
problem_id
stringlengths 18
22
| source
stringclasses 1
value | task_type
stringclasses 1
value | in_source_id
stringlengths 13
58
| prompt
stringlengths 1.71k
18.9k
| golden_diff
stringlengths 145
5.13k
| verification_info
stringlengths 465
23.6k
| num_tokens_prompt
int64 556
4.1k
| num_tokens_diff
int64 47
1.02k
|
|---|---|---|---|---|---|---|---|---|
gh_patches_debug_1403
|
rasdani/github-patches
|
git_diff
|
dotkom__onlineweb4-402
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Sort list of users when adding marks
When adding a mark, the list of user which the mark should relate to is not sorted. It should be. (It is probably sorted on realname instead of username)
- Change the list to display realname instead of username.
- Make sure it's sorted.
(Bonus would be to have a select2js-ish search on it as well, but don't use time on it.)
</issue>
<code>
[start of apps/authentication/models.py]
1 # -*- coding: utf-8 -*-
2
3 import datetime
4 from pytz import timezone
5
6 from django.conf import settings
7 from django.contrib.auth.models import AbstractUser
8 from django.db import models
9 from django.utils.translation import ugettext as _
10 from django.utils import timezone
11
12
13 # If this list is changed, remember to check that the year property on
14 # OnlineUser is still correct!
15 FIELD_OF_STUDY_CHOICES = [
16 (0, _(u'Gjest')),
17 (1, _(u'Bachelor i Informatikk (BIT)')),
18 # master degrees take up the interval [10,30>
19 (10, _(u'Software (SW)')),
20 (11, _(u'Informasjonsforvaltning (DIF)')),
21 (12, _(u'Komplekse Datasystemer (KDS)')),
22 (13, _(u'Spillteknologi (SPT)')),
23 (14, _(u'Intelligente Systemer (IRS)')),
24 (15, _(u'Helseinformatikk (MSMEDTEK)')),
25 (30, _(u'Annen mastergrad')),
26 (80, _(u'PhD')),
27 (90, _(u'International')),
28 (100, _(u'Annet Onlinemedlem')),
29 ]
30
31 class OnlineUser(AbstractUser):
32
33 IMAGE_FOLDER = "images/profiles"
34 IMAGE_EXTENSIONS = ['.jpg', '.jpeg', '.gif', '.png']
35
36 # Online related fields
37 field_of_study = models.SmallIntegerField(_(u"studieretning"), choices=FIELD_OF_STUDY_CHOICES, default=0)
38 started_date = models.DateField(_(u"startet studie"), default=timezone.now().date())
39 compiled = models.BooleanField(_(u"kompilert"), default=False)
40
41 # Email
42 infomail = models.BooleanField(_(u"vil ha infomail"), default=True)
43
44 # Address
45 phone_number = models.CharField(_(u"telefonnummer"), max_length=20, blank=True, null=True)
46 address = models.CharField(_(u"adresse"), max_length=30, blank=True, null=True)
47 zip_code = models.CharField(_(u"postnummer"), max_length=4, blank=True, null=True)
48
49 # Other
50 allergies = models.TextField(_(u"allergier"), blank=True, null=True)
51 mark_rules = models.BooleanField(_(u"godtatt prikkeregler"), default=False)
52 rfid = models.CharField(_(u"RFID"), max_length=50, blank=True, null=True)
53 nickname = models.CharField(_(u"nickname"), max_length=50, blank=True, null=True)
54 website = models.URLField(_(u"hjemmeside"), blank=True, null=True)
55
56
57 image = models.ImageField(_(u"bilde"), max_length=200, upload_to=IMAGE_FOLDER, blank=True, null=True,
58 default=settings.DEFAULT_PROFILE_PICTURE_URL)
59
60 # NTNU credentials
61 ntnu_username = models.CharField(_(u"NTNU-brukernavn"), max_length=10, blank=True, null=True)
62
63 # TODO profile pictures
64 # TODO checkbox for forwarding of @online.ntnu.no mail
65
66 @property
67 def is_member(self):
68 """
69 Returns true if the User object is associated with Online.
70 """
71 if AllowedUsername.objects.filter(username=self.ntnu_username).filter(expiration_date__gte=timezone.now()).count() > 0:
72 return True
73 return False
74
75 def get_full_name(self):
76 """
77 Returns the first_name plus the last_name, with a space in between.
78 """
79 full_name = u'%s %s' % (self.first_name, self.last_name)
80 return full_name.strip()
81
82 def get_email(self):
83 return self.get_emails().filter(primary = True)[0]
84
85 def get_emails(self):
86 return Email.objects.all().filter(user = self)
87
88 @property
89 def year(self):
90 today = timezone.now().date()
91 started = self.started_date
92
93 # We say that a year is 360 days incase we are a bit slower to
94 # add users one year.
95 year = ((today - started).days / 360) + 1
96
97 if self.field_of_study == 0 or self.field_of_study == 100: # others
98 return 0
99 # dont return a bachelor student as 4th or 5th grade
100 elif self.field_of_study == 1: # bachelor
101 if year > 3:
102 return 3
103 return year
104 elif 9 < self.field_of_study < 30: # 10-29 is considered master
105 if year >= 2:
106 return 5
107 return 4
108 elif self.field_of_study == 80: # phd
109 return year + 5
110 elif self.field_of_study == 90: # international
111 if year == 1:
112 return 1
113 return 4
114
115 def __unicode__(self):
116 return self.get_full_name()
117
118 class Meta:
119 verbose_name = _(u"brukerprofil")
120 verbose_name_plural = _(u"brukerprofiler")
121
122
123 class Email(models.Model):
124 user = models.ForeignKey(OnlineUser, related_name="email_user")
125 email = models.EmailField(_(u"epostadresse"), unique=True)
126 primary = models.BooleanField(_(u"aktiv"), default=False)
127 verified = models.BooleanField(_(u"verifisert"), default=False)
128
129 def __unicode__(self):
130 return self.email
131
132 class Meta:
133 verbose_name = _(u"epostadresse")
134 verbose_name_plural = _(u"epostadresser")
135
136
137 class RegisterToken(models.Model):
138 user = models.ForeignKey(OnlineUser, related_name="register_user")
139 email = models.EmailField(_(u"epost"), max_length=254)
140 token = models.CharField(_(u"token"), max_length=32)
141 created = models.DateTimeField(_(u"opprettet dato"), editable=False, auto_now_add=True)
142
143 @property
144 def is_valid(self):
145 valid_period = datetime.timedelta(days=1)
146 now = timezone.now()
147 return now < self.created + valid_period
148
149
150 class AllowedUsername(models.Model):
151 """
152 Holds usernames that are considered valid members of Online and the time they expire.
153 """
154 username = models.CharField(_(u"brukernavn"), max_length=10)
155 registered = models.DateField(_(u"registrert"))
156 note = models.CharField(_(u"notat"), max_length=100)
157 description = models.TextField(_(u"beskrivelse"), blank=True, null=True)
158 expiration_date = models.DateField(_(u"utløpsdato"))
159
160 @property
161 def is_active(self):
162 return timezone.now().date() < self.expiration_date
163
164 def __unicode__(self):
165 return self.username
166
167 class Meta:
168 verbose_name = _(u"tillatt brukernavn")
169 verbose_name_plural = _(u"tillatte brukernavn")
170 ordering = (u"username",)
171
[end of apps/authentication/models.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/apps/authentication/models.py b/apps/authentication/models.py
--- a/apps/authentication/models.py
+++ b/apps/authentication/models.py
@@ -116,6 +116,7 @@
return self.get_full_name()
class Meta:
+ ordering = ['first_name', 'last_name']
verbose_name = _(u"brukerprofil")
verbose_name_plural = _(u"brukerprofiler")
|
{"golden_diff": "diff --git a/apps/authentication/models.py b/apps/authentication/models.py\n--- a/apps/authentication/models.py\n+++ b/apps/authentication/models.py\n@@ -116,6 +116,7 @@\n return self.get_full_name()\n \n class Meta:\n+ ordering = ['first_name', 'last_name']\n verbose_name = _(u\"brukerprofil\")\n verbose_name_plural = _(u\"brukerprofiler\")\n", "issue": "Sort list of users when adding marks\nWhen adding a mark, the list of user which the mark should relate to is not sorted. It should be. (It is probably sorted on realname instead of username)\n- Change the list to display realname instead of username.\n- Make sure it's sorted.\n\n(Bonus would be to have a select2js-ish search on it as well, but don't use time on it.)\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\nimport datetime\nfrom pytz import timezone\n\nfrom django.conf import settings\nfrom django.contrib.auth.models import AbstractUser\nfrom django.db import models\nfrom django.utils.translation import ugettext as _\nfrom django.utils import timezone\n\n\n# If this list is changed, remember to check that the year property on\n# OnlineUser is still correct!\nFIELD_OF_STUDY_CHOICES = [\n (0, _(u'Gjest')),\n (1, _(u'Bachelor i Informatikk (BIT)')),\n # master degrees take up the interval [10,30>\n (10, _(u'Software (SW)')),\n (11, _(u'Informasjonsforvaltning (DIF)')),\n (12, _(u'Komplekse Datasystemer (KDS)')),\n (13, _(u'Spillteknologi (SPT)')),\n (14, _(u'Intelligente Systemer (IRS)')),\n (15, _(u'Helseinformatikk (MSMEDTEK)')),\n (30, _(u'Annen mastergrad')),\n (80, _(u'PhD')),\n (90, _(u'International')),\n (100, _(u'Annet Onlinemedlem')),\n]\n\nclass OnlineUser(AbstractUser):\n\n IMAGE_FOLDER = \"images/profiles\"\n IMAGE_EXTENSIONS = ['.jpg', '.jpeg', '.gif', '.png']\n \n # Online related fields\n field_of_study = models.SmallIntegerField(_(u\"studieretning\"), choices=FIELD_OF_STUDY_CHOICES, default=0)\n started_date = models.DateField(_(u\"startet studie\"), default=timezone.now().date())\n compiled = models.BooleanField(_(u\"kompilert\"), default=False)\n\n # Email\n infomail = models.BooleanField(_(u\"vil ha infomail\"), default=True)\n\n # Address\n phone_number = models.CharField(_(u\"telefonnummer\"), max_length=20, blank=True, null=True)\n address = models.CharField(_(u\"adresse\"), max_length=30, blank=True, null=True)\n zip_code = models.CharField(_(u\"postnummer\"), max_length=4, blank=True, null=True)\n\n # Other\n allergies = models.TextField(_(u\"allergier\"), blank=True, null=True)\n mark_rules = models.BooleanField(_(u\"godtatt prikkeregler\"), default=False)\n rfid = models.CharField(_(u\"RFID\"), max_length=50, blank=True, null=True)\n nickname = models.CharField(_(u\"nickname\"), max_length=50, blank=True, null=True)\n website = models.URLField(_(u\"hjemmeside\"), blank=True, null=True)\n\n\n image = models.ImageField(_(u\"bilde\"), max_length=200, upload_to=IMAGE_FOLDER, blank=True, null=True,\n default=settings.DEFAULT_PROFILE_PICTURE_URL)\n\n # NTNU credentials\n ntnu_username = models.CharField(_(u\"NTNU-brukernavn\"), max_length=10, blank=True, null=True)\n\n # TODO profile pictures\n # TODO checkbox for forwarding of @online.ntnu.no mail\n \n @property\n def is_member(self):\n \"\"\"\n Returns true if the User object is associated with Online.\n \"\"\"\n if AllowedUsername.objects.filter(username=self.ntnu_username).filter(expiration_date__gte=timezone.now()).count() > 0:\n return True\n return False\n\n def get_full_name(self):\n \"\"\"\n Returns the first_name plus the last_name, with a space in between.\n \"\"\"\n full_name = u'%s %s' % (self.first_name, self.last_name)\n return full_name.strip()\n\n def get_email(self):\n return self.get_emails().filter(primary = True)[0]\n\n def get_emails(self):\n return Email.objects.all().filter(user = self)\n\n @property\n def year(self):\n today = timezone.now().date()\n started = self.started_date\n\n # We say that a year is 360 days incase we are a bit slower to\n # add users one year.\n year = ((today - started).days / 360) + 1\n\n if self.field_of_study == 0 or self.field_of_study == 100: # others\n return 0\n # dont return a bachelor student as 4th or 5th grade\n elif self.field_of_study == 1: # bachelor\n if year > 3:\n return 3\n return year\n elif 9 < self.field_of_study < 30: # 10-29 is considered master\n if year >= 2:\n return 5\n return 4\n elif self.field_of_study == 80: # phd\n return year + 5\n elif self.field_of_study == 90: # international\n if year == 1:\n return 1\n return 4\n\n def __unicode__(self):\n return self.get_full_name()\n\n class Meta:\n verbose_name = _(u\"brukerprofil\")\n verbose_name_plural = _(u\"brukerprofiler\")\n\n\nclass Email(models.Model):\n user = models.ForeignKey(OnlineUser, related_name=\"email_user\")\n email = models.EmailField(_(u\"epostadresse\"), unique=True)\n primary = models.BooleanField(_(u\"aktiv\"), default=False)\n verified = models.BooleanField(_(u\"verifisert\"), default=False)\n\n def __unicode__(self):\n return self.email\n\n class Meta:\n verbose_name = _(u\"epostadresse\")\n verbose_name_plural = _(u\"epostadresser\")\n\n\nclass RegisterToken(models.Model):\n user = models.ForeignKey(OnlineUser, related_name=\"register_user\")\n email = models.EmailField(_(u\"epost\"), max_length=254)\n token = models.CharField(_(u\"token\"), max_length=32)\n created = models.DateTimeField(_(u\"opprettet dato\"), editable=False, auto_now_add=True)\n\n @property\n def is_valid(self):\n valid_period = datetime.timedelta(days=1)\n now = timezone.now()\n return now < self.created + valid_period \n\n\nclass AllowedUsername(models.Model):\n \"\"\"\n Holds usernames that are considered valid members of Online and the time they expire.\n \"\"\"\n username = models.CharField(_(u\"brukernavn\"), max_length=10)\n registered = models.DateField(_(u\"registrert\"))\n note = models.CharField(_(u\"notat\"), max_length=100)\n description = models.TextField(_(u\"beskrivelse\"), blank=True, null=True)\n expiration_date = models.DateField(_(u\"utl\u00f8psdato\"))\n\n @property\n def is_active(self):\n return timezone.now().date() < self.expiration_date\n\n def __unicode__(self):\n return self.username\n\n class Meta:\n verbose_name = _(u\"tillatt brukernavn\")\n verbose_name_plural = _(u\"tillatte brukernavn\")\n ordering = (u\"username\",)\n", "path": "apps/authentication/models.py"}]}
| 2,615 | 92 |
gh_patches_debug_25973
|
rasdani/github-patches
|
git_diff
|
pex-tool__pex-435
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
pex 1.2.14 breaks entrypoint targeting when PEX_PYTHON is present
with 1.2.13, targeting an entrypoint with `-e` et al results in an attempt to load that entrypoint at runtime:
```
[omerta ~]$ pip install pex==1.2.13 2>&1 >/dev/null
[omerta ~]$ pex --version
pex 1.2.13
[omerta ~]$ pex -e 'pants.bin.pants_loader:main' pantsbuild.pants -o /tmp/pants.pex
[omerta ~]$ /tmp/pants.pex
Traceback (most recent call last):
File ".bootstrap/_pex/pex.py", line 365, in execute
File ".bootstrap/_pex/pex.py", line 293, in _wrap_coverage
File ".bootstrap/_pex/pex.py", line 325, in _wrap_profiling
File ".bootstrap/_pex/pex.py", line 408, in _execute
File ".bootstrap/_pex/pex.py", line 466, in execute_entry
File ".bootstrap/_pex/pex.py", line 480, in execute_pkg_resources
File ".bootstrap/pkg_resources/__init__.py", line 2297, in resolve
ImportError: No module named pants_loader
```
with 1.2.14, it seems to be re-execing against the `PEX_PYTHON` interpreter sans args which results in a bare repl when the pex is run:
```
[omerta ~]$ pip install pex==1.2.14 2>&1 >/dev/null
[omerta ~]$ pex --version
pex 1.2.14
[omerta ~]$ pex -e 'pants.bin.pants_loader:main' pantsbuild.pants -o /tmp/pants.pex
[omerta ~]$ PEX_VERBOSE=9 /tmp/pants.pex
pex: Please build pex with the subprocess32 module for more reliable requirement installation and interpreter execution.
pex: Selecting runtime interpreter based on pexrc: 0.1ms
pex: Re-executing: cmdline="['/opt/ee/python/2.7/bin/python2.7']", sys.executable="/Users/kwilson/Python/CPython-2.7.13/bin/python2.7", PEX_PYTHON="None", PEX_PYTHON_PATH="None", COMPATIBILITY_CONSTRAINTS="[]"
Python 2.7.10 (default, Dec 16 2015, 14:09:45)
[GCC 4.2.1 Compatible Apple LLVM 7.0.2 (clang-700.1.81)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>>
```
cc @CMLivingston since this appears related to #427
</issue>
<code>
[start of pex/pex_bootstrapper.py]
1 # Copyright 2014 Pants project contributors (see CONTRIBUTORS.md).
2 # Licensed under the Apache License, Version 2.0 (see LICENSE).
3 from __future__ import print_function
4 import os
5 import sys
6
7 from .common import die, open_zip
8 from .executor import Executor
9 from .interpreter import PythonInterpreter
10 from .interpreter_constraints import matched_interpreters
11 from .tracer import TRACER
12 from .variables import ENV
13
14 __all__ = ('bootstrap_pex',)
15
16
17 def pex_info_name(entry_point):
18 """Return the PEX-INFO for an entry_point"""
19 return os.path.join(entry_point, 'PEX-INFO')
20
21
22 def is_compressed(entry_point):
23 return os.path.exists(entry_point) and not os.path.exists(pex_info_name(entry_point))
24
25
26 def read_pexinfo_from_directory(entry_point):
27 with open(pex_info_name(entry_point), 'rb') as fp:
28 return fp.read()
29
30
31 def read_pexinfo_from_zip(entry_point):
32 with open_zip(entry_point) as zf:
33 return zf.read('PEX-INFO')
34
35
36 def read_pex_info_content(entry_point):
37 """Return the raw content of a PEX-INFO."""
38 if is_compressed(entry_point):
39 return read_pexinfo_from_zip(entry_point)
40 else:
41 return read_pexinfo_from_directory(entry_point)
42
43
44 def get_pex_info(entry_point):
45 """Return the PexInfo object for an entry point."""
46 from . import pex_info
47
48 pex_info_content = read_pex_info_content(entry_point)
49 if pex_info_content:
50 return pex_info.PexInfo.from_json(pex_info_content)
51 raise ValueError('Invalid entry_point: %s' % entry_point)
52
53
54 def find_in_path(target_interpreter):
55 if os.path.exists(target_interpreter):
56 return target_interpreter
57
58 for directory in os.getenv('PATH', '').split(os.pathsep):
59 try_path = os.path.join(directory, target_interpreter)
60 if os.path.exists(try_path):
61 return try_path
62
63
64 def find_compatible_interpreters(pex_python_path, compatibility_constraints):
65 """Find all compatible interpreters on the system within the supplied constraints and use
66 PEX_PYTHON_PATH if it is set. If not, fall back to interpreters on $PATH.
67 """
68 if pex_python_path:
69 interpreters = []
70 for binary in pex_python_path.split(os.pathsep):
71 try:
72 interpreters.append(PythonInterpreter.from_binary(binary))
73 except Executor.ExecutionError:
74 print("Python interpreter %s in PEX_PYTHON_PATH failed to load properly." % binary,
75 file=sys.stderr)
76 if not interpreters:
77 die('PEX_PYTHON_PATH was defined, but no valid interpreters could be identified. Exiting.')
78 else:
79 if not os.getenv('PATH', ''):
80 # no $PATH, use sys.executable
81 interpreters = [PythonInterpreter.get()]
82 else:
83 # get all qualifying interpreters found in $PATH
84 interpreters = PythonInterpreter.all()
85
86 return list(matched_interpreters(
87 interpreters, compatibility_constraints, meet_all_constraints=True))
88
89
90 def _select_pex_python_interpreter(target_python, compatibility_constraints):
91 target = find_in_path(target_python)
92
93 if not target:
94 die('Failed to find interpreter specified by PEX_PYTHON: %s' % target)
95 if compatibility_constraints:
96 pi = PythonInterpreter.from_binary(target)
97 if not list(matched_interpreters([pi], compatibility_constraints, meet_all_constraints=True)):
98 die('Interpreter specified by PEX_PYTHON (%s) is not compatible with specified '
99 'interpreter constraints: %s' % (target, str(compatibility_constraints)))
100 if not os.path.exists(target):
101 die('Target interpreter specified by PEX_PYTHON %s does not exist. Exiting.' % target)
102 return target
103
104
105 def _select_interpreter(pex_python_path, compatibility_constraints):
106 compatible_interpreters = find_compatible_interpreters(
107 pex_python_path, compatibility_constraints)
108
109 if not compatible_interpreters:
110 die('Failed to find compatible interpreter for constraints: %s'
111 % str(compatibility_constraints))
112 # TODO: https://github.com/pantsbuild/pex/issues/430
113 target = min(compatible_interpreters).binary
114
115 if os.path.exists(target) and os.path.realpath(target) != os.path.realpath(sys.executable):
116 return target
117
118
119 def maybe_reexec_pex(compatibility_constraints):
120 """
121 Handle environment overrides for the Python interpreter to use when executing this pex.
122
123 This function supports interpreter filtering based on interpreter constraints stored in PEX-INFO
124 metadata. If PEX_PYTHON is set in a pexrc, it attempts to obtain the binary location of the
125 interpreter specified by PEX_PYTHON. If PEX_PYTHON_PATH is set, it attempts to search the path for
126 a matching interpreter in accordance with the interpreter constraints. If both variables are
127 present in a pexrc, this function gives precedence to PEX_PYTHON_PATH and errors out if no
128 compatible interpreters can be found on said path. If neither variable is set, fall through to
129 plain pex execution using PATH searching or the currently executing interpreter.
130
131 :param compatibility_constraints: list of requirements-style strings that constrain the
132 Python interpreter to re-exec this pex with.
133
134 """
135 if ENV.SHOULD_EXIT_BOOTSTRAP_REEXEC:
136 return
137
138 selected_interpreter = None
139 with TRACER.timed('Selecting runtime interpreter based on pexrc', V=3):
140 if ENV.PEX_PYTHON and not ENV.PEX_PYTHON_PATH:
141 # preserve PEX_PYTHON re-exec for backwards compatibility
142 # TODO: Kill this off completely in favor of PEX_PYTHON_PATH
143 # https://github.com/pantsbuild/pex/issues/431
144 selected_interpreter = _select_pex_python_interpreter(ENV.PEX_PYTHON,
145 compatibility_constraints)
146 elif ENV.PEX_PYTHON_PATH:
147 selected_interpreter = _select_interpreter(ENV.PEX_PYTHON_PATH, compatibility_constraints)
148
149 if selected_interpreter:
150 ENV.delete('PEX_PYTHON')
151 ENV.delete('PEX_PYTHON_PATH')
152 ENV.SHOULD_EXIT_BOOTSTRAP_REEXEC = True
153 cmdline = [selected_interpreter] + sys.argv[1:]
154 TRACER.log('Re-executing: cmdline="%s", sys.executable="%s", PEX_PYTHON="%s", '
155 'PEX_PYTHON_PATH="%s", COMPATIBILITY_CONSTRAINTS="%s"'
156 % (cmdline, sys.executable, ENV.PEX_PYTHON, ENV.PEX_PYTHON_PATH,
157 compatibility_constraints))
158 os.execve(selected_interpreter, cmdline, ENV.copy())
159
160
161 def bootstrap_pex(entry_point):
162 from .finders import register_finders
163 register_finders()
164 pex_info = get_pex_info(entry_point)
165 maybe_reexec_pex(pex_info.interpreter_constraints)
166
167 from . import pex
168 pex.PEX(entry_point).execute()
169
170
171 def bootstrap_pex_env(entry_point):
172 """Bootstrap the current runtime environment using a given pex."""
173 from .environment import PEXEnvironment
174 from .finders import register_finders
175 from .pex_info import PexInfo
176
177 register_finders()
178
179 PEXEnvironment(entry_point, PexInfo.from_pex(entry_point)).activate()
180
[end of pex/pex_bootstrapper.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/pex/pex_bootstrapper.py b/pex/pex_bootstrapper.py
--- a/pex/pex_bootstrapper.py
+++ b/pex/pex_bootstrapper.py
@@ -1,6 +1,7 @@
# Copyright 2014 Pants project contributors (see CONTRIBUTORS.md).
# Licensed under the Apache License, Version 2.0 (see LICENSE).
from __future__ import print_function
+
import os
import sys
@@ -147,14 +148,14 @@
selected_interpreter = _select_interpreter(ENV.PEX_PYTHON_PATH, compatibility_constraints)
if selected_interpreter:
- ENV.delete('PEX_PYTHON')
- ENV.delete('PEX_PYTHON_PATH')
- ENV.SHOULD_EXIT_BOOTSTRAP_REEXEC = True
- cmdline = [selected_interpreter] + sys.argv[1:]
+ cmdline = [selected_interpreter] + sys.argv
TRACER.log('Re-executing: cmdline="%s", sys.executable="%s", PEX_PYTHON="%s", '
'PEX_PYTHON_PATH="%s", COMPATIBILITY_CONSTRAINTS="%s"'
% (cmdline, sys.executable, ENV.PEX_PYTHON, ENV.PEX_PYTHON_PATH,
compatibility_constraints))
+ ENV.delete('PEX_PYTHON')
+ ENV.delete('PEX_PYTHON_PATH')
+ ENV.SHOULD_EXIT_BOOTSTRAP_REEXEC = True
os.execve(selected_interpreter, cmdline, ENV.copy())
|
{"golden_diff": "diff --git a/pex/pex_bootstrapper.py b/pex/pex_bootstrapper.py\n--- a/pex/pex_bootstrapper.py\n+++ b/pex/pex_bootstrapper.py\n@@ -1,6 +1,7 @@\n # Copyright 2014 Pants project contributors (see CONTRIBUTORS.md).\n # Licensed under the Apache License, Version 2.0 (see LICENSE).\n from __future__ import print_function\n+\n import os\n import sys\n \n@@ -147,14 +148,14 @@\n selected_interpreter = _select_interpreter(ENV.PEX_PYTHON_PATH, compatibility_constraints)\n \n if selected_interpreter:\n- ENV.delete('PEX_PYTHON')\n- ENV.delete('PEX_PYTHON_PATH')\n- ENV.SHOULD_EXIT_BOOTSTRAP_REEXEC = True\n- cmdline = [selected_interpreter] + sys.argv[1:]\n+ cmdline = [selected_interpreter] + sys.argv\n TRACER.log('Re-executing: cmdline=\"%s\", sys.executable=\"%s\", PEX_PYTHON=\"%s\", '\n 'PEX_PYTHON_PATH=\"%s\", COMPATIBILITY_CONSTRAINTS=\"%s\"'\n % (cmdline, sys.executable, ENV.PEX_PYTHON, ENV.PEX_PYTHON_PATH,\n compatibility_constraints))\n+ ENV.delete('PEX_PYTHON')\n+ ENV.delete('PEX_PYTHON_PATH')\n+ ENV.SHOULD_EXIT_BOOTSTRAP_REEXEC = True\n os.execve(selected_interpreter, cmdline, ENV.copy())\n", "issue": "pex 1.2.14 breaks entrypoint targeting when PEX_PYTHON is present\nwith 1.2.13, targeting an entrypoint with `-e` et al results in an attempt to load that entrypoint at runtime:\r\n\r\n```\r\n[omerta ~]$ pip install pex==1.2.13 2>&1 >/dev/null\r\n[omerta ~]$ pex --version\r\npex 1.2.13\r\n[omerta ~]$ pex -e 'pants.bin.pants_loader:main' pantsbuild.pants -o /tmp/pants.pex\r\n[omerta ~]$ /tmp/pants.pex\r\nTraceback (most recent call last):\r\n File \".bootstrap/_pex/pex.py\", line 365, in execute\r\n File \".bootstrap/_pex/pex.py\", line 293, in _wrap_coverage\r\n File \".bootstrap/_pex/pex.py\", line 325, in _wrap_profiling\r\n File \".bootstrap/_pex/pex.py\", line 408, in _execute\r\n File \".bootstrap/_pex/pex.py\", line 466, in execute_entry\r\n File \".bootstrap/_pex/pex.py\", line 480, in execute_pkg_resources\r\n File \".bootstrap/pkg_resources/__init__.py\", line 2297, in resolve\r\nImportError: No module named pants_loader\r\n```\r\n\r\nwith 1.2.14, it seems to be re-execing against the `PEX_PYTHON` interpreter sans args which results in a bare repl when the pex is run:\r\n\r\n```\r\n[omerta ~]$ pip install pex==1.2.14 2>&1 >/dev/null\r\n[omerta ~]$ pex --version\r\npex 1.2.14\r\n[omerta ~]$ pex -e 'pants.bin.pants_loader:main' pantsbuild.pants -o /tmp/pants.pex\r\n[omerta ~]$ PEX_VERBOSE=9 /tmp/pants.pex\r\npex: Please build pex with the subprocess32 module for more reliable requirement installation and interpreter execution.\r\npex: Selecting runtime interpreter based on pexrc: 0.1ms\r\npex: Re-executing: cmdline=\"['/opt/ee/python/2.7/bin/python2.7']\", sys.executable=\"/Users/kwilson/Python/CPython-2.7.13/bin/python2.7\", PEX_PYTHON=\"None\", PEX_PYTHON_PATH=\"None\", COMPATIBILITY_CONSTRAINTS=\"[]\"\r\nPython 2.7.10 (default, Dec 16 2015, 14:09:45) \r\n[GCC 4.2.1 Compatible Apple LLVM 7.0.2 (clang-700.1.81)] on darwin\r\nType \"help\", \"copyright\", \"credits\" or \"license\" for more information.\r\n>>> \r\n```\r\n\r\ncc @CMLivingston since this appears related to #427 \n", "before_files": [{"content": "# Copyright 2014 Pants project contributors (see CONTRIBUTORS.md).\n# Licensed under the Apache License, Version 2.0 (see LICENSE).\nfrom __future__ import print_function\nimport os\nimport sys\n\nfrom .common import die, open_zip\nfrom .executor import Executor\nfrom .interpreter import PythonInterpreter\nfrom .interpreter_constraints import matched_interpreters\nfrom .tracer import TRACER\nfrom .variables import ENV\n\n__all__ = ('bootstrap_pex',)\n\n\ndef pex_info_name(entry_point):\n \"\"\"Return the PEX-INFO for an entry_point\"\"\"\n return os.path.join(entry_point, 'PEX-INFO')\n\n\ndef is_compressed(entry_point):\n return os.path.exists(entry_point) and not os.path.exists(pex_info_name(entry_point))\n\n\ndef read_pexinfo_from_directory(entry_point):\n with open(pex_info_name(entry_point), 'rb') as fp:\n return fp.read()\n\n\ndef read_pexinfo_from_zip(entry_point):\n with open_zip(entry_point) as zf:\n return zf.read('PEX-INFO')\n\n\ndef read_pex_info_content(entry_point):\n \"\"\"Return the raw content of a PEX-INFO.\"\"\"\n if is_compressed(entry_point):\n return read_pexinfo_from_zip(entry_point)\n else:\n return read_pexinfo_from_directory(entry_point)\n\n\ndef get_pex_info(entry_point):\n \"\"\"Return the PexInfo object for an entry point.\"\"\"\n from . import pex_info\n\n pex_info_content = read_pex_info_content(entry_point)\n if pex_info_content:\n return pex_info.PexInfo.from_json(pex_info_content)\n raise ValueError('Invalid entry_point: %s' % entry_point)\n\n\ndef find_in_path(target_interpreter):\n if os.path.exists(target_interpreter):\n return target_interpreter\n\n for directory in os.getenv('PATH', '').split(os.pathsep):\n try_path = os.path.join(directory, target_interpreter)\n if os.path.exists(try_path):\n return try_path\n\n\ndef find_compatible_interpreters(pex_python_path, compatibility_constraints):\n \"\"\"Find all compatible interpreters on the system within the supplied constraints and use\n PEX_PYTHON_PATH if it is set. If not, fall back to interpreters on $PATH.\n \"\"\"\n if pex_python_path:\n interpreters = []\n for binary in pex_python_path.split(os.pathsep):\n try:\n interpreters.append(PythonInterpreter.from_binary(binary))\n except Executor.ExecutionError:\n print(\"Python interpreter %s in PEX_PYTHON_PATH failed to load properly.\" % binary,\n file=sys.stderr)\n if not interpreters:\n die('PEX_PYTHON_PATH was defined, but no valid interpreters could be identified. Exiting.')\n else:\n if not os.getenv('PATH', ''):\n # no $PATH, use sys.executable\n interpreters = [PythonInterpreter.get()]\n else:\n # get all qualifying interpreters found in $PATH\n interpreters = PythonInterpreter.all()\n\n return list(matched_interpreters(\n interpreters, compatibility_constraints, meet_all_constraints=True))\n\n\ndef _select_pex_python_interpreter(target_python, compatibility_constraints):\n target = find_in_path(target_python)\n\n if not target:\n die('Failed to find interpreter specified by PEX_PYTHON: %s' % target)\n if compatibility_constraints:\n pi = PythonInterpreter.from_binary(target)\n if not list(matched_interpreters([pi], compatibility_constraints, meet_all_constraints=True)):\n die('Interpreter specified by PEX_PYTHON (%s) is not compatible with specified '\n 'interpreter constraints: %s' % (target, str(compatibility_constraints)))\n if not os.path.exists(target):\n die('Target interpreter specified by PEX_PYTHON %s does not exist. Exiting.' % target)\n return target\n\n\ndef _select_interpreter(pex_python_path, compatibility_constraints):\n compatible_interpreters = find_compatible_interpreters(\n pex_python_path, compatibility_constraints)\n\n if not compatible_interpreters:\n die('Failed to find compatible interpreter for constraints: %s'\n % str(compatibility_constraints))\n # TODO: https://github.com/pantsbuild/pex/issues/430\n target = min(compatible_interpreters).binary\n\n if os.path.exists(target) and os.path.realpath(target) != os.path.realpath(sys.executable):\n return target\n\n\ndef maybe_reexec_pex(compatibility_constraints):\n \"\"\"\n Handle environment overrides for the Python interpreter to use when executing this pex.\n\n This function supports interpreter filtering based on interpreter constraints stored in PEX-INFO\n metadata. If PEX_PYTHON is set in a pexrc, it attempts to obtain the binary location of the\n interpreter specified by PEX_PYTHON. If PEX_PYTHON_PATH is set, it attempts to search the path for\n a matching interpreter in accordance with the interpreter constraints. If both variables are\n present in a pexrc, this function gives precedence to PEX_PYTHON_PATH and errors out if no\n compatible interpreters can be found on said path. If neither variable is set, fall through to\n plain pex execution using PATH searching or the currently executing interpreter.\n\n :param compatibility_constraints: list of requirements-style strings that constrain the\n Python interpreter to re-exec this pex with.\n\n \"\"\"\n if ENV.SHOULD_EXIT_BOOTSTRAP_REEXEC:\n return\n\n selected_interpreter = None\n with TRACER.timed('Selecting runtime interpreter based on pexrc', V=3):\n if ENV.PEX_PYTHON and not ENV.PEX_PYTHON_PATH:\n # preserve PEX_PYTHON re-exec for backwards compatibility\n # TODO: Kill this off completely in favor of PEX_PYTHON_PATH\n # https://github.com/pantsbuild/pex/issues/431\n selected_interpreter = _select_pex_python_interpreter(ENV.PEX_PYTHON,\n compatibility_constraints)\n elif ENV.PEX_PYTHON_PATH:\n selected_interpreter = _select_interpreter(ENV.PEX_PYTHON_PATH, compatibility_constraints)\n\n if selected_interpreter:\n ENV.delete('PEX_PYTHON')\n ENV.delete('PEX_PYTHON_PATH')\n ENV.SHOULD_EXIT_BOOTSTRAP_REEXEC = True\n cmdline = [selected_interpreter] + sys.argv[1:]\n TRACER.log('Re-executing: cmdline=\"%s\", sys.executable=\"%s\", PEX_PYTHON=\"%s\", '\n 'PEX_PYTHON_PATH=\"%s\", COMPATIBILITY_CONSTRAINTS=\"%s\"'\n % (cmdline, sys.executable, ENV.PEX_PYTHON, ENV.PEX_PYTHON_PATH,\n compatibility_constraints))\n os.execve(selected_interpreter, cmdline, ENV.copy())\n\n\ndef bootstrap_pex(entry_point):\n from .finders import register_finders\n register_finders()\n pex_info = get_pex_info(entry_point)\n maybe_reexec_pex(pex_info.interpreter_constraints)\n\n from . import pex\n pex.PEX(entry_point).execute()\n\n\ndef bootstrap_pex_env(entry_point):\n \"\"\"Bootstrap the current runtime environment using a given pex.\"\"\"\n from .environment import PEXEnvironment\n from .finders import register_finders\n from .pex_info import PexInfo\n\n register_finders()\n\n PEXEnvironment(entry_point, PexInfo.from_pex(entry_point)).activate()\n", "path": "pex/pex_bootstrapper.py"}]}
| 3,244 | 330 |
gh_patches_debug_28309
|
rasdani/github-patches
|
git_diff
|
pre-commit__pre-commit-1142
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
include version information in error log
would be useful to include things like:
- pre-commit version
- sys.version
- sys.executable
</issue>
<code>
[start of pre_commit/error_handler.py]
1 from __future__ import absolute_import
2 from __future__ import print_function
3 from __future__ import unicode_literals
4
5 import contextlib
6 import os.path
7 import traceback
8
9 import six
10
11 from pre_commit import five
12 from pre_commit import output
13 from pre_commit.store import Store
14
15
16 class FatalError(RuntimeError):
17 pass
18
19
20 def _to_bytes(exc):
21 try:
22 return bytes(exc)
23 except Exception:
24 return six.text_type(exc).encode('UTF-8')
25
26
27 def _log_and_exit(msg, exc, formatted):
28 error_msg = b''.join((
29 five.to_bytes(msg), b': ',
30 five.to_bytes(type(exc).__name__), b': ',
31 _to_bytes(exc), b'\n',
32 ))
33 output.write(error_msg)
34 store = Store()
35 log_path = os.path.join(store.directory, 'pre-commit.log')
36 output.write_line('Check the log at {}'.format(log_path))
37 with open(log_path, 'wb') as log:
38 output.write(error_msg, stream=log)
39 output.write_line(formatted, stream=log)
40 raise SystemExit(1)
41
42
43 @contextlib.contextmanager
44 def error_handler():
45 try:
46 yield
47 except (Exception, KeyboardInterrupt) as e:
48 if isinstance(e, FatalError):
49 msg = 'An error has occurred'
50 elif isinstance(e, KeyboardInterrupt):
51 msg = 'Interrupted (^C)'
52 else:
53 msg = 'An unexpected error has occurred'
54 _log_and_exit(msg, e, traceback.format_exc())
55
[end of pre_commit/error_handler.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/pre_commit/error_handler.py b/pre_commit/error_handler.py
--- a/pre_commit/error_handler.py
+++ b/pre_commit/error_handler.py
@@ -4,10 +4,12 @@
import contextlib
import os.path
+import sys
import traceback
import six
+import pre_commit.constants as C
from pre_commit import five
from pre_commit import output
from pre_commit.store import Store
@@ -34,9 +36,36 @@
store = Store()
log_path = os.path.join(store.directory, 'pre-commit.log')
output.write_line('Check the log at {}'.format(log_path))
+
with open(log_path, 'wb') as log:
+ output.write_line(
+ '### version information\n```', stream=log,
+ )
+ output.write_line(
+ 'pre-commit.version: {}'.format(C.VERSION), stream=log,
+ )
+ output.write_line(
+ 'sys.version:\n{}'.format(
+ '\n'.join(
+ [
+ ' {}'.format(line)
+ for line in sys.version.splitlines()
+ ],
+ ),
+ ),
+ stream=log,
+ )
+ output.write_line(
+ 'sys.executable: {}'.format(sys.executable), stream=log,
+ )
+ output.write_line('os.name: {}'.format(os.name), stream=log)
+ output.write_line(
+ 'sys.platform: {}\n```'.format(sys.platform), stream=log,
+ )
+ output.write_line('### error information\n```', stream=log)
output.write(error_msg, stream=log)
output.write_line(formatted, stream=log)
+ output.write('\n```\n', stream=log)
raise SystemExit(1)
|
{"golden_diff": "diff --git a/pre_commit/error_handler.py b/pre_commit/error_handler.py\n--- a/pre_commit/error_handler.py\n+++ b/pre_commit/error_handler.py\n@@ -4,10 +4,12 @@\n \n import contextlib\n import os.path\n+import sys\n import traceback\n \n import six\n \n+import pre_commit.constants as C\n from pre_commit import five\n from pre_commit import output\n from pre_commit.store import Store\n@@ -34,9 +36,36 @@\n store = Store()\n log_path = os.path.join(store.directory, 'pre-commit.log')\n output.write_line('Check the log at {}'.format(log_path))\n+\n with open(log_path, 'wb') as log:\n+ output.write_line(\n+ '### version information\\n```', stream=log,\n+ )\n+ output.write_line(\n+ 'pre-commit.version: {}'.format(C.VERSION), stream=log,\n+ )\n+ output.write_line(\n+ 'sys.version:\\n{}'.format(\n+ '\\n'.join(\n+ [\n+ ' {}'.format(line)\n+ for line in sys.version.splitlines()\n+ ],\n+ ),\n+ ),\n+ stream=log,\n+ )\n+ output.write_line(\n+ 'sys.executable: {}'.format(sys.executable), stream=log,\n+ )\n+ output.write_line('os.name: {}'.format(os.name), stream=log)\n+ output.write_line(\n+ 'sys.platform: {}\\n```'.format(sys.platform), stream=log,\n+ )\n+ output.write_line('### error information\\n```', stream=log)\n output.write(error_msg, stream=log)\n output.write_line(formatted, stream=log)\n+ output.write('\\n```\\n', stream=log)\n raise SystemExit(1)\n", "issue": "include version information in error log\nwould be useful to include things like:\r\n\r\n- pre-commit version\r\n- sys.version\r\n- sys.executable\n", "before_files": [{"content": "from __future__ import absolute_import\nfrom __future__ import print_function\nfrom __future__ import unicode_literals\n\nimport contextlib\nimport os.path\nimport traceback\n\nimport six\n\nfrom pre_commit import five\nfrom pre_commit import output\nfrom pre_commit.store import Store\n\n\nclass FatalError(RuntimeError):\n pass\n\n\ndef _to_bytes(exc):\n try:\n return bytes(exc)\n except Exception:\n return six.text_type(exc).encode('UTF-8')\n\n\ndef _log_and_exit(msg, exc, formatted):\n error_msg = b''.join((\n five.to_bytes(msg), b': ',\n five.to_bytes(type(exc).__name__), b': ',\n _to_bytes(exc), b'\\n',\n ))\n output.write(error_msg)\n store = Store()\n log_path = os.path.join(store.directory, 'pre-commit.log')\n output.write_line('Check the log at {}'.format(log_path))\n with open(log_path, 'wb') as log:\n output.write(error_msg, stream=log)\n output.write_line(formatted, stream=log)\n raise SystemExit(1)\n\n\[email protected]\ndef error_handler():\n try:\n yield\n except (Exception, KeyboardInterrupt) as e:\n if isinstance(e, FatalError):\n msg = 'An error has occurred'\n elif isinstance(e, KeyboardInterrupt):\n msg = 'Interrupted (^C)'\n else:\n msg = 'An unexpected error has occurred'\n _log_and_exit(msg, e, traceback.format_exc())\n", "path": "pre_commit/error_handler.py"}]}
| 988 | 378 |
gh_patches_debug_32024
|
rasdani/github-patches
|
git_diff
|
medtagger__MedTagger-391
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Remove error about not picking category properly
## Current Behavior
When user access labeling page without choosing the category via the category page he/she receives an error about not choosing the category properly. While this is necessary for preventing users accessing this page, it makes development more difficult. Every time when front-end loads, developer has to go back to category page.
## Expected Behavior
There shouldn't be an error about not picking category properly.
## Steps to Reproduce the Problem
1. Go to labeling page `/labeling` without going through category page.
## Additional comment (optional)
We should probably get category using `queryParams` like before and load current category on marker page.
</issue>
<code>
[start of backend/medtagger/api/tasks/service_rest.py]
1 """Module responsible for definition of Tasks service available via HTTP REST API."""
2 from typing import Any
3
4 from flask import request
5 from flask_restplus import Resource
6
7 from medtagger.api import api
8 from medtagger.api.tasks import business, serializers
9 from medtagger.api.security import login_required, role_required
10 from medtagger.database.models import LabelTag
11
12 tasks_ns = api.namespace('tasks', 'Methods related with tasks')
13
14
15 @tasks_ns.route('')
16 class Tasks(Resource):
17 """Endpoint that manages tasks."""
18
19 @staticmethod
20 @login_required
21 @tasks_ns.marshal_with(serializers.out__task)
22 @tasks_ns.doc(security='token')
23 @tasks_ns.doc(description='Return all available tasks.')
24 @tasks_ns.doc(responses={200: 'Success'})
25 def get() -> Any:
26 """Return all available tasks."""
27 return business.get_tasks()
28
29 @staticmethod
30 @login_required
31 @role_required('admin')
32 @tasks_ns.expect(serializers.in__task)
33 @tasks_ns.marshal_with(serializers.out__task)
34 @tasks_ns.doc(security='token')
35 @tasks_ns.doc(description='Create new Task.')
36 @tasks_ns.doc(responses={201: 'Success'})
37 def post() -> Any:
38 """Create new Task."""
39 payload = request.json
40
41 key = payload['key']
42 name = payload['name']
43 image_path = payload['image_path']
44 datasets_keys = payload['datasets_keys']
45 tags = [LabelTag(tag['key'], tag['name'], tag['tools']) for tag in payload['tags']]
46
47 return business.create_task(key, name, image_path, datasets_keys, tags), 201
48
[end of backend/medtagger/api/tasks/service_rest.py]
[start of backend/medtagger/api/tasks/business.py]
1 """Module responsible for business logic in all Tasks endpoints."""
2 from typing import List
3
4 from medtagger.database.models import Task, LabelTag
5 from medtagger.repositories import (
6 tasks as TasksRepository,
7 )
8
9
10 def get_tasks() -> List[Task]:
11 """Fetch all tasks.
12
13 :return: list of tasks
14 """
15 return TasksRepository.get_all_tasks()
16
17
18 def create_task(key: str, name: str, image_path: str, datasets_keys: List[str], tags: List[LabelTag]) -> Task:
19 """Create new Task.
20
21 :param key: unique key representing Task
22 :param name: name which describes this Task
23 :param image_path: path to the image which is located on the frontend
24 :param datasets_keys: Keys of Datasets that Task takes Scans from
25 :param tags: Label Tags that will be created and assigned to Task
26 :return: Task object
27 """
28 return TasksRepository.add_task(key, name, image_path, datasets_keys, tags)
29
[end of backend/medtagger/api/tasks/business.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/backend/medtagger/api/tasks/business.py b/backend/medtagger/api/tasks/business.py
--- a/backend/medtagger/api/tasks/business.py
+++ b/backend/medtagger/api/tasks/business.py
@@ -1,6 +1,9 @@
"""Module responsible for business logic in all Tasks endpoints."""
from typing import List
+from sqlalchemy.orm.exc import NoResultFound
+
+from medtagger.api.exceptions import NotFoundException
from medtagger.database.models import Task, LabelTag
from medtagger.repositories import (
tasks as TasksRepository,
@@ -15,6 +18,17 @@
return TasksRepository.get_all_tasks()
+def get_task_for_key(task_key: str) -> Task:
+ """Fetch Task for given key.
+
+ :return: Task
+ """
+ try:
+ return TasksRepository.get_task_by_key(task_key)
+ except NoResultFound:
+ raise NotFoundException('Did not found task for {} key!'.format(task_key))
+
+
def create_task(key: str, name: str, image_path: str, datasets_keys: List[str], tags: List[LabelTag]) -> Task:
"""Create new Task.
diff --git a/backend/medtagger/api/tasks/service_rest.py b/backend/medtagger/api/tasks/service_rest.py
--- a/backend/medtagger/api/tasks/service_rest.py
+++ b/backend/medtagger/api/tasks/service_rest.py
@@ -43,5 +43,19 @@
image_path = payload['image_path']
datasets_keys = payload['datasets_keys']
tags = [LabelTag(tag['key'], tag['name'], tag['tools']) for tag in payload['tags']]
-
return business.create_task(key, name, image_path, datasets_keys, tags), 201
+
+
+@tasks_ns.route('/<string:task_key>')
+class Task(Resource):
+ """Endpoint that manages single task."""
+
+ @staticmethod
+ @login_required
+ @tasks_ns.marshal_with(serializers.out__task)
+ @tasks_ns.doc(security='token')
+ @tasks_ns.doc(description='Get task for given key.')
+ @tasks_ns.doc(responses={200: 'Success', 404: 'Could not find task'})
+ def get(task_key: str) -> Any:
+ """Return task for given key."""
+ return business.get_task_for_key(task_key)
|
{"golden_diff": "diff --git a/backend/medtagger/api/tasks/business.py b/backend/medtagger/api/tasks/business.py\n--- a/backend/medtagger/api/tasks/business.py\n+++ b/backend/medtagger/api/tasks/business.py\n@@ -1,6 +1,9 @@\n \"\"\"Module responsible for business logic in all Tasks endpoints.\"\"\"\n from typing import List\n \n+from sqlalchemy.orm.exc import NoResultFound\n+\n+from medtagger.api.exceptions import NotFoundException\n from medtagger.database.models import Task, LabelTag\n from medtagger.repositories import (\n tasks as TasksRepository,\n@@ -15,6 +18,17 @@\n return TasksRepository.get_all_tasks()\n \n \n+def get_task_for_key(task_key: str) -> Task:\n+ \"\"\"Fetch Task for given key.\n+\n+ :return: Task\n+ \"\"\"\n+ try:\n+ return TasksRepository.get_task_by_key(task_key)\n+ except NoResultFound:\n+ raise NotFoundException('Did not found task for {} key!'.format(task_key))\n+\n+\n def create_task(key: str, name: str, image_path: str, datasets_keys: List[str], tags: List[LabelTag]) -> Task:\n \"\"\"Create new Task.\n \ndiff --git a/backend/medtagger/api/tasks/service_rest.py b/backend/medtagger/api/tasks/service_rest.py\n--- a/backend/medtagger/api/tasks/service_rest.py\n+++ b/backend/medtagger/api/tasks/service_rest.py\n@@ -43,5 +43,19 @@\n image_path = payload['image_path']\n datasets_keys = payload['datasets_keys']\n tags = [LabelTag(tag['key'], tag['name'], tag['tools']) for tag in payload['tags']]\n-\n return business.create_task(key, name, image_path, datasets_keys, tags), 201\n+\n+\n+@tasks_ns.route('/<string:task_key>')\n+class Task(Resource):\n+ \"\"\"Endpoint that manages single task.\"\"\"\n+\n+ @staticmethod\n+ @login_required\n+ @tasks_ns.marshal_with(serializers.out__task)\n+ @tasks_ns.doc(security='token')\n+ @tasks_ns.doc(description='Get task for given key.')\n+ @tasks_ns.doc(responses={200: 'Success', 404: 'Could not find task'})\n+ def get(task_key: str) -> Any:\n+ \"\"\"Return task for given key.\"\"\"\n+ return business.get_task_for_key(task_key)\n", "issue": "Remove error about not picking category properly\n## Current Behavior\r\n\r\nWhen user access labeling page without choosing the category via the category page he/she receives an error about not choosing the category properly. While this is necessary for preventing users accessing this page, it makes development more difficult. Every time when front-end loads, developer has to go back to category page.\r\n\r\n## Expected Behavior\r\n\r\nThere shouldn't be an error about not picking category properly. \r\n\r\n## Steps to Reproduce the Problem\r\n\r\n 1. Go to labeling page `/labeling` without going through category page.\r\n\r\n## Additional comment (optional)\r\n\r\nWe should probably get category using `queryParams` like before and load current category on marker page.\r\n\n", "before_files": [{"content": "\"\"\"Module responsible for definition of Tasks service available via HTTP REST API.\"\"\"\nfrom typing import Any\n\nfrom flask import request\nfrom flask_restplus import Resource\n\nfrom medtagger.api import api\nfrom medtagger.api.tasks import business, serializers\nfrom medtagger.api.security import login_required, role_required\nfrom medtagger.database.models import LabelTag\n\ntasks_ns = api.namespace('tasks', 'Methods related with tasks')\n\n\n@tasks_ns.route('')\nclass Tasks(Resource):\n \"\"\"Endpoint that manages tasks.\"\"\"\n\n @staticmethod\n @login_required\n @tasks_ns.marshal_with(serializers.out__task)\n @tasks_ns.doc(security='token')\n @tasks_ns.doc(description='Return all available tasks.')\n @tasks_ns.doc(responses={200: 'Success'})\n def get() -> Any:\n \"\"\"Return all available tasks.\"\"\"\n return business.get_tasks()\n\n @staticmethod\n @login_required\n @role_required('admin')\n @tasks_ns.expect(serializers.in__task)\n @tasks_ns.marshal_with(serializers.out__task)\n @tasks_ns.doc(security='token')\n @tasks_ns.doc(description='Create new Task.')\n @tasks_ns.doc(responses={201: 'Success'})\n def post() -> Any:\n \"\"\"Create new Task.\"\"\"\n payload = request.json\n\n key = payload['key']\n name = payload['name']\n image_path = payload['image_path']\n datasets_keys = payload['datasets_keys']\n tags = [LabelTag(tag['key'], tag['name'], tag['tools']) for tag in payload['tags']]\n\n return business.create_task(key, name, image_path, datasets_keys, tags), 201\n", "path": "backend/medtagger/api/tasks/service_rest.py"}, {"content": "\"\"\"Module responsible for business logic in all Tasks endpoints.\"\"\"\nfrom typing import List\n\nfrom medtagger.database.models import Task, LabelTag\nfrom medtagger.repositories import (\n tasks as TasksRepository,\n)\n\n\ndef get_tasks() -> List[Task]:\n \"\"\"Fetch all tasks.\n\n :return: list of tasks\n \"\"\"\n return TasksRepository.get_all_tasks()\n\n\ndef create_task(key: str, name: str, image_path: str, datasets_keys: List[str], tags: List[LabelTag]) -> Task:\n \"\"\"Create new Task.\n\n :param key: unique key representing Task\n :param name: name which describes this Task\n :param image_path: path to the image which is located on the frontend\n :param datasets_keys: Keys of Datasets that Task takes Scans from\n :param tags: Label Tags that will be created and assigned to Task\n :return: Task object\n \"\"\"\n return TasksRepository.add_task(key, name, image_path, datasets_keys, tags)\n", "path": "backend/medtagger/api/tasks/business.py"}]}
| 1,426 | 526 |
gh_patches_debug_7569
|
rasdani/github-patches
|
git_diff
|
pre-commit__pre-commit-1881
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Parallel execution ran into "patch does not apply"
I modified a bunch of repos using `pre-commit` in parallel and ran `git commit` at the same time, with unstaged changes. The pre-commit processes did `[WARNING] Unstaged files detected.`, stashed the changes in a pach, ran, and then tried to reapply the patches.
Some repos failed with:
```
[WARNING] Stashed changes conflicted with hook auto-fixes... Rolling back fixes...
An unexpected error has occurred: CalledProcessError: command: ('/usr/local/Cellar/git/2.31.1/libexec/git-core/git', '-c', 'core.autocrlf=false', 'apply', '--whitespace=nowarn', '/Users/chainz/.cache/pre-commit/patch1618586253')
return code: 1
expected return code: 0
stdout: (none)
stderr:
error: patch failed: .github/workflows/main.yml:21
error: .github/workflows/main.yml: patch does not apply
Check the log at /Users/chainz/.cache/pre-commit/pre-commit.log
```
It looks like this is due to use of the unix timestamp as the only differentiator in patch file paths, causing the parallely-created patches to clobber each other.
`pre-commit.log` says:
### version information
```
pre-commit version: 2.12.0
sys.version:
3.9.4 (default, Apr 5 2021, 01:49:30)
[Clang 12.0.0 (clang-1200.0.32.29)]
sys.executable: /usr/local/Cellar/pre-commit/2.12.0/libexec/bin/python3
os.name: posix
sys.platform: darwin
```
### error information
```
An unexpected error has occurred: CalledProcessError: command: ('/usr/local/Cellar/git/2.31.1/libexec/git-core/git', '-c', 'core.autocrlf=false', 'apply', '--whitespace=nowarn', '/Users/chainz/.cache/pre-commit/patch1618586253')
return code: 1
expected return code: 0
stdout: (none)
stderr:
error: patch failed: .github/workflows/main.yml:21
error: .github/workflows/main.yml: patch does not apply
```
```
Traceback (most recent call last):
File "/usr/local/Cellar/pre-commit/2.12.0/libexec/lib/python3.9/site-packages/pre_commit/staged_files_only.py", line 20, in _git_apply
cmd_output_b('git', *args)
File "/usr/local/Cellar/pre-commit/2.12.0/libexec/lib/python3.9/site-packages/pre_commit/util.py", line 154, in cmd_output_b
raise CalledProcessError(returncode, cmd, retcode, stdout_b, stderr_b)
pre_commit.util.CalledProcessError: command: ('/usr/local/Cellar/git/2.31.1/libexec/git-core/git', 'apply', '--whitespace=nowarn', '/Users/chainz/.cache/pre-commit/patch1618586253')
return code: 1
expected return code: 0
stdout: (none)
stderr:
error: patch failed: .github/workflows/main.yml:21
error: .github/workflows/main.yml: patch does not apply
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/usr/local/Cellar/pre-commit/2.12.0/libexec/lib/python3.9/site-packages/pre_commit/staged_files_only.py", line 68, in _unstaged_changes_cleared
_git_apply(patch_filename)
File "/usr/local/Cellar/pre-commit/2.12.0/libexec/lib/python3.9/site-packages/pre_commit/staged_files_only.py", line 23, in _git_apply
cmd_output_b('git', '-c', 'core.autocrlf=false', *args)
File "/usr/local/Cellar/pre-commit/2.12.0/libexec/lib/python3.9/site-packages/pre_commit/util.py", line 154, in cmd_output_b
raise CalledProcessError(returncode, cmd, retcode, stdout_b, stderr_b)
pre_commit.util.CalledProcessError: command: ('/usr/local/Cellar/git/2.31.1/libexec/git-core/git', '-c', 'core.autocrlf=false', 'apply', '--whitespace=nowarn', '/Users/chainz/.cache/pre-commit/patch1618586253')
return code: 1
expected return code: 0
stdout: (none)
stderr:
error: patch failed: .github/workflows/main.yml:21
error: .github/workflows/main.yml: patch does not apply
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/usr/local/Cellar/pre-commit/2.12.0/libexec/lib/python3.9/site-packages/pre_commit/staged_files_only.py", line 20, in _git_apply
cmd_output_b('git', *args)
File "/usr/local/Cellar/pre-commit/2.12.0/libexec/lib/python3.9/site-packages/pre_commit/util.py", line 154, in cmd_output_b
raise CalledProcessError(returncode, cmd, retcode, stdout_b, stderr_b)
pre_commit.util.CalledProcessError: command: ('/usr/local/Cellar/git/2.31.1/libexec/git-core/git', 'apply', '--whitespace=nowarn', '/Users/chainz/.cache/pre-commit/patch1618586253')
return code: 1
expected return code: 0
stdout: (none)
stderr:
error: patch failed: .github/workflows/main.yml:21
error: .github/workflows/main.yml: patch does not apply
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/usr/local/Cellar/pre-commit/2.12.0/libexec/lib/python3.9/site-packages/pre_commit/error_handler.py", line 65, in error_handler
yield
File "/usr/local/Cellar/pre-commit/2.12.0/libexec/lib/python3.9/site-packages/pre_commit/main.py", line 357, in main
return hook_impl(
File "/usr/local/Cellar/pre-commit/2.12.0/libexec/lib/python3.9/site-packages/pre_commit/commands/hook_impl.py", line 227, in hook_impl
return retv | run(config, store, ns)
File "/usr/local/Cellar/pre-commit/2.12.0/libexec/lib/python3.9/site-packages/pre_commit/commands/run.py", line 408, in run
return _run_hooks(config, hooks, args, environ)
File "/usr/local/Cellar/[email protected]/3.9.4/Frameworks/Python.framework/Versions/3.9/lib/python3.9/contextlib.py", line 513, in __exit__
raise exc_details[1]
File "/usr/local/Cellar/[email protected]/3.9.4/Frameworks/Python.framework/Versions/3.9/lib/python3.9/contextlib.py", line 498, in __exit__
if cb(*exc_details):
File "/usr/local/Cellar/[email protected]/3.9.4/Frameworks/Python.framework/Versions/3.9/lib/python3.9/contextlib.py", line 124, in __exit__
next(self.gen)
File "/usr/local/Cellar/pre-commit/2.12.0/libexec/lib/python3.9/site-packages/pre_commit/staged_files_only.py", line 93, in staged_files_only
yield
File "/usr/local/Cellar/[email protected]/3.9.4/Frameworks/Python.framework/Versions/3.9/lib/python3.9/contextlib.py", line 124, in __exit__
next(self.gen)
File "/usr/local/Cellar/pre-commit/2.12.0/libexec/lib/python3.9/site-packages/pre_commit/staged_files_only.py", line 78, in _unstaged_changes_cleared
_git_apply(patch_filename)
File "/usr/local/Cellar/pre-commit/2.12.0/libexec/lib/python3.9/site-packages/pre_commit/staged_files_only.py", line 23, in _git_apply
cmd_output_b('git', '-c', 'core.autocrlf=false', *args)
File "/usr/local/Cellar/pre-commit/2.12.0/libexec/lib/python3.9/site-packages/pre_commit/util.py", line 154, in cmd_output_b
raise CalledProcessError(returncode, cmd, retcode, stdout_b, stderr_b)
pre_commit.util.CalledProcessError: command: ('/usr/local/Cellar/git/2.31.1/libexec/git-core/git', '-c', 'core.autocrlf=false', 'apply', '--whitespace=nowarn', '/Users/chainz/.cache/pre-commit/patch1618586253')
return code: 1
expected return code: 0
stdout: (none)
stderr:
error: patch failed: .github/workflows/main.yml:21
error: .github/workflows/main.yml: patch does not apply
```
</issue>
<code>
[start of pre_commit/staged_files_only.py]
1 import contextlib
2 import logging
3 import os.path
4 import time
5 from typing import Generator
6
7 from pre_commit import git
8 from pre_commit.util import CalledProcessError
9 from pre_commit.util import cmd_output
10 from pre_commit.util import cmd_output_b
11 from pre_commit.xargs import xargs
12
13
14 logger = logging.getLogger('pre_commit')
15
16
17 def _git_apply(patch: str) -> None:
18 args = ('apply', '--whitespace=nowarn', patch)
19 try:
20 cmd_output_b('git', *args)
21 except CalledProcessError:
22 # Retry with autocrlf=false -- see #570
23 cmd_output_b('git', '-c', 'core.autocrlf=false', *args)
24
25
26 @contextlib.contextmanager
27 def _intent_to_add_cleared() -> Generator[None, None, None]:
28 intent_to_add = git.intent_to_add_files()
29 if intent_to_add:
30 logger.warning('Unstaged intent-to-add files detected.')
31
32 xargs(('git', 'rm', '--cached', '--'), intent_to_add)
33 try:
34 yield
35 finally:
36 xargs(('git', 'add', '--intent-to-add', '--'), intent_to_add)
37 else:
38 yield
39
40
41 @contextlib.contextmanager
42 def _unstaged_changes_cleared(patch_dir: str) -> Generator[None, None, None]:
43 tree = cmd_output('git', 'write-tree')[1].strip()
44 retcode, diff_stdout_binary, _ = cmd_output_b(
45 'git', 'diff-index', '--ignore-submodules', '--binary',
46 '--exit-code', '--no-color', '--no-ext-diff', tree, '--',
47 retcode=None,
48 )
49 if retcode and diff_stdout_binary.strip():
50 patch_filename = f'patch{int(time.time())}'
51 patch_filename = os.path.join(patch_dir, patch_filename)
52 logger.warning('Unstaged files detected.')
53 logger.info(f'Stashing unstaged files to {patch_filename}.')
54 # Save the current unstaged changes as a patch
55 os.makedirs(patch_dir, exist_ok=True)
56 with open(patch_filename, 'wb') as patch_file:
57 patch_file.write(diff_stdout_binary)
58
59 # prevent recursive post-checkout hooks (#1418)
60 no_checkout_env = dict(os.environ, _PRE_COMMIT_SKIP_POST_CHECKOUT='1')
61 cmd_output_b('git', 'checkout', '--', '.', env=no_checkout_env)
62
63 try:
64 yield
65 finally:
66 # Try to apply the patch we saved
67 try:
68 _git_apply(patch_filename)
69 except CalledProcessError:
70 logger.warning(
71 'Stashed changes conflicted with hook auto-fixes... '
72 'Rolling back fixes...',
73 )
74 # We failed to apply the patch, presumably due to fixes made
75 # by hooks.
76 # Roll back the changes made by hooks.
77 cmd_output_b('git', 'checkout', '--', '.', env=no_checkout_env)
78 _git_apply(patch_filename)
79
80 logger.info(f'Restored changes from {patch_filename}.')
81 else:
82 # There weren't any staged files so we don't need to do anything
83 # special
84 yield
85
86
87 @contextlib.contextmanager
88 def staged_files_only(patch_dir: str) -> Generator[None, None, None]:
89 """Clear any unstaged changes from the git working directory inside this
90 context.
91 """
92 with _intent_to_add_cleared(), _unstaged_changes_cleared(patch_dir):
93 yield
94
[end of pre_commit/staged_files_only.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/pre_commit/staged_files_only.py b/pre_commit/staged_files_only.py
--- a/pre_commit/staged_files_only.py
+++ b/pre_commit/staged_files_only.py
@@ -47,7 +47,7 @@
retcode=None,
)
if retcode and diff_stdout_binary.strip():
- patch_filename = f'patch{int(time.time())}'
+ patch_filename = f'patch{int(time.time())}-{os.getpid()}'
patch_filename = os.path.join(patch_dir, patch_filename)
logger.warning('Unstaged files detected.')
logger.info(f'Stashing unstaged files to {patch_filename}.')
|
{"golden_diff": "diff --git a/pre_commit/staged_files_only.py b/pre_commit/staged_files_only.py\n--- a/pre_commit/staged_files_only.py\n+++ b/pre_commit/staged_files_only.py\n@@ -47,7 +47,7 @@\n retcode=None,\n )\n if retcode and diff_stdout_binary.strip():\n- patch_filename = f'patch{int(time.time())}'\n+ patch_filename = f'patch{int(time.time())}-{os.getpid()}'\n patch_filename = os.path.join(patch_dir, patch_filename)\n logger.warning('Unstaged files detected.')\n logger.info(f'Stashing unstaged files to {patch_filename}.')\n", "issue": "Parallel execution ran into \"patch does not apply\"\nI modified a bunch of repos using `pre-commit` in parallel and ran `git commit` at the same time, with unstaged changes. The pre-commit processes did `[WARNING] Unstaged files detected.`, stashed the changes in a pach, ran, and then tried to reapply the patches.\r\n\r\nSome repos failed with:\r\n\r\n\r\n```\r\n[WARNING] Stashed changes conflicted with hook auto-fixes... Rolling back fixes...\r\nAn unexpected error has occurred: CalledProcessError: command: ('/usr/local/Cellar/git/2.31.1/libexec/git-core/git', '-c', 'core.autocrlf=false', 'apply', '--whitespace=nowarn', '/Users/chainz/.cache/pre-commit/patch1618586253')\r\nreturn code: 1\r\nexpected return code: 0\r\nstdout: (none)\r\nstderr:\r\n error: patch failed: .github/workflows/main.yml:21\r\n error: .github/workflows/main.yml: patch does not apply\r\n\r\nCheck the log at /Users/chainz/.cache/pre-commit/pre-commit.log\r\n```\r\n\r\nIt looks like this is due to use of the unix timestamp as the only differentiator in patch file paths, causing the parallely-created patches to clobber each other.\r\n\r\n`pre-commit.log` says:\r\n\r\n### version information\r\n\r\n```\r\npre-commit version: 2.12.0\r\nsys.version:\r\n 3.9.4 (default, Apr 5 2021, 01:49:30) \r\n [Clang 12.0.0 (clang-1200.0.32.29)]\r\nsys.executable: /usr/local/Cellar/pre-commit/2.12.0/libexec/bin/python3\r\nos.name: posix\r\nsys.platform: darwin\r\n```\r\n\r\n### error information\r\n\r\n```\r\nAn unexpected error has occurred: CalledProcessError: command: ('/usr/local/Cellar/git/2.31.1/libexec/git-core/git', '-c', 'core.autocrlf=false', 'apply', '--whitespace=nowarn', '/Users/chainz/.cache/pre-commit/patch1618586253')\r\nreturn code: 1\r\nexpected return code: 0\r\nstdout: (none)\r\nstderr:\r\n error: patch failed: .github/workflows/main.yml:21\r\n error: .github/workflows/main.yml: patch does not apply\r\n \r\n```\r\n\r\n```\r\nTraceback (most recent call last):\r\n File \"/usr/local/Cellar/pre-commit/2.12.0/libexec/lib/python3.9/site-packages/pre_commit/staged_files_only.py\", line 20, in _git_apply\r\n cmd_output_b('git', *args)\r\n File \"/usr/local/Cellar/pre-commit/2.12.0/libexec/lib/python3.9/site-packages/pre_commit/util.py\", line 154, in cmd_output_b\r\n raise CalledProcessError(returncode, cmd, retcode, stdout_b, stderr_b)\r\npre_commit.util.CalledProcessError: command: ('/usr/local/Cellar/git/2.31.1/libexec/git-core/git', 'apply', '--whitespace=nowarn', '/Users/chainz/.cache/pre-commit/patch1618586253')\r\nreturn code: 1\r\nexpected return code: 0\r\nstdout: (none)\r\nstderr:\r\n error: patch failed: .github/workflows/main.yml:21\r\n error: .github/workflows/main.yml: patch does not apply\r\n \r\n\r\nDuring handling of the above exception, another exception occurred:\r\n\r\nTraceback (most recent call last):\r\n File \"/usr/local/Cellar/pre-commit/2.12.0/libexec/lib/python3.9/site-packages/pre_commit/staged_files_only.py\", line 68, in _unstaged_changes_cleared\r\n _git_apply(patch_filename)\r\n File \"/usr/local/Cellar/pre-commit/2.12.0/libexec/lib/python3.9/site-packages/pre_commit/staged_files_only.py\", line 23, in _git_apply\r\n cmd_output_b('git', '-c', 'core.autocrlf=false', *args)\r\n File \"/usr/local/Cellar/pre-commit/2.12.0/libexec/lib/python3.9/site-packages/pre_commit/util.py\", line 154, in cmd_output_b\r\n raise CalledProcessError(returncode, cmd, retcode, stdout_b, stderr_b)\r\npre_commit.util.CalledProcessError: command: ('/usr/local/Cellar/git/2.31.1/libexec/git-core/git', '-c', 'core.autocrlf=false', 'apply', '--whitespace=nowarn', '/Users/chainz/.cache/pre-commit/patch1618586253')\r\nreturn code: 1\r\nexpected return code: 0\r\nstdout: (none)\r\nstderr:\r\n error: patch failed: .github/workflows/main.yml:21\r\n error: .github/workflows/main.yml: patch does not apply\r\n \r\n\r\nDuring handling of the above exception, another exception occurred:\r\n\r\nTraceback (most recent call last):\r\n File \"/usr/local/Cellar/pre-commit/2.12.0/libexec/lib/python3.9/site-packages/pre_commit/staged_files_only.py\", line 20, in _git_apply\r\n cmd_output_b('git', *args)\r\n File \"/usr/local/Cellar/pre-commit/2.12.0/libexec/lib/python3.9/site-packages/pre_commit/util.py\", line 154, in cmd_output_b\r\n raise CalledProcessError(returncode, cmd, retcode, stdout_b, stderr_b)\r\npre_commit.util.CalledProcessError: command: ('/usr/local/Cellar/git/2.31.1/libexec/git-core/git', 'apply', '--whitespace=nowarn', '/Users/chainz/.cache/pre-commit/patch1618586253')\r\nreturn code: 1\r\nexpected return code: 0\r\nstdout: (none)\r\nstderr:\r\n error: patch failed: .github/workflows/main.yml:21\r\n error: .github/workflows/main.yml: patch does not apply\r\n \r\n\r\nDuring handling of the above exception, another exception occurred:\r\n\r\nTraceback (most recent call last):\r\n File \"/usr/local/Cellar/pre-commit/2.12.0/libexec/lib/python3.9/site-packages/pre_commit/error_handler.py\", line 65, in error_handler\r\n yield\r\n File \"/usr/local/Cellar/pre-commit/2.12.0/libexec/lib/python3.9/site-packages/pre_commit/main.py\", line 357, in main\r\n return hook_impl(\r\n File \"/usr/local/Cellar/pre-commit/2.12.0/libexec/lib/python3.9/site-packages/pre_commit/commands/hook_impl.py\", line 227, in hook_impl\r\n return retv | run(config, store, ns)\r\n File \"/usr/local/Cellar/pre-commit/2.12.0/libexec/lib/python3.9/site-packages/pre_commit/commands/run.py\", line 408, in run\r\n return _run_hooks(config, hooks, args, environ)\r\n File \"/usr/local/Cellar/[email protected]/3.9.4/Frameworks/Python.framework/Versions/3.9/lib/python3.9/contextlib.py\", line 513, in __exit__\r\n raise exc_details[1]\r\n File \"/usr/local/Cellar/[email protected]/3.9.4/Frameworks/Python.framework/Versions/3.9/lib/python3.9/contextlib.py\", line 498, in __exit__\r\n if cb(*exc_details):\r\n File \"/usr/local/Cellar/[email protected]/3.9.4/Frameworks/Python.framework/Versions/3.9/lib/python3.9/contextlib.py\", line 124, in __exit__\r\n next(self.gen)\r\n File \"/usr/local/Cellar/pre-commit/2.12.0/libexec/lib/python3.9/site-packages/pre_commit/staged_files_only.py\", line 93, in staged_files_only\r\n yield\r\n File \"/usr/local/Cellar/[email protected]/3.9.4/Frameworks/Python.framework/Versions/3.9/lib/python3.9/contextlib.py\", line 124, in __exit__\r\n next(self.gen)\r\n File \"/usr/local/Cellar/pre-commit/2.12.0/libexec/lib/python3.9/site-packages/pre_commit/staged_files_only.py\", line 78, in _unstaged_changes_cleared\r\n _git_apply(patch_filename)\r\n File \"/usr/local/Cellar/pre-commit/2.12.0/libexec/lib/python3.9/site-packages/pre_commit/staged_files_only.py\", line 23, in _git_apply\r\n cmd_output_b('git', '-c', 'core.autocrlf=false', *args)\r\n File \"/usr/local/Cellar/pre-commit/2.12.0/libexec/lib/python3.9/site-packages/pre_commit/util.py\", line 154, in cmd_output_b\r\n raise CalledProcessError(returncode, cmd, retcode, stdout_b, stderr_b)\r\npre_commit.util.CalledProcessError: command: ('/usr/local/Cellar/git/2.31.1/libexec/git-core/git', '-c', 'core.autocrlf=false', 'apply', '--whitespace=nowarn', '/Users/chainz/.cache/pre-commit/patch1618586253')\r\nreturn code: 1\r\nexpected return code: 0\r\nstdout: (none)\r\nstderr:\r\n error: patch failed: .github/workflows/main.yml:21\r\n error: .github/workflows/main.yml: patch does not apply\r\n```\n", "before_files": [{"content": "import contextlib\nimport logging\nimport os.path\nimport time\nfrom typing import Generator\n\nfrom pre_commit import git\nfrom pre_commit.util import CalledProcessError\nfrom pre_commit.util import cmd_output\nfrom pre_commit.util import cmd_output_b\nfrom pre_commit.xargs import xargs\n\n\nlogger = logging.getLogger('pre_commit')\n\n\ndef _git_apply(patch: str) -> None:\n args = ('apply', '--whitespace=nowarn', patch)\n try:\n cmd_output_b('git', *args)\n except CalledProcessError:\n # Retry with autocrlf=false -- see #570\n cmd_output_b('git', '-c', 'core.autocrlf=false', *args)\n\n\[email protected]\ndef _intent_to_add_cleared() -> Generator[None, None, None]:\n intent_to_add = git.intent_to_add_files()\n if intent_to_add:\n logger.warning('Unstaged intent-to-add files detected.')\n\n xargs(('git', 'rm', '--cached', '--'), intent_to_add)\n try:\n yield\n finally:\n xargs(('git', 'add', '--intent-to-add', '--'), intent_to_add)\n else:\n yield\n\n\[email protected]\ndef _unstaged_changes_cleared(patch_dir: str) -> Generator[None, None, None]:\n tree = cmd_output('git', 'write-tree')[1].strip()\n retcode, diff_stdout_binary, _ = cmd_output_b(\n 'git', 'diff-index', '--ignore-submodules', '--binary',\n '--exit-code', '--no-color', '--no-ext-diff', tree, '--',\n retcode=None,\n )\n if retcode and diff_stdout_binary.strip():\n patch_filename = f'patch{int(time.time())}'\n patch_filename = os.path.join(patch_dir, patch_filename)\n logger.warning('Unstaged files detected.')\n logger.info(f'Stashing unstaged files to {patch_filename}.')\n # Save the current unstaged changes as a patch\n os.makedirs(patch_dir, exist_ok=True)\n with open(patch_filename, 'wb') as patch_file:\n patch_file.write(diff_stdout_binary)\n\n # prevent recursive post-checkout hooks (#1418)\n no_checkout_env = dict(os.environ, _PRE_COMMIT_SKIP_POST_CHECKOUT='1')\n cmd_output_b('git', 'checkout', '--', '.', env=no_checkout_env)\n\n try:\n yield\n finally:\n # Try to apply the patch we saved\n try:\n _git_apply(patch_filename)\n except CalledProcessError:\n logger.warning(\n 'Stashed changes conflicted with hook auto-fixes... '\n 'Rolling back fixes...',\n )\n # We failed to apply the patch, presumably due to fixes made\n # by hooks.\n # Roll back the changes made by hooks.\n cmd_output_b('git', 'checkout', '--', '.', env=no_checkout_env)\n _git_apply(patch_filename)\n\n logger.info(f'Restored changes from {patch_filename}.')\n else:\n # There weren't any staged files so we don't need to do anything\n # special\n yield\n\n\[email protected]\ndef staged_files_only(patch_dir: str) -> Generator[None, None, None]:\n \"\"\"Clear any unstaged changes from the git working directory inside this\n context.\n \"\"\"\n with _intent_to_add_cleared(), _unstaged_changes_cleared(patch_dir):\n yield\n", "path": "pre_commit/staged_files_only.py"}]}
| 3,616 | 141 |
gh_patches_debug_16371
|
rasdani/github-patches
|
git_diff
|
encode__starlette-163
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Routes that were working on 0.5.5 not working on 0.6.2
Greetings, thanks for the project.
I am having issues after upgrading where it seems one of my routes is getting converted to a coroutine somewhere and not awaited and then is being passed down all the middleware.
```
Traceback (most recent call last):
File "../lib/python3.7/site-packages/uvicorn/protocols/http/httptools_impl.py", line 387, in run_asgi
result = await asgi(self.receive, self.send)
File "../lib/python3.7/site-packages/uvicorn/middleware/message_logger.py", line 59, in __call__
await self.inner(self.receive, self.send)
File "../lib/python3.7/site-packages/uvicorn/middleware/debug.py", line 80, in __call__
await asgi(receive, self.send)
File "../lib/python3.7/site-packages/starlette/exceptions.py", line 69, in app
raise exc from None
File "../lib/python3.7/site-packages/starlette/exceptions.py", line 61, in app
await instance(receive, sender)
TypeError: 'coroutine' object is not callable
```
</issue>
<code>
[start of starlette/routing.py]
1 import asyncio
2 import inspect
3 import re
4 import typing
5 from concurrent.futures import ThreadPoolExecutor
6
7 from starlette.datastructures import URL
8 from starlette.exceptions import HTTPException
9 from starlette.graphql import GraphQLApp
10 from starlette.requests import Request
11 from starlette.responses import PlainTextResponse
12 from starlette.types import ASGIApp, ASGIInstance, Receive, Scope, Send
13 from starlette.websockets import WebSocket, WebSocketClose
14
15
16 class NoMatchFound(Exception):
17 pass
18
19
20 def request_response(func: typing.Callable) -> ASGIApp:
21 """
22 Takes a function or coroutine `func(request) -> response`,
23 and returns an ASGI application.
24 """
25 is_coroutine = asyncio.iscoroutinefunction(func)
26
27 def app(scope: Scope) -> ASGIInstance:
28 async def awaitable(receive: Receive, send: Send) -> None:
29 request = Request(scope, receive=receive)
30 if is_coroutine:
31 response = await func(request)
32 else:
33 response = func(request)
34 await response(receive, send)
35
36 return awaitable
37
38 return app
39
40
41 def websocket_session(func: typing.Callable) -> ASGIApp:
42 """
43 Takes a coroutine `func(session)`, and returns an ASGI application.
44 """
45
46 def app(scope: Scope) -> ASGIInstance:
47 async def awaitable(receive: Receive, send: Send) -> None:
48 session = WebSocket(scope, receive=receive, send=send)
49 await func(session)
50
51 return awaitable
52
53 return app
54
55
56 def get_name(endpoint: typing.Callable) -> str:
57 if inspect.isfunction(endpoint) or inspect.isclass(endpoint):
58 return endpoint.__name__
59 return endpoint.__class__.__name__
60
61
62 def replace_params(path: str, **path_params: str) -> str:
63 for key, value in path_params.items():
64 path = path.replace("{" + key + "}", value)
65 return path
66
67
68 class BaseRoute:
69 def matches(self, scope: Scope) -> typing.Tuple[bool, Scope]:
70 raise NotImplementedError() # pragma: no cover
71
72 def url_path_for(self, name: str, **path_params: str) -> URL:
73 raise NotImplementedError() # pragma: no cover
74
75 def __call__(self, scope: Scope) -> ASGIInstance:
76 raise NotImplementedError() # pragma: no cover
77
78
79 class Route(BaseRoute):
80 def __init__(
81 self, path: str, *, endpoint: typing.Callable, methods: typing.List[str] = None
82 ) -> None:
83 self.path = path
84 self.endpoint = endpoint
85 self.name = get_name(endpoint)
86
87 if inspect.isfunction(endpoint):
88 self.app = request_response(endpoint)
89 if methods is None:
90 methods = ["GET"]
91 else:
92 self.app = endpoint
93
94 self.methods = methods
95 regex = "^" + path + "$"
96 regex = re.sub("{([a-zA-Z_][a-zA-Z0-9_]*)}", r"(?P<\1>[^/]+)", regex)
97 self.path_regex = re.compile(regex)
98 self.param_names = set(self.path_regex.groupindex.keys())
99
100 def matches(self, scope: Scope) -> typing.Tuple[bool, Scope]:
101 if scope["type"] == "http":
102 match = self.path_regex.match(scope["path"])
103 if match:
104 path_params = dict(scope.get("path_params", {}))
105 path_params.update(match.groupdict())
106 child_scope = dict(scope)
107 child_scope["path_params"] = path_params
108 return True, child_scope
109 return False, {}
110
111 def url_path_for(self, name: str, **path_params: str) -> URL:
112 if name != self.name or self.param_names != set(path_params.keys()):
113 raise NoMatchFound()
114 return URL(scheme="http", path=replace_params(self.path, **path_params))
115
116 def __call__(self, scope: Scope) -> ASGIInstance:
117 if self.methods and scope["method"] not in self.methods:
118 if "app" in scope:
119 raise HTTPException(status_code=405)
120 return PlainTextResponse("Method Not Allowed", status_code=405)
121 return self.app(scope)
122
123 def __eq__(self, other: typing.Any) -> bool:
124 return (
125 isinstance(other, Route)
126 and self.path == other.path
127 and self.endpoint == other.endpoint
128 and self.methods == other.methods
129 )
130
131
132 class WebSocketRoute(BaseRoute):
133 def __init__(self, path: str, *, endpoint: typing.Callable) -> None:
134 self.path = path
135 self.endpoint = endpoint
136 self.name = get_name(endpoint)
137
138 if inspect.isfunction(endpoint):
139 self.app = websocket_session(endpoint)
140 else:
141 self.app = endpoint
142
143 regex = "^" + path + "$"
144 regex = re.sub("{([a-zA-Z_][a-zA-Z0-9_]*)}", r"(?P<\1>[^/]+)", regex)
145 self.path_regex = re.compile(regex)
146 self.param_names = set(self.path_regex.groupindex.keys())
147
148 def matches(self, scope: Scope) -> typing.Tuple[bool, Scope]:
149 if scope["type"] == "websocket":
150 match = self.path_regex.match(scope["path"])
151 if match:
152 path_params = dict(scope.get("path_params", {}))
153 path_params.update(match.groupdict())
154 child_scope = dict(scope)
155 child_scope["path_params"] = path_params
156 return True, child_scope
157 return False, {}
158
159 def url_path_for(self, name: str, **path_params: str) -> URL:
160 if name != self.name or self.param_names != set(path_params.keys()):
161 raise NoMatchFound()
162 return URL(scheme="ws", path=replace_params(self.path, **path_params))
163
164 def __call__(self, scope: Scope) -> ASGIInstance:
165 return self.app(scope)
166
167 def __eq__(self, other: typing.Any) -> bool:
168 return (
169 isinstance(other, WebSocketRoute)
170 and self.path == other.path
171 and self.endpoint == other.endpoint
172 )
173
174
175 class Mount(BaseRoute):
176 def __init__(self, path: str, app: ASGIApp) -> None:
177 self.path = path
178 self.app = app
179 regex = "^" + path
180 regex = re.sub("{([a-zA-Z_][a-zA-Z0-9_]*)}", r"(?P<\1>[^/]*)", regex)
181 self.path_regex = re.compile(regex)
182
183 @property
184 def routes(self) -> typing.List[BaseRoute]:
185 return getattr(self.app, "routes", None)
186
187 def matches(self, scope: Scope) -> typing.Tuple[bool, Scope]:
188 match = self.path_regex.match(scope["path"])
189 if match:
190 path_params = dict(scope.get("path_params", {}))
191 path_params.update(match.groupdict())
192 child_scope = dict(scope)
193 child_scope["path_params"] = path_params
194 child_scope["root_path"] = scope.get("root_path", "") + match.string
195 child_scope["path"] = scope["path"][match.span()[1] :]
196 return True, child_scope
197 return False, {}
198
199 def url_path_for(self, name: str, **path_params: str) -> URL:
200 for route in self.routes or []:
201 try:
202 url = route.url_path_for(name, **path_params)
203 return URL(scheme=url.scheme, path=self.path + url.path)
204 except NoMatchFound as exc:
205 pass
206 raise NoMatchFound()
207
208 def __call__(self, scope: Scope) -> ASGIInstance:
209 return self.app(scope)
210
211 def __eq__(self, other: typing.Any) -> bool:
212 return (
213 isinstance(other, Mount)
214 and self.path == other.path
215 and self.app == other.app
216 )
217
218
219 class Router:
220 def __init__(
221 self, routes: typing.List[BaseRoute] = None, default: ASGIApp = None
222 ) -> None:
223 self.routes = [] if routes is None else routes
224 self.default = self.not_found if default is None else default
225
226 def mount(self, path: str, app: ASGIApp) -> None:
227 route = Mount(path, app=app)
228 self.routes.append(route)
229
230 def add_route(
231 self, path: str, endpoint: typing.Callable, methods: typing.List[str] = None
232 ) -> None:
233 route = Route(path, endpoint=endpoint, methods=methods)
234 self.routes.append(route)
235
236 def add_graphql_route(
237 self, path: str, schema: typing.Any, executor: typing.Any = None
238 ) -> None:
239 app = GraphQLApp(schema=schema, executor=executor)
240 self.add_route(path, endpoint=app)
241
242 def add_websocket_route(self, path: str, endpoint: typing.Callable) -> None:
243 route = WebSocketRoute(path, endpoint=endpoint)
244 self.routes.append(route)
245
246 def route(self, path: str, methods: typing.List[str] = None) -> typing.Callable:
247 def decorator(func: typing.Callable) -> typing.Callable:
248 self.add_route(path, func, methods=methods)
249 return func
250
251 return decorator
252
253 def websocket_route(self, path: str) -> typing.Callable:
254 def decorator(func: typing.Callable) -> typing.Callable:
255 self.add_websocket_route(path, func)
256 return func
257
258 return decorator
259
260 def not_found(self, scope: Scope) -> ASGIInstance:
261 if scope["type"] == "websocket":
262 return WebSocketClose()
263
264 # If we're running inside a starlette application then raise an
265 # exception, so that the configurable exception handler can deal with
266 # returning the response. For plain ASGI apps, just return the response.
267 if "app" in scope:
268 raise HTTPException(status_code=404)
269 return PlainTextResponse("Not Found", status_code=404)
270
271 def url_path_for(self, name: str, **path_params: str) -> URL:
272 for route in self.routes:
273 try:
274 return route.url_path_for(name, **path_params)
275 except NoMatchFound as exc:
276 pass
277 raise NoMatchFound()
278
279 def __call__(self, scope: Scope) -> ASGIInstance:
280 assert scope["type"] in ("http", "websocket")
281
282 if "router" not in scope:
283 scope["router"] = self
284
285 for route in self.routes:
286 matched, child_scope = route.matches(scope)
287 if matched:
288 return route(child_scope)
289 return self.not_found(scope)
290
291 def __eq__(self, other: typing.Any) -> bool:
292 return isinstance(other, Router) and self.routes == other.routes
293
[end of starlette/routing.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/starlette/routing.py b/starlette/routing.py
--- a/starlette/routing.py
+++ b/starlette/routing.py
@@ -84,7 +84,7 @@
self.endpoint = endpoint
self.name = get_name(endpoint)
- if inspect.isfunction(endpoint):
+ if inspect.isfunction(endpoint) or inspect.ismethod(endpoint):
self.app = request_response(endpoint)
if methods is None:
methods = ["GET"]
@@ -135,7 +135,7 @@
self.endpoint = endpoint
self.name = get_name(endpoint)
- if inspect.isfunction(endpoint):
+ if inspect.isfunction(endpoint) or inspect.ismethod(endpoint):
self.app = websocket_session(endpoint)
else:
self.app = endpoint
|
{"golden_diff": "diff --git a/starlette/routing.py b/starlette/routing.py\n--- a/starlette/routing.py\n+++ b/starlette/routing.py\n@@ -84,7 +84,7 @@\n self.endpoint = endpoint\n self.name = get_name(endpoint)\n \n- if inspect.isfunction(endpoint):\n+ if inspect.isfunction(endpoint) or inspect.ismethod(endpoint):\n self.app = request_response(endpoint)\n if methods is None:\n methods = [\"GET\"]\n@@ -135,7 +135,7 @@\n self.endpoint = endpoint\n self.name = get_name(endpoint)\n \n- if inspect.isfunction(endpoint):\n+ if inspect.isfunction(endpoint) or inspect.ismethod(endpoint):\n self.app = websocket_session(endpoint)\n else:\n self.app = endpoint\n", "issue": "Routes that were working on 0.5.5 not working on 0.6.2\nGreetings, thanks for the project. \r\n\r\nI am having issues after upgrading where it seems one of my routes is getting converted to a coroutine somewhere and not awaited and then is being passed down all the middleware.\r\n\r\n```\r\nTraceback (most recent call last):\r\n File \"../lib/python3.7/site-packages/uvicorn/protocols/http/httptools_impl.py\", line 387, in run_asgi\r\n result = await asgi(self.receive, self.send)\r\n File \"../lib/python3.7/site-packages/uvicorn/middleware/message_logger.py\", line 59, in __call__\r\n await self.inner(self.receive, self.send)\r\n File \"../lib/python3.7/site-packages/uvicorn/middleware/debug.py\", line 80, in __call__\r\n await asgi(receive, self.send)\r\n File \"../lib/python3.7/site-packages/starlette/exceptions.py\", line 69, in app\r\n raise exc from None\r\n File \"../lib/python3.7/site-packages/starlette/exceptions.py\", line 61, in app\r\n await instance(receive, sender)\r\nTypeError: 'coroutine' object is not callable\r\n```\n", "before_files": [{"content": "import asyncio\nimport inspect\nimport re\nimport typing\nfrom concurrent.futures import ThreadPoolExecutor\n\nfrom starlette.datastructures import URL\nfrom starlette.exceptions import HTTPException\nfrom starlette.graphql import GraphQLApp\nfrom starlette.requests import Request\nfrom starlette.responses import PlainTextResponse\nfrom starlette.types import ASGIApp, ASGIInstance, Receive, Scope, Send\nfrom starlette.websockets import WebSocket, WebSocketClose\n\n\nclass NoMatchFound(Exception):\n pass\n\n\ndef request_response(func: typing.Callable) -> ASGIApp:\n \"\"\"\n Takes a function or coroutine `func(request) -> response`,\n and returns an ASGI application.\n \"\"\"\n is_coroutine = asyncio.iscoroutinefunction(func)\n\n def app(scope: Scope) -> ASGIInstance:\n async def awaitable(receive: Receive, send: Send) -> None:\n request = Request(scope, receive=receive)\n if is_coroutine:\n response = await func(request)\n else:\n response = func(request)\n await response(receive, send)\n\n return awaitable\n\n return app\n\n\ndef websocket_session(func: typing.Callable) -> ASGIApp:\n \"\"\"\n Takes a coroutine `func(session)`, and returns an ASGI application.\n \"\"\"\n\n def app(scope: Scope) -> ASGIInstance:\n async def awaitable(receive: Receive, send: Send) -> None:\n session = WebSocket(scope, receive=receive, send=send)\n await func(session)\n\n return awaitable\n\n return app\n\n\ndef get_name(endpoint: typing.Callable) -> str:\n if inspect.isfunction(endpoint) or inspect.isclass(endpoint):\n return endpoint.__name__\n return endpoint.__class__.__name__\n\n\ndef replace_params(path: str, **path_params: str) -> str:\n for key, value in path_params.items():\n path = path.replace(\"{\" + key + \"}\", value)\n return path\n\n\nclass BaseRoute:\n def matches(self, scope: Scope) -> typing.Tuple[bool, Scope]:\n raise NotImplementedError() # pragma: no cover\n\n def url_path_for(self, name: str, **path_params: str) -> URL:\n raise NotImplementedError() # pragma: no cover\n\n def __call__(self, scope: Scope) -> ASGIInstance:\n raise NotImplementedError() # pragma: no cover\n\n\nclass Route(BaseRoute):\n def __init__(\n self, path: str, *, endpoint: typing.Callable, methods: typing.List[str] = None\n ) -> None:\n self.path = path\n self.endpoint = endpoint\n self.name = get_name(endpoint)\n\n if inspect.isfunction(endpoint):\n self.app = request_response(endpoint)\n if methods is None:\n methods = [\"GET\"]\n else:\n self.app = endpoint\n\n self.methods = methods\n regex = \"^\" + path + \"$\"\n regex = re.sub(\"{([a-zA-Z_][a-zA-Z0-9_]*)}\", r\"(?P<\\1>[^/]+)\", regex)\n self.path_regex = re.compile(regex)\n self.param_names = set(self.path_regex.groupindex.keys())\n\n def matches(self, scope: Scope) -> typing.Tuple[bool, Scope]:\n if scope[\"type\"] == \"http\":\n match = self.path_regex.match(scope[\"path\"])\n if match:\n path_params = dict(scope.get(\"path_params\", {}))\n path_params.update(match.groupdict())\n child_scope = dict(scope)\n child_scope[\"path_params\"] = path_params\n return True, child_scope\n return False, {}\n\n def url_path_for(self, name: str, **path_params: str) -> URL:\n if name != self.name or self.param_names != set(path_params.keys()):\n raise NoMatchFound()\n return URL(scheme=\"http\", path=replace_params(self.path, **path_params))\n\n def __call__(self, scope: Scope) -> ASGIInstance:\n if self.methods and scope[\"method\"] not in self.methods:\n if \"app\" in scope:\n raise HTTPException(status_code=405)\n return PlainTextResponse(\"Method Not Allowed\", status_code=405)\n return self.app(scope)\n\n def __eq__(self, other: typing.Any) -> bool:\n return (\n isinstance(other, Route)\n and self.path == other.path\n and self.endpoint == other.endpoint\n and self.methods == other.methods\n )\n\n\nclass WebSocketRoute(BaseRoute):\n def __init__(self, path: str, *, endpoint: typing.Callable) -> None:\n self.path = path\n self.endpoint = endpoint\n self.name = get_name(endpoint)\n\n if inspect.isfunction(endpoint):\n self.app = websocket_session(endpoint)\n else:\n self.app = endpoint\n\n regex = \"^\" + path + \"$\"\n regex = re.sub(\"{([a-zA-Z_][a-zA-Z0-9_]*)}\", r\"(?P<\\1>[^/]+)\", regex)\n self.path_regex = re.compile(regex)\n self.param_names = set(self.path_regex.groupindex.keys())\n\n def matches(self, scope: Scope) -> typing.Tuple[bool, Scope]:\n if scope[\"type\"] == \"websocket\":\n match = self.path_regex.match(scope[\"path\"])\n if match:\n path_params = dict(scope.get(\"path_params\", {}))\n path_params.update(match.groupdict())\n child_scope = dict(scope)\n child_scope[\"path_params\"] = path_params\n return True, child_scope\n return False, {}\n\n def url_path_for(self, name: str, **path_params: str) -> URL:\n if name != self.name or self.param_names != set(path_params.keys()):\n raise NoMatchFound()\n return URL(scheme=\"ws\", path=replace_params(self.path, **path_params))\n\n def __call__(self, scope: Scope) -> ASGIInstance:\n return self.app(scope)\n\n def __eq__(self, other: typing.Any) -> bool:\n return (\n isinstance(other, WebSocketRoute)\n and self.path == other.path\n and self.endpoint == other.endpoint\n )\n\n\nclass Mount(BaseRoute):\n def __init__(self, path: str, app: ASGIApp) -> None:\n self.path = path\n self.app = app\n regex = \"^\" + path\n regex = re.sub(\"{([a-zA-Z_][a-zA-Z0-9_]*)}\", r\"(?P<\\1>[^/]*)\", regex)\n self.path_regex = re.compile(regex)\n\n @property\n def routes(self) -> typing.List[BaseRoute]:\n return getattr(self.app, \"routes\", None)\n\n def matches(self, scope: Scope) -> typing.Tuple[bool, Scope]:\n match = self.path_regex.match(scope[\"path\"])\n if match:\n path_params = dict(scope.get(\"path_params\", {}))\n path_params.update(match.groupdict())\n child_scope = dict(scope)\n child_scope[\"path_params\"] = path_params\n child_scope[\"root_path\"] = scope.get(\"root_path\", \"\") + match.string\n child_scope[\"path\"] = scope[\"path\"][match.span()[1] :]\n return True, child_scope\n return False, {}\n\n def url_path_for(self, name: str, **path_params: str) -> URL:\n for route in self.routes or []:\n try:\n url = route.url_path_for(name, **path_params)\n return URL(scheme=url.scheme, path=self.path + url.path)\n except NoMatchFound as exc:\n pass\n raise NoMatchFound()\n\n def __call__(self, scope: Scope) -> ASGIInstance:\n return self.app(scope)\n\n def __eq__(self, other: typing.Any) -> bool:\n return (\n isinstance(other, Mount)\n and self.path == other.path\n and self.app == other.app\n )\n\n\nclass Router:\n def __init__(\n self, routes: typing.List[BaseRoute] = None, default: ASGIApp = None\n ) -> None:\n self.routes = [] if routes is None else routes\n self.default = self.not_found if default is None else default\n\n def mount(self, path: str, app: ASGIApp) -> None:\n route = Mount(path, app=app)\n self.routes.append(route)\n\n def add_route(\n self, path: str, endpoint: typing.Callable, methods: typing.List[str] = None\n ) -> None:\n route = Route(path, endpoint=endpoint, methods=methods)\n self.routes.append(route)\n\n def add_graphql_route(\n self, path: str, schema: typing.Any, executor: typing.Any = None\n ) -> None:\n app = GraphQLApp(schema=schema, executor=executor)\n self.add_route(path, endpoint=app)\n\n def add_websocket_route(self, path: str, endpoint: typing.Callable) -> None:\n route = WebSocketRoute(path, endpoint=endpoint)\n self.routes.append(route)\n\n def route(self, path: str, methods: typing.List[str] = None) -> typing.Callable:\n def decorator(func: typing.Callable) -> typing.Callable:\n self.add_route(path, func, methods=methods)\n return func\n\n return decorator\n\n def websocket_route(self, path: str) -> typing.Callable:\n def decorator(func: typing.Callable) -> typing.Callable:\n self.add_websocket_route(path, func)\n return func\n\n return decorator\n\n def not_found(self, scope: Scope) -> ASGIInstance:\n if scope[\"type\"] == \"websocket\":\n return WebSocketClose()\n\n # If we're running inside a starlette application then raise an\n # exception, so that the configurable exception handler can deal with\n # returning the response. For plain ASGI apps, just return the response.\n if \"app\" in scope:\n raise HTTPException(status_code=404)\n return PlainTextResponse(\"Not Found\", status_code=404)\n\n def url_path_for(self, name: str, **path_params: str) -> URL:\n for route in self.routes:\n try:\n return route.url_path_for(name, **path_params)\n except NoMatchFound as exc:\n pass\n raise NoMatchFound()\n\n def __call__(self, scope: Scope) -> ASGIInstance:\n assert scope[\"type\"] in (\"http\", \"websocket\")\n\n if \"router\" not in scope:\n scope[\"router\"] = self\n\n for route in self.routes:\n matched, child_scope = route.matches(scope)\n if matched:\n return route(child_scope)\n return self.not_found(scope)\n\n def __eq__(self, other: typing.Any) -> bool:\n return isinstance(other, Router) and self.routes == other.routes\n", "path": "starlette/routing.py"}]}
| 3,929 | 169 |
gh_patches_debug_48344
|
rasdani/github-patches
|
git_diff
|
interlegis__sapl-1749
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Formatar mudança de linha nos campos text do crud
As mudanças de linha `\n` dos campos TextField, ao que parece, estão sendo exibidas nas telas de leitura do crud.
Por exemplo no campo `observacao` de `DocumentoAdministrativo`.
</issue>
<code>
[start of sapl/crispy_layout_mixin.py]
1 from math import ceil
2
3 import rtyaml
4 from crispy_forms.bootstrap import FormActions
5 from crispy_forms.helper import FormHelper
6 from crispy_forms.layout import HTML, Div, Fieldset, Layout, Submit
7 from django import template
8 from django.core.urlresolvers import reverse, reverse_lazy
9 from django.utils import formats
10 from django.utils.translation import ugettext as _
11
12
13 def heads_and_tails(list_of_lists):
14 for alist in list_of_lists:
15 yield alist[0], alist[1:]
16
17
18 def to_column(name_span):
19 fieldname, span = name_span
20 return Div(fieldname, css_class='col-md-%d' % span)
21
22
23 def to_row(names_spans):
24 return Div(*map(to_column, names_spans), css_class='row-fluid')
25
26
27 def to_fieldsets(fields):
28 for field in fields:
29 if isinstance(field, list):
30 legend, row_specs = field[0], field[1:]
31 rows = [to_row(name_span_list) for name_span_list in row_specs]
32 yield Fieldset(legend, *rows)
33 else:
34 yield field
35
36
37 def form_actions(more=[Div(css_class='clearfix')],
38 label=_('Salvar'), name='salvar', css_class='pull-right', disabled=True):
39
40 if disabled:
41 doubleclick = 'this.form.submit();this.disabled=true;'
42 else:
43 doubleclick = 'return true;'
44
45 return FormActions(
46 Submit(name, label, css_class=css_class,
47 # para impedir resubmissão do form
48 onclick=doubleclick),
49 *more)
50
51
52 class SaplFormLayout(Layout):
53
54 def __init__(self, *fields, cancel_label=_('Cancelar'),
55 save_label=_('Salvar'), actions=None):
56
57 buttons = actions
58 if not buttons:
59 buttons = form_actions(label=save_label, more=[
60 HTML('<a href="{{ view.cancel_url }}"'
61 ' class="btn btn-inverse">%s</a>' % cancel_label)
62 if cancel_label else None])
63
64 _fields = list(to_fieldsets(fields))
65 if buttons:
66 _fields += [to_row([(buttons, 12)])]
67 super(SaplFormLayout, self).__init__(*_fields)
68
69
70 def get_field_display(obj, fieldname):
71 field = ''
72 try:
73 field = obj._meta.get_field(fieldname)
74 except Exception as e:
75 """ nos casos que o fieldname não é um field_model,
76 ele pode ser um aggregate, annotate, um property, um manager,
77 ou mesmo uma método no model.
78 """
79 value = getattr(obj, fieldname)
80 try:
81 verbose_name = value.model._meta.verbose_name
82 except AttributeError:
83 verbose_name = ''
84
85 else:
86 verbose_name = str(field.verbose_name)\
87 if hasattr(field, 'verbose_name') else ''
88
89 if hasattr(field, 'choices') and field.choices:
90 value = getattr(obj, 'get_%s_display' % fieldname)()
91 else:
92 value = getattr(obj, fieldname)
93
94 str_type_from_value = str(type(value))
95 str_type_from_field = str(type(field))
96
97 if value is None:
98 display = ''
99 elif '.date' in str_type_from_value:
100 display = formats.date_format(value, "SHORT_DATE_FORMAT")
101 elif 'bool' in str_type_from_value:
102 display = _('Sim') if value else _('Não')
103 elif 'ImageFieldFile' in str(type(value)):
104 if value:
105 display = '<img src="{}" />'.format(value.url)
106 else:
107 display = ''
108 elif 'FieldFile' in str_type_from_value:
109 if value:
110 display = '<a href="{}">{}</a>'.format(
111 value.url,
112 value.name.split('/')[-1:][0])
113 else:
114 display = ''
115 elif 'ManyRelatedManager' in str_type_from_value\
116 or 'RelatedManager' in str_type_from_value\
117 or 'GenericRelatedObjectManager' in str_type_from_value:
118 display = '<ul>'
119 for v in value.all():
120 display += '<li>%s</li>' % str(v)
121 display += '</ul>'
122 if not verbose_name:
123 if hasattr(field, 'related_model'):
124 verbose_name = str(
125 field.related_model._meta.verbose_name_plural)
126 elif hasattr(field, 'model'):
127 verbose_name = str(field.model._meta.verbose_name_plural)
128 elif 'GenericForeignKey' in str_type_from_field:
129 display = '<a href="{}">{}</a>'.format(
130 reverse(
131 '%s:%s_detail' % (
132 value._meta.app_config.name, obj.content_type.model),
133 args=(value.id,)),
134 value)
135 else:
136 display = str(value)
137 return verbose_name, display
138
139
140 class CrispyLayoutFormMixin:
141
142 @property
143 def layout_key(self):
144 if hasattr(super(CrispyLayoutFormMixin, self), 'layout_key'):
145 return super(CrispyLayoutFormMixin, self).layout_key
146 else:
147 return self.model.__name__
148
149 @property
150 def layout_key_set(self):
151 if hasattr(super(CrispyLayoutFormMixin, self), 'layout_key_set'):
152 return super(CrispyLayoutFormMixin, self).layout_key_set
153 else:
154 obj = self.crud if hasattr(self, 'crud') else self
155 return getattr(obj.model,
156 obj.model_set).field.model.__name__
157
158 def get_layout(self):
159 yaml_layout = '%s/layouts.yaml' % self.model._meta.app_config.label
160 return read_layout_from_yaml(yaml_layout, self.layout_key)
161
162 def get_layout_set(self):
163 obj = self.crud if hasattr(self, 'crud') else self
164 yaml_layout = '%s/layouts.yaml' % getattr(
165 obj.model, obj.model_set).field.model._meta.app_config.label
166 return read_layout_from_yaml(yaml_layout, self.layout_key_set)
167
168 @property
169 def fields(self):
170 if hasattr(self, 'form_class') and self.form_class:
171 return None
172 else:
173 '''Returns all fields in the layout'''
174 return [fieldname for legend_rows in self.get_layout()
175 for row in legend_rows[1:]
176 for fieldname, span in row]
177
178 def get_form(self, form_class=None):
179 try:
180 form = super(CrispyLayoutFormMixin, self).get_form(form_class)
181 except AttributeError:
182 # simply return None if there is no get_form on super
183 pass
184 else:
185 if self.layout_key:
186 form.helper = FormHelper()
187 form.helper.layout = SaplFormLayout(*self.get_layout())
188 return form
189
190 @property
191 def list_field_names(self):
192 '''The list of field names to display on table
193
194 This base implementation returns the field names
195 in the first fieldset of the layout.
196 '''
197 obj = self.crud if hasattr(self, 'crud') else self
198 if hasattr(obj, 'list_field_names') and obj.list_field_names:
199 return obj.list_field_names
200 rows = self.get_layout()[0][1:]
201 return [fieldname for row in rows for fieldname, __ in row]
202
203 @property
204 def list_field_names_set(self):
205 '''The list of field names to display on table
206
207 This base implementation returns the field names
208 in the first fieldset of the layout.
209 '''
210 rows = self.get_layout_set()[0][1:]
211 return [fieldname for row in rows for fieldname, __ in row]
212
213 def get_column(self, fieldname, span):
214 obj = self.get_object()
215
216 func = None
217 if '|' in fieldname:
218 fieldname, func = tuple(fieldname.split('|'))
219
220 if func:
221 verbose_name, text = getattr(self, func)(obj, fieldname)
222 else:
223 verbose_name, text = get_field_display(obj, fieldname)
224
225 return {
226 'id': fieldname,
227 'span': span,
228 'verbose_name': verbose_name,
229 'text': text,
230 }
231
232 def fk_urlize_for_detail(self, obj, fieldname):
233
234 field = obj._meta.get_field(fieldname)
235 value = getattr(obj, fieldname)
236
237 display = '<a href="{}">{}</a>'.format(
238 reverse(
239 '%s:%s_detail' % (
240 value._meta.app_config.name, value._meta.model_name),
241 args=(value.id,)),
242 value)
243
244 return field.verbose_name, display
245
246 def m2m_urlize_for_detail(self, obj, fieldname):
247
248 manager, fieldname = tuple(fieldname.split('__'))
249
250 manager = getattr(obj, manager)
251
252 verbose_name = manager.model._meta.verbose_name
253 display = ''
254 for item in manager.all():
255 obj_m2m = getattr(item, fieldname)
256
257 if obj == obj_m2m:
258 continue
259
260 verbose_name = item._meta.get_field(fieldname).verbose_name
261
262 display += '<li><a href="{}">{}</a></li>'.format(
263 reverse(
264 '%s:%s_detail' % (
265 obj_m2m._meta.app_config.name, obj_m2m._meta.model_name),
266 args=(obj_m2m.id,)),
267 obj_m2m)
268
269 display += ''
270
271 if display:
272 display = '<ul>%s</ul>' % display
273 else:
274 verbose_name = ''
275
276 return verbose_name, display
277
278 @property
279 def layout_display(self):
280
281 return [
282 {'legend': legend,
283 'rows': [[self.get_column(fieldname, span)
284 for fieldname, span in row]
285 for row in rows]
286 } for legend, rows in heads_and_tails(self.get_layout())]
287
288
289 def read_yaml_from_file(yaml_layout):
290 # TODO cache this at application level
291 t = template.loader.get_template(yaml_layout)
292 # aqui é importante converter para str pois, dependendo do ambiente,
293 # o rtyaml pode usar yaml.CSafeLoader, que exige str ou stream
294 rendered = str(t.render())
295 return rtyaml.load(rendered)
296
297
298 def read_layout_from_yaml(yaml_layout, key):
299 # TODO cache this at application level
300 yaml = read_yaml_from_file(yaml_layout)
301 base = yaml[key]
302
303 def line_to_namespans(line):
304 split = [cell.split(':') for cell in line.split()]
305 namespans = [[s[0], int(s[1]) if len(s) > 1 else 0] for s in split]
306 remaining = 12 - sum(s for n, s in namespans)
307 nondefined = [ns for ns in namespans if not ns[1]]
308 while nondefined:
309 span = ceil(remaining / len(nondefined))
310 namespan = nondefined.pop(0)
311 namespan[1] = span
312 remaining = remaining - span
313 return list(map(tuple, namespans))
314
315 return [[legend] + [line_to_namespans(l) for l in lines]
316 for legend, lines in base.items()]
317
[end of sapl/crispy_layout_mixin.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/sapl/crispy_layout_mixin.py b/sapl/crispy_layout_mixin.py
--- a/sapl/crispy_layout_mixin.py
+++ b/sapl/crispy_layout_mixin.py
@@ -132,6 +132,8 @@
value._meta.app_config.name, obj.content_type.model),
args=(value.id,)),
value)
+ elif 'TextField' in str_type_from_field:
+ display = value.replace('\n', '<br/>')
else:
display = str(value)
return verbose_name, display
|
{"golden_diff": "diff --git a/sapl/crispy_layout_mixin.py b/sapl/crispy_layout_mixin.py\n--- a/sapl/crispy_layout_mixin.py\n+++ b/sapl/crispy_layout_mixin.py\n@@ -132,6 +132,8 @@\n value._meta.app_config.name, obj.content_type.model),\n args=(value.id,)),\n value)\n+ elif 'TextField' in str_type_from_field:\n+ display = value.replace('\\n', '<br/>')\n else:\n display = str(value)\n return verbose_name, display\n", "issue": "Formatar mudan\u00e7a de linha nos campos text do crud\nAs mudan\u00e7as de linha `\\n` dos campos TextField, ao que parece, est\u00e3o sendo exibidas nas telas de leitura do crud.\r\n\r\nPor exemplo no campo `observacao` de `DocumentoAdministrativo`.\n", "before_files": [{"content": "from math import ceil\n\nimport rtyaml\nfrom crispy_forms.bootstrap import FormActions\nfrom crispy_forms.helper import FormHelper\nfrom crispy_forms.layout import HTML, Div, Fieldset, Layout, Submit\nfrom django import template\nfrom django.core.urlresolvers import reverse, reverse_lazy\nfrom django.utils import formats\nfrom django.utils.translation import ugettext as _\n\n\ndef heads_and_tails(list_of_lists):\n for alist in list_of_lists:\n yield alist[0], alist[1:]\n\n\ndef to_column(name_span):\n fieldname, span = name_span\n return Div(fieldname, css_class='col-md-%d' % span)\n\n\ndef to_row(names_spans):\n return Div(*map(to_column, names_spans), css_class='row-fluid')\n\n\ndef to_fieldsets(fields):\n for field in fields:\n if isinstance(field, list):\n legend, row_specs = field[0], field[1:]\n rows = [to_row(name_span_list) for name_span_list in row_specs]\n yield Fieldset(legend, *rows)\n else:\n yield field\n\n\ndef form_actions(more=[Div(css_class='clearfix')],\n label=_('Salvar'), name='salvar', css_class='pull-right', disabled=True):\n\n if disabled:\n doubleclick = 'this.form.submit();this.disabled=true;'\n else:\n doubleclick = 'return true;'\n\n return FormActions(\n Submit(name, label, css_class=css_class,\n # para impedir resubmiss\u00e3o do form\n onclick=doubleclick),\n *more)\n\n\nclass SaplFormLayout(Layout):\n\n def __init__(self, *fields, cancel_label=_('Cancelar'),\n save_label=_('Salvar'), actions=None):\n\n buttons = actions\n if not buttons:\n buttons = form_actions(label=save_label, more=[\n HTML('<a href=\"{{ view.cancel_url }}\"'\n ' class=\"btn btn-inverse\">%s</a>' % cancel_label)\n if cancel_label else None])\n\n _fields = list(to_fieldsets(fields))\n if buttons:\n _fields += [to_row([(buttons, 12)])]\n super(SaplFormLayout, self).__init__(*_fields)\n\n\ndef get_field_display(obj, fieldname):\n field = ''\n try:\n field = obj._meta.get_field(fieldname)\n except Exception as e:\n \"\"\" nos casos que o fieldname n\u00e3o \u00e9 um field_model,\n ele pode ser um aggregate, annotate, um property, um manager,\n ou mesmo uma m\u00e9todo no model.\n \"\"\"\n value = getattr(obj, fieldname)\n try:\n verbose_name = value.model._meta.verbose_name\n except AttributeError:\n verbose_name = ''\n\n else:\n verbose_name = str(field.verbose_name)\\\n if hasattr(field, 'verbose_name') else ''\n\n if hasattr(field, 'choices') and field.choices:\n value = getattr(obj, 'get_%s_display' % fieldname)()\n else:\n value = getattr(obj, fieldname)\n\n str_type_from_value = str(type(value))\n str_type_from_field = str(type(field))\n\n if value is None:\n display = ''\n elif '.date' in str_type_from_value:\n display = formats.date_format(value, \"SHORT_DATE_FORMAT\")\n elif 'bool' in str_type_from_value:\n display = _('Sim') if value else _('N\u00e3o')\n elif 'ImageFieldFile' in str(type(value)):\n if value:\n display = '<img src=\"{}\" />'.format(value.url)\n else:\n display = ''\n elif 'FieldFile' in str_type_from_value:\n if value:\n display = '<a href=\"{}\">{}</a>'.format(\n value.url,\n value.name.split('/')[-1:][0])\n else:\n display = ''\n elif 'ManyRelatedManager' in str_type_from_value\\\n or 'RelatedManager' in str_type_from_value\\\n or 'GenericRelatedObjectManager' in str_type_from_value:\n display = '<ul>'\n for v in value.all():\n display += '<li>%s</li>' % str(v)\n display += '</ul>'\n if not verbose_name:\n if hasattr(field, 'related_model'):\n verbose_name = str(\n field.related_model._meta.verbose_name_plural)\n elif hasattr(field, 'model'):\n verbose_name = str(field.model._meta.verbose_name_plural)\n elif 'GenericForeignKey' in str_type_from_field:\n display = '<a href=\"{}\">{}</a>'.format(\n reverse(\n '%s:%s_detail' % (\n value._meta.app_config.name, obj.content_type.model),\n args=(value.id,)),\n value)\n else:\n display = str(value)\n return verbose_name, display\n\n\nclass CrispyLayoutFormMixin:\n\n @property\n def layout_key(self):\n if hasattr(super(CrispyLayoutFormMixin, self), 'layout_key'):\n return super(CrispyLayoutFormMixin, self).layout_key\n else:\n return self.model.__name__\n\n @property\n def layout_key_set(self):\n if hasattr(super(CrispyLayoutFormMixin, self), 'layout_key_set'):\n return super(CrispyLayoutFormMixin, self).layout_key_set\n else:\n obj = self.crud if hasattr(self, 'crud') else self\n return getattr(obj.model,\n obj.model_set).field.model.__name__\n\n def get_layout(self):\n yaml_layout = '%s/layouts.yaml' % self.model._meta.app_config.label\n return read_layout_from_yaml(yaml_layout, self.layout_key)\n\n def get_layout_set(self):\n obj = self.crud if hasattr(self, 'crud') else self\n yaml_layout = '%s/layouts.yaml' % getattr(\n obj.model, obj.model_set).field.model._meta.app_config.label\n return read_layout_from_yaml(yaml_layout, self.layout_key_set)\n\n @property\n def fields(self):\n if hasattr(self, 'form_class') and self.form_class:\n return None\n else:\n '''Returns all fields in the layout'''\n return [fieldname for legend_rows in self.get_layout()\n for row in legend_rows[1:]\n for fieldname, span in row]\n\n def get_form(self, form_class=None):\n try:\n form = super(CrispyLayoutFormMixin, self).get_form(form_class)\n except AttributeError:\n # simply return None if there is no get_form on super\n pass\n else:\n if self.layout_key:\n form.helper = FormHelper()\n form.helper.layout = SaplFormLayout(*self.get_layout())\n return form\n\n @property\n def list_field_names(self):\n '''The list of field names to display on table\n\n This base implementation returns the field names\n in the first fieldset of the layout.\n '''\n obj = self.crud if hasattr(self, 'crud') else self\n if hasattr(obj, 'list_field_names') and obj.list_field_names:\n return obj.list_field_names\n rows = self.get_layout()[0][1:]\n return [fieldname for row in rows for fieldname, __ in row]\n\n @property\n def list_field_names_set(self):\n '''The list of field names to display on table\n\n This base implementation returns the field names\n in the first fieldset of the layout.\n '''\n rows = self.get_layout_set()[0][1:]\n return [fieldname for row in rows for fieldname, __ in row]\n\n def get_column(self, fieldname, span):\n obj = self.get_object()\n\n func = None\n if '|' in fieldname:\n fieldname, func = tuple(fieldname.split('|'))\n\n if func:\n verbose_name, text = getattr(self, func)(obj, fieldname)\n else:\n verbose_name, text = get_field_display(obj, fieldname)\n\n return {\n 'id': fieldname,\n 'span': span,\n 'verbose_name': verbose_name,\n 'text': text,\n }\n\n def fk_urlize_for_detail(self, obj, fieldname):\n\n field = obj._meta.get_field(fieldname)\n value = getattr(obj, fieldname)\n\n display = '<a href=\"{}\">{}</a>'.format(\n reverse(\n '%s:%s_detail' % (\n value._meta.app_config.name, value._meta.model_name),\n args=(value.id,)),\n value)\n\n return field.verbose_name, display\n\n def m2m_urlize_for_detail(self, obj, fieldname):\n\n manager, fieldname = tuple(fieldname.split('__'))\n\n manager = getattr(obj, manager)\n\n verbose_name = manager.model._meta.verbose_name\n display = ''\n for item in manager.all():\n obj_m2m = getattr(item, fieldname)\n\n if obj == obj_m2m:\n continue\n\n verbose_name = item._meta.get_field(fieldname).verbose_name\n\n display += '<li><a href=\"{}\">{}</a></li>'.format(\n reverse(\n '%s:%s_detail' % (\n obj_m2m._meta.app_config.name, obj_m2m._meta.model_name),\n args=(obj_m2m.id,)),\n obj_m2m)\n\n display += ''\n\n if display:\n display = '<ul>%s</ul>' % display\n else:\n verbose_name = ''\n\n return verbose_name, display\n\n @property\n def layout_display(self):\n\n return [\n {'legend': legend,\n 'rows': [[self.get_column(fieldname, span)\n for fieldname, span in row]\n for row in rows]\n } for legend, rows in heads_and_tails(self.get_layout())]\n\n\ndef read_yaml_from_file(yaml_layout):\n # TODO cache this at application level\n t = template.loader.get_template(yaml_layout)\n # aqui \u00e9 importante converter para str pois, dependendo do ambiente,\n # o rtyaml pode usar yaml.CSafeLoader, que exige str ou stream\n rendered = str(t.render())\n return rtyaml.load(rendered)\n\n\ndef read_layout_from_yaml(yaml_layout, key):\n # TODO cache this at application level\n yaml = read_yaml_from_file(yaml_layout)\n base = yaml[key]\n\n def line_to_namespans(line):\n split = [cell.split(':') for cell in line.split()]\n namespans = [[s[0], int(s[1]) if len(s) > 1 else 0] for s in split]\n remaining = 12 - sum(s for n, s in namespans)\n nondefined = [ns for ns in namespans if not ns[1]]\n while nondefined:\n span = ceil(remaining / len(nondefined))\n namespan = nondefined.pop(0)\n namespan[1] = span\n remaining = remaining - span\n return list(map(tuple, namespans))\n\n return [[legend] + [line_to_namespans(l) for l in lines]\n for legend, lines in base.items()]\n", "path": "sapl/crispy_layout_mixin.py"}]}
| 3,826 | 126 |
gh_patches_debug_25052
|
rasdani/github-patches
|
git_diff
|
Pylons__pyramid-2759
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Drop Python 3.3 support
This is a placeholder for Pyramid 1.8 to drop Python 3.3 support.
Creating a new issue, splitting it off from https://github.com/Pylons/pyramid/issues/2368.
</issue>
<code>
[start of setup.py]
1 ##############################################################################
2 #
3 # Copyright (c) 2008-2013 Agendaless Consulting and Contributors.
4 # All Rights Reserved.
5 #
6 # This software is subject to the provisions of the BSD-like license at
7 # http://www.repoze.org/LICENSE.txt. A copy of the license should accompany
8 # this distribution. THIS SOFTWARE IS PROVIDED "AS IS" AND ANY AND ALL
9 # EXPRESS OR IMPLIED WARRANTIES ARE DISCLAIMED, INCLUDING, BUT NOT LIMITED TO,
10 # THE IMPLIED WARRANTIES OF TITLE, MERCHANTABILITY, AGAINST INFRINGEMENT, AND
11 # FITNESS FOR A PARTICULAR PURPOSE
12 #
13 ##############################################################################
14
15 import os
16 import sys
17
18 from setuptools import setup, find_packages
19
20 py_version = sys.version_info[:2]
21 is_pypy = '__pypy__' in sys.builtin_module_names
22
23 PY3 = py_version[0] == 3
24
25 if PY3:
26 if py_version < (3, 3) and not is_pypy: # PyPy3 masquerades as Python 3.2...
27 raise RuntimeError('On Python 3, Pyramid requires Python 3.3 or better')
28 else:
29 if py_version < (2, 6):
30 raise RuntimeError('On Python 2, Pyramid requires Python 2.6 or better')
31
32 here = os.path.abspath(os.path.dirname(__file__))
33 try:
34 with open(os.path.join(here, 'README.rst')) as f:
35 README = f.read()
36 with open(os.path.join(here, 'CHANGES.txt')) as f:
37 CHANGES = f.read()
38 except IOError:
39 README = CHANGES = ''
40
41 install_requires = [
42 'setuptools',
43 'WebOb >= 1.3.1', # request.domain and CookieProfile
44 'repoze.lru >= 0.4', # py3 compat
45 'zope.interface >= 3.8.0', # has zope.interface.registry
46 'zope.deprecation >= 3.5.0', # py3 compat
47 'venusian >= 1.0a3', # ``ignore``
48 'translationstring >= 0.4', # py3 compat
49 'PasteDeploy >= 1.5.0', # py3 compat
50 ]
51
52 tests_require = [
53 'WebTest >= 1.3.1', # py3 compat
54 ]
55
56 if not PY3:
57 tests_require.append('zope.component>=3.11.0')
58
59 docs_extras = [
60 'Sphinx >= 1.3.5',
61 'docutils',
62 'repoze.sphinx.autointerface',
63 'pylons_sphinx_latesturl',
64 'pylons-sphinx-themes',
65 'sphinxcontrib-programoutput',
66 ]
67
68 testing_extras = tests_require + [
69 'nose',
70 'coverage',
71 'virtualenv', # for scaffolding tests
72 ]
73
74 setup(name='pyramid',
75 version='1.8.dev0',
76 description='The Pyramid Web Framework, a Pylons project',
77 long_description=README + '\n\n' + CHANGES,
78 classifiers=[
79 "Development Status :: 6 - Mature",
80 "Intended Audience :: Developers",
81 "Programming Language :: Python",
82 "Programming Language :: Python :: 2.7",
83 "Programming Language :: Python :: 3",
84 "Programming Language :: Python :: 3.3",
85 "Programming Language :: Python :: 3.4",
86 "Programming Language :: Python :: 3.5",
87 "Programming Language :: Python :: Implementation :: CPython",
88 "Programming Language :: Python :: Implementation :: PyPy",
89 "Framework :: Pyramid",
90 "Topic :: Internet :: WWW/HTTP",
91 "Topic :: Internet :: WWW/HTTP :: WSGI",
92 "License :: Repoze Public License",
93 ],
94 keywords='web wsgi pylons pyramid',
95 author="Chris McDonough, Agendaless Consulting",
96 author_email="[email protected]",
97 url="https://trypyramid.com",
98 license="BSD-derived (http://www.repoze.org/LICENSE.txt)",
99 packages=find_packages(),
100 include_package_data=True,
101 zip_safe=False,
102 install_requires=install_requires,
103 extras_require={
104 'testing': testing_extras,
105 'docs': docs_extras,
106 },
107 tests_require=tests_require,
108 test_suite="pyramid.tests",
109 entry_points="""\
110 [pyramid.scaffold]
111 starter=pyramid.scaffolds:StarterProjectTemplate
112 zodb=pyramid.scaffolds:ZODBProjectTemplate
113 alchemy=pyramid.scaffolds:AlchemyProjectTemplate
114 [pyramid.pshell_runner]
115 python=pyramid.scripts.pshell:python_shell_runner
116 [console_scripts]
117 pcreate = pyramid.scripts.pcreate:main
118 pserve = pyramid.scripts.pserve:main
119 pshell = pyramid.scripts.pshell:main
120 proutes = pyramid.scripts.proutes:main
121 pviews = pyramid.scripts.pviews:main
122 ptweens = pyramid.scripts.ptweens:main
123 prequest = pyramid.scripts.prequest:main
124 pdistreport = pyramid.scripts.pdistreport:main
125 [paste.server_runner]
126 wsgiref = pyramid.scripts.pserve:wsgiref_server_runner
127 cherrypy = pyramid.scripts.pserve:cherrypy_server_runner
128 """
129 )
130
[end of setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -18,16 +18,15 @@
from setuptools import setup, find_packages
py_version = sys.version_info[:2]
-is_pypy = '__pypy__' in sys.builtin_module_names
PY3 = py_version[0] == 3
if PY3:
- if py_version < (3, 3) and not is_pypy: # PyPy3 masquerades as Python 3.2...
- raise RuntimeError('On Python 3, Pyramid requires Python 3.3 or better')
+ if py_version < (3, 4):
+ raise RuntimeError('On Python 3, Pyramid requires Python 3.4 or better')
else:
- if py_version < (2, 6):
- raise RuntimeError('On Python 2, Pyramid requires Python 2.6 or better')
+ if py_version < (2, 7):
+ raise RuntimeError('On Python 2, Pyramid requires Python 2.7 or better')
here = os.path.abspath(os.path.dirname(__file__))
try:
@@ -81,7 +80,6 @@
"Programming Language :: Python",
"Programming Language :: Python :: 2.7",
"Programming Language :: Python :: 3",
- "Programming Language :: Python :: 3.3",
"Programming Language :: Python :: 3.4",
"Programming Language :: Python :: 3.5",
"Programming Language :: Python :: Implementation :: CPython",
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -18,16 +18,15 @@\n from setuptools import setup, find_packages\n \n py_version = sys.version_info[:2]\n-is_pypy = '__pypy__' in sys.builtin_module_names\n \n PY3 = py_version[0] == 3\n \n if PY3:\n- if py_version < (3, 3) and not is_pypy: # PyPy3 masquerades as Python 3.2...\n- raise RuntimeError('On Python 3, Pyramid requires Python 3.3 or better')\n+ if py_version < (3, 4):\n+ raise RuntimeError('On Python 3, Pyramid requires Python 3.4 or better')\n else:\n- if py_version < (2, 6):\n- raise RuntimeError('On Python 2, Pyramid requires Python 2.6 or better')\n+ if py_version < (2, 7):\n+ raise RuntimeError('On Python 2, Pyramid requires Python 2.7 or better')\n \n here = os.path.abspath(os.path.dirname(__file__))\n try:\n@@ -81,7 +80,6 @@\n \"Programming Language :: Python\",\n \"Programming Language :: Python :: 2.7\",\n \"Programming Language :: Python :: 3\",\n- \"Programming Language :: Python :: 3.3\",\n \"Programming Language :: Python :: 3.4\",\n \"Programming Language :: Python :: 3.5\",\n \"Programming Language :: Python :: Implementation :: CPython\",\n", "issue": "Drop Python 3.3 support\nThis is a placeholder for Pyramid 1.8 to drop Python 3.3 support.\n\nCreating a new issue, splitting it off from https://github.com/Pylons/pyramid/issues/2368.\n\n", "before_files": [{"content": "##############################################################################\n#\n# Copyright (c) 2008-2013 Agendaless Consulting and Contributors.\n# All Rights Reserved.\n#\n# This software is subject to the provisions of the BSD-like license at\n# http://www.repoze.org/LICENSE.txt. A copy of the license should accompany\n# this distribution. THIS SOFTWARE IS PROVIDED \"AS IS\" AND ANY AND ALL\n# EXPRESS OR IMPLIED WARRANTIES ARE DISCLAIMED, INCLUDING, BUT NOT LIMITED TO,\n# THE IMPLIED WARRANTIES OF TITLE, MERCHANTABILITY, AGAINST INFRINGEMENT, AND\n# FITNESS FOR A PARTICULAR PURPOSE\n#\n##############################################################################\n\nimport os\nimport sys\n\nfrom setuptools import setup, find_packages\n\npy_version = sys.version_info[:2]\nis_pypy = '__pypy__' in sys.builtin_module_names\n\nPY3 = py_version[0] == 3\n\nif PY3:\n if py_version < (3, 3) and not is_pypy: # PyPy3 masquerades as Python 3.2...\n raise RuntimeError('On Python 3, Pyramid requires Python 3.3 or better')\nelse:\n if py_version < (2, 6):\n raise RuntimeError('On Python 2, Pyramid requires Python 2.6 or better')\n\nhere = os.path.abspath(os.path.dirname(__file__))\ntry:\n with open(os.path.join(here, 'README.rst')) as f:\n README = f.read()\n with open(os.path.join(here, 'CHANGES.txt')) as f:\n CHANGES = f.read()\nexcept IOError:\n README = CHANGES = ''\n\ninstall_requires = [\n 'setuptools',\n 'WebOb >= 1.3.1', # request.domain and CookieProfile\n 'repoze.lru >= 0.4', # py3 compat\n 'zope.interface >= 3.8.0', # has zope.interface.registry\n 'zope.deprecation >= 3.5.0', # py3 compat\n 'venusian >= 1.0a3', # ``ignore``\n 'translationstring >= 0.4', # py3 compat\n 'PasteDeploy >= 1.5.0', # py3 compat\n ]\n\ntests_require = [\n 'WebTest >= 1.3.1', # py3 compat\n ]\n\nif not PY3:\n tests_require.append('zope.component>=3.11.0')\n\ndocs_extras = [\n 'Sphinx >= 1.3.5',\n 'docutils',\n 'repoze.sphinx.autointerface',\n 'pylons_sphinx_latesturl',\n 'pylons-sphinx-themes',\n 'sphinxcontrib-programoutput',\n ]\n\ntesting_extras = tests_require + [\n 'nose',\n 'coverage',\n 'virtualenv', # for scaffolding tests\n ]\n\nsetup(name='pyramid',\n version='1.8.dev0',\n description='The Pyramid Web Framework, a Pylons project',\n long_description=README + '\\n\\n' + CHANGES,\n classifiers=[\n \"Development Status :: 6 - Mature\",\n \"Intended Audience :: Developers\",\n \"Programming Language :: Python\",\n \"Programming Language :: Python :: 2.7\",\n \"Programming Language :: Python :: 3\",\n \"Programming Language :: Python :: 3.3\",\n \"Programming Language :: Python :: 3.4\",\n \"Programming Language :: Python :: 3.5\",\n \"Programming Language :: Python :: Implementation :: CPython\",\n \"Programming Language :: Python :: Implementation :: PyPy\",\n \"Framework :: Pyramid\",\n \"Topic :: Internet :: WWW/HTTP\",\n \"Topic :: Internet :: WWW/HTTP :: WSGI\",\n \"License :: Repoze Public License\",\n ],\n keywords='web wsgi pylons pyramid',\n author=\"Chris McDonough, Agendaless Consulting\",\n author_email=\"[email protected]\",\n url=\"https://trypyramid.com\",\n license=\"BSD-derived (http://www.repoze.org/LICENSE.txt)\",\n packages=find_packages(),\n include_package_data=True,\n zip_safe=False,\n install_requires=install_requires,\n extras_require={\n 'testing': testing_extras,\n 'docs': docs_extras,\n },\n tests_require=tests_require,\n test_suite=\"pyramid.tests\",\n entry_points=\"\"\"\\\n [pyramid.scaffold]\n starter=pyramid.scaffolds:StarterProjectTemplate\n zodb=pyramid.scaffolds:ZODBProjectTemplate\n alchemy=pyramid.scaffolds:AlchemyProjectTemplate\n [pyramid.pshell_runner]\n python=pyramid.scripts.pshell:python_shell_runner\n [console_scripts]\n pcreate = pyramid.scripts.pcreate:main\n pserve = pyramid.scripts.pserve:main\n pshell = pyramid.scripts.pshell:main\n proutes = pyramid.scripts.proutes:main\n pviews = pyramid.scripts.pviews:main\n ptweens = pyramid.scripts.ptweens:main\n prequest = pyramid.scripts.prequest:main\n pdistreport = pyramid.scripts.pdistreport:main\n [paste.server_runner]\n wsgiref = pyramid.scripts.pserve:wsgiref_server_runner\n cherrypy = pyramid.scripts.pserve:cherrypy_server_runner\n \"\"\"\n )\n", "path": "setup.py"}]}
| 2,020 | 337 |
gh_patches_debug_19166
|
rasdani/github-patches
|
git_diff
|
airctic__icevision-870
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Add EfficientDet AdvProp-AA
## 🚀 Feature
Add EfficientDet AdvProp-AA pretrained backbones for D0-D5
See https://github.com/google/automl/blob/master/efficientdet/Det-AdvProp.md
</issue>
<code>
[start of icevision/models/ross/efficientdet/backbones.py]
1 __all__ = [
2 "tf_lite0",
3 "tf_lite1",
4 "tf_lite2",
5 "tf_lite3",
6 "tf_d0",
7 "tf_d1",
8 "tf_d2",
9 "tf_d3",
10 "tf_d4",
11 "tf_d5",
12 "tf_d6",
13 "tf_d7",
14 "tf_d7x",
15 "d0",
16 "d1",
17 "d2",
18 "d3",
19 "d4",
20 "d5",
21 "d6",
22 "d7",
23 "d7x",
24 ]
25
26 from icevision.models.ross.efficientdet.utils import *
27
28
29 tf_lite0 = EfficientDetBackboneConfig(model_name="tf_efficientdet_lite0")
30 tf_lite1 = EfficientDetBackboneConfig(model_name="tf_efficientdet_lite1")
31 tf_lite2 = EfficientDetBackboneConfig(model_name="tf_efficientdet_lite2")
32 tf_lite3 = EfficientDetBackboneConfig(model_name="tf_efficientdet_lite3")
33
34 tf_d0 = EfficientDetBackboneConfig(model_name="tf_efficientdet_d0")
35 tf_d1 = EfficientDetBackboneConfig(model_name="tf_efficientdet_d1")
36 tf_d2 = EfficientDetBackboneConfig(model_name="tf_efficientdet_d2")
37 tf_d3 = EfficientDetBackboneConfig(model_name="tf_efficientdet_d3")
38 tf_d4 = EfficientDetBackboneConfig(model_name="tf_efficientdet_d4")
39 tf_d5 = EfficientDetBackboneConfig(model_name="tf_efficientdet_d5")
40 tf_d6 = EfficientDetBackboneConfig(model_name="tf_efficientdet_d6")
41 tf_d7 = EfficientDetBackboneConfig(model_name="tf_efficientdet_d7")
42 tf_d7x = EfficientDetBackboneConfig(model_name="tf_efficientdet_d7x")
43
44 d0 = EfficientDetBackboneConfig(model_name="efficientdet_d0")
45 d1 = EfficientDetBackboneConfig(model_name="efficientdet_d1")
46 d2 = EfficientDetBackboneConfig(model_name="efficientdet_d2")
47 d3 = EfficientDetBackboneConfig(model_name="efficientdet_d3")
48 d4 = EfficientDetBackboneConfig(model_name="efficientdet_d4")
49 d5 = EfficientDetBackboneConfig(model_name="efficientdet_d5")
50 d6 = EfficientDetBackboneConfig(model_name="efficientdet_d6")
51 d7 = EfficientDetBackboneConfig(model_name="efficientdet_d7")
52 d7x = EfficientDetBackboneConfig(model_name="efficientdet_d7x")
53
[end of icevision/models/ross/efficientdet/backbones.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/icevision/models/ross/efficientdet/backbones.py b/icevision/models/ross/efficientdet/backbones.py
--- a/icevision/models/ross/efficientdet/backbones.py
+++ b/icevision/models/ross/efficientdet/backbones.py
@@ -21,6 +21,12 @@
"d6",
"d7",
"d7x",
+ "tf_d0_ap",
+ "tf_d1_ap",
+ "tf_d2_ap",
+ "tf_d3_ap",
+ "tf_d4_ap",
+ "tf_d5_ap",
]
from icevision.models.ross.efficientdet.utils import *
@@ -50,3 +56,10 @@
d6 = EfficientDetBackboneConfig(model_name="efficientdet_d6")
d7 = EfficientDetBackboneConfig(model_name="efficientdet_d7")
d7x = EfficientDetBackboneConfig(model_name="efficientdet_d7x")
+
+tf_d0_ap = EfficientDetBackboneConfig(model_name="tf_efficientdet_d0_ap")
+tf_d1_ap = EfficientDetBackboneConfig(model_name="tf_efficientdet_d1_ap")
+tf_d2_ap = EfficientDetBackboneConfig(model_name="tf_efficientdet_d2_ap")
+tf_d3_ap = EfficientDetBackboneConfig(model_name="tf_efficientdet_d3_ap")
+tf_d4_ap = EfficientDetBackboneConfig(model_name="tf_efficientdet_d4_ap")
+tf_d5_ap = EfficientDetBackboneConfig(model_name="tf_efficientdet_d5_ap")
|
{"golden_diff": "diff --git a/icevision/models/ross/efficientdet/backbones.py b/icevision/models/ross/efficientdet/backbones.py\n--- a/icevision/models/ross/efficientdet/backbones.py\n+++ b/icevision/models/ross/efficientdet/backbones.py\n@@ -21,6 +21,12 @@\n \"d6\",\n \"d7\",\n \"d7x\",\n+ \"tf_d0_ap\",\n+ \"tf_d1_ap\",\n+ \"tf_d2_ap\",\n+ \"tf_d3_ap\",\n+ \"tf_d4_ap\",\n+ \"tf_d5_ap\",\n ]\n \n from icevision.models.ross.efficientdet.utils import *\n@@ -50,3 +56,10 @@\n d6 = EfficientDetBackboneConfig(model_name=\"efficientdet_d6\")\n d7 = EfficientDetBackboneConfig(model_name=\"efficientdet_d7\")\n d7x = EfficientDetBackboneConfig(model_name=\"efficientdet_d7x\")\n+\n+tf_d0_ap = EfficientDetBackboneConfig(model_name=\"tf_efficientdet_d0_ap\")\n+tf_d1_ap = EfficientDetBackboneConfig(model_name=\"tf_efficientdet_d1_ap\")\n+tf_d2_ap = EfficientDetBackboneConfig(model_name=\"tf_efficientdet_d2_ap\")\n+tf_d3_ap = EfficientDetBackboneConfig(model_name=\"tf_efficientdet_d3_ap\")\n+tf_d4_ap = EfficientDetBackboneConfig(model_name=\"tf_efficientdet_d4_ap\")\n+tf_d5_ap = EfficientDetBackboneConfig(model_name=\"tf_efficientdet_d5_ap\")\n", "issue": "Add EfficientDet AdvProp-AA\n## \ud83d\ude80 Feature\r\nAdd EfficientDet AdvProp-AA pretrained backbones for D0-D5\r\n\r\nSee https://github.com/google/automl/blob/master/efficientdet/Det-AdvProp.md\n", "before_files": [{"content": "__all__ = [\n \"tf_lite0\",\n \"tf_lite1\",\n \"tf_lite2\",\n \"tf_lite3\",\n \"tf_d0\",\n \"tf_d1\",\n \"tf_d2\",\n \"tf_d3\",\n \"tf_d4\",\n \"tf_d5\",\n \"tf_d6\",\n \"tf_d7\",\n \"tf_d7x\",\n \"d0\",\n \"d1\",\n \"d2\",\n \"d3\",\n \"d4\",\n \"d5\",\n \"d6\",\n \"d7\",\n \"d7x\",\n]\n\nfrom icevision.models.ross.efficientdet.utils import *\n\n\ntf_lite0 = EfficientDetBackboneConfig(model_name=\"tf_efficientdet_lite0\")\ntf_lite1 = EfficientDetBackboneConfig(model_name=\"tf_efficientdet_lite1\")\ntf_lite2 = EfficientDetBackboneConfig(model_name=\"tf_efficientdet_lite2\")\ntf_lite3 = EfficientDetBackboneConfig(model_name=\"tf_efficientdet_lite3\")\n\ntf_d0 = EfficientDetBackboneConfig(model_name=\"tf_efficientdet_d0\")\ntf_d1 = EfficientDetBackboneConfig(model_name=\"tf_efficientdet_d1\")\ntf_d2 = EfficientDetBackboneConfig(model_name=\"tf_efficientdet_d2\")\ntf_d3 = EfficientDetBackboneConfig(model_name=\"tf_efficientdet_d3\")\ntf_d4 = EfficientDetBackboneConfig(model_name=\"tf_efficientdet_d4\")\ntf_d5 = EfficientDetBackboneConfig(model_name=\"tf_efficientdet_d5\")\ntf_d6 = EfficientDetBackboneConfig(model_name=\"tf_efficientdet_d6\")\ntf_d7 = EfficientDetBackboneConfig(model_name=\"tf_efficientdet_d7\")\ntf_d7x = EfficientDetBackboneConfig(model_name=\"tf_efficientdet_d7x\")\n\nd0 = EfficientDetBackboneConfig(model_name=\"efficientdet_d0\")\nd1 = EfficientDetBackboneConfig(model_name=\"efficientdet_d1\")\nd2 = EfficientDetBackboneConfig(model_name=\"efficientdet_d2\")\nd3 = EfficientDetBackboneConfig(model_name=\"efficientdet_d3\")\nd4 = EfficientDetBackboneConfig(model_name=\"efficientdet_d4\")\nd5 = EfficientDetBackboneConfig(model_name=\"efficientdet_d5\")\nd6 = EfficientDetBackboneConfig(model_name=\"efficientdet_d6\")\nd7 = EfficientDetBackboneConfig(model_name=\"efficientdet_d7\")\nd7x = EfficientDetBackboneConfig(model_name=\"efficientdet_d7x\")\n", "path": "icevision/models/ross/efficientdet/backbones.py"}]}
| 1,238 | 348 |
gh_patches_debug_5896
|
rasdani/github-patches
|
git_diff
|
buildbot__buildbot-7295
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Address PEP 706 - Filter for tarfile.extractall
Given proposal improves security of tarfile extraction to help avoid CVE-2007-4559.
- In Python 3.12-3.13, a DeprecationWarning is emitted and extraction uses `fully_trusted` filter.
- In Python 3.14+, it will use the `data` filter.
It seems given proposal was backported also to older version of Python.
Reference: https://peps.python.org/pep-0706/
</issue>
<code>
[start of master/buildbot/process/remotetransfer.py]
1 # This file is part of Buildbot. Buildbot is free software: you can
2 # redistribute it and/or modify it under the terms of the GNU General Public
3 # License as published by the Free Software Foundation, version 2.
4 #
5 # This program is distributed in the hope that it will be useful, but WITHOUT
6 # ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS
7 # FOR A PARTICULAR PURPOSE. See the GNU General Public License for more
8 # details.
9 #
10 # You should have received a copy of the GNU General Public License along with
11 # this program; if not, write to the Free Software Foundation, Inc., 51
12 # Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA.
13 #
14 # Copyright Buildbot Team Members
15
16 """
17 module for regrouping all FileWriterImpl and FileReaderImpl away from steps
18 """
19
20 import os
21 import tarfile
22 import tempfile
23 from io import BytesIO
24
25 from buildbot.util import bytes2unicode
26 from buildbot.util import unicode2bytes
27 from buildbot.worker.protocols import base
28
29
30 class FileWriter(base.FileWriterImpl):
31
32 """
33 Helper class that acts as a file-object with write access
34 """
35
36 def __init__(self, destfile, maxsize, mode):
37 # Create missing directories.
38 destfile = os.path.abspath(destfile)
39 dirname = os.path.dirname(destfile)
40 if not os.path.exists(dirname):
41 os.makedirs(dirname)
42
43 self.destfile = destfile
44 self.mode = mode
45 fd, self.tmpname = tempfile.mkstemp(dir=dirname, prefix='buildbot-transfer-')
46 self.fp = os.fdopen(fd, 'wb')
47 self.remaining = maxsize
48
49 def remote_write(self, data):
50 """
51 Called from remote worker to write L{data} to L{fp} within boundaries
52 of L{maxsize}
53
54 @type data: C{string}
55 @param data: String of data to write
56 """
57 data = unicode2bytes(data)
58 if self.remaining is not None:
59 if len(data) > self.remaining:
60 data = data[:self.remaining]
61 self.fp.write(data)
62 self.remaining = self.remaining - len(data)
63 else:
64 self.fp.write(data)
65
66 def remote_utime(self, accessed_modified):
67 os.utime(self.destfile, accessed_modified)
68
69 def remote_close(self):
70 """
71 Called by remote worker to state that no more data will be transferred
72 """
73 self.fp.close()
74 self.fp = None
75 # on windows, os.rename does not automatically unlink, so do it
76 # manually
77 if os.path.exists(self.destfile):
78 os.unlink(self.destfile)
79 os.rename(self.tmpname, self.destfile)
80 self.tmpname = None
81 if self.mode is not None:
82 os.chmod(self.destfile, self.mode)
83
84 def cancel(self):
85 # unclean shutdown, the file is probably truncated, so delete it
86 # altogether rather than deliver a corrupted file
87 fp = getattr(self, "fp", None)
88 if fp:
89 fp.close()
90 if self.destfile and os.path.exists(self.destfile):
91 os.unlink(self.destfile)
92 if self.tmpname and os.path.exists(self.tmpname):
93 os.unlink(self.tmpname)
94
95
96 class DirectoryWriter(FileWriter):
97
98 """
99 A DirectoryWriter is implemented as a FileWriter, with an added post-processing
100 step to unpack the archive, once the transfer has completed.
