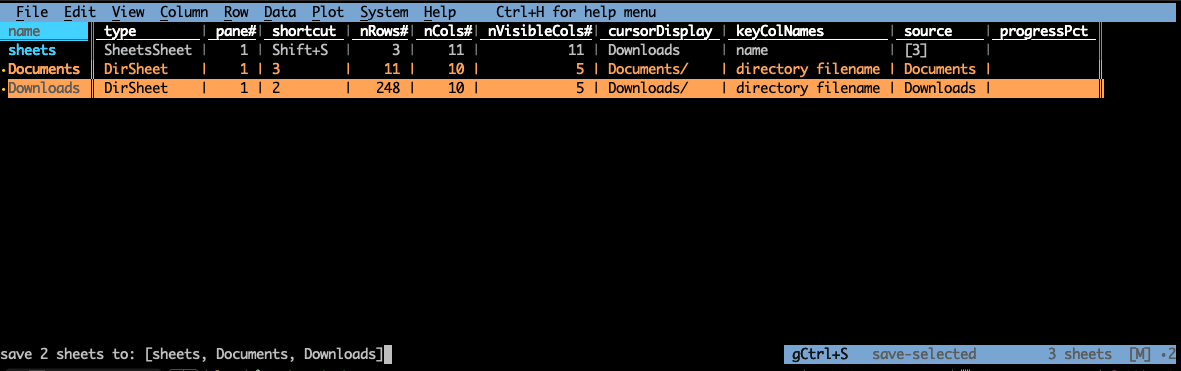
**Steps to reproduce with sample data and a .vd**
Open a number of sheets, go to `sheets-stack` select a few and do `save-selected`. This gives a stringified list rather than a proper name.
**Additional context**
Commit: https://github.com/saulpw/visidata/commit/9ce048d0378de0211e53f1591d79c8fbed39dff1
This seems to work:
`IndexSheet.addCommand('g^S', 'save-selected', 'vd.saveSheets(inputPath("save %d sheets to: " % nSelectedRows, value="_".join(vs.name or "blank" for vs in source)), *selectedRows, confirm_overwrite=options.confirm_overwrite)', 'save all selected sheets to given file or directory')`
</issue>
<code>
[start of visidata/textsheet.py]
1 import textwrap
2
3 from visidata import vd, BaseSheet, options, Sheet, ColumnItem, asyncthread
4 from visidata import Column, ColumnItem, vlen
5 from visidata import globalCommand, VisiData
6 import visidata
7
8
9 vd.option('wrap', False, 'wrap text to fit window width on TextSheet')
10 vd.option('save_filetype', '', 'specify default file type to save as', replay=True)
11
12
13 ## text viewer
14 # rowdef: (linenum, str)
15 class TextSheet(Sheet):
16 'Displays any iterable source, with linewrap if ``options.wrap`` is set.'
17 rowtype = 'lines' # rowdef: [linenum, text]
18 filetype = 'txt'
19 columns = [
20 ColumnItem('linenum', 0, type=int, width=0),
21 ColumnItem('text', 1),
22 ]
23
24 def iterload(self):
25 yield from self.readlines(self.source)
26
27 def readlines(self, source):
28 winWidth = min(self.columns[1].width or 78, self.windowWidth-2)
29 wrap = self.options.wrap
30 for startingLine, text in enumerate(source):
31 if wrap and text:
32 for i, L in enumerate(textwrap.wrap(str(text), width=winWidth)):
33 yield [startingLine+i+1, L]
34 else:
35 yield [startingLine+1, text]
36
37 def sysopen(sheet, linenum=0):
38 @asyncthread
39 def writelines(sheet, fn):
40 with open(fn, 'w') as fp:
41 for row in sheet.rows:
42 fp.write(row[1])
43 fp.write('\n')
44
45 import tempfile
46 with tempfile.NamedTemporaryFile() as temp:
47 writelines(sheet, temp.name)
48 vd.launchEditor(temp.name, '+%s' % linenum)
49 sheet.rows = []
50 for r in sheet.readlines(visidata.Path(temp.name)):
51 sheet.addRow(r)
52
53
54 # .source is list of source text lines to 'load'
55 # .sourceSheet is Sheet error came from
56 class ErrorSheet(TextSheet):
57 precious = False
58
59
60 class ErrorsSheet(Sheet):
61 columns = [
62 Column('nlines', type=vlen),
63 ColumnItem('lastline', -1)
64 ]
65 def reload(self):
66 self.rows = self.source
67
68 def openRow(self, row):
69 return ErrorSheet(source=self.cursorRow)
70
71 @VisiData.property
72 def allErrorsSheet(self):
73 return ErrorsSheet("errors_all", source=vd.lastErrors)
74
75 @VisiData.property
76 def recentErrorsSheet(self):
77 error = vd.lastErrors[-1] if vd.lastErrors else ''
78 return ErrorSheet("errors_recent", source=error)
79
80
81
82 BaseSheet.addCommand('^E', 'error-recent', 'vd.lastErrors and vd.push(recentErrorsSheet) or status("no error")', 'view traceback for most recent error')
83 BaseSheet.addCommand('g^E', 'errors-all', 'vd.push(vd.allErrorsSheet)', 'view traceback for most recent errors')
84
85 Sheet.addCommand(None, 'view-cell', 'vd.push(ErrorSheet("%s[%s].%s" % (name, cursorRowIndex, cursorCol.name), sourceSheet=sheet, source=cursorDisplay.splitlines()))', 'view contents of current cell in a new sheet'),
86 Sheet.addCommand('z^E', 'error-cell', 'vd.push(ErrorSheet(sheet.name+"_cell_error", sourceSheet=sheet, source=getattr(cursorCell, "error", None) or fail("no error this cell")))', 'view traceback for error in current cell')
87
88 TextSheet.addCommand('^O', 'sysopen-sheet', 'sheet.sysopen(sheet.cursorRowIndex)', 'open copy of text sheet in $EDITOR and reload on exit')
89
90
91 TextSheet.class_options.save_filetype = 'txt'
92
93 vd.addGlobals({'TextSheet': TextSheet, 'ErrorSheet': ErrorSheet})
94
[end of visidata/textsheet.py]
[start of visidata/save.py]
1 from visidata import *
2
3
4 vd.option('confirm_overwrite', True, 'whether to prompt for overwrite confirmation on save')
5 vd.option('safe_error', '#ERR', 'error string to use while saving', replay=True)
6
7 @Sheet.api
8 def safe_trdict(vs):
9 'returns string.translate dictionary for replacing tabs and newlines'
10 if options.safety_first:
11 delim = vs.options.delimiter
12 return {
13 0: '', # strip NUL completely
14 ord(delim): vs.options.tsv_safe_tab, # \t
15 10: vs.options.tsv_safe_newline, # \n
16 13: vs.options.tsv_safe_newline, # \r
17 }
18 return {}
19
20
21 @Sheet.api
22 def iterdispvals(sheet, *cols, format=False):
23 'For each row in sheet, yield OrderedDict of values for given cols. Values are typed if format=False, or a formatted display string if format=True.'
24 if not cols:
25 cols = sheet.visibleCols
26
27 transformers = collections.OrderedDict() # list of transformers for each column in order
28 for col in cols:
29 transformers[col] = [ col.type ]
30 if format:
31 transformers[col].append(col.format)
32 trdict = sheet.safe_trdict()
33 if trdict:
34 transformers[col].append(lambda v,trdict=trdict: v.translate(trdict))
35
36 options_safe_error = options.safe_error
37 for r in Progress(sheet.rows):
38 dispvals = collections.OrderedDict() # [col] -> value
39 for col, transforms in transformers.items():
40 try:
41 dispval = col.getValue(r)
42
43 except Exception as e:
44 vd.exceptionCaught(e)
45 dispval = options_safe_error or str(e)
46
47 try:
48 for t in transforms:
49 if dispval is None:
50 break
51 elif isinstance(dispval, TypedExceptionWrapper):
52 dispval = options_safe_error or str(dispval)
53 break
54 else:
55 dispval = t(dispval)
56
57 if dispval is None and format:
58 dispval = ''
59 except Exception as e:
60 dispval = str(dispval)
61
62 dispvals[col] = dispval
63
64 yield dispvals
65
66
67 @Sheet.api
68 def itervals(sheet, *cols, format=False):
69 for row in sheet.iterdispvals(*cols, format=format):
70 yield [row[c] for c in cols]
71
72 @BaseSheet.api
73 def getDefaultSaveName(sheet):
74 src = getattr(sheet, 'source', None)
75 if hasattr(src, 'scheme') and src.scheme:
76 return src.name + src.suffix
77 if isinstance(src, Path):
78 if sheet.options.is_set('save_filetype', sheet):
79 # if save_filetype is over-ridden from default, use it as the extension
80 return str(src.with_suffix('')) + '.' + sheet.options.save_filetype
81 return str(src)
82 else:
83 return sheet.name+'.'+getattr(sheet, 'filetype', options.save_filetype)
84
85
86 @VisiData.api
87 def save_cols(vd, cols):
88 sheet = cols[0].sheet
89 vs = copy(sheet)
90 vs.columns = list(cols)
91 vs.rows = sheet.rows
92 if len(cols) == 1:
93 savedcoltxt = cols[0].name + ' column'
94 else:
95 savedcoltxt = '%s columns' % len(cols)
96 path = vd.inputPath('save %s to: ' % savedcoltxt, value=vs.getDefaultSaveName())
97 vd.saveSheets(path, vs, confirm_overwrite=options.confirm_overwrite)
98
99
100 @VisiData.api
101 def saveSheets(vd, givenpath, *vsheets, confirm_overwrite=False):
102 'Save all *vsheets* to *givenpath*.'
103
104 filetype = givenpath.ext or options.save_filetype
105
106 vd.clearCaches()
107
108 savefunc = getattr(vsheets[0], 'save_' + filetype, None) or getattr(vd, 'save_' + filetype, None)
109
110 if savefunc is None:
111 savefunc = getattr(vd, 'save_' + options.save_filetype, None) or vd.fail('no function to save as type %s, set options.save_filetype' % filetype)
112 vd.warning(f'save for {filetype} unavailable, using {options.save_filetype}')
113
114 if givenpath.exists() and confirm_overwrite:
115 vd.confirm("%s already exists. overwrite? " % givenpath.given)
116
117 vd.status('saving %s sheets to %s as %s' % (len(vsheets), givenpath.given, filetype))
118
119 if not givenpath.given.endswith('/'): # forcibly specify save individual files into directory by ending path with /
120 for vs in vsheets:
121 vs.hasBeenModified = False
122 return vd.execAsync(savefunc, givenpath, *vsheets)
123
124 # more than one sheet; either no specific multisave for save filetype, or path ends with /
125
126 # save as individual files in the givenpath directory
127 try:
128 os.makedirs(givenpath, exist_ok=True)
129 except FileExistsError:
130 pass
131
132 if not givenpath.is_dir():
133 vd.fail(f'cannot save multiple {filetype} sheets to non-dir')
134
135 def _savefiles(vsheets, givenpath, savefunc, filetype):
136 for vs in vsheets:
137 p = Path((givenpath / vs.name).with_suffix('.'+filetype))
138 savefunc(p, vs)
139 vs.hasBeenModified = False
140 return vd.execAsync(_savefiles, vsheets, givenpath, savefunc, filetype)
141
142
143 @VisiData.api
144 def save_txt(vd, p, *vsheets):
145 with p.open_text(mode='w', encoding=vsheets[0].options.encoding) as fp:
146 for vs in vsheets:
147 unitsep = vs.options.delimiter
148 rowsep = vs.options.row_delimiter
149 for dispvals in vs.iterdispvals(*vs.visibleCols, format=True):
150 fp.write(unitsep.join(dispvals.values()))
151 fp.write(rowsep)
152 vd.status('%s save finished' % p)
153
154
155 BaseSheet.addCommand('^S', 'save-sheet', 'vd.saveSheets(inputPath("save to: ", value=getDefaultSaveName()), sheet, confirm_overwrite=options.confirm_overwrite)', 'save current sheet to filename in format determined by extension (default .tsv)')
156 BaseSheet.addCommand('g^S', 'save-all', 'vd.saveSheets(inputPath("save all sheets to: "), *vd.stackedSheets, confirm_overwrite=options.confirm_overwrite)', 'save all sheets to given file or directory)')
157 IndexSheet.addCommand('g^S', 'save-selected', 'vd.saveSheets(inputPath("save %d sheets to: " % nSelectedRows, value=str(source)), *selectedRows, confirm_overwrite=options.confirm_overwrite)', 'save all selected sheets to given file or directory')
158 Sheet.addCommand('', 'save-col', 'save_cols([cursorCol])', 'save current column only to filename in format determined by extension (default .tsv)')
159 Sheet.addCommand('', 'save-col-keys', 'save_cols(keyCols + [cursorCol])', 'save key columns and current column to filename in format determined by extension (default .tsv)')
160
[end of visidata/save.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/visidata/save.py b/visidata/save.py
--- a/visidata/save.py
+++ b/visidata/save.py
@@ -107,11 +107,16 @@
savefunc = getattr(vsheets[0], 'save_' + filetype, None) or getattr(vd, 'save_' + filetype, None)
+ using_save_filetype = False
+
if savefunc is None:
savefunc = getattr(vd, 'save_' + options.save_filetype, None) or vd.fail('no function to save as type %s, set options.save_filetype' % filetype)
vd.warning(f'save for {filetype} unavailable, using {options.save_filetype}')
+ using_save_filetype = True
- if givenpath.exists() and confirm_overwrite:
+ if using_save_filetype and givenpath.exists() and confirm_overwrite:
+ vd.confirm("%s already exists. overwrite with %s? " % (givenpath.given, options.save_filetype))
+ elif givenpath.exists() and confirm_overwrite:
vd.confirm("%s already exists. overwrite? " % givenpath.given)
vd.status('saving %s sheets to %s as %s' % (len(vsheets), givenpath.given, filetype))
@@ -119,9 +124,13 @@
if not givenpath.given.endswith('/'): # forcibly specify save individual files into directory by ending path with /
for vs in vsheets:
vs.hasBeenModified = False
+ # savefuncs(vd, p, *vsheets) will have 2 argcount (*vsheets does not get counted as an arg)
+ # savefuncs(vd, p, vs) will have 3 argcount (vs counts as an arg, along with vd, path)
+ if savefunc.__code__.co_argcount == 3 and len(vsheets) > 1:
+ vd.fail(f'cannot save multiple {filetype} sheets to non-dir')
return vd.execAsync(savefunc, givenpath, *vsheets)
- # more than one sheet; either no specific multisave for save filetype, or path ends with /
+ # path is a dir
# save as individual files in the givenpath directory
try:
diff --git a/visidata/textsheet.py b/visidata/textsheet.py
--- a/visidata/textsheet.py
+++ b/visidata/textsheet.py
@@ -7,7 +7,7 @@
vd.option('wrap', False, 'wrap text to fit window width on TextSheet')
-vd.option('save_filetype', '', 'specify default file type to save as', replay=True)
+vd.option('save_filetype', 'tsv', 'specify default file type to save as', replay=True)
## text viewer
|
{"golden_diff": "diff --git a/visidata/save.py b/visidata/save.py\n--- a/visidata/save.py\n+++ b/visidata/save.py\n@@ -107,11 +107,16 @@\n \n savefunc = getattr(vsheets[0], 'save_' + filetype, None) or getattr(vd, 'save_' + filetype, None)\n \n+ using_save_filetype = False\n+\n if savefunc is None:\n savefunc = getattr(vd, 'save_' + options.save_filetype, None) or vd.fail('no function to save as type %s, set options.save_filetype' % filetype)\n vd.warning(f'save for {filetype} unavailable, using {options.save_filetype}')\n+ using_save_filetype = True\n \n- if givenpath.exists() and confirm_overwrite:\n+ if using_save_filetype and givenpath.exists() and confirm_overwrite:\n+ vd.confirm(\"%s already exists. overwrite with %s? \" % (givenpath.given, options.save_filetype))\n+ elif givenpath.exists() and confirm_overwrite:\n vd.confirm(\"%s already exists. overwrite? \" % givenpath.given)\n \n vd.status('saving %s sheets to %s as %s' % (len(vsheets), givenpath.given, filetype))\n@@ -119,9 +124,13 @@\n if not givenpath.given.endswith('/'): # forcibly specify save individual files into directory by ending path with /\n for vs in vsheets:\n vs.hasBeenModified = False\n+ # savefuncs(vd, p, *vsheets) will have 2 argcount (*vsheets does not get counted as an arg)\n+ # savefuncs(vd, p, vs) will have 3 argcount (vs counts as an arg, along with vd, path)\n+ if savefunc.__code__.co_argcount == 3 and len(vsheets) > 1:\n+ vd.fail(f'cannot save multiple {filetype} sheets to non-dir')\n return vd.execAsync(savefunc, givenpath, *vsheets)\n \n- # more than one sheet; either no specific multisave for save filetype, or path ends with /\n+ # path is a dir\n \n # save as individual files in the givenpath directory\n try:\ndiff --git a/visidata/textsheet.py b/visidata/textsheet.py\n--- a/visidata/textsheet.py\n+++ b/visidata/textsheet.py\n@@ -7,7 +7,7 @@\n \n \n vd.option('wrap', False, 'wrap text to fit window width on TextSheet')\n-vd.option('save_filetype', '', 'specify default file type to save as', replay=True)\n+vd.option('save_filetype', 'tsv', 'specify default file type to save as', replay=True)\n \n \n ## text viewer\n", "issue": "[save-selected] default save filename is not valid\n**Small description**\r\nWhen doing a `save-selected` the default sheet name is invalid, see the screenshot below\r\n\r\n**Expected result**\r\nFor the suggested file name to be valid and useable. Maybe something like '`sheet1_sheet2_.csv`'.\r\n\r\n**Actual result with screenshot**\r\n\r\n\r\n**Steps to reproduce with sample data and a .vd**\r\nOpen a number of sheets, go to `sheets-stack` select a few and do `save-selected`. This gives a stringified list rather than a proper name.\r\n\r\n**Additional context**\r\nCommit: https://github.com/saulpw/visidata/commit/9ce048d0378de0211e53f1591d79c8fbed39dff1\r\n\r\nThis seems to work:\r\n`IndexSheet.addCommand('g^S', 'save-selected', 'vd.saveSheets(inputPath(\"save %d sheets to: \" % nSelectedRows, value=\"_\".join(vs.name or \"blank\" for vs in source)), *selectedRows, confirm_overwrite=options.confirm_overwrite)', 'save all selected sheets to given file or directory')`\r\n\n", "before_files": [{"content": "import textwrap\n\nfrom visidata import vd, BaseSheet, options, Sheet, ColumnItem, asyncthread\nfrom visidata import Column, ColumnItem, vlen\nfrom visidata import globalCommand, VisiData\nimport visidata\n\n\nvd.option('wrap', False, 'wrap text to fit window width on TextSheet')\nvd.option('save_filetype', '', 'specify default file type to save as', replay=True)\n\n\n## text viewer\n# rowdef: (linenum, str)\nclass TextSheet(Sheet):\n 'Displays any iterable source, with linewrap if ``options.wrap`` is set.'\n rowtype = 'lines' # rowdef: [linenum, text]\n filetype = 'txt'\n columns = [\n ColumnItem('linenum', 0, type=int, width=0),\n ColumnItem('text', 1),\n ]\n\n def iterload(self):\n yield from self.readlines(self.source)\n\n def readlines(self, source):\n winWidth = min(self.columns[1].width or 78, self.windowWidth-2)\n wrap = self.options.wrap\n for startingLine, text in enumerate(source):\n if wrap and text:\n for i, L in enumerate(textwrap.wrap(str(text), width=winWidth)):\n yield [startingLine+i+1, L]\n else:\n yield [startingLine+1, text]\n\n def sysopen(sheet, linenum=0):\n @asyncthread\n def writelines(sheet, fn):\n with open(fn, 'w') as fp:\n for row in sheet.rows:\n fp.write(row[1])\n fp.write('\\n')\n\n import tempfile\n with tempfile.NamedTemporaryFile() as temp:\n writelines(sheet, temp.name)\n vd.launchEditor(temp.name, '+%s' % linenum)\n sheet.rows = []\n for r in sheet.readlines(visidata.Path(temp.name)):\n sheet.addRow(r)\n\n\n# .source is list of source text lines to 'load'\n# .sourceSheet is Sheet error came from\nclass ErrorSheet(TextSheet):\n precious = False\n\n\nclass ErrorsSheet(Sheet):\n columns = [\n Column('nlines', type=vlen),\n ColumnItem('lastline', -1)\n ]\n def reload(self):\n self.rows = self.source\n\n def openRow(self, row):\n return ErrorSheet(source=self.cursorRow)\n\[email protected]\ndef allErrorsSheet(self):\n return ErrorsSheet(\"errors_all\", source=vd.lastErrors)\n\[email protected]\ndef recentErrorsSheet(self):\n error = vd.lastErrors[-1] if vd.lastErrors else ''\n return ErrorSheet(\"errors_recent\", source=error)\n\n\n\nBaseSheet.addCommand('^E', 'error-recent', 'vd.lastErrors and vd.push(recentErrorsSheet) or status(\"no error\")', 'view traceback for most recent error')\nBaseSheet.addCommand('g^E', 'errors-all', 'vd.push(vd.allErrorsSheet)', 'view traceback for most recent errors')\n\nSheet.addCommand(None, 'view-cell', 'vd.push(ErrorSheet(\"%s[%s].%s\" % (name, cursorRowIndex, cursorCol.name), sourceSheet=sheet, source=cursorDisplay.splitlines()))', 'view contents of current cell in a new sheet'),\nSheet.addCommand('z^E', 'error-cell', 'vd.push(ErrorSheet(sheet.name+\"_cell_error\", sourceSheet=sheet, source=getattr(cursorCell, \"error\", None) or fail(\"no error this cell\")))', 'view traceback for error in current cell')\n\nTextSheet.addCommand('^O', 'sysopen-sheet', 'sheet.sysopen(sheet.cursorRowIndex)', 'open copy of text sheet in $EDITOR and reload on exit')\n\n\nTextSheet.class_options.save_filetype = 'txt'\n\nvd.addGlobals({'TextSheet': TextSheet, 'ErrorSheet': ErrorSheet})\n", "path": "visidata/textsheet.py"}, {"content": "from visidata import *\n\n\nvd.option('confirm_overwrite', True, 'whether to prompt for overwrite confirmation on save')\nvd.option('safe_error', '#ERR', 'error string to use while saving', replay=True)\n\[email protected]\ndef safe_trdict(vs):\n 'returns string.translate dictionary for replacing tabs and newlines'\n if options.safety_first:\n delim = vs.options.delimiter\n return {\n 0: '', # strip NUL completely\n ord(delim): vs.options.tsv_safe_tab, # \\t\n 10: vs.options.tsv_safe_newline, # \\n\n 13: vs.options.tsv_safe_newline, # \\r\n }\n return {}\n\n\[email protected]\ndef iterdispvals(sheet, *cols, format=False):\n 'For each row in sheet, yield OrderedDict of values for given cols. Values are typed if format=False, or a formatted display string if format=True.'\n if not cols:\n cols = sheet.visibleCols\n\n transformers = collections.OrderedDict() # list of transformers for each column in order\n for col in cols:\n transformers[col] = [ col.type ]\n if format:\n transformers[col].append(col.format)\n trdict = sheet.safe_trdict()\n if trdict:\n transformers[col].append(lambda v,trdict=trdict: v.translate(trdict))\n\n options_safe_error = options.safe_error\n for r in Progress(sheet.rows):\n dispvals = collections.OrderedDict() # [col] -> value\n for col, transforms in transformers.items():\n try:\n dispval = col.getValue(r)\n\n except Exception as e:\n vd.exceptionCaught(e)\n dispval = options_safe_error or str(e)\n\n try:\n for t in transforms:\n if dispval is None:\n break\n elif isinstance(dispval, TypedExceptionWrapper):\n dispval = options_safe_error or str(dispval)\n break\n else:\n dispval = t(dispval)\n\n if dispval is None and format:\n dispval = ''\n except Exception as e:\n dispval = str(dispval)\n\n dispvals[col] = dispval\n\n yield dispvals\n\n\[email protected]\ndef itervals(sheet, *cols, format=False):\n for row in sheet.iterdispvals(*cols, format=format):\n yield [row[c] for c in cols]\n\[email protected]\ndef getDefaultSaveName(sheet):\n src = getattr(sheet, 'source', None)\n if hasattr(src, 'scheme') and src.scheme:\n return src.name + src.suffix\n if isinstance(src, Path):\n if sheet.options.is_set('save_filetype', sheet):\n # if save_filetype is over-ridden from default, use it as the extension\n return str(src.with_suffix('')) + '.' + sheet.options.save_filetype\n return str(src)\n else:\n return sheet.name+'.'+getattr(sheet, 'filetype', options.save_filetype)\n\n\[email protected]\ndef save_cols(vd, cols):\n sheet = cols[0].sheet\n vs = copy(sheet)\n vs.columns = list(cols)\n vs.rows = sheet.rows\n if len(cols) == 1:\n savedcoltxt = cols[0].name + ' column'\n else:\n savedcoltxt = '%s columns' % len(cols)\n path = vd.inputPath('save %s to: ' % savedcoltxt, value=vs.getDefaultSaveName())\n vd.saveSheets(path, vs, confirm_overwrite=options.confirm_overwrite)\n\n\[email protected]\ndef saveSheets(vd, givenpath, *vsheets, confirm_overwrite=False):\n 'Save all *vsheets* to *givenpath*.'\n\n filetype = givenpath.ext or options.save_filetype\n\n vd.clearCaches()\n\n savefunc = getattr(vsheets[0], 'save_' + filetype, None) or getattr(vd, 'save_' + filetype, None)\n\n if savefunc is None:\n savefunc = getattr(vd, 'save_' + options.save_filetype, None) or vd.fail('no function to save as type %s, set options.save_filetype' % filetype)\n vd.warning(f'save for {filetype} unavailable, using {options.save_filetype}')\n\n if givenpath.exists() and confirm_overwrite:\n vd.confirm(\"%s already exists. overwrite? \" % givenpath.given)\n\n vd.status('saving %s sheets to %s as %s' % (len(vsheets), givenpath.given, filetype))\n\n if not givenpath.given.endswith('/'): # forcibly specify save individual files into directory by ending path with /\n for vs in vsheets:\n vs.hasBeenModified = False\n return vd.execAsync(savefunc, givenpath, *vsheets)\n\n # more than one sheet; either no specific multisave for save filetype, or path ends with /\n\n # save as individual files in the givenpath directory\n try:\n os.makedirs(givenpath, exist_ok=True)\n except FileExistsError:\n pass\n\n if not givenpath.is_dir():\n vd.fail(f'cannot save multiple {filetype} sheets to non-dir')\n\n def _savefiles(vsheets, givenpath, savefunc, filetype):\n for vs in vsheets:\n p = Path((givenpath / vs.name).with_suffix('.'+filetype))\n savefunc(p, vs)\n vs.hasBeenModified = False\n return vd.execAsync(_savefiles, vsheets, givenpath, savefunc, filetype)\n\n\[email protected]\ndef save_txt(vd, p, *vsheets):\n with p.open_text(mode='w', encoding=vsheets[0].options.encoding) as fp:\n for vs in vsheets:\n unitsep = vs.options.delimiter\n rowsep = vs.options.row_delimiter\n for dispvals in vs.iterdispvals(*vs.visibleCols, format=True):\n fp.write(unitsep.join(dispvals.values()))\n fp.write(rowsep)\n vd.status('%s save finished' % p)\n\n\nBaseSheet.addCommand('^S', 'save-sheet', 'vd.saveSheets(inputPath(\"save to: \", value=getDefaultSaveName()), sheet, confirm_overwrite=options.confirm_overwrite)', 'save current sheet to filename in format determined by extension (default .tsv)')\nBaseSheet.addCommand('g^S', 'save-all', 'vd.saveSheets(inputPath(\"save all sheets to: \"), *vd.stackedSheets, confirm_overwrite=options.confirm_overwrite)', 'save all sheets to given file or directory)')\nIndexSheet.addCommand('g^S', 'save-selected', 'vd.saveSheets(inputPath(\"save %d sheets to: \" % nSelectedRows, value=str(source)), *selectedRows, confirm_overwrite=options.confirm_overwrite)', 'save all selected sheets to given file or directory')\nSheet.addCommand('', 'save-col', 'save_cols([cursorCol])', 'save current column only to filename in format determined by extension (default .tsv)')\nSheet.addCommand('', 'save-col-keys', 'save_cols(keyCols + [cursorCol])', 'save key columns and current column to filename in format determined by extension (default .tsv)')\n", "path": "visidata/save.py"}]}
| 3,817 | 617 |
gh_patches_debug_21295
|
rasdani/github-patches
|
git_diff
|
sublimelsp__LSP-1512
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Recursive variable expansion in lsp_execute command
**Is your feature request related to a problem? Please describe.**
The documentation states ...
```js
[
// ...
{
"caption": "Thread First",
"command": "lsp_execute",
"args": {
"command_name": "thread-first",
"command_args": ["${file_uri}", 0, 0]
}
}
]
```
Note: `command_args` is optional depending on the `workspace/executeCommand` that are supported by the LSP server.
The following **variables will be expanded, but only if they are top-level array items** and not within nested arrays or objects:
The **LemMinX** language server provides a validation command which expects [textDocumentIdentifie](https://microsoft.github.io/language-server-protocol/specification#textDocumentIdentifier) as first parameter.
see: https://github.com/eclipse/lemminx/pull/938
The proper command definition in ST would look like
```
[
{
"caption": "XML: Validate File",
"command": "lsp_execute",
"args": {
"command_name": "xml.validation.current.file",
"command_args": [{"uri": "${file_uri}"}]
}
}
]
```
Unfortunatelly `${file_uri}` is not expanded as it is not in the top-level array.
**Describe the solution you'd like**
The most flexible and straight forward solution would probably be to support recursive variable expansions in all nested arrays and objects.
**Describe alternatives you've considered**
An `$document_id` variable which is expanded to `{"uri": "file:///path/to/file.xml"}` would do the job as well. The command definition would look as follows then.
```
[
{
"caption": "XML: Validate File",
"command": "lsp_execute",
"args": {
"command_name": "xml.validation.current.file",
"command_args": ["$document_id"]
}
}
]
```
</issue>
<code>
[start of plugin/execute_command.py]
1 import sublime
2 from .core.protocol import Error
3 from .core.protocol import ExecuteCommandParams
4 from .core.registry import LspTextCommand
5 from .core.typing import List, Optional, Any
6 from .core.views import uri_from_view, offset_to_point, region_to_range
7
8
9 class LspExecuteCommand(LspTextCommand):
10
11 capability = 'executeCommandProvider'
12
13 def run(self,
14 edit: sublime.Edit,
15 command_name: Optional[str] = None,
16 command_args: Optional[List[Any]] = None,
17 session_name: Optional[str] = None,
18 event: Optional[dict] = None) -> None:
19 session = self.session_by_name(session_name) if session_name else self.best_session(self.capability)
20 if session and command_name:
21 if command_args:
22 self._expand_variables(command_args)
23 params = {"command": command_name} # type: ExecuteCommandParams
24 if command_args:
25 params["arguments"] = command_args
26
27 def handle_response(response: Any) -> None:
28 assert command_name
29 if isinstance(response, Error):
30 sublime.message_dialog("command {} failed. Reason: {}".format(command_name, str(response)))
31 return
32 msg = "command {} completed".format(command_name)
33 if response:
34 msg += "with response: {}".format(response)
35 window = self.view.window()
36 if window:
37 window.status_message(msg)
38
39 session.execute_command(params).then(handle_response)
40
41 def _expand_variables(self, command_args: List[Any]) -> None:
42 region = self.view.sel()[0]
43 for i, arg in enumerate(command_args):
44 if arg in ["$file_uri", "${file_uri}"]:
45 command_args[i] = uri_from_view(self.view)
46 elif arg in ["$selection", "${selection}"]:
47 command_args[i] = self.view.substr(region)
48 elif arg in ["$offset", "${offset}"]:
49 command_args[i] = region.b
50 elif arg in ["$selection_begin", "${selection_begin}"]:
51 command_args[i] = region.begin()
52 elif arg in ["$selection_end", "${selection_end}"]:
53 command_args[i] = region.end()
54 elif arg in ["$position", "${position}"]:
55 command_args[i] = offset_to_point(self.view, region.b).to_lsp()
56 elif arg in ["$range", "${range}"]:
57 command_args[i] = region_to_range(self.view, region).to_lsp()
58
[end of plugin/execute_command.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/plugin/execute_command.py b/plugin/execute_command.py
--- a/plugin/execute_command.py
+++ b/plugin/execute_command.py
@@ -3,7 +3,7 @@
from .core.protocol import ExecuteCommandParams
from .core.registry import LspTextCommand
from .core.typing import List, Optional, Any
-from .core.views import uri_from_view, offset_to_point, region_to_range
+from .core.views import uri_from_view, offset_to_point, region_to_range, text_document_identifier
class LspExecuteCommand(LspTextCommand):
@@ -41,6 +41,8 @@
def _expand_variables(self, command_args: List[Any]) -> None:
region = self.view.sel()[0]
for i, arg in enumerate(command_args):
+ if arg in ["$document_id", "${document_id}"]:
+ command_args[i] = text_document_identifier(self.view)
if arg in ["$file_uri", "${file_uri}"]:
command_args[i] = uri_from_view(self.view)
elif arg in ["$selection", "${selection}"]:
|
{"golden_diff": "diff --git a/plugin/execute_command.py b/plugin/execute_command.py\n--- a/plugin/execute_command.py\n+++ b/plugin/execute_command.py\n@@ -3,7 +3,7 @@\n from .core.protocol import ExecuteCommandParams\n from .core.registry import LspTextCommand\n from .core.typing import List, Optional, Any\n-from .core.views import uri_from_view, offset_to_point, region_to_range\n+from .core.views import uri_from_view, offset_to_point, region_to_range, text_document_identifier\n \n \n class LspExecuteCommand(LspTextCommand):\n@@ -41,6 +41,8 @@\n def _expand_variables(self, command_args: List[Any]) -> None:\n region = self.view.sel()[0]\n for i, arg in enumerate(command_args):\n+ if arg in [\"$document_id\", \"${document_id}\"]:\n+ command_args[i] = text_document_identifier(self.view)\n if arg in [\"$file_uri\", \"${file_uri}\"]:\n command_args[i] = uri_from_view(self.view)\n elif arg in [\"$selection\", \"${selection}\"]:\n", "issue": "Recursive variable expansion in lsp_execute command\n**Is your feature request related to a problem? Please describe.**\r\n\r\nThe documentation states ...\r\n\r\n```js\r\n[\r\n // ...\r\n {\r\n \"caption\": \"Thread First\",\r\n \"command\": \"lsp_execute\",\r\n \"args\": {\r\n \"command_name\": \"thread-first\",\r\n \"command_args\": [\"${file_uri}\", 0, 0]\r\n }\r\n }\r\n]\r\n```\r\n\r\nNote: `command_args` is optional depending on the `workspace/executeCommand` that are supported by the LSP server.\r\nThe following **variables will be expanded, but only if they are top-level array items** and not within nested arrays or objects:\r\n\r\nThe **LemMinX** language server provides a validation command which expects [textDocumentIdentifie](https://microsoft.github.io/language-server-protocol/specification#textDocumentIdentifier) as first parameter.\r\n\r\nsee: https://github.com/eclipse/lemminx/pull/938\r\n\r\nThe proper command definition in ST would look like\r\n\r\n```\r\n[\r\n\t{\r\n\t\t\"caption\": \"XML: Validate File\",\r\n\t\t\"command\": \"lsp_execute\",\r\n\t\t\"args\": {\r\n\t\t\t\"command_name\": \"xml.validation.current.file\",\r\n\t\t\t\"command_args\": [{\"uri\": \"${file_uri}\"}]\r\n\t\t}\r\n\t}\r\n]\r\n```\r\n\r\nUnfortunatelly `${file_uri}` is not expanded as it is not in the top-level array.\r\n\r\n**Describe the solution you'd like**\r\n\r\nThe most flexible and straight forward solution would probably be to support recursive variable expansions in all nested arrays and objects.\r\n\r\n**Describe alternatives you've considered**\r\n\r\nAn `$document_id` variable which is expanded to `{\"uri\": \"file:///path/to/file.xml\"}` would do the job as well. The command definition would look as follows then.\r\n\r\n```\r\n[\r\n\t{\r\n\t\t\"caption\": \"XML: Validate File\",\r\n\t\t\"command\": \"lsp_execute\",\r\n\t\t\"args\": {\r\n\t\t\t\"command_name\": \"xml.validation.current.file\",\r\n\t\t\t\"command_args\": [\"$document_id\"]\r\n\t\t}\r\n\t}\r\n]\r\n```\r\n\r\n\r\n\r\n\n", "before_files": [{"content": "import sublime\nfrom .core.protocol import Error\nfrom .core.protocol import ExecuteCommandParams\nfrom .core.registry import LspTextCommand\nfrom .core.typing import List, Optional, Any\nfrom .core.views import uri_from_view, offset_to_point, region_to_range\n\n\nclass LspExecuteCommand(LspTextCommand):\n\n capability = 'executeCommandProvider'\n\n def run(self,\n edit: sublime.Edit,\n command_name: Optional[str] = None,\n command_args: Optional[List[Any]] = None,\n session_name: Optional[str] = None,\n event: Optional[dict] = None) -> None:\n session = self.session_by_name(session_name) if session_name else self.best_session(self.capability)\n if session and command_name:\n if command_args:\n self._expand_variables(command_args)\n params = {\"command\": command_name} # type: ExecuteCommandParams\n if command_args:\n params[\"arguments\"] = command_args\n\n def handle_response(response: Any) -> None:\n assert command_name\n if isinstance(response, Error):\n sublime.message_dialog(\"command {} failed. Reason: {}\".format(command_name, str(response)))\n return\n msg = \"command {} completed\".format(command_name)\n if response:\n msg += \"with response: {}\".format(response)\n window = self.view.window()\n if window:\n window.status_message(msg)\n\n session.execute_command(params).then(handle_response)\n\n def _expand_variables(self, command_args: List[Any]) -> None:\n region = self.view.sel()[0]\n for i, arg in enumerate(command_args):\n if arg in [\"$file_uri\", \"${file_uri}\"]:\n command_args[i] = uri_from_view(self.view)\n elif arg in [\"$selection\", \"${selection}\"]:\n command_args[i] = self.view.substr(region)\n elif arg in [\"$offset\", \"${offset}\"]:\n command_args[i] = region.b\n elif arg in [\"$selection_begin\", \"${selection_begin}\"]:\n command_args[i] = region.begin()\n elif arg in [\"$selection_end\", \"${selection_end}\"]:\n command_args[i] = region.end()\n elif arg in [\"$position\", \"${position}\"]:\n command_args[i] = offset_to_point(self.view, region.b).to_lsp()\n elif arg in [\"$range\", \"${range}\"]:\n command_args[i] = region_to_range(self.view, region).to_lsp()\n", "path": "plugin/execute_command.py"}]}
| 1,612 | 236 |
gh_patches_debug_28886
|
rasdani/github-patches
|
git_diff
|
nltk__nltk-2787
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Remove outdated names in init.py
Cf #2508
</issue>
<code>
[start of nltk/__init__.py]
1 # Natural Language Toolkit (NLTK)
2 #
3 # Copyright (C) 2001-2021 NLTK Project
4 # Authors: Steven Bird <[email protected]>
5 # Edward Loper <[email protected]>
6 # URL: <http://nltk.org/>
7 # For license information, see LICENSE.TXT
8
9 """
10 The Natural Language Toolkit (NLTK) is an open source Python library
11 for Natural Language Processing. A free online book is available.
12 (If you use the library for academic research, please cite the book.)
13
14 Steven Bird, Ewan Klein, and Edward Loper (2009).
15 Natural Language Processing with Python. O'Reilly Media Inc.
16 http://nltk.org/book
17
18 isort:skip_file
19 """
20
21 import os
22
23 # //////////////////////////////////////////////////////
24 # Metadata
25 # //////////////////////////////////////////////////////
26
27 # Version. For each new release, the version number should be updated
28 # in the file VERSION.
29 try:
30 # If a VERSION file exists, use it!
31 version_file = os.path.join(os.path.dirname(__file__), "VERSION")
32 with open(version_file) as infile:
33 __version__ = infile.read().strip()
34 except NameError:
35 __version__ = "unknown (running code interactively?)"
36 except OSError as ex:
37 __version__ = "unknown (%s)" % ex
38
39 if __doc__ is not None: # fix for the ``python -OO``
40 __doc__ += "\n@version: " + __version__
41
42
43 # Copyright notice
44 __copyright__ = """\
45 Copyright (C) 2001-2021 NLTK Project.
46
47 Distributed and Licensed under the Apache License, Version 2.0,
48 which is included by reference.
49 """
50
51 __license__ = "Apache License, Version 2.0"
52 # Description of the toolkit, keywords, and the project's primary URL.
53 __longdescr__ = """\
54 The Natural Language Toolkit (NLTK) is a Python package for
55 natural language processing. NLTK requires Python 2.6 or higher."""
56 __keywords__ = [
57 "NLP",
58 "CL",
59 "natural language processing",
60 "computational linguistics",
61 "parsing",
62 "tagging",
63 "tokenizing",
64 "syntax",
65 "linguistics",
66 "language",
67 "natural language",
68 "text analytics",
69 ]
70 __url__ = "http://nltk.org/"
71
72 # Maintainer, contributors, etc.
73 __maintainer__ = "Steven Bird, Edward Loper, Ewan Klein"
74 __maintainer_email__ = "[email protected]"
75 __author__ = __maintainer__
76 __author_email__ = __maintainer_email__
77
78 # "Trove" classifiers for Python Package Index.
79 __classifiers__ = [
80 "Development Status :: 5 - Production/Stable",
81 "Intended Audience :: Developers",
82 "Intended Audience :: Education",
83 "Intended Audience :: Information Technology",
84 "Intended Audience :: Science/Research",
85 "License :: OSI Approved :: Apache Software License",
86 "Operating System :: OS Independent",
87 "Programming Language :: Python :: 2.6",
88 "Programming Language :: Python :: 2.7",
89 "Topic :: Scientific/Engineering",
90 "Topic :: Scientific/Engineering :: Artificial Intelligence",
91 "Topic :: Scientific/Engineering :: Human Machine Interfaces",
92 "Topic :: Scientific/Engineering :: Information Analysis",
93 "Topic :: Text Processing",
94 "Topic :: Text Processing :: Filters",
95 "Topic :: Text Processing :: General",
96 "Topic :: Text Processing :: Indexing",
97 "Topic :: Text Processing :: Linguistic",
98 ]
99
100 from nltk.internals import config_java
101
102 # support numpy from pypy
103 try:
104 import numpypy
105 except ImportError:
106 pass
107
108 # Override missing methods on environments where it cannot be used like GAE.
109 import subprocess
110
111 if not hasattr(subprocess, "PIPE"):
112
113 def _fake_PIPE(*args, **kwargs):
114 raise NotImplementedError("subprocess.PIPE is not supported.")
115
116 subprocess.PIPE = _fake_PIPE
117 if not hasattr(subprocess, "Popen"):
118
119 def _fake_Popen(*args, **kwargs):
120 raise NotImplementedError("subprocess.Popen is not supported.")
121
122 subprocess.Popen = _fake_Popen
123
124 ###########################################################
125 # TOP-LEVEL MODULES
126 ###########################################################
127
128 # Import top-level functionality into top-level namespace
129
130 from nltk.collocations import *
131 from nltk.decorators import decorator, memoize
132 from nltk.featstruct import *
133 from nltk.grammar import *
134 from nltk.probability import *
135 from nltk.text import *
136 from nltk.tree import *
137 from nltk.util import *
138 from nltk.jsontags import *
139
140 ###########################################################
141 # PACKAGES
142 ###########################################################
143
144 from nltk.chunk import *
145 from nltk.classify import *
146 from nltk.inference import *
147 from nltk.metrics import *
148 from nltk.parse import *
149 from nltk.tag import *
150 from nltk.tokenize import *
151 from nltk.translate import *
152 from nltk.sem import *
153 from nltk.stem import *
154
155 # Packages which can be lazily imported
156 # (a) we don't import *
157 # (b) they're slow to import or have run-time dependencies
158 # that can safely fail at run time
159
160 from nltk import lazyimport
161
162 app = lazyimport.LazyModule("nltk.app", locals(), globals())
163 chat = lazyimport.LazyModule("nltk.chat", locals(), globals())
164 corpus = lazyimport.LazyModule("nltk.corpus", locals(), globals())
165 draw = lazyimport.LazyModule("nltk.draw", locals(), globals())
166 toolbox = lazyimport.LazyModule("nltk.toolbox", locals(), globals())
167
168 # Optional loading
169
170 try:
171 import numpy
172 except ImportError:
173 pass
174 else:
175 from nltk import cluster
176
177 from nltk.downloader import download, download_shell
178
179 try:
180 import tkinter
181 except ImportError:
182 pass
183 else:
184 try:
185 from nltk.downloader import download_gui
186 except RuntimeError as e:
187 import warnings
188
189 warnings.warn(
190 "Corpus downloader GUI not loaded "
191 "(RuntimeError during import: %s)" % str(e)
192 )
193
194 # explicitly import all top-level modules (ensuring
195 # they override the same names inadvertently imported
196 # from a subpackage)
197
198 from nltk import ccg, chunk, classify, collocations
199 from nltk import data, featstruct, grammar, help, inference, metrics
200 from nltk import misc, parse, probability, sem, stem, wsd
201 from nltk import tag, tbl, text, tokenize, translate, tree, treetransforms, util
202
203
204 # FIXME: override any accidentally imported demo, see https://github.com/nltk/nltk/issues/2116
205 def demo():
206 print("To run the demo code for a module, type nltk.module.demo()")
207
[end of nltk/__init__.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/nltk/__init__.py b/nltk/__init__.py
--- a/nltk/__init__.py
+++ b/nltk/__init__.py
@@ -52,7 +52,7 @@
# Description of the toolkit, keywords, and the project's primary URL.
__longdescr__ = """\
The Natural Language Toolkit (NLTK) is a Python package for
-natural language processing. NLTK requires Python 2.6 or higher."""
+natural language processing. NLTK requires Python 3.6, 3.7, 3.8, or 3.9."""
__keywords__ = [
"NLP",
"CL",
@@ -70,7 +70,7 @@
__url__ = "http://nltk.org/"
# Maintainer, contributors, etc.
-__maintainer__ = "Steven Bird, Edward Loper, Ewan Klein"
+__maintainer__ = "Steven Bird"
__maintainer_email__ = "[email protected]"
__author__ = __maintainer__
__author_email__ = __maintainer_email__
@@ -84,8 +84,10 @@
"Intended Audience :: Science/Research",
"License :: OSI Approved :: Apache Software License",
"Operating System :: OS Independent",
- "Programming Language :: Python :: 2.6",
- "Programming Language :: Python :: 2.7",
+ "Programming Language :: Python :: 3.6",
+ "Programming Language :: Python :: 3.7",
+ "Programming Language :: Python :: 3.8",
+ "Programming Language :: Python :: 3.9",
"Topic :: Scientific/Engineering",
"Topic :: Scientific/Engineering :: Artificial Intelligence",
"Topic :: Scientific/Engineering :: Human Machine Interfaces",
|
{"golden_diff": "diff --git a/nltk/__init__.py b/nltk/__init__.py\n--- a/nltk/__init__.py\n+++ b/nltk/__init__.py\n@@ -52,7 +52,7 @@\n # Description of the toolkit, keywords, and the project's primary URL.\n __longdescr__ = \"\"\"\\\n The Natural Language Toolkit (NLTK) is a Python package for\n-natural language processing. NLTK requires Python 2.6 or higher.\"\"\"\n+natural language processing. NLTK requires Python 3.6, 3.7, 3.8, or 3.9.\"\"\"\n __keywords__ = [\n \"NLP\",\n \"CL\",\n@@ -70,7 +70,7 @@\n __url__ = \"http://nltk.org/\"\n \n # Maintainer, contributors, etc.\n-__maintainer__ = \"Steven Bird, Edward Loper, Ewan Klein\"\n+__maintainer__ = \"Steven Bird\"\n __maintainer_email__ = \"[email protected]\"\n __author__ = __maintainer__\n __author_email__ = __maintainer_email__\n@@ -84,8 +84,10 @@\n \"Intended Audience :: Science/Research\",\n \"License :: OSI Approved :: Apache Software License\",\n \"Operating System :: OS Independent\",\n- \"Programming Language :: Python :: 2.6\",\n- \"Programming Language :: Python :: 2.7\",\n+ \"Programming Language :: Python :: 3.6\",\n+ \"Programming Language :: Python :: 3.7\",\n+ \"Programming Language :: Python :: 3.8\",\n+ \"Programming Language :: Python :: 3.9\",\n \"Topic :: Scientific/Engineering\",\n \"Topic :: Scientific/Engineering :: Artificial Intelligence\",\n \"Topic :: Scientific/Engineering :: Human Machine Interfaces\",\n", "issue": "Remove outdated names in init.py\nCf #2508 \r\n\n", "before_files": [{"content": "# Natural Language Toolkit (NLTK)\n#\n# Copyright (C) 2001-2021 NLTK Project\n# Authors: Steven Bird <[email protected]>\n# Edward Loper <[email protected]>\n# URL: <http://nltk.org/>\n# For license information, see LICENSE.TXT\n\n\"\"\"\nThe Natural Language Toolkit (NLTK) is an open source Python library\nfor Natural Language Processing. A free online book is available.\n(If you use the library for academic research, please cite the book.)\n\nSteven Bird, Ewan Klein, and Edward Loper (2009).\nNatural Language Processing with Python. O'Reilly Media Inc.\nhttp://nltk.org/book\n\nisort:skip_file\n\"\"\"\n\nimport os\n\n# //////////////////////////////////////////////////////\n# Metadata\n# //////////////////////////////////////////////////////\n\n# Version. For each new release, the version number should be updated\n# in the file VERSION.\ntry:\n # If a VERSION file exists, use it!\n version_file = os.path.join(os.path.dirname(__file__), \"VERSION\")\n with open(version_file) as infile:\n __version__ = infile.read().strip()\nexcept NameError:\n __version__ = \"unknown (running code interactively?)\"\nexcept OSError as ex:\n __version__ = \"unknown (%s)\" % ex\n\nif __doc__ is not None: # fix for the ``python -OO``\n __doc__ += \"\\n@version: \" + __version__\n\n\n# Copyright notice\n__copyright__ = \"\"\"\\\nCopyright (C) 2001-2021 NLTK Project.\n\nDistributed and Licensed under the Apache License, Version 2.0,\nwhich is included by reference.\n\"\"\"\n\n__license__ = \"Apache License, Version 2.0\"\n# Description of the toolkit, keywords, and the project's primary URL.\n__longdescr__ = \"\"\"\\\nThe Natural Language Toolkit (NLTK) is a Python package for\nnatural language processing. NLTK requires Python 2.6 or higher.\"\"\"\n__keywords__ = [\n \"NLP\",\n \"CL\",\n \"natural language processing\",\n \"computational linguistics\",\n \"parsing\",\n \"tagging\",\n \"tokenizing\",\n \"syntax\",\n \"linguistics\",\n \"language\",\n \"natural language\",\n \"text analytics\",\n]\n__url__ = \"http://nltk.org/\"\n\n# Maintainer, contributors, etc.\n__maintainer__ = \"Steven Bird, Edward Loper, Ewan Klein\"\n__maintainer_email__ = \"[email protected]\"\n__author__ = __maintainer__\n__author_email__ = __maintainer_email__\n\n# \"Trove\" classifiers for Python Package Index.\n__classifiers__ = [\n \"Development Status :: 5 - Production/Stable\",\n \"Intended Audience :: Developers\",\n \"Intended Audience :: Education\",\n \"Intended Audience :: Information Technology\",\n \"Intended Audience :: Science/Research\",\n \"License :: OSI Approved :: Apache Software License\",\n \"Operating System :: OS Independent\",\n \"Programming Language :: Python :: 2.6\",\n \"Programming Language :: Python :: 2.7\",\n \"Topic :: Scientific/Engineering\",\n \"Topic :: Scientific/Engineering :: Artificial Intelligence\",\n \"Topic :: Scientific/Engineering :: Human Machine Interfaces\",\n \"Topic :: Scientific/Engineering :: Information Analysis\",\n \"Topic :: Text Processing\",\n \"Topic :: Text Processing :: Filters\",\n \"Topic :: Text Processing :: General\",\n \"Topic :: Text Processing :: Indexing\",\n \"Topic :: Text Processing :: Linguistic\",\n]\n\nfrom nltk.internals import config_java\n\n# support numpy from pypy\ntry:\n import numpypy\nexcept ImportError:\n pass\n\n# Override missing methods on environments where it cannot be used like GAE.\nimport subprocess\n\nif not hasattr(subprocess, \"PIPE\"):\n\n def _fake_PIPE(*args, **kwargs):\n raise NotImplementedError(\"subprocess.PIPE is not supported.\")\n\n subprocess.PIPE = _fake_PIPE\nif not hasattr(subprocess, \"Popen\"):\n\n def _fake_Popen(*args, **kwargs):\n raise NotImplementedError(\"subprocess.Popen is not supported.\")\n\n subprocess.Popen = _fake_Popen\n\n###########################################################\n# TOP-LEVEL MODULES\n###########################################################\n\n# Import top-level functionality into top-level namespace\n\nfrom nltk.collocations import *\nfrom nltk.decorators import decorator, memoize\nfrom nltk.featstruct import *\nfrom nltk.grammar import *\nfrom nltk.probability import *\nfrom nltk.text import *\nfrom nltk.tree import *\nfrom nltk.util import *\nfrom nltk.jsontags import *\n\n###########################################################\n# PACKAGES\n###########################################################\n\nfrom nltk.chunk import *\nfrom nltk.classify import *\nfrom nltk.inference import *\nfrom nltk.metrics import *\nfrom nltk.parse import *\nfrom nltk.tag import *\nfrom nltk.tokenize import *\nfrom nltk.translate import *\nfrom nltk.sem import *\nfrom nltk.stem import *\n\n# Packages which can be lazily imported\n# (a) we don't import *\n# (b) they're slow to import or have run-time dependencies\n# that can safely fail at run time\n\nfrom nltk import lazyimport\n\napp = lazyimport.LazyModule(\"nltk.app\", locals(), globals())\nchat = lazyimport.LazyModule(\"nltk.chat\", locals(), globals())\ncorpus = lazyimport.LazyModule(\"nltk.corpus\", locals(), globals())\ndraw = lazyimport.LazyModule(\"nltk.draw\", locals(), globals())\ntoolbox = lazyimport.LazyModule(\"nltk.toolbox\", locals(), globals())\n\n# Optional loading\n\ntry:\n import numpy\nexcept ImportError:\n pass\nelse:\n from nltk import cluster\n\nfrom nltk.downloader import download, download_shell\n\ntry:\n import tkinter\nexcept ImportError:\n pass\nelse:\n try:\n from nltk.downloader import download_gui\n except RuntimeError as e:\n import warnings\n\n warnings.warn(\n \"Corpus downloader GUI not loaded \"\n \"(RuntimeError during import: %s)\" % str(e)\n )\n\n# explicitly import all top-level modules (ensuring\n# they override the same names inadvertently imported\n# from a subpackage)\n\nfrom nltk import ccg, chunk, classify, collocations\nfrom nltk import data, featstruct, grammar, help, inference, metrics\nfrom nltk import misc, parse, probability, sem, stem, wsd\nfrom nltk import tag, tbl, text, tokenize, translate, tree, treetransforms, util\n\n\n# FIXME: override any accidentally imported demo, see https://github.com/nltk/nltk/issues/2116\ndef demo():\n print(\"To run the demo code for a module, type nltk.module.demo()\")\n", "path": "nltk/__init__.py"}]}
| 2,498 | 389 |
gh_patches_debug_25760
|
rasdani/github-patches
|
git_diff
|
kedro-org__kedro-2891
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Add `kedro catalog resolve` CLI command
## Description
Child of #2603
</issue>
<code>
[start of kedro/framework/cli/catalog.py]
1 """A collection of CLI commands for working with Kedro catalog."""
2 from collections import defaultdict
3 from itertools import chain
4
5 import click
6 import yaml
7 from click import secho
8
9 from kedro.framework.cli.utils import KedroCliError, env_option, split_string
10 from kedro.framework.project import pipelines, settings
11 from kedro.framework.session import KedroSession
12 from kedro.framework.startup import ProjectMetadata
13
14
15 def _create_session(package_name: str, **kwargs):
16 kwargs.setdefault("save_on_close", False)
17 try:
18 return KedroSession.create(package_name, **kwargs)
19 except Exception as exc:
20 raise KedroCliError(
21 f"Unable to instantiate Kedro session.\nError: {exc}"
22 ) from exc
23
24
25 # noqa: missing-function-docstring
26 @click.group(name="Kedro")
27 def catalog_cli(): # pragma: no cover
28 pass
29
30
31 @catalog_cli.group()
32 def catalog():
33 """Commands for working with catalog."""
34
35
36 # noqa: too-many-locals,protected-access
37 @catalog.command("list")
38 @env_option
39 @click.option(
40 "--pipeline",
41 "-p",
42 type=str,
43 default="",
44 help="Name of the modular pipeline to run. If not set, "
45 "the project pipeline is run by default.",
46 callback=split_string,
47 )
48 @click.pass_obj
49 def list_datasets(metadata: ProjectMetadata, pipeline, env):
50 """Show datasets per type."""
51 title = "Datasets in '{}' pipeline"
52 not_mentioned = "Datasets not mentioned in pipeline"
53 mentioned = "Datasets mentioned in pipeline"
54 factories = "Datasets generated from factories"
55
56 session = _create_session(metadata.package_name, env=env)
57 context = session.load_context()
58
59 data_catalog = context.catalog
60 datasets_meta = data_catalog._data_sets
61 catalog_ds = set(data_catalog.list())
62
63 target_pipelines = pipeline or pipelines.keys()
64
65 result = {}
66 for pipe in target_pipelines:
67 pl_obj = pipelines.get(pipe)
68 if pl_obj:
69 pipeline_ds = pl_obj.data_sets()
70 else:
71 existing_pls = ", ".join(sorted(pipelines.keys()))
72 raise KedroCliError(
73 f"'{pipe}' pipeline not found! Existing pipelines: {existing_pls}"
74 )
75
76 unused_ds = catalog_ds - pipeline_ds
77 default_ds = pipeline_ds - catalog_ds
78 used_ds = catalog_ds - unused_ds
79
80 # resolve any factory datasets in the pipeline
81 factory_ds_by_type = defaultdict(list)
82 for ds_name in default_ds:
83 matched_pattern = data_catalog._match_pattern(
84 data_catalog._dataset_patterns, ds_name
85 )
86 if matched_pattern:
87 ds_config = data_catalog._resolve_config(ds_name, matched_pattern)
88 factory_ds_by_type[ds_config["type"]].append(ds_name)
89
90 default_ds = default_ds - set(chain.from_iterable(factory_ds_by_type.values()))
91
92 unused_by_type = _map_type_to_datasets(unused_ds, datasets_meta)
93 used_by_type = _map_type_to_datasets(used_ds, datasets_meta)
94
95 if default_ds:
96 used_by_type["DefaultDataset"].extend(default_ds)
97
98 data = (
99 (mentioned, dict(used_by_type)),
100 (factories, dict(factory_ds_by_type)),
101 (not_mentioned, dict(unused_by_type)),
102 )
103 result[title.format(pipe)] = {key: value for key, value in data if value}
104 secho(yaml.dump(result))
105
106
107 def _map_type_to_datasets(datasets, datasets_meta):
108 """Build dictionary with a dataset type as a key and list of
109 datasets of the specific type as a value.
110 """
111 mapping = defaultdict(list)
112 for dataset in datasets:
113 is_param = dataset.startswith("params:") or dataset == "parameters"
114 if not is_param:
115 ds_type = datasets_meta[dataset].__class__.__name__
116 if dataset not in mapping[ds_type]:
117 mapping[ds_type].append(dataset)
118 return mapping
119
120
121 @catalog.command("create")
122 @env_option(help="Environment to create Data Catalog YAML file in. Defaults to `base`.")
123 @click.option(
124 "--pipeline",
125 "-p",
126 "pipeline_name",
127 type=str,
128 required=True,
129 help="Name of a pipeline.",
130 )
131 @click.pass_obj
132 def create_catalog(metadata: ProjectMetadata, pipeline_name, env):
133 """Create Data Catalog YAML configuration with missing datasets.
134
135 Add ``MemoryDataset`` datasets to Data Catalog YAML configuration
136 file for each dataset in a registered pipeline if it is missing from
137 the ``DataCatalog``.
138
139 The catalog configuration will be saved to
140 `<conf_source>/<env>/catalog/<pipeline_name>.yml` file.
141 """
142 env = env or "base"
143 session = _create_session(metadata.package_name, env=env)
144 context = session.load_context()
145
146 pipeline = pipelines.get(pipeline_name)
147
148 if not pipeline:
149 existing_pipelines = ", ".join(sorted(pipelines.keys()))
150 raise KedroCliError(
151 f"'{pipeline_name}' pipeline not found! Existing pipelines: {existing_pipelines}"
152 )
153
154 pipe_datasets = {
155 ds_name
156 for ds_name in pipeline.data_sets()
157 if not ds_name.startswith("params:") and ds_name != "parameters"
158 }
159
160 catalog_datasets = {
161 ds_name
162 for ds_name in context.catalog._data_sets.keys() # noqa: protected-access
163 if not ds_name.startswith("params:") and ds_name != "parameters"
164 }
165
166 # Datasets that are missing in Data Catalog
167 missing_ds = sorted(pipe_datasets - catalog_datasets)
168 if missing_ds:
169 catalog_path = (
170 context.project_path
171 / settings.CONF_SOURCE
172 / env
173 / f"catalog_{pipeline_name}.yml"
174 )
175 _add_missing_datasets_to_catalog(missing_ds, catalog_path)
176 click.echo(f"Data Catalog YAML configuration was created: {catalog_path}")
177 else:
178 click.echo("All datasets are already configured.")
179
180
181 def _add_missing_datasets_to_catalog(missing_ds, catalog_path):
182 if catalog_path.is_file():
183 catalog_config = yaml.safe_load(catalog_path.read_text()) or {}
184 else:
185 catalog_config = {}
186
187 for ds_name in missing_ds:
188 catalog_config[ds_name] = {"type": "MemoryDataset"}
189
190 # Create only `catalog` folder under existing environment
191 # (all parent folders must exist).
192 catalog_path.parent.mkdir(exist_ok=True)
193 with catalog_path.open(mode="w") as catalog_file:
194 yaml.safe_dump(catalog_config, catalog_file, default_flow_style=False)
195
196
197 @catalog.command("rank")
198 @env_option
199 @click.pass_obj
200 def rank_catalog_factories(metadata: ProjectMetadata, env):
201 """List all dataset factories in the catalog, ranked by priority by which they are matched."""
202 session = _create_session(metadata.package_name, env=env)
203 context = session.load_context()
204
205 catalog_factories = context.catalog._dataset_patterns
206 if catalog_factories:
207 click.echo(yaml.dump(list(catalog_factories.keys())))
208 else:
209 click.echo("There are no dataset factories in the catalog.")
210
[end of kedro/framework/cli/catalog.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/kedro/framework/cli/catalog.py b/kedro/framework/cli/catalog.py
--- a/kedro/framework/cli/catalog.py
+++ b/kedro/framework/cli/catalog.py
@@ -207,3 +207,51 @@
click.echo(yaml.dump(list(catalog_factories.keys())))
else:
click.echo("There are no dataset factories in the catalog.")
+
+
[email protected]("resolve")
+@env_option
[email protected]_obj
+def resolve_patterns(metadata: ProjectMetadata, env):
+ """Resolve catalog factories against pipeline datasets"""
+
+ session = _create_session(metadata.package_name, env=env)
+ context = session.load_context()
+
+ data_catalog = context.catalog
+ catalog_config = context.config_loader["catalog"]
+
+ explicit_datasets = {
+ ds_name: ds_config
+ for ds_name, ds_config in catalog_config.items()
+ if not data_catalog._is_pattern(ds_name)
+ }
+
+ target_pipelines = pipelines.keys()
+ datasets = set()
+
+ for pipe in target_pipelines:
+ pl_obj = pipelines.get(pipe)
+ if pl_obj:
+ datasets.update(pl_obj.data_sets())
+
+ for ds_name in datasets:
+ is_param = ds_name.startswith("params:") or ds_name == "parameters"
+ if ds_name in explicit_datasets or is_param:
+ continue
+
+ matched_pattern = data_catalog._match_pattern(
+ data_catalog._dataset_patterns, ds_name
+ )
+ if matched_pattern:
+ ds_config = data_catalog._resolve_config(ds_name, matched_pattern)
+ ds_config["filepath"] = _trim_filepath(
+ str(context.project_path) + "/", ds_config["filepath"]
+ )
+ explicit_datasets[ds_name] = ds_config
+
+ secho(yaml.dump(explicit_datasets))
+
+
+def _trim_filepath(project_path: str, file_path: str):
+ return file_path.replace(project_path, "", 1)
|
{"golden_diff": "diff --git a/kedro/framework/cli/catalog.py b/kedro/framework/cli/catalog.py\n--- a/kedro/framework/cli/catalog.py\n+++ b/kedro/framework/cli/catalog.py\n@@ -207,3 +207,51 @@\n click.echo(yaml.dump(list(catalog_factories.keys())))\n else:\n click.echo(\"There are no dataset factories in the catalog.\")\n+\n+\[email protected](\"resolve\")\n+@env_option\[email protected]_obj\n+def resolve_patterns(metadata: ProjectMetadata, env):\n+ \"\"\"Resolve catalog factories against pipeline datasets\"\"\"\n+\n+ session = _create_session(metadata.package_name, env=env)\n+ context = session.load_context()\n+\n+ data_catalog = context.catalog\n+ catalog_config = context.config_loader[\"catalog\"]\n+\n+ explicit_datasets = {\n+ ds_name: ds_config\n+ for ds_name, ds_config in catalog_config.items()\n+ if not data_catalog._is_pattern(ds_name)\n+ }\n+\n+ target_pipelines = pipelines.keys()\n+ datasets = set()\n+\n+ for pipe in target_pipelines:\n+ pl_obj = pipelines.get(pipe)\n+ if pl_obj:\n+ datasets.update(pl_obj.data_sets())\n+\n+ for ds_name in datasets:\n+ is_param = ds_name.startswith(\"params:\") or ds_name == \"parameters\"\n+ if ds_name in explicit_datasets or is_param:\n+ continue\n+\n+ matched_pattern = data_catalog._match_pattern(\n+ data_catalog._dataset_patterns, ds_name\n+ )\n+ if matched_pattern:\n+ ds_config = data_catalog._resolve_config(ds_name, matched_pattern)\n+ ds_config[\"filepath\"] = _trim_filepath(\n+ str(context.project_path) + \"/\", ds_config[\"filepath\"]\n+ )\n+ explicit_datasets[ds_name] = ds_config\n+\n+ secho(yaml.dump(explicit_datasets))\n+\n+\n+def _trim_filepath(project_path: str, file_path: str):\n+ return file_path.replace(project_path, \"\", 1)\n", "issue": "Add `kedro catalog resolve` CLI command\n## Description\r\nChild of #2603 \n", "before_files": [{"content": "\"\"\"A collection of CLI commands for working with Kedro catalog.\"\"\"\nfrom collections import defaultdict\nfrom itertools import chain\n\nimport click\nimport yaml\nfrom click import secho\n\nfrom kedro.framework.cli.utils import KedroCliError, env_option, split_string\nfrom kedro.framework.project import pipelines, settings\nfrom kedro.framework.session import KedroSession\nfrom kedro.framework.startup import ProjectMetadata\n\n\ndef _create_session(package_name: str, **kwargs):\n kwargs.setdefault(\"save_on_close\", False)\n try:\n return KedroSession.create(package_name, **kwargs)\n except Exception as exc:\n raise KedroCliError(\n f\"Unable to instantiate Kedro session.\\nError: {exc}\"\n ) from exc\n\n\n# noqa: missing-function-docstring\[email protected](name=\"Kedro\")\ndef catalog_cli(): # pragma: no cover\n pass\n\n\n@catalog_cli.group()\ndef catalog():\n \"\"\"Commands for working with catalog.\"\"\"\n\n\n# noqa: too-many-locals,protected-access\[email protected](\"list\")\n@env_option\[email protected](\n \"--pipeline\",\n \"-p\",\n type=str,\n default=\"\",\n help=\"Name of the modular pipeline to run. If not set, \"\n \"the project pipeline is run by default.\",\n callback=split_string,\n)\[email protected]_obj\ndef list_datasets(metadata: ProjectMetadata, pipeline, env):\n \"\"\"Show datasets per type.\"\"\"\n title = \"Datasets in '{}' pipeline\"\n not_mentioned = \"Datasets not mentioned in pipeline\"\n mentioned = \"Datasets mentioned in pipeline\"\n factories = \"Datasets generated from factories\"\n\n session = _create_session(metadata.package_name, env=env)\n context = session.load_context()\n\n data_catalog = context.catalog\n datasets_meta = data_catalog._data_sets\n catalog_ds = set(data_catalog.list())\n\n target_pipelines = pipeline or pipelines.keys()\n\n result = {}\n for pipe in target_pipelines:\n pl_obj = pipelines.get(pipe)\n if pl_obj:\n pipeline_ds = pl_obj.data_sets()\n else:\n existing_pls = \", \".join(sorted(pipelines.keys()))\n raise KedroCliError(\n f\"'{pipe}' pipeline not found! Existing pipelines: {existing_pls}\"\n )\n\n unused_ds = catalog_ds - pipeline_ds\n default_ds = pipeline_ds - catalog_ds\n used_ds = catalog_ds - unused_ds\n\n # resolve any factory datasets in the pipeline\n factory_ds_by_type = defaultdict(list)\n for ds_name in default_ds:\n matched_pattern = data_catalog._match_pattern(\n data_catalog._dataset_patterns, ds_name\n )\n if matched_pattern:\n ds_config = data_catalog._resolve_config(ds_name, matched_pattern)\n factory_ds_by_type[ds_config[\"type\"]].append(ds_name)\n\n default_ds = default_ds - set(chain.from_iterable(factory_ds_by_type.values()))\n\n unused_by_type = _map_type_to_datasets(unused_ds, datasets_meta)\n used_by_type = _map_type_to_datasets(used_ds, datasets_meta)\n\n if default_ds:\n used_by_type[\"DefaultDataset\"].extend(default_ds)\n\n data = (\n (mentioned, dict(used_by_type)),\n (factories, dict(factory_ds_by_type)),\n (not_mentioned, dict(unused_by_type)),\n )\n result[title.format(pipe)] = {key: value for key, value in data if value}\n secho(yaml.dump(result))\n\n\ndef _map_type_to_datasets(datasets, datasets_meta):\n \"\"\"Build dictionary with a dataset type as a key and list of\n datasets of the specific type as a value.\n \"\"\"\n mapping = defaultdict(list)\n for dataset in datasets:\n is_param = dataset.startswith(\"params:\") or dataset == \"parameters\"\n if not is_param:\n ds_type = datasets_meta[dataset].__class__.__name__\n if dataset not in mapping[ds_type]:\n mapping[ds_type].append(dataset)\n return mapping\n\n\[email protected](\"create\")\n@env_option(help=\"Environment to create Data Catalog YAML file in. Defaults to `base`.\")\[email protected](\n \"--pipeline\",\n \"-p\",\n \"pipeline_name\",\n type=str,\n required=True,\n help=\"Name of a pipeline.\",\n)\[email protected]_obj\ndef create_catalog(metadata: ProjectMetadata, pipeline_name, env):\n \"\"\"Create Data Catalog YAML configuration with missing datasets.\n\n Add ``MemoryDataset`` datasets to Data Catalog YAML configuration\n file for each dataset in a registered pipeline if it is missing from\n the ``DataCatalog``.\n\n The catalog configuration will be saved to\n `<conf_source>/<env>/catalog/<pipeline_name>.yml` file.\n \"\"\"\n env = env or \"base\"\n session = _create_session(metadata.package_name, env=env)\n context = session.load_context()\n\n pipeline = pipelines.get(pipeline_name)\n\n if not pipeline:\n existing_pipelines = \", \".join(sorted(pipelines.keys()))\n raise KedroCliError(\n f\"'{pipeline_name}' pipeline not found! Existing pipelines: {existing_pipelines}\"\n )\n\n pipe_datasets = {\n ds_name\n for ds_name in pipeline.data_sets()\n if not ds_name.startswith(\"params:\") and ds_name != \"parameters\"\n }\n\n catalog_datasets = {\n ds_name\n for ds_name in context.catalog._data_sets.keys() # noqa: protected-access\n if not ds_name.startswith(\"params:\") and ds_name != \"parameters\"\n }\n\n # Datasets that are missing in Data Catalog\n missing_ds = sorted(pipe_datasets - catalog_datasets)\n if missing_ds:\n catalog_path = (\n context.project_path\n / settings.CONF_SOURCE\n / env\n / f\"catalog_{pipeline_name}.yml\"\n )\n _add_missing_datasets_to_catalog(missing_ds, catalog_path)\n click.echo(f\"Data Catalog YAML configuration was created: {catalog_path}\")\n else:\n click.echo(\"All datasets are already configured.\")\n\n\ndef _add_missing_datasets_to_catalog(missing_ds, catalog_path):\n if catalog_path.is_file():\n catalog_config = yaml.safe_load(catalog_path.read_text()) or {}\n else:\n catalog_config = {}\n\n for ds_name in missing_ds:\n catalog_config[ds_name] = {\"type\": \"MemoryDataset\"}\n\n # Create only `catalog` folder under existing environment\n # (all parent folders must exist).\n catalog_path.parent.mkdir(exist_ok=True)\n with catalog_path.open(mode=\"w\") as catalog_file:\n yaml.safe_dump(catalog_config, catalog_file, default_flow_style=False)\n\n\[email protected](\"rank\")\n@env_option\[email protected]_obj\ndef rank_catalog_factories(metadata: ProjectMetadata, env):\n \"\"\"List all dataset factories in the catalog, ranked by priority by which they are matched.\"\"\"\n session = _create_session(metadata.package_name, env=env)\n context = session.load_context()\n\n catalog_factories = context.catalog._dataset_patterns\n if catalog_factories:\n click.echo(yaml.dump(list(catalog_factories.keys())))\n else:\n click.echo(\"There are no dataset factories in the catalog.\")\n", "path": "kedro/framework/cli/catalog.py"}]}
| 2,626 | 436 |
gh_patches_debug_8499
|
rasdani/github-patches
|
git_diff
|
openai__gym-994
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
MuJoCo env Box initialization causes warnings
In gym/gym/envs/mujoco/mujoco_env.py on line 46, Box object initialization is missing dtype=np.float32 parameter which causes autodetect warning spam.
</issue>
<code>
[start of gym/envs/mujoco/mujoco_env.py]
1 import os
2
3 from gym import error, spaces
4 from gym.utils import seeding
5 import numpy as np
6 from os import path
7 import gym
8 import six
9
10 try:
11 import mujoco_py
12 except ImportError as e:
13 raise error.DependencyNotInstalled("{}. (HINT: you need to install mujoco_py, and also perform the setup instructions here: https://github.com/openai/mujoco-py/.)".format(e))
14
15 class MujocoEnv(gym.Env):
16 """Superclass for all MuJoCo environments.
17 """
18
19 def __init__(self, model_path, frame_skip):
20 if model_path.startswith("/"):
21 fullpath = model_path
22 else:
23 fullpath = os.path.join(os.path.dirname(__file__), "assets", model_path)
24 if not path.exists(fullpath):
25 raise IOError("File %s does not exist" % fullpath)
26 self.frame_skip = frame_skip
27 self.model = mujoco_py.load_model_from_path(fullpath)
28 self.sim = mujoco_py.MjSim(self.model)
29 self.data = self.sim.data
30 self.viewer = None
31
32 self.metadata = {
33 'render.modes': ['human', 'rgb_array'],
34 'video.frames_per_second': int(np.round(1.0 / self.dt))
35 }
36
37 self.init_qpos = self.sim.data.qpos.ravel().copy()
38 self.init_qvel = self.sim.data.qvel.ravel().copy()
39 observation, _reward, done, _info = self.step(np.zeros(self.model.nu))
40 assert not done
41 self.obs_dim = observation.size
42
43 bounds = self.model.actuator_ctrlrange.copy()
44 low = bounds[:, 0]
45 high = bounds[:, 1]
46 self.action_space = spaces.Box(low=low, high=high)
47
48 high = np.inf*np.ones(self.obs_dim)
49 low = -high
50 self.observation_space = spaces.Box(low, high)
51
52 self.seed()
53
54 def seed(self, seed=None):
55 self.np_random, seed = seeding.np_random(seed)
56 return [seed]
57
58 # methods to override:
59 # ----------------------------
60
61 def reset_model(self):
62 """
63 Reset the robot degrees of freedom (qpos and qvel).
64 Implement this in each subclass.
65 """
66 raise NotImplementedError
67
68 def viewer_setup(self):
69 """
70 This method is called when the viewer is initialized and after every reset
71 Optionally implement this method, if you need to tinker with camera position
72 and so forth.
73 """
74 pass
75
76 # -----------------------------
77
78 def reset(self):
79 self.sim.reset()
80 ob = self.reset_model()
81 if self.viewer is not None:
82 self.viewer_setup()
83 return ob
84
85 def set_state(self, qpos, qvel):
86 assert qpos.shape == (self.model.nq,) and qvel.shape == (self.model.nv,)
87 old_state = self.sim.get_state()
88 new_state = mujoco_py.MjSimState(old_state.time, qpos, qvel,
89 old_state.act, old_state.udd_state)
90 self.sim.set_state(new_state)
91 self.sim.forward()
92
93 @property
94 def dt(self):
95 return self.model.opt.timestep * self.frame_skip
96
97 def do_simulation(self, ctrl, n_frames):
98 self.sim.data.ctrl[:] = ctrl
99 for _ in range(n_frames):
100 self.sim.step()
101
102 def render(self, mode='human'):
103 if mode == 'rgb_array':
104 self._get_viewer().render()
105 # window size used for old mujoco-py:
106 width, height = 500, 500
107 data = self._get_viewer().read_pixels(width, height, depth=False)
108 # original image is upside-down, so flip it
109 return data[::-1, :, :]
110 elif mode == 'human':
111 self._get_viewer().render()
112
113 def close(self):
114 if self.viewer is not None:
115 self.viewer.finish()
116 self.viewer = None
117
118 def _get_viewer(self):
119 if self.viewer is None:
120 self.viewer = mujoco_py.MjViewer(self.sim)
121 self.viewer_setup()
122 return self.viewer
123
124 def get_body_com(self, body_name):
125 return self.data.get_body_xpos(body_name)
126
127 def state_vector(self):
128 return np.concatenate([
129 self.sim.data.qpos.flat,
130 self.sim.data.qvel.flat
131 ])
132
[end of gym/envs/mujoco/mujoco_env.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/gym/envs/mujoco/mujoco_env.py b/gym/envs/mujoco/mujoco_env.py
--- a/gym/envs/mujoco/mujoco_env.py
+++ b/gym/envs/mujoco/mujoco_env.py
@@ -43,11 +43,11 @@
bounds = self.model.actuator_ctrlrange.copy()
low = bounds[:, 0]
high = bounds[:, 1]
- self.action_space = spaces.Box(low=low, high=high)
+ self.action_space = spaces.Box(low=low, high=high, dtype=np.float32)
high = np.inf*np.ones(self.obs_dim)
low = -high
- self.observation_space = spaces.Box(low, high)
+ self.observation_space = spaces.Box(low, high, dtype=np.float32)
self.seed()
|
{"golden_diff": "diff --git a/gym/envs/mujoco/mujoco_env.py b/gym/envs/mujoco/mujoco_env.py\n--- a/gym/envs/mujoco/mujoco_env.py\n+++ b/gym/envs/mujoco/mujoco_env.py\n@@ -43,11 +43,11 @@\n bounds = self.model.actuator_ctrlrange.copy()\n low = bounds[:, 0]\n high = bounds[:, 1]\n- self.action_space = spaces.Box(low=low, high=high)\n+ self.action_space = spaces.Box(low=low, high=high, dtype=np.float32)\n \n high = np.inf*np.ones(self.obs_dim)\n low = -high\n- self.observation_space = spaces.Box(low, high)\n+ self.observation_space = spaces.Box(low, high, dtype=np.float32)\n \n self.seed()\n", "issue": "MuJoCo env Box initialization causes warnings\nIn gym/gym/envs/mujoco/mujoco_env.py on line 46, Box object initialization is missing dtype=np.float32 parameter which causes autodetect warning spam.\n", "before_files": [{"content": "import os\n\nfrom gym import error, spaces\nfrom gym.utils import seeding\nimport numpy as np\nfrom os import path\nimport gym\nimport six\n\ntry:\n import mujoco_py\nexcept ImportError as e:\n raise error.DependencyNotInstalled(\"{}. (HINT: you need to install mujoco_py, and also perform the setup instructions here: https://github.com/openai/mujoco-py/.)\".format(e))\n\nclass MujocoEnv(gym.Env):\n \"\"\"Superclass for all MuJoCo environments.\n \"\"\"\n\n def __init__(self, model_path, frame_skip):\n if model_path.startswith(\"/\"):\n fullpath = model_path\n else:\n fullpath = os.path.join(os.path.dirname(__file__), \"assets\", model_path)\n if not path.exists(fullpath):\n raise IOError(\"File %s does not exist\" % fullpath)\n self.frame_skip = frame_skip\n self.model = mujoco_py.load_model_from_path(fullpath)\n self.sim = mujoco_py.MjSim(self.model)\n self.data = self.sim.data\n self.viewer = None\n\n self.metadata = {\n 'render.modes': ['human', 'rgb_array'],\n 'video.frames_per_second': int(np.round(1.0 / self.dt))\n }\n\n self.init_qpos = self.sim.data.qpos.ravel().copy()\n self.init_qvel = self.sim.data.qvel.ravel().copy()\n observation, _reward, done, _info = self.step(np.zeros(self.model.nu))\n assert not done\n self.obs_dim = observation.size\n\n bounds = self.model.actuator_ctrlrange.copy()\n low = bounds[:, 0]\n high = bounds[:, 1]\n self.action_space = spaces.Box(low=low, high=high)\n\n high = np.inf*np.ones(self.obs_dim)\n low = -high\n self.observation_space = spaces.Box(low, high)\n\n self.seed()\n\n def seed(self, seed=None):\n self.np_random, seed = seeding.np_random(seed)\n return [seed]\n\n # methods to override:\n # ----------------------------\n\n def reset_model(self):\n \"\"\"\n Reset the robot degrees of freedom (qpos and qvel).\n Implement this in each subclass.\n \"\"\"\n raise NotImplementedError\n\n def viewer_setup(self):\n \"\"\"\n This method is called when the viewer is initialized and after every reset\n Optionally implement this method, if you need to tinker with camera position\n and so forth.\n \"\"\"\n pass\n\n # -----------------------------\n\n def reset(self):\n self.sim.reset()\n ob = self.reset_model()\n if self.viewer is not None:\n self.viewer_setup()\n return ob\n\n def set_state(self, qpos, qvel):\n assert qpos.shape == (self.model.nq,) and qvel.shape == (self.model.nv,)\n old_state = self.sim.get_state()\n new_state = mujoco_py.MjSimState(old_state.time, qpos, qvel,\n old_state.act, old_state.udd_state)\n self.sim.set_state(new_state)\n self.sim.forward()\n\n @property\n def dt(self):\n return self.model.opt.timestep * self.frame_skip\n\n def do_simulation(self, ctrl, n_frames):\n self.sim.data.ctrl[:] = ctrl\n for _ in range(n_frames):\n self.sim.step()\n\n def render(self, mode='human'):\n if mode == 'rgb_array':\n self._get_viewer().render()\n # window size used for old mujoco-py:\n width, height = 500, 500\n data = self._get_viewer().read_pixels(width, height, depth=False)\n # original image is upside-down, so flip it\n return data[::-1, :, :]\n elif mode == 'human':\n self._get_viewer().render()\n\n def close(self):\n if self.viewer is not None:\n self.viewer.finish()\n self.viewer = None\n\n def _get_viewer(self):\n if self.viewer is None:\n self.viewer = mujoco_py.MjViewer(self.sim)\n self.viewer_setup()\n return self.viewer\n\n def get_body_com(self, body_name):\n return self.data.get_body_xpos(body_name)\n\n def state_vector(self):\n return np.concatenate([\n self.sim.data.qpos.flat,\n self.sim.data.qvel.flat\n ])\n", "path": "gym/envs/mujoco/mujoco_env.py"}]}
| 1,831 | 194 |
gh_patches_debug_1868
|
rasdani/github-patches
|
git_diff
|
cloud-custodian__cloud-custodian-3075
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
GCP: Firewalls resource policy fails with no resource attribute 'Firewall'
When running this policy custodian fails:
- policies:
- name: firewall-test
resource: gcp.firewall
The error returned is:
AttributeError: 'Resource' object has no attribute 'firewall'
</issue>
<code>
[start of tools/c7n_gcp/c7n_gcp/resources/network.py]
1 # Copyright 2018 Capital One Services, LLC
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14 from c7n_gcp.query import QueryResourceManager, TypeInfo
15
16 from c7n_gcp.provider import resources
17
18
19 @resources.register('vpc')
20 class Network(QueryResourceManager):
21
22 class resource_type(TypeInfo):
23 service = 'compute'
24 version = 'v1'
25 component = 'networks'
26 scope_template = "projects/{}/global/networks"
27
28
29 @resources.register('subnet')
30 class Subnet(QueryResourceManager):
31
32 class resource_type(TypeInfo):
33 service = 'compute'
34 version = 'v1'
35 component = 'networks'
36 enum_spec = ('aggregatedList', 'items.*.subnetworks[]', None)
37 scope_template = "projects/{}/aggregated/subnetworks"
38
39
40 @resources.register('firewall')
41 class Firewall(QueryResourceManager):
42
43 class resource_type(TypeInfo):
44 service = 'compute'
45 version = 'v1'
46 component = 'firewall'
47 scope_template = "projects/{}/global/firewalls"
48
49
50 @resources.register('router')
51 class Router(QueryResourceManager):
52
53 class resource_type(TypeInfo):
54 service = 'compute'
55 version = 'v1'
56 component = 'routers'
57 enum_spec = ('aggregatedList', 'items.*.routers[]', None)
58 scope_template = "projects/{}/aggregated/routers"
59
60
61 @resources.register('route')
62 class Route(QueryResourceManager):
63
64 class resource_type(TypeInfo):
65 service = 'compute'
66 version = 'v1'
67 component = 'routes'
68 scope_template = "projects/{}/global/routes"
69
[end of tools/c7n_gcp/c7n_gcp/resources/network.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/tools/c7n_gcp/c7n_gcp/resources/network.py b/tools/c7n_gcp/c7n_gcp/resources/network.py
--- a/tools/c7n_gcp/c7n_gcp/resources/network.py
+++ b/tools/c7n_gcp/c7n_gcp/resources/network.py
@@ -43,8 +43,7 @@
class resource_type(TypeInfo):
service = 'compute'
version = 'v1'
- component = 'firewall'
- scope_template = "projects/{}/global/firewalls"
+ component = 'firewalls'
@resources.register('router')
|
{"golden_diff": "diff --git a/tools/c7n_gcp/c7n_gcp/resources/network.py b/tools/c7n_gcp/c7n_gcp/resources/network.py\n--- a/tools/c7n_gcp/c7n_gcp/resources/network.py\n+++ b/tools/c7n_gcp/c7n_gcp/resources/network.py\n@@ -43,8 +43,7 @@\n class resource_type(TypeInfo):\n service = 'compute'\n version = 'v1'\n- component = 'firewall'\n- scope_template = \"projects/{}/global/firewalls\"\n+ component = 'firewalls'\n \n \n @resources.register('router')\n", "issue": "GCP: Firewalls resource policy fails with no resource attribute 'Firewall'\nWhen running this policy custodian fails: \r\n\r\n- policies:\r\n - name: firewall-test\r\n resource: gcp.firewall\r\n\r\nThe error returned is:\r\nAttributeError: 'Resource' object has no attribute 'firewall'\n", "before_files": [{"content": "# Copyright 2018 Capital One Services, LLC\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\nfrom c7n_gcp.query import QueryResourceManager, TypeInfo\n\nfrom c7n_gcp.provider import resources\n\n\[email protected]('vpc')\nclass Network(QueryResourceManager):\n\n class resource_type(TypeInfo):\n service = 'compute'\n version = 'v1'\n component = 'networks'\n scope_template = \"projects/{}/global/networks\"\n\n\[email protected]('subnet')\nclass Subnet(QueryResourceManager):\n\n class resource_type(TypeInfo):\n service = 'compute'\n version = 'v1'\n component = 'networks'\n enum_spec = ('aggregatedList', 'items.*.subnetworks[]', None)\n scope_template = \"projects/{}/aggregated/subnetworks\"\n\n\[email protected]('firewall')\nclass Firewall(QueryResourceManager):\n\n class resource_type(TypeInfo):\n service = 'compute'\n version = 'v1'\n component = 'firewall'\n scope_template = \"projects/{}/global/firewalls\"\n\n\[email protected]('router')\nclass Router(QueryResourceManager):\n\n class resource_type(TypeInfo):\n service = 'compute'\n version = 'v1'\n component = 'routers'\n enum_spec = ('aggregatedList', 'items.*.routers[]', None)\n scope_template = \"projects/{}/aggregated/routers\"\n\n\[email protected]('route')\nclass Route(QueryResourceManager):\n\n class resource_type(TypeInfo):\n service = 'compute'\n version = 'v1'\n component = 'routes'\n scope_template = \"projects/{}/global/routes\"\n", "path": "tools/c7n_gcp/c7n_gcp/resources/network.py"}]}
| 1,203 | 135 |
gh_patches_debug_32966
|
rasdani/github-patches
|
git_diff
|
rotki__rotki-160
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Providing a non-existing argument should fail gracefully
## Problem Definition
When a non-existing argument is provided to rotkehlchen at the moment an exception is thrown.
```
__main__.py: error: unrecognized arguments: --lol
CRITICAL:root:Traceback (most recent call last):
File "/home/lefteris/w/rotkehlchen/rotkehlchen/__main__.py", line 12, in main
rotkehlchen_server = RotkehlchenServer()
File "/home/lefteris/w/rotkehlchen/rotkehlchen/server.py", line 25, in __init__
self.args = app_args()
File "/home/lefteris/w/rotkehlchen/rotkehlchen/args.py", line 91, in app_args
args = p.parse_args()
File "/usr/lib64/python3.7/argparse.py", line 1752, in parse_args
self.error(msg % ' '.join(argv))
File "/usr/lib64/python3.7/argparse.py", line 2501, in error
self.exit(2, _('%(prog)s: error: %(message)s\n') % args)
File "/usr/lib64/python3.7/argparse.py", line 2488, in exit
_sys.exit(status)
SystemExit: 2
```
## Task
Instead of throwing an exception, an error message should be displayed and the program should exit gracefully.
</issue>
<code>
[start of rotkehlchen/__main__.py]
1 from gevent import monkey
2 monkey.patch_all()
3 import logging
4 logger = logging.getLogger(__name__)
5
6
7 def main():
8 import traceback
9 import sys
10 from rotkehlchen.server import RotkehlchenServer
11 try:
12 rotkehlchen_server = RotkehlchenServer()
13 except SystemExit as e:
14 if e.code is None or e.code == 0:
15 sys.exit(0)
16 else:
17 tb = traceback.format_exc()
18 logging.critical(tb)
19 print("Failed to start rotkehlchen backend:\n{}".format(tb))
20 sys.exit(1)
21 except: # noqa
22 tb = traceback.format_exc()
23 logging.critical(tb)
24 print("Failed to start rotkehlchen backend:\n{}".format(tb))
25 sys.exit(1)
26
27 rotkehlchen_server.main()
28
29
30 if __name__ == '__main__':
31 main()
32
[end of rotkehlchen/__main__.py]
[start of rotkehlchen/args.py]
1 #!/usr/bin/env python
2 import argparse
3 from rotkehlchen.config import default_data_directory
4
5
6 def app_args() -> argparse.Namespace:
7 """ Parse the arguments and create and return the arguments object"""
8 p = argparse.ArgumentParser(description='Rotkehlchen Crypto Portfolio Management')
9
10 p.add_argument(
11 '--output',
12 help=(
13 'A path to a file for logging all output. If nothing is given'
14 'stdout is used'
15 )
16 )
17 p.add_argument(
18 '--sleep-secs',
19 type=int,
20 default=20,
21 help="Seconds to sleep during the main loop"
22 )
23 p.add_argument(
24 '--notify',
25 action='store_true',
26 help=(
27 'If given then the tool will send notifications via '
28 'notify-send.'
29 )
30 )
31 p.add_argument(
32 '--data-dir',
33 help='The directory where all data and configs are placed',
34 default=default_data_directory()
35 )
36 p.add_argument(
37 '--zerorpc-port',
38 help='The port on which to open a zerorpc server for communication with the UI',
39 default=4242
40 )
41 p.add_argument(
42 '--ethrpc-port',
43 help="The port on which to communicate with an ethereum client's RPC.",
44 default=8545,
45 )
46 p.add_argument(
47 '--logfile',
48 help='The name of the file to write log entries to',
49 default='rotkehlchen.log',
50 )
51 p.add_argument(
52 '--logtarget',
53 help='Choose where logging entries will be sent. Valid values are "file and "stdout"',
54 choices=['stdout', 'file'],
55 default='file',
56 )
57 p.add_argument(
58 '--loglevel',
59 help='Choose the logging level',
60 choices=['debug', 'info', 'warn', 'error', 'critical'],
61 default='debug'
62 )
63 p.add_argument(
64 '--logfromothermodules',
65 help=(
66 'If given then logs from all imported modules that use the '
67 'logging system will also be visible.'
68 ),
69 action='store_true',
70 )
71
72 args = p.parse_args()
73
74 return args
75
[end of rotkehlchen/args.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/rotkehlchen/__main__.py b/rotkehlchen/__main__.py
--- a/rotkehlchen/__main__.py
+++ b/rotkehlchen/__main__.py
@@ -1,6 +1,8 @@
+import logging
+
from gevent import monkey
+
monkey.patch_all()
-import logging
logger = logging.getLogger(__name__)
@@ -11,8 +13,10 @@
try:
rotkehlchen_server = RotkehlchenServer()
except SystemExit as e:
- if e.code is None or e.code == 0:
- sys.exit(0)
+ if e.code is None or e.code == 0 or e.code == 2:
+ # exit_code 2 is for invalid arguments
+ exit_code = 0 if e.code is None else e.code
+ sys.exit(exit_code)
else:
tb = traceback.format_exc()
logging.critical(tb)
diff --git a/rotkehlchen/args.py b/rotkehlchen/args.py
--- a/rotkehlchen/args.py
+++ b/rotkehlchen/args.py
@@ -1,11 +1,28 @@
#!/usr/bin/env python
import argparse
+import sys
+
from rotkehlchen.config import default_data_directory
+from rotkehlchen.utils import get_system_spec
+
+
+class VersionAction(argparse.Action):
+ def __init__(self, option_strings, dest, nargs=None, required=False, **kwargs):
+ if nargs is not None:
+ raise ValueError("nargs not allowed")
+ super().__init__(option_strings, dest, **kwargs)
+
+ def __call__(self, parser, namespace, values, option_string=None):
+ print(get_system_spec()['rotkehlchen'])
+ sys.exit(0)
def app_args() -> argparse.Namespace:
""" Parse the arguments and create and return the arguments object"""
- p = argparse.ArgumentParser(description='Rotkehlchen Crypto Portfolio Management')
+ p = argparse.ArgumentParser(
+ prog='rotkehlchen',
+ description='Rotkehlchen Crypto Portfolio Management',
+ )
p.add_argument(
'--output',
@@ -68,6 +85,11 @@
),
action='store_true',
)
+ p.add_argument(
+ 'version',
+ help='Shows the rotkehlchen version',
+ action=VersionAction,
+ )
args = p.parse_args()
|
{"golden_diff": "diff --git a/rotkehlchen/__main__.py b/rotkehlchen/__main__.py\n--- a/rotkehlchen/__main__.py\n+++ b/rotkehlchen/__main__.py\n@@ -1,6 +1,8 @@\n+import logging\n+\n from gevent import monkey\n+\n monkey.patch_all()\n-import logging\n logger = logging.getLogger(__name__)\n \n \n@@ -11,8 +13,10 @@\n try:\n rotkehlchen_server = RotkehlchenServer()\n except SystemExit as e:\n- if e.code is None or e.code == 0:\n- sys.exit(0)\n+ if e.code is None or e.code == 0 or e.code == 2:\n+ # exit_code 2 is for invalid arguments\n+ exit_code = 0 if e.code is None else e.code\n+ sys.exit(exit_code)\n else:\n tb = traceback.format_exc()\n logging.critical(tb)\ndiff --git a/rotkehlchen/args.py b/rotkehlchen/args.py\n--- a/rotkehlchen/args.py\n+++ b/rotkehlchen/args.py\n@@ -1,11 +1,28 @@\n #!/usr/bin/env python\n import argparse\n+import sys\n+\n from rotkehlchen.config import default_data_directory\n+from rotkehlchen.utils import get_system_spec\n+\n+\n+class VersionAction(argparse.Action):\n+ def __init__(self, option_strings, dest, nargs=None, required=False, **kwargs):\n+ if nargs is not None:\n+ raise ValueError(\"nargs not allowed\")\n+ super().__init__(option_strings, dest, **kwargs)\n+\n+ def __call__(self, parser, namespace, values, option_string=None):\n+ print(get_system_spec()['rotkehlchen'])\n+ sys.exit(0)\n \n \n def app_args() -> argparse.Namespace:\n \"\"\" Parse the arguments and create and return the arguments object\"\"\"\n- p = argparse.ArgumentParser(description='Rotkehlchen Crypto Portfolio Management')\n+ p = argparse.ArgumentParser(\n+ prog='rotkehlchen',\n+ description='Rotkehlchen Crypto Portfolio Management',\n+ )\n \n p.add_argument(\n '--output',\n@@ -68,6 +85,11 @@\n ),\n action='store_true',\n )\n+ p.add_argument(\n+ 'version',\n+ help='Shows the rotkehlchen version',\n+ action=VersionAction,\n+ )\n \n args = p.parse_args()\n", "issue": "Providing a non-existing argument should fail gracefully\n## Problem Definition\r\n\r\nWhen a non-existing argument is provided to rotkehlchen at the moment an exception is thrown.\r\n\r\n```\r\n__main__.py: error: unrecognized arguments: --lol \r\nCRITICAL:root:Traceback (most recent call last): \r\n File \"/home/lefteris/w/rotkehlchen/rotkehlchen/__main__.py\", line 12, in main\r\n rotkehlchen_server = RotkehlchenServer()\r\n File \"/home/lefteris/w/rotkehlchen/rotkehlchen/server.py\", line 25, in __init__\r\n self.args = app_args()\r\n File \"/home/lefteris/w/rotkehlchen/rotkehlchen/args.py\", line 91, in app_args\r\n args = p.parse_args()\r\n File \"/usr/lib64/python3.7/argparse.py\", line 1752, in parse_args\r\n self.error(msg % ' '.join(argv))\r\n File \"/usr/lib64/python3.7/argparse.py\", line 2501, in error\r\n self.exit(2, _('%(prog)s: error: %(message)s\\n') % args)\r\n File \"/usr/lib64/python3.7/argparse.py\", line 2488, in exit\r\n _sys.exit(status)\r\nSystemExit: 2\r\n```\r\n\r\n\r\n\r\n## Task\r\n\r\nInstead of throwing an exception, an error message should be displayed and the program should exit gracefully.\n", "before_files": [{"content": "from gevent import monkey\nmonkey.patch_all()\nimport logging\nlogger = logging.getLogger(__name__)\n\n\ndef main():\n import traceback\n import sys\n from rotkehlchen.server import RotkehlchenServer\n try:\n rotkehlchen_server = RotkehlchenServer()\n except SystemExit as e:\n if e.code is None or e.code == 0:\n sys.exit(0)\n else:\n tb = traceback.format_exc()\n logging.critical(tb)\n print(\"Failed to start rotkehlchen backend:\\n{}\".format(tb))\n sys.exit(1)\n except: # noqa\n tb = traceback.format_exc()\n logging.critical(tb)\n print(\"Failed to start rotkehlchen backend:\\n{}\".format(tb))\n sys.exit(1)\n\n rotkehlchen_server.main()\n\n\nif __name__ == '__main__':\n main()\n", "path": "rotkehlchen/__main__.py"}, {"content": "#!/usr/bin/env python\nimport argparse\nfrom rotkehlchen.config import default_data_directory\n\n\ndef app_args() -> argparse.Namespace:\n \"\"\" Parse the arguments and create and return the arguments object\"\"\"\n p = argparse.ArgumentParser(description='Rotkehlchen Crypto Portfolio Management')\n\n p.add_argument(\n '--output',\n help=(\n 'A path to a file for logging all output. If nothing is given'\n 'stdout is used'\n )\n )\n p.add_argument(\n '--sleep-secs',\n type=int,\n default=20,\n help=\"Seconds to sleep during the main loop\"\n )\n p.add_argument(\n '--notify',\n action='store_true',\n help=(\n 'If given then the tool will send notifications via '\n 'notify-send.'\n )\n )\n p.add_argument(\n '--data-dir',\n help='The directory where all data and configs are placed',\n default=default_data_directory()\n )\n p.add_argument(\n '--zerorpc-port',\n help='The port on which to open a zerorpc server for communication with the UI',\n default=4242\n )\n p.add_argument(\n '--ethrpc-port',\n help=\"The port on which to communicate with an ethereum client's RPC.\",\n default=8545,\n )\n p.add_argument(\n '--logfile',\n help='The name of the file to write log entries to',\n default='rotkehlchen.log',\n )\n p.add_argument(\n '--logtarget',\n help='Choose where logging entries will be sent. Valid values are \"file and \"stdout\"',\n choices=['stdout', 'file'],\n default='file',\n )\n p.add_argument(\n '--loglevel',\n help='Choose the logging level',\n choices=['debug', 'info', 'warn', 'error', 'critical'],\n default='debug'\n )\n p.add_argument(\n '--logfromothermodules',\n help=(\n 'If given then logs from all imported modules that use the '\n 'logging system will also be visible.'\n ),\n action='store_true',\n )\n\n args = p.parse_args()\n\n return args\n", "path": "rotkehlchen/args.py"}]}
| 1,752 | 552 |
gh_patches_debug_11041
|
rasdani/github-patches
|
git_diff
|
cloud-custodian__cloud-custodian-4913
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
c7n-mailer - azure functions error when using SendGrid
Using a simple policy to queue a notification from the example [here](https://cloudcustodian.io/docs/tools/c7n-mailer.html#using-on-azure).
I see the following two errors:
1. Default Template
```
Invalid template reference default.j2
default.j2
```
2. Fetching contents of an object
```
local variable 'bpayload' referenced before assignment
Traceback (most recent call last):
File "/home/site/wwwroot/c7n_mailer/azure_mailer/sendgrid_delivery.py", line 129, in _sendgrid_mail_from_email_message
body = message.get_content()
AttributeError: 'MIMEText' object has no attribute 'get_content'
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/home/site/wwwroot/c7n_mailer/azure_mailer/azure_queue_processor.py", line 137, in _deliver_email
return sendgrid_delivery.sendgrid_handler(queue_message, email_messages)
File "/home/site/wwwroot/c7n_mailer/azure_mailer/sendgrid_delivery.py", line 92, in sendgrid_handler
mail = SendGridDelivery._sendgrid_mail_from_email_message(message)
File "/home/site/wwwroot/c7n_mailer/azure_mailer/sendgrid_delivery.py", line 132, in _sendgrid_mail_from_email_message
body = message.get_payload(decode=True).decode('utf-8')
File "/usr/local/lib/python3.6/email/message.py", line 286, in get_payload
value, defects = decode_b(b''.join(bpayload.splitlines()))
UnboundLocalError: local variable 'bpayload' referenced before assignment
```
</issue>
<code>
[start of tools/c7n_mailer/c7n_mailer/azure_mailer/deploy.py]
1 # Copyright 2016-2017 Capital One Services, LLC
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14 from __future__ import (absolute_import, division, print_function,
15 unicode_literals)
16
17 import copy
18 import json
19 import logging
20 import os
21
22 try:
23 from c7n_azure.function_package import FunctionPackage
24 from c7n_azure.functionapp_utils import FunctionAppUtilities
25 from c7n_azure.policy import AzureFunctionMode
26 from c7n_azure.session import Session
27 from c7n_azure.utils import StringUtils
28 from c7n.utils import local_session
29 except ImportError:
30 FunctionPackage = None
31 pass
32
33
34 def cache_path():
35 return os.path.join(os.path.dirname(__file__), 'cache')
36
37
38 def build_function_package(config, function_name, sub_id):
39 schedule = config.get('function_schedule', '0 */10 * * * *')
40
41 cache_override_path = cache_path()
42
43 function_path = function_name + "_" + sub_id
44
45 # Build package
46 package = FunctionPackage(
47 function_name,
48 os.path.join(os.path.dirname(__file__), 'function.py'),
49 target_sub_ids=[sub_id],
50 cache_override_path=cache_override_path)
51
52 package.build(None,
53 modules=['c7n', 'c7n-azure', 'c7n-mailer'],
54 non_binary_packages=['pyyaml', 'pycparser', 'tabulate', 'jmespath',
55 'datadog', 'MarkupSafe', 'simplejson', 'pyrsistent'],
56 excluded_packages=['azure-cli-core', 'distlib', 'future', 'futures'])
57
58 package.pkg.add_contents(
59 function_path + '/function.json',
60 contents=package.get_function_config({'mode':
61 {'type': 'azure-periodic',
62 'schedule': schedule}}))
63
64 # Add mail templates
65 for d in set(config['templates_folders']):
66 if not os.path.exists(d):
67 continue
68 for t in [f for f in os.listdir(d) if os.path.splitext(f)[1] == '.j2']:
69 with open(os.path.join(d, t)) as fh:
70 package.pkg.add_contents(function_path + '/msg-templates/%s' % t, fh.read())
71
72 function_config = copy.deepcopy(config)
73 function_config['templates_folders'] = [function_path + '/msg-templates/']
74 package.pkg.add_contents(
75 function_path + '/config.json',
76 contents=json.dumps(function_config))
77
78 package.close()
79 return package
80
81
82 def provision(config):
83 log = logging.getLogger('c7n_mailer.azure.deploy')
84
85 function_name = config.get('function_name', 'mailer')
86 function_properties = config.get('function_properties', {})
87
88 # service plan is parse first, because its location might be shared with storage & insights
89 service_plan = AzureFunctionMode.extract_properties(function_properties,
90 'servicePlan',
91 {
92 'name': 'cloud-custodian',
93 'location': 'eastus',
94 'resource_group_name': 'cloud-custodian',
95 'sku_tier': 'Dynamic', # consumption plan
96 'sku_name': 'Y1'
97 })
98
99 location = service_plan.get('location', 'eastus')
100 rg_name = service_plan['resource_group_name']
101
102 sub_id = local_session(Session).get_subscription_id()
103 suffix = StringUtils.naming_hash(rg_name + sub_id)
104
105 storage_account = AzureFunctionMode.extract_properties(function_properties,
106 'storageAccount',
107 {'name': 'mailerstorage' + suffix,
108 'location': location,
109 'resource_group_name': rg_name})
110
111 app_insights = AzureFunctionMode.extract_properties(function_properties,
112 'appInsights',
113 {'name': service_plan['name'],
114 'location': location,
115 'resource_group_name': rg_name})
116
117 function_app_name = FunctionAppUtilities.get_function_name(
118 '-'.join([service_plan['name'], function_name]), suffix)
119 FunctionAppUtilities.validate_function_name(function_app_name)
120
121 params = FunctionAppUtilities.FunctionAppInfrastructureParameters(
122 app_insights=app_insights,
123 service_plan=service_plan,
124 storage_account=storage_account,
125 function_app_resource_group_name=service_plan['resource_group_name'],
126 function_app_name=function_app_name)
127
128 FunctionAppUtilities.deploy_function_app(params)
129
130 log.info("Building function package for %s" % function_app_name)
131 package = build_function_package(config, function_name, sub_id)
132
133 log.info("Function package built, size is %dMB" % (package.pkg.size / (1024 * 1024)))
134
135 FunctionAppUtilities.publish_functions_package(params, package)
136
[end of tools/c7n_mailer/c7n_mailer/azure_mailer/deploy.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/tools/c7n_mailer/c7n_mailer/azure_mailer/deploy.py b/tools/c7n_mailer/c7n_mailer/azure_mailer/deploy.py
--- a/tools/c7n_mailer/c7n_mailer/azure_mailer/deploy.py
+++ b/tools/c7n_mailer/c7n_mailer/azure_mailer/deploy.py
@@ -70,7 +70,10 @@
package.pkg.add_contents(function_path + '/msg-templates/%s' % t, fh.read())
function_config = copy.deepcopy(config)
- function_config['templates_folders'] = [function_path + '/msg-templates/']
+
+ functions_full_template_path = '/home/site/wwwroot/' + function_path + '/msg-templates/'
+ function_config['templates_folders'] = [functions_full_template_path]
+
package.pkg.add_contents(
function_path + '/config.json',
contents=json.dumps(function_config))
|
{"golden_diff": "diff --git a/tools/c7n_mailer/c7n_mailer/azure_mailer/deploy.py b/tools/c7n_mailer/c7n_mailer/azure_mailer/deploy.py\n--- a/tools/c7n_mailer/c7n_mailer/azure_mailer/deploy.py\n+++ b/tools/c7n_mailer/c7n_mailer/azure_mailer/deploy.py\n@@ -70,7 +70,10 @@\n package.pkg.add_contents(function_path + '/msg-templates/%s' % t, fh.read())\n \n function_config = copy.deepcopy(config)\n- function_config['templates_folders'] = [function_path + '/msg-templates/']\n+\n+ functions_full_template_path = '/home/site/wwwroot/' + function_path + '/msg-templates/'\n+ function_config['templates_folders'] = [functions_full_template_path]\n+\n package.pkg.add_contents(\n function_path + '/config.json',\n contents=json.dumps(function_config))\n", "issue": "c7n-mailer - azure functions error when using SendGrid\nUsing a simple policy to queue a notification from the example [here](https://cloudcustodian.io/docs/tools/c7n-mailer.html#using-on-azure).\r\n\r\nI see the following two errors:\r\n\r\n1. Default Template\r\n```\r\nInvalid template reference default.j2\r\ndefault.j2\r\n```\r\n\r\n2. Fetching contents of an object\r\n```\r\nlocal variable 'bpayload' referenced before assignment\r\nTraceback (most recent call last):\r\n File \"/home/site/wwwroot/c7n_mailer/azure_mailer/sendgrid_delivery.py\", line 129, in _sendgrid_mail_from_email_message\r\n body = message.get_content()\r\nAttributeError: 'MIMEText' object has no attribute 'get_content'\r\n\r\nDuring handling of the above exception, another exception occurred:\r\n\r\nTraceback (most recent call last):\r\n File \"/home/site/wwwroot/c7n_mailer/azure_mailer/azure_queue_processor.py\", line 137, in _deliver_email\r\n return sendgrid_delivery.sendgrid_handler(queue_message, email_messages)\r\n File \"/home/site/wwwroot/c7n_mailer/azure_mailer/sendgrid_delivery.py\", line 92, in sendgrid_handler\r\n mail = SendGridDelivery._sendgrid_mail_from_email_message(message)\r\n File \"/home/site/wwwroot/c7n_mailer/azure_mailer/sendgrid_delivery.py\", line 132, in _sendgrid_mail_from_email_message\r\n body = message.get_payload(decode=True).decode('utf-8')\r\n File \"/usr/local/lib/python3.6/email/message.py\", line 286, in get_payload\r\n value, defects = decode_b(b''.join(bpayload.splitlines()))\r\nUnboundLocalError: local variable 'bpayload' referenced before assignment\r\n```\n", "before_files": [{"content": "# Copyright 2016-2017 Capital One Services, LLC\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\nfrom __future__ import (absolute_import, division, print_function,\n unicode_literals)\n\nimport copy\nimport json\nimport logging\nimport os\n\ntry:\n from c7n_azure.function_package import FunctionPackage\n from c7n_azure.functionapp_utils import FunctionAppUtilities\n from c7n_azure.policy import AzureFunctionMode\n from c7n_azure.session import Session\n from c7n_azure.utils import StringUtils\n from c7n.utils import local_session\nexcept ImportError:\n FunctionPackage = None\n pass\n\n\ndef cache_path():\n return os.path.join(os.path.dirname(__file__), 'cache')\n\n\ndef build_function_package(config, function_name, sub_id):\n schedule = config.get('function_schedule', '0 */10 * * * *')\n\n cache_override_path = cache_path()\n\n function_path = function_name + \"_\" + sub_id\n\n # Build package\n package = FunctionPackage(\n function_name,\n os.path.join(os.path.dirname(__file__), 'function.py'),\n target_sub_ids=[sub_id],\n cache_override_path=cache_override_path)\n\n package.build(None,\n modules=['c7n', 'c7n-azure', 'c7n-mailer'],\n non_binary_packages=['pyyaml', 'pycparser', 'tabulate', 'jmespath',\n 'datadog', 'MarkupSafe', 'simplejson', 'pyrsistent'],\n excluded_packages=['azure-cli-core', 'distlib', 'future', 'futures'])\n\n package.pkg.add_contents(\n function_path + '/function.json',\n contents=package.get_function_config({'mode':\n {'type': 'azure-periodic',\n 'schedule': schedule}}))\n\n # Add mail templates\n for d in set(config['templates_folders']):\n if not os.path.exists(d):\n continue\n for t in [f for f in os.listdir(d) if os.path.splitext(f)[1] == '.j2']:\n with open(os.path.join(d, t)) as fh:\n package.pkg.add_contents(function_path + '/msg-templates/%s' % t, fh.read())\n\n function_config = copy.deepcopy(config)\n function_config['templates_folders'] = [function_path + '/msg-templates/']\n package.pkg.add_contents(\n function_path + '/config.json',\n contents=json.dumps(function_config))\n\n package.close()\n return package\n\n\ndef provision(config):\n log = logging.getLogger('c7n_mailer.azure.deploy')\n\n function_name = config.get('function_name', 'mailer')\n function_properties = config.get('function_properties', {})\n\n # service plan is parse first, because its location might be shared with storage & insights\n service_plan = AzureFunctionMode.extract_properties(function_properties,\n 'servicePlan',\n {\n 'name': 'cloud-custodian',\n 'location': 'eastus',\n 'resource_group_name': 'cloud-custodian',\n 'sku_tier': 'Dynamic', # consumption plan\n 'sku_name': 'Y1'\n })\n\n location = service_plan.get('location', 'eastus')\n rg_name = service_plan['resource_group_name']\n\n sub_id = local_session(Session).get_subscription_id()\n suffix = StringUtils.naming_hash(rg_name + sub_id)\n\n storage_account = AzureFunctionMode.extract_properties(function_properties,\n 'storageAccount',\n {'name': 'mailerstorage' + suffix,\n 'location': location,\n 'resource_group_name': rg_name})\n\n app_insights = AzureFunctionMode.extract_properties(function_properties,\n 'appInsights',\n {'name': service_plan['name'],\n 'location': location,\n 'resource_group_name': rg_name})\n\n function_app_name = FunctionAppUtilities.get_function_name(\n '-'.join([service_plan['name'], function_name]), suffix)\n FunctionAppUtilities.validate_function_name(function_app_name)\n\n params = FunctionAppUtilities.FunctionAppInfrastructureParameters(\n app_insights=app_insights,\n service_plan=service_plan,\n storage_account=storage_account,\n function_app_resource_group_name=service_plan['resource_group_name'],\n function_app_name=function_app_name)\n\n FunctionAppUtilities.deploy_function_app(params)\n\n log.info(\"Building function package for %s\" % function_app_name)\n package = build_function_package(config, function_name, sub_id)\n\n log.info(\"Function package built, size is %dMB\" % (package.pkg.size / (1024 * 1024)))\n\n FunctionAppUtilities.publish_functions_package(params, package)\n", "path": "tools/c7n_mailer/c7n_mailer/azure_mailer/deploy.py"}]}
| 2,357 | 206 |
gh_patches_debug_12206
|
rasdani/github-patches
|
git_diff
|
praw-dev__praw-1145
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
`reddit.user.moderator_subreddits()` has a limit of 100 subreddits that is not documented.
## Issue Description
`reddit.user.moderator_subreddits()` is a method for `reddit.user` that [returns a ListingGenerator of the subreddits that the currently authenticated user is a moderator of](https://praw.readthedocs.io/en/latest/code_overview/reddit/user.html). It works fine, but there is actually a **hard limit of 100 subreddits returned** through this method, and that limit is currently not documented for the method. I tested this with my bot u/AssistantBOT, which is currently moderating 600+ public and private subreddits, and the method only returns the top 100 subreddits it's a mod of, sorted by most subscribers to least subscribers.
I believe this limit should be documented in the method. It's true that the vast majority of users are unlikely to encounter this issue, but it is something that could dramatically affect what a user is expecting in their results.
I would make a pull request, but I already have one PR #1137 that's awaiting review for a feature addition and I don't want to add something unrelated to that PR directly. The new method I proposed, `.moderated()`, can actually overcome the limitations of `moderator_subreddits()`, however, so if it's a good idea to add this documentation to that PR, then I'll do so.
**Edit:** I'll make a new Documentation PR once ##1137 gets merged.
## System Information
- PRAW Version: 6.4.0
- Python Version: 3.5.1
- Operating System: Windows 10 Pro
</issue>
<code>
[start of praw/models/user.py]
1 """Provides the User class."""
2 from ..const import API_PATH
3 from ..models import Preferences
4 from ..util.cache import cachedproperty
5 from .base import PRAWBase
6 from .listing.generator import ListingGenerator
7 from .reddit.redditor import Redditor
8 from .reddit.subreddit import Subreddit
9
10
11 class User(PRAWBase):
12 """The user class provides methods for the currently authenticated user."""
13
14 @cachedproperty
15 def preferences(self):
16 """Get an instance of :class:`.Preferences`.
17
18 The preferences can be accessed as a ``dict`` like so:
19
20 .. code-block:: python
21
22 preferences = reddit.user.preferences()
23 print(preferences['show_link_flair'])
24
25 Preferences can be updated via:
26
27 .. code-block:: python
28
29 reddit.user.preferences.update(show_link_flair=True)
30
31 The :meth:`.Preferences.update` method returns the new state of the
32 preferences as a ``dict``, which can be used to check whether a
33 change went through. Changes with invalid types or parameter names
34 fail silently.
35
36 .. code-block:: python
37
38 original_preferences = reddit.user.preferences()
39 new_preferences = reddit.user.preferences.update(invalid_param=123)
40 print(original_preferences == new_preferences) # True, no change
41
42
43 """
44 return Preferences(self._reddit)
45
46 def __init__(self, reddit):
47 """Initialize a User instance.
48
49 This class is intended to be interfaced with through ``reddit.user``.
50
51 """
52 super(User, self).__init__(reddit, _data=None)
53
54 def blocked(self):
55 """Return a RedditorList of blocked Redditors."""
56 return self._reddit.get(API_PATH["blocked"])
57
58 def contributor_subreddits(self, **generator_kwargs):
59 """Return a ListingGenerator of subreddits user is a contributor of.
60
61 Additional keyword arguments are passed in the initialization of
62 :class:`.ListingGenerator`.
63
64 """
65 return ListingGenerator(
66 self._reddit, API_PATH["my_contributor"], **generator_kwargs
67 )
68
69 def friends(self):
70 """Return a RedditorList of friends."""
71 return self._reddit.get(API_PATH["friends"])
72
73 def karma(self):
74 """Return a dictionary mapping subreddits to their karma."""
75 karma_map = {}
76 for row in self._reddit.get(API_PATH["karma"])["data"]:
77 subreddit = Subreddit(self._reddit, row["sr"])
78 del row["sr"]
79 karma_map[subreddit] = row
80 return karma_map
81
82 def me(self, use_cache=True): # pylint: disable=invalid-name
83 """Return a :class:`.Redditor` instance for the authenticated user.
84
85 In :attr:`~praw.Reddit.read_only` mode, this method returns ``None``.
86
87 :param use_cache: When true, and if this function has been previously
88 called, returned the cached version (default: True).
89
90 .. note:: If you change the Reddit instance's authorization, you might
91 want to refresh the cached value. Prefer using separate Reddit
92 instances, however, for distinct authorizations.
93
94 """
95 if self._reddit.read_only:
96 return None
97 if "_me" not in self.__dict__ or not use_cache:
98 user_data = self._reddit.get(API_PATH["me"])
99 self._me = Redditor(self._reddit, _data=user_data)
100 return self._me
101
102 def moderator_subreddits(self, **generator_kwargs):
103 """Return a ListingGenerator of subreddits the user is a moderator of.
104
105 Additional keyword arguments are passed in the initialization of
106 :class:`.ListingGenerator`.
107
108 """
109 return ListingGenerator(
110 self._reddit, API_PATH["my_moderator"], **generator_kwargs
111 )
112
113 def multireddits(self):
114 """Return a list of multireddits belonging to the user."""
115 return self._reddit.get(API_PATH["my_multireddits"])
116
117 def subreddits(self, **generator_kwargs):
118 """Return a ListingGenerator of subreddits the user is subscribed to.
119
120 Additional keyword arguments are passed in the initialization of
121 :class:`.ListingGenerator`.
122
123 """
124 return ListingGenerator(
125 self._reddit, API_PATH["my_subreddits"], **generator_kwargs
126 )
127
[end of praw/models/user.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/praw/models/user.py b/praw/models/user.py
--- a/praw/models/user.py
+++ b/praw/models/user.py
@@ -105,6 +105,18 @@
Additional keyword arguments are passed in the initialization of
:class:`.ListingGenerator`.
+ .. note:: This method will return a maximum of 100 moderated
+ subreddits, ordered by subscriber count. To retrieve more than
+ 100 moderated subreddits, please see :meth:`.Redditor.moderated`.
+
+ Usage:
+
+ .. code-block:: python
+
+ for subreddit in reddit.user.moderator_subreddits():
+ print(subreddit.display_name)
+
+
"""
return ListingGenerator(
self._reddit, API_PATH["my_moderator"], **generator_kwargs
|
{"golden_diff": "diff --git a/praw/models/user.py b/praw/models/user.py\n--- a/praw/models/user.py\n+++ b/praw/models/user.py\n@@ -105,6 +105,18 @@\n Additional keyword arguments are passed in the initialization of\n :class:`.ListingGenerator`.\n \n+ .. note:: This method will return a maximum of 100 moderated\n+ subreddits, ordered by subscriber count. To retrieve more than\n+ 100 moderated subreddits, please see :meth:`.Redditor.moderated`.\n+\n+ Usage:\n+\n+ .. code-block:: python\n+\n+ for subreddit in reddit.user.moderator_subreddits():\n+ print(subreddit.display_name)\n+\n+\n \"\"\"\n return ListingGenerator(\n self._reddit, API_PATH[\"my_moderator\"], **generator_kwargs\n", "issue": "`reddit.user.moderator_subreddits()` has a limit of 100 subreddits that is not documented.\n## Issue Description\r\n\r\n`reddit.user.moderator_subreddits()` is a method for `reddit.user` that [returns a ListingGenerator of the subreddits that the currently authenticated user is a moderator of](https://praw.readthedocs.io/en/latest/code_overview/reddit/user.html). It works fine, but there is actually a **hard limit of 100 subreddits returned** through this method, and that limit is currently not documented for the method. I tested this with my bot u/AssistantBOT, which is currently moderating 600+ public and private subreddits, and the method only returns the top 100 subreddits it's a mod of, sorted by most subscribers to least subscribers. \r\n\r\nI believe this limit should be documented in the method. It's true that the vast majority of users are unlikely to encounter this issue, but it is something that could dramatically affect what a user is expecting in their results.\r\n\r\nI would make a pull request, but I already have one PR #1137 that's awaiting review for a feature addition and I don't want to add something unrelated to that PR directly. The new method I proposed, `.moderated()`, can actually overcome the limitations of `moderator_subreddits()`, however, so if it's a good idea to add this documentation to that PR, then I'll do so. \r\n\r\n\r\n**Edit:** I'll make a new Documentation PR once ##1137 gets merged.\r\n\r\n## System Information\r\n\r\n- PRAW Version: 6.4.0\r\n- Python Version: 3.5.1\r\n- Operating System: Windows 10 Pro\r\n\n", "before_files": [{"content": "\"\"\"Provides the User class.\"\"\"\nfrom ..const import API_PATH\nfrom ..models import Preferences\nfrom ..util.cache import cachedproperty\nfrom .base import PRAWBase\nfrom .listing.generator import ListingGenerator\nfrom .reddit.redditor import Redditor\nfrom .reddit.subreddit import Subreddit\n\n\nclass User(PRAWBase):\n \"\"\"The user class provides methods for the currently authenticated user.\"\"\"\n\n @cachedproperty\n def preferences(self):\n \"\"\"Get an instance of :class:`.Preferences`.\n\n The preferences can be accessed as a ``dict`` like so:\n\n .. code-block:: python\n\n preferences = reddit.user.preferences()\n print(preferences['show_link_flair'])\n\n Preferences can be updated via:\n\n .. code-block:: python\n\n reddit.user.preferences.update(show_link_flair=True)\n\n The :meth:`.Preferences.update` method returns the new state of the\n preferences as a ``dict``, which can be used to check whether a\n change went through. Changes with invalid types or parameter names\n fail silently.\n\n .. code-block:: python\n\n original_preferences = reddit.user.preferences()\n new_preferences = reddit.user.preferences.update(invalid_param=123)\n print(original_preferences == new_preferences) # True, no change\n\n\n \"\"\"\n return Preferences(self._reddit)\n\n def __init__(self, reddit):\n \"\"\"Initialize a User instance.\n\n This class is intended to be interfaced with through ``reddit.user``.\n\n \"\"\"\n super(User, self).__init__(reddit, _data=None)\n\n def blocked(self):\n \"\"\"Return a RedditorList of blocked Redditors.\"\"\"\n return self._reddit.get(API_PATH[\"blocked\"])\n\n def contributor_subreddits(self, **generator_kwargs):\n \"\"\"Return a ListingGenerator of subreddits user is a contributor of.\n\n Additional keyword arguments are passed in the initialization of\n :class:`.ListingGenerator`.\n\n \"\"\"\n return ListingGenerator(\n self._reddit, API_PATH[\"my_contributor\"], **generator_kwargs\n )\n\n def friends(self):\n \"\"\"Return a RedditorList of friends.\"\"\"\n return self._reddit.get(API_PATH[\"friends\"])\n\n def karma(self):\n \"\"\"Return a dictionary mapping subreddits to their karma.\"\"\"\n karma_map = {}\n for row in self._reddit.get(API_PATH[\"karma\"])[\"data\"]:\n subreddit = Subreddit(self._reddit, row[\"sr\"])\n del row[\"sr\"]\n karma_map[subreddit] = row\n return karma_map\n\n def me(self, use_cache=True): # pylint: disable=invalid-name\n \"\"\"Return a :class:`.Redditor` instance for the authenticated user.\n\n In :attr:`~praw.Reddit.read_only` mode, this method returns ``None``.\n\n :param use_cache: When true, and if this function has been previously\n called, returned the cached version (default: True).\n\n .. note:: If you change the Reddit instance's authorization, you might\n want to refresh the cached value. Prefer using separate Reddit\n instances, however, for distinct authorizations.\n\n \"\"\"\n if self._reddit.read_only:\n return None\n if \"_me\" not in self.__dict__ or not use_cache:\n user_data = self._reddit.get(API_PATH[\"me\"])\n self._me = Redditor(self._reddit, _data=user_data)\n return self._me\n\n def moderator_subreddits(self, **generator_kwargs):\n \"\"\"Return a ListingGenerator of subreddits the user is a moderator of.\n\n Additional keyword arguments are passed in the initialization of\n :class:`.ListingGenerator`.\n\n \"\"\"\n return ListingGenerator(\n self._reddit, API_PATH[\"my_moderator\"], **generator_kwargs\n )\n\n def multireddits(self):\n \"\"\"Return a list of multireddits belonging to the user.\"\"\"\n return self._reddit.get(API_PATH[\"my_multireddits\"])\n\n def subreddits(self, **generator_kwargs):\n \"\"\"Return a ListingGenerator of subreddits the user is subscribed to.\n\n Additional keyword arguments are passed in the initialization of\n :class:`.ListingGenerator`.\n\n \"\"\"\n return ListingGenerator(\n self._reddit, API_PATH[\"my_subreddits\"], **generator_kwargs\n )\n", "path": "praw/models/user.py"}]}
| 2,107 | 187 |
gh_patches_debug_15242
|
rasdani/github-patches
|
git_diff
|
openstates__openstates-scrapers-2513
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
PR failing since at least 2018-09-06
PR has been failing since 2018-09-06
Based on automated runs it appears that PR has not run successfully in 6 days (2018-09-06).
```
00:38:39 ERROR pupa: cannot resolve pseudo id to Person: ~{"name": "Ram\u00f3n L. Cruz Burgos"}
00:38:39 ERROR pupa: cannot resolve pseudo id to Person: ~{"name": "Angel Buler\u00edn Ramos"}
00:38:39 ERROR pupa: cannot resolve pseudo id to Person: ~{"name": "\u00c1ngel Mart\u00ednez Santiago"}
00:38:39 ERROR pupa: cannot resolve pseudo id to Person: ~{"name": "Manuel A. Natal Albelo"}
00:38:39 ERROR pupa: cannot resolve pseudo id to Person: ~{"name": "Eduardo Bhatia Gautier"}
00:38:39 ERROR pupa: cannot resolve pseudo id to Person: ~{"name": "Zoe Laboy Alvarado"}
00:38:39 ERROR pupa: cannot resolve pseudo id to Person: ~{"name": "An\u00edbal Jos\u00e9 Torres Torres"}
00:38:39 ERROR pupa: cannot resolve pseudo id to Person: ~{"name": "Carmelo J. R\u00edos Santiago"}
00:38:39 ERROR pupa: cannot resolve pseudo id to Person: ~{"name": "Itzamar Pe\u00f1a Ram\u00edrez"}
00:38:39 ERROR pupa: cannot resolve pseudo id to Person: ~{"name": "Carlos A. Bianchi Angler\u00f3"}
00:38:39 ERROR pupa: cannot resolve pseudo id to Person: ~{"name": "Jos\u00e9 Vargas Vidot"}
00:38:39 ERROR pupa: cannot resolve pseudo id to Person: ~{"name": "Angel Mart\u00ednez Santiago"}
00:38:39 ERROR pupa: cannot resolve pseudo id to Person: ~{"name": "Eduardo Bhatia Gauthier"}
00:38:39 ERROR pupa: cannot resolve pseudo id to Person: ~{"name": "Miguel Romero Lugo"}
00:38:39 ERROR pupa: cannot resolve pseudo id to Person: ~{"name": "Margarita Nolasco Santiago"}
00:38:39 ERROR pupa: cannot resolve pseudo id to Person: ~{"name": "Luis R. Ortiz Lugo"}
00:38:39 ERROR pupa: cannot resolve pseudo id to Person: ~{"name": "Urayo\u00e1n Hern\u00e1ndez Alvarado"}
00:38:39 ERROR pupa: cannot resolve pseudo id to Person: ~{"name": "Jos\u00e9 M. Varela Fern\u00e1ndez"}
loaded Open States pupa settings...
pr (scrape, import)
people: {}
committees: {}
bills: {}
import jurisdictions...
import organizations...
import people...
import posts...
import memberships...
Traceback (most recent call last):
File "/opt/openstates/venv-pupa//bin/pupa", line 11, in <module>
load_entry_point('pupa', 'console_scripts', 'pupa')()
File "/opt/openstates/venv-pupa/src/pupa/pupa/cli/__main__.py", line 68, in main
subcommands[args.subcommand].handle(args, other)
File "/opt/openstates/venv-pupa/src/pupa/pupa/cli/commands/update.py", line 260, in handle
return self.do_handle(args, other, juris)
File "/opt/openstates/venv-pupa/src/pupa/pupa/cli/commands/update.py", line 307, in do_handle
report['import'] = self.do_import(juris, args)
File "/opt/openstates/venv-pupa/src/pupa/pupa/cli/commands/update.py", line 211, in do_import
report.update(membership_importer.import_directory(datadir))
File "/opt/openstates/venv-pupa/src/pupa/pupa/importers/base.py", line 196, in import_directory
return self.import_data(json_stream())
File "/opt/openstates/venv-pupa/src/pupa/pupa/importers/base.py", line 233, in import_data
obj_id, what = self.import_item(data)
File "/opt/openstates/venv-pupa/src/pupa/pupa/importers/base.py", line 254, in import_item
data = self.prepare_for_db(data)
File "/opt/openstates/venv-pupa/src/pupa/pupa/importers/memberships.py", line 47, in prepare_for_db
data['organization_id'] = self.org_importer.resolve_json_id(data['organization_id'])
File "/opt/openstates/venv-pupa/src/pupa/pupa/importers/base.py", line 171, in resolve_json_id
raise UnresolvedIdError(errmsg)
pupa.exceptions.UnresolvedIdError: cannot resolve pseudo id to Organization: ~{"classification": "party", "name": "Independiente"}
```
Visit http://bobsled.openstates.org for more info.
</issue>
<code>
[start of openstates/pr/people.py]
1 # -*- coding: utf-8 -*-
2 import re
3 from pupa.scrape import Person, Scraper
4 from openstates.utils import LXMLMixin, validate_phone_number
5
6
7 class PRPersonScraper(Scraper, LXMLMixin):
8 def scrape(self, chamber=None):
9 term = self.jurisdiction.legislative_sessions[-1]['identifier']
10 chambers = [chamber] if chamber is not None else ['upper', 'lower']
11 for chamber in chambers:
12 yield from getattr(self, 'scrape_' + chamber + '_chamber')(term)
13
14 def scrape_upper_chamber(self, term):
15 url = 'https://senado.pr.gov/Pages/Senadores.aspx'
16
17 doc = self.lxmlize(url)
18 links = self.get_nodes(doc, '//ul[@class="senadores-list"]/li/a/@href')
19
20 for link in links:
21 senator_page = self.lxmlize(link)
22 profile_links = self.get_nodes(senator_page, '//ul[@class="profiles-links"]/li')
23
24 name_text = self.get_node(senator_page, '//span[@class="name"]').text_content().strip()
25 name = re.sub(r'^Hon\.', '', name_text, flags=re.IGNORECASE).strip()
26 party = profile_links[0].text_content().strip()
27 photo_url = self.get_node(senator_page, '//div[@class="avatar"]//img/@src')
28
29 if profile_links[1].text_content().strip() == "Senador por Distrito":
30 district_text = self.get_node(
31 senator_page,
32 '//div[@class="module-distrito"]//span[@class="headline"]').text_content()
33 district = district_text.replace('DISTRITO', '', 1).replace('\u200b', '').strip()
34 elif profile_links[1].text_content().strip() == "Senador por Acumulación":
35 district = "At-Large"
36
37 phone_node = self.get_node(senator_page, '//a[@class="contact-data tel"]')
38 phone = phone_node.text_content().strip()
39 email_node = self.get_node(senator_page, '//a[@class="contact-data email"]')
40 email = email_node.text_content().replace('\u200b', '').strip()
41
42 person = Person(primary_org='upper',
43 district=district,
44 name=name,
45 party=party,
46 image=photo_url)
47 person.add_contact_detail(type='email',
48 value=email,
49 note='Capitol Office')
50 person.add_contact_detail(type='voice',
51 value=phone,
52 note='Capitol Office')
53 person.add_link(link)
54 person.add_source(link)
55
56 yield person
57
58 def scrape_lower_chamber(self, term):
59 # E-mail contact is now hidden behind webforms. Sadness.
60
61 party_map = {'PNP': 'Partido Nuevo Progresista',
62 'PPD': u'Partido Popular Democr\xe1tico',
63 'PIP': u'Partido Independentista Puertorrique\u00F1o',
64 }
65
66 url = 'http://www.tucamarapr.org/dnncamara/ComposiciondelaCamara/Biografia.aspx'
67 page = self.lxmlize(url)
68
69 member_nodes = self.get_nodes(page, '//li[@class="selectionRep"]')
70 for member_node in member_nodes:
71 member_info = member_node.text_content().strip().split("\n")
72
73 name = re.sub(r'^Hon\.', '', member_info[0]).strip()
74 district_text = member_info[-1].strip()
75 if district_text == 'Representante por Acumulación':
76 district = 'At-Large'
77 else:
78 district = district_text.replace("Representante del Distrito ", "").strip()
79 photo_url = self.get_node(member_node, './/img/@src')
80
81 rep_link = self.get_node(member_node, ".//a/@href")
82 rep_page = self.lxmlize(rep_link)
83
84 party_node = self.get_node(rep_page, '//span[@class="partyBio"]')
85 party_text = party_node.text_content().strip()
86 party = party_map[party_text]
87
88 address = self.get_node(rep_page, '//h6').text.strip().split("\n")[0].strip()
89
90 # Only grabs the first validated phone number found.
91 # Typically, representatives have multiple phone numbers.
92 phone_node = self.get_node(
93 rep_page,
94 '//span[@class="data-type" and contains(text(), "Tel.")]')
95 phone = None
96 possible_phones = phone_node.text.strip().split("\n")
97 for phone_attempt in possible_phones:
98 # Don't keep searching phone numbers if a good one is found.
99 if phone:
100 break
101
102 phone_text = re.sub(r'^Tel\.[\s]*', '', phone_attempt).strip()
103 if validate_phone_number(phone_text):
104 phone = phone_text
105
106 fax_node = self.get_node(
107 rep_page,
108 '//span[@class="data-type" and contains(text(), "Fax.")]')
109 fax = None
110 if fax_node:
111 fax_text = fax_node.text.strip()
112 fax_text = re.sub(r'^Fax\.[\s]*', '', fax_text).strip()
113 if validate_phone_number(fax_text):
114 fax = fax_text
115
116 person = Person(primary_org='lower',
117 district=district,
118 name=name,
119 party=party,
120 image=photo_url)
121
122 person.add_link(rep_link)
123 person.add_source(rep_link)
124 person.add_source(url)
125
126 if address:
127 person.add_contact_detail(type='address',
128 value=address,
129 note='Capitol Office')
130 if phone:
131 person.add_contact_detail(type='voice',
132 value=phone,
133 note='Capitol Office')
134 if fax:
135 person.add_contact_detail(type='fax',
136 value=fax,
137 note='Capitol Office')
138
139 yield person
140
[end of openstates/pr/people.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/openstates/pr/people.py b/openstates/pr/people.py
--- a/openstates/pr/people.py
+++ b/openstates/pr/people.py
@@ -24,6 +24,10 @@
name_text = self.get_node(senator_page, '//span[@class="name"]').text_content().strip()
name = re.sub(r'^Hon\.', '', name_text, flags=re.IGNORECASE).strip()
party = profile_links[0].text_content().strip()
+ # Translate to English since being an Independent is a universal construct
+ if party == "Independiente":
+ party = "Independent"
+
photo_url = self.get_node(senator_page, '//div[@class="avatar"]//img/@src')
if profile_links[1].text_content().strip() == "Senador por Distrito":
|
{"golden_diff": "diff --git a/openstates/pr/people.py b/openstates/pr/people.py\n--- a/openstates/pr/people.py\n+++ b/openstates/pr/people.py\n@@ -24,6 +24,10 @@\n name_text = self.get_node(senator_page, '//span[@class=\"name\"]').text_content().strip()\n name = re.sub(r'^Hon\\.', '', name_text, flags=re.IGNORECASE).strip()\n party = profile_links[0].text_content().strip()\n+ # Translate to English since being an Independent is a universal construct\n+ if party == \"Independiente\":\n+ party = \"Independent\"\n+\n photo_url = self.get_node(senator_page, '//div[@class=\"avatar\"]//img/@src')\n \n if profile_links[1].text_content().strip() == \"Senador por Distrito\":\n", "issue": "PR failing since at least 2018-09-06\nPR has been failing since 2018-09-06\n\nBased on automated runs it appears that PR has not run successfully in 6 days (2018-09-06).\n\n\n```\n 00:38:39 ERROR pupa: cannot resolve pseudo id to Person: ~{\"name\": \"Ram\\u00f3n L. Cruz Burgos\"}\n00:38:39 ERROR pupa: cannot resolve pseudo id to Person: ~{\"name\": \"Angel Buler\\u00edn Ramos\"}\n00:38:39 ERROR pupa: cannot resolve pseudo id to Person: ~{\"name\": \"\\u00c1ngel Mart\\u00ednez Santiago\"}\n00:38:39 ERROR pupa: cannot resolve pseudo id to Person: ~{\"name\": \"Manuel A. Natal Albelo\"}\n00:38:39 ERROR pupa: cannot resolve pseudo id to Person: ~{\"name\": \"Eduardo Bhatia Gautier\"}\n00:38:39 ERROR pupa: cannot resolve pseudo id to Person: ~{\"name\": \"Zoe Laboy Alvarado\"}\n00:38:39 ERROR pupa: cannot resolve pseudo id to Person: ~{\"name\": \"An\\u00edbal Jos\\u00e9 Torres Torres\"}\n00:38:39 ERROR pupa: cannot resolve pseudo id to Person: ~{\"name\": \"Carmelo J. R\\u00edos Santiago\"}\n00:38:39 ERROR pupa: cannot resolve pseudo id to Person: ~{\"name\": \"Itzamar Pe\\u00f1a Ram\\u00edrez\"}\n00:38:39 ERROR pupa: cannot resolve pseudo id to Person: ~{\"name\": \"Carlos A. Bianchi Angler\\u00f3\"}\n00:38:39 ERROR pupa: cannot resolve pseudo id to Person: ~{\"name\": \"Jos\\u00e9 Vargas Vidot\"}\n00:38:39 ERROR pupa: cannot resolve pseudo id to Person: ~{\"name\": \"Angel Mart\\u00ednez Santiago\"}\n00:38:39 ERROR pupa: cannot resolve pseudo id to Person: ~{\"name\": \"Eduardo Bhatia Gauthier\"}\n00:38:39 ERROR pupa: cannot resolve pseudo id to Person: ~{\"name\": \"Miguel Romero Lugo\"}\n00:38:39 ERROR pupa: cannot resolve pseudo id to Person: ~{\"name\": \"Margarita Nolasco Santiago\"}\n00:38:39 ERROR pupa: cannot resolve pseudo id to Person: ~{\"name\": \"Luis R. Ortiz Lugo\"}\n00:38:39 ERROR pupa: cannot resolve pseudo id to Person: ~{\"name\": \"Urayo\\u00e1n Hern\\u00e1ndez Alvarado\"}\n00:38:39 ERROR pupa: cannot resolve pseudo id to Person: ~{\"name\": \"Jos\\u00e9 M. Varela Fern\\u00e1ndez\"}\nloaded Open States pupa settings...\npr (scrape, import)\n people: {}\n committees: {}\n bills: {}\nimport jurisdictions...\nimport organizations...\nimport people...\nimport posts...\nimport memberships...\nTraceback (most recent call last):\n File \"/opt/openstates/venv-pupa//bin/pupa\", line 11, in <module>\n load_entry_point('pupa', 'console_scripts', 'pupa')()\n File \"/opt/openstates/venv-pupa/src/pupa/pupa/cli/__main__.py\", line 68, in main\n subcommands[args.subcommand].handle(args, other)\n File \"/opt/openstates/venv-pupa/src/pupa/pupa/cli/commands/update.py\", line 260, in handle\n return self.do_handle(args, other, juris)\n File \"/opt/openstates/venv-pupa/src/pupa/pupa/cli/commands/update.py\", line 307, in do_handle\n report['import'] = self.do_import(juris, args)\n File \"/opt/openstates/venv-pupa/src/pupa/pupa/cli/commands/update.py\", line 211, in do_import\n report.update(membership_importer.import_directory(datadir))\n File \"/opt/openstates/venv-pupa/src/pupa/pupa/importers/base.py\", line 196, in import_directory\n return self.import_data(json_stream())\n File \"/opt/openstates/venv-pupa/src/pupa/pupa/importers/base.py\", line 233, in import_data\n obj_id, what = self.import_item(data)\n File \"/opt/openstates/venv-pupa/src/pupa/pupa/importers/base.py\", line 254, in import_item\n data = self.prepare_for_db(data)\n File \"/opt/openstates/venv-pupa/src/pupa/pupa/importers/memberships.py\", line 47, in prepare_for_db\n data['organization_id'] = self.org_importer.resolve_json_id(data['organization_id'])\n File \"/opt/openstates/venv-pupa/src/pupa/pupa/importers/base.py\", line 171, in resolve_json_id\n raise UnresolvedIdError(errmsg)\npupa.exceptions.UnresolvedIdError: cannot resolve pseudo id to Organization: ~{\"classification\": \"party\", \"name\": \"Independiente\"}\n```\n\nVisit http://bobsled.openstates.org for more info.\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\nimport re\nfrom pupa.scrape import Person, Scraper\nfrom openstates.utils import LXMLMixin, validate_phone_number\n\n\nclass PRPersonScraper(Scraper, LXMLMixin):\n def scrape(self, chamber=None):\n term = self.jurisdiction.legislative_sessions[-1]['identifier']\n chambers = [chamber] if chamber is not None else ['upper', 'lower']\n for chamber in chambers:\n yield from getattr(self, 'scrape_' + chamber + '_chamber')(term)\n\n def scrape_upper_chamber(self, term):\n url = 'https://senado.pr.gov/Pages/Senadores.aspx'\n\n doc = self.lxmlize(url)\n links = self.get_nodes(doc, '//ul[@class=\"senadores-list\"]/li/a/@href')\n\n for link in links:\n senator_page = self.lxmlize(link)\n profile_links = self.get_nodes(senator_page, '//ul[@class=\"profiles-links\"]/li')\n\n name_text = self.get_node(senator_page, '//span[@class=\"name\"]').text_content().strip()\n name = re.sub(r'^Hon\\.', '', name_text, flags=re.IGNORECASE).strip()\n party = profile_links[0].text_content().strip()\n photo_url = self.get_node(senator_page, '//div[@class=\"avatar\"]//img/@src')\n\n if profile_links[1].text_content().strip() == \"Senador por Distrito\":\n district_text = self.get_node(\n senator_page,\n '//div[@class=\"module-distrito\"]//span[@class=\"headline\"]').text_content()\n district = district_text.replace('DISTRITO', '', 1).replace('\\u200b', '').strip()\n elif profile_links[1].text_content().strip() == \"Senador por Acumulaci\u00f3n\":\n district = \"At-Large\"\n\n phone_node = self.get_node(senator_page, '//a[@class=\"contact-data tel\"]')\n phone = phone_node.text_content().strip()\n email_node = self.get_node(senator_page, '//a[@class=\"contact-data email\"]')\n email = email_node.text_content().replace('\\u200b', '').strip()\n\n person = Person(primary_org='upper',\n district=district,\n name=name,\n party=party,\n image=photo_url)\n person.add_contact_detail(type='email',\n value=email,\n note='Capitol Office')\n person.add_contact_detail(type='voice',\n value=phone,\n note='Capitol Office')\n person.add_link(link)\n person.add_source(link)\n\n yield person\n\n def scrape_lower_chamber(self, term):\n # E-mail contact is now hidden behind webforms. Sadness.\n\n party_map = {'PNP': 'Partido Nuevo Progresista',\n 'PPD': u'Partido Popular Democr\\xe1tico',\n 'PIP': u'Partido Independentista Puertorrique\\u00F1o',\n }\n\n url = 'http://www.tucamarapr.org/dnncamara/ComposiciondelaCamara/Biografia.aspx'\n page = self.lxmlize(url)\n\n member_nodes = self.get_nodes(page, '//li[@class=\"selectionRep\"]')\n for member_node in member_nodes:\n member_info = member_node.text_content().strip().split(\"\\n\")\n\n name = re.sub(r'^Hon\\.', '', member_info[0]).strip()\n district_text = member_info[-1].strip()\n if district_text == 'Representante por Acumulaci\u00f3n':\n district = 'At-Large'\n else:\n district = district_text.replace(\"Representante del Distrito \", \"\").strip()\n photo_url = self.get_node(member_node, './/img/@src')\n\n rep_link = self.get_node(member_node, \".//a/@href\")\n rep_page = self.lxmlize(rep_link)\n\n party_node = self.get_node(rep_page, '//span[@class=\"partyBio\"]')\n party_text = party_node.text_content().strip()\n party = party_map[party_text]\n\n address = self.get_node(rep_page, '//h6').text.strip().split(\"\\n\")[0].strip()\n\n # Only grabs the first validated phone number found.\n # Typically, representatives have multiple phone numbers.\n phone_node = self.get_node(\n rep_page,\n '//span[@class=\"data-type\" and contains(text(), \"Tel.\")]')\n phone = None\n possible_phones = phone_node.text.strip().split(\"\\n\")\n for phone_attempt in possible_phones:\n # Don't keep searching phone numbers if a good one is found.\n if phone:\n break\n\n phone_text = re.sub(r'^Tel\\.[\\s]*', '', phone_attempt).strip()\n if validate_phone_number(phone_text):\n phone = phone_text\n\n fax_node = self.get_node(\n rep_page,\n '//span[@class=\"data-type\" and contains(text(), \"Fax.\")]')\n fax = None\n if fax_node:\n fax_text = fax_node.text.strip()\n fax_text = re.sub(r'^Fax\\.[\\s]*', '', fax_text).strip()\n if validate_phone_number(fax_text):\n fax = fax_text\n\n person = Person(primary_org='lower',\n district=district,\n name=name,\n party=party,\n image=photo_url)\n\n person.add_link(rep_link)\n person.add_source(rep_link)\n person.add_source(url)\n\n if address:\n person.add_contact_detail(type='address',\n value=address,\n note='Capitol Office')\n if phone:\n person.add_contact_detail(type='voice',\n value=phone,\n note='Capitol Office')\n if fax:\n person.add_contact_detail(type='fax',\n value=fax,\n note='Capitol Office')\n\n yield person\n", "path": "openstates/pr/people.py"}]}
| 3,358 | 180 |
gh_patches_debug_35975
|
rasdani/github-patches
|
git_diff
|
ckan__ckan-7933
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Some patch actions raise `ckan.logic.NotAuthorized` even though `context['ignore_auth'] = True`
## CKAN version
2.9+
## Describe the bug
The patch action functions in [ckan/logic/action/patch.py](https://github.com/ckan/ckan/tree/master/ckan/logic/action/patch.py) create a separate `show_context: Context` object that is used with a show action to retrieve the resource that is being patched. For almost all of these patch functions, the `'ignore_auth'` value from the patch action's input `context: Context` argument is not propagated to the `show_context` object. As a result, patching some resource types with `'ignore_auth': True` in the patch action's `Context` unexpectedly fails with a `ckan.logic.NotAuthorized` error.
Only [`package_patch()`](https://github.com/ckan/ckan/blob/master/ckan/logic/action/patch.py#L14) correctly propagates this value. The other four patch action functions are affected:
* [`resource_patch()`](https://github.com/ckan/ckan/blob/master/ckan/logic/action/patch.py#L57)
* [`group_patch()`](https://github.com/ckan/ckan/blob/master/ckan/logic/action/patch.py#L88)
* [`organization_patch()`](https://github.com/ckan/ckan/blob/master/ckan/logic/action/patch.py#L122)
* [`user_patch()`](https://github.com/ckan/ckan/blob/master/ckan/logic/action/patch.py#L157)
## Example
The following code snippet uses the Plugin Toolkit to access the [`user_patch()` function](https://github.com/ckan/ckan/blob/master/ckan/logic/action/patch.py#L157). This will fail if `user` is not authorized to perform `'user_show'`, because `'ignore_auth'` [is not propagated to `show_context`](https://github.com/ckan/ckan/blob/master/ckan/logic/action/patch.py#L171) in `user_patch()`.
```python
toolkit.get_action('user_patch')(
context={
'user': user,
'ignore_auth': True,
},
)
```
A problem like this showed up while I was modifying some code in the `ckanext-ldap` plugin. I believe the reason is that at the time this is being called, a currently not-logged-in user is being passed, and such a user cannot perform `'user_show'`. Regardless, I would have expected that with `'ignore_auth'` being passed into the patch function, the action would succeed, or at least would not return an authorization error.
## Suggested fix
### Easy
The easiest thing to do is just add `'ignore_auth': context.get('ignore_auth', False)` to each of the `show_context` definitions that are missing them.
### Robust
A more robust fix would be to introduce a helper function, `_create_show_context()` (defined below), that each function can call to create the `show_context` object. That way, future changes to the `show_context` will be propagated to all of the patch functions.
It is worth noting that I have absolutely no clue what the `'for_update'` key does. I couldn't find any documentation about it. It seems to be used in the database interaction code, but I'm not really familiar with working with databases. In any case: this key is not set consistently in the `show_context` objects across the various patch functions, so in the code below, it is an optional parameter that can be passed into the new function.
```python
def _create_show_context(context: Context, for_update: bool = False) -> Context:
'''Create a Context that can be used with a user_show action call.
This method is internal. It is meant to be used by the patch action
functions to generate a Context that can be used with a show action
corresponding to the type of the patch action. The show action is
used to retrieve the item that will be patched.
The ``show_context`` is derived from the original patch Context,
which is the ``context`` input argument. Certain values are propagated
from the input ``context`` to the returned ``show_context``.
:param context: Context from the original patch request
:type context: Context
:param for_update: if ``True``, then ``show_context['for_update'] = True``.
If ``False`` (the default), then ``'for_update'`` will not be
explicitly set in ``show_context``.
:type for_update: bool
:returns: A Context, ``show_context``, with the appropriate settings.
'''
show_context: Context = {
'model': context['model'],
'session': context['session'],
'user': context['user'],
'auth_user_obj': context['auth_user_obj'],
'ignore_auth': context.get('ignore_auth', False),
}
if for_update:
show_context['for_update'] = True
return show_context
```
</issue>
<code>
[start of ckan/logic/action/patch.py]
1 # encoding: utf-8
2
3 '''API functions for partial updates of existing data in CKAN'''
4
5 from ckan.logic import (
6 get_action as _get_action,
7 check_access as _check_access,
8 get_or_bust as _get_or_bust,
9 )
10 from ckan.types import Context, DataDict
11 from ckan.types.logic import ActionResult
12
13
14 def package_patch(
15 context: Context, data_dict: DataDict) -> ActionResult.PackagePatch:
16 '''Patch a dataset (package).
17
18 :param id: the id or name of the dataset
19 :type id: string
20
21 The difference between the update and patch methods is that the patch will
22 perform an update of the provided parameters, while leaving all other
23 parameters unchanged, whereas the update methods deletes all parameters
24 not explicitly provided in the data_dict.
25
26 You are able to partially update and/or create resources with
27 package_patch. If you are updating existing resources be sure to provide
28 the resource id. Existing resources excluded from the package_patch
29 data_dict will be removed. Resources in the package data_dict without
30 an id will be treated as new resources and will be added. New resources
31 added with the patch method do not create the default views.
32
33 You must be authorized to edit the dataset and the groups that it belongs
34 to.