101 """
102
103 def __init__(self, destroot, maxsize, compress, mode):
104 self.destroot = destroot
105 self.compress = compress
106
107 self.fd, self.tarname = tempfile.mkstemp(prefix='buildbot-transfer-')
108 os.close(self.fd)
109
110 super().__init__(self.tarname, maxsize, mode)
111
112 def remote_unpack(self):
113 """
114 Called by remote worker to state that no more data will be transferred
115 """
116 # Make sure remote_close is called, otherwise atomic rename won't happen
117 self.remote_close()
118
119 # Map configured compression to a TarFile setting
120 if self.compress == 'bz2':
121 mode = 'r|bz2'
122 elif self.compress == 'gz':
123 mode = 'r|gz'
124 else:
125 mode = 'r'
126
127 # Unpack archive and clean up after self
128 with tarfile.open(name=self.tarname, mode=mode) as archive:
129 archive.extractall(path=self.destroot)
130 os.remove(self.tarname)
131
132
133 class FileReader(base.FileReaderImpl):
134
135 """
136 Helper class that acts as a file-object with read access
137 """
138
139 def __init__(self, fp):
140 self.fp = fp
141
142 def remote_read(self, maxlength):
143 """
144 Called from remote worker to read at most L{maxlength} bytes of data
145
146 @type maxlength: C{integer}
147 @param maxlength: Maximum number of data bytes that can be returned
148
149 @return: Data read from L{fp}
150 @rtype: C{string} of bytes read from file
151 """
152 if self.fp is None:
153 return ''
154
155 data = self.fp.read(maxlength)
156 return data
157
158 def remote_close(self):
159 """
160 Called by remote worker to state that no more data will be transferred
161 """
162 if self.fp is not None:
163 self.fp.close()
164 self.fp = None
165
166
167 class StringFileWriter(base.FileWriterImpl):
168
169 """
170 FileWriter class that just puts received data into a buffer.
171
172 Used to upload a file from worker for inline processing rather than
173 writing into a file on master.
174 """
175
176 def __init__(self):
177 self.buffer = ""
178
179 def remote_write(self, data):
180 self.buffer += bytes2unicode(data)
181
182 def remote_close(self):
183 pass
184
185
186 class StringFileReader(FileReader):
187
188 """
189 FileWriter class that just buid send data from a string.
190
191 Used to download a file to worker from local string rather than first
192 writing into a file on master.
193 """
194
195 def __init__(self, s):
196 s = unicode2bytes(s)
197 super().__init__(BytesIO(s))
198
[end of master/buildbot/process/remotetransfer.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/master/buildbot/process/remotetransfer.py b/master/buildbot/process/remotetransfer.py
--- a/master/buildbot/process/remotetransfer.py
+++ b/master/buildbot/process/remotetransfer.py
@@ -126,7 +126,10 @@
# Unpack archive and clean up after self
with tarfile.open(name=self.tarname, mode=mode) as archive:
- archive.extractall(path=self.destroot)
+ if hasattr(tarfile, 'data_filter'):
+ archive.extractall(path=self.destroot, filter='data')
+ else:
+ archive.extractall(path=self.destroot)
os.remove(self.tarname)
|
{"golden_diff": "diff --git a/master/buildbot/process/remotetransfer.py b/master/buildbot/process/remotetransfer.py\n--- a/master/buildbot/process/remotetransfer.py\n+++ b/master/buildbot/process/remotetransfer.py\n@@ -126,7 +126,10 @@\n \n # Unpack archive and clean up after self\n with tarfile.open(name=self.tarname, mode=mode) as archive:\n- archive.extractall(path=self.destroot)\n+ if hasattr(tarfile, 'data_filter'):\n+ archive.extractall(path=self.destroot, filter='data')\n+ else:\n+ archive.extractall(path=self.destroot)\n os.remove(self.tarname)\n", "issue": "Address PEP 706 - Filter for tarfile.extractall\nGiven proposal improves security of tarfile extraction to help avoid CVE-2007-4559.\r\n\r\n- In Python 3.12-3.13, a DeprecationWarning is emitted and extraction uses `fully_trusted` filter.\r\n- In Python 3.14+, it will use the `data` filter.\r\n\r\nIt seems given proposal was backported also to older version of Python.\r\n\r\nReference: https://peps.python.org/pep-0706/\r\n\n", "before_files": [{"content": "# This file is part of Buildbot. Buildbot is free software: you can\n# redistribute it and/or modify it under the terms of the GNU General Public\n# License as published by the Free Software Foundation, version 2.\n#\n# This program is distributed in the hope that it will be useful, but WITHOUT\n# ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS\n# FOR A PARTICULAR PURPOSE. See the GNU General Public License for more\n# details.\n#\n# You should have received a copy of the GNU General Public License along with\n# this program; if not, write to the Free Software Foundation, Inc., 51\n# Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA.\n#\n# Copyright Buildbot Team Members\n\n\"\"\"\nmodule for regrouping all FileWriterImpl and FileReaderImpl away from steps\n\"\"\"\n\nimport os\nimport tarfile\nimport tempfile\nfrom io import BytesIO\n\nfrom buildbot.util import bytes2unicode\nfrom buildbot.util import unicode2bytes\nfrom buildbot.worker.protocols import base\n\n\nclass FileWriter(base.FileWriterImpl):\n\n \"\"\"\n Helper class that acts as a file-object with write access\n \"\"\"\n\n def __init__(self, destfile, maxsize, mode):\n # Create missing directories.\n destfile = os.path.abspath(destfile)\n dirname = os.path.dirname(destfile)\n if not os.path.exists(dirname):\n os.makedirs(dirname)\n\n self.destfile = destfile\n self.mode = mode\n fd, self.tmpname = tempfile.mkstemp(dir=dirname, prefix='buildbot-transfer-')\n self.fp = os.fdopen(fd, 'wb')\n self.remaining = maxsize\n\n def remote_write(self, data):\n \"\"\"\n Called from remote worker to write L{data} to L{fp} within boundaries\n of L{maxsize}\n\n @type data: C{string}\n @param data: String of data to write\n \"\"\"\n data = unicode2bytes(data)\n if self.remaining is not None:\n if len(data) > self.remaining:\n data = data[:self.remaining]\n self.fp.write(data)\n self.remaining = self.remaining - len(data)\n else:\n self.fp.write(data)\n\n def remote_utime(self, accessed_modified):\n os.utime(self.destfile, accessed_modified)\n\n def remote_close(self):\n \"\"\"\n Called by remote worker to state that no more data will be transferred\n \"\"\"\n self.fp.close()\n self.fp = None\n # on windows, os.rename does not automatically unlink, so do it\n # manually\n if os.path.exists(self.destfile):\n os.unlink(self.destfile)\n os.rename(self.tmpname, self.destfile)\n self.tmpname = None\n if self.mode is not None:\n os.chmod(self.destfile, self.mode)\n\n def cancel(self):\n # unclean shutdown, the file is probably truncated, so delete it\n # altogether rather than deliver a corrupted file\n fp = getattr(self, \"fp\", None)\n if fp:\n fp.close()\n if self.destfile and os.path.exists(self.destfile):\n os.unlink(self.destfile)\n if self.tmpname and os.path.exists(self.tmpname):\n os.unlink(self.tmpname)\n\n\nclass DirectoryWriter(FileWriter):\n\n \"\"\"\n A DirectoryWriter is implemented as a FileWriter, with an added post-processing\n step to unpack the archive, once the transfer has completed.\n \"\"\"\n\n def __init__(self, destroot, maxsize, compress, mode):\n self.destroot = destroot\n self.compress = compress\n\n self.fd, self.tarname = tempfile.mkstemp(prefix='buildbot-transfer-')\n os.close(self.fd)\n\n super().__init__(self.tarname, maxsize, mode)\n\n def remote_unpack(self):\n \"\"\"\n Called by remote worker to state that no more data will be transferred\n \"\"\"\n # Make sure remote_close is called, otherwise atomic rename won't happen\n self.remote_close()\n\n # Map configured compression to a TarFile setting\n if self.compress == 'bz2':\n mode = 'r|bz2'\n elif self.compress == 'gz':\n mode = 'r|gz'\n else:\n mode = 'r'\n\n # Unpack archive and clean up after self\n with tarfile.open(name=self.tarname, mode=mode) as archive:\n archive.extractall(path=self.destroot)\n os.remove(self.tarname)\n\n\nclass FileReader(base.FileReaderImpl):\n\n \"\"\"\n Helper class that acts as a file-object with read access\n \"\"\"\n\n def __init__(self, fp):\n self.fp = fp\n\n def remote_read(self, maxlength):\n \"\"\"\n Called from remote worker to read at most L{maxlength} bytes of data\n\n @type maxlength: C{integer}\n @param maxlength: Maximum number of data bytes that can be returned\n\n @return: Data read from L{fp}\n @rtype: C{string} of bytes read from file\n \"\"\"\n if self.fp is None:\n return ''\n\n data = self.fp.read(maxlength)\n return data\n\n def remote_close(self):\n \"\"\"\n Called by remote worker to state that no more data will be transferred\n \"\"\"\n if self.fp is not None:\n self.fp.close()\n self.fp = None\n\n\nclass StringFileWriter(base.FileWriterImpl):\n\n \"\"\"\n FileWriter class that just puts received data into a buffer.\n\n Used to upload a file from worker for inline processing rather than\n writing into a file on master.\n \"\"\"\n\n def __init__(self):\n self.buffer = \"\"\n\n def remote_write(self, data):\n self.buffer += bytes2unicode(data)\n\n def remote_close(self):\n pass\n\n\nclass StringFileReader(FileReader):\n\n \"\"\"\n FileWriter class that just buid send data from a string.\n\n Used to download a file to worker from local string rather than first\n writing into a file on master.\n \"\"\"\n\n def __init__(self, s):\n s = unicode2bytes(s)\n super().__init__(BytesIO(s))\n", "path": "master/buildbot/process/remotetransfer.py"}]}
| 2,484 | 153 |
gh_patches_debug_20891
|
rasdani/github-patches
|
git_diff
|
zigpy__zha-device-handlers-392
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[Device Support Request] Add support for updated Legrand Dimmer switch w/o neutral
**Is your feature request related to a problem? Please describe.**
I've updated the firmware of my Legrand Dimmer switch w/o neutral for which support was added in https://github.com/zigpy/zha-device-handlers/issues/299
Before OTA upgrade:
- app_version: 0
- hw_version: 1
- stack_version: 64
- sw_build_id: 01a (26)
- zcl_version: 2
- Firmware: 0x03401a00
After OTA upgrade (2020-06-08):
- app_version: 0
- hw_version: 6
- stack_version: 66
- sw_build_id: 02b (43)
- zcl_version: 2
- Firmware: 0x002b4203
And now it reports a new `GreenPowerProxy` endpoint with id 242:
```
{
"node_descriptor": "<NodeDescriptor byte1=17 byte2=64 mac_capability_flags=142 manufacturer_code=4129 maximum_buffer_size=89 maximum_incoming_transfer_size=63 server_mask=10752 maximum_outgoing_transfer_size=63 descriptor_capability_field=0>",
"endpoints": {
"1": {
"profile_id": 260,
"device_type": "0x0100",
"in_clusters": [
"0x0000",
"0x0003",
"0x0004",
"0x0005",
"0x0006",
"0x0008",
"0x000f",
"0xfc01"
],
"out_clusters": [
"0x0000",
"0x0019",
"0xfc01"
]
},
"242": {
"profile_id": 41440,
"device_type": "0x0061",
"in_clusters": [],
"out_clusters": [
"0x0021"
]
}
},
"manufacturer": " Legrand",
"model": " Dimmer switch w/o neutral",
"class": "zigpy.device.Device"
}
```
The issue is that prevents the quirk from matching:
```
2020-06-17 06:45:05 DEBUG (MainThread) [zigpy.quirks.registry] Checking quirks for Legrand Dimmer switch w/o neutral (00:04:74:00:00:8b:0e:a2)
2020-06-17 06:45:05 DEBUG (MainThread) [zigpy.quirks.registry] Considering <class 'zhaquirks.legrand.dimmer.DimmerWithoutNeutral'>
2020-06-17 06:45:05 DEBUG (MainThread) [zigpy.quirks.registry] Fail because endpoint list mismatch: {1} {1, 242}
```
**Describe the solution you'd like**
Could the quirk be updated to also support new firmwares?
**Device signature - this can be acquired by removing the device from ZHA and pairing it again from the add devices screen. Be sure to add the entire content of the log panel after pairing the device to a code block below this line.**
TODO
**Additional context**

</issue>
<code>
[start of zhaquirks/legrand/dimmer.py]
1 """Device handler for Legrand Dimmer switch w/o neutral."""
2 from zigpy.profiles import zha
3 from zigpy.quirks import CustomCluster, CustomDevice
4 import zigpy.types as t
5 from zigpy.zcl.clusters.general import (
6 Basic,
7 BinaryInput,
8 Groups,
9 Identify,
10 LevelControl,
11 OnOff,
12 Ota,
13 Scenes,
14 )
15 from zigpy.zcl.clusters.manufacturer_specific import ManufacturerSpecificCluster
16
17 from . import LEGRAND
18 from ..const import (
19 DEVICE_TYPE,
20 ENDPOINTS,
21 INPUT_CLUSTERS,
22 MODELS_INFO,
23 OUTPUT_CLUSTERS,
24 PROFILE_ID,
25 )
26
27 MANUFACTURER_SPECIFIC_CLUSTER_ID = 0xFC01 # decimal = 64513
28
29
30 class LegrandCluster(CustomCluster, ManufacturerSpecificCluster):
31 """LegrandCluster."""
32
33 cluster_id = MANUFACTURER_SPECIFIC_CLUSTER_ID
34 name = "LegrandCluster"
35 ep_attribute = "legrand_cluster"
36 attributes = {
37 0x0000: ("dimmer", t.data16),
38 0x0001: ("led_dark", t.Bool),
39 0x0002: ("led_on", t.Bool),
40 }
41 server_commands = {}
42 client_commands = {}
43
44
45 class DimmerWithoutNeutral(CustomDevice):
46 """Dimmer switch w/o neutral."""
47
48 signature = {
49 # <SimpleDescriptor endpoint=1 profile=260 device_type=256
50 # device_version=1
51 # input_clusters=[0, 3, 4, 8, 6, 5, 15, 64513]
52 # output_clusters=[0, 64513, 25]>
53 MODELS_INFO: [(f" {LEGRAND}", " Dimmer switch w/o neutral")],
54 ENDPOINTS: {
55 1: {
56 PROFILE_ID: zha.PROFILE_ID,
57 DEVICE_TYPE: zha.DeviceType.ON_OFF_LIGHT,
58 INPUT_CLUSTERS: [
59 Basic.cluster_id,
60 Identify.cluster_id,
61 Groups.cluster_id,
62 OnOff.cluster_id,
63 LevelControl.cluster_id,
64 Scenes.cluster_id,
65 BinaryInput.cluster_id,
66 MANUFACTURER_SPECIFIC_CLUSTER_ID,
67 ],
68 OUTPUT_CLUSTERS: [
69 Basic.cluster_id,
70 MANUFACTURER_SPECIFIC_CLUSTER_ID,
71 Ota.cluster_id,
72 ],
73 }
74 },
75 }
76
77 replacement = {
78 ENDPOINTS: {
79 1: {
80 PROFILE_ID: zha.PROFILE_ID,
81 DEVICE_TYPE: zha.DeviceType.ON_OFF_LIGHT,
82 INPUT_CLUSTERS: [
83 Basic.cluster_id,
84 Identify.cluster_id,
85 Groups.cluster_id,
86 OnOff.cluster_id,
87 LevelControl.cluster_id,
88 Scenes.cluster_id,
89 BinaryInput.cluster_id,
90 LegrandCluster,
91 ],
92 OUTPUT_CLUSTERS: [Basic.cluster_id, LegrandCluster, Ota.cluster_id],
93 }
94 }
95 }
96
[end of zhaquirks/legrand/dimmer.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/zhaquirks/legrand/dimmer.py b/zhaquirks/legrand/dimmer.py
--- a/zhaquirks/legrand/dimmer.py
+++ b/zhaquirks/legrand/dimmer.py
@@ -93,3 +93,42 @@
}
}
}
+
+
+class DimmerWithoutNeutral2(DimmerWithoutNeutral):
+ """Dimmer switch w/o neutral 2."""
+
+ signature = {
+ # <SimpleDescriptor endpoint=1 profile=260 device_type=256
+ # device_version=1
+ # input_clusters=[0, 3, 4, 8, 6, 5, 15, 64513]
+ # output_clusters=[0, 64513, 25]>
+ MODELS_INFO: [(f" {LEGRAND}", " Dimmer switch w/o neutral")],
+ ENDPOINTS: {
+ 1: {
+ PROFILE_ID: zha.PROFILE_ID,
+ DEVICE_TYPE: zha.DeviceType.ON_OFF_LIGHT,
+ INPUT_CLUSTERS: [
+ Basic.cluster_id,
+ Identify.cluster_id,
+ Groups.cluster_id,
+ OnOff.cluster_id,
+ LevelControl.cluster_id,
+ Scenes.cluster_id,
+ BinaryInput.cluster_id,
+ MANUFACTURER_SPECIFIC_CLUSTER_ID,
+ ],
+ OUTPUT_CLUSTERS: [
+ Basic.cluster_id,
+ MANUFACTURER_SPECIFIC_CLUSTER_ID,
+ Ota.cluster_id,
+ ],
+ },
+ 242: {
+ PROFILE_ID: 41440,
+ DEVICE_TYPE: 0x0061,
+ INPUT_CLUSTERS: [],
+ OUTPUT_CLUSTERS: [0x0021],
+ },
+ },
+ }
|
{"golden_diff": "diff --git a/zhaquirks/legrand/dimmer.py b/zhaquirks/legrand/dimmer.py\n--- a/zhaquirks/legrand/dimmer.py\n+++ b/zhaquirks/legrand/dimmer.py\n@@ -93,3 +93,42 @@\n }\n }\n }\n+\n+\n+class DimmerWithoutNeutral2(DimmerWithoutNeutral):\n+ \"\"\"Dimmer switch w/o neutral 2.\"\"\"\n+\n+ signature = {\n+ # <SimpleDescriptor endpoint=1 profile=260 device_type=256\n+ # device_version=1\n+ # input_clusters=[0, 3, 4, 8, 6, 5, 15, 64513]\n+ # output_clusters=[0, 64513, 25]>\n+ MODELS_INFO: [(f\" {LEGRAND}\", \" Dimmer switch w/o neutral\")],\n+ ENDPOINTS: {\n+ 1: {\n+ PROFILE_ID: zha.PROFILE_ID,\n+ DEVICE_TYPE: zha.DeviceType.ON_OFF_LIGHT,\n+ INPUT_CLUSTERS: [\n+ Basic.cluster_id,\n+ Identify.cluster_id,\n+ Groups.cluster_id,\n+ OnOff.cluster_id,\n+ LevelControl.cluster_id,\n+ Scenes.cluster_id,\n+ BinaryInput.cluster_id,\n+ MANUFACTURER_SPECIFIC_CLUSTER_ID,\n+ ],\n+ OUTPUT_CLUSTERS: [\n+ Basic.cluster_id,\n+ MANUFACTURER_SPECIFIC_CLUSTER_ID,\n+ Ota.cluster_id,\n+ ],\n+ },\n+ 242: {\n+ PROFILE_ID: 41440,\n+ DEVICE_TYPE: 0x0061,\n+ INPUT_CLUSTERS: [],\n+ OUTPUT_CLUSTERS: [0x0021],\n+ },\n+ },\n+ }\n", "issue": "[Device Support Request] Add support for updated Legrand Dimmer switch w/o neutral\n**Is your feature request related to a problem? Please describe.**\r\n\r\nI've updated the firmware of my Legrand Dimmer switch w/o neutral for which support was added in https://github.com/zigpy/zha-device-handlers/issues/299\r\n\r\nBefore OTA upgrade:\r\n- app_version: 0\r\n- hw_version: 1\r\n- stack_version: 64\r\n- sw_build_id: 01a (26)\r\n- zcl_version: 2\r\n- Firmware: 0x03401a00\r\n\r\nAfter OTA upgrade (2020-06-08):\r\n- app_version: 0\r\n- hw_version: 6\r\n- stack_version: 66\r\n- sw_build_id: 02b (43)\r\n- zcl_version: 2\r\n- Firmware: 0x002b4203\r\n\r\nAnd now it reports a new `GreenPowerProxy` endpoint with id 242:\r\n\r\n```\r\n{\r\n \"node_descriptor\": \"<NodeDescriptor byte1=17 byte2=64 mac_capability_flags=142 manufacturer_code=4129 maximum_buffer_size=89 maximum_incoming_transfer_size=63 server_mask=10752 maximum_outgoing_transfer_size=63 descriptor_capability_field=0>\",\r\n \"endpoints\": {\r\n \"1\": {\r\n \"profile_id\": 260,\r\n \"device_type\": \"0x0100\",\r\n \"in_clusters\": [\r\n \"0x0000\",\r\n \"0x0003\",\r\n \"0x0004\",\r\n \"0x0005\",\r\n \"0x0006\",\r\n \"0x0008\",\r\n \"0x000f\",\r\n \"0xfc01\"\r\n ],\r\n \"out_clusters\": [\r\n \"0x0000\",\r\n \"0x0019\",\r\n \"0xfc01\"\r\n ]\r\n },\r\n \"242\": {\r\n \"profile_id\": 41440,\r\n \"device_type\": \"0x0061\",\r\n \"in_clusters\": [],\r\n \"out_clusters\": [\r\n \"0x0021\"\r\n ]\r\n }\r\n },\r\n \"manufacturer\": \" Legrand\",\r\n \"model\": \" Dimmer switch w/o neutral\",\r\n \"class\": \"zigpy.device.Device\"\r\n}\r\n```\r\n\r\n\r\nThe issue is that prevents the quirk from matching:\r\n\r\n```\r\n2020-06-17 06:45:05 DEBUG (MainThread) [zigpy.quirks.registry] Checking quirks for Legrand Dimmer switch w/o neutral (00:04:74:00:00:8b:0e:a2)\r\n2020-06-17 06:45:05 DEBUG (MainThread) [zigpy.quirks.registry] Considering <class 'zhaquirks.legrand.dimmer.DimmerWithoutNeutral'>\r\n2020-06-17 06:45:05 DEBUG (MainThread) [zigpy.quirks.registry] Fail because endpoint list mismatch: {1} {1, 242}\r\n```\r\n\r\n**Describe the solution you'd like**\r\n\r\nCould the quirk be updated to also support new firmwares?\r\n\r\n**Device signature - this can be acquired by removing the device from ZHA and pairing it again from the add devices screen. Be sure to add the entire content of the log panel after pairing the device to a code block below this line.**\r\n\r\nTODO\r\n\r\n**Additional context**\r\n\r\n\n", "before_files": [{"content": "\"\"\"Device handler for Legrand Dimmer switch w/o neutral.\"\"\"\nfrom zigpy.profiles import zha\nfrom zigpy.quirks import CustomCluster, CustomDevice\nimport zigpy.types as t\nfrom zigpy.zcl.clusters.general import (\n Basic,\n BinaryInput,\n Groups,\n Identify,\n LevelControl,\n OnOff,\n Ota,\n Scenes,\n)\nfrom zigpy.zcl.clusters.manufacturer_specific import ManufacturerSpecificCluster\n\nfrom . import LEGRAND\nfrom ..const import (\n DEVICE_TYPE,\n ENDPOINTS,\n INPUT_CLUSTERS,\n MODELS_INFO,\n OUTPUT_CLUSTERS,\n PROFILE_ID,\n)\n\nMANUFACTURER_SPECIFIC_CLUSTER_ID = 0xFC01 # decimal = 64513\n\n\nclass LegrandCluster(CustomCluster, ManufacturerSpecificCluster):\n \"\"\"LegrandCluster.\"\"\"\n\n cluster_id = MANUFACTURER_SPECIFIC_CLUSTER_ID\n name = \"LegrandCluster\"\n ep_attribute = \"legrand_cluster\"\n attributes = {\n 0x0000: (\"dimmer\", t.data16),\n 0x0001: (\"led_dark\", t.Bool),\n 0x0002: (\"led_on\", t.Bool),\n }\n server_commands = {}\n client_commands = {}\n\n\nclass DimmerWithoutNeutral(CustomDevice):\n \"\"\"Dimmer switch w/o neutral.\"\"\"\n\n signature = {\n # <SimpleDescriptor endpoint=1 profile=260 device_type=256\n # device_version=1\n # input_clusters=[0, 3, 4, 8, 6, 5, 15, 64513]\n # output_clusters=[0, 64513, 25]>\n MODELS_INFO: [(f\" {LEGRAND}\", \" Dimmer switch w/o neutral\")],\n ENDPOINTS: {\n 1: {\n PROFILE_ID: zha.PROFILE_ID,\n DEVICE_TYPE: zha.DeviceType.ON_OFF_LIGHT,\n INPUT_CLUSTERS: [\n Basic.cluster_id,\n Identify.cluster_id,\n Groups.cluster_id,\n OnOff.cluster_id,\n LevelControl.cluster_id,\n Scenes.cluster_id,\n BinaryInput.cluster_id,\n MANUFACTURER_SPECIFIC_CLUSTER_ID,\n ],\n OUTPUT_CLUSTERS: [\n Basic.cluster_id,\n MANUFACTURER_SPECIFIC_CLUSTER_ID,\n Ota.cluster_id,\n ],\n }\n },\n }\n\n replacement = {\n ENDPOINTS: {\n 1: {\n PROFILE_ID: zha.PROFILE_ID,\n DEVICE_TYPE: zha.DeviceType.ON_OFF_LIGHT,\n INPUT_CLUSTERS: [\n Basic.cluster_id,\n Identify.cluster_id,\n Groups.cluster_id,\n OnOff.cluster_id,\n LevelControl.cluster_id,\n Scenes.cluster_id,\n BinaryInput.cluster_id,\n LegrandCluster,\n ],\n OUTPUT_CLUSTERS: [Basic.cluster_id, LegrandCluster, Ota.cluster_id],\n }\n }\n }\n", "path": "zhaquirks/legrand/dimmer.py"}]}
| 2,234 | 415 |
gh_patches_debug_31905
|
rasdani/github-patches
|
git_diff
|
kivy__kivy-1092
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
StackLayout spacing added to top padding
When using a StackLayout, the spacing is added to the top padding.
To see the problem, run kivycatalog and change the spacing property for the StackLayout example to 20.
Tested on 1.6.0 and master.
</issue>
<code>
[start of kivy/uix/stacklayout.py]
1 '''
2 Stack Layout
3 ============
4
5 .. only:: html
6
7 .. image:: images/stacklayout.gif
8 :align: right
9
10 .. only:: latex
11
12 .. image:: images/stacklayout.png
13 :align: right
14
15 .. versionadded:: 1.0.5
16
17 :class:`StackLayout` arranges children vertically or horizontally, as many
18 as the layout can fit.
19
20
21 .. warning:
22
23 This is experimental and subject to change as long as this warning notice is
24 present.
25
26 '''
27
28 __all__ = ('StackLayout', )
29
30 from kivy.uix.layout import Layout
31 from kivy.properties import NumericProperty, OptionProperty, \
32 ReferenceListProperty, VariableListProperty
33
34
35 class StackLayout(Layout):
36 '''Stack layout class. See module documentation for more information.
37 '''
38
39 spacing = VariableListProperty([0, 0], length=2)
40 '''Spacing between children: [spacing_horizontal, spacing_vertical].
41
42 spacing also accepts a one argument form [spacing].
43
44 :data:`spacing` is a :class:`~kivy.properties.VariableListProperty`, default to
45 [0, 0].
46 '''
47
48 padding = VariableListProperty([0, 0, 0, 0])
49 '''Padding between layout box and children: [padding_left, padding_top,
50 padding_right, padding_bottom].
51
52 padding also accepts a two argument form [padding_horizontal,
53 padding_vertical] and a one argument form [padding].
54
55 .. versionchanged:: 1.7.0
56
57 Replaced NumericProperty with VariableListProperty.
58
59 :data:`padding` is a :class:`~kivy.properties.VariableListProperty`, default to
60 [0, 0, 0, 0].
61 '''
62
63 orientation = OptionProperty('lr-tb', options=(
64 'lr-tb', 'tb-lr', 'rl-tb', 'tb-rl', 'lr-bt', 'bt-lr', 'rl-bt', 'bt-rl'))
65 '''Orientation of the layout.
66
67 :data:`orientation` is an :class:`~kivy.properties.OptionProperty`, default
68 to 'lr-tb'.
69
70 Valid orientations are: 'lr-tb', 'tb-lr', 'rl-tb', 'tb-rl', 'lr-bt',
71 'bt-lr', 'rl-bt', 'bt-rl'
72
73 .. versionchanged:: 1.5.0
74
75 :data:`orientation` now correctly handles all valid combinations of
76 'lr','rl','tb','bt'. Before this version only 'lr-tb' and
77 'tb-lr' were supported, and 'tb-lr' was misnamed and placed
78 widgets from bottom to top and from right to left (reversed compared
79 to what was expected).
80
81 .. note::
82
83 lr mean Left to Right.
84 rl mean Right to Left.
85 tb mean Top to Bottom.
86 bt mean Bottom to Top.
87 '''
88
89 minimum_width = NumericProperty(0)
90 '''Minimum width needed to contain all children.
91
92 .. versionadded:: 1.0.8
93
94 :data:`minimum_width` is a :class:`kivy.properties.NumericProperty`, default
95 to 0.
96 '''
97
98 minimum_height = NumericProperty(0)
99 '''Minimum height needed to contain all children.
100
101 .. versionadded:: 1.0.8
102
103 :data:`minimum_height` is a :class:`kivy.properties.NumericProperty`,
104 default to 0.
105 '''
106
107 minimum_size = ReferenceListProperty(minimum_width, minimum_height)
108 '''Minimum size needed to contain all children.
109
110 .. versionadded:: 1.0.8
111
112 :data:`minimum_size` is a :class:`~kivy.properties.ReferenceListProperty` of
113 (:data:`minimum_width`, :data:`minimum_height`) properties.
114 '''
115
116 def __init__(self, **kwargs):
117 super(StackLayout, self).__init__(**kwargs)
118 self.bind(
119 padding=self._trigger_layout,
120 spacing=self._trigger_layout,
121 children=self._trigger_layout,
122 orientation=self._trigger_layout,
123 size=self._trigger_layout,
124 pos=self._trigger_layout)
125
126 def do_layout(self, *largs):
127 # optimize layout by preventing looking at the same attribute in a loop
128 selfpos = self.pos
129 selfsize = self.size
130 orientation = self.orientation.split('-')
131 padding_left = self.padding[0]
132 padding_top = self.padding[1]
133 padding_right = self.padding[2]
134 padding_bottom = self.padding[3]
135
136 padding_x = padding_left + padding_right
137 padding_y = padding_top + padding_bottom
138 spacing_x, spacing_y = self.spacing
139
140 lc = []
141
142 # Determine which direction and in what order to place the widgets
143 posattr = [0] * 2
144 posdelta = [0] * 2
145 posstart = [0] * 2
146 for i in (0, 1):
147 posattr[i] = 1 * (orientation[i] in ('tb', 'bt'))
148 k = posattr[i]
149 if orientation[i] == 'lr':
150 # left to right
151 posdelta[i] = 1
152 posstart[i] = selfpos[k] + padding_left
153 elif orientation[i] == 'bt':
154 # bottom to top
155 posdelta[i] = 1
156 posstart[i] = selfpos[k] + padding_bottom
157 elif orientation[i] == 'rl':
158 # right to left
159 posdelta[i] = -1
160 posstart[i] = selfpos[k] + selfsize[k] - padding_right
161 else:
162 # top to bottom
163 posdelta[i] = -1
164 posstart[i] = selfpos[k] + selfsize[k] - padding_top
165
166 innerattr, outerattr = posattr
167 ustart, vstart = posstart
168 deltau, deltav = posdelta
169 del posattr, posdelta, posstart
170
171 u = ustart # inner loop position variable
172 v = vstart # outer loop position variable
173
174 # space calculation, used for determining when a row or column is full
175
176 if orientation[0] in ('lr', 'rl'):
177 lu = self.size[innerattr] - padding_x
178 sv = padding_y # size in v-direction, for minimum_size property
179 su = padding_x # size in h-direction
180 spacing_u = spacing_x
181 spacing_v = spacing_y
182 else:
183 lu = self.size[innerattr] - padding_y
184 sv = padding_x # size in v-direction, for minimum_size property
185 su = padding_y # size in h-direction
186 spacing_u = spacing_y
187 spacing_v = spacing_x
188
189 # space calculation, row height or column width, for arranging widgets
190 lv = 0
191
192 urev = (deltau < 0)
193 vrev = (deltav < 0)
194 for c in reversed(self.children):
195 # Issue#823: ReferenceListProperty doesn't allow changing
196 # individual properties.
197 # when the above issue is fixed we can remove csize from below and
198 # access c.size[i] directly
199 csize = c.size[:] # we need to update the whole tuple at once.
200 if c.size_hint[0]:
201 # calculate width
202 csize[0] = c.size_hint[0] * (selfsize[0] - padding_x)
203 if c.size_hint[1]:
204 # calculate height
205 csize[1] = c.size_hint[1] * (selfsize[1] - padding_y)
206 c.size = tuple(csize)
207
208 # does the widget fit in the row/column?
209 if lu - c.size[innerattr] >= 0:
210 lc.append(c)
211 lu -= c.size[innerattr] + spacing_u
212 lv = max(lv, c.size[outerattr])
213 continue
214
215 # push the line
216 sv += lv + spacing_v
217 for c2 in lc:
218 if urev:
219 u -= c2.size[innerattr] + spacing_u
220 p = [0, 0] # issue #823
221 p[innerattr] = u
222 p[outerattr] = v
223 if vrev:
224 # v position is actually the top/right side of the widget
225 # when going from high to low coordinate values,
226 # we need to subtract the height/width from the position.
227 p[outerattr] -= c2.size[outerattr]
228 c2.pos = tuple(p) # issue #823
229 if not urev:
230 u += c2.size[innerattr] + spacing_u
231
232 v += deltav * lv
233 v += deltav * spacing_v
234 lc = [c]
235 lv = c.size[outerattr]
236 lu = selfsize[innerattr] - su - c.size[innerattr] - spacing_u
237 u = ustart
238
239 if lc:
240 # push the last (incomplete) line
241 sv += lv + spacing_v
242 for c2 in lc:
243 if urev:
244 u -= c2.size[innerattr] + spacing_u
245 p = [0, 0] # issue #823
246 p[innerattr] = u
247 p[outerattr] = v
248 if vrev:
249 p[outerattr] -= c2.size[outerattr]
250 c2.pos = tuple(p) # issue #823
251 if not urev:
252 u += c2.size[innerattr] + spacing_u
253
254 minsize = self.minimum_size[:] # issue #823
255 minsize[outerattr] = sv
256 self.minimum_size = tuple(minsize)
257
[end of kivy/uix/stacklayout.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/kivy/uix/stacklayout.py b/kivy/uix/stacklayout.py
--- a/kivy/uix/stacklayout.py
+++ b/kivy/uix/stacklayout.py
@@ -216,7 +216,7 @@
sv += lv + spacing_v
for c2 in lc:
if urev:
- u -= c2.size[innerattr] + spacing_u
+ u -= c2.size[innerattr]
p = [0, 0] # issue #823
p[innerattr] = u
p[outerattr] = v
@@ -226,7 +226,9 @@
# we need to subtract the height/width from the position.
p[outerattr] -= c2.size[outerattr]
c2.pos = tuple(p) # issue #823
- if not urev:
+ if urev:
+ u -= spacing_u
+ else:
u += c2.size[innerattr] + spacing_u
v += deltav * lv
@@ -241,14 +243,16 @@
sv += lv + spacing_v
for c2 in lc:
if urev:
- u -= c2.size[innerattr] + spacing_u
+ u -= c2.size[innerattr]
p = [0, 0] # issue #823
p[innerattr] = u
p[outerattr] = v
if vrev:
p[outerattr] -= c2.size[outerattr]
c2.pos = tuple(p) # issue #823
- if not urev:
+ if urev:
+ u -= spacing_u
+ else:
u += c2.size[innerattr] + spacing_u
minsize = self.minimum_size[:] # issue #823
|
{"golden_diff": "diff --git a/kivy/uix/stacklayout.py b/kivy/uix/stacklayout.py\n--- a/kivy/uix/stacklayout.py\n+++ b/kivy/uix/stacklayout.py\n@@ -216,7 +216,7 @@\n sv += lv + spacing_v\n for c2 in lc:\n if urev:\n- u -= c2.size[innerattr] + spacing_u\n+ u -= c2.size[innerattr]\n p = [0, 0] # issue #823\n p[innerattr] = u\n p[outerattr] = v\n@@ -226,7 +226,9 @@\n # we need to subtract the height/width from the position.\n p[outerattr] -= c2.size[outerattr]\n c2.pos = tuple(p) # issue #823\n- if not urev:\n+ if urev:\n+ u -= spacing_u\n+ else:\n u += c2.size[innerattr] + spacing_u\n \n v += deltav * lv\n@@ -241,14 +243,16 @@\n sv += lv + spacing_v\n for c2 in lc:\n if urev:\n- u -= c2.size[innerattr] + spacing_u\n+ u -= c2.size[innerattr]\n p = [0, 0] # issue #823\n p[innerattr] = u\n p[outerattr] = v\n if vrev:\n p[outerattr] -= c2.size[outerattr]\n c2.pos = tuple(p) # issue #823\n- if not urev:\n+ if urev:\n+ u -= spacing_u\n+ else:\n u += c2.size[innerattr] + spacing_u\n \n minsize = self.minimum_size[:] # issue #823\n", "issue": "StackLayout spacing added to top padding\nWhen using a StackLayout, the spacing is added to the top padding.\n\nTo see the problem, run kivycatalog and change the spacing property for the StackLayout example to 20.\n\nTested on 1.6.0 and master.\n\n", "before_files": [{"content": "'''\nStack Layout\n============\n\n.. only:: html\n\n .. image:: images/stacklayout.gif\n :align: right\n\n.. only:: latex\n\n .. image:: images/stacklayout.png\n :align: right\n\n.. versionadded:: 1.0.5\n\n:class:`StackLayout` arranges children vertically or horizontally, as many\nas the layout can fit.\n\n\n.. warning:\n\n This is experimental and subject to change as long as this warning notice is\n present.\n\n'''\n\n__all__ = ('StackLayout', )\n\nfrom kivy.uix.layout import Layout\nfrom kivy.properties import NumericProperty, OptionProperty, \\\n ReferenceListProperty, VariableListProperty\n\n\nclass StackLayout(Layout):\n '''Stack layout class. See module documentation for more information.\n '''\n\n spacing = VariableListProperty([0, 0], length=2)\n '''Spacing between children: [spacing_horizontal, spacing_vertical].\n\n spacing also accepts a one argument form [spacing].\n\n :data:`spacing` is a :class:`~kivy.properties.VariableListProperty`, default to\n [0, 0].\n '''\n\n padding = VariableListProperty([0, 0, 0, 0])\n '''Padding between layout box and children: [padding_left, padding_top,\n padding_right, padding_bottom].\n\n padding also accepts a two argument form [padding_horizontal,\n padding_vertical] and a one argument form [padding].\n\n .. versionchanged:: 1.7.0\n\n Replaced NumericProperty with VariableListProperty.\n\n :data:`padding` is a :class:`~kivy.properties.VariableListProperty`, default to\n [0, 0, 0, 0].\n '''\n\n orientation = OptionProperty('lr-tb', options=(\n 'lr-tb', 'tb-lr', 'rl-tb', 'tb-rl', 'lr-bt', 'bt-lr', 'rl-bt', 'bt-rl'))\n '''Orientation of the layout.\n\n :data:`orientation` is an :class:`~kivy.properties.OptionProperty`, default\n to 'lr-tb'.\n\n Valid orientations are: 'lr-tb', 'tb-lr', 'rl-tb', 'tb-rl', 'lr-bt',\n 'bt-lr', 'rl-bt', 'bt-rl'\n\n .. versionchanged:: 1.5.0\n\n :data:`orientation` now correctly handles all valid combinations of\n 'lr','rl','tb','bt'. Before this version only 'lr-tb' and\n 'tb-lr' were supported, and 'tb-lr' was misnamed and placed\n widgets from bottom to top and from right to left (reversed compared\n to what was expected).\n\n .. note::\n\n lr mean Left to Right.\n rl mean Right to Left.\n tb mean Top to Bottom.\n bt mean Bottom to Top.\n '''\n\n minimum_width = NumericProperty(0)\n '''Minimum width needed to contain all children.\n\n .. versionadded:: 1.0.8\n\n :data:`minimum_width` is a :class:`kivy.properties.NumericProperty`, default\n to 0.\n '''\n\n minimum_height = NumericProperty(0)\n '''Minimum height needed to contain all children.\n\n .. versionadded:: 1.0.8\n\n :data:`minimum_height` is a :class:`kivy.properties.NumericProperty`,\n default to 0.\n '''\n\n minimum_size = ReferenceListProperty(minimum_width, minimum_height)\n '''Minimum size needed to contain all children.\n\n .. versionadded:: 1.0.8\n\n :data:`minimum_size` is a :class:`~kivy.properties.ReferenceListProperty` of\n (:data:`minimum_width`, :data:`minimum_height`) properties.\n '''\n\n def __init__(self, **kwargs):\n super(StackLayout, self).__init__(**kwargs)\n self.bind(\n padding=self._trigger_layout,\n spacing=self._trigger_layout,\n children=self._trigger_layout,\n orientation=self._trigger_layout,\n size=self._trigger_layout,\n pos=self._trigger_layout)\n\n def do_layout(self, *largs):\n # optimize layout by preventing looking at the same attribute in a loop\n selfpos = self.pos\n selfsize = self.size\n orientation = self.orientation.split('-')\n padding_left = self.padding[0]\n padding_top = self.padding[1]\n padding_right = self.padding[2]\n padding_bottom = self.padding[3]\n\n padding_x = padding_left + padding_right\n padding_y = padding_top + padding_bottom\n spacing_x, spacing_y = self.spacing\n\n lc = []\n\n # Determine which direction and in what order to place the widgets\n posattr = [0] * 2\n posdelta = [0] * 2\n posstart = [0] * 2\n for i in (0, 1):\n posattr[i] = 1 * (orientation[i] in ('tb', 'bt'))\n k = posattr[i]\n if orientation[i] == 'lr':\n # left to right\n posdelta[i] = 1\n posstart[i] = selfpos[k] + padding_left\n elif orientation[i] == 'bt':\n # bottom to top\n posdelta[i] = 1\n posstart[i] = selfpos[k] + padding_bottom\n elif orientation[i] == 'rl':\n # right to left\n posdelta[i] = -1\n posstart[i] = selfpos[k] + selfsize[k] - padding_right\n else:\n # top to bottom\n posdelta[i] = -1\n posstart[i] = selfpos[k] + selfsize[k] - padding_top\n\n innerattr, outerattr = posattr\n ustart, vstart = posstart\n deltau, deltav = posdelta\n del posattr, posdelta, posstart\n\n u = ustart # inner loop position variable\n v = vstart # outer loop position variable\n\n # space calculation, used for determining when a row or column is full\n\n if orientation[0] in ('lr', 'rl'):\n lu = self.size[innerattr] - padding_x\n sv = padding_y # size in v-direction, for minimum_size property\n su = padding_x # size in h-direction\n spacing_u = spacing_x\n spacing_v = spacing_y\n else:\n lu = self.size[innerattr] - padding_y\n sv = padding_x # size in v-direction, for minimum_size property\n su = padding_y # size in h-direction\n spacing_u = spacing_y\n spacing_v = spacing_x\n\n # space calculation, row height or column width, for arranging widgets\n lv = 0\n\n urev = (deltau < 0)\n vrev = (deltav < 0)\n for c in reversed(self.children):\n # Issue#823: ReferenceListProperty doesn't allow changing\n # individual properties.\n # when the above issue is fixed we can remove csize from below and\n # access c.size[i] directly\n csize = c.size[:] # we need to update the whole tuple at once.\n if c.size_hint[0]:\n # calculate width\n csize[0] = c.size_hint[0] * (selfsize[0] - padding_x)\n if c.size_hint[1]:\n # calculate height\n csize[1] = c.size_hint[1] * (selfsize[1] - padding_y)\n c.size = tuple(csize)\n\n # does the widget fit in the row/column?\n if lu - c.size[innerattr] >= 0:\n lc.append(c)\n lu -= c.size[innerattr] + spacing_u\n lv = max(lv, c.size[outerattr])\n continue\n\n # push the line\n sv += lv + spacing_v\n for c2 in lc:\n if urev:\n u -= c2.size[innerattr] + spacing_u\n p = [0, 0] # issue #823\n p[innerattr] = u\n p[outerattr] = v\n if vrev:\n # v position is actually the top/right side of the widget\n # when going from high to low coordinate values,\n # we need to subtract the height/width from the position.\n p[outerattr] -= c2.size[outerattr]\n c2.pos = tuple(p) # issue #823\n if not urev:\n u += c2.size[innerattr] + spacing_u\n\n v += deltav * lv\n v += deltav * spacing_v\n lc = [c]\n lv = c.size[outerattr]\n lu = selfsize[innerattr] - su - c.size[innerattr] - spacing_u\n u = ustart\n\n if lc:\n # push the last (incomplete) line\n sv += lv + spacing_v\n for c2 in lc:\n if urev:\n u -= c2.size[innerattr] + spacing_u\n p = [0, 0] # issue #823\n p[innerattr] = u\n p[outerattr] = v\n if vrev:\n p[outerattr] -= c2.size[outerattr]\n c2.pos = tuple(p) # issue #823\n if not urev:\n u += c2.size[innerattr] + spacing_u\n\n minsize = self.minimum_size[:] # issue #823\n minsize[outerattr] = sv\n self.minimum_size = tuple(minsize)\n", "path": "kivy/uix/stacklayout.py"}]}
| 3,417 | 429 |
gh_patches_debug_25654
|
rasdani/github-patches
|
git_diff
|
bokeh__bokeh-5348
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Depreciated example
https://github.com/bokeh/bokeh/blob/0.12.3/examples/embed/simple/simple.py
```
Because the ``resources`` argument is no longer needed, it is deprecated and no longer has any effect.
```
The link is also broken:
http://bokeh.pydata.org/en/latest/docs/user_guide/embedding.html#components
</issue>
<code>
[start of examples/embed/simple/simple.py]
1 '''This example demonstrates embedding a standalone Bokeh document
2 into a simple Flask application, with a basic HTML web form.
3
4 To view the example, run:
5
6 python simple.py
7
8 in this directory, and navigate to:
9
10 http://localhost:5000
11
12 '''
13 from __future__ import print_function
14
15 import flask
16
17 from bokeh.embed import components
18 from bokeh.plotting import figure
19 from bokeh.resources import INLINE
20 from bokeh.util.string import encode_utf8
21
22 app = flask.Flask(__name__)
23
24 colors = {
25 'Black': '#000000',
26 'Red': '#FF0000',
27 'Green': '#00FF00',
28 'Blue': '#0000FF',
29 }
30
31 def getitem(obj, item, default):
32 if item not in obj:
33 return default
34 else:
35 return obj[item]
36
37 @app.route("/")
38 def polynomial():
39 """ Very simple embedding of a polynomial chart
40
41 """
42
43 # Grab the inputs arguments from the URL
44 # This is automated by the button
45 args = flask.request.args
46
47 # Get all the form arguments in the url with defaults
48 color = colors[getitem(args, 'color', 'Black')]
49 _from = int(getitem(args, '_from', 0))
50 to = int(getitem(args, 'to', 10))
51
52 # Create a polynomial line graph
53 x = list(range(_from, to + 1))
54 fig = figure(title="Polynomial")
55 fig.line(x, [i ** 2 for i in x], color=color, line_width=2)
56
57 # Configure resources to include BokehJS inline in the document.
58 # For more details see:
59 # http://bokeh.pydata.org/en/latest/docs/reference/resources_embedding.html#bokeh-embed
60 js_resources = INLINE.render_js()
61 css_resources = INLINE.render_css()
62
63 # For more details see:
64 # http://bokeh.pydata.org/en/latest/docs/user_guide/embedding.html#components
65 script, div = components(fig, INLINE)
66 html = flask.render_template(
67 'embed.html',
68 plot_script=script,
69 plot_div=div,
70 js_resources=js_resources,
71 css_resources=css_resources,
72 color=color,
73 _from=_from,
74 to=to
75 )
76 return encode_utf8(html)
77
78 if __name__ == "__main__":
79 print(__doc__)
80 app.run()
81
[end of examples/embed/simple/simple.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/examples/embed/simple/simple.py b/examples/embed/simple/simple.py
--- a/examples/embed/simple/simple.py
+++ b/examples/embed/simple/simple.py
@@ -41,7 +41,6 @@
"""
# Grab the inputs arguments from the URL
- # This is automated by the button
args = flask.request.args
# Get all the form arguments in the url with defaults
@@ -49,20 +48,15 @@
_from = int(getitem(args, '_from', 0))
to = int(getitem(args, 'to', 10))
- # Create a polynomial line graph
+ # Create a polynomial line graph with those arguments
x = list(range(_from, to + 1))
fig = figure(title="Polynomial")
fig.line(x, [i ** 2 for i in x], color=color, line_width=2)
- # Configure resources to include BokehJS inline in the document.
- # For more details see:
- # http://bokeh.pydata.org/en/latest/docs/reference/resources_embedding.html#bokeh-embed
js_resources = INLINE.render_js()
css_resources = INLINE.render_css()
- # For more details see:
- # http://bokeh.pydata.org/en/latest/docs/user_guide/embedding.html#components
- script, div = components(fig, INLINE)
+ script, div = components(fig)
html = flask.render_template(
'embed.html',
plot_script=script,
|
{"golden_diff": "diff --git a/examples/embed/simple/simple.py b/examples/embed/simple/simple.py\n--- a/examples/embed/simple/simple.py\n+++ b/examples/embed/simple/simple.py\n@@ -41,7 +41,6 @@\n \"\"\"\n \n # Grab the inputs arguments from the URL\n- # This is automated by the button\n args = flask.request.args\n \n # Get all the form arguments in the url with defaults\n@@ -49,20 +48,15 @@\n _from = int(getitem(args, '_from', 0))\n to = int(getitem(args, 'to', 10))\n \n- # Create a polynomial line graph\n+ # Create a polynomial line graph with those arguments\n x = list(range(_from, to + 1))\n fig = figure(title=\"Polynomial\")\n fig.line(x, [i ** 2 for i in x], color=color, line_width=2)\n \n- # Configure resources to include BokehJS inline in the document.\n- # For more details see:\n- # http://bokeh.pydata.org/en/latest/docs/reference/resources_embedding.html#bokeh-embed\n js_resources = INLINE.render_js()\n css_resources = INLINE.render_css()\n \n- # For more details see:\n- # http://bokeh.pydata.org/en/latest/docs/user_guide/embedding.html#components\n- script, div = components(fig, INLINE)\n+ script, div = components(fig)\n html = flask.render_template(\n 'embed.html',\n plot_script=script,\n", "issue": "Depreciated example\nhttps://github.com/bokeh/bokeh/blob/0.12.3/examples/embed/simple/simple.py\n\n```\nBecause the ``resources`` argument is no longer needed, it is deprecated and no longer has any effect.\n```\n\nThe link is also broken:\nhttp://bokeh.pydata.org/en/latest/docs/user_guide/embedding.html#components\n\n", "before_files": [{"content": "'''This example demonstrates embedding a standalone Bokeh document\ninto a simple Flask application, with a basic HTML web form.\n\nTo view the example, run:\n\n python simple.py\n\nin this directory, and navigate to:\n\n http://localhost:5000\n\n'''\nfrom __future__ import print_function\n\nimport flask\n\nfrom bokeh.embed import components\nfrom bokeh.plotting import figure\nfrom bokeh.resources import INLINE\nfrom bokeh.util.string import encode_utf8\n\napp = flask.Flask(__name__)\n\ncolors = {\n 'Black': '#000000',\n 'Red': '#FF0000',\n 'Green': '#00FF00',\n 'Blue': '#0000FF',\n}\n\ndef getitem(obj, item, default):\n if item not in obj:\n return default\n else:\n return obj[item]\n\[email protected](\"/\")\ndef polynomial():\n \"\"\" Very simple embedding of a polynomial chart\n\n \"\"\"\n\n # Grab the inputs arguments from the URL\n # This is automated by the button\n args = flask.request.args\n\n # Get all the form arguments in the url with defaults\n color = colors[getitem(args, 'color', 'Black')]\n _from = int(getitem(args, '_from', 0))\n to = int(getitem(args, 'to', 10))\n\n # Create a polynomial line graph\n x = list(range(_from, to + 1))\n fig = figure(title=\"Polynomial\")\n fig.line(x, [i ** 2 for i in x], color=color, line_width=2)\n\n # Configure resources to include BokehJS inline in the document.\n # For more details see:\n # http://bokeh.pydata.org/en/latest/docs/reference/resources_embedding.html#bokeh-embed\n js_resources = INLINE.render_js()\n css_resources = INLINE.render_css()\n\n # For more details see:\n # http://bokeh.pydata.org/en/latest/docs/user_guide/embedding.html#components\n script, div = components(fig, INLINE)\n html = flask.render_template(\n 'embed.html',\n plot_script=script,\n plot_div=div,\n js_resources=js_resources,\n css_resources=css_resources,\n color=color,\n _from=_from,\n to=to\n )\n return encode_utf8(html)\n\nif __name__ == \"__main__\":\n print(__doc__)\n app.run()\n", "path": "examples/embed/simple/simple.py"}]}
| 1,301 | 331 |
gh_patches_debug_3980
|
rasdani/github-patches
|
git_diff
|
data-for-change__anyway-291
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Improve cluster accuracy
Cluster aggregates markers in `in_cluster` is using box instead of a circle parameter calculation which I think may cause duplications and inaccuracy
</issue>
<code>
[start of static/pymapcluster.py]
1 ##
2 import globalmaptiles as globaltiles
3 from math import cos, sin, atan2, sqrt
4 import time
5 ##
6
7 def center_geolocation(geolocations):
8 """
9 Provide a relatively accurate center lat, lon returned as a list pair, given
10 a list of list pairs.
11 ex: in: geolocations = ((lat1,lon1), (lat2,lon2),)
12 out: (center_lat, center_lon)
13 """
14 x = 0
15 y = 0
16 z = 0
17
18 for lat, lon in geolocations:
19 lat = float(lat)
20 lon = float(lon)
21 x += cos(lat) * cos(lon)
22 y += cos(lat) * sin(lon)
23 z += sin(lat)
24
25 x = float(x / len(geolocations))
26 y = float(y / len(geolocations))
27 z = float(z / len(geolocations))
28
29 return (atan2(y, x), atan2(z, sqrt(x * x + y * y)))
30
31 def latlng_to_zoompixels(mercator, lat, lng, zoom):
32 mx, my = mercator.LatLonToMeters(lat, lng)
33 pix = mercator.MetersToPixels(mx, my, zoom)
34 return pix
35
36 def in_cluster(center, radius, point):
37 return (point[0] >= center[0] - radius) and (point[0] <= center[0] + radius) \
38 and (point[1] >= center[1] - radius) and (point[1] <= center[1] + radius)
39
40 def cluster_markers(mercator, latlngs, zoom, gridsize=50):
41 """
42 Args:
43 mercator: instance of GlobalMercator()
44 latlngs: list of (lat,lng) tuple
45 zoom: current zoom level
46 gridsize: cluster radius (in pixels in current zoom level)
47 Returns:
48 centers: list of indices in latlngs of points used as centers
49 clusters: list of same length as latlngs giving assigning each point to
50 a cluster
51 """
52 start_time = time.time()
53 centers = []
54 clusters = []
55 sizes = []
56 latlngs = map(lambda latlng: latlng.serialize(), latlngs)
57 for i, latlng in enumerate(latlngs):
58 lat = latlng['latitude']
59 lng = latlng['longitude']
60 point_pix = latlng_to_zoompixels(mercator, lat, lng, zoom)
61 assigned = False
62 for cidx, c in enumerate(centers):
63 center = latlngs[c]
64 center = latlng_to_zoompixels(mercator, center['latitude'], center['longitude'], zoom)
65 if in_cluster(center, gridsize, point_pix):
66 # Assign point to cluster
67 clusters.append(cidx)
68 sizes[cidx] += 1
69 assigned = True
70 break
71 if not assigned:
72 # Create new cluster for point
73 #TODO center_geolocation the center!
74 centers.append(i)
75 sizes.append(1)
76 clusters.append(len(centers) - 1)
77
78 print('time for cluster_markers: ' + str(time.time() - start_time))
79 return centers, clusters, sizes
80
81 def create_clusters_centers(markers, zoom, radius):
82 mercator = globaltiles.GlobalMercator()
83 centers, clusters, sizes = cluster_markers(mercator, markers, zoom, radius)
84 centers_markers = [markers[i] for i in centers]
85 return centers_markers, clusters, sizes
86
87 def get_cluster_json(clust_marker, clust_size):
88 return {
89 'longitude': clust_marker.longitude,
90 'latitude': clust_marker.latitude,
91 'size': clust_size
92 }
93
94 def get_cluster_size(index, clusters):
95 from collections import Counter
96 #TODO: don't call Counter for every cluster in the array
97 return Counter(clusters)[index]
98
99 def generate_clusters_json(markers, zoom, radius=50):
100 centers, clusters, sizes = create_clusters_centers(markers, zoom, radius)
101 json_clusts=[]
102
103 for i, point in enumerate(centers):
104 json_clusts.append(get_cluster_json(point, sizes[i]))
105
106 return {
107 'clusters': json_clusts
108 }
109
110 ##
111 if __name__ == '__main__':
112 ##
113 mercator = globaltiles.GlobalMercator()
114 latlngs = [(28.43, 8), (28.43, 8), (28.44, 8), (35, 8)]
115 centers, clusters = cluster_markers(mercator, latlngs, 21)
116 ##
[end of static/pymapcluster.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/static/pymapcluster.py b/static/pymapcluster.py
--- a/static/pymapcluster.py
+++ b/static/pymapcluster.py
@@ -34,8 +34,7 @@
return pix
def in_cluster(center, radius, point):
- return (point[0] >= center[0] - radius) and (point[0] <= center[0] + radius) \
- and (point[1] >= center[1] - radius) and (point[1] <= center[1] + radius)
+ return sqrt((point[0] - center[0])**2 + (point[1] - center[1])**2) <= radius
def cluster_markers(mercator, latlngs, zoom, gridsize=50):
"""
|
{"golden_diff": "diff --git a/static/pymapcluster.py b/static/pymapcluster.py\n--- a/static/pymapcluster.py\n+++ b/static/pymapcluster.py\n@@ -34,8 +34,7 @@\n return pix\n \n def in_cluster(center, radius, point):\n- return (point[0] >= center[0] - radius) and (point[0] <= center[0] + radius) \\\n- and (point[1] >= center[1] - radius) and (point[1] <= center[1] + radius)\n+ return sqrt((point[0] - center[0])**2 + (point[1] - center[1])**2) <= radius\n \n def cluster_markers(mercator, latlngs, zoom, gridsize=50):\n \"\"\"\n", "issue": "Improve cluster accuracy\nCluster aggregates markers in `in_cluster` is using box instead of a circle parameter calculation which I think may cause duplications and inaccuracy\n\n", "before_files": [{"content": "##\nimport globalmaptiles as globaltiles\nfrom math import cos, sin, atan2, sqrt\nimport time\n##\n \ndef center_geolocation(geolocations):\n \"\"\"\n Provide a relatively accurate center lat, lon returned as a list pair, given\n a list of list pairs.\n ex: in: geolocations = ((lat1,lon1), (lat2,lon2),)\n out: (center_lat, center_lon)\n \"\"\"\n x = 0\n y = 0\n z = 0\n \n for lat, lon in geolocations:\n lat = float(lat)\n lon = float(lon)\n x += cos(lat) * cos(lon)\n y += cos(lat) * sin(lon)\n z += sin(lat)\n \n x = float(x / len(geolocations))\n y = float(y / len(geolocations))\n z = float(z / len(geolocations))\n \n return (atan2(y, x), atan2(z, sqrt(x * x + y * y)))\n\ndef latlng_to_zoompixels(mercator, lat, lng, zoom):\n mx, my = mercator.LatLonToMeters(lat, lng)\n pix = mercator.MetersToPixels(mx, my, zoom)\n return pix\n\ndef in_cluster(center, radius, point):\n return (point[0] >= center[0] - radius) and (point[0] <= center[0] + radius) \\\n and (point[1] >= center[1] - radius) and (point[1] <= center[1] + radius)\n\ndef cluster_markers(mercator, latlngs, zoom, gridsize=50):\n \"\"\"\n Args:\n mercator: instance of GlobalMercator()\n latlngs: list of (lat,lng) tuple\n zoom: current zoom level\n gridsize: cluster radius (in pixels in current zoom level)\n Returns:\n centers: list of indices in latlngs of points used as centers\n clusters: list of same length as latlngs giving assigning each point to\n a cluster\n \"\"\"\n start_time = time.time()\n centers = []\n clusters = []\n sizes = []\n latlngs = map(lambda latlng: latlng.serialize(), latlngs)\n for i, latlng in enumerate(latlngs):\n lat = latlng['latitude']\n lng = latlng['longitude']\n point_pix = latlng_to_zoompixels(mercator, lat, lng, zoom)\n assigned = False\n for cidx, c in enumerate(centers):\n center = latlngs[c]\n center = latlng_to_zoompixels(mercator, center['latitude'], center['longitude'], zoom)\n if in_cluster(center, gridsize, point_pix):\n # Assign point to cluster\n clusters.append(cidx)\n sizes[cidx] += 1\n assigned = True\n break\n if not assigned:\n # Create new cluster for point\n #TODO center_geolocation the center!\n centers.append(i)\n sizes.append(1)\n clusters.append(len(centers) - 1)\n\n print('time for cluster_markers: ' + str(time.time() - start_time))\n return centers, clusters, sizes\n\ndef create_clusters_centers(markers, zoom, radius):\n mercator = globaltiles.GlobalMercator()\n centers, clusters, sizes = cluster_markers(mercator, markers, zoom, radius)\n centers_markers = [markers[i] for i in centers]\n return centers_markers, clusters, sizes\n\ndef get_cluster_json(clust_marker, clust_size):\n return {\n 'longitude': clust_marker.longitude,\n 'latitude': clust_marker.latitude,\n 'size': clust_size\n }\n\ndef get_cluster_size(index, clusters):\n from collections import Counter\n #TODO: don't call Counter for every cluster in the array\n return Counter(clusters)[index]\n\ndef generate_clusters_json(markers, zoom, radius=50):\n centers, clusters, sizes = create_clusters_centers(markers, zoom, radius)\n json_clusts=[]\n\n for i, point in enumerate(centers):\n json_clusts.append(get_cluster_json(point, sizes[i]))\n\n return {\n 'clusters': json_clusts\n }\n\n##\nif __name__ == '__main__':\n ##\n mercator = globaltiles.GlobalMercator()\n latlngs = [(28.43, 8), (28.43, 8), (28.44, 8), (35, 8)]\n centers, clusters = cluster_markers(mercator, latlngs, 21)\n ##", "path": "static/pymapcluster.py"}]}
| 1,818 | 174 |
gh_patches_debug_29806
|
rasdani/github-patches
|
git_diff
|
DataDog__dd-trace-py-4802
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Celery tags include a raw dictionary that is difficult to use in APM
<!--
Thanks for taking the time for reporting an issue!
Before reporting an issue on dd-trace-py, please be sure to provide all
necessary information.
If you're hitting a bug, make sure that you're using the latest version of this
library.
-->
### Summary of problem
When using celery, context is automatically added to spans as tags from various argument calls. One of the tags for celery is `delivery_info`, which is a dict that provides valuable routing data. This data is difficult to use currently since we can't create facets or filters in APM with the raw dictionary as a string. (Image below)
I expect the dict values should be added as separate tag data, such that `celery.delivery_info.exchange`, `celery.delivery_info.priority`, etc are all separate tags.
<img width="727" alt="image" src="https://user-images.githubusercontent.com/1430167/206885304-9b20bdc5-097a-4e60-ad4e-8b29063092ef.png">
### Which version of dd-trace-py are you using?
1.4.0
### Which version of pip are you using?
22.3
### Which libraries and their versions are you using?
<details>
<summary>`pip freeze`</summary>
celery==5.2.2
</details>
### How can we reproduce your problem?
Run celery with ddtrace with celery integration enabled and observe the resulting tags on the `celery.run` span.
### What is the result that you get?
`celery.run` span has a tag:value pair roughly matching the following (dict is a string repr) `celery.delivery_info: "{'exchange':'', 'routing_key':'queue_name', ...}"`
### What is the result that you expected?
`celery.run` span should have tag:value pairs for each child key in the dictionary
`celery.delivery_info.exchange:''`
`celery.delivery_info.routing_key:'queue_name'`
</issue>
<code>
[start of ddtrace/contrib/celery/utils.py]
1 from typing import Any
2 from typing import Dict
3 from weakref import WeakValueDictionary
4
5 from ddtrace.span import Span
6
7 from .constants import CTX_KEY
8
9
10 TAG_KEYS = frozenset(
11 [
12 ("compression", "celery.compression"),
13 ("correlation_id", "celery.correlation_id"),
14 ("countdown", "celery.countdown"),
15 ("delivery_info", "celery.delivery_info"),
16 ("eta", "celery.eta"),
17 ("exchange", "celery.exchange"),
18 ("expires", "celery.expires"),
19 ("hostname", "celery.hostname"),
20 ("id", "celery.id"),
21 ("priority", "celery.priority"),
22 ("queue", "celery.queue"),
23 ("reply_to", "celery.reply_to"),
24 ("retries", "celery.retries"),
25 ("routing_key", "celery.routing_key"),
26 ("serializer", "celery.serializer"),
27 ("timelimit", "celery.timelimit"),
28 # Celery 4.0 uses `origin` instead of `hostname`; this change preserves
29 # the same name for the tag despite Celery version
30 ("origin", "celery.hostname"),
31 ("state", "celery.state"),
32 ]
33 )
34
35
36 def set_tags_from_context(span, context):
37 # type: (Span, Dict[str, Any]) -> None
38 """Helper to extract meta values from a Celery Context"""
39
40 for key, tag_name in TAG_KEYS:
41 value = context.get(key)
42
43 # Skip this key if it is not set
44 if value is None or value == "":
45 continue
46
47 # Skip `timelimit` if it is not set (its default/unset value is a
48 # tuple or a list of `None` values
49 if key == "timelimit" and all(_ is None for _ in value):
50 continue
51
52 # Skip `retries` if its value is `0`
53 if key == "retries" and value == 0:
54 continue
55
56 span.set_tag(tag_name, value)
57
58
59 def attach_span(task, task_id, span, is_publish=False):
60 """Helper to propagate a `Span` for the given `Task` instance. This
61 function uses a `WeakValueDictionary` that stores a Datadog Span using
62 the `(task_id, is_publish)` as a key. This is useful when information must be
63 propagated from one Celery signal to another.
64
65 DEV: We use (task_id, is_publish) for the key to ensure that publishing a
66 task from within another task does not cause any conflicts.
67
68 This mostly happens when either a task fails and a retry policy is in place,
69 or when a task is manually retried (e.g. `task.retry()`), we end up trying
70 to publish a task with the same id as the task currently running.
71
72 Previously publishing the new task would overwrite the existing `celery.run` span
73 in the `weak_dict` causing that span to be forgotten and never finished.
74
75 NOTE: We cannot test for this well yet, because we do not run a celery worker,
76 and cannot run `task.apply_async()`
77 """
78 weak_dict = getattr(task, CTX_KEY, None)
79 if weak_dict is None:
80 weak_dict = WeakValueDictionary()
81 setattr(task, CTX_KEY, weak_dict)
82
83 weak_dict[(task_id, is_publish)] = span
84
85
86 def detach_span(task, task_id, is_publish=False):
87 """Helper to remove a `Span` in a Celery task when it's propagated.
88 This function handles tasks where the `Span` is not attached.
89 """
90 weak_dict = getattr(task, CTX_KEY, None)
91 if weak_dict is None:
92 return
93
94 # DEV: See note in `attach_span` for key info
95 try:
96 del weak_dict[(task_id, is_publish)]
97 except KeyError:
98 pass
99
100
101 def retrieve_span(task, task_id, is_publish=False):
102 """Helper to retrieve an active `Span` stored in a `Task`
103 instance
104 """
105 weak_dict = getattr(task, CTX_KEY, None)
106 if weak_dict is None:
107 return
108 else:
109 # DEV: See note in `attach_span` for key info
110 return weak_dict.get((task_id, is_publish))
111
112
113 def retrieve_task_id(context):
114 """Helper to retrieve the `Task` identifier from the message `body`.
115 This helper supports Protocol Version 1 and 2. The Protocol is well
116 detailed in the official documentation:
117 http://docs.celeryproject.org/en/latest/internals/protocol.html
118 """
119 headers = context.get("headers")
120 body = context.get("body")
121 if headers:
122 # Protocol Version 2 (default from Celery 4.0)
123 return headers.get("id")
124 else:
125 # Protocol Version 1
126 return body.get("id")
127
[end of ddtrace/contrib/celery/utils.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/ddtrace/contrib/celery/utils.py b/ddtrace/contrib/celery/utils.py
--- a/ddtrace/contrib/celery/utils.py
+++ b/ddtrace/contrib/celery/utils.py
@@ -2,6 +2,7 @@
from typing import Dict
from weakref import WeakValueDictionary
+from ddtrace.contrib.trace_utils import set_flattened_tags
from ddtrace.span import Span
from .constants import CTX_KEY
@@ -33,27 +34,37 @@
)
+def should_skip_context_value(key, value):
+ # type: (str, Any) -> bool
+ # Skip this key if it is not set
+ if value is None or value == "":
+ return True
+
+ # Skip `timelimit` if it is not set (its default/unset value is a
+ # tuple or a list of `None` values
+ if key == "timelimit" and all(_ is None for _ in value):
+ return True
+
+ # Skip `retries` if its value is `0`
+ if key == "retries" and value == 0:
+ return True
+
+ return False
+
+
def set_tags_from_context(span, context):
# type: (Span, Dict[str, Any]) -> None
"""Helper to extract meta values from a Celery Context"""
+ context_tags = []
for key, tag_name in TAG_KEYS:
value = context.get(key)
-
- # Skip this key if it is not set
- if value is None or value == "":
- continue
-
- # Skip `timelimit` if it is not set (its default/unset value is a
- # tuple or a list of `None` values
- if key == "timelimit" and all(_ is None for _ in value):
+ if should_skip_context_value(key, value):
continue
- # Skip `retries` if its value is `0`
- if key == "retries" and value == 0:
- continue
+ context_tags.append((tag_name, value))
- span.set_tag(tag_name, value)
+ set_flattened_tags(span, context_tags)
def attach_span(task, task_id, span, is_publish=False):
|
{"golden_diff": "diff --git a/ddtrace/contrib/celery/utils.py b/ddtrace/contrib/celery/utils.py\n--- a/ddtrace/contrib/celery/utils.py\n+++ b/ddtrace/contrib/celery/utils.py\n@@ -2,6 +2,7 @@\n from typing import Dict\n from weakref import WeakValueDictionary\n \n+from ddtrace.contrib.trace_utils import set_flattened_tags\n from ddtrace.span import Span\n \n from .constants import CTX_KEY\n@@ -33,27 +34,37 @@\n )\n \n \n+def should_skip_context_value(key, value):\n+ # type: (str, Any) -> bool\n+ # Skip this key if it is not set\n+ if value is None or value == \"\":\n+ return True\n+\n+ # Skip `timelimit` if it is not set (its default/unset value is a\n+ # tuple or a list of `None` values\n+ if key == \"timelimit\" and all(_ is None for _ in value):\n+ return True\n+\n+ # Skip `retries` if its value is `0`\n+ if key == \"retries\" and value == 0:\n+ return True\n+\n+ return False\n+\n+\n def set_tags_from_context(span, context):\n # type: (Span, Dict[str, Any]) -> None\n \"\"\"Helper to extract meta values from a Celery Context\"\"\"\n \n+ context_tags = []\n for key, tag_name in TAG_KEYS:\n value = context.get(key)\n-\n- # Skip this key if it is not set\n- if value is None or value == \"\":\n- continue\n-\n- # Skip `timelimit` if it is not set (its default/unset value is a\n- # tuple or a list of `None` values\n- if key == \"timelimit\" and all(_ is None for _ in value):\n+ if should_skip_context_value(key, value):\n continue\n \n- # Skip `retries` if its value is `0`\n- if key == \"retries\" and value == 0:\n- continue\n+ context_tags.append((tag_name, value))\n \n- span.set_tag(tag_name, value)\n+ set_flattened_tags(span, context_tags)\n \n \n def attach_span(task, task_id, span, is_publish=False):\n", "issue": "Celery tags include a raw dictionary that is difficult to use in APM\n<!--\r\nThanks for taking the time for reporting an issue!\r\n\r\nBefore reporting an issue on dd-trace-py, please be sure to provide all\r\nnecessary information.\r\n\r\nIf you're hitting a bug, make sure that you're using the latest version of this\r\nlibrary.\r\n-->\r\n\r\n### Summary of problem\r\nWhen using celery, context is automatically added to spans as tags from various argument calls. One of the tags for celery is `delivery_info`, which is a dict that provides valuable routing data. This data is difficult to use currently since we can't create facets or filters in APM with the raw dictionary as a string. (Image below)\r\n\r\nI expect the dict values should be added as separate tag data, such that `celery.delivery_info.exchange`, `celery.delivery_info.priority`, etc are all separate tags.\r\n\r\n<img width=\"727\" alt=\"image\" src=\"https://user-images.githubusercontent.com/1430167/206885304-9b20bdc5-097a-4e60-ad4e-8b29063092ef.png\">\r\n\r\n\r\n### Which version of dd-trace-py are you using?\r\n1.4.0\r\n\r\n\r\n### Which version of pip are you using?\r\n22.3\r\n\r\n\r\n### Which libraries and their versions are you using?\r\n\r\n<details>\r\n <summary>`pip freeze`</summary>\r\n celery==5.2.2\r\n</details>\r\n\r\n### How can we reproduce your problem?\r\nRun celery with ddtrace with celery integration enabled and observe the resulting tags on the `celery.run` span.\r\n\r\n\r\n### What is the result that you get?\r\n`celery.run` span has a tag:value pair roughly matching the following (dict is a string repr) `celery.delivery_info: \"{'exchange':'', 'routing_key':'queue_name', ...}\"`\r\n\r\n### What is the result that you expected?\r\n`celery.run` span should have tag:value pairs for each child key in the dictionary\r\n`celery.delivery_info.exchange:''`\r\n`celery.delivery_info.routing_key:'queue_name'`\n", "before_files": [{"content": "from typing import Any\nfrom typing import Dict\nfrom weakref import WeakValueDictionary\n\nfrom ddtrace.span import Span\n\nfrom .constants import CTX_KEY\n\n\nTAG_KEYS = frozenset(\n [\n (\"compression\", \"celery.compression\"),\n (\"correlation_id\", \"celery.correlation_id\"),\n (\"countdown\", \"celery.countdown\"),\n (\"delivery_info\", \"celery.delivery_info\"),\n (\"eta\", \"celery.eta\"),\n (\"exchange\", \"celery.exchange\"),\n (\"expires\", \"celery.expires\"),\n (\"hostname\", \"celery.hostname\"),\n (\"id\", \"celery.id\"),\n (\"priority\", \"celery.priority\"),\n (\"queue\", \"celery.queue\"),\n (\"reply_to\", \"celery.reply_to\"),\n (\"retries\", \"celery.retries\"),\n (\"routing_key\", \"celery.routing_key\"),\n (\"serializer\", \"celery.serializer\"),\n (\"timelimit\", \"celery.timelimit\"),\n # Celery 4.0 uses `origin` instead of `hostname`; this change preserves\n # the same name for the tag despite Celery version\n (\"origin\", \"celery.hostname\"),\n (\"state\", \"celery.state\"),\n ]\n)\n\n\ndef set_tags_from_context(span, context):\n # type: (Span, Dict[str, Any]) -> None\n \"\"\"Helper to extract meta values from a Celery Context\"\"\"\n\n for key, tag_name in TAG_KEYS:\n value = context.get(key)\n\n # Skip this key if it is not set\n if value is None or value == \"\":\n continue\n\n # Skip `timelimit` if it is not set (its default/unset value is a\n # tuple or a list of `None` values\n if key == \"timelimit\" and all(_ is None for _ in value):\n continue\n\n # Skip `retries` if its value is `0`\n if key == \"retries\" and value == 0:\n continue\n\n span.set_tag(tag_name, value)\n\n\ndef attach_span(task, task_id, span, is_publish=False):\n \"\"\"Helper to propagate a `Span` for the given `Task` instance. This\n function uses a `WeakValueDictionary` that stores a Datadog Span using\n the `(task_id, is_publish)` as a key. This is useful when information must be\n propagated from one Celery signal to another.\n\n DEV: We use (task_id, is_publish) for the key to ensure that publishing a\n task from within another task does not cause any conflicts.\n\n This mostly happens when either a task fails and a retry policy is in place,\n or when a task is manually retried (e.g. `task.retry()`), we end up trying\n to publish a task with the same id as the task currently running.\n\n Previously publishing the new task would overwrite the existing `celery.run` span\n in the `weak_dict` causing that span to be forgotten and never finished.\n\n NOTE: We cannot test for this well yet, because we do not run a celery worker,\n and cannot run `task.apply_async()`\n \"\"\"\n weak_dict = getattr(task, CTX_KEY, None)\n if weak_dict is None:\n weak_dict = WeakValueDictionary()\n setattr(task, CTX_KEY, weak_dict)\n\n weak_dict[(task_id, is_publish)] = span\n\n\ndef detach_span(task, task_id, is_publish=False):\n \"\"\"Helper to remove a `Span` in a Celery task when it's propagated.\n This function handles tasks where the `Span` is not attached.\n \"\"\"\n weak_dict = getattr(task, CTX_KEY, None)\n if weak_dict is None:\n return\n\n # DEV: See note in `attach_span` for key info\n try:\n del weak_dict[(task_id, is_publish)]\n except KeyError:\n pass\n\n\ndef retrieve_span(task, task_id, is_publish=False):\n \"\"\"Helper to retrieve an active `Span` stored in a `Task`\n instance\n \"\"\"\n weak_dict = getattr(task, CTX_KEY, None)\n if weak_dict is None:\n return\n else:\n # DEV: See note in `attach_span` for key info\n return weak_dict.get((task_id, is_publish))\n\n\ndef retrieve_task_id(context):\n \"\"\"Helper to retrieve the `Task` identifier from the message `body`.\n This helper supports Protocol Version 1 and 2. The Protocol is well\n detailed in the official documentation:\n http://docs.celeryproject.org/en/latest/internals/protocol.html\n \"\"\"\n headers = context.get(\"headers\")\n body = context.get(\"body\")\n if headers:\n # Protocol Version 2 (default from Celery 4.0)\n return headers.get(\"id\")\n else:\n # Protocol Version 1\n return body.get(\"id\")\n", "path": "ddtrace/contrib/celery/utils.py"}]}
| 2,336 | 514 |
gh_patches_debug_6729
|
rasdani/github-patches
|
git_diff
|
OCHA-DAP__hdx-ckan-1829
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Organization view pages result in 500 error
Only on stag. I tested several different orgs.

</issue>
<code>
[start of ckanext-hdx_search/ckanext/hdx_search/plugin.py]
1 import logging, re
2 import ckan.plugins as plugins
3 import ckan.plugins.toolkit as tk
4 import ckan.lib.plugins as lib_plugins
5
6 def convert_country(q):
7 for c in tk.get_action('group_list')({'user':'127.0.0.1'},{'all_fields': True}):
8 if re.findall(c['display_name'].lower(),q.lower()):
9 q += ' '+c['name']
10 return q
11
12 class HDXSearchPlugin(plugins.SingletonPlugin):
13 plugins.implements(plugins.IConfigurer, inherit=False)
14 plugins.implements(plugins.IRoutes, inherit=True)
15 plugins.implements(plugins.ITemplateHelpers, inherit=False)
16 plugins.implements(plugins.IPackageController, inherit=True)
17
18 def update_config(self, config):
19 tk.add_template_directory(config, 'templates')
20
21 def get_helpers(self):
22 return {}
23
24 def before_map(self, map):
25 map.connect('search', '/search',
26 controller='ckanext.hdx_search.controllers.search_controller:HDXSearchController', action='search')
27 map.connect('simple_search',
28 '/dataset', controller='ckanext.hdx_search.controllers.simple_search_controller:HDXSimpleSearchController', action='package_search')
29 return map
30
31 def after_map(self, map):
32 map.connect('search', '/search',
33 controller='ckanext.hdx_search.controllers.search_controller:HDXSearchController', action='search')
34 map.connect('simple_search',
35 '/dataset', controller='ckanext.hdx_search.controllers.simple_search_controller:HDXSimpleSearchController', action='package_search')
36 return map
37
38 def before_search(self, search_params):
39 search_params['q'] = convert_country(search_params['q'])
40 if 'facet.field' in search_params and 'vocab_Topics' not in search_params['facet.field']:
41 search_params['facet.field'].append('vocab_Topics')
42
43 # If indicator flag is set, search only that type
44 if 'ext_indicator' in search_params['extras']:
45 if int(search_params['extras']['ext_indicator']) == 1:
46 search_params['fq'] = search_params['fq'] + ' +extras_indicator:1'
47 elif int(search_params['extras']['ext_indicator']) == 0:
48 search_params['fq'] = search_params[
49 'fq'] + ' -extras_indicator:1'
50 return search_params
51
52 def after_search(self, search_results, search_params):
53 return search_results
54
55 def before_view(self, pkg_dict):
56 return pkg_dict
57
[end of ckanext-hdx_search/ckanext/hdx_search/plugin.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/ckanext-hdx_search/ckanext/hdx_search/plugin.py b/ckanext-hdx_search/ckanext/hdx_search/plugin.py
--- a/ckanext-hdx_search/ckanext/hdx_search/plugin.py
+++ b/ckanext-hdx_search/ckanext/hdx_search/plugin.py
@@ -36,7 +36,7 @@
return map
def before_search(self, search_params):
- search_params['q'] = convert_country(search_params['q'])
+ #search_params['q'] = convert_country(search_params['q'])
if 'facet.field' in search_params and 'vocab_Topics' not in search_params['facet.field']:
search_params['facet.field'].append('vocab_Topics')
|
{"golden_diff": "diff --git a/ckanext-hdx_search/ckanext/hdx_search/plugin.py b/ckanext-hdx_search/ckanext/hdx_search/plugin.py\n--- a/ckanext-hdx_search/ckanext/hdx_search/plugin.py\n+++ b/ckanext-hdx_search/ckanext/hdx_search/plugin.py\n@@ -36,7 +36,7 @@\n return map\n \n def before_search(self, search_params):\n- search_params['q'] = convert_country(search_params['q'])\n+ #search_params['q'] = convert_country(search_params['q'])\n if 'facet.field' in search_params and 'vocab_Topics' not in search_params['facet.field']:\n search_params['facet.field'].append('vocab_Topics')\n", "issue": "Organization view pages result in 500 error\nOnly on stag. I tested several different orgs. \n\n\n\n", "before_files": [{"content": "import logging, re\nimport ckan.plugins as plugins\nimport ckan.plugins.toolkit as tk\nimport ckan.lib.plugins as lib_plugins\n\ndef convert_country(q):\n for c in tk.get_action('group_list')({'user':'127.0.0.1'},{'all_fields': True}):\n if re.findall(c['display_name'].lower(),q.lower()):\n q += ' '+c['name']\n return q\n\nclass HDXSearchPlugin(plugins.SingletonPlugin):\n plugins.implements(plugins.IConfigurer, inherit=False)\n plugins.implements(plugins.IRoutes, inherit=True)\n plugins.implements(plugins.ITemplateHelpers, inherit=False)\n plugins.implements(plugins.IPackageController, inherit=True)\n\n def update_config(self, config):\n tk.add_template_directory(config, 'templates')\n\n def get_helpers(self):\n return {}\n\n def before_map(self, map):\n map.connect('search', '/search',\n controller='ckanext.hdx_search.controllers.search_controller:HDXSearchController', action='search')\n map.connect('simple_search',\n '/dataset', controller='ckanext.hdx_search.controllers.simple_search_controller:HDXSimpleSearchController', action='package_search')\n return map\n\n def after_map(self, map):\n map.connect('search', '/search',\n controller='ckanext.hdx_search.controllers.search_controller:HDXSearchController', action='search')\n map.connect('simple_search',\n '/dataset', controller='ckanext.hdx_search.controllers.simple_search_controller:HDXSimpleSearchController', action='package_search')\n return map\n\n def before_search(self, search_params):\n search_params['q'] = convert_country(search_params['q'])\n if 'facet.field' in search_params and 'vocab_Topics' not in search_params['facet.field']:\n search_params['facet.field'].append('vocab_Topics')\n\n # If indicator flag is set, search only that type\n if 'ext_indicator' in search_params['extras']:\n if int(search_params['extras']['ext_indicator']) == 1:\n search_params['fq'] = search_params['fq'] + ' +extras_indicator:1'\n elif int(search_params['extras']['ext_indicator']) == 0:\n search_params['fq'] = search_params[\n 'fq'] + ' -extras_indicator:1'\n return search_params\n\n def after_search(self, search_results, search_params):\n return search_results\n\n def before_view(self, pkg_dict):\n return pkg_dict\n", "path": "ckanext-hdx_search/ckanext/hdx_search/plugin.py"}]}
| 1,280 | 168 |
gh_patches_debug_241
|
rasdani/github-patches
|
git_diff
|
PyGithub__PyGithub-1807
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Adding new attribute fails in case new name is the last in the list
### Problem Statement
```bash
$ python scripts/add_attribute.py Permissions triage bool
Traceback (most recent call last):
File "<...>\PyGithub\scripts\add_attribute.py", line 124, in <module>
line = lines[i].rstrip()
IndexError: list index out of range
```
--> Adding a new attribute at the end of the existing list of attributes in class `Permissions` fails.
--> In this case the last attribute name was "push", so "triage" comes last.
https://github.com/PyGithub/PyGithub/blob/34d097ce473601624722b90fc5d0396011dd3acb/github/Permissions.py#L63-L72
### Solution Approach
In case the new attribute name will result in adding it at the end of the list of attributes, then the processing within the script at https://github.com/PyGithub/PyGithub/blob/master/scripts/add_attribute.py#L89 was already processing the next source code line which already contains the `_initAttributes` function.
Subsequently at https://github.com/PyGithub/PyGithub/blob/master/scripts/add_attribute.py#L122 `inInit` is set to `False`, but only checked again after reading already the next line. This means the following code block will never again notice the place of the `_initAttributes` and fails at the end of the file due to endless loop.
Problem can be fixed by conditionally remembering we already reached the `_initAttributes` function, so replace:
https://github.com/PyGithub/PyGithub/blob/34d097ce473601624722b90fc5d0396011dd3acb/scripts/add_attribute.py#L122
with
```python
inInit = True if line == " def _initAttributes(self):" else False
```
Adding new attribute fails in case new name is the last in the list
### Problem Statement
```bash
$ python scripts/add_attribute.py Permissions triage bool
Traceback (most recent call last):
File "<...>\PyGithub\scripts\add_attribute.py", line 124, in <module>
line = lines[i].rstrip()
IndexError: list index out of range
```
--> Adding a new attribute at the end of the existing list of attributes in class `Permissions` fails.
--> In this case the last attribute name was "push", so "triage" comes last.
https://github.com/PyGithub/PyGithub/blob/34d097ce473601624722b90fc5d0396011dd3acb/github/Permissions.py#L63-L72
### Solution Approach
In case the new attribute name will result in adding it at the end of the list of attributes, then the processing within the script at https://github.com/PyGithub/PyGithub/blob/master/scripts/add_attribute.py#L89 was already processing the next source code line which already contains the `_initAttributes` function.
Subsequently at https://github.com/PyGithub/PyGithub/blob/master/scripts/add_attribute.py#L122 `inInit` is set to `False`, but only checked again after reading already the next line. This means the following code block will never again notice the place of the `_initAttributes` and fails at the end of the file due to endless loop.
Problem can be fixed by conditionally remembering we already reached the `_initAttributes` function, so replace:
https://github.com/PyGithub/PyGithub/blob/34d097ce473601624722b90fc5d0396011dd3acb/scripts/add_attribute.py#L122
with
```python
inInit = True if line == " def _initAttributes(self):" else False
```
</issue>
<code>
[start of scripts/add_attribute.py]
1 #!/usr/bin/env python
2
3 ############################ Copyrights and license ############################
4 # #
5 # Copyright 2013 Vincent Jacques <[email protected]> #
6 # Copyright 2014 Thialfihar <[email protected]> #
7 # Copyright 2014 Vincent Jacques <[email protected]> #
8 # Copyright 2016 Peter Buckley <[email protected]> #
9 # Copyright 2018 sfdye <[email protected]> #
10 # Copyright 2018 bbi-yggy <[email protected]> #
11 # #
12 # This file is part of PyGithub. #
13 # http://pygithub.readthedocs.io/ #
14 # #
15 # PyGithub is free software: you can redistribute it and/or modify it under #
16 # the terms of the GNU Lesser General Public License as published by the Free #
17 # Software Foundation, either version 3 of the License, or (at your option) #
18 # any later version. #
19 # #
20 # PyGithub is distributed in the hope that it will be useful, but WITHOUT ANY #
21 # WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS #
22 # FOR A PARTICULAR PURPOSE. See the GNU Lesser General Public License for more #
23 # details. #
24 # #
25 # You should have received a copy of the GNU Lesser General Public License #
26 # along with PyGithub. If not, see <http://www.gnu.org/licenses/>. #
27 # #
28 ################################################################################
29
30 import os.path
31 import sys
32
33 className, attributeName, attributeType = sys.argv[1:4]
34 if len(sys.argv) > 4:
35 attributeClassType = sys.argv[4]
36 else:
37 attributeClassType = ""
38
39
40 types = {
41 "string": (
42 "string",
43 None,
44 'self._makeStringAttribute(attributes["' + attributeName + '"])',
45 ),
46 "int": (
47 "integer",
48 None,
49 'self._makeIntAttribute(attributes["' + attributeName + '"])',
50 ),
51 "bool": (
52 "bool",
53 None,
54 'self._makeBoolAttribute(attributes["' + attributeName + '"])',
55 ),
56 "datetime": (
57 "datetime.datetime",
58 "(str, unicode)",
59 'self._makeDatetimeAttribute(attributes["' + attributeName + '"])',
60 ),
61 "class": (
62 ":class:`" + attributeClassType + "`",
63 None,
64 "self._makeClassAttribute("
65 + attributeClassType
66 + ', attributes["'
67 + attributeName
68 + '"])',
69 ),
70 }
71
72 attributeDocType, attributeAssertType, attributeValue = types[attributeType]
73
74
75 fileName = os.path.join("github", className + ".py")
76
77 with open(fileName) as f:
78 lines = list(f)
79
80 newLines = []
81
82 i = 0
83
84 added = False
85
86 isCompletable = True
87 isProperty = False
88 while not added:
89 line = lines[i].rstrip()
90 i += 1
91 if line.startswith("class "):
92 if "NonCompletableGithubObject" in line:
93 isCompletable = False
94 elif line == " @property":
95 isProperty = True
96 elif line.startswith(" def "):
97 attrName = line[8:-7]
98 # Properties will be inserted after __repr__, but before any other function.
99 if attrName != "__repr__" and (
100 attrName == "_identity" or attrName > attributeName or not isProperty
101 ):
102 if not isProperty:
103 newLines.append(" @property")
104 newLines.append(" def " + attributeName + "(self):")
105 newLines.append(' """')
106 newLines.append(" :type: " + attributeDocType)
107 newLines.append(' """')
108 if isCompletable:
109 newLines.append(
110 " self._completeIfNotSet(self._" + attributeName + ")"
111 )
112 newLines.append(" return self._" + attributeName + ".value")
113 newLines.append("")
114 if isProperty:
115 newLines.append(" @property")
116 added = True
117 isProperty = False
118 newLines.append(line)
119
120 added = False
121
122 inInit = False
123 while not added:
124 line = lines[i].rstrip()
125 i += 1
126 if line == " def _initAttributes(self):":
127 inInit = True
128 if inInit:
129 if not line or line.endswith(" = github.GithubObject.NotSet"):
130 if line:
131 attrName = line[14:-29]
132 if not line or attrName > attributeName:
133 newLines.append(
134 " self._" + attributeName + " = github.GithubObject.NotSet"
135 )
136 added = True
137 newLines.append(line)
138
139 added = False
140
141 inUse = False
142 while not added:
143 try:
144 line = lines[i].rstrip()
145 except IndexError:
146 line = ""
147 i += 1
148 if line == " def _useAttributes(self, attributes):":
149 inUse = True
150 if inUse:
151 if not line or line.endswith(" in attributes: # pragma no branch"):
152 if line:
153 attrName = line[12:-36]
154 if not line or attrName > attributeName:
155 newLines.append(
156 ' if "'
157 + attributeName
158 + '" in attributes: # pragma no branch'
159 )
160 if attributeAssertType:
161 newLines.append(
162 ' assert attributes["'
163 + attributeName
164 + '"] is None or isinstance(attributes["'
165 + attributeName
166 + '"], '
167 + attributeAssertType
168 + '), attributes["'
169 + attributeName
170 + '"]'
171 )
172 newLines.append(
173 " self._" + attributeName + " = " + attributeValue
174 )
175 added = True
176 newLines.append(line)
177
178
179 while i < len(lines):
180 line = lines[i].rstrip()
181 i += 1
182 newLines.append(line)
183
184 with open(fileName, "w") as f:
185 for line in newLines:
186 f.write(line + "\n")
187
[end of scripts/add_attribute.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/scripts/add_attribute.py b/scripts/add_attribute.py
--- a/scripts/add_attribute.py
+++ b/scripts/add_attribute.py
@@ -119,7 +119,7 @@
added = False
-inInit = False
+inInit = line.endswith("def _initAttributes(self):")
while not added:
line = lines[i].rstrip()
i += 1
|
{"golden_diff": "diff --git a/scripts/add_attribute.py b/scripts/add_attribute.py\n--- a/scripts/add_attribute.py\n+++ b/scripts/add_attribute.py\n@@ -119,7 +119,7 @@\n \n added = False\n \n-inInit = False\n+inInit = line.endswith(\"def _initAttributes(self):\")\n while not added:\n line = lines[i].rstrip()\n i += 1\n", "issue": "Adding new attribute fails in case new name is the last in the list\n### Problem Statement\r\n\r\n```bash\r\n$ python scripts/add_attribute.py Permissions triage bool\r\nTraceback (most recent call last):\r\n File \"<...>\\PyGithub\\scripts\\add_attribute.py\", line 124, in <module>\r\n line = lines[i].rstrip()\r\nIndexError: list index out of range\r\n```\r\n--> Adding a new attribute at the end of the existing list of attributes in class `Permissions` fails.\r\n--> In this case the last attribute name was \"push\", so \"triage\" comes last.\r\nhttps://github.com/PyGithub/PyGithub/blob/34d097ce473601624722b90fc5d0396011dd3acb/github/Permissions.py#L63-L72\r\n\r\n### Solution Approach\r\n\r\nIn case the new attribute name will result in adding it at the end of the list of attributes, then the processing within the script at https://github.com/PyGithub/PyGithub/blob/master/scripts/add_attribute.py#L89 was already processing the next source code line which already contains the `_initAttributes` function.\r\nSubsequently at https://github.com/PyGithub/PyGithub/blob/master/scripts/add_attribute.py#L122 `inInit` is set to `False`, but only checked again after reading already the next line. This means the following code block will never again notice the place of the `_initAttributes` and fails at the end of the file due to endless loop.\r\n\r\nProblem can be fixed by conditionally remembering we already reached the `_initAttributes` function, so replace:\r\nhttps://github.com/PyGithub/PyGithub/blob/34d097ce473601624722b90fc5d0396011dd3acb/scripts/add_attribute.py#L122\r\n\r\nwith\r\n\r\n```python\r\ninInit = True if line == \" def _initAttributes(self):\" else False\r\n```\nAdding new attribute fails in case new name is the last in the list\n### Problem Statement\r\n\r\n```bash\r\n$ python scripts/add_attribute.py Permissions triage bool\r\nTraceback (most recent call last):\r\n File \"<...>\\PyGithub\\scripts\\add_attribute.py\", line 124, in <module>\r\n line = lines[i].rstrip()\r\nIndexError: list index out of range\r\n```\r\n--> Adding a new attribute at the end of the existing list of attributes in class `Permissions` fails.\r\n--> In this case the last attribute name was \"push\", so \"triage\" comes last.\r\nhttps://github.com/PyGithub/PyGithub/blob/34d097ce473601624722b90fc5d0396011dd3acb/github/Permissions.py#L63-L72\r\n\r\n### Solution Approach\r\n\r\nIn case the new attribute name will result in adding it at the end of the list of attributes, then the processing within the script at https://github.com/PyGithub/PyGithub/blob/master/scripts/add_attribute.py#L89 was already processing the next source code line which already contains the `_initAttributes` function.\r\nSubsequently at https://github.com/PyGithub/PyGithub/blob/master/scripts/add_attribute.py#L122 `inInit` is set to `False`, but only checked again after reading already the next line. This means the following code block will never again notice the place of the `_initAttributes` and fails at the end of the file due to endless loop.\r\n\r\nProblem can be fixed by conditionally remembering we already reached the `_initAttributes` function, so replace:\r\nhttps://github.com/PyGithub/PyGithub/blob/34d097ce473601624722b90fc5d0396011dd3acb/scripts/add_attribute.py#L122\r\n\r\nwith\r\n\r\n```python\r\ninInit = True if line == \" def _initAttributes(self):\" else False\r\n```\n", "before_files": [{"content": "#!/usr/bin/env python\n\n############################ Copyrights and license ############################\n# #\n# Copyright 2013 Vincent Jacques <[email protected]> #\n# Copyright 2014 Thialfihar <[email protected]> #\n# Copyright 2014 Vincent Jacques <[email protected]> #\n# Copyright 2016 Peter Buckley <[email protected]> #\n# Copyright 2018 sfdye <[email protected]> #\n# Copyright 2018 bbi-yggy <[email protected]> #\n# #\n# This file is part of PyGithub. #\n# http://pygithub.readthedocs.io/ #\n# #\n# PyGithub is free software: you can redistribute it and/or modify it under #\n# the terms of the GNU Lesser General Public License as published by the Free #\n# Software Foundation, either version 3 of the License, or (at your option) #\n# any later version. #\n# #\n# PyGithub is distributed in the hope that it will be useful, but WITHOUT ANY #\n# WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS #\n# FOR A PARTICULAR PURPOSE. See the GNU Lesser General Public License for more #\n# details. #\n# #\n# You should have received a copy of the GNU Lesser General Public License #\n# along with PyGithub. If not, see <http://www.gnu.org/licenses/>. #\n# #\n################################################################################\n\nimport os.path\nimport sys\n\nclassName, attributeName, attributeType = sys.argv[1:4]\nif len(sys.argv) > 4:\n attributeClassType = sys.argv[4]\nelse:\n attributeClassType = \"\"\n\n\ntypes = {\n \"string\": (\n \"string\",\n None,\n 'self._makeStringAttribute(attributes[\"' + attributeName + '\"])',\n ),\n \"int\": (\n \"integer\",\n None,\n 'self._makeIntAttribute(attributes[\"' + attributeName + '\"])',\n ),\n \"bool\": (\n \"bool\",\n None,\n 'self._makeBoolAttribute(attributes[\"' + attributeName + '\"])',\n ),\n \"datetime\": (\n \"datetime.datetime\",\n \"(str, unicode)\",\n 'self._makeDatetimeAttribute(attributes[\"' + attributeName + '\"])',\n ),\n \"class\": (\n \":class:`\" + attributeClassType + \"`\",\n None,\n \"self._makeClassAttribute(\"\n + attributeClassType\n + ', attributes[\"'\n + attributeName\n + '\"])',\n ),\n}\n\nattributeDocType, attributeAssertType, attributeValue = types[attributeType]\n\n\nfileName = os.path.join(\"github\", className + \".py\")\n\nwith open(fileName) as f:\n lines = list(f)\n\nnewLines = []\n\ni = 0\n\nadded = False\n\nisCompletable = True\nisProperty = False\nwhile not added:\n line = lines[i].rstrip()\n i += 1\n if line.startswith(\"class \"):\n if \"NonCompletableGithubObject\" in line:\n isCompletable = False\n elif line == \" @property\":\n isProperty = True\n elif line.startswith(\" def \"):\n attrName = line[8:-7]\n # Properties will be inserted after __repr__, but before any other function.\n if attrName != \"__repr__\" and (\n attrName == \"_identity\" or attrName > attributeName or not isProperty\n ):\n if not isProperty:\n newLines.append(\" @property\")\n newLines.append(\" def \" + attributeName + \"(self):\")\n newLines.append(' \"\"\"')\n newLines.append(\" :type: \" + attributeDocType)\n newLines.append(' \"\"\"')\n if isCompletable:\n newLines.append(\n \" self._completeIfNotSet(self._\" + attributeName + \")\"\n )\n newLines.append(\" return self._\" + attributeName + \".value\")\n newLines.append(\"\")\n if isProperty:\n newLines.append(\" @property\")\n added = True\n isProperty = False\n newLines.append(line)\n\nadded = False\n\ninInit = False\nwhile not added:\n line = lines[i].rstrip()\n i += 1\n if line == \" def _initAttributes(self):\":\n inInit = True\n if inInit:\n if not line or line.endswith(\" = github.GithubObject.NotSet\"):\n if line:\n attrName = line[14:-29]\n if not line or attrName > attributeName:\n newLines.append(\n \" self._\" + attributeName + \" = github.GithubObject.NotSet\"\n )\n added = True\n newLines.append(line)\n\nadded = False\n\ninUse = False\nwhile not added:\n try:\n line = lines[i].rstrip()\n except IndexError:\n line = \"\"\n i += 1\n if line == \" def _useAttributes(self, attributes):\":\n inUse = True\n if inUse:\n if not line or line.endswith(\" in attributes: # pragma no branch\"):\n if line:\n attrName = line[12:-36]\n if not line or attrName > attributeName:\n newLines.append(\n ' if \"'\n + attributeName\n + '\" in attributes: # pragma no branch'\n )\n if attributeAssertType:\n newLines.append(\n ' assert attributes[\"'\n + attributeName\n + '\"] is None or isinstance(attributes[\"'\n + attributeName\n + '\"], '\n + attributeAssertType\n + '), attributes[\"'\n + attributeName\n + '\"]'\n )\n newLines.append(\n \" self._\" + attributeName + \" = \" + attributeValue\n )\n added = True\n newLines.append(line)\n\n\nwhile i < len(lines):\n line = lines[i].rstrip()\n i += 1\n newLines.append(line)\n\nwith open(fileName, \"w\") as f:\n for line in newLines:\n f.write(line + \"\\n\")\n", "path": "scripts/add_attribute.py"}]}
| 3,193 | 84 |
gh_patches_debug_19736
|
rasdani/github-patches
|
git_diff
|
Cog-Creators__Red-DiscordBot-3649
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Dev cog is missing `__name__` in its environment
# Other bugs
#### What were you trying to do?
I tried to run this code with `[p]eval`:
```py
from typing import TypeVar
T = TypeVar("T")
```
#### What were you expecting to happen?
I expected it to run successfully.
#### What actually happened?
I got error:
```
Traceback (most recent call last):
File "/home/ubuntu/red-venv/lib/python3.8/site-packages/redbot/core/dev_commands.py", line 192, in _eval
result = await func()
File "<string>", line 3, in func
File "<string>", line 2, in <module>
File "/usr/lib/python3.8/typing.py", line 603, in __init__
def_mod = sys._getframe(1).f_globals['__name__'] # for pickling
KeyError: '__name__'
```
#### How can we reproduce this issue?
Run the snippet above with `[p]eval` command.
---
Personally, I would just assign `__main__` to `__name__` variable, but I'm open to other options.
</issue>
<code>
[start of redbot/core/dev_commands.py]
1 import ast
2 import asyncio
3 import aiohttp
4 import inspect
5 import io
6 import textwrap
7 import traceback
8 import types
9 import re
10 from contextlib import redirect_stdout
11 from copy import copy
12
13 import discord
14
15 from . import checks, commands
16 from .i18n import Translator
17 from .utils.chat_formatting import box, pagify
18 from .utils.predicates import MessagePredicate
19
20 """
21 Notice:
22
23 95% of the below code came from R.Danny which can be found here:
24
25 https://github.com/Rapptz/RoboDanny/blob/master/cogs/repl.py
26 """
27
28 _ = Translator("Dev", __file__)
29
30 START_CODE_BLOCK_RE = re.compile(r"^((```py)(?=\s)|(```))")
31
32
33 class Dev(commands.Cog):
34 """Various development focused utilities."""
35
36 def __init__(self):
37 super().__init__()
38 self._last_result = None
39 self.sessions = set()
40
41 @staticmethod
42 def async_compile(source, filename, mode):
43 return compile(source, filename, mode, flags=ast.PyCF_ALLOW_TOP_LEVEL_AWAIT, optimize=0)
44
45 @staticmethod
46 async def maybe_await(coro):
47 for i in range(2):
48 if inspect.isawaitable(coro):
49 coro = await coro
50 else:
51 return coro
52 return coro
53
54 @staticmethod
55 def cleanup_code(content):
56 """Automatically removes code blocks from the code."""
57 # remove ```py\n```
58 if content.startswith("```") and content.endswith("```"):
59 return START_CODE_BLOCK_RE.sub("", content)[:-3]
60
61 # remove `foo`
62 return content.strip("` \n")
63
64 @staticmethod
65 def get_syntax_error(e):
66 """Format a syntax error to send to the user.
67
68 Returns a string representation of the error formatted as a codeblock.
69 """
70 if e.text is None:
71 return box("{0.__class__.__name__}: {0}".format(e), lang="py")
72 return box(
73 "{0.text}\n{1:>{0.offset}}\n{2}: {0}".format(e, "^", type(e).__name__), lang="py"
74 )
75
76 @staticmethod
77 def get_pages(msg: str):
78 """Pagify the given message for output to the user."""
79 return pagify(msg, delims=["\n", " "], priority=True, shorten_by=10)
80
81 @staticmethod
82 def sanitize_output(ctx: commands.Context, input_: str) -> str:
83 """Hides the bot's token from a string."""
84 token = ctx.bot.http.token
85 return re.sub(re.escape(token), "[EXPUNGED]", input_, re.I)
86
87 @commands.command()
88 @checks.is_owner()
89 async def debug(self, ctx, *, code):
90 """Evaluate a statement of python code.
91
92 The bot will always respond with the return value of the code.
93 If the return value of the code is a coroutine, it will be awaited,
94 and the result of that will be the bot's response.
95
96 Note: Only one statement may be evaluated. Using certain restricted
97 keywords, e.g. yield, will result in a syntax error. For multiple
98 lines or asynchronous code, see [p]repl or [p]eval.
99
100 Environment Variables:
101 ctx - command invokation context
102 bot - bot object
103 channel - the current channel object
104 author - command author's member object
105 message - the command's message object
106 discord - discord.py library
107 commands - redbot.core.commands
108 _ - The result of the last dev command.
109 """
110 env = {
111 "bot": ctx.bot,
112 "ctx": ctx,
113 "channel": ctx.channel,
114 "author": ctx.author,
115 "guild": ctx.guild,
116 "message": ctx.message,
117 "asyncio": asyncio,
118 "aiohttp": aiohttp,
119 "discord": discord,
120 "commands": commands,
121 "_": self._last_result,
122 }
123
124 code = self.cleanup_code(code)
125
126 try:
127 compiled = self.async_compile(code, "<string>", "eval")
128 result = await self.maybe_await(eval(compiled, env))
129 except SyntaxError as e:
130 await ctx.send(self.get_syntax_error(e))
131 return
132 except Exception as e:
133 await ctx.send(box("{}: {!s}".format(type(e).__name__, e), lang="py"))
134 return
135
136 self._last_result = result
137 result = self.sanitize_output(ctx, str(result))
138
139 await ctx.send_interactive(self.get_pages(result), box_lang="py")
140
141 @commands.command(name="eval")
142 @checks.is_owner()
143 async def _eval(self, ctx, *, body: str):
144 """Execute asynchronous code.
145
146 This command wraps code into the body of an async function and then
147 calls and awaits it. The bot will respond with anything printed to
148 stdout, as well as the return value of the function.
149
150 The code can be within a codeblock, inline code or neither, as long
151 as they are not mixed and they are formatted correctly.
152
153 Environment Variables:
154 ctx - command invokation context
155 bot - bot object
156 channel - the current channel object
157 author - command author's member object
158 message - the command's message object
159 discord - discord.py library
160 commands - redbot.core.commands
161 _ - The result of the last dev command.
162 """
163 env = {
164 "bot": ctx.bot,
165 "ctx": ctx,
166 "channel": ctx.channel,
167 "author": ctx.author,
168 "guild": ctx.guild,
169 "message": ctx.message,
170 "asyncio": asyncio,
171 "aiohttp": aiohttp,
172 "discord": discord,
173 "commands": commands,
174 "_": self._last_result,
175 }
176
177 body = self.cleanup_code(body)
178 stdout = io.StringIO()
179
180 to_compile = "async def func():\n%s" % textwrap.indent(body, " ")
181
182 try:
183 compiled = self.async_compile(to_compile, "<string>", "exec")
184 exec(compiled, env)
185 except SyntaxError as e:
186 return await ctx.send(self.get_syntax_error(e))
187
188 func = env["func"]
189 result = None
190 try:
191 with redirect_stdout(stdout):
192 result = await func()
193 except:
194 printed = "{}{}".format(stdout.getvalue(), traceback.format_exc())
195 else:
196 printed = stdout.getvalue()
197 await ctx.tick()
198
199 if result is not None:
200 self._last_result = result
201 msg = "{}{}".format(printed, result)
202 else:
203 msg = printed
204 msg = self.sanitize_output(ctx, msg)
205
206 await ctx.send_interactive(self.get_pages(msg), box_lang="py")
207
208 @commands.command()
209 @checks.is_owner()
210 async def repl(self, ctx):
211 """Open an interactive REPL.
212
213 The REPL will only recognise code as messages which start with a
214 backtick. This includes codeblocks, and as such multiple lines can be
215 evaluated.
216 """
217 variables = {
218 "ctx": ctx,
219 "bot": ctx.bot,
220 "message": ctx.message,
221 "guild": ctx.guild,
222 "channel": ctx.channel,
223 "author": ctx.author,
224 "asyncio": asyncio,
225 "_": None,
226 "__builtins__": __builtins__,
227 }
228
229 if ctx.channel.id in self.sessions:
230 await ctx.send(
231 _("Already running a REPL session in this channel. Exit it with `quit`.")
232 )
233 return
234
235 self.sessions.add(ctx.channel.id)
236 await ctx.send(_("Enter code to execute or evaluate. `exit()` or `quit` to exit."))
237
238 while True:
239 response = await ctx.bot.wait_for("message", check=MessagePredicate.regex(r"^`", ctx))
240
241 cleaned = self.cleanup_code(response.content)
242
243 if cleaned in ("quit", "exit", "exit()"):
244 await ctx.send(_("Exiting."))
245 self.sessions.remove(ctx.channel.id)
246 return
247
248 executor = None
249 if cleaned.count("\n") == 0:
250 # single statement, potentially 'eval'
251 try:
252 code = self.async_compile(cleaned, "<repl session>", "eval")
253 except SyntaxError:
254 pass
255 else:
256 executor = eval
257
258 if executor is None:
259 try:
260 code = self.async_compile(cleaned, "<repl session>", "exec")
261 except SyntaxError as e:
262 await ctx.send(self.get_syntax_error(e))
263 continue
264
265 variables["message"] = response
266
267 stdout = io.StringIO()
268
269 msg = ""
270
271 try:
272 with redirect_stdout(stdout):
273 if executor is None:
274 result = types.FunctionType(code, variables)()
275 else:
276 result = executor(code, variables)
277 result = await self.maybe_await(result)
278 except:
279 value = stdout.getvalue()
280 msg = "{}{}".format(value, traceback.format_exc())
281 else:
282 value = stdout.getvalue()
283 if result is not None:
284 msg = "{}{}".format(value, result)
285 variables["_"] = result
286 elif value:
287 msg = "{}".format(value)
288
289 msg = self.sanitize_output(ctx, msg)
290
291 try:
292 await ctx.send_interactive(self.get_pages(msg), box_lang="py")
293 except discord.Forbidden:
294 pass
295 except discord.HTTPException as e:
296 await ctx.send(_("Unexpected error: `{}`").format(e))
297
298 @commands.command()
299 @checks.is_owner()
300 async def mock(self, ctx, user: discord.Member, *, command):
301 """Mock another user invoking a command.
302
303 The prefix must not be entered.
304 """
305 msg = copy(ctx.message)
306 msg.author = user
307 msg.content = ctx.prefix + command
308
309 ctx.bot.dispatch("message", msg)
310
311 @commands.command(name="mockmsg")
312 @checks.is_owner()
313 async def mock_msg(self, ctx, user: discord.Member, *, content: str):
314 """Dispatch a message event as if it were sent by a different user.
315
316 Only reads the raw content of the message. Attachments, embeds etc. are
317 ignored.
318 """
319 old_author = ctx.author
320 old_content = ctx.message.content
321 ctx.message.author = user
322 ctx.message.content = content
323
324 ctx.bot.dispatch("message", ctx.message)
325
326 # If we change the author and content back too quickly,
327 # the bot won't process the mocked message in time.
328 await asyncio.sleep(2)
329 ctx.message.author = old_author
330 ctx.message.content = old_content
331
[end of redbot/core/dev_commands.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/redbot/core/dev_commands.py b/redbot/core/dev_commands.py
--- a/redbot/core/dev_commands.py
+++ b/redbot/core/dev_commands.py
@@ -119,6 +119,7 @@
"discord": discord,
"commands": commands,
"_": self._last_result,
+ "__name__": "__main__",
}
code = self.cleanup_code(code)
@@ -172,6 +173,7 @@
"discord": discord,
"commands": commands,
"_": self._last_result,
+ "__name__": "__main__",
}
body = self.cleanup_code(body)
@@ -224,6 +226,7 @@
"asyncio": asyncio,
"_": None,
"__builtins__": __builtins__,
+ "__name__": "__main__",
}
if ctx.channel.id in self.sessions:
|
{"golden_diff": "diff --git a/redbot/core/dev_commands.py b/redbot/core/dev_commands.py\n--- a/redbot/core/dev_commands.py\n+++ b/redbot/core/dev_commands.py\n@@ -119,6 +119,7 @@\n \"discord\": discord,\n \"commands\": commands,\n \"_\": self._last_result,\n+ \"__name__\": \"__main__\",\n }\n \n code = self.cleanup_code(code)\n@@ -172,6 +173,7 @@\n \"discord\": discord,\n \"commands\": commands,\n \"_\": self._last_result,\n+ \"__name__\": \"__main__\",\n }\n \n body = self.cleanup_code(body)\n@@ -224,6 +226,7 @@\n \"asyncio\": asyncio,\n \"_\": None,\n \"__builtins__\": __builtins__,\n+ \"__name__\": \"__main__\",\n }\n \n if ctx.channel.id in self.sessions:\n", "issue": "Dev cog is missing `__name__` in its environment\n# Other bugs\r\n\r\n#### What were you trying to do?\r\n\r\nI tried to run this code with `[p]eval`:\r\n```py\r\nfrom typing import TypeVar\r\nT = TypeVar(\"T\")\r\n```\r\n\r\n#### What were you expecting to happen?\r\n\r\nI expected it to run successfully.\r\n\r\n#### What actually happened?\r\n\r\nI got error:\r\n```\r\nTraceback (most recent call last):\r\n File \"/home/ubuntu/red-venv/lib/python3.8/site-packages/redbot/core/dev_commands.py\", line 192, in _eval\r\n result = await func()\r\n File \"<string>\", line 3, in func\r\n File \"<string>\", line 2, in <module>\r\n File \"/usr/lib/python3.8/typing.py\", line 603, in __init__\r\n def_mod = sys._getframe(1).f_globals['__name__'] # for pickling\r\nKeyError: '__name__'\r\n```\r\n\r\n#### How can we reproduce this issue?\r\n\r\nRun the snippet above with `[p]eval` command.\r\n\r\n---\r\n\r\nPersonally, I would just assign `__main__` to `__name__` variable, but I'm open to other options.\r\n\n", "before_files": [{"content": "import ast\nimport asyncio\nimport aiohttp\nimport inspect\nimport io\nimport textwrap\nimport traceback\nimport types\nimport re\nfrom contextlib import redirect_stdout\nfrom copy import copy\n\nimport discord\n\nfrom . import checks, commands\nfrom .i18n import Translator\nfrom .utils.chat_formatting import box, pagify\nfrom .utils.predicates import MessagePredicate\n\n\"\"\"\nNotice:\n\n95% of the below code came from R.Danny which can be found here:\n\nhttps://github.com/Rapptz/RoboDanny/blob/master/cogs/repl.py\n\"\"\"\n\n_ = Translator(\"Dev\", __file__)\n\nSTART_CODE_BLOCK_RE = re.compile(r\"^((```py)(?=\\s)|(```))\")\n\n\nclass Dev(commands.Cog):\n \"\"\"Various development focused utilities.\"\"\"\n\n def __init__(self):\n super().__init__()\n self._last_result = None\n self.sessions = set()\n\n @staticmethod\n def async_compile(source, filename, mode):\n return compile(source, filename, mode, flags=ast.PyCF_ALLOW_TOP_LEVEL_AWAIT, optimize=0)\n\n @staticmethod\n async def maybe_await(coro):\n for i in range(2):\n if inspect.isawaitable(coro):\n coro = await coro\n else:\n return coro\n return coro\n\n @staticmethod\n def cleanup_code(content):\n \"\"\"Automatically removes code blocks from the code.\"\"\"\n # remove ```py\\n```\n if content.startswith(\"```\") and content.endswith(\"```\"):\n return START_CODE_BLOCK_RE.sub(\"\", content)[:-3]\n\n # remove `foo`\n return content.strip(\"` \\n\")\n\n @staticmethod\n def get_syntax_error(e):\n \"\"\"Format a syntax error to send to the user.\n\n Returns a string representation of the error formatted as a codeblock.\n \"\"\"\n if e.text is None:\n return box(\"{0.__class__.__name__}: {0}\".format(e), lang=\"py\")\n return box(\n \"{0.text}\\n{1:>{0.offset}}\\n{2}: {0}\".format(e, \"^\", type(e).__name__), lang=\"py\"\n )\n\n @staticmethod\n def get_pages(msg: str):\n \"\"\"Pagify the given message for output to the user.\"\"\"\n return pagify(msg, delims=[\"\\n\", \" \"], priority=True, shorten_by=10)\n\n @staticmethod\n def sanitize_output(ctx: commands.Context, input_: str) -> str:\n \"\"\"Hides the bot's token from a string.\"\"\"\n token = ctx.bot.http.token\n return re.sub(re.escape(token), \"[EXPUNGED]\", input_, re.I)\n\n @commands.command()\n @checks.is_owner()\n async def debug(self, ctx, *, code):\n \"\"\"Evaluate a statement of python code.\n\n The bot will always respond with the return value of the code.\n If the return value of the code is a coroutine, it will be awaited,\n and the result of that will be the bot's response.\n\n Note: Only one statement may be evaluated. Using certain restricted\n keywords, e.g. yield, will result in a syntax error. For multiple\n lines or asynchronous code, see [p]repl or [p]eval.\n\n Environment Variables:\n ctx - command invokation context\n bot - bot object\n channel - the current channel object\n author - command author's member object\n message - the command's message object\n discord - discord.py library\n commands - redbot.core.commands\n _ - The result of the last dev command.\n \"\"\"\n env = {\n \"bot\": ctx.bot,\n \"ctx\": ctx,\n \"channel\": ctx.channel,\n \"author\": ctx.author,\n \"guild\": ctx.guild,\n \"message\": ctx.message,\n \"asyncio\": asyncio,\n \"aiohttp\": aiohttp,\n \"discord\": discord,\n \"commands\": commands,\n \"_\": self._last_result,\n }\n\n code = self.cleanup_code(code)\n\n try:\n compiled = self.async_compile(code, \"<string>\", \"eval\")\n result = await self.maybe_await(eval(compiled, env))\n except SyntaxError as e:\n await ctx.send(self.get_syntax_error(e))\n return\n except Exception as e:\n await ctx.send(box(\"{}: {!s}\".format(type(e).__name__, e), lang=\"py\"))\n return\n\n self._last_result = result\n result = self.sanitize_output(ctx, str(result))\n\n await ctx.send_interactive(self.get_pages(result), box_lang=\"py\")\n\n @commands.command(name=\"eval\")\n @checks.is_owner()\n async def _eval(self, ctx, *, body: str):\n \"\"\"Execute asynchronous code.\n\n This command wraps code into the body of an async function and then\n calls and awaits it. The bot will respond with anything printed to\n stdout, as well as the return value of the function.\n\n The code can be within a codeblock, inline code or neither, as long\n as they are not mixed and they are formatted correctly.\n\n Environment Variables:\n ctx - command invokation context\n bot - bot object\n channel - the current channel object\n author - command author's member object\n message - the command's message object\n discord - discord.py library\n commands - redbot.core.commands\n _ - The result of the last dev command.\n \"\"\"\n env = {\n \"bot\": ctx.bot,\n \"ctx\": ctx,\n \"channel\": ctx.channel,\n \"author\": ctx.author,\n \"guild\": ctx.guild,\n \"message\": ctx.message,\n \"asyncio\": asyncio,\n \"aiohttp\": aiohttp,\n \"discord\": discord,\n \"commands\": commands,\n \"_\": self._last_result,\n }\n\n body = self.cleanup_code(body)\n stdout = io.StringIO()\n\n to_compile = \"async def func():\\n%s\" % textwrap.indent(body, \" \")\n\n try:\n compiled = self.async_compile(to_compile, \"<string>\", \"exec\")\n exec(compiled, env)\n except SyntaxError as e:\n return await ctx.send(self.get_syntax_error(e))\n\n func = env[\"func\"]\n result = None\n try:\n with redirect_stdout(stdout):\n result = await func()\n except:\n printed = \"{}{}\".format(stdout.getvalue(), traceback.format_exc())\n else:\n printed = stdout.getvalue()\n await ctx.tick()\n\n if result is not None:\n self._last_result = result\n msg = \"{}{}\".format(printed, result)\n else:\n msg = printed\n msg = self.sanitize_output(ctx, msg)\n\n await ctx.send_interactive(self.get_pages(msg), box_lang=\"py\")\n\n @commands.command()\n @checks.is_owner()\n async def repl(self, ctx):\n \"\"\"Open an interactive REPL.\n\n The REPL will only recognise code as messages which start with a\n backtick. This includes codeblocks, and as such multiple lines can be\n evaluated.\n \"\"\"\n variables = {\n \"ctx\": ctx,\n \"bot\": ctx.bot,\n \"message\": ctx.message,\n \"guild\": ctx.guild,\n \"channel\": ctx.channel,\n \"author\": ctx.author,\n \"asyncio\": asyncio,\n \"_\": None,\n \"__builtins__\": __builtins__,\n }\n\n if ctx.channel.id in self.sessions:\n await ctx.send(\n _(\"Already running a REPL session in this channel. Exit it with `quit`.\")\n )\n return\n\n self.sessions.add(ctx.channel.id)\n await ctx.send(_(\"Enter code to execute or evaluate. `exit()` or `quit` to exit.\"))\n\n while True:\n response = await ctx.bot.wait_for(\"message\", check=MessagePredicate.regex(r\"^`\", ctx))\n\n cleaned = self.cleanup_code(response.content)\n\n if cleaned in (\"quit\", \"exit\", \"exit()\"):\n await ctx.send(_(\"Exiting.\"))\n self.sessions.remove(ctx.channel.id)\n return\n\n executor = None\n if cleaned.count(\"\\n\") == 0:\n # single statement, potentially 'eval'\n try:\n code = self.async_compile(cleaned, \"<repl session>\", \"eval\")\n except SyntaxError:\n pass\n else:\n executor = eval\n\n if executor is None:\n try:\n code = self.async_compile(cleaned, \"<repl session>\", \"exec\")\n except SyntaxError as e:\n await ctx.send(self.get_syntax_error(e))\n continue\n\n variables[\"message\"] = response\n\n stdout = io.StringIO()\n\n msg = \"\"\n\n try:\n with redirect_stdout(stdout):\n if executor is None:\n result = types.FunctionType(code, variables)()\n else:\n result = executor(code, variables)\n result = await self.maybe_await(result)\n except:\n value = stdout.getvalue()\n msg = \"{}{}\".format(value, traceback.format_exc())\n else:\n value = stdout.getvalue()\n if result is not None:\n msg = \"{}{}\".format(value, result)\n variables[\"_\"] = result\n elif value:\n msg = \"{}\".format(value)\n\n msg = self.sanitize_output(ctx, msg)\n\n try:\n await ctx.send_interactive(self.get_pages(msg), box_lang=\"py\")\n except discord.Forbidden:\n pass\n except discord.HTTPException as e:\n await ctx.send(_(\"Unexpected error: `{}`\").format(e))\n\n @commands.command()\n @checks.is_owner()\n async def mock(self, ctx, user: discord.Member, *, command):\n \"\"\"Mock another user invoking a command.\n\n The prefix must not be entered.\n \"\"\"\n msg = copy(ctx.message)\n msg.author = user\n msg.content = ctx.prefix + command\n\n ctx.bot.dispatch(\"message\", msg)\n\n @commands.command(name=\"mockmsg\")\n @checks.is_owner()\n async def mock_msg(self, ctx, user: discord.Member, *, content: str):\n \"\"\"Dispatch a message event as if it were sent by a different user.\n\n Only reads the raw content of the message. Attachments, embeds etc. are\n ignored.\n \"\"\"\n old_author = ctx.author\n old_content = ctx.message.content\n ctx.message.author = user\n ctx.message.content = content\n\n ctx.bot.dispatch(\"message\", ctx.message)\n\n # If we change the author and content back too quickly,\n # the bot won't process the mocked message in time.\n await asyncio.sleep(2)\n ctx.message.author = old_author\n ctx.message.content = old_content\n", "path": "redbot/core/dev_commands.py"}]}
| 4,005 | 204 |
gh_patches_debug_12807
|
rasdani/github-patches
|
git_diff
|
bridgecrewio__checkov-1086
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
CKV_AWS_119 - DynamoDB table encryption
**Describe the bug**
In general DynamoDB tables are encrypted by default and this can't be turned off, you can change it to use a KMS key of your choice. Therefore the check description is incorrect.
Further infos can be found in the API documentation https://docs.aws.amazon.com/amazondynamodb/latest/APIReference/API_SSESpecification.html
</issue>
<code>
[start of checkov/terraform/checks/resource/aws/DynamoDBTablesEncrypted.py]
1 from checkov.common.models.enums import CheckCategories
2 from checkov.terraform.checks.resource.base_resource_value_check import BaseResourceValueCheck
3
4
5 class DynamoDBTablesEncrypted(BaseResourceValueCheck):
6 def __init__(self):
7 name = "Ensure DynamoDB Tables are encrypted"
8 id = "CKV_AWS_119"
9 supported_resources = ['aws_dynamodb_table']
10 categories = [CheckCategories.NETWORKING]
11 super().__init__(name=name, id=id, categories=categories, supported_resources=supported_resources)
12
13 def get_inspected_key(self):
14 return "server_side_encryption/[0]/enabled"
15
16
17 check = DynamoDBTablesEncrypted()
18
[end of checkov/terraform/checks/resource/aws/DynamoDBTablesEncrypted.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/checkov/terraform/checks/resource/aws/DynamoDBTablesEncrypted.py b/checkov/terraform/checks/resource/aws/DynamoDBTablesEncrypted.py
--- a/checkov/terraform/checks/resource/aws/DynamoDBTablesEncrypted.py
+++ b/checkov/terraform/checks/resource/aws/DynamoDBTablesEncrypted.py
@@ -4,10 +4,10 @@
class DynamoDBTablesEncrypted(BaseResourceValueCheck):
def __init__(self):
- name = "Ensure DynamoDB Tables are encrypted"
+ name = "Ensure DynamoDB Tables are encrypted using KMS"
id = "CKV_AWS_119"
- supported_resources = ['aws_dynamodb_table']
- categories = [CheckCategories.NETWORKING]
+ supported_resources = ["aws_dynamodb_table"]
+ categories = [CheckCategories.ENCRYPTION]
super().__init__(name=name, id=id, categories=categories, supported_resources=supported_resources)
def get_inspected_key(self):
|
{"golden_diff": "diff --git a/checkov/terraform/checks/resource/aws/DynamoDBTablesEncrypted.py b/checkov/terraform/checks/resource/aws/DynamoDBTablesEncrypted.py\n--- a/checkov/terraform/checks/resource/aws/DynamoDBTablesEncrypted.py\n+++ b/checkov/terraform/checks/resource/aws/DynamoDBTablesEncrypted.py\n@@ -4,10 +4,10 @@\n \n class DynamoDBTablesEncrypted(BaseResourceValueCheck):\n def __init__(self):\n- name = \"Ensure DynamoDB Tables are encrypted\"\n+ name = \"Ensure DynamoDB Tables are encrypted using KMS\"\n id = \"CKV_AWS_119\"\n- supported_resources = ['aws_dynamodb_table']\n- categories = [CheckCategories.NETWORKING]\n+ supported_resources = [\"aws_dynamodb_table\"]\n+ categories = [CheckCategories.ENCRYPTION]\n super().__init__(name=name, id=id, categories=categories, supported_resources=supported_resources)\n \n def get_inspected_key(self):\n", "issue": "CKV_AWS_119 - DynamoDB table encryption\n**Describe the bug**\r\nIn general DynamoDB tables are encrypted by default and this can't be turned off, you can change it to use a KMS key of your choice. Therefore the check description is incorrect.\r\n\r\nFurther infos can be found in the API documentation https://docs.aws.amazon.com/amazondynamodb/latest/APIReference/API_SSESpecification.html\r\n\r\n\n", "before_files": [{"content": "from checkov.common.models.enums import CheckCategories\nfrom checkov.terraform.checks.resource.base_resource_value_check import BaseResourceValueCheck\n\n\nclass DynamoDBTablesEncrypted(BaseResourceValueCheck):\n def __init__(self):\n name = \"Ensure DynamoDB Tables are encrypted\"\n id = \"CKV_AWS_119\"\n supported_resources = ['aws_dynamodb_table']\n categories = [CheckCategories.NETWORKING]\n super().__init__(name=name, id=id, categories=categories, supported_resources=supported_resources)\n\n def get_inspected_key(self):\n return \"server_side_encryption/[0]/enabled\"\n\n\ncheck = DynamoDBTablesEncrypted()\n", "path": "checkov/terraform/checks/resource/aws/DynamoDBTablesEncrypted.py"}]}
| 813 | 217 |
gh_patches_debug_6434
|
rasdani/github-patches
|
git_diff
|
python-pillow__Pillow-6973
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Cannot identify .fits file
### What did you do?
Tried using pillow for opening/handling a .fits file for training a machine learning model. According to the documentation opening/reading fits files should be enabled? Or am I misunderstanding how a fits file should be opened?
From Issue [4054](https://github.com/python-pillow/Pillow/issues/4054)/ PR 6056
> I've created PR https://github.com/python-pillow/Pillow/pull/6056 to resolve this. If that is merged, you should no longer have to worry about register_handler(), but can instead just Image.open("sample.fits").
### What did you expect to happen?
Not recieving a "cannot identify error" while using Image.open. Expected the function to work as with other supported file formats. The .fits files in question are not corrupted, and can be opened as normal with other software.
### What happened?
```python
from PIL import Image
with Image.open('example.fits') as im:
im.verify()
```
```
---------------------------------------------------------------------------
UnidentifiedImageError Traceback (most recent call last)
Cell In [38], line 2
1 from PIL import FitsImagePlugin, ImageFile
----> 2 with Image.open('example.fits') as im:
3 im.verify()
File ~\AppData\Local\Packages\PythonSoftwareFoundation.Python.3.10_qbz5n2kfra8p0\LocalCache\local-packages\Python310\site-packages\PIL\Image.py:3186, in open(fp, mode, formats)
3184 for message in accept_warnings:
3185 warnings.warn(message)
-> 3186 raise UnidentifiedImageError(
3187 "cannot identify image file %r" % (filename if filename else fp)
3188 )
UnidentifiedImageError: cannot identify image file 'example.fits'
```
### What are your OS, Python and Pillow versions?
* OS: windows 10
* Python: 3.10
* Pillow: 9.3.0
<!--
Please include **code** that reproduces the issue and whenever possible, an **image** that demonstrates the issue. Please upload images to GitHub, not to third-party file hosting sites. If necessary, add the image to a zip or tar archive.
The best reproductions are self-contained scripts with minimal dependencies. If you are using a framework such as Plone, Django, or Buildout, try to replicate the issue just using Pillow.
-->
</issue>
<code>
[start of src/PIL/FitsImagePlugin.py]
1 #
2 # The Python Imaging Library
3 # $Id$
4 #
5 # FITS file handling
6 #
7 # Copyright (c) 1998-2003 by Fredrik Lundh
8 #
9 # See the README file for information on usage and redistribution.
10 #
11
12 import math
13
14 from . import Image, ImageFile
15
16
17 def _accept(prefix):
18 return prefix[:6] == b"SIMPLE"
19
20
21 class FitsImageFile(ImageFile.ImageFile):
22 format = "FITS"
23 format_description = "FITS"
24
25 def _open(self):
26 headers = {}
27 while True:
28 header = self.fp.read(80)
29 if not header:
30 msg = "Truncated FITS file"
31 raise OSError(msg)
32 keyword = header[:8].strip()
33 if keyword == b"END":
34 break
35 value = header[8:].strip()
36 if value.startswith(b"="):
37 value = value[1:].strip()
38 if not headers and (not _accept(keyword) or value != b"T"):
39 msg = "Not a FITS file"
40 raise SyntaxError(msg)
41 headers[keyword] = value
42
43 naxis = int(headers[b"NAXIS"])
44 if naxis == 0:
45 msg = "No image data"
46 raise ValueError(msg)
47 elif naxis == 1:
48 self._size = 1, int(headers[b"NAXIS1"])
49 else:
50 self._size = int(headers[b"NAXIS1"]), int(headers[b"NAXIS2"])
51
52 number_of_bits = int(headers[b"BITPIX"])
53 if number_of_bits == 8:
54 self.mode = "L"
55 elif number_of_bits == 16:
56 self.mode = "I"
57 # rawmode = "I;16S"
58 elif number_of_bits == 32:
59 self.mode = "I"
60 elif number_of_bits in (-32, -64):
61 self.mode = "F"
62 # rawmode = "F" if number_of_bits == -32 else "F;64F"
63
64 offset = math.ceil(self.fp.tell() / 2880) * 2880
65 self.tile = [("raw", (0, 0) + self.size, offset, (self.mode, 0, -1))]
66
67
68 # --------------------------------------------------------------------
69 # Registry
70
71 Image.register_open(FitsImageFile.format, FitsImageFile, _accept)
72
73 Image.register_extensions(FitsImageFile.format, [".fit", ".fits"])
74
[end of src/PIL/FitsImagePlugin.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/PIL/FitsImagePlugin.py b/src/PIL/FitsImagePlugin.py
--- a/src/PIL/FitsImagePlugin.py
+++ b/src/PIL/FitsImagePlugin.py
@@ -32,7 +32,7 @@
keyword = header[:8].strip()
if keyword == b"END":
break
- value = header[8:].strip()
+ value = header[8:].split(b"/")[0].strip()
if value.startswith(b"="):
value = value[1:].strip()
if not headers and (not _accept(keyword) or value != b"T"):
|
{"golden_diff": "diff --git a/src/PIL/FitsImagePlugin.py b/src/PIL/FitsImagePlugin.py\n--- a/src/PIL/FitsImagePlugin.py\n+++ b/src/PIL/FitsImagePlugin.py\n@@ -32,7 +32,7 @@\n keyword = header[:8].strip()\n if keyword == b\"END\":\n break\n- value = header[8:].strip()\n+ value = header[8:].split(b\"/\")[0].strip()\n if value.startswith(b\"=\"):\n value = value[1:].strip()\n if not headers and (not _accept(keyword) or value != b\"T\"):\n", "issue": "Cannot identify .fits file\n### What did you do?\r\nTried using pillow for opening/handling a .fits file for training a machine learning model. According to the documentation opening/reading fits files should be enabled? Or am I misunderstanding how a fits file should be opened? \r\n\r\n\r\nFrom Issue [4054](https://github.com/python-pillow/Pillow/issues/4054)/ PR 6056\r\n\r\n> I've created PR https://github.com/python-pillow/Pillow/pull/6056 to resolve this. If that is merged, you should no longer have to worry about register_handler(), but can instead just Image.open(\"sample.fits\").\r\n\r\n\r\n### What did you expect to happen?\r\nNot recieving a \"cannot identify error\" while using Image.open. Expected the function to work as with other supported file formats. The .fits files in question are not corrupted, and can be opened as normal with other software. \r\n\r\n### What happened?\r\n```python\r\nfrom PIL import Image\r\nwith Image.open('example.fits') as im:\r\n im.verify()\r\n```\r\n\r\n```\r\n---------------------------------------------------------------------------\r\nUnidentifiedImageError Traceback (most recent call last)\r\nCell In [38], line 2\r\n 1 from PIL import FitsImagePlugin, ImageFile\r\n----> 2 with Image.open('example.fits') as im:\r\n 3 im.verify()\r\n\r\nFile ~\\AppData\\Local\\Packages\\PythonSoftwareFoundation.Python.3.10_qbz5n2kfra8p0\\LocalCache\\local-packages\\Python310\\site-packages\\PIL\\Image.py:3186, in open(fp, mode, formats)\r\n 3184 for message in accept_warnings:\r\n 3185 warnings.warn(message)\r\n-> 3186 raise UnidentifiedImageError(\r\n 3187 \"cannot identify image file %r\" % (filename if filename else fp)\r\n 3188 )\r\n\r\nUnidentifiedImageError: cannot identify image file 'example.fits'\r\n```\r\n### What are your OS, Python and Pillow versions?\r\n\r\n* OS: windows 10\r\n* Python: 3.10\r\n* Pillow: 9.3.0\r\n\r\n<!--\r\nPlease include **code** that reproduces the issue and whenever possible, an **image** that demonstrates the issue. Please upload images to GitHub, not to third-party file hosting sites. If necessary, add the image to a zip or tar archive.\r\n\r\nThe best reproductions are self-contained scripts with minimal dependencies. If you are using a framework such as Plone, Django, or Buildout, try to replicate the issue just using Pillow.\r\n-->\r\n\r\n\n", "before_files": [{"content": "#\n# The Python Imaging Library\n# $Id$\n#\n# FITS file handling\n#\n# Copyright (c) 1998-2003 by Fredrik Lundh\n#\n# See the README file for information on usage and redistribution.\n#\n\nimport math\n\nfrom . import Image, ImageFile\n\n\ndef _accept(prefix):\n return prefix[:6] == b\"SIMPLE\"\n\n\nclass FitsImageFile(ImageFile.ImageFile):\n format = \"FITS\"\n format_description = \"FITS\"\n\n def _open(self):\n headers = {}\n while True:\n header = self.fp.read(80)\n if not header:\n msg = \"Truncated FITS file\"\n raise OSError(msg)\n keyword = header[:8].strip()\n if keyword == b\"END\":\n break\n value = header[8:].strip()\n if value.startswith(b\"=\"):\n value = value[1:].strip()\n if not headers and (not _accept(keyword) or value != b\"T\"):\n msg = \"Not a FITS file\"\n raise SyntaxError(msg)\n headers[keyword] = value\n\n naxis = int(headers[b\"NAXIS\"])\n if naxis == 0:\n msg = \"No image data\"\n raise ValueError(msg)\n elif naxis == 1:\n self._size = 1, int(headers[b\"NAXIS1\"])\n else:\n self._size = int(headers[b\"NAXIS1\"]), int(headers[b\"NAXIS2\"])\n\n number_of_bits = int(headers[b\"BITPIX\"])\n if number_of_bits == 8:\n self.mode = \"L\"\n elif number_of_bits == 16:\n self.mode = \"I\"\n # rawmode = \"I;16S\"\n elif number_of_bits == 32:\n self.mode = \"I\"\n elif number_of_bits in (-32, -64):\n self.mode = \"F\"\n # rawmode = \"F\" if number_of_bits == -32 else \"F;64F\"\n\n offset = math.ceil(self.fp.tell() / 2880) * 2880\n self.tile = [(\"raw\", (0, 0) + self.size, offset, (self.mode, 0, -1))]\n\n\n# --------------------------------------------------------------------\n# Registry\n\nImage.register_open(FitsImageFile.format, FitsImageFile, _accept)\n\nImage.register_extensions(FitsImageFile.format, [\".fit\", \".fits\"])\n", "path": "src/PIL/FitsImagePlugin.py"}]}
| 1,780 | 136 |
gh_patches_debug_15674
|
rasdani/github-patches
|
git_diff
|
mesonbuild__meson-10230
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Unhandled python exception with 0.62 on windows (0.61 ok)
**Describe the bug**
When running meson 0.62 on win32 and a project using `dependency()` (ex glib):
Unhandled python exception
ModuleNotFoundError: No module named 'mesonbuild.dependencies.data'
```
Traceback (most recent call last):
File "mesonbuild\mesonmain.py", line 151, in run
File "mesonbuild\msetup.py", line 301, in run
File "mesonbuild\msetup.py", line 185, in generate
File "mesonbuild\msetup.py", line 229, in _generate
File "mesonbuild\interpreter\interpreter.py", line 2698, in run
File "mesonbuild\interpreterbase\interpreterbase.py", line 149, in run
File "mesonbuild\interpreterbase\interpreterbase.py", line 174, in evaluate_codeblock
File "mesonbuild\interpreterbase\interpreterbase.py", line 167, in evaluate_codeblock
File "mesonbuild\interpreterbase\interpreterbase.py", line 182, in evaluate_statement
File "mesonbuild\interpreterbase\interpreterbase.py", line 567, in assignment
File "mesonbuild\interpreterbase\interpreterbase.py", line 180, in evaluate_statement
File "mesonbuild\interpreterbase\interpreterbase.py", line 455, in function_call
File "mesonbuild\interpreterbase\decorators.py", line 768, in wrapped
File "mesonbuild\interpreterbase\decorators.py", line 768, in wrapped
File "mesonbuild\interpreterbase\decorators.py", line 768, in wrapped
[Previous line repeated 5 more times]
File "mesonbuild\interpreterbase\decorators.py", line 109, in wrapped
File "mesonbuild\interpreterbase\decorators.py", line 127, in wrapped
File "mesonbuild\interpreterbase\decorators.py", line 277, in wrapper
File "mesonbuild\interpreter\interpreter.py", line 1620, in func_dependency
File "mesonbuild\interpreter\dependencyfallbacks.py", line 352, in lookup
File "mesonbuild\interpreter\dependencyfallbacks.py", line 93, in _do_dependency
File "mesonbuild\dependencies\detect.py", line 112, in find_external_dependency
File "mesonbuild\dependencies\cmake.py", line 135, in __init__
File "mesonbuild\dependencies\cmake.py", line 183, in _get_cmake_info
File "mesonbuild\dependencies\cmake.py", line 614, in _call_cmake
File "mesonbuild\dependencies\cmake.py", line 585, in _setup_cmake_dir
File "importlib\resources.py", line 103, in read_text
File "importlib\resources.py", line 82, in open_text
File "importlib\resources.py", line 43, in open_binary
File "importlib\_common.py", line 66, in get_package
File "importlib\_common.py", line 57, in resolve
File "importlib\__init__.py", line 126, in import_module
File "<frozen importlib._bootstrap>", line 1050, in _gcd_import
File "<frozen importlib._bootstrap>", line 1027, in _find_and_load
File "<frozen importlib._bootstrap>", line 1004, in _find_and_load_unlocked
ModuleNotFoundError: No module named 'mesonbuild.dependencies.data'
```
**To Reproduce**
project('foo')
pcre = dependency('libpcre')
**system parameters**
meson 0.62 (MSI) on windev VM (https://developer.microsoft.com/en-us/windows/downloads/virtual-machines/)
works as expected on 0.61
</issue>
<code>
[start of packaging/hook-mesonbuild.py]
1 #!hint/python3
2
3 """
4 PyInstaller hook to make mesonbuild include everything it needs to.
5 """
6
7 import os
8 from glob import glob
9
10 hiddenimports = []
11
12 def get_all_modules_from_dir(dirname):
13 '''
14 Get all modules required for Meson itself from directories.
15 '''
16 modname = os.path.basename(dirname)
17 modules = [os.path.splitext(os.path.split(x)[1])[0] for x in glob(os.path.join(dirname, '*'))]
18 modules = ['mesonbuild.' + modname + '.' + x for x in modules if not x.startswith('_')]
19 return modules
20
21 hiddenimports += get_all_modules_from_dir('mesonbuild/modules')
22 hiddenimports += get_all_modules_from_dir('mesonbuild/scripts')
23
24 # Python packagers want to be minimal and only copy the things
25 # that they can see being used. They are blind to many things.
26 hiddenimports += [
27 # we run distutils as a subprocess via INTROSPECT_COMMAND.
28 'distutils.archive_util',
29 'distutils.cmd',
30 'distutils.config',
31 'distutils.core',
32 'distutils.debug',
33 'distutils.dep_util',
34 'distutils.dir_util',
35 'distutils.dist',
36 'distutils.errors',
37 'distutils.extension',
38 'distutils.fancy_getopt',
39 'distutils.file_util',
40 'distutils.spawn',
41 'distutils.util',
42 'distutils.version',
43 'distutils.command.build_ext',
44 'distutils.command.build',
45 'distutils.command.install',
46
47 # needed for gtk's find_program() scripts
48 'filecmp',
49 ]
50
[end of packaging/hook-mesonbuild.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/packaging/hook-mesonbuild.py b/packaging/hook-mesonbuild.py
--- a/packaging/hook-mesonbuild.py
+++ b/packaging/hook-mesonbuild.py
@@ -7,6 +7,9 @@
import os
from glob import glob
+from PyInstaller.utils.hooks import collect_data_files
+
+datas = []
hiddenimports = []
def get_all_modules_from_dir(dirname):
@@ -18,6 +21,10 @@
modules = ['mesonbuild.' + modname + '.' + x for x in modules if not x.startswith('_')]
return modules
+datas += collect_data_files('mesonbuild.scripts')
+datas += collect_data_files('mesonbuild.cmake.data')
+datas += collect_data_files('mesonbuild.dependencies.data')
+
hiddenimports += get_all_modules_from_dir('mesonbuild/modules')
hiddenimports += get_all_modules_from_dir('mesonbuild/scripts')
|
{"golden_diff": "diff --git a/packaging/hook-mesonbuild.py b/packaging/hook-mesonbuild.py\n--- a/packaging/hook-mesonbuild.py\n+++ b/packaging/hook-mesonbuild.py\n@@ -7,6 +7,9 @@\n import os\n from glob import glob\n \n+from PyInstaller.utils.hooks import collect_data_files\n+\n+datas = []\n hiddenimports = []\n \n def get_all_modules_from_dir(dirname):\n@@ -18,6 +21,10 @@\n modules = ['mesonbuild.' + modname + '.' + x for x in modules if not x.startswith('_')]\n return modules\n \n+datas += collect_data_files('mesonbuild.scripts')\n+datas += collect_data_files('mesonbuild.cmake.data')\n+datas += collect_data_files('mesonbuild.dependencies.data')\n+\n hiddenimports += get_all_modules_from_dir('mesonbuild/modules')\n hiddenimports += get_all_modules_from_dir('mesonbuild/scripts')\n", "issue": "Unhandled python exception with 0.62 on windows (0.61 ok)\n**Describe the bug**\r\nWhen running meson 0.62 on win32 and a project using `dependency()` (ex glib):\r\n\r\nUnhandled python exception\r\nModuleNotFoundError: No module named 'mesonbuild.dependencies.data'\r\n\r\n```\r\nTraceback (most recent call last):\r\n File \"mesonbuild\\mesonmain.py\", line 151, in run\r\n File \"mesonbuild\\msetup.py\", line 301, in run\r\n File \"mesonbuild\\msetup.py\", line 185, in generate\r\n File \"mesonbuild\\msetup.py\", line 229, in _generate\r\n File \"mesonbuild\\interpreter\\interpreter.py\", line 2698, in run\r\n File \"mesonbuild\\interpreterbase\\interpreterbase.py\", line 149, in run\r\n File \"mesonbuild\\interpreterbase\\interpreterbase.py\", line 174, in evaluate_codeblock\r\n File \"mesonbuild\\interpreterbase\\interpreterbase.py\", line 167, in evaluate_codeblock\r\n File \"mesonbuild\\interpreterbase\\interpreterbase.py\", line 182, in evaluate_statement\r\n File \"mesonbuild\\interpreterbase\\interpreterbase.py\", line 567, in assignment\r\n File \"mesonbuild\\interpreterbase\\interpreterbase.py\", line 180, in evaluate_statement\r\n File \"mesonbuild\\interpreterbase\\interpreterbase.py\", line 455, in function_call\r\n File \"mesonbuild\\interpreterbase\\decorators.py\", line 768, in wrapped\r\n File \"mesonbuild\\interpreterbase\\decorators.py\", line 768, in wrapped\r\n File \"mesonbuild\\interpreterbase\\decorators.py\", line 768, in wrapped\r\n [Previous line repeated 5 more times]\r\n File \"mesonbuild\\interpreterbase\\decorators.py\", line 109, in wrapped\r\n File \"mesonbuild\\interpreterbase\\decorators.py\", line 127, in wrapped\r\n File \"mesonbuild\\interpreterbase\\decorators.py\", line 277, in wrapper\r\n File \"mesonbuild\\interpreter\\interpreter.py\", line 1620, in func_dependency\r\n File \"mesonbuild\\interpreter\\dependencyfallbacks.py\", line 352, in lookup\r\n File \"mesonbuild\\interpreter\\dependencyfallbacks.py\", line 93, in _do_dependency\r\n File \"mesonbuild\\dependencies\\detect.py\", line 112, in find_external_dependency\r\n File \"mesonbuild\\dependencies\\cmake.py\", line 135, in __init__\r\n File \"mesonbuild\\dependencies\\cmake.py\", line 183, in _get_cmake_info\r\n File \"mesonbuild\\dependencies\\cmake.py\", line 614, in _call_cmake\r\n File \"mesonbuild\\dependencies\\cmake.py\", line 585, in _setup_cmake_dir\r\n File \"importlib\\resources.py\", line 103, in read_text\r\n File \"importlib\\resources.py\", line 82, in open_text\r\n File \"importlib\\resources.py\", line 43, in open_binary\r\n File \"importlib\\_common.py\", line 66, in get_package\r\n File \"importlib\\_common.py\", line 57, in resolve\r\n File \"importlib\\__init__.py\", line 126, in import_module\r\n File \"<frozen importlib._bootstrap>\", line 1050, in _gcd_import\r\n File \"<frozen importlib._bootstrap>\", line 1027, in _find_and_load\r\n File \"<frozen importlib._bootstrap>\", line 1004, in _find_and_load_unlocked\r\nModuleNotFoundError: No module named 'mesonbuild.dependencies.data'\r\n```\r\n\r\n**To Reproduce**\r\nproject('foo')\r\npcre = dependency('libpcre')\r\n\r\n**system parameters**\r\nmeson 0.62 (MSI) on windev VM (https://developer.microsoft.com/en-us/windows/downloads/virtual-machines/)\r\nworks as expected on 0.61\n", "before_files": [{"content": "#!hint/python3\n\n\"\"\"\nPyInstaller hook to make mesonbuild include everything it needs to.\n\"\"\"\n\nimport os\nfrom glob import glob\n\nhiddenimports = []\n\ndef get_all_modules_from_dir(dirname):\n '''\n Get all modules required for Meson itself from directories.\n '''\n modname = os.path.basename(dirname)\n modules = [os.path.splitext(os.path.split(x)[1])[0] for x in glob(os.path.join(dirname, '*'))]\n modules = ['mesonbuild.' + modname + '.' + x for x in modules if not x.startswith('_')]\n return modules\n\nhiddenimports += get_all_modules_from_dir('mesonbuild/modules')\nhiddenimports += get_all_modules_from_dir('mesonbuild/scripts')\n\n# Python packagers want to be minimal and only copy the things\n# that they can see being used. They are blind to many things.\nhiddenimports += [\n # we run distutils as a subprocess via INTROSPECT_COMMAND.\n 'distutils.archive_util',\n 'distutils.cmd',\n 'distutils.config',\n 'distutils.core',\n 'distutils.debug',\n 'distutils.dep_util',\n 'distutils.dir_util',\n 'distutils.dist',\n 'distutils.errors',\n 'distutils.extension',\n 'distutils.fancy_getopt',\n 'distutils.file_util',\n 'distutils.spawn',\n 'distutils.util',\n 'distutils.version',\n 'distutils.command.build_ext',\n 'distutils.command.build',\n 'distutils.command.install',\n\n # needed for gtk's find_program() scripts\n 'filecmp',\n]\n", "path": "packaging/hook-mesonbuild.py"}]}
| 1,914 | 207 |
gh_patches_debug_240
|
rasdani/github-patches
|
git_diff
|
ipython__ipython-3013
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
cython_pyximport reload broken in python3
python3.3 notebook, tested in 0.13.1 but the code looks the same in HEAD:
%%cython_pyximport foo
def f(x):
return 4.0*x
execute twice and you get
```
/usr/lib/python3/dist-packages/IPython/extensions/cythonmagic.py in cython_pyximport(self, line, cell)
99 if module_name in self._reloads:
100 module = self._reloads[module_name]
--> 101 reload(module)
102 else:
103 __import__(module_name)
NameError: global name 'reload' is not defined
```
imp.reload should be used here
</issue>
<code>
[start of IPython/extensions/cythonmagic.py]
1 # -*- coding: utf-8 -*-
2 """
3 =====================
4 Cython related magics
5 =====================
6
7 Usage
8 =====
9
10 ``%%cython``
11
12 {CYTHON_DOC}
13
14 ``%%cython_inline``
15
16 {CYTHON_INLINE_DOC}
17
18 ``%%cython_pyximport``
19
20 {CYTHON_PYXIMPORT_DOC}
21
22 Author:
23 * Brian Granger
24
25 Parts of this code were taken from Cython.inline.
26 """
27 #-----------------------------------------------------------------------------
28 # Copyright (C) 2010-2011, IPython Development Team.
29 #
30 # Distributed under the terms of the Modified BSD License.
31 #
32 # The full license is in the file COPYING.txt, distributed with this software.
33 #-----------------------------------------------------------------------------
34
35 from __future__ import print_function
36
37 import imp
38 import io
39 import os
40 import re
41 import sys
42 import time
43
44 try:
45 import hashlib
46 except ImportError:
47 import md5 as hashlib
48
49 from distutils.core import Distribution, Extension
50 from distutils.command.build_ext import build_ext
51
52 from IPython.core import display
53 from IPython.core import magic_arguments
54 from IPython.core.magic import Magics, magics_class, cell_magic
55 from IPython.testing.skipdoctest import skip_doctest
56 from IPython.utils import py3compat
57
58 import Cython
59 from Cython.Compiler.Errors import CompileError
60 from Cython.Build.Dependencies import cythonize
61
62
63 @magics_class
64 class CythonMagics(Magics):
65
66 def __init__(self, shell):
67 super(CythonMagics,self).__init__(shell)
68 self._reloads = {}
69 self._code_cache = {}
70
71 def _import_all(self, module):
72 for k,v in module.__dict__.items():
73 if not k.startswith('__'):
74 self.shell.push({k:v})
75
76 @cell_magic
77 def cython_inline(self, line, cell):
78 """Compile and run a Cython code cell using Cython.inline.
79
80 This magic simply passes the body of the cell to Cython.inline
81 and returns the result. If the variables `a` and `b` are defined
82 in the user's namespace, here is a simple example that returns
83 their sum::
84
85 %%cython_inline
86 return a+b
87
88 For most purposes, we recommend the usage of the `%%cython` magic.
89 """
90 locs = self.shell.user_global_ns
91 globs = self.shell.user_ns
92 return Cython.inline(cell, locals=locs, globals=globs)
93
94 @cell_magic
95 def cython_pyximport(self, line, cell):
96 """Compile and import a Cython code cell using pyximport.
97
98 The contents of the cell are written to a `.pyx` file in the current
99 working directory, which is then imported using `pyximport`. This
100 magic requires a module name to be passed::
101
102 %%cython_pyximport modulename
103 def f(x):
104 return 2.0*x
105
106 The compiled module is then imported and all of its symbols are
107 injected into the user's namespace. For most purposes, we recommend
108 the usage of the `%%cython` magic.
109 """
110 module_name = line.strip()
111 if not module_name:
112 raise ValueError('module name must be given')
113 fname = module_name + '.pyx'
114 with io.open(fname, 'w', encoding='utf-8') as f:
115 f.write(cell)
116 if 'pyximport' not in sys.modules:
117 import pyximport
118 pyximport.install(reload_support=True)
119 if module_name in self._reloads:
120 module = self._reloads[module_name]
121 reload(module)
122 else:
123 __import__(module_name)
124 module = sys.modules[module_name]
125 self._reloads[module_name] = module
126 self._import_all(module)
127
128 @magic_arguments.magic_arguments()
129 @magic_arguments.argument(
130 '-c', '--compile-args', action='append', default=[],
131 help="Extra flags to pass to compiler via the `extra_compile_args` "
132 "Extension flag (can be specified multiple times)."
133 )
134 @magic_arguments.argument(
135 '--link-args', action='append', default=[],
136 help="Extra flags to pass to linker via the `extra_link_args` "
137 "Extension flag (can be specified multiple times)."
138 )
139 @magic_arguments.argument(
140 '-l', '--lib', action='append', default=[],
141 help="Add a library to link the extension against (can be specified "
142 "multiple times)."
143 )
144 @magic_arguments.argument(
145 '-L', dest='library_dirs', metavar='dir', action='append', default=[],
146 help="Add a path to the list of libary directories (can be specified "
147 "multiple times)."
148 )
149 @magic_arguments.argument(
150 '-I', '--include', action='append', default=[],
151 help="Add a path to the list of include directories (can be specified "
152 "multiple times)."
153 )
154 @magic_arguments.argument(
155 '-+', '--cplus', action='store_true', default=False,
156 help="Output a C++ rather than C file."
157 )
158 @magic_arguments.argument(
159 '-f', '--force', action='store_true', default=False,
160 help="Force the compilation of a new module, even if the source has been "
161 "previously compiled."
162 )
163 @magic_arguments.argument(
164 '-a', '--annotate', action='store_true', default=False,
165 help="Produce a colorized HTML version of the source."
166 )
167 @cell_magic
168 def cython(self, line, cell):
169 """Compile and import everything from a Cython code cell.
170
171 The contents of the cell are written to a `.pyx` file in the
172 directory `IPYTHONDIR/cython` using a filename with the hash of the
173 code. This file is then cythonized and compiled. The resulting module
174 is imported and all of its symbols are injected into the user's
175 namespace. The usage is similar to that of `%%cython_pyximport` but
176 you don't have to pass a module name::
177
178 %%cython
179 def f(x):
180 return 2.0*x
181
182 To compile OpenMP codes, pass the required `--compile-args`
183 and `--link-args`. For example with gcc::
184
185 %%cython --compile-args=-fopenmp --link-args=-fopenmp
186 ...
187 """
188 args = magic_arguments.parse_argstring(self.cython, line)
189 code = cell if cell.endswith('\n') else cell+'\n'
190 lib_dir = os.path.join(self.shell.ipython_dir, 'cython')
191 quiet = True
192 key = code, sys.version_info, sys.executable, Cython.__version__
193
194 if not os.path.exists(lib_dir):
195 os.makedirs(lib_dir)
196
197 if args.force:
198 # Force a new module name by adding the current time to the
199 # key which is hashed to determine the module name.
200 key += time.time(),
201
202 module_name = "_cython_magic_" + hashlib.md5(str(key).encode('utf-8')).hexdigest()
203 module_path = os.path.join(lib_dir, module_name + self.so_ext)
204
205 have_module = os.path.isfile(module_path)
206 need_cythonize = not have_module
207
208 if args.annotate:
209 html_file = os.path.join(lib_dir, module_name + '.html')
210 if not os.path.isfile(html_file):
211 need_cythonize = True
212
213 if need_cythonize:
214 c_include_dirs = args.include
215 if 'numpy' in code:
216 import numpy
217 c_include_dirs.append(numpy.get_include())
218 pyx_file = os.path.join(lib_dir, module_name + '.pyx')
219 pyx_file = py3compat.cast_bytes_py2(pyx_file, encoding=sys.getfilesystemencoding())
220 with io.open(pyx_file, 'w', encoding='utf-8') as f:
221 f.write(code)
222 extension = Extension(
223 name = module_name,
224 sources = [pyx_file],
225 include_dirs = c_include_dirs,
226 library_dirs = args.library_dirs,
227 extra_compile_args = args.compile_args,
228 extra_link_args = args.link_args,
229 libraries = args.lib,
230 language = 'c++' if args.cplus else 'c',
231 )
232 build_extension = self._get_build_extension()
233 try:
234 opts = dict(
235 quiet=quiet,
236 annotate = args.annotate,
237 force = True,
238 )
239 build_extension.extensions = cythonize([extension], **opts)
240 except CompileError:
241 return
242
243 if not have_module:
244 build_extension.build_temp = os.path.dirname(pyx_file)
245 build_extension.build_lib = lib_dir
246 build_extension.run()
247 self._code_cache[key] = module_name
248
249 module = imp.load_dynamic(module_name, module_path)
250 self._import_all(module)
251
252 if args.annotate:
253 try:
254 with io.open(html_file, encoding='utf-8') as f:
255 annotated_html = f.read()
256 except IOError as e:
257 # File could not be opened. Most likely the user has a version
258 # of Cython before 0.15.1 (when `cythonize` learned the
259 # `force` keyword argument) and has already compiled this
260 # exact source without annotation.
261 print('Cython completed successfully but the annotated '
262 'source could not be read.', file=sys.stderr)
263 print(e, file=sys.stderr)
264 else:
265 return display.HTML(self.clean_annotated_html(annotated_html))
266
267 @property
268 def so_ext(self):
269 """The extension suffix for compiled modules."""
270 try:
271 return self._so_ext
272 except AttributeError:
273 self._so_ext = self._get_build_extension().get_ext_filename('')
274 return self._so_ext
275
276 def _get_build_extension(self):
277 dist = Distribution()
278 config_files = dist.find_config_files()
279 try:
280 config_files.remove('setup.cfg')
281 except ValueError:
282 pass
283 dist.parse_config_files(config_files)
284 build_extension = build_ext(dist)
285 build_extension.finalize_options()
286 return build_extension
287
288 @staticmethod
289 def clean_annotated_html(html):
290 """Clean up the annotated HTML source.
291
292 Strips the link to the generated C or C++ file, which we do not
293 present to the user.
294 """
295 r = re.compile('<p>Raw output: <a href="(.*)">(.*)</a>')
296 html = '\n'.join(l for l in html.splitlines() if not r.match(l))
297 return html
298
299 __doc__ = __doc__.format(
300 CYTHON_DOC = ' '*8 + CythonMagics.cython.__doc__,
301 CYTHON_INLINE_DOC = ' '*8 + CythonMagics.cython_inline.__doc__,
302 CYTHON_PYXIMPORT_DOC = ' '*8 + CythonMagics.cython_pyximport.__doc__,
303 )
304
305 def load_ipython_extension(ip):
306 """Load the extension in IPython."""
307 ip.register_magics(CythonMagics)
308
[end of IPython/extensions/cythonmagic.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/IPython/extensions/cythonmagic.py b/IPython/extensions/cythonmagic.py
--- a/IPython/extensions/cythonmagic.py
+++ b/IPython/extensions/cythonmagic.py
@@ -41,6 +41,11 @@
import sys
import time
+try:
+ reload
+except NameError: # Python 3
+ from imp import reload
+
try:
import hashlib
except ImportError:
|
{"golden_diff": "diff --git a/IPython/extensions/cythonmagic.py b/IPython/extensions/cythonmagic.py\n--- a/IPython/extensions/cythonmagic.py\n+++ b/IPython/extensions/cythonmagic.py\n@@ -41,6 +41,11 @@\n import sys\n import time\n \n+try:\n+ reload\n+except NameError: # Python 3\n+ from imp import reload\n+\n try:\n import hashlib\n except ImportError:\n", "issue": "cython_pyximport reload broken in python3\npython3.3 notebook, tested in 0.13.1 but the code looks the same in HEAD:\n\n%%cython_pyximport foo\ndef f(x):\n return 4.0*x\n\nexecute twice and you get \n\n```\n/usr/lib/python3/dist-packages/IPython/extensions/cythonmagic.py in cython_pyximport(self, line, cell)\n 99 if module_name in self._reloads:\n 100 module = self._reloads[module_name]\n--> 101 reload(module)\n 102 else:\n 103 __import__(module_name)\n\nNameError: global name 'reload' is not defined\n```\n\nimp.reload should be used here\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\"\"\"\n=====================\nCython related magics\n=====================\n\nUsage\n=====\n\n``%%cython``\n\n{CYTHON_DOC}\n\n``%%cython_inline``\n\n{CYTHON_INLINE_DOC}\n\n``%%cython_pyximport``\n\n{CYTHON_PYXIMPORT_DOC}\n\nAuthor:\n* Brian Granger\n\nParts of this code were taken from Cython.inline.\n\"\"\"\n#-----------------------------------------------------------------------------\n# Copyright (C) 2010-2011, IPython Development Team.\n#\n# Distributed under the terms of the Modified BSD License.\n#\n# The full license is in the file COPYING.txt, distributed with this software.\n#-----------------------------------------------------------------------------\n\nfrom __future__ import print_function\n\nimport imp\nimport io\nimport os\nimport re\nimport sys\nimport time\n\ntry:\n import hashlib\nexcept ImportError:\n import md5 as hashlib\n\nfrom distutils.core import Distribution, Extension\nfrom distutils.command.build_ext import build_ext\n\nfrom IPython.core import display\nfrom IPython.core import magic_arguments\nfrom IPython.core.magic import Magics, magics_class, cell_magic\nfrom IPython.testing.skipdoctest import skip_doctest\nfrom IPython.utils import py3compat\n\nimport Cython\nfrom Cython.Compiler.Errors import CompileError\nfrom Cython.Build.Dependencies import cythonize\n\n\n@magics_class\nclass CythonMagics(Magics):\n\n def __init__(self, shell):\n super(CythonMagics,self).__init__(shell)\n self._reloads = {}\n self._code_cache = {}\n\n def _import_all(self, module):\n for k,v in module.__dict__.items():\n if not k.startswith('__'):\n self.shell.push({k:v})\n\n @cell_magic\n def cython_inline(self, line, cell):\n \"\"\"Compile and run a Cython code cell using Cython.inline.\n\n This magic simply passes the body of the cell to Cython.inline\n and returns the result. If the variables `a` and `b` are defined\n in the user's namespace, here is a simple example that returns\n their sum::\n\n %%cython_inline\n return a+b\n\n For most purposes, we recommend the usage of the `%%cython` magic.\n \"\"\"\n locs = self.shell.user_global_ns\n globs = self.shell.user_ns\n return Cython.inline(cell, locals=locs, globals=globs)\n\n @cell_magic\n def cython_pyximport(self, line, cell):\n \"\"\"Compile and import a Cython code cell using pyximport.\n\n The contents of the cell are written to a `.pyx` file in the current\n working directory, which is then imported using `pyximport`. This\n magic requires a module name to be passed::\n\n %%cython_pyximport modulename\n def f(x):\n return 2.0*x\n\n The compiled module is then imported and all of its symbols are\n injected into the user's namespace. For most purposes, we recommend\n the usage of the `%%cython` magic.\n \"\"\"\n module_name = line.strip()\n if not module_name:\n raise ValueError('module name must be given')\n fname = module_name + '.pyx'\n with io.open(fname, 'w', encoding='utf-8') as f:\n f.write(cell)\n if 'pyximport' not in sys.modules:\n import pyximport\n pyximport.install(reload_support=True)\n if module_name in self._reloads:\n module = self._reloads[module_name]\n reload(module)\n else:\n __import__(module_name)\n module = sys.modules[module_name]\n self._reloads[module_name] = module\n self._import_all(module)\n\n @magic_arguments.magic_arguments()\n @magic_arguments.argument(\n '-c', '--compile-args', action='append', default=[],\n help=\"Extra flags to pass to compiler via the `extra_compile_args` \"\n \"Extension flag (can be specified multiple times).\"\n )\n @magic_arguments.argument(\n '--link-args', action='append', default=[],\n help=\"Extra flags to pass to linker via the `extra_link_args` \"\n \"Extension flag (can be specified multiple times).\"\n )\n @magic_arguments.argument(\n '-l', '--lib', action='append', default=[],\n help=\"Add a library to link the extension against (can be specified \"\n \"multiple times).\"\n )\n @magic_arguments.argument(\n '-L', dest='library_dirs', metavar='dir', action='append', default=[],\n help=\"Add a path to the list of libary directories (can be specified \"\n \"multiple times).\"\n )\n @magic_arguments.argument(\n '-I', '--include', action='append', default=[],\n help=\"Add a path to the list of include directories (can be specified \"\n \"multiple times).\"\n )\n @magic_arguments.argument(\n '-+', '--cplus', action='store_true', default=False,\n help=\"Output a C++ rather than C file.\"\n )\n @magic_arguments.argument(\n '-f', '--force', action='store_true', default=False,\n help=\"Force the compilation of a new module, even if the source has been \"\n \"previously compiled.\"\n )\n @magic_arguments.argument(\n '-a', '--annotate', action='store_true', default=False,\n help=\"Produce a colorized HTML version of the source.\"\n )\n @cell_magic\n def cython(self, line, cell):\n \"\"\"Compile and import everything from a Cython code cell.\n\n The contents of the cell are written to a `.pyx` file in the\n directory `IPYTHONDIR/cython` using a filename with the hash of the\n code. This file is then cythonized and compiled. The resulting module\n is imported and all of its symbols are injected into the user's\n namespace. The usage is similar to that of `%%cython_pyximport` but\n you don't have to pass a module name::\n\n %%cython\n def f(x):\n return 2.0*x\n\n To compile OpenMP codes, pass the required `--compile-args`\n and `--link-args`. For example with gcc::\n\n %%cython --compile-args=-fopenmp --link-args=-fopenmp\n ...\n \"\"\"\n args = magic_arguments.parse_argstring(self.cython, line)\n code = cell if cell.endswith('\\n') else cell+'\\n'\n lib_dir = os.path.join(self.shell.ipython_dir, 'cython')\n quiet = True\n key = code, sys.version_info, sys.executable, Cython.__version__\n\n if not os.path.exists(lib_dir):\n os.makedirs(lib_dir)\n\n if args.force:\n # Force a new module name by adding the current time to the\n # key which is hashed to determine the module name.\n key += time.time(),\n\n module_name = \"_cython_magic_\" + hashlib.md5(str(key).encode('utf-8')).hexdigest()\n module_path = os.path.join(lib_dir, module_name + self.so_ext)\n\n have_module = os.path.isfile(module_path)\n need_cythonize = not have_module\n\n if args.annotate:\n html_file = os.path.join(lib_dir, module_name + '.html')\n if not os.path.isfile(html_file):\n need_cythonize = True\n\n if need_cythonize:\n c_include_dirs = args.include\n if 'numpy' in code:\n import numpy\n c_include_dirs.append(numpy.get_include())\n pyx_file = os.path.join(lib_dir, module_name + '.pyx')\n pyx_file = py3compat.cast_bytes_py2(pyx_file, encoding=sys.getfilesystemencoding())\n with io.open(pyx_file, 'w', encoding='utf-8') as f:\n f.write(code)\n extension = Extension(\n name = module_name,\n sources = [pyx_file],\n include_dirs = c_include_dirs,\n library_dirs = args.library_dirs,\n extra_compile_args = args.compile_args,\n extra_link_args = args.link_args,\n libraries = args.lib,\n language = 'c++' if args.cplus else 'c',\n )\n build_extension = self._get_build_extension()\n try:\n opts = dict(\n quiet=quiet,\n annotate = args.annotate,\n force = True,\n )\n build_extension.extensions = cythonize([extension], **opts)\n except CompileError:\n return\n\n if not have_module:\n build_extension.build_temp = os.path.dirname(pyx_file)\n build_extension.build_lib = lib_dir\n build_extension.run()\n self._code_cache[key] = module_name\n\n module = imp.load_dynamic(module_name, module_path)\n self._import_all(module)\n\n if args.annotate:\n try:\n with io.open(html_file, encoding='utf-8') as f:\n annotated_html = f.read()\n except IOError as e:\n # File could not be opened. Most likely the user has a version\n # of Cython before 0.15.1 (when `cythonize` learned the\n # `force` keyword argument) and has already compiled this\n # exact source without annotation.\n print('Cython completed successfully but the annotated '\n 'source could not be read.', file=sys.stderr)\n print(e, file=sys.stderr)\n else:\n return display.HTML(self.clean_annotated_html(annotated_html))\n\n @property\n def so_ext(self):\n \"\"\"The extension suffix for compiled modules.\"\"\"\n try:\n return self._so_ext\n except AttributeError:\n self._so_ext = self._get_build_extension().get_ext_filename('')\n return self._so_ext\n\n def _get_build_extension(self):\n dist = Distribution()\n config_files = dist.find_config_files()\n try:\n config_files.remove('setup.cfg')\n except ValueError:\n pass\n dist.parse_config_files(config_files)\n build_extension = build_ext(dist)\n build_extension.finalize_options()\n return build_extension\n\n @staticmethod\n def clean_annotated_html(html):\n \"\"\"Clean up the annotated HTML source.\n\n Strips the link to the generated C or C++ file, which we do not\n present to the user.\n \"\"\"\n r = re.compile('<p>Raw output: <a href=\"(.*)\">(.*)</a>')\n html = '\\n'.join(l for l in html.splitlines() if not r.match(l))\n return html\n\n__doc__ = __doc__.format(\n CYTHON_DOC = ' '*8 + CythonMagics.cython.__doc__,\n CYTHON_INLINE_DOC = ' '*8 + CythonMagics.cython_inline.__doc__,\n CYTHON_PYXIMPORT_DOC = ' '*8 + CythonMagics.cython_pyximport.__doc__,\n)\n\ndef load_ipython_extension(ip):\n \"\"\"Load the extension in IPython.\"\"\"\n ip.register_magics(CythonMagics)\n", "path": "IPython/extensions/cythonmagic.py"}]}
| 3,922 | 94 |
gh_patches_debug_19687
|
rasdani/github-patches
|
git_diff
|
facebookresearch__ParlAI-1625
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
No module named 'parlai_internal'
https://parl.ai/projects/wizard_of_wikipedia/
When running ```python projects/wizard_of_wikipedia/scripts/eval_retrieval_model.py``` I get the following error:
```
Traceback (most recent call last):
File "projects/wizard_of_wikipedia/scripts/eval_retrieval_model.py", line 48, in <module>
eval_model(parser)
File "/home/ml/jwang301/Development/ParlAI/parlai/scripts/eval_model.py", line 68, in eval_model
agent = create_agent(opt, requireModelExists=True)
File "/home/ml/jwang301/Development/ParlAI/parlai/core/agents.py", line 554, in create_agent
model = load_agent_module(opt)
File "/home/ml/jwang301/Development/ParlAI/parlai/core/agents.py", line 407, in load_agent_module
model_class = get_agent_module(new_opt['model'])
File "/home/ml/jwang301/Development/ParlAI/parlai/core/agents.py", line 516, in get_agent_module
my_module = importlib.import_module(module_name)
File "/home/ml/jwang301/anaconda2/envs/ParlAI/lib/python3.6/importlib/__init__.py", line 126, in import_module
return _bootstrap._gcd_import(name[level:], package, level)
File "<frozen importlib._bootstrap>", line 994, in _gcd_import
File "<frozen importlib._bootstrap>", line 971, in _find_and_load
File "<frozen importlib._bootstrap>", line 941, in _find_and_load_unlocked
File "<frozen importlib._bootstrap>", line 219, in _call_with_frames_removed
File "<frozen importlib._bootstrap>", line 994, in _gcd_import
File "<frozen importlib._bootstrap>", line 971, in _find_and_load
File "<frozen importlib._bootstrap>", line 941, in _find_and_load_unlocked
File "<frozen importlib._bootstrap>", line 219, in _call_with_frames_removed
File "<frozen importlib._bootstrap>", line 994, in _gcd_import
File "<frozen importlib._bootstrap>", line 971, in _find_and_load
File "<frozen importlib._bootstrap>", line 941, in _find_and_load_unlocked
File "<frozen importlib._bootstrap>", line 219, in _call_with_frames_removed
File "<frozen importlib._bootstrap>", line 994, in _gcd_import
File "<frozen importlib._bootstrap>", line 971, in _find_and_load
File "<frozen importlib._bootstrap>", line 953, in _find_and_load_unlocked
ModuleNotFoundError: No module named 'parlai_internal'
```
I'm assuming this is accidental since the wiki is public.
</issue>
<code>
[start of projects/wizard_of_wikipedia/scripts/eval_retrieval_model.py]
1 #!/usr/bin/env python3
2
3 # Copyright (c) Facebook, Inc. and its affiliates.
4 # This source code is licensed under the MIT license found in the
5 # LICENSE file in the root directory of this source tree.
6 from parlai.core.params import ParlaiParser
7 from parlai.scripts.eval_model import eval_model
8 from parlai.zoo.wizard_of_wikipedia\
9 .full_dialogue_retrieval_model import download
10 from projects.wizard_of_wikipedia.wizard_transformer_ranker\
11 .wizard_transformer_ranker import WizardTransformerRankerAgent
12
13 """Evaluate pre-trained retrieval model on the full Wizard Dialogue task.
14
15 NOTE: Metrics here differ slightly to those reported in the paper as a result
16 of code changes.
17
18 Results on seen test set:
19 Hits@1/100: 86.7
20
21 Results on unseen test set (run with flag
22 `-t wizard_of_wikipedia:WizardDialogKnowledge:topic_split`):
23 Hits@1/100: 68.96
24 """
25
26 if __name__ == '__main__':
27 parser = ParlaiParser(add_model_args=True)
28 parser.add_argument('-n', '--num-examples', default=100000000)
29 parser.add_argument('-d', '--display-examples', type='bool', default=False)
30 parser.add_argument('-ltim', '--log-every-n-secs', type=float, default=2)
31 WizardTransformerRankerAgent.add_cmdline_args(parser)
32 parser.set_defaults(
33 task='wizard_of_wikipedia',
34 model='projects:wizard_of_wikipedia:wizard_transformer_ranker',
35 model_file='models:wizard_of_wikipedia/full_dialogue_retrieval_model/model',
36 datatype='test',
37 n_heads=6,
38 ffn_size=1200,
39 embeddings_scale=False,
40 delimiter=' __SOC__ ',
41 n_positions=1000,
42 legacy=True
43 )
44
45 opt = parser.parse_args()
46 download(opt['datapath']) # download pretrained retrieval model
47
48 eval_model(parser)
49
[end of projects/wizard_of_wikipedia/scripts/eval_retrieval_model.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/projects/wizard_of_wikipedia/scripts/eval_retrieval_model.py b/projects/wizard_of_wikipedia/scripts/eval_retrieval_model.py
--- a/projects/wizard_of_wikipedia/scripts/eval_retrieval_model.py
+++ b/projects/wizard_of_wikipedia/scripts/eval_retrieval_model.py
@@ -29,7 +29,7 @@
parser.add_argument('-d', '--display-examples', type='bool', default=False)
parser.add_argument('-ltim', '--log-every-n-secs', type=float, default=2)
WizardTransformerRankerAgent.add_cmdline_args(parser)
- parser.set_defaults(
+ parser.set_params(
task='wizard_of_wikipedia',
model='projects:wizard_of_wikipedia:wizard_transformer_ranker',
model_file='models:wizard_of_wikipedia/full_dialogue_retrieval_model/model',
@@ -45,4 +45,4 @@
opt = parser.parse_args()
download(opt['datapath']) # download pretrained retrieval model
- eval_model(parser)
+ eval_model(opt)
|
{"golden_diff": "diff --git a/projects/wizard_of_wikipedia/scripts/eval_retrieval_model.py b/projects/wizard_of_wikipedia/scripts/eval_retrieval_model.py\n--- a/projects/wizard_of_wikipedia/scripts/eval_retrieval_model.py\n+++ b/projects/wizard_of_wikipedia/scripts/eval_retrieval_model.py\n@@ -29,7 +29,7 @@\n parser.add_argument('-d', '--display-examples', type='bool', default=False)\n parser.add_argument('-ltim', '--log-every-n-secs', type=float, default=2)\n WizardTransformerRankerAgent.add_cmdline_args(parser)\n- parser.set_defaults(\n+ parser.set_params(\n task='wizard_of_wikipedia',\n model='projects:wizard_of_wikipedia:wizard_transformer_ranker',\n model_file='models:wizard_of_wikipedia/full_dialogue_retrieval_model/model',\n@@ -45,4 +45,4 @@\n opt = parser.parse_args()\n download(opt['datapath']) # download pretrained retrieval model\n \n- eval_model(parser)\n+ eval_model(opt)\n", "issue": "No module named 'parlai_internal'\nhttps://parl.ai/projects/wizard_of_wikipedia/\r\n\r\nWhen running ```python projects/wizard_of_wikipedia/scripts/eval_retrieval_model.py``` I get the following error:\r\n\r\n```\r\nTraceback (most recent call last):\r\n File \"projects/wizard_of_wikipedia/scripts/eval_retrieval_model.py\", line 48, in <module>\r\n eval_model(parser)\r\n File \"/home/ml/jwang301/Development/ParlAI/parlai/scripts/eval_model.py\", line 68, in eval_model\r\n agent = create_agent(opt, requireModelExists=True)\r\n File \"/home/ml/jwang301/Development/ParlAI/parlai/core/agents.py\", line 554, in create_agent\r\n model = load_agent_module(opt)\r\n File \"/home/ml/jwang301/Development/ParlAI/parlai/core/agents.py\", line 407, in load_agent_module\r\n model_class = get_agent_module(new_opt['model'])\r\n File \"/home/ml/jwang301/Development/ParlAI/parlai/core/agents.py\", line 516, in get_agent_module\r\n my_module = importlib.import_module(module_name)\r\n File \"/home/ml/jwang301/anaconda2/envs/ParlAI/lib/python3.6/importlib/__init__.py\", line 126, in import_module\r\n return _bootstrap._gcd_import(name[level:], package, level)\r\n File \"<frozen importlib._bootstrap>\", line 994, in _gcd_import\r\n File \"<frozen importlib._bootstrap>\", line 971, in _find_and_load\r\n File \"<frozen importlib._bootstrap>\", line 941, in _find_and_load_unlocked\r\n File \"<frozen importlib._bootstrap>\", line 219, in _call_with_frames_removed\r\n File \"<frozen importlib._bootstrap>\", line 994, in _gcd_import\r\n File \"<frozen importlib._bootstrap>\", line 971, in _find_and_load\r\n File \"<frozen importlib._bootstrap>\", line 941, in _find_and_load_unlocked\r\n File \"<frozen importlib._bootstrap>\", line 219, in _call_with_frames_removed\r\n File \"<frozen importlib._bootstrap>\", line 994, in _gcd_import\r\n File \"<frozen importlib._bootstrap>\", line 971, in _find_and_load\r\n File \"<frozen importlib._bootstrap>\", line 941, in _find_and_load_unlocked\r\n File \"<frozen importlib._bootstrap>\", line 219, in _call_with_frames_removed\r\n File \"<frozen importlib._bootstrap>\", line 994, in _gcd_import\r\n File \"<frozen importlib._bootstrap>\", line 971, in _find_and_load\r\n File \"<frozen importlib._bootstrap>\", line 953, in _find_and_load_unlocked\r\nModuleNotFoundError: No module named 'parlai_internal'\r\n```\r\n\r\nI'm assuming this is accidental since the wiki is public. \n", "before_files": [{"content": "#!/usr/bin/env python3\n\n# Copyright (c) Facebook, Inc. and its affiliates.\n# This source code is licensed under the MIT license found in the\n# LICENSE file in the root directory of this source tree.\nfrom parlai.core.params import ParlaiParser\nfrom parlai.scripts.eval_model import eval_model\nfrom parlai.zoo.wizard_of_wikipedia\\\n .full_dialogue_retrieval_model import download\nfrom projects.wizard_of_wikipedia.wizard_transformer_ranker\\\n .wizard_transformer_ranker import WizardTransformerRankerAgent\n\n\"\"\"Evaluate pre-trained retrieval model on the full Wizard Dialogue task.\n\nNOTE: Metrics here differ slightly to those reported in the paper as a result\nof code changes.\n\nResults on seen test set:\nHits@1/100: 86.7\n\nResults on unseen test set (run with flag\n`-t wizard_of_wikipedia:WizardDialogKnowledge:topic_split`):\nHits@1/100: 68.96\n\"\"\"\n\nif __name__ == '__main__':\n parser = ParlaiParser(add_model_args=True)\n parser.add_argument('-n', '--num-examples', default=100000000)\n parser.add_argument('-d', '--display-examples', type='bool', default=False)\n parser.add_argument('-ltim', '--log-every-n-secs', type=float, default=2)\n WizardTransformerRankerAgent.add_cmdline_args(parser)\n parser.set_defaults(\n task='wizard_of_wikipedia',\n model='projects:wizard_of_wikipedia:wizard_transformer_ranker',\n model_file='models:wizard_of_wikipedia/full_dialogue_retrieval_model/model',\n datatype='test',\n n_heads=6,\n ffn_size=1200,\n embeddings_scale=False,\n delimiter=' __SOC__ ',\n n_positions=1000,\n legacy=True\n )\n\n opt = parser.parse_args()\n download(opt['datapath']) # download pretrained retrieval model\n\n eval_model(parser)\n", "path": "projects/wizard_of_wikipedia/scripts/eval_retrieval_model.py"}]}
| 1,775 | 234 |
gh_patches_debug_24238
|
rasdani/github-patches
|
git_diff
|
rwth-i6__returnn-1320
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
PyTorch `weight_decay` ambiguity with shared params
The code logic of `_get_optimizer_param_groups` branch with activated weight decay can not run in its current form. Iterating over all named modules while at the same time iterating recursively over parameters will yield the same parameter multiple times with a different module reference.
In my case this was:
```python
<class 'i6_experiments.users.rossenbach.experiments.librispeech.tts_architecture_improvement_23.pytorch_networks.ctc_aligner_v1.Model'>
<class 'torch.nn.modules.sparse.Embedding'>
```
for
`speaker_embedding.weight`
This means we need a completely new logic if we want to exclude some modules.
</issue>
<code>
[start of returnn/torch/updater.py]
1 """
2 This module covers the optimizer (SGD, Adam, etc) logic,
3 and model param update logic in general.
4 """
5
6 from __future__ import annotations
7
8 import torch
9 import typing
10
11 from returnn.log import log
12
13 _OptimizerClassesDictInitialized = False
14 _OptimizerClassesDict = {}
15
16
17 def _init_optimizer_classes_dict():
18 """
19 Initializes a global dictionary with all optimizers available in PyTorch.
20 """
21 global _OptimizerClassesDictInitialized
22 if _OptimizerClassesDictInitialized:
23 return
24 _OptimizerClassesDictInitialized = True
25 for name, cls in list(vars(torch.optim).items()):
26 assert isinstance(name, str)
27 # Check if cls is a valid subclass of torch.optim.Optimizer
28 if not isinstance(cls, type) or not issubclass(cls, torch.optim.Optimizer):
29 continue
30 assert name not in _OptimizerClassesDict
31 _OptimizerClassesDict[name.lower()] = cls
32
33
34 def get_optimizer_class(class_name):
35 """
36 :param str|function|type[torch.optim.Optimizer] class_name: Optimizer data, e.g. "adam", torch.optim.Adam...
37 :return: Optimizer class
38 :rtype: type[torch.optim.Optimizer]
39 """
40 _init_optimizer_classes_dict()
41 if isinstance(class_name, type):
42 assert issubclass(class_name, torch.optim.Optimizer)
43 elif callable(class_name):
44 class_name = class_name()
45 else:
46 assert isinstance(class_name, str)
47 assert (
48 class_name.lower() in _OptimizerClassesDict
49 ), "%s not found in the available torch optimizers list: %s." % (
50 class_name.lower(),
51 ", ".join("'%s'" % key for key in _OptimizerClassesDict),
52 )
53 class_name = _OptimizerClassesDict[class_name.lower()]
54
55 return class_name
56
57
58 def _get_class_init_kwargs(optim_class):
59 """
60 Obtains the keyword arguments of the class provided as parameter that the user can add to their optimizer.
61
62 :param type[torch.optim.Optimizer] optim_class: Optimizer class.
63 :return: Keyword arguments of the provided class.
64 :rtype: List[str]
65 """
66 from returnn.util.basic import collect_class_init_kwargs
67
68 optim_class_init_kwargs = collect_class_init_kwargs(optim_class)
69 # We already provide params by default, remove it so that the user doesn't add it to the optimizer dict.
70 optim_class_init_kwargs.remove("params")
71
72 return optim_class_init_kwargs
73
74
75 class Updater(object):
76 """
77 Wraps a torch.optim.Optimizer, and extends it by some further functionality.
78 """
79
80 def __init__(self, config, network, initial_learning_rate=1.0):
81 """
82 :param returnn.config.Config config: config defining the training conditions.
83 :param torch.nn.Module network: PyTorch Module defining the network.
84 :param float initial_learning_rate:
85 """
86 self.config = config
87 self.learning_rate = initial_learning_rate
88 self.network = network
89 self.optimizer = None # type: typing.Optional[torch.optim.Optimizer]
90
91 def set_learning_rate(self, value):
92 """
93 Updates the learning rate of the optimizer at each (sub)epoch.
94
95 :param float value: New learning rate.
96 """
97 for param_group in self.optimizer.param_groups:
98 param_group["lr"] = value
99
100 def get_current_step_learning_rate(self):
101 """
102 Obtains an updated learning rate for the current training step inside a (sub)epoch.
103 """
104 pass
105
106 def create_optimizer(self):
107 """
108 Creates an optimizer and stores it in self.optimizer.
109 """
110 optimizer_opts = self.config.typed_value("optimizer", None)
111 if optimizer_opts is None:
112 raise ValueError("config field 'optimizer' needs to be set explicitely for the Torch backend")
113 self.optimizer = self._create_optimizer(optimizer_opts)
114
115 def load_optimizer(self, filename):
116 """
117 Loads a torch.optim.Optimizer from disk and stores it in self.optimizer.
118
119 :param str filename: File from which to load the optimizer state.
120 """
121 print("Load optimizer %s" % filename, file=log.v4)
122 optimizer_state = torch.load(filename)
123 self.optimizer.load_state_dict(optimizer_state)
124
125 def save_optimizer(self, filename):
126 """
127 Saves the state of self.optimizer to a file.
128
129 :param str filename: File in which to save the optimizer state.
130 """
131 print("Save optimizer under %s" % filename, file=log.v4)
132 torch.save(self.optimizer.state_dict(), filename)
133
134 def get_optimizer(self):
135 """
136 :return: Wrapped optimizer object.
137 :rtype: torch.optim.Optimizer
138 """
139 return self.optimizer
140
141 def _create_optimizer(self, optimizer_opts):
142 """
143 Returns a valid optimizer considering the dictionary given by the user in the config.
144
145 :param dict[str]|str optimizer_opts: Optimizer configuration specified by the user.
146 If it's a dict, it must contain "class" with the optimizer name or callable.
147 If it's a str, it must be the optimizer name.
148 :return: A valid optimizer.
149 :rtype: torch.optim.Optimizer
150 """
151 lr = self.learning_rate
152
153 # If the parameter is already a valid optimizer, return it without further processing
154 if isinstance(optimizer_opts, torch.optim.Optimizer):
155 return optimizer_opts
156 elif callable(optimizer_opts):
157 optimizer_opts = {"class": optimizer_opts}
158 else:
159 if not isinstance(optimizer_opts, dict):
160 raise ValueError("'optimizer' must of type dict, callable or torch.optim.Optimizer instance.")
161 if "class" not in optimizer_opts:
162 raise ValueError("'class' field of 'optimizer' dict was not set (use e.g. 'SGD', 'Adam', ...)")
163 optimizer_opts = optimizer_opts.copy()
164
165 # Resolve the optimizer class
166 optim_class_name = optimizer_opts.pop("class")
167 optim_class = get_optimizer_class(optim_class_name)
168
169 # Resolve the optimizer arguments
170 opt_kwargs = optimizer_opts.copy()
171 optim_class_init_kwargs = _get_class_init_kwargs(optim_class)
172 # epsilon is named eps in torch.
173 # If the user specified it as epsilon, parse it as eps for the optimizer
174 if "eps" in optim_class_init_kwargs and "epsilon" in opt_kwargs:
175 opt_kwargs["eps"] = opt_kwargs.pop("epsilon")
176 if "learning_rate" in optimizer_opts:
177 raise ValueError("'learning_rate' should be set outside of the 'optimizer' dict.")
178 lr = lr * optimizer_opts.get("learning_rate_multiplier", 1.0)
179 opt_kwargs["lr"] = lr
180
181 param_groups = self._get_optimizer_param_groups(optim_class, opt_kwargs)
182 optimizer = optim_class(param_groups, **opt_kwargs)
183 print("Optimizer: %s" % optimizer, file=log.v1)
184 assert isinstance(optimizer, torch.optim.Optimizer)
185
186 return optimizer
187
188 def _create_default_optimizer(self):
189 """
190 :return: SGD optimizer.
191 :rtype: torch.optim.SGD
192 """
193 print("Create SGD optimizer (default).", file=log.v2)
194 optimizer = torch.optim.SGD(self.network.parameters(), lr=self.learning_rate)
195
196 return optimizer
197
198 def _get_optimizer_param_groups(self, optim_class, optimizer_opts):
199 """
200 The weight_decay parameter from AdamW affects the weights of layers such as LayerNorm and Embedding.
201 This function creates a blacklist of network modules and splits the optimizer groups in two:
202 those who will receive weight decay, and those who won't receive it.
203 The weight_decay parameter of the rest of the optimizers is L2 regularization.
204
205 For further reading, see https://github.com/karpathy/minGPT/pull/24#issuecomment-679316025 and
206 https://discuss.pytorch.org/t/weight-decay-in-the-optimizers-is-a-bad-idea-especially-with-batchnorm/16994.
207
208 This code is based on https://github.com/karpathy/minGPT (MIT license):
209 https://github.com/karpathy/minGPT/blob/3ed14b2cec0dfdad3f4b2831f2b4a86d11aef150/mingpt/model.py#L136.
210
211 :param type[torch.optim.Optimizer] optim_class: Optimizer class.
212 :param dict[str] optimizer_opts: Optimizer configuration specified by the user.
213 :return: List of configurations for the different sets of parameters.
214 :rtype: List[Dict[str]]
215 """
216 network_params = self.network.parameters()
217
218 # By default insert the weight_decay constraints in the optimizer, as this is default PyTorch behavior.
219 # If the user doesn't accept this, throw an error message.
220 assert self.config.bool("decouple_constraints", True), (
221 "L2/weight_decay constraints are decoupled in PyTorch, but "
222 "decouple_constraints=False was explicitly specified in the config."
223 )
224
225 # Split in parameter groups only if decouple_constraints is set and the optimizer accepts weight_decay.
226 cls_init_kwargs = _get_class_init_kwargs(optim_class)
227 if "weight_decay" not in cls_init_kwargs:
228 assert (
229 "weight_decay" not in optimizer_opts
230 ), "weight_decay not accepted by the chosen optimizer. Accepted values: %s" % ", ".join(
231 "%s" % optim_name for optim_name in cls_init_kwargs
232 )
233 return [{"params": network_params}]
234
235 weight_decay = optimizer_opts.get("weight_decay", 0.0)
236 if not weight_decay:
237 return [{"params": network_params}]
238
239 # Distinguish between parameters with and without weight_decay/L2 regularization.
240 # Parameters without weight decay: biases + LayerNorm/Embedding layers.
241 wd_params = set()
242 no_wd_params = set()
243 blacklist_wd_modules = (torch.nn.LayerNorm, torch.nn.Embedding)
244 for mn, m in self.network.named_modules():
245 for pn, p in m.named_parameters():
246 fpn = "%s.%s" % (mn, pn) if mn else pn # Full param name
247 if pn.endswith("bias"):
248 no_wd_params.add(fpn)
249 elif pn.endswith("weight") and isinstance(m, blacklist_wd_modules):
250 no_wd_params.add(fpn)
251 else:
252 wd_params.add(fpn)
253
254 param_dict = {pn: p for pn, p in self.network.named_parameters()}
255 optim_groups = [
256 {"params": [param_dict[pn] for pn in sorted(list(wd_params))], "weight_decay": weight_decay},
257 {"params": [param_dict[pn] for pn in sorted(list(no_wd_params))], "weight_decay": 0.0},
258 ]
259
260 return optim_groups
261
[end of returnn/torch/updater.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/returnn/torch/updater.py b/returnn/torch/updater.py
--- a/returnn/torch/updater.py
+++ b/returnn/torch/updater.py
@@ -7,8 +7,10 @@
import torch
import typing
+from typing import Set
from returnn.log import log
+from returnn.util.basic import RefIdEq
_OptimizerClassesDictInitialized = False
_OptimizerClassesDict = {}
@@ -241,8 +243,14 @@
wd_params = set()
no_wd_params = set()
blacklist_wd_modules = (torch.nn.LayerNorm, torch.nn.Embedding)
+ # Tracker of visited parameters to only add each parameter once, in case two modules share common parameters.
+ # We need the wrapper class RefIdEq because Parameters are compared by value and not by reference.
+ visited_params: Set[RefIdEq[torch.nn.Parameter]] = set()
for mn, m in self.network.named_modules():
for pn, p in m.named_parameters():
+ if RefIdEq(p) in visited_params:
+ continue
+ visited_params.add(RefIdEq(p))
fpn = "%s.%s" % (mn, pn) if mn else pn # Full param name
if pn.endswith("bias"):
no_wd_params.add(fpn)
|
{"golden_diff": "diff --git a/returnn/torch/updater.py b/returnn/torch/updater.py\n--- a/returnn/torch/updater.py\n+++ b/returnn/torch/updater.py\n@@ -7,8 +7,10 @@\n \n import torch\n import typing\n+from typing import Set\n \n from returnn.log import log\n+from returnn.util.basic import RefIdEq\n \n _OptimizerClassesDictInitialized = False\n _OptimizerClassesDict = {}\n@@ -241,8 +243,14 @@\n wd_params = set()\n no_wd_params = set()\n blacklist_wd_modules = (torch.nn.LayerNorm, torch.nn.Embedding)\n+ # Tracker of visited parameters to only add each parameter once, in case two modules share common parameters.\n+ # We need the wrapper class RefIdEq because Parameters are compared by value and not by reference.\n+ visited_params: Set[RefIdEq[torch.nn.Parameter]] = set()\n for mn, m in self.network.named_modules():\n for pn, p in m.named_parameters():\n+ if RefIdEq(p) in visited_params:\n+ continue\n+ visited_params.add(RefIdEq(p))\n fpn = \"%s.%s\" % (mn, pn) if mn else pn # Full param name\n if pn.endswith(\"bias\"):\n no_wd_params.add(fpn)\n", "issue": "PyTorch `weight_decay` ambiguity with shared params\nThe code logic of `_get_optimizer_param_groups` branch with activated weight decay can not run in its current form. Iterating over all named modules while at the same time iterating recursively over parameters will yield the same parameter multiple times with a different module reference. \r\n\r\nIn my case this was:\r\n```python\r\n<class 'i6_experiments.users.rossenbach.experiments.librispeech.tts_architecture_improvement_23.pytorch_networks.ctc_aligner_v1.Model'> \r\n<class 'torch.nn.modules.sparse.Embedding'> \r\n```\r\nfor\r\n`speaker_embedding.weight`\r\n\r\nThis means we need a completely new logic if we want to exclude some modules.\r\n\n", "before_files": [{"content": "\"\"\"\nThis module covers the optimizer (SGD, Adam, etc) logic,\nand model param update logic in general.\n\"\"\"\n\nfrom __future__ import annotations\n\nimport torch\nimport typing\n\nfrom returnn.log import log\n\n_OptimizerClassesDictInitialized = False\n_OptimizerClassesDict = {}\n\n\ndef _init_optimizer_classes_dict():\n \"\"\"\n Initializes a global dictionary with all optimizers available in PyTorch.\n \"\"\"\n global _OptimizerClassesDictInitialized\n if _OptimizerClassesDictInitialized:\n return\n _OptimizerClassesDictInitialized = True\n for name, cls in list(vars(torch.optim).items()):\n assert isinstance(name, str)\n # Check if cls is a valid subclass of torch.optim.Optimizer\n if not isinstance(cls, type) or not issubclass(cls, torch.optim.Optimizer):\n continue\n assert name not in _OptimizerClassesDict\n _OptimizerClassesDict[name.lower()] = cls\n\n\ndef get_optimizer_class(class_name):\n \"\"\"\n :param str|function|type[torch.optim.Optimizer] class_name: Optimizer data, e.g. \"adam\", torch.optim.Adam...\n :return: Optimizer class\n :rtype: type[torch.optim.Optimizer]\n \"\"\"\n _init_optimizer_classes_dict()\n if isinstance(class_name, type):\n assert issubclass(class_name, torch.optim.Optimizer)\n elif callable(class_name):\n class_name = class_name()\n else:\n assert isinstance(class_name, str)\n assert (\n class_name.lower() in _OptimizerClassesDict\n ), \"%s not found in the available torch optimizers list: %s.\" % (\n class_name.lower(),\n \", \".join(\"'%s'\" % key for key in _OptimizerClassesDict),\n )\n class_name = _OptimizerClassesDict[class_name.lower()]\n\n return class_name\n\n\ndef _get_class_init_kwargs(optim_class):\n \"\"\"\n Obtains the keyword arguments of the class provided as parameter that the user can add to their optimizer.\n\n :param type[torch.optim.Optimizer] optim_class: Optimizer class.\n :return: Keyword arguments of the provided class.\n :rtype: List[str]\n \"\"\"\n from returnn.util.basic import collect_class_init_kwargs\n\n optim_class_init_kwargs = collect_class_init_kwargs(optim_class)\n # We already provide params by default, remove it so that the user doesn't add it to the optimizer dict.\n optim_class_init_kwargs.remove(\"params\")\n\n return optim_class_init_kwargs\n\n\nclass Updater(object):\n \"\"\"\n Wraps a torch.optim.Optimizer, and extends it by some further functionality.\n \"\"\"\n\n def __init__(self, config, network, initial_learning_rate=1.0):\n \"\"\"\n :param returnn.config.Config config: config defining the training conditions.\n :param torch.nn.Module network: PyTorch Module defining the network.\n :param float initial_learning_rate:\n \"\"\"\n self.config = config\n self.learning_rate = initial_learning_rate\n self.network = network\n self.optimizer = None # type: typing.Optional[torch.optim.Optimizer]\n\n def set_learning_rate(self, value):\n \"\"\"\n Updates the learning rate of the optimizer at each (sub)epoch.\n\n :param float value: New learning rate.\n \"\"\"\n for param_group in self.optimizer.param_groups:\n param_group[\"lr\"] = value\n\n def get_current_step_learning_rate(self):\n \"\"\"\n Obtains an updated learning rate for the current training step inside a (sub)epoch.\n \"\"\"\n pass\n\n def create_optimizer(self):\n \"\"\"\n Creates an optimizer and stores it in self.optimizer.\n \"\"\"\n optimizer_opts = self.config.typed_value(\"optimizer\", None)\n if optimizer_opts is None:\n raise ValueError(\"config field 'optimizer' needs to be set explicitely for the Torch backend\")\n self.optimizer = self._create_optimizer(optimizer_opts)\n\n def load_optimizer(self, filename):\n \"\"\"\n Loads a torch.optim.Optimizer from disk and stores it in self.optimizer.\n\n :param str filename: File from which to load the optimizer state.\n \"\"\"\n print(\"Load optimizer %s\" % filename, file=log.v4)\n optimizer_state = torch.load(filename)\n self.optimizer.load_state_dict(optimizer_state)\n\n def save_optimizer(self, filename):\n \"\"\"\n Saves the state of self.optimizer to a file.\n\n :param str filename: File in which to save the optimizer state.\n \"\"\"\n print(\"Save optimizer under %s\" % filename, file=log.v4)\n torch.save(self.optimizer.state_dict(), filename)\n\n def get_optimizer(self):\n \"\"\"\n :return: Wrapped optimizer object.\n :rtype: torch.optim.Optimizer\n \"\"\"\n return self.optimizer\n\n def _create_optimizer(self, optimizer_opts):\n \"\"\"\n Returns a valid optimizer considering the dictionary given by the user in the config.\n\n :param dict[str]|str optimizer_opts: Optimizer configuration specified by the user.\n If it's a dict, it must contain \"class\" with the optimizer name or callable.\n If it's a str, it must be the optimizer name.\n :return: A valid optimizer.\n :rtype: torch.optim.Optimizer\n \"\"\"\n lr = self.learning_rate\n\n # If the parameter is already a valid optimizer, return it without further processing\n if isinstance(optimizer_opts, torch.optim.Optimizer):\n return optimizer_opts\n elif callable(optimizer_opts):\n optimizer_opts = {\"class\": optimizer_opts}\n else:\n if not isinstance(optimizer_opts, dict):\n raise ValueError(\"'optimizer' must of type dict, callable or torch.optim.Optimizer instance.\")\n if \"class\" not in optimizer_opts:\n raise ValueError(\"'class' field of 'optimizer' dict was not set (use e.g. 'SGD', 'Adam', ...)\")\n optimizer_opts = optimizer_opts.copy()\n\n # Resolve the optimizer class\n optim_class_name = optimizer_opts.pop(\"class\")\n optim_class = get_optimizer_class(optim_class_name)\n\n # Resolve the optimizer arguments\n opt_kwargs = optimizer_opts.copy()\n optim_class_init_kwargs = _get_class_init_kwargs(optim_class)\n # epsilon is named eps in torch.\n # If the user specified it as epsilon, parse it as eps for the optimizer\n if \"eps\" in optim_class_init_kwargs and \"epsilon\" in opt_kwargs:\n opt_kwargs[\"eps\"] = opt_kwargs.pop(\"epsilon\")\n if \"learning_rate\" in optimizer_opts:\n raise ValueError(\"'learning_rate' should be set outside of the 'optimizer' dict.\")\n lr = lr * optimizer_opts.get(\"learning_rate_multiplier\", 1.0)\n opt_kwargs[\"lr\"] = lr\n\n param_groups = self._get_optimizer_param_groups(optim_class, opt_kwargs)\n optimizer = optim_class(param_groups, **opt_kwargs)\n print(\"Optimizer: %s\" % optimizer, file=log.v1)\n assert isinstance(optimizer, torch.optim.Optimizer)\n\n return optimizer\n\n def _create_default_optimizer(self):\n \"\"\"\n :return: SGD optimizer.\n :rtype: torch.optim.SGD\n \"\"\"\n print(\"Create SGD optimizer (default).\", file=log.v2)\n optimizer = torch.optim.SGD(self.network.parameters(), lr=self.learning_rate)\n\n return optimizer\n\n def _get_optimizer_param_groups(self, optim_class, optimizer_opts):\n \"\"\"\n The weight_decay parameter from AdamW affects the weights of layers such as LayerNorm and Embedding.\n This function creates a blacklist of network modules and splits the optimizer groups in two:\n those who will receive weight decay, and those who won't receive it.\n The weight_decay parameter of the rest of the optimizers is L2 regularization.\n\n For further reading, see https://github.com/karpathy/minGPT/pull/24#issuecomment-679316025 and\n https://discuss.pytorch.org/t/weight-decay-in-the-optimizers-is-a-bad-idea-especially-with-batchnorm/16994.\n\n This code is based on https://github.com/karpathy/minGPT (MIT license):\n https://github.com/karpathy/minGPT/blob/3ed14b2cec0dfdad3f4b2831f2b4a86d11aef150/mingpt/model.py#L136.\n\n :param type[torch.optim.Optimizer] optim_class: Optimizer class.\n :param dict[str] optimizer_opts: Optimizer configuration specified by the user.\n :return: List of configurations for the different sets of parameters.\n :rtype: List[Dict[str]]\n \"\"\"\n network_params = self.network.parameters()\n\n # By default insert the weight_decay constraints in the optimizer, as this is default PyTorch behavior.\n # If the user doesn't accept this, throw an error message.\n assert self.config.bool(\"decouple_constraints\", True), (\n \"L2/weight_decay constraints are decoupled in PyTorch, but \"\n \"decouple_constraints=False was explicitly specified in the config.\"\n )\n\n # Split in parameter groups only if decouple_constraints is set and the optimizer accepts weight_decay.\n cls_init_kwargs = _get_class_init_kwargs(optim_class)\n if \"weight_decay\" not in cls_init_kwargs:\n assert (\n \"weight_decay\" not in optimizer_opts\n ), \"weight_decay not accepted by the chosen optimizer. Accepted values: %s\" % \", \".join(\n \"%s\" % optim_name for optim_name in cls_init_kwargs\n )\n return [{\"params\": network_params}]\n\n weight_decay = optimizer_opts.get(\"weight_decay\", 0.0)\n if not weight_decay:\n return [{\"params\": network_params}]\n\n # Distinguish between parameters with and without weight_decay/L2 regularization.\n # Parameters without weight decay: biases + LayerNorm/Embedding layers.\n wd_params = set()\n no_wd_params = set()\n blacklist_wd_modules = (torch.nn.LayerNorm, torch.nn.Embedding)\n for mn, m in self.network.named_modules():\n for pn, p in m.named_parameters():\n fpn = \"%s.%s\" % (mn, pn) if mn else pn # Full param name\n if pn.endswith(\"bias\"):\n no_wd_params.add(fpn)\n elif pn.endswith(\"weight\") and isinstance(m, blacklist_wd_modules):\n no_wd_params.add(fpn)\n else:\n wd_params.add(fpn)\n\n param_dict = {pn: p for pn, p in self.network.named_parameters()}\n optim_groups = [\n {\"params\": [param_dict[pn] for pn in sorted(list(wd_params))], \"weight_decay\": weight_decay},\n {\"params\": [param_dict[pn] for pn in sorted(list(no_wd_params))], \"weight_decay\": 0.0},\n ]\n\n return optim_groups\n", "path": "returnn/torch/updater.py"}]}
| 3,707 | 297 |
gh_patches_debug_34331
|
rasdani/github-patches
|
git_diff
|
scoutapp__scout_apm_python-494
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Require Celery app reference to read configuration
We had a customer whose Celery tasks weren't reporting whilst their Django views were. It turns out they had configured in the Django settings file, which isn't applied when Celery runs. This is because it doesn't run "under" Django through `manage.py`, but separately through `celery worker`.
The django pattern is to use [Celery's `app.config_from_object`](https://docs.celeryproject.org/en/latest/reference/celery.html#celery.Celery.config_from_object) to read the Django settings. If we then read out of there for the scout settings, we would again allow shared configuration between the two.
This would need changing the Celery install process to take an `app` argument:
```python
app = celery.Celery(..)
...
scout_apm.celery.install(app)
```
We should work without this for backwards compatibility reasons, but throw a warninng when it's not passed as I predict this issue will appear repeatedly if we don't encourage users this way.
</issue>
<code>
[start of src/scout_apm/celery.py]
1 # coding=utf-8
2 from __future__ import absolute_import, division, print_function, unicode_literals
3
4 import datetime as dt
5
6 from celery.signals import before_task_publish, task_postrun, task_prerun
7
8 import scout_apm.core
9 from scout_apm.compat import datetime_to_timestamp
10 from scout_apm.core.tracked_request import TrackedRequest
11
12
13 def before_publish_callback(headers=None, properties=None, **kwargs):
14 if "scout_task_start" not in headers:
15 headers["scout_task_start"] = datetime_to_timestamp(dt.datetime.utcnow())
16
17
18 def prerun_callback(task=None, **kwargs):
19 tracked_request = TrackedRequest.instance()
20 tracked_request.is_real_request = True
21
22 start = getattr(task.request, "scout_task_start", None)
23 if start is not None:
24 now = datetime_to_timestamp(dt.datetime.utcnow())
25 try:
26 queue_time = now - start
27 except TypeError:
28 pass
29 else:
30 tracked_request.tag("queue_time", queue_time)
31
32 task_id = getattr(task.request, "id", None)
33 if task_id:
34 tracked_request.tag("task_id", task_id)
35 parent_task_id = getattr(task.request, "parent_id", None)
36 if parent_task_id:
37 tracked_request.tag("parent_task_id", parent_task_id)
38
39 delivery_info = task.request.delivery_info
40 tracked_request.tag("is_eager", delivery_info.get("is_eager", False))
41 tracked_request.tag("exchange", delivery_info.get("exchange", "unknown"))
42 tracked_request.tag("routing_key", delivery_info.get("routing_key", "unknown"))
43 tracked_request.tag("queue", delivery_info.get("queue", "unknown"))
44
45 tracked_request.start_span(operation=("Job/" + task.name))
46
47
48 def postrun_callback(task=None, **kwargs):
49 tracked_request = TrackedRequest.instance()
50 tracked_request.stop_span()
51
52
53 def install():
54 installed = scout_apm.core.install()
55 if not installed:
56 return
57
58 before_task_publish.connect(before_publish_callback)
59 task_prerun.connect(prerun_callback)
60 task_postrun.connect(postrun_callback)
61
62
63 def uninstall():
64 before_task_publish.disconnect(before_publish_callback)
65 task_prerun.disconnect(prerun_callback)
66 task_postrun.disconnect(postrun_callback)
67
[end of src/scout_apm/celery.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/scout_apm/celery.py b/src/scout_apm/celery.py
--- a/src/scout_apm/celery.py
+++ b/src/scout_apm/celery.py
@@ -7,15 +7,16 @@
import scout_apm.core
from scout_apm.compat import datetime_to_timestamp
+from scout_apm.core.config import scout_config
from scout_apm.core.tracked_request import TrackedRequest
-def before_publish_callback(headers=None, properties=None, **kwargs):
+def before_task_publish_callback(headers=None, properties=None, **kwargs):
if "scout_task_start" not in headers:
headers["scout_task_start"] = datetime_to_timestamp(dt.datetime.utcnow())
-def prerun_callback(task=None, **kwargs):
+def task_prerun_callback(task=None, **kwargs):
tracked_request = TrackedRequest.instance()
tracked_request.is_real_request = True
@@ -45,22 +46,39 @@
tracked_request.start_span(operation=("Job/" + task.name))
-def postrun_callback(task=None, **kwargs):
+def task_postrun_callback(task=None, **kwargs):
tracked_request = TrackedRequest.instance()
tracked_request.stop_span()
-def install():
+def install(app=None):
+ if app is not None:
+ copy_configuration(app)
+
installed = scout_apm.core.install()
if not installed:
return
- before_task_publish.connect(before_publish_callback)
- task_prerun.connect(prerun_callback)
- task_postrun.connect(postrun_callback)
+ before_task_publish.connect(before_task_publish_callback)
+ task_prerun.connect(task_prerun_callback)
+ task_postrun.connect(task_postrun_callback)
+
+
+def copy_configuration(app):
+ prefix = "scout_"
+ prefix_len = len(prefix)
+
+ to_set = {}
+ for key, value in app.conf.items():
+ key_lower = key.lower()
+ if key_lower.startswith(prefix) and len(key_lower) > prefix_len:
+ scout_key = key_lower[prefix_len:]
+ to_set[scout_key] = value
+
+ scout_config.set(**to_set)
def uninstall():
- before_task_publish.disconnect(before_publish_callback)
- task_prerun.disconnect(prerun_callback)
- task_postrun.disconnect(postrun_callback)
+ before_task_publish.disconnect(before_task_publish_callback)
+ task_prerun.disconnect(task_prerun_callback)
+ task_postrun.disconnect(task_postrun_callback)
|
{"golden_diff": "diff --git a/src/scout_apm/celery.py b/src/scout_apm/celery.py\n--- a/src/scout_apm/celery.py\n+++ b/src/scout_apm/celery.py\n@@ -7,15 +7,16 @@\n \n import scout_apm.core\n from scout_apm.compat import datetime_to_timestamp\n+from scout_apm.core.config import scout_config\n from scout_apm.core.tracked_request import TrackedRequest\n \n \n-def before_publish_callback(headers=None, properties=None, **kwargs):\n+def before_task_publish_callback(headers=None, properties=None, **kwargs):\n if \"scout_task_start\" not in headers:\n headers[\"scout_task_start\"] = datetime_to_timestamp(dt.datetime.utcnow())\n \n \n-def prerun_callback(task=None, **kwargs):\n+def task_prerun_callback(task=None, **kwargs):\n tracked_request = TrackedRequest.instance()\n tracked_request.is_real_request = True\n \n@@ -45,22 +46,39 @@\n tracked_request.start_span(operation=(\"Job/\" + task.name))\n \n \n-def postrun_callback(task=None, **kwargs):\n+def task_postrun_callback(task=None, **kwargs):\n tracked_request = TrackedRequest.instance()\n tracked_request.stop_span()\n \n \n-def install():\n+def install(app=None):\n+ if app is not None:\n+ copy_configuration(app)\n+\n installed = scout_apm.core.install()\n if not installed:\n return\n \n- before_task_publish.connect(before_publish_callback)\n- task_prerun.connect(prerun_callback)\n- task_postrun.connect(postrun_callback)\n+ before_task_publish.connect(before_task_publish_callback)\n+ task_prerun.connect(task_prerun_callback)\n+ task_postrun.connect(task_postrun_callback)\n+\n+\n+def copy_configuration(app):\n+ prefix = \"scout_\"\n+ prefix_len = len(prefix)\n+\n+ to_set = {}\n+ for key, value in app.conf.items():\n+ key_lower = key.lower()\n+ if key_lower.startswith(prefix) and len(key_lower) > prefix_len:\n+ scout_key = key_lower[prefix_len:]\n+ to_set[scout_key] = value\n+\n+ scout_config.set(**to_set)\n \n \n def uninstall():\n- before_task_publish.disconnect(before_publish_callback)\n- task_prerun.disconnect(prerun_callback)\n- task_postrun.disconnect(postrun_callback)\n+ before_task_publish.disconnect(before_task_publish_callback)\n+ task_prerun.disconnect(task_prerun_callback)\n+ task_postrun.disconnect(task_postrun_callback)\n", "issue": "Require Celery app reference to read configuration\nWe had a customer whose Celery tasks weren't reporting whilst their Django views were. It turns out they had configured in the Django settings file, which isn't applied when Celery runs. This is because it doesn't run \"under\" Django through `manage.py`, but separately through `celery worker`.\r\n\r\nThe django pattern is to use [Celery's `app.config_from_object`](https://docs.celeryproject.org/en/latest/reference/celery.html#celery.Celery.config_from_object) to read the Django settings. If we then read out of there for the scout settings, we would again allow shared configuration between the two.\r\n\r\nThis would need changing the Celery install process to take an `app` argument:\r\n\r\n```python\r\napp = celery.Celery(..)\r\n...\r\nscout_apm.celery.install(app)\r\n```\r\n\r\nWe should work without this for backwards compatibility reasons, but throw a warninng when it's not passed as I predict this issue will appear repeatedly if we don't encourage users this way.\n", "before_files": [{"content": "# coding=utf-8\nfrom __future__ import absolute_import, division, print_function, unicode_literals\n\nimport datetime as dt\n\nfrom celery.signals import before_task_publish, task_postrun, task_prerun\n\nimport scout_apm.core\nfrom scout_apm.compat import datetime_to_timestamp\nfrom scout_apm.core.tracked_request import TrackedRequest\n\n\ndef before_publish_callback(headers=None, properties=None, **kwargs):\n if \"scout_task_start\" not in headers:\n headers[\"scout_task_start\"] = datetime_to_timestamp(dt.datetime.utcnow())\n\n\ndef prerun_callback(task=None, **kwargs):\n tracked_request = TrackedRequest.instance()\n tracked_request.is_real_request = True\n\n start = getattr(task.request, \"scout_task_start\", None)\n if start is not None:\n now = datetime_to_timestamp(dt.datetime.utcnow())\n try:\n queue_time = now - start\n except TypeError:\n pass\n else:\n tracked_request.tag(\"queue_time\", queue_time)\n\n task_id = getattr(task.request, \"id\", None)\n if task_id:\n tracked_request.tag(\"task_id\", task_id)\n parent_task_id = getattr(task.request, \"parent_id\", None)\n if parent_task_id:\n tracked_request.tag(\"parent_task_id\", parent_task_id)\n\n delivery_info = task.request.delivery_info\n tracked_request.tag(\"is_eager\", delivery_info.get(\"is_eager\", False))\n tracked_request.tag(\"exchange\", delivery_info.get(\"exchange\", \"unknown\"))\n tracked_request.tag(\"routing_key\", delivery_info.get(\"routing_key\", \"unknown\"))\n tracked_request.tag(\"queue\", delivery_info.get(\"queue\", \"unknown\"))\n\n tracked_request.start_span(operation=(\"Job/\" + task.name))\n\n\ndef postrun_callback(task=None, **kwargs):\n tracked_request = TrackedRequest.instance()\n tracked_request.stop_span()\n\n\ndef install():\n installed = scout_apm.core.install()\n if not installed:\n return\n\n before_task_publish.connect(before_publish_callback)\n task_prerun.connect(prerun_callback)\n task_postrun.connect(postrun_callback)\n\n\ndef uninstall():\n before_task_publish.disconnect(before_publish_callback)\n task_prerun.disconnect(prerun_callback)\n task_postrun.disconnect(postrun_callback)\n", "path": "src/scout_apm/celery.py"}]}
| 1,378 | 556 |
gh_patches_debug_1947
|
rasdani/github-patches
|
git_diff
|
wagtail__wagtail-6433
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Change code block style in the docs
The colours in our existing code blocks fail WCAG AA on contrast: https://webaim.org/resources/contrastchecker/?fcolor=408090&bcolor=EEFFCC
See an example here: https://docs.wagtail.io/en/stable/advanced_topics/performance.html#cache
It looks like ``sphinx-rtd-theme`` uses a different style for their own docs: https://sphinx-rtd-theme.readthedocs.io/en/latest/demo/demo.html#code-blocks so maybe we should switch to that.
</issue>
<code>
[start of docs/conf.py]
1 # -*- coding: utf-8 -*-
2 #
3 # Wagtail documentation build configuration file, created by
4 # sphinx-quickstart on Tue Jan 14 17:38:55 2014.
5 #
6 # This file is execfile()d with the current directory set to its
7 # containing dir.
8 #
9 # Note that not all possible configuration values are present in this
10 # autogenerated file.
11 #
12 # All configuration values have a default; values that are commented out
13 # serve to show the default.
14
15 import sys
16 import os
17
18 from datetime import datetime
19
20
21 # on_rtd is whether we are on readthedocs.org, this line of code grabbed from docs.readthedocs.org
22 on_rtd = os.environ.get('READTHEDOCS', None) == 'True'
23
24 if not on_rtd: # only import and set the theme if we're building docs locally
25 import sphinx_rtd_theme
26 html_theme = 'sphinx_rtd_theme'
27 html_theme_path = [sphinx_rtd_theme.get_html_theme_path()]
28
29 # If extensions (or modules to document with autodoc) are in another directory,
30 # add these directories to sys.path here. If the directory is relative to the
31 # documentation root, use os.path.abspath to make it absolute, like shown here.
32 sys.path.insert(0, os.path.abspath('..'))
33
34 # Autodoc may need to import some models modules which require django settings
35 # be configured
36 os.environ['DJANGO_SETTINGS_MODULE'] = 'wagtail.tests.settings'
37 import django
38 django.setup()
39
40 # Use SQLite3 database engine so it doesn't attempt to use psycopg2 on RTD
41 os.environ['DATABASE_ENGINE'] = 'django.db.backends.sqlite3'
42
43
44 # -- General configuration ------------------------------------------------
45
46 # If your documentation needs a minimal Sphinx version, state it here.
47 #needs_sphinx = '1.0'
48
49 # Add any Sphinx extension module names here, as strings. They can be
50 # extensions coming with Sphinx (named 'sphinx.ext.*') or your custom
51 # ones.
52 extensions = [
53 'sphinx.ext.autodoc',
54 'sphinx.ext.intersphinx',
55 ]
56
57 if not on_rtd:
58 extensions.append('sphinxcontrib.spelling')
59
60 # Add any paths that contain templates here, relative to this directory.
61 templates_path = ['_templates']
62
63 # The suffix of source filenames.
64 source_suffix = '.rst'
65
66 # The encoding of source files.
67 #source_encoding = 'utf-8-sig'
68
69 # The master toctree document.
70 master_doc = 'index'
71
72 # General information about the project.
73 project = u'Wagtail'
74 copyright = u'{year:d}, Torchbox'.format(year=datetime.now().year)
75
76 # The version info for the project you're documenting, acts as replacement for
77 # |version| and |release|, also used in various other places throughout the
78 # built documents.
79
80 # Get Wagtail version
81 from wagtail import __version__, VERSION
82
83 # The short X.Y version.
84 version = '{}.{}'.format(VERSION[0], VERSION[1])
85 # The full version, including alpha/beta/rc tags.
86 release = __version__
87
88 # The language for content autogenerated by Sphinx. Refer to documentation
89 # for a list of supported languages.
90 #language = None
91
92 # There are two options for replacing |today|: either, you set today to some
93 # non-false value, then it is used:
94 #today = ''
95 # Else, today_fmt is used as the format for a strftime call.
96 #today_fmt = '%B %d, %Y'
97
98 # List of patterns, relative to source directory, that match files and
99 # directories to ignore when looking for source files.
100 exclude_patterns = ['_build']
101
102 # The reST default role (used for this markup: `text`) to use for all
103 # documents.
104 #default_role = None
105
106 # If true, '()' will be appended to :func: etc. cross-reference text.
107 #add_function_parentheses = True
108
109 # If true, the current module name will be prepended to all description
110 # unit titles (such as .. function::).
111 #add_module_names = True
112
113 # If true, sectionauthor and moduleauthor directives will be shown in the
114 # output. They are ignored by default.
115 #show_authors = False
116
117 # The name of the Pygments (syntax highlighting) style to use.
118 pygments_style = 'sphinx'
119
120 # A list of ignored prefixes for module index sorting.
121 #modindex_common_prefix = []
122
123 # If true, keep warnings as "system message" paragraphs in the built documents.
124 #keep_warnings = False
125
126
127 # splhinxcontrib.spelling settings
128
129 spelling_lang = 'en_GB'
130 spelling_word_list_filename='spelling_wordlist.txt'
131
132 # sphinx.ext.intersphinx settings
133 intersphinx_mapping = {
134 'django': ('https://docs.djangoproject.com/en/stable/', 'https://docs.djangoproject.com/en/stable/_objects/')
135 }
136
137
138 # -- Options for HTML output ----------------------------------------------
139
140
141 # Theme options are theme-specific and customize the look and feel of a theme
142 # further. For a list of options available for each theme, see the
143 # documentation.
144 #html_theme_options = {}
145
146
147
148 # The name for this set of Sphinx documents. If None, it defaults to
149 # "<project> v<release> documentation".
150 #html_title = None
151
152 # A shorter title for the navigation bar. Default is the same as html_title.
153 #html_short_title = None
154
155 # The name of an image file (relative to this directory) to place at the top
156 # of the sidebar.
157 html_logo = 'logo.png'
158
159 # The name of an image file (within the static path) to use as favicon of the
160 # docs. This file should be a Windows icon file (.ico) being 16x16 or 32x32
161 # pixels large.
162 html_favicon = 'favicon.ico'
163
164 # Add any paths that contain custom static files (such as style sheets) here,
165 # relative to this directory. They are copied after the builtin static files,
166 # so a file named "default.css" will overwrite the builtin "default.css".
167 html_static_path = ['_static']
168
169 # Add any extra paths that contain custom files (such as robots.txt or
170 # .htaccess) here, relative to this directory. These files are copied
171 # directly to the root of the documentation.
172 #html_extra_path = []
173
174 # If not '', a 'Last updated on:' timestamp is inserted at every page bottom,
175 # using the given strftime format.
176 #html_last_updated_fmt = '%b %d, %Y'
177
178 # If true, SmartyPants will be used to convert quotes and dashes to
179 # typographically correct entities.
180 #html_use_smartypants = True
181
182 # Custom sidebar templates, maps document names to template names.
183 #html_sidebars = {}
184
185 # Additional templates that should be rendered to pages, maps page names to
186 # template names.
187 #html_additional_pages = {}
188
189 # If false, no module index is generated.
190 #html_domain_indices = True
191
192 # If false, no index is generated.
193 #html_use_index = True
194
195 # If true, the index is split into individual pages for each letter.
196 #html_split_index = False
197
198 # If true, links to the reST sources are added to the pages.
199 #html_show_sourcelink = True
200
201 # If true, "Created using Sphinx" is shown in the HTML footer. Default is True.
202 #html_show_sphinx = True
203
204 # If true, "(C) Copyright ..." is shown in the HTML footer. Default is True.
205 #html_show_copyright = True
206
207 # If true, an OpenSearch description file will be output, and all pages will
208 # contain a <link> tag referring to it. The value of this option must be the
209 # base URL from which the finished HTML is served.
210 #html_use_opensearch = ''
211
212 # This is the file name suffix for HTML files (e.g. ".xhtml").
213 #html_file_suffix = None
214
215 # Output file base name for HTML help builder.
216 htmlhelp_basename = 'Wagtaildoc'
217
218
219 # -- Options for LaTeX output ---------------------------------------------
220
221 latex_elements = {
222 # The paper size ('letterpaper' or 'a4paper').
223 #'papersize': 'letterpaper',
224
225 # The font size ('10pt', '11pt' or '12pt').
226 #'pointsize': '10pt',
227
228 # Additional stuff for the LaTeX preamble.
229 #'preamble': '',
230 }
231
232 # Grouping the document tree into LaTeX files. List of tuples
233 # (source start file, target name, title,
234 # author, documentclass [howto, manual, or own class]).
235 latex_documents = [
236 ('index', 'Wagtail.tex', u'Wagtail Documentation',
237 u'Torchbox', 'manual'),
238 ]
239
240 # The name of an image file (relative to this directory) to place at the top of
241 # the title page.
242 #latex_logo = None
243
244 # For "manual" documents, if this is true, then toplevel headings are parts,
245 # not chapters.
246 #latex_use_parts = False
247
248 # If true, show page references after internal links.
249 #latex_show_pagerefs = False
250
251 # If true, show URL addresses after external links.
252 #latex_show_urls = False
253
254 # Documents to append as an appendix to all manuals.
255 #latex_appendices = []
256
257 # If false, no module index is generated.
258 #latex_domain_indices = True
259
260
261 # -- Options for manual page output ---------------------------------------
262
263 # One entry per manual page. List of tuples
264 # (source start file, name, description, authors, manual section).
265 man_pages = [
266 ('index', 'wagtail', u'Wagtail Documentation',
267 [u'Torchbox'], 1)
268 ]
269
270 # If true, show URL addresses after external links.
271 #man_show_urls = False
272
273
274 # -- Options for Texinfo output -------------------------------------------
275
276 # Grouping the document tree into Texinfo files. List of tuples
277 # (source start file, target name, title, author,
278 # dir menu entry, description, category)
279 texinfo_documents = [
280 ('index', 'Wagtail', u'Wagtail Documentation',
281 u'Torchbox', 'Wagtail', 'One line description of project.',
282 'Miscellaneous'),
283 ]
284
285 # Documents to append as an appendix to all manuals.
286 #texinfo_appendices = []
287
288 # If false, no module index is generated.
289 #texinfo_domain_indices = True
290
291 # How to display URL addresses: 'footnote', 'no', or 'inline'.
292 #texinfo_show_urls = 'footnote'
293
294 # If true, do not generate a @detailmenu in the "Top" node's menu.
295 #texinfo_no_detailmenu = False
296
297
298 def setup(app):
299 app.add_css_file('css/custom.css')
300 app.add_js_file('js/banner.js')
301
[end of docs/conf.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/docs/conf.py b/docs/conf.py
--- a/docs/conf.py
+++ b/docs/conf.py
@@ -115,7 +115,7 @@
#show_authors = False
# The name of the Pygments (syntax highlighting) style to use.
-pygments_style = 'sphinx'
+pygments_style = 'default'
# A list of ignored prefixes for module index sorting.
#modindex_common_prefix = []
|
{"golden_diff": "diff --git a/docs/conf.py b/docs/conf.py\n--- a/docs/conf.py\n+++ b/docs/conf.py\n@@ -115,7 +115,7 @@\n #show_authors = False\n \n # The name of the Pygments (syntax highlighting) style to use.\n-pygments_style = 'sphinx'\n+pygments_style = 'default'\n \n # A list of ignored prefixes for module index sorting.\n #modindex_common_prefix = []\n", "issue": "Change code block style in the docs\nThe colours in our existing code blocks fail WCAG AA on contrast: https://webaim.org/resources/contrastchecker/?fcolor=408090&bcolor=EEFFCC\r\n\r\nSee an example here: https://docs.wagtail.io/en/stable/advanced_topics/performance.html#cache\r\n\r\nIt looks like ``sphinx-rtd-theme`` uses a different style for their own docs: https://sphinx-rtd-theme.readthedocs.io/en/latest/demo/demo.html#code-blocks so maybe we should switch to that.\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n#\n# Wagtail documentation build configuration file, created by\n# sphinx-quickstart on Tue Jan 14 17:38:55 2014.\n#\n# This file is execfile()d with the current directory set to its\n# containing dir.\n#\n# Note that not all possible configuration values are present in this\n# autogenerated file.\n#\n# All configuration values have a default; values that are commented out\n# serve to show the default.\n\nimport sys\nimport os\n\nfrom datetime import datetime\n\n\n# on_rtd is whether we are on readthedocs.org, this line of code grabbed from docs.readthedocs.org\non_rtd = os.environ.get('READTHEDOCS', None) == 'True'\n\nif not on_rtd: # only import and set the theme if we're building docs locally\n import sphinx_rtd_theme\n html_theme = 'sphinx_rtd_theme'\n html_theme_path = [sphinx_rtd_theme.get_html_theme_path()]\n\n# If extensions (or modules to document with autodoc) are in another directory,\n# add these directories to sys.path here. If the directory is relative to the\n# documentation root, use os.path.abspath to make it absolute, like shown here.\nsys.path.insert(0, os.path.abspath('..'))\n\n# Autodoc may need to import some models modules which require django settings\n# be configured\nos.environ['DJANGO_SETTINGS_MODULE'] = 'wagtail.tests.settings'\nimport django\ndjango.setup()\n\n# Use SQLite3 database engine so it doesn't attempt to use psycopg2 on RTD\nos.environ['DATABASE_ENGINE'] = 'django.db.backends.sqlite3'\n\n\n# -- General configuration ------------------------------------------------\n\n# If your documentation needs a minimal Sphinx version, state it here.\n#needs_sphinx = '1.0'\n\n# Add any Sphinx extension module names here, as strings. They can be\n# extensions coming with Sphinx (named 'sphinx.ext.*') or your custom\n# ones.\nextensions = [\n 'sphinx.ext.autodoc',\n 'sphinx.ext.intersphinx',\n]\n\nif not on_rtd:\n extensions.append('sphinxcontrib.spelling')\n\n# Add any paths that contain templates here, relative to this directory.\ntemplates_path = ['_templates']\n\n# The suffix of source filenames.\nsource_suffix = '.rst'\n\n# The encoding of source files.\n#source_encoding = 'utf-8-sig'\n\n# The master toctree document.\nmaster_doc = 'index'\n\n# General information about the project.\nproject = u'Wagtail'\ncopyright = u'{year:d}, Torchbox'.format(year=datetime.now().year)\n\n# The version info for the project you're documenting, acts as replacement for\n# |version| and |release|, also used in various other places throughout the\n# built documents.\n\n# Get Wagtail version\nfrom wagtail import __version__, VERSION\n\n# The short X.Y version.\nversion = '{}.{}'.format(VERSION[0], VERSION[1])\n# The full version, including alpha/beta/rc tags.\nrelease = __version__\n\n# The language for content autogenerated by Sphinx. Refer to documentation\n# for a list of supported languages.\n#language = None\n\n# There are two options for replacing |today|: either, you set today to some\n# non-false value, then it is used:\n#today = ''\n# Else, today_fmt is used as the format for a strftime call.\n#today_fmt = '%B %d, %Y'\n\n# List of patterns, relative to source directory, that match files and\n# directories to ignore when looking for source files.\nexclude_patterns = ['_build']\n\n# The reST default role (used for this markup: `text`) to use for all\n# documents.\n#default_role = None\n\n# If true, '()' will be appended to :func: etc. cross-reference text.\n#add_function_parentheses = True\n\n# If true, the current module name will be prepended to all description\n# unit titles (such as .. function::).\n#add_module_names = True\n\n# If true, sectionauthor and moduleauthor directives will be shown in the\n# output. They are ignored by default.\n#show_authors = False\n\n# The name of the Pygments (syntax highlighting) style to use.\npygments_style = 'sphinx'\n\n# A list of ignored prefixes for module index sorting.\n#modindex_common_prefix = []\n\n# If true, keep warnings as \"system message\" paragraphs in the built documents.\n#keep_warnings = False\n\n\n# splhinxcontrib.spelling settings\n\nspelling_lang = 'en_GB'\nspelling_word_list_filename='spelling_wordlist.txt'\n\n# sphinx.ext.intersphinx settings\nintersphinx_mapping = {\n 'django': ('https://docs.djangoproject.com/en/stable/', 'https://docs.djangoproject.com/en/stable/_objects/')\n}\n\n\n# -- Options for HTML output ----------------------------------------------\n\n\n# Theme options are theme-specific and customize the look and feel of a theme\n# further. For a list of options available for each theme, see the\n# documentation.\n#html_theme_options = {}\n\n\n\n# The name for this set of Sphinx documents. If None, it defaults to\n# \"<project> v<release> documentation\".\n#html_title = None\n\n# A shorter title for the navigation bar. Default is the same as html_title.\n#html_short_title = None\n\n# The name of an image file (relative to this directory) to place at the top\n# of the sidebar.\nhtml_logo = 'logo.png'\n\n# The name of an image file (within the static path) to use as favicon of the\n# docs. This file should be a Windows icon file (.ico) being 16x16 or 32x32\n# pixels large.\nhtml_favicon = 'favicon.ico'\n\n# Add any paths that contain custom static files (such as style sheets) here,\n# relative to this directory. They are copied after the builtin static files,\n# so a file named \"default.css\" will overwrite the builtin \"default.css\".\nhtml_static_path = ['_static']\n\n# Add any extra paths that contain custom files (such as robots.txt or\n# .htaccess) here, relative to this directory. These files are copied\n# directly to the root of the documentation.\n#html_extra_path = []\n\n# If not '', a 'Last updated on:' timestamp is inserted at every page bottom,\n# using the given strftime format.\n#html_last_updated_fmt = '%b %d, %Y'\n\n# If true, SmartyPants will be used to convert quotes and dashes to\n# typographically correct entities.\n#html_use_smartypants = True\n\n# Custom sidebar templates, maps document names to template names.\n#html_sidebars = {}\n\n# Additional templates that should be rendered to pages, maps page names to\n# template names.\n#html_additional_pages = {}\n\n# If false, no module index is generated.\n#html_domain_indices = True\n\n# If false, no index is generated.\n#html_use_index = True\n\n# If true, the index is split into individual pages for each letter.\n#html_split_index = False\n\n# If true, links to the reST sources are added to the pages.\n#html_show_sourcelink = True\n\n# If true, \"Created using Sphinx\" is shown in the HTML footer. Default is True.\n#html_show_sphinx = True\n\n# If true, \"(C) Copyright ...\" is shown in the HTML footer. Default is True.\n#html_show_copyright = True\n\n# If true, an OpenSearch description file will be output, and all pages will\n# contain a <link> tag referring to it. The value of this option must be the\n# base URL from which the finished HTML is served.\n#html_use_opensearch = ''\n\n# This is the file name suffix for HTML files (e.g. \".xhtml\").\n#html_file_suffix = None\n\n# Output file base name for HTML help builder.\nhtmlhelp_basename = 'Wagtaildoc'\n\n\n# -- Options for LaTeX output ---------------------------------------------\n\nlatex_elements = {\n# The paper size ('letterpaper' or 'a4paper').\n#'papersize': 'letterpaper',\n\n# The font size ('10pt', '11pt' or '12pt').\n#'pointsize': '10pt',\n\n# Additional stuff for the LaTeX preamble.\n#'preamble': '',\n}\n\n# Grouping the document tree into LaTeX files. List of tuples\n# (source start file, target name, title,\n# author, documentclass [howto, manual, or own class]).\nlatex_documents = [\n ('index', 'Wagtail.tex', u'Wagtail Documentation',\n u'Torchbox', 'manual'),\n]\n\n# The name of an image file (relative to this directory) to place at the top of\n# the title page.\n#latex_logo = None\n\n# For \"manual\" documents, if this is true, then toplevel headings are parts,\n# not chapters.\n#latex_use_parts = False\n\n# If true, show page references after internal links.\n#latex_show_pagerefs = False\n\n# If true, show URL addresses after external links.\n#latex_show_urls = False\n\n# Documents to append as an appendix to all manuals.\n#latex_appendices = []\n\n# If false, no module index is generated.\n#latex_domain_indices = True\n\n\n# -- Options for manual page output ---------------------------------------\n\n# One entry per manual page. List of tuples\n# (source start file, name, description, authors, manual section).\nman_pages = [\n ('index', 'wagtail', u'Wagtail Documentation',\n [u'Torchbox'], 1)\n]\n\n# If true, show URL addresses after external links.\n#man_show_urls = False\n\n\n# -- Options for Texinfo output -------------------------------------------\n\n# Grouping the document tree into Texinfo files. List of tuples\n# (source start file, target name, title, author,\n# dir menu entry, description, category)\ntexinfo_documents = [\n ('index', 'Wagtail', u'Wagtail Documentation',\n u'Torchbox', 'Wagtail', 'One line description of project.',\n 'Miscellaneous'),\n]\n\n# Documents to append as an appendix to all manuals.\n#texinfo_appendices = []\n\n# If false, no module index is generated.\n#texinfo_domain_indices = True\n\n# How to display URL addresses: 'footnote', 'no', or 'inline'.\n#texinfo_show_urls = 'footnote'\n\n# If true, do not generate a @detailmenu in the \"Top\" node's menu.\n#texinfo_no_detailmenu = False\n\n\ndef setup(app):\n app.add_css_file('css/custom.css')\n app.add_js_file('js/banner.js')\n", "path": "docs/conf.py"}]}
| 3,794 | 96 |
gh_patches_debug_34575
|
rasdani/github-patches
|
git_diff
|
facebookresearch__hydra-1673
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[Bug] Cannot use `target` kwarg when instantiating with `hydra.utils.instantiate()`
# 🐛 Bug
## Description
`hydra.utils.instantiate()` seems to fail when trying to instantiate a class with a keyword argument called `target`.
It seems like the two keys `_target_` and `target` are clashing, and this raises a
`TypeError: _call_target() got multiple values for argument 'target'`.
## Checklist
- [x] I checked on the latest version of Hydra
- [x] I created a minimal repro (See [this](https://stackoverflow.com/help/minimal-reproducible-example) for tips).
## To reproduce
**Minimal Code/Config snippet to reproduce**
Available as a Colab Gists:
https://colab.research.google.com/gist/fabiocarrara/6bf5abaecf3f84c1e83239f8af3b8219/hydra_instantiate_bug.ipynb
**Stack trace/error message**
```
TypeError Traceback (most recent call last)
<ipython-input-4-616e52dc8a9b> in <module>()
----> 1 foo = hydra.utils.instantiate(cfg.bar)
2 foo.target
/usr/local/lib/python3.7/dist-packages/hydra/_internal/instantiate/_instantiate2.py in instantiate(config, *args, **kwargs)
178 _convert_ = config.pop(_Keys.CONVERT, ConvertMode.NONE)
179
--> 180 return instantiate_node(config, *args, recursive=_recursive_, convert=_convert_)
181 else:
182 raise InstantiationException(
/usr/local/lib/python3.7/dist-packages/hydra/_internal/instantiate/_instantiate2.py in instantiate_node(node, convert, recursive, *args)
247 )
248 kwargs[key] = _convert_node(value, convert)
--> 249 return _call_target(target, *args, **kwargs)
250 else:
251 # If ALL or PARTIAL non structured, instantiate in dict and resolve interpolations eagerly.
TypeError: _call_target() got multiple values for argument 'target'
```
## Expected Behavior
`target` should be a permitted key name for callable/constructor's kwargs.
## System information
- **Hydra Version** : 1.1
- **Python version** : 3.7.10 (Colab)
- **Virtual environment type and version** : none
- **Operating system** : Colab
</issue>
<code>
[start of hydra/_internal/instantiate/_instantiate2.py]
1 # Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved
2
3 import copy
4 import sys
5 from enum import Enum
6 from typing import Any, Callable, Sequence, Tuple, Union
7
8 from omegaconf import OmegaConf, SCMode
9 from omegaconf._utils import is_structured_config
10
11 from hydra._internal.utils import _locate
12 from hydra.errors import InstantiationException
13 from hydra.types import ConvertMode, TargetConf
14
15
16 class _Keys(str, Enum):
17 """Special keys in configs used by instantiate."""
18
19 TARGET = "_target_"
20 CONVERT = "_convert_"
21 RECURSIVE = "_recursive_"
22 ARGS = "_args_"
23
24
25 def _is_target(x: Any) -> bool:
26 if isinstance(x, dict):
27 return "_target_" in x
28 if OmegaConf.is_dict(x):
29 return "_target_" in x
30 return False
31
32
33 def _extract_pos_args(*input_args: Any, **kwargs: Any) -> Tuple[Any, Any]:
34 config_args = kwargs.pop(_Keys.ARGS, ())
35 output_args = config_args
36
37 if isinstance(config_args, Sequence):
38 if len(input_args) > 0:
39 output_args = input_args
40 else:
41 raise InstantiationException(
42 f"Unsupported _args_ type: {type(config_args).__name__}. value: {config_args}"
43 )
44
45 return output_args, kwargs
46
47
48 def _call_target(target: Callable, *args, **kwargs) -> Any: # type: ignore
49 """Call target (type) with args and kwargs."""
50 try:
51 args, kwargs = _extract_pos_args(*args, **kwargs)
52 # detaching configs from parent.
53 # At this time, everything is resolved and the parent link can cause
54 # issues when serializing objects in some scenarios.
55 for arg in args:
56 if OmegaConf.is_config(arg):
57 arg._set_parent(None)
58 for v in kwargs.values():
59 if OmegaConf.is_config(v):
60 v._set_parent(None)
61
62 return target(*args, **kwargs)
63 except Exception as e:
64 raise type(e)(
65 f"Error instantiating '{_convert_target_to_string(target)}' : {e}"
66 ).with_traceback(sys.exc_info()[2])
67
68
69 def _convert_target_to_string(t: Any) -> Any:
70 if isinstance(t, type):
71 return f"{t.__module__}.{t.__name__}"
72 elif callable(t):
73 return f"{t.__module__}.{t.__qualname__}"
74 else:
75 return t
76
77
78 def _prepare_input_dict(d: Any) -> Any:
79 res: Any
80 if isinstance(d, dict):
81 res = {}
82 for k, v in d.items():
83 if k == "_target_":
84 v = _convert_target_to_string(d["_target_"])
85 elif isinstance(v, (dict, list)):
86 v = _prepare_input_dict(v)
87 res[k] = v
88 elif isinstance(d, list):
89 res = []
90 for v in d:
91 if isinstance(v, (list, dict)):
92 v = _prepare_input_dict(v)
93 res.append(v)
94 else:
95 assert False
96 return res
97
98
99 def _resolve_target(
100 target: Union[str, type, Callable[..., Any]]
101 ) -> Union[type, Callable[..., Any]]:
102 """Resolve target string, type or callable into type or callable."""
103 if isinstance(target, str):
104 return _locate(target)
105 if isinstance(target, type):
106 return target
107 if callable(target):
108 return target
109 raise InstantiationException(
110 f"Unsupported target type: {type(target).__name__}. value: {target}"
111 )
112
113
114 def instantiate(config: Any, *args: Any, **kwargs: Any) -> Any:
115 """
116 :param config: An config object describing what to call and what params to use.
117 In addition to the parameters, the config must contain:
118 _target_ : target class or callable name (str)
119 And may contain:
120 _args_: List-like of positional arguments to pass to the target
121 _recursive_: Construct nested objects as well (bool).
122 True by default.
123 may be overridden via a _recursive_ key in
124 the kwargs
125 _convert_: Conversion strategy
126 none : Passed objects are DictConfig and ListConfig, default
127 partial : Passed objects are converted to dict and list, with
128 the exception of Structured Configs (and their fields).
129 all : Passed objects are dicts, lists and primitives without
130 a trace of OmegaConf containers
131 _args_: List-like of positional arguments
132 :param args: Optional positional parameters pass-through
133 :param kwargs: Optional named parameters to override
134 parameters in the config object. Parameters not present
135 in the config objects are being passed as is to the target.
136 IMPORTANT: dataclasses instances in kwargs are interpreted as config
137 and cannot be used as passthrough
138 :return: if _target_ is a class name: the instantiated object
139 if _target_ is a callable: the return value of the call
140 """
141
142 # Return None if config is None
143 if config is None:
144 return None
145
146 # TargetConf edge case
147 if isinstance(config, TargetConf) and config._target_ == "???":
148 # Specific check to give a good warning about failure to annotate _target_ as a string.
149 raise InstantiationException(
150 f"Missing value for {type(config).__name__}._target_. Check that it's properly annotated and overridden."
151 f"\nA common problem is forgetting to annotate _target_ as a string : '_target_: str = ...'"
152 )
153
154 if isinstance(config, dict):
155 config = _prepare_input_dict(config)
156
157 kwargs = _prepare_input_dict(kwargs)
158
159 # Structured Config always converted first to OmegaConf
160 if is_structured_config(config) or isinstance(config, dict):
161 config = OmegaConf.structured(config, flags={"allow_objects": True})
162
163 if OmegaConf.is_dict(config):
164 # Finalize config (convert targets to strings, merge with kwargs)
165 config_copy = copy.deepcopy(config)
166 config_copy._set_flag(
167 flags=["allow_objects", "struct", "readonly"], values=[True, False, False]
168 )
169 config_copy._set_parent(config._get_parent())
170 config = config_copy
171
172 if kwargs:
173 config = OmegaConf.merge(config, kwargs)
174
175 OmegaConf.resolve(config)
176
177 _recursive_ = config.pop(_Keys.RECURSIVE, True)
178 _convert_ = config.pop(_Keys.CONVERT, ConvertMode.NONE)
179
180 return instantiate_node(config, *args, recursive=_recursive_, convert=_convert_)
181 else:
182 raise InstantiationException(
183 "Top level config has to be OmegaConf DictConfig, plain dict, or a Structured Config class or instance"
184 )
185
186
187 def _convert_node(node: Any, convert: Union[ConvertMode, str]) -> Any:
188 if OmegaConf.is_config(node):
189 if convert == ConvertMode.ALL:
190 node = OmegaConf.to_container(node, resolve=True)
191 elif convert == ConvertMode.PARTIAL:
192 node = OmegaConf.to_container(
193 node, resolve=True, structured_config_mode=SCMode.DICT_CONFIG
194 )
195 return node
196
197
198 def instantiate_node(
199 node: Any,
200 *args: Any,
201 convert: Union[str, ConvertMode] = ConvertMode.NONE,
202 recursive: bool = True,
203 ) -> Any:
204 # Return None if config is None
205 if node is None or (OmegaConf.is_config(node) and node._is_none()):
206 return None
207
208 if not OmegaConf.is_config(node):
209 return node
210
211 # Override parent modes from config if specified
212 if OmegaConf.is_dict(node):
213 # using getitem instead of get(key, default) because OmegaConf will raise an exception
214 # if the key type is incompatible on get.
215 convert = node[_Keys.CONVERT] if _Keys.CONVERT in node else convert
216 recursive = node[_Keys.RECURSIVE] if _Keys.RECURSIVE in node else recursive
217
218 if not isinstance(recursive, bool):
219 raise TypeError(f"_recursive_ flag must be a bool, got {type(recursive)}")
220
221 # If OmegaConf list, create new list of instances if recursive
222 if OmegaConf.is_list(node):
223 items = [
224 instantiate_node(item, convert=convert, recursive=recursive)
225 for item in node._iter_ex(resolve=True)
226 ]
227
228 if convert in (ConvertMode.ALL, ConvertMode.PARTIAL):
229 # If ALL or PARTIAL, use plain list as container
230 return items
231 else:
232 # Otherwise, use ListConfig as container
233 lst = OmegaConf.create(items, flags={"allow_objects": True})
234 lst._set_parent(node)
235 return lst
236
237 elif OmegaConf.is_dict(node):
238 exclude_keys = set({"_target_", "_convert_", "_recursive_"})
239 if _is_target(node):
240 target = _resolve_target(node.get(_Keys.TARGET))
241 kwargs = {}
242 for key, value in node.items():
243 if key not in exclude_keys:
244 if recursive:
245 value = instantiate_node(
246 value, convert=convert, recursive=recursive
247 )
248 kwargs[key] = _convert_node(value, convert)
249 return _call_target(target, *args, **kwargs)
250 else:
251 # If ALL or PARTIAL non structured, instantiate in dict and resolve interpolations eagerly.
252 if convert == ConvertMode.ALL or (
253 convert == ConvertMode.PARTIAL and node._metadata.object_type is None
254 ):
255 dict_items = {}
256 for key, value in node.items():
257 # list items inherits recursive flag from the containing dict.
258 dict_items[key] = instantiate_node(
259 value, convert=convert, recursive=recursive
260 )
261 return dict_items
262 else:
263 # Otherwise use DictConfig and resolve interpolations lazily.
264 cfg = OmegaConf.create({}, flags={"allow_objects": True})
265 for key, value in node.items():
266 cfg[key] = instantiate_node(
267 value, convert=convert, recursive=recursive
268 )
269 cfg._set_parent(node)
270 cfg._metadata.object_type = node._metadata.object_type
271 return cfg
272
273 else:
274 assert False, f"Unexpected config type : {type(node).__name__}"
275
[end of hydra/_internal/instantiate/_instantiate2.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/hydra/_internal/instantiate/_instantiate2.py b/hydra/_internal/instantiate/_instantiate2.py
--- a/hydra/_internal/instantiate/_instantiate2.py
+++ b/hydra/_internal/instantiate/_instantiate2.py
@@ -45,7 +45,7 @@
return output_args, kwargs
-def _call_target(target: Callable, *args, **kwargs) -> Any: # type: ignore
+def _call_target(_target_: Callable, *args, **kwargs) -> Any: # type: ignore
"""Call target (type) with args and kwargs."""
try:
args, kwargs = _extract_pos_args(*args, **kwargs)
@@ -59,10 +59,10 @@
if OmegaConf.is_config(v):
v._set_parent(None)
- return target(*args, **kwargs)
+ return _target_(*args, **kwargs)
except Exception as e:
raise type(e)(
- f"Error instantiating '{_convert_target_to_string(target)}' : {e}"
+ f"Error instantiating '{_convert_target_to_string(_target_)}' : {e}"
).with_traceback(sys.exc_info()[2])
@@ -237,7 +237,7 @@
elif OmegaConf.is_dict(node):
exclude_keys = set({"_target_", "_convert_", "_recursive_"})
if _is_target(node):
- target = _resolve_target(node.get(_Keys.TARGET))
+ _target_ = _resolve_target(node.get(_Keys.TARGET))
kwargs = {}
for key, value in node.items():
if key not in exclude_keys:
@@ -246,7 +246,7 @@
value, convert=convert, recursive=recursive
)
kwargs[key] = _convert_node(value, convert)
- return _call_target(target, *args, **kwargs)
+ return _call_target(_target_, *args, **kwargs)
else:
# If ALL or PARTIAL non structured, instantiate in dict and resolve interpolations eagerly.
if convert == ConvertMode.ALL or (
|
{"golden_diff": "diff --git a/hydra/_internal/instantiate/_instantiate2.py b/hydra/_internal/instantiate/_instantiate2.py\n--- a/hydra/_internal/instantiate/_instantiate2.py\n+++ b/hydra/_internal/instantiate/_instantiate2.py\n@@ -45,7 +45,7 @@\n return output_args, kwargs\n \n \n-def _call_target(target: Callable, *args, **kwargs) -> Any: # type: ignore\n+def _call_target(_target_: Callable, *args, **kwargs) -> Any: # type: ignore\n \"\"\"Call target (type) with args and kwargs.\"\"\"\n try:\n args, kwargs = _extract_pos_args(*args, **kwargs)\n@@ -59,10 +59,10 @@\n if OmegaConf.is_config(v):\n v._set_parent(None)\n \n- return target(*args, **kwargs)\n+ return _target_(*args, **kwargs)\n except Exception as e:\n raise type(e)(\n- f\"Error instantiating '{_convert_target_to_string(target)}' : {e}\"\n+ f\"Error instantiating '{_convert_target_to_string(_target_)}' : {e}\"\n ).with_traceback(sys.exc_info()[2])\n \n \n@@ -237,7 +237,7 @@\n elif OmegaConf.is_dict(node):\n exclude_keys = set({\"_target_\", \"_convert_\", \"_recursive_\"})\n if _is_target(node):\n- target = _resolve_target(node.get(_Keys.TARGET))\n+ _target_ = _resolve_target(node.get(_Keys.TARGET))\n kwargs = {}\n for key, value in node.items():\n if key not in exclude_keys:\n@@ -246,7 +246,7 @@\n value, convert=convert, recursive=recursive\n )\n kwargs[key] = _convert_node(value, convert)\n- return _call_target(target, *args, **kwargs)\n+ return _call_target(_target_, *args, **kwargs)\n else:\n # If ALL or PARTIAL non structured, instantiate in dict and resolve interpolations eagerly.\n if convert == ConvertMode.ALL or (\n", "issue": "[Bug] Cannot use `target` kwarg when instantiating with `hydra.utils.instantiate()`\n# \ud83d\udc1b Bug\r\n## Description\r\n`hydra.utils.instantiate()` seems to fail when trying to instantiate a class with a keyword argument called `target`.\r\nIt seems like the two keys `_target_` and `target` are clashing, and this raises a \r\n`TypeError: _call_target() got multiple values for argument 'target'`.\r\n\r\n## Checklist\r\n- [x] I checked on the latest version of Hydra\r\n- [x] I created a minimal repro (See [this](https://stackoverflow.com/help/minimal-reproducible-example) for tips).\r\n\r\n## To reproduce\r\n\r\n**Minimal Code/Config snippet to reproduce**\r\nAvailable as a Colab Gists:\r\nhttps://colab.research.google.com/gist/fabiocarrara/6bf5abaecf3f84c1e83239f8af3b8219/hydra_instantiate_bug.ipynb\r\n\r\n**Stack trace/error message**\r\n```\r\nTypeError Traceback (most recent call last)\r\n<ipython-input-4-616e52dc8a9b> in <module>()\r\n----> 1 foo = hydra.utils.instantiate(cfg.bar)\r\n 2 foo.target\r\n\r\n/usr/local/lib/python3.7/dist-packages/hydra/_internal/instantiate/_instantiate2.py in instantiate(config, *args, **kwargs)\r\n 178 _convert_ = config.pop(_Keys.CONVERT, ConvertMode.NONE)\r\n 179 \r\n--> 180 return instantiate_node(config, *args, recursive=_recursive_, convert=_convert_)\r\n 181 else:\r\n 182 raise InstantiationException(\r\n\r\n/usr/local/lib/python3.7/dist-packages/hydra/_internal/instantiate/_instantiate2.py in instantiate_node(node, convert, recursive, *args)\r\n 247 )\r\n 248 kwargs[key] = _convert_node(value, convert)\r\n--> 249 return _call_target(target, *args, **kwargs)\r\n 250 else:\r\n 251 # If ALL or PARTIAL non structured, instantiate in dict and resolve interpolations eagerly.\r\n\r\nTypeError: _call_target() got multiple values for argument 'target'\r\n```\r\n\r\n## Expected Behavior\r\n`target` should be a permitted key name for callable/constructor's kwargs.\r\n\r\n## System information\r\n- **Hydra Version** : 1.1\r\n- **Python version** : 3.7.10 (Colab)\r\n- **Virtual environment type and version** : none\r\n- **Operating system** : Colab\r\n\n", "before_files": [{"content": "# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved\n\nimport copy\nimport sys\nfrom enum import Enum\nfrom typing import Any, Callable, Sequence, Tuple, Union\n\nfrom omegaconf import OmegaConf, SCMode\nfrom omegaconf._utils import is_structured_config\n\nfrom hydra._internal.utils import _locate\nfrom hydra.errors import InstantiationException\nfrom hydra.types import ConvertMode, TargetConf\n\n\nclass _Keys(str, Enum):\n \"\"\"Special keys in configs used by instantiate.\"\"\"\n\n TARGET = \"_target_\"\n CONVERT = \"_convert_\"\n RECURSIVE = \"_recursive_\"\n ARGS = \"_args_\"\n\n\ndef _is_target(x: Any) -> bool:\n if isinstance(x, dict):\n return \"_target_\" in x\n if OmegaConf.is_dict(x):\n return \"_target_\" in x\n return False\n\n\ndef _extract_pos_args(*input_args: Any, **kwargs: Any) -> Tuple[Any, Any]:\n config_args = kwargs.pop(_Keys.ARGS, ())\n output_args = config_args\n\n if isinstance(config_args, Sequence):\n if len(input_args) > 0:\n output_args = input_args\n else:\n raise InstantiationException(\n f\"Unsupported _args_ type: {type(config_args).__name__}. value: {config_args}\"\n )\n\n return output_args, kwargs\n\n\ndef _call_target(target: Callable, *args, **kwargs) -> Any: # type: ignore\n \"\"\"Call target (type) with args and kwargs.\"\"\"\n try:\n args, kwargs = _extract_pos_args(*args, **kwargs)\n # detaching configs from parent.\n # At this time, everything is resolved and the parent link can cause\n # issues when serializing objects in some scenarios.\n for arg in args:\n if OmegaConf.is_config(arg):\n arg._set_parent(None)\n for v in kwargs.values():\n if OmegaConf.is_config(v):\n v._set_parent(None)\n\n return target(*args, **kwargs)\n except Exception as e:\n raise type(e)(\n f\"Error instantiating '{_convert_target_to_string(target)}' : {e}\"\n ).with_traceback(sys.exc_info()[2])\n\n\ndef _convert_target_to_string(t: Any) -> Any:\n if isinstance(t, type):\n return f\"{t.__module__}.{t.__name__}\"\n elif callable(t):\n return f\"{t.__module__}.{t.__qualname__}\"\n else:\n return t\n\n\ndef _prepare_input_dict(d: Any) -> Any:\n res: Any\n if isinstance(d, dict):\n res = {}\n for k, v in d.items():\n if k == \"_target_\":\n v = _convert_target_to_string(d[\"_target_\"])\n elif isinstance(v, (dict, list)):\n v = _prepare_input_dict(v)\n res[k] = v\n elif isinstance(d, list):\n res = []\n for v in d:\n if isinstance(v, (list, dict)):\n v = _prepare_input_dict(v)\n res.append(v)\n else:\n assert False\n return res\n\n\ndef _resolve_target(\n target: Union[str, type, Callable[..., Any]]\n) -> Union[type, Callable[..., Any]]:\n \"\"\"Resolve target string, type or callable into type or callable.\"\"\"\n if isinstance(target, str):\n return _locate(target)\n if isinstance(target, type):\n return target\n if callable(target):\n return target\n raise InstantiationException(\n f\"Unsupported target type: {type(target).__name__}. value: {target}\"\n )\n\n\ndef instantiate(config: Any, *args: Any, **kwargs: Any) -> Any:\n \"\"\"\n :param config: An config object describing what to call and what params to use.\n In addition to the parameters, the config must contain:\n _target_ : target class or callable name (str)\n And may contain:\n _args_: List-like of positional arguments to pass to the target\n _recursive_: Construct nested objects as well (bool).\n True by default.\n may be overridden via a _recursive_ key in\n the kwargs\n _convert_: Conversion strategy\n none : Passed objects are DictConfig and ListConfig, default\n partial : Passed objects are converted to dict and list, with\n the exception of Structured Configs (and their fields).\n all : Passed objects are dicts, lists and primitives without\n a trace of OmegaConf containers\n _args_: List-like of positional arguments\n :param args: Optional positional parameters pass-through\n :param kwargs: Optional named parameters to override\n parameters in the config object. Parameters not present\n in the config objects are being passed as is to the target.\n IMPORTANT: dataclasses instances in kwargs are interpreted as config\n and cannot be used as passthrough\n :return: if _target_ is a class name: the instantiated object\n if _target_ is a callable: the return value of the call\n \"\"\"\n\n # Return None if config is None\n if config is None:\n return None\n\n # TargetConf edge case\n if isinstance(config, TargetConf) and config._target_ == \"???\":\n # Specific check to give a good warning about failure to annotate _target_ as a string.\n raise InstantiationException(\n f\"Missing value for {type(config).__name__}._target_. Check that it's properly annotated and overridden.\"\n f\"\\nA common problem is forgetting to annotate _target_ as a string : '_target_: str = ...'\"\n )\n\n if isinstance(config, dict):\n config = _prepare_input_dict(config)\n\n kwargs = _prepare_input_dict(kwargs)\n\n # Structured Config always converted first to OmegaConf\n if is_structured_config(config) or isinstance(config, dict):\n config = OmegaConf.structured(config, flags={\"allow_objects\": True})\n\n if OmegaConf.is_dict(config):\n # Finalize config (convert targets to strings, merge with kwargs)\n config_copy = copy.deepcopy(config)\n config_copy._set_flag(\n flags=[\"allow_objects\", \"struct\", \"readonly\"], values=[True, False, False]\n )\n config_copy._set_parent(config._get_parent())\n config = config_copy\n\n if kwargs:\n config = OmegaConf.merge(config, kwargs)\n\n OmegaConf.resolve(config)\n\n _recursive_ = config.pop(_Keys.RECURSIVE, True)\n _convert_ = config.pop(_Keys.CONVERT, ConvertMode.NONE)\n\n return instantiate_node(config, *args, recursive=_recursive_, convert=_convert_)\n else:\n raise InstantiationException(\n \"Top level config has to be OmegaConf DictConfig, plain dict, or a Structured Config class or instance\"\n )\n\n\ndef _convert_node(node: Any, convert: Union[ConvertMode, str]) -> Any:\n if OmegaConf.is_config(node):\n if convert == ConvertMode.ALL:\n node = OmegaConf.to_container(node, resolve=True)\n elif convert == ConvertMode.PARTIAL:\n node = OmegaConf.to_container(\n node, resolve=True, structured_config_mode=SCMode.DICT_CONFIG\n )\n return node\n\n\ndef instantiate_node(\n node: Any,\n *args: Any,\n convert: Union[str, ConvertMode] = ConvertMode.NONE,\n recursive: bool = True,\n) -> Any:\n # Return None if config is None\n if node is None or (OmegaConf.is_config(node) and node._is_none()):\n return None\n\n if not OmegaConf.is_config(node):\n return node\n\n # Override parent modes from config if specified\n if OmegaConf.is_dict(node):\n # using getitem instead of get(key, default) because OmegaConf will raise an exception\n # if the key type is incompatible on get.\n convert = node[_Keys.CONVERT] if _Keys.CONVERT in node else convert\n recursive = node[_Keys.RECURSIVE] if _Keys.RECURSIVE in node else recursive\n\n if not isinstance(recursive, bool):\n raise TypeError(f\"_recursive_ flag must be a bool, got {type(recursive)}\")\n\n # If OmegaConf list, create new list of instances if recursive\n if OmegaConf.is_list(node):\n items = [\n instantiate_node(item, convert=convert, recursive=recursive)\n for item in node._iter_ex(resolve=True)\n ]\n\n if convert in (ConvertMode.ALL, ConvertMode.PARTIAL):\n # If ALL or PARTIAL, use plain list as container\n return items\n else:\n # Otherwise, use ListConfig as container\n lst = OmegaConf.create(items, flags={\"allow_objects\": True})\n lst._set_parent(node)\n return lst\n\n elif OmegaConf.is_dict(node):\n exclude_keys = set({\"_target_\", \"_convert_\", \"_recursive_\"})\n if _is_target(node):\n target = _resolve_target(node.get(_Keys.TARGET))\n kwargs = {}\n for key, value in node.items():\n if key not in exclude_keys:\n if recursive:\n value = instantiate_node(\n value, convert=convert, recursive=recursive\n )\n kwargs[key] = _convert_node(value, convert)\n return _call_target(target, *args, **kwargs)\n else:\n # If ALL or PARTIAL non structured, instantiate in dict and resolve interpolations eagerly.\n if convert == ConvertMode.ALL or (\n convert == ConvertMode.PARTIAL and node._metadata.object_type is None\n ):\n dict_items = {}\n for key, value in node.items():\n # list items inherits recursive flag from the containing dict.\n dict_items[key] = instantiate_node(\n value, convert=convert, recursive=recursive\n )\n return dict_items\n else:\n # Otherwise use DictConfig and resolve interpolations lazily.\n cfg = OmegaConf.create({}, flags={\"allow_objects\": True})\n for key, value in node.items():\n cfg[key] = instantiate_node(\n value, convert=convert, recursive=recursive\n )\n cfg._set_parent(node)\n cfg._metadata.object_type = node._metadata.object_type\n return cfg\n\n else:\n assert False, f\"Unexpected config type : {type(node).__name__}\"\n", "path": "hydra/_internal/instantiate/_instantiate2.py"}]}
| 4,060 | 470 |
gh_patches_debug_37924
|
rasdani/github-patches
|
git_diff
|
boto__botocore-165
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Add compat for legacy operation methods on waiters
While pulling in https://github.com/boto/botocore/pull/437,
I noticed that we aren't handling the 'error' matcher properly
because of a CLI customization that will raise an error on
non 200 responses. This handles that case so, for example, the
command
`aws rds wait db-instance-deleted --db-instance-identifier foo`
will work as expected. Previously, the error was being propogated
and the CLI command would exit with a non-zero RC and a client error
message.
cc @kyleknap @danielgtaylor
</issue>
<code>
[start of botocore/paginate.py]
1 # Copyright (c) 2013 Amazon.com, Inc. or its affiliates. All Rights Reserved
2 #
3 # Permission is hereby granted, free of charge, to any person obtaining a
4 # copy of this software and associated documentation files (the
5 # "Software"), to deal in the Software without restriction, including
6 # without limitation the rights to use, copy, modify, merge, publish, dis-
7 # tribute, sublicense, and/or sell copies of the Software, and to permit
8 # persons to whom the Software is furnished to do so, subject to the fol-
9 # lowing conditions:
10 #
11 # The above copyright notice and this permission notice shall be included
12 # in all copies or substantial portions of the Software.
13 #
14 # THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS
15 # OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABIL-
16 # ITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT
17 # SHALL THE AUTHOR BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY,
18 # WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
19 # OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS
20 # IN THE SOFTWARE.
21 #
22 from itertools import tee
23 try:
24 from itertools import zip_longest
25 except ImportError:
26 # Python2.x is izip_longest.
27 from itertools import izip_longest as zip_longest
28
29 try:
30 zip
31 except NameError:
32 # Python2.x is izip.
33 from itertools import izip as zip
34
35 import jmespath
36 from botocore.exceptions import PaginationError
37
38
39 class Paginator(object):
40 def __init__(self, operation):
41 self._operation = operation
42 self._pagination_cfg = operation.pagination
43 self._output_token = self._get_output_tokens(self._pagination_cfg)
44 self._input_token = self._get_input_tokens(self._pagination_cfg)
45 self._more_results = self._get_more_results_token(self._pagination_cfg)
46 self._result_keys = self._get_result_keys(self._pagination_cfg)
47
48 @property
49 def result_keys(self):
50 return self._result_keys
51
52 def _get_output_tokens(self, config):
53 output = []
54 output_token = config['output_token']
55 if not isinstance(output_token, list):
56 output_token = [output_token]
57 for config in output_token:
58 output.append(jmespath.compile(config))
59 return output
60
61 def _get_input_tokens(self, config):
62 input_token = self._pagination_cfg['py_input_token']
63 if not isinstance(input_token, list):
64 input_token = [input_token]
65 return input_token
66
67 def _get_more_results_token(self, config):
68 more_results = config.get('more_key')
69 if more_results is not None:
70 return jmespath.compile(more_results)
71
72 def _get_result_keys(self, config):
73 result_key = config.get('result_key')
74 if result_key is not None:
75 if not isinstance(result_key, list):
76 result_key = [result_key]
77 return result_key
78
79 def paginate(self, endpoint, **kwargs):
80 """Paginate responses to an operation.
81
82 The responses to some operations are too large for a single response.
83 When this happens, the service will indicate that there are more
84 results in its response. This method handles the details of how
85 to detect when this happens and how to retrieve more results.
86
87 This method returns an iterator. Each element in the iterator
88 is the result of an ``Operation.call`` call, so each element is
89 a tuple of (``http_response``, ``parsed_result``).
90
91 """
92 page_params = self._extract_paging_params(kwargs)
93 return PageIterator(self._operation, self._input_token,
94 self._output_token, self._more_results,
95 self._result_keys, page_params['max_items'],
96 page_params['starting_token'],
97 endpoint, kwargs)
98
99 def _extract_paging_params(self, kwargs):
100 return {
101 'max_items': kwargs.pop('max_items', None),
102 'starting_token': kwargs.pop('starting_token', None),
103 }
104
105
106 class PageIterator(object):
107 def __init__(self, operation, input_token, output_token, more_results,
108 result_key, max_items, starting_token, endpoint, op_kwargs):
109 self._operation = operation
110 self._input_token = input_token
111 self._output_token = output_token
112 self._more_results = more_results
113 self._result_key = result_key
114 self._max_items = max_items
115 self._starting_token = starting_token
116 self._endpoint = endpoint
117 self._op_kwargs = op_kwargs
118 self._resume_token = None
119
120 @property
121 def resume_token(self):
122 """Token to specify to resume pagination."""
123 return self._resume_token
124
125 @resume_token.setter
126 def resume_token(self, value):
127 if isinstance(value, list):
128 self._resume_token = '___'.join([str(v) for v in value])
129
130 def __iter__(self):
131 current_kwargs = self._op_kwargs
132 endpoint = self._endpoint
133 previous_next_token = None
134 next_token = [None for _ in range(len(self._input_token))]
135 # The number of items from result_key we've seen so far.
136 total_items = 0
137 first_request = True
138 primary_result_key = self._result_key[0]
139 starting_truncation = 0
140 self._inject_starting_token(current_kwargs)
141 while True:
142 http_response, parsed = self._operation.call(endpoint,
143 **current_kwargs)
144 if first_request:
145 # The first request is handled differently. We could
146 # possibly have a resume/starting token that tells us where
147 # to index into the retrieved page.
148 if self._starting_token is not None:
149 starting_truncation = self._handle_first_request(
150 parsed, primary_result_key, starting_truncation)
151 first_request = False
152 num_current_response = len(parsed.get(primary_result_key, []))
153 truncate_amount = 0
154 if self._max_items is not None:
155 truncate_amount = (total_items + num_current_response) \
156 - self._max_items
157 if truncate_amount > 0:
158 self._truncate_response(parsed, primary_result_key,
159 truncate_amount, starting_truncation,
160 next_token)
161 yield http_response, parsed
162 break
163 else:
164 yield http_response, parsed
165 total_items += num_current_response
166 next_token = self._get_next_token(parsed)
167 if all(t is None for t in next_token):
168 break
169 if self._max_items is not None and \
170 total_items == self._max_items:
171 # We're on a page boundary so we can set the current
172 # next token to be the resume token.
173 self.resume_token = next_token
174 break
175 if previous_next_token is not None and \
176 previous_next_token == next_token:
177 message = ("The same next token was received "
178 "twice: %s" % next_token)
179 raise PaginationError(message=message)
180 self._inject_token_into_kwargs(current_kwargs, next_token)
181 previous_next_token = next_token
182
183 def _inject_starting_token(self, op_kwargs):
184 # If the user has specified a starting token we need to
185 # inject that into the operation's kwargs.
186 if self._starting_token is not None:
187 # Don't need to do anything special if there is no starting
188 # token specified.
189 next_token = self._parse_starting_token()[0]
190 self._inject_token_into_kwargs(op_kwargs, next_token)
191
192 def _inject_token_into_kwargs(self, op_kwargs, next_token):
193 for name, token in zip(self._input_token, next_token):
194 if token is None or token == 'None':
195 continue
196 op_kwargs[name] = token
197
198 def _handle_first_request(self, parsed, primary_result_key,
199 starting_truncation):
200 # First we need to slice into the array and only return
201 # the truncated amount.
202 starting_truncation = self._parse_starting_token()[1]
203 parsed[primary_result_key] = parsed[
204 primary_result_key][starting_truncation:]
205 # We also need to truncate any secondary result keys
206 # because they were not truncated in the previous last
207 # response.
208 for token in self._result_key:
209 if token == primary_result_key:
210 continue
211 parsed[token] = []
212 return starting_truncation
213
214 def _truncate_response(self, parsed, primary_result_key, truncate_amount,
215 starting_truncation, next_token):
216 original = parsed.get(primary_result_key, [])
217 amount_to_keep = len(original) - truncate_amount
218 truncated = original[:amount_to_keep]
219 parsed[primary_result_key] = truncated
220 # The issue here is that even though we know how much we've truncated
221 # we need to account for this globally including any starting
222 # left truncation. For example:
223 # Raw response: [0,1,2,3]
224 # Starting index: 1
225 # Max items: 1
226 # Starting left truncation: [1, 2, 3]
227 # End right truncation for max items: [1]
228 # However, even though we only kept 1, this is post
229 # left truncation so the next starting index should be 2, not 1
230 # (left_truncation + amount_to_keep).
231 next_token.append(str(amount_to_keep + starting_truncation))
232 self.resume_token = next_token
233
234 def _get_next_token(self, parsed):
235 if self._more_results is not None:
236 if not self._more_results.search(parsed):
237 return [None]
238 next_tokens = []
239 for token in self._output_token:
240 next_tokens.append(token.search(parsed))
241 return next_tokens
242
243 def result_key_iters(self):
244 teed_results = tee(self, len(self._result_key))
245 return [ResultKeyIterator(i, result_key) for i, result_key
246 in zip(teed_results, self._result_key)]
247
248 def build_full_result(self):
249 iterators = self.result_key_iters()
250 response = {}
251 key_names = [i.result_key for i in iterators]
252 for key in key_names:
253 response[key] = []
254 for vals in zip_longest(*iterators):
255 for k, val in zip(key_names, vals):
256 if val is not None:
257 response[k].append(val)
258 if self.resume_token is not None:
259 response['NextToken'] = self.resume_token
260 return response
261
262 def _parse_starting_token(self):
263 if self._starting_token is None:
264 return None
265 parts = self._starting_token.split('___')
266 next_token = []
267 index = 0
268 if len(parts) == len(self._input_token) + 1:
269 try:
270 index = int(parts.pop())
271 except ValueError:
272 raise ValueError("Bad starting token: %s" %
273 self._starting_token)
274 for part in parts:
275 if part == 'None':
276 next_token.append(None)
277 else:
278 next_token.append(part)
279 return next_token, index
280
281
282 class ResultKeyIterator(object):
283 """Iterates over the results of paginated responses."""
284 def __init__(self, pages_iterator, result_key):
285 self._pages_iterator = pages_iterator
286 self.result_key = result_key
287
288 def __iter__(self):
289 for _, page in self._pages_iterator:
290 for result in page.get(self.result_key, []):
291 yield result
292
[end of botocore/paginate.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/botocore/paginate.py b/botocore/paginate.py
--- a/botocore/paginate.py
+++ b/botocore/paginate.py
@@ -105,18 +105,22 @@
class PageIterator(object):
def __init__(self, operation, input_token, output_token, more_results,
- result_key, max_items, starting_token, endpoint, op_kwargs):
+ result_keys, max_items, starting_token, endpoint, op_kwargs):
self._operation = operation
self._input_token = input_token
self._output_token = output_token
self._more_results = more_results
- self._result_key = result_key
+ self._result_keys = result_keys
self._max_items = max_items
self._starting_token = starting_token
self._endpoint = endpoint
self._op_kwargs = op_kwargs
self._resume_token = None
+ @property
+ def result_keys(self):
+ return self._result_keys
+
@property
def resume_token(self):
"""Token to specify to resume pagination."""
@@ -135,7 +139,7 @@
# The number of items from result_key we've seen so far.
total_items = 0
first_request = True
- primary_result_key = self._result_key[0]
+ primary_result_key = self.result_keys[0]
starting_truncation = 0
self._inject_starting_token(current_kwargs)
while True:
@@ -205,7 +209,7 @@
# We also need to truncate any secondary result keys
# because they were not truncated in the previous last
# response.
- for token in self._result_key:
+ for token in self.result_keys:
if token == primary_result_key:
continue
parsed[token] = []
@@ -241,9 +245,9 @@
return next_tokens
def result_key_iters(self):
- teed_results = tee(self, len(self._result_key))
+ teed_results = tee(self, len(self.result_keys))
return [ResultKeyIterator(i, result_key) for i, result_key
- in zip(teed_results, self._result_key)]
+ in zip(teed_results, self.result_keys)]
def build_full_result(self):
iterators = self.result_key_iters()
|
{"golden_diff": "diff --git a/botocore/paginate.py b/botocore/paginate.py\n--- a/botocore/paginate.py\n+++ b/botocore/paginate.py\n@@ -105,18 +105,22 @@\n \n class PageIterator(object):\n def __init__(self, operation, input_token, output_token, more_results,\n- result_key, max_items, starting_token, endpoint, op_kwargs):\n+ result_keys, max_items, starting_token, endpoint, op_kwargs):\n self._operation = operation\n self._input_token = input_token\n self._output_token = output_token\n self._more_results = more_results\n- self._result_key = result_key\n+ self._result_keys = result_keys\n self._max_items = max_items\n self._starting_token = starting_token\n self._endpoint = endpoint\n self._op_kwargs = op_kwargs\n self._resume_token = None\n \n+ @property\n+ def result_keys(self):\n+ return self._result_keys\n+\n @property\n def resume_token(self):\n \"\"\"Token to specify to resume pagination.\"\"\"\n@@ -135,7 +139,7 @@\n # The number of items from result_key we've seen so far.\n total_items = 0\n first_request = True\n- primary_result_key = self._result_key[0]\n+ primary_result_key = self.result_keys[0]\n starting_truncation = 0\n self._inject_starting_token(current_kwargs)\n while True:\n@@ -205,7 +209,7 @@\n # We also need to truncate any secondary result keys\n # because they were not truncated in the previous last\n # response.\n- for token in self._result_key:\n+ for token in self.result_keys:\n if token == primary_result_key:\n continue\n parsed[token] = []\n@@ -241,9 +245,9 @@\n return next_tokens\n \n def result_key_iters(self):\n- teed_results = tee(self, len(self._result_key))\n+ teed_results = tee(self, len(self.result_keys))\n return [ResultKeyIterator(i, result_key) for i, result_key\n- in zip(teed_results, self._result_key)]\n+ in zip(teed_results, self.result_keys)]\n \n def build_full_result(self):\n iterators = self.result_key_iters()\n", "issue": "Add compat for legacy operation methods on waiters\nWhile pulling in https://github.com/boto/botocore/pull/437,\nI noticed that we aren't handling the 'error' matcher properly\nbecause of a CLI customization that will raise an error on\nnon 200 responses. This handles that case so, for example, the\ncommand\n`aws rds wait db-instance-deleted --db-instance-identifier foo`\nwill work as expected. Previously, the error was being propogated\nand the CLI command would exit with a non-zero RC and a client error\nmessage.\n\ncc @kyleknap @danielgtaylor \n\n", "before_files": [{"content": "# Copyright (c) 2013 Amazon.com, Inc. or its affiliates. All Rights Reserved\n#\n# Permission is hereby granted, free of charge, to any person obtaining a\n# copy of this software and associated documentation files (the\n# \"Software\"), to deal in the Software without restriction, including\n# without limitation the rights to use, copy, modify, merge, publish, dis-\n# tribute, sublicense, and/or sell copies of the Software, and to permit\n# persons to whom the Software is furnished to do so, subject to the fol-\n# lowing conditions:\n#\n# The above copyright notice and this permission notice shall be included\n# in all copies or substantial portions of the Software.\n#\n# THE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY KIND, EXPRESS\n# OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABIL-\n# ITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT\n# SHALL THE AUTHOR BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY,\n# WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,\n# OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS\n# IN THE SOFTWARE.\n#\nfrom itertools import tee\ntry:\n from itertools import zip_longest\nexcept ImportError:\n # Python2.x is izip_longest.\n from itertools import izip_longest as zip_longest\n\ntry:\n zip\nexcept NameError:\n # Python2.x is izip.\n from itertools import izip as zip\n\nimport jmespath\nfrom botocore.exceptions import PaginationError\n\n\nclass Paginator(object):\n def __init__(self, operation):\n self._operation = operation\n self._pagination_cfg = operation.pagination\n self._output_token = self._get_output_tokens(self._pagination_cfg)\n self._input_token = self._get_input_tokens(self._pagination_cfg)\n self._more_results = self._get_more_results_token(self._pagination_cfg)\n self._result_keys = self._get_result_keys(self._pagination_cfg)\n\n @property\n def result_keys(self):\n return self._result_keys\n\n def _get_output_tokens(self, config):\n output = []\n output_token = config['output_token']\n if not isinstance(output_token, list):\n output_token = [output_token]\n for config in output_token:\n output.append(jmespath.compile(config))\n return output\n\n def _get_input_tokens(self, config):\n input_token = self._pagination_cfg['py_input_token']\n if not isinstance(input_token, list):\n input_token = [input_token]\n return input_token\n\n def _get_more_results_token(self, config):\n more_results = config.get('more_key')\n if more_results is not None:\n return jmespath.compile(more_results)\n\n def _get_result_keys(self, config):\n result_key = config.get('result_key')\n if result_key is not None:\n if not isinstance(result_key, list):\n result_key = [result_key]\n return result_key\n\n def paginate(self, endpoint, **kwargs):\n \"\"\"Paginate responses to an operation.\n\n The responses to some operations are too large for a single response.\n When this happens, the service will indicate that there are more\n results in its response. This method handles the details of how\n to detect when this happens and how to retrieve more results.\n\n This method returns an iterator. Each element in the iterator\n is the result of an ``Operation.call`` call, so each element is\n a tuple of (``http_response``, ``parsed_result``).\n\n \"\"\"\n page_params = self._extract_paging_params(kwargs)\n return PageIterator(self._operation, self._input_token,\n self._output_token, self._more_results,\n self._result_keys, page_params['max_items'],\n page_params['starting_token'],\n endpoint, kwargs)\n\n def _extract_paging_params(self, kwargs):\n return {\n 'max_items': kwargs.pop('max_items', None),\n 'starting_token': kwargs.pop('starting_token', None),\n }\n\n\nclass PageIterator(object):\n def __init__(self, operation, input_token, output_token, more_results,\n result_key, max_items, starting_token, endpoint, op_kwargs):\n self._operation = operation\n self._input_token = input_token\n self._output_token = output_token\n self._more_results = more_results\n self._result_key = result_key\n self._max_items = max_items\n self._starting_token = starting_token\n self._endpoint = endpoint\n self._op_kwargs = op_kwargs\n self._resume_token = None\n\n @property\n def resume_token(self):\n \"\"\"Token to specify to resume pagination.\"\"\"\n return self._resume_token\n\n @resume_token.setter\n def resume_token(self, value):\n if isinstance(value, list):\n self._resume_token = '___'.join([str(v) for v in value])\n\n def __iter__(self):\n current_kwargs = self._op_kwargs\n endpoint = self._endpoint\n previous_next_token = None\n next_token = [None for _ in range(len(self._input_token))]\n # The number of items from result_key we've seen so far.\n total_items = 0\n first_request = True\n primary_result_key = self._result_key[0]\n starting_truncation = 0\n self._inject_starting_token(current_kwargs)\n while True:\n http_response, parsed = self._operation.call(endpoint,\n **current_kwargs)\n if first_request:\n # The first request is handled differently. We could\n # possibly have a resume/starting token that tells us where\n # to index into the retrieved page.\n if self._starting_token is not None:\n starting_truncation = self._handle_first_request(\n parsed, primary_result_key, starting_truncation)\n first_request = False\n num_current_response = len(parsed.get(primary_result_key, []))\n truncate_amount = 0\n if self._max_items is not None:\n truncate_amount = (total_items + num_current_response) \\\n - self._max_items\n if truncate_amount > 0:\n self._truncate_response(parsed, primary_result_key,\n truncate_amount, starting_truncation,\n next_token)\n yield http_response, parsed\n break\n else:\n yield http_response, parsed\n total_items += num_current_response\n next_token = self._get_next_token(parsed)\n if all(t is None for t in next_token):\n break\n if self._max_items is not None and \\\n total_items == self._max_items:\n # We're on a page boundary so we can set the current\n # next token to be the resume token.\n self.resume_token = next_token\n break\n if previous_next_token is not None and \\\n previous_next_token == next_token:\n message = (\"The same next token was received \"\n \"twice: %s\" % next_token)\n raise PaginationError(message=message)\n self._inject_token_into_kwargs(current_kwargs, next_token)\n previous_next_token = next_token\n\n def _inject_starting_token(self, op_kwargs):\n # If the user has specified a starting token we need to\n # inject that into the operation's kwargs.\n if self._starting_token is not None:\n # Don't need to do anything special if there is no starting\n # token specified.\n next_token = self._parse_starting_token()[0]\n self._inject_token_into_kwargs(op_kwargs, next_token)\n\n def _inject_token_into_kwargs(self, op_kwargs, next_token):\n for name, token in zip(self._input_token, next_token):\n if token is None or token == 'None':\n continue\n op_kwargs[name] = token\n\n def _handle_first_request(self, parsed, primary_result_key,\n starting_truncation):\n # First we need to slice into the array and only return\n # the truncated amount.\n starting_truncation = self._parse_starting_token()[1]\n parsed[primary_result_key] = parsed[\n primary_result_key][starting_truncation:]\n # We also need to truncate any secondary result keys\n # because they were not truncated in the previous last\n # response.\n for token in self._result_key:\n if token == primary_result_key:\n continue\n parsed[token] = []\n return starting_truncation\n\n def _truncate_response(self, parsed, primary_result_key, truncate_amount,\n starting_truncation, next_token):\n original = parsed.get(primary_result_key, [])\n amount_to_keep = len(original) - truncate_amount\n truncated = original[:amount_to_keep]\n parsed[primary_result_key] = truncated\n # The issue here is that even though we know how much we've truncated\n # we need to account for this globally including any starting\n # left truncation. For example:\n # Raw response: [0,1,2,3]\n # Starting index: 1\n # Max items: 1\n # Starting left truncation: [1, 2, 3]\n # End right truncation for max items: [1]\n # However, even though we only kept 1, this is post\n # left truncation so the next starting index should be 2, not 1\n # (left_truncation + amount_to_keep).\n next_token.append(str(amount_to_keep + starting_truncation))\n self.resume_token = next_token\n\n def _get_next_token(self, parsed):\n if self._more_results is not None:\n if not self._more_results.search(parsed):\n return [None]\n next_tokens = []\n for token in self._output_token:\n next_tokens.append(token.search(parsed))\n return next_tokens\n\n def result_key_iters(self):\n teed_results = tee(self, len(self._result_key))\n return [ResultKeyIterator(i, result_key) for i, result_key\n in zip(teed_results, self._result_key)]\n\n def build_full_result(self):\n iterators = self.result_key_iters()\n response = {}\n key_names = [i.result_key for i in iterators]\n for key in key_names:\n response[key] = []\n for vals in zip_longest(*iterators):\n for k, val in zip(key_names, vals):\n if val is not None:\n response[k].append(val)\n if self.resume_token is not None:\n response['NextToken'] = self.resume_token\n return response\n\n def _parse_starting_token(self):\n if self._starting_token is None:\n return None\n parts = self._starting_token.split('___')\n next_token = []\n index = 0\n if len(parts) == len(self._input_token) + 1:\n try:\n index = int(parts.pop())\n except ValueError:\n raise ValueError(\"Bad starting token: %s\" %\n self._starting_token)\n for part in parts:\n if part == 'None':\n next_token.append(None)\n else:\n next_token.append(part)\n return next_token, index\n\n\nclass ResultKeyIterator(object):\n \"\"\"Iterates over the results of paginated responses.\"\"\"\n def __init__(self, pages_iterator, result_key):\n self._pages_iterator = pages_iterator\n self.result_key = result_key\n\n def __iter__(self):\n for _, page in self._pages_iterator:\n for result in page.get(self.result_key, []):\n yield result\n", "path": "botocore/paginate.py"}]}
| 3,937 | 533 |
gh_patches_debug_4940
|
rasdani/github-patches
|
git_diff
|
conan-io__conan-3440
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
scm.subfolder support only one level of subfolders (not foo/baz/bar)
conan v1.6.1, Windows 10, Python 3.6
I'm moving our codebase to conan packages and encountered following error. I have to specify not single directory in `scm.subfolder` attribute, but multiple ones:
```python
scm = {
"type": "git",
"subfolder": "foo/baz/bar",
"url": "auto",
"revision": "auto",
}
```
The reason is that I shouldn't change paths in `#include` directives today and I will update paths in the future.
With such recipe conan fails to build missing packages, i.e.
`conan install . --build missing` fails with an strange error:
`FileNotFoundError: [WinError 3] The system cannot find the path specified: 'C:\\.conan2\\gk8g1phl\\1\\foo\\baz\bar`
I think that source of this problem is this line:
https://github.com/conan-io/conan/blob/develop/conans/client/tools/scm.py#L20
Could you call `os.makedirs` instead of `os.mkdir`?
- [*] I've read the [CONTRIBUTING guide](https://raw.githubusercontent.com/conan-io/conan/develop/.github/CONTRIBUTING.md).
- [*] I've specified the Conan version, operating system version and any tool that can be relevant.
- [*] I've explained the steps to reproduce the error or the motivation/use case of the question/suggestion.
</issue>
<code>
[start of conans/client/tools/scm.py]
1 import os
2
3 import re
4 import subprocess
5 from six.moves.urllib.parse import urlparse, quote_plus
6 from subprocess import CalledProcessError, PIPE, STDOUT
7
8 from conans.client.tools.env import no_op, environment_append
9 from conans.client.tools.files import chdir
10 from conans.errors import ConanException
11 from conans.util.files import decode_text, to_file_bytes
12
13
14 class Git(object):
15
16 def __init__(self, folder=None, verify_ssl=True, username=None, password=None, force_english=True,
17 runner=None):
18 self.folder = folder or os.getcwd()
19 if not os.path.exists(self.folder):
20 os.mkdir(self.folder)
21 self._verify_ssl = verify_ssl
22 self._force_eng = force_english
23 self._username = username
24 self._password = password
25 self._runner = runner
26
27 def run(self, command):
28 command = "git %s" % command
29 with chdir(self.folder) if self.folder else no_op():
30 with environment_append({"LC_ALL": "en_US.UTF-8"}) if self._force_eng else no_op():
31 if not self._runner:
32 return subprocess.check_output(command, shell=True).decode().strip()
33 else:
34 return self._runner(command)
35
36 def get_url_with_credentials(self, url):
37 if not self._username or not self._password:
38 return url
39 if urlparse(url).password:
40 return url
41
42 user_enc = quote_plus(self._username)
43 pwd_enc = quote_plus(self._password)
44 url = url.replace("://", "://" + user_enc + ":" + pwd_enc + "@", 1)
45 return url
46
47 def _configure_ssl_verify(self):
48 return self.run("config http.sslVerify %s" % ("true" if self._verify_ssl else "false"))
49
50 def clone(self, url, branch=None):
51 url = self.get_url_with_credentials(url)
52 if os.path.exists(url):
53 url = url.replace("\\", "/") # Windows local directory
54 if os.path.exists(self.folder) and os.listdir(self.folder):
55 if not branch:
56 raise ConanException("The destination folder '%s' is not empty, "
57 "specify a branch to checkout (not a tag or commit) "
58 "or specify a 'subfolder' "
59 "attribute in the 'scm'" % self.folder)
60 output = self.run("init")
61 output += self._configure_ssl_verify()
62 output += self.run('remote add origin "%s"' % url)
63 output += self.run("fetch ")
64 output += self.run("checkout -t origin/%s" % branch)
65 else:
66 branch_cmd = "--branch %s" % branch if branch else ""
67 output = self.run('clone "%s" . %s' % (url, branch_cmd))
68 output += self._configure_ssl_verify()
69
70 return output
71
72 def checkout(self, element, submodule=None):
73 self._check_git_repo()
74 output = self.run('checkout "%s"' % element)
75
76 if submodule:
77 if submodule == "shallow":
78 output += self.run("submodule sync")
79 output += self.run("submodule update --init")
80 elif submodule == "recursive":
81 output += self.run("submodule sync --recursive")
82 output += self.run("submodule update --init --recursive")
83 else:
84 raise ConanException("Invalid 'submodule' attribute value in the 'scm'. "
85 "Unknown value '%s'. Allowed values: ['shallow', 'recursive']" % submodule)
86 # Element can be a tag, branch or commit
87 return output
88
89 def excluded_files(self):
90 try:
91
92 file_paths = [os.path.normpath(os.path.join(os.path.relpath(folder, self.folder), el)).replace("\\", "/")
93 for folder, dirpaths, fs in os.walk(self.folder)
94 for el in fs + dirpaths]
95 p = subprocess.Popen(['git', 'check-ignore', '--stdin'],
96 stdout=PIPE, stdin=PIPE, stderr=STDOUT, cwd=self.folder)
97 paths = to_file_bytes("\n".join(file_paths))
98 grep_stdout = decode_text(p.communicate(input=paths)[0])
99 tmp = grep_stdout.splitlines()
100 except CalledProcessError:
101 tmp = []
102 return tmp
103
104 def get_remote_url(self, remote_name=None):
105 self._check_git_repo()
106 remote_name = remote_name or "origin"
107 try:
108 remotes = self.run("remote -v")
109 for remote in remotes.splitlines():
110 try:
111 name, url = remote.split(None, 1)
112 url, _ = url.rsplit(None, 1)
113 if name == remote_name:
114 return url
115 except Exception:
116 pass
117 except subprocess.CalledProcessError:
118 pass
119 return None
120
121 def get_commit(self):
122 self._check_git_repo()
123 try:
124 commit = self.run("rev-parse HEAD")
125 commit = commit.strip()
126 return commit
127 except Exception as e:
128 raise ConanException("Unable to get git commit from %s\n%s" % (self.folder, str(e)))
129
130 get_revision = get_commit
131
132 def _check_git_repo(self):
133 try:
134 self.run("status")
135 except Exception:
136 raise ConanException("Not a valid git repository")
137
138 def get_branch(self):
139 self._check_git_repo()
140 try:
141 status = self.run("status -bs --porcelain")
142 # ## feature/scm_branch...myorigin/feature/scm_branch
143 branch = status.splitlines()[0].split("...")[0].strip("#").strip()
144 # Replace non alphanumeric
145 branch = re.sub('[^0-9a-zA-Z]+', '_', branch)
146 return branch
147 except Exception as e:
148 raise ConanException("Unable to get git branch from %s\n%s" % (self.folder, str(e)))
149
[end of conans/client/tools/scm.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/conans/client/tools/scm.py b/conans/client/tools/scm.py
--- a/conans/client/tools/scm.py
+++ b/conans/client/tools/scm.py
@@ -17,7 +17,7 @@
runner=None):
self.folder = folder or os.getcwd()
if not os.path.exists(self.folder):
- os.mkdir(self.folder)
+ os.makedirs(self.folder)
self._verify_ssl = verify_ssl
self._force_eng = force_english
self._username = username
|
{"golden_diff": "diff --git a/conans/client/tools/scm.py b/conans/client/tools/scm.py\n--- a/conans/client/tools/scm.py\n+++ b/conans/client/tools/scm.py\n@@ -17,7 +17,7 @@\n runner=None):\n self.folder = folder or os.getcwd()\n if not os.path.exists(self.folder):\n- os.mkdir(self.folder)\n+ os.makedirs(self.folder)\n self._verify_ssl = verify_ssl\n self._force_eng = force_english\n self._username = username\n", "issue": "scm.subfolder support only one level of subfolders (not foo/baz/bar)\nconan v1.6.1, Windows 10, Python 3.6\r\n\r\nI'm moving our codebase to conan packages and encountered following error. I have to specify not single directory in `scm.subfolder` attribute, but multiple ones:\r\n```python\r\nscm = {\r\n \"type\": \"git\",\r\n \"subfolder\": \"foo/baz/bar\",\r\n \"url\": \"auto\",\r\n \"revision\": \"auto\",\r\n }\r\n``` \r\nThe reason is that I shouldn't change paths in `#include` directives today and I will update paths in the future.\r\n\r\nWith such recipe conan fails to build missing packages, i.e.\r\n`conan install . --build missing` fails with an strange error:\r\n`FileNotFoundError: [WinError 3] The system cannot find the path specified: 'C:\\\\.conan2\\\\gk8g1phl\\\\1\\\\foo\\\\baz\\bar`\r\n\r\nI think that source of this problem is this line:\r\nhttps://github.com/conan-io/conan/blob/develop/conans/client/tools/scm.py#L20\r\n\r\nCould you call `os.makedirs` instead of `os.mkdir`?\r\n\r\n- [*] I've read the [CONTRIBUTING guide](https://raw.githubusercontent.com/conan-io/conan/develop/.github/CONTRIBUTING.md).\r\n- [*] I've specified the Conan version, operating system version and any tool that can be relevant.\r\n- [*] I've explained the steps to reproduce the error or the motivation/use case of the question/suggestion.\r\n\r\n\n", "before_files": [{"content": "import os\n\nimport re\nimport subprocess\nfrom six.moves.urllib.parse import urlparse, quote_plus\nfrom subprocess import CalledProcessError, PIPE, STDOUT\n\nfrom conans.client.tools.env import no_op, environment_append\nfrom conans.client.tools.files import chdir\nfrom conans.errors import ConanException\nfrom conans.util.files import decode_text, to_file_bytes\n\n\nclass Git(object):\n\n def __init__(self, folder=None, verify_ssl=True, username=None, password=None, force_english=True,\n runner=None):\n self.folder = folder or os.getcwd()\n if not os.path.exists(self.folder):\n os.mkdir(self.folder)\n self._verify_ssl = verify_ssl\n self._force_eng = force_english\n self._username = username\n self._password = password\n self._runner = runner\n\n def run(self, command):\n command = \"git %s\" % command\n with chdir(self.folder) if self.folder else no_op():\n with environment_append({\"LC_ALL\": \"en_US.UTF-8\"}) if self._force_eng else no_op():\n if not self._runner:\n return subprocess.check_output(command, shell=True).decode().strip()\n else:\n return self._runner(command)\n\n def get_url_with_credentials(self, url):\n if not self._username or not self._password:\n return url\n if urlparse(url).password:\n return url\n\n user_enc = quote_plus(self._username)\n pwd_enc = quote_plus(self._password)\n url = url.replace(\"://\", \"://\" + user_enc + \":\" + pwd_enc + \"@\", 1)\n return url\n\n def _configure_ssl_verify(self):\n return self.run(\"config http.sslVerify %s\" % (\"true\" if self._verify_ssl else \"false\"))\n\n def clone(self, url, branch=None):\n url = self.get_url_with_credentials(url)\n if os.path.exists(url):\n url = url.replace(\"\\\\\", \"/\") # Windows local directory\n if os.path.exists(self.folder) and os.listdir(self.folder):\n if not branch:\n raise ConanException(\"The destination folder '%s' is not empty, \"\n \"specify a branch to checkout (not a tag or commit) \"\n \"or specify a 'subfolder' \"\n \"attribute in the 'scm'\" % self.folder)\n output = self.run(\"init\")\n output += self._configure_ssl_verify()\n output += self.run('remote add origin \"%s\"' % url)\n output += self.run(\"fetch \")\n output += self.run(\"checkout -t origin/%s\" % branch)\n else:\n branch_cmd = \"--branch %s\" % branch if branch else \"\"\n output = self.run('clone \"%s\" . %s' % (url, branch_cmd))\n output += self._configure_ssl_verify()\n\n return output\n\n def checkout(self, element, submodule=None):\n self._check_git_repo()\n output = self.run('checkout \"%s\"' % element)\n\n if submodule:\n if submodule == \"shallow\":\n output += self.run(\"submodule sync\")\n output += self.run(\"submodule update --init\")\n elif submodule == \"recursive\":\n output += self.run(\"submodule sync --recursive\")\n output += self.run(\"submodule update --init --recursive\")\n else:\n raise ConanException(\"Invalid 'submodule' attribute value in the 'scm'. \"\n \"Unknown value '%s'. Allowed values: ['shallow', 'recursive']\" % submodule)\n # Element can be a tag, branch or commit\n return output\n\n def excluded_files(self):\n try:\n\n file_paths = [os.path.normpath(os.path.join(os.path.relpath(folder, self.folder), el)).replace(\"\\\\\", \"/\")\n for folder, dirpaths, fs in os.walk(self.folder)\n for el in fs + dirpaths]\n p = subprocess.Popen(['git', 'check-ignore', '--stdin'],\n stdout=PIPE, stdin=PIPE, stderr=STDOUT, cwd=self.folder)\n paths = to_file_bytes(\"\\n\".join(file_paths))\n grep_stdout = decode_text(p.communicate(input=paths)[0])\n tmp = grep_stdout.splitlines()\n except CalledProcessError:\n tmp = []\n return tmp\n\n def get_remote_url(self, remote_name=None):\n self._check_git_repo()\n remote_name = remote_name or \"origin\"\n try:\n remotes = self.run(\"remote -v\")\n for remote in remotes.splitlines():\n try:\n name, url = remote.split(None, 1)\n url, _ = url.rsplit(None, 1)\n if name == remote_name:\n return url\n except Exception:\n pass\n except subprocess.CalledProcessError:\n pass\n return None\n\n def get_commit(self):\n self._check_git_repo()\n try:\n commit = self.run(\"rev-parse HEAD\")\n commit = commit.strip()\n return commit\n except Exception as e:\n raise ConanException(\"Unable to get git commit from %s\\n%s\" % (self.folder, str(e)))\n\n get_revision = get_commit\n\n def _check_git_repo(self):\n try:\n self.run(\"status\")\n except Exception:\n raise ConanException(\"Not a valid git repository\")\n\n def get_branch(self):\n self._check_git_repo()\n try:\n status = self.run(\"status -bs --porcelain\")\n # ## feature/scm_branch...myorigin/feature/scm_branch\n branch = status.splitlines()[0].split(\"...\")[0].strip(\"#\").strip()\n # Replace non alphanumeric\n branch = re.sub('[^0-9a-zA-Z]+', '_', branch)\n return branch\n except Exception as e:\n raise ConanException(\"Unable to get git branch from %s\\n%s\" % (self.folder, str(e)))\n", "path": "conans/client/tools/scm.py"}]}
| 2,482 | 114 |
gh_patches_debug_271
|
rasdani/github-patches
|
git_diff
|
codespell-project__codespell-3218
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Codespell don't handle KeyboardInterrupt exception
This should be catched and the program should stop gracefully but instead show default stack trace:
```
^CTraceback (most recent call last):
File "/home/kuba/.local/bin/codespell", line 8, in <module>
sys.exit(_script_main())
^^^^^^^^^^^^^^
File "/home/kuba/.local/lib/python3.12/site-packages/codespell_lib/_codespell.py", line 1017, in _script_main
return main(*sys.argv[1:])
^^^^^^^^^^^^^^^^^^^
File "/home/kuba/.local/lib/python3.12/site-packages/codespell_lib/_codespell.py", line 1185, in main
bad_count += parse_file(
^^^^^^^^^^^
File "/home/kuba/.local/lib/python3.12/site-packages/codespell_lib/_codespell.py", line 903, in parse_file
check_matches = extract_words_iter(line, word_regex, ignore_word_regex)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/kuba/.local/lib/python3.12/site-packages/codespell_lib/_codespell.py", line 793, in extract_words_iter
return list(word_regex.finditer(_ignore_word_sub(text, ignore_word_regex)))
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
KeyboardInterrupt
```
There is no need to show `KeyboardInterrupt` exception stack trace.