35 '''
36 _check_access('package_patch', context, data_dict)
37
38 show_context: Context = {
39 'model': context['model'],
40 'session': context['session'],
41 'user': context['user'],
42 'auth_user_obj': context['auth_user_obj'],
43 'ignore_auth': context.get('ignore_auth', False),
44 'for_update': True
45 }
46
47 package_dict = _get_action('package_show')(
48 show_context,
49 {'id': _get_or_bust(data_dict, 'id')})
50
51 patched = dict(package_dict)
52 patched.update(data_dict)
53 patched['id'] = package_dict['id']
54 return _get_action('package_update')(context, patched)
55
56
57 def resource_patch(context: Context,
58 data_dict: DataDict) -> ActionResult.ResourcePatch:
59 '''Patch a resource
60
61 :param id: the id of the resource
62 :type id: string
63
64 The difference between the update and patch methods is that the patch will
65 perform an update of the provided parameters, while leaving all other
66 parameters unchanged, whereas the update methods deletes all parameters
67 not explicitly provided in the data_dict
68 '''
69 _check_access('resource_patch', context, data_dict)
70
71 show_context: Context = {
72 'model': context['model'],
73 'session': context['session'],
74 'user': context['user'],
75 'auth_user_obj': context['auth_user_obj'],
76 'for_update': True
77 }
78
79 resource_dict = _get_action('resource_show')(
80 show_context,
81 {'id': _get_or_bust(data_dict, 'id')})
82
83 patched = dict(resource_dict)
84 patched.update(data_dict)
85 return _get_action('resource_update')(context, patched)
86
87
88 def group_patch(context: Context,
89 data_dict: DataDict) -> ActionResult.GroupPatch:
90 '''Patch a group
91
92 :param id: the id or name of the group
93 :type id: string
94
95 The difference between the update and patch methods is that the patch will
96 perform an update of the provided parameters, while leaving all other
97 parameters unchanged, whereas the update methods deletes all parameters
98 not explicitly provided in the data_dict
99 '''
100 _check_access('group_patch', context, data_dict)
101
102 show_context: Context = {
103 'model': context['model'],
104 'session': context['session'],
105 'user': context['user'],
106 'auth_user_obj': context['auth_user_obj'],
107 }
108
109 group_dict = _get_action('group_show')(
110 show_context,
111 {'id': _get_or_bust(data_dict, 'id')})
112
113 patched = dict(group_dict)
114 patched.pop('display_name', None)
115 patched.update(data_dict)
116
117 patch_context = context.copy()
118 patch_context['allow_partial_update'] = True
119 return _get_action('group_update')(patch_context, patched)
120
121
122 def organization_patch(
123 context: Context,
124 data_dict: DataDict) -> ActionResult.OrganizationPatch:
125 '''Patch an organization
126
127 :param id: the id or name of the organization
128 :type id: string
129
130 The difference between the update and patch methods is that the patch will
131 perform an update of the provided parameters, while leaving all other
132 parameters unchanged, whereas the update methods deletes all parameters
133 not explicitly provided in the data_dict
134 '''
135 _check_access('organization_patch', context, data_dict)
136
137 show_context: Context = {
138 'model': context['model'],
139 'session': context['session'],
140 'user': context['user'],
141 'auth_user_obj': context['auth_user_obj'],
142 }
143
144 organization_dict = _get_action('organization_show')(
145 show_context,
146 {'id': _get_or_bust(data_dict, 'id')})
147
148 patched = dict(organization_dict)
149 patched.pop('display_name', None)
150 patched.update(data_dict)
151
152 patch_context = context.copy()
153 patch_context['allow_partial_update'] = True
154 return _get_action('organization_update')(patch_context, patched)
155
156
157 def user_patch(context: Context,
158 data_dict: DataDict) -> ActionResult.UserPatch:
159 '''Patch a user
160
161 :param id: the id or name of the user
162 :type id: string
163
164 The difference between the update and patch methods is that the patch will
165 perform an update of the provided parameters, while leaving all other
166 parameters unchanged, whereas the update methods deletes all parameters
167 not explicitly provided in the data_dict
168 '''
169 _check_access('user_patch', context, data_dict)
170
171 show_context: Context = {
172 'model': context['model'],
173 'session': context['session'],
174 'user': context['user'],
175 'auth_user_obj': context['auth_user_obj'],
176 }
177
178 user_dict = _get_action('user_show')(
179 show_context,
180 {'id': _get_or_bust(data_dict, 'id')})
181
182 patched = dict(user_dict)
183 patched.pop('display_name', None)
184 patched.update(data_dict)
185 return _get_action('user_update')(context, patched)
186
[end of ckan/logic/action/patch.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/ckan/logic/action/patch.py b/ckan/logic/action/patch.py
--- a/ckan/logic/action/patch.py
+++ b/ckan/logic/action/patch.py
@@ -6,6 +6,7 @@
get_action as _get_action,
check_access as _check_access,
get_or_bust as _get_or_bust,
+ fresh_context as _fresh_context
)
from ckan.types import Context, DataDict
from ckan.types.logic import ActionResult
@@ -68,13 +69,8 @@
'''
_check_access('resource_patch', context, data_dict)
- show_context: Context = {
- 'model': context['model'],
- 'session': context['session'],
- 'user': context['user'],
- 'auth_user_obj': context['auth_user_obj'],
- 'for_update': True
- }
+ show_context: Context = _fresh_context(context)
+ show_context.update({'for_update': True})
resource_dict = _get_action('resource_show')(
show_context,
@@ -99,12 +95,7 @@
'''
_check_access('group_patch', context, data_dict)
- show_context: Context = {
- 'model': context['model'],
- 'session': context['session'],
- 'user': context['user'],
- 'auth_user_obj': context['auth_user_obj'],
- }
+ show_context: Context = _fresh_context(context)
group_dict = _get_action('group_show')(
show_context,
@@ -134,12 +125,7 @@
'''
_check_access('organization_patch', context, data_dict)
- show_context: Context = {
- 'model': context['model'],
- 'session': context['session'],
- 'user': context['user'],
- 'auth_user_obj': context['auth_user_obj'],
- }
+ show_context: Context = _fresh_context(context)
organization_dict = _get_action('organization_show')(
show_context,
@@ -168,12 +154,7 @@
'''
_check_access('user_patch', context, data_dict)
- show_context: Context = {
- 'model': context['model'],
- 'session': context['session'],
- 'user': context['user'],
- 'auth_user_obj': context['auth_user_obj'],
- }
+ show_context: Context = _fresh_context(context)
user_dict = _get_action('user_show')(
show_context,
|
{"golden_diff": "diff --git a/ckan/logic/action/patch.py b/ckan/logic/action/patch.py\n--- a/ckan/logic/action/patch.py\n+++ b/ckan/logic/action/patch.py\n@@ -6,6 +6,7 @@\n get_action as _get_action,\n check_access as _check_access,\n get_or_bust as _get_or_bust,\n+ fresh_context as _fresh_context\n )\n from ckan.types import Context, DataDict\n from ckan.types.logic import ActionResult\n@@ -68,13 +69,8 @@\n '''\n _check_access('resource_patch', context, data_dict)\n \n- show_context: Context = {\n- 'model': context['model'],\n- 'session': context['session'],\n- 'user': context['user'],\n- 'auth_user_obj': context['auth_user_obj'],\n- 'for_update': True\n- }\n+ show_context: Context = _fresh_context(context)\n+ show_context.update({'for_update': True})\n \n resource_dict = _get_action('resource_show')(\n show_context,\n@@ -99,12 +95,7 @@\n '''\n _check_access('group_patch', context, data_dict)\n \n- show_context: Context = {\n- 'model': context['model'],\n- 'session': context['session'],\n- 'user': context['user'],\n- 'auth_user_obj': context['auth_user_obj'],\n- }\n+ show_context: Context = _fresh_context(context)\n \n group_dict = _get_action('group_show')(\n show_context,\n@@ -134,12 +125,7 @@\n '''\n _check_access('organization_patch', context, data_dict)\n \n- show_context: Context = {\n- 'model': context['model'],\n- 'session': context['session'],\n- 'user': context['user'],\n- 'auth_user_obj': context['auth_user_obj'],\n- }\n+ show_context: Context = _fresh_context(context)\n \n organization_dict = _get_action('organization_show')(\n show_context,\n@@ -168,12 +154,7 @@\n '''\n _check_access('user_patch', context, data_dict)\n \n- show_context: Context = {\n- 'model': context['model'],\n- 'session': context['session'],\n- 'user': context['user'],\n- 'auth_user_obj': context['auth_user_obj'],\n- }\n+ show_context: Context = _fresh_context(context)\n \n user_dict = _get_action('user_show')(\n show_context,\n", "issue": "Some patch actions raise `ckan.logic.NotAuthorized` even though `context['ignore_auth'] = True`\n## CKAN version\r\n\r\n2.9+\r\n\r\n## Describe the bug\r\n\r\nThe patch action functions in [ckan/logic/action/patch.py](https://github.com/ckan/ckan/tree/master/ckan/logic/action/patch.py) create a separate `show_context: Context` object that is used with a show action to retrieve the resource that is being patched. For almost all of these patch functions, the `'ignore_auth'` value from the patch action's input `context: Context` argument is not propagated to the `show_context` object. As a result, patching some resource types with `'ignore_auth': True` in the patch action's `Context` unexpectedly fails with a `ckan.logic.NotAuthorized` error.\r\n\r\nOnly [`package_patch()`](https://github.com/ckan/ckan/blob/master/ckan/logic/action/patch.py#L14) correctly propagates this value. The other four patch action functions are affected:\r\n\r\n* [`resource_patch()`](https://github.com/ckan/ckan/blob/master/ckan/logic/action/patch.py#L57)\r\n* [`group_patch()`](https://github.com/ckan/ckan/blob/master/ckan/logic/action/patch.py#L88)\r\n* [`organization_patch()`](https://github.com/ckan/ckan/blob/master/ckan/logic/action/patch.py#L122)\r\n* [`user_patch()`](https://github.com/ckan/ckan/blob/master/ckan/logic/action/patch.py#L157)\r\n\r\n## Example\r\n\r\nThe following code snippet uses the Plugin Toolkit to access the [`user_patch()` function](https://github.com/ckan/ckan/blob/master/ckan/logic/action/patch.py#L157). This will fail if `user` is not authorized to perform `'user_show'`, because `'ignore_auth'` [is not propagated to `show_context`](https://github.com/ckan/ckan/blob/master/ckan/logic/action/patch.py#L171) in `user_patch()`.\r\n\r\n```python\r\ntoolkit.get_action('user_patch')(\r\n context={\r\n 'user': user,\r\n 'ignore_auth': True,\r\n },\r\n)\r\n```\r\n\r\nA problem like this showed up while I was modifying some code in the `ckanext-ldap` plugin. I believe the reason is that at the time this is being called, a currently not-logged-in user is being passed, and such a user cannot perform `'user_show'`. Regardless, I would have expected that with `'ignore_auth'` being passed into the patch function, the action would succeed, or at least would not return an authorization error.\r\n\r\n## Suggested fix\r\n\r\n### Easy\r\n\r\nThe easiest thing to do is just add `'ignore_auth': context.get('ignore_auth', False)` to each of the `show_context` definitions that are missing them.\r\n\r\n### Robust\r\n\r\nA more robust fix would be to introduce a helper function, `_create_show_context()` (defined below), that each function can call to create the `show_context` object. That way, future changes to the `show_context` will be propagated to all of the patch functions.\r\n\r\nIt is worth noting that I have absolutely no clue what the `'for_update'` key does. I couldn't find any documentation about it. It seems to be used in the database interaction code, but I'm not really familiar with working with databases. In any case: this key is not set consistently in the `show_context` objects across the various patch functions, so in the code below, it is an optional parameter that can be passed into the new function.\r\n\r\n```python\r\ndef _create_show_context(context: Context, for_update: bool = False) -> Context:\r\n '''Create a Context that can be used with a user_show action call.\r\n\r\n This method is internal. It is meant to be used by the patch action\r\n functions to generate a Context that can be used with a show action\r\n corresponding to the type of the patch action. The show action is\r\n used to retrieve the item that will be patched.\r\n\r\n The ``show_context`` is derived from the original patch Context,\r\n which is the ``context`` input argument. Certain values are propagated\r\n from the input ``context`` to the returned ``show_context``.\r\n\r\n :param context: Context from the original patch request\r\n :type context: Context\r\n\r\n :param for_update: if ``True``, then ``show_context['for_update'] = True``.\r\n If ``False`` (the default), then ``'for_update'`` will not be\r\n explicitly set in ``show_context``.\r\n :type for_update: bool\r\n\r\n :returns: A Context, ``show_context``, with the appropriate settings.\r\n '''\r\n show_context: Context = {\r\n 'model': context['model'],\r\n 'session': context['session'],\r\n 'user': context['user'],\r\n 'auth_user_obj': context['auth_user_obj'],\r\n 'ignore_auth': context.get('ignore_auth', False),\r\n }\r\n\r\n if for_update:\r\n show_context['for_update'] = True\r\n\r\n return show_context\r\n```\n", "before_files": [{"content": "# encoding: utf-8\n\n'''API functions for partial updates of existing data in CKAN'''\n\nfrom ckan.logic import (\n get_action as _get_action,\n check_access as _check_access,\n get_or_bust as _get_or_bust,\n)\nfrom ckan.types import Context, DataDict\nfrom ckan.types.logic import ActionResult\n\n\ndef package_patch(\n context: Context, data_dict: DataDict) -> ActionResult.PackagePatch:\n '''Patch a dataset (package).\n\n :param id: the id or name of the dataset\n :type id: string\n\n The difference between the update and patch methods is that the patch will\n perform an update of the provided parameters, while leaving all other\n parameters unchanged, whereas the update methods deletes all parameters\n not explicitly provided in the data_dict.\n\n You are able to partially update and/or create resources with\n package_patch. If you are updating existing resources be sure to provide\n the resource id. Existing resources excluded from the package_patch\n data_dict will be removed. Resources in the package data_dict without\n an id will be treated as new resources and will be added. New resources\n added with the patch method do not create the default views.\n\n You must be authorized to edit the dataset and the groups that it belongs\n to.\n '''\n _check_access('package_patch', context, data_dict)\n\n show_context: Context = {\n 'model': context['model'],\n 'session': context['session'],\n 'user': context['user'],\n 'auth_user_obj': context['auth_user_obj'],\n 'ignore_auth': context.get('ignore_auth', False),\n 'for_update': True\n }\n\n package_dict = _get_action('package_show')(\n show_context,\n {'id': _get_or_bust(data_dict, 'id')})\n\n patched = dict(package_dict)\n patched.update(data_dict)\n patched['id'] = package_dict['id']\n return _get_action('package_update')(context, patched)\n\n\ndef resource_patch(context: Context,\n data_dict: DataDict) -> ActionResult.ResourcePatch:\n '''Patch a resource\n\n :param id: the id of the resource\n :type id: string\n\n The difference between the update and patch methods is that the patch will\n perform an update of the provided parameters, while leaving all other\n parameters unchanged, whereas the update methods deletes all parameters\n not explicitly provided in the data_dict\n '''\n _check_access('resource_patch', context, data_dict)\n\n show_context: Context = {\n 'model': context['model'],\n 'session': context['session'],\n 'user': context['user'],\n 'auth_user_obj': context['auth_user_obj'],\n 'for_update': True\n }\n\n resource_dict = _get_action('resource_show')(\n show_context,\n {'id': _get_or_bust(data_dict, 'id')})\n\n patched = dict(resource_dict)\n patched.update(data_dict)\n return _get_action('resource_update')(context, patched)\n\n\ndef group_patch(context: Context,\n data_dict: DataDict) -> ActionResult.GroupPatch:\n '''Patch a group\n\n :param id: the id or name of the group\n :type id: string\n\n The difference between the update and patch methods is that the patch will\n perform an update of the provided parameters, while leaving all other\n parameters unchanged, whereas the update methods deletes all parameters\n not explicitly provided in the data_dict\n '''\n _check_access('group_patch', context, data_dict)\n\n show_context: Context = {\n 'model': context['model'],\n 'session': context['session'],\n 'user': context['user'],\n 'auth_user_obj': context['auth_user_obj'],\n }\n\n group_dict = _get_action('group_show')(\n show_context,\n {'id': _get_or_bust(data_dict, 'id')})\n\n patched = dict(group_dict)\n patched.pop('display_name', None)\n patched.update(data_dict)\n\n patch_context = context.copy()\n patch_context['allow_partial_update'] = True\n return _get_action('group_update')(patch_context, patched)\n\n\ndef organization_patch(\n context: Context,\n data_dict: DataDict) -> ActionResult.OrganizationPatch:\n '''Patch an organization\n\n :param id: the id or name of the organization\n :type id: string\n\n The difference between the update and patch methods is that the patch will\n perform an update of the provided parameters, while leaving all other\n parameters unchanged, whereas the update methods deletes all parameters\n not explicitly provided in the data_dict\n '''\n _check_access('organization_patch', context, data_dict)\n\n show_context: Context = {\n 'model': context['model'],\n 'session': context['session'],\n 'user': context['user'],\n 'auth_user_obj': context['auth_user_obj'],\n }\n\n organization_dict = _get_action('organization_show')(\n show_context,\n {'id': _get_or_bust(data_dict, 'id')})\n\n patched = dict(organization_dict)\n patched.pop('display_name', None)\n patched.update(data_dict)\n\n patch_context = context.copy()\n patch_context['allow_partial_update'] = True\n return _get_action('organization_update')(patch_context, patched)\n\n\ndef user_patch(context: Context,\n data_dict: DataDict) -> ActionResult.UserPatch:\n '''Patch a user\n\n :param id: the id or name of the user\n :type id: string\n\n The difference between the update and patch methods is that the patch will\n perform an update of the provided parameters, while leaving all other\n parameters unchanged, whereas the update methods deletes all parameters\n not explicitly provided in the data_dict\n '''\n _check_access('user_patch', context, data_dict)\n\n show_context: Context = {\n 'model': context['model'],\n 'session': context['session'],\n 'user': context['user'],\n 'auth_user_obj': context['auth_user_obj'],\n }\n\n user_dict = _get_action('user_show')(\n show_context,\n {'id': _get_or_bust(data_dict, 'id')})\n\n patched = dict(user_dict)\n patched.pop('display_name', None)\n patched.update(data_dict)\n return _get_action('user_update')(context, patched)\n", "path": "ckan/logic/action/patch.py"}]}
| 3,486 | 573 |
gh_patches_debug_7401
|
rasdani/github-patches
|
git_diff
|
kubeflow__pipelines-1399
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Bug: Dataset not found in US
I'm getting an error while running the BigQuery kfp component to export some data from BQ to GCS. It says: `google.api_core.exceptions.NotFound: 404 Not found: xxx was not found in location US` which is correct, because the dataset is in EU, but I couldn't find any way to change the default behaviour of looking for datasets in the US.
On our regular codebase we specify the location on the BigQuery client initialisation, but the code here just uses the default: https://github.com/danicat/pipelines/blob/master/component_sdk/python/kfp_component/google/bigquery/_query.py
It is a one line change in the code, but I don't know how to rebuild the ml-pipeline container. The developer guide doesn't mention how to do it (but it does explain how to build containers for other components of the solution).
Please help! :)
</issue>
<code>
[start of component_sdk/python/kfp_component/google/bigquery/_query.py]
1 # Copyright 2018 Google LLC
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 import json
16 import logging
17
18 from google.cloud import bigquery
19 from google.api_core import exceptions
20
21 from kfp_component.core import KfpExecutionContext, display
22 from .. import common as gcp_common
23
24 # TODO(hongyes): make this path configurable as a environment variable
25 KFP_OUTPUT_PATH = '/tmp/kfp/output/'
26
27 def query(query, project_id, dataset_id=None, table_id=None,
28 output_gcs_path=None, dataset_location='US', job_config=None):
29 """Submit a query to Bigquery service and dump outputs to Bigquery table or
30 a GCS blob.
31
32 Args:
33 query (str): The query used by Bigquery service to fetch the results.
34 project_id (str): The project to execute the query job.
35 dataset_id (str): The ID of the persistent dataset to keep the results
36 of the query. If the dataset does not exist, the operation will
37 create a new one.
38 table_id (str): The ID of the table to keep the results of the query. If
39 absent, the operation will generate a random id for the table.
40 output_gcs_path (str): The GCS blob path to dump the query results to.
41 dataset_location (str): The location to create the dataset. Defaults to `US`.
42 job_config (dict): The full config spec for the query job.
43 Returns:
44 The API representation of the completed query job.
45 """
46 client = bigquery.Client(project=project_id)
47 if not job_config:
48 job_config = bigquery.QueryJobConfig()
49 job_config.create_disposition = bigquery.job.CreateDisposition.CREATE_IF_NEEDED
50 job_config.write_disposition = bigquery.job.WriteDisposition.WRITE_TRUNCATE
51 job_id = None
52 def cancel():
53 if job_id:
54 client.cancel_job(job_id)
55 with KfpExecutionContext(on_cancel=cancel) as ctx:
56 job_id = 'query_' + ctx.context_id()
57 query_job = _get_job(client, job_id)
58 table_ref = None
59 if not query_job:
60 dataset_ref = _prepare_dataset_ref(client, dataset_id, output_gcs_path,
61 dataset_location)
62 if dataset_ref:
63 if not table_id:
64 table_id = job_id
65 table_ref = dataset_ref.table(table_id)
66 job_config.destination = table_ref
67 query_job = client.query(query, job_config, job_id=job_id)
68 _display_job_link(project_id, job_id)
69 query_job.result() # Wait for query to finish
70 if output_gcs_path:
71 job_id = 'extract_' + ctx.context_id()
72 extract_job = _get_job(client, job_id)
73 logging.info('Extracting data from table {} to {}.'.format(str(table_ref), output_gcs_path))
74 if not extract_job:
75 extract_job = client.extract_table(table_ref, output_gcs_path)
76 extract_job.result() # Wait for export to finish
77 _dump_outputs(query_job, output_gcs_path, table_ref)
78 return query_job.to_api_repr()
79
80 def _get_job(client, job_id):
81 try:
82 return client.get_job(job_id)
83 except exceptions.NotFound:
84 return None
85
86 def _prepare_dataset_ref(client, dataset_id, output_gcs_path, dataset_location):
87 if not output_gcs_path and not dataset_id:
88 return None
89
90 if not dataset_id:
91 dataset_id = 'kfp_tmp_dataset'
92 dataset_ref = client.dataset(dataset_id)
93 dataset = _get_dataset(client, dataset_ref)
94 if not dataset:
95 logging.info('Creating dataset {}'.format(dataset_id))
96 dataset = _create_dataset(client, dataset_ref, dataset_location)
97 return dataset_ref
98
99 def _get_dataset(client, dataset_ref):
100 try:
101 return client.get_dataset(dataset_ref)
102 except exceptions.NotFound:
103 return None
104
105 def _create_dataset(client, dataset_ref, location):
106 dataset = bigquery.Dataset(dataset_ref)
107 dataset.location = location
108 return client.create_dataset(dataset)
109
110 def _display_job_link(project_id, job_id):
111 display.display(display.Link(
112 href= 'https://console.cloud.google.com/bigquery?project={}'
113 '&j={}&page=queryresults'.format(project_id, job_id),
114 text='Query Details'
115 ))
116
117 def _dump_outputs(job, output_path, table_ref):
118 gcp_common.dump_file(KFP_OUTPUT_PATH + 'bigquery/query-job.json',
119 json.dumps(job.to_api_repr()))
120 if not output_path:
121 output_path = ''
122 gcp_common.dump_file(KFP_OUTPUT_PATH + 'bigquery/query-output-path.txt',
123 output_path)
124 (dataset_id, table_id) = (table_ref.dataset_id, table_ref.table_id) if table_ref else ('', '')
125 gcp_common.dump_file(KFP_OUTPUT_PATH + 'bigquery/query-dataset-id.txt',
126 dataset_id)
127 gcp_common.dump_file(KFP_OUTPUT_PATH + 'bigquery/query-table-id.txt',
128 table_id)
129
[end of component_sdk/python/kfp_component/google/bigquery/_query.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/component_sdk/python/kfp_component/google/bigquery/_query.py b/component_sdk/python/kfp_component/google/bigquery/_query.py
--- a/component_sdk/python/kfp_component/google/bigquery/_query.py
+++ b/component_sdk/python/kfp_component/google/bigquery/_query.py
@@ -43,7 +43,7 @@
Returns:
The API representation of the completed query job.
"""
- client = bigquery.Client(project=project_id)
+ client = bigquery.Client(project=project_id, location=dataset_location)
if not job_config:
job_config = bigquery.QueryJobConfig()
job_config.create_disposition = bigquery.job.CreateDisposition.CREATE_IF_NEEDED
|
{"golden_diff": "diff --git a/component_sdk/python/kfp_component/google/bigquery/_query.py b/component_sdk/python/kfp_component/google/bigquery/_query.py\n--- a/component_sdk/python/kfp_component/google/bigquery/_query.py\n+++ b/component_sdk/python/kfp_component/google/bigquery/_query.py\n@@ -43,7 +43,7 @@\n Returns:\n The API representation of the completed query job.\n \"\"\"\n- client = bigquery.Client(project=project_id)\n+ client = bigquery.Client(project=project_id, location=dataset_location)\n if not job_config:\n job_config = bigquery.QueryJobConfig()\n job_config.create_disposition = bigquery.job.CreateDisposition.CREATE_IF_NEEDED\n", "issue": "Bug: Dataset not found in US\nI'm getting an error while running the BigQuery kfp component to export some data from BQ to GCS. It says: `google.api_core.exceptions.NotFound: 404 Not found: xxx was not found in location US` which is correct, because the dataset is in EU, but I couldn't find any way to change the default behaviour of looking for datasets in the US.\r\n\r\nOn our regular codebase we specify the location on the BigQuery client initialisation, but the code here just uses the default: https://github.com/danicat/pipelines/blob/master/component_sdk/python/kfp_component/google/bigquery/_query.py\r\n\r\nIt is a one line change in the code, but I don't know how to rebuild the ml-pipeline container. The developer guide doesn't mention how to do it (but it does explain how to build containers for other components of the solution).\r\n\r\nPlease help! :)\n", "before_files": [{"content": "# Copyright 2018 Google LLC\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport json\nimport logging\n\nfrom google.cloud import bigquery\nfrom google.api_core import exceptions\n\nfrom kfp_component.core import KfpExecutionContext, display\nfrom .. import common as gcp_common\n\n# TODO(hongyes): make this path configurable as a environment variable\nKFP_OUTPUT_PATH = '/tmp/kfp/output/'\n\ndef query(query, project_id, dataset_id=None, table_id=None, \n output_gcs_path=None, dataset_location='US', job_config=None):\n \"\"\"Submit a query to Bigquery service and dump outputs to Bigquery table or \n a GCS blob.\n \n Args:\n query (str): The query used by Bigquery service to fetch the results.\n project_id (str): The project to execute the query job.\n dataset_id (str): The ID of the persistent dataset to keep the results\n of the query. If the dataset does not exist, the operation will \n create a new one.\n table_id (str): The ID of the table to keep the results of the query. If\n absent, the operation will generate a random id for the table.\n output_gcs_path (str): The GCS blob path to dump the query results to.\n dataset_location (str): The location to create the dataset. Defaults to `US`.\n job_config (dict): The full config spec for the query job.\n Returns:\n The API representation of the completed query job.\n \"\"\"\n client = bigquery.Client(project=project_id)\n if not job_config:\n job_config = bigquery.QueryJobConfig()\n job_config.create_disposition = bigquery.job.CreateDisposition.CREATE_IF_NEEDED\n job_config.write_disposition = bigquery.job.WriteDisposition.WRITE_TRUNCATE\n job_id = None\n def cancel():\n if job_id:\n client.cancel_job(job_id)\n with KfpExecutionContext(on_cancel=cancel) as ctx:\n job_id = 'query_' + ctx.context_id()\n query_job = _get_job(client, job_id)\n table_ref = None\n if not query_job:\n dataset_ref = _prepare_dataset_ref(client, dataset_id, output_gcs_path, \n dataset_location)\n if dataset_ref:\n if not table_id:\n table_id = job_id\n table_ref = dataset_ref.table(table_id)\n job_config.destination = table_ref\n query_job = client.query(query, job_config, job_id=job_id)\n _display_job_link(project_id, job_id)\n query_job.result() # Wait for query to finish\n if output_gcs_path:\n job_id = 'extract_' + ctx.context_id()\n extract_job = _get_job(client, job_id)\n logging.info('Extracting data from table {} to {}.'.format(str(table_ref), output_gcs_path))\n if not extract_job:\n extract_job = client.extract_table(table_ref, output_gcs_path)\n extract_job.result() # Wait for export to finish\n _dump_outputs(query_job, output_gcs_path, table_ref)\n return query_job.to_api_repr()\n\ndef _get_job(client, job_id):\n try:\n return client.get_job(job_id)\n except exceptions.NotFound:\n return None\n\ndef _prepare_dataset_ref(client, dataset_id, output_gcs_path, dataset_location):\n if not output_gcs_path and not dataset_id:\n return None\n \n if not dataset_id:\n dataset_id = 'kfp_tmp_dataset'\n dataset_ref = client.dataset(dataset_id)\n dataset = _get_dataset(client, dataset_ref)\n if not dataset:\n logging.info('Creating dataset {}'.format(dataset_id))\n dataset = _create_dataset(client, dataset_ref, dataset_location)\n return dataset_ref\n\ndef _get_dataset(client, dataset_ref):\n try:\n return client.get_dataset(dataset_ref)\n except exceptions.NotFound:\n return None\n\ndef _create_dataset(client, dataset_ref, location):\n dataset = bigquery.Dataset(dataset_ref)\n dataset.location = location\n return client.create_dataset(dataset)\n\ndef _display_job_link(project_id, job_id):\n display.display(display.Link(\n href= 'https://console.cloud.google.com/bigquery?project={}'\n '&j={}&page=queryresults'.format(project_id, job_id),\n text='Query Details'\n ))\n\ndef _dump_outputs(job, output_path, table_ref):\n gcp_common.dump_file(KFP_OUTPUT_PATH + 'bigquery/query-job.json', \n json.dumps(job.to_api_repr()))\n if not output_path:\n output_path = ''\n gcp_common.dump_file(KFP_OUTPUT_PATH + 'bigquery/query-output-path.txt', \n output_path)\n (dataset_id, table_id) = (table_ref.dataset_id, table_ref.table_id) if table_ref else ('', '')\n gcp_common.dump_file(KFP_OUTPUT_PATH + 'bigquery/query-dataset-id.txt', \n dataset_id)\n gcp_common.dump_file(KFP_OUTPUT_PATH + 'bigquery/query-table-id.txt', \n table_id)\n", "path": "component_sdk/python/kfp_component/google/bigquery/_query.py"}]}
| 2,207 | 149 |
gh_patches_debug_28389
|
rasdani/github-patches
|
git_diff
|
freedomofpress__securedrop-5575
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Test result combination scripts can be removed
## Description
We have a couple of scripts for combining test results in CI that are no longer being used and can be deleted:
```
devops/scripts/combine-junit.py
devops/scripts/combine-junit-test-results.sh
```
</issue>
<code>
[start of devops/scripts/combine-junit.py]
1 #!/usr/bin/env python
2 #
3 # Corey Goldberg, Dec 2012
4 # Original source from gist.github.com/cgoldberg/4320815
5
6 import os
7 import sys
8 import xml.etree.ElementTree as ET
9
10
11 """Merge multiple JUnit XML files into a single results file.
12
13 Output dumps to sdtdout.
14
15 example usage:
16 $ python merge_junit_results.py results1.xml results2.xml > results.xml
17 """
18
19
20 def main():
21 args = sys.argv[1:]
22 if not args:
23 usage()
24 sys.exit(2)
25 if '-h' in args or '--help' in args:
26 usage()
27 sys.exit(2)
28 merge_results(args[:])
29
30
31 def merge_results(xml_files):
32 failures = 0
33 tests = 0
34 errors = 0
35 time = 0.0
36 cases = []
37
38 for file_name in xml_files:
39 # We disable bandit checking to permit B314, which recommends use
40 # of defusedxml to protect against malicious XML files. This code
41 # path only runs in CI, not on developer workstations, and the XML
42 # output is generated by testinfra on staging machines.
43 tree = ET.parse(file_name) # nosec
44 test_suite = tree.getroot()
45 failures += int(test_suite.attrib['failures'])
46 tests += int(test_suite.attrib['tests'])
47 errors += int(test_suite.attrib['errors'])
48 time += float(test_suite.attrib['time'])
49 cases.append(test_suite.getchildren())
50
51 new_root = ET.Element('testsuite')
52 new_root.attrib['failures'] = '%s' % failures
53 new_root.attrib['tests'] = '%s' % tests
54 new_root.attrib['errors'] = '%s' % errors
55 new_root.attrib['time'] = '%s' % time
56 for case in cases:
57 new_root.extend(case)
58 new_tree = ET.ElementTree(new_root)
59 ET.dump(new_tree)
60
61
62 def usage():
63 this_file = os.path.basename(__file__)
64 print('Usage: %s results1.xml results2.xml' % this_file)
65
66
67 if __name__ == '__main__':
68 main()
69
[end of devops/scripts/combine-junit.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/devops/scripts/combine-junit.py b/devops/scripts/combine-junit.py
deleted file mode 100755
--- a/devops/scripts/combine-junit.py
+++ /dev/null
@@ -1,68 +0,0 @@
-#!/usr/bin/env python
-#
-# Corey Goldberg, Dec 2012
-# Original source from gist.github.com/cgoldberg/4320815
-
-import os
-import sys
-import xml.etree.ElementTree as ET
-
-
-"""Merge multiple JUnit XML files into a single results file.
-
-Output dumps to sdtdout.
-
-example usage:
- $ python merge_junit_results.py results1.xml results2.xml > results.xml
-"""
-
-
-def main():
- args = sys.argv[1:]
- if not args:
- usage()
- sys.exit(2)
- if '-h' in args or '--help' in args:
- usage()
- sys.exit(2)
- merge_results(args[:])
-
-
-def merge_results(xml_files):
- failures = 0
- tests = 0
- errors = 0
- time = 0.0
- cases = []
-
- for file_name in xml_files:
- # We disable bandit checking to permit B314, which recommends use
- # of defusedxml to protect against malicious XML files. This code
- # path only runs in CI, not on developer workstations, and the XML
- # output is generated by testinfra on staging machines.
- tree = ET.parse(file_name) # nosec
- test_suite = tree.getroot()
- failures += int(test_suite.attrib['failures'])
- tests += int(test_suite.attrib['tests'])
- errors += int(test_suite.attrib['errors'])
- time += float(test_suite.attrib['time'])
- cases.append(test_suite.getchildren())
-
- new_root = ET.Element('testsuite')
- new_root.attrib['failures'] = '%s' % failures
- new_root.attrib['tests'] = '%s' % tests
- new_root.attrib['errors'] = '%s' % errors
- new_root.attrib['time'] = '%s' % time
- for case in cases:
- new_root.extend(case)
- new_tree = ET.ElementTree(new_root)
- ET.dump(new_tree)
-
-
-def usage():
- this_file = os.path.basename(__file__)
- print('Usage: %s results1.xml results2.xml' % this_file)
-
-
-if __name__ == '__main__':
- main()
|
{"golden_diff": "diff --git a/devops/scripts/combine-junit.py b/devops/scripts/combine-junit.py\ndeleted file mode 100755\n--- a/devops/scripts/combine-junit.py\n+++ /dev/null\n@@ -1,68 +0,0 @@\n-#!/usr/bin/env python\n-#\n-# Corey Goldberg, Dec 2012\n-# Original source from gist.github.com/cgoldberg/4320815\n-\n-import os\n-import sys\n-import xml.etree.ElementTree as ET\n-\n-\n-\"\"\"Merge multiple JUnit XML files into a single results file.\n-\n-Output dumps to sdtdout.\n-\n-example usage:\n- $ python merge_junit_results.py results1.xml results2.xml > results.xml\n-\"\"\"\n-\n-\n-def main():\n- args = sys.argv[1:]\n- if not args:\n- usage()\n- sys.exit(2)\n- if '-h' in args or '--help' in args:\n- usage()\n- sys.exit(2)\n- merge_results(args[:])\n-\n-\n-def merge_results(xml_files):\n- failures = 0\n- tests = 0\n- errors = 0\n- time = 0.0\n- cases = []\n-\n- for file_name in xml_files:\n- # We disable bandit checking to permit B314, which recommends use\n- # of defusedxml to protect against malicious XML files. This code\n- # path only runs in CI, not on developer workstations, and the XML\n- # output is generated by testinfra on staging machines.\n- tree = ET.parse(file_name) # nosec\n- test_suite = tree.getroot()\n- failures += int(test_suite.attrib['failures'])\n- tests += int(test_suite.attrib['tests'])\n- errors += int(test_suite.attrib['errors'])\n- time += float(test_suite.attrib['time'])\n- cases.append(test_suite.getchildren())\n-\n- new_root = ET.Element('testsuite')\n- new_root.attrib['failures'] = '%s' % failures\n- new_root.attrib['tests'] = '%s' % tests\n- new_root.attrib['errors'] = '%s' % errors\n- new_root.attrib['time'] = '%s' % time\n- for case in cases:\n- new_root.extend(case)\n- new_tree = ET.ElementTree(new_root)\n- ET.dump(new_tree)\n-\n-\n-def usage():\n- this_file = os.path.basename(__file__)\n- print('Usage: %s results1.xml results2.xml' % this_file)\n-\n-\n-if __name__ == '__main__':\n- main()\n", "issue": "Test result combination scripts can be removed\n## Description\r\n\r\nWe have a couple of scripts for combining test results in CI that are no longer being used and can be deleted:\r\n```\r\ndevops/scripts/combine-junit.py\r\ndevops/scripts/combine-junit-test-results.sh\r\n```\r\n\n", "before_files": [{"content": "#!/usr/bin/env python\n#\n# Corey Goldberg, Dec 2012\n# Original source from gist.github.com/cgoldberg/4320815\n\nimport os\nimport sys\nimport xml.etree.ElementTree as ET\n\n\n\"\"\"Merge multiple JUnit XML files into a single results file.\n\nOutput dumps to sdtdout.\n\nexample usage:\n $ python merge_junit_results.py results1.xml results2.xml > results.xml\n\"\"\"\n\n\ndef main():\n args = sys.argv[1:]\n if not args:\n usage()\n sys.exit(2)\n if '-h' in args or '--help' in args:\n usage()\n sys.exit(2)\n merge_results(args[:])\n\n\ndef merge_results(xml_files):\n failures = 0\n tests = 0\n errors = 0\n time = 0.0\n cases = []\n\n for file_name in xml_files:\n # We disable bandit checking to permit B314, which recommends use\n # of defusedxml to protect against malicious XML files. This code\n # path only runs in CI, not on developer workstations, and the XML\n # output is generated by testinfra on staging machines.\n tree = ET.parse(file_name) # nosec\n test_suite = tree.getroot()\n failures += int(test_suite.attrib['failures'])\n tests += int(test_suite.attrib['tests'])\n errors += int(test_suite.attrib['errors'])\n time += float(test_suite.attrib['time'])\n cases.append(test_suite.getchildren())\n\n new_root = ET.Element('testsuite')\n new_root.attrib['failures'] = '%s' % failures\n new_root.attrib['tests'] = '%s' % tests\n new_root.attrib['errors'] = '%s' % errors\n new_root.attrib['time'] = '%s' % time\n for case in cases:\n new_root.extend(case)\n new_tree = ET.ElementTree(new_root)\n ET.dump(new_tree)\n\n\ndef usage():\n this_file = os.path.basename(__file__)\n print('Usage: %s results1.xml results2.xml' % this_file)\n\n\nif __name__ == '__main__':\n main()\n", "path": "devops/scripts/combine-junit.py"}]}
| 1,211 | 586 |
gh_patches_debug_8914
|
rasdani/github-patches
|
git_diff
|
microsoft__knossos-ksc-629
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Calls to "main"
In merging #550 I find I need ``ks::main``.
Looking at this comment in
https://github.com/microsoft/knossos-ksc/blob/18f654086f349cceb59c30dcbc8de2c534dcb5ec/src/ksc/Cgen.hs#L801
I wonder is it time to look at removing that?
</issue>
<code>
[start of src/python/ksc/utils.py]
1 from dataclasses import dataclass
2 from typing import Tuple, Union
3 from collections import namedtuple
4 import itertools
5
6 import importlib.util
7 import os
8 import numpy as np
9 import subprocess
10 import sysconfig
11 import sys
12 from tempfile import NamedTemporaryFile
13
14 from ksc.type import Type, tangent_type, make_tuple_if_many
15
16 class KRecord:
17 """
18 A smoother namedtuple -- like https://pythonhosted.org/pyrecord but using the existing class syntax.
19 Like a 3.7 dataclass, but don't need to decorate each derived class
20
21 Derive a class from KRecord, declare its fields, and use keyword args in __init__
22
23 def MyClass(KRecord):
24 cost: float
25 names: List[String]
26
27 def __init__(cost, names):
28 super().__init__(cost=cost, names=names)
29
30 And now you have a nice little record class.
31
32 Construct a MyClass:
33 a = MyClass(1.3, ["fred", "conor", "una"])
34
35 Compare two MyClasses
36 if a == b: ...
37
38 Etc
39 """
40
41 def __init__(self, **args):
42 for (nt,v) in args.items():
43 # assert nt in self.__annotations__ # <- This check will fail for chains of derived classes -- only the deepest has __annotations__ ready yet.
44 setattr(self, nt, v)
45
46 def __eq__(self, that):
47 if type(self) != type(that):
48 return False
49
50 for nt in self.__annotations__:
51 if getattr(self, nt) != getattr(that,nt):
52 return False
53 return True
54
55
56
57
58 def ensure_list_of_lists(l):
59 """return input, wrapped in a singleton list if its first element is not a list
60
61 ensure_list_of_lists([]) = []
62 ensure_list_of_lists([1]) = [[1]]
63 ensure_list_of_lists([[1]]) = [[1]]
64 ensure_list_of_lists([[1,2]]) = [[1, 2]]
65 ensure_list_of_lists([[1,2], [3,4]]) = [[1, 2], [3, 4]]
66 """
67
68 if not isinstance(l, list):
69 raise ValueError("Expect a list")
70 if len(l) < 1: # Empty list is empty list
71 return l
72 if not isinstance(l[0], list):
73 return [l]
74 else:
75 return l
76
77 def paren(s):
78 return "(" + s + ")"
79
80 PYTHON_MODULE_NAME = "ks_mod"
81
82 def import_module_from_path(module_name, path):
83 # These three lines are for loading a module from a file in Python 3.5+
84 # https://bugs.python.org/issue21436
85 spec = importlib.util.spec_from_file_location(module_name, path)
86 py_out = importlib.util.module_from_spec(spec)
87 spec.loader.exec_module(py_out)
88 return py_out
89
90 def translate_and_import(source_file_name, *args):
91 from ksc.translate import translate
92 py_out = translate(*args, source_file_name, with_main=False)
93 with NamedTemporaryFile(mode="w", suffix=".py", delete=False) as f:
94 f.write(f"# AUTOGEN from {source_file_name} via ksc.utils.translate_and_import")
95 f.write(py_out)
96
97 print(f.name)
98 return import_module_from_path(PYTHON_MODULE_NAME, f.name)
99
100 def subprocess_run(cmd, env=None):
101 return subprocess.run(cmd, stdout=subprocess.PIPE, env=env).stdout.decode().strip("\n")
102
103 def get_ksc_paths():
104 if "KSC_RUNTIME_DIR" in os.environ:
105 ksc_runtime_dir = os.environ["KSC_RUNTIME_DIR"]
106 else:
107 ksc_runtime_dir = "./src/runtime"
108
109 if "KSC_PATH" in os.environ:
110 ksc_path = os.environ["KSC_PATH"]
111 else:
112 ksc_path = "./build/bin/ksc"
113
114 return ksc_path,ksc_runtime_dir
115
116
117 def generate_cpp_from_ks(ks_str, generate_derivatives = False, use_aten = False):
118 ksc_path,_ksc_runtime_dir = get_ksc_paths()
119
120 with NamedTemporaryFile(mode="w", suffix=".ks", delete=False) as fks:
121 fks.write(ks_str)
122 try:
123 with NamedTemporaryFile(mode="w", suffix=".kso", delete=False) as fkso:
124 with NamedTemporaryFile(mode="w", suffix=".cpp", delete=False) as fcpp:
125 print("generate_cpp_from_ks:", ksc_path, fks.name)
126 e = subprocess.run([
127 ksc_path,
128 "--generate-cpp" if generate_derivatives else "--generate-cpp-without-diffs",
129 "--ks-source-file", "src/runtime/prelude.ks",
130 *(("--ks-source-file", "src/runtime/prelude-aten.ks") if use_aten else ()),
131 "--ks-source-file", fks.name,
132 "--ks-output-file", fkso.name,
133 "--cpp-output-file", fcpp.name
134 ], capture_output=True, check=True)
135 print(e.stdout.decode('ascii'))
136 print(e.stderr.decode('ascii'))
137 except subprocess.CalledProcessError as e:
138 print(f"files {fks.name} {fkso.name} {fcpp.name}")
139 print(f"ks_str=\n{ks_str}")
140 print(e.output.decode('ascii'))
141 print(e.stderr.decode('ascii'))
142 raise
143
144
145 # Read from CPP back to string
146 with open(fcpp.name) as f:
147 out = f.read()
148
149 # only delete these file if no error
150 os.unlink(fks.name)
151 os.unlink(fcpp.name)
152 os.unlink(fkso.name)
153
154 return out
155
156 def build_py_module_from_cpp(cpp_str, pybind11_path, use_aten=False):
157 _ksc_path,ksc_runtime_dir = get_ksc_paths()
158
159 with NamedTemporaryFile(mode="w", suffix=".cpp", delete=False) as fcpp:
160 fcpp.write(cpp_str)
161
162 extension_suffix = sysconfig.get_config_var('EXT_SUFFIX')
163 if extension_suffix is None:
164 extension_suffix = sysconfig.get_config_var('SO')
165
166 with NamedTemporaryFile(mode="w", suffix=extension_suffix, delete=False) as fpymod:
167 pass
168 module_path = fpymod.name
169 module_name = os.path.basename(module_path).split(".")[0]
170 python_includes = subprocess_run(
171 [sys.executable, "-m", "pybind11", "--includes"],
172 env={"PYTHONPATH": "extern/pybind11"}
173 )
174 try:
175 cmd = (f"g++ -I{ksc_runtime_dir} -I{pybind11_path}/include "
176 + python_includes
177 + " -Wall -Wno-unused-variable -Wno-unused-but-set-variable"
178 " -fmax-errors=1"
179 " -std=c++17"
180 " -O3"
181 " -fPIC"
182 " -shared"
183 + (" -DKS_INCLUDE_ATEN" if use_aten else "")
184 + f" -DPYTHON_MODULE_NAME={module_name}"
185 f" -o {module_path} "
186 + fcpp.name)
187 print(cmd)
188 subprocess.run(cmd, shell=True, capture_output=True, check=True)
189 except subprocess.CalledProcessError as e:
190 print(f"cpp_file={fcpp.name}")
191 print(cmd)
192 print(e.output.decode('utf-8'))
193 print(e.stderr.decode('utf-8'))
194
195 raise
196
197 os.unlink(fcpp.name)
198 return module_name, module_path
199
200 def mangleType(ty):
201 return ty.shortstr()
202
203 def mangleTypes(tys):
204 return "".join(mangleType(ty) for ty in tys)
205
206
207 def encode_name(s : str) -> str:
208 # TODO: this could be faster
209 return s.\
210 replace('@',"$a").\
211 replace(',',"$_").\
212 replace('.',"$o").\
213 replace('[',"$6").\
214 replace(']',"$9").\
215 replace('<',"$d").\
216 replace('>',"$b").\
217 replace('*',"$x").\
218 replace(':',"$8")
219
220 def generate_and_compile_cpp_from_ks(ks_str, name_to_call, arg_types, return_type=None, generate_derivatives=False, use_aten=False, pybind11_path="extern/pybind11"):
221
222 generated_cpp_source = generate_cpp_from_ks(ks_str, generate_derivatives=generate_derivatives, use_aten=use_aten)
223
224 cpp_str = """
225 #include "knossos-pybind.h"
226
227 """ + generated_cpp_source + """
228
229 int ks::main(ks::allocator *) { return 0; };
230
231 """
232
233 args_str = mangleTypes(arg_types)
234 name_str = encode_name(f"{name_to_call}@{args_str}")
235 declarations = f"""
236 m.def("entry", with_ks_allocator(&ks::{name_str}));
237 """
238
239 if generate_derivatives:
240 darg_types = [tangent_type(ty) for ty in arg_types]
241 args_tuple_str = mangleType(make_tuple_if_many(arg_types))
242 dargs_tuple_str = mangleType(make_tuple_if_many(darg_types))
243 dreturn_type_str = mangleType(tangent_type(return_type))
244
245 fwd_name = encode_name(f"fwd${name_to_call}@{args_tuple_str}")
246 declarations += f"""
247 m.def("fwd_entry", with_ks_allocator(&ks::{fwd_name}));
248 """
249
250 rev_name = encode_name(f"rev${name_to_call}@{args_tuple_str}")
251 declarations += f"""
252 m.def("rev_entry", with_ks_allocator(&ks::{rev_name}));
253 """
254
255 cpp_str += """
256 PYBIND11_MODULE(PYTHON_MODULE_NAME, m) {
257 m.def("reset_allocator", []{g_alloc.reset();});
258 m.def("allocator_top", []{ return g_alloc.mark();});
259 m.def("allocator_peak", []{ return g_alloc.peak();});
260
261 declare_tensor_2<double>(m, "Tensor_2_Float");
262 declare_tensor_2<int>(m, "Tensor_2_Integer");
263
264 """ + declarations + """
265 }
266 """
267 pybindcpppath = "obj/pybind.cpp"
268 print(f"Saving to {pybindcpppath}")
269 os.makedirs(os.path.dirname(pybindcpppath), exist_ok=True)
270 with open(pybindcpppath, "w") as fcpp:
271 fcpp.write(cpp_str)
272
273 module_name, module_path = build_py_module_from_cpp(cpp_str, pybind11_path, use_aten=use_aten)
274 return import_module_from_path(module_name, module_path)
275
276 def ndgrid_inds(sz):
277 """
278 Return a sequnce of tuples of indices as if generated by nested comprehensions.
279 Example:
280 ndgrid_inds((ni,nj))
281 Returns the same sequence as
282 [(i,j) for i in range(ni) for j in range(nj)]
283
284 The iterates are always tuples so
285 ndgrid_inds(4)
286 returns
287 [(0,), (1,), (2,), (3,)]
288
289 """
290
291 return itertools.product(*map(range, sz))
292
293
[end of src/python/ksc/utils.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/python/ksc/utils.py b/src/python/ksc/utils.py
--- a/src/python/ksc/utils.py
+++ b/src/python/ksc/utils.py
@@ -221,14 +221,11 @@
generated_cpp_source = generate_cpp_from_ks(ks_str, generate_derivatives=generate_derivatives, use_aten=use_aten)
- cpp_str = """
-#include "knossos-pybind.h"
+ cpp_str = f"""
+ #include "knossos-pybind.h"
+ {generated_cpp_source}
-""" + generated_cpp_source + """
-
-int ks::main(ks::allocator *) { return 0; };
-
-"""
+ """
args_str = mangleTypes(arg_types)
name_str = encode_name(f"{name_to_call}@{args_str}")
|
{"golden_diff": "diff --git a/src/python/ksc/utils.py b/src/python/ksc/utils.py\n--- a/src/python/ksc/utils.py\n+++ b/src/python/ksc/utils.py\n@@ -221,14 +221,11 @@\n \n generated_cpp_source = generate_cpp_from_ks(ks_str, generate_derivatives=generate_derivatives, use_aten=use_aten)\n \n- cpp_str = \"\"\"\n-#include \"knossos-pybind.h\"\n+ cpp_str = f\"\"\"\n+ #include \"knossos-pybind.h\"\n+ {generated_cpp_source}\n \n-\"\"\" + generated_cpp_source + \"\"\"\n-\n-int ks::main(ks::allocator *) { return 0; };\n-\n-\"\"\"\n+ \"\"\"\n \n args_str = mangleTypes(arg_types)\n name_str = encode_name(f\"{name_to_call}@{args_str}\")\n", "issue": "Calls to \"main\"\nIn merging #550 I find I need ``ks::main``. \r\nLooking at this comment in \r\nhttps://github.com/microsoft/knossos-ksc/blob/18f654086f349cceb59c30dcbc8de2c534dcb5ec/src/ksc/Cgen.hs#L801\r\n\r\nI wonder is it time to look at removing that?\n", "before_files": [{"content": "from dataclasses import dataclass\nfrom typing import Tuple, Union\nfrom collections import namedtuple\nimport itertools\n\nimport importlib.util\nimport os\nimport numpy as np\nimport subprocess\nimport sysconfig\nimport sys\nfrom tempfile import NamedTemporaryFile\n\nfrom ksc.type import Type, tangent_type, make_tuple_if_many\n\nclass KRecord:\n \"\"\"\n A smoother namedtuple -- like https://pythonhosted.org/pyrecord but using the existing class syntax.\n Like a 3.7 dataclass, but don't need to decorate each derived class\n\n Derive a class from KRecord, declare its fields, and use keyword args in __init__\n\n def MyClass(KRecord):\n cost: float\n names: List[String]\n\n def __init__(cost, names):\n super().__init__(cost=cost, names=names)\n\n And now you have a nice little record class.\n\n Construct a MyClass:\n a = MyClass(1.3, [\"fred\", \"conor\", \"una\"])\n\n Compare two MyClasses\n if a == b: ...\n \n Etc\n \"\"\"\n\n def __init__(self, **args):\n for (nt,v) in args.items():\n # assert nt in self.__annotations__ # <- This check will fail for chains of derived classes -- only the deepest has __annotations__ ready yet.\n setattr(self, nt, v)\n\n def __eq__(self, that):\n if type(self) != type(that):\n return False\n\n for nt in self.__annotations__:\n if getattr(self, nt) != getattr(that,nt):\n return False\n return True\n\n\n\n\ndef ensure_list_of_lists(l):\n \"\"\"return input, wrapped in a singleton list if its first element is not a list\n\n ensure_list_of_lists([]) = []\n ensure_list_of_lists([1]) = [[1]]\n ensure_list_of_lists([[1]]) = [[1]]\n ensure_list_of_lists([[1,2]]) = [[1, 2]]\n ensure_list_of_lists([[1,2], [3,4]]) = [[1, 2], [3, 4]]\n \"\"\"\n\n if not isinstance(l, list):\n raise ValueError(\"Expect a list\")\n if len(l) < 1: # Empty list is empty list\n return l\n if not isinstance(l[0], list):\n return [l]\n else:\n return l\n\ndef paren(s):\n return \"(\" + s + \")\"\n\nPYTHON_MODULE_NAME = \"ks_mod\"\n\ndef import_module_from_path(module_name, path):\n # These three lines are for loading a module from a file in Python 3.5+\n # https://bugs.python.org/issue21436\n spec = importlib.util.spec_from_file_location(module_name, path)\n py_out = importlib.util.module_from_spec(spec)\n spec.loader.exec_module(py_out)\n return py_out\n\ndef translate_and_import(source_file_name, *args):\n from ksc.translate import translate\n py_out = translate(*args, source_file_name, with_main=False)\n with NamedTemporaryFile(mode=\"w\", suffix=\".py\", delete=False) as f:\n f.write(f\"# AUTOGEN from {source_file_name} via ksc.utils.translate_and_import\")\n f.write(py_out)\n\n print(f.name)\n return import_module_from_path(PYTHON_MODULE_NAME, f.name)\n\ndef subprocess_run(cmd, env=None):\n return subprocess.run(cmd, stdout=subprocess.PIPE, env=env).stdout.decode().strip(\"\\n\")\n\ndef get_ksc_paths():\n if \"KSC_RUNTIME_DIR\" in os.environ:\n ksc_runtime_dir = os.environ[\"KSC_RUNTIME_DIR\"]\n else:\n ksc_runtime_dir = \"./src/runtime\"\n\n if \"KSC_PATH\" in os.environ:\n ksc_path = os.environ[\"KSC_PATH\"]\n else:\n ksc_path = \"./build/bin/ksc\"\n \n return ksc_path,ksc_runtime_dir\n\n\ndef generate_cpp_from_ks(ks_str, generate_derivatives = False, use_aten = False):\n ksc_path,_ksc_runtime_dir = get_ksc_paths()\n\n with NamedTemporaryFile(mode=\"w\", suffix=\".ks\", delete=False) as fks:\n fks.write(ks_str)\n try:\n with NamedTemporaryFile(mode=\"w\", suffix=\".kso\", delete=False) as fkso:\n with NamedTemporaryFile(mode=\"w\", suffix=\".cpp\", delete=False) as fcpp:\n print(\"generate_cpp_from_ks:\", ksc_path, fks.name)\n e = subprocess.run([\n ksc_path,\n \"--generate-cpp\" if generate_derivatives else \"--generate-cpp-without-diffs\",\n \"--ks-source-file\", \"src/runtime/prelude.ks\",\n *((\"--ks-source-file\", \"src/runtime/prelude-aten.ks\") if use_aten else ()),\n \"--ks-source-file\", fks.name,\n \"--ks-output-file\", fkso.name,\n \"--cpp-output-file\", fcpp.name\n ], capture_output=True, check=True)\n print(e.stdout.decode('ascii'))\n print(e.stderr.decode('ascii'))\n except subprocess.CalledProcessError as e:\n print(f\"files {fks.name} {fkso.name} {fcpp.name}\")\n print(f\"ks_str=\\n{ks_str}\")\n print(e.output.decode('ascii'))\n print(e.stderr.decode('ascii'))\n raise\n\n\n # Read from CPP back to string\n with open(fcpp.name) as f:\n out = f.read()\n\n # only delete these file if no error\n os.unlink(fks.name)\n os.unlink(fcpp.name)\n os.unlink(fkso.name)\n\n return out\n\ndef build_py_module_from_cpp(cpp_str, pybind11_path, use_aten=False):\n _ksc_path,ksc_runtime_dir = get_ksc_paths()\n\n with NamedTemporaryFile(mode=\"w\", suffix=\".cpp\", delete=False) as fcpp:\n fcpp.write(cpp_str)\n\n extension_suffix = sysconfig.get_config_var('EXT_SUFFIX')\n if extension_suffix is None:\n extension_suffix = sysconfig.get_config_var('SO')\n\n with NamedTemporaryFile(mode=\"w\", suffix=extension_suffix, delete=False) as fpymod:\n pass\n module_path = fpymod.name\n module_name = os.path.basename(module_path).split(\".\")[0]\n python_includes = subprocess_run(\n [sys.executable, \"-m\", \"pybind11\", \"--includes\"],\n env={\"PYTHONPATH\": \"extern/pybind11\"}\n )\n try:\n cmd = (f\"g++ -I{ksc_runtime_dir} -I{pybind11_path}/include \"\n + python_includes\n + \" -Wall -Wno-unused-variable -Wno-unused-but-set-variable\"\n \" -fmax-errors=1\"\n \" -std=c++17\"\n \" -O3\"\n \" -fPIC\"\n \" -shared\"\n + (\" -DKS_INCLUDE_ATEN\" if use_aten else \"\")\n + f\" -DPYTHON_MODULE_NAME={module_name}\"\n f\" -o {module_path} \"\n + fcpp.name)\n print(cmd)\n subprocess.run(cmd, shell=True, capture_output=True, check=True)\n except subprocess.CalledProcessError as e:\n print(f\"cpp_file={fcpp.name}\")\n print(cmd)\n print(e.output.decode('utf-8'))\n print(e.stderr.decode('utf-8'))\n\n raise\n \n os.unlink(fcpp.name)\n return module_name, module_path\n\ndef mangleType(ty):\n return ty.shortstr()\n\ndef mangleTypes(tys):\n return \"\".join(mangleType(ty) for ty in tys)\n\n\ndef encode_name(s : str) -> str:\n # TODO: this could be faster\n return s.\\\n replace('@',\"$a\").\\\n replace(',',\"$_\").\\\n replace('.',\"$o\").\\\n replace('[',\"$6\").\\\n replace(']',\"$9\").\\\n replace('<',\"$d\").\\\n replace('>',\"$b\").\\\n replace('*',\"$x\").\\\n replace(':',\"$8\")\n\ndef generate_and_compile_cpp_from_ks(ks_str, name_to_call, arg_types, return_type=None, generate_derivatives=False, use_aten=False, pybind11_path=\"extern/pybind11\"):\n\n generated_cpp_source = generate_cpp_from_ks(ks_str, generate_derivatives=generate_derivatives, use_aten=use_aten)\n\n cpp_str = \"\"\"\n#include \"knossos-pybind.h\"\n\n\"\"\" + generated_cpp_source + \"\"\"\n\nint ks::main(ks::allocator *) { return 0; };\n\n\"\"\"\n\n args_str = mangleTypes(arg_types)\n name_str = encode_name(f\"{name_to_call}@{args_str}\")\n declarations = f\"\"\"\n m.def(\"entry\", with_ks_allocator(&ks::{name_str}));\n \"\"\"\n\n if generate_derivatives:\n darg_types = [tangent_type(ty) for ty in arg_types]\n args_tuple_str = mangleType(make_tuple_if_many(arg_types))\n dargs_tuple_str = mangleType(make_tuple_if_many(darg_types))\n dreturn_type_str = mangleType(tangent_type(return_type))\n\n fwd_name = encode_name(f\"fwd${name_to_call}@{args_tuple_str}\")\n declarations += f\"\"\"\n m.def(\"fwd_entry\", with_ks_allocator(&ks::{fwd_name}));\n \"\"\"\n\n rev_name = encode_name(f\"rev${name_to_call}@{args_tuple_str}\")\n declarations += f\"\"\"\n m.def(\"rev_entry\", with_ks_allocator(&ks::{rev_name}));\n \"\"\"\n\n cpp_str += \"\"\"\nPYBIND11_MODULE(PYTHON_MODULE_NAME, m) {\n m.def(\"reset_allocator\", []{g_alloc.reset();});\n m.def(\"allocator_top\", []{ return g_alloc.mark();});\n m.def(\"allocator_peak\", []{ return g_alloc.peak();});\n\n declare_tensor_2<double>(m, \"Tensor_2_Float\");\n declare_tensor_2<int>(m, \"Tensor_2_Integer\");\n\n\"\"\" + declarations + \"\"\"\n}\n\"\"\"\n pybindcpppath = \"obj/pybind.cpp\"\n print(f\"Saving to {pybindcpppath}\") \n os.makedirs(os.path.dirname(pybindcpppath), exist_ok=True)\n with open(pybindcpppath, \"w\") as fcpp:\n fcpp.write(cpp_str)\n\n module_name, module_path = build_py_module_from_cpp(cpp_str, pybind11_path, use_aten=use_aten)\n return import_module_from_path(module_name, module_path)\n\ndef ndgrid_inds(sz):\n \"\"\"\n Return a sequnce of tuples of indices as if generated by nested comprehensions.\n Example:\n ndgrid_inds((ni,nj))\n Returns the same sequence as\n [(i,j) for i in range(ni) for j in range(nj)]\n\n The iterates are always tuples so\n ndgrid_inds(4)\n returns\n [(0,), (1,), (2,), (3,)] \n\n \"\"\"\n\n return itertools.product(*map(range, sz))\n\n", "path": "src/python/ksc/utils.py"}]}
| 3,840 | 187 |
gh_patches_debug_9288
|
rasdani/github-patches
|
git_diff
|
microsoft__nni-2375
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
BUG in spos evolution part
I trained the spos from scratch with supernet.py, but failed to load the checkpoints. It turned out there was a mismatch between load and save part.
In the save part https://github.com/microsoft/nni/blob/69dfbf5e976cf75e89949af4764928dde631a3f6/src/sdk/pynni/nni/nas/pytorch/callbacks.py#L136, no dict was used. But in the load part, https://github.com/microsoft/nni/blob/69dfbf5e976cf75e89949af4764928dde631a3f6/examples/nas/spos/network.py#L151, key 'state_dict' was used. It failed to load the checkpoint. After removing 'state_dict', checkpoint could be loaded and problem was solved.
</issue>
<code>
[start of examples/nas/spos/network.py]
1 # Copyright (c) Microsoft Corporation.
2 # Licensed under the MIT license.
3
4 import os
5 import pickle
6 import re
7
8 import torch
9 import torch.nn as nn
10 from nni.nas.pytorch import mutables
11
12 from blocks import ShuffleNetBlock, ShuffleXceptionBlock
13
14
15 class ShuffleNetV2OneShot(nn.Module):
16 block_keys = [
17 'shufflenet_3x3',
18 'shufflenet_5x5',
19 'shufflenet_7x7',
20 'xception_3x3',
21 ]
22
23 def __init__(self, input_size=224, first_conv_channels=16, last_conv_channels=1024, n_classes=1000,
24 op_flops_path="./data/op_flops_dict.pkl"):
25 super().__init__()
26
27 assert input_size % 32 == 0
28 with open(os.path.join(os.path.dirname(__file__), op_flops_path), "rb") as fp:
29 self._op_flops_dict = pickle.load(fp)
30
31 self.stage_blocks = [4, 4, 8, 4]
32 self.stage_channels = [64, 160, 320, 640]
33 self._parsed_flops = dict()
34 self._input_size = input_size
35 self._feature_map_size = input_size
36 self._first_conv_channels = first_conv_channels
37 self._last_conv_channels = last_conv_channels
38 self._n_classes = n_classes
39
40 # building first layer
41 self.first_conv = nn.Sequential(
42 nn.Conv2d(3, first_conv_channels, 3, 2, 1, bias=False),
43 nn.BatchNorm2d(first_conv_channels, affine=False),
44 nn.ReLU(inplace=True),
45 )
46 self._feature_map_size //= 2
47
48 p_channels = first_conv_channels
49 features = []
50 for num_blocks, channels in zip(self.stage_blocks, self.stage_channels):
51 features.extend(self._make_blocks(num_blocks, p_channels, channels))
52 p_channels = channels
53 self.features = nn.Sequential(*features)
54
55 self.conv_last = nn.Sequential(
56 nn.Conv2d(p_channels, last_conv_channels, 1, 1, 0, bias=False),
57 nn.BatchNorm2d(last_conv_channels, affine=False),
58 nn.ReLU(inplace=True),
59 )
60 self.globalpool = nn.AvgPool2d(self._feature_map_size)
61 self.dropout = nn.Dropout(0.1)
62 self.classifier = nn.Sequential(
63 nn.Linear(last_conv_channels, n_classes, bias=False),
64 )
65
66 self._initialize_weights()
67
68 def _make_blocks(self, blocks, in_channels, channels):
69 result = []
70 for i in range(blocks):
71 stride = 2 if i == 0 else 1
72 inp = in_channels if i == 0 else channels
73 oup = channels
74
75 base_mid_channels = channels // 2
76 mid_channels = int(base_mid_channels) # prepare for scale
77 choice_block = mutables.LayerChoice([
78 ShuffleNetBlock(inp, oup, mid_channels=mid_channels, ksize=3, stride=stride),
79 ShuffleNetBlock(inp, oup, mid_channels=mid_channels, ksize=5, stride=stride),
80 ShuffleNetBlock(inp, oup, mid_channels=mid_channels, ksize=7, stride=stride),
81 ShuffleXceptionBlock(inp, oup, mid_channels=mid_channels, stride=stride)
82 ])
83 result.append(choice_block)
84
85 # find the corresponding flops
86 flop_key = (inp, oup, mid_channels, self._feature_map_size, self._feature_map_size, stride)
87 self._parsed_flops[choice_block.key] = [
88 self._op_flops_dict["{}_stride_{}".format(k, stride)][flop_key] for k in self.block_keys
89 ]
90 if stride == 2:
91 self._feature_map_size //= 2
92 return result
93
94 def forward(self, x):
95 bs = x.size(0)
96 x = self.first_conv(x)
97 x = self.features(x)
98 x = self.conv_last(x)
99 x = self.globalpool(x)
100
101 x = self.dropout(x)
102 x = x.contiguous().view(bs, -1)
103 x = self.classifier(x)
104 return x
105
106 def get_candidate_flops(self, candidate):
107 conv1_flops = self._op_flops_dict["conv1"][(3, self._first_conv_channels,
108 self._input_size, self._input_size, 2)]
109 # Should use `last_conv_channels` here, but megvii insists that it's `n_classes`. Keeping it.
110 # https://github.com/megvii-model/SinglePathOneShot/blob/36eed6cf083497ffa9cfe7b8da25bb0b6ba5a452/src/Supernet/flops.py#L313
111 rest_flops = self._op_flops_dict["rest_operation"][(self.stage_channels[-1], self._n_classes,
112 self._feature_map_size, self._feature_map_size, 1)]
113 total_flops = conv1_flops + rest_flops
114 for k, m in candidate.items():
115 parsed_flops_dict = self._parsed_flops[k]
116 if isinstance(m, dict): # to be compatible with classical nas format
117 total_flops += parsed_flops_dict[m["_idx"]]
118 else:
119 total_flops += parsed_flops_dict[torch.max(m, 0)[1]]
120 return total_flops
121
122 def _initialize_weights(self):
123 for name, m in self.named_modules():
124 if isinstance(m, nn.Conv2d):
125 if 'first' in name:
126 nn.init.normal_(m.weight, 0, 0.01)
127 else:
128 nn.init.normal_(m.weight, 0, 1.0 / m.weight.shape[1])
129 if m.bias is not None:
130 nn.init.constant_(m.bias, 0)
131 elif isinstance(m, nn.BatchNorm2d):
132 if m.weight is not None:
133 nn.init.constant_(m.weight, 1)
134 if m.bias is not None:
135 nn.init.constant_(m.bias, 0.0001)
136 nn.init.constant_(m.running_mean, 0)
137 elif isinstance(m, nn.BatchNorm1d):
138 nn.init.constant_(m.weight, 1)
139 if m.bias is not None:
140 nn.init.constant_(m.bias, 0.0001)
141 nn.init.constant_(m.running_mean, 0)
142 elif isinstance(m, nn.Linear):
143 nn.init.normal_(m.weight, 0, 0.01)
144 if m.bias is not None:
145 nn.init.constant_(m.bias, 0)
146
147
148 def load_and_parse_state_dict(filepath="./data/checkpoint-150000.pth.tar"):
149 checkpoint = torch.load(filepath, map_location=torch.device("cpu"))
150 result = dict()
151 for k, v in checkpoint["state_dict"].items():
152 if k.startswith("module."):
153 k = k[len("module."):]
154 result[k] = v
155 return result
156
[end of examples/nas/spos/network.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/examples/nas/spos/network.py b/examples/nas/spos/network.py
--- a/examples/nas/spos/network.py
+++ b/examples/nas/spos/network.py
@@ -147,8 +147,10 @@
def load_and_parse_state_dict(filepath="./data/checkpoint-150000.pth.tar"):
checkpoint = torch.load(filepath, map_location=torch.device("cpu"))
+ if "state_dict" in checkpoint:
+ checkpoint = checkpoint["state_dict"]
result = dict()
- for k, v in checkpoint["state_dict"].items():
+ for k, v in checkpoint.items():
if k.startswith("module."):
k = k[len("module."):]
result[k] = v
|
{"golden_diff": "diff --git a/examples/nas/spos/network.py b/examples/nas/spos/network.py\n--- a/examples/nas/spos/network.py\n+++ b/examples/nas/spos/network.py\n@@ -147,8 +147,10 @@\n \n def load_and_parse_state_dict(filepath=\"./data/checkpoint-150000.pth.tar\"):\n checkpoint = torch.load(filepath, map_location=torch.device(\"cpu\"))\n+ if \"state_dict\" in checkpoint:\n+ checkpoint = checkpoint[\"state_dict\"]\n result = dict()\n- for k, v in checkpoint[\"state_dict\"].items():\n+ for k, v in checkpoint.items():\n if k.startswith(\"module.\"):\n k = k[len(\"module.\"):]\n result[k] = v\n", "issue": "BUG in spos evolution part\nI trained the spos from scratch with supernet.py, but failed to load the checkpoints. It turned out there was a mismatch between load and save part. \r\n\r\nIn the save part https://github.com/microsoft/nni/blob/69dfbf5e976cf75e89949af4764928dde631a3f6/src/sdk/pynni/nni/nas/pytorch/callbacks.py#L136, no dict was used. But in the load part, https://github.com/microsoft/nni/blob/69dfbf5e976cf75e89949af4764928dde631a3f6/examples/nas/spos/network.py#L151, key 'state_dict' was used. It failed to load the checkpoint. After removing 'state_dict', checkpoint could be loaded and problem was solved.\r\n\r\n\n", "before_files": [{"content": "# Copyright (c) Microsoft Corporation.\n# Licensed under the MIT license.\n\nimport os\nimport pickle\nimport re\n\nimport torch\nimport torch.nn as nn\nfrom nni.nas.pytorch import mutables\n\nfrom blocks import ShuffleNetBlock, ShuffleXceptionBlock\n\n\nclass ShuffleNetV2OneShot(nn.Module):\n block_keys = [\n 'shufflenet_3x3',\n 'shufflenet_5x5',\n 'shufflenet_7x7',\n 'xception_3x3',\n ]\n\n def __init__(self, input_size=224, first_conv_channels=16, last_conv_channels=1024, n_classes=1000,\n op_flops_path=\"./data/op_flops_dict.pkl\"):\n super().__init__()\n\n assert input_size % 32 == 0\n with open(os.path.join(os.path.dirname(__file__), op_flops_path), \"rb\") as fp:\n self._op_flops_dict = pickle.load(fp)\n\n self.stage_blocks = [4, 4, 8, 4]\n self.stage_channels = [64, 160, 320, 640]\n self._parsed_flops = dict()\n self._input_size = input_size\n self._feature_map_size = input_size\n self._first_conv_channels = first_conv_channels\n self._last_conv_channels = last_conv_channels\n self._n_classes = n_classes\n\n # building first layer\n self.first_conv = nn.Sequential(\n nn.Conv2d(3, first_conv_channels, 3, 2, 1, bias=False),\n nn.BatchNorm2d(first_conv_channels, affine=False),\n nn.ReLU(inplace=True),\n )\n self._feature_map_size //= 2\n\n p_channels = first_conv_channels\n features = []\n for num_blocks, channels in zip(self.stage_blocks, self.stage_channels):\n features.extend(self._make_blocks(num_blocks, p_channels, channels))\n p_channels = channels\n self.features = nn.Sequential(*features)\n\n self.conv_last = nn.Sequential(\n nn.Conv2d(p_channels, last_conv_channels, 1, 1, 0, bias=False),\n nn.BatchNorm2d(last_conv_channels, affine=False),\n nn.ReLU(inplace=True),\n )\n self.globalpool = nn.AvgPool2d(self._feature_map_size)\n self.dropout = nn.Dropout(0.1)\n self.classifier = nn.Sequential(\n nn.Linear(last_conv_channels, n_classes, bias=False),\n )\n\n self._initialize_weights()\n\n def _make_blocks(self, blocks, in_channels, channels):\n result = []\n for i in range(blocks):\n stride = 2 if i == 0 else 1\n inp = in_channels if i == 0 else channels\n oup = channels\n\n base_mid_channels = channels // 2\n mid_channels = int(base_mid_channels) # prepare for scale\n choice_block = mutables.LayerChoice([\n ShuffleNetBlock(inp, oup, mid_channels=mid_channels, ksize=3, stride=stride),\n ShuffleNetBlock(inp, oup, mid_channels=mid_channels, ksize=5, stride=stride),\n ShuffleNetBlock(inp, oup, mid_channels=mid_channels, ksize=7, stride=stride),\n ShuffleXceptionBlock(inp, oup, mid_channels=mid_channels, stride=stride)\n ])\n result.append(choice_block)\n\n # find the corresponding flops\n flop_key = (inp, oup, mid_channels, self._feature_map_size, self._feature_map_size, stride)\n self._parsed_flops[choice_block.key] = [\n self._op_flops_dict[\"{}_stride_{}\".format(k, stride)][flop_key] for k in self.block_keys\n ]\n if stride == 2:\n self._feature_map_size //= 2\n return result\n\n def forward(self, x):\n bs = x.size(0)\n x = self.first_conv(x)\n x = self.features(x)\n x = self.conv_last(x)\n x = self.globalpool(x)\n\n x = self.dropout(x)\n x = x.contiguous().view(bs, -1)\n x = self.classifier(x)\n return x\n\n def get_candidate_flops(self, candidate):\n conv1_flops = self._op_flops_dict[\"conv1\"][(3, self._first_conv_channels,\n self._input_size, self._input_size, 2)]\n # Should use `last_conv_channels` here, but megvii insists that it's `n_classes`. Keeping it.\n # https://github.com/megvii-model/SinglePathOneShot/blob/36eed6cf083497ffa9cfe7b8da25bb0b6ba5a452/src/Supernet/flops.py#L313\n rest_flops = self._op_flops_dict[\"rest_operation\"][(self.stage_channels[-1], self._n_classes,\n self._feature_map_size, self._feature_map_size, 1)]\n total_flops = conv1_flops + rest_flops\n for k, m in candidate.items():\n parsed_flops_dict = self._parsed_flops[k]\n if isinstance(m, dict): # to be compatible with classical nas format\n total_flops += parsed_flops_dict[m[\"_idx\"]]\n else:\n total_flops += parsed_flops_dict[torch.max(m, 0)[1]]\n return total_flops\n\n def _initialize_weights(self):\n for name, m in self.named_modules():\n if isinstance(m, nn.Conv2d):\n if 'first' in name:\n nn.init.normal_(m.weight, 0, 0.01)\n else:\n nn.init.normal_(m.weight, 0, 1.0 / m.weight.shape[1])\n if m.bias is not None:\n nn.init.constant_(m.bias, 0)\n elif isinstance(m, nn.BatchNorm2d):\n if m.weight is not None:\n nn.init.constant_(m.weight, 1)\n if m.bias is not None:\n nn.init.constant_(m.bias, 0.0001)\n nn.init.constant_(m.running_mean, 0)\n elif isinstance(m, nn.BatchNorm1d):\n nn.init.constant_(m.weight, 1)\n if m.bias is not None:\n nn.init.constant_(m.bias, 0.0001)\n nn.init.constant_(m.running_mean, 0)\n elif isinstance(m, nn.Linear):\n nn.init.normal_(m.weight, 0, 0.01)\n if m.bias is not None:\n nn.init.constant_(m.bias, 0)\n\n\ndef load_and_parse_state_dict(filepath=\"./data/checkpoint-150000.pth.tar\"):\n checkpoint = torch.load(filepath, map_location=torch.device(\"cpu\"))\n result = dict()\n for k, v in checkpoint[\"state_dict\"].items():\n if k.startswith(\"module.\"):\n k = k[len(\"module.\"):]\n result[k] = v\n return result\n", "path": "examples/nas/spos/network.py"}]}
| 2,673 | 163 |
gh_patches_debug_14255
|
rasdani/github-patches
|
git_diff
|
pyca__cryptography-513
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
KDF Interfaces
Who has opinions? This is relevant for HKDF in #490 and upcoming PBKDF2.
Here's a straw man to knock down:
``` python
# This API is a bit challenging since each KDF has different features
# (salt/no salt, maximum time, output length, iteration count, etc)
kdf = PBKDF2(iterations, digest, backend)
key = kdf.derive("key/password", "salt")
kdf.verify("key/password", salt="salt", key)
kdf = HKDF(algorithm, key_length, info, backend)
key = kdf.derive("key/password", "salt")
kdf.verify("key/password", salt="salt", key)
kdf = BCrypt(work_factor=100, backend)
key = kdf.derive("key/password")
kdf.verify("key/password", key)
kdf = SCrypt(key_length, salt_size=16, max_time=0.1, max_mem=4, backend)
key = kdf.derive("key/password") # really need to get key/salt out since auto-generated
kdf.verify("key/password", key)
```
There are also calibration routines available for some of these KDFs. (scrypt has one as well as CommonCrypto's `CCCalibratePBKDF` for PBKDF2).
</issue>
<code>
[start of cryptography/hazmat/primitives/interfaces.py]
1 # Licensed under the Apache License, Version 2.0 (the "License");
2 # you may not use this file except in compliance with the License.
3 # You may obtain a copy of the License at
4 #
5 # http://www.apache.org/licenses/LICENSE-2.0
6 #
7 # Unless required by applicable law or agreed to in writing, software
8 # distributed under the License is distributed on an "AS IS" BASIS,
9 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
10 # implied.
11 # See the License for the specific language governing permissions and
12 # limitations under the License.
13
14 from __future__ import absolute_import, division, print_function
15
16 import abc
17
18 import six
19
20
21 class CipherAlgorithm(six.with_metaclass(abc.ABCMeta)):
22 @abc.abstractproperty
23 def name(self):
24 """
25 A string naming this mode (e.g. "AES", "Camellia").
26 """
27
28 @abc.abstractproperty
29 def key_size(self):
30 """
31 The size of the key being used as an integer in bits (e.g. 128, 256).
32 """
33
34
35 class BlockCipherAlgorithm(six.with_metaclass(abc.ABCMeta)):
36 @abc.abstractproperty
37 def block_size(self):
38 """
39 The size of a block as an integer in bits (e.g. 64, 128).
40 """
41
42
43 class Mode(six.with_metaclass(abc.ABCMeta)):
44 @abc.abstractproperty
45 def name(self):
46 """
47 A string naming this mode (e.g. "ECB", "CBC").
48 """
49
50 @abc.abstractmethod
51 def validate_for_algorithm(self, algorithm):
52 """
53 Checks that all the necessary invariants of this (mode, algorithm)
54 combination are met.
55 """
56
57
58 class ModeWithInitializationVector(six.with_metaclass(abc.ABCMeta)):
59 @abc.abstractproperty
60 def initialization_vector(self):
61 """
62 The value of the initialization vector for this mode as bytes.
63 """
64
65
66 class ModeWithNonce(six.with_metaclass(abc.ABCMeta)):
67 @abc.abstractproperty
68 def nonce(self):
69 """
70 The value of the nonce for this mode as bytes.
71 """
72
73
74 class ModeWithAuthenticationTag(six.with_metaclass(abc.ABCMeta)):
75 @abc.abstractproperty
76 def tag(self):
77 """
78 The value of the tag supplied to the constructor of this mode.
79 """
80
81
82 class CipherContext(six.with_metaclass(abc.ABCMeta)):
83 @abc.abstractmethod
84 def update(self, data):
85 """
86 Processes the provided bytes through the cipher and returns the results
87 as bytes.
88 """
89
90 @abc.abstractmethod
91 def finalize(self):
92 """
93 Returns the results of processing the final block as bytes.
94 """
95
96
97 class AEADCipherContext(six.with_metaclass(abc.ABCMeta)):
98 @abc.abstractmethod
99 def authenticate_additional_data(self, data):
100 """
101 Authenticates the provided bytes.
102 """
103
104
105 class AEADEncryptionContext(six.with_metaclass(abc.ABCMeta)):
106 @abc.abstractproperty
107 def tag(self):
108 """
109 Returns tag bytes. This is only available after encryption is
110 finalized.
111 """
112
113
114 class PaddingContext(six.with_metaclass(abc.ABCMeta)):
115 @abc.abstractmethod
116 def update(self, data):
117 """
118 Pads the provided bytes and returns any available data as bytes.
119 """
120
121 @abc.abstractmethod
122 def finalize(self):
123 """
124 Finalize the padding, returns bytes.
125 """
126
127
128 class HashAlgorithm(six.with_metaclass(abc.ABCMeta)):
129 @abc.abstractproperty
130 def name(self):
131 """
132 A string naming this algorithm (e.g. "sha256", "md5").
133 """
134
135 @abc.abstractproperty
136 def digest_size(self):
137 """
138 The size of the resulting digest in bytes.
139 """
140
141 @abc.abstractproperty
142 def block_size(self):
143 """
144 The internal block size of the hash algorithm in bytes.
145 """
146
147
148 class HashContext(six.with_metaclass(abc.ABCMeta)):
149 @abc.abstractproperty
150 def algorithm(self):
151 """
152 A HashAlgorithm that will be used by this context.
153 """
154
155 @abc.abstractmethod
156 def update(self, data):
157 """
158 Processes the provided bytes through the hash.
159 """
160
161 @abc.abstractmethod
162 def finalize(self):
163 """
164 Finalizes the hash context and returns the hash digest as bytes.
165 """
166
167 @abc.abstractmethod
168 def copy(self):
169 """
170 Return a HashContext that is a copy of the current context.
171 """
172
173
174 class RSAPrivateKey(six.with_metaclass(abc.ABCMeta)):
175 @abc.abstractproperty
176 def modulus(self):
177 """
178 The public modulus of the RSA key.
179 """
180
181 @abc.abstractproperty
182 def public_exponent(self):
183 """
184 The public exponent of the RSA key.
185 """
186
187 @abc.abstractproperty
188 def key_length(self):
189 """
190 The bit length of the public modulus.
191 """
192
193 @abc.abstractmethod
194 def public_key(self):
195 """
196 The RSAPublicKey associated with this private key.
197 """
198
199 @abc.abstractproperty
200 def n(self):
201 """
202 The public modulus of the RSA key. Alias for modulus.
203 """
204
205 @abc.abstractproperty
206 def p(self):
207 """
208 One of the two primes used to generate d.
209 """
210
211 @abc.abstractproperty
212 def q(self):
213 """
214 One of the two primes used to generate d.
215 """
216
217 @abc.abstractproperty
218 def d(self):
219 """
220 The private exponent. This can be calculated using p and q.
221 """
222
223 @abc.abstractproperty
224 def e(self):
225 """
226 The public exponent of the RSA key. Alias for public_exponent.
227 """
228
229
230 class RSAPublicKey(six.with_metaclass(abc.ABCMeta)):
231 @abc.abstractproperty
232 def modulus(self):
233 """
234 The public modulus of the RSA key.
235 """
236
237 @abc.abstractproperty
238 def public_exponent(self):
239 """
240 The public exponent of the RSA key.
241 """
242
243 @abc.abstractproperty
244 def key_length(self):
245 """
246 The bit length of the public modulus.
247 """
248
249 @abc.abstractproperty
250 def n(self):
251 """
252 The public modulus of the RSA key. Alias for modulus.
253 """
254
255 @abc.abstractproperty
256 def e(self):
257 """
258 The public exponent of the RSA key. Alias for public_exponent.
259 """
260
[end of cryptography/hazmat/primitives/interfaces.py]
[start of cryptography/exceptions.py]
1 # Licensed under the Apache License, Version 2.0 (the "License");
2 # you may not use this file except in compliance with the License.
3 # You may obtain a copy of the License at
4 #
5 # http://www.apache.org/licenses/LICENSE-2.0
6 #
7 # Unless required by applicable law or agreed to in writing, software
8 # distributed under the License is distributed on an "AS IS" BASIS,
9 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
10 # implied.
11 # See the License for the specific language governing permissions and
12 # limitations under the License.
13
14
15 class UnsupportedAlgorithm(Exception):
16 pass
17
18
19 class AlreadyFinalized(Exception):
20 pass
21
22
23 class AlreadyUpdated(Exception):
24 pass
25
26
27 class NotYetFinalized(Exception):
28 pass
29
30
31 class InvalidTag(Exception):
32 pass
33
34
35 class InvalidSignature(Exception):
36 pass
37
38
39 class InternalError(Exception):
40 pass
41
[end of cryptography/exceptions.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/cryptography/exceptions.py b/cryptography/exceptions.py
--- a/cryptography/exceptions.py
+++ b/cryptography/exceptions.py
@@ -38,3 +38,7 @@
class InternalError(Exception):
pass
+
+
+class InvalidKey(Exception):
+ pass
diff --git a/cryptography/hazmat/primitives/interfaces.py b/cryptography/hazmat/primitives/interfaces.py
--- a/cryptography/hazmat/primitives/interfaces.py
+++ b/cryptography/hazmat/primitives/interfaces.py
@@ -257,3 +257,19 @@
"""
The public exponent of the RSA key. Alias for public_exponent.
"""
+
+
+class KeyDerivationFunction(six.with_metaclass(abc.ABCMeta)):
+ @abc.abstractmethod
+ def derive(self, key_material):
+ """
+ Deterministically generates and returns a new key based on the existing
+ key material.
+ """
+
+ @abc.abstractmethod
+ def verify(self, key_material, expected_key):
+ """
+ Checks whether the key generated by the key material matches the
+ expected derived key. Raises an exception if they do not match.
+ """
|
{"golden_diff": "diff --git a/cryptography/exceptions.py b/cryptography/exceptions.py\n--- a/cryptography/exceptions.py\n+++ b/cryptography/exceptions.py\n@@ -38,3 +38,7 @@\n \n class InternalError(Exception):\n pass\n+\n+\n+class InvalidKey(Exception):\n+ pass\ndiff --git a/cryptography/hazmat/primitives/interfaces.py b/cryptography/hazmat/primitives/interfaces.py\n--- a/cryptography/hazmat/primitives/interfaces.py\n+++ b/cryptography/hazmat/primitives/interfaces.py\n@@ -257,3 +257,19 @@\n \"\"\"\n The public exponent of the RSA key. Alias for public_exponent.\n \"\"\"\n+\n+\n+class KeyDerivationFunction(six.with_metaclass(abc.ABCMeta)):\n+ @abc.abstractmethod\n+ def derive(self, key_material):\n+ \"\"\"\n+ Deterministically generates and returns a new key based on the existing\n+ key material.\n+ \"\"\"\n+\n+ @abc.abstractmethod\n+ def verify(self, key_material, expected_key):\n+ \"\"\"\n+ Checks whether the key generated by the key material matches the\n+ expected derived key. Raises an exception if they do not match.\n+ \"\"\"\n", "issue": "KDF Interfaces\nWho has opinions? This is relevant for HKDF in #490 and upcoming PBKDF2.\n\nHere's a straw man to knock down:\n\n``` python\n# This API is a bit challenging since each KDF has different features \n# (salt/no salt, maximum time, output length, iteration count, etc)\n\nkdf = PBKDF2(iterations, digest, backend)\nkey = kdf.derive(\"key/password\", \"salt\")\nkdf.verify(\"key/password\", salt=\"salt\", key)\n\nkdf = HKDF(algorithm, key_length, info, backend)\nkey = kdf.derive(\"key/password\", \"salt\")\nkdf.verify(\"key/password\", salt=\"salt\", key)\n\nkdf = BCrypt(work_factor=100, backend)\nkey = kdf.derive(\"key/password\")\nkdf.verify(\"key/password\", key)\n\nkdf = SCrypt(key_length, salt_size=16, max_time=0.1, max_mem=4, backend)\nkey = kdf.derive(\"key/password\") # really need to get key/salt out since auto-generated\nkdf.verify(\"key/password\", key)\n```\n\nThere are also calibration routines available for some of these KDFs. (scrypt has one as well as CommonCrypto's `CCCalibratePBKDF` for PBKDF2).\n\n", "before_files": [{"content": "# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or\n# implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nfrom __future__ import absolute_import, division, print_function\n\nimport abc\n\nimport six\n\n\nclass CipherAlgorithm(six.with_metaclass(abc.ABCMeta)):\n @abc.abstractproperty\n def name(self):\n \"\"\"\n A string naming this mode (e.g. \"AES\", \"Camellia\").\n \"\"\"\n\n @abc.abstractproperty\n def key_size(self):\n \"\"\"\n The size of the key being used as an integer in bits (e.g. 128, 256).\n \"\"\"\n\n\nclass BlockCipherAlgorithm(six.with_metaclass(abc.ABCMeta)):\n @abc.abstractproperty\n def block_size(self):\n \"\"\"\n The size of a block as an integer in bits (e.g. 64, 128).\n \"\"\"\n\n\nclass Mode(six.with_metaclass(abc.ABCMeta)):\n @abc.abstractproperty\n def name(self):\n \"\"\"\n A string naming this mode (e.g. \"ECB\", \"CBC\").\n \"\"\"\n\n @abc.abstractmethod\n def validate_for_algorithm(self, algorithm):\n \"\"\"\n Checks that all the necessary invariants of this (mode, algorithm)\n combination are met.\n \"\"\"\n\n\nclass ModeWithInitializationVector(six.with_metaclass(abc.ABCMeta)):\n @abc.abstractproperty\n def initialization_vector(self):\n \"\"\"\n The value of the initialization vector for this mode as bytes.\n \"\"\"\n\n\nclass ModeWithNonce(six.with_metaclass(abc.ABCMeta)):\n @abc.abstractproperty\n def nonce(self):\n \"\"\"\n The value of the nonce for this mode as bytes.\n \"\"\"\n\n\nclass ModeWithAuthenticationTag(six.with_metaclass(abc.ABCMeta)):\n @abc.abstractproperty\n def tag(self):\n \"\"\"\n The value of the tag supplied to the constructor of this mode.\n \"\"\"\n\n\nclass CipherContext(six.with_metaclass(abc.ABCMeta)):\n @abc.abstractmethod\n def update(self, data):\n \"\"\"\n Processes the provided bytes through the cipher and returns the results\n as bytes.\n \"\"\"\n\n @abc.abstractmethod\n def finalize(self):\n \"\"\"\n Returns the results of processing the final block as bytes.\n \"\"\"\n\n\nclass AEADCipherContext(six.with_metaclass(abc.ABCMeta)):\n @abc.abstractmethod\n def authenticate_additional_data(self, data):\n \"\"\"\n Authenticates the provided bytes.\n \"\"\"\n\n\nclass AEADEncryptionContext(six.with_metaclass(abc.ABCMeta)):\n @abc.abstractproperty\n def tag(self):\n \"\"\"\n Returns tag bytes. This is only available after encryption is\n finalized.\n \"\"\"\n\n\nclass PaddingContext(six.with_metaclass(abc.ABCMeta)):\n @abc.abstractmethod\n def update(self, data):\n \"\"\"\n Pads the provided bytes and returns any available data as bytes.\n \"\"\"\n\n @abc.abstractmethod\n def finalize(self):\n \"\"\"\n Finalize the padding, returns bytes.\n \"\"\"\n\n\nclass HashAlgorithm(six.with_metaclass(abc.ABCMeta)):\n @abc.abstractproperty\n def name(self):\n \"\"\"\n A string naming this algorithm (e.g. \"sha256\", \"md5\").\n \"\"\"\n\n @abc.abstractproperty\n def digest_size(self):\n \"\"\"\n The size of the resulting digest in bytes.\n \"\"\"\n\n @abc.abstractproperty\n def block_size(self):\n \"\"\"\n The internal block size of the hash algorithm in bytes.\n \"\"\"\n\n\nclass HashContext(six.with_metaclass(abc.ABCMeta)):\n @abc.abstractproperty\n def algorithm(self):\n \"\"\"\n A HashAlgorithm that will be used by this context.\n \"\"\"\n\n @abc.abstractmethod\n def update(self, data):\n \"\"\"\n Processes the provided bytes through the hash.\n \"\"\"\n\n @abc.abstractmethod\n def finalize(self):\n \"\"\"\n Finalizes the hash context and returns the hash digest as bytes.\n \"\"\"\n\n @abc.abstractmethod\n def copy(self):\n \"\"\"\n Return a HashContext that is a copy of the current context.\n \"\"\"\n\n\nclass RSAPrivateKey(six.with_metaclass(abc.ABCMeta)):\n @abc.abstractproperty\n def modulus(self):\n \"\"\"\n The public modulus of the RSA key.\n \"\"\"\n\n @abc.abstractproperty\n def public_exponent(self):\n \"\"\"\n The public exponent of the RSA key.\n \"\"\"\n\n @abc.abstractproperty\n def key_length(self):\n \"\"\"\n The bit length of the public modulus.\n \"\"\"\n\n @abc.abstractmethod\n def public_key(self):\n \"\"\"\n The RSAPublicKey associated with this private key.\n \"\"\"\n\n @abc.abstractproperty\n def n(self):\n \"\"\"\n The public modulus of the RSA key. Alias for modulus.\n \"\"\"\n\n @abc.abstractproperty\n def p(self):\n \"\"\"\n One of the two primes used to generate d.\n \"\"\"\n\n @abc.abstractproperty\n def q(self):\n \"\"\"\n One of the two primes used to generate d.\n \"\"\"\n\n @abc.abstractproperty\n def d(self):\n \"\"\"\n The private exponent. This can be calculated using p and q.\n \"\"\"\n\n @abc.abstractproperty\n def e(self):\n \"\"\"\n The public exponent of the RSA key. Alias for public_exponent.\n \"\"\"\n\n\nclass RSAPublicKey(six.with_metaclass(abc.ABCMeta)):\n @abc.abstractproperty\n def modulus(self):\n \"\"\"\n The public modulus of the RSA key.\n \"\"\"\n\n @abc.abstractproperty\n def public_exponent(self):\n \"\"\"\n The public exponent of the RSA key.\n \"\"\"\n\n @abc.abstractproperty\n def key_length(self):\n \"\"\"\n The bit length of the public modulus.\n \"\"\"\n\n @abc.abstractproperty\n def n(self):\n \"\"\"\n The public modulus of the RSA key. Alias for modulus.\n \"\"\"\n\n @abc.abstractproperty\n def e(self):\n \"\"\"\n The public exponent of the RSA key. Alias for public_exponent.\n \"\"\"\n", "path": "cryptography/hazmat/primitives/interfaces.py"}, {"content": "# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or\n# implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\nclass UnsupportedAlgorithm(Exception):\n pass\n\n\nclass AlreadyFinalized(Exception):\n pass\n\n\nclass AlreadyUpdated(Exception):\n pass\n\n\nclass NotYetFinalized(Exception):\n pass\n\n\nclass InvalidTag(Exception):\n pass\n\n\nclass InvalidSignature(Exception):\n pass\n\n\nclass InternalError(Exception):\n pass\n", "path": "cryptography/exceptions.py"}]}
| 3,204 | 263 |
gh_patches_debug_29418
|
rasdani/github-patches
|
git_diff
|
litestar-org__litestar-1731
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Bug: Premature instantiation of nested models
### Description
Assume two dataclasses `Person `and `Address`. `Person `contains an `address` (see MCVE).
Using `DataDTO[Person]` in a route handler results in a `TypeError(\"Address.__init__() missing 1 required positional argument: 'id'\")` because it tries to initialize the nested `Address` (which fails because the `address.id` is excluded from the `WriteDTO`).
### URL to code causing the issue
https://discord.com/channels/919193495116337154/1110854577575698463
### MCVE
```python
from dataclasses import dataclass
import uuid
from litestar import Litestar, post
from litestar.dto.factory import DTOConfig, DTOData
from litestar.dto.factory.stdlib import DataclassDTO
@dataclass
class Address:
id: uuid.UUID
street: str
city: str
@dataclass
class Person:
id: uuid.UUID
name: str
email: str
address: Address
class WriteDTO(DataclassDTO[Person]):
config = DTOConfig(exclude={"id", "address.id"})
@post("/person", dto=WriteDTO, return_dto=None, sync_to_thread=False)
def create_person(data: DTOData[Person]) -> str:
return "Success"
app = Litestar([create_person])
```
### Steps to reproduce
```bash
curl -X 'POST' \
'http://127.0.0.1:8000/person' \
-H 'accept: text/plain' \
-H 'Content-Type: application/json' \
-d '{
"name": "test",
"email": "test",
"address": {
"street": "test",
"city": "test"
}
}'
```
### Screenshots
```bash
""
```
### Logs
```bash
INFO: 127.0.0.1:36960 - "POST /person HTTP/1.1" 500 Internal Server Error
```
### Litestar Version
2.0.0a7
### Platform
- [X] Linux
- [X] Mac
- [X] Windows
- [ ] Other (Please specify in the description above)
</issue>
<code>
[start of litestar/dto/factory/_backends/utils.py]
1 from __future__ import annotations
2
3 from typing import TYPE_CHECKING, Collection, Mapping, TypeVar, cast
4
5 from msgspec import UNSET
6 from typing_extensions import get_origin
7
8 from litestar.dto.factory import Mark
9
10 from .types import (
11 CollectionType,
12 CompositeType,
13 MappingType,
14 NestedFieldInfo,
15 SimpleType,
16 TransferType,
17 TupleType,
18 UnionType,
19 )
20
21 if TYPE_CHECKING:
22 from typing import AbstractSet, Any, Iterable
23
24 from litestar.dto.factory.types import FieldDefinition, RenameStrategy
25 from litestar.dto.types import ForType
26
27 from .types import FieldDefinitionsType
28
29 __all__ = (
30 "RenameStrategies",
31 "build_annotation_for_backend",
32 "create_transfer_model_type_annotation",
33 "should_exclude_field",
34 "transfer_data",
35 )
36
37 T = TypeVar("T")
38
39
40 def build_annotation_for_backend(annotation: Any, model: type[T]) -> type[T] | type[Iterable[T]]:
41 """A helper to re-build a generic outer type with new inner type.
42
43 Args:
44 annotation: The original annotation on the handler signature
45 model: The data container type
46
47 Returns:
48 Annotation with new inner type if applicable.
49 """
50 origin = get_origin(annotation)
51 if not origin:
52 return model
53 try:
54 return origin[model] # type:ignore[no-any-return]
55 except TypeError: # pragma: no cover
56 return annotation.copy_with((model,)) # type:ignore[no-any-return]
57
58
59 def should_exclude_field(field_definition: FieldDefinition, exclude: AbstractSet[str], dto_for: ForType) -> bool:
60 """Returns ``True`` where a field should be excluded from data transfer.
61
62 Args:
63 field_definition: defined DTO field
64 exclude: names of fields to exclude
65 dto_for: indicates whether the DTO is for the request body or response.
66
67 Returns:
68 ``True`` if the field should not be included in any data transfer.
69 """
70 field_name = field_definition.name
71 dto_field = field_definition.dto_field
72 excluded = field_name in exclude
73 private = dto_field and dto_field.mark is Mark.PRIVATE
74 read_only_for_write = dto_for == "data" and dto_field and dto_field.mark is Mark.READ_ONLY
75 return bool(excluded or private or read_only_for_write)
76
77
78 class RenameStrategies:
79 """Useful renaming strategies than be used with :class:`DTOConfig`"""
80
81 def __init__(self, renaming_strategy: RenameStrategy) -> None:
82 self.renaming_strategy = renaming_strategy
83
84 def __call__(self, field_name: str) -> str:
85 if not isinstance(self.renaming_strategy, str):
86 return self.renaming_strategy(field_name)
87
88 return cast(str, getattr(self, self.renaming_strategy)(field_name))
89
90 @staticmethod
91 def upper(field_name: str) -> str:
92 return field_name.upper()
93
94 @staticmethod
95 def lower(field_name: str) -> str:
96 return field_name.lower()
97
98 @staticmethod
99 def camel(field_name: str) -> str:
100 return RenameStrategies._camelize(field_name)
101
102 @staticmethod
103 def pascal(field_name: str) -> str:
104 return RenameStrategies._camelize(field_name, capitalize_first_letter=True)
105
106 @staticmethod
107 def _camelize(string: str, capitalize_first_letter: bool = False) -> str:
108 """Convert a string to camel case.
109
110 Args:
111 string (str): The string to convert
112 capitalize_first_letter (bool): Default is False, a True value will convert to PascalCase
113 Returns:
114 str: The string converted to camel case or Pascal case
115 """
116 return "".join(
117 word if index == 0 and not capitalize_first_letter else word.capitalize()
118 for index, word in enumerate(string.split("_"))
119 )
120
121
122 def transfer_data(
123 destination_type: type[T],
124 source_data: Any | Collection[Any],
125 field_definitions: FieldDefinitionsType,
126 dto_for: ForType = "data",
127 ) -> T | Collection[T]:
128 """Create instance or iterable of instances of ``destination_type``.
129
130 Args:
131 destination_type: the model type received by the DTO on type narrowing.
132 source_data: data that has been parsed and validated via the backend.
133 field_definitions: model field definitions.
134 dto_for: indicates whether the DTO is for the request body or response.
135
136 Returns:
137 Data parsed into ``destination_type``.
138 """
139 if not isinstance(source_data, Mapping) and isinstance(source_data, Collection):
140 return type(source_data)(
141 transfer_data(destination_type, item, field_definitions, dto_for) # type:ignore[call-arg]
142 for item in source_data
143 )
144 return transfer_instance_data(destination_type, source_data, field_definitions, dto_for)
145
146
147 def transfer_instance_data(
148 destination_type: type[T], source_instance: Any, field_definitions: FieldDefinitionsType, dto_for: ForType
149 ) -> T:
150 """Create instance of ``destination_type`` with data from ``source_instance``.
151
152 Args:
153 destination_type: the model type received by the DTO on type narrowing.
154 source_instance: primitive data that has been parsed and validated via the backend.
155 field_definitions: model field definitions.
156 dto_for: indicates whether the DTO is for the request body or response.
157
158 Returns:
159 Data parsed into ``model_type``.
160 """
161 unstructured_data = {}
162 source_is_mapping = isinstance(source_instance, Mapping)
163
164 def filter_missing(value: Any) -> bool:
165 return value is UNSET
166
167 for field_definition in field_definitions:
168 transfer_type = field_definition.transfer_type
169 source_name = field_definition.serialization_name if dto_for == "data" else field_definition.name
170 destination_name = field_definition.name if dto_for == "data" else field_definition.serialization_name
171 source_value = source_instance[source_name] if source_is_mapping else getattr(source_instance, source_name)
172 if field_definition.is_partial and dto_for == "data" and filter_missing(source_value):
173 continue
174 unstructured_data[destination_name] = transfer_type_data(source_value, transfer_type, dto_for)
175 return destination_type(**unstructured_data)
176
177
178 def transfer_type_data(source_value: Any, transfer_type: TransferType, dto_for: ForType) -> Any:
179 if isinstance(transfer_type, SimpleType) and transfer_type.nested_field_info:
180 dest_type = transfer_type.parsed_type.annotation if dto_for == "data" else transfer_type.nested_field_info.model
181 return transfer_nested_simple_type_data(dest_type, transfer_type.nested_field_info, dto_for, source_value)
182 if isinstance(transfer_type, UnionType) and transfer_type.has_nested:
183 return transfer_nested_union_type_data(transfer_type, dto_for, source_value)
184 if isinstance(transfer_type, CollectionType) and transfer_type.has_nested:
185 return transfer_nested_collection_type_data(
186 transfer_type.parsed_type.origin, transfer_type, dto_for, source_value
187 )
188 return source_value
189
190
191 def transfer_nested_collection_type_data(
192 origin_type: type[Any], transfer_type: CollectionType, dto_for: ForType, source_value: Any
193 ) -> Any:
194 return origin_type(transfer_type_data(item, transfer_type.inner_type, dto_for) for item in source_value)
195
196
197 def transfer_nested_simple_type_data(
198 destination_type: type[Any], nested_field_info: NestedFieldInfo, dto_for: ForType, source_value: Any
199 ) -> Any:
200 return transfer_instance_data(
201 destination_type,
202 source_value,
203 nested_field_info.field_definitions,
204 dto_for,
205 )
206
207
208 def transfer_nested_union_type_data(transfer_type: UnionType, dto_for: ForType, source_value: Any) -> Any:
209 for inner_type in transfer_type.inner_types:
210 if isinstance(inner_type, CompositeType):
211 raise RuntimeError("Composite inner types not (yet) supported for nested unions.")
212
213 if inner_type.nested_field_info and isinstance(
214 source_value,
215 inner_type.nested_field_info.model if dto_for == "data" else inner_type.parsed_type.annotation,
216 ):
217 return transfer_instance_data(
218 inner_type.parsed_type.annotation if dto_for == "data" else inner_type.nested_field_info.model,
219 source_value,
220 inner_type.nested_field_info.field_definitions,
221 dto_for,
222 )
223 return source_value
224
225
226 def create_transfer_model_type_annotation(transfer_type: TransferType) -> Any:
227 """Create a type annotation for a transfer model.
228
229 Uses the parsed type that originates from the data model and the transfer model generated to represent a nested
230 type to reconstruct the type annotation for the transfer model.
231 """
232 if isinstance(transfer_type, SimpleType):
233 if transfer_type.nested_field_info:
234 return transfer_type.nested_field_info.model
235 return transfer_type.parsed_type.annotation
236
237 if isinstance(transfer_type, CollectionType):
238 return create_transfer_model_collection_type(transfer_type)
239
240 if isinstance(transfer_type, MappingType):
241 return create_transfer_model_mapping_type(transfer_type)
242
243 if isinstance(transfer_type, TupleType):
244 return create_transfer_model_tuple_type(transfer_type)
245
246 if isinstance(transfer_type, UnionType):
247 return create_transfer_model_union_type(transfer_type)
248
249 raise RuntimeError(f"Unexpected transfer type: {type(transfer_type)}")
250
251
252 def create_transfer_model_collection_type(transfer_type: CollectionType) -> Any:
253 generic_collection_type = transfer_type.parsed_type.safe_generic_origin
254 inner_type = create_transfer_model_type_annotation(transfer_type.inner_type)
255 if transfer_type.parsed_type.origin is tuple:
256 return generic_collection_type[inner_type, ...]
257 return generic_collection_type[inner_type]
258
259
260 def create_transfer_model_tuple_type(transfer_type: TupleType) -> Any:
261 inner_types = tuple(create_transfer_model_type_annotation(t) for t in transfer_type.inner_types)
262 return transfer_type.parsed_type.safe_generic_origin[inner_types]
263
264
265 def create_transfer_model_union_type(transfer_type: UnionType) -> Any:
266 inner_types = tuple(create_transfer_model_type_annotation(t) for t in transfer_type.inner_types)
267 return transfer_type.parsed_type.safe_generic_origin[inner_types]
268
269
270 def create_transfer_model_mapping_type(transfer_type: MappingType) -> Any:
271 key_type = create_transfer_model_type_annotation(transfer_type.key_type)
272 value_type = create_transfer_model_type_annotation(transfer_type.value_type)
273 return transfer_type.parsed_type.safe_generic_origin[key_type, value_type]
274
[end of litestar/dto/factory/_backends/utils.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/litestar/dto/factory/_backends/utils.py b/litestar/dto/factory/_backends/utils.py
--- a/litestar/dto/factory/_backends/utils.py
+++ b/litestar/dto/factory/_backends/utils.py
@@ -171,13 +171,23 @@
source_value = source_instance[source_name] if source_is_mapping else getattr(source_instance, source_name)
if field_definition.is_partial and dto_for == "data" and filter_missing(source_value):
continue
- unstructured_data[destination_name] = transfer_type_data(source_value, transfer_type, dto_for)
+ unstructured_data[destination_name] = transfer_type_data(
+ source_value, transfer_type, dto_for, nested_as_dict=destination_type is dict
+ )
return destination_type(**unstructured_data)
-def transfer_type_data(source_value: Any, transfer_type: TransferType, dto_for: ForType) -> Any:
+def transfer_type_data(
+ source_value: Any, transfer_type: TransferType, dto_for: ForType, nested_as_dict: bool = False
+) -> Any:
if isinstance(transfer_type, SimpleType) and transfer_type.nested_field_info:
- dest_type = transfer_type.parsed_type.annotation if dto_for == "data" else transfer_type.nested_field_info.model
+ if nested_as_dict:
+ dest_type = dict
+ else:
+ dest_type = (
+ transfer_type.parsed_type.annotation if dto_for == "data" else transfer_type.nested_field_info.model
+ )
+
return transfer_nested_simple_type_data(dest_type, transfer_type.nested_field_info, dto_for, source_value)
if isinstance(transfer_type, UnionType) and transfer_type.has_nested:
return transfer_nested_union_type_data(transfer_type, dto_for, source_value)
|
{"golden_diff": "diff --git a/litestar/dto/factory/_backends/utils.py b/litestar/dto/factory/_backends/utils.py\n--- a/litestar/dto/factory/_backends/utils.py\n+++ b/litestar/dto/factory/_backends/utils.py\n@@ -171,13 +171,23 @@\n source_value = source_instance[source_name] if source_is_mapping else getattr(source_instance, source_name)\n if field_definition.is_partial and dto_for == \"data\" and filter_missing(source_value):\n continue\n- unstructured_data[destination_name] = transfer_type_data(source_value, transfer_type, dto_for)\n+ unstructured_data[destination_name] = transfer_type_data(\n+ source_value, transfer_type, dto_for, nested_as_dict=destination_type is dict\n+ )\n return destination_type(**unstructured_data)\n \n \n-def transfer_type_data(source_value: Any, transfer_type: TransferType, dto_for: ForType) -> Any:\n+def transfer_type_data(\n+ source_value: Any, transfer_type: TransferType, dto_for: ForType, nested_as_dict: bool = False\n+) -> Any:\n if isinstance(transfer_type, SimpleType) and transfer_type.nested_field_info:\n- dest_type = transfer_type.parsed_type.annotation if dto_for == \"data\" else transfer_type.nested_field_info.model\n+ if nested_as_dict:\n+ dest_type = dict\n+ else:\n+ dest_type = (\n+ transfer_type.parsed_type.annotation if dto_for == \"data\" else transfer_type.nested_field_info.model\n+ )\n+\n return transfer_nested_simple_type_data(dest_type, transfer_type.nested_field_info, dto_for, source_value)\n if isinstance(transfer_type, UnionType) and transfer_type.has_nested:\n return transfer_nested_union_type_data(transfer_type, dto_for, source_value)\n", "issue": "Bug: Premature instantiation of nested models\n### Description\n\nAssume two dataclasses `Person `and `Address`. `Person `contains an `address` (see MCVE).\r\nUsing `DataDTO[Person]` in a route handler results in a `TypeError(\\\"Address.__init__() missing 1 required positional argument: 'id'\\\")` because it tries to initialize the nested `Address` (which fails because the `address.id` is excluded from the `WriteDTO`).\n\n### URL to code causing the issue\n\nhttps://discord.com/channels/919193495116337154/1110854577575698463\n\n### MCVE\n\n```python\nfrom dataclasses import dataclass\r\nimport uuid\r\n\r\nfrom litestar import Litestar, post\r\nfrom litestar.dto.factory import DTOConfig, DTOData\r\nfrom litestar.dto.factory.stdlib import DataclassDTO\r\n\r\n@dataclass\r\nclass Address:\r\n id: uuid.UUID\r\n street: str\r\n city: str\r\n\r\n@dataclass\r\nclass Person:\r\n id: uuid.UUID\r\n name: str\r\n email: str\r\n address: Address\r\n\r\nclass WriteDTO(DataclassDTO[Person]):\r\n config = DTOConfig(exclude={\"id\", \"address.id\"})\r\n\r\n@post(\"/person\", dto=WriteDTO, return_dto=None, sync_to_thread=False)\r\ndef create_person(data: DTOData[Person]) -> str:\r\n return \"Success\"\r\n\r\napp = Litestar([create_person])\n```\n\n\n### Steps to reproduce\n\n```bash\ncurl -X 'POST' \\\r\n 'http://127.0.0.1:8000/person' \\\r\n -H 'accept: text/plain' \\\r\n -H 'Content-Type: application/json' \\\r\n -d '{\r\n \"name\": \"test\",\r\n \"email\": \"test\",\r\n \"address\": {\r\n \"street\": \"test\",\r\n \"city\": \"test\"\r\n }\r\n}'\n```\n\n\n### Screenshots\n\n```bash\n\"\"\n```\n\n\n### Logs\n\n```bash\nINFO: 127.0.0.1:36960 - \"POST /person HTTP/1.1\" 500 Internal Server Error\n```\n\n\n### Litestar Version\n\n2.0.0a7\n\n### Platform\n\n- [X] Linux\n- [X] Mac\n- [X] Windows\n- [ ] Other (Please specify in the description above)\n", "before_files": [{"content": "from __future__ import annotations\n\nfrom typing import TYPE_CHECKING, Collection, Mapping, TypeVar, cast\n\nfrom msgspec import UNSET\nfrom typing_extensions import get_origin\n\nfrom litestar.dto.factory import Mark\n\nfrom .types import (\n CollectionType,\n CompositeType,\n MappingType,\n NestedFieldInfo,\n SimpleType,\n TransferType,\n TupleType,\n UnionType,\n)\n\nif TYPE_CHECKING:\n from typing import AbstractSet, Any, Iterable\n\n from litestar.dto.factory.types import FieldDefinition, RenameStrategy\n from litestar.dto.types import ForType\n\n from .types import FieldDefinitionsType\n\n__all__ = (\n \"RenameStrategies\",\n \"build_annotation_for_backend\",\n \"create_transfer_model_type_annotation\",\n \"should_exclude_field\",\n \"transfer_data\",\n)\n\nT = TypeVar(\"T\")\n\n\ndef build_annotation_for_backend(annotation: Any, model: type[T]) -> type[T] | type[Iterable[T]]:\n \"\"\"A helper to re-build a generic outer type with new inner type.\n\n Args:\n annotation: The original annotation on the handler signature\n model: The data container type\n\n Returns:\n Annotation with new inner type if applicable.\n \"\"\"\n origin = get_origin(annotation)\n if not origin:\n return model\n try:\n return origin[model] # type:ignore[no-any-return]\n except TypeError: # pragma: no cover\n return annotation.copy_with((model,)) # type:ignore[no-any-return]\n\n\ndef should_exclude_field(field_definition: FieldDefinition, exclude: AbstractSet[str], dto_for: ForType) -> bool:\n \"\"\"Returns ``True`` where a field should be excluded from data transfer.\n\n Args:\n field_definition: defined DTO field\n exclude: names of fields to exclude\n dto_for: indicates whether the DTO is for the request body or response.\n\n Returns:\n ``True`` if the field should not be included in any data transfer.\n \"\"\"\n field_name = field_definition.name\n dto_field = field_definition.dto_field\n excluded = field_name in exclude\n private = dto_field and dto_field.mark is Mark.PRIVATE\n read_only_for_write = dto_for == \"data\" and dto_field and dto_field.mark is Mark.READ_ONLY\n return bool(excluded or private or read_only_for_write)\n\n\nclass RenameStrategies:\n \"\"\"Useful renaming strategies than be used with :class:`DTOConfig`\"\"\"\n\n def __init__(self, renaming_strategy: RenameStrategy) -> None:\n self.renaming_strategy = renaming_strategy\n\n def __call__(self, field_name: str) -> str:\n if not isinstance(self.renaming_strategy, str):\n return self.renaming_strategy(field_name)\n\n return cast(str, getattr(self, self.renaming_strategy)(field_name))\n\n @staticmethod\n def upper(field_name: str) -> str:\n return field_name.upper()\n\n @staticmethod\n def lower(field_name: str) -> str:\n return field_name.lower()\n\n @staticmethod\n def camel(field_name: str) -> str:\n return RenameStrategies._camelize(field_name)\n\n @staticmethod\n def pascal(field_name: str) -> str:\n return RenameStrategies._camelize(field_name, capitalize_first_letter=True)\n\n @staticmethod\n def _camelize(string: str, capitalize_first_letter: bool = False) -> str:\n \"\"\"Convert a string to camel case.\n\n Args:\n string (str): The string to convert\n capitalize_first_letter (bool): Default is False, a True value will convert to PascalCase\n Returns:\n str: The string converted to camel case or Pascal case\n \"\"\"\n return \"\".join(\n word if index == 0 and not capitalize_first_letter else word.capitalize()\n for index, word in enumerate(string.split(\"_\"))\n )\n\n\ndef transfer_data(\n destination_type: type[T],\n source_data: Any | Collection[Any],\n field_definitions: FieldDefinitionsType,\n dto_for: ForType = \"data\",\n) -> T | Collection[T]:\n \"\"\"Create instance or iterable of instances of ``destination_type``.\n\n Args:\n destination_type: the model type received by the DTO on type narrowing.\n source_data: data that has been parsed and validated via the backend.\n field_definitions: model field definitions.\n dto_for: indicates whether the DTO is for the request body or response.\n\n Returns:\n Data parsed into ``destination_type``.\n \"\"\"\n if not isinstance(source_data, Mapping) and isinstance(source_data, Collection):\n return type(source_data)(\n transfer_data(destination_type, item, field_definitions, dto_for) # type:ignore[call-arg]\n for item in source_data\n )\n return transfer_instance_data(destination_type, source_data, field_definitions, dto_for)\n\n\ndef transfer_instance_data(\n destination_type: type[T], source_instance: Any, field_definitions: FieldDefinitionsType, dto_for: ForType\n) -> T:\n \"\"\"Create instance of ``destination_type`` with data from ``source_instance``.\n\n Args:\n destination_type: the model type received by the DTO on type narrowing.\n source_instance: primitive data that has been parsed and validated via the backend.\n field_definitions: model field definitions.\n dto_for: indicates whether the DTO is for the request body or response.\n\n Returns:\n Data parsed into ``model_type``.\n \"\"\"\n unstructured_data = {}\n source_is_mapping = isinstance(source_instance, Mapping)\n\n def filter_missing(value: Any) -> bool:\n return value is UNSET\n\n for field_definition in field_definitions:\n transfer_type = field_definition.transfer_type\n source_name = field_definition.serialization_name if dto_for == \"data\" else field_definition.name\n destination_name = field_definition.name if dto_for == \"data\" else field_definition.serialization_name\n source_value = source_instance[source_name] if source_is_mapping else getattr(source_instance, source_name)\n if field_definition.is_partial and dto_for == \"data\" and filter_missing(source_value):\n continue\n unstructured_data[destination_name] = transfer_type_data(source_value, transfer_type, dto_for)\n return destination_type(**unstructured_data)\n\n\ndef transfer_type_data(source_value: Any, transfer_type: TransferType, dto_for: ForType) -> Any:\n if isinstance(transfer_type, SimpleType) and transfer_type.nested_field_info:\n dest_type = transfer_type.parsed_type.annotation if dto_for == \"data\" else transfer_type.nested_field_info.model\n return transfer_nested_simple_type_data(dest_type, transfer_type.nested_field_info, dto_for, source_value)\n if isinstance(transfer_type, UnionType) and transfer_type.has_nested:\n return transfer_nested_union_type_data(transfer_type, dto_for, source_value)\n if isinstance(transfer_type, CollectionType) and transfer_type.has_nested:\n return transfer_nested_collection_type_data(\n transfer_type.parsed_type.origin, transfer_type, dto_for, source_value\n )\n return source_value\n\n\ndef transfer_nested_collection_type_data(\n origin_type: type[Any], transfer_type: CollectionType, dto_for: ForType, source_value: Any\n) -> Any:\n return origin_type(transfer_type_data(item, transfer_type.inner_type, dto_for) for item in source_value)\n\n\ndef transfer_nested_simple_type_data(\n destination_type: type[Any], nested_field_info: NestedFieldInfo, dto_for: ForType, source_value: Any\n) -> Any:\n return transfer_instance_data(\n destination_type,\n source_value,\n nested_field_info.field_definitions,\n dto_for,\n )\n\n\ndef transfer_nested_union_type_data(transfer_type: UnionType, dto_for: ForType, source_value: Any) -> Any:\n for inner_type in transfer_type.inner_types:\n if isinstance(inner_type, CompositeType):\n raise RuntimeError(\"Composite inner types not (yet) supported for nested unions.\")\n\n if inner_type.nested_field_info and isinstance(\n source_value,\n inner_type.nested_field_info.model if dto_for == \"data\" else inner_type.parsed_type.annotation,\n ):\n return transfer_instance_data(\n inner_type.parsed_type.annotation if dto_for == \"data\" else inner_type.nested_field_info.model,\n source_value,\n inner_type.nested_field_info.field_definitions,\n dto_for,\n )\n return source_value\n\n\ndef create_transfer_model_type_annotation(transfer_type: TransferType) -> Any:\n \"\"\"Create a type annotation for a transfer model.\n\n Uses the parsed type that originates from the data model and the transfer model generated to represent a nested\n type to reconstruct the type annotation for the transfer model.\n \"\"\"\n if isinstance(transfer_type, SimpleType):\n if transfer_type.nested_field_info:\n return transfer_type.nested_field_info.model\n return transfer_type.parsed_type.annotation\n\n if isinstance(transfer_type, CollectionType):\n return create_transfer_model_collection_type(transfer_type)\n\n if isinstance(transfer_type, MappingType):\n return create_transfer_model_mapping_type(transfer_type)\n\n if isinstance(transfer_type, TupleType):\n return create_transfer_model_tuple_type(transfer_type)\n\n if isinstance(transfer_type, UnionType):\n return create_transfer_model_union_type(transfer_type)\n\n raise RuntimeError(f\"Unexpected transfer type: {type(transfer_type)}\")\n\n\ndef create_transfer_model_collection_type(transfer_type: CollectionType) -> Any:\n generic_collection_type = transfer_type.parsed_type.safe_generic_origin\n inner_type = create_transfer_model_type_annotation(transfer_type.inner_type)\n if transfer_type.parsed_type.origin is tuple:\n return generic_collection_type[inner_type, ...]\n return generic_collection_type[inner_type]\n\n\ndef create_transfer_model_tuple_type(transfer_type: TupleType) -> Any:\n inner_types = tuple(create_transfer_model_type_annotation(t) for t in transfer_type.inner_types)\n return transfer_type.parsed_type.safe_generic_origin[inner_types]\n\n\ndef create_transfer_model_union_type(transfer_type: UnionType) -> Any:\n inner_types = tuple(create_transfer_model_type_annotation(t) for t in transfer_type.inner_types)\n return transfer_type.parsed_type.safe_generic_origin[inner_types]\n\n\ndef create_transfer_model_mapping_type(transfer_type: MappingType) -> Any:\n key_type = create_transfer_model_type_annotation(transfer_type.key_type)\n value_type = create_transfer_model_type_annotation(transfer_type.value_type)\n return transfer_type.parsed_type.safe_generic_origin[key_type, value_type]\n", "path": "litestar/dto/factory/_backends/utils.py"}]}
| 4,053 | 402 |
gh_patches_debug_35326
|
rasdani/github-patches
|
git_diff
|
internetarchive__openlibrary-8575
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Bad matches in works Mass tagging system
I was trying to add subject "Comedy" to the works and these are the first matches I get

And when I try to manually search for the exact match there are many more subjects with word "coming" that have less works than the actual "Comedy". I think the exact matches should be the first one in the list or at least be boosted.
### Evidence / Screenshot (if possible)
### Relevant url?
<!-- `https://openlibrary.org/...` -->
### Steps to Reproduce
<!-- What steps caused you to find the bug? -->
1. Go to ...
2. Do ...
<!-- What actually happened after these steps? What did you expect to happen? -->
* Actual:
* Expected:
### Details
- **Logged in (Y/N)?**
- **Browser type/version?**
- **Operating system?**
- **Environment (prod/dev/local)?** prod
<!-- If not sure, put prod -->
### Proposal & Constraints
<!-- What is the proposed solution / implementation? Is there a precedent of this approach succeeding elsewhere? -->
### Related files
<!-- Files related to this issue; this is super useful for new contributors who might want to help! If you're not sure, leave this blank; a maintainer will add them. -->
### Stakeholders
<!-- @ tag stakeholders of this bug -->
</issue>
<code>
[start of openlibrary/plugins/openlibrary/bulk_tag.py]
1 from infogami.utils import delegate
2 from infogami.utils.view import render_template, public
3 from openlibrary.utils import uniq
4 import web
5 import json
6
7
8 class tags_partials(delegate.page):
9 path = "/tags/partials"
10 encoding = "json"
11
12 def GET(self):
13 i = web.input(key=None)
14
15 works = i.work_ids
16
17 tagging_menu = render_template('subjects/tagging_menu', works)
18
19 partials = {
20 'tagging_menu': str(tagging_menu),
21 }
22
23 return delegate.RawText(json.dumps(partials))
24
25
26 class bulk_tag_works(delegate.page):
27 path = "/tags/bulk_tag_works"
28
29 def POST(self):
30 i = web.input(work_ids='', tag_subjects='{}')
31 works = i.work_ids.split(',')
32 incoming_subjects = json.loads(i.tag_subjects)
33 docs_to_update = []
34
35 for work in works:
36 w = web.ctx.site.get(f"/works/{work}")
37 current_subjects = {
38 'subjects': uniq(w.get('subjects', '')),
39 'subject_people': uniq(w.get('subject_people', '')),
40 'subject_places': uniq(w.get('subject_places', '')),
41 'subject_times': uniq(w.get('subject_times', '')),
42 }
43 for subject_type, subject_list in incoming_subjects.items():
44 if subject_list:
45 current_subjects[subject_type] = uniq( # dedupe incoming subjects
46 current_subjects[subject_type] + subject_list
47 )
48 w[subject_type] = current_subjects[subject_type]
49
50 docs_to_update.append(
51 w.dict()
52 ) # need to convert class to raw dict in order for save_many to work
53
54 web.ctx.site.save_many(docs_to_update, comment="Bulk tagging works")
55
56 def response(msg, status="success"):
57 return delegate.RawText(
58 json.dumps({status: msg}), content_type="application/json"
59 )
60
61 return response('Tagged works successfully')
62
63
64 def setup():
65 pass
66
[end of openlibrary/plugins/openlibrary/bulk_tag.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/openlibrary/plugins/openlibrary/bulk_tag.py b/openlibrary/plugins/openlibrary/bulk_tag.py
--- a/openlibrary/plugins/openlibrary/bulk_tag.py
+++ b/openlibrary/plugins/openlibrary/bulk_tag.py
@@ -5,31 +5,16 @@
import json
-class tags_partials(delegate.page):
- path = "/tags/partials"
- encoding = "json"
-
- def GET(self):
- i = web.input(key=None)
-
- works = i.work_ids
-
- tagging_menu = render_template('subjects/tagging_menu', works)
-
- partials = {
- 'tagging_menu': str(tagging_menu),
- }
-
- return delegate.RawText(json.dumps(partials))
-
-
class bulk_tag_works(delegate.page):
path = "/tags/bulk_tag_works"
def POST(self):
- i = web.input(work_ids='', tag_subjects='{}')
+ i = web.input(work_ids='', tags_to_add='', tags_to_remove='')
+
works = i.work_ids.split(',')
- incoming_subjects = json.loads(i.tag_subjects)
+ tags_to_add = json.loads(i.tags_to_add or '{}')
+ tags_to_remove = json.loads(i.tags_to_remove or '{}')
+
docs_to_update = []
for work in works:
@@ -40,13 +25,22 @@
'subject_places': uniq(w.get('subject_places', '')),
'subject_times': uniq(w.get('subject_times', '')),
}
- for subject_type, subject_list in incoming_subjects.items():
- if subject_list:
+ for subject_type, add_list in tags_to_add.items():
+ if add_list:
current_subjects[subject_type] = uniq( # dedupe incoming subjects
- current_subjects[subject_type] + subject_list
+ current_subjects[subject_type] + add_list
)
w[subject_type] = current_subjects[subject_type]
+ for subject_type, remove_list in tags_to_remove.items():
+ if remove_list:
+ current_subjects[subject_type] = [
+ item
+ for item in current_subjects[subject_type]
+ if item not in remove_list
+ ]
+ w[subject_type] = current_subjects[subject_type]
+
docs_to_update.append(
w.dict()
) # need to convert class to raw dict in order for save_many to work
|
{"golden_diff": "diff --git a/openlibrary/plugins/openlibrary/bulk_tag.py b/openlibrary/plugins/openlibrary/bulk_tag.py\n--- a/openlibrary/plugins/openlibrary/bulk_tag.py\n+++ b/openlibrary/plugins/openlibrary/bulk_tag.py\n@@ -5,31 +5,16 @@\n import json\n \n \n-class tags_partials(delegate.page):\n- path = \"/tags/partials\"\n- encoding = \"json\"\n-\n- def GET(self):\n- i = web.input(key=None)\n-\n- works = i.work_ids\n-\n- tagging_menu = render_template('subjects/tagging_menu', works)\n-\n- partials = {\n- 'tagging_menu': str(tagging_menu),\n- }\n-\n- return delegate.RawText(json.dumps(partials))\n-\n-\n class bulk_tag_works(delegate.page):\n path = \"/tags/bulk_tag_works\"\n \n def POST(self):\n- i = web.input(work_ids='', tag_subjects='{}')\n+ i = web.input(work_ids='', tags_to_add='', tags_to_remove='')\n+\n works = i.work_ids.split(',')\n- incoming_subjects = json.loads(i.tag_subjects)\n+ tags_to_add = json.loads(i.tags_to_add or '{}')\n+ tags_to_remove = json.loads(i.tags_to_remove or '{}')\n+\n docs_to_update = []\n \n for work in works:\n@@ -40,13 +25,22 @@\n 'subject_places': uniq(w.get('subject_places', '')),\n 'subject_times': uniq(w.get('subject_times', '')),\n }\n- for subject_type, subject_list in incoming_subjects.items():\n- if subject_list:\n+ for subject_type, add_list in tags_to_add.items():\n+ if add_list:\n current_subjects[subject_type] = uniq( # dedupe incoming subjects\n- current_subjects[subject_type] + subject_list\n+ current_subjects[subject_type] + add_list\n )\n w[subject_type] = current_subjects[subject_type]\n \n+ for subject_type, remove_list in tags_to_remove.items():\n+ if remove_list:\n+ current_subjects[subject_type] = [\n+ item\n+ for item in current_subjects[subject_type]\n+ if item not in remove_list\n+ ]\n+ w[subject_type] = current_subjects[subject_type]\n+\n docs_to_update.append(\n w.dict()\n ) # need to convert class to raw dict in order for save_many to work\n", "issue": "Bad matches in works Mass tagging system\nI was trying to add subject \"Comedy\" to the works and these are the first matches I get \r\n\r\nAnd when I try to manually search for the exact match there are many more subjects with word \"coming\" that have less works than the actual \"Comedy\". I think the exact matches should be the first one in the list or at least be boosted.\r\n\r\n### Evidence / Screenshot (if possible)\r\n\r\n### Relevant url?\r\n<!-- `https://openlibrary.org/...` -->\r\n\r\n### Steps to Reproduce\r\n<!-- What steps caused you to find the bug? -->\r\n1. Go to ...\r\n2. Do ...\r\n\r\n<!-- What actually happened after these steps? What did you expect to happen? -->\r\n* Actual:\r\n* Expected:\r\n\r\n### Details\r\n\r\n- **Logged in (Y/N)?**\r\n- **Browser type/version?**\r\n- **Operating system?**\r\n- **Environment (prod/dev/local)?** prod\r\n<!-- If not sure, put prod -->\r\n\r\n### Proposal & Constraints\r\n<!-- What is the proposed solution / implementation? Is there a precedent of this approach succeeding elsewhere? -->\r\n\r\n### Related files\r\n<!-- Files related to this issue; this is super useful for new contributors who might want to help! If you're not sure, leave this blank; a maintainer will add them. -->\r\n\r\n### Stakeholders\r\n<!-- @ tag stakeholders of this bug -->\r\n\n", "before_files": [{"content": "from infogami.utils import delegate\nfrom infogami.utils.view import render_template, public\nfrom openlibrary.utils import uniq\nimport web\nimport json\n\n\nclass tags_partials(delegate.page):\n path = \"/tags/partials\"\n encoding = \"json\"\n\n def GET(self):\n i = web.input(key=None)\n\n works = i.work_ids\n\n tagging_menu = render_template('subjects/tagging_menu', works)\n\n partials = {\n 'tagging_menu': str(tagging_menu),\n }\n\n return delegate.RawText(json.dumps(partials))\n\n\nclass bulk_tag_works(delegate.page):\n path = \"/tags/bulk_tag_works\"\n\n def POST(self):\n i = web.input(work_ids='', tag_subjects='{}')\n works = i.work_ids.split(',')\n incoming_subjects = json.loads(i.tag_subjects)\n docs_to_update = []\n\n for work in works:\n w = web.ctx.site.get(f\"/works/{work}\")\n current_subjects = {\n 'subjects': uniq(w.get('subjects', '')),\n 'subject_people': uniq(w.get('subject_people', '')),\n 'subject_places': uniq(w.get('subject_places', '')),\n 'subject_times': uniq(w.get('subject_times', '')),\n }\n for subject_type, subject_list in incoming_subjects.items():\n if subject_list:\n current_subjects[subject_type] = uniq( # dedupe incoming subjects\n current_subjects[subject_type] + subject_list\n )\n w[subject_type] = current_subjects[subject_type]\n\n docs_to_update.append(\n w.dict()\n ) # need to convert class to raw dict in order for save_many to work\n\n web.ctx.site.save_many(docs_to_update, comment=\"Bulk tagging works\")\n\n def response(msg, status=\"success\"):\n return delegate.RawText(\n json.dumps({status: msg}), content_type=\"application/json\"\n )\n\n return response('Tagged works successfully')\n\n\ndef setup():\n pass\n", "path": "openlibrary/plugins/openlibrary/bulk_tag.py"}]}
| 1,436 | 536 |
gh_patches_debug_6109
|
rasdani/github-patches
|
git_diff
|
facebookresearch__ParlAI-2281
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
projects/convai2/interactive.py not using new message force_set feature
**Bug description**
The code hasn't been updated for the force_set.
**Reproduction steps**
python projects/convai2/interactive.py -mf models:convai2/seq2seq/convai2_self_seq2seq_model -m legacy:seq2seq:0 --no_cuda
**Expected behavior**
to just chat
**Logs**
```
Traceback (most recent call last):
File "projects/convai2/interactive.py", line 126, in <module>
interactive(parser.parse_args(print_args=False), print_parser=parser)
File "projects/convai2/interactive.py", line 105, in interactive
acts[0]['text'] = bot_persona + acts[0].get('text', 'hi')
File "/home/ubuntu/anaconda3/envs/pytorch_p36/lib/python3.6/site-packages/parlai-0.1.0-py3.6.egg/parlai/core/message.py", line 26, in __setitem__
'please use the function `force_set(key, value)`.'.format(key)
RuntimeError: Message already contains key `text`. If this was intentional, please use the function `force_set(key, value)`.
```
**Additional context**
possible fix
```
index 61ead742..9d478d75 100644
--- a/projects/convai2/interactive.py
+++ b/projects/convai2/interactive.py
@@ -102,7 +102,8 @@ def interactive(opt, print_parser=None):
acts[0] = agents[0].act()
# add the persona on to the first message
if cnt == 0:
- acts[0]['text'] = bot_persona + acts[0].get('text', 'hi')
+ #acts[0]['text'] = bot_persona + acts[0].get('text', 'hi')
+ acts[0].force_set('text',bot_persona + acts[0].get('text', 'hi'))
agents[1].observe(acts[0])
```
</issue>
<code>
[start of projects/convai2/interactive.py]
1 #!/usr/bin/env python3
2
3 # Copyright (c) Facebook, Inc. and its affiliates.
4 # This source code is licensed under the MIT license found in the
5 # LICENSE file in the root directory of this source tree.
6 """
7 Basic script which allows local human keyboard input to talk to a trained model.
8
9 Examples
10 --------
11
12 .. code-block:: shell
13
14 python projects/convai2/interactive.py -mf models:convai2/kvmemnn/model
15
16 When prompted, chat with the both, you will both be assigned personalities!
17 Use "[DONE]" to indicate you are done with that chat partner, and want a new one.
18 """
19 from parlai.core.params import ParlaiParser
20 from parlai.core.agents import create_agent
21 from parlai.core.worlds import create_task
22 from parlai.agents.repeat_label.repeat_label import RepeatLabelAgent
23 from parlai.agents.local_human.local_human import LocalHumanAgent
24
25 import random
26
27
28 def setup_args(parser=None):
29 if parser is None:
30 parser = ParlaiParser(True, True, 'Interactive chat with a model')
31 parser.add_argument('-d', '--display-examples', type='bool', default=False)
32 parser.add_argument(
33 '--display-prettify',
34 type='bool',
35 default=False,
36 help='Set to use a prettytable when displaying '
37 'examples with text candidates',
38 )
39 parser.add_argument(
40 '--display-ignore-fields',
41 type=str,
42 default='label_candidates,text_candidates',
43 help='Do not display these fields',
44 )
45 parser.set_defaults(model_file='models:convai2/kvmemnn/model')
46 LocalHumanAgent.add_cmdline_args(parser)
47 return parser
48
49
50 def interactive(opt, print_parser=None):
51 if print_parser is not None:
52 if print_parser is True and isinstance(opt, ParlaiParser):
53 print_parser = opt
54 elif print_parser is False:
55 print_parser = None
56 if isinstance(opt, ParlaiParser):
57 print('[ Deprecated Warning: interactive should be passed opt not Parser ]')
58 opt = opt.parse_args()
59 opt['task'] = 'parlai.agents.local_human.local_human:LocalHumanAgent'
60 # Create model and assign it to the specified task
61 agent = create_agent(opt, requireModelExists=True)
62 world = create_task(opt, agent)
63 if print_parser:
64 # Show arguments after loading model
65 print_parser.opt = agent.opt
66 print_parser.print_args()
67
68 # Create ConvAI2 data so we can assign personas.
69 convai2_opt = opt.copy()
70 convai2_opt['task'] = 'convai2:both'
71 convai2_agent = RepeatLabelAgent(convai2_opt)
72 convai2_world = create_task(convai2_opt, convai2_agent)
73
74 def get_new_personas():
75 # Find a new episode
76 while True:
77 convai2_world.parley()
78 msg = convai2_world.get_acts()[0]
79 if msg['episode_done']:
80 convai2_world.parley()
81 msg = convai2_world.get_acts()[0]
82 break
83 txt = msg.get('text', '').split('\n')
84 bot_persona = ""
85 for t in txt:
86 if t.startswith("partner's persona:"):
87 print(t.replace("partner's ", 'your '))
88 if t.startswith('your persona:'):
89 bot_persona += t + '\n'
90 print("Enter [DONE] if you want a new partner at any time.")
91 return bot_persona
92
93 # Now run interactive mode, chatting with personas!
94 cnt = 0
95 while True:
96 if cnt == 0:
97 bot_persona = get_new_personas()
98 # Run the parts of world.parley() in turn,
99 # but insert persona into user message.
100 acts = world.acts
101 agents = world.agents
102 acts[0] = agents[0].act()
103 # add the persona on to the first message
104 if cnt == 0:
105 acts[0]['text'] = bot_persona + acts[0].get('text', 'hi')
106 agents[1].observe(acts[0])
107 acts[1] = agents[1].act()
108 agents[0].observe(acts[1])
109 world.update_counters()
110 cnt = cnt + 1
111
112 if opt.get('display_examples'):
113 print("---")
114 print(world.display())
115 if world.episode_done():
116 print("CHAT DONE ")
117 print("In case you were curious you were talking to this bot:")
118 print(bot_persona.split('\n'))
119 print("\n... preparing new chat... \n")
120 cnt = 0
121
122
123 if __name__ == '__main__':
124 random.seed(42)
125 parser = setup_args()
126 interactive(parser.parse_args(print_args=False), print_parser=parser)
127
[end of projects/convai2/interactive.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/projects/convai2/interactive.py b/projects/convai2/interactive.py
--- a/projects/convai2/interactive.py
+++ b/projects/convai2/interactive.py
@@ -102,7 +102,7 @@
acts[0] = agents[0].act()
# add the persona on to the first message
if cnt == 0:
- acts[0]['text'] = bot_persona + acts[0].get('text', 'hi')
+ acts[0].force_set('text', bot_persona + acts[0].get('text', 'hi'))
agents[1].observe(acts[0])
acts[1] = agents[1].act()
agents[0].observe(acts[1])
|
{"golden_diff": "diff --git a/projects/convai2/interactive.py b/projects/convai2/interactive.py\n--- a/projects/convai2/interactive.py\n+++ b/projects/convai2/interactive.py\n@@ -102,7 +102,7 @@\n acts[0] = agents[0].act()\n # add the persona on to the first message\n if cnt == 0:\n- acts[0]['text'] = bot_persona + acts[0].get('text', 'hi')\n+ acts[0].force_set('text', bot_persona + acts[0].get('text', 'hi'))\n agents[1].observe(acts[0])\n acts[1] = agents[1].act()\n agents[0].observe(acts[1])\n", "issue": "projects/convai2/interactive.py not using new message force_set feature\n**Bug description**\r\nThe code hasn't been updated for the force_set.\r\n\r\n**Reproduction steps**\r\npython projects/convai2/interactive.py -mf models:convai2/seq2seq/convai2_self_seq2seq_model -m legacy:seq2seq:0 --no_cuda\r\n\r\n**Expected behavior**\r\nto just chat\r\n\r\n**Logs**\r\n\r\n```\r\nTraceback (most recent call last):\r\n File \"projects/convai2/interactive.py\", line 126, in <module>\r\n interactive(parser.parse_args(print_args=False), print_parser=parser)\r\n File \"projects/convai2/interactive.py\", line 105, in interactive\r\n acts[0]['text'] = bot_persona + acts[0].get('text', 'hi')\r\n File \"/home/ubuntu/anaconda3/envs/pytorch_p36/lib/python3.6/site-packages/parlai-0.1.0-py3.6.egg/parlai/core/message.py\", line 26, in __setitem__\r\n 'please use the function `force_set(key, value)`.'.format(key)\r\nRuntimeError: Message already contains key `text`. If this was intentional, please use the function `force_set(key, value)`.\r\n```\r\n\r\n**Additional context**\r\npossible fix\r\n```\r\nindex 61ead742..9d478d75 100644\r\n--- a/projects/convai2/interactive.py\r\n+++ b/projects/convai2/interactive.py\r\n@@ -102,7 +102,8 @@ def interactive(opt, print_parser=None):\r\n acts[0] = agents[0].act()\r\n # add the persona on to the first message\r\n if cnt == 0:\r\n- acts[0]['text'] = bot_persona + acts[0].get('text', 'hi')\r\n+ #acts[0]['text'] = bot_persona + acts[0].get('text', 'hi')\r\n+ acts[0].force_set('text',bot_persona + acts[0].get('text', 'hi'))\r\n agents[1].observe(acts[0])\r\n\r\n```\r\n\n", "before_files": [{"content": "#!/usr/bin/env python3\n\n# Copyright (c) Facebook, Inc. and its affiliates.\n# This source code is licensed under the MIT license found in the\n# LICENSE file in the root directory of this source tree.\n\"\"\"\nBasic script which allows local human keyboard input to talk to a trained model.\n\nExamples\n--------\n\n.. code-block:: shell\n\n python projects/convai2/interactive.py -mf models:convai2/kvmemnn/model\n\nWhen prompted, chat with the both, you will both be assigned personalities!\nUse \"[DONE]\" to indicate you are done with that chat partner, and want a new one.\n\"\"\"\nfrom parlai.core.params import ParlaiParser\nfrom parlai.core.agents import create_agent\nfrom parlai.core.worlds import create_task\nfrom parlai.agents.repeat_label.repeat_label import RepeatLabelAgent\nfrom parlai.agents.local_human.local_human import LocalHumanAgent\n\nimport random\n\n\ndef setup_args(parser=None):\n if parser is None:\n parser = ParlaiParser(True, True, 'Interactive chat with a model')\n parser.add_argument('-d', '--display-examples', type='bool', default=False)\n parser.add_argument(\n '--display-prettify',\n type='bool',\n default=False,\n help='Set to use a prettytable when displaying '\n 'examples with text candidates',\n )\n parser.add_argument(\n '--display-ignore-fields',\n type=str,\n default='label_candidates,text_candidates',\n help='Do not display these fields',\n )\n parser.set_defaults(model_file='models:convai2/kvmemnn/model')\n LocalHumanAgent.add_cmdline_args(parser)\n return parser\n\n\ndef interactive(opt, print_parser=None):\n if print_parser is not None:\n if print_parser is True and isinstance(opt, ParlaiParser):\n print_parser = opt\n elif print_parser is False:\n print_parser = None\n if isinstance(opt, ParlaiParser):\n print('[ Deprecated Warning: interactive should be passed opt not Parser ]')\n opt = opt.parse_args()\n opt['task'] = 'parlai.agents.local_human.local_human:LocalHumanAgent'\n # Create model and assign it to the specified task\n agent = create_agent(opt, requireModelExists=True)\n world = create_task(opt, agent)\n if print_parser:\n # Show arguments after loading model\n print_parser.opt = agent.opt\n print_parser.print_args()\n\n # Create ConvAI2 data so we can assign personas.\n convai2_opt = opt.copy()\n convai2_opt['task'] = 'convai2:both'\n convai2_agent = RepeatLabelAgent(convai2_opt)\n convai2_world = create_task(convai2_opt, convai2_agent)\n\n def get_new_personas():\n # Find a new episode\n while True:\n convai2_world.parley()\n msg = convai2_world.get_acts()[0]\n if msg['episode_done']:\n convai2_world.parley()\n msg = convai2_world.get_acts()[0]\n break\n txt = msg.get('text', '').split('\\n')\n bot_persona = \"\"\n for t in txt:\n if t.startswith(\"partner's persona:\"):\n print(t.replace(\"partner's \", 'your '))\n if t.startswith('your persona:'):\n bot_persona += t + '\\n'\n print(\"Enter [DONE] if you want a new partner at any time.\")\n return bot_persona\n\n # Now run interactive mode, chatting with personas!\n cnt = 0\n while True:\n if cnt == 0:\n bot_persona = get_new_personas()\n # Run the parts of world.parley() in turn,\n # but insert persona into user message.\n acts = world.acts\n agents = world.agents\n acts[0] = agents[0].act()\n # add the persona on to the first message\n if cnt == 0:\n acts[0]['text'] = bot_persona + acts[0].get('text', 'hi')\n agents[1].observe(acts[0])\n acts[1] = agents[1].act()\n agents[0].observe(acts[1])\n world.update_counters()\n cnt = cnt + 1\n\n if opt.get('display_examples'):\n print(\"---\")\n print(world.display())\n if world.episode_done():\n print(\"CHAT DONE \")\n print(\"In case you were curious you were talking to this bot:\")\n print(bot_persona.split('\\n'))\n print(\"\\n... preparing new chat... \\n\")\n cnt = 0\n\n\nif __name__ == '__main__':\n random.seed(42)\n parser = setup_args()\n interactive(parser.parse_args(print_args=False), print_parser=parser)\n", "path": "projects/convai2/interactive.py"}]}
| 2,318 | 170 |
gh_patches_debug_4267
|
rasdani/github-patches
|
git_diff
|
web2py__web2py-1381
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
XML helper and incorrect HTML
XML crashes while trying to sanitize some sorts of incorrect html.
For example:
```
a = '</em></em>' # wrong html
b = XML(a, sanitize=True)
```
Result:
`<type 'exceptions.IndexError'> pop from empty list`
</issue>
<code>
[start of gluon/sanitizer.py]
1 #!/usr/bin/env python
2 # -*- coding: utf-8 -*-
3 """
4 | From http://aspn.activestate.com/ASPN/Cookbook/Python/Recipe/496942
5 | Submitter: Josh Goldfoot (other recipes)
6 | Last Updated: 2006/08/05
7 | Version: 1.0
8
9 Cross-site scripting (XSS) defense
10 -----------------------------------
11 """
12
13 from ._compat import HTMLParser, urlparse, entitydefs, basestring
14 from cgi import escape
15 from formatter import AbstractFormatter
16 from xml.sax.saxutils import quoteattr
17
18 __all__ = ['sanitize']
19
20
21 def xssescape(text):
22 """Gets rid of < and > and & and, for good measure, :"""
23
24 return escape(text, quote=True).replace(':', ':')
25
26
27 class XssCleaner(HTMLParser):
28
29 def __init__(
30 self,
31 permitted_tags=[
32 'a',
33 'b',
34 'blockquote',
35 'br/',
36 'i',
37 'li',
38 'ol',
39 'ul',
40 'p',
41 'cite',
42 'code',
43 'pre',
44 'img/',
45 ],
46 allowed_attributes={'a': ['href', 'title'], 'img': ['src', 'alt'
47 ], 'blockquote': ['type']},
48 strip_disallowed=False
49 ):
50
51 HTMLParser.__init__(self)
52 self.result = ''
53 self.open_tags = []
54 self.permitted_tags = [i for i in permitted_tags if i[-1] != '/']
55 self.requires_no_close = [i[:-1] for i in permitted_tags
56 if i[-1] == '/']
57 self.permitted_tags += self.requires_no_close
58 self.allowed_attributes = allowed_attributes
59
60 # The only schemes allowed in URLs (for href and src attributes).
61 # Adding "javascript" or "vbscript" to this list would not be smart.
62
63 self.allowed_schemes = ['http', 'https', 'ftp', 'mailto']
64
65 #to strip or escape disallowed tags?
66 self.strip_disallowed = strip_disallowed
67 # there might be data after final closing tag, that is to be ignored
68 self.in_disallowed = [False]
69
70 def handle_data(self, data):
71 if data and not self.in_disallowed[-1]:
72 self.result += xssescape(data)
73
74 def handle_charref(self, ref):
75 if self.in_disallowed[-1]:
76 return
77 elif len(ref) < 7 and (ref.isdigit() or ref == 'x27'): # x27 is a special case for apostrophe
78 self.result += '&#%s;' % ref
79 else:
80 self.result += xssescape('&#%s' % ref)
81
82 def handle_entityref(self, ref):
83 if self.in_disallowed[-1]:
84 return
85 elif ref in entitydefs:
86 self.result += '&%s;' % ref
87 else:
88 self.result += xssescape('&%s' % ref)
89
90 def handle_comment(self, comment):
91 if self.in_disallowed[-1]:
92 return
93 elif comment:
94 self.result += xssescape('<!--%s-->' % comment)
95
96 def handle_starttag(
97 self,
98 tag,
99 attrs
100 ):
101 if tag not in self.permitted_tags:
102 self.in_disallowed.append(True)
103 if (not self.strip_disallowed):
104 self.result += xssescape('<%s>' % tag)
105 else:
106 self.in_disallowed.append(False)
107 bt = '<' + tag
108 if tag in self.allowed_attributes:
109 attrs = dict(attrs)
110 self.allowed_attributes_here = [x for x in
111 self.allowed_attributes[tag] if x in attrs
112 and len(attrs[x]) > 0]
113 for attribute in self.allowed_attributes_here:
114 if attribute in ['href', 'src', 'background']:
115 if self.url_is_acceptable(attrs[attribute]):
116 bt += ' %s="%s"' % (attribute,
117 attrs[attribute])
118 else:
119 bt += ' %s=%s' % (xssescape(attribute),
120 quoteattr(attrs[attribute]))
121 # deal with <a> without href and <img> without src
122 if bt == '<a' or bt == '<img':
123 return
124 if tag in self.requires_no_close:
125 bt += ' /'
126 bt += '>'
127 self.result += bt
128 if tag not in self.requires_no_close: self.open_tags.insert(0, tag)
129
130 def handle_endtag(self, tag):
131 bracketed = '</%s>' % tag
132 self.in_disallowed.pop()
133 if tag not in self.permitted_tags:
134 if (not self.strip_disallowed):
135 self.result += xssescape(bracketed)
136 elif tag in self.open_tags:
137 self.result += bracketed
138 self.open_tags.remove(tag)
139
140 def url_is_acceptable(self, url):
141 """
142 Accepts relative, absolute, and mailto urls
143 """
144
145 if url.startswith('#'):
146 return True
147 else:
148 parsed = urlparse(url)
149 return ((parsed[0] in self.allowed_schemes and '.' in parsed[1]) or
150 (parsed[0] in self.allowed_schemes and '@' in parsed[2]) or
151 (parsed[0] == '' and parsed[2].startswith('/')))
152
153 def strip(self, rawstring, escape=True):
154 """
155 Returns the argument stripped of potentially harmful
156 HTML or Javascript code
157
158 @type escape: boolean
159 @param escape: If True (default) it escapes the potentially harmful
160 content, otherwise remove it
161 """
162
163 if not isinstance(rawstring, str):
164 return str(rawstring)
165 for tag in self.requires_no_close:
166 rawstring = rawstring.replace("<%s/>" % tag, "<%s />" % tag)
167 if not escape:
168 self.strip_disallowed = True
169 self.result = ''
170 self.feed(rawstring)
171 for endtag in self.open_tags:
172 if endtag not in self.requires_no_close:
173 self.result += '</%s>' % endtag
174 return self.result
175
176 def xtags(self):
177 """
178 Returns a printable string informing the user which tags are allowed
179 """
180
181 tg = ''
182 for x in sorted(self.permitted_tags):
183 tg += '<' + x
184 if x in self.allowed_attributes:
185 for y in self.allowed_attributes[x]:
186 tg += ' %s=""' % y
187 tg += '> '
188 return xssescape(tg.strip())
189
190
191 def sanitize(text, permitted_tags=[
192 'a',
193 'b',
194 'blockquote',
195 'br/',
196 'i',
197 'li',
198 'ol',
199 'ul',
200 'p',
201 'cite',
202 'code',
203 'pre',
204 'img/',
205 'h1', 'h2', 'h3', 'h4', 'h5', 'h6',
206 'table', 'tbody', 'thead', 'tfoot', 'tr', 'td', 'div',
207 'strong', 'span',
208 ],
209 allowed_attributes={
210 'a': ['href', 'title'],
211 'img': ['src', 'alt'],
212 'blockquote': ['type'],
213 'td': ['colspan'],
214 },
215 escape=True):
216 if not isinstance(text, basestring):
217 return str(text)
218 return XssCleaner(permitted_tags=permitted_tags,
219 allowed_attributes=allowed_attributes).strip(text, escape)
220
[end of gluon/sanitizer.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/gluon/sanitizer.py b/gluon/sanitizer.py
--- a/gluon/sanitizer.py
+++ b/gluon/sanitizer.py
@@ -129,7 +129,7 @@
def handle_endtag(self, tag):
bracketed = '</%s>' % tag
- self.in_disallowed.pop()
+ self.in_disallowed and self.in_disallowed.pop()
if tag not in self.permitted_tags:
if (not self.strip_disallowed):
self.result += xssescape(bracketed)
|
{"golden_diff": "diff --git a/gluon/sanitizer.py b/gluon/sanitizer.py\n--- a/gluon/sanitizer.py\n+++ b/gluon/sanitizer.py\n@@ -129,7 +129,7 @@\n \n def handle_endtag(self, tag):\n bracketed = '</%s>' % tag\n- self.in_disallowed.pop()\n+ self.in_disallowed and self.in_disallowed.pop()\n if tag not in self.permitted_tags:\n if (not self.strip_disallowed):\n self.result += xssescape(bracketed)\n", "issue": "XML helper and incorrect HTML\nXML crashes while trying to sanitize some sorts of incorrect html.\n\nFor example:\n\n```\na = '</em></em>' # wrong html\nb = XML(a, sanitize=True)\n```\n\nResult:\n`<type 'exceptions.IndexError'> pop from empty list`\n\n", "before_files": [{"content": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n\"\"\"\n| From http://aspn.activestate.com/ASPN/Cookbook/Python/Recipe/496942\n| Submitter: Josh Goldfoot (other recipes)\n| Last Updated: 2006/08/05\n| Version: 1.0\n\nCross-site scripting (XSS) defense\n-----------------------------------\n\"\"\"\n\nfrom ._compat import HTMLParser, urlparse, entitydefs, basestring\nfrom cgi import escape\nfrom formatter import AbstractFormatter\nfrom xml.sax.saxutils import quoteattr\n\n__all__ = ['sanitize']\n\n\ndef xssescape(text):\n \"\"\"Gets rid of < and > and & and, for good measure, :\"\"\"\n\n return escape(text, quote=True).replace(':', ':')\n\n\nclass XssCleaner(HTMLParser):\n\n def __init__(\n self,\n permitted_tags=[\n 'a',\n 'b',\n 'blockquote',\n 'br/',\n 'i',\n 'li',\n 'ol',\n 'ul',\n 'p',\n 'cite',\n 'code',\n 'pre',\n 'img/',\n ],\n allowed_attributes={'a': ['href', 'title'], 'img': ['src', 'alt'\n ], 'blockquote': ['type']},\n strip_disallowed=False\n ):\n\n HTMLParser.__init__(self)\n self.result = ''\n self.open_tags = []\n self.permitted_tags = [i for i in permitted_tags if i[-1] != '/']\n self.requires_no_close = [i[:-1] for i in permitted_tags\n if i[-1] == '/']\n self.permitted_tags += self.requires_no_close\n self.allowed_attributes = allowed_attributes\n\n # The only schemes allowed in URLs (for href and src attributes).\n # Adding \"javascript\" or \"vbscript\" to this list would not be smart.\n\n self.allowed_schemes = ['http', 'https', 'ftp', 'mailto']\n\n #to strip or escape disallowed tags?\n self.strip_disallowed = strip_disallowed\n # there might be data after final closing tag, that is to be ignored\n self.in_disallowed = [False]\n\n def handle_data(self, data):\n if data and not self.in_disallowed[-1]:\n self.result += xssescape(data)\n\n def handle_charref(self, ref):\n if self.in_disallowed[-1]:\n return\n elif len(ref) < 7 and (ref.isdigit() or ref == 'x27'): # x27 is a special case for apostrophe\n self.result += '&#%s;' % ref\n else:\n self.result += xssescape('&#%s' % ref)\n\n def handle_entityref(self, ref):\n if self.in_disallowed[-1]:\n return\n elif ref in entitydefs:\n self.result += '&%s;' % ref\n else:\n self.result += xssescape('&%s' % ref)\n\n def handle_comment(self, comment):\n if self.in_disallowed[-1]:\n return\n elif comment:\n self.result += xssescape('<!--%s-->' % comment)\n\n def handle_starttag(\n self,\n tag,\n attrs\n ):\n if tag not in self.permitted_tags:\n self.in_disallowed.append(True)\n if (not self.strip_disallowed):\n self.result += xssescape('<%s>' % tag)\n else:\n self.in_disallowed.append(False)\n bt = '<' + tag\n if tag in self.allowed_attributes:\n attrs = dict(attrs)\n self.allowed_attributes_here = [x for x in\n self.allowed_attributes[tag] if x in attrs\n and len(attrs[x]) > 0]\n for attribute in self.allowed_attributes_here:\n if attribute in ['href', 'src', 'background']:\n if self.url_is_acceptable(attrs[attribute]):\n bt += ' %s=\"%s\"' % (attribute,\n attrs[attribute])\n else:\n bt += ' %s=%s' % (xssescape(attribute),\n quoteattr(attrs[attribute]))\n # deal with <a> without href and <img> without src\n if bt == '<a' or bt == '<img':\n return\n if tag in self.requires_no_close:\n bt += ' /'\n bt += '>'\n self.result += bt\n if tag not in self.requires_no_close: self.open_tags.insert(0, tag)\n\n def handle_endtag(self, tag):\n bracketed = '</%s>' % tag\n self.in_disallowed.pop()\n if tag not in self.permitted_tags:\n if (not self.strip_disallowed):\n self.result += xssescape(bracketed)\n elif tag in self.open_tags:\n self.result += bracketed\n self.open_tags.remove(tag)\n\n def url_is_acceptable(self, url):\n \"\"\"\n Accepts relative, absolute, and mailto urls\n \"\"\"\n\n if url.startswith('#'):\n return True\n else:\n parsed = urlparse(url)\n return ((parsed[0] in self.allowed_schemes and '.' in parsed[1]) or\n (parsed[0] in self.allowed_schemes and '@' in parsed[2]) or\n (parsed[0] == '' and parsed[2].startswith('/')))\n\n def strip(self, rawstring, escape=True):\n \"\"\"\n Returns the argument stripped of potentially harmful\n HTML or Javascript code\n\n @type escape: boolean\n @param escape: If True (default) it escapes the potentially harmful\n content, otherwise remove it\n \"\"\"\n\n if not isinstance(rawstring, str):\n return str(rawstring)\n for tag in self.requires_no_close:\n rawstring = rawstring.replace(\"<%s/>\" % tag, \"<%s />\" % tag)\n if not escape:\n self.strip_disallowed = True\n self.result = ''\n self.feed(rawstring)\n for endtag in self.open_tags:\n if endtag not in self.requires_no_close:\n self.result += '</%s>' % endtag\n return self.result\n\n def xtags(self):\n \"\"\"\n Returns a printable string informing the user which tags are allowed\n \"\"\"\n\n tg = ''\n for x in sorted(self.permitted_tags):\n tg += '<' + x\n if x in self.allowed_attributes:\n for y in self.allowed_attributes[x]:\n tg += ' %s=\"\"' % y\n tg += '> '\n return xssescape(tg.strip())\n\n\ndef sanitize(text, permitted_tags=[\n 'a',\n 'b',\n 'blockquote',\n 'br/',\n 'i',\n 'li',\n 'ol',\n 'ul',\n 'p',\n 'cite',\n 'code',\n 'pre',\n 'img/',\n 'h1', 'h2', 'h3', 'h4', 'h5', 'h6',\n 'table', 'tbody', 'thead', 'tfoot', 'tr', 'td', 'div',\n 'strong', 'span',\n],\n allowed_attributes={\n 'a': ['href', 'title'],\n 'img': ['src', 'alt'],\n 'blockquote': ['type'],\n 'td': ['colspan'],\n },\n escape=True):\n if not isinstance(text, basestring):\n return str(text)\n return XssCleaner(permitted_tags=permitted_tags,\n allowed_attributes=allowed_attributes).strip(text, escape)\n", "path": "gluon/sanitizer.py"}]}
| 2,766 | 126 |
gh_patches_debug_43718
|
rasdani/github-patches
|
git_diff
|
python-telegram-bot__python-telegram-bot-608
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
add ability to handle only edited messages updates
Actually if you want to develop a bot where when a user edits his message it replies "you edited this message" or a bot that in groups kicks users that edit their messages (let's imagine a strange rule), there is not a handler to handle only edited messages.
messagehandler just handles any messages and not only those edited. So a handler or a filter to handle only edited messages is needed. Thanks
</issue>
<code>
[start of telegram/ext/messagehandler.py]
1 #!/usr/bin/env python
2 #
3 # A library that provides a Python interface to the Telegram Bot API
4 # Copyright (C) 2015-2017
5 # Leandro Toledo de Souza <[email protected]>
6 #
7 # This program is free software: you can redistribute it and/or modify
8 # it under the terms of the GNU Lesser Public License as published by
9 # the Free Software Foundation, either version 3 of the License, or
10 # (at your option) any later version.
11 #
12 # This program is distributed in the hope that it will be useful,
13 # but WITHOUT ANY WARRANTY; without even the implied warranty of
14 # MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
15 # GNU Lesser Public License for more details.
16 #
17 # You should have received a copy of the GNU Lesser Public License
18 # along with this program. If not, see [http://www.gnu.org/licenses/].
19 """ This module contains the MessageHandler class """
20 import warnings
21
22 from .handler import Handler
23 from telegram import Update
24
25
26 class MessageHandler(Handler):
27 """
28 Handler class to handle telegram messages. Messages are Telegram Updates
29 that do not contain a command. They might contain text, media or status
30 updates.
31
32 Args:
33 filters (telegram.ext.BaseFilter): A filter inheriting from
34 :class:`telegram.ext.filters.BaseFilter`. Standard filters can be found in
35 :class:`telegram.ext.filters.Filters`. Filters can be combined using bitwise
36 operators (& for and, | for or).
37 callback (function): A function that takes ``bot, update`` as
38 positional arguments. It will be called when the ``check_update``
39 has determined that an update should be processed by this handler.
40 allow_edited (Optional[bool]): If the handler should also accept edited messages.
41 Default is ``False``
42 pass_update_queue (optional[bool]): If the handler should be passed the
43 update queue as a keyword argument called ``update_queue``. It can
44 be used to insert updates. Default is ``False``
45 pass_user_data (optional[bool]): If set to ``True``, a keyword argument called
46 ``user_data`` will be passed to the callback function. It will be a ``dict`` you
47 can use to keep any data related to the user that sent the update. For each update of
48 the same user, it will be the same ``dict``. Default is ``False``.
49 pass_chat_data (optional[bool]): If set to ``True``, a keyword argument called
50 ``chat_data`` will be passed to the callback function. It will be a ``dict`` you
51 can use to keep any data related to the chat that the update was sent in.
52 For each update in the same chat, it will be the same ``dict``. Default is ``False``.
53 message_updates (Optional[bool]): Should "normal" message updates be handled? Default is
54 ``True``.
55 channel_post_updates (Optional[bool]): Should channel posts updates be handled? Default is
56 ``True``.
57
58 """
59
60 def __init__(self,
61 filters,
62 callback,
63 allow_edited=False,
64 pass_update_queue=False,
65 pass_job_queue=False,
66 pass_user_data=False,
67 pass_chat_data=False,
68 message_updates=True,
69 channel_post_updates=True):
70 if not message_updates and not channel_post_updates:
71 raise ValueError('Both message_updates & channel_post_updates are False')
72
73 super(MessageHandler, self).__init__(
74 callback,
75 pass_update_queue=pass_update_queue,
76 pass_job_queue=pass_job_queue,
77 pass_user_data=pass_user_data,
78 pass_chat_data=pass_chat_data)
79 self.filters = filters
80 self.allow_edited = allow_edited
81 self.message_updates = message_updates
82 self.channel_post_updates = channel_post_updates
83
84 # We put this up here instead of with the rest of checking code
85 # in check_update since we don't wanna spam a ton
86 if isinstance(self.filters, list):
87 warnings.warn('Using a list of filters in MessageHandler is getting '
88 'deprecated, please use bitwise operators (& and |) '
89 'instead. More info: https://git.io/vPTbc.')
90
91 def _is_allowed_message(self, update):
92 return (self.message_updates
93 and (update.message or (update.edited_message and self.allow_edited)))
94
95 def _is_allowed_channel_post(self, update):
96 return (self.channel_post_updates
97 and (update.channel_post or (update.edited_channel_post and self.allow_edited)))
98
99 def check_update(self, update):
100 if (isinstance(update, Update)
101 and (self._is_allowed_message(update) or self._is_allowed_channel_post(update))):
102
103 if not self.filters:
104 res = True
105
106 else:
107 message = update.effective_message
108 if isinstance(self.filters, list):
109 res = any(func(message) for func in self.filters)
110 else:
111 res = self.filters(message)
112
113 else:
114 res = False
115
116 return res
117
118 def handle_update(self, update, dispatcher):
119 optional_args = self.collect_optional_args(dispatcher, update)
120
121 return self.callback(dispatcher.bot, update, **optional_args)
122
[end of telegram/ext/messagehandler.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/telegram/ext/messagehandler.py b/telegram/ext/messagehandler.py
--- a/telegram/ext/messagehandler.py
+++ b/telegram/ext/messagehandler.py
@@ -37,8 +37,6 @@
callback (function): A function that takes ``bot, update`` as
positional arguments. It will be called when the ``check_update``
has determined that an update should be processed by this handler.
- allow_edited (Optional[bool]): If the handler should also accept edited messages.
- Default is ``False``
pass_update_queue (optional[bool]): If the handler should be passed the
update queue as a keyword argument called ``update_queue``. It can
be used to insert updates. Default is ``False``
@@ -52,8 +50,12 @@
For each update in the same chat, it will be the same ``dict``. Default is ``False``.
message_updates (Optional[bool]): Should "normal" message updates be handled? Default is
``True``.
+ allow_edited (Optional[bool]): If the handler should also accept edited messages.
+ Default is ``False`` - Deprecated. use edited updates instead.
channel_post_updates (Optional[bool]): Should channel posts updates be handled? Default is
``True``.
+ edited_updates (Optional[bool]): Should "edited" message updates be handled? Default is
+ ``False``.
"""
@@ -66,9 +68,14 @@
pass_user_data=False,
pass_chat_data=False,
message_updates=True,
- channel_post_updates=True):
- if not message_updates and not channel_post_updates:
- raise ValueError('Both message_updates & channel_post_updates are False')
+ channel_post_updates=True,
+ edited_updates=False):
+ if not message_updates and not channel_post_updates and not edited_updates:
+ raise ValueError(
+ 'message_updates, channel_post_updates and edited_updates are all False')
+ if allow_edited:
+ warnings.warn('allow_edited is getting deprecated, please use edited_updates instead')
+ edited_updates = allow_edited
super(MessageHandler, self).__init__(
callback,
@@ -77,9 +84,9 @@
pass_user_data=pass_user_data,
pass_chat_data=pass_chat_data)
self.filters = filters
- self.allow_edited = allow_edited
self.message_updates = message_updates
self.channel_post_updates = channel_post_updates
+ self.edited_updates = edited_updates
# We put this up here instead of with the rest of checking code
# in check_update since we don't wanna spam a ton
@@ -88,17 +95,13 @@
'deprecated, please use bitwise operators (& and |) '
'instead. More info: https://git.io/vPTbc.')