</issue>
<code>
[start of codespell_lib/__main__.py]
1 import sys
2
3 from ._codespell import _script_main
4
5 if __name__ == "__main__":
6 sys.exit(_script_main())
7
[end of codespell_lib/__main__.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/codespell_lib/__main__.py b/codespell_lib/__main__.py
--- a/codespell_lib/__main__.py
+++ b/codespell_lib/__main__.py
@@ -3,4 +3,7 @@
from ._codespell import _script_main
if __name__ == "__main__":
- sys.exit(_script_main())
+ try:
+ sys.exit(_script_main())
+ except KeyboardInterrupt:
+ pass
|
{"golden_diff": "diff --git a/codespell_lib/__main__.py b/codespell_lib/__main__.py\n--- a/codespell_lib/__main__.py\n+++ b/codespell_lib/__main__.py\n@@ -3,4 +3,7 @@\n from ._codespell import _script_main\n \n if __name__ == \"__main__\":\n- sys.exit(_script_main())\n+ try:\n+ sys.exit(_script_main())\n+ except KeyboardInterrupt:\n+ pass\n", "issue": "Codespell don't handle KeyboardInterrupt exception\nThis should be catched and the program should stop gracefully but instead show default stack trace:\r\n\r\n```\r\n^CTraceback (most recent call last):\r\n File \"/home/kuba/.local/bin/codespell\", line 8, in <module>\r\n sys.exit(_script_main())\r\n ^^^^^^^^^^^^^^\r\n File \"/home/kuba/.local/lib/python3.12/site-packages/codespell_lib/_codespell.py\", line 1017, in _script_main\r\n return main(*sys.argv[1:])\r\n ^^^^^^^^^^^^^^^^^^^\r\n File \"/home/kuba/.local/lib/python3.12/site-packages/codespell_lib/_codespell.py\", line 1185, in main\r\n bad_count += parse_file(\r\n ^^^^^^^^^^^\r\n File \"/home/kuba/.local/lib/python3.12/site-packages/codespell_lib/_codespell.py\", line 903, in parse_file\r\n check_matches = extract_words_iter(line, word_regex, ignore_word_regex)\r\n ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^\r\n File \"/home/kuba/.local/lib/python3.12/site-packages/codespell_lib/_codespell.py\", line 793, in extract_words_iter\r\n return list(word_regex.finditer(_ignore_word_sub(text, ignore_word_regex)))\r\n ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^\r\nKeyboardInterrupt\r\n```\r\n\r\nThere is no need to show `KeyboardInterrupt` exception stack trace.\n", "before_files": [{"content": "import sys\n\nfrom ._codespell import _script_main\n\nif __name__ == \"__main__\":\n sys.exit(_script_main())\n", "path": "codespell_lib/__main__.py"}]}
| 912 | 100 |
gh_patches_debug_9054
|
rasdani/github-patches
|
git_diff
|
python__peps-632
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
pep2rss disregards PEPs written in reStructuredText format
This can be seen at https://www.python.org/dev/peps/peps.rss/ where the last (most recent) RSS entry is the last PEP written in plaintext.
</issue>
<code>
[start of pep2rss.py]
1 #!/usr/bin/env python
2
3 # usage: pep-hook.py $REPOS $REV
4 # (standard post-commit args)
5
6 import os, glob, time, datetime, stat, re, sys
7 import codecs
8 import PyRSS2Gen as rssgen
9
10 RSS_PATH = os.path.join(sys.argv[1], 'peps.rss')
11
12 def firstline_startingwith(full_path, text):
13 for line in codecs.open(full_path, encoding="utf-8"):
14 if line.startswith(text):
15 return line[len(text):].strip()
16 return None
17
18 # get list of peps with creation time (from "Created:" string in pep .txt)
19 peps = glob.glob('pep-*.txt')
20 def pep_creation_dt(full_path):
21 created_str = firstline_startingwith(full_path, 'Created:')
22 # bleh, I was hoping to avoid re but some PEPs editorialize
23 # on the Created line
24 m = re.search(r'''(\d+-\w+-\d{4})''', created_str)
25 if not m:
26 # some older ones have an empty line, that's okay, if it's old
27 # we ipso facto don't care about it.
28 # "return None" would make the most sense but datetime objects
29 # refuse to compare with that. :-|
30 return datetime.datetime(*time.localtime(0)[:6])
31 created_str = m.group(1)
32 try:
33 t = time.strptime(created_str, '%d-%b-%Y')
34 except ValueError:
35 t = time.strptime(created_str, '%d-%B-%Y')
36 return datetime.datetime(*t[:6])
37 peps_with_dt = [(pep_creation_dt(full_path), full_path) for full_path in peps]
38 # sort peps by date, newest first
39 peps_with_dt.sort(reverse=True)
40
41 # generate rss items for 10 most recent peps
42 items = []
43 for dt, full_path in peps_with_dt[:10]:
44 try:
45 n = int(full_path.split('-')[-1].split('.')[0])
46 except ValueError:
47 pass
48 title = firstline_startingwith(full_path, 'Title:')
49 author = firstline_startingwith(full_path, 'Author:')
50 url = 'http://www.python.org/dev/peps/pep-%0.4d' % n
51 item = rssgen.RSSItem(
52 title = 'PEP %d: %s' % (n, title),
53 link = url,
54 description = 'Author: %s' % author,
55 guid = rssgen.Guid(url),
56 pubDate = dt)
57 items.append(item)
58
59 # the rss envelope
60 desc = """
61 Newest Python Enhancement Proposals (PEPs) - Information on new
62 language features, and some meta-information like release
63 procedure and schedules
64 """.strip()
65 rss = rssgen.RSS2(
66 title = 'Newest Python PEPs',
67 link = 'http://www.python.org/dev/peps',
68 description = desc,
69 lastBuildDate = datetime.datetime.now(),
70 items = items)
71
72 with open(RSS_PATH, 'w') as fp:
73 fp.write(rss.to_xml())
74
[end of pep2rss.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/pep2rss.py b/pep2rss.py
--- a/pep2rss.py
+++ b/pep2rss.py
@@ -15,8 +15,10 @@
return line[len(text):].strip()
return None
-# get list of peps with creation time (from "Created:" string in pep .txt)
+# get list of peps with creation time
+# (from "Created:" string in pep .rst or .txt)
peps = glob.glob('pep-*.txt')
+peps.extend(glob.glob('pep-*.rst'))
def pep_creation_dt(full_path):
created_str = firstline_startingwith(full_path, 'Created:')
# bleh, I was hoping to avoid re but some PEPs editorialize
|
{"golden_diff": "diff --git a/pep2rss.py b/pep2rss.py\n--- a/pep2rss.py\n+++ b/pep2rss.py\n@@ -15,8 +15,10 @@\n return line[len(text):].strip()\n return None\n \n-# get list of peps with creation time (from \"Created:\" string in pep .txt)\n+# get list of peps with creation time\n+# (from \"Created:\" string in pep .rst or .txt)\n peps = glob.glob('pep-*.txt')\n+peps.extend(glob.glob('pep-*.rst'))\n def pep_creation_dt(full_path):\n created_str = firstline_startingwith(full_path, 'Created:')\n # bleh, I was hoping to avoid re but some PEPs editorialize\n", "issue": "pep2rss disregards PEPs written in reStructuredText format\nThis can be seen at https://www.python.org/dev/peps/peps.rss/ where the last (most recent) RSS entry is the last PEP written in plaintext.\n", "before_files": [{"content": "#!/usr/bin/env python\n\n# usage: pep-hook.py $REPOS $REV\n# (standard post-commit args)\n\nimport os, glob, time, datetime, stat, re, sys\nimport codecs\nimport PyRSS2Gen as rssgen\n\nRSS_PATH = os.path.join(sys.argv[1], 'peps.rss')\n\ndef firstline_startingwith(full_path, text):\n for line in codecs.open(full_path, encoding=\"utf-8\"):\n if line.startswith(text):\n return line[len(text):].strip()\n return None\n\n# get list of peps with creation time (from \"Created:\" string in pep .txt)\npeps = glob.glob('pep-*.txt')\ndef pep_creation_dt(full_path):\n created_str = firstline_startingwith(full_path, 'Created:')\n # bleh, I was hoping to avoid re but some PEPs editorialize\n # on the Created line\n m = re.search(r'''(\\d+-\\w+-\\d{4})''', created_str)\n if not m:\n # some older ones have an empty line, that's okay, if it's old\n # we ipso facto don't care about it.\n # \"return None\" would make the most sense but datetime objects\n # refuse to compare with that. :-|\n return datetime.datetime(*time.localtime(0)[:6])\n created_str = m.group(1)\n try:\n t = time.strptime(created_str, '%d-%b-%Y')\n except ValueError:\n t = time.strptime(created_str, '%d-%B-%Y')\n return datetime.datetime(*t[:6])\npeps_with_dt = [(pep_creation_dt(full_path), full_path) for full_path in peps]\n# sort peps by date, newest first\npeps_with_dt.sort(reverse=True)\n\n# generate rss items for 10 most recent peps\nitems = []\nfor dt, full_path in peps_with_dt[:10]:\n try:\n n = int(full_path.split('-')[-1].split('.')[0])\n except ValueError:\n pass\n title = firstline_startingwith(full_path, 'Title:')\n author = firstline_startingwith(full_path, 'Author:')\n url = 'http://www.python.org/dev/peps/pep-%0.4d' % n\n item = rssgen.RSSItem(\n title = 'PEP %d: %s' % (n, title),\n link = url,\n description = 'Author: %s' % author,\n guid = rssgen.Guid(url),\n pubDate = dt)\n items.append(item)\n\n# the rss envelope\ndesc = \"\"\"\nNewest Python Enhancement Proposals (PEPs) - Information on new\nlanguage features, and some meta-information like release\nprocedure and schedules\n\"\"\".strip()\nrss = rssgen.RSS2(\n title = 'Newest Python PEPs',\n link = 'http://www.python.org/dev/peps',\n description = desc,\n lastBuildDate = datetime.datetime.now(),\n items = items)\n\nwith open(RSS_PATH, 'w') as fp:\n fp.write(rss.to_xml())\n", "path": "pep2rss.py"}]}
| 1,404 | 175 |
gh_patches_debug_8897
|
rasdani/github-patches
|
git_diff
|
spack__spack-22300
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
hwloc: added missing ncurses dependency
</issue>
<code>
[start of var/spack/repos/builtin/packages/hwloc/package.py]
1 # Copyright 2013-2021 Lawrence Livermore National Security, LLC and other
2 # Spack Project Developers. See the top-level COPYRIGHT file for details.
3 #
4 # SPDX-License-Identifier: (Apache-2.0 OR MIT)
5 import sys
6
7
8 class Hwloc(AutotoolsPackage):
9 """The Hardware Locality (hwloc) software project.
10
11 The Portable Hardware Locality (hwloc) software package
12 provides a portable abstraction (across OS, versions,
13 architectures, ...) of the hierarchical topology of modern
14 architectures, including NUMA memory nodes, sockets, shared
15 caches, cores and simultaneous multithreading. It also gathers
16 various system attributes such as cache and memory information
17 as well as the locality of I/O devices such as network
18 interfaces, InfiniBand HCAs or GPUs. It primarily aims at
19 helping applications with gathering information about modern
20 computing hardware so as to exploit it accordingly and
21 efficiently.
22 """
23
24 homepage = "http://www.open-mpi.org/projects/hwloc/"
25 url = "https://download.open-mpi.org/release/hwloc/v2.0/hwloc-2.0.2.tar.gz"
26 list_url = "http://www.open-mpi.org/software/hwloc/"
27 list_depth = 2
28 git = 'https://github.com/open-mpi/hwloc.git'
29
30 maintainers = ['bgoglin']
31
32 version('master', branch='master')
33 version('2.4.1', sha256='4267fe1193a8989f3ab7563a7499e047e77e33fed8f4dec16822a7aebcf78459')
34 version('2.4.0', sha256='30404065dc1d6872b0181269d0bb2424fbbc6e3b0a80491aa373109554006544')
35 version('2.3.0', sha256='155480620c98b43ddf9ca66a6c318b363ca24acb5ff0683af9d25d9324f59836')
36 version('2.2.0', sha256='2defba03ddd91761b858cbbdc2e3a6e27b44e94696dbfa21380191328485a433')
37 version('2.1.0', sha256='1fb8cc1438de548e16ec3bb9e4b2abb9f7ce5656f71c0906583819fcfa8c2031')
38 version('2.0.2', sha256='27dcfe42e3fb3422b72ce48b48bf601c0a3e46e850ee72d9bdd17b5863b6e42c')
39 version('2.0.1', sha256='f1156df22fc2365a31a3dc5f752c53aad49e34a5e22d75ed231cd97eaa437f9d')
40 version('2.0.0', sha256='a0d425a0fc7c7e3f2c92a272ffaffbd913005556b4443e1887d2e1718d902887')
41 version('1.11.13', sha256='a8f781ae4d347708a07d95e7549039887f151ed7f92263238527dfb0a3709b9d')
42 version('1.11.12', sha256='f1d49433e605dd653a77e1478a78cee095787d554a94afe40d1376bca6708ca5')
43 version('1.11.11', sha256='74329da3be1b25de8e98a712adb28b14e561889244bf3a8138afe91ab18e0b3a')
44 version('1.11.10', sha256='0a2530b739d9ebf60c4c1e86adb5451a20d9e78f7798cf78d0147cc6df328aac')
45 version('1.11.9', sha256='85b978995b67db0b1a12dd1a73b09ef3d39f8e3cb09f8b9c60cf04633acce46c')
46 version('1.11.8', sha256='8af89b1164a330e36d18210360ea9bb305e19f9773d1c882855d261a13054ea8')
47 version('1.11.7', sha256='ac16bed9cdd3c63bca1fe1ac3de522a1376b1487c4fc85b7b19592e28fd98e26')
48 version('1.11.6', sha256='67963f15197e6b551539c4ed95a4f8882be9a16cf336300902004361cf89bdee')
49 version('1.11.5', sha256='da2c780fce9b5440a1a7d1caf78f637feff9181a9d1ca090278cae4bea71b3df')
50 version('1.11.4', sha256='1b6a58049c31ce36aff162cf4332998fd468486bd08fdfe0249a47437311512d')
51 version('1.11.3', sha256='03a1cc63f23fed7e17e4d4369a75dc77d5c145111b8578b70e0964a12712dea0')
52 version('1.11.2', sha256='d11f091ed54c56c325ffca1083113a405fcd8a25d5888af64f5cd6cf587b7b0a')
53 version('1.11.1', sha256='b41f877d79b6026640943d57ef25311299378450f2995d507a5e633da711be61')
54 version('1.9', sha256='9fb572daef35a1c8608d1a6232a4a9f56846bab2854c50562dfb9a7be294f4e8')
55
56 variant('nvml', default=False, description="Support NVML device discovery")
57 variant('gl', default=False, description="Support GL device discovery")
58 variant('cuda', default=False, description="Support CUDA devices")
59 variant('libxml2', default=True, description="Build with libxml2")
60 variant('libudev', default=False, description="Build with libudev")
61 variant('pci', default=(sys.platform != 'darwin'),
62 description="Support analyzing devices on PCI bus")
63 variant('shared', default=True, description="Build shared libraries")
64 variant(
65 'cairo',
66 default=False,
67 description='Enable the Cairo back-end of hwloc\'s lstopo command'
68 )
69 variant(
70 'netloc',
71 default=False,
72 description="Enable netloc [requires MPI]"
73 )
74
75 # netloc isn't available until version 2.0.0
76 conflicts('+netloc', when="@:1.99.99")
77
78 # libudev isn't available until version 1.11.0
79 conflicts('+libudev', when="@:1.10")
80
81 depends_on('pkgconfig', type='build')
82 depends_on('m4', type='build', when='@master')
83 depends_on('autoconf', type='build', when='@master')
84 depends_on('automake', type='build', when='@master')
85 depends_on('libtool', type='build', when='@master')
86 depends_on('cuda', when='+nvml')
87 depends_on('cuda', when='+cuda')
88 depends_on('gl', when='+gl')
89 depends_on('libpciaccess', when='+pci')
90 depends_on('libxml2', when='+libxml2')
91 depends_on('cairo', when='+cairo')
92 depends_on('numactl', when='@:1.11.11 platform=linux')
93
94 # When mpi=openmpi, this introduces an unresolvable dependency.
95 # See https://github.com/spack/spack/issues/15836 for details
96 depends_on('mpi', when='+netloc')
97
98 def url_for_version(self, version):
99 return "http://www.open-mpi.org/software/hwloc/v%s/downloads/hwloc-%s.tar.gz" % (version.up_to(2), version)
100
101 def configure_args(self):
102 args = [
103 # Disable OpenCL, since hwloc might pick up an OpenCL
104 # library at build time that is then not found at run time
105 # (Alternatively, we could require OpenCL as dependency.)
106 "--disable-opencl",
107 ]
108 if '+netloc' in self.spec:
109 args.append('--enable-netloc')
110
111 args.extend(self.enable_or_disable('cairo'))
112 args.extend(self.enable_or_disable('nvml'))
113 args.extend(self.enable_or_disable('gl'))
114 args.extend(self.enable_or_disable('cuda'))
115 args.extend(self.enable_or_disable('libxml2'))
116 args.extend(self.enable_or_disable('libudev'))
117 args.extend(self.enable_or_disable('pci'))
118 args.extend(self.enable_or_disable('shared'))
119
120 return args
121
[end of var/spack/repos/builtin/packages/hwloc/package.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/var/spack/repos/builtin/packages/hwloc/package.py b/var/spack/repos/builtin/packages/hwloc/package.py
--- a/var/spack/repos/builtin/packages/hwloc/package.py
+++ b/var/spack/repos/builtin/packages/hwloc/package.py
@@ -91,6 +91,10 @@
depends_on('cairo', when='+cairo')
depends_on('numactl', when='@:1.11.11 platform=linux')
+ # see https://github.com/open-mpi/hwloc/pull/417
+ depends_on('ncurses ~termlib', when='@:2.2')
+ depends_on('ncurses')
+
# When mpi=openmpi, this introduces an unresolvable dependency.
# See https://github.com/spack/spack/issues/15836 for details
depends_on('mpi', when='+netloc')
|
{"golden_diff": "diff --git a/var/spack/repos/builtin/packages/hwloc/package.py b/var/spack/repos/builtin/packages/hwloc/package.py\n--- a/var/spack/repos/builtin/packages/hwloc/package.py\n+++ b/var/spack/repos/builtin/packages/hwloc/package.py\n@@ -91,6 +91,10 @@\n depends_on('cairo', when='+cairo')\n depends_on('numactl', when='@:1.11.11 platform=linux')\n \n+ # see https://github.com/open-mpi/hwloc/pull/417\n+ depends_on('ncurses ~termlib', when='@:2.2')\n+ depends_on('ncurses')\n+\n # When mpi=openmpi, this introduces an unresolvable dependency.\n # See https://github.com/spack/spack/issues/15836 for details\n depends_on('mpi', when='+netloc')\n", "issue": "hwloc: added missing ncurses dependency\n\n", "before_files": [{"content": "# Copyright 2013-2021 Lawrence Livermore National Security, LLC and other\n# Spack Project Developers. See the top-level COPYRIGHT file for details.\n#\n# SPDX-License-Identifier: (Apache-2.0 OR MIT)\nimport sys\n\n\nclass Hwloc(AutotoolsPackage):\n \"\"\"The Hardware Locality (hwloc) software project.\n\n The Portable Hardware Locality (hwloc) software package\n provides a portable abstraction (across OS, versions,\n architectures, ...) of the hierarchical topology of modern\n architectures, including NUMA memory nodes, sockets, shared\n caches, cores and simultaneous multithreading. It also gathers\n various system attributes such as cache and memory information\n as well as the locality of I/O devices such as network\n interfaces, InfiniBand HCAs or GPUs. It primarily aims at\n helping applications with gathering information about modern\n computing hardware so as to exploit it accordingly and\n efficiently.\n \"\"\"\n\n homepage = \"http://www.open-mpi.org/projects/hwloc/\"\n url = \"https://download.open-mpi.org/release/hwloc/v2.0/hwloc-2.0.2.tar.gz\"\n list_url = \"http://www.open-mpi.org/software/hwloc/\"\n list_depth = 2\n git = 'https://github.com/open-mpi/hwloc.git'\n\n maintainers = ['bgoglin']\n\n version('master', branch='master')\n version('2.4.1', sha256='4267fe1193a8989f3ab7563a7499e047e77e33fed8f4dec16822a7aebcf78459')\n version('2.4.0', sha256='30404065dc1d6872b0181269d0bb2424fbbc6e3b0a80491aa373109554006544')\n version('2.3.0', sha256='155480620c98b43ddf9ca66a6c318b363ca24acb5ff0683af9d25d9324f59836')\n version('2.2.0', sha256='2defba03ddd91761b858cbbdc2e3a6e27b44e94696dbfa21380191328485a433')\n version('2.1.0', sha256='1fb8cc1438de548e16ec3bb9e4b2abb9f7ce5656f71c0906583819fcfa8c2031')\n version('2.0.2', sha256='27dcfe42e3fb3422b72ce48b48bf601c0a3e46e850ee72d9bdd17b5863b6e42c')\n version('2.0.1', sha256='f1156df22fc2365a31a3dc5f752c53aad49e34a5e22d75ed231cd97eaa437f9d')\n version('2.0.0', sha256='a0d425a0fc7c7e3f2c92a272ffaffbd913005556b4443e1887d2e1718d902887')\n version('1.11.13', sha256='a8f781ae4d347708a07d95e7549039887f151ed7f92263238527dfb0a3709b9d')\n version('1.11.12', sha256='f1d49433e605dd653a77e1478a78cee095787d554a94afe40d1376bca6708ca5')\n version('1.11.11', sha256='74329da3be1b25de8e98a712adb28b14e561889244bf3a8138afe91ab18e0b3a')\n version('1.11.10', sha256='0a2530b739d9ebf60c4c1e86adb5451a20d9e78f7798cf78d0147cc6df328aac')\n version('1.11.9', sha256='85b978995b67db0b1a12dd1a73b09ef3d39f8e3cb09f8b9c60cf04633acce46c')\n version('1.11.8', sha256='8af89b1164a330e36d18210360ea9bb305e19f9773d1c882855d261a13054ea8')\n version('1.11.7', sha256='ac16bed9cdd3c63bca1fe1ac3de522a1376b1487c4fc85b7b19592e28fd98e26')\n version('1.11.6', sha256='67963f15197e6b551539c4ed95a4f8882be9a16cf336300902004361cf89bdee')\n version('1.11.5', sha256='da2c780fce9b5440a1a7d1caf78f637feff9181a9d1ca090278cae4bea71b3df')\n version('1.11.4', sha256='1b6a58049c31ce36aff162cf4332998fd468486bd08fdfe0249a47437311512d')\n version('1.11.3', sha256='03a1cc63f23fed7e17e4d4369a75dc77d5c145111b8578b70e0964a12712dea0')\n version('1.11.2', sha256='d11f091ed54c56c325ffca1083113a405fcd8a25d5888af64f5cd6cf587b7b0a')\n version('1.11.1', sha256='b41f877d79b6026640943d57ef25311299378450f2995d507a5e633da711be61')\n version('1.9', sha256='9fb572daef35a1c8608d1a6232a4a9f56846bab2854c50562dfb9a7be294f4e8')\n\n variant('nvml', default=False, description=\"Support NVML device discovery\")\n variant('gl', default=False, description=\"Support GL device discovery\")\n variant('cuda', default=False, description=\"Support CUDA devices\")\n variant('libxml2', default=True, description=\"Build with libxml2\")\n variant('libudev', default=False, description=\"Build with libudev\")\n variant('pci', default=(sys.platform != 'darwin'),\n description=\"Support analyzing devices on PCI bus\")\n variant('shared', default=True, description=\"Build shared libraries\")\n variant(\n 'cairo',\n default=False,\n description='Enable the Cairo back-end of hwloc\\'s lstopo command'\n )\n variant(\n 'netloc',\n default=False,\n description=\"Enable netloc [requires MPI]\"\n )\n\n # netloc isn't available until version 2.0.0\n conflicts('+netloc', when=\"@:1.99.99\")\n\n # libudev isn't available until version 1.11.0\n conflicts('+libudev', when=\"@:1.10\")\n\n depends_on('pkgconfig', type='build')\n depends_on('m4', type='build', when='@master')\n depends_on('autoconf', type='build', when='@master')\n depends_on('automake', type='build', when='@master')\n depends_on('libtool', type='build', when='@master')\n depends_on('cuda', when='+nvml')\n depends_on('cuda', when='+cuda')\n depends_on('gl', when='+gl')\n depends_on('libpciaccess', when='+pci')\n depends_on('libxml2', when='+libxml2')\n depends_on('cairo', when='+cairo')\n depends_on('numactl', when='@:1.11.11 platform=linux')\n\n # When mpi=openmpi, this introduces an unresolvable dependency.\n # See https://github.com/spack/spack/issues/15836 for details\n depends_on('mpi', when='+netloc')\n\n def url_for_version(self, version):\n return \"http://www.open-mpi.org/software/hwloc/v%s/downloads/hwloc-%s.tar.gz\" % (version.up_to(2), version)\n\n def configure_args(self):\n args = [\n # Disable OpenCL, since hwloc might pick up an OpenCL\n # library at build time that is then not found at run time\n # (Alternatively, we could require OpenCL as dependency.)\n \"--disable-opencl\",\n ]\n if '+netloc' in self.spec:\n args.append('--enable-netloc')\n\n args.extend(self.enable_or_disable('cairo'))\n args.extend(self.enable_or_disable('nvml'))\n args.extend(self.enable_or_disable('gl'))\n args.extend(self.enable_or_disable('cuda'))\n args.extend(self.enable_or_disable('libxml2'))\n args.extend(self.enable_or_disable('libudev'))\n args.extend(self.enable_or_disable('pci'))\n args.extend(self.enable_or_disable('shared'))\n\n return args\n", "path": "var/spack/repos/builtin/packages/hwloc/package.py"}]}
| 3,402 | 204 |
gh_patches_debug_14253
|
rasdani/github-patches
|
git_diff
|
oppia__oppia-7996
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Exploration Cards Show "Invalid date" as date
**Describe the bug**
In the library, exploration cards have `Invalid date` in the lower right-hand corner.
**To Reproduce**
Steps to reproduce the behavior:
1. Go to https://oppiatestserver.appspot.com/library
**Observed behavior**
The exploration cards show `Invalid date`
**Expected behavior**
The cards should show the creation date.
**Screenshots**

**Desktop (please complete the following information; delete this section if the issue does not arise on desktop):**
- OS: macOS
- Browser: Firefox
- Version: 2.8.7
Publish change button has overflowing text
**Describe the bug**
Publish change text while publishing a collection moves out of the button box.
**To Reproduce**
Steps to reproduce the behavior:
1. Create a collection and check the publish button. The text moves out of the button box.
**Screenshots**
<img width="1440" alt="Screenshot 2019-11-14 at 12 35 14 AM" src="https://user-images.githubusercontent.com/15226041/68795290-a9a08b80-0676-11ea-8b46-57b6b68c3077.png">
**Desktop (please complete the following information; delete this section if the issue does not arise on desktop):**
- OS: Mac
- Browser: Chrome
</issue>
<code>
[start of scripts/typescript_checks.py]
1 # Copyright 2019 The Oppia Authors. All Rights Reserved.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS-IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 """File for compiling and checking typescript."""
16 from __future__ import absolute_import # pylint: disable=import-only-modules
17 from __future__ import unicode_literals # pylint: disable=import-only-modules
18
19 import json
20 import os
21 import shutil
22 import subprocess
23 import sys
24
25 import python_utils
26
27 COMPILED_JS_DIR = os.path.join('local_compiled_js_for_test', '')
28 TSCONFIG_FILEPATH = 'tsconfig-for-compile-check.json'
29
30
31 def validate_compiled_js_dir():
32 """Validates that compiled js dir matches out dir in tsconfig."""
33 with python_utils.open_file(TSCONFIG_FILEPATH, 'r') as f:
34 config_data = json.load(f)
35 out_dir = os.path.join(config_data['compilerOptions']['outDir'], '')
36 if out_dir != COMPILED_JS_DIR:
37 raise Exception(
38 'COMPILED_JS_DIR: %s does not match the output directory '
39 'in %s: %s' % (COMPILED_JS_DIR, TSCONFIG_FILEPATH, out_dir))
40
41
42 def compile_and_check_typescript():
43 """Compiles typescript files and checks the compilation errors."""
44 node_path = os.path.join(os.pardir, 'oppia_tools/node-10.15.3')
45 os.environ['PATH'] = '%s/bin:' % node_path + os.environ['PATH']
46
47 validate_compiled_js_dir()
48
49 if os.path.exists(COMPILED_JS_DIR):
50 shutil.rmtree(COMPILED_JS_DIR)
51
52 python_utils.PRINT('Compiling and testing typescript...')
53 cmd = [
54 './node_modules/typescript/bin/tsc', '--project',
55 TSCONFIG_FILEPATH]
56 process = subprocess.Popen(cmd, stdout=subprocess.PIPE)
57 if os.path.exists(COMPILED_JS_DIR):
58 shutil.rmtree(COMPILED_JS_DIR)
59 error_messages = []
60 for line in iter(process.stdout.readline, ''):
61 error_messages.append(line)
62 if error_messages:
63 python_utils.PRINT('Errors found during compilation\n')
64 for message in error_messages:
65 python_utils.PRINT(message)
66 sys.exit(1)
67 else:
68 python_utils.PRINT('Compilation successful!')
69
70
71 # The 'no coverage' pragma is used as this line is un-testable. This is because
72 # it will only be called when typescript_checks.py is used as a script.
73 if __name__ == '__main__': # pragma: no cover
74 compile_and_check_typescript()
75
[end of scripts/typescript_checks.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/scripts/typescript_checks.py b/scripts/typescript_checks.py
--- a/scripts/typescript_checks.py
+++ b/scripts/typescript_checks.py
@@ -54,11 +54,11 @@
'./node_modules/typescript/bin/tsc', '--project',
TSCONFIG_FILEPATH]
process = subprocess.Popen(cmd, stdout=subprocess.PIPE)
- if os.path.exists(COMPILED_JS_DIR):
- shutil.rmtree(COMPILED_JS_DIR)
error_messages = []
for line in iter(process.stdout.readline, ''):
error_messages.append(line)
+ if os.path.exists(COMPILED_JS_DIR):
+ shutil.rmtree(COMPILED_JS_DIR)
if error_messages:
python_utils.PRINT('Errors found during compilation\n')
for message in error_messages:
|
{"golden_diff": "diff --git a/scripts/typescript_checks.py b/scripts/typescript_checks.py\n--- a/scripts/typescript_checks.py\n+++ b/scripts/typescript_checks.py\n@@ -54,11 +54,11 @@\n './node_modules/typescript/bin/tsc', '--project',\n TSCONFIG_FILEPATH]\n process = subprocess.Popen(cmd, stdout=subprocess.PIPE)\n- if os.path.exists(COMPILED_JS_DIR):\n- shutil.rmtree(COMPILED_JS_DIR)\n error_messages = []\n for line in iter(process.stdout.readline, ''):\n error_messages.append(line)\n+ if os.path.exists(COMPILED_JS_DIR):\n+ shutil.rmtree(COMPILED_JS_DIR)\n if error_messages:\n python_utils.PRINT('Errors found during compilation\\n')\n for message in error_messages:\n", "issue": "Exploration Cards Show \"Invalid date\" as date\n**Describe the bug**\r\nIn the library, exploration cards have `Invalid date` in the lower right-hand corner.\r\n\r\n**To Reproduce**\r\nSteps to reproduce the behavior:\r\n 1. Go to https://oppiatestserver.appspot.com/library\r\n\r\n**Observed behavior**\r\nThe exploration cards show `Invalid date`\r\n\r\n**Expected behavior**\r\nThe cards should show the creation date.\r\n\r\n**Screenshots**\r\n\r\n\r\n\r\n**Desktop (please complete the following information; delete this section if the issue does not arise on desktop):**\r\n - OS: macOS\r\n - Browser: Firefox\r\n - Version: 2.8.7\nPublish change button has overflowing text\n**Describe the bug**\r\nPublish change text while publishing a collection moves out of the button box.\r\n\r\n**To Reproduce**\r\nSteps to reproduce the behavior:\r\n 1. Create a collection and check the publish button. The text moves out of the button box.\r\n\r\n**Screenshots**\r\n<img width=\"1440\" alt=\"Screenshot 2019-11-14 at 12 35 14 AM\" src=\"https://user-images.githubusercontent.com/15226041/68795290-a9a08b80-0676-11ea-8b46-57b6b68c3077.png\">\r\n\r\n\r\n**Desktop (please complete the following information; delete this section if the issue does not arise on desktop):**\r\n - OS: Mac\r\n - Browser: Chrome\r\n\r\n\n", "before_files": [{"content": "# Copyright 2019 The Oppia Authors. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS-IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"File for compiling and checking typescript.\"\"\"\nfrom __future__ import absolute_import # pylint: disable=import-only-modules\nfrom __future__ import unicode_literals # pylint: disable=import-only-modules\n\nimport json\nimport os\nimport shutil\nimport subprocess\nimport sys\n\nimport python_utils\n\nCOMPILED_JS_DIR = os.path.join('local_compiled_js_for_test', '')\nTSCONFIG_FILEPATH = 'tsconfig-for-compile-check.json'\n\n\ndef validate_compiled_js_dir():\n \"\"\"Validates that compiled js dir matches out dir in tsconfig.\"\"\"\n with python_utils.open_file(TSCONFIG_FILEPATH, 'r') as f:\n config_data = json.load(f)\n out_dir = os.path.join(config_data['compilerOptions']['outDir'], '')\n if out_dir != COMPILED_JS_DIR:\n raise Exception(\n 'COMPILED_JS_DIR: %s does not match the output directory '\n 'in %s: %s' % (COMPILED_JS_DIR, TSCONFIG_FILEPATH, out_dir))\n\n\ndef compile_and_check_typescript():\n \"\"\"Compiles typescript files and checks the compilation errors.\"\"\"\n node_path = os.path.join(os.pardir, 'oppia_tools/node-10.15.3')\n os.environ['PATH'] = '%s/bin:' % node_path + os.environ['PATH']\n\n validate_compiled_js_dir()\n\n if os.path.exists(COMPILED_JS_DIR):\n shutil.rmtree(COMPILED_JS_DIR)\n\n python_utils.PRINT('Compiling and testing typescript...')\n cmd = [\n './node_modules/typescript/bin/tsc', '--project',\n TSCONFIG_FILEPATH]\n process = subprocess.Popen(cmd, stdout=subprocess.PIPE)\n if os.path.exists(COMPILED_JS_DIR):\n shutil.rmtree(COMPILED_JS_DIR)\n error_messages = []\n for line in iter(process.stdout.readline, ''):\n error_messages.append(line)\n if error_messages:\n python_utils.PRINT('Errors found during compilation\\n')\n for message in error_messages:\n python_utils.PRINT(message)\n sys.exit(1)\n else:\n python_utils.PRINT('Compilation successful!')\n\n\n# The 'no coverage' pragma is used as this line is un-testable. This is because\n# it will only be called when typescript_checks.py is used as a script.\nif __name__ == '__main__': # pragma: no cover\n compile_and_check_typescript()\n", "path": "scripts/typescript_checks.py"}]}
| 1,751 | 168 |
gh_patches_debug_6136
|
rasdani/github-patches
|
git_diff
|
joke2k__faker-466
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Error in running faker tests
Hi,
I use ```Python 3.5.2```.
I downloaded v0.7.3 archive from GH.
When I ran ``` python3 setup.py test```, I get a Fail; when I run ```python3 -m unittest -v faker.tests```, I get 'OK'
Did I do something the wrong way, since ipaddress is required for python 2.x or python 3.2?
Here's the full output
```
python3 setup.py test
running test
running egg_info
creating Faker.egg-info
writing top-level names to Faker.egg-info/top_level.txt
writing entry points to Faker.egg-info/entry_points.txt
writing requirements to Faker.egg-info/requires.txt
writing Faker.egg-info/PKG-INFO
writing dependency_links to Faker.egg-info/dependency_links.txt
writing manifest file 'Faker.egg-info/SOURCES.txt'
reading manifest file 'Faker.egg-info/SOURCES.txt'
reading manifest template 'MANIFEST.in'
warning: no files found matching '*.md'
writing manifest file 'Faker.egg-info/SOURCES.txt'
running build_ext
Traceback (most recent call last):
File "setup.py", line 78, in <module>
'ipaddress',
File "/usr/lib/python3.5/distutils/core.py", line 148, in setup
dist.run_commands()
File "/usr/lib/python3.5/distutils/dist.py", line 955, in run_commands
self.run_command(cmd)
File "/usr/lib/python3.5/distutils/dist.py", line 974, in run_command
cmd_obj.run()
File "/usr/lib/python3.5/site-packages/setuptools/command/test.py", line 159, in run
self.with_project_on_sys_path(self.run_tests)
File "/usr/lib/python3.5/site-packages/setuptools/command/test.py", line 140, in with_project_on_sys_path
func()
File "/usr/lib/python3.5/site-packages/setuptools/command/test.py", line 180, in run_tests
testRunner=self._resolve_as_ep(self.test_runner),
File "/usr/lib/python3.5/unittest/main.py", line 93, in __init__
self.parseArgs(argv)
File "/usr/lib/python3.5/unittest/main.py", line 140, in parseArgs
self.createTests()
File "/usr/lib/python3.5/unittest/main.py", line 147, in createTests
self.module)
File "/usr/lib/python3.5/unittest/loader.py", line 219, in loadTestsFromNames
suites = [self.loadTestsFromName(name, module) for name in names]
File "/usr/lib/python3.5/unittest/loader.py", line 219, in <listcomp>
suites = [self.loadTestsFromName(name, module) for name in names]
File "/usr/lib/python3.5/unittest/loader.py", line 190, in loadTestsFromName
return self.loadTestsFromModule(obj)
File "/usr/lib/python3.5/site-packages/setuptools/command/test.py", line 30, in loadTestsFromModule
for file in resource_listdir(module.__name__, ''):
File "/usr/lib/python3.5/site-packages/pkg_resources/__init__.py", line 1170, in resource_listdir
resource_name
File "/usr/lib/python3.5/site-packages/pkg_resources/__init__.py", line 1466, in resource_listdir
return self._listdir(self._fn(self.module_path, resource_name))
File "/usr/lib/python3.5/site-packages/pkg_resources/__init__.py", line 1505, in _listdir
"Can't perform this operation for unregistered loader type"
NotImplementedError: Can't perform this operation for unregistered loader type
```
```
python3 -m unittest -v faker.tests
test_add_provider_gives_priority_to_newly_added_provider (faker.tests.FactoryTestCase) ... ok
test_binary (faker.tests.FactoryTestCase) ... ok
test_command (faker.tests.FactoryTestCase) ... ok
test_command_custom_provider (faker.tests.FactoryTestCase) ... ok
test_date_time_between_dates (faker.tests.FactoryTestCase) ... ok
test_date_time_between_dates_with_tzinfo (faker.tests.FactoryTestCase) ... ok
test_date_time_this_period (faker.tests.FactoryTestCase) ... ok
test_date_time_this_period_with_tzinfo (faker.tests.FactoryTestCase) ... ok
test_datetime_safe (faker.tests.FactoryTestCase) ... ok
test_datetimes_with_and_without_tzinfo (faker.tests.FactoryTestCase) ... ok
test_documentor (faker.tests.FactoryTestCase) ... /tmp/faker-0.7.3/faker/documentor.py:51: DeprecationWarning: inspect.getargspec() is deprecated, use inspect.signature() instead
argspec = inspect.getargspec(method)
ok
test_email (faker.tests.FactoryTestCase) ... ok
test_format_calls_formatter_on_provider (faker.tests.FactoryTestCase) ... ok
test_format_transfers_arguments_to_formatter (faker.tests.FactoryTestCase) ... ok
test_get_formatter_returns_callable (faker.tests.FactoryTestCase) ... ok
test_get_formatter_returns_correct_formatter (faker.tests.FactoryTestCase) ... ok
test_get_formatter_throws_exception_on_incorrect_formatter (faker.tests.FactoryTestCase) ... ok
test_ipv4 (faker.tests.FactoryTestCase) ... ok
test_ipv6 (faker.tests.FactoryTestCase) ... ok
test_language_code (faker.tests.FactoryTestCase) ... ok
test_magic_call_calls_format (faker.tests.FactoryTestCase) ... ok
test_magic_call_calls_format_with_arguments (faker.tests.FactoryTestCase) ... ok
test_no_words_paragraph (faker.tests.FactoryTestCase) ... ok
test_no_words_sentence (faker.tests.FactoryTestCase) ... ok
test_parse_returns_same_string_when_it_contains_no_curly_braces (faker.tests.FactoryTestCase) ... ok
test_parse_returns_string_with_tokens_replaced_by_formatters (faker.tests.FactoryTestCase) ... ok
test_password (faker.tests.FactoryTestCase) ... ok
test_prefix_suffix_always_string (faker.tests.FactoryTestCase) ... ok
test_random_element (faker.tests.FactoryTestCase) ... ok
test_random_pystr_characters (faker.tests.FactoryTestCase) ... ok
test_random_sample_unique (faker.tests.FactoryTestCase) ... ok
test_slugify (faker.tests.FactoryTestCase) ... ok
test_timezone_conversion (faker.tests.FactoryTestCase) ... ok
test_us_ssn_valid (faker.tests.FactoryTestCase) ... ok
test_get_random (faker.tests.GeneratorTestCase) ... ok
test_random_seed_doesnt_seed_system_random (faker.tests.GeneratorTestCase) ... ok
test_add_dicts (faker.tests.UtilsTestCase) ... ok
test_choice_distribution (faker.tests.UtilsTestCase) ... ok
test_find_available_locales (faker.tests.UtilsTestCase) ... ok
test_find_available_providers (faker.tests.UtilsTestCase) ... ok
----------------------------------------------------------------------
Ran 40 tests in 15.249s
OK
```
</issue>
<code>
[start of setup.py]
1 #!/usr/bin/env python
2 # coding=utf-8
3
4 import os
5 import io
6
7 from setuptools import setup, find_packages
8
9 here = os.path.abspath(os.path.dirname(__file__))
10 README = io.open(os.path.join(here, 'README.rst'), encoding="utf8").read()
11
12
13 version = '0.7.7'
14
15 # this module can be zip-safe if the zipimporter implements iter_modules or if
16 # pkgutil.iter_importer_modules has registered a dispatch for the zipimporter.
17 try:
18 import pkgutil
19 import zipimport
20 zip_safe = hasattr(zipimport.zipimporter, "iter_modules") or \
21 zipimport.zipimporter in pkgutil.iter_importer_modules.registry.keys()
22 except (ImportError, AttributeError):
23 zip_safe = False
24
25 setup(
26 name='Faker',
27 version=version,
28 description="Faker is a Python package that generates fake data for you.",
29 long_description=README,
30 entry_points={
31 'console_scripts': ['faker=faker.cli:execute_from_command_line'],
32 },
33 classifiers=[
34 # See https://pypi.python.org/pypi?%3Aaction=list_classifiers
35 'Development Status :: 3 - Alpha',
36 'Environment :: Console',
37 'Intended Audience :: Developers',
38 'Programming Language :: Python',
39 'Programming Language :: Python :: 2',
40 'Programming Language :: Python :: 2.7',
41 'Programming Language :: Python :: 3',
42 'Programming Language :: Python :: 3.4',
43 'Programming Language :: Python :: 3.5',
44 'Topic :: Software Development :: Libraries :: Python Modules',
45 'Topic :: Software Development :: Testing',
46 'Topic :: Utilities',
47 'License :: OSI Approved :: MIT License'
48 ],
49 keywords='faker fixtures data test mock generator',
50 author='joke2k',
51 author_email='[email protected]',
52 url='https://github.com/joke2k/faker',
53 license='MIT License',
54 packages=find_packages(exclude=("docs",)),
55 platforms=["any"],
56 test_suite='faker.tests',
57 zip_safe=zip_safe,
58 install_requires=[
59 "python-dateutil>=2.4",
60 "six",
61 ],
62 extras_require={
63 ':python_version=="2.7"': [
64 'ipaddress',
65 ],
66 ':python_version=="3.0"': [
67 'importlib',
68 ],
69 ':python_version=="3.2"': [
70 'ipaddress',
71 ],
72 }
73 )
74
[end of setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -51,9 +51,9 @@
author_email='[email protected]',
url='https://github.com/joke2k/faker',
license='MIT License',
- packages=find_packages(exclude=("docs",)),
+ packages=find_packages(exclude=("docs", "tests",)),
platforms=["any"],
- test_suite='faker.tests',
+ test_suite='tests',
zip_safe=zip_safe,
install_requires=[
"python-dateutil>=2.4",
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -51,9 +51,9 @@\n author_email='[email protected]',\n url='https://github.com/joke2k/faker',\n license='MIT License',\n- packages=find_packages(exclude=(\"docs\",)),\n+ packages=find_packages(exclude=(\"docs\", \"tests\",)),\n platforms=[\"any\"],\n- test_suite='faker.tests',\n+ test_suite='tests',\n zip_safe=zip_safe,\n install_requires=[\n \"python-dateutil>=2.4\",\n", "issue": "Error in running faker tests\nHi,\r\n\r\nI use ```Python 3.5.2```.\r\n\r\nI downloaded v0.7.3 archive from GH.\r\n\r\nWhen I ran ``` python3 setup.py test```, I get a Fail; when I run ```python3 -m unittest -v faker.tests```, I get 'OK'\r\n\r\nDid I do something the wrong way, since ipaddress is required for python 2.x or python 3.2?\r\n\r\nHere's the full output\r\n\r\n```\r\npython3 setup.py test\r\nrunning test\r\nrunning egg_info\r\ncreating Faker.egg-info\r\nwriting top-level names to Faker.egg-info/top_level.txt\r\nwriting entry points to Faker.egg-info/entry_points.txt\r\nwriting requirements to Faker.egg-info/requires.txt\r\nwriting Faker.egg-info/PKG-INFO\r\nwriting dependency_links to Faker.egg-info/dependency_links.txt\r\nwriting manifest file 'Faker.egg-info/SOURCES.txt'\r\nreading manifest file 'Faker.egg-info/SOURCES.txt'\r\nreading manifest template 'MANIFEST.in'\r\nwarning: no files found matching '*.md'\r\nwriting manifest file 'Faker.egg-info/SOURCES.txt'\r\nrunning build_ext\r\nTraceback (most recent call last):\r\n File \"setup.py\", line 78, in <module>\r\n 'ipaddress',\r\n File \"/usr/lib/python3.5/distutils/core.py\", line 148, in setup\r\n dist.run_commands()\r\n File \"/usr/lib/python3.5/distutils/dist.py\", line 955, in run_commands\r\n self.run_command(cmd)\r\n File \"/usr/lib/python3.5/distutils/dist.py\", line 974, in run_command\r\n cmd_obj.run()\r\n File \"/usr/lib/python3.5/site-packages/setuptools/command/test.py\", line 159, in run\r\n self.with_project_on_sys_path(self.run_tests)\r\n File \"/usr/lib/python3.5/site-packages/setuptools/command/test.py\", line 140, in with_project_on_sys_path\r\n func()\r\n File \"/usr/lib/python3.5/site-packages/setuptools/command/test.py\", line 180, in run_tests\r\n testRunner=self._resolve_as_ep(self.test_runner),\r\n File \"/usr/lib/python3.5/unittest/main.py\", line 93, in __init__\r\n self.parseArgs(argv)\r\n File \"/usr/lib/python3.5/unittest/main.py\", line 140, in parseArgs\r\n self.createTests()\r\n File \"/usr/lib/python3.5/unittest/main.py\", line 147, in createTests\r\n self.module)\r\n File \"/usr/lib/python3.5/unittest/loader.py\", line 219, in loadTestsFromNames\r\n suites = [self.loadTestsFromName(name, module) for name in names]\r\n File \"/usr/lib/python3.5/unittest/loader.py\", line 219, in <listcomp>\r\n suites = [self.loadTestsFromName(name, module) for name in names]\r\n File \"/usr/lib/python3.5/unittest/loader.py\", line 190, in loadTestsFromName\r\n return self.loadTestsFromModule(obj)\r\n File \"/usr/lib/python3.5/site-packages/setuptools/command/test.py\", line 30, in loadTestsFromModule\r\n for file in resource_listdir(module.__name__, ''):\r\n File \"/usr/lib/python3.5/site-packages/pkg_resources/__init__.py\", line 1170, in resource_listdir\r\n resource_name\r\n File \"/usr/lib/python3.5/site-packages/pkg_resources/__init__.py\", line 1466, in resource_listdir\r\n return self._listdir(self._fn(self.module_path, resource_name))\r\n File \"/usr/lib/python3.5/site-packages/pkg_resources/__init__.py\", line 1505, in _listdir\r\n \"Can't perform this operation for unregistered loader type\"\r\nNotImplementedError: Can't perform this operation for unregistered loader type\r\n\r\n```\r\n\r\n```\r\npython3 -m unittest -v faker.tests\r\ntest_add_provider_gives_priority_to_newly_added_provider (faker.tests.FactoryTestCase) ... ok\r\ntest_binary (faker.tests.FactoryTestCase) ... ok\r\ntest_command (faker.tests.FactoryTestCase) ... ok\r\ntest_command_custom_provider (faker.tests.FactoryTestCase) ... ok\r\ntest_date_time_between_dates (faker.tests.FactoryTestCase) ... ok\r\ntest_date_time_between_dates_with_tzinfo (faker.tests.FactoryTestCase) ... ok\r\ntest_date_time_this_period (faker.tests.FactoryTestCase) ... ok\r\ntest_date_time_this_period_with_tzinfo (faker.tests.FactoryTestCase) ... ok\r\ntest_datetime_safe (faker.tests.FactoryTestCase) ... ok\r\ntest_datetimes_with_and_without_tzinfo (faker.tests.FactoryTestCase) ... ok\r\ntest_documentor (faker.tests.FactoryTestCase) ... /tmp/faker-0.7.3/faker/documentor.py:51: DeprecationWarning: inspect.getargspec() is deprecated, use inspect.signature() instead\r\n argspec = inspect.getargspec(method)\r\nok\r\ntest_email (faker.tests.FactoryTestCase) ... ok\r\ntest_format_calls_formatter_on_provider (faker.tests.FactoryTestCase) ... ok\r\ntest_format_transfers_arguments_to_formatter (faker.tests.FactoryTestCase) ... ok\r\ntest_get_formatter_returns_callable (faker.tests.FactoryTestCase) ... ok\r\ntest_get_formatter_returns_correct_formatter (faker.tests.FactoryTestCase) ... ok\r\ntest_get_formatter_throws_exception_on_incorrect_formatter (faker.tests.FactoryTestCase) ... ok\r\ntest_ipv4 (faker.tests.FactoryTestCase) ... ok\r\ntest_ipv6 (faker.tests.FactoryTestCase) ... ok\r\ntest_language_code (faker.tests.FactoryTestCase) ... ok\r\ntest_magic_call_calls_format (faker.tests.FactoryTestCase) ... ok\r\ntest_magic_call_calls_format_with_arguments (faker.tests.FactoryTestCase) ... ok\r\ntest_no_words_paragraph (faker.tests.FactoryTestCase) ... ok\r\ntest_no_words_sentence (faker.tests.FactoryTestCase) ... ok\r\ntest_parse_returns_same_string_when_it_contains_no_curly_braces (faker.tests.FactoryTestCase) ... ok\r\ntest_parse_returns_string_with_tokens_replaced_by_formatters (faker.tests.FactoryTestCase) ... ok\r\ntest_password (faker.tests.FactoryTestCase) ... ok\r\ntest_prefix_suffix_always_string (faker.tests.FactoryTestCase) ... ok\r\ntest_random_element (faker.tests.FactoryTestCase) ... ok\r\ntest_random_pystr_characters (faker.tests.FactoryTestCase) ... ok\r\ntest_random_sample_unique (faker.tests.FactoryTestCase) ... ok\r\ntest_slugify (faker.tests.FactoryTestCase) ... ok\r\ntest_timezone_conversion (faker.tests.FactoryTestCase) ... ok\r\ntest_us_ssn_valid (faker.tests.FactoryTestCase) ... ok\r\ntest_get_random (faker.tests.GeneratorTestCase) ... ok\r\ntest_random_seed_doesnt_seed_system_random (faker.tests.GeneratorTestCase) ... ok\r\ntest_add_dicts (faker.tests.UtilsTestCase) ... ok\r\ntest_choice_distribution (faker.tests.UtilsTestCase) ... ok\r\ntest_find_available_locales (faker.tests.UtilsTestCase) ... ok\r\ntest_find_available_providers (faker.tests.UtilsTestCase) ... ok\r\n\r\n----------------------------------------------------------------------\r\nRan 40 tests in 15.249s\r\n\r\nOK\r\n\r\n```\n", "before_files": [{"content": "#!/usr/bin/env python\n# coding=utf-8\n\nimport os\nimport io\n\nfrom setuptools import setup, find_packages\n\nhere = os.path.abspath(os.path.dirname(__file__))\nREADME = io.open(os.path.join(here, 'README.rst'), encoding=\"utf8\").read()\n\n\nversion = '0.7.7'\n\n# this module can be zip-safe if the zipimporter implements iter_modules or if\n# pkgutil.iter_importer_modules has registered a dispatch for the zipimporter.\ntry:\n import pkgutil\n import zipimport\n zip_safe = hasattr(zipimport.zipimporter, \"iter_modules\") or \\\n zipimport.zipimporter in pkgutil.iter_importer_modules.registry.keys()\nexcept (ImportError, AttributeError):\n zip_safe = False\n\nsetup(\n name='Faker',\n version=version,\n description=\"Faker is a Python package that generates fake data for you.\",\n long_description=README,\n entry_points={\n 'console_scripts': ['faker=faker.cli:execute_from_command_line'],\n },\n classifiers=[\n # See https://pypi.python.org/pypi?%3Aaction=list_classifiers\n 'Development Status :: 3 - Alpha',\n 'Environment :: Console',\n 'Intended Audience :: Developers',\n 'Programming Language :: Python',\n 'Programming Language :: Python :: 2',\n 'Programming Language :: Python :: 2.7',\n 'Programming Language :: Python :: 3',\n 'Programming Language :: Python :: 3.4',\n 'Programming Language :: Python :: 3.5',\n 'Topic :: Software Development :: Libraries :: Python Modules',\n 'Topic :: Software Development :: Testing',\n 'Topic :: Utilities',\n 'License :: OSI Approved :: MIT License'\n ],\n keywords='faker fixtures data test mock generator',\n author='joke2k',\n author_email='[email protected]',\n url='https://github.com/joke2k/faker',\n license='MIT License',\n packages=find_packages(exclude=(\"docs\",)),\n platforms=[\"any\"],\n test_suite='faker.tests',\n zip_safe=zip_safe,\n install_requires=[\n \"python-dateutil>=2.4\",\n \"six\",\n ],\n extras_require={\n ':python_version==\"2.7\"': [\n 'ipaddress',\n ],\n ':python_version==\"3.0\"': [\n 'importlib',\n ],\n ':python_version==\"3.2\"': [\n 'ipaddress',\n ],\n }\n)\n", "path": "setup.py"}]}
| 2,709 | 129 |
gh_patches_debug_33380
|
rasdani/github-patches
|
git_diff
|
apache__airflow-26343
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
API Endpoints - /xcomEntries/{xcom_key} cannot deserialize customized xcom backend
### Description
We use S3 as our xcom backend database and write serialize/deserialize method for xcoms.
However, when we want to access xcom through REST API, it returns the s3 file url instead of the deserialized value. Could you please add the feature to support customized xcom backend for REST API access?
### Use case/motivation
_No response_
### Related issues
_No response_
### Are you willing to submit a PR?
- [ ] Yes I am willing to submit a PR!
### Code of Conduct
- [X] I agree to follow this project's [Code of Conduct](https://github.com/apache/airflow/blob/main/CODE_OF_CONDUCT.md)
</issue>
<code>
[start of airflow/api_connexion/endpoints/xcom_endpoint.py]
1 # Licensed to the Apache Software Foundation (ASF) under one
2 # or more contributor license agreements. See the NOTICE file
3 # distributed with this work for additional information
4 # regarding copyright ownership. The ASF licenses this file
5 # to you under the Apache License, Version 2.0 (the
6 # "License"); you may not use this file except in compliance
7 # with the License. You may obtain a copy of the License at
8 #
9 # http://www.apache.org/licenses/LICENSE-2.0
10 #
11 # Unless required by applicable law or agreed to in writing,
12 # software distributed under the License is distributed on an
13 # "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
14 # KIND, either express or implied. See the License for the
15 # specific language governing permissions and limitations
16 # under the License.
17 from typing import Optional
18
19 from flask import g
20 from sqlalchemy import and_
21 from sqlalchemy.orm import Session
22
23 from airflow.api_connexion import security
24 from airflow.api_connexion.exceptions import NotFound
25 from airflow.api_connexion.parameters import check_limit, format_parameters
26 from airflow.api_connexion.schemas.xcom_schema import XComCollection, xcom_collection_schema, xcom_schema
27 from airflow.api_connexion.types import APIResponse
28 from airflow.models import DagRun as DR, XCom
29 from airflow.security import permissions
30 from airflow.utils.airflow_flask_app import get_airflow_app
31 from airflow.utils.session import NEW_SESSION, provide_session
32
33
34 @security.requires_access(
35 [
36 (permissions.ACTION_CAN_READ, permissions.RESOURCE_DAG),
37 (permissions.ACTION_CAN_READ, permissions.RESOURCE_DAG_RUN),
38 (permissions.ACTION_CAN_READ, permissions.RESOURCE_TASK_INSTANCE),
39 (permissions.ACTION_CAN_READ, permissions.RESOURCE_XCOM),
40 ],
41 )
42 @format_parameters({"limit": check_limit})
43 @provide_session
44 def get_xcom_entries(
45 *,
46 dag_id: str,
47 dag_run_id: str,
48 task_id: str,
49 limit: Optional[int],
50 offset: Optional[int] = None,
51 session: Session = NEW_SESSION,
52 ) -> APIResponse:
53 """Get all XCom values"""
54 query = session.query(XCom)
55 if dag_id == '~':
56 appbuilder = get_airflow_app().appbuilder
57 readable_dag_ids = appbuilder.sm.get_readable_dag_ids(g.user)
58 query = query.filter(XCom.dag_id.in_(readable_dag_ids))
59 query = query.join(DR, and_(XCom.dag_id == DR.dag_id, XCom.run_id == DR.run_id))
60 else:
61 query = query.filter(XCom.dag_id == dag_id)
62 query = query.join(DR, and_(XCom.dag_id == DR.dag_id, XCom.run_id == DR.run_id))
63
64 if task_id != '~':
65 query = query.filter(XCom.task_id == task_id)
66 if dag_run_id != '~':
67 query = query.filter(DR.run_id == dag_run_id)
68 query = query.order_by(DR.execution_date, XCom.task_id, XCom.dag_id, XCom.key)
69 total_entries = query.count()
70 query = query.offset(offset).limit(limit)
71 return xcom_collection_schema.dump(XComCollection(xcom_entries=query.all(), total_entries=total_entries))
72
73
74 @security.requires_access(
75 [
76 (permissions.ACTION_CAN_READ, permissions.RESOURCE_DAG),
77 (permissions.ACTION_CAN_READ, permissions.RESOURCE_DAG_RUN),
78 (permissions.ACTION_CAN_READ, permissions.RESOURCE_TASK_INSTANCE),
79 (permissions.ACTION_CAN_READ, permissions.RESOURCE_XCOM),
80 ],
81 )
82 @provide_session
83 def get_xcom_entry(
84 *,
85 dag_id: str,
86 task_id: str,
87 dag_run_id: str,
88 xcom_key: str,
89 session: Session = NEW_SESSION,
90 ) -> APIResponse:
91 """Get an XCom entry"""
92 query = session.query(XCom).filter(XCom.dag_id == dag_id, XCom.task_id == task_id, XCom.key == xcom_key)
93 query = query.join(DR, and_(XCom.dag_id == DR.dag_id, XCom.run_id == DR.run_id))
94 query = query.filter(DR.run_id == dag_run_id)
95
96 query_object = query.one_or_none()
97 if not query_object:
98 raise NotFound("XCom entry not found")
99 return xcom_schema.dump(query_object)
100
[end of airflow/api_connexion/endpoints/xcom_endpoint.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/airflow/api_connexion/endpoints/xcom_endpoint.py b/airflow/api_connexion/endpoints/xcom_endpoint.py
--- a/airflow/api_connexion/endpoints/xcom_endpoint.py
+++ b/airflow/api_connexion/endpoints/xcom_endpoint.py
@@ -14,6 +14,7 @@
# KIND, either express or implied. See the License for the
# specific language governing permissions and limitations
# under the License.
+import copy
from typing import Optional
from flask import g
@@ -68,7 +69,7 @@
query = query.order_by(DR.execution_date, XCom.task_id, XCom.dag_id, XCom.key)
total_entries = query.count()
query = query.offset(offset).limit(limit)
- return xcom_collection_schema.dump(XComCollection(xcom_entries=query.all(), total_entries=total_entries))
+ return xcom_collection_schema.dump(XComCollection(xcom_entries=query, total_entries=total_entries))
@security.requires_access(
@@ -86,14 +87,28 @@
task_id: str,
dag_run_id: str,
xcom_key: str,
+ deserialize: bool = False,
session: Session = NEW_SESSION,
) -> APIResponse:
"""Get an XCom entry"""
- query = session.query(XCom).filter(XCom.dag_id == dag_id, XCom.task_id == task_id, XCom.key == xcom_key)
+ if deserialize:
+ query = session.query(XCom, XCom.value)
+ else:
+ query = session.query(XCom)
+
+ query = query.filter(XCom.dag_id == dag_id, XCom.task_id == task_id, XCom.key == xcom_key)
query = query.join(DR, and_(XCom.dag_id == DR.dag_id, XCom.run_id == DR.run_id))
query = query.filter(DR.run_id == dag_run_id)
- query_object = query.one_or_none()
- if not query_object:
+ item = query.one_or_none()
+ if item is None:
raise NotFound("XCom entry not found")
- return xcom_schema.dump(query_object)
+
+ if deserialize:
+ xcom, value = item
+ stub = copy.copy(xcom)
+ stub.value = value
+ stub.value = XCom.deserialize_value(stub)
+ item = stub
+
+ return xcom_schema.dump(item)
|
{"golden_diff": "diff --git a/airflow/api_connexion/endpoints/xcom_endpoint.py b/airflow/api_connexion/endpoints/xcom_endpoint.py\n--- a/airflow/api_connexion/endpoints/xcom_endpoint.py\n+++ b/airflow/api_connexion/endpoints/xcom_endpoint.py\n@@ -14,6 +14,7 @@\n # KIND, either express or implied. See the License for the\n # specific language governing permissions and limitations\n # under the License.\n+import copy\n from typing import Optional\n \n from flask import g\n@@ -68,7 +69,7 @@\n query = query.order_by(DR.execution_date, XCom.task_id, XCom.dag_id, XCom.key)\n total_entries = query.count()\n query = query.offset(offset).limit(limit)\n- return xcom_collection_schema.dump(XComCollection(xcom_entries=query.all(), total_entries=total_entries))\n+ return xcom_collection_schema.dump(XComCollection(xcom_entries=query, total_entries=total_entries))\n \n \n @security.requires_access(\n@@ -86,14 +87,28 @@\n task_id: str,\n dag_run_id: str,\n xcom_key: str,\n+ deserialize: bool = False,\n session: Session = NEW_SESSION,\n ) -> APIResponse:\n \"\"\"Get an XCom entry\"\"\"\n- query = session.query(XCom).filter(XCom.dag_id == dag_id, XCom.task_id == task_id, XCom.key == xcom_key)\n+ if deserialize:\n+ query = session.query(XCom, XCom.value)\n+ else:\n+ query = session.query(XCom)\n+\n+ query = query.filter(XCom.dag_id == dag_id, XCom.task_id == task_id, XCom.key == xcom_key)\n query = query.join(DR, and_(XCom.dag_id == DR.dag_id, XCom.run_id == DR.run_id))\n query = query.filter(DR.run_id == dag_run_id)\n \n- query_object = query.one_or_none()\n- if not query_object:\n+ item = query.one_or_none()\n+ if item is None:\n raise NotFound(\"XCom entry not found\")\n- return xcom_schema.dump(query_object)\n+\n+ if deserialize:\n+ xcom, value = item\n+ stub = copy.copy(xcom)\n+ stub.value = value\n+ stub.value = XCom.deserialize_value(stub)\n+ item = stub\n+\n+ return xcom_schema.dump(item)\n", "issue": "API Endpoints - /xcomEntries/{xcom_key} cannot deserialize customized xcom backend\n### Description\n\nWe use S3 as our xcom backend database and write serialize/deserialize method for xcoms.\r\nHowever, when we want to access xcom through REST API, it returns the s3 file url instead of the deserialized value. Could you please add the feature to support customized xcom backend for REST API access?\n\n### Use case/motivation\n\n_No response_\n\n### Related issues\n\n_No response_\n\n### Are you willing to submit a PR?\n\n- [ ] Yes I am willing to submit a PR!\n\n### Code of Conduct\n\n- [X] I agree to follow this project's [Code of Conduct](https://github.com/apache/airflow/blob/main/CODE_OF_CONDUCT.md)\n\n", "before_files": [{"content": "# Licensed to the Apache Software Foundation (ASF) under one\n# or more contributor license agreements. See the NOTICE file\n# distributed with this work for additional information\n# regarding copyright ownership. The ASF licenses this file\n# to you under the Apache License, Version 2.0 (the\n# \"License\"); you may not use this file except in compliance\n# with the License. You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing,\n# software distributed under the License is distributed on an\n# \"AS IS\" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY\n# KIND, either express or implied. See the License for the\n# specific language governing permissions and limitations\n# under the License.\nfrom typing import Optional\n\nfrom flask import g\nfrom sqlalchemy import and_\nfrom sqlalchemy.orm import Session\n\nfrom airflow.api_connexion import security\nfrom airflow.api_connexion.exceptions import NotFound\nfrom airflow.api_connexion.parameters import check_limit, format_parameters\nfrom airflow.api_connexion.schemas.xcom_schema import XComCollection, xcom_collection_schema, xcom_schema\nfrom airflow.api_connexion.types import APIResponse\nfrom airflow.models import DagRun as DR, XCom\nfrom airflow.security import permissions\nfrom airflow.utils.airflow_flask_app import get_airflow_app\nfrom airflow.utils.session import NEW_SESSION, provide_session\n\n\[email protected]_access(\n [\n (permissions.ACTION_CAN_READ, permissions.RESOURCE_DAG),\n (permissions.ACTION_CAN_READ, permissions.RESOURCE_DAG_RUN),\n (permissions.ACTION_CAN_READ, permissions.RESOURCE_TASK_INSTANCE),\n (permissions.ACTION_CAN_READ, permissions.RESOURCE_XCOM),\n ],\n)\n@format_parameters({\"limit\": check_limit})\n@provide_session\ndef get_xcom_entries(\n *,\n dag_id: str,\n dag_run_id: str,\n task_id: str,\n limit: Optional[int],\n offset: Optional[int] = None,\n session: Session = NEW_SESSION,\n) -> APIResponse:\n \"\"\"Get all XCom values\"\"\"\n query = session.query(XCom)\n if dag_id == '~':\n appbuilder = get_airflow_app().appbuilder\n readable_dag_ids = appbuilder.sm.get_readable_dag_ids(g.user)\n query = query.filter(XCom.dag_id.in_(readable_dag_ids))\n query = query.join(DR, and_(XCom.dag_id == DR.dag_id, XCom.run_id == DR.run_id))\n else:\n query = query.filter(XCom.dag_id == dag_id)\n query = query.join(DR, and_(XCom.dag_id == DR.dag_id, XCom.run_id == DR.run_id))\n\n if task_id != '~':\n query = query.filter(XCom.task_id == task_id)\n if dag_run_id != '~':\n query = query.filter(DR.run_id == dag_run_id)\n query = query.order_by(DR.execution_date, XCom.task_id, XCom.dag_id, XCom.key)\n total_entries = query.count()\n query = query.offset(offset).limit(limit)\n return xcom_collection_schema.dump(XComCollection(xcom_entries=query.all(), total_entries=total_entries))\n\n\[email protected]_access(\n [\n (permissions.ACTION_CAN_READ, permissions.RESOURCE_DAG),\n (permissions.ACTION_CAN_READ, permissions.RESOURCE_DAG_RUN),\n (permissions.ACTION_CAN_READ, permissions.RESOURCE_TASK_INSTANCE),\n (permissions.ACTION_CAN_READ, permissions.RESOURCE_XCOM),\n ],\n)\n@provide_session\ndef get_xcom_entry(\n *,\n dag_id: str,\n task_id: str,\n dag_run_id: str,\n xcom_key: str,\n session: Session = NEW_SESSION,\n) -> APIResponse:\n \"\"\"Get an XCom entry\"\"\"\n query = session.query(XCom).filter(XCom.dag_id == dag_id, XCom.task_id == task_id, XCom.key == xcom_key)\n query = query.join(DR, and_(XCom.dag_id == DR.dag_id, XCom.run_id == DR.run_id))\n query = query.filter(DR.run_id == dag_run_id)\n\n query_object = query.one_or_none()\n if not query_object:\n raise NotFound(\"XCom entry not found\")\n return xcom_schema.dump(query_object)\n", "path": "airflow/api_connexion/endpoints/xcom_endpoint.py"}]}
| 1,831 | 538 |
gh_patches_debug_8166
|
rasdani/github-patches
|
git_diff
|
cornellius-gp__gpytorch-1977
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[Bug] IF-construction leads to RuntimeError in polynomial kernel
# 🐛 Bug
I wanted to train a gp-model, so I made everything like in [tutorials](https://docs.gpytorch.ai/en/stable/examples/04_Variational_and_Approximate_GPs/SVGP_Multitask_GP_Regression.html). The code works with Linear and RBF kernels, but it does not work with Polynomial kernel.
It crushes with RuntimeError while inference. And from what I see in the code there might be several reasons why:
- misprint (if and else should be vice versa)
- pytorch changed the behavior of `torch.addmm`
- or maybe there is smth I do not understand :)
Please, look at the text below.
## To reproduce
** Code snippet to reproduce **
```python
import torch
import gpytorch
class MultitaskGPModel(gpytorch.models.ApproximateGP):
def __init__(self, grid_size=4, num_latents=2, grid_bounds=[(0., 31.)], num_tasks=256):
variational_distribution = gpytorch.variational.CholeskyVariationalDistribution(
grid_size, batch_shape=torch.Size([num_latents])
)
variational_strategy = gpytorch.variational.LMCVariationalStrategy(
gpytorch.variational.GridInterpolationVariationalStrategy(self, grid_size, grid_bounds, variational_distribution),
num_tasks=num_tasks,
num_latents=num_latents,
latent_dim=-1
)
super().__init__(variational_strategy)
self.mean_module = gpytorch.means.ConstantMean(batch_shape=torch.Size([num_latents]))
self.covar_module = gpytorch.kernels.ScaleKernel(
gpytorch.kernels.PolynomialKernel(batch_shape=torch.Size([num_latents]), power=2),
batch_shape=torch.Size([num_latents])
)
def forward(self, x):
mean_x = self.mean_module(x)
covar_x = self.covar_module(x)
return gpytorch.distributions.MultivariateNormal(mean_x, covar_x)
gp_layer = MultitaskGPModel()
likelihood = gpytorch.likelihoods.MultitaskGaussianLikelihood(num_tasks=256)
x = torch.randint(32, size=(1,), dtype=torch.float32).unsqueeze(1)
noise = gp_layer(x)
noise = likelihood(noise)
noise = noise.rsample((2, 2))
```
** Stack trace/error message **
```
---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
/tmp/ipykernel_15909/3264522926.py in <module>
31 x = torch.randint(32, size=(1,), dtype=torch.float32).unsqueeze(1)
32
---> 33 noise = gp_layer(x)
34 noise = likelihood(noise)
35 noise = noise.rsample((2, 2))
~/anaconda3/lib/python3.8/site-packages/gpytorch/models/approximate_gp.py in __call__(self, inputs, prior, **kwargs)
79 if inputs.dim() == 1:
80 inputs = inputs.unsqueeze(-1)
---> 81 return self.variational_strategy(inputs, prior=prior, **kwargs)
~/anaconda3/lib/python3.8/site-packages/gpytorch/variational/lmc_variational_strategy.py in __call__(self, x, task_indices, prior, **kwargs)
186 or ~gpytorch.distributions.MultivariateNormal (... x N)
187 """
--> 188 latent_dist = self.base_variational_strategy(x, prior=prior, **kwargs)
189 num_batch = len(latent_dist.batch_shape)
190 latent_dim = num_batch + self.latent_dim
~/anaconda3/lib/python3.8/site-packages/gpytorch/variational/_variational_strategy.py in __call__(self, x, prior, **kwargs)
108 # (Maybe) initialize variational distribution
109 if not self.variational_params_initialized.item():
--> 110 prior_dist = self.prior_distribution
111 self._variational_distribution.initialize_variational_distribution(prior_dist)
112 self.variational_params_initialized.fill_(1)
~/anaconda3/lib/python3.8/site-packages/gpytorch/utils/memoize.py in g(self, *args, **kwargs)
57 kwargs_pkl = pickle.dumps(kwargs)
58 if not _is_in_cache(self, cache_name, *args, kwargs_pkl=kwargs_pkl):
---> 59 return _add_to_cache(self, cache_name, method(self, *args, **kwargs), *args, kwargs_pkl=kwargs_pkl)
60 return _get_from_cache(self, cache_name, *args, kwargs_pkl=kwargs_pkl)
61
~/anaconda3/lib/python3.8/site-packages/gpytorch/variational/grid_interpolation_variational_strategy.py in prior_distribution(self)
74 def prior_distribution(self):
75 out = self.model.forward(self.inducing_points)
---> 76 res = MultivariateNormal(out.mean, out.lazy_covariance_matrix.add_jitter())
77 return res
78
~/anaconda3/lib/python3.8/site-packages/gpytorch/lazy/lazy_evaluated_kernel_tensor.py in add_jitter(self, jitter_val)
275
276 def add_jitter(self, jitter_val=1e-3):
--> 277 return self.evaluate_kernel().add_jitter(jitter_val)
278
279 def _unsqueeze_batch(self, dim):
~/anaconda3/lib/python3.8/site-packages/gpytorch/utils/memoize.py in g(self, *args, **kwargs)
57 kwargs_pkl = pickle.dumps(kwargs)
58 if not _is_in_cache(self, cache_name, *args, kwargs_pkl=kwargs_pkl):
---> 59 return _add_to_cache(self, cache_name, method(self, *args, **kwargs), *args, kwargs_pkl=kwargs_pkl)
60 return _get_from_cache(self, cache_name, *args, kwargs_pkl=kwargs_pkl)
61
~/anaconda3/lib/python3.8/site-packages/gpytorch/lazy/lazy_evaluated_kernel_tensor.py in evaluate_kernel(self)
330 temp_active_dims = self.kernel.active_dims
331 self.kernel.active_dims = None
--> 332 res = self.kernel(
333 x1,
334 x2,
~/anaconda3/lib/python3.8/site-packages/gpytorch/kernels/kernel.py in __call__(self, x1, x2, diag, last_dim_is_batch, **params)
400 res = LazyEvaluatedKernelTensor(x1_, x2_, kernel=self, last_dim_is_batch=last_dim_is_batch, **params)
401 else:
--> 402 res = lazify(super(Kernel, self).__call__(x1_, x2_, last_dim_is_batch=last_dim_is_batch, **params))
403 return res
404
~/anaconda3/lib/python3.8/site-packages/gpytorch/module.py in __call__(self, *inputs, **kwargs)
28
29 def __call__(self, *inputs, **kwargs):
---> 30 outputs = self.forward(*inputs, **kwargs)
31 if isinstance(outputs, list):
32 return [_validate_module_outputs(output) for output in outputs]
~/anaconda3/lib/python3.8/site-packages/gpytorch/kernels/scale_kernel.py in forward(self, x1, x2, last_dim_is_batch, diag, **params)
101
102 def forward(self, x1, x2, last_dim_is_batch=False, diag=False, **params):
--> 103 orig_output = self.base_kernel.forward(x1, x2, diag=diag, last_dim_is_batch=last_dim_is_batch, **params)
104 outputscales = self.outputscale
105 if last_dim_is_batch:
~/anaconda3/lib/python3.8/site-packages/gpytorch/kernels/polynomial_kernel.py in forward(self, x1, x2, diag, last_dim_is_batch, **params)
95
96 if x1.dim() == 2 and x2.dim() == 2:
---> 97 return torch.addmm(offset, x1, x2.transpose(-2, -1)).pow(self.power)
98 else:
99 return (torch.matmul(x1, x2.transpose(-2, -1)) + offset).pow(self.power)
RuntimeError: expand(torch.FloatTensor{[2, 1, 1]}, size=[4, 4]): the number of sizes provided (2) must be greater or equal to the number of dimensions in the tensor (3)
```
## System information
GPyTorch Version: 1.6.0
PyTorch Version : 1.11.0+cu113
Computer OS: Ubuntu 18.04.6 LTS
## Additional context
I see in [`polynomial_kernel.py`](https://github.com/cornellius-gp/gpytorch/blob/master/gpytorch/kernels/polynomial_kernel.py) this piece of code:
```python
offset = self.offset.view(*self.batch_shape, 1, 1)
...
if x1.dim() == 2 and x2.dim() == 2:
return torch.addmm(offset, x1, x2.transpose(-2, -1)).pow(self.power)
```
So the tensor `offset` has at least 3 dimensions or more, while `x1` and `x2` have exactly 2 dimensions, but `torch.addmm` will not work with such sizes. I do not know why such construction is needed, because the code from else-part would do the same but without an error.
</issue>
<code>
[start of gpytorch/kernels/polynomial_kernel.py]
1 #!/usr/bin/env python3
2
3 from typing import Optional
4
5 import torch
6
7 from ..constraints import Interval, Positive
8 from ..priors import Prior
9 from .kernel import Kernel
10
11
12 class PolynomialKernel(Kernel):
13 r"""
14 Computes a covariance matrix based on the Polynomial kernel
15 between inputs :math:`\mathbf{x_1}` and :math:`\mathbf{x_2}`:
16
17 .. math::
18 \begin{equation*}
19 k_\text{Poly}(\mathbf{x_1}, \mathbf{x_2}) = (\mathbf{x_1}^\top
20 \mathbf{x_2} + c)^{d}.
21 \end{equation*}
22
23 where
24
25 * :math:`c` is an :attr:`offset` parameter.
26
27 Args:
28 :attr:`offset_prior` (:class:`gpytorch.priors.Prior`):
29 Prior over the offset parameter (default `None`).
30 :attr:`offset_constraint` (Constraint, optional):
31 Constraint to place on offset parameter. Default: `Positive`.
32 :attr:`active_dims` (list):
33 List of data dimensions to operate on.
34 `len(active_dims)` should equal `num_dimensions`.
35 """
36
37 def __init__(
38 self,
39 power: int,
40 offset_prior: Optional[Prior] = None,
41 offset_constraint: Optional[Interval] = None,
42 **kwargs,
43 ):
44 super().__init__(**kwargs)
45 if offset_constraint is None:
46 offset_constraint = Positive()
47
48 self.register_parameter(name="raw_offset", parameter=torch.nn.Parameter(torch.zeros(*self.batch_shape, 1)))
49
50 # We want the power to be a float so we dont have to worry about its device / dtype.
51 if torch.is_tensor(power):
52 if power.numel() > 1:
53 raise RuntimeError("Cant create a Polynomial kernel with more than one power")
54 else:
55 power = power.item()
56
57 self.power = power
58
59 if offset_prior is not None:
60 if not isinstance(offset_prior, Prior):
61 raise TypeError("Expected gpytorch.priors.Prior but got " + type(offset_prior).__name__)
62 self.register_prior("offset_prior", offset_prior, lambda m: m.offset, lambda m, v: m._set_offset(v))
63
64 self.register_constraint("raw_offset", offset_constraint)
65
66 @property
67 def offset(self) -> torch.Tensor:
68 return self.raw_offset_constraint.transform(self.raw_offset)
69
70 @offset.setter
71 def offset(self, value: torch.Tensor) -> None:
72 self._set_offset(value)
73
74 def _set_offset(self, value: torch.Tensor) -> None:
75 if not torch.is_tensor(value):
76 value = torch.as_tensor(value).to(self.raw_offset)
77 self.initialize(raw_offset=self.raw_offset_constraint.inverse_transform(value))
78
79 def forward(
80 self,
81 x1: torch.Tensor,
82 x2: torch.Tensor,
83 diag: Optional[bool] = False,
84 last_dim_is_batch: Optional[bool] = False,
85 **params,
86 ) -> torch.Tensor:
87 offset = self.offset.view(*self.batch_shape, 1, 1)
88
89 if last_dim_is_batch:
90 x1 = x1.transpose(-1, -2).unsqueeze(-1)
91 x2 = x2.transpose(-1, -2).unsqueeze(-1)
92
93 if diag:
94 return ((x1 * x2).sum(dim=-1) + self.offset).pow(self.power)
95
96 if x1.dim() == 2 and x2.dim() == 2:
97 return torch.addmm(offset, x1, x2.transpose(-2, -1)).pow(self.power)
98 else:
99 return (torch.matmul(x1, x2.transpose(-2, -1)) + offset).pow(self.power)
100
[end of gpytorch/kernels/polynomial_kernel.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/gpytorch/kernels/polynomial_kernel.py b/gpytorch/kernels/polynomial_kernel.py
--- a/gpytorch/kernels/polynomial_kernel.py
+++ b/gpytorch/kernels/polynomial_kernel.py
@@ -93,7 +93,7 @@
if diag:
return ((x1 * x2).sum(dim=-1) + self.offset).pow(self.power)
- if x1.dim() == 2 and x2.dim() == 2:
+ if (x1.dim() == 2 and x2.dim() == 2) and offset.dim() == 2:
return torch.addmm(offset, x1, x2.transpose(-2, -1)).pow(self.power)
else:
return (torch.matmul(x1, x2.transpose(-2, -1)) + offset).pow(self.power)
|
{"golden_diff": "diff --git a/gpytorch/kernels/polynomial_kernel.py b/gpytorch/kernels/polynomial_kernel.py\n--- a/gpytorch/kernels/polynomial_kernel.py\n+++ b/gpytorch/kernels/polynomial_kernel.py\n@@ -93,7 +93,7 @@\n if diag:\n return ((x1 * x2).sum(dim=-1) + self.offset).pow(self.power)\n \n- if x1.dim() == 2 and x2.dim() == 2:\n+ if (x1.dim() == 2 and x2.dim() == 2) and offset.dim() == 2:\n return torch.addmm(offset, x1, x2.transpose(-2, -1)).pow(self.power)\n else:\n return (torch.matmul(x1, x2.transpose(-2, -1)) + offset).pow(self.power)\n", "issue": "[Bug] IF-construction leads to RuntimeError in polynomial kernel \n# \ud83d\udc1b Bug\r\n\r\nI wanted to train a gp-model, so I made everything like in [tutorials](https://docs.gpytorch.ai/en/stable/examples/04_Variational_and_Approximate_GPs/SVGP_Multitask_GP_Regression.html). The code works with Linear and RBF kernels, but it does not work with Polynomial kernel.\r\nIt crushes with RuntimeError while inference. And from what I see in the code there might be several reasons why:\r\n- misprint (if and else should be vice versa)\r\n- pytorch changed the behavior of `torch.addmm`\r\n- or maybe there is smth I do not understand :)\r\n\r\nPlease, look at the text below.\r\n\r\n## To reproduce\r\n\r\n** Code snippet to reproduce **\r\n```python\r\nimport torch\r\nimport gpytorch\r\n\r\nclass MultitaskGPModel(gpytorch.models.ApproximateGP):\r\n def __init__(self, grid_size=4, num_latents=2, grid_bounds=[(0., 31.)], num_tasks=256):\r\n variational_distribution = gpytorch.variational.CholeskyVariationalDistribution(\r\n grid_size, batch_shape=torch.Size([num_latents])\r\n )\r\n variational_strategy = gpytorch.variational.LMCVariationalStrategy(\r\n gpytorch.variational.GridInterpolationVariationalStrategy(self, grid_size, grid_bounds, variational_distribution),\r\n num_tasks=num_tasks,\r\n num_latents=num_latents,\r\n latent_dim=-1\r\n )\r\n super().__init__(variational_strategy)\r\n\r\n self.mean_module = gpytorch.means.ConstantMean(batch_shape=torch.Size([num_latents]))\r\n self.covar_module = gpytorch.kernels.ScaleKernel(\r\n gpytorch.kernels.PolynomialKernel(batch_shape=torch.Size([num_latents]), power=2),\r\n batch_shape=torch.Size([num_latents])\r\n )\r\n \r\n def forward(self, x):\r\n mean_x = self.mean_module(x)\r\n covar_x = self.covar_module(x)\r\n return gpytorch.distributions.MultivariateNormal(mean_x, covar_x)\r\n \r\ngp_layer = MultitaskGPModel()\r\nlikelihood = gpytorch.likelihoods.MultitaskGaussianLikelihood(num_tasks=256)\r\n\r\nx = torch.randint(32, size=(1,), dtype=torch.float32).unsqueeze(1)\r\n\r\nnoise = gp_layer(x)\r\nnoise = likelihood(noise)\r\nnoise = noise.rsample((2, 2))\r\n```\r\n\r\n** Stack trace/error message **\r\n```\r\n---------------------------------------------------------------------------\r\nRuntimeError Traceback (most recent call last)\r\n/tmp/ipykernel_15909/3264522926.py in <module>\r\n 31 x = torch.randint(32, size=(1,), dtype=torch.float32).unsqueeze(1)\r\n 32 \r\n---> 33 noise = gp_layer(x)\r\n 34 noise = likelihood(noise)\r\n 35 noise = noise.rsample((2, 2))\r\n\r\n~/anaconda3/lib/python3.8/site-packages/gpytorch/models/approximate_gp.py in __call__(self, inputs, prior, **kwargs)\r\n 79 if inputs.dim() == 1:\r\n 80 inputs = inputs.unsqueeze(-1)\r\n---> 81 return self.variational_strategy(inputs, prior=prior, **kwargs)\r\n\r\n~/anaconda3/lib/python3.8/site-packages/gpytorch/variational/lmc_variational_strategy.py in __call__(self, x, task_indices, prior, **kwargs)\r\n 186 or ~gpytorch.distributions.MultivariateNormal (... x N)\r\n 187 \"\"\"\r\n--> 188 latent_dist = self.base_variational_strategy(x, prior=prior, **kwargs)\r\n 189 num_batch = len(latent_dist.batch_shape)\r\n 190 latent_dim = num_batch + self.latent_dim\r\n\r\n~/anaconda3/lib/python3.8/site-packages/gpytorch/variational/_variational_strategy.py in __call__(self, x, prior, **kwargs)\r\n 108 # (Maybe) initialize variational distribution\r\n 109 if not self.variational_params_initialized.item():\r\n--> 110 prior_dist = self.prior_distribution\r\n 111 self._variational_distribution.initialize_variational_distribution(prior_dist)\r\n 112 self.variational_params_initialized.fill_(1)\r\n\r\n~/anaconda3/lib/python3.8/site-packages/gpytorch/utils/memoize.py in g(self, *args, **kwargs)\r\n 57 kwargs_pkl = pickle.dumps(kwargs)\r\n 58 if not _is_in_cache(self, cache_name, *args, kwargs_pkl=kwargs_pkl):\r\n---> 59 return _add_to_cache(self, cache_name, method(self, *args, **kwargs), *args, kwargs_pkl=kwargs_pkl)\r\n 60 return _get_from_cache(self, cache_name, *args, kwargs_pkl=kwargs_pkl)\r\n 61 \r\n\r\n~/anaconda3/lib/python3.8/site-packages/gpytorch/variational/grid_interpolation_variational_strategy.py in prior_distribution(self)\r\n 74 def prior_distribution(self):\r\n 75 out = self.model.forward(self.inducing_points)\r\n---> 76 res = MultivariateNormal(out.mean, out.lazy_covariance_matrix.add_jitter())\r\n 77 return res\r\n 78 \r\n\r\n~/anaconda3/lib/python3.8/site-packages/gpytorch/lazy/lazy_evaluated_kernel_tensor.py in add_jitter(self, jitter_val)\r\n 275 \r\n 276 def add_jitter(self, jitter_val=1e-3):\r\n--> 277 return self.evaluate_kernel().add_jitter(jitter_val)\r\n 278 \r\n 279 def _unsqueeze_batch(self, dim):\r\n\r\n~/anaconda3/lib/python3.8/site-packages/gpytorch/utils/memoize.py in g(self, *args, **kwargs)\r\n 57 kwargs_pkl = pickle.dumps(kwargs)\r\n 58 if not _is_in_cache(self, cache_name, *args, kwargs_pkl=kwargs_pkl):\r\n---> 59 return _add_to_cache(self, cache_name, method(self, *args, **kwargs), *args, kwargs_pkl=kwargs_pkl)\r\n 60 return _get_from_cache(self, cache_name, *args, kwargs_pkl=kwargs_pkl)\r\n 61 \r\n\r\n~/anaconda3/lib/python3.8/site-packages/gpytorch/lazy/lazy_evaluated_kernel_tensor.py in evaluate_kernel(self)\r\n 330 temp_active_dims = self.kernel.active_dims\r\n 331 self.kernel.active_dims = None\r\n--> 332 res = self.kernel(\r\n 333 x1,\r\n 334 x2,\r\n\r\n~/anaconda3/lib/python3.8/site-packages/gpytorch/kernels/kernel.py in __call__(self, x1, x2, diag, last_dim_is_batch, **params)\r\n 400 res = LazyEvaluatedKernelTensor(x1_, x2_, kernel=self, last_dim_is_batch=last_dim_is_batch, **params)\r\n 401 else:\r\n--> 402 res = lazify(super(Kernel, self).__call__(x1_, x2_, last_dim_is_batch=last_dim_is_batch, **params))\r\n 403 return res\r\n 404 \r\n\r\n~/anaconda3/lib/python3.8/site-packages/gpytorch/module.py in __call__(self, *inputs, **kwargs)\r\n 28 \r\n 29 def __call__(self, *inputs, **kwargs):\r\n---> 30 outputs = self.forward(*inputs, **kwargs)\r\n 31 if isinstance(outputs, list):\r\n 32 return [_validate_module_outputs(output) for output in outputs]\r\n\r\n~/anaconda3/lib/python3.8/site-packages/gpytorch/kernels/scale_kernel.py in forward(self, x1, x2, last_dim_is_batch, diag, **params)\r\n 101 \r\n 102 def forward(self, x1, x2, last_dim_is_batch=False, diag=False, **params):\r\n--> 103 orig_output = self.base_kernel.forward(x1, x2, diag=diag, last_dim_is_batch=last_dim_is_batch, **params)\r\n 104 outputscales = self.outputscale\r\n 105 if last_dim_is_batch:\r\n\r\n~/anaconda3/lib/python3.8/site-packages/gpytorch/kernels/polynomial_kernel.py in forward(self, x1, x2, diag, last_dim_is_batch, **params)\r\n 95 \r\n 96 if x1.dim() == 2 and x2.dim() == 2:\r\n---> 97 return torch.addmm(offset, x1, x2.transpose(-2, -1)).pow(self.power)\r\n 98 else:\r\n 99 return (torch.matmul(x1, x2.transpose(-2, -1)) + offset).pow(self.power)\r\n\r\nRuntimeError: expand(torch.FloatTensor{[2, 1, 1]}, size=[4, 4]): the number of sizes provided (2) must be greater or equal to the number of dimensions in the tensor (3)\r\n```\r\n\r\n## System information\r\n\r\nGPyTorch Version: 1.6.0\r\nPyTorch Version : 1.11.0+cu113\r\nComputer OS: Ubuntu 18.04.6 LTS \r\n\r\n## Additional context\r\nI see in [`polynomial_kernel.py`](https://github.com/cornellius-gp/gpytorch/blob/master/gpytorch/kernels/polynomial_kernel.py) this piece of code:\r\n\r\n```python\r\noffset = self.offset.view(*self.batch_shape, 1, 1)\r\n...\r\nif x1.dim() == 2 and x2.dim() == 2:\r\n return torch.addmm(offset, x1, x2.transpose(-2, -1)).pow(self.power)\r\n```\r\n\r\nSo the tensor `offset` has at least 3 dimensions or more, while `x1` and `x2` have exactly 2 dimensions, but `torch.addmm` will not work with such sizes. I do not know why such construction is needed, because the code from else-part would do the same but without an error.\n", "before_files": [{"content": "#!/usr/bin/env python3\n\nfrom typing import Optional\n\nimport torch\n\nfrom ..constraints import Interval, Positive\nfrom ..priors import Prior\nfrom .kernel import Kernel\n\n\nclass PolynomialKernel(Kernel):\n r\"\"\"\n Computes a covariance matrix based on the Polynomial kernel\n between inputs :math:`\\mathbf{x_1}` and :math:`\\mathbf{x_2}`:\n\n .. math::\n \\begin{equation*}\n k_\\text{Poly}(\\mathbf{x_1}, \\mathbf{x_2}) = (\\mathbf{x_1}^\\top\n \\mathbf{x_2} + c)^{d}.\n \\end{equation*}\n\n where\n\n * :math:`c` is an :attr:`offset` parameter.\n\n Args:\n :attr:`offset_prior` (:class:`gpytorch.priors.Prior`):\n Prior over the offset parameter (default `None`).\n :attr:`offset_constraint` (Constraint, optional):\n Constraint to place on offset parameter. Default: `Positive`.\n :attr:`active_dims` (list):\n List of data dimensions to operate on.\n `len(active_dims)` should equal `num_dimensions`.\n \"\"\"\n\n def __init__(\n self,\n power: int,\n offset_prior: Optional[Prior] = None,\n offset_constraint: Optional[Interval] = None,\n **kwargs,\n ):\n super().__init__(**kwargs)\n if offset_constraint is None:\n offset_constraint = Positive()\n\n self.register_parameter(name=\"raw_offset\", parameter=torch.nn.Parameter(torch.zeros(*self.batch_shape, 1)))\n\n # We want the power to be a float so we dont have to worry about its device / dtype.\n if torch.is_tensor(power):\n if power.numel() > 1:\n raise RuntimeError(\"Cant create a Polynomial kernel with more than one power\")\n else:\n power = power.item()\n\n self.power = power\n\n if offset_prior is not None:\n if not isinstance(offset_prior, Prior):\n raise TypeError(\"Expected gpytorch.priors.Prior but got \" + type(offset_prior).__name__)\n self.register_prior(\"offset_prior\", offset_prior, lambda m: m.offset, lambda m, v: m._set_offset(v))\n\n self.register_constraint(\"raw_offset\", offset_constraint)\n\n @property\n def offset(self) -> torch.Tensor:\n return self.raw_offset_constraint.transform(self.raw_offset)\n\n @offset.setter\n def offset(self, value: torch.Tensor) -> None:\n self._set_offset(value)\n\n def _set_offset(self, value: torch.Tensor) -> None:\n if not torch.is_tensor(value):\n value = torch.as_tensor(value).to(self.raw_offset)\n self.initialize(raw_offset=self.raw_offset_constraint.inverse_transform(value))\n\n def forward(\n self,\n x1: torch.Tensor,\n x2: torch.Tensor,\n diag: Optional[bool] = False,\n last_dim_is_batch: Optional[bool] = False,\n **params,\n ) -> torch.Tensor:\n offset = self.offset.view(*self.batch_shape, 1, 1)\n\n if last_dim_is_batch:\n x1 = x1.transpose(-1, -2).unsqueeze(-1)\n x2 = x2.transpose(-1, -2).unsqueeze(-1)\n\n if diag:\n return ((x1 * x2).sum(dim=-1) + self.offset).pow(self.power)\n\n if x1.dim() == 2 and x2.dim() == 2:\n return torch.addmm(offset, x1, x2.transpose(-2, -1)).pow(self.power)\n else:\n return (torch.matmul(x1, x2.transpose(-2, -1)) + offset).pow(self.power)\n", "path": "gpytorch/kernels/polynomial_kernel.py"}]}
| 3,830 | 184 |
gh_patches_debug_23835
|
rasdani/github-patches
|
git_diff
|
ResonantGeoData__ResonantGeoData-70
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Add an endpoint to get status of workers
It would be useful to know if we have any workers associated with the system, and, if so, if they are busy.
Specifically, this could probably be something like is done in girder_worker (see https://github.com/girder/girder_worker/blob/master/girder_worker/girder_plugin/api/worker.py#L40-L55). For this purpose, the celery app can be reached via `from rgd import celery_app`.
Ideally, this let's us determine the following conditions:
- The broker is unavailable
- There are no workers
- The number of idle workers
- The number of busy workers (and, ideally, what they are busy doing)
In the future, we may have multiple worker pools (for instance, for GPU and non-GPU tasks), so this will probably change exactly what gets reported in the future.
</issue>
<code>
[start of setup.py]
1 from setuptools import setup
2
3 setup(
4 name='resonantgeodata',
5 version='0.1',
6 python_requires='>=3.8.0',
7 install_requires=[
8 'boto3',
9 'celery!=4.4.4',
10 'django',
11 'django-admin-display',
12 'django-allauth',
13 'django-cleanup',
14 'django-configurations[database]',
15 'django-cors-headers',
16 'django-crispy-forms',
17 'django-extensions',
18 'django-storages',
19 'djangorestframework',
20 'docker',
21 'drf-yasg',
22 'gputil',
23 'psycopg2',
24 'python-magic',
25 'rules',
26 'uritemplate',
27 'whitenoise[brotli]',
28 # Production-only
29 'django-storages',
30 'gunicorn',
31 # Development-only
32 'django-debug-toolbar',
33 'django-minio-storage',
34 ],
35 )
36
[end of setup.py]
[start of core/urls.py]
1 from django.urls import path
2
3 from . import views
4
5 urlpatterns = [
6 path('', views.index, name='index'),
7 path('algorithms/', views.algorithms, name='algorithms'),
8 path(
9 'algorithms/<str:creator>/<int:pk>/',
10 views.AlgorithmDetailView.as_view(),
11 name='algorithm-detail',
12 ),
13 path(
14 'algorithms/<str:creator>/<int:pk>/delete/',
15 views.AlgorithmDeleteView.as_view(),
16 name='delete-algorithm',
17 ),
18 path('algorithms/new/', views.AlgorithmCreateView.as_view(), name='new-algorithm'),
19 path('jobs/', views.jobs, name='jobs'),
20 path('jobs/new/', views.JobCreateView.as_view(), name='new-job'),
21 path('jobs/<str:creator>/<int:pk>/', views.JobDetailView.as_view(), name='job-detail'),
22 path('tasks/', views.tasks, name='tasks'),
23 path('task/<int:pk>-<str:name>/', views.TaskDetailView.as_view(), name='task-detail'),
24 path('api/download/<model>/<int:id>/<field>', views.download_file, name='download-file'),
25 ]
26
27 handler500 = views.handler500
28
[end of core/urls.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/core/urls.py b/core/urls.py
--- a/core/urls.py
+++ b/core/urls.py
@@ -1,7 +1,11 @@
+from django.contrib import admin
from django.urls import path
+from djproxy.urls import generate_routes
from . import views
+
+admin.site.index_template = 'admin/add_flower.html'
urlpatterns = [
path('', views.index, name='index'),
path('algorithms/', views.algorithms, name='algorithms'),
@@ -22,6 +26,6 @@
path('tasks/', views.tasks, name='tasks'),
path('task/<int:pk>-<str:name>/', views.TaskDetailView.as_view(), name='task-detail'),
path('api/download/<model>/<int:id>/<field>', views.download_file, name='download-file'),
-]
+] + generate_routes({'flower-proxy': {'base_url': 'http://flower:5555/', 'prefix': '/flower/'}})
handler500 = views.handler500
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -17,6 +17,7 @@
'django-extensions',
'django-storages',
'djangorestframework',
+ 'djproxy',
'docker',
'drf-yasg',
'gputil',
|
{"golden_diff": "diff --git a/core/urls.py b/core/urls.py\n--- a/core/urls.py\n+++ b/core/urls.py\n@@ -1,7 +1,11 @@\n+from django.contrib import admin\n from django.urls import path\n+from djproxy.urls import generate_routes\n \n from . import views\n \n+\n+admin.site.index_template = 'admin/add_flower.html'\n urlpatterns = [\n path('', views.index, name='index'),\n path('algorithms/', views.algorithms, name='algorithms'),\n@@ -22,6 +26,6 @@\n path('tasks/', views.tasks, name='tasks'),\n path('task/<int:pk>-<str:name>/', views.TaskDetailView.as_view(), name='task-detail'),\n path('api/download/<model>/<int:id>/<field>', views.download_file, name='download-file'),\n-]\n+] + generate_routes({'flower-proxy': {'base_url': 'http://flower:5555/', 'prefix': '/flower/'}})\n \n handler500 = views.handler500\ndiff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -17,6 +17,7 @@\n 'django-extensions',\n 'django-storages',\n 'djangorestframework',\n+ 'djproxy',\n 'docker',\n 'drf-yasg',\n 'gputil',\n", "issue": "Add an endpoint to get status of workers\nIt would be useful to know if we have any workers associated with the system, and, if so, if they are busy.\r\n\r\nSpecifically, this could probably be something like is done in girder_worker (see https://github.com/girder/girder_worker/blob/master/girder_worker/girder_plugin/api/worker.py#L40-L55). For this purpose, the celery app can be reached via `from rgd import celery_app`.\r\n\r\nIdeally, this let's us determine the following conditions:\r\n- The broker is unavailable \r\n- There are no workers\r\n- The number of idle workers\r\n- The number of busy workers (and, ideally, what they are busy doing)\r\n\r\nIn the future, we may have multiple worker pools (for instance, for GPU and non-GPU tasks), so this will probably change exactly what gets reported in the future.\n", "before_files": [{"content": "from setuptools import setup\n\nsetup(\n name='resonantgeodata',\n version='0.1',\n python_requires='>=3.8.0',\n install_requires=[\n 'boto3',\n 'celery!=4.4.4',\n 'django',\n 'django-admin-display',\n 'django-allauth',\n 'django-cleanup',\n 'django-configurations[database]',\n 'django-cors-headers',\n 'django-crispy-forms',\n 'django-extensions',\n 'django-storages',\n 'djangorestframework',\n 'docker',\n 'drf-yasg',\n 'gputil',\n 'psycopg2',\n 'python-magic',\n 'rules',\n 'uritemplate',\n 'whitenoise[brotli]',\n # Production-only\n 'django-storages',\n 'gunicorn',\n # Development-only\n 'django-debug-toolbar',\n 'django-minio-storage',\n ],\n)\n", "path": "setup.py"}, {"content": "from django.urls import path\n\nfrom . import views\n\nurlpatterns = [\n path('', views.index, name='index'),\n path('algorithms/', views.algorithms, name='algorithms'),\n path(\n 'algorithms/<str:creator>/<int:pk>/',\n views.AlgorithmDetailView.as_view(),\n name='algorithm-detail',\n ),\n path(\n 'algorithms/<str:creator>/<int:pk>/delete/',\n views.AlgorithmDeleteView.as_view(),\n name='delete-algorithm',\n ),\n path('algorithms/new/', views.AlgorithmCreateView.as_view(), name='new-algorithm'),\n path('jobs/', views.jobs, name='jobs'),\n path('jobs/new/', views.JobCreateView.as_view(), name='new-job'),\n path('jobs/<str:creator>/<int:pk>/', views.JobDetailView.as_view(), name='job-detail'),\n path('tasks/', views.tasks, name='tasks'),\n path('task/<int:pk>-<str:name>/', views.TaskDetailView.as_view(), name='task-detail'),\n path('api/download/<model>/<int:id>/<field>', views.download_file, name='download-file'),\n]\n\nhandler500 = views.handler500\n", "path": "core/urls.py"}]}
| 1,306 | 296 |
gh_patches_debug_34050
|
rasdani/github-patches
|
git_diff
|
iterative__dvc-307
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Add a test for partial repro, when first few steps do not require reproduction
</issue>
<code>
[start of dvc/repository_change.py]
1 import os
2
3 from dvc.exceptions import DvcException
4 from dvc.git_wrapper import GitWrapper
5 from dvc.executor import Executor
6 from dvc.logger import Logger
7 from dvc.path.data_item import DataDirError, DataItemInStatusDirError
8 from dvc.path.stated_data_item import StatedDataItem
9 from dvc.utils import cached_property
10 from dvc.config import ConfigI
11
12 class RepositoryChangeError(DvcException):
13 def __init__(self, msg):
14 DvcException.__init__(self, 'Repository change error: {}'.format(msg))
15
16
17 class RepositoryChange(object):
18 """Pre-condition: git repository has no changes"""
19
20 def __init__(self, command, settings, stdout, stderr, shell=False):
21 self._settings = settings
22
23 stemps_before = self.data_file_timesteps()
24
25 Logger.debug(u'[Repository change] Exec command: {}. stdout={}, stderr={}, shell={}'.format(
26 command,
27 stdout,
28 stderr,
29 shell))
30 Executor.exec_cmd_only_success(command.split(' '), stdout, stderr, shell=shell)
31
32 stemps_after = self.data_file_timesteps()
33
34 sym_diff = stemps_after ^ stemps_before
35 self._modified_content_filenames = set([filename for filename, timestemp in sym_diff])
36
37 Logger.debug(u'[Repository change] Identified modifications: {}'.format(
38 u', '.join(self._modified_content_filenames)))
39
40 self._stated_data_items = []
41 self._externally_created_files = []
42 self._created_status_files = []
43 self._init_file_states()
44
45 @property
46 def modified_content_data_items(self):
47 return [self._settings.path_factory.data_item(file) for file in self._modified_content_filenames]
48
49 @cached_property
50 def removed_data_items(self):
51 return [x for x in self._stated_data_items if x.is_removed]
52
53 @cached_property
54 def modified_data_items(self):
55 return [x for x in self._stated_data_items if x.is_modified]
56
57 @cached_property
58 def new_data_items(self):
59 return [x for x in self._stated_data_items if x.is_new]
60
61 @cached_property
62 def unusual_data_items(self):
63 return [x for x in self._stated_data_items if x.is_unusual]
64
65 @property
66 def changed_data_items(self):
67 res = set(self.new_data_items + self.modified_data_items + self.modified_content_data_items)
68 return list(res)
69
70 def _add_stated_data_item(self, state, file):
71 try:
72 item = self._settings.path_factory.stated_data_item(state, file)
73 self._stated_data_items.append(item)
74 Logger.debug('[Repository change] Add status: {} {}'.format(
75 item.status,
76 item.data.dvc))
77 except DataItemInStatusDirError:
78 self._created_status_files.append(file)
79 except DataDirError:
80 self._externally_created_files.append(file)
81 pass
82
83 def _init_file_states(self):
84 statuses = GitWrapper.git_file_statuses()
85
86 for status, file in statuses:
87 file_path = os.path.join(self._settings.git.git_dir_abs, file)
88
89 if not os.path.isdir(file_path):
90 self._add_stated_data_item(status, file_path)
91 else:
92 files = []
93 self.get_all_files_from_dir(file_path, files)
94 state = StatedDataItem.STATUS_UNTRACKED + StatedDataItem.STATUS_UNTRACKED
95 for f in files:
96 self._add_stated_data_item(state, f)
97 pass
98
99 def get_all_files_from_dir(self, dir, result):
100 files = os.listdir(dir)
101 for f in files:
102 path = os.path.join(dir, f)
103 if os.path.isfile(path):
104 result.append(path)
105 else:
106 self.get_all_files_from_dir(path, result)
107 pass
108
109 @property
110 def externally_created_files(self):
111 return self._externally_created_files
112
113 @property
114 def created_status_files(self):
115 return self._created_status_files
116
117 def data_file_timesteps(self):
118 res = set()
119 for root, dirs, files in os.walk(self._settings.git.git_dir_abs):
120 if root.startswith(os.path.join(self._settings.git.git_dir_abs, ConfigI.CONFIG_DIR)):
121 continue
122
123 for file in files:
124 filename = os.path.join(root, file)
125 if os.path.exists(filename):
126 timestemp = os.path.getmtime(filename)
127 res.add((filename, timestemp))
128
129 return res
130
[end of dvc/repository_change.py]
[start of dvc/path/data_item.py]
1 import os
2 import stat
3
4 from dvc.config import ConfigI
5 from dvc.path.path import Path
6 from dvc.exceptions import DvcException
7 from dvc.system import System
8 from dvc.utils import cached_property
9 from dvc.data_cloud import file_md5
10 from dvc.state_file import CacheStateFile, LocalStateFile
11
12
13 class DataItemError(DvcException):
14 def __init__(self, msg):
15 super(DataItemError, self).__init__('Data item error: {}'.format(msg))
16
17
18 class DataDirError(DvcException):
19 def __init__(self, msg):
20 super(DataDirError, self).__init__(msg)
21
22
23 class DataItemInStatusDirError(DataDirError):
24 def __init__(self, file):
25 msg = 'File "{}" is in state directory'.format(file)
26 super(DataItemInStatusDirError, self).__init__(msg)
27
28
29 class NotInGitDirError(DataDirError):
30 def __init__(self, file, git_dir):
31 msg = 'File "{}" is not in git directory "{}"'.format(file, git_dir)
32 super(NotInGitDirError, self).__init__(msg)
33
34
35 class DataItem(object):
36 STATE_FILE_SUFFIX = '.state'
37 LOCAL_STATE_FILE_SUFFIX = '.local_state'
38 CACHE_STATE_FILE_SUFFIX = '.cache_state'
39 CACHE_FILE_SEP = '_'
40
41 def __init__(self, data_file, git, config, cache_file=None):
42 self._git = git
43 self._config = config
44 self._cache_file = cache_file
45
46 self._data = Path(data_file, git)
47
48 if not self._data.abs.startswith(self._git.git_dir_abs):
49 raise NotInGitDirError(data_file, self._git.git_dir_abs)
50
51 if self._data.abs.startswith(self.state_dir_abs):
52 raise DataItemInStatusDirError(data_file)
53
54 pass
55
56 def copy(self, cache_file=None):
57 if not cache_file:
58 cache_file = self._cache_file
59
60 return DataItem(self._data.abs, self._git, self._config, cache_file)
61
62 def __hash__(self):
63 return self.data.dvc.__hash__()
64
65 def __eq__(self, other):
66 if other == None:
67 return False
68
69 return self.data.dvc == other.data.dvc
70
71 @property
72 def data(self):
73 return self._data
74
75 @cached_property
76 def state_dir(self):
77 return os.path.join(self._git.git_dir_abs, self._config.state_dir)
78
79 def _state(self, suffix):
80 state_file = os.path.join(self.state_dir, self.data.dvc + suffix)
81 return Path(state_file, self._git)
82
83 @cached_property
84 def state(self):
85 return self._state(self.STATE_FILE_SUFFIX)
86
87 @cached_property
88 def cache_dir_abs(self):
89 return os.path.join(self._git.git_dir_abs, ConfigI.CACHE_DIR)
90
91 @cached_property
92 def local_state(self):
93 return self._state(self.LOCAL_STATE_FILE_SUFFIX)
94
95 @cached_property
96 def cache_state(self):
97 return self._state(self.CACHE_STATE_FILE_SUFFIX)
98
99 @cached_property
100 def cache_dir(self):
101 return os.path.join(self._git.git_dir_abs, self._config.cache_dir)
102
103 @property
104 def cache(self):
105 cache_dir = self.cache_dir_abs
106
107 if self._cache_file:
108 file_name = os.path.relpath(os.path.realpath(self._cache_file), cache_dir)
109 else:
110 file_name = CacheStateFile.load(self).md5
111
112 cache_file = os.path.join(cache_dir, file_name)
113 return Path(cache_file, self._git)
114
115 @cached_property
116 def state_dir_abs(self):
117 return os.path.join(self._git.git_dir_abs, ConfigI.STATE_DIR)
118
119 def move_data_to_cache(self):
120 md5 = file_md5(self.data.relative)[0]
121 self._cache_file = os.path.join(self.cache_dir_abs, md5)
122 self._git.modify_gitignore([self.data.relative])
123 if not os.path.isfile(self.cache.relative):
124 System.hardlink(self.data.relative, self.cache.relative)
125 os.chmod(self.data.relative, stat.S_IREAD)
126
127 cache_state = CacheStateFile(self).save()
128
129 local_state = LocalStateFile(self).save()
130 self._git.modify_gitignore([self.local_state.relative])
131
[end of dvc/path/data_item.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/dvc/path/data_item.py b/dvc/path/data_item.py
--- a/dvc/path/data_item.py
+++ b/dvc/path/data_item.py
@@ -20,9 +20,9 @@
super(DataDirError, self).__init__(msg)
-class DataItemInStatusDirError(DataDirError):
+class DataItemInConfigDirError(DataDirError):
def __init__(self, file):
- msg = 'File "{}" is in state directory'.format(file)
+ msg = 'File "{}" is in config directory'.format(file)
super(DataItemInStatusDirError, self).__init__(msg)
@@ -48,10 +48,8 @@
if not self._data.abs.startswith(self._git.git_dir_abs):
raise NotInGitDirError(data_file, self._git.git_dir_abs)
- if self._data.abs.startswith(self.state_dir_abs):
- raise DataItemInStatusDirError(data_file)
-
- pass
+ if self._data.abs.startswith(os.path.join(self._git.git_dir_abs, self._config.CONFIG_DIR)):
+ raise DataItemInConfigDirError(data_file)
def copy(self, cache_file=None):
if not cache_file:
diff --git a/dvc/repository_change.py b/dvc/repository_change.py
--- a/dvc/repository_change.py
+++ b/dvc/repository_change.py
@@ -4,7 +4,7 @@
from dvc.git_wrapper import GitWrapper
from dvc.executor import Executor
from dvc.logger import Logger
-from dvc.path.data_item import DataDirError, DataItemInStatusDirError
+from dvc.path.data_item import DataDirError, DataItemInConfigDirError
from dvc.path.stated_data_item import StatedDataItem
from dvc.utils import cached_property
from dvc.config import ConfigI
@@ -74,7 +74,7 @@
Logger.debug('[Repository change] Add status: {} {}'.format(
item.status,
item.data.dvc))
- except DataItemInStatusDirError:
+ except DataItemInConfigDirError:
self._created_status_files.append(file)
except DataDirError:
self._externally_created_files.append(file)
|
{"golden_diff": "diff --git a/dvc/path/data_item.py b/dvc/path/data_item.py\n--- a/dvc/path/data_item.py\n+++ b/dvc/path/data_item.py\n@@ -20,9 +20,9 @@\n super(DataDirError, self).__init__(msg)\n \n \n-class DataItemInStatusDirError(DataDirError):\n+class DataItemInConfigDirError(DataDirError):\n def __init__(self, file):\n- msg = 'File \"{}\" is in state directory'.format(file)\n+ msg = 'File \"{}\" is in config directory'.format(file)\n super(DataItemInStatusDirError, self).__init__(msg)\n \n \n@@ -48,10 +48,8 @@\n if not self._data.abs.startswith(self._git.git_dir_abs):\n raise NotInGitDirError(data_file, self._git.git_dir_abs)\n \n- if self._data.abs.startswith(self.state_dir_abs):\n- raise DataItemInStatusDirError(data_file)\n-\n- pass\n+ if self._data.abs.startswith(os.path.join(self._git.git_dir_abs, self._config.CONFIG_DIR)):\n+ raise DataItemInConfigDirError(data_file)\n \n def copy(self, cache_file=None):\n if not cache_file:\ndiff --git a/dvc/repository_change.py b/dvc/repository_change.py\n--- a/dvc/repository_change.py\n+++ b/dvc/repository_change.py\n@@ -4,7 +4,7 @@\n from dvc.git_wrapper import GitWrapper\n from dvc.executor import Executor\n from dvc.logger import Logger\n-from dvc.path.data_item import DataDirError, DataItemInStatusDirError\n+from dvc.path.data_item import DataDirError, DataItemInConfigDirError\n from dvc.path.stated_data_item import StatedDataItem\n from dvc.utils import cached_property\n from dvc.config import ConfigI\n@@ -74,7 +74,7 @@\n Logger.debug('[Repository change] Add status: {} {}'.format(\n item.status,\n item.data.dvc))\n- except DataItemInStatusDirError:\n+ except DataItemInConfigDirError:\n self._created_status_files.append(file)\n except DataDirError:\n self._externally_created_files.append(file)\n", "issue": "Add a test for partial repro, when first few steps do not require reproduction\n\n", "before_files": [{"content": "import os\n\nfrom dvc.exceptions import DvcException\nfrom dvc.git_wrapper import GitWrapper\nfrom dvc.executor import Executor\nfrom dvc.logger import Logger\nfrom dvc.path.data_item import DataDirError, DataItemInStatusDirError\nfrom dvc.path.stated_data_item import StatedDataItem\nfrom dvc.utils import cached_property\nfrom dvc.config import ConfigI\n\nclass RepositoryChangeError(DvcException):\n def __init__(self, msg):\n DvcException.__init__(self, 'Repository change error: {}'.format(msg))\n\n\nclass RepositoryChange(object):\n \"\"\"Pre-condition: git repository has no changes\"\"\"\n\n def __init__(self, command, settings, stdout, stderr, shell=False):\n self._settings = settings\n\n stemps_before = self.data_file_timesteps()\n\n Logger.debug(u'[Repository change] Exec command: {}. stdout={}, stderr={}, shell={}'.format(\n command,\n stdout,\n stderr,\n shell))\n Executor.exec_cmd_only_success(command.split(' '), stdout, stderr, shell=shell)\n\n stemps_after = self.data_file_timesteps()\n\n sym_diff = stemps_after ^ stemps_before\n self._modified_content_filenames = set([filename for filename, timestemp in sym_diff])\n\n Logger.debug(u'[Repository change] Identified modifications: {}'.format(\n u', '.join(self._modified_content_filenames)))\n\n self._stated_data_items = []\n self._externally_created_files = []\n self._created_status_files = []\n self._init_file_states()\n\n @property\n def modified_content_data_items(self):\n return [self._settings.path_factory.data_item(file) for file in self._modified_content_filenames]\n\n @cached_property\n def removed_data_items(self):\n return [x for x in self._stated_data_items if x.is_removed]\n\n @cached_property\n def modified_data_items(self):\n return [x for x in self._stated_data_items if x.is_modified]\n\n @cached_property\n def new_data_items(self):\n return [x for x in self._stated_data_items if x.is_new]\n\n @cached_property\n def unusual_data_items(self):\n return [x for x in self._stated_data_items if x.is_unusual]\n\n @property\n def changed_data_items(self):\n res = set(self.new_data_items + self.modified_data_items + self.modified_content_data_items)\n return list(res)\n\n def _add_stated_data_item(self, state, file):\n try:\n item = self._settings.path_factory.stated_data_item(state, file)\n self._stated_data_items.append(item)\n Logger.debug('[Repository change] Add status: {} {}'.format(\n item.status,\n item.data.dvc))\n except DataItemInStatusDirError:\n self._created_status_files.append(file)\n except DataDirError:\n self._externally_created_files.append(file)\n pass\n\n def _init_file_states(self):\n statuses = GitWrapper.git_file_statuses()\n\n for status, file in statuses:\n file_path = os.path.join(self._settings.git.git_dir_abs, file)\n\n if not os.path.isdir(file_path):\n self._add_stated_data_item(status, file_path)\n else:\n files = []\n self.get_all_files_from_dir(file_path, files)\n state = StatedDataItem.STATUS_UNTRACKED + StatedDataItem.STATUS_UNTRACKED\n for f in files:\n self._add_stated_data_item(state, f)\n pass\n\n def get_all_files_from_dir(self, dir, result):\n files = os.listdir(dir)\n for f in files:\n path = os.path.join(dir, f)\n if os.path.isfile(path):\n result.append(path)\n else:\n self.get_all_files_from_dir(path, result)\n pass\n\n @property\n def externally_created_files(self):\n return self._externally_created_files\n\n @property\n def created_status_files(self):\n return self._created_status_files\n\n def data_file_timesteps(self):\n res = set()\n for root, dirs, files in os.walk(self._settings.git.git_dir_abs):\n if root.startswith(os.path.join(self._settings.git.git_dir_abs, ConfigI.CONFIG_DIR)):\n continue\n\n for file in files:\n filename = os.path.join(root, file)\n if os.path.exists(filename):\n timestemp = os.path.getmtime(filename)\n res.add((filename, timestemp))\n\n return res\n", "path": "dvc/repository_change.py"}, {"content": "import os\nimport stat\n\nfrom dvc.config import ConfigI\nfrom dvc.path.path import Path\nfrom dvc.exceptions import DvcException\nfrom dvc.system import System\nfrom dvc.utils import cached_property\nfrom dvc.data_cloud import file_md5\nfrom dvc.state_file import CacheStateFile, LocalStateFile\n\n\nclass DataItemError(DvcException):\n def __init__(self, msg):\n super(DataItemError, self).__init__('Data item error: {}'.format(msg))\n\n\nclass DataDirError(DvcException):\n def __init__(self, msg):\n super(DataDirError, self).__init__(msg)\n\n\nclass DataItemInStatusDirError(DataDirError):\n def __init__(self, file):\n msg = 'File \"{}\" is in state directory'.format(file)\n super(DataItemInStatusDirError, self).__init__(msg)\n\n\nclass NotInGitDirError(DataDirError):\n def __init__(self, file, git_dir):\n msg = 'File \"{}\" is not in git directory \"{}\"'.format(file, git_dir)\n super(NotInGitDirError, self).__init__(msg)\n\n\nclass DataItem(object):\n STATE_FILE_SUFFIX = '.state'\n LOCAL_STATE_FILE_SUFFIX = '.local_state'\n CACHE_STATE_FILE_SUFFIX = '.cache_state'\n CACHE_FILE_SEP = '_'\n\n def __init__(self, data_file, git, config, cache_file=None):\n self._git = git\n self._config = config\n self._cache_file = cache_file\n\n self._data = Path(data_file, git)\n\n if not self._data.abs.startswith(self._git.git_dir_abs):\n raise NotInGitDirError(data_file, self._git.git_dir_abs)\n\n if self._data.abs.startswith(self.state_dir_abs):\n raise DataItemInStatusDirError(data_file)\n\n pass\n\n def copy(self, cache_file=None):\n if not cache_file:\n cache_file = self._cache_file\n\n return DataItem(self._data.abs, self._git, self._config, cache_file)\n\n def __hash__(self):\n return self.data.dvc.__hash__()\n\n def __eq__(self, other):\n if other == None:\n return False\n\n return self.data.dvc == other.data.dvc\n\n @property\n def data(self):\n return self._data\n\n @cached_property\n def state_dir(self):\n return os.path.join(self._git.git_dir_abs, self._config.state_dir)\n\n def _state(self, suffix):\n state_file = os.path.join(self.state_dir, self.data.dvc + suffix)\n return Path(state_file, self._git)\n\n @cached_property\n def state(self):\n return self._state(self.STATE_FILE_SUFFIX)\n\n @cached_property\n def cache_dir_abs(self):\n return os.path.join(self._git.git_dir_abs, ConfigI.CACHE_DIR)\n\n @cached_property\n def local_state(self):\n return self._state(self.LOCAL_STATE_FILE_SUFFIX)\n\n @cached_property\n def cache_state(self):\n return self._state(self.CACHE_STATE_FILE_SUFFIX)\n\n @cached_property\n def cache_dir(self):\n return os.path.join(self._git.git_dir_abs, self._config.cache_dir)\n\n @property\n def cache(self):\n cache_dir = self.cache_dir_abs\n\n if self._cache_file:\n file_name = os.path.relpath(os.path.realpath(self._cache_file), cache_dir)\n else:\n file_name = CacheStateFile.load(self).md5\n\n cache_file = os.path.join(cache_dir, file_name)\n return Path(cache_file, self._git)\n\n @cached_property\n def state_dir_abs(self):\n return os.path.join(self._git.git_dir_abs, ConfigI.STATE_DIR)\n\n def move_data_to_cache(self):\n md5 = file_md5(self.data.relative)[0]\n self._cache_file = os.path.join(self.cache_dir_abs, md5)\n self._git.modify_gitignore([self.data.relative])\n if not os.path.isfile(self.cache.relative):\n System.hardlink(self.data.relative, self.cache.relative)\n os.chmod(self.data.relative, stat.S_IREAD)\n\n cache_state = CacheStateFile(self).save()\n\n local_state = LocalStateFile(self).save()\n self._git.modify_gitignore([self.local_state.relative])\n", "path": "dvc/path/data_item.py"}]}
| 3,069 | 482 |
gh_patches_debug_44618
|
rasdani/github-patches
|
git_diff
|
PokemonGoF__PokemonGo-Bot-4144
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Keep heaviest pokemon
### Edited by moderator:
Submitting a request to have an option in the config to keep pokemon by their stats.
Example: Recycle pokemon by size.
---
#### Original Post:
Hi,
Is there a way to keep pokemons based on their weight or size instead of only iv or cp ?
Thanks
</issue>
<code>
[start of pokemongo_bot/cell_workers/transfer_pokemon.py]
1 import json
2 import os
3
4 from pokemongo_bot import inventory
5 from pokemongo_bot.human_behaviour import action_delay
6 from pokemongo_bot.base_task import BaseTask
7 from pokemongo_bot.inventory import Pokemons, Pokemon
8
9
10 class TransferPokemon(BaseTask):
11 SUPPORTED_TASK_API_VERSION = 1
12
13 def initialize(self):
14 self.transfer_wait_min = self.config.get('transfer_wait_min', 1)
15 self.transfer_wait_max = self.config.get('transfer_wait_max', 4)
16
17 def work(self):
18 pokemon_groups = self._release_pokemon_get_groups()
19 for pokemon_id, group in pokemon_groups.iteritems():
20 pokemon_name = Pokemons.name_for(pokemon_id)
21 keep_best, keep_best_cp, keep_best_iv = self._validate_keep_best_config(pokemon_name)
22
23 if keep_best:
24 best_pokemon_ids = set()
25 order_criteria = 'none'
26 if keep_best_cp >= 1:
27 cp_limit = keep_best_cp
28 best_cp_pokemons = sorted(group, key=lambda x: (x.cp, x.iv), reverse=True)[:cp_limit]
29 best_pokemon_ids = set(pokemon.id for pokemon in best_cp_pokemons)
30 order_criteria = 'cp'
31
32 if keep_best_iv >= 1:
33 iv_limit = keep_best_iv
34 best_iv_pokemons = sorted(group, key=lambda x: (x.iv, x.cp), reverse=True)[:iv_limit]
35 best_pokemon_ids |= set(pokemon.id for pokemon in best_iv_pokemons)
36 if order_criteria == 'cp':
37 order_criteria = 'cp and iv'
38 else:
39 order_criteria = 'iv'
40
41 # remove best pokemons from all pokemons array
42 all_pokemons = group
43 best_pokemons = []
44 for best_pokemon_id in best_pokemon_ids:
45 for pokemon in all_pokemons:
46 if best_pokemon_id == pokemon.id:
47 all_pokemons.remove(pokemon)
48 best_pokemons.append(pokemon)
49
50 transfer_pokemons = [pokemon for pokemon in all_pokemons if self.should_release_pokemon(pokemon,True)]
51
52 if transfer_pokemons:
53 if best_pokemons:
54 self.emit_event(
55 'keep_best_release',
56 formatted="Keeping best {amount} {pokemon}, based on {criteria}",
57 data={
58 'amount': len(best_pokemons),
59 'pokemon': pokemon_name,
60 'criteria': order_criteria
61 }
62 )
63 for pokemon in transfer_pokemons:
64 self.release_pokemon(pokemon)
65 else:
66 group = sorted(group, key=lambda x: x.cp, reverse=True)
67 for pokemon in group:
68 if self.should_release_pokemon(pokemon):
69 self.release_pokemon(pokemon)
70
71 def _release_pokemon_get_groups(self):
72 pokemon_groups = {}
73 # TODO: Use new inventory everywhere and then remove the inventory update
74 for pokemon in inventory.pokemons(True).all():
75 if pokemon.in_fort or pokemon.is_favorite:
76 continue
77
78 group_id = pokemon.pokemon_id
79
80 if group_id not in pokemon_groups:
81 pokemon_groups[group_id] = []
82
83 pokemon_groups[group_id].append(pokemon)
84
85 return pokemon_groups
86
87 def should_release_pokemon(self, pokemon, keep_best_mode = False):
88 release_config = self._get_release_config_for(pokemon.name)
89
90 if (keep_best_mode
91 and not release_config.has_key('never_release')
92 and not release_config.has_key('always_release')
93 and not release_config.has_key('release_below_cp')
94 and not release_config.has_key('release_below_iv')):
95 return True
96
97 cp_iv_logic = release_config.get('logic')
98 if not cp_iv_logic:
99 cp_iv_logic = self._get_release_config_for('any').get('logic', 'and')
100
101 release_results = {
102 'cp': False,
103 'iv': False,
104 }
105
106 if release_config.get('never_release', False):
107 return False
108
109 if release_config.get('always_release', False):
110 return True
111
112 release_cp = release_config.get('release_below_cp', 0)
113 if pokemon.cp < release_cp:
114 release_results['cp'] = True
115
116 release_iv = release_config.get('release_below_iv', 0)
117 if pokemon.iv < release_iv:
118 release_results['iv'] = True
119
120 logic_to_function = {
121 'or': lambda x, y: x or y,
122 'and': lambda x, y: x and y
123 }
124
125 if logic_to_function[cp_iv_logic](*release_results.values()):
126 self.emit_event(
127 'future_pokemon_release',
128 formatted="Releasing {pokemon} [CP {cp}] [IV {iv}] based on rule: CP < {below_cp} {cp_iv_logic} IV < {below_iv}",
129 data={
130 'pokemon': pokemon.name,
131 'cp': pokemon.cp,
132 'iv': pokemon.iv,
133 'below_cp': release_cp,
134 'cp_iv_logic': cp_iv_logic.upper(),
135 'below_iv': release_iv
136 }
137 )
138
139 return logic_to_function[cp_iv_logic](*release_results.values())
140
141 def release_pokemon(self, pokemon):
142 """
143
144 :type pokemon: Pokemon
145 """
146 try:
147 if self.bot.config.test:
148 candy_awarded = 1
149 else:
150 response_dict = self.bot.api.release_pokemon(pokemon_id=pokemon.id)
151 candy_awarded = response_dict['responses']['RELEASE_POKEMON']['candy_awarded']
152 except KeyError:
153 return
154
155 # We could refresh here too, but adding 1 saves a inventory request
156 candy = inventory.candies().get(pokemon.pokemon_id)
157 candy.add(candy_awarded)
158 inventory.pokemons().remove(pokemon.id)
159 self.bot.metrics.released_pokemon()
160 self.emit_event(
161 'pokemon_release',
162 formatted='Exchanged {pokemon} [CP {cp}] [IV {iv}] for candy.',
163 data={
164 'pokemon': pokemon.name,
165 'cp': pokemon.cp,
166 'iv': pokemon.iv,
167 'ncp': pokemon.cp_percent,
168 'dps': pokemon.moveset.dps
169 }
170 )
171 action_delay(self.transfer_wait_min, self.transfer_wait_max)
172
173 def _get_release_config_for(self, pokemon):
174 release_config = self.bot.config.release.get(pokemon)
175 if not release_config:
176 release_config = self.bot.config.release.get('any')
177 if not release_config:
178 release_config = {}
179 return release_config
180
181 def _validate_keep_best_config(self, pokemon_name):
182 keep_best = False
183
184 release_config = self._get_release_config_for(pokemon_name)
185
186 keep_best_cp = release_config.get('keep_best_cp', 0)
187 keep_best_iv = release_config.get('keep_best_iv', 0)
188
189 if keep_best_cp or keep_best_iv:
190 keep_best = True
191 try:
192 keep_best_cp = int(keep_best_cp)
193 except ValueError:
194 keep_best_cp = 0
195
196 try:
197 keep_best_iv = int(keep_best_iv)
198 except ValueError:
199 keep_best_iv = 0
200
201 if keep_best_cp < 0 or keep_best_iv < 0:
202 keep_best = False
203
204 if keep_best_cp == 0 and keep_best_iv == 0:
205 keep_best = False
206
207 return keep_best, keep_best_cp, keep_best_iv
208
[end of pokemongo_bot/cell_workers/transfer_pokemon.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/pokemongo_bot/cell_workers/transfer_pokemon.py b/pokemongo_bot/cell_workers/transfer_pokemon.py
--- a/pokemongo_bot/cell_workers/transfer_pokemon.py
+++ b/pokemongo_bot/cell_workers/transfer_pokemon.py
@@ -4,8 +4,7 @@
from pokemongo_bot import inventory
from pokemongo_bot.human_behaviour import action_delay
from pokemongo_bot.base_task import BaseTask
-from pokemongo_bot.inventory import Pokemons, Pokemon
-
+from pokemongo_bot.inventory import Pokemons, Pokemon, Attack
class TransferPokemon(BaseTask):
SUPPORTED_TASK_API_VERSION = 1
@@ -19,10 +18,13 @@
for pokemon_id, group in pokemon_groups.iteritems():
pokemon_name = Pokemons.name_for(pokemon_id)
keep_best, keep_best_cp, keep_best_iv = self._validate_keep_best_config(pokemon_name)
-
+ #TODO continue list possible criteria
+ keep_best_possible_criteria = ['cp','iv', 'iv_attack', 'iv_defense', 'iv_stamina', 'moveset.attack_perfection','moveset.defense_perfection','hp','hp_max']
+ keep_best_custom, keep_best_criteria, keep_amount = self._validate_keep_best_config_custom(pokemon_name, keep_best_possible_criteria)
+
+ best_pokemon_ids = set()
+ order_criteria = 'none'
if keep_best:
- best_pokemon_ids = set()
- order_criteria = 'none'
if keep_best_cp >= 1:
cp_limit = keep_best_cp
best_cp_pokemons = sorted(group, key=lambda x: (x.cp, x.iv), reverse=True)[:cp_limit]
@@ -36,8 +38,14 @@
if order_criteria == 'cp':
order_criteria = 'cp and iv'
else:
- order_criteria = 'iv'
-
+ order_criteria = 'iv'
+ elif keep_best_custom:
+ limit = keep_amount
+ best_pokemons = sorted(group, key=lambda x: keep_best_criteria, reverse=True)[:limit]
+ best_pokemon_ids = set(pokemon.id for pokemon in best_pokemons)
+ order_criteria = ' and '.join(keep_best_criteria)
+
+ if keep_best or keep_best_custom:
# remove best pokemons from all pokemons array
all_pokemons = group
best_pokemons = []
@@ -76,7 +84,7 @@
continue
group_id = pokemon.pokemon_id
-
+
if group_id not in pokemon_groups:
pokemon_groups[group_id] = []
@@ -178,6 +186,32 @@
release_config = {}
return release_config
+ def _validate_keep_best_config_custom(self, pokemon_name, keep_best_possible_custom):
+ keep_best = False
+
+ release_config = self._get_release_config_for(pokemon_name)
+ keep_best_custom = release_config.get('keep_best_custom', '')
+ keep_amount = release_config.get('amount', 0)
+
+ if keep_best_custom and keep_amount:
+ keep_best = True
+
+ keep_best_custom = keep_best_custom.split(',')
+ for _str in keep_best_custom:
+ if _str not in keep_best_possible_custom:
+ keep_best = False
+ break
+
+ try:
+ keep_amount = int(keep_amount)
+ except ValueError:
+ keep_best = False
+
+ if keep_amount < 0:
+ keep_best = False
+
+ return keep_best, keep_best_custom, keep_amount
+
def _validate_keep_best_config(self, pokemon_name):
keep_best = False
@@ -185,7 +219,7 @@
keep_best_cp = release_config.get('keep_best_cp', 0)
keep_best_iv = release_config.get('keep_best_iv', 0)
-
+
if keep_best_cp or keep_best_iv:
keep_best = True
try:
@@ -197,7 +231,7 @@
keep_best_iv = int(keep_best_iv)
except ValueError:
keep_best_iv = 0
-
+
if keep_best_cp < 0 or keep_best_iv < 0:
keep_best = False
|
{"golden_diff": "diff --git a/pokemongo_bot/cell_workers/transfer_pokemon.py b/pokemongo_bot/cell_workers/transfer_pokemon.py\n--- a/pokemongo_bot/cell_workers/transfer_pokemon.py\n+++ b/pokemongo_bot/cell_workers/transfer_pokemon.py\n@@ -4,8 +4,7 @@\n from pokemongo_bot import inventory\n from pokemongo_bot.human_behaviour import action_delay\n from pokemongo_bot.base_task import BaseTask\n-from pokemongo_bot.inventory import Pokemons, Pokemon\n-\n+from pokemongo_bot.inventory import Pokemons, Pokemon, Attack\n \n class TransferPokemon(BaseTask):\n SUPPORTED_TASK_API_VERSION = 1\n@@ -19,10 +18,13 @@\n for pokemon_id, group in pokemon_groups.iteritems():\n pokemon_name = Pokemons.name_for(pokemon_id)\n keep_best, keep_best_cp, keep_best_iv = self._validate_keep_best_config(pokemon_name)\n-\n+ #TODO continue list possible criteria\n+ keep_best_possible_criteria = ['cp','iv', 'iv_attack', 'iv_defense', 'iv_stamina', 'moveset.attack_perfection','moveset.defense_perfection','hp','hp_max']\n+ keep_best_custom, keep_best_criteria, keep_amount = self._validate_keep_best_config_custom(pokemon_name, keep_best_possible_criteria)\n+ \n+ best_pokemon_ids = set()\n+ order_criteria = 'none'\n if keep_best:\n- best_pokemon_ids = set()\n- order_criteria = 'none'\n if keep_best_cp >= 1:\n cp_limit = keep_best_cp\n best_cp_pokemons = sorted(group, key=lambda x: (x.cp, x.iv), reverse=True)[:cp_limit]\n@@ -36,8 +38,14 @@\n if order_criteria == 'cp':\n order_criteria = 'cp and iv'\n else:\n- order_criteria = 'iv'\n-\n+ order_criteria = 'iv' \n+ elif keep_best_custom:\n+ limit = keep_amount\n+ best_pokemons = sorted(group, key=lambda x: keep_best_criteria, reverse=True)[:limit]\n+ best_pokemon_ids = set(pokemon.id for pokemon in best_pokemons)\n+ order_criteria = ' and '.join(keep_best_criteria)\n+ \n+ if keep_best or keep_best_custom:\n # remove best pokemons from all pokemons array\n all_pokemons = group\n best_pokemons = []\n@@ -76,7 +84,7 @@\n continue\n \n group_id = pokemon.pokemon_id\n-\n+ \n if group_id not in pokemon_groups:\n pokemon_groups[group_id] = []\n \n@@ -178,6 +186,32 @@\n release_config = {}\n return release_config\n \n+ def _validate_keep_best_config_custom(self, pokemon_name, keep_best_possible_custom):\n+ keep_best = False\n+\n+ release_config = self._get_release_config_for(pokemon_name) \n+ keep_best_custom = release_config.get('keep_best_custom', '')\n+ keep_amount = release_config.get('amount', 0)\n+\n+ if keep_best_custom and keep_amount:\n+ keep_best = True\n+ \n+ keep_best_custom = keep_best_custom.split(',')\n+ for _str in keep_best_custom:\n+ if _str not in keep_best_possible_custom:\n+ keep_best = False\n+ break\n+\n+ try:\n+ keep_amount = int(keep_amount)\n+ except ValueError:\n+ keep_best = False\n+ \n+ if keep_amount < 0:\n+ keep_best = False\n+ \n+ return keep_best, keep_best_custom, keep_amount\n+ \n def _validate_keep_best_config(self, pokemon_name):\n keep_best = False\n \n@@ -185,7 +219,7 @@\n \n keep_best_cp = release_config.get('keep_best_cp', 0)\n keep_best_iv = release_config.get('keep_best_iv', 0)\n-\n+ \n if keep_best_cp or keep_best_iv:\n keep_best = True\n try:\n@@ -197,7 +231,7 @@\n keep_best_iv = int(keep_best_iv)\n except ValueError:\n keep_best_iv = 0\n-\n+ \n if keep_best_cp < 0 or keep_best_iv < 0:\n keep_best = False\n", "issue": "Keep heaviest pokemon\n### Edited by moderator:\n\nSubmitting a request to have an option in the config to keep pokemon by their stats.\nExample: Recycle pokemon by size.\n\n---\n#### Original Post:\n\nHi,\n\nIs there a way to keep pokemons based on their weight or size instead of only iv or cp ?\n\nThanks\n\n", "before_files": [{"content": "import json\nimport os\n\nfrom pokemongo_bot import inventory\nfrom pokemongo_bot.human_behaviour import action_delay\nfrom pokemongo_bot.base_task import BaseTask\nfrom pokemongo_bot.inventory import Pokemons, Pokemon\n\n\nclass TransferPokemon(BaseTask):\n SUPPORTED_TASK_API_VERSION = 1\n\n def initialize(self):\n self.transfer_wait_min = self.config.get('transfer_wait_min', 1)\n self.transfer_wait_max = self.config.get('transfer_wait_max', 4)\n\n def work(self):\n pokemon_groups = self._release_pokemon_get_groups()\n for pokemon_id, group in pokemon_groups.iteritems():\n pokemon_name = Pokemons.name_for(pokemon_id)\n keep_best, keep_best_cp, keep_best_iv = self._validate_keep_best_config(pokemon_name)\n\n if keep_best:\n best_pokemon_ids = set()\n order_criteria = 'none'\n if keep_best_cp >= 1:\n cp_limit = keep_best_cp\n best_cp_pokemons = sorted(group, key=lambda x: (x.cp, x.iv), reverse=True)[:cp_limit]\n best_pokemon_ids = set(pokemon.id for pokemon in best_cp_pokemons)\n order_criteria = 'cp'\n\n if keep_best_iv >= 1:\n iv_limit = keep_best_iv\n best_iv_pokemons = sorted(group, key=lambda x: (x.iv, x.cp), reverse=True)[:iv_limit]\n best_pokemon_ids |= set(pokemon.id for pokemon in best_iv_pokemons)\n if order_criteria == 'cp':\n order_criteria = 'cp and iv'\n else:\n order_criteria = 'iv'\n\n # remove best pokemons from all pokemons array\n all_pokemons = group\n best_pokemons = []\n for best_pokemon_id in best_pokemon_ids:\n for pokemon in all_pokemons:\n if best_pokemon_id == pokemon.id:\n all_pokemons.remove(pokemon)\n best_pokemons.append(pokemon)\n\n transfer_pokemons = [pokemon for pokemon in all_pokemons if self.should_release_pokemon(pokemon,True)]\n\n if transfer_pokemons:\n if best_pokemons:\n self.emit_event(\n 'keep_best_release',\n formatted=\"Keeping best {amount} {pokemon}, based on {criteria}\",\n data={\n 'amount': len(best_pokemons),\n 'pokemon': pokemon_name,\n 'criteria': order_criteria\n }\n )\n for pokemon in transfer_pokemons:\n self.release_pokemon(pokemon)\n else:\n group = sorted(group, key=lambda x: x.cp, reverse=True)\n for pokemon in group:\n if self.should_release_pokemon(pokemon):\n self.release_pokemon(pokemon)\n\n def _release_pokemon_get_groups(self):\n pokemon_groups = {}\n # TODO: Use new inventory everywhere and then remove the inventory update\n for pokemon in inventory.pokemons(True).all():\n if pokemon.in_fort or pokemon.is_favorite:\n continue\n\n group_id = pokemon.pokemon_id\n\n if group_id not in pokemon_groups:\n pokemon_groups[group_id] = []\n\n pokemon_groups[group_id].append(pokemon)\n\n return pokemon_groups\n\n def should_release_pokemon(self, pokemon, keep_best_mode = False):\n release_config = self._get_release_config_for(pokemon.name)\n\n if (keep_best_mode\n and not release_config.has_key('never_release')\n and not release_config.has_key('always_release')\n and not release_config.has_key('release_below_cp')\n and not release_config.has_key('release_below_iv')):\n return True\n\n cp_iv_logic = release_config.get('logic')\n if not cp_iv_logic:\n cp_iv_logic = self._get_release_config_for('any').get('logic', 'and')\n\n release_results = {\n 'cp': False,\n 'iv': False,\n }\n\n if release_config.get('never_release', False):\n return False\n\n if release_config.get('always_release', False):\n return True\n\n release_cp = release_config.get('release_below_cp', 0)\n if pokemon.cp < release_cp:\n release_results['cp'] = True\n\n release_iv = release_config.get('release_below_iv', 0)\n if pokemon.iv < release_iv:\n release_results['iv'] = True\n\n logic_to_function = {\n 'or': lambda x, y: x or y,\n 'and': lambda x, y: x and y\n }\n\n if logic_to_function[cp_iv_logic](*release_results.values()):\n self.emit_event(\n 'future_pokemon_release',\n formatted=\"Releasing {pokemon} [CP {cp}] [IV {iv}] based on rule: CP < {below_cp} {cp_iv_logic} IV < {below_iv}\",\n data={\n 'pokemon': pokemon.name,\n 'cp': pokemon.cp,\n 'iv': pokemon.iv,\n 'below_cp': release_cp,\n 'cp_iv_logic': cp_iv_logic.upper(),\n 'below_iv': release_iv\n }\n )\n\n return logic_to_function[cp_iv_logic](*release_results.values())\n\n def release_pokemon(self, pokemon):\n \"\"\"\n\n :type pokemon: Pokemon\n \"\"\"\n try:\n if self.bot.config.test:\n candy_awarded = 1\n else:\n response_dict = self.bot.api.release_pokemon(pokemon_id=pokemon.id)\n candy_awarded = response_dict['responses']['RELEASE_POKEMON']['candy_awarded']\n except KeyError:\n return\n\n # We could refresh here too, but adding 1 saves a inventory request\n candy = inventory.candies().get(pokemon.pokemon_id)\n candy.add(candy_awarded)\n inventory.pokemons().remove(pokemon.id)\n self.bot.metrics.released_pokemon()\n self.emit_event(\n 'pokemon_release',\n formatted='Exchanged {pokemon} [CP {cp}] [IV {iv}] for candy.',\n data={\n 'pokemon': pokemon.name,\n 'cp': pokemon.cp,\n 'iv': pokemon.iv,\n 'ncp': pokemon.cp_percent,\n 'dps': pokemon.moveset.dps\n }\n )\n action_delay(self.transfer_wait_min, self.transfer_wait_max)\n\n def _get_release_config_for(self, pokemon):\n release_config = self.bot.config.release.get(pokemon)\n if not release_config:\n release_config = self.bot.config.release.get('any')\n if not release_config:\n release_config = {}\n return release_config\n\n def _validate_keep_best_config(self, pokemon_name):\n keep_best = False\n\n release_config = self._get_release_config_for(pokemon_name)\n\n keep_best_cp = release_config.get('keep_best_cp', 0)\n keep_best_iv = release_config.get('keep_best_iv', 0)\n\n if keep_best_cp or keep_best_iv:\n keep_best = True\n try:\n keep_best_cp = int(keep_best_cp)\n except ValueError:\n keep_best_cp = 0\n\n try:\n keep_best_iv = int(keep_best_iv)\n except ValueError:\n keep_best_iv = 0\n\n if keep_best_cp < 0 or keep_best_iv < 0:\n keep_best = False\n\n if keep_best_cp == 0 and keep_best_iv == 0:\n keep_best = False\n\n return keep_best, keep_best_cp, keep_best_iv\n", "path": "pokemongo_bot/cell_workers/transfer_pokemon.py"}]}
| 2,737 | 955 |
gh_patches_debug_25147
|
rasdani/github-patches
|
git_diff
|
microsoft__torchgeo-1065
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
EuroSAT Dataset URL not being secure anymore
### Description
As `url = "https://madm.dfki.de/files/sentinel/EuroSATallBands.zip"` is not secure anymore, downloading the EuroSat dataset is blocked by default by certify.
We might need to either change the zip source or remove the `https`
### Steps to reproduce
Load the EuroSAT dataset
```python
from torchgeo.datasets import EuroSAT
eurosat_train = EuroSAT(download=True)
```
### Version
0.4.0
</issue>
<code>
[start of torchgeo/datasets/eurosat.py]
1 # Copyright (c) Microsoft Corporation. All rights reserved.
2 # Licensed under the MIT License.
3
4 """EuroSAT dataset."""
5
6 import os
7 from typing import Callable, Dict, Optional, Sequence, cast
8
9 import matplotlib.pyplot as plt
10 import numpy as np
11 import torch
12 from torch import Tensor
13
14 from .geo import NonGeoClassificationDataset
15 from .utils import check_integrity, download_url, extract_archive, rasterio_loader
16
17
18 class EuroSAT(NonGeoClassificationDataset):
19 """EuroSAT dataset.
20
21 The `EuroSAT <https://github.com/phelber/EuroSAT>`__ dataset is based on Sentinel-2
22 satellite images covering 13 spectral bands and consists of 10 target classes with
23 a total of 27,000 labeled and geo-referenced images.
24
25 Dataset format:
26
27 * rasters are 13-channel GeoTiffs
28 * labels are values in the range [0,9]
29
30 Dataset classes:
31
32 * Industrial Buildings
33 * Residential Buildings
34 * Annual Crop
35 * Permanent Crop
36 * River
37 * Sea and Lake
38 * Herbaceous Vegetation
39 * Highway
40 * Pasture
41 * Forest
42
43 This dataset uses the train/val/test splits defined in the "In-domain representation
44 learning for remote sensing" paper:
45
46 * https://arxiv.org/abs/1911.06721
47
48 If you use this dataset in your research, please cite the following papers:
49
50 * https://ieeexplore.ieee.org/document/8736785
51 * https://ieeexplore.ieee.org/document/8519248
52 """
53
54 url = "https://madm.dfki.de/files/sentinel/EuroSATallBands.zip" # 2.0 GB download
55 filename = "EuroSATallBands.zip"
56 md5 = "5ac12b3b2557aa56e1826e981e8e200e"
57
58 # For some reason the class directories are actually nested in this directory
59 base_dir = os.path.join(
60 "ds", "images", "remote_sensing", "otherDatasets", "sentinel_2", "tif"
61 )
62
63 splits = ["train", "val", "test"]
64 split_urls = {
65 "train": "https://storage.googleapis.com/remote_sensing_representations/eurosat-train.txt", # noqa: E501
66 "val": "https://storage.googleapis.com/remote_sensing_representations/eurosat-val.txt", # noqa: E501
67 "test": "https://storage.googleapis.com/remote_sensing_representations/eurosat-test.txt", # noqa: E501
68 }
69 split_md5s = {
70 "train": "908f142e73d6acdf3f482c5e80d851b1",
71 "val": "95de90f2aa998f70a3b2416bfe0687b4",
72 "test": "7ae5ab94471417b6e315763121e67c5f",
73 }
74 classes = [
75 "Industrial Buildings",
76 "Residential Buildings",
77 "Annual Crop",
78 "Permanent Crop",
79 "River",
80 "Sea and Lake",
81 "Herbaceous Vegetation",
82 "Highway",
83 "Pasture",
84 "Forest",
85 ]
86
87 all_band_names = (
88 "B01",
89 "B02",
90 "B03",
91 "B04",
92 "B05",
93 "B06",
94 "B07",
95 "B08",
96 "B08A",
97 "B09",
98 "B10",
99 "B11",
100 "B12",
101 )
102
103 rgb_bands = ("B04", "B03", "B02")
104
105 BAND_SETS = {"all": all_band_names, "rgb": rgb_bands}
106
107 def __init__(
108 self,
109 root: str = "data",
110 split: str = "train",
111 bands: Sequence[str] = BAND_SETS["all"],
112 transforms: Optional[Callable[[Dict[str, Tensor]], Dict[str, Tensor]]] = None,
113 download: bool = False,
114 checksum: bool = False,
115 ) -> None:
116 """Initialize a new EuroSAT dataset instance.
117
118 Args:
119 root: root directory where dataset can be found
120 split: one of "train", "val", or "test"
121 bands: a sequence of band names to load
122 transforms: a function/transform that takes input sample and its target as
123 entry and returns a transformed version
124 download: if True, download dataset and store it in the root directory
125 checksum: if True, check the MD5 of the downloaded files (may be slow)
126
127 Raises:
128 AssertionError: if ``split`` argument is invalid
129 RuntimeError: if ``download=False`` and data is not found, or checksums
130 don't match
131
132 .. versionadded:: 0.3
133 The *bands* parameter.
134 """
135 self.root = root
136 self.transforms = transforms
137 self.download = download
138 self.checksum = checksum
139
140 assert split in ["train", "val", "test"]
141
142 self._validate_bands(bands)
143 self.bands = bands
144 self.band_indices = Tensor(
145 [self.all_band_names.index(b) for b in bands if b in self.all_band_names]
146 ).long()
147
148 self._verify()
149
150 valid_fns = set()
151 with open(os.path.join(self.root, f"eurosat-{split}.txt")) as f:
152 for fn in f:
153 valid_fns.add(fn.strip().replace(".jpg", ".tif"))
154 is_in_split: Callable[[str], bool] = lambda x: os.path.basename(x) in valid_fns
155
156 super().__init__(
157 root=os.path.join(root, self.base_dir),
158 transforms=transforms,
159 loader=rasterio_loader,
160 is_valid_file=is_in_split,
161 )
162
163 def __getitem__(self, index: int) -> Dict[str, Tensor]:
164 """Return an index within the dataset.
165
166 Args:
167 index: index to return
168 Returns:
169 data and label at that index
170 """
171 image, label = self._load_image(index)
172
173 image = torch.index_select(image, dim=0, index=self.band_indices).float()
174 sample = {"image": image, "label": label}
175
176 if self.transforms is not None:
177 sample = self.transforms(sample)
178
179 return sample
180
181 def _check_integrity(self) -> bool:
182 """Check integrity of dataset.
183
184 Returns:
185 True if dataset files are found and/or MD5s match, else False
186 """
187 integrity: bool = check_integrity(
188 os.path.join(self.root, self.filename), self.md5 if self.checksum else None
189 )
190 return integrity
191
192 def _verify(self) -> None:
193 """Verify the integrity of the dataset.
194
195 Raises:
196 RuntimeError: if ``download=False`` but dataset is missing or checksum fails
197 """
198 # Check if the files already exist
199 filepath = os.path.join(self.root, self.base_dir)
200 if os.path.exists(filepath):
201 return
202
203 # Check if zip file already exists (if so then extract)
204 if self._check_integrity():
205 self._extract()
206 return
207
208 # Check if the user requested to download the dataset
209 if not self.download:
210 raise RuntimeError(
211 "Dataset not found in `root` directory and `download=False`, "
212 "either specify a different `root` directory or use `download=True` "
213 "to automatically download the dataset."
214 )
215
216 # Download and extract the dataset
217 self._download()
218 self._extract()
219
220 def _download(self) -> None:
221 """Download the dataset."""
222 download_url(
223 self.url,
224 self.root,
225 filename=self.filename,
226 md5=self.md5 if self.checksum else None,
227 )
228 for split in self.splits:
229 download_url(
230 self.split_urls[split],
231 self.root,
232 filename=f"eurosat-{split}.txt",
233 md5=self.split_md5s[split] if self.checksum else None,
234 )
235
236 def _extract(self) -> None:
237 """Extract the dataset."""
238 filepath = os.path.join(self.root, self.filename)
239 extract_archive(filepath)
240
241 def _validate_bands(self, bands: Sequence[str]) -> None:
242 """Validate list of bands.
243
244 Args:
245 bands: user-provided sequence of bands to load
246
247 Raises:
248 AssertionError: if ``bands`` is not a sequence
249 ValueError: if an invalid band name is provided
250
251 .. versionadded:: 0.3
252 """
253 assert isinstance(bands, Sequence), "'bands' must be a sequence"
254 for band in bands:
255 if band not in self.all_band_names:
256 raise ValueError(f"'{band}' is an invalid band name.")
257
258 def plot(
259 self,
260 sample: Dict[str, Tensor],
261 show_titles: bool = True,
262 suptitle: Optional[str] = None,
263 ) -> plt.Figure:
264 """Plot a sample from the dataset.
265
266 Args:
267 sample: a sample returned by :meth:`NonGeoClassificationDataset.__getitem__`
268 show_titles: flag indicating whether to show titles above each panel
269 suptitle: optional string to use as a suptitle
270
271 Returns:
272 a matplotlib Figure with the rendered sample
273
274 Raises:
275 ValueError: if RGB bands are not found in dataset
276
277 .. versionadded:: 0.2
278 """
279 rgb_indices = []
280 for band in self.rgb_bands:
281 if band in self.bands:
282 rgb_indices.append(self.bands.index(band))
283 else:
284 raise ValueError("Dataset doesn't contain some of the RGB bands")
285
286 image = np.take(sample["image"].numpy(), indices=rgb_indices, axis=0)
287 image = np.rollaxis(image, 0, 3)
288 image = np.clip(image / 3000, 0, 1)
289
290 label = cast(int, sample["label"].item())
291 label_class = self.classes[label]
292
293 showing_predictions = "prediction" in sample
294 if showing_predictions:
295 prediction = cast(int, sample["prediction"].item())
296 prediction_class = self.classes[prediction]
297
298 fig, ax = plt.subplots(figsize=(4, 4))
299 ax.imshow(image)
300 ax.axis("off")
301 if show_titles:
302 title = f"Label: {label_class}"
303 if showing_predictions:
304 title += f"\nPrediction: {prediction_class}"
305 ax.set_title(title)
306
307 if suptitle is not None:
308 plt.suptitle(suptitle)
309 return fig
310
[end of torchgeo/datasets/eurosat.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/torchgeo/datasets/eurosat.py b/torchgeo/datasets/eurosat.py
--- a/torchgeo/datasets/eurosat.py
+++ b/torchgeo/datasets/eurosat.py
@@ -51,7 +51,9 @@
* https://ieeexplore.ieee.org/document/8519248
"""
- url = "https://madm.dfki.de/files/sentinel/EuroSATallBands.zip" # 2.0 GB download
+ # TODO: Change to https after https://github.com/phelber/EuroSAT/issues/10 is
+ # resolved
+ url = "http://madm.dfki.de/files/sentinel/EuroSATallBands.zip" # 2.0 GB download
filename = "EuroSATallBands.zip"
md5 = "5ac12b3b2557aa56e1826e981e8e200e"
@@ -104,6 +106,8 @@
BAND_SETS = {"all": all_band_names, "rgb": rgb_bands}
+ # TODO: reset checksum to False after https://github.com/phelber/EuroSAT/issues/10
+ # is resolved
def __init__(
self,
root: str = "data",
@@ -111,7 +115,7 @@
bands: Sequence[str] = BAND_SETS["all"],
transforms: Optional[Callable[[Dict[str, Tensor]], Dict[str, Tensor]]] = None,
download: bool = False,
- checksum: bool = False,
+ checksum: bool = True,
) -> None:
"""Initialize a new EuroSAT dataset instance.
|
{"golden_diff": "diff --git a/torchgeo/datasets/eurosat.py b/torchgeo/datasets/eurosat.py\n--- a/torchgeo/datasets/eurosat.py\n+++ b/torchgeo/datasets/eurosat.py\n@@ -51,7 +51,9 @@\n * https://ieeexplore.ieee.org/document/8519248\n \"\"\"\n \n- url = \"https://madm.dfki.de/files/sentinel/EuroSATallBands.zip\" # 2.0 GB download\n+ # TODO: Change to https after https://github.com/phelber/EuroSAT/issues/10 is\n+ # resolved\n+ url = \"http://madm.dfki.de/files/sentinel/EuroSATallBands.zip\" # 2.0 GB download\n filename = \"EuroSATallBands.zip\"\n md5 = \"5ac12b3b2557aa56e1826e981e8e200e\"\n \n@@ -104,6 +106,8 @@\n \n BAND_SETS = {\"all\": all_band_names, \"rgb\": rgb_bands}\n \n+ # TODO: reset checksum to False after https://github.com/phelber/EuroSAT/issues/10\n+ # is resolved\n def __init__(\n self,\n root: str = \"data\",\n@@ -111,7 +115,7 @@\n bands: Sequence[str] = BAND_SETS[\"all\"],\n transforms: Optional[Callable[[Dict[str, Tensor]], Dict[str, Tensor]]] = None,\n download: bool = False,\n- checksum: bool = False,\n+ checksum: bool = True,\n ) -> None:\n \"\"\"Initialize a new EuroSAT dataset instance.\n", "issue": "EuroSAT Dataset URL not being secure anymore\n### Description\r\n\r\nAs `url = \"https://madm.dfki.de/files/sentinel/EuroSATallBands.zip\"` is not secure anymore, downloading the EuroSat dataset is blocked by default by certify.\r\n\r\nWe might need to either change the zip source or remove the `https`\r\n\r\n### Steps to reproduce\r\n\r\nLoad the EuroSAT dataset\r\n```python\r\nfrom torchgeo.datasets import EuroSAT\r\neurosat_train = EuroSAT(download=True)\r\n```\r\n\r\n### Version\r\n\r\n0.4.0\n", "before_files": [{"content": "# Copyright (c) Microsoft Corporation. All rights reserved.\n# Licensed under the MIT License.\n\n\"\"\"EuroSAT dataset.\"\"\"\n\nimport os\nfrom typing import Callable, Dict, Optional, Sequence, cast\n\nimport matplotlib.pyplot as plt\nimport numpy as np\nimport torch\nfrom torch import Tensor\n\nfrom .geo import NonGeoClassificationDataset\nfrom .utils import check_integrity, download_url, extract_archive, rasterio_loader\n\n\nclass EuroSAT(NonGeoClassificationDataset):\n \"\"\"EuroSAT dataset.\n\n The `EuroSAT <https://github.com/phelber/EuroSAT>`__ dataset is based on Sentinel-2\n satellite images covering 13 spectral bands and consists of 10 target classes with\n a total of 27,000 labeled and geo-referenced images.\n\n Dataset format:\n\n * rasters are 13-channel GeoTiffs\n * labels are values in the range [0,9]\n\n Dataset classes:\n\n * Industrial Buildings\n * Residential Buildings\n * Annual Crop\n * Permanent Crop\n * River\n * Sea and Lake\n * Herbaceous Vegetation\n * Highway\n * Pasture\n * Forest\n\n This dataset uses the train/val/test splits defined in the \"In-domain representation\n learning for remote sensing\" paper:\n\n * https://arxiv.org/abs/1911.06721\n\n If you use this dataset in your research, please cite the following papers:\n\n * https://ieeexplore.ieee.org/document/8736785\n * https://ieeexplore.ieee.org/document/8519248\n \"\"\"\n\n url = \"https://madm.dfki.de/files/sentinel/EuroSATallBands.zip\" # 2.0 GB download\n filename = \"EuroSATallBands.zip\"\n md5 = \"5ac12b3b2557aa56e1826e981e8e200e\"\n\n # For some reason the class directories are actually nested in this directory\n base_dir = os.path.join(\n \"ds\", \"images\", \"remote_sensing\", \"otherDatasets\", \"sentinel_2\", \"tif\"\n )\n\n splits = [\"train\", \"val\", \"test\"]\n split_urls = {\n \"train\": \"https://storage.googleapis.com/remote_sensing_representations/eurosat-train.txt\", # noqa: E501\n \"val\": \"https://storage.googleapis.com/remote_sensing_representations/eurosat-val.txt\", # noqa: E501\n \"test\": \"https://storage.googleapis.com/remote_sensing_representations/eurosat-test.txt\", # noqa: E501\n }\n split_md5s = {\n \"train\": \"908f142e73d6acdf3f482c5e80d851b1\",\n \"val\": \"95de90f2aa998f70a3b2416bfe0687b4\",\n \"test\": \"7ae5ab94471417b6e315763121e67c5f\",\n }\n classes = [\n \"Industrial Buildings\",\n \"Residential Buildings\",\n \"Annual Crop\",\n \"Permanent Crop\",\n \"River\",\n \"Sea and Lake\",\n \"Herbaceous Vegetation\",\n \"Highway\",\n \"Pasture\",\n \"Forest\",\n ]\n\n all_band_names = (\n \"B01\",\n \"B02\",\n \"B03\",\n \"B04\",\n \"B05\",\n \"B06\",\n \"B07\",\n \"B08\",\n \"B08A\",\n \"B09\",\n \"B10\",\n \"B11\",\n \"B12\",\n )\n\n rgb_bands = (\"B04\", \"B03\", \"B02\")\n\n BAND_SETS = {\"all\": all_band_names, \"rgb\": rgb_bands}\n\n def __init__(\n self,\n root: str = \"data\",\n split: str = \"train\",\n bands: Sequence[str] = BAND_SETS[\"all\"],\n transforms: Optional[Callable[[Dict[str, Tensor]], Dict[str, Tensor]]] = None,\n download: bool = False,\n checksum: bool = False,\n ) -> None:\n \"\"\"Initialize a new EuroSAT dataset instance.\n\n Args:\n root: root directory where dataset can be found\n split: one of \"train\", \"val\", or \"test\"\n bands: a sequence of band names to load\n transforms: a function/transform that takes input sample and its target as\n entry and returns a transformed version\n download: if True, download dataset and store it in the root directory\n checksum: if True, check the MD5 of the downloaded files (may be slow)\n\n Raises:\n AssertionError: if ``split`` argument is invalid\n RuntimeError: if ``download=False`` and data is not found, or checksums\n don't match\n\n .. versionadded:: 0.3\n The *bands* parameter.\n \"\"\"\n self.root = root\n self.transforms = transforms\n self.download = download\n self.checksum = checksum\n\n assert split in [\"train\", \"val\", \"test\"]\n\n self._validate_bands(bands)\n self.bands = bands\n self.band_indices = Tensor(\n [self.all_band_names.index(b) for b in bands if b in self.all_band_names]\n ).long()\n\n self._verify()\n\n valid_fns = set()\n with open(os.path.join(self.root, f\"eurosat-{split}.txt\")) as f:\n for fn in f:\n valid_fns.add(fn.strip().replace(\".jpg\", \".tif\"))\n is_in_split: Callable[[str], bool] = lambda x: os.path.basename(x) in valid_fns\n\n super().__init__(\n root=os.path.join(root, self.base_dir),\n transforms=transforms,\n loader=rasterio_loader,\n is_valid_file=is_in_split,\n )\n\n def __getitem__(self, index: int) -> Dict[str, Tensor]:\n \"\"\"Return an index within the dataset.\n\n Args:\n index: index to return\n Returns:\n data and label at that index\n \"\"\"\n image, label = self._load_image(index)\n\n image = torch.index_select(image, dim=0, index=self.band_indices).float()\n sample = {\"image\": image, \"label\": label}\n\n if self.transforms is not None:\n sample = self.transforms(sample)\n\n return sample\n\n def _check_integrity(self) -> bool:\n \"\"\"Check integrity of dataset.\n\n Returns:\n True if dataset files are found and/or MD5s match, else False\n \"\"\"\n integrity: bool = check_integrity(\n os.path.join(self.root, self.filename), self.md5 if self.checksum else None\n )\n return integrity\n\n def _verify(self) -> None:\n \"\"\"Verify the integrity of the dataset.\n\n Raises:\n RuntimeError: if ``download=False`` but dataset is missing or checksum fails\n \"\"\"\n # Check if the files already exist\n filepath = os.path.join(self.root, self.base_dir)\n if os.path.exists(filepath):\n return\n\n # Check if zip file already exists (if so then extract)\n if self._check_integrity():\n self._extract()\n return\n\n # Check if the user requested to download the dataset\n if not self.download:\n raise RuntimeError(\n \"Dataset not found in `root` directory and `download=False`, \"\n \"either specify a different `root` directory or use `download=True` \"\n \"to automatically download the dataset.\"\n )\n\n # Download and extract the dataset\n self._download()\n self._extract()\n\n def _download(self) -> None:\n \"\"\"Download the dataset.\"\"\"\n download_url(\n self.url,\n self.root,\n filename=self.filename,\n md5=self.md5 if self.checksum else None,\n )\n for split in self.splits:\n download_url(\n self.split_urls[split],\n self.root,\n filename=f\"eurosat-{split}.txt\",\n md5=self.split_md5s[split] if self.checksum else None,\n )\n\n def _extract(self) -> None:\n \"\"\"Extract the dataset.\"\"\"\n filepath = os.path.join(self.root, self.filename)\n extract_archive(filepath)\n\n def _validate_bands(self, bands: Sequence[str]) -> None:\n \"\"\"Validate list of bands.\n\n Args:\n bands: user-provided sequence of bands to load\n\n Raises:\n AssertionError: if ``bands`` is not a sequence\n ValueError: if an invalid band name is provided\n\n .. versionadded:: 0.3\n \"\"\"\n assert isinstance(bands, Sequence), \"'bands' must be a sequence\"\n for band in bands:\n if band not in self.all_band_names:\n raise ValueError(f\"'{band}' is an invalid band name.\")\n\n def plot(\n self,\n sample: Dict[str, Tensor],\n show_titles: bool = True,\n suptitle: Optional[str] = None,\n ) -> plt.Figure:\n \"\"\"Plot a sample from the dataset.\n\n Args:\n sample: a sample returned by :meth:`NonGeoClassificationDataset.__getitem__`\n show_titles: flag indicating whether to show titles above each panel\n suptitle: optional string to use as a suptitle\n\n Returns:\n a matplotlib Figure with the rendered sample\n\n Raises:\n ValueError: if RGB bands are not found in dataset\n\n .. versionadded:: 0.2\n \"\"\"\n rgb_indices = []\n for band in self.rgb_bands:\n if band in self.bands:\n rgb_indices.append(self.bands.index(band))\n else:\n raise ValueError(\"Dataset doesn't contain some of the RGB bands\")\n\n image = np.take(sample[\"image\"].numpy(), indices=rgb_indices, axis=0)\n image = np.rollaxis(image, 0, 3)\n image = np.clip(image / 3000, 0, 1)\n\n label = cast(int, sample[\"label\"].item())\n label_class = self.classes[label]\n\n showing_predictions = \"prediction\" in sample\n if showing_predictions:\n prediction = cast(int, sample[\"prediction\"].item())\n prediction_class = self.classes[prediction]\n\n fig, ax = plt.subplots(figsize=(4, 4))\n ax.imshow(image)\n ax.axis(\"off\")\n if show_titles:\n title = f\"Label: {label_class}\"\n if showing_predictions:\n title += f\"\\nPrediction: {prediction_class}\"\n ax.set_title(title)\n\n if suptitle is not None:\n plt.suptitle(suptitle)\n return fig\n", "path": "torchgeo/datasets/eurosat.py"}]}
| 3,895 | 398 |
gh_patches_debug_20217
|
rasdani/github-patches
|
git_diff
|
python-gitlab__python-gitlab-1655
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Feature Request: Support Milestone Promotion
## Description of the problem, including code/CLI snippet
This request is for supporting the ability to 'promote' a project milestone to a group one. This exists in the Gitlab API.
Specifically, https://docs.gitlab.com/ee/api/milestones.html#promote-project-milestone-to-a-group-milestone
## Expected Behavior
`project.milestones.promote(milestone_id)`
## Actual Behavior
Promotion not supported
## Specifications
- python-gitlab version: latest
- API version you are using (v3/v4): v4
- Gitlab server version (or gitlab.com): Any
</issue>
<code>
[start of gitlab/v4/objects/milestones.py]
1 from gitlab import cli
2 from gitlab import exceptions as exc
3 from gitlab import types
4 from gitlab.base import RequiredOptional, RESTManager, RESTObject, RESTObjectList
5 from gitlab.mixins import CRUDMixin, ObjectDeleteMixin, SaveMixin
6
7 from .issues import GroupIssue, GroupIssueManager, ProjectIssue, ProjectIssueManager
8 from .merge_requests import (
9 GroupMergeRequest,
10 ProjectMergeRequest,
11 ProjectMergeRequestManager,
12 )
13
14 __all__ = [
15 "GroupMilestone",
16 "GroupMilestoneManager",
17 "ProjectMilestone",
18 "ProjectMilestoneManager",
19 ]
20
21
22 class GroupMilestone(SaveMixin, ObjectDeleteMixin, RESTObject):
23 _short_print_attr = "title"
24
25 @cli.register_custom_action("GroupMilestone")
26 @exc.on_http_error(exc.GitlabListError)
27 def issues(self, **kwargs):
28 """List issues related to this milestone.
29
30 Args:
31 all (bool): If True, return all the items, without pagination
32 per_page (int): Number of items to retrieve per request
33 page (int): ID of the page to return (starts with page 1)
34 as_list (bool): If set to False and no pagination option is
35 defined, return a generator instead of a list
36 **kwargs: Extra options to send to the server (e.g. sudo)
37
38 Raises:
39 GitlabAuthenticationError: If authentication is not correct
40 GitlabListError: If the list could not be retrieved
41
42 Returns:
43 RESTObjectList: The list of issues
44 """
45
46 path = "%s/%s/issues" % (self.manager.path, self.get_id())
47 data_list = self.manager.gitlab.http_list(path, as_list=False, **kwargs)
48 manager = GroupIssueManager(self.manager.gitlab, parent=self.manager._parent)
49 # FIXME(gpocentek): the computed manager path is not correct
50 return RESTObjectList(manager, GroupIssue, data_list)
51
52 @cli.register_custom_action("GroupMilestone")
53 @exc.on_http_error(exc.GitlabListError)
54 def merge_requests(self, **kwargs):
55 """List the merge requests related to this milestone.
56
57 Args:
58 all (bool): If True, return all the items, without pagination
59 per_page (int): Number of items to retrieve per request
60 page (int): ID of the page to return (starts with page 1)
61 as_list (bool): If set to False and no pagination option is
62 defined, return a generator instead of a list
63 **kwargs: Extra options to send to the server (e.g. sudo)
64
65 Raises:
66 GitlabAuthenticationError: If authentication is not correct
67 GitlabListError: If the list could not be retrieved
68
69 Returns:
70 RESTObjectList: The list of merge requests
71 """
72 path = "%s/%s/merge_requests" % (self.manager.path, self.get_id())
73 data_list = self.manager.gitlab.http_list(path, as_list=False, **kwargs)
74 manager = GroupIssueManager(self.manager.gitlab, parent=self.manager._parent)
75 # FIXME(gpocentek): the computed manager path is not correct
76 return RESTObjectList(manager, GroupMergeRequest, data_list)
77
78
79 class GroupMilestoneManager(CRUDMixin, RESTManager):
80 _path = "/groups/%(group_id)s/milestones"
81 _obj_cls = GroupMilestone
82 _from_parent_attrs = {"group_id": "id"}
83 _create_attrs = RequiredOptional(
84 required=("title",), optional=("description", "due_date", "start_date")
85 )
86 _update_attrs = RequiredOptional(
87 optional=("title", "description", "due_date", "start_date", "state_event"),
88 )
89 _list_filters = ("iids", "state", "search")
90 _types = {"iids": types.ListAttribute}
91
92
93 class ProjectMilestone(SaveMixin, ObjectDeleteMixin, RESTObject):
94 _short_print_attr = "title"
95
96 @cli.register_custom_action("ProjectMilestone")
97 @exc.on_http_error(exc.GitlabListError)
98 def issues(self, **kwargs):
99 """List issues related to this milestone.
100
101 Args:
102 all (bool): If True, return all the items, without pagination
103 per_page (int): Number of items to retrieve per request
104 page (int): ID of the page to return (starts with page 1)
105 as_list (bool): If set to False and no pagination option is
106 defined, return a generator instead of a list
107 **kwargs: Extra options to send to the server (e.g. sudo)
108
109 Raises:
110 GitlabAuthenticationError: If authentication is not correct
111 GitlabListError: If the list could not be retrieved
112
113 Returns:
114 RESTObjectList: The list of issues
115 """
116
117 path = "%s/%s/issues" % (self.manager.path, self.get_id())
118 data_list = self.manager.gitlab.http_list(path, as_list=False, **kwargs)
119 manager = ProjectIssueManager(self.manager.gitlab, parent=self.manager._parent)
120 # FIXME(gpocentek): the computed manager path is not correct
121 return RESTObjectList(manager, ProjectIssue, data_list)
122
123 @cli.register_custom_action("ProjectMilestone")
124 @exc.on_http_error(exc.GitlabListError)
125 def merge_requests(self, **kwargs):
126 """List the merge requests related to this milestone.
127
128 Args:
129 all (bool): If True, return all the items, without pagination
130 per_page (int): Number of items to retrieve per request
131 page (int): ID of the page to return (starts with page 1)
132 as_list (bool): If set to False and no pagination option is
133 defined, return a generator instead of a list
134 **kwargs: Extra options to send to the server (e.g. sudo)
135
136 Raises:
137 GitlabAuthenticationError: If authentication is not correct
138 GitlabListError: If the list could not be retrieved
139
140 Returns:
141 RESTObjectList: The list of merge requests
142 """
143 path = "%s/%s/merge_requests" % (self.manager.path, self.get_id())
144 data_list = self.manager.gitlab.http_list(path, as_list=False, **kwargs)
145 manager = ProjectMergeRequestManager(
146 self.manager.gitlab, parent=self.manager._parent
147 )
148 # FIXME(gpocentek): the computed manager path is not correct
149 return RESTObjectList(manager, ProjectMergeRequest, data_list)
150
151
152 class ProjectMilestoneManager(CRUDMixin, RESTManager):
153 _path = "/projects/%(project_id)s/milestones"
154 _obj_cls = ProjectMilestone
155 _from_parent_attrs = {"project_id": "id"}
156 _create_attrs = RequiredOptional(
157 required=("title",),
158 optional=("description", "due_date", "start_date", "state_event"),
159 )
160 _update_attrs = RequiredOptional(
161 optional=("title", "description", "due_date", "start_date", "state_event"),
162 )
163 _list_filters = ("iids", "state", "search")
164 _types = {"iids": types.ListAttribute}
165
[end of gitlab/v4/objects/milestones.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/gitlab/v4/objects/milestones.py b/gitlab/v4/objects/milestones.py
--- a/gitlab/v4/objects/milestones.py
+++ b/gitlab/v4/objects/milestones.py
@@ -2,7 +2,7 @@
from gitlab import exceptions as exc
from gitlab import types
from gitlab.base import RequiredOptional, RESTManager, RESTObject, RESTObjectList
-from gitlab.mixins import CRUDMixin, ObjectDeleteMixin, SaveMixin
+from gitlab.mixins import CRUDMixin, ObjectDeleteMixin, PromoteMixin, SaveMixin
from .issues import GroupIssue, GroupIssueManager, ProjectIssue, ProjectIssueManager
from .merge_requests import (
@@ -90,8 +90,9 @@
_types = {"iids": types.ListAttribute}
-class ProjectMilestone(SaveMixin, ObjectDeleteMixin, RESTObject):
+class ProjectMilestone(PromoteMixin, SaveMixin, ObjectDeleteMixin, RESTObject):
_short_print_attr = "title"
+ _update_uses_post = True
@cli.register_custom_action("ProjectMilestone")
@exc.on_http_error(exc.GitlabListError)
|
{"golden_diff": "diff --git a/gitlab/v4/objects/milestones.py b/gitlab/v4/objects/milestones.py\n--- a/gitlab/v4/objects/milestones.py\n+++ b/gitlab/v4/objects/milestones.py\n@@ -2,7 +2,7 @@\n from gitlab import exceptions as exc\n from gitlab import types\n from gitlab.base import RequiredOptional, RESTManager, RESTObject, RESTObjectList\n-from gitlab.mixins import CRUDMixin, ObjectDeleteMixin, SaveMixin\n+from gitlab.mixins import CRUDMixin, ObjectDeleteMixin, PromoteMixin, SaveMixin\n \n from .issues import GroupIssue, GroupIssueManager, ProjectIssue, ProjectIssueManager\n from .merge_requests import (\n@@ -90,8 +90,9 @@\n _types = {\"iids\": types.ListAttribute}\n \n \n-class ProjectMilestone(SaveMixin, ObjectDeleteMixin, RESTObject):\n+class ProjectMilestone(PromoteMixin, SaveMixin, ObjectDeleteMixin, RESTObject):\n _short_print_attr = \"title\"\n+ _update_uses_post = True\n \n @cli.register_custom_action(\"ProjectMilestone\")\n @exc.on_http_error(exc.GitlabListError)\n", "issue": "Feature Request: Support Milestone Promotion\n## Description of the problem, including code/CLI snippet\r\nThis request is for supporting the ability to 'promote' a project milestone to a group one. This exists in the Gitlab API.\r\n\r\nSpecifically, https://docs.gitlab.com/ee/api/milestones.html#promote-project-milestone-to-a-group-milestone\r\n\r\n## Expected Behavior\r\n\r\n`project.milestones.promote(milestone_id)`\r\n\r\n## Actual Behavior\r\n\r\nPromotion not supported\r\n\r\n## Specifications\r\n\r\n - python-gitlab version: latest\r\n - API version you are using (v3/v4): v4\r\n - Gitlab server version (or gitlab.com): Any\r\n\n", "before_files": [{"content": "from gitlab import cli\nfrom gitlab import exceptions as exc\nfrom gitlab import types\nfrom gitlab.base import RequiredOptional, RESTManager, RESTObject, RESTObjectList\nfrom gitlab.mixins import CRUDMixin, ObjectDeleteMixin, SaveMixin\n\nfrom .issues import GroupIssue, GroupIssueManager, ProjectIssue, ProjectIssueManager\nfrom .merge_requests import (\n GroupMergeRequest,\n ProjectMergeRequest,\n ProjectMergeRequestManager,\n)\n\n__all__ = [\n \"GroupMilestone\",\n \"GroupMilestoneManager\",\n \"ProjectMilestone\",\n \"ProjectMilestoneManager\",\n]\n\n\nclass GroupMilestone(SaveMixin, ObjectDeleteMixin, RESTObject):\n _short_print_attr = \"title\"\n\n @cli.register_custom_action(\"GroupMilestone\")\n @exc.on_http_error(exc.GitlabListError)\n def issues(self, **kwargs):\n \"\"\"List issues related to this milestone.\n\n Args:\n all (bool): If True, return all the items, without pagination\n per_page (int): Number of items to retrieve per request\n page (int): ID of the page to return (starts with page 1)\n as_list (bool): If set to False and no pagination option is\n defined, return a generator instead of a list\n **kwargs: Extra options to send to the server (e.g. sudo)\n\n Raises:\n GitlabAuthenticationError: If authentication is not correct\n GitlabListError: If the list could not be retrieved\n\n Returns:\n RESTObjectList: The list of issues\n \"\"\"\n\n path = \"%s/%s/issues\" % (self.manager.path, self.get_id())\n data_list = self.manager.gitlab.http_list(path, as_list=False, **kwargs)\n manager = GroupIssueManager(self.manager.gitlab, parent=self.manager._parent)\n # FIXME(gpocentek): the computed manager path is not correct\n return RESTObjectList(manager, GroupIssue, data_list)\n\n @cli.register_custom_action(\"GroupMilestone\")\n @exc.on_http_error(exc.GitlabListError)\n def merge_requests(self, **kwargs):\n \"\"\"List the merge requests related to this milestone.\n\n Args:\n all (bool): If True, return all the items, without pagination\n per_page (int): Number of items to retrieve per request\n page (int): ID of the page to return (starts with page 1)\n as_list (bool): If set to False and no pagination option is\n defined, return a generator instead of a list\n **kwargs: Extra options to send to the server (e.g. sudo)\n\n Raises:\n GitlabAuthenticationError: If authentication is not correct\n GitlabListError: If the list could not be retrieved\n\n Returns:\n RESTObjectList: The list of merge requests\n \"\"\"\n path = \"%s/%s/merge_requests\" % (self.manager.path, self.get_id())\n data_list = self.manager.gitlab.http_list(path, as_list=False, **kwargs)\n manager = GroupIssueManager(self.manager.gitlab, parent=self.manager._parent)\n # FIXME(gpocentek): the computed manager path is not correct\n return RESTObjectList(manager, GroupMergeRequest, data_list)\n\n\nclass GroupMilestoneManager(CRUDMixin, RESTManager):\n _path = \"/groups/%(group_id)s/milestones\"\n _obj_cls = GroupMilestone\n _from_parent_attrs = {\"group_id\": \"id\"}\n _create_attrs = RequiredOptional(\n required=(\"title\",), optional=(\"description\", \"due_date\", \"start_date\")\n )\n _update_attrs = RequiredOptional(\n optional=(\"title\", \"description\", \"due_date\", \"start_date\", \"state_event\"),\n )\n _list_filters = (\"iids\", \"state\", \"search\")\n _types = {\"iids\": types.ListAttribute}\n\n\nclass ProjectMilestone(SaveMixin, ObjectDeleteMixin, RESTObject):\n _short_print_attr = \"title\"\n\n @cli.register_custom_action(\"ProjectMilestone\")\n @exc.on_http_error(exc.GitlabListError)\n def issues(self, **kwargs):\n \"\"\"List issues related to this milestone.\n\n Args:\n all (bool): If True, return all the items, without pagination\n per_page (int): Number of items to retrieve per request\n page (int): ID of the page to return (starts with page 1)\n as_list (bool): If set to False and no pagination option is\n defined, return a generator instead of a list\n **kwargs: Extra options to send to the server (e.g. sudo)\n\n Raises:\n GitlabAuthenticationError: If authentication is not correct\n GitlabListError: If the list could not be retrieved\n\n Returns:\n RESTObjectList: The list of issues\n \"\"\"\n\n path = \"%s/%s/issues\" % (self.manager.path, self.get_id())\n data_list = self.manager.gitlab.http_list(path, as_list=False, **kwargs)\n manager = ProjectIssueManager(self.manager.gitlab, parent=self.manager._parent)\n # FIXME(gpocentek): the computed manager path is not correct\n return RESTObjectList(manager, ProjectIssue, data_list)\n\n @cli.register_custom_action(\"ProjectMilestone\")\n @exc.on_http_error(exc.GitlabListError)\n def merge_requests(self, **kwargs):\n \"\"\"List the merge requests related to this milestone.\n\n Args:\n all (bool): If True, return all the items, without pagination\n per_page (int): Number of items to retrieve per request\n page (int): ID of the page to return (starts with page 1)\n as_list (bool): If set to False and no pagination option is\n defined, return a generator instead of a list\n **kwargs: Extra options to send to the server (e.g. sudo)\n\n Raises:\n GitlabAuthenticationError: If authentication is not correct\n GitlabListError: If the list could not be retrieved\n\n Returns:\n RESTObjectList: The list of merge requests\n \"\"\"\n path = \"%s/%s/merge_requests\" % (self.manager.path, self.get_id())\n data_list = self.manager.gitlab.http_list(path, as_list=False, **kwargs)\n manager = ProjectMergeRequestManager(\n self.manager.gitlab, parent=self.manager._parent\n )\n # FIXME(gpocentek): the computed manager path is not correct\n return RESTObjectList(manager, ProjectMergeRequest, data_list)\n\n\nclass ProjectMilestoneManager(CRUDMixin, RESTManager):\n _path = \"/projects/%(project_id)s/milestones\"\n _obj_cls = ProjectMilestone\n _from_parent_attrs = {\"project_id\": \"id\"}\n _create_attrs = RequiredOptional(\n required=(\"title\",),\n optional=(\"description\", \"due_date\", \"start_date\", \"state_event\"),\n )\n _update_attrs = RequiredOptional(\n optional=(\"title\", \"description\", \"due_date\", \"start_date\", \"state_event\"),\n )\n _list_filters = (\"iids\", \"state\", \"search\")\n _types = {\"iids\": types.ListAttribute}\n", "path": "gitlab/v4/objects/milestones.py"}]}
| 2,629 | 258 |
gh_patches_debug_66361
|
rasdani/github-patches
|
git_diff
|
opsdroid__opsdroid-737
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Cannot disconnect from SQLite
<!-- Before you post an issue or if you are unsure about something join our gitter channel https://gitter.im/opsdroid/ and ask away! We are more than happy to help you. -->
# Description
SQLite database connector can’t disconnect because of wrong method signature.
## Steps to Reproduce
Enable the SQLite database module, then try to shut down the bot.
## Expected Functionality
The bot should shut down.
## Experienced Functionality
This error message on the console, and the bot remains running (but with the connectors already disconnected).
```
ERROR opsdroid.core: {'message': 'Task exception was never retrieved', 'exception': TypeError('disconnect() takes 1 positional argument but 2 were given',), 'future': <Task finished coro=<OpsDroid.handle_signal() done, defined at /home/polesz/.local/lib/python3.6/site-packages/opsdroid/core.py:121> exception=TypeError('disconnect() takes 1 positional argument but 2 were given',)>}
```
## Versions
- **Opsdroid version:** 0.13.0
- **Python version:** 3.6.6 (bundled with Fedora 28)
- **OS/Docker version:** Fedora 28, no Docker involved
## Additional information
It seems the method signature of `Database.disconnect()` is wrong (should be `async def disconnect(self, opsdroid)`) or the caller (`OpsDroid.unload()`) should not pass the `opsdroid` instance to `database.disconnect()` (personally i’d vote for the former).
</issue>
<code>
[start of opsdroid/database/__init__.py]
1 """A base class for databases to inherit from."""
2
3
4 class Database():
5 """A base database.
6
7 Database classes are used to persist key/value pairs in a database.
8
9 """
10
11 def __init__(self, config):
12 """Create the database.
13
14 Set some basic properties from the database config such as the name
15 of this database. It could also be a good place to setup properties
16 to hold things like the database connection object and the database
17 name.
18
19 Args:
20 config (dict): The config for this database specified in the
21 `configuration.yaml` file.
22
23 """
24 self.name = ""
25 self.config = config
26 self.client = None
27 self.database = None
28
29 async def connect(self, opsdroid):
30 """Connect to database service and store the connection object.
31
32 This method should connect to the given database using a native
33 python library for that database. The library will most likely involve
34 a connection object which will be used by the put and get methods.
35 This object should be stored in self.
36
37 Args:
38 opsdroid (OpsDroid): An instance of the opsdroid core.
39
40 """
41 raise NotImplementedError
42
43 async def disconnect(self):
44 """Disconnect from the database.
45
46 This method should disconnect from the given database using a native
47 python library for that database.
48
49 """
50 pass
51
52 async def put(self, key, data):
53 """Store the data object in a database against the key.
54
55 The data object will need to be serialised in a sensible way which
56 suits the database being used and allows for reconstruction of the
57 object.
58
59 Args:
60 key (string): The key to store the data object under.
61 data (object): The data object to store.
62
63 Returns:
64 bool: True for data successfully stored, False otherwise.
65
66 """
67 raise NotImplementedError
68
69 async def get(self, key):
70 """Return a data object for a given key.
71
72 Args:
73 key (string): The key to lookup in the database.
74
75 Returns:
76 object or None: The data object stored for that key, or None if no
77 object found for that key.
78
79 """
80 raise NotImplementedError
81
[end of opsdroid/database/__init__.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/opsdroid/database/__init__.py b/opsdroid/database/__init__.py
--- a/opsdroid/database/__init__.py
+++ b/opsdroid/database/__init__.py
@@ -40,7 +40,7 @@
"""
raise NotImplementedError
- async def disconnect(self):
+ async def disconnect(self, opsdroid):
"""Disconnect from the database.
This method should disconnect from the given database using a native
|
{"golden_diff": "diff --git a/opsdroid/database/__init__.py b/opsdroid/database/__init__.py\n--- a/opsdroid/database/__init__.py\n+++ b/opsdroid/database/__init__.py\n@@ -40,7 +40,7 @@\n \"\"\"\n raise NotImplementedError\n \n- async def disconnect(self):\n+ async def disconnect(self, opsdroid):\n \"\"\"Disconnect from the database.\n \n This method should disconnect from the given database using a native\n", "issue": "Cannot disconnect from SQLite\n<!-- Before you post an issue or if you are unsure about something join our gitter channel https://gitter.im/opsdroid/ and ask away! We are more than happy to help you. -->\r\n# Description\r\nSQLite database connector can\u2019t disconnect because of wrong method signature.\r\n\r\n## Steps to Reproduce\r\nEnable the SQLite database module, then try to shut down the bot.\r\n\r\n\r\n## Expected Functionality\r\nThe bot should shut down.\r\n\r\n## Experienced Functionality\r\nThis error message on the console, and the bot remains running (but with the connectors already disconnected).\r\n\r\n```\r\nERROR opsdroid.core: {'message': 'Task exception was never retrieved', 'exception': TypeError('disconnect() takes 1 positional argument but 2 were given',), 'future': <Task finished coro=<OpsDroid.handle_signal() done, defined at /home/polesz/.local/lib/python3.6/site-packages/opsdroid/core.py:121> exception=TypeError('disconnect() takes 1 positional argument but 2 were given',)>}\r\n```\r\n\r\n## Versions\r\n- **Opsdroid version:** 0.13.0\r\n- **Python version:** 3.6.6 (bundled with Fedora 28)\r\n- **OS/Docker version:** Fedora 28, no Docker involved\r\n\r\n## Additional information\r\nIt seems the method signature of `Database.disconnect()` is wrong (should be `async def disconnect(self, opsdroid)`) or the caller (`OpsDroid.unload()`) should not pass the `opsdroid` instance to `database.disconnect()` (personally i\u2019d vote for the former).\n", "before_files": [{"content": "\"\"\"A base class for databases to inherit from.\"\"\"\n\n\nclass Database():\n \"\"\"A base database.\n\n Database classes are used to persist key/value pairs in a database.\n\n \"\"\"\n\n def __init__(self, config):\n \"\"\"Create the database.\n\n Set some basic properties from the database config such as the name\n of this database. It could also be a good place to setup properties\n to hold things like the database connection object and the database\n name.\n\n Args:\n config (dict): The config for this database specified in the\n `configuration.yaml` file.\n\n \"\"\"\n self.name = \"\"\n self.config = config\n self.client = None\n self.database = None\n\n async def connect(self, opsdroid):\n \"\"\"Connect to database service and store the connection object.\n\n This method should connect to the given database using a native\n python library for that database. The library will most likely involve\n a connection object which will be used by the put and get methods.\n This object should be stored in self.\n\n Args:\n opsdroid (OpsDroid): An instance of the opsdroid core.\n\n \"\"\"\n raise NotImplementedError\n\n async def disconnect(self):\n \"\"\"Disconnect from the database.\n\n This method should disconnect from the given database using a native\n python library for that database.\n\n \"\"\"\n pass\n\n async def put(self, key, data):\n \"\"\"Store the data object in a database against the key.\n\n The data object will need to be serialised in a sensible way which\n suits the database being used and allows for reconstruction of the\n object.\n\n Args:\n key (string): The key to store the data object under.\n data (object): The data object to store.\n\n Returns:\n bool: True for data successfully stored, False otherwise.\n\n \"\"\"\n raise NotImplementedError\n\n async def get(self, key):\n \"\"\"Return a data object for a given key.\n\n Args:\n key (string): The key to lookup in the database.\n\n Returns:\n object or None: The data object stored for that key, or None if no\n object found for that key.\n\n \"\"\"\n raise NotImplementedError\n", "path": "opsdroid/database/__init__.py"}]}
| 1,517 | 105 |
gh_patches_debug_8557
|
rasdani/github-patches
|
git_diff
|
mesonbuild__meson-3498
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
MSI Installer: Support upgrade
I just attempted to upgrade from meson `0.42.1` to `0.43` and was presented with this screen using the MSI installer

At the very least, that error message should be a bit more clear.
Besides that - a huge :+1: for having a windows installer!
</issue>
<code>
[start of msi/createmsi.py]
1 #!/usr/bin/env python3
2
3 # Copyright 2017 The Meson development team
4 #
5 # Licensed under the Apache License, Version 2.0 (the "License");
6 # you may not use this file except in compliance with the License.
7 # You may obtain a copy of the License at
8 #
9 # http://www.apache.org/licenses/LICENSE-2.0
10 #
11 # Unless required by applicable law or agreed to in writing, software
12 # distributed under the License is distributed on an "AS IS" BASIS,
13 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
14 # See the License for the specific language governing permissions and
15 # limitations under the License.
16
17 import sys, os, subprocess, shutil, uuid
18 from glob import glob
19 import platform
20 import xml.etree.ElementTree as ET
21
22 sys.path.append(os.getcwd())
23 from mesonbuild import coredata
24
25 def gen_guid():
26 return str(uuid.uuid4()).upper()
27
28 class Node:
29 def __init__(self, dirs, files):
30 assert(isinstance(dirs, list))
31 assert(isinstance(files, list))
32 self.dirs = dirs
33 self.files = files
34
35 class PackageGenerator:
36
37 def __init__(self):
38 self.product_name = 'Meson Build System'
39 self.manufacturer = 'The Meson Development Team'
40 self.version = coredata.version.replace('dev', '')
41 self.guid = 'DF5B3ECA-4A31-43E3-8CE4-97FC8A97212E'
42 self.update_guid = '141527EE-E28A-4D14-97A4-92E6075D28B2'
43 self.main_xml = 'meson.wxs'
44 self.main_o = 'meson.wixobj'
45 self.bytesize = 32 if '32' in platform.architecture()[0] else 64
46 # rely on the environment variable since python architecture may not be the same as system architecture
47 if 'PROGRAMFILES(X86)' in os.environ:
48 self.bytesize = 64
49 self.final_output = 'meson-%s-%d.msi' % (self.version, self.bytesize)
50 self.staging_dirs = ['dist', 'dist2']
51 if self.bytesize == 64:
52 self.progfile_dir = 'ProgramFiles64Folder'
53 redist_glob = 'C:\\Program Files (x86)\\Microsoft Visual Studio\\2017\\Community\\VC\\Redist\\MSVC\\*\\MergeModules\\Microsoft_VC141_CRT_x64.msm'
54 else:
55 self.progfile_dir = 'ProgramFilesFolder'
56 redist_glob = 'C:\\Program Files\\Microsoft Visual Studio\\2017\\Community\\VC\\Redist\\MSVC\\*\\MergeModules\\Microsoft_VC141_CRT_x86.msm'
57 trials = glob(redist_glob)
58 if len(trials) != 1:
59 sys.exit('There are more than one potential redist dirs.')
60 self.redist_path = trials[0]
61 self.component_num = 0
62 self.feature_properties = {
63 self.staging_dirs[0]: {
64 'Id': 'MainProgram',
65 'Title': 'Meson',
66 'Description': 'Meson executables',
67 'Level': '1',
68 'Absent': 'disallow',
69 },
70 self.staging_dirs[1]: {
71 'Id': 'NinjaProgram',
72 'Title': 'Ninja',
73 'Description': 'Ninja build tool',
74 'Level': '1',
75 }
76 }
77 self.feature_components = {}
78 for sd in self.staging_dirs:
79 self.feature_components[sd] = []
80
81 def build_dist(self):
82 for sdir in self.staging_dirs:
83 if os.path.exists(sdir):
84 shutil.rmtree(sdir)
85 main_stage, ninja_stage = self.staging_dirs
86 modules = [os.path.splitext(os.path.split(x)[1])[0] for x in glob(os.path.join('mesonbuild/modules/*'))]
87 modules = ['mesonbuild.modules.' + x for x in modules if not x.startswith('_')]
88 modulestr = ','.join(modules)
89 python = shutil.which('python')
90 cxfreeze = os.path.join(os.path.dirname(python), "Scripts", "cxfreeze")
91 if not os.path.isfile(cxfreeze):
92 print("ERROR: This script requires cx_freeze module")
93 sys.exit(1)
94
95 subprocess.check_call([python,
96 cxfreeze,
97 '--target-dir',
98 main_stage,
99 '--include-modules',
100 modulestr,
101 'meson.py'])
102 if not os.path.exists(os.path.join(main_stage, 'meson.exe')):
103 sys.exit('Meson exe missing from staging dir.')
104 os.mkdir(ninja_stage)
105 shutil.copy(shutil.which('ninja'), ninja_stage)
106 if not os.path.exists(os.path.join(ninja_stage, 'ninja.exe')):
107 sys.exit('Ninja exe missing from staging dir.')
108
109 def generate_files(self):
110 self.root = ET.Element('Wix', {'xmlns': 'http://schemas.microsoft.com/wix/2006/wi'})
111 product = ET.SubElement(self.root, 'Product', {
112 'Name': self.product_name,
113 'Manufacturer': 'The Meson Development Team',
114 'Id': self.guid,
115 'UpgradeCode': self.update_guid,
116 'Language': '1033',
117 'Codepage': '1252',
118 'Version': self.version,
119 })
120
121 package = ET.SubElement(product, 'Package', {
122 'Id': '*',
123 'Keywords': 'Installer',
124 'Description': 'Meson %s installer' % self.version,
125 'Comments': 'Meson is a high performance build system',
126 'Manufacturer': 'The Meson Development Team',
127 'InstallerVersion': '500',
128 'Languages': '1033',
129 'Compressed': 'yes',
130 'SummaryCodepage': '1252',
131 })
132
133 if self.bytesize == 64:
134 package.set('Platform', 'x64')
135 ET.SubElement(product, 'Media', {
136 'Id': '1',
137 'Cabinet': 'meson.cab',
138 'EmbedCab': 'yes',
139 })
140 targetdir = ET.SubElement(product, 'Directory', {
141 'Id': 'TARGETDIR',
142 'Name': 'SourceDir',
143 })
144 progfiledir = ET.SubElement(targetdir, 'Directory', {
145 'Id': self.progfile_dir,
146 })
147 installdir = ET.SubElement(progfiledir, 'Directory', {
148 'Id': 'INSTALLDIR',
149 'Name': 'Meson',
150 })
151 ET.SubElement(installdir, 'Merge', {
152 'Id': 'VCRedist',
153 'SourceFile': self.redist_path,
154 'DiskId': '1',
155 'Language': '0',
156 })
157
158 ET.SubElement(product, 'Property', {
159 'Id': 'WIXUI_INSTALLDIR',
160 'Value': 'INSTALLDIR',
161 })
162 ET.SubElement(product, 'UIRef', {
163 'Id': 'WixUI_FeatureTree',
164 })
165 for sd in self.staging_dirs:
166 assert(os.path.isdir(sd))
167 top_feature = ET.SubElement(product, 'Feature', {
168 'Id': 'Complete',
169 'Title': 'Meson ' + self.version,
170 'Description': 'The complete package',
171 'Display': 'expand',
172 'Level': '1',
173 'ConfigurableDirectory': 'INSTALLDIR',
174 })
175 for sd in self.staging_dirs:
176 nodes = {}
177 for root, dirs, files in os.walk(sd):
178 cur_node = Node(dirs, files)
179 nodes[root] = cur_node
180 self.create_xml(nodes, sd, installdir, sd)
181 self.build_features(nodes, top_feature, sd)
182 vcredist_feature = ET.SubElement(top_feature, 'Feature', {
183 'Id': 'VCRedist',
184 'Title': 'Visual C++ runtime',
185 'AllowAdvertise': 'no',
186 'Display': 'hidden',
187 'Level': '1',
188 })
189 ET.SubElement(vcredist_feature, 'MergeRef', {'Id': 'VCRedist'})
190 ET.ElementTree(self.root).write(self.main_xml, encoding='utf-8', xml_declaration=True)
191 # ElementTree can not do prettyprinting so do it manually
192 import xml.dom.minidom
193 doc = xml.dom.minidom.parse(self.main_xml)
194 with open(self.main_xml, 'w') as of:
195 of.write(doc.toprettyxml())
196
197 def build_features(self, nodes, top_feature, staging_dir):
198 feature = ET.SubElement(top_feature, 'Feature', self.feature_properties[staging_dir])
199 for component_id in self.feature_components[staging_dir]:
200 ET.SubElement(feature, 'ComponentRef', {
201 'Id': component_id,
202 })
203
204 def create_xml(self, nodes, current_dir, parent_xml_node, staging_dir):
205 cur_node = nodes[current_dir]
206 if cur_node.files:
207 component_id = 'ApplicationFiles%d' % self.component_num
208 comp_xml_node = ET.SubElement(parent_xml_node, 'Component', {
209 'Id': component_id,
210 'Guid': gen_guid(),
211 })
212 self.feature_components[staging_dir].append(component_id)
213 if self.bytesize == 64:
214 comp_xml_node.set('Win64', 'yes')
215 if self.component_num == 0:
216 ET.SubElement(comp_xml_node, 'Environment', {
217 'Id': 'Environment',
218 'Name': 'PATH',
219 'Part': 'last',
220 'System': 'yes',
221 'Action': 'set',
222 'Value': '[INSTALLDIR]',
223 })
224 self.component_num += 1
225 for f in cur_node.files:
226 file_id = os.path.join(current_dir, f).replace('\\', '_').replace('#', '_').replace('-', '_')
227 ET.SubElement(comp_xml_node, 'File', {
228 'Id': file_id,
229 'Name': f,
230 'Source': os.path.join(current_dir, f),
231 })
232
233 for dirname in cur_node.dirs:
234 dir_id = os.path.join(current_dir, dirname).replace('\\', '_').replace('/', '_')
235 dir_node = ET.SubElement(parent_xml_node, 'Directory', {
236 'Id': dir_id,
237 'Name': dirname,
238 })
239 self.create_xml(nodes, os.path.join(current_dir, dirname), dir_node, staging_dir)
240
241 def build_package(self):
242 wixdir = 'c:\\Program Files\\Wix Toolset v3.11\\bin'
243 if not os.path.isdir(wixdir):
244 wixdir = 'c:\\Program Files (x86)\\Wix Toolset v3.11\\bin'
245 if not os.path.isdir(wixdir):
246 print("ERROR: This script requires WIX")
247 sys.exit(1)
248 subprocess.check_call([os.path.join(wixdir, 'candle'), self.main_xml])
249 subprocess.check_call([os.path.join(wixdir, 'light'),
250 '-ext', 'WixUIExtension',
251 '-cultures:en-us',
252 '-dWixUILicenseRtf=msi\\License.rtf',
253 '-out', self.final_output,
254 self.main_o])
255
256 if __name__ == '__main__':
257 if not os.path.exists('meson.py'):
258 sys.exit(print('Run me in the top level source dir.'))
259 subprocess.check_call(['pip', 'install', '--upgrade', 'cx_freeze'])
260
261 p = PackageGenerator()
262 p.build_dist()
263 p.generate_files()
264 p.build_package()
265
[end of msi/createmsi.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/msi/createmsi.py b/msi/createmsi.py
--- a/msi/createmsi.py
+++ b/msi/createmsi.py
@@ -38,7 +38,7 @@
self.product_name = 'Meson Build System'
self.manufacturer = 'The Meson Development Team'
self.version = coredata.version.replace('dev', '')
- self.guid = 'DF5B3ECA-4A31-43E3-8CE4-97FC8A97212E'
+ self.guid = '*'
self.update_guid = '141527EE-E28A-4D14-97A4-92E6075D28B2'
self.main_xml = 'meson.wxs'
self.main_o = 'meson.wixobj'
|
{"golden_diff": "diff --git a/msi/createmsi.py b/msi/createmsi.py\n--- a/msi/createmsi.py\n+++ b/msi/createmsi.py\n@@ -38,7 +38,7 @@\n self.product_name = 'Meson Build System'\n self.manufacturer = 'The Meson Development Team'\n self.version = coredata.version.replace('dev', '')\n- self.guid = 'DF5B3ECA-4A31-43E3-8CE4-97FC8A97212E'\n+ self.guid = '*'\n self.update_guid = '141527EE-E28A-4D14-97A4-92E6075D28B2'\n self.main_xml = 'meson.wxs'\n self.main_o = 'meson.wixobj'\n", "issue": "MSI Installer: Support upgrade\nI just attempted to upgrade from meson `0.42.1` to `0.43` and was presented with this screen using the MSI installer\r\n\r\n\r\n\r\nAt the very least, that error message should be a bit more clear.\r\n\r\nBesides that - a huge :+1: for having a windows installer!\n", "before_files": [{"content": "#!/usr/bin/env python3\n\n# Copyright 2017 The Meson development team\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport sys, os, subprocess, shutil, uuid\nfrom glob import glob\nimport platform\nimport xml.etree.ElementTree as ET\n\nsys.path.append(os.getcwd())\nfrom mesonbuild import coredata\n\ndef gen_guid():\n return str(uuid.uuid4()).upper()\n\nclass Node:\n def __init__(self, dirs, files):\n assert(isinstance(dirs, list))\n assert(isinstance(files, list))\n self.dirs = dirs\n self.files = files\n\nclass PackageGenerator:\n\n def __init__(self):\n self.product_name = 'Meson Build System'\n self.manufacturer = 'The Meson Development Team'\n self.version = coredata.version.replace('dev', '')\n self.guid = 'DF5B3ECA-4A31-43E3-8CE4-97FC8A97212E'\n self.update_guid = '141527EE-E28A-4D14-97A4-92E6075D28B2'\n self.main_xml = 'meson.wxs'\n self.main_o = 'meson.wixobj'\n self.bytesize = 32 if '32' in platform.architecture()[0] else 64\n # rely on the environment variable since python architecture may not be the same as system architecture\n if 'PROGRAMFILES(X86)' in os.environ:\n self.bytesize = 64\n self.final_output = 'meson-%s-%d.msi' % (self.version, self.bytesize)\n self.staging_dirs = ['dist', 'dist2']\n if self.bytesize == 64:\n self.progfile_dir = 'ProgramFiles64Folder'\n redist_glob = 'C:\\\\Program Files (x86)\\\\Microsoft Visual Studio\\\\2017\\\\Community\\\\VC\\\\Redist\\\\MSVC\\\\*\\\\MergeModules\\\\Microsoft_VC141_CRT_x64.msm'\n else:\n self.progfile_dir = 'ProgramFilesFolder'\n redist_glob = 'C:\\\\Program Files\\\\Microsoft Visual Studio\\\\2017\\\\Community\\\\VC\\\\Redist\\\\MSVC\\\\*\\\\MergeModules\\\\Microsoft_VC141_CRT_x86.msm'\n trials = glob(redist_glob)\n if len(trials) != 1:\n sys.exit('There are more than one potential redist dirs.')\n self.redist_path = trials[0]\n self.component_num = 0\n self.feature_properties = {\n self.staging_dirs[0]: {\n 'Id': 'MainProgram',\n 'Title': 'Meson',\n 'Description': 'Meson executables',\n 'Level': '1',\n 'Absent': 'disallow',\n },\n self.staging_dirs[1]: {\n 'Id': 'NinjaProgram',\n 'Title': 'Ninja',\n 'Description': 'Ninja build tool',\n 'Level': '1',\n }\n }\n self.feature_components = {}\n for sd in self.staging_dirs:\n self.feature_components[sd] = []\n\n def build_dist(self):\n for sdir in self.staging_dirs:\n if os.path.exists(sdir):\n shutil.rmtree(sdir)\n main_stage, ninja_stage = self.staging_dirs\n modules = [os.path.splitext(os.path.split(x)[1])[0] for x in glob(os.path.join('mesonbuild/modules/*'))]\n modules = ['mesonbuild.modules.' + x for x in modules if not x.startswith('_')]\n modulestr = ','.join(modules)\n python = shutil.which('python')\n cxfreeze = os.path.join(os.path.dirname(python), \"Scripts\", \"cxfreeze\")\n if not os.path.isfile(cxfreeze):\n print(\"ERROR: This script requires cx_freeze module\")\n sys.exit(1)\n\n subprocess.check_call([python,\n cxfreeze,\n '--target-dir',\n main_stage,\n '--include-modules',\n modulestr,\n 'meson.py'])\n if not os.path.exists(os.path.join(main_stage, 'meson.exe')):\n sys.exit('Meson exe missing from staging dir.')\n os.mkdir(ninja_stage)\n shutil.copy(shutil.which('ninja'), ninja_stage)\n if not os.path.exists(os.path.join(ninja_stage, 'ninja.exe')):\n sys.exit('Ninja exe missing from staging dir.')\n\n def generate_files(self):\n self.root = ET.Element('Wix', {'xmlns': 'http://schemas.microsoft.com/wix/2006/wi'})\n product = ET.SubElement(self.root, 'Product', {\n 'Name': self.product_name,\n 'Manufacturer': 'The Meson Development Team',\n 'Id': self.guid,\n 'UpgradeCode': self.update_guid,\n 'Language': '1033',\n 'Codepage': '1252',\n 'Version': self.version,\n })\n\n package = ET.SubElement(product, 'Package', {\n 'Id': '*',\n 'Keywords': 'Installer',\n 'Description': 'Meson %s installer' % self.version,\n 'Comments': 'Meson is a high performance build system',\n 'Manufacturer': 'The Meson Development Team',\n 'InstallerVersion': '500',\n 'Languages': '1033',\n 'Compressed': 'yes',\n 'SummaryCodepage': '1252',\n })\n\n if self.bytesize == 64:\n package.set('Platform', 'x64')\n ET.SubElement(product, 'Media', {\n 'Id': '1',\n 'Cabinet': 'meson.cab',\n 'EmbedCab': 'yes',\n })\n targetdir = ET.SubElement(product, 'Directory', {\n 'Id': 'TARGETDIR',\n 'Name': 'SourceDir',\n })\n progfiledir = ET.SubElement(targetdir, 'Directory', {\n 'Id': self.progfile_dir,\n })\n installdir = ET.SubElement(progfiledir, 'Directory', {\n 'Id': 'INSTALLDIR',\n 'Name': 'Meson',\n })\n ET.SubElement(installdir, 'Merge', {\n 'Id': 'VCRedist',\n 'SourceFile': self.redist_path,\n 'DiskId': '1',\n 'Language': '0',\n })\n\n ET.SubElement(product, 'Property', {\n 'Id': 'WIXUI_INSTALLDIR',\n 'Value': 'INSTALLDIR',\n })\n ET.SubElement(product, 'UIRef', {\n 'Id': 'WixUI_FeatureTree',\n })\n for sd in self.staging_dirs:\n assert(os.path.isdir(sd))\n top_feature = ET.SubElement(product, 'Feature', {\n 'Id': 'Complete',\n 'Title': 'Meson ' + self.version,\n 'Description': 'The complete package',\n 'Display': 'expand',\n 'Level': '1',\n 'ConfigurableDirectory': 'INSTALLDIR',\n })\n for sd in self.staging_dirs:\n nodes = {}\n for root, dirs, files in os.walk(sd):\n cur_node = Node(dirs, files)\n nodes[root] = cur_node\n self.create_xml(nodes, sd, installdir, sd)\n self.build_features(nodes, top_feature, sd)\n vcredist_feature = ET.SubElement(top_feature, 'Feature', {\n 'Id': 'VCRedist',\n 'Title': 'Visual C++ runtime',\n 'AllowAdvertise': 'no',\n 'Display': 'hidden',\n 'Level': '1',\n })\n ET.SubElement(vcredist_feature, 'MergeRef', {'Id': 'VCRedist'})\n ET.ElementTree(self.root).write(self.main_xml, encoding='utf-8', xml_declaration=True)\n # ElementTree can not do prettyprinting so do it manually\n import xml.dom.minidom\n doc = xml.dom.minidom.parse(self.main_xml)\n with open(self.main_xml, 'w') as of:\n of.write(doc.toprettyxml())\n\n def build_features(self, nodes, top_feature, staging_dir):\n feature = ET.SubElement(top_feature, 'Feature', self.feature_properties[staging_dir])\n for component_id in self.feature_components[staging_dir]:\n ET.SubElement(feature, 'ComponentRef', {\n 'Id': component_id,\n })\n\n def create_xml(self, nodes, current_dir, parent_xml_node, staging_dir):\n cur_node = nodes[current_dir]\n if cur_node.files:\n component_id = 'ApplicationFiles%d' % self.component_num\n comp_xml_node = ET.SubElement(parent_xml_node, 'Component', {\n 'Id': component_id,\n 'Guid': gen_guid(),\n })\n self.feature_components[staging_dir].append(component_id)\n if self.bytesize == 64:\n comp_xml_node.set('Win64', 'yes')\n if self.component_num == 0:\n ET.SubElement(comp_xml_node, 'Environment', {\n 'Id': 'Environment',\n 'Name': 'PATH',\n 'Part': 'last',\n 'System': 'yes',\n 'Action': 'set',\n 'Value': '[INSTALLDIR]',\n })\n self.component_num += 1\n for f in cur_node.files:\n file_id = os.path.join(current_dir, f).replace('\\\\', '_').replace('#', '_').replace('-', '_')\n ET.SubElement(comp_xml_node, 'File', {\n 'Id': file_id,\n 'Name': f,\n 'Source': os.path.join(current_dir, f),\n })\n\n for dirname in cur_node.dirs:\n dir_id = os.path.join(current_dir, dirname).replace('\\\\', '_').replace('/', '_')\n dir_node = ET.SubElement(parent_xml_node, 'Directory', {\n 'Id': dir_id,\n 'Name': dirname,\n })\n self.create_xml(nodes, os.path.join(current_dir, dirname), dir_node, staging_dir)\n\n def build_package(self):\n wixdir = 'c:\\\\Program Files\\\\Wix Toolset v3.11\\\\bin'\n if not os.path.isdir(wixdir):\n wixdir = 'c:\\\\Program Files (x86)\\\\Wix Toolset v3.11\\\\bin'\n if not os.path.isdir(wixdir):\n print(\"ERROR: This script requires WIX\")\n sys.exit(1)\n subprocess.check_call([os.path.join(wixdir, 'candle'), self.main_xml])\n subprocess.check_call([os.path.join(wixdir, 'light'),\n '-ext', 'WixUIExtension',\n '-cultures:en-us',\n '-dWixUILicenseRtf=msi\\\\License.rtf',\n '-out', self.final_output,\n self.main_o])\n\nif __name__ == '__main__':\n if not os.path.exists('meson.py'):\n sys.exit(print('Run me in the top level source dir.'))\n subprocess.check_call(['pip', 'install', '--upgrade', 'cx_freeze'])\n\n p = PackageGenerator()\n p.build_dist()\n p.generate_files()\n p.build_package()\n", "path": "msi/createmsi.py"}]}
| 3,910 | 197 |
gh_patches_debug_32631
|
rasdani/github-patches
|
git_diff
|
pallets__werkzeug-2493
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Upgrading to 2.2.x results in type errors when importing from werkzeug.routing
After upgrading to werkzeug 2.2.1 importing any class from `werkzeug.routing` results in an error from mypy if `no_implicit_reexport=True`. This was not the case in previous versions as `werkzeug.routing` was a single file submodule.
### Reproduction
Given `eg.py`:
```python
from werkzeug.routing import Rule
```
With `werkzeug==2.2.1`
```shell
$ mypy eg.py --strict
eg.py:1: error: Module "werkzeug.routing" does not explicitly export attribute "Rule"; implicit reexport disabled [attr-defined]
Found 1 error in 1 file (checked 1 source file)
```
With `werkzeug==2.1.0`
```shell
$ mypy eg.py --strict
Success: no issues found in 1 source file```
```
### Environment:
- Python version: 3.10
- Werkzeug version: 2.2.1
</issue>
<code>
[start of src/werkzeug/routing/__init__.py]
1 """When it comes to combining multiple controller or view functions
2 (however you want to call them) you need a dispatcher. A simple way
3 would be applying regular expression tests on the ``PATH_INFO`` and
4 calling registered callback functions that return the value then.
5
6 This module implements a much more powerful system than simple regular
7 expression matching because it can also convert values in the URLs and
8 build URLs.
9
10 Here a simple example that creates a URL map for an application with
11 two subdomains (www and kb) and some URL rules:
12
13 .. code-block:: python
14
15 m = Map([
16 # Static URLs
17 Rule('/', endpoint='static/index'),
18 Rule('/about', endpoint='static/about'),
19 Rule('/help', endpoint='static/help'),
20 # Knowledge Base
21 Subdomain('kb', [
22 Rule('/', endpoint='kb/index'),
23 Rule('/browse/', endpoint='kb/browse'),
24 Rule('/browse/<int:id>/', endpoint='kb/browse'),
25 Rule('/browse/<int:id>/<int:page>', endpoint='kb/browse')
26 ])
27 ], default_subdomain='www')
28
29 If the application doesn't use subdomains it's perfectly fine to not set
30 the default subdomain and not use the `Subdomain` rule factory. The
31 endpoint in the rules can be anything, for example import paths or
32 unique identifiers. The WSGI application can use those endpoints to get the
33 handler for that URL. It doesn't have to be a string at all but it's
34 recommended.
35
36 Now it's possible to create a URL adapter for one of the subdomains and
37 build URLs:
38
39 .. code-block:: python
40
41 c = m.bind('example.com')
42
43 c.build("kb/browse", dict(id=42))
44 'http://kb.example.com/browse/42/'
45
46 c.build("kb/browse", dict())
47 'http://kb.example.com/browse/'
48
49 c.build("kb/browse", dict(id=42, page=3))
50 'http://kb.example.com/browse/42/3'
51
52 c.build("static/about")
53 '/about'
54
55 c.build("static/index", force_external=True)
56 'http://www.example.com/'
57
58 c = m.bind('example.com', subdomain='kb')
59
60 c.build("static/about")
61 'http://www.example.com/about'
62
63 The first argument to bind is the server name *without* the subdomain.
64 Per default it will assume that the script is mounted on the root, but
65 often that's not the case so you can provide the real mount point as
66 second argument:
67
68 .. code-block:: python
69
70 c = m.bind('example.com', '/applications/example')
71
72 The third argument can be the subdomain, if not given the default
73 subdomain is used. For more details about binding have a look at the
74 documentation of the `MapAdapter`.
75
76 And here is how you can match URLs:
77
78 .. code-block:: python
79
80 c = m.bind('example.com')
81
82 c.match("/")
83 ('static/index', {})
84
85 c.match("/about")
86 ('static/about', {})
87
88 c = m.bind('example.com', '/', 'kb')
89
90 c.match("/")
91 ('kb/index', {})
92
93 c.match("/browse/42/23")
94 ('kb/browse', {'id': 42, 'page': 23})
95
96 If matching fails you get a ``NotFound`` exception, if the rule thinks
97 it's a good idea to redirect (for example because the URL was defined
98 to have a slash at the end but the request was missing that slash) it
99 will raise a ``RequestRedirect`` exception. Both are subclasses of
100 ``HTTPException`` so you can use those errors as responses in the
101 application.
102
103 If matching succeeded but the URL rule was incompatible to the given
104 method (for example there were only rules for ``GET`` and ``HEAD`` but
105 routing tried to match a ``POST`` request) a ``MethodNotAllowed``
106 exception is raised.
107 """
108 from .converters import AnyConverter
109 from .converters import BaseConverter
110 from .converters import FloatConverter
111 from .converters import IntegerConverter
112 from .converters import PathConverter
113 from .converters import UnicodeConverter
114 from .converters import UUIDConverter
115 from .converters import ValidationError
116 from .exceptions import BuildError
117 from .exceptions import NoMatch
118 from .exceptions import RequestAliasRedirect
119 from .exceptions import RequestPath
120 from .exceptions import RequestRedirect
121 from .exceptions import RoutingException
122 from .exceptions import WebsocketMismatch
123 from .map import Map
124 from .map import MapAdapter
125 from .matcher import StateMachineMatcher
126 from .rules import EndpointPrefix
127 from .rules import parse_converter_args
128 from .rules import Rule
129 from .rules import RuleFactory
130 from .rules import RuleTemplate
131 from .rules import RuleTemplateFactory
132 from .rules import Subdomain
133 from .rules import Submount
134
[end of src/werkzeug/routing/__init__.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/werkzeug/routing/__init__.py b/src/werkzeug/routing/__init__.py
--- a/src/werkzeug/routing/__init__.py
+++ b/src/werkzeug/routing/__init__.py
@@ -105,29 +105,29 @@
routing tried to match a ``POST`` request) a ``MethodNotAllowed``
exception is raised.
"""
-from .converters import AnyConverter
-from .converters import BaseConverter
-from .converters import FloatConverter
-from .converters import IntegerConverter
-from .converters import PathConverter
-from .converters import UnicodeConverter
-from .converters import UUIDConverter
-from .converters import ValidationError
-from .exceptions import BuildError
-from .exceptions import NoMatch
-from .exceptions import RequestAliasRedirect
-from .exceptions import RequestPath
-from .exceptions import RequestRedirect
-from .exceptions import RoutingException
-from .exceptions import WebsocketMismatch
-from .map import Map
-from .map import MapAdapter
-from .matcher import StateMachineMatcher
-from .rules import EndpointPrefix
-from .rules import parse_converter_args
-from .rules import Rule
-from .rules import RuleFactory
-from .rules import RuleTemplate
-from .rules import RuleTemplateFactory
-from .rules import Subdomain
-from .rules import Submount
+from .converters import AnyConverter as AnyConverter
+from .converters import BaseConverter as BaseConverter
+from .converters import FloatConverter as FloatConverter
+from .converters import IntegerConverter as IntegerConverter
+from .converters import PathConverter as PathConverter
+from .converters import UnicodeConverter as UnicodeConverter
+from .converters import UUIDConverter as UUIDConverter
+from .converters import ValidationError as ValidationError
+from .exceptions import BuildError as BuildError
+from .exceptions import NoMatch as NoMatch
+from .exceptions import RequestAliasRedirect as RequestAliasRedirect
+from .exceptions import RequestPath as RequestPath
+from .exceptions import RequestRedirect as RequestRedirect
+from .exceptions import RoutingException as RoutingException
+from .exceptions import WebsocketMismatch as WebsocketMismatch
+from .map import Map as Map
+from .map import MapAdapter as MapAdapter
+from .matcher import StateMachineMatcher as StateMachineMatcher
+from .rules import EndpointPrefix as EndpointPrefix
+from .rules import parse_converter_args as parse_converter_args
+from .rules import Rule as Rule
+from .rules import RuleFactory as RuleFactory
+from .rules import RuleTemplate as RuleTemplate
+from .rules import RuleTemplateFactory as RuleTemplateFactory
+from .rules import Subdomain as Subdomain
+from .rules import Submount as Submount
|
{"golden_diff": "diff --git a/src/werkzeug/routing/__init__.py b/src/werkzeug/routing/__init__.py\n--- a/src/werkzeug/routing/__init__.py\n+++ b/src/werkzeug/routing/__init__.py\n@@ -105,29 +105,29 @@\n routing tried to match a ``POST`` request) a ``MethodNotAllowed``\n exception is raised.\n \"\"\"\n-from .converters import AnyConverter\n-from .converters import BaseConverter\n-from .converters import FloatConverter\n-from .converters import IntegerConverter\n-from .converters import PathConverter\n-from .converters import UnicodeConverter\n-from .converters import UUIDConverter\n-from .converters import ValidationError\n-from .exceptions import BuildError\n-from .exceptions import NoMatch\n-from .exceptions import RequestAliasRedirect\n-from .exceptions import RequestPath\n-from .exceptions import RequestRedirect\n-from .exceptions import RoutingException\n-from .exceptions import WebsocketMismatch\n-from .map import Map\n-from .map import MapAdapter\n-from .matcher import StateMachineMatcher\n-from .rules import EndpointPrefix\n-from .rules import parse_converter_args\n-from .rules import Rule\n-from .rules import RuleFactory\n-from .rules import RuleTemplate\n-from .rules import RuleTemplateFactory\n-from .rules import Subdomain\n-from .rules import Submount\n+from .converters import AnyConverter as AnyConverter\n+from .converters import BaseConverter as BaseConverter\n+from .converters import FloatConverter as FloatConverter\n+from .converters import IntegerConverter as IntegerConverter\n+from .converters import PathConverter as PathConverter\n+from .converters import UnicodeConverter as UnicodeConverter\n+from .converters import UUIDConverter as UUIDConverter\n+from .converters import ValidationError as ValidationError\n+from .exceptions import BuildError as BuildError\n+from .exceptions import NoMatch as NoMatch\n+from .exceptions import RequestAliasRedirect as RequestAliasRedirect\n+from .exceptions import RequestPath as RequestPath\n+from .exceptions import RequestRedirect as RequestRedirect\n+from .exceptions import RoutingException as RoutingException\n+from .exceptions import WebsocketMismatch as WebsocketMismatch\n+from .map import Map as Map\n+from .map import MapAdapter as MapAdapter\n+from .matcher import StateMachineMatcher as StateMachineMatcher\n+from .rules import EndpointPrefix as EndpointPrefix\n+from .rules import parse_converter_args as parse_converter_args\n+from .rules import Rule as Rule\n+from .rules import RuleFactory as RuleFactory\n+from .rules import RuleTemplate as RuleTemplate\n+from .rules import RuleTemplateFactory as RuleTemplateFactory\n+from .rules import Subdomain as Subdomain\n+from .rules import Submount as Submount\n", "issue": "Upgrading to 2.2.x results in type errors when importing from werkzeug.routing\nAfter upgrading to werkzeug 2.2.1 importing any class from `werkzeug.routing` results in an error from mypy if `no_implicit_reexport=True`. This was not the case in previous versions as `werkzeug.routing` was a single file submodule. \r\n\r\n\r\n### Reproduction\r\nGiven `eg.py`:\r\n```python\r\nfrom werkzeug.routing import Rule\r\n```\r\nWith `werkzeug==2.2.1`\r\n```shell\r\n$ mypy eg.py --strict\r\neg.py:1: error: Module \"werkzeug.routing\" does not explicitly export attribute \"Rule\"; implicit reexport disabled [attr-defined]\r\nFound 1 error in 1 file (checked 1 source file)\r\n```\r\n\r\nWith `werkzeug==2.1.0`\r\n```shell\r\n$ mypy eg.py --strict\r\nSuccess: no issues found in 1 source file```\r\n```\r\n\r\n### Environment:\r\n\r\n- Python version: 3.10\r\n- Werkzeug version: 2.2.1\r\n\n", "before_files": [{"content": "\"\"\"When it comes to combining multiple controller or view functions\n(however you want to call them) you need a dispatcher. A simple way\nwould be applying regular expression tests on the ``PATH_INFO`` and\ncalling registered callback functions that return the value then.\n\nThis module implements a much more powerful system than simple regular\nexpression matching because it can also convert values in the URLs and\nbuild URLs.\n\nHere a simple example that creates a URL map for an application with\ntwo subdomains (www and kb) and some URL rules:\n\n.. code-block:: python\n\n m = Map([\n # Static URLs\n Rule('/', endpoint='static/index'),\n Rule('/about', endpoint='static/about'),\n Rule('/help', endpoint='static/help'),\n # Knowledge Base\n Subdomain('kb', [\n Rule('/', endpoint='kb/index'),\n Rule('/browse/', endpoint='kb/browse'),\n Rule('/browse/<int:id>/', endpoint='kb/browse'),\n Rule('/browse/<int:id>/<int:page>', endpoint='kb/browse')\n ])\n ], default_subdomain='www')\n\nIf the application doesn't use subdomains it's perfectly fine to not set\nthe default subdomain and not use the `Subdomain` rule factory. The\nendpoint in the rules can be anything, for example import paths or\nunique identifiers. The WSGI application can use those endpoints to get the\nhandler for that URL. It doesn't have to be a string at all but it's\nrecommended.\n\nNow it's possible to create a URL adapter for one of the subdomains and\nbuild URLs:\n\n.. code-block:: python\n\n c = m.bind('example.com')\n\n c.build(\"kb/browse\", dict(id=42))\n 'http://kb.example.com/browse/42/'\n\n c.build(\"kb/browse\", dict())\n 'http://kb.example.com/browse/'\n\n c.build(\"kb/browse\", dict(id=42, page=3))\n 'http://kb.example.com/browse/42/3'\n\n c.build(\"static/about\")\n '/about'\n\n c.build(\"static/index\", force_external=True)\n 'http://www.example.com/'\n\n c = m.bind('example.com', subdomain='kb')\n\n c.build(\"static/about\")\n 'http://www.example.com/about'\n\nThe first argument to bind is the server name *without* the subdomain.\nPer default it will assume that the script is mounted on the root, but\noften that's not the case so you can provide the real mount point as\nsecond argument:\n\n.. code-block:: python\n\n c = m.bind('example.com', '/applications/example')\n\nThe third argument can be the subdomain, if not given the default\nsubdomain is used. For more details about binding have a look at the\ndocumentation of the `MapAdapter`.\n\nAnd here is how you can match URLs:\n\n.. code-block:: python\n\n c = m.bind('example.com')\n\n c.match(\"/\")\n ('static/index', {})\n\n c.match(\"/about\")\n ('static/about', {})\n\n c = m.bind('example.com', '/', 'kb')\n\n c.match(\"/\")\n ('kb/index', {})\n\n c.match(\"/browse/42/23\")\n ('kb/browse', {'id': 42, 'page': 23})\n\nIf matching fails you get a ``NotFound`` exception, if the rule thinks\nit's a good idea to redirect (for example because the URL was defined\nto have a slash at the end but the request was missing that slash) it\nwill raise a ``RequestRedirect`` exception. Both are subclasses of\n``HTTPException`` so you can use those errors as responses in the\napplication.\n\nIf matching succeeded but the URL rule was incompatible to the given\nmethod (for example there were only rules for ``GET`` and ``HEAD`` but\nrouting tried to match a ``POST`` request) a ``MethodNotAllowed``\nexception is raised.\n\"\"\"\nfrom .converters import AnyConverter\nfrom .converters import BaseConverter\nfrom .converters import FloatConverter\nfrom .converters import IntegerConverter\nfrom .converters import PathConverter\nfrom .converters import UnicodeConverter\nfrom .converters import UUIDConverter\nfrom .converters import ValidationError\nfrom .exceptions import BuildError\nfrom .exceptions import NoMatch\nfrom .exceptions import RequestAliasRedirect\nfrom .exceptions import RequestPath\nfrom .exceptions import RequestRedirect\nfrom .exceptions import RoutingException\nfrom .exceptions import WebsocketMismatch\nfrom .map import Map\nfrom .map import MapAdapter\nfrom .matcher import StateMachineMatcher\nfrom .rules import EndpointPrefix\nfrom .rules import parse_converter_args\nfrom .rules import Rule\nfrom .rules import RuleFactory\nfrom .rules import RuleTemplate\nfrom .rules import RuleTemplateFactory\nfrom .rules import Subdomain\nfrom .rules import Submount\n", "path": "src/werkzeug/routing/__init__.py"}]}
| 2,106 | 578 |
gh_patches_debug_23941
|
rasdani/github-patches
|
git_diff
|
getsentry__sentry-python-781
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Sets are not breadth-limited
I've got huge repr-s of sets that are included in the stack trace variables without truncation. As I see in `serializer.py`, `Mapping` and `Sequence` are limited to 10 items, but `typing.Set` is not handled yet.
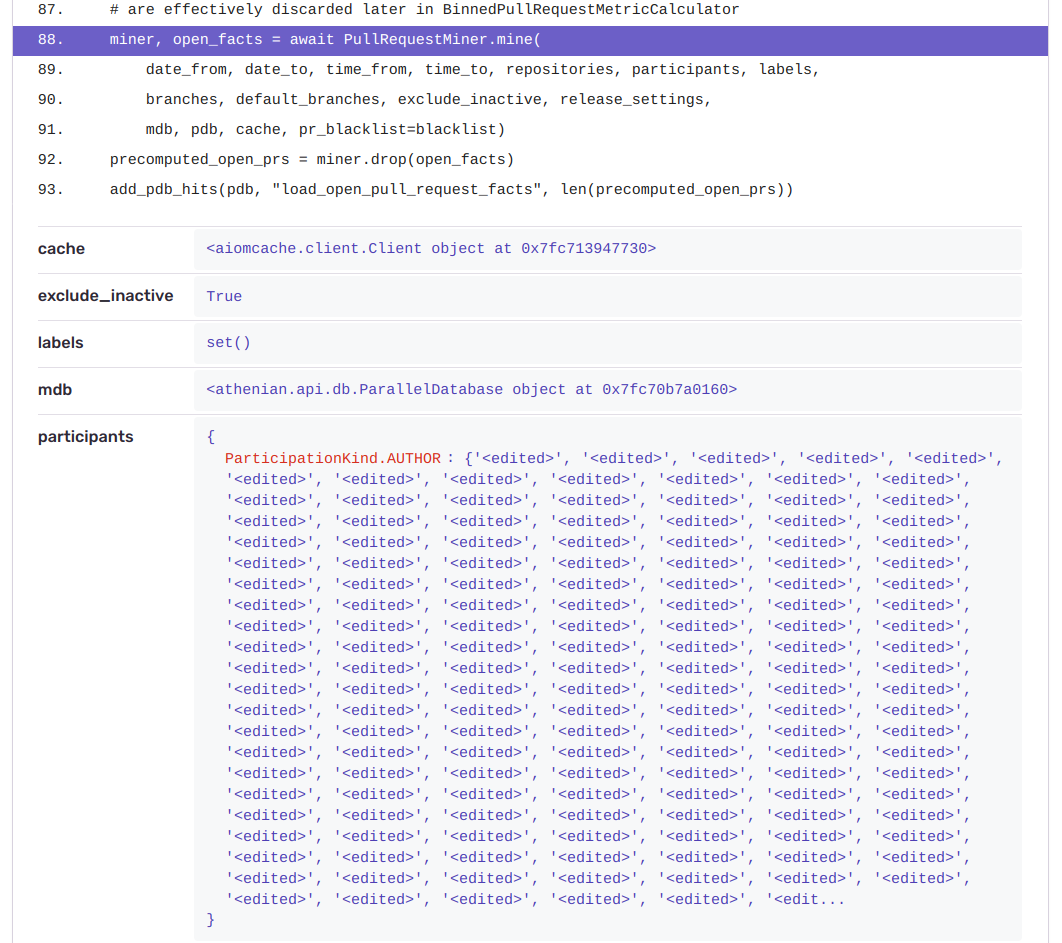
</issue>
<code>
[start of sentry_sdk/serializer.py]
1 import sys
2
3 from datetime import datetime
4
5 from sentry_sdk.utils import (
6 AnnotatedValue,
7 capture_internal_exception,
8 disable_capture_event,
9 safe_repr,
10 strip_string,
11 format_timestamp,
12 )
13
14 from sentry_sdk._compat import text_type, PY2, string_types, number_types, iteritems
15
16 from sentry_sdk._types import MYPY
17
18 if MYPY:
19 from types import TracebackType
20
21 from typing import Any
22 from typing import Dict
23 from typing import List
24 from typing import Optional
25 from typing import Callable
26 from typing import Union
27 from typing import ContextManager
28 from typing import Type
29
30 from sentry_sdk._types import NotImplementedType, Event
31
32 ReprProcessor = Callable[[Any, Dict[str, Any]], Union[NotImplementedType, str]]
33 Segment = Union[str, int]
34
35
36 if PY2:
37 # Importing ABCs from collections is deprecated, and will stop working in 3.8
38 # https://github.com/python/cpython/blob/master/Lib/collections/__init__.py#L49
39 from collections import Mapping, Sequence
40
41 serializable_str_types = string_types
42
43 else:
44 # New in 3.3
45 # https://docs.python.org/3/library/collections.abc.html
46 from collections.abc import Mapping, Sequence
47
48 # Bytes are technically not strings in Python 3, but we can serialize them
49 serializable_str_types = (str, bytes)
50
51 MAX_DATABAG_DEPTH = 5
52 MAX_DATABAG_BREADTH = 10
53 CYCLE_MARKER = u"<cyclic>"
54
55
56 global_repr_processors = [] # type: List[ReprProcessor]
57
58
59 def add_global_repr_processor(processor):
60 # type: (ReprProcessor) -> None
61 global_repr_processors.append(processor)
62
63
64 class Memo(object):
65 __slots__ = ("_ids", "_objs")
66
67 def __init__(self):
68 # type: () -> None
69 self._ids = {} # type: Dict[int, Any]
70 self._objs = [] # type: List[Any]
71
72 def memoize(self, obj):
73 # type: (Any) -> ContextManager[bool]
74 self._objs.append(obj)
75 return self
76
77 def __enter__(self):
78 # type: () -> bool
79 obj = self._objs[-1]
80 if id(obj) in self._ids:
81 return True
82 else:
83 self._ids[id(obj)] = obj
84 return False
85
86 def __exit__(
87 self,
88 ty, # type: Optional[Type[BaseException]]
89 value, # type: Optional[BaseException]
90 tb, # type: Optional[TracebackType]
91 ):
92 # type: (...) -> None
93 self._ids.pop(id(self._objs.pop()), None)
94
95
96 def serialize(event, **kwargs):
97 # type: (Event, **Any) -> Event
98 memo = Memo()
99 path = [] # type: List[Segment]
100 meta_stack = [] # type: List[Dict[str, Any]]
101
102 def _annotate(**meta):
103 # type: (**Any) -> None
104 while len(meta_stack) <= len(path):
105 try:
106 segment = path[len(meta_stack) - 1]
107 node = meta_stack[-1].setdefault(text_type(segment), {})
108 except IndexError:
109 node = {}
110
111 meta_stack.append(node)
112
113 meta_stack[-1].setdefault("", {}).update(meta)
114
115 def _should_repr_strings():
116 # type: () -> Optional[bool]
117 """
118 By default non-serializable objects are going through
119 safe_repr(). For certain places in the event (local vars) we
120 want to repr() even things that are JSON-serializable to
121 make their type more apparent. For example, it's useful to
122 see the difference between a unicode-string and a bytestring
123 when viewing a stacktrace.
124
125 For container-types we still don't do anything different.
126 Generally we just try to make the Sentry UI present exactly
127 what a pretty-printed repr would look like.
128
129 :returns: `True` if we are somewhere in frame variables, and `False` if
130 we are in a position where we will never encounter frame variables
131 when recursing (for example, we're in `event.extra`). `None` if we
132 are not (yet) in frame variables, but might encounter them when
133 recursing (e.g. we're in `event.exception`)
134 """
135 try:
136 p0 = path[0]
137 if p0 == "stacktrace" and path[1] == "frames" and path[3] == "vars":
138 return True
139
140 if (
141 p0 in ("threads", "exception")
142 and path[1] == "values"
143 and path[3] == "stacktrace"
144 and path[4] == "frames"
145 and path[6] == "vars"
146 ):
147 return True
148 except IndexError:
149 return None
150
151 return False
152
153 def _is_databag():
154 # type: () -> Optional[bool]
155 """
156 A databag is any value that we need to trim.
157
158 :returns: Works like `_should_repr_strings()`. `True` for "yes",
159 `False` for :"no", `None` for "maybe soon".
160 """
161 try:
162 rv = _should_repr_strings()
163 if rv in (True, None):
164 return rv
165
166 p0 = path[0]
167 if p0 == "request" and path[1] == "data":
168 return True
169
170 if p0 == "breadcrumbs":
171 path[1]
172 return True
173
174 if p0 == "extra":
175 return True
176
177 except IndexError:
178 return None
179
180 return False
181
182 def _serialize_node(
183 obj, # type: Any
184 is_databag=None, # type: Optional[bool]
185 should_repr_strings=None, # type: Optional[bool]
186 segment=None, # type: Optional[Segment]
187 remaining_breadth=None, # type: Optional[int]
188 remaining_depth=None, # type: Optional[int]
189 ):
190 # type: (...) -> Any
191 if segment is not None:
192 path.append(segment)
193
194 try:
195 with memo.memoize(obj) as result:
196 if result:
197 return CYCLE_MARKER
198
199 return _serialize_node_impl(
200 obj,
201 is_databag=is_databag,
202 should_repr_strings=should_repr_strings,
203 remaining_depth=remaining_depth,
204 remaining_breadth=remaining_breadth,
205 )
206 except BaseException:
207 capture_internal_exception(sys.exc_info())
208
209 if is_databag:
210 return u"<failed to serialize, use init(debug=True) to see error logs>"
211
212 return None
213 finally:
214 if segment is not None:
215 path.pop()
216 del meta_stack[len(path) + 1 :]
217
218 def _flatten_annotated(obj):
219 # type: (Any) -> Any
220 if isinstance(obj, AnnotatedValue):
221 _annotate(**obj.metadata)
222 obj = obj.value
223 return obj
224
225 def _serialize_node_impl(
226 obj, is_databag, should_repr_strings, remaining_depth, remaining_breadth
227 ):
228 # type: (Any, Optional[bool], Optional[bool], Optional[int], Optional[int]) -> Any
229 if should_repr_strings is None:
230 should_repr_strings = _should_repr_strings()
231
232 if is_databag is None:
233 is_databag = _is_databag()
234
235 if is_databag and remaining_depth is None:
236 remaining_depth = MAX_DATABAG_DEPTH
237 if is_databag and remaining_breadth is None:
238 remaining_breadth = MAX_DATABAG_BREADTH
239
240 obj = _flatten_annotated(obj)
241
242 if remaining_depth is not None and remaining_depth <= 0:
243 _annotate(rem=[["!limit", "x"]])
244 if is_databag:
245 return _flatten_annotated(strip_string(safe_repr(obj)))
246 return None
247
248 if is_databag and global_repr_processors:
249 hints = {"memo": memo, "remaining_depth": remaining_depth}
250 for processor in global_repr_processors:
251 result = processor(obj, hints)
252 if result is not NotImplemented:
253 return _flatten_annotated(result)
254
255 if obj is None or isinstance(obj, (bool, number_types)):
256 return obj if not should_repr_strings else safe_repr(obj)
257
258 elif isinstance(obj, datetime):
259 return (
260 text_type(format_timestamp(obj))
261 if not should_repr_strings
262 else safe_repr(obj)
263 )
264
265 elif isinstance(obj, Mapping):
266 # Create temporary copy here to avoid calling too much code that
267 # might mutate our dictionary while we're still iterating over it.
268 obj = dict(iteritems(obj))
269
270 rv_dict = {} # type: Dict[str, Any]
271 i = 0
272
273 for k, v in iteritems(obj):
274 if remaining_breadth is not None and i >= remaining_breadth:
275 _annotate(len=len(obj))
276 break
277
278 str_k = text_type(k)
279 v = _serialize_node(
280 v,
281 segment=str_k,
282 should_repr_strings=should_repr_strings,
283 is_databag=is_databag,
284 remaining_depth=remaining_depth - 1
285 if remaining_depth is not None
286 else None,
287 remaining_breadth=remaining_breadth,
288 )
289 rv_dict[str_k] = v
290 i += 1
291
292 return rv_dict
293
294 elif not isinstance(obj, serializable_str_types) and isinstance(obj, Sequence):
295 rv_list = []
296
297 for i, v in enumerate(obj):
298 if remaining_breadth is not None and i >= remaining_breadth:
299 _annotate(len=len(obj))
300 break
301
302 rv_list.append(
303 _serialize_node(
304 v,
305 segment=i,
306 should_repr_strings=should_repr_strings,
307 is_databag=is_databag,
308 remaining_depth=remaining_depth - 1
309 if remaining_depth is not None
310 else None,
311 remaining_breadth=remaining_breadth,
312 )
313 )
314
315 return rv_list
316
317 if should_repr_strings:
318 obj = safe_repr(obj)
319 else:
320 if isinstance(obj, bytes):
321 obj = obj.decode("utf-8", "replace")
322
323 if not isinstance(obj, string_types):
324 obj = safe_repr(obj)
325
326 return _flatten_annotated(strip_string(obj))
327
328 disable_capture_event.set(True)
329 try:
330 rv = _serialize_node(event, **kwargs)
331 if meta_stack and isinstance(rv, dict):
332 rv["_meta"] = meta_stack[0]
333
334 return rv
335 finally:
336 disable_capture_event.set(False)
337
[end of sentry_sdk/serializer.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/sentry_sdk/serializer.py b/sentry_sdk/serializer.py
--- a/sentry_sdk/serializer.py
+++ b/sentry_sdk/serializer.py
@@ -36,14 +36,14 @@
if PY2:
# Importing ABCs from collections is deprecated, and will stop working in 3.8
# https://github.com/python/cpython/blob/master/Lib/collections/__init__.py#L49
- from collections import Mapping, Sequence
+ from collections import Mapping, Sequence, Set
serializable_str_types = string_types
else:
# New in 3.3
# https://docs.python.org/3/library/collections.abc.html
- from collections.abc import Mapping, Sequence
+ from collections.abc import Mapping, Sequence, Set
# Bytes are technically not strings in Python 3, but we can serialize them
serializable_str_types = (str, bytes)
@@ -291,7 +291,9 @@
return rv_dict
- elif not isinstance(obj, serializable_str_types) and isinstance(obj, Sequence):
+ elif not isinstance(obj, serializable_str_types) and isinstance(
+ obj, (Set, Sequence)
+ ):
rv_list = []
for i, v in enumerate(obj):
|
{"golden_diff": "diff --git a/sentry_sdk/serializer.py b/sentry_sdk/serializer.py\n--- a/sentry_sdk/serializer.py\n+++ b/sentry_sdk/serializer.py\n@@ -36,14 +36,14 @@\n if PY2:\n # Importing ABCs from collections is deprecated, and will stop working in 3.8\n # https://github.com/python/cpython/blob/master/Lib/collections/__init__.py#L49\n- from collections import Mapping, Sequence\n+ from collections import Mapping, Sequence, Set\n \n serializable_str_types = string_types\n \n else:\n # New in 3.3\n # https://docs.python.org/3/library/collections.abc.html\n- from collections.abc import Mapping, Sequence\n+ from collections.abc import Mapping, Sequence, Set\n \n # Bytes are technically not strings in Python 3, but we can serialize them\n serializable_str_types = (str, bytes)\n@@ -291,7 +291,9 @@\n \n return rv_dict\n \n- elif not isinstance(obj, serializable_str_types) and isinstance(obj, Sequence):\n+ elif not isinstance(obj, serializable_str_types) and isinstance(\n+ obj, (Set, Sequence)\n+ ):\n rv_list = []\n \n for i, v in enumerate(obj):\n", "issue": "Sets are not breadth-limited\nI've got huge repr-s of sets that are included in the stack trace variables without truncation. As I see in `serializer.py`, `Mapping` and `Sequence` are limited to 10 items, but `typing.Set` is not handled yet.\r\n\r\n\r\n\r\n\n", "before_files": [{"content": "import sys\n\nfrom datetime import datetime\n\nfrom sentry_sdk.utils import (\n AnnotatedValue,\n capture_internal_exception,\n disable_capture_event,\n safe_repr,\n strip_string,\n format_timestamp,\n)\n\nfrom sentry_sdk._compat import text_type, PY2, string_types, number_types, iteritems\n\nfrom sentry_sdk._types import MYPY\n\nif MYPY:\n from types import TracebackType\n\n from typing import Any\n from typing import Dict\n from typing import List\n from typing import Optional\n from typing import Callable\n from typing import Union\n from typing import ContextManager\n from typing import Type\n\n from sentry_sdk._types import NotImplementedType, Event\n\n ReprProcessor = Callable[[Any, Dict[str, Any]], Union[NotImplementedType, str]]\n Segment = Union[str, int]\n\n\nif PY2:\n # Importing ABCs from collections is deprecated, and will stop working in 3.8\n # https://github.com/python/cpython/blob/master/Lib/collections/__init__.py#L49\n from collections import Mapping, Sequence\n\n serializable_str_types = string_types\n\nelse:\n # New in 3.3\n # https://docs.python.org/3/library/collections.abc.html\n from collections.abc import Mapping, Sequence\n\n # Bytes are technically not strings in Python 3, but we can serialize them\n serializable_str_types = (str, bytes)\n\nMAX_DATABAG_DEPTH = 5\nMAX_DATABAG_BREADTH = 10\nCYCLE_MARKER = u\"<cyclic>\"\n\n\nglobal_repr_processors = [] # type: List[ReprProcessor]\n\n\ndef add_global_repr_processor(processor):\n # type: (ReprProcessor) -> None\n global_repr_processors.append(processor)\n\n\nclass Memo(object):\n __slots__ = (\"_ids\", \"_objs\")\n\n def __init__(self):\n # type: () -> None\n self._ids = {} # type: Dict[int, Any]\n self._objs = [] # type: List[Any]\n\n def memoize(self, obj):\n # type: (Any) -> ContextManager[bool]\n self._objs.append(obj)\n return self\n\n def __enter__(self):\n # type: () -> bool\n obj = self._objs[-1]\n if id(obj) in self._ids:\n return True\n else:\n self._ids[id(obj)] = obj\n return False\n\n def __exit__(\n self,\n ty, # type: Optional[Type[BaseException]]\n value, # type: Optional[BaseException]\n tb, # type: Optional[TracebackType]\n ):\n # type: (...) -> None\n self._ids.pop(id(self._objs.pop()), None)\n\n\ndef serialize(event, **kwargs):\n # type: (Event, **Any) -> Event\n memo = Memo()\n path = [] # type: List[Segment]\n meta_stack = [] # type: List[Dict[str, Any]]\n\n def _annotate(**meta):\n # type: (**Any) -> None\n while len(meta_stack) <= len(path):\n try:\n segment = path[len(meta_stack) - 1]\n node = meta_stack[-1].setdefault(text_type(segment), {})\n except IndexError:\n node = {}\n\n meta_stack.append(node)\n\n meta_stack[-1].setdefault(\"\", {}).update(meta)\n\n def _should_repr_strings():\n # type: () -> Optional[bool]\n \"\"\"\n By default non-serializable objects are going through\n safe_repr(). For certain places in the event (local vars) we\n want to repr() even things that are JSON-serializable to\n make their type more apparent. For example, it's useful to\n see the difference between a unicode-string and a bytestring\n when viewing a stacktrace.\n\n For container-types we still don't do anything different.\n Generally we just try to make the Sentry UI present exactly\n what a pretty-printed repr would look like.\n\n :returns: `True` if we are somewhere in frame variables, and `False` if\n we are in a position where we will never encounter frame variables\n when recursing (for example, we're in `event.extra`). `None` if we\n are not (yet) in frame variables, but might encounter them when\n recursing (e.g. we're in `event.exception`)\n \"\"\"\n try:\n p0 = path[0]\n if p0 == \"stacktrace\" and path[1] == \"frames\" and path[3] == \"vars\":\n return True\n\n if (\n p0 in (\"threads\", \"exception\")\n and path[1] == \"values\"\n and path[3] == \"stacktrace\"\n and path[4] == \"frames\"\n and path[6] == \"vars\"\n ):\n return True\n except IndexError:\n return None\n\n return False\n\n def _is_databag():\n # type: () -> Optional[bool]\n \"\"\"\n A databag is any value that we need to trim.\n\n :returns: Works like `_should_repr_strings()`. `True` for \"yes\",\n `False` for :\"no\", `None` for \"maybe soon\".\n \"\"\"\n try:\n rv = _should_repr_strings()\n if rv in (True, None):\n return rv\n\n p0 = path[0]\n if p0 == \"request\" and path[1] == \"data\":\n return True\n\n if p0 == \"breadcrumbs\":\n path[1]\n return True\n\n if p0 == \"extra\":\n return True\n\n except IndexError:\n return None\n\n return False\n\n def _serialize_node(\n obj, # type: Any\n is_databag=None, # type: Optional[bool]\n should_repr_strings=None, # type: Optional[bool]\n segment=None, # type: Optional[Segment]\n remaining_breadth=None, # type: Optional[int]\n remaining_depth=None, # type: Optional[int]\n ):\n # type: (...) -> Any\n if segment is not None:\n path.append(segment)\n\n try:\n with memo.memoize(obj) as result:\n if result:\n return CYCLE_MARKER\n\n return _serialize_node_impl(\n obj,\n is_databag=is_databag,\n should_repr_strings=should_repr_strings,\n remaining_depth=remaining_depth,\n remaining_breadth=remaining_breadth,\n )\n except BaseException:\n capture_internal_exception(sys.exc_info())\n\n if is_databag:\n return u\"<failed to serialize, use init(debug=True) to see error logs>\"\n\n return None\n finally:\n if segment is not None:\n path.pop()\n del meta_stack[len(path) + 1 :]\n\n def _flatten_annotated(obj):\n # type: (Any) -> Any\n if isinstance(obj, AnnotatedValue):\n _annotate(**obj.metadata)\n obj = obj.value\n return obj\n\n def _serialize_node_impl(\n obj, is_databag, should_repr_strings, remaining_depth, remaining_breadth\n ):\n # type: (Any, Optional[bool], Optional[bool], Optional[int], Optional[int]) -> Any\n if should_repr_strings is None:\n should_repr_strings = _should_repr_strings()\n\n if is_databag is None:\n is_databag = _is_databag()\n\n if is_databag and remaining_depth is None:\n remaining_depth = MAX_DATABAG_DEPTH\n if is_databag and remaining_breadth is None:\n remaining_breadth = MAX_DATABAG_BREADTH\n\n obj = _flatten_annotated(obj)\n\n if remaining_depth is not None and remaining_depth <= 0:\n _annotate(rem=[[\"!limit\", \"x\"]])\n if is_databag:\n return _flatten_annotated(strip_string(safe_repr(obj)))\n return None\n\n if is_databag and global_repr_processors:\n hints = {\"memo\": memo, \"remaining_depth\": remaining_depth}\n for processor in global_repr_processors:\n result = processor(obj, hints)\n if result is not NotImplemented:\n return _flatten_annotated(result)\n\n if obj is None or isinstance(obj, (bool, number_types)):\n return obj if not should_repr_strings else safe_repr(obj)\n\n elif isinstance(obj, datetime):\n return (\n text_type(format_timestamp(obj))\n if not should_repr_strings\n else safe_repr(obj)\n )\n\n elif isinstance(obj, Mapping):\n # Create temporary copy here to avoid calling too much code that\n # might mutate our dictionary while we're still iterating over it.\n obj = dict(iteritems(obj))\n\n rv_dict = {} # type: Dict[str, Any]\n i = 0\n\n for k, v in iteritems(obj):\n if remaining_breadth is not None and i >= remaining_breadth:\n _annotate(len=len(obj))\n break\n\n str_k = text_type(k)\n v = _serialize_node(\n v,\n segment=str_k,\n should_repr_strings=should_repr_strings,\n is_databag=is_databag,\n remaining_depth=remaining_depth - 1\n if remaining_depth is not None\n else None,\n remaining_breadth=remaining_breadth,\n )\n rv_dict[str_k] = v\n i += 1\n\n return rv_dict\n\n elif not isinstance(obj, serializable_str_types) and isinstance(obj, Sequence):\n rv_list = []\n\n for i, v in enumerate(obj):\n if remaining_breadth is not None and i >= remaining_breadth:\n _annotate(len=len(obj))\n break\n\n rv_list.append(\n _serialize_node(\n v,\n segment=i,\n should_repr_strings=should_repr_strings,\n is_databag=is_databag,\n remaining_depth=remaining_depth - 1\n if remaining_depth is not None\n else None,\n remaining_breadth=remaining_breadth,\n )\n )\n\n return rv_list\n\n if should_repr_strings:\n obj = safe_repr(obj)\n else:\n if isinstance(obj, bytes):\n obj = obj.decode(\"utf-8\", \"replace\")\n\n if not isinstance(obj, string_types):\n obj = safe_repr(obj)\n\n return _flatten_annotated(strip_string(obj))\n\n disable_capture_event.set(True)\n try:\n rv = _serialize_node(event, **kwargs)\n if meta_stack and isinstance(rv, dict):\n rv[\"_meta\"] = meta_stack[0]\n\n return rv\n finally:\n disable_capture_event.set(False)\n", "path": "sentry_sdk/serializer.py"}]}
| 3,934 | 288 |
gh_patches_debug_5744
|
rasdani/github-patches
|
git_diff
|
ciudadanointeligente__votainteligente-portal-electoral-427
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
La página de agregar antecedentes no dice mucho.
Actualmente agregar más antecedentes puede ser accedida desde una sola parte:

Y debería ser accesible desde el mail de felicitaciones, la lista de tus propuestas.
Y además debería poder proveer de ejemplos que te permitan hacer de tu propuesta una más completa.
Por ejemplo en la parte donde dice "Background" debería decir algo así como:
"Puedes agregar más antecedentes? como por ejemplo, en qué año se inició el problema? o quizás cuantas veces han intentado darle solución?"
Además debería poder utilizarse esta información en el detalle de la propuesta.
<!---
@huboard:{"order":50.8644609375,"milestone_order":237,"custom_state":""}
-->
</issue>
<code>
[start of popular_proposal/forms/forms.py]
1 # coding=utf-8
2 from django import forms
3 from popular_proposal.models import (ProposalTemporaryData,
4 ProposalLike,
5 PopularProposal)
6 from votainteligente.send_mails import send_mail
7 from django.utils.translation import ugettext as _
8 from django.contrib.sites.models import Site
9 from .form_texts import TEXTS, TOPIC_CHOICES, WHEN_CHOICES
10 from popolo.models import Area
11 from collections import OrderedDict
12
13
14 class TextsFormMixin():
15
16 def add_texts_to_fields(self):
17 for field in self.fields:
18 if field in TEXTS.keys():
19 texts = TEXTS[field]
20 if 'label' in texts.keys() and texts['label']:
21 self.fields[field].label = texts['label']
22 if 'help_text' in texts.keys() and texts['help_text']:
23 self.fields[field].help_text = texts['help_text']
24 if 'placeholder' in texts.keys() and texts['placeholder']:
25 self.fields[field].widget.attrs[
26 'placeholder'] = texts['placeholder']
27 if 'long_text' in texts.keys() and texts['long_text']:
28 self.fields[field].widget.attrs[
29 'long_text'] = texts['long_text']
30 if 'step' in texts.keys() and texts['step']:
31 self.fields[field].widget.attrs['tab_text'] = texts['step']
32
33
34 def get_user_organizations_choicefield(user=None):
35 if user is None or not user.is_authenticated():
36 return None
37
38 if user.enrollments.all():
39 choices = [('', 'Lo haré a nombre personal')]
40 for enrollment in user.enrollments.all():
41 choice = (enrollment.organization.id, enrollment.organization.name)
42 choices.append(choice)
43 label = _(u'¿Esta promesa es a nombre de un grupo ciudadano?')
44 return forms.ChoiceField(choices=choices,
45 label=label)
46 return None
47
48 wizard_forms_fields = [
49 {
50 'template': 'popular_proposal/wizard/form_step.html',
51 'explation_template': "popular_proposal/steps/paso1.html",
52 'fields': OrderedDict([
53 ('problem', forms.CharField(max_length=512,
54 widget=forms.Textarea(),
55 ))
56 ])
57 },
58 {
59 'template': 'popular_proposal/wizard/form_step.html',
60 'explation_template': "popular_proposal/steps/paso2.html",
61 'fields': OrderedDict([(
62 'causes', forms.CharField(max_length=256,
63 widget=forms.Textarea(),
64 )
65
66 )])
67 },
68 {
69 'template': 'popular_proposal/wizard/paso3.html',
70 'explation_template': "popular_proposal/steps/paso3.html",
71 'fields': OrderedDict([(
72 'clasification', forms.ChoiceField(choices=TOPIC_CHOICES,
73 widget=forms.Select())
74 ), (
75
76 'solution', forms.CharField(max_length=512,
77 widget=forms.Textarea(),
78 )
79 )])
80 },
81 {
82 'template': 'popular_proposal/wizard/form_step.html',
83 'explation_template': "popular_proposal/steps/paso4.html",
84 'fields': OrderedDict([(
85 'solution_at_the_end', forms.CharField(widget=forms.Textarea(),
86 required=False)
87
88 ),
89 ('when', forms.ChoiceField(widget=forms.Select(),
90 choices=WHEN_CHOICES))
91 ])
92 },
93 {
94 'template': 'popular_proposal/wizard/paso5.html',
95 'explation_template': "popular_proposal/steps/paso5.html",
96 'fields': OrderedDict([
97 ('title', forms.CharField(max_length=256,
98 widget=forms.TextInput())),
99 ('organization', get_user_organizations_choicefield),
100 ('terms_and_conditions', forms.BooleanField(
101 error_messages={'required':
102 _(u'Debes aceptar nuestros Términos y \
103 Condiciones')}
104 )
105 )
106 ])
107 }
108 ]
109
110
111 def get_form_list(wizard_forms_fields=wizard_forms_fields, **kwargs):
112 form_list = []
113 counter = 0
114 for step in wizard_forms_fields:
115 counter += 1
116 fields_dict = OrderedDict()
117 for field in step['fields']:
118 tha_field = step['fields'][field]
119 if hasattr(tha_field, '__call__'):
120 executed_field = tha_field.__call__(**kwargs)
121 if executed_field is not None:
122 fields_dict[field] = executed_field
123 else:
124 fields_dict[field] = tha_field
125
126 def __init__(self, *args, **kwargs):
127 super(forms.Form, self).__init__(*args, **kwargs)
128 self.add_texts_to_fields()
129 cls_attrs = {"__init__": __init__,
130 "explanation_template": step['explation_template'],
131 "template": step['template']}
132 form_class = type('Step%d' % (counter),
133 (forms.Form, TextsFormMixin, object), cls_attrs)
134 form_class.base_fields = fields_dict
135 form_list.append(form_class)
136 return form_list
137
138
139 class ProposalFormBase(forms.Form, TextsFormMixin):
140 def set_fields(self):
141 for steps in wizard_forms_fields:
142 for field_name in steps['fields']:
143 field = steps['fields'][field_name]
144 if hasattr(field, '__call__'):
145 kwargs = {'user': self.proposer}
146 field = field.__call__(**kwargs)
147 if field is None:
148 continue
149 self.fields[field_name] = field
150
151 def __init__(self, *args, **kwargs):
152 self.proposer = kwargs.pop('proposer', None)
153 super(ProposalFormBase, self).__init__(*args, **kwargs)
154 self.set_fields()
155 self.add_texts_to_fields()
156
157
158 class ProposalForm(ProposalFormBase):
159 def __init__(self, *args, **kwargs):
160 self.area = kwargs.pop('area')
161 super(ProposalForm, self).__init__(*args, **kwargs)
162
163 def save(self):
164 t_data = ProposalTemporaryData.objects.create(proposer=self.proposer,
165 area=self.area,
166 data=self.cleaned_data)
167 t_data.notify_new()
168 return t_data
169
170
171 class UpdateProposalForm(forms.ModelForm):
172 def __init__(self, *args, **kwargs):
173 return super(UpdateProposalForm, self).__init__(*args, **kwargs)
174
175 class Meta:
176 model = PopularProposal
177 fields = ['background', 'image']
178
179
180 class CommentsForm(forms.Form):
181 def __init__(self, *args, **kwargs):
182 self.temporary_data = kwargs.pop('temporary_data')
183 self.moderator = kwargs.pop('moderator')
184 super(CommentsForm, self).__init__(*args, **kwargs)
185 for field in self.temporary_data.comments.keys():
186 help_text = _(u'La ciudadana dijo: %s') % self.temporary_data.data.get(field, u'')
187 comments = self.temporary_data.comments[field]
188 if comments:
189 help_text += _(u' <b>Y tus comentarios fueron: %s </b>') % comments
190 self.fields[field] = forms.CharField(required=False, help_text=help_text)
191
192 def save(self, *args, **kwargs):
193 for field_key in self.cleaned_data.keys():
194 self.temporary_data.comments[field_key] = self.cleaned_data[field_key]
195 self.temporary_data.status = ProposalTemporaryData.Statuses.InTheirSide
196 self.temporary_data.save()
197 comments = {}
198 for key in self.temporary_data.data.keys():
199 if self.temporary_data.comments[key]:
200 comments[key] = {
201 'original': self.temporary_data.data[key],
202 'comments': self.temporary_data.comments[key]
203 }
204
205 site = Site.objects.get_current()
206 mail_context = {
207 'area': self.temporary_data.area,
208 'temporary_data': self.temporary_data,
209 'moderator': self.moderator,
210 'comments': comments,
211 'site': site,
212
213 }
214 send_mail(mail_context, 'popular_proposal_moderation',
215 to=[self.temporary_data.proposer.email])
216 return self.temporary_data
217
218
219 class RejectionForm(forms.Form):
220 reason = forms.CharField()
221
222 def __init__(self, *args, **kwargs):
223 self.temporary_data = kwargs.pop('temporary_data')
224 self.moderator = kwargs.pop('moderator')
225 super(RejectionForm, self).__init__(*args, **kwargs)
226
227 def reject(self):
228 self.temporary_data.reject(self.cleaned_data['reason'])
229
230
231 class ProposalTemporaryDataUpdateForm(ProposalFormBase):
232 overall_comments = forms.CharField(required=False, label=_(u'Comentarios sobre tu revisón'))
233
234 def __init__(self, *args, **kwargs):
235 self.proposer = kwargs.pop('proposer')
236 self.temporary_data = kwargs.pop('temporary_data')
237 super(ProposalTemporaryDataUpdateForm, self).__init__(*args, **kwargs)
238 self.initial = self.temporary_data.data
239 for comment_key in self.temporary_data.comments.keys():
240 comment = self.temporary_data.comments[comment_key]
241 if comment:
242 self.fields[comment_key].help_text += _(' <b>Commentarios: %s </b>') % (comment)
243
244 def save(self):
245 self.overall_comments = self.cleaned_data.pop('overall_comments')
246 self.temporary_data.data = self.cleaned_data
247 self.temporary_data.overall_comments = self.overall_comments
248 self.temporary_data.status = ProposalTemporaryData.Statuses.InOurSide
249 self.temporary_data.save()
250 return self.temporary_data
251
252 def get_overall_comments(self):
253 return self.cleaned_data.get('overall_comments', '')
254
255
256 class SubscriptionForm(forms.Form):
257 def __init__(self, *args, **kwargs):
258 self.user = kwargs.pop('user')
259 self.proposal = kwargs.pop('proposal')
260 super(SubscriptionForm, self).__init__(*args, **kwargs)
261
262 def subscribe(self):
263 like = ProposalLike.objects.create(user=self.user,
264 proposal=self.proposal)
265 return like
266
267
268 class AreaForm(forms.Form):
269 area = forms.ChoiceField()
270 explanation_template = "popular_proposal/steps/select_area.html"
271
272 def __init__(self, *args, **kwargs):
273 super(AreaForm, self).__init__(*args, **kwargs)
274 self.fields['area'].choices = [(a.id, a.name) for a in Area.objects.all()]
275
276 def clean(self):
277 cleaned_data = super(AreaForm, self).clean()
278 area = Area.objects.get(id=cleaned_data['area'])
279 cleaned_data['area'] = area
280 return cleaned_data
281
[end of popular_proposal/forms/forms.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/popular_proposal/forms/forms.py b/popular_proposal/forms/forms.py
--- a/popular_proposal/forms/forms.py
+++ b/popular_proposal/forms/forms.py
@@ -175,6 +175,10 @@
class Meta:
model = PopularProposal
fields = ['background', 'image']
+ labels = {'background': _(u'Más antecedentes sobre tu propuesta.'),
+ 'image': _(u'¿Tienes alguna imagen para compartir?')
+ }
+ help_texts = {'background': _(u'Ejemplo: Durante el año 2011, existió una iniciativa de otra comunidad que no llegó a buen puerto.')}
class CommentsForm(forms.Form):
|
{"golden_diff": "diff --git a/popular_proposal/forms/forms.py b/popular_proposal/forms/forms.py\n--- a/popular_proposal/forms/forms.py\n+++ b/popular_proposal/forms/forms.py\n@@ -175,6 +175,10 @@\n class Meta:\n model = PopularProposal\n fields = ['background', 'image']\n+ labels = {'background': _(u'M\u00e1s antecedentes sobre tu propuesta.'),\n+ 'image': _(u'\u00bfTienes alguna imagen para compartir?')\n+ }\n+ help_texts = {'background': _(u'Ejemplo: Durante el a\u00f1o 2011, existi\u00f3 una iniciativa de otra comunidad que no lleg\u00f3 a buen puerto.')}\n \n \n class CommentsForm(forms.Form):\n", "issue": "La p\u00e1gina de agregar antecedentes no dice mucho.\nActualmente agregar m\u00e1s antecedentes puede ser accedida desde una sola parte:\n\n\nY deber\u00eda ser accesible desde el mail de felicitaciones, la lista de tus propuestas.\nY adem\u00e1s deber\u00eda poder proveer de ejemplos que te permitan hacer de tu propuesta una m\u00e1s completa.\nPor ejemplo en la parte donde dice \"Background\" deber\u00eda decir algo as\u00ed como: \n \"Puedes agregar m\u00e1s antecedentes? como por ejemplo, en qu\u00e9 a\u00f1o se inici\u00f3 el problema? o quiz\u00e1s cuantas veces han intentado darle soluci\u00f3n?\"\n\nAdem\u00e1s deber\u00eda poder utilizarse esta informaci\u00f3n en el detalle de la propuesta.\n\n<!---\n@huboard:{\"order\":50.8644609375,\"milestone_order\":237,\"custom_state\":\"\"}\n-->\n\n", "before_files": [{"content": "# coding=utf-8\nfrom django import forms\nfrom popular_proposal.models import (ProposalTemporaryData,\n ProposalLike,\n PopularProposal)\nfrom votainteligente.send_mails import send_mail\nfrom django.utils.translation import ugettext as _\nfrom django.contrib.sites.models import Site\nfrom .form_texts import TEXTS, TOPIC_CHOICES, WHEN_CHOICES\nfrom popolo.models import Area\nfrom collections import OrderedDict\n\n\nclass TextsFormMixin():\n\n def add_texts_to_fields(self):\n for field in self.fields:\n if field in TEXTS.keys():\n texts = TEXTS[field]\n if 'label' in texts.keys() and texts['label']:\n self.fields[field].label = texts['label']\n if 'help_text' in texts.keys() and texts['help_text']:\n self.fields[field].help_text = texts['help_text']\n if 'placeholder' in texts.keys() and texts['placeholder']:\n self.fields[field].widget.attrs[\n 'placeholder'] = texts['placeholder']\n if 'long_text' in texts.keys() and texts['long_text']:\n self.fields[field].widget.attrs[\n 'long_text'] = texts['long_text']\n if 'step' in texts.keys() and texts['step']:\n self.fields[field].widget.attrs['tab_text'] = texts['step']\n\n\ndef get_user_organizations_choicefield(user=None):\n if user is None or not user.is_authenticated():\n return None\n\n if user.enrollments.all():\n choices = [('', 'Lo har\u00e9 a nombre personal')]\n for enrollment in user.enrollments.all():\n choice = (enrollment.organization.id, enrollment.organization.name)\n choices.append(choice)\n label = _(u'\u00bfEsta promesa es a nombre de un grupo ciudadano?')\n return forms.ChoiceField(choices=choices,\n label=label)\n return None\n\nwizard_forms_fields = [\n {\n 'template': 'popular_proposal/wizard/form_step.html',\n 'explation_template': \"popular_proposal/steps/paso1.html\",\n 'fields': OrderedDict([\n ('problem', forms.CharField(max_length=512,\n widget=forms.Textarea(),\n ))\n ])\n },\n {\n 'template': 'popular_proposal/wizard/form_step.html',\n 'explation_template': \"popular_proposal/steps/paso2.html\",\n 'fields': OrderedDict([(\n 'causes', forms.CharField(max_length=256,\n widget=forms.Textarea(),\n )\n\n )])\n },\n {\n 'template': 'popular_proposal/wizard/paso3.html',\n 'explation_template': \"popular_proposal/steps/paso3.html\",\n 'fields': OrderedDict([(\n 'clasification', forms.ChoiceField(choices=TOPIC_CHOICES,\n widget=forms.Select())\n ), (\n\n 'solution', forms.CharField(max_length=512,\n widget=forms.Textarea(),\n )\n )])\n },\n {\n 'template': 'popular_proposal/wizard/form_step.html',\n 'explation_template': \"popular_proposal/steps/paso4.html\",\n 'fields': OrderedDict([(\n 'solution_at_the_end', forms.CharField(widget=forms.Textarea(),\n required=False)\n\n ),\n ('when', forms.ChoiceField(widget=forms.Select(),\n choices=WHEN_CHOICES))\n ])\n },\n {\n 'template': 'popular_proposal/wizard/paso5.html',\n 'explation_template': \"popular_proposal/steps/paso5.html\",\n 'fields': OrderedDict([\n ('title', forms.CharField(max_length=256,\n widget=forms.TextInput())),\n ('organization', get_user_organizations_choicefield),\n ('terms_and_conditions', forms.BooleanField(\n error_messages={'required':\n _(u'Debes aceptar nuestros T\u00e9rminos y \\\nCondiciones')}\n )\n )\n ])\n }\n]\n\n\ndef get_form_list(wizard_forms_fields=wizard_forms_fields, **kwargs):\n form_list = []\n counter = 0\n for step in wizard_forms_fields:\n counter += 1\n fields_dict = OrderedDict()\n for field in step['fields']:\n tha_field = step['fields'][field]\n if hasattr(tha_field, '__call__'):\n executed_field = tha_field.__call__(**kwargs)\n if executed_field is not None:\n fields_dict[field] = executed_field\n else:\n fields_dict[field] = tha_field\n\n def __init__(self, *args, **kwargs):\n super(forms.Form, self).__init__(*args, **kwargs)\n self.add_texts_to_fields()\n cls_attrs = {\"__init__\": __init__,\n \"explanation_template\": step['explation_template'],\n \"template\": step['template']}\n form_class = type('Step%d' % (counter),\n (forms.Form, TextsFormMixin, object), cls_attrs)\n form_class.base_fields = fields_dict\n form_list.append(form_class)\n return form_list\n\n\nclass ProposalFormBase(forms.Form, TextsFormMixin):\n def set_fields(self):\n for steps in wizard_forms_fields:\n for field_name in steps['fields']:\n field = steps['fields'][field_name]\n if hasattr(field, '__call__'):\n kwargs = {'user': self.proposer}\n field = field.__call__(**kwargs)\n if field is None:\n continue\n self.fields[field_name] = field\n\n def __init__(self, *args, **kwargs):\n self.proposer = kwargs.pop('proposer', None)\n super(ProposalFormBase, self).__init__(*args, **kwargs)\n self.set_fields()\n self.add_texts_to_fields()\n\n\nclass ProposalForm(ProposalFormBase):\n def __init__(self, *args, **kwargs):\n self.area = kwargs.pop('area')\n super(ProposalForm, self).__init__(*args, **kwargs)\n\n def save(self):\n t_data = ProposalTemporaryData.objects.create(proposer=self.proposer,\n area=self.area,\n data=self.cleaned_data)\n t_data.notify_new()\n return t_data\n\n\nclass UpdateProposalForm(forms.ModelForm):\n def __init__(self, *args, **kwargs):\n return super(UpdateProposalForm, self).__init__(*args, **kwargs)\n\n class Meta:\n model = PopularProposal\n fields = ['background', 'image']\n\n\nclass CommentsForm(forms.Form):\n def __init__(self, *args, **kwargs):\n self.temporary_data = kwargs.pop('temporary_data')\n self.moderator = kwargs.pop('moderator')\n super(CommentsForm, self).__init__(*args, **kwargs)\n for field in self.temporary_data.comments.keys():\n help_text = _(u'La ciudadana dijo: %s') % self.temporary_data.data.get(field, u'')\n comments = self.temporary_data.comments[field]\n if comments:\n help_text += _(u' <b>Y tus comentarios fueron: %s </b>') % comments\n self.fields[field] = forms.CharField(required=False, help_text=help_text)\n\n def save(self, *args, **kwargs):\n for field_key in self.cleaned_data.keys():\n self.temporary_data.comments[field_key] = self.cleaned_data[field_key]\n self.temporary_data.status = ProposalTemporaryData.Statuses.InTheirSide\n self.temporary_data.save()\n comments = {}\n for key in self.temporary_data.data.keys():\n if self.temporary_data.comments[key]:\n comments[key] = {\n 'original': self.temporary_data.data[key],\n 'comments': self.temporary_data.comments[key]\n }\n\n site = Site.objects.get_current()\n mail_context = {\n 'area': self.temporary_data.area,\n 'temporary_data': self.temporary_data,\n 'moderator': self.moderator,\n 'comments': comments,\n 'site': site,\n\n }\n send_mail(mail_context, 'popular_proposal_moderation',\n to=[self.temporary_data.proposer.email])\n return self.temporary_data\n\n\nclass RejectionForm(forms.Form):\n reason = forms.CharField()\n\n def __init__(self, *args, **kwargs):\n self.temporary_data = kwargs.pop('temporary_data')\n self.moderator = kwargs.pop('moderator')\n super(RejectionForm, self).__init__(*args, **kwargs)\n\n def reject(self):\n self.temporary_data.reject(self.cleaned_data['reason'])\n\n\nclass ProposalTemporaryDataUpdateForm(ProposalFormBase):\n overall_comments = forms.CharField(required=False, label=_(u'Comentarios sobre tu revis\u00f3n'))\n\n def __init__(self, *args, **kwargs):\n self.proposer = kwargs.pop('proposer')\n self.temporary_data = kwargs.pop('temporary_data')\n super(ProposalTemporaryDataUpdateForm, self).__init__(*args, **kwargs)\n self.initial = self.temporary_data.data\n for comment_key in self.temporary_data.comments.keys():\n comment = self.temporary_data.comments[comment_key]\n if comment:\n self.fields[comment_key].help_text += _(' <b>Commentarios: %s </b>') % (comment)\n\n def save(self):\n self.overall_comments = self.cleaned_data.pop('overall_comments')\n self.temporary_data.data = self.cleaned_data\n self.temporary_data.overall_comments = self.overall_comments\n self.temporary_data.status = ProposalTemporaryData.Statuses.InOurSide\n self.temporary_data.save()\n return self.temporary_data\n\n def get_overall_comments(self):\n return self.cleaned_data.get('overall_comments', '')\n\n\nclass SubscriptionForm(forms.Form):\n def __init__(self, *args, **kwargs):\n self.user = kwargs.pop('user')\n self.proposal = kwargs.pop('proposal')\n super(SubscriptionForm, self).__init__(*args, **kwargs)\n\n def subscribe(self):\n like = ProposalLike.objects.create(user=self.user,\n proposal=self.proposal)\n return like\n\n\nclass AreaForm(forms.Form):\n area = forms.ChoiceField()\n explanation_template = \"popular_proposal/steps/select_area.html\"\n\n def __init__(self, *args, **kwargs):\n super(AreaForm, self).__init__(*args, **kwargs)\n self.fields['area'].choices = [(a.id, a.name) for a in Area.objects.all()]\n\n def clean(self):\n cleaned_data = super(AreaForm, self).clean()\n area = Area.objects.get(id=cleaned_data['area'])\n cleaned_data['area'] = area\n return cleaned_data\n", "path": "popular_proposal/forms/forms.py"}]}
| 3,848 | 160 |
gh_patches_debug_5431
|
rasdani/github-patches
|
git_diff
|
tournesol-app__tournesol-244
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Set up end-to-end tests
</issue>
<code>
[start of backend/settings/settings.py]
1 """
2 Django settings for settings project.
3
4 Generated by 'django-admin startproject' using Django 3.2.4.
5
6 For more information on this file, see
7 https://docs.djangoproject.com/en/3.2/topics/settings/
8
9 For the full list of settings and their values, see
10 https://docs.djangoproject.com/en/3.2/ref/settings/
11 """
12 import os
13 import yaml
14
15 from collections import OrderedDict
16 from pathlib import Path
17
18 # Build paths inside the project like this: BASE_DIR / 'subdir'.
19 BASE_DIR = Path(__file__).resolve().parent.parent
20
21
22 server_settings = {}
23 SETTINGS_FILE = (
24 "SETTINGS_FILE" in os.environ
25 and os.environ["SETTINGS_FILE"]
26 or "/etc/django/settings-tournesol.yaml"
27 )
28 try:
29 with open(SETTINGS_FILE, "r") as f:
30 server_settings = yaml.full_load(f)
31 except FileNotFoundError:
32 print("No local settings.")
33 pass
34
35 # Quick-start development settings - unsuitable for production
36 # See https://docs.djangoproject.com/en/3.2/howto/deployment/checklist/
37
38 # SECURITY WARNING: keep the secret key used in production secret!
39 SECRET_KEY = server_settings.get('SECRET_KEY', 'django-insecure-(=8(97oj$3)!#j!+^&bh_+5v5&1pfpzmaos#z80c!ia5@9#jz1')
40
41 # SECURITY WARNING: don't run with debug turned on in production!
42 DEBUG = server_settings.get('DEBUG', False)
43
44 ALLOWED_HOSTS = server_settings.get('ALLOWED_HOSTS', ['127.0.0.1', 'localhost'])
45
46 STATIC_URL = "/static/"
47 MEDIA_URL = "/media/"
48
49 # It is considered quite unsafe to use the /tmp directory, so we might as well use a dedicated root folder in HOME
50 base_folder = f"{os.environ.get('HOME')}/.tournesol"
51 STATIC_ROOT = server_settings.get('STATIC_ROOT', f"{base_folder}{STATIC_URL}")
52 MEDIA_ROOT = server_settings.get('MEDIA_ROOT', f"{base_folder}{MEDIA_URL}")
53
54 MAIN_URL = server_settings.get('MAIN_URL', 'http://localhost:8000/')
55
56 # Application definition
57
58 INSTALLED_APPS = [
59 "django.contrib.admin",
60 "django.contrib.auth",
61 "django.contrib.contenttypes",
62 "django.contrib.sessions",
63 "django.contrib.messages",
64 "django.contrib.staticfiles",
65 "django_prometheus",
66 "core",
67 "tournesol",
68 "ml",
69 "oauth2_provider",
70 "corsheaders",
71 "rest_framework",
72 "drf_spectacular",
73 'rest_registration',
74 ]
75
76 REST_REGISTRATION_MAIN_URL = server_settings.get('REST_REGISTRATION_MAIN_URL', 'http://127.0.0.1:3000/')
77 REST_REGISTRATION = {
78 'REGISTER_VERIFICATION_ENABLED': True,
79 'REGISTER_VERIFICATION_URL': REST_REGISTRATION_MAIN_URL + 'verify-user/',
80 'REGISTER_VERIFICATION_ONE_TIME_USE': True,
81 'RESET_PASSWORD_VERIFICATION_ENABLED': True,
82 'RESET_PASSWORD_VERIFICATION_URL': REST_REGISTRATION_MAIN_URL + 'reset-password/',
83 'RESET_PASSWORD_FAIL_WHEN_USER_NOT_FOUND': False, # to be set to True to prevent user enumeration
84 'RESET_PASSWORD_VERIFICATION_ONE_TIME_USE': True,
85 'REGISTER_EMAIL_SERIALIZER_CLASS': 'core.serializers.user.RegisterEmailSerializer',
86 'REGISTER_EMAIL_VERIFICATION_ENABLED': True,
87 'REGISTER_EMAIL_VERIFICATION_URL': REST_REGISTRATION_MAIN_URL + 'verify-email/',
88 'REGISTER_SERIALIZER_CLASS': 'core.serializers.user.RegisterUserSerializer',
89 'VERIFICATION_FROM_EMAIL': '[email protected]',
90 }
91
92 EMAIL_BACKEND = server_settings.get('EMAIL_BACKEND', 'django.core.mail.backends.console.EmailBackend')
93 EMAIL_HOST = server_settings.get('EMAIL_HOST', '')
94 EMAIL_PORT = server_settings.get('EMAIL_PORT', '')
95 EMAIL_HOST_USER = server_settings.get('EMAIL_HOST_USER', '')
96 EMAIL_HOST_PASSWORD = server_settings.get('EMAIL_HOST_PASSWORD', '')
97 EMAIL_USE_TLS = server_settings.get('EMAIL_USE_TLS', '')
98 EMAIL_USE_SSL = server_settings.get('EMAIL_USE_SSL', '')
99
100
101 # Modèle utilisateur utilisé par Django (1.5+)
102 AUTH_USER_MODEL = "core.user"
103
104 MIDDLEWARE = [
105 "django_prometheus.middleware.PrometheusBeforeMiddleware",
106 "django.middleware.security.SecurityMiddleware",
107 "django.contrib.sessions.middleware.SessionMiddleware",
108 "corsheaders.middleware.CorsMiddleware",
109 "django.middleware.common.CommonMiddleware",
110 "django.middleware.csrf.CsrfViewMiddleware",
111 "django.contrib.auth.middleware.AuthenticationMiddleware",
112 "django.contrib.messages.middleware.MessageMiddleware",
113 "django.middleware.clickjacking.XFrameOptionsMiddleware",
114 "django_prometheus.middleware.PrometheusAfterMiddleware",
115 ]
116
117 ROOT_URLCONF = "settings.urls"
118
119 TEMPLATES = [
120 {
121 "BACKEND": "django.template.backends.django.DjangoTemplates",
122 "DIRS": [BASE_DIR / "templates"],
123 "APP_DIRS": True,
124 "OPTIONS": {
125 "context_processors": [
126 "django.template.context_processors.debug",
127 "django.template.context_processors.request",
128 "django.contrib.auth.context_processors.auth",
129 "django.contrib.messages.context_processors.messages",
130 ],
131 },
132 },
133 ]
134
135 WSGI_APPLICATION = "settings.wsgi.application"
136
137
138 # Database
139 # https://docs.djangoproject.com/en/3.2/ref/settings/#databases
140
141 DATABASES = OrderedDict([
142 ['default', {
143 'ENGINE': 'django_prometheus.db.backends.postgresql',
144 'NAME': server_settings.get('DATABASE_NAME', 'tournesol'),
145 'USER': server_settings.get('DATABASE_USER', 'postgres'),
146 'PASSWORD': server_settings.get('DATABASE_PASSWORD', 'password'),
147 'HOST': server_settings.get("DATABASE_HOST", 'localhost'),
148 'PORT': server_settings.get("DATABASE_PORT", 5432),
149 'NUMBER': 42
150 }]
151 ])
152
153 DRF_RECAPTCHA_PUBLIC_KEY = server_settings.get("DRF_RECAPTCHA_PUBLIC_KEY", 'dsfsdfdsfsdfsdfsdf')
154 DRF_RECAPTCHA_SECRET_KEY = server_settings.get("DRF_RECAPTCHA_SECRET_KEY", 'dsfsdfdsfsdf')
155
156
157 # Password validation
158 # https://docs.djangoproject.com/en/3.2/ref/settings/#auth-password-validators
159
160 AUTH_PASSWORD_VALIDATORS = [
161 {
162 "NAME": "django.contrib.auth.password_validation.UserAttributeSimilarityValidator",
163 },
164 {
165 "NAME": "django.contrib.auth.password_validation.MinimumLengthValidator",
166 },
167 {
168 "NAME": "django.contrib.auth.password_validation.CommonPasswordValidator",
169 },
170 {
171 "NAME": "django.contrib.auth.password_validation.NumericPasswordValidator",
172 },
173 ]
174
175
176 # Internationalization
177 # https://docs.djangoproject.com/en/3.2/topics/i18n/
178
179 LANGUAGE_CODE = "en-us"
180
181 TIME_ZONE = "UTC"
182
183 USE_I18N = True
184
185 USE_L10N = True
186
187 USE_TZ = True
188
189
190 # Default primary key field type
191 # https://docs.djangoproject.com/en/3.2/ref/settings/#default-auto-field
192
193 DEFAULT_AUTO_FIELD = "django.db.models.BigAutoField"
194
195 OAUTH2_PROVIDER = {
196 "OIDC_ENABLED": server_settings.get("OIDC_ENABLED", False),
197 "OIDC_RSA_PRIVATE_KEY": server_settings.get(
198 "OIDC_RSA_PRIVATE_KEY", "dsfsdfdsfsdfsdfsdf"
199 ),
200 "SCOPES": {
201 "openid": "OpenID Connect scope",
202 "read": "Read scope",
203 "write": "Write scope",
204 "groups": "Access to your groups",
205 },
206 "OAUTH2_VALIDATOR_CLASS": "core.oauth_validator.CustomOAuth2Validator",
207 "OIDC_ISS_ENDPOINT": server_settings.get("OIDC_ISS_ENDPOINT", ""),
208 "ACCESS_TOKEN_EXPIRE_SECONDS": server_settings.get(
209 "ACCESS_TOKEN_EXPIRE_SECONDS", 36000
210 ), # 10h
211 "REFRESH_TOKEN_EXPIRE_SECONDS": server_settings.get(
212 "REFRESH_TOKEN_EXPIRE_SECONDS", 604800
213 ), # 1w
214 }
215 LOGIN_URL = server_settings.get('LOGIN_URL', '')
216
217 CORS_ALLOWED_ORIGINS = server_settings.get("CORS_ALLOWED_ORIGINS", [])
218 CORS_ALLOW_CREDENTIALS = server_settings.get("CORS_ALLOW_CREDENTIALS", False)
219
220 REST_FRAMEWORK = {
221 # Use Django's standard `django.contrib.auth` permissions,
222 # or allow read-only access for unauthenticated users.