- def _is_allowed_message(self, update):
- return (self.message_updates
- and (update.message or (update.edited_message and self.allow_edited)))
-
- def _is_allowed_channel_post(self, update):
- return (self.channel_post_updates
- and (update.channel_post or (update.edited_channel_post and self.allow_edited)))
+ def _is_allowed_update(self, update):
+ return any([(self.message_updates and update.message),
+ (self.edited_updates and update.edited_message),
+ (self.channel_post_updates and update.channel_post)])
def check_update(self, update):
- if (isinstance(update, Update)
- and (self._is_allowed_message(update) or self._is_allowed_channel_post(update))):
+ if isinstance(update, Update) and self._is_allowed_update(update):
if not self.filters:
res = True
|
{"golden_diff": "diff --git a/telegram/ext/messagehandler.py b/telegram/ext/messagehandler.py\n--- a/telegram/ext/messagehandler.py\n+++ b/telegram/ext/messagehandler.py\n@@ -37,8 +37,6 @@\n callback (function): A function that takes ``bot, update`` as\n positional arguments. It will be called when the ``check_update``\n has determined that an update should be processed by this handler.\n- allow_edited (Optional[bool]): If the handler should also accept edited messages.\n- Default is ``False``\n pass_update_queue (optional[bool]): If the handler should be passed the\n update queue as a keyword argument called ``update_queue``. It can\n be used to insert updates. Default is ``False``\n@@ -52,8 +50,12 @@\n For each update in the same chat, it will be the same ``dict``. Default is ``False``.\n message_updates (Optional[bool]): Should \"normal\" message updates be handled? Default is\n ``True``.\n+ allow_edited (Optional[bool]): If the handler should also accept edited messages.\n+ Default is ``False`` - Deprecated. use edited updates instead.\n channel_post_updates (Optional[bool]): Should channel posts updates be handled? Default is\n ``True``.\n+ edited_updates (Optional[bool]): Should \"edited\" message updates be handled? Default is\n+ ``False``.\n \n \"\"\"\n \n@@ -66,9 +68,14 @@\n pass_user_data=False,\n pass_chat_data=False,\n message_updates=True,\n- channel_post_updates=True):\n- if not message_updates and not channel_post_updates:\n- raise ValueError('Both message_updates & channel_post_updates are False')\n+ channel_post_updates=True,\n+ edited_updates=False):\n+ if not message_updates and not channel_post_updates and not edited_updates:\n+ raise ValueError(\n+ 'message_updates, channel_post_updates and edited_updates are all False')\n+ if allow_edited:\n+ warnings.warn('allow_edited is getting deprecated, please use edited_updates instead')\n+ edited_updates = allow_edited\n \n super(MessageHandler, self).__init__(\n callback,\n@@ -77,9 +84,9 @@\n pass_user_data=pass_user_data,\n pass_chat_data=pass_chat_data)\n self.filters = filters\n- self.allow_edited = allow_edited\n self.message_updates = message_updates\n self.channel_post_updates = channel_post_updates\n+ self.edited_updates = edited_updates\n \n # We put this up here instead of with the rest of checking code\n # in check_update since we don't wanna spam a ton\n@@ -88,17 +95,13 @@\n 'deprecated, please use bitwise operators (& and |) '\n 'instead. More info: https://git.io/vPTbc.')\n \n- def _is_allowed_message(self, update):\n- return (self.message_updates\n- and (update.message or (update.edited_message and self.allow_edited)))\n-\n- def _is_allowed_channel_post(self, update):\n- return (self.channel_post_updates\n- and (update.channel_post or (update.edited_channel_post and self.allow_edited)))\n+ def _is_allowed_update(self, update):\n+ return any([(self.message_updates and update.message),\n+ (self.edited_updates and update.edited_message),\n+ (self.channel_post_updates and update.channel_post)])\n \n def check_update(self, update):\n- if (isinstance(update, Update)\n- and (self._is_allowed_message(update) or self._is_allowed_channel_post(update))):\n+ if isinstance(update, Update) and self._is_allowed_update(update):\n \n if not self.filters:\n res = True\n", "issue": "add ability to handle only edited messages updates\nActually if you want to develop a bot where when a user edits his message it replies \"you edited this message\" or a bot that in groups kicks users that edit their messages (let's imagine a strange rule), there is not a handler to handle only edited messages.\r\n\r\nmessagehandler just handles any messages and not only those edited. So a handler or a filter to handle only edited messages is needed. Thanks\r\n\r\n\r\n\n", "before_files": [{"content": "#!/usr/bin/env python\n#\n# A library that provides a Python interface to the Telegram Bot API\n# Copyright (C) 2015-2017\n# Leandro Toledo de Souza <[email protected]>\n#\n# This program is free software: you can redistribute it and/or modify\n# it under the terms of the GNU Lesser Public License as published by\n# the Free Software Foundation, either version 3 of the License, or\n# (at your option) any later version.\n#\n# This program is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU Lesser Public License for more details.\n#\n# You should have received a copy of the GNU Lesser Public License\n# along with this program. If not, see [http://www.gnu.org/licenses/].\n\"\"\" This module contains the MessageHandler class \"\"\"\nimport warnings\n\nfrom .handler import Handler\nfrom telegram import Update\n\n\nclass MessageHandler(Handler):\n \"\"\"\n Handler class to handle telegram messages. Messages are Telegram Updates\n that do not contain a command. They might contain text, media or status\n updates.\n\n Args:\n filters (telegram.ext.BaseFilter): A filter inheriting from\n :class:`telegram.ext.filters.BaseFilter`. Standard filters can be found in\n :class:`telegram.ext.filters.Filters`. Filters can be combined using bitwise\n operators (& for and, | for or).\n callback (function): A function that takes ``bot, update`` as\n positional arguments. It will be called when the ``check_update``\n has determined that an update should be processed by this handler.\n allow_edited (Optional[bool]): If the handler should also accept edited messages.\n Default is ``False``\n pass_update_queue (optional[bool]): If the handler should be passed the\n update queue as a keyword argument called ``update_queue``. It can\n be used to insert updates. Default is ``False``\n pass_user_data (optional[bool]): If set to ``True``, a keyword argument called\n ``user_data`` will be passed to the callback function. It will be a ``dict`` you\n can use to keep any data related to the user that sent the update. For each update of\n the same user, it will be the same ``dict``. Default is ``False``.\n pass_chat_data (optional[bool]): If set to ``True``, a keyword argument called\n ``chat_data`` will be passed to the callback function. It will be a ``dict`` you\n can use to keep any data related to the chat that the update was sent in.\n For each update in the same chat, it will be the same ``dict``. Default is ``False``.\n message_updates (Optional[bool]): Should \"normal\" message updates be handled? Default is\n ``True``.\n channel_post_updates (Optional[bool]): Should channel posts updates be handled? Default is\n ``True``.\n\n \"\"\"\n\n def __init__(self,\n filters,\n callback,\n allow_edited=False,\n pass_update_queue=False,\n pass_job_queue=False,\n pass_user_data=False,\n pass_chat_data=False,\n message_updates=True,\n channel_post_updates=True):\n if not message_updates and not channel_post_updates:\n raise ValueError('Both message_updates & channel_post_updates are False')\n\n super(MessageHandler, self).__init__(\n callback,\n pass_update_queue=pass_update_queue,\n pass_job_queue=pass_job_queue,\n pass_user_data=pass_user_data,\n pass_chat_data=pass_chat_data)\n self.filters = filters\n self.allow_edited = allow_edited\n self.message_updates = message_updates\n self.channel_post_updates = channel_post_updates\n\n # We put this up here instead of with the rest of checking code\n # in check_update since we don't wanna spam a ton\n if isinstance(self.filters, list):\n warnings.warn('Using a list of filters in MessageHandler is getting '\n 'deprecated, please use bitwise operators (& and |) '\n 'instead. More info: https://git.io/vPTbc.')\n\n def _is_allowed_message(self, update):\n return (self.message_updates\n and (update.message or (update.edited_message and self.allow_edited)))\n\n def _is_allowed_channel_post(self, update):\n return (self.channel_post_updates\n and (update.channel_post or (update.edited_channel_post and self.allow_edited)))\n\n def check_update(self, update):\n if (isinstance(update, Update)\n and (self._is_allowed_message(update) or self._is_allowed_channel_post(update))):\n\n if not self.filters:\n res = True\n\n else:\n message = update.effective_message\n if isinstance(self.filters, list):\n res = any(func(message) for func in self.filters)\n else:\n res = self.filters(message)\n\n else:\n res = False\n\n return res\n\n def handle_update(self, update, dispatcher):\n optional_args = self.collect_optional_args(dispatcher, update)\n\n return self.callback(dispatcher.bot, update, **optional_args)\n", "path": "telegram/ext/messagehandler.py"}]}
| 2,006 | 815 |
gh_patches_debug_4579
|
rasdani/github-patches
|
git_diff
|
zigpy__zha-device-handlers-289
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Hue dimmer (rwl020) off short press
Hi,
I have Hue Dimmer controller integrated in Hass Core via ZHA and Bellows (zigpy). The quirk is set to a [long press of the Off button as show here](https://github.com/dmulcahey/zha-device-handlers/blob/5c726a717a4d1dc3930b177f346e852bede9ee63/zhaquirks/philips/rwl021.py#L117). However it seems device is sending this on the short press and not sending any long press for the Off button. The event on Hass is:
```
{
"event_type": "zha_event",
"data": {
"unique_id": "xx:xx:xx:xx:xx:1:0x0006",
"device_ieee": "xx:xx:xx:xx",
"endpoint_id": 1,
"cluster_id": 6,
"command": "off_with_effect",
"args": [
0,
0
]
},
"origin": "LOCAL",
"time_fired": "2020-03-05T05:49:25.119524+00:00",
"context": {
"id": "xxxxxxxxxxxx",
"parent_id": null,
"user_id": null
}
}
```
Based on quirk code, it should be `long press` with no args but it is `short press` with `args [0,0]`.
This hue dimmer is with latest firmware (upgraded using Hue bridge before paring dimmer with ZHA).
Thanks.
</issue>
<code>
[start of zhaquirks/philips/rwl021.py]
1 """Phillips RWL021 device."""
2 from zigpy.profiles import zha, zll
3 from zigpy.quirks import CustomCluster, CustomDevice
4 import zigpy.types as t
5 from zigpy.zcl.clusters.general import (
6 Basic,
7 BinaryInput,
8 Groups,
9 Identify,
10 LevelControl,
11 OnOff,
12 Ota,
13 PowerConfiguration,
14 Scenes,
15 )
16
17 from ..const import (
18 ARGS,
19 CLUSTER_ID,
20 COMMAND,
21 COMMAND_OFF_WITH_EFFECT,
22 COMMAND_ON,
23 COMMAND_STEP,
24 DEVICE_TYPE,
25 DIM_DOWN,
26 DIM_UP,
27 ENDPOINT_ID,
28 ENDPOINTS,
29 INPUT_CLUSTERS,
30 LONG_PRESS,
31 OUTPUT_CLUSTERS,
32 PROFILE_ID,
33 SHORT_PRESS,
34 TURN_OFF,
35 TURN_ON,
36 )
37
38 DIAGNOSTICS_CLUSTER_ID = 0x0B05 # decimal = 2821
39
40
41 class BasicCluster(CustomCluster, Basic):
42 """Centralite acceleration cluster."""
43
44 attributes = Basic.attributes.copy()
45 attributes.update({0x0031: ("phillips", t.bitmap16)})
46
47
48 class PhilipsRWL021(CustomDevice):
49 """Phillips RWL021 device."""
50
51 signature = {
52 # <SimpleDescriptor endpoint=1 profile=49246 device_type=2096
53 # device_version=2
54 # input_clusters=[0]
55 # output_clusters=[0, 3, 4, 6, 8, 5]>
56 ENDPOINTS: {
57 1: {
58 PROFILE_ID: zll.PROFILE_ID,
59 DEVICE_TYPE: zll.DeviceType.SCENE_CONTROLLER,
60 INPUT_CLUSTERS: [Basic.cluster_id],
61 OUTPUT_CLUSTERS: [
62 Basic.cluster_id,
63 Identify.cluster_id,
64 Groups.cluster_id,
65 OnOff.cluster_id,
66 LevelControl.cluster_id,
67 Scenes.cluster_id,
68 ],
69 },
70 # <SimpleDescriptor endpoint=2 profile=260 device_type=12
71 # device_version=0
72 # input_clusters=[0, 1, 3, 15, 64512]
73 # output_clusters=[25]>
74 2: {
75 PROFILE_ID: zha.PROFILE_ID,
76 DEVICE_TYPE: zha.DeviceType.SIMPLE_SENSOR,
77 INPUT_CLUSTERS: [
78 Basic.cluster_id,
79 PowerConfiguration.cluster_id,
80 Identify.cluster_id,
81 BinaryInput.cluster_id,
82 64512,
83 ],
84 OUTPUT_CLUSTERS: [Ota.cluster_id],
85 },
86 }
87 }
88
89 replacement = {
90 ENDPOINTS: {
91 1: {
92 INPUT_CLUSTERS: [Basic.cluster_id],
93 OUTPUT_CLUSTERS: [
94 Basic.cluster_id,
95 Identify.cluster_id,
96 Groups.cluster_id,
97 OnOff.cluster_id,
98 LevelControl.cluster_id,
99 Scenes.cluster_id,
100 ],
101 },
102 2: {
103 INPUT_CLUSTERS: [
104 BasicCluster,
105 PowerConfiguration.cluster_id,
106 Identify.cluster_id,
107 BinaryInput.cluster_id,
108 64512,
109 ],
110 OUTPUT_CLUSTERS: [Ota.cluster_id],
111 },
112 }
113 }
114
115 device_automation_triggers = {
116 (SHORT_PRESS, TURN_ON): {COMMAND: COMMAND_ON},
117 (LONG_PRESS, TURN_OFF): {COMMAND: COMMAND_OFF_WITH_EFFECT},
118 (SHORT_PRESS, DIM_UP): {
119 COMMAND: COMMAND_STEP,
120 CLUSTER_ID: 8,
121 ENDPOINT_ID: 1,
122 ARGS: [0, 30, 9],
123 },
124 (LONG_PRESS, DIM_UP): {
125 COMMAND: COMMAND_STEP,
126 CLUSTER_ID: 8,
127 ENDPOINT_ID: 1,
128 ARGS: [0, 56, 9],
129 },
130 (SHORT_PRESS, DIM_DOWN): {
131 COMMAND: COMMAND_STEP,
132 CLUSTER_ID: 8,
133 ENDPOINT_ID: 1,
134 ARGS: [1, 30, 9],
135 },
136 (LONG_PRESS, DIM_DOWN): {
137 COMMAND: COMMAND_STEP,
138 CLUSTER_ID: 8,
139 ENDPOINT_ID: 1,
140 ARGS: [1, 56, 9],
141 },
142 }
143
[end of zhaquirks/philips/rwl021.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/zhaquirks/philips/rwl021.py b/zhaquirks/philips/rwl021.py
--- a/zhaquirks/philips/rwl021.py
+++ b/zhaquirks/philips/rwl021.py
@@ -114,7 +114,7 @@
device_automation_triggers = {
(SHORT_PRESS, TURN_ON): {COMMAND: COMMAND_ON},
- (LONG_PRESS, TURN_OFF): {COMMAND: COMMAND_OFF_WITH_EFFECT},
+ (SHORT_PRESS, TURN_OFF): {COMMAND: COMMAND_OFF_WITH_EFFECT},
(SHORT_PRESS, DIM_UP): {
COMMAND: COMMAND_STEP,
CLUSTER_ID: 8,
|
{"golden_diff": "diff --git a/zhaquirks/philips/rwl021.py b/zhaquirks/philips/rwl021.py\n--- a/zhaquirks/philips/rwl021.py\n+++ b/zhaquirks/philips/rwl021.py\n@@ -114,7 +114,7 @@\n \n device_automation_triggers = {\n (SHORT_PRESS, TURN_ON): {COMMAND: COMMAND_ON},\n- (LONG_PRESS, TURN_OFF): {COMMAND: COMMAND_OFF_WITH_EFFECT},\n+ (SHORT_PRESS, TURN_OFF): {COMMAND: COMMAND_OFF_WITH_EFFECT},\n (SHORT_PRESS, DIM_UP): {\n COMMAND: COMMAND_STEP,\n CLUSTER_ID: 8,\n", "issue": "Hue dimmer (rwl020) off short press\nHi,\r\n\r\nI have Hue Dimmer controller integrated in Hass Core via ZHA and Bellows (zigpy). The quirk is set to a [long press of the Off button as show here](https://github.com/dmulcahey/zha-device-handlers/blob/5c726a717a4d1dc3930b177f346e852bede9ee63/zhaquirks/philips/rwl021.py#L117). However it seems device is sending this on the short press and not sending any long press for the Off button. The event on Hass is:\r\n\r\n```\r\n{\r\n \"event_type\": \"zha_event\",\r\n \"data\": {\r\n \"unique_id\": \"xx:xx:xx:xx:xx:1:0x0006\",\r\n \"device_ieee\": \"xx:xx:xx:xx\",\r\n \"endpoint_id\": 1,\r\n \"cluster_id\": 6,\r\n \"command\": \"off_with_effect\",\r\n \"args\": [\r\n 0,\r\n 0\r\n ]\r\n },\r\n \"origin\": \"LOCAL\",\r\n \"time_fired\": \"2020-03-05T05:49:25.119524+00:00\",\r\n \"context\": {\r\n \"id\": \"xxxxxxxxxxxx\",\r\n \"parent_id\": null,\r\n \"user_id\": null\r\n }\r\n}\r\n```\r\nBased on quirk code, it should be `long press` with no args but it is `short press` with `args [0,0]`.\r\n\r\nThis hue dimmer is with latest firmware (upgraded using Hue bridge before paring dimmer with ZHA).\r\n\r\nThanks.\n", "before_files": [{"content": "\"\"\"Phillips RWL021 device.\"\"\"\nfrom zigpy.profiles import zha, zll\nfrom zigpy.quirks import CustomCluster, CustomDevice\nimport zigpy.types as t\nfrom zigpy.zcl.clusters.general import (\n Basic,\n BinaryInput,\n Groups,\n Identify,\n LevelControl,\n OnOff,\n Ota,\n PowerConfiguration,\n Scenes,\n)\n\nfrom ..const import (\n ARGS,\n CLUSTER_ID,\n COMMAND,\n COMMAND_OFF_WITH_EFFECT,\n COMMAND_ON,\n COMMAND_STEP,\n DEVICE_TYPE,\n DIM_DOWN,\n DIM_UP,\n ENDPOINT_ID,\n ENDPOINTS,\n INPUT_CLUSTERS,\n LONG_PRESS,\n OUTPUT_CLUSTERS,\n PROFILE_ID,\n SHORT_PRESS,\n TURN_OFF,\n TURN_ON,\n)\n\nDIAGNOSTICS_CLUSTER_ID = 0x0B05 # decimal = 2821\n\n\nclass BasicCluster(CustomCluster, Basic):\n \"\"\"Centralite acceleration cluster.\"\"\"\n\n attributes = Basic.attributes.copy()\n attributes.update({0x0031: (\"phillips\", t.bitmap16)})\n\n\nclass PhilipsRWL021(CustomDevice):\n \"\"\"Phillips RWL021 device.\"\"\"\n\n signature = {\n # <SimpleDescriptor endpoint=1 profile=49246 device_type=2096\n # device_version=2\n # input_clusters=[0]\n # output_clusters=[0, 3, 4, 6, 8, 5]>\n ENDPOINTS: {\n 1: {\n PROFILE_ID: zll.PROFILE_ID,\n DEVICE_TYPE: zll.DeviceType.SCENE_CONTROLLER,\n INPUT_CLUSTERS: [Basic.cluster_id],\n OUTPUT_CLUSTERS: [\n Basic.cluster_id,\n Identify.cluster_id,\n Groups.cluster_id,\n OnOff.cluster_id,\n LevelControl.cluster_id,\n Scenes.cluster_id,\n ],\n },\n # <SimpleDescriptor endpoint=2 profile=260 device_type=12\n # device_version=0\n # input_clusters=[0, 1, 3, 15, 64512]\n # output_clusters=[25]>\n 2: {\n PROFILE_ID: zha.PROFILE_ID,\n DEVICE_TYPE: zha.DeviceType.SIMPLE_SENSOR,\n INPUT_CLUSTERS: [\n Basic.cluster_id,\n PowerConfiguration.cluster_id,\n Identify.cluster_id,\n BinaryInput.cluster_id,\n 64512,\n ],\n OUTPUT_CLUSTERS: [Ota.cluster_id],\n },\n }\n }\n\n replacement = {\n ENDPOINTS: {\n 1: {\n INPUT_CLUSTERS: [Basic.cluster_id],\n OUTPUT_CLUSTERS: [\n Basic.cluster_id,\n Identify.cluster_id,\n Groups.cluster_id,\n OnOff.cluster_id,\n LevelControl.cluster_id,\n Scenes.cluster_id,\n ],\n },\n 2: {\n INPUT_CLUSTERS: [\n BasicCluster,\n PowerConfiguration.cluster_id,\n Identify.cluster_id,\n BinaryInput.cluster_id,\n 64512,\n ],\n OUTPUT_CLUSTERS: [Ota.cluster_id],\n },\n }\n }\n\n device_automation_triggers = {\n (SHORT_PRESS, TURN_ON): {COMMAND: COMMAND_ON},\n (LONG_PRESS, TURN_OFF): {COMMAND: COMMAND_OFF_WITH_EFFECT},\n (SHORT_PRESS, DIM_UP): {\n COMMAND: COMMAND_STEP,\n CLUSTER_ID: 8,\n ENDPOINT_ID: 1,\n ARGS: [0, 30, 9],\n },\n (LONG_PRESS, DIM_UP): {\n COMMAND: COMMAND_STEP,\n CLUSTER_ID: 8,\n ENDPOINT_ID: 1,\n ARGS: [0, 56, 9],\n },\n (SHORT_PRESS, DIM_DOWN): {\n COMMAND: COMMAND_STEP,\n CLUSTER_ID: 8,\n ENDPOINT_ID: 1,\n ARGS: [1, 30, 9],\n },\n (LONG_PRESS, DIM_DOWN): {\n COMMAND: COMMAND_STEP,\n CLUSTER_ID: 8,\n ENDPOINT_ID: 1,\n ARGS: [1, 56, 9],\n },\n }\n", "path": "zhaquirks/philips/rwl021.py"}]}
| 2,185 | 158 |
gh_patches_debug_7076
|
rasdani/github-patches
|
git_diff
|
ipython__ipython-6586
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
notebook.start_kernel is undefined
Hi, in notificationarea.js, when we need to restart a kernel we call `notebook.start_kernel` which doesn't exist. Not sure how you guys were planning to handle this, but I took a stab at it.
thanks!
</issue>
<code>
[start of IPython/html/services/sessions/handlers.py]
1 """Tornado handlers for the sessions web service."""
2
3 # Copyright (c) IPython Development Team.
4 # Distributed under the terms of the Modified BSD License.
5
6 import json
7
8 from tornado import web
9
10 from ...base.handlers import IPythonHandler, json_errors
11 from IPython.utils.jsonutil import date_default
12 from IPython.html.utils import url_path_join, url_escape
13 from IPython.kernel.kernelspec import NoSuchKernel
14
15
16 class SessionRootHandler(IPythonHandler):
17
18 @web.authenticated
19 @json_errors
20 def get(self):
21 # Return a list of running sessions
22 sm = self.session_manager
23 sessions = sm.list_sessions()
24 self.finish(json.dumps(sessions, default=date_default))
25
26 @web.authenticated
27 @json_errors
28 def post(self):
29 # Creates a new session
30 #(unless a session already exists for the named nb)
31 sm = self.session_manager
32 cm = self.contents_manager
33 km = self.kernel_manager
34
35 model = self.get_json_body()
36 if model is None:
37 raise web.HTTPError(400, "No JSON data provided")
38 try:
39 name = model['notebook']['name']
40 except KeyError:
41 raise web.HTTPError(400, "Missing field in JSON data: notebook.name")
42 try:
43 path = model['notebook']['path']
44 except KeyError:
45 raise web.HTTPError(400, "Missing field in JSON data: notebook.path")
46 try:
47 kernel_name = model['kernel']['name']
48 except KeyError:
49 self.log.debug("No kernel name specified, using default kernel")
50 kernel_name = None
51
52 # Check to see if session exists
53 if sm.session_exists(name=name, path=path):
54 model = sm.get_session(name=name, path=path)
55 else:
56 try:
57 model = sm.create_session(name=name, path=path, kernel_name=kernel_name)
58 except NoSuchKernel:
59 msg = ("The '%s' kernel is not available. Please pick another "
60 "suitable kernel instead, or install that kernel." % kernel_name)
61 status_msg = '%s not found' % kernel_name
62 self.log.warn('Kernel not found: %s' % kernel_name)
63 self.set_status(501)
64 self.finish(json.dumps(dict(message=msg, short_message=status_msg)))
65 return
66
67 location = url_path_join(self.base_url, 'api', 'sessions', model['id'])
68 self.set_header('Location', url_escape(location))
69 self.set_status(201)
70 self.finish(json.dumps(model, default=date_default))
71
72 class SessionHandler(IPythonHandler):
73
74 SUPPORTED_METHODS = ('GET', 'PATCH', 'DELETE')
75
76 @web.authenticated
77 @json_errors
78 def get(self, session_id):
79 # Returns the JSON model for a single session
80 sm = self.session_manager
81 model = sm.get_session(session_id=session_id)
82 self.finish(json.dumps(model, default=date_default))
83
84 @web.authenticated
85 @json_errors
86 def patch(self, session_id):
87 # Currently, this handler is strictly for renaming notebooks
88 sm = self.session_manager
89 model = self.get_json_body()
90 if model is None:
91 raise web.HTTPError(400, "No JSON data provided")
92 changes = {}
93 if 'notebook' in model:
94 notebook = model['notebook']
95 if 'name' in notebook:
96 changes['name'] = notebook['name']
97 if 'path' in notebook:
98 changes['path'] = notebook['path']
99
100 sm.update_session(session_id, **changes)
101 model = sm.get_session(session_id=session_id)
102 self.finish(json.dumps(model, default=date_default))
103
104 @web.authenticated
105 @json_errors
106 def delete(self, session_id):
107 # Deletes the session with given session_id
108 sm = self.session_manager
109 sm.delete_session(session_id)
110 self.set_status(204)
111 self.finish()
112
113
114 #-----------------------------------------------------------------------------
115 # URL to handler mappings
116 #-----------------------------------------------------------------------------
117
118 _session_id_regex = r"(?P<session_id>\w+-\w+-\w+-\w+-\w+)"
119
120 default_handlers = [
121 (r"/api/sessions/%s" % _session_id_regex, SessionHandler),
122 (r"/api/sessions", SessionRootHandler)
123 ]
124
125
[end of IPython/html/services/sessions/handlers.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/IPython/html/services/sessions/handlers.py b/IPython/html/services/sessions/handlers.py
--- a/IPython/html/services/sessions/handlers.py
+++ b/IPython/html/services/sessions/handlers.py
@@ -106,7 +106,11 @@
def delete(self, session_id):
# Deletes the session with given session_id
sm = self.session_manager
- sm.delete_session(session_id)
+ try:
+ sm.delete_session(session_id)
+ except KeyError:
+ # the kernel was deleted but the session wasn't!
+ raise web.HTTPError(410, "Kernel deleted before session")
self.set_status(204)
self.finish()
|
{"golden_diff": "diff --git a/IPython/html/services/sessions/handlers.py b/IPython/html/services/sessions/handlers.py\n--- a/IPython/html/services/sessions/handlers.py\n+++ b/IPython/html/services/sessions/handlers.py\n@@ -106,7 +106,11 @@\n def delete(self, session_id):\n # Deletes the session with given session_id\n sm = self.session_manager\n- sm.delete_session(session_id)\n+ try:\n+ sm.delete_session(session_id)\n+ except KeyError:\n+ # the kernel was deleted but the session wasn't!\n+ raise web.HTTPError(410, \"Kernel deleted before session\")\n self.set_status(204)\n self.finish()\n", "issue": "notebook.start_kernel is undefined\nHi, in notificationarea.js, when we need to restart a kernel we call `notebook.start_kernel` which doesn't exist. Not sure how you guys were planning to handle this, but I took a stab at it.\n\nthanks!\n\n", "before_files": [{"content": "\"\"\"Tornado handlers for the sessions web service.\"\"\"\n\n# Copyright (c) IPython Development Team.\n# Distributed under the terms of the Modified BSD License.\n\nimport json\n\nfrom tornado import web\n\nfrom ...base.handlers import IPythonHandler, json_errors\nfrom IPython.utils.jsonutil import date_default\nfrom IPython.html.utils import url_path_join, url_escape\nfrom IPython.kernel.kernelspec import NoSuchKernel\n\n\nclass SessionRootHandler(IPythonHandler):\n\n @web.authenticated\n @json_errors\n def get(self):\n # Return a list of running sessions\n sm = self.session_manager\n sessions = sm.list_sessions()\n self.finish(json.dumps(sessions, default=date_default))\n\n @web.authenticated\n @json_errors\n def post(self):\n # Creates a new session\n #(unless a session already exists for the named nb)\n sm = self.session_manager\n cm = self.contents_manager\n km = self.kernel_manager\n\n model = self.get_json_body()\n if model is None:\n raise web.HTTPError(400, \"No JSON data provided\")\n try:\n name = model['notebook']['name']\n except KeyError:\n raise web.HTTPError(400, \"Missing field in JSON data: notebook.name\")\n try:\n path = model['notebook']['path']\n except KeyError:\n raise web.HTTPError(400, \"Missing field in JSON data: notebook.path\")\n try:\n kernel_name = model['kernel']['name']\n except KeyError:\n self.log.debug(\"No kernel name specified, using default kernel\")\n kernel_name = None\n\n # Check to see if session exists\n if sm.session_exists(name=name, path=path):\n model = sm.get_session(name=name, path=path)\n else:\n try:\n model = sm.create_session(name=name, path=path, kernel_name=kernel_name)\n except NoSuchKernel:\n msg = (\"The '%s' kernel is not available. Please pick another \"\n \"suitable kernel instead, or install that kernel.\" % kernel_name)\n status_msg = '%s not found' % kernel_name\n self.log.warn('Kernel not found: %s' % kernel_name)\n self.set_status(501)\n self.finish(json.dumps(dict(message=msg, short_message=status_msg)))\n return\n\n location = url_path_join(self.base_url, 'api', 'sessions', model['id'])\n self.set_header('Location', url_escape(location))\n self.set_status(201)\n self.finish(json.dumps(model, default=date_default))\n\nclass SessionHandler(IPythonHandler):\n\n SUPPORTED_METHODS = ('GET', 'PATCH', 'DELETE')\n\n @web.authenticated\n @json_errors\n def get(self, session_id):\n # Returns the JSON model for a single session\n sm = self.session_manager\n model = sm.get_session(session_id=session_id)\n self.finish(json.dumps(model, default=date_default))\n\n @web.authenticated\n @json_errors\n def patch(self, session_id):\n # Currently, this handler is strictly for renaming notebooks\n sm = self.session_manager\n model = self.get_json_body()\n if model is None:\n raise web.HTTPError(400, \"No JSON data provided\")\n changes = {}\n if 'notebook' in model:\n notebook = model['notebook']\n if 'name' in notebook:\n changes['name'] = notebook['name']\n if 'path' in notebook:\n changes['path'] = notebook['path']\n\n sm.update_session(session_id, **changes)\n model = sm.get_session(session_id=session_id)\n self.finish(json.dumps(model, default=date_default))\n\n @web.authenticated\n @json_errors\n def delete(self, session_id):\n # Deletes the session with given session_id\n sm = self.session_manager\n sm.delete_session(session_id)\n self.set_status(204)\n self.finish()\n\n\n#-----------------------------------------------------------------------------\n# URL to handler mappings\n#-----------------------------------------------------------------------------\n\n_session_id_regex = r\"(?P<session_id>\\w+-\\w+-\\w+-\\w+-\\w+)\"\n\ndefault_handlers = [\n (r\"/api/sessions/%s\" % _session_id_regex, SessionHandler),\n (r\"/api/sessions\", SessionRootHandler)\n]\n\n", "path": "IPython/html/services/sessions/handlers.py"}]}
| 1,802 | 160 |
gh_patches_debug_16104
|
rasdani/github-patches
|
git_diff
|
bridgecrewio__checkov-5687
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
CKV_AZURE_153 - Not available for linux_web_app_slot & azurerm_windows_web_app_slot
**Describe the issue**
It seems that the best practice CKV_AZURE_153 is not being checked against the following Terraform resources:
- azurerm_linux_web_app_slot
- azurerm_windows_web_app_slot
CKV_AZURE_153 is used to "Ensure web app redirects all HTTP traffic to HTTPS in Azure App Service"
**Examples**
Same as with "azurerm_app_service_slot"
**Version (please complete the following information):**
N/A
**Additional context**
It seems that the check needs to be adjusted cc https://registry.terraform.io/providers/hashicorp/azurerm/latest/docs/resources/app_service_slot

</issue>
<code>
[start of checkov/terraform/checks/resource/azure/AppServiceSlotHTTPSOnly.py]
1 from checkov.common.models.enums import CheckCategories
2 from checkov.terraform.checks.resource.base_resource_value_check import BaseResourceValueCheck
3
4
5 class AppServiceSlotHTTPSOnly(BaseResourceValueCheck):
6 def __init__(self):
7 name = "Ensure web app redirects all HTTP traffic to HTTPS in Azure App Service Slot"
8 id = "CKV_AZURE_153"
9 supported_resources = ['azurerm_app_service_slot']
10 categories = [CheckCategories.NETWORKING]
11 super().__init__(name=name, id=id, categories=categories, supported_resources=supported_resources)
12
13 def get_inspected_key(self):
14 return 'https_only/[0]'
15
16
17 check = AppServiceSlotHTTPSOnly()
18
[end of checkov/terraform/checks/resource/azure/AppServiceSlotHTTPSOnly.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/checkov/terraform/checks/resource/azure/AppServiceSlotHTTPSOnly.py b/checkov/terraform/checks/resource/azure/AppServiceSlotHTTPSOnly.py
--- a/checkov/terraform/checks/resource/azure/AppServiceSlotHTTPSOnly.py
+++ b/checkov/terraform/checks/resource/azure/AppServiceSlotHTTPSOnly.py
@@ -6,12 +6,12 @@
def __init__(self):
name = "Ensure web app redirects all HTTP traffic to HTTPS in Azure App Service Slot"
id = "CKV_AZURE_153"
- supported_resources = ['azurerm_app_service_slot']
+ supported_resources = ["azurerm_app_service_slot", "azurerm_linux_web_app_slot", "azurerm_windows_web_app_slot"]
categories = [CheckCategories.NETWORKING]
super().__init__(name=name, id=id, categories=categories, supported_resources=supported_resources)
def get_inspected_key(self):
- return 'https_only/[0]'
+ return "https_only/[0]"
check = AppServiceSlotHTTPSOnly()
|
{"golden_diff": "diff --git a/checkov/terraform/checks/resource/azure/AppServiceSlotHTTPSOnly.py b/checkov/terraform/checks/resource/azure/AppServiceSlotHTTPSOnly.py\n--- a/checkov/terraform/checks/resource/azure/AppServiceSlotHTTPSOnly.py\n+++ b/checkov/terraform/checks/resource/azure/AppServiceSlotHTTPSOnly.py\n@@ -6,12 +6,12 @@\n def __init__(self):\n name = \"Ensure web app redirects all HTTP traffic to HTTPS in Azure App Service Slot\"\n id = \"CKV_AZURE_153\"\n- supported_resources = ['azurerm_app_service_slot']\n+ supported_resources = [\"azurerm_app_service_slot\", \"azurerm_linux_web_app_slot\", \"azurerm_windows_web_app_slot\"]\n categories = [CheckCategories.NETWORKING]\n super().__init__(name=name, id=id, categories=categories, supported_resources=supported_resources)\n \n def get_inspected_key(self):\n- return 'https_only/[0]'\n+ return \"https_only/[0]\"\n \n \n check = AppServiceSlotHTTPSOnly()\n", "issue": "CKV_AZURE_153 - Not available for linux_web_app_slot & azurerm_windows_web_app_slot\n**Describe the issue**\r\nIt seems that the best practice CKV_AZURE_153 is not being checked against the following Terraform resources:\r\n\r\n- azurerm_linux_web_app_slot\r\n- azurerm_windows_web_app_slot\r\n\r\nCKV_AZURE_153 is used to \"Ensure web app redirects all HTTP traffic to HTTPS in Azure App Service\"\r\n\r\n**Examples**\r\n\r\nSame as with \"azurerm_app_service_slot\"\r\n\r\n**Version (please complete the following information):**\r\nN/A\r\n\r\n**Additional context**\r\n\r\nIt seems that the check needs to be adjusted cc https://registry.terraform.io/providers/hashicorp/azurerm/latest/docs/resources/app_service_slot\r\n\r\n\r\n\r\n\n", "before_files": [{"content": "from checkov.common.models.enums import CheckCategories\nfrom checkov.terraform.checks.resource.base_resource_value_check import BaseResourceValueCheck\n\n\nclass AppServiceSlotHTTPSOnly(BaseResourceValueCheck):\n def __init__(self):\n name = \"Ensure web app redirects all HTTP traffic to HTTPS in Azure App Service Slot\"\n id = \"CKV_AZURE_153\"\n supported_resources = ['azurerm_app_service_slot']\n categories = [CheckCategories.NETWORKING]\n super().__init__(name=name, id=id, categories=categories, supported_resources=supported_resources)\n\n def get_inspected_key(self):\n return 'https_only/[0]'\n\n\ncheck = AppServiceSlotHTTPSOnly()\n", "path": "checkov/terraform/checks/resource/azure/AppServiceSlotHTTPSOnly.py"}]}
| 960 | 235 |
gh_patches_debug_51247
|
rasdani/github-patches
|
git_diff
|
conda__conda-4729
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
cannot import conda.fetch.cache_fn_url
I'm using conda 4.3.2, and the function `conda.fetch.cache_fn_url` does not exist anymore. What to do?
</issue>
<code>
[start of conda/exports.py]
1 # -*- coding: utf-8 -*-
2 from __future__ import absolute_import, division, print_function, unicode_literals
3
4 from functools import partial
5 from logging import getLogger
6 from warnings import warn
7
8 log = getLogger(__name__)
9
10 from . import CondaError # NOQA
11 CondaError = CondaError
12
13 from . import compat, plan # NOQA
14 compat, plan = compat, plan
15
16 from .api import get_index # NOQA
17 get_index = get_index
18
19 from .cli.common import (Completer, InstalledPackages, add_parser_channels, add_parser_prefix, # NOQA
20 specs_from_args, spec_from_line, specs_from_url) # NOQA
21 Completer, InstalledPackages = Completer, InstalledPackages
22 add_parser_channels, add_parser_prefix = add_parser_channels, add_parser_prefix
23 specs_from_args, spec_from_line = specs_from_args, spec_from_line
24 specs_from_url = specs_from_url
25
26 from .cli.conda_argparse import ArgumentParser # NOQA
27 ArgumentParser = ArgumentParser
28
29 from .common.compat import PY3, StringIO, input, iteritems, string_types, text_type # NOQA
30 PY3, StringIO, input, iteritems, string_types, text_type = PY3, StringIO, input, iteritems, string_types, text_type # NOQA
31 from .connection import CondaSession # NOQA
32 CondaSession = CondaSession
33
34 from .gateways.disk.link import lchmod # NOQA
35 lchmod = lchmod
36
37 from .fetch import TmpDownload # NOQA
38 TmpDownload = TmpDownload
39 handle_proxy_407 = lambda x, y: warn("handle_proxy_407 is deprecated. "
40 "Now handled by CondaSession.")
41 from .core.index import dist_str_in_index, fetch_index # NOQA
42 dist_str_in_index, fetch_index = dist_str_in_index, fetch_index
43 from .core.package_cache import download, rm_fetched # NOQA
44 download, rm_fetched = download, rm_fetched
45
46 from .install import package_cache, prefix_placeholder, rm_rf, symlink_conda # NOQA
47 package_cache, prefix_placeholder, rm_rf, symlink_conda = package_cache, prefix_placeholder, rm_rf, symlink_conda # NOQA
48
49 from .gateways.disk.delete import delete_trash, move_to_trash # NOQA
50 delete_trash, move_to_trash = delete_trash, move_to_trash
51
52 from .core.linked_data import is_linked, linked, linked_data # NOQA
53 is_linked, linked, linked_data = is_linked, linked, linked_data
54
55 from .misc import untracked, walk_prefix # NOQA
56 untracked, walk_prefix = untracked, walk_prefix
57
58 from .resolve import MatchSpec, NoPackagesFound, Resolve, Unsatisfiable, normalized_version # NOQA
59 MatchSpec, NoPackagesFound, Resolve = MatchSpec, NoPackagesFound, Resolve
60 Unsatisfiable, normalized_version = Unsatisfiable, normalized_version
61
62 from .signature import KEYS, KEYS_DIR, hash_file, verify # NOQA
63 KEYS, KEYS_DIR = KEYS, KEYS_DIR
64 hash_file, verify = hash_file, verify
65
66 from .utils import (human_bytes, hashsum_file, md5_file, memoized, unix_path_to_win, # NOQA
67 win_path_to_unix, url_path) # NOQA
68 human_bytes, hashsum_file, md5_file = human_bytes, hashsum_file, md5_file
69 memoized, unix_path_to_win = memoized, unix_path_to_win
70 win_path_to_unix, url_path = win_path_to_unix, url_path
71
72 from .config import sys_rc_path # NOQA
73 sys_rc_path = sys_rc_path
74
75 from .version import VersionOrder # NOQA
76 VersionOrder = VersionOrder
77
78
79 import conda.base.context # NOQA
80 from conda.base.context import get_prefix as context_get_prefix, non_x86_linux_machines # NOQA
81 non_x86_linux_machines = non_x86_linux_machines
82
83 from ._vendor.auxlib.entity import EntityEncoder # NOQA
84 EntityEncoder = EntityEncoder
85 from .base.constants import DEFAULT_CHANNELS, DEFAULT_CHANNELS_WIN, DEFAULT_CHANNELS_UNIX # NOQA
86 DEFAULT_CHANNELS, DEFAULT_CHANNELS_WIN, DEFAULT_CHANNELS_UNIX = DEFAULT_CHANNELS, DEFAULT_CHANNELS_WIN, DEFAULT_CHANNELS_UNIX # NOQA
87 get_prefix = partial(context_get_prefix, conda.base.context.context)
88 get_default_urls = lambda: DEFAULT_CHANNELS
89
90 arch_name = conda.base.context.context.arch_name
91 binstar_upload = conda.base.context.context.binstar_upload
92 bits = conda.base.context.context.bits
93 default_prefix = conda.base.context.context.default_prefix
94 default_python = conda.base.context.context.default_python
95 envs_dirs = conda.base.context.context.envs_dirs
96 pkgs_dirs = conda.base.context.context.pkgs_dirs
97 platform = conda.base.context.context.platform
98 root_dir = conda.base.context.context.root_prefix
99 root_writable = conda.base.context.context.root_writable
100 subdir = conda.base.context.context.subdir
101 from .models.channel import get_conda_build_local_url # NOQA
102 get_rc_urls = lambda: list(conda.base.context.context.channels)
103 get_local_urls = lambda: list(get_conda_build_local_url()) or []
104 load_condarc = lambda fn: conda.base.context.reset_context([fn])
105 from .exceptions import PaddingError # NOQA
106 PaddingError = PaddingError
107 from .gateways.disk.link import CrossPlatformStLink # NOQA
108 CrossPlatformStLink = CrossPlatformStLink
109
110 from .models.enums import FileMode # NOQA
111 FileMode = FileMode
112 from .models.enums import PathType # NOQA
113 PathType = PathType
114
115
116 if PY3:
117 import configparser # NOQA # pragma: py2 no cover
118 else:
119 import ConfigParser as configparser # NOQA # pragma: py3 no cover
120 configparser = configparser
121
122
123 from .compat import TemporaryDirectory # NOQA
124 TemporaryDirectory = TemporaryDirectory
125
126 from .gateways.subprocess import ACTIVE_SUBPROCESSES, subprocess_call # NOQA
127 ACTIVE_SUBPROCESSES, subprocess_call = ACTIVE_SUBPROCESSES, subprocess_call
128
[end of conda/exports.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/conda/exports.py b/conda/exports.py
--- a/conda/exports.py
+++ b/conda/exports.py
@@ -125,3 +125,6 @@
from .gateways.subprocess import ACTIVE_SUBPROCESSES, subprocess_call # NOQA
ACTIVE_SUBPROCESSES, subprocess_call = ACTIVE_SUBPROCESSES, subprocess_call
+
+from .core.repodata import cache_fn_url # NOQA
+cache_fn_url = cache_fn_url
|
{"golden_diff": "diff --git a/conda/exports.py b/conda/exports.py\n--- a/conda/exports.py\n+++ b/conda/exports.py\n@@ -125,3 +125,6 @@\n \n from .gateways.subprocess import ACTIVE_SUBPROCESSES, subprocess_call # NOQA\n ACTIVE_SUBPROCESSES, subprocess_call = ACTIVE_SUBPROCESSES, subprocess_call\n+\n+from .core.repodata import cache_fn_url # NOQA\n+cache_fn_url = cache_fn_url\n", "issue": "cannot import conda.fetch.cache_fn_url\nI'm using conda 4.3.2, and the function `conda.fetch.cache_fn_url` does not exist anymore. What to do?\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\nfrom __future__ import absolute_import, division, print_function, unicode_literals\n\nfrom functools import partial\nfrom logging import getLogger\nfrom warnings import warn\n\nlog = getLogger(__name__)\n\nfrom . import CondaError # NOQA\nCondaError = CondaError\n\nfrom . import compat, plan # NOQA\ncompat, plan = compat, plan\n\nfrom .api import get_index # NOQA\nget_index = get_index\n\nfrom .cli.common import (Completer, InstalledPackages, add_parser_channels, add_parser_prefix, # NOQA\n specs_from_args, spec_from_line, specs_from_url) # NOQA\nCompleter, InstalledPackages = Completer, InstalledPackages\nadd_parser_channels, add_parser_prefix = add_parser_channels, add_parser_prefix\nspecs_from_args, spec_from_line = specs_from_args, spec_from_line\nspecs_from_url = specs_from_url\n\nfrom .cli.conda_argparse import ArgumentParser # NOQA\nArgumentParser = ArgumentParser\n\nfrom .common.compat import PY3, StringIO, input, iteritems, string_types, text_type # NOQA\nPY3, StringIO, input, iteritems, string_types, text_type = PY3, StringIO, input, iteritems, string_types, text_type # NOQA\nfrom .connection import CondaSession # NOQA\nCondaSession = CondaSession\n\nfrom .gateways.disk.link import lchmod # NOQA\nlchmod = lchmod\n\nfrom .fetch import TmpDownload # NOQA\nTmpDownload = TmpDownload\nhandle_proxy_407 = lambda x, y: warn(\"handle_proxy_407 is deprecated. \"\n \"Now handled by CondaSession.\")\nfrom .core.index import dist_str_in_index, fetch_index # NOQA\ndist_str_in_index, fetch_index = dist_str_in_index, fetch_index\nfrom .core.package_cache import download, rm_fetched # NOQA\ndownload, rm_fetched = download, rm_fetched\n\nfrom .install import package_cache, prefix_placeholder, rm_rf, symlink_conda # NOQA\npackage_cache, prefix_placeholder, rm_rf, symlink_conda = package_cache, prefix_placeholder, rm_rf, symlink_conda # NOQA\n\nfrom .gateways.disk.delete import delete_trash, move_to_trash # NOQA\ndelete_trash, move_to_trash = delete_trash, move_to_trash\n\nfrom .core.linked_data import is_linked, linked, linked_data # NOQA\nis_linked, linked, linked_data = is_linked, linked, linked_data\n\nfrom .misc import untracked, walk_prefix # NOQA\nuntracked, walk_prefix = untracked, walk_prefix\n\nfrom .resolve import MatchSpec, NoPackagesFound, Resolve, Unsatisfiable, normalized_version # NOQA\nMatchSpec, NoPackagesFound, Resolve = MatchSpec, NoPackagesFound, Resolve\nUnsatisfiable, normalized_version = Unsatisfiable, normalized_version\n\nfrom .signature import KEYS, KEYS_DIR, hash_file, verify # NOQA\nKEYS, KEYS_DIR = KEYS, KEYS_DIR\nhash_file, verify = hash_file, verify\n\nfrom .utils import (human_bytes, hashsum_file, md5_file, memoized, unix_path_to_win, # NOQA\n win_path_to_unix, url_path) # NOQA\nhuman_bytes, hashsum_file, md5_file = human_bytes, hashsum_file, md5_file\nmemoized, unix_path_to_win = memoized, unix_path_to_win\nwin_path_to_unix, url_path = win_path_to_unix, url_path\n\nfrom .config import sys_rc_path # NOQA\nsys_rc_path = sys_rc_path\n\nfrom .version import VersionOrder # NOQA\nVersionOrder = VersionOrder\n\n\nimport conda.base.context # NOQA\nfrom conda.base.context import get_prefix as context_get_prefix, non_x86_linux_machines # NOQA\nnon_x86_linux_machines = non_x86_linux_machines\n\nfrom ._vendor.auxlib.entity import EntityEncoder # NOQA\nEntityEncoder = EntityEncoder\nfrom .base.constants import DEFAULT_CHANNELS, DEFAULT_CHANNELS_WIN, DEFAULT_CHANNELS_UNIX # NOQA\nDEFAULT_CHANNELS, DEFAULT_CHANNELS_WIN, DEFAULT_CHANNELS_UNIX = DEFAULT_CHANNELS, DEFAULT_CHANNELS_WIN, DEFAULT_CHANNELS_UNIX # NOQA\nget_prefix = partial(context_get_prefix, conda.base.context.context)\nget_default_urls = lambda: DEFAULT_CHANNELS\n\narch_name = conda.base.context.context.arch_name\nbinstar_upload = conda.base.context.context.binstar_upload\nbits = conda.base.context.context.bits\ndefault_prefix = conda.base.context.context.default_prefix\ndefault_python = conda.base.context.context.default_python\nenvs_dirs = conda.base.context.context.envs_dirs\npkgs_dirs = conda.base.context.context.pkgs_dirs\nplatform = conda.base.context.context.platform\nroot_dir = conda.base.context.context.root_prefix\nroot_writable = conda.base.context.context.root_writable\nsubdir = conda.base.context.context.subdir\nfrom .models.channel import get_conda_build_local_url # NOQA\nget_rc_urls = lambda: list(conda.base.context.context.channels)\nget_local_urls = lambda: list(get_conda_build_local_url()) or []\nload_condarc = lambda fn: conda.base.context.reset_context([fn])\nfrom .exceptions import PaddingError # NOQA\nPaddingError = PaddingError\nfrom .gateways.disk.link import CrossPlatformStLink # NOQA\nCrossPlatformStLink = CrossPlatformStLink\n\nfrom .models.enums import FileMode # NOQA\nFileMode = FileMode\nfrom .models.enums import PathType # NOQA\nPathType = PathType\n\n\nif PY3:\n import configparser # NOQA # pragma: py2 no cover\nelse:\n import ConfigParser as configparser # NOQA # pragma: py3 no cover\nconfigparser = configparser\n\n\nfrom .compat import TemporaryDirectory # NOQA\nTemporaryDirectory = TemporaryDirectory\n\nfrom .gateways.subprocess import ACTIVE_SUBPROCESSES, subprocess_call # NOQA\nACTIVE_SUBPROCESSES, subprocess_call = ACTIVE_SUBPROCESSES, subprocess_call\n", "path": "conda/exports.py"}]}
| 2,204 | 111 |
gh_patches_debug_56500
|
rasdani/github-patches
|
git_diff
|
canonical__microk8s-2048
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Microk8s on armhf architecture
Hi all,
The armhf binary is missing and not available right now, which means that some users cannot install microk8s on Ubuntu. For example, if you use the armhf image for Raspberry Pi, you cannot install microk8s:
> ubuntu@battlecruiser:~$ sudo snap install microk8s --classic
> error: snap "microk8s" is not available on stable for this architecture (armhf)
> but exists on other architectures (amd64, arm64, ppc64el).
It would be really good if we could also get the build compiled for this architecture and make officially available.
Cheers,
- Calvin
</issue>
<code>
[start of scripts/wrappers/common/utils.py]
1 import getpass
2 import json
3 import os
4 import platform
5 import subprocess
6 import sys
7 import time
8 from pathlib import Path
9
10 import click
11 import yaml
12
13 kubeconfig = "--kubeconfig=" + os.path.expandvars("${SNAP_DATA}/credentials/client.config")
14
15
16 def get_current_arch():
17 # architecture mapping
18 arch_mapping = {"aarch64": "arm64", "x86_64": "amd64"}
19
20 return arch_mapping[platform.machine()]
21
22
23 def snap_data() -> Path:
24 try:
25 return Path(os.environ["SNAP_DATA"])
26 except KeyError:
27 return Path("/var/snap/microk8s/current")
28
29
30 def run(*args, die=True):
31 # Add wrappers to $PATH
32 env = os.environ.copy()
33 env["PATH"] += ":%s" % os.environ["SNAP"]
34 result = subprocess.run(
35 args, stdin=subprocess.PIPE, stdout=subprocess.PIPE, stderr=subprocess.PIPE, env=env
36 )
37
38 try:
39 result.check_returncode()
40 except subprocess.CalledProcessError as err:
41 if die:
42 if result.stderr:
43 print(result.stderr.decode("utf-8"))
44 print(err)
45 sys.exit(1)
46 else:
47 raise
48
49 return result.stdout.decode("utf-8")
50
51
52 def is_cluster_ready():
53 try:
54 service_output = kubectl_get("all")
55 node_output = kubectl_get("nodes")
56 # Make sure to compare with the word " Ready " with spaces.
57 if " Ready " in node_output and "service/kubernetes" in service_output:
58 return True
59 else:
60 return False
61 except Exception:
62 return False
63
64
65 def is_ha_enabled():
66 ha_lock = os.path.expandvars("${SNAP_DATA}/var/lock/ha-cluster")
67 return os.path.isfile(ha_lock)
68
69
70 def get_dqlite_info():
71 cluster_dir = os.path.expandvars("${SNAP_DATA}/var/kubernetes/backend")
72 snap_path = os.environ.get("SNAP")
73
74 info = []
75
76 if not is_ha_enabled():
77 return info
78
79 waits = 10
80 while waits > 0:
81 try:
82 with open("{}/info.yaml".format(cluster_dir), mode="r") as f:
83 data = yaml.load(f, Loader=yaml.FullLoader)
84 out = subprocess.check_output(
85 "{snappath}/bin/dqlite -s file://{dbdir}/cluster.yaml -c {dbdir}/cluster.crt "
86 "-k {dbdir}/cluster.key -f json k8s .cluster".format(
87 snappath=snap_path, dbdir=cluster_dir
88 ).split(),
89 timeout=4,
90 )
91 if data["Address"] in out.decode():
92 break
93 else:
94 time.sleep(5)
95 waits -= 1
96 except (subprocess.CalledProcessError, subprocess.TimeoutExpired):
97 time.sleep(2)
98 waits -= 1
99
100 if waits == 0:
101 return info
102
103 nodes = json.loads(out.decode())
104 for n in nodes:
105 if n["Role"] == 0:
106 info.append((n["Address"], "voter"))
107 if n["Role"] == 1:
108 info.append((n["Address"], "standby"))
109 if n["Role"] == 2:
110 info.append((n["Address"], "spare"))
111 return info
112
113
114 def is_cluster_locked():
115 if (snap_data() / "var/lock/clustered.lock").exists():
116 click.echo("This MicroK8s deployment is acting as a node in a cluster.")
117 click.echo("Please use the master node.")
118 sys.exit(1)
119
120
121 def wait_for_ready(timeout):
122 start_time = time.time()
123
124 while True:
125 if is_cluster_ready():
126 return True
127 elif timeout and time.time() > start_time + timeout:
128 return False
129 else:
130 time.sleep(2)
131
132
133 def exit_if_stopped():
134 stoppedLockFile = os.path.expandvars("${SNAP_DATA}/var/lock/stopped.lock")
135 if os.path.isfile(stoppedLockFile):
136 print("microk8s is not running, try microk8s start")
137 exit(0)
138
139
140 def exit_if_no_permission():
141 user = getpass.getuser()
142 # test if we can access the default kubeconfig
143 clientConfigFile = os.path.expandvars("${SNAP_DATA}/credentials/client.config")
144 if not os.access(clientConfigFile, os.R_OK):
145 print("Insufficient permissions to access MicroK8s.")
146 print(
147 "You can either try again with sudo or add the user {} to the 'microk8s' group:".format(
148 user
149 )
150 )
151 print("")
152 print(" sudo usermod -a -G microk8s {}".format(user))
153 print(" sudo chown -f -R $USER ~/.kube")
154 print("")
155 print(
156 "After this, reload the user groups either via a reboot or by running 'newgrp microk8s'."
157 )
158 exit(1)
159
160
161 def ensure_started():
162 if (snap_data() / "var/lock/stopped.lock").exists():
163 click.echo("microk8s is not running, try microk8s start", err=True)
164 sys.exit(1)
165
166
167 def kubectl_get(cmd, namespace="--all-namespaces"):
168 if namespace == "--all-namespaces":
169 return run("kubectl", kubeconfig, "get", cmd, "--all-namespaces", die=False)
170 else:
171 return run("kubectl", kubeconfig, "get", cmd, "-n", namespace, die=False)
172
173
174 def kubectl_get_clusterroles():
175 return run(
176 "kubectl", kubeconfig, "get", "clusterroles", "--show-kind", "--no-headers", die=False
177 )
178
179
180 def get_available_addons(arch):
181 addon_dataset = os.path.expandvars("${SNAP}/addon-lists.yaml")
182 available = []
183 with open(addon_dataset, "r") as file:
184 # The FullLoader parameter handles the conversion from YAML
185 # scalar values to Python the dictionary format
186 addons = yaml.load(file, Loader=yaml.FullLoader)
187 for addon in addons["microk8s-addons"]["addons"]:
188 if arch in addon["supported_architectures"]:
189 available.append(addon)
190
191 available = sorted(available, key=lambda k: k["name"])
192 return available
193
194
195 def get_addon_by_name(addons, name):
196 filtered_addon = []
197 for addon in addons:
198 if name == addon["name"]:
199 filtered_addon.append(addon)
200 return filtered_addon
201
202
203 def is_service_expected_to_start(service):
204 """
205 Check if a service is supposed to start
206 :param service: the service name
207 :return: True if the service is meant to start
208 """
209 lock_path = os.path.expandvars("${SNAP_DATA}/var/lock")
210 lock = "{}/{}".format(lock_path, service)
211 return os.path.exists(lock_path) and not os.path.isfile(lock)
212
213
214 def set_service_expected_to_start(service, start=True):
215 """
216 Check if a service is not expected to start.
217 :param service: the service name
218 :param start: should the service start or not
219 """
220 lock_path = os.path.expandvars("${SNAP_DATA}/var/lock")
221 lock = "{}/{}".format(lock_path, service)
222 if start:
223 os.remove(lock)
224 else:
225 fd = os.open(lock, os.O_CREAT, mode=0o700)
226 os.close(fd)
227
228
229 def check_help_flag(addons: list) -> bool:
230 """Checks to see if a help message needs to be printed for an addon.
231
232 Not all addons check for help flags themselves. Until they do, intercept
233 calls to print help text and print out a generic message to that effect.
234 """
235 addon = addons[0]
236 if any(arg in addons for arg in ("-h", "--help")) and addon != "kubeflow":
237 print("Addon %s does not yet have a help message." % addon)
238 print("For more information about it, visit https://microk8s.io/docs/addons")
239 return True
240 return False
241
242
243 def xable(action: str, addons: list, xabled_addons: list):
244 """Enables or disables the given addons.
245
246 Collated into a single function since the logic is identical other than
247 the script names.
248 """
249 actions = Path(__file__).absolute().parent / "../../../actions"
250 existing_addons = {sh.with_suffix("").name[7:] for sh in actions.glob("enable.*.sh")}
251
252 # Backwards compatibility with enabling multiple addons at once, e.g.
253 # `microk8s.enable foo bar:"baz"`
254 if all(a.split(":")[0] in existing_addons for a in addons) and len(addons) > 1:
255 for addon in addons:
256 if addon in xabled_addons and addon != "kubeflow":
257 click.echo("Addon %s is already %sd." % (addon, action))
258 else:
259 addon, *args = addon.split(":")
260 wait_for_ready(timeout=30)
261 p = subprocess.run([str(actions / ("%s.%s.sh" % (action, addon)))] + args)
262 if p.returncode:
263 sys.exit(p.returncode)
264 wait_for_ready(timeout=30)
265
266 # The new way of xabling addons, that allows for unix-style argument passing,
267 # such as `microk8s.enable foo --bar`.
268 else:
269 addon, *args = addons[0].split(":")
270
271 if addon in xabled_addons and addon != "kubeflow":
272 click.echo("Addon %s is already %sd." % (addon, action))
273 sys.exit(0)
274
275 if addon not in existing_addons:
276 click.echo("Nothing to do for `%s`." % addon, err=True)
277 sys.exit(1)
278
279 if args and addons[1:]:
280 click.echo(
281 "Can't pass string arguments and flag arguments simultaneously!\n"
282 "{0} an addon with only one argument style at a time:\n"
283 "\n"
284 " microk8s {1} foo:'bar'\n"
285 "or\n"
286 " microk8s {1} foo --bar\n".format(action.title(), action)
287 )
288 sys.exit(1)
289
290 wait_for_ready(timeout=30)
291 script = [str(actions / ("%s.%s.sh" % (action, addon)))]
292 if args:
293 p = subprocess.run(script + args)
294 else:
295 p = subprocess.run(script + list(addons[1:]))
296
297 if p.returncode:
298 sys.exit(p.returncode)
299
300 wait_for_ready(timeout=30)
301
[end of scripts/wrappers/common/utils.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/scripts/wrappers/common/utils.py b/scripts/wrappers/common/utils.py
--- a/scripts/wrappers/common/utils.py
+++ b/scripts/wrappers/common/utils.py
@@ -15,7 +15,7 @@
def get_current_arch():
# architecture mapping
- arch_mapping = {"aarch64": "arm64", "x86_64": "amd64"}
+ arch_mapping = {"aarch64": "arm64", "armv7l": "armhf", "x86_64": "amd64"}
return arch_mapping[platform.machine()]
|
{"golden_diff": "diff --git a/scripts/wrappers/common/utils.py b/scripts/wrappers/common/utils.py\n--- a/scripts/wrappers/common/utils.py\n+++ b/scripts/wrappers/common/utils.py\n@@ -15,7 +15,7 @@\n \n def get_current_arch():\n # architecture mapping\n- arch_mapping = {\"aarch64\": \"arm64\", \"x86_64\": \"amd64\"}\n+ arch_mapping = {\"aarch64\": \"arm64\", \"armv7l\": \"armhf\", \"x86_64\": \"amd64\"}\n \n return arch_mapping[platform.machine()]\n", "issue": "Microk8s on armhf architecture\nHi all, \r\n\r\nThe armhf binary is missing and not available right now, which means that some users cannot install microk8s on Ubuntu. For example, if you use the armhf image for Raspberry Pi, you cannot install microk8s: \r\n\r\n> ubuntu@battlecruiser:~$ sudo snap install microk8s --classic\r\n> error: snap \"microk8s\" is not available on stable for this architecture (armhf)\r\n> but exists on other architectures (amd64, arm64, ppc64el).\r\n\r\nIt would be really good if we could also get the build compiled for this architecture and make officially available. \r\n\r\nCheers,\r\n\r\n- Calvin \n", "before_files": [{"content": "import getpass\nimport json\nimport os\nimport platform\nimport subprocess\nimport sys\nimport time\nfrom pathlib import Path\n\nimport click\nimport yaml\n\nkubeconfig = \"--kubeconfig=\" + os.path.expandvars(\"${SNAP_DATA}/credentials/client.config\")\n\n\ndef get_current_arch():\n # architecture mapping\n arch_mapping = {\"aarch64\": \"arm64\", \"x86_64\": \"amd64\"}\n\n return arch_mapping[platform.machine()]\n\n\ndef snap_data() -> Path:\n try:\n return Path(os.environ[\"SNAP_DATA\"])\n except KeyError:\n return Path(\"/var/snap/microk8s/current\")\n\n\ndef run(*args, die=True):\n # Add wrappers to $PATH\n env = os.environ.copy()\n env[\"PATH\"] += \":%s\" % os.environ[\"SNAP\"]\n result = subprocess.run(\n args, stdin=subprocess.PIPE, stdout=subprocess.PIPE, stderr=subprocess.PIPE, env=env\n )\n\n try:\n result.check_returncode()\n except subprocess.CalledProcessError as err:\n if die:\n if result.stderr:\n print(result.stderr.decode(\"utf-8\"))\n print(err)\n sys.exit(1)\n else:\n raise\n\n return result.stdout.decode(\"utf-8\")\n\n\ndef is_cluster_ready():\n try:\n service_output = kubectl_get(\"all\")\n node_output = kubectl_get(\"nodes\")\n # Make sure to compare with the word \" Ready \" with spaces.\n if \" Ready \" in node_output and \"service/kubernetes\" in service_output:\n return True\n else:\n return False\n except Exception:\n return False\n\n\ndef is_ha_enabled():\n ha_lock = os.path.expandvars(\"${SNAP_DATA}/var/lock/ha-cluster\")\n return os.path.isfile(ha_lock)\n\n\ndef get_dqlite_info():\n cluster_dir = os.path.expandvars(\"${SNAP_DATA}/var/kubernetes/backend\")\n snap_path = os.environ.get(\"SNAP\")\n\n info = []\n\n if not is_ha_enabled():\n return info\n\n waits = 10\n while waits > 0:\n try:\n with open(\"{}/info.yaml\".format(cluster_dir), mode=\"r\") as f:\n data = yaml.load(f, Loader=yaml.FullLoader)\n out = subprocess.check_output(\n \"{snappath}/bin/dqlite -s file://{dbdir}/cluster.yaml -c {dbdir}/cluster.crt \"\n \"-k {dbdir}/cluster.key -f json k8s .cluster\".format(\n snappath=snap_path, dbdir=cluster_dir\n ).split(),\n timeout=4,\n )\n if data[\"Address\"] in out.decode():\n break\n else:\n time.sleep(5)\n waits -= 1\n except (subprocess.CalledProcessError, subprocess.TimeoutExpired):\n time.sleep(2)\n waits -= 1\n\n if waits == 0:\n return info\n\n nodes = json.loads(out.decode())\n for n in nodes:\n if n[\"Role\"] == 0:\n info.append((n[\"Address\"], \"voter\"))\n if n[\"Role\"] == 1:\n info.append((n[\"Address\"], \"standby\"))\n if n[\"Role\"] == 2:\n info.append((n[\"Address\"], \"spare\"))\n return info\n\n\ndef is_cluster_locked():\n if (snap_data() / \"var/lock/clustered.lock\").exists():\n click.echo(\"This MicroK8s deployment is acting as a node in a cluster.\")\n click.echo(\"Please use the master node.\")\n sys.exit(1)\n\n\ndef wait_for_ready(timeout):\n start_time = time.time()\n\n while True:\n if is_cluster_ready():\n return True\n elif timeout and time.time() > start_time + timeout:\n return False\n else:\n time.sleep(2)\n\n\ndef exit_if_stopped():\n stoppedLockFile = os.path.expandvars(\"${SNAP_DATA}/var/lock/stopped.lock\")\n if os.path.isfile(stoppedLockFile):\n print(\"microk8s is not running, try microk8s start\")\n exit(0)\n\n\ndef exit_if_no_permission():\n user = getpass.getuser()\n # test if we can access the default kubeconfig\n clientConfigFile = os.path.expandvars(\"${SNAP_DATA}/credentials/client.config\")\n if not os.access(clientConfigFile, os.R_OK):\n print(\"Insufficient permissions to access MicroK8s.\")\n print(\n \"You can either try again with sudo or add the user {} to the 'microk8s' group:\".format(\n user\n )\n )\n print(\"\")\n print(\" sudo usermod -a -G microk8s {}\".format(user))\n print(\" sudo chown -f -R $USER ~/.kube\")\n print(\"\")\n print(\n \"After this, reload the user groups either via a reboot or by running 'newgrp microk8s'.\"\n )\n exit(1)\n\n\ndef ensure_started():\n if (snap_data() / \"var/lock/stopped.lock\").exists():\n click.echo(\"microk8s is not running, try microk8s start\", err=True)\n sys.exit(1)\n\n\ndef kubectl_get(cmd, namespace=\"--all-namespaces\"):\n if namespace == \"--all-namespaces\":\n return run(\"kubectl\", kubeconfig, \"get\", cmd, \"--all-namespaces\", die=False)\n else:\n return run(\"kubectl\", kubeconfig, \"get\", cmd, \"-n\", namespace, die=False)\n\n\ndef kubectl_get_clusterroles():\n return run(\n \"kubectl\", kubeconfig, \"get\", \"clusterroles\", \"--show-kind\", \"--no-headers\", die=False\n )\n\n\ndef get_available_addons(arch):\n addon_dataset = os.path.expandvars(\"${SNAP}/addon-lists.yaml\")\n available = []\n with open(addon_dataset, \"r\") as file:\n # The FullLoader parameter handles the conversion from YAML\n # scalar values to Python the dictionary format\n addons = yaml.load(file, Loader=yaml.FullLoader)\n for addon in addons[\"microk8s-addons\"][\"addons\"]:\n if arch in addon[\"supported_architectures\"]:\n available.append(addon)\n\n available = sorted(available, key=lambda k: k[\"name\"])\n return available\n\n\ndef get_addon_by_name(addons, name):\n filtered_addon = []\n for addon in addons:\n if name == addon[\"name\"]:\n filtered_addon.append(addon)\n return filtered_addon\n\n\ndef is_service_expected_to_start(service):\n \"\"\"\n Check if a service is supposed to start\n :param service: the service name\n :return: True if the service is meant to start\n \"\"\"\n lock_path = os.path.expandvars(\"${SNAP_DATA}/var/lock\")\n lock = \"{}/{}\".format(lock_path, service)\n return os.path.exists(lock_path) and not os.path.isfile(lock)\n\n\ndef set_service_expected_to_start(service, start=True):\n \"\"\"\n Check if a service is not expected to start.\n :param service: the service name\n :param start: should the service start or not\n \"\"\"\n lock_path = os.path.expandvars(\"${SNAP_DATA}/var/lock\")\n lock = \"{}/{}\".format(lock_path, service)\n if start:\n os.remove(lock)\n else:\n fd = os.open(lock, os.O_CREAT, mode=0o700)\n os.close(fd)\n\n\ndef check_help_flag(addons: list) -> bool:\n \"\"\"Checks to see if a help message needs to be printed for an addon.\n\n Not all addons check for help flags themselves. Until they do, intercept\n calls to print help text and print out a generic message to that effect.\n \"\"\"\n addon = addons[0]\n if any(arg in addons for arg in (\"-h\", \"--help\")) and addon != \"kubeflow\":\n print(\"Addon %s does not yet have a help message.\" % addon)\n print(\"For more information about it, visit https://microk8s.io/docs/addons\")\n return True\n return False\n\n\ndef xable(action: str, addons: list, xabled_addons: list):\n \"\"\"Enables or disables the given addons.\n\n Collated into a single function since the logic is identical other than\n the script names.\n \"\"\"\n actions = Path(__file__).absolute().parent / \"../../../actions\"\n existing_addons = {sh.with_suffix(\"\").name[7:] for sh in actions.glob(\"enable.*.sh\")}\n\n # Backwards compatibility with enabling multiple addons at once, e.g.\n # `microk8s.enable foo bar:\"baz\"`\n if all(a.split(\":\")[0] in existing_addons for a in addons) and len(addons) > 1:\n for addon in addons:\n if addon in xabled_addons and addon != \"kubeflow\":\n click.echo(\"Addon %s is already %sd.\" % (addon, action))\n else:\n addon, *args = addon.split(\":\")\n wait_for_ready(timeout=30)\n p = subprocess.run([str(actions / (\"%s.%s.sh\" % (action, addon)))] + args)\n if p.returncode:\n sys.exit(p.returncode)\n wait_for_ready(timeout=30)\n\n # The new way of xabling addons, that allows for unix-style argument passing,\n # such as `microk8s.enable foo --bar`.\n else:\n addon, *args = addons[0].split(\":\")\n\n if addon in xabled_addons and addon != \"kubeflow\":\n click.echo(\"Addon %s is already %sd.\" % (addon, action))\n sys.exit(0)\n\n if addon not in existing_addons:\n click.echo(\"Nothing to do for `%s`.\" % addon, err=True)\n sys.exit(1)\n\n if args and addons[1:]:\n click.echo(\n \"Can't pass string arguments and flag arguments simultaneously!\\n\"\n \"{0} an addon with only one argument style at a time:\\n\"\n \"\\n\"\n \" microk8s {1} foo:'bar'\\n\"\n \"or\\n\"\n \" microk8s {1} foo --bar\\n\".format(action.title(), action)\n )\n sys.exit(1)\n\n wait_for_ready(timeout=30)\n script = [str(actions / (\"%s.%s.sh\" % (action, addon)))]\n if args:\n p = subprocess.run(script + args)\n else:\n p = subprocess.run(script + list(addons[1:]))\n\n if p.returncode:\n sys.exit(p.returncode)\n\n wait_for_ready(timeout=30)\n", "path": "scripts/wrappers/common/utils.py"}]}
| 3,835 | 140 |
gh_patches_debug_16189
|
rasdani/github-patches
|
git_diff
|
HypothesisWorks__hypothesis-1711
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Move over to new pytest plugin API
We're currently using `pytest.mark.hookwrapper` in our pytest plugin. According to @RonnyPfannschmidt this API is soon to be deprecated and we should be using ` pytest.hookimpl(hookwrapper=True)` instead.
Hopefully this should be a simple matter of changing the code over to use the new decorator, but it's Hypothesis development so I'm sure something exciting will break. 😆 😢
</issue>
<code>
[start of hypothesis-python/src/hypothesis/extra/pytestplugin.py]
1 # coding=utf-8
2 #
3 # This file is part of Hypothesis, which may be found at
4 # https://github.com/HypothesisWorks/hypothesis-python
5 #
6 # Most of this work is copyright (C) 2013-2018 David R. MacIver
7 # ([email protected]), but it contains contributions by others. See
8 # CONTRIBUTING.rst for a full list of people who may hold copyright, and
9 # consult the git log if you need to determine who owns an individual
10 # contribution.
11 #
12 # This Source Code Form is subject to the terms of the Mozilla Public License,
13 # v. 2.0. If a copy of the MPL was not distributed with this file, You can
14 # obtain one at http://mozilla.org/MPL/2.0/.
15 #
16 # END HEADER
17
18 from __future__ import absolute_import, division, print_function
19
20 from distutils.version import LooseVersion
21
22 import pytest
23
24 from hypothesis import Verbosity, core, settings
25 from hypothesis._settings import note_deprecation
26 from hypothesis.internal.compat import OrderedDict, text_type
27 from hypothesis.internal.detection import is_hypothesis_test
28 from hypothesis.reporting import default as default_reporter, with_reporter
29 from hypothesis.statistics import collector
30
31 LOAD_PROFILE_OPTION = "--hypothesis-profile"
32 VERBOSITY_OPTION = "--hypothesis-verbosity"
33 PRINT_STATISTICS_OPTION = "--hypothesis-show-statistics"
34 SEED_OPTION = "--hypothesis-seed"
35
36
37 class StoringReporter(object):
38 def __init__(self, config):
39 self.config = config
40 self.results = []
41
42 def __call__(self, msg):
43 if self.config.getoption("capture", "fd") == "no":
44 default_reporter(msg)
45 if not isinstance(msg, text_type):
46 msg = repr(msg)
47 self.results.append(msg)
48
49
50 def pytest_addoption(parser):
51 group = parser.getgroup("hypothesis", "Hypothesis")
52 group.addoption(
53 LOAD_PROFILE_OPTION,
54 action="store",
55 help="Load in a registered hypothesis.settings profile",
56 )
57 group.addoption(
58 VERBOSITY_OPTION,
59 action="store",
60 choices=[opt.name for opt in Verbosity],
61 help="Override profile with verbosity setting specified",
62 )
63 group.addoption(
64 PRINT_STATISTICS_OPTION,
65 action="store_true",
66 help="Configure when statistics are printed",
67 default=False,
68 )
69 group.addoption(
70 SEED_OPTION, action="store", help="Set a seed to use for all Hypothesis tests"
71 )
72
73
74 def pytest_report_header(config):
75 profile = config.getoption(LOAD_PROFILE_OPTION)
76 if not profile:
77 profile = settings._current_profile
78 settings_str = settings.get_profile(profile).show_changed()
79 if settings_str != "":
80 settings_str = " -> %s" % (settings_str)
81 return "hypothesis profile %r%s" % (profile, settings_str)
82
83
84 def pytest_configure(config):
85 core.running_under_pytest = True
86 profile = config.getoption(LOAD_PROFILE_OPTION)
87 if profile:
88 settings.load_profile(profile)
89 verbosity_name = config.getoption(VERBOSITY_OPTION)
90 if verbosity_name:
91 verbosity_value = Verbosity[verbosity_name]
92 profile_name = "%s-with-%s-verbosity" % (
93 settings._current_profile,
94 verbosity_name,
95 )
96 # register_profile creates a new profile, exactly like the current one,
97 # with the extra values given (in this case 'verbosity')
98 settings.register_profile(profile_name, verbosity=verbosity_value)
99 settings.load_profile(profile_name)
100 seed = config.getoption(SEED_OPTION)
101 if seed is not None:
102 try:
103 seed = int(seed)
104 except ValueError:
105 pass
106 core.global_force_seed = seed
107 config.addinivalue_line("markers", "hypothesis: Tests which use hypothesis.")
108
109
110 gathered_statistics = OrderedDict() # type: dict
111
112
113 @pytest.mark.hookwrapper
114 def pytest_runtest_call(item):
115 if not (hasattr(item, "obj") and is_hypothesis_test(item.obj)):
116 yield
117 else:
118 store = StoringReporter(item.config)
119
120 def note_statistics(stats):
121 lines = [item.nodeid + ":", ""] + stats.get_description() + [""]
122 gathered_statistics[item.nodeid] = lines
123 item.hypothesis_statistics = lines
124
125 with collector.with_value(note_statistics):
126 with with_reporter(store):
127 yield
128 if store.results:
129 item.hypothesis_report_information = list(store.results)
130
131
132 @pytest.mark.hookwrapper
133 def pytest_runtest_makereport(item, call):
134 report = (yield).get_result()
135 if hasattr(item, "hypothesis_report_information"):
136 report.sections.append(
137 ("Hypothesis", "\n".join(item.hypothesis_report_information))
138 )
139 if hasattr(item, "hypothesis_statistics") and report.when == "teardown":
140 # Running on pytest < 3.5 where user_properties doesn't exist, fall
141 # back on the global gathered_statistics (which breaks under xdist)
142 if hasattr(report, "user_properties"): # pragma: no branch
143 val = ("hypothesis-stats", item.hypothesis_statistics)
144 # Workaround for https://github.com/pytest-dev/pytest/issues/4034
145 if isinstance(report.user_properties, tuple):
146 report.user_properties += (val,)
147 else:
148 report.user_properties.append(val)
149
150
151 def pytest_terminal_summary(terminalreporter):
152 if not terminalreporter.config.getoption(PRINT_STATISTICS_OPTION):
153 return
154 terminalreporter.section("Hypothesis Statistics")
155
156 if LooseVersion(pytest.__version__) < "3.5": # pragma: no cover
157 if not gathered_statistics:
158 terminalreporter.write_line(
159 "Reporting Hypothesis statistics with pytest-xdist enabled "
160 "requires pytest >= 3.5"
161 )
162 for lines in gathered_statistics.values():
163 for li in lines:
164 terminalreporter.write_line(li)
165 return
166
167 # terminalreporter.stats is a dict, where the empty string appears to
168 # always be the key for a list of _pytest.reports.TestReport objects
169 # (where we stored the statistics data in pytest_runtest_makereport above)
170 for test_report in terminalreporter.stats.get("", []):
171 for name, lines in test_report.user_properties:
172 if name == "hypothesis-stats" and test_report.when == "teardown":
173 for li in lines:
174 terminalreporter.write_line(li)
175
176
177 def pytest_collection_modifyitems(items):
178 for item in items:
179 if not isinstance(item, pytest.Function):
180 continue
181 if is_hypothesis_test(item.obj):
182 item.add_marker("hypothesis")
183 if getattr(item.obj, "is_hypothesis_strategy_function", False):
184
185 def note_strategy_is_not_test(*args, **kwargs):
186 note_deprecation(
187 "%s is a function that returns a Hypothesis strategy, "
188 "but pytest has collected it as a test function. This "
189 "is useless as the function body will never be executed."
190 "To define a test function, use @given instead of "
191 "@composite." % (item.nodeid,),
192 since="2018-11-02",
193 )
194
195 item.obj = note_strategy_is_not_test
196
197
198 def load():
199 pass
200
[end of hypothesis-python/src/hypothesis/extra/pytestplugin.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/hypothesis-python/src/hypothesis/extra/pytestplugin.py b/hypothesis-python/src/hypothesis/extra/pytestplugin.py
--- a/hypothesis-python/src/hypothesis/extra/pytestplugin.py
+++ b/hypothesis-python/src/hypothesis/extra/pytestplugin.py
@@ -110,7 +110,7 @@
gathered_statistics = OrderedDict() # type: dict
[email protected]
[email protected](hookwrapper=True)
def pytest_runtest_call(item):
if not (hasattr(item, "obj") and is_hypothesis_test(item.obj)):
yield
@@ -129,7 +129,7 @@
item.hypothesis_report_information = list(store.results)
[email protected]
[email protected](hookwrapper=True)
def pytest_runtest_makereport(item, call):
report = (yield).get_result()
if hasattr(item, "hypothesis_report_information"):
|
{"golden_diff": "diff --git a/hypothesis-python/src/hypothesis/extra/pytestplugin.py b/hypothesis-python/src/hypothesis/extra/pytestplugin.py\n--- a/hypothesis-python/src/hypothesis/extra/pytestplugin.py\n+++ b/hypothesis-python/src/hypothesis/extra/pytestplugin.py\n@@ -110,7 +110,7 @@\n gathered_statistics = OrderedDict() # type: dict\n \n \[email protected]\[email protected](hookwrapper=True)\n def pytest_runtest_call(item):\n if not (hasattr(item, \"obj\") and is_hypothesis_test(item.obj)):\n yield\n@@ -129,7 +129,7 @@\n item.hypothesis_report_information = list(store.results)\n \n \[email protected]\[email protected](hookwrapper=True)\n def pytest_runtest_makereport(item, call):\n report = (yield).get_result()\n if hasattr(item, \"hypothesis_report_information\"):\n", "issue": "Move over to new pytest plugin API\nWe're currently using `pytest.mark.hookwrapper` in our pytest plugin. According to @RonnyPfannschmidt this API is soon to be deprecated and we should be using ` pytest.hookimpl(hookwrapper=True)` instead.\r\n\r\nHopefully this should be a simple matter of changing the code over to use the new decorator, but it's Hypothesis development so I'm sure something exciting will break. \ud83d\ude06 \ud83d\ude22 \n", "before_files": [{"content": "# coding=utf-8\n#\n# This file is part of Hypothesis, which may be found at\n# https://github.com/HypothesisWorks/hypothesis-python\n#\n# Most of this work is copyright (C) 2013-2018 David R. MacIver\n# ([email protected]), but it contains contributions by others. See\n# CONTRIBUTING.rst for a full list of people who may hold copyright, and\n# consult the git log if you need to determine who owns an individual\n# contribution.\n#\n# This Source Code Form is subject to the terms of the Mozilla Public License,\n# v. 2.0. If a copy of the MPL was not distributed with this file, You can\n# obtain one at http://mozilla.org/MPL/2.0/.\n#\n# END HEADER\n\nfrom __future__ import absolute_import, division, print_function\n\nfrom distutils.version import LooseVersion\n\nimport pytest\n\nfrom hypothesis import Verbosity, core, settings\nfrom hypothesis._settings import note_deprecation\nfrom hypothesis.internal.compat import OrderedDict, text_type\nfrom hypothesis.internal.detection import is_hypothesis_test\nfrom hypothesis.reporting import default as default_reporter, with_reporter\nfrom hypothesis.statistics import collector\n\nLOAD_PROFILE_OPTION = \"--hypothesis-profile\"\nVERBOSITY_OPTION = \"--hypothesis-verbosity\"\nPRINT_STATISTICS_OPTION = \"--hypothesis-show-statistics\"\nSEED_OPTION = \"--hypothesis-seed\"\n\n\nclass StoringReporter(object):\n def __init__(self, config):\n self.config = config\n self.results = []\n\n def __call__(self, msg):\n if self.config.getoption(\"capture\", \"fd\") == \"no\":\n default_reporter(msg)\n if not isinstance(msg, text_type):\n msg = repr(msg)\n self.results.append(msg)\n\n\ndef pytest_addoption(parser):\n group = parser.getgroup(\"hypothesis\", \"Hypothesis\")\n group.addoption(\n LOAD_PROFILE_OPTION,\n action=\"store\",\n help=\"Load in a registered hypothesis.settings profile\",\n )\n group.addoption(\n VERBOSITY_OPTION,\n action=\"store\",\n choices=[opt.name for opt in Verbosity],\n help=\"Override profile with verbosity setting specified\",\n )\n group.addoption(\n PRINT_STATISTICS_OPTION,\n action=\"store_true\",\n help=\"Configure when statistics are printed\",\n default=False,\n )\n group.addoption(\n SEED_OPTION, action=\"store\", help=\"Set a seed to use for all Hypothesis tests\"\n )\n\n\ndef pytest_report_header(config):\n profile = config.getoption(LOAD_PROFILE_OPTION)\n if not profile:\n profile = settings._current_profile\n settings_str = settings.get_profile(profile).show_changed()\n if settings_str != \"\":\n settings_str = \" -> %s\" % (settings_str)\n return \"hypothesis profile %r%s\" % (profile, settings_str)\n\n\ndef pytest_configure(config):\n core.running_under_pytest = True\n profile = config.getoption(LOAD_PROFILE_OPTION)\n if profile:\n settings.load_profile(profile)\n verbosity_name = config.getoption(VERBOSITY_OPTION)\n if verbosity_name:\n verbosity_value = Verbosity[verbosity_name]\n profile_name = \"%s-with-%s-verbosity\" % (\n settings._current_profile,\n verbosity_name,\n )\n # register_profile creates a new profile, exactly like the current one,\n # with the extra values given (in this case 'verbosity')\n settings.register_profile(profile_name, verbosity=verbosity_value)\n settings.load_profile(profile_name)\n seed = config.getoption(SEED_OPTION)\n if seed is not None:\n try:\n seed = int(seed)\n except ValueError:\n pass\n core.global_force_seed = seed\n config.addinivalue_line(\"markers\", \"hypothesis: Tests which use hypothesis.\")\n\n\ngathered_statistics = OrderedDict() # type: dict\n\n\[email protected]\ndef pytest_runtest_call(item):\n if not (hasattr(item, \"obj\") and is_hypothesis_test(item.obj)):\n yield\n else:\n store = StoringReporter(item.config)\n\n def note_statistics(stats):\n lines = [item.nodeid + \":\", \"\"] + stats.get_description() + [\"\"]\n gathered_statistics[item.nodeid] = lines\n item.hypothesis_statistics = lines\n\n with collector.with_value(note_statistics):\n with with_reporter(store):\n yield\n if store.results:\n item.hypothesis_report_information = list(store.results)\n\n\[email protected]\ndef pytest_runtest_makereport(item, call):\n report = (yield).get_result()\n if hasattr(item, \"hypothesis_report_information\"):\n report.sections.append(\n (\"Hypothesis\", \"\\n\".join(item.hypothesis_report_information))\n )\n if hasattr(item, \"hypothesis_statistics\") and report.when == \"teardown\":\n # Running on pytest < 3.5 where user_properties doesn't exist, fall\n # back on the global gathered_statistics (which breaks under xdist)\n if hasattr(report, \"user_properties\"): # pragma: no branch\n val = (\"hypothesis-stats\", item.hypothesis_statistics)\n # Workaround for https://github.com/pytest-dev/pytest/issues/4034\n if isinstance(report.user_properties, tuple):\n report.user_properties += (val,)\n else:\n report.user_properties.append(val)\n\n\ndef pytest_terminal_summary(terminalreporter):\n if not terminalreporter.config.getoption(PRINT_STATISTICS_OPTION):\n return\n terminalreporter.section(\"Hypothesis Statistics\")\n\n if LooseVersion(pytest.__version__) < \"3.5\": # pragma: no cover\n if not gathered_statistics:\n terminalreporter.write_line(\n \"Reporting Hypothesis statistics with pytest-xdist enabled \"\n \"requires pytest >= 3.5\"\n )\n for lines in gathered_statistics.values():\n for li in lines:\n terminalreporter.write_line(li)\n return\n\n # terminalreporter.stats is a dict, where the empty string appears to\n # always be the key for a list of _pytest.reports.TestReport objects\n # (where we stored the statistics data in pytest_runtest_makereport above)\n for test_report in terminalreporter.stats.get(\"\", []):\n for name, lines in test_report.user_properties:\n if name == \"hypothesis-stats\" and test_report.when == \"teardown\":\n for li in lines:\n terminalreporter.write_line(li)\n\n\ndef pytest_collection_modifyitems(items):\n for item in items:\n if not isinstance(item, pytest.Function):\n continue\n if is_hypothesis_test(item.obj):\n item.add_marker(\"hypothesis\")\n if getattr(item.obj, \"is_hypothesis_strategy_function\", False):\n\n def note_strategy_is_not_test(*args, **kwargs):\n note_deprecation(\n \"%s is a function that returns a Hypothesis strategy, \"\n \"but pytest has collected it as a test function. This \"\n \"is useless as the function body will never be executed.\"\n \"To define a test function, use @given instead of \"\n \"@composite.\" % (item.nodeid,),\n since=\"2018-11-02\",\n )\n\n item.obj = note_strategy_is_not_test\n\n\ndef load():\n pass\n", "path": "hypothesis-python/src/hypothesis/extra/pytestplugin.py"}]}
| 2,739 | 222 |
gh_patches_debug_21294
|
rasdani/github-patches
|
git_diff
|
rucio__rucio-952
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
setup_clients.py classifiers needs to be a list, not tuples
Motivation
----------
Classifiers were changed to tuple, which does not work, needs to be a list.
</issue>
<code>
[start of setup_rucio_client.py]
1 # Copyright 2014-2018 CERN for the benefit of the ATLAS collaboration.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14 #
15 # Authors:
16 # - Vincent Garonne <[email protected]>, 2014-2018
17 # - Martin Barisits <[email protected]>, 2017
18
19 import os
20 import re
21 import shutil
22 import subprocess
23 import sys
24
25 from distutils.command.sdist import sdist as _sdist # pylint:disable=no-name-in-module,import-error
26 from setuptools import setup
27
28 sys.path.insert(0, os.path.abspath('lib/'))
29
30 from rucio import version # noqa
31
32 if sys.version_info < (2, 5):
33 print('ERROR: Rucio requires at least Python 2.6 to run.')
34 sys.exit(1)
35 sys.path.insert(0, os.path.abspath('lib/'))
36
37
38 # Arguments to the setup script to build Basic/Lite distributions
39 COPY_ARGS = sys.argv[1:]
40 NAME = 'rucio-clients'
41 IS_RELEASE = False
42 PACKAGES = ['rucio', 'rucio.client', 'rucio.common',
43 'rucio.rse.protocols', 'rucio.rse', 'rucio.tests']
44 REQUIREMENTS_FILES = ['tools/pip-requires-client']
45 DESCRIPTION = "Rucio Client Lite Package"
46 DATA_FILES = [('etc/', ['etc/rse-accounts.cfg.template', 'etc/rucio.cfg.template', 'etc/rucio.cfg.atlas.client.template']),
47 ('tools/', ['tools/pip-requires-client', ]), ]
48
49 SCRIPTS = ['bin/rucio', 'bin/rucio-admin']
50 if os.path.exists('build/'):
51 shutil.rmtree('build/')
52 if os.path.exists('lib/rucio_clients.egg-info/'):
53 shutil.rmtree('lib/rucio_clients.egg-info/')
54 if os.path.exists('lib/rucio.egg-info/'):
55 shutil.rmtree('lib/rucio.egg-info/')
56
57 SSH_EXTRAS = ['paramiko==1.18.4']
58 KERBEROS_EXTRAS = ['kerberos>=1.2.5', 'pykerberos>=1.1.14', 'requests-kerberos>=0.11.0']
59 SWIFT_EXTRAS = ['python-swiftclient>=3.5.0', ]
60 EXTRAS_REQUIRES = dict(ssh=SSH_EXTRAS,
61 kerberos=KERBEROS_EXTRAS,
62 swift=SWIFT_EXTRAS)
63
64 if '--release' in COPY_ARGS:
65 IS_RELEASE = True
66 COPY_ARGS.remove('--release')
67
68
69 # If Sphinx is installed on the box running setup.py,
70 # enable setup.py to build the documentation, otherwise,
71 # just ignore it
72 cmdclass = {}
73
74 try:
75 from sphinx.setup_command import BuildDoc
76
77 class local_BuildDoc(BuildDoc):
78 '''
79 local_BuildDoc
80 '''
81 def run(self):
82 '''
83 run
84 '''
85 for builder in ['html']: # 'man','latex'
86 self.builder = builder
87 self.finalize_options()
88 BuildDoc.run(self)
89 cmdclass['build_sphinx'] = local_BuildDoc
90 except Exception:
91 pass
92
93
94 def get_reqs_from_file(requirements_file):
95 '''
96 get_reqs_from_file
97 '''
98 if os.path.exists(requirements_file):
99 return open(requirements_file, 'r').read().split('\n')
100 return []
101
102
103 def parse_requirements(requirements_files):
104 '''
105 parse_requirements
106 '''
107 requirements = []
108 for requirements_file in requirements_files:
109 for line in get_reqs_from_file(requirements_file):
110 if re.match(r'\s*-e\s+', line):
111 requirements.append(re.sub(r'\s*-e\s+.*#egg=(.*)$', r'\1', line))
112 elif re.match(r'\s*-f\s+', line):
113 pass
114 else:
115 requirements.append(line)
116 return requirements
117
118
119 def parse_dependency_links(requirements_files):
120 '''
121 parse_dependency_links
122 '''
123 dependency_links = []
124 for requirements_file in requirements_files:
125 for line in get_reqs_from_file(requirements_file):
126 if re.match(r'(\s*#)|(\s*$)', line):
127 continue
128 if re.match(r'\s*-[ef]\s+', line):
129 dependency_links.append(re.sub(r'\s*-[ef]\s+', '', line))
130 return dependency_links
131
132
133 def write_requirements():
134 '''
135 write_requirements
136 '''
137 venv = os.environ.get('VIRTUAL_ENV', None)
138 if venv is not None:
139 req_file = open("requirements.txt", "w")
140 output = subprocess.Popen(["pip", "freeze", "-l"], stdout=subprocess.PIPE)
141 requirements = output.communicate()[0].strip()
142 req_file.write(requirements)
143 req_file.close()
144
145
146 REQUIRES = parse_requirements(requirements_files=REQUIREMENTS_FILES)
147 DEPEND_LINKS = parse_dependency_links(requirements_files=REQUIREMENTS_FILES)
148
149
150 class CustomSdist(_sdist):
151 '''
152 CustomSdist
153 '''
154 user_options = [
155 ('packaging=', None, "Some option to indicate what should be packaged")
156 ] + _sdist.user_options
157
158 def __init__(self, *args, **kwargs):
159 '''
160 __init__
161 '''
162 _sdist.__init__(self, *args, **kwargs)
163 self.packaging = "default value for this option"
164
165 def get_file_list(self):
166 '''
167 get_file_list
168 '''
169 print("Chosen packaging option: " + NAME)
170 self.distribution.data_files = DATA_FILES
171 _sdist.get_file_list(self)
172
173
174 cmdclass['sdist'] = CustomSdist
175
176 setup(
177 name=NAME,
178 version=version.version_string(),
179 packages=PACKAGES,
180 package_dir={'': 'lib'},
181 data_files=DATA_FILES,
182 script_args=COPY_ARGS,
183 cmdclass=cmdclass,
184 include_package_data=True,
185 scripts=SCRIPTS,
186 # doc=cmdclass,
187 author="Rucio",
188 author_email="[email protected]",
189 description=DESCRIPTION,
190 license="Apache License, Version 2.0",
191 url="http://rucio.cern.ch/",
192 python_requires=">=2.6, !=3.0.*, !=3.1.*, !=3.2.*, !=3.3.*",
193 classifiers=(
194 'Development Status :: 5 - Production/Stable',
195 'License :: OSI Approved :: Apache Software License',
196 'Intended Audience :: Information Technology',
197 'Intended Audience :: System Administrators',
198 'Operating System :: POSIX :: Linux',
199 'Natural Language :: English',
200 'Programming Language :: Python',
201 'Programming Language :: Python :: 2.6',
202 'Programming Language :: Python :: 2.7',
203 'Programming Language :: Python :: 3',
204 'Programming Language :: Python :: 3.4',
205 'Programming Language :: Python :: 3.5',
206 'Programming Language :: Python :: 3.6',
207 'Programming Language :: Python :: Implementation :: CPython',
208 'Programming Language :: Python :: Implementation :: PyPy',
209 'Environment :: No Input/Output (Daemon)'
210 ),
211 install_requires=REQUIRES,
212 extras_require=EXTRAS_REQUIRES,
213 dependency_links=DEPEND_LINKS,
214 )
215
[end of setup_rucio_client.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/setup_rucio_client.py b/setup_rucio_client.py
--- a/setup_rucio_client.py
+++ b/setup_rucio_client.py
@@ -190,7 +190,7 @@
license="Apache License, Version 2.0",
url="http://rucio.cern.ch/",
python_requires=">=2.6, !=3.0.*, !=3.1.*, !=3.2.*, !=3.3.*",
- classifiers=(
+ classifiers=[
'Development Status :: 5 - Production/Stable',
'License :: OSI Approved :: Apache Software License',
'Intended Audience :: Information Technology',
@@ -207,7 +207,7 @@
'Programming Language :: Python :: Implementation :: CPython',
'Programming Language :: Python :: Implementation :: PyPy',
'Environment :: No Input/Output (Daemon)'
- ),
+ ],
install_requires=REQUIRES,
extras_require=EXTRAS_REQUIRES,
dependency_links=DEPEND_LINKS,
|
{"golden_diff": "diff --git a/setup_rucio_client.py b/setup_rucio_client.py\n--- a/setup_rucio_client.py\n+++ b/setup_rucio_client.py\n@@ -190,7 +190,7 @@\n license=\"Apache License, Version 2.0\",\n url=\"http://rucio.cern.ch/\",\n python_requires=\">=2.6, !=3.0.*, !=3.1.*, !=3.2.*, !=3.3.*\",\n- classifiers=(\n+ classifiers=[\n 'Development Status :: 5 - Production/Stable',\n 'License :: OSI Approved :: Apache Software License',\n 'Intended Audience :: Information Technology',\n@@ -207,7 +207,7 @@\n 'Programming Language :: Python :: Implementation :: CPython',\n 'Programming Language :: Python :: Implementation :: PyPy',\n 'Environment :: No Input/Output (Daemon)'\n- ),\n+ ],\n install_requires=REQUIRES,\n extras_require=EXTRAS_REQUIRES,\n dependency_links=DEPEND_LINKS,\n", "issue": "setup_clients.py classifiers needs to be a list, not tuples\nMotivation\r\n----------\r\nClassifiers were changed to tuple, which does not work, needs to be a list.\n", "before_files": [{"content": "# Copyright 2014-2018 CERN for the benefit of the ATLAS collaboration.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n#\n# Authors:\n# - Vincent Garonne <[email protected]>, 2014-2018\n# - Martin Barisits <[email protected]>, 2017\n\nimport os\nimport re\nimport shutil\nimport subprocess\nimport sys\n\nfrom distutils.command.sdist import sdist as _sdist # pylint:disable=no-name-in-module,import-error\nfrom setuptools import setup\n\nsys.path.insert(0, os.path.abspath('lib/'))\n\nfrom rucio import version # noqa\n\nif sys.version_info < (2, 5):\n print('ERROR: Rucio requires at least Python 2.6 to run.')\n sys.exit(1)\nsys.path.insert(0, os.path.abspath('lib/'))\n\n\n# Arguments to the setup script to build Basic/Lite distributions\nCOPY_ARGS = sys.argv[1:]\nNAME = 'rucio-clients'\nIS_RELEASE = False\nPACKAGES = ['rucio', 'rucio.client', 'rucio.common',\n 'rucio.rse.protocols', 'rucio.rse', 'rucio.tests']\nREQUIREMENTS_FILES = ['tools/pip-requires-client']\nDESCRIPTION = \"Rucio Client Lite Package\"\nDATA_FILES = [('etc/', ['etc/rse-accounts.cfg.template', 'etc/rucio.cfg.template', 'etc/rucio.cfg.atlas.client.template']),\n ('tools/', ['tools/pip-requires-client', ]), ]\n\nSCRIPTS = ['bin/rucio', 'bin/rucio-admin']\nif os.path.exists('build/'):\n shutil.rmtree('build/')\nif os.path.exists('lib/rucio_clients.egg-info/'):\n shutil.rmtree('lib/rucio_clients.egg-info/')\nif os.path.exists('lib/rucio.egg-info/'):\n shutil.rmtree('lib/rucio.egg-info/')\n\nSSH_EXTRAS = ['paramiko==1.18.4']\nKERBEROS_EXTRAS = ['kerberos>=1.2.5', 'pykerberos>=1.1.14', 'requests-kerberos>=0.11.0']\nSWIFT_EXTRAS = ['python-swiftclient>=3.5.0', ]\nEXTRAS_REQUIRES = dict(ssh=SSH_EXTRAS,\n kerberos=KERBEROS_EXTRAS,\n swift=SWIFT_EXTRAS)\n\nif '--release' in COPY_ARGS:\n IS_RELEASE = True\n COPY_ARGS.remove('--release')\n\n\n# If Sphinx is installed on the box running setup.py,\n# enable setup.py to build the documentation, otherwise,\n# just ignore it\ncmdclass = {}\n\ntry:\n from sphinx.setup_command import BuildDoc\n\n class local_BuildDoc(BuildDoc):\n '''\n local_BuildDoc\n '''\n def run(self):\n '''\n run\n '''\n for builder in ['html']: # 'man','latex'\n self.builder = builder\n self.finalize_options()\n BuildDoc.run(self)\n cmdclass['build_sphinx'] = local_BuildDoc\nexcept Exception:\n pass\n\n\ndef get_reqs_from_file(requirements_file):\n '''\n get_reqs_from_file\n '''\n if os.path.exists(requirements_file):\n return open(requirements_file, 'r').read().split('\\n')\n return []\n\n\ndef parse_requirements(requirements_files):\n '''\n parse_requirements\n '''\n requirements = []\n for requirements_file in requirements_files:\n for line in get_reqs_from_file(requirements_file):\n if re.match(r'\\s*-e\\s+', line):\n requirements.append(re.sub(r'\\s*-e\\s+.*#egg=(.*)$', r'\\1', line))\n elif re.match(r'\\s*-f\\s+', line):\n pass\n else:\n requirements.append(line)\n return requirements\n\n\ndef parse_dependency_links(requirements_files):\n '''\n parse_dependency_links\n '''\n dependency_links = []\n for requirements_file in requirements_files:\n for line in get_reqs_from_file(requirements_file):\n if re.match(r'(\\s*#)|(\\s*$)', line):\n continue\n if re.match(r'\\s*-[ef]\\s+', line):\n dependency_links.append(re.sub(r'\\s*-[ef]\\s+', '', line))\n return dependency_links\n\n\ndef write_requirements():\n '''\n write_requirements\n '''\n venv = os.environ.get('VIRTUAL_ENV', None)\n if venv is not None:\n req_file = open(\"requirements.txt\", \"w\")\n output = subprocess.Popen([\"pip\", \"freeze\", \"-l\"], stdout=subprocess.PIPE)\n requirements = output.communicate()[0].strip()\n req_file.write(requirements)\n req_file.close()\n\n\nREQUIRES = parse_requirements(requirements_files=REQUIREMENTS_FILES)\nDEPEND_LINKS = parse_dependency_links(requirements_files=REQUIREMENTS_FILES)\n\n\nclass CustomSdist(_sdist):\n '''\n CustomSdist\n '''\n user_options = [\n ('packaging=', None, \"Some option to indicate what should be packaged\")\n ] + _sdist.user_options\n\n def __init__(self, *args, **kwargs):\n '''\n __init__\n '''\n _sdist.__init__(self, *args, **kwargs)\n self.packaging = \"default value for this option\"\n\n def get_file_list(self):\n '''\n get_file_list\n '''\n print(\"Chosen packaging option: \" + NAME)\n self.distribution.data_files = DATA_FILES\n _sdist.get_file_list(self)\n\n\ncmdclass['sdist'] = CustomSdist\n\nsetup(\n name=NAME,\n version=version.version_string(),\n packages=PACKAGES,\n package_dir={'': 'lib'},\n data_files=DATA_FILES,\n script_args=COPY_ARGS,\n cmdclass=cmdclass,\n include_package_data=True,\n scripts=SCRIPTS,\n # doc=cmdclass,\n author=\"Rucio\",\n author_email=\"[email protected]\",\n description=DESCRIPTION,\n license=\"Apache License, Version 2.0\",\n url=\"http://rucio.cern.ch/\",\n python_requires=\">=2.6, !=3.0.*, !=3.1.*, !=3.2.*, !=3.3.*\",\n classifiers=(\n 'Development Status :: 5 - Production/Stable',\n 'License :: OSI Approved :: Apache Software License',\n 'Intended Audience :: Information Technology',\n 'Intended Audience :: System Administrators',\n 'Operating System :: POSIX :: Linux',\n 'Natural Language :: English',\n 'Programming Language :: Python',\n 'Programming Language :: Python :: 2.6',\n 'Programming Language :: Python :: 2.7',\n 'Programming Language :: Python :: 3',\n 'Programming Language :: Python :: 3.4',\n 'Programming Language :: Python :: 3.5',\n 'Programming Language :: Python :: 3.6',\n 'Programming Language :: Python :: Implementation :: CPython',\n 'Programming Language :: Python :: Implementation :: PyPy',\n 'Environment :: No Input/Output (Daemon)'\n ),\n install_requires=REQUIRES,\n extras_require=EXTRAS_REQUIRES,\n dependency_links=DEPEND_LINKS,\n)\n", "path": "setup_rucio_client.py"}]}
| 2,804 | 223 |
gh_patches_debug_5599
|
rasdani/github-patches
|
git_diff
|
sql-machine-learning__elasticdl-1830
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
worker pod crashes when get task
```
2020-03-12 22:03:32.300671: W tensorflow/core/kernels/data/generator_dataset_op.cc:103] Error occurred when finalizing GeneratorDataset iterator: Cancelled: Operation was cancelled
Traceback (most recent call last):
File "/usr/lib/python3.6/runpy.py", line 193, in _run_module_as_main
"__main__", mod_spec)
File "/usr/lib/python3.6/runpy.py", line 85, in _run_code
exec(code, run_globals)
File "/elasticdl/python/worker/main.py", line 44, in <module>
main()
File "/elasticdl/python/worker/main.py", line 40, in main
worker.run()
File "/elasticdl/python/worker/worker.py", line 1144, in run
self._train_and_evaluate()
File "/elasticdl/python/worker/worker.py", line 1074, in _train_and_evaluate
self._minibatch_size, err_msg
File "/elasticdl/python/worker/task_data_service.py", line 86, in report_record_done
task = self._pending_tasks[0]
IndexError: deque index out of range
```
</issue>
<code>
[start of elasticdl/python/worker/task_data_service.py]
1 import threading
2 import time
3 from collections import deque
4
5 import tensorflow as tf
6
7 from elasticdl.proto import elasticdl_pb2
8 from elasticdl.python.common.constants import TaskExecCounterKey
9 from elasticdl.python.common.log_utils import default_logger as logger
10 from elasticdl.python.data.reader.data_reader_factory import create_data_reader
11
12
13 class TaskDataService(object):
14 def __init__(
15 self, worker, training_with_evaluation, data_reader_params=None
16 ):
17 self._worker = worker
18 self._create_data_reader_fn = create_data_reader
19 if self._worker._custom_data_reader is not None:
20 self._create_data_reader_fn = self._worker._custom_data_reader
21 self._training_with_evaluation = training_with_evaluation
22 self._lock = threading.Lock()
23 self._pending_dataset = True
24 self._pending_train_end_callback_task = None
25 if data_reader_params:
26 self.data_reader = self._create_data_reader_fn(
27 data_origin=None, **data_reader_params
28 )
29 else:
30 self.data_reader = self._create_data_reader_fn(data_origin=None)
31 self._warm_up_task = None
32 self._has_warmed_up = False
33 self._failed_record_count = 0
34 self._reported_record_count = 0
35 self._current_task = None
36 self._pending_tasks = deque()
37
38 def _reset(self):
39 """
40 Reset pending tasks and record counts
41 """
42 self._reported_record_count = 0
43 self._failed_record_count = 0
44 self._pending_tasks = deque()
45 self._current_task = None
46
47 def get_current_task(self):
48 return self._current_task
49
50 def _do_report_task(self, task, err_msg=""):
51 if self._failed_record_count != 0:
52 exec_counters = {
53 TaskExecCounterKey.FAIL_COUNT: self._failed_record_count
54 }
55 else:
56 exec_counters = None
57 self._worker.report_task_result(
58 task.task_id, err_msg, exec_counters=exec_counters
59 )
60
61 def _log_fail_records(self, task, err_msg):
62 task_len = task.end - task.start
63 msg = (
64 "records ({f}/{t}) failure, possible "
65 "in task_id: {task_id} "
66 'reason "{err_msg}"'
67 ).format(
68 task_id=task.task_id,
69 err_msg=err_msg,
70 f=self._failed_record_count,
71 t=task_len,
72 )
73 logger.warning(msg)
74
75 def report_record_done(self, count, err_msg=""):
76 """
77 Report the number of records in the latest processed batch,
78 so TaskDataService knows if some pending tasks are finished
79 and report_task_result to the master.
80 Return True if there are some finished tasks, False otherwise.
81 """
82 self._reported_record_count += count
83 if err_msg:
84 self._failed_record_count += count
85
86 task = self._pending_tasks[0]
87 total_record_num = task.end - task.start
88 if self._reported_record_count >= total_record_num:
89 if err_msg:
90 self._log_fail_records(task, err_msg)
91
92 # Keep popping tasks until the reported record count is less
93 # than the size of the current data since `batch_size` may be
94 # larger than `task.end - task.start`
95 with self._lock:
96 while self._pending_tasks and self._reported_record_count >= (
97 self._pending_tasks[0].end - self._pending_tasks[0].start
98 ):
99 task = self._pending_tasks[0]
100 self._reported_record_count -= task.end - task.start
101 self._pending_tasks.popleft()
102 self._do_report_task(task, err_msg)
103 self._failed_record_count = 0
104 if self._pending_tasks:
105 self._current_task = self._pending_tasks[0]
106 return True
107 return False
108
109 def get_dataset_gen(self, task):
110 """
111 If a task exists, this creates a generator, which could be used to
112 creating a `tf.data.Dataset` object in further.
113 """
114 if not task:
115 return None
116 tasks = [task]
117
118 def gen():
119 for task in tasks:
120 for data in self.data_reader.read_records(task):
121 if data:
122 yield data
123
124 return gen
125
126 def get_dataset_by_task(self, task):
127 if task is None:
128 return None
129 gen = self.get_dataset_gen(task)
130 dataset = tf.data.Dataset.from_generator(
131 gen, self.data_reader.records_output_types
132 )
133 return dataset
134
135 def get_train_end_callback_task(self):
136 return self._pending_train_end_callback_task
137
138 def clear_train_end_callback_task(self):
139 self._pending_train_end_callback_task = None
140
141 def get_dataset(self):
142 """
143 If there's more data, this creates a `tf.data.Dataset` object.
144 Otherwise, this returns `None`.
145 """
146 if self._pending_dataset:
147 if self._pending_tasks:
148 logger.error(
149 "Cannot get new dataset when there are pending tasks"
150 )
151 return None
152 self._reset()
153 # We use a task to perform warm-up for data reader in order
154 # to collect useful metadata. Note that we only performs
155 # data fetching for this task and `break` instantly to make
156 # sure `read_records()` is executed without iterating all the
157 # records so this should not be time consuming.
158 if self._warm_up_task is None and not self._has_warmed_up:
159 while True:
160 task = self._worker.get_task()
161 if task.type != elasticdl_pb2.WAIT:
162 break
163 time.sleep(2)
164 if task.type == elasticdl_pb2.TRAIN_END_CALLBACK:
165 self._pending_train_end_callback_task = task
166 return None
167 elif not task.shard_name:
168 logger.info("No more task, stopping")
169 return None
170 else:
171 self._warm_up_task = task
172 for _ in self.data_reader.read_records(task):
173 break
174 self._has_warmed_up = True
175 ds = tf.data.Dataset.from_generator(
176 self._gen, self.data_reader.records_output_types
177 )
178 self._pending_dataset = False
179 return ds
180 else:
181 return None
182
183 def _gen(self):
184 """
185 A generator supports the iter() protocol (e.g. a generator function),
186 used to create a `tf.data.Dataset` object from a list of tasks.
187 """
188 while True:
189 # Make sure we also generate data from the warm-up task.
190 if self._warm_up_task is not None and self._has_warmed_up:
191 task = self._warm_up_task
192 self._warm_up_task = None
193 else:
194 task = self._worker.get_task()
195 if not task.shard_name:
196 if task.type == elasticdl_pb2.WAIT:
197 self._pending_dataset = True
198 logger.info("No tasks for now, maybe more later")
199 else:
200 logger.info("No more task, stopping")
201 break
202 with self._lock:
203 if task.type == elasticdl_pb2.TRAIN_END_CALLBACK:
204 self._pending_train_end_callback_task = task
205 continue
206
207 self._pending_tasks.append(task)
208 if len(self._pending_tasks) == 1:
209 self._current_task = task
210 for data in self.data_reader.read_records(task):
211 if data:
212 yield data
213
[end of elasticdl/python/worker/task_data_service.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/elasticdl/python/worker/task_data_service.py b/elasticdl/python/worker/task_data_service.py
--- a/elasticdl/python/worker/task_data_service.py
+++ b/elasticdl/python/worker/task_data_service.py
@@ -83,6 +83,9 @@
if err_msg:
self._failed_record_count += count
+ # TODO(qijun) This is a workaround for #1829
+ if not self._pending_tasks:
+ return False
task = self._pending_tasks[0]
total_record_num = task.end - task.start
if self._reported_record_count >= total_record_num:
|
{"golden_diff": "diff --git a/elasticdl/python/worker/task_data_service.py b/elasticdl/python/worker/task_data_service.py\n--- a/elasticdl/python/worker/task_data_service.py\n+++ b/elasticdl/python/worker/task_data_service.py\n@@ -83,6 +83,9 @@\n if err_msg:\n self._failed_record_count += count\n \n+ # TODO(qijun) This is a workaround for #1829\n+ if not self._pending_tasks:\n+ return False\n task = self._pending_tasks[0]\n total_record_num = task.end - task.start\n if self._reported_record_count >= total_record_num:\n", "issue": "worker pod crashes when get task\n```\r\n2020-03-12 22:03:32.300671: W tensorflow/core/kernels/data/generator_dataset_op.cc:103] Error occurred when finalizing GeneratorDataset iterator: Cancelled: Operation was cancelled\r\nTraceback (most recent call last):\r\n File \"/usr/lib/python3.6/runpy.py\", line 193, in _run_module_as_main\r\n \"__main__\", mod_spec)\r\n File \"/usr/lib/python3.6/runpy.py\", line 85, in _run_code\r\n exec(code, run_globals)\r\n File \"/elasticdl/python/worker/main.py\", line 44, in <module>\r\n main()\r\n File \"/elasticdl/python/worker/main.py\", line 40, in main\r\n worker.run()\r\n File \"/elasticdl/python/worker/worker.py\", line 1144, in run\r\n self._train_and_evaluate()\r\n File \"/elasticdl/python/worker/worker.py\", line 1074, in _train_and_evaluate\r\n self._minibatch_size, err_msg\r\n File \"/elasticdl/python/worker/task_data_service.py\", line 86, in report_record_done\r\n task = self._pending_tasks[0]\r\nIndexError: deque index out of range\r\n```\n", "before_files": [{"content": "import threading\nimport time\nfrom collections import deque\n\nimport tensorflow as tf\n\nfrom elasticdl.proto import elasticdl_pb2\nfrom elasticdl.python.common.constants import TaskExecCounterKey\nfrom elasticdl.python.common.log_utils import default_logger as logger\nfrom elasticdl.python.data.reader.data_reader_factory import create_data_reader\n\n\nclass TaskDataService(object):\n def __init__(\n self, worker, training_with_evaluation, data_reader_params=None\n ):\n self._worker = worker\n self._create_data_reader_fn = create_data_reader\n if self._worker._custom_data_reader is not None:\n self._create_data_reader_fn = self._worker._custom_data_reader\n self._training_with_evaluation = training_with_evaluation\n self._lock = threading.Lock()\n self._pending_dataset = True\n self._pending_train_end_callback_task = None\n if data_reader_params:\n self.data_reader = self._create_data_reader_fn(\n data_origin=None, **data_reader_params\n )\n else:\n self.data_reader = self._create_data_reader_fn(data_origin=None)\n self._warm_up_task = None\n self._has_warmed_up = False\n self._failed_record_count = 0\n self._reported_record_count = 0\n self._current_task = None\n self._pending_tasks = deque()\n\n def _reset(self):\n \"\"\"\n Reset pending tasks and record counts\n \"\"\"\n self._reported_record_count = 0\n self._failed_record_count = 0\n self._pending_tasks = deque()\n self._current_task = None\n\n def get_current_task(self):\n return self._current_task\n\n def _do_report_task(self, task, err_msg=\"\"):\n if self._failed_record_count != 0:\n exec_counters = {\n TaskExecCounterKey.FAIL_COUNT: self._failed_record_count\n }\n else:\n exec_counters = None\n self._worker.report_task_result(\n task.task_id, err_msg, exec_counters=exec_counters\n )\n\n def _log_fail_records(self, task, err_msg):\n task_len = task.end - task.start\n msg = (\n \"records ({f}/{t}) failure, possible \"\n \"in task_id: {task_id} \"\n 'reason \"{err_msg}\"'\n ).format(\n task_id=task.task_id,\n err_msg=err_msg,\n f=self._failed_record_count,\n t=task_len,\n )\n logger.warning(msg)\n\n def report_record_done(self, count, err_msg=\"\"):\n \"\"\"\n Report the number of records in the latest processed batch,\n so TaskDataService knows if some pending tasks are finished\n and report_task_result to the master.\n Return True if there are some finished tasks, False otherwise.\n \"\"\"\n self._reported_record_count += count\n if err_msg:\n self._failed_record_count += count\n\n task = self._pending_tasks[0]\n total_record_num = task.end - task.start\n if self._reported_record_count >= total_record_num:\n if err_msg:\n self._log_fail_records(task, err_msg)\n\n # Keep popping tasks until the reported record count is less\n # than the size of the current data since `batch_size` may be\n # larger than `task.end - task.start`\n with self._lock:\n while self._pending_tasks and self._reported_record_count >= (\n self._pending_tasks[0].end - self._pending_tasks[0].start\n ):\n task = self._pending_tasks[0]\n self._reported_record_count -= task.end - task.start\n self._pending_tasks.popleft()\n self._do_report_task(task, err_msg)\n self._failed_record_count = 0\n if self._pending_tasks:\n self._current_task = self._pending_tasks[0]\n return True\n return False\n\n def get_dataset_gen(self, task):\n \"\"\"\n If a task exists, this creates a generator, which could be used to\n creating a `tf.data.Dataset` object in further.\n \"\"\"\n if not task:\n return None\n tasks = [task]\n\n def gen():\n for task in tasks:\n for data in self.data_reader.read_records(task):\n if data:\n yield data\n\n return gen\n\n def get_dataset_by_task(self, task):\n if task is None:\n return None\n gen = self.get_dataset_gen(task)\n dataset = tf.data.Dataset.from_generator(\n gen, self.data_reader.records_output_types\n )\n return dataset\n\n def get_train_end_callback_task(self):\n return self._pending_train_end_callback_task\n\n def clear_train_end_callback_task(self):\n self._pending_train_end_callback_task = None\n\n def get_dataset(self):\n \"\"\"\n If there's more data, this creates a `tf.data.Dataset` object.\n Otherwise, this returns `None`.\n \"\"\"\n if self._pending_dataset:\n if self._pending_tasks:\n logger.error(\n \"Cannot get new dataset when there are pending tasks\"\n )\n return None\n self._reset()\n # We use a task to perform warm-up for data reader in order\n # to collect useful metadata. Note that we only performs\n # data fetching for this task and `break` instantly to make\n # sure `read_records()` is executed without iterating all the\n # records so this should not be time consuming.\n if self._warm_up_task is None and not self._has_warmed_up:\n while True:\n task = self._worker.get_task()\n if task.type != elasticdl_pb2.WAIT:\n break\n time.sleep(2)\n if task.type == elasticdl_pb2.TRAIN_END_CALLBACK:\n self._pending_train_end_callback_task = task\n return None\n elif not task.shard_name:\n logger.info(\"No more task, stopping\")\n return None\n else:\n self._warm_up_task = task\n for _ in self.data_reader.read_records(task):\n break\n self._has_warmed_up = True\n ds = tf.data.Dataset.from_generator(\n self._gen, self.data_reader.records_output_types\n )\n self._pending_dataset = False\n return ds\n else:\n return None\n\n def _gen(self):\n \"\"\"\n A generator supports the iter() protocol (e.g. a generator function),\n used to create a `tf.data.Dataset` object from a list of tasks.\n \"\"\"\n while True:\n # Make sure we also generate data from the warm-up task.\n if self._warm_up_task is not None and self._has_warmed_up:\n task = self._warm_up_task\n self._warm_up_task = None\n else:\n task = self._worker.get_task()\n if not task.shard_name:\n if task.type == elasticdl_pb2.WAIT:\n self._pending_dataset = True\n logger.info(\"No tasks for now, maybe more later\")\n else:\n logger.info(\"No more task, stopping\")\n break\n with self._lock:\n if task.type == elasticdl_pb2.TRAIN_END_CALLBACK:\n self._pending_train_end_callback_task = task\n continue\n\n self._pending_tasks.append(task)\n if len(self._pending_tasks) == 1:\n self._current_task = task\n for data in self.data_reader.read_records(task):\n if data:\n yield data\n", "path": "elasticdl/python/worker/task_data_service.py"}]}
| 2,969 | 144 |
gh_patches_debug_24101
|
rasdani/github-patches
|
git_diff
|
azavea__raster-vision-844
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Get Sphinx to render Google-style API docs correctly
In the API docs on RTD https://docs.rastervision.io/en/latest/api.html, the line breaks in the docs aren't rendered correctly. In particular, the `lr` argument for the PyTorch backends is on the same line as the `batch_size` argument, which obscures the `lr` argument. I think this is because we are using Google style PyDocs which aren't natively supported by Sphinx. However, there is a plugin for doing this:
https://stackoverflow.com/questions/7033239/how-to-preserve-line-breaks-when-generating-python-docs-using-sphinx
</issue>
<code>
[start of docs/conf.py]
1 from pallets_sphinx_themes import ProjectLink, get_version
2
3 # -*- coding: utf-8 -*-
4 #
5 # Configuration file for the Sphinx documentation builder.
6 #
7 # This file does only contain a selection of the most common options. For a
8 # full list see the documentation:
9 # http://www.sphinx-doc.org/en/stable/config
10
11 # -- Path setup --------------------------------------------------------------
12
13 # If extensions (or modules to document with autodoc) are in another directory,
14 # add these directories to sys.path here. If the directory is relative to the
15 # documentation root, use os.path.abspath to make it absolute, like shown here.
16 #
17 # import os
18 # import sys
19 # sys.path.insert(0, os.path.abspath('.'))
20
21
22 # -- Project information -----------------------------------------------------
23
24 project = 'Raster Vision'
25 copyright = '2018, Azavea'
26 author = 'Azavea'
27
28 # The short X.Y version
29 version = '0.10'
30 # The full version, including alpha/beta/rc tags
31 release = '0.10.0'
32
33
34 # -- General configuration ---------------------------------------------------
35
36 # If your documentation needs a minimal Sphinx version, state it here.
37 #
38 # needs_sphinx = '1.0'
39
40 # Add any Sphinx extension module names here, as strings. They can be
41 # extensions coming with Sphinx (named 'sphinx.ext.*') or your custom
42 # ones.
43 extensions = [
44 'sphinx.ext.autodoc',
45 'sphinx.ext.intersphinx',
46 'pallets_sphinx_themes',
47 'sphinxcontrib.programoutput'
48 ]
49
50 # https://read-the-docs.readthedocs.io/en/latest/faq.html#i-get-import-errors-on-libraries-that-depend-on-c-modules
51 import sys
52 from unittest.mock import MagicMock
53
54 class Mock(MagicMock):
55 @classmethod
56 def __getattr__(cls, name):
57 return MagicMock()
58
59 MOCK_MODULES = ['pyproj', 'h5py']
60 sys.modules.update((mod_name, Mock()) for mod_name in MOCK_MODULES)
61
62 autodoc_mock_imports = ['torch', 'torchvision', 'pycocotools']
63
64 intersphinx_mapping = {'python': ('https://docs.python.org/3/', None)}
65
66 # Add any paths that contain templates here, relative to this directory.
67 templates_path = ['_templates']
68
69 # The suffix(es) of source filenames.
70 # You can specify multiple suffix as a list of string:
71 #
72 # source_suffix = ['.rst', '.md']
73 source_suffix = '.rst'
74
75 # The master toctree document.
76 master_doc = 'index'
77
78 # The language for content autogenerated by Sphinx. Refer to documentation
79 # for a list of supported languages.
80 #
81 # This is also used if you do content translation via gettext catalogs.
82 # Usually you set "language" from the command line for these cases.
83 language = None
84
85 # List of patterns, relative to source directory, that match files and
86 # directories to ignore when looking for source files.
87 # This pattern also affects html_static_path and html_extra_path .
88 exclude_patterns = ['_build', 'Thumbs.db', '.DS_Store', 'README.md']
89
90 # The name of the Pygments (syntax highlighting) style to use.
91 # pygments_style = 'sphinx'
92
93 # HTML -----------------------------------------------------------------
94
95 html_theme = 'click'
96 html_theme_options = {'index_sidebar_logo': False}
97 html_context = {
98 'project_links': [
99 ProjectLink('Quickstart', 'quickstart.html'),
100 ProjectLink('Documentation TOC', 'index.html#documentation'),
101 ProjectLink('API Reference TOC', 'index.html#api-reference'),
102 ProjectLink('Project Website', 'https://rastervision.io/'),
103 ProjectLink('PyPI releases', 'https://pypi.org/project/rastervision/'),
104 ProjectLink('GitHub', 'https://github.com/azavea/raster-vision'),
105 ProjectLink('Gitter Channel', 'https://gitter.im/azavea/raster-vision'),
106 ProjectLink('Raster Vision Examples', 'https://github.com/azavea/raster-vision-examples'),
107 ProjectLink('AWS Batch Setup', 'https://github.com/azavea/raster-vision-aws'),
108 ProjectLink('Issue Tracker', 'https://github.com/azavea/raster-vision/issues/'),
109 ProjectLink('CHANGELOG', 'changelog.html'),
110 ProjectLink('Azavea', 'https://www.azavea.com/'),
111 ],
112 'css_files': [
113 '_static/rastervision.css',
114 'https://media.readthedocs.org/css/badge_only.css'
115 ]
116 }
117 html_sidebars = {
118 'index': ['project.html', 'versions.html', 'searchbox.html'],
119 '**': ['project.html', 'localtoc.html', 'relations.html', 'versions.html', 'searchbox.html'],
120 }
121 singlehtml_sidebars = {'index': ['project.html', 'versions.html', 'localtoc.html']}
122 html_static_path = ['_static']
123 html_favicon = '_static/raster-vision-icon.png'
124 html_logo = '_static/raster-vision-logo.png'
125 html_title = 'Raster Vision Documentation ({})'.format(version)
126 html_show_sourcelink = False
127 html_domain_indices = False
128 html_experimental_html5_writer = True
129
130 # -- Options for HTMLHelp output ---------------------------------------------
131
132 # Output file base name for HTML help builder.
133 htmlhelp_basename = 'RasterVisiondoc'
134
135
136 # -- Options for LaTeX output ------------------------------------------------
137
138 latex_elements = {
139 # The paper size ('letterpaper' or 'a4paper').
140 #
141 # 'papersize': 'letterpaper',
142
143 # The font size ('10pt', '11pt' or '12pt').
144 #
145 # 'pointsize': '10pt',
146
147 # Additional stuff for the LaTeX preamble.
148 #
149 # 'preamble': '',
150
151 # Latex figure (float) alignment
152 #
153 # 'figure_align': 'htbp',
154 }
155
156 # Grouping the document tree into LaTeX files. List of tuples
157 # (source start file, target name, title,
158 # author, documentclass [howto, manual, or own class]).
159 latex_documents = [
160 (master_doc, 'RasterVision.tex', 'Raster Vision Documentation',
161 'Azavea', 'manual'),
162 ]
163
164
165 # -- Options for manual page output ------------------------------------------
166
167 # One entry per manual page. List of tuples
168 # (source start file, name, description, authors, manual section).
169 man_pages = [
170 (master_doc, 'RasterVisoin-{}.tex', html_title,
171 [author], 'manual')
172 ]
173
174
175 # -- Options for Texinfo output ----------------------------------------------
176
177 # Grouping the document tree into Texinfo files. List of tuples
178 # (source start file, target name, title, author,
179 # dir menu entry, description, category)
180 texinfo_documents = [
181 (master_doc, 'RasterVision', 'Raster Vision Documentation',
182 author, 'RasterVision', 'One line description of project.',
183 'Miscellaneous'),
184 ]
185
186
187 # -- Extension configuration -------------------------------------------------
188
189 programoutput_prompt_template = '> {command}\n{output}'
190
191 # -- Options for todo extension ----------------------------------------------
192
193 # If true, `todo` and `todoList` produce output, else they produce nothing.
194 todo_include_todos = True
195
[end of docs/conf.py]
[start of rastervision/backend/pytorch_chip_classification_config.py]
1 from copy import deepcopy
2
3 import rastervision as rv
4
5 from rastervision.backend.pytorch_chip_classification import (
6 PyTorchChipClassification)
7 from rastervision.backend.simple_backend_config import (
8 SimpleBackendConfig, SimpleBackendConfigBuilder)
9 from rastervision.backend.api import PYTORCH_CHIP_CLASSIFICATION
10
11
12 class TrainOptions():
13 def __init__(self,
14 batch_size=None,
15 lr=None,
16 one_cycle=None,
17 num_epochs=None,
18 model_arch=None,
19 sync_interval=None,
20 debug=None,
21 log_tensorboard=None,
22 run_tensorboard=None):
23 self.batch_size = batch_size
24 self.lr = lr
25 self.one_cycle = one_cycle
26 self.num_epochs = num_epochs
27 self.model_arch = model_arch
28 self.sync_interval = sync_interval
29 self.debug = debug
30 self.log_tensorboard = log_tensorboard
31 self.run_tensorboard = run_tensorboard
32
33 def __setattr__(self, name, value):
34 if name in ['batch_size', 'num_epochs', 'sync_interval']:
35 value = int(value) if isinstance(value, float) else value
36 super().__setattr__(name, value)
37
38
39 class PyTorchChipClassificationConfig(SimpleBackendConfig):
40 train_opts_class = TrainOptions
41 backend_type = PYTORCH_CHIP_CLASSIFICATION
42 backend_class = PyTorchChipClassification
43
44
45 class PyTorchChipClassificationConfigBuilder(SimpleBackendConfigBuilder):
46 config_class = PyTorchChipClassificationConfig
47
48 def _applicable_tasks(self):
49 return [rv.CHIP_CLASSIFICATION]
50
51 def with_train_options(self,
52 batch_size=8,
53 lr=1e-4,
54 one_cycle=True,
55 num_epochs=1,
56 model_arch='resnet18',
57 sync_interval=1,
58 debug=False,
59 log_tensorboard=True,
60 run_tensorboard=True):
61 """Set options for training models.
62
63 Args:
64 batch_size: (int) the batch size
65 weight_decay: (float) the weight decay
66 lr: (float) the learning rate if using a fixed LR
67 (ie. one_cycle is False),
68 or the maximum LR to use if one_cycle is True
69 one_cycle: (bool) True if cyclic learning rate scheduler should
70 be used. This
71 cycles the LR once during the course of training and seems to
72 result in a pretty consistent improvement. See lr for more
73 details.
74 num_epochs: (int) number of epochs (sweeps through training set) to
75 train model for
76 model_arch: (str) classification model backbone to use for UNet
77 architecture. Any option in torchvision.models is valid, for
78 example, resnet18.
79 sync_interval: (int) sync training directory to cloud every
80 sync_interval epochs.
81 debug: (bool) if True, save debug chips (ie. visualizations of
82 input to model during training) during training and use
83 single-core for creating minibatches.
84 log_tensorboard: (bool) if True, write events to Tensorboard log
85 file
86 run_tensorboard: (bool) if True, run a Tensorboard server at
87 port 6006 that uses the logs generated by the log_tensorboard
88 option
89 """
90 b = deepcopy(self)
91 b.train_opts = TrainOptions(
92 batch_size=batch_size,
93 lr=lr,
94 one_cycle=one_cycle,
95 num_epochs=num_epochs,
96 model_arch=model_arch,
97 sync_interval=sync_interval,
98 debug=debug,
99 log_tensorboard=log_tensorboard,
100 run_tensorboard=run_tensorboard)
101 return b
102
103 def with_pretrained_uri(self, pretrained_uri):
104 """pretrained_uri should be uri of exported model file."""
105 return super().with_pretrained_uri(pretrained_uri)
106
[end of rastervision/backend/pytorch_chip_classification_config.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/docs/conf.py b/docs/conf.py
--- a/docs/conf.py
+++ b/docs/conf.py
@@ -44,7 +44,8 @@
'sphinx.ext.autodoc',
'sphinx.ext.intersphinx',
'pallets_sphinx_themes',
- 'sphinxcontrib.programoutput'
+ 'sphinxcontrib.programoutput',
+ 'sphinxcontrib.napoleon',
]
# https://read-the-docs.readthedocs.io/en/latest/faq.html#i-get-import-errors-on-libraries-that-depend-on-c-modules
diff --git a/rastervision/backend/pytorch_chip_classification_config.py b/rastervision/backend/pytorch_chip_classification_config.py
--- a/rastervision/backend/pytorch_chip_classification_config.py
+++ b/rastervision/backend/pytorch_chip_classification_config.py
@@ -73,9 +73,8 @@
details.
num_epochs: (int) number of epochs (sweeps through training set) to
train model for
- model_arch: (str) classification model backbone to use for UNet
- architecture. Any option in torchvision.models is valid, for
- example, resnet18.
+ model_arch: (str) Any classification model option in
+ torchvision.models is valid, for example, resnet18.
sync_interval: (int) sync training directory to cloud every
sync_interval epochs.
debug: (bool) if True, save debug chips (ie. visualizations of
|
{"golden_diff": "diff --git a/docs/conf.py b/docs/conf.py\n--- a/docs/conf.py\n+++ b/docs/conf.py\n@@ -44,7 +44,8 @@\n 'sphinx.ext.autodoc',\n 'sphinx.ext.intersphinx',\n 'pallets_sphinx_themes',\n- 'sphinxcontrib.programoutput'\n+ 'sphinxcontrib.programoutput',\n+ 'sphinxcontrib.napoleon',\n ]\n \n # https://read-the-docs.readthedocs.io/en/latest/faq.html#i-get-import-errors-on-libraries-that-depend-on-c-modules\ndiff --git a/rastervision/backend/pytorch_chip_classification_config.py b/rastervision/backend/pytorch_chip_classification_config.py\n--- a/rastervision/backend/pytorch_chip_classification_config.py\n+++ b/rastervision/backend/pytorch_chip_classification_config.py\n@@ -73,9 +73,8 @@\n details.\n num_epochs: (int) number of epochs (sweeps through training set) to\n train model for\n- model_arch: (str) classification model backbone to use for UNet\n- architecture. Any option in torchvision.models is valid, for\n- example, resnet18.\n+ model_arch: (str) Any classification model option in\n+ torchvision.models is valid, for example, resnet18.\n sync_interval: (int) sync training directory to cloud every\n sync_interval epochs.\n debug: (bool) if True, save debug chips (ie. visualizations of\n", "issue": "Get Sphinx to render Google-style API docs correctly\nIn the API docs on RTD https://docs.rastervision.io/en/latest/api.html, the line breaks in the docs aren't rendered correctly. In particular, the `lr` argument for the PyTorch backends is on the same line as the `batch_size` argument, which obscures the `lr` argument. I think this is because we are using Google style PyDocs which aren't natively supported by Sphinx. However, there is a plugin for doing this:\r\n\r\nhttps://stackoverflow.com/questions/7033239/how-to-preserve-line-breaks-when-generating-python-docs-using-sphinx\n", "before_files": [{"content": "from pallets_sphinx_themes import ProjectLink, get_version\n\n# -*- coding: utf-8 -*-\n#\n# Configuration file for the Sphinx documentation builder.\n#\n# This file does only contain a selection of the most common options. For a\n# full list see the documentation:\n# http://www.sphinx-doc.org/en/stable/config\n\n# -- Path setup --------------------------------------------------------------\n\n# If extensions (or modules to document with autodoc) are in another directory,\n# add these directories to sys.path here. If the directory is relative to the\n# documentation root, use os.path.abspath to make it absolute, like shown here.\n#\n# import os\n# import sys\n# sys.path.insert(0, os.path.abspath('.'))\n\n\n# -- Project information -----------------------------------------------------\n\nproject = 'Raster Vision'\ncopyright = '2018, Azavea'\nauthor = 'Azavea'\n\n# The short X.Y version\nversion = '0.10'\n# The full version, including alpha/beta/rc tags\nrelease = '0.10.0'\n\n\n# -- General configuration ---------------------------------------------------\n\n# If your documentation needs a minimal Sphinx version, state it here.\n#\n# needs_sphinx = '1.0'\n\n# Add any Sphinx extension module names here, as strings. They can be\n# extensions coming with Sphinx (named 'sphinx.ext.*') or your custom\n# ones.\nextensions = [\n 'sphinx.ext.autodoc',\n 'sphinx.ext.intersphinx',\n 'pallets_sphinx_themes',\n 'sphinxcontrib.programoutput'\n]\n\n# https://read-the-docs.readthedocs.io/en/latest/faq.html#i-get-import-errors-on-libraries-that-depend-on-c-modules\nimport sys\nfrom unittest.mock import MagicMock\n\nclass Mock(MagicMock):\n @classmethod\n def __getattr__(cls, name):\n return MagicMock()\n\nMOCK_MODULES = ['pyproj', 'h5py']\nsys.modules.update((mod_name, Mock()) for mod_name in MOCK_MODULES)\n\nautodoc_mock_imports = ['torch', 'torchvision', 'pycocotools']\n\nintersphinx_mapping = {'python': ('https://docs.python.org/3/', None)}\n\n# Add any paths that contain templates here, relative to this directory.\ntemplates_path = ['_templates']\n\n# The suffix(es) of source filenames.\n# You can specify multiple suffix as a list of string:\n#\n# source_suffix = ['.rst', '.md']\nsource_suffix = '.rst'\n\n# The master toctree document.\nmaster_doc = 'index'\n\n# The language for content autogenerated by Sphinx. Refer to documentation\n# for a list of supported languages.\n#\n# This is also used if you do content translation via gettext catalogs.\n# Usually you set \"language\" from the command line for these cases.\nlanguage = None\n\n# List of patterns, relative to source directory, that match files and\n# directories to ignore when looking for source files.\n# This pattern also affects html_static_path and html_extra_path .\nexclude_patterns = ['_build', 'Thumbs.db', '.DS_Store', 'README.md']\n\n# The name of the Pygments (syntax highlighting) style to use.\n# pygments_style = 'sphinx'\n\n# HTML -----------------------------------------------------------------\n\nhtml_theme = 'click'\nhtml_theme_options = {'index_sidebar_logo': False}\nhtml_context = {\n 'project_links': [\n ProjectLink('Quickstart', 'quickstart.html'),\n ProjectLink('Documentation TOC', 'index.html#documentation'),\n ProjectLink('API Reference TOC', 'index.html#api-reference'),\n ProjectLink('Project Website', 'https://rastervision.io/'),\n ProjectLink('PyPI releases', 'https://pypi.org/project/rastervision/'),\n ProjectLink('GitHub', 'https://github.com/azavea/raster-vision'),\n ProjectLink('Gitter Channel', 'https://gitter.im/azavea/raster-vision'),\n ProjectLink('Raster Vision Examples', 'https://github.com/azavea/raster-vision-examples'),\n ProjectLink('AWS Batch Setup', 'https://github.com/azavea/raster-vision-aws'),\n ProjectLink('Issue Tracker', 'https://github.com/azavea/raster-vision/issues/'),\n ProjectLink('CHANGELOG', 'changelog.html'),\n ProjectLink('Azavea', 'https://www.azavea.com/'),\n ],\n 'css_files': [\n '_static/rastervision.css',\n 'https://media.readthedocs.org/css/badge_only.css'\n ]\n}\nhtml_sidebars = {\n 'index': ['project.html', 'versions.html', 'searchbox.html'],\n '**': ['project.html', 'localtoc.html', 'relations.html', 'versions.html', 'searchbox.html'],\n}\nsinglehtml_sidebars = {'index': ['project.html', 'versions.html', 'localtoc.html']}\nhtml_static_path = ['_static']\nhtml_favicon = '_static/raster-vision-icon.png'\nhtml_logo = '_static/raster-vision-logo.png'\nhtml_title = 'Raster Vision Documentation ({})'.format(version)\nhtml_show_sourcelink = False\nhtml_domain_indices = False\nhtml_experimental_html5_writer = True\n\n# -- Options for HTMLHelp output ---------------------------------------------\n\n# Output file base name for HTML help builder.\nhtmlhelp_basename = 'RasterVisiondoc'\n\n\n# -- Options for LaTeX output ------------------------------------------------\n\nlatex_elements = {\n # The paper size ('letterpaper' or 'a4paper').\n #\n # 'papersize': 'letterpaper',\n\n # The font size ('10pt', '11pt' or '12pt').\n #\n # 'pointsize': '10pt',\n\n # Additional stuff for the LaTeX preamble.\n #\n # 'preamble': '',\n\n # Latex figure (float) alignment\n #\n # 'figure_align': 'htbp',\n}\n\n# Grouping the document tree into LaTeX files. List of tuples\n# (source start file, target name, title,\n# author, documentclass [howto, manual, or own class]).\nlatex_documents = [\n (master_doc, 'RasterVision.tex', 'Raster Vision Documentation',\n 'Azavea', 'manual'),\n]\n\n\n# -- Options for manual page output ------------------------------------------\n\n# One entry per manual page. List of tuples\n# (source start file, name, description, authors, manual section).\nman_pages = [\n (master_doc, 'RasterVisoin-{}.tex', html_title,\n [author], 'manual')\n]\n\n\n# -- Options for Texinfo output ----------------------------------------------\n\n# Grouping the document tree into Texinfo files. List of tuples\n# (source start file, target name, title, author,\n# dir menu entry, description, category)\ntexinfo_documents = [\n (master_doc, 'RasterVision', 'Raster Vision Documentation',\n author, 'RasterVision', 'One line description of project.',\n 'Miscellaneous'),\n]\n\n\n# -- Extension configuration -------------------------------------------------\n\nprogramoutput_prompt_template = '> {command}\\n{output}'\n\n# -- Options for todo extension ----------------------------------------------\n\n# If true, `todo` and `todoList` produce output, else they produce nothing.\ntodo_include_todos = True\n", "path": "docs/conf.py"}, {"content": "from copy import deepcopy\n\nimport rastervision as rv\n\nfrom rastervision.backend.pytorch_chip_classification import (\n PyTorchChipClassification)\nfrom rastervision.backend.simple_backend_config import (\n SimpleBackendConfig, SimpleBackendConfigBuilder)\nfrom rastervision.backend.api import PYTORCH_CHIP_CLASSIFICATION\n\n\nclass TrainOptions():\n def __init__(self,\n batch_size=None,\n lr=None,\n one_cycle=None,\n num_epochs=None,\n model_arch=None,\n sync_interval=None,\n debug=None,\n log_tensorboard=None,\n run_tensorboard=None):\n self.batch_size = batch_size\n self.lr = lr\n self.one_cycle = one_cycle\n self.num_epochs = num_epochs\n self.model_arch = model_arch\n self.sync_interval = sync_interval\n self.debug = debug\n self.log_tensorboard = log_tensorboard\n self.run_tensorboard = run_tensorboard\n\n def __setattr__(self, name, value):\n if name in ['batch_size', 'num_epochs', 'sync_interval']:\n value = int(value) if isinstance(value, float) else value\n super().__setattr__(name, value)\n\n\nclass PyTorchChipClassificationConfig(SimpleBackendConfig):\n train_opts_class = TrainOptions\n backend_type = PYTORCH_CHIP_CLASSIFICATION\n backend_class = PyTorchChipClassification\n\n\nclass PyTorchChipClassificationConfigBuilder(SimpleBackendConfigBuilder):\n config_class = PyTorchChipClassificationConfig\n\n def _applicable_tasks(self):\n return [rv.CHIP_CLASSIFICATION]\n\n def with_train_options(self,\n batch_size=8,\n lr=1e-4,\n one_cycle=True,\n num_epochs=1,\n model_arch='resnet18',\n sync_interval=1,\n debug=False,\n log_tensorboard=True,\n run_tensorboard=True):\n \"\"\"Set options for training models.\n\n Args:\n batch_size: (int) the batch size\n weight_decay: (float) the weight decay\n lr: (float) the learning rate if using a fixed LR\n (ie. one_cycle is False),\n or the maximum LR to use if one_cycle is True\n one_cycle: (bool) True if cyclic learning rate scheduler should\n be used. This\n cycles the LR once during the course of training and seems to\n result in a pretty consistent improvement. See lr for more\n details.\n num_epochs: (int) number of epochs (sweeps through training set) to\n train model for\n model_arch: (str) classification model backbone to use for UNet\n architecture. Any option in torchvision.models is valid, for\n example, resnet18.\n sync_interval: (int) sync training directory to cloud every\n sync_interval epochs.\n debug: (bool) if True, save debug chips (ie. visualizations of\n input to model during training) during training and use\n single-core for creating minibatches.\n log_tensorboard: (bool) if True, write events to Tensorboard log\n file\n run_tensorboard: (bool) if True, run a Tensorboard server at\n port 6006 that uses the logs generated by the log_tensorboard\n option\n \"\"\"\n b = deepcopy(self)\n b.train_opts = TrainOptions(\n batch_size=batch_size,\n lr=lr,\n one_cycle=one_cycle,\n num_epochs=num_epochs,\n model_arch=model_arch,\n sync_interval=sync_interval,\n debug=debug,\n log_tensorboard=log_tensorboard,\n run_tensorboard=run_tensorboard)\n return b\n\n def with_pretrained_uri(self, pretrained_uri):\n \"\"\"pretrained_uri should be uri of exported model file.\"\"\"\n return super().with_pretrained_uri(pretrained_uri)\n", "path": "rastervision/backend/pytorch_chip_classification_config.py"}]}
| 3,760 | 327 |
gh_patches_debug_40253
|
rasdani/github-patches
|
git_diff
|
openai__gym-1376
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Cannot use gym.utils.play.PlayPlot
```
from gym.utils.play import play, PlayPlot
def callback(obs_t, obs_tp1, action, rew, done, info):
return [rew,]
env_plotter = PlayPlot(callback, 30 * 5, ["reward"])
env = gym.make("IceHockey-v0")
```
I got : self.fig, self.ax = plt.subplots(num_plots) NameError: name 'plt' is not defined
</issue>
<code>
[start of gym/utils/play.py]
1 import gym
2 import pygame
3 import sys
4 import time
5 import matplotlib
6 import argparse
7 try:
8 matplotlib.use('GTK3Agg')
9 import matplotlib.pyplot as plt
10 except Exception:
11 pass
12
13
14 import pyglet.window as pw
15
16 from collections import deque
17 from pygame.locals import HWSURFACE, DOUBLEBUF, RESIZABLE, VIDEORESIZE
18 from threading import Thread
19
20 parser = argparse.ArgumentParser()
21 parser.add_argument('--env', type=str, default='MontezumaRevengeNoFrameskip-v4', help='Define Environment')
22 args = parser.parse_args()
23
24 def display_arr(screen, arr, video_size, transpose):
25 arr_min, arr_max = arr.min(), arr.max()
26 arr = 255.0 * (arr - arr_min) / (arr_max - arr_min)
27 pyg_img = pygame.surfarray.make_surface(arr.swapaxes(0, 1) if transpose else arr)
28 pyg_img = pygame.transform.scale(pyg_img, video_size)
29 screen.blit(pyg_img, (0,0))
30
31 def play(env, transpose=True, fps=30, zoom=None, callback=None, keys_to_action=None):
32 """Allows one to play the game using keyboard.
33
34 To simply play the game use:
35
36 play(gym.make("Pong-v3"))
37
38 Above code works also if env is wrapped, so it's particularly useful in
39 verifying that the frame-level preprocessing does not render the game
40 unplayable.
41
42 If you wish to plot real time statistics as you play, you can use
43 gym.utils.play.PlayPlot. Here's a sample code for plotting the reward
44 for last 5 second of gameplay.
45
46 def callback(obs_t, obs_tp1, rew, done, info):
47 return [rew,]
48 env_plotter = EnvPlotter(callback, 30 * 5, ["reward"])
49
50 env = gym.make("Pong-v3")
51 play(env, callback=env_plotter.callback)
52
53
54 Arguments
55 ---------
56 env: gym.Env
57 Environment to use for playing.
58 transpose: bool
59 If True the output of observation is transposed.
60 Defaults to true.
61 fps: int
62 Maximum number of steps of the environment to execute every second.
63 Defaults to 30.
64 zoom: float
65 Make screen edge this many times bigger
66 callback: lambda or None
67 Callback if a callback is provided it will be executed after
68 every step. It takes the following input:
69 obs_t: observation before performing action
70 obs_tp1: observation after performing action
71 action: action that was executed
72 rew: reward that was received
73 done: whether the environment is done or not
74 info: debug info
75 keys_to_action: dict: tuple(int) -> int or None
76 Mapping from keys pressed to action performed.
77 For example if pressed 'w' and space at the same time is supposed
78 to trigger action number 2 then key_to_action dict would look like this:
79
80 {
81 # ...
82 sorted(ord('w'), ord(' ')) -> 2
83 # ...
84 }
85 If None, default key_to_action mapping for that env is used, if provided.
86 """
87
88 obs_s = env.observation_space
89 assert type(obs_s) == gym.spaces.box.Box
90 assert len(obs_s.shape) == 2 or (len(obs_s.shape) == 3 and obs_s.shape[2] in [1,3])
91
92 if keys_to_action is None:
93 if hasattr(env, 'get_keys_to_action'):
94 keys_to_action = env.get_keys_to_action()
95 elif hasattr(env.unwrapped, 'get_keys_to_action'):
96 keys_to_action = env.unwrapped.get_keys_to_action()
97 else:
98 assert False, env.spec.id + " does not have explicit key to action mapping, " + \
99 "please specify one manually"
100 relevant_keys = set(sum(map(list, keys_to_action.keys()),[]))
101
102 if transpose:
103 video_size = env.observation_space.shape[1], env.observation_space.shape[0]
104 else:
105 video_size = env.observation_space.shape[0], env.observation_space.shape[1]
106
107 if zoom is not None:
108 video_size = int(video_size[0] * zoom), int(video_size[1] * zoom)
109
110 pressed_keys = []
111 running = True
112 env_done = True
113
114 screen = pygame.display.set_mode(video_size)
115 clock = pygame.time.Clock()
116
117
118 while running:
119 if env_done:
120 env_done = False
121 obs = env.reset()
122 else:
123 action = keys_to_action.get(tuple(sorted(pressed_keys)), 0)
124 prev_obs = obs
125 obs, rew, env_done, info = env.step(action)
126 if callback is not None:
127 callback(prev_obs, obs, action, rew, env_done, info)
128 if obs is not None:
129 if len(obs.shape) == 2:
130 obs = obs[:, :, None]
131 if obs.shape[2] == 1:
132 obs = obs.repeat(3, axis=2)
133 display_arr(screen, obs, transpose=transpose, video_size=video_size)
134
135 # process pygame events
136 for event in pygame.event.get():
137 # test events, set key states
138 if event.type == pygame.KEYDOWN:
139 if event.key in relevant_keys:
140 pressed_keys.append(event.key)
141 elif event.key == 27:
142 running = False
143 elif event.type == pygame.KEYUP:
144 if event.key in relevant_keys:
145 pressed_keys.remove(event.key)
146 elif event.type == pygame.QUIT:
147 running = False
148 elif event.type == VIDEORESIZE:
149 video_size = event.size
150 screen = pygame.display.set_mode(video_size)
151 print(video_size)
152
153 pygame.display.flip()
154 clock.tick(fps)
155 pygame.quit()
156
157 class PlayPlot(object):
158 def __init__(self, callback, horizon_timesteps, plot_names):
159 self.data_callback = callback
160 self.horizon_timesteps = horizon_timesteps
161 self.plot_names = plot_names
162
163 num_plots = len(self.plot_names)
164 self.fig, self.ax = plt.subplots(num_plots)
165 if num_plots == 1:
166 self.ax = [self.ax]
167 for axis, name in zip(self.ax, plot_names):
168 axis.set_title(name)
169 self.t = 0
170 self.cur_plot = [None for _ in range(num_plots)]
171 self.data = [deque(maxlen=horizon_timesteps) for _ in range(num_plots)]
172
173 def callback(self, obs_t, obs_tp1, action, rew, done, info):
174 points = self.data_callback(obs_t, obs_tp1, action, rew, done, info)
175 for point, data_series in zip(points, self.data):
176 data_series.append(point)
177 self.t += 1
178
179 xmin, xmax = max(0, self.t - self.horizon_timesteps), self.t
180
181 for i, plot in enumerate(self.cur_plot):
182 if plot is not None:
183 plot.remove()
184 self.cur_plot[i] = self.ax[i].scatter(range(xmin, xmax), list(self.data[i]))
185 self.ax[i].set_xlim(xmin, xmax)
186 plt.pause(0.000001)
187
188
189 if __name__ == '__main__':
190 env = gym.make(args.env)
191 play(env, zoom=4, fps=60)
192
[end of gym/utils/play.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/gym/utils/play.py b/gym/utils/play.py
--- a/gym/utils/play.py
+++ b/gym/utils/play.py
@@ -1,25 +1,18 @@
import gym
import pygame
-import sys
-import time
import matplotlib
import argparse
+from gym import logger
try:
- matplotlib.use('GTK3Agg')
+ matplotlib.use('TkAgg')
import matplotlib.pyplot as plt
-except Exception:
- pass
-
-
-import pyglet.window as pw
+except ImportError as e:
+ logger.warn('failed to set matplotlib backend, plotting will not work: %s' % str(e))
+ plt = None
from collections import deque
-from pygame.locals import HWSURFACE, DOUBLEBUF, RESIZABLE, VIDEORESIZE
-from threading import Thread
+from pygame.locals import VIDEORESIZE
-parser = argparse.ArgumentParser()
-parser.add_argument('--env', type=str, default='MontezumaRevengeNoFrameskip-v4', help='Define Environment')
-args = parser.parse_args()
def display_arr(screen, arr, video_size, transpose):
arr_min, arr_max = arr.min(), arr.max()
@@ -33,7 +26,7 @@
To simply play the game use:
- play(gym.make("Pong-v3"))
+ play(gym.make("Pong-v4"))
Above code works also if env is wrapped, so it's particularly useful in
verifying that the frame-level preprocessing does not render the game
@@ -43,12 +36,12 @@
gym.utils.play.PlayPlot. Here's a sample code for plotting the reward
for last 5 second of gameplay.
- def callback(obs_t, obs_tp1, rew, done, info):
+ def callback(obs_t, obs_tp1, action, rew, done, info):
return [rew,]
- env_plotter = EnvPlotter(callback, 30 * 5, ["reward"])
+ plotter = PlayPlot(callback, 30 * 5, ["reward"])
- env = gym.make("Pong-v3")
- play(env, callback=env_plotter.callback)
+ env = gym.make("Pong-v4")
+ play(env, callback=plotter.callback)
Arguments
@@ -160,6 +153,8 @@
self.horizon_timesteps = horizon_timesteps
self.plot_names = plot_names
+ assert plt is not None, "matplotlib backend failed, plotting will not work"
+
num_plots = len(self.plot_names)
self.fig, self.ax = plt.subplots(num_plots)
if num_plots == 1:
@@ -181,11 +176,18 @@
for i, plot in enumerate(self.cur_plot):
if plot is not None:
plot.remove()
- self.cur_plot[i] = self.ax[i].scatter(range(xmin, xmax), list(self.data[i]))
+ self.cur_plot[i] = self.ax[i].scatter(range(xmin, xmax), list(self.data[i]), c='blue')
self.ax[i].set_xlim(xmin, xmax)
plt.pause(0.000001)
-if __name__ == '__main__':
+def main():
+ parser = argparse.ArgumentParser()
+ parser.add_argument('--env', type=str, default='MontezumaRevengeNoFrameskip-v4', help='Define Environment')
+ args = parser.parse_args()
env = gym.make(args.env)
play(env, zoom=4, fps=60)
+
+
+if __name__ == '__main__':
+ main()
|
{"golden_diff": "diff --git a/gym/utils/play.py b/gym/utils/play.py\n--- a/gym/utils/play.py\n+++ b/gym/utils/play.py\n@@ -1,25 +1,18 @@\n import gym\n import pygame\n-import sys\n-import time\n import matplotlib\n import argparse\n+from gym import logger\n try:\n- matplotlib.use('GTK3Agg')\n+ matplotlib.use('TkAgg')\n import matplotlib.pyplot as plt\n-except Exception:\n- pass\n-\n-\n-import pyglet.window as pw\n+except ImportError as e:\n+ logger.warn('failed to set matplotlib backend, plotting will not work: %s' % str(e))\n+ plt = None\n \n from collections import deque\n-from pygame.locals import HWSURFACE, DOUBLEBUF, RESIZABLE, VIDEORESIZE\n-from threading import Thread\n+from pygame.locals import VIDEORESIZE\n \n-parser = argparse.ArgumentParser()\n-parser.add_argument('--env', type=str, default='MontezumaRevengeNoFrameskip-v4', help='Define Environment')\n-args = parser.parse_args()\n \t\n def display_arr(screen, arr, video_size, transpose):\n arr_min, arr_max = arr.min(), arr.max()\n@@ -33,7 +26,7 @@\n \n To simply play the game use:\n \n- play(gym.make(\"Pong-v3\"))\n+ play(gym.make(\"Pong-v4\"))\n \n Above code works also if env is wrapped, so it's particularly useful in\n verifying that the frame-level preprocessing does not render the game\n@@ -43,12 +36,12 @@\n gym.utils.play.PlayPlot. Here's a sample code for plotting the reward\n for last 5 second of gameplay.\n \n- def callback(obs_t, obs_tp1, rew, done, info):\n+ def callback(obs_t, obs_tp1, action, rew, done, info):\n return [rew,]\n- env_plotter = EnvPlotter(callback, 30 * 5, [\"reward\"])\n+ plotter = PlayPlot(callback, 30 * 5, [\"reward\"])\n \n- env = gym.make(\"Pong-v3\")\n- play(env, callback=env_plotter.callback)\n+ env = gym.make(\"Pong-v4\")\n+ play(env, callback=plotter.callback)\n \n \n Arguments\n@@ -160,6 +153,8 @@\n self.horizon_timesteps = horizon_timesteps\n self.plot_names = plot_names\n \n+ assert plt is not None, \"matplotlib backend failed, plotting will not work\"\n+\n num_plots = len(self.plot_names)\n self.fig, self.ax = plt.subplots(num_plots)\n if num_plots == 1:\n@@ -181,11 +176,18 @@\n for i, plot in enumerate(self.cur_plot):\n if plot is not None:\n plot.remove()\n- self.cur_plot[i] = self.ax[i].scatter(range(xmin, xmax), list(self.data[i]))\n+ self.cur_plot[i] = self.ax[i].scatter(range(xmin, xmax), list(self.data[i]), c='blue')\n self.ax[i].set_xlim(xmin, xmax)\n plt.pause(0.000001)\n \n \n-if __name__ == '__main__':\n+def main():\n+ parser = argparse.ArgumentParser()\n+ parser.add_argument('--env', type=str, default='MontezumaRevengeNoFrameskip-v4', help='Define Environment')\n+ args = parser.parse_args()\n env = gym.make(args.env)\n play(env, zoom=4, fps=60)\n+\n+\n+if __name__ == '__main__':\n+ main()\n", "issue": "Cannot use gym.utils.play.PlayPlot\n```\r\nfrom gym.utils.play import play, PlayPlot\r\ndef callback(obs_t, obs_tp1, action, rew, done, info):\r\n return [rew,]\r\nenv_plotter = PlayPlot(callback, 30 * 5, [\"reward\"])\r\nenv = gym.make(\"IceHockey-v0\")\r\n```\r\nI got : self.fig, self.ax = plt.subplots(num_plots) NameError: name 'plt' is not defined\n", "before_files": [{"content": "import gym\nimport pygame\nimport sys\nimport time\nimport matplotlib\nimport argparse\ntry:\n matplotlib.use('GTK3Agg')\n import matplotlib.pyplot as plt\nexcept Exception:\n pass\n\n\nimport pyglet.window as pw\n\nfrom collections import deque\nfrom pygame.locals import HWSURFACE, DOUBLEBUF, RESIZABLE, VIDEORESIZE\nfrom threading import Thread\n\nparser = argparse.ArgumentParser()\nparser.add_argument('--env', type=str, default='MontezumaRevengeNoFrameskip-v4', help='Define Environment')\nargs = parser.parse_args()\n\t\ndef display_arr(screen, arr, video_size, transpose):\n arr_min, arr_max = arr.min(), arr.max()\n arr = 255.0 * (arr - arr_min) / (arr_max - arr_min)\n pyg_img = pygame.surfarray.make_surface(arr.swapaxes(0, 1) if transpose else arr)\n pyg_img = pygame.transform.scale(pyg_img, video_size)\n screen.blit(pyg_img, (0,0))\n\ndef play(env, transpose=True, fps=30, zoom=None, callback=None, keys_to_action=None):\n \"\"\"Allows one to play the game using keyboard.\n\n To simply play the game use:\n\n play(gym.make(\"Pong-v3\"))\n\n Above code works also if env is wrapped, so it's particularly useful in\n verifying that the frame-level preprocessing does not render the game\n unplayable.\n\n If you wish to plot real time statistics as you play, you can use\n gym.utils.play.PlayPlot. Here's a sample code for plotting the reward\n for last 5 second of gameplay.\n\n def callback(obs_t, obs_tp1, rew, done, info):\n return [rew,]\n env_plotter = EnvPlotter(callback, 30 * 5, [\"reward\"])\n\n env = gym.make(\"Pong-v3\")\n play(env, callback=env_plotter.callback)\n\n\n Arguments\n ---------\n env: gym.Env\n Environment to use for playing.\n transpose: bool\n If True the output of observation is transposed.\n Defaults to true.\n fps: int\n Maximum number of steps of the environment to execute every second.\n Defaults to 30.\n zoom: float\n Make screen edge this many times bigger\n callback: lambda or None\n Callback if a callback is provided it will be executed after\n every step. It takes the following input:\n obs_t: observation before performing action\n obs_tp1: observation after performing action\n action: action that was executed\n rew: reward that was received\n done: whether the environment is done or not\n info: debug info\n keys_to_action: dict: tuple(int) -> int or None\n Mapping from keys pressed to action performed.\n For example if pressed 'w' and space at the same time is supposed\n to trigger action number 2 then key_to_action dict would look like this:\n\n {\n # ...\n sorted(ord('w'), ord(' ')) -> 2\n # ...\n }\n If None, default key_to_action mapping for that env is used, if provided.\n \"\"\"\n\n obs_s = env.observation_space\n assert type(obs_s) == gym.spaces.box.Box\n assert len(obs_s.shape) == 2 or (len(obs_s.shape) == 3 and obs_s.shape[2] in [1,3])\n\n if keys_to_action is None:\n if hasattr(env, 'get_keys_to_action'):\n keys_to_action = env.get_keys_to_action()\n elif hasattr(env.unwrapped, 'get_keys_to_action'):\n keys_to_action = env.unwrapped.get_keys_to_action()\n else:\n assert False, env.spec.id + \" does not have explicit key to action mapping, \" + \\\n \"please specify one manually\"\n relevant_keys = set(sum(map(list, keys_to_action.keys()),[]))\n\n if transpose:\n video_size = env.observation_space.shape[1], env.observation_space.shape[0]\n else:\n video_size = env.observation_space.shape[0], env.observation_space.shape[1]\n\n if zoom is not None:\n video_size = int(video_size[0] * zoom), int(video_size[1] * zoom)\n\n pressed_keys = []\n running = True\n env_done = True\n\n screen = pygame.display.set_mode(video_size)\n clock = pygame.time.Clock()\n\n\n while running:\n if env_done:\n env_done = False\n obs = env.reset()\n else:\n action = keys_to_action.get(tuple(sorted(pressed_keys)), 0)\n prev_obs = obs\n obs, rew, env_done, info = env.step(action)\n if callback is not None:\n callback(prev_obs, obs, action, rew, env_done, info)\n if obs is not None:\n if len(obs.shape) == 2:\n obs = obs[:, :, None]\n if obs.shape[2] == 1:\n obs = obs.repeat(3, axis=2)\n display_arr(screen, obs, transpose=transpose, video_size=video_size)\n\n # process pygame events\n for event in pygame.event.get():\n # test events, set key states\n if event.type == pygame.KEYDOWN:\n if event.key in relevant_keys:\n pressed_keys.append(event.key)\n elif event.key == 27:\n running = False\n elif event.type == pygame.KEYUP:\n if event.key in relevant_keys:\n pressed_keys.remove(event.key)\n elif event.type == pygame.QUIT:\n running = False\n elif event.type == VIDEORESIZE:\n video_size = event.size\n screen = pygame.display.set_mode(video_size)\n print(video_size)\n\n pygame.display.flip()\n clock.tick(fps)\n pygame.quit()\n\nclass PlayPlot(object):\n def __init__(self, callback, horizon_timesteps, plot_names):\n self.data_callback = callback\n self.horizon_timesteps = horizon_timesteps\n self.plot_names = plot_names\n\n num_plots = len(self.plot_names)\n self.fig, self.ax = plt.subplots(num_plots)\n if num_plots == 1:\n self.ax = [self.ax]\n for axis, name in zip(self.ax, plot_names):\n axis.set_title(name)\n self.t = 0\n self.cur_plot = [None for _ in range(num_plots)]\n self.data = [deque(maxlen=horizon_timesteps) for _ in range(num_plots)]\n\n def callback(self, obs_t, obs_tp1, action, rew, done, info):\n points = self.data_callback(obs_t, obs_tp1, action, rew, done, info)\n for point, data_series in zip(points, self.data):\n data_series.append(point)\n self.t += 1\n\n xmin, xmax = max(0, self.t - self.horizon_timesteps), self.t\n\n for i, plot in enumerate(self.cur_plot):\n if plot is not None:\n plot.remove()\n self.cur_plot[i] = self.ax[i].scatter(range(xmin, xmax), list(self.data[i]))\n self.ax[i].set_xlim(xmin, xmax)\n plt.pause(0.000001)\n\n\nif __name__ == '__main__':\n env = gym.make(args.env)\n play(env, zoom=4, fps=60)\n", "path": "gym/utils/play.py"}]}
| 2,706 | 797 |
gh_patches_debug_13960
|
rasdani/github-patches
|
git_diff
|
uccser__cs-unplugged-1464
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
HTML can be inserted into a user's Plugging it in challenge templates
### The steps are:
- [Open any programming challenge on PII](https://www.csunplugged.org/en/plugging-it-in/binary-numbers/how-binary-digits-work/binary-numbers-no-calculations/)
- Submit this code in the answer box:
- `</script><script type="text/javascript">console.log("hi")</script>`
- It must be all on one line
- Adapt to your desired level of maliciousness
- Refresh the page
When the user re-requests the page, the submitted 'code' is loaded [in the HTML template](https://github.com/uccser/cs-unplugged/blob/develop/csunplugged/templates/plugging_it_in/programming-challenge.html#L191). The first `</script>` closes the script that assigns the variables, and what follows is loaded as a new HTML script tag. The resulting HTML is sent to the user and executes 'as normal'.