223 "DEFAULT_PERMISSION_CLASSES": [
224 "rest_framework.permissions.IsAuthenticated",
225 ],
226 "DEFAULT_FILTER_BACKENDS": ("django_filters.rest_framework.DjangoFilterBackend",),
227 "DEFAULT_SCHEMA_CLASS": "drf_spectacular.openapi.AutoSchema",
228 "DEFAULT_PAGINATION_CLASS": "rest_framework.pagination.LimitOffsetPagination",
229 "PAGE_SIZE": 30,
230 # important to have no basic auth here
231 # as we are using Apache with basic auth
232 # https://stackoverflow.com/questions/40094823/django-rest-framework-invalid-username-password
233 "DEFAULT_AUTHENTICATION_CLASSES": (
234 "oauth2_provider.contrib.rest_framework.OAuth2Authentication",
235 ),
236 # custom exception handling
237 "DEFAULT_THROTTLE_CLASSES": [
238 "rest_framework.throttling.AnonRateThrottle",
239 "rest_framework.throttling.UserRateThrottle",
240 ],
241 "DEFAULT_THROTTLE_RATES": {"anon": "10000/hour", "user": "1000000/hour"},
242 }
243
244
245 # Maximal value for a rating (0-100)
246 # 0 means left video is best, 100 means right video is best
247 MAX_VALUE = 100.0
248
249 CRITERIAS_DICT = OrderedDict(
250 [
251 ("largely_recommended", "Should be largely recommended"),
252 ("reliability", "Reliable and not misleading"),
253 ("importance", "Important and actionable"),
254 ("engaging", "Engaging and thought-provoking"),
255 ("pedagogy", "Clear and pedagogical"),
256 ("layman_friendly", "Layman-friendly"),
257 ("diversity_inclusion", "Diversity and Inclusion"),
258 ("backfire_risk", "Resilience to backfiring risks"),
259 ("better_habits", "Encourages better habits"),
260 ("entertaining_relaxing", "Entertaining and relaxing"),
261 ]
262 )
263
264 CRITERIAS = list(CRITERIAS_DICT.keys())
265
266 # maximal weight to assign to a rating for a particular feature, see #41
267 MAX_FEATURE_WEIGHT = 8
268
269 SPECTACULAR_SETTINGS = {
270 "SWAGGER_UI_SETTINGS": {
271 "deepLinking": True,
272 "persistAuthorization": True,
273 "oauth2RedirectUrl": MAIN_URL + "docs/",
274 },
275 'SWAGGER_UI_OAUTH2_CONFIG': {
276 "clientId": server_settings.get("SWAGGER_UI_OAUTH2_CLIENT_ID",""),
277 "clientSecret": server_settings.get("SWAGGER_UI_OAUTH2_CLIENT_SECRET",""),
278 "appName": "Swagger UI",
279 "scopes": "read write groups",
280 },
281 'SECURITY': [{
282 'oauth2': ['read write groups'],
283 }],
284 'OAUTH2_FLOWS': ["password"],
285 'OAUTH2_AUTHORIZATION_URL': None,
286 'OAUTH2_TOKEN_URL': MAIN_URL + "o/token/",
287 'OAUTH2_REFRESH_URL': MAIN_URL + "o/token/",
288 'OAUTH2_SCOPES': "read write groups",
289 }
290
291 YOUTUBE_API_KEY = os.environ.get("YOUTUBE_API_KEY", "")
292
293 LOGGING = {
294 'version': 1,
295 'disable_existing_loggers': False,
296 'handlers': {
297 'console': {
298 'class': 'logging.StreamHandler',
299 },
300 },
301 'root': {
302 'handlers': ['console'],
303 'level': os.environ.get("DJANGO_LOG_LEVEL", "DEBUG"),
304 },
305 }
306
[end of backend/settings/settings.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/backend/settings/settings.py b/backend/settings/settings.py
--- a/backend/settings/settings.py
+++ b/backend/settings/settings.py
@@ -73,7 +73,7 @@
'rest_registration',
]
-REST_REGISTRATION_MAIN_URL = server_settings.get('REST_REGISTRATION_MAIN_URL', 'http://127.0.0.1:3000/')
+REST_REGISTRATION_MAIN_URL = server_settings.get('REST_REGISTRATION_MAIN_URL', 'http://localhost:3000/')
REST_REGISTRATION = {
'REGISTER_VERIFICATION_ENABLED': True,
'REGISTER_VERIFICATION_URL': REST_REGISTRATION_MAIN_URL + 'verify-user/',
|
{"golden_diff": "diff --git a/backend/settings/settings.py b/backend/settings/settings.py\n--- a/backend/settings/settings.py\n+++ b/backend/settings/settings.py\n@@ -73,7 +73,7 @@\n 'rest_registration',\n ]\n \n-REST_REGISTRATION_MAIN_URL = server_settings.get('REST_REGISTRATION_MAIN_URL', 'http://127.0.0.1:3000/')\n+REST_REGISTRATION_MAIN_URL = server_settings.get('REST_REGISTRATION_MAIN_URL', 'http://localhost:3000/')\n REST_REGISTRATION = {\n 'REGISTER_VERIFICATION_ENABLED': True,\n 'REGISTER_VERIFICATION_URL': REST_REGISTRATION_MAIN_URL + 'verify-user/',\n", "issue": "Set up end-to-end tests\n\n", "before_files": [{"content": "\"\"\"\nDjango settings for settings project.\n\nGenerated by 'django-admin startproject' using Django 3.2.4.\n\nFor more information on this file, see\nhttps://docs.djangoproject.com/en/3.2/topics/settings/\n\nFor the full list of settings and their values, see\nhttps://docs.djangoproject.com/en/3.2/ref/settings/\n\"\"\"\nimport os\nimport yaml\n\nfrom collections import OrderedDict\nfrom pathlib import Path\n\n# Build paths inside the project like this: BASE_DIR / 'subdir'.\nBASE_DIR = Path(__file__).resolve().parent.parent\n\n\nserver_settings = {}\nSETTINGS_FILE = (\n \"SETTINGS_FILE\" in os.environ\n and os.environ[\"SETTINGS_FILE\"]\n or \"/etc/django/settings-tournesol.yaml\"\n)\ntry:\n with open(SETTINGS_FILE, \"r\") as f:\n server_settings = yaml.full_load(f)\nexcept FileNotFoundError:\n print(\"No local settings.\")\n pass\n\n# Quick-start development settings - unsuitable for production\n# See https://docs.djangoproject.com/en/3.2/howto/deployment/checklist/\n\n# SECURITY WARNING: keep the secret key used in production secret!\nSECRET_KEY = server_settings.get('SECRET_KEY', 'django-insecure-(=8(97oj$3)!#j!+^&bh_+5v5&1pfpzmaos#z80c!ia5@9#jz1')\n\n# SECURITY WARNING: don't run with debug turned on in production!\nDEBUG = server_settings.get('DEBUG', False)\n\nALLOWED_HOSTS = server_settings.get('ALLOWED_HOSTS', ['127.0.0.1', 'localhost'])\n\nSTATIC_URL = \"/static/\"\nMEDIA_URL = \"/media/\"\n\n# It is considered quite unsafe to use the /tmp directory, so we might as well use a dedicated root folder in HOME\nbase_folder = f\"{os.environ.get('HOME')}/.tournesol\"\nSTATIC_ROOT = server_settings.get('STATIC_ROOT', f\"{base_folder}{STATIC_URL}\")\nMEDIA_ROOT = server_settings.get('MEDIA_ROOT', f\"{base_folder}{MEDIA_URL}\")\n\nMAIN_URL = server_settings.get('MAIN_URL', 'http://localhost:8000/')\n\n# Application definition\n\nINSTALLED_APPS = [\n \"django.contrib.admin\",\n \"django.contrib.auth\",\n \"django.contrib.contenttypes\",\n \"django.contrib.sessions\",\n \"django.contrib.messages\",\n \"django.contrib.staticfiles\",\n \"django_prometheus\",\n \"core\",\n \"tournesol\",\n \"ml\",\n \"oauth2_provider\",\n \"corsheaders\",\n \"rest_framework\",\n \"drf_spectacular\",\n 'rest_registration',\n]\n\nREST_REGISTRATION_MAIN_URL = server_settings.get('REST_REGISTRATION_MAIN_URL', 'http://127.0.0.1:3000/')\nREST_REGISTRATION = {\n 'REGISTER_VERIFICATION_ENABLED': True,\n 'REGISTER_VERIFICATION_URL': REST_REGISTRATION_MAIN_URL + 'verify-user/',\n 'REGISTER_VERIFICATION_ONE_TIME_USE': True,\n 'RESET_PASSWORD_VERIFICATION_ENABLED': True,\n 'RESET_PASSWORD_VERIFICATION_URL': REST_REGISTRATION_MAIN_URL + 'reset-password/',\n 'RESET_PASSWORD_FAIL_WHEN_USER_NOT_FOUND': False, # to be set to True to prevent user enumeration\n 'RESET_PASSWORD_VERIFICATION_ONE_TIME_USE': True,\n 'REGISTER_EMAIL_SERIALIZER_CLASS': 'core.serializers.user.RegisterEmailSerializer',\n 'REGISTER_EMAIL_VERIFICATION_ENABLED': True,\n 'REGISTER_EMAIL_VERIFICATION_URL': REST_REGISTRATION_MAIN_URL + 'verify-email/',\n 'REGISTER_SERIALIZER_CLASS': 'core.serializers.user.RegisterUserSerializer',\n 'VERIFICATION_FROM_EMAIL': '[email protected]',\n}\n\nEMAIL_BACKEND = server_settings.get('EMAIL_BACKEND', 'django.core.mail.backends.console.EmailBackend')\nEMAIL_HOST = server_settings.get('EMAIL_HOST', '')\nEMAIL_PORT = server_settings.get('EMAIL_PORT', '')\nEMAIL_HOST_USER = server_settings.get('EMAIL_HOST_USER', '')\nEMAIL_HOST_PASSWORD = server_settings.get('EMAIL_HOST_PASSWORD', '')\nEMAIL_USE_TLS = server_settings.get('EMAIL_USE_TLS', '')\nEMAIL_USE_SSL = server_settings.get('EMAIL_USE_SSL', '')\n\n\n# Mod\u00e8le utilisateur utilis\u00e9 par Django (1.5+)\nAUTH_USER_MODEL = \"core.user\"\n\nMIDDLEWARE = [\n \"django_prometheus.middleware.PrometheusBeforeMiddleware\",\n \"django.middleware.security.SecurityMiddleware\",\n \"django.contrib.sessions.middleware.SessionMiddleware\",\n \"corsheaders.middleware.CorsMiddleware\",\n \"django.middleware.common.CommonMiddleware\",\n \"django.middleware.csrf.CsrfViewMiddleware\",\n \"django.contrib.auth.middleware.AuthenticationMiddleware\",\n \"django.contrib.messages.middleware.MessageMiddleware\",\n \"django.middleware.clickjacking.XFrameOptionsMiddleware\",\n \"django_prometheus.middleware.PrometheusAfterMiddleware\",\n]\n\nROOT_URLCONF = \"settings.urls\"\n\nTEMPLATES = [\n {\n \"BACKEND\": \"django.template.backends.django.DjangoTemplates\",\n \"DIRS\": [BASE_DIR / \"templates\"],\n \"APP_DIRS\": True,\n \"OPTIONS\": {\n \"context_processors\": [\n \"django.template.context_processors.debug\",\n \"django.template.context_processors.request\",\n \"django.contrib.auth.context_processors.auth\",\n \"django.contrib.messages.context_processors.messages\",\n ],\n },\n },\n]\n\nWSGI_APPLICATION = \"settings.wsgi.application\"\n\n\n# Database\n# https://docs.djangoproject.com/en/3.2/ref/settings/#databases\n\nDATABASES = OrderedDict([\n ['default', {\n 'ENGINE': 'django_prometheus.db.backends.postgresql',\n 'NAME': server_settings.get('DATABASE_NAME', 'tournesol'),\n 'USER': server_settings.get('DATABASE_USER', 'postgres'),\n 'PASSWORD': server_settings.get('DATABASE_PASSWORD', 'password'),\n 'HOST': server_settings.get(\"DATABASE_HOST\", 'localhost'),\n 'PORT': server_settings.get(\"DATABASE_PORT\", 5432),\n 'NUMBER': 42\n }]\n])\n\nDRF_RECAPTCHA_PUBLIC_KEY = server_settings.get(\"DRF_RECAPTCHA_PUBLIC_KEY\", 'dsfsdfdsfsdfsdfsdf')\nDRF_RECAPTCHA_SECRET_KEY = server_settings.get(\"DRF_RECAPTCHA_SECRET_KEY\", 'dsfsdfdsfsdf')\n\n\n# Password validation\n# https://docs.djangoproject.com/en/3.2/ref/settings/#auth-password-validators\n\nAUTH_PASSWORD_VALIDATORS = [\n {\n \"NAME\": \"django.contrib.auth.password_validation.UserAttributeSimilarityValidator\",\n },\n {\n \"NAME\": \"django.contrib.auth.password_validation.MinimumLengthValidator\",\n },\n {\n \"NAME\": \"django.contrib.auth.password_validation.CommonPasswordValidator\",\n },\n {\n \"NAME\": \"django.contrib.auth.password_validation.NumericPasswordValidator\",\n },\n]\n\n\n# Internationalization\n# https://docs.djangoproject.com/en/3.2/topics/i18n/\n\nLANGUAGE_CODE = \"en-us\"\n\nTIME_ZONE = \"UTC\"\n\nUSE_I18N = True\n\nUSE_L10N = True\n\nUSE_TZ = True\n\n\n# Default primary key field type\n# https://docs.djangoproject.com/en/3.2/ref/settings/#default-auto-field\n\nDEFAULT_AUTO_FIELD = \"django.db.models.BigAutoField\"\n\nOAUTH2_PROVIDER = {\n \"OIDC_ENABLED\": server_settings.get(\"OIDC_ENABLED\", False),\n \"OIDC_RSA_PRIVATE_KEY\": server_settings.get(\n \"OIDC_RSA_PRIVATE_KEY\", \"dsfsdfdsfsdfsdfsdf\"\n ),\n \"SCOPES\": {\n \"openid\": \"OpenID Connect scope\",\n \"read\": \"Read scope\",\n \"write\": \"Write scope\",\n \"groups\": \"Access to your groups\",\n },\n \"OAUTH2_VALIDATOR_CLASS\": \"core.oauth_validator.CustomOAuth2Validator\",\n \"OIDC_ISS_ENDPOINT\": server_settings.get(\"OIDC_ISS_ENDPOINT\", \"\"),\n \"ACCESS_TOKEN_EXPIRE_SECONDS\": server_settings.get(\n \"ACCESS_TOKEN_EXPIRE_SECONDS\", 36000\n ), # 10h\n \"REFRESH_TOKEN_EXPIRE_SECONDS\": server_settings.get(\n \"REFRESH_TOKEN_EXPIRE_SECONDS\", 604800\n ), # 1w\n}\nLOGIN_URL = server_settings.get('LOGIN_URL', '')\n\nCORS_ALLOWED_ORIGINS = server_settings.get(\"CORS_ALLOWED_ORIGINS\", [])\nCORS_ALLOW_CREDENTIALS = server_settings.get(\"CORS_ALLOW_CREDENTIALS\", False)\n\nREST_FRAMEWORK = {\n # Use Django's standard `django.contrib.auth` permissions,\n # or allow read-only access for unauthenticated users.\n \"DEFAULT_PERMISSION_CLASSES\": [\n \"rest_framework.permissions.IsAuthenticated\",\n ],\n \"DEFAULT_FILTER_BACKENDS\": (\"django_filters.rest_framework.DjangoFilterBackend\",),\n \"DEFAULT_SCHEMA_CLASS\": \"drf_spectacular.openapi.AutoSchema\",\n \"DEFAULT_PAGINATION_CLASS\": \"rest_framework.pagination.LimitOffsetPagination\",\n \"PAGE_SIZE\": 30,\n # important to have no basic auth here\n # as we are using Apache with basic auth\n # https://stackoverflow.com/questions/40094823/django-rest-framework-invalid-username-password\n \"DEFAULT_AUTHENTICATION_CLASSES\": (\n \"oauth2_provider.contrib.rest_framework.OAuth2Authentication\",\n ),\n # custom exception handling\n \"DEFAULT_THROTTLE_CLASSES\": [\n \"rest_framework.throttling.AnonRateThrottle\",\n \"rest_framework.throttling.UserRateThrottle\",\n ],\n \"DEFAULT_THROTTLE_RATES\": {\"anon\": \"10000/hour\", \"user\": \"1000000/hour\"},\n}\n\n\n# Maximal value for a rating (0-100)\n# 0 means left video is best, 100 means right video is best\nMAX_VALUE = 100.0\n\nCRITERIAS_DICT = OrderedDict(\n [\n (\"largely_recommended\", \"Should be largely recommended\"),\n (\"reliability\", \"Reliable and not misleading\"),\n (\"importance\", \"Important and actionable\"),\n (\"engaging\", \"Engaging and thought-provoking\"),\n (\"pedagogy\", \"Clear and pedagogical\"),\n (\"layman_friendly\", \"Layman-friendly\"),\n (\"diversity_inclusion\", \"Diversity and Inclusion\"),\n (\"backfire_risk\", \"Resilience to backfiring risks\"),\n (\"better_habits\", \"Encourages better habits\"),\n (\"entertaining_relaxing\", \"Entertaining and relaxing\"),\n ]\n)\n\nCRITERIAS = list(CRITERIAS_DICT.keys())\n\n# maximal weight to assign to a rating for a particular feature, see #41\nMAX_FEATURE_WEIGHT = 8\n\nSPECTACULAR_SETTINGS = {\n \"SWAGGER_UI_SETTINGS\": {\n \"deepLinking\": True,\n \"persistAuthorization\": True,\n \"oauth2RedirectUrl\": MAIN_URL + \"docs/\",\n },\n 'SWAGGER_UI_OAUTH2_CONFIG': {\n \"clientId\": server_settings.get(\"SWAGGER_UI_OAUTH2_CLIENT_ID\",\"\"),\n \"clientSecret\": server_settings.get(\"SWAGGER_UI_OAUTH2_CLIENT_SECRET\",\"\"),\n \"appName\": \"Swagger UI\",\n \"scopes\": \"read write groups\",\n },\n 'SECURITY': [{\n 'oauth2': ['read write groups'],\n }],\n 'OAUTH2_FLOWS': [\"password\"],\n 'OAUTH2_AUTHORIZATION_URL': None,\n 'OAUTH2_TOKEN_URL': MAIN_URL + \"o/token/\",\n 'OAUTH2_REFRESH_URL': MAIN_URL + \"o/token/\",\n 'OAUTH2_SCOPES': \"read write groups\",\n}\n\nYOUTUBE_API_KEY = os.environ.get(\"YOUTUBE_API_KEY\", \"\")\n\nLOGGING = {\n 'version': 1,\n 'disable_existing_loggers': False,\n 'handlers': {\n 'console': {\n 'class': 'logging.StreamHandler',\n },\n },\n 'root': {\n 'handlers': ['console'],\n 'level': os.environ.get(\"DJANGO_LOG_LEVEL\", \"DEBUG\"),\n },\n}\n", "path": "backend/settings/settings.py"}]}
| 3,931 | 140 |
gh_patches_debug_40240
|
rasdani/github-patches
|
git_diff
|
getsentry__sentry-python-382
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Integration with Pyramid tweens
The common case in Pyramid is to handle exception with [tweens](https://docs.pylonsproject.org/projects/pyramid/en/latest/glossary.html#term-tween) that seat atop of main Pyramid handling function. With a current integration [approach](https://docs.sentry.io/platforms/python/pyramid/) each exception occurring in main function goes to sentry. Is there a way to track just those errors that were not handled in tweens?
</issue>
<code>
[start of sentry_sdk/integrations/pyramid.py]
1 from __future__ import absolute_import
2
3 import os
4 import sys
5 import weakref
6
7 from pyramid.httpexceptions import HTTPException # type: ignore
8 from pyramid.request import Request # type: ignore
9
10 from sentry_sdk.hub import Hub, _should_send_default_pii
11 from sentry_sdk.utils import capture_internal_exceptions, event_from_exception
12 from sentry_sdk._compat import reraise, iteritems
13
14 from sentry_sdk.integrations import Integration
15 from sentry_sdk.integrations._wsgi_common import RequestExtractor
16 from sentry_sdk.integrations.wsgi import SentryWsgiMiddleware
17
18 if False:
19 from pyramid.response import Response # type: ignore
20 from typing import Any
21 from sentry_sdk.integrations.wsgi import _ScopedResponse
22 from typing import Callable
23 from typing import Dict
24 from typing import Optional
25 from webob.cookies import RequestCookies # type: ignore
26 from webob.compat import cgi_FieldStorage # type: ignore
27
28 from sentry_sdk.utils import ExcInfo
29
30
31 if getattr(Request, "authenticated_userid", None):
32
33 def authenticated_userid(request):
34 # type: (Request) -> Optional[Any]
35 return request.authenticated_userid
36
37
38 else:
39 # bw-compat for pyramid < 1.5
40 from pyramid.security import authenticated_userid # type: ignore
41
42
43 class PyramidIntegration(Integration):
44 identifier = "pyramid"
45
46 transaction_style = None
47
48 def __init__(self, transaction_style="route_name"):
49 # type: (str) -> None
50 TRANSACTION_STYLE_VALUES = ("route_name", "route_pattern")
51 if transaction_style not in TRANSACTION_STYLE_VALUES:
52 raise ValueError(
53 "Invalid value for transaction_style: %s (must be in %s)"
54 % (transaction_style, TRANSACTION_STYLE_VALUES)
55 )
56 self.transaction_style = transaction_style
57
58 @staticmethod
59 def setup_once():
60 # type: () -> None
61 from pyramid.router import Router # type: ignore
62
63 old_handle_request = Router.handle_request
64
65 def sentry_patched_handle_request(self, request, *args, **kwargs):
66 # type: (Any, Request, *Any, **Any) -> Response
67 hub = Hub.current
68 integration = hub.get_integration(PyramidIntegration)
69 if integration is None:
70 return old_handle_request(self, request, *args, **kwargs)
71
72 with hub.configure_scope() as scope:
73 scope.add_event_processor(
74 _make_event_processor(weakref.ref(request), integration)
75 )
76
77 try:
78 return old_handle_request(self, request, *args, **kwargs)
79 except Exception:
80 exc_info = sys.exc_info()
81 _capture_exception(exc_info)
82 reraise(*exc_info)
83
84 Router.handle_request = sentry_patched_handle_request
85
86 old_wsgi_call = Router.__call__
87
88 def sentry_patched_wsgi_call(self, environ, start_response):
89 # type: (Any, Dict[str, str], Callable) -> _ScopedResponse
90 hub = Hub.current
91 integration = hub.get_integration(PyramidIntegration)
92 if integration is None:
93 return old_wsgi_call(self, environ, start_response)
94
95 return SentryWsgiMiddleware(lambda *a, **kw: old_wsgi_call(self, *a, **kw))(
96 environ, start_response
97 )
98
99 Router.__call__ = sentry_patched_wsgi_call
100
101
102 def _capture_exception(exc_info, **kwargs):
103 # type: (ExcInfo, **Any) -> None
104 if exc_info[0] is None or issubclass(exc_info[0], HTTPException):
105 return
106 hub = Hub.current
107 if hub.get_integration(PyramidIntegration) is None:
108 return
109 event, hint = event_from_exception(
110 exc_info,
111 client_options=hub.client.options,
112 mechanism={"type": "pyramid", "handled": False},
113 )
114
115 hub.capture_event(event, hint=hint)
116
117
118 class PyramidRequestExtractor(RequestExtractor):
119 def url(self):
120 return self.request.path_url
121
122 def env(self):
123 # type: () -> Dict[str, str]
124 return self.request.environ
125
126 def cookies(self):
127 # type: () -> RequestCookies
128 return self.request.cookies
129
130 def raw_data(self):
131 # type: () -> str
132 return self.request.text
133
134 def form(self):
135 # type: () -> Dict[str, str]
136 return {
137 key: value
138 for key, value in iteritems(self.request.POST)
139 if not getattr(value, "filename", None)
140 }
141
142 def files(self):
143 # type: () -> Dict[str, cgi_FieldStorage]
144 return {
145 key: value
146 for key, value in iteritems(self.request.POST)
147 if getattr(value, "filename", None)
148 }
149
150 def size_of_file(self, postdata):
151 # type: (cgi_FieldStorage) -> int
152 file = postdata.file
153 try:
154 return os.fstat(file.fileno()).st_size
155 except Exception:
156 return 0
157
158
159 def _make_event_processor(weak_request, integration):
160 # type: (Callable[[], Request], PyramidIntegration) -> Callable
161 def event_processor(event, hint):
162 # type: (Dict[str, Any], Dict[str, Any]) -> Dict[str, Any]
163 request = weak_request()
164 if request is None:
165 return event
166
167 try:
168 if integration.transaction_style == "route_name":
169 event["transaction"] = request.matched_route.name
170 elif integration.transaction_style == "route_pattern":
171 event["transaction"] = request.matched_route.pattern
172 except Exception:
173 pass
174
175 with capture_internal_exceptions():
176 PyramidRequestExtractor(request).extract_into_event(event)
177
178 if _should_send_default_pii():
179 with capture_internal_exceptions():
180 user_info = event.setdefault("user", {})
181 user_info["id"] = authenticated_userid(request)
182
183 return event
184
185 return event_processor
186
[end of sentry_sdk/integrations/pyramid.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/sentry_sdk/integrations/pyramid.py b/sentry_sdk/integrations/pyramid.py
--- a/sentry_sdk/integrations/pyramid.py
+++ b/sentry_sdk/integrations/pyramid.py
@@ -59,6 +59,7 @@
def setup_once():
# type: () -> None
from pyramid.router import Router # type: ignore
+ from pyramid.request import Request # type: ignore
old_handle_request = Router.handle_request
@@ -66,23 +67,34 @@
# type: (Any, Request, *Any, **Any) -> Response
hub = Hub.current
integration = hub.get_integration(PyramidIntegration)
- if integration is None:
- return old_handle_request(self, request, *args, **kwargs)
-
- with hub.configure_scope() as scope:
- scope.add_event_processor(
- _make_event_processor(weakref.ref(request), integration)
- )
+ if integration is not None:
+ with hub.configure_scope() as scope:
+ scope.add_event_processor(
+ _make_event_processor(weakref.ref(request), integration)
+ )
- try:
- return old_handle_request(self, request, *args, **kwargs)
- except Exception:
- exc_info = sys.exc_info()
- _capture_exception(exc_info)
- reraise(*exc_info)
+ return old_handle_request(self, request, *args, **kwargs)
Router.handle_request = sentry_patched_handle_request
+ if hasattr(Request, "invoke_exception_view"):
+ old_invoke_exception_view = Request.invoke_exception_view
+
+ def sentry_patched_invoke_exception_view(self, *args, **kwargs):
+ rv = old_invoke_exception_view(self, *args, **kwargs)
+
+ if (
+ self.exc_info
+ and all(self.exc_info)
+ and rv.status_int == 500
+ and Hub.current.get_integration(PyramidIntegration) is not None
+ ):
+ _capture_exception(self.exc_info)
+
+ return rv
+
+ Request.invoke_exception_view = sentry_patched_invoke_exception_view
+
old_wsgi_call = Router.__call__
def sentry_patched_wsgi_call(self, environ, start_response):
@@ -92,15 +104,23 @@
if integration is None:
return old_wsgi_call(self, environ, start_response)
- return SentryWsgiMiddleware(lambda *a, **kw: old_wsgi_call(self, *a, **kw))(
+ def sentry_patched_inner_wsgi_call(environ, start_response):
+ try:
+ return old_wsgi_call(self, environ, start_response)
+ except Exception:
+ einfo = sys.exc_info()
+ _capture_exception(einfo)
+ reraise(*einfo)
+
+ return SentryWsgiMiddleware(sentry_patched_inner_wsgi_call)(
environ, start_response
)
Router.__call__ = sentry_patched_wsgi_call
-def _capture_exception(exc_info, **kwargs):
- # type: (ExcInfo, **Any) -> None
+def _capture_exception(exc_info):
+ # type: (ExcInfo) -> None
if exc_info[0] is None or issubclass(exc_info[0], HTTPException):
return
hub = Hub.current
|
{"golden_diff": "diff --git a/sentry_sdk/integrations/pyramid.py b/sentry_sdk/integrations/pyramid.py\n--- a/sentry_sdk/integrations/pyramid.py\n+++ b/sentry_sdk/integrations/pyramid.py\n@@ -59,6 +59,7 @@\n def setup_once():\n # type: () -> None\n from pyramid.router import Router # type: ignore\n+ from pyramid.request import Request # type: ignore\n \n old_handle_request = Router.handle_request\n \n@@ -66,23 +67,34 @@\n # type: (Any, Request, *Any, **Any) -> Response\n hub = Hub.current\n integration = hub.get_integration(PyramidIntegration)\n- if integration is None:\n- return old_handle_request(self, request, *args, **kwargs)\n-\n- with hub.configure_scope() as scope:\n- scope.add_event_processor(\n- _make_event_processor(weakref.ref(request), integration)\n- )\n+ if integration is not None:\n+ with hub.configure_scope() as scope:\n+ scope.add_event_processor(\n+ _make_event_processor(weakref.ref(request), integration)\n+ )\n \n- try:\n- return old_handle_request(self, request, *args, **kwargs)\n- except Exception:\n- exc_info = sys.exc_info()\n- _capture_exception(exc_info)\n- reraise(*exc_info)\n+ return old_handle_request(self, request, *args, **kwargs)\n \n Router.handle_request = sentry_patched_handle_request\n \n+ if hasattr(Request, \"invoke_exception_view\"):\n+ old_invoke_exception_view = Request.invoke_exception_view\n+\n+ def sentry_patched_invoke_exception_view(self, *args, **kwargs):\n+ rv = old_invoke_exception_view(self, *args, **kwargs)\n+\n+ if (\n+ self.exc_info\n+ and all(self.exc_info)\n+ and rv.status_int == 500\n+ and Hub.current.get_integration(PyramidIntegration) is not None\n+ ):\n+ _capture_exception(self.exc_info)\n+\n+ return rv\n+\n+ Request.invoke_exception_view = sentry_patched_invoke_exception_view\n+\n old_wsgi_call = Router.__call__\n \n def sentry_patched_wsgi_call(self, environ, start_response):\n@@ -92,15 +104,23 @@\n if integration is None:\n return old_wsgi_call(self, environ, start_response)\n \n- return SentryWsgiMiddleware(lambda *a, **kw: old_wsgi_call(self, *a, **kw))(\n+ def sentry_patched_inner_wsgi_call(environ, start_response):\n+ try:\n+ return old_wsgi_call(self, environ, start_response)\n+ except Exception:\n+ einfo = sys.exc_info()\n+ _capture_exception(einfo)\n+ reraise(*einfo)\n+\n+ return SentryWsgiMiddleware(sentry_patched_inner_wsgi_call)(\n environ, start_response\n )\n \n Router.__call__ = sentry_patched_wsgi_call\n \n \n-def _capture_exception(exc_info, **kwargs):\n- # type: (ExcInfo, **Any) -> None\n+def _capture_exception(exc_info):\n+ # type: (ExcInfo) -> None\n if exc_info[0] is None or issubclass(exc_info[0], HTTPException):\n return\n hub = Hub.current\n", "issue": "Integration with Pyramid tweens\nThe common case in Pyramid is to handle exception with [tweens](https://docs.pylonsproject.org/projects/pyramid/en/latest/glossary.html#term-tween) that seat atop of main Pyramid handling function. With a current integration [approach](https://docs.sentry.io/platforms/python/pyramid/) each exception occurring in main function goes to sentry. Is there a way to track just those errors that were not handled in tweens?\n", "before_files": [{"content": "from __future__ import absolute_import\n\nimport os\nimport sys\nimport weakref\n\nfrom pyramid.httpexceptions import HTTPException # type: ignore\nfrom pyramid.request import Request # type: ignore\n\nfrom sentry_sdk.hub import Hub, _should_send_default_pii\nfrom sentry_sdk.utils import capture_internal_exceptions, event_from_exception\nfrom sentry_sdk._compat import reraise, iteritems\n\nfrom sentry_sdk.integrations import Integration\nfrom sentry_sdk.integrations._wsgi_common import RequestExtractor\nfrom sentry_sdk.integrations.wsgi import SentryWsgiMiddleware\n\nif False:\n from pyramid.response import Response # type: ignore\n from typing import Any\n from sentry_sdk.integrations.wsgi import _ScopedResponse\n from typing import Callable\n from typing import Dict\n from typing import Optional\n from webob.cookies import RequestCookies # type: ignore\n from webob.compat import cgi_FieldStorage # type: ignore\n\n from sentry_sdk.utils import ExcInfo\n\n\nif getattr(Request, \"authenticated_userid\", None):\n\n def authenticated_userid(request):\n # type: (Request) -> Optional[Any]\n return request.authenticated_userid\n\n\nelse:\n # bw-compat for pyramid < 1.5\n from pyramid.security import authenticated_userid # type: ignore\n\n\nclass PyramidIntegration(Integration):\n identifier = \"pyramid\"\n\n transaction_style = None\n\n def __init__(self, transaction_style=\"route_name\"):\n # type: (str) -> None\n TRANSACTION_STYLE_VALUES = (\"route_name\", \"route_pattern\")\n if transaction_style not in TRANSACTION_STYLE_VALUES:\n raise ValueError(\n \"Invalid value for transaction_style: %s (must be in %s)\"\n % (transaction_style, TRANSACTION_STYLE_VALUES)\n )\n self.transaction_style = transaction_style\n\n @staticmethod\n def setup_once():\n # type: () -> None\n from pyramid.router import Router # type: ignore\n\n old_handle_request = Router.handle_request\n\n def sentry_patched_handle_request(self, request, *args, **kwargs):\n # type: (Any, Request, *Any, **Any) -> Response\n hub = Hub.current\n integration = hub.get_integration(PyramidIntegration)\n if integration is None:\n return old_handle_request(self, request, *args, **kwargs)\n\n with hub.configure_scope() as scope:\n scope.add_event_processor(\n _make_event_processor(weakref.ref(request), integration)\n )\n\n try:\n return old_handle_request(self, request, *args, **kwargs)\n except Exception:\n exc_info = sys.exc_info()\n _capture_exception(exc_info)\n reraise(*exc_info)\n\n Router.handle_request = sentry_patched_handle_request\n\n old_wsgi_call = Router.__call__\n\n def sentry_patched_wsgi_call(self, environ, start_response):\n # type: (Any, Dict[str, str], Callable) -> _ScopedResponse\n hub = Hub.current\n integration = hub.get_integration(PyramidIntegration)\n if integration is None:\n return old_wsgi_call(self, environ, start_response)\n\n return SentryWsgiMiddleware(lambda *a, **kw: old_wsgi_call(self, *a, **kw))(\n environ, start_response\n )\n\n Router.__call__ = sentry_patched_wsgi_call\n\n\ndef _capture_exception(exc_info, **kwargs):\n # type: (ExcInfo, **Any) -> None\n if exc_info[0] is None or issubclass(exc_info[0], HTTPException):\n return\n hub = Hub.current\n if hub.get_integration(PyramidIntegration) is None:\n return\n event, hint = event_from_exception(\n exc_info,\n client_options=hub.client.options,\n mechanism={\"type\": \"pyramid\", \"handled\": False},\n )\n\n hub.capture_event(event, hint=hint)\n\n\nclass PyramidRequestExtractor(RequestExtractor):\n def url(self):\n return self.request.path_url\n\n def env(self):\n # type: () -> Dict[str, str]\n return self.request.environ\n\n def cookies(self):\n # type: () -> RequestCookies\n return self.request.cookies\n\n def raw_data(self):\n # type: () -> str\n return self.request.text\n\n def form(self):\n # type: () -> Dict[str, str]\n return {\n key: value\n for key, value in iteritems(self.request.POST)\n if not getattr(value, \"filename\", None)\n }\n\n def files(self):\n # type: () -> Dict[str, cgi_FieldStorage]\n return {\n key: value\n for key, value in iteritems(self.request.POST)\n if getattr(value, \"filename\", None)\n }\n\n def size_of_file(self, postdata):\n # type: (cgi_FieldStorage) -> int\n file = postdata.file\n try:\n return os.fstat(file.fileno()).st_size\n except Exception:\n return 0\n\n\ndef _make_event_processor(weak_request, integration):\n # type: (Callable[[], Request], PyramidIntegration) -> Callable\n def event_processor(event, hint):\n # type: (Dict[str, Any], Dict[str, Any]) -> Dict[str, Any]\n request = weak_request()\n if request is None:\n return event\n\n try:\n if integration.transaction_style == \"route_name\":\n event[\"transaction\"] = request.matched_route.name\n elif integration.transaction_style == \"route_pattern\":\n event[\"transaction\"] = request.matched_route.pattern\n except Exception:\n pass\n\n with capture_internal_exceptions():\n PyramidRequestExtractor(request).extract_into_event(event)\n\n if _should_send_default_pii():\n with capture_internal_exceptions():\n user_info = event.setdefault(\"user\", {})\n user_info[\"id\"] = authenticated_userid(request)\n\n return event\n\n return event_processor\n", "path": "sentry_sdk/integrations/pyramid.py"}]}
| 2,385 | 745 |
gh_patches_debug_37224
|
rasdani/github-patches
|
git_diff
|
bridgecrewio__checkov-5254
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Checkov Managed Disk Encryption check in Bicep IaC failing
**Describe the issue**
Checkov Managed Disk Encryption check will fail despite having the required check in Bicep code. It will only be successful if both checks are in the code, but need to be hashed out.
**Examples**
```
resource Disks 'Microsoft.Compute/disks@2022-07-02' = [for (disk, i) in dataDisks: {
name: disk.diskName
location: location
tags: tags
sku: {
name: disk.storageAccountType
}
zones: [
avZone
]
properties: {
creationData: {
createOption: 'Empty'
}
diskSizeGB: disk.diskSizeGB
// encryption: {
// type: 'EncryptionAtRestWithCustomerKey'
// diskEncryptionSetId: diskEncryptionSetId
// }
encryption: {
type: 'EncryptionAtRestWithCustomerKey'
diskEncryptionSetId: diskEncryptionSetId
}
// encryptionSettingsCollection: {
// enabled: true
// encryptionSettings: [
// {
// diskEncryptionKey: {
// secretUrl: keyURL
// sourceVault: {
// id: keyVaultId
// }
// }
// }
// ]
// }
}
}]
```
**Version :**
- Latest
**Additional context**
Even if I remove the commented out sections, the check will fail. If I have the "encryptionSettingsCollection" block, the check will fail. It will only work if it is formatted like the above.
</issue>
<code>
[start of checkov/arm/checks/resource/AzureManagedDiscEncryption.py]
1 from __future__ import annotations
2
3 from typing import Any
4
5 from checkov.common.models.enums import CheckResult, CheckCategories
6 from checkov.arm.base_resource_check import BaseResourceCheck
7
8
9 class AzureManagedDiscEncryption(BaseResourceCheck):
10 def __init__(self) -> None:
11 name = "Ensure Azure managed disk have encryption enabled"
12 id = "CKV_AZURE_2"
13 supported_resources = ("Microsoft.Compute/disks",)
14 categories = (CheckCategories.ENCRYPTION,)
15 super().__init__(name=name, id=id, categories=categories, supported_resources=supported_resources)
16
17 def scan_resource_conf(self, conf: dict[str, Any]) -> CheckResult:
18 if "properties" in conf:
19 if "encryptionSettingsCollection" in conf["properties"]:
20 if "enabled" in conf["properties"]["encryptionSettingsCollection"]:
21 if str(conf["properties"]["encryptionSettingsCollection"]["enabled"]).lower() == "true":
22 return CheckResult.PASSED
23 elif "encryptionSettings" in conf["properties"]:
24 if "enabled" in conf["properties"]["encryptionSettings"]:
25 if str(conf["properties"]["encryptionSettings"]["enabled"]).lower() == "true":
26 return CheckResult.PASSED
27 return CheckResult.FAILED
28
29
30 check = AzureManagedDiscEncryption()
31
[end of checkov/arm/checks/resource/AzureManagedDiscEncryption.py]
[start of checkov/arm/base_resource_check.py]
1 from __future__ import annotations
2
3 from abc import abstractmethod
4 from collections.abc import Iterable
5 from typing import Any, Callable
6
7 from checkov.arm.registry import arm_resource_registry
8 from checkov.bicep.checks.resource.registry import registry as bicep_registry
9 from checkov.common.checks.base_check import BaseCheck
10 from checkov.common.models.enums import CheckCategories, CheckResult
11 from checkov.common.multi_signature import multi_signature
12
13
14 class BaseResourceCheck(BaseCheck):
15 def __init__(
16 self,
17 name: str,
18 id: str,
19 categories: "Iterable[CheckCategories]",
20 supported_resources: "Iterable[str]",
21 guideline: str | None = None,
22 ) -> None:
23 super().__init__(
24 name=name,
25 id=id,
26 categories=categories,
27 supported_entities=supported_resources,
28 block_type="resource",
29 guideline=guideline,
30 )
31 self.supported_resources = supported_resources
32 arm_resource_registry.register(self)
33 # leverage ARM checks to use with bicep runner
34 bicep_registry.register(self)
35
36 def scan_entity_conf(self, conf: dict[str, Any], entity_type: str) -> CheckResult: # type:ignore[override] # it's ok
37 self.entity_type = entity_type
38
39 # the "existing" key indicates a Bicep resource
40 if "existing" in conf:
41 if conf["existing"] is True:
42 # the existing keyword is used to retrieve information about an already deployed resource
43 return CheckResult.UNKNOWN
44
45 self.api_version = conf["api_version"]
46 conf["config"]["apiVersion"] = conf["api_version"] # set for better reusability of existing ARM checks
47
48 return self.scan_resource_conf(conf["config"], entity_type) # type:ignore[no-any-return] # issue with multi_signature annotation
49
50 self.api_version = None
51
52 return self.scan_resource_conf(conf, entity_type) # type:ignore[no-any-return] # issue with multi_signature annotation
53
54 @multi_signature()
55 @abstractmethod
56 def scan_resource_conf(self, conf: dict[str, Any], entity_type: str) -> CheckResult:
57 raise NotImplementedError()
58
59 @classmethod
60 @scan_resource_conf.add_signature(args=["self", "conf"])
61 def _scan_resource_conf_self_conf(cls, wrapped: Callable[..., CheckResult]) -> Callable[..., CheckResult]:
62 def wrapper(self: BaseCheck, conf: dict[str, Any], entity_type: str | None = None) -> CheckResult:
63 # keep default argument for entity_type so old code, that doesn't set it, will work.
64 return wrapped(self, conf)
65
66 return wrapper
67
[end of checkov/arm/base_resource_check.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/checkov/arm/base_resource_check.py b/checkov/arm/base_resource_check.py
--- a/checkov/arm/base_resource_check.py
+++ b/checkov/arm/base_resource_check.py
@@ -45,7 +45,12 @@
self.api_version = conf["api_version"]
conf["config"]["apiVersion"] = conf["api_version"] # set for better reusability of existing ARM checks
- return self.scan_resource_conf(conf["config"], entity_type) # type:ignore[no-any-return] # issue with multi_signature annotation
+ resource_conf = conf["config"]
+ if "loop_type" in resource_conf:
+ # this means the whole resource block is surrounded by a for loop
+ resource_conf = resource_conf["config"]
+
+ return self.scan_resource_conf(resource_conf, entity_type) # type:ignore[no-any-return] # issue with multi_signature annotation
self.api_version = None
diff --git a/checkov/arm/checks/resource/AzureManagedDiscEncryption.py b/checkov/arm/checks/resource/AzureManagedDiscEncryption.py
--- a/checkov/arm/checks/resource/AzureManagedDiscEncryption.py
+++ b/checkov/arm/checks/resource/AzureManagedDiscEncryption.py
@@ -4,6 +4,7 @@
from checkov.common.models.enums import CheckResult, CheckCategories
from checkov.arm.base_resource_check import BaseResourceCheck
+from checkov.common.util.data_structures_utils import find_in_dict
class AzureManagedDiscEncryption(BaseResourceCheck):
@@ -15,15 +16,21 @@
super().__init__(name=name, id=id, categories=categories, supported_resources=supported_resources)
def scan_resource_conf(self, conf: dict[str, Any]) -> CheckResult:
- if "properties" in conf:
- if "encryptionSettingsCollection" in conf["properties"]:
- if "enabled" in conf["properties"]["encryptionSettingsCollection"]:
- if str(conf["properties"]["encryptionSettingsCollection"]["enabled"]).lower() == "true":
- return CheckResult.PASSED
- elif "encryptionSettings" in conf["properties"]:
- if "enabled" in conf["properties"]["encryptionSettings"]:
- if str(conf["properties"]["encryptionSettings"]["enabled"]).lower() == "true":
- return CheckResult.PASSED
+ properties = conf.get("properties")
+ if properties:
+ encryption = properties.get("encryption")
+ if encryption:
+ # if the block exists, then it is enabled
+ return CheckResult.PASSED
+
+ encryption_enabled = find_in_dict(input_dict=properties, key_path="encryptionSettingsCollection/enabled")
+ if str(encryption_enabled).lower() == "true":
+ return CheckResult.PASSED
+
+ encryption_enabled = find_in_dict(input_dict=properties, key_path="encryptionSettings/enabled")
+ if str(encryption_enabled).lower() == "true":
+ return CheckResult.PASSED
+
return CheckResult.FAILED
|
{"golden_diff": "diff --git a/checkov/arm/base_resource_check.py b/checkov/arm/base_resource_check.py\n--- a/checkov/arm/base_resource_check.py\n+++ b/checkov/arm/base_resource_check.py\n@@ -45,7 +45,12 @@\n self.api_version = conf[\"api_version\"]\n conf[\"config\"][\"apiVersion\"] = conf[\"api_version\"] # set for better reusability of existing ARM checks\n \n- return self.scan_resource_conf(conf[\"config\"], entity_type) # type:ignore[no-any-return] # issue with multi_signature annotation\n+ resource_conf = conf[\"config\"]\n+ if \"loop_type\" in resource_conf:\n+ # this means the whole resource block is surrounded by a for loop\n+ resource_conf = resource_conf[\"config\"]\n+\n+ return self.scan_resource_conf(resource_conf, entity_type) # type:ignore[no-any-return] # issue with multi_signature annotation\n \n self.api_version = None\n \ndiff --git a/checkov/arm/checks/resource/AzureManagedDiscEncryption.py b/checkov/arm/checks/resource/AzureManagedDiscEncryption.py\n--- a/checkov/arm/checks/resource/AzureManagedDiscEncryption.py\n+++ b/checkov/arm/checks/resource/AzureManagedDiscEncryption.py\n@@ -4,6 +4,7 @@\n \n from checkov.common.models.enums import CheckResult, CheckCategories\n from checkov.arm.base_resource_check import BaseResourceCheck\n+from checkov.common.util.data_structures_utils import find_in_dict\n \n \n class AzureManagedDiscEncryption(BaseResourceCheck):\n@@ -15,15 +16,21 @@\n super().__init__(name=name, id=id, categories=categories, supported_resources=supported_resources)\n \n def scan_resource_conf(self, conf: dict[str, Any]) -> CheckResult:\n- if \"properties\" in conf:\n- if \"encryptionSettingsCollection\" in conf[\"properties\"]:\n- if \"enabled\" in conf[\"properties\"][\"encryptionSettingsCollection\"]:\n- if str(conf[\"properties\"][\"encryptionSettingsCollection\"][\"enabled\"]).lower() == \"true\":\n- return CheckResult.PASSED\n- elif \"encryptionSettings\" in conf[\"properties\"]:\n- if \"enabled\" in conf[\"properties\"][\"encryptionSettings\"]:\n- if str(conf[\"properties\"][\"encryptionSettings\"][\"enabled\"]).lower() == \"true\":\n- return CheckResult.PASSED\n+ properties = conf.get(\"properties\")\n+ if properties:\n+ encryption = properties.get(\"encryption\")\n+ if encryption:\n+ # if the block exists, then it is enabled\n+ return CheckResult.PASSED\n+\n+ encryption_enabled = find_in_dict(input_dict=properties, key_path=\"encryptionSettingsCollection/enabled\")\n+ if str(encryption_enabled).lower() == \"true\":\n+ return CheckResult.PASSED\n+\n+ encryption_enabled = find_in_dict(input_dict=properties, key_path=\"encryptionSettings/enabled\")\n+ if str(encryption_enabled).lower() == \"true\":\n+ return CheckResult.PASSED\n+\n return CheckResult.FAILED\n", "issue": "Checkov Managed Disk Encryption check in Bicep IaC failing\n**Describe the issue**\r\nCheckov Managed Disk Encryption check will fail despite having the required check in Bicep code. It will only be successful if both checks are in the code, but need to be hashed out.\r\n\r\n**Examples**\r\n```\r\nresource Disks 'Microsoft.Compute/disks@2022-07-02' = [for (disk, i) in dataDisks: {\r\n name: disk.diskName\r\n location: location\r\n tags: tags\r\n sku: {\r\n name: disk.storageAccountType\r\n }\r\n zones: [\r\n avZone\r\n ]\r\n properties: {\r\n creationData: {\r\n createOption: 'Empty'\r\n }\r\n diskSizeGB: disk.diskSizeGB\r\n // encryption: {\r\n // type: 'EncryptionAtRestWithCustomerKey'\r\n // diskEncryptionSetId: diskEncryptionSetId\r\n // }\r\n encryption: {\r\n type: 'EncryptionAtRestWithCustomerKey'\r\n diskEncryptionSetId: diskEncryptionSetId\r\n }\r\n // encryptionSettingsCollection: {\r\n // enabled: true\r\n // encryptionSettings: [\r\n // {\r\n // diskEncryptionKey: {\r\n // secretUrl: keyURL\r\n // sourceVault: {\r\n // id: keyVaultId\r\n // }\r\n // }\r\n // }\r\n // ]\r\n // }\r\n }\r\n}]\r\n```\r\n\r\n**Version :**\r\n - Latest\r\n\r\n**Additional context**\r\nEven if I remove the commented out sections, the check will fail. If I have the \"encryptionSettingsCollection\" block, the check will fail. It will only work if it is formatted like the above.\r\n\n", "before_files": [{"content": "from __future__ import annotations\n\nfrom typing import Any\n\nfrom checkov.common.models.enums import CheckResult, CheckCategories\nfrom checkov.arm.base_resource_check import BaseResourceCheck\n\n\nclass AzureManagedDiscEncryption(BaseResourceCheck):\n def __init__(self) -> None:\n name = \"Ensure Azure managed disk have encryption enabled\"\n id = \"CKV_AZURE_2\"\n supported_resources = (\"Microsoft.Compute/disks\",)\n categories = (CheckCategories.ENCRYPTION,)\n super().__init__(name=name, id=id, categories=categories, supported_resources=supported_resources)\n\n def scan_resource_conf(self, conf: dict[str, Any]) -> CheckResult:\n if \"properties\" in conf:\n if \"encryptionSettingsCollection\" in conf[\"properties\"]:\n if \"enabled\" in conf[\"properties\"][\"encryptionSettingsCollection\"]:\n if str(conf[\"properties\"][\"encryptionSettingsCollection\"][\"enabled\"]).lower() == \"true\":\n return CheckResult.PASSED\n elif \"encryptionSettings\" in conf[\"properties\"]:\n if \"enabled\" in conf[\"properties\"][\"encryptionSettings\"]:\n if str(conf[\"properties\"][\"encryptionSettings\"][\"enabled\"]).lower() == \"true\":\n return CheckResult.PASSED\n return CheckResult.FAILED\n\n\ncheck = AzureManagedDiscEncryption()\n", "path": "checkov/arm/checks/resource/AzureManagedDiscEncryption.py"}, {"content": "from __future__ import annotations\n\nfrom abc import abstractmethod\nfrom collections.abc import Iterable\nfrom typing import Any, Callable\n\nfrom checkov.arm.registry import arm_resource_registry\nfrom checkov.bicep.checks.resource.registry import registry as bicep_registry\nfrom checkov.common.checks.base_check import BaseCheck\nfrom checkov.common.models.enums import CheckCategories, CheckResult\nfrom checkov.common.multi_signature import multi_signature\n\n\nclass BaseResourceCheck(BaseCheck):\n def __init__(\n self,\n name: str,\n id: str,\n categories: \"Iterable[CheckCategories]\",\n supported_resources: \"Iterable[str]\",\n guideline: str | None = None,\n ) -> None:\n super().__init__(\n name=name,\n id=id,\n categories=categories,\n supported_entities=supported_resources,\n block_type=\"resource\",\n guideline=guideline,\n )\n self.supported_resources = supported_resources\n arm_resource_registry.register(self)\n # leverage ARM checks to use with bicep runner\n bicep_registry.register(self)\n\n def scan_entity_conf(self, conf: dict[str, Any], entity_type: str) -> CheckResult: # type:ignore[override] # it's ok\n self.entity_type = entity_type\n\n # the \"existing\" key indicates a Bicep resource\n if \"existing\" in conf:\n if conf[\"existing\"] is True:\n # the existing keyword is used to retrieve information about an already deployed resource\n return CheckResult.UNKNOWN\n\n self.api_version = conf[\"api_version\"]\n conf[\"config\"][\"apiVersion\"] = conf[\"api_version\"] # set for better reusability of existing ARM checks\n\n return self.scan_resource_conf(conf[\"config\"], entity_type) # type:ignore[no-any-return] # issue with multi_signature annotation\n\n self.api_version = None\n\n return self.scan_resource_conf(conf, entity_type) # type:ignore[no-any-return] # issue with multi_signature annotation\n\n @multi_signature()\n @abstractmethod\n def scan_resource_conf(self, conf: dict[str, Any], entity_type: str) -> CheckResult:\n raise NotImplementedError()\n\n @classmethod\n @scan_resource_conf.add_signature(args=[\"self\", \"conf\"])\n def _scan_resource_conf_self_conf(cls, wrapped: Callable[..., CheckResult]) -> Callable[..., CheckResult]:\n def wrapper(self: BaseCheck, conf: dict[str, Any], entity_type: str | None = None) -> CheckResult:\n # keep default argument for entity_type so old code, that doesn't set it, will work.\n return wrapped(self, conf)\n\n return wrapper\n", "path": "checkov/arm/base_resource_check.py"}]}
| 1,962 | 652 |
gh_patches_debug_29839
|
rasdani/github-patches
|
git_diff
|
aws-cloudformation__cfn-lint-598
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
E3020 - ACM Validation - Linter error
*cfn-lint version: 0.11.1*
Hello!
So I have the below snippet of code:
```
r7XXXZZb04efXXXYYYZZ2b8cc0b2aa1f132XXXYYYZZZCNAMERecordSet:
Type: AWS::Route53::RecordSet
Properties:
HostedZoneId: !Ref rHostedZone
Comment: domain CNAME record.
Name: !Join ["", ["_75XXXTTT04efa8c2052b8ccXXXYYZZZ.XXXYYYZZZ.", !Ref pDomainName, "."]]
Type: CNAME
TTL: '300'
ResourceRecords:
- _14062XXXXYYY6b1f37eb361e9XXXYYYZZZ.acm-validations.aws
```
Unfortunately linter reports it as a E3020 error.
```
E3020 CNAME record (_14062XXXXYYY6b1f37eb361e9XXXYYYZZZ.acm-validations.aws) does not contain a valid domain name
dns/dns-production.template:645:7
```
Is that a proper behaviour? Resource is created properly - and the record works as it should - why then linter complains about it?
</issue>
<code>
[start of src/cfnlint/rules/resources/route53/RecordSet.py]
1 """
2 Copyright 2019 Amazon.com, Inc. or its affiliates. All Rights Reserved.
3
4 Permission is hereby granted, free of charge, to any person obtaining a copy of this
5 software and associated documentation files (the "Software"), to deal in the Software
6 without restriction, including without limitation the rights to use, copy, modify,
7 merge, publish, distribute, sublicense, and/or sell copies of the Software, and to
8 permit persons to whom the Software is furnished to do so.
9
10 THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED,
11 INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A
12 PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT
13 HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION
14 OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE
15 SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
16 """
17 import re
18 from cfnlint import CloudFormationLintRule
19 from cfnlint import RuleMatch
20 from cfnlint.helpers import REGEX_IPV4, REGEX_IPV6, REGEX_ALPHANUMERIC
21
22
23 class RecordSet(CloudFormationLintRule):
24 """Check Route53 Recordset Configuration"""
25 id = 'E3020'
26 shortdesc = 'Validate Route53 RecordSets'
27 description = 'Check if all RecordSets are correctly configured'
28 source_url = 'https://docs.aws.amazon.com/Route53/latest/DeveloperGuide/ResourceRecordTypes.html'
29 tags = ['resources', 'route53', 'record_set']
30
31 REGEX_DOMAINNAME = re.compile(r'^(([a-zA-Z0-9]|[a-zA-Z0-9][a-zA-Z0-9\-]*[a-zA-Z0-9])\.)*([A-Za-z0-9]|[A-Za-z0-9][A-Za-z0-9\-]*[A-Za-z0-9])(.)$')
32 REGEX_TXT = re.compile(r'^("[^"]{1,255}" *)*"[^"]{1,255}"$')
33
34 def check_a_record(self, path, recordset):
35 """Check A record Configuration"""
36 matches = []
37
38 resource_records = recordset.get('ResourceRecords')
39 for index, record in enumerate(resource_records):
40
41 if not isinstance(record, dict):
42 tree = path[:] + ['ResourceRecords', index]
43
44 # Check if a valid IPv4 address is specified
45 if not re.match(REGEX_IPV4, record):
46 message = 'A record ({}) is not a valid IPv4 address'
47 matches.append(RuleMatch(tree, message.format(record)))
48
49 return matches
50
51 def check_aaaa_record(self, path, recordset):
52 """Check AAAA record Configuration"""
53 matches = []
54
55 resource_records = recordset.get('ResourceRecords')
56 for index, record in enumerate(resource_records):
57
58 if not isinstance(record, dict):
59 tree = path[:] + ['ResourceRecords', index]
60
61 # Check if a valid IPv4 address is specified
62 if not re.match(REGEX_IPV6, record):
63 message = 'AAAA record ({}) is not a valid IPv6 address'
64 matches.append(RuleMatch(tree, message.format(record)))
65
66 return matches
67
68 def check_caa_record(self, path, recordset):
69 """Check CAA record Configuration"""
70 matches = []
71
72 resource_records = recordset.get('ResourceRecords')
73
74 for index, record in enumerate(resource_records):
75 tree = path[:] + ['ResourceRecords', index]
76
77 if not isinstance(record, dict):
78 # Split the record up to the mandatory settings (flags tag "value")
79 items = record.split(' ', 2)
80
81 # Check if the 3 settings are given.
82 if len(items) != 3:
83 message = 'CAA record must contain 3 settings (flags tag "value"), record contains {} settings.'
84 matches.append(RuleMatch(tree, message.format(len(items))))
85 else:
86 # Check the flag value
87 if not items[0].isdigit():
88 message = 'CAA record flag setting ({}) should be of type Integer.'
89 matches.append(RuleMatch(tree, message.format(items[0])))
90 else:
91 if int(items[0]) not in [0, 128]:
92 message = 'Invalid CAA record flag setting ({}) given, must be 0 or 128.'
93 matches.append(RuleMatch(tree, message.format(items[0])))
94
95 # Check the tag value
96 if not re.match(REGEX_ALPHANUMERIC, items[1]):
97 message = 'Invalid CAA record tag setting {}. Value has to be alphanumeric.'
98 matches.append(RuleMatch(tree, message.format(items[0])))
99
100 # Check the value
101 if not items[2].startswith('"') or not items[2].endswith('"'):
102 message = 'CAA record value setting has to be enclosed in double quotation marks (").'
103 matches.append(RuleMatch(tree, message))
104
105 return matches
106
107 def check_cname_record(self, path, recordset):
108 """Check CNAME record Configuration"""
109 matches = []
110
111 resource_records = recordset.get('ResourceRecords')
112 if len(resource_records) > 1:
113 message = 'A CNAME recordset can only contain 1 value'
114 matches.append(RuleMatch(path + ['ResourceRecords'], message))
115 else:
116 for index, record in enumerate(resource_records):
117 if not isinstance(record, dict):
118 tree = path[:] + ['ResourceRecords', index]
119 if (not re.match(self.REGEX_DOMAINNAME, record)
120 # ACM Route 53 validation uses invalid CNAMEs starting with `_`,
121 # special-case them rather than complicate the regex.
122 and not record.endswith('.acm-validations.aws.')):
123 message = 'CNAME record ({}) does not contain a valid domain name'
124 matches.append(RuleMatch(tree, message.format(record)))
125
126 return matches
127
128 def check_mx_record(self, path, recordset):
129 """Check MX record Configuration"""
130 matches = []
131
132 resource_records = recordset.get('ResourceRecords')
133
134 for index, record in enumerate(resource_records):
135 tree = path[:] + ['ResourceRecords', index]
136
137 if not isinstance(record, dict):
138 # Split the record up to the mandatory settings (priority domainname)
139 items = record.split(' ')
140
141 # Check if the 3 settings are given.
142 if len(items) != 2:
143 message = 'MX record must contain 2 settings (priority domainname), record contains {} settings.'
144 matches.append(RuleMatch(tree, message.format(len(items), record)))
145 else:
146 # Check the priority value
147 if not items[0].isdigit():
148 message = 'MX record priority setting ({}) should be of type Integer.'
149 matches.append(RuleMatch(tree, message.format(items[0], record)))
150 else:
151 if not 0 <= int(items[0]) <= 65535:
152 message = 'Invalid MX record priority setting ({}) given, must be between 0 and 65535.'
153 matches.append(RuleMatch(tree, message.format(items[0], record)))
154
155 # Check the domainname value
156 if not re.match(self.REGEX_DOMAINNAME, items[1]):
157 matches.append(RuleMatch(tree, message.format(items[1])))
158
159 return matches
160
161 def check_txt_record(self, path, recordset):
162 """Check TXT record Configuration"""
163 matches = []
164
165 # Check quotation of the records
166 resource_records = recordset.get('ResourceRecords')
167
168 for index, record in enumerate(resource_records):
169 tree = path[:] + ['ResourceRecords', index]
170
171 if not isinstance(record, dict) and not re.match(self.REGEX_TXT, record):
172 message = 'TXT record is not structured as one or more items up to 255 characters ' \
173 'enclosed in double quotation marks at {0}'
174 matches.append(RuleMatch(
175 tree,
176 (
177 message.format('/'.join(map(str, tree)))
178 ),
179 ))
180
181 return matches
182
183 def check_recordset(self, path, recordset):
184 """Check record configuration"""
185
186 matches = []
187 recordset_type = recordset.get('Type')
188
189 # Skip Intrinsic functions
190 if not isinstance(recordset_type, dict):
191 if not recordset.get('AliasTarget'):
192 # If no Alias is specified, ResourceRecords has to be specified
193 if not recordset.get('ResourceRecords'):
194 message = 'Property ResourceRecords missing at {}'
195 matches.append(RuleMatch(path, message.format('/'.join(map(str, path)))))
196 # Record type specific checks
197 elif recordset_type == 'A':
198 matches.extend(self.check_a_record(path, recordset))
199 elif recordset_type == 'AAAA':
200 matches.extend(self.check_aaaa_record(path, recordset))
201 elif recordset_type == 'CAA':
202 matches.extend(self.check_caa_record(path, recordset))
203 elif recordset_type == 'CNAME':
204 matches.extend(self.check_cname_record(path, recordset))
205 elif recordset_type == 'MX':
206 matches.extend(self.check_mx_record(path, recordset))
207 elif recordset_type == 'TXT':
208 matches.extend(self.check_txt_record(path, recordset))
209
210 return matches
211
212 def match(self, cfn):
213 """Check RecordSets and RecordSetGroups Properties"""
214
215 matches = []
216
217 recordsets = cfn.get_resources(['AWS::Route53::RecordSet'])
218
219 for name, recordset in recordsets.items():
220 path = ['Resources', name, 'Properties']
221
222 if isinstance(recordset, dict):
223 props = recordset.get('Properties')
224 if props:
225 matches.extend(self.check_recordset(path, props))
226
227 recordsetgroups = cfn.get_resource_properties(['AWS::Route53::RecordSetGroup', 'RecordSets'])
228
229 for recordsetgroup in recordsetgroups:
230 path = recordsetgroup['Path']
231 value = recordsetgroup['Value']
232 if isinstance(value, list):
233 for index, recordset in enumerate(value):
234 tree = path[:] + [index]
235 matches.extend(self.check_recordset(tree, recordset))
236
237 return matches
238
[end of src/cfnlint/rules/resources/route53/RecordSet.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/cfnlint/rules/resources/route53/RecordSet.py b/src/cfnlint/rules/resources/route53/RecordSet.py
--- a/src/cfnlint/rules/resources/route53/RecordSet.py
+++ b/src/cfnlint/rules/resources/route53/RecordSet.py
@@ -30,6 +30,7 @@
REGEX_DOMAINNAME = re.compile(r'^(([a-zA-Z0-9]|[a-zA-Z0-9][a-zA-Z0-9\-]*[a-zA-Z0-9])\.)*([A-Za-z0-9]|[A-Za-z0-9][A-Za-z0-9\-]*[A-Za-z0-9])(.)$')
REGEX_TXT = re.compile(r'^("[^"]{1,255}" *)*"[^"]{1,255}"$')
+ REGEX_CNAME_VALIDATIONS = re.compile(r'^.*\.acm-validations\.aws\.?$')
def check_a_record(self, path, recordset):
"""Check A record Configuration"""
@@ -116,10 +117,10 @@
for index, record in enumerate(resource_records):
if not isinstance(record, dict):
tree = path[:] + ['ResourceRecords', index]
- if (not re.match(self.REGEX_DOMAINNAME, record)
- # ACM Route 53 validation uses invalid CNAMEs starting with `_`,
- # special-case them rather than complicate the regex.
- and not record.endswith('.acm-validations.aws.')):
+ if (not re.match(self.REGEX_DOMAINNAME, record) and
+ not re.match(self.REGEX_CNAME_VALIDATIONS, record)):
+ # ACM Route 53 validation uses invalid CNAMEs starting with `_`,
+ # special-case them rather than complicate the regex.
message = 'CNAME record ({}) does not contain a valid domain name'
matches.append(RuleMatch(tree, message.format(record)))
|
{"golden_diff": "diff --git a/src/cfnlint/rules/resources/route53/RecordSet.py b/src/cfnlint/rules/resources/route53/RecordSet.py\n--- a/src/cfnlint/rules/resources/route53/RecordSet.py\n+++ b/src/cfnlint/rules/resources/route53/RecordSet.py\n@@ -30,6 +30,7 @@\n \n REGEX_DOMAINNAME = re.compile(r'^(([a-zA-Z0-9]|[a-zA-Z0-9][a-zA-Z0-9\\-]*[a-zA-Z0-9])\\.)*([A-Za-z0-9]|[A-Za-z0-9][A-Za-z0-9\\-]*[A-Za-z0-9])(.)$')\n REGEX_TXT = re.compile(r'^(\"[^\"]{1,255}\" *)*\"[^\"]{1,255}\"$')\n+ REGEX_CNAME_VALIDATIONS = re.compile(r'^.*\\.acm-validations\\.aws\\.?$')\n \n def check_a_record(self, path, recordset):\n \"\"\"Check A record Configuration\"\"\"\n@@ -116,10 +117,10 @@\n for index, record in enumerate(resource_records):\n if not isinstance(record, dict):\n tree = path[:] + ['ResourceRecords', index]\n- if (not re.match(self.REGEX_DOMAINNAME, record)\n- # ACM Route 53 validation uses invalid CNAMEs starting with `_`,\n- # special-case them rather than complicate the regex.\n- and not record.endswith('.acm-validations.aws.')):\n+ if (not re.match(self.REGEX_DOMAINNAME, record) and\n+ not re.match(self.REGEX_CNAME_VALIDATIONS, record)):\n+ # ACM Route 53 validation uses invalid CNAMEs starting with `_`,\n+ # special-case them rather than complicate the regex.\n message = 'CNAME record ({}) does not contain a valid domain name'\n matches.append(RuleMatch(tree, message.format(record)))\n", "issue": "E3020 - ACM Validation - Linter error\n*cfn-lint version: 0.11.1*\r\n\r\nHello!\r\n\r\nSo I have the below snippet of code:\r\n```\r\n r7XXXZZb04efXXXYYYZZ2b8cc0b2aa1f132XXXYYYZZZCNAMERecordSet:\r\n Type: AWS::Route53::RecordSet\r\n Properties:\r\n HostedZoneId: !Ref rHostedZone\r\n Comment: domain CNAME record.\r\n Name: !Join [\"\", [\"_75XXXTTT04efa8c2052b8ccXXXYYZZZ.XXXYYYZZZ.\", !Ref pDomainName, \".\"]]\r\n Type: CNAME\r\n TTL: '300'\r\n ResourceRecords:\r\n - _14062XXXXYYY6b1f37eb361e9XXXYYYZZZ.acm-validations.aws\r\n```\r\n\r\nUnfortunately linter reports it as a E3020 error.\r\n\r\n```\r\nE3020 CNAME record (_14062XXXXYYY6b1f37eb361e9XXXYYYZZZ.acm-validations.aws) does not contain a valid domain name\r\ndns/dns-production.template:645:7\r\n```\r\n\r\nIs that a proper behaviour? Resource is created properly - and the record works as it should - why then linter complains about it?\r\n\n", "before_files": [{"content": "\"\"\"\n Copyright 2019 Amazon.com, Inc. or its affiliates. All Rights Reserved.\n\n Permission is hereby granted, free of charge, to any person obtaining a copy of this\n software and associated documentation files (the \"Software\"), to deal in the Software\n without restriction, including without limitation the rights to use, copy, modify,\n merge, publish, distribute, sublicense, and/or sell copies of the Software, and to\n permit persons to whom the Software is furnished to do so.\n\n THE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED,\n INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A\n PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT\n HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION\n OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE\n SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.\n\"\"\"\nimport re\nfrom cfnlint import CloudFormationLintRule\nfrom cfnlint import RuleMatch\nfrom cfnlint.helpers import REGEX_IPV4, REGEX_IPV6, REGEX_ALPHANUMERIC\n\n\nclass RecordSet(CloudFormationLintRule):\n \"\"\"Check Route53 Recordset Configuration\"\"\"\n id = 'E3020'\n shortdesc = 'Validate Route53 RecordSets'\n description = 'Check if all RecordSets are correctly configured'\n source_url = 'https://docs.aws.amazon.com/Route53/latest/DeveloperGuide/ResourceRecordTypes.html'\n tags = ['resources', 'route53', 'record_set']\n\n REGEX_DOMAINNAME = re.compile(r'^(([a-zA-Z0-9]|[a-zA-Z0-9][a-zA-Z0-9\\-]*[a-zA-Z0-9])\\.)*([A-Za-z0-9]|[A-Za-z0-9][A-Za-z0-9\\-]*[A-Za-z0-9])(.)$')\n REGEX_TXT = re.compile(r'^(\"[^\"]{1,255}\" *)*\"[^\"]{1,255}\"$')\n\n def check_a_record(self, path, recordset):\n \"\"\"Check A record Configuration\"\"\"\n matches = []\n\n resource_records = recordset.get('ResourceRecords')\n for index, record in enumerate(resource_records):\n\n if not isinstance(record, dict):\n tree = path[:] + ['ResourceRecords', index]\n\n # Check if a valid IPv4 address is specified\n if not re.match(REGEX_IPV4, record):\n message = 'A record ({}) is not a valid IPv4 address'\n matches.append(RuleMatch(tree, message.format(record)))\n\n return matches\n\n def check_aaaa_record(self, path, recordset):\n \"\"\"Check AAAA record Configuration\"\"\"\n matches = []\n\n resource_records = recordset.get('ResourceRecords')\n for index, record in enumerate(resource_records):\n\n if not isinstance(record, dict):\n tree = path[:] + ['ResourceRecords', index]\n\n # Check if a valid IPv4 address is specified\n if not re.match(REGEX_IPV6, record):\n message = 'AAAA record ({}) is not a valid IPv6 address'\n matches.append(RuleMatch(tree, message.format(record)))\n\n return matches\n\n def check_caa_record(self, path, recordset):\n \"\"\"Check CAA record Configuration\"\"\"\n matches = []\n\n resource_records = recordset.get('ResourceRecords')\n\n for index, record in enumerate(resource_records):\n tree = path[:] + ['ResourceRecords', index]\n\n if not isinstance(record, dict):\n # Split the record up to the mandatory settings (flags tag \"value\")\n items = record.split(' ', 2)\n\n # Check if the 3 settings are given.\n if len(items) != 3:\n message = 'CAA record must contain 3 settings (flags tag \"value\"), record contains {} settings.'\n matches.append(RuleMatch(tree, message.format(len(items))))\n else:\n # Check the flag value\n if not items[0].isdigit():\n message = 'CAA record flag setting ({}) should be of type Integer.'\n matches.append(RuleMatch(tree, message.format(items[0])))\n else:\n if int(items[0]) not in [0, 128]:\n message = 'Invalid CAA record flag setting ({}) given, must be 0 or 128.'\n matches.append(RuleMatch(tree, message.format(items[0])))\n\n # Check the tag value\n if not re.match(REGEX_ALPHANUMERIC, items[1]):\n message = 'Invalid CAA record tag setting {}. Value has to be alphanumeric.'\n matches.append(RuleMatch(tree, message.format(items[0])))\n\n # Check the value\n if not items[2].startswith('\"') or not items[2].endswith('\"'):\n message = 'CAA record value setting has to be enclosed in double quotation marks (\").'\n matches.append(RuleMatch(tree, message))\n\n return matches\n\n def check_cname_record(self, path, recordset):\n \"\"\"Check CNAME record Configuration\"\"\"\n matches = []\n\n resource_records = recordset.get('ResourceRecords')\n if len(resource_records) > 1:\n message = 'A CNAME recordset can only contain 1 value'\n matches.append(RuleMatch(path + ['ResourceRecords'], message))\n else:\n for index, record in enumerate(resource_records):\n if not isinstance(record, dict):\n tree = path[:] + ['ResourceRecords', index]\n if (not re.match(self.REGEX_DOMAINNAME, record)\n # ACM Route 53 validation uses invalid CNAMEs starting with `_`,\n # special-case them rather than complicate the regex.\n and not record.endswith('.acm-validations.aws.')):\n message = 'CNAME record ({}) does not contain a valid domain name'\n matches.append(RuleMatch(tree, message.format(record)))\n\n return matches\n\n def check_mx_record(self, path, recordset):\n \"\"\"Check MX record Configuration\"\"\"\n matches = []\n\n resource_records = recordset.get('ResourceRecords')\n\n for index, record in enumerate(resource_records):\n tree = path[:] + ['ResourceRecords', index]\n\n if not isinstance(record, dict):\n # Split the record up to the mandatory settings (priority domainname)\n items = record.split(' ')\n\n # Check if the 3 settings are given.\n if len(items) != 2:\n message = 'MX record must contain 2 settings (priority domainname), record contains {} settings.'\n matches.append(RuleMatch(tree, message.format(len(items), record)))\n else:\n # Check the priority value\n if not items[0].isdigit():\n message = 'MX record priority setting ({}) should be of type Integer.'\n matches.append(RuleMatch(tree, message.format(items[0], record)))\n else:\n if not 0 <= int(items[0]) <= 65535:\n message = 'Invalid MX record priority setting ({}) given, must be between 0 and 65535.'\n matches.append(RuleMatch(tree, message.format(items[0], record)))\n\n # Check the domainname value\n if not re.match(self.REGEX_DOMAINNAME, items[1]):\n matches.append(RuleMatch(tree, message.format(items[1])))\n\n return matches\n\n def check_txt_record(self, path, recordset):\n \"\"\"Check TXT record Configuration\"\"\"\n matches = []\n\n # Check quotation of the records\n resource_records = recordset.get('ResourceRecords')\n\n for index, record in enumerate(resource_records):\n tree = path[:] + ['ResourceRecords', index]\n\n if not isinstance(record, dict) and not re.match(self.REGEX_TXT, record):\n message = 'TXT record is not structured as one or more items up to 255 characters ' \\\n 'enclosed in double quotation marks at {0}'\n matches.append(RuleMatch(\n tree,\n (\n message.format('/'.join(map(str, tree)))\n ),\n ))\n\n return matches\n\n def check_recordset(self, path, recordset):\n \"\"\"Check record configuration\"\"\"\n\n matches = []\n recordset_type = recordset.get('Type')\n\n # Skip Intrinsic functions\n if not isinstance(recordset_type, dict):\n if not recordset.get('AliasTarget'):\n # If no Alias is specified, ResourceRecords has to be specified\n if not recordset.get('ResourceRecords'):\n message = 'Property ResourceRecords missing at {}'\n matches.append(RuleMatch(path, message.format('/'.join(map(str, path)))))\n # Record type specific checks\n elif recordset_type == 'A':\n matches.extend(self.check_a_record(path, recordset))\n elif recordset_type == 'AAAA':\n matches.extend(self.check_aaaa_record(path, recordset))\n elif recordset_type == 'CAA':\n matches.extend(self.check_caa_record(path, recordset))\n elif recordset_type == 'CNAME':\n matches.extend(self.check_cname_record(path, recordset))\n elif recordset_type == 'MX':\n matches.extend(self.check_mx_record(path, recordset))\n elif recordset_type == 'TXT':\n matches.extend(self.check_txt_record(path, recordset))\n\n return matches\n\n def match(self, cfn):\n \"\"\"Check RecordSets and RecordSetGroups Properties\"\"\"\n\n matches = []\n\n recordsets = cfn.get_resources(['AWS::Route53::RecordSet'])\n\n for name, recordset in recordsets.items():\n path = ['Resources', name, 'Properties']\n\n if isinstance(recordset, dict):\n props = recordset.get('Properties')\n if props:\n matches.extend(self.check_recordset(path, props))\n\n recordsetgroups = cfn.get_resource_properties(['AWS::Route53::RecordSetGroup', 'RecordSets'])\n\n for recordsetgroup in recordsetgroups:\n path = recordsetgroup['Path']\n value = recordsetgroup['Value']\n if isinstance(value, list):\n for index, recordset in enumerate(value):\n tree = path[:] + [index]\n matches.extend(self.check_recordset(tree, recordset))\n\n return matches\n", "path": "src/cfnlint/rules/resources/route53/RecordSet.py"}]}
| 3,678 | 433 |
gh_patches_debug_23225
|
rasdani/github-patches
|
git_diff
|
replicate__cog-843
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Set python package version explicitly and expose in package
The cog python package sets version metadata but this has never been updated:
```python
In [1]: from importlib.metadata import version
In [2]: version('cog')
Out[2]: '0.0.1'
```
In addition, there's no `__version__` property on the package. This isn't essential but it would be nice to have this too:
```python
In [3]: import cog
In [4]: cog.__version__
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
Cell In [4], line 1
----> 1 cog.__version__
AttributeError: module 'cog' has no attribute '__version__'
```
It would be really nice to do this in a way that:
- returns the same version from both of the above
- returns the tagged version in tagged builds (e.g. `0.3.4`)
- appends git metadata when not on a tagged build (e.g. `0.3.4-dev+630e696`)
</issue>
<code>
[start of python/cog/__init__.py]
1 from pydantic import BaseModel
2
3 from .predictor import BasePredictor
4 from .types import File, Input, Path
5
6 __all__ = [
7 "BaseModel",
8 "BasePredictor",
9 "File",
10 "Input",
11 "Path",
12 ]
13
[end of python/cog/__init__.py]
[start of python/setup.py]
1 import setuptools
2
3 with open("../README.md", "r", encoding="utf-8") as fh:
4 long_description = fh.read()
5
6
7 setuptools.setup(
8 name="cog",
9 version="0.0.1",
10 author_email="[email protected]",
11 description="Containers for machine learning",
12 long_description=long_description,
13 long_description_content_type="text/markdown",
14 url="https://github.com/replicate/cog",
15 license="Apache License 2.0",
16 python_requires=">=3.6.0",
17 install_requires=[
18 # intentionally loose. perhaps these should be vendored to not collide with user code?
19 "attrs>=20.1,<23",
20 "fastapi>=0.75.2,<1",
21 "opentelemetry-exporter-otlp>=1.11.1,<2",
22 "opentelemetry-sdk>=1.11.1,<2",
23 "protobuf<=3.20.3",
24 "pydantic>=1,<2",
25 "PyYAML",
26 "redis>=4,<5",
27 "requests>=2,<3",
28 "typing_extensions>=4.1.0",
29 "uvicorn[standard]>=0.12,<1",
30 ],
31 packages=setuptools.find_packages(),
32 )
33
[end of python/setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/python/cog/__init__.py b/python/cog/__init__.py
--- a/python/cog/__init__.py
+++ b/python/cog/__init__.py
@@ -3,7 +3,14 @@
from .predictor import BasePredictor
from .types import File, Input, Path
+try:
+ from ._version import __version__
+except ImportError:
+ __version__ = "0.0.0+unknown"
+
+
__all__ = [
+ "__version__",
"BaseModel",
"BasePredictor",
"File",
diff --git a/python/setup.py b/python/setup.py
deleted file mode 100644
--- a/python/setup.py
+++ /dev/null
@@ -1,32 +0,0 @@
-import setuptools
-
-with open("../README.md", "r", encoding="utf-8") as fh:
- long_description = fh.read()
-
-
-setuptools.setup(
- name="cog",
- version="0.0.1",
- author_email="[email protected]",
- description="Containers for machine learning",
- long_description=long_description,
- long_description_content_type="text/markdown",
- url="https://github.com/replicate/cog",
- license="Apache License 2.0",
- python_requires=">=3.6.0",
- install_requires=[
- # intentionally loose. perhaps these should be vendored to not collide with user code?
- "attrs>=20.1,<23",
- "fastapi>=0.75.2,<1",
- "opentelemetry-exporter-otlp>=1.11.1,<2",
- "opentelemetry-sdk>=1.11.1,<2",
- "protobuf<=3.20.3",
- "pydantic>=1,<2",
- "PyYAML",
- "redis>=4,<5",
- "requests>=2,<3",
- "typing_extensions>=4.1.0",
- "uvicorn[standard]>=0.12,<1",
- ],
- packages=setuptools.find_packages(),
-)
|
{"golden_diff": "diff --git a/python/cog/__init__.py b/python/cog/__init__.py\n--- a/python/cog/__init__.py\n+++ b/python/cog/__init__.py\n@@ -3,7 +3,14 @@\n from .predictor import BasePredictor\n from .types import File, Input, Path\n \n+try:\n+ from ._version import __version__\n+except ImportError:\n+ __version__ = \"0.0.0+unknown\"\n+\n+\n __all__ = [\n+ \"__version__\",\n \"BaseModel\",\n \"BasePredictor\",\n \"File\",\ndiff --git a/python/setup.py b/python/setup.py\ndeleted file mode 100644\n--- a/python/setup.py\n+++ /dev/null\n@@ -1,32 +0,0 @@\n-import setuptools\n-\n-with open(\"../README.md\", \"r\", encoding=\"utf-8\") as fh:\n- long_description = fh.read()\n-\n-\n-setuptools.setup(\n- name=\"cog\",\n- version=\"0.0.1\",\n- author_email=\"[email protected]\",\n- description=\"Containers for machine learning\",\n- long_description=long_description,\n- long_description_content_type=\"text/markdown\",\n- url=\"https://github.com/replicate/cog\",\n- license=\"Apache License 2.0\",\n- python_requires=\">=3.6.0\",\n- install_requires=[\n- # intentionally loose. perhaps these should be vendored to not collide with user code?\n- \"attrs>=20.1,<23\",\n- \"fastapi>=0.75.2,<1\",\n- \"opentelemetry-exporter-otlp>=1.11.1,<2\",\n- \"opentelemetry-sdk>=1.11.1,<2\",\n- \"protobuf<=3.20.3\",\n- \"pydantic>=1,<2\",\n- \"PyYAML\",\n- \"redis>=4,<5\",\n- \"requests>=2,<3\",\n- \"typing_extensions>=4.1.0\",\n- \"uvicorn[standard]>=0.12,<1\",\n- ],\n- packages=setuptools.find_packages(),\n-)\n", "issue": "Set python package version explicitly and expose in package\nThe cog python package sets version metadata but this has never been updated:\r\n\r\n```python\r\nIn [1]: from importlib.metadata import version\r\n\r\nIn [2]: version('cog')\r\nOut[2]: '0.0.1'\r\n```\r\n\r\nIn addition, there's no `__version__` property on the package. This isn't essential but it would be nice to have this too:\r\n\r\n```python\r\nIn [3]: import cog\r\n\r\nIn [4]: cog.__version__\r\n---------------------------------------------------------------------------\r\nAttributeError Traceback (most recent call last)\r\nCell In [4], line 1\r\n----> 1 cog.__version__\r\n\r\nAttributeError: module 'cog' has no attribute '__version__'\r\n```\r\n\r\nIt would be really nice to do this in a way that:\r\n\r\n- returns the same version from both of the above\r\n- returns the tagged version in tagged builds (e.g. `0.3.4`)\r\n- appends git metadata when not on a tagged build (e.g. `0.3.4-dev+630e696`)\r\n\r\n\n", "before_files": [{"content": "from pydantic import BaseModel\n\nfrom .predictor import BasePredictor\nfrom .types import File, Input, Path\n\n__all__ = [\n \"BaseModel\",\n \"BasePredictor\",\n \"File\",\n \"Input\",\n \"Path\",\n]\n", "path": "python/cog/__init__.py"}, {"content": "import setuptools\n\nwith open(\"../README.md\", \"r\", encoding=\"utf-8\") as fh:\n long_description = fh.read()\n\n\nsetuptools.setup(\n name=\"cog\",\n version=\"0.0.1\",\n author_email=\"[email protected]\",\n description=\"Containers for machine learning\",\n long_description=long_description,\n long_description_content_type=\"text/markdown\",\n url=\"https://github.com/replicate/cog\",\n license=\"Apache License 2.0\",\n python_requires=\">=3.6.0\",\n install_requires=[\n # intentionally loose. perhaps these should be vendored to not collide with user code?\n \"attrs>=20.1,<23\",\n \"fastapi>=0.75.2,<1\",\n \"opentelemetry-exporter-otlp>=1.11.1,<2\",\n \"opentelemetry-sdk>=1.11.1,<2\",\n \"protobuf<=3.20.3\",\n \"pydantic>=1,<2\",\n \"PyYAML\",\n \"redis>=4,<5\",\n \"requests>=2,<3\",\n \"typing_extensions>=4.1.0\",\n \"uvicorn[standard]>=0.12,<1\",\n ],\n packages=setuptools.find_packages(),\n)\n", "path": "python/setup.py"}]}
| 1,197 | 481 |
gh_patches_debug_28138
|
rasdani/github-patches
|
git_diff
|
open-mmlab__mmdetection-1050
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
When resize_keep_ratio is False, rescaling for masks does not work.
Thanks for your error report and we appreciate it a lot.
**Checklist**
1. I have searched related issues but cannot get the expected help.
2. The bug has not been fixed in the latest version.
**Describe the bug**
When `resize_keep_ratio=False`, rescaling for masks in loading the dataset will not work. The error is:
```
Scale must be a number or tuple of int, but got <class 'numpy.ndarray'>
```
</issue>
<code>
[start of mmdet/datasets/transforms.py]
1 import mmcv
2 import numpy as np
3 import torch
4
5 __all__ = [
6 'ImageTransform', 'BboxTransform', 'MaskTransform', 'SegMapTransform',
7 'Numpy2Tensor'
8 ]
9
10
11 class ImageTransform(object):
12 """Preprocess an image.
13
14 1. rescale the image to expected size
15 2. normalize the image
16 3. flip the image (if needed)
17 4. pad the image (if needed)
18 5. transpose to (c, h, w)
19 """
20
21 def __init__(self,
22 mean=(0, 0, 0),
23 std=(1, 1, 1),
24 to_rgb=True,
25 size_divisor=None):
26 self.mean = np.array(mean, dtype=np.float32)
27 self.std = np.array(std, dtype=np.float32)
28 self.to_rgb = to_rgb
29 self.size_divisor = size_divisor
30
31 def __call__(self, img, scale, flip=False, keep_ratio=True):
32 if keep_ratio:
33 img, scale_factor = mmcv.imrescale(img, scale, return_scale=True)
34 else:
35 img, w_scale, h_scale = mmcv.imresize(
36 img, scale, return_scale=True)
37 scale_factor = np.array(
38 [w_scale, h_scale, w_scale, h_scale], dtype=np.float32)
39 img_shape = img.shape
40 img = mmcv.imnormalize(img, self.mean, self.std, self.to_rgb)
41 if flip:
42 img = mmcv.imflip(img)
43 if self.size_divisor is not None:
44 img = mmcv.impad_to_multiple(img, self.size_divisor)
45 pad_shape = img.shape
46 else:
47 pad_shape = img_shape
48 img = img.transpose(2, 0, 1)
49 return img, img_shape, pad_shape, scale_factor
50
51
52 def bbox_flip(bboxes, img_shape):
53 """Flip bboxes horizontally.
54
55 Args:
56 bboxes(ndarray): shape (..., 4*k)
57 img_shape(tuple): (height, width)
58 """
59 assert bboxes.shape[-1] % 4 == 0
60 w = img_shape[1]
61 flipped = bboxes.copy()
62 flipped[..., 0::4] = w - bboxes[..., 2::4] - 1
63 flipped[..., 2::4] = w - bboxes[..., 0::4] - 1
64 return flipped
65
66
67 class BboxTransform(object):
68 """Preprocess gt bboxes.
69
70 1. rescale bboxes according to image size
71 2. flip bboxes (if needed)
72 3. pad the first dimension to `max_num_gts`
73 """
74
75 def __init__(self, max_num_gts=None):
76 self.max_num_gts = max_num_gts
77
78 def __call__(self, bboxes, img_shape, scale_factor, flip=False):
79 gt_bboxes = bboxes * scale_factor
80 if flip:
81 gt_bboxes = bbox_flip(gt_bboxes, img_shape)
82 gt_bboxes[:, 0::2] = np.clip(gt_bboxes[:, 0::2], 0, img_shape[1] - 1)
83 gt_bboxes[:, 1::2] = np.clip(gt_bboxes[:, 1::2], 0, img_shape[0] - 1)
84 if self.max_num_gts is None:
85 return gt_bboxes
86 else:
87 num_gts = gt_bboxes.shape[0]
88 padded_bboxes = np.zeros((self.max_num_gts, 4), dtype=np.float32)
89 padded_bboxes[:num_gts, :] = gt_bboxes
90 return padded_bboxes
91
92
93 class MaskTransform(object):
94 """Preprocess masks.
95
96 1. resize masks to expected size and stack to a single array
97 2. flip the masks (if needed)
98 3. pad the masks (if needed)
99 """
100
101 def __call__(self, masks, pad_shape, scale_factor, flip=False):
102 masks = [
103 mmcv.imrescale(mask, scale_factor, interpolation='nearest')
104 for mask in masks
105 ]
106 if flip:
107 masks = [mask[:, ::-1] for mask in masks]
108 padded_masks = [
109 mmcv.impad(mask, pad_shape[:2], pad_val=0) for mask in masks
110 ]
111 padded_masks = np.stack(padded_masks, axis=0)
112 return padded_masks
113
114
115 class SegMapTransform(object):
116 """Preprocess semantic segmentation maps.
117
118 1. rescale the segmentation map to expected size
119 3. flip the image (if needed)
120 4. pad the image (if needed)
121 """
122
123 def __init__(self, size_divisor=None):
124 self.size_divisor = size_divisor
125
126 def __call__(self, img, scale, flip=False, keep_ratio=True):
127 if keep_ratio:
128 img = mmcv.imrescale(img, scale, interpolation='nearest')
129 else:
130 img = mmcv.imresize(img, scale, interpolation='nearest')
131 if flip:
132 img = mmcv.imflip(img)
133 if self.size_divisor is not None:
134 img = mmcv.impad_to_multiple(img, self.size_divisor)
135 return img
136
137
138 class Numpy2Tensor(object):
139
140 def __init__(self):
141 pass
142
143 def __call__(self, *args):
144 if len(args) == 1:
145 return torch.from_numpy(args[0])
146 else:
147 return tuple([torch.from_numpy(np.array(array)) for array in args])
148
[end of mmdet/datasets/transforms.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/mmdet/datasets/transforms.py b/mmdet/datasets/transforms.py
--- a/mmdet/datasets/transforms.py
+++ b/mmdet/datasets/transforms.py
@@ -34,8 +34,8 @@
else:
img, w_scale, h_scale = mmcv.imresize(
img, scale, return_scale=True)
- scale_factor = np.array(
- [w_scale, h_scale, w_scale, h_scale], dtype=np.float32)
+ scale_factor = np.array([w_scale, h_scale, w_scale, h_scale],
+ dtype=np.float32)
img_shape = img.shape
img = mmcv.imnormalize(img, self.mean, self.std, self.to_rgb)
if flip:
@@ -99,10 +99,24 @@
"""
def __call__(self, masks, pad_shape, scale_factor, flip=False):
- masks = [
- mmcv.imrescale(mask, scale_factor, interpolation='nearest')
- for mask in masks
- ]
+ # aspect ratio unchanged
+ if isinstance(scale_factor, float):
+ masks = [
+ mmcv.imrescale(mask, scale_factor, interpolation='nearest')
+ for mask in masks
+ ]
+ # aspect ratio changed
+ else:
+ w_ratio, h_ratio = scale_factor[:2]
+ if masks:
+ h, w = masks[0].shape[:2]
+ new_h = int(np.round(h * h_ratio))
+ new_w = int(np.round(w * w_ratio))
+ new_size = (new_w, new_h)
+ masks = [
+ mmcv.imresize(mask, new_size, interpolation='nearest')
+ for mask in masks
+ ]
if flip:
masks = [mask[:, ::-1] for mask in masks]
padded_masks = [
|
{"golden_diff": "diff --git a/mmdet/datasets/transforms.py b/mmdet/datasets/transforms.py\n--- a/mmdet/datasets/transforms.py\n+++ b/mmdet/datasets/transforms.py\n@@ -34,8 +34,8 @@\n else:\n img, w_scale, h_scale = mmcv.imresize(\n img, scale, return_scale=True)\n- scale_factor = np.array(\n- [w_scale, h_scale, w_scale, h_scale], dtype=np.float32)\n+ scale_factor = np.array([w_scale, h_scale, w_scale, h_scale],\n+ dtype=np.float32)\n img_shape = img.shape\n img = mmcv.imnormalize(img, self.mean, self.std, self.to_rgb)\n if flip:\n@@ -99,10 +99,24 @@\n \"\"\"\n \n def __call__(self, masks, pad_shape, scale_factor, flip=False):\n- masks = [\n- mmcv.imrescale(mask, scale_factor, interpolation='nearest')\n- for mask in masks\n- ]\n+ # aspect ratio unchanged\n+ if isinstance(scale_factor, float):\n+ masks = [\n+ mmcv.imrescale(mask, scale_factor, interpolation='nearest')\n+ for mask in masks\n+ ]\n+ # aspect ratio changed\n+ else:\n+ w_ratio, h_ratio = scale_factor[:2]\n+ if masks:\n+ h, w = masks[0].shape[:2]\n+ new_h = int(np.round(h * h_ratio))\n+ new_w = int(np.round(w * w_ratio))\n+ new_size = (new_w, new_h)\n+ masks = [\n+ mmcv.imresize(mask, new_size, interpolation='nearest')\n+ for mask in masks\n+ ]\n if flip:\n masks = [mask[:, ::-1] for mask in masks]\n padded_masks = [\n", "issue": "When resize_keep_ratio is False, rescaling for masks does not work.\nThanks for your error report and we appreciate it a lot.\r\n\r\n**Checklist**\r\n1. I have searched related issues but cannot get the expected help.\r\n2. The bug has not been fixed in the latest version.\r\n\r\n**Describe the bug**\r\n\r\nWhen `resize_keep_ratio=False`, rescaling for masks in loading the dataset will not work. The error is:\r\n```\r\nScale must be a number or tuple of int, but got <class 'numpy.ndarray'>\r\n```\r\n\n", "before_files": [{"content": "import mmcv\nimport numpy as np\nimport torch\n\n__all__ = [\n 'ImageTransform', 'BboxTransform', 'MaskTransform', 'SegMapTransform',\n 'Numpy2Tensor'\n]\n\n\nclass ImageTransform(object):\n \"\"\"Preprocess an image.\n\n 1. rescale the image to expected size\n 2. normalize the image\n 3. flip the image (if needed)\n 4. pad the image (if needed)\n 5. transpose to (c, h, w)\n \"\"\"\n\n def __init__(self,\n mean=(0, 0, 0),\n std=(1, 1, 1),\n to_rgb=True,\n size_divisor=None):\n self.mean = np.array(mean, dtype=np.float32)\n self.std = np.array(std, dtype=np.float32)\n self.to_rgb = to_rgb\n self.size_divisor = size_divisor\n\n def __call__(self, img, scale, flip=False, keep_ratio=True):\n if keep_ratio:\n img, scale_factor = mmcv.imrescale(img, scale, return_scale=True)\n else:\n img, w_scale, h_scale = mmcv.imresize(\n img, scale, return_scale=True)\n scale_factor = np.array(\n [w_scale, h_scale, w_scale, h_scale], dtype=np.float32)\n img_shape = img.shape\n img = mmcv.imnormalize(img, self.mean, self.std, self.to_rgb)\n if flip:\n img = mmcv.imflip(img)\n if self.size_divisor is not None:\n img = mmcv.impad_to_multiple(img, self.size_divisor)\n pad_shape = img.shape\n else:\n pad_shape = img_shape\n img = img.transpose(2, 0, 1)\n return img, img_shape, pad_shape, scale_factor\n\n\ndef bbox_flip(bboxes, img_shape):\n \"\"\"Flip bboxes horizontally.\n\n Args:\n bboxes(ndarray): shape (..., 4*k)\n img_shape(tuple): (height, width)\n \"\"\"\n assert bboxes.shape[-1] % 4 == 0\n w = img_shape[1]\n flipped = bboxes.copy()\n flipped[..., 0::4] = w - bboxes[..., 2::4] - 1\n flipped[..., 2::4] = w - bboxes[..., 0::4] - 1\n return flipped\n\n\nclass BboxTransform(object):\n \"\"\"Preprocess gt bboxes.\n\n 1. rescale bboxes according to image size\n 2. flip bboxes (if needed)\n 3. pad the first dimension to `max_num_gts`\n \"\"\"\n\n def __init__(self, max_num_gts=None):\n self.max_num_gts = max_num_gts\n\n def __call__(self, bboxes, img_shape, scale_factor, flip=False):\n gt_bboxes = bboxes * scale_factor\n if flip:\n gt_bboxes = bbox_flip(gt_bboxes, img_shape)\n gt_bboxes[:, 0::2] = np.clip(gt_bboxes[:, 0::2], 0, img_shape[1] - 1)\n gt_bboxes[:, 1::2] = np.clip(gt_bboxes[:, 1::2], 0, img_shape[0] - 1)\n if self.max_num_gts is None:\n return gt_bboxes\n else:\n num_gts = gt_bboxes.shape[0]\n padded_bboxes = np.zeros((self.max_num_gts, 4), dtype=np.float32)\n padded_bboxes[:num_gts, :] = gt_bboxes\n return padded_bboxes\n\n\nclass MaskTransform(object):\n \"\"\"Preprocess masks.\n\n 1. resize masks to expected size and stack to a single array\n 2. flip the masks (if needed)\n 3. pad the masks (if needed)\n \"\"\"\n\n def __call__(self, masks, pad_shape, scale_factor, flip=False):\n masks = [\n mmcv.imrescale(mask, scale_factor, interpolation='nearest')\n for mask in masks\n ]\n if flip:\n masks = [mask[:, ::-1] for mask in masks]\n padded_masks = [\n mmcv.impad(mask, pad_shape[:2], pad_val=0) for mask in masks\n ]\n padded_masks = np.stack(padded_masks, axis=0)\n return padded_masks\n\n\nclass SegMapTransform(object):\n \"\"\"Preprocess semantic segmentation maps.\n\n 1. rescale the segmentation map to expected size\n 3. flip the image (if needed)\n 4. pad the image (if needed)\n \"\"\"\n\n def __init__(self, size_divisor=None):\n self.size_divisor = size_divisor\n\n def __call__(self, img, scale, flip=False, keep_ratio=True):\n if keep_ratio:\n img = mmcv.imrescale(img, scale, interpolation='nearest')\n else:\n img = mmcv.imresize(img, scale, interpolation='nearest')\n if flip:\n img = mmcv.imflip(img)\n if self.size_divisor is not None:\n img = mmcv.impad_to_multiple(img, self.size_divisor)\n return img\n\n\nclass Numpy2Tensor(object):\n\n def __init__(self):\n pass\n\n def __call__(self, *args):\n if len(args) == 1:\n return torch.from_numpy(args[0])\n else:\n return tuple([torch.from_numpy(np.array(array)) for array in args])\n", "path": "mmdet/datasets/transforms.py"}]}
| 2,212 | 417 |
gh_patches_debug_6614
|
rasdani/github-patches
|
git_diff
|
horovod__horovod-1180
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
TF estimators and horovod.spark
**Environment:**
1. Framework: (TensorFlow, Keras, PyTorch, MXNet)
TensorFlow
2. Framework version:
1.13.1
3. Horovod version:
0.16
4. MPI version:
3.0.0
5. CUDA version:
N/A
6. NCCL version:
N/A
7. Python version:
3.5
8. OS and version:
Amazon Linux AMI release 2018.03
**Your question:**
Is there any guidance on how to use horovod.spark with TF estimators? I've been able to train models using TF-Keras and horovod.spark in the style of the keras_spark_rossman.py example script, but I'm curious about how horovod.spark would work with Estimator's?
Moreover, I think I'm just confused about how horovod.spark actually works - is it okay to instantiate an Estimator instance inside the input_fn for a horovod.spark.run() call, or will that mean each worker has a different starting point for the model?
</issue>
<code>
[start of horovod/spark/__init__.py]
1 # Copyright 2019 Uber Technologies, Inc. All Rights Reserved.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14 # ==============================================================================
15
16 import os
17 import pyspark
18 from six.moves import queue
19 import sys
20 import threading
21
22 from horovod.spark.task import task_service
23 from horovod.run.common.util import codec, env as env_util, safe_shell_exec, \
24 timeout, host_hash, secret
25 from horovod.run.common.util import settings as hvd_settings
26 from horovod.spark.driver import driver_service, job_id
27
28
29 def _task_fn(index, driver_addresses, settings):
30 task = task_service.SparkTaskService(index, settings.key)
31 try:
32 driver_client = driver_service.SparkDriverClient(driver_addresses, settings.key, settings.verbose)
33 driver_client.register_task(index, task.addresses(), host_hash.host_hash())
34 task.wait_for_initial_registration(settings.timeout)
35 # Tasks ping each other in a circular fashion to determine interfaces reachable within
36 # the cluster.
37 next_task_index = (index + 1) % settings.num_proc
38 next_task_addresses = driver_client.all_task_addresses(next_task_index)
39 # We request interface matching to weed out all the NAT'ed interfaces.
40 next_task_client = \
41 task_service.SparkTaskClient(next_task_index, next_task_addresses,
42 settings.key, settings.verbose,
43 match_intf=True)
44 driver_client.register_task_to_task_addresses(next_task_index, next_task_client.addresses())
45 task_indices_on_this_host = driver_client.task_host_hash_indices(
46 host_hash.host_hash())
47 if task_indices_on_this_host[0] == index:
48 # Task with first index will execute orted that will run mpirun_exec_fn for all tasks.
49 task.wait_for_command_start(settings.timeout)
50 task.wait_for_command_termination()
51 else:
52 # The rest of tasks need to wait for the first task to finish.
53 first_task_addresses = driver_client.all_task_addresses(task_indices_on_this_host[0])
54 first_task_client = \
55 task_service.SparkTaskClient(task_indices_on_this_host[0],
56 first_task_addresses, settings.key,
57 settings.verbose)
58 first_task_client.wait_for_command_termination()
59 return task.fn_result()
60 finally:
61 task.shutdown()
62
63
64 def _make_mapper(driver_addresses, settings):
65 def _mapper(index, _):
66 yield _task_fn(index, driver_addresses, settings)
67 return _mapper
68
69
70 def _make_spark_thread(spark_context, spark_job_group, driver, result_queue,
71 settings):
72 def run_spark():
73 try:
74 spark_context.setJobGroup(spark_job_group,
75 "Horovod Spark Run",
76 interruptOnCancel=True)
77 procs = spark_context.range(0, numSlices=settings.num_proc)
78 # We assume that folks caring about security will enable Spark RPC
79 # encryption, thus ensuring that key that is passed here remains
80 # secret.
81 result = procs.mapPartitionsWithIndex(_make_mapper(driver.addresses(), settings)).collect()
82 result_queue.put(result)
83 except:
84 driver.notify_spark_job_failed()
85 raise
86
87 spark_thread = threading.Thread(target=run_spark)
88 spark_thread.start()
89 return spark_thread
90
91
92 def run(fn, args=(), kwargs={}, num_proc=None, start_timeout=None, env=None,
93 stdout=None, stderr=None, verbose=1):
94 """
95 Runs Horovod in Spark. Runs `num_proc` processes executing `fn` using the same amount of Spark tasks.
96
97 Args:
98 fn: Function to run.
99 args: Arguments to pass to `fn`.
100 kwargs: Keyword arguments to pass to `fn`.
101 num_proc: Number of Horovod processes. Defaults to `spark.default.parallelism`.
102 start_timeout: Timeout for Spark tasks to spawn, register and start running the code, in seconds.
103 If not set, falls back to `HOROVOD_SPARK_START_TIMEOUT` environment variable value.
104 If it is not set as well, defaults to 600 seconds.
105 env: Environment dictionary to use in Horovod run. Defaults to `os.environ`.
106 stdout: Horovod stdout is redirected to this stream. Defaults to sys.stdout.
107 stderr: Horovod stderr is redirected to this stream. Defaults to sys.stderr.
108 verbose: Debug output verbosity (0-2). Defaults to 1.
109
110 Returns:
111 List of results returned by running `fn` on each rank.
112 """
113
114 if start_timeout is None:
115 # Lookup default timeout from the environment variable.
116 start_timeout = int(os.getenv('HOROVOD_SPARK_START_TIMEOUT', '600'))
117
118 tmout = timeout.Timeout(start_timeout,
119 message='Timed out waiting for {activity}. Please check that you have '
120 'enough resources to run all Horovod processes. Each Horovod '
121 'process runs in a Spark task. You may need to increase the '
122 'start_timeout parameter to a larger value if your Spark resources '
123 'are allocated on-demand.')
124 settings = hvd_settings.Settings(verbose=verbose,
125 key=secret.make_secret_key(),
126 timeout=tmout)
127
128 spark_context = pyspark.SparkContext._active_spark_context
129 if spark_context is None:
130 raise Exception('Could not find an active SparkContext, are you '
131 'running in a PySpark session?')
132
133 if num_proc is None:
134 num_proc = spark_context.defaultParallelism
135 if settings.verbose >= 1:
136 print('Running %d processes (inferred from spark.default.parallelism)...' % num_proc)
137 else:
138 if settings.verbose >= 1:
139 print('Running %d processes...' % num_proc)
140 settings.num_proc = num_proc
141
142 result_queue = queue.Queue(1)
143
144 spark_job_group = 'horovod.spark.run.%d' % job_id.next_job_id()
145 driver = driver_service.SparkDriverService(settings.num_proc, fn, args, kwargs,
146 settings.key)
147 spark_thread = _make_spark_thread(spark_context, spark_job_group, driver,
148 result_queue, settings)
149 try:
150 driver.wait_for_initial_registration(settings.timeout)
151 if settings.verbose >= 2:
152 print('Initial Spark task registration is complete.')
153 task_clients = [
154 task_service.SparkTaskClient(index,
155 driver.task_addresses_for_driver(index),
156 settings.key, settings.verbose)
157 for index in range(settings.num_proc)]
158 for task_client in task_clients:
159 task_client.notify_initial_registration_complete()
160 driver.wait_for_task_to_task_address_updates(settings.timeout)
161 if settings.verbose >= 2:
162 print('Spark task-to-task address registration is complete.')
163
164 # Determine a set of common interfaces for task-to-task communication.
165 common_intfs = set(driver.task_addresses_for_tasks(0).keys())
166 for index in range(1, settings.num_proc):
167 common_intfs.intersection_update(driver.task_addresses_for_tasks(index).keys())
168 if not common_intfs:
169 raise Exception('Unable to find a set of common task-to-task communication interfaces: %s'
170 % [(index, driver.task_addresses_for_tasks(index)) for index in range(settings.num_proc)])
171
172 # Determine the index grouping based on host hashes.
173 # Barrel shift until index 0 is in the first host.
174 host_hashes = list(driver.task_host_hash_indices().keys())
175 host_hashes.sort()
176 while 0 not in driver.task_host_hash_indices()[host_hashes[0]]:
177 host_hashes = host_hashes[1:] + host_hashes[:1]
178
179 ranks_to_indices = []
180 for host_hash in host_hashes:
181 ranks_to_indices += driver.task_host_hash_indices()[host_hash]
182 driver.set_ranks_to_indices(ranks_to_indices)
183
184 if env is None:
185 env = os.environ.copy()
186
187 # Pass secret key through the environment variables.
188 env[secret.HOROVOD_SECRET_KEY] = codec.dumps_base64(settings.key)
189
190 mpirun_command = (
191 'mpirun --allow-run-as-root --tag-output '
192 '-np {num_proc} -H {hosts} '
193 '-bind-to none -map-by slot '
194 '-mca pml ob1 -mca btl ^openib -mca btl_tcp_if_include {common_intfs} '
195 '-x NCCL_DEBUG=INFO -x NCCL_SOCKET_IFNAME={common_intfs} '
196 '{env} ' # expect a lot of environment variables
197 '-mca plm_rsh_agent "{python} -m horovod.spark.driver.mpirun_rsh {encoded_driver_addresses} {settings}" '
198 '{python} -m horovod.spark.task.mpirun_exec_fn {encoded_driver_addresses} {settings}'
199 .format(num_proc=settings.num_proc,
200 hosts=','.join('%s:%d' % (host_hash, len(driver.task_host_hash_indices()[host_hash]))
201 for host_hash in host_hashes),
202 common_intfs=','.join(common_intfs),
203 env=' '.join('-x %s' % key for key in env.keys() if env_util.is_exportable(key)),
204 python=sys.executable,
205 encoded_driver_addresses=codec.dumps_base64(driver.addresses()),
206 settings=codec.dumps_base64(settings)))
207 if settings.verbose >= 2:
208 print('+ %s' % mpirun_command)
209 exit_code = safe_shell_exec.execute(mpirun_command, env, stdout, stderr)
210 if exit_code != 0:
211 raise Exception('mpirun exited with code %d, see the error above.' % exit_code)
212 except:
213 # Terminate Spark job.
214 spark_context.cancelJobGroup(spark_job_group)
215
216 # Re-raise exception.
217 raise
218 finally:
219 spark_thread.join()
220 driver.shutdown()
221
222 # Make sure Spark Job did not fail.
223 driver.check_for_spark_job_failure()
224
225 # If there's no exception, execution results are in this queue.
226 results = result_queue.get_nowait()
227 return [results[index] for index in ranks_to_indices]
228
[end of horovod/spark/__init__.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/horovod/spark/__init__.py b/horovod/spark/__init__.py
--- a/horovod/spark/__init__.py
+++ b/horovod/spark/__init__.py
@@ -13,6 +13,12 @@
# limitations under the License.
# ==============================================================================
+# Workaround for https://issues.apache.org/jira/browse/SPARK-22674
+# This fix also requires the user to make this same change at the top of their
+# training script before importing pyspark (on serialization).
+import collections
+collections.namedtuple.__hijack = 1
+
import os
import pyspark
from six.moves import queue
|
{"golden_diff": "diff --git a/horovod/spark/__init__.py b/horovod/spark/__init__.py\n--- a/horovod/spark/__init__.py\n+++ b/horovod/spark/__init__.py\n@@ -13,6 +13,12 @@\n # limitations under the License.\n # ==============================================================================\n \n+# Workaround for https://issues.apache.org/jira/browse/SPARK-22674\n+# This fix also requires the user to make this same change at the top of their\n+# training script before importing pyspark (on serialization).\n+import collections\n+collections.namedtuple.__hijack = 1\n+\n import os\n import pyspark\n from six.moves import queue\n", "issue": "TF estimators and horovod.spark\n**Environment:**\r\n1. Framework: (TensorFlow, Keras, PyTorch, MXNet)\r\nTensorFlow\r\n2. Framework version:\r\n1.13.1\r\n3. Horovod version:\r\n0.16\r\n4. MPI version:\r\n3.0.0\r\n5. CUDA version:\r\nN/A\r\n6. NCCL version:\r\nN/A\r\n7. Python version:\r\n3.5\r\n8. OS and version:\r\nAmazon Linux AMI release 2018.03\r\n\r\n**Your question:**\r\nIs there any guidance on how to use horovod.spark with TF estimators? I've been able to train models using TF-Keras and horovod.spark in the style of the keras_spark_rossman.py example script, but I'm curious about how horovod.spark would work with Estimator's?\r\n\r\nMoreover, I think I'm just confused about how horovod.spark actually works - is it okay to instantiate an Estimator instance inside the input_fn for a horovod.spark.run() call, or will that mean each worker has a different starting point for the model?\n", "before_files": [{"content": "# Copyright 2019 Uber Technologies, Inc. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n# ==============================================================================\n\nimport os\nimport pyspark\nfrom six.moves import queue\nimport sys\nimport threading\n\nfrom horovod.spark.task import task_service\nfrom horovod.run.common.util import codec, env as env_util, safe_shell_exec, \\\n timeout, host_hash, secret\nfrom horovod.run.common.util import settings as hvd_settings\nfrom horovod.spark.driver import driver_service, job_id\n\n\ndef _task_fn(index, driver_addresses, settings):\n task = task_service.SparkTaskService(index, settings.key)\n try:\n driver_client = driver_service.SparkDriverClient(driver_addresses, settings.key, settings.verbose)\n driver_client.register_task(index, task.addresses(), host_hash.host_hash())\n task.wait_for_initial_registration(settings.timeout)\n # Tasks ping each other in a circular fashion to determine interfaces reachable within\n # the cluster.\n next_task_index = (index + 1) % settings.num_proc\n next_task_addresses = driver_client.all_task_addresses(next_task_index)\n # We request interface matching to weed out all the NAT'ed interfaces.\n next_task_client = \\\n task_service.SparkTaskClient(next_task_index, next_task_addresses,\n settings.key, settings.verbose,\n match_intf=True)\n driver_client.register_task_to_task_addresses(next_task_index, next_task_client.addresses())\n task_indices_on_this_host = driver_client.task_host_hash_indices(\n host_hash.host_hash())\n if task_indices_on_this_host[0] == index:\n # Task with first index will execute orted that will run mpirun_exec_fn for all tasks.\n task.wait_for_command_start(settings.timeout)\n task.wait_for_command_termination()\n else:\n # The rest of tasks need to wait for the first task to finish.\n first_task_addresses = driver_client.all_task_addresses(task_indices_on_this_host[0])\n first_task_client = \\\n task_service.SparkTaskClient(task_indices_on_this_host[0],\n first_task_addresses, settings.key,\n settings.verbose)\n first_task_client.wait_for_command_termination()\n return task.fn_result()\n finally:\n task.shutdown()\n\n\ndef _make_mapper(driver_addresses, settings):\n def _mapper(index, _):\n yield _task_fn(index, driver_addresses, settings)\n return _mapper\n\n\ndef _make_spark_thread(spark_context, spark_job_group, driver, result_queue,\n settings):\n def run_spark():\n try:\n spark_context.setJobGroup(spark_job_group,\n \"Horovod Spark Run\",\n interruptOnCancel=True)\n procs = spark_context.range(0, numSlices=settings.num_proc)\n # We assume that folks caring about security will enable Spark RPC\n # encryption, thus ensuring that key that is passed here remains\n # secret.\n result = procs.mapPartitionsWithIndex(_make_mapper(driver.addresses(), settings)).collect()\n result_queue.put(result)\n except:\n driver.notify_spark_job_failed()\n raise\n\n spark_thread = threading.Thread(target=run_spark)\n spark_thread.start()\n return spark_thread\n\n\ndef run(fn, args=(), kwargs={}, num_proc=None, start_timeout=None, env=None,\n stdout=None, stderr=None, verbose=1):\n \"\"\"\n Runs Horovod in Spark. Runs `num_proc` processes executing `fn` using the same amount of Spark tasks.\n\n Args:\n fn: Function to run.\n args: Arguments to pass to `fn`.\n kwargs: Keyword arguments to pass to `fn`.\n num_proc: Number of Horovod processes. Defaults to `spark.default.parallelism`.\n start_timeout: Timeout for Spark tasks to spawn, register and start running the code, in seconds.\n If not set, falls back to `HOROVOD_SPARK_START_TIMEOUT` environment variable value.\n If it is not set as well, defaults to 600 seconds.\n env: Environment dictionary to use in Horovod run. Defaults to `os.environ`.\n stdout: Horovod stdout is redirected to this stream. Defaults to sys.stdout.\n stderr: Horovod stderr is redirected to this stream. Defaults to sys.stderr.\n verbose: Debug output verbosity (0-2). Defaults to 1.\n\n Returns:\n List of results returned by running `fn` on each rank.\n \"\"\"\n\n if start_timeout is None:\n # Lookup default timeout from the environment variable.\n start_timeout = int(os.getenv('HOROVOD_SPARK_START_TIMEOUT', '600'))\n\n tmout = timeout.Timeout(start_timeout,\n message='Timed out waiting for {activity}. Please check that you have '\n 'enough resources to run all Horovod processes. Each Horovod '\n 'process runs in a Spark task. You may need to increase the '\n 'start_timeout parameter to a larger value if your Spark resources '\n 'are allocated on-demand.')\n settings = hvd_settings.Settings(verbose=verbose,\n key=secret.make_secret_key(),\n timeout=tmout)\n\n spark_context = pyspark.SparkContext._active_spark_context\n if spark_context is None:\n raise Exception('Could not find an active SparkContext, are you '\n 'running in a PySpark session?')\n\n if num_proc is None:\n num_proc = spark_context.defaultParallelism\n if settings.verbose >= 1:\n print('Running %d processes (inferred from spark.default.parallelism)...' % num_proc)\n else:\n if settings.verbose >= 1:\n print('Running %d processes...' % num_proc)\n settings.num_proc = num_proc\n\n result_queue = queue.Queue(1)\n\n spark_job_group = 'horovod.spark.run.%d' % job_id.next_job_id()\n driver = driver_service.SparkDriverService(settings.num_proc, fn, args, kwargs,\n settings.key)\n spark_thread = _make_spark_thread(spark_context, spark_job_group, driver,\n result_queue, settings)\n try:\n driver.wait_for_initial_registration(settings.timeout)\n if settings.verbose >= 2:\n print('Initial Spark task registration is complete.')\n task_clients = [\n task_service.SparkTaskClient(index,\n driver.task_addresses_for_driver(index),\n settings.key, settings.verbose)\n for index in range(settings.num_proc)]\n for task_client in task_clients:\n task_client.notify_initial_registration_complete()\n driver.wait_for_task_to_task_address_updates(settings.timeout)\n if settings.verbose >= 2:\n print('Spark task-to-task address registration is complete.')\n\n # Determine a set of common interfaces for task-to-task communication.\n common_intfs = set(driver.task_addresses_for_tasks(0).keys())\n for index in range(1, settings.num_proc):\n common_intfs.intersection_update(driver.task_addresses_for_tasks(index).keys())\n if not common_intfs:\n raise Exception('Unable to find a set of common task-to-task communication interfaces: %s'\n % [(index, driver.task_addresses_for_tasks(index)) for index in range(settings.num_proc)])\n\n # Determine the index grouping based on host hashes.\n # Barrel shift until index 0 is in the first host.\n host_hashes = list(driver.task_host_hash_indices().keys())\n host_hashes.sort()\n while 0 not in driver.task_host_hash_indices()[host_hashes[0]]:\n host_hashes = host_hashes[1:] + host_hashes[:1]\n\n ranks_to_indices = []\n for host_hash in host_hashes:\n ranks_to_indices += driver.task_host_hash_indices()[host_hash]\n driver.set_ranks_to_indices(ranks_to_indices)\n\n if env is None:\n env = os.environ.copy()\n\n # Pass secret key through the environment variables.\n env[secret.HOROVOD_SECRET_KEY] = codec.dumps_base64(settings.key)\n\n mpirun_command = (\n 'mpirun --allow-run-as-root --tag-output '\n '-np {num_proc} -H {hosts} '\n '-bind-to none -map-by slot '\n '-mca pml ob1 -mca btl ^openib -mca btl_tcp_if_include {common_intfs} '\n '-x NCCL_DEBUG=INFO -x NCCL_SOCKET_IFNAME={common_intfs} '\n '{env} ' # expect a lot of environment variables\n '-mca plm_rsh_agent \"{python} -m horovod.spark.driver.mpirun_rsh {encoded_driver_addresses} {settings}\" '\n '{python} -m horovod.spark.task.mpirun_exec_fn {encoded_driver_addresses} {settings}'\n .format(num_proc=settings.num_proc,\n hosts=','.join('%s:%d' % (host_hash, len(driver.task_host_hash_indices()[host_hash]))\n for host_hash in host_hashes),\n common_intfs=','.join(common_intfs),\n env=' '.join('-x %s' % key for key in env.keys() if env_util.is_exportable(key)),\n python=sys.executable,\n encoded_driver_addresses=codec.dumps_base64(driver.addresses()),\n settings=codec.dumps_base64(settings)))\n if settings.verbose >= 2:\n print('+ %s' % mpirun_command)\n exit_code = safe_shell_exec.execute(mpirun_command, env, stdout, stderr)\n if exit_code != 0:\n raise Exception('mpirun exited with code %d, see the error above.' % exit_code)\n except:\n # Terminate Spark job.\n spark_context.cancelJobGroup(spark_job_group)\n\n # Re-raise exception.\n raise\n finally:\n spark_thread.join()\n driver.shutdown()\n\n # Make sure Spark Job did not fail.\n driver.check_for_spark_job_failure()\n\n # If there's no exception, execution results are in this queue.\n results = result_queue.get_nowait()\n return [results[index] for index in ranks_to_indices]\n", "path": "horovod/spark/__init__.py"}]}
| 3,598 | 156 |
gh_patches_debug_30953
|
rasdani/github-patches
|
git_diff
|
kartoza__prj.app-1136
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Bulk attendee upload is broken
I am gettting an error uploading attendees using a CSV. I have done it successfully in the past using the same format CSV. For now, I have attended the participants manually.
Attached is my upload csv with the emails replaced with [email protected] to preserve privacy.
[attendees.txt](https://github.com/kartoza/prj.app/files/4202985/attendees.txt)
</issue>
<code>
[start of django_project/certification/views/attendee.py]
1 # coding=utf-8
2 import csv
3 from django.db import transaction
4 from django.urls import reverse
5 from django.views.generic import (
6 CreateView, FormView)
7 from braces.views import LoginRequiredMixin, FormMessagesMixin
8 from certification.models import (
9 Attendee, CertifyingOrganisation, CourseAttendee, Course
10 )
11 from certification.forms import AttendeeForm, CsvAttendeeForm
12
13
14 class AttendeeMixin(object):
15 """Mixin class to provide standard settings for Attendee."""
16
17 model = Attendee
18 form_class = AttendeeForm
19
20
21 class AttendeeCreateView(LoginRequiredMixin, AttendeeMixin, CreateView):
22 """Create view for Attendee."""
23
24 context_object_name = 'attendee'
25 template_name = 'attendee/create.html'
26
27 def get_success_url(self):
28 """Define the redirect URL.
29
30 After successful creation of the object, the User will be redirected
31 to the create course attendee page.
32
33 :returns: URL
34 :rtype: HttpResponse
35 """
36 add_to_course = self.request.POST.get('add_to_course')
37 if add_to_course is None:
38 success_url = reverse('courseattendee-create', kwargs={
39 'project_slug': self.project_slug,
40 'organisation_slug': self.organisation_slug,
41 'slug': self.course_slug,
42 })
43 else:
44 success_url = reverse('course-detail', kwargs={
45 'project_slug': self.project_slug,
46 'organisation_slug': self.organisation_slug,
47 'slug': self.course_slug,
48 })
49 return success_url
50
51 def get_context_data(self, **kwargs):
52 """Get the context data which is passed to a template.
53
54 :param kwargs: Any arguments to pass to the superclass.
55 :type kwargs: dict
56
57 :returns: Context data which will be passed to the template.
58 :rtype: dict
59 """
60
61 context = super(
62 AttendeeCreateView, self).get_context_data(**kwargs)
63 return context
64
65 def get_form_kwargs(self):
66 """Get keyword arguments from form.
67
68 :returns keyword argument from the form
69 :rtype: dict
70 """
71
72 kwargs = super(AttendeeCreateView, self).get_form_kwargs()
73 self.project_slug = self.kwargs.get('project_slug', None)
74 self.organisation_slug = self.kwargs.get('organisation_slug', None)
75 self.course_slug = self.kwargs.get('slug', None)
76 self.certifying_organisation = \
77 CertifyingOrganisation.objects.get(slug=self.organisation_slug)
78 kwargs.update({
79 'user': self.request.user,
80 'certifying_organisation': self.certifying_organisation
81 })
82 return kwargs
83
84 def form_valid(self, form):
85 add_to_course = self.request.POST.get('add_to_course')
86 if add_to_course is None:
87 if form.is_valid():
88 form.save()
89 else:
90 if form.is_valid():
91 object = form.save()
92 course_slug = self.kwargs.get('slug', None)
93 course = Course.objects.get(slug=course_slug)
94 course_attendee = CourseAttendee(
95 attendee=object,
96 course=course,
97 author=self.request.user
98 )
99 course_attendee.save()
100 return super(AttendeeCreateView, self).form_valid(form)
101
102
103 class CsvUploadView(FormMessagesMixin, LoginRequiredMixin, FormView):
104 """
105 Allow upload of attendees through CSV file.
106 """
107
108 context_object_name = 'csvupload'
109 form_class = CsvAttendeeForm
110 template_name = 'attendee/upload_attendee_csv.html'
111
112 def get_success_url(self):
113 """Define the redirect URL.
114
115 After successful creation of the object, the User will be redirected
116 to the Course detail page.
117
118 :returns: URL
119 :rtype: HttpResponse
120 """
121
122 return reverse('course-detail', kwargs={
123 'project_slug': self.project_slug,
124 'organisation_slug': self.organisation_slug,
125 'slug': self.slug,
126 })
127
128 def get_context_data(self, **kwargs):
129 """Get the context data which is passed to a template.
130
131 :param kwargs: Any arguments to pass to the superclass.
132 :type kwargs: dict
133
134 :returns: Context data which will be passed to the template.
135 :rtype: dict
136 """
137
138 context = super(
139 CsvUploadView, self).get_context_data(**kwargs)
140 context['certifyingorganisation'] = \
141 CertifyingOrganisation.objects.get(slug=self.organisation_slug)
142 context['course'] = Course.objects.get(slug=self.slug)
143 return context
144
145 def get_form_kwargs(self):
146 """Get keyword arguments from form.
147
148 :returns keyword argument from the form
149 :rtype: dict
150 """
151
152 kwargs = super(CsvUploadView, self).get_form_kwargs()
153 self.project_slug = self.kwargs.get('project_slug', None)
154 self.organisation_slug = self.kwargs.get('organisation_slug', None)
155 self.slug = self.kwargs.get('slug', None)
156 self.course = Course.objects.get(slug=self.slug)
157 self.certifying_organisation = \
158 CertifyingOrganisation.objects.get(slug=self.organisation_slug)
159 return kwargs
160
161 @transaction.atomic()
162 def post(self, request, *args, **kwargs):
163 """Get form instance from upload.
164
165 After successful creation of the object,the User
166 will be redirected to the create course attendee page.
167
168 :returns: URL
169 :rtype: HttpResponse
170 """
171 form_class = self.get_form_class()
172 form = self.get_form(form_class)
173 attendees_file = request.FILES.get('file')
174 course = Course.objects.get(slug=self.slug)
175 if form.is_valid():
176 if attendees_file:
177 reader = csv.reader(attendees_file, delimiter=',')
178 next(reader)
179 attendee_count = 0
180 course_attendee_count = 0
181 for row in reader:
182 # We should have logic here to first see if the attendee
183 # already exists and if they do, just add them to the
184 # course
185 attendee = Attendee(
186 firstname=row[0],
187 surname=row[1],
188 email=row[2],
189 certifying_organisation=self.certifying_organisation,
190 author=self.request.user,
191 )
192 try:
193 attendee.save()
194 attendee_count += 1
195 except: # noqa
196 # Could not save - probably they exist already
197 attendee = None
198
199 if not attendee:
200 # put more checks in case attendee
201 # does not already exist
202 continue
203
204 course_attendee = CourseAttendee(
205 attendee=attendee,
206 course=course,
207 author=self.request.user,
208 )
209 try:
210 course_attendee.save()
211 course_attendee_count += 1
212 except: # noqa
213 # They are probably already associated with a course
214 pass
215
216 self.form_valid_message = (
217 '%i new attendees were created, and %i attendees were '
218 'added to the course: % s' % (
219 attendee_count, course_attendee_count, self.course)
220 )
221
222 self.form_invalid_message = (
223 'Something wrong happened while running the upload. '
224 'Please contact site support to help resolving the issue.')
225 return self.form_valid(form)
226
227 else:
228 return self.form_invalid(form)
229
[end of django_project/certification/views/attendee.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/django_project/certification/views/attendee.py b/django_project/certification/views/attendee.py
--- a/django_project/certification/views/attendee.py
+++ b/django_project/certification/views/attendee.py
@@ -1,4 +1,5 @@
# coding=utf-8
+import io
import csv
from django.db import transaction
from django.urls import reverse
@@ -171,11 +172,13 @@
form_class = self.get_form_class()
form = self.get_form(form_class)
attendees_file = request.FILES.get('file')
+ attendees_file.seek(0)
course = Course.objects.get(slug=self.slug)
if form.is_valid():
if attendees_file:
- reader = csv.reader(attendees_file, delimiter=',')
- next(reader)
+ reader = csv.DictReader(
+ io.StringIO(attendees_file.read().decode('utf-8'))
+ )
attendee_count = 0
course_attendee_count = 0
for row in reader:
@@ -183,9 +186,9 @@
# already exists and if they do, just add them to the
# course
attendee = Attendee(
- firstname=row[0],
- surname=row[1],
- email=row[2],
+ firstname=row['First Name'],
+ surname=row['Surname'],
+ email=row['Email'],
certifying_organisation=self.certifying_organisation,
author=self.request.user,
)
|
{"golden_diff": "diff --git a/django_project/certification/views/attendee.py b/django_project/certification/views/attendee.py\n--- a/django_project/certification/views/attendee.py\n+++ b/django_project/certification/views/attendee.py\n@@ -1,4 +1,5 @@\n # coding=utf-8\n+import io\n import csv\n from django.db import transaction\n from django.urls import reverse\n@@ -171,11 +172,13 @@\n form_class = self.get_form_class()\n form = self.get_form(form_class)\n attendees_file = request.FILES.get('file')\n+ attendees_file.seek(0)\n course = Course.objects.get(slug=self.slug)\n if form.is_valid():\n if attendees_file:\n- reader = csv.reader(attendees_file, delimiter=',')\n- next(reader)\n+ reader = csv.DictReader(\n+ io.StringIO(attendees_file.read().decode('utf-8'))\n+ )\n attendee_count = 0\n course_attendee_count = 0\n for row in reader:\n@@ -183,9 +186,9 @@\n # already exists and if they do, just add them to the\n # course\n attendee = Attendee(\n- firstname=row[0],\n- surname=row[1],\n- email=row[2],\n+ firstname=row['First Name'],\n+ surname=row['Surname'],\n+ email=row['Email'],\n certifying_organisation=self.certifying_organisation,\n author=self.request.user,\n )\n", "issue": "Bulk attendee upload is broken\nI am gettting an error uploading attendees using a CSV. I have done it successfully in the past using the same format CSV. For now, I have attended the participants manually.\r\n\r\nAttached is my upload csv with the emails replaced with [email protected] to preserve privacy.\r\n\r\n[attendees.txt](https://github.com/kartoza/prj.app/files/4202985/attendees.txt)\r\n\n", "before_files": [{"content": "# coding=utf-8\nimport csv\nfrom django.db import transaction\nfrom django.urls import reverse\nfrom django.views.generic import (\n CreateView, FormView)\nfrom braces.views import LoginRequiredMixin, FormMessagesMixin\nfrom certification.models import (\n Attendee, CertifyingOrganisation, CourseAttendee, Course\n)\nfrom certification.forms import AttendeeForm, CsvAttendeeForm\n\n\nclass AttendeeMixin(object):\n \"\"\"Mixin class to provide standard settings for Attendee.\"\"\"\n\n model = Attendee\n form_class = AttendeeForm\n\n\nclass AttendeeCreateView(LoginRequiredMixin, AttendeeMixin, CreateView):\n \"\"\"Create view for Attendee.\"\"\"\n\n context_object_name = 'attendee'\n template_name = 'attendee/create.html'\n\n def get_success_url(self):\n \"\"\"Define the redirect URL.\n\n After successful creation of the object, the User will be redirected\n to the create course attendee page.\n\n :returns: URL\n :rtype: HttpResponse\n \"\"\"\n add_to_course = self.request.POST.get('add_to_course')\n if add_to_course is None:\n success_url = reverse('courseattendee-create', kwargs={\n 'project_slug': self.project_slug,\n 'organisation_slug': self.organisation_slug,\n 'slug': self.course_slug,\n })\n else:\n success_url = reverse('course-detail', kwargs={\n 'project_slug': self.project_slug,\n 'organisation_slug': self.organisation_slug,\n 'slug': self.course_slug,\n })\n return success_url\n\n def get_context_data(self, **kwargs):\n \"\"\"Get the context data which is passed to a template.\n\n :param kwargs: Any arguments to pass to the superclass.\n :type kwargs: dict\n\n :returns: Context data which will be passed to the template.\n :rtype: dict\n \"\"\"\n\n context = super(\n AttendeeCreateView, self).get_context_data(**kwargs)\n return context\n\n def get_form_kwargs(self):\n \"\"\"Get keyword arguments from form.\n\n :returns keyword argument from the form\n :rtype: dict\n \"\"\"\n\n kwargs = super(AttendeeCreateView, self).get_form_kwargs()\n self.project_slug = self.kwargs.get('project_slug', None)\n self.organisation_slug = self.kwargs.get('organisation_slug', None)\n self.course_slug = self.kwargs.get('slug', None)\n self.certifying_organisation = \\\n CertifyingOrganisation.objects.get(slug=self.organisation_slug)\n kwargs.update({\n 'user': self.request.user,\n 'certifying_organisation': self.certifying_organisation\n })\n return kwargs\n\n def form_valid(self, form):\n add_to_course = self.request.POST.get('add_to_course')\n if add_to_course is None:\n if form.is_valid():\n form.save()\n else:\n if form.is_valid():\n object = form.save()\n course_slug = self.kwargs.get('slug', None)\n course = Course.objects.get(slug=course_slug)\n course_attendee = CourseAttendee(\n attendee=object,\n course=course,\n author=self.request.user\n )\n course_attendee.save()\n return super(AttendeeCreateView, self).form_valid(form)\n\n\nclass CsvUploadView(FormMessagesMixin, LoginRequiredMixin, FormView):\n \"\"\"\n Allow upload of attendees through CSV file.\n \"\"\"\n\n context_object_name = 'csvupload'\n form_class = CsvAttendeeForm\n template_name = 'attendee/upload_attendee_csv.html'\n\n def get_success_url(self):\n \"\"\"Define the redirect URL.\n\n After successful creation of the object, the User will be redirected\n to the Course detail page.\n\n :returns: URL\n :rtype: HttpResponse\n \"\"\"\n\n return reverse('course-detail', kwargs={\n 'project_slug': self.project_slug,\n 'organisation_slug': self.organisation_slug,\n 'slug': self.slug,\n })\n\n def get_context_data(self, **kwargs):\n \"\"\"Get the context data which is passed to a template.\n\n :param kwargs: Any arguments to pass to the superclass.\n :type kwargs: dict\n\n :returns: Context data which will be passed to the template.\n :rtype: dict\n \"\"\"\n\n context = super(\n CsvUploadView, self).get_context_data(**kwargs)\n context['certifyingorganisation'] = \\\n CertifyingOrganisation.objects.get(slug=self.organisation_slug)\n context['course'] = Course.objects.get(slug=self.slug)\n return context\n\n def get_form_kwargs(self):\n \"\"\"Get keyword arguments from form.\n\n :returns keyword argument from the form\n :rtype: dict\n \"\"\"\n\n kwargs = super(CsvUploadView, self).get_form_kwargs()\n self.project_slug = self.kwargs.get('project_slug', None)\n self.organisation_slug = self.kwargs.get('organisation_slug', None)\n self.slug = self.kwargs.get('slug', None)\n self.course = Course.objects.get(slug=self.slug)\n self.certifying_organisation = \\\n CertifyingOrganisation.objects.get(slug=self.organisation_slug)\n return kwargs\n\n @transaction.atomic()\n def post(self, request, *args, **kwargs):\n \"\"\"Get form instance from upload.\n\n After successful creation of the object,the User\n will be redirected to the create course attendee page.\n\n :returns: URL\n :rtype: HttpResponse\n \"\"\"\n form_class = self.get_form_class()\n form = self.get_form(form_class)\n attendees_file = request.FILES.get('file')\n course = Course.objects.get(slug=self.slug)\n if form.is_valid():\n if attendees_file:\n reader = csv.reader(attendees_file, delimiter=',')\n next(reader)\n attendee_count = 0\n course_attendee_count = 0\n for row in reader:\n # We should have logic here to first see if the attendee\n # already exists and if they do, just add them to the\n # course\n attendee = Attendee(\n firstname=row[0],\n surname=row[1],\n email=row[2],\n certifying_organisation=self.certifying_organisation,\n author=self.request.user,\n )\n try:\n attendee.save()\n attendee_count += 1\n except: # noqa\n # Could not save - probably they exist already\n attendee = None\n\n if not attendee:\n # put more checks in case attendee\n # does not already exist\n continue\n\n course_attendee = CourseAttendee(\n attendee=attendee,\n course=course,\n author=self.request.user,\n )\n try:\n course_attendee.save()\n course_attendee_count += 1\n except: # noqa\n # They are probably already associated with a course\n pass\n\n self.form_valid_message = (\n '%i new attendees were created, and %i attendees were '\n 'added to the course: % s' % (\n attendee_count, course_attendee_count, self.course)\n )\n\n self.form_invalid_message = (\n 'Something wrong happened while running the upload. '\n 'Please contact site support to help resolving the issue.')\n return self.form_valid(form)\n\n else:\n return self.form_invalid(form)\n", "path": "django_project/certification/views/attendee.py"}]}
| 2,772 | 335 |
gh_patches_debug_656
|
rasdani/github-patches
|
git_diff
|
pex-tool__pex-2081
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Release 2.1.126
On the docket:
+ [x] Resolve sdist builds can race and fail. #2078
</issue>
<code>
[start of pex/version.py]
1 # Copyright 2015 Pants project contributors (see CONTRIBUTORS.md).
2 # Licensed under the Apache License, Version 2.0 (see LICENSE).
3
4 __version__ = "2.1.125"
5
[end of pex/version.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/pex/version.py b/pex/version.py
--- a/pex/version.py
+++ b/pex/version.py
@@ -1,4 +1,4 @@
# Copyright 2015 Pants project contributors (see CONTRIBUTORS.md).
# Licensed under the Apache License, Version 2.0 (see LICENSE).
-__version__ = "2.1.125"
+__version__ = "2.1.126"
|
{"golden_diff": "diff --git a/pex/version.py b/pex/version.py\n--- a/pex/version.py\n+++ b/pex/version.py\n@@ -1,4 +1,4 @@\n # Copyright 2015 Pants project contributors (see CONTRIBUTORS.md).\n # Licensed under the Apache License, Version 2.0 (see LICENSE).\n \n-__version__ = \"2.1.125\"\n+__version__ = \"2.1.126\"\n", "issue": "Release 2.1.126\nOn the docket:\r\n+ [x] Resolve sdist builds can race and fail. #2078 \n", "before_files": [{"content": "# Copyright 2015 Pants project contributors (see CONTRIBUTORS.md).\n# Licensed under the Apache License, Version 2.0 (see LICENSE).\n\n__version__ = \"2.1.125\"\n", "path": "pex/version.py"}]}
| 617 | 98 |
gh_patches_debug_22628
|
rasdani/github-patches
|
git_diff
|
beetbox__beets-5160
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
`unimported`'s `ignore_subdirectories` doesn't work
### Problem
```sh
beet unimported
```
Leads to directories specified in `ignore_subdirectories` still being listed
### Setup
* OS: Arch Linux
* Python version: 3.11.7
* beets version: 1.6.1
* Turning off plugins made problem go away (yes/no): n/a
My configuration (output of `beet config`) is:
```yaml
unimported:
ignore_extensions: jpg png txt md org mod
ignore_subdirectories: Unsorted import
```
`ignore_extensions` works as expected though
</issue>
<code>
[start of beetsplug/unimported.py]
1 # This file is part of beets.
2 # Copyright 2019, Joris Jensen
3 #
4 # Permission is hereby granted, free of charge, to any person obtaining
5 # a copy of this software and associated documentation files (the
6 # "Software"), to deal in the Software without restriction, including
7 # without limitation the rights to use, copy, modify, merge, publish,
8 # distribute, sublicense, and/or sell copies of the Software, and to
9 # permit persons to whom the Software is furnished to do so, subject to
10 # the following conditions:
11 #
12 # The above copyright notice and this permission notice shall be
13 # included in all copies or substantial portions of the Software.
14
15 """
16 List all files in the library folder which are not listed in the
17 beets library database, including art files
18 """
19
20 import os
21
22 from beets import util
23 from beets.plugins import BeetsPlugin
24 from beets.ui import Subcommand, print_
25
26 __author__ = "https://github.com/MrNuggelz"
27
28
29 class Unimported(BeetsPlugin):
30 def __init__(self):
31 super().__init__()
32 self.config.add({"ignore_extensions": [], "ignore_subdirectories": []})
33
34 def commands(self):
35 def print_unimported(lib, opts, args):
36 ignore_exts = [
37 ("." + x).encode()
38 for x in self.config["ignore_extensions"].as_str_seq()
39 ]
40 ignore_dirs = [
41 os.path.join(lib.directory, x.encode())
42 for x in self.config["ignore_subdirectories"].as_str_seq()
43 ]
44 in_folder = {
45 os.path.join(r, file)
46 for r, d, f in os.walk(lib.directory)
47 for file in f
48 if not any(
49 [file.endswith(ext) for ext in ignore_exts]
50 + [r in ignore_dirs]
51 )
52 }
53 in_library = {x.path for x in lib.items()}
54 art_files = {x.artpath for x in lib.albums()}
55 for f in in_folder - in_library - art_files:
56 print_(util.displayable_path(f))
57
58 unimported = Subcommand(
59 "unimported",
60 help="list all files in the library folder which are not listed"
61 " in the beets library database",
62 )
63 unimported.func = print_unimported
64 return [unimported]
65
[end of beetsplug/unimported.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/beetsplug/unimported.py b/beetsplug/unimported.py
--- a/beetsplug/unimported.py
+++ b/beetsplug/unimported.py
@@ -41,15 +41,17 @@
os.path.join(lib.directory, x.encode())
for x in self.config["ignore_subdirectories"].as_str_seq()
]
- in_folder = {
- os.path.join(r, file)
- for r, d, f in os.walk(lib.directory)
- for file in f
- if not any(
- [file.endswith(ext) for ext in ignore_exts]
- + [r in ignore_dirs]
- )
- }
+ in_folder = set()
+ for root, _, files in os.walk(lib.directory):
+ # do not traverse if root is a child of an ignored directory
+ if any(root.startswith(ignored) for ignored in ignore_dirs):
+ continue
+ for file in files:
+ # ignore files with ignored extensions
+ if any(file.endswith(ext) for ext in ignore_exts):
+ continue
+ in_folder.add(os.path.join(root, file))
+
in_library = {x.path for x in lib.items()}
art_files = {x.artpath for x in lib.albums()}
for f in in_folder - in_library - art_files:
|
{"golden_diff": "diff --git a/beetsplug/unimported.py b/beetsplug/unimported.py\n--- a/beetsplug/unimported.py\n+++ b/beetsplug/unimported.py\n@@ -41,15 +41,17 @@\n os.path.join(lib.directory, x.encode())\n for x in self.config[\"ignore_subdirectories\"].as_str_seq()\n ]\n- in_folder = {\n- os.path.join(r, file)\n- for r, d, f in os.walk(lib.directory)\n- for file in f\n- if not any(\n- [file.endswith(ext) for ext in ignore_exts]\n- + [r in ignore_dirs]\n- )\n- }\n+ in_folder = set()\n+ for root, _, files in os.walk(lib.directory):\n+ # do not traverse if root is a child of an ignored directory\n+ if any(root.startswith(ignored) for ignored in ignore_dirs):\n+ continue\n+ for file in files:\n+ # ignore files with ignored extensions\n+ if any(file.endswith(ext) for ext in ignore_exts):\n+ continue\n+ in_folder.add(os.path.join(root, file))\n+\n in_library = {x.path for x in lib.items()}\n art_files = {x.artpath for x in lib.albums()}\n for f in in_folder - in_library - art_files:\n", "issue": "`unimported`'s `ignore_subdirectories` doesn't work\n### Problem\r\n\r\n\r\n```sh\r\nbeet unimported\r\n```\r\n\r\nLeads to directories specified in `ignore_subdirectories` still being listed\r\n\r\n### Setup\r\n\r\n* OS: Arch Linux\r\n* Python version: 3.11.7 \r\n* beets version: 1.6.1\r\n* Turning off plugins made problem go away (yes/no): n/a\r\n\r\nMy configuration (output of `beet config`) is:\r\n\r\n```yaml\r\nunimported:\r\n ignore_extensions: jpg png txt md org mod\r\n ignore_subdirectories: Unsorted import\r\n```\r\n`ignore_extensions` works as expected though\r\n\r\n\n", "before_files": [{"content": "# This file is part of beets.\n# Copyright 2019, Joris Jensen\n#\n# Permission is hereby granted, free of charge, to any person obtaining\n# a copy of this software and associated documentation files (the\n# \"Software\"), to deal in the Software without restriction, including\n# without limitation the rights to use, copy, modify, merge, publish,\n# distribute, sublicense, and/or sell copies of the Software, and to\n# permit persons to whom the Software is furnished to do so, subject to\n# the following conditions:\n#\n# The above copyright notice and this permission notice shall be\n# included in all copies or substantial portions of the Software.\n\n\"\"\"\nList all files in the library folder which are not listed in the\n beets library database, including art files\n\"\"\"\n\nimport os\n\nfrom beets import util\nfrom beets.plugins import BeetsPlugin\nfrom beets.ui import Subcommand, print_\n\n__author__ = \"https://github.com/MrNuggelz\"\n\n\nclass Unimported(BeetsPlugin):\n def __init__(self):\n super().__init__()\n self.config.add({\"ignore_extensions\": [], \"ignore_subdirectories\": []})\n\n def commands(self):\n def print_unimported(lib, opts, args):\n ignore_exts = [\n (\".\" + x).encode()\n for x in self.config[\"ignore_extensions\"].as_str_seq()\n ]\n ignore_dirs = [\n os.path.join(lib.directory, x.encode())\n for x in self.config[\"ignore_subdirectories\"].as_str_seq()\n ]\n in_folder = {\n os.path.join(r, file)\n for r, d, f in os.walk(lib.directory)\n for file in f\n if not any(\n [file.endswith(ext) for ext in ignore_exts]\n + [r in ignore_dirs]\n )\n }\n in_library = {x.path for x in lib.items()}\n art_files = {x.artpath for x in lib.albums()}\n for f in in_folder - in_library - art_files:\n print_(util.displayable_path(f))\n\n unimported = Subcommand(\n \"unimported\",\n help=\"list all files in the library folder which are not listed\"\n \" in the beets library database\",\n )\n unimported.func = print_unimported\n return [unimported]\n", "path": "beetsplug/unimported.py"}]}
| 1,310 | 296 |
gh_patches_debug_51699
|
rasdani/github-patches
|
git_diff
|
comic__grand-challenge.org-2885
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
The Phase (algorithm) input and output selects are annoying to use in the admin
A select 2 widget would be better.
</issue>
<code>
[start of app/grandchallenge/evaluation/admin.py]
1 from django.contrib import admin
2 from django.core.exceptions import ObjectDoesNotExist, ValidationError
3 from django.forms import ModelForm
4
5 from grandchallenge.challenges.models import ChallengeRequest
6 from grandchallenge.components.admin import (
7 ComponentImageAdmin,
8 cancel_jobs,
9 deprovision_jobs,
10 requeue_jobs,
11 )
12 from grandchallenge.core.admin import (
13 GroupObjectPermissionAdmin,
14 UserObjectPermissionAdmin,
15 )
16 from grandchallenge.core.templatetags.remove_whitespace import oxford_comma
17 from grandchallenge.evaluation.models import (
18 Evaluation,
19 EvaluationGroupObjectPermission,
20 EvaluationUserObjectPermission,
21 Method,
22 MethodGroupObjectPermission,
23 MethodUserObjectPermission,
24 Phase,
25 PhaseGroupObjectPermission,
26 PhaseUserObjectPermission,
27 Submission,
28 SubmissionGroupObjectPermission,
29 SubmissionUserObjectPermission,
30 )
31 from grandchallenge.evaluation.tasks import create_evaluation
32 from grandchallenge.evaluation.utils import SubmissionKindChoices
33
34
35 class PhaseAdminForm(ModelForm):
36 class Meta:
37 model = Phase
38 fields = "__all__"
39
40 def clean(self):
41 cleaned_data = super().clean()
42
43 duplicate_interfaces = {
44 *cleaned_data.get("algorithm_inputs", [])
45 }.intersection({*cleaned_data.get("algorithm_outputs", [])})
46
47 if duplicate_interfaces:
48 raise ValidationError(
49 f"The sets of Algorithm Inputs and Algorithm Outputs must be unique: "
50 f"{oxford_comma(duplicate_interfaces)} present in both"
51 )
52
53 submission_kind = cleaned_data["submission_kind"]
54 total_number_of_submissions_allowed = cleaned_data[
55 "total_number_of_submissions_allowed"
56 ]
57
58 if (
59 submission_kind == SubmissionKindChoices.ALGORITHM
60 and not total_number_of_submissions_allowed
61 ):
62 try:
63 request = ChallengeRequest.objects.get(
64 short_name=self.instance.challenge.short_name
65 )
66 error_addition = f"The corresponding challenge request lists the following limits: Preliminary phase: {request.phase_1_number_of_submissions_per_team * request.expected_number_of_teams} Final test phase: {request.phase_2_number_of_submissions_per_team * request.expected_number_of_teams}. Set the limits according to the phase type. "
67 except ObjectDoesNotExist:
68 error_addition = "There is no corresponding challenge request."
69 raise ValidationError(
70 "For phases that take an algorithm as submission input, "
71 "the total_number_of_submissions_allowed needs to be set. "
72 + error_addition
73 )
74
75 return cleaned_data
76
77
78 @admin.register(Phase)
79 class PhaseAdmin(admin.ModelAdmin):
80 ordering = ("challenge",)
81 list_display = (
82 "slug",
83 "title",
84 "challenge",
85 "submission_kind",
86 "open_for_submissions",
87 "submissions_open_at",
88 "submissions_close_at",
89 "submissions_limit_per_user_per_period",
90 )
91 search_fields = ("pk", "title", "slug", "challenge__short_name")
92 list_filter = (
93 "submission_kind",
94 "challenge__short_name",
95 )
96 form = PhaseAdminForm
97
98 @admin.display(boolean=True)
99 def open_for_submissions(self, instance):
100 return instance.open_for_submissions
101
102
103 @admin.action(
104 description="Reevaluate selected submissions",
105 permissions=("change",),
106 )
107 def reevaluate_submissions(modeladmin, request, queryset):
108 """Creates a new evaluation for an existing submission"""
109 for submission in queryset:
110 create_evaluation.apply_async(
111 kwargs={"submission_pk": str(submission.pk)}
112 )
113
114
115 @admin.register(Submission)
116 class SubmissionAdmin(admin.ModelAdmin):
117 ordering = ("-created",)
118 list_display = ("pk", "created", "phase", "creator")
119 list_filter = ("phase__challenge__short_name",)
120 search_fields = ("pk", "creator__username", "phase__slug")
121 readonly_fields = (
122 "creator",
123 "phase",
124 "predictions_file",
125 "algorithm_image",
126 )
127 actions = (reevaluate_submissions,)
128
129
130 @admin.register(Evaluation)
131 class EvaluationAdmin(admin.ModelAdmin):
132 ordering = ("-created",)
133 list_display = ("pk", "created", "submission", "status", "error_message")
134 list_filter = ("submission__phase__challenge__short_name", "status")
135 list_select_related = (
136 "submission__phase__challenge",
137 "submission__creator",
138 )
139 search_fields = (
140 "pk",
141 "submission__pk",
142 "submission__phase__challenge__short_name",
143 "submission__creator__username",
144 )
145 readonly_fields = (
146 "status",
147 "submission",
148 "method",
149 "inputs",
150 "outputs",
151 "attempt",
152 "stdout",
153 "stderr",
154 "error_message",
155 "input_prefixes",
156 "task_on_success",
157 "task_on_failure",
158 "runtime_metrics",
159 )
160 actions = (requeue_jobs, cancel_jobs, deprovision_jobs)
161
162
163 admin.site.register(PhaseUserObjectPermission, UserObjectPermissionAdmin)
164 admin.site.register(PhaseGroupObjectPermission, GroupObjectPermissionAdmin)
165 admin.site.register(Method, ComponentImageAdmin)
166 admin.site.register(MethodUserObjectPermission, UserObjectPermissionAdmin)
167 admin.site.register(MethodGroupObjectPermission, GroupObjectPermissionAdmin)
168 admin.site.register(SubmissionUserObjectPermission, UserObjectPermissionAdmin)
169 admin.site.register(
170 SubmissionGroupObjectPermission, GroupObjectPermissionAdmin
171 )
172 admin.site.register(EvaluationUserObjectPermission, UserObjectPermissionAdmin)
173 admin.site.register(
174 EvaluationGroupObjectPermission, GroupObjectPermissionAdmin
175 )
176
[end of app/grandchallenge/evaluation/admin.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/app/grandchallenge/evaluation/admin.py b/app/grandchallenge/evaluation/admin.py
--- a/app/grandchallenge/evaluation/admin.py
+++ b/app/grandchallenge/evaluation/admin.py
@@ -93,6 +93,13 @@
"submission_kind",
"challenge__short_name",
)
+ autocomplete_fields = (
+ "inputs",
+ "outputs",
+ "algorithm_inputs",
+ "algorithm_outputs",
+ "archive",
+ )
form = PhaseAdminForm
@admin.display(boolean=True)
|
{"golden_diff": "diff --git a/app/grandchallenge/evaluation/admin.py b/app/grandchallenge/evaluation/admin.py\n--- a/app/grandchallenge/evaluation/admin.py\n+++ b/app/grandchallenge/evaluation/admin.py\n@@ -93,6 +93,13 @@\n \"submission_kind\",\n \"challenge__short_name\",\n )\n+ autocomplete_fields = (\n+ \"inputs\",\n+ \"outputs\",\n+ \"algorithm_inputs\",\n+ \"algorithm_outputs\",\n+ \"archive\",\n+ )\n form = PhaseAdminForm\n \n @admin.display(boolean=True)\n", "issue": "The Phase (algorithm) input and output selects are annoying to use in the admin\nA select 2 widget would be better.\n", "before_files": [{"content": "from django.contrib import admin\nfrom django.core.exceptions import ObjectDoesNotExist, ValidationError\nfrom django.forms import ModelForm\n\nfrom grandchallenge.challenges.models import ChallengeRequest\nfrom grandchallenge.components.admin import (\n ComponentImageAdmin,\n cancel_jobs,\n deprovision_jobs,\n requeue_jobs,\n)\nfrom grandchallenge.core.admin import (\n GroupObjectPermissionAdmin,\n UserObjectPermissionAdmin,\n)\nfrom grandchallenge.core.templatetags.remove_whitespace import oxford_comma\nfrom grandchallenge.evaluation.models import (\n Evaluation,\n EvaluationGroupObjectPermission,\n EvaluationUserObjectPermission,\n Method,\n MethodGroupObjectPermission,\n MethodUserObjectPermission,\n Phase,\n PhaseGroupObjectPermission,\n PhaseUserObjectPermission,\n Submission,\n SubmissionGroupObjectPermission,\n SubmissionUserObjectPermission,\n)\nfrom grandchallenge.evaluation.tasks import create_evaluation\nfrom grandchallenge.evaluation.utils import SubmissionKindChoices\n\n\nclass PhaseAdminForm(ModelForm):\n class Meta:\n model = Phase\n fields = \"__all__\"\n\n def clean(self):\n cleaned_data = super().clean()\n\n duplicate_interfaces = {\n *cleaned_data.get(\"algorithm_inputs\", [])\n }.intersection({*cleaned_data.get(\"algorithm_outputs\", [])})\n\n if duplicate_interfaces:\n raise ValidationError(\n f\"The sets of Algorithm Inputs and Algorithm Outputs must be unique: \"\n f\"{oxford_comma(duplicate_interfaces)} present in both\"\n )\n\n submission_kind = cleaned_data[\"submission_kind\"]\n total_number_of_submissions_allowed = cleaned_data[\n \"total_number_of_submissions_allowed\"\n ]\n\n if (\n submission_kind == SubmissionKindChoices.ALGORITHM\n and not total_number_of_submissions_allowed\n ):\n try:\n request = ChallengeRequest.objects.get(\n short_name=self.instance.challenge.short_name\n )\n error_addition = f\"The corresponding challenge request lists the following limits: Preliminary phase: {request.phase_1_number_of_submissions_per_team * request.expected_number_of_teams} Final test phase: {request.phase_2_number_of_submissions_per_team * request.expected_number_of_teams}. Set the limits according to the phase type. \"\n except ObjectDoesNotExist:\n error_addition = \"There is no corresponding challenge request.\"\n raise ValidationError(\n \"For phases that take an algorithm as submission input, \"\n \"the total_number_of_submissions_allowed needs to be set. \"\n + error_addition\n )\n\n return cleaned_data\n\n\[email protected](Phase)\nclass PhaseAdmin(admin.ModelAdmin):\n ordering = (\"challenge\",)\n list_display = (\n \"slug\",\n \"title\",\n \"challenge\",\n \"submission_kind\",\n \"open_for_submissions\",\n \"submissions_open_at\",\n \"submissions_close_at\",\n \"submissions_limit_per_user_per_period\",\n )\n search_fields = (\"pk\", \"title\", \"slug\", \"challenge__short_name\")\n list_filter = (\n \"submission_kind\",\n \"challenge__short_name\",\n )\n form = PhaseAdminForm\n\n @admin.display(boolean=True)\n def open_for_submissions(self, instance):\n return instance.open_for_submissions\n\n\[email protected](\n description=\"Reevaluate selected submissions\",\n permissions=(\"change\",),\n)\ndef reevaluate_submissions(modeladmin, request, queryset):\n \"\"\"Creates a new evaluation for an existing submission\"\"\"\n for submission in queryset:\n create_evaluation.apply_async(\n kwargs={\"submission_pk\": str(submission.pk)}\n )\n\n\[email protected](Submission)\nclass SubmissionAdmin(admin.ModelAdmin):\n ordering = (\"-created\",)\n list_display = (\"pk\", \"created\", \"phase\", \"creator\")\n list_filter = (\"phase__challenge__short_name\",)\n search_fields = (\"pk\", \"creator__username\", \"phase__slug\")\n readonly_fields = (\n \"creator\",\n \"phase\",\n \"predictions_file\",\n \"algorithm_image\",\n )\n actions = (reevaluate_submissions,)\n\n\[email protected](Evaluation)\nclass EvaluationAdmin(admin.ModelAdmin):\n ordering = (\"-created\",)\n list_display = (\"pk\", \"created\", \"submission\", \"status\", \"error_message\")\n list_filter = (\"submission__phase__challenge__short_name\", \"status\")\n list_select_related = (\n \"submission__phase__challenge\",\n \"submission__creator\",\n )\n search_fields = (\n \"pk\",\n \"submission__pk\",\n \"submission__phase__challenge__short_name\",\n \"submission__creator__username\",\n )\n readonly_fields = (\n \"status\",\n \"submission\",\n \"method\",\n \"inputs\",\n \"outputs\",\n \"attempt\",\n \"stdout\",\n \"stderr\",\n \"error_message\",\n \"input_prefixes\",\n \"task_on_success\",\n \"task_on_failure\",\n \"runtime_metrics\",\n )\n actions = (requeue_jobs, cancel_jobs, deprovision_jobs)\n\n\nadmin.site.register(PhaseUserObjectPermission, UserObjectPermissionAdmin)\nadmin.site.register(PhaseGroupObjectPermission, GroupObjectPermissionAdmin)\nadmin.site.register(Method, ComponentImageAdmin)\nadmin.site.register(MethodUserObjectPermission, UserObjectPermissionAdmin)\nadmin.site.register(MethodGroupObjectPermission, GroupObjectPermissionAdmin)\nadmin.site.register(SubmissionUserObjectPermission, UserObjectPermissionAdmin)\nadmin.site.register(\n SubmissionGroupObjectPermission, GroupObjectPermissionAdmin\n)\nadmin.site.register(EvaluationUserObjectPermission, UserObjectPermissionAdmin)\nadmin.site.register(\n EvaluationGroupObjectPermission, GroupObjectPermissionAdmin\n)\n", "path": "app/grandchallenge/evaluation/admin.py"}]}
| 2,147 | 121 |
gh_patches_debug_31966
|
rasdani/github-patches
|
git_diff
|
nilearn__nilearn-3739
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[DOC] improve instructions in "Default Mode Network extraction of ADHD dataset" example
### Is there an existing issue for this?
- [X] I have searched the existing issues
### Describe your proposed suggestion in detail.
It seems the instructions in [this example](https://nilearn.github.io/dev/auto_examples/04_glm_first_level/plot_adhd_dmn.html#default-mode-network-extraction-of-adhd-dataset) need some improvement. There was a confusion mentioned on [NeuroStar](https://neurostars.org/t/why-is-there-glm-for-resting-state-data/25841). After discussing with @Remi-Gau, we concluded that maybe we can add one or two lines saying that in this example we extract the activity of a seed region and then use the extracted signal as regressor in a GLM and this will yield the correlation of each region with the seed region.
### List any pages that would be impacted.
https://nilearn.github.io/dev/auto_examples/04_glm_first_level/plot_adhd_dmn.html#default-mode-network-extraction-of-adhd-dataset
</issue>
<code>
[start of examples/04_glm_first_level/plot_adhd_dmn.py]
1 """
2 Default Mode Network extraction of ADHD dataset
3 ===============================================
4
5 This example shows a full step-by-step workflow of fitting a GLM to data
6 extracted from a seed on the Posterior Cingulate Cortex and saving the results.
7
8 More specifically:
9
10 1. A sequence of fMRI volumes are loaded.
11 2. A design matrix with the Posterior Cingulate Cortex seed is defined.
12 3. A GLM is applied to the dataset (effect/covariance,
13 then contrast estimation).
14 4. The Default Mode Network is displayed.
15
16 .. include:: ../../../examples/masker_note.rst
17
18 """
19 import numpy as np
20 from nilearn import datasets, plotting
21 from nilearn.glm.first_level import (
22 FirstLevelModel,
23 make_first_level_design_matrix,
24 )
25 from nilearn.maskers import NiftiSpheresMasker
26
27 #########################################################################
28 # Prepare data and analysis parameters
29 # ------------------------------------
30 # Prepare the data.
31 adhd_dataset = datasets.fetch_adhd(n_subjects=1)
32
33 # Prepare timing
34 t_r = 2.0
35 slice_time_ref = 0.0
36 n_scans = 176
37
38 # Prepare seed
39 pcc_coords = (0, -53, 26)
40
41 #########################################################################
42 # Estimate contrasts
43 # ------------------
44 # Specify the contrasts.
45 seed_masker = NiftiSpheresMasker(
46 [pcc_coords],
47 radius=10,
48 detrend=True,
49 standardize="zscore_sample",
50 low_pass=0.1,
51 high_pass=0.01,
52 t_r=2.0,
53 memory="nilearn_cache",
54 memory_level=1,
55 verbose=0,
56 )
57 seed_time_series = seed_masker.fit_transform(adhd_dataset.func[0])
58 frametimes = np.linspace(0, (n_scans - 1) * t_r, n_scans)
59 design_matrix = make_first_level_design_matrix(
60 frametimes,
61 hrf_model="spm",
62 add_regs=seed_time_series,
63 add_reg_names=["pcc_seed"],
64 )
65 dmn_contrast = np.array([1] + [0] * (design_matrix.shape[1] - 1))
66 contrasts = {"seed_based_glm": dmn_contrast}
67
68 #########################################################################
69 # Perform first level analysis
70 # ----------------------------
71 # Setup and fit GLM.
72 first_level_model = FirstLevelModel(t_r=t_r, slice_time_ref=slice_time_ref)
73 first_level_model = first_level_model.fit(
74 run_imgs=adhd_dataset.func[0], design_matrices=design_matrix
75 )
76
77 #########################################################################
78 # Estimate the contrast.
79 print("Contrast seed_based_glm computed.")
80 z_map = first_level_model.compute_contrast(
81 contrasts["seed_based_glm"], output_type="z_score"
82 )
83
84 # Saving snapshots of the contrasts
85 filename = "dmn_z_map.png"
86 display = plotting.plot_stat_map(
87 z_map, threshold=3.0, title="Seed based GLM", cut_coords=pcc_coords
88 )
89 display.add_markers(
90 marker_coords=[pcc_coords], marker_color="g", marker_size=300
91 )
92 display.savefig(filename)
93 print(f"Save z-map in '{filename}'.")
94
95 ###########################################################################
96 # Generating a report
97 # -------------------
98 # It can be useful to quickly generate a
99 # portable, ready-to-view report with most of the pertinent information.
100 # This is easy to do if you have a fitted model and the list of contrasts,
101 # which we do here.
102 from nilearn.reporting import make_glm_report
103
104 report = make_glm_report(
105 first_level_model,
106 contrasts=contrasts,
107 title="ADHD DMN Report",
108 cluster_threshold=15,
109 min_distance=8.0,
110 plot_type="glass",
111 )
112
113 #########################################################################
114 # We have several ways to access the report:
115
116 # report # This report can be viewed in a notebook
117 # report.save_as_html('report.html')
118 # report.open_in_browser()
119
[end of examples/04_glm_first_level/plot_adhd_dmn.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/examples/04_glm_first_level/plot_adhd_dmn.py b/examples/04_glm_first_level/plot_adhd_dmn.py
--- a/examples/04_glm_first_level/plot_adhd_dmn.py
+++ b/examples/04_glm_first_level/plot_adhd_dmn.py
@@ -2,8 +2,11 @@
Default Mode Network extraction of ADHD dataset
===============================================
-This example shows a full step-by-step workflow of fitting a GLM to data
+This example shows a full step-by-step workflow of fitting a GLM to signal
extracted from a seed on the Posterior Cingulate Cortex and saving the results.
+More precisely, this example shows how to use a signal extracted from a
+seed region as the regressor in a GLM to determine the correlation
+of each region in the dataset with the seed region.
More specifically:
@@ -39,9 +42,9 @@
pcc_coords = (0, -53, 26)
#########################################################################
-# Estimate contrasts
-# ------------------
-# Specify the contrasts.
+# Extract the seed region's time course
+# -------------------------------------
+# Extract the time course of the seed region.
seed_masker = NiftiSpheresMasker(
[pcc_coords],
radius=10,
@@ -56,6 +59,22 @@
)
seed_time_series = seed_masker.fit_transform(adhd_dataset.func[0])
frametimes = np.linspace(0, (n_scans - 1) * t_r, n_scans)
+
+#########################################################################
+# Plot the time course of the seed region.
+import matplotlib.pyplot as plt
+
+fig = plt.figure(figsize=(9, 3))
+ax = fig.add_subplot(111)
+ax.plot(frametimes, seed_time_series, linewidth=2, label="seed region")
+ax.legend(loc=2)
+ax.set_title("Time course of the seed region")
+plt.show()
+
+#########################################################################
+# Estimate contrasts
+# ------------------
+# Specify the contrasts.
design_matrix = make_first_level_design_matrix(
frametimes,
hrf_model="spm",
|
{"golden_diff": "diff --git a/examples/04_glm_first_level/plot_adhd_dmn.py b/examples/04_glm_first_level/plot_adhd_dmn.py\n--- a/examples/04_glm_first_level/plot_adhd_dmn.py\n+++ b/examples/04_glm_first_level/plot_adhd_dmn.py\n@@ -2,8 +2,11 @@\n Default Mode Network extraction of ADHD dataset\n ===============================================\n \n-This example shows a full step-by-step workflow of fitting a GLM to data\n+This example shows a full step-by-step workflow of fitting a GLM to signal\n extracted from a seed on the Posterior Cingulate Cortex and saving the results.\n+More precisely, this example shows how to use a signal extracted from a\n+seed region as the regressor in a GLM to determine the correlation\n+of each region in the dataset with the seed region.\n \n More specifically:\n \n@@ -39,9 +42,9 @@\n pcc_coords = (0, -53, 26)\n \n #########################################################################\n-# Estimate contrasts\n-# ------------------\n-# Specify the contrasts.\n+# Extract the seed region's time course\n+# -------------------------------------\n+# Extract the time course of the seed region.\n seed_masker = NiftiSpheresMasker(\n [pcc_coords],\n radius=10,\n@@ -56,6 +59,22 @@\n )\n seed_time_series = seed_masker.fit_transform(adhd_dataset.func[0])\n frametimes = np.linspace(0, (n_scans - 1) * t_r, n_scans)\n+\n+#########################################################################\n+# Plot the time course of the seed region.\n+import matplotlib.pyplot as plt\n+\n+fig = plt.figure(figsize=(9, 3))\n+ax = fig.add_subplot(111)\n+ax.plot(frametimes, seed_time_series, linewidth=2, label=\"seed region\")\n+ax.legend(loc=2)\n+ax.set_title(\"Time course of the seed region\")\n+plt.show()\n+\n+#########################################################################\n+# Estimate contrasts\n+# ------------------\n+# Specify the contrasts.\n design_matrix = make_first_level_design_matrix(\n frametimes,\n hrf_model=\"spm\",\n", "issue": "[DOC] improve instructions in \"Default Mode Network extraction of ADHD dataset\" example\n### Is there an existing issue for this?\r\n\r\n- [X] I have searched the existing issues\r\n\r\n### Describe your proposed suggestion in detail.\r\n\r\nIt seems the instructions in [this example](https://nilearn.github.io/dev/auto_examples/04_glm_first_level/plot_adhd_dmn.html#default-mode-network-extraction-of-adhd-dataset) need some improvement. There was a confusion mentioned on [NeuroStar](https://neurostars.org/t/why-is-there-glm-for-resting-state-data/25841). After discussing with @Remi-Gau, we concluded that maybe we can add one or two lines saying that in this example we extract the activity of a seed region and then use the extracted signal as regressor in a GLM and this will yield the correlation of each region with the seed region.\r\n\r\n### List any pages that would be impacted.\r\n\r\nhttps://nilearn.github.io/dev/auto_examples/04_glm_first_level/plot_adhd_dmn.html#default-mode-network-extraction-of-adhd-dataset\n", "before_files": [{"content": "\"\"\"\nDefault Mode Network extraction of ADHD dataset\n===============================================\n\nThis example shows a full step-by-step workflow of fitting a GLM to data\nextracted from a seed on the Posterior Cingulate Cortex and saving the results.\n\nMore specifically:\n\n1. A sequence of fMRI volumes are loaded.\n2. A design matrix with the Posterior Cingulate Cortex seed is defined.\n3. A GLM is applied to the dataset (effect/covariance,\n then contrast estimation).\n4. The Default Mode Network is displayed.\n\n.. include:: ../../../examples/masker_note.rst\n\n\"\"\"\nimport numpy as np\nfrom nilearn import datasets, plotting\nfrom nilearn.glm.first_level import (\n FirstLevelModel,\n make_first_level_design_matrix,\n)\nfrom nilearn.maskers import NiftiSpheresMasker\n\n#########################################################################\n# Prepare data and analysis parameters\n# ------------------------------------\n# Prepare the data.\nadhd_dataset = datasets.fetch_adhd(n_subjects=1)\n\n# Prepare timing\nt_r = 2.0\nslice_time_ref = 0.0\nn_scans = 176\n\n# Prepare seed\npcc_coords = (0, -53, 26)\n\n#########################################################################\n# Estimate contrasts\n# ------------------\n# Specify the contrasts.\nseed_masker = NiftiSpheresMasker(\n [pcc_coords],\n radius=10,\n detrend=True,\n standardize=\"zscore_sample\",\n low_pass=0.1,\n high_pass=0.01,\n t_r=2.0,\n memory=\"nilearn_cache\",\n memory_level=1,\n verbose=0,\n)\nseed_time_series = seed_masker.fit_transform(adhd_dataset.func[0])\nframetimes = np.linspace(0, (n_scans - 1) * t_r, n_scans)\ndesign_matrix = make_first_level_design_matrix(\n frametimes,\n hrf_model=\"spm\",\n add_regs=seed_time_series,\n add_reg_names=[\"pcc_seed\"],\n)\ndmn_contrast = np.array([1] + [0] * (design_matrix.shape[1] - 1))\ncontrasts = {\"seed_based_glm\": dmn_contrast}\n\n#########################################################################\n# Perform first level analysis\n# ----------------------------\n# Setup and fit GLM.\nfirst_level_model = FirstLevelModel(t_r=t_r, slice_time_ref=slice_time_ref)\nfirst_level_model = first_level_model.fit(\n run_imgs=adhd_dataset.func[0], design_matrices=design_matrix\n)\n\n#########################################################################\n# Estimate the contrast.\nprint(\"Contrast seed_based_glm computed.\")\nz_map = first_level_model.compute_contrast(\n contrasts[\"seed_based_glm\"], output_type=\"z_score\"\n)\n\n# Saving snapshots of the contrasts\nfilename = \"dmn_z_map.png\"\ndisplay = plotting.plot_stat_map(\n z_map, threshold=3.0, title=\"Seed based GLM\", cut_coords=pcc_coords\n)\ndisplay.add_markers(\n marker_coords=[pcc_coords], marker_color=\"g\", marker_size=300\n)\ndisplay.savefig(filename)\nprint(f\"Save z-map in '{filename}'.\")\n\n###########################################################################\n# Generating a report\n# -------------------\n# It can be useful to quickly generate a\n# portable, ready-to-view report with most of the pertinent information.\n# This is easy to do if you have a fitted model and the list of contrasts,\n# which we do here.\nfrom nilearn.reporting import make_glm_report\n\nreport = make_glm_report(\n first_level_model,\n contrasts=contrasts,\n title=\"ADHD DMN Report\",\n cluster_threshold=15,\n min_distance=8.0,\n plot_type=\"glass\",\n)\n\n#########################################################################\n# We have several ways to access the report:\n\n# report # This report can be viewed in a notebook\n# report.save_as_html('report.html')\n# report.open_in_browser()\n", "path": "examples/04_glm_first_level/plot_adhd_dmn.py"}]}
| 1,877 | 465 |
gh_patches_debug_3953
|
rasdani/github-patches
|
git_diff
|
chainer__chainer-7178
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Emit warning if compiled in Debug mode
In debug mode ChainerX runs significantly slower.
However sometimes it's difficult notice that.
</issue>
<code>
[start of chainerx/__init__.py]
1 import os
2 import sys
3
4
5 if sys.version_info[0] < 3:
6 _available = False
7 else:
8 try:
9 from chainerx import _core
10 _available = True
11 except Exception:
12 _available = False
13
14
15 if _available:
16 from numpy import dtype # NOQA
17 from numpy import (
18 bool_, int8, int16, int32, int64, uint8, float16, float32, float64) # NOQA
19 all_dtypes = (
20 bool_, int8, int16, int32, int64, uint8, float16, float32, float64)
21
22 from chainerx._core import * # NOQA
23 from chainerx._core import _to_cupy # NOQA
24
25 from builtins import bool, int, float # NOQA
26
27 from chainerx import _device # NOQA
28
29 from chainerx.creation.from_data import asanyarray # NOQA
30 from chainerx.creation.from_data import fromfile # NOQA
31 from chainerx.creation.from_data import fromfunction # NOQA
32 from chainerx.creation.from_data import fromiter # NOQA
33 from chainerx.creation.from_data import fromstring # NOQA
34 from chainerx.creation.from_data import loadtxt # NOQA
35
36 from chainerx.manipulation.shape import ravel # NOQA
37
38 from chainerx.math.misc import clip # NOQA
39
40 from chainerx import random # NOQA
41
42 _global_context = _core.Context()
43 _core.set_global_default_context(_global_context)
44
45 # Implements ndarray methods in Python
46 from chainerx import _ndarray
47 _ndarray.populate()
48
49 # Temporary workaround implementations that fall back to NumPy/CuPy's
50 # respective functions.
51 from chainerx import _fallback_workarounds
52 _fallback_workarounds.populate()
53
54 # Dynamically inject docstrings
55 from chainerx import _docs
56 _docs.set_docs()
57
58 from chainerx import _cuda
59 # Share memory pool with CuPy.
60 if bool(int(os.getenv('CHAINERX_CUDA_CUPY_SHARE_ALLOCATOR', '0'))):
61 _cuda.cupy_share_allocator()
62 else:
63 class ndarray(object):
64
65 """Dummy class for type testing."""
66
67 def __init__(self, *args, **kwargs):
68 raise RuntimeError('chainerx is not available.')
69
70
71 def is_available():
72 return _available
73
[end of chainerx/__init__.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/chainerx/__init__.py b/chainerx/__init__.py
--- a/chainerx/__init__.py
+++ b/chainerx/__init__.py
@@ -1,5 +1,6 @@
import os
import sys
+import warnings
if sys.version_info[0] < 3:
@@ -70,3 +71,9 @@
def is_available():
return _available
+
+
+if _available and _core._is_debug():
+ # Warn if the ChainerX core binary is built in debug mode
+ warnings.warn(
+ 'ChainerX core binary is built in debug mode.', stacklevel=2)
|
{"golden_diff": "diff --git a/chainerx/__init__.py b/chainerx/__init__.py\n--- a/chainerx/__init__.py\n+++ b/chainerx/__init__.py\n@@ -1,5 +1,6 @@\n import os\n import sys\n+import warnings\n \n \n if sys.version_info[0] < 3:\n@@ -70,3 +71,9 @@\n \n def is_available():\n return _available\n+\n+\n+if _available and _core._is_debug():\n+ # Warn if the ChainerX core binary is built in debug mode\n+ warnings.warn(\n+ 'ChainerX core binary is built in debug mode.', stacklevel=2)\n", "issue": "Emit warning if compiled in Debug mode\nIn debug mode ChainerX runs significantly slower.\r\nHowever sometimes it's difficult notice that.\n", "before_files": [{"content": "import os\nimport sys\n\n\nif sys.version_info[0] < 3:\n _available = False\nelse:\n try:\n from chainerx import _core\n _available = True\n except Exception:\n _available = False\n\n\nif _available:\n from numpy import dtype # NOQA\n from numpy import (\n bool_, int8, int16, int32, int64, uint8, float16, float32, float64) # NOQA\n all_dtypes = (\n bool_, int8, int16, int32, int64, uint8, float16, float32, float64)\n\n from chainerx._core import * # NOQA\n from chainerx._core import _to_cupy # NOQA\n\n from builtins import bool, int, float # NOQA\n\n from chainerx import _device # NOQA\n\n from chainerx.creation.from_data import asanyarray # NOQA\n from chainerx.creation.from_data import fromfile # NOQA\n from chainerx.creation.from_data import fromfunction # NOQA\n from chainerx.creation.from_data import fromiter # NOQA\n from chainerx.creation.from_data import fromstring # NOQA\n from chainerx.creation.from_data import loadtxt # NOQA\n\n from chainerx.manipulation.shape import ravel # NOQA\n\n from chainerx.math.misc import clip # NOQA\n\n from chainerx import random # NOQA\n\n _global_context = _core.Context()\n _core.set_global_default_context(_global_context)\n\n # Implements ndarray methods in Python\n from chainerx import _ndarray\n _ndarray.populate()\n\n # Temporary workaround implementations that fall back to NumPy/CuPy's\n # respective functions.\n from chainerx import _fallback_workarounds\n _fallback_workarounds.populate()\n\n # Dynamically inject docstrings\n from chainerx import _docs\n _docs.set_docs()\n\n from chainerx import _cuda\n # Share memory pool with CuPy.\n if bool(int(os.getenv('CHAINERX_CUDA_CUPY_SHARE_ALLOCATOR', '0'))):\n _cuda.cupy_share_allocator()\nelse:\n class ndarray(object):\n\n \"\"\"Dummy class for type testing.\"\"\"\n\n def __init__(self, *args, **kwargs):\n raise RuntimeError('chainerx is not available.')\n\n\ndef is_available():\n return _available\n", "path": "chainerx/__init__.py"}]}
| 1,275 | 148 |
gh_patches_debug_3679
|
rasdani/github-patches
|
git_diff
|
pydantic__pydantic-4424
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
ImportError: cannot import name 'dataclass_transform' from 'typing_extensions' (1.10.0a1)
### Initial Checks
- [X] I have searched GitHub for a duplicate issue and I'm sure this is something new
- [X] I have searched Google & StackOverflow for a solution and couldn't find anything
- [X] I have read and followed [the docs](https://pydantic-docs.helpmanual.io) and still think this is a bug
- [X] I am confident that the issue is with pydantic (not my code, or another library in the ecosystem like [FastAPI](https://fastapi.tiangolo.com) or [mypy](https://mypy.readthedocs.io/en/stable))
### Description
the setup.py as to be adjusted (requirements.txt is)
https://github.com/pydantic/pydantic/blob/9d2e1c40cb0c839771afaf503cbf6590aa335f57/setup.py#L132-L134
### Example Code
```Python
pip install --upgrade typing_extensions=4.0.1
python -c "import pydantic.utils; print(pydantic.utils.version_info())"
```
### Python, Pydantic & OS Version
```Text
I use 1.10.0a1.
~/venv/openapi3/bin/python -c "import pydantic.utils; print(pydantic.utils.version_info())"
Traceback (most recent call last):
File "<string>", line 1, in <module>
File …/lib/python3.9/site-packages/pydantic/__init__.py", line 2, in <module>
from . import dataclasses
File "…/lib/python3.9/site-packages/pydantic/dataclasses.py", line 39, in <module>
from typing_extensions import dataclass_transform
ImportError: cannot import name 'dataclass_transform' from 'typing_extensions' (…/lib/python3.9/site-packages/typing_extensions.py)
```
### Affected Components
- [X] [Compatibility between releases](https://pydantic-docs.helpmanual.io/changelog/)
- [ ] [Data validation/parsing](https://pydantic-docs.helpmanual.io/usage/models/#basic-model-usage)
- [ ] [Data serialization](https://pydantic-docs.helpmanual.io/usage/exporting_models/) - `.dict()` and `.json()`
- [ ] [JSON Schema](https://pydantic-docs.helpmanual.io/usage/schema/)
- [X] [Dataclasses](https://pydantic-docs.helpmanual.io/usage/dataclasses/)
- [ ] [Model Config](https://pydantic-docs.helpmanual.io/usage/model_config/)
- [ ] [Field Types](https://pydantic-docs.helpmanual.io/usage/types/) - adding or changing a particular data type
- [ ] [Function validation decorator](https://pydantic-docs.helpmanual.io/usage/validation_decorator/)
- [ ] [Generic Models](https://pydantic-docs.helpmanual.io/usage/models/#generic-models)
- [ ] [Other Model behaviour](https://pydantic-docs.helpmanual.io/usage/models/) - `construct()`, pickling, private attributes, ORM mode
- [ ] [Settings Management](https://pydantic-docs.helpmanual.io/usage/settings/)
- [ ] [Plugins](https://pydantic-docs.helpmanual.io/) and integration with other tools - mypy, FastAPI, python-devtools, Hypothesis, VS Code, PyCharm, etc.
</issue>
<code>
[start of setup.py]
1 import os
2 import re
3 import sys
4 from importlib.machinery import SourceFileLoader
5 from pathlib import Path
6
7 from setuptools import setup
8
9 if os.name == 'nt':
10 from setuptools.command import build_ext
11
12 def get_export_symbols(self, ext):
13 """
14 Slightly modified from:
15 https://github.com/python/cpython/blob/8849e5962ba481d5d414b3467a256aba2134b4da\
16 /Lib/distutils/command/build_ext.py#L686-L703
17 """
18 # Patch from: https://bugs.python.org/issue35893
19 parts = ext.name.split('.')
20 if parts[-1] == '__init__':
21 suffix = parts[-2]
22 else:
23 suffix = parts[-1]
24
25 # from here on unchanged
26 try:
27 # Unicode module name support as defined in PEP-489
28 # https://www.python.org/dev/peps/pep-0489/#export-hook-name
29 suffix.encode('ascii')
30 except UnicodeEncodeError:
31 suffix = 'U' + suffix.encode('punycode').replace(b'-', b'_').decode('ascii')
32
33 initfunc_name = 'PyInit_' + suffix
34 if initfunc_name not in ext.export_symbols:
35 ext.export_symbols.append(initfunc_name)
36 return ext.export_symbols
37
38 build_ext.build_ext.get_export_symbols = get_export_symbols
39
40
41 class ReplaceLinks:
42 def __init__(self):
43 self.links = set()
44
45 def replace_issues(self, m):
46 id = m.group(1)
47 self.links.add(f'.. _#{id}: https://github.com/pydantic/pydantic/issues/{id}')
48 return f'`#{id}`_'
49
50 def replace_users(self, m):
51 name = m.group(2)
52 self.links.add(f'.. _@{name}: https://github.com/{name}')
53 return f'{m.group(1)}`@{name}`_'
54
55 def extra(self):
56 return '\n\n' + '\n'.join(sorted(self.links)) + '\n'
57
58
59 description = 'Data validation and settings management using python type hints'
60 THIS_DIR = Path(__file__).resolve().parent
61 try:
62 history = (THIS_DIR / 'HISTORY.md').read_text(encoding='utf-8')
63 history = re.sub(r'#(\d+)', r'[#\1](https://github.com/pydantic/pydantic/issues/\1)', history)
64 history = re.sub(r'( +)@([\w\-]+)', r'\1[@\2](https://github.com/\2)', history, flags=re.I)
65 history = re.sub('@@', '@', history)
66
67 long_description = (THIS_DIR / 'README.md').read_text(encoding='utf-8') + '\n\n' + history
68 except FileNotFoundError:
69 long_description = description + '.\n\nSee https://pydantic-docs.helpmanual.io/ for documentation.'
70
71 # avoid loading the package before requirements are installed:
72 version = SourceFileLoader('version', 'pydantic/version.py').load_module()
73
74 ext_modules = None
75 if not any(arg in sys.argv for arg in ['clean', 'check']) and 'SKIP_CYTHON' not in os.environ:
76 try:
77 from Cython.Build import cythonize
78 except ImportError:
79 pass
80 else:
81 # For cython test coverage install with `make build-trace`
82 compiler_directives = {}
83 if 'CYTHON_TRACE' in sys.argv:
84 compiler_directives['linetrace'] = True
85 # Set CFLAG to all optimizations (-O3)
86 # Any additional CFLAGS will be appended. Only the last optimization flag will have effect
87 os.environ['CFLAGS'] = '-O3 ' + os.environ.get('CFLAGS', '')
88 ext_modules = cythonize(
89 'pydantic/*.py',
90 exclude=['pydantic/generics.py'],
91 nthreads=int(os.getenv('CYTHON_NTHREADS', 0)),
92 language_level=3,
93 compiler_directives=compiler_directives,
94 )
95
96 setup(
97 name='pydantic',
98 version=str(version.VERSION),
99 description=description,
100 long_description=long_description,
101 long_description_content_type='text/markdown',
102 classifiers=[
103 'Development Status :: 5 - Production/Stable',
104 'Programming Language :: Python',
105 'Programming Language :: Python :: 3',
106 'Programming Language :: Python :: 3 :: Only',
107 'Programming Language :: Python :: 3.7',
108 'Programming Language :: Python :: 3.8',
109 'Programming Language :: Python :: 3.9',
110 'Programming Language :: Python :: 3.10',
111 'Programming Language :: Python :: 3.11',
112 'Intended Audience :: Developers',
113 'Intended Audience :: Information Technology',
114 'Intended Audience :: System Administrators',
115 'License :: OSI Approved :: MIT License',
116 'Operating System :: Unix',
117 'Operating System :: POSIX :: Linux',
118 'Environment :: Console',
119 'Environment :: MacOS X',
120 'Framework :: Hypothesis',
121 'Topic :: Software Development :: Libraries :: Python Modules',
122 'Topic :: Internet',
123 ],
124 author='Samuel Colvin',
125 author_email='[email protected]',
126 url='https://github.com/pydantic/pydantic',
127 license='MIT',
128 packages=['pydantic'],
129 package_data={'pydantic': ['py.typed']},
130 python_requires='>=3.7',
131 zip_safe=False, # https://mypy.readthedocs.io/en/latest/installed_packages.html
132 install_requires=[
133 'typing-extensions>=4.0.1'
134 ],
135 extras_require={
136 'email': ['email-validator>=1.0.3'],
137 'dotenv': ['python-dotenv>=0.10.4'],
138 },
139 ext_modules=ext_modules,
140 entry_points={'hypothesis': ['_ = pydantic._hypothesis_plugin']},
141 )
142
[end of setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -130,7 +130,7 @@
python_requires='>=3.7',
zip_safe=False, # https://mypy.readthedocs.io/en/latest/installed_packages.html
install_requires=[
- 'typing-extensions>=4.0.1'
+ 'typing-extensions>=4.1.0'
],
extras_require={
'email': ['email-validator>=1.0.3'],
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -130,7 +130,7 @@\n python_requires='>=3.7',\n zip_safe=False, # https://mypy.readthedocs.io/en/latest/installed_packages.html\n install_requires=[\n- 'typing-extensions>=4.0.1'\n+ 'typing-extensions>=4.1.0'\n ],\n extras_require={\n 'email': ['email-validator>=1.0.3'],\n", "issue": "ImportError: cannot import name 'dataclass_transform' from 'typing_extensions' (1.10.0a1)\n### Initial Checks\n\n- [X] I have searched GitHub for a duplicate issue and I'm sure this is something new\n- [X] I have searched Google & StackOverflow for a solution and couldn't find anything\n- [X] I have read and followed [the docs](https://pydantic-docs.helpmanual.io) and still think this is a bug\n- [X] I am confident that the issue is with pydantic (not my code, or another library in the ecosystem like [FastAPI](https://fastapi.tiangolo.com) or [mypy](https://mypy.readthedocs.io/en/stable))\n\n\n### Description\n\nthe setup.py as to be adjusted (requirements.txt is)\r\nhttps://github.com/pydantic/pydantic/blob/9d2e1c40cb0c839771afaf503cbf6590aa335f57/setup.py#L132-L134\n\n### Example Code\n\n```Python\npip install --upgrade typing_extensions=4.0.1\r\npython -c \"import pydantic.utils; print(pydantic.utils.version_info())\"\n```\n\n\n### Python, Pydantic & OS Version\n\n```Text\nI use 1.10.0a1.\r\n\r\n~/venv/openapi3/bin/python -c \"import pydantic.utils; print(pydantic.utils.version_info())\"\r\nTraceback (most recent call last):\r\n File \"<string>\", line 1, in <module>\r\n File \u2026/lib/python3.9/site-packages/pydantic/__init__.py\", line 2, in <module>\r\n from . import dataclasses\r\n File \"\u2026/lib/python3.9/site-packages/pydantic/dataclasses.py\", line 39, in <module>\r\n from typing_extensions import dataclass_transform\r\nImportError: cannot import name 'dataclass_transform' from 'typing_extensions' (\u2026/lib/python3.9/site-packages/typing_extensions.py)\n```\n\n\n### Affected Components\n\n- [X] [Compatibility between releases](https://pydantic-docs.helpmanual.io/changelog/)\n- [ ] [Data validation/parsing](https://pydantic-docs.helpmanual.io/usage/models/#basic-model-usage)\n- [ ] [Data serialization](https://pydantic-docs.helpmanual.io/usage/exporting_models/) - `.dict()` and `.json()`\n- [ ] [JSON Schema](https://pydantic-docs.helpmanual.io/usage/schema/)\n- [X] [Dataclasses](https://pydantic-docs.helpmanual.io/usage/dataclasses/)\n- [ ] [Model Config](https://pydantic-docs.helpmanual.io/usage/model_config/)\n- [ ] [Field Types](https://pydantic-docs.helpmanual.io/usage/types/) - adding or changing a particular data type\n- [ ] [Function validation decorator](https://pydantic-docs.helpmanual.io/usage/validation_decorator/)\n- [ ] [Generic Models](https://pydantic-docs.helpmanual.io/usage/models/#generic-models)\n- [ ] [Other Model behaviour](https://pydantic-docs.helpmanual.io/usage/models/) - `construct()`, pickling, private attributes, ORM mode\n- [ ] [Settings Management](https://pydantic-docs.helpmanual.io/usage/settings/)\n- [ ] [Plugins](https://pydantic-docs.helpmanual.io/) and integration with other tools - mypy, FastAPI, python-devtools, Hypothesis, VS Code, PyCharm, etc.\n", "before_files": [{"content": "import os\nimport re\nimport sys\nfrom importlib.machinery import SourceFileLoader\nfrom pathlib import Path\n\nfrom setuptools import setup\n\nif os.name == 'nt':\n from setuptools.command import build_ext\n\n def get_export_symbols(self, ext):\n \"\"\"\n Slightly modified from:\n https://github.com/python/cpython/blob/8849e5962ba481d5d414b3467a256aba2134b4da\\\n /Lib/distutils/command/build_ext.py#L686-L703\n \"\"\"\n # Patch from: https://bugs.python.org/issue35893\n parts = ext.name.split('.')\n if parts[-1] == '__init__':\n suffix = parts[-2]\n else:\n suffix = parts[-1]\n\n # from here on unchanged\n try:\n # Unicode module name support as defined in PEP-489\n # https://www.python.org/dev/peps/pep-0489/#export-hook-name\n suffix.encode('ascii')\n except UnicodeEncodeError:\n suffix = 'U' + suffix.encode('punycode').replace(b'-', b'_').decode('ascii')\n\n initfunc_name = 'PyInit_' + suffix\n if initfunc_name not in ext.export_symbols:\n ext.export_symbols.append(initfunc_name)\n return ext.export_symbols\n\n build_ext.build_ext.get_export_symbols = get_export_symbols\n\n\nclass ReplaceLinks:\n def __init__(self):\n self.links = set()\n\n def replace_issues(self, m):\n id = m.group(1)\n self.links.add(f'.. _#{id}: https://github.com/pydantic/pydantic/issues/{id}')\n return f'`#{id}`_'\n\n def replace_users(self, m):\n name = m.group(2)\n self.links.add(f'.. _@{name}: https://github.com/{name}')\n return f'{m.group(1)}`@{name}`_'\n\n def extra(self):\n return '\\n\\n' + '\\n'.join(sorted(self.links)) + '\\n'\n\n\ndescription = 'Data validation and settings management using python type hints'\nTHIS_DIR = Path(__file__).resolve().parent\ntry:\n history = (THIS_DIR / 'HISTORY.md').read_text(encoding='utf-8')\n history = re.sub(r'#(\\d+)', r'[#\\1](https://github.com/pydantic/pydantic/issues/\\1)', history)\n history = re.sub(r'( +)@([\\w\\-]+)', r'\\1[@\\2](https://github.com/\\2)', history, flags=re.I)\n history = re.sub('@@', '@', history)\n\n long_description = (THIS_DIR / 'README.md').read_text(encoding='utf-8') + '\\n\\n' + history\nexcept FileNotFoundError:\n long_description = description + '.\\n\\nSee https://pydantic-docs.helpmanual.io/ for documentation.'\n\n# avoid loading the package before requirements are installed:\nversion = SourceFileLoader('version', 'pydantic/version.py').load_module()\n\next_modules = None\nif not any(arg in sys.argv for arg in ['clean', 'check']) and 'SKIP_CYTHON' not in os.environ:\n try:\n from Cython.Build import cythonize\n except ImportError:\n pass\n else:\n # For cython test coverage install with `make build-trace`\n compiler_directives = {}\n if 'CYTHON_TRACE' in sys.argv:\n compiler_directives['linetrace'] = True\n # Set CFLAG to all optimizations (-O3)\n # Any additional CFLAGS will be appended. Only the last optimization flag will have effect\n os.environ['CFLAGS'] = '-O3 ' + os.environ.get('CFLAGS', '')\n ext_modules = cythonize(\n 'pydantic/*.py',\n exclude=['pydantic/generics.py'],\n nthreads=int(os.getenv('CYTHON_NTHREADS', 0)),\n language_level=3,\n compiler_directives=compiler_directives,\n )\n\nsetup(\n name='pydantic',\n version=str(version.VERSION),\n description=description,\n long_description=long_description,\n long_description_content_type='text/markdown',\n classifiers=[\n 'Development Status :: 5 - Production/Stable',\n 'Programming Language :: Python',\n 'Programming Language :: Python :: 3',\n 'Programming Language :: Python :: 3 :: Only',\n 'Programming Language :: Python :: 3.7',\n 'Programming Language :: Python :: 3.8',\n 'Programming Language :: Python :: 3.9',\n 'Programming Language :: Python :: 3.10',\n 'Programming Language :: Python :: 3.11',\n 'Intended Audience :: Developers',\n 'Intended Audience :: Information Technology',\n 'Intended Audience :: System Administrators',\n 'License :: OSI Approved :: MIT License',\n 'Operating System :: Unix',\n 'Operating System :: POSIX :: Linux',\n 'Environment :: Console',\n 'Environment :: MacOS X',\n 'Framework :: Hypothesis',\n 'Topic :: Software Development :: Libraries :: Python Modules',\n 'Topic :: Internet',\n ],\n author='Samuel Colvin',\n author_email='[email protected]',\n url='https://github.com/pydantic/pydantic',\n license='MIT',\n packages=['pydantic'],\n package_data={'pydantic': ['py.typed']},\n python_requires='>=3.7',\n zip_safe=False, # https://mypy.readthedocs.io/en/latest/installed_packages.html\n install_requires=[\n 'typing-extensions>=4.0.1'\n ],\n extras_require={\n 'email': ['email-validator>=1.0.3'],\n 'dotenv': ['python-dotenv>=0.10.4'],\n },\n ext_modules=ext_modules,\n entry_points={'hypothesis': ['_ = pydantic._hypothesis_plugin']},\n)\n", "path": "setup.py"}]}
| 2,940 | 115 |
gh_patches_debug_37459
|
rasdani/github-patches
|
git_diff
|
StackStorm__st2-4736
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Orquesta workflow execution is stuck with canceling status
##### SUMMARY
If user cancels an orquesta workflow execution immediately after it was launched, there is a possibility where the workflow execution will be stuck in a canceling status. The cancelation failed because the workflow execution record has not been created yet.
##### ISSUE TYPE
- Bug Report
##### STACKSTORM VERSION
st2 v2.8 -> v3.1
##### OS / ENVIRONMENT / INSTALL METHOD
This affects all distros and installs.
##### STEPS TO REPRODUCE
Launch an orquesta workflow execution with one or more nested subworkflows. Cancel the workflow execution almostly immediately after it was launched.
##### EXPECTED RESULTS
Workflow execution should be in canceled state.
##### ACTUAL RESULTS
Workflow execution is stuck in canceling state.
</issue>
<code>
[start of contrib/runners/orquesta_runner/orquesta_runner/orquesta_runner.py]
1 # Copyright 2019 Extreme Networks, Inc.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 from __future__ import absolute_import
16
17 import uuid
18
19 import six
20 from oslo_config import cfg
21
22 from orquesta import exceptions as wf_exc
23 from orquesta import statuses as wf_statuses
24
25 from st2common.constants import action as ac_const
26 from st2common import log as logging
27 from st2common.models.api import notification as notify_api_models
28 from st2common.persistence import execution as ex_db_access
29 from st2common.persistence import liveaction as lv_db_access
30 from st2common.runners import base as runners
31 from st2common.services import action as ac_svc
32 from st2common.services import workflows as wf_svc
33 from st2common.util import api as api_util
34 from st2common.util import ujson
35
36 __all__ = [
37 'OrquestaRunner',
38 'get_runner',
39 'get_metadata'
40 ]
41
42
43 LOG = logging.getLogger(__name__)
44
45
46 class OrquestaRunner(runners.AsyncActionRunner):
47
48 @staticmethod
49 def get_workflow_definition(entry_point):
50 with open(entry_point, 'r') as def_file:
51 return def_file.read()
52
53 def _get_notify_config(self):
54 return (
55 notify_api_models.NotificationsHelper.from_model(notify_model=self.liveaction.notify)
56 if self.liveaction.notify
57 else None
58 )
59
60 def _construct_context(self, wf_ex):
61 ctx = ujson.fast_deepcopy(self.context)
62 ctx['workflow_execution'] = str(wf_ex.id)
63
64 return ctx
65
66 def _construct_st2_context(self):
67 st2_ctx = {
68 'st2': {
69 'action_execution_id': str(self.execution.id),
70 'api_url': api_util.get_full_public_api_url(),
71 'user': self.execution.context.get('user', cfg.CONF.system_user.user),
72 'pack': self.execution.context.get('pack', None)
73 }
74 }
75
76 if self.execution.context.get('api_user'):
77 st2_ctx['st2']['api_user'] = self.execution.context.get('api_user')
78
79 if self.execution.context.get('source_channel'):
80 st2_ctx['st2']['source_channel'] = self.execution.context.get('source_channel')
81
82 if self.execution.context:
83 st2_ctx['parent'] = self.execution.context
84
85 return st2_ctx
86
87 def run(self, action_parameters):
88 # Read workflow definition from file.
89 wf_def = self.get_workflow_definition(self.entry_point)
90
91 try:
92 # Request workflow execution.
93 st2_ctx = self._construct_st2_context()
94 notify_cfg = self._get_notify_config()
95 wf_ex_db = wf_svc.request(wf_def, self.execution, st2_ctx, notify_cfg)
96 except wf_exc.WorkflowInspectionError as e:
97 status = ac_const.LIVEACTION_STATUS_FAILED
98 result = {'errors': e.args[1], 'output': None}
99 return (status, result, self.context)
100 except Exception as e:
101 status = ac_const.LIVEACTION_STATUS_FAILED
102 result = {'errors': [{'message': six.text_type(e)}], 'output': None}
103 return (status, result, self.context)
104
105 if wf_ex_db.status in wf_statuses.COMPLETED_STATUSES:
106 status = wf_ex_db.status
107 result = {'output': wf_ex_db.output or None}
108
109 if wf_ex_db.status in wf_statuses.ABENDED_STATUSES:
110 result['errors'] = wf_ex_db.errors
111
112 for wf_ex_error in wf_ex_db.errors:
113 msg = '[%s] Workflow execution completed with errors.'
114 LOG.error(msg, str(self.execution.id), extra=wf_ex_error)
115
116 return (status, result, self.context)
117
118 # Set return values.
119 status = ac_const.LIVEACTION_STATUS_RUNNING
120 partial_results = {}
121 ctx = self._construct_context(wf_ex_db)
122
123 return (status, partial_results, ctx)
124
125 @staticmethod
126 def task_pauseable(ac_ex):
127 wf_ex_pauseable = (
128 ac_ex.runner['name'] in ac_const.WORKFLOW_RUNNER_TYPES and
129 ac_ex.status == ac_const.LIVEACTION_STATUS_RUNNING
130 )
131
132 return wf_ex_pauseable
133
134 def pause(self):
135 # Pause the target workflow.
136 wf_ex_db = wf_svc.request_pause(self.execution)
137
138 # Request pause of tasks that are workflows and still running.
139 for child_ex_id in self.execution.children:
140 child_ex = ex_db_access.ActionExecution.get(id=child_ex_id)
141 if self.task_pauseable(child_ex):
142 ac_svc.request_pause(
143 lv_db_access.LiveAction.get(id=child_ex.liveaction['id']),
144 self.context.get('user', None)
145 )
146
147 if wf_ex_db.status == wf_statuses.PAUSING or ac_svc.is_children_active(self.liveaction.id):
148 status = ac_const.LIVEACTION_STATUS_PAUSING
149 else:
150 status = ac_const.LIVEACTION_STATUS_PAUSED
151
152 return (
153 status,
154 self.liveaction.result,
155 self.liveaction.context
156 )
157
158 @staticmethod
159 def task_resumeable(ac_ex):
160 wf_ex_resumeable = (
161 ac_ex.runner['name'] in ac_const.WORKFLOW_RUNNER_TYPES and
162 ac_ex.status == ac_const.LIVEACTION_STATUS_PAUSED
163 )
164
165 return wf_ex_resumeable
166
167 def resume(self):
168 # Resume the target workflow.
169 wf_ex_db = wf_svc.request_resume(self.execution)
170
171 # Request resume of tasks that are workflows and still running.
172 for child_ex_id in self.execution.children:
173 child_ex = ex_db_access.ActionExecution.get(id=child_ex_id)
174 if self.task_resumeable(child_ex):
175 ac_svc.request_resume(
176 lv_db_access.LiveAction.get(id=child_ex.liveaction['id']),
177 self.context.get('user', None)
178 )
179
180 return (
181 wf_ex_db.status if wf_ex_db else ac_const.LIVEACTION_STATUS_RUNNING,
182 self.liveaction.result,
183 self.liveaction.context
184 )
185
186 @staticmethod
187 def task_cancelable(ac_ex):
188 wf_ex_cancelable = (
189 ac_ex.runner['name'] in ac_const.WORKFLOW_RUNNER_TYPES and
190 ac_ex.status in ac_const.LIVEACTION_CANCELABLE_STATES
191 )
192
193 ac_ex_cancelable = (
194 ac_ex.runner['name'] not in ac_const.WORKFLOW_RUNNER_TYPES and
195 ac_ex.status in ac_const.LIVEACTION_DELAYED_STATES
196 )
197
198 return wf_ex_cancelable or ac_ex_cancelable
199
200 def cancel(self):
201 # Cancel the target workflow.
202 wf_svc.request_cancellation(self.execution)
203
204 # Request cancellation of tasks that are workflows and still running.
205 for child_ex_id in self.execution.children:
206 child_ex = ex_db_access.ActionExecution.get(id=child_ex_id)
207 if self.task_cancelable(child_ex):
208 ac_svc.request_cancellation(
209 lv_db_access.LiveAction.get(id=child_ex.liveaction['id']),
210 self.context.get('user', None)
211 )
212
213 status = (
214 ac_const.LIVEACTION_STATUS_CANCELING
215 if ac_svc.is_children_active(self.liveaction.id)
216 else ac_const.LIVEACTION_STATUS_CANCELED
217 )
218
219 return (
220 status,
221 self.liveaction.result,
222 self.liveaction.context
223 )
224
225
226 def get_runner():
227 return OrquestaRunner(str(uuid.uuid4()))
228
229
230 def get_metadata():
231 return runners.get_metadata('orquesta_runner')[0]
232
[end of contrib/runners/orquesta_runner/orquesta_runner/orquesta_runner.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/contrib/runners/orquesta_runner/orquesta_runner/orquesta_runner.py b/contrib/runners/orquesta_runner/orquesta_runner/orquesta_runner.py
--- a/contrib/runners/orquesta_runner/orquesta_runner/orquesta_runner.py
+++ b/contrib/runners/orquesta_runner/orquesta_runner/orquesta_runner.py
@@ -14,6 +14,8 @@
from __future__ import absolute_import
+import sys
+import traceback
import uuid
import six
@@ -24,6 +26,7 @@
from st2common.constants import action as ac_const
from st2common import log as logging
+from st2common.exceptions import workflow as wf_svc_exc
from st2common.models.api import notification as notify_api_models
from st2common.persistence import execution as ex_db_access
from st2common.persistence import liveaction as lv_db_access
@@ -198,8 +201,29 @@
return wf_ex_cancelable or ac_ex_cancelable
def cancel(self):
- # Cancel the target workflow.
- wf_svc.request_cancellation(self.execution)
+ result = None
+
+ # Try to cancel the target workflow execution.
+ try:
+ wf_svc.request_cancellation(self.execution)
+ # If workflow execution is not found because the action execution is cancelled
+ # before the workflow execution is created or if the workflow execution is
+ # already completed, then ignore the exception and proceed with cancellation.
+ except (wf_svc_exc.WorkflowExecutionNotFoundException,
+ wf_svc_exc.WorkflowExecutionIsCompletedException):
+ pass
+ # If there is an unknown exception, then log the error. Continue with the
+ # cancelation sequence below to cancel children and determine final status.
+ # If we rethrow the exception here, the workflow will be stuck in a canceling
+ # state with no options for user to clean up. It is safer to continue with
+ # the cancel then to revert back to some other statuses because the workflow
+ # execution will be in an unknown state.
+ except Exception:
+ _, ex, tb = sys.exc_info()
+ msg = 'Error encountered when canceling workflow execution. %s'
+ result = {'error': msg % str(ex), 'traceback': ''.join(traceback.format_tb(tb, 20))}
+ msg = '[%s] Error encountered when canceling workflow execution.'
+ LOG.exception(msg, str(self.execution.id))
# Request cancellation of tasks that are workflows and still running.
for child_ex_id in self.execution.children:
@@ -218,7 +242,7 @@
return (
status,
- self.liveaction.result,
+ result if result else self.liveaction.result,
self.liveaction.context
)
|
{"golden_diff": "diff --git a/contrib/runners/orquesta_runner/orquesta_runner/orquesta_runner.py b/contrib/runners/orquesta_runner/orquesta_runner/orquesta_runner.py\n--- a/contrib/runners/orquesta_runner/orquesta_runner/orquesta_runner.py\n+++ b/contrib/runners/orquesta_runner/orquesta_runner/orquesta_runner.py\n@@ -14,6 +14,8 @@\n \n from __future__ import absolute_import\n \n+import sys\n+import traceback\n import uuid\n \n import six\n@@ -24,6 +26,7 @@\n \n from st2common.constants import action as ac_const\n from st2common import log as logging\n+from st2common.exceptions import workflow as wf_svc_exc\n from st2common.models.api import notification as notify_api_models\n from st2common.persistence import execution as ex_db_access\n from st2common.persistence import liveaction as lv_db_access\n@@ -198,8 +201,29 @@\n return wf_ex_cancelable or ac_ex_cancelable\n \n def cancel(self):\n- # Cancel the target workflow.\n- wf_svc.request_cancellation(self.execution)\n+ result = None\n+\n+ # Try to cancel the target workflow execution.\n+ try:\n+ wf_svc.request_cancellation(self.execution)\n+ # If workflow execution is not found because the action execution is cancelled\n+ # before the workflow execution is created or if the workflow execution is\n+ # already completed, then ignore the exception and proceed with cancellation.\n+ except (wf_svc_exc.WorkflowExecutionNotFoundException,\n+ wf_svc_exc.WorkflowExecutionIsCompletedException):\n+ pass\n+ # If there is an unknown exception, then log the error. Continue with the\n+ # cancelation sequence below to cancel children and determine final status.\n+ # If we rethrow the exception here, the workflow will be stuck in a canceling\n+ # state with no options for user to clean up. It is safer to continue with\n+ # the cancel then to revert back to some other statuses because the workflow\n+ # execution will be in an unknown state.\n+ except Exception:\n+ _, ex, tb = sys.exc_info()\n+ msg = 'Error encountered when canceling workflow execution. %s'\n+ result = {'error': msg % str(ex), 'traceback': ''.join(traceback.format_tb(tb, 20))}\n+ msg = '[%s] Error encountered when canceling workflow execution.'\n+ LOG.exception(msg, str(self.execution.id))\n \n # Request cancellation of tasks that are workflows and still running.\n for child_ex_id in self.execution.children:\n@@ -218,7 +242,7 @@\n \n return (\n status,\n- self.liveaction.result,\n+ result if result else self.liveaction.result,\n self.liveaction.context\n )\n", "issue": "Orquesta workflow execution is stuck with canceling status\n##### SUMMARY\r\n\r\nIf user cancels an orquesta workflow execution immediately after it was launched, there is a possibility where the workflow execution will be stuck in a canceling status. The cancelation failed because the workflow execution record has not been created yet.\r\n\r\n##### ISSUE TYPE\r\n - Bug Report\r\n\r\n##### STACKSTORM VERSION\r\nst2 v2.8 -> v3.1\r\n\r\n##### OS / ENVIRONMENT / INSTALL METHOD\r\nThis affects all distros and installs.\r\n\r\n##### STEPS TO REPRODUCE\r\nLaunch an orquesta workflow execution with one or more nested subworkflows. Cancel the workflow execution almostly immediately after it was launched.\r\n\r\n##### EXPECTED RESULTS\r\nWorkflow execution should be in canceled state.\r\n\r\n##### ACTUAL RESULTS\r\nWorkflow execution is stuck in canceling state.\n", "before_files": [{"content": "# Copyright 2019 Extreme Networks, Inc.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nfrom __future__ import absolute_import\n\nimport uuid\n\nimport six\nfrom oslo_config import cfg\n\nfrom orquesta import exceptions as wf_exc\nfrom orquesta import statuses as wf_statuses\n\nfrom st2common.constants import action as ac_const\nfrom st2common import log as logging\nfrom st2common.models.api import notification as notify_api_models\nfrom st2common.persistence import execution as ex_db_access\nfrom st2common.persistence import liveaction as lv_db_access\nfrom st2common.runners import base as runners\nfrom st2common.services import action as ac_svc\nfrom st2common.services import workflows as wf_svc\nfrom st2common.util import api as api_util\nfrom st2common.util import ujson\n\n__all__ = [\n 'OrquestaRunner',\n 'get_runner',\n 'get_metadata'\n]\n\n\nLOG = logging.getLogger(__name__)\n\n\nclass OrquestaRunner(runners.AsyncActionRunner):\n\n @staticmethod\n def get_workflow_definition(entry_point):\n with open(entry_point, 'r') as def_file:\n return def_file.read()\n\n def _get_notify_config(self):\n return (\n notify_api_models.NotificationsHelper.from_model(notify_model=self.liveaction.notify)\n if self.liveaction.notify\n else None\n )\n\n def _construct_context(self, wf_ex):\n ctx = ujson.fast_deepcopy(self.context)\n ctx['workflow_execution'] = str(wf_ex.id)\n\n return ctx\n\n def _construct_st2_context(self):\n st2_ctx = {\n 'st2': {\n 'action_execution_id': str(self.execution.id),\n 'api_url': api_util.get_full_public_api_url(),\n 'user': self.execution.context.get('user', cfg.CONF.system_user.user),\n 'pack': self.execution.context.get('pack', None)\n }\n }\n\n if self.execution.context.get('api_user'):\n st2_ctx['st2']['api_user'] = self.execution.context.get('api_user')\n\n if self.execution.context.get('source_channel'):\n st2_ctx['st2']['source_channel'] = self.execution.context.get('source_channel')\n\n if self.execution.context:\n st2_ctx['parent'] = self.execution.context\n\n return st2_ctx\n\n def run(self, action_parameters):\n # Read workflow definition from file.\n wf_def = self.get_workflow_definition(self.entry_point)\n\n try:\n # Request workflow execution.\n st2_ctx = self._construct_st2_context()\n notify_cfg = self._get_notify_config()\n wf_ex_db = wf_svc.request(wf_def, self.execution, st2_ctx, notify_cfg)\n except wf_exc.WorkflowInspectionError as e:\n status = ac_const.LIVEACTION_STATUS_FAILED\n result = {'errors': e.args[1], 'output': None}\n return (status, result, self.context)\n except Exception as e:\n status = ac_const.LIVEACTION_STATUS_FAILED\n result = {'errors': [{'message': six.text_type(e)}], 'output': None}\n return (status, result, self.context)\n\n if wf_ex_db.status in wf_statuses.COMPLETED_STATUSES:\n status = wf_ex_db.status\n result = {'output': wf_ex_db.output or None}\n\n if wf_ex_db.status in wf_statuses.ABENDED_STATUSES:\n result['errors'] = wf_ex_db.errors\n\n for wf_ex_error in wf_ex_db.errors:\n msg = '[%s] Workflow execution completed with errors.'\n LOG.error(msg, str(self.execution.id), extra=wf_ex_error)\n\n return (status, result, self.context)\n\n # Set return values.\n status = ac_const.LIVEACTION_STATUS_RUNNING\n partial_results = {}\n ctx = self._construct_context(wf_ex_db)\n\n return (status, partial_results, ctx)\n\n @staticmethod\n def task_pauseable(ac_ex):\n wf_ex_pauseable = (\n ac_ex.runner['name'] in ac_const.WORKFLOW_RUNNER_TYPES and\n ac_ex.status == ac_const.LIVEACTION_STATUS_RUNNING\n )\n\n return wf_ex_pauseable\n\n def pause(self):\n # Pause the target workflow.\n wf_ex_db = wf_svc.request_pause(self.execution)\n\n # Request pause of tasks that are workflows and still running.\n for child_ex_id in self.execution.children:\n child_ex = ex_db_access.ActionExecution.get(id=child_ex_id)\n if self.task_pauseable(child_ex):\n ac_svc.request_pause(\n lv_db_access.LiveAction.get(id=child_ex.liveaction['id']),\n self.context.get('user', None)\n )\n\n if wf_ex_db.status == wf_statuses.PAUSING or ac_svc.is_children_active(self.liveaction.id):\n status = ac_const.LIVEACTION_STATUS_PAUSING\n else:\n status = ac_const.LIVEACTION_STATUS_PAUSED\n\n return (\n status,\n self.liveaction.result,\n self.liveaction.context\n )\n\n @staticmethod\n def task_resumeable(ac_ex):\n wf_ex_resumeable = (\n ac_ex.runner['name'] in ac_const.WORKFLOW_RUNNER_TYPES and\n ac_ex.status == ac_const.LIVEACTION_STATUS_PAUSED\n )\n\n return wf_ex_resumeable\n\n def resume(self):\n # Resume the target workflow.\n wf_ex_db = wf_svc.request_resume(self.execution)\n\n # Request resume of tasks that are workflows and still running.\n for child_ex_id in self.execution.children:\n child_ex = ex_db_access.ActionExecution.get(id=child_ex_id)\n if self.task_resumeable(child_ex):\n ac_svc.request_resume(\n lv_db_access.LiveAction.get(id=child_ex.liveaction['id']),\n self.context.get('user', None)\n )\n\n return (\n wf_ex_db.status if wf_ex_db else ac_const.LIVEACTION_STATUS_RUNNING,\n self.liveaction.result,\n self.liveaction.context\n )\n\n @staticmethod\n def task_cancelable(ac_ex):\n wf_ex_cancelable = (\n ac_ex.runner['name'] in ac_const.WORKFLOW_RUNNER_TYPES and\n ac_ex.status in ac_const.LIVEACTION_CANCELABLE_STATES\n )\n\n ac_ex_cancelable = (\n ac_ex.runner['name'] not in ac_const.WORKFLOW_RUNNER_TYPES and\n ac_ex.status in ac_const.LIVEACTION_DELAYED_STATES\n )\n\n return wf_ex_cancelable or ac_ex_cancelable\n\n def cancel(self):\n # Cancel the target workflow.\n wf_svc.request_cancellation(self.execution)\n\n # Request cancellation of tasks that are workflows and still running.\n for child_ex_id in self.execution.children:\n child_ex = ex_db_access.ActionExecution.get(id=child_ex_id)\n if self.task_cancelable(child_ex):\n ac_svc.request_cancellation(\n lv_db_access.LiveAction.get(id=child_ex.liveaction['id']),\n self.context.get('user', None)\n )\n\n status = (\n ac_const.LIVEACTION_STATUS_CANCELING\n if ac_svc.is_children_active(self.liveaction.id)\n else ac_const.LIVEACTION_STATUS_CANCELED\n )\n\n return (\n status,\n self.liveaction.result,\n self.liveaction.context\n )\n\n\ndef get_runner():\n return OrquestaRunner(str(uuid.uuid4()))\n\n\ndef get_metadata():\n return runners.get_metadata('orquesta_runner')[0]\n", "path": "contrib/runners/orquesta_runner/orquesta_runner/orquesta_runner.py"}]}
| 3,030 | 617 |
gh_patches_debug_41016
|
rasdani/github-patches
|
git_diff
|
kubeflow__pipelines-3486
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[Component] AutoML Tables component should show link as an artifact
/cc @jessiezcc
/cc @jingzhang36
/assign @Ark-kun
It will be helpful if components in
https://github.com/kubeflow/pipelines/tree/b89aabbce5d48fca10817c3ed3ecc2acf6c0066a/components/gcp/automl can show related AutoML tables url as markdown artifacts.
e.g.
> We would like to be able to click on a link that would take us from the component’s page to an AutoML Tables models page
</issue>
<code>
[start of components/gcp/automl/create_model_for_tables/component.py]
1 # Copyright 2019 Google LLC
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 from typing import NamedTuple
16
17
18 def automl_create_model_for_tables(
19 gcp_project_id: str,
20 gcp_region: str,
21 display_name: str,
22 dataset_id: str,
23 target_column_path: str = None,
24 input_feature_column_paths: list = None,
25 optimization_objective: str = 'MAXIMIZE_AU_PRC',
26 train_budget_milli_node_hours: int = 1000,
27 ) -> NamedTuple('Outputs', [('model_path', str), ('model_id', str)]):
28 import sys
29 import subprocess
30 subprocess.run([sys.executable, '-m', 'pip', 'install', 'google-cloud-automl==0.4.0', '--quiet', '--no-warn-script-location'], env={'PIP_DISABLE_PIP_VERSION_CHECK': '1'}, check=True)
31
32 from google.cloud import automl
33 client = automl.AutoMlClient()
34
35 location_path = client.location_path(gcp_project_id, gcp_region)
36 model_dict = {
37 'display_name': display_name,
38 'dataset_id': dataset_id,
39 'tables_model_metadata': {
40 'target_column_spec': automl.types.ColumnSpec(name=target_column_path),
41 'input_feature_column_specs': [automl.types.ColumnSpec(name=path) for path in input_feature_column_paths] if input_feature_column_paths else None,
42 'optimization_objective': optimization_objective,
43 'train_budget_milli_node_hours': train_budget_milli_node_hours,
44 },
45 }
46
47 create_model_response = client.create_model(location_path, model_dict)
48 print('Create model operation: {}'.format(create_model_response.operation))
49 result = create_model_response.result()
50 print(result)
51 model_name = result.name
52 model_id = model_name.rsplit('/', 1)[-1]
53 return (model_name, model_id)
54
55
56 if __name__ == '__main__':
57 import kfp
58 kfp.components.func_to_container_op(automl_create_model_for_tables, output_component_file='component.yaml', base_image='python:3.7')
59
[end of components/gcp/automl/create_model_for_tables/component.py]
[start of components/gcp/automl/create_dataset_for_tables/component.py]
1 # Copyright 2019 Google LLC
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 from typing import NamedTuple
16
17
18 def automl_create_dataset_for_tables(
19 gcp_project_id: str,
20 gcp_region: str,
21 display_name: str,
22 description: str = None,
23 tables_dataset_metadata: dict = {},
24 retry=None, #=google.api_core.gapic_v1.method.DEFAULT,
25 timeout: float = None, #=google.api_core.gapic_v1.method.DEFAULT,
26 metadata: dict = None,
27 ) -> NamedTuple('Outputs', [('dataset_path', str), ('create_time', str), ('dataset_id', str)]):
28 '''automl_create_dataset_for_tables creates an empty Dataset for AutoML tables
29 '''
30 import sys
31 import subprocess
32 subprocess.run([sys.executable, '-m', 'pip', 'install', 'google-cloud-automl==0.4.0', '--quiet', '--no-warn-script-location'], env={'PIP_DISABLE_PIP_VERSION_CHECK': '1'}, check=True)
33
34 import google
35 from google.cloud import automl
36 client = automl.AutoMlClient()
37
38 location_path = client.location_path(gcp_project_id, gcp_region)
39 dataset_dict = {
40 'display_name': display_name,
41 'description': description,
42 'tables_dataset_metadata': tables_dataset_metadata,
43 }
44 dataset = client.create_dataset(
45 location_path,
46 dataset_dict,
47 retry or google.api_core.gapic_v1.method.DEFAULT,
48 timeout or google.api_core.gapic_v1.method.DEFAULT,
49 metadata,
50 )
51 print(dataset)
52 dataset_id = dataset.name.rsplit('/', 1)[-1]
53 return (dataset.name, dataset.create_time, dataset_id)
54
55
56 if __name__ == '__main__':
57 import kfp
58 kfp.components.func_to_container_op(automl_create_dataset_for_tables, output_component_file='component.yaml', base_image='python:3.7')
59
[end of components/gcp/automl/create_dataset_for_tables/component.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/components/gcp/automl/create_dataset_for_tables/component.py b/components/gcp/automl/create_dataset_for_tables/component.py
--- a/components/gcp/automl/create_dataset_for_tables/component.py
+++ b/components/gcp/automl/create_dataset_for_tables/component.py
@@ -24,13 +24,9 @@
retry=None, #=google.api_core.gapic_v1.method.DEFAULT,
timeout: float = None, #=google.api_core.gapic_v1.method.DEFAULT,
metadata: dict = None,
-) -> NamedTuple('Outputs', [('dataset_path', str), ('create_time', str), ('dataset_id', str)]):
+) -> NamedTuple('Outputs', [('dataset_path', str), ('create_time', str), ('dataset_id', str), ('dataset_url', 'URI')]):
'''automl_create_dataset_for_tables creates an empty Dataset for AutoML tables
'''
- import sys
- import subprocess
- subprocess.run([sys.executable, '-m', 'pip', 'install', 'google-cloud-automl==0.4.0', '--quiet', '--no-warn-script-location'], env={'PIP_DISABLE_PIP_VERSION_CHECK': '1'}, check=True)
-
import google
from google.cloud import automl
client = automl.AutoMlClient()
@@ -50,9 +46,19 @@
)
print(dataset)
dataset_id = dataset.name.rsplit('/', 1)[-1]
- return (dataset.name, dataset.create_time, dataset_id)
+ dataset_url = 'https://console.cloud.google.com/automl-tables/locations/{region}/datasets/{dataset_id}/schemav2?project={project_id}'.format(
+ project_id=gcp_project_id,
+ region=gcp_region,
+ dataset_id=dataset_id,
+ )
+ return (dataset.name, dataset.create_time, dataset_id, dataset_url)
if __name__ == '__main__':
import kfp
- kfp.components.func_to_container_op(automl_create_dataset_for_tables, output_component_file='component.yaml', base_image='python:3.7')
+ kfp.components.func_to_container_op(
+ automl_create_dataset_for_tables,
+ output_component_file='component.yaml',
+ base_image='python:3.7',
+ packages_to_install=['google-cloud-automl==0.4.0']
+ )
diff --git a/components/gcp/automl/create_model_for_tables/component.py b/components/gcp/automl/create_model_for_tables/component.py
--- a/components/gcp/automl/create_model_for_tables/component.py
+++ b/components/gcp/automl/create_model_for_tables/component.py
@@ -24,11 +24,7 @@
input_feature_column_paths: list = None,
optimization_objective: str = 'MAXIMIZE_AU_PRC',
train_budget_milli_node_hours: int = 1000,
-) -> NamedTuple('Outputs', [('model_path', str), ('model_id', str)]):
- import sys
- import subprocess
- subprocess.run([sys.executable, '-m', 'pip', 'install', 'google-cloud-automl==0.4.0', '--quiet', '--no-warn-script-location'], env={'PIP_DISABLE_PIP_VERSION_CHECK': '1'}, check=True)
-
+) -> NamedTuple('Outputs', [('model_path', str), ('model_id', str), ('model_page_url', 'URI'),]):
from google.cloud import automl
client = automl.AutoMlClient()
@@ -50,9 +46,21 @@
print(result)
model_name = result.name
model_id = model_name.rsplit('/', 1)[-1]
- return (model_name, model_id)
+ model_url = 'https://console.cloud.google.com/automl-tables/locations/{region}/datasets/{dataset_id};modelId={model_id};task=basic/train?project={project_id}'.format(
+ project_id=gcp_project_id,
+ region=gcp_region,
+ dataset_id=dataset_id,
+ model_id=model_id,
+ )
+
+ return (model_name, model_id, model_url)
if __name__ == '__main__':
import kfp
- kfp.components.func_to_container_op(automl_create_model_for_tables, output_component_file='component.yaml', base_image='python:3.7')
+ kfp.components.func_to_container_op(
+ automl_create_model_for_tables,
+ output_component_file='component.yaml',
+ base_image='python:3.7',
+ packages_to_install=['google-cloud-automl==0.4.0']
+ )
|
{"golden_diff": "diff --git a/components/gcp/automl/create_dataset_for_tables/component.py b/components/gcp/automl/create_dataset_for_tables/component.py\n--- a/components/gcp/automl/create_dataset_for_tables/component.py\n+++ b/components/gcp/automl/create_dataset_for_tables/component.py\n@@ -24,13 +24,9 @@\n retry=None, #=google.api_core.gapic_v1.method.DEFAULT,\n timeout: float = None, #=google.api_core.gapic_v1.method.DEFAULT,\n metadata: dict = None,\n-) -> NamedTuple('Outputs', [('dataset_path', str), ('create_time', str), ('dataset_id', str)]):\n+) -> NamedTuple('Outputs', [('dataset_path', str), ('create_time', str), ('dataset_id', str), ('dataset_url', 'URI')]):\n '''automl_create_dataset_for_tables creates an empty Dataset for AutoML tables\n '''\n- import sys\n- import subprocess\n- subprocess.run([sys.executable, '-m', 'pip', 'install', 'google-cloud-automl==0.4.0', '--quiet', '--no-warn-script-location'], env={'PIP_DISABLE_PIP_VERSION_CHECK': '1'}, check=True)\n-\n import google\n from google.cloud import automl\n client = automl.AutoMlClient()\n@@ -50,9 +46,19 @@\n )\n print(dataset)\n dataset_id = dataset.name.rsplit('/', 1)[-1]\n- return (dataset.name, dataset.create_time, dataset_id)\n+ dataset_url = 'https://console.cloud.google.com/automl-tables/locations/{region}/datasets/{dataset_id}/schemav2?project={project_id}'.format(\n+ project_id=gcp_project_id,\n+ region=gcp_region,\n+ dataset_id=dataset_id,\n+ )\n+ return (dataset.name, dataset.create_time, dataset_id, dataset_url)\n \n \n if __name__ == '__main__':\n import kfp\n- kfp.components.func_to_container_op(automl_create_dataset_for_tables, output_component_file='component.yaml', base_image='python:3.7')\n+ kfp.components.func_to_container_op(\n+ automl_create_dataset_for_tables,\n+ output_component_file='component.yaml',\n+ base_image='python:3.7',\n+ packages_to_install=['google-cloud-automl==0.4.0']\n+ )\ndiff --git a/components/gcp/automl/create_model_for_tables/component.py b/components/gcp/automl/create_model_for_tables/component.py\n--- a/components/gcp/automl/create_model_for_tables/component.py\n+++ b/components/gcp/automl/create_model_for_tables/component.py\n@@ -24,11 +24,7 @@\n input_feature_column_paths: list = None,\n optimization_objective: str = 'MAXIMIZE_AU_PRC',\n train_budget_milli_node_hours: int = 1000,\n-) -> NamedTuple('Outputs', [('model_path', str), ('model_id', str)]):\n- import sys\n- import subprocess\n- subprocess.run([sys.executable, '-m', 'pip', 'install', 'google-cloud-automl==0.4.0', '--quiet', '--no-warn-script-location'], env={'PIP_DISABLE_PIP_VERSION_CHECK': '1'}, check=True)\n-\n+) -> NamedTuple('Outputs', [('model_path', str), ('model_id', str), ('model_page_url', 'URI'),]):\n from google.cloud import automl\n client = automl.AutoMlClient()\n \n@@ -50,9 +46,21 @@\n print(result)\n model_name = result.name\n model_id = model_name.rsplit('/', 1)[-1]\n- return (model_name, model_id)\n+ model_url = 'https://console.cloud.google.com/automl-tables/locations/{region}/datasets/{dataset_id};modelId={model_id};task=basic/train?project={project_id}'.format(\n+ project_id=gcp_project_id,\n+ region=gcp_region,\n+ dataset_id=dataset_id,\n+ model_id=model_id,\n+ )\n+\n+ return (model_name, model_id, model_url)\n \n \n if __name__ == '__main__':\n import kfp\n- kfp.components.func_to_container_op(automl_create_model_for_tables, output_component_file='component.yaml', base_image='python:3.7')\n+ kfp.components.func_to_container_op(\n+ automl_create_model_for_tables,\n+ output_component_file='component.yaml',\n+ base_image='python:3.7',\n+ packages_to_install=['google-cloud-automl==0.4.0']\n+ )\n", "issue": "[Component] AutoML Tables component should show link as an artifact\n/cc @jessiezcc \r\n/cc @jingzhang36 \r\n/assign @Ark-kun \r\n\r\nIt will be helpful if components in \r\nhttps://github.com/kubeflow/pipelines/tree/b89aabbce5d48fca10817c3ed3ecc2acf6c0066a/components/gcp/automl can show related AutoML tables url as markdown artifacts.\r\n\r\ne.g.\r\n> We would like to be able to click on a link that would take us from the component\u2019s page to an AutoML Tables models page\n", "before_files": [{"content": "# Copyright 2019 Google LLC\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nfrom typing import NamedTuple\n\n\ndef automl_create_model_for_tables(\n gcp_project_id: str,\n gcp_region: str,\n display_name: str,\n dataset_id: str,\n target_column_path: str = None,\n input_feature_column_paths: list = None,\n optimization_objective: str = 'MAXIMIZE_AU_PRC',\n train_budget_milli_node_hours: int = 1000,\n) -> NamedTuple('Outputs', [('model_path', str), ('model_id', str)]):\n import sys\n import subprocess\n subprocess.run([sys.executable, '-m', 'pip', 'install', 'google-cloud-automl==0.4.0', '--quiet', '--no-warn-script-location'], env={'PIP_DISABLE_PIP_VERSION_CHECK': '1'}, check=True)\n\n from google.cloud import automl\n client = automl.AutoMlClient()\n\n location_path = client.location_path(gcp_project_id, gcp_region)\n model_dict = {\n 'display_name': display_name,\n 'dataset_id': dataset_id,\n 'tables_model_metadata': {\n 'target_column_spec': automl.types.ColumnSpec(name=target_column_path),\n 'input_feature_column_specs': [automl.types.ColumnSpec(name=path) for path in input_feature_column_paths] if input_feature_column_paths else None,\n 'optimization_objective': optimization_objective,\n 'train_budget_milli_node_hours': train_budget_milli_node_hours,\n },\n }\n\n create_model_response = client.create_model(location_path, model_dict)\n print('Create model operation: {}'.format(create_model_response.operation))\n result = create_model_response.result()\n print(result)\n model_name = result.name\n model_id = model_name.rsplit('/', 1)[-1]\n return (model_name, model_id)\n\n\nif __name__ == '__main__':\n import kfp\n kfp.components.func_to_container_op(automl_create_model_for_tables, output_component_file='component.yaml', base_image='python:3.7')\n", "path": "components/gcp/automl/create_model_for_tables/component.py"}, {"content": "# Copyright 2019 Google LLC\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nfrom typing import NamedTuple\n\n\ndef automl_create_dataset_for_tables(\n gcp_project_id: str,\n gcp_region: str,\n display_name: str,\n description: str = None,\n tables_dataset_metadata: dict = {},\n retry=None, #=google.api_core.gapic_v1.method.DEFAULT,\n timeout: float = None, #=google.api_core.gapic_v1.method.DEFAULT,\n metadata: dict = None,\n) -> NamedTuple('Outputs', [('dataset_path', str), ('create_time', str), ('dataset_id', str)]):\n '''automl_create_dataset_for_tables creates an empty Dataset for AutoML tables\n '''\n import sys\n import subprocess\n subprocess.run([sys.executable, '-m', 'pip', 'install', 'google-cloud-automl==0.4.0', '--quiet', '--no-warn-script-location'], env={'PIP_DISABLE_PIP_VERSION_CHECK': '1'}, check=True)\n\n import google\n from google.cloud import automl\n client = automl.AutoMlClient()\n\n location_path = client.location_path(gcp_project_id, gcp_region)\n dataset_dict = {\n 'display_name': display_name,\n 'description': description,\n 'tables_dataset_metadata': tables_dataset_metadata,\n }\n dataset = client.create_dataset(\n location_path,\n dataset_dict,\n retry or google.api_core.gapic_v1.method.DEFAULT,\n timeout or google.api_core.gapic_v1.method.DEFAULT,\n metadata,\n )\n print(dataset)\n dataset_id = dataset.name.rsplit('/', 1)[-1]\n return (dataset.name, dataset.create_time, dataset_id)\n\n\nif __name__ == '__main__':\n import kfp\n kfp.components.func_to_container_op(automl_create_dataset_for_tables, output_component_file='component.yaml', base_image='python:3.7')\n", "path": "components/gcp/automl/create_dataset_for_tables/component.py"}]}
| 2,033 | 1,017 |
gh_patches_debug_17018
|
rasdani/github-patches
|
git_diff
|
googleapis__google-auth-library-python-569
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Add support for Python 3.8
</issue>
<code>
[start of noxfile.py]
1 # Copyright 2019 Google LLC
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 import nox
16
17 TEST_DEPENDENCIES = [
18 "flask",
19 "freezegun",
20 "mock",
21 "oauth2client",
22 "pyopenssl",
23 "pytest",
24 "pytest-cov",
25 "pytest-localserver",
26 "requests",
27 "urllib3",
28 "cryptography",
29 "responses",
30 "grpcio",
31 ]
32 BLACK_VERSION = "black==19.3b0"
33 BLACK_PATHS = ["google", "tests", "noxfile.py", "setup.py", "docs/conf.py"]
34
35
36 @nox.session(python="3.7")
37 def lint(session):
38 session.install("flake8", "flake8-import-order", "docutils", BLACK_VERSION)
39 session.install(".")
40 session.run("black", "--check", *BLACK_PATHS)
41 session.run(
42 "flake8",
43 "--import-order-style=google",
44 "--application-import-names=google,tests,system_tests",
45 "google",
46 "tests",
47 )
48 session.run(
49 "python", "setup.py", "check", "--metadata", "--restructuredtext", "--strict"
50 )
51
52
53 @nox.session(python="3.6")
54 def blacken(session):
55 """Run black.
56
57 Format code to uniform standard.
58
59 This currently uses Python 3.6 due to the automated Kokoro run of synthtool.
60 That run uses an image that doesn't have 3.6 installed. Before updating this
61 check the state of the `gcp_ubuntu_config` we use for that Kokoro run.
62 """
63 session.install(BLACK_VERSION)
64 session.run("black", *BLACK_PATHS)
65
66
67 @nox.session(python=["2.7", "3.5", "3.6", "3.7"])
68 def unit(session):
69 session.install(*TEST_DEPENDENCIES)
70 session.install(".")
71 session.run(
72 "pytest", "--cov=google.auth", "--cov=google.oauth2", "--cov=tests", "tests"
73 )
74
75
76 @nox.session(python="3.7")
77 def cover(session):
78 session.install(*TEST_DEPENDENCIES)
79 session.install(".")
80 session.run(
81 "pytest",
82 "--cov=google.auth",
83 "--cov=google.oauth2",
84 "--cov=tests",
85 "--cov-report=",
86 "tests",
87 )
88 session.run("coverage", "report", "--show-missing", "--fail-under=100")
89
90
91 @nox.session(python="3.7")
92 def docgen(session):
93 session.env["SPHINX_APIDOC_OPTIONS"] = "members,inherited-members,show-inheritance"
94 session.install(*TEST_DEPENDENCIES)
95 session.install("sphinx")
96 session.install(".")
97 session.run("rm", "-r", "docs/reference")
98 session.run(
99 "sphinx-apidoc",
100 "--output-dir",
101 "docs/reference",
102 "--separate",
103 "--module-first",
104 "google",
105 )
106
107
108 @nox.session(python="3.7")
109 def docs(session):
110 session.install("sphinx", "-r", "docs/requirements-docs.txt")
111 session.install(".")
112 session.run("make", "-C", "docs", "html")
113
114
115 @nox.session(python="pypy")
116 def pypy(session):
117 session.install(*TEST_DEPENDENCIES)
118 session.install(".")
119 session.run(
120 "pytest", "--cov=google.auth", "--cov=google.oauth2", "--cov=tests", "tests"
121 )
122
[end of noxfile.py]
[start of setup.py]
1 # Copyright 2014 Google Inc.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 import io
16
17 from setuptools import find_packages
18 from setuptools import setup
19
20
21 DEPENDENCIES = (
22 "cachetools>=2.0.0,<5.0",
23 "pyasn1-modules>=0.2.1",
24 # rsa==4.5 is the last version to support 2.7
25 # https://github.com/sybrenstuvel/python-rsa/issues/152#issuecomment-643470233
26 'rsa<4.6; python_version < "3.5"',
27 'rsa>=3.1.4,<5; python_version >= "3.5"',
28 "setuptools>=40.3.0",
29 "six>=1.9.0",
30 )
31
32
33 with io.open("README.rst", "r") as fh:
34 long_description = fh.read()
35
36 version = "1.19.2"
37
38 setup(
39 name="google-auth",
40 version=version,
41 author="Google Cloud Platform",
42 author_email="[email protected]",
43 description="Google Authentication Library",
44 long_description=long_description,
45 url="https://github.com/googleapis/google-auth-library-python",
46 packages=find_packages(exclude=("tests*", "system_tests*")),
47 namespace_packages=("google",),
48 install_requires=DEPENDENCIES,
49 python_requires=">=2.7,!=3.0.*,!=3.1.*,!=3.2.*,!=3.3.*",
50 license="Apache 2.0",
51 keywords="google auth oauth client",
52 classifiers=[
53 "Programming Language :: Python :: 2",
54 "Programming Language :: Python :: 2.7",
55 "Programming Language :: Python :: 3",
56 "Programming Language :: Python :: 3.5",
57 "Programming Language :: Python :: 3.6",
58 "Programming Language :: Python :: 3.7",
59 "Development Status :: 5 - Production/Stable",
60 "Intended Audience :: Developers",
61 "License :: OSI Approved :: Apache Software License",
62 "Operating System :: POSIX",
63 "Operating System :: Microsoft :: Windows",
64 "Operating System :: MacOS :: MacOS X",
65 "Operating System :: OS Independent",
66 "Topic :: Internet :: WWW/HTTP",
67 ],
68 )
69
[end of setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/noxfile.py b/noxfile.py
--- a/noxfile.py
+++ b/noxfile.py
@@ -64,7 +64,7 @@
session.run("black", *BLACK_PATHS)
[email protected](python=["2.7", "3.5", "3.6", "3.7"])
[email protected](python=["2.7", "3.5", "3.6", "3.7", "3.8"])
def unit(session):
session.install(*TEST_DEPENDENCIES)
session.install(".")
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -56,6 +56,7 @@
"Programming Language :: Python :: 3.5",
"Programming Language :: Python :: 3.6",
"Programming Language :: Python :: 3.7",
+ "Programming Language :: Python :: 3.8",
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Developers",
"License :: OSI Approved :: Apache Software License",
|
{"golden_diff": "diff --git a/noxfile.py b/noxfile.py\n--- a/noxfile.py\n+++ b/noxfile.py\n@@ -64,7 +64,7 @@\n session.run(\"black\", *BLACK_PATHS)\n \n \[email protected](python=[\"2.7\", \"3.5\", \"3.6\", \"3.7\"])\[email protected](python=[\"2.7\", \"3.5\", \"3.6\", \"3.7\", \"3.8\"])\n def unit(session):\n session.install(*TEST_DEPENDENCIES)\n session.install(\".\")\ndiff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -56,6 +56,7 @@\n \"Programming Language :: Python :: 3.5\",\n \"Programming Language :: Python :: 3.6\",\n \"Programming Language :: Python :: 3.7\",\n+ \"Programming Language :: Python :: 3.8\",\n \"Development Status :: 5 - Production/Stable\",\n \"Intended Audience :: Developers\",\n \"License :: OSI Approved :: Apache Software License\",\n", "issue": "Add support for Python 3.8\n\n", "before_files": [{"content": "# Copyright 2019 Google LLC\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport nox\n\nTEST_DEPENDENCIES = [\n \"flask\",\n \"freezegun\",\n \"mock\",\n \"oauth2client\",\n \"pyopenssl\",\n \"pytest\",\n \"pytest-cov\",\n \"pytest-localserver\",\n \"requests\",\n \"urllib3\",\n \"cryptography\",\n \"responses\",\n \"grpcio\",\n]\nBLACK_VERSION = \"black==19.3b0\"\nBLACK_PATHS = [\"google\", \"tests\", \"noxfile.py\", \"setup.py\", \"docs/conf.py\"]\n\n\[email protected](python=\"3.7\")\ndef lint(session):\n session.install(\"flake8\", \"flake8-import-order\", \"docutils\", BLACK_VERSION)\n session.install(\".\")\n session.run(\"black\", \"--check\", *BLACK_PATHS)\n session.run(\n \"flake8\",\n \"--import-order-style=google\",\n \"--application-import-names=google,tests,system_tests\",\n \"google\",\n \"tests\",\n )\n session.run(\n \"python\", \"setup.py\", \"check\", \"--metadata\", \"--restructuredtext\", \"--strict\"\n )\n\n\[email protected](python=\"3.6\")\ndef blacken(session):\n \"\"\"Run black.\n\n Format code to uniform standard.\n\n This currently uses Python 3.6 due to the automated Kokoro run of synthtool.\n That run uses an image that doesn't have 3.6 installed. Before updating this\n check the state of the `gcp_ubuntu_config` we use for that Kokoro run.\n \"\"\"\n session.install(BLACK_VERSION)\n session.run(\"black\", *BLACK_PATHS)\n\n\[email protected](python=[\"2.7\", \"3.5\", \"3.6\", \"3.7\"])\ndef unit(session):\n session.install(*TEST_DEPENDENCIES)\n session.install(\".\")\n session.run(\n \"pytest\", \"--cov=google.auth\", \"--cov=google.oauth2\", \"--cov=tests\", \"tests\"\n )\n\n\[email protected](python=\"3.7\")\ndef cover(session):\n session.install(*TEST_DEPENDENCIES)\n session.install(\".\")\n session.run(\n \"pytest\",\n \"--cov=google.auth\",\n \"--cov=google.oauth2\",\n \"--cov=tests\",\n \"--cov-report=\",\n \"tests\",\n )\n session.run(\"coverage\", \"report\", \"--show-missing\", \"--fail-under=100\")\n\n\[email protected](python=\"3.7\")\ndef docgen(session):\n session.env[\"SPHINX_APIDOC_OPTIONS\"] = \"members,inherited-members,show-inheritance\"\n session.install(*TEST_DEPENDENCIES)\n session.install(\"sphinx\")\n session.install(\".\")\n session.run(\"rm\", \"-r\", \"docs/reference\")\n session.run(\n \"sphinx-apidoc\",\n \"--output-dir\",\n \"docs/reference\",\n \"--separate\",\n \"--module-first\",\n \"google\",\n )\n\n\[email protected](python=\"3.7\")\ndef docs(session):\n session.install(\"sphinx\", \"-r\", \"docs/requirements-docs.txt\")\n session.install(\".\")\n session.run(\"make\", \"-C\", \"docs\", \"html\")\n\n\[email protected](python=\"pypy\")\ndef pypy(session):\n session.install(*TEST_DEPENDENCIES)\n session.install(\".\")\n session.run(\n \"pytest\", \"--cov=google.auth\", \"--cov=google.oauth2\", \"--cov=tests\", \"tests\"\n )\n", "path": "noxfile.py"}, {"content": "# Copyright 2014 Google Inc.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport io\n\nfrom setuptools import find_packages\nfrom setuptools import setup\n\n\nDEPENDENCIES = (\n \"cachetools>=2.0.0,<5.0\",\n \"pyasn1-modules>=0.2.1\",\n # rsa==4.5 is the last version to support 2.7\n # https://github.com/sybrenstuvel/python-rsa/issues/152#issuecomment-643470233\n 'rsa<4.6; python_version < \"3.5\"',\n 'rsa>=3.1.4,<5; python_version >= \"3.5\"',\n \"setuptools>=40.3.0\",\n \"six>=1.9.0\",\n)\n\n\nwith io.open(\"README.rst\", \"r\") as fh:\n long_description = fh.read()\n\nversion = \"1.19.2\"\n\nsetup(\n name=\"google-auth\",\n version=version,\n author=\"Google Cloud Platform\",\n author_email=\"[email protected]\",\n description=\"Google Authentication Library\",\n long_description=long_description,\n url=\"https://github.com/googleapis/google-auth-library-python\",\n packages=find_packages(exclude=(\"tests*\", \"system_tests*\")),\n namespace_packages=(\"google\",),\n install_requires=DEPENDENCIES,\n python_requires=\">=2.7,!=3.0.*,!=3.1.*,!=3.2.*,!=3.3.*\",\n license=\"Apache 2.0\",\n keywords=\"google auth oauth client\",\n classifiers=[\n \"Programming Language :: Python :: 2\",\n \"Programming Language :: Python :: 2.7\",\n \"Programming Language :: Python :: 3\",\n \"Programming Language :: Python :: 3.5\",\n \"Programming Language :: Python :: 3.6\",\n \"Programming Language :: Python :: 3.7\",\n \"Development Status :: 5 - Production/Stable\",\n \"Intended Audience :: Developers\",\n \"License :: OSI Approved :: Apache Software License\",\n \"Operating System :: POSIX\",\n \"Operating System :: Microsoft :: Windows\",\n \"Operating System :: MacOS :: MacOS X\",\n \"Operating System :: OS Independent\",\n \"Topic :: Internet :: WWW/HTTP\",\n ],\n)\n", "path": "setup.py"}]}
| 2,426 | 238 |
gh_patches_debug_16859
|
rasdani/github-patches
|
git_diff
|
sanic-org__sanic-2416
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Cancel tasks with a message where appropriate
[cancel()](https://docs.python.org/3/library/asyncio-task.html#asyncio.Task.cancel) also accepts a "msg" argument, might it be a good idea for this "message" to be added to places like https://github.com/sanic-org/sanic/blob/f7abf3db1bd4e79cd5121327359fc9021fab7ff3/sanic/server/protocols/http_protocol.py#L172 that are otherwise calling cancel() with no explanatory message? if this is the CancelledError this user is getting, a simple message there would save everyone a lot of time.
_Originally posted by @zzzeek in https://github.com/sanic-org/sanic/issues/2296#issuecomment-983881945_
---
Where we are able to in Py3.9, we should add a message to `cancel()`.
</issue>
<code>
[start of sanic/server/protocols/http_protocol.py]
1 from __future__ import annotations
2
3 from typing import TYPE_CHECKING, Optional
4
5 from sanic.touchup.meta import TouchUpMeta
6
7
8 if TYPE_CHECKING: # no cov
9 from sanic.app import Sanic
10
11 from asyncio import CancelledError
12 from time import monotonic as current_time
13
14 from sanic.exceptions import RequestTimeout, ServiceUnavailable
15 from sanic.http import Http, Stage
16 from sanic.log import error_logger, logger
17 from sanic.models.server_types import ConnInfo
18 from sanic.request import Request
19 from sanic.server.protocols.base_protocol import SanicProtocol
20
21
22 class HttpProtocol(SanicProtocol, metaclass=TouchUpMeta):
23 """
24 This class provides implements the HTTP 1.1 protocol on top of our
25 Sanic Server transport
26 """
27
28 __touchup__ = (
29 "send",
30 "connection_task",
31 )
32 __slots__ = (
33 # request params
34 "request",
35 # request config
36 "request_handler",
37 "request_timeout",
38 "response_timeout",
39 "keep_alive_timeout",
40 "request_max_size",
41 "request_class",
42 "error_handler",
43 # enable or disable access log purpose
44 "access_log",
45 # connection management
46 "state",
47 "url",
48 "_handler_task",
49 "_http",
50 "_exception",
51 "recv_buffer",
52 )
53
54 def __init__(
55 self,
56 *,
57 loop,
58 app: Sanic,
59 signal=None,
60 connections=None,
61 state=None,
62 unix=None,
63 **kwargs,
64 ):
65 super().__init__(
66 loop=loop,
67 app=app,
68 signal=signal,
69 connections=connections,
70 unix=unix,
71 )
72 self.url = None
73 self.request: Optional[Request] = None
74 self.access_log = self.app.config.ACCESS_LOG
75 self.request_handler = self.app.handle_request
76 self.error_handler = self.app.error_handler
77 self.request_timeout = self.app.config.REQUEST_TIMEOUT
78 self.response_timeout = self.app.config.RESPONSE_TIMEOUT
79 self.keep_alive_timeout = self.app.config.KEEP_ALIVE_TIMEOUT
80 self.request_max_size = self.app.config.REQUEST_MAX_SIZE
81 self.request_class = self.app.request_class or Request
82 self.state = state if state else {}
83 if "requests_count" not in self.state:
84 self.state["requests_count"] = 0
85 self._exception = None
86
87 def _setup_connection(self):
88 self._http = Http(self)
89 self._time = current_time()
90 self.check_timeouts()
91
92 async def connection_task(self): # no cov
93 """
94 Run a HTTP connection.
95
96 Timeouts and some additional error handling occur here, while most of
97 everything else happens in class Http or in code called from there.
98 """
99 try:
100 self._setup_connection()
101 await self.app.dispatch(
102 "http.lifecycle.begin",
103 inline=True,
104 context={"conn_info": self.conn_info},
105 )
106 await self._http.http1()
107 except CancelledError:
108 pass
109 except Exception:
110 error_logger.exception("protocol.connection_task uncaught")
111 finally:
112 if (
113 self.app.debug
114 and self._http
115 and self.transport
116 and not self._http.upgrade_websocket
117 ):
118 ip = self.transport.get_extra_info("peername")
119 error_logger.error(
120 "Connection lost before response written"
121 f" @ {ip} {self._http.request}"
122 )
123 self._http = None
124 self._task = None
125 try:
126 self.close()
127 except BaseException:
128 error_logger.exception("Closing failed")
129 finally:
130 await self.app.dispatch(
131 "http.lifecycle.complete",
132 inline=True,
133 context={"conn_info": self.conn_info},
134 )
135 # Important to keep this Ellipsis here for the TouchUp module
136 ...
137
138 def check_timeouts(self):
139 """
140 Runs itself periodically to enforce any expired timeouts.
141 """
142 try:
143 if not self._task:
144 return
145 duration = current_time() - self._time
146 stage = self._http.stage
147 if stage is Stage.IDLE and duration > self.keep_alive_timeout:
148 logger.debug("KeepAlive Timeout. Closing connection.")
149 elif stage is Stage.REQUEST and duration > self.request_timeout:
150 logger.debug("Request Timeout. Closing connection.")
151 self._http.exception = RequestTimeout("Request Timeout")
152 elif stage is Stage.HANDLER and self._http.upgrade_websocket:
153 logger.debug("Handling websocket. Timeouts disabled.")
154 return
155 elif (
156 stage in (Stage.HANDLER, Stage.RESPONSE, Stage.FAILED)
157 and duration > self.response_timeout
158 ):
159 logger.debug("Response Timeout. Closing connection.")
160 self._http.exception = ServiceUnavailable("Response Timeout")
161 else:
162 interval = (
163 min(
164 self.keep_alive_timeout,
165 self.request_timeout,
166 self.response_timeout,
167 )
168 / 2
169 )
170 self.loop.call_later(max(0.1, interval), self.check_timeouts)
171 return
172 self._task.cancel()
173 except Exception:
174 error_logger.exception("protocol.check_timeouts")
175
176 async def send(self, data): # no cov
177 """
178 Writes HTTP data with backpressure control.
179 """
180 await self._can_write.wait()
181 if self.transport.is_closing():
182 raise CancelledError
183 await self.app.dispatch(
184 "http.lifecycle.send",
185 inline=True,
186 context={"data": data},
187 )
188 self.transport.write(data)
189 self._time = current_time()
190
191 def close_if_idle(self) -> bool:
192 """
193 Close the connection if a request is not being sent or received
194
195 :return: boolean - True if closed, false if staying open
196 """
197 if self._http is None or self._http.stage is Stage.IDLE:
198 self.close()
199 return True
200 return False
201
202 # -------------------------------------------- #
203 # Only asyncio.Protocol callbacks below this
204 # -------------------------------------------- #
205
206 def connection_made(self, transport):
207 """
208 HTTP-protocol-specific new connection handler
209 """
210 try:
211 # TODO: Benchmark to find suitable write buffer limits
212 transport.set_write_buffer_limits(low=16384, high=65536)
213 self.connections.add(self)
214 self.transport = transport
215 self._task = self.loop.create_task(self.connection_task())
216 self.recv_buffer = bytearray()
217 self.conn_info = ConnInfo(self.transport, unix=self._unix)
218 except Exception:
219 error_logger.exception("protocol.connect_made")
220
221 def data_received(self, data: bytes):
222
223 try:
224 self._time = current_time()
225 if not data:
226 return self.close()
227 self.recv_buffer += data
228
229 if (
230 len(self.recv_buffer) >= self.app.config.REQUEST_BUFFER_SIZE
231 and self.transport
232 ):
233 self.transport.pause_reading()
234
235 if self._data_received:
236 self._data_received.set()
237 except Exception:
238 error_logger.exception("protocol.data_received")
239
[end of sanic/server/protocols/http_protocol.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/sanic/server/protocols/http_protocol.py b/sanic/server/protocols/http_protocol.py
--- a/sanic/server/protocols/http_protocol.py
+++ b/sanic/server/protocols/http_protocol.py
@@ -8,6 +8,8 @@
if TYPE_CHECKING: # no cov
from sanic.app import Sanic
+import sys
+
from asyncio import CancelledError
from time import monotonic as current_time
@@ -169,7 +171,10 @@
)
self.loop.call_later(max(0.1, interval), self.check_timeouts)
return
- self._task.cancel()
+ cancel_msg_args = ()
+ if sys.version_info >= (3, 9):
+ cancel_msg_args = ("Cancel connection task with a timeout",)
+ self._task.cancel(*cancel_msg_args)
except Exception:
error_logger.exception("protocol.check_timeouts")
|
{"golden_diff": "diff --git a/sanic/server/protocols/http_protocol.py b/sanic/server/protocols/http_protocol.py\n--- a/sanic/server/protocols/http_protocol.py\n+++ b/sanic/server/protocols/http_protocol.py\n@@ -8,6 +8,8 @@\n if TYPE_CHECKING: # no cov\n from sanic.app import Sanic\n \n+import sys\n+\n from asyncio import CancelledError\n from time import monotonic as current_time\n \n@@ -169,7 +171,10 @@\n )\n self.loop.call_later(max(0.1, interval), self.check_timeouts)\n return\n- self._task.cancel()\n+ cancel_msg_args = ()\n+ if sys.version_info >= (3, 9):\n+ cancel_msg_args = (\"Cancel connection task with a timeout\",)\n+ self._task.cancel(*cancel_msg_args)\n except Exception:\n error_logger.exception(\"protocol.check_timeouts\")\n", "issue": "Cancel tasks with a message where appropriate\n[cancel()](https://docs.python.org/3/library/asyncio-task.html#asyncio.Task.cancel) also accepts a \"msg\" argument, might it be a good idea for this \"message\" to be added to places like https://github.com/sanic-org/sanic/blob/f7abf3db1bd4e79cd5121327359fc9021fab7ff3/sanic/server/protocols/http_protocol.py#L172 that are otherwise calling cancel() with no explanatory message? if this is the CancelledError this user is getting, a simple message there would save everyone a lot of time.\r\n\r\n_Originally posted by @zzzeek in https://github.com/sanic-org/sanic/issues/2296#issuecomment-983881945_\r\n\r\n---\r\n\r\nWhere we are able to in Py3.9, we should add a message to `cancel()`.\n", "before_files": [{"content": "from __future__ import annotations\n\nfrom typing import TYPE_CHECKING, Optional\n\nfrom sanic.touchup.meta import TouchUpMeta\n\n\nif TYPE_CHECKING: # no cov\n from sanic.app import Sanic\n\nfrom asyncio import CancelledError\nfrom time import monotonic as current_time\n\nfrom sanic.exceptions import RequestTimeout, ServiceUnavailable\nfrom sanic.http import Http, Stage\nfrom sanic.log import error_logger, logger\nfrom sanic.models.server_types import ConnInfo\nfrom sanic.request import Request\nfrom sanic.server.protocols.base_protocol import SanicProtocol\n\n\nclass HttpProtocol(SanicProtocol, metaclass=TouchUpMeta):\n \"\"\"\n This class provides implements the HTTP 1.1 protocol on top of our\n Sanic Server transport\n \"\"\"\n\n __touchup__ = (\n \"send\",\n \"connection_task\",\n )\n __slots__ = (\n # request params\n \"request\",\n # request config\n \"request_handler\",\n \"request_timeout\",\n \"response_timeout\",\n \"keep_alive_timeout\",\n \"request_max_size\",\n \"request_class\",\n \"error_handler\",\n # enable or disable access log purpose\n \"access_log\",\n # connection management\n \"state\",\n \"url\",\n \"_handler_task\",\n \"_http\",\n \"_exception\",\n \"recv_buffer\",\n )\n\n def __init__(\n self,\n *,\n loop,\n app: Sanic,\n signal=None,\n connections=None,\n state=None,\n unix=None,\n **kwargs,\n ):\n super().__init__(\n loop=loop,\n app=app,\n signal=signal,\n connections=connections,\n unix=unix,\n )\n self.url = None\n self.request: Optional[Request] = None\n self.access_log = self.app.config.ACCESS_LOG\n self.request_handler = self.app.handle_request\n self.error_handler = self.app.error_handler\n self.request_timeout = self.app.config.REQUEST_TIMEOUT\n self.response_timeout = self.app.config.RESPONSE_TIMEOUT\n self.keep_alive_timeout = self.app.config.KEEP_ALIVE_TIMEOUT\n self.request_max_size = self.app.config.REQUEST_MAX_SIZE\n self.request_class = self.app.request_class or Request\n self.state = state if state else {}\n if \"requests_count\" not in self.state:\n self.state[\"requests_count\"] = 0\n self._exception = None\n\n def _setup_connection(self):\n self._http = Http(self)\n self._time = current_time()\n self.check_timeouts()\n\n async def connection_task(self): # no cov\n \"\"\"\n Run a HTTP connection.\n\n Timeouts and some additional error handling occur here, while most of\n everything else happens in class Http or in code called from there.\n \"\"\"\n try:\n self._setup_connection()\n await self.app.dispatch(\n \"http.lifecycle.begin\",\n inline=True,\n context={\"conn_info\": self.conn_info},\n )\n await self._http.http1()\n except CancelledError:\n pass\n except Exception:\n error_logger.exception(\"protocol.connection_task uncaught\")\n finally:\n if (\n self.app.debug\n and self._http\n and self.transport\n and not self._http.upgrade_websocket\n ):\n ip = self.transport.get_extra_info(\"peername\")\n error_logger.error(\n \"Connection lost before response written\"\n f\" @ {ip} {self._http.request}\"\n )\n self._http = None\n self._task = None\n try:\n self.close()\n except BaseException:\n error_logger.exception(\"Closing failed\")\n finally:\n await self.app.dispatch(\n \"http.lifecycle.complete\",\n inline=True,\n context={\"conn_info\": self.conn_info},\n )\n # Important to keep this Ellipsis here for the TouchUp module\n ...\n\n def check_timeouts(self):\n \"\"\"\n Runs itself periodically to enforce any expired timeouts.\n \"\"\"\n try:\n if not self._task:\n return\n duration = current_time() - self._time\n stage = self._http.stage\n if stage is Stage.IDLE and duration > self.keep_alive_timeout:\n logger.debug(\"KeepAlive Timeout. Closing connection.\")\n elif stage is Stage.REQUEST and duration > self.request_timeout:\n logger.debug(\"Request Timeout. Closing connection.\")\n self._http.exception = RequestTimeout(\"Request Timeout\")\n elif stage is Stage.HANDLER and self._http.upgrade_websocket:\n logger.debug(\"Handling websocket. Timeouts disabled.\")\n return\n elif (\n stage in (Stage.HANDLER, Stage.RESPONSE, Stage.FAILED)\n and duration > self.response_timeout\n ):\n logger.debug(\"Response Timeout. Closing connection.\")\n self._http.exception = ServiceUnavailable(\"Response Timeout\")\n else:\n interval = (\n min(\n self.keep_alive_timeout,\n self.request_timeout,\n self.response_timeout,\n )\n / 2\n )\n self.loop.call_later(max(0.1, interval), self.check_timeouts)\n return\n self._task.cancel()\n except Exception:\n error_logger.exception(\"protocol.check_timeouts\")\n\n async def send(self, data): # no cov\n \"\"\"\n Writes HTTP data with backpressure control.\n \"\"\"\n await self._can_write.wait()\n if self.transport.is_closing():\n raise CancelledError\n await self.app.dispatch(\n \"http.lifecycle.send\",\n inline=True,\n context={\"data\": data},\n )\n self.transport.write(data)\n self._time = current_time()\n\n def close_if_idle(self) -> bool:\n \"\"\"\n Close the connection if a request is not being sent or received\n\n :return: boolean - True if closed, false if staying open\n \"\"\"\n if self._http is None or self._http.stage is Stage.IDLE:\n self.close()\n return True\n return False\n\n # -------------------------------------------- #\n # Only asyncio.Protocol callbacks below this\n # -------------------------------------------- #\n\n def connection_made(self, transport):\n \"\"\"\n HTTP-protocol-specific new connection handler\n \"\"\"\n try:\n # TODO: Benchmark to find suitable write buffer limits\n transport.set_write_buffer_limits(low=16384, high=65536)\n self.connections.add(self)\n self.transport = transport\n self._task = self.loop.create_task(self.connection_task())\n self.recv_buffer = bytearray()\n self.conn_info = ConnInfo(self.transport, unix=self._unix)\n except Exception:\n error_logger.exception(\"protocol.connect_made\")\n\n def data_received(self, data: bytes):\n\n try:\n self._time = current_time()\n if not data:\n return self.close()\n self.recv_buffer += data\n\n if (\n len(self.recv_buffer) >= self.app.config.REQUEST_BUFFER_SIZE\n and self.transport\n ):\n self.transport.pause_reading()\n\n if self._data_received:\n self._data_received.set()\n except Exception:\n error_logger.exception(\"protocol.data_received\")\n", "path": "sanic/server/protocols/http_protocol.py"}]}
| 2,864 | 200 |
gh_patches_debug_26020
|
rasdani/github-patches
|
git_diff
|
holoviz__panel-3379
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
The active parameter from Accordions layout does not work properly
Hi everyone !
I tried to use the Accordion layout, but when I tried to open by default another Accordion than the first one, it is impossible.
The _active_ parameter only works when it is [0]. In the example below setting _active_ to [1] will not open the second Accordion.
Remarks:
By setting _toggle=True_, it will open correctly.
It is also correctly opened when setting _active=[0,1]_.
But despite several attempts it is impossible to open a single index different from 0 without _toggle=True_.
Here's some code example ( from [https://panel.holoviz.org/reference/layouts/Accordion.html](url) ) :
```
import panel as pn
pn.extension()
from bokeh.plotting import figure
p1 = figure(width=300, height=300, name='Scatter', margin=5)
p1.scatter([0, 1, 2, 3, 4, 5, 6], [0, 1, 2, 3, 2, 1, 0])
p2 = figure(width=300, height=300, name='Line', margin=5)
p2.line([0, 1, 2, 3, 4, 5, 6], [0, 1, 2, 3, 2, 1, 0])
accordion = pn.Accordion(('Scatter', p1), p2, active=[1])
accordion
```

Exemple with _toggle=True_ :
</issue>
<code>
[start of panel/layout/accordion.py]
1 import param
2
3 from bokeh.models import Column as BkColumn, CustomJS
4
5 from .base import NamedListPanel
6 from .card import Card
7
8
9 class Accordion(NamedListPanel):
10
11 active_header_background = param.String(default='#ccc', doc="""
12 Color for currently active headers.""")
13
14 active = param.List(default=[], doc="""
15 List of indexes of active cards.""")
16
17 header_color = param.String(doc="""
18 A valid CSS color to apply to the expand button.""")
19
20 header_background = param.String(doc="""
21 A valid CSS color for the header background.""")
22
23 toggle = param.Boolean(default=False, doc="""
24 Whether to toggle between active cards or allow multiple cards""")
25
26 _bokeh_model = BkColumn
27
28 _rename = {'active': None, 'active_header_background': None,
29 'header_background': None, 'objects': 'children',
30 'dynamic': None, 'toggle': None, 'header_color': None}
31
32 _toggle = """
33 for (var child of accordion.children) {
34 if ((child.id !== cb_obj.id) && (child.collapsed == cb_obj.collapsed) && !cb_obj.collapsed) {
35 child.collapsed = !cb_obj.collapsed
36 }
37 }
38 """
39
40 _synced_properties = [
41 'active_header_background', 'header_background', 'width',
42 'sizing_mode', 'width_policy', 'height_policy', 'header_color'
43 ]
44
45 def __init__(self, *objects, **params):
46 super().__init__(*objects, **params)
47 self._updating_active = False
48 self.param.watch(self._update_active, ['active'])
49 self.param.watch(self._update_cards, self._synced_properties)
50
51 def _get_objects(self, model, old_objects, doc, root, comm=None):
52 """
53 Returns new child models for the layout while reusing unchanged
54 models and cleaning up any dropped objects.
55 """
56 from panel.pane.base import RerenderError, panel
57 new_models = []
58 if len(self._names) != len(self):
59 raise ValueError('Accordion names do not match objects, ensure '
60 'that the Tabs.objects are not modified '
61 'directly. Found %d names, expected %d.' %
62 (len(self._names), len(self)))
63 for i, (name, pane) in enumerate(zip(self._names, self)):
64 pane = panel(pane, name=name)
65 self.objects[i] = pane
66
67 for obj in old_objects:
68 if obj not in self.objects:
69 self._panels[id(obj)]._cleanup(root)
70
71 params = {k: v for k, v in self.param.values().items()
72 if k in self._synced_properties}
73
74 ref = root.ref['id']
75 current_objects = list(self)
76 for i, (name, pane) in enumerate(zip(self._names, self)):
77 params.update(self._apply_style(i))
78 if id(pane) in self._panels:
79 card = self._panels[id(pane)]
80 else:
81 card = Card(
82 pane, title=name, css_classes=['accordion'],
83 header_css_classes=['accordion-header'],
84 margin=self.margin
85 )
86 card.param.watch(self._set_active, ['collapsed'])
87 self._panels[id(pane)] = card
88 card.param.update(**params)
89 if ref in card._models:
90 panel = card._models[ref][0]
91 else:
92 try:
93 panel = card._get_model(doc, root, model, comm)
94 if self.toggle:
95 cb = CustomJS(args={'accordion': model}, code=self._toggle)
96 panel.js_on_change('collapsed', cb)
97 except RerenderError:
98 return self._get_objects(model, current_objects[:i], doc, root, comm)
99 new_models.append(panel)
100 self._update_cards()
101 self._update_active()
102 return new_models
103
104 def _cleanup(self, root):
105 for panel in self._panels.values():
106 panel._cleanup(root)
107 super()._cleanup(root)
108
109 def _apply_style(self, i):
110 if i == 0:
111 margin = (5, 5, 0, 5)
112 elif i == (len(self)-1):
113 margin = (0, 5, 5, 5)
114 else:
115 margin = (0, 5, 0, 5)
116 return dict(margin=margin, collapsed = i not in self.active)
117
118 def _set_active(self, *events):
119 if self._updating_active:
120 return
121 self._updating_active = True
122 try:
123 if self.toggle and not events[0].new:
124 active = [list(self._panels.values()).index(events[0].obj)]
125 else:
126 active = []
127 for i, pane in enumerate(self.objects):
128 if id(pane) not in self._panels:
129 continue
130 elif not self._panels[id(pane)].collapsed:
131 active.append(i)
132
133 if not self.toggle or active:
134 self.active = active
135 finally:
136 self._updating_active = False
137
138 def _update_active(self, *events):
139 if self._updating_active:
140 return
141 self._updating_active = True
142 try:
143 for i, pane in enumerate(self.objects):
144 if id(pane) not in self._panels:
145 continue
146 self._panels[id(pane)].collapsed = i not in self.active
147 finally:
148 self._updating_active = False
149
150 def _update_cards(self, *events):
151 params = {k: v for k, v in self.param.values().items()
152 if k in self._synced_properties}
153 for panel in self._panels.values():
154 panel.param.update(**params)
155
[end of panel/layout/accordion.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/panel/layout/accordion.py b/panel/layout/accordion.py
--- a/panel/layout/accordion.py
+++ b/panel/layout/accordion.py
@@ -73,6 +73,7 @@
ref = root.ref['id']
current_objects = list(self)
+ self._updating_active = True
for i, (name, pane) in enumerate(zip(self._names, self)):
params.update(self._apply_style(i))
if id(pane) in self._panels:
@@ -97,6 +98,9 @@
except RerenderError:
return self._get_objects(model, current_objects[:i], doc, root, comm)
new_models.append(panel)
+
+ self._updating_active = False
+ self._set_active()
self._update_cards()
self._update_active()
return new_models
@@ -120,7 +124,7 @@
return
self._updating_active = True
try:
- if self.toggle and not events[0].new:
+ if self.toggle and events and not events[0].new:
active = [list(self._panels.values()).index(events[0].obj)]
else:
active = []
|
{"golden_diff": "diff --git a/panel/layout/accordion.py b/panel/layout/accordion.py\n--- a/panel/layout/accordion.py\n+++ b/panel/layout/accordion.py\n@@ -73,6 +73,7 @@\n \n ref = root.ref['id']\n current_objects = list(self)\n+ self._updating_active = True\n for i, (name, pane) in enumerate(zip(self._names, self)):\n params.update(self._apply_style(i))\n if id(pane) in self._panels:\n@@ -97,6 +98,9 @@\n except RerenderError:\n return self._get_objects(model, current_objects[:i], doc, root, comm)\n new_models.append(panel)\n+\n+ self._updating_active = False\n+ self._set_active()\n self._update_cards()\n self._update_active()\n return new_models\n@@ -120,7 +124,7 @@\n return\n self._updating_active = True\n try:\n- if self.toggle and not events[0].new:\n+ if self.toggle and events and not events[0].new:\n active = [list(self._panels.values()).index(events[0].obj)]\n else:\n active = []\n", "issue": "The active parameter from Accordions layout does not work properly\nHi everyone !\r\n\r\nI tried to use the Accordion layout, but when I tried to open by default another Accordion than the first one, it is impossible. \r\n\r\nThe _active_ parameter only works when it is [0]. In the example below setting _active_ to [1] will not open the second Accordion. \r\n\r\nRemarks: \r\nBy setting _toggle=True_, it will open correctly. \r\nIt is also correctly opened when setting _active=[0,1]_.\r\nBut despite several attempts it is impossible to open a single index different from 0 without _toggle=True_. \r\n\r\nHere's some code example ( from [https://panel.holoviz.org/reference/layouts/Accordion.html](url) ) :\r\n\r\n```\r\nimport panel as pn\r\npn.extension()\r\nfrom bokeh.plotting import figure\r\n\r\np1 = figure(width=300, height=300, name='Scatter', margin=5)\r\np1.scatter([0, 1, 2, 3, 4, 5, 6], [0, 1, 2, 3, 2, 1, 0])\r\n\r\np2 = figure(width=300, height=300, name='Line', margin=5)\r\np2.line([0, 1, 2, 3, 4, 5, 6], [0, 1, 2, 3, 2, 1, 0])\r\n\r\naccordion = pn.Accordion(('Scatter', p1), p2, active=[1])\r\naccordion\r\n```\r\n\r\n\r\n\r\n\r\nExemple with _toggle=True_ : \r\n\r\n\r\n\r\n\r\n\r\n\n", "before_files": [{"content": "import param\n\nfrom bokeh.models import Column as BkColumn, CustomJS\n\nfrom .base import NamedListPanel\nfrom .card import Card\n\n\nclass Accordion(NamedListPanel):\n \n active_header_background = param.String(default='#ccc', doc=\"\"\"\n Color for currently active headers.\"\"\")\n\n active = param.List(default=[], doc=\"\"\"\n List of indexes of active cards.\"\"\")\n\n header_color = param.String(doc=\"\"\"\n A valid CSS color to apply to the expand button.\"\"\")\n\n header_background = param.String(doc=\"\"\"\n A valid CSS color for the header background.\"\"\")\n\n toggle = param.Boolean(default=False, doc=\"\"\"\n Whether to toggle between active cards or allow multiple cards\"\"\")\n\n _bokeh_model = BkColumn\n \n _rename = {'active': None, 'active_header_background': None,\n 'header_background': None, 'objects': 'children',\n 'dynamic': None, 'toggle': None, 'header_color': None}\n\n _toggle = \"\"\"\n for (var child of accordion.children) {\n if ((child.id !== cb_obj.id) && (child.collapsed == cb_obj.collapsed) && !cb_obj.collapsed) {\n child.collapsed = !cb_obj.collapsed\n }\n }\n \"\"\"\n\n _synced_properties = [\n 'active_header_background', 'header_background', 'width',\n 'sizing_mode', 'width_policy', 'height_policy', 'header_color'\n ]\n\n def __init__(self, *objects, **params):\n super().__init__(*objects, **params)\n self._updating_active = False\n self.param.watch(self._update_active, ['active'])\n self.param.watch(self._update_cards, self._synced_properties)\n\n def _get_objects(self, model, old_objects, doc, root, comm=None):\n \"\"\"\n Returns new child models for the layout while reusing unchanged\n models and cleaning up any dropped objects.\n \"\"\"\n from panel.pane.base import RerenderError, panel\n new_models = []\n if len(self._names) != len(self):\n raise ValueError('Accordion names do not match objects, ensure '\n 'that the Tabs.objects are not modified '\n 'directly. Found %d names, expected %d.' %\n (len(self._names), len(self)))\n for i, (name, pane) in enumerate(zip(self._names, self)):\n pane = panel(pane, name=name)\n self.objects[i] = pane\n\n for obj in old_objects:\n if obj not in self.objects:\n self._panels[id(obj)]._cleanup(root)\n\n params = {k: v for k, v in self.param.values().items()\n if k in self._synced_properties}\n\n ref = root.ref['id']\n current_objects = list(self)\n for i, (name, pane) in enumerate(zip(self._names, self)):\n params.update(self._apply_style(i))\n if id(pane) in self._panels:\n card = self._panels[id(pane)]\n else:\n card = Card(\n pane, title=name, css_classes=['accordion'],\n header_css_classes=['accordion-header'],\n margin=self.margin\n )\n card.param.watch(self._set_active, ['collapsed'])\n self._panels[id(pane)] = card\n card.param.update(**params)\n if ref in card._models:\n panel = card._models[ref][0]\n else:\n try:\n panel = card._get_model(doc, root, model, comm)\n if self.toggle:\n cb = CustomJS(args={'accordion': model}, code=self._toggle)\n panel.js_on_change('collapsed', cb)\n except RerenderError:\n return self._get_objects(model, current_objects[:i], doc, root, comm)\n new_models.append(panel)\n self._update_cards()\n self._update_active()\n return new_models\n\n def _cleanup(self, root):\n for panel in self._panels.values():\n panel._cleanup(root)\n super()._cleanup(root)\n\n def _apply_style(self, i):\n if i == 0:\n margin = (5, 5, 0, 5)\n elif i == (len(self)-1):\n margin = (0, 5, 5, 5)\n else:\n margin = (0, 5, 0, 5)\n return dict(margin=margin, collapsed = i not in self.active)\n\n def _set_active(self, *events):\n if self._updating_active:\n return\n self._updating_active = True\n try:\n if self.toggle and not events[0].new:\n active = [list(self._panels.values()).index(events[0].obj)]\n else:\n active = []\n for i, pane in enumerate(self.objects):\n if id(pane) not in self._panels:\n continue\n elif not self._panels[id(pane)].collapsed:\n active.append(i)\n \n if not self.toggle or active:\n self.active = active\n finally:\n self._updating_active = False\n\n def _update_active(self, *events):\n if self._updating_active:\n return\n self._updating_active = True\n try:\n for i, pane in enumerate(self.objects):\n if id(pane) not in self._panels:\n continue\n self._panels[id(pane)].collapsed = i not in self.active\n finally:\n self._updating_active = False\n\n def _update_cards(self, *events):\n params = {k: v for k, v in self.param.values().items()\n if k in self._synced_properties}\n for panel in self._panels.values():\n panel.param.update(**params)\n", "path": "panel/layout/accordion.py"}]}
| 2,601 | 269 |
gh_patches_debug_32750
|
rasdani/github-patches
|
git_diff
|
cal-itp__benefits-602
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Enrollment: Success (signed out): Use the full-screen with no image
Use the fullscreen view instead
</issue>
<code>
[start of benefits/enrollment/views.py]
1 """
2 The enrollment application: view definitions for the benefits enrollment flow.
3 """
4 import logging
5
6 from django.conf import settings
7 from django.http import JsonResponse
8 from django.template.response import TemplateResponse
9 from django.urls import reverse
10 from django.utils.decorators import decorator_from_middleware
11 from django.utils.translation import pgettext, gettext as _
12
13 from benefits.core import models, session, viewmodels
14 from benefits.core.middleware import EligibleSessionRequired, VerifierSessionRequired, pageview_decorator
15 from . import api, forms
16
17
18 logger = logging.getLogger(__name__)
19
20
21 def _index(request):
22 """Helper handles GET requests to enrollment index."""
23 agency = session.agency(request)
24
25 tokenize_button = "tokenize_card"
26 tokenize_retry_form = forms.CardTokenizeFailForm("enrollment:retry")
27 tokenize_success_form = forms.CardTokenizeSuccessForm(auto_id=True, label_suffix="")
28
29 page = viewmodels.Page(
30 title=_("enrollment.pages.index.title"),
31 content_title=_("enrollment.pages.index.content_title"),
32 icon=viewmodels.Icon("idcardcheck", pgettext("image alt text", "core.icons.idcardcheck")),
33 paragraphs=[_("enrollment.pages.index.p[0]"), _("enrollment.pages.index.p[1]"), _("enrollment.pages.index.p[2]")],
34 classes="text-lg-center",
35 forms=[tokenize_retry_form, tokenize_success_form],
36 buttons=[
37 viewmodels.Button.primary(
38 text=_("enrollment.buttons.payment_partner"), id=tokenize_button, url=f"#{tokenize_button}"
39 ),
40 ],
41 )
42 context = {}
43 context.update(page.context_dict())
44
45 # add agency details
46 agency_vm = viewmodels.TransitAgency(agency)
47 context.update(agency_vm.context_dict())
48
49 # and payment processor details
50 processor_vm = viewmodels.PaymentProcessor(
51 model=agency.payment_processor,
52 access_token_url=reverse("enrollment:token"),
53 element_id=f"#{tokenize_button}",
54 color="#046b99",
55 name=f"{agency.long_name} {_('partnered with')} {agency.payment_processor.name}",
56 )
57 context.update(processor_vm.context_dict())
58 logger.warning(f"card_tokenize_url: {context['payment_processor'].card_tokenize_url}")
59
60 # the tokenize form URLs are injected to page-generated Javascript
61 context["forms"] = {
62 "tokenize_retry": reverse(tokenize_retry_form.action_url),
63 "tokenize_success": reverse(tokenize_success_form.action_url),
64 }
65
66 return TemplateResponse(request, "enrollment/index.html", context)
67
68
69 def _enroll(request):
70 """Helper calls the enrollment APIs."""
71 logger.debug("Read tokenized card")
72 form = forms.CardTokenizeSuccessForm(request.POST)
73 if not form.is_valid():
74 raise Exception("Invalid card token form")
75 card_token = form.cleaned_data.get("card_token")
76
77 eligibility = session.eligibility(request)
78 if eligibility:
79 logger.debug(f"Session contains an {models.EligibilityType.__name__}")
80 else:
81 raise Exception("Session contains no eligibility information")
82
83 agency = session.agency(request)
84
85 response = api.Client(agency).enroll(card_token, eligibility.group_id)
86
87 if response.success:
88 return success(request)
89 else:
90 raise Exception("Updated customer_id does not match enrolled customer_id")
91
92
93 @decorator_from_middleware(EligibleSessionRequired)
94 def token(request):
95 """View handler for the enrollment auth token."""
96 if not session.enrollment_token_valid(request):
97 agency = session.agency(request)
98 response = api.Client(agency).access_token()
99 session.update(request, enrollment_token=response.access_token, enrollment_token_exp=response.expiry)
100
101 data = {"token": session.enrollment_token(request)}
102
103 return JsonResponse(data)
104
105
106 @decorator_from_middleware(EligibleSessionRequired)
107 def index(request):
108 """View handler for the enrollment landing page."""
109 session.update(request, origin=reverse("enrollment:index"))
110
111 if request.method == "POST":
112 response = _enroll(request)
113 else:
114 response = _index(request)
115
116 return response
117
118
119 @decorator_from_middleware(EligibleSessionRequired)
120 def retry(request):
121 """View handler for a recoverable failure condition."""
122 if request.method == "POST":
123 form = forms.CardTokenizeFailForm(request.POST)
124 if form.is_valid():
125 agency = session.agency(request)
126 page = viewmodels.Page(
127 title=_("enrollment.pages.retry.title"),
128 icon=viewmodels.Icon("bankcardquestion", pgettext("image alt text", "core.icons.bankcardquestion")),
129 content_title=_("enrollment.pages.retry.title"),
130 paragraphs=[_("enrollment.pages.retry.p[0]")],
131 buttons=viewmodels.Button.agency_contact_links(agency),
132 )
133 page.buttons.append(viewmodels.Button.primary(text=_("core.buttons.retry"), url=session.origin(request)))
134 return TemplateResponse(request, "enrollment/retry.html", page.context_dict())
135 else:
136 raise Exception("Invalid retry submission.")
137 else:
138 raise Exception("This view method only supports POST.")
139
140
141 @pageview_decorator
142 @decorator_from_middleware(VerifierSessionRequired)
143 def success(request):
144 """View handler for the final success page."""
145 request.path = "/enrollment/success"
146 session.update(request, origin=reverse("enrollment:success"))
147 verifier = session.verifier(request)
148
149 if verifier.requires_authentication:
150 if settings.OAUTH_CLIENT_NAME is None:
151 raise Exception("EligibilityVerifier requires authentication, but OAUTH_CLIENT_NAME is None")
152
153 if session.logged_in(request):
154 button = viewmodels.Button.logout()
155 page = viewmodels.Page(
156 title=_("enrollment.pages.success.title"),
157 icon=viewmodels.Icon("bankcardcheck", pgettext("image alt text", "core.icons.bankcardcheck")),
158 content_title=_("enrollment.pages.success.content_title"),
159 button=button,
160 classes="logged-in",
161 )
162 else:
163 page = viewmodels.Page(
164 title=_("enrollment.pages.success.title"),
165 content_title=_("enrollment.pages.success.logout.title"),
166 classes="logged-out",
167 )
168 else:
169 page = viewmodels.Page(
170 title=_("enrollment.pages.success.title"),
171 content_title=_("enrollment.pages.success.content_title"),
172 icon=viewmodels.Icon("bankcardcheck", pgettext("image alt text", "core.icons.bankcardcheck")),
173 )
174
175 help_link = reverse("core:help")
176 context_dict = {**page.context_dict(), **{"help_link": help_link}}
177
178 return TemplateResponse(request, "enrollment/success.html", context_dict)
179
[end of benefits/enrollment/views.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/benefits/enrollment/views.py b/benefits/enrollment/views.py
--- a/benefits/enrollment/views.py
+++ b/benefits/enrollment/views.py
@@ -145,32 +145,26 @@
request.path = "/enrollment/success"
session.update(request, origin=reverse("enrollment:success"))
verifier = session.verifier(request)
+ icon = viewmodels.Icon("bankcardcheck", pgettext("image alt text", "core.icons.bankcardcheck"))
+ page = viewmodels.Page(
+ title=_("enrollment.pages.success.title"),
+ content_title=_("enrollment.pages.success.content_title"),
+ )
if verifier.requires_authentication:
if settings.OAUTH_CLIENT_NAME is None:
raise Exception("EligibilityVerifier requires authentication, but OAUTH_CLIENT_NAME is None")
if session.logged_in(request):
- button = viewmodels.Button.logout()
- page = viewmodels.Page(
- title=_("enrollment.pages.success.title"),
- icon=viewmodels.Icon("bankcardcheck", pgettext("image alt text", "core.icons.bankcardcheck")),
- content_title=_("enrollment.pages.success.content_title"),
- button=button,
- classes="logged-in",
- )
+ page.buttons = [viewmodels.Button.logout()]
+ page.classes = ["logged-in"]
+ page.icon = icon
else:
- page = viewmodels.Page(
- title=_("enrollment.pages.success.title"),
- content_title=_("enrollment.pages.success.logout.title"),
- classes="logged-out",
- )
+ page.classes = ["logged-out"]
+ page.content_title = _("enrollment.pages.success.logout.title")
+ page.noimage = True
else:
- page = viewmodels.Page(
- title=_("enrollment.pages.success.title"),
- content_title=_("enrollment.pages.success.content_title"),
- icon=viewmodels.Icon("bankcardcheck", pgettext("image alt text", "core.icons.bankcardcheck")),
- )
+ page.icon = icon
help_link = reverse("core:help")
context_dict = {**page.context_dict(), **{"help_link": help_link}}
|
{"golden_diff": "diff --git a/benefits/enrollment/views.py b/benefits/enrollment/views.py\n--- a/benefits/enrollment/views.py\n+++ b/benefits/enrollment/views.py\n@@ -145,32 +145,26 @@\n request.path = \"/enrollment/success\"\n session.update(request, origin=reverse(\"enrollment:success\"))\n verifier = session.verifier(request)\n+ icon = viewmodels.Icon(\"bankcardcheck\", pgettext(\"image alt text\", \"core.icons.bankcardcheck\"))\n+ page = viewmodels.Page(\n+ title=_(\"enrollment.pages.success.title\"),\n+ content_title=_(\"enrollment.pages.success.content_title\"),\n+ )\n \n if verifier.requires_authentication:\n if settings.OAUTH_CLIENT_NAME is None:\n raise Exception(\"EligibilityVerifier requires authentication, but OAUTH_CLIENT_NAME is None\")\n \n if session.logged_in(request):\n- button = viewmodels.Button.logout()\n- page = viewmodels.Page(\n- title=_(\"enrollment.pages.success.title\"),\n- icon=viewmodels.Icon(\"bankcardcheck\", pgettext(\"image alt text\", \"core.icons.bankcardcheck\")),\n- content_title=_(\"enrollment.pages.success.content_title\"),\n- button=button,\n- classes=\"logged-in\",\n- )\n+ page.buttons = [viewmodels.Button.logout()]\n+ page.classes = [\"logged-in\"]\n+ page.icon = icon\n else:\n- page = viewmodels.Page(\n- title=_(\"enrollment.pages.success.title\"),\n- content_title=_(\"enrollment.pages.success.logout.title\"),\n- classes=\"logged-out\",\n- )\n+ page.classes = [\"logged-out\"]\n+ page.content_title = _(\"enrollment.pages.success.logout.title\")\n+ page.noimage = True\n else:\n- page = viewmodels.Page(\n- title=_(\"enrollment.pages.success.title\"),\n- content_title=_(\"enrollment.pages.success.content_title\"),\n- icon=viewmodels.Icon(\"bankcardcheck\", pgettext(\"image alt text\", \"core.icons.bankcardcheck\")),\n- )\n+ page.icon = icon\n \n help_link = reverse(\"core:help\")\n context_dict = {**page.context_dict(), **{\"help_link\": help_link}}\n", "issue": "Enrollment: Success (signed out): Use the full-screen with no image\n\r\n\r\nUse the fullscreen view instead\n", "before_files": [{"content": "\"\"\"\nThe enrollment application: view definitions for the benefits enrollment flow.\n\"\"\"\nimport logging\n\nfrom django.conf import settings\nfrom django.http import JsonResponse\nfrom django.template.response import TemplateResponse\nfrom django.urls import reverse\nfrom django.utils.decorators import decorator_from_middleware\nfrom django.utils.translation import pgettext, gettext as _\n\nfrom benefits.core import models, session, viewmodels\nfrom benefits.core.middleware import EligibleSessionRequired, VerifierSessionRequired, pageview_decorator\nfrom . import api, forms\n\n\nlogger = logging.getLogger(__name__)\n\n\ndef _index(request):\n \"\"\"Helper handles GET requests to enrollment index.\"\"\"\n agency = session.agency(request)\n\n tokenize_button = \"tokenize_card\"\n tokenize_retry_form = forms.CardTokenizeFailForm(\"enrollment:retry\")\n tokenize_success_form = forms.CardTokenizeSuccessForm(auto_id=True, label_suffix=\"\")\n\n page = viewmodels.Page(\n title=_(\"enrollment.pages.index.title\"),\n content_title=_(\"enrollment.pages.index.content_title\"),\n icon=viewmodels.Icon(\"idcardcheck\", pgettext(\"image alt text\", \"core.icons.idcardcheck\")),\n paragraphs=[_(\"enrollment.pages.index.p[0]\"), _(\"enrollment.pages.index.p[1]\"), _(\"enrollment.pages.index.p[2]\")],\n classes=\"text-lg-center\",\n forms=[tokenize_retry_form, tokenize_success_form],\n buttons=[\n viewmodels.Button.primary(\n text=_(\"enrollment.buttons.payment_partner\"), id=tokenize_button, url=f\"#{tokenize_button}\"\n ),\n ],\n )\n context = {}\n context.update(page.context_dict())\n\n # add agency details\n agency_vm = viewmodels.TransitAgency(agency)\n context.update(agency_vm.context_dict())\n\n # and payment processor details\n processor_vm = viewmodels.PaymentProcessor(\n model=agency.payment_processor,\n access_token_url=reverse(\"enrollment:token\"),\n element_id=f\"#{tokenize_button}\",\n color=\"#046b99\",\n name=f\"{agency.long_name} {_('partnered with')} {agency.payment_processor.name}\",\n )\n context.update(processor_vm.context_dict())\n logger.warning(f\"card_tokenize_url: {context['payment_processor'].card_tokenize_url}\")\n\n # the tokenize form URLs are injected to page-generated Javascript\n context[\"forms\"] = {\n \"tokenize_retry\": reverse(tokenize_retry_form.action_url),\n \"tokenize_success\": reverse(tokenize_success_form.action_url),\n }\n\n return TemplateResponse(request, \"enrollment/index.html\", context)\n\n\ndef _enroll(request):\n \"\"\"Helper calls the enrollment APIs.\"\"\"\n logger.debug(\"Read tokenized card\")\n form = forms.CardTokenizeSuccessForm(request.POST)\n if not form.is_valid():\n raise Exception(\"Invalid card token form\")\n card_token = form.cleaned_data.get(\"card_token\")\n\n eligibility = session.eligibility(request)\n if eligibility:\n logger.debug(f\"Session contains an {models.EligibilityType.__name__}\")\n else:\n raise Exception(\"Session contains no eligibility information\")\n\n agency = session.agency(request)\n\n response = api.Client(agency).enroll(card_token, eligibility.group_id)\n\n if response.success:\n return success(request)\n else:\n raise Exception(\"Updated customer_id does not match enrolled customer_id\")\n\n\n@decorator_from_middleware(EligibleSessionRequired)\ndef token(request):\n \"\"\"View handler for the enrollment auth token.\"\"\"\n if not session.enrollment_token_valid(request):\n agency = session.agency(request)\n response = api.Client(agency).access_token()\n session.update(request, enrollment_token=response.access_token, enrollment_token_exp=response.expiry)\n\n data = {\"token\": session.enrollment_token(request)}\n\n return JsonResponse(data)\n\n\n@decorator_from_middleware(EligibleSessionRequired)\ndef index(request):\n \"\"\"View handler for the enrollment landing page.\"\"\"\n session.update(request, origin=reverse(\"enrollment:index\"))\n\n if request.method == \"POST\":\n response = _enroll(request)\n else:\n response = _index(request)\n\n return response\n\n\n@decorator_from_middleware(EligibleSessionRequired)\ndef retry(request):\n \"\"\"View handler for a recoverable failure condition.\"\"\"\n if request.method == \"POST\":\n form = forms.CardTokenizeFailForm(request.POST)\n if form.is_valid():\n agency = session.agency(request)\n page = viewmodels.Page(\n title=_(\"enrollment.pages.retry.title\"),\n icon=viewmodels.Icon(\"bankcardquestion\", pgettext(\"image alt text\", \"core.icons.bankcardquestion\")),\n content_title=_(\"enrollment.pages.retry.title\"),\n paragraphs=[_(\"enrollment.pages.retry.p[0]\")],\n buttons=viewmodels.Button.agency_contact_links(agency),\n )\n page.buttons.append(viewmodels.Button.primary(text=_(\"core.buttons.retry\"), url=session.origin(request)))\n return TemplateResponse(request, \"enrollment/retry.html\", page.context_dict())\n else:\n raise Exception(\"Invalid retry submission.\")\n else:\n raise Exception(\"This view method only supports POST.\")\n\n\n@pageview_decorator\n@decorator_from_middleware(VerifierSessionRequired)\ndef success(request):\n \"\"\"View handler for the final success page.\"\"\"\n request.path = \"/enrollment/success\"\n session.update(request, origin=reverse(\"enrollment:success\"))\n verifier = session.verifier(request)\n\n if verifier.requires_authentication:\n if settings.OAUTH_CLIENT_NAME is None:\n raise Exception(\"EligibilityVerifier requires authentication, but OAUTH_CLIENT_NAME is None\")\n\n if session.logged_in(request):\n button = viewmodels.Button.logout()\n page = viewmodels.Page(\n title=_(\"enrollment.pages.success.title\"),\n icon=viewmodels.Icon(\"bankcardcheck\", pgettext(\"image alt text\", \"core.icons.bankcardcheck\")),\n content_title=_(\"enrollment.pages.success.content_title\"),\n button=button,\n classes=\"logged-in\",\n )\n else:\n page = viewmodels.Page(\n title=_(\"enrollment.pages.success.title\"),\n content_title=_(\"enrollment.pages.success.logout.title\"),\n classes=\"logged-out\",\n )\n else:\n page = viewmodels.Page(\n title=_(\"enrollment.pages.success.title\"),\n content_title=_(\"enrollment.pages.success.content_title\"),\n icon=viewmodels.Icon(\"bankcardcheck\", pgettext(\"image alt text\", \"core.icons.bankcardcheck\")),\n )\n\n help_link = reverse(\"core:help\")\n context_dict = {**page.context_dict(), **{\"help_link\": help_link}}\n\n return TemplateResponse(request, \"enrollment/success.html\", context_dict)\n", "path": "benefits/enrollment/views.py"}]}
| 2,434 | 468 |
gh_patches_debug_8167
|
rasdani/github-patches
|
git_diff
|
PaddlePaddle__PaddleDetection-1567
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
使用yolov3_mobilenet_v1_voc.yml训练时出错
Traceback (most recent call last):
File "tools/train.py", line 372, in <module>
main()
File "tools/train.py", line 70, in main
cfg = load_config(FLAGS.config)
File "/home/aistudio/PaddleDetection/ppdet/core/workspace.py", line 86, in load_config
cfg = merge_config(yaml.load(f, Loader=yaml.Loader), cfg)
File "/home/aistudio/PaddleDetection/ppdet/core/workspace.py", line 143, in merge_config
dct['train_batch_size'] = dct['TrainReader']['batch_size']
KeyError: 'batch_size'
</issue>
<code>
[start of ppdet/core/workspace.py]
1 # Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 from __future__ import absolute_import
16 from __future__ import print_function
17 from __future__ import division
18
19 import importlib
20 import os
21 import sys
22
23 import yaml
24 import copy
25 import collections
26
27 from .config.schema import SchemaDict, SharedConfig, extract_schema
28 from .config.yaml_helpers import serializable
29
30 __all__ = [
31 'global_config',
32 'load_config',
33 'merge_config',
34 'get_registered_modules',
35 'create',
36 'register',
37 'serializable',
38 'dump_value',
39 ]
40
41
42 def dump_value(value):
43 # XXX this is hackish, but collections.abc is not available in python 2
44 if hasattr(value, '__dict__') or isinstance(value, (dict, tuple, list)):
45 value = yaml.dump(value, default_flow_style=True)
46 value = value.replace('\n', '')
47 value = value.replace('...', '')
48 return "'{}'".format(value)
49 else:
50 # primitive types
51 return str(value)
52
53
54 class AttrDict(dict):
55 """Single level attribute dict, NOT recursive"""
56
57 def __init__(self, **kwargs):
58 super(AttrDict, self).__init__()
59 super(AttrDict, self).update(kwargs)
60
61 def __getattr__(self, key):
62 if key in self:
63 return self[key]
64 raise AttributeError("object has no attribute '{}'".format(key))
65
66
67 global_config = AttrDict()
68
69 READER_KEY = '_READER_'
70
71
72 def load_config(file_path):
73 """
74 Load config from file.
75
76 Args:
77 file_path (str): Path of the config file to be loaded.
78
79 Returns: global config
80 """
81 _, ext = os.path.splitext(file_path)
82 assert ext in ['.yml', '.yaml'], "only support yaml files for now"
83
84 cfg = AttrDict()
85 with open(file_path) as f:
86 cfg = merge_config(yaml.load(f, Loader=yaml.Loader), cfg)
87
88 if READER_KEY in cfg:
89 reader_cfg = cfg[READER_KEY]
90 if reader_cfg.startswith("~"):
91 reader_cfg = os.path.expanduser(reader_cfg)
92 if not reader_cfg.startswith('/'):
93 reader_cfg = os.path.join(os.path.dirname(file_path), reader_cfg)
94
95 with open(reader_cfg) as f:
96 merge_config(yaml.load(f, Loader=yaml.Loader))
97 del cfg[READER_KEY]
98
99 merge_config(cfg)
100
101 return global_config
102
103
104 def dict_merge(dct, merge_dct):
105 """ Recursive dict merge. Inspired by :meth:``dict.update()``, instead of
106 updating only top-level keys, dict_merge recurses down into dicts nested
107 to an arbitrary depth, updating keys. The ``merge_dct`` is merged into
108 ``dct``.
109
110 Args:
111 dct: dict onto which the merge is executed
112 merge_dct: dct merged into dct
113
114 Returns: dct
115 """
116 for k, v in merge_dct.items():
117 if (k in dct and isinstance(dct[k], dict) and
118 isinstance(merge_dct[k], collections.Mapping)):
119 dict_merge(dct[k], merge_dct[k])
120 else:
121 dct[k] = merge_dct[k]
122 return dct
123
124
125 def merge_config(config, another_cfg=None):
126 """
127 Merge config into global config or another_cfg.
128
129 Args:
130 config (dict): Config to be merged.
131
132 Returns: global config
133 """
134 global global_config
135 dct = another_cfg if another_cfg is not None else global_config
136 dct = dict_merge(dct, config)
137
138 # NOTE: training batch size defined only in TrainReader, sychornized
139 # batch size config to global, models can get batch size config
140 # from global config when building model.
141 # batch size in evaluation or inference can also be added here
142 if 'TrainReader' in dct:
143 dct['train_batch_size'] = dct['TrainReader']['batch_size']
144
145 return dct
146
147
148 def get_registered_modules():
149 return {k: v for k, v in global_config.items() if isinstance(v, SchemaDict)}
150
151
152 def make_partial(cls):
153 if isinstance(cls.__op__, str):
154 sep = cls.__op__.split('.')
155 op_name = sep[-1]
156 op_module = importlib.import_module('.'.join(sep[:-1]))
157 else:
158 op_name = cls.__op__.__name__
159 op_module = importlib.import_module(cls.__op__.__module__)
160
161 if not hasattr(op_module, op_name):
162 import logging
163 logger = logging.getLogger(__name__)
164 logger.warn('{} OP not found, maybe a newer version of paddle '
165 'is required.'.format(cls.__op__))
166 return cls
167
168 op = getattr(op_module, op_name)
169 cls.__category__ = getattr(cls, '__category__', None) or 'op'
170
171 def partial_apply(self, *args, **kwargs):
172 kwargs_ = self.__dict__.copy()
173 kwargs_.update(kwargs)
174 return op(*args, **kwargs_)
175
176 if getattr(cls, '__append_doc__', True): # XXX should default to True?