I haven't been able to submit code that executes while also not breaking every PII challenge page. When the page does break, deleting your cookies for CSU allows you to get it working again
### Three potential fixes
- [Escape the submitted code.](https://docs.djangoproject.com/en/3.1/ref/utils/#module-django.utils.html)
- It was already escaped, the problem is that [it gets un-escaped](https://docs.djangoproject.com/en/2.2/ref/templates/language/#automatic-html-escaping) in order to load as a variable.
- So we would need to un-escape it in JS rather than HTML, and doing so will be tricky
(`'}}<` etc is loaded into the answer box)
- Don't load the user submitted code into the HTML template, and instead request it in JS
- Will be slower, another request is needed
- Load the submitted code in the HTML, not as a variable, but straight into the <textarea> answer box.
- This is how it's done in CodeWOF
- Since it's in a <textarea> everything is rendered as plaintext
</issue>
<code>
[start of csunplugged/config/__init__.py]
1 """Module for Django system configuration."""
2
3 __version__ = "6.0.0"
4
[end of csunplugged/config/__init__.py]
[start of csunplugged/plugging_it_in/views.py]
1 """Views for the plugging_it_in application."""
2
3 from django.http import HttpResponse
4 from django.http import Http404
5
6 import json
7 import requests
8
9 from django.shortcuts import get_object_or_404
10 from django.views import generic
11 from django.views import View
12 from django.urls import reverse
13 from django.conf import settings
14 from django.core.exceptions import ObjectDoesNotExist
15 from utils.translated_first import translated_first
16 from utils.group_lessons_by_age import group_lessons_by_age
17
18 from topics.models import (
19 Topic,
20 ProgrammingChallenge,
21 Lesson
22 )
23
24
25 class IndexView(generic.ListView):
26 """View for the topics application homepage."""
27
28 template_name = "plugging_it_in/index.html"
29 context_object_name = "programming_topics"
30
31 def get_queryset(self):
32 """Get queryset of all topics.
33
34 Returns:
35 Queryset of Topic objects ordered by name.
36 """
37 programming_topics = Topic.objects.order_by(
38 "name"
39 ).exclude(
40 programming_challenges__isnull=True
41 ).prefetch_related(
42 "programming_challenges",
43 "lessons",
44 )
45 return translated_first(programming_topics)
46
47 def get_context_data(self, **kwargs):
48 """Provide the context data for the index view.
49
50 Returns:
51 Dictionary of context data.
52 """
53 # Call the base implementation first to get a context
54 context = super(IndexView, self).get_context_data(**kwargs)
55 for topic in self.object_list:
56 topic.grouped_lessons = group_lessons_by_age(
57 topic.lessons.all(),
58 only_programming_exercises=True
59 )
60 return context
61
62
63 class AboutView(generic.TemplateView):
64 """View for the about page that renders from a template."""
65
66 template_name = "plugging_it_in/about.html"
67
68
69 class ProgrammingChallengeListView(generic.DetailView):
70 """View showing all the programming exercises for a specific lesson."""
71
72 model = Lesson
73 template_name = "plugging_it_in/lesson.html"
74
75 def get_object(self, **kwargs):
76 """Retrieve object for the lesson view.
77
78 Returns:
79 Lesson object, or raises 404 error if not found.
80 """
81 return get_object_or_404(
82 self.model.objects.select_related(),
83 topic__slug=self.kwargs.get("topic_slug", None),
84 slug=self.kwargs.get("lesson_slug", None),
85 )
86
87 def get_context_data(self, **kwargs):
88 """Provide the context data for the programming challenge list view.
89
90 Returns:
91 Dictionary of context data.
92 """
93 # Call the base implementation first to get a context
94 context = super(ProgrammingChallengeListView, self).get_context_data(**kwargs)
95
96 context["topic"] = self.object.topic
97
98 context["lesson"] = self.object
99
100 # Add in a QuerySet of all the connected programming exercises for this topic
101 context["programming_challenges"] = self.object.retrieve_related_programming_challenges(
102 ).prefetch_related('implementations')
103 return context
104
105
106 class ProgrammingChallengeView(generic.DetailView):
107 """View for a specific programming challenge."""
108
109 model = ProgrammingChallenge
110 template_name = "plugging_it_in/programming-challenge.html"
111 context_object_name = "programming_challenge"
112
113 def get_object(self, **kwargs):
114 """Retrieve object for the programming challenge view.
115
116 Returns:
117 ProgrammingChallenge object, or raises 404 error if not found.
118 """
119 return get_object_or_404(
120 self.model.objects.select_related(),
121 topic__slug=self.kwargs.get("topic_slug", None),
122 slug=self.kwargs.get("programming_challenge_slug", None)
123 )
124
125 def get_context_data(self, **kwargs):
126 """Provide the context data for the programming challenge view.
127
128 Returns:
129 Dictionary of context data.
130 """
131 # Call the base implementation first to get a context
132 context = super(ProgrammingChallengeView, self).get_context_data(**kwargs)
133
134 context["topic"] = self.object.topic
135
136 try:
137 lesson_slug = self.kwargs.get("lesson_slug", None)
138 lesson = Lesson.objects.get(slug=lesson_slug)
139 context["lesson"] = lesson
140 challlenges = lesson.retrieve_related_programming_challenges("Python")
141 context["programming_challenges"] = challlenges
142 context["programming_exercises_json"] = json.dumps(list(challlenges.values()))
143 except ObjectDoesNotExist:
144 raise Http404("Lesson does not exist")
145
146 context["implementations"] = self.object.ordered_implementations()
147
148 related_test_cases = self.object.related_test_cases()
149 context["test_cases_json"] = json.dumps(list(related_test_cases.values()))
150 context["test_cases"] = related_test_cases
151 context["jobe_proxy_url"] = reverse('plugging_it_in:jobe_proxy')
152 context["saved_attempts"] = self.request.session.get('saved_attempts', {})
153
154 return context
155
156
157 class JobeProxyView(View):
158 """Proxy for Jobe Server."""
159
160 def post(self, request, *args, **kwargs):
161 """Forward on request to Jobe from the frontend and adds API key if this is needed.
162
163 Returns:
164 The response from the Jobe server.
165 """
166 # Extracting data from the request body
167 body_unicode = request.body.decode('utf-8')
168 body = json.dumps(json.loads(body_unicode))
169
170 headers = {"Content-type": "application/json; charset=utf-8",
171 "Accept": "application/json"}
172
173 # Set API key for production
174 if hasattr(settings, 'JOBE_API_KEY'):
175 headers["X-API-KEY"] = settings.JOBE_API_KEY
176
177 response = requests.post(settings.JOBE_SERVER_URL + "/jobe/index.php/restapi/runs/",
178 data=body, headers=headers)
179 return HttpResponse(response.text)
180
181
182 class SaveAttemptView(View):
183 """View to save the users challenge attempt."""
184
185 def post(self, request):
186 """Save the users attempt to a Django session."""
187 body_unicode = request.body.decode('utf-8')
188 body = json.loads(body_unicode)
189
190 request.session['saved_attempts'] = request.session.get('saved_attempts', {})
191
192 # To stop a "passed" or "failed" status being overridden by "started"
193 if (not (body["status"] == "started"
194 and request.session.get('saved_attempts', {}).get(body["challenge"], {}).get("status", "")
195 in {'passed', 'failed'})
196 and body["attempt"] != ""):
197 request.session['saved_attempts'][body["challenge"]] = {
198 "status": body["status"],
199 "code": body["attempt"]
200 }
201 return HttpResponse("Saved the attempt.")
202 else:
203 return HttpResponse("Response does not need to be saved.")
204
[end of csunplugged/plugging_it_in/views.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/csunplugged/config/__init__.py b/csunplugged/config/__init__.py
--- a/csunplugged/config/__init__.py
+++ b/csunplugged/config/__init__.py
@@ -1,3 +1,3 @@
"""Module for Django system configuration."""
-__version__ = "6.0.0"
+__version__ = "6.0.1"
diff --git a/csunplugged/plugging_it_in/views.py b/csunplugged/plugging_it_in/views.py
--- a/csunplugged/plugging_it_in/views.py
+++ b/csunplugged/plugging_it_in/views.py
@@ -150,6 +150,10 @@
context["test_cases"] = related_test_cases
context["jobe_proxy_url"] = reverse('plugging_it_in:jobe_proxy')
context["saved_attempts"] = self.request.session.get('saved_attempts', {})
+ try:
+ context["previous_submission"] = context["saved_attempts"][self.object.slug]['code']
+ except KeyError:
+ context["previous_submission"] = ''
return context
|
{"golden_diff": "diff --git a/csunplugged/config/__init__.py b/csunplugged/config/__init__.py\n--- a/csunplugged/config/__init__.py\n+++ b/csunplugged/config/__init__.py\n@@ -1,3 +1,3 @@\n \"\"\"Module for Django system configuration.\"\"\"\n \n-__version__ = \"6.0.0\"\n+__version__ = \"6.0.1\"\ndiff --git a/csunplugged/plugging_it_in/views.py b/csunplugged/plugging_it_in/views.py\n--- a/csunplugged/plugging_it_in/views.py\n+++ b/csunplugged/plugging_it_in/views.py\n@@ -150,6 +150,10 @@\n context[\"test_cases\"] = related_test_cases\n context[\"jobe_proxy_url\"] = reverse('plugging_it_in:jobe_proxy')\n context[\"saved_attempts\"] = self.request.session.get('saved_attempts', {})\n+ try:\n+ context[\"previous_submission\"] = context[\"saved_attempts\"][self.object.slug]['code']\n+ except KeyError:\n+ context[\"previous_submission\"] = ''\n \n return context\n", "issue": "HTML can be inserted into a user's Plugging it in challenge templates\n### The steps are:\r\n- [Open any programming challenge on PII](https://www.csunplugged.org/en/plugging-it-in/binary-numbers/how-binary-digits-work/binary-numbers-no-calculations/)\r\n- Submit this code in the answer box:\r\n - `</script><script type=\"text/javascript\">console.log(\"hi\")</script>`\r\n - It must be all on one line\r\n - Adapt to your desired level of maliciousness\r\n- Refresh the page\r\n\r\nWhen the user re-requests the page, the submitted 'code' is loaded [in the HTML template](https://github.com/uccser/cs-unplugged/blob/develop/csunplugged/templates/plugging_it_in/programming-challenge.html#L191). The first `</script>` closes the script that assigns the variables, and what follows is loaded as a new HTML script tag. The resulting HTML is sent to the user and executes 'as normal'.\r\n\r\nI haven't been able to submit code that executes while also not breaking every PII challenge page. When the page does break, deleting your cookies for CSU allows you to get it working again\r\n\r\n### Three potential fixes\r\n- [Escape the submitted code.](https://docs.djangoproject.com/en/3.1/ref/utils/#module-django.utils.html)\r\n - It was already escaped, the problem is that [it gets un-escaped](https://docs.djangoproject.com/en/2.2/ref/templates/language/#automatic-html-escaping) in order to load as a variable.\r\n - So we would need to un-escape it in JS rather than HTML, and doing so will be tricky\r\n(`'}}<` etc is loaded into the answer box)\r\n- Don't load the user submitted code into the HTML template, and instead request it in JS\r\n - Will be slower, another request is needed\r\n- Load the submitted code in the HTML, not as a variable, but straight into the <textarea> answer box.\r\n - This is how it's done in CodeWOF\r\n - Since it's in a <textarea> everything is rendered as plaintext\n", "before_files": [{"content": "\"\"\"Module for Django system configuration.\"\"\"\n\n__version__ = \"6.0.0\"\n", "path": "csunplugged/config/__init__.py"}, {"content": "\"\"\"Views for the plugging_it_in application.\"\"\"\n\nfrom django.http import HttpResponse\nfrom django.http import Http404\n\nimport json\nimport requests\n\nfrom django.shortcuts import get_object_or_404\nfrom django.views import generic\nfrom django.views import View\nfrom django.urls import reverse\nfrom django.conf import settings\nfrom django.core.exceptions import ObjectDoesNotExist\nfrom utils.translated_first import translated_first\nfrom utils.group_lessons_by_age import group_lessons_by_age\n\nfrom topics.models import (\n Topic,\n ProgrammingChallenge,\n Lesson\n)\n\n\nclass IndexView(generic.ListView):\n \"\"\"View for the topics application homepage.\"\"\"\n\n template_name = \"plugging_it_in/index.html\"\n context_object_name = \"programming_topics\"\n\n def get_queryset(self):\n \"\"\"Get queryset of all topics.\n\n Returns:\n Queryset of Topic objects ordered by name.\n \"\"\"\n programming_topics = Topic.objects.order_by(\n \"name\"\n ).exclude(\n programming_challenges__isnull=True\n ).prefetch_related(\n \"programming_challenges\",\n \"lessons\",\n )\n return translated_first(programming_topics)\n\n def get_context_data(self, **kwargs):\n \"\"\"Provide the context data for the index view.\n\n Returns:\n Dictionary of context data.\n \"\"\"\n # Call the base implementation first to get a context\n context = super(IndexView, self).get_context_data(**kwargs)\n for topic in self.object_list:\n topic.grouped_lessons = group_lessons_by_age(\n topic.lessons.all(),\n only_programming_exercises=True\n )\n return context\n\n\nclass AboutView(generic.TemplateView):\n \"\"\"View for the about page that renders from a template.\"\"\"\n\n template_name = \"plugging_it_in/about.html\"\n\n\nclass ProgrammingChallengeListView(generic.DetailView):\n \"\"\"View showing all the programming exercises for a specific lesson.\"\"\"\n\n model = Lesson\n template_name = \"plugging_it_in/lesson.html\"\n\n def get_object(self, **kwargs):\n \"\"\"Retrieve object for the lesson view.\n\n Returns:\n Lesson object, or raises 404 error if not found.\n \"\"\"\n return get_object_or_404(\n self.model.objects.select_related(),\n topic__slug=self.kwargs.get(\"topic_slug\", None),\n slug=self.kwargs.get(\"lesson_slug\", None),\n )\n\n def get_context_data(self, **kwargs):\n \"\"\"Provide the context data for the programming challenge list view.\n\n Returns:\n Dictionary of context data.\n \"\"\"\n # Call the base implementation first to get a context\n context = super(ProgrammingChallengeListView, self).get_context_data(**kwargs)\n\n context[\"topic\"] = self.object.topic\n\n context[\"lesson\"] = self.object\n\n # Add in a QuerySet of all the connected programming exercises for this topic\n context[\"programming_challenges\"] = self.object.retrieve_related_programming_challenges(\n ).prefetch_related('implementations')\n return context\n\n\nclass ProgrammingChallengeView(generic.DetailView):\n \"\"\"View for a specific programming challenge.\"\"\"\n\n model = ProgrammingChallenge\n template_name = \"plugging_it_in/programming-challenge.html\"\n context_object_name = \"programming_challenge\"\n\n def get_object(self, **kwargs):\n \"\"\"Retrieve object for the programming challenge view.\n\n Returns:\n ProgrammingChallenge object, or raises 404 error if not found.\n \"\"\"\n return get_object_or_404(\n self.model.objects.select_related(),\n topic__slug=self.kwargs.get(\"topic_slug\", None),\n slug=self.kwargs.get(\"programming_challenge_slug\", None)\n )\n\n def get_context_data(self, **kwargs):\n \"\"\"Provide the context data for the programming challenge view.\n\n Returns:\n Dictionary of context data.\n \"\"\"\n # Call the base implementation first to get a context\n context = super(ProgrammingChallengeView, self).get_context_data(**kwargs)\n\n context[\"topic\"] = self.object.topic\n\n try:\n lesson_slug = self.kwargs.get(\"lesson_slug\", None)\n lesson = Lesson.objects.get(slug=lesson_slug)\n context[\"lesson\"] = lesson\n challlenges = lesson.retrieve_related_programming_challenges(\"Python\")\n context[\"programming_challenges\"] = challlenges\n context[\"programming_exercises_json\"] = json.dumps(list(challlenges.values()))\n except ObjectDoesNotExist:\n raise Http404(\"Lesson does not exist\")\n\n context[\"implementations\"] = self.object.ordered_implementations()\n\n related_test_cases = self.object.related_test_cases()\n context[\"test_cases_json\"] = json.dumps(list(related_test_cases.values()))\n context[\"test_cases\"] = related_test_cases\n context[\"jobe_proxy_url\"] = reverse('plugging_it_in:jobe_proxy')\n context[\"saved_attempts\"] = self.request.session.get('saved_attempts', {})\n\n return context\n\n\nclass JobeProxyView(View):\n \"\"\"Proxy for Jobe Server.\"\"\"\n\n def post(self, request, *args, **kwargs):\n \"\"\"Forward on request to Jobe from the frontend and adds API key if this is needed.\n\n Returns:\n The response from the Jobe server.\n \"\"\"\n # Extracting data from the request body\n body_unicode = request.body.decode('utf-8')\n body = json.dumps(json.loads(body_unicode))\n\n headers = {\"Content-type\": \"application/json; charset=utf-8\",\n \"Accept\": \"application/json\"}\n\n # Set API key for production\n if hasattr(settings, 'JOBE_API_KEY'):\n headers[\"X-API-KEY\"] = settings.JOBE_API_KEY\n\n response = requests.post(settings.JOBE_SERVER_URL + \"/jobe/index.php/restapi/runs/\",\n data=body, headers=headers)\n return HttpResponse(response.text)\n\n\nclass SaveAttemptView(View):\n \"\"\"View to save the users challenge attempt.\"\"\"\n\n def post(self, request):\n \"\"\"Save the users attempt to a Django session.\"\"\"\n body_unicode = request.body.decode('utf-8')\n body = json.loads(body_unicode)\n\n request.session['saved_attempts'] = request.session.get('saved_attempts', {})\n\n # To stop a \"passed\" or \"failed\" status being overridden by \"started\"\n if (not (body[\"status\"] == \"started\"\n and request.session.get('saved_attempts', {}).get(body[\"challenge\"], {}).get(\"status\", \"\")\n in {'passed', 'failed'})\n and body[\"attempt\"] != \"\"):\n request.session['saved_attempts'][body[\"challenge\"]] = {\n \"status\": body[\"status\"],\n \"code\": body[\"attempt\"]\n }\n return HttpResponse(\"Saved the attempt.\")\n else:\n return HttpResponse(\"Response does not need to be saved.\")\n", "path": "csunplugged/plugging_it_in/views.py"}]}
| 3,001 | 246 |
gh_patches_debug_25141
|
rasdani/github-patches
|
git_diff
|
bridgecrewio__checkov-3080
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
CKV_AWS_233 Ensure Create before destroy for ACM certificates false positive reading plan
**Describe the issue**
This check raises a false positive for the following resource which does have that lifecycle hook enabled.
**Examples**
Checkov run with:
```
checkov --file plan.json --output junitxml --output cli --output-file-path checkov-out --repo-root-for-plan-enrichment . --download-external-modules True > out.log 2>&1
```
Section in the plan.json:
```
{
"address": "module.my_module.aws_acm_certificate.my_cert",
"mode": "managed",
"type": "aws_acm_certificate",
"name": "my_cert",
"provider_name": "registry.terraform.io/hashicorp/aws",
"schema_version": 0,
"values": {
"arn": "CENSORED",
"certificate_authority_arn": "",
"certificate_body": null,
"certificate_chain": null,
"domain_name": "CENSORED",
"domain_validation_options": [
{
"domain_name": "CENSORED",
"resource_record_name": "CENSORED",
"resource_record_type": "CNAME",
"resource_record_value": "CENSORED"
}
],
"id": "CENSORED",
"options": [
{
"certificate_transparency_logging_preference": "ENABLED"
}
],
"private_key": null,
"status": "ISSUED",
"subject_alternative_names": [
"CENSORED"
],
"tags": {},
"tags_all": {},
"validation_emails": [],
"validation_method": "DNS",
"validation_option": []
},
"sensitive_values": {
"domain_validation_options": [
{}
],
"options": [
{}
],
"subject_alternative_names": [
false
],
"tags": {},
"tags_all": {},
"validation_emails": [],
"validation_option": []
}
}
```
Terraform code:
```terraform
resource "aws_acm_certificate" "my_cert" {
domain_name = local.domain_name
validation_method = "DNS"
lifecycle {
create_before_destroy = true
}
}
```
Error:
```
Check: CKV_AWS_233: "Ensure Create before destroy for ACM certificates"
FAILED for resource: aws_acm_certificate.my_cert
File: ../my-file.tf:1-8
1 | resource "aws_acm_certificate" "my_cert" {
2 | domain_name = local.domain_name
3 | validation_method = "DNS"
4 |
5 | lifecycle {
6 | create_before_destroy = true
7 | }
8 | }
```
**Version:**
- Checkov Version: 2.0.1200
**Additional context**
Add any other context about the problem here.
</issue>
<code>
[start of checkov/terraform/plan_runner.py]
1 import logging
2 import os
3 import platform
4
5 from typing import Optional, List, Type
6
7 from checkov.common.graph.checks_infra.registry import BaseRegistry
8 from checkov.common.graph.db_connectors.networkx.networkx_db_connector import NetworkxConnector
9 from checkov.terraform.graph_manager import TerraformGraphManager
10 from checkov.terraform.graph_builder.local_graph import TerraformLocalGraph
11 from checkov.common.graph.graph_builder.local_graph import LocalGraph
12 from checkov.common.checks_infra.registry import get_graph_checks_registry
13 from checkov.common.graph.graph_builder.graph_components.attribute_names import CustomAttributes
14 from checkov.common.output.record import Record
15 from checkov.common.output.report import Report, CheckType
16 from checkov.common.runners.base_runner import CHECKOV_CREATE_GRAPH
17 from checkov.runner_filter import RunnerFilter
18 from checkov.terraform.checks.resource.registry import resource_registry
19 from checkov.terraform.context_parsers.registry import parser_registry
20 from checkov.terraform.plan_utils import create_definitions, build_definitions_context
21 from checkov.terraform.runner import Runner as TerraformRunner, merge_reports
22
23
24 class Runner(TerraformRunner):
25 check_type = CheckType.TERRAFORM_PLAN
26
27 def __init__(self, graph_class: Type[LocalGraph] = TerraformLocalGraph,
28 graph_manager: Optional[TerraformGraphManager] = None,
29 db_connector: NetworkxConnector = NetworkxConnector(),
30 external_registries: Optional[List[BaseRegistry]] = None,
31 source: str = "Terraform"):
32 super().__init__(graph_class=graph_class, graph_manager=graph_manager, db_connector=db_connector,
33 external_registries=external_registries, source=source)
34 self.file_extensions = ['.json'] # override what gets set from the TF runner
35 self.definitions = None
36 self.context = None
37 self.graph_registry = get_graph_checks_registry(super().check_type)
38
39 block_type_registries = {
40 'resource': resource_registry,
41 }
42
43 def run(
44 self,
45 root_folder: Optional[str] = None,
46 external_checks_dir: Optional[List[str]] = None,
47 files: Optional[List[str]] = None,
48 runner_filter: RunnerFilter = RunnerFilter(),
49 collect_skip_comments: bool = True
50 ) -> Report:
51 report = Report(self.check_type)
52 parsing_errors = {}
53 if self.definitions is None or self.context is None:
54 self.definitions, definitions_raw = create_definitions(root_folder, files, runner_filter, parsing_errors)
55 self.context = build_definitions_context(self.definitions, definitions_raw)
56 if CHECKOV_CREATE_GRAPH:
57 graph = self.graph_manager.build_graph_from_definitions(self.definitions, render_variables=False)
58 self.graph_manager.save_graph(graph)
59
60 if external_checks_dir:
61 for directory in external_checks_dir:
62 resource_registry.load_external_checks(directory)
63 self.graph_registry.load_external_checks(directory)
64 self.check_tf_definition(report, root_folder, runner_filter)
65 report.add_parsing_errors(parsing_errors.keys())
66
67 if self.definitions:
68 graph_report = self.get_graph_checks_report(root_folder, runner_filter)
69 merge_reports(report, graph_report)
70 return report
71
72 def check_tf_definition(self, report, root_folder, runner_filter, collect_skip_comments=True):
73 for full_file_path, definition in self.definitions.items():
74 if platform.system() == "Windows":
75 temp = os.path.split(full_file_path)[0]
76 scanned_file = f"/{os.path.relpath(full_file_path,temp)}"
77 else:
78 scanned_file = f"/{os.path.relpath(full_file_path)}"
79 logging.debug(f"Scanning file: {scanned_file}")
80 for block_type in definition.keys():
81 if block_type in self.block_type_registries.keys():
82 self.run_block(definition[block_type], None, full_file_path, root_folder, report, scanned_file,
83 block_type, runner_filter)
84
85 def run_block(self, entities,
86 definition_context,
87 full_file_path, root_folder, report, scanned_file,
88 block_type, runner_filter=None, entity_context_path_header=None,
89 module_referrer: Optional[str] = None):
90 registry = self.block_type_registries[block_type]
91 if registry:
92 for entity in entities:
93 context_parser = parser_registry.context_parsers[block_type]
94 definition_path = context_parser.get_entity_context_path(entity)
95 entity_id = ".".join(definition_path)
96 # Entity can exist only once per dir, for file as well
97 entity_context = self.get_entity_context(definition_path, full_file_path)
98 entity_lines_range = [entity_context.get('start_line'), entity_context.get('end_line')]
99 entity_code_lines = entity_context.get('code_lines')
100 entity_address = entity_context.get('address')
101
102 results = registry.scan(scanned_file, entity, [], runner_filter)
103 for check, check_result in results.items():
104 record = Record(check_id=check.id, bc_check_id=check.bc_id, check_name=check.name,
105 check_result=check_result,
106 code_block=entity_code_lines, file_path=scanned_file,
107 file_line_range=entity_lines_range,
108 resource=entity_id, resource_address=entity_address, evaluations=None,
109 check_class=check.__class__.__module__, file_abs_path=full_file_path,
110 severity=check.severity)
111 record.set_guideline(check.guideline)
112 report.add_record(record=record)
113
114 def get_entity_context_and_evaluations(self, entity):
115 raw_context = self.get_entity_context(entity[CustomAttributes.BLOCK_NAME].split("."),
116 entity[CustomAttributes.FILE_PATH])
117 raw_context['definition_path'] = entity[CustomAttributes.BLOCK_NAME].split('.')
118 return raw_context, None
119
120 def get_entity_context(self, definition_path, full_file_path):
121 entity_id = ".".join(definition_path)
122 return self.context.get(full_file_path, {}).get(entity_id)
123
[end of checkov/terraform/plan_runner.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/checkov/terraform/plan_runner.py b/checkov/terraform/plan_runner.py
--- a/checkov/terraform/plan_runner.py
+++ b/checkov/terraform/plan_runner.py
@@ -20,6 +20,14 @@
from checkov.terraform.plan_utils import create_definitions, build_definitions_context
from checkov.terraform.runner import Runner as TerraformRunner, merge_reports
+# set of check IDs with lifecycle condition
+TF_LIFECYCLE_CHECK_IDS = {
+ "CKV_AWS_217",
+ "CKV_AWS_233",
+ "CKV_AWS_237",
+ "CKV_GCP_82",
+}
+
class Runner(TerraformRunner):
check_type = CheckType.TERRAFORM_PLAN
@@ -101,6 +109,10 @@
results = registry.scan(scanned_file, entity, [], runner_filter)
for check, check_result in results.items():
+ if check.id in TF_LIFECYCLE_CHECK_IDS:
+ # can't be evaluated in TF plan
+ continue
+
record = Record(check_id=check.id, bc_check_id=check.bc_id, check_name=check.name,
check_result=check_result,
code_block=entity_code_lines, file_path=scanned_file,
|
{"golden_diff": "diff --git a/checkov/terraform/plan_runner.py b/checkov/terraform/plan_runner.py\n--- a/checkov/terraform/plan_runner.py\n+++ b/checkov/terraform/plan_runner.py\n@@ -20,6 +20,14 @@\n from checkov.terraform.plan_utils import create_definitions, build_definitions_context\n from checkov.terraform.runner import Runner as TerraformRunner, merge_reports\n \n+# set of check IDs with lifecycle condition\n+TF_LIFECYCLE_CHECK_IDS = {\n+ \"CKV_AWS_217\",\n+ \"CKV_AWS_233\",\n+ \"CKV_AWS_237\",\n+ \"CKV_GCP_82\",\n+}\n+\n \n class Runner(TerraformRunner):\n check_type = CheckType.TERRAFORM_PLAN\n@@ -101,6 +109,10 @@\n \n results = registry.scan(scanned_file, entity, [], runner_filter)\n for check, check_result in results.items():\n+ if check.id in TF_LIFECYCLE_CHECK_IDS:\n+ # can't be evaluated in TF plan\n+ continue\n+\n record = Record(check_id=check.id, bc_check_id=check.bc_id, check_name=check.name,\n check_result=check_result,\n code_block=entity_code_lines, file_path=scanned_file,\n", "issue": "CKV_AWS_233 Ensure Create before destroy for ACM certificates false positive reading plan\n**Describe the issue**\r\nThis check raises a false positive for the following resource which does have that lifecycle hook enabled.\r\n\r\n**Examples**\r\n\r\nCheckov run with:\r\n\r\n```\r\ncheckov --file plan.json --output junitxml --output cli --output-file-path checkov-out --repo-root-for-plan-enrichment . --download-external-modules True > out.log 2>&1\r\n```\r\n\r\nSection in the plan.json:\r\n\r\n```\r\n{\r\n \"address\": \"module.my_module.aws_acm_certificate.my_cert\",\r\n \"mode\": \"managed\",\r\n \"type\": \"aws_acm_certificate\",\r\n \"name\": \"my_cert\",\r\n \"provider_name\": \"registry.terraform.io/hashicorp/aws\",\r\n \"schema_version\": 0,\r\n \"values\": {\r\n \"arn\": \"CENSORED\",\r\n \"certificate_authority_arn\": \"\",\r\n \"certificate_body\": null,\r\n \"certificate_chain\": null,\r\n \"domain_name\": \"CENSORED\",\r\n \"domain_validation_options\": [\r\n {\r\n \"domain_name\": \"CENSORED\",\r\n \"resource_record_name\": \"CENSORED\",\r\n \"resource_record_type\": \"CNAME\",\r\n \"resource_record_value\": \"CENSORED\"\r\n }\r\n ],\r\n \"id\": \"CENSORED\",\r\n \"options\": [\r\n {\r\n \"certificate_transparency_logging_preference\": \"ENABLED\"\r\n }\r\n ],\r\n \"private_key\": null,\r\n \"status\": \"ISSUED\",\r\n \"subject_alternative_names\": [\r\n \"CENSORED\"\r\n ],\r\n \"tags\": {},\r\n \"tags_all\": {},\r\n \"validation_emails\": [],\r\n \"validation_method\": \"DNS\",\r\n \"validation_option\": []\r\n },\r\n \"sensitive_values\": {\r\n \"domain_validation_options\": [\r\n {}\r\n ],\r\n \"options\": [\r\n {}\r\n ],\r\n \"subject_alternative_names\": [\r\n false\r\n ],\r\n \"tags\": {},\r\n \"tags_all\": {},\r\n \"validation_emails\": [],\r\n \"validation_option\": []\r\n }\r\n}\r\n\r\n```\r\n\r\nTerraform code:\r\n\r\n```terraform\r\nresource \"aws_acm_certificate\" \"my_cert\" {\r\n domain_name = local.domain_name\r\n validation_method = \"DNS\"\r\n\r\n lifecycle {\r\n create_before_destroy = true\r\n }\r\n}\r\n```\r\n\r\nError:\r\n\r\n```\r\nCheck: CKV_AWS_233: \"Ensure Create before destroy for ACM certificates\"\r\n\tFAILED for resource: aws_acm_certificate.my_cert\r\n\tFile: ../my-file.tf:1-8\r\n\r\n\t\t1 | resource \"aws_acm_certificate\" \"my_cert\" {\r\n\t\t2 | domain_name = local.domain_name\r\n\t\t3 | validation_method = \"DNS\"\r\n\t\t4 | \r\n\t\t5 | lifecycle {\r\n\t\t6 | create_before_destroy = true\r\n\t\t7 | }\r\n\t\t8 | }\r\n```\r\n\r\n**Version:**\r\n - Checkov Version: 2.0.1200\r\n\r\n**Additional context**\r\nAdd any other context about the problem here.\r\n\n", "before_files": [{"content": "import logging\nimport os\nimport platform\n\nfrom typing import Optional, List, Type\n\nfrom checkov.common.graph.checks_infra.registry import BaseRegistry\nfrom checkov.common.graph.db_connectors.networkx.networkx_db_connector import NetworkxConnector\nfrom checkov.terraform.graph_manager import TerraformGraphManager\nfrom checkov.terraform.graph_builder.local_graph import TerraformLocalGraph\nfrom checkov.common.graph.graph_builder.local_graph import LocalGraph\nfrom checkov.common.checks_infra.registry import get_graph_checks_registry\nfrom checkov.common.graph.graph_builder.graph_components.attribute_names import CustomAttributes\nfrom checkov.common.output.record import Record\nfrom checkov.common.output.report import Report, CheckType\nfrom checkov.common.runners.base_runner import CHECKOV_CREATE_GRAPH\nfrom checkov.runner_filter import RunnerFilter\nfrom checkov.terraform.checks.resource.registry import resource_registry\nfrom checkov.terraform.context_parsers.registry import parser_registry\nfrom checkov.terraform.plan_utils import create_definitions, build_definitions_context\nfrom checkov.terraform.runner import Runner as TerraformRunner, merge_reports\n\n\nclass Runner(TerraformRunner):\n check_type = CheckType.TERRAFORM_PLAN\n\n def __init__(self, graph_class: Type[LocalGraph] = TerraformLocalGraph,\n graph_manager: Optional[TerraformGraphManager] = None,\n db_connector: NetworkxConnector = NetworkxConnector(),\n external_registries: Optional[List[BaseRegistry]] = None,\n source: str = \"Terraform\"):\n super().__init__(graph_class=graph_class, graph_manager=graph_manager, db_connector=db_connector,\n external_registries=external_registries, source=source)\n self.file_extensions = ['.json'] # override what gets set from the TF runner\n self.definitions = None\n self.context = None\n self.graph_registry = get_graph_checks_registry(super().check_type)\n\n block_type_registries = {\n 'resource': resource_registry,\n }\n\n def run(\n self,\n root_folder: Optional[str] = None,\n external_checks_dir: Optional[List[str]] = None,\n files: Optional[List[str]] = None,\n runner_filter: RunnerFilter = RunnerFilter(),\n collect_skip_comments: bool = True\n ) -> Report:\n report = Report(self.check_type)\n parsing_errors = {}\n if self.definitions is None or self.context is None:\n self.definitions, definitions_raw = create_definitions(root_folder, files, runner_filter, parsing_errors)\n self.context = build_definitions_context(self.definitions, definitions_raw)\n if CHECKOV_CREATE_GRAPH:\n graph = self.graph_manager.build_graph_from_definitions(self.definitions, render_variables=False)\n self.graph_manager.save_graph(graph)\n\n if external_checks_dir:\n for directory in external_checks_dir:\n resource_registry.load_external_checks(directory)\n self.graph_registry.load_external_checks(directory)\n self.check_tf_definition(report, root_folder, runner_filter)\n report.add_parsing_errors(parsing_errors.keys())\n\n if self.definitions:\n graph_report = self.get_graph_checks_report(root_folder, runner_filter)\n merge_reports(report, graph_report)\n return report\n\n def check_tf_definition(self, report, root_folder, runner_filter, collect_skip_comments=True):\n for full_file_path, definition in self.definitions.items():\n if platform.system() == \"Windows\":\n temp = os.path.split(full_file_path)[0]\n scanned_file = f\"/{os.path.relpath(full_file_path,temp)}\"\n else:\n scanned_file = f\"/{os.path.relpath(full_file_path)}\"\n logging.debug(f\"Scanning file: {scanned_file}\")\n for block_type in definition.keys():\n if block_type in self.block_type_registries.keys():\n self.run_block(definition[block_type], None, full_file_path, root_folder, report, scanned_file,\n block_type, runner_filter)\n\n def run_block(self, entities,\n definition_context,\n full_file_path, root_folder, report, scanned_file,\n block_type, runner_filter=None, entity_context_path_header=None,\n module_referrer: Optional[str] = None):\n registry = self.block_type_registries[block_type]\n if registry:\n for entity in entities:\n context_parser = parser_registry.context_parsers[block_type]\n definition_path = context_parser.get_entity_context_path(entity)\n entity_id = \".\".join(definition_path)\n # Entity can exist only once per dir, for file as well\n entity_context = self.get_entity_context(definition_path, full_file_path)\n entity_lines_range = [entity_context.get('start_line'), entity_context.get('end_line')]\n entity_code_lines = entity_context.get('code_lines')\n entity_address = entity_context.get('address')\n\n results = registry.scan(scanned_file, entity, [], runner_filter)\n for check, check_result in results.items():\n record = Record(check_id=check.id, bc_check_id=check.bc_id, check_name=check.name,\n check_result=check_result,\n code_block=entity_code_lines, file_path=scanned_file,\n file_line_range=entity_lines_range,\n resource=entity_id, resource_address=entity_address, evaluations=None,\n check_class=check.__class__.__module__, file_abs_path=full_file_path,\n severity=check.severity)\n record.set_guideline(check.guideline)\n report.add_record(record=record)\n\n def get_entity_context_and_evaluations(self, entity):\n raw_context = self.get_entity_context(entity[CustomAttributes.BLOCK_NAME].split(\".\"),\n entity[CustomAttributes.FILE_PATH])\n raw_context['definition_path'] = entity[CustomAttributes.BLOCK_NAME].split('.')\n return raw_context, None\n\n def get_entity_context(self, definition_path, full_file_path):\n entity_id = \".\".join(definition_path)\n return self.context.get(full_file_path, {}).get(entity_id)\n", "path": "checkov/terraform/plan_runner.py"}]}
| 2,692 | 295 |
gh_patches_debug_12469
|
rasdani/github-patches
|
git_diff
|
pytorch__TensorRT-2490
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Expose ISelectLayer in dynamo.conversion.impl
</issue>
<code>
[start of py/torch_tensorrt/dynamo/conversion/impl/condition/ops.py]
1 from typing import Optional, Union
2
3 import numpy as np
4 import tensorrt as trt
5 import torch
6 from torch.fx.node import Target
7 from torch_tensorrt.dynamo._SourceIR import SourceIR
8 from torch_tensorrt.dynamo.conversion._ConversionContext import ConversionContext
9 from torch_tensorrt.dynamo.conversion.converter_utils import (
10 broadcastable,
11 get_trt_tensor,
12 )
13 from torch_tensorrt.dynamo.conversion.impl.slice import expand
14 from torch_tensorrt.fx.converters.converter_utils import set_layer_name
15 from torch_tensorrt.fx.types import TRTTensor
16
17
18 def where(
19 ctx: ConversionContext,
20 target: Target,
21 source_ir: Optional[SourceIR],
22 name: str,
23 input: Union[TRTTensor, np.ndarray, torch.Tensor],
24 other: Union[TRTTensor, np.ndarray, torch.Tensor],
25 condition: Union[TRTTensor, np.ndarray, torch.Tensor],
26 ) -> TRTTensor:
27 if not (broadcastable(input, other)):
28 assert "The two torch tensors should be broadcastable"
29
30 x_shape = list(input.shape)
31 y_shape = list(other.shape)
32 condition_shape = list(condition.shape)
33
34 output_shape = list(torch.broadcast_shapes(condition_shape, x_shape, y_shape))
35
36 # expand shape
37 if not isinstance(condition, TRTTensor):
38 assert condition.dtype in (torch.bool, np.bool_), "condition dtype is not bool"
39 if condition_shape != output_shape:
40 condition = (
41 condition.expand(output_shape)
42 if isinstance(condition, torch.Tensor)
43 else np.broadcast_to(condition, output_shape)
44 )
45 condition_val = get_trt_tensor(ctx, condition, f"{name}_condition")
46 else:
47 assert condition.dtype == trt.bool, "mask dtype is not bool!"
48 if condition_shape != output_shape:
49 condition_val = expand(
50 ctx, target, source_ir, f"{name}_expand", condition, output_shape
51 )
52 else:
53 condition_val = condition
54
55 if not isinstance(input, TRTTensor):
56 if x_shape != output_shape:
57 # special case where 1 element in input
58 if len(input.shape) == 0:
59 input = (
60 input.unsqueeze(0)
61 if isinstance(input, torch.Tensor)
62 else np.expand_dims(input, axis=0)
63 )
64 input = (
65 input.expand(output_shape)
66 if isinstance(input, torch.Tensor)
67 else np.broadcast_to(input, output_shape)
68 )
69 x_val = get_trt_tensor(ctx, input, f"{name}_x")
70 else:
71 x_val = input
72 if x_shape != output_shape:
73 x_val = expand(
74 ctx, target, source_ir, f"{name}_x_expand", input, output_shape
75 )
76
77 if not isinstance(other, TRTTensor):
78 if y_shape != output_shape:
79 # special case where 1 element in other
80 if len(other.shape) == 0:
81 other = (
82 other.unsqueeze(0)
83 if isinstance(other, torch.Tensor)
84 else np.expand_dims(other, axis=0)
85 )
86 other = (
87 other.expand(output_shape)
88 if isinstance(other, torch.Tensor)
89 else np.broadcast_to(other, output_shape)
90 )
91 y_val = get_trt_tensor(ctx, other, f"{name}_y")
92 else:
93 y_val = other
94 if y_shape != output_shape:
95 y_val = expand(
96 ctx, target, source_ir, f"{name}_y_expand", y_val, output_shape
97 )
98
99 select_layer = ctx.net.add_select(condition_val, x_val, y_val)
100
101 set_layer_name(select_layer, target, f"{name}_select")
102
103 return select_layer.get_output(0)
104
[end of py/torch_tensorrt/dynamo/conversion/impl/condition/ops.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/py/torch_tensorrt/dynamo/conversion/impl/condition/ops.py b/py/torch_tensorrt/dynamo/conversion/impl/condition/ops.py
--- a/py/torch_tensorrt/dynamo/conversion/impl/condition/ops.py
+++ b/py/torch_tensorrt/dynamo/conversion/impl/condition/ops.py
@@ -96,8 +96,18 @@
ctx, target, source_ir, f"{name}_y_expand", y_val, output_shape
)
- select_layer = ctx.net.add_select(condition_val, x_val, y_val)
+ return select(ctx, target, source_ir, name, x_val, y_val, condition_val)
- set_layer_name(select_layer, target, f"{name}_select")
+def select(
+ ctx: ConversionContext,
+ target: Target,
+ source_ir: Optional[SourceIR],
+ name: str,
+ input: TRTTensor,
+ other: TRTTensor,
+ condition: TRTTensor,
+) -> TRTTensor:
+ select_layer = ctx.net.add_select(condition, input, other)
+ set_layer_name(select_layer, target, name + "_select", source_ir)
return select_layer.get_output(0)
|
{"golden_diff": "diff --git a/py/torch_tensorrt/dynamo/conversion/impl/condition/ops.py b/py/torch_tensorrt/dynamo/conversion/impl/condition/ops.py\n--- a/py/torch_tensorrt/dynamo/conversion/impl/condition/ops.py\n+++ b/py/torch_tensorrt/dynamo/conversion/impl/condition/ops.py\n@@ -96,8 +96,18 @@\n ctx, target, source_ir, f\"{name}_y_expand\", y_val, output_shape\n )\n \n- select_layer = ctx.net.add_select(condition_val, x_val, y_val)\n+ return select(ctx, target, source_ir, name, x_val, y_val, condition_val)\n \n- set_layer_name(select_layer, target, f\"{name}_select\")\n \n+def select(\n+ ctx: ConversionContext,\n+ target: Target,\n+ source_ir: Optional[SourceIR],\n+ name: str,\n+ input: TRTTensor,\n+ other: TRTTensor,\n+ condition: TRTTensor,\n+) -> TRTTensor:\n+ select_layer = ctx.net.add_select(condition, input, other)\n+ set_layer_name(select_layer, target, name + \"_select\", source_ir)\n return select_layer.get_output(0)\n", "issue": "Expose ISelectLayer in dynamo.conversion.impl\n\n", "before_files": [{"content": "from typing import Optional, Union\n\nimport numpy as np\nimport tensorrt as trt\nimport torch\nfrom torch.fx.node import Target\nfrom torch_tensorrt.dynamo._SourceIR import SourceIR\nfrom torch_tensorrt.dynamo.conversion._ConversionContext import ConversionContext\nfrom torch_tensorrt.dynamo.conversion.converter_utils import (\n broadcastable,\n get_trt_tensor,\n)\nfrom torch_tensorrt.dynamo.conversion.impl.slice import expand\nfrom torch_tensorrt.fx.converters.converter_utils import set_layer_name\nfrom torch_tensorrt.fx.types import TRTTensor\n\n\ndef where(\n ctx: ConversionContext,\n target: Target,\n source_ir: Optional[SourceIR],\n name: str,\n input: Union[TRTTensor, np.ndarray, torch.Tensor],\n other: Union[TRTTensor, np.ndarray, torch.Tensor],\n condition: Union[TRTTensor, np.ndarray, torch.Tensor],\n) -> TRTTensor:\n if not (broadcastable(input, other)):\n assert \"The two torch tensors should be broadcastable\"\n\n x_shape = list(input.shape)\n y_shape = list(other.shape)\n condition_shape = list(condition.shape)\n\n output_shape = list(torch.broadcast_shapes(condition_shape, x_shape, y_shape))\n\n # expand shape\n if not isinstance(condition, TRTTensor):\n assert condition.dtype in (torch.bool, np.bool_), \"condition dtype is not bool\"\n if condition_shape != output_shape:\n condition = (\n condition.expand(output_shape)\n if isinstance(condition, torch.Tensor)\n else np.broadcast_to(condition, output_shape)\n )\n condition_val = get_trt_tensor(ctx, condition, f\"{name}_condition\")\n else:\n assert condition.dtype == trt.bool, \"mask dtype is not bool!\"\n if condition_shape != output_shape:\n condition_val = expand(\n ctx, target, source_ir, f\"{name}_expand\", condition, output_shape\n )\n else:\n condition_val = condition\n\n if not isinstance(input, TRTTensor):\n if x_shape != output_shape:\n # special case where 1 element in input\n if len(input.shape) == 0:\n input = (\n input.unsqueeze(0)\n if isinstance(input, torch.Tensor)\n else np.expand_dims(input, axis=0)\n )\n input = (\n input.expand(output_shape)\n if isinstance(input, torch.Tensor)\n else np.broadcast_to(input, output_shape)\n )\n x_val = get_trt_tensor(ctx, input, f\"{name}_x\")\n else:\n x_val = input\n if x_shape != output_shape:\n x_val = expand(\n ctx, target, source_ir, f\"{name}_x_expand\", input, output_shape\n )\n\n if not isinstance(other, TRTTensor):\n if y_shape != output_shape:\n # special case where 1 element in other\n if len(other.shape) == 0:\n other = (\n other.unsqueeze(0)\n if isinstance(other, torch.Tensor)\n else np.expand_dims(other, axis=0)\n )\n other = (\n other.expand(output_shape)\n if isinstance(other, torch.Tensor)\n else np.broadcast_to(other, output_shape)\n )\n y_val = get_trt_tensor(ctx, other, f\"{name}_y\")\n else:\n y_val = other\n if y_shape != output_shape:\n y_val = expand(\n ctx, target, source_ir, f\"{name}_y_expand\", y_val, output_shape\n )\n\n select_layer = ctx.net.add_select(condition_val, x_val, y_val)\n\n set_layer_name(select_layer, target, f\"{name}_select\")\n\n return select_layer.get_output(0)\n", "path": "py/torch_tensorrt/dynamo/conversion/impl/condition/ops.py"}]}
| 1,564 | 276 |
gh_patches_debug_4305
|
rasdani/github-patches
|
git_diff
|
pypa__pipenv-5148
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
CLI docs broken
### Issue description
[CLI docs](https://pipenv.pypa.io/en/latest/cli/)
[CLI docs source](https://pipenv.pypa.io/en/latest/_sources/cli.rst.txt)
### Expected result
CLI docs
### Actual result
Empty page
</issue>
<code>
[start of docs/conf.py]
1 #
2 # pipenv documentation build configuration file, created by
3 # sphinx-quickstart on Mon Jan 30 13:28:36 2017.
4 #
5 # This file is execfile()d with the current directory set to its
6 # containing dir.
7 #
8 # Note that not all possible configuration values are present in this
9 # autogenerated file.
10 #
11 # All configuration values have a default; values that are commented out
12 # serve to show the default.
13
14 # If extensions (or modules to document with autodoc) are in another directory,
15 # add these directories to sys.path here. If the directory is relative to the
16 # documentation root, use os.path.abspath to make it absolute, like shown here.
17 #
18 import os
19
20 # Path hackery to get current version number.
21 here = os.path.abspath(os.path.dirname(__file__))
22
23 about = {}
24 with open(os.path.join(here, "..", "pipenv", "__version__.py")) as f:
25 exec(f.read(), about)
26
27 # Hackery to get the CLI docs to generate
28 import click
29
30 import pipenv.vendor.click
31
32 click.Command = pipenv.vendor.click.Command
33 click.Group = pipenv.vendor.click.Group
34
35 # -- General configuration ------------------------------------------------
36
37 # If your documentation needs a minimal Sphinx version, state it here.
38 #
39 # needs_sphinx = '1.0'
40
41 # Add any Sphinx extension module names here, as strings. They can be
42 # extensions coming with Sphinx (named 'sphinx.ext.*') or your custom
43 # ones.
44 extensions = [
45 "sphinx.ext.autodoc",
46 "sphinx.ext.todo",
47 "sphinx.ext.coverage",
48 "sphinx.ext.viewcode",
49 "sphinx_click",
50 ]
51
52 # Add any paths that contain templates here, relative to this directory.
53 templates_path = ["_templates"]
54
55 # The suffix(es) of source filenames.
56 # You can specify multiple suffix as a list of string:
57 #
58 # source_suffix = ['.rst', '.md']
59 source_suffix = ".rst"
60
61 # The master toctree document.
62 master_doc = "index"
63
64 # General information about the project.
65 project = "pipenv"
66 copyright = '2020. A project founded by Kenneth Reitz and maintained by <a href="https://www.pypa.io/en/latest/">Python Packaging Authority (PyPA).</a>'
67 author = "Python Packaging Authority"
68
69 # The version info for the project you're documenting, acts as replacement for
70 # |version| and |release|, also used in various other places throughout the
71 # built documents.
72 #
73 # The short X.Y version.
74 version = about["__version__"]
75 # The full version, including alpha/beta/rc tags.
76 release = about["__version__"]
77
78 # The language for content autogenerated by Sphinx. Refer to documentation
79 # for a list of supported languages.
80 #
81 # This is also used if you do content translation via gettext catalogs.
82 # Usually you set "language" from the command line for these cases.
83 language = None
84
85 # List of patterns, relative to source directory, that match files and
86 # directories to ignore when looking for source files.
87 # This patterns also effect to html_static_path and html_extra_path
88 exclude_patterns = ["_build", "Thumbs.db", ".DS_Store"]
89
90 # The name of the Pygments (syntax highlighting) style to use.
91 pygments_style = "sphinx"
92
93 # If true, `todo` and `todoList` produce output, else they produce nothing.
94 todo_include_todos = True
95
96 # -- Options for HTML output ----------------------------------------------
97
98 # The theme to use for HTML and HTML Help pages. See the documentation for
99 # a list of builtin themes.
100 #
101 html_theme = "alabaster"
102
103 # Theme options are theme-specific and customize the look and feel of a theme
104 # further. For a list of options available for each theme, see the
105 # documentation.
106 #
107 html_theme_options = {
108 "show_powered_by": False,
109 "github_user": "pypa",
110 "github_repo": "pipenv",
111 "github_banner": False,
112 "show_related": False,
113 }
114
115 html_sidebars = {
116 "index": ["sidebarlogo.html", "sourcelink.html", "searchbox.html", "hacks.html"],
117 "**": [
118 "sidebarlogo.html",
119 "localtoc.html",
120 "relations.html",
121 "sourcelink.html",
122 "searchbox.html",
123 "hacks.html",
124 ],
125 }
126
127
128 # Add any paths that contain custom static files (such as style sheets) here,
129 # relative to this directory. They are copied after the builtin static files,
130 # so a file named "default.css" will overwrite the builtin "default.css".
131 html_static_path = ["_static"]
132
133
134 def setup(app):
135 app.add_css_file("custom.css")
136
137
138 # -- Options for HTMLHelp output ------------------------------------------
139
140 # Output file base name for HTML help builder.
141 htmlhelp_basename = "pipenvdoc"
142
143
144 # -- Options for LaTeX output ---------------------------------------------
145
146 latex_elements = {
147 # The paper size ('letterpaper' or 'a4paper').
148 #
149 # 'papersize': 'letterpaper',
150 # The font size ('10pt', '11pt' or '12pt').
151 #
152 # 'pointsize': '10pt',
153 # Additional stuff for the LaTeX preamble.
154 #
155 # 'preamble': '',
156 # Latex figure (float) alignment
157 #
158 # 'figure_align': 'htbp',
159 }
160
161 # Grouping the document tree into LaTeX files. List of tuples
162 # (source start file, target name, title,
163 # author, documentclass [howto, manual, or own class]).
164 latex_documents = [
165 (master_doc, "pipenv.tex", "pipenv Documentation", "Kenneth Reitz", "manual"),
166 ]
167
168
169 # -- Options for manual page output ---------------------------------------
170
171 # One entry per manual page. List of tuples
172 # (source start file, name, description, authors, manual section).
173 man_pages = [(master_doc, "pipenv", "pipenv Documentation", [author], 1)]
174
175
176 # -- Options for Texinfo output -------------------------------------------
177
178 # Grouping the document tree into Texinfo files. List of tuples
179 # (source start file, target name, title, author,
180 # dir menu entry, description, category)
181 texinfo_documents = [
182 (
183 master_doc,
184 "pipenv",
185 "pipenv Documentation",
186 author,
187 "pipenv",
188 "One line description of project.",
189 "Miscellaneous",
190 ),
191 ]
192
193
194 # -- Options for Epub output ----------------------------------------------
195
196 # Bibliographic Dublin Core info.
197 epub_title = project
198 epub_author = author
199 epub_publisher = author
200 epub_copyright = copyright
201
202 # The unique identifier of the text. This can be a ISBN number
203 # or the project homepage.
204 #
205 # epub_identifier = ''
206
207 # A unique identification for the text.
208 #
209 # epub_uid = ''
210
211 # A list of files that should not be packed into the epub file.
212 epub_exclude_files = ["search.html"]
213
[end of docs/conf.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/docs/conf.py b/docs/conf.py
--- a/docs/conf.py
+++ b/docs/conf.py
@@ -31,7 +31,7 @@
click.Command = pipenv.vendor.click.Command
click.Group = pipenv.vendor.click.Group
-
+click.BaseCommand = pipenv.vendor.click.BaseCommand
# -- General configuration ------------------------------------------------
# If your documentation needs a minimal Sphinx version, state it here.
|
{"golden_diff": "diff --git a/docs/conf.py b/docs/conf.py\n--- a/docs/conf.py\n+++ b/docs/conf.py\n@@ -31,7 +31,7 @@\n \n click.Command = pipenv.vendor.click.Command\n click.Group = pipenv.vendor.click.Group\n-\n+click.BaseCommand = pipenv.vendor.click.BaseCommand\n # -- General configuration ------------------------------------------------\n \n # If your documentation needs a minimal Sphinx version, state it here.\n", "issue": "CLI docs broken\n### Issue description\r\n[CLI docs](https://pipenv.pypa.io/en/latest/cli/)\r\n[CLI docs source](https://pipenv.pypa.io/en/latest/_sources/cli.rst.txt)\r\n\r\n### Expected result\r\nCLI docs\r\n\r\n### Actual result\r\nEmpty page\n", "before_files": [{"content": "#\n# pipenv documentation build configuration file, created by\n# sphinx-quickstart on Mon Jan 30 13:28:36 2017.\n#\n# This file is execfile()d with the current directory set to its\n# containing dir.\n#\n# Note that not all possible configuration values are present in this\n# autogenerated file.\n#\n# All configuration values have a default; values that are commented out\n# serve to show the default.\n\n# If extensions (or modules to document with autodoc) are in another directory,\n# add these directories to sys.path here. If the directory is relative to the\n# documentation root, use os.path.abspath to make it absolute, like shown here.\n#\nimport os\n\n# Path hackery to get current version number.\nhere = os.path.abspath(os.path.dirname(__file__))\n\nabout = {}\nwith open(os.path.join(here, \"..\", \"pipenv\", \"__version__.py\")) as f:\n exec(f.read(), about)\n\n# Hackery to get the CLI docs to generate\nimport click\n\nimport pipenv.vendor.click\n\nclick.Command = pipenv.vendor.click.Command\nclick.Group = pipenv.vendor.click.Group\n\n# -- General configuration ------------------------------------------------\n\n# If your documentation needs a minimal Sphinx version, state it here.\n#\n# needs_sphinx = '1.0'\n\n# Add any Sphinx extension module names here, as strings. They can be\n# extensions coming with Sphinx (named 'sphinx.ext.*') or your custom\n# ones.\nextensions = [\n \"sphinx.ext.autodoc\",\n \"sphinx.ext.todo\",\n \"sphinx.ext.coverage\",\n \"sphinx.ext.viewcode\",\n \"sphinx_click\",\n]\n\n# Add any paths that contain templates here, relative to this directory.\ntemplates_path = [\"_templates\"]\n\n# The suffix(es) of source filenames.\n# You can specify multiple suffix as a list of string:\n#\n# source_suffix = ['.rst', '.md']\nsource_suffix = \".rst\"\n\n# The master toctree document.\nmaster_doc = \"index\"\n\n# General information about the project.\nproject = \"pipenv\"\ncopyright = '2020. A project founded by Kenneth Reitz and maintained by <a href=\"https://www.pypa.io/en/latest/\">Python Packaging Authority (PyPA).</a>'\nauthor = \"Python Packaging Authority\"\n\n# The version info for the project you're documenting, acts as replacement for\n# |version| and |release|, also used in various other places throughout the\n# built documents.\n#\n# The short X.Y version.\nversion = about[\"__version__\"]\n# The full version, including alpha/beta/rc tags.\nrelease = about[\"__version__\"]\n\n# The language for content autogenerated by Sphinx. Refer to documentation\n# for a list of supported languages.\n#\n# This is also used if you do content translation via gettext catalogs.\n# Usually you set \"language\" from the command line for these cases.\nlanguage = None\n\n# List of patterns, relative to source directory, that match files and\n# directories to ignore when looking for source files.\n# This patterns also effect to html_static_path and html_extra_path\nexclude_patterns = [\"_build\", \"Thumbs.db\", \".DS_Store\"]\n\n# The name of the Pygments (syntax highlighting) style to use.\npygments_style = \"sphinx\"\n\n# If true, `todo` and `todoList` produce output, else they produce nothing.\ntodo_include_todos = True\n\n# -- Options for HTML output ----------------------------------------------\n\n# The theme to use for HTML and HTML Help pages. See the documentation for\n# a list of builtin themes.\n#\nhtml_theme = \"alabaster\"\n\n# Theme options are theme-specific and customize the look and feel of a theme\n# further. For a list of options available for each theme, see the\n# documentation.\n#\nhtml_theme_options = {\n \"show_powered_by\": False,\n \"github_user\": \"pypa\",\n \"github_repo\": \"pipenv\",\n \"github_banner\": False,\n \"show_related\": False,\n}\n\nhtml_sidebars = {\n \"index\": [\"sidebarlogo.html\", \"sourcelink.html\", \"searchbox.html\", \"hacks.html\"],\n \"**\": [\n \"sidebarlogo.html\",\n \"localtoc.html\",\n \"relations.html\",\n \"sourcelink.html\",\n \"searchbox.html\",\n \"hacks.html\",\n ],\n}\n\n\n# Add any paths that contain custom static files (such as style sheets) here,\n# relative to this directory. They are copied after the builtin static files,\n# so a file named \"default.css\" will overwrite the builtin \"default.css\".\nhtml_static_path = [\"_static\"]\n\n\ndef setup(app):\n app.add_css_file(\"custom.css\")\n\n\n# -- Options for HTMLHelp output ------------------------------------------\n\n# Output file base name for HTML help builder.\nhtmlhelp_basename = \"pipenvdoc\"\n\n\n# -- Options for LaTeX output ---------------------------------------------\n\nlatex_elements = {\n # The paper size ('letterpaper' or 'a4paper').\n #\n # 'papersize': 'letterpaper',\n # The font size ('10pt', '11pt' or '12pt').\n #\n # 'pointsize': '10pt',\n # Additional stuff for the LaTeX preamble.\n #\n # 'preamble': '',\n # Latex figure (float) alignment\n #\n # 'figure_align': 'htbp',\n}\n\n# Grouping the document tree into LaTeX files. List of tuples\n# (source start file, target name, title,\n# author, documentclass [howto, manual, or own class]).\nlatex_documents = [\n (master_doc, \"pipenv.tex\", \"pipenv Documentation\", \"Kenneth Reitz\", \"manual\"),\n]\n\n\n# -- Options for manual page output ---------------------------------------\n\n# One entry per manual page. List of tuples\n# (source start file, name, description, authors, manual section).\nman_pages = [(master_doc, \"pipenv\", \"pipenv Documentation\", [author], 1)]\n\n\n# -- Options for Texinfo output -------------------------------------------\n\n# Grouping the document tree into Texinfo files. List of tuples\n# (source start file, target name, title, author,\n# dir menu entry, description, category)\ntexinfo_documents = [\n (\n master_doc,\n \"pipenv\",\n \"pipenv Documentation\",\n author,\n \"pipenv\",\n \"One line description of project.\",\n \"Miscellaneous\",\n ),\n]\n\n\n# -- Options for Epub output ----------------------------------------------\n\n# Bibliographic Dublin Core info.\nepub_title = project\nepub_author = author\nepub_publisher = author\nepub_copyright = copyright\n\n# The unique identifier of the text. This can be a ISBN number\n# or the project homepage.\n#\n# epub_identifier = ''\n\n# A unique identification for the text.\n#\n# epub_uid = ''\n\n# A list of files that should not be packed into the epub file.\nepub_exclude_files = [\"search.html\"]\n", "path": "docs/conf.py"}]}
| 2,627 | 89 |
gh_patches_debug_32476
|
rasdani/github-patches
|
git_diff
|
freqtrade__freqtrade-3217
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
askVolume and bidVolume in VolumePairList
Hi,
I come back with the discussion with @hroff-1902 we have about askVolume and bidVolume.
If i have well understood it filtered based on the volume of the best bid/ask.
It means like if Bitcoin have a bid with 30 dollar and a shitcoin have a bid at 3000 dollar it will update the pairlist and put before in the list shitcoin vs BTC ?
Many tks.
askVolume and bidVolume in VolumePairList
Hi,
I come back with the discussion with @hroff-1902 we have about askVolume and bidVolume.
If i have well understood it filtered based on the volume of the best bid/ask.
It means like if Bitcoin have a bid with 30 dollar and a shitcoin have a bid at 3000 dollar it will update the pairlist and put before in the list shitcoin vs BTC ?
Many tks.
</issue>
<code>
[start of freqtrade/configuration/deprecated_settings.py]
1 """
2 Functions to handle deprecated settings
3 """
4
5 import logging
6 from typing import Any, Dict
7
8 from freqtrade.exceptions import OperationalException
9
10
11 logger = logging.getLogger(__name__)
12
13
14 def check_conflicting_settings(config: Dict[str, Any],
15 section1: str, name1: str,
16 section2: str, name2: str) -> None:
17 section1_config = config.get(section1, {})
18 section2_config = config.get(section2, {})
19 if name1 in section1_config and name2 in section2_config:
20 raise OperationalException(
21 f"Conflicting settings `{section1}.{name1}` and `{section2}.{name2}` "
22 "(DEPRECATED) detected in the configuration file. "
23 "This deprecated setting will be removed in the next versions of Freqtrade. "
24 f"Please delete it from your configuration and use the `{section1}.{name1}` "
25 "setting instead."
26 )
27
28
29 def process_deprecated_setting(config: Dict[str, Any],
30 section1: str, name1: str,
31 section2: str, name2: str) -> None:
32 section2_config = config.get(section2, {})
33
34 if name2 in section2_config:
35 logger.warning(
36 "DEPRECATED: "
37 f"The `{section2}.{name2}` setting is deprecated and "
38 "will be removed in the next versions of Freqtrade. "
39 f"Please use the `{section1}.{name1}` setting in your configuration instead."
40 )
41 section1_config = config.get(section1, {})
42 section1_config[name1] = section2_config[name2]
43
44
45 def process_temporary_deprecated_settings(config: Dict[str, Any]) -> None:
46
47 check_conflicting_settings(config, 'ask_strategy', 'use_sell_signal',
48 'experimental', 'use_sell_signal')
49 check_conflicting_settings(config, 'ask_strategy', 'sell_profit_only',
50 'experimental', 'sell_profit_only')
51 check_conflicting_settings(config, 'ask_strategy', 'ignore_roi_if_buy_signal',
52 'experimental', 'ignore_roi_if_buy_signal')
53
54 process_deprecated_setting(config, 'ask_strategy', 'use_sell_signal',
55 'experimental', 'use_sell_signal')
56 process_deprecated_setting(config, 'ask_strategy', 'sell_profit_only',
57 'experimental', 'sell_profit_only')
58 process_deprecated_setting(config, 'ask_strategy', 'ignore_roi_if_buy_signal',
59 'experimental', 'ignore_roi_if_buy_signal')
60
61 if not config.get('pairlists') and not config.get('pairlists'):
62 config['pairlists'] = [{'method': 'StaticPairList'}]
63 logger.warning(
64 "DEPRECATED: "
65 "Pairlists must be defined explicitly in the future."
66 "Defaulting to StaticPairList for now.")
67
68 if config.get('pairlist', {}).get("method") == 'VolumePairList':
69 logger.warning(
70 "DEPRECATED: "
71 f"Using VolumePairList in pairlist is deprecated and must be moved to pairlists. "
72 "Please refer to the docs on configuration details")
73 pl = {'method': 'VolumePairList'}
74 pl.update(config.get('pairlist', {}).get('config'))
75 config['pairlists'].append(pl)
76
77 if config.get('pairlist', {}).get('config', {}).get('precision_filter'):
78 logger.warning(
79 "DEPRECATED: "
80 f"Using precision_filter setting is deprecated and has been replaced by"
81 "PrecisionFilter. Please refer to the docs on configuration details")
82 config['pairlists'].append({'method': 'PrecisionFilter'})
83
84 if (config.get('edge', {}).get('enabled', False)
85 and 'capital_available_percentage' in config.get('edge', {})):
86 logger.warning(
87 "DEPRECATED: "
88 "Using 'edge.capital_available_percentage' has been deprecated in favor of "
89 "'tradable_balance_ratio'. Please migrate your configuration to "
90 "'tradable_balance_ratio' and remove 'capital_available_percentage' "
91 "from the edge configuration."
92 )
93
[end of freqtrade/configuration/deprecated_settings.py]
[start of freqtrade/pairlist/VolumePairList.py]
1 """
2 Volume PairList provider
3
4 Provides lists as configured in config.json
5
6 """
7 import logging
8 from datetime import datetime
9 from typing import Any, Dict, List
10
11 from freqtrade.exceptions import OperationalException
12 from freqtrade.pairlist.IPairList import IPairList
13
14 logger = logging.getLogger(__name__)
15
16 SORT_VALUES = ['askVolume', 'bidVolume', 'quoteVolume']
17
18
19 class VolumePairList(IPairList):
20
21 def __init__(self, exchange, pairlistmanager, config: Dict[str, Any], pairlistconfig: dict,
22 pairlist_pos: int) -> None:
23 super().__init__(exchange, pairlistmanager, config, pairlistconfig, pairlist_pos)
24
25 if 'number_assets' not in self._pairlistconfig:
26 raise OperationalException(
27 f'`number_assets` not specified. Please check your configuration '
28 'for "pairlist.config.number_assets"')
29 self._number_pairs = self._pairlistconfig['number_assets']
30 self._sort_key = self._pairlistconfig.get('sort_key', 'quoteVolume')
31 self._min_value = self._pairlistconfig.get('min_value', 0)
32 self.refresh_period = self._pairlistconfig.get('refresh_period', 1800)
33
34 if not self._exchange.exchange_has('fetchTickers'):
35 raise OperationalException(
36 'Exchange does not support dynamic whitelist.'
37 'Please edit your config and restart the bot'
38 )
39 if not self._validate_keys(self._sort_key):
40 raise OperationalException(
41 f'key {self._sort_key} not in {SORT_VALUES}')
42
43 @property
44 def needstickers(self) -> bool:
45 """
46 Boolean property defining if tickers are necessary.
47 If no Pairlist requries tickers, an empty List is passed
48 as tickers argument to filter_pairlist
49 """
50 return True
51
52 def _validate_keys(self, key):
53 return key in SORT_VALUES
54
55 def short_desc(self) -> str:
56 """
57 Short whitelist method description - used for startup-messages
58 """
59 return f"{self.name} - top {self._pairlistconfig['number_assets']} volume pairs."
60
61 def filter_pairlist(self, pairlist: List[str], tickers: Dict) -> List[str]:
62 """
63 Filters and sorts pairlist and returns the whitelist again.
64 Called on each bot iteration - please use internal caching if necessary
65 :param pairlist: pairlist to filter or sort
66 :param tickers: Tickers (from exchange.get_tickers()). May be cached.
67 :return: new whitelist
68 """
69 # Generate dynamic whitelist
70 # Must always run if this pairlist is not the first in the list.
71 if (self._pairlist_pos != 0 or
72 (self._last_refresh + self.refresh_period < datetime.now().timestamp())):
73
74 self._last_refresh = int(datetime.now().timestamp())
75 pairs = self._gen_pair_whitelist(pairlist, tickers,
76 self._config['stake_currency'],
77 self._sort_key, self._min_value)
78 else:
79 pairs = pairlist
80 self.log_on_refresh(logger.info, f"Searching {self._number_pairs} pairs: {pairs}")
81 return pairs
82
83 def _gen_pair_whitelist(self, pairlist: List[str], tickers: Dict,
84 base_currency: str, key: str, min_val: int) -> List[str]:
85 """
86 Updates the whitelist with with a dynamically generated list
87 :param base_currency: base currency as str
88 :param key: sort key (defaults to 'quoteVolume')
89 :param tickers: Tickers (from exchange.get_tickers()).
90 :return: List of pairs
91 """
92 if self._pairlist_pos == 0:
93 # If VolumePairList is the first in the list, use fresh pairlist
94 # Check if pair quote currency equals to the stake currency.
95 filtered_tickers = [v for k, v in tickers.items()
96 if (self._exchange.get_pair_quote_currency(k) == base_currency
97 and v[key] is not None)]
98 else:
99 # If other pairlist is in front, use the incomming pairlist.
100 filtered_tickers = [v for k, v in tickers.items() if k in pairlist]
101
102 if min_val > 0:
103 filtered_tickers = list(filter(lambda t: t[key] > min_val, filtered_tickers))
104
105 sorted_tickers = sorted(filtered_tickers, reverse=True, key=lambda t: t[key])
106
107 # Validate whitelist to only have active market pairs
108 pairs = self._whitelist_for_active_markets([s['symbol'] for s in sorted_tickers])
109 pairs = self._verify_blacklist(pairs, aswarning=False)
110 # Limit to X number of pairs
111 pairs = pairs[:self._number_pairs]
112
113 return pairs
114
[end of freqtrade/pairlist/VolumePairList.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/freqtrade/configuration/deprecated_settings.py b/freqtrade/configuration/deprecated_settings.py
--- a/freqtrade/configuration/deprecated_settings.py
+++ b/freqtrade/configuration/deprecated_settings.py
@@ -58,29 +58,6 @@
process_deprecated_setting(config, 'ask_strategy', 'ignore_roi_if_buy_signal',
'experimental', 'ignore_roi_if_buy_signal')
- if not config.get('pairlists') and not config.get('pairlists'):
- config['pairlists'] = [{'method': 'StaticPairList'}]
- logger.warning(
- "DEPRECATED: "
- "Pairlists must be defined explicitly in the future."
- "Defaulting to StaticPairList for now.")
-
- if config.get('pairlist', {}).get("method") == 'VolumePairList':
- logger.warning(
- "DEPRECATED: "
- f"Using VolumePairList in pairlist is deprecated and must be moved to pairlists. "
- "Please refer to the docs on configuration details")
- pl = {'method': 'VolumePairList'}
- pl.update(config.get('pairlist', {}).get('config'))
- config['pairlists'].append(pl)
-
- if config.get('pairlist', {}).get('config', {}).get('precision_filter'):
- logger.warning(
- "DEPRECATED: "
- f"Using precision_filter setting is deprecated and has been replaced by"
- "PrecisionFilter. Please refer to the docs on configuration details")
- config['pairlists'].append({'method': 'PrecisionFilter'})
-
if (config.get('edge', {}).get('enabled', False)
and 'capital_available_percentage' in config.get('edge', {})):
logger.warning(
diff --git a/freqtrade/pairlist/VolumePairList.py b/freqtrade/pairlist/VolumePairList.py
--- a/freqtrade/pairlist/VolumePairList.py
+++ b/freqtrade/pairlist/VolumePairList.py
@@ -39,6 +39,10 @@
if not self._validate_keys(self._sort_key):
raise OperationalException(
f'key {self._sort_key} not in {SORT_VALUES}')
+ if self._sort_key != 'quoteVolume':
+ logger.warning(
+ "DEPRECATED: using any key other than quoteVolume for VolumePairList is deprecated."
+ )
@property
def needstickers(self) -> bool:
|
{"golden_diff": "diff --git a/freqtrade/configuration/deprecated_settings.py b/freqtrade/configuration/deprecated_settings.py\n--- a/freqtrade/configuration/deprecated_settings.py\n+++ b/freqtrade/configuration/deprecated_settings.py\n@@ -58,29 +58,6 @@\n process_deprecated_setting(config, 'ask_strategy', 'ignore_roi_if_buy_signal',\n 'experimental', 'ignore_roi_if_buy_signal')\n \n- if not config.get('pairlists') and not config.get('pairlists'):\n- config['pairlists'] = [{'method': 'StaticPairList'}]\n- logger.warning(\n- \"DEPRECATED: \"\n- \"Pairlists must be defined explicitly in the future.\"\n- \"Defaulting to StaticPairList for now.\")\n-\n- if config.get('pairlist', {}).get(\"method\") == 'VolumePairList':\n- logger.warning(\n- \"DEPRECATED: \"\n- f\"Using VolumePairList in pairlist is deprecated and must be moved to pairlists. \"\n- \"Please refer to the docs on configuration details\")\n- pl = {'method': 'VolumePairList'}\n- pl.update(config.get('pairlist', {}).get('config'))\n- config['pairlists'].append(pl)\n-\n- if config.get('pairlist', {}).get('config', {}).get('precision_filter'):\n- logger.warning(\n- \"DEPRECATED: \"\n- f\"Using precision_filter setting is deprecated and has been replaced by\"\n- \"PrecisionFilter. Please refer to the docs on configuration details\")\n- config['pairlists'].append({'method': 'PrecisionFilter'})\n-\n if (config.get('edge', {}).get('enabled', False)\n and 'capital_available_percentage' in config.get('edge', {})):\n logger.warning(\ndiff --git a/freqtrade/pairlist/VolumePairList.py b/freqtrade/pairlist/VolumePairList.py\n--- a/freqtrade/pairlist/VolumePairList.py\n+++ b/freqtrade/pairlist/VolumePairList.py\n@@ -39,6 +39,10 @@\n if not self._validate_keys(self._sort_key):\n raise OperationalException(\n f'key {self._sort_key} not in {SORT_VALUES}')\n+ if self._sort_key != 'quoteVolume':\n+ logger.warning(\n+ \"DEPRECATED: using any key other than quoteVolume for VolumePairList is deprecated.\"\n+ )\n \n @property\n def needstickers(self) -> bool:\n", "issue": "askVolume and bidVolume in VolumePairList\nHi,\r\n\r\nI come back with the discussion with @hroff-1902 we have about askVolume and bidVolume.\r\nIf i have well understood it filtered based on the volume of the best bid/ask.\r\n\r\nIt means like if Bitcoin have a bid with 30 dollar and a shitcoin have a bid at 3000 dollar it will update the pairlist and put before in the list shitcoin vs BTC ?\r\n\r\nMany tks.\naskVolume and bidVolume in VolumePairList\nHi,\r\n\r\nI come back with the discussion with @hroff-1902 we have about askVolume and bidVolume.\r\nIf i have well understood it filtered based on the volume of the best bid/ask.\r\n\r\nIt means like if Bitcoin have a bid with 30 dollar and a shitcoin have a bid at 3000 dollar it will update the pairlist and put before in the list shitcoin vs BTC ?\r\n\r\nMany tks.\n", "before_files": [{"content": "\"\"\"\nFunctions to handle deprecated settings\n\"\"\"\n\nimport logging\nfrom typing import Any, Dict\n\nfrom freqtrade.exceptions import OperationalException\n\n\nlogger = logging.getLogger(__name__)\n\n\ndef check_conflicting_settings(config: Dict[str, Any],\n section1: str, name1: str,\n section2: str, name2: str) -> None:\n section1_config = config.get(section1, {})\n section2_config = config.get(section2, {})\n if name1 in section1_config and name2 in section2_config:\n raise OperationalException(\n f\"Conflicting settings `{section1}.{name1}` and `{section2}.{name2}` \"\n \"(DEPRECATED) detected in the configuration file. \"\n \"This deprecated setting will be removed in the next versions of Freqtrade. \"\n f\"Please delete it from your configuration and use the `{section1}.{name1}` \"\n \"setting instead.\"\n )\n\n\ndef process_deprecated_setting(config: Dict[str, Any],\n section1: str, name1: str,\n section2: str, name2: str) -> None:\n section2_config = config.get(section2, {})\n\n if name2 in section2_config:\n logger.warning(\n \"DEPRECATED: \"\n f\"The `{section2}.{name2}` setting is deprecated and \"\n \"will be removed in the next versions of Freqtrade. \"\n f\"Please use the `{section1}.{name1}` setting in your configuration instead.\"\n )\n section1_config = config.get(section1, {})\n section1_config[name1] = section2_config[name2]\n\n\ndef process_temporary_deprecated_settings(config: Dict[str, Any]) -> None:\n\n check_conflicting_settings(config, 'ask_strategy', 'use_sell_signal',\n 'experimental', 'use_sell_signal')\n check_conflicting_settings(config, 'ask_strategy', 'sell_profit_only',\n 'experimental', 'sell_profit_only')\n check_conflicting_settings(config, 'ask_strategy', 'ignore_roi_if_buy_signal',\n 'experimental', 'ignore_roi_if_buy_signal')\n\n process_deprecated_setting(config, 'ask_strategy', 'use_sell_signal',\n 'experimental', 'use_sell_signal')\n process_deprecated_setting(config, 'ask_strategy', 'sell_profit_only',\n 'experimental', 'sell_profit_only')\n process_deprecated_setting(config, 'ask_strategy', 'ignore_roi_if_buy_signal',\n 'experimental', 'ignore_roi_if_buy_signal')\n\n if not config.get('pairlists') and not config.get('pairlists'):\n config['pairlists'] = [{'method': 'StaticPairList'}]\n logger.warning(\n \"DEPRECATED: \"\n \"Pairlists must be defined explicitly in the future.\"\n \"Defaulting to StaticPairList for now.\")\n\n if config.get('pairlist', {}).get(\"method\") == 'VolumePairList':\n logger.warning(\n \"DEPRECATED: \"\n f\"Using VolumePairList in pairlist is deprecated and must be moved to pairlists. \"\n \"Please refer to the docs on configuration details\")\n pl = {'method': 'VolumePairList'}\n pl.update(config.get('pairlist', {}).get('config'))\n config['pairlists'].append(pl)\n\n if config.get('pairlist', {}).get('config', {}).get('precision_filter'):\n logger.warning(\n \"DEPRECATED: \"\n f\"Using precision_filter setting is deprecated and has been replaced by\"\n \"PrecisionFilter. Please refer to the docs on configuration details\")\n config['pairlists'].append({'method': 'PrecisionFilter'})\n\n if (config.get('edge', {}).get('enabled', False)\n and 'capital_available_percentage' in config.get('edge', {})):\n logger.warning(\n \"DEPRECATED: \"\n \"Using 'edge.capital_available_percentage' has been deprecated in favor of \"\n \"'tradable_balance_ratio'. Please migrate your configuration to \"\n \"'tradable_balance_ratio' and remove 'capital_available_percentage' \"\n \"from the edge configuration.\"\n )\n", "path": "freqtrade/configuration/deprecated_settings.py"}, {"content": "\"\"\"\nVolume PairList provider\n\nProvides lists as configured in config.json\n\n \"\"\"\nimport logging\nfrom datetime import datetime\nfrom typing import Any, Dict, List\n\nfrom freqtrade.exceptions import OperationalException\nfrom freqtrade.pairlist.IPairList import IPairList\n\nlogger = logging.getLogger(__name__)\n\nSORT_VALUES = ['askVolume', 'bidVolume', 'quoteVolume']\n\n\nclass VolumePairList(IPairList):\n\n def __init__(self, exchange, pairlistmanager, config: Dict[str, Any], pairlistconfig: dict,\n pairlist_pos: int) -> None:\n super().__init__(exchange, pairlistmanager, config, pairlistconfig, pairlist_pos)\n\n if 'number_assets' not in self._pairlistconfig:\n raise OperationalException(\n f'`number_assets` not specified. Please check your configuration '\n 'for \"pairlist.config.number_assets\"')\n self._number_pairs = self._pairlistconfig['number_assets']\n self._sort_key = self._pairlistconfig.get('sort_key', 'quoteVolume')\n self._min_value = self._pairlistconfig.get('min_value', 0)\n self.refresh_period = self._pairlistconfig.get('refresh_period', 1800)\n\n if not self._exchange.exchange_has('fetchTickers'):\n raise OperationalException(\n 'Exchange does not support dynamic whitelist.'\n 'Please edit your config and restart the bot'\n )\n if not self._validate_keys(self._sort_key):\n raise OperationalException(\n f'key {self._sort_key} not in {SORT_VALUES}')\n\n @property\n def needstickers(self) -> bool:\n \"\"\"\n Boolean property defining if tickers are necessary.\n If no Pairlist requries tickers, an empty List is passed\n as tickers argument to filter_pairlist\n \"\"\"\n return True\n\n def _validate_keys(self, key):\n return key in SORT_VALUES\n\n def short_desc(self) -> str:\n \"\"\"\n Short whitelist method description - used for startup-messages\n \"\"\"\n return f\"{self.name} - top {self._pairlistconfig['number_assets']} volume pairs.\"\n\n def filter_pairlist(self, pairlist: List[str], tickers: Dict) -> List[str]:\n \"\"\"\n Filters and sorts pairlist and returns the whitelist again.\n Called on each bot iteration - please use internal caching if necessary\n :param pairlist: pairlist to filter or sort\n :param tickers: Tickers (from exchange.get_tickers()). May be cached.\n :return: new whitelist\n \"\"\"\n # Generate dynamic whitelist\n # Must always run if this pairlist is not the first in the list.\n if (self._pairlist_pos != 0 or\n (self._last_refresh + self.refresh_period < datetime.now().timestamp())):\n\n self._last_refresh = int(datetime.now().timestamp())\n pairs = self._gen_pair_whitelist(pairlist, tickers,\n self._config['stake_currency'],\n self._sort_key, self._min_value)\n else:\n pairs = pairlist\n self.log_on_refresh(logger.info, f\"Searching {self._number_pairs} pairs: {pairs}\")\n return pairs\n\n def _gen_pair_whitelist(self, pairlist: List[str], tickers: Dict,\n base_currency: str, key: str, min_val: int) -> List[str]:\n \"\"\"\n Updates the whitelist with with a dynamically generated list\n :param base_currency: base currency as str\n :param key: sort key (defaults to 'quoteVolume')\n :param tickers: Tickers (from exchange.get_tickers()).\n :return: List of pairs\n \"\"\"\n if self._pairlist_pos == 0:\n # If VolumePairList is the first in the list, use fresh pairlist\n # Check if pair quote currency equals to the stake currency.\n filtered_tickers = [v for k, v in tickers.items()\n if (self._exchange.get_pair_quote_currency(k) == base_currency\n and v[key] is not None)]\n else:\n # If other pairlist is in front, use the incomming pairlist.\n filtered_tickers = [v for k, v in tickers.items() if k in pairlist]\n\n if min_val > 0:\n filtered_tickers = list(filter(lambda t: t[key] > min_val, filtered_tickers))\n\n sorted_tickers = sorted(filtered_tickers, reverse=True, key=lambda t: t[key])\n\n # Validate whitelist to only have active market pairs\n pairs = self._whitelist_for_active_markets([s['symbol'] for s in sorted_tickers])\n pairs = self._verify_blacklist(pairs, aswarning=False)\n # Limit to X number of pairs\n pairs = pairs[:self._number_pairs]\n\n return pairs\n", "path": "freqtrade/pairlist/VolumePairList.py"}]}
| 3,091 | 534 |
gh_patches_debug_34327
|
rasdani/github-patches
|
git_diff
|
translate__pootle-6695
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Use XHR for user select2 widgets
on a site with a lot of users the admin widgets are very slow and unnecessarily push a full list of users
</issue>
<code>
[start of pootle/apps/pootle_app/views/admin/permissions.py]
1 # -*- coding: utf-8 -*-
2 #
3 # Copyright (C) Pootle contributors.
4 #
5 # This file is a part of the Pootle project. It is distributed under the GPL3
6 # or later license. See the LICENSE file for a copy of the license and the
7 # AUTHORS file for copyright and authorship information.
8
9 from django import forms
10 from django.contrib.auth import get_user_model
11
12 from pootle.core.decorators import get_object_or_404
13 from pootle.core.exceptions import Http400
14 from pootle.core.views.admin import PootleAdminFormView
15 from pootle.core.views.mixins import PootleJSONMixin
16 from pootle.i18n.gettext import ugettext as _
17 from pootle_app.forms import PermissionsUsersSearchForm
18 from pootle_app.models import Directory
19 from pootle_app.models.permissions import (PermissionSet,
20 get_permission_contenttype)
21 from pootle_app.views.admin import util
22 from pootle_misc.forms import GroupedModelChoiceField
23
24
25 User = get_user_model()
26
27 PERMISSIONS = {
28 'positive': ['view', 'suggest', 'translate', 'review', 'administrate'],
29 'negative': ['hide'],
30 }
31
32
33 class PermissionFormField(forms.ModelMultipleChoiceField):
34
35 def label_from_instance(self, instance):
36 return _(instance.name)
37
38
39 def admin_permissions(request, current_directory, template, ctx):
40 language = ctx.get('language', None)
41
42 negative_permissions_excl = list(PERMISSIONS['negative'])
43 positive_permissions_excl = list(PERMISSIONS['positive'])
44
45 # Don't provide means to alter access permissions under /<lang_code>/*
46 # In other words: only allow setting access permissions for the root
47 # and the `/projects/<code>/` directories
48 if language is not None:
49 access_permissions = ['view', 'hide']
50 negative_permissions_excl.extend(access_permissions)
51 positive_permissions_excl.extend(access_permissions)
52
53 content_type = get_permission_contenttype()
54
55 positive_permissions_qs = content_type.permission_set.exclude(
56 codename__in=negative_permissions_excl,
57 )
58 negative_permissions_qs = content_type.permission_set.exclude(
59 codename__in=positive_permissions_excl,
60 )
61
62 base_queryset = User.objects.filter(is_active=1).exclude(
63 id__in=current_directory.permission_sets.values_list('user_id',
64 flat=True),)
65 choice_groups = [(None, base_queryset.filter(
66 username__in=('nobody', 'default')
67 ))]
68
69 choice_groups.append((
70 _('All Users'),
71 base_queryset.exclude(username__in=('nobody',
72 'default')).order_by('username'),
73 ))
74
75 class PermissionSetForm(forms.ModelForm):
76
77 class Meta(object):
78 model = PermissionSet
79 fields = ('user', 'directory', 'positive_permissions',
80 'negative_permissions')
81
82 directory = forms.ModelChoiceField(
83 queryset=Directory.objects.filter(pk=current_directory.pk),
84 initial=current_directory.pk,
85 widget=forms.HiddenInput,
86 )
87 user = GroupedModelChoiceField(
88 label=_('Username'),
89 choice_groups=choice_groups,
90 queryset=User.objects.all(),
91 required=True,
92 widget=forms.Select(attrs={
93 'class': 'js-select2 select2-username',
94 }),
95 )
96 positive_permissions = PermissionFormField(
97 label=_('Add Permissions'),
98 queryset=positive_permissions_qs,
99 required=False,
100 widget=forms.SelectMultiple(attrs={
101 'class': 'js-select2 select2-multiple',
102 'data-placeholder': _('Select one or more permissions'),
103 }),
104 )
105 negative_permissions = PermissionFormField(
106 label=_('Revoke Permissions'),
107 queryset=negative_permissions_qs,
108 required=False,
109 widget=forms.SelectMultiple(attrs={
110 'class': 'js-select2 select2-multiple',
111 'data-placeholder': _('Select one or more permissions'),
112 }),
113 )
114
115 def __init__(self, *args, **kwargs):
116 super(PermissionSetForm, self).__init__(*args, **kwargs)
117
118 # Don't display extra negative permissions field where they
119 # are not applicable
120 if language is not None:
121 del self.fields['negative_permissions']
122
123 link = lambda instance: unicode(instance.user)
124 directory_permissions = current_directory.permission_sets \
125 .order_by('user').all()
126
127 return util.edit(request, template, PermissionSet, ctx, link,
128 linkfield='user', queryset=directory_permissions,
129 can_delete=True, form=PermissionSetForm)
130
131
132 class PermissionsUsersJSON(PootleJSONMixin, PootleAdminFormView):
133 form_class = PermissionsUsersSearchForm
134
135 @property
136 def directory(self):
137 return get_object_or_404(
138 Directory.objects,
139 pk=self.kwargs["directory"])
140
141 def get_context_data(self, **kwargs):
142 context = super(
143 PermissionsUsersJSON, self).get_context_data(**kwargs)
144 form = context["form"]
145 return (
146 dict(items=form.search())
147 if form.is_valid()
148 else dict(items=[]))
149
150 def get_form_kwargs(self):
151 kwargs = super(PermissionsUsersJSON, self).get_form_kwargs()
152 kwargs["directory"] = self.directory
153 return kwargs
154
155 def form_valid(self, form):
156 return self.render_to_response(
157 self.get_context_data(form=form))
158
159 def form_invalid(self, form):
160 raise Http400(form.errors)
161
[end of pootle/apps/pootle_app/views/admin/permissions.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/pootle/apps/pootle_app/views/admin/permissions.py b/pootle/apps/pootle_app/views/admin/permissions.py
--- a/pootle/apps/pootle_app/views/admin/permissions.py
+++ b/pootle/apps/pootle_app/views/admin/permissions.py
@@ -8,11 +8,13 @@
from django import forms
from django.contrib.auth import get_user_model
+from django.urls import reverse
from pootle.core.decorators import get_object_or_404
from pootle.core.exceptions import Http400
from pootle.core.views.admin import PootleAdminFormView
from pootle.core.views.mixins import PootleJSONMixin
+from pootle.core.views.widgets import RemoteSelectWidget
from pootle.i18n.gettext import ugettext as _
from pootle_app.forms import PermissionsUsersSearchForm
from pootle_app.models import Directory
@@ -89,10 +91,11 @@
choice_groups=choice_groups,
queryset=User.objects.all(),
required=True,
- widget=forms.Select(attrs={
- 'class': 'js-select2 select2-username',
- }),
- )
+ widget=RemoteSelectWidget(
+ attrs={
+ "data-s2-placeholder": _("Search for users to add"),
+ 'class': ('js-select2-remote select2-username '
+ 'js-s2-new-members')}))
positive_permissions = PermissionFormField(
label=_('Add Permissions'),
queryset=positive_permissions_qs,
@@ -115,6 +118,10 @@
def __init__(self, *args, **kwargs):
super(PermissionSetForm, self).__init__(*args, **kwargs)
+ self.fields["user"].widget.attrs["data-select2-url"] = reverse(
+ "pootle-permissions-users",
+ kwargs=dict(directory=current_directory.pk))
+
# Don't display extra negative permissions field where they
# are not applicable
if language is not None:
|
{"golden_diff": "diff --git a/pootle/apps/pootle_app/views/admin/permissions.py b/pootle/apps/pootle_app/views/admin/permissions.py\n--- a/pootle/apps/pootle_app/views/admin/permissions.py\n+++ b/pootle/apps/pootle_app/views/admin/permissions.py\n@@ -8,11 +8,13 @@\n \n from django import forms\n from django.contrib.auth import get_user_model\n+from django.urls import reverse\n \n from pootle.core.decorators import get_object_or_404\n from pootle.core.exceptions import Http400\n from pootle.core.views.admin import PootleAdminFormView\n from pootle.core.views.mixins import PootleJSONMixin\n+from pootle.core.views.widgets import RemoteSelectWidget\n from pootle.i18n.gettext import ugettext as _\n from pootle_app.forms import PermissionsUsersSearchForm\n from pootle_app.models import Directory\n@@ -89,10 +91,11 @@\n choice_groups=choice_groups,\n queryset=User.objects.all(),\n required=True,\n- widget=forms.Select(attrs={\n- 'class': 'js-select2 select2-username',\n- }),\n- )\n+ widget=RemoteSelectWidget(\n+ attrs={\n+ \"data-s2-placeholder\": _(\"Search for users to add\"),\n+ 'class': ('js-select2-remote select2-username '\n+ 'js-s2-new-members')}))\n positive_permissions = PermissionFormField(\n label=_('Add Permissions'),\n queryset=positive_permissions_qs,\n@@ -115,6 +118,10 @@\n def __init__(self, *args, **kwargs):\n super(PermissionSetForm, self).__init__(*args, **kwargs)\n \n+ self.fields[\"user\"].widget.attrs[\"data-select2-url\"] = reverse(\n+ \"pootle-permissions-users\",\n+ kwargs=dict(directory=current_directory.pk))\n+\n # Don't display extra negative permissions field where they\n # are not applicable\n if language is not None:\n", "issue": "Use XHR for user select2 widgets\non a site with a lot of users the admin widgets are very slow and unnecessarily push a full list of users\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n#\n# Copyright (C) Pootle contributors.\n#\n# This file is a part of the Pootle project. It is distributed under the GPL3\n# or later license. See the LICENSE file for a copy of the license and the\n# AUTHORS file for copyright and authorship information.\n\nfrom django import forms\nfrom django.contrib.auth import get_user_model\n\nfrom pootle.core.decorators import get_object_or_404\nfrom pootle.core.exceptions import Http400\nfrom pootle.core.views.admin import PootleAdminFormView\nfrom pootle.core.views.mixins import PootleJSONMixin\nfrom pootle.i18n.gettext import ugettext as _\nfrom pootle_app.forms import PermissionsUsersSearchForm\nfrom pootle_app.models import Directory\nfrom pootle_app.models.permissions import (PermissionSet,\n get_permission_contenttype)\nfrom pootle_app.views.admin import util\nfrom pootle_misc.forms import GroupedModelChoiceField\n\n\nUser = get_user_model()\n\nPERMISSIONS = {\n 'positive': ['view', 'suggest', 'translate', 'review', 'administrate'],\n 'negative': ['hide'],\n}\n\n\nclass PermissionFormField(forms.ModelMultipleChoiceField):\n\n def label_from_instance(self, instance):\n return _(instance.name)\n\n\ndef admin_permissions(request, current_directory, template, ctx):\n language = ctx.get('language', None)\n\n negative_permissions_excl = list(PERMISSIONS['negative'])\n positive_permissions_excl = list(PERMISSIONS['positive'])\n\n # Don't provide means to alter access permissions under /<lang_code>/*\n # In other words: only allow setting access permissions for the root\n # and the `/projects/<code>/` directories\n if language is not None:\n access_permissions = ['view', 'hide']\n negative_permissions_excl.extend(access_permissions)\n positive_permissions_excl.extend(access_permissions)\n\n content_type = get_permission_contenttype()\n\n positive_permissions_qs = content_type.permission_set.exclude(\n codename__in=negative_permissions_excl,\n )\n negative_permissions_qs = content_type.permission_set.exclude(\n codename__in=positive_permissions_excl,\n )\n\n base_queryset = User.objects.filter(is_active=1).exclude(\n id__in=current_directory.permission_sets.values_list('user_id',\n flat=True),)\n choice_groups = [(None, base_queryset.filter(\n username__in=('nobody', 'default')\n ))]\n\n choice_groups.append((\n _('All Users'),\n base_queryset.exclude(username__in=('nobody',\n 'default')).order_by('username'),\n ))\n\n class PermissionSetForm(forms.ModelForm):\n\n class Meta(object):\n model = PermissionSet\n fields = ('user', 'directory', 'positive_permissions',\n 'negative_permissions')\n\n directory = forms.ModelChoiceField(\n queryset=Directory.objects.filter(pk=current_directory.pk),\n initial=current_directory.pk,\n widget=forms.HiddenInput,\n )\n user = GroupedModelChoiceField(\n label=_('Username'),\n choice_groups=choice_groups,\n queryset=User.objects.all(),\n required=True,\n widget=forms.Select(attrs={\n 'class': 'js-select2 select2-username',\n }),\n )\n positive_permissions = PermissionFormField(\n label=_('Add Permissions'),\n queryset=positive_permissions_qs,\n required=False,\n widget=forms.SelectMultiple(attrs={\n 'class': 'js-select2 select2-multiple',\n 'data-placeholder': _('Select one or more permissions'),\n }),\n )\n negative_permissions = PermissionFormField(\n label=_('Revoke Permissions'),\n queryset=negative_permissions_qs,\n required=False,\n widget=forms.SelectMultiple(attrs={\n 'class': 'js-select2 select2-multiple',\n 'data-placeholder': _('Select one or more permissions'),\n }),\n )\n\n def __init__(self, *args, **kwargs):\n super(PermissionSetForm, self).__init__(*args, **kwargs)\n\n # Don't display extra negative permissions field where they\n # are not applicable\n if language is not None:\n del self.fields['negative_permissions']\n\n link = lambda instance: unicode(instance.user)\n directory_permissions = current_directory.permission_sets \\\n .order_by('user').all()\n\n return util.edit(request, template, PermissionSet, ctx, link,\n linkfield='user', queryset=directory_permissions,\n can_delete=True, form=PermissionSetForm)\n\n\nclass PermissionsUsersJSON(PootleJSONMixin, PootleAdminFormView):\n form_class = PermissionsUsersSearchForm\n\n @property\n def directory(self):\n return get_object_or_404(\n Directory.objects,\n pk=self.kwargs[\"directory\"])\n\n def get_context_data(self, **kwargs):\n context = super(\n PermissionsUsersJSON, self).get_context_data(**kwargs)\n form = context[\"form\"]\n return (\n dict(items=form.search())\n if form.is_valid()\n else dict(items=[]))\n\n def get_form_kwargs(self):\n kwargs = super(PermissionsUsersJSON, self).get_form_kwargs()\n kwargs[\"directory\"] = self.directory\n return kwargs\n\n def form_valid(self, form):\n return self.render_to_response(\n self.get_context_data(form=form))\n\n def form_invalid(self, form):\n raise Http400(form.errors)\n", "path": "pootle/apps/pootle_app/views/admin/permissions.py"}]}
| 2,102 | 443 |
gh_patches_debug_14892
|
rasdani/github-patches
|
git_diff
|
mitmproxy__mitmproxy-2659
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
command console.choose.cmd crashes when given no arguments
Enter mitmproxy console, issue a command like:
console.choose.cmd
... and press return.
</issue>
<code>
[start of mitmproxy/command.py]
1 """
2 This module manges and invokes typed commands.
3 """
4 import inspect
5 import typing
6 import shlex
7 import textwrap
8 import functools
9 import sys
10
11 from mitmproxy.utils import typecheck
12 from mitmproxy import exceptions
13 from mitmproxy import flow
14
15
16 Cuts = typing.Sequence[
17 typing.Sequence[typing.Union[str, bytes]]
18 ]
19
20
21 def typename(t: type, ret: bool) -> str:
22 """
23 Translates a type to an explanatory string. If ret is True, we're
24 looking at a return type, else we're looking at a parameter type.
25 """
26 if issubclass(t, (str, int, bool)):
27 return t.__name__
28 elif t == typing.Sequence[flow.Flow]:
29 return "[flow]" if ret else "flowspec"
30 elif t == typing.Sequence[str]:
31 return "[str]"
32 elif t == Cuts:
33 return "[cuts]" if ret else "cutspec"
34 elif t == flow.Flow:
35 return "flow"
36 else: # pragma: no cover
37 raise NotImplementedError(t)
38
39
40 class Command:
41 def __init__(self, manager, path, func) -> None:
42 self.path = path
43 self.manager = manager
44 self.func = func
45 sig = inspect.signature(self.func)
46 self.help = None
47 if func.__doc__:
48 txt = func.__doc__.strip()
49 self.help = "\n".join(textwrap.wrap(txt))
50
51 self.has_positional = False
52 for i in sig.parameters.values():
53 # This is the kind for *args paramters
54 if i.kind == i.VAR_POSITIONAL:
55 self.has_positional = True
56 self.paramtypes = [v.annotation for v in sig.parameters.values()]
57 self.returntype = sig.return_annotation
58
59 def paramnames(self) -> typing.Sequence[str]:
60 v = [typename(i, False) for i in self.paramtypes]
61 if self.has_positional:
62 v[-1] = "*" + v[-1]
63 return v
64
65 def retname(self) -> str:
66 return typename(self.returntype, True) if self.returntype else ""
67
68 def signature_help(self) -> str:
69 params = " ".join(self.paramnames())
70 ret = self.retname()
71 if ret:
72 ret = " -> " + ret
73 return "%s %s%s" % (self.path, params, ret)
74
75 def call(self, args: typing.Sequence[str]):
76 """
77 Call the command with a list of arguments. At this point, all
78 arguments are strings.
79 """
80 if not self.has_positional and (len(self.paramtypes) != len(args)):
81 raise exceptions.CommandError("Usage: %s" % self.signature_help())
82
83 remainder = [] # type: typing.Sequence[str]
84 if self.has_positional:
85 remainder = args[len(self.paramtypes) - 1:]
86 args = args[:len(self.paramtypes) - 1]
87
88 pargs = []
89 for i in range(len(args)):
90 if typecheck.check_command_type(args[i], self.paramtypes[i]):
91 pargs.append(args[i])
92 else:
93 pargs.append(parsearg(self.manager, args[i], self.paramtypes[i]))
94
95 if remainder:
96 chk = typecheck.check_command_type(
97 remainder,
98 typing.Sequence[self.paramtypes[-1]] # type: ignore
99 )
100 if chk:
101 pargs.extend(remainder)
102 else:
103 raise exceptions.CommandError("Invalid value type.")
104
105 with self.manager.master.handlecontext():
106 ret = self.func(*pargs)
107
108 if not typecheck.check_command_type(ret, self.returntype):
109 raise exceptions.CommandError("Command returned unexpected data")
110
111 return ret
112
113
114 class CommandManager:
115 def __init__(self, master):
116 self.master = master
117 self.commands = {}
118
119 def collect_commands(self, addon):
120 for i in dir(addon):
121 if not i.startswith("__"):
122 o = getattr(addon, i)
123 if hasattr(o, "command_path"):
124 self.add(o.command_path, o)
125
126 def add(self, path: str, func: typing.Callable):
127 self.commands[path] = Command(self, path, func)
128
129 def call_args(self, path, args):
130 """
131 Call a command using a list of string arguments. May raise CommandError.
132 """
133 if path not in self.commands:
134 raise exceptions.CommandError("Unknown command: %s" % path)
135 return self.commands[path].call(args)
136
137 def call(self, cmdstr: str):
138 """
139 Call a command using a string. May raise CommandError.
140 """
141 parts = shlex.split(cmdstr)
142 if not len(parts) >= 1:
143 raise exceptions.CommandError("Invalid command: %s" % cmdstr)
144 return self.call_args(parts[0], parts[1:])
145
146 def dump(self, out=sys.stdout) -> None:
147 cmds = list(self.commands.values())
148 cmds.sort(key=lambda x: x.signature_help())
149 for c in cmds:
150 for hl in (c.help or "").splitlines():
151 print("# " + hl, file=out)
152 print(c.signature_help(), file=out)
153 print(file=out)
154
155
156 def parsearg(manager: CommandManager, spec: str, argtype: type) -> typing.Any:
157 """
158 Convert a string to a argument to the appropriate type.
159 """
160 if issubclass(argtype, str):
161 return spec
162 elif argtype == bool:
163 if spec == "true":
164 return True
165 elif spec == "false":
166 return False
167 else:
168 raise exceptions.CommandError(
169 "Booleans are 'true' or 'false', got %s" % spec
170 )
171 elif issubclass(argtype, int):
172 try:
173 return int(spec)
174 except ValueError as e:
175 raise exceptions.CommandError("Expected an integer, got %s." % spec)
176 elif argtype == typing.Sequence[flow.Flow]:
177 return manager.call_args("view.resolve", [spec])
178 elif argtype == Cuts:
179 return manager.call_args("cut", [spec])
180 elif argtype == flow.Flow:
181 flows = manager.call_args("view.resolve", [spec])
182 if len(flows) != 1:
183 raise exceptions.CommandError(
184 "Command requires one flow, specification matched %s." % len(flows)
185 )
186 return flows[0]
187 elif argtype == typing.Sequence[str]:
188 return [i.strip() for i in spec.split(",")]
189 else:
190 raise exceptions.CommandError("Unsupported argument type: %s" % argtype)
191
192
193 def command(path):
194 def decorator(function):
195 @functools.wraps(function)
196 def wrapper(*args, **kwargs):
197 return function(*args, **kwargs)
198 wrapper.__dict__["command_path"] = path
199 return wrapper
200 return decorator
201
[end of mitmproxy/command.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/mitmproxy/command.py b/mitmproxy/command.py
--- a/mitmproxy/command.py
+++ b/mitmproxy/command.py
@@ -190,10 +190,19 @@
raise exceptions.CommandError("Unsupported argument type: %s" % argtype)
+def verify_arg_signature(f: typing.Callable, args: list, kwargs: dict) -> None:
+ sig = inspect.signature(f)
+ try:
+ sig.bind(*args, **kwargs)
+ except TypeError as v:
+ raise exceptions.CommandError("Argument mismatch: %s" % v.args[0])
+
+
def command(path):
def decorator(function):
@functools.wraps(function)
def wrapper(*args, **kwargs):
+ verify_arg_signature(function, args, kwargs)
return function(*args, **kwargs)
wrapper.__dict__["command_path"] = path
return wrapper
|
{"golden_diff": "diff --git a/mitmproxy/command.py b/mitmproxy/command.py\n--- a/mitmproxy/command.py\n+++ b/mitmproxy/command.py\n@@ -190,10 +190,19 @@\n raise exceptions.CommandError(\"Unsupported argument type: %s\" % argtype)\n \n \n+def verify_arg_signature(f: typing.Callable, args: list, kwargs: dict) -> None:\n+ sig = inspect.signature(f)\n+ try:\n+ sig.bind(*args, **kwargs)\n+ except TypeError as v:\n+ raise exceptions.CommandError(\"Argument mismatch: %s\" % v.args[0])\n+\n+\n def command(path):\n def decorator(function):\n @functools.wraps(function)\n def wrapper(*args, **kwargs):\n+ verify_arg_signature(function, args, kwargs)\n return function(*args, **kwargs)\n wrapper.__dict__[\"command_path\"] = path\n return wrapper\n", "issue": "command console.choose.cmd crashes when given no arguments\nEnter mitmproxy console, issue a command like:\r\n\r\n console.choose.cmd\r\n\r\n... and press return. \n", "before_files": [{"content": "\"\"\"\n This module manges and invokes typed commands.\n\"\"\"\nimport inspect\nimport typing\nimport shlex\nimport textwrap\nimport functools\nimport sys\n\nfrom mitmproxy.utils import typecheck\nfrom mitmproxy import exceptions\nfrom mitmproxy import flow\n\n\nCuts = typing.Sequence[\n typing.Sequence[typing.Union[str, bytes]]\n]\n\n\ndef typename(t: type, ret: bool) -> str:\n \"\"\"\n Translates a type to an explanatory string. If ret is True, we're\n looking at a return type, else we're looking at a parameter type.\n \"\"\"\n if issubclass(t, (str, int, bool)):\n return t.__name__\n elif t == typing.Sequence[flow.Flow]:\n return \"[flow]\" if ret else \"flowspec\"\n elif t == typing.Sequence[str]:\n return \"[str]\"\n elif t == Cuts:\n return \"[cuts]\" if ret else \"cutspec\"\n elif t == flow.Flow:\n return \"flow\"\n else: # pragma: no cover\n raise NotImplementedError(t)\n\n\nclass Command:\n def __init__(self, manager, path, func) -> None:\n self.path = path\n self.manager = manager\n self.func = func\n sig = inspect.signature(self.func)\n self.help = None\n if func.__doc__:\n txt = func.__doc__.strip()\n self.help = \"\\n\".join(textwrap.wrap(txt))\n\n self.has_positional = False\n for i in sig.parameters.values():\n # This is the kind for *args paramters\n if i.kind == i.VAR_POSITIONAL:\n self.has_positional = True\n self.paramtypes = [v.annotation for v in sig.parameters.values()]\n self.returntype = sig.return_annotation\n\n def paramnames(self) -> typing.Sequence[str]:\n v = [typename(i, False) for i in self.paramtypes]\n if self.has_positional:\n v[-1] = \"*\" + v[-1]\n return v\n\n def retname(self) -> str:\n return typename(self.returntype, True) if self.returntype else \"\"\n\n def signature_help(self) -> str:\n params = \" \".join(self.paramnames())\n ret = self.retname()\n if ret:\n ret = \" -> \" + ret\n return \"%s %s%s\" % (self.path, params, ret)\n\n def call(self, args: typing.Sequence[str]):\n \"\"\"\n Call the command with a list of arguments. At this point, all\n arguments are strings.\n \"\"\"\n if not self.has_positional and (len(self.paramtypes) != len(args)):\n raise exceptions.CommandError(\"Usage: %s\" % self.signature_help())\n\n remainder = [] # type: typing.Sequence[str]\n if self.has_positional:\n remainder = args[len(self.paramtypes) - 1:]\n args = args[:len(self.paramtypes) - 1]\n\n pargs = []\n for i in range(len(args)):\n if typecheck.check_command_type(args[i], self.paramtypes[i]):\n pargs.append(args[i])\n else:\n pargs.append(parsearg(self.manager, args[i], self.paramtypes[i]))\n\n if remainder:\n chk = typecheck.check_command_type(\n remainder,\n typing.Sequence[self.paramtypes[-1]] # type: ignore\n )\n if chk:\n pargs.extend(remainder)\n else:\n raise exceptions.CommandError(\"Invalid value type.\")\n\n with self.manager.master.handlecontext():\n ret = self.func(*pargs)\n\n if not typecheck.check_command_type(ret, self.returntype):\n raise exceptions.CommandError(\"Command returned unexpected data\")\n\n return ret\n\n\nclass CommandManager:\n def __init__(self, master):\n self.master = master\n self.commands = {}\n\n def collect_commands(self, addon):\n for i in dir(addon):\n if not i.startswith(\"__\"):\n o = getattr(addon, i)\n if hasattr(o, \"command_path\"):\n self.add(o.command_path, o)\n\n def add(self, path: str, func: typing.Callable):\n self.commands[path] = Command(self, path, func)\n\n def call_args(self, path, args):\n \"\"\"\n Call a command using a list of string arguments. May raise CommandError.\n \"\"\"\n if path not in self.commands:\n raise exceptions.CommandError(\"Unknown command: %s\" % path)\n return self.commands[path].call(args)\n\n def call(self, cmdstr: str):\n \"\"\"\n Call a command using a string. May raise CommandError.\n \"\"\"\n parts = shlex.split(cmdstr)\n if not len(parts) >= 1:\n raise exceptions.CommandError(\"Invalid command: %s\" % cmdstr)\n return self.call_args(parts[0], parts[1:])\n\n def dump(self, out=sys.stdout) -> None:\n cmds = list(self.commands.values())\n cmds.sort(key=lambda x: x.signature_help())\n for c in cmds:\n for hl in (c.help or \"\").splitlines():\n print(\"# \" + hl, file=out)\n print(c.signature_help(), file=out)\n print(file=out)\n\n\ndef parsearg(manager: CommandManager, spec: str, argtype: type) -> typing.Any:\n \"\"\"\n Convert a string to a argument to the appropriate type.\n \"\"\"\n if issubclass(argtype, str):\n return spec\n elif argtype == bool:\n if spec == \"true\":\n return True\n elif spec == \"false\":\n return False\n else:\n raise exceptions.CommandError(\n \"Booleans are 'true' or 'false', got %s\" % spec\n )\n elif issubclass(argtype, int):\n try:\n return int(spec)\n except ValueError as e:\n raise exceptions.CommandError(\"Expected an integer, got %s.\" % spec)\n elif argtype == typing.Sequence[flow.Flow]:\n return manager.call_args(\"view.resolve\", [spec])\n elif argtype == Cuts:\n return manager.call_args(\"cut\", [spec])\n elif argtype == flow.Flow:\n flows = manager.call_args(\"view.resolve\", [spec])\n if len(flows) != 1:\n raise exceptions.CommandError(\n \"Command requires one flow, specification matched %s.\" % len(flows)\n )\n return flows[0]\n elif argtype == typing.Sequence[str]:\n return [i.strip() for i in spec.split(\",\")]\n else:\n raise exceptions.CommandError(\"Unsupported argument type: %s\" % argtype)\n\n\ndef command(path):\n def decorator(function):\n @functools.wraps(function)\n def wrapper(*args, **kwargs):\n return function(*args, **kwargs)\n wrapper.__dict__[\"command_path\"] = path\n return wrapper\n return decorator\n", "path": "mitmproxy/command.py"}]}
| 2,532 | 200 |
gh_patches_debug_31695
|
rasdani/github-patches
|
git_diff
|
DistrictDataLabs__yellowbrick-652
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Fix second image in KElbowVisualizer documentation
The second image that was added to the `KElbowVisualizer` documentation in PR #635 is not rendering correctly because the `elbow_is_behind.png` file is not generated by the `elbow.py` file, but was added separately.
- [x] Expand `KElbowVisualizer` documentation in `elbow.rst`
- [x] Add example showing how to hide timing and use `calinski_harabaz` scoring metric
- [x] Update `elbow.py` to generate new image for the documentation.
</issue>
<code>
[start of docs/api/cluster/elbow.py]
1 # Clustering Evaluation Imports
2 from functools import partial
3
4 from sklearn.cluster import MiniBatchKMeans
5 from sklearn.datasets import make_blobs as sk_make_blobs
6
7 from yellowbrick.cluster import KElbowVisualizer
8
9 # Helpers for easy dataset creation
10 N_SAMPLES = 1000
11 N_FEATURES = 12
12 SHUFFLE = True
13
14 # Make blobs partial
15 make_blobs = partial(sk_make_blobs, n_samples=N_SAMPLES, n_features=N_FEATURES, shuffle=SHUFFLE)
16
17
18 if __name__ == '__main__':
19 # Make 8 blobs dataset
20 X, y = make_blobs(centers=8)
21
22 # Instantiate the clustering model and visualizer
23 # Instantiate the clustering model and visualizer
24 visualizer = KElbowVisualizer(MiniBatchKMeans(), k=(4,12))
25
26 visualizer.fit(X) # Fit the training data to the visualizer
27 visualizer.poof(outpath="images/elbow.png") # Draw/show/poof the data
28
[end of docs/api/cluster/elbow.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/docs/api/cluster/elbow.py b/docs/api/cluster/elbow.py
--- a/docs/api/cluster/elbow.py
+++ b/docs/api/cluster/elbow.py
@@ -1,27 +1,55 @@
-# Clustering Evaluation Imports
-from functools import partial
+#!/usr/bin/env python
-from sklearn.cluster import MiniBatchKMeans
-from sklearn.datasets import make_blobs as sk_make_blobs
+"""
+Generate images for the elbow plot documentation.
+"""
-from yellowbrick.cluster import KElbowVisualizer
+# Import necessary modules
+import matplotlib.pyplot as plt
-# Helpers for easy dataset creation
-N_SAMPLES = 1000
-N_FEATURES = 12
-SHUFFLE = True
+from sklearn.cluster import KMeans
+from sklearn.datasets import make_blobs
+from yellowbrick.cluster import KElbowVisualizer
-# Make blobs partial
-make_blobs = partial(sk_make_blobs, n_samples=N_SAMPLES, n_features=N_FEATURES, shuffle=SHUFFLE)
+def draw_elbow(path="images/elbow.png"):
+ # Generate synthetic dataset with 8 blobs
+ X, y = make_blobs(
+ centers=8, n_features=12, n_samples=1000,
+ shuffle=True, random_state=42
+ )
-if __name__ == '__main__':
- # Make 8 blobs dataset
- X, y = make_blobs(centers=8)
+ # Create a new figure to draw the clustering visualizer on
+ _, ax = plt.subplots()
# Instantiate the clustering model and visualizer
+ model = KMeans()
+ visualizer = KElbowVisualizer(model, ax=ax, k=(4,12))
+
+ visualizer.fit(X) # Fit the data to the visualizer
+ visualizer.poof(outpath=path) # Draw/show/poof the data
+
+
+def draw_calinski_harabaz(path="images/calinski_harabaz.png"):
+ # Generate synthetic dataset with 8 blobs
+ X, y = make_blobs(
+ centers=8, n_features=12, n_samples=1000,
+ shuffle=True, random_state=42
+ )
+
+ # Create a new figure to draw the clustering visualizer on
+ _, ax = plt.subplots()
+
# Instantiate the clustering model and visualizer
- visualizer = KElbowVisualizer(MiniBatchKMeans(), k=(4,12))
+ model = KMeans()
+ visualizer = KElbowVisualizer(
+ model, ax=ax, k=(4,12),
+ metric='calinski_harabaz', timings=False
+ )
+ visualizer.fit(X) # Fit the data to the visualizer
+ visualizer.poof(outpath=path) # Draw/show/poof the data
- visualizer.fit(X) # Fit the training data to the visualizer
- visualizer.poof(outpath="images/elbow.png") # Draw/show/poof the data
+
+if __name__ == '__main__':
+ draw_elbow()
+ draw_calinski_harabaz()
|
{"golden_diff": "diff --git a/docs/api/cluster/elbow.py b/docs/api/cluster/elbow.py\n--- a/docs/api/cluster/elbow.py\n+++ b/docs/api/cluster/elbow.py\n@@ -1,27 +1,55 @@\n-# Clustering Evaluation Imports\n-from functools import partial\n+#!/usr/bin/env python\n \n-from sklearn.cluster import MiniBatchKMeans\n-from sklearn.datasets import make_blobs as sk_make_blobs\n+\"\"\"\n+Generate images for the elbow plot documentation.\n+\"\"\"\n \n-from yellowbrick.cluster import KElbowVisualizer\n+# Import necessary modules\n+import matplotlib.pyplot as plt\n \n-# Helpers for easy dataset creation\n-N_SAMPLES = 1000\n-N_FEATURES = 12\n-SHUFFLE = True\n+from sklearn.cluster import KMeans\n+from sklearn.datasets import make_blobs\n+from yellowbrick.cluster import KElbowVisualizer\n \n-# Make blobs partial\n-make_blobs = partial(sk_make_blobs, n_samples=N_SAMPLES, n_features=N_FEATURES, shuffle=SHUFFLE)\n \n+def draw_elbow(path=\"images/elbow.png\"):\n+ # Generate synthetic dataset with 8 blobs\n+ X, y = make_blobs(\n+ centers=8, n_features=12, n_samples=1000,\n+ shuffle=True, random_state=42\n+ )\n \n-if __name__ == '__main__':\n- # Make 8 blobs dataset\n- X, y = make_blobs(centers=8)\n+ # Create a new figure to draw the clustering visualizer on\n+ _, ax = plt.subplots()\n \n # Instantiate the clustering model and visualizer\n+ model = KMeans()\n+ visualizer = KElbowVisualizer(model, ax=ax, k=(4,12))\n+\n+ visualizer.fit(X) # Fit the data to the visualizer\n+ visualizer.poof(outpath=path) # Draw/show/poof the data\n+\n+\n+def draw_calinski_harabaz(path=\"images/calinski_harabaz.png\"):\n+ # Generate synthetic dataset with 8 blobs\n+ X, y = make_blobs(\n+ centers=8, n_features=12, n_samples=1000,\n+ shuffle=True, random_state=42\n+ )\n+\n+ # Create a new figure to draw the clustering visualizer on\n+ _, ax = plt.subplots()\n+\n # Instantiate the clustering model and visualizer\n- visualizer = KElbowVisualizer(MiniBatchKMeans(), k=(4,12))\n+ model = KMeans()\n+ visualizer = KElbowVisualizer(\n+ model, ax=ax, k=(4,12),\n+ metric='calinski_harabaz', timings=False\n+ )\n+ visualizer.fit(X) # Fit the data to the visualizer\n+ visualizer.poof(outpath=path) # Draw/show/poof the data\n \n- visualizer.fit(X) # Fit the training data to the visualizer\n- visualizer.poof(outpath=\"images/elbow.png\") # Draw/show/poof the data\n+\n+if __name__ == '__main__':\n+ draw_elbow()\n+ draw_calinski_harabaz()\n", "issue": "Fix second image in KElbowVisualizer documentation\nThe second image that was added to the `KElbowVisualizer` documentation in PR #635 is not rendering correctly because the `elbow_is_behind.png` file is not generated by the `elbow.py` file, but was added separately.\r\n\r\n- [x] Expand `KElbowVisualizer` documentation in `elbow.rst`\r\n- [x] Add example showing how to hide timing and use `calinski_harabaz` scoring metric\r\n- [x] Update `elbow.py` to generate new image for the documentation.\r\n\r\n\r\n\n", "before_files": [{"content": "# Clustering Evaluation Imports\nfrom functools import partial\n\nfrom sklearn.cluster import MiniBatchKMeans\nfrom sklearn.datasets import make_blobs as sk_make_blobs\n\nfrom yellowbrick.cluster import KElbowVisualizer\n\n# Helpers for easy dataset creation\nN_SAMPLES = 1000\nN_FEATURES = 12\nSHUFFLE = True\n\n# Make blobs partial\nmake_blobs = partial(sk_make_blobs, n_samples=N_SAMPLES, n_features=N_FEATURES, shuffle=SHUFFLE)\n\n\nif __name__ == '__main__':\n # Make 8 blobs dataset\n X, y = make_blobs(centers=8)\n\n # Instantiate the clustering model and visualizer\n # Instantiate the clustering model and visualizer\n visualizer = KElbowVisualizer(MiniBatchKMeans(), k=(4,12))\n\n visualizer.fit(X) # Fit the training data to the visualizer\n visualizer.poof(outpath=\"images/elbow.png\") # Draw/show/poof the data\n", "path": "docs/api/cluster/elbow.py"}]}
| 938 | 712 |
gh_patches_debug_10321
|
rasdani/github-patches
|
git_diff
|
numpy__numpy-9552
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
test_warning_calls "invalid escape sequence \s" on Python 3.6 daily wheel builds.
New errors today (13 August), for Linux and OSX:
```
======================================================================
ERROR: numpy.tests.test_warnings.test_warning_calls
----------------------------------------------------------------------
Traceback (most recent call last):
File "/venv/lib/python3.6/site-packages/nose/case.py", line 198, in runTest
self.test(*self.arg)
File "/venv/lib/python3.6/site-packages/numpy/tests/test_warnings.py", line 79, in test_warning_calls
tree = ast.parse(file.read())
File "/usr/lib/python3.6/ast.py", line 35, in parse
return compile(source, filename, mode, PyCF_ONLY_AST)
File "<unknown>", line 184
SyntaxError: invalid escape sequence \s
```
https://travis-ci.org/MacPython/numpy-wheels/jobs/264023630
https://travis-ci.org/MacPython/numpy-wheels/jobs/264023631
https://travis-ci.org/MacPython/numpy-wheels/jobs/264023635
</issue>
<code>
[start of numpy/doc/basics.py]
1 """
2 ============
3 Array basics
4 ============
5
6 Array types and conversions between types
7 =========================================
8
9 NumPy supports a much greater variety of numerical types than Python does.
10 This section shows which are available, and how to modify an array's data-type.
11
12 ============ ==========================================================
13 Data type Description
14 ============ ==========================================================
15 ``bool_`` Boolean (True or False) stored as a byte
16 ``int_`` Default integer type (same as C ``long``; normally either
17 ``int64`` or ``int32``)
18 intc Identical to C ``int`` (normally ``int32`` or ``int64``)
19 intp Integer used for indexing (same as C ``ssize_t``; normally
20 either ``int32`` or ``int64``)
21 int8 Byte (-128 to 127)
22 int16 Integer (-32768 to 32767)
23 int32 Integer (-2147483648 to 2147483647)
24 int64 Integer (-9223372036854775808 to 9223372036854775807)
25 uint8 Unsigned integer (0 to 255)
26 uint16 Unsigned integer (0 to 65535)
27 uint32 Unsigned integer (0 to 4294967295)
28 uint64 Unsigned integer (0 to 18446744073709551615)
29 ``float_`` Shorthand for ``float64``.
30 float16 Half precision float: sign bit, 5 bits exponent,
31 10 bits mantissa
32 float32 Single precision float: sign bit, 8 bits exponent,
33 23 bits mantissa
34 float64 Double precision float: sign bit, 11 bits exponent,
35 52 bits mantissa
36 ``complex_`` Shorthand for ``complex128``.
37 complex64 Complex number, represented by two 32-bit floats (real
38 and imaginary components)
39 complex128 Complex number, represented by two 64-bit floats (real
40 and imaginary components)
41 ============ ==========================================================
42
43 Additionally to ``intc`` the platform dependent C integer types ``short``,
44 ``long``, ``longlong`` and their unsigned versions are defined.
45
46 NumPy numerical types are instances of ``dtype`` (data-type) objects, each
47 having unique characteristics. Once you have imported NumPy using
48
49 ::
50
51 >>> import numpy as np
52
53 the dtypes are available as ``np.bool_``, ``np.float32``, etc.
54
55 Advanced types, not listed in the table above, are explored in
56 section :ref:`structured_arrays`.
57
58 There are 5 basic numerical types representing booleans (bool), integers (int),
59 unsigned integers (uint) floating point (float) and complex. Those with numbers
60 in their name indicate the bitsize of the type (i.e. how many bits are needed
61 to represent a single value in memory). Some types, such as ``int`` and
62 ``intp``, have differing bitsizes, dependent on the platforms (e.g. 32-bit
63 vs. 64-bit machines). This should be taken into account when interfacing
64 with low-level code (such as C or Fortran) where the raw memory is addressed.
65
66 Data-types can be used as functions to convert python numbers to array scalars
67 (see the array scalar section for an explanation), python sequences of numbers
68 to arrays of that type, or as arguments to the dtype keyword that many numpy
69 functions or methods accept. Some examples::
70
71 >>> import numpy as np
72 >>> x = np.float32(1.0)
73 >>> x
74 1.0
75 >>> y = np.int_([1,2,4])
76 >>> y
77 array([1, 2, 4])
78 >>> z = np.arange(3, dtype=np.uint8)
79 >>> z
80 array([0, 1, 2], dtype=uint8)
81
82 Array types can also be referred to by character codes, mostly to retain
83 backward compatibility with older packages such as Numeric. Some
84 documentation may still refer to these, for example::
85
86 >>> np.array([1, 2, 3], dtype='f')
87 array([ 1., 2., 3.], dtype=float32)
88
89 We recommend using dtype objects instead.
90
91 To convert the type of an array, use the .astype() method (preferred) or
92 the type itself as a function. For example: ::
93
94 >>> z.astype(float) #doctest: +NORMALIZE_WHITESPACE
95 array([ 0., 1., 2.])
96 >>> np.int8(z)
97 array([0, 1, 2], dtype=int8)
98
99 Note that, above, we use the *Python* float object as a dtype. NumPy knows
100 that ``int`` refers to ``np.int_``, ``bool`` means ``np.bool_``,
101 that ``float`` is ``np.float_`` and ``complex`` is ``np.complex_``.
102 The other data-types do not have Python equivalents.
103
104 To determine the type of an array, look at the dtype attribute::
105
106 >>> z.dtype
107 dtype('uint8')
108
109 dtype objects also contain information about the type, such as its bit-width
110 and its byte-order. The data type can also be used indirectly to query
111 properties of the type, such as whether it is an integer::
112
113 >>> d = np.dtype(int)
114 >>> d
115 dtype('int32')
116
117 >>> np.issubdtype(d, np.integer)
118 True
119
120 >>> np.issubdtype(d, np.floating)
121 False
122
123
124 Array Scalars
125 =============
126
127 NumPy generally returns elements of arrays as array scalars (a scalar
128 with an associated dtype). Array scalars differ from Python scalars, but
129 for the most part they can be used interchangeably (the primary
130 exception is for versions of Python older than v2.x, where integer array
131 scalars cannot act as indices for lists and tuples). There are some
132 exceptions, such as when code requires very specific attributes of a scalar
133 or when it checks specifically whether a value is a Python scalar. Generally,
134 problems are easily fixed by explicitly converting array scalars
135 to Python scalars, using the corresponding Python type function
136 (e.g., ``int``, ``float``, ``complex``, ``str``, ``unicode``).
137
138 The primary advantage of using array scalars is that
139 they preserve the array type (Python may not have a matching scalar type
140 available, e.g. ``int16``). Therefore, the use of array scalars ensures
141 identical behaviour between arrays and scalars, irrespective of whether the
142 value is inside an array or not. NumPy scalars also have many of the same
143 methods arrays do.
144
145 Extended Precision
146 ==================
147
148 Python's floating-point numbers are usually 64-bit floating-point numbers,
149 nearly equivalent to ``np.float64``. In some unusual situations it may be
150 useful to use floating-point numbers with more precision. Whether this
151 is possible in numpy depends on the hardware and on the development
152 environment: specifically, x86 machines provide hardware floating-point
153 with 80-bit precision, and while most C compilers provide this as their
154 ``long double`` type, MSVC (standard for Windows builds) makes
155 ``long double`` identical to ``double`` (64 bits). NumPy makes the
156 compiler's ``long double`` available as ``np.longdouble`` (and
157 ``np.clongdouble`` for the complex numbers). You can find out what your
158 numpy provides with ``np.finfo(np.longdouble)``.
159
160 NumPy does not provide a dtype with more precision than C
161 ``long double``\s; in particular, the 128-bit IEEE quad precision
162 data type (FORTRAN's ``REAL*16``\) is not available.
163
164 For efficient memory alignment, ``np.longdouble`` is usually stored
165 padded with zero bits, either to 96 or 128 bits. Which is more efficient
166 depends on hardware and development environment; typically on 32-bit
167 systems they are padded to 96 bits, while on 64-bit systems they are
168 typically padded to 128 bits. ``np.longdouble`` is padded to the system
169 default; ``np.float96`` and ``np.float128`` are provided for users who
170 want specific padding. In spite of the names, ``np.float96`` and
171 ``np.float128`` provide only as much precision as ``np.longdouble``,
172 that is, 80 bits on most x86 machines and 64 bits in standard
173 Windows builds.
174
175 Be warned that even if ``np.longdouble`` offers more precision than
176 python ``float``, it is easy to lose that extra precision, since
177 python often forces values to pass through ``float``. For example,
178 the ``%`` formatting operator requires its arguments to be converted
179 to standard python types, and it is therefore impossible to preserve
180 extended precision even if many decimal places are requested. It can
181 be useful to test your code with the value
182 ``1 + np.finfo(np.longdouble).eps``.
183
184 """
185 from __future__ import division, absolute_import, print_function
186
[end of numpy/doc/basics.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/numpy/doc/basics.py b/numpy/doc/basics.py
--- a/numpy/doc/basics.py
+++ b/numpy/doc/basics.py
@@ -158,8 +158,8 @@
numpy provides with ``np.finfo(np.longdouble)``.
NumPy does not provide a dtype with more precision than C
-``long double``\s; in particular, the 128-bit IEEE quad precision
-data type (FORTRAN's ``REAL*16``\) is not available.
+``long double``\\s; in particular, the 128-bit IEEE quad precision
+data type (FORTRAN's ``REAL*16``\\) is not available.
For efficient memory alignment, ``np.longdouble`` is usually stored
padded with zero bits, either to 96 or 128 bits. Which is more efficient
|
{"golden_diff": "diff --git a/numpy/doc/basics.py b/numpy/doc/basics.py\n--- a/numpy/doc/basics.py\n+++ b/numpy/doc/basics.py\n@@ -158,8 +158,8 @@\n numpy provides with ``np.finfo(np.longdouble)``.\n \n NumPy does not provide a dtype with more precision than C\n-``long double``\\s; in particular, the 128-bit IEEE quad precision\n-data type (FORTRAN's ``REAL*16``\\) is not available.\n+``long double``\\\\s; in particular, the 128-bit IEEE quad precision\n+data type (FORTRAN's ``REAL*16``\\\\) is not available.\n \n For efficient memory alignment, ``np.longdouble`` is usually stored\n padded with zero bits, either to 96 or 128 bits. Which is more efficient\n", "issue": "test_warning_calls \"invalid escape sequence \\s\" on Python 3.6 daily wheel builds.\nNew errors today (13 August), for Linux and OSX:\r\n\r\n```\r\n======================================================================\r\nERROR: numpy.tests.test_warnings.test_warning_calls\r\n----------------------------------------------------------------------\r\nTraceback (most recent call last):\r\n File \"/venv/lib/python3.6/site-packages/nose/case.py\", line 198, in runTest\r\n self.test(*self.arg)\r\n File \"/venv/lib/python3.6/site-packages/numpy/tests/test_warnings.py\", line 79, in test_warning_calls\r\n tree = ast.parse(file.read())\r\n File \"/usr/lib/python3.6/ast.py\", line 35, in parse\r\n return compile(source, filename, mode, PyCF_ONLY_AST)\r\n File \"<unknown>\", line 184\r\nSyntaxError: invalid escape sequence \\s\r\n```\r\n\r\nhttps://travis-ci.org/MacPython/numpy-wheels/jobs/264023630\r\nhttps://travis-ci.org/MacPython/numpy-wheels/jobs/264023631\r\nhttps://travis-ci.org/MacPython/numpy-wheels/jobs/264023635\n", "before_files": [{"content": "\"\"\"\n============\nArray basics\n============\n\nArray types and conversions between types\n=========================================\n\nNumPy supports a much greater variety of numerical types than Python does.\nThis section shows which are available, and how to modify an array's data-type.\n\n============ ==========================================================\nData type Description\n============ ==========================================================\n``bool_`` Boolean (True or False) stored as a byte\n``int_`` Default integer type (same as C ``long``; normally either\n ``int64`` or ``int32``)\nintc Identical to C ``int`` (normally ``int32`` or ``int64``)\nintp Integer used for indexing (same as C ``ssize_t``; normally\n either ``int32`` or ``int64``)\nint8 Byte (-128 to 127)\nint16 Integer (-32768 to 32767)\nint32 Integer (-2147483648 to 2147483647)\nint64 Integer (-9223372036854775808 to 9223372036854775807)\nuint8 Unsigned integer (0 to 255)\nuint16 Unsigned integer (0 to 65535)\nuint32 Unsigned integer (0 to 4294967295)\nuint64 Unsigned integer (0 to 18446744073709551615)\n``float_`` Shorthand for ``float64``.\nfloat16 Half precision float: sign bit, 5 bits exponent,\n 10 bits mantissa\nfloat32 Single precision float: sign bit, 8 bits exponent,\n 23 bits mantissa\nfloat64 Double precision float: sign bit, 11 bits exponent,\n 52 bits mantissa\n``complex_`` Shorthand for ``complex128``.\ncomplex64 Complex number, represented by two 32-bit floats (real\n and imaginary components)\ncomplex128 Complex number, represented by two 64-bit floats (real\n and imaginary components)\n============ ==========================================================\n\nAdditionally to ``intc`` the platform dependent C integer types ``short``,\n``long``, ``longlong`` and their unsigned versions are defined.\n\nNumPy numerical types are instances of ``dtype`` (data-type) objects, each\nhaving unique characteristics. Once you have imported NumPy using\n\n ::\n\n >>> import numpy as np\n\nthe dtypes are available as ``np.bool_``, ``np.float32``, etc.\n\nAdvanced types, not listed in the table above, are explored in\nsection :ref:`structured_arrays`.\n\nThere are 5 basic numerical types representing booleans (bool), integers (int),\nunsigned integers (uint) floating point (float) and complex. Those with numbers\nin their name indicate the bitsize of the type (i.e. how many bits are needed\nto represent a single value in memory). Some types, such as ``int`` and\n``intp``, have differing bitsizes, dependent on the platforms (e.g. 32-bit\nvs. 64-bit machines). This should be taken into account when interfacing\nwith low-level code (such as C or Fortran) where the raw memory is addressed.\n\nData-types can be used as functions to convert python numbers to array scalars\n(see the array scalar section for an explanation), python sequences of numbers\nto arrays of that type, or as arguments to the dtype keyword that many numpy\nfunctions or methods accept. Some examples::\n\n >>> import numpy as np\n >>> x = np.float32(1.0)\n >>> x\n 1.0\n >>> y = np.int_([1,2,4])\n >>> y\n array([1, 2, 4])\n >>> z = np.arange(3, dtype=np.uint8)\n >>> z\n array([0, 1, 2], dtype=uint8)\n\nArray types can also be referred to by character codes, mostly to retain\nbackward compatibility with older packages such as Numeric. Some\ndocumentation may still refer to these, for example::\n\n >>> np.array([1, 2, 3], dtype='f')\n array([ 1., 2., 3.], dtype=float32)\n\nWe recommend using dtype objects instead.\n\nTo convert the type of an array, use the .astype() method (preferred) or\nthe type itself as a function. For example: ::\n\n >>> z.astype(float) #doctest: +NORMALIZE_WHITESPACE\n array([ 0., 1., 2.])\n >>> np.int8(z)\n array([0, 1, 2], dtype=int8)\n\nNote that, above, we use the *Python* float object as a dtype. NumPy knows\nthat ``int`` refers to ``np.int_``, ``bool`` means ``np.bool_``,\nthat ``float`` is ``np.float_`` and ``complex`` is ``np.complex_``.\nThe other data-types do not have Python equivalents.\n\nTo determine the type of an array, look at the dtype attribute::\n\n >>> z.dtype\n dtype('uint8')\n\ndtype objects also contain information about the type, such as its bit-width\nand its byte-order. The data type can also be used indirectly to query\nproperties of the type, such as whether it is an integer::\n\n >>> d = np.dtype(int)\n >>> d\n dtype('int32')\n\n >>> np.issubdtype(d, np.integer)\n True\n\n >>> np.issubdtype(d, np.floating)\n False\n\n\nArray Scalars\n=============\n\nNumPy generally returns elements of arrays as array scalars (a scalar\nwith an associated dtype). Array scalars differ from Python scalars, but\nfor the most part they can be used interchangeably (the primary\nexception is for versions of Python older than v2.x, where integer array\nscalars cannot act as indices for lists and tuples). There are some\nexceptions, such as when code requires very specific attributes of a scalar\nor when it checks specifically whether a value is a Python scalar. Generally,\nproblems are easily fixed by explicitly converting array scalars\nto Python scalars, using the corresponding Python type function\n(e.g., ``int``, ``float``, ``complex``, ``str``, ``unicode``).\n\nThe primary advantage of using array scalars is that\nthey preserve the array type (Python may not have a matching scalar type\navailable, e.g. ``int16``). Therefore, the use of array scalars ensures\nidentical behaviour between arrays and scalars, irrespective of whether the\nvalue is inside an array or not. NumPy scalars also have many of the same\nmethods arrays do.\n\nExtended Precision\n==================\n\nPython's floating-point numbers are usually 64-bit floating-point numbers,\nnearly equivalent to ``np.float64``. In some unusual situations it may be\nuseful to use floating-point numbers with more precision. Whether this\nis possible in numpy depends on the hardware and on the development\nenvironment: specifically, x86 machines provide hardware floating-point\nwith 80-bit precision, and while most C compilers provide this as their\n``long double`` type, MSVC (standard for Windows builds) makes\n``long double`` identical to ``double`` (64 bits). NumPy makes the\ncompiler's ``long double`` available as ``np.longdouble`` (and\n``np.clongdouble`` for the complex numbers). You can find out what your\nnumpy provides with ``np.finfo(np.longdouble)``.\n\nNumPy does not provide a dtype with more precision than C\n``long double``\\s; in particular, the 128-bit IEEE quad precision\ndata type (FORTRAN's ``REAL*16``\\) is not available.\n\nFor efficient memory alignment, ``np.longdouble`` is usually stored\npadded with zero bits, either to 96 or 128 bits. Which is more efficient\ndepends on hardware and development environment; typically on 32-bit\nsystems they are padded to 96 bits, while on 64-bit systems they are\ntypically padded to 128 bits. ``np.longdouble`` is padded to the system\ndefault; ``np.float96`` and ``np.float128`` are provided for users who\nwant specific padding. In spite of the names, ``np.float96`` and\n``np.float128`` provide only as much precision as ``np.longdouble``,\nthat is, 80 bits on most x86 machines and 64 bits in standard\nWindows builds.\n\nBe warned that even if ``np.longdouble`` offers more precision than\npython ``float``, it is easy to lose that extra precision, since\npython often forces values to pass through ``float``. For example,\nthe ``%`` formatting operator requires its arguments to be converted\nto standard python types, and it is therefore impossible to preserve\nextended precision even if many decimal places are requested. It can\nbe useful to test your code with the value\n``1 + np.finfo(np.longdouble).eps``.\n\n\"\"\"\nfrom __future__ import division, absolute_import, print_function\n", "path": "numpy/doc/basics.py"}]}
| 3,304 | 192 |
gh_patches_debug_43081
|
rasdani/github-patches
|
git_diff
|
open-telemetry__opentelemetry-python-contrib-236
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Make sure rpc instrumentations follow semantic conventions
Specs: https://github.com/open-telemetry/opentelemetry-specification/blob/master/specification/trace/semantic_conventions/rpc.md
</issue>
<code>
[start of instrumentation/opentelemetry-instrumentation-grpc/src/opentelemetry/instrumentation/grpc/_server.py]
1 # Copyright The OpenTelemetry Authors
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 # pylint:disable=relative-beyond-top-level
16 # pylint:disable=arguments-differ
17 # pylint:disable=no-member
18 # pylint:disable=signature-differs
19
20 """
21 Implementation of the service-side open-telemetry interceptor.
22 """
23
24 import logging
25 from contextlib import contextmanager
26
27 import grpc
28
29 from opentelemetry import propagators, trace
30 from opentelemetry.context import attach, detach
31 from opentelemetry.trace.propagation.textmap import DictGetter
32 from opentelemetry.trace.status import Status, StatusCode
33
34 logger = logging.getLogger(__name__)
35
36
37 # wrap an RPC call
38 # see https://github.com/grpc/grpc/issues/18191
39 def _wrap_rpc_behavior(handler, continuation):
40 if handler is None:
41 return None
42
43 if handler.request_streaming and handler.response_streaming:
44 behavior_fn = handler.stream_stream
45 handler_factory = grpc.stream_stream_rpc_method_handler
46 elif handler.request_streaming and not handler.response_streaming:
47 behavior_fn = handler.stream_unary
48 handler_factory = grpc.stream_unary_rpc_method_handler
49 elif not handler.request_streaming and handler.response_streaming:
50 behavior_fn = handler.unary_stream
51 handler_factory = grpc.unary_stream_rpc_method_handler
52 else:
53 behavior_fn = handler.unary_unary
54 handler_factory = grpc.unary_unary_rpc_method_handler
55
56 return handler_factory(
57 continuation(
58 behavior_fn, handler.request_streaming, handler.response_streaming
59 ),
60 request_deserializer=handler.request_deserializer,
61 response_serializer=handler.response_serializer,
62 )
63
64
65 # pylint:disable=abstract-method
66 class _OpenTelemetryServicerContext(grpc.ServicerContext):
67 def __init__(self, servicer_context, active_span):
68 self._servicer_context = servicer_context
69 self._active_span = active_span
70 self.code = grpc.StatusCode.OK
71 self.details = None
72 super().__init__()
73
74 def is_active(self, *args, **kwargs):
75 return self._servicer_context.is_active(*args, **kwargs)
76
77 def time_remaining(self, *args, **kwargs):
78 return self._servicer_context.time_remaining(*args, **kwargs)
79
80 def cancel(self, *args, **kwargs):
81 return self._servicer_context.cancel(*args, **kwargs)
82
83 def add_callback(self, *args, **kwargs):
84 return self._servicer_context.add_callback(*args, **kwargs)
85
86 def disable_next_message_compression(self):
87 return self._service_context.disable_next_message_compression()
88
89 def invocation_metadata(self, *args, **kwargs):
90 return self._servicer_context.invocation_metadata(*args, **kwargs)
91
92 def peer(self):
93 return self._servicer_context.peer()
94
95 def peer_identities(self):
96 return self._servicer_context.peer_identities()
97
98 def peer_identity_key(self):
99 return self._servicer_context.peer_identity_key()
100
101 def auth_context(self):
102 return self._servicer_context.auth_context()
103
104 def set_compression(self, compression):
105 return self._servicer_context.set_compression(compression)
106
107 def send_initial_metadata(self, *args, **kwargs):
108 return self._servicer_context.send_initial_metadata(*args, **kwargs)
109
110 def set_trailing_metadata(self, *args, **kwargs):
111 return self._servicer_context.set_trailing_metadata(*args, **kwargs)
112
113 def abort(self, code, details):
114 self.code = code
115 self.details = details
116 self._active_span.set_attribute("rpc.grpc.status_code", code.name)
117 self._active_span.set_status(
118 Status(status_code=StatusCode.ERROR, description=details)
119 )
120 return self._servicer_context.abort(code, details)
121
122 def abort_with_status(self, status):
123 return self._servicer_context.abort_with_status(status)
124
125 def set_code(self, code):
126 self.code = code
127 # use details if we already have it, otherwise the status description
128 details = self.details or code.value[1]
129 self._active_span.set_attribute("rpc.grpc.status_code", code.name)
130 self._active_span.set_status(
131 Status(status_code=StatusCode.ERROR, description=details)
132 )
133 return self._servicer_context.set_code(code)
134
135 def set_details(self, details):
136 self.details = details
137 self._active_span.set_status(
138 Status(status_code=StatusCode.ERROR, description=details)
139 )
140 return self._servicer_context.set_details(details)
141
142
143 # pylint:disable=abstract-method
144 # pylint:disable=no-self-use
145 # pylint:disable=unused-argument
146 class OpenTelemetryServerInterceptor(grpc.ServerInterceptor):
147 """
148 A gRPC server interceptor, to add OpenTelemetry.
149
150 Usage::
151
152 tracer = some OpenTelemetry tracer
153
154 interceptors = [
155 OpenTelemetryServerInterceptor(tracer),
156 ]
157
158 server = grpc.server(
159 futures.ThreadPoolExecutor(max_workers=concurrency),
160 interceptors = interceptors)
161
162 """
163
164 def __init__(self, tracer):
165 self._tracer = tracer
166 self._carrier_getter = DictGetter()
167
168 @contextmanager
169 def _set_remote_context(self, servicer_context):
170 metadata = servicer_context.invocation_metadata()
171 if metadata:
172 md_dict = {md.key: md.value for md in metadata}
173 ctx = propagators.extract(self._carrier_getter, md_dict)
174 token = attach(ctx)
175 try:
176 yield
177 finally:
178 detach(token)
179 else:
180 yield
181
182 def _start_span(self, handler_call_details, context):
183
184 attributes = {
185 "rpc.method": handler_call_details.method,
186 "rpc.system": "grpc",
187 "rpc.grpc.status_code": grpc.StatusCode.OK,
188 }
189
190 metadata = dict(context.invocation_metadata())
191 if "user-agent" in metadata:
192 attributes["rpc.user_agent"] = metadata["user-agent"]
193
194 # Split up the peer to keep with how other telemetry sources
195 # do it. This looks like:
196 # * ipv6:[::1]:57284
197 # * ipv4:127.0.0.1:57284
198 # * ipv4:10.2.1.1:57284,127.0.0.1:57284
199 #
200 try:
201 host, port = (
202 context.peer().split(",")[0].split(":", 1)[1].rsplit(":", 1)
203 )
204
205 # other telemetry sources convert this, so we will too
206 if host in ("[::1]", "127.0.0.1"):
207 host = "localhost"
208
209 attributes.update({"net.peer.name": host, "net.peer.port": port})
210 except IndexError:
211 logger.warning("Failed to parse peer address '%s'", context.peer())
212
213 return self._tracer.start_as_current_span(
214 name=handler_call_details.method,
215 kind=trace.SpanKind.SERVER,
216 attributes=attributes,
217 )
218
219 def intercept_service(self, continuation, handler_call_details):
220 def telemetry_wrapper(behavior, request_streaming, response_streaming):
221 def telemetry_interceptor(request_or_iterator, context):
222
223 with self._set_remote_context(context):
224 with self._start_span(
225 handler_call_details, context
226 ) as span:
227 # wrap the context
228 context = _OpenTelemetryServicerContext(context, span)
229
230 # And now we run the actual RPC.
231 try:
232 return behavior(request_or_iterator, context)
233 except Exception as error:
234 # Bare exceptions are likely to be gRPC aborts, which
235 # we handle in our context wrapper.
236 # Here, we're interested in uncaught exceptions.
237 # pylint:disable=unidiomatic-typecheck
238 if type(error) != Exception:
239 span.record_exception(error)
240 raise error
241
242 return telemetry_interceptor
243
244 return _wrap_rpc_behavior(
245 continuation(handler_call_details), telemetry_wrapper
246 )
247
[end of instrumentation/opentelemetry-instrumentation-grpc/src/opentelemetry/instrumentation/grpc/_server.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/instrumentation/opentelemetry-instrumentation-grpc/src/opentelemetry/instrumentation/grpc/_server.py b/instrumentation/opentelemetry-instrumentation-grpc/src/opentelemetry/instrumentation/grpc/_server.py
--- a/instrumentation/opentelemetry-instrumentation-grpc/src/opentelemetry/instrumentation/grpc/_server.py
+++ b/instrumentation/opentelemetry-instrumentation-grpc/src/opentelemetry/instrumentation/grpc/_server.py
@@ -113,9 +113,12 @@
def abort(self, code, details):
self.code = code
self.details = details
- self._active_span.set_attribute("rpc.grpc.status_code", code.name)
+ self._active_span.set_attribute("rpc.grpc.status_code", code.value[0])
self._active_span.set_status(
- Status(status_code=StatusCode.ERROR, description=details)
+ Status(
+ status_code=StatusCode.ERROR,
+ description="{}:{}".format(code, details),
+ )
)
return self._servicer_context.abort(code, details)
@@ -126,17 +129,25 @@
self.code = code
# use details if we already have it, otherwise the status description
details = self.details or code.value[1]
- self._active_span.set_attribute("rpc.grpc.status_code", code.name)
- self._active_span.set_status(
- Status(status_code=StatusCode.ERROR, description=details)
- )
+ self._active_span.set_attribute("rpc.grpc.status_code", code.value[0])
+ if code != grpc.StatusCode.OK:
+ self._active_span.set_status(
+ Status(
+ status_code=StatusCode.ERROR,
+ description="{}:{}".format(code, details),
+ )
+ )
return self._servicer_context.set_code(code)
def set_details(self, details):
self.details = details
- self._active_span.set_status(
- Status(status_code=StatusCode.ERROR, description=details)
- )
+ if self.code != grpc.StatusCode.OK:
+ self._active_span.set_status(
+ Status(
+ status_code=StatusCode.ERROR,
+ description="{}:{}".format(self.code, details),
+ )
+ )
return self._servicer_context.set_details(details)
@@ -181,12 +192,20 @@
def _start_span(self, handler_call_details, context):
+ # standard attributes
attributes = {
- "rpc.method": handler_call_details.method,
"rpc.system": "grpc",
- "rpc.grpc.status_code": grpc.StatusCode.OK,
+ "rpc.grpc.status_code": grpc.StatusCode.OK.value[0],
}
+ # if we have details about the call, split into service and method
+ if handler_call_details.method:
+ service, method = handler_call_details.method.lstrip("/").split(
+ "/", 1
+ )
+ attributes.update({"rpc.method": method, "rpc.service": service})
+
+ # add some attributes from the metadata
metadata = dict(context.invocation_metadata())
if "user-agent" in metadata:
attributes["rpc.user_agent"] = metadata["user-agent"]
@@ -198,15 +217,15 @@
# * ipv4:10.2.1.1:57284,127.0.0.1:57284
#
try:
- host, port = (
+ ip, port = (
context.peer().split(",")[0].split(":", 1)[1].rsplit(":", 1)
)
+ attributes.update({"net.peer.ip": ip, "net.peer.port": port})
- # other telemetry sources convert this, so we will too
- if host in ("[::1]", "127.0.0.1"):
- host = "localhost"
+ # other telemetry sources add this, so we will too
+ if ip in ("[::1]", "127.0.0.1"):
+ attributes["net.peer.name"] = "localhost"
- attributes.update({"net.peer.name": host, "net.peer.port": port})
except IndexError:
logger.warning("Failed to parse peer address '%s'", context.peer())
|
{"golden_diff": "diff --git a/instrumentation/opentelemetry-instrumentation-grpc/src/opentelemetry/instrumentation/grpc/_server.py b/instrumentation/opentelemetry-instrumentation-grpc/src/opentelemetry/instrumentation/grpc/_server.py\n--- a/instrumentation/opentelemetry-instrumentation-grpc/src/opentelemetry/instrumentation/grpc/_server.py\n+++ b/instrumentation/opentelemetry-instrumentation-grpc/src/opentelemetry/instrumentation/grpc/_server.py\n@@ -113,9 +113,12 @@\n def abort(self, code, details):\n self.code = code\n self.details = details\n- self._active_span.set_attribute(\"rpc.grpc.status_code\", code.name)\n+ self._active_span.set_attribute(\"rpc.grpc.status_code\", code.value[0])\n self._active_span.set_status(\n- Status(status_code=StatusCode.ERROR, description=details)\n+ Status(\n+ status_code=StatusCode.ERROR,\n+ description=\"{}:{}\".format(code, details),\n+ )\n )\n return self._servicer_context.abort(code, details)\n \n@@ -126,17 +129,25 @@\n self.code = code\n # use details if we already have it, otherwise the status description\n details = self.details or code.value[1]\n- self._active_span.set_attribute(\"rpc.grpc.status_code\", code.name)\n- self._active_span.set_status(\n- Status(status_code=StatusCode.ERROR, description=details)\n- )\n+ self._active_span.set_attribute(\"rpc.grpc.status_code\", code.value[0])\n+ if code != grpc.StatusCode.OK:\n+ self._active_span.set_status(\n+ Status(\n+ status_code=StatusCode.ERROR,\n+ description=\"{}:{}\".format(code, details),\n+ )\n+ )\n return self._servicer_context.set_code(code)\n \n def set_details(self, details):\n self.details = details\n- self._active_span.set_status(\n- Status(status_code=StatusCode.ERROR, description=details)\n- )\n+ if self.code != grpc.StatusCode.OK:\n+ self._active_span.set_status(\n+ Status(\n+ status_code=StatusCode.ERROR,\n+ description=\"{}:{}\".format(self.code, details),\n+ )\n+ )\n return self._servicer_context.set_details(details)\n \n \n@@ -181,12 +192,20 @@\n \n def _start_span(self, handler_call_details, context):\n \n+ # standard attributes\n attributes = {\n- \"rpc.method\": handler_call_details.method,\n \"rpc.system\": \"grpc\",\n- \"rpc.grpc.status_code\": grpc.StatusCode.OK,\n+ \"rpc.grpc.status_code\": grpc.StatusCode.OK.value[0],\n }\n \n+ # if we have details about the call, split into service and method\n+ if handler_call_details.method:\n+ service, method = handler_call_details.method.lstrip(\"/\").split(\n+ \"/\", 1\n+ )\n+ attributes.update({\"rpc.method\": method, \"rpc.service\": service})\n+\n+ # add some attributes from the metadata\n metadata = dict(context.invocation_metadata())\n if \"user-agent\" in metadata:\n attributes[\"rpc.user_agent\"] = metadata[\"user-agent\"]\n@@ -198,15 +217,15 @@\n # * ipv4:10.2.1.1:57284,127.0.0.1:57284\n #\n try:\n- host, port = (\n+ ip, port = (\n context.peer().split(\",\")[0].split(\":\", 1)[1].rsplit(\":\", 1)\n )\n+ attributes.update({\"net.peer.ip\": ip, \"net.peer.port\": port})\n \n- # other telemetry sources convert this, so we will too\n- if host in (\"[::1]\", \"127.0.0.1\"):\n- host = \"localhost\"\n+ # other telemetry sources add this, so we will too\n+ if ip in (\"[::1]\", \"127.0.0.1\"):\n+ attributes[\"net.peer.name\"] = \"localhost\"\n \n- attributes.update({\"net.peer.name\": host, \"net.peer.port\": port})\n except IndexError:\n logger.warning(\"Failed to parse peer address '%s'\", context.peer())\n", "issue": "Make sure rpc instrumentations follow semantic conventions\nSpecs: https://github.com/open-telemetry/opentelemetry-specification/blob/master/specification/trace/semantic_conventions/rpc.md\n", "before_files": [{"content": "# Copyright The OpenTelemetry Authors\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n# pylint:disable=relative-beyond-top-level\n# pylint:disable=arguments-differ\n# pylint:disable=no-member\n# pylint:disable=signature-differs\n\n\"\"\"\nImplementation of the service-side open-telemetry interceptor.\n\"\"\"\n\nimport logging\nfrom contextlib import contextmanager\n\nimport grpc\n\nfrom opentelemetry import propagators, trace\nfrom opentelemetry.context import attach, detach\nfrom opentelemetry.trace.propagation.textmap import DictGetter\nfrom opentelemetry.trace.status import Status, StatusCode\n\nlogger = logging.getLogger(__name__)\n\n\n# wrap an RPC call\n# see https://github.com/grpc/grpc/issues/18191\ndef _wrap_rpc_behavior(handler, continuation):\n if handler is None:\n return None\n\n if handler.request_streaming and handler.response_streaming:\n behavior_fn = handler.stream_stream\n handler_factory = grpc.stream_stream_rpc_method_handler\n elif handler.request_streaming and not handler.response_streaming:\n behavior_fn = handler.stream_unary\n handler_factory = grpc.stream_unary_rpc_method_handler\n elif not handler.request_streaming and handler.response_streaming:\n behavior_fn = handler.unary_stream\n handler_factory = grpc.unary_stream_rpc_method_handler\n else:\n behavior_fn = handler.unary_unary\n handler_factory = grpc.unary_unary_rpc_method_handler\n\n return handler_factory(\n continuation(\n behavior_fn, handler.request_streaming, handler.response_streaming\n ),\n request_deserializer=handler.request_deserializer,\n response_serializer=handler.response_serializer,\n )\n\n\n# pylint:disable=abstract-method\nclass _OpenTelemetryServicerContext(grpc.ServicerContext):\n def __init__(self, servicer_context, active_span):\n self._servicer_context = servicer_context\n self._active_span = active_span\n self.code = grpc.StatusCode.OK\n self.details = None\n super().__init__()\n\n def is_active(self, *args, **kwargs):\n return self._servicer_context.is_active(*args, **kwargs)\n\n def time_remaining(self, *args, **kwargs):\n return self._servicer_context.time_remaining(*args, **kwargs)\n\n def cancel(self, *args, **kwargs):\n return self._servicer_context.cancel(*args, **kwargs)\n\n def add_callback(self, *args, **kwargs):\n return self._servicer_context.add_callback(*args, **kwargs)\n\n def disable_next_message_compression(self):\n return self._service_context.disable_next_message_compression()\n\n def invocation_metadata(self, *args, **kwargs):\n return self._servicer_context.invocation_metadata(*args, **kwargs)\n\n def peer(self):\n return self._servicer_context.peer()\n\n def peer_identities(self):\n return self._servicer_context.peer_identities()\n\n def peer_identity_key(self):\n return self._servicer_context.peer_identity_key()\n\n def auth_context(self):\n return self._servicer_context.auth_context()\n\n def set_compression(self, compression):\n return self._servicer_context.set_compression(compression)\n\n def send_initial_metadata(self, *args, **kwargs):\n return self._servicer_context.send_initial_metadata(*args, **kwargs)\n\n def set_trailing_metadata(self, *args, **kwargs):\n return self._servicer_context.set_trailing_metadata(*args, **kwargs)\n\n def abort(self, code, details):\n self.code = code\n self.details = details\n self._active_span.set_attribute(\"rpc.grpc.status_code\", code.name)\n self._active_span.set_status(\n Status(status_code=StatusCode.ERROR, description=details)\n )\n return self._servicer_context.abort(code, details)\n\n def abort_with_status(self, status):\n return self._servicer_context.abort_with_status(status)\n\n def set_code(self, code):\n self.code = code\n # use details if we already have it, otherwise the status description\n details = self.details or code.value[1]\n self._active_span.set_attribute(\"rpc.grpc.status_code\", code.name)\n self._active_span.set_status(\n Status(status_code=StatusCode.ERROR, description=details)\n )\n return self._servicer_context.set_code(code)\n\n def set_details(self, details):\n self.details = details\n self._active_span.set_status(\n Status(status_code=StatusCode.ERROR, description=details)\n )\n return self._servicer_context.set_details(details)\n\n\n# pylint:disable=abstract-method\n# pylint:disable=no-self-use\n# pylint:disable=unused-argument\nclass OpenTelemetryServerInterceptor(grpc.ServerInterceptor):\n \"\"\"\n A gRPC server interceptor, to add OpenTelemetry.\n\n Usage::\n\n tracer = some OpenTelemetry tracer\n\n interceptors = [\n OpenTelemetryServerInterceptor(tracer),\n ]\n\n server = grpc.server(\n futures.ThreadPoolExecutor(max_workers=concurrency),\n interceptors = interceptors)\n\n \"\"\"\n\n def __init__(self, tracer):\n self._tracer = tracer\n self._carrier_getter = DictGetter()\n\n @contextmanager\n def _set_remote_context(self, servicer_context):\n metadata = servicer_context.invocation_metadata()\n if metadata:\n md_dict = {md.key: md.value for md in metadata}\n ctx = propagators.extract(self._carrier_getter, md_dict)\n token = attach(ctx)\n try:\n yield\n finally:\n detach(token)\n else:\n yield\n\n def _start_span(self, handler_call_details, context):\n\n attributes = {\n \"rpc.method\": handler_call_details.method,\n \"rpc.system\": \"grpc\",\n \"rpc.grpc.status_code\": grpc.StatusCode.OK,\n }\n\n metadata = dict(context.invocation_metadata())\n if \"user-agent\" in metadata:\n attributes[\"rpc.user_agent\"] = metadata[\"user-agent\"]\n\n # Split up the peer to keep with how other telemetry sources\n # do it. This looks like:\n # * ipv6:[::1]:57284\n # * ipv4:127.0.0.1:57284\n # * ipv4:10.2.1.1:57284,127.0.0.1:57284\n #\n try:\n host, port = (\n context.peer().split(\",\")[0].split(\":\", 1)[1].rsplit(\":\", 1)\n )\n\n # other telemetry sources convert this, so we will too\n if host in (\"[::1]\", \"127.0.0.1\"):\n host = \"localhost\"\n\n attributes.update({\"net.peer.name\": host, \"net.peer.port\": port})\n except IndexError:\n logger.warning(\"Failed to parse peer address '%s'\", context.peer())\n\n return self._tracer.start_as_current_span(\n name=handler_call_details.method,\n kind=trace.SpanKind.SERVER,\n attributes=attributes,\n )\n\n def intercept_service(self, continuation, handler_call_details):\n def telemetry_wrapper(behavior, request_streaming, response_streaming):\n def telemetry_interceptor(request_or_iterator, context):\n\n with self._set_remote_context(context):\n with self._start_span(\n handler_call_details, context\n ) as span:\n # wrap the context\n context = _OpenTelemetryServicerContext(context, span)\n\n # And now we run the actual RPC.\n try:\n return behavior(request_or_iterator, context)\n except Exception as error:\n # Bare exceptions are likely to be gRPC aborts, which\n # we handle in our context wrapper.\n # Here, we're interested in uncaught exceptions.\n # pylint:disable=unidiomatic-typecheck\n if type(error) != Exception:\n span.record_exception(error)\n raise error\n\n return telemetry_interceptor\n\n return _wrap_rpc_behavior(\n continuation(handler_call_details), telemetry_wrapper\n )\n", "path": "instrumentation/opentelemetry-instrumentation-grpc/src/opentelemetry/instrumentation/grpc/_server.py"}]}
| 3,078 | 947 |
gh_patches_debug_21348
|
rasdani/github-patches
|
git_diff
|
readthedocs__readthedocs.org-7839
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Improve performance for concurrency builds DB query
We start getting timeout when calling `/api/v2/builds/concurrent/` from builders to know `(limit_reached, concurrent, max_concurrent)` for a particular project.
We need to improve the queryset that works over the `Build` model because sometimes it takes ~4s or more. It usually takes ~200ms, so I guess this is because the project is/has subprojects/translations since in that case the query gets more complex.
This is the query we need to optimize,
https://github.com/readthedocs/readthedocs.org/blob/2e9cb8dd85c5f8a55ab085abe58082fe3f2c6799/readthedocs/builds/querysets.py#L129-L177
Sentry issues: https://sentry.io/organizations/read-the-docs/issues/1719520575/?project=148442&query=is%3Aunresolved&statsPeriod=14d
</issue>
<code>
[start of readthedocs/builds/querysets.py]
1 """Build and Version QuerySet classes."""
2 import logging
3
4 from django.db import models
5 from django.db.models import Q
6
7 from readthedocs.core.utils.extend import SettingsOverrideObject
8 from readthedocs.projects import constants
9 from readthedocs.projects.models import Project
10
11 from .constants import BUILD_STATE_TRIGGERED, BUILD_STATE_FINISHED
12
13
14 log = logging.getLogger(__name__)
15
16
17 __all__ = ['VersionQuerySet', 'BuildQuerySet', 'RelatedBuildQuerySet']
18
19
20 class VersionQuerySetBase(models.QuerySet):
21
22 """Versions take into account their own privacy_level setting."""
23
24 use_for_related_fields = True
25
26 def _add_user_repos(self, queryset, user):
27 if user.has_perm('builds.view_version'):
28 return self.all()
29 if user.is_authenticated:
30 projects_pk = user.projects.all().values_list('pk', flat=True)
31 user_queryset = self.filter(project__in=projects_pk)
32 queryset = user_queryset | queryset
33 return queryset
34
35 def public(self, user=None, project=None, only_active=True,
36 include_hidden=True, only_built=False):
37 queryset = self.filter(privacy_level=constants.PUBLIC)
38 if user:
39 queryset = self._add_user_repos(queryset, user)
40 if project:
41 queryset = queryset.filter(project=project)
42 if only_active:
43 queryset = queryset.filter(active=True)
44 if only_built:
45 queryset = queryset.filter(built=True)
46 if not include_hidden:
47 queryset = queryset.filter(hidden=False)
48 return queryset.distinct()
49
50 def protected(self, user=None, project=None, only_active=True):
51 queryset = self.filter(
52 privacy_level__in=[constants.PUBLIC, constants.PROTECTED],
53 )
54 if user:
55 queryset = self._add_user_repos(queryset, user)
56 if project:
57 queryset = queryset.filter(project=project)
58 if only_active:
59 queryset = queryset.filter(active=True)
60 return queryset.distinct()
61
62 def private(self, user=None, project=None, only_active=True):
63 queryset = self.filter(privacy_level__in=[constants.PRIVATE])
64 if user:
65 queryset = self._add_user_repos(queryset, user)
66 if project:
67 queryset = queryset.filter(project=project)
68 if only_active:
69 queryset = queryset.filter(active=True)
70 return queryset.distinct()
71
72 def api(self, user=None, detail=True):
73 if detail:
74 return self.public(user, only_active=False)
75
76 queryset = self.none()
77 if user:
78 queryset = self._add_user_repos(queryset, user)
79 return queryset.distinct()
80
81 def for_project(self, project):
82 """Return all versions for a project, including translations."""
83 return self.filter(
84 models.Q(project=project) |
85 models.Q(project__main_language_project=project),
86 )
87
88
89 class VersionQuerySet(SettingsOverrideObject):
90 _default_class = VersionQuerySetBase
91
92
93 class BuildQuerySetBase(models.QuerySet):
94
95 """
96 Build objects that are privacy aware.
97
98 i.e. they take into account the privacy of the Version that they relate to.
99 """
100
101 use_for_related_fields = True
102
103 def _add_user_repos(self, queryset, user=None):
104 if user.has_perm('builds.view_version'):
105 return self.all()
106 if user.is_authenticated:
107 projects_pk = user.projects.all().values_list('pk', flat=True)
108 user_queryset = self.filter(project__in=projects_pk)
109 queryset = user_queryset | queryset
110 return queryset
111
112 def public(self, user=None, project=None):
113 queryset = self.filter(version__privacy_level=constants.PUBLIC)
114 if user:
115 queryset = self._add_user_repos(queryset, user)
116 if project:
117 queryset = queryset.filter(project=project)
118 return queryset.distinct()
119
120 def api(self, user=None, detail=True):
121 if detail:
122 return self.public(user)
123
124 queryset = self.none()
125 if user:
126 queryset = self._add_user_repos(queryset, user)
127 return queryset.distinct()
128
129 def concurrent(self, project):
130 """
131 Check if the max build concurrency for this project was reached.
132
133 - regular project: counts concurrent builds
134
135 - translation: concurrent builds of all the translations + builds of main project
136
137 .. note::
138
139 If the project/translation belongs to an organization, we count all concurrent
140 builds for all the projects from the organization.
141
142 :rtype: tuple
143 :returns: limit_reached, number of concurrent builds, number of max concurrent
144 """
145 limit_reached = False
146 query = Q(project__slug=project.slug)
147
148 if project.main_language_project:
149 # Project is a translation, counts all builds of all the translations
150 query |= Q(project__main_language_project=project.main_language_project)
151 query |= Q(project__slug=project.main_language_project.slug)
152
153 elif project.translations.exists():
154 # The project has translations, counts their builds as well
155 query |= Q(project__in=project.translations.all())
156
157 # If the project belongs to an organization, count all the projects
158 # from this organization as well
159 organization = project.organizations.first()
160 if organization:
161 query |= Q(project__in=organization.projects.all())
162
163 concurrent = (
164 self.filter(query)
165 .exclude(state__in=[BUILD_STATE_TRIGGERED, BUILD_STATE_FINISHED])
166 ).distinct().count()
167
168 max_concurrent = Project.objects.max_concurrent_builds(project)
169 log.info(
170 'Concurrent builds. project=%s running=%s max=%s',
171 project.slug,
172 concurrent,
173 max_concurrent,
174 )
175 if concurrent >= max_concurrent:
176 limit_reached = True
177 return (limit_reached, concurrent, max_concurrent)
178
179
180 class BuildQuerySet(SettingsOverrideObject):
181 _default_class = BuildQuerySetBase
182
183
184 class RelatedBuildQuerySetBase(models.QuerySet):
185
186 """For models with association to a project through :py:class:`Build`."""
187
188 use_for_related_fields = True
189
190 def _add_user_repos(self, queryset, user=None):
191 if user.has_perm('builds.view_version'):
192 return self.all()
193 if user.is_authenticated:
194 projects_pk = user.projects.all().values_list('pk', flat=True)
195 user_queryset = self.filter(build__project__in=projects_pk)
196 queryset = user_queryset | queryset
197 return queryset
198
199 def public(self, user=None, project=None):
200 queryset = self.filter(build__version__privacy_level=constants.PUBLIC)
201 if user:
202 queryset = self._add_user_repos(queryset, user)
203 if project:
204 queryset = queryset.filter(build__project=project)
205 return queryset.distinct()
206
207 def api(self, user=None):
208 return self.public(user)
209
210
211 class RelatedBuildQuerySet(SettingsOverrideObject):
212 _default_class = RelatedBuildQuerySetBase
213 _override_setting = 'RELATED_BUILD_MANAGER'
214
[end of readthedocs/builds/querysets.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/readthedocs/builds/querysets.py b/readthedocs/builds/querysets.py
--- a/readthedocs/builds/querysets.py
+++ b/readthedocs/builds/querysets.py
@@ -1,8 +1,10 @@
"""Build and Version QuerySet classes."""
+import datetime
import logging
from django.db import models
from django.db.models import Q
+from django.utils import timezone
from readthedocs.core.utils.extend import SettingsOverrideObject
from readthedocs.projects import constants
@@ -143,7 +145,11 @@
:returns: limit_reached, number of concurrent builds, number of max concurrent
"""
limit_reached = False
- query = Q(project__slug=project.slug)
+ query = Q(
+ project__slug=project.slug,
+ # Limit builds to 5 hours ago to speed up the query
+ date__gte=timezone.now() - datetime.timedelta(hours=5),
+ )
if project.main_language_project:
# Project is a translation, counts all builds of all the translations
|
{"golden_diff": "diff --git a/readthedocs/builds/querysets.py b/readthedocs/builds/querysets.py\n--- a/readthedocs/builds/querysets.py\n+++ b/readthedocs/builds/querysets.py\n@@ -1,8 +1,10 @@\n \"\"\"Build and Version QuerySet classes.\"\"\"\n+import datetime\n import logging\n \n from django.db import models\n from django.db.models import Q\n+from django.utils import timezone\n \n from readthedocs.core.utils.extend import SettingsOverrideObject\n from readthedocs.projects import constants\n@@ -143,7 +145,11 @@\n :returns: limit_reached, number of concurrent builds, number of max concurrent\n \"\"\"\n limit_reached = False\n- query = Q(project__slug=project.slug)\n+ query = Q(\n+ project__slug=project.slug,\n+ # Limit builds to 5 hours ago to speed up the query\n+ date__gte=timezone.now() - datetime.timedelta(hours=5),\n+ )\n \n if project.main_language_project:\n # Project is a translation, counts all builds of all the translations\n", "issue": "Improve performance for concurrency builds DB query\nWe start getting timeout when calling `/api/v2/builds/concurrent/` from builders to know `(limit_reached, concurrent, max_concurrent)` for a particular project.\r\n\r\nWe need to improve the queryset that works over the `Build` model because sometimes it takes ~4s or more. It usually takes ~200ms, so I guess this is because the project is/has subprojects/translations since in that case the query gets more complex.\r\n\r\nThis is the query we need to optimize,\r\n\r\nhttps://github.com/readthedocs/readthedocs.org/blob/2e9cb8dd85c5f8a55ab085abe58082fe3f2c6799/readthedocs/builds/querysets.py#L129-L177\r\n\r\nSentry issues: https://sentry.io/organizations/read-the-docs/issues/1719520575/?project=148442&query=is%3Aunresolved&statsPeriod=14d\n", "before_files": [{"content": "\"\"\"Build and Version QuerySet classes.\"\"\"\nimport logging\n\nfrom django.db import models\nfrom django.db.models import Q\n\nfrom readthedocs.core.utils.extend import SettingsOverrideObject\nfrom readthedocs.projects import constants\nfrom readthedocs.projects.models import Project\n\nfrom .constants import BUILD_STATE_TRIGGERED, BUILD_STATE_FINISHED\n\n\nlog = logging.getLogger(__name__)\n\n\n__all__ = ['VersionQuerySet', 'BuildQuerySet', 'RelatedBuildQuerySet']\n\n\nclass VersionQuerySetBase(models.QuerySet):\n\n \"\"\"Versions take into account their own privacy_level setting.\"\"\"\n\n use_for_related_fields = True\n\n def _add_user_repos(self, queryset, user):\n if user.has_perm('builds.view_version'):\n return self.all()\n if user.is_authenticated:\n projects_pk = user.projects.all().values_list('pk', flat=True)\n user_queryset = self.filter(project__in=projects_pk)\n queryset = user_queryset | queryset\n return queryset\n\n def public(self, user=None, project=None, only_active=True,\n include_hidden=True, only_built=False):\n queryset = self.filter(privacy_level=constants.PUBLIC)\n if user:\n queryset = self._add_user_repos(queryset, user)\n if project:\n queryset = queryset.filter(project=project)\n if only_active:\n queryset = queryset.filter(active=True)\n if only_built:\n queryset = queryset.filter(built=True)\n if not include_hidden:\n queryset = queryset.filter(hidden=False)\n return queryset.distinct()\n\n def protected(self, user=None, project=None, only_active=True):\n queryset = self.filter(\n privacy_level__in=[constants.PUBLIC, constants.PROTECTED],\n )\n if user:\n queryset = self._add_user_repos(queryset, user)\n if project:\n queryset = queryset.filter(project=project)\n if only_active:\n queryset = queryset.filter(active=True)\n return queryset.distinct()\n\n def private(self, user=None, project=None, only_active=True):\n queryset = self.filter(privacy_level__in=[constants.PRIVATE])\n if user:\n queryset = self._add_user_repos(queryset, user)\n if project:\n queryset = queryset.filter(project=project)\n if only_active:\n queryset = queryset.filter(active=True)\n return queryset.distinct()\n\n def api(self, user=None, detail=True):\n if detail:\n return self.public(user, only_active=False)\n\n queryset = self.none()\n if user:\n queryset = self._add_user_repos(queryset, user)\n return queryset.distinct()\n\n def for_project(self, project):\n \"\"\"Return all versions for a project, including translations.\"\"\"\n return self.filter(\n models.Q(project=project) |\n models.Q(project__main_language_project=project),\n )\n\n\nclass VersionQuerySet(SettingsOverrideObject):\n _default_class = VersionQuerySetBase\n\n\nclass BuildQuerySetBase(models.QuerySet):\n\n \"\"\"\n Build objects that are privacy aware.\n\n i.e. they take into account the privacy of the Version that they relate to.\n \"\"\"\n\n use_for_related_fields = True\n\n def _add_user_repos(self, queryset, user=None):\n if user.has_perm('builds.view_version'):\n return self.all()\n if user.is_authenticated:\n projects_pk = user.projects.all().values_list('pk', flat=True)\n user_queryset = self.filter(project__in=projects_pk)\n queryset = user_queryset | queryset\n return queryset\n\n def public(self, user=None, project=None):\n queryset = self.filter(version__privacy_level=constants.PUBLIC)\n if user:\n queryset = self._add_user_repos(queryset, user)\n if project:\n queryset = queryset.filter(project=project)\n return queryset.distinct()\n\n def api(self, user=None, detail=True):\n if detail:\n return self.public(user)\n\n queryset = self.none()\n if user:\n queryset = self._add_user_repos(queryset, user)\n return queryset.distinct()\n\n def concurrent(self, project):\n \"\"\"\n Check if the max build concurrency for this project was reached.\n\n - regular project: counts concurrent builds\n\n - translation: concurrent builds of all the translations + builds of main project\n\n .. note::\n\n If the project/translation belongs to an organization, we count all concurrent\n builds for all the projects from the organization.\n\n :rtype: tuple\n :returns: limit_reached, number of concurrent builds, number of max concurrent\n \"\"\"\n limit_reached = False\n query = Q(project__slug=project.slug)\n\n if project.main_language_project:\n # Project is a translation, counts all builds of all the translations\n query |= Q(project__main_language_project=project.main_language_project)\n query |= Q(project__slug=project.main_language_project.slug)\n\n elif project.translations.exists():\n # The project has translations, counts their builds as well\n query |= Q(project__in=project.translations.all())\n\n # If the project belongs to an organization, count all the projects\n # from this organization as well\n organization = project.organizations.first()\n if organization:\n query |= Q(project__in=organization.projects.all())\n\n concurrent = (\n self.filter(query)\n .exclude(state__in=[BUILD_STATE_TRIGGERED, BUILD_STATE_FINISHED])\n ).distinct().count()\n\n max_concurrent = Project.objects.max_concurrent_builds(project)\n log.info(\n 'Concurrent builds. project=%s running=%s max=%s',\n project.slug,\n concurrent,\n max_concurrent,\n )\n if concurrent >= max_concurrent:\n limit_reached = True\n return (limit_reached, concurrent, max_concurrent)\n\n\nclass BuildQuerySet(SettingsOverrideObject):\n _default_class = BuildQuerySetBase\n\n\nclass RelatedBuildQuerySetBase(models.QuerySet):\n\n \"\"\"For models with association to a project through :py:class:`Build`.\"\"\"\n\n use_for_related_fields = True\n\n def _add_user_repos(self, queryset, user=None):\n if user.has_perm('builds.view_version'):\n return self.all()\n if user.is_authenticated:\n projects_pk = user.projects.all().values_list('pk', flat=True)\n user_queryset = self.filter(build__project__in=projects_pk)\n queryset = user_queryset | queryset\n return queryset\n\n def public(self, user=None, project=None):\n queryset = self.filter(build__version__privacy_level=constants.PUBLIC)\n if user:\n queryset = self._add_user_repos(queryset, user)\n if project:\n queryset = queryset.filter(build__project=project)\n return queryset.distinct()\n\n def api(self, user=None):\n return self.public(user)\n\n\nclass RelatedBuildQuerySet(SettingsOverrideObject):\n _default_class = RelatedBuildQuerySetBase\n _override_setting = 'RELATED_BUILD_MANAGER'\n", "path": "readthedocs/builds/querysets.py"}]}
| 2,796 | 237 |
gh_patches_debug_6683
|
rasdani/github-patches
|
git_diff
|
TabbycatDebate__tabbycat-1178
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Email draw/custom email/motions page formatting error
Running the latest develop branch v2.3.0A.
The message box on the email draw/custom email motions page is obscured/broken as per the picture running Windows 10/Google Chrome.
Error reproduced on a Mac/Google Chrome.

</issue>
<code>
[start of tabbycat/notifications/forms.py]
1 from django import forms
2 from django.conf import settings
3 from django.core.mail import send_mail
4 from django.utils.translation import gettext as _, gettext_lazy
5 from django_summernote.widgets import SummernoteWidget
6
7
8 class TestEmailForm(forms.Form):
9 """Simple form that just sends a test email."""
10
11 recipient = forms.EmailField(label=gettext_lazy("Recipient email address"), required=True)
12
13 def send_email(self, host):
14 send_mail(
15 _("Test email from %(host)s") % {'host': host},
16 _("Congratulations! If you're reading this message, your email "
17 "backend on %(host)s looks all good to go!") % {'host': host},
18 settings.DEFAULT_FROM_EMAIL,
19 [self.cleaned_data['recipient']],
20 )
21 return self.cleaned_data['recipient']
22
23
24 class BasicEmailForm(forms.Form):
25 """A base class for an email form with fields for subject/message
26
27 Note that the list of recipients is handled by Vue, bypassing this Form."""
28
29 subject_line = forms.CharField(label=_("Subject"), required=True, max_length=78)
30 message_body = forms.CharField(label=_("Message"), required=True, widget=SummernoteWidget(attrs={'height': 150}))
31
[end of tabbycat/notifications/forms.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/tabbycat/notifications/forms.py b/tabbycat/notifications/forms.py
--- a/tabbycat/notifications/forms.py
+++ b/tabbycat/notifications/forms.py
@@ -27,4 +27,5 @@
Note that the list of recipients is handled by Vue, bypassing this Form."""
subject_line = forms.CharField(label=_("Subject"), required=True, max_length=78)
- message_body = forms.CharField(label=_("Message"), required=True, widget=SummernoteWidget(attrs={'height': 150}))
+ message_body = forms.CharField(label=_("Message"), required=True, widget=SummernoteWidget(
+ attrs={'height': 150, 'class': 'form-summernote'}))
|
{"golden_diff": "diff --git a/tabbycat/notifications/forms.py b/tabbycat/notifications/forms.py\n--- a/tabbycat/notifications/forms.py\n+++ b/tabbycat/notifications/forms.py\n@@ -27,4 +27,5 @@\n Note that the list of recipients is handled by Vue, bypassing this Form.\"\"\"\n \n subject_line = forms.CharField(label=_(\"Subject\"), required=True, max_length=78)\n- message_body = forms.CharField(label=_(\"Message\"), required=True, widget=SummernoteWidget(attrs={'height': 150}))\n+ message_body = forms.CharField(label=_(\"Message\"), required=True, widget=SummernoteWidget(\n+ attrs={'height': 150, 'class': 'form-summernote'}))\n", "issue": "Email draw/custom email/motions page formatting error\nRunning the latest develop branch v2.3.0A.\r\n\r\nThe message box on the email draw/custom email motions page is obscured/broken as per the picture running Windows 10/Google Chrome. \r\n\r\nError reproduced on a Mac/Google Chrome. \r\n\r\n\r\n\n", "before_files": [{"content": "from django import forms\nfrom django.conf import settings\nfrom django.core.mail import send_mail\nfrom django.utils.translation import gettext as _, gettext_lazy\nfrom django_summernote.widgets import SummernoteWidget\n\n\nclass TestEmailForm(forms.Form):\n \"\"\"Simple form that just sends a test email.\"\"\"\n\n recipient = forms.EmailField(label=gettext_lazy(\"Recipient email address\"), required=True)\n\n def send_email(self, host):\n send_mail(\n _(\"Test email from %(host)s\") % {'host': host},\n _(\"Congratulations! If you're reading this message, your email \"\n \"backend on %(host)s looks all good to go!\") % {'host': host},\n settings.DEFAULT_FROM_EMAIL,\n [self.cleaned_data['recipient']],\n )\n return self.cleaned_data['recipient']\n\n\nclass BasicEmailForm(forms.Form):\n \"\"\"A base class for an email form with fields for subject/message\n\n Note that the list of recipients is handled by Vue, bypassing this Form.\"\"\"\n\n subject_line = forms.CharField(label=_(\"Subject\"), required=True, max_length=78)\n message_body = forms.CharField(label=_(\"Message\"), required=True, widget=SummernoteWidget(attrs={'height': 150}))\n", "path": "tabbycat/notifications/forms.py"}]}
| 972 | 160 |
gh_patches_debug_10669
|
rasdani/github-patches
|
git_diff
|
strawberry-graphql__strawberry-1451
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
from_pydantic error if pydantic models contains contains fields that are resolver field in strawberry type
Hi :),
i have a pydantic model that i want to convert to strawberry type using from_pydantic() method. The pydantic model contains fields that are resolver field in the strawberry type model.
```python
from .pydantic_models import Post as PostModel
# Strawberry type
@strawberry.experimental.pydantic.type(name="Post", model=PostModel)
class PostType:
user: Optional[LazyType["UserType", "api_gateway.user"]] = strawberry.field(name="user", resolver=resolve_user)
create_date: auto
text: auto
```
```python
# pydantic_models.py
from pydantic import BaseModel
# pydantic model
class Post(BaseModel):
user: Optional["User"]
create_date: datetime = Field(default_factory=datetime.utcnow)
text: str
```
**Actual Behavior**
----------------------------------
__init__() got an unexpected keyword argument user
**Steps to Reproduce the Problem**
----------------------------------
pydantic_post = Post(user=None, text="Hello World!") #create pydantic instance
posttype = PostType.from_pydantic(pydantic_post) # not work - error
This also not work:
pydantic_post = Post(text="Hello World!")
posttype = PostType.from_pydantic(pydantic_post) # also not work
Thx
</issue>
<code>
[start of strawberry/experimental/pydantic/conversion.py]
1 from typing import Union, cast
2
3 from strawberry.enum import EnumDefinition
4 from strawberry.field import StrawberryField
5 from strawberry.type import StrawberryList, StrawberryOptional, StrawberryType
6 from strawberry.union import StrawberryUnion
7
8
9 def _convert_from_pydantic_to_strawberry_type(
10 type_: Union[StrawberryType, type], data_from_model=None, extra=None
11 ):
12 data = data_from_model if data_from_model is not None else extra
13
14 if isinstance(type_, StrawberryOptional):
15 if data is None:
16 return data
17 return _convert_from_pydantic_to_strawberry_type(
18 type_.of_type, data_from_model=data, extra=extra
19 )
20 if isinstance(type_, StrawberryUnion):
21 for option_type in type_.types:
22 if hasattr(option_type, "_pydantic_type"):
23 source_type = option_type._pydantic_type # type: ignore
24 else:
25 source_type = cast(type, option_type)
26 if isinstance(data, source_type):
27 return _convert_from_pydantic_to_strawberry_type(
28 option_type, data_from_model=data, extra=extra
29 )
30 if isinstance(type_, EnumDefinition):
31 return data
32 if isinstance(type_, StrawberryList):
33 items = []
34 for index, item in enumerate(data):
35 items.append(
36 _convert_from_pydantic_to_strawberry_type(
37 type_.of_type,
38 data_from_model=item,
39 extra=extra[index] if extra else None,
40 )
41 )
42
43 return items
44
45 if hasattr(type_, "_type_definition"):
46 # in the case of an interface, the concrete type may be more specific
47 # than the type in the field definition
48 if hasattr(type(data), "_strawberry_type"):
49 type_ = type(data)._strawberry_type
50 return convert_pydantic_model_to_strawberry_class(
51 type_, model_instance=data_from_model, extra=extra
52 )
53
54 return data
55
56
57 def convert_pydantic_model_to_strawberry_class(cls, *, model_instance=None, extra=None):
58 extra = extra or {}
59 kwargs = {}
60
61 for field in cls._type_definition.fields:
62 field = cast(StrawberryField, field)
63 python_name = field.python_name
64
65 data_from_extra = extra.get(python_name, None)
66 data_from_model = (
67 getattr(model_instance, python_name, None) if model_instance else None
68 )
69 kwargs[python_name] = _convert_from_pydantic_to_strawberry_type(
70 field.type, data_from_model, extra=data_from_extra
71 )
72
73 return cls(**kwargs)
74
[end of strawberry/experimental/pydantic/conversion.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/strawberry/experimental/pydantic/conversion.py b/strawberry/experimental/pydantic/conversion.py
--- a/strawberry/experimental/pydantic/conversion.py
+++ b/strawberry/experimental/pydantic/conversion.py
@@ -66,8 +66,12 @@
data_from_model = (
getattr(model_instance, python_name, None) if model_instance else None
)
- kwargs[python_name] = _convert_from_pydantic_to_strawberry_type(
- field.type, data_from_model, extra=data_from_extra
- )
+
+ # only convert and add fields to kwargs if they are present in the `__init__`
+ # method of the class
+ if field.init:
+ kwargs[python_name] = _convert_from_pydantic_to_strawberry_type(
+ field.type, data_from_model, extra=data_from_extra
+ )
return cls(**kwargs)
|
{"golden_diff": "diff --git a/strawberry/experimental/pydantic/conversion.py b/strawberry/experimental/pydantic/conversion.py\n--- a/strawberry/experimental/pydantic/conversion.py\n+++ b/strawberry/experimental/pydantic/conversion.py\n@@ -66,8 +66,12 @@\n data_from_model = (\n getattr(model_instance, python_name, None) if model_instance else None\n )\n- kwargs[python_name] = _convert_from_pydantic_to_strawberry_type(\n- field.type, data_from_model, extra=data_from_extra\n- )\n+\n+ # only convert and add fields to kwargs if they are present in the `__init__`\n+ # method of the class\n+ if field.init:\n+ kwargs[python_name] = _convert_from_pydantic_to_strawberry_type(\n+ field.type, data_from_model, extra=data_from_extra\n+ )\n \n return cls(**kwargs)\n", "issue": "from_pydantic error if pydantic models contains contains fields that are resolver field in strawberry type\nHi :),\r\ni have a pydantic model that i want to convert to strawberry type using from_pydantic() method. The pydantic model contains fields that are resolver field in the strawberry type model.\r\n\r\n```python\r\n\r\nfrom .pydantic_models import Post as PostModel\r\n\r\n# Strawberry type \r\[email protected](name=\"Post\", model=PostModel)\r\nclass PostType:\r\n user: Optional[LazyType[\"UserType\", \"api_gateway.user\"]] = strawberry.field(name=\"user\", resolver=resolve_user)\r\n create_date: auto\r\n text: auto\r\n```\r\n\r\n```python\r\n\r\n# pydantic_models.py\r\n\r\nfrom pydantic import BaseModel\r\n\r\n# pydantic model\r\nclass Post(BaseModel):\r\n user: Optional[\"User\"]\r\n create_date: datetime = Field(default_factory=datetime.utcnow)\r\n text: str\r\n```\r\n\r\n**Actual Behavior**\r\n----------------------------------\r\n__init__() got an unexpected keyword argument user\r\n\r\n**Steps to Reproduce the Problem**\r\n----------------------------------\r\npydantic_post = Post(user=None, text=\"Hello World!\") #create pydantic instance\r\nposttype = PostType.from_pydantic(pydantic_post) # not work - error\r\n\r\nThis also not work:\r\npydantic_post = Post(text=\"Hello World!\")\r\nposttype = PostType.from_pydantic(pydantic_post) # also not work\r\n\r\nThx\r\n\r\n\r\n\n", "before_files": [{"content": "from typing import Union, cast\n\nfrom strawberry.enum import EnumDefinition\nfrom strawberry.field import StrawberryField\nfrom strawberry.type import StrawberryList, StrawberryOptional, StrawberryType\nfrom strawberry.union import StrawberryUnion\n\n\ndef _convert_from_pydantic_to_strawberry_type(\n type_: Union[StrawberryType, type], data_from_model=None, extra=None\n):\n data = data_from_model if data_from_model is not None else extra\n\n if isinstance(type_, StrawberryOptional):\n if data is None:\n return data\n return _convert_from_pydantic_to_strawberry_type(\n type_.of_type, data_from_model=data, extra=extra\n )\n if isinstance(type_, StrawberryUnion):\n for option_type in type_.types:\n if hasattr(option_type, \"_pydantic_type\"):\n source_type = option_type._pydantic_type # type: ignore\n else:\n source_type = cast(type, option_type)\n if isinstance(data, source_type):\n return _convert_from_pydantic_to_strawberry_type(\n option_type, data_from_model=data, extra=extra\n )\n if isinstance(type_, EnumDefinition):\n return data\n if isinstance(type_, StrawberryList):\n items = []\n for index, item in enumerate(data):\n items.append(\n _convert_from_pydantic_to_strawberry_type(\n type_.of_type,\n data_from_model=item,\n extra=extra[index] if extra else None,\n )\n )\n\n return items\n\n if hasattr(type_, \"_type_definition\"):\n # in the case of an interface, the concrete type may be more specific\n # than the type in the field definition\n if hasattr(type(data), \"_strawberry_type\"):\n type_ = type(data)._strawberry_type\n return convert_pydantic_model_to_strawberry_class(\n type_, model_instance=data_from_model, extra=extra\n )\n\n return data\n\n\ndef convert_pydantic_model_to_strawberry_class(cls, *, model_instance=None, extra=None):\n extra = extra or {}\n kwargs = {}\n\n for field in cls._type_definition.fields:\n field = cast(StrawberryField, field)\n python_name = field.python_name\n\n data_from_extra = extra.get(python_name, None)\n data_from_model = (\n getattr(model_instance, python_name, None) if model_instance else None\n )\n kwargs[python_name] = _convert_from_pydantic_to_strawberry_type(\n field.type, data_from_model, extra=data_from_extra\n )\n\n return cls(**kwargs)\n", "path": "strawberry/experimental/pydantic/conversion.py"}]}
| 1,547 | 214 |
gh_patches_debug_23824
|
rasdani/github-patches
|
git_diff
|
internetarchive__openlibrary-4260
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
(PYL-W0102) Dangerous default argument
## Description
Mutable Default Arguments: https://docs.python-guide.org/writing/gotchas/
Do not use a mutable like `list` or `dictionary` as a default value to an argument. Python’s default arguments are evaluated once when the function is defined. Using a mutable default argument and mutating it will mutate that object for all future calls to the function as well.
## Occurrences
There are 23 occurrences of this issue in the repository.
See all occurrences on DeepSource → [deepsource.io/gh/HarshCasper/openlibrary-1/issue/PYL-W0102/occurrences/](https://deepsource.io/gh/HarshCasper/openlibrary-1/issue/PYL-W0102/occurrences/)
</issue>
<code>
[start of openlibrary/plugins/upstream/adapter.py]
1 """Adapter to provide upstream URL structure over existing Open Library Infobase interface.
2
3 Upstream requires:
4
5 /user/.* -> /people/.*
6 /b/.* -> /books/.*
7 /a/.* -> /authors/.*
8
9 This adapter module is a filter that sits above an Infobase server and fakes the new URL structure.
10 """
11 import simplejson
12 import web
13
14 import six
15 from six.moves import urllib
16
17
18 urls = (
19 '/([^/]*)/get', 'get',
20 '/([^/]*)/get_many', 'get_many',
21 '/([^/]*)/things', 'things',
22 '/([^/]*)/versions', 'versions',
23 '/([^/]*)/new_key', 'new_key',
24 '/([^/]*)/save(/.*)', 'save',
25 '/([^/]*)/save_many', 'save_many',
26 '/([^/]*)/reindex', 'reindex',
27 '/([^/]*)/account/(.*)', 'account',
28 '/([^/]*)/count_edits_by_user', 'count_edits_by_user',
29 '/.*', 'proxy'
30 )
31 app = web.application(urls, globals())
32
33 convertions = {
34 # '/people/': '/user/',
35 # '/books/': '/b/',
36 # '/authors/': '/a/',
37 # '/languages/': '/l/',
38 '/templates/': '/upstream/templates/',
39 '/macros/': '/upstream/macros/',
40 '/js/': '/upstream/js/',
41 '/css/': '/upstream/css/',
42 '/old/templates/': '/templates/',
43 '/old/macros/': '/macros/',
44 '/old/js/': '/js/',
45 '/old/css/': '/css/',
46 }
47
48 # inverse of convertions
49 iconversions = dict((v, k) for k, v in convertions.items())
50
51 class proxy:
52 def delegate(self, *args):
53 self.args = args
54 self.input = web.input(_method='GET', _unicode=False)
55 self.path = web.ctx.path
56
57 if web.ctx.method in ['POST', 'PUT']:
58 self.data = web.data()
59 else:
60 self.data = None
61
62 headers = dict((k[len('HTTP_'):].replace('-', '_').lower(), v) for k, v in web.ctx.environ.items())
63
64 self.before_request()
65 try:
66 server = web.config.infobase_server
67 req = urllib.request.Request(server + self.path + '?' + urllib.parse.urlencode(self.input), self.data, headers=headers)
68 req.get_method = lambda: web.ctx.method
69 response = urllib.request.urlopen(req)
70 except urllib.error.HTTPError as e:
71 response = e
72 self.status_code = response.code
73 self.status_msg = response.msg
74 self.output = response.read()
75
76 self.headers = dict(response.headers.items())
77 for k in ['transfer-encoding', 'server', 'connection', 'date']:
78 self.headers.pop(k, None)
79
80 if self.status_code == 200:
81 self.after_request()
82 else:
83 self.process_error()
84
85 web.ctx.status = "%s %s" % (self.status_code, self.status_msg)
86 web.ctx.headers = self.headers.items()
87 return self.output
88
89 GET = POST = PUT = DELETE = delegate
90
91 def before_request(self):
92 if 'key' in self.input:
93 self.input.key = convert_key(self.input.key)
94
95 def after_request(self):
96 if self.output:
97 d = simplejson.loads(self.output)
98 d = unconvert_dict(d)
99 self.output = simplejson.dumps(d)
100
101 def process_error(self):
102 if self.output:
103 d = simplejson.loads(self.output)
104 if 'key' in d:
105 d['key'] = unconvert_key(d['key'])
106 self.output = simplejson.dumps(d)
107
108 def convert_key(key, mapping=convertions):
109 """
110 >>> convert_key("/authors/OL1A", {'/authors/': '/a/'})
111 '/a/OL1A'
112 """
113 if key is None:
114 return None
115 elif key == '/':
116 return '/upstream'
117
118 for new, old in mapping.items():
119 if key.startswith(new):
120 key2 = old + key[len(new):]
121 return key2
122 return key
123
124 def convert_dict(d, mapping=convertions):
125 """
126 >>> convert_dict({'author': {'key': '/authors/OL1A'}}, {'/authors/': '/a/'})
127 {'author': {'key': '/a/OL1A'}}
128 """
129 if isinstance(d, dict):
130 if 'key' in d:
131 d['key'] = convert_key(d['key'], mapping)
132 for k, v in d.items():
133 d[k] = convert_dict(v, mapping)
134 return d
135 elif isinstance(d, list):
136 return [convert_dict(x, mapping) for x in d]
137 else:
138 return d
139
140 def unconvert_key(key):
141 if key == '/upstream':
142 return '/'
143 return convert_key(key, iconversions)
144
145 def unconvert_dict(d):
146 return convert_dict(d, iconversions)
147
148 class get(proxy):
149 def before_request(self):
150 i = self.input
151 if 'key' in i:
152 i.key = convert_key(i.key)
153
154 class get_many(proxy):
155 def before_request(self):
156 if 'keys' in self.input:
157 keys = self.input['keys']
158 keys = simplejson.loads(keys)
159 keys = [convert_key(k) for k in keys]
160 self.input['keys'] = simplejson.dumps(keys)
161
162 def after_request(self):
163 d = simplejson.loads(self.output)
164 d = dict((unconvert_key(k), unconvert_dict(v)) for k, v in d.items())
165 self.output = simplejson.dumps(d)
166
167 class things(proxy):
168 def before_request(self):
169 if 'query' in self.input:
170 q = self.input.query
171 q = simplejson.loads(q)
172
173 def convert_keys(q):
174 if isinstance(q, dict):
175 return dict((k, convert_keys(v)) for k, v in q.items())
176 elif isinstance(q, list):
177 return [convert_keys(x) for x in q]
178 elif isinstance(q, six.string_types):
179 return convert_key(q)
180 else:
181 return q
182 self.input.query = simplejson.dumps(convert_keys(q))
183
184 def after_request(self):
185 if self.output:
186 d = simplejson.loads(self.output)
187
188 if self.input.get('details', '').lower() == 'true':
189 d = unconvert_dict(d)
190 else:
191 d = [unconvert_key(key) for key in d]
192
193 self.output = simplejson.dumps(d)
194
195 class versions(proxy):
196 def before_request(self):
197 if 'query' in self.input:
198 q = self.input.query
199 q = simplejson.loads(q)
200 if 'key' in q:
201 q['key'] = convert_key(q['key'])
202 if 'author' in q:
203 q['author'] = convert_key(q['author'])
204 self.input.query = simplejson.dumps(q)
205
206 def after_request(self):
207 if self.output:
208 d = simplejson.loads(self.output)
209 for v in d:
210 v['author'] = v['author'] and unconvert_key(v['author'])
211 v['key'] = unconvert_key(v['key'])
212 self.output = simplejson.dumps(d)
213
214 class new_key(proxy):
215 def after_request(self):
216 if self.output:
217 d = simplejson.loads(self.output)
218 d = unconvert_key(d)
219 self.output = simplejson.dumps(d)
220
221 class save(proxy):
222 def before_request(self):
223 self.path = '/%s/save%s' % (self.args[0], convert_key(self.args[1]))
224 d = simplejson.loads(self.data)
225 d = convert_dict(d)
226 self.data = simplejson.dumps(d)
227
228 class save_many(proxy):
229 def before_request(self):
230 i = web.input(_method="POST")
231 if 'query' in i:
232 q = simplejson.loads(i['query'])
233 q = convert_dict(q)
234 i['query'] = simplejson.dumps(q)
235 self.data = urllib.parse.urlencode(i)
236
237 class reindex(proxy):
238 def before_request(self):
239 i = web.input(_method="POST")
240 if 'keys' in i:
241 keys = [convert_key(k) for k in simplejson.loads(i['keys'])]
242 i['keys'] = simplejson.dumps(keys)
243 self.data = urllib.parse.urlencode(i)
244
245 class account(proxy):
246 def before_request(self):
247 i = self.input
248 if 'username' in i and i.username.startswith('/'):
249 i.username = convert_key(i.username)
250
251 def main():
252 import sys
253 import os
254 web.config.infobase_server = sys.argv[1].rstrip('/')
255 os.environ['REAL_SCRIPT_NAME'] = ''
256
257 sys.argv[1:] = sys.argv[2:]
258 app.run()
259
260 if __name__ == '__main__':
261 main()
262
[end of openlibrary/plugins/upstream/adapter.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/openlibrary/plugins/upstream/adapter.py b/openlibrary/plugins/upstream/adapter.py
--- a/openlibrary/plugins/upstream/adapter.py
+++ b/openlibrary/plugins/upstream/adapter.py
@@ -105,11 +105,13 @@
d['key'] = unconvert_key(d['key'])
self.output = simplejson.dumps(d)
-def convert_key(key, mapping=convertions):
+
+def convert_key(key, mapping=None):
"""
>>> convert_key("/authors/OL1A", {'/authors/': '/a/'})
'/a/OL1A'
"""
+ mapping = mapping or convertions
if key is None:
return None
elif key == '/':
@@ -121,11 +123,13 @@
return key2
return key
-def convert_dict(d, mapping=convertions):
+
+def convert_dict(d, mapping=None):
"""
>>> convert_dict({'author': {'key': '/authors/OL1A'}}, {'/authors/': '/a/'})
{'author': {'key': '/a/OL1A'}}
"""
+ mapping = mapping or convertions
if isinstance(d, dict):
if 'key' in d:
d['key'] = convert_key(d['key'], mapping)
|
{"golden_diff": "diff --git a/openlibrary/plugins/upstream/adapter.py b/openlibrary/plugins/upstream/adapter.py\n--- a/openlibrary/plugins/upstream/adapter.py\n+++ b/openlibrary/plugins/upstream/adapter.py\n@@ -105,11 +105,13 @@\n d['key'] = unconvert_key(d['key'])\n self.output = simplejson.dumps(d)\n \n-def convert_key(key, mapping=convertions):\n+\n+def convert_key(key, mapping=None):\n \"\"\"\n >>> convert_key(\"/authors/OL1A\", {'/authors/': '/a/'})\n '/a/OL1A'\n \"\"\"\n+ mapping = mapping or convertions\n if key is None:\n return None\n elif key == '/':\n@@ -121,11 +123,13 @@\n return key2\n return key\n \n-def convert_dict(d, mapping=convertions):\n+\n+def convert_dict(d, mapping=None):\n \"\"\"\n >>> convert_dict({'author': {'key': '/authors/OL1A'}}, {'/authors/': '/a/'})\n {'author': {'key': '/a/OL1A'}}\n \"\"\"\n+ mapping = mapping or convertions\n if isinstance(d, dict):\n if 'key' in d:\n d['key'] = convert_key(d['key'], mapping)\n", "issue": "(PYL-W0102) Dangerous default argument\n## Description\r\nMutable Default Arguments: https://docs.python-guide.org/writing/gotchas/\r\n\r\nDo not use a mutable like `list` or `dictionary` as a default value to an argument. Python\u2019s default arguments are evaluated once when the function is defined. Using a mutable default argument and mutating it will mutate that object for all future calls to the function as well.\r\n\r\n## Occurrences\r\nThere are 23 occurrences of this issue in the repository.\r\n\r\nSee all occurrences on DeepSource → [deepsource.io/gh/HarshCasper/openlibrary-1/issue/PYL-W0102/occurrences/](https://deepsource.io/gh/HarshCasper/openlibrary-1/issue/PYL-W0102/occurrences/)\r\n\n", "before_files": [{"content": "\"\"\"Adapter to provide upstream URL structure over existing Open Library Infobase interface.\n\nUpstream requires:\n\n /user/.* -> /people/.*\n /b/.* -> /books/.*\n /a/.* -> /authors/.*\n\nThis adapter module is a filter that sits above an Infobase server and fakes the new URL structure.\n\"\"\"\nimport simplejson\nimport web\n\nimport six\nfrom six.moves import urllib\n\n\nurls = (\n '/([^/]*)/get', 'get',\n '/([^/]*)/get_many', 'get_many',\n '/([^/]*)/things', 'things',\n '/([^/]*)/versions', 'versions',\n '/([^/]*)/new_key', 'new_key',\n '/([^/]*)/save(/.*)', 'save',\n '/([^/]*)/save_many', 'save_many',\n '/([^/]*)/reindex', 'reindex',\n '/([^/]*)/account/(.*)', 'account',\n '/([^/]*)/count_edits_by_user', 'count_edits_by_user',\n '/.*', 'proxy'\n)\napp = web.application(urls, globals())\n\nconvertions = {\n# '/people/': '/user/',\n# '/books/': '/b/',\n# '/authors/': '/a/',\n# '/languages/': '/l/',\n '/templates/': '/upstream/templates/',\n '/macros/': '/upstream/macros/',\n '/js/': '/upstream/js/',\n '/css/': '/upstream/css/',\n '/old/templates/': '/templates/',\n '/old/macros/': '/macros/',\n '/old/js/': '/js/',\n '/old/css/': '/css/',\n}\n\n# inverse of convertions\niconversions = dict((v, k) for k, v in convertions.items())\n\nclass proxy:\n def delegate(self, *args):\n self.args = args\n self.input = web.input(_method='GET', _unicode=False)\n self.path = web.ctx.path\n\n if web.ctx.method in ['POST', 'PUT']:\n self.data = web.data()\n else:\n self.data = None\n\n headers = dict((k[len('HTTP_'):].replace('-', '_').lower(), v) for k, v in web.ctx.environ.items())\n\n self.before_request()\n try:\n server = web.config.infobase_server\n req = urllib.request.Request(server + self.path + '?' + urllib.parse.urlencode(self.input), self.data, headers=headers)\n req.get_method = lambda: web.ctx.method\n response = urllib.request.urlopen(req)\n except urllib.error.HTTPError as e:\n response = e\n self.status_code = response.code\n self.status_msg = response.msg\n self.output = response.read()\n\n self.headers = dict(response.headers.items())\n for k in ['transfer-encoding', 'server', 'connection', 'date']:\n self.headers.pop(k, None)\n\n if self.status_code == 200:\n self.after_request()\n else:\n self.process_error()\n\n web.ctx.status = \"%s %s\" % (self.status_code, self.status_msg)\n web.ctx.headers = self.headers.items()\n return self.output\n\n GET = POST = PUT = DELETE = delegate\n\n def before_request(self):\n if 'key' in self.input:\n self.input.key = convert_key(self.input.key)\n\n def after_request(self):\n if self.output:\n d = simplejson.loads(self.output)\n d = unconvert_dict(d)\n self.output = simplejson.dumps(d)\n\n def process_error(self):\n if self.output:\n d = simplejson.loads(self.output)\n if 'key' in d:\n d['key'] = unconvert_key(d['key'])\n self.output = simplejson.dumps(d)\n\ndef convert_key(key, mapping=convertions):\n \"\"\"\n >>> convert_key(\"/authors/OL1A\", {'/authors/': '/a/'})\n '/a/OL1A'\n \"\"\"\n if key is None:\n return None\n elif key == '/':\n return '/upstream'\n\n for new, old in mapping.items():\n if key.startswith(new):\n key2 = old + key[len(new):]\n return key2\n return key\n\ndef convert_dict(d, mapping=convertions):\n \"\"\"\n >>> convert_dict({'author': {'key': '/authors/OL1A'}}, {'/authors/': '/a/'})\n {'author': {'key': '/a/OL1A'}}\n \"\"\"\n if isinstance(d, dict):\n if 'key' in d:\n d['key'] = convert_key(d['key'], mapping)\n for k, v in d.items():\n d[k] = convert_dict(v, mapping)\n return d\n elif isinstance(d, list):\n return [convert_dict(x, mapping) for x in d]\n else:\n return d\n\ndef unconvert_key(key):\n if key == '/upstream':\n return '/'\n return convert_key(key, iconversions)\n\ndef unconvert_dict(d):\n return convert_dict(d, iconversions)\n\nclass get(proxy):\n def before_request(self):\n i = self.input\n if 'key' in i:\n i.key = convert_key(i.key)\n\nclass get_many(proxy):\n def before_request(self):\n if 'keys' in self.input:\n keys = self.input['keys']\n keys = simplejson.loads(keys)\n keys = [convert_key(k) for k in keys]\n self.input['keys'] = simplejson.dumps(keys)\n\n def after_request(self):\n d = simplejson.loads(self.output)\n d = dict((unconvert_key(k), unconvert_dict(v)) for k, v in d.items())\n self.output = simplejson.dumps(d)\n\nclass things(proxy):\n def before_request(self):\n if 'query' in self.input:\n q = self.input.query\n q = simplejson.loads(q)\n\n def convert_keys(q):\n if isinstance(q, dict):\n return dict((k, convert_keys(v)) for k, v in q.items())\n elif isinstance(q, list):\n return [convert_keys(x) for x in q]\n elif isinstance(q, six.string_types):\n return convert_key(q)\n else:\n return q\n self.input.query = simplejson.dumps(convert_keys(q))\n\n def after_request(self):\n if self.output:\n d = simplejson.loads(self.output)\n\n if self.input.get('details', '').lower() == 'true':\n d = unconvert_dict(d)\n else:\n d = [unconvert_key(key) for key in d]\n\n self.output = simplejson.dumps(d)\n\nclass versions(proxy):\n def before_request(self):\n if 'query' in self.input:\n q = self.input.query\n q = simplejson.loads(q)\n if 'key' in q:\n q['key'] = convert_key(q['key'])\n if 'author' in q:\n q['author'] = convert_key(q['author'])\n self.input.query = simplejson.dumps(q)\n\n def after_request(self):\n if self.output:\n d = simplejson.loads(self.output)\n for v in d:\n v['author'] = v['author'] and unconvert_key(v['author'])\n v['key'] = unconvert_key(v['key'])\n self.output = simplejson.dumps(d)\n\nclass new_key(proxy):\n def after_request(self):\n if self.output:\n d = simplejson.loads(self.output)\n d = unconvert_key(d)\n self.output = simplejson.dumps(d)\n\nclass save(proxy):\n def before_request(self):\n self.path = '/%s/save%s' % (self.args[0], convert_key(self.args[1]))\n d = simplejson.loads(self.data)\n d = convert_dict(d)\n self.data = simplejson.dumps(d)\n\nclass save_many(proxy):\n def before_request(self):\n i = web.input(_method=\"POST\")\n if 'query' in i:\n q = simplejson.loads(i['query'])\n q = convert_dict(q)\n i['query'] = simplejson.dumps(q)\n self.data = urllib.parse.urlencode(i)\n\nclass reindex(proxy):\n def before_request(self):\n i = web.input(_method=\"POST\")\n if 'keys' in i:\n keys = [convert_key(k) for k in simplejson.loads(i['keys'])]\n i['keys'] = simplejson.dumps(keys)\n self.data = urllib.parse.urlencode(i)\n\nclass account(proxy):\n def before_request(self):\n i = self.input\n if 'username' in i and i.username.startswith('/'):\n i.username = convert_key(i.username)\n\ndef main():\n import sys\n import os\n web.config.infobase_server = sys.argv[1].rstrip('/')\n os.environ['REAL_SCRIPT_NAME'] = ''\n\n sys.argv[1:] = sys.argv[2:]\n app.run()\n\nif __name__ == '__main__':\n main()\n", "path": "openlibrary/plugins/upstream/adapter.py"}]}
| 3,323 | 288 |
gh_patches_debug_6173
|
rasdani/github-patches
|
git_diff
|
ipython__ipython-7883
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Making stdin optional when creating new kernels
It would be useful for the `ExecutePreprocessor` (and other things that want to automatically run notebooks on the fly) to be able to easily disable `stdin` -- otherwise, if there is something like a call to `input`, it causes the preprocessor to just hang and eventually time out. I think this would just involve adding a new kwarg to this function: https://github.com/ipython/ipython/blob/master/IPython/kernel/manager.py#L417 and then calling `kc.start_channels(stdin=stdin)`, where `stdin` is whatever value that was passed in (True by default).
Questions:
1. Is there some other way to do this that I missed?
2. If not, does this change sound ok? If so, I'll go ahead and make a PR for it and add an option to disable stdin to the `ExecutePreprocessor` as well.
</issue>
<code>
[start of IPython/nbconvert/preprocessors/execute.py]
1 """Module containing a preprocessor that removes the outputs from code cells"""
2
3 # Copyright (c) IPython Development Team.
4 # Distributed under the terms of the Modified BSD License.
5
6 import os
7
8 try:
9 from queue import Empty # Py 3
10 except ImportError:
11 from Queue import Empty # Py 2
12
13 from IPython.utils.traitlets import List, Unicode
14
15 from IPython.nbformat.v4 import output_from_msg
16 from .base import Preprocessor
17 from IPython.utils.traitlets import Integer
18
19
20 class ExecutePreprocessor(Preprocessor):
21 """
22 Executes all the cells in a notebook
23 """
24
25 timeout = Integer(30, config=True,
26 help="The time to wait (in seconds) for output from executions."
27 )
28
29 extra_arguments = List(Unicode)
30
31 def preprocess(self, nb, resources):
32 from IPython.kernel import run_kernel
33 kernel_name = nb.metadata.get('kernelspec', {}).get('name', 'python')
34 self.log.info("Executing notebook with kernel: %s" % kernel_name)
35 with run_kernel(kernel_name=kernel_name,
36 extra_arguments=self.extra_arguments,
37 stderr=open(os.devnull, 'w')) as kc:
38 self.kc = kc
39 nb, resources = super(ExecutePreprocessor, self).preprocess(nb, resources)
40 return nb, resources
41
42 def preprocess_cell(self, cell, resources, cell_index):
43 """
44 Apply a transformation on each code cell. See base.py for details.
45 """
46 if cell.cell_type != 'code':
47 return cell, resources
48 try:
49 outputs = self.run_cell(cell)
50 except Exception as e:
51 self.log.error("failed to run cell: " + repr(e))
52 self.log.error(str(cell.source))
53 raise
54 cell.outputs = outputs
55 return cell, resources
56
57 def run_cell(self, cell):
58 msg_id = self.kc.execute(cell.source)
59 self.log.debug("Executing cell:\n%s", cell.source)
60 # wait for finish, with timeout
61 while True:
62 try:
63 msg = self.kc.shell_channel.get_msg(timeout=self.timeout)
64 except Empty:
65 self.log.error("Timeout waiting for execute reply")
66 raise
67 if msg['parent_header'].get('msg_id') == msg_id:
68 break
69 else:
70 # not our reply
71 continue
72
73 outs = []
74
75 while True:
76 try:
77 msg = self.kc.iopub_channel.get_msg(timeout=self.timeout)
78 except Empty:
79 self.log.warn("Timeout waiting for IOPub output")
80 break
81 if msg['parent_header'].get('msg_id') != msg_id:
82 # not an output from our execution
83 continue
84
85 msg_type = msg['msg_type']
86 self.log.debug("output: %s", msg_type)
87 content = msg['content']
88
89 # set the prompt number for the input and the output
90 if 'execution_count' in content:
91 cell['execution_count'] = content['execution_count']
92
93 if msg_type == 'status':
94 if content['execution_state'] == 'idle':
95 break
96 else:
97 continue
98 elif msg_type == 'execute_input':
99 continue
100 elif msg_type == 'clear_output':
101 outs = []
102 continue
103
104 try:
105 out = output_from_msg(msg)
106 except ValueError:
107 self.log.error("unhandled iopub msg: " + msg_type)
108 else:
109 outs.append(out)
110
111 return outs
112
[end of IPython/nbconvert/preprocessors/execute.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/IPython/nbconvert/preprocessors/execute.py b/IPython/nbconvert/preprocessors/execute.py
--- a/IPython/nbconvert/preprocessors/execute.py
+++ b/IPython/nbconvert/preprocessors/execute.py
@@ -36,6 +36,7 @@
extra_arguments=self.extra_arguments,
stderr=open(os.devnull, 'w')) as kc:
self.kc = kc
+ self.kc.allow_stdin = False
nb, resources = super(ExecutePreprocessor, self).preprocess(nb, resources)
return nb, resources
|
{"golden_diff": "diff --git a/IPython/nbconvert/preprocessors/execute.py b/IPython/nbconvert/preprocessors/execute.py\n--- a/IPython/nbconvert/preprocessors/execute.py\n+++ b/IPython/nbconvert/preprocessors/execute.py\n@@ -36,6 +36,7 @@\n extra_arguments=self.extra_arguments,\n stderr=open(os.devnull, 'w')) as kc:\n self.kc = kc\n+ self.kc.allow_stdin = False\n nb, resources = super(ExecutePreprocessor, self).preprocess(nb, resources)\n return nb, resources\n", "issue": "Making stdin optional when creating new kernels\nIt would be useful for the `ExecutePreprocessor` (and other things that want to automatically run notebooks on the fly) to be able to easily disable `stdin` -- otherwise, if there is something like a call to `input`, it causes the preprocessor to just hang and eventually time out. I think this would just involve adding a new kwarg to this function: https://github.com/ipython/ipython/blob/master/IPython/kernel/manager.py#L417 and then calling `kc.start_channels(stdin=stdin)`, where `stdin` is whatever value that was passed in (True by default).\n\nQuestions:\n1. Is there some other way to do this that I missed?\n2. If not, does this change sound ok? If so, I'll go ahead and make a PR for it and add an option to disable stdin to the `ExecutePreprocessor` as well.\n\n", "before_files": [{"content": "\"\"\"Module containing a preprocessor that removes the outputs from code cells\"\"\"\n\n# Copyright (c) IPython Development Team.\n# Distributed under the terms of the Modified BSD License.\n\nimport os\n\ntry:\n from queue import Empty # Py 3\nexcept ImportError:\n from Queue import Empty # Py 2\n\nfrom IPython.utils.traitlets import List, Unicode\n\nfrom IPython.nbformat.v4 import output_from_msg\nfrom .base import Preprocessor\nfrom IPython.utils.traitlets import Integer\n\n\nclass ExecutePreprocessor(Preprocessor):\n \"\"\"\n Executes all the cells in a notebook\n \"\"\"\n \n timeout = Integer(30, config=True,\n help=\"The time to wait (in seconds) for output from executions.\"\n )\n \n extra_arguments = List(Unicode)\n\n def preprocess(self, nb, resources):\n from IPython.kernel import run_kernel\n kernel_name = nb.metadata.get('kernelspec', {}).get('name', 'python')\n self.log.info(\"Executing notebook with kernel: %s\" % kernel_name)\n with run_kernel(kernel_name=kernel_name,\n extra_arguments=self.extra_arguments,\n stderr=open(os.devnull, 'w')) as kc:\n self.kc = kc\n nb, resources = super(ExecutePreprocessor, self).preprocess(nb, resources)\n return nb, resources\n\n def preprocess_cell(self, cell, resources, cell_index):\n \"\"\"\n Apply a transformation on each code cell. See base.py for details.\n \"\"\"\n if cell.cell_type != 'code':\n return cell, resources\n try:\n outputs = self.run_cell(cell)\n except Exception as e:\n self.log.error(\"failed to run cell: \" + repr(e))\n self.log.error(str(cell.source))\n raise\n cell.outputs = outputs\n return cell, resources\n\n def run_cell(self, cell):\n msg_id = self.kc.execute(cell.source)\n self.log.debug(\"Executing cell:\\n%s\", cell.source)\n # wait for finish, with timeout\n while True:\n try:\n msg = self.kc.shell_channel.get_msg(timeout=self.timeout)\n except Empty:\n self.log.error(\"Timeout waiting for execute reply\")\n raise\n if msg['parent_header'].get('msg_id') == msg_id:\n break\n else:\n # not our reply\n continue\n \n outs = []\n\n while True:\n try:\n msg = self.kc.iopub_channel.get_msg(timeout=self.timeout)\n except Empty:\n self.log.warn(\"Timeout waiting for IOPub output\")\n break\n if msg['parent_header'].get('msg_id') != msg_id:\n # not an output from our execution\n continue\n\n msg_type = msg['msg_type']\n self.log.debug(\"output: %s\", msg_type)\n content = msg['content']\n\n # set the prompt number for the input and the output\n if 'execution_count' in content:\n cell['execution_count'] = content['execution_count']\n\n if msg_type == 'status':\n if content['execution_state'] == 'idle':\n break\n else:\n continue\n elif msg_type == 'execute_input':\n continue\n elif msg_type == 'clear_output':\n outs = []\n continue\n\n try:\n out = output_from_msg(msg)\n except ValueError:\n self.log.error(\"unhandled iopub msg: \" + msg_type)\n else:\n outs.append(out)\n\n return outs\n", "path": "IPython/nbconvert/preprocessors/execute.py"}]}
| 1,719 | 127 |
gh_patches_debug_2176
|
rasdani/github-patches
|
git_diff
|
PrefectHQ__prefect-2467
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Feature/#2439 prefect server telemetry
**Thanks for contributing to Prefect!**
Please describe your work and make sure your PR:
- [x] adds new tests (if appropriate)
- [x] updates `CHANGELOG.md` (if appropriate)
- [x] updates docstrings for any new functions or function arguments, including `docs/outline.toml` for API reference docs (if appropriate)
Note that your PR will not be reviewed unless all three boxes are checked.
## What does this PR change?
This PR closes #2467 and adds some minimal telemetry to Prefect Server.
## Why is this PR important?
This is the first step into collecting usage information that can help the Prefect team understand how Prefect Server is being used and how we can make it better.
</issue>
<code>
[start of src/prefect/cli/server.py]
1 import os
2 import shutil
3 import subprocess
4 import tempfile
5 import time
6 from pathlib import Path
7
8 import click
9 import yaml
10
11 import prefect
12 from prefect import config
13 from prefect.utilities.configuration import set_temporary_config
14 from prefect.utilities.docker_util import platform_is_linux, get_docker_ip
15
16
17 def make_env(fname=None):
18 # replace localhost with postgres to use docker-compose dns
19 PREFECT_ENV = dict(
20 DB_CONNECTION_URL=config.server.database.connection_url.replace(
21 "localhost", "postgres"
22 ),
23 GRAPHQL_HOST_PORT=config.server.graphql.host_port,
24 UI_HOST_PORT=config.server.ui.host_port,
25 )
26
27 APOLLO_ENV = dict(
28 HASURA_API_URL="http://hasura:{}/v1alpha1/graphql".format(
29 config.server.hasura.port
30 ),
31 HASURA_WS_URL="ws://hasura:{}/v1alpha1/graphql".format(
32 config.server.hasura.port
33 ),
34 PREFECT_API_URL="http://graphql:{port}{path}".format(
35 port=config.server.graphql.port, path=config.server.graphql.path
36 ),
37 PREFECT_API_HEALTH_URL="http://graphql:{port}/health".format(
38 port=config.server.graphql.port
39 ),
40 APOLLO_HOST_PORT=config.server.host_port,
41 )
42
43 POSTGRES_ENV = dict(
44 POSTGRES_HOST_PORT=config.server.database.host_port,
45 POSTGRES_USER=config.server.database.username,
46 POSTGRES_PASSWORD=config.server.database.password,
47 POSTGRES_DB=config.server.database.name,
48 )
49
50 UI_ENV = dict(GRAPHQL_URL=config.server.ui.graphql_url)
51
52 HASURA_ENV = dict(HASURA_HOST_PORT=config.server.hasura.host_port)
53
54 ENV = os.environ.copy()
55 ENV.update(**PREFECT_ENV, **APOLLO_ENV, **POSTGRES_ENV, **UI_ENV, **HASURA_ENV)
56
57 if fname is not None:
58 list_of_pairs = [
59 "{k}={repr(v)}".format(k=k, v=v)
60 if "\n" in v
61 else "{k}={v}".format(k=k, v=v)
62 for k, v in ENV.items()
63 ]
64 with open(fname, "w") as f:
65 f.write("\n".join(list_of_pairs))
66 return ENV.copy()
67
68
69 @click.group(hidden=True)
70 def server():
71 """
72 Commands for interacting with the Prefect Core server
73
74 \b
75 Usage:
76 $ prefect server ...
77
78 \b
79 Arguments:
80 start ...
81
82 \b
83 Examples:
84 $ prefect server start
85 ...
86 """
87
88
89 @server.command(hidden=True)
90 @click.option(
91 "--version",
92 "-v",
93 help="The server image versions to use (for example, '0.10.0' or 'master')",
94 hidden=True,
95 )
96 @click.option(
97 "--skip-pull",
98 help="Pass this flag to skip pulling new images (if available)",
99 is_flag=True,
100 hidden=True,
101 )
102 @click.option(
103 "--no-upgrade",
104 "-n",
105 help="Pass this flag to avoid running a database upgrade when the database spins up",
106 is_flag=True,
107 hidden=True,
108 )
109 @click.option(
110 "--no-ui",
111 "-u",
112 help="Pass this flag to avoid starting the UI",
113 is_flag=True,
114 hidden=True,
115 )
116 @click.option(
117 "--postgres-port",
118 help="The port used to serve Postgres",
119 default=config.server.database.host_port,
120 type=str,
121 hidden=True,
122 )
123 @click.option(
124 "--hasura-port",
125 help="The port used to serve Hasura",
126 default=config.server.hasura.host_port,
127 type=str,
128 hidden=True,
129 )
130 @click.option(
131 "--graphql-port",
132 help="The port used to serve the GraphQL API",
133 default=config.server.graphql.host_port,
134 type=str,
135 hidden=True,
136 )
137 @click.option(
138 "--ui-port",
139 help="The port used to serve the UI",
140 default=config.server.ui.host_port,
141 type=str,
142 hidden=True,
143 )
144 @click.option(
145 "--server-port",
146 help="The port used to serve the Core server",
147 default=config.server.host_port,
148 type=str,
149 hidden=True,
150 )
151 @click.option(
152 "--no-postgres-port",
153 help="Disable port map of Postgres to host",
154 is_flag=True,
155 hidden=True,
156 )
157 @click.option(
158 "--no-hasura-port",
159 help="Disable port map of Hasura to host",
160 is_flag=True,
161 hidden=True,
162 )
163 @click.option(
164 "--no-graphql-port",
165 help="Disable port map of the GraphqlAPI to host",
166 is_flag=True,
167 hidden=True,
168 )
169 @click.option(
170 "--no-ui-port", help="Disable port map of the UI to host", is_flag=True, hidden=True
171 )
172 @click.option(
173 "--no-server-port",
174 help="Disable port map of the Core server to host",
175 is_flag=True,
176 hidden=True,
177 )
178 def start(
179 version,
180 skip_pull,
181 no_upgrade,
182 no_ui,
183 postgres_port,
184 hasura_port,
185 graphql_port,
186 ui_port,
187 server_port,
188 no_postgres_port,
189 no_hasura_port,
190 no_graphql_port,
191 no_ui_port,
192 no_server_port,
193 ):
194 """
195 This command spins up all infrastructure and services for the Prefect Core server
196
197 \b
198 Options:
199 --version, -v TEXT The server image versions to use (for example, '0.10.0' or 'master')
200 Defaults to the current installed Prefect version.
201 --skip-pull Flag to skip pulling new images (if available)
202 --no-upgrade, -n Flag to avoid running a database upgrade when the database spins up
203 --no-ui, -u Flag to avoid starting the UI
204
205 \b
206 --postgres-port TEXT Port used to serve Postgres, defaults to '5432'
207 --hasura-port TEXT Port used to serve Hasura, defaults to '3001'
208 --graphql-port TEXT Port used to serve the GraphQL API, defaults to '4001'
209 --ui-port TEXT Port used to serve the UI, defaults to '8080'
210 --server-port TEXT Port used to serve the Core server, defaults to '4200'
211
212 \b
213 --no-postgres-port Disable port map of Postgres to host
214 --no-hasura-port Disable port map of Hasura to host
215 --no-graphql-port Disable port map of the GraphQL API to host
216 --no-ui-port Disable port map of the UI to host
217 --no-server-port Disable port map of the Core server to host
218 """
219
220 docker_dir = Path(__file__).parents[0]
221 compose_dir_path = docker_dir
222
223 # Remove port mappings if specified
224 if (
225 no_postgres_port
226 or no_hasura_port
227 or no_graphql_port
228 or no_ui_port
229 or no_server_port
230 or platform_is_linux()
231 ):
232 temp_dir = tempfile.gettempdir()
233 temp_path = os.path.join(temp_dir, "docker-compose.yml")
234 shutil.copy2(os.path.join(docker_dir, "docker-compose.yml"), temp_path)
235
236 with open(temp_path, "r") as file:
237 y = yaml.safe_load(file)
238
239 if no_postgres_port:
240 del y["services"]["postgres"]["ports"]
241
242 if no_hasura_port:
243 del y["services"]["hasura"]["ports"]
244
245 if no_graphql_port:
246 del y["services"]["graphql"]["ports"]
247
248 if no_ui_port:
249 del y["services"]["ui"]["ports"]
250
251 if no_server_port:
252 del y["services"]["apollo"]["ports"]
253
254 if platform_is_linux():
255 docker_internal_ip = get_docker_ip()
256 for service in list(y["services"]):
257 y["services"][service]["extra_hosts"] = [
258 "host.docker.internal:{}".format(docker_internal_ip)
259 ]
260
261 with open(temp_path, "w") as f:
262 y = yaml.safe_dump(y, f)
263
264 compose_dir_path = temp_dir
265
266 # Temporary config set for port allocation
267 with set_temporary_config(
268 {
269 "server.database.host_port": postgres_port,
270 "server.hasura.host_port": hasura_port,
271 "server.graphql.host_port": graphql_port,
272 "server.ui.host_port": ui_port,
273 "server.host_port": server_port,
274 }
275 ):
276 env = make_env()
277
278 if "PREFECT_SERVER_TAG" not in env:
279 env.update(
280 PREFECT_SERVER_TAG=version
281 or (
282 "master"
283 if len(prefect.__version__.split("+")) > 1
284 else prefect.__version__
285 )
286 )
287 if "PREFECT_SERVER_DB_CMD" not in env:
288 cmd = (
289 "prefect-server database upgrade -y"
290 if not no_upgrade
291 else "echo 'DATABASE MIGRATIONS SKIPPED'"
292 )
293 env.update(PREFECT_SERVER_DB_CMD=cmd)
294
295 proc = None
296 try:
297 if not skip_pull:
298 subprocess.check_call(
299 ["docker-compose", "pull"], cwd=compose_dir_path, env=env
300 )
301
302 cmd = ["docker-compose", "up"]
303 if no_ui:
304 cmd += ["--scale", "ui=0"]
305 proc = subprocess.Popen(cmd, cwd=compose_dir_path, env=env)
306 while True:
307 time.sleep(0.5)
308 except:
309 click.secho(
310 "Exception caught; killing services (press ctrl-C to force)",
311 fg="white",
312 bg="red",
313 )
314 subprocess.check_output(
315 ["docker-compose", "down"], cwd=compose_dir_path, env=env
316 )
317 if proc:
318 proc.kill()
319 raise
320
[end of src/prefect/cli/server.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/prefect/cli/server.py b/src/prefect/cli/server.py
--- a/src/prefect/cli/server.py
+++ b/src/prefect/cli/server.py
@@ -38,6 +38,9 @@
port=config.server.graphql.port
),
APOLLO_HOST_PORT=config.server.host_port,
+ PREFECT_SERVER__TELEMETRY__ENABLED=(
+ "true" if config.server.telemetry.enabled is True else "false"
+ ),
)
POSTGRES_ENV = dict(
|
{"golden_diff": "diff --git a/src/prefect/cli/server.py b/src/prefect/cli/server.py\n--- a/src/prefect/cli/server.py\n+++ b/src/prefect/cli/server.py\n@@ -38,6 +38,9 @@\n port=config.server.graphql.port\n ),\n APOLLO_HOST_PORT=config.server.host_port,\n+ PREFECT_SERVER__TELEMETRY__ENABLED=(\n+ \"true\" if config.server.telemetry.enabled is True else \"false\"\n+ ),\n )\n \n POSTGRES_ENV = dict(\n", "issue": "Feature/#2439 prefect server telemetry\n**Thanks for contributing to Prefect!**\r\n\r\nPlease describe your work and make sure your PR:\r\n\r\n- [x] adds new tests (if appropriate)\r\n- [x] updates `CHANGELOG.md` (if appropriate)\r\n- [x] updates docstrings for any new functions or function arguments, including `docs/outline.toml` for API reference docs (if appropriate)\r\n\r\nNote that your PR will not be reviewed unless all three boxes are checked.\r\n\r\n## What does this PR change?\r\n\r\nThis PR closes #2467 and adds some minimal telemetry to Prefect Server.\r\n\r\n## Why is this PR important?\r\n\r\nThis is the first step into collecting usage information that can help the Prefect team understand how Prefect Server is being used and how we can make it better.\r\n\n", "before_files": [{"content": "import os\nimport shutil\nimport subprocess\nimport tempfile\nimport time\nfrom pathlib import Path\n\nimport click\nimport yaml\n\nimport prefect\nfrom prefect import config\nfrom prefect.utilities.configuration import set_temporary_config\nfrom prefect.utilities.docker_util import platform_is_linux, get_docker_ip\n\n\ndef make_env(fname=None):\n # replace localhost with postgres to use docker-compose dns\n PREFECT_ENV = dict(\n DB_CONNECTION_URL=config.server.database.connection_url.replace(\n \"localhost\", \"postgres\"\n ),\n GRAPHQL_HOST_PORT=config.server.graphql.host_port,\n UI_HOST_PORT=config.server.ui.host_port,\n )\n\n APOLLO_ENV = dict(\n HASURA_API_URL=\"http://hasura:{}/v1alpha1/graphql\".format(\n config.server.hasura.port\n ),\n HASURA_WS_URL=\"ws://hasura:{}/v1alpha1/graphql\".format(\n config.server.hasura.port\n ),\n PREFECT_API_URL=\"http://graphql:{port}{path}\".format(\n port=config.server.graphql.port, path=config.server.graphql.path\n ),\n PREFECT_API_HEALTH_URL=\"http://graphql:{port}/health\".format(\n port=config.server.graphql.port\n ),\n APOLLO_HOST_PORT=config.server.host_port,\n )\n\n POSTGRES_ENV = dict(\n POSTGRES_HOST_PORT=config.server.database.host_port,\n POSTGRES_USER=config.server.database.username,\n POSTGRES_PASSWORD=config.server.database.password,\n POSTGRES_DB=config.server.database.name,\n )\n\n UI_ENV = dict(GRAPHQL_URL=config.server.ui.graphql_url)\n\n HASURA_ENV = dict(HASURA_HOST_PORT=config.server.hasura.host_port)\n\n ENV = os.environ.copy()\n ENV.update(**PREFECT_ENV, **APOLLO_ENV, **POSTGRES_ENV, **UI_ENV, **HASURA_ENV)\n\n if fname is not None:\n list_of_pairs = [\n \"{k}={repr(v)}\".format(k=k, v=v)\n if \"\\n\" in v\n else \"{k}={v}\".format(k=k, v=v)\n for k, v in ENV.items()\n ]\n with open(fname, \"w\") as f:\n f.write(\"\\n\".join(list_of_pairs))\n return ENV.copy()\n\n\[email protected](hidden=True)\ndef server():\n \"\"\"\n Commands for interacting with the Prefect Core server\n\n \\b\n Usage:\n $ prefect server ...\n\n \\b\n Arguments:\n start ...\n\n \\b\n Examples:\n $ prefect server start\n ...\n \"\"\"\n\n\[email protected](hidden=True)\[email protected](\n \"--version\",\n \"-v\",\n help=\"The server image versions to use (for example, '0.10.0' or 'master')\",\n hidden=True,\n)\[email protected](\n \"--skip-pull\",\n help=\"Pass this flag to skip pulling new images (if available)\",\n is_flag=True,\n hidden=True,\n)\[email protected](\n \"--no-upgrade\",\n \"-n\",\n help=\"Pass this flag to avoid running a database upgrade when the database spins up\",\n is_flag=True,\n hidden=True,\n)\[email protected](\n \"--no-ui\",\n \"-u\",\n help=\"Pass this flag to avoid starting the UI\",\n is_flag=True,\n hidden=True,\n)\[email protected](\n \"--postgres-port\",\n help=\"The port used to serve Postgres\",\n default=config.server.database.host_port,\n type=str,\n hidden=True,\n)\[email protected](\n \"--hasura-port\",\n help=\"The port used to serve Hasura\",\n default=config.server.hasura.host_port,\n type=str,\n hidden=True,\n)\[email protected](\n \"--graphql-port\",\n help=\"The port used to serve the GraphQL API\",\n default=config.server.graphql.host_port,\n type=str,\n hidden=True,\n)\[email protected](\n \"--ui-port\",\n help=\"The port used to serve the UI\",\n default=config.server.ui.host_port,\n type=str,\n hidden=True,\n)\[email protected](\n \"--server-port\",\n help=\"The port used to serve the Core server\",\n default=config.server.host_port,\n type=str,\n hidden=True,\n)\[email protected](\n \"--no-postgres-port\",\n help=\"Disable port map of Postgres to host\",\n is_flag=True,\n hidden=True,\n)\[email protected](\n \"--no-hasura-port\",\n help=\"Disable port map of Hasura to host\",\n is_flag=True,\n hidden=True,\n)\[email protected](\n \"--no-graphql-port\",\n help=\"Disable port map of the GraphqlAPI to host\",\n is_flag=True,\n hidden=True,\n)\[email protected](\n \"--no-ui-port\", help=\"Disable port map of the UI to host\", is_flag=True, hidden=True\n)\[email protected](\n \"--no-server-port\",\n help=\"Disable port map of the Core server to host\",\n is_flag=True,\n hidden=True,\n)\ndef start(\n version,\n skip_pull,\n no_upgrade,\n no_ui,\n postgres_port,\n hasura_port,\n graphql_port,\n ui_port,\n server_port,\n no_postgres_port,\n no_hasura_port,\n no_graphql_port,\n no_ui_port,\n no_server_port,\n):\n \"\"\"\n This command spins up all infrastructure and services for the Prefect Core server\n\n \\b\n Options:\n --version, -v TEXT The server image versions to use (for example, '0.10.0' or 'master')\n Defaults to the current installed Prefect version.\n --skip-pull Flag to skip pulling new images (if available)\n --no-upgrade, -n Flag to avoid running a database upgrade when the database spins up\n --no-ui, -u Flag to avoid starting the UI\n\n \\b\n --postgres-port TEXT Port used to serve Postgres, defaults to '5432'\n --hasura-port TEXT Port used to serve Hasura, defaults to '3001'\n --graphql-port TEXT Port used to serve the GraphQL API, defaults to '4001'\n --ui-port TEXT Port used to serve the UI, defaults to '8080'\n --server-port TEXT Port used to serve the Core server, defaults to '4200'\n\n \\b\n --no-postgres-port Disable port map of Postgres to host\n --no-hasura-port Disable port map of Hasura to host\n --no-graphql-port Disable port map of the GraphQL API to host\n --no-ui-port Disable port map of the UI to host\n --no-server-port Disable port map of the Core server to host\n \"\"\"\n\n docker_dir = Path(__file__).parents[0]\n compose_dir_path = docker_dir\n\n # Remove port mappings if specified\n if (\n no_postgres_port\n or no_hasura_port\n or no_graphql_port\n or no_ui_port\n or no_server_port\n or platform_is_linux()\n ):\n temp_dir = tempfile.gettempdir()\n temp_path = os.path.join(temp_dir, \"docker-compose.yml\")\n shutil.copy2(os.path.join(docker_dir, \"docker-compose.yml\"), temp_path)\n\n with open(temp_path, \"r\") as file:\n y = yaml.safe_load(file)\n\n if no_postgres_port:\n del y[\"services\"][\"postgres\"][\"ports\"]\n\n if no_hasura_port:\n del y[\"services\"][\"hasura\"][\"ports\"]\n\n if no_graphql_port:\n del y[\"services\"][\"graphql\"][\"ports\"]\n\n if no_ui_port:\n del y[\"services\"][\"ui\"][\"ports\"]\n\n if no_server_port:\n del y[\"services\"][\"apollo\"][\"ports\"]\n\n if platform_is_linux():\n docker_internal_ip = get_docker_ip()\n for service in list(y[\"services\"]):\n y[\"services\"][service][\"extra_hosts\"] = [\n \"host.docker.internal:{}\".format(docker_internal_ip)\n ]\n\n with open(temp_path, \"w\") as f:\n y = yaml.safe_dump(y, f)\n\n compose_dir_path = temp_dir\n\n # Temporary config set for port allocation\n with set_temporary_config(\n {\n \"server.database.host_port\": postgres_port,\n \"server.hasura.host_port\": hasura_port,\n \"server.graphql.host_port\": graphql_port,\n \"server.ui.host_port\": ui_port,\n \"server.host_port\": server_port,\n }\n ):\n env = make_env()\n\n if \"PREFECT_SERVER_TAG\" not in env:\n env.update(\n PREFECT_SERVER_TAG=version\n or (\n \"master\"\n if len(prefect.__version__.split(\"+\")) > 1\n else prefect.__version__\n )\n )\n if \"PREFECT_SERVER_DB_CMD\" not in env:\n cmd = (\n \"prefect-server database upgrade -y\"\n if not no_upgrade\n else \"echo 'DATABASE MIGRATIONS SKIPPED'\"\n )\n env.update(PREFECT_SERVER_DB_CMD=cmd)\n\n proc = None\n try:\n if not skip_pull:\n subprocess.check_call(\n [\"docker-compose\", \"pull\"], cwd=compose_dir_path, env=env\n )\n\n cmd = [\"docker-compose\", \"up\"]\n if no_ui:\n cmd += [\"--scale\", \"ui=0\"]\n proc = subprocess.Popen(cmd, cwd=compose_dir_path, env=env)\n while True:\n time.sleep(0.5)\n except:\n click.secho(\n \"Exception caught; killing services (press ctrl-C to force)\",\n fg=\"white\",\n bg=\"red\",\n )\n subprocess.check_output(\n [\"docker-compose\", \"down\"], cwd=compose_dir_path, env=env\n )\n if proc:\n proc.kill()\n raise\n", "path": "src/prefect/cli/server.py"}]}
| 3,699 | 117 |
gh_patches_debug_35313
|
rasdani/github-patches
|
git_diff
|
ocadotechnology__aimmo-143
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Improve error handling when getting worker actions.
Have `AvatarWrapper.decide_action` default to setting a `WaitAction` if anything goes wrong.
</issue>
<code>
[start of aimmo-game/simulation/avatar/avatar_wrapper.py]
1 import logging
2 import requests
3
4 from simulation.action import ACTIONS, MoveAction
5
6 LOGGER = logging.getLogger(__name__)
7
8
9 class AvatarWrapper(object):
10 """
11 The application's view of a character, not to be confused with "Avatar",
12 the player-supplied code.
13 """
14
15 def __init__(self, player_id, initial_location, worker_url, avatar_appearance):
16 self.player_id = player_id
17 self.location = initial_location
18 self.health = 5
19 self.score = 0
20 self.events = []
21 self.avatar_appearance = avatar_appearance
22 self.worker_url = worker_url
23 self.fog_of_war_modifier = 0
24 self._action = None
25
26 @property
27 def action(self):
28 return self._action
29
30 @property
31 def is_moving(self):
32 return isinstance(self.action, MoveAction)
33
34 def decide_action(self, state_view):
35 try:
36 data = requests.post(self.worker_url, json=state_view).json()
37 except ValueError as err:
38 LOGGER.info('Failed to get turn result: %s', err)
39 return False
40 else:
41 try:
42 action_data = data['action']
43 action_type = action_data['action_type']
44 action_args = action_data.get('options', {})
45 action_args['avatar'] = self
46 action = ACTIONS[action_type](**action_args)
47 except (KeyError, ValueError) as err:
48 LOGGER.info('Bad action data supplied: %s', err)
49 return False
50 else:
51 self._action = action
52 return True
53
54 def clear_action(self):
55 self._action = None
56
57 def die(self, respawn_location):
58 # TODO: extract settings for health and score loss on death
59 self.health = 5
60 self.score = max(0, self.score - 2)
61 self.location = respawn_location
62
63 def add_event(self, event):
64 self.events.append(event)
65
66 def serialise(self):
67 return {
68 'events': [
69 # {
70 # 'event_name': event.__class__.__name__.lower(),
71 # 'event_options': event.__dict__,
72 # } for event in self.events
73 ],
74 'health': self.health,
75 'location': self.location.serialise(),
76 'score': self.score,
77 }
78
79 def __repr__(self):
80 return 'Avatar(id={}, location={}, health={}, score={})'.format(self.player_id, self.location, self.health, self.score)
81
[end of aimmo-game/simulation/avatar/avatar_wrapper.py]
[start of aimmo-game/service.py]
1 #!/usr/bin/env python
2 import logging
3 import os
4 import sys
5
6 # If we monkey patch during testing then Django fails to create a DB enironment
7 if __name__ == '__main__':
8 import eventlet
9 eventlet.monkey_patch()
10
11 import flask
12 from flask_socketio import SocketIO, emit
13
14 from six.moves import range
15
16 from simulation.turn_manager import state_provider
17 from simulation import map_generator
18 from simulation.avatar.avatar_manager import AvatarManager
19 from simulation.location import Location
20 from simulation.game_state import GameState
21 from simulation.turn_manager import ConcurrentTurnManager
22 from simulation.turn_manager import SequentialTurnManager
23 from simulation.worker_manager import WORKER_MANAGERS
24
25 app = flask.Flask(__name__)
26 socketio = SocketIO()
27
28 worker_manager = None
29
30
31 def to_cell_type(cell):
32 if not cell.habitable:
33 return 1
34 if cell.generates_score:
35 return 2
36 return 0
37
38
39 def player_dict(avatar):
40 # TODO: implement better colour functionality: will eventually fall off end of numbers
41 colour = "#%06x" % (avatar.player_id * 4999)
42 return {
43 'id': avatar.player_id,
44 'x': avatar.location.x,
45 'y': avatar.location.y,
46 'health': avatar.health,
47 'score': avatar.score,
48 'rotation': 0,
49 "colours": {
50 "bodyStroke": "#0ff",
51 "bodyFill": colour,
52 "eyeStroke": "#aff",
53 "eyeFill": "#eff",
54 }
55 }
56
57
58 def get_world_state():
59 with state_provider as game_state:
60 world = game_state.world_map
61 num_cols = world.num_cols
62 num_rows = world.num_rows
63 grid = [[to_cell_type(world.get_cell(Location(x, y)))
64 for y in range(num_rows)]
65 for x in range(num_cols)]
66 player_data = {p.player_id: player_dict(p) for p in game_state.avatar_manager.avatars}
67 return {
68 'players': player_data,
69 'score_locations': [(cell.location.x, cell.location.y) for cell in world.score_cells()],
70 'pickup_locations': [(cell.location.x, cell.location.y) for cell in world.pickup_cells()],
71 'map_changed': True, # TODO: experiment with only sending deltas (not if not required)
72 'width': num_cols,
73 'height': num_rows,
74 'layout': grid,
75 }
76
77
78 @socketio.on('connect')
79 def world_update_on_connect():
80 emit(
81 'world-update',
82 get_world_state(),
83 )
84
85
86 def send_world_update():
87 socketio.emit(
88 'world-update',
89 get_world_state(),
90 broadcast=True,
91 )
92
93
94 @app.route('/')
95 def healthcheck():
96 return 'HEALTHY'
97
98
99 @app.route('/player/<player_id>')
100 def player_data(player_id):
101 player_id = int(player_id)
102 return flask.jsonify({
103 'code': worker_manager.get_code(player_id),
104 'options': {}, # Game options
105 'state': None,
106 })
107
108
109 def run_game():
110 global worker_manager
111
112 print("Running game...")
113 my_map = map_generator.generate_map(10, 10, 0.1)
114 player_manager = AvatarManager()
115 game_state = GameState(my_map, player_manager)
116 turn_manager = ConcurrentTurnManager(game_state=game_state, end_turn_callback=send_world_update)
117 WorkerManagerClass = WORKER_MANAGERS[os.environ.get('WORKER_MANAGER', 'local')]
118 worker_manager = WorkerManagerClass(
119 game_state=game_state,
120 users_url=os.environ.get('GAME_API_URL', 'http://localhost:8000/players/api/games/')
121 )
122 worker_manager.start()
123 turn_manager.start()
124
125
126 if __name__ == '__main__':
127 logging.basicConfig(level=logging.DEBUG)
128
129 socketio.init_app(app, resource=os.environ.get('SOCKETIO_RESOURCE', 'socket.io'))
130 run_game()
131 socketio.run(
132 app,
133 debug=False,
134 host=sys.argv[1],
135 port=int(sys.argv[2]),
136 use_reloader=False,
137 )
138
[end of aimmo-game/service.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/aimmo-game/service.py b/aimmo-game/service.py
--- a/aimmo-game/service.py
+++ b/aimmo-game/service.py
@@ -124,7 +124,7 @@
if __name__ == '__main__':
- logging.basicConfig(level=logging.DEBUG)
+ logging.basicConfig(level=logging.INFO)
socketio.init_app(app, resource=os.environ.get('SOCKETIO_RESOURCE', 'socket.io'))
run_game()
diff --git a/aimmo-game/simulation/avatar/avatar_wrapper.py b/aimmo-game/simulation/avatar/avatar_wrapper.py
--- a/aimmo-game/simulation/avatar/avatar_wrapper.py
+++ b/aimmo-game/simulation/avatar/avatar_wrapper.py
@@ -1,7 +1,7 @@
import logging
import requests
-from simulation.action import ACTIONS, MoveAction
+from simulation.action import ACTIONS, MoveAction, WaitAction
LOGGER = logging.getLogger(__name__)
@@ -31,25 +31,34 @@
def is_moving(self):
return isinstance(self.action, MoveAction)
+ def _fetch_action(self, state_view):
+ return requests.post(self.worker_url, json=state_view).json()
+
+ def _construct_action(self, data):
+ action_data = data['action']
+ action_type = action_data['action_type']
+ action_args = action_data.get('options', {})
+ action_args['avatar'] = self
+ return ACTIONS[action_type](**action_args)
+
def decide_action(self, state_view):
try:
- data = requests.post(self.worker_url, json=state_view).json()
- except ValueError as err:
- LOGGER.info('Failed to get turn result: %s', err)
- return False
+ data = self._fetch_action(state_view)
+ action = self._construct_action(data)
+
+ except (KeyError, ValueError) as err:
+ LOGGER.info('Bad action data supplied: %s', err)
+ except requests.exceptions.ConnectionError:
+ LOGGER.info('Could not connect to worker, probably not ready yet')
+ except Exception:
+ LOGGER.exception("Unknown error while fetching turn data")
+
else:
- try:
- action_data = data['action']
- action_type = action_data['action_type']
- action_args = action_data.get('options', {})
- action_args['avatar'] = self
- action = ACTIONS[action_type](**action_args)
- except (KeyError, ValueError) as err:
- LOGGER.info('Bad action data supplied: %s', err)
- return False
- else:
- self._action = action
- return True
+ self._action = action
+ return True
+
+ self._action = WaitAction(self)
+ return False
def clear_action(self):
self._action = None
|
{"golden_diff": "diff --git a/aimmo-game/service.py b/aimmo-game/service.py\n--- a/aimmo-game/service.py\n+++ b/aimmo-game/service.py\n@@ -124,7 +124,7 @@\n \n \n if __name__ == '__main__':\n- logging.basicConfig(level=logging.DEBUG)\n+ logging.basicConfig(level=logging.INFO)\n \n socketio.init_app(app, resource=os.environ.get('SOCKETIO_RESOURCE', 'socket.io'))\n run_game()\ndiff --git a/aimmo-game/simulation/avatar/avatar_wrapper.py b/aimmo-game/simulation/avatar/avatar_wrapper.py\n--- a/aimmo-game/simulation/avatar/avatar_wrapper.py\n+++ b/aimmo-game/simulation/avatar/avatar_wrapper.py\n@@ -1,7 +1,7 @@\n import logging\n import requests\n \n-from simulation.action import ACTIONS, MoveAction\n+from simulation.action import ACTIONS, MoveAction, WaitAction\n \n LOGGER = logging.getLogger(__name__)\n \n@@ -31,25 +31,34 @@\n def is_moving(self):\n return isinstance(self.action, MoveAction)\n \n+ def _fetch_action(self, state_view):\n+ return requests.post(self.worker_url, json=state_view).json()\n+\n+ def _construct_action(self, data):\n+ action_data = data['action']\n+ action_type = action_data['action_type']\n+ action_args = action_data.get('options', {})\n+ action_args['avatar'] = self\n+ return ACTIONS[action_type](**action_args)\n+\n def decide_action(self, state_view):\n try:\n- data = requests.post(self.worker_url, json=state_view).json()\n- except ValueError as err:\n- LOGGER.info('Failed to get turn result: %s', err)\n- return False\n+ data = self._fetch_action(state_view)\n+ action = self._construct_action(data)\n+\n+ except (KeyError, ValueError) as err:\n+ LOGGER.info('Bad action data supplied: %s', err)\n+ except requests.exceptions.ConnectionError:\n+ LOGGER.info('Could not connect to worker, probably not ready yet')\n+ except Exception:\n+ LOGGER.exception(\"Unknown error while fetching turn data\")\n+\n else:\n- try:\n- action_data = data['action']\n- action_type = action_data['action_type']\n- action_args = action_data.get('options', {})\n- action_args['avatar'] = self\n- action = ACTIONS[action_type](**action_args)\n- except (KeyError, ValueError) as err:\n- LOGGER.info('Bad action data supplied: %s', err)\n- return False\n- else:\n- self._action = action\n- return True\n+ self._action = action\n+ return True\n+\n+ self._action = WaitAction(self)\n+ return False\n \n def clear_action(self):\n self._action = None\n", "issue": "Improve error handling when getting worker actions.\nHave `AvatarWrapper.decide_action` default to setting a `WaitAction` if anything goes wrong.\n\n", "before_files": [{"content": "import logging\nimport requests\n\nfrom simulation.action import ACTIONS, MoveAction\n\nLOGGER = logging.getLogger(__name__)\n\n\nclass AvatarWrapper(object):\n \"\"\"\n The application's view of a character, not to be confused with \"Avatar\",\n the player-supplied code.\n \"\"\"\n\n def __init__(self, player_id, initial_location, worker_url, avatar_appearance):\n self.player_id = player_id\n self.location = initial_location\n self.health = 5\n self.score = 0\n self.events = []\n self.avatar_appearance = avatar_appearance\n self.worker_url = worker_url\n self.fog_of_war_modifier = 0\n self._action = None\n\n @property\n def action(self):\n return self._action\n\n @property\n def is_moving(self):\n return isinstance(self.action, MoveAction)\n\n def decide_action(self, state_view):\n try:\n data = requests.post(self.worker_url, json=state_view).json()\n except ValueError as err:\n LOGGER.info('Failed to get turn result: %s', err)\n return False\n else:\n try:\n action_data = data['action']\n action_type = action_data['action_type']\n action_args = action_data.get('options', {})\n action_args['avatar'] = self\n action = ACTIONS[action_type](**action_args)\n except (KeyError, ValueError) as err:\n LOGGER.info('Bad action data supplied: %s', err)\n return False\n else:\n self._action = action\n return True\n\n def clear_action(self):\n self._action = None\n\n def die(self, respawn_location):\n # TODO: extract settings for health and score loss on death\n self.health = 5\n self.score = max(0, self.score - 2)\n self.location = respawn_location\n\n def add_event(self, event):\n self.events.append(event)\n\n def serialise(self):\n return {\n 'events': [\n # {\n # 'event_name': event.__class__.__name__.lower(),\n # 'event_options': event.__dict__,\n # } for event in self.events\n ],\n 'health': self.health,\n 'location': self.location.serialise(),\n 'score': self.score,\n }\n\n def __repr__(self):\n return 'Avatar(id={}, location={}, health={}, score={})'.format(self.player_id, self.location, self.health, self.score)\n", "path": "aimmo-game/simulation/avatar/avatar_wrapper.py"}, {"content": "#!/usr/bin/env python\nimport logging\nimport os\nimport sys\n\n# If we monkey patch during testing then Django fails to create a DB enironment\nif __name__ == '__main__':\n import eventlet\n eventlet.monkey_patch()\n\nimport flask\nfrom flask_socketio import SocketIO, emit\n\nfrom six.moves import range\n\nfrom simulation.turn_manager import state_provider\nfrom simulation import map_generator\nfrom simulation.avatar.avatar_manager import AvatarManager\nfrom simulation.location import Location\nfrom simulation.game_state import GameState\nfrom simulation.turn_manager import ConcurrentTurnManager\nfrom simulation.turn_manager import SequentialTurnManager\nfrom simulation.worker_manager import WORKER_MANAGERS\n\napp = flask.Flask(__name__)\nsocketio = SocketIO()\n\nworker_manager = None\n\n\ndef to_cell_type(cell):\n if not cell.habitable:\n return 1\n if cell.generates_score:\n return 2\n return 0\n\n\ndef player_dict(avatar):\n # TODO: implement better colour functionality: will eventually fall off end of numbers\n colour = \"#%06x\" % (avatar.player_id * 4999)\n return {\n 'id': avatar.player_id,\n 'x': avatar.location.x,\n 'y': avatar.location.y,\n 'health': avatar.health,\n 'score': avatar.score,\n 'rotation': 0,\n \"colours\": {\n \"bodyStroke\": \"#0ff\",\n \"bodyFill\": colour,\n \"eyeStroke\": \"#aff\",\n \"eyeFill\": \"#eff\",\n }\n }\n\n\ndef get_world_state():\n with state_provider as game_state:\n world = game_state.world_map\n num_cols = world.num_cols\n num_rows = world.num_rows\n grid = [[to_cell_type(world.get_cell(Location(x, y)))\n for y in range(num_rows)]\n for x in range(num_cols)]\n player_data = {p.player_id: player_dict(p) for p in game_state.avatar_manager.avatars}\n return {\n 'players': player_data,\n 'score_locations': [(cell.location.x, cell.location.y) for cell in world.score_cells()],\n 'pickup_locations': [(cell.location.x, cell.location.y) for cell in world.pickup_cells()],\n 'map_changed': True, # TODO: experiment with only sending deltas (not if not required)\n 'width': num_cols,\n 'height': num_rows,\n 'layout': grid,\n }\n\n\[email protected]('connect')\ndef world_update_on_connect():\n emit(\n 'world-update',\n get_world_state(),\n )\n\n\ndef send_world_update():\n socketio.emit(\n 'world-update',\n get_world_state(),\n broadcast=True,\n )\n\n\[email protected]('/')\ndef healthcheck():\n return 'HEALTHY'\n\n\[email protected]('/player/<player_id>')\ndef player_data(player_id):\n player_id = int(player_id)\n return flask.jsonify({\n 'code': worker_manager.get_code(player_id),\n 'options': {}, # Game options\n 'state': None,\n })\n\n\ndef run_game():\n global worker_manager\n\n print(\"Running game...\")\n my_map = map_generator.generate_map(10, 10, 0.1)\n player_manager = AvatarManager()\n game_state = GameState(my_map, player_manager)\n turn_manager = ConcurrentTurnManager(game_state=game_state, end_turn_callback=send_world_update)\n WorkerManagerClass = WORKER_MANAGERS[os.environ.get('WORKER_MANAGER', 'local')]\n worker_manager = WorkerManagerClass(\n game_state=game_state,\n users_url=os.environ.get('GAME_API_URL', 'http://localhost:8000/players/api/games/')\n )\n worker_manager.start()\n turn_manager.start()\n\n\nif __name__ == '__main__':\n logging.basicConfig(level=logging.DEBUG)\n\n socketio.init_app(app, resource=os.environ.get('SOCKETIO_RESOURCE', 'socket.io'))\n run_game()\n socketio.run(\n app,\n debug=False,\n host=sys.argv[1],\n port=int(sys.argv[2]),\n use_reloader=False,\n )\n", "path": "aimmo-game/service.py"}]}
| 2,478 | 622 |
gh_patches_debug_29293
|
rasdani/github-patches
|
git_diff
|
pytorch__ignite-1132
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Misleading ValueError - Accuracy Metric Multilabel
## 🐛 Bug description
When using Accuracy.update() with both inputs having the second dimension 1, e.g. in my case `torch.Size([256,1])` the raised error message is misleading.
To reproduce
```
from ignite.metrics import Accuracy
import torch
acc = Accuracy(is_multilabel=True)
acc.update((torch.zeros((256,1)), torch.zeros((256,1))))
```
`ValueError: y and y_pred must have same shape of (batch_size, num_categories, ...).`
In this case the y and y_pred do have the same shape but the issue is that it's not an accepted multilabel input (the `and y.shape[1] != 1` in the following code block from `_check_shape` in `_BaseClassification`). This should be indicated in the error message (or the if statement changed).
What is the argument to not allow a `y.shape[1]` of 1?
```
if self._is_multilabel and not (y.shape == y_pred.shape and y.ndimension() > 1 and y.shape[1] != 1):
raise ValueError("y and y_pred must have same shape of (batch_size, num_categories, ...).")
```
## Environment
- PyTorch Version (e.g., 1.4):
- Ignite Version (e.g., 0.3.0): 0.3.0
- OS (e.g., Linux): Linux
- How you installed Ignite (`conda`, `pip`, source): conda
- Python version:
- Any other relevant information:
</issue>
<code>
[start of ignite/metrics/accuracy.py]
1 from typing import Callable, Optional, Sequence, Union
2
3 import torch
4
5 from ignite.exceptions import NotComputableError
6 from ignite.metrics.metric import Metric, reinit__is_reduced, sync_all_reduce
7
8 __all__ = ["Accuracy"]
9
10
11 class _BaseClassification(Metric):
12 def __init__(
13 self,
14 output_transform: Callable = lambda x: x,
15 is_multilabel: bool = False,
16 device: Optional[Union[str, torch.device]] = None,
17 ):
18 self._is_multilabel = is_multilabel
19 self._type = None
20 self._num_classes = None
21 super(_BaseClassification, self).__init__(output_transform=output_transform, device=device)
22
23 def reset(self) -> None:
24 self._type = None
25 self._num_classes = None
26
27 def _check_shape(self, output: Sequence[torch.Tensor]) -> None:
28 y_pred, y = output
29
30 if not (y.ndimension() == y_pred.ndimension() or y.ndimension() + 1 == y_pred.ndimension()):
31 raise ValueError(
32 "y must have shape of (batch_size, ...) and y_pred must have "
33 "shape of (batch_size, num_categories, ...) or (batch_size, ...), "
34 "but given {} vs {}.".format(y.shape, y_pred.shape)
35 )
36
37 y_shape = y.shape
38 y_pred_shape = y_pred.shape
39
40 if y.ndimension() + 1 == y_pred.ndimension():
41 y_pred_shape = (y_pred_shape[0],) + y_pred_shape[2:]
42
43 if not (y_shape == y_pred_shape):
44 raise ValueError("y and y_pred must have compatible shapes.")
45
46 if self._is_multilabel and not (y.shape == y_pred.shape and y.ndimension() > 1 and y.shape[1] != 1):
47 raise ValueError("y and y_pred must have same shape of (batch_size, num_categories, ...).")
48
49 def _check_binary_multilabel_cases(self, output: Sequence[torch.Tensor]) -> None:
50 y_pred, y = output
51
52 if not torch.equal(y, y ** 2):
53 raise ValueError("For binary cases, y must be comprised of 0's and 1's.")
54
55 if not torch.equal(y_pred, y_pred ** 2):
56 raise ValueError("For binary cases, y_pred must be comprised of 0's and 1's.")
57
58 def _check_type(self, output: Sequence[torch.Tensor]) -> None:
59 y_pred, y = output
60
61 if y.ndimension() + 1 == y_pred.ndimension():
62 num_classes = y_pred.shape[1]
63 if num_classes == 1:
64 update_type = "binary"
65 self._check_binary_multilabel_cases((y_pred, y))
66 else:
67 update_type = "multiclass"
68 elif y.ndimension() == y_pred.ndimension():
69 self._check_binary_multilabel_cases((y_pred, y))
70
71 if self._is_multilabel:
72 update_type = "multilabel"
73 num_classes = y_pred.shape[1]
74 else:
75 update_type = "binary"
76 num_classes = 1
77 else:
78 raise RuntimeError(
79 "Invalid shapes of y (shape={}) and y_pred (shape={}), check documentation."
80 " for expected shapes of y and y_pred.".format(y.shape, y_pred.shape)
81 )
82 if self._type is None:
83 self._type = update_type
84 self._num_classes = num_classes
85 else:
86 if self._type != update_type:
87 raise RuntimeError("Input data type has changed from {} to {}.".format(self._type, update_type))
88 if self._num_classes != num_classes:
89 raise ValueError(
90 "Input data number of classes has changed from {} to {}".format(self._num_classes, num_classes)
91 )
92
93
94 class Accuracy(_BaseClassification):
95 """
96 Calculates the accuracy for binary, multiclass and multilabel data.
97
98 - `update` must receive output of the form `(y_pred, y)` or `{'y_pred': y_pred, 'y': y}`.
99 - `y_pred` must be in the following shape (batch_size, num_categories, ...) or (batch_size, ...).
100 - `y` must be in the following shape (batch_size, ...).
101 - `y` and `y_pred` must be in the following shape of (batch_size, num_categories, ...) for multilabel cases.
102
103 In binary and multilabel cases, the elements of `y` and `y_pred` should have 0 or 1 values. Thresholding of
104 predictions can be done as below:
105
106 .. code-block:: python
107
108 def thresholded_output_transform(output):
109 y_pred, y = output
110 y_pred = torch.round(y_pred)
111 return y_pred, y
112
113 binary_accuracy = Accuracy(thresholded_output_transform)
114
115
116 Args:
117 output_transform (callable, optional): a callable that is used to transform the
118 :class:`~ignite.engine.Engine`'s `process_function`'s output into the
119 form expected by the metric. This can be useful if, for example, you have a multi-output model and
120 you want to compute the metric with respect to one of the outputs.
121 is_multilabel (bool, optional): flag to use in multilabel case. By default, False.
122 device (str of torch.device, optional): unused argument.
123
124 """
125
126 def __init__(
127 self,
128 output_transform: Callable = lambda x: x,
129 is_multilabel: bool = False,
130 device: Optional[Union[str, torch.device]] = None,
131 ):
132 self._num_correct = None
133 self._num_examples = None
134 super(Accuracy, self).__init__(output_transform=output_transform, is_multilabel=is_multilabel, device=device)
135
136 @reinit__is_reduced
137 def reset(self) -> None:
138 self._num_correct = 0
139 self._num_examples = 0
140 super(Accuracy, self).reset()
141
142 @reinit__is_reduced
143 def update(self, output: Sequence[torch.Tensor]) -> None:
144 y_pred, y = output
145 self._check_shape((y_pred, y))
146 self._check_type((y_pred, y))
147
148 if self._type == "binary":
149 correct = torch.eq(y_pred.view(-1).to(y), y.view(-1))
150 elif self._type == "multiclass":
151 indices = torch.argmax(y_pred, dim=1)
152 correct = torch.eq(indices, y).view(-1)
153 elif self._type == "multilabel":
154 # if y, y_pred shape is (N, C, ...) -> (N x ..., C)
155 num_classes = y_pred.size(1)
156 last_dim = y_pred.ndimension()
157 y_pred = torch.transpose(y_pred, 1, last_dim - 1).reshape(-1, num_classes)
158 y = torch.transpose(y, 1, last_dim - 1).reshape(-1, num_classes)
159 correct = torch.all(y == y_pred.type_as(y), dim=-1)
160
161 self._num_correct += torch.sum(correct).item()
162 self._num_examples += correct.shape[0]
163
164 @sync_all_reduce("_num_examples", "_num_correct")
165 def compute(self) -> torch.Tensor:
166 if self._num_examples == 0:
167 raise NotComputableError("Accuracy must have at least one example before it can be computed.")
168 return self._num_correct / self._num_examples
169
[end of ignite/metrics/accuracy.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/ignite/metrics/accuracy.py b/ignite/metrics/accuracy.py
--- a/ignite/metrics/accuracy.py
+++ b/ignite/metrics/accuracy.py
@@ -43,8 +43,10 @@
if not (y_shape == y_pred_shape):
raise ValueError("y and y_pred must have compatible shapes.")
- if self._is_multilabel and not (y.shape == y_pred.shape and y.ndimension() > 1 and y.shape[1] != 1):
- raise ValueError("y and y_pred must have same shape of (batch_size, num_categories, ...).")
+ if self._is_multilabel and not (y.shape == y_pred.shape and y.ndimension() > 1 and y.shape[1] > 1):
+ raise ValueError(
+ "y and y_pred must have same shape of (batch_size, num_categories, ...) and num_categories > 1."
+ )
def _check_binary_multilabel_cases(self, output: Sequence[torch.Tensor]) -> None:
y_pred, y = output
@@ -98,7 +100,8 @@
- `update` must receive output of the form `(y_pred, y)` or `{'y_pred': y_pred, 'y': y}`.
- `y_pred` must be in the following shape (batch_size, num_categories, ...) or (batch_size, ...).
- `y` must be in the following shape (batch_size, ...).
- - `y` and `y_pred` must be in the following shape of (batch_size, num_categories, ...) for multilabel cases.
+ - `y` and `y_pred` must be in the following shape of (batch_size, num_categories, ...) and
+ num_categories must be greater than 1 for multilabel cases.
In binary and multilabel cases, the elements of `y` and `y_pred` should have 0 or 1 values. Thresholding of
predictions can be done as below:
|
{"golden_diff": "diff --git a/ignite/metrics/accuracy.py b/ignite/metrics/accuracy.py\n--- a/ignite/metrics/accuracy.py\n+++ b/ignite/metrics/accuracy.py\n@@ -43,8 +43,10 @@\n if not (y_shape == y_pred_shape):\n raise ValueError(\"y and y_pred must have compatible shapes.\")\n \n- if self._is_multilabel and not (y.shape == y_pred.shape and y.ndimension() > 1 and y.shape[1] != 1):\n- raise ValueError(\"y and y_pred must have same shape of (batch_size, num_categories, ...).\")\n+ if self._is_multilabel and not (y.shape == y_pred.shape and y.ndimension() > 1 and y.shape[1] > 1):\n+ raise ValueError(\n+ \"y and y_pred must have same shape of (batch_size, num_categories, ...) and num_categories > 1.\"\n+ )\n \n def _check_binary_multilabel_cases(self, output: Sequence[torch.Tensor]) -> None:\n y_pred, y = output\n@@ -98,7 +100,8 @@\n - `update` must receive output of the form `(y_pred, y)` or `{'y_pred': y_pred, 'y': y}`.\n - `y_pred` must be in the following shape (batch_size, num_categories, ...) or (batch_size, ...).\n - `y` must be in the following shape (batch_size, ...).\n- - `y` and `y_pred` must be in the following shape of (batch_size, num_categories, ...) for multilabel cases.\n+ - `y` and `y_pred` must be in the following shape of (batch_size, num_categories, ...) and\n+ num_categories must be greater than 1 for multilabel cases.\n \n In binary and multilabel cases, the elements of `y` and `y_pred` should have 0 or 1 values. Thresholding of\n predictions can be done as below:\n", "issue": "Misleading ValueError - Accuracy Metric Multilabel\n## \ud83d\udc1b Bug description\r\n\r\n\r\nWhen using Accuracy.update() with both inputs having the second dimension 1, e.g. in my case `torch.Size([256,1])` the raised error message is misleading.\r\n\r\nTo reproduce \r\n```\r\nfrom ignite.metrics import Accuracy\r\nimport torch\r\nacc = Accuracy(is_multilabel=True)\r\nacc.update((torch.zeros((256,1)), torch.zeros((256,1))))\r\n```\r\n`ValueError: y and y_pred must have same shape of (batch_size, num_categories, ...).`\r\n\r\nIn this case the y and y_pred do have the same shape but the issue is that it's not an accepted multilabel input (the `and y.shape[1] != 1` in the following code block from `_check_shape` in `_BaseClassification`). This should be indicated in the error message (or the if statement changed).\r\n\r\nWhat is the argument to not allow a `y.shape[1]` of 1?\r\n\r\n```\r\nif self._is_multilabel and not (y.shape == y_pred.shape and y.ndimension() > 1 and y.shape[1] != 1):\r\n raise ValueError(\"y and y_pred must have same shape of (batch_size, num_categories, ...).\")\r\n```\r\n\r\n\r\n## Environment\r\n\r\n - PyTorch Version (e.g., 1.4): \r\n - Ignite Version (e.g., 0.3.0): 0.3.0\r\n - OS (e.g., Linux): Linux\r\n - How you installed Ignite (`conda`, `pip`, source): conda\r\n - Python version:\r\n - Any other relevant information:\r\n\n", "before_files": [{"content": "from typing import Callable, Optional, Sequence, Union\n\nimport torch\n\nfrom ignite.exceptions import NotComputableError\nfrom ignite.metrics.metric import Metric, reinit__is_reduced, sync_all_reduce\n\n__all__ = [\"Accuracy\"]\n\n\nclass _BaseClassification(Metric):\n def __init__(\n self,\n output_transform: Callable = lambda x: x,\n is_multilabel: bool = False,\n device: Optional[Union[str, torch.device]] = None,\n ):\n self._is_multilabel = is_multilabel\n self._type = None\n self._num_classes = None\n super(_BaseClassification, self).__init__(output_transform=output_transform, device=device)\n\n def reset(self) -> None:\n self._type = None\n self._num_classes = None\n\n def _check_shape(self, output: Sequence[torch.Tensor]) -> None:\n y_pred, y = output\n\n if not (y.ndimension() == y_pred.ndimension() or y.ndimension() + 1 == y_pred.ndimension()):\n raise ValueError(\n \"y must have shape of (batch_size, ...) and y_pred must have \"\n \"shape of (batch_size, num_categories, ...) or (batch_size, ...), \"\n \"but given {} vs {}.\".format(y.shape, y_pred.shape)\n )\n\n y_shape = y.shape\n y_pred_shape = y_pred.shape\n\n if y.ndimension() + 1 == y_pred.ndimension():\n y_pred_shape = (y_pred_shape[0],) + y_pred_shape[2:]\n\n if not (y_shape == y_pred_shape):\n raise ValueError(\"y and y_pred must have compatible shapes.\")\n\n if self._is_multilabel and not (y.shape == y_pred.shape and y.ndimension() > 1 and y.shape[1] != 1):\n raise ValueError(\"y and y_pred must have same shape of (batch_size, num_categories, ...).\")\n\n def _check_binary_multilabel_cases(self, output: Sequence[torch.Tensor]) -> None:\n y_pred, y = output\n\n if not torch.equal(y, y ** 2):\n raise ValueError(\"For binary cases, y must be comprised of 0's and 1's.\")\n\n if not torch.equal(y_pred, y_pred ** 2):\n raise ValueError(\"For binary cases, y_pred must be comprised of 0's and 1's.\")\n\n def _check_type(self, output: Sequence[torch.Tensor]) -> None:\n y_pred, y = output\n\n if y.ndimension() + 1 == y_pred.ndimension():\n num_classes = y_pred.shape[1]\n if num_classes == 1:\n update_type = \"binary\"\n self._check_binary_multilabel_cases((y_pred, y))\n else:\n update_type = \"multiclass\"\n elif y.ndimension() == y_pred.ndimension():\n self._check_binary_multilabel_cases((y_pred, y))\n\n if self._is_multilabel:\n update_type = \"multilabel\"\n num_classes = y_pred.shape[1]\n else:\n update_type = \"binary\"\n num_classes = 1\n else:\n raise RuntimeError(\n \"Invalid shapes of y (shape={}) and y_pred (shape={}), check documentation.\"\n \" for expected shapes of y and y_pred.\".format(y.shape, y_pred.shape)\n )\n if self._type is None:\n self._type = update_type\n self._num_classes = num_classes\n else:\n if self._type != update_type:\n raise RuntimeError(\"Input data type has changed from {} to {}.\".format(self._type, update_type))\n if self._num_classes != num_classes:\n raise ValueError(\n \"Input data number of classes has changed from {} to {}\".format(self._num_classes, num_classes)\n )\n\n\nclass Accuracy(_BaseClassification):\n \"\"\"\n Calculates the accuracy for binary, multiclass and multilabel data.\n\n - `update` must receive output of the form `(y_pred, y)` or `{'y_pred': y_pred, 'y': y}`.\n - `y_pred` must be in the following shape (batch_size, num_categories, ...) or (batch_size, ...).\n - `y` must be in the following shape (batch_size, ...).\n - `y` and `y_pred` must be in the following shape of (batch_size, num_categories, ...) for multilabel cases.\n\n In binary and multilabel cases, the elements of `y` and `y_pred` should have 0 or 1 values. Thresholding of\n predictions can be done as below:\n\n .. code-block:: python\n\n def thresholded_output_transform(output):\n y_pred, y = output\n y_pred = torch.round(y_pred)\n return y_pred, y\n\n binary_accuracy = Accuracy(thresholded_output_transform)\n\n\n Args:\n output_transform (callable, optional): a callable that is used to transform the\n :class:`~ignite.engine.Engine`'s `process_function`'s output into the\n form expected by the metric. This can be useful if, for example, you have a multi-output model and\n you want to compute the metric with respect to one of the outputs.\n is_multilabel (bool, optional): flag to use in multilabel case. By default, False.\n device (str of torch.device, optional): unused argument.\n\n \"\"\"\n\n def __init__(\n self,\n output_transform: Callable = lambda x: x,\n is_multilabel: bool = False,\n device: Optional[Union[str, torch.device]] = None,\n ):\n self._num_correct = None\n self._num_examples = None\n super(Accuracy, self).__init__(output_transform=output_transform, is_multilabel=is_multilabel, device=device)\n\n @reinit__is_reduced\n def reset(self) -> None:\n self._num_correct = 0\n self._num_examples = 0\n super(Accuracy, self).reset()\n\n @reinit__is_reduced\n def update(self, output: Sequence[torch.Tensor]) -> None:\n y_pred, y = output\n self._check_shape((y_pred, y))\n self._check_type((y_pred, y))\n\n if self._type == \"binary\":\n correct = torch.eq(y_pred.view(-1).to(y), y.view(-1))\n elif self._type == \"multiclass\":\n indices = torch.argmax(y_pred, dim=1)\n correct = torch.eq(indices, y).view(-1)\n elif self._type == \"multilabel\":\n # if y, y_pred shape is (N, C, ...) -> (N x ..., C)\n num_classes = y_pred.size(1)\n last_dim = y_pred.ndimension()\n y_pred = torch.transpose(y_pred, 1, last_dim - 1).reshape(-1, num_classes)\n y = torch.transpose(y, 1, last_dim - 1).reshape(-1, num_classes)\n correct = torch.all(y == y_pred.type_as(y), dim=-1)\n\n self._num_correct += torch.sum(correct).item()\n self._num_examples += correct.shape[0]\n\n @sync_all_reduce(\"_num_examples\", \"_num_correct\")\n def compute(self) -> torch.Tensor:\n if self._num_examples == 0:\n raise NotComputableError(\"Accuracy must have at least one example before it can be computed.\")\n return self._num_correct / self._num_examples\n", "path": "ignite/metrics/accuracy.py"}]}
| 2,942 | 446 |
gh_patches_debug_40601
|
rasdani/github-patches
|
git_diff
|
pytorch__TensorRT-1738
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
✨[Feature] Create Decorator for Python functions Incompatible with Legacy Torch Versions
## Context
Some functions in the code base are incompatible with certain versions of Torch such as 1.13.1. Adding a general-purpose utility decorator which detects whether the Torch version is incompatible with certain key functions could be helpful in notifying the user when such mismatches occur.
## Desired Solution
A decorator of the form:
```python
@req_torch_version(2)
def f(...):
```
This decorator would throw a clear error when the detected Torch version differs from that required to use the decorated function.
## Temporary Alternative
A temporary alternative, which is already in use in PR #1731, is to add logic to each function with compatibility issues, raising an error if any versioning issues are detected. While this is a functional solution, it is difficult to scale and can lead to repetitive code.
## Additional Context
Certain imports are also not compatible across Torch versions (as in `import torchdynamo` in Torch 1.13 versus `import torch._dynamo` in 2.0). To resolve this issue, the imports can be moved inside the functions using them so as to encapsulate all version-specific code within one area.
</issue>
<code>
[start of py/torch_tensorrt/fx/tracer/dispatch_tracer/aten_tracer.py]
1 import copy
2 import sys
3 from contextlib import contextmanager
4 from typing import Any, Callable, Dict, Generator, List, Optional, Set, Tuple, Union
5
6 import torch
7
8 if not torch.__version__.startswith("1"):
9 import torch._dynamo as torchdynamo
10
11 from torch.fx.passes.infra.pass_base import PassResult
12
13 from torch_tensorrt.fx.passes.lower_basic_pass_aten import (
14 compose_bmm,
15 compose_chunk,
16 compose_getitem_slice,
17 remove_ops,
18 replace_aten_op_with_indices,
19 replace_aten_reshape_alias_with_replace,
20 replace_builtin_ops,
21 replace_inplace_ops,
22 replace_native_layernorm_with_layernorm,
23 replace_transpose_mm_op_with_linear,
24 run_const_fold,
25 )
26 from typing_extensions import TypeAlias
27
28 Value: TypeAlias = Union[
29 Tuple["Value", ...],
30 List["Value"],
31 Dict[str, "Value"],
32 ]
33
34
35 class DynamoConfig:
36 """
37 Manage Exir-specific configurations of Dynamo.
38 """
39
40 def __init__(
41 self,
42 capture_scalar_outputs: bool = True,
43 guard_nn_modules: bool = True,
44 dynamic_shapes: bool = True,
45 specialize_int_float: bool = True,
46 verbose: bool = True,
47 ) -> None:
48
49 self.capture_scalar_outputs = capture_scalar_outputs
50 self.guard_nn_modules = guard_nn_modules
51 self.dynamic_shapes = dynamic_shapes
52 self.specialize_int_float = specialize_int_float
53 self.verbose = verbose
54
55 def activate(self) -> None:
56 torchdynamo.config.capture_scalar_outputs = self.capture_scalar_outputs
57 torchdynamo.config.guard_nn_modules = self.guard_nn_modules
58 torchdynamo.config.dynamic_shapes = self.dynamic_shapes
59 torchdynamo.config.specialize_int_float = self.specialize_int_float
60 torchdynamo.config.verbose = self.verbose
61
62 def deactivate(self) -> None:
63 torchdynamo.config.capture_scalar_outputs = True
64 torchdynamo.config.guard_nn_modules = True
65 torchdynamo.config.dynamic_shapes = True
66 torchdynamo.config.specialize_int_float = True
67 torchdynamo.config.verbose = True
68
69
70 @contextmanager
71 def using_config(config: DynamoConfig) -> Generator[DynamoConfig, None, None]:
72 config.activate()
73 try:
74 yield config
75 finally:
76 config.deactivate()
77
78
79 @contextmanager
80 def setting_python_recursive_limit(limit: int = 10000) -> Generator[None, None, None]:
81 """
82 Temporarily increase the python interpreter stack recursion limit.
83 This is mostly used for pickling large scale modules.
84 """
85 default = sys.getrecursionlimit()
86 if limit > default:
87 sys.setrecursionlimit(limit)
88 try:
89 yield
90 finally:
91 sys.setrecursionlimit(default)
92
93
94 def dynamo_trace(
95 f: Callable[..., Value],
96 # pyre-ignore
97 args: Tuple[Any, ...],
98 aten_graph: bool,
99 tracing_mode: str = "real",
100 dynamo_config: Optional[DynamoConfig] = None,
101 ) -> Tuple[torch.fx.GraphModule, Set]:
102 """
103 TODO: Once we fully migrate to torchdynamo frontend, we will remove
104 this config option alltogether. For now, it helps with quick
105 experiments with playing around with TorchDynamo
106 """
107 if torch.__version__.startswith("1"):
108 raise ValueError(
109 f"The aten tracer requires Torch version >= 2.0. Detected version {torch.__version__}"
110 )
111
112 if dynamo_config is None:
113 dynamo_config = DynamoConfig()
114 with using_config(dynamo_config), setting_python_recursive_limit(2000):
115 torchdynamo.reset()
116 try:
117 return torchdynamo.export(
118 f,
119 *copy.deepcopy(args),
120 aten_graph=aten_graph,
121 tracing_mode=tracing_mode,
122 )
123 except torchdynamo.exc.Unsupported as exc:
124 raise RuntimeError(
125 "The user code is using a feature we don't support. "
126 "Please try torchdynamo.explain() to get possible the reasons",
127 ) from exc
128 except Exception as exc:
129 raise RuntimeError(
130 "torchdynamo internal error occured. Please see above stacktrace"
131 ) from exc
132
133
134 def trace(f, args, *rest):
135 graph_module, guards = dynamo_trace(f, args, True, "symbolic")
136 return graph_module, guards
137
138
139 def opt_trace(f, args, *rest):
140 """
141 Optimized trace with necessary passes which re-compose some ops or replace some ops
142 These passes should be general and functional purpose
143 """
144 passes_list = [
145 compose_bmm,
146 compose_chunk,
147 compose_getitem_slice,
148 replace_aten_reshape_alias_with_replace,
149 replace_aten_op_with_indices,
150 replace_transpose_mm_op_with_linear, # after compose_bmm
151 replace_native_layernorm_with_layernorm,
152 remove_ops,
153 replace_builtin_ops, # after replace_native_layernorm_with_layernorm
154 replace_inplace_ops, # remove it once functionalization is enabled
155 ]
156
157 fx_module, _ = trace(f, args)
158 print(fx_module.graph)
159 for passes in passes_list:
160 pr: PassResult = passes(fx_module)
161 fx_module = pr.graph_module
162
163 fx_module(*args)
164
165 fx_module = run_const_fold(fx_module)
166 print(fx_module.graph)
167 return fx_module
168
[end of py/torch_tensorrt/fx/tracer/dispatch_tracer/aten_tracer.py]
[start of py/torch_tensorrt/fx/utils.py]
1 from enum import Enum
2 from typing import List
3
4 # @manual=//deeplearning/trt/python:py_tensorrt
5 import tensorrt as trt
6 import torch
7 from functorch import make_fx
8 from functorch.experimental import functionalize
9 from torch_tensorrt.fx.passes.lower_basic_pass import (
10 replace_op_with_indices,
11 run_const_fold,
12 )
13
14 from .types import Shape, TRTDataType
15
16
17 class LowerPrecision(Enum):
18 FP32 = "fp32"
19 FP16 = "fp16"
20 INT8 = "int8"
21
22
23 def torch_dtype_to_trt(dtype: torch.dtype) -> TRTDataType:
24 """
25 Convert PyTorch data types to TensorRT data types.
26
27 Args:
28 dtype (torch.dtype): A PyTorch data type.
29
30 Returns:
31 The equivalent TensorRT data type.
32 """
33 if trt.__version__ >= "7.0" and dtype == torch.bool:
34 return trt.bool
35 elif dtype == torch.int8:
36 return trt.int8
37 elif dtype == torch.int32:
38 return trt.int32
39 elif dtype == torch.float16:
40 return trt.float16
41 elif dtype == torch.float32:
42 return trt.float32
43 else:
44 raise TypeError("%s is not supported by tensorrt" % dtype)
45
46
47 def torch_dtype_from_trt(dtype: TRTDataType) -> torch.dtype:
48 """
49 Convert TensorRT data types to PyTorch data types.
50
51 Args:
52 dtype (TRTDataType): A TensorRT data type.
53
54 Returns:
55 The equivalent PyTorch data type.
56 """
57 if dtype == trt.int8:
58 return torch.int8
59 elif trt.__version__ >= "7.0" and dtype == trt.bool:
60 return torch.bool
61 elif dtype == trt.int32:
62 return torch.int32
63 elif dtype == trt.float16:
64 return torch.float16
65 elif dtype == trt.float32:
66 return torch.float32
67 else:
68 raise TypeError("%s is not supported by torch" % dtype)
69
70
71 def get_dynamic_dims(shape: Shape) -> List[int]:
72 """
73 This function finds the dynamic dimensions in the given
74 shape. A dimension is dynamic if it's -1.
75
76 Args:
77 shape (Shape): A sequence of integer that represents
78 the shape of a tensor.
79
80 Returns:
81 A list of integers contains all the dynamic dimensions
82 in the given shape
83 """
84 dynamic_dims = []
85
86 for i, s in enumerate(shape):
87 if s == -1:
88 dynamic_dims.append(i)
89
90 return dynamic_dims
91
92
93 def proxytensor_trace(mod, inputs):
94
95 mod.eval()
96
97 def f(*inp):
98 return mod(*inp)
99
100 mod = make_fx(functionalize(f))(*inputs)
101
102 # Remove const operation. For ex, nn.Linear has transpose operation on weight
103 mod.graph.eliminate_dead_code()
104 mod = run_const_fold(mod)
105 mod = replace_op_with_indices(mod)
106 return mod
107
[end of py/torch_tensorrt/fx/utils.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/py/torch_tensorrt/fx/tracer/dispatch_tracer/aten_tracer.py b/py/torch_tensorrt/fx/tracer/dispatch_tracer/aten_tracer.py
--- a/py/torch_tensorrt/fx/tracer/dispatch_tracer/aten_tracer.py
+++ b/py/torch_tensorrt/fx/tracer/dispatch_tracer/aten_tracer.py
@@ -9,7 +9,7 @@
import torch._dynamo as torchdynamo
from torch.fx.passes.infra.pass_base import PassResult
-
+from torch_tensorrt.fx.utils import req_torch_version
from torch_tensorrt.fx.passes.lower_basic_pass_aten import (
compose_bmm,
compose_chunk,
@@ -91,6 +91,7 @@
sys.setrecursionlimit(default)
+@req_torch_version("2.0")
def dynamo_trace(
f: Callable[..., Value],
# pyre-ignore
@@ -104,11 +105,6 @@
this config option alltogether. For now, it helps with quick
experiments with playing around with TorchDynamo
"""
- if torch.__version__.startswith("1"):
- raise ValueError(
- f"The aten tracer requires Torch version >= 2.0. Detected version {torch.__version__}"
- )
-
if dynamo_config is None:
dynamo_config = DynamoConfig()
with using_config(dynamo_config), setting_python_recursive_limit(2000):
@@ -131,11 +127,13 @@
) from exc
+@req_torch_version("2.0")
def trace(f, args, *rest):
graph_module, guards = dynamo_trace(f, args, True, "symbolic")
return graph_module, guards
+@req_torch_version("2.0")
def opt_trace(f, args, *rest):
"""
Optimized trace with necessary passes which re-compose some ops or replace some ops
diff --git a/py/torch_tensorrt/fx/utils.py b/py/torch_tensorrt/fx/utils.py
--- a/py/torch_tensorrt/fx/utils.py
+++ b/py/torch_tensorrt/fx/utils.py
@@ -1,5 +1,6 @@
from enum import Enum
-from typing import List
+from typing import List, Callable
+from packaging import version
# @manual=//deeplearning/trt/python:py_tensorrt
import tensorrt as trt
@@ -104,3 +105,36 @@
mod = run_const_fold(mod)
mod = replace_op_with_indices(mod)
return mod
+
+
+def req_torch_version(min_torch_version: str = "2.dev"):
+ """
+ Create a decorator which verifies the Torch version installed
+ against a specified version range
+
+ Args:
+ min_torch_version (str): The minimum required Torch version
+ for the decorated function to work properly
+
+ Returns:
+ A decorator which raises a descriptive error message if
+ an unsupported Torch version is used
+ """
+
+ def nested_decorator(f: Callable):
+ def function_wrapper(*args, **kwargs):
+ # Parse minimum and current Torch versions
+ min_version = version.parse(min_torch_version)
+ current_version = version.parse(torch.__version__)
+
+ if current_version < min_version:
+ raise AssertionError(
+ f"Expected Torch version {min_torch_version} or greater, "
+ + f"when calling {f}. Detected version {torch.__version__}"
+ )
+ else:
+ return f(*args, **kwargs)
+
+ return function_wrapper
+
+ return nested_decorator
|
{"golden_diff": "diff --git a/py/torch_tensorrt/fx/tracer/dispatch_tracer/aten_tracer.py b/py/torch_tensorrt/fx/tracer/dispatch_tracer/aten_tracer.py\n--- a/py/torch_tensorrt/fx/tracer/dispatch_tracer/aten_tracer.py\n+++ b/py/torch_tensorrt/fx/tracer/dispatch_tracer/aten_tracer.py\n@@ -9,7 +9,7 @@\n import torch._dynamo as torchdynamo\n \n from torch.fx.passes.infra.pass_base import PassResult\n-\n+from torch_tensorrt.fx.utils import req_torch_version\n from torch_tensorrt.fx.passes.lower_basic_pass_aten import (\n compose_bmm,\n compose_chunk,\n@@ -91,6 +91,7 @@\n sys.setrecursionlimit(default)\n \n \n+@req_torch_version(\"2.0\")\n def dynamo_trace(\n f: Callable[..., Value],\n # pyre-ignore\n@@ -104,11 +105,6 @@\n this config option alltogether. For now, it helps with quick\n experiments with playing around with TorchDynamo\n \"\"\"\n- if torch.__version__.startswith(\"1\"):\n- raise ValueError(\n- f\"The aten tracer requires Torch version >= 2.0. Detected version {torch.__version__}\"\n- )\n-\n if dynamo_config is None:\n dynamo_config = DynamoConfig()\n with using_config(dynamo_config), setting_python_recursive_limit(2000):\n@@ -131,11 +127,13 @@\n ) from exc\n \n \n+@req_torch_version(\"2.0\")\n def trace(f, args, *rest):\n graph_module, guards = dynamo_trace(f, args, True, \"symbolic\")\n return graph_module, guards\n \n \n+@req_torch_version(\"2.0\")\n def opt_trace(f, args, *rest):\n \"\"\"\n Optimized trace with necessary passes which re-compose some ops or replace some ops\ndiff --git a/py/torch_tensorrt/fx/utils.py b/py/torch_tensorrt/fx/utils.py\n--- a/py/torch_tensorrt/fx/utils.py\n+++ b/py/torch_tensorrt/fx/utils.py\n@@ -1,5 +1,6 @@\n from enum import Enum\n-from typing import List\n+from typing import List, Callable\n+from packaging import version\n \n # @manual=//deeplearning/trt/python:py_tensorrt\n import tensorrt as trt\n@@ -104,3 +105,36 @@\n mod = run_const_fold(mod)\n mod = replace_op_with_indices(mod)\n return mod\n+\n+\n+def req_torch_version(min_torch_version: str = \"2.dev\"):\n+ \"\"\"\n+ Create a decorator which verifies the Torch version installed\n+ against a specified version range\n+\n+ Args:\n+ min_torch_version (str): The minimum required Torch version\n+ for the decorated function to work properly\n+\n+ Returns:\n+ A decorator which raises a descriptive error message if\n+ an unsupported Torch version is used\n+ \"\"\"\n+\n+ def nested_decorator(f: Callable):\n+ def function_wrapper(*args, **kwargs):\n+ # Parse minimum and current Torch versions\n+ min_version = version.parse(min_torch_version)\n+ current_version = version.parse(torch.__version__)\n+\n+ if current_version < min_version:\n+ raise AssertionError(\n+ f\"Expected Torch version {min_torch_version} or greater, \"\n+ + f\"when calling {f}. Detected version {torch.__version__}\"\n+ )\n+ else:\n+ return f(*args, **kwargs)\n+\n+ return function_wrapper\n+\n+ return nested_decorator\n", "issue": "\u2728[Feature] Create Decorator for Python functions Incompatible with Legacy Torch Versions\n## Context\r\nSome functions in the code base are incompatible with certain versions of Torch such as 1.13.1. Adding a general-purpose utility decorator which detects whether the Torch version is incompatible with certain key functions could be helpful in notifying the user when such mismatches occur.\r\n\r\n## Desired Solution\r\nA decorator of the form:\r\n```python\r\n@req_torch_version(2)\r\ndef f(...):\r\n```\r\nThis decorator would throw a clear error when the detected Torch version differs from that required to use the decorated function.\r\n\r\n## Temporary Alternative\r\nA temporary alternative, which is already in use in PR #1731, is to add logic to each function with compatibility issues, raising an error if any versioning issues are detected. While this is a functional solution, it is difficult to scale and can lead to repetitive code.\r\n\r\n## Additional Context\r\nCertain imports are also not compatible across Torch versions (as in `import torchdynamo` in Torch 1.13 versus `import torch._dynamo` in 2.0). To resolve this issue, the imports can be moved inside the functions using them so as to encapsulate all version-specific code within one area.\n", "before_files": [{"content": "import copy\nimport sys\nfrom contextlib import contextmanager\nfrom typing import Any, Callable, Dict, Generator, List, Optional, Set, Tuple, Union\n\nimport torch\n\nif not torch.__version__.startswith(\"1\"):\n import torch._dynamo as torchdynamo\n\nfrom torch.fx.passes.infra.pass_base import PassResult\n\nfrom torch_tensorrt.fx.passes.lower_basic_pass_aten import (\n compose_bmm,\n compose_chunk,\n compose_getitem_slice,\n remove_ops,\n replace_aten_op_with_indices,\n replace_aten_reshape_alias_with_replace,\n replace_builtin_ops,\n replace_inplace_ops,\n replace_native_layernorm_with_layernorm,\n replace_transpose_mm_op_with_linear,\n run_const_fold,\n)\nfrom typing_extensions import TypeAlias\n\nValue: TypeAlias = Union[\n Tuple[\"Value\", ...],\n List[\"Value\"],\n Dict[str, \"Value\"],\n]\n\n\nclass DynamoConfig:\n \"\"\"\n Manage Exir-specific configurations of Dynamo.\n \"\"\"\n\n def __init__(\n self,\n capture_scalar_outputs: bool = True,\n guard_nn_modules: bool = True,\n dynamic_shapes: bool = True,\n specialize_int_float: bool = True,\n verbose: bool = True,\n ) -> None:\n\n self.capture_scalar_outputs = capture_scalar_outputs\n self.guard_nn_modules = guard_nn_modules\n self.dynamic_shapes = dynamic_shapes\n self.specialize_int_float = specialize_int_float\n self.verbose = verbose\n\n def activate(self) -> None:\n torchdynamo.config.capture_scalar_outputs = self.capture_scalar_outputs\n torchdynamo.config.guard_nn_modules = self.guard_nn_modules\n torchdynamo.config.dynamic_shapes = self.dynamic_shapes\n torchdynamo.config.specialize_int_float = self.specialize_int_float\n torchdynamo.config.verbose = self.verbose\n\n def deactivate(self) -> None:\n torchdynamo.config.capture_scalar_outputs = True\n torchdynamo.config.guard_nn_modules = True\n torchdynamo.config.dynamic_shapes = True\n torchdynamo.config.specialize_int_float = True\n torchdynamo.config.verbose = True\n\n\n@contextmanager\ndef using_config(config: DynamoConfig) -> Generator[DynamoConfig, None, None]:\n config.activate()\n try:\n yield config\n finally:\n config.deactivate()\n\n\n@contextmanager\ndef setting_python_recursive_limit(limit: int = 10000) -> Generator[None, None, None]:\n \"\"\"\n Temporarily increase the python interpreter stack recursion limit.\n This is mostly used for pickling large scale modules.\n \"\"\"\n default = sys.getrecursionlimit()\n if limit > default:\n sys.setrecursionlimit(limit)\n try:\n yield\n finally:\n sys.setrecursionlimit(default)\n\n\ndef dynamo_trace(\n f: Callable[..., Value],\n # pyre-ignore\n args: Tuple[Any, ...],\n aten_graph: bool,\n tracing_mode: str = \"real\",\n dynamo_config: Optional[DynamoConfig] = None,\n) -> Tuple[torch.fx.GraphModule, Set]:\n \"\"\"\n TODO: Once we fully migrate to torchdynamo frontend, we will remove\n this config option alltogether. For now, it helps with quick\n experiments with playing around with TorchDynamo\n \"\"\"\n if torch.__version__.startswith(\"1\"):\n raise ValueError(\n f\"The aten tracer requires Torch version >= 2.0. Detected version {torch.__version__}\"\n )\n\n if dynamo_config is None:\n dynamo_config = DynamoConfig()\n with using_config(dynamo_config), setting_python_recursive_limit(2000):\n torchdynamo.reset()\n try:\n return torchdynamo.export(\n f,\n *copy.deepcopy(args),\n aten_graph=aten_graph,\n tracing_mode=tracing_mode,\n )\n except torchdynamo.exc.Unsupported as exc:\n raise RuntimeError(\n \"The user code is using a feature we don't support. \"\n \"Please try torchdynamo.explain() to get possible the reasons\",\n ) from exc\n except Exception as exc:\n raise RuntimeError(\n \"torchdynamo internal error occured. Please see above stacktrace\"\n ) from exc\n\n\ndef trace(f, args, *rest):\n graph_module, guards = dynamo_trace(f, args, True, \"symbolic\")\n return graph_module, guards\n\n\ndef opt_trace(f, args, *rest):\n \"\"\"\n Optimized trace with necessary passes which re-compose some ops or replace some ops\n These passes should be general and functional purpose\n \"\"\"\n passes_list = [\n compose_bmm,\n compose_chunk,\n compose_getitem_slice,\n replace_aten_reshape_alias_with_replace,\n replace_aten_op_with_indices,\n replace_transpose_mm_op_with_linear, # after compose_bmm\n replace_native_layernorm_with_layernorm,\n remove_ops,\n replace_builtin_ops, # after replace_native_layernorm_with_layernorm\n replace_inplace_ops, # remove it once functionalization is enabled\n ]\n\n fx_module, _ = trace(f, args)\n print(fx_module.graph)\n for passes in passes_list:\n pr: PassResult = passes(fx_module)\n fx_module = pr.graph_module\n\n fx_module(*args)\n\n fx_module = run_const_fold(fx_module)\n print(fx_module.graph)\n return fx_module\n", "path": "py/torch_tensorrt/fx/tracer/dispatch_tracer/aten_tracer.py"}, {"content": "from enum import Enum\nfrom typing import List\n\n# @manual=//deeplearning/trt/python:py_tensorrt\nimport tensorrt as trt\nimport torch\nfrom functorch import make_fx\nfrom functorch.experimental import functionalize\nfrom torch_tensorrt.fx.passes.lower_basic_pass import (\n replace_op_with_indices,\n run_const_fold,\n)\n\nfrom .types import Shape, TRTDataType\n\n\nclass LowerPrecision(Enum):\n FP32 = \"fp32\"\n FP16 = \"fp16\"\n INT8 = \"int8\"\n\n\ndef torch_dtype_to_trt(dtype: torch.dtype) -> TRTDataType:\n \"\"\"\n Convert PyTorch data types to TensorRT data types.\n\n Args:\n dtype (torch.dtype): A PyTorch data type.\n\n Returns:\n The equivalent TensorRT data type.\n \"\"\"\n if trt.__version__ >= \"7.0\" and dtype == torch.bool:\n return trt.bool\n elif dtype == torch.int8:\n return trt.int8\n elif dtype == torch.int32:\n return trt.int32\n elif dtype == torch.float16:\n return trt.float16\n elif dtype == torch.float32:\n return trt.float32\n else:\n raise TypeError(\"%s is not supported by tensorrt\" % dtype)\n\n\ndef torch_dtype_from_trt(dtype: TRTDataType) -> torch.dtype:\n \"\"\"\n Convert TensorRT data types to PyTorch data types.\n\n Args:\n dtype (TRTDataType): A TensorRT data type.\n\n Returns:\n The equivalent PyTorch data type.\n \"\"\"\n if dtype == trt.int8:\n return torch.int8\n elif trt.__version__ >= \"7.0\" and dtype == trt.bool:\n return torch.bool\n elif dtype == trt.int32:\n return torch.int32\n elif dtype == trt.float16:\n return torch.float16\n elif dtype == trt.float32:\n return torch.float32\n else:\n raise TypeError(\"%s is not supported by torch\" % dtype)\n\n\ndef get_dynamic_dims(shape: Shape) -> List[int]:\n \"\"\"\n This function finds the dynamic dimensions in the given\n shape. A dimension is dynamic if it's -1.\n\n Args:\n shape (Shape): A sequence of integer that represents\n the shape of a tensor.\n\n Returns:\n A list of integers contains all the dynamic dimensions\n in the given shape\n \"\"\"\n dynamic_dims = []\n\n for i, s in enumerate(shape):\n if s == -1:\n dynamic_dims.append(i)\n\n return dynamic_dims\n\n\ndef proxytensor_trace(mod, inputs):\n\n mod.eval()\n\n def f(*inp):\n return mod(*inp)\n\n mod = make_fx(functionalize(f))(*inputs)\n\n # Remove const operation. For ex, nn.Linear has transpose operation on weight\n mod.graph.eliminate_dead_code()\n mod = run_const_fold(mod)\n mod = replace_op_with_indices(mod)\n return mod\n", "path": "py/torch_tensorrt/fx/utils.py"}]}
| 3,306 | 813 |
gh_patches_debug_1266
|
rasdani/github-patches
|
git_diff
|
aio-libs-abandoned__aioredis-py-1048
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[2.0] Type annotations break mypy
I tried porting an existing project to aioredis 2.0. I've got it almost working, but the type annotations that have been added are too strict (and in some cases just wrong) and break mypy. The main problem is that all the functions that take keys annotate them as `str`, when `bytes` (and I think several other types) are perfectly acceptable and are used in my code. The same applies to `register_script`.
The `min` and `max` arguments of `zrangebylex` and `zrevrangebylex` are annotated as int, but they're used for lexicographical sorting so are string-like.
Getting the type annotations right is a fair large undertaking. If there is a desire to release 2.0 soon I'd suggest deleting `py.typed` so that mypy doesn't see this package as annotated. There are annotations for redis-py in typeshed; perhaps that would be a good place to start, although I've occasionally also had issues there.
</issue>
<code>
[start of setup.py]
1 import os.path
2 import re
3
4 from setuptools import find_packages, setup
5
6
7 def read(*parts):
8 with open(os.path.join(*parts)) as f:
9 return f.read().strip()
10
11
12 def read_version():
13 regexp = re.compile(r"^__version__\W*=\W*\"([\d.abrc]+)\"")
14 init_py = os.path.join(os.path.dirname(__file__), "aioredis", "__init__.py")
15 with open(init_py) as f:
16 for line in f:
17 match = regexp.match(line)
18 if match is not None:
19 return match.group(1)
20 raise RuntimeError(f"Cannot find version in {init_py}")
21
22
23 classifiers = [
24 "License :: OSI Approved :: MIT License",
25 "Development Status :: 4 - Beta",
26 "Programming Language :: Python",
27 "Programming Language :: Python :: 3",
28 "Programming Language :: Python :: 3.6",
29 "Programming Language :: Python :: 3.7",
30 "Programming Language :: Python :: 3 :: Only",
31 "Operating System :: POSIX",
32 "Environment :: Web Environment",
33 "Intended Audience :: Developers",
34 "Topic :: Software Development",
35 "Topic :: Software Development :: Libraries",
36 "Framework :: AsyncIO",
37 ]
38
39 setup(
40 name="aioredis",
41 version=read_version(),
42 description="asyncio (PEP 3156) Redis support",
43 long_description="\n\n".join((read("README.md"), read("CHANGELOG.md"))),
44 long_description_content_type="text/markdown",
45 classifiers=classifiers,
46 platforms=["POSIX"],
47 url="https://github.com/aio-libs/aioredis",
48 license="MIT",
49 packages=find_packages(exclude=["tests"]),
50 install_requires=[
51 "async-timeout",
52 "typing-extensions",
53 ],
54 extras_require={
55 "hiredis": 'hiredis>=1.0; implementation_name=="cpython"',
56 },
57 python_requires=">=3.6",
58 include_package_data=True,
59 )
60
[end of setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -54,6 +54,7 @@
extras_require={
"hiredis": 'hiredis>=1.0; implementation_name=="cpython"',
},
+ package_data={"aioredis": ["py.typed"]},
python_requires=">=3.6",
include_package_data=True,
)
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -54,6 +54,7 @@\n extras_require={\n \"hiredis\": 'hiredis>=1.0; implementation_name==\"cpython\"',\n },\n+ package_data={\"aioredis\": [\"py.typed\"]},\n python_requires=\">=3.6\",\n include_package_data=True,\n )\n", "issue": "[2.0] Type annotations break mypy\nI tried porting an existing project to aioredis 2.0. I've got it almost working, but the type annotations that have been added are too strict (and in some cases just wrong) and break mypy. The main problem is that all the functions that take keys annotate them as `str`, when `bytes` (and I think several other types) are perfectly acceptable and are used in my code. The same applies to `register_script`.\r\n\r\nThe `min` and `max` arguments of `zrangebylex` and `zrevrangebylex` are annotated as int, but they're used for lexicographical sorting so are string-like.\r\n\r\nGetting the type annotations right is a fair large undertaking. If there is a desire to release 2.0 soon I'd suggest deleting `py.typed` so that mypy doesn't see this package as annotated. There are annotations for redis-py in typeshed; perhaps that would be a good place to start, although I've occasionally also had issues there.\n", "before_files": [{"content": "import os.path\nimport re\n\nfrom setuptools import find_packages, setup\n\n\ndef read(*parts):\n with open(os.path.join(*parts)) as f:\n return f.read().strip()\n\n\ndef read_version():\n regexp = re.compile(r\"^__version__\\W*=\\W*\\\"([\\d.abrc]+)\\\"\")\n init_py = os.path.join(os.path.dirname(__file__), \"aioredis\", \"__init__.py\")\n with open(init_py) as f:\n for line in f:\n match = regexp.match(line)\n if match is not None:\n return match.group(1)\n raise RuntimeError(f\"Cannot find version in {init_py}\")\n\n\nclassifiers = [\n \"License :: OSI Approved :: MIT License\",\n \"Development Status :: 4 - Beta\",\n \"Programming Language :: Python\",\n \"Programming Language :: Python :: 3\",\n \"Programming Language :: Python :: 3.6\",\n \"Programming Language :: Python :: 3.7\",\n \"Programming Language :: Python :: 3 :: Only\",\n \"Operating System :: POSIX\",\n \"Environment :: Web Environment\",\n \"Intended Audience :: Developers\",\n \"Topic :: Software Development\",\n \"Topic :: Software Development :: Libraries\",\n \"Framework :: AsyncIO\",\n]\n\nsetup(\n name=\"aioredis\",\n version=read_version(),\n description=\"asyncio (PEP 3156) Redis support\",\n long_description=\"\\n\\n\".join((read(\"README.md\"), read(\"CHANGELOG.md\"))),\n long_description_content_type=\"text/markdown\",\n classifiers=classifiers,\n platforms=[\"POSIX\"],\n url=\"https://github.com/aio-libs/aioredis\",\n license=\"MIT\",\n packages=find_packages(exclude=[\"tests\"]),\n install_requires=[\n \"async-timeout\",\n \"typing-extensions\",\n ],\n extras_require={\n \"hiredis\": 'hiredis>=1.0; implementation_name==\"cpython\"',\n },\n python_requires=\">=3.6\",\n include_package_data=True,\n)\n", "path": "setup.py"}]}
| 1,300 | 90 |
gh_patches_debug_9756
|
rasdani/github-patches
|
git_diff
|
facebookresearch__fairscale-210
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
an error importing AMP in fairscale when using a Pytorch version less than 1.6
## 🐛 Bug
<!-- A clear and concise description of what the bug is. -->
## Command
## To Reproduce
<img width="737" alt="Screenshot 2020-11-23 at 08 21 28" src="https://user-images.githubusercontent.com/12861981/99949945-c2f11300-2d73-11eb-87f2-17a02e64da75.png">
Steps to reproduce the behavior:
<!-- If you were running a command, post the exact command that you were running -->
1.
2.
3.
<!-- If you have a code sample, error messages, stack traces, please provide it here as well -->
## Expected behavior
<!-- A clear and concise description of what you expected to happen. -->
## Environment
Please copy and paste the output from the
environment collection script from PyTorch
(or fill out the checklist below manually).
You can run the script with:
```
# For security purposes, please check the contents of collect_env.py before running it.
python -m torch.utils.collect_env
```
- PyTorch Version (e.g., 1.0):
- OS (e.g., Linux):
- How you installed PyTorch (`conda`, `pip`, source):
- Build command you used (if compiling from source):
- Python version:
- CUDA/cuDNN version:
- GPU models and configuration:
- Any other relevant information:
## Additional context
<!-- Add any other context about the problem here. -->
</issue>
<code>
[start of fairscale/optim/__init__.py]
1 # Copyright (c) Facebook, Inc. and its affiliates. All rights reserved.
2 #
3 # This source code is licensed under the BSD license found in the
4 # LICENSE file in the root directory of this source tree.
5
6 """
7 :mod:`fairscale.optim` is a package implementing various torch optimization algorithms.
8 """
9
10 try:
11 from .adam import Adam, Precision
12 except ImportError: # pragma: no cover
13 pass # pragma: no cover
14 from .adascale import AdaScale
15 from .grad_scaler import GradScaler
16 from .oss import OSS
17
[end of fairscale/optim/__init__.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/fairscale/optim/__init__.py b/fairscale/optim/__init__.py
--- a/fairscale/optim/__init__.py
+++ b/fairscale/optim/__init__.py
@@ -6,11 +6,16 @@
"""
:mod:`fairscale.optim` is a package implementing various torch optimization algorithms.
"""
+import logging
+
+from .adascale import AdaScale
+from .oss import OSS
try:
from .adam import Adam, Precision
except ImportError: # pragma: no cover
pass # pragma: no cover
-from .adascale import AdaScale
-from .grad_scaler import GradScaler
-from .oss import OSS
+try:
+ from .grad_scaler import GradScaler
+except ImportError:
+ logging.warning("Torch AMP is not available on this platform")
|
{"golden_diff": "diff --git a/fairscale/optim/__init__.py b/fairscale/optim/__init__.py\n--- a/fairscale/optim/__init__.py\n+++ b/fairscale/optim/__init__.py\n@@ -6,11 +6,16 @@\n \"\"\"\n :mod:`fairscale.optim` is a package implementing various torch optimization algorithms.\n \"\"\"\n+import logging\n+\n+from .adascale import AdaScale\n+from .oss import OSS\n \n try:\n from .adam import Adam, Precision\n except ImportError: # pragma: no cover\n pass # pragma: no cover\n-from .adascale import AdaScale\n-from .grad_scaler import GradScaler\n-from .oss import OSS\n+try:\n+ from .grad_scaler import GradScaler\n+except ImportError:\n+ logging.warning(\"Torch AMP is not available on this platform\")\n", "issue": "an error importing AMP in fairscale when using a Pytorch version less than 1.6\n## \ud83d\udc1b Bug\r\n\r\n<!-- A clear and concise description of what the bug is. -->\r\n\r\n## Command\r\n\r\n## To Reproduce\r\n\r\n<img width=\"737\" alt=\"Screenshot 2020-11-23 at 08 21 28\" src=\"https://user-images.githubusercontent.com/12861981/99949945-c2f11300-2d73-11eb-87f2-17a02e64da75.png\">\r\n\r\n\r\nSteps to reproduce the behavior:\r\n\r\n<!-- If you were running a command, post the exact command that you were running -->\r\n\r\n1.\r\n2.\r\n3.\r\n\r\n<!-- If you have a code sample, error messages, stack traces, please provide it here as well -->\r\n\r\n## Expected behavior\r\n\r\n<!-- A clear and concise description of what you expected to happen. -->\r\n\r\n## Environment\r\n\r\nPlease copy and paste the output from the\r\nenvironment collection script from PyTorch\r\n(or fill out the checklist below manually).\r\n\r\nYou can run the script with:\r\n```\r\n# For security purposes, please check the contents of collect_env.py before running it.\r\npython -m torch.utils.collect_env\r\n```\r\n\r\n - PyTorch Version (e.g., 1.0):\r\n - OS (e.g., Linux):\r\n - How you installed PyTorch (`conda`, `pip`, source):\r\n - Build command you used (if compiling from source):\r\n - Python version:\r\n - CUDA/cuDNN version:\r\n - GPU models and configuration:\r\n - Any other relevant information:\r\n\r\n## Additional context\r\n\r\n<!-- Add any other context about the problem here. -->\r\n\n", "before_files": [{"content": "# Copyright (c) Facebook, Inc. and its affiliates. All rights reserved.\n#\n# This source code is licensed under the BSD license found in the\n# LICENSE file in the root directory of this source tree.\n\n\"\"\"\n:mod:`fairscale.optim` is a package implementing various torch optimization algorithms.\n\"\"\"\n\ntry:\n from .adam import Adam, Precision\nexcept ImportError: # pragma: no cover\n pass # pragma: no cover\nfrom .adascale import AdaScale\nfrom .grad_scaler import GradScaler\nfrom .oss import OSS\n", "path": "fairscale/optim/__init__.py"}]}
| 1,050 | 186 |
gh_patches_debug_25635
|
rasdani/github-patches
|
git_diff
|
DDMAL__CantusDB-706
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
`/articles` has different url and does not show article previews
On OldCantus, `/news` is a valid url and returns a page showing a list of articles with titles and article details/previews.
On NewCantus, `/news` (http://206.12.88.113/news) returns a 404Error and the resulting list of articles at `/articles` does not contain previews of article contents.
Additionally, the page on OldCantus paginates the list of articles, while on NewCantus it does not (very possible it has this behaviour programmed but just doesn't have enough articles...)
OldCantus:
<img width="960" alt="image" src="https://github.com/DDMAL/CantusDB/assets/11023634/153c9a31-5ea1-4e8a-a646-cde3bd7982f7">
NewCantus:
<img width="923" alt="image" src="https://github.com/DDMAL/CantusDB/assets/11023634/0b59df5a-b195-49d1-9c77-6cb920f23958">
</issue>
<code>
[start of django/cantusdb_project/articles/urls.py]
1 from django.urls import path
2 from articles.views import ArticleDetailView
3 from articles.views import ArticleListView
4
5 urlpatterns = [
6 path("articles/", ArticleListView.as_view(), name="article-list"),
7 path("article/<int:pk>", ArticleDetailView.as_view(), name="article-detail"),
8 ]
9
[end of django/cantusdb_project/articles/urls.py]
[start of django/cantusdb_project/articles/views.py]
1 from django.shortcuts import render
2 from django.views.generic import DetailView, ListView
3 from articles.models import Article
4
5
6 class ArticleDetailView(DetailView):
7 model = Article
8 context_object_name = "article"
9 template_name = "article_detail.html"
10
11
12 class ArticleListView(ListView):
13 model = Article
14 queryset = Article.objects.order_by("-date_created")
15 paginate_by = 100
16 context_object_name = "articles"
17 template_name = "article_list.html"
18
[end of django/cantusdb_project/articles/views.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/django/cantusdb_project/articles/urls.py b/django/cantusdb_project/articles/urls.py
--- a/django/cantusdb_project/articles/urls.py
+++ b/django/cantusdb_project/articles/urls.py
@@ -1,8 +1,12 @@
from django.urls import path
-from articles.views import ArticleDetailView
-from articles.views import ArticleListView
+from articles.views import (
+ ArticleDetailView,
+ ArticleListView,
+ article_list_redirect_from_old_path,
+)
urlpatterns = [
path("articles/", ArticleListView.as_view(), name="article-list"),
path("article/<int:pk>", ArticleDetailView.as_view(), name="article-detail"),
+ path("news/", article_list_redirect_from_old_path),
]
diff --git a/django/cantusdb_project/articles/views.py b/django/cantusdb_project/articles/views.py
--- a/django/cantusdb_project/articles/views.py
+++ b/django/cantusdb_project/articles/views.py
@@ -1,4 +1,5 @@
-from django.shortcuts import render
+from django.shortcuts import render, redirect
+from django.urls.base import reverse
from django.views.generic import DetailView, ListView
from articles.models import Article
@@ -12,6 +13,10 @@
class ArticleListView(ListView):
model = Article
queryset = Article.objects.order_by("-date_created")
- paginate_by = 100
+ paginate_by = 10
context_object_name = "articles"
template_name = "article_list.html"
+
+
+def article_list_redirect_from_old_path(request):
+ return redirect(reverse("article-list"))
|
{"golden_diff": "diff --git a/django/cantusdb_project/articles/urls.py b/django/cantusdb_project/articles/urls.py\n--- a/django/cantusdb_project/articles/urls.py\n+++ b/django/cantusdb_project/articles/urls.py\n@@ -1,8 +1,12 @@\n from django.urls import path\n-from articles.views import ArticleDetailView\n-from articles.views import ArticleListView\n+from articles.views import (\n+ ArticleDetailView,\n+ ArticleListView,\n+ article_list_redirect_from_old_path,\n+)\n \n urlpatterns = [\n path(\"articles/\", ArticleListView.as_view(), name=\"article-list\"),\n path(\"article/<int:pk>\", ArticleDetailView.as_view(), name=\"article-detail\"),\n+ path(\"news/\", article_list_redirect_from_old_path),\n ]\ndiff --git a/django/cantusdb_project/articles/views.py b/django/cantusdb_project/articles/views.py\n--- a/django/cantusdb_project/articles/views.py\n+++ b/django/cantusdb_project/articles/views.py\n@@ -1,4 +1,5 @@\n-from django.shortcuts import render\n+from django.shortcuts import render, redirect\n+from django.urls.base import reverse\n from django.views.generic import DetailView, ListView\n from articles.models import Article\n \n@@ -12,6 +13,10 @@\n class ArticleListView(ListView):\n model = Article\n queryset = Article.objects.order_by(\"-date_created\")\n- paginate_by = 100\n+ paginate_by = 10\n context_object_name = \"articles\"\n template_name = \"article_list.html\"\n+\n+\n+def article_list_redirect_from_old_path(request):\n+ return redirect(reverse(\"article-list\"))\n", "issue": "`/articles` has different url and does not show article previews\nOn OldCantus, `/news` is a valid url and returns a page showing a list of articles with titles and article details/previews.\r\n\r\nOn NewCantus, `/news` (http://206.12.88.113/news) returns a 404Error and the resulting list of articles at `/articles` does not contain previews of article contents. \r\n\r\nAdditionally, the page on OldCantus paginates the list of articles, while on NewCantus it does not (very possible it has this behaviour programmed but just doesn't have enough articles...)\r\n\r\nOldCantus:\r\n<img width=\"960\" alt=\"image\" src=\"https://github.com/DDMAL/CantusDB/assets/11023634/153c9a31-5ea1-4e8a-a646-cde3bd7982f7\">\r\n\r\n\r\nNewCantus:\r\n\r\n<img width=\"923\" alt=\"image\" src=\"https://github.com/DDMAL/CantusDB/assets/11023634/0b59df5a-b195-49d1-9c77-6cb920f23958\">\r\n\r\n\n", "before_files": [{"content": "from django.urls import path\nfrom articles.views import ArticleDetailView\nfrom articles.views import ArticleListView\n\nurlpatterns = [\n path(\"articles/\", ArticleListView.as_view(), name=\"article-list\"),\n path(\"article/<int:pk>\", ArticleDetailView.as_view(), name=\"article-detail\"),\n]\n", "path": "django/cantusdb_project/articles/urls.py"}, {"content": "from django.shortcuts import render\nfrom django.views.generic import DetailView, ListView\nfrom articles.models import Article\n\n\nclass ArticleDetailView(DetailView):\n model = Article\n context_object_name = \"article\"\n template_name = \"article_detail.html\"\n\n\nclass ArticleListView(ListView):\n model = Article\n queryset = Article.objects.order_by(\"-date_created\")\n paginate_by = 100\n context_object_name = \"articles\"\n template_name = \"article_list.html\"\n", "path": "django/cantusdb_project/articles/views.py"}]}
| 1,054 | 358 |
gh_patches_debug_12375
|
rasdani/github-patches
|
git_diff
|
pytorch__vision-6095
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
`Tensor.to` does not work with feature as reference
`torch.Tensor.to` accepts a tensor reference object as input in which case it converts to the reference dtype and device:
```py
>>> a = torch.zeros((), dtype=torch.float)
>>> b = torch.ones((), dtype=torch.int)
>>> b
tensor(1, dtype=torch.int32)
>>> b.to(a)
tensor(1.)
```
This also works for our custom features:
```py
>>> data = torch.rand(3, 2, 2)
>>> image = features.Image(data.to(torch.float64))
>>> image
Image([[[0.9595, 0.0947],
[0.9553, 0.5563]],
[[0.5435, 0.2975],
[0.3037, 0.0863]],
[[0.6253, 0.3481],
[0.3518, 0.4499]]], dtype=torch.float64)
>>> image.to(torch.float32)
Image([[[0.9595, 0.0947],
[0.9553, 0.5563]],
[[0.5435, 0.2975],
[0.3037, 0.0863]],
[[0.6253, 0.3481],
[0.3518, 0.4499]]])
>>> image.to(data)
Image([[[0.9595, 0.0947],
[0.9553, 0.5563]],
[[0.5435, 0.2975],
[0.3037, 0.0863]],
[[0.6253, 0.3481],
[0.3518, 0.4499]]])
```
However, it doesn't work if we want to convert a plain tensor and use a custom feature as reference:
```py
>>> data.to(image)
AttributeError: 'Tensor' object has no attribute 'color_space'
```
cc @bjuncek @pmeier
</issue>
<code>
[start of torchvision/prototype/features/_feature.py]
1 from __future__ import annotations
2
3 from types import ModuleType
4 from typing import Any, Callable, cast, List, Mapping, Optional, Sequence, Tuple, Type, TypeVar, Union
5
6 import PIL.Image
7 import torch
8 from torch._C import _TensorBase, DisableTorchFunction
9 from torchvision.transforms import InterpolationMode
10
11 F = TypeVar("F", bound="_Feature")
12 FillType = Union[int, float, Sequence[int], Sequence[float], None]
13 FillTypeJIT = Union[int, float, List[float], None]
14
15
16 def is_simple_tensor(inpt: Any) -> bool:
17 return isinstance(inpt, torch.Tensor) and not isinstance(inpt, _Feature)
18
19
20 class _Feature(torch.Tensor):
21 __F: Optional[ModuleType] = None
22
23 def __new__(
24 cls: Type[F],
25 data: Any,
26 *,
27 dtype: Optional[torch.dtype] = None,
28 device: Optional[Union[torch.device, str, int]] = None,
29 requires_grad: bool = False,
30 ) -> F:
31 return cast(
32 F,
33 torch.Tensor._make_subclass(
34 cast(_TensorBase, cls),
35 torch.as_tensor(data, dtype=dtype, device=device), # type: ignore[arg-type]
36 requires_grad,
37 ),
38 )
39
40 @classmethod
41 def new_like(
42 cls: Type[F],
43 other: F,
44 data: Any,
45 *,
46 dtype: Optional[torch.dtype] = None,
47 device: Optional[Union[torch.device, str, int]] = None,
48 requires_grad: Optional[bool] = None,
49 **kwargs: Any,
50 ) -> F:
51 return cls(
52 data,
53 dtype=dtype if dtype is not None else other.dtype,
54 device=device if device is not None else other.device,
55 requires_grad=requires_grad if requires_grad is not None else other.requires_grad,
56 **kwargs,
57 )
58
59 @classmethod
60 def __torch_function__(
61 cls,
62 func: Callable[..., torch.Tensor],
63 types: Tuple[Type[torch.Tensor], ...],
64 args: Sequence[Any] = (),
65 kwargs: Optional[Mapping[str, Any]] = None,
66 ) -> torch.Tensor:
67 """For general information about how the __torch_function__ protocol works,
68 see https://pytorch.org/docs/stable/notes/extending.html#extending-torch
69
70 TL;DR: Every time a PyTorch operator is called, it goes through the inputs and looks for the
71 ``__torch_function__`` method. If one is found, it is invoked with the operator as ``func`` as well as the
72 ``args`` and ``kwargs`` of the original call.
73
74 The default behavior of :class:`~torch.Tensor`'s is to retain a custom tensor type. For the :class:`Feature`
75 use case, this has two downsides:
76
77 1. Since some :class:`Feature`'s require metadata to be constructed, the default wrapping, i.e.
78 ``return cls(func(*args, **kwargs))``, will fail for them.
79 2. For most operations, there is no way of knowing if the input type is still valid for the output.
80
81 For these reasons, the automatic output wrapping is turned off for most operators.
82
83 Exceptions to this are:
84
85 - :func:`torch.clone`
86 - :meth:`torch.Tensor.to`
87 """
88 kwargs = kwargs or dict()
89 with DisableTorchFunction():
90 output = func(*args, **kwargs)
91
92 if func is torch.Tensor.clone:
93 return cls.new_like(args[0], output)
94 elif func is torch.Tensor.to:
95 return cls.new_like(args[0], output, dtype=output.dtype, device=output.device)
96 else:
97 return output
98
99 def _make_repr(self, **kwargs: Any) -> str:
100 # This is a poor man's implementation of the proposal in https://github.com/pytorch/pytorch/issues/76532.
101 # If that ever gets implemented, remove this in favor of the solution on the `torch.Tensor` class.
102 extra_repr = ", ".join(f"{key}={value}" for key, value in kwargs.items())
103 return f"{super().__repr__()[:-1]}, {extra_repr})"
104
105 @property
106 def _F(self) -> ModuleType:
107 # This implements a lazy import of the functional to get around the cyclic import. This import is deferred
108 # until the first time we need reference to the functional module and it's shared across all instances of
109 # the class. This approach avoids the DataLoader issue described at
110 # https://github.com/pytorch/vision/pull/6476#discussion_r953588621
111 if _Feature.__F is None:
112 from ..transforms import functional
113
114 _Feature.__F = functional
115 return _Feature.__F
116
117 def horizontal_flip(self) -> _Feature:
118 return self
119
120 def vertical_flip(self) -> _Feature:
121 return self
122
123 # TODO: We have to ignore override mypy error as there is torch.Tensor built-in deprecated op: Tensor.resize
124 # https://github.com/pytorch/pytorch/blob/e8727994eb7cdb2ab642749d6549bc497563aa06/torch/_tensor.py#L588-L593
125 def resize( # type: ignore[override]
126 self,
127 size: List[int],
128 interpolation: InterpolationMode = InterpolationMode.BILINEAR,
129 max_size: Optional[int] = None,
130 antialias: bool = False,
131 ) -> _Feature:
132 return self
133
134 def crop(self, top: int, left: int, height: int, width: int) -> _Feature:
135 return self
136
137 def center_crop(self, output_size: List[int]) -> _Feature:
138 return self
139
140 def resized_crop(
141 self,
142 top: int,
143 left: int,
144 height: int,
145 width: int,
146 size: List[int],
147 interpolation: InterpolationMode = InterpolationMode.BILINEAR,
148 antialias: bool = False,
149 ) -> _Feature:
150 return self
151
152 def pad(
153 self,
154 padding: Union[int, List[int]],
155 fill: FillTypeJIT = None,
156 padding_mode: str = "constant",
157 ) -> _Feature:
158 return self
159
160 def rotate(
161 self,
162 angle: float,
163 interpolation: InterpolationMode = InterpolationMode.NEAREST,
164 expand: bool = False,
165 fill: FillTypeJIT = None,
166 center: Optional[List[float]] = None,
167 ) -> _Feature:
168 return self
169
170 def affine(
171 self,
172 angle: Union[int, float],
173 translate: List[float],
174 scale: float,
175 shear: List[float],
176 interpolation: InterpolationMode = InterpolationMode.NEAREST,
177 fill: FillTypeJIT = None,
178 center: Optional[List[float]] = None,
179 ) -> _Feature:
180 return self
181
182 def perspective(
183 self,
184 perspective_coeffs: List[float],
185 interpolation: InterpolationMode = InterpolationMode.BILINEAR,
186 fill: FillTypeJIT = None,
187 ) -> _Feature:
188 return self
189
190 def elastic(
191 self,
192 displacement: torch.Tensor,
193 interpolation: InterpolationMode = InterpolationMode.BILINEAR,
194 fill: FillTypeJIT = None,
195 ) -> _Feature:
196 return self
197
198 def adjust_brightness(self, brightness_factor: float) -> _Feature:
199 return self
200
201 def adjust_saturation(self, saturation_factor: float) -> _Feature:
202 return self
203
204 def adjust_contrast(self, contrast_factor: float) -> _Feature:
205 return self
206
207 def adjust_sharpness(self, sharpness_factor: float) -> _Feature:
208 return self
209
210 def adjust_hue(self, hue_factor: float) -> _Feature:
211 return self
212
213 def adjust_gamma(self, gamma: float, gain: float = 1) -> _Feature:
214 return self
215
216 def posterize(self, bits: int) -> _Feature:
217 return self
218
219 def solarize(self, threshold: float) -> _Feature:
220 return self
221
222 def autocontrast(self) -> _Feature:
223 return self
224
225 def equalize(self) -> _Feature:
226 return self
227
228 def invert(self) -> _Feature:
229 return self
230
231 def gaussian_blur(self, kernel_size: List[int], sigma: Optional[List[float]] = None) -> _Feature:
232 return self
233
234
235 InputType = Union[torch.Tensor, PIL.Image.Image, _Feature]
236 InputTypeJIT = torch.Tensor
237
[end of torchvision/prototype/features/_feature.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/torchvision/prototype/features/_feature.py b/torchvision/prototype/features/_feature.py
--- a/torchvision/prototype/features/_feature.py
+++ b/torchvision/prototype/features/_feature.py
@@ -89,6 +89,13 @@
with DisableTorchFunction():
output = func(*args, **kwargs)
+ # The __torch_function__ protocol will invoke this method on all types involved in the computation by walking
+ # the MRO upwards. For example, `torch.Tensor(...).to(features.Image(...))` will invoke
+ # `features.Image.__torch_function__` first. The check below makes sure that we do not try to wrap in such a
+ # case.
+ if not isinstance(args[0], cls):
+ return output
+
if func is torch.Tensor.clone:
return cls.new_like(args[0], output)
elif func is torch.Tensor.to:
|
{"golden_diff": "diff --git a/torchvision/prototype/features/_feature.py b/torchvision/prototype/features/_feature.py\n--- a/torchvision/prototype/features/_feature.py\n+++ b/torchvision/prototype/features/_feature.py\n@@ -89,6 +89,13 @@\n with DisableTorchFunction():\n output = func(*args, **kwargs)\n \n+ # The __torch_function__ protocol will invoke this method on all types involved in the computation by walking\n+ # the MRO upwards. For example, `torch.Tensor(...).to(features.Image(...))` will invoke\n+ # `features.Image.__torch_function__` first. The check below makes sure that we do not try to wrap in such a\n+ # case.\n+ if not isinstance(args[0], cls):\n+ return output\n+\n if func is torch.Tensor.clone:\n return cls.new_like(args[0], output)\n elif func is torch.Tensor.to:\n", "issue": "`Tensor.to` does not work with feature as reference\n`torch.Tensor.to` accepts a tensor reference object as input in which case it converts to the reference dtype and device:\r\n\r\n```py\r\n>>> a = torch.zeros((), dtype=torch.float)\r\n>>> b = torch.ones((), dtype=torch.int)\r\n>>> b\r\ntensor(1, dtype=torch.int32)\r\n>>> b.to(a)\r\ntensor(1.)\r\n```\r\n\r\nThis also works for our custom features:\r\n\r\n```py\r\n>>> data = torch.rand(3, 2, 2)\r\n>>> image = features.Image(data.to(torch.float64))\r\n>>> image\r\nImage([[[0.9595, 0.0947],\r\n [0.9553, 0.5563]],\r\n [[0.5435, 0.2975],\r\n [0.3037, 0.0863]],\r\n [[0.6253, 0.3481],\r\n [0.3518, 0.4499]]], dtype=torch.float64)\r\n>>> image.to(torch.float32)\r\nImage([[[0.9595, 0.0947],\r\n [0.9553, 0.5563]],\r\n [[0.5435, 0.2975],\r\n [0.3037, 0.0863]],\r\n [[0.6253, 0.3481],\r\n [0.3518, 0.4499]]])\r\n>>> image.to(data)\r\nImage([[[0.9595, 0.0947],\r\n [0.9553, 0.5563]],\r\n [[0.5435, 0.2975],\r\n [0.3037, 0.0863]],\r\n [[0.6253, 0.3481],\r\n [0.3518, 0.4499]]])\r\n\r\n```\r\n\r\nHowever, it doesn't work if we want to convert a plain tensor and use a custom feature as reference:\r\n\r\n```py\r\n>>> data.to(image)\r\nAttributeError: 'Tensor' object has no attribute 'color_space'\r\n```\n\ncc @bjuncek @pmeier\n", "before_files": [{"content": "from __future__ import annotations\n\nfrom types import ModuleType\nfrom typing import Any, Callable, cast, List, Mapping, Optional, Sequence, Tuple, Type, TypeVar, Union\n\nimport PIL.Image\nimport torch\nfrom torch._C import _TensorBase, DisableTorchFunction\nfrom torchvision.transforms import InterpolationMode\n\nF = TypeVar(\"F\", bound=\"_Feature\")\nFillType = Union[int, float, Sequence[int], Sequence[float], None]\nFillTypeJIT = Union[int, float, List[float], None]\n\n\ndef is_simple_tensor(inpt: Any) -> bool:\n return isinstance(inpt, torch.Tensor) and not isinstance(inpt, _Feature)\n\n\nclass _Feature(torch.Tensor):\n __F: Optional[ModuleType] = None\n\n def __new__(\n cls: Type[F],\n data: Any,\n *,\n dtype: Optional[torch.dtype] = None,\n device: Optional[Union[torch.device, str, int]] = None,\n requires_grad: bool = False,\n ) -> F:\n return cast(\n F,\n torch.Tensor._make_subclass(\n cast(_TensorBase, cls),\n torch.as_tensor(data, dtype=dtype, device=device), # type: ignore[arg-type]\n requires_grad,\n ),\n )\n\n @classmethod\n def new_like(\n cls: Type[F],\n other: F,\n data: Any,\n *,\n dtype: Optional[torch.dtype] = None,\n device: Optional[Union[torch.device, str, int]] = None,\n requires_grad: Optional[bool] = None,\n **kwargs: Any,\n ) -> F:\n return cls(\n data,\n dtype=dtype if dtype is not None else other.dtype,\n device=device if device is not None else other.device,\n requires_grad=requires_grad if requires_grad is not None else other.requires_grad,\n **kwargs,\n )\n\n @classmethod\n def __torch_function__(\n cls,\n func: Callable[..., torch.Tensor],\n types: Tuple[Type[torch.Tensor], ...],\n args: Sequence[Any] = (),\n kwargs: Optional[Mapping[str, Any]] = None,\n ) -> torch.Tensor:\n \"\"\"For general information about how the __torch_function__ protocol works,\n see https://pytorch.org/docs/stable/notes/extending.html#extending-torch\n\n TL;DR: Every time a PyTorch operator is called, it goes through the inputs and looks for the\n ``__torch_function__`` method. If one is found, it is invoked with the operator as ``func`` as well as the\n ``args`` and ``kwargs`` of the original call.\n\n The default behavior of :class:`~torch.Tensor`'s is to retain a custom tensor type. For the :class:`Feature`\n use case, this has two downsides:\n\n 1. Since some :class:`Feature`'s require metadata to be constructed, the default wrapping, i.e.\n ``return cls(func(*args, **kwargs))``, will fail for them.\n 2. For most operations, there is no way of knowing if the input type is still valid for the output.\n\n For these reasons, the automatic output wrapping is turned off for most operators.\n\n Exceptions to this are:\n\n - :func:`torch.clone`\n - :meth:`torch.Tensor.to`\n \"\"\"\n kwargs = kwargs or dict()\n with DisableTorchFunction():\n output = func(*args, **kwargs)\n\n if func is torch.Tensor.clone:\n return cls.new_like(args[0], output)\n elif func is torch.Tensor.to:\n return cls.new_like(args[0], output, dtype=output.dtype, device=output.device)\n else:\n return output\n\n def _make_repr(self, **kwargs: Any) -> str:\n # This is a poor man's implementation of the proposal in https://github.com/pytorch/pytorch/issues/76532.\n # If that ever gets implemented, remove this in favor of the solution on the `torch.Tensor` class.\n extra_repr = \", \".join(f\"{key}={value}\" for key, value in kwargs.items())\n return f\"{super().__repr__()[:-1]}, {extra_repr})\"\n\n @property\n def _F(self) -> ModuleType:\n # This implements a lazy import of the functional to get around the cyclic import. This import is deferred\n # until the first time we need reference to the functional module and it's shared across all instances of\n # the class. This approach avoids the DataLoader issue described at\n # https://github.com/pytorch/vision/pull/6476#discussion_r953588621\n if _Feature.__F is None:\n from ..transforms import functional\n\n _Feature.__F = functional\n return _Feature.__F\n\n def horizontal_flip(self) -> _Feature:\n return self\n\n def vertical_flip(self) -> _Feature:\n return self\n\n # TODO: We have to ignore override mypy error as there is torch.Tensor built-in deprecated op: Tensor.resize\n # https://github.com/pytorch/pytorch/blob/e8727994eb7cdb2ab642749d6549bc497563aa06/torch/_tensor.py#L588-L593\n def resize( # type: ignore[override]\n self,\n size: List[int],\n interpolation: InterpolationMode = InterpolationMode.BILINEAR,\n max_size: Optional[int] = None,\n antialias: bool = False,\n ) -> _Feature:\n return self\n\n def crop(self, top: int, left: int, height: int, width: int) -> _Feature:\n return self\n\n def center_crop(self, output_size: List[int]) -> _Feature:\n return self\n\n def resized_crop(\n self,\n top: int,\n left: int,\n height: int,\n width: int,\n size: List[int],\n interpolation: InterpolationMode = InterpolationMode.BILINEAR,\n antialias: bool = False,\n ) -> _Feature:\n return self\n\n def pad(\n self,\n padding: Union[int, List[int]],\n fill: FillTypeJIT = None,\n padding_mode: str = \"constant\",\n ) -> _Feature:\n return self\n\n def rotate(\n self,\n angle: float,\n interpolation: InterpolationMode = InterpolationMode.NEAREST,\n expand: bool = False,\n fill: FillTypeJIT = None,\n center: Optional[List[float]] = None,\n ) -> _Feature:\n return self\n\n def affine(\n self,\n angle: Union[int, float],\n translate: List[float],\n scale: float,\n shear: List[float],\n interpolation: InterpolationMode = InterpolationMode.NEAREST,\n fill: FillTypeJIT = None,\n center: Optional[List[float]] = None,\n ) -> _Feature:\n return self\n\n def perspective(\n self,\n perspective_coeffs: List[float],\n interpolation: InterpolationMode = InterpolationMode.BILINEAR,\n fill: FillTypeJIT = None,\n ) -> _Feature:\n return self\n\n def elastic(\n self,\n displacement: torch.Tensor,\n interpolation: InterpolationMode = InterpolationMode.BILINEAR,\n fill: FillTypeJIT = None,\n ) -> _Feature:\n return self\n\n def adjust_brightness(self, brightness_factor: float) -> _Feature:\n return self\n\n def adjust_saturation(self, saturation_factor: float) -> _Feature:\n return self\n\n def adjust_contrast(self, contrast_factor: float) -> _Feature:\n return self\n\n def adjust_sharpness(self, sharpness_factor: float) -> _Feature:\n return self\n\n def adjust_hue(self, hue_factor: float) -> _Feature:\n return self\n\n def adjust_gamma(self, gamma: float, gain: float = 1) -> _Feature:\n return self\n\n def posterize(self, bits: int) -> _Feature:\n return self\n\n def solarize(self, threshold: float) -> _Feature:\n return self\n\n def autocontrast(self) -> _Feature:\n return self\n\n def equalize(self) -> _Feature:\n return self\n\n def invert(self) -> _Feature:\n return self\n\n def gaussian_blur(self, kernel_size: List[int], sigma: Optional[List[float]] = None) -> _Feature:\n return self\n\n\nInputType = Union[torch.Tensor, PIL.Image.Image, _Feature]\nInputTypeJIT = torch.Tensor\n", "path": "torchvision/prototype/features/_feature.py"}]}
| 3,559 | 205 |
gh_patches_debug_17146
|
rasdani/github-patches
|
git_diff
|
facebookresearch__nevergrad-270
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Setup adds files directly to the root of sys.prefix
The arguments to `setup.py` add files directly to the root of `sys.prefix`, instead of in a nevergrad-specific subsubdirectory.
## Steps to reproduce
```console
jwnimmer@call-cc:~/issue$ python3 -m virtualenv --python python3 scratch
Already using interpreter /usr/bin/python3
Using base prefix '/usr'
New python executable in /home/jwnimmer/issue/scratch/bin/python3
Also creating executable in /home/jwnimmer/issue/scratch/bin/python
Installing setuptools, pkg_resources, pip, wheel...done.
jwnimmer@call-cc:~/issue$ scratch/bin/pip install 'nevergrad == 0.2.2'
Collecting nevergrad==0.2.2
Downloading https://files.pythonhosted.org/packages/46/04/b2f4673771fbd2fd07143f44a4f2880f8cbaa08a0cc32bdf287eef99c1d7/nevergrad-0.2.2-py3-none-any.whl (170kB)
... etc ...
... etc ...
Installing collected packages: typing-extensions, numpy, scipy, joblib, scikit-learn, bayesian-optimization, cma, six, python-dateutil, pytz, pandas, nevergrad
Successfully installed bayesian-optimization-1.0.1 cma-2.7.0 joblib-0.13.2 nevergrad-0.2.2 numpy-1.16.4 pandas-0.24.2 python-dateutil-2.8.0 pytz-2019.1 scikit-learn-0.21.2 scipy-1.3.0 six-1.12.0 typing-extensions-3.7.4
jwnimmer@call-cc:~/issue$ ls -l scratch
total 80
-rw-rw-r-- 1 jwnimmer jwnimmer 84 Jul 23 14:08 bench.txt
drwxrwxr-x 2 jwnimmer jwnimmer 4096 Jul 23 14:08 bin
-rw-rw-r-- 1 jwnimmer jwnimmer 102 Jul 23 14:08 dev.txt
drwxrwxr-x 2 jwnimmer jwnimmer 4096 Jul 23 14:07 include
drwxrwxr-x 3 jwnimmer jwnimmer 4096 Jul 23 14:07 lib
-rw-rw-r-- 1 jwnimmer jwnimmer 1086 Jul 23 14:08 LICENSE
-rw-rw-r-- 1 jwnimmer jwnimmer 94 Jul 23 14:08 main.txt
drwxrwxr-x 3 jwnimmer jwnimmer 4096 Jul 23 14:08 nevergrad
-rw-rw-r-- 1 jwnimmer jwnimmer 59 Jul 23 14:07 pip-selfcheck.json
drwxrwxr-x 3 jwnimmer jwnimmer 4096 Jul 23 14:07 share
```
## Observed Results
The `sys.prefix` contains spurious files:
```
LICENSE
bench.txt
dev.txt
main.txt
nevergrad/*
```
## Expected Results
Only standardized files and folders (bin, lib, share, ...) exist in the root of `sys.prefix`.
## Relevant Code
https://github.com/facebookresearch/nevergrad/blob/aabb4475b04fc10e668cd1ed6783d24107c72390/setup.py#L68-L70
## Additional thoughts
I am sure why the `LICENSE` or `*.txt` files are being explicitly installed in the first place. I believe that information is already available in the metadata. If they are to be installed, they should be in a nevergrad-specific subfolder.
I suspect the nevergrad examples are probably better installed using `packages=` or `package_data=` argument, not `data_files=`.
</issue>
<code>
[start of setup.py]
1 #!/usr/bin/env python
2 # Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved.
3 #
4 # This source code is licensed under the MIT license found in the
5 # LICENSE file in the root directory of this source tree.
6
7 import re
8 from pathlib import Path
9 from typing import Dict, List, Match
10 from setuptools import setup
11 from setuptools import find_packages
12
13
14 # read requirements
15
16 requirements: Dict[str, List[str]] = {}
17 for extra in ["dev", "bench", "main"]:
18 requirements[extra] = Path(f"requirements/{extra}.txt").read_text().splitlines()
19
20
21 # build long description
22
23 with open("README.md", "r", encoding="utf-8") as fh:
24 long_description = fh.read()
25
26
27 def _replace_relative_links(regex: Match[str]) -> str:
28 """Converts relative links into links to master
29 """
30 string = regex.group()
31 link = regex.group("link")
32 name = regex.group("name")
33 if not link.startswith("http") and Path(link).exists():
34 githuburl = ("github.com/facebookresearch/nevergrad/blob/master" if not link.endswith(".gif") else
35 "raw.githubusercontent.com/facebookresearch/nevergrad/master")
36 string = f"[{name}](https://{githuburl}/{link})"
37 return string
38
39
40 pattern = re.compile(r"\[(?P<name>.+?)\]\((?P<link>\S+?)\)")
41 long_description = re.sub(pattern, _replace_relative_links, long_description)
42
43
44 # find version
45
46 init_str = Path("nevergrad/__init__.py").read_text()
47 match = re.search(r"^__version__ = \"(?P<version>[\w\.]+?)\"$", init_str, re.MULTILINE)
48 assert match is not None, "Could not find version in nevergrad/__init__.py"
49 version = match.group("version")
50
51
52 # setup
53
54 setup(
55 name="nevergrad",
56 version=version,
57 license="MIT",
58 description="A Python toolbox for performing gradient-free optimization",
59 long_description=long_description,
60 long_description_content_type="text/markdown",
61 author="Facebook AI Research",
62 url="https://github.com/facebookresearch/nevergrad",
63 packages=find_packages(),
64 classifiers=["License :: OSI Approved :: MIT License",
65 "Intended Audience :: Science/Research",
66 "Topic :: Scientific/Engineering",
67 "Programming Language :: Python"],
68 data_files=[("", ["LICENSE", "requirements/main.txt", "requirements/dev.txt", "requirements/bench.txt"]),
69 ("nevergrad", ["nevergrad/benchmark/additional/example.py",
70 "nevergrad/instrumentation/examples/script.py"])],
71 install_requires=requirements["main"],
72 extras_require={"all": requirements["dev"] + requirements["bench"],
73 "dev": requirements["dev"],
74 "benchmark": requirements["bench"]}
75 )
76
[end of setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -65,11 +65,9 @@
"Intended Audience :: Science/Research",
"Topic :: Scientific/Engineering",
"Programming Language :: Python"],
- data_files=[("", ["LICENSE", "requirements/main.txt", "requirements/dev.txt", "requirements/bench.txt"]),
- ("nevergrad", ["nevergrad/benchmark/additional/example.py",
- "nevergrad/instrumentation/examples/script.py"])],
install_requires=requirements["main"],
extras_require={"all": requirements["dev"] + requirements["bench"],
"dev": requirements["dev"],
- "benchmark": requirements["bench"]}
+ "benchmark": requirements["bench"]},
+ package_data={"nevergrad": ["py.typed", "*.csv", "*.py", "functions/photonics/src/*"]},
)
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -65,11 +65,9 @@\n \"Intended Audience :: Science/Research\",\n \"Topic :: Scientific/Engineering\",\n \"Programming Language :: Python\"],\n- data_files=[(\"\", [\"LICENSE\", \"requirements/main.txt\", \"requirements/dev.txt\", \"requirements/bench.txt\"]),\n- (\"nevergrad\", [\"nevergrad/benchmark/additional/example.py\",\n- \"nevergrad/instrumentation/examples/script.py\"])],\n install_requires=requirements[\"main\"],\n extras_require={\"all\": requirements[\"dev\"] + requirements[\"bench\"],\n \"dev\": requirements[\"dev\"],\n- \"benchmark\": requirements[\"bench\"]}\n+ \"benchmark\": requirements[\"bench\"]},\n+ package_data={\"nevergrad\": [\"py.typed\", \"*.csv\", \"*.py\", \"functions/photonics/src/*\"]},\n )\n", "issue": "Setup adds files directly to the root of sys.prefix\nThe arguments to `setup.py` add files directly to the root of `sys.prefix`, instead of in a nevergrad-specific subsubdirectory.\r\n\r\n## Steps to reproduce\r\n\r\n```console\r\njwnimmer@call-cc:~/issue$ python3 -m virtualenv --python python3 scratch\r\nAlready using interpreter /usr/bin/python3\r\nUsing base prefix '/usr'\r\nNew python executable in /home/jwnimmer/issue/scratch/bin/python3\r\nAlso creating executable in /home/jwnimmer/issue/scratch/bin/python\r\nInstalling setuptools, pkg_resources, pip, wheel...done.\r\n\r\njwnimmer@call-cc:~/issue$ scratch/bin/pip install 'nevergrad == 0.2.2'\r\nCollecting nevergrad==0.2.2\r\n Downloading https://files.pythonhosted.org/packages/46/04/b2f4673771fbd2fd07143f44a4f2880f8cbaa08a0cc32bdf287eef99c1d7/nevergrad-0.2.2-py3-none-any.whl (170kB)\r\n... etc ...\r\n... etc ...\r\nInstalling collected packages: typing-extensions, numpy, scipy, joblib, scikit-learn, bayesian-optimization, cma, six, python-dateutil, pytz, pandas, nevergrad\r\nSuccessfully installed bayesian-optimization-1.0.1 cma-2.7.0 joblib-0.13.2 nevergrad-0.2.2 numpy-1.16.4 pandas-0.24.2 python-dateutil-2.8.0 pytz-2019.1 scikit-learn-0.21.2 scipy-1.3.0 six-1.12.0 typing-extensions-3.7.4\r\n\r\njwnimmer@call-cc:~/issue$ ls -l scratch\r\ntotal 80\r\n-rw-rw-r-- 1 jwnimmer jwnimmer 84 Jul 23 14:08 bench.txt\r\ndrwxrwxr-x 2 jwnimmer jwnimmer 4096 Jul 23 14:08 bin\r\n-rw-rw-r-- 1 jwnimmer jwnimmer 102 Jul 23 14:08 dev.txt\r\ndrwxrwxr-x 2 jwnimmer jwnimmer 4096 Jul 23 14:07 include\r\ndrwxrwxr-x 3 jwnimmer jwnimmer 4096 Jul 23 14:07 lib\r\n-rw-rw-r-- 1 jwnimmer jwnimmer 1086 Jul 23 14:08 LICENSE\r\n-rw-rw-r-- 1 jwnimmer jwnimmer 94 Jul 23 14:08 main.txt\r\ndrwxrwxr-x 3 jwnimmer jwnimmer 4096 Jul 23 14:08 nevergrad\r\n-rw-rw-r-- 1 jwnimmer jwnimmer 59 Jul 23 14:07 pip-selfcheck.json\r\ndrwxrwxr-x 3 jwnimmer jwnimmer 4096 Jul 23 14:07 share\r\n```\r\n\r\n## Observed Results\r\n\r\nThe `sys.prefix` contains spurious files:\r\n```\r\nLICENSE\r\nbench.txt\r\ndev.txt\r\nmain.txt\r\nnevergrad/*\r\n```\r\n\r\n## Expected Results\r\n\r\nOnly standardized files and folders (bin, lib, share, ...) exist in the root of `sys.prefix`.\r\n\r\n## Relevant Code\r\n\r\nhttps://github.com/facebookresearch/nevergrad/blob/aabb4475b04fc10e668cd1ed6783d24107c72390/setup.py#L68-L70\r\n\r\n## Additional thoughts\r\n\r\nI am sure why the `LICENSE` or `*.txt` files are being explicitly installed in the first place. I believe that information is already available in the metadata. If they are to be installed, they should be in a nevergrad-specific subfolder.\r\n\r\nI suspect the nevergrad examples are probably better installed using `packages=` or `package_data=` argument, not `data_files=`.\n", "before_files": [{"content": "#!/usr/bin/env python\n# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved.\n#\n# This source code is licensed under the MIT license found in the\n# LICENSE file in the root directory of this source tree.\n\nimport re\nfrom pathlib import Path\nfrom typing import Dict, List, Match\nfrom setuptools import setup\nfrom setuptools import find_packages\n\n\n# read requirements\n\nrequirements: Dict[str, List[str]] = {}\nfor extra in [\"dev\", \"bench\", \"main\"]:\n requirements[extra] = Path(f\"requirements/{extra}.txt\").read_text().splitlines()\n\n\n# build long description\n\nwith open(\"README.md\", \"r\", encoding=\"utf-8\") as fh:\n long_description = fh.read()\n\n\ndef _replace_relative_links(regex: Match[str]) -> str:\n \"\"\"Converts relative links into links to master\n \"\"\"\n string = regex.group()\n link = regex.group(\"link\")\n name = regex.group(\"name\")\n if not link.startswith(\"http\") and Path(link).exists():\n githuburl = (\"github.com/facebookresearch/nevergrad/blob/master\" if not link.endswith(\".gif\") else\n \"raw.githubusercontent.com/facebookresearch/nevergrad/master\")\n string = f\"[{name}](https://{githuburl}/{link})\"\n return string\n\n\npattern = re.compile(r\"\\[(?P<name>.+?)\\]\\((?P<link>\\S+?)\\)\")\nlong_description = re.sub(pattern, _replace_relative_links, long_description)\n\n\n# find version\n\ninit_str = Path(\"nevergrad/__init__.py\").read_text()\nmatch = re.search(r\"^__version__ = \\\"(?P<version>[\\w\\.]+?)\\\"$\", init_str, re.MULTILINE)\nassert match is not None, \"Could not find version in nevergrad/__init__.py\"\nversion = match.group(\"version\")\n\n\n# setup\n\nsetup(\n name=\"nevergrad\",\n version=version,\n license=\"MIT\",\n description=\"A Python toolbox for performing gradient-free optimization\",\n long_description=long_description,\n long_description_content_type=\"text/markdown\",\n author=\"Facebook AI Research\",\n url=\"https://github.com/facebookresearch/nevergrad\",\n packages=find_packages(),\n classifiers=[\"License :: OSI Approved :: MIT License\",\n \"Intended Audience :: Science/Research\",\n \"Topic :: Scientific/Engineering\",\n \"Programming Language :: Python\"],\n data_files=[(\"\", [\"LICENSE\", \"requirements/main.txt\", \"requirements/dev.txt\", \"requirements/bench.txt\"]),\n (\"nevergrad\", [\"nevergrad/benchmark/additional/example.py\",\n \"nevergrad/instrumentation/examples/script.py\"])],\n install_requires=requirements[\"main\"],\n extras_require={\"all\": requirements[\"dev\"] + requirements[\"bench\"],\n \"dev\": requirements[\"dev\"],\n \"benchmark\": requirements[\"bench\"]}\n)\n", "path": "setup.py"}]}
| 2,240 | 191 |
gh_patches_debug_41311
|
rasdani/github-patches
|
git_diff
|
deepchecks__deepchecks-1522
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[FEAT] Enable ignoring Null values in the Is Single Value check
**Is your feature request related to a problem? Please describe.**
Currently, if the data has both a single value and NaNs in the same column, this column will be considered to have 2 unique values.
**Describe the solution you'd like**
Add a Boolean parameter telling the check to disregard NaN's
**Additional context**
Issue raised by @galsr in the [Deepchecks Community](https://join.slack.com/t/deepcheckscommunity/shared_invite/zt-1973c7twx-Ytb7_yJefTT4PmnMZj2p7A) support channel.
</issue>
<code>
[start of docs/source/checks/tabular/data_integrity/plot_is_single_value.py]
1 # -*- coding: utf-8 -*-
2 """
3 Is Single Value
4 ***************
5 """
6
7 #%%
8 # Imports
9 # =======
10
11 import pandas as pd
12 from sklearn.datasets import load_iris
13
14 from deepchecks.tabular.checks import IsSingleValue
15
16 #%%
17 # Load Data
18 # =========
19
20 iris = load_iris()
21 X = iris.data
22 df = pd.DataFrame({'a':[3,4,1], 'b':[2,2,2], 'c':[None, None, None], 'd':['a', 4, 6]})
23 df
24
25 #%%
26 # See functionality
27 # =================
28
29 IsSingleValue().run(pd.DataFrame(X))
30
31 #%%
32
33 IsSingleValue().run(pd.DataFrame({'a':[3,4], 'b':[2,2], 'c':[None, None], 'd':['a', 4]}))
34
35 #%%
36
37 sv = IsSingleValue()
38 sv.run(df)
39
40 #%%
41
42 sv_ignore = IsSingleValue(ignore_columns=['b','c'])
43 sv_ignore.run(df)
44
[end of docs/source/checks/tabular/data_integrity/plot_is_single_value.py]
[start of deepchecks/tabular/checks/data_integrity/is_single_value.py]
1 # ----------------------------------------------------------------------------
2 # Copyright (C) 2021-2022 Deepchecks (https://www.deepchecks.com)
3 #
4 # This file is part of Deepchecks.
5 # Deepchecks is distributed under the terms of the GNU Affero General
6 # Public License (version 3 or later).
7 # You should have received a copy of the GNU Affero General Public License
8 # along with Deepchecks. If not, see <http://www.gnu.org/licenses/>.
9 # ----------------------------------------------------------------------------
10 #
11 """Module contains is_single_value check."""
12 from typing import List, Union
13
14 from deepchecks.core import CheckResult, ConditionCategory, ConditionResult
15 from deepchecks.tabular import Context, SingleDatasetCheck
16 from deepchecks.tabular.utils.messages import get_condition_passed_message
17 from deepchecks.utils.dataframes import select_from_dataframe
18 from deepchecks.utils.typing import Hashable
19
20 __all__ = ['IsSingleValue']
21
22
23 class IsSingleValue(SingleDatasetCheck):
24 """Check if there are columns which have only a single unique value in all rows.
25
26 Parameters
27 ----------
28 columns : Union[Hashable, List[Hashable]] , default: None
29 Columns to check, if none are given checks all
30 columns except ignored ones.
31 ignore_columns : Union[Hashable, List[Hashable]] , default: None
32 Columns to ignore, if none given checks based
33 on columns variable.
34 """
35
36 def __init__(
37 self,
38 columns: Union[Hashable, List[Hashable], None] = None,
39 ignore_columns: Union[Hashable, List[Hashable], None] = None,
40 **kwargs
41 ):
42 super().__init__(**kwargs)
43 self.columns = columns
44 self.ignore_columns = ignore_columns
45
46 def run_logic(self, context: Context, dataset_type: str = 'train') -> CheckResult:
47 """Run check.
48
49 Returns
50 -------
51 CheckResult
52 value of result is a dict of all columns with number of unique values in format {column: number_of_uniques}
53 display is a series with columns that have only one unique
54 """
55 # Validate parameters
56 if dataset_type == 'train':
57 df = context.train.data
58 else:
59 df = context.test.data
60
61 df = select_from_dataframe(df, self.columns, self.ignore_columns)
62
63 num_unique_per_col = df.nunique(dropna=False)
64 is_single_unique_value = (num_unique_per_col == 1)
65
66 if is_single_unique_value.any():
67 # get names of columns with one unique value
68 # pylint: disable=unsubscriptable-object
69 cols_with_single = is_single_unique_value[is_single_unique_value].index.to_list()
70 uniques = df.loc[:, cols_with_single].head(1)
71 uniques.index = ['Single unique value']
72 display = ['The following columns have only one unique value', uniques]
73 else:
74 display = None
75
76 return CheckResult(num_unique_per_col.to_dict(), header='Single Value in Column', display=display)
77
78 def add_condition_not_single_value(self):
79 """Add condition - not single value."""
80 name = 'Does not contain only a single value'
81
82 def condition(result):
83 single_value_cols = [k for k, v in result.items() if v == 1]
84 if single_value_cols:
85 details = f'Found {len(single_value_cols)} out of {len(result)} columns with a single value: ' \
86 f'{single_value_cols}'
87 return ConditionResult(ConditionCategory.FAIL, details)
88 else:
89 return ConditionResult(ConditionCategory.PASS, get_condition_passed_message(result))
90
91 return self.add_condition(name, condition)
92
[end of deepchecks/tabular/checks/data_integrity/is_single_value.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/deepchecks/tabular/checks/data_integrity/is_single_value.py b/deepchecks/tabular/checks/data_integrity/is_single_value.py
--- a/deepchecks/tabular/checks/data_integrity/is_single_value.py
+++ b/deepchecks/tabular/checks/data_integrity/is_single_value.py
@@ -11,6 +11,8 @@
"""Module contains is_single_value check."""
from typing import List, Union
+import pandas as pd
+
from deepchecks.core import CheckResult, ConditionCategory, ConditionResult
from deepchecks.tabular import Context, SingleDatasetCheck
from deepchecks.tabular.utils.messages import get_condition_passed_message
@@ -31,17 +33,21 @@
ignore_columns : Union[Hashable, List[Hashable]] , default: None
Columns to ignore, if none given checks based
on columns variable.
+ ignore_nan : bool, default True
+ Whether to ignore NaN values in a column when counting the number of unique values.
"""
def __init__(
self,
columns: Union[Hashable, List[Hashable], None] = None,
ignore_columns: Union[Hashable, List[Hashable], None] = None,
+ ignore_nan: bool = True,
**kwargs
):
super().__init__(**kwargs)
self.columns = columns
self.ignore_columns = ignore_columns
+ self.ignore_nan = ignore_nan
def run_logic(self, context: Context, dataset_type: str = 'train') -> CheckResult:
"""Run check.
@@ -60,14 +66,17 @@
df = select_from_dataframe(df, self.columns, self.ignore_columns)
- num_unique_per_col = df.nunique(dropna=False)
+ num_unique_per_col = df.nunique(dropna=self.ignore_nan)
is_single_unique_value = (num_unique_per_col == 1)
if is_single_unique_value.any():
# get names of columns with one unique value
# pylint: disable=unsubscriptable-object
cols_with_single = is_single_unique_value[is_single_unique_value].index.to_list()
- uniques = df.loc[:, cols_with_single].head(1)
+ uniques = pd.DataFrame({
+ column_name: [column.sort_values(kind='mergesort').values[0]]
+ for column_name, column in df.loc[:, cols_with_single].items()
+ })
uniques.index = ['Single unique value']
display = ['The following columns have only one unique value', uniques]
else:
diff --git a/docs/source/checks/tabular/data_integrity/plot_is_single_value.py b/docs/source/checks/tabular/data_integrity/plot_is_single_value.py
--- a/docs/source/checks/tabular/data_integrity/plot_is_single_value.py
+++ b/docs/source/checks/tabular/data_integrity/plot_is_single_value.py
@@ -8,6 +8,7 @@
# Imports
# =======
+import numpy as np
import pandas as pd
from sklearn.datasets import load_iris
@@ -41,3 +42,14 @@
sv_ignore = IsSingleValue(ignore_columns=['b','c'])
sv_ignore.run(df)
+
+#%%
+
+# Ignoring NaN values
+
+IsSingleValue(ignore_nan=True).run(pd.DataFrame({
+ 'a': [3, np.nan],
+ 'b': [2, 2],
+ 'c': [None, np.nan],
+ 'd': ['a', 4]
+}))
|
{"golden_diff": "diff --git a/deepchecks/tabular/checks/data_integrity/is_single_value.py b/deepchecks/tabular/checks/data_integrity/is_single_value.py\n--- a/deepchecks/tabular/checks/data_integrity/is_single_value.py\n+++ b/deepchecks/tabular/checks/data_integrity/is_single_value.py\n@@ -11,6 +11,8 @@\n \"\"\"Module contains is_single_value check.\"\"\"\n from typing import List, Union\n \n+import pandas as pd\n+\n from deepchecks.core import CheckResult, ConditionCategory, ConditionResult\n from deepchecks.tabular import Context, SingleDatasetCheck\n from deepchecks.tabular.utils.messages import get_condition_passed_message\n@@ -31,17 +33,21 @@\n ignore_columns : Union[Hashable, List[Hashable]] , default: None\n Columns to ignore, if none given checks based\n on columns variable.\n+ ignore_nan : bool, default True\n+ Whether to ignore NaN values in a column when counting the number of unique values.\n \"\"\"\n \n def __init__(\n self,\n columns: Union[Hashable, List[Hashable], None] = None,\n ignore_columns: Union[Hashable, List[Hashable], None] = None,\n+ ignore_nan: bool = True,\n **kwargs\n ):\n super().__init__(**kwargs)\n self.columns = columns\n self.ignore_columns = ignore_columns\n+ self.ignore_nan = ignore_nan\n \n def run_logic(self, context: Context, dataset_type: str = 'train') -> CheckResult:\n \"\"\"Run check.\n@@ -60,14 +66,17 @@\n \n df = select_from_dataframe(df, self.columns, self.ignore_columns)\n \n- num_unique_per_col = df.nunique(dropna=False)\n+ num_unique_per_col = df.nunique(dropna=self.ignore_nan)\n is_single_unique_value = (num_unique_per_col == 1)\n \n if is_single_unique_value.any():\n # get names of columns with one unique value\n # pylint: disable=unsubscriptable-object\n cols_with_single = is_single_unique_value[is_single_unique_value].index.to_list()\n- uniques = df.loc[:, cols_with_single].head(1)\n+ uniques = pd.DataFrame({\n+ column_name: [column.sort_values(kind='mergesort').values[0]]\n+ for column_name, column in df.loc[:, cols_with_single].items()\n+ })\n uniques.index = ['Single unique value']\n display = ['The following columns have only one unique value', uniques]\n else:\ndiff --git a/docs/source/checks/tabular/data_integrity/plot_is_single_value.py b/docs/source/checks/tabular/data_integrity/plot_is_single_value.py\n--- a/docs/source/checks/tabular/data_integrity/plot_is_single_value.py\n+++ b/docs/source/checks/tabular/data_integrity/plot_is_single_value.py\n@@ -8,6 +8,7 @@\n # Imports\n # =======\n \n+import numpy as np\n import pandas as pd\n from sklearn.datasets import load_iris\n \n@@ -41,3 +42,14 @@\n \n sv_ignore = IsSingleValue(ignore_columns=['b','c'])\n sv_ignore.run(df)\n+\n+#%%\n+\n+# Ignoring NaN values\n+\n+IsSingleValue(ignore_nan=True).run(pd.DataFrame({\n+ 'a': [3, np.nan], \n+ 'b': [2, 2],\n+ 'c': [None, np.nan], \n+ 'd': ['a', 4]\n+}))\n", "issue": "[FEAT] Enable ignoring Null values in the Is Single Value check\n**Is your feature request related to a problem? Please describe.**\r\nCurrently, if the data has both a single value and NaNs in the same column, this column will be considered to have 2 unique values.\r\n\r\n**Describe the solution you'd like**\r\nAdd a Boolean parameter telling the check to disregard NaN's\r\n\r\n**Additional context**\r\nIssue raised by @galsr in the [Deepchecks Community](https://join.slack.com/t/deepcheckscommunity/shared_invite/zt-1973c7twx-Ytb7_yJefTT4PmnMZj2p7A) support channel. \n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\"\"\"\nIs Single Value\n***************\n\"\"\"\n\n#%%\n# Imports\n# =======\n\nimport pandas as pd\nfrom sklearn.datasets import load_iris\n\nfrom deepchecks.tabular.checks import IsSingleValue\n\n#%%\n# Load Data\n# =========\n\niris = load_iris()\nX = iris.data\ndf = pd.DataFrame({'a':[3,4,1], 'b':[2,2,2], 'c':[None, None, None], 'd':['a', 4, 6]})\ndf\n\n#%%\n# See functionality\n# =================\n\nIsSingleValue().run(pd.DataFrame(X))\n\n#%%\n\nIsSingleValue().run(pd.DataFrame({'a':[3,4], 'b':[2,2], 'c':[None, None], 'd':['a', 4]}))\n\n#%%\n\nsv = IsSingleValue()\nsv.run(df)\n\n#%%\n\nsv_ignore = IsSingleValue(ignore_columns=['b','c'])\nsv_ignore.run(df)\n", "path": "docs/source/checks/tabular/data_integrity/plot_is_single_value.py"}, {"content": "# ----------------------------------------------------------------------------\n# Copyright (C) 2021-2022 Deepchecks (https://www.deepchecks.com)\n#\n# This file is part of Deepchecks.\n# Deepchecks is distributed under the terms of the GNU Affero General\n# Public License (version 3 or later).\n# You should have received a copy of the GNU Affero General Public License\n# along with Deepchecks. If not, see <http://www.gnu.org/licenses/>.\n# ----------------------------------------------------------------------------\n#\n\"\"\"Module contains is_single_value check.\"\"\"\nfrom typing import List, Union\n\nfrom deepchecks.core import CheckResult, ConditionCategory, ConditionResult\nfrom deepchecks.tabular import Context, SingleDatasetCheck\nfrom deepchecks.tabular.utils.messages import get_condition_passed_message\nfrom deepchecks.utils.dataframes import select_from_dataframe\nfrom deepchecks.utils.typing import Hashable\n\n__all__ = ['IsSingleValue']\n\n\nclass IsSingleValue(SingleDatasetCheck):\n \"\"\"Check if there are columns which have only a single unique value in all rows.\n\n Parameters\n ----------\n columns : Union[Hashable, List[Hashable]] , default: None\n Columns to check, if none are given checks all\n columns except ignored ones.\n ignore_columns : Union[Hashable, List[Hashable]] , default: None\n Columns to ignore, if none given checks based\n on columns variable.\n \"\"\"\n\n def __init__(\n self,\n columns: Union[Hashable, List[Hashable], None] = None,\n ignore_columns: Union[Hashable, List[Hashable], None] = None,\n **kwargs\n ):\n super().__init__(**kwargs)\n self.columns = columns\n self.ignore_columns = ignore_columns\n\n def run_logic(self, context: Context, dataset_type: str = 'train') -> CheckResult:\n \"\"\"Run check.\n\n Returns\n -------\n CheckResult\n value of result is a dict of all columns with number of unique values in format {column: number_of_uniques}\n display is a series with columns that have only one unique\n \"\"\"\n # Validate parameters\n if dataset_type == 'train':\n df = context.train.data\n else:\n df = context.test.data\n\n df = select_from_dataframe(df, self.columns, self.ignore_columns)\n\n num_unique_per_col = df.nunique(dropna=False)\n is_single_unique_value = (num_unique_per_col == 1)\n\n if is_single_unique_value.any():\n # get names of columns with one unique value\n # pylint: disable=unsubscriptable-object\n cols_with_single = is_single_unique_value[is_single_unique_value].index.to_list()\n uniques = df.loc[:, cols_with_single].head(1)\n uniques.index = ['Single unique value']\n display = ['The following columns have only one unique value', uniques]\n else:\n display = None\n\n return CheckResult(num_unique_per_col.to_dict(), header='Single Value in Column', display=display)\n\n def add_condition_not_single_value(self):\n \"\"\"Add condition - not single value.\"\"\"\n name = 'Does not contain only a single value'\n\n def condition(result):\n single_value_cols = [k for k, v in result.items() if v == 1]\n if single_value_cols:\n details = f'Found {len(single_value_cols)} out of {len(result)} columns with a single value: ' \\\n f'{single_value_cols}'\n return ConditionResult(ConditionCategory.FAIL, details)\n else:\n return ConditionResult(ConditionCategory.PASS, get_condition_passed_message(result))\n\n return self.add_condition(name, condition)\n", "path": "deepchecks/tabular/checks/data_integrity/is_single_value.py"}]}
| 1,978 | 769 |
gh_patches_debug_13084
|
rasdani/github-patches
|
git_diff
|
NVIDIA__NeMo-5261
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Fix links to speaker identification notebook
# What does this PR do ?
Fixes #5258
**Collection**: [Note which collection this PR will affect]
# Changelog
- Add specific line by line info of high level changes in this PR.
# Usage
* You can potentially add a usage example below
```python
# Add a code snippet demonstrating how to use this
```
# Before your PR is "Ready for review"
**Pre checks**:
- [ ] Make sure you read and followed [Contributor guidelines](https://github.com/NVIDIA/NeMo/blob/main/CONTRIBUTING.md)
- [ ] Did you write any new necessary tests?
- [ ] Did you add or update any necessary documentation?
- [ ] Does the PR affect components that are optional to install? (Ex: Numba, Pynini, Apex etc)
- [ ] Reviewer: Does the PR have correct import guards for all optional libraries?
**PR Type**:
- [ ] New Feature
- [ ] Bugfix
- [ ] Documentation
If you haven't finished some of the above items you can still open "Draft" PR.
## Who can review?
Anyone in the community is free to review the PR once the checks have passed.
[Contributor guidelines](https://github.com/NVIDIA/NeMo/blob/main/CONTRIBUTING.md) contains specific people who can review PRs to various areas.
# Additional Information
* Related to # (issue)
</issue>
<code>
[start of examples/speaker_tasks/recognition/speaker_reco.py]
1 # Copyright (c) 2020, NVIDIA CORPORATION. All rights reserved.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 import os
16
17 import pytorch_lightning as pl
18 import torch
19 from omegaconf import OmegaConf
20 from pytorch_lightning import seed_everything
21
22 from nemo.collections.asr.models import EncDecSpeakerLabelModel
23 from nemo.core.config import hydra_runner
24 from nemo.utils import logging
25 from nemo.utils.exp_manager import exp_manager
26
27 """
28 Basic run (on GPU for 10 epochs for 2 class training):
29 EXP_NAME=sample_run
30 python ./speaker_reco.py --config-path='conf' --config-name='SpeakerNet_recognition_3x2x512.yaml' \
31 trainer.max_epochs=10 \
32 model.train_ds.batch_size=64 model.validation_ds.batch_size=64 \
33 model.train_ds.manifest_filepath="<train_manifest>" model.validation_ds.manifest_filepath="<dev_manifest>" \
34 model.test_ds.manifest_filepath="<test_manifest>" \
35 trainer.devices=1 \
36 model.decoder.params.num_classes=2 \
37 exp_manager.name=$EXP_NAME +exp_manager.use_datetime_version=False \
38 exp_manager.exp_dir='./speaker_exps'
39
40 See https://github.com/NVIDIA/NeMo/blob/main/tutorials/speaker_tasks/Speaker_Recognition_Verification.ipynb for notebook tutorial
41
42 Optional: Use tarred dataset to speech up data loading.
43 Prepare ONE manifest that contains all training data you would like to include. Validation should use non-tarred dataset.
44 Note that it's possible that tarred datasets impacts validation scores because it drop values in order to have same amount of files per tarfile;
45 Scores might be off since some data is missing.
46
47 Use the `convert_to_tarred_audio_dataset.py` script under <NEMO_ROOT>/speech_recognition/scripts in order to prepare tarred audio dataset.
48 For details, please see TarredAudioToClassificationLabelDataset in <NEMO_ROOT>/nemo/collections/asr/data/audio_to_label.py
49 """
50
51 seed_everything(42)
52
53
54 @hydra_runner(config_path="conf", config_name="SpeakerNet_verification_3x2x256.yaml")
55 def main(cfg):
56
57 logging.info(f'Hydra config: {OmegaConf.to_yaml(cfg)}')
58 trainer = pl.Trainer(**cfg.trainer)
59 log_dir = exp_manager(trainer, cfg.get("exp_manager", None))
60 speaker_model = EncDecSpeakerLabelModel(cfg=cfg.model, trainer=trainer)
61 trainer.fit(speaker_model)
62 if not trainer.fast_dev_run:
63 model_path = os.path.join(log_dir, '..', 'spkr.nemo')
64 speaker_model.save_to(model_path)
65
66 torch.distributed.destroy_process_group()
67 if hasattr(cfg.model, 'test_ds') and cfg.model.test_ds.manifest_filepath is not None:
68 if trainer.is_global_zero:
69 trainer = pl.Trainer(devices=1, accelerator=cfg.trainer.accelerator, strategy=cfg.trainer.strategy)
70 if speaker_model.prepare_test(trainer):
71 trainer.test(speaker_model)
72
73
74 if __name__ == '__main__':
75 main()
76
[end of examples/speaker_tasks/recognition/speaker_reco.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/examples/speaker_tasks/recognition/speaker_reco.py b/examples/speaker_tasks/recognition/speaker_reco.py
--- a/examples/speaker_tasks/recognition/speaker_reco.py
+++ b/examples/speaker_tasks/recognition/speaker_reco.py
@@ -37,7 +37,7 @@
exp_manager.name=$EXP_NAME +exp_manager.use_datetime_version=False \
exp_manager.exp_dir='./speaker_exps'
-See https://github.com/NVIDIA/NeMo/blob/main/tutorials/speaker_tasks/Speaker_Recognition_Verification.ipynb for notebook tutorial
+See https://github.com/NVIDIA/NeMo/blob/main/tutorials/speaker_tasks/Speaker_Identification_Verification.ipynb for notebook tutorial
Optional: Use tarred dataset to speech up data loading.
Prepare ONE manifest that contains all training data you would like to include. Validation should use non-tarred dataset.
|
{"golden_diff": "diff --git a/examples/speaker_tasks/recognition/speaker_reco.py b/examples/speaker_tasks/recognition/speaker_reco.py\n--- a/examples/speaker_tasks/recognition/speaker_reco.py\n+++ b/examples/speaker_tasks/recognition/speaker_reco.py\n@@ -37,7 +37,7 @@\n exp_manager.name=$EXP_NAME +exp_manager.use_datetime_version=False \\\n exp_manager.exp_dir='./speaker_exps'\n \n-See https://github.com/NVIDIA/NeMo/blob/main/tutorials/speaker_tasks/Speaker_Recognition_Verification.ipynb for notebook tutorial\n+See https://github.com/NVIDIA/NeMo/blob/main/tutorials/speaker_tasks/Speaker_Identification_Verification.ipynb for notebook tutorial\n \n Optional: Use tarred dataset to speech up data loading.\n Prepare ONE manifest that contains all training data you would like to include. Validation should use non-tarred dataset.\n", "issue": "Fix links to speaker identification notebook\n# What does this PR do ?\r\n\r\nFixes #5258\r\n\r\n**Collection**: [Note which collection this PR will affect]\r\n\r\n# Changelog \r\n- Add specific line by line info of high level changes in this PR.\r\n\r\n# Usage\r\n* You can potentially add a usage example below\r\n\r\n```python\r\n# Add a code snippet demonstrating how to use this \r\n```\r\n\r\n# Before your PR is \"Ready for review\"\r\n**Pre checks**:\r\n- [ ] Make sure you read and followed [Contributor guidelines](https://github.com/NVIDIA/NeMo/blob/main/CONTRIBUTING.md)\r\n- [ ] Did you write any new necessary tests?\r\n- [ ] Did you add or update any necessary documentation?\r\n- [ ] Does the PR affect components that are optional to install? (Ex: Numba, Pynini, Apex etc)\r\n - [ ] Reviewer: Does the PR have correct import guards for all optional libraries?\r\n \r\n**PR Type**:\r\n- [ ] New Feature\r\n- [ ] Bugfix\r\n- [ ] Documentation\r\n\r\nIf you haven't finished some of the above items you can still open \"Draft\" PR.\r\n\r\n\r\n## Who can review?\r\n\r\nAnyone in the community is free to review the PR once the checks have passed. \r\n[Contributor guidelines](https://github.com/NVIDIA/NeMo/blob/main/CONTRIBUTING.md) contains specific people who can review PRs to various areas.\r\n\r\n# Additional Information\r\n* Related to # (issue)\r\n\n", "before_files": [{"content": "# Copyright (c) 2020, NVIDIA CORPORATION. All rights reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport os\n\nimport pytorch_lightning as pl\nimport torch\nfrom omegaconf import OmegaConf\nfrom pytorch_lightning import seed_everything\n\nfrom nemo.collections.asr.models import EncDecSpeakerLabelModel\nfrom nemo.core.config import hydra_runner\nfrom nemo.utils import logging\nfrom nemo.utils.exp_manager import exp_manager\n\n\"\"\"\nBasic run (on GPU for 10 epochs for 2 class training):\nEXP_NAME=sample_run\npython ./speaker_reco.py --config-path='conf' --config-name='SpeakerNet_recognition_3x2x512.yaml' \\\n trainer.max_epochs=10 \\\n model.train_ds.batch_size=64 model.validation_ds.batch_size=64 \\\n model.train_ds.manifest_filepath=\"<train_manifest>\" model.validation_ds.manifest_filepath=\"<dev_manifest>\" \\\n model.test_ds.manifest_filepath=\"<test_manifest>\" \\\n trainer.devices=1 \\\n model.decoder.params.num_classes=2 \\\n exp_manager.name=$EXP_NAME +exp_manager.use_datetime_version=False \\\n exp_manager.exp_dir='./speaker_exps'\n\nSee https://github.com/NVIDIA/NeMo/blob/main/tutorials/speaker_tasks/Speaker_Recognition_Verification.ipynb for notebook tutorial\n\nOptional: Use tarred dataset to speech up data loading.\n Prepare ONE manifest that contains all training data you would like to include. Validation should use non-tarred dataset.\n Note that it's possible that tarred datasets impacts validation scores because it drop values in order to have same amount of files per tarfile; \n Scores might be off since some data is missing. \n \n Use the `convert_to_tarred_audio_dataset.py` script under <NEMO_ROOT>/speech_recognition/scripts in order to prepare tarred audio dataset.\n For details, please see TarredAudioToClassificationLabelDataset in <NEMO_ROOT>/nemo/collections/asr/data/audio_to_label.py\n\"\"\"\n\nseed_everything(42)\n\n\n@hydra_runner(config_path=\"conf\", config_name=\"SpeakerNet_verification_3x2x256.yaml\")\ndef main(cfg):\n\n logging.info(f'Hydra config: {OmegaConf.to_yaml(cfg)}')\n trainer = pl.Trainer(**cfg.trainer)\n log_dir = exp_manager(trainer, cfg.get(\"exp_manager\", None))\n speaker_model = EncDecSpeakerLabelModel(cfg=cfg.model, trainer=trainer)\n trainer.fit(speaker_model)\n if not trainer.fast_dev_run:\n model_path = os.path.join(log_dir, '..', 'spkr.nemo')\n speaker_model.save_to(model_path)\n\n torch.distributed.destroy_process_group()\n if hasattr(cfg.model, 'test_ds') and cfg.model.test_ds.manifest_filepath is not None:\n if trainer.is_global_zero:\n trainer = pl.Trainer(devices=1, accelerator=cfg.trainer.accelerator, strategy=cfg.trainer.strategy)\n if speaker_model.prepare_test(trainer):\n trainer.test(speaker_model)\n\n\nif __name__ == '__main__':\n main()\n", "path": "examples/speaker_tasks/recognition/speaker_reco.py"}]}
| 1,787 | 195 |
gh_patches_debug_11070
|
rasdani/github-patches
|
git_diff
|
pymedusa__Medusa-2780
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[APP SUBMITTED]: TypeError: level must be an integer
### INFO
**Python Version**: `2.7.9 (default, Sep 17 2016, 20:26:04) [GCC 4.9.2]`
**Operating System**: `Linux-4.4.38-v7+-armv7l-with-debian-8.0`
**Locale**: `UTF-8`
**Branch**: [develop](../tree/develop)
**Database**: `44.8`
**Commit**: pymedusa/Medusa@289e34a0ff1556d94f314ee1d268036bccbc19ba
**Link to Log**: https://gist.github.com/fab36c448ceab560ac5437227d5f393a
### ERROR
<pre>
2017-05-10 00:06:46 ERROR SEARCHQUEUE-MANUAL-274431 :: [Danishbits] :: [289e34a] Failed parsing provider. Traceback: 'Traceback (most recent call last):\n File "/home/pi/Medusa/medusa/providers/torrent/html/danishbits.py", line 174, in parse\n title, seeders, leechers)\n File "/home/pi/Medusa/medusa/logger/adapters/style.py", line 79, in log\n self.logger.log(level, brace_msg, **kwargs)\n File "/usr/lib/python2.7/logging/__init__.py", line 1482, in log\n self.logger.log(level, msg, *args, **kwargs)\n File "/usr/lib/python2.7/logging/__init__.py", line 1220, in log\n raise TypeError("level must be an integer")\nTypeError: level must be an integer\n'
Traceback (most recent call last):
File "/home/pi/Medusa/<a href="../blob/289e34a0ff1556d94f314ee1d268036bccbc19ba/medusa/providers/torrent/html/danishbits.py#L174">medusa/providers/torrent/html/danishbits.py</a>", line 174, in parse
title, seeders, leechers)
File "/home/pi/Medusa/<a href="../blob/289e34a0ff1556d94f314ee1d268036bccbc19ba/medusa/logger/adapters/style.py#L79">medusa/logger/adapters/style.py</a>", line 79, in log
self.logger.log(level, brace_msg, **kwargs)
File "/usr/lib/python2.7/logging/__init__.py", line 1482, in log
self.logger.log(level, msg, *args, **kwargs)
File "/usr/lib/python2.7/logging/__init__.py", line 1220, in log
raise TypeError("level must be an integer")
TypeError: level must be an integer
</pre>
---
_STAFF NOTIFIED_: @pymedusa/support @pymedusa/moderators
</issue>
<code>
[start of medusa/providers/torrent/html/danishbits.py]
1 # coding=utf-8
2
3 """Provider code for Danishbits."""
4
5 from __future__ import unicode_literals
6
7 import logging
8 import traceback
9
10 from dateutil import parser
11
12 from medusa import tv
13 from medusa.bs4_parser import BS4Parser
14 from medusa.helper.common import (
15 convert_size,
16 try_int,
17 )
18 from medusa.logger.adapters.style import BraceAdapter
19 from medusa.providers.torrent.torrent_provider import TorrentProvider
20
21 from requests.compat import urljoin
22 from requests.utils import dict_from_cookiejar
23
24 log = BraceAdapter(logging.getLogger(__name__))
25 log.logger.addHandler(logging.NullHandler())
26
27
28 class DanishbitsProvider(TorrentProvider):
29 """Danishbits Torrent provider."""
30
31 def __init__(self):
32 """Initialize the class."""
33 super(self.__class__, self).__init__('Danishbits')
34
35 # Credentials
36 self.username = None
37 self.password = None
38
39 # URLs
40 self.url = 'https://danishbits.org'
41 self.urls = {
42 'login': urljoin(self.url, 'login.php'),
43 'search': urljoin(self.url, 'torrents.php'),
44 }
45
46 # Proper Strings
47
48 # Miscellaneous Options
49 self.freeleech = True
50
51 # Torrent Stats
52 self.minseed = 0
53 self.minleech = 0
54
55 # Cache
56 self.cache = tv.Cache(self, min_time=10) # Only poll Danishbits every 10 minutes max
57
58 def search(self, search_strings, age=0, ep_obj=None):
59 """
60 Search a provider and parse the results.
61
62 :param search_strings: A dict with mode (key) and the search value (value)
63 :param age: Not used
64 :param ep_obj: Not used
65 :returns: A list of search results (structure)
66 """
67 results = []
68 if not self.login():
69 return results
70
71 # Search Params
72 search_params = {
73 'action': 'newbrowse',
74 'group': 3,
75 'search': '',
76 }
77
78 for mode in search_strings:
79 log.debug('Search mode: {0}', mode)
80
81 for search_string in search_strings[mode]:
82
83 if mode != 'RSS':
84 log.debug('Search string: {search}',
85 {'search': search_string})
86
87 search_params['search'] = search_string
88 response = self.get_url(self.urls['search'], params=search_params, returns='response')
89 if not response or not response.text:
90 log.debug('No data returned from provider')
91 continue
92
93 results += self.parse(response.text, mode)
94
95 return results
96
97 def parse(self, data, mode):
98 """
99 Parse search results for items.
100
101 :param data: The raw response from a search
102 :param mode: The current mode used to search, e.g. RSS
103
104 :return: A list of items found
105 """
106 # Units
107 units = ['B', 'KB', 'MB', 'GB', 'TB', 'PB']
108
109 def process_column_header(td):
110 result = ''
111 if td.img:
112 result = td.img.get('title')
113 if not result:
114 result = td.get_text(strip=True)
115 return result
116
117 items = []
118
119 with BS4Parser(data, 'html5lib') as html:
120 torrent_table = html.find('table', id='torrent_table')
121 torrent_rows = torrent_table('tr') if torrent_table else []
122
123 # Continue only if at least one release is found
124 if len(torrent_rows) < 2:
125 log.debug('Data returned from provider does not contain any torrents')
126 return items
127
128 # Literal: Navn, Størrelse, Kommentarer, Tilføjet, Snatches, Seeders, Leechers
129 # Translation: Name, Size, Comments, Added, Snatches, Seeders, Leechers
130 labels = [process_column_header(label) for label in torrent_rows[0]('td')]
131
132 # Skip column headers
133 for row in torrent_rows[1:]:
134 cells = row('td')
135 if len(cells) < len(labels):
136 continue
137
138 try:
139 title = row.find(class_='croptorrenttext').get_text(strip=True)
140 download_url = urljoin(self.url, row.find(title='Direkte download link')['href'])
141 if not all([title, download_url]):
142 continue
143
144 seeders = try_int(cells[labels.index('Seeders')].get_text(strip=True))
145 leechers = try_int(cells[labels.index('Leechers')].get_text(strip=True))
146
147 # Filter unseeded torrent
148 if seeders < min(self.minseed, 1):
149 if mode != 'RSS':
150 log.debug("Discarding torrent because it doesn't meet the"
151 " minimum seeders: {0}. Seeders: {1}",
152 title, seeders)
153 continue
154
155 freeleech = row.find(class_='freeleech')
156 if self.freeleech and not freeleech:
157 continue
158
159 torrent_size = cells[labels.index('Størrelse')].contents[0]
160 size = convert_size(torrent_size, units=units) or -1
161 pubdate_raw = cells[labels.index('Tilføjet')].find('span')['title']
162 pubdate = parser.parse(pubdate_raw, fuzzy=True) if pubdate_raw else None
163
164 item = {
165 'title': title,
166 'link': download_url,
167 'size': size,
168 'seeders': seeders,
169 'leechers': leechers,
170 'pubdate': pubdate,
171 }
172 if mode != 'RSS':
173 log.log('Found result: {0} with {1} seeders and {2} leechers',
174 title, seeders, leechers)
175
176 items.append(item)
177 except (AttributeError, TypeError, KeyError, ValueError, IndexError):
178 log.error('Failed parsing provider. Traceback: {0!r}',
179 traceback.format_exc())
180
181 return items
182
183 def login(self):
184 """Login method used for logging in before doing search and torrent downloads."""
185 if any(dict_from_cookiejar(self.session.cookies).values()):
186 return True
187
188 login_params = {
189 'username': self.username,
190 'password': self.password,
191 'keeplogged': 1,
192 'langlang': '',
193 'login': 'Login',
194 }
195
196 response = self.get_url(self.urls['login'], post_data=login_params, returns='response')
197 if not response or not response.text:
198 log.warning('Unable to connect to provider')
199 self.session.cookies.clear()
200 return False
201
202 if '<title>Login :: Danishbits.org</title>' in response.text:
203 log.warning('Invalid username or password. Check your settings')
204 self.session.cookies.clear()
205 return False
206
207 return True
208
209
210 provider = DanishbitsProvider()
211
[end of medusa/providers/torrent/html/danishbits.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/medusa/providers/torrent/html/danishbits.py b/medusa/providers/torrent/html/danishbits.py
--- a/medusa/providers/torrent/html/danishbits.py
+++ b/medusa/providers/torrent/html/danishbits.py
@@ -170,8 +170,8 @@
'pubdate': pubdate,
}
if mode != 'RSS':
- log.log('Found result: {0} with {1} seeders and {2} leechers',
- title, seeders, leechers)
+ log.debug('Found result: {0} with {1} seeders and {2} leechers',
+ title, seeders, leechers)
items.append(item)
except (AttributeError, TypeError, KeyError, ValueError, IndexError):
|
{"golden_diff": "diff --git a/medusa/providers/torrent/html/danishbits.py b/medusa/providers/torrent/html/danishbits.py\n--- a/medusa/providers/torrent/html/danishbits.py\n+++ b/medusa/providers/torrent/html/danishbits.py\n@@ -170,8 +170,8 @@\n 'pubdate': pubdate,\n }\n if mode != 'RSS':\n- log.log('Found result: {0} with {1} seeders and {2} leechers',\n- title, seeders, leechers)\n+ log.debug('Found result: {0} with {1} seeders and {2} leechers',\n+ title, seeders, leechers)\n \n items.append(item)\n except (AttributeError, TypeError, KeyError, ValueError, IndexError):\n", "issue": "[APP SUBMITTED]: TypeError: level must be an integer\n### INFO\n**Python Version**: `2.7.9 (default, Sep 17 2016, 20:26:04) [GCC 4.9.2]`\n**Operating System**: `Linux-4.4.38-v7+-armv7l-with-debian-8.0`\n**Locale**: `UTF-8`\n**Branch**: [develop](../tree/develop)\n**Database**: `44.8`\n**Commit**: pymedusa/Medusa@289e34a0ff1556d94f314ee1d268036bccbc19ba\n**Link to Log**: https://gist.github.com/fab36c448ceab560ac5437227d5f393a\n### ERROR\n<pre>\n2017-05-10 00:06:46 ERROR SEARCHQUEUE-MANUAL-274431 :: [Danishbits] :: [289e34a] Failed parsing provider. Traceback: 'Traceback (most recent call last):\\n File \"/home/pi/Medusa/medusa/providers/torrent/html/danishbits.py\", line 174, in parse\\n title, seeders, leechers)\\n File \"/home/pi/Medusa/medusa/logger/adapters/style.py\", line 79, in log\\n self.logger.log(level, brace_msg, **kwargs)\\n File \"/usr/lib/python2.7/logging/__init__.py\", line 1482, in log\\n self.logger.log(level, msg, *args, **kwargs)\\n File \"/usr/lib/python2.7/logging/__init__.py\", line 1220, in log\\n raise TypeError(\"level must be an integer\")\\nTypeError: level must be an integer\\n'\nTraceback (most recent call last):\n File \"/home/pi/Medusa/<a href=\"../blob/289e34a0ff1556d94f314ee1d268036bccbc19ba/medusa/providers/torrent/html/danishbits.py#L174\">medusa/providers/torrent/html/danishbits.py</a>\", line 174, in parse\n title, seeders, leechers)\n File \"/home/pi/Medusa/<a href=\"../blob/289e34a0ff1556d94f314ee1d268036bccbc19ba/medusa/logger/adapters/style.py#L79\">medusa/logger/adapters/style.py</a>\", line 79, in log\n self.logger.log(level, brace_msg, **kwargs)\n File \"/usr/lib/python2.7/logging/__init__.py\", line 1482, in log\n self.logger.log(level, msg, *args, **kwargs)\n File \"/usr/lib/python2.7/logging/__init__.py\", line 1220, in log\n raise TypeError(\"level must be an integer\")\nTypeError: level must be an integer\n</pre>\n---\n_STAFF NOTIFIED_: @pymedusa/support @pymedusa/moderators\n", "before_files": [{"content": "# coding=utf-8\n\n\"\"\"Provider code for Danishbits.\"\"\"\n\nfrom __future__ import unicode_literals\n\nimport logging\nimport traceback\n\nfrom dateutil import parser\n\nfrom medusa import tv\nfrom medusa.bs4_parser import BS4Parser\nfrom medusa.helper.common import (\n convert_size,\n try_int,\n)\nfrom medusa.logger.adapters.style import BraceAdapter\nfrom medusa.providers.torrent.torrent_provider import TorrentProvider\n\nfrom requests.compat import urljoin\nfrom requests.utils import dict_from_cookiejar\n\nlog = BraceAdapter(logging.getLogger(__name__))\nlog.logger.addHandler(logging.NullHandler())\n\n\nclass DanishbitsProvider(TorrentProvider):\n \"\"\"Danishbits Torrent provider.\"\"\"\n\n def __init__(self):\n \"\"\"Initialize the class.\"\"\"\n super(self.__class__, self).__init__('Danishbits')\n\n # Credentials\n self.username = None\n self.password = None\n\n # URLs\n self.url = 'https://danishbits.org'\n self.urls = {\n 'login': urljoin(self.url, 'login.php'),\n 'search': urljoin(self.url, 'torrents.php'),\n }\n\n # Proper Strings\n\n # Miscellaneous Options\n self.freeleech = True\n\n # Torrent Stats\n self.minseed = 0\n self.minleech = 0\n\n # Cache\n self.cache = tv.Cache(self, min_time=10) # Only poll Danishbits every 10 minutes max\n\n def search(self, search_strings, age=0, ep_obj=None):\n \"\"\"\n Search a provider and parse the results.\n\n :param search_strings: A dict with mode (key) and the search value (value)\n :param age: Not used\n :param ep_obj: Not used\n :returns: A list of search results (structure)\n \"\"\"\n results = []\n if not self.login():\n return results\n\n # Search Params\n search_params = {\n 'action': 'newbrowse',\n 'group': 3,\n 'search': '',\n }\n\n for mode in search_strings:\n log.debug('Search mode: {0}', mode)\n\n for search_string in search_strings[mode]:\n\n if mode != 'RSS':\n log.debug('Search string: {search}',\n {'search': search_string})\n\n search_params['search'] = search_string\n response = self.get_url(self.urls['search'], params=search_params, returns='response')\n if not response or not response.text:\n log.debug('No data returned from provider')\n continue\n\n results += self.parse(response.text, mode)\n\n return results\n\n def parse(self, data, mode):\n \"\"\"\n Parse search results for items.\n\n :param data: The raw response from a search\n :param mode: The current mode used to search, e.g. RSS\n\n :return: A list of items found\n \"\"\"\n # Units\n units = ['B', 'KB', 'MB', 'GB', 'TB', 'PB']\n\n def process_column_header(td):\n result = ''\n if td.img:\n result = td.img.get('title')\n if not result:\n result = td.get_text(strip=True)\n return result\n\n items = []\n\n with BS4Parser(data, 'html5lib') as html:\n torrent_table = html.find('table', id='torrent_table')\n torrent_rows = torrent_table('tr') if torrent_table else []\n\n # Continue only if at least one release is found\n if len(torrent_rows) < 2:\n log.debug('Data returned from provider does not contain any torrents')\n return items\n\n # Literal: Navn, St\u00f8rrelse, Kommentarer, Tilf\u00f8jet, Snatches, Seeders, Leechers\n # Translation: Name, Size, Comments, Added, Snatches, Seeders, Leechers\n labels = [process_column_header(label) for label in torrent_rows[0]('td')]\n\n # Skip column headers\n for row in torrent_rows[1:]:\n cells = row('td')\n if len(cells) < len(labels):\n continue\n\n try:\n title = row.find(class_='croptorrenttext').get_text(strip=True)\n download_url = urljoin(self.url, row.find(title='Direkte download link')['href'])\n if not all([title, download_url]):\n continue\n\n seeders = try_int(cells[labels.index('Seeders')].get_text(strip=True))\n leechers = try_int(cells[labels.index('Leechers')].get_text(strip=True))\n\n # Filter unseeded torrent\n if seeders < min(self.minseed, 1):\n if mode != 'RSS':\n log.debug(\"Discarding torrent because it doesn't meet the\"\n \" minimum seeders: {0}. Seeders: {1}\",\n title, seeders)\n continue\n\n freeleech = row.find(class_='freeleech')\n if self.freeleech and not freeleech:\n continue\n\n torrent_size = cells[labels.index('St\u00f8rrelse')].contents[0]\n size = convert_size(torrent_size, units=units) or -1\n pubdate_raw = cells[labels.index('Tilf\u00f8jet')].find('span')['title']\n pubdate = parser.parse(pubdate_raw, fuzzy=True) if pubdate_raw else None\n\n item = {\n 'title': title,\n 'link': download_url,\n 'size': size,\n 'seeders': seeders,\n 'leechers': leechers,\n 'pubdate': pubdate,\n }\n if mode != 'RSS':\n log.log('Found result: {0} with {1} seeders and {2} leechers',\n title, seeders, leechers)\n\n items.append(item)\n except (AttributeError, TypeError, KeyError, ValueError, IndexError):\n log.error('Failed parsing provider. Traceback: {0!r}',\n traceback.format_exc())\n\n return items\n\n def login(self):\n \"\"\"Login method used for logging in before doing search and torrent downloads.\"\"\"\n if any(dict_from_cookiejar(self.session.cookies).values()):\n return True\n\n login_params = {\n 'username': self.username,\n 'password': self.password,\n 'keeplogged': 1,\n 'langlang': '',\n 'login': 'Login',\n }\n\n response = self.get_url(self.urls['login'], post_data=login_params, returns='response')\n if not response or not response.text:\n log.warning('Unable to connect to provider')\n self.session.cookies.clear()\n return False\n\n if '<title>Login :: Danishbits.org</title>' in response.text:\n log.warning('Invalid username or password. Check your settings')\n self.session.cookies.clear()\n return False\n\n return True\n\n\nprovider = DanishbitsProvider()\n", "path": "medusa/providers/torrent/html/danishbits.py"}]}
| 3,309 | 183 |
gh_patches_debug_41916
|
rasdani/github-patches
|
git_diff
|
freedomofpress__securedrop-2649
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Missing translation for 'This field is required' across all languages
# Bug
## Description
When navigating to `/login` and pressing submit on an empty, the default (English) error message string is displayed.
## Steps to Reproduce
1. Click on the localized equivalent of 'Check for a response`
2. Click submit (while leaving an empty string)
3. Observe the error message.
## Expected Behavior
The error message should be displayed in the localized language.
## Actual Behavior
The message is displayed in English.
</issue>
<code>
[start of securedrop/source_app/forms.py]
1 from flask_babel import gettext
2 from flask_wtf import FlaskForm
3 from wtforms import PasswordField
4 from wtforms.validators import InputRequired, Regexp, Length
5
6 from db import Source
7
8
9 class LoginForm(FlaskForm):
10 codename = PasswordField('codename', validators=[
11 InputRequired(message=gettext('This field is required.')),
12 Length(1, Source.MAX_CODENAME_LEN,
13 message=gettext('Field must be between 1 and '
14 '{max_codename_len} characters long.'.format(
15 max_codename_len=Source.MAX_CODENAME_LEN))),
16 # Make sure to allow dashes since some words in the wordlist have them
17 Regexp(r'[\sA-Za-z0-9-]+$', message=gettext('Invalid input.'))
18 ])
19
[end of securedrop/source_app/forms.py]
[start of securedrop/journalist_app/forms.py]
1 # -*- coding: utf-8 -*-
2
3 from flask_babel import gettext
4 from flask_wtf import FlaskForm
5 from wtforms import (TextAreaField, TextField, BooleanField, HiddenField,
6 ValidationError)
7 from wtforms.validators import InputRequired, Optional
8
9 from db import Journalist
10
11
12 def otp_secret_validation(form, field):
13 strip_whitespace = field.data.replace(' ', '')
14 if len(strip_whitespace) != 40:
15 raise ValidationError(gettext('Field must be 40 characters long but '
16 'got {num_chars}.'.format(
17 num_chars=len(strip_whitespace)
18 )))
19
20
21 def minimum_length_validation(form, field):
22 if len(field.data) < Journalist.MIN_USERNAME_LEN:
23 raise ValidationError(
24 gettext('Field must be at least {min_chars} '
25 'characters long but only got '
26 '{num_chars}.'.format(
27 min_chars=Journalist.MIN_USERNAME_LEN,
28 num_chars=len(field.data))))
29
30
31 class NewUserForm(FlaskForm):
32 username = TextField('username', validators=[
33 InputRequired(message=gettext('This field is required.')),
34 minimum_length_validation
35 ])
36 password = HiddenField('password')
37 is_admin = BooleanField('is_admin')
38 is_hotp = BooleanField('is_hotp')
39 otp_secret = TextField('otp_secret', validators=[
40 otp_secret_validation,
41 Optional()
42 ])
43
44
45 class ReplyForm(FlaskForm):
46 message = TextAreaField(
47 u'Message',
48 id="content-area",
49 validators=[
50 InputRequired(message=gettext('You cannot send an empty reply.')),
51 ],
52 )
53
[end of securedrop/journalist_app/forms.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/securedrop/journalist_app/forms.py b/securedrop/journalist_app/forms.py
--- a/securedrop/journalist_app/forms.py
+++ b/securedrop/journalist_app/forms.py
@@ -1,6 +1,6 @@
# -*- coding: utf-8 -*-
-from flask_babel import gettext
+from flask_babel import lazy_gettext
from flask_wtf import FlaskForm
from wtforms import (TextAreaField, TextField, BooleanField, HiddenField,
ValidationError)
@@ -12,25 +12,26 @@
def otp_secret_validation(form, field):
strip_whitespace = field.data.replace(' ', '')
if len(strip_whitespace) != 40:
- raise ValidationError(gettext('Field must be 40 characters long but '
- 'got {num_chars}.'.format(
- num_chars=len(strip_whitespace)
- )))
+ raise ValidationError(lazy_gettext(
+ 'Field must be 40 characters long but '
+ 'got {num_chars}.'.format(
+ num_chars=len(strip_whitespace)
+ )))
def minimum_length_validation(form, field):
if len(field.data) < Journalist.MIN_USERNAME_LEN:
raise ValidationError(
- gettext('Field must be at least {min_chars} '
- 'characters long but only got '
- '{num_chars}.'.format(
- min_chars=Journalist.MIN_USERNAME_LEN,
- num_chars=len(field.data))))
+ lazy_gettext('Field must be at least {min_chars} '
+ 'characters long but only got '
+ '{num_chars}.'.format(
+ min_chars=Journalist.MIN_USERNAME_LEN,
+ num_chars=len(field.data))))
class NewUserForm(FlaskForm):
username = TextField('username', validators=[
- InputRequired(message=gettext('This field is required.')),
+ InputRequired(message=lazy_gettext('This field is required.')),
minimum_length_validation
])
password = HiddenField('password')
@@ -47,6 +48,7 @@
u'Message',
id="content-area",
validators=[
- InputRequired(message=gettext('You cannot send an empty reply.')),
+ InputRequired(message=lazy_gettext(
+ 'You cannot send an empty reply.')),
],
)
diff --git a/securedrop/source_app/forms.py b/securedrop/source_app/forms.py
--- a/securedrop/source_app/forms.py
+++ b/securedrop/source_app/forms.py
@@ -1,4 +1,4 @@
-from flask_babel import gettext
+from flask_babel import lazy_gettext
from flask_wtf import FlaskForm
from wtforms import PasswordField
from wtforms.validators import InputRequired, Regexp, Length
@@ -8,11 +8,12 @@
class LoginForm(FlaskForm):
codename = PasswordField('codename', validators=[
- InputRequired(message=gettext('This field is required.')),
+ InputRequired(message=lazy_gettext('This field is required.')),
Length(1, Source.MAX_CODENAME_LEN,
- message=gettext('Field must be between 1 and '
- '{max_codename_len} characters long.'.format(
- max_codename_len=Source.MAX_CODENAME_LEN))),
+ message=lazy_gettext(
+ 'Field must be between 1 and '
+ '{max_codename_len} characters long.'.format(
+ max_codename_len=Source.MAX_CODENAME_LEN))),
# Make sure to allow dashes since some words in the wordlist have them
- Regexp(r'[\sA-Za-z0-9-]+$', message=gettext('Invalid input.'))
+ Regexp(r'[\sA-Za-z0-9-]+$', message=lazy_gettext('Invalid input.'))
])
|
{"golden_diff": "diff --git a/securedrop/journalist_app/forms.py b/securedrop/journalist_app/forms.py\n--- a/securedrop/journalist_app/forms.py\n+++ b/securedrop/journalist_app/forms.py\n@@ -1,6 +1,6 @@\n # -*- coding: utf-8 -*-\n \n-from flask_babel import gettext\n+from flask_babel import lazy_gettext\n from flask_wtf import FlaskForm\n from wtforms import (TextAreaField, TextField, BooleanField, HiddenField,\n ValidationError)\n@@ -12,25 +12,26 @@\n def otp_secret_validation(form, field):\n strip_whitespace = field.data.replace(' ', '')\n if len(strip_whitespace) != 40:\n- raise ValidationError(gettext('Field must be 40 characters long but '\n- 'got {num_chars}.'.format(\n- num_chars=len(strip_whitespace)\n- )))\n+ raise ValidationError(lazy_gettext(\n+ 'Field must be 40 characters long but '\n+ 'got {num_chars}.'.format(\n+ num_chars=len(strip_whitespace)\n+ )))\n \n \n def minimum_length_validation(form, field):\n if len(field.data) < Journalist.MIN_USERNAME_LEN:\n raise ValidationError(\n- gettext('Field must be at least {min_chars} '\n- 'characters long but only got '\n- '{num_chars}.'.format(\n- min_chars=Journalist.MIN_USERNAME_LEN,\n- num_chars=len(field.data))))\n+ lazy_gettext('Field must be at least {min_chars} '\n+ 'characters long but only got '\n+ '{num_chars}.'.format(\n+ min_chars=Journalist.MIN_USERNAME_LEN,\n+ num_chars=len(field.data))))\n \n \n class NewUserForm(FlaskForm):\n username = TextField('username', validators=[\n- InputRequired(message=gettext('This field is required.')),\n+ InputRequired(message=lazy_gettext('This field is required.')),\n minimum_length_validation\n ])\n password = HiddenField('password')\n@@ -47,6 +48,7 @@\n u'Message',\n id=\"content-area\",\n validators=[\n- InputRequired(message=gettext('You cannot send an empty reply.')),\n+ InputRequired(message=lazy_gettext(\n+ 'You cannot send an empty reply.')),\n ],\n )\ndiff --git a/securedrop/source_app/forms.py b/securedrop/source_app/forms.py\n--- a/securedrop/source_app/forms.py\n+++ b/securedrop/source_app/forms.py\n@@ -1,4 +1,4 @@\n-from flask_babel import gettext\n+from flask_babel import lazy_gettext\n from flask_wtf import FlaskForm\n from wtforms import PasswordField\n from wtforms.validators import InputRequired, Regexp, Length\n@@ -8,11 +8,12 @@\n \n class LoginForm(FlaskForm):\n codename = PasswordField('codename', validators=[\n- InputRequired(message=gettext('This field is required.')),\n+ InputRequired(message=lazy_gettext('This field is required.')),\n Length(1, Source.MAX_CODENAME_LEN,\n- message=gettext('Field must be between 1 and '\n- '{max_codename_len} characters long.'.format(\n- max_codename_len=Source.MAX_CODENAME_LEN))),\n+ message=lazy_gettext(\n+ 'Field must be between 1 and '\n+ '{max_codename_len} characters long.'.format(\n+ max_codename_len=Source.MAX_CODENAME_LEN))),\n # Make sure to allow dashes since some words in the wordlist have them\n- Regexp(r'[\\sA-Za-z0-9-]+$', message=gettext('Invalid input.'))\n+ Regexp(r'[\\sA-Za-z0-9-]+$', message=lazy_gettext('Invalid input.'))\n ])\n", "issue": "Missing translation for 'This field is required' across all languages\n# Bug\r\n\r\n## Description\r\n\r\nWhen navigating to `/login` and pressing submit on an empty, the default (English) error message string is displayed.\r\n\r\n## Steps to Reproduce\r\n\r\n1. Click on the localized equivalent of 'Check for a response`\r\n2. Click submit (while leaving an empty string)\r\n3. Observe the error message.\r\n\r\n## Expected Behavior\r\nThe error message should be displayed in the localized language.\r\n\r\n## Actual Behavior\r\n\r\nThe message is displayed in English.\n", "before_files": [{"content": "from flask_babel import gettext\nfrom flask_wtf import FlaskForm\nfrom wtforms import PasswordField\nfrom wtforms.validators import InputRequired, Regexp, Length\n\nfrom db import Source\n\n\nclass LoginForm(FlaskForm):\n codename = PasswordField('codename', validators=[\n InputRequired(message=gettext('This field is required.')),\n Length(1, Source.MAX_CODENAME_LEN,\n message=gettext('Field must be between 1 and '\n '{max_codename_len} characters long.'.format(\n max_codename_len=Source.MAX_CODENAME_LEN))),\n # Make sure to allow dashes since some words in the wordlist have them\n Regexp(r'[\\sA-Za-z0-9-]+$', message=gettext('Invalid input.'))\n ])\n", "path": "securedrop/source_app/forms.py"}, {"content": "# -*- coding: utf-8 -*-\n\nfrom flask_babel import gettext\nfrom flask_wtf import FlaskForm\nfrom wtforms import (TextAreaField, TextField, BooleanField, HiddenField,\n ValidationError)\nfrom wtforms.validators import InputRequired, Optional\n\nfrom db import Journalist\n\n\ndef otp_secret_validation(form, field):\n strip_whitespace = field.data.replace(' ', '')\n if len(strip_whitespace) != 40:\n raise ValidationError(gettext('Field must be 40 characters long but '\n 'got {num_chars}.'.format(\n num_chars=len(strip_whitespace)\n )))\n\n\ndef minimum_length_validation(form, field):\n if len(field.data) < Journalist.MIN_USERNAME_LEN:\n raise ValidationError(\n gettext('Field must be at least {min_chars} '\n 'characters long but only got '\n '{num_chars}.'.format(\n min_chars=Journalist.MIN_USERNAME_LEN,\n num_chars=len(field.data))))\n\n\nclass NewUserForm(FlaskForm):\n username = TextField('username', validators=[\n InputRequired(message=gettext('This field is required.')),\n minimum_length_validation\n ])\n password = HiddenField('password')\n is_admin = BooleanField('is_admin')\n is_hotp = BooleanField('is_hotp')\n otp_secret = TextField('otp_secret', validators=[\n otp_secret_validation,\n Optional()\n ])\n\n\nclass ReplyForm(FlaskForm):\n message = TextAreaField(\n u'Message',\n id=\"content-area\",\n validators=[\n InputRequired(message=gettext('You cannot send an empty reply.')),\n ],\n )\n", "path": "securedrop/journalist_app/forms.py"}]}
| 1,297 | 822 |
gh_patches_debug_19209
|
rasdani/github-patches
|
git_diff
|
freedomofpress__securedrop-4309
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
On the Admin Workstation, N SecureDrop updater processes are started if N network interfaces are enabled in Tails
## Description
If a Tails Admin Workstation has more than one network interface, the SecureDrop network manager hook that checks for updates will run for each active NIC. (For example, if a workstation has both Ethernet and Wifi enabled.)
This is confusing to end users and may result in multiple update processes clobbering each other's changes.
## Steps to Reproduce
On an Admin Workstation:
- revert to an earlier SecureDrop version:
```
cd ~/Persistent/securedrop
git checkout 0.10.0
```
- enable multiple network connections (eg Ethernet and Wifi) and wait for their Tor connections to come up
## Expected Behavior
A single instance of the Securedrop Updater is started.
## Actual Behavior
Multiple instances of the SecureDrop Updater are started.
</issue>
<code>
[start of journalist_gui/journalist_gui/SecureDropUpdater.py]
1 #!/usr/bin/python
2 from PyQt5 import QtGui, QtWidgets
3 from PyQt5.QtCore import QThread, pyqtSignal
4 import subprocess
5 import os
6 import re
7 import pexpect
8
9 from journalist_gui import updaterUI, strings, resources_rc # noqa
10
11
12 FLAG_LOCATION = "/home/amnesia/Persistent/.securedrop/securedrop_update.flag" # noqa
13 ESCAPE_POD = re.compile(r'\x1B\[[0-?]*[ -/]*[@-~]')
14
15
16 class SetupThread(QThread):
17 signal = pyqtSignal('PyQt_PyObject')
18
19 def __init__(self):
20 QThread.__init__(self)
21 self.output = ""
22 self.update_success = False
23 self.failure_reason = ""
24
25 def run(self):
26 sdadmin_path = '/home/amnesia/Persistent/securedrop/securedrop-admin'
27 update_command = [sdadmin_path, 'setup']
28
29 # Create flag file to indicate we should resume failed updates on
30 # reboot. Don't create the flag if it already exists.
31 if not os.path.exists(FLAG_LOCATION):
32 open(FLAG_LOCATION, 'a').close()
33
34 try:
35 self.output = subprocess.check_output(
36 update_command,
37 stderr=subprocess.STDOUT).decode('utf-8')
38 if 'Failed to install' in self.output:
39 self.update_success = False
40 self.failure_reason = strings.update_failed_generic_reason
41 else:
42 self.update_success = True
43 except subprocess.CalledProcessError as e:
44 self.output += e.output.decode('utf-8')
45 self.update_success = False
46 self.failure_reason = strings.update_failed_generic_reason
47 result = {'status': self.update_success,
48 'output': self.output,
49 'failure_reason': self.failure_reason}
50 self.signal.emit(result)
51
52
53 # This thread will handle the ./securedrop-admin update command
54 class UpdateThread(QThread):
55 signal = pyqtSignal('PyQt_PyObject')
56
57 def __init__(self):
58 QThread.__init__(self)
59 self.output = ""
60 self.update_success = False
61 self.failure_reason = ""
62
63 def run(self):
64 sdadmin_path = '/home/amnesia/Persistent/securedrop/securedrop-admin'
65 update_command = [sdadmin_path, 'update']
66 try:
67 self.output = subprocess.check_output(
68 update_command,
69 stderr=subprocess.STDOUT).decode('utf-8')
70 if "Signature verification successful" in self.output:
71 self.update_success = True
72 else:
73 self.failure_reason = strings.update_failed_generic_reason
74 except subprocess.CalledProcessError as e:
75 self.update_success = False
76 self.output += e.output.decode('utf-8')
77 if 'Signature verification failed' in self.output:
78 self.failure_reason = strings.update_failed_sig_failure
79 else:
80 self.failure_reason = strings.update_failed_generic_reason
81 result = {'status': self.update_success,
82 'output': self.output,
83 'failure_reason': self.failure_reason}
84 self.signal.emit(result)
85
86
87 # This thread will handle the ./securedrop-admin tailsconfig command
88 class TailsconfigThread(QThread):
89 signal = pyqtSignal('PyQt_PyObject')
90
91 def __init__(self):
92 QThread.__init__(self)
93 self.output = ""
94 self.update_success = False
95 self.failure_reason = ""
96 self.sudo_password = ""
97
98 def run(self):
99 tailsconfig_command = ("/home/amnesia/Persistent/"
100 "securedrop/securedrop-admin "
101 "tailsconfig")
102 try:
103 child = pexpect.spawn(tailsconfig_command)
104 child.expect('SUDO password:')
105 self.output += child.before.decode('utf-8')
106 child.sendline(self.sudo_password)
107 child.expect(pexpect.EOF)
108 self.output += child.before.decode('utf-8')
109 child.close()
110
111 # For Tailsconfig to be considered a success, we expect no
112 # failures in the Ansible output.
113 if child.exitstatus:
114 self.update_success = False
115 self.failure_reason = strings.tailsconfig_failed_generic_reason # noqa
116 else:
117 self.update_success = True
118 except pexpect.exceptions.TIMEOUT:
119 self.update_success = False
120 self.failure_reason = strings.tailsconfig_failed_sudo_password
121
122 except subprocess.CalledProcessError:
123 self.update_success = False
124 self.failure_reason = strings.tailsconfig_failed_generic_reason
125 result = {'status': self.update_success,
126 'output': ESCAPE_POD.sub('', self.output),
127 'failure_reason': self.failure_reason}
128 self.signal.emit(result)
129
130
131 class UpdaterApp(QtWidgets.QMainWindow, updaterUI.Ui_MainWindow):
132
133 def __init__(self, parent=None):
134 super(UpdaterApp, self).__init__(parent)
135 self.setupUi(self)
136 self.statusbar.setSizeGripEnabled(False)
137 self.output = strings.initial_text_box
138 self.plainTextEdit.setPlainText(self.output)
139 self.update_success = False
140
141 pixmap = QtGui.QPixmap(":/images/static/banner.png")
142 self.label_2.setPixmap(pixmap)
143 self.label_2.setScaledContents(True)
144
145 self.progressBar.setProperty("value", 0)
146 self.setWindowTitle(strings.window_title)
147 self.setWindowIcon(QtGui.QIcon(':/images/static/securedrop_icon.png'))
148 self.label.setText(strings.update_in_progress)
149
150 self.tabWidget.setTabText(self.tabWidget.indexOf(self.tab),
151 strings.main_tab)
152 self.tabWidget.setTabText(self.tabWidget.indexOf(self.tab_2),
153 strings.output_tab)
154
155 # Connect buttons to their functions.
156 self.pushButton.setText(strings.install_later_button)
157 self.pushButton.setStyleSheet("""background-color: lightgrey;
158 min-height: 2em;
159 border-radius: 10px""")
160 self.pushButton.clicked.connect(self.close)
161 self.pushButton_2.setText(strings.install_update_button)
162 self.pushButton_2.setStyleSheet("""background-color: #E6FFEB;
163 min-height: 2em;
164 border-radius: 10px;""")
165 self.pushButton_2.clicked.connect(self.update_securedrop)
166 self.update_thread = UpdateThread()
167 self.update_thread.signal.connect(self.update_status)
168 self.tails_thread = TailsconfigThread()
169 self.tails_thread.signal.connect(self.tails_status)
170 self.setup_thread = SetupThread()
171 self.setup_thread.signal.connect(self.setup_status)
172
173 # At the end of this function, we will try to do tailsconfig.
174 # A new slot will handle tailsconfig output
175 def setup_status(self, result):
176 "This is the slot for setup thread"
177 self.output += result['output']
178 self.update_success = result['status']
179 self.failure_reason = result['failure_reason']
180 self.progressBar.setProperty("value", 60)
181 self.plainTextEdit.setPlainText(self.output)
182 self.plainTextEdit.setReadOnly = True
183 if not self.update_success: # Failed to do setup
184 self.pushButton.setEnabled(True)
185 self.pushButton_2.setEnabled(True)
186 self.update_status_bar_and_output(self.failure_reason)
187 self.progressBar.setProperty("value", 0)
188 self.alert_failure(self.failure_reason)
189 return
190 self.progressBar.setProperty("value", 70)
191 self.call_tailsconfig()
192
193 # This will update the output text after the git commands.
194 def update_status(self, result):
195 "This is the slot for update thread"
196 self.output += result['output']
197 self.update_success = result['status']
198 self.failure_reason = result['failure_reason']
199 self.progressBar.setProperty("value", 40)
200 self.plainTextEdit.setPlainText(self.output)
201 self.plainTextEdit.setReadOnly = True
202 if not self.update_success: # Failed to do update
203 self.pushButton.setEnabled(True)
204 self.pushButton_2.setEnabled(True)
205 self.update_status_bar_and_output(self.failure_reason)
206 self.progressBar.setProperty("value", 0)
207 self.alert_failure(self.failure_reason)
208 return
209 self.progressBar.setProperty("value", 50)
210 self.update_status_bar_and_output(strings.doing_setup)
211 self.setup_thread.start()
212
213 def update_status_bar_and_output(self, status_message):
214 """This method updates the status bar and the output window with the
215 status_message."""
216 self.statusbar.showMessage(status_message)
217 self.output += status_message + '\n'
218 self.plainTextEdit.setPlainText(self.output)
219
220 def call_tailsconfig(self):
221 # Now let us work on tailsconfig part
222 if self.update_success:
223 # Get sudo password and add an enter key as tailsconfig command
224 # expects
225 sudo_password = self.get_sudo_password()
226 if not sudo_password:
227 self.update_success = False
228 self.failure_reason = strings.missing_sudo_password
229 self.on_failure()
230 return
231 self.tails_thread.sudo_password = sudo_password + '\n'
232 self.update_status_bar_and_output(strings.updating_tails_env)
233 self.tails_thread.start()
234 else:
235 self.on_failure()
236
237 def tails_status(self, result):
238 "This is the slot for Tailsconfig thread"
239 self.output += result['output']
240 self.update_success = result['status']
241 self.failure_reason = result['failure_reason']
242 self.plainTextEdit.setPlainText(self.output)
243 self.progressBar.setProperty("value", 80)
244 if self.update_success:
245 # Remove flag file indicating an update is in progress
246 os.remove(FLAG_LOCATION)
247 self.update_status_bar_and_output(strings.finished)
248 self.progressBar.setProperty("value", 100)
249 self.alert_success()
250 else:
251 self.on_failure()
252
253 def on_failure(self):
254 self.update_status_bar_and_output(self.failure_reason)
255 self.alert_failure(self.failure_reason)
256 # Now everything is done, enable the button.
257 self.pushButton.setEnabled(True)
258 self.pushButton_2.setEnabled(True)
259 self.progressBar.setProperty("value", 0)
260
261 def update_securedrop(self):
262 self.pushButton_2.setEnabled(False)
263 self.pushButton.setEnabled(False)
264 self.progressBar.setProperty("value", 10)
265 self.update_status_bar_and_output(strings.fetching_update)
266 self.update_thread.start()
267
268 def alert_success(self):
269 self.success_dialog = QtWidgets.QMessageBox()
270 self.success_dialog.setIcon(QtWidgets.QMessageBox.Information)
271 self.success_dialog.setText(strings.finished_dialog_message)
272 self.success_dialog.setWindowTitle(strings.finished_dialog_title)
273 self.success_dialog.show()
274
275 def alert_failure(self, failure_reason):
276 self.error_dialog = QtWidgets.QMessageBox()
277 self.error_dialog.setIcon(QtWidgets.QMessageBox.Critical)
278 self.error_dialog.setText(self.failure_reason)
279 self.error_dialog.setWindowTitle(strings.update_failed_dialog_title)
280 self.error_dialog.show()
281
282 def get_sudo_password(self):
283 sudo_password, ok_is_pressed = QtWidgets.QInputDialog.getText(
284 self, "Tails Administrator password", strings.sudo_password_text,
285 QtWidgets.QLineEdit.Password, "")
286 if ok_is_pressed and sudo_password:
287 return sudo_password
288 else:
289 return None
290
[end of journalist_gui/journalist_gui/SecureDropUpdater.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/journalist_gui/journalist_gui/SecureDropUpdater.py b/journalist_gui/journalist_gui/SecureDropUpdater.py
--- a/journalist_gui/journalist_gui/SecureDropUpdater.py
+++ b/journalist_gui/journalist_gui/SecureDropUpdater.py
@@ -5,6 +5,8 @@
import os
import re
import pexpect
+import socket
+import sys
from journalist_gui import updaterUI, strings, resources_rc # noqa
@@ -13,6 +15,25 @@
ESCAPE_POD = re.compile(r'\x1B\[[0-?]*[ -/]*[@-~]')
+def prevent_second_instance(app: QtWidgets.QApplication, name: str) -> None: # noqa
+
+ # Null byte triggers abstract namespace
+ IDENTIFIER = '\0' + name
+ ALREADY_BOUND_ERRNO = 98
+
+ app.instance_binding = socket.socket(socket.AF_UNIX, socket.SOCK_DGRAM)
+ try:
+ app.instance_binding.bind(IDENTIFIER)
+ except OSError as e:
+ if e.errno == ALREADY_BOUND_ERRNO:
+ err_dialog = QtWidgets.QMessageBox()
+ err_dialog.setText(name + ' is already running.')
+ err_dialog.exec()
+ sys.exit()
+ else:
+ raise
+
+
class SetupThread(QThread):
signal = pyqtSignal('PyQt_PyObject')
|
{"golden_diff": "diff --git a/journalist_gui/journalist_gui/SecureDropUpdater.py b/journalist_gui/journalist_gui/SecureDropUpdater.py\n--- a/journalist_gui/journalist_gui/SecureDropUpdater.py\n+++ b/journalist_gui/journalist_gui/SecureDropUpdater.py\n@@ -5,6 +5,8 @@\n import os\n import re\n import pexpect\n+import socket\n+import sys\n \n from journalist_gui import updaterUI, strings, resources_rc # noqa\n \n@@ -13,6 +15,25 @@\n ESCAPE_POD = re.compile(r'\\x1B\\[[0-?]*[ -/]*[@-~]')\n \n \n+def prevent_second_instance(app: QtWidgets.QApplication, name: str) -> None: # noqa\n+\n+ # Null byte triggers abstract namespace\n+ IDENTIFIER = '\\0' + name\n+ ALREADY_BOUND_ERRNO = 98\n+\n+ app.instance_binding = socket.socket(socket.AF_UNIX, socket.SOCK_DGRAM)\n+ try:\n+ app.instance_binding.bind(IDENTIFIER)\n+ except OSError as e:\n+ if e.errno == ALREADY_BOUND_ERRNO:\n+ err_dialog = QtWidgets.QMessageBox()\n+ err_dialog.setText(name + ' is already running.')\n+ err_dialog.exec()\n+ sys.exit()\n+ else:\n+ raise\n+\n+\n class SetupThread(QThread):\n signal = pyqtSignal('PyQt_PyObject')\n", "issue": "On the Admin Workstation, N SecureDrop updater processes are started if N network interfaces are enabled in Tails\n## Description\r\n\r\nIf a Tails Admin Workstation has more than one network interface, the SecureDrop network manager hook that checks for updates will run for each active NIC. (For example, if a workstation has both Ethernet and Wifi enabled.)\r\n\r\nThis is confusing to end users and may result in multiple update processes clobbering each other's changes.\r\n\r\n## Steps to Reproduce\r\n\r\nOn an Admin Workstation:\r\n- revert to an earlier SecureDrop version:\r\n```\r\ncd ~/Persistent/securedrop\r\ngit checkout 0.10.0\r\n```\r\n- enable multiple network connections (eg Ethernet and Wifi) and wait for their Tor connections to come up\r\n\r\n## Expected Behavior\r\nA single instance of the Securedrop Updater is started.\r\n\r\n## Actual Behavior\r\nMultiple instances of the SecureDrop Updater are started.\r\n\n", "before_files": [{"content": "#!/usr/bin/python\nfrom PyQt5 import QtGui, QtWidgets\nfrom PyQt5.QtCore import QThread, pyqtSignal\nimport subprocess\nimport os\nimport re\nimport pexpect\n\nfrom journalist_gui import updaterUI, strings, resources_rc # noqa\n\n\nFLAG_LOCATION = \"/home/amnesia/Persistent/.securedrop/securedrop_update.flag\" # noqa\nESCAPE_POD = re.compile(r'\\x1B\\[[0-?]*[ -/]*[@-~]')\n\n\nclass SetupThread(QThread):\n signal = pyqtSignal('PyQt_PyObject')\n\n def __init__(self):\n QThread.__init__(self)\n self.output = \"\"\n self.update_success = False\n self.failure_reason = \"\"\n\n def run(self):\n sdadmin_path = '/home/amnesia/Persistent/securedrop/securedrop-admin'\n update_command = [sdadmin_path, 'setup']\n\n # Create flag file to indicate we should resume failed updates on\n # reboot. Don't create the flag if it already exists.\n if not os.path.exists(FLAG_LOCATION):\n open(FLAG_LOCATION, 'a').close()\n\n try:\n self.output = subprocess.check_output(\n update_command,\n stderr=subprocess.STDOUT).decode('utf-8')\n if 'Failed to install' in self.output:\n self.update_success = False\n self.failure_reason = strings.update_failed_generic_reason\n else:\n self.update_success = True\n except subprocess.CalledProcessError as e:\n self.output += e.output.decode('utf-8')\n self.update_success = False\n self.failure_reason = strings.update_failed_generic_reason\n result = {'status': self.update_success,\n 'output': self.output,\n 'failure_reason': self.failure_reason}\n self.signal.emit(result)\n\n\n# This thread will handle the ./securedrop-admin update command\nclass UpdateThread(QThread):\n signal = pyqtSignal('PyQt_PyObject')\n\n def __init__(self):\n QThread.__init__(self)\n self.output = \"\"\n self.update_success = False\n self.failure_reason = \"\"\n\n def run(self):\n sdadmin_path = '/home/amnesia/Persistent/securedrop/securedrop-admin'\n update_command = [sdadmin_path, 'update']\n try:\n self.output = subprocess.check_output(\n update_command,\n stderr=subprocess.STDOUT).decode('utf-8')\n if \"Signature verification successful\" in self.output:\n self.update_success = True\n else:\n self.failure_reason = strings.update_failed_generic_reason\n except subprocess.CalledProcessError as e:\n self.update_success = False\n self.output += e.output.decode('utf-8')\n if 'Signature verification failed' in self.output:\n self.failure_reason = strings.update_failed_sig_failure\n else:\n self.failure_reason = strings.update_failed_generic_reason\n result = {'status': self.update_success,\n 'output': self.output,\n 'failure_reason': self.failure_reason}\n self.signal.emit(result)\n\n\n# This thread will handle the ./securedrop-admin tailsconfig command\nclass TailsconfigThread(QThread):\n signal = pyqtSignal('PyQt_PyObject')\n\n def __init__(self):\n QThread.__init__(self)\n self.output = \"\"\n self.update_success = False\n self.failure_reason = \"\"\n self.sudo_password = \"\"\n\n def run(self):\n tailsconfig_command = (\"/home/amnesia/Persistent/\"\n \"securedrop/securedrop-admin \"\n \"tailsconfig\")\n try:\n child = pexpect.spawn(tailsconfig_command)\n child.expect('SUDO password:')\n self.output += child.before.decode('utf-8')\n child.sendline(self.sudo_password)\n child.expect(pexpect.EOF)\n self.output += child.before.decode('utf-8')\n child.close()\n\n # For Tailsconfig to be considered a success, we expect no\n # failures in the Ansible output.\n if child.exitstatus:\n self.update_success = False\n self.failure_reason = strings.tailsconfig_failed_generic_reason # noqa\n else:\n self.update_success = True\n except pexpect.exceptions.TIMEOUT:\n self.update_success = False\n self.failure_reason = strings.tailsconfig_failed_sudo_password\n\n except subprocess.CalledProcessError:\n self.update_success = False\n self.failure_reason = strings.tailsconfig_failed_generic_reason\n result = {'status': self.update_success,\n 'output': ESCAPE_POD.sub('', self.output),\n 'failure_reason': self.failure_reason}\n self.signal.emit(result)\n\n\nclass UpdaterApp(QtWidgets.QMainWindow, updaterUI.Ui_MainWindow):\n\n def __init__(self, parent=None):\n super(UpdaterApp, self).__init__(parent)\n self.setupUi(self)\n self.statusbar.setSizeGripEnabled(False)\n self.output = strings.initial_text_box\n self.plainTextEdit.setPlainText(self.output)\n self.update_success = False\n\n pixmap = QtGui.QPixmap(\":/images/static/banner.png\")\n self.label_2.setPixmap(pixmap)\n self.label_2.setScaledContents(True)\n\n self.progressBar.setProperty(\"value\", 0)\n self.setWindowTitle(strings.window_title)\n self.setWindowIcon(QtGui.QIcon(':/images/static/securedrop_icon.png'))\n self.label.setText(strings.update_in_progress)\n\n self.tabWidget.setTabText(self.tabWidget.indexOf(self.tab),\n strings.main_tab)\n self.tabWidget.setTabText(self.tabWidget.indexOf(self.tab_2),\n strings.output_tab)\n\n # Connect buttons to their functions.\n self.pushButton.setText(strings.install_later_button)\n self.pushButton.setStyleSheet(\"\"\"background-color: lightgrey;\n min-height: 2em;\n border-radius: 10px\"\"\")\n self.pushButton.clicked.connect(self.close)\n self.pushButton_2.setText(strings.install_update_button)\n self.pushButton_2.setStyleSheet(\"\"\"background-color: #E6FFEB;\n min-height: 2em;\n border-radius: 10px;\"\"\")\n self.pushButton_2.clicked.connect(self.update_securedrop)\n self.update_thread = UpdateThread()\n self.update_thread.signal.connect(self.update_status)\n self.tails_thread = TailsconfigThread()\n self.tails_thread.signal.connect(self.tails_status)\n self.setup_thread = SetupThread()\n self.setup_thread.signal.connect(self.setup_status)\n\n # At the end of this function, we will try to do tailsconfig.\n # A new slot will handle tailsconfig output\n def setup_status(self, result):\n \"This is the slot for setup thread\"\n self.output += result['output']\n self.update_success = result['status']\n self.failure_reason = result['failure_reason']\n self.progressBar.setProperty(\"value\", 60)\n self.plainTextEdit.setPlainText(self.output)\n self.plainTextEdit.setReadOnly = True\n if not self.update_success: # Failed to do setup\n self.pushButton.setEnabled(True)\n self.pushButton_2.setEnabled(True)\n self.update_status_bar_and_output(self.failure_reason)\n self.progressBar.setProperty(\"value\", 0)\n self.alert_failure(self.failure_reason)\n return\n self.progressBar.setProperty(\"value\", 70)\n self.call_tailsconfig()\n\n # This will update the output text after the git commands.\n def update_status(self, result):\n \"This is the slot for update thread\"\n self.output += result['output']\n self.update_success = result['status']\n self.failure_reason = result['failure_reason']\n self.progressBar.setProperty(\"value\", 40)\n self.plainTextEdit.setPlainText(self.output)\n self.plainTextEdit.setReadOnly = True\n if not self.update_success: # Failed to do update\n self.pushButton.setEnabled(True)\n self.pushButton_2.setEnabled(True)\n self.update_status_bar_and_output(self.failure_reason)\n self.progressBar.setProperty(\"value\", 0)\n self.alert_failure(self.failure_reason)\n return\n self.progressBar.setProperty(\"value\", 50)\n self.update_status_bar_and_output(strings.doing_setup)\n self.setup_thread.start()\n\n def update_status_bar_and_output(self, status_message):\n \"\"\"This method updates the status bar and the output window with the\n status_message.\"\"\"\n self.statusbar.showMessage(status_message)\n self.output += status_message + '\\n'\n self.plainTextEdit.setPlainText(self.output)\n\n def call_tailsconfig(self):\n # Now let us work on tailsconfig part\n if self.update_success:\n # Get sudo password and add an enter key as tailsconfig command\n # expects\n sudo_password = self.get_sudo_password()\n if not sudo_password:\n self.update_success = False\n self.failure_reason = strings.missing_sudo_password\n self.on_failure()\n return\n self.tails_thread.sudo_password = sudo_password + '\\n'\n self.update_status_bar_and_output(strings.updating_tails_env)\n self.tails_thread.start()\n else:\n self.on_failure()\n\n def tails_status(self, result):\n \"This is the slot for Tailsconfig thread\"\n self.output += result['output']\n self.update_success = result['status']\n self.failure_reason = result['failure_reason']\n self.plainTextEdit.setPlainText(self.output)\n self.progressBar.setProperty(\"value\", 80)\n if self.update_success:\n # Remove flag file indicating an update is in progress\n os.remove(FLAG_LOCATION)\n self.update_status_bar_and_output(strings.finished)\n self.progressBar.setProperty(\"value\", 100)\n self.alert_success()\n else:\n self.on_failure()\n\n def on_failure(self):\n self.update_status_bar_and_output(self.failure_reason)\n self.alert_failure(self.failure_reason)\n # Now everything is done, enable the button.\n self.pushButton.setEnabled(True)\n self.pushButton_2.setEnabled(True)\n self.progressBar.setProperty(\"value\", 0)\n\n def update_securedrop(self):\n self.pushButton_2.setEnabled(False)\n self.pushButton.setEnabled(False)\n self.progressBar.setProperty(\"value\", 10)\n self.update_status_bar_and_output(strings.fetching_update)\n self.update_thread.start()\n\n def alert_success(self):\n self.success_dialog = QtWidgets.QMessageBox()\n self.success_dialog.setIcon(QtWidgets.QMessageBox.Information)\n self.success_dialog.setText(strings.finished_dialog_message)\n self.success_dialog.setWindowTitle(strings.finished_dialog_title)\n self.success_dialog.show()\n\n def alert_failure(self, failure_reason):\n self.error_dialog = QtWidgets.QMessageBox()\n self.error_dialog.setIcon(QtWidgets.QMessageBox.Critical)\n self.error_dialog.setText(self.failure_reason)\n self.error_dialog.setWindowTitle(strings.update_failed_dialog_title)\n self.error_dialog.show()\n\n def get_sudo_password(self):\n sudo_password, ok_is_pressed = QtWidgets.QInputDialog.getText(\n self, \"Tails Administrator password\", strings.sudo_password_text,\n QtWidgets.QLineEdit.Password, \"\")\n if ok_is_pressed and sudo_password:\n return sudo_password\n else:\n return None\n", "path": "journalist_gui/journalist_gui/SecureDropUpdater.py"}]}
| 3,831 | 314 |
gh_patches_debug_16621
|
rasdani/github-patches
|
git_diff
|
pre-commit__pre-commit-1997
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Docker inspect fails when running with Docker in Docker
When trying to run pre commits with `docker_image` language via GitLabs Docker in Docker approach the docker inspect fails, and so pre-commit throws an error when trying to get the mount path.
The [code](https://github.com/pre-commit/pre-commit/blob/fe436f1eb09dfdd67032b4f9f8dfa543fb99cf06/pre_commit/languages/docker.py#L39) for this already has a fall back of "return path" but doesn't handle the docker command failing.
Could the code for this be modified to handle the docker inspect failing?
More details of docker in docker are [here](https://docs.gitlab.com/ee/ci/docker/using_docker_build.html#use-the-docker-executor-with-the-docker-image-docker-in-docker)
Full logs of the failure:
### version information
```
pre-commit version: 2.13.0
sys.version:
3.6.9 (default, Jan 26 2021, 15:33:00)
[GCC 8.4.0]
sys.executable: /usr/bin/python3
os.name: posix
sys.platform: linux
```
### error information
```
An unexpected error has occurred: CalledProcessError: command: ('/usr/bin/docker', 'inspect', 'runner-dmrvfsu-project-35395-concurrent-0')
return code: 1
expected return code: 0
stdout:
[]
stderr:
Error: No such object: runner-dmrvfsu-project-35395-concurrent-0
```
```
Traceback (most recent call last):
File "/usr/local/lib/python3.6/dist-packages/pre_commit/error_handler.py", line 65, in error_handler
yield
File "/usr/local/lib/python3.6/dist-packages/pre_commit/main.py", line 385, in main
return run(args.config, store, args)
File "/usr/local/lib/python3.6/dist-packages/pre_commit/commands/run.py", line 410, in run
return _run_hooks(config, hooks, skips, args, environ)
File "/usr/local/lib/python3.6/dist-packages/pre_commit/commands/run.py", line 288, in _run_hooks
verbose=args.verbose, use_color=args.color,
File "/usr/local/lib/python3.6/dist-packages/pre_commit/commands/run.py", line 194, in _run_single_hook
retcode, out = language.run_hook(hook, filenames, use_color)
File "/usr/local/lib/python3.6/dist-packages/pre_commit/languages/docker_image.py", line 19, in run_hook
cmd = docker_cmd() + hook.cmd
File "/usr/local/lib/python3.6/dist-packages/pre_commit/languages/docker.py", line 107, in docker_cmd
'-v', f'{_get_docker_path(os.getcwd())}:/src:rw,Z',
File "/usr/local/lib/python3.6/dist-packages/pre_commit/languages/docker.py", line 34, in _get_docker_path
_, out, _ = cmd_output_b('docker', 'inspect', hostname)
File "/usr/local/lib/python3.6/dist-packages/pre_commit/util.py", line 154, in cmd_output_b
raise CalledProcessError(returncode, cmd, retcode, stdout_b, stderr_b)
pre_commit.util.CalledProcessError: command: ('/usr/bin/docker', 'inspect', 'runner-dmrvfsu-project-35395-concurrent-0')
return code: 1
expected return code: 0
stdout:
[]
stderr:
Error: No such object: runner-dmrvfsu-project-35395-concurrent-0
```
</issue>
<code>
[start of pre_commit/languages/docker.py]
1 import hashlib
2 import json
3 import os
4 from typing import Sequence
5 from typing import Tuple
6
7 import pre_commit.constants as C
8 from pre_commit.hook import Hook
9 from pre_commit.languages import helpers
10 from pre_commit.prefix import Prefix
11 from pre_commit.util import clean_path_on_failure
12 from pre_commit.util import cmd_output_b
13
14 ENVIRONMENT_DIR = 'docker'
15 PRE_COMMIT_LABEL = 'PRE_COMMIT'
16 get_default_version = helpers.basic_get_default_version
17 healthy = helpers.basic_healthy
18
19
20 def _is_in_docker() -> bool:
21 try:
22 with open('/proc/1/cgroup', 'rb') as f:
23 return b'docker' in f.read()
24 except FileNotFoundError:
25 return False
26
27
28 def _get_container_id() -> str:
29 # It's assumed that we already check /proc/1/cgroup in _is_in_docker. The
30 # cpuset cgroup controller existed since cgroups were introduced so this
31 # way of getting the container ID is pretty reliable.
32 with open('/proc/1/cgroup', 'rb') as f:
33 for line in f.readlines():
34 if line.split(b':')[1] == b'cpuset':
35 return os.path.basename(line.split(b':')[2]).strip().decode()
36 raise RuntimeError('Failed to find the container ID in /proc/1/cgroup.')
37
38
39 def _get_docker_path(path: str) -> str:
40 if not _is_in_docker():
41 return path
42
43 container_id = _get_container_id()
44
45 _, out, _ = cmd_output_b('docker', 'inspect', container_id)
46
47 container, = json.loads(out)
48 for mount in container['Mounts']:
49 src_path = mount['Source']
50 to_path = mount['Destination']
51 if os.path.commonpath((path, to_path)) == to_path:
52 # So there is something in common,
53 # and we can proceed remapping it
54 return path.replace(to_path, src_path)
55 # we're in Docker, but the path is not mounted, cannot really do anything,
56 # so fall back to original path
57 return path
58
59
60 def md5(s: str) -> str: # pragma: win32 no cover
61 return hashlib.md5(s.encode()).hexdigest()
62
63
64 def docker_tag(prefix: Prefix) -> str: # pragma: win32 no cover
65 md5sum = md5(os.path.basename(prefix.prefix_dir)).lower()
66 return f'pre-commit-{md5sum}'
67
68
69 def build_docker_image(
70 prefix: Prefix,
71 *,
72 pull: bool,
73 ) -> None: # pragma: win32 no cover
74 cmd: Tuple[str, ...] = (
75 'docker', 'build',
76 '--tag', docker_tag(prefix),
77 '--label', PRE_COMMIT_LABEL,
78 )
79 if pull:
80 cmd += ('--pull',)
81 # This must come last for old versions of docker. See #477
82 cmd += ('.',)
83 helpers.run_setup_cmd(prefix, cmd)
84
85
86 def install_environment(
87 prefix: Prefix, version: str, additional_dependencies: Sequence[str],
88 ) -> None: # pragma: win32 no cover
89 helpers.assert_version_default('docker', version)
90 helpers.assert_no_additional_deps('docker', additional_dependencies)
91
92 directory = prefix.path(
93 helpers.environment_dir(ENVIRONMENT_DIR, C.DEFAULT),
94 )
95
96 # Docker doesn't really have relevant disk environment, but pre-commit
97 # still needs to cleanup its state files on failure
98 with clean_path_on_failure(directory):
99 build_docker_image(prefix, pull=True)
100 os.mkdir(directory)
101
102
103 def get_docker_user() -> Tuple[str, ...]: # pragma: win32 no cover
104 try:
105 return ('-u', f'{os.getuid()}:{os.getgid()}')
106 except AttributeError:
107 return ()
108
109
110 def docker_cmd() -> Tuple[str, ...]: # pragma: win32 no cover
111 return (
112 'docker', 'run',
113 '--rm',
114 *get_docker_user(),
115 # https://docs.docker.com/engine/reference/commandline/run/#mount-volumes-from-container-volumes-from
116 # The `Z` option tells Docker to label the content with a private
117 # unshared label. Only the current container can use a private volume.
118 '-v', f'{_get_docker_path(os.getcwd())}:/src:rw,Z',
119 '--workdir', '/src',
120 )
121
122
123 def run_hook(
124 hook: Hook,
125 file_args: Sequence[str],
126 color: bool,
127 ) -> Tuple[int, bytes]: # pragma: win32 no cover
128 # Rebuild the docker image in case it has gone missing, as many people do
129 # automated cleanup of docker images.
130 build_docker_image(hook.prefix, pull=False)
131
132 entry_exe, *cmd_rest = hook.cmd
133
134 entry_tag = ('--entrypoint', entry_exe, docker_tag(hook.prefix))
135 cmd = (*docker_cmd(), *entry_tag, *cmd_rest)
136 return helpers.run_xargs(hook, cmd, file_args, color=color)
137
[end of pre_commit/languages/docker.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/pre_commit/languages/docker.py b/pre_commit/languages/docker.py
--- a/pre_commit/languages/docker.py
+++ b/pre_commit/languages/docker.py
@@ -8,6 +8,7 @@
from pre_commit.hook import Hook
from pre_commit.languages import helpers
from pre_commit.prefix import Prefix
+from pre_commit.util import CalledProcessError
from pre_commit.util import clean_path_on_failure
from pre_commit.util import cmd_output_b
@@ -42,7 +43,11 @@
container_id = _get_container_id()
- _, out, _ = cmd_output_b('docker', 'inspect', container_id)
+ try:
+ _, out, _ = cmd_output_b('docker', 'inspect', container_id)
+ except CalledProcessError:
+ # self-container was not visible from here (perhaps docker-in-docker)
+ return path
container, = json.loads(out)
for mount in container['Mounts']:
|
{"golden_diff": "diff --git a/pre_commit/languages/docker.py b/pre_commit/languages/docker.py\n--- a/pre_commit/languages/docker.py\n+++ b/pre_commit/languages/docker.py\n@@ -8,6 +8,7 @@\n from pre_commit.hook import Hook\n from pre_commit.languages import helpers\n from pre_commit.prefix import Prefix\n+from pre_commit.util import CalledProcessError\n from pre_commit.util import clean_path_on_failure\n from pre_commit.util import cmd_output_b\n \n@@ -42,7 +43,11 @@\n \n container_id = _get_container_id()\n \n- _, out, _ = cmd_output_b('docker', 'inspect', container_id)\n+ try:\n+ _, out, _ = cmd_output_b('docker', 'inspect', container_id)\n+ except CalledProcessError:\n+ # self-container was not visible from here (perhaps docker-in-docker)\n+ return path\n \n container, = json.loads(out)\n for mount in container['Mounts']:\n", "issue": "Docker inspect fails when running with Docker in Docker\nWhen trying to run pre commits with `docker_image` language via GitLabs Docker in Docker approach the docker inspect fails, and so pre-commit throws an error when trying to get the mount path.\r\n\r\nThe [code](https://github.com/pre-commit/pre-commit/blob/fe436f1eb09dfdd67032b4f9f8dfa543fb99cf06/pre_commit/languages/docker.py#L39) for this already has a fall back of \"return path\" but doesn't handle the docker command failing.\r\n\r\nCould the code for this be modified to handle the docker inspect failing?\r\n\r\nMore details of docker in docker are [here](https://docs.gitlab.com/ee/ci/docker/using_docker_build.html#use-the-docker-executor-with-the-docker-image-docker-in-docker)\r\n\r\n\r\nFull logs of the failure:\r\n\r\n\r\n### version information\r\n\r\n```\r\npre-commit version: 2.13.0\r\nsys.version:\r\n 3.6.9 (default, Jan 26 2021, 15:33:00) \r\n [GCC 8.4.0]\r\nsys.executable: /usr/bin/python3\r\nos.name: posix\r\nsys.platform: linux\r\n```\r\n\r\n### error information\r\n\r\n```\r\nAn unexpected error has occurred: CalledProcessError: command: ('/usr/bin/docker', 'inspect', 'runner-dmrvfsu-project-35395-concurrent-0')\r\nreturn code: 1\r\nexpected return code: 0\r\nstdout:\r\n []\r\n \r\nstderr:\r\n Error: No such object: runner-dmrvfsu-project-35395-concurrent-0\r\n \r\n```\r\n\r\n```\r\nTraceback (most recent call last):\r\n File \"/usr/local/lib/python3.6/dist-packages/pre_commit/error_handler.py\", line 65, in error_handler\r\n yield\r\n File \"/usr/local/lib/python3.6/dist-packages/pre_commit/main.py\", line 385, in main\r\n return run(args.config, store, args)\r\n File \"/usr/local/lib/python3.6/dist-packages/pre_commit/commands/run.py\", line 410, in run\r\n return _run_hooks(config, hooks, skips, args, environ)\r\n File \"/usr/local/lib/python3.6/dist-packages/pre_commit/commands/run.py\", line 288, in _run_hooks\r\n verbose=args.verbose, use_color=args.color,\r\n File \"/usr/local/lib/python3.6/dist-packages/pre_commit/commands/run.py\", line 194, in _run_single_hook\r\n retcode, out = language.run_hook(hook, filenames, use_color)\r\n File \"/usr/local/lib/python3.6/dist-packages/pre_commit/languages/docker_image.py\", line 19, in run_hook\r\n cmd = docker_cmd() + hook.cmd\r\n File \"/usr/local/lib/python3.6/dist-packages/pre_commit/languages/docker.py\", line 107, in docker_cmd\r\n '-v', f'{_get_docker_path(os.getcwd())}:/src:rw,Z',\r\n File \"/usr/local/lib/python3.6/dist-packages/pre_commit/languages/docker.py\", line 34, in _get_docker_path\r\n _, out, _ = cmd_output_b('docker', 'inspect', hostname)\r\n File \"/usr/local/lib/python3.6/dist-packages/pre_commit/util.py\", line 154, in cmd_output_b\r\n raise CalledProcessError(returncode, cmd, retcode, stdout_b, stderr_b)\r\npre_commit.util.CalledProcessError: command: ('/usr/bin/docker', 'inspect', 'runner-dmrvfsu-project-35395-concurrent-0')\r\nreturn code: 1\r\nexpected return code: 0\r\nstdout:\r\n []\r\n \r\nstderr:\r\n Error: No such object: runner-dmrvfsu-project-35395-concurrent-0\r\n```\n", "before_files": [{"content": "import hashlib\nimport json\nimport os\nfrom typing import Sequence\nfrom typing import Tuple\n\nimport pre_commit.constants as C\nfrom pre_commit.hook import Hook\nfrom pre_commit.languages import helpers\nfrom pre_commit.prefix import Prefix\nfrom pre_commit.util import clean_path_on_failure\nfrom pre_commit.util import cmd_output_b\n\nENVIRONMENT_DIR = 'docker'\nPRE_COMMIT_LABEL = 'PRE_COMMIT'\nget_default_version = helpers.basic_get_default_version\nhealthy = helpers.basic_healthy\n\n\ndef _is_in_docker() -> bool:\n try:\n with open('/proc/1/cgroup', 'rb') as f:\n return b'docker' in f.read()\n except FileNotFoundError:\n return False\n\n\ndef _get_container_id() -> str:\n # It's assumed that we already check /proc/1/cgroup in _is_in_docker. The\n # cpuset cgroup controller existed since cgroups were introduced so this\n # way of getting the container ID is pretty reliable.\n with open('/proc/1/cgroup', 'rb') as f:\n for line in f.readlines():\n if line.split(b':')[1] == b'cpuset':\n return os.path.basename(line.split(b':')[2]).strip().decode()\n raise RuntimeError('Failed to find the container ID in /proc/1/cgroup.')\n\n\ndef _get_docker_path(path: str) -> str:\n if not _is_in_docker():\n return path\n\n container_id = _get_container_id()\n\n _, out, _ = cmd_output_b('docker', 'inspect', container_id)\n\n container, = json.loads(out)\n for mount in container['Mounts']:\n src_path = mount['Source']\n to_path = mount['Destination']\n if os.path.commonpath((path, to_path)) == to_path:\n # So there is something in common,\n # and we can proceed remapping it\n return path.replace(to_path, src_path)\n # we're in Docker, but the path is not mounted, cannot really do anything,\n # so fall back to original path\n return path\n\n\ndef md5(s: str) -> str: # pragma: win32 no cover\n return hashlib.md5(s.encode()).hexdigest()\n\n\ndef docker_tag(prefix: Prefix) -> str: # pragma: win32 no cover\n md5sum = md5(os.path.basename(prefix.prefix_dir)).lower()\n return f'pre-commit-{md5sum}'\n\n\ndef build_docker_image(\n prefix: Prefix,\n *,\n pull: bool,\n) -> None: # pragma: win32 no cover\n cmd: Tuple[str, ...] = (\n 'docker', 'build',\n '--tag', docker_tag(prefix),\n '--label', PRE_COMMIT_LABEL,\n )\n if pull:\n cmd += ('--pull',)\n # This must come last for old versions of docker. See #477\n cmd += ('.',)\n helpers.run_setup_cmd(prefix, cmd)\n\n\ndef install_environment(\n prefix: Prefix, version: str, additional_dependencies: Sequence[str],\n) -> None: # pragma: win32 no cover\n helpers.assert_version_default('docker', version)\n helpers.assert_no_additional_deps('docker', additional_dependencies)\n\n directory = prefix.path(\n helpers.environment_dir(ENVIRONMENT_DIR, C.DEFAULT),\n )\n\n # Docker doesn't really have relevant disk environment, but pre-commit\n # still needs to cleanup its state files on failure\n with clean_path_on_failure(directory):\n build_docker_image(prefix, pull=True)\n os.mkdir(directory)\n\n\ndef get_docker_user() -> Tuple[str, ...]: # pragma: win32 no cover\n try:\n return ('-u', f'{os.getuid()}:{os.getgid()}')\n except AttributeError:\n return ()\n\n\ndef docker_cmd() -> Tuple[str, ...]: # pragma: win32 no cover\n return (\n 'docker', 'run',\n '--rm',\n *get_docker_user(),\n # https://docs.docker.com/engine/reference/commandline/run/#mount-volumes-from-container-volumes-from\n # The `Z` option tells Docker to label the content with a private\n # unshared label. Only the current container can use a private volume.\n '-v', f'{_get_docker_path(os.getcwd())}:/src:rw,Z',\n '--workdir', '/src',\n )\n\n\ndef run_hook(\n hook: Hook,\n file_args: Sequence[str],\n color: bool,\n) -> Tuple[int, bytes]: # pragma: win32 no cover\n # Rebuild the docker image in case it has gone missing, as many people do\n # automated cleanup of docker images.\n build_docker_image(hook.prefix, pull=False)\n\n entry_exe, *cmd_rest = hook.cmd\n\n entry_tag = ('--entrypoint', entry_exe, docker_tag(hook.prefix))\n cmd = (*docker_cmd(), *entry_tag, *cmd_rest)\n return helpers.run_xargs(hook, cmd, file_args, color=color)\n", "path": "pre_commit/languages/docker.py"}]}
| 2,789 | 209 |
gh_patches_debug_10060
|
rasdani/github-patches
|
git_diff
|
freqtrade__freqtrade-2100
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Strategy list is space separated
`--strategy-list Strat1,Strat2` produces an error while `--strategy-list Strat1 Strat2` works
It became a space separated list somehow while its description states it's a comma-separated list:
```
--strategy-list STRATEGY_LIST [STRATEGY_LIST ...]
Provide **a comma-separated list** of strategies to
backtest. Please note that ticker-interval needs to be
set either in config or via command line. When using
this together with `--export trades`, the strategy-
name is injected into the filename (so `backtest-
data.json` becomes `backtest-data-
DefaultStrategy.json`
```
Which direction this should be fixed to?
</issue>
<code>
[start of freqtrade/configuration/cli_options.py]
1 """
2 Definition of cli arguments used in arguments.py
3 """
4 import argparse
5 import os
6
7 from freqtrade import __version__, constants
8
9
10 def check_int_positive(value: str) -> int:
11 try:
12 uint = int(value)
13 if uint <= 0:
14 raise ValueError
15 except ValueError:
16 raise argparse.ArgumentTypeError(
17 f"{value} is invalid for this parameter, should be a positive integer value"
18 )
19 return uint
20
21
22 class Arg:
23 # Optional CLI arguments
24 def __init__(self, *args, **kwargs):
25 self.cli = args
26 self.kwargs = kwargs
27
28
29 # List of available command line options
30 AVAILABLE_CLI_OPTIONS = {
31 # Common options
32 "verbosity": Arg(
33 '-v', '--verbose',
34 help='Verbose mode (-vv for more, -vvv to get all messages).',
35 action='count',
36 default=0,
37 ),
38 "logfile": Arg(
39 '--logfile',
40 help='Log to the file specified.',
41 metavar='FILE',
42 ),
43 "version": Arg(
44 '-V', '--version',
45 action='version',
46 version=f'%(prog)s {__version__}',
47 ),
48 "config": Arg(
49 '-c', '--config',
50 help=f'Specify configuration file (default: `{constants.DEFAULT_CONFIG}`). '
51 f'Multiple --config options may be used. '
52 f'Can be set to `-` to read config from stdin.',
53 action='append',
54 metavar='PATH',
55 ),
56 "datadir": Arg(
57 '-d', '--datadir',
58 help='Path to backtest data.',
59 metavar='PATH',
60 ),
61 # Main options
62 "strategy": Arg(
63 '-s', '--strategy',
64 help='Specify strategy class name (default: `%(default)s`).',
65 metavar='NAME',
66 default='DefaultStrategy',
67 ),
68 "strategy_path": Arg(
69 '--strategy-path',
70 help='Specify additional strategy lookup path.',
71 metavar='PATH',
72 ),
73 "db_url": Arg(
74 '--db-url',
75 help=f'Override trades database URL, this is useful in custom deployments '
76 f'(default: `{constants.DEFAULT_DB_PROD_URL}` for Live Run mode, '
77 f'`{constants.DEFAULT_DB_DRYRUN_URL}` for Dry Run).',
78 metavar='PATH',
79 ),
80 "sd_notify": Arg(
81 '--sd-notify',
82 help='Notify systemd service manager.',
83 action='store_true',
84 ),
85 # Optimize common
86 "ticker_interval": Arg(
87 '-i', '--ticker-interval',
88 help='Specify ticker interval (`1m`, `5m`, `30m`, `1h`, `1d`).',
89 ),
90 "timerange": Arg(
91 '--timerange',
92 help='Specify what timerange of data to use.',
93 ),
94 "max_open_trades": Arg(
95 '--max_open_trades',
96 help='Specify max_open_trades to use.',
97 type=int,
98 metavar='INT',
99 ),
100 "stake_amount": Arg(
101 '--stake_amount',
102 help='Specify stake_amount.',
103 type=float,
104 ),
105 "refresh_pairs": Arg(
106 '-r', '--refresh-pairs-cached',
107 help='Refresh the pairs files in tests/testdata with the latest data from the '
108 'exchange. Use it if you want to run your optimization commands with '
109 'up-to-date data.',
110 action='store_true',
111 ),
112 # Backtesting
113 "position_stacking": Arg(
114 '--eps', '--enable-position-stacking',
115 help='Allow buying the same pair multiple times (position stacking).',
116 action='store_true',
117 default=False,
118 ),
119 "use_max_market_positions": Arg(
120 '--dmmp', '--disable-max-market-positions',
121 help='Disable applying `max_open_trades` during backtest '
122 '(same as setting `max_open_trades` to a very high number).',
123 action='store_false',
124 default=True,
125 ),
126 "live": Arg(
127 '-l', '--live',
128 help='Use live data.',
129 action='store_true',
130 ),
131 "strategy_list": Arg(
132 '--strategy-list',
133 help='Provide a comma-separated list of strategies to backtest. '
134 'Please note that ticker-interval needs to be set either in config '
135 'or via command line. When using this together with `--export trades`, '
136 'the strategy-name is injected into the filename '
137 '(so `backtest-data.json` becomes `backtest-data-DefaultStrategy.json`',
138 nargs='+',
139 ),
140 "export": Arg(
141 '--export',
142 help='Export backtest results, argument are: trades. '
143 'Example: `--export=trades`',
144 ),
145 "exportfilename": Arg(
146 '--export-filename',
147 help='Save backtest results to the file with this filename (default: `%(default)s`). '
148 'Requires `--export` to be set as well. '
149 'Example: `--export-filename=user_data/backtest_data/backtest_today.json`',
150 metavar='PATH',
151 default=os.path.join('user_data', 'backtest_data',
152 'backtest-result.json'),
153 ),
154 # Edge
155 "stoploss_range": Arg(
156 '--stoplosses',
157 help='Defines a range of stoploss values against which edge will assess the strategy. '
158 'The format is "min,max,step" (without any space). '
159 'Example: `--stoplosses=-0.01,-0.1,-0.001`',
160 ),
161 # Hyperopt
162 "hyperopt": Arg(
163 '--customhyperopt',
164 help='Specify hyperopt class name (default: `%(default)s`).',
165 metavar='NAME',
166 default=constants.DEFAULT_HYPEROPT,
167 ),
168 "hyperopt_path": Arg(
169 '--hyperopt-path',
170 help='Specify additional lookup path for Hyperopts and Hyperopt Loss functions.',
171 metavar='PATH',
172 ),
173 "epochs": Arg(
174 '-e', '--epochs',
175 help='Specify number of epochs (default: %(default)d).',
176 type=check_int_positive,
177 metavar='INT',
178 default=constants.HYPEROPT_EPOCH,
179 ),
180 "spaces": Arg(
181 '-s', '--spaces',
182 help='Specify which parameters to hyperopt. Space-separated list. '
183 'Default: `%(default)s`.',
184 choices=['all', 'buy', 'sell', 'roi', 'stoploss'],
185 nargs='+',
186 default='all',
187 ),
188 "print_all": Arg(
189 '--print-all',
190 help='Print all results, not only the best ones.',
191 action='store_true',
192 default=False,
193 ),
194 "hyperopt_jobs": Arg(
195 '-j', '--job-workers',
196 help='The number of concurrently running jobs for hyperoptimization '
197 '(hyperopt worker processes). '
198 'If -1 (default), all CPUs are used, for -2, all CPUs but one are used, etc. '
199 'If 1 is given, no parallel computing code is used at all.',
200 type=int,
201 metavar='JOBS',
202 default=-1,
203 ),
204 "hyperopt_random_state": Arg(
205 '--random-state',
206 help='Set random state to some positive integer for reproducible hyperopt results.',
207 type=check_int_positive,
208 metavar='INT',
209 ),
210 "hyperopt_min_trades": Arg(
211 '--min-trades',
212 help="Set minimal desired number of trades for evaluations in the hyperopt "
213 "optimization path (default: 1).",
214 type=check_int_positive,
215 metavar='INT',
216 default=1,
217 ),
218 "hyperopt_continue": Arg(
219 "--continue",
220 help="Continue hyperopt from previous runs. "
221 "By default, temporary files will be removed and hyperopt will start from scratch.",
222 default=False,
223 action='store_true',
224 ),
225 "hyperopt_loss": Arg(
226 '--hyperopt-loss',
227 help='Specify the class name of the hyperopt loss function class (IHyperOptLoss). '
228 'Different functions can generate completely different results, '
229 'since the target for optimization is different. (default: `%(default)s`).',
230 metavar='NAME',
231 default=constants.DEFAULT_HYPEROPT_LOSS,
232 ),
233 # List exchanges
234 "print_one_column": Arg(
235 '-1', '--one-column',
236 help='Print exchanges in one column.',
237 action='store_true',
238 ),
239 # Script options
240 "pairs": Arg(
241 '-p', '--pairs',
242 help='Show profits for only these pairs. Pairs are comma-separated.',
243 ),
244 # Download data
245 "pairs_file": Arg(
246 '--pairs-file',
247 help='File containing a list of pairs to download.',
248 metavar='FILE',
249 ),
250 "days": Arg(
251 '--days',
252 help='Download data for given number of days.',
253 type=check_int_positive,
254 metavar='INT',
255 ),
256 "exchange": Arg(
257 '--exchange',
258 help=f'Exchange name (default: `{constants.DEFAULT_EXCHANGE}`). '
259 f'Only valid if no config is provided.',
260 ),
261 "timeframes": Arg(
262 '-t', '--timeframes',
263 help=f'Specify which tickers to download. Space-separated list. '
264 f'Default: `{constants.DEFAULT_DOWNLOAD_TICKER_INTERVALS}`.',
265 choices=['1m', '3m', '5m', '15m', '30m', '1h', '2h', '4h',
266 '6h', '8h', '12h', '1d', '3d', '1w'],
267 nargs='+',
268 ),
269 "erase": Arg(
270 '--erase',
271 help='Clean all existing data for the selected exchange/pairs/timeframes.',
272 action='store_true',
273 ),
274 # Plot dataframe
275 "indicators1": Arg(
276 '--indicators1',
277 help='Set indicators from your strategy you want in the first row of the graph. '
278 'Comma-separated list. Example: `ema3,ema5`. Default: `%(default)s`.',
279 default='sma,ema3,ema5',
280 ),
281 "indicators2": Arg(
282 '--indicators2',
283 help='Set indicators from your strategy you want in the third row of the graph. '
284 'Comma-separated list. Example: `fastd,fastk`. Default: `%(default)s`.',
285 default='macd,macdsignal',
286 ),
287 "plot_limit": Arg(
288 '--plot-limit',
289 help='Specify tick limit for plotting. Notice: too high values cause huge files. '
290 'Default: %(default)s.',
291 type=check_int_positive,
292 metavar='INT',
293 default=750,
294 ),
295 "trade_source": Arg(
296 '--trade-source',
297 help='Specify the source for trades (Can be DB or file (backtest file)) '
298 'Default: %(default)s',
299 choices=["DB", "file"],
300 default="file",
301 ),
302 }
303
[end of freqtrade/configuration/cli_options.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/freqtrade/configuration/cli_options.py b/freqtrade/configuration/cli_options.py
--- a/freqtrade/configuration/cli_options.py
+++ b/freqtrade/configuration/cli_options.py
@@ -130,7 +130,7 @@
),
"strategy_list": Arg(
'--strategy-list',
- help='Provide a comma-separated list of strategies to backtest. '
+ help='Provide a space-separated list of strategies to backtest. '
'Please note that ticker-interval needs to be set either in config '
'or via command line. When using this together with `--export trades`, '
'the strategy-name is injected into the filename '
|
{"golden_diff": "diff --git a/freqtrade/configuration/cli_options.py b/freqtrade/configuration/cli_options.py\n--- a/freqtrade/configuration/cli_options.py\n+++ b/freqtrade/configuration/cli_options.py\n@@ -130,7 +130,7 @@\n ),\n \"strategy_list\": Arg(\n '--strategy-list',\n- help='Provide a comma-separated list of strategies to backtest. '\n+ help='Provide a space-separated list of strategies to backtest. '\n 'Please note that ticker-interval needs to be set either in config '\n 'or via command line. When using this together with `--export trades`, '\n 'the strategy-name is injected into the filename '\n", "issue": "Strategy list is space separated\n`--strategy-list Strat1,Strat2` produces an error while `--strategy-list Strat1 Strat2` works\r\n\r\nIt became a space separated list somehow while its description states it's a comma-separated list:\r\n```\r\n --strategy-list STRATEGY_LIST [STRATEGY_LIST ...]\r\n Provide **a comma-separated list** of strategies to\r\n backtest. Please note that ticker-interval needs to be\r\n set either in config or via command line. When using\r\n this together with `--export trades`, the strategy-\r\n name is injected into the filename (so `backtest-\r\n data.json` becomes `backtest-data-\r\n DefaultStrategy.json`\r\n```\r\n\r\nWhich direction this should be fixed to?\r\n\n", "before_files": [{"content": "\"\"\"\nDefinition of cli arguments used in arguments.py\n\"\"\"\nimport argparse\nimport os\n\nfrom freqtrade import __version__, constants\n\n\ndef check_int_positive(value: str) -> int:\n try:\n uint = int(value)\n if uint <= 0:\n raise ValueError\n except ValueError:\n raise argparse.ArgumentTypeError(\n f\"{value} is invalid for this parameter, should be a positive integer value\"\n )\n return uint\n\n\nclass Arg:\n # Optional CLI arguments\n def __init__(self, *args, **kwargs):\n self.cli = args\n self.kwargs = kwargs\n\n\n# List of available command line options\nAVAILABLE_CLI_OPTIONS = {\n # Common options\n \"verbosity\": Arg(\n '-v', '--verbose',\n help='Verbose mode (-vv for more, -vvv to get all messages).',\n action='count',\n default=0,\n ),\n \"logfile\": Arg(\n '--logfile',\n help='Log to the file specified.',\n metavar='FILE',\n ),\n \"version\": Arg(\n '-V', '--version',\n action='version',\n version=f'%(prog)s {__version__}',\n ),\n \"config\": Arg(\n '-c', '--config',\n help=f'Specify configuration file (default: `{constants.DEFAULT_CONFIG}`). '\n f'Multiple --config options may be used. '\n f'Can be set to `-` to read config from stdin.',\n action='append',\n metavar='PATH',\n ),\n \"datadir\": Arg(\n '-d', '--datadir',\n help='Path to backtest data.',\n metavar='PATH',\n ),\n # Main options\n \"strategy\": Arg(\n '-s', '--strategy',\n help='Specify strategy class name (default: `%(default)s`).',\n metavar='NAME',\n default='DefaultStrategy',\n ),\n \"strategy_path\": Arg(\n '--strategy-path',\n help='Specify additional strategy lookup path.',\n metavar='PATH',\n ),\n \"db_url\": Arg(\n '--db-url',\n help=f'Override trades database URL, this is useful in custom deployments '\n f'(default: `{constants.DEFAULT_DB_PROD_URL}` for Live Run mode, '\n f'`{constants.DEFAULT_DB_DRYRUN_URL}` for Dry Run).',\n metavar='PATH',\n ),\n \"sd_notify\": Arg(\n '--sd-notify',\n help='Notify systemd service manager.',\n action='store_true',\n ),\n # Optimize common\n \"ticker_interval\": Arg(\n '-i', '--ticker-interval',\n help='Specify ticker interval (`1m`, `5m`, `30m`, `1h`, `1d`).',\n ),\n \"timerange\": Arg(\n '--timerange',\n help='Specify what timerange of data to use.',\n ),\n \"max_open_trades\": Arg(\n '--max_open_trades',\n help='Specify max_open_trades to use.',\n type=int,\n metavar='INT',\n ),\n \"stake_amount\": Arg(\n '--stake_amount',\n help='Specify stake_amount.',\n type=float,\n ),\n \"refresh_pairs\": Arg(\n '-r', '--refresh-pairs-cached',\n help='Refresh the pairs files in tests/testdata with the latest data from the '\n 'exchange. Use it if you want to run your optimization commands with '\n 'up-to-date data.',\n action='store_true',\n ),\n # Backtesting\n \"position_stacking\": Arg(\n '--eps', '--enable-position-stacking',\n help='Allow buying the same pair multiple times (position stacking).',\n action='store_true',\n default=False,\n ),\n \"use_max_market_positions\": Arg(\n '--dmmp', '--disable-max-market-positions',\n help='Disable applying `max_open_trades` during backtest '\n '(same as setting `max_open_trades` to a very high number).',\n action='store_false',\n default=True,\n ),\n \"live\": Arg(\n '-l', '--live',\n help='Use live data.',\n action='store_true',\n ),\n \"strategy_list\": Arg(\n '--strategy-list',\n help='Provide a comma-separated list of strategies to backtest. '\n 'Please note that ticker-interval needs to be set either in config '\n 'or via command line. When using this together with `--export trades`, '\n 'the strategy-name is injected into the filename '\n '(so `backtest-data.json` becomes `backtest-data-DefaultStrategy.json`',\n nargs='+',\n ),\n \"export\": Arg(\n '--export',\n help='Export backtest results, argument are: trades. '\n 'Example: `--export=trades`',\n ),\n \"exportfilename\": Arg(\n '--export-filename',\n help='Save backtest results to the file with this filename (default: `%(default)s`). '\n 'Requires `--export` to be set as well. '\n 'Example: `--export-filename=user_data/backtest_data/backtest_today.json`',\n metavar='PATH',\n default=os.path.join('user_data', 'backtest_data',\n 'backtest-result.json'),\n ),\n # Edge\n \"stoploss_range\": Arg(\n '--stoplosses',\n help='Defines a range of stoploss values against which edge will assess the strategy. '\n 'The format is \"min,max,step\" (without any space). '\n 'Example: `--stoplosses=-0.01,-0.1,-0.001`',\n ),\n # Hyperopt\n \"hyperopt\": Arg(\n '--customhyperopt',\n help='Specify hyperopt class name (default: `%(default)s`).',\n metavar='NAME',\n default=constants.DEFAULT_HYPEROPT,\n ),\n \"hyperopt_path\": Arg(\n '--hyperopt-path',\n help='Specify additional lookup path for Hyperopts and Hyperopt Loss functions.',\n metavar='PATH',\n ),\n \"epochs\": Arg(\n '-e', '--epochs',\n help='Specify number of epochs (default: %(default)d).',\n type=check_int_positive,\n metavar='INT',\n default=constants.HYPEROPT_EPOCH,\n ),\n \"spaces\": Arg(\n '-s', '--spaces',\n help='Specify which parameters to hyperopt. Space-separated list. '\n 'Default: `%(default)s`.',\n choices=['all', 'buy', 'sell', 'roi', 'stoploss'],\n nargs='+',\n default='all',\n ),\n \"print_all\": Arg(\n '--print-all',\n help='Print all results, not only the best ones.',\n action='store_true',\n default=False,\n ),\n \"hyperopt_jobs\": Arg(\n '-j', '--job-workers',\n help='The number of concurrently running jobs for hyperoptimization '\n '(hyperopt worker processes). '\n 'If -1 (default), all CPUs are used, for -2, all CPUs but one are used, etc. '\n 'If 1 is given, no parallel computing code is used at all.',\n type=int,\n metavar='JOBS',\n default=-1,\n ),\n \"hyperopt_random_state\": Arg(\n '--random-state',\n help='Set random state to some positive integer for reproducible hyperopt results.',\n type=check_int_positive,\n metavar='INT',\n ),\n \"hyperopt_min_trades\": Arg(\n '--min-trades',\n help=\"Set minimal desired number of trades for evaluations in the hyperopt \"\n \"optimization path (default: 1).\",\n type=check_int_positive,\n metavar='INT',\n default=1,\n ),\n \"hyperopt_continue\": Arg(\n \"--continue\",\n help=\"Continue hyperopt from previous runs. \"\n \"By default, temporary files will be removed and hyperopt will start from scratch.\",\n default=False,\n action='store_true',\n ),\n \"hyperopt_loss\": Arg(\n '--hyperopt-loss',\n help='Specify the class name of the hyperopt loss function class (IHyperOptLoss). '\n 'Different functions can generate completely different results, '\n 'since the target for optimization is different. (default: `%(default)s`).',\n metavar='NAME',\n default=constants.DEFAULT_HYPEROPT_LOSS,\n ),\n # List exchanges\n \"print_one_column\": Arg(\n '-1', '--one-column',\n help='Print exchanges in one column.',\n action='store_true',\n ),\n # Script options\n \"pairs\": Arg(\n '-p', '--pairs',\n help='Show profits for only these pairs. Pairs are comma-separated.',\n ),\n # Download data\n \"pairs_file\": Arg(\n '--pairs-file',\n help='File containing a list of pairs to download.',\n metavar='FILE',\n ),\n \"days\": Arg(\n '--days',\n help='Download data for given number of days.',\n type=check_int_positive,\n metavar='INT',\n ),\n \"exchange\": Arg(\n '--exchange',\n help=f'Exchange name (default: `{constants.DEFAULT_EXCHANGE}`). '\n f'Only valid if no config is provided.',\n ),\n \"timeframes\": Arg(\n '-t', '--timeframes',\n help=f'Specify which tickers to download. Space-separated list. '\n f'Default: `{constants.DEFAULT_DOWNLOAD_TICKER_INTERVALS}`.',\n choices=['1m', '3m', '5m', '15m', '30m', '1h', '2h', '4h',\n '6h', '8h', '12h', '1d', '3d', '1w'],\n nargs='+',\n ),\n \"erase\": Arg(\n '--erase',\n help='Clean all existing data for the selected exchange/pairs/timeframes.',\n action='store_true',\n ),\n # Plot dataframe\n \"indicators1\": Arg(\n '--indicators1',\n help='Set indicators from your strategy you want in the first row of the graph. '\n 'Comma-separated list. Example: `ema3,ema5`. Default: `%(default)s`.',\n default='sma,ema3,ema5',\n ),\n \"indicators2\": Arg(\n '--indicators2',\n help='Set indicators from your strategy you want in the third row of the graph. '\n 'Comma-separated list. Example: `fastd,fastk`. Default: `%(default)s`.',\n default='macd,macdsignal',\n ),\n \"plot_limit\": Arg(\n '--plot-limit',\n help='Specify tick limit for plotting. Notice: too high values cause huge files. '\n 'Default: %(default)s.',\n type=check_int_positive,\n metavar='INT',\n default=750,\n ),\n \"trade_source\": Arg(\n '--trade-source',\n help='Specify the source for trades (Can be DB or file (backtest file)) '\n 'Default: %(default)s',\n choices=[\"DB\", \"file\"],\n default=\"file\",\n ),\n}\n", "path": "freqtrade/configuration/cli_options.py"}]}
| 3,873 | 145 |
gh_patches_debug_8510
|
rasdani/github-patches
|
git_diff
|
ibis-project__ibis-8417
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
docs: explain you only need to close a conn.raw_sql() if you are running a query that returns results
### Please describe the issue
I was following the advise of https://ibis-project.org/how-to/extending/sql#backend.raw_sql, and closing the returned cursor.
But the actual SQL I was running was an `EXPLAIN SELECT ...` query. I was getting errors, eventually after a lot of headscratching I think I have found that I do NOT want to close the cursor after this query.
Possible actions:
1. be more precise with what sorts of SQL statements require the close.
2. make it so ALL queries require a close, so there is no distinction.
3. UX: make the returned object itself closable, so I don't have to do `from contextlib import closing` and I can just do `with conn.raw_sql(x) as cursor:`
### Code of Conduct
- [X] I agree to follow this project's Code of Conduct
</issue>
<code>
[start of ibis/config.py]
1 from __future__ import annotations
2
3 import contextlib
4 from typing import Annotated, Any, Callable, Optional
5
6 from public import public
7
8 import ibis.common.exceptions as com
9 from ibis.common.grounds import Annotable
10 from ibis.common.patterns import Between
11
12 PosInt = Annotated[int, Between(lower=0)]
13
14
15 class Config(Annotable):
16 def get(self, key: str) -> Any:
17 value = self
18 for field in key.split("."):
19 value = getattr(value, field)
20 return value
21
22 def set(self, key: str, value: Any) -> None:
23 *prefix, key = key.split(".")
24 conf = self
25 for field in prefix:
26 conf = getattr(conf, field)
27 setattr(conf, key, value)
28
29 @contextlib.contextmanager
30 def _with_temporary(self, options):
31 try:
32 old = {}
33 for key, value in options.items():
34 old[key] = self.get(key)
35 self.set(key, value)
36 yield
37 finally:
38 for key, value in old.items():
39 self.set(key, value)
40
41 def __call__(self, options):
42 return self._with_temporary(options)
43
44
45 class ContextAdjustment(Config):
46 """Options related to time context adjustment.
47
48 Attributes
49 ----------
50 time_col : str
51 Name of the timestamp column for execution with a `timecontext`. See
52 `ibis/expr/timecontext.py` for details.
53
54 """
55
56 time_col: str = "time"
57
58
59 class SQL(Config):
60 """SQL-related options.
61
62 Attributes
63 ----------
64 default_limit : int | None
65 Number of rows to be retrieved for a table expression without an
66 explicit limit. [](`None`) means no limit.
67 default_dialect : str
68 Dialect to use for printing SQL when the backend cannot be determined.
69
70 """
71
72 default_limit: Optional[PosInt] = None
73 default_dialect: str = "duckdb"
74
75
76 class Interactive(Config):
77 """Options controlling the interactive repr.
78
79 Attributes
80 ----------
81 max_rows : int
82 Maximum rows to pretty print.
83 max_columns : int | None
84 The maximum number of columns to pretty print. If 0 (the default), the
85 number of columns will be inferred from output console size. Set to
86 `None` for no limit.
87 max_length : int
88 Maximum length for pretty-printed arrays and maps.
89 max_string : int
90 Maximum length for pretty-printed strings.
91 max_depth : int
92 Maximum depth for nested data types.
93 show_types : bool
94 Show the inferred type of value expressions in the interactive repr.
95
96 """
97
98 max_rows: int = 10
99 max_columns: Optional[int] = 0
100 max_length: int = 2
101 max_string: int = 80
102 max_depth: int = 1
103 show_types: bool = True
104
105
106 class Repr(Config):
107 """Expression printing options.
108
109 Attributes
110 ----------
111 depth : int
112 The maximum number of expression nodes to print when repring.
113 table_columns : int
114 The number of columns to show in leaf table expressions.
115 table_rows : int
116 The number of rows to show for in memory tables.
117 query_text_length : int
118 The maximum number of characters to show in the `query` field repr of
119 SQLQueryResult operations.
120 show_types : bool
121 Show the inferred type of value expressions in the repr.
122 interactive : bool
123 Options controlling the interactive repr.
124
125 """
126
127 depth: Optional[PosInt] = None
128 table_columns: Optional[PosInt] = None
129 table_rows: PosInt = 10
130 query_text_length: PosInt = 80
131 show_types: bool = False
132 interactive: Interactive = Interactive()
133
134
135 class Options(Config):
136 """Ibis configuration options.
137
138 Attributes
139 ----------
140 interactive : bool
141 Show the first few rows of computing an expression when in a repl.
142 repr : Repr
143 Options controlling expression printing.
144 verbose : bool
145 Run in verbose mode if [](`True`)
146 verbose_log: Callable[[str], None] | None
147 A callable to use when logging.
148 graphviz_repr : bool
149 Render expressions as GraphViz PNGs when running in a Jupyter notebook.
150 default_backend : Optional[ibis.backends.BaseBackend], default None
151 The default backend to use for execution, defaults to DuckDB if not
152 set.
153 context_adjustment : ContextAdjustment
154 Options related to time context adjustment.
155 sql: SQL
156 SQL-related options.
157 clickhouse : Config | None
158 Clickhouse specific options.
159 dask : Config | None
160 Dask specific options.
161 impala : Config | None
162 Impala specific options.
163 pandas : Config | None
164 Pandas specific options.
165 pyspark : Config | None
166 PySpark specific options.
167
168 """
169
170 interactive: bool = False
171 repr: Repr = Repr()
172 verbose: bool = False
173 verbose_log: Optional[Callable] = None
174 graphviz_repr: bool = False
175 default_backend: Optional[Any] = None
176 context_adjustment: ContextAdjustment = ContextAdjustment()
177 sql: SQL = SQL()
178 clickhouse: Optional[Config] = None
179 dask: Optional[Config] = None
180 impala: Optional[Config] = None
181 pandas: Optional[Config] = None
182 pyspark: Optional[Config] = None
183
184
185 def _default_backend() -> Any:
186 if (backend := options.default_backend) is not None:
187 return backend
188
189 try:
190 import duckdb as _ # noqa: F401
191 except ImportError:
192 raise com.IbisError(
193 """\
194 You have used a function that relies on the default backend, but the default
195 backend (DuckDB) is not installed.
196
197 You may specify an alternate backend to use, e.g.
198
199 ibis.set_backend("polars")
200
201 or to install the DuckDB backend, run:
202
203 pip install 'ibis-framework[duckdb]'
204
205 or
206
207 conda install -c conda-forge ibis-framework
208
209 For more information on available backends, visit https://ibis-project.org/install
210 """
211 )
212
213 import ibis
214
215 options.default_backend = con = ibis.duckdb.connect(":memory:")
216 return con
217
218
219 options = Options()
220
221
222 @public
223 def option_context(key, new_value):
224 return options({key: new_value})
225
226
227 public(options=options)
228
[end of ibis/config.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/ibis/config.py b/ibis/config.py
--- a/ibis/config.py
+++ b/ibis/config.py
@@ -147,7 +147,7 @@
A callable to use when logging.
graphviz_repr : bool
Render expressions as GraphViz PNGs when running in a Jupyter notebook.
- default_backend : Optional[ibis.backends.BaseBackend], default None
+ default_backend : Optional[ibis.backends.BaseBackend]
The default backend to use for execution, defaults to DuckDB if not
set.
context_adjustment : ContextAdjustment
|
{"golden_diff": "diff --git a/ibis/config.py b/ibis/config.py\n--- a/ibis/config.py\n+++ b/ibis/config.py\n@@ -147,7 +147,7 @@\n A callable to use when logging.\n graphviz_repr : bool\n Render expressions as GraphViz PNGs when running in a Jupyter notebook.\n- default_backend : Optional[ibis.backends.BaseBackend], default None\n+ default_backend : Optional[ibis.backends.BaseBackend]\n The default backend to use for execution, defaults to DuckDB if not\n set.\n context_adjustment : ContextAdjustment\n", "issue": "docs: explain you only need to close a conn.raw_sql() if you are running a query that returns results\n### Please describe the issue\n\nI was following the advise of https://ibis-project.org/how-to/extending/sql#backend.raw_sql, and closing the returned cursor.\r\n\r\nBut the actual SQL I was running was an `EXPLAIN SELECT ...` query. I was getting errors, eventually after a lot of headscratching I think I have found that I do NOT want to close the cursor after this query.\r\n\r\nPossible actions:\r\n1. be more precise with what sorts of SQL statements require the close.\r\n2. make it so ALL queries require a close, so there is no distinction.\r\n3. UX: make the returned object itself closable, so I don't have to do `from contextlib import closing` and I can just do `with conn.raw_sql(x) as cursor:`\n\n### Code of Conduct\n\n- [X] I agree to follow this project's Code of Conduct\n", "before_files": [{"content": "from __future__ import annotations\n\nimport contextlib\nfrom typing import Annotated, Any, Callable, Optional\n\nfrom public import public\n\nimport ibis.common.exceptions as com\nfrom ibis.common.grounds import Annotable\nfrom ibis.common.patterns import Between\n\nPosInt = Annotated[int, Between(lower=0)]\n\n\nclass Config(Annotable):\n def get(self, key: str) -> Any:\n value = self\n for field in key.split(\".\"):\n value = getattr(value, field)\n return value\n\n def set(self, key: str, value: Any) -> None:\n *prefix, key = key.split(\".\")\n conf = self\n for field in prefix:\n conf = getattr(conf, field)\n setattr(conf, key, value)\n\n @contextlib.contextmanager\n def _with_temporary(self, options):\n try:\n old = {}\n for key, value in options.items():\n old[key] = self.get(key)\n self.set(key, value)\n yield\n finally:\n for key, value in old.items():\n self.set(key, value)\n\n def __call__(self, options):\n return self._with_temporary(options)\n\n\nclass ContextAdjustment(Config):\n \"\"\"Options related to time context adjustment.\n\n Attributes\n ----------\n time_col : str\n Name of the timestamp column for execution with a `timecontext`. See\n `ibis/expr/timecontext.py` for details.\n\n \"\"\"\n\n time_col: str = \"time\"\n\n\nclass SQL(Config):\n \"\"\"SQL-related options.\n\n Attributes\n ----------\n default_limit : int | None\n Number of rows to be retrieved for a table expression without an\n explicit limit. [](`None`) means no limit.\n default_dialect : str\n Dialect to use for printing SQL when the backend cannot be determined.\n\n \"\"\"\n\n default_limit: Optional[PosInt] = None\n default_dialect: str = \"duckdb\"\n\n\nclass Interactive(Config):\n \"\"\"Options controlling the interactive repr.\n\n Attributes\n ----------\n max_rows : int\n Maximum rows to pretty print.\n max_columns : int | None\n The maximum number of columns to pretty print. If 0 (the default), the\n number of columns will be inferred from output console size. Set to\n `None` for no limit.\n max_length : int\n Maximum length for pretty-printed arrays and maps.\n max_string : int\n Maximum length for pretty-printed strings.\n max_depth : int\n Maximum depth for nested data types.\n show_types : bool\n Show the inferred type of value expressions in the interactive repr.\n\n \"\"\"\n\n max_rows: int = 10\n max_columns: Optional[int] = 0\n max_length: int = 2\n max_string: int = 80\n max_depth: int = 1\n show_types: bool = True\n\n\nclass Repr(Config):\n \"\"\"Expression printing options.\n\n Attributes\n ----------\n depth : int\n The maximum number of expression nodes to print when repring.\n table_columns : int\n The number of columns to show in leaf table expressions.\n table_rows : int\n The number of rows to show for in memory tables.\n query_text_length : int\n The maximum number of characters to show in the `query` field repr of\n SQLQueryResult operations.\n show_types : bool\n Show the inferred type of value expressions in the repr.\n interactive : bool\n Options controlling the interactive repr.\n\n \"\"\"\n\n depth: Optional[PosInt] = None\n table_columns: Optional[PosInt] = None\n table_rows: PosInt = 10\n query_text_length: PosInt = 80\n show_types: bool = False\n interactive: Interactive = Interactive()\n\n\nclass Options(Config):\n \"\"\"Ibis configuration options.\n\n Attributes\n ----------\n interactive : bool\n Show the first few rows of computing an expression when in a repl.\n repr : Repr\n Options controlling expression printing.\n verbose : bool\n Run in verbose mode if [](`True`)\n verbose_log: Callable[[str], None] | None\n A callable to use when logging.\n graphviz_repr : bool\n Render expressions as GraphViz PNGs when running in a Jupyter notebook.\n default_backend : Optional[ibis.backends.BaseBackend], default None\n The default backend to use for execution, defaults to DuckDB if not\n set.\n context_adjustment : ContextAdjustment\n Options related to time context adjustment.\n sql: SQL\n SQL-related options.\n clickhouse : Config | None\n Clickhouse specific options.\n dask : Config | None\n Dask specific options.\n impala : Config | None\n Impala specific options.\n pandas : Config | None\n Pandas specific options.\n pyspark : Config | None\n PySpark specific options.\n\n \"\"\"\n\n interactive: bool = False\n repr: Repr = Repr()\n verbose: bool = False\n verbose_log: Optional[Callable] = None\n graphviz_repr: bool = False\n default_backend: Optional[Any] = None\n context_adjustment: ContextAdjustment = ContextAdjustment()\n sql: SQL = SQL()\n clickhouse: Optional[Config] = None\n dask: Optional[Config] = None\n impala: Optional[Config] = None\n pandas: Optional[Config] = None\n pyspark: Optional[Config] = None\n\n\ndef _default_backend() -> Any:\n if (backend := options.default_backend) is not None:\n return backend\n\n try:\n import duckdb as _ # noqa: F401\n except ImportError:\n raise com.IbisError(\n \"\"\"\\\nYou have used a function that relies on the default backend, but the default\nbackend (DuckDB) is not installed.\n\nYou may specify an alternate backend to use, e.g.\n\nibis.set_backend(\"polars\")\n\nor to install the DuckDB backend, run:\n\n pip install 'ibis-framework[duckdb]'\n\nor\n\n conda install -c conda-forge ibis-framework\n\nFor more information on available backends, visit https://ibis-project.org/install\n\"\"\"\n )\n\n import ibis\n\n options.default_backend = con = ibis.duckdb.connect(\":memory:\")\n return con\n\n\noptions = Options()\n\n\n@public\ndef option_context(key, new_value):\n return options({key: new_value})\n\n\npublic(options=options)\n", "path": "ibis/config.py"}]}
| 2,757 | 135 |
gh_patches_debug_1846
|
rasdani/github-patches
|
git_diff
|
liqd__a4-meinberlin-2082
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
dashboard: district "gesamtstädtisch" ist ---
in dashboard the default district is "---" and should be changed to "Gesamtstädtisch"
</issue>
<code>
[start of meinberlin/apps/projects/forms.py]
1 from django import forms
2 from django.conf import settings
3 from django.contrib.auth import get_user_model
4 from django.core.exceptions import ValidationError
5 from django.utils.translation import ugettext_lazy as _
6
7 from adhocracy4.dashboard.forms import ProjectDashboardForm
8 from adhocracy4.maps import widgets as maps_widgets
9 from adhocracy4.projects.models import Project
10 from meinberlin.apps.users import fields as user_fields
11
12 from .models import ModeratorInvite
13 from .models import ParticipantInvite
14
15 User = get_user_model()
16
17
18 class InviteForm(forms.ModelForm):
19 accept = forms.CharField(required=False)
20 reject = forms.CharField(required=False)
21
22 def clean(self):
23 data = self.data
24 if 'accept' not in data and 'reject' not in data:
25 raise ValidationError('Reject or accept')
26 return data
27
28 def is_accepted(self):
29 data = self.data
30 return 'accept' in data and 'reject' not in data
31
32
33 class ParticipantInviteForm(InviteForm):
34
35 class Meta:
36 model = ParticipantInvite
37 fields = ['accept', 'reject']
38
39
40 class ModeratorInviteForm(InviteForm):
41
42 class Meta:
43 model = ModeratorInvite
44 fields = ['accept', 'reject']
45
46
47 class InviteUsersFromEmailForm(forms.Form):
48 add_users = user_fields.CommaSeparatedEmailField(
49 required=False,
50 label=_('Invite users via email')
51 )
52
53 add_users_upload = user_fields.EmailFileField(
54 required=False,
55 label=_('Invite users via file upload'),
56 help_text=_('Upload a csv file containing email addresses.')
57 )
58
59 def __init__(self, *args, **kwargs):
60 labels = kwargs.pop('labels', None)
61 super().__init__(*args, **kwargs)
62
63 if labels:
64 self.fields['add_users'].label = labels[0]
65 self.fields['add_users_upload'].label = labels[1]
66
67 def clean(self):
68 cleaned_data = super().clean()
69 add_users = self.data.get('add_users')
70 add_users_upload = self.files.get('add_users_upload')
71 if not self.errors and not add_users and not add_users_upload:
72 raise ValidationError(
73 _('Please enter email addresses or upload a file'))
74 return cleaned_data
75
76
77 class TopicForm(ProjectDashboardForm):
78
79 class Meta:
80 model = Project
81 fields = ['topics']
82 required_for_project_publish = ['topics']
83
84
85 class PointForm(ProjectDashboardForm):
86
87 class Meta:
88 model = Project
89 fields = ['administrative_district', 'point']
90 required_for_project_publish = []
91 widgets = {
92 'point': maps_widgets.MapChoosePointWidget(
93 polygon=settings.BERLIN_POLYGON)
94 }
95
[end of meinberlin/apps/projects/forms.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/meinberlin/apps/projects/forms.py b/meinberlin/apps/projects/forms.py
--- a/meinberlin/apps/projects/forms.py
+++ b/meinberlin/apps/projects/forms.py
@@ -92,3 +92,7 @@
'point': maps_widgets.MapChoosePointWidget(
polygon=settings.BERLIN_POLYGON)
}
+
+ def __init__(self, *args, **kwargs):
+ super().__init__(*args, **kwargs)
+ self.fields['administrative_district'].empty_label = _('City wide')
|
{"golden_diff": "diff --git a/meinberlin/apps/projects/forms.py b/meinberlin/apps/projects/forms.py\n--- a/meinberlin/apps/projects/forms.py\n+++ b/meinberlin/apps/projects/forms.py\n@@ -92,3 +92,7 @@\n 'point': maps_widgets.MapChoosePointWidget(\n polygon=settings.BERLIN_POLYGON)\n }\n+\n+ def __init__(self, *args, **kwargs):\n+ super().__init__(*args, **kwargs)\n+ self.fields['administrative_district'].empty_label = _('City wide')\n", "issue": "dashboard: district \"gesamtst\u00e4dtisch\" ist ---\nin dashboard the default district is \"---\" and should be changed to \"Gesamtst\u00e4dtisch\"\n", "before_files": [{"content": "from django import forms\nfrom django.conf import settings\nfrom django.contrib.auth import get_user_model\nfrom django.core.exceptions import ValidationError\nfrom django.utils.translation import ugettext_lazy as _\n\nfrom adhocracy4.dashboard.forms import ProjectDashboardForm\nfrom adhocracy4.maps import widgets as maps_widgets\nfrom adhocracy4.projects.models import Project\nfrom meinberlin.apps.users import fields as user_fields\n\nfrom .models import ModeratorInvite\nfrom .models import ParticipantInvite\n\nUser = get_user_model()\n\n\nclass InviteForm(forms.ModelForm):\n accept = forms.CharField(required=False)\n reject = forms.CharField(required=False)\n\n def clean(self):\n data = self.data\n if 'accept' not in data and 'reject' not in data:\n raise ValidationError('Reject or accept')\n return data\n\n def is_accepted(self):\n data = self.data\n return 'accept' in data and 'reject' not in data\n\n\nclass ParticipantInviteForm(InviteForm):\n\n class Meta:\n model = ParticipantInvite\n fields = ['accept', 'reject']\n\n\nclass ModeratorInviteForm(InviteForm):\n\n class Meta:\n model = ModeratorInvite\n fields = ['accept', 'reject']\n\n\nclass InviteUsersFromEmailForm(forms.Form):\n add_users = user_fields.CommaSeparatedEmailField(\n required=False,\n label=_('Invite users via email')\n )\n\n add_users_upload = user_fields.EmailFileField(\n required=False,\n label=_('Invite users via file upload'),\n help_text=_('Upload a csv file containing email addresses.')\n )\n\n def __init__(self, *args, **kwargs):\n labels = kwargs.pop('labels', None)\n super().__init__(*args, **kwargs)\n\n if labels:\n self.fields['add_users'].label = labels[0]\n self.fields['add_users_upload'].label = labels[1]\n\n def clean(self):\n cleaned_data = super().clean()\n add_users = self.data.get('add_users')\n add_users_upload = self.files.get('add_users_upload')\n if not self.errors and not add_users and not add_users_upload:\n raise ValidationError(\n _('Please enter email addresses or upload a file'))\n return cleaned_data\n\n\nclass TopicForm(ProjectDashboardForm):\n\n class Meta:\n model = Project\n fields = ['topics']\n required_for_project_publish = ['topics']\n\n\nclass PointForm(ProjectDashboardForm):\n\n class Meta:\n model = Project\n fields = ['administrative_district', 'point']\n required_for_project_publish = []\n widgets = {\n 'point': maps_widgets.MapChoosePointWidget(\n polygon=settings.BERLIN_POLYGON)\n }\n", "path": "meinberlin/apps/projects/forms.py"}]}
| 1,323 | 120 |
gh_patches_debug_8690
|
rasdani/github-patches
|
git_diff
|
urllib3__urllib3-2379
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Collect mypy requirements in their own file
We currently install mypy dependencies one by one:
https://github.com/urllib3/urllib3/blob/0a4839af7103e9ad71d26bf5ba7914e765577efe/noxfile.py#L162-L169
It was fine initially, but we currently install 8 dependencies that way. That's slower than necessary and isn't a format tools like dependabot can understand.
Instead, put those dependencies in a file called `mypy-requirements.txt` and install them just like we install dev-requirements.txt:
https://github.com/urllib3/urllib3/blob/0a4839af7103e9ad71d26bf5ba7914e765577efe/noxfile.py#L23
</issue>
<code>
[start of noxfile.py]
1 import os
2 import shutil
3 import subprocess
4
5 import nox
6
7 SOURCE_FILES = [
8 "docs/",
9 "dummyserver/",
10 "src/",
11 "test/",
12 "noxfile.py",
13 "setup.py",
14 ]
15
16
17 def tests_impl(
18 session: nox.Session,
19 extras: str = "socks,secure,brotli",
20 byte_string_comparisons: bool = True,
21 ) -> None:
22 # Install deps and the package itself.
23 session.install("-r", "dev-requirements.txt")
24 session.install(f".[{extras}]")
25
26 # Show the pip version.
27 session.run("pip", "--version")
28 # Print the Python version and bytesize.
29 session.run("python", "--version")
30 session.run("python", "-c", "import struct; print(struct.calcsize('P') * 8)")
31 # Print OpenSSL information.
32 session.run("python", "-m", "OpenSSL.debug")
33
34 # Inspired from https://github.com/pyca/cryptography
35 # We use parallel mode and then combine here so that coverage.py will take
36 # the paths like .tox/pyXY/lib/pythonX.Y/site-packages/urllib3/__init__.py
37 # and collapse them into src/urllib3/__init__.py.
38
39 session.run(
40 "python",
41 *(("-bb",) if byte_string_comparisons else ()),
42 "-m",
43 "coverage",
44 "run",
45 "--parallel-mode",
46 "-m",
47 "pytest",
48 "-r",
49 "a",
50 "--tb=native",
51 "--no-success-flaky-report",
52 *(session.posargs or ("test/",)),
53 env={"PYTHONWARNINGS": "always::DeprecationWarning"},
54 )
55 session.run("coverage", "combine")
56 session.run("coverage", "report", "-m")
57 session.run("coverage", "xml")
58
59
60 @nox.session(python=["3.7", "3.8", "3.9", "3.10", "pypy"])
61 def test(session: nox.Session) -> None:
62 tests_impl(session)
63
64
65 @nox.session(python=["2.7"])
66 def unsupported_python2(session: nox.Session) -> None:
67 # Can't check both returncode and output with session.run
68 process = subprocess.run(
69 ["python", "setup.py", "install"],
70 env={**session.env},
71 text=True,
72 capture_output=True,
73 )
74 assert process.returncode == 1
75 print(process.stderr)
76 assert "Unsupported Python version" in process.stderr
77
78
79 @nox.session(python=["3"])
80 def test_brotlipy(session: nox.Session) -> None:
81 """Check that if 'brotlipy' is installed instead of 'brotli' or
82 'brotlicffi' that we still don't blow up.
83 """
84 session.install("brotlipy")
85 tests_impl(session, extras="socks,secure", byte_string_comparisons=False)
86
87
88 def git_clone(session: nox.Session, git_url: str) -> None:
89 session.run("git", "clone", "--depth", "1", git_url, external=True)
90
91
92 @nox.session()
93 def downstream_botocore(session: nox.Session) -> None:
94 root = os.getcwd()
95 tmp_dir = session.create_tmp()
96
97 session.cd(tmp_dir)
98 git_clone(session, "https://github.com/boto/botocore")
99 session.chdir("botocore")
100 session.run("git", "rev-parse", "HEAD", external=True)
101 session.run("python", "scripts/ci/install")
102
103 session.cd(root)
104 session.install(".", silent=False)
105 session.cd(f"{tmp_dir}/botocore")
106
107 session.run("python", "-c", "import urllib3; print(urllib3.__version__)")
108 session.run("python", "scripts/ci/run-tests")
109
110
111 @nox.session()
112 def downstream_requests(session: nox.Session) -> None:
113 root = os.getcwd()
114 tmp_dir = session.create_tmp()
115
116 session.cd(tmp_dir)
117 git_clone(session, "https://github.com/psf/requests")
118 session.chdir("requests")
119 session.run("git", "apply", f"{root}/ci/requests.patch", external=True)
120 session.run("git", "rev-parse", "HEAD", external=True)
121 session.install(".[socks]", silent=False)
122 session.install("-r", "requirements-dev.txt", silent=False)
123
124 session.cd(root)
125 session.install(".", silent=False)
126 session.cd(f"{tmp_dir}/requests")
127
128 session.run("python", "-c", "import urllib3; print(urllib3.__version__)")
129 session.run("pytest", "tests")
130
131
132 @nox.session()
133 def format(session: nox.Session) -> None:
134 """Run code formatters."""
135 session.install("pre-commit")
136 session.run("pre-commit", "--version")
137
138 process = subprocess.run(
139 ["pre-commit", "run", "--all-files"],
140 env=session.env,
141 text=True,
142 stdout=subprocess.PIPE,
143 stderr=subprocess.STDOUT,
144 )
145 # Ensure that pre-commit itself ran successfully
146 assert process.returncode in (0, 1)
147
148 lint(session)
149
150
151 @nox.session
152 def lint(session: nox.Session) -> None:
153 session.install("pre-commit")
154 session.run("pre-commit", "run", "--all-files")
155
156 mypy(session)
157
158
159 @nox.session(python="3.8")
160 def mypy(session: nox.Session) -> None:
161 """Run mypy."""
162 session.install("mypy==0.910")
163 session.install("idna>=2.0.0")
164 session.install("cryptography>=1.3.4")
165 session.install("tornado>=6.1")
166 session.install("pytest>=6.2")
167 session.install("trustme==0.9.0")
168 session.install("types-python-dateutil")
169 session.install("nox")
170 session.run("mypy", "--version")
171 session.run(
172 "mypy",
173 "src/urllib3",
174 "dummyserver",
175 "noxfile.py",
176 "test/__init__.py",
177 "test/conftest.py",
178 "test/port_helpers.py",
179 "test/test_retry.py",
180 "test/test_wait.py",
181 "test/tz_stub.py",
182 )
183
184
185 @nox.session
186 def docs(session: nox.Session) -> None:
187 session.install("-r", "docs/requirements.txt")
188 session.install(".[socks,secure,brotli]")
189
190 session.chdir("docs")
191 if os.path.exists("_build"):
192 shutil.rmtree("_build")
193 session.run("sphinx-build", "-b", "html", "-W", ".", "_build/html")
194
[end of noxfile.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/noxfile.py b/noxfile.py
--- a/noxfile.py
+++ b/noxfile.py
@@ -159,14 +159,7 @@
@nox.session(python="3.8")
def mypy(session: nox.Session) -> None:
"""Run mypy."""
- session.install("mypy==0.910")
- session.install("idna>=2.0.0")
- session.install("cryptography>=1.3.4")
- session.install("tornado>=6.1")
- session.install("pytest>=6.2")
- session.install("trustme==0.9.0")
- session.install("types-python-dateutil")
- session.install("nox")
+ session.install("-r", "mypy-requirements.txt")
session.run("mypy", "--version")
session.run(
"mypy",
|
{"golden_diff": "diff --git a/noxfile.py b/noxfile.py\n--- a/noxfile.py\n+++ b/noxfile.py\n@@ -159,14 +159,7 @@\n @nox.session(python=\"3.8\")\n def mypy(session: nox.Session) -> None:\n \"\"\"Run mypy.\"\"\"\n- session.install(\"mypy==0.910\")\n- session.install(\"idna>=2.0.0\")\n- session.install(\"cryptography>=1.3.4\")\n- session.install(\"tornado>=6.1\")\n- session.install(\"pytest>=6.2\")\n- session.install(\"trustme==0.9.0\")\n- session.install(\"types-python-dateutil\")\n- session.install(\"nox\")\n+ session.install(\"-r\", \"mypy-requirements.txt\")\n session.run(\"mypy\", \"--version\")\n session.run(\n \"mypy\",\n", "issue": "Collect mypy requirements in their own file\nWe currently install mypy dependencies one by one:\r\n\r\nhttps://github.com/urllib3/urllib3/blob/0a4839af7103e9ad71d26bf5ba7914e765577efe/noxfile.py#L162-L169\r\n\r\nIt was fine initially, but we currently install 8 dependencies that way. That's slower than necessary and isn't a format tools like dependabot can understand.\r\n\r\nInstead, put those dependencies in a file called `mypy-requirements.txt` and install them just like we install dev-requirements.txt:\r\n\r\nhttps://github.com/urllib3/urllib3/blob/0a4839af7103e9ad71d26bf5ba7914e765577efe/noxfile.py#L23\n", "before_files": [{"content": "import os\nimport shutil\nimport subprocess\n\nimport nox\n\nSOURCE_FILES = [\n \"docs/\",\n \"dummyserver/\",\n \"src/\",\n \"test/\",\n \"noxfile.py\",\n \"setup.py\",\n]\n\n\ndef tests_impl(\n session: nox.Session,\n extras: str = \"socks,secure,brotli\",\n byte_string_comparisons: bool = True,\n) -> None:\n # Install deps and the package itself.\n session.install(\"-r\", \"dev-requirements.txt\")\n session.install(f\".[{extras}]\")\n\n # Show the pip version.\n session.run(\"pip\", \"--version\")\n # Print the Python version and bytesize.\n session.run(\"python\", \"--version\")\n session.run(\"python\", \"-c\", \"import struct; print(struct.calcsize('P') * 8)\")\n # Print OpenSSL information.\n session.run(\"python\", \"-m\", \"OpenSSL.debug\")\n\n # Inspired from https://github.com/pyca/cryptography\n # We use parallel mode and then combine here so that coverage.py will take\n # the paths like .tox/pyXY/lib/pythonX.Y/site-packages/urllib3/__init__.py\n # and collapse them into src/urllib3/__init__.py.\n\n session.run(\n \"python\",\n *((\"-bb\",) if byte_string_comparisons else ()),\n \"-m\",\n \"coverage\",\n \"run\",\n \"--parallel-mode\",\n \"-m\",\n \"pytest\",\n \"-r\",\n \"a\",\n \"--tb=native\",\n \"--no-success-flaky-report\",\n *(session.posargs or (\"test/\",)),\n env={\"PYTHONWARNINGS\": \"always::DeprecationWarning\"},\n )\n session.run(\"coverage\", \"combine\")\n session.run(\"coverage\", \"report\", \"-m\")\n session.run(\"coverage\", \"xml\")\n\n\[email protected](python=[\"3.7\", \"3.8\", \"3.9\", \"3.10\", \"pypy\"])\ndef test(session: nox.Session) -> None:\n tests_impl(session)\n\n\[email protected](python=[\"2.7\"])\ndef unsupported_python2(session: nox.Session) -> None:\n # Can't check both returncode and output with session.run\n process = subprocess.run(\n [\"python\", \"setup.py\", \"install\"],\n env={**session.env},\n text=True,\n capture_output=True,\n )\n assert process.returncode == 1\n print(process.stderr)\n assert \"Unsupported Python version\" in process.stderr\n\n\[email protected](python=[\"3\"])\ndef test_brotlipy(session: nox.Session) -> None:\n \"\"\"Check that if 'brotlipy' is installed instead of 'brotli' or\n 'brotlicffi' that we still don't blow up.\n \"\"\"\n session.install(\"brotlipy\")\n tests_impl(session, extras=\"socks,secure\", byte_string_comparisons=False)\n\n\ndef git_clone(session: nox.Session, git_url: str) -> None:\n session.run(\"git\", \"clone\", \"--depth\", \"1\", git_url, external=True)\n\n\[email protected]()\ndef downstream_botocore(session: nox.Session) -> None:\n root = os.getcwd()\n tmp_dir = session.create_tmp()\n\n session.cd(tmp_dir)\n git_clone(session, \"https://github.com/boto/botocore\")\n session.chdir(\"botocore\")\n session.run(\"git\", \"rev-parse\", \"HEAD\", external=True)\n session.run(\"python\", \"scripts/ci/install\")\n\n session.cd(root)\n session.install(\".\", silent=False)\n session.cd(f\"{tmp_dir}/botocore\")\n\n session.run(\"python\", \"-c\", \"import urllib3; print(urllib3.__version__)\")\n session.run(\"python\", \"scripts/ci/run-tests\")\n\n\[email protected]()\ndef downstream_requests(session: nox.Session) -> None:\n root = os.getcwd()\n tmp_dir = session.create_tmp()\n\n session.cd(tmp_dir)\n git_clone(session, \"https://github.com/psf/requests\")\n session.chdir(\"requests\")\n session.run(\"git\", \"apply\", f\"{root}/ci/requests.patch\", external=True)\n session.run(\"git\", \"rev-parse\", \"HEAD\", external=True)\n session.install(\".[socks]\", silent=False)\n session.install(\"-r\", \"requirements-dev.txt\", silent=False)\n\n session.cd(root)\n session.install(\".\", silent=False)\n session.cd(f\"{tmp_dir}/requests\")\n\n session.run(\"python\", \"-c\", \"import urllib3; print(urllib3.__version__)\")\n session.run(\"pytest\", \"tests\")\n\n\[email protected]()\ndef format(session: nox.Session) -> None:\n \"\"\"Run code formatters.\"\"\"\n session.install(\"pre-commit\")\n session.run(\"pre-commit\", \"--version\")\n\n process = subprocess.run(\n [\"pre-commit\", \"run\", \"--all-files\"],\n env=session.env,\n text=True,\n stdout=subprocess.PIPE,\n stderr=subprocess.STDOUT,\n )\n # Ensure that pre-commit itself ran successfully\n assert process.returncode in (0, 1)\n\n lint(session)\n\n\[email protected]\ndef lint(session: nox.Session) -> None:\n session.install(\"pre-commit\")\n session.run(\"pre-commit\", \"run\", \"--all-files\")\n\n mypy(session)\n\n\[email protected](python=\"3.8\")\ndef mypy(session: nox.Session) -> None:\n \"\"\"Run mypy.\"\"\"\n session.install(\"mypy==0.910\")\n session.install(\"idna>=2.0.0\")\n session.install(\"cryptography>=1.3.4\")\n session.install(\"tornado>=6.1\")\n session.install(\"pytest>=6.2\")\n session.install(\"trustme==0.9.0\")\n session.install(\"types-python-dateutil\")\n session.install(\"nox\")\n session.run(\"mypy\", \"--version\")\n session.run(\n \"mypy\",\n \"src/urllib3\",\n \"dummyserver\",\n \"noxfile.py\",\n \"test/__init__.py\",\n \"test/conftest.py\",\n \"test/port_helpers.py\",\n \"test/test_retry.py\",\n \"test/test_wait.py\",\n \"test/tz_stub.py\",\n )\n\n\[email protected]\ndef docs(session: nox.Session) -> None:\n session.install(\"-r\", \"docs/requirements.txt\")\n session.install(\".[socks,secure,brotli]\")\n\n session.chdir(\"docs\")\n if os.path.exists(\"_build\"):\n shutil.rmtree(\"_build\")\n session.run(\"sphinx-build\", \"-b\", \"html\", \"-W\", \".\", \"_build/html\")\n", "path": "noxfile.py"}]}
| 2,660 | 200 |
gh_patches_debug_29241
|
rasdani/github-patches
|
git_diff
|
ytdl-org__youtube-dl-14548
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
parliamentlive.tv has stopped working
## Please follow the guide below
- You will be asked some questions and requested to provide some information, please read them **carefully** and answer honestly
- Put an `x` into all the boxes [ ] relevant to your *issue* (like this: `[x]`)
- Use the *Preview* tab to see what your issue will actually look like
---
### Make sure you are using the *latest* version: run `youtube-dl --version` and ensure your version is *2017.10.15.1*. If it's not, read [this FAQ entry](https://github.com/rg3/youtube-dl/blob/master/README.md#how-do-i-update-youtube-dl) and update. Issues with outdated version will be rejected.
- [X] I've **verified** and **I assure** that I'm running youtube-dl **2017.10.15.1**
### Before submitting an *issue* make sure you have:
- [X] At least skimmed through the [README](https://github.com/rg3/youtube-dl/blob/master/README.md), **most notably** the [FAQ](https://github.com/rg3/youtube-dl#faq) and [BUGS](https://github.com/rg3/youtube-dl#bugs) sections
- [X] [Searched](https://github.com/rg3/youtube-dl/search?type=Issues) the bugtracker for similar issues including closed ones
### What is the purpose of your *issue*?
- [X] Bug report (encountered problems with youtube-dl)
- [ ] Site support request (request for adding support for a new site)
- [ ] Feature request (request for a new functionality)
- [ ] Question
- [ ] Other
---
### The following sections concretize particular purposed issues, you can erase any section (the contents between triple ---) not applicable to your *issue*
---
### If the purpose of this *issue* is a *bug report*, *site support request* or you are not completely sure provide the full verbose output as follows:
Add the `-v` flag to **your command line** you run youtube-dl with (`youtube-dl -v <your command line>`), copy the **whole** output and insert it here. It should look similar to one below (replace it with **your** log inserted between triple ```):
```
youtube-dl --verbose http://parliamentlive.tv/Event/Index/1c220590-96fc-4cb6-976f-ade4f23f0b65
[debug] System config: []
[debug] User config: []
[debug] Custom config: []
[debug] Command-line args: [u'--verbose', u'http://parliamentlive.tv/Event/Index/1c220590-96fc-4cb6-976f-ade4f23f0b65']
[debug] Encodings: locale UTF-8, fs utf-8, out UTF-8, pref UTF-8
[debug] youtube-dl version 2017.10.15.1
[debug] Python version 2.7.10 - Darwin-17.0.0-x86_64-i386-64bit
[debug] exe versions: ffmpeg 3.4, ffprobe 3.4, rtmpdump 2.4
[debug] Proxy map: {}
[parliamentlive.tv] 1c220590-96fc-4cb6-976f-ade4f23f0b65: Downloading webpage
ERROR: Unable to extract kaltura widget config; please report this issue on https://yt-dl.org/bug . Make sure you are using the latest version; type youtube-dl -U to update. Be sure to call youtube-dl with the --verbose flag and include its complete output.
Traceback (most recent call last):
File "/usr/local/bin/youtube-dl/youtube_dl/YoutubeDL.py", line 784, in extract_info
ie_result = ie.extract(url)
File "/usr/local/bin/youtube-dl/youtube_dl/extractor/common.py", line 434, in extract
ie_result = self._real_extract(url)
File "/usr/local/bin/youtube-dl/youtube_dl/extractor/parliamentliveuk.py", line 32, in _real_extract
webpage, 'kaltura widget config'), video_id)
File "/usr/local/bin/youtube-dl/youtube_dl/extractor/common.py", line 797, in _search_regex
raise RegexNotFoundError('Unable to extract %s' % _name)
RegexNotFoundError: Unable to extract kaltura widget config; please report this issue on https://yt-dl.org/bug . Make sure you are using the latest version; type youtube-dl -U to update. Be sure to call youtube-dl with the --verbose flag and include its complete output.
```
---
### If the purpose of this *issue* is a *site support request* please provide all kinds of example URLs support for which should be included (replace following example URLs by **yours**):
- Single video: http://parliamentlive.tv/Event/Index/1c220590-96fc-4cb6-976f-ade4f23f0b65
Note that **youtube-dl does not support sites dedicated to [copyright infringement](https://github.com/rg3/youtube-dl#can-you-add-support-for-this-anime-video-site-or-site-which-shows-current-movies-for-free)**. In order for site support request to be accepted all provided example URLs should not violate any copyrights.
---
### Description of your *issue*, suggested solution and other information
Parliamentlive.tv seems to have stopped working. The above error log is for the first video I tried but I have recreated this on several videos on the site.
</issue>
<code>
[start of youtube_dl/extractor/parliamentliveuk.py]
1 from __future__ import unicode_literals
2
3 from .common import InfoExtractor
4
5
6 class ParliamentLiveUKIE(InfoExtractor):
7 IE_NAME = 'parliamentlive.tv'
8 IE_DESC = 'UK parliament videos'
9 _VALID_URL = r'(?i)https?://(?:www\.)?parliamentlive\.tv/Event/Index/(?P<id>[\da-f]{8}-[\da-f]{4}-[\da-f]{4}-[\da-f]{4}-[\da-f]{12})'
10
11 _TESTS = [{
12 'url': 'http://parliamentlive.tv/Event/Index/c1e9d44d-fd6c-4263-b50f-97ed26cc998b',
13 'info_dict': {
14 'id': 'c1e9d44d-fd6c-4263-b50f-97ed26cc998b',
15 'ext': 'mp4',
16 'title': 'Home Affairs Committee',
17 'uploader_id': 'FFMPEG-01',
18 'timestamp': 1422696664,
19 'upload_date': '20150131',
20 },
21 }, {
22 'url': 'http://parliamentlive.tv/event/index/3f24936f-130f-40bf-9a5d-b3d6479da6a4',
23 'only_matching': True,
24 }]
25
26 def _real_extract(self, url):
27 video_id = self._match_id(url)
28 webpage = self._download_webpage(
29 'http://vodplayer.parliamentlive.tv/?mid=' + video_id, video_id)
30 widget_config = self._parse_json(self._search_regex(
31 r'kWidgetConfig\s*=\s*({.+});',
32 webpage, 'kaltura widget config'), video_id)
33 kaltura_url = 'kaltura:%s:%s' % (widget_config['wid'][1:], widget_config['entry_id'])
34 event_title = self._download_json(
35 'http://parliamentlive.tv/Event/GetShareVideo/' + video_id, video_id)['event']['title']
36 return {
37 '_type': 'url_transparent',
38 'id': video_id,
39 'title': event_title,
40 'description': '',
41 'url': kaltura_url,
42 'ie_key': 'Kaltura',
43 }
44
[end of youtube_dl/extractor/parliamentliveuk.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/youtube_dl/extractor/parliamentliveuk.py b/youtube_dl/extractor/parliamentliveuk.py
--- a/youtube_dl/extractor/parliamentliveuk.py
+++ b/youtube_dl/extractor/parliamentliveuk.py
@@ -11,7 +11,7 @@
_TESTS = [{
'url': 'http://parliamentlive.tv/Event/Index/c1e9d44d-fd6c-4263-b50f-97ed26cc998b',
'info_dict': {
- 'id': 'c1e9d44d-fd6c-4263-b50f-97ed26cc998b',
+ 'id': '1_af9nv9ym',
'ext': 'mp4',
'title': 'Home Affairs Committee',
'uploader_id': 'FFMPEG-01',
@@ -28,14 +28,14 @@
webpage = self._download_webpage(
'http://vodplayer.parliamentlive.tv/?mid=' + video_id, video_id)
widget_config = self._parse_json(self._search_regex(
- r'kWidgetConfig\s*=\s*({.+});',
+ r'(?s)kWidgetConfig\s*=\s*({.+});',
webpage, 'kaltura widget config'), video_id)
- kaltura_url = 'kaltura:%s:%s' % (widget_config['wid'][1:], widget_config['entry_id'])
+ kaltura_url = 'kaltura:%s:%s' % (
+ widget_config['wid'][1:], widget_config['entry_id'])
event_title = self._download_json(
'http://parliamentlive.tv/Event/GetShareVideo/' + video_id, video_id)['event']['title']
return {
'_type': 'url_transparent',
- 'id': video_id,
'title': event_title,
'description': '',
'url': kaltura_url,
|
{"golden_diff": "diff --git a/youtube_dl/extractor/parliamentliveuk.py b/youtube_dl/extractor/parliamentliveuk.py\n--- a/youtube_dl/extractor/parliamentliveuk.py\n+++ b/youtube_dl/extractor/parliamentliveuk.py\n@@ -11,7 +11,7 @@\n _TESTS = [{\n 'url': 'http://parliamentlive.tv/Event/Index/c1e9d44d-fd6c-4263-b50f-97ed26cc998b',\n 'info_dict': {\n- 'id': 'c1e9d44d-fd6c-4263-b50f-97ed26cc998b',\n+ 'id': '1_af9nv9ym',\n 'ext': 'mp4',\n 'title': 'Home Affairs Committee',\n 'uploader_id': 'FFMPEG-01',\n@@ -28,14 +28,14 @@\n webpage = self._download_webpage(\n 'http://vodplayer.parliamentlive.tv/?mid=' + video_id, video_id)\n widget_config = self._parse_json(self._search_regex(\n- r'kWidgetConfig\\s*=\\s*({.+});',\n+ r'(?s)kWidgetConfig\\s*=\\s*({.+});',\n webpage, 'kaltura widget config'), video_id)\n- kaltura_url = 'kaltura:%s:%s' % (widget_config['wid'][1:], widget_config['entry_id'])\n+ kaltura_url = 'kaltura:%s:%s' % (\n+ widget_config['wid'][1:], widget_config['entry_id'])\n event_title = self._download_json(\n 'http://parliamentlive.tv/Event/GetShareVideo/' + video_id, video_id)['event']['title']\n return {\n '_type': 'url_transparent',\n- 'id': video_id,\n 'title': event_title,\n 'description': '',\n 'url': kaltura_url,\n", "issue": "parliamentlive.tv has stopped working\n## Please follow the guide below\r\n\r\n- You will be asked some questions and requested to provide some information, please read them **carefully** and answer honestly\r\n- Put an `x` into all the boxes [ ] relevant to your *issue* (like this: `[x]`)\r\n- Use the *Preview* tab to see what your issue will actually look like\r\n\r\n---\r\n\r\n### Make sure you are using the *latest* version: run `youtube-dl --version` and ensure your version is *2017.10.15.1*. If it's not, read [this FAQ entry](https://github.com/rg3/youtube-dl/blob/master/README.md#how-do-i-update-youtube-dl) and update. Issues with outdated version will be rejected.\r\n- [X] I've **verified** and **I assure** that I'm running youtube-dl **2017.10.15.1**\r\n\r\n### Before submitting an *issue* make sure you have:\r\n- [X] At least skimmed through the [README](https://github.com/rg3/youtube-dl/blob/master/README.md), **most notably** the [FAQ](https://github.com/rg3/youtube-dl#faq) and [BUGS](https://github.com/rg3/youtube-dl#bugs) sections\r\n- [X] [Searched](https://github.com/rg3/youtube-dl/search?type=Issues) the bugtracker for similar issues including closed ones\r\n\r\n### What is the purpose of your *issue*?\r\n- [X] Bug report (encountered problems with youtube-dl)\r\n- [ ] Site support request (request for adding support for a new site)\r\n- [ ] Feature request (request for a new functionality)\r\n- [ ] Question\r\n- [ ] Other\r\n\r\n---\r\n\r\n### The following sections concretize particular purposed issues, you can erase any section (the contents between triple ---) not applicable to your *issue*\r\n\r\n---\r\n\r\n### If the purpose of this *issue* is a *bug report*, *site support request* or you are not completely sure provide the full verbose output as follows:\r\n\r\nAdd the `-v` flag to **your command line** you run youtube-dl with (`youtube-dl -v <your command line>`), copy the **whole** output and insert it here. It should look similar to one below (replace it with **your** log inserted between triple ```):\r\n\r\n```\r\nyoutube-dl --verbose http://parliamentlive.tv/Event/Index/1c220590-96fc-4cb6-976f-ade4f23f0b65\r\n[debug] System config: []\r\n[debug] User config: []\r\n[debug] Custom config: []\r\n[debug] Command-line args: [u'--verbose', u'http://parliamentlive.tv/Event/Index/1c220590-96fc-4cb6-976f-ade4f23f0b65']\r\n[debug] Encodings: locale UTF-8, fs utf-8, out UTF-8, pref UTF-8\r\n[debug] youtube-dl version 2017.10.15.1\r\n[debug] Python version 2.7.10 - Darwin-17.0.0-x86_64-i386-64bit\r\n[debug] exe versions: ffmpeg 3.4, ffprobe 3.4, rtmpdump 2.4\r\n[debug] Proxy map: {}\r\n[parliamentlive.tv] 1c220590-96fc-4cb6-976f-ade4f23f0b65: Downloading webpage\r\nERROR: Unable to extract kaltura widget config; please report this issue on https://yt-dl.org/bug . Make sure you are using the latest version; type youtube-dl -U to update. Be sure to call youtube-dl with the --verbose flag and include its complete output.\r\nTraceback (most recent call last):\r\n File \"/usr/local/bin/youtube-dl/youtube_dl/YoutubeDL.py\", line 784, in extract_info\r\n ie_result = ie.extract(url)\r\n File \"/usr/local/bin/youtube-dl/youtube_dl/extractor/common.py\", line 434, in extract\r\n ie_result = self._real_extract(url)\r\n File \"/usr/local/bin/youtube-dl/youtube_dl/extractor/parliamentliveuk.py\", line 32, in _real_extract\r\n webpage, 'kaltura widget config'), video_id)\r\n File \"/usr/local/bin/youtube-dl/youtube_dl/extractor/common.py\", line 797, in _search_regex\r\n raise RegexNotFoundError('Unable to extract %s' % _name)\r\nRegexNotFoundError: Unable to extract kaltura widget config; please report this issue on https://yt-dl.org/bug . Make sure you are using the latest version; type youtube-dl -U to update. Be sure to call youtube-dl with the --verbose flag and include its complete output.\r\n```\r\n\r\n---\r\n\r\n### If the purpose of this *issue* is a *site support request* please provide all kinds of example URLs support for which should be included (replace following example URLs by **yours**):\r\n- Single video: http://parliamentlive.tv/Event/Index/1c220590-96fc-4cb6-976f-ade4f23f0b65\r\n\r\nNote that **youtube-dl does not support sites dedicated to [copyright infringement](https://github.com/rg3/youtube-dl#can-you-add-support-for-this-anime-video-site-or-site-which-shows-current-movies-for-free)**. In order for site support request to be accepted all provided example URLs should not violate any copyrights.\r\n\r\n---\r\n\r\n### Description of your *issue*, suggested solution and other information\r\n\r\nParliamentlive.tv seems to have stopped working. The above error log is for the first video I tried but I have recreated this on several videos on the site.\n", "before_files": [{"content": "from __future__ import unicode_literals\n\nfrom .common import InfoExtractor\n\n\nclass ParliamentLiveUKIE(InfoExtractor):\n IE_NAME = 'parliamentlive.tv'\n IE_DESC = 'UK parliament videos'\n _VALID_URL = r'(?i)https?://(?:www\\.)?parliamentlive\\.tv/Event/Index/(?P<id>[\\da-f]{8}-[\\da-f]{4}-[\\da-f]{4}-[\\da-f]{4}-[\\da-f]{12})'\n\n _TESTS = [{\n 'url': 'http://parliamentlive.tv/Event/Index/c1e9d44d-fd6c-4263-b50f-97ed26cc998b',\n 'info_dict': {\n 'id': 'c1e9d44d-fd6c-4263-b50f-97ed26cc998b',\n 'ext': 'mp4',\n 'title': 'Home Affairs Committee',\n 'uploader_id': 'FFMPEG-01',\n 'timestamp': 1422696664,\n 'upload_date': '20150131',\n },\n }, {\n 'url': 'http://parliamentlive.tv/event/index/3f24936f-130f-40bf-9a5d-b3d6479da6a4',\n 'only_matching': True,\n }]\n\n def _real_extract(self, url):\n video_id = self._match_id(url)\n webpage = self._download_webpage(\n 'http://vodplayer.parliamentlive.tv/?mid=' + video_id, video_id)\n widget_config = self._parse_json(self._search_regex(\n r'kWidgetConfig\\s*=\\s*({.+});',\n webpage, 'kaltura widget config'), video_id)\n kaltura_url = 'kaltura:%s:%s' % (widget_config['wid'][1:], widget_config['entry_id'])\n event_title = self._download_json(\n 'http://parliamentlive.tv/Event/GetShareVideo/' + video_id, video_id)['event']['title']\n return {\n '_type': 'url_transparent',\n 'id': video_id,\n 'title': event_title,\n 'description': '',\n 'url': kaltura_url,\n 'ie_key': 'Kaltura',\n }\n", "path": "youtube_dl/extractor/parliamentliveuk.py"}]}
| 2,478 | 451 |
gh_patches_debug_3816
|
rasdani/github-patches
|
git_diff
|
ray-project__ray-7877
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[ray] Build failure when installing from source
<!--Please include [tune], [rllib], [autoscaler] etc. in the issue title if relevant-->
### What is the problem?
I am trying to install ray from source. However, I receive the following error during the install process:
```
HEAD is now at 8ffe41c apply cpython patch bpo-39492 for the reference count issue
+ /usr/bin/python setup.py bdist_wheel
usage: setup.py [global_opts] cmd1 [cmd1_opts] [cmd2 [cmd2_opts] ...]
or: setup.py --help [cmd1 cmd2 ...]
or: setup.py --help-commands
or: setup.py cmd --help
error: invalid command 'bdist_wheel'
Traceback (most recent call last):
File "setup.py", line 178, in <module>
setup(
File "/usr/lib/python3.8/site-packages/setuptools/__init__.py", line 144, in setup
return distutils.core.setup(**attrs)
File "/usr/lib/python3.8/distutils/core.py", line 148, in setup
dist.run_commands()
File "/usr/lib/python3.8/distutils/dist.py", line 966, in run_commands
self.run_command(cmd)
File "/usr/lib/python3.8/distutils/dist.py", line 985, in run_command
cmd_obj.run()
File "/usr/lib/python3.8/distutils/command/build.py", line 135, in run
self.run_command(cmd_name)
File "/usr/lib/python3.8/distutils/cmd.py", line 313, in run_command
self.distribution.run_command(command)
File "/usr/lib/python3.8/distutils/dist.py", line 985, in run_command
cmd_obj.run()
File "setup.py", line 107, in run
subprocess.check_call(command)
File "/usr/lib/python3.8/subprocess.py", line 364, in check_call
raise CalledProcessError(retcode, cmd)
subprocess.CalledProcessError: Command '['../build.sh', '-p', '/usr/bin/python']' returned non-zero exit status 1.
```
Note: `error invalid command 'bdist_wheel'`
*Ray version and other system information (Python version, TensorFlow version, OS):*
ray: 0.8.4
python: 3.8.2
os: Arch Linux
### Reproduction (REQUIRED)
Please provide a script that can be run to reproduce the issue. The script should have **no external library dependencies** (i.e., use fake or mock data / environments):
If we cannot run your script, we cannot fix your issue.
- [ ] I have verified my script runs in a clean environment and reproduces the issue.
- [ ] I have verified the issue also occurs with the [latest wheels](https://ray.readthedocs.io/en/latest/installation.html).
The above does not apply since this is a build issue.
</issue>
<code>
[start of python/setup.py]
1 from itertools import chain
2 import os
3 import re
4 import shutil
5 import subprocess
6 import sys
7
8 from setuptools import setup, find_packages, Distribution
9 import setuptools.command.build_ext as _build_ext
10
11 # Ideally, we could include these files by putting them in a
12 # MANIFEST.in or using the package_data argument to setup, but the
13 # MANIFEST.in gets applied at the very beginning when setup.py runs
14 # before these files have been created, so we have to move the files
15 # manually.
16
17 # NOTE: The lists below must be kept in sync with ray/BUILD.bazel.
18 ray_files = [
19 "ray/core/src/ray/thirdparty/redis/src/redis-server",
20 "ray/core/src/ray/gcs/redis_module/libray_redis_module.so",
21 "ray/core/src/plasma/plasma_store_server",
22 "ray/_raylet.so",
23 "ray/core/src/ray/raylet/raylet_monitor",
24 "ray/core/src/ray/gcs/gcs_server",
25 "ray/core/src/ray/raylet/raylet",
26 "ray/streaming/_streaming.so",
27 ]
28
29 build_java = os.getenv("RAY_INSTALL_JAVA") == "1"
30 if build_java:
31 ray_files.append("ray/jars/ray_dist.jar")
32
33 # These are the directories where automatically generated Python protobuf
34 # bindings are created.
35 generated_python_directories = [
36 "ray/core/generated",
37 "ray/streaming/generated",
38 ]
39
40 optional_ray_files = []
41
42 ray_autoscaler_files = [
43 "ray/autoscaler/aws/example-full.yaml",
44 "ray/autoscaler/azure/example-full.yaml",
45 "ray/autoscaler/gcp/example-full.yaml",
46 "ray/autoscaler/local/example-full.yaml",
47 "ray/autoscaler/kubernetes/example-full.yaml",
48 "ray/autoscaler/kubernetes/kubectl-rsync.sh",
49 "ray/autoscaler/ray-schema.json"
50 ]
51
52 ray_project_files = [
53 "ray/projects/schema.json", "ray/projects/templates/cluster_template.yaml",
54 "ray/projects/templates/project_template.yaml",
55 "ray/projects/templates/requirements.txt"
56 ]
57
58 ray_dashboard_files = [
59 os.path.join(dirpath, filename)
60 for dirpath, dirnames, filenames in os.walk("ray/dashboard/client/build")
61 for filename in filenames
62 ]
63
64 optional_ray_files += ray_autoscaler_files
65 optional_ray_files += ray_project_files
66 optional_ray_files += ray_dashboard_files
67
68 if "RAY_USE_NEW_GCS" in os.environ and os.environ["RAY_USE_NEW_GCS"] == "on":
69 ray_files += [
70 "ray/core/src/credis/build/src/libmember.so",
71 "ray/core/src/credis/build/src/libmaster.so",
72 "ray/core/src/credis/redis/src/redis-server"
73 ]
74
75 extras = {
76 "debug": [],
77 "dashboard": ["requests"],
78 "serve": ["uvicorn", "pygments", "werkzeug", "flask", "pandas", "blist"],
79 "tune": ["tabulate", "tensorboardX", "pandas"]
80 }
81
82 extras["rllib"] = extras["tune"] + [
83 "atari_py",
84 "dm_tree",
85 "gym[atari]",
86 "lz4",
87 "opencv-python-headless",
88 "pyyaml",
89 "scipy",
90 ]
91
92 extras["streaming"] = ["msgpack >= 0.6.2"]
93
94 extras["all"] = list(set(chain.from_iterable(extras.values())))
95
96
97 class build_ext(_build_ext.build_ext):
98 def run(self):
99 # Note: We are passing in sys.executable so that we use the same
100 # version of Python to build packages inside the build.sh script. Note
101 # that certain flags will not be passed along such as --user or sudo.
102 # TODO(rkn): Fix this.
103 command = ["../build.sh", "-p", sys.executable]
104 if build_java:
105 # Also build binaries for Java if the above env variable exists.
106 command += ["-l", "python,java"]
107 subprocess.check_call(command)
108
109 # We also need to install pickle5 along with Ray, so make sure that the
110 # relevant non-Python pickle5 files get copied.
111 pickle5_files = self.walk_directory("./ray/pickle5_files/pickle5")
112
113 thirdparty_files = self.walk_directory("./ray/thirdparty_files")
114
115 files_to_include = ray_files + pickle5_files + thirdparty_files
116
117 # Copy over the autogenerated protobuf Python bindings.
118 for directory in generated_python_directories:
119 for filename in os.listdir(directory):
120 if filename[-3:] == ".py":
121 files_to_include.append(os.path.join(directory, filename))
122
123 for filename in files_to_include:
124 self.move_file(filename)
125
126 # Try to copy over the optional files.
127 for filename in optional_ray_files:
128 try:
129 self.move_file(filename)
130 except Exception:
131 print("Failed to copy optional file {}. This is ok."
132 .format(filename))
133
134 def walk_directory(self, directory):
135 file_list = []
136 for (root, dirs, filenames) in os.walk(directory):
137 for name in filenames:
138 file_list.append(os.path.join(root, name))
139 return file_list
140
141 def move_file(self, filename):
142 # TODO(rkn): This feels very brittle. It may not handle all cases. See
143 # https://github.com/apache/arrow/blob/master/python/setup.py for an
144 # example.
145 source = filename
146 destination = os.path.join(self.build_lib, filename)
147 # Create the target directory if it doesn't already exist.
148 parent_directory = os.path.dirname(destination)
149 if not os.path.exists(parent_directory):
150 os.makedirs(parent_directory)
151 if not os.path.exists(destination):
152 print("Copying {} to {}.".format(source, destination))
153 shutil.copy(source, destination, follow_symlinks=True)
154
155
156 class BinaryDistribution(Distribution):
157 def has_ext_modules(self):
158 return True
159
160
161 def find_version(*filepath):
162 # Extract version information from filepath
163 here = os.path.abspath(os.path.dirname(__file__))
164 with open(os.path.join(here, *filepath)) as fp:
165 version_match = re.search(r"^__version__ = ['\"]([^'\"]*)['\"]",
166 fp.read(), re.M)
167 if version_match:
168 return version_match.group(1)
169 raise RuntimeError("Unable to find version string.")
170
171
172 requires = [
173 "numpy >= 1.16", "filelock", "jsonschema", "click", "colorama", "pyyaml",
174 "redis >= 3.3.2", "protobuf >= 3.8.0", "py-spy >= 0.2.0", "aiohttp",
175 "google", "grpcio"
176 ]
177
178 setup(
179 name="ray",
180 version=find_version("ray", "__init__.py"),
181 author="Ray Team",
182 author_email="[email protected]",
183 description=("A system for parallel and distributed Python that unifies "
184 "the ML ecosystem."),
185 long_description=open("../README.rst").read(),
186 url="https://github.com/ray-project/ray",
187 keywords=("ray distributed parallel machine-learning "
188 "reinforcement-learning deep-learning python"),
189 packages=find_packages(),
190 cmdclass={"build_ext": build_ext},
191 # The BinaryDistribution argument triggers build_ext.
192 distclass=BinaryDistribution,
193 install_requires=requires,
194 setup_requires=["cython >= 0.29.14"],
195 extras_require=extras,
196 entry_points={
197 "console_scripts": [
198 "ray=ray.scripts.scripts:main",
199 "rllib=ray.rllib.scripts:cli [rllib]", "tune=ray.tune.scripts:cli"
200 ]
201 },
202 include_package_data=True,
203 zip_safe=False,
204 license="Apache 2.0")
205
[end of python/setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/python/setup.py b/python/setup.py
--- a/python/setup.py
+++ b/python/setup.py
@@ -191,7 +191,7 @@
# The BinaryDistribution argument triggers build_ext.
distclass=BinaryDistribution,
install_requires=requires,
- setup_requires=["cython >= 0.29.14"],
+ setup_requires=["cython >= 0.29.14", "wheel"],
extras_require=extras,
entry_points={
"console_scripts": [
|
{"golden_diff": "diff --git a/python/setup.py b/python/setup.py\n--- a/python/setup.py\n+++ b/python/setup.py\n@@ -191,7 +191,7 @@\n # The BinaryDistribution argument triggers build_ext.\n distclass=BinaryDistribution,\n install_requires=requires,\n- setup_requires=[\"cython >= 0.29.14\"],\n+ setup_requires=[\"cython >= 0.29.14\", \"wheel\"],\n extras_require=extras,\n entry_points={\n \"console_scripts\": [\n", "issue": "[ray] Build failure when installing from source\n<!--Please include [tune], [rllib], [autoscaler] etc. in the issue title if relevant-->\r\n\r\n### What is the problem?\r\nI am trying to install ray from source. However, I receive the following error during the install process:\r\n```\r\nHEAD is now at 8ffe41c apply cpython patch bpo-39492 for the reference count issue\r\n+ /usr/bin/python setup.py bdist_wheel\r\nusage: setup.py [global_opts] cmd1 [cmd1_opts] [cmd2 [cmd2_opts] ...]\r\n or: setup.py --help [cmd1 cmd2 ...]\r\n or: setup.py --help-commands\r\n or: setup.py cmd --help\r\n\r\nerror: invalid command 'bdist_wheel'\r\nTraceback (most recent call last):\r\n File \"setup.py\", line 178, in <module>\r\n setup(\r\n File \"/usr/lib/python3.8/site-packages/setuptools/__init__.py\", line 144, in setup\r\n return distutils.core.setup(**attrs)\r\n File \"/usr/lib/python3.8/distutils/core.py\", line 148, in setup\r\n dist.run_commands()\r\n File \"/usr/lib/python3.8/distutils/dist.py\", line 966, in run_commands\r\n self.run_command(cmd)\r\n File \"/usr/lib/python3.8/distutils/dist.py\", line 985, in run_command\r\n cmd_obj.run()\r\n File \"/usr/lib/python3.8/distutils/command/build.py\", line 135, in run\r\n self.run_command(cmd_name)\r\n File \"/usr/lib/python3.8/distutils/cmd.py\", line 313, in run_command\r\n self.distribution.run_command(command)\r\n File \"/usr/lib/python3.8/distutils/dist.py\", line 985, in run_command\r\n cmd_obj.run()\r\n File \"setup.py\", line 107, in run\r\n subprocess.check_call(command)\r\n File \"/usr/lib/python3.8/subprocess.py\", line 364, in check_call\r\n raise CalledProcessError(retcode, cmd)\r\nsubprocess.CalledProcessError: Command '['../build.sh', '-p', '/usr/bin/python']' returned non-zero exit status 1.\r\n```\r\n\r\nNote: `error invalid command 'bdist_wheel'`\r\n\r\n*Ray version and other system information (Python version, TensorFlow version, OS):*\r\nray: 0.8.4\r\npython: 3.8.2\r\nos: Arch Linux\r\n\r\n### Reproduction (REQUIRED)\r\nPlease provide a script that can be run to reproduce the issue. The script should have **no external library dependencies** (i.e., use fake or mock data / environments):\r\n\r\nIf we cannot run your script, we cannot fix your issue.\r\n\r\n- [ ] I have verified my script runs in a clean environment and reproduces the issue.\r\n- [ ] I have verified the issue also occurs with the [latest wheels](https://ray.readthedocs.io/en/latest/installation.html).\r\n\r\nThe above does not apply since this is a build issue.\r\n\n", "before_files": [{"content": "from itertools import chain\nimport os\nimport re\nimport shutil\nimport subprocess\nimport sys\n\nfrom setuptools import setup, find_packages, Distribution\nimport setuptools.command.build_ext as _build_ext\n\n# Ideally, we could include these files by putting them in a\n# MANIFEST.in or using the package_data argument to setup, but the\n# MANIFEST.in gets applied at the very beginning when setup.py runs\n# before these files have been created, so we have to move the files\n# manually.\n\n# NOTE: The lists below must be kept in sync with ray/BUILD.bazel.\nray_files = [\n \"ray/core/src/ray/thirdparty/redis/src/redis-server\",\n \"ray/core/src/ray/gcs/redis_module/libray_redis_module.so\",\n \"ray/core/src/plasma/plasma_store_server\",\n \"ray/_raylet.so\",\n \"ray/core/src/ray/raylet/raylet_monitor\",\n \"ray/core/src/ray/gcs/gcs_server\",\n \"ray/core/src/ray/raylet/raylet\",\n \"ray/streaming/_streaming.so\",\n]\n\nbuild_java = os.getenv(\"RAY_INSTALL_JAVA\") == \"1\"\nif build_java:\n ray_files.append(\"ray/jars/ray_dist.jar\")\n\n# These are the directories where automatically generated Python protobuf\n# bindings are created.\ngenerated_python_directories = [\n \"ray/core/generated\",\n \"ray/streaming/generated\",\n]\n\noptional_ray_files = []\n\nray_autoscaler_files = [\n \"ray/autoscaler/aws/example-full.yaml\",\n \"ray/autoscaler/azure/example-full.yaml\",\n \"ray/autoscaler/gcp/example-full.yaml\",\n \"ray/autoscaler/local/example-full.yaml\",\n \"ray/autoscaler/kubernetes/example-full.yaml\",\n \"ray/autoscaler/kubernetes/kubectl-rsync.sh\",\n \"ray/autoscaler/ray-schema.json\"\n]\n\nray_project_files = [\n \"ray/projects/schema.json\", \"ray/projects/templates/cluster_template.yaml\",\n \"ray/projects/templates/project_template.yaml\",\n \"ray/projects/templates/requirements.txt\"\n]\n\nray_dashboard_files = [\n os.path.join(dirpath, filename)\n for dirpath, dirnames, filenames in os.walk(\"ray/dashboard/client/build\")\n for filename in filenames\n]\n\noptional_ray_files += ray_autoscaler_files\noptional_ray_files += ray_project_files\noptional_ray_files += ray_dashboard_files\n\nif \"RAY_USE_NEW_GCS\" in os.environ and os.environ[\"RAY_USE_NEW_GCS\"] == \"on\":\n ray_files += [\n \"ray/core/src/credis/build/src/libmember.so\",\n \"ray/core/src/credis/build/src/libmaster.so\",\n \"ray/core/src/credis/redis/src/redis-server\"\n ]\n\nextras = {\n \"debug\": [],\n \"dashboard\": [\"requests\"],\n \"serve\": [\"uvicorn\", \"pygments\", \"werkzeug\", \"flask\", \"pandas\", \"blist\"],\n \"tune\": [\"tabulate\", \"tensorboardX\", \"pandas\"]\n}\n\nextras[\"rllib\"] = extras[\"tune\"] + [\n \"atari_py\",\n \"dm_tree\",\n \"gym[atari]\",\n \"lz4\",\n \"opencv-python-headless\",\n \"pyyaml\",\n \"scipy\",\n]\n\nextras[\"streaming\"] = [\"msgpack >= 0.6.2\"]\n\nextras[\"all\"] = list(set(chain.from_iterable(extras.values())))\n\n\nclass build_ext(_build_ext.build_ext):\n def run(self):\n # Note: We are passing in sys.executable so that we use the same\n # version of Python to build packages inside the build.sh script. Note\n # that certain flags will not be passed along such as --user or sudo.\n # TODO(rkn): Fix this.\n command = [\"../build.sh\", \"-p\", sys.executable]\n if build_java:\n # Also build binaries for Java if the above env variable exists.\n command += [\"-l\", \"python,java\"]\n subprocess.check_call(command)\n\n # We also need to install pickle5 along with Ray, so make sure that the\n # relevant non-Python pickle5 files get copied.\n pickle5_files = self.walk_directory(\"./ray/pickle5_files/pickle5\")\n\n thirdparty_files = self.walk_directory(\"./ray/thirdparty_files\")\n\n files_to_include = ray_files + pickle5_files + thirdparty_files\n\n # Copy over the autogenerated protobuf Python bindings.\n for directory in generated_python_directories:\n for filename in os.listdir(directory):\n if filename[-3:] == \".py\":\n files_to_include.append(os.path.join(directory, filename))\n\n for filename in files_to_include:\n self.move_file(filename)\n\n # Try to copy over the optional files.\n for filename in optional_ray_files:\n try:\n self.move_file(filename)\n except Exception:\n print(\"Failed to copy optional file {}. This is ok.\"\n .format(filename))\n\n def walk_directory(self, directory):\n file_list = []\n for (root, dirs, filenames) in os.walk(directory):\n for name in filenames:\n file_list.append(os.path.join(root, name))\n return file_list\n\n def move_file(self, filename):\n # TODO(rkn): This feels very brittle. It may not handle all cases. See\n # https://github.com/apache/arrow/blob/master/python/setup.py for an\n # example.\n source = filename\n destination = os.path.join(self.build_lib, filename)\n # Create the target directory if it doesn't already exist.\n parent_directory = os.path.dirname(destination)\n if not os.path.exists(parent_directory):\n os.makedirs(parent_directory)\n if not os.path.exists(destination):\n print(\"Copying {} to {}.\".format(source, destination))\n shutil.copy(source, destination, follow_symlinks=True)\n\n\nclass BinaryDistribution(Distribution):\n def has_ext_modules(self):\n return True\n\n\ndef find_version(*filepath):\n # Extract version information from filepath\n here = os.path.abspath(os.path.dirname(__file__))\n with open(os.path.join(here, *filepath)) as fp:\n version_match = re.search(r\"^__version__ = ['\\\"]([^'\\\"]*)['\\\"]\",\n fp.read(), re.M)\n if version_match:\n return version_match.group(1)\n raise RuntimeError(\"Unable to find version string.\")\n\n\nrequires = [\n \"numpy >= 1.16\", \"filelock\", \"jsonschema\", \"click\", \"colorama\", \"pyyaml\",\n \"redis >= 3.3.2\", \"protobuf >= 3.8.0\", \"py-spy >= 0.2.0\", \"aiohttp\",\n \"google\", \"grpcio\"\n]\n\nsetup(\n name=\"ray\",\n version=find_version(\"ray\", \"__init__.py\"),\n author=\"Ray Team\",\n author_email=\"[email protected]\",\n description=(\"A system for parallel and distributed Python that unifies \"\n \"the ML ecosystem.\"),\n long_description=open(\"../README.rst\").read(),\n url=\"https://github.com/ray-project/ray\",\n keywords=(\"ray distributed parallel machine-learning \"\n \"reinforcement-learning deep-learning python\"),\n packages=find_packages(),\n cmdclass={\"build_ext\": build_ext},\n # The BinaryDistribution argument triggers build_ext.\n distclass=BinaryDistribution,\n install_requires=requires,\n setup_requires=[\"cython >= 0.29.14\"],\n extras_require=extras,\n entry_points={\n \"console_scripts\": [\n \"ray=ray.scripts.scripts:main\",\n \"rllib=ray.rllib.scripts:cli [rllib]\", \"tune=ray.tune.scripts:cli\"\n ]\n },\n include_package_data=True,\n zip_safe=False,\n license=\"Apache 2.0\")\n", "path": "python/setup.py"}]}
| 3,388 | 114 |
gh_patches_debug_39165
|
rasdani/github-patches
|
git_diff
|
celery__kombu-295
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Mongodb url is broken in Kombu 3.0.1
Upgrading to version 3.0.1, a mongodb url like mongodb://localhost/wq fails as the // gets converted to / by some code in transport/mongodb.py - basically it seems to boil down to this code:-
```
if '/' in hostname[10:]:
if not client.userid:
hostname = hostname.replace('/' + client.virtual_host, '/')
else:
hostname = hostname.replace('/' + client.virtual_host, '/' + authdb)
```
by default virtual_host == '/' so basically hostname becomes:-
mongodb:/localhost/wq instead of mongodb://localhost/wq causing the MongoClient to fail wit a port not an integer error.
right now can work around this by setting the url to mongodb:////localhost/wq but its a kludge.
mongodb transport no longer honors configured port.
The mongodb transport in kombu version 2.1.3 (version according to pypi) has changed the BrokerConnection arguments that it uses. We are passing in hostname, port, and transport in as separate BrokerConnection arguments, but the mongodb transport now expects to get all that information out of hostname, which it assumes is a mongodb:// URI.
For some history, version 1.5.0 changed the parse_url() function so that the port was no longer parsed out of mongodb:// URIs. So we were forced to pass the hostname, port, and transport in as separate BrokerConnection arguments. Now, we are being forced back to passing a mongodb:// URI in as the hostname.
</issue>
<code>
[start of kombu/transport/mongodb.py]
1 """
2 kombu.transport.mongodb
3 =======================
4
5 MongoDB transport.
6
7 :copyright: (c) 2010 - 2013 by Flavio Percoco Premoli.
8 :license: BSD, see LICENSE for more details.
9
10 """
11 from __future__ import absolute_import
12
13 import pymongo
14
15 from pymongo import errors
16 from anyjson import loads, dumps
17 from pymongo import MongoClient
18
19 from kombu.five import Empty
20 from kombu.syn import _detect_environment
21 from kombu.utils.encoding import bytes_to_str
22
23 from . import virtual
24
25 DEFAULT_HOST = '127.0.0.1'
26 DEFAULT_PORT = 27017
27
28 __author__ = """\
29 Flavio [FlaPer87] Percoco Premoli <[email protected]>;\
30 Scott Lyons <[email protected]>;\
31 """
32
33
34 class Channel(virtual.Channel):
35 _client = None
36 supports_fanout = True
37 _fanout_queues = {}
38
39 def __init__(self, *vargs, **kwargs):
40 super_ = super(Channel, self)
41 super_.__init__(*vargs, **kwargs)
42
43 self._queue_cursors = {}
44 self._queue_readcounts = {}
45
46 def _new_queue(self, queue, **kwargs):
47 pass
48
49 def _get(self, queue):
50 try:
51 if queue in self._fanout_queues:
52 msg = next(self._queue_cursors[queue])
53 self._queue_readcounts[queue] += 1
54 return loads(bytes_to_str(msg['payload']))
55 else:
56 msg = self.client.command(
57 'findandmodify', 'messages',
58 query={'queue': queue},
59 sort={'_id': pymongo.ASCENDING}, remove=True,
60 )
61 except errors.OperationFailure as exc:
62 if 'No matching object found' in exc.args[0]:
63 raise Empty()
64 raise
65 except StopIteration:
66 raise Empty()
67
68 # as of mongo 2.0 empty results won't raise an error
69 if msg['value'] is None:
70 raise Empty()
71 return loads(bytes_to_str(msg['value']['payload']))
72
73 def _size(self, queue):
74 if queue in self._fanout_queues:
75 return (self._queue_cursors[queue].count() -
76 self._queue_readcounts[queue])
77
78 return self.client.messages.find({'queue': queue}).count()
79
80 def _put(self, queue, message, **kwargs):
81 self.client.messages.insert({'payload': dumps(message),
82 'queue': queue})
83
84 def _purge(self, queue):
85 size = self._size(queue)
86 if queue in self._fanout_queues:
87 cursor = self._queue_cursors[queue]
88 cursor.rewind()
89 self._queue_cursors[queue] = cursor.skip(cursor.count())
90 else:
91 self.client.messages.remove({'queue': queue})
92 return size
93
94 def _open(self, scheme='mongodb://'):
95 # See mongodb uri documentation:
96 # http://www.mongodb.org/display/DOCS/Connections
97 client = self.connection.client
98 options = client.transport_options
99 hostname = client.hostname or DEFAULT_HOST
100 dbname = client.virtual_host
101
102 if dbname in ['/', None]:
103 dbname = "kombu_default"
104 if not hostname.startswith(scheme):
105 hostname = scheme + hostname
106
107 if not hostname[len(scheme):]:
108 hostname += 'localhost'
109
110 # XXX What does this do? [ask]
111 urest = hostname[len(scheme):]
112 if '/' in urest:
113 if not client.userid:
114 urest = urest.replace('/' + client.virtual_host, '/')
115 hostname = ''.join([scheme, urest])
116
117 # At this point we expect the hostname to be something like
118 # (considering replica set form too):
119 #
120 # mongodb://[username:password@]host1[:port1][,host2[:port2],
121 # ...[,hostN[:portN]]][/[?options]]
122 options.setdefault('auto_start_request', True)
123 mongoconn = MongoClient(
124 host=hostname, ssl=client.ssl,
125 auto_start_request=options['auto_start_request'],
126 use_greenlets=_detect_environment() != 'default',
127 )
128 database = getattr(mongoconn, dbname)
129
130 version = mongoconn.server_info()['version']
131 if tuple(map(int, version.split('.')[:2])) < (1, 3):
132 raise NotImplementedError(
133 'Kombu requires MongoDB version 1.3+ (server is {0})'.format(
134 version))
135
136 self.db = database
137 col = database.messages
138 col.ensure_index([('queue', 1), ('_id', 1)], background=True)
139
140 if 'messages.broadcast' not in database.collection_names():
141 capsize = options.get('capped_queue_size') or 100000
142 database.create_collection('messages.broadcast',
143 size=capsize, capped=True)
144
145 self.bcast = getattr(database, 'messages.broadcast')
146 self.bcast.ensure_index([('queue', 1)])
147
148 self.routing = getattr(database, 'messages.routing')
149 self.routing.ensure_index([('queue', 1), ('exchange', 1)])
150 return database
151
152 #TODO: Store a more complete exchange metatable in the routing collection
153 def get_table(self, exchange):
154 """Get table of bindings for ``exchange``."""
155 localRoutes = frozenset(self.state.exchanges[exchange]['table'])
156 brokerRoutes = self.client.messages.routing.find(
157 {'exchange': exchange}
158 )
159
160 return localRoutes | frozenset((r['routing_key'],
161 r['pattern'],
162 r['queue']) for r in brokerRoutes)
163
164 def _put_fanout(self, exchange, message, **kwargs):
165 """Deliver fanout message."""
166 self.client.messages.broadcast.insert({'payload': dumps(message),
167 'queue': exchange})
168
169 def _queue_bind(self, exchange, routing_key, pattern, queue):
170 if self.typeof(exchange).type == 'fanout':
171 cursor = self.bcast.find(query={'queue': exchange},
172 sort=[('$natural', 1)], tailable=True)
173 # Fast forward the cursor past old events
174 self._queue_cursors[queue] = cursor.skip(cursor.count())
175 self._queue_readcounts[queue] = cursor.count()
176 self._fanout_queues[queue] = exchange
177
178 meta = {'exchange': exchange,
179 'queue': queue,
180 'routing_key': routing_key,
181 'pattern': pattern}
182 self.client.messages.routing.update(meta, meta, upsert=True)
183
184 def queue_delete(self, queue, **kwargs):
185 self.routing.remove({'queue': queue})
186 super(Channel, self).queue_delete(queue, **kwargs)
187 if queue in self._fanout_queues:
188 self._queue_cursors[queue].close()
189 self._queue_cursors.pop(queue, None)
190 self._fanout_queues.pop(queue, None)
191
192 @property
193 def client(self):
194 if self._client is None:
195 self._client = self._open()
196 return self._client
197
198
199 class Transport(virtual.Transport):
200 Channel = Channel
201
202 can_parse_url = True
203 polling_interval = 1
204 default_port = DEFAULT_PORT
205 connection_errors = (
206 virtual.Transport.connection_errors + (errors.ConnectionFailure, )
207 )
208 channel_errors = (
209 virtual.Transport.channel_errors + (
210 errors.ConnectionFailure,
211 errors.OperationFailure)
212 )
213 driver_type = 'mongodb'
214 driver_name = 'pymongo'
215
216 def driver_version(self):
217 return pymongo.version
218
[end of kombu/transport/mongodb.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/kombu/transport/mongodb.py b/kombu/transport/mongodb.py
--- a/kombu/transport/mongodb.py
+++ b/kombu/transport/mongodb.py
@@ -14,7 +14,7 @@
from pymongo import errors
from anyjson import loads, dumps
-from pymongo import MongoClient
+from pymongo import MongoClient, uri_parser
from kombu.five import Empty
from kombu.syn import _detect_environment
@@ -91,38 +91,52 @@
self.client.messages.remove({'queue': queue})
return size
- def _open(self, scheme='mongodb://'):
+ def _parse_uri(self, scheme='mongodb://'):
# See mongodb uri documentation:
- # http://www.mongodb.org/display/DOCS/Connections
+ # http://docs.mongodb.org/manual/reference/connection-string/
client = self.connection.client
- options = client.transport_options
- hostname = client.hostname or DEFAULT_HOST
- dbname = client.virtual_host
+ hostname = client.hostname
- if dbname in ['/', None]:
- dbname = "kombu_default"
if not hostname.startswith(scheme):
hostname = scheme + hostname
if not hostname[len(scheme):]:
- hostname += 'localhost'
-
- # XXX What does this do? [ask]
- urest = hostname[len(scheme):]
- if '/' in urest:
- if not client.userid:
- urest = urest.replace('/' + client.virtual_host, '/')
- hostname = ''.join([scheme, urest])
-
- # At this point we expect the hostname to be something like
- # (considering replica set form too):
- #
- # mongodb://[username:password@]host1[:port1][,host2[:port2],
- # ...[,hostN[:portN]]][/[?options]]
- options.setdefault('auto_start_request', True)
+ hostname += DEFAULT_HOST
+
+ if client.userid and '@' not in hostname:
+ head, tail = hostname.split('://')
+
+ credentials = client.userid
+ if client.password:
+ credentials += ':' + client.password
+
+ hostname = head + '://' + credentials + '@' + tail
+
+ port = client.port if client.port is not None else DEFAULT_PORT
+
+ parsed = uri_parser.parse_uri(hostname, port)
+
+ dbname = parsed['database'] or client.virtual_host
+
+ if dbname in ('/', None):
+ dbname = 'kombu_default'
+
+ options = {'auto_start_request': True,
+ 'ssl': client.ssl,
+ 'connectTimeoutMS': int(client.connect_timeout * 1000)
+ if client.connect_timeout else None}
+ options.update(client.transport_options)
+ options.update(parsed['options'])
+
+ return hostname, dbname, options
+
+ def _open(self, scheme='mongodb://'):
+ hostname, dbname, options = self._parse_uri(scheme=scheme)
+
mongoconn = MongoClient(
- host=hostname, ssl=client.ssl,
+ host=hostname, ssl=options['ssl'],
auto_start_request=options['auto_start_request'],
+ connectTimeoutMS=options['connectTimeoutMS'],
use_greenlets=_detect_environment() != 'default',
)
database = getattr(mongoconn, dbname)
|
{"golden_diff": "diff --git a/kombu/transport/mongodb.py b/kombu/transport/mongodb.py\n--- a/kombu/transport/mongodb.py\n+++ b/kombu/transport/mongodb.py\n@@ -14,7 +14,7 @@\n \n from pymongo import errors\n from anyjson import loads, dumps\n-from pymongo import MongoClient\n+from pymongo import MongoClient, uri_parser\n \n from kombu.five import Empty\n from kombu.syn import _detect_environment\n@@ -91,38 +91,52 @@\n self.client.messages.remove({'queue': queue})\n return size\n \n- def _open(self, scheme='mongodb://'):\n+ def _parse_uri(self, scheme='mongodb://'):\n # See mongodb uri documentation:\n- # http://www.mongodb.org/display/DOCS/Connections\n+ # http://docs.mongodb.org/manual/reference/connection-string/\n client = self.connection.client\n- options = client.transport_options\n- hostname = client.hostname or DEFAULT_HOST\n- dbname = client.virtual_host\n+ hostname = client.hostname\n \n- if dbname in ['/', None]:\n- dbname = \"kombu_default\"\n if not hostname.startswith(scheme):\n hostname = scheme + hostname\n \n if not hostname[len(scheme):]:\n- hostname += 'localhost'\n-\n- # XXX What does this do? [ask]\n- urest = hostname[len(scheme):]\n- if '/' in urest:\n- if not client.userid:\n- urest = urest.replace('/' + client.virtual_host, '/')\n- hostname = ''.join([scheme, urest])\n-\n- # At this point we expect the hostname to be something like\n- # (considering replica set form too):\n- #\n- # mongodb://[username:password@]host1[:port1][,host2[:port2],\n- # ...[,hostN[:portN]]][/[?options]]\n- options.setdefault('auto_start_request', True)\n+ hostname += DEFAULT_HOST\n+\n+ if client.userid and '@' not in hostname:\n+ head, tail = hostname.split('://')\n+\n+ credentials = client.userid\n+ if client.password:\n+ credentials += ':' + client.password\n+\n+ hostname = head + '://' + credentials + '@' + tail\n+\n+ port = client.port if client.port is not None else DEFAULT_PORT\n+\n+ parsed = uri_parser.parse_uri(hostname, port)\n+\n+ dbname = parsed['database'] or client.virtual_host\n+\n+ if dbname in ('/', None):\n+ dbname = 'kombu_default'\n+\n+ options = {'auto_start_request': True,\n+ 'ssl': client.ssl,\n+ 'connectTimeoutMS': int(client.connect_timeout * 1000)\n+ if client.connect_timeout else None}\n+ options.update(client.transport_options)\n+ options.update(parsed['options'])\n+\n+ return hostname, dbname, options\n+\n+ def _open(self, scheme='mongodb://'):\n+ hostname, dbname, options = self._parse_uri(scheme=scheme)\n+\n mongoconn = MongoClient(\n- host=hostname, ssl=client.ssl,\n+ host=hostname, ssl=options['ssl'],\n auto_start_request=options['auto_start_request'],\n+ connectTimeoutMS=options['connectTimeoutMS'],\n use_greenlets=_detect_environment() != 'default',\n )\n database = getattr(mongoconn, dbname)\n", "issue": "Mongodb url is broken in Kombu 3.0.1\nUpgrading to version 3.0.1, a mongodb url like mongodb://localhost/wq fails as the // gets converted to / by some code in transport/mongodb.py - basically it seems to boil down to this code:-\n\n```\n if '/' in hostname[10:]:\n if not client.userid:\n hostname = hostname.replace('/' + client.virtual_host, '/')\n else:\n hostname = hostname.replace('/' + client.virtual_host, '/' + authdb)\n```\n\nby default virtual_host == '/' so basically hostname becomes:-\n\nmongodb:/localhost/wq instead of mongodb://localhost/wq causing the MongoClient to fail wit a port not an integer error.\n\nright now can work around this by setting the url to mongodb:////localhost/wq but its a kludge.\n\nmongodb transport no longer honors configured port.\nThe mongodb transport in kombu version 2.1.3 (version according to pypi) has changed the BrokerConnection arguments that it uses. We are passing in hostname, port, and transport in as separate BrokerConnection arguments, but the mongodb transport now expects to get all that information out of hostname, which it assumes is a mongodb:// URI.\n\nFor some history, version 1.5.0 changed the parse_url() function so that the port was no longer parsed out of mongodb:// URIs. So we were forced to pass the hostname, port, and transport in as separate BrokerConnection arguments. Now, we are being forced back to passing a mongodb:// URI in as the hostname.\n\n", "before_files": [{"content": "\"\"\"\nkombu.transport.mongodb\n=======================\n\nMongoDB transport.\n\n:copyright: (c) 2010 - 2013 by Flavio Percoco Premoli.\n:license: BSD, see LICENSE for more details.\n\n\"\"\"\nfrom __future__ import absolute_import\n\nimport pymongo\n\nfrom pymongo import errors\nfrom anyjson import loads, dumps\nfrom pymongo import MongoClient\n\nfrom kombu.five import Empty\nfrom kombu.syn import _detect_environment\nfrom kombu.utils.encoding import bytes_to_str\n\nfrom . import virtual\n\nDEFAULT_HOST = '127.0.0.1'\nDEFAULT_PORT = 27017\n\n__author__ = \"\"\"\\\nFlavio [FlaPer87] Percoco Premoli <[email protected]>;\\\nScott Lyons <[email protected]>;\\\n\"\"\"\n\n\nclass Channel(virtual.Channel):\n _client = None\n supports_fanout = True\n _fanout_queues = {}\n\n def __init__(self, *vargs, **kwargs):\n super_ = super(Channel, self)\n super_.__init__(*vargs, **kwargs)\n\n self._queue_cursors = {}\n self._queue_readcounts = {}\n\n def _new_queue(self, queue, **kwargs):\n pass\n\n def _get(self, queue):\n try:\n if queue in self._fanout_queues:\n msg = next(self._queue_cursors[queue])\n self._queue_readcounts[queue] += 1\n return loads(bytes_to_str(msg['payload']))\n else:\n msg = self.client.command(\n 'findandmodify', 'messages',\n query={'queue': queue},\n sort={'_id': pymongo.ASCENDING}, remove=True,\n )\n except errors.OperationFailure as exc:\n if 'No matching object found' in exc.args[0]:\n raise Empty()\n raise\n except StopIteration:\n raise Empty()\n\n # as of mongo 2.0 empty results won't raise an error\n if msg['value'] is None:\n raise Empty()\n return loads(bytes_to_str(msg['value']['payload']))\n\n def _size(self, queue):\n if queue in self._fanout_queues:\n return (self._queue_cursors[queue].count() -\n self._queue_readcounts[queue])\n\n return self.client.messages.find({'queue': queue}).count()\n\n def _put(self, queue, message, **kwargs):\n self.client.messages.insert({'payload': dumps(message),\n 'queue': queue})\n\n def _purge(self, queue):\n size = self._size(queue)\n if queue in self._fanout_queues:\n cursor = self._queue_cursors[queue]\n cursor.rewind()\n self._queue_cursors[queue] = cursor.skip(cursor.count())\n else:\n self.client.messages.remove({'queue': queue})\n return size\n\n def _open(self, scheme='mongodb://'):\n # See mongodb uri documentation:\n # http://www.mongodb.org/display/DOCS/Connections\n client = self.connection.client\n options = client.transport_options\n hostname = client.hostname or DEFAULT_HOST\n dbname = client.virtual_host\n\n if dbname in ['/', None]:\n dbname = \"kombu_default\"\n if not hostname.startswith(scheme):\n hostname = scheme + hostname\n\n if not hostname[len(scheme):]:\n hostname += 'localhost'\n\n # XXX What does this do? [ask]\n urest = hostname[len(scheme):]\n if '/' in urest:\n if not client.userid:\n urest = urest.replace('/' + client.virtual_host, '/')\n hostname = ''.join([scheme, urest])\n\n # At this point we expect the hostname to be something like\n # (considering replica set form too):\n #\n # mongodb://[username:password@]host1[:port1][,host2[:port2],\n # ...[,hostN[:portN]]][/[?options]]\n options.setdefault('auto_start_request', True)\n mongoconn = MongoClient(\n host=hostname, ssl=client.ssl,\n auto_start_request=options['auto_start_request'],\n use_greenlets=_detect_environment() != 'default',\n )\n database = getattr(mongoconn, dbname)\n\n version = mongoconn.server_info()['version']\n if tuple(map(int, version.split('.')[:2])) < (1, 3):\n raise NotImplementedError(\n 'Kombu requires MongoDB version 1.3+ (server is {0})'.format(\n version))\n\n self.db = database\n col = database.messages\n col.ensure_index([('queue', 1), ('_id', 1)], background=True)\n\n if 'messages.broadcast' not in database.collection_names():\n capsize = options.get('capped_queue_size') or 100000\n database.create_collection('messages.broadcast',\n size=capsize, capped=True)\n\n self.bcast = getattr(database, 'messages.broadcast')\n self.bcast.ensure_index([('queue', 1)])\n\n self.routing = getattr(database, 'messages.routing')\n self.routing.ensure_index([('queue', 1), ('exchange', 1)])\n return database\n\n #TODO: Store a more complete exchange metatable in the routing collection\n def get_table(self, exchange):\n \"\"\"Get table of bindings for ``exchange``.\"\"\"\n localRoutes = frozenset(self.state.exchanges[exchange]['table'])\n brokerRoutes = self.client.messages.routing.find(\n {'exchange': exchange}\n )\n\n return localRoutes | frozenset((r['routing_key'],\n r['pattern'],\n r['queue']) for r in brokerRoutes)\n\n def _put_fanout(self, exchange, message, **kwargs):\n \"\"\"Deliver fanout message.\"\"\"\n self.client.messages.broadcast.insert({'payload': dumps(message),\n 'queue': exchange})\n\n def _queue_bind(self, exchange, routing_key, pattern, queue):\n if self.typeof(exchange).type == 'fanout':\n cursor = self.bcast.find(query={'queue': exchange},\n sort=[('$natural', 1)], tailable=True)\n # Fast forward the cursor past old events\n self._queue_cursors[queue] = cursor.skip(cursor.count())\n self._queue_readcounts[queue] = cursor.count()\n self._fanout_queues[queue] = exchange\n\n meta = {'exchange': exchange,\n 'queue': queue,\n 'routing_key': routing_key,\n 'pattern': pattern}\n self.client.messages.routing.update(meta, meta, upsert=True)\n\n def queue_delete(self, queue, **kwargs):\n self.routing.remove({'queue': queue})\n super(Channel, self).queue_delete(queue, **kwargs)\n if queue in self._fanout_queues:\n self._queue_cursors[queue].close()\n self._queue_cursors.pop(queue, None)\n self._fanout_queues.pop(queue, None)\n\n @property\n def client(self):\n if self._client is None:\n self._client = self._open()\n return self._client\n\n\nclass Transport(virtual.Transport):\n Channel = Channel\n\n can_parse_url = True\n polling_interval = 1\n default_port = DEFAULT_PORT\n connection_errors = (\n virtual.Transport.connection_errors + (errors.ConnectionFailure, )\n )\n channel_errors = (\n virtual.Transport.channel_errors + (\n errors.ConnectionFailure,\n errors.OperationFailure)\n )\n driver_type = 'mongodb'\n driver_name = 'pymongo'\n\n def driver_version(self):\n return pymongo.version\n", "path": "kombu/transport/mongodb.py"}]}
| 3,054 | 742 |
gh_patches_debug_18611
|
rasdani/github-patches
|
git_diff
|
jupyterhub__zero-to-jupyterhub-k8s-574
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Cull_idle fails for some users with non ascii usernames
At the moment Cull Idle queries the API for the users with inactive running servers and sends a `DELETE` to the endpoint users/USERNAME/server. https://github.com/jupyterhub/zero-to-jupyterhub-k8s/blob/706a8f7637881ace06b66c90c5267019d75d2cf0/images/hub/cull_idle_servers.py#L69 This works for most users, but fails with users with non ASCII usernames as the api responds with a 404.
By url-encoding the username we can make sure it works for every user.
Cull_idle fails for some users with non ascii usernames
At the moment Cull Idle queries the API for the users with inactive running servers and sends a `DELETE` to the endpoint users/USERNAME/server. https://github.com/jupyterhub/zero-to-jupyterhub-k8s/blob/706a8f7637881ace06b66c90c5267019d75d2cf0/images/hub/cull_idle_servers.py#L69 This works for most users, but fails with users with non ASCII usernames as the api responds with a 404.
By url-encoding the username we can make sure it works for every user.
</issue>
<code>
[start of images/hub/cull_idle_servers.py]
1 #!/usr/bin/env python3
2 # Imported from https://github.com/jupyterhub/jupyterhub/blob/0.8.0rc1/examples/cull-idle/cull_idle_servers.py
3 """script to monitor and cull idle single-user servers
4
5 Caveats:
6
7 last_activity is not updated with high frequency,
8 so cull timeout should be greater than the sum of:
9
10 - single-user websocket ping interval (default: 30s)
11 - JupyterHub.last_activity_interval (default: 5 minutes)
12
13 You can run this as a service managed by JupyterHub with this in your config::
14
15
16 c.JupyterHub.services = [
17 {
18 'name': 'cull-idle',
19 'admin': True,
20 'command': 'python cull_idle_servers.py --timeout=3600'.split(),
21 }
22 ]
23
24 Or run it manually by generating an API token and storing it in `JUPYTERHUB_API_TOKEN`:
25
26 export JUPYTERHUB_API_TOKEN=`jupyterhub token`
27 python cull_idle_servers.py [--timeout=900] [--url=http://127.0.0.1:8081/hub/api]
28 """
29
30 import datetime
31 import json
32 import os
33
34 from dateutil.parser import parse as parse_date
35
36 from tornado.gen import coroutine
37 from tornado.log import app_log
38 from tornado.httpclient import AsyncHTTPClient, HTTPRequest
39 from tornado.ioloop import IOLoop, PeriodicCallback
40 from tornado.options import define, options, parse_command_line
41
42
43 @coroutine
44 def cull_idle(url, api_token, timeout, cull_users=False):
45 """Shutdown idle single-user servers
46
47 If cull_users, inactive *users* will be deleted as well.
48 """
49 auth_header = {
50 'Authorization': 'token %s' % api_token
51 }
52 req = HTTPRequest(url=url + '/users',
53 headers=auth_header,
54 )
55 now = datetime.datetime.utcnow()
56 cull_limit = now - datetime.timedelta(seconds=timeout)
57 client = AsyncHTTPClient()
58 resp = yield client.fetch(req)
59 users = json.loads(resp.body.decode('utf8', 'replace'))
60 futures = []
61
62 @coroutine
63 def cull_one(user, last_activity):
64 """cull one user"""
65
66 # shutdown server first. Hub doesn't allow deleting users with running servers.
67 if user['server']:
68 app_log.info("Culling server for %s (inactive since %s)", user['name'], last_activity)
69 req = HTTPRequest(url=url + '/users/%s/server' % user['name'],
70 method='DELETE',
71 headers=auth_header,
72 )
73 resp = yield client.fetch(req)
74 if resp.code == 202:
75 msg = "Server for {} is slow to stop.".format(user['name'])
76 if cull_users:
77 app_log.warning(msg + " Not culling user yet.")
78 # return here so we don't continue to cull the user
79 # which will fail if the server is still trying to shutdown
80 return
81 app_log.warning(msg)
82 if cull_users:
83 app_log.info("Culling user %s (inactive since %s)", user['name'], last_activity)
84 req = HTTPRequest(url=url + '/users/%s' % user['name'],
85 method='DELETE',
86 headers=auth_header,
87 )
88 yield client.fetch(req)
89
90 for user in users:
91 if not user['server'] and not cull_users:
92 # server not running and not culling users, nothing to do
93 continue
94 if not user['last_activity']:
95 continue
96 last_activity = parse_date(user['last_activity'])
97 if last_activity < cull_limit:
98 # user might be in a transition (e.g. starting or stopping)
99 # don't try to cull if this is happening
100 if user['pending']:
101 app_log.warning("Not culling user %s with pending %s", user['name'], user['pending'])
102 continue
103 futures.append((user['name'], cull_one(user, last_activity)))
104 else:
105 app_log.debug("Not culling %s (active since %s)", user['name'], last_activity)
106
107 for (name, f) in futures:
108 try:
109 yield f
110 except Exception:
111 app_log.exception("Error culling %s", name)
112 else:
113 app_log.debug("Finished culling %s", name)
114
115
116 if __name__ == '__main__':
117 define('url', default=os.environ.get('JUPYTERHUB_API_URL'), help="The JupyterHub API URL")
118 define('timeout', default=600, help="The idle timeout (in seconds)")
119 define('cull_every', default=0, help="The interval (in seconds) for checking for idle servers to cull")
120 define('cull_users', default=False,
121 help="""Cull users in addition to servers.
122 This is for use in temporary-user cases such as tmpnb.""",
123 )
124
125 parse_command_line()
126 if not options.cull_every:
127 options.cull_every = options.timeout // 2
128 api_token = os.environ['JUPYTERHUB_API_TOKEN']
129
130 try:
131 AsyncHTTPClient.configure("tornado.curl_httpclient.CurlAsyncHTTPClient")
132 except ImportError as e:
133 app_log.warning("Could not load pycurl: %s\npycurl is recommended if you have a large number of users.", e)
134
135 loop = IOLoop.current()
136 cull = lambda : cull_idle(options.url, api_token, options.timeout, options.cull_users)
137 # schedule first cull immediately
138 # because PeriodicCallback doesn't start until the end of the first interval
139 loop.add_callback(cull)
140 # schedule periodic cull
141 pc = PeriodicCallback(cull, 1e3 * options.cull_every)
142 pc.start()
143 try:
144 loop.start()
145 except KeyboardInterrupt:
146 pass
147
[end of images/hub/cull_idle_servers.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/images/hub/cull_idle_servers.py b/images/hub/cull_idle_servers.py
--- a/images/hub/cull_idle_servers.py
+++ b/images/hub/cull_idle_servers.py
@@ -31,6 +31,11 @@
import json
import os
+try:
+ from urllib.parse import quote
+except ImportError:
+ from urllib import quote
+
from dateutil.parser import parse as parse_date
from tornado.gen import coroutine
@@ -66,7 +71,7 @@
# shutdown server first. Hub doesn't allow deleting users with running servers.
if user['server']:
app_log.info("Culling server for %s (inactive since %s)", user['name'], last_activity)
- req = HTTPRequest(url=url + '/users/%s/server' % user['name'],
+ req = HTTPRequest(url=url + '/users/%s/server' % quote(user['name']),
method='DELETE',
headers=auth_header,
)
|
{"golden_diff": "diff --git a/images/hub/cull_idle_servers.py b/images/hub/cull_idle_servers.py\n--- a/images/hub/cull_idle_servers.py\n+++ b/images/hub/cull_idle_servers.py\n@@ -31,6 +31,11 @@\n import json\n import os\n \n+try:\n+ from urllib.parse import quote\n+except ImportError:\n+ from urllib import quote\n+\n from dateutil.parser import parse as parse_date\n \n from tornado.gen import coroutine\n@@ -66,7 +71,7 @@\n # shutdown server first. Hub doesn't allow deleting users with running servers.\n if user['server']:\n app_log.info(\"Culling server for %s (inactive since %s)\", user['name'], last_activity)\n- req = HTTPRequest(url=url + '/users/%s/server' % user['name'],\n+ req = HTTPRequest(url=url + '/users/%s/server' % quote(user['name']),\n method='DELETE',\n headers=auth_header,\n )\n", "issue": "Cull_idle fails for some users with non ascii usernames\nAt the moment Cull Idle queries the API for the users with inactive running servers and sends a `DELETE` to the endpoint users/USERNAME/server. https://github.com/jupyterhub/zero-to-jupyterhub-k8s/blob/706a8f7637881ace06b66c90c5267019d75d2cf0/images/hub/cull_idle_servers.py#L69 This works for most users, but fails with users with non ASCII usernames as the api responds with a 404.\r\n\r\nBy url-encoding the username we can make sure it works for every user.\nCull_idle fails for some users with non ascii usernames\nAt the moment Cull Idle queries the API for the users with inactive running servers and sends a `DELETE` to the endpoint users/USERNAME/server. https://github.com/jupyterhub/zero-to-jupyterhub-k8s/blob/706a8f7637881ace06b66c90c5267019d75d2cf0/images/hub/cull_idle_servers.py#L69 This works for most users, but fails with users with non ASCII usernames as the api responds with a 404.\r\n\r\nBy url-encoding the username we can make sure it works for every user.\n", "before_files": [{"content": "#!/usr/bin/env python3\n# Imported from https://github.com/jupyterhub/jupyterhub/blob/0.8.0rc1/examples/cull-idle/cull_idle_servers.py\n\"\"\"script to monitor and cull idle single-user servers\n\nCaveats:\n\nlast_activity is not updated with high frequency,\nso cull timeout should be greater than the sum of:\n\n- single-user websocket ping interval (default: 30s)\n- JupyterHub.last_activity_interval (default: 5 minutes)\n\nYou can run this as a service managed by JupyterHub with this in your config::\n\n\n c.JupyterHub.services = [\n {\n 'name': 'cull-idle',\n 'admin': True,\n 'command': 'python cull_idle_servers.py --timeout=3600'.split(),\n }\n ]\n\nOr run it manually by generating an API token and storing it in `JUPYTERHUB_API_TOKEN`:\n\n export JUPYTERHUB_API_TOKEN=`jupyterhub token`\n python cull_idle_servers.py [--timeout=900] [--url=http://127.0.0.1:8081/hub/api]\n\"\"\"\n\nimport datetime\nimport json\nimport os\n\nfrom dateutil.parser import parse as parse_date\n\nfrom tornado.gen import coroutine\nfrom tornado.log import app_log\nfrom tornado.httpclient import AsyncHTTPClient, HTTPRequest\nfrom tornado.ioloop import IOLoop, PeriodicCallback\nfrom tornado.options import define, options, parse_command_line\n\n\n@coroutine\ndef cull_idle(url, api_token, timeout, cull_users=False):\n \"\"\"Shutdown idle single-user servers\n\n If cull_users, inactive *users* will be deleted as well.\n \"\"\"\n auth_header = {\n 'Authorization': 'token %s' % api_token\n }\n req = HTTPRequest(url=url + '/users',\n headers=auth_header,\n )\n now = datetime.datetime.utcnow()\n cull_limit = now - datetime.timedelta(seconds=timeout)\n client = AsyncHTTPClient()\n resp = yield client.fetch(req)\n users = json.loads(resp.body.decode('utf8', 'replace'))\n futures = []\n\n @coroutine\n def cull_one(user, last_activity):\n \"\"\"cull one user\"\"\"\n\n # shutdown server first. Hub doesn't allow deleting users with running servers.\n if user['server']:\n app_log.info(\"Culling server for %s (inactive since %s)\", user['name'], last_activity)\n req = HTTPRequest(url=url + '/users/%s/server' % user['name'],\n method='DELETE',\n headers=auth_header,\n )\n resp = yield client.fetch(req)\n if resp.code == 202:\n msg = \"Server for {} is slow to stop.\".format(user['name'])\n if cull_users:\n app_log.warning(msg + \" Not culling user yet.\")\n # return here so we don't continue to cull the user\n # which will fail if the server is still trying to shutdown\n return\n app_log.warning(msg)\n if cull_users:\n app_log.info(\"Culling user %s (inactive since %s)\", user['name'], last_activity)\n req = HTTPRequest(url=url + '/users/%s' % user['name'],\n method='DELETE',\n headers=auth_header,\n )\n yield client.fetch(req)\n\n for user in users:\n if not user['server'] and not cull_users:\n # server not running and not culling users, nothing to do\n continue\n if not user['last_activity']:\n continue\n last_activity = parse_date(user['last_activity'])\n if last_activity < cull_limit:\n # user might be in a transition (e.g. starting or stopping)\n # don't try to cull if this is happening\n if user['pending']:\n app_log.warning(\"Not culling user %s with pending %s\", user['name'], user['pending'])\n continue\n futures.append((user['name'], cull_one(user, last_activity)))\n else:\n app_log.debug(\"Not culling %s (active since %s)\", user['name'], last_activity)\n\n for (name, f) in futures:\n try:\n yield f\n except Exception:\n app_log.exception(\"Error culling %s\", name)\n else:\n app_log.debug(\"Finished culling %s\", name)\n\n\nif __name__ == '__main__':\n define('url', default=os.environ.get('JUPYTERHUB_API_URL'), help=\"The JupyterHub API URL\")\n define('timeout', default=600, help=\"The idle timeout (in seconds)\")\n define('cull_every', default=0, help=\"The interval (in seconds) for checking for idle servers to cull\")\n define('cull_users', default=False,\n help=\"\"\"Cull users in addition to servers.\n This is for use in temporary-user cases such as tmpnb.\"\"\",\n )\n\n parse_command_line()\n if not options.cull_every:\n options.cull_every = options.timeout // 2\n api_token = os.environ['JUPYTERHUB_API_TOKEN']\n\n try:\n AsyncHTTPClient.configure(\"tornado.curl_httpclient.CurlAsyncHTTPClient\")\n except ImportError as e:\n app_log.warning(\"Could not load pycurl: %s\\npycurl is recommended if you have a large number of users.\", e)\n\n loop = IOLoop.current()\n cull = lambda : cull_idle(options.url, api_token, options.timeout, options.cull_users)\n # schedule first cull immediately\n # because PeriodicCallback doesn't start until the end of the first interval\n loop.add_callback(cull)\n # schedule periodic cull\n pc = PeriodicCallback(cull, 1e3 * options.cull_every)\n pc.start()\n try:\n loop.start()\n except KeyboardInterrupt:\n pass\n", "path": "images/hub/cull_idle_servers.py"}]}
| 2,464 | 214 |
gh_patches_debug_23214
|
rasdani/github-patches
|
git_diff
|
pretalx__pretalx-84
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
resetting schedule to an old version can make submissions unavailable
1. create submission: sub1
2. publish a schedule containing only sub1: ScheduleA
3. create submission: sub2
4. publish a schedule containing both sub1 and sub2: ScheduleB
5. reset the current draft to ScheduleA
Sub2 is not part of the current draft and should therefore be visible in the list on the right. But the list is empty. Resetting the draft to ScheduleB restores the talk.
resetting schedule to an old version can make submissions unavailable
1. create submission: sub1
2. publish a schedule containing only sub1: ScheduleA
3. create submission: sub2
4. publish a schedule containing both sub1 and sub2: ScheduleB
5. reset the current draft to ScheduleA
Sub2 is not part of the current draft and should therefore be visible in the list on the right. But the list is empty. Resetting the draft to ScheduleB restores the talk.
resetting schedule to an old version can make submissions unavailable
1. create submission: sub1
2. publish a schedule containing only sub1: ScheduleA
3. create submission: sub2
4. publish a schedule containing both sub1 and sub2: ScheduleB
5. reset the current draft to ScheduleA
Sub2 is not part of the current draft and should therefore be visible in the list on the right. But the list is empty. Resetting the draft to ScheduleB restores the talk.
</issue>
<code>
[start of src/pretalx/schedule/models/schedule.py]
1 from collections import defaultdict
2 from contextlib import suppress
3
4 import pytz
5 from django.db import models, transaction
6 from django.template.loader import get_template
7 from django.utils.functional import cached_property
8 from django.utils.timezone import now, override as tzoverride
9 from django.utils.translation import override, ugettext_lazy as _
10
11 from pretalx.common.mixins import LogMixin
12 from pretalx.mail.models import QueuedMail
13 from pretalx.person.models import User
14 from pretalx.submission.models import SubmissionStates
15
16
17 class Schedule(LogMixin, models.Model):
18 event = models.ForeignKey(
19 to='event.Event',
20 on_delete=models.PROTECT,
21 related_name='schedules',
22 )
23 version = models.CharField(
24 max_length=200,
25 null=True, blank=True,
26 )
27 published = models.DateTimeField(
28 null=True, blank=True
29 )
30
31 class Meta:
32 ordering = ('-published', )
33 unique_together = (('event', 'version'), )
34
35 @transaction.atomic
36 def freeze(self, name, user=None):
37 from pretalx.schedule.models import TalkSlot
38 if self.version:
39 raise Exception(f'Cannot freeze schedule version: already versioned as "{self.version}".')
40
41 self.version = name
42 self.published = now()
43 self.save(update_fields=['published', 'version'])
44 self.log_action('pretalx.schedule.release', person=user, orga=True)
45
46 wip_schedule = Schedule.objects.create(event=self.event)
47
48 # Set visibility
49 self.talks.filter(
50 start__isnull=False, submission__state=SubmissionStates.CONFIRMED, is_visible=False
51 ).update(is_visible=True)
52 self.talks.filter(is_visible=True).exclude(
53 start__isnull=False, submission__state=SubmissionStates.CONFIRMED
54 ).update(is_visible=False)
55
56 talks = []
57 for talk in self.talks.select_related('submission', 'room').all():
58 talks.append(talk.copy_to_schedule(wip_schedule, save=False))
59 TalkSlot.objects.bulk_create(talks)
60
61 self.notify_speakers()
62
63 with suppress(AttributeError):
64 del wip_schedule.event.wip_schedule
65
66 return self, wip_schedule
67
68 def unfreeze(self, user=None):
69 from pretalx.schedule.models import TalkSlot
70 if not self.version:
71 raise Exception('Cannot unfreeze schedule version: not released yet.')
72 self.event.wip_schedule.talks.all().delete()
73 self.event.wip_schedule.delete()
74 wip_schedule = Schedule.objects.create(event=self.event)
75 talks = []
76 for talk in self.talks.all():
77 talks.append(talk.copy_to_schedule(wip_schedule, save=False))
78 TalkSlot.objects.bulk_create(talks)
79 return self, wip_schedule
80
81 @cached_property
82 def scheduled_talks(self):
83 return self.talks.filter(
84 room__isnull=False,
85 start__isnull=False,
86 )
87
88 @cached_property
89 def previous_schedule(self):
90 return self.event.schedules.filter(published__lt=self.published).order_by('-published').first()
91
92 @cached_property
93 def changes(self):
94 tz = pytz.timezone(self.event.timezone)
95 result = {
96 'count': 0,
97 'action': 'update',
98 'new_talks': [],
99 'canceled_talks': [],
100 'moved_talks': [],
101 }
102 if not self.previous_schedule:
103 result['action'] = 'create'
104 return result
105
106 new_slots = set(
107 talk
108 for talk in self.talks.select_related('submission', 'submission__event', 'room').all()
109 if talk.is_visible
110 )
111 old_slots = set(
112 talk
113 for talk in self.previous_schedule.talks.select_related('submission', 'submission__event', 'room').all()
114 if talk.is_visible
115 )
116
117 new_submissions = set(talk.submission for talk in new_slots)
118 old_submissions = set(talk.submission for talk in old_slots)
119
120 new_slot_by_submission = {talk.submission: talk for talk in new_slots}
121 old_slot_by_submission = {talk.submission: talk for talk in old_slots}
122
123 result['new_talks'] = [new_slot_by_submission.get(s) for s in new_submissions - old_submissions]
124 result['canceled_talks'] = [old_slot_by_submission.get(s) for s in old_submissions - new_submissions]
125
126 for submission in (new_submissions & old_submissions):
127 old_slot = old_slot_by_submission.get(submission)
128 new_slot = new_slot_by_submission.get(submission)
129 if new_slot.room and not old_slot.room:
130 result['new_talks'].append(new_slot)
131 elif not new_slot.room and old_slot.room:
132 result['canceled_talks'].append(new_slot)
133 elif old_slot.start != new_slot.start or old_slot.room != new_slot.room:
134 if new_slot.room:
135 result['moved_talks'].append({
136 'submission': submission,
137 'old_start': old_slot.start.astimezone(tz),
138 'new_start': new_slot.start.astimezone(tz),
139 'old_room': old_slot.room.name,
140 'new_room': new_slot.room.name,
141 })
142
143 result['count'] = len(result['new_talks']) + len(result['canceled_talks']) + len(result['moved_talks'])
144 return result
145
146 def notify_speakers(self):
147 tz = pytz.timezone(self.event.timezone)
148 speakers = defaultdict(lambda: {'create': [], 'update': []})
149 if self.changes['action'] == 'create':
150 speakers = {
151 speaker: {'create': self.talks.filter(submission__speakers=speaker), 'update': []}
152 for speaker in User.objects.filter(submissions__slots__schedule=self)
153 }
154 else:
155 if self.changes['count'] == len(self.changes['canceled_talks']):
156 return
157
158 for new_talk in self.changes['new_talks']:
159 for speaker in new_talk.submission.speakers.all():
160 speakers[speaker]['create'].append(new_talk)
161 for moved_talk in self.changes['moved_talks']:
162 for speaker in moved_talk['submission'].speakers.all():
163 speakers[speaker]['update'].append(moved_talk)
164 for speaker in speakers:
165 with override(speaker.locale), tzoverride(tz):
166 text = get_template('schedule/speaker_notification.txt').render(
167 {'speaker': speaker, **speakers[speaker]}
168 )
169 QueuedMail.objects.create(
170 event=self.event,
171 to=speaker.email,
172 reply_to=self.event.email,
173 subject=_('[{event}] New schedule!').format(event=self.event.slug),
174 text=text
175 )
176
177 def __str__(self) -> str:
178 return str(self.version) or _(f'WIP Schedule for {self.event}')
179
[end of src/pretalx/schedule/models/schedule.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/pretalx/schedule/models/schedule.py b/src/pretalx/schedule/models/schedule.py
--- a/src/pretalx/schedule/models/schedule.py
+++ b/src/pretalx/schedule/models/schedule.py
@@ -69,13 +69,25 @@
from pretalx.schedule.models import TalkSlot
if not self.version:
raise Exception('Cannot unfreeze schedule version: not released yet.')
+
+ # collect all talks, which have been added since this schedule (#72)
+ submission_ids = self.talks.all().values_list('submission_id', flat=True)
+ talks = self.event.wip_schedule.talks \
+ .exclude(submission_id__in=submission_ids) \
+ .union(self.talks.all())
+
+ wip_schedule = Schedule.objects.create(event=self.event)
+ new_talks = []
+ for talk in talks:
+ new_talks.append(talk.copy_to_schedule(wip_schedule, save=False))
+ TalkSlot.objects.bulk_create(new_talks)
+
self.event.wip_schedule.talks.all().delete()
self.event.wip_schedule.delete()
- wip_schedule = Schedule.objects.create(event=self.event)
- talks = []
- for talk in self.talks.all():
- talks.append(talk.copy_to_schedule(wip_schedule, save=False))
- TalkSlot.objects.bulk_create(talks)
+
+ with suppress(AttributeError):
+ del wip_schedule.event.wip_schedule
+
return self, wip_schedule
@cached_property
|
{"golden_diff": "diff --git a/src/pretalx/schedule/models/schedule.py b/src/pretalx/schedule/models/schedule.py\n--- a/src/pretalx/schedule/models/schedule.py\n+++ b/src/pretalx/schedule/models/schedule.py\n@@ -69,13 +69,25 @@\n from pretalx.schedule.models import TalkSlot\n if not self.version:\n raise Exception('Cannot unfreeze schedule version: not released yet.')\n+\n+ # collect all talks, which have been added since this schedule (#72)\n+ submission_ids = self.talks.all().values_list('submission_id', flat=True)\n+ talks = self.event.wip_schedule.talks \\\n+ .exclude(submission_id__in=submission_ids) \\\n+ .union(self.talks.all())\n+\n+ wip_schedule = Schedule.objects.create(event=self.event)\n+ new_talks = []\n+ for talk in talks:\n+ new_talks.append(talk.copy_to_schedule(wip_schedule, save=False))\n+ TalkSlot.objects.bulk_create(new_talks)\n+\n self.event.wip_schedule.talks.all().delete()\n self.event.wip_schedule.delete()\n- wip_schedule = Schedule.objects.create(event=self.event)\n- talks = []\n- for talk in self.talks.all():\n- talks.append(talk.copy_to_schedule(wip_schedule, save=False))\n- TalkSlot.objects.bulk_create(talks)\n+\n+ with suppress(AttributeError):\n+ del wip_schedule.event.wip_schedule\n+\n return self, wip_schedule\n \n @cached_property\n", "issue": "resetting schedule to an old version can make submissions unavailable\n1. create submission: sub1\r\n2. publish a schedule containing only sub1: ScheduleA\r\n3. create submission: sub2\r\n4. publish a schedule containing both sub1 and sub2: ScheduleB\r\n5. reset the current draft to ScheduleA\r\n\r\nSub2 is not part of the current draft and should therefore be visible in the list on the right. But the list is empty. Resetting the draft to ScheduleB restores the talk.\nresetting schedule to an old version can make submissions unavailable\n1. create submission: sub1\r\n2. publish a schedule containing only sub1: ScheduleA\r\n3. create submission: sub2\r\n4. publish a schedule containing both sub1 and sub2: ScheduleB\r\n5. reset the current draft to ScheduleA\r\n\r\nSub2 is not part of the current draft and should therefore be visible in the list on the right. But the list is empty. Resetting the draft to ScheduleB restores the talk.\nresetting schedule to an old version can make submissions unavailable\n1. create submission: sub1\r\n2. publish a schedule containing only sub1: ScheduleA\r\n3. create submission: sub2\r\n4. publish a schedule containing both sub1 and sub2: ScheduleB\r\n5. reset the current draft to ScheduleA\r\n\r\nSub2 is not part of the current draft and should therefore be visible in the list on the right. But the list is empty. Resetting the draft to ScheduleB restores the talk.\n", "before_files": [{"content": "from collections import defaultdict\nfrom contextlib import suppress\n\nimport pytz\nfrom django.db import models, transaction\nfrom django.template.loader import get_template\nfrom django.utils.functional import cached_property\nfrom django.utils.timezone import now, override as tzoverride\nfrom django.utils.translation import override, ugettext_lazy as _\n\nfrom pretalx.common.mixins import LogMixin\nfrom pretalx.mail.models import QueuedMail\nfrom pretalx.person.models import User\nfrom pretalx.submission.models import SubmissionStates\n\n\nclass Schedule(LogMixin, models.Model):\n event = models.ForeignKey(\n to='event.Event',\n on_delete=models.PROTECT,\n related_name='schedules',\n )\n version = models.CharField(\n max_length=200,\n null=True, blank=True,\n )\n published = models.DateTimeField(\n null=True, blank=True\n )\n\n class Meta:\n ordering = ('-published', )\n unique_together = (('event', 'version'), )\n\n @transaction.atomic\n def freeze(self, name, user=None):\n from pretalx.schedule.models import TalkSlot\n if self.version:\n raise Exception(f'Cannot freeze schedule version: already versioned as \"{self.version}\".')\n\n self.version = name\n self.published = now()\n self.save(update_fields=['published', 'version'])\n self.log_action('pretalx.schedule.release', person=user, orga=True)\n\n wip_schedule = Schedule.objects.create(event=self.event)\n\n # Set visibility\n self.talks.filter(\n start__isnull=False, submission__state=SubmissionStates.CONFIRMED, is_visible=False\n ).update(is_visible=True)\n self.talks.filter(is_visible=True).exclude(\n start__isnull=False, submission__state=SubmissionStates.CONFIRMED\n ).update(is_visible=False)\n\n talks = []\n for talk in self.talks.select_related('submission', 'room').all():\n talks.append(talk.copy_to_schedule(wip_schedule, save=False))\n TalkSlot.objects.bulk_create(talks)\n\n self.notify_speakers()\n\n with suppress(AttributeError):\n del wip_schedule.event.wip_schedule\n\n return self, wip_schedule\n\n def unfreeze(self, user=None):\n from pretalx.schedule.models import TalkSlot\n if not self.version:\n raise Exception('Cannot unfreeze schedule version: not released yet.')\n self.event.wip_schedule.talks.all().delete()\n self.event.wip_schedule.delete()\n wip_schedule = Schedule.objects.create(event=self.event)\n talks = []\n for talk in self.talks.all():\n talks.append(talk.copy_to_schedule(wip_schedule, save=False))\n TalkSlot.objects.bulk_create(talks)\n return self, wip_schedule\n\n @cached_property\n def scheduled_talks(self):\n return self.talks.filter(\n room__isnull=False,\n start__isnull=False,\n )\n\n @cached_property\n def previous_schedule(self):\n return self.event.schedules.filter(published__lt=self.published).order_by('-published').first()\n\n @cached_property\n def changes(self):\n tz = pytz.timezone(self.event.timezone)\n result = {\n 'count': 0,\n 'action': 'update',\n 'new_talks': [],\n 'canceled_talks': [],\n 'moved_talks': [],\n }\n if not self.previous_schedule:\n result['action'] = 'create'\n return result\n\n new_slots = set(\n talk\n for talk in self.talks.select_related('submission', 'submission__event', 'room').all()\n if talk.is_visible\n )\n old_slots = set(\n talk\n for talk in self.previous_schedule.talks.select_related('submission', 'submission__event', 'room').all()\n if talk.is_visible\n )\n\n new_submissions = set(talk.submission for talk in new_slots)\n old_submissions = set(talk.submission for talk in old_slots)\n\n new_slot_by_submission = {talk.submission: talk for talk in new_slots}\n old_slot_by_submission = {talk.submission: talk for talk in old_slots}\n\n result['new_talks'] = [new_slot_by_submission.get(s) for s in new_submissions - old_submissions]\n result['canceled_talks'] = [old_slot_by_submission.get(s) for s in old_submissions - new_submissions]\n\n for submission in (new_submissions & old_submissions):\n old_slot = old_slot_by_submission.get(submission)\n new_slot = new_slot_by_submission.get(submission)\n if new_slot.room and not old_slot.room:\n result['new_talks'].append(new_slot)\n elif not new_slot.room and old_slot.room:\n result['canceled_talks'].append(new_slot)\n elif old_slot.start != new_slot.start or old_slot.room != new_slot.room:\n if new_slot.room:\n result['moved_talks'].append({\n 'submission': submission,\n 'old_start': old_slot.start.astimezone(tz),\n 'new_start': new_slot.start.astimezone(tz),\n 'old_room': old_slot.room.name,\n 'new_room': new_slot.room.name,\n })\n\n result['count'] = len(result['new_talks']) + len(result['canceled_talks']) + len(result['moved_talks'])\n return result\n\n def notify_speakers(self):\n tz = pytz.timezone(self.event.timezone)\n speakers = defaultdict(lambda: {'create': [], 'update': []})\n if self.changes['action'] == 'create':\n speakers = {\n speaker: {'create': self.talks.filter(submission__speakers=speaker), 'update': []}\n for speaker in User.objects.filter(submissions__slots__schedule=self)\n }\n else:\n if self.changes['count'] == len(self.changes['canceled_talks']):\n return\n\n for new_talk in self.changes['new_talks']:\n for speaker in new_talk.submission.speakers.all():\n speakers[speaker]['create'].append(new_talk)\n for moved_talk in self.changes['moved_talks']:\n for speaker in moved_talk['submission'].speakers.all():\n speakers[speaker]['update'].append(moved_talk)\n for speaker in speakers:\n with override(speaker.locale), tzoverride(tz):\n text = get_template('schedule/speaker_notification.txt').render(\n {'speaker': speaker, **speakers[speaker]}\n )\n QueuedMail.objects.create(\n event=self.event,\n to=speaker.email,\n reply_to=self.event.email,\n subject=_('[{event}] New schedule!').format(event=self.event.slug),\n text=text\n )\n\n def __str__(self) -> str:\n return str(self.version) or _(f'WIP Schedule for {self.event}')\n", "path": "src/pretalx/schedule/models/schedule.py"}]}
| 2,792 | 348 |
gh_patches_debug_12881
|
rasdani/github-patches
|
git_diff
|
Lightning-AI__pytorch-lightning-771
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
ModelCheckpoint Filepath Doesn't Use Logger Save Dir
# 🐛 Bug
Not sure if this is intended, but the model checkpoint isn't using the same directory as the logger, even if the logger exists. I would have expected this line [here](https://github.com/PyTorchLightning/pytorch-lightning/blob/588ad8377167c0b7d29cf4f362dbf42015f7568d/pytorch_lightning/trainer/callback_config.py#L28) to be `self.logger.save_dir` instead of `self.default_save_path`.
Thank you,
-Collin
</issue>
<code>
[start of pytorch_lightning/trainer/callback_config.py]
1 import os
2 from abc import ABC
3
4 from pytorch_lightning.callbacks import ModelCheckpoint, EarlyStopping
5
6
7 class TrainerCallbackConfigMixin(ABC):
8
9 def __init__(self):
10 # this is just a summary on variables used in this abstract class,
11 # the proper values/initialisation should be done in child class
12 self.default_save_path = None
13 self.save_checkpoint = None
14 self.slurm_job_id = None
15
16 def configure_checkpoint_callback(self):
17 """
18 Weight path set in this priority:
19 Checkpoint_callback's path (if passed in).
20 User provided weights_saved_path
21 Otherwise use os.getcwd()
22 """
23 if self.checkpoint_callback is True:
24 # init a default one
25 if self.logger is not None:
26 ckpt_path = os.path.join(
27 self.default_save_path,
28 self.logger.name,
29 f'version_{self.logger.version}',
30 "checkpoints"
31 )
32 else:
33 ckpt_path = os.path.join(self.default_save_path, "checkpoints")
34
35 self.checkpoint_callback = ModelCheckpoint(
36 filepath=ckpt_path
37 )
38 elif self.checkpoint_callback is False:
39 self.checkpoint_callback = None
40
41 if self.checkpoint_callback:
42 # set the path for the callbacks
43 self.checkpoint_callback.save_function = self.save_checkpoint
44
45 # if checkpoint callback used, then override the weights path
46 self.weights_save_path = self.checkpoint_callback.filepath
47
48 # if weights_save_path is still none here, set to current working dir
49 if self.weights_save_path is None:
50 self.weights_save_path = self.default_save_path
51
52 def configure_early_stopping(self, early_stop_callback):
53 if early_stop_callback is True:
54 self.early_stop_callback = EarlyStopping(
55 monitor='val_loss',
56 patience=3,
57 strict=True,
58 verbose=True,
59 mode='min'
60 )
61 self.enable_early_stop = True
62 elif early_stop_callback is None:
63 self.early_stop_callback = EarlyStopping(
64 monitor='val_loss',
65 patience=3,
66 strict=False,
67 verbose=False,
68 mode='min'
69 )
70 self.enable_early_stop = True
71 elif not early_stop_callback:
72 self.early_stop_callback = None
73 self.enable_early_stop = False
74 else:
75 self.early_stop_callback = early_stop_callback
76 self.enable_early_stop = True
77
[end of pytorch_lightning/trainer/callback_config.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/pytorch_lightning/trainer/callback_config.py b/pytorch_lightning/trainer/callback_config.py
--- a/pytorch_lightning/trainer/callback_config.py
+++ b/pytorch_lightning/trainer/callback_config.py
@@ -23,8 +23,11 @@
if self.checkpoint_callback is True:
# init a default one
if self.logger is not None:
+ save_dir = (getattr(self.logger, 'save_dir', None) or
+ getattr(self.logger, '_save_dir', None) or
+ self.default_save_path)
ckpt_path = os.path.join(
- self.default_save_path,
+ save_dir,
self.logger.name,
f'version_{self.logger.version}',
"checkpoints"
|
{"golden_diff": "diff --git a/pytorch_lightning/trainer/callback_config.py b/pytorch_lightning/trainer/callback_config.py\n--- a/pytorch_lightning/trainer/callback_config.py\n+++ b/pytorch_lightning/trainer/callback_config.py\n@@ -23,8 +23,11 @@\n if self.checkpoint_callback is True:\n # init a default one\n if self.logger is not None:\n+ save_dir = (getattr(self.logger, 'save_dir', None) or\n+ getattr(self.logger, '_save_dir', None) or\n+ self.default_save_path)\n ckpt_path = os.path.join(\n- self.default_save_path,\n+ save_dir,\n self.logger.name,\n f'version_{self.logger.version}',\n \"checkpoints\"\n", "issue": "ModelCheckpoint Filepath Doesn't Use Logger Save Dir\n# \ud83d\udc1b Bug\r\n\r\nNot sure if this is intended, but the model checkpoint isn't using the same directory as the logger, even if the logger exists. I would have expected this line [here](https://github.com/PyTorchLightning/pytorch-lightning/blob/588ad8377167c0b7d29cf4f362dbf42015f7568d/pytorch_lightning/trainer/callback_config.py#L28) to be `self.logger.save_dir` instead of `self.default_save_path`. \r\n\r\nThank you,\r\n-Collin\n", "before_files": [{"content": "import os\nfrom abc import ABC\n\nfrom pytorch_lightning.callbacks import ModelCheckpoint, EarlyStopping\n\n\nclass TrainerCallbackConfigMixin(ABC):\n\n def __init__(self):\n # this is just a summary on variables used in this abstract class,\n # the proper values/initialisation should be done in child class\n self.default_save_path = None\n self.save_checkpoint = None\n self.slurm_job_id = None\n\n def configure_checkpoint_callback(self):\n \"\"\"\n Weight path set in this priority:\n Checkpoint_callback's path (if passed in).\n User provided weights_saved_path\n Otherwise use os.getcwd()\n \"\"\"\n if self.checkpoint_callback is True:\n # init a default one\n if self.logger is not None:\n ckpt_path = os.path.join(\n self.default_save_path,\n self.logger.name,\n f'version_{self.logger.version}',\n \"checkpoints\"\n )\n else:\n ckpt_path = os.path.join(self.default_save_path, \"checkpoints\")\n\n self.checkpoint_callback = ModelCheckpoint(\n filepath=ckpt_path\n )\n elif self.checkpoint_callback is False:\n self.checkpoint_callback = None\n\n if self.checkpoint_callback:\n # set the path for the callbacks\n self.checkpoint_callback.save_function = self.save_checkpoint\n\n # if checkpoint callback used, then override the weights path\n self.weights_save_path = self.checkpoint_callback.filepath\n\n # if weights_save_path is still none here, set to current working dir\n if self.weights_save_path is None:\n self.weights_save_path = self.default_save_path\n\n def configure_early_stopping(self, early_stop_callback):\n if early_stop_callback is True:\n self.early_stop_callback = EarlyStopping(\n monitor='val_loss',\n patience=3,\n strict=True,\n verbose=True,\n mode='min'\n )\n self.enable_early_stop = True\n elif early_stop_callback is None:\n self.early_stop_callback = EarlyStopping(\n monitor='val_loss',\n patience=3,\n strict=False,\n verbose=False,\n mode='min'\n )\n self.enable_early_stop = True\n elif not early_stop_callback:\n self.early_stop_callback = None\n self.enable_early_stop = False\n else:\n self.early_stop_callback = early_stop_callback\n self.enable_early_stop = True\n", "path": "pytorch_lightning/trainer/callback_config.py"}]}
| 1,349 | 165 |
gh_patches_debug_573
|
rasdani/github-patches
|
git_diff
|
google-research__text-to-text-transfer-transformer-351
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Unable to import tensorflow_gcs_config in t5_trivia colab notebook
Upon running line `import tensorflow_gcs_config` (in t5_trivia colab notebook, setup section) I get this error,
```
---------------------------------------------------------------------------
NotImplementedError Traceback (most recent call last)
<ipython-input-2-3bb7f36f8553> in <module>()
----> 1 import tensorflow_gcs_config
1 frames
/usr/local/lib/python3.6/dist-packages/tensorflow_gcs_config/__init__.py in _load_library(filename, lib)
55 raise NotImplementedError(
56 "unable to open file: " +
---> 57 "{}, from paths: {}\ncaused by: {}".format(filename, filenames, errs))
58
59 _gcs_config_so = _load_library("_gcs_config_ops.so")
NotImplementedError: unable to open file: _gcs_config_ops.so, from paths: ['/usr/local/lib/python3.6/dist-packages/tensorflow_gcs_config/_gcs_config_ops.so']
caused by: ['/usr/local/lib/python3.6/dist-packages/tensorflow_gcs_config/_gcs_config_ops.so: undefined symbol: _ZN10tensorflow15OpKernelContext5inputEN4absl11string_viewEPPKNS_6TensorE']
```
`tf.__version__` is '2.3.0'
</issue>
<code>
[start of t5/version.py]
1 # Copyright 2020 The T5 Authors.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 # Lint as: python3
16 r"""Separate file for storing the current version of T5.
17
18 Stored in a separate file so that setup.py can reference the version without
19 pulling in all the dependencies in __init__.py.
20 """
21 __version__ = '0.6.3'
22
[end of t5/version.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/t5/version.py b/t5/version.py
--- a/t5/version.py
+++ b/t5/version.py
@@ -18,4 +18,4 @@
Stored in a separate file so that setup.py can reference the version without
pulling in all the dependencies in __init__.py.
"""
-__version__ = '0.6.3'
+__version__ = '0.6.4'
|
{"golden_diff": "diff --git a/t5/version.py b/t5/version.py\n--- a/t5/version.py\n+++ b/t5/version.py\n@@ -18,4 +18,4 @@\n Stored in a separate file so that setup.py can reference the version without\n pulling in all the dependencies in __init__.py.\n \"\"\"\n-__version__ = '0.6.3'\n+__version__ = '0.6.4'\n", "issue": "Unable to import tensorflow_gcs_config in t5_trivia colab notebook\nUpon running line `import tensorflow_gcs_config` (in t5_trivia colab notebook, setup section) I get this error,\r\n```\r\n---------------------------------------------------------------------------\r\nNotImplementedError Traceback (most recent call last)\r\n<ipython-input-2-3bb7f36f8553> in <module>()\r\n----> 1 import tensorflow_gcs_config\r\n\r\n1 frames\r\n/usr/local/lib/python3.6/dist-packages/tensorflow_gcs_config/__init__.py in _load_library(filename, lib)\r\n 55 raise NotImplementedError(\r\n 56 \"unable to open file: \" +\r\n---> 57 \"{}, from paths: {}\\ncaused by: {}\".format(filename, filenames, errs))\r\n 58 \r\n 59 _gcs_config_so = _load_library(\"_gcs_config_ops.so\")\r\n\r\nNotImplementedError: unable to open file: _gcs_config_ops.so, from paths: ['/usr/local/lib/python3.6/dist-packages/tensorflow_gcs_config/_gcs_config_ops.so']\r\ncaused by: ['/usr/local/lib/python3.6/dist-packages/tensorflow_gcs_config/_gcs_config_ops.so: undefined symbol: _ZN10tensorflow15OpKernelContext5inputEN4absl11string_viewEPPKNS_6TensorE']\r\n```\r\n`tf.__version__` is '2.3.0'\n", "before_files": [{"content": "# Copyright 2020 The T5 Authors.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n# Lint as: python3\nr\"\"\"Separate file for storing the current version of T5.\n\nStored in a separate file so that setup.py can reference the version without\npulling in all the dependencies in __init__.py.\n\"\"\"\n__version__ = '0.6.3'\n", "path": "t5/version.py"}]}
| 1,074 | 91 |
gh_patches_debug_14719
|
rasdani/github-patches
|
git_diff
|
conan-io__conan-center-index-7436
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[request] imguizmo/1.83
### Package Details
* Package Name/Version: **imguizmo/1.83**
* Changelog: **https://github.com/CedricGuillemet/ImGuizmo/releases/tag/1.83**
The above mentioned version is newly released by the upstream project and not yet available as a recipe. Please add this version.
</issue>
<code>
[start of recipes/imguizmo/all/conanfile.py]
1 import os
2 import glob
3 from conans import ConanFile, CMake, tools
4
5
6 class ImGuizmoConan(ConanFile):
7 name = "imguizmo"
8 url = "https://github.com/conan-io/conan-center-index"
9 homepage = "https://github.com/CedricGuillemet/ImGuizmo"
10 description = "Immediate mode 3D gizmo for scene editing and other controls based on Dear Imgui"
11 topics = ("conan", "imgui", "3d", "graphics", "guizmo")
12 license = "MIT"
13 settings = "os", "arch", "compiler", "build_type"
14
15 exports_sources = ["CMakeLists.txt"]
16 generators = "cmake"
17 requires = "imgui/1.82"
18
19 options = {
20 "shared": [True, False],
21 "fPIC": [True, False]
22 }
23 default_options = {
24 "shared": False,
25 "fPIC": True
26 }
27
28 _cmake = None
29
30 @property
31 def _source_subfolder(self):
32 return "source_subfolder"
33
34 def config_options(self):
35 if self.settings.os == "Windows":
36 del self.options.fPIC
37
38 def configure(self):
39 if self.options.shared:
40 del self.options.fPIC
41
42 def source(self):
43 tools.get(**self.conan_data["sources"][self.version])
44 extracted_dir = glob.glob("ImGuizmo-*/")[0]
45 os.rename(extracted_dir, self._source_subfolder)
46
47 def _configure_cmake(self):
48 if self._cmake:
49 return self._cmake
50 self._cmake = CMake(self)
51 self._cmake.configure()
52 return self._cmake
53
54 def build(self):
55 cmake = self._configure_cmake()
56 cmake.build()
57
58 def package(self):
59 self.copy(pattern="LICENSE", dst="licenses", src=self._source_subfolder)
60 cmake = self._configure_cmake()
61 cmake.install()
62
63 def package_info(self):
64 self.cpp_info.libs = ["imguizmo"]
65
[end of recipes/imguizmo/all/conanfile.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/recipes/imguizmo/all/conanfile.py b/recipes/imguizmo/all/conanfile.py
--- a/recipes/imguizmo/all/conanfile.py
+++ b/recipes/imguizmo/all/conanfile.py
@@ -14,7 +14,6 @@
exports_sources = ["CMakeLists.txt"]
generators = "cmake"
- requires = "imgui/1.82"
options = {
"shared": [True, False],
@@ -44,6 +43,12 @@
extracted_dir = glob.glob("ImGuizmo-*/")[0]
os.rename(extracted_dir, self._source_subfolder)
+ def requirements(self):
+ if self.version == "cci.20210223":
+ self.requires("imgui/1.82")
+ else:
+ self.requires("imgui/1.83")
+
def _configure_cmake(self):
if self._cmake:
return self._cmake
|
{"golden_diff": "diff --git a/recipes/imguizmo/all/conanfile.py b/recipes/imguizmo/all/conanfile.py\n--- a/recipes/imguizmo/all/conanfile.py\n+++ b/recipes/imguizmo/all/conanfile.py\n@@ -14,7 +14,6 @@\n \n exports_sources = [\"CMakeLists.txt\"]\n generators = \"cmake\"\n- requires = \"imgui/1.82\"\n \n options = {\n \"shared\": [True, False],\n@@ -44,6 +43,12 @@\n extracted_dir = glob.glob(\"ImGuizmo-*/\")[0]\n os.rename(extracted_dir, self._source_subfolder)\n \n+ def requirements(self):\n+ if self.version == \"cci.20210223\":\n+ self.requires(\"imgui/1.82\")\n+ else:\n+ self.requires(\"imgui/1.83\")\n+\n def _configure_cmake(self):\n if self._cmake:\n return self._cmake\n", "issue": "[request] imguizmo/1.83\n### Package Details\r\n * Package Name/Version: **imguizmo/1.83**\r\n * Changelog: **https://github.com/CedricGuillemet/ImGuizmo/releases/tag/1.83**\r\n\r\nThe above mentioned version is newly released by the upstream project and not yet available as a recipe. Please add this version.\n", "before_files": [{"content": "import os\nimport glob\nfrom conans import ConanFile, CMake, tools\n\n\nclass ImGuizmoConan(ConanFile):\n name = \"imguizmo\"\n url = \"https://github.com/conan-io/conan-center-index\"\n homepage = \"https://github.com/CedricGuillemet/ImGuizmo\"\n description = \"Immediate mode 3D gizmo for scene editing and other controls based on Dear Imgui\"\n topics = (\"conan\", \"imgui\", \"3d\", \"graphics\", \"guizmo\")\n license = \"MIT\"\n settings = \"os\", \"arch\", \"compiler\", \"build_type\"\n\n exports_sources = [\"CMakeLists.txt\"]\n generators = \"cmake\"\n requires = \"imgui/1.82\"\n\n options = {\n \"shared\": [True, False],\n \"fPIC\": [True, False]\n }\n default_options = {\n \"shared\": False,\n \"fPIC\": True\n }\n\n _cmake = None\n\n @property\n def _source_subfolder(self):\n return \"source_subfolder\"\n\n def config_options(self):\n if self.settings.os == \"Windows\":\n del self.options.fPIC\n\n def configure(self):\n if self.options.shared:\n del self.options.fPIC\n\n def source(self):\n tools.get(**self.conan_data[\"sources\"][self.version])\n extracted_dir = glob.glob(\"ImGuizmo-*/\")[0]\n os.rename(extracted_dir, self._source_subfolder)\n\n def _configure_cmake(self):\n if self._cmake:\n return self._cmake\n self._cmake = CMake(self)\n self._cmake.configure()\n return self._cmake\n\n def build(self):\n cmake = self._configure_cmake()\n cmake.build()\n\n def package(self):\n self.copy(pattern=\"LICENSE\", dst=\"licenses\", src=self._source_subfolder)\n cmake = self._configure_cmake()\n cmake.install()\n\n def package_info(self):\n self.cpp_info.libs = [\"imguizmo\"]\n", "path": "recipes/imguizmo/all/conanfile.py"}]}
| 1,220 | 233 |
gh_patches_debug_3362
|
rasdani/github-patches
|
git_diff
|
sunpy__sunpy-4468
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
sunpy logo link broken
The link to "sunpy logo" here: https://sunpy.org/about#acknowledging-sunpy-in-posters-and-talks just redirects to the same page instead of a logo.
</issue>
<code>
[start of docs/conf.py]
1 """
2 Configuration file for the Sphinx documentation builder.
3
4 isort:skip_file
5 """
6 # flake8: NOQA: E402
7
8 # -- stdlib imports ------------------------------------------------------------
9 import os
10 import sys
11 import datetime
12 from pkg_resources import get_distribution, DistributionNotFound
13
14 # -- Check for dependencies ----------------------------------------------------
15
16 doc_requires = get_distribution("sunpy").requires(extras=("docs",))
17 missing_requirements = []
18 for requirement in doc_requires:
19 try:
20 get_distribution(requirement)
21 except Exception as e:
22 missing_requirements.append(requirement.name)
23 if missing_requirements:
24 print(
25 f"The {' '.join(missing_requirements)} package(s) could not be found and "
26 "is needed to build the documentation, please install the 'docs' requirements."
27 )
28 sys.exit(1)
29
30 # -- Read the Docs Specific Configuration --------------------------------------
31
32 # This needs to be done before sunpy is imported
33 on_rtd = os.environ.get('READTHEDOCS', None) == 'True'
34 if on_rtd:
35 os.environ['SUNPY_CONFIGDIR'] = '/home/docs/'
36 os.environ['HOME'] = '/home/docs/'
37 os.environ['LANG'] = 'C'
38 os.environ['LC_ALL'] = 'C'
39
40 # -- Non stdlib imports --------------------------------------------------------
41
42 import ruamel.yaml as yaml # NOQA
43 from sphinx_gallery.sorting import ExplicitOrder # NOQA
44 from sphinx_gallery.sorting import ExampleTitleSortKey # NOQA
45
46 import sunpy # NOQA
47 from sunpy import __version__ # NOQA
48
49 # -- Project information -------------------------------------------------------
50
51 project = 'SunPy'
52 author = 'The SunPy Community'
53 copyright = '{}, {}'.format(datetime.datetime.now().year, author)
54
55 # The full version, including alpha/beta/rc tags
56 release = __version__
57 is_development = '.dev' in __version__
58
59 # -- SunPy Sample Data and Config ----------------------------------------------
60
61 # We set the logger to debug so that we can see any sample data download errors
62 # in the CI, especially RTD.
63 ori_level = sunpy.log.level
64 sunpy.log.setLevel("DEBUG")
65 import sunpy.data.sample # NOQA
66 sunpy.log.setLevel(ori_level)
67
68 # For the linkcheck
69 linkcheck_ignore = [r"https://doi.org/\d+",
70 r"https://riot.im/\d+",
71 r"https://github.com/\d+",
72 r"https://docs.sunpy.org/\d+"]
73 linkcheck_anchors = False
74
75 # This is added to the end of RST files - a good place to put substitutions to
76 # be used globally.
77 rst_epilog = """
78 .. SunPy
79 .. _SunPy: https://sunpy.org
80 .. _`SunPy mailing list`: https://groups.google.com/group/sunpy
81 .. _`SunPy dev mailing list`: https://groups.google.com/group/sunpy-dev
82 """
83
84 # -- General configuration -----------------------------------------------------
85
86 # Suppress warnings about overriding directives as we overload some of the
87 # doctest extensions.
88 suppress_warnings = ['app.add_directive', ]
89
90 # Add any Sphinx extension module names here, as strings. They can be
91 # extensions coming with Sphinx (named 'sphinx.ext.*') or your custom
92 # ones.
93 extensions = [
94 'matplotlib.sphinxext.plot_directive',
95 'sphinx_automodapi.automodapi',
96 'sphinx_automodapi.smart_resolver',
97 'sphinx_gallery.gen_gallery',
98 'sphinx.ext.autodoc',
99 'sphinx.ext.coverage',
100 'sphinx.ext.doctest',
101 'sphinx.ext.inheritance_diagram',
102 'sphinx.ext.intersphinx',
103 'sphinx.ext.mathjax',
104 'sphinx.ext.napoleon',
105 'sphinx.ext.todo',
106 'sphinx.ext.viewcode',
107 'sunpy.util.sphinx.changelog',
108 'sunpy.util.sphinx.doctest',
109 'sunpy.util.sphinx.generate',
110 ]
111
112 # Add any paths that contain templates here, relative to this directory.
113 # templates_path = ['_templates']
114
115 # List of patterns, relative to source directory, that match files and
116 # directories to ignore when looking for source files.
117 # This pattern also affects html_static_path and html_extra_path.
118 exclude_patterns = ['_build', 'Thumbs.db', '.DS_Store']
119
120 # The suffix(es) of source filenames.
121 # You can specify multiple suffix as a list of string:
122 source_suffix = '.rst'
123
124 # The master toctree document.
125 master_doc = 'index'
126
127 # The reST default role (used for this markup: `text`) to use for all
128 # documents. Set to the "smart" one.
129 default_role = 'obj'
130
131 # Disable having a separate return type row
132 napoleon_use_rtype = False
133
134 # Disable google style docstrings
135 napoleon_google_docstring = False
136
137 # -- Options for intersphinx extension -----------------------------------------
138
139 # Example configuration for intersphinx: refer to the Python standard library.
140 intersphinx_mapping = {
141 'python': ('https://docs.python.org/3/',
142 (None, 'http://www.astropy.org/astropy-data/intersphinx/python3.inv')),
143 'numpy': ('https://numpy.org/doc/stable/',
144 (None, 'http://www.astropy.org/astropy-data/intersphinx/numpy.inv')),
145 'scipy': ('https://docs.scipy.org/doc/scipy/reference/',
146 (None, 'http://www.astropy.org/astropy-data/intersphinx/scipy.inv')),
147 'matplotlib': ('https://matplotlib.org/',
148 (None, 'http://www.astropy.org/astropy-data/intersphinx/matplotlib.inv')),
149 'astropy': ('https://docs.astropy.org/en/stable/', None),
150 'sqlalchemy': ('https://docs.sqlalchemy.org/en/latest/', None),
151 'pandas': ('https://pandas.pydata.org/pandas-docs/stable/', None),
152 'skimage': ('https://scikit-image.org/docs/stable/', None),
153 'drms': ('https://docs.sunpy.org/projects/drms/en/stable/', None),
154 'parfive': ('https://parfive.readthedocs.io/en/latest/', None),
155 'reproject': ('https://reproject.readthedocs.io/en/stable/', None),
156 }
157
158 # -- Options for HTML output ---------------------------------------------------
159
160 # The theme to use for HTML and HTML Help pages. See the documentation for
161 # a list of builtin themes.
162
163 from sunpy_sphinx_theme.conf import * # NOQA
164
165 # Add any paths that contain custom static files (such as style sheets) here,
166 # relative to this directory. They are copied after the builtin static files,
167 # so a file named "default.css" will overwrite the builtin "default.css".
168 # html_static_path = ['_static']
169
170 # Render inheritance diagrams in SVG
171 graphviz_output_format = "svg"
172
173 graphviz_dot_args = [
174 '-Nfontsize=10',
175 '-Nfontname=Helvetica Neue, Helvetica, Arial, sans-serif',
176 '-Efontsize=10',
177 '-Efontname=Helvetica Neue, Helvetica, Arial, sans-serif',
178 '-Gfontsize=10',
179 '-Gfontname=Helvetica Neue, Helvetica, Arial, sans-serif'
180 ]
181
182 # -- Sphinx Gallery ------------------------------------------------------------
183
184 sphinx_gallery_conf = {
185 'backreferences_dir': os.path.join('generated', 'modules'),
186 'filename_pattern': '^((?!skip_).)*$',
187 'examples_dirs': os.path.join('..', 'examples'),
188 'subsection_order': ExplicitOrder([
189 '../examples/acquiring_data',
190 '../examples/map',
191 '../examples/map_transformations',
192 '../examples/time_series',
193 '../examples/units_and_coordinates',
194 '../examples/plotting',
195 '../examples/differential_rotation',
196 '../examples/saving_and_loading_data',
197 '../examples/computer_vision_techniques',
198 '../examples/developer_tools'
199 ]),
200 'within_subsection_order': ExampleTitleSortKey,
201 'gallery_dirs': os.path.join('generated', 'gallery'),
202 'default_thumb_file': os.path.join('logo', 'sunpy_icon_128x128.png'),
203 'abort_on_example_error': False,
204 'plot_gallery': 'True',
205 'remove_config_comments': True,
206 'doc_module': ('sunpy'),
207 }
208
209 # -- Stability Page ------------------------------------------------------------
210
211 with open('./dev_guide/sunpy_stability.yaml', 'r') as estability:
212 sunpy_modules = yaml.load(estability.read(), Loader=yaml.Loader)
213
214 html_context = {
215 'sunpy_modules': sunpy_modules
216 }
217
218
219 def rstjinja(app, docname, source):
220 """
221 Render our pages as a jinja template for fancy templating goodness.
222 """
223 # Make sure we're outputting HTML
224 if app.builder.format != 'html':
225 return
226 src = source[0]
227 if "Current status" in src[:20]:
228 rendered = app.builder.templates.render_string(
229 src, app.config.html_context
230 )
231 source[0] = rendered
232
233
234 # -- Sphinx setup --------------------------------------------------------------
235 def setup(app):
236 # Generate the stability page
237 app.connect("source-read", rstjinja)
238
239 # The theme conf provides a fix for circle ci redirections
240 fix_circleci(app)
241
[end of docs/conf.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/docs/conf.py b/docs/conf.py
--- a/docs/conf.py
+++ b/docs/conf.py
@@ -67,7 +67,7 @@
# For the linkcheck
linkcheck_ignore = [r"https://doi.org/\d+",
- r"https://riot.im/\d+",
+ r"https://element.io/\d+",
r"https://github.com/\d+",
r"https://docs.sunpy.org/\d+"]
linkcheck_anchors = False
|
{"golden_diff": "diff --git a/docs/conf.py b/docs/conf.py\n--- a/docs/conf.py\n+++ b/docs/conf.py\n@@ -67,7 +67,7 @@\n \n # For the linkcheck\n linkcheck_ignore = [r\"https://doi.org/\\d+\",\n- r\"https://riot.im/\\d+\",\n+ r\"https://element.io/\\d+\",\n r\"https://github.com/\\d+\",\n r\"https://docs.sunpy.org/\\d+\"]\n linkcheck_anchors = False\n", "issue": "sunpy logo link broken\nThe link to \"sunpy logo\" here: https://sunpy.org/about#acknowledging-sunpy-in-posters-and-talks just redirects to the same page instead of a logo.\n", "before_files": [{"content": "\"\"\"\nConfiguration file for the Sphinx documentation builder.\n\nisort:skip_file\n\"\"\"\n# flake8: NOQA: E402\n\n# -- stdlib imports ------------------------------------------------------------\nimport os\nimport sys\nimport datetime\nfrom pkg_resources import get_distribution, DistributionNotFound\n\n# -- Check for dependencies ----------------------------------------------------\n\ndoc_requires = get_distribution(\"sunpy\").requires(extras=(\"docs\",))\nmissing_requirements = []\nfor requirement in doc_requires:\n try:\n get_distribution(requirement)\n except Exception as e:\n missing_requirements.append(requirement.name)\nif missing_requirements:\n print(\n f\"The {' '.join(missing_requirements)} package(s) could not be found and \"\n \"is needed to build the documentation, please install the 'docs' requirements.\"\n )\n sys.exit(1)\n\n# -- Read the Docs Specific Configuration --------------------------------------\n\n# This needs to be done before sunpy is imported\non_rtd = os.environ.get('READTHEDOCS', None) == 'True'\nif on_rtd:\n os.environ['SUNPY_CONFIGDIR'] = '/home/docs/'\n os.environ['HOME'] = '/home/docs/'\n os.environ['LANG'] = 'C'\n os.environ['LC_ALL'] = 'C'\n\n# -- Non stdlib imports --------------------------------------------------------\n\nimport ruamel.yaml as yaml # NOQA\nfrom sphinx_gallery.sorting import ExplicitOrder # NOQA\nfrom sphinx_gallery.sorting import ExampleTitleSortKey # NOQA\n\nimport sunpy # NOQA\nfrom sunpy import __version__ # NOQA\n\n# -- Project information -------------------------------------------------------\n\nproject = 'SunPy'\nauthor = 'The SunPy Community'\ncopyright = '{}, {}'.format(datetime.datetime.now().year, author)\n\n# The full version, including alpha/beta/rc tags\nrelease = __version__\nis_development = '.dev' in __version__\n\n# -- SunPy Sample Data and Config ----------------------------------------------\n\n# We set the logger to debug so that we can see any sample data download errors\n# in the CI, especially RTD.\nori_level = sunpy.log.level\nsunpy.log.setLevel(\"DEBUG\")\nimport sunpy.data.sample # NOQA\nsunpy.log.setLevel(ori_level)\n\n# For the linkcheck\nlinkcheck_ignore = [r\"https://doi.org/\\d+\",\n r\"https://riot.im/\\d+\",\n r\"https://github.com/\\d+\",\n r\"https://docs.sunpy.org/\\d+\"]\nlinkcheck_anchors = False\n\n# This is added to the end of RST files - a good place to put substitutions to\n# be used globally.\nrst_epilog = \"\"\"\n.. SunPy\n.. _SunPy: https://sunpy.org\n.. _`SunPy mailing list`: https://groups.google.com/group/sunpy\n.. _`SunPy dev mailing list`: https://groups.google.com/group/sunpy-dev\n\"\"\"\n\n# -- General configuration -----------------------------------------------------\n\n# Suppress warnings about overriding directives as we overload some of the\n# doctest extensions.\nsuppress_warnings = ['app.add_directive', ]\n\n# Add any Sphinx extension module names here, as strings. They can be\n# extensions coming with Sphinx (named 'sphinx.ext.*') or your custom\n# ones.\nextensions = [\n 'matplotlib.sphinxext.plot_directive',\n 'sphinx_automodapi.automodapi',\n 'sphinx_automodapi.smart_resolver',\n 'sphinx_gallery.gen_gallery',\n 'sphinx.ext.autodoc',\n 'sphinx.ext.coverage',\n 'sphinx.ext.doctest',\n 'sphinx.ext.inheritance_diagram',\n 'sphinx.ext.intersphinx',\n 'sphinx.ext.mathjax',\n 'sphinx.ext.napoleon',\n 'sphinx.ext.todo',\n 'sphinx.ext.viewcode',\n 'sunpy.util.sphinx.changelog',\n 'sunpy.util.sphinx.doctest',\n 'sunpy.util.sphinx.generate',\n]\n\n# Add any paths that contain templates here, relative to this directory.\n# templates_path = ['_templates']\n\n# List of patterns, relative to source directory, that match files and\n# directories to ignore when looking for source files.\n# This pattern also affects html_static_path and html_extra_path.\nexclude_patterns = ['_build', 'Thumbs.db', '.DS_Store']\n\n# The suffix(es) of source filenames.\n# You can specify multiple suffix as a list of string:\nsource_suffix = '.rst'\n\n# The master toctree document.\nmaster_doc = 'index'\n\n# The reST default role (used for this markup: `text`) to use for all\n# documents. Set to the \"smart\" one.\ndefault_role = 'obj'\n\n# Disable having a separate return type row\nnapoleon_use_rtype = False\n\n# Disable google style docstrings\nnapoleon_google_docstring = False\n\n# -- Options for intersphinx extension -----------------------------------------\n\n# Example configuration for intersphinx: refer to the Python standard library.\nintersphinx_mapping = {\n 'python': ('https://docs.python.org/3/',\n (None, 'http://www.astropy.org/astropy-data/intersphinx/python3.inv')),\n 'numpy': ('https://numpy.org/doc/stable/',\n (None, 'http://www.astropy.org/astropy-data/intersphinx/numpy.inv')),\n 'scipy': ('https://docs.scipy.org/doc/scipy/reference/',\n (None, 'http://www.astropy.org/astropy-data/intersphinx/scipy.inv')),\n 'matplotlib': ('https://matplotlib.org/',\n (None, 'http://www.astropy.org/astropy-data/intersphinx/matplotlib.inv')),\n 'astropy': ('https://docs.astropy.org/en/stable/', None),\n 'sqlalchemy': ('https://docs.sqlalchemy.org/en/latest/', None),\n 'pandas': ('https://pandas.pydata.org/pandas-docs/stable/', None),\n 'skimage': ('https://scikit-image.org/docs/stable/', None),\n 'drms': ('https://docs.sunpy.org/projects/drms/en/stable/', None),\n 'parfive': ('https://parfive.readthedocs.io/en/latest/', None),\n 'reproject': ('https://reproject.readthedocs.io/en/stable/', None),\n}\n\n# -- Options for HTML output ---------------------------------------------------\n\n# The theme to use for HTML and HTML Help pages. See the documentation for\n# a list of builtin themes.\n\nfrom sunpy_sphinx_theme.conf import * # NOQA\n\n# Add any paths that contain custom static files (such as style sheets) here,\n# relative to this directory. They are copied after the builtin static files,\n# so a file named \"default.css\" will overwrite the builtin \"default.css\".\n# html_static_path = ['_static']\n\n# Render inheritance diagrams in SVG\ngraphviz_output_format = \"svg\"\n\ngraphviz_dot_args = [\n '-Nfontsize=10',\n '-Nfontname=Helvetica Neue, Helvetica, Arial, sans-serif',\n '-Efontsize=10',\n '-Efontname=Helvetica Neue, Helvetica, Arial, sans-serif',\n '-Gfontsize=10',\n '-Gfontname=Helvetica Neue, Helvetica, Arial, sans-serif'\n]\n\n# -- Sphinx Gallery ------------------------------------------------------------\n\nsphinx_gallery_conf = {\n 'backreferences_dir': os.path.join('generated', 'modules'),\n 'filename_pattern': '^((?!skip_).)*$',\n 'examples_dirs': os.path.join('..', 'examples'),\n 'subsection_order': ExplicitOrder([\n '../examples/acquiring_data',\n '../examples/map',\n '../examples/map_transformations',\n '../examples/time_series',\n '../examples/units_and_coordinates',\n '../examples/plotting',\n '../examples/differential_rotation',\n '../examples/saving_and_loading_data',\n '../examples/computer_vision_techniques',\n '../examples/developer_tools'\n ]),\n 'within_subsection_order': ExampleTitleSortKey,\n 'gallery_dirs': os.path.join('generated', 'gallery'),\n 'default_thumb_file': os.path.join('logo', 'sunpy_icon_128x128.png'),\n 'abort_on_example_error': False,\n 'plot_gallery': 'True',\n 'remove_config_comments': True,\n 'doc_module': ('sunpy'),\n}\n\n# -- Stability Page ------------------------------------------------------------\n\nwith open('./dev_guide/sunpy_stability.yaml', 'r') as estability:\n sunpy_modules = yaml.load(estability.read(), Loader=yaml.Loader)\n\nhtml_context = {\n 'sunpy_modules': sunpy_modules\n}\n\n\ndef rstjinja(app, docname, source):\n \"\"\"\n Render our pages as a jinja template for fancy templating goodness.\n \"\"\"\n # Make sure we're outputting HTML\n if app.builder.format != 'html':\n return\n src = source[0]\n if \"Current status\" in src[:20]:\n rendered = app.builder.templates.render_string(\n src, app.config.html_context\n )\n source[0] = rendered\n\n\n# -- Sphinx setup --------------------------------------------------------------\ndef setup(app):\n # Generate the stability page\n app.connect(\"source-read\", rstjinja)\n\n # The theme conf provides a fix for circle ci redirections\n fix_circleci(app)\n", "path": "docs/conf.py"}]}
| 3,174 | 108 |
gh_patches_debug_11581
|
rasdani/github-patches
|
git_diff
|
urllib3__urllib3-2816
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Make our downstream integration tests re-runnable
Currently our downstream tests both clone a git repository into the venv created by nox. Due to how the setup is written the nox session will fail when run a second time due to the repository already existing. It would be nice to be able to run:
`$ nox -rs downstream_requests` over and over without needing to reclone the repository or manually configure the test setup.
I think checking that the repository exists and if so not applying the git patches and continuing as normal would work okay for this case?
</issue>
<code>
[start of noxfile.py]
1 import os
2 import shutil
3 import subprocess
4 import sys
5
6 import nox
7
8 SOURCE_FILES = [
9 "docs/",
10 "dummyserver/",
11 "src/",
12 "test/",
13 "noxfile.py",
14 "setup.py",
15 ]
16
17
18 def tests_impl(
19 session: nox.Session,
20 extras: str = "socks,secure,brotli,zstd",
21 byte_string_comparisons: bool = True,
22 ) -> None:
23 # Install deps and the package itself.
24 session.install("-r", "dev-requirements.txt")
25 session.install(f".[{extras}]")
26
27 # Show the pip version.
28 session.run("pip", "--version")
29 # Print the Python version and bytesize.
30 session.run("python", "--version")
31 session.run("python", "-c", "import struct; print(struct.calcsize('P') * 8)")
32 # Print OpenSSL information.
33 session.run("python", "-m", "OpenSSL.debug")
34
35 memray_supported = True
36 if sys.implementation.name != "cpython" or sys.version_info < (3, 8):
37 memray_supported = False # pytest-memray requires CPython 3.8+
38 elif sys.platform == "win32":
39 memray_supported = False
40
41 # Inspired from https://hynek.me/articles/ditch-codecov-python/
42 # We use parallel mode and then combine in a later CI step
43 session.run(
44 "python",
45 *(("-bb",) if byte_string_comparisons else ()),
46 "-m",
47 "coverage",
48 "run",
49 "--parallel-mode",
50 "-m",
51 "pytest",
52 *("--memray", "--hide-memray-summary") if memray_supported else (),
53 "-v",
54 "-ra",
55 f"--color={'yes' if 'GITHUB_ACTIONS' in os.environ else 'auto'}",
56 "--tb=native",
57 "--no-success-flaky-report",
58 *(session.posargs or ("test/",)),
59 env={"PYTHONWARNINGS": "always::DeprecationWarning"},
60 )
61
62
63 @nox.session(python=["3.7", "3.8", "3.9", "3.10", "3.11", "pypy"])
64 def test(session: nox.Session) -> None:
65 tests_impl(session)
66
67
68 @nox.session(python=["2.7"])
69 def unsupported_setup_py(session: nox.Session) -> None:
70 # Can't check both returncode and output with session.run
71 process = subprocess.run(
72 ["python", "setup.py", "install"],
73 env={**session.env},
74 text=True,
75 capture_output=True,
76 )
77 assert process.returncode == 1
78 print(process.stderr)
79 assert "Please use `python -m pip install .` instead." in process.stderr
80
81
82 @nox.session(python=["3"])
83 def test_brotlipy(session: nox.Session) -> None:
84 """Check that if 'brotlipy' is installed instead of 'brotli' or
85 'brotlicffi' that we still don't blow up.
86 """
87 session.install("brotlipy")
88 tests_impl(session, extras="socks,secure", byte_string_comparisons=False)
89
90
91 def git_clone(session: nox.Session, git_url: str) -> None:
92 session.run("git", "clone", "--depth", "1", git_url, external=True)
93
94
95 @nox.session()
96 def downstream_botocore(session: nox.Session) -> None:
97 root = os.getcwd()
98 tmp_dir = session.create_tmp()
99
100 session.cd(tmp_dir)
101 git_clone(session, "https://github.com/boto/botocore")
102 session.chdir("botocore")
103 for patch in [
104 "0001-Mark-100-Continue-tests-as-failing.patch",
105 "0002-Stop-relying-on-removed-DEFAULT_CIPHERS.patch",
106 ]:
107 session.run("git", "apply", f"{root}/ci/{patch}", external=True)
108 session.run("git", "rev-parse", "HEAD", external=True)
109 session.run("python", "scripts/ci/install")
110
111 session.cd(root)
112 session.install(".", silent=False)
113 session.cd(f"{tmp_dir}/botocore")
114
115 session.run("python", "-c", "import urllib3; print(urllib3.__version__)")
116 session.run("python", "scripts/ci/run-tests")
117
118
119 @nox.session()
120 def downstream_requests(session: nox.Session) -> None:
121 root = os.getcwd()
122 tmp_dir = session.create_tmp()
123
124 session.cd(tmp_dir)
125 git_clone(session, "https://github.com/psf/requests")
126 session.chdir("requests")
127 session.run(
128 "git", "apply", f"{root}/ci/0003-requests-removed-warnings.patch", external=True
129 )
130 session.run(
131 "git", "apply", f"{root}/ci/0004-requests-chunked-requests.patch", external=True
132 )
133 session.run("git", "rev-parse", "HEAD", external=True)
134 session.install(".[socks]", silent=False)
135 session.install("-r", "requirements-dev.txt", silent=False)
136
137 session.cd(root)
138 session.install(".", silent=False)
139 session.cd(f"{tmp_dir}/requests")
140
141 session.run("python", "-c", "import urllib3; print(urllib3.__version__)")
142 session.run("pytest", "tests")
143
144
145 @nox.session()
146 def format(session: nox.Session) -> None:
147 """Run code formatters."""
148 lint(session)
149
150
151 @nox.session
152 def lint(session: nox.Session) -> None:
153 session.install("pre-commit")
154 session.run("pre-commit", "run", "--all-files")
155
156 mypy(session)
157
158
159 @nox.session(python="3.8")
160 def mypy(session: nox.Session) -> None:
161 """Run mypy."""
162 session.install("-r", "mypy-requirements.txt")
163 session.run("mypy", "--version")
164 session.run(
165 "mypy",
166 "dummyserver",
167 "noxfile.py",
168 "src/urllib3",
169 "test",
170 )
171
172
173 @nox.session
174 def docs(session: nox.Session) -> None:
175 session.install("-r", "docs/requirements.txt")
176 session.install(".[socks,secure,brotli,zstd]")
177
178 session.chdir("docs")
179 if os.path.exists("_build"):
180 shutil.rmtree("_build")
181 session.run("sphinx-build", "-b", "html", "-W", ".", "_build/html")
182
[end of noxfile.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/noxfile.py b/noxfile.py
--- a/noxfile.py
+++ b/noxfile.py
@@ -89,7 +89,21 @@
def git_clone(session: nox.Session, git_url: str) -> None:
- session.run("git", "clone", "--depth", "1", git_url, external=True)
+ """We either clone the target repository or if already exist
+ simply reset the state and pull.
+ """
+ expected_directory = git_url.split("/")[-1]
+
+ if expected_directory.endswith(".git"):
+ expected_directory = expected_directory[:-4]
+
+ if not os.path.isdir(expected_directory):
+ session.run("git", "clone", "--depth", "1", git_url, external=True)
+ else:
+ session.run(
+ "git", "-C", expected_directory, "reset", "--hard", "HEAD", external=True
+ )
+ session.run("git", "-C", expected_directory, "pull", external=True)
@nox.session()
|
{"golden_diff": "diff --git a/noxfile.py b/noxfile.py\n--- a/noxfile.py\n+++ b/noxfile.py\n@@ -89,7 +89,21 @@\n \n \n def git_clone(session: nox.Session, git_url: str) -> None:\n- session.run(\"git\", \"clone\", \"--depth\", \"1\", git_url, external=True)\n+ \"\"\"We either clone the target repository or if already exist\n+ simply reset the state and pull.\n+ \"\"\"\n+ expected_directory = git_url.split(\"/\")[-1]\n+\n+ if expected_directory.endswith(\".git\"):\n+ expected_directory = expected_directory[:-4]\n+\n+ if not os.path.isdir(expected_directory):\n+ session.run(\"git\", \"clone\", \"--depth\", \"1\", git_url, external=True)\n+ else:\n+ session.run(\n+ \"git\", \"-C\", expected_directory, \"reset\", \"--hard\", \"HEAD\", external=True\n+ )\n+ session.run(\"git\", \"-C\", expected_directory, \"pull\", external=True)\n \n \n @nox.session()\n", "issue": "Make our downstream integration tests re-runnable\nCurrently our downstream tests both clone a git repository into the venv created by nox. Due to how the setup is written the nox session will fail when run a second time due to the repository already existing. It would be nice to be able to run:\r\n\r\n`$ nox -rs downstream_requests` over and over without needing to reclone the repository or manually configure the test setup.\r\n\r\nI think checking that the repository exists and if so not applying the git patches and continuing as normal would work okay for this case?\n", "before_files": [{"content": "import os\nimport shutil\nimport subprocess\nimport sys\n\nimport nox\n\nSOURCE_FILES = [\n \"docs/\",\n \"dummyserver/\",\n \"src/\",\n \"test/\",\n \"noxfile.py\",\n \"setup.py\",\n]\n\n\ndef tests_impl(\n session: nox.Session,\n extras: str = \"socks,secure,brotli,zstd\",\n byte_string_comparisons: bool = True,\n) -> None:\n # Install deps and the package itself.\n session.install(\"-r\", \"dev-requirements.txt\")\n session.install(f\".[{extras}]\")\n\n # Show the pip version.\n session.run(\"pip\", \"--version\")\n # Print the Python version and bytesize.\n session.run(\"python\", \"--version\")\n session.run(\"python\", \"-c\", \"import struct; print(struct.calcsize('P') * 8)\")\n # Print OpenSSL information.\n session.run(\"python\", \"-m\", \"OpenSSL.debug\")\n\n memray_supported = True\n if sys.implementation.name != \"cpython\" or sys.version_info < (3, 8):\n memray_supported = False # pytest-memray requires CPython 3.8+\n elif sys.platform == \"win32\":\n memray_supported = False\n\n # Inspired from https://hynek.me/articles/ditch-codecov-python/\n # We use parallel mode and then combine in a later CI step\n session.run(\n \"python\",\n *((\"-bb\",) if byte_string_comparisons else ()),\n \"-m\",\n \"coverage\",\n \"run\",\n \"--parallel-mode\",\n \"-m\",\n \"pytest\",\n *(\"--memray\", \"--hide-memray-summary\") if memray_supported else (),\n \"-v\",\n \"-ra\",\n f\"--color={'yes' if 'GITHUB_ACTIONS' in os.environ else 'auto'}\",\n \"--tb=native\",\n \"--no-success-flaky-report\",\n *(session.posargs or (\"test/\",)),\n env={\"PYTHONWARNINGS\": \"always::DeprecationWarning\"},\n )\n\n\[email protected](python=[\"3.7\", \"3.8\", \"3.9\", \"3.10\", \"3.11\", \"pypy\"])\ndef test(session: nox.Session) -> None:\n tests_impl(session)\n\n\[email protected](python=[\"2.7\"])\ndef unsupported_setup_py(session: nox.Session) -> None:\n # Can't check both returncode and output with session.run\n process = subprocess.run(\n [\"python\", \"setup.py\", \"install\"],\n env={**session.env},\n text=True,\n capture_output=True,\n )\n assert process.returncode == 1\n print(process.stderr)\n assert \"Please use `python -m pip install .` instead.\" in process.stderr\n\n\[email protected](python=[\"3\"])\ndef test_brotlipy(session: nox.Session) -> None:\n \"\"\"Check that if 'brotlipy' is installed instead of 'brotli' or\n 'brotlicffi' that we still don't blow up.\n \"\"\"\n session.install(\"brotlipy\")\n tests_impl(session, extras=\"socks,secure\", byte_string_comparisons=False)\n\n\ndef git_clone(session: nox.Session, git_url: str) -> None:\n session.run(\"git\", \"clone\", \"--depth\", \"1\", git_url, external=True)\n\n\[email protected]()\ndef downstream_botocore(session: nox.Session) -> None:\n root = os.getcwd()\n tmp_dir = session.create_tmp()\n\n session.cd(tmp_dir)\n git_clone(session, \"https://github.com/boto/botocore\")\n session.chdir(\"botocore\")\n for patch in [\n \"0001-Mark-100-Continue-tests-as-failing.patch\",\n \"0002-Stop-relying-on-removed-DEFAULT_CIPHERS.patch\",\n ]:\n session.run(\"git\", \"apply\", f\"{root}/ci/{patch}\", external=True)\n session.run(\"git\", \"rev-parse\", \"HEAD\", external=True)\n session.run(\"python\", \"scripts/ci/install\")\n\n session.cd(root)\n session.install(\".\", silent=False)\n session.cd(f\"{tmp_dir}/botocore\")\n\n session.run(\"python\", \"-c\", \"import urllib3; print(urllib3.__version__)\")\n session.run(\"python\", \"scripts/ci/run-tests\")\n\n\[email protected]()\ndef downstream_requests(session: nox.Session) -> None:\n root = os.getcwd()\n tmp_dir = session.create_tmp()\n\n session.cd(tmp_dir)\n git_clone(session, \"https://github.com/psf/requests\")\n session.chdir(\"requests\")\n session.run(\n \"git\", \"apply\", f\"{root}/ci/0003-requests-removed-warnings.patch\", external=True\n )\n session.run(\n \"git\", \"apply\", f\"{root}/ci/0004-requests-chunked-requests.patch\", external=True\n )\n session.run(\"git\", \"rev-parse\", \"HEAD\", external=True)\n session.install(\".[socks]\", silent=False)\n session.install(\"-r\", \"requirements-dev.txt\", silent=False)\n\n session.cd(root)\n session.install(\".\", silent=False)\n session.cd(f\"{tmp_dir}/requests\")\n\n session.run(\"python\", \"-c\", \"import urllib3; print(urllib3.__version__)\")\n session.run(\"pytest\", \"tests\")\n\n\[email protected]()\ndef format(session: nox.Session) -> None:\n \"\"\"Run code formatters.\"\"\"\n lint(session)\n\n\[email protected]\ndef lint(session: nox.Session) -> None:\n session.install(\"pre-commit\")\n session.run(\"pre-commit\", \"run\", \"--all-files\")\n\n mypy(session)\n\n\[email protected](python=\"3.8\")\ndef mypy(session: nox.Session) -> None:\n \"\"\"Run mypy.\"\"\"\n session.install(\"-r\", \"mypy-requirements.txt\")\n session.run(\"mypy\", \"--version\")\n session.run(\n \"mypy\",\n \"dummyserver\",\n \"noxfile.py\",\n \"src/urllib3\",\n \"test\",\n )\n\n\[email protected]\ndef docs(session: nox.Session) -> None:\n session.install(\"-r\", \"docs/requirements.txt\")\n session.install(\".[socks,secure,brotli,zstd]\")\n\n session.chdir(\"docs\")\n if os.path.exists(\"_build\"):\n shutil.rmtree(\"_build\")\n session.run(\"sphinx-build\", \"-b\", \"html\", \"-W\", \".\", \"_build/html\")\n", "path": "noxfile.py"}]}
| 2,513 | 231 |
gh_patches_debug_21811
|
rasdani/github-patches
|
git_diff
|
bridgecrewio__checkov-1132
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
CKV_AWS_134: Skip Memcache engine
**Describe the bug**
"snapshot_retention_limit" - parameter only for "Redis" engine and in my TF module for Memcache it doesn't exist. But when I run "checkov" I got the following:
```
Check: CKV_AWS_134: "Ensure that Amazon ElastiCache Redis clusters have automatic backup turned on"
FAILED for resource: aws_elasticache_cluster.memcached
File: /tf.json:0-0
Guide: https://docs.bridgecrew.io/docs/ensure-that-amazon-elasticache-redis-clusters-have-automatic-backup-turned-on
```
**Terraform module**
```
### ElastiCache Memcached CLuster
resource "aws_elasticache_cluster" "memcached" {
cluster_id = lower("${var.basename}-Memcached-Cluster")
engine = var.engine
engine_version = var.engine_version
port = var.port
parameter_group_name = module.common.parameter_group_name
node_type = var.node_type
num_cache_nodes = var.num_cache_nodes
az_mode = var.az_mode
subnet_group_name = module.common.subnet_group_name
security_group_ids = [module.common.sg_id]
apply_immediately = true
tags = var.tags
}
```
**memcache.tf**
```
### ElastiCache: Memcashed Cluster
module "elasticache-memcached" {
source = "../../modules/elasticache/memcached"
basename = local.basename
vpc_id = module.vpc.id
subnets = module.private-subnets.ids
engine_version = "1.6.6"
parameter_group_family = "memcached1.6"
node_type = "cache.t3.small"
num_cache_nodes = 2
# Enable az_mode, when num_cache_nodes > 1
az_mode = "cross-az"
cidr_groups = { ALL = "0.0.0.0/0" }
tags = local.base_tags
}
```
**Expected behavior**
If engine is "memcache" then check must be skipped.
**Desktop:**
- OS: macOS Big Sur - 11.2.1
- Checkov Version: 2.0.77
</issue>
<code>
[start of checkov/terraform/checks/resource/aws/ElasticCacheAutomaticBackup.py]
1 from checkov.common.models.enums import CheckCategories, CheckResult
2 from checkov.terraform.checks.resource.base_resource_negative_value_check import BaseResourceNegativeValueCheck
3
4
5 class ElasticCacheAutomaticBackup(BaseResourceNegativeValueCheck):
6 def __init__(self):
7 name = "Ensure that Amazon ElastiCache Redis clusters have automatic backup turned on"
8 id = "CKV_AWS_134"
9 supported_resources = ['aws_elasticache_cluster']
10 categories = [CheckCategories.BACKUP_AND_RECOVERY]
11 super().__init__(name=name, id=id, categories=categories, supported_resources=supported_resources,
12 missing_attribute_result=CheckResult.FAILED)
13
14 def get_inspected_key(self):
15 return 'snapshot_retention_limit'
16
17 def get_forbidden_values(self):
18 return [0]
19
20
21 check = ElasticCacheAutomaticBackup()
22
[end of checkov/terraform/checks/resource/aws/ElasticCacheAutomaticBackup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/checkov/terraform/checks/resource/aws/ElasticCacheAutomaticBackup.py b/checkov/terraform/checks/resource/aws/ElasticCacheAutomaticBackup.py
--- a/checkov/terraform/checks/resource/aws/ElasticCacheAutomaticBackup.py
+++ b/checkov/terraform/checks/resource/aws/ElasticCacheAutomaticBackup.py
@@ -6,13 +6,24 @@
def __init__(self):
name = "Ensure that Amazon ElastiCache Redis clusters have automatic backup turned on"
id = "CKV_AWS_134"
- supported_resources = ['aws_elasticache_cluster']
+ supported_resources = ["aws_elasticache_cluster"]
categories = [CheckCategories.BACKUP_AND_RECOVERY]
- super().__init__(name=name, id=id, categories=categories, supported_resources=supported_resources,
- missing_attribute_result=CheckResult.FAILED)
+ super().__init__(
+ name=name,
+ id=id,
+ categories=categories,
+ supported_resources=supported_resources,
+ missing_attribute_result=CheckResult.FAILED,
+ )
+
+ def scan_resource_conf(self, conf):
+ if conf.get("engine") == ["memcached"]:
+ return CheckResult.UNKNOWN
+
+ return super().scan_resource_conf(conf)
def get_inspected_key(self):
- return 'snapshot_retention_limit'
+ return "snapshot_retention_limit"
def get_forbidden_values(self):
return [0]
|
{"golden_diff": "diff --git a/checkov/terraform/checks/resource/aws/ElasticCacheAutomaticBackup.py b/checkov/terraform/checks/resource/aws/ElasticCacheAutomaticBackup.py\n--- a/checkov/terraform/checks/resource/aws/ElasticCacheAutomaticBackup.py\n+++ b/checkov/terraform/checks/resource/aws/ElasticCacheAutomaticBackup.py\n@@ -6,13 +6,24 @@\n def __init__(self):\n name = \"Ensure that Amazon ElastiCache Redis clusters have automatic backup turned on\"\n id = \"CKV_AWS_134\"\n- supported_resources = ['aws_elasticache_cluster']\n+ supported_resources = [\"aws_elasticache_cluster\"]\n categories = [CheckCategories.BACKUP_AND_RECOVERY]\n- super().__init__(name=name, id=id, categories=categories, supported_resources=supported_resources,\n- missing_attribute_result=CheckResult.FAILED)\n+ super().__init__(\n+ name=name,\n+ id=id,\n+ categories=categories,\n+ supported_resources=supported_resources,\n+ missing_attribute_result=CheckResult.FAILED,\n+ )\n+\n+ def scan_resource_conf(self, conf):\n+ if conf.get(\"engine\") == [\"memcached\"]:\n+ return CheckResult.UNKNOWN\n+\n+ return super().scan_resource_conf(conf)\n \n def get_inspected_key(self):\n- return 'snapshot_retention_limit'\n+ return \"snapshot_retention_limit\"\n \n def get_forbidden_values(self):\n return [0]\n", "issue": "CKV_AWS_134: Skip Memcache engine\n**Describe the bug**\r\n\"snapshot_retention_limit\" - parameter only for \"Redis\" engine and in my TF module for Memcache it doesn't exist. But when I run \"checkov\" I got the following:\r\n\r\n```\r\nCheck: CKV_AWS_134: \"Ensure that Amazon ElastiCache Redis clusters have automatic backup turned on\"\r\n\tFAILED for resource: aws_elasticache_cluster.memcached\r\n\tFile: /tf.json:0-0\r\n\tGuide: https://docs.bridgecrew.io/docs/ensure-that-amazon-elasticache-redis-clusters-have-automatic-backup-turned-on\r\n```\r\n\r\n**Terraform module**\r\n```\r\n### ElastiCache Memcached CLuster\r\nresource \"aws_elasticache_cluster\" \"memcached\" {\r\n cluster_id = lower(\"${var.basename}-Memcached-Cluster\")\r\n\r\n engine = var.engine\r\n engine_version = var.engine_version\r\n port = var.port\r\n parameter_group_name = module.common.parameter_group_name\r\n\r\n node_type = var.node_type\r\n num_cache_nodes = var.num_cache_nodes\r\n az_mode = var.az_mode\r\n\r\n subnet_group_name = module.common.subnet_group_name\r\n security_group_ids = [module.common.sg_id]\r\n\r\n apply_immediately = true\r\n\r\n tags = var.tags\r\n}\r\n```\r\n\r\n**memcache.tf**\r\n```\r\n### ElastiCache: Memcashed Cluster\r\nmodule \"elasticache-memcached\" {\r\n source = \"../../modules/elasticache/memcached\"\r\n\r\n basename = local.basename\r\n vpc_id = module.vpc.id\r\n subnets = module.private-subnets.ids\r\n\r\n engine_version = \"1.6.6\"\r\n parameter_group_family = \"memcached1.6\"\r\n node_type = \"cache.t3.small\"\r\n num_cache_nodes = 2\r\n\r\n # Enable az_mode, when num_cache_nodes > 1\r\n az_mode = \"cross-az\"\r\n\r\n cidr_groups = { ALL = \"0.0.0.0/0\" }\r\n\r\n tags = local.base_tags\r\n}\r\n```\r\n\r\n**Expected behavior**\r\nIf engine is \"memcache\" then check must be skipped.\r\n\r\n**Desktop:**\r\n - OS: macOS Big Sur - 11.2.1\r\n - Checkov Version: 2.0.77\r\n\n", "before_files": [{"content": "from checkov.common.models.enums import CheckCategories, CheckResult\nfrom checkov.terraform.checks.resource.base_resource_negative_value_check import BaseResourceNegativeValueCheck\n\n\nclass ElasticCacheAutomaticBackup(BaseResourceNegativeValueCheck):\n def __init__(self):\n name = \"Ensure that Amazon ElastiCache Redis clusters have automatic backup turned on\"\n id = \"CKV_AWS_134\"\n supported_resources = ['aws_elasticache_cluster']\n categories = [CheckCategories.BACKUP_AND_RECOVERY]\n super().__init__(name=name, id=id, categories=categories, supported_resources=supported_resources,\n missing_attribute_result=CheckResult.FAILED)\n\n def get_inspected_key(self):\n return 'snapshot_retention_limit'\n\n def get_forbidden_values(self):\n return [0]\n\n\ncheck = ElasticCacheAutomaticBackup()\n", "path": "checkov/terraform/checks/resource/aws/ElasticCacheAutomaticBackup.py"}]}
| 1,268 | 316 |
gh_patches_debug_26450
|
rasdani/github-patches
|
git_diff
|
hylang__hy-2129
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Remove internal `importlib` frames from traceback
Python 3.x uses `_call_with_frames_removed` to remove internal frames from tracebacks. I tried it in #1687, but couldn't get it to work; might be due to this [Python issue](https://bugs.python.org/issue23773).
Regardless, it would be good to remove those frames somehow.
</issue>
<code>
[start of hy/errors.py]
1 import os
2 import re
3 import sys
4 import traceback
5 import pkgutil
6
7 from functools import reduce
8 from colorama import Fore
9 from contextlib import contextmanager
10 from hy import _initialize_env_var
11
12 _hy_filter_internal_errors = _initialize_env_var('HY_FILTER_INTERNAL_ERRORS',
13 True)
14 COLORED = _initialize_env_var('HY_COLORED_ERRORS', False)
15
16
17 class HyError(Exception):
18 pass
19
20
21 class HyInternalError(HyError):
22 """Unexpected errors occurring during compilation or parsing of Hy code.
23
24 Errors sub-classing this are not intended to be user-facing, and will,
25 hopefully, never be seen by users!
26 """
27
28
29 class HyLanguageError(HyError):
30 """Errors caused by invalid use of the Hy language.
31
32 This, and any errors inheriting from this, are user-facing.
33 """
34
35 def __init__(self, message, expression=None, filename=None, source=None,
36 lineno=1, colno=1):
37 """
38 Parameters
39 ----------
40 message: str
41 The message to display for this error.
42 expression: HyObject, optional
43 The Hy expression generating this error.
44 filename: str, optional
45 The filename for the source code generating this error.
46 Expression-provided information will take precedence of this value.
47 source: str, optional
48 The actual source code generating this error. Expression-provided
49 information will take precedence of this value.
50 lineno: int, optional
51 The line number of the error. Expression-provided information will
52 take precedence of this value.
53 colno: int, optional
54 The column number of the error. Expression-provided information
55 will take precedence of this value.
56 """
57 self.msg = message
58 self.compute_lineinfo(expression, filename, source, lineno, colno)
59
60 if isinstance(self, SyntaxError):
61 syntax_error_args = (self.filename, self.lineno, self.offset,
62 self.text)
63 super(HyLanguageError, self).__init__(message, syntax_error_args)
64 else:
65 super(HyLanguageError, self).__init__(message)
66
67 def compute_lineinfo(self, expression, filename, source, lineno, colno):
68
69 # NOTE: We use `SyntaxError`'s field names (i.e. `text`, `offset`,
70 # `msg`) for compatibility and print-outs.
71 self.text = getattr(expression, 'source', source)
72 self.filename = getattr(expression, 'filename', filename)
73
74 if self.text:
75 lines = self.text.splitlines()
76
77 self.lineno = getattr(expression, 'start_line', lineno)
78 self.offset = getattr(expression, 'start_column', colno)
79 end_column = getattr(expression, 'end_column',
80 len(lines[self.lineno-1]))
81 end_line = getattr(expression, 'end_line', self.lineno)
82
83 # Trim the source down to the essentials.
84 self.text = '\n'.join(lines[self.lineno-1:end_line])
85
86 if end_column:
87 if self.lineno == end_line:
88 self.arrow_offset = end_column
89 else:
90 self.arrow_offset = len(self.text[0])
91
92 self.arrow_offset -= self.offset
93 else:
94 self.arrow_offset = None
95 else:
96 # We could attempt to extract the source given a filename, but we
97 # don't.
98 self.lineno = lineno
99 self.offset = colno
100 self.arrow_offset = None
101
102 def __str__(self):
103 """Provide an exception message that includes SyntaxError-like source
104 line information when available.
105 """
106 # Syntax errors are special and annotate the traceback (instead of what
107 # we would do in the message that follows the traceback).
108 if isinstance(self, SyntaxError):
109 return super(HyLanguageError, self).__str__()
110 # When there isn't extra source information, use the normal message.
111 elif not self.text:
112 return super(HyLanguageError, self).__str__()
113
114 # Re-purpose Python's builtin syntax error formatting.
115 output = traceback.format_exception_only(
116 SyntaxError,
117 SyntaxError(self.msg, (self.filename, self.lineno, self.offset,
118 self.text)))
119
120 arrow_idx, _ = next(((i, x) for i, x in enumerate(output)
121 if x.strip() == '^'),
122 (None, None))
123 if arrow_idx:
124 msg_idx = arrow_idx + 1
125 else:
126 msg_idx, _ = next((i, x) for i, x in enumerate(output)
127 if x.startswith('SyntaxError: '))
128
129 # Get rid of erroneous error-type label.
130 output[msg_idx] = re.sub('^SyntaxError: ', '', output[msg_idx])
131
132 # Extend the text arrow, when given enough source info.
133 if arrow_idx and self.arrow_offset:
134 output[arrow_idx] = '{}{}^\n'.format(output[arrow_idx].rstrip('\n'),
135 '-' * (self.arrow_offset - 1))
136
137 if COLORED:
138 output[msg_idx:] = [Fore.YELLOW + o + Fore.RESET for o in output[msg_idx:]]
139 if arrow_idx:
140 output[arrow_idx] = Fore.GREEN + output[arrow_idx] + Fore.RESET
141 for idx, line in enumerate(output[::msg_idx]):
142 if line.strip().startswith(
143 'File "{}", line'.format(self.filename)):
144 output[idx] = Fore.RED + line + Fore.RESET
145
146 # This resulting string will come after a "<class-name>:" prompt, so
147 # put it down a line.
148 output.insert(0, '\n')
149
150 # Avoid "...expected str instance, ColoredString found"
151 return reduce(lambda x, y: x + y, output)
152
153
154 class HyCompileError(HyInternalError):
155 """Unexpected errors occurring within the compiler."""
156
157
158 class HyTypeError(HyLanguageError, TypeError):
159 """TypeError occurring during the normal use of Hy."""
160
161
162 class HyNameError(HyLanguageError, NameError):
163 """NameError occurring during the normal use of Hy."""
164
165
166 class HyRequireError(HyLanguageError):
167 """Errors arising during the use of `require`
168
169 This, and any errors inheriting from this, are user-facing.
170 """
171
172
173 class HyMacroExpansionError(HyLanguageError):
174 """Errors caused by invalid use of Hy macros.
175
176 This, and any errors inheriting from this, are user-facing.
177 """
178
179
180 class HyEvalError(HyLanguageError):
181 """Errors occurring during code evaluation at compile-time.
182
183 These errors distinguish unexpected errors within the compilation process
184 (i.e. `HyInternalError`s) from unrelated errors in user code evaluated by
185 the compiler (e.g. in `eval-and-compile`).
186
187 This, and any errors inheriting from this, are user-facing.
188 """
189
190
191 class HyIOError(HyInternalError, IOError):
192 """ Subclass used to distinguish between IOErrors raised by Hy itself as
193 opposed to Hy programs.
194 """
195
196
197 class HySyntaxError(HyLanguageError, SyntaxError):
198 """Error during the Lexing of a Hython expression."""
199
200
201 class HyWrapperError(HyError, TypeError):
202 """Errors caused by language model object wrapping.
203
204 These can be caused by improper user-level use of a macro, so they're
205 not really "internal". If they arise due to anything else, they're an
206 internal/compiler problem, though.
207 """
208
209
210 def _module_filter_name(module_name):
211 try:
212 compiler_loader = pkgutil.get_loader(module_name)
213 if not compiler_loader:
214 return None
215
216 filename = compiler_loader.get_filename(module_name)
217 if not filename:
218 return None
219
220 if compiler_loader.is_package(module_name):
221 # Use the package directory (e.g. instead of `.../__init__.py`) so
222 # that we can filter all modules in a package.
223 return os.path.dirname(filename)
224 else:
225 # Normalize filename endings, because tracebacks will use `pyc` when
226 # the loader says `py`.
227 return filename.replace('.pyc', '.py')
228 except Exception:
229 return None
230
231
232 _tb_hidden_modules = {m for m in map(_module_filter_name,
233 ['hy.compiler', 'hy.lex',
234 'hy.cmdline', 'hy.lex.parser',
235 'hy.importer', 'hy._compat',
236 'hy.macros', 'hy.models',
237 'hy.core.result_macros',
238 'rply'])
239 if m is not None}
240
241
242 def hy_exc_filter(exc_type, exc_value, exc_traceback):
243 """Produce exceptions print-outs with all frames originating from the
244 modules in `_tb_hidden_modules` filtered out.
245
246 The frames are actually filtered by each module's filename and only when a
247 subclass of `HyLanguageError` is emitted.
248
249 This does not remove the frames from the actual tracebacks, so debugging
250 will show everything.
251 """
252 # frame = (filename, line number, function name*, text)
253 new_tb = []
254 for frame in traceback.extract_tb(exc_traceback):
255 if not (frame[0].replace('.pyc', '.py') in _tb_hidden_modules or
256 os.path.dirname(frame[0]) in _tb_hidden_modules):
257 new_tb += [frame]
258
259 lines = traceback.format_list(new_tb)
260
261 lines.insert(0, "Traceback (most recent call last):\n")
262
263 lines.extend(traceback.format_exception_only(exc_type, exc_value))
264 output = ''.join(lines)
265
266 return output
267
268
269 def hy_exc_handler(exc_type, exc_value, exc_traceback):
270 """A `sys.excepthook` handler that uses `hy_exc_filter` to
271 remove internal Hy frames from a traceback print-out.
272 """
273 if os.environ.get('HY_DEBUG', False):
274 return sys.__excepthook__(exc_type, exc_value, exc_traceback)
275
276 try:
277 output = hy_exc_filter(exc_type, exc_value, exc_traceback)
278 sys.stderr.write(output)
279 sys.stderr.flush()
280 except Exception:
281 sys.__excepthook__(exc_type, exc_value, exc_traceback)
282
283
284 @contextmanager
285 def filtered_hy_exceptions():
286 """Temporarily apply a `sys.excepthook` that filters Hy internal frames
287 from tracebacks.
288
289 Filtering can be controlled by the variable
290 `hy.errors._hy_filter_internal_errors` and environment variable
291 `HY_FILTER_INTERNAL_ERRORS`.
292 """
293 global _hy_filter_internal_errors
294 if _hy_filter_internal_errors:
295 current_hook = sys.excepthook
296 sys.excepthook = hy_exc_handler
297 yield
298 sys.excepthook = current_hook
299 else:
300 yield
301
[end of hy/errors.py]
[start of hy/_compat.py]
1 import sys
2
3 PY3_7 = sys.version_info >= (3, 7)
4 PY3_8 = sys.version_info >= (3, 8)
5 PY3_9 = sys.version_info >= (3, 9)
6 PY3_10 = sys.version_info >= (3, 10)
7
8
9 if not PY3_9:
10 # Shim `ast.unparse`.
11 import ast, astor.code_gen
12 ast.unparse = astor.code_gen.to_source
13
14
15 if not PY3_7:
16 # Shim `asyncio.run`.
17 import asyncio
18 def f(coro):
19 return asyncio.get_event_loop().run_until_complete(coro)
20 asyncio.run = f
21
[end of hy/_compat.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/hy/_compat.py b/hy/_compat.py
--- a/hy/_compat.py
+++ b/hy/_compat.py
@@ -1,9 +1,11 @@
import sys
+import platform
PY3_7 = sys.version_info >= (3, 7)
PY3_8 = sys.version_info >= (3, 8)
PY3_9 = sys.version_info >= (3, 9)
PY3_10 = sys.version_info >= (3, 10)
+PYPY = platform.python_implementation() == "PyPy"
if not PY3_9:
diff --git a/hy/errors.py b/hy/errors.py
--- a/hy/errors.py
+++ b/hy/errors.py
@@ -8,6 +8,7 @@
from colorama import Fore
from contextlib import contextmanager
from hy import _initialize_env_var
+from hy._compat import PYPY
_hy_filter_internal_errors = _initialize_env_var('HY_FILTER_INTERNAL_ERRORS',
True)
@@ -238,6 +239,13 @@
'rply'])
if m is not None}
+# We can't derive these easily from just their module names due
+# to missing magic attributes in internal importlib modules
+_tb_hidden_modules.update(
+ f"<builtin>/frozen {x}" if PYPY else f"<frozen {x}>"
+ for x in ("importlib._bootstrap", "importlib._bootstrap_external")
+)
+
def hy_exc_filter(exc_type, exc_value, exc_traceback):
"""Produce exceptions print-outs with all frames originating from the
|
{"golden_diff": "diff --git a/hy/_compat.py b/hy/_compat.py\n--- a/hy/_compat.py\n+++ b/hy/_compat.py\n@@ -1,9 +1,11 @@\n import sys\n+import platform\n \n PY3_7 = sys.version_info >= (3, 7)\n PY3_8 = sys.version_info >= (3, 8)\n PY3_9 = sys.version_info >= (3, 9)\n PY3_10 = sys.version_info >= (3, 10)\n+PYPY = platform.python_implementation() == \"PyPy\"\n \n \n if not PY3_9:\ndiff --git a/hy/errors.py b/hy/errors.py\n--- a/hy/errors.py\n+++ b/hy/errors.py\n@@ -8,6 +8,7 @@\n from colorama import Fore\n from contextlib import contextmanager\n from hy import _initialize_env_var\n+from hy._compat import PYPY\n \n _hy_filter_internal_errors = _initialize_env_var('HY_FILTER_INTERNAL_ERRORS',\n True)\n@@ -238,6 +239,13 @@\n 'rply'])\n if m is not None}\n \n+# We can't derive these easily from just their module names due\n+# to missing magic attributes in internal importlib modules\n+_tb_hidden_modules.update(\n+ f\"<builtin>/frozen {x}\" if PYPY else f\"<frozen {x}>\"\n+ for x in (\"importlib._bootstrap\", \"importlib._bootstrap_external\")\n+)\n+\n \n def hy_exc_filter(exc_type, exc_value, exc_traceback):\n \"\"\"Produce exceptions print-outs with all frames originating from the\n", "issue": "Remove internal `importlib` frames from traceback\nPython 3.x uses `_call_with_frames_removed` to remove internal frames from tracebacks. I tried it in #1687, but couldn't get it to work; might be due to this [Python issue](https://bugs.python.org/issue23773). \r\nRegardless, it would be good to remove those frames somehow.\n", "before_files": [{"content": "import os\nimport re\nimport sys\nimport traceback\nimport pkgutil\n\nfrom functools import reduce\nfrom colorama import Fore\nfrom contextlib import contextmanager\nfrom hy import _initialize_env_var\n\n_hy_filter_internal_errors = _initialize_env_var('HY_FILTER_INTERNAL_ERRORS',\n True)\nCOLORED = _initialize_env_var('HY_COLORED_ERRORS', False)\n\n\nclass HyError(Exception):\n pass\n\n\nclass HyInternalError(HyError):\n \"\"\"Unexpected errors occurring during compilation or parsing of Hy code.\n\n Errors sub-classing this are not intended to be user-facing, and will,\n hopefully, never be seen by users!\n \"\"\"\n\n\nclass HyLanguageError(HyError):\n \"\"\"Errors caused by invalid use of the Hy language.\n\n This, and any errors inheriting from this, are user-facing.\n \"\"\"\n\n def __init__(self, message, expression=None, filename=None, source=None,\n lineno=1, colno=1):\n \"\"\"\n Parameters\n ----------\n message: str\n The message to display for this error.\n expression: HyObject, optional\n The Hy expression generating this error.\n filename: str, optional\n The filename for the source code generating this error.\n Expression-provided information will take precedence of this value.\n source: str, optional\n The actual source code generating this error. Expression-provided\n information will take precedence of this value.\n lineno: int, optional\n The line number of the error. Expression-provided information will\n take precedence of this value.\n colno: int, optional\n The column number of the error. Expression-provided information\n will take precedence of this value.\n \"\"\"\n self.msg = message\n self.compute_lineinfo(expression, filename, source, lineno, colno)\n\n if isinstance(self, SyntaxError):\n syntax_error_args = (self.filename, self.lineno, self.offset,\n self.text)\n super(HyLanguageError, self).__init__(message, syntax_error_args)\n else:\n super(HyLanguageError, self).__init__(message)\n\n def compute_lineinfo(self, expression, filename, source, lineno, colno):\n\n # NOTE: We use `SyntaxError`'s field names (i.e. `text`, `offset`,\n # `msg`) for compatibility and print-outs.\n self.text = getattr(expression, 'source', source)\n self.filename = getattr(expression, 'filename', filename)\n\n if self.text:\n lines = self.text.splitlines()\n\n self.lineno = getattr(expression, 'start_line', lineno)\n self.offset = getattr(expression, 'start_column', colno)\n end_column = getattr(expression, 'end_column',\n len(lines[self.lineno-1]))\n end_line = getattr(expression, 'end_line', self.lineno)\n\n # Trim the source down to the essentials.\n self.text = '\\n'.join(lines[self.lineno-1:end_line])\n\n if end_column:\n if self.lineno == end_line:\n self.arrow_offset = end_column\n else:\n self.arrow_offset = len(self.text[0])\n\n self.arrow_offset -= self.offset\n else:\n self.arrow_offset = None\n else:\n # We could attempt to extract the source given a filename, but we\n # don't.\n self.lineno = lineno\n self.offset = colno\n self.arrow_offset = None\n\n def __str__(self):\n \"\"\"Provide an exception message that includes SyntaxError-like source\n line information when available.\n \"\"\"\n # Syntax errors are special and annotate the traceback (instead of what\n # we would do in the message that follows the traceback).\n if isinstance(self, SyntaxError):\n return super(HyLanguageError, self).__str__()\n # When there isn't extra source information, use the normal message.\n elif not self.text:\n return super(HyLanguageError, self).__str__()\n\n # Re-purpose Python's builtin syntax error formatting.\n output = traceback.format_exception_only(\n SyntaxError,\n SyntaxError(self.msg, (self.filename, self.lineno, self.offset,\n self.text)))\n\n arrow_idx, _ = next(((i, x) for i, x in enumerate(output)\n if x.strip() == '^'),\n (None, None))\n if arrow_idx:\n msg_idx = arrow_idx + 1\n else:\n msg_idx, _ = next((i, x) for i, x in enumerate(output)\n if x.startswith('SyntaxError: '))\n\n # Get rid of erroneous error-type label.\n output[msg_idx] = re.sub('^SyntaxError: ', '', output[msg_idx])\n\n # Extend the text arrow, when given enough source info.\n if arrow_idx and self.arrow_offset:\n output[arrow_idx] = '{}{}^\\n'.format(output[arrow_idx].rstrip('\\n'),\n '-' * (self.arrow_offset - 1))\n\n if COLORED:\n output[msg_idx:] = [Fore.YELLOW + o + Fore.RESET for o in output[msg_idx:]]\n if arrow_idx:\n output[arrow_idx] = Fore.GREEN + output[arrow_idx] + Fore.RESET\n for idx, line in enumerate(output[::msg_idx]):\n if line.strip().startswith(\n 'File \"{}\", line'.format(self.filename)):\n output[idx] = Fore.RED + line + Fore.RESET\n\n # This resulting string will come after a \"<class-name>:\" prompt, so\n # put it down a line.\n output.insert(0, '\\n')\n\n # Avoid \"...expected str instance, ColoredString found\"\n return reduce(lambda x, y: x + y, output)\n\n\nclass HyCompileError(HyInternalError):\n \"\"\"Unexpected errors occurring within the compiler.\"\"\"\n\n\nclass HyTypeError(HyLanguageError, TypeError):\n \"\"\"TypeError occurring during the normal use of Hy.\"\"\"\n\n\nclass HyNameError(HyLanguageError, NameError):\n \"\"\"NameError occurring during the normal use of Hy.\"\"\"\n\n\nclass HyRequireError(HyLanguageError):\n \"\"\"Errors arising during the use of `require`\n\n This, and any errors inheriting from this, are user-facing.\n \"\"\"\n\n\nclass HyMacroExpansionError(HyLanguageError):\n \"\"\"Errors caused by invalid use of Hy macros.\n\n This, and any errors inheriting from this, are user-facing.\n \"\"\"\n\n\nclass HyEvalError(HyLanguageError):\n \"\"\"Errors occurring during code evaluation at compile-time.\n\n These errors distinguish unexpected errors within the compilation process\n (i.e. `HyInternalError`s) from unrelated errors in user code evaluated by\n the compiler (e.g. in `eval-and-compile`).\n\n This, and any errors inheriting from this, are user-facing.\n \"\"\"\n\n\nclass HyIOError(HyInternalError, IOError):\n \"\"\" Subclass used to distinguish between IOErrors raised by Hy itself as\n opposed to Hy programs.\n \"\"\"\n\n\nclass HySyntaxError(HyLanguageError, SyntaxError):\n \"\"\"Error during the Lexing of a Hython expression.\"\"\"\n\n\nclass HyWrapperError(HyError, TypeError):\n \"\"\"Errors caused by language model object wrapping.\n\n These can be caused by improper user-level use of a macro, so they're\n not really \"internal\". If they arise due to anything else, they're an\n internal/compiler problem, though.\n \"\"\"\n\n\ndef _module_filter_name(module_name):\n try:\n compiler_loader = pkgutil.get_loader(module_name)\n if not compiler_loader:\n return None\n\n filename = compiler_loader.get_filename(module_name)\n if not filename:\n return None\n\n if compiler_loader.is_package(module_name):\n # Use the package directory (e.g. instead of `.../__init__.py`) so\n # that we can filter all modules in a package.\n return os.path.dirname(filename)\n else:\n # Normalize filename endings, because tracebacks will use `pyc` when\n # the loader says `py`.\n return filename.replace('.pyc', '.py')\n except Exception:\n return None\n\n\n_tb_hidden_modules = {m for m in map(_module_filter_name,\n ['hy.compiler', 'hy.lex',\n 'hy.cmdline', 'hy.lex.parser',\n 'hy.importer', 'hy._compat',\n 'hy.macros', 'hy.models',\n 'hy.core.result_macros',\n 'rply'])\n if m is not None}\n\n\ndef hy_exc_filter(exc_type, exc_value, exc_traceback):\n \"\"\"Produce exceptions print-outs with all frames originating from the\n modules in `_tb_hidden_modules` filtered out.\n\n The frames are actually filtered by each module's filename and only when a\n subclass of `HyLanguageError` is emitted.\n\n This does not remove the frames from the actual tracebacks, so debugging\n will show everything.\n \"\"\"\n # frame = (filename, line number, function name*, text)\n new_tb = []\n for frame in traceback.extract_tb(exc_traceback):\n if not (frame[0].replace('.pyc', '.py') in _tb_hidden_modules or\n os.path.dirname(frame[0]) in _tb_hidden_modules):\n new_tb += [frame]\n\n lines = traceback.format_list(new_tb)\n\n lines.insert(0, \"Traceback (most recent call last):\\n\")\n\n lines.extend(traceback.format_exception_only(exc_type, exc_value))\n output = ''.join(lines)\n\n return output\n\n\ndef hy_exc_handler(exc_type, exc_value, exc_traceback):\n \"\"\"A `sys.excepthook` handler that uses `hy_exc_filter` to\n remove internal Hy frames from a traceback print-out.\n \"\"\"\n if os.environ.get('HY_DEBUG', False):\n return sys.__excepthook__(exc_type, exc_value, exc_traceback)\n\n try:\n output = hy_exc_filter(exc_type, exc_value, exc_traceback)\n sys.stderr.write(output)\n sys.stderr.flush()\n except Exception:\n sys.__excepthook__(exc_type, exc_value, exc_traceback)\n\n\n@contextmanager\ndef filtered_hy_exceptions():\n \"\"\"Temporarily apply a `sys.excepthook` that filters Hy internal frames\n from tracebacks.\n\n Filtering can be controlled by the variable\n `hy.errors._hy_filter_internal_errors` and environment variable\n `HY_FILTER_INTERNAL_ERRORS`.\n \"\"\"\n global _hy_filter_internal_errors\n if _hy_filter_internal_errors:\n current_hook = sys.excepthook\n sys.excepthook = hy_exc_handler\n yield\n sys.excepthook = current_hook\n else:\n yield\n", "path": "hy/errors.py"}, {"content": "import sys\n\nPY3_7 = sys.version_info >= (3, 7)\nPY3_8 = sys.version_info >= (3, 8)\nPY3_9 = sys.version_info >= (3, 9)\nPY3_10 = sys.version_info >= (3, 10)\n\n\nif not PY3_9:\n # Shim `ast.unparse`.\n import ast, astor.code_gen\n ast.unparse = astor.code_gen.to_source\n\n\nif not PY3_7:\n # Shim `asyncio.run`.\n import asyncio\n def f(coro):\n return asyncio.get_event_loop().run_until_complete(coro)\n asyncio.run = f\n", "path": "hy/_compat.py"}]}
| 3,908 | 356 |
gh_patches_debug_18549
|
rasdani/github-patches
|
git_diff
|
catalyst-team__catalyst-1234
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
TracingCallback fails in ConfigAPI
## 🐛 Bug Report
<!-- A clear and concise description of what the bug is. -->
When running TracingCallback the run fails with an RuntimeError.
Apparently, inside the callback, there is a [transfer from any device to `cpu`](https://github.com/catalyst-team/catalyst/blob/a927bed68c1abcd3d28811d1d3d9d7b95e0861a1/catalyst/callbacks/tracing.py#L150) of batch which is used for tracing. And when the `runner.model` is on `cuda` it fails.
### How To Reproduce
Steps to reproduce the behavior:
1. Add
```
trace:
_target_: TracingCallback
input_key: *model_input
logdir: *logdir
```
to [mnist_stages config](https://github.com/catalyst-team/catalyst/blob/master/examples/mnist_stages/config.yml).
2. `sh mnist_stages/run_config.sh`
<!-- If you have a code sample, error messages, stack traces, please provide it here as well -->
### Expected behavior
<!-- A clear and concise description of what you expected to happen. -->
`RuntimeError: Input type (torch.FloatTensor) and weight type (torch.cuda.FloatTensor) should be the same`
### Environment
```bash
# example checklist, fill with your info
Catalyst version: 21.05
PyTorch version: 1.7.1
Is debug build: No
CUDA used to build PyTorch: 10.2
TensorFlow version: N/A
TensorBoard version: N/A
OS: Linux Mint 19.3 Tricia
GCC version: (Ubuntu 7.5.0-3ubuntu1~18.04) 7.5.0
CMake version: version 3.10.2
Python version: 3.8
Is CUDA available: Yes
CUDA runtime version: 9.1.85
GPU models and configuration:
GPU 0: GeForce RTX 2070 SUPER
GPU 1: Quadro P4000
Nvidia driver version: 460.32.03
cuDNN version: Could not collect
```
### Additional context
<!-- Add any other context about the problem here. -->
### Checklist
- [x] bug description
- [x] steps to reproduce
- [x] expected behavior
- [x] environment
- [ ] code sample / screenshots
### FAQ
Please review the FAQ before submitting an issue:
- [ ] I have read the [documentation and FAQ](https://catalyst-team.github.io/catalyst/)
- [ ] I have reviewed the [minimal examples section](https://github.com/catalyst-team/catalyst#minimal-examples)
- [ ] I have checked the [changelog](https://github.com/catalyst-team/catalyst/blob/master/CHANGELOG.md) for main framework updates
- [ ] I have read the [contribution guide](https://github.com/catalyst-team/catalyst/blob/master/CONTRIBUTING.md)
- [ ] I have joined [Catalyst slack (#__questions channel)](https://join.slack.com/t/catalyst-team-core/shared_invite/zt-d9miirnn-z86oKDzFMKlMG4fgFdZafw) for issue discussion
</issue>
<code>
[start of catalyst/callbacks/tracing.py]
1 from typing import List, TYPE_CHECKING, Union
2 from pathlib import Path
3
4 import torch
5
6 from catalyst.core import Callback, CallbackNode, CallbackOrder
7 from catalyst.utils.torch import any2device
8 from catalyst.utils.tracing import trace_model
9
10 if TYPE_CHECKING:
11 from catalyst.core import IRunner
12
13
14 class TracingCallback(Callback):
15 """
16 Callback for model tracing.
17
18 Args:
19 input_key: input key from ``runner.batch`` to use for model tracing
20 logdir: path to folder for saving
21 filename: filename
22 method_name: Model's method name that will be used as entrypoint during tracing
23
24 Example:
25
26 .. code-block:: python
27
28 import os
29
30 import torch
31 from torch import nn
32 from torch.utils.data import DataLoader
33
34 from catalyst import dl
35 from catalyst.data import ToTensor
36 from catalyst.contrib.datasets import MNIST
37 from catalyst.contrib.nn.modules import Flatten
38
39 loaders = {
40 "train": DataLoader(
41 MNIST(
42 os.getcwd(), train=False, download=True, transform=ToTensor()
43 ),
44 batch_size=32,
45 ),
46 "valid": DataLoader(
47 MNIST(
48 os.getcwd(), train=False, download=True, transform=ToTensor()
49 ),
50 batch_size=32,
51 ),
52 }
53
54 model = nn.Sequential(
55 Flatten(), nn.Linear(784, 512), nn.ReLU(), nn.Linear(512, 10)
56 )
57 criterion = nn.CrossEntropyLoss()
58 optimizer = torch.optim.Adam(model.parameters(), lr=1e-2)
59 runner = dl.SupervisedRunner()
60 runner.train(
61 model=model,
62 callbacks=[dl.TracingCallback(input_key="features", logdir="./logs")],
63 loaders=loaders,
64 criterion=criterion,
65 optimizer=optimizer,
66 num_epochs=1,
67 logdir="./logs",
68 )
69 """
70
71 def __init__(
72 self,
73 input_key: Union[str, List[str]],
74 logdir: Union[str, Path] = None,
75 filename: str = "traced_model.pth",
76 method_name: str = "forward",
77 ):
78 """
79 Callback for model tracing.
80
81 Args:
82 input_key: input key from ``runner.batch`` to use for model tracing
83 logdir: path to folder for saving
84 filename: filename
85 method_name: Model's method name that will be used as entrypoint during tracing
86
87 Example:
88 .. code-block:: python
89
90 import os
91
92 import torch
93 from torch import nn
94 from torch.utils.data import DataLoader
95
96 from catalyst import dl
97 from catalyst.data import ToTensor
98 from catalyst.contrib.datasets import MNIST
99 from catalyst.contrib.nn.modules import Flatten
100
101 loaders = {
102 "train": DataLoader(
103 MNIST(
104 os.getcwd(), train=False, download=True, transform=ToTensor()
105 ),
106 batch_size=32,
107 ),
108 "valid": DataLoader(
109 MNIST(
110 os.getcwd(), train=False, download=True, transform=ToTensor()
111 ),
112 batch_size=32,
113 ),
114 }
115
116 model = nn.Sequential(
117 Flatten(), nn.Linear(784, 512), nn.ReLU(), nn.Linear(512, 10)
118 )
119 criterion = nn.CrossEntropyLoss()
120 optimizer = torch.optim.Adam(model.parameters(), lr=1e-2)
121 runner = dl.SupervisedRunner()
122 runner.train(
123 model=model,
124 callbacks=[dl.TracingCallback(input_key="features", logdir="./logs")],
125 loaders=loaders,
126 criterion=criterion,
127 optimizer=optimizer,
128 num_epochs=1,
129 logdir="./logs",
130 )
131 """
132 super().__init__(order=CallbackOrder.ExternalExtra, node=CallbackNode.Master)
133 if logdir is not None:
134 self.filename = str(Path(logdir) / filename)
135 else:
136 self.filename = filename
137 self.method_name = method_name
138
139 self.input_key = [input_key] if isinstance(input_key, str) else input_key
140
141 def on_stage_end(self, runner: "IRunner") -> None:
142 """
143 On stage end action.
144
145 Args:
146 runner: runner for experiment
147 """
148 model = runner.model
149 batch = tuple(runner.batch[key] for key in self.input_key)
150 batch = any2device(batch, "cpu")
151 traced_model = trace_model(model=model, batch=batch, method_name=self.method_name)
152 torch.jit.save(traced_model, self.filename)
153
154
155 __all__ = ["TracingCallback"]
156
[end of catalyst/callbacks/tracing.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/catalyst/callbacks/tracing.py b/catalyst/callbacks/tracing.py
--- a/catalyst/callbacks/tracing.py
+++ b/catalyst/callbacks/tracing.py
@@ -4,7 +4,6 @@
import torch
from catalyst.core import Callback, CallbackNode, CallbackOrder
-from catalyst.utils.torch import any2device
from catalyst.utils.tracing import trace_model
if TYPE_CHECKING:
@@ -145,9 +144,9 @@
Args:
runner: runner for experiment
"""
- model = runner.model
+ model = runner.engine.sync_device(runner.model)
batch = tuple(runner.batch[key] for key in self.input_key)
- batch = any2device(batch, "cpu")
+ batch = runner.engine.sync_device(batch)
traced_model = trace_model(model=model, batch=batch, method_name=self.method_name)
torch.jit.save(traced_model, self.filename)
|
{"golden_diff": "diff --git a/catalyst/callbacks/tracing.py b/catalyst/callbacks/tracing.py\n--- a/catalyst/callbacks/tracing.py\n+++ b/catalyst/callbacks/tracing.py\n@@ -4,7 +4,6 @@\n import torch\n \n from catalyst.core import Callback, CallbackNode, CallbackOrder\n-from catalyst.utils.torch import any2device\n from catalyst.utils.tracing import trace_model\n \n if TYPE_CHECKING:\n@@ -145,9 +144,9 @@\n Args:\n runner: runner for experiment\n \"\"\"\n- model = runner.model\n+ model = runner.engine.sync_device(runner.model)\n batch = tuple(runner.batch[key] for key in self.input_key)\n- batch = any2device(batch, \"cpu\")\n+ batch = runner.engine.sync_device(batch)\n traced_model = trace_model(model=model, batch=batch, method_name=self.method_name)\n torch.jit.save(traced_model, self.filename)\n", "issue": "TracingCallback fails in ConfigAPI\n## \ud83d\udc1b Bug Report\r\n<!-- A clear and concise description of what the bug is. -->\r\nWhen running TracingCallback the run fails with an RuntimeError.\r\n\r\nApparently, inside the callback, there is a [transfer from any device to `cpu`](https://github.com/catalyst-team/catalyst/blob/a927bed68c1abcd3d28811d1d3d9d7b95e0861a1/catalyst/callbacks/tracing.py#L150) of batch which is used for tracing. And when the `runner.model` is on `cuda` it fails.\r\n\r\n### How To Reproduce\r\nSteps to reproduce the behavior:\r\n1. Add \r\n```\r\n trace:\r\n _target_: TracingCallback\r\n input_key: *model_input\r\n logdir: *logdir\r\n```\r\nto [mnist_stages config](https://github.com/catalyst-team/catalyst/blob/master/examples/mnist_stages/config.yml).\r\n2. `sh mnist_stages/run_config.sh`\r\n\r\n<!-- If you have a code sample, error messages, stack traces, please provide it here as well --> \r\n\r\n### Expected behavior\r\n<!-- A clear and concise description of what you expected to happen. -->\r\n`RuntimeError: Input type (torch.FloatTensor) and weight type (torch.cuda.FloatTensor) should be the same`\r\n\r\n\r\n### Environment\r\n```bash\r\n# example checklist, fill with your info\r\nCatalyst version: 21.05\r\nPyTorch version: 1.7.1\r\nIs debug build: No\r\nCUDA used to build PyTorch: 10.2\r\nTensorFlow version: N/A\r\nTensorBoard version: N/A\r\n\r\nOS: Linux Mint 19.3 Tricia\r\nGCC version: (Ubuntu 7.5.0-3ubuntu1~18.04) 7.5.0\r\nCMake version: version 3.10.2\r\n\r\nPython version: 3.8\r\nIs CUDA available: Yes\r\nCUDA runtime version: 9.1.85\r\nGPU models and configuration:\r\nGPU 0: GeForce RTX 2070 SUPER\r\nGPU 1: Quadro P4000\r\n\r\nNvidia driver version: 460.32.03\r\ncuDNN version: Could not collect\r\n```\r\n\r\n\r\n### Additional context\r\n<!-- Add any other context about the problem here. -->\r\n\r\n\r\n### Checklist\r\n- [x] bug description\r\n- [x] steps to reproduce\r\n- [x] expected behavior\r\n- [x] environment\r\n- [ ] code sample / screenshots\r\n \r\n### FAQ\r\nPlease review the FAQ before submitting an issue:\r\n- [ ] I have read the [documentation and FAQ](https://catalyst-team.github.io/catalyst/)\r\n- [ ] I have reviewed the [minimal examples section](https://github.com/catalyst-team/catalyst#minimal-examples)\r\n- [ ] I have checked the [changelog](https://github.com/catalyst-team/catalyst/blob/master/CHANGELOG.md) for main framework updates\r\n- [ ] I have read the [contribution guide](https://github.com/catalyst-team/catalyst/blob/master/CONTRIBUTING.md)\r\n- [ ] I have joined [Catalyst slack (#__questions channel)](https://join.slack.com/t/catalyst-team-core/shared_invite/zt-d9miirnn-z86oKDzFMKlMG4fgFdZafw) for issue discussion\r\n\n", "before_files": [{"content": "from typing import List, TYPE_CHECKING, Union\nfrom pathlib import Path\n\nimport torch\n\nfrom catalyst.core import Callback, CallbackNode, CallbackOrder\nfrom catalyst.utils.torch import any2device\nfrom catalyst.utils.tracing import trace_model\n\nif TYPE_CHECKING:\n from catalyst.core import IRunner\n\n\nclass TracingCallback(Callback):\n \"\"\"\n Callback for model tracing.\n\n Args:\n input_key: input key from ``runner.batch`` to use for model tracing\n logdir: path to folder for saving\n filename: filename\n method_name: Model's method name that will be used as entrypoint during tracing\n\n Example:\n\n .. code-block:: python\n\n import os\n\n import torch\n from torch import nn\n from torch.utils.data import DataLoader\n\n from catalyst import dl\n from catalyst.data import ToTensor\n from catalyst.contrib.datasets import MNIST\n from catalyst.contrib.nn.modules import Flatten\n\n loaders = {\n \"train\": DataLoader(\n MNIST(\n os.getcwd(), train=False, download=True, transform=ToTensor()\n ),\n batch_size=32,\n ),\n \"valid\": DataLoader(\n MNIST(\n os.getcwd(), train=False, download=True, transform=ToTensor()\n ),\n batch_size=32,\n ),\n }\n\n model = nn.Sequential(\n Flatten(), nn.Linear(784, 512), nn.ReLU(), nn.Linear(512, 10)\n )\n criterion = nn.CrossEntropyLoss()\n optimizer = torch.optim.Adam(model.parameters(), lr=1e-2)\n runner = dl.SupervisedRunner()\n runner.train(\n model=model,\n callbacks=[dl.TracingCallback(input_key=\"features\", logdir=\"./logs\")],\n loaders=loaders,\n criterion=criterion,\n optimizer=optimizer,\n num_epochs=1,\n logdir=\"./logs\",\n )\n \"\"\"\n\n def __init__(\n self,\n input_key: Union[str, List[str]],\n logdir: Union[str, Path] = None,\n filename: str = \"traced_model.pth\",\n method_name: str = \"forward\",\n ):\n \"\"\"\n Callback for model tracing.\n\n Args:\n input_key: input key from ``runner.batch`` to use for model tracing\n logdir: path to folder for saving\n filename: filename\n method_name: Model's method name that will be used as entrypoint during tracing\n\n Example:\n .. code-block:: python\n\n import os\n\n import torch\n from torch import nn\n from torch.utils.data import DataLoader\n\n from catalyst import dl\n from catalyst.data import ToTensor\n from catalyst.contrib.datasets import MNIST\n from catalyst.contrib.nn.modules import Flatten\n\n loaders = {\n \"train\": DataLoader(\n MNIST(\n os.getcwd(), train=False, download=True, transform=ToTensor()\n ),\n batch_size=32,\n ),\n \"valid\": DataLoader(\n MNIST(\n os.getcwd(), train=False, download=True, transform=ToTensor()\n ),\n batch_size=32,\n ),\n }\n\n model = nn.Sequential(\n Flatten(), nn.Linear(784, 512), nn.ReLU(), nn.Linear(512, 10)\n )\n criterion = nn.CrossEntropyLoss()\n optimizer = torch.optim.Adam(model.parameters(), lr=1e-2)\n runner = dl.SupervisedRunner()\n runner.train(\n model=model,\n callbacks=[dl.TracingCallback(input_key=\"features\", logdir=\"./logs\")],\n loaders=loaders,\n criterion=criterion,\n optimizer=optimizer,\n num_epochs=1,\n logdir=\"./logs\",\n )\n \"\"\"\n super().__init__(order=CallbackOrder.ExternalExtra, node=CallbackNode.Master)\n if logdir is not None:\n self.filename = str(Path(logdir) / filename)\n else:\n self.filename = filename\n self.method_name = method_name\n\n self.input_key = [input_key] if isinstance(input_key, str) else input_key\n\n def on_stage_end(self, runner: \"IRunner\") -> None:\n \"\"\"\n On stage end action.\n\n Args:\n runner: runner for experiment\n \"\"\"\n model = runner.model\n batch = tuple(runner.batch[key] for key in self.input_key)\n batch = any2device(batch, \"cpu\")\n traced_model = trace_model(model=model, batch=batch, method_name=self.method_name)\n torch.jit.save(traced_model, self.filename)\n\n\n__all__ = [\"TracingCallback\"]\n", "path": "catalyst/callbacks/tracing.py"}]}
| 2,641 | 206 |
gh_patches_debug_48934
|
rasdani/github-patches
|
git_diff
|
pfnet__pytorch-pfn-extras-363
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Tests package is not correctly excluded
Currently test codes are installed to site-packages.
`setuptools.find_packages(exclude=['tests'])` needs to be fixed.
</issue>
<code>
[start of setup.py]
1 import os
2 import setuptools
3
4
5 here = os.path.abspath(os.path.dirname(__file__))
6 # Get __version__ variable
7 exec(open(os.path.join(here, 'pytorch_pfn_extras', '_version.py')).read())
8
9
10 setuptools.setup(
11 name='pytorch-pfn-extras',
12 version=__version__, # NOQA
13 description='Supplementary components to accelerate research and '
14 'development in PyTorch.',
15 author='Preferred Networks, Inc.',
16 license='MIT License',
17 install_requires=['numpy', 'torch'],
18 extras_require={
19 'test': ['pytest'],
20 'onnx': ['onnx'],
21 },
22 python_requires='>=3.6.0',
23 packages=setuptools.find_packages(exclude=['tests']),
24 package_data={'pytorch_pfn_extras': ['py.typed']},
25 )
26
[end of setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -20,6 +20,6 @@
'onnx': ['onnx'],
},
python_requires='>=3.6.0',
- packages=setuptools.find_packages(exclude=['tests']),
+ packages=setuptools.find_packages(exclude=['tests', 'tests.*']),
package_data={'pytorch_pfn_extras': ['py.typed']},
)
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -20,6 +20,6 @@\n 'onnx': ['onnx'],\n },\n python_requires='>=3.6.0',\n- packages=setuptools.find_packages(exclude=['tests']),\n+ packages=setuptools.find_packages(exclude=['tests', 'tests.*']),\n package_data={'pytorch_pfn_extras': ['py.typed']},\n )\n", "issue": "Tests package is not correctly excluded\nCurrently test codes are installed to site-packages.\r\n\r\n`setuptools.find_packages(exclude=['tests'])` needs to be fixed.\n", "before_files": [{"content": "import os\nimport setuptools\n\n\nhere = os.path.abspath(os.path.dirname(__file__))\n# Get __version__ variable\nexec(open(os.path.join(here, 'pytorch_pfn_extras', '_version.py')).read())\n\n\nsetuptools.setup(\n name='pytorch-pfn-extras',\n version=__version__, # NOQA\n description='Supplementary components to accelerate research and '\n 'development in PyTorch.',\n author='Preferred Networks, Inc.',\n license='MIT License',\n install_requires=['numpy', 'torch'],\n extras_require={\n 'test': ['pytest'],\n 'onnx': ['onnx'],\n },\n python_requires='>=3.6.0',\n packages=setuptools.find_packages(exclude=['tests']),\n package_data={'pytorch_pfn_extras': ['py.typed']},\n)\n", "path": "setup.py"}]}
| 780 | 99 |
gh_patches_debug_22060
|
rasdani/github-patches
|
git_diff
|
interlegis__sapl-1788
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Cargo de Comissão - permite atribuir cargo indicado como único para mais de um membro
Não deve permitir atribuir o mesmo cargo assinalado como único para mais de um membro da comissão. O cargo deve estar vago.
</issue>
<code>
[start of sapl/comissoes/forms.py]
1 from django import forms
2 from django.contrib.contenttypes.models import ContentType
3 from django.core.exceptions import ValidationError
4 from django.db import transaction
5 from django.db.models import Q
6 from django.forms import ModelForm
7 from django.utils.translation import ugettext_lazy as _
8
9 from sapl.base.models import Autor, TipoAutor
10 from sapl.comissoes.models import (Comissao, Composicao, DocumentoAcessorio,
11 Participacao, Reuniao)
12 from sapl.parlamentares.models import Legislatura, Mandato, Parlamentar
13
14
15 class ParticipacaoCreateForm(forms.ModelForm):
16
17 parent_pk = forms.CharField(required=False) # widget=forms.HiddenInput())
18
19 class Meta:
20 model = Participacao
21 exclude = ['composicao']
22
23 def __init__(self, user=None, **kwargs):
24 super(ParticipacaoCreateForm, self).__init__(**kwargs)
25
26 if self.instance:
27 comissao = kwargs['initial']
28 comissao_pk = int(comissao['parent_pk'])
29 composicao = Composicao.objects.get(id=comissao_pk)
30 participantes = composicao.participacao_set.all()
31 id_part = [p.parlamentar.id for p in participantes]
32 else:
33 id_part = []
34
35 qs = self.create_participacao()
36
37 parlamentares = Mandato.objects.filter(qs,
38 parlamentar__ativo=True
39 ).prefetch_related('parlamentar').\
40 values_list('parlamentar',
41 flat=True).distinct()
42
43 qs = Parlamentar.objects.filter(id__in=parlamentares).distinct().\
44 exclude(id__in=id_part)
45 eligible = self.verifica()
46 result = list(set(qs) & set(eligible))
47 if not cmp(result, eligible): # se igual a 0 significa que o qs e o eli são iguais!
48 self.fields['parlamentar'].queryset = qs
49 else:
50 ids = [e.id for e in eligible]
51 qs = Parlamentar.objects.filter(id__in=ids)
52 self.fields['parlamentar'].queryset = qs
53
54 def create_participacao(self):
55 composicao = Composicao.objects.get(id=self.initial['parent_pk'])
56 data_inicio_comissao = composicao.periodo.data_inicio
57 data_fim_comissao = composicao.periodo.data_fim
58 q1 = Q(data_fim_mandato__isnull=False,
59 data_fim_mandato__gte=data_inicio_comissao)
60 q2 = Q(data_inicio_mandato__gte=data_inicio_comissao) \
61 & Q(data_inicio_mandato__lte=data_fim_comissao)
62 q3 = Q(data_fim_mandato__isnull=True,
63 data_inicio_mandato__lte=data_inicio_comissao)
64 qs = q1 | q2 | q3
65 return qs
66
67 def verifica(self):
68 composicao = Composicao.objects.get(id=self.initial['parent_pk'])
69 participantes = composicao.participacao_set.all()
70 participantes_id = [p.parlamentar.id for p in participantes]
71 parlamentares = Parlamentar.objects.all().exclude(
72 id__in=participantes_id).order_by('nome_completo')
73 parlamentares = [p for p in parlamentares if p.ativo]
74
75 lista = []
76
77 for p in parlamentares:
78 mandatos = p.mandato_set.all()
79 for m in mandatos:
80 data_inicio = m.data_inicio_mandato
81 data_fim = m.data_fim_mandato
82 comp_data_inicio = composicao.periodo.data_inicio
83 comp_data_fim = composicao.periodo.data_fim
84 if (data_fim and data_fim >= comp_data_inicio)\
85 or (data_inicio >= comp_data_inicio and data_inicio <= comp_data_fim)\
86 or (data_fim is None and data_inicio <= comp_data_inicio):
87 lista.append(p)
88
89 lista = list(set(lista))
90
91 return lista
92
93
94 class ParticipacaoEditForm(forms.ModelForm):
95
96 parent_pk = forms.CharField(required=False) # widget=forms.HiddenInput())
97 nome_parlamentar = forms.CharField(required=False, label='Parlamentar')
98
99 class Meta:
100 model = Participacao
101 fields = ['nome_parlamentar', 'parlamentar', 'cargo', 'titular',
102 'data_designacao', 'data_desligamento',
103 'motivo_desligamento', 'observacao']
104 widgets = {
105 'parlamentar': forms.HiddenInput(),
106 }
107
108 def __init__(self, user=None, **kwargs):
109 super(ParticipacaoEditForm, self).__init__(**kwargs)
110 self.initial['nome_parlamentar'] = Parlamentar.objects.get(
111 id=self.initial['parlamentar']).nome_parlamentar
112 self.fields['nome_parlamentar'].widget.attrs['disabled'] = 'disabled'
113
114
115 class ComissaoForm(forms.ModelForm):
116
117 class Meta:
118 model = Comissao
119 fields = '__all__'
120
121 def clean(self):
122 super(ComissaoForm, self).clean()
123
124 if not self.is_valid():
125 return self.cleaned_data
126
127 if self.cleaned_data['data_extincao']:
128 if (self.cleaned_data['data_extincao'] <
129 self.cleaned_data['data_criacao']):
130 msg = _('Data de extinção não pode ser menor que a de criação')
131 raise ValidationError(msg)
132 return self.cleaned_data
133
134 @transaction.atomic
135 def save(self, commit=True):
136 comissao = super(ComissaoForm, self).save(commit)
137 content_type = ContentType.objects.get_for_model(Comissao)
138 object_id = comissao.pk
139 tipo = TipoAutor.objects.get(descricao__icontains='Comiss')
140 nome = comissao.sigla + ' - ' + comissao.nome
141 Autor.objects.create(
142 content_type=content_type,
143 object_id=object_id,
144 tipo=tipo,
145 nome=nome
146 )
147 return comissao
148
149
150 class ReuniaoForm(ModelForm):
151
152 comissao = forms.ModelChoiceField(queryset=Comissao.objects.all(),
153 widget=forms.HiddenInput())
154
155 class Meta:
156 model = Reuniao
157 exclude = ['cod_andamento_reuniao']
158
159 def clean(self):
160 super(ReuniaoForm, self).clean()
161
162 if not self.is_valid():
163 return self.cleaned_data
164
165 if self.cleaned_data['hora_fim']:
166 if (self.cleaned_data['hora_fim'] <
167 self.cleaned_data['hora_inicio']):
168 msg = _('A hora de término da reunião não pode ser menor que a de início')
169 raise ValidationError(msg)
170 return self.cleaned_data
171
172 class DocumentoAcessorioCreateForm(forms.ModelForm):
173
174 parent_pk = forms.CharField(required=False) # widget=forms.HiddenInput())
175
176 class Meta:
177 model = DocumentoAcessorio
178 exclude = ['reuniao']
179
180 def __init__(self, user=None, **kwargs):
181 super(DocumentoAcessorioCreateForm, self).__init__(**kwargs)
182
183 if self.instance:
184 reuniao = Reuniao.objects.get(id=self.initial['parent_pk'])
185 comissao = reuniao.comissao
186 comissao_pk = comissao.id
187 documentos = reuniao.documentoacessorio_set.all()
188 return self.create_documentoacessorio()
189
190
191 def create_documentoacessorio(self):
192 reuniao = Reuniao.objects.get(id=self.initial['parent_pk'])
193
194
195 class DocumentoAcessorioEditForm(forms.ModelForm):
196
197 parent_pk = forms.CharField(required=False) # widget=forms.HiddenInput())
198
199 class Meta:
200 model = DocumentoAcessorio
201 fields = ['nome', 'data', 'autor', 'ementa',
202 'indexacao', 'arquivo']
203
204 def __init__(self, user=None, **kwargs):
205 super(DocumentoAcessorioEditForm, self).__init__(**kwargs)
206
207
[end of sapl/comissoes/forms.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/sapl/comissoes/forms.py b/sapl/comissoes/forms.py
--- a/sapl/comissoes/forms.py
+++ b/sapl/comissoes/forms.py
@@ -18,6 +18,7 @@
class Meta:
model = Participacao
+ fields = '__all__'
exclude = ['composicao']
def __init__(self, user=None, **kwargs):
@@ -51,6 +52,21 @@
qs = Parlamentar.objects.filter(id__in=ids)
self.fields['parlamentar'].queryset = qs
+
+ def clean(self):
+ cleaned_data = super(ParticipacaoCreateForm, self).clean()
+
+ if not self.is_valid():
+ return cleaned_data
+
+ composicao = Composicao.objects.get(id=self.initial['parent_pk'])
+ cargos_unicos = [c.cargo.nome for c in composicao.participacao_set.filter(cargo__unico=True)]
+
+ if cleaned_data['cargo'].nome in cargos_unicos:
+ msg = _('Este cargo é único para esta Comissão.')
+ raise ValidationError(msg)
+
+
def create_participacao(self):
composicao = Composicao.objects.get(id=self.initial['parent_pk'])
data_inicio_comissao = composicao.periodo.data_inicio
|
{"golden_diff": "diff --git a/sapl/comissoes/forms.py b/sapl/comissoes/forms.py\n--- a/sapl/comissoes/forms.py\n+++ b/sapl/comissoes/forms.py\n@@ -18,6 +18,7 @@\n \n class Meta:\n model = Participacao\n+ fields = '__all__'\n exclude = ['composicao']\n \n def __init__(self, user=None, **kwargs):\n@@ -51,6 +52,21 @@\n qs = Parlamentar.objects.filter(id__in=ids)\n self.fields['parlamentar'].queryset = qs\n \n+\n+ def clean(self):\n+ cleaned_data = super(ParticipacaoCreateForm, self).clean()\n+\n+ if not self.is_valid():\n+ return cleaned_data\n+\n+ composicao = Composicao.objects.get(id=self.initial['parent_pk'])\n+ cargos_unicos = [c.cargo.nome for c in composicao.participacao_set.filter(cargo__unico=True)]\n+\n+ if cleaned_data['cargo'].nome in cargos_unicos:\n+ msg = _('Este cargo \u00e9 \u00fanico para esta Comiss\u00e3o.')\n+ raise ValidationError(msg)\n+\n+\n def create_participacao(self):\n composicao = Composicao.objects.get(id=self.initial['parent_pk'])\n data_inicio_comissao = composicao.periodo.data_inicio\n", "issue": "Cargo de Comiss\u00e3o - permite atribuir cargo indicado como \u00fanico para mais de um membro\nN\u00e3o deve permitir atribuir o mesmo cargo assinalado como \u00fanico para mais de um membro da comiss\u00e3o. O cargo deve estar vago.\n", "before_files": [{"content": "from django import forms\nfrom django.contrib.contenttypes.models import ContentType\nfrom django.core.exceptions import ValidationError\nfrom django.db import transaction\nfrom django.db.models import Q\nfrom django.forms import ModelForm\nfrom django.utils.translation import ugettext_lazy as _\n\nfrom sapl.base.models import Autor, TipoAutor\nfrom sapl.comissoes.models import (Comissao, Composicao, DocumentoAcessorio,\n Participacao, Reuniao)\nfrom sapl.parlamentares.models import Legislatura, Mandato, Parlamentar\n\n\nclass ParticipacaoCreateForm(forms.ModelForm):\n\n parent_pk = forms.CharField(required=False) # widget=forms.HiddenInput())\n\n class Meta:\n model = Participacao\n exclude = ['composicao']\n\n def __init__(self, user=None, **kwargs):\n super(ParticipacaoCreateForm, self).__init__(**kwargs)\n\n if self.instance:\n comissao = kwargs['initial']\n comissao_pk = int(comissao['parent_pk'])\n composicao = Composicao.objects.get(id=comissao_pk)\n participantes = composicao.participacao_set.all()\n id_part = [p.parlamentar.id for p in participantes]\n else:\n id_part = []\n\n qs = self.create_participacao()\n\n parlamentares = Mandato.objects.filter(qs,\n parlamentar__ativo=True\n ).prefetch_related('parlamentar').\\\n values_list('parlamentar',\n flat=True).distinct()\n\n qs = Parlamentar.objects.filter(id__in=parlamentares).distinct().\\\n exclude(id__in=id_part)\n eligible = self.verifica()\n result = list(set(qs) & set(eligible))\n if not cmp(result, eligible): # se igual a 0 significa que o qs e o eli s\u00e3o iguais!\n self.fields['parlamentar'].queryset = qs\n else:\n ids = [e.id for e in eligible]\n qs = Parlamentar.objects.filter(id__in=ids)\n self.fields['parlamentar'].queryset = qs\n\n def create_participacao(self):\n composicao = Composicao.objects.get(id=self.initial['parent_pk'])\n data_inicio_comissao = composicao.periodo.data_inicio\n data_fim_comissao = composicao.periodo.data_fim\n q1 = Q(data_fim_mandato__isnull=False,\n data_fim_mandato__gte=data_inicio_comissao)\n q2 = Q(data_inicio_mandato__gte=data_inicio_comissao) \\\n & Q(data_inicio_mandato__lte=data_fim_comissao)\n q3 = Q(data_fim_mandato__isnull=True,\n data_inicio_mandato__lte=data_inicio_comissao)\n qs = q1 | q2 | q3\n return qs\n\n def verifica(self):\n composicao = Composicao.objects.get(id=self.initial['parent_pk'])\n participantes = composicao.participacao_set.all()\n participantes_id = [p.parlamentar.id for p in participantes]\n parlamentares = Parlamentar.objects.all().exclude(\n id__in=participantes_id).order_by('nome_completo')\n parlamentares = [p for p in parlamentares if p.ativo]\n\n lista = []\n\n for p in parlamentares:\n mandatos = p.mandato_set.all()\n for m in mandatos:\n data_inicio = m.data_inicio_mandato\n data_fim = m.data_fim_mandato\n comp_data_inicio = composicao.periodo.data_inicio\n comp_data_fim = composicao.periodo.data_fim\n if (data_fim and data_fim >= comp_data_inicio)\\\n or (data_inicio >= comp_data_inicio and data_inicio <= comp_data_fim)\\\n or (data_fim is None and data_inicio <= comp_data_inicio):\n lista.append(p)\n\n lista = list(set(lista))\n\n return lista\n\n\nclass ParticipacaoEditForm(forms.ModelForm):\n\n parent_pk = forms.CharField(required=False) # widget=forms.HiddenInput())\n nome_parlamentar = forms.CharField(required=False, label='Parlamentar')\n\n class Meta:\n model = Participacao\n fields = ['nome_parlamentar', 'parlamentar', 'cargo', 'titular',\n 'data_designacao', 'data_desligamento',\n 'motivo_desligamento', 'observacao']\n widgets = {\n 'parlamentar': forms.HiddenInput(),\n }\n\n def __init__(self, user=None, **kwargs):\n super(ParticipacaoEditForm, self).__init__(**kwargs)\n self.initial['nome_parlamentar'] = Parlamentar.objects.get(\n id=self.initial['parlamentar']).nome_parlamentar\n self.fields['nome_parlamentar'].widget.attrs['disabled'] = 'disabled'\n\n\nclass ComissaoForm(forms.ModelForm):\n\n class Meta:\n model = Comissao\n fields = '__all__'\n\n def clean(self):\n super(ComissaoForm, self).clean()\n\n if not self.is_valid():\n return self.cleaned_data\n\n if self.cleaned_data['data_extincao']:\n if (self.cleaned_data['data_extincao'] <\n self.cleaned_data['data_criacao']):\n msg = _('Data de extin\u00e7\u00e3o n\u00e3o pode ser menor que a de cria\u00e7\u00e3o')\n raise ValidationError(msg)\n return self.cleaned_data\n\n @transaction.atomic\n def save(self, commit=True):\n comissao = super(ComissaoForm, self).save(commit)\n content_type = ContentType.objects.get_for_model(Comissao)\n object_id = comissao.pk\n tipo = TipoAutor.objects.get(descricao__icontains='Comiss')\n nome = comissao.sigla + ' - ' + comissao.nome\n Autor.objects.create(\n content_type=content_type,\n object_id=object_id,\n tipo=tipo,\n nome=nome\n )\n return comissao\n\n\nclass ReuniaoForm(ModelForm):\n\n comissao = forms.ModelChoiceField(queryset=Comissao.objects.all(),\n widget=forms.HiddenInput())\n\n class Meta:\n model = Reuniao\n exclude = ['cod_andamento_reuniao']\n\n def clean(self):\n super(ReuniaoForm, self).clean()\n\n if not self.is_valid():\n return self.cleaned_data\n\n if self.cleaned_data['hora_fim']:\n if (self.cleaned_data['hora_fim'] <\n self.cleaned_data['hora_inicio']):\n msg = _('A hora de t\u00e9rmino da reuni\u00e3o n\u00e3o pode ser menor que a de in\u00edcio')\n raise ValidationError(msg)\n return self.cleaned_data\n\nclass DocumentoAcessorioCreateForm(forms.ModelForm):\n\n parent_pk = forms.CharField(required=False) # widget=forms.HiddenInput())\n\n class Meta:\n model = DocumentoAcessorio\n exclude = ['reuniao']\n\n def __init__(self, user=None, **kwargs):\n super(DocumentoAcessorioCreateForm, self).__init__(**kwargs)\n\n if self.instance:\n reuniao = Reuniao.objects.get(id=self.initial['parent_pk'])\n comissao = reuniao.comissao\n comissao_pk = comissao.id\n documentos = reuniao.documentoacessorio_set.all()\n return self.create_documentoacessorio()\n\n\n def create_documentoacessorio(self):\n reuniao = Reuniao.objects.get(id=self.initial['parent_pk'])\n\n\nclass DocumentoAcessorioEditForm(forms.ModelForm):\n\n parent_pk = forms.CharField(required=False) # widget=forms.HiddenInput())\n\n class Meta:\n model = DocumentoAcessorio\n fields = ['nome', 'data', 'autor', 'ementa',\n 'indexacao', 'arquivo']\n\n def __init__(self, user=None, **kwargs):\n super(DocumentoAcessorioEditForm, self).__init__(**kwargs)\n\n", "path": "sapl/comissoes/forms.py"}]}
| 2,869 | 303 |
gh_patches_debug_4038
|
rasdani/github-patches
|
git_diff
|
streamlit__streamlit-6129
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Regression in v1.18.0 `st.metric`'s `help` tooltip position
### Checklist
- [X] I have searched the [existing issues](https://github.com/streamlit/streamlit/issues) for similar issues.
- [X] I added a very descriptive title to this issue.
- [X] I have provided sufficient information below to help reproduce this issue.
### Summary
[Reported](https://discuss.streamlit.io/t/version-1-18-0/37501/3?u=snehankekre) by @marduk2 on our forum. The `help` tooltip for `st.metric` has changed positions in v1.18.0 and appears under the metric label instead of to its right.
### Reproducible Code Example
```Python
import streamlit as st
st.title("'Help' tooltips in st.metric render in a weird position")
st.metric(
label="Example metric",
help="Something doesn't feel right...",
value=150.59,
delta="Very high",
)
```
### Steps To Reproduce
1. Run the app
### Expected Behavior

### Current Behavior

### Is this a regression?
- [X] Yes, this used to work in a previous version.
### Debug info
- Streamlit version: 1.18.0
- Python version: 3.9
- Operating System: macOS
- Browser: Chrome
- Virtual environment: NA
### Additional Information
_No response_
### Are you willing to submit a PR?
- [ ] Yes, I am willing to submit a PR!
</issue>
<code>
[start of e2e/scripts/st_metric.py]
1 # Copyright (c) Streamlit Inc. (2018-2022) Snowflake Inc. (2022)
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 import streamlit as st
16
17 col1, col2, col3 = st.columns(3)
18
19 with col1:
20 st.metric("User growth", 123, 123, "normal")
21 with col2:
22 st.metric("S&P 500", -4.56, -50)
23 with col3:
24 st.metric("Apples I've eaten", "23k", " -20", "off")
25
26 " "
27
28 col1, col2, col3 = st.columns(3)
29
30 with col1:
31 st.selectbox("Pick one", [])
32 with col2:
33 st.metric("Test 2", -4.56, 1.23, "inverse")
34 with col3:
35 st.slider("Pick another")
36
37
38 with col1:
39 st.metric("Test 3", -4.56, 1.23, label_visibility="visible")
40 with col2:
41 st.metric("Test 4", -4.56, 1.23, label_visibility="hidden")
42 with col3:
43 st.metric("Test 5", -4.56, 1.23, label_visibility="collapsed")
44
[end of e2e/scripts/st_metric.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/e2e/scripts/st_metric.py b/e2e/scripts/st_metric.py
--- a/e2e/scripts/st_metric.py
+++ b/e2e/scripts/st_metric.py
@@ -41,3 +41,13 @@
st.metric("Test 4", -4.56, 1.23, label_visibility="hidden")
with col3:
st.metric("Test 5", -4.56, 1.23, label_visibility="collapsed")
+
+col1, col2, col3, col4, col5, col6, col7, col8 = st.columns(8)
+
+with col1:
+ st.metric(
+ label="Example metric",
+ help="Something should feel right",
+ value=150.59,
+ delta="Very high",
+ )
|
{"golden_diff": "diff --git a/e2e/scripts/st_metric.py b/e2e/scripts/st_metric.py\n--- a/e2e/scripts/st_metric.py\n+++ b/e2e/scripts/st_metric.py\n@@ -41,3 +41,13 @@\n st.metric(\"Test 4\", -4.56, 1.23, label_visibility=\"hidden\")\n with col3:\n st.metric(\"Test 5\", -4.56, 1.23, label_visibility=\"collapsed\")\n+\n+col1, col2, col3, col4, col5, col6, col7, col8 = st.columns(8)\n+\n+with col1:\n+ st.metric(\n+ label=\"Example metric\",\n+ help=\"Something should feel right\",\n+ value=150.59,\n+ delta=\"Very high\",\n+ )\n", "issue": "Regression in v1.18.0 `st.metric`'s `help` tooltip position\n### Checklist\r\n\r\n- [X] I have searched the [existing issues](https://github.com/streamlit/streamlit/issues) for similar issues.\r\n- [X] I added a very descriptive title to this issue.\r\n- [X] I have provided sufficient information below to help reproduce this issue.\r\n\r\n### Summary\r\n\r\n[Reported](https://discuss.streamlit.io/t/version-1-18-0/37501/3?u=snehankekre) by @marduk2 on our forum. The `help` tooltip for `st.metric` has changed positions in v1.18.0 and appears under the metric label instead of to its right.\r\n\r\n### Reproducible Code Example\r\n\r\n```Python\r\nimport streamlit as st\r\n\r\nst.title(\"'Help' tooltips in st.metric render in a weird position\")\r\n\r\nst.metric(\r\n label=\"Example metric\",\r\n help=\"Something doesn't feel right...\",\r\n value=150.59,\r\n delta=\"Very high\",\r\n)\r\n```\r\n\r\n\r\n### Steps To Reproduce\r\n\r\n1. Run the app\r\n\r\n### Expected Behavior\r\n\r\n\r\n\r\n\r\n### Current Behavior\r\n\r\n\r\n\r\n\r\n### Is this a regression?\r\n\r\n- [X] Yes, this used to work in a previous version.\r\n\r\n### Debug info\r\n\r\n- Streamlit version: 1.18.0\r\n- Python version: 3.9\r\n- Operating System: macOS\r\n- Browser: Chrome\r\n- Virtual environment: NA\r\n\r\n\r\n### Additional Information\r\n\r\n_No response_\r\n\r\n### Are you willing to submit a PR?\r\n\r\n- [ ] Yes, I am willing to submit a PR!\n", "before_files": [{"content": "# Copyright (c) Streamlit Inc. (2018-2022) Snowflake Inc. (2022)\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport streamlit as st\n\ncol1, col2, col3 = st.columns(3)\n\nwith col1:\n st.metric(\"User growth\", 123, 123, \"normal\")\nwith col2:\n st.metric(\"S&P 500\", -4.56, -50)\nwith col3:\n st.metric(\"Apples I've eaten\", \"23k\", \" -20\", \"off\")\n\n\" \"\n\ncol1, col2, col3 = st.columns(3)\n\nwith col1:\n st.selectbox(\"Pick one\", [])\nwith col2:\n st.metric(\"Test 2\", -4.56, 1.23, \"inverse\")\nwith col3:\n st.slider(\"Pick another\")\n\n\nwith col1:\n st.metric(\"Test 3\", -4.56, 1.23, label_visibility=\"visible\")\nwith col2:\n st.metric(\"Test 4\", -4.56, 1.23, label_visibility=\"hidden\")\nwith col3:\n st.metric(\"Test 5\", -4.56, 1.23, label_visibility=\"collapsed\")\n", "path": "e2e/scripts/st_metric.py"}]}
| 1,498 | 186 |
gh_patches_debug_37087
|
rasdani/github-patches
|
git_diff
|
inventree__InvenTree-5632
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[BUG] Exchange rate provider is closed now
### Please verify that this bug has NOT been raised before.
- [X] I checked and didn't find a similar issue
### Describe the bug*
Our current default exchange rate provider is closed now - and the change was not smooth either. See https://github.com/Formicka/exchangerate.host/issues/236#issuecomment-1738539199
We need to:
1) Disable the CI checks for now
2) Implement an alternative
3) (Optional) Bring down ApiLayer once and for all before they close all APIs we need
### Steps to Reproduce
Look at any current [CI](https://github.com/inventree/InvenTree/actions/runs/6333198194/job/17202067465?pr=5582)
### Expected behaviour
Updating exchange rates
### Deployment Method
- [X] Docker
- [X] Bare metal
### Version Information
Every version>0.6.0 and a couble before are probably effected.
### Please verify if you can reproduce this bug on the demo site.
- [X] I can reproduce this bug on the demo site.
### Relevant log output
_No response_
</issue>
<code>
[start of InvenTree/InvenTree/exchange.py]
1 """Exchangerate backend to use `exchangerate.host` to get rates."""
2
3 import ssl
4 from urllib.error import URLError
5 from urllib.request import urlopen
6
7 from django.db.utils import OperationalError
8
9 import certifi
10 from djmoney.contrib.exchange.backends.base import SimpleExchangeBackend
11
12 from common.settings import currency_code_default, currency_codes
13
14
15 class InvenTreeExchange(SimpleExchangeBackend):
16 """Backend for automatically updating currency exchange rates.
17
18 Uses the `exchangerate.host` service API
19 """
20
21 name = "InvenTreeExchange"
22
23 def __init__(self):
24 """Set API url."""
25 self.url = "https://api.exchangerate.host/latest"
26
27 super().__init__()
28
29 def get_params(self):
30 """Placeholder to set API key. Currently not required by `exchangerate.host`."""
31 # No API key is required
32 return {
33 }
34
35 def get_response(self, **kwargs):
36 """Custom code to get response from server.
37
38 Note: Adds a 5-second timeout
39 """
40 url = self.get_url(**kwargs)
41
42 try:
43 context = ssl.create_default_context(cafile=certifi.where())
44 response = urlopen(url, timeout=5, context=context)
45 return response.read()
46 except Exception:
47 # Something has gone wrong, but we can just try again next time
48 # Raise a TypeError so the outer function can handle this
49 raise TypeError
50
51 def update_rates(self, base_currency=None):
52 """Set the requested currency codes and get rates."""
53 # Set default - see B008
54 if base_currency is None:
55 base_currency = currency_code_default()
56
57 symbols = ','.join(currency_codes())
58
59 try:
60 super().update_rates(base=base_currency, symbols=symbols)
61 # catch connection errors
62 except URLError:
63 print('Encountered connection error while updating')
64 except TypeError:
65 print('Exchange returned invalid response')
66 except OperationalError as e:
67 if 'SerializationFailure' in e.__cause__.__class__.__name__:
68 print('Serialization Failure while updating exchange rates')
69 # We are just going to swallow this exception because the
70 # exchange rates will be updated later by the scheduled task
71 else:
72 # Other operational errors probably are still show stoppers
73 # so reraise them so that the log contains the stacktrace
74 raise
75
[end of InvenTree/InvenTree/exchange.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/InvenTree/InvenTree/exchange.py b/InvenTree/InvenTree/exchange.py
--- a/InvenTree/InvenTree/exchange.py
+++ b/InvenTree/InvenTree/exchange.py
@@ -1,12 +1,11 @@
-"""Exchangerate backend to use `exchangerate.host` to get rates."""
+"""Exchangerate backend to use `frankfurter.app` to get rates."""
-import ssl
+from decimal import Decimal
from urllib.error import URLError
-from urllib.request import urlopen
from django.db.utils import OperationalError
-import certifi
+import requests
from djmoney.contrib.exchange.backends.base import SimpleExchangeBackend
from common.settings import currency_code_default, currency_codes
@@ -15,19 +14,19 @@
class InvenTreeExchange(SimpleExchangeBackend):
"""Backend for automatically updating currency exchange rates.
- Uses the `exchangerate.host` service API
+ Uses the `frankfurter.app` service API
"""
name = "InvenTreeExchange"
def __init__(self):
"""Set API url."""
- self.url = "https://api.exchangerate.host/latest"
+ self.url = "https://api.frankfurter.app/latest"
super().__init__()
def get_params(self):
- """Placeholder to set API key. Currently not required by `exchangerate.host`."""
+ """Placeholder to set API key. Currently not required by `frankfurter.app`."""
# No API key is required
return {
}
@@ -40,14 +39,22 @@
url = self.get_url(**kwargs)
try:
- context = ssl.create_default_context(cafile=certifi.where())
- response = urlopen(url, timeout=5, context=context)
- return response.read()
+ response = requests.get(url=url, timeout=5)
+ return response.content
except Exception:
# Something has gone wrong, but we can just try again next time
# Raise a TypeError so the outer function can handle this
raise TypeError
+ def get_rates(self, **params):
+ """Intersect the requested currency codes with the available codes."""
+ rates = super().get_rates(**params)
+
+ # Add the base currency to the rates
+ rates[params["base_currency"]] = Decimal("1.0")
+
+ return rates
+
def update_rates(self, base_currency=None):
"""Set the requested currency codes and get rates."""
# Set default - see B008
|
{"golden_diff": "diff --git a/InvenTree/InvenTree/exchange.py b/InvenTree/InvenTree/exchange.py\n--- a/InvenTree/InvenTree/exchange.py\n+++ b/InvenTree/InvenTree/exchange.py\n@@ -1,12 +1,11 @@\n-\"\"\"Exchangerate backend to use `exchangerate.host` to get rates.\"\"\"\n+\"\"\"Exchangerate backend to use `frankfurter.app` to get rates.\"\"\"\n \n-import ssl\n+from decimal import Decimal\n from urllib.error import URLError\n-from urllib.request import urlopen\n \n from django.db.utils import OperationalError\n \n-import certifi\n+import requests\n from djmoney.contrib.exchange.backends.base import SimpleExchangeBackend\n \n from common.settings import currency_code_default, currency_codes\n@@ -15,19 +14,19 @@\n class InvenTreeExchange(SimpleExchangeBackend):\n \"\"\"Backend for automatically updating currency exchange rates.\n \n- Uses the `exchangerate.host` service API\n+ Uses the `frankfurter.app` service API\n \"\"\"\n \n name = \"InvenTreeExchange\"\n \n def __init__(self):\n \"\"\"Set API url.\"\"\"\n- self.url = \"https://api.exchangerate.host/latest\"\n+ self.url = \"https://api.frankfurter.app/latest\"\n \n super().__init__()\n \n def get_params(self):\n- \"\"\"Placeholder to set API key. Currently not required by `exchangerate.host`.\"\"\"\n+ \"\"\"Placeholder to set API key. Currently not required by `frankfurter.app`.\"\"\"\n # No API key is required\n return {\n }\n@@ -40,14 +39,22 @@\n url = self.get_url(**kwargs)\n \n try:\n- context = ssl.create_default_context(cafile=certifi.where())\n- response = urlopen(url, timeout=5, context=context)\n- return response.read()\n+ response = requests.get(url=url, timeout=5)\n+ return response.content\n except Exception:\n # Something has gone wrong, but we can just try again next time\n # Raise a TypeError so the outer function can handle this\n raise TypeError\n \n+ def get_rates(self, **params):\n+ \"\"\"Intersect the requested currency codes with the available codes.\"\"\"\n+ rates = super().get_rates(**params)\n+\n+ # Add the base currency to the rates\n+ rates[params[\"base_currency\"]] = Decimal(\"1.0\")\n+\n+ return rates\n+\n def update_rates(self, base_currency=None):\n \"\"\"Set the requested currency codes and get rates.\"\"\"\n # Set default - see B008\n", "issue": "[BUG] Exchange rate provider is closed now\n### Please verify that this bug has NOT been raised before.\n\n- [X] I checked and didn't find a similar issue\n\n### Describe the bug*\n\nOur current default exchange rate provider is closed now - and the change was not smooth either. See https://github.com/Formicka/exchangerate.host/issues/236#issuecomment-1738539199\r\n\r\nWe need to:\r\n1) Disable the CI checks for now\r\n2) Implement an alternative\r\n3) (Optional) Bring down ApiLayer once and for all before they close all APIs we need\n\n### Steps to Reproduce\n\nLook at any current [CI](https://github.com/inventree/InvenTree/actions/runs/6333198194/job/17202067465?pr=5582)\n\n### Expected behaviour\n\nUpdating exchange rates\n\n### Deployment Method\n\n- [X] Docker\n- [X] Bare metal\n\n### Version Information\n\nEvery version>0.6.0 and a couble before are probably effected.\n\n### Please verify if you can reproduce this bug on the demo site.\n\n- [X] I can reproduce this bug on the demo site.\n\n### Relevant log output\n\n_No response_\n", "before_files": [{"content": "\"\"\"Exchangerate backend to use `exchangerate.host` to get rates.\"\"\"\n\nimport ssl\nfrom urllib.error import URLError\nfrom urllib.request import urlopen\n\nfrom django.db.utils import OperationalError\n\nimport certifi\nfrom djmoney.contrib.exchange.backends.base import SimpleExchangeBackend\n\nfrom common.settings import currency_code_default, currency_codes\n\n\nclass InvenTreeExchange(SimpleExchangeBackend):\n \"\"\"Backend for automatically updating currency exchange rates.\n\n Uses the `exchangerate.host` service API\n \"\"\"\n\n name = \"InvenTreeExchange\"\n\n def __init__(self):\n \"\"\"Set API url.\"\"\"\n self.url = \"https://api.exchangerate.host/latest\"\n\n super().__init__()\n\n def get_params(self):\n \"\"\"Placeholder to set API key. Currently not required by `exchangerate.host`.\"\"\"\n # No API key is required\n return {\n }\n\n def get_response(self, **kwargs):\n \"\"\"Custom code to get response from server.\n\n Note: Adds a 5-second timeout\n \"\"\"\n url = self.get_url(**kwargs)\n\n try:\n context = ssl.create_default_context(cafile=certifi.where())\n response = urlopen(url, timeout=5, context=context)\n return response.read()\n except Exception:\n # Something has gone wrong, but we can just try again next time\n # Raise a TypeError so the outer function can handle this\n raise TypeError\n\n def update_rates(self, base_currency=None):\n \"\"\"Set the requested currency codes and get rates.\"\"\"\n # Set default - see B008\n if base_currency is None:\n base_currency = currency_code_default()\n\n symbols = ','.join(currency_codes())\n\n try:\n super().update_rates(base=base_currency, symbols=symbols)\n # catch connection errors\n except URLError:\n print('Encountered connection error while updating')\n except TypeError:\n print('Exchange returned invalid response')\n except OperationalError as e:\n if 'SerializationFailure' in e.__cause__.__class__.__name__:\n print('Serialization Failure while updating exchange rates')\n # We are just going to swallow this exception because the\n # exchange rates will be updated later by the scheduled task\n else:\n # Other operational errors probably are still show stoppers\n # so reraise them so that the log contains the stacktrace\n raise\n", "path": "InvenTree/InvenTree/exchange.py"}]}
| 1,469 | 575 |
gh_patches_debug_31374
|
rasdani/github-patches
|
git_diff
|
pyjanitor-devs__pyjanitor-746
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[DOC] Update docs to have timeseries section
# Brief Description of Fix
<!-- Please describe the fix in terms of a "before" and "after". In other words, what's not so good about the current docs
page, and what you would like to see it become.
Example starter wording is provided. -->
Currently, the docs do not have a section for the timeseries module.
I would like to propose a change, such that now the docs will have details on the timerseries functions.
# Relevant Context
<!-- Please put here, in bullet points, links to the relevant docs page. A few starting template points are available
to get you started. -->
- [Link to documentation page](https://ericmjl.github.io/pyjanitor/reference/index.html)
- [Link to exact file to be edited](https://github.com/ericmjl/pyjanitor/blob/dev/docs/reference/index.rst)
</issue>
<code>
[start of janitor/timeseries.py]
1 """
2 Time series-specific data testing and cleaning functions.
3 """
4
5 import pandas as pd
6 import pandas_flavor as pf
7
8 from janitor import check
9
10
11 @pf.register_dataframe_method
12 def fill_missing_timestamps(
13 df: pd.DataFrame,
14 frequency: str,
15 first_time_stamp: pd.Timestamp = None,
16 last_time_stamp: pd.Timestamp = None,
17 ) -> pd.DataFrame:
18 """
19 Fill dataframe with missing timestamps based on a defined frequency.
20
21 If timestamps are missing,
22 this function will reindex the dataframe.
23 If timestamps are not missing,
24 then the function will return the dataframe unmodified.
25 Example usage:
26 .. code-block:: python
27
28 df = (
29 pd.DataFrame(...)
30 .fill_missing_timestamps(frequency="1H")
31 )
32
33 :param df: Dataframe which needs to be tested for missing timestamps
34 :param frequency: frequency i.e. sampling frequency of the data.
35 Acceptable frequency strings are available
36 `here <https://pandas.pydata.org/pandas-docs/stable/>`_
37 Check offset aliases under time series in user guide
38 :param first_time_stamp: timestamp expected to start from
39 Defaults to None.
40 If no input is provided assumes the minimum value in time_series
41 :param last_time_stamp: timestamp expected to end with.
42 Defaults to None.
43 If no input is provided, assumes the maximum value in time_series
44 :returns: dataframe that has a complete set of contiguous datetimes.
45 """
46 # Check all the inputs are the correct data type
47 check("frequency", frequency, [str])
48 check("first_time_stamp", first_time_stamp, [pd.Timestamp, type(None)])
49 check("last_time_stamp", last_time_stamp, [pd.Timestamp, type(None)])
50
51 if first_time_stamp is None:
52 first_time_stamp = df.index.min()
53 if last_time_stamp is None:
54 last_time_stamp = df.index.max()
55
56 # Generate expected timestamps
57 expected_timestamps = pd.date_range(
58 start=first_time_stamp, end=last_time_stamp, freq=frequency
59 )
60
61 return df.reindex(expected_timestamps)
62
63
64 def _get_missing_timestamps(
65 df: pd.DataFrame,
66 frequency: str,
67 first_time_stamp: pd.Timestamp = None,
68 last_time_stamp: pd.Timestamp = None,
69 ) -> pd.DataFrame:
70 """
71 Return the timestamps that are missing in a dataframe.
72
73 This function takes in a dataframe,
74 and checks its index against a dataframe
75 that contains the expected timestamps.
76 Here, we assume that the expected timestamps
77 are going to be of a larger size
78 than the timestamps available in the input dataframe ``df``.
79
80 If there are any missing timestamps in the input dataframe,
81 this function will return those missing timestamps
82 from the expected dataframe.
83 """
84 expected_df = df.fill_missing_timestamps(
85 frequency, first_time_stamp, last_time_stamp
86 )
87
88 missing_timestamps = expected_df.index.difference(df.index)
89
90 return expected_df.loc[missing_timestamps]
91
92
93 @pf.register_dataframe_method
94 def sort_timestamps_monotonically(
95 df: pd.DataFrame, direction: str = "increasing", strict: bool = False
96 ) -> pd.DataFrame:
97 """
98 Sort dataframe such that index is monotonic.
99
100 If timestamps are monotonic,
101 this function will return the dataframe unmodified.
102 If timestamps are not monotonic,
103 then the function will sort the dataframe.
104
105 Example usage:
106
107 .. code-block:: python
108
109 df = (
110 pd.DataFrame(...)
111 .sort_timestamps_monotonically(direction='increasing')
112 )
113
114 :param df: Dataframe which needs to be tested for monotonicity
115 :param direction: type of monotonicity desired.
116 Acceptable arguments are:
117 1. increasing
118 2. decreasing
119 :param strict: flag to enable/disable strict monotonicity.
120 If set to True,
121 will remove duplicates in the index,
122 by retaining first occurrence of value in index.
123 If set to False,
124 will not test for duplicates in the index.
125 Defaults to False.
126 :returns: Dataframe that has monotonically increasing
127 (or decreasing) timestamps.
128 """
129 # Check all the inputs are the correct data type
130 check("df", df, [pd.DataFrame])
131 check("direction", direction, [str])
132 check("strict", strict, [bool])
133
134 # Remove duplicates if requested
135 if strict:
136 df = df[~df.index.duplicated(keep="first")]
137
138 # Sort timestamps
139 if direction == "increasing":
140 df = df.sort_index()
141 else:
142 df = df.sort_index(ascending=False)
143
144 # Return the dataframe
145 return df
146
[end of janitor/timeseries.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/janitor/timeseries.py b/janitor/timeseries.py
--- a/janitor/timeseries.py
+++ b/janitor/timeseries.py
@@ -1,6 +1,4 @@
-"""
-Time series-specific data testing and cleaning functions.
-"""
+""" Time series-specific data cleaning functions. """
import pandas as pd
import pandas_flavor as pf
@@ -22,9 +20,28 @@
this function will reindex the dataframe.
If timestamps are not missing,
then the function will return the dataframe unmodified.
- Example usage:
+
+ Functional usage example:
+
+ .. code-block:: python
+
+ import pandas as pd
+ import janitor.timeseries
+
+ df = pd.DataFrame(...)
+
+ df = janitor.timeseries.fill_missing_timestamps(
+ df=df,
+ frequency="1H",
+ )
+
+ Method chaining example:
+
.. code-block:: python
+ import pandas as pd
+ import janitor.timeseries
+
df = (
pd.DataFrame(...)
.fill_missing_timestamps(frequency="1H")
@@ -102,13 +119,29 @@
If timestamps are not monotonic,
then the function will sort the dataframe.
- Example usage:
+ Functional usage example:
.. code-block:: python
+ import pandas as pd
+ import janitor.timeseries
+
+ df = pd.DataFrame(...)
+
+ df = janitor.timeseries.sort_timestamps_monotonically(
+ direction="increasing"
+ )
+
+ Method chaining example:
+
+ .. code-block:: python
+
+ import pandas as pd
+ import janitor.timeseries
+
df = (
pd.DataFrame(...)
- .sort_timestamps_monotonically(direction='increasing')
+ .sort_timestamps_monotonically(direction="increasing")
)
:param df: Dataframe which needs to be tested for monotonicity
|
{"golden_diff": "diff --git a/janitor/timeseries.py b/janitor/timeseries.py\n--- a/janitor/timeseries.py\n+++ b/janitor/timeseries.py\n@@ -1,6 +1,4 @@\n-\"\"\"\n-Time series-specific data testing and cleaning functions.\n-\"\"\"\n+\"\"\" Time series-specific data cleaning functions. \"\"\"\n \n import pandas as pd\n import pandas_flavor as pf\n@@ -22,9 +20,28 @@\n this function will reindex the dataframe.\n If timestamps are not missing,\n then the function will return the dataframe unmodified.\n- Example usage:\n+\n+ Functional usage example:\n+\n+ .. code-block:: python\n+\n+ import pandas as pd\n+ import janitor.timeseries\n+\n+ df = pd.DataFrame(...)\n+\n+ df = janitor.timeseries.fill_missing_timestamps(\n+ df=df,\n+ frequency=\"1H\",\n+ )\n+\n+ Method chaining example:\n+\n .. code-block:: python\n \n+ import pandas as pd\n+ import janitor.timeseries\n+\n df = (\n pd.DataFrame(...)\n .fill_missing_timestamps(frequency=\"1H\")\n@@ -102,13 +119,29 @@\n If timestamps are not monotonic,\n then the function will sort the dataframe.\n \n- Example usage:\n+ Functional usage example:\n \n .. code-block:: python\n \n+ import pandas as pd\n+ import janitor.timeseries\n+\n+ df = pd.DataFrame(...)\n+\n+ df = janitor.timeseries.sort_timestamps_monotonically(\n+ direction=\"increasing\"\n+ )\n+\n+ Method chaining example:\n+\n+ .. code-block:: python\n+\n+ import pandas as pd\n+ import janitor.timeseries\n+\n df = (\n pd.DataFrame(...)\n- .sort_timestamps_monotonically(direction='increasing')\n+ .sort_timestamps_monotonically(direction=\"increasing\")\n )\n \n :param df: Dataframe which needs to be tested for monotonicity\n", "issue": "[DOC] Update docs to have timeseries section\n# Brief Description of Fix\r\n\r\n<!-- Please describe the fix in terms of a \"before\" and \"after\". In other words, what's not so good about the current docs\r\npage, and what you would like to see it become.\r\n\r\nExample starter wording is provided. -->\r\n\r\nCurrently, the docs do not have a section for the timeseries module.\r\n\r\nI would like to propose a change, such that now the docs will have details on the timerseries functions.\r\n\r\n# Relevant Context\r\n\r\n<!-- Please put here, in bullet points, links to the relevant docs page. A few starting template points are available\r\nto get you started. -->\r\n\r\n- [Link to documentation page](https://ericmjl.github.io/pyjanitor/reference/index.html)\r\n- [Link to exact file to be edited](https://github.com/ericmjl/pyjanitor/blob/dev/docs/reference/index.rst)\r\n\n", "before_files": [{"content": "\"\"\"\nTime series-specific data testing and cleaning functions.\n\"\"\"\n\nimport pandas as pd\nimport pandas_flavor as pf\n\nfrom janitor import check\n\n\[email protected]_dataframe_method\ndef fill_missing_timestamps(\n df: pd.DataFrame,\n frequency: str,\n first_time_stamp: pd.Timestamp = None,\n last_time_stamp: pd.Timestamp = None,\n) -> pd.DataFrame:\n \"\"\"\n Fill dataframe with missing timestamps based on a defined frequency.\n\n If timestamps are missing,\n this function will reindex the dataframe.\n If timestamps are not missing,\n then the function will return the dataframe unmodified.\n Example usage:\n .. code-block:: python\n\n df = (\n pd.DataFrame(...)\n .fill_missing_timestamps(frequency=\"1H\")\n )\n\n :param df: Dataframe which needs to be tested for missing timestamps\n :param frequency: frequency i.e. sampling frequency of the data.\n Acceptable frequency strings are available\n `here <https://pandas.pydata.org/pandas-docs/stable/>`_\n Check offset aliases under time series in user guide\n :param first_time_stamp: timestamp expected to start from\n Defaults to None.\n If no input is provided assumes the minimum value in time_series\n :param last_time_stamp: timestamp expected to end with.\n Defaults to None.\n If no input is provided, assumes the maximum value in time_series\n :returns: dataframe that has a complete set of contiguous datetimes.\n \"\"\"\n # Check all the inputs are the correct data type\n check(\"frequency\", frequency, [str])\n check(\"first_time_stamp\", first_time_stamp, [pd.Timestamp, type(None)])\n check(\"last_time_stamp\", last_time_stamp, [pd.Timestamp, type(None)])\n\n if first_time_stamp is None:\n first_time_stamp = df.index.min()\n if last_time_stamp is None:\n last_time_stamp = df.index.max()\n\n # Generate expected timestamps\n expected_timestamps = pd.date_range(\n start=first_time_stamp, end=last_time_stamp, freq=frequency\n )\n\n return df.reindex(expected_timestamps)\n\n\ndef _get_missing_timestamps(\n df: pd.DataFrame,\n frequency: str,\n first_time_stamp: pd.Timestamp = None,\n last_time_stamp: pd.Timestamp = None,\n) -> pd.DataFrame:\n \"\"\"\n Return the timestamps that are missing in a dataframe.\n\n This function takes in a dataframe,\n and checks its index against a dataframe\n that contains the expected timestamps.\n Here, we assume that the expected timestamps\n are going to be of a larger size\n than the timestamps available in the input dataframe ``df``.\n\n If there are any missing timestamps in the input dataframe,\n this function will return those missing timestamps\n from the expected dataframe.\n \"\"\"\n expected_df = df.fill_missing_timestamps(\n frequency, first_time_stamp, last_time_stamp\n )\n\n missing_timestamps = expected_df.index.difference(df.index)\n\n return expected_df.loc[missing_timestamps]\n\n\[email protected]_dataframe_method\ndef sort_timestamps_monotonically(\n df: pd.DataFrame, direction: str = \"increasing\", strict: bool = False\n) -> pd.DataFrame:\n \"\"\"\n Sort dataframe such that index is monotonic.\n\n If timestamps are monotonic,\n this function will return the dataframe unmodified.\n If timestamps are not monotonic,\n then the function will sort the dataframe.\n\n Example usage:\n\n .. code-block:: python\n\n df = (\n pd.DataFrame(...)\n .sort_timestamps_monotonically(direction='increasing')\n )\n\n :param df: Dataframe which needs to be tested for monotonicity\n :param direction: type of monotonicity desired.\n Acceptable arguments are:\n 1. increasing\n 2. decreasing\n :param strict: flag to enable/disable strict monotonicity.\n If set to True,\n will remove duplicates in the index,\n by retaining first occurrence of value in index.\n If set to False,\n will not test for duplicates in the index.\n Defaults to False.\n :returns: Dataframe that has monotonically increasing\n (or decreasing) timestamps.\n \"\"\"\n # Check all the inputs are the correct data type\n check(\"df\", df, [pd.DataFrame])\n check(\"direction\", direction, [str])\n check(\"strict\", strict, [bool])\n\n # Remove duplicates if requested\n if strict:\n df = df[~df.index.duplicated(keep=\"first\")]\n\n # Sort timestamps\n if direction == \"increasing\":\n df = df.sort_index()\n else:\n df = df.sort_index(ascending=False)\n\n # Return the dataframe\n return df\n", "path": "janitor/timeseries.py"}]}
| 2,073 | 442 |
gh_patches_debug_12316
|
rasdani/github-patches
|
git_diff
|
jupyterhub__zero-to-jupyterhub-k8s-1156
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
cost estimator fails to run
To reproduce:
- Launch the cost estimator on binder https://mybinder.org/v2/gh/jupyterhub/zero-to-jupyterhub-k8s/master?filepath=doc/ntbk/draw_function.ipynb
- Run the first cell
- Observe a traceback similar to the following:
```
---------------------------------------------------------------------------
AssertionError Traceback (most recent call last)
<ipython-input-1-de8d1e48d121> in <module>
----> 1 from z2jh import cost_display, disk, machines
2 machines
~/doc/ntbk/z2jh/__init__.py in <module>
1 """Helper functions to calculate cost."""
2
----> 3 from .cost import cost_display, disk
4 from .cost import machines_list as machines
~/doc/ntbk/z2jh/cost.py in <module>
39 thisrow.append(jj.text.strip())
40 rows.append(thisrow)
---> 41 df = pd.DataFrame(rows[:-1], columns=header)
42 all_dfs.append(df)
43
/srv/conda/lib/python3.6/site-packages/pandas/core/frame.py in __init__(self, data, index, columns, dtype, copy)
433 if is_named_tuple(data[0]) and columns is None:
434 columns = data[0]._fields
--> 435 arrays, columns = to_arrays(data, columns, dtype=dtype)
436 columns = ensure_index(columns)
437
/srv/conda/lib/python3.6/site-packages/pandas/core/internals/construction.py in to_arrays(data, columns, coerce_float, dtype)
402 if isinstance(data[0], (list, tuple)):
403 return _list_to_arrays(data, columns, coerce_float=coerce_float,
--> 404 dtype=dtype)
405 elif isinstance(data[0], compat.Mapping):
406 return _list_of_dict_to_arrays(data, columns,
/srv/conda/lib/python3.6/site-packages/pandas/core/internals/construction.py in _list_to_arrays(data, columns, coerce_float, dtype)
434 content = list(lib.to_object_array(data).T)
435 return _convert_object_array(content, columns, dtype=dtype,
--> 436 coerce_float=coerce_float)
437
438
/srv/conda/lib/python3.6/site-packages/pandas/core/internals/construction.py in _convert_object_array(content, columns, coerce_float, dtype)
490 raise AssertionError('{col:d} columns passed, passed data had '
491 '{con} columns'.format(col=len(columns),
--> 492 con=len(content)))
493
494 # provide soft conversion of object dtypes
AssertionError: 10 columns passed, passed data had 5 columns
```
</issue>
<code>
[start of doc/ntbk/z2jh/cost.py]
1 import numpy as np
2 from datetime import datetime as py_dtime
3 from datetime import timedelta
4 import pandas as pd
5 import requests
6 from bs4 import BeautifulSoup as bs4
7
8 from bqplot import LinearScale, Axis, Lines, Figure, DateScale
9 from bqplot.interacts import HandDraw
10 from ipywidgets import widgets
11 from IPython.display import display
12 import locale
13 import warnings
14 warnings.filterwarnings('ignore')
15 locale.setlocale(locale.LC_ALL, '')
16
17 # --- MACHINE COSTS ---
18 http = requests.get('https://cloud.google.com/compute/pricing')
19 http = bs4(http.text)
20
21 # Munge the cost data
22 all_dfs = []
23 for table in http.find_all('table'):
24 header = table.find_all('th')
25 header = [item.text for item in header]
26
27 data = table.find_all('tr')[1:]
28 rows = []
29 for ii in data:
30 thisrow = []
31 for jj in ii.find_all('td'):
32 if 'default' in jj.attrs.keys():
33 thisrow.append(jj.attrs['default'])
34 elif 'ore-hourly' in jj.attrs.keys():
35 thisrow.append(jj.attrs['ore-hourly'].strip('$'))
36 elif 'ore-monthly' in jj.attrs.keys():
37 thisrow.append(jj.attrs['ore-monthly'].strip('$'))
38 else:
39 thisrow.append(jj.text.strip())
40 rows.append(thisrow)
41 df = pd.DataFrame(rows[:-1], columns=header)
42 all_dfs.append(df)
43
44 # Pull out our reference dataframes
45 disk = [df for df in all_dfs if 'Price (per GB / month)' in df.columns][0]
46
47 machines_list = pd.concat([df for df in all_dfs if 'Machine type' in df.columns]).dropna()
48 machines_list = machines_list.drop('Preemptible price (USD)', axis=1)
49 machines_list = machines_list.rename(columns={'Price (USD)': 'Price (USD / hr)'})
50 active_machine = machines_list.iloc[0]
51
52 # Base costs, all per day
53 disk['Price (per GB / month)'] = disk['Price (per GB / month)'].astype(float)
54 cost_storage_hdd = disk[disk['Type'] == 'Standard provisioned space']['Price (per GB / month)'].values[0]
55 cost_storage_hdd /= 30. # To make it per day
56 cost_storage_ssd = disk[disk['Type'] == 'SSD provisioned space']['Price (per GB / month)'].values[0]
57 cost_storage_ssd /= 30. # To make it per day
58 storage_cost = {False: 0, 'ssd': cost_storage_ssd, 'hdd': cost_storage_hdd}
59
60 # --- WIDGET ---
61 date_start = py_dtime(2017, 1, 1, 0)
62 n_step_min = 2
63
64 def autoscale(y, window_minutes=30, user_buffer=10):
65 # Weights for the autoscaling
66 weights = np.logspace(0, 2, window_minutes)[::-1]
67 weights /= np.sum(weights)
68
69 y = np.hstack([np.zeros(window_minutes), y])
70 y_scaled = y.copy()
71 for ii in np.arange(window_minutes, len(y_scaled)):
72 window = y[ii:ii - window_minutes:-1]
73 window_mean = np.average(window, weights=weights)
74 y_scaled[ii] = window_mean + user_buffer
75 return y_scaled[window_minutes:]
76
77
78 def integrate_cost(machines, cost_per_day):
79 cost_per_minute = cost_per_day / (24. * 60. / n_step_min) # 24 hrs * 60 min / N minutes per step
80 cost = np.nansum([ii * cost_per_minute for ii in machines])
81 return cost
82
83 def calculate_machines_needed(users, mem_per_user, active_machine):
84 memory_per_machine = float(active_machine['Memory'].values[0].replace('GB', ''))
85 total_gigs_needed = [ii * mem_per_user for ii in users]
86 total_machines_needed = [int(np.ceil(ii / memory_per_machine)) for ii in total_gigs_needed]
87 return total_machines_needed
88
89 def create_date_range(n_days):
90 delta = timedelta(n_days)
91 date_stop = date_start + delta
92 date_range = pd.date_range(date_start, date_stop, freq='{}min'.format(n_step_min))
93 return date_stop, date_range
94
95
96 def cost_display(n_days=7):
97
98 users = widgets.IntText(value=8, description='Number of total users')
99 storage_per_user = widgets.IntText(value=10, description='Storage per user (GB)')
100 mem_per_user = widgets.IntText(value=2, description="RAM per user (GB)")
101 machines = widgets.Dropdown(description='Machine',
102 options=machines_list['Machine type'].values.tolist())
103 persistent = widgets.Dropdown(description="Persistent Storage?",
104 options={'HDD': 'hdd', 'SSD': 'ssd'},
105 value='hdd')
106 autoscaling = widgets.Checkbox(value=False, description='Autoscaling?')
107 text_avg_num_machine = widgets.Text(value='', description='Average # Machines:')
108 text_cost_machine = widgets.Text(value='', description='Machine Cost:')
109 text_cost_storage = widgets.Text(value='', description='Storage Cost:')
110 text_cost_total = widgets.Text(value='', description='Total Cost:')
111
112 hr = widgets.HTML(value="---")
113
114 # Define axes limits
115 y_max = 100.
116 date_stop, date_range = create_date_range(n_days)
117
118 # Create axes and extra variables for the viz
119 xs_hd = DateScale(min=date_start, max=date_stop, )
120 ys_hd = LinearScale(min=0., max=y_max)
121
122 # Shading for weekends
123 is_weekend = np.where([ii in [6, 7] for ii in date_range.dayofweek], 1, 0)
124 is_weekend = is_weekend * (float(y_max) + 50.)
125 is_weekend[is_weekend == 0] = -10
126 line_fill = Lines(x=date_range, y=is_weekend,
127 scales={'x': xs_hd, 'y': ys_hd}, colors=['black'],
128 fill_opacities=[.2], fill='bottom')
129
130 # Set up hand draw widget
131 line_hd = Lines(x=date_range, y=10 * np.ones(len(date_range)),
132 scales={'x': xs_hd, 'y': ys_hd}, colors=['#E46E2E'])
133 line_users = Lines(x=date_range, y=10 * np.ones(len(date_range)),
134 scales={'x': xs_hd, 'y': ys_hd}, colors=['#e5e5e5'])
135 line_autoscale = Lines(x=date_range, y=10 * np.ones(len(date_range)),
136 scales={'x': xs_hd, 'y': ys_hd}, colors=['#000000'])
137 handdraw = HandDraw(lines=line_hd)
138 xax = Axis(scale=xs_hd, label='Day', grid_lines='none',
139 tick_format='%b %d')
140 yax = Axis(scale=ys_hd, label='Numer of Users',
141 orientation='vertical', grid_lines='none')
142 # FIXME add `line_autoscale` when autoscale is enabled
143 fig = Figure(marks=[line_fill, line_hd, line_users],
144 axes=[xax, yax], interaction=handdraw)
145
146 def _update_cost(change):
147 # Pull values from the plot
148 max_users = max(handdraw.lines.y)
149 max_buffer = max_users * 1.05 # 5% buffer
150 line_users.y = [max_buffer] * len(handdraw.lines.y)
151 if max_users > users.value:
152 users.value = max_users
153
154 autoscaled_users = autoscale(handdraw.lines.y)
155 line_autoscale.y = autoscaled_users
156
157 # Calculate costs
158 active_machine = machines_list[machines_list['Machine type'] == machines.value]
159 machine_cost = active_machine['Price (USD / hr)'].values.astype(float) * 24 # To make it cost per day
160 users_for_cost = autoscaled_users if autoscaling.value is True else [max_buffer] * len(handdraw.lines.y)
161 num_machines = calculate_machines_needed(users_for_cost, mem_per_user.value, active_machine)
162 avg_num_machines = np.mean(num_machines)
163 cost_machine = integrate_cost(num_machines, machine_cost)
164 cost_storage = integrate_cost(num_machines, storage_cost[persistent.value] * storage_per_user.value)
165 cost_total = cost_machine + cost_storage
166
167 # Set the values
168 for iwidget, icost in [(text_cost_machine, cost_machine),
169 (text_cost_storage, cost_storage),
170 (text_cost_total, cost_total),
171 (text_avg_num_machine, avg_num_machines)]:
172 if iwidget is not text_avg_num_machine:
173 icost = locale.currency(icost, grouping=True)
174 else:
175 icost = '{:.2f}'.format(icost)
176 iwidget.value = icost
177
178 # Set the color
179 if autoscaling.value is True:
180 line_autoscale.colors = ['#000000']
181 line_users.colors = ['#e5e5e5']
182 else:
183 line_autoscale.colors = ['#e5e5e5']
184 line_users.colors = ['#000000']
185
186 line_hd.observe(_update_cost, names='y')
187 # autoscaling.observe(_update_cost) # FIXME Uncomment when we implement autoscaling
188 persistent.observe(_update_cost)
189 machines.observe(_update_cost)
190 storage_per_user.observe(_update_cost)
191 mem_per_user.observe(_update_cost)
192
193 # Show it
194 fig.title = 'Draw your usage pattern over time.'
195 # FIXME autoscaling when it's ready
196 display(users, machines, mem_per_user, storage_per_user, persistent, fig, hr,
197 text_cost_machine, text_avg_num_machine, text_cost_storage, text_cost_total)
198 return fig
199
[end of doc/ntbk/z2jh/cost.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/doc/ntbk/z2jh/cost.py b/doc/ntbk/z2jh/cost.py
--- a/doc/ntbk/z2jh/cost.py
+++ b/doc/ntbk/z2jh/cost.py
@@ -15,16 +15,16 @@
locale.setlocale(locale.LC_ALL, '')
# --- MACHINE COSTS ---
-http = requests.get('https://cloud.google.com/compute/pricing')
-http = bs4(http.text)
+resp = requests.get('https://cloud.google.com/compute/pricing')
+html = bs4(resp.text)
# Munge the cost data
all_dfs = []
-for table in http.find_all('table'):
- header = table.find_all('th')
+for table in html.find_all('table'):
+ header = table.find('thead').find_all('th')
header = [item.text for item in header]
- data = table.find_all('tr')[1:]
+ data = table.find('tbody').find_all('tr')
rows = []
for ii in data:
thisrow = []
|
{"golden_diff": "diff --git a/doc/ntbk/z2jh/cost.py b/doc/ntbk/z2jh/cost.py\n--- a/doc/ntbk/z2jh/cost.py\n+++ b/doc/ntbk/z2jh/cost.py\n@@ -15,16 +15,16 @@\n locale.setlocale(locale.LC_ALL, '')\n \n # --- MACHINE COSTS ---\n-http = requests.get('https://cloud.google.com/compute/pricing')\n-http = bs4(http.text)\n+resp = requests.get('https://cloud.google.com/compute/pricing')\n+html = bs4(resp.text)\n \n # Munge the cost data\n all_dfs = []\n-for table in http.find_all('table'):\n- header = table.find_all('th')\n+for table in html.find_all('table'):\n+ header = table.find('thead').find_all('th')\n header = [item.text for item in header]\n \n- data = table.find_all('tr')[1:]\n+ data = table.find('tbody').find_all('tr')\n rows = []\n for ii in data:\n thisrow = []\n", "issue": "cost estimator fails to run\nTo reproduce:\r\n\r\n- Launch the cost estimator on binder https://mybinder.org/v2/gh/jupyterhub/zero-to-jupyterhub-k8s/master?filepath=doc/ntbk/draw_function.ipynb\r\n- Run the first cell\r\n- Observe a traceback similar to the following:\r\n\r\n```\r\n---------------------------------------------------------------------------\r\nAssertionError Traceback (most recent call last)\r\n<ipython-input-1-de8d1e48d121> in <module>\r\n----> 1 from z2jh import cost_display, disk, machines\r\n 2 machines\r\n\r\n~/doc/ntbk/z2jh/__init__.py in <module>\r\n 1 \"\"\"Helper functions to calculate cost.\"\"\"\r\n 2 \r\n----> 3 from .cost import cost_display, disk\r\n 4 from .cost import machines_list as machines\r\n\r\n~/doc/ntbk/z2jh/cost.py in <module>\r\n 39 thisrow.append(jj.text.strip())\r\n 40 rows.append(thisrow)\r\n---> 41 df = pd.DataFrame(rows[:-1], columns=header)\r\n 42 all_dfs.append(df)\r\n 43 \r\n\r\n/srv/conda/lib/python3.6/site-packages/pandas/core/frame.py in __init__(self, data, index, columns, dtype, copy)\r\n 433 if is_named_tuple(data[0]) and columns is None:\r\n 434 columns = data[0]._fields\r\n--> 435 arrays, columns = to_arrays(data, columns, dtype=dtype)\r\n 436 columns = ensure_index(columns)\r\n 437 \r\n\r\n/srv/conda/lib/python3.6/site-packages/pandas/core/internals/construction.py in to_arrays(data, columns, coerce_float, dtype)\r\n 402 if isinstance(data[0], (list, tuple)):\r\n 403 return _list_to_arrays(data, columns, coerce_float=coerce_float,\r\n--> 404 dtype=dtype)\r\n 405 elif isinstance(data[0], compat.Mapping):\r\n 406 return _list_of_dict_to_arrays(data, columns,\r\n\r\n/srv/conda/lib/python3.6/site-packages/pandas/core/internals/construction.py in _list_to_arrays(data, columns, coerce_float, dtype)\r\n 434 content = list(lib.to_object_array(data).T)\r\n 435 return _convert_object_array(content, columns, dtype=dtype,\r\n--> 436 coerce_float=coerce_float)\r\n 437 \r\n 438 \r\n\r\n/srv/conda/lib/python3.6/site-packages/pandas/core/internals/construction.py in _convert_object_array(content, columns, coerce_float, dtype)\r\n 490 raise AssertionError('{col:d} columns passed, passed data had '\r\n 491 '{con} columns'.format(col=len(columns),\r\n--> 492 con=len(content)))\r\n 493 \r\n 494 # provide soft conversion of object dtypes\r\n\r\nAssertionError: 10 columns passed, passed data had 5 columns\r\n```\n", "before_files": [{"content": "import numpy as np\nfrom datetime import datetime as py_dtime\nfrom datetime import timedelta\nimport pandas as pd\nimport requests\nfrom bs4 import BeautifulSoup as bs4\n\nfrom bqplot import LinearScale, Axis, Lines, Figure, DateScale\nfrom bqplot.interacts import HandDraw\nfrom ipywidgets import widgets\nfrom IPython.display import display\nimport locale\nimport warnings\nwarnings.filterwarnings('ignore')\nlocale.setlocale(locale.LC_ALL, '')\n\n# --- MACHINE COSTS ---\nhttp = requests.get('https://cloud.google.com/compute/pricing')\nhttp = bs4(http.text)\n\n# Munge the cost data\nall_dfs = []\nfor table in http.find_all('table'):\n header = table.find_all('th')\n header = [item.text for item in header]\n\n data = table.find_all('tr')[1:]\n rows = []\n for ii in data:\n thisrow = []\n for jj in ii.find_all('td'):\n if 'default' in jj.attrs.keys():\n thisrow.append(jj.attrs['default'])\n elif 'ore-hourly' in jj.attrs.keys():\n thisrow.append(jj.attrs['ore-hourly'].strip('$'))\n elif 'ore-monthly' in jj.attrs.keys():\n thisrow.append(jj.attrs['ore-monthly'].strip('$'))\n else:\n thisrow.append(jj.text.strip())\n rows.append(thisrow)\n df = pd.DataFrame(rows[:-1], columns=header)\n all_dfs.append(df)\n\n# Pull out our reference dataframes\ndisk = [df for df in all_dfs if 'Price (per GB / month)' in df.columns][0]\n\nmachines_list = pd.concat([df for df in all_dfs if 'Machine type' in df.columns]).dropna()\nmachines_list = machines_list.drop('Preemptible price (USD)', axis=1)\nmachines_list = machines_list.rename(columns={'Price (USD)': 'Price (USD / hr)'})\nactive_machine = machines_list.iloc[0]\n\n# Base costs, all per day\ndisk['Price (per GB / month)'] = disk['Price (per GB / month)'].astype(float)\ncost_storage_hdd = disk[disk['Type'] == 'Standard provisioned space']['Price (per GB / month)'].values[0]\ncost_storage_hdd /= 30. # To make it per day\ncost_storage_ssd = disk[disk['Type'] == 'SSD provisioned space']['Price (per GB / month)'].values[0]\ncost_storage_ssd /= 30. # To make it per day\nstorage_cost = {False: 0, 'ssd': cost_storage_ssd, 'hdd': cost_storage_hdd}\n\n# --- WIDGET ---\ndate_start = py_dtime(2017, 1, 1, 0)\nn_step_min = 2\n\ndef autoscale(y, window_minutes=30, user_buffer=10):\n # Weights for the autoscaling\n weights = np.logspace(0, 2, window_minutes)[::-1]\n weights /= np.sum(weights)\n\n y = np.hstack([np.zeros(window_minutes), y])\n y_scaled = y.copy()\n for ii in np.arange(window_minutes, len(y_scaled)):\n window = y[ii:ii - window_minutes:-1]\n window_mean = np.average(window, weights=weights)\n y_scaled[ii] = window_mean + user_buffer\n return y_scaled[window_minutes:]\n\n\ndef integrate_cost(machines, cost_per_day):\n cost_per_minute = cost_per_day / (24. * 60. / n_step_min) # 24 hrs * 60 min / N minutes per step\n cost = np.nansum([ii * cost_per_minute for ii in machines])\n return cost\n\ndef calculate_machines_needed(users, mem_per_user, active_machine):\n memory_per_machine = float(active_machine['Memory'].values[0].replace('GB', ''))\n total_gigs_needed = [ii * mem_per_user for ii in users]\n total_machines_needed = [int(np.ceil(ii / memory_per_machine)) for ii in total_gigs_needed]\n return total_machines_needed\n\ndef create_date_range(n_days):\n delta = timedelta(n_days)\n date_stop = date_start + delta\n date_range = pd.date_range(date_start, date_stop, freq='{}min'.format(n_step_min))\n return date_stop, date_range\n\n\ndef cost_display(n_days=7):\n\n users = widgets.IntText(value=8, description='Number of total users')\n storage_per_user = widgets.IntText(value=10, description='Storage per user (GB)')\n mem_per_user = widgets.IntText(value=2, description=\"RAM per user (GB)\")\n machines = widgets.Dropdown(description='Machine',\n options=machines_list['Machine type'].values.tolist())\n persistent = widgets.Dropdown(description=\"Persistent Storage?\",\n options={'HDD': 'hdd', 'SSD': 'ssd'},\n value='hdd')\n autoscaling = widgets.Checkbox(value=False, description='Autoscaling?')\n text_avg_num_machine = widgets.Text(value='', description='Average # Machines:')\n text_cost_machine = widgets.Text(value='', description='Machine Cost:')\n text_cost_storage = widgets.Text(value='', description='Storage Cost:')\n text_cost_total = widgets.Text(value='', description='Total Cost:')\n\n hr = widgets.HTML(value=\"---\")\n\n # Define axes limits\n y_max = 100.\n date_stop, date_range = create_date_range(n_days)\n\n # Create axes and extra variables for the viz\n xs_hd = DateScale(min=date_start, max=date_stop, )\n ys_hd = LinearScale(min=0., max=y_max)\n\n # Shading for weekends\n is_weekend = np.where([ii in [6, 7] for ii in date_range.dayofweek], 1, 0)\n is_weekend = is_weekend * (float(y_max) + 50.)\n is_weekend[is_weekend == 0] = -10\n line_fill = Lines(x=date_range, y=is_weekend,\n scales={'x': xs_hd, 'y': ys_hd}, colors=['black'],\n fill_opacities=[.2], fill='bottom')\n\n # Set up hand draw widget\n line_hd = Lines(x=date_range, y=10 * np.ones(len(date_range)),\n scales={'x': xs_hd, 'y': ys_hd}, colors=['#E46E2E'])\n line_users = Lines(x=date_range, y=10 * np.ones(len(date_range)),\n scales={'x': xs_hd, 'y': ys_hd}, colors=['#e5e5e5'])\n line_autoscale = Lines(x=date_range, y=10 * np.ones(len(date_range)),\n scales={'x': xs_hd, 'y': ys_hd}, colors=['#000000'])\n handdraw = HandDraw(lines=line_hd)\n xax = Axis(scale=xs_hd, label='Day', grid_lines='none',\n tick_format='%b %d')\n yax = Axis(scale=ys_hd, label='Numer of Users',\n orientation='vertical', grid_lines='none')\n # FIXME add `line_autoscale` when autoscale is enabled\n fig = Figure(marks=[line_fill, line_hd, line_users],\n axes=[xax, yax], interaction=handdraw)\n\n def _update_cost(change):\n # Pull values from the plot\n max_users = max(handdraw.lines.y)\n max_buffer = max_users * 1.05 # 5% buffer\n line_users.y = [max_buffer] * len(handdraw.lines.y)\n if max_users > users.value:\n users.value = max_users\n\n autoscaled_users = autoscale(handdraw.lines.y)\n line_autoscale.y = autoscaled_users\n\n # Calculate costs\n active_machine = machines_list[machines_list['Machine type'] == machines.value]\n machine_cost = active_machine['Price (USD / hr)'].values.astype(float) * 24 # To make it cost per day\n users_for_cost = autoscaled_users if autoscaling.value is True else [max_buffer] * len(handdraw.lines.y)\n num_machines = calculate_machines_needed(users_for_cost, mem_per_user.value, active_machine)\n avg_num_machines = np.mean(num_machines)\n cost_machine = integrate_cost(num_machines, machine_cost)\n cost_storage = integrate_cost(num_machines, storage_cost[persistent.value] * storage_per_user.value)\n cost_total = cost_machine + cost_storage\n\n # Set the values\n for iwidget, icost in [(text_cost_machine, cost_machine),\n (text_cost_storage, cost_storage),\n (text_cost_total, cost_total),\n (text_avg_num_machine, avg_num_machines)]:\n if iwidget is not text_avg_num_machine:\n icost = locale.currency(icost, grouping=True)\n else:\n icost = '{:.2f}'.format(icost)\n iwidget.value = icost\n\n # Set the color\n if autoscaling.value is True:\n line_autoscale.colors = ['#000000']\n line_users.colors = ['#e5e5e5']\n else:\n line_autoscale.colors = ['#e5e5e5']\n line_users.colors = ['#000000']\n\n line_hd.observe(_update_cost, names='y')\n # autoscaling.observe(_update_cost) # FIXME Uncomment when we implement autoscaling\n persistent.observe(_update_cost)\n machines.observe(_update_cost)\n storage_per_user.observe(_update_cost)\n mem_per_user.observe(_update_cost)\n\n # Show it\n fig.title = 'Draw your usage pattern over time.'\n # FIXME autoscaling when it's ready\n display(users, machines, mem_per_user, storage_per_user, persistent, fig, hr,\n text_cost_machine, text_avg_num_machine, text_cost_storage, text_cost_total)\n return fig\n", "path": "doc/ntbk/z2jh/cost.py"}]}
| 3,887 | 237 |
gh_patches_debug_9814
|
rasdani/github-patches
|
git_diff
|
facebookresearch__hydra-2613
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[Bug] The nevergrad sweeper is not properly handling quoted strings
# 🐛 Bug
## Description
The nevergrad sweeper does not properly handle quoted strings (this also manifests in other problems, e.g., with `null` values).
## Checklist
- [X] I checked on the latest version of Hydra
- [X] I created a minimal repro (See [this](https://stackoverflow.com/help/minimal-reproducible-example) for tips).
## To reproduce
** Minimal Code/Config snippet to reproduce **
```bash
python example/my_app.py -m hydra.sweeper.optim.budget=1 hydra.sweeper.optim.num_workers=1 +key="'a&b'"
```
** Stack trace/error message **
```
[2023-03-15 13:01:58,886][HYDRA] NevergradSweeper(optimizer=OnePlusOne, budget=1, num_workers=1) minimization
[2023-03-15 13:01:58,886][HYDRA] with parametrization Dict(+key=a&b,batch_size=Scalar{Cl(4,16,b),Int}[sigma=Scalar{exp=2.03}],db=Choice(choices=Tuple(mnist,cifar),indices=Array{(1,2),SoftmaxSampling}),dropout=Scalar{Cl(0,1,b)}[sigma=Scalar{exp=2.03}],lr=Log{exp=2.00}):{'db': 'mnist', 'lr': 0.020000000000000004, 'dropout': 0.5, 'batch_size': 10, '+key': 'a&b'}
[2023-03-15 13:01:58,888][HYDRA] Sweep output dir: multirun/2023-03-15/13-01-57
LexerNoViableAltException: +key=a&b
```
## Expected Behavior
It should work, passing the override `+key='a&b'` to the job being launched.
## System information
- **Hydra Version** : latest master
- **Python version** : Python 3.9
</issue>
<code>
[start of plugins/hydra_nevergrad_sweeper/hydra_plugins/hydra_nevergrad_sweeper/_impl.py]
1 # Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved
2 import logging
3 import math
4 from typing import (
5 Any,
6 Dict,
7 List,
8 MutableMapping,
9 MutableSequence,
10 Optional,
11 Tuple,
12 Union,
13 )
14
15 import nevergrad as ng
16 from hydra.core import utils
17 from hydra.core.override_parser.overrides_parser import OverridesParser
18 from hydra.core.override_parser.types import (
19 ChoiceSweep,
20 IntervalSweep,
21 Override,
22 Transformer,
23 )
24 from hydra.core.plugins import Plugins
25 from hydra.plugins.launcher import Launcher
26 from hydra.plugins.sweeper import Sweeper
27 from hydra.types import HydraContext, TaskFunction
28 from omegaconf import DictConfig, ListConfig, OmegaConf
29
30 from .config import OptimConf, ScalarConfigSpec
31
32 log = logging.getLogger(__name__)
33
34
35 def create_nevergrad_param_from_config(
36 config: Union[MutableSequence[Any], MutableMapping[str, Any]]
37 ) -> Any:
38 if isinstance(config, MutableSequence):
39 if isinstance(config, ListConfig):
40 config = OmegaConf.to_container(config, resolve=True) # type: ignore
41 return ng.p.Choice(config)
42 if isinstance(config, MutableMapping):
43 specs = ScalarConfigSpec(**config)
44 init = ["init", "lower", "upper"]
45 init_params = {x: getattr(specs, x) for x in init}
46 if not specs.log:
47 scalar = ng.p.Scalar(**init_params)
48 if specs.step is not None:
49 scalar.set_mutation(sigma=specs.step)
50 else:
51 if specs.step is not None:
52 init_params["exponent"] = specs.step
53 scalar = ng.p.Log(**init_params)
54 if specs.integer:
55 scalar.set_integer_casting()
56 return scalar
57 return config
58
59
60 def create_nevergrad_parameter_from_override(override: Override) -> Any:
61 val = override.value()
62 if not override.is_sweep_override():
63 return val
64 if override.is_choice_sweep():
65 assert isinstance(val, ChoiceSweep)
66 vals = [x for x in override.sweep_iterator(transformer=Transformer.encode)]
67 if "ordered" in val.tags:
68 return ng.p.TransitionChoice(vals)
69 else:
70 return ng.p.Choice(vals)
71 elif override.is_range_sweep():
72 vals = [x for x in override.sweep_iterator(transformer=Transformer.encode)]
73 return ng.p.Choice(vals)
74 elif override.is_interval_sweep():
75 assert isinstance(val, IntervalSweep)
76 if "log" in val.tags:
77 scalar = ng.p.Log(lower=val.start, upper=val.end)
78 else:
79 scalar = ng.p.Scalar(lower=val.start, upper=val.end) # type: ignore
80 if isinstance(val.start, int):
81 scalar.set_integer_casting()
82 return scalar
83
84
85 class NevergradSweeperImpl(Sweeper):
86 def __init__(
87 self,
88 optim: OptimConf,
89 parametrization: Optional[DictConfig],
90 ):
91 self.opt_config = optim
92 self.config: Optional[DictConfig] = None
93 self.launcher: Optional[Launcher] = None
94 self.hydra_context: Optional[HydraContext] = None
95 self.job_results = None
96 self.parametrization: Dict[str, Any] = {}
97 if parametrization is not None:
98 assert isinstance(parametrization, DictConfig)
99 self.parametrization = {
100 str(x): create_nevergrad_param_from_config(y)
101 for x, y in parametrization.items()
102 }
103 self.job_idx: Optional[int] = None
104
105 def setup(
106 self,
107 *,
108 hydra_context: HydraContext,
109 task_function: TaskFunction,
110 config: DictConfig,
111 ) -> None:
112 self.job_idx = 0
113 self.config = config
114 self.hydra_context = hydra_context
115 self.launcher = Plugins.instance().instantiate_launcher(
116 hydra_context=hydra_context, task_function=task_function, config=config
117 )
118
119 def sweep(self, arguments: List[str]) -> None:
120 assert self.config is not None
121 assert self.launcher is not None
122 assert self.job_idx is not None
123 direction = -1 if self.opt_config.maximize else 1
124 name = "maximization" if self.opt_config.maximize else "minimization"
125 # Override the parametrization from commandline
126 params = dict(self.parametrization)
127
128 parser = OverridesParser.create()
129 parsed = parser.parse_overrides(arguments)
130
131 for override in parsed:
132 params[
133 override.get_key_element()
134 ] = create_nevergrad_parameter_from_override(override)
135
136 parametrization = ng.p.Dict(**params)
137 parametrization.function.deterministic = not self.opt_config.noisy
138 parametrization.random_state.seed(self.opt_config.seed)
139 # log and build the optimizer
140 opt = self.opt_config.optimizer
141 remaining_budget = self.opt_config.budget
142 nw = self.opt_config.num_workers
143 log.info(
144 f"NevergradSweeper(optimizer={opt}, budget={remaining_budget}, "
145 f"num_workers={nw}) {name}"
146 )
147 log.info(f"with parametrization {parametrization}")
148 log.info(f"Sweep output dir: {self.config.hydra.sweep.dir}")
149 optimizer = ng.optimizers.registry[opt](parametrization, remaining_budget, nw)
150 # loop!
151 all_returns: List[Any] = []
152 best: Tuple[float, ng.p.Parameter] = (float("inf"), parametrization)
153 while remaining_budget > 0:
154 batch = min(nw, remaining_budget)
155 remaining_budget -= batch
156 candidates = [optimizer.ask() for _ in range(batch)]
157 overrides = list(
158 tuple(f"{x}={y}" for x, y in c.value.items()) for c in candidates
159 )
160 self.validate_batch_is_legal(overrides)
161 returns = self.launcher.launch(overrides, initial_job_idx=self.job_idx)
162 # would have been nice to avoid waiting for all jobs to finish
163 # aka batch size Vs steady state (launching a new job whenever one is done)
164 self.job_idx += len(returns)
165 # check job status and prepare losses
166 failures = 0
167 for cand, ret in zip(candidates, returns):
168 if ret.status == utils.JobStatus.COMPLETED:
169 rectified_loss = direction * ret.return_value
170 else:
171 rectified_loss = math.inf
172 failures += 1
173 try:
174 ret.return_value
175 except Exception as e:
176 log.warning(f"Returning infinity for failed experiment: {e}")
177 optimizer.tell(cand, rectified_loss)
178 if rectified_loss < best[0]:
179 best = (rectified_loss, cand)
180 # raise if too many failures
181 if failures / len(returns) > self.opt_config.max_failure_rate:
182 log.error(
183 f"Failed {failures} times out of {len(returns)} "
184 f"with max_failure_rate={self.opt_config.max_failure_rate}"
185 )
186 for ret in returns:
187 ret.return_value # delegate raising to JobReturn, with actual traceback
188 all_returns.extend(returns)
189 recom = optimizer.provide_recommendation()
190 results_to_serialize = {
191 "name": "nevergrad",
192 "best_evaluated_params": best[1].value,
193 "best_evaluated_result": direction * best[0],
194 }
195 OmegaConf.save(
196 OmegaConf.create(results_to_serialize),
197 f"{self.config.hydra.sweep.dir}/optimization_results.yaml",
198 )
199 log.info(
200 "Best parameters: %s", " ".join(f"{x}={y}" for x, y in recom.value.items())
201 )
202
[end of plugins/hydra_nevergrad_sweeper/hydra_plugins/hydra_nevergrad_sweeper/_impl.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/plugins/hydra_nevergrad_sweeper/hydra_plugins/hydra_nevergrad_sweeper/_impl.py b/plugins/hydra_nevergrad_sweeper/hydra_plugins/hydra_nevergrad_sweeper/_impl.py
--- a/plugins/hydra_nevergrad_sweeper/hydra_plugins/hydra_nevergrad_sweeper/_impl.py
+++ b/plugins/hydra_nevergrad_sweeper/hydra_plugins/hydra_nevergrad_sweeper/_impl.py
@@ -60,7 +60,7 @@
def create_nevergrad_parameter_from_override(override: Override) -> Any:
val = override.value()
if not override.is_sweep_override():
- return val
+ return override.get_value_element_as_str()
if override.is_choice_sweep():
assert isinstance(val, ChoiceSweep)
vals = [x for x in override.sweep_iterator(transformer=Transformer.encode)]
|
{"golden_diff": "diff --git a/plugins/hydra_nevergrad_sweeper/hydra_plugins/hydra_nevergrad_sweeper/_impl.py b/plugins/hydra_nevergrad_sweeper/hydra_plugins/hydra_nevergrad_sweeper/_impl.py\n--- a/plugins/hydra_nevergrad_sweeper/hydra_plugins/hydra_nevergrad_sweeper/_impl.py\n+++ b/plugins/hydra_nevergrad_sweeper/hydra_plugins/hydra_nevergrad_sweeper/_impl.py\n@@ -60,7 +60,7 @@\n def create_nevergrad_parameter_from_override(override: Override) -> Any:\n val = override.value()\n if not override.is_sweep_override():\n- return val\n+ return override.get_value_element_as_str()\n if override.is_choice_sweep():\n assert isinstance(val, ChoiceSweep)\n vals = [x for x in override.sweep_iterator(transformer=Transformer.encode)]\n", "issue": "[Bug] The nevergrad sweeper is not properly handling quoted strings\n# \ud83d\udc1b Bug\r\n## Description\r\n\r\nThe nevergrad sweeper does not properly handle quoted strings (this also manifests in other problems, e.g., with `null` values).\r\n\r\n\r\n## Checklist\r\n- [X] I checked on the latest version of Hydra\r\n- [X] I created a minimal repro (See [this](https://stackoverflow.com/help/minimal-reproducible-example) for tips).\r\n\r\n## To reproduce\r\n\r\n** Minimal Code/Config snippet to reproduce **\r\n\r\n```bash\r\npython example/my_app.py -m hydra.sweeper.optim.budget=1 hydra.sweeper.optim.num_workers=1 +key=\"'a&b'\"\r\n```\r\n\r\n** Stack trace/error message **\r\n```\r\n[2023-03-15 13:01:58,886][HYDRA] NevergradSweeper(optimizer=OnePlusOne, budget=1, num_workers=1) minimization\r\n[2023-03-15 13:01:58,886][HYDRA] with parametrization Dict(+key=a&b,batch_size=Scalar{Cl(4,16,b),Int}[sigma=Scalar{exp=2.03}],db=Choice(choices=Tuple(mnist,cifar),indices=Array{(1,2),SoftmaxSampling}),dropout=Scalar{Cl(0,1,b)}[sigma=Scalar{exp=2.03}],lr=Log{exp=2.00}):{'db': 'mnist', 'lr': 0.020000000000000004, 'dropout': 0.5, 'batch_size': 10, '+key': 'a&b'}\r\n[2023-03-15 13:01:58,888][HYDRA] Sweep output dir: multirun/2023-03-15/13-01-57\r\nLexerNoViableAltException: +key=a&b\r\n```\r\n\r\n## Expected Behavior\r\nIt should work, passing the override `+key='a&b'` to the job being launched.\r\n\r\n## System information\r\n- **Hydra Version** : latest master\r\n- **Python version** : Python 3.9\n", "before_files": [{"content": "# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved\nimport logging\nimport math\nfrom typing import (\n Any,\n Dict,\n List,\n MutableMapping,\n MutableSequence,\n Optional,\n Tuple,\n Union,\n)\n\nimport nevergrad as ng\nfrom hydra.core import utils\nfrom hydra.core.override_parser.overrides_parser import OverridesParser\nfrom hydra.core.override_parser.types import (\n ChoiceSweep,\n IntervalSweep,\n Override,\n Transformer,\n)\nfrom hydra.core.plugins import Plugins\nfrom hydra.plugins.launcher import Launcher\nfrom hydra.plugins.sweeper import Sweeper\nfrom hydra.types import HydraContext, TaskFunction\nfrom omegaconf import DictConfig, ListConfig, OmegaConf\n\nfrom .config import OptimConf, ScalarConfigSpec\n\nlog = logging.getLogger(__name__)\n\n\ndef create_nevergrad_param_from_config(\n config: Union[MutableSequence[Any], MutableMapping[str, Any]]\n) -> Any:\n if isinstance(config, MutableSequence):\n if isinstance(config, ListConfig):\n config = OmegaConf.to_container(config, resolve=True) # type: ignore\n return ng.p.Choice(config)\n if isinstance(config, MutableMapping):\n specs = ScalarConfigSpec(**config)\n init = [\"init\", \"lower\", \"upper\"]\n init_params = {x: getattr(specs, x) for x in init}\n if not specs.log:\n scalar = ng.p.Scalar(**init_params)\n if specs.step is not None:\n scalar.set_mutation(sigma=specs.step)\n else:\n if specs.step is not None:\n init_params[\"exponent\"] = specs.step\n scalar = ng.p.Log(**init_params)\n if specs.integer:\n scalar.set_integer_casting()\n return scalar\n return config\n\n\ndef create_nevergrad_parameter_from_override(override: Override) -> Any:\n val = override.value()\n if not override.is_sweep_override():\n return val\n if override.is_choice_sweep():\n assert isinstance(val, ChoiceSweep)\n vals = [x for x in override.sweep_iterator(transformer=Transformer.encode)]\n if \"ordered\" in val.tags:\n return ng.p.TransitionChoice(vals)\n else:\n return ng.p.Choice(vals)\n elif override.is_range_sweep():\n vals = [x for x in override.sweep_iterator(transformer=Transformer.encode)]\n return ng.p.Choice(vals)\n elif override.is_interval_sweep():\n assert isinstance(val, IntervalSweep)\n if \"log\" in val.tags:\n scalar = ng.p.Log(lower=val.start, upper=val.end)\n else:\n scalar = ng.p.Scalar(lower=val.start, upper=val.end) # type: ignore\n if isinstance(val.start, int):\n scalar.set_integer_casting()\n return scalar\n\n\nclass NevergradSweeperImpl(Sweeper):\n def __init__(\n self,\n optim: OptimConf,\n parametrization: Optional[DictConfig],\n ):\n self.opt_config = optim\n self.config: Optional[DictConfig] = None\n self.launcher: Optional[Launcher] = None\n self.hydra_context: Optional[HydraContext] = None\n self.job_results = None\n self.parametrization: Dict[str, Any] = {}\n if parametrization is not None:\n assert isinstance(parametrization, DictConfig)\n self.parametrization = {\n str(x): create_nevergrad_param_from_config(y)\n for x, y in parametrization.items()\n }\n self.job_idx: Optional[int] = None\n\n def setup(\n self,\n *,\n hydra_context: HydraContext,\n task_function: TaskFunction,\n config: DictConfig,\n ) -> None:\n self.job_idx = 0\n self.config = config\n self.hydra_context = hydra_context\n self.launcher = Plugins.instance().instantiate_launcher(\n hydra_context=hydra_context, task_function=task_function, config=config\n )\n\n def sweep(self, arguments: List[str]) -> None:\n assert self.config is not None\n assert self.launcher is not None\n assert self.job_idx is not None\n direction = -1 if self.opt_config.maximize else 1\n name = \"maximization\" if self.opt_config.maximize else \"minimization\"\n # Override the parametrization from commandline\n params = dict(self.parametrization)\n\n parser = OverridesParser.create()\n parsed = parser.parse_overrides(arguments)\n\n for override in parsed:\n params[\n override.get_key_element()\n ] = create_nevergrad_parameter_from_override(override)\n\n parametrization = ng.p.Dict(**params)\n parametrization.function.deterministic = not self.opt_config.noisy\n parametrization.random_state.seed(self.opt_config.seed)\n # log and build the optimizer\n opt = self.opt_config.optimizer\n remaining_budget = self.opt_config.budget\n nw = self.opt_config.num_workers\n log.info(\n f\"NevergradSweeper(optimizer={opt}, budget={remaining_budget}, \"\n f\"num_workers={nw}) {name}\"\n )\n log.info(f\"with parametrization {parametrization}\")\n log.info(f\"Sweep output dir: {self.config.hydra.sweep.dir}\")\n optimizer = ng.optimizers.registry[opt](parametrization, remaining_budget, nw)\n # loop!\n all_returns: List[Any] = []\n best: Tuple[float, ng.p.Parameter] = (float(\"inf\"), parametrization)\n while remaining_budget > 0:\n batch = min(nw, remaining_budget)\n remaining_budget -= batch\n candidates = [optimizer.ask() for _ in range(batch)]\n overrides = list(\n tuple(f\"{x}={y}\" for x, y in c.value.items()) for c in candidates\n )\n self.validate_batch_is_legal(overrides)\n returns = self.launcher.launch(overrides, initial_job_idx=self.job_idx)\n # would have been nice to avoid waiting for all jobs to finish\n # aka batch size Vs steady state (launching a new job whenever one is done)\n self.job_idx += len(returns)\n # check job status and prepare losses\n failures = 0\n for cand, ret in zip(candidates, returns):\n if ret.status == utils.JobStatus.COMPLETED:\n rectified_loss = direction * ret.return_value\n else:\n rectified_loss = math.inf\n failures += 1\n try:\n ret.return_value\n except Exception as e:\n log.warning(f\"Returning infinity for failed experiment: {e}\")\n optimizer.tell(cand, rectified_loss)\n if rectified_loss < best[0]:\n best = (rectified_loss, cand)\n # raise if too many failures\n if failures / len(returns) > self.opt_config.max_failure_rate:\n log.error(\n f\"Failed {failures} times out of {len(returns)} \"\n f\"with max_failure_rate={self.opt_config.max_failure_rate}\"\n )\n for ret in returns:\n ret.return_value # delegate raising to JobReturn, with actual traceback\n all_returns.extend(returns)\n recom = optimizer.provide_recommendation()\n results_to_serialize = {\n \"name\": \"nevergrad\",\n \"best_evaluated_params\": best[1].value,\n \"best_evaluated_result\": direction * best[0],\n }\n OmegaConf.save(\n OmegaConf.create(results_to_serialize),\n f\"{self.config.hydra.sweep.dir}/optimization_results.yaml\",\n )\n log.info(\n \"Best parameters: %s\", \" \".join(f\"{x}={y}\" for x, y in recom.value.items())\n )\n", "path": "plugins/hydra_nevergrad_sweeper/hydra_plugins/hydra_nevergrad_sweeper/_impl.py"}]}
| 3,255 | 209 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.