177 if sys.version_info[0] > 2:
178 cls.__doc__ = "Wrapper for `{}` OP".format(op.__name__)
179 cls.__init__.__doc__ = op.__doc__
180 cls.__call__ = partial_apply
181 cls.__call__.__doc__ = op.__doc__
182 else:
183 # XXX work around for python 2
184 partial_apply.__doc__ = op.__doc__
185 cls.__call__ = partial_apply
186 return cls
187
188
189 def register(cls):
190 """
191 Register a given module class.
192
193 Args:
194 cls (type): Module class to be registered.
195
196 Returns: cls
197 """
198 if cls.__name__ in global_config:
199 raise ValueError("Module class already registered: {}".format(
200 cls.__name__))
201 if hasattr(cls, '__op__'):
202 cls = make_partial(cls)
203 global_config[cls.__name__] = extract_schema(cls)
204 return cls
205
206
207 def create(cls_or_name, **kwargs):
208 """
209 Create an instance of given module class.
210
211 Args:
212 cls_or_name (type or str): Class of which to create instance.
213
214 Returns: instance of type `cls_or_name`
215 """
216 assert type(cls_or_name) in [type, str
217 ], "should be a class or name of a class"
218 name = type(cls_or_name) == str and cls_or_name or cls_or_name.__name__
219 assert name in global_config and \
220 isinstance(global_config[name], SchemaDict), \
221 "the module {} is not registered".format(name)
222 config = global_config[name]
223 config.update(kwargs)
224 config.validate()
225 cls = getattr(config.pymodule, name)
226
227 kwargs = {}
228 kwargs.update(global_config[name])
229
230 # parse `shared` annoation of registered modules
231 if getattr(config, 'shared', None):
232 for k in config.shared:
233 target_key = config[k]
234 shared_conf = config.schema[k].default
235 assert isinstance(shared_conf, SharedConfig)
236 if target_key is not None and not isinstance(target_key,
237 SharedConfig):
238 continue # value is given for the module
239 elif shared_conf.key in global_config:
240 # `key` is present in config
241 kwargs[k] = global_config[shared_conf.key]
242 else:
243 kwargs[k] = shared_conf.default_value
244
245 # parse `inject` annoation of registered modules
246 if getattr(config, 'inject', None):
247 for k in config.inject:
248 target_key = config[k]
249 # optional dependency
250 if target_key is None:
251 continue
252 # also accept dictionaries and serialized objects
253 if isinstance(target_key, dict) or hasattr(target_key, '__dict__'):
254 continue
255 elif isinstance(target_key, str):
256 if target_key not in global_config:
257 raise ValueError("Missing injection config:", target_key)
258 target = global_config[target_key]
259 if isinstance(target, SchemaDict):
260 kwargs[k] = create(target_key)
261 elif hasattr(target, '__dict__'): # serialized object
262 kwargs[k] = target
263 else:
264 raise ValueError("Unsupported injection type:", target_key)
265 # prevent modification of global config values of reference types
266 # (e.g., list, dict) from within the created module instances
267 kwargs = copy.deepcopy(kwargs)
268 return cls(**kwargs)
269
[end of ppdet/core/workspace.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/ppdet/core/workspace.py b/ppdet/core/workspace.py
--- a/ppdet/core/workspace.py
+++ b/ppdet/core/workspace.py
@@ -139,7 +139,7 @@
# batch size config to global, models can get batch size config
# from global config when building model.
# batch size in evaluation or inference can also be added here
- if 'TrainReader' in dct:
+ if 'TrainReader' in dct and 'batch_size' in dct['TrainReader']:
dct['train_batch_size'] = dct['TrainReader']['batch_size']
return dct
|
{"golden_diff": "diff --git a/ppdet/core/workspace.py b/ppdet/core/workspace.py\n--- a/ppdet/core/workspace.py\n+++ b/ppdet/core/workspace.py\n@@ -139,7 +139,7 @@\n # batch size config to global, models can get batch size config\n # from global config when building model.\n # batch size in evaluation or inference can also be added here\n- if 'TrainReader' in dct:\n+ if 'TrainReader' in dct and 'batch_size' in dct['TrainReader']:\n dct['train_batch_size'] = dct['TrainReader']['batch_size']\n \n return dct\n", "issue": "\u4f7f\u7528yolov3_mobilenet_v1_voc.yml\u8bad\u7ec3\u65f6\u51fa\u9519\nTraceback (most recent call last):\r\n File \"tools/train.py\", line 372, in <module>\r\n main()\r\n File \"tools/train.py\", line 70, in main\r\n cfg = load_config(FLAGS.config)\r\n File \"/home/aistudio/PaddleDetection/ppdet/core/workspace.py\", line 86, in load_config\r\n cfg = merge_config(yaml.load(f, Loader=yaml.Loader), cfg)\r\n File \"/home/aistudio/PaddleDetection/ppdet/core/workspace.py\", line 143, in merge_config\r\n dct['train_batch_size'] = dct['TrainReader']['batch_size']\r\nKeyError: 'batch_size'\n", "before_files": [{"content": "# Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nfrom __future__ import absolute_import\nfrom __future__ import print_function\nfrom __future__ import division\n\nimport importlib\nimport os\nimport sys\n\nimport yaml\nimport copy\nimport collections\n\nfrom .config.schema import SchemaDict, SharedConfig, extract_schema\nfrom .config.yaml_helpers import serializable\n\n__all__ = [\n 'global_config',\n 'load_config',\n 'merge_config',\n 'get_registered_modules',\n 'create',\n 'register',\n 'serializable',\n 'dump_value',\n]\n\n\ndef dump_value(value):\n # XXX this is hackish, but collections.abc is not available in python 2\n if hasattr(value, '__dict__') or isinstance(value, (dict, tuple, list)):\n value = yaml.dump(value, default_flow_style=True)\n value = value.replace('\\n', '')\n value = value.replace('...', '')\n return \"'{}'\".format(value)\n else:\n # primitive types\n return str(value)\n\n\nclass AttrDict(dict):\n \"\"\"Single level attribute dict, NOT recursive\"\"\"\n\n def __init__(self, **kwargs):\n super(AttrDict, self).__init__()\n super(AttrDict, self).update(kwargs)\n\n def __getattr__(self, key):\n if key in self:\n return self[key]\n raise AttributeError(\"object has no attribute '{}'\".format(key))\n\n\nglobal_config = AttrDict()\n\nREADER_KEY = '_READER_'\n\n\ndef load_config(file_path):\n \"\"\"\n Load config from file.\n\n Args:\n file_path (str): Path of the config file to be loaded.\n\n Returns: global config\n \"\"\"\n _, ext = os.path.splitext(file_path)\n assert ext in ['.yml', '.yaml'], \"only support yaml files for now\"\n\n cfg = AttrDict()\n with open(file_path) as f:\n cfg = merge_config(yaml.load(f, Loader=yaml.Loader), cfg)\n\n if READER_KEY in cfg:\n reader_cfg = cfg[READER_KEY]\n if reader_cfg.startswith(\"~\"):\n reader_cfg = os.path.expanduser(reader_cfg)\n if not reader_cfg.startswith('/'):\n reader_cfg = os.path.join(os.path.dirname(file_path), reader_cfg)\n\n with open(reader_cfg) as f:\n merge_config(yaml.load(f, Loader=yaml.Loader))\n del cfg[READER_KEY]\n\n merge_config(cfg)\n\n return global_config\n\n\ndef dict_merge(dct, merge_dct):\n \"\"\" Recursive dict merge. Inspired by :meth:``dict.update()``, instead of\n updating only top-level keys, dict_merge recurses down into dicts nested\n to an arbitrary depth, updating keys. The ``merge_dct`` is merged into\n ``dct``.\n\n Args:\n dct: dict onto which the merge is executed\n merge_dct: dct merged into dct\n\n Returns: dct\n \"\"\"\n for k, v in merge_dct.items():\n if (k in dct and isinstance(dct[k], dict) and\n isinstance(merge_dct[k], collections.Mapping)):\n dict_merge(dct[k], merge_dct[k])\n else:\n dct[k] = merge_dct[k]\n return dct\n\n\ndef merge_config(config, another_cfg=None):\n \"\"\"\n Merge config into global config or another_cfg.\n\n Args:\n config (dict): Config to be merged.\n\n Returns: global config\n \"\"\"\n global global_config\n dct = another_cfg if another_cfg is not None else global_config\n dct = dict_merge(dct, config)\n\n # NOTE: training batch size defined only in TrainReader, sychornized\n # batch size config to global, models can get batch size config\n # from global config when building model.\n # batch size in evaluation or inference can also be added here\n if 'TrainReader' in dct:\n dct['train_batch_size'] = dct['TrainReader']['batch_size']\n\n return dct\n\n\ndef get_registered_modules():\n return {k: v for k, v in global_config.items() if isinstance(v, SchemaDict)}\n\n\ndef make_partial(cls):\n if isinstance(cls.__op__, str):\n sep = cls.__op__.split('.')\n op_name = sep[-1]\n op_module = importlib.import_module('.'.join(sep[:-1]))\n else:\n op_name = cls.__op__.__name__\n op_module = importlib.import_module(cls.__op__.__module__)\n\n if not hasattr(op_module, op_name):\n import logging\n logger = logging.getLogger(__name__)\n logger.warn('{} OP not found, maybe a newer version of paddle '\n 'is required.'.format(cls.__op__))\n return cls\n\n op = getattr(op_module, op_name)\n cls.__category__ = getattr(cls, '__category__', None) or 'op'\n\n def partial_apply(self, *args, **kwargs):\n kwargs_ = self.__dict__.copy()\n kwargs_.update(kwargs)\n return op(*args, **kwargs_)\n\n if getattr(cls, '__append_doc__', True): # XXX should default to True?\n if sys.version_info[0] > 2:\n cls.__doc__ = \"Wrapper for `{}` OP\".format(op.__name__)\n cls.__init__.__doc__ = op.__doc__\n cls.__call__ = partial_apply\n cls.__call__.__doc__ = op.__doc__\n else:\n # XXX work around for python 2\n partial_apply.__doc__ = op.__doc__\n cls.__call__ = partial_apply\n return cls\n\n\ndef register(cls):\n \"\"\"\n Register a given module class.\n\n Args:\n cls (type): Module class to be registered.\n\n Returns: cls\n \"\"\"\n if cls.__name__ in global_config:\n raise ValueError(\"Module class already registered: {}\".format(\n cls.__name__))\n if hasattr(cls, '__op__'):\n cls = make_partial(cls)\n global_config[cls.__name__] = extract_schema(cls)\n return cls\n\n\ndef create(cls_or_name, **kwargs):\n \"\"\"\n Create an instance of given module class.\n\n Args:\n cls_or_name (type or str): Class of which to create instance.\n\n Returns: instance of type `cls_or_name`\n \"\"\"\n assert type(cls_or_name) in [type, str\n ], \"should be a class or name of a class\"\n name = type(cls_or_name) == str and cls_or_name or cls_or_name.__name__\n assert name in global_config and \\\n isinstance(global_config[name], SchemaDict), \\\n \"the module {} is not registered\".format(name)\n config = global_config[name]\n config.update(kwargs)\n config.validate()\n cls = getattr(config.pymodule, name)\n\n kwargs = {}\n kwargs.update(global_config[name])\n\n # parse `shared` annoation of registered modules\n if getattr(config, 'shared', None):\n for k in config.shared:\n target_key = config[k]\n shared_conf = config.schema[k].default\n assert isinstance(shared_conf, SharedConfig)\n if target_key is not None and not isinstance(target_key,\n SharedConfig):\n continue # value is given for the module\n elif shared_conf.key in global_config:\n # `key` is present in config\n kwargs[k] = global_config[shared_conf.key]\n else:\n kwargs[k] = shared_conf.default_value\n\n # parse `inject` annoation of registered modules\n if getattr(config, 'inject', None):\n for k in config.inject:\n target_key = config[k]\n # optional dependency\n if target_key is None:\n continue\n # also accept dictionaries and serialized objects\n if isinstance(target_key, dict) or hasattr(target_key, '__dict__'):\n continue\n elif isinstance(target_key, str):\n if target_key not in global_config:\n raise ValueError(\"Missing injection config:\", target_key)\n target = global_config[target_key]\n if isinstance(target, SchemaDict):\n kwargs[k] = create(target_key)\n elif hasattr(target, '__dict__'): # serialized object\n kwargs[k] = target\n else:\n raise ValueError(\"Unsupported injection type:\", target_key)\n # prevent modification of global config values of reference types\n # (e.g., list, dict) from within the created module instances\n kwargs = copy.deepcopy(kwargs)\n return cls(**kwargs)\n", "path": "ppdet/core/workspace.py"}]}
| 3,350 | 138 |
gh_patches_debug_12879
|
rasdani/github-patches
|
git_diff
|
apluslms__a-plus-771
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
HTML Plugin admin interface does not show relevant information
Some times we have to copy plugins from previous course instances to the current instance. However, it is difficult to know which plugin belongs to the course we want.
**Current view**

**Proposed view**

HTML Plugin admin interface does not show relevant information
Some times we have to copy plugins from previous course instances to the current instance. However, it is difficult to know which plugin belongs to the course we want.
**Current view**

**Proposed view**

</issue>
<code>
[start of apps/admin.py]
1 from django.contrib import admin
2
3 from .models import (
4 BaseTab,
5 HTMLTab,
6 ExternalEmbeddedTab,
7 ExternalIFrameTab,
8 BasePlugin,
9 RSSPlugin,
10 HTMLPlugin,
11 ExternalIFramePlugin,
12 )
13
14
15 admin.site.register(BaseTab)
16 admin.site.register(HTMLTab)
17 admin.site.register(ExternalEmbeddedTab)
18 admin.site.register(ExternalIFrameTab)
19 admin.site.register(BasePlugin)
20 admin.site.register(RSSPlugin)
21 admin.site.register(HTMLPlugin)
22 admin.site.register(ExternalIFramePlugin)
23
[end of apps/admin.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/apps/admin.py b/apps/admin.py
--- a/apps/admin.py
+++ b/apps/admin.py
@@ -11,6 +11,12 @@
ExternalIFramePlugin,
)
+class HTMLPluginAdmin(admin.ModelAdmin):
+ list_display_links = ["title"]
+ list_display = ["title", "course_instance_id", "container_type", "views"]
+
+ def course_instance_id(self, obj):
+ return obj.container_pk
admin.site.register(BaseTab)
admin.site.register(HTMLTab)
@@ -18,5 +24,5 @@
admin.site.register(ExternalIFrameTab)
admin.site.register(BasePlugin)
admin.site.register(RSSPlugin)
-admin.site.register(HTMLPlugin)
+admin.site.register(HTMLPlugin, HTMLPluginAdmin)
admin.site.register(ExternalIFramePlugin)
|
{"golden_diff": "diff --git a/apps/admin.py b/apps/admin.py\n--- a/apps/admin.py\n+++ b/apps/admin.py\n@@ -11,6 +11,12 @@\n ExternalIFramePlugin,\n )\n \n+class HTMLPluginAdmin(admin.ModelAdmin):\n+ list_display_links = [\"title\"]\n+ list_display = [\"title\", \"course_instance_id\", \"container_type\", \"views\"]\n+\n+ def course_instance_id(self, obj):\n+ return obj.container_pk\n \n admin.site.register(BaseTab)\n admin.site.register(HTMLTab)\n@@ -18,5 +24,5 @@\n admin.site.register(ExternalIFrameTab)\n admin.site.register(BasePlugin)\n admin.site.register(RSSPlugin)\n-admin.site.register(HTMLPlugin)\n+admin.site.register(HTMLPlugin, HTMLPluginAdmin)\n admin.site.register(ExternalIFramePlugin)\n", "issue": "HTML Plugin admin interface does not show relevant information\nSome times we have to copy plugins from previous course instances to the current instance. However, it is difficult to know which plugin belongs to the course we want.\r\n\r\n**Current view**\r\n\r\n\r\n**Proposed view**\r\n\r\n\nHTML Plugin admin interface does not show relevant information\nSome times we have to copy plugins from previous course instances to the current instance. However, it is difficult to know which plugin belongs to the course we want.\r\n\r\n**Current view**\r\n\r\n\r\n**Proposed view**\r\n\r\n\n", "before_files": [{"content": "from django.contrib import admin\n\nfrom .models import (\n BaseTab,\n HTMLTab,\n ExternalEmbeddedTab,\n ExternalIFrameTab,\n BasePlugin,\n RSSPlugin,\n HTMLPlugin,\n ExternalIFramePlugin,\n)\n\n\nadmin.site.register(BaseTab)\nadmin.site.register(HTMLTab)\nadmin.site.register(ExternalEmbeddedTab)\nadmin.site.register(ExternalIFrameTab)\nadmin.site.register(BasePlugin)\nadmin.site.register(RSSPlugin)\nadmin.site.register(HTMLPlugin)\nadmin.site.register(ExternalIFramePlugin)\n", "path": "apps/admin.py"}]}
| 1,036 | 175 |
gh_patches_debug_14189
|
rasdani/github-patches
|
git_diff
|
readthedocs__readthedocs.org-11153
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Notifications: always show notifications on build details' page
It seems that in https://github.com/readthedocs/readthedocs.org/pull/11117 we introduced a bug that it only shows the notifications for the build to users that have permissions over that project in particular --which is wrong. Since the project is public, it should show the notifications to all the users with access to the build detail's page.
</issue>
<code>
[start of readthedocs/builds/views.py]
1 """Views for builds app."""
2
3 import textwrap
4 from urllib.parse import urlparse
5
6 import structlog
7 from django.conf import settings
8 from django.contrib import messages
9 from django.contrib.auth.decorators import login_required
10 from django.http import HttpResponseForbidden, HttpResponseRedirect
11 from django.shortcuts import get_object_or_404
12 from django.urls import reverse
13 from django.utils.decorators import method_decorator
14 from django.views.generic import DetailView, ListView
15 from requests.utils import quote
16
17 from readthedocs.builds.constants import BUILD_FINAL_STATES
18 from readthedocs.builds.filters import BuildListFilter
19 from readthedocs.builds.models import Build, Version
20 from readthedocs.core.permissions import AdminPermission
21 from readthedocs.core.utils import cancel_build, trigger_build
22 from readthedocs.doc_builder.exceptions import BuildAppError
23 from readthedocs.projects.models import Project
24
25 log = structlog.get_logger(__name__)
26
27
28 class BuildBase:
29 model = Build
30
31 def get_queryset(self):
32 self.project_slug = self.kwargs.get("project_slug", None)
33 self.project = get_object_or_404(
34 Project.objects.public(self.request.user),
35 slug=self.project_slug,
36 )
37 queryset = Build.objects.public(
38 user=self.request.user,
39 project=self.project,
40 ).select_related("project", "version")
41
42 return queryset
43
44
45 class BuildTriggerMixin:
46 @method_decorator(login_required)
47 def post(self, request, project_slug):
48 commit_to_retrigger = None
49 project = get_object_or_404(Project, slug=project_slug)
50
51 if not AdminPermission.is_admin(request.user, project):
52 return HttpResponseForbidden()
53
54 version_slug = request.POST.get("version_slug")
55 build_pk = request.POST.get("build_pk")
56
57 if build_pk:
58 # Filter over external versions only when re-triggering a specific build
59 version = get_object_or_404(
60 Version.external.public(self.request.user),
61 slug=version_slug,
62 project=project,
63 )
64
65 build_to_retrigger = get_object_or_404(
66 Build.objects.all(),
67 pk=build_pk,
68 version=version,
69 )
70 if build_to_retrigger != Build.objects.filter(version=version).first():
71 messages.add_message(
72 request,
73 messages.ERROR,
74 "This build can't be re-triggered because it's "
75 "not the latest build for this version.",
76 )
77 return HttpResponseRedirect(request.path)
78
79 # Set either the build to re-trigger it or None
80 if build_to_retrigger:
81 commit_to_retrigger = build_to_retrigger.commit
82 log.info(
83 "Re-triggering build.",
84 project_slug=project.slug,
85 version_slug=version.slug,
86 build_commit=build_to_retrigger.commit,
87 build_id=build_to_retrigger.pk,
88 )
89 else:
90 # Use generic query when triggering a normal build
91 version = get_object_or_404(
92 self._get_versions(project),
93 slug=version_slug,
94 )
95
96 update_docs_task, build = trigger_build(
97 project=project,
98 version=version,
99 commit=commit_to_retrigger,
100 )
101 if (update_docs_task, build) == (None, None):
102 # Build was skipped
103 messages.add_message(
104 request,
105 messages.WARNING,
106 "This project is currently disabled and can't trigger new builds.",
107 )
108 return HttpResponseRedirect(
109 reverse("builds_project_list", args=[project.slug]),
110 )
111
112 return HttpResponseRedirect(
113 reverse("builds_detail", args=[project.slug, build.pk]),
114 )
115
116 def _get_versions(self, project):
117 return Version.internal.public(
118 user=self.request.user,
119 project=project,
120 )
121
122
123 class BuildList(BuildBase, BuildTriggerMixin, ListView):
124 def get_context_data(self, **kwargs):
125 context = super().get_context_data(**kwargs)
126
127 active_builds = (
128 self.get_queryset()
129 .exclude(
130 state__in=BUILD_FINAL_STATES,
131 )
132 .values("id")
133 )
134
135 context["project"] = self.project
136 context["active_builds"] = active_builds
137 context["versions"] = self._get_versions(self.project)
138
139 builds = self.get_queryset()
140 if settings.RTD_EXT_THEME_ENABLED:
141 filter = BuildListFilter(self.request.GET, queryset=builds)
142 context["filter"] = filter
143 builds = filter.qs
144 context["build_qs"] = builds
145
146 return context
147
148
149 class BuildDetail(BuildBase, DetailView):
150 pk_url_kwarg = "build_pk"
151
152 @method_decorator(login_required)
153 def post(self, request, project_slug, build_pk):
154 project = get_object_or_404(Project, slug=project_slug)
155 build = get_object_or_404(project.builds, pk=build_pk)
156
157 if not AdminPermission.is_admin(request.user, project):
158 return HttpResponseForbidden()
159
160 cancel_build(build)
161
162 return HttpResponseRedirect(
163 reverse("builds_detail", args=[project.slug, build.pk]),
164 )
165
166 def get_context_data(self, **kwargs):
167 context = super().get_context_data(**kwargs)
168 context["project"] = self.project
169
170 build = self.get_object()
171
172 if not build.notifications.filter(
173 message_id=BuildAppError.GENERIC_WITH_BUILD_ID
174 ).exists():
175 # Do not suggest to open an issue if the error is not generic
176 return context
177
178 scheme = (
179 "https://github.com/rtfd/readthedocs.org/issues/new"
180 "?title={title}{build_id}"
181 "&body={body}"
182 )
183
184 # TODO: we could use ``.github/ISSUE_TEMPLATE.md`` here, but we would
185 # need to add some variables to it which could impact in the UX when
186 # filling an issue from the web
187 body = """
188 ## Details:
189
190 * Project URL: https://readthedocs.org/projects/{project_slug}/
191 * Build URL(if applicable): https://readthedocs.org{build_path}
192 * Read the Docs username(if applicable): {username}
193
194 ## Expected Result
195
196 *A description of what you wanted to happen*
197
198 ## Actual Result
199
200 *A description of what actually happened*""".format(
201 project_slug=self.project,
202 build_path=self.request.path,
203 username=self.request.user,
204 )
205
206 scheme_dict = {
207 "title": quote("Build error with build id #"),
208 "build_id": context["build"].id,
209 "body": quote(textwrap.dedent(body)),
210 }
211
212 issue_url = scheme.format(**scheme_dict)
213 issue_url = urlparse(issue_url).geturl()
214 context["issue_url"] = issue_url
215 context["notifications"] = build.notifications.all()
216 return context
217
[end of readthedocs/builds/views.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/readthedocs/builds/views.py b/readthedocs/builds/views.py
--- a/readthedocs/builds/views.py
+++ b/readthedocs/builds/views.py
@@ -168,6 +168,7 @@
context["project"] = self.project
build = self.get_object()
+ context["notifications"] = build.notifications.all()
if not build.notifications.filter(
message_id=BuildAppError.GENERIC_WITH_BUILD_ID
@@ -212,5 +213,5 @@
issue_url = scheme.format(**scheme_dict)
issue_url = urlparse(issue_url).geturl()
context["issue_url"] = issue_url
- context["notifications"] = build.notifications.all()
+
return context
|
{"golden_diff": "diff --git a/readthedocs/builds/views.py b/readthedocs/builds/views.py\n--- a/readthedocs/builds/views.py\n+++ b/readthedocs/builds/views.py\n@@ -168,6 +168,7 @@\n context[\"project\"] = self.project\n \n build = self.get_object()\n+ context[\"notifications\"] = build.notifications.all()\n \n if not build.notifications.filter(\n message_id=BuildAppError.GENERIC_WITH_BUILD_ID\n@@ -212,5 +213,5 @@\n issue_url = scheme.format(**scheme_dict)\n issue_url = urlparse(issue_url).geturl()\n context[\"issue_url\"] = issue_url\n- context[\"notifications\"] = build.notifications.all()\n+\n return context\n", "issue": "Notifications: always show notifications on build details' page\nIt seems that in https://github.com/readthedocs/readthedocs.org/pull/11117 we introduced a bug that it only shows the notifications for the build to users that have permissions over that project in particular --which is wrong. Since the project is public, it should show the notifications to all the users with access to the build detail's page.\n", "before_files": [{"content": "\"\"\"Views for builds app.\"\"\"\n\nimport textwrap\nfrom urllib.parse import urlparse\n\nimport structlog\nfrom django.conf import settings\nfrom django.contrib import messages\nfrom django.contrib.auth.decorators import login_required\nfrom django.http import HttpResponseForbidden, HttpResponseRedirect\nfrom django.shortcuts import get_object_or_404\nfrom django.urls import reverse\nfrom django.utils.decorators import method_decorator\nfrom django.views.generic import DetailView, ListView\nfrom requests.utils import quote\n\nfrom readthedocs.builds.constants import BUILD_FINAL_STATES\nfrom readthedocs.builds.filters import BuildListFilter\nfrom readthedocs.builds.models import Build, Version\nfrom readthedocs.core.permissions import AdminPermission\nfrom readthedocs.core.utils import cancel_build, trigger_build\nfrom readthedocs.doc_builder.exceptions import BuildAppError\nfrom readthedocs.projects.models import Project\n\nlog = structlog.get_logger(__name__)\n\n\nclass BuildBase:\n model = Build\n\n def get_queryset(self):\n self.project_slug = self.kwargs.get(\"project_slug\", None)\n self.project = get_object_or_404(\n Project.objects.public(self.request.user),\n slug=self.project_slug,\n )\n queryset = Build.objects.public(\n user=self.request.user,\n project=self.project,\n ).select_related(\"project\", \"version\")\n\n return queryset\n\n\nclass BuildTriggerMixin:\n @method_decorator(login_required)\n def post(self, request, project_slug):\n commit_to_retrigger = None\n project = get_object_or_404(Project, slug=project_slug)\n\n if not AdminPermission.is_admin(request.user, project):\n return HttpResponseForbidden()\n\n version_slug = request.POST.get(\"version_slug\")\n build_pk = request.POST.get(\"build_pk\")\n\n if build_pk:\n # Filter over external versions only when re-triggering a specific build\n version = get_object_or_404(\n Version.external.public(self.request.user),\n slug=version_slug,\n project=project,\n )\n\n build_to_retrigger = get_object_or_404(\n Build.objects.all(),\n pk=build_pk,\n version=version,\n )\n if build_to_retrigger != Build.objects.filter(version=version).first():\n messages.add_message(\n request,\n messages.ERROR,\n \"This build can't be re-triggered because it's \"\n \"not the latest build for this version.\",\n )\n return HttpResponseRedirect(request.path)\n\n # Set either the build to re-trigger it or None\n if build_to_retrigger:\n commit_to_retrigger = build_to_retrigger.commit\n log.info(\n \"Re-triggering build.\",\n project_slug=project.slug,\n version_slug=version.slug,\n build_commit=build_to_retrigger.commit,\n build_id=build_to_retrigger.pk,\n )\n else:\n # Use generic query when triggering a normal build\n version = get_object_or_404(\n self._get_versions(project),\n slug=version_slug,\n )\n\n update_docs_task, build = trigger_build(\n project=project,\n version=version,\n commit=commit_to_retrigger,\n )\n if (update_docs_task, build) == (None, None):\n # Build was skipped\n messages.add_message(\n request,\n messages.WARNING,\n \"This project is currently disabled and can't trigger new builds.\",\n )\n return HttpResponseRedirect(\n reverse(\"builds_project_list\", args=[project.slug]),\n )\n\n return HttpResponseRedirect(\n reverse(\"builds_detail\", args=[project.slug, build.pk]),\n )\n\n def _get_versions(self, project):\n return Version.internal.public(\n user=self.request.user,\n project=project,\n )\n\n\nclass BuildList(BuildBase, BuildTriggerMixin, ListView):\n def get_context_data(self, **kwargs):\n context = super().get_context_data(**kwargs)\n\n active_builds = (\n self.get_queryset()\n .exclude(\n state__in=BUILD_FINAL_STATES,\n )\n .values(\"id\")\n )\n\n context[\"project\"] = self.project\n context[\"active_builds\"] = active_builds\n context[\"versions\"] = self._get_versions(self.project)\n\n builds = self.get_queryset()\n if settings.RTD_EXT_THEME_ENABLED:\n filter = BuildListFilter(self.request.GET, queryset=builds)\n context[\"filter\"] = filter\n builds = filter.qs\n context[\"build_qs\"] = builds\n\n return context\n\n\nclass BuildDetail(BuildBase, DetailView):\n pk_url_kwarg = \"build_pk\"\n\n @method_decorator(login_required)\n def post(self, request, project_slug, build_pk):\n project = get_object_or_404(Project, slug=project_slug)\n build = get_object_or_404(project.builds, pk=build_pk)\n\n if not AdminPermission.is_admin(request.user, project):\n return HttpResponseForbidden()\n\n cancel_build(build)\n\n return HttpResponseRedirect(\n reverse(\"builds_detail\", args=[project.slug, build.pk]),\n )\n\n def get_context_data(self, **kwargs):\n context = super().get_context_data(**kwargs)\n context[\"project\"] = self.project\n\n build = self.get_object()\n\n if not build.notifications.filter(\n message_id=BuildAppError.GENERIC_WITH_BUILD_ID\n ).exists():\n # Do not suggest to open an issue if the error is not generic\n return context\n\n scheme = (\n \"https://github.com/rtfd/readthedocs.org/issues/new\"\n \"?title={title}{build_id}\"\n \"&body={body}\"\n )\n\n # TODO: we could use ``.github/ISSUE_TEMPLATE.md`` here, but we would\n # need to add some variables to it which could impact in the UX when\n # filling an issue from the web\n body = \"\"\"\n ## Details:\n\n * Project URL: https://readthedocs.org/projects/{project_slug}/\n * Build URL(if applicable): https://readthedocs.org{build_path}\n * Read the Docs username(if applicable): {username}\n\n ## Expected Result\n\n *A description of what you wanted to happen*\n\n ## Actual Result\n\n *A description of what actually happened*\"\"\".format(\n project_slug=self.project,\n build_path=self.request.path,\n username=self.request.user,\n )\n\n scheme_dict = {\n \"title\": quote(\"Build error with build id #\"),\n \"build_id\": context[\"build\"].id,\n \"body\": quote(textwrap.dedent(body)),\n }\n\n issue_url = scheme.format(**scheme_dict)\n issue_url = urlparse(issue_url).geturl()\n context[\"issue_url\"] = issue_url\n context[\"notifications\"] = build.notifications.all()\n return context\n", "path": "readthedocs/builds/views.py"}]}
| 2,617 | 164 |
gh_patches_debug_27831
|
rasdani/github-patches
|
git_diff
|
carpentries__amy-648
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Modify members API call so that JSON includes user ID
Right now the 'members' API gives us name and email - the JSON should include each person's user ID as well.
</issue>
<code>
[start of api/serializers.py]
1 from rest_framework import serializers
2
3 from workshops.models import Badge, Airport, Person, Event, TodoItem, Tag
4
5
6 class PersonUsernameSerializer(serializers.ModelSerializer):
7 name = serializers.CharField(source='get_full_name')
8 user = serializers.CharField(source='username')
9
10 class Meta:
11 model = Person
12 fields = ('name', 'user', )
13
14
15 class PersonNameEmailSerializer(serializers.ModelSerializer):
16 name = serializers.CharField(source='get_full_name')
17
18 class Meta:
19 model = Person
20 fields = ('name', 'email')
21
22
23 class ExportBadgesSerializer(serializers.ModelSerializer):
24 persons = PersonUsernameSerializer(many=True, source='person_set')
25
26 class Meta:
27 model = Badge
28 fields = ('name', 'persons')
29
30
31 class ExportInstructorLocationsSerializer(serializers.ModelSerializer):
32 name = serializers.CharField(source='fullname')
33 instructors = PersonUsernameSerializer(many=True, source='person_set')
34
35 class Meta:
36 model = Airport
37 fields = ('name', 'latitude', 'longitude', 'instructors', 'country')
38
39
40 class TagSerializer(serializers.ModelSerializer):
41 class Meta:
42 model = Tag
43 fields = ('name', )
44
45
46 class EventSerializer(serializers.ModelSerializer):
47 humandate = serializers.CharField(source='human_readable_date')
48 country = serializers.CharField()
49 start = serializers.DateField(format=None)
50 end = serializers.DateField(format=None)
51 url = serializers.URLField(source='website_url')
52 eventbrite_id = serializers.CharField(source='reg_key')
53 tags = TagSerializer(many=True)
54
55 class Meta:
56 model = Event
57 fields = (
58 'slug', 'start', 'end', 'url', 'humandate', 'contact', 'country',
59 'venue', 'address', 'latitude', 'longitude', 'eventbrite_id',
60 'tags',
61 )
62
63
64 class TodoSerializer(serializers.ModelSerializer):
65 content = serializers.SerializerMethodField()
66 start = serializers.DateField(format=None, source='due')
67
68 class Meta:
69 model = TodoItem
70 fields = (
71 'content', 'start',
72 )
73
74 def get_content(self, obj):
75 """Return HTML containing interesting information for admins. This
76 will be displayed on labels in the timeline."""
77
78 return '<a href="{url}">{event}</a><br><small>{todo}</small>'.format(
79 url=obj.event.get_absolute_url(),
80 event=obj.event.get_ident(),
81 todo=obj.title,
82 )
83
[end of api/serializers.py]
[start of api/views.py]
1 import datetime
2
3 from django.db.models import Q
4 from rest_framework.generics import ListAPIView
5 from rest_framework.metadata import SimpleMetadata
6 from rest_framework.permissions import (
7 IsAuthenticatedOrReadOnly, IsAuthenticated
8 )
9 from rest_framework.response import Response
10 from rest_framework.reverse import reverse
11 from rest_framework.views import APIView
12
13 from workshops.models import Badge, Airport, Event, TodoItem, Tag
14 from workshops.util import get_members, default_membership_cutoff
15
16 from .serializers import (
17 PersonNameEmailSerializer,
18 ExportBadgesSerializer,
19 ExportInstructorLocationsSerializer,
20 EventSerializer,
21 TodoSerializer,
22 )
23
24
25 class QueryMetadata(SimpleMetadata):
26 """Additionally include info about query parameters."""
27
28 def determine_metadata(self, request, view):
29 data = super().determine_metadata(request, view)
30
31 try:
32 data['query_params'] = view.get_query_params_description()
33 except AttributeError:
34 pass
35
36 return data
37
38
39 class ApiRoot(APIView):
40 def get(self, request, format=None):
41 return Response({
42 'export-badges': reverse('api:export-badges', request=request,
43 format=format),
44 'export-instructors': reverse('api:export-instructors',
45 request=request, format=format),
46 'export-members': reverse('api:export-members', request=request,
47 format=format),
48 'events-published': reverse('api:events-published',
49 request=request, format=format),
50 'user-todos': reverse('api:user-todos',
51 request=request, format=format),
52 })
53
54
55 class ExportBadgesView(ListAPIView):
56 """List all badges and people who have them."""
57 permission_classes = (IsAuthenticatedOrReadOnly, )
58 paginator = None # disable pagination
59
60 queryset = Badge.objects.prefetch_related('person_set')
61 serializer_class = ExportBadgesSerializer
62
63
64 class ExportInstructorLocationsView(ListAPIView):
65 """List all airports and instructors located near them."""
66 permission_classes = (IsAuthenticatedOrReadOnly, )
67 paginator = None # disable pagination
68
69 queryset = Airport.objects.exclude(person=None) \
70 .prefetch_related('person_set')
71 serializer_class = ExportInstructorLocationsSerializer
72
73
74 class ExportMembersView(ListAPIView):
75 """Show everyone who qualifies as an SCF member."""
76 permission_classes = (IsAuthenticatedOrReadOnly, )
77 paginator = None # disable pagination
78
79 serializer_class = PersonNameEmailSerializer
80
81 def get_queryset(self):
82 earliest_default, latest_default = default_membership_cutoff()
83
84 earliest = self.request.query_params.get('earliest', None)
85 if earliest is not None:
86 try:
87 earliest = datetime.datetime.strptime(earliest, '%Y-%m-%d') \
88 .date()
89 except ValueError:
90 earliest = earliest_default
91 else:
92 earliest = earliest_default
93
94 latest = self.request.query_params.get('latest', None)
95 if latest is not None:
96 try:
97 latest = datetime.datetime.strptime(latest, '%Y-%m-%d').date()
98 except ValueError:
99 latest = latest_default
100 else:
101 latest = latest_default
102
103 return get_members(earliest, latest)
104
105 def get_query_params_description(self):
106 return {
107 'earliest': 'Date of earliest workshop someone taught at.'
108 ' Defaults to -2*365 days from current date.',
109 'latest': 'Date of latest workshop someone taught at.'
110 ' Defaults to current date.',
111 }
112
113
114 class PublishedEvents(ListAPIView):
115 """List published events."""
116
117 # only events that have both a starting date and a URL
118 permission_classes = (IsAuthenticatedOrReadOnly, )
119 paginator = None # disable pagination
120
121 serializer_class = EventSerializer
122
123 metadata_class = QueryMetadata
124
125 def get_queryset(self):
126 """Optionally restrict the returned event set to events hosted by
127 specific host or administered by specific admin."""
128 queryset = Event.objects.published_events()
129
130 administrator = self.request.query_params.get('administrator', None)
131 if administrator is not None:
132 queryset = queryset.filter(administrator__pk=administrator)
133
134 host = self.request.query_params.get('host', None)
135 if host is not None:
136 queryset = queryset.filter(host__pk=host)
137
138 tags = self.request.query_params.getlist('tag', None)
139 if tags:
140 tags = Tag.objects.filter(name__in=tags)
141 for tag in tags:
142 queryset = queryset.filter(tags=tag)
143
144 return queryset
145
146 def get_query_params_description(self):
147 return {
148 'administrator': 'ID of the organization responsible for admin '
149 'work on events.',
150 'host': 'ID of the organization hosting the event.',
151 'tag': "Events' tag(s). You can use this parameter multiple "
152 "times.",
153 }
154
155
156 class UserTodoItems(ListAPIView):
157 permission_classes = (IsAuthenticated, )
158 paginator = None
159 serializer_class = TodoSerializer
160
161 def get_queryset(self):
162 """Return current TODOs for currently logged in user."""
163 return TodoItem.objects.user(self.request.user) \
164 .incomplete() \
165 .exclude(due=None) \
166 .select_related('event')
167
[end of api/views.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/api/serializers.py b/api/serializers.py
--- a/api/serializers.py
+++ b/api/serializers.py
@@ -12,12 +12,12 @@
fields = ('name', 'user', )
-class PersonNameEmailSerializer(serializers.ModelSerializer):
+class PersonNameEmailUsernameSerializer(serializers.ModelSerializer):
name = serializers.CharField(source='get_full_name')
class Meta:
model = Person
- fields = ('name', 'email')
+ fields = ('name', 'email', 'username')
class ExportBadgesSerializer(serializers.ModelSerializer):
diff --git a/api/views.py b/api/views.py
--- a/api/views.py
+++ b/api/views.py
@@ -14,7 +14,7 @@
from workshops.util import get_members, default_membership_cutoff
from .serializers import (
- PersonNameEmailSerializer,
+ PersonNameEmailUsernameSerializer,
ExportBadgesSerializer,
ExportInstructorLocationsSerializer,
EventSerializer,
@@ -73,10 +73,10 @@
class ExportMembersView(ListAPIView):
"""Show everyone who qualifies as an SCF member."""
- permission_classes = (IsAuthenticatedOrReadOnly, )
+ permission_classes = (IsAuthenticated, )
paginator = None # disable pagination
- serializer_class = PersonNameEmailSerializer
+ serializer_class = PersonNameEmailUsernameSerializer
def get_queryset(self):
earliest_default, latest_default = default_membership_cutoff()
|
{"golden_diff": "diff --git a/api/serializers.py b/api/serializers.py\n--- a/api/serializers.py\n+++ b/api/serializers.py\n@@ -12,12 +12,12 @@\n fields = ('name', 'user', )\n \n \n-class PersonNameEmailSerializer(serializers.ModelSerializer):\n+class PersonNameEmailUsernameSerializer(serializers.ModelSerializer):\n name = serializers.CharField(source='get_full_name')\n \n class Meta:\n model = Person\n- fields = ('name', 'email')\n+ fields = ('name', 'email', 'username')\n \n \n class ExportBadgesSerializer(serializers.ModelSerializer):\ndiff --git a/api/views.py b/api/views.py\n--- a/api/views.py\n+++ b/api/views.py\n@@ -14,7 +14,7 @@\n from workshops.util import get_members, default_membership_cutoff\n \n from .serializers import (\n- PersonNameEmailSerializer,\n+ PersonNameEmailUsernameSerializer,\n ExportBadgesSerializer,\n ExportInstructorLocationsSerializer,\n EventSerializer,\n@@ -73,10 +73,10 @@\n \n class ExportMembersView(ListAPIView):\n \"\"\"Show everyone who qualifies as an SCF member.\"\"\"\n- permission_classes = (IsAuthenticatedOrReadOnly, )\n+ permission_classes = (IsAuthenticated, )\n paginator = None # disable pagination\n \n- serializer_class = PersonNameEmailSerializer\n+ serializer_class = PersonNameEmailUsernameSerializer\n \n def get_queryset(self):\n earliest_default, latest_default = default_membership_cutoff()\n", "issue": "Modify members API call so that JSON includes user ID\nRight now the 'members' API gives us name and email - the JSON should include each person's user ID as well.\n\n", "before_files": [{"content": "from rest_framework import serializers\n\nfrom workshops.models import Badge, Airport, Person, Event, TodoItem, Tag\n\n\nclass PersonUsernameSerializer(serializers.ModelSerializer):\n name = serializers.CharField(source='get_full_name')\n user = serializers.CharField(source='username')\n\n class Meta:\n model = Person\n fields = ('name', 'user', )\n\n\nclass PersonNameEmailSerializer(serializers.ModelSerializer):\n name = serializers.CharField(source='get_full_name')\n\n class Meta:\n model = Person\n fields = ('name', 'email')\n\n\nclass ExportBadgesSerializer(serializers.ModelSerializer):\n persons = PersonUsernameSerializer(many=True, source='person_set')\n\n class Meta:\n model = Badge\n fields = ('name', 'persons')\n\n\nclass ExportInstructorLocationsSerializer(serializers.ModelSerializer):\n name = serializers.CharField(source='fullname')\n instructors = PersonUsernameSerializer(many=True, source='person_set')\n\n class Meta:\n model = Airport\n fields = ('name', 'latitude', 'longitude', 'instructors', 'country')\n\n\nclass TagSerializer(serializers.ModelSerializer):\n class Meta:\n model = Tag\n fields = ('name', )\n\n\nclass EventSerializer(serializers.ModelSerializer):\n humandate = serializers.CharField(source='human_readable_date')\n country = serializers.CharField()\n start = serializers.DateField(format=None)\n end = serializers.DateField(format=None)\n url = serializers.URLField(source='website_url')\n eventbrite_id = serializers.CharField(source='reg_key')\n tags = TagSerializer(many=True)\n\n class Meta:\n model = Event\n fields = (\n 'slug', 'start', 'end', 'url', 'humandate', 'contact', 'country',\n 'venue', 'address', 'latitude', 'longitude', 'eventbrite_id',\n 'tags',\n )\n\n\nclass TodoSerializer(serializers.ModelSerializer):\n content = serializers.SerializerMethodField()\n start = serializers.DateField(format=None, source='due')\n\n class Meta:\n model = TodoItem\n fields = (\n 'content', 'start',\n )\n\n def get_content(self, obj):\n \"\"\"Return HTML containing interesting information for admins. This\n will be displayed on labels in the timeline.\"\"\"\n\n return '<a href=\"{url}\">{event}</a><br><small>{todo}</small>'.format(\n url=obj.event.get_absolute_url(),\n event=obj.event.get_ident(),\n todo=obj.title,\n )\n", "path": "api/serializers.py"}, {"content": "import datetime\n\nfrom django.db.models import Q\nfrom rest_framework.generics import ListAPIView\nfrom rest_framework.metadata import SimpleMetadata\nfrom rest_framework.permissions import (\n IsAuthenticatedOrReadOnly, IsAuthenticated\n)\nfrom rest_framework.response import Response\nfrom rest_framework.reverse import reverse\nfrom rest_framework.views import APIView\n\nfrom workshops.models import Badge, Airport, Event, TodoItem, Tag\nfrom workshops.util import get_members, default_membership_cutoff\n\nfrom .serializers import (\n PersonNameEmailSerializer,\n ExportBadgesSerializer,\n ExportInstructorLocationsSerializer,\n EventSerializer,\n TodoSerializer,\n)\n\n\nclass QueryMetadata(SimpleMetadata):\n \"\"\"Additionally include info about query parameters.\"\"\"\n\n def determine_metadata(self, request, view):\n data = super().determine_metadata(request, view)\n\n try:\n data['query_params'] = view.get_query_params_description()\n except AttributeError:\n pass\n\n return data\n\n\nclass ApiRoot(APIView):\n def get(self, request, format=None):\n return Response({\n 'export-badges': reverse('api:export-badges', request=request,\n format=format),\n 'export-instructors': reverse('api:export-instructors',\n request=request, format=format),\n 'export-members': reverse('api:export-members', request=request,\n format=format),\n 'events-published': reverse('api:events-published',\n request=request, format=format),\n 'user-todos': reverse('api:user-todos',\n request=request, format=format),\n })\n\n\nclass ExportBadgesView(ListAPIView):\n \"\"\"List all badges and people who have them.\"\"\"\n permission_classes = (IsAuthenticatedOrReadOnly, )\n paginator = None # disable pagination\n\n queryset = Badge.objects.prefetch_related('person_set')\n serializer_class = ExportBadgesSerializer\n\n\nclass ExportInstructorLocationsView(ListAPIView):\n \"\"\"List all airports and instructors located near them.\"\"\"\n permission_classes = (IsAuthenticatedOrReadOnly, )\n paginator = None # disable pagination\n\n queryset = Airport.objects.exclude(person=None) \\\n .prefetch_related('person_set')\n serializer_class = ExportInstructorLocationsSerializer\n\n\nclass ExportMembersView(ListAPIView):\n \"\"\"Show everyone who qualifies as an SCF member.\"\"\"\n permission_classes = (IsAuthenticatedOrReadOnly, )\n paginator = None # disable pagination\n\n serializer_class = PersonNameEmailSerializer\n\n def get_queryset(self):\n earliest_default, latest_default = default_membership_cutoff()\n\n earliest = self.request.query_params.get('earliest', None)\n if earliest is not None:\n try:\n earliest = datetime.datetime.strptime(earliest, '%Y-%m-%d') \\\n .date()\n except ValueError:\n earliest = earliest_default\n else:\n earliest = earliest_default\n\n latest = self.request.query_params.get('latest', None)\n if latest is not None:\n try:\n latest = datetime.datetime.strptime(latest, '%Y-%m-%d').date()\n except ValueError:\n latest = latest_default\n else:\n latest = latest_default\n\n return get_members(earliest, latest)\n\n def get_query_params_description(self):\n return {\n 'earliest': 'Date of earliest workshop someone taught at.'\n ' Defaults to -2*365 days from current date.',\n 'latest': 'Date of latest workshop someone taught at.'\n ' Defaults to current date.',\n }\n\n\nclass PublishedEvents(ListAPIView):\n \"\"\"List published events.\"\"\"\n\n # only events that have both a starting date and a URL\n permission_classes = (IsAuthenticatedOrReadOnly, )\n paginator = None # disable pagination\n\n serializer_class = EventSerializer\n\n metadata_class = QueryMetadata\n\n def get_queryset(self):\n \"\"\"Optionally restrict the returned event set to events hosted by\n specific host or administered by specific admin.\"\"\"\n queryset = Event.objects.published_events()\n\n administrator = self.request.query_params.get('administrator', None)\n if administrator is not None:\n queryset = queryset.filter(administrator__pk=administrator)\n\n host = self.request.query_params.get('host', None)\n if host is not None:\n queryset = queryset.filter(host__pk=host)\n\n tags = self.request.query_params.getlist('tag', None)\n if tags:\n tags = Tag.objects.filter(name__in=tags)\n for tag in tags:\n queryset = queryset.filter(tags=tag)\n\n return queryset\n\n def get_query_params_description(self):\n return {\n 'administrator': 'ID of the organization responsible for admin '\n 'work on events.',\n 'host': 'ID of the organization hosting the event.',\n 'tag': \"Events' tag(s). You can use this parameter multiple \"\n \"times.\",\n }\n\n\nclass UserTodoItems(ListAPIView):\n permission_classes = (IsAuthenticated, )\n paginator = None\n serializer_class = TodoSerializer\n\n def get_queryset(self):\n \"\"\"Return current TODOs for currently logged in user.\"\"\"\n return TodoItem.objects.user(self.request.user) \\\n .incomplete() \\\n .exclude(due=None) \\\n .select_related('event')\n", "path": "api/views.py"}]}
| 2,748 | 316 |
gh_patches_debug_4044
|
rasdani/github-patches
|
git_diff
|
dask__dask-2003
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
dask.array test failures on OS X
Got this on an OS X machine where I ran the test suite out of curiosity (with Python 3.6):
```
____________________________________________________________________________ test_coarsen ____________________________________________________________________________
Traceback (most recent call last):
File "/Users/buildbot/antoine/dask/dask/array/tests/test_array_core.py", line 628, in test_coarsen
assert_eq(chunk.coarsen(np.sum, x, {0: 2, 1: 4}),
File "/Users/buildbot/antoine/dask/dask/array/chunk.py", line 148, in coarsen
return reduction(x.reshape(newshape), axis=tuple(range(1, x.ndim * 2, 2)))
TypeError: 'float' object cannot be interpreted as an integer
______________________________________________________________________ test_coarsen_with_excess ______________________________________________________________________
Traceback (most recent call last):
File "/Users/buildbot/antoine/dask/dask/array/tests/test_array_core.py", line 637, in test_coarsen_with_excess
np.array([0, 5]))
File "/Users/buildbot/antoine/dask/dask/array/utils.py", line 51, in assert_eq
a = a.compute(get=get_sync)
File "/Users/buildbot/antoine/dask/dask/base.py", line 94, in compute
(result,) = compute(self, traverse=False, **kwargs)
File "/Users/buildbot/antoine/dask/dask/base.py", line 201, in compute
results = get(dsk, keys, **kwargs)
File "/Users/buildbot/antoine/dask/dask/async.py", line 544, in get_sync
raise_on_exception=True, **kwargs)
File "/Users/buildbot/antoine/dask/dask/async.py", line 487, in get_async
fire_task()
File "/Users/buildbot/antoine/dask/dask/async.py", line 483, in fire_task
callback=queue.put)
File "/Users/buildbot/antoine/dask/dask/async.py", line 532, in apply_sync
res = func(*args, **kwds)
File "/Users/buildbot/antoine/dask/dask/async.py", line 266, in execute_task
result = _execute_task(task, data)
File "/Users/buildbot/antoine/dask/dask/async.py", line 247, in _execute_task
return func(*args2)
File "/Users/buildbot/antoine/dask/dask/array/chunk.py", line 148, in coarsen
return reduction(x.reshape(newshape), axis=tuple(range(1, x.ndim * 2, 2)))
TypeError: 'float' object cannot be interpreted as an integer
____________________________________________________________________________ test_coarsen ____________________________________________________________________________
Traceback (most recent call last):
File "/Users/buildbot/antoine/dask/dask/array/tests/test_chunk.py", line 98, in test_coarsen
y = coarsen(np.sum, x, {0: 2, 1: 4})
File "/Users/buildbot/antoine/dask/dask/array/chunk.py", line 148, in coarsen
return reduction(x.reshape(newshape), axis=tuple(range(1, x.ndim * 2, 2)))
TypeError: 'float' object cannot be interpreted as an integer
```
</issue>
<code>
[start of dask/array/chunk.py]
1 """ A set of NumPy functions to apply per chunk """
2 from __future__ import absolute_import, division, print_function
3
4 from collections import Container, Iterable, Sequence
5 from functools import wraps
6
7 from toolz import concat
8 import numpy as np
9 from . import numpy_compat as npcompat
10
11 from ..compatibility import getargspec
12 from ..utils import ignoring
13
14
15 def keepdims_wrapper(a_callable):
16 """
17 A wrapper for functions that don't provide keepdims to ensure that they do.
18 """
19
20 if "keepdims" in getargspec(a_callable).args:
21 return a_callable
22
23 @wraps(a_callable)
24 def keepdims_wrapped_callable(x, axis=None, keepdims=None, *args, **kwargs):
25 r = a_callable(x, axis=axis, *args, **kwargs)
26
27 if not keepdims:
28 return r
29
30 axes = axis
31
32 if axes is None:
33 axes = range(x.ndim)
34
35 if not isinstance(axes, (Container, Iterable, Sequence)):
36 axes = [axes]
37
38 r_slice = tuple()
39 for each_axis in range(x.ndim):
40 if each_axis in axes:
41 r_slice += (None,)
42 else:
43 r_slice += (slice(None),)
44
45 r = r[r_slice]
46
47 return r
48
49 return keepdims_wrapped_callable
50
51
52 # Wrap NumPy functions to ensure they provide keepdims.
53 sum = keepdims_wrapper(np.sum)
54 prod = keepdims_wrapper(np.prod)
55 min = keepdims_wrapper(np.min)
56 max = keepdims_wrapper(np.max)
57 argmin = keepdims_wrapper(np.argmin)
58 nanargmin = keepdims_wrapper(np.nanargmin)
59 argmax = keepdims_wrapper(np.argmax)
60 nanargmax = keepdims_wrapper(np.nanargmax)
61 any = keepdims_wrapper(np.any)
62 all = keepdims_wrapper(np.all)
63 nansum = keepdims_wrapper(np.nansum)
64
65 try:
66 from numpy import nanprod, nancumprod, nancumsum
67 except ImportError: # pragma: no cover
68 nanprod = npcompat.nanprod
69 nancumprod = npcompat.nancumprod
70 nancumsum = npcompat.nancumsum
71
72 nanprod = keepdims_wrapper(nanprod)
73 nancumprod = keepdims_wrapper(nancumprod)
74 nancumsum = keepdims_wrapper(nancumsum)
75
76 nanmin = keepdims_wrapper(np.nanmin)
77 nanmax = keepdims_wrapper(np.nanmax)
78 mean = keepdims_wrapper(np.mean)
79
80 with ignoring(AttributeError):
81 nanmean = keepdims_wrapper(np.nanmean)
82
83 var = keepdims_wrapper(np.var)
84
85 with ignoring(AttributeError):
86 nanvar = keepdims_wrapper(np.nanvar)
87
88 std = keepdims_wrapper(np.std)
89
90 with ignoring(AttributeError):
91 nanstd = keepdims_wrapper(np.nanstd)
92
93
94 def coarsen(reduction, x, axes, trim_excess=False):
95 """ Coarsen array by applying reduction to fixed size neighborhoods
96
97 Parameters
98 ----------
99 reduction: function
100 Function like np.sum, np.mean, etc...
101 x: np.ndarray
102 Array to be coarsened
103 axes: dict
104 Mapping of axis to coarsening factor
105
106 Examples
107 --------
108 >>> x = np.array([1, 2, 3, 4, 5, 6])
109 >>> coarsen(np.sum, x, {0: 2})
110 array([ 3, 7, 11])
111 >>> coarsen(np.max, x, {0: 3})
112 array([3, 6])
113
114 Provide dictionary of scale per dimension
115
116 >>> x = np.arange(24).reshape((4, 6))
117 >>> x
118 array([[ 0, 1, 2, 3, 4, 5],
119 [ 6, 7, 8, 9, 10, 11],
120 [12, 13, 14, 15, 16, 17],
121 [18, 19, 20, 21, 22, 23]])
122
123 >>> coarsen(np.min, x, {0: 2, 1: 3})
124 array([[ 0, 3],
125 [12, 15]])
126
127 You must avoid excess elements explicitly
128
129 >>> x = np.array([1, 2, 3, 4, 5, 6, 7, 8])
130 >>> coarsen(np.min, x, {0: 3}, trim_excess=True)
131 array([1, 4])
132 """
133 # Insert singleton dimensions if they don't exist already
134 for i in range(x.ndim):
135 if i not in axes:
136 axes[i] = 1
137
138 if trim_excess:
139 ind = tuple(slice(0, -(d % axes[i]))
140 if d % axes[i] else
141 slice(None, None) for i, d in enumerate(x.shape))
142 x = x[ind]
143
144 # (10, 10) -> (5, 2, 5, 2)
145 newshape = tuple(concat([(x.shape[i] / axes[i], axes[i])
146 for i in range(x.ndim)]))
147
148 return reduction(x.reshape(newshape), axis=tuple(range(1, x.ndim * 2, 2)))
149
150
151 def trim(x, axes=None):
152 """ Trim boundaries off of array
153
154 >>> x = np.arange(24).reshape((4, 6))
155 >>> trim(x, axes={0: 0, 1: 1})
156 array([[ 1, 2, 3, 4],
157 [ 7, 8, 9, 10],
158 [13, 14, 15, 16],
159 [19, 20, 21, 22]])
160
161 >>> trim(x, axes={0: 1, 1: 1})
162 array([[ 7, 8, 9, 10],
163 [13, 14, 15, 16]])
164 """
165 if isinstance(axes, int):
166 axes = [axes] * x.ndim
167 if isinstance(axes, dict):
168 axes = [axes.get(i, 0) for i in range(x.ndim)]
169
170 return x[tuple(slice(ax, -ax if ax else None) for ax in axes)]
171
172
173 try:
174 from numpy import broadcast_to
175 except ImportError: # pragma: no cover
176 broadcast_to = npcompat.broadcast_to
177
178
179 def topk(k, x):
180 """ Top k elements of an array
181
182 >>> topk(2, np.array([5, 1, 3, 6]))
183 array([6, 5])
184 """
185 # http://stackoverflow.com/a/23734295/616616 by larsmans
186 k = np.minimum(k, len(x))
187 ind = np.argpartition(x, -k)[-k:]
188 return np.sort(x[ind])[::-1]
189
190
191 def arange(start, stop, step, length, dtype):
192 res = np.arange(start, stop, step, dtype)
193 return res[:-1] if len(res) > length else res
194
[end of dask/array/chunk.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/dask/array/chunk.py b/dask/array/chunk.py
--- a/dask/array/chunk.py
+++ b/dask/array/chunk.py
@@ -142,7 +142,7 @@
x = x[ind]
# (10, 10) -> (5, 2, 5, 2)
- newshape = tuple(concat([(x.shape[i] / axes[i], axes[i])
+ newshape = tuple(concat([(x.shape[i] // axes[i], axes[i])
for i in range(x.ndim)]))
return reduction(x.reshape(newshape), axis=tuple(range(1, x.ndim * 2, 2)))
|
{"golden_diff": "diff --git a/dask/array/chunk.py b/dask/array/chunk.py\n--- a/dask/array/chunk.py\n+++ b/dask/array/chunk.py\n@@ -142,7 +142,7 @@\n x = x[ind]\n \n # (10, 10) -> (5, 2, 5, 2)\n- newshape = tuple(concat([(x.shape[i] / axes[i], axes[i])\n+ newshape = tuple(concat([(x.shape[i] // axes[i], axes[i])\n for i in range(x.ndim)]))\n \n return reduction(x.reshape(newshape), axis=tuple(range(1, x.ndim * 2, 2)))\n", "issue": "dask.array test failures on OS X\nGot this on an OS X machine where I ran the test suite out of curiosity (with Python 3.6):\r\n```\r\n____________________________________________________________________________ test_coarsen ____________________________________________________________________________\r\nTraceback (most recent call last):\r\n File \"/Users/buildbot/antoine/dask/dask/array/tests/test_array_core.py\", line 628, in test_coarsen\r\n assert_eq(chunk.coarsen(np.sum, x, {0: 2, 1: 4}),\r\n File \"/Users/buildbot/antoine/dask/dask/array/chunk.py\", line 148, in coarsen\r\n return reduction(x.reshape(newshape), axis=tuple(range(1, x.ndim * 2, 2)))\r\nTypeError: 'float' object cannot be interpreted as an integer\r\n______________________________________________________________________ test_coarsen_with_excess ______________________________________________________________________\r\nTraceback (most recent call last):\r\n File \"/Users/buildbot/antoine/dask/dask/array/tests/test_array_core.py\", line 637, in test_coarsen_with_excess\r\n np.array([0, 5]))\r\n File \"/Users/buildbot/antoine/dask/dask/array/utils.py\", line 51, in assert_eq\r\n a = a.compute(get=get_sync)\r\n File \"/Users/buildbot/antoine/dask/dask/base.py\", line 94, in compute\r\n (result,) = compute(self, traverse=False, **kwargs)\r\n File \"/Users/buildbot/antoine/dask/dask/base.py\", line 201, in compute\r\n results = get(dsk, keys, **kwargs)\r\n File \"/Users/buildbot/antoine/dask/dask/async.py\", line 544, in get_sync\r\n raise_on_exception=True, **kwargs)\r\n File \"/Users/buildbot/antoine/dask/dask/async.py\", line 487, in get_async\r\n fire_task()\r\n File \"/Users/buildbot/antoine/dask/dask/async.py\", line 483, in fire_task\r\n callback=queue.put)\r\n File \"/Users/buildbot/antoine/dask/dask/async.py\", line 532, in apply_sync\r\n res = func(*args, **kwds)\r\n File \"/Users/buildbot/antoine/dask/dask/async.py\", line 266, in execute_task\r\n result = _execute_task(task, data)\r\n File \"/Users/buildbot/antoine/dask/dask/async.py\", line 247, in _execute_task\r\n return func(*args2)\r\n File \"/Users/buildbot/antoine/dask/dask/array/chunk.py\", line 148, in coarsen\r\n return reduction(x.reshape(newshape), axis=tuple(range(1, x.ndim * 2, 2)))\r\nTypeError: 'float' object cannot be interpreted as an integer\r\n____________________________________________________________________________ test_coarsen ____________________________________________________________________________\r\nTraceback (most recent call last):\r\n File \"/Users/buildbot/antoine/dask/dask/array/tests/test_chunk.py\", line 98, in test_coarsen\r\n y = coarsen(np.sum, x, {0: 2, 1: 4})\r\n File \"/Users/buildbot/antoine/dask/dask/array/chunk.py\", line 148, in coarsen\r\n return reduction(x.reshape(newshape), axis=tuple(range(1, x.ndim * 2, 2)))\r\nTypeError: 'float' object cannot be interpreted as an integer\r\n```\r\n\n", "before_files": [{"content": "\"\"\" A set of NumPy functions to apply per chunk \"\"\"\nfrom __future__ import absolute_import, division, print_function\n\nfrom collections import Container, Iterable, Sequence\nfrom functools import wraps\n\nfrom toolz import concat\nimport numpy as np\nfrom . import numpy_compat as npcompat\n\nfrom ..compatibility import getargspec\nfrom ..utils import ignoring\n\n\ndef keepdims_wrapper(a_callable):\n \"\"\"\n A wrapper for functions that don't provide keepdims to ensure that they do.\n \"\"\"\n\n if \"keepdims\" in getargspec(a_callable).args:\n return a_callable\n\n @wraps(a_callable)\n def keepdims_wrapped_callable(x, axis=None, keepdims=None, *args, **kwargs):\n r = a_callable(x, axis=axis, *args, **kwargs)\n\n if not keepdims:\n return r\n\n axes = axis\n\n if axes is None:\n axes = range(x.ndim)\n\n if not isinstance(axes, (Container, Iterable, Sequence)):\n axes = [axes]\n\n r_slice = tuple()\n for each_axis in range(x.ndim):\n if each_axis in axes:\n r_slice += (None,)\n else:\n r_slice += (slice(None),)\n\n r = r[r_slice]\n\n return r\n\n return keepdims_wrapped_callable\n\n\n# Wrap NumPy functions to ensure they provide keepdims.\nsum = keepdims_wrapper(np.sum)\nprod = keepdims_wrapper(np.prod)\nmin = keepdims_wrapper(np.min)\nmax = keepdims_wrapper(np.max)\nargmin = keepdims_wrapper(np.argmin)\nnanargmin = keepdims_wrapper(np.nanargmin)\nargmax = keepdims_wrapper(np.argmax)\nnanargmax = keepdims_wrapper(np.nanargmax)\nany = keepdims_wrapper(np.any)\nall = keepdims_wrapper(np.all)\nnansum = keepdims_wrapper(np.nansum)\n\ntry:\n from numpy import nanprod, nancumprod, nancumsum\nexcept ImportError: # pragma: no cover\n nanprod = npcompat.nanprod\n nancumprod = npcompat.nancumprod\n nancumsum = npcompat.nancumsum\n\nnanprod = keepdims_wrapper(nanprod)\nnancumprod = keepdims_wrapper(nancumprod)\nnancumsum = keepdims_wrapper(nancumsum)\n\nnanmin = keepdims_wrapper(np.nanmin)\nnanmax = keepdims_wrapper(np.nanmax)\nmean = keepdims_wrapper(np.mean)\n\nwith ignoring(AttributeError):\n nanmean = keepdims_wrapper(np.nanmean)\n\nvar = keepdims_wrapper(np.var)\n\nwith ignoring(AttributeError):\n nanvar = keepdims_wrapper(np.nanvar)\n\nstd = keepdims_wrapper(np.std)\n\nwith ignoring(AttributeError):\n nanstd = keepdims_wrapper(np.nanstd)\n\n\ndef coarsen(reduction, x, axes, trim_excess=False):\n \"\"\" Coarsen array by applying reduction to fixed size neighborhoods\n\n Parameters\n ----------\n reduction: function\n Function like np.sum, np.mean, etc...\n x: np.ndarray\n Array to be coarsened\n axes: dict\n Mapping of axis to coarsening factor\n\n Examples\n --------\n >>> x = np.array([1, 2, 3, 4, 5, 6])\n >>> coarsen(np.sum, x, {0: 2})\n array([ 3, 7, 11])\n >>> coarsen(np.max, x, {0: 3})\n array([3, 6])\n\n Provide dictionary of scale per dimension\n\n >>> x = np.arange(24).reshape((4, 6))\n >>> x\n array([[ 0, 1, 2, 3, 4, 5],\n [ 6, 7, 8, 9, 10, 11],\n [12, 13, 14, 15, 16, 17],\n [18, 19, 20, 21, 22, 23]])\n\n >>> coarsen(np.min, x, {0: 2, 1: 3})\n array([[ 0, 3],\n [12, 15]])\n\n You must avoid excess elements explicitly\n\n >>> x = np.array([1, 2, 3, 4, 5, 6, 7, 8])\n >>> coarsen(np.min, x, {0: 3}, trim_excess=True)\n array([1, 4])\n \"\"\"\n # Insert singleton dimensions if they don't exist already\n for i in range(x.ndim):\n if i not in axes:\n axes[i] = 1\n\n if trim_excess:\n ind = tuple(slice(0, -(d % axes[i]))\n if d % axes[i] else\n slice(None, None) for i, d in enumerate(x.shape))\n x = x[ind]\n\n # (10, 10) -> (5, 2, 5, 2)\n newshape = tuple(concat([(x.shape[i] / axes[i], axes[i])\n for i in range(x.ndim)]))\n\n return reduction(x.reshape(newshape), axis=tuple(range(1, x.ndim * 2, 2)))\n\n\ndef trim(x, axes=None):\n \"\"\" Trim boundaries off of array\n\n >>> x = np.arange(24).reshape((4, 6))\n >>> trim(x, axes={0: 0, 1: 1})\n array([[ 1, 2, 3, 4],\n [ 7, 8, 9, 10],\n [13, 14, 15, 16],\n [19, 20, 21, 22]])\n\n >>> trim(x, axes={0: 1, 1: 1})\n array([[ 7, 8, 9, 10],\n [13, 14, 15, 16]])\n \"\"\"\n if isinstance(axes, int):\n axes = [axes] * x.ndim\n if isinstance(axes, dict):\n axes = [axes.get(i, 0) for i in range(x.ndim)]\n\n return x[tuple(slice(ax, -ax if ax else None) for ax in axes)]\n\n\ntry:\n from numpy import broadcast_to\nexcept ImportError: # pragma: no cover\n broadcast_to = npcompat.broadcast_to\n\n\ndef topk(k, x):\n \"\"\" Top k elements of an array\n\n >>> topk(2, np.array([5, 1, 3, 6]))\n array([6, 5])\n \"\"\"\n # http://stackoverflow.com/a/23734295/616616 by larsmans\n k = np.minimum(k, len(x))\n ind = np.argpartition(x, -k)[-k:]\n return np.sort(x[ind])[::-1]\n\n\ndef arange(start, stop, step, length, dtype):\n res = np.arange(start, stop, step, dtype)\n return res[:-1] if len(res) > length else res\n", "path": "dask/array/chunk.py"}]}
| 3,388 | 152 |
gh_patches_debug_21253
|
rasdani/github-patches
|
git_diff
|
streamlit__streamlit-7061
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Some labels in Altair charts are hard to see in dark mode
### Summary
Streamlit has an awesome feature where it changes the label colors of Altair charts when you switch to dark mode. Sweet!
However, it seems that some labels were omitted and thus remain almost illegibly dark in dark mode.
### Steps to reproduce
Run this code snippet [taken from the Altair documentation](https://altair-viz.github.io/gallery/grouped_bar_chart.html):
```python
from vega_datasets import data
st.subheader("barley example")
source = data.barley()
st.write(source)
st.write(
alt.Chart(source)
.mark_bar()
.encode(x="year:O", y="sum(yield):Q", color="year:N", column="site:N")
)
```
### Expected vs actual behavior
In light mode it displays properly:

but in dark mode some of the labels have remained black and are almost impossible to read:

**Note:** I have marked the errors in red.
### Is this a regression?
Not sure.
### Debug info
- Streamlit version: `Streamlit, version 0.82.0`
- Python version: `Python 3.8.5`
- PipEnv: `pipenv, version 2020.11.15`
- OS version: `Ubuntu 20.04.2 LTS`
- Browser version: `Version 91.0.4472.77 (Official Build) (x86_64)`
</issue>
<code>
[start of e2e/scripts/st_arrow_altair_chart.py]
1 # Copyright (c) Streamlit Inc. (2018-2022) Snowflake Inc. (2022)
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 import altair as alt
16 import numpy as np
17 import pandas as pd
18
19 import streamlit as st
20
21 np.random.seed(0)
22
23 data = np.random.randn(200, 3)
24 df = pd.DataFrame(data, columns=["a", "b", "c"])
25 chart = alt.Chart(df).mark_circle().encode(x="a", y="b", size="c", color="c")
26 st._arrow_altair_chart(chart, theme=None)
27
28 st.write("Show default vega lite theme:")
29 st._arrow_altair_chart(chart, theme=None)
30
31 st.write("Show streamlit theme:")
32 st._arrow_altair_chart(chart, theme="streamlit")
33
34 st.write("Overwrite theme config:")
35 chart = (
36 alt.Chart(df, usermeta={"embedOptions": {"theme": None}})
37 .mark_circle()
38 .encode(x="a", y="b", size="c", color="c")
39 )
40 st._arrow_altair_chart(chart, theme="streamlit")
41
42 data = pd.DataFrame(
43 {
44 "a": ["A", "B", "C", "D", "E", "F", "G", "H", "I"],
45 "b": [28, 55, 43, 91, 81, 53, 19, 87, 52],
46 }
47 )
48
49 chart = alt.Chart(data).mark_bar().encode(x="a", y="b")
50
51 st.write("Bar chart with default theme:")
52 st._arrow_altair_chart(chart)
53
54 st.write("Bar chart with streamlit theme:")
55 st._arrow_altair_chart(chart, theme="streamlit")
56
57 st.write("Bar chart with overwritten theme props:")
58 st._arrow_altair_chart(chart.configure_mark(color="black"), theme="streamlit")
59
60 # mark_arc was added in 4.2, but we have to support altair 4.0-4.1, so we
61 # have to skip this part of the test when testing min versions.
62 major, minor, patch = alt.__version__.split(".")
63 if not (major == "4" and minor < "2"):
64
65 source = pd.DataFrame(
66 {"category": [1, 2, 3, 4, 5, 6], "value": [4, 6, 10, 3, 7, 8]}
67 )
68
69 chart = (
70 alt.Chart(source)
71 .mark_arc(innerRadius=50)
72 .encode(
73 theta=alt.Theta(field="value", type="quantitative"),
74 color=alt.Color(field="category", type="nominal"),
75 )
76 )
77
78 st.write("Pie Chart with more than 4 Legend items")
79 st._arrow_altair_chart(chart, theme="streamlit")
80
[end of e2e/scripts/st_arrow_altair_chart.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/e2e/scripts/st_arrow_altair_chart.py b/e2e/scripts/st_arrow_altair_chart.py
--- a/e2e/scripts/st_arrow_altair_chart.py
+++ b/e2e/scripts/st_arrow_altair_chart.py
@@ -48,12 +48,6 @@
chart = alt.Chart(data).mark_bar().encode(x="a", y="b")
-st.write("Bar chart with default theme:")
-st._arrow_altair_chart(chart)
-
-st.write("Bar chart with streamlit theme:")
-st._arrow_altair_chart(chart, theme="streamlit")
-
st.write("Bar chart with overwritten theme props:")
st._arrow_altair_chart(chart.configure_mark(color="black"), theme="streamlit")
@@ -77,3 +71,20 @@
st.write("Pie Chart with more than 4 Legend items")
st._arrow_altair_chart(chart, theme="streamlit")
+
+# taken from vega_datasets barley example
+barley = alt.UrlData(
+ "https://cdn.jsdelivr.net/npm/[email protected]/data/barley.json"
+)
+
+barley_chart = (
+ alt.Chart(barley)
+ .mark_bar()
+ .encode(x="year:O", y="sum(yield):Q", color="year:N", column="site:N")
+)
+
+st.write("Grouped Bar Chart with default theme:")
+st.altair_chart(barley_chart, theme=None)
+
+st.write("Grouped Bar Chart with streamlit theme:")
+st.altair_chart(barley_chart, theme="streamlit")
|
{"golden_diff": "diff --git a/e2e/scripts/st_arrow_altair_chart.py b/e2e/scripts/st_arrow_altair_chart.py\n--- a/e2e/scripts/st_arrow_altair_chart.py\n+++ b/e2e/scripts/st_arrow_altair_chart.py\n@@ -48,12 +48,6 @@\n \n chart = alt.Chart(data).mark_bar().encode(x=\"a\", y=\"b\")\n \n-st.write(\"Bar chart with default theme:\")\n-st._arrow_altair_chart(chart)\n-\n-st.write(\"Bar chart with streamlit theme:\")\n-st._arrow_altair_chart(chart, theme=\"streamlit\")\n-\n st.write(\"Bar chart with overwritten theme props:\")\n st._arrow_altair_chart(chart.configure_mark(color=\"black\"), theme=\"streamlit\")\n \n@@ -77,3 +71,20 @@\n \n st.write(\"Pie Chart with more than 4 Legend items\")\n st._arrow_altair_chart(chart, theme=\"streamlit\")\n+\n+# taken from vega_datasets barley example\n+barley = alt.UrlData(\n+ \"https://cdn.jsdelivr.net/npm/[email protected]/data/barley.json\"\n+)\n+\n+barley_chart = (\n+ alt.Chart(barley)\n+ .mark_bar()\n+ .encode(x=\"year:O\", y=\"sum(yield):Q\", color=\"year:N\", column=\"site:N\")\n+)\n+\n+st.write(\"Grouped Bar Chart with default theme:\")\n+st.altair_chart(barley_chart, theme=None)\n+\n+st.write(\"Grouped Bar Chart with streamlit theme:\")\n+st.altair_chart(barley_chart, theme=\"streamlit\")\n", "issue": "Some labels in Altair charts are hard to see in dark mode\n### Summary\r\n\r\nStreamlit has an awesome feature where it changes the label colors of Altair charts when you switch to dark mode. Sweet!\r\n\r\nHowever, it seems that some labels were omitted and thus remain almost illegibly dark in dark mode.\r\n\r\n### Steps to reproduce\r\n\r\nRun this code snippet [taken from the Altair documentation](https://altair-viz.github.io/gallery/grouped_bar_chart.html):\r\n\r\n```python\r\nfrom vega_datasets import data\r\n\r\nst.subheader(\"barley example\")\r\nsource = data.barley()\r\nst.write(source)\r\nst.write(\r\n alt.Chart(source)\r\n .mark_bar()\r\n .encode(x=\"year:O\", y=\"sum(yield):Q\", color=\"year:N\", column=\"site:N\")\r\n)\r\n```\r\n\r\n### Expected vs actual behavior\r\n\r\nIn light mode it displays properly:\r\n\r\n\r\n\r\nbut in dark mode some of the labels have remained black and are almost impossible to read:\r\n\r\n\r\n\r\n**Note:** I have marked the errors in red.\r\n\r\n### Is this a regression?\r\n\r\nNot sure.\r\n\r\n### Debug info\r\n\r\n- Streamlit version: `Streamlit, version 0.82.0`\r\n- Python version: `Python 3.8.5`\r\n- PipEnv: `pipenv, version 2020.11.15`\r\n- OS version: `Ubuntu 20.04.2 LTS`\r\n- Browser version: `Version 91.0.4472.77 (Official Build) (x86_64)`\r\n\n", "before_files": [{"content": "# Copyright (c) Streamlit Inc. (2018-2022) Snowflake Inc. (2022)\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport altair as alt\nimport numpy as np\nimport pandas as pd\n\nimport streamlit as st\n\nnp.random.seed(0)\n\ndata = np.random.randn(200, 3)\ndf = pd.DataFrame(data, columns=[\"a\", \"b\", \"c\"])\nchart = alt.Chart(df).mark_circle().encode(x=\"a\", y=\"b\", size=\"c\", color=\"c\")\nst._arrow_altair_chart(chart, theme=None)\n\nst.write(\"Show default vega lite theme:\")\nst._arrow_altair_chart(chart, theme=None)\n\nst.write(\"Show streamlit theme:\")\nst._arrow_altair_chart(chart, theme=\"streamlit\")\n\nst.write(\"Overwrite theme config:\")\nchart = (\n alt.Chart(df, usermeta={\"embedOptions\": {\"theme\": None}})\n .mark_circle()\n .encode(x=\"a\", y=\"b\", size=\"c\", color=\"c\")\n)\nst._arrow_altair_chart(chart, theme=\"streamlit\")\n\ndata = pd.DataFrame(\n {\n \"a\": [\"A\", \"B\", \"C\", \"D\", \"E\", \"F\", \"G\", \"H\", \"I\"],\n \"b\": [28, 55, 43, 91, 81, 53, 19, 87, 52],\n }\n)\n\nchart = alt.Chart(data).mark_bar().encode(x=\"a\", y=\"b\")\n\nst.write(\"Bar chart with default theme:\")\nst._arrow_altair_chart(chart)\n\nst.write(\"Bar chart with streamlit theme:\")\nst._arrow_altair_chart(chart, theme=\"streamlit\")\n\nst.write(\"Bar chart with overwritten theme props:\")\nst._arrow_altair_chart(chart.configure_mark(color=\"black\"), theme=\"streamlit\")\n\n# mark_arc was added in 4.2, but we have to support altair 4.0-4.1, so we\n# have to skip this part of the test when testing min versions.\nmajor, minor, patch = alt.__version__.split(\".\")\nif not (major == \"4\" and minor < \"2\"):\n\n source = pd.DataFrame(\n {\"category\": [1, 2, 3, 4, 5, 6], \"value\": [4, 6, 10, 3, 7, 8]}\n )\n\n chart = (\n alt.Chart(source)\n .mark_arc(innerRadius=50)\n .encode(\n theta=alt.Theta(field=\"value\", type=\"quantitative\"),\n color=alt.Color(field=\"category\", type=\"nominal\"),\n )\n )\n\n st.write(\"Pie Chart with more than 4 Legend items\")\n st._arrow_altair_chart(chart, theme=\"streamlit\")\n", "path": "e2e/scripts/st_arrow_altair_chart.py"}]}
| 1,887 | 347 |
gh_patches_debug_39555
|
rasdani/github-patches
|
git_diff
|
python-discord__bot-703
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Username, discriminator, and avatar changes are not synced with the database
At the moment, we do not synchronize changes in the username, discriminator, or avatar hash of our members with the database. The reason is that we only check for changes with an [`on_member_update` event listener](https://github.com/python-discord/bot/blob/a4f9d2a5323ca492e895ebd80a1515488b0c3e6c/bot/cogs/sync/cog.py#L145) and the changes listed above fire an [`on_user_update`](https://discordpy.readthedocs.io/en/latest/api.html#discord.on_user_update) event, not an [`on_member_update`](https://discordpy.readthedocs.io/en/latest/api.html#discord.on_member_update) event.
The solution is simple: Add an `on_user_update` event listener that looks for avatar, username, and discriminator changes and let the `on_member_update` look for changes in the roles of the member.
</issue>
<code>
[start of bot/cogs/sync/cog.py]
1 import logging
2 from typing import Callable, Iterable
3
4 from discord import Guild, Member, Role
5 from discord.ext import commands
6 from discord.ext.commands import Cog, Context
7
8 from bot import constants
9 from bot.api import ResponseCodeError
10 from bot.bot import Bot
11 from bot.cogs.sync import syncers
12
13 log = logging.getLogger(__name__)
14
15
16 class Sync(Cog):
17 """Captures relevant events and sends them to the site."""
18
19 # The server to synchronize events on.
20 # Note that setting this wrongly will result in things getting deleted
21 # that possibly shouldn't be.
22 SYNC_SERVER_ID = constants.Guild.id
23
24 # An iterable of callables that are called when the bot is ready.
25 ON_READY_SYNCERS: Iterable[Callable[[Bot, Guild], None]] = (
26 syncers.sync_roles,
27 syncers.sync_users
28 )
29
30 def __init__(self, bot: Bot) -> None:
31 self.bot = bot
32
33 self.bot.loop.create_task(self.sync_guild())
34
35 async def sync_guild(self) -> None:
36 """Syncs the roles/users of the guild with the database."""
37 await self.bot.wait_until_ready()
38 guild = self.bot.get_guild(self.SYNC_SERVER_ID)
39 if guild is not None:
40 for syncer in self.ON_READY_SYNCERS:
41 syncer_name = syncer.__name__[5:] # drop off `sync_`
42 log.info("Starting `%s` syncer.", syncer_name)
43 total_created, total_updated, total_deleted = await syncer(self.bot, guild)
44 if total_deleted is None:
45 log.info(
46 f"`{syncer_name}` syncer finished, created `{total_created}`, updated `{total_updated}`."
47 )
48 else:
49 log.info(
50 f"`{syncer_name}` syncer finished, created `{total_created}`, updated `{total_updated}`, "
51 f"deleted `{total_deleted}`."
52 )
53
54 @Cog.listener()
55 async def on_guild_role_create(self, role: Role) -> None:
56 """Adds newly create role to the database table over the API."""
57 await self.bot.api_client.post(
58 'bot/roles',
59 json={
60 'colour': role.colour.value,
61 'id': role.id,
62 'name': role.name,
63 'permissions': role.permissions.value,
64 'position': role.position,
65 }
66 )
67
68 @Cog.listener()
69 async def on_guild_role_delete(self, role: Role) -> None:
70 """Deletes role from the database when it's deleted from the guild."""
71 await self.bot.api_client.delete(f'bot/roles/{role.id}')
72
73 @Cog.listener()
74 async def on_guild_role_update(self, before: Role, after: Role) -> None:
75 """Syncs role with the database if any of the stored attributes were updated."""
76 if (
77 before.name != after.name
78 or before.colour != after.colour
79 or before.permissions != after.permissions
80 or before.position != after.position
81 ):
82 await self.bot.api_client.put(
83 f'bot/roles/{after.id}',
84 json={
85 'colour': after.colour.value,
86 'id': after.id,
87 'name': after.name,
88 'permissions': after.permissions.value,
89 'position': after.position,
90 }
91 )
92
93 @Cog.listener()
94 async def on_member_join(self, member: Member) -> None:
95 """
96 Adds a new user or updates existing user to the database when a member joins the guild.
97
98 If the joining member is a user that is already known to the database (i.e., a user that
99 previously left), it will update the user's information. If the user is not yet known by
100 the database, the user is added.
101 """
102 packed = {
103 'avatar_hash': member.avatar,
104 'discriminator': int(member.discriminator),
105 'id': member.id,
106 'in_guild': True,
107 'name': member.name,
108 'roles': sorted(role.id for role in member.roles)
109 }
110
111 got_error = False
112
113 try:
114 # First try an update of the user to set the `in_guild` field and other
115 # fields that may have changed since the last time we've seen them.
116 await self.bot.api_client.put(f'bot/users/{member.id}', json=packed)
117
118 except ResponseCodeError as e:
119 # If we didn't get 404, something else broke - propagate it up.
120 if e.response.status != 404:
121 raise
122
123 got_error = True # yikes
124
125 if got_error:
126 # If we got `404`, the user is new. Create them.
127 await self.bot.api_client.post('bot/users', json=packed)
128
129 @Cog.listener()
130 async def on_member_remove(self, member: Member) -> None:
131 """Updates the user information when a member leaves the guild."""
132 await self.bot.api_client.put(
133 f'bot/users/{member.id}',
134 json={
135 'avatar_hash': member.avatar,
136 'discriminator': int(member.discriminator),
137 'id': member.id,
138 'in_guild': False,
139 'name': member.name,
140 'roles': sorted(role.id for role in member.roles)
141 }
142 )
143
144 @Cog.listener()
145 async def on_member_update(self, before: Member, after: Member) -> None:
146 """Updates the user information if any of relevant attributes have changed."""
147 if (
148 before.name != after.name
149 or before.avatar != after.avatar
150 or before.discriminator != after.discriminator
151 or before.roles != after.roles
152 ):
153 try:
154 await self.bot.api_client.put(
155 'bot/users/' + str(after.id),
156 json={
157 'avatar_hash': after.avatar,
158 'discriminator': int(after.discriminator),
159 'id': after.id,
160 'in_guild': True,
161 'name': after.name,
162 'roles': sorted(role.id for role in after.roles)
163 }
164 )
165 except ResponseCodeError as e:
166 if e.response.status != 404:
167 raise
168
169 log.warning(
170 "Unable to update user, got 404. "
171 "Assuming race condition from join event."
172 )
173
174 @commands.group(name='sync')
175 @commands.has_permissions(administrator=True)
176 async def sync_group(self, ctx: Context) -> None:
177 """Run synchronizations between the bot and site manually."""
178
179 @sync_group.command(name='roles')
180 @commands.has_permissions(administrator=True)
181 async def sync_roles_command(self, ctx: Context) -> None:
182 """Manually synchronize the guild's roles with the roles on the site."""
183 initial_response = await ctx.send("📊 Synchronizing roles.")
184 total_created, total_updated, total_deleted = await syncers.sync_roles(self.bot, ctx.guild)
185 await initial_response.edit(
186 content=(
187 f"👌 Role synchronization complete, created **{total_created}** "
188 f", updated **{total_created}** roles, and deleted **{total_deleted}** roles."
189 )
190 )
191
192 @sync_group.command(name='users')
193 @commands.has_permissions(administrator=True)
194 async def sync_users_command(self, ctx: Context) -> None:
195 """Manually synchronize the guild's users with the users on the site."""
196 initial_response = await ctx.send("📊 Synchronizing users.")
197 total_created, total_updated, total_deleted = await syncers.sync_users(self.bot, ctx.guild)
198 await initial_response.edit(
199 content=(
200 f"👌 User synchronization complete, created **{total_created}** "
201 f"and updated **{total_created}** users."
202 )
203 )
204
[end of bot/cogs/sync/cog.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/bot/cogs/sync/cog.py b/bot/cogs/sync/cog.py
--- a/bot/cogs/sync/cog.py
+++ b/bot/cogs/sync/cog.py
@@ -1,7 +1,7 @@
import logging
-from typing import Callable, Iterable
+from typing import Callable, Dict, Iterable, Union
-from discord import Guild, Member, Role
+from discord import Guild, Member, Role, User
from discord.ext import commands
from discord.ext.commands import Cog, Context
@@ -51,6 +51,15 @@
f"deleted `{total_deleted}`."
)
+ async def patch_user(self, user_id: int, updated_information: Dict[str, Union[str, int]]) -> None:
+ """Send a PATCH request to partially update a user in the database."""
+ try:
+ await self.bot.api_client.patch("bot/users/" + str(user_id), json=updated_information)
+ except ResponseCodeError as e:
+ if e.response.status != 404:
+ raise
+ log.warning("Unable to update user, got 404. Assuming race condition from join event.")
+
@Cog.listener()
async def on_guild_role_create(self, role: Role) -> None:
"""Adds newly create role to the database table over the API."""
@@ -143,33 +152,21 @@
@Cog.listener()
async def on_member_update(self, before: Member, after: Member) -> None:
- """Updates the user information if any of relevant attributes have changed."""
- if (
- before.name != after.name
- or before.avatar != after.avatar
- or before.discriminator != after.discriminator
- or before.roles != after.roles
- ):
- try:
- await self.bot.api_client.put(
- 'bot/users/' + str(after.id),
- json={
- 'avatar_hash': after.avatar,
- 'discriminator': int(after.discriminator),
- 'id': after.id,
- 'in_guild': True,
- 'name': after.name,
- 'roles': sorted(role.id for role in after.roles)
- }
- )
- except ResponseCodeError as e:
- if e.response.status != 404:
- raise
-
- log.warning(
- "Unable to update user, got 404. "
- "Assuming race condition from join event."
- )
+ """Update the roles of the member in the database if a change is detected."""
+ if before.roles != after.roles:
+ updated_information = {"roles": sorted(role.id for role in after.roles)}
+ await self.patch_user(after.id, updated_information=updated_information)
+
+ @Cog.listener()
+ async def on_user_update(self, before: User, after: User) -> None:
+ """Update the user information in the database if a relevant change is detected."""
+ if any(getattr(before, attr) != getattr(after, attr) for attr in ("name", "discriminator", "avatar")):
+ updated_information = {
+ "name": after.name,
+ "discriminator": int(after.discriminator),
+ "avatar_hash": after.avatar,
+ }
+ await self.patch_user(after.id, updated_information=updated_information)
@commands.group(name='sync')
@commands.has_permissions(administrator=True)
|
{"golden_diff": "diff --git a/bot/cogs/sync/cog.py b/bot/cogs/sync/cog.py\n--- a/bot/cogs/sync/cog.py\n+++ b/bot/cogs/sync/cog.py\n@@ -1,7 +1,7 @@\n import logging\n-from typing import Callable, Iterable\n+from typing import Callable, Dict, Iterable, Union\n \n-from discord import Guild, Member, Role\n+from discord import Guild, Member, Role, User\n from discord.ext import commands\n from discord.ext.commands import Cog, Context\n \n@@ -51,6 +51,15 @@\n f\"deleted `{total_deleted}`.\"\n )\n \n+ async def patch_user(self, user_id: int, updated_information: Dict[str, Union[str, int]]) -> None:\n+ \"\"\"Send a PATCH request to partially update a user in the database.\"\"\"\n+ try:\n+ await self.bot.api_client.patch(\"bot/users/\" + str(user_id), json=updated_information)\n+ except ResponseCodeError as e:\n+ if e.response.status != 404:\n+ raise\n+ log.warning(\"Unable to update user, got 404. Assuming race condition from join event.\")\n+\n @Cog.listener()\n async def on_guild_role_create(self, role: Role) -> None:\n \"\"\"Adds newly create role to the database table over the API.\"\"\"\n@@ -143,33 +152,21 @@\n \n @Cog.listener()\n async def on_member_update(self, before: Member, after: Member) -> None:\n- \"\"\"Updates the user information if any of relevant attributes have changed.\"\"\"\n- if (\n- before.name != after.name\n- or before.avatar != after.avatar\n- or before.discriminator != after.discriminator\n- or before.roles != after.roles\n- ):\n- try:\n- await self.bot.api_client.put(\n- 'bot/users/' + str(after.id),\n- json={\n- 'avatar_hash': after.avatar,\n- 'discriminator': int(after.discriminator),\n- 'id': after.id,\n- 'in_guild': True,\n- 'name': after.name,\n- 'roles': sorted(role.id for role in after.roles)\n- }\n- )\n- except ResponseCodeError as e:\n- if e.response.status != 404:\n- raise\n-\n- log.warning(\n- \"Unable to update user, got 404. \"\n- \"Assuming race condition from join event.\"\n- )\n+ \"\"\"Update the roles of the member in the database if a change is detected.\"\"\"\n+ if before.roles != after.roles:\n+ updated_information = {\"roles\": sorted(role.id for role in after.roles)}\n+ await self.patch_user(after.id, updated_information=updated_information)\n+\n+ @Cog.listener()\n+ async def on_user_update(self, before: User, after: User) -> None:\n+ \"\"\"Update the user information in the database if a relevant change is detected.\"\"\"\n+ if any(getattr(before, attr) != getattr(after, attr) for attr in (\"name\", \"discriminator\", \"avatar\")):\n+ updated_information = {\n+ \"name\": after.name,\n+ \"discriminator\": int(after.discriminator),\n+ \"avatar_hash\": after.avatar,\n+ }\n+ await self.patch_user(after.id, updated_information=updated_information)\n \n @commands.group(name='sync')\n @commands.has_permissions(administrator=True)\n", "issue": "Username, discriminator, and avatar changes are not synced with the database\nAt the moment, we do not synchronize changes in the username, discriminator, or avatar hash of our members with the database. The reason is that we only check for changes with an [`on_member_update` event listener](https://github.com/python-discord/bot/blob/a4f9d2a5323ca492e895ebd80a1515488b0c3e6c/bot/cogs/sync/cog.py#L145) and the changes listed above fire an [`on_user_update`](https://discordpy.readthedocs.io/en/latest/api.html#discord.on_user_update) event, not an [`on_member_update`](https://discordpy.readthedocs.io/en/latest/api.html#discord.on_member_update) event.\r\n\r\nThe solution is simple: Add an `on_user_update` event listener that looks for avatar, username, and discriminator changes and let the `on_member_update` look for changes in the roles of the member.\r\n\n", "before_files": [{"content": "import logging\nfrom typing import Callable, Iterable\n\nfrom discord import Guild, Member, Role\nfrom discord.ext import commands\nfrom discord.ext.commands import Cog, Context\n\nfrom bot import constants\nfrom bot.api import ResponseCodeError\nfrom bot.bot import Bot\nfrom bot.cogs.sync import syncers\n\nlog = logging.getLogger(__name__)\n\n\nclass Sync(Cog):\n \"\"\"Captures relevant events and sends them to the site.\"\"\"\n\n # The server to synchronize events on.\n # Note that setting this wrongly will result in things getting deleted\n # that possibly shouldn't be.\n SYNC_SERVER_ID = constants.Guild.id\n\n # An iterable of callables that are called when the bot is ready.\n ON_READY_SYNCERS: Iterable[Callable[[Bot, Guild], None]] = (\n syncers.sync_roles,\n syncers.sync_users\n )\n\n def __init__(self, bot: Bot) -> None:\n self.bot = bot\n\n self.bot.loop.create_task(self.sync_guild())\n\n async def sync_guild(self) -> None:\n \"\"\"Syncs the roles/users of the guild with the database.\"\"\"\n await self.bot.wait_until_ready()\n guild = self.bot.get_guild(self.SYNC_SERVER_ID)\n if guild is not None:\n for syncer in self.ON_READY_SYNCERS:\n syncer_name = syncer.__name__[5:] # drop off `sync_`\n log.info(\"Starting `%s` syncer.\", syncer_name)\n total_created, total_updated, total_deleted = await syncer(self.bot, guild)\n if total_deleted is None:\n log.info(\n f\"`{syncer_name}` syncer finished, created `{total_created}`, updated `{total_updated}`.\"\n )\n else:\n log.info(\n f\"`{syncer_name}` syncer finished, created `{total_created}`, updated `{total_updated}`, \"\n f\"deleted `{total_deleted}`.\"\n )\n\n @Cog.listener()\n async def on_guild_role_create(self, role: Role) -> None:\n \"\"\"Adds newly create role to the database table over the API.\"\"\"\n await self.bot.api_client.post(\n 'bot/roles',\n json={\n 'colour': role.colour.value,\n 'id': role.id,\n 'name': role.name,\n 'permissions': role.permissions.value,\n 'position': role.position,\n }\n )\n\n @Cog.listener()\n async def on_guild_role_delete(self, role: Role) -> None:\n \"\"\"Deletes role from the database when it's deleted from the guild.\"\"\"\n await self.bot.api_client.delete(f'bot/roles/{role.id}')\n\n @Cog.listener()\n async def on_guild_role_update(self, before: Role, after: Role) -> None:\n \"\"\"Syncs role with the database if any of the stored attributes were updated.\"\"\"\n if (\n before.name != after.name\n or before.colour != after.colour\n or before.permissions != after.permissions\n or before.position != after.position\n ):\n await self.bot.api_client.put(\n f'bot/roles/{after.id}',\n json={\n 'colour': after.colour.value,\n 'id': after.id,\n 'name': after.name,\n 'permissions': after.permissions.value,\n 'position': after.position,\n }\n )\n\n @Cog.listener()\n async def on_member_join(self, member: Member) -> None:\n \"\"\"\n Adds a new user or updates existing user to the database when a member joins the guild.\n\n If the joining member is a user that is already known to the database (i.e., a user that\n previously left), it will update the user's information. If the user is not yet known by\n the database, the user is added.\n \"\"\"\n packed = {\n 'avatar_hash': member.avatar,\n 'discriminator': int(member.discriminator),\n 'id': member.id,\n 'in_guild': True,\n 'name': member.name,\n 'roles': sorted(role.id for role in member.roles)\n }\n\n got_error = False\n\n try:\n # First try an update of the user to set the `in_guild` field and other\n # fields that may have changed since the last time we've seen them.\n await self.bot.api_client.put(f'bot/users/{member.id}', json=packed)\n\n except ResponseCodeError as e:\n # If we didn't get 404, something else broke - propagate it up.\n if e.response.status != 404:\n raise\n\n got_error = True # yikes\n\n if got_error:\n # If we got `404`, the user is new. Create them.\n await self.bot.api_client.post('bot/users', json=packed)\n\n @Cog.listener()\n async def on_member_remove(self, member: Member) -> None:\n \"\"\"Updates the user information when a member leaves the guild.\"\"\"\n await self.bot.api_client.put(\n f'bot/users/{member.id}',\n json={\n 'avatar_hash': member.avatar,\n 'discriminator': int(member.discriminator),\n 'id': member.id,\n 'in_guild': False,\n 'name': member.name,\n 'roles': sorted(role.id for role in member.roles)\n }\n )\n\n @Cog.listener()\n async def on_member_update(self, before: Member, after: Member) -> None:\n \"\"\"Updates the user information if any of relevant attributes have changed.\"\"\"\n if (\n before.name != after.name\n or before.avatar != after.avatar\n or before.discriminator != after.discriminator\n or before.roles != after.roles\n ):\n try:\n await self.bot.api_client.put(\n 'bot/users/' + str(after.id),\n json={\n 'avatar_hash': after.avatar,\n 'discriminator': int(after.discriminator),\n 'id': after.id,\n 'in_guild': True,\n 'name': after.name,\n 'roles': sorted(role.id for role in after.roles)\n }\n )\n except ResponseCodeError as e:\n if e.response.status != 404:\n raise\n\n log.warning(\n \"Unable to update user, got 404. \"\n \"Assuming race condition from join event.\"\n )\n\n @commands.group(name='sync')\n @commands.has_permissions(administrator=True)\n async def sync_group(self, ctx: Context) -> None:\n \"\"\"Run synchronizations between the bot and site manually.\"\"\"\n\n @sync_group.command(name='roles')\n @commands.has_permissions(administrator=True)\n async def sync_roles_command(self, ctx: Context) -> None:\n \"\"\"Manually synchronize the guild's roles with the roles on the site.\"\"\"\n initial_response = await ctx.send(\"\ud83d\udcca Synchronizing roles.\")\n total_created, total_updated, total_deleted = await syncers.sync_roles(self.bot, ctx.guild)\n await initial_response.edit(\n content=(\n f\"\ud83d\udc4c Role synchronization complete, created **{total_created}** \"\n f\", updated **{total_created}** roles, and deleted **{total_deleted}** roles.\"\n )\n )\n\n @sync_group.command(name='users')\n @commands.has_permissions(administrator=True)\n async def sync_users_command(self, ctx: Context) -> None:\n \"\"\"Manually synchronize the guild's users with the users on the site.\"\"\"\n initial_response = await ctx.send(\"\ud83d\udcca Synchronizing users.\")\n total_created, total_updated, total_deleted = await syncers.sync_users(self.bot, ctx.guild)\n await initial_response.edit(\n content=(\n f\"\ud83d\udc4c User synchronization complete, created **{total_created}** \"\n f\"and updated **{total_created}** users.\"\n )\n )\n", "path": "bot/cogs/sync/cog.py"}]}
| 2,928 | 756 |
gh_patches_debug_21722
|
rasdani/github-patches
|
git_diff
|
HypothesisWorks__hypothesis-2409
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
from_type() does not resolve forward references outside of function annotations
The sample code:
```python
import typing as T
import hypothesis as H
import hypothesis.strategies as S
class Tree(T.NamedTuple):
val: int
l: T.Optional["Tree"]
r: T.Optional["Tree"]
def size(self):
return 1 + (self.l.size() if self.l else 0) + (self.r.size() if self.r else 0)
@H.given(t = S.infer)
def test_tree(t: Tree):
if t.size() > 3:
assert False
H.note(t)
else:
assert True
```
(Part of) the stack trace:
```
platform darwin -- Python 3.6.1, pytest-3.2.1, py-1.4.34, pluggy-0.4.0
rootdir: /Users/desmond/Documents/code/code-python/Try1/tests, inifile:
plugins: xonsh-0.5.12, hypothesis-3.38.9
collected 4 items
foo_test.py ...F
foo_test.py:36 (test_tree)
args = (<class 'foo_test.Tree'>,), kwargs = {}, kwargs_cache_key = set()
cache_key = (<function from_type at 0x112216a60>, ((<class 'type'>, <class 'foo_test.Tree'>),), frozenset())
result = builds(Tree, l=builds(lazy_error), r=builds(lazy_error), val=integers())
@proxies(fn)
def cached_strategy(*args, **kwargs):
kwargs_cache_key = set()
try:
for k, v in kwargs.items():
kwargs_cache_key.add((k, convert_value(v)))
except TypeError:
return fn(*args, **kwargs)
cache_key = (
fn,
tuple(map(convert_value, args)), frozenset(kwargs_cache_key))
try:
> return STRATEGY_CACHE[cache_key]
/Users/desmond/anaconda3/lib/python3.6/site-packages/hypothesis/strategies.py:107:
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
self = {(<function booleans at 0x112763e18>, (), frozenset()): booleans(), (<function fractions at 0x112216d90>, ((<class 'No...(tuples(), fixed_dictionaries({})).map(lambda value: target(*value[0], **value[1])),
'val': WideRangeIntStrategy()}))}
key = (<function from_type at 0x112216a60>, ((<class 'type'>, <class 'foo_test.Tree'>),), frozenset())
def __getitem__(self, key):
> i = self.keys_to_indices[key]
E KeyError: (<function from_type at 0x112216a60>, ((<class 'type'>, <class 'foo_test.Tree'>),), frozenset())
```
</issue>
<code>
[start of hypothesis-python/src/hypothesis/internal/compat.py]
1 # This file is part of Hypothesis, which may be found at
2 # https://github.com/HypothesisWorks/hypothesis/
3 #
4 # Most of this work is copyright (C) 2013-2020 David R. MacIver
5 # ([email protected]), but it contains contributions by others. See
6 # CONTRIBUTING.rst for a full list of people who may hold copyright, and
7 # consult the git log if you need to determine who owns an individual
8 # contribution.
9 #
10 # This Source Code Form is subject to the terms of the Mozilla Public License,
11 # v. 2.0. If a copy of the MPL was not distributed with this file, You can
12 # obtain one at https://mozilla.org/MPL/2.0/.
13 #
14 # END HEADER
15
16 import codecs
17 import importlib
18 import inspect
19 import platform
20 import sys
21 import time
22 import typing
23
24 PYPY = platform.python_implementation() == "PyPy"
25 CAN_PACK_HALF_FLOAT = sys.version_info[:2] >= (3, 6)
26 WINDOWS = platform.system() == "Windows"
27
28
29 def bit_length(n):
30 return n.bit_length()
31
32
33 def str_to_bytes(s):
34 return s.encode(a_good_encoding())
35
36
37 def escape_unicode_characters(s):
38 return codecs.encode(s, "unicode_escape").decode("ascii")
39
40
41 def int_from_bytes(data):
42 return int.from_bytes(data, "big")
43
44
45 def int_to_bytes(i, size):
46 return i.to_bytes(size, "big")
47
48
49 def int_to_byte(i):
50 return bytes([i])
51
52
53 def benchmark_time():
54 return time.monotonic()
55
56
57 def a_good_encoding():
58 return "utf-8"
59
60
61 def to_unicode(x):
62 if isinstance(x, str):
63 return x
64 else:
65 return x.decode(a_good_encoding())
66
67
68 def qualname(f):
69 try:
70 return f.__qualname__
71 except AttributeError:
72 return f.__name__
73
74
75 try:
76 # These types are new in Python 3.7, but also (partially) backported to the
77 # typing backport on PyPI. Use if possible; or fall back to older names.
78 typing_root_type = (typing._Final, typing._GenericAlias) # type: ignore
79 ForwardRef = typing.ForwardRef # type: ignore
80 except AttributeError:
81 typing_root_type = (typing.TypingMeta, typing.TypeVar) # type: ignore
82 try:
83 typing_root_type += (typing._Union,) # type: ignore
84 except AttributeError:
85 pass
86 ForwardRef = typing._ForwardRef # type: ignore
87
88
89 def is_typed_named_tuple(cls):
90 """Return True if cls is probably a subtype of `typing.NamedTuple`.
91
92 Unfortunately types created with `class T(NamedTuple):` actually
93 subclass `tuple` directly rather than NamedTuple. This is annoying,
94 and means we just have to hope that nobody defines a different tuple
95 subclass with similar attributes.
96 """
97 return (
98 issubclass(cls, tuple)
99 and hasattr(cls, "_fields")
100 and hasattr(cls, "_field_types")
101 )
102
103
104 if sys.version_info[:2] < (3, 6):
105 # When we drop support for Python 3.5, `get_type_hints` and
106 # `is_typed_named_tuple` should be moved to reflection.py
107
108 def get_type_hints(thing):
109 if inspect.isclass(thing) and not hasattr(thing, "__signature__"):
110 if is_typed_named_tuple(thing):
111 # Special handling for typing.NamedTuple
112 return thing._field_types # type: ignore
113 thing = thing.__init__ # type: ignore
114 try:
115 spec = inspect.getfullargspec(thing)
116 return {
117 k: v
118 for k, v in spec.annotations.items()
119 if k in (spec.args + spec.kwonlyargs) and isinstance(v, type)
120 }
121 except TypeError:
122 return {}
123
124
125 else:
126
127 def get_type_hints(thing):
128 if inspect.isclass(thing) and not hasattr(thing, "__signature__"):
129 if is_typed_named_tuple(thing):
130 # Special handling for typing.NamedTuple
131 return thing._field_types # type: ignore
132 thing = thing.__init__ # type: ignore
133 try:
134 return typing.get_type_hints(thing)
135 except TypeError:
136 return {}
137
138
139 importlib_invalidate_caches = getattr(importlib, "invalidate_caches", lambda: ())
140
141
142 def update_code_location(code, newfile, newlineno):
143 """Take a code object and lie shamelessly about where it comes from.
144
145 Why do we want to do this? It's for really shallow reasons involving
146 hiding the hypothesis_temporary_module code from test runners like
147 pytest's verbose mode. This is a vastly disproportionate terrible
148 hack that I've done purely for vanity, and if you're reading this
149 code you're probably here because it's broken something and now
150 you're angry at me. Sorry.
151 """
152 if hasattr(code, "replace"):
153 # Python 3.8 added positional-only params (PEP 570), and thus changed
154 # the layout of code objects. In beta1, the `.replace()` method was
155 # added to facilitate future-proof code. See BPO-37032 for details.
156 return code.replace(co_filename=newfile, co_firstlineno=newlineno)
157
158 # This field order is accurate for 3.5 - 3.7, but not 3.8 when a new field
159 # was added for positional-only arguments. However it also added a .replace()
160 # method that we use instead of field indices, so they're fine as-is.
161 CODE_FIELD_ORDER = [
162 "co_argcount",
163 "co_kwonlyargcount",
164 "co_nlocals",
165 "co_stacksize",
166 "co_flags",
167 "co_code",
168 "co_consts",
169 "co_names",
170 "co_varnames",
171 "co_filename",
172 "co_name",
173 "co_firstlineno",
174 "co_lnotab",
175 "co_freevars",
176 "co_cellvars",
177 ]
178 unpacked = [getattr(code, name) for name in CODE_FIELD_ORDER]
179 unpacked[CODE_FIELD_ORDER.index("co_filename")] = newfile
180 unpacked[CODE_FIELD_ORDER.index("co_firstlineno")] = newlineno
181 return type(code)(*unpacked)
182
183
184 def cast_unicode(s, encoding=None):
185 if isinstance(s, bytes):
186 return s.decode(encoding or a_good_encoding(), "replace")
187 return s
188
189
190 def get_stream_enc(stream, default=None):
191 return getattr(stream, "encoding", None) or default
192
193
194 # Under Python 2, math.floor and math.ceil return floats, which cannot
195 # represent large integers - eg `float(2**53) == float(2**53 + 1)`.
196 # We therefore implement them entirely in (long) integer operations.
197 # We use the same trick on Python 3, because Numpy values and other
198 # custom __floor__ or __ceil__ methods may convert via floats.
199 # See issue #1667, Numpy issue 9068.
200 def floor(x):
201 y = int(x)
202 if y != x and x < 0:
203 return y - 1
204 return y
205
206
207 def ceil(x):
208 y = int(x)
209 if y != x and x > 0:
210 return y + 1
211 return y
212
213
214 try:
215 from django.test import TransactionTestCase
216
217 def bad_django_TestCase(runner):
218 if runner is None:
219 return False
220 if not isinstance(runner, TransactionTestCase):
221 return False
222
223 from hypothesis.extra.django._impl import HypothesisTestCase
224
225 return not isinstance(runner, HypothesisTestCase)
226
227
228 except Exception:
229 # Can't use ImportError, because of e.g. Django config errors
230 def bad_django_TestCase(runner):
231 return False
232
[end of hypothesis-python/src/hypothesis/internal/compat.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/hypothesis-python/src/hypothesis/internal/compat.py b/hypothesis-python/src/hypothesis/internal/compat.py
--- a/hypothesis-python/src/hypothesis/internal/compat.py
+++ b/hypothesis-python/src/hypothesis/internal/compat.py
@@ -125,14 +125,25 @@
else:
def get_type_hints(thing):
- if inspect.isclass(thing) and not hasattr(thing, "__signature__"):
- if is_typed_named_tuple(thing):
- # Special handling for typing.NamedTuple
- return thing._field_types # type: ignore
- thing = thing.__init__ # type: ignore
+ """Like the typing version, but tries harder and never errors.
+
+ Tries harder: if the thing to inspect is a class but typing.get_type_hints
+ raises an error or returns no hints, then this function will try calling it
+ on the __init__ method. This second step often helps with user-defined
+ classes on older versions of Python.
+
+ Never errors: instead of raising TypeError for uninspectable objects, or
+ NameError for unresolvable forward references, just return an empty dict.
+ """
try:
- return typing.get_type_hints(thing)
- except TypeError:
+ hints = typing.get_type_hints(thing)
+ except (TypeError, NameError):
+ hints = {}
+ if hints or not inspect.isclass(thing):
+ return hints
+ try:
+ return typing.get_type_hints(thing.__init__)
+ except (TypeError, NameError, AttributeError):
return {}
|
{"golden_diff": "diff --git a/hypothesis-python/src/hypothesis/internal/compat.py b/hypothesis-python/src/hypothesis/internal/compat.py\n--- a/hypothesis-python/src/hypothesis/internal/compat.py\n+++ b/hypothesis-python/src/hypothesis/internal/compat.py\n@@ -125,14 +125,25 @@\n else:\n \n def get_type_hints(thing):\n- if inspect.isclass(thing) and not hasattr(thing, \"__signature__\"):\n- if is_typed_named_tuple(thing):\n- # Special handling for typing.NamedTuple\n- return thing._field_types # type: ignore\n- thing = thing.__init__ # type: ignore\n+ \"\"\"Like the typing version, but tries harder and never errors.\n+\n+ Tries harder: if the thing to inspect is a class but typing.get_type_hints\n+ raises an error or returns no hints, then this function will try calling it\n+ on the __init__ method. This second step often helps with user-defined\n+ classes on older versions of Python.\n+\n+ Never errors: instead of raising TypeError for uninspectable objects, or\n+ NameError for unresolvable forward references, just return an empty dict.\n+ \"\"\"\n try:\n- return typing.get_type_hints(thing)\n- except TypeError:\n+ hints = typing.get_type_hints(thing)\n+ except (TypeError, NameError):\n+ hints = {}\n+ if hints or not inspect.isclass(thing):\n+ return hints\n+ try:\n+ return typing.get_type_hints(thing.__init__)\n+ except (TypeError, NameError, AttributeError):\n return {}\n", "issue": "from_type() does not resolve forward references outside of function annotations\nThe sample code:\r\n```python\r\nimport typing as T\r\n\r\nimport hypothesis as H\r\nimport hypothesis.strategies as S\r\n\r\nclass Tree(T.NamedTuple):\r\n val: int\r\n l: T.Optional[\"Tree\"]\r\n r: T.Optional[\"Tree\"]\r\n def size(self):\r\n return 1 + (self.l.size() if self.l else 0) + (self.r.size() if self.r else 0)\r\n\r\[email protected](t = S.infer)\r\ndef test_tree(t: Tree):\r\n if t.size() > 3:\r\n assert False\r\n H.note(t)\r\n else:\r\n assert True\r\n```\r\n\r\n(Part of) the stack trace:\r\n```\r\nplatform darwin -- Python 3.6.1, pytest-3.2.1, py-1.4.34, pluggy-0.4.0\r\nrootdir: /Users/desmond/Documents/code/code-python/Try1/tests, inifile:\r\nplugins: xonsh-0.5.12, hypothesis-3.38.9\r\ncollected 4 items\r\nfoo_test.py ...F\r\nfoo_test.py:36 (test_tree)\r\nargs = (<class 'foo_test.Tree'>,), kwargs = {}, kwargs_cache_key = set()\r\ncache_key = (<function from_type at 0x112216a60>, ((<class 'type'>, <class 'foo_test.Tree'>),), frozenset())\r\nresult = builds(Tree, l=builds(lazy_error), r=builds(lazy_error), val=integers())\r\n\r\n @proxies(fn)\r\n def cached_strategy(*args, **kwargs):\r\n kwargs_cache_key = set()\r\n try:\r\n for k, v in kwargs.items():\r\n kwargs_cache_key.add((k, convert_value(v)))\r\n except TypeError:\r\n return fn(*args, **kwargs)\r\n cache_key = (\r\n fn,\r\n tuple(map(convert_value, args)), frozenset(kwargs_cache_key))\r\n try:\r\n> return STRATEGY_CACHE[cache_key]\r\n\r\n/Users/desmond/anaconda3/lib/python3.6/site-packages/hypothesis/strategies.py:107: \r\n_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ \r\n\r\nself = {(<function booleans at 0x112763e18>, (), frozenset()): booleans(), (<function fractions at 0x112216d90>, ((<class 'No...(tuples(), fixed_dictionaries({})).map(lambda value: target(*value[0], **value[1])),\r\n 'val': WideRangeIntStrategy()}))}\r\nkey = (<function from_type at 0x112216a60>, ((<class 'type'>, <class 'foo_test.Tree'>),), frozenset())\r\n\r\n def __getitem__(self, key):\r\n> i = self.keys_to_indices[key]\r\nE KeyError: (<function from_type at 0x112216a60>, ((<class 'type'>, <class 'foo_test.Tree'>),), frozenset())\r\n\r\n```\n", "before_files": [{"content": "# This file is part of Hypothesis, which may be found at\n# https://github.com/HypothesisWorks/hypothesis/\n#\n# Most of this work is copyright (C) 2013-2020 David R. MacIver\n# ([email protected]), but it contains contributions by others. See\n# CONTRIBUTING.rst for a full list of people who may hold copyright, and\n# consult the git log if you need to determine who owns an individual\n# contribution.\n#\n# This Source Code Form is subject to the terms of the Mozilla Public License,\n# v. 2.0. If a copy of the MPL was not distributed with this file, You can\n# obtain one at https://mozilla.org/MPL/2.0/.\n#\n# END HEADER\n\nimport codecs\nimport importlib\nimport inspect\nimport platform\nimport sys\nimport time\nimport typing\n\nPYPY = platform.python_implementation() == \"PyPy\"\nCAN_PACK_HALF_FLOAT = sys.version_info[:2] >= (3, 6)\nWINDOWS = platform.system() == \"Windows\"\n\n\ndef bit_length(n):\n return n.bit_length()\n\n\ndef str_to_bytes(s):\n return s.encode(a_good_encoding())\n\n\ndef escape_unicode_characters(s):\n return codecs.encode(s, \"unicode_escape\").decode(\"ascii\")\n\n\ndef int_from_bytes(data):\n return int.from_bytes(data, \"big\")\n\n\ndef int_to_bytes(i, size):\n return i.to_bytes(size, \"big\")\n\n\ndef int_to_byte(i):\n return bytes([i])\n\n\ndef benchmark_time():\n return time.monotonic()\n\n\ndef a_good_encoding():\n return \"utf-8\"\n\n\ndef to_unicode(x):\n if isinstance(x, str):\n return x\n else:\n return x.decode(a_good_encoding())\n\n\ndef qualname(f):\n try:\n return f.__qualname__\n except AttributeError:\n return f.__name__\n\n\ntry:\n # These types are new in Python 3.7, but also (partially) backported to the\n # typing backport on PyPI. Use if possible; or fall back to older names.\n typing_root_type = (typing._Final, typing._GenericAlias) # type: ignore\n ForwardRef = typing.ForwardRef # type: ignore\nexcept AttributeError:\n typing_root_type = (typing.TypingMeta, typing.TypeVar) # type: ignore\n try:\n typing_root_type += (typing._Union,) # type: ignore\n except AttributeError:\n pass\n ForwardRef = typing._ForwardRef # type: ignore\n\n\ndef is_typed_named_tuple(cls):\n \"\"\"Return True if cls is probably a subtype of `typing.NamedTuple`.\n\n Unfortunately types created with `class T(NamedTuple):` actually\n subclass `tuple` directly rather than NamedTuple. This is annoying,\n and means we just have to hope that nobody defines a different tuple\n subclass with similar attributes.\n \"\"\"\n return (\n issubclass(cls, tuple)\n and hasattr(cls, \"_fields\")\n and hasattr(cls, \"_field_types\")\n )\n\n\nif sys.version_info[:2] < (3, 6):\n # When we drop support for Python 3.5, `get_type_hints` and\n # `is_typed_named_tuple` should be moved to reflection.py\n\n def get_type_hints(thing):\n if inspect.isclass(thing) and not hasattr(thing, \"__signature__\"):\n if is_typed_named_tuple(thing):\n # Special handling for typing.NamedTuple\n return thing._field_types # type: ignore\n thing = thing.__init__ # type: ignore\n try:\n spec = inspect.getfullargspec(thing)\n return {\n k: v\n for k, v in spec.annotations.items()\n if k in (spec.args + spec.kwonlyargs) and isinstance(v, type)\n }\n except TypeError:\n return {}\n\n\nelse:\n\n def get_type_hints(thing):\n if inspect.isclass(thing) and not hasattr(thing, \"__signature__\"):\n if is_typed_named_tuple(thing):\n # Special handling for typing.NamedTuple\n return thing._field_types # type: ignore\n thing = thing.__init__ # type: ignore\n try:\n return typing.get_type_hints(thing)\n except TypeError:\n return {}\n\n\nimportlib_invalidate_caches = getattr(importlib, \"invalidate_caches\", lambda: ())\n\n\ndef update_code_location(code, newfile, newlineno):\n \"\"\"Take a code object and lie shamelessly about where it comes from.\n\n Why do we want to do this? It's for really shallow reasons involving\n hiding the hypothesis_temporary_module code from test runners like\n pytest's verbose mode. This is a vastly disproportionate terrible\n hack that I've done purely for vanity, and if you're reading this\n code you're probably here because it's broken something and now\n you're angry at me. Sorry.\n \"\"\"\n if hasattr(code, \"replace\"):\n # Python 3.8 added positional-only params (PEP 570), and thus changed\n # the layout of code objects. In beta1, the `.replace()` method was\n # added to facilitate future-proof code. See BPO-37032 for details.\n return code.replace(co_filename=newfile, co_firstlineno=newlineno)\n\n # This field order is accurate for 3.5 - 3.7, but not 3.8 when a new field\n # was added for positional-only arguments. However it also added a .replace()\n # method that we use instead of field indices, so they're fine as-is.\n CODE_FIELD_ORDER = [\n \"co_argcount\",\n \"co_kwonlyargcount\",\n \"co_nlocals\",\n \"co_stacksize\",\n \"co_flags\",\n \"co_code\",\n \"co_consts\",\n \"co_names\",\n \"co_varnames\",\n \"co_filename\",\n \"co_name\",\n \"co_firstlineno\",\n \"co_lnotab\",\n \"co_freevars\",\n \"co_cellvars\",\n ]\n unpacked = [getattr(code, name) for name in CODE_FIELD_ORDER]\n unpacked[CODE_FIELD_ORDER.index(\"co_filename\")] = newfile\n unpacked[CODE_FIELD_ORDER.index(\"co_firstlineno\")] = newlineno\n return type(code)(*unpacked)\n\n\ndef cast_unicode(s, encoding=None):\n if isinstance(s, bytes):\n return s.decode(encoding or a_good_encoding(), \"replace\")\n return s\n\n\ndef get_stream_enc(stream, default=None):\n return getattr(stream, \"encoding\", None) or default\n\n\n# Under Python 2, math.floor and math.ceil return floats, which cannot\n# represent large integers - eg `float(2**53) == float(2**53 + 1)`.\n# We therefore implement them entirely in (long) integer operations.\n# We use the same trick on Python 3, because Numpy values and other\n# custom __floor__ or __ceil__ methods may convert via floats.\n# See issue #1667, Numpy issue 9068.\ndef floor(x):\n y = int(x)\n if y != x and x < 0:\n return y - 1\n return y\n\n\ndef ceil(x):\n y = int(x)\n if y != x and x > 0:\n return y + 1\n return y\n\n\ntry:\n from django.test import TransactionTestCase\n\n def bad_django_TestCase(runner):\n if runner is None:\n return False\n if not isinstance(runner, TransactionTestCase):\n return False\n\n from hypothesis.extra.django._impl import HypothesisTestCase\n\n return not isinstance(runner, HypothesisTestCase)\n\n\nexcept Exception:\n # Can't use ImportError, because of e.g. Django config errors\n def bad_django_TestCase(runner):\n return False\n", "path": "hypothesis-python/src/hypothesis/internal/compat.py"}]}
| 3,568 | 361 |
gh_patches_debug_16987
|
rasdani/github-patches
|
git_diff
|
strawberry-graphql__strawberry-1233
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
The export-schema command fails when trying to import local modules
</issue>
<code>
[start of strawberry/cli/commands/export_schema.py]
1 import click
2
3 from strawberry import Schema
4 from strawberry.printer import print_schema
5 from strawberry.utils.importer import import_module_symbol
6
7
8 @click.command(short_help="Exports the schema")
9 @click.argument("schema", type=str)
10 def export_schema(schema: str):
11 try:
12 schema_symbol = import_module_symbol(schema, default_symbol_name="schema")
13 except (ImportError, AttributeError) as exc:
14 message = str(exc)
15 raise click.BadArgumentUsage(message)
16 if not isinstance(schema_symbol, Schema):
17 message = "The `schema` must be an instance of strawberry.Schema"
18 raise click.BadArgumentUsage(message)
19 print(print_schema(schema_symbol))
20
[end of strawberry/cli/commands/export_schema.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/strawberry/cli/commands/export_schema.py b/strawberry/cli/commands/export_schema.py
--- a/strawberry/cli/commands/export_schema.py
+++ b/strawberry/cli/commands/export_schema.py
@@ -1,3 +1,5 @@
+import sys
+
import click
from strawberry import Schema
@@ -7,7 +9,20 @@
@click.command(short_help="Exports the schema")
@click.argument("schema", type=str)
-def export_schema(schema: str):
[email protected](
+ "--app-dir",
+ default=".",
+ type=str,
+ show_default=True,
+ help=(
+ "Look for the module in the specified directory, by adding this to the "
+ "PYTHONPATH. Defaults to the current working directory. "
+ "Works the same as `--app-dir` in uvicorn."
+ ),
+)
+def export_schema(schema: str, app_dir):
+ sys.path.insert(0, app_dir)
+
try:
schema_symbol = import_module_symbol(schema, default_symbol_name="schema")
except (ImportError, AttributeError) as exc:
|
{"golden_diff": "diff --git a/strawberry/cli/commands/export_schema.py b/strawberry/cli/commands/export_schema.py\n--- a/strawberry/cli/commands/export_schema.py\n+++ b/strawberry/cli/commands/export_schema.py\n@@ -1,3 +1,5 @@\n+import sys\n+\n import click\n \n from strawberry import Schema\n@@ -7,7 +9,20 @@\n \n @click.command(short_help=\"Exports the schema\")\n @click.argument(\"schema\", type=str)\n-def export_schema(schema: str):\[email protected](\n+ \"--app-dir\",\n+ default=\".\",\n+ type=str,\n+ show_default=True,\n+ help=(\n+ \"Look for the module in the specified directory, by adding this to the \"\n+ \"PYTHONPATH. Defaults to the current working directory. \"\n+ \"Works the same as `--app-dir` in uvicorn.\"\n+ ),\n+)\n+def export_schema(schema: str, app_dir):\n+ sys.path.insert(0, app_dir)\n+\n try:\n schema_symbol = import_module_symbol(schema, default_symbol_name=\"schema\")\n except (ImportError, AttributeError) as exc:\n", "issue": "The export-schema command fails when trying to import local modules\n\n", "before_files": [{"content": "import click\n\nfrom strawberry import Schema\nfrom strawberry.printer import print_schema\nfrom strawberry.utils.importer import import_module_symbol\n\n\[email protected](short_help=\"Exports the schema\")\[email protected](\"schema\", type=str)\ndef export_schema(schema: str):\n try:\n schema_symbol = import_module_symbol(schema, default_symbol_name=\"schema\")\n except (ImportError, AttributeError) as exc:\n message = str(exc)\n raise click.BadArgumentUsage(message)\n if not isinstance(schema_symbol, Schema):\n message = \"The `schema` must be an instance of strawberry.Schema\"\n raise click.BadArgumentUsage(message)\n print(print_schema(schema_symbol))\n", "path": "strawberry/cli/commands/export_schema.py"}]}
| 720 | 249 |
gh_patches_debug_12871
|
rasdani/github-patches
|
git_diff
|
archlinux__archinstall-2069
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
locale language only en_US
archlinux-2023.09.01-x86_64.iso
</issue>
<code>
[start of archinstall/lib/locale/locale.py]
1 from typing import Iterator, List
2
3 from ..exceptions import ServiceException, SysCallError
4 from ..general import SysCommand
5 from ..output import error
6
7
8 def list_keyboard_languages() -> Iterator[str]:
9 for line in SysCommand("localectl --no-pager list-keymaps", environment_vars={'SYSTEMD_COLORS': '0'}):
10 yield line.decode('UTF-8').strip()
11
12
13 def list_locales() -> List[str]:
14 with open('/etc/locale.gen', 'r') as fp:
15 locales = []
16 # before the list of locales begins there's an empty line with a '#' in front
17 # so we'll collect the localels from bottom up and halt when we're donw
18 entries = fp.readlines()
19 entries.reverse()
20
21 for entry in entries:
22 text = entry.replace('#', '').strip()
23 if text == '':
24 break
25 locales.append(text)
26
27 locales.reverse()
28 return locales
29
30
31 def list_x11_keyboard_languages() -> Iterator[str]:
32 for line in SysCommand("localectl --no-pager list-x11-keymap-layouts", environment_vars={'SYSTEMD_COLORS': '0'}):
33 yield line.decode('UTF-8').strip()
34
35
36 def verify_keyboard_layout(layout :str) -> bool:
37 for language in list_keyboard_languages():
38 if layout.lower() == language.lower():
39 return True
40 return False
41
42
43 def verify_x11_keyboard_layout(layout :str) -> bool:
44 for language in list_x11_keyboard_languages():
45 if layout.lower() == language.lower():
46 return True
47 return False
48
49
50 def set_kb_layout(locale :str) -> bool:
51 if len(locale.strip()):
52 if not verify_keyboard_layout(locale):
53 error(f"Invalid keyboard locale specified: {locale}")
54 return False
55
56 try:
57 SysCommand(f'localectl set-keymap {locale}')
58 except SysCallError as err:
59 raise ServiceException(f"Unable to set locale '{locale}' for console: {err}")
60
61 return True
62
63 return False
64
65
66 def list_timezones() -> Iterator[str]:
67 for line in SysCommand("timedatectl --no-pager list-timezones", environment_vars={'SYSTEMD_COLORS': '0'}):
68 yield line.decode('UTF-8').strip()
69
[end of archinstall/lib/locale/locale.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/archinstall/lib/locale/locale.py b/archinstall/lib/locale/locale.py
--- a/archinstall/lib/locale/locale.py
+++ b/archinstall/lib/locale/locale.py
@@ -11,21 +11,14 @@
def list_locales() -> List[str]:
- with open('/etc/locale.gen', 'r') as fp:
- locales = []
- # before the list of locales begins there's an empty line with a '#' in front
- # so we'll collect the localels from bottom up and halt when we're donw
- entries = fp.readlines()
- entries.reverse()
-
- for entry in entries:
- text = entry.replace('#', '').strip()
- if text == '':
- break
- locales.append(text)
-
- locales.reverse()
- return locales
+ locales = []
+
+ with open('/usr/share/i18n/SUPPORTED') as file:
+ for line in file:
+ if line != 'C.UTF-8 UTF-8\n':
+ locales.append(line.rstrip())
+
+ return locales
def list_x11_keyboard_languages() -> Iterator[str]:
|
{"golden_diff": "diff --git a/archinstall/lib/locale/locale.py b/archinstall/lib/locale/locale.py\n--- a/archinstall/lib/locale/locale.py\n+++ b/archinstall/lib/locale/locale.py\n@@ -11,21 +11,14 @@\n \n \n def list_locales() -> List[str]:\n-\twith open('/etc/locale.gen', 'r') as fp:\n-\t\tlocales = []\n-\t\t# before the list of locales begins there's an empty line with a '#' in front\n-\t\t# so we'll collect the localels from bottom up and halt when we're donw\n-\t\tentries = fp.readlines()\n-\t\tentries.reverse()\n-\n-\t\tfor entry in entries:\n-\t\t\ttext = entry.replace('#', '').strip()\n-\t\t\tif text == '':\n-\t\t\t\tbreak\n-\t\t\tlocales.append(text)\n-\n-\t\tlocales.reverse()\n-\t\treturn locales\n+\tlocales = []\n+\n+\twith open('/usr/share/i18n/SUPPORTED') as file:\n+\t\tfor line in file:\n+\t\t\tif line != 'C.UTF-8 UTF-8\\n':\n+\t\t\t\tlocales.append(line.rstrip())\n+\n+\treturn locales\n \n \n def list_x11_keyboard_languages() -> Iterator[str]:\n", "issue": "locale language only en_US\narchlinux-2023.09.01-x86_64.iso\n", "before_files": [{"content": "from typing import Iterator, List\n\nfrom ..exceptions import ServiceException, SysCallError\nfrom ..general import SysCommand\nfrom ..output import error\n\n\ndef list_keyboard_languages() -> Iterator[str]:\n\tfor line in SysCommand(\"localectl --no-pager list-keymaps\", environment_vars={'SYSTEMD_COLORS': '0'}):\n\t\tyield line.decode('UTF-8').strip()\n\n\ndef list_locales() -> List[str]:\n\twith open('/etc/locale.gen', 'r') as fp:\n\t\tlocales = []\n\t\t# before the list of locales begins there's an empty line with a '#' in front\n\t\t# so we'll collect the localels from bottom up and halt when we're donw\n\t\tentries = fp.readlines()\n\t\tentries.reverse()\n\n\t\tfor entry in entries:\n\t\t\ttext = entry.replace('#', '').strip()\n\t\t\tif text == '':\n\t\t\t\tbreak\n\t\t\tlocales.append(text)\n\n\t\tlocales.reverse()\n\t\treturn locales\n\n\ndef list_x11_keyboard_languages() -> Iterator[str]:\n\tfor line in SysCommand(\"localectl --no-pager list-x11-keymap-layouts\", environment_vars={'SYSTEMD_COLORS': '0'}):\n\t\tyield line.decode('UTF-8').strip()\n\n\ndef verify_keyboard_layout(layout :str) -> bool:\n\tfor language in list_keyboard_languages():\n\t\tif layout.lower() == language.lower():\n\t\t\treturn True\n\treturn False\n\n\ndef verify_x11_keyboard_layout(layout :str) -> bool:\n\tfor language in list_x11_keyboard_languages():\n\t\tif layout.lower() == language.lower():\n\t\t\treturn True\n\treturn False\n\n\ndef set_kb_layout(locale :str) -> bool:\n\tif len(locale.strip()):\n\t\tif not verify_keyboard_layout(locale):\n\t\t\terror(f\"Invalid keyboard locale specified: {locale}\")\n\t\t\treturn False\n\n\t\ttry:\n\t\t\tSysCommand(f'localectl set-keymap {locale}')\n\t\texcept SysCallError as err:\n\t\t\traise ServiceException(f\"Unable to set locale '{locale}' for console: {err}\")\n\n\t\treturn True\n\n\treturn False\n\n\ndef list_timezones() -> Iterator[str]:\n\tfor line in SysCommand(\"timedatectl --no-pager list-timezones\", environment_vars={'SYSTEMD_COLORS': '0'}):\n\t\tyield line.decode('UTF-8').strip()\n", "path": "archinstall/lib/locale/locale.py"}]}
| 1,193 | 255 |
gh_patches_debug_25472
|
rasdani/github-patches
|
git_diff
|
ephios-dev__ephios-772
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Allow users with management permissions to make events visible for all groups
Allow users with management permissions to make events visible for all groups by attributing the global permission instead of an object-level permission. Make sure that all views respect the global permission.
Also reword the label of the management checkbox on the GroupForm, as we are now using "ephios instance" as a label for the settings that require the is_staff flag
</issue>
<code>
[start of ephios/core/forms/users.py]
1 from crispy_forms.bootstrap import FormActions
2 from crispy_forms.helper import FormHelper
3 from crispy_forms.layout import Field, Fieldset, Layout, Submit
4 from django import forms
5 from django.contrib.auth.models import Group
6 from django.db.models import Q
7 from django.forms import (
8 CharField,
9 CheckboxSelectMultiple,
10 DateField,
11 DecimalField,
12 Form,
13 ModelForm,
14 ModelMultipleChoiceField,
15 MultipleChoiceField,
16 inlineformset_factory,
17 )
18 from django.urls import reverse
19 from django.utils.translation import gettext as _
20 from django_select2.forms import Select2MultipleWidget, Select2Widget
21 from guardian.shortcuts import assign_perm, get_objects_for_group, remove_perm
22
23 from ephios.core.consequences import WorkingHoursConsequenceHandler
24 from ephios.core.models import QualificationGrant, UserProfile
25 from ephios.core.services.notifications.backends import enabled_notification_backends
26 from ephios.core.services.notifications.types import enabled_notification_types
27 from ephios.core.widgets import MultiUserProfileWidget
28 from ephios.extra.crispy import AbortLink
29 from ephios.extra.permissions import PermissionField, PermissionFormMixin
30 from ephios.extra.widgets import CustomDateInput
31 from ephios.modellogging.log import add_log_recorder
32 from ephios.modellogging.recorders import DerivedFieldsLogRecorder
33
34 MANAGEMENT_PERMISSIONS = [
35 "auth.add_group",
36 "auth.change_group",
37 "auth.delete_group",
38 "auth.view_group",
39 "core.add_userprofile",
40 "core.change_userprofile",
41 "core.delete_userprofile",
42 "core.view_userprofile",
43 "core.view_event",
44 "core.add_event",
45 "core.change_event",
46 "core.delete_event",
47 "core.view_eventtype",
48 "core.add_eventtype",
49 "core.change_eventtype",
50 "core.delete_eventtype",
51 "core.view_qualification",
52 "core.add_qualification",
53 "core.change_qualification",
54 "core.delete_qualification",
55 "modellogging.view_logentry",
56 ]
57
58
59 def get_group_permission_log_fields(group):
60 # This lives here because it is closely related to the fields on GroupForm below
61 if not group.pk:
62 return {}
63 perms = set(group.permissions.values_list("codename", flat=True))
64
65 return {
66 _("Can view past events"): "view_past_event" in perms,
67 _("Can add events"): "add_event" in perms,
68 _("Can edit users"): "change_userprofile" in perms,
69 _("Can manage ephios"): "change_group" in perms,
70 # force evaluation of querysets
71 _("Can publish events for groups"): set(
72 get_objects_for_group(group, "publish_event_for_group", klass=Group)
73 ),
74 _("Can decide working hours for groups"): set(
75 get_objects_for_group(group, "decide_workinghours_for_group", klass=Group)
76 ),
77 }
78
79
80 class GroupForm(PermissionFormMixin, ModelForm):
81 can_view_past_event = PermissionField(
82 label=_("Can view past events"), permissions=["core.view_past_event"], required=False
83 )
84
85 is_planning_group = PermissionField(
86 label=_("Can add events"),
87 permissions=["core.add_event", "core.delete_event"],
88 required=False,
89 )
90 publish_event_for_group = ModelMultipleChoiceField(
91 label=_("Can publish events for groups"),
92 queryset=Group.objects.all(),
93 required=False,
94 help_text=_("Choose groups that this group can make events visible for."),
95 widget=Select2MultipleWidget,
96 )
97 decide_workinghours_for_group = ModelMultipleChoiceField(
98 label=_("Can decide working hours for groups"),
99 queryset=Group.objects.all(),
100 required=False,
101 help_text=_(
102 "Choose groups that the group you are currently editing can decide whether to grant working hours for."
103 ),
104 widget=Select2MultipleWidget,
105 )
106
107 is_hr_group = PermissionField(
108 label=_("Can edit users"),
109 help_text=_(
110 "If checked, users in this group can view, add, edit and delete users. They can also manage group memberships for their own groups."
111 ),
112 permissions=[
113 "core.add_userprofile",
114 "core.change_userprofile",
115 "core.delete_userprofile",
116 "core.view_userprofile",
117 ],
118 required=False,
119 )
120 is_management_group = PermissionField(
121 label=_("Can manage ephios"),
122 help_text=_(
123 "If checked, users in this group can manage users, groups, all group memberships, eventtypes and qualifications"
124 ),
125 permissions=MANAGEMENT_PERMISSIONS,
126 required=False,
127 )
128
129 users = ModelMultipleChoiceField(
130 label=_("Users"), queryset=UserProfile.objects.all(), widget=MultiUserProfileWidget
131 )
132
133 class Meta:
134 model = Group
135 fields = ["name"]
136
137 def __init__(self, **kwargs):
138 if (group := kwargs.get("instance", None)) is not None:
139 kwargs["initial"] = {
140 "users": group.user_set.all(),
141 "publish_event_for_group": get_objects_for_group(
142 group, "publish_event_for_group", klass=Group
143 ),
144 "decide_workinghours_for_group": get_objects_for_group(
145 group, "decide_workinghours_for_group", klass=Group
146 ),
147 **kwargs.get("initial", {}),
148 }
149 self.permission_target = group
150 super().__init__(**kwargs)
151 self.helper = FormHelper()
152 self.helper.layout = Layout(
153 Field("name"),
154 Field("users"),
155 Field("can_view_past_event"),
156 Fieldset(
157 _("Management"),
158 Field("is_hr_group", title="This permission is included with the management role."),
159 "is_management_group",
160 ),
161 Fieldset(
162 _("Planning"),
163 Field(
164 "is_planning_group",
165 title="This permission is included with the management role.",
166 ),
167 Field("publish_event_for_group", wrapper_class="publish-select"),
168 "decide_workinghours_for_group",
169 ),
170 FormActions(
171 Submit("submit", _("Save"), css_class="float-end"),
172 AbortLink(href=reverse("core:group_list")),
173 ),
174 )
175
176 def save(self, commit=True):
177 add_log_recorder(self.instance, DerivedFieldsLogRecorder(get_group_permission_log_fields))
178 group = super().save(commit)
179
180 group.user_set.set(self.cleaned_data["users"])
181
182 remove_perm("publish_event_for_group", group, Group.objects.all())
183 if group.permissions.filter(codename="add_event").exists():
184 assign_perm(
185 "publish_event_for_group", group, self.cleaned_data["publish_event_for_group"]
186 )
187
188 if "decide_workinghours_for_group" in self.changed_data:
189 remove_perm("decide_workinghours_for_group", group, Group.objects.all())
190 assign_perm(
191 "decide_workinghours_for_group",
192 group,
193 self.cleaned_data["decide_workinghours_for_group"],
194 )
195
196 group.save() # logging
197 return group
198
199
200 class UserProfileForm(ModelForm):
201 groups = ModelMultipleChoiceField(
202 label=_("Groups"),
203 queryset=Group.objects.all(),
204 widget=Select2MultipleWidget,
205 required=False,
206 disabled=True, # explicitly enable for users with `change_group` permission
207 )
208
209 def __init__(self, *args, **kwargs):
210 request = kwargs.pop("request")
211 super().__init__(*args, **kwargs)
212 self.locked_groups = set()
213 if request.user.has_perm("auth.change_group"):
214 self.fields["groups"].disabled = False
215 elif allowed_groups := request.user.groups:
216 self.fields["groups"].disabled = False
217 self.fields["groups"].queryset = allowed_groups
218 if self.instance.pk:
219 self.locked_groups = set(self.instance.groups.exclude(id__in=allowed_groups.all()))
220 if self.locked_groups:
221 self.fields["groups"].help_text = _(
222 "The user is also member of <b>{groups}</b>, but you are not allowed to manage memberships for those groups."
223 ).format(groups=", ".join((group.name for group in self.locked_groups)))
224
225 field_order = [
226 "email",
227 "first_name",
228 "last_name",
229 "date_of_birth",
230 "phone",
231 "groups",
232 "is_active",
233 ]
234
235 class Meta:
236 model = UserProfile
237 fields = ["email", "first_name", "last_name", "date_of_birth", "phone", "is_active"]
238 widgets = {"date_of_birth": CustomDateInput}
239 help_texts = {
240 "is_active": _("Inactive users cannot log in and do not get any notifications.")
241 }
242 labels = {"is_active": _("Active user")}
243
244 def save(self, commit=True):
245 userprofile = super().save(commit)
246 userprofile.groups.set(
247 Group.objects.filter(
248 Q(id__in=self.cleaned_data["groups"]) | Q(id__in=(g.id for g in self.locked_groups))
249 )
250 )
251 userprofile.save()
252 return userprofile
253
254
255 class QualificationGrantForm(ModelForm):
256 model = QualificationGrant
257
258 class Meta:
259 fields = ["qualification", "expires"]
260 widgets = {"qualification": Select2Widget}
261
262 def __init__(self, *args, **kwargs):
263 super().__init__(*args, **kwargs)
264 if hasattr(self, "instance") and self.instance.pk:
265 # Hide the field and simply display the qualification name in the template
266 self.fields["qualification"].disabled = True
267 self.fields["qualification"].widget = forms.HiddenInput()
268 self.fields["qualification"].title = self.instance.qualification.title
269
270
271 QualificationGrantFormset = inlineformset_factory(
272 UserProfile,
273 QualificationGrant,
274 form=QualificationGrantForm,
275 extra=0,
276 )
277
278
279 class QualificationGrantFormsetHelper(FormHelper):
280 def __init__(self, *args, **kwargs):
281 super().__init__(*args, **kwargs)
282 self.label_class = "col-md-4"
283 self.field_class = "col-md-8"
284
285
286 class WorkingHourRequestForm(Form):
287 when = DateField(widget=CustomDateInput, label=_("Date"))
288 hours = DecimalField(label=_("Hours of work"), min_value=0.5)
289 reason = CharField(label=_("Occasion"))
290
291 def __init__(self, *args, **kwargs):
292 self.request = kwargs.pop("request")
293 super().__init__(*args, **kwargs)
294 self.helper = FormHelper(self)
295 self.helper.layout = Layout(
296 Field("when"),
297 Field("hours"),
298 Field("reason"),
299 FormActions(
300 Submit("submit", _("Send"), css_class="float-end"),
301 AbortLink(href=reverse("core:profile")),
302 ),
303 )
304
305 def create_consequence(self):
306 WorkingHoursConsequenceHandler.create(
307 user=self.request.user,
308 when=self.cleaned_data["when"],
309 hours=float(self.cleaned_data["hours"]),
310 reason=self.cleaned_data["reason"],
311 )
312
313
314 class UserNotificationPreferenceForm(Form):
315 def __init__(self, *args, **kwargs):
316 self.user = kwargs.pop("user")
317 super().__init__(*args, **kwargs)
318
319 preferences = self.user.preferences["notifications__notifications"]
320 for notification_type in enabled_notification_types():
321 if notification_type.unsubscribe_allowed:
322 self.fields[notification_type.slug] = MultipleChoiceField(
323 label=notification_type.title,
324 choices=[
325 (backend.slug, backend.title) for backend in enabled_notification_backends()
326 ],
327 initial=preferences.get(notification_type.slug, {}),
328 widget=CheckboxSelectMultiple,
329 required=False,
330 )
331
332 def update_preferences(self):
333 self.user.preferences["notifications__notifications"] = self.cleaned_data
334
[end of ephios/core/forms/users.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/ephios/core/forms/users.py b/ephios/core/forms/users.py
--- a/ephios/core/forms/users.py
+++ b/ephios/core/forms/users.py
@@ -31,7 +31,7 @@
from ephios.modellogging.log import add_log_recorder
from ephios.modellogging.recorders import DerivedFieldsLogRecorder
-MANAGEMENT_PERMISSIONS = [
+CORE_MANAGEMENT_PERMISSIONS = [
"auth.add_group",
"auth.change_group",
"auth.delete_group",
@@ -52,6 +52,7 @@
"core.add_qualification",
"core.change_qualification",
"core.delete_qualification",
+ "auth.publish_event_for_group",
"modellogging.view_logentry",
]
@@ -118,11 +119,11 @@
required=False,
)
is_management_group = PermissionField(
- label=_("Can manage ephios"),
+ label=_("Can manage permissions and qualifications"),
help_text=_(
"If checked, users in this group can manage users, groups, all group memberships, eventtypes and qualifications"
),
- permissions=MANAGEMENT_PERMISSIONS,
+ permissions=CORE_MANAGEMENT_PERMISSIONS,
required=False,
)
|
{"golden_diff": "diff --git a/ephios/core/forms/users.py b/ephios/core/forms/users.py\n--- a/ephios/core/forms/users.py\n+++ b/ephios/core/forms/users.py\n@@ -31,7 +31,7 @@\n from ephios.modellogging.log import add_log_recorder\n from ephios.modellogging.recorders import DerivedFieldsLogRecorder\n \n-MANAGEMENT_PERMISSIONS = [\n+CORE_MANAGEMENT_PERMISSIONS = [\n \"auth.add_group\",\n \"auth.change_group\",\n \"auth.delete_group\",\n@@ -52,6 +52,7 @@\n \"core.add_qualification\",\n \"core.change_qualification\",\n \"core.delete_qualification\",\n+ \"auth.publish_event_for_group\",\n \"modellogging.view_logentry\",\n ]\n \n@@ -118,11 +119,11 @@\n required=False,\n )\n is_management_group = PermissionField(\n- label=_(\"Can manage ephios\"),\n+ label=_(\"Can manage permissions and qualifications\"),\n help_text=_(\n \"If checked, users in this group can manage users, groups, all group memberships, eventtypes and qualifications\"\n ),\n- permissions=MANAGEMENT_PERMISSIONS,\n+ permissions=CORE_MANAGEMENT_PERMISSIONS,\n required=False,\n )\n", "issue": "Allow users with management permissions to make events visible for all groups\nAllow users with management permissions to make events visible for all groups by attributing the global permission instead of an object-level permission. Make sure that all views respect the global permission.\r\nAlso reword the label of the management checkbox on the GroupForm, as we are now using \"ephios instance\" as a label for the settings that require the is_staff flag\n", "before_files": [{"content": "from crispy_forms.bootstrap import FormActions\nfrom crispy_forms.helper import FormHelper\nfrom crispy_forms.layout import Field, Fieldset, Layout, Submit\nfrom django import forms\nfrom django.contrib.auth.models import Group\nfrom django.db.models import Q\nfrom django.forms import (\n CharField,\n CheckboxSelectMultiple,\n DateField,\n DecimalField,\n Form,\n ModelForm,\n ModelMultipleChoiceField,\n MultipleChoiceField,\n inlineformset_factory,\n)\nfrom django.urls import reverse\nfrom django.utils.translation import gettext as _\nfrom django_select2.forms import Select2MultipleWidget, Select2Widget\nfrom guardian.shortcuts import assign_perm, get_objects_for_group, remove_perm\n\nfrom ephios.core.consequences import WorkingHoursConsequenceHandler\nfrom ephios.core.models import QualificationGrant, UserProfile\nfrom ephios.core.services.notifications.backends import enabled_notification_backends\nfrom ephios.core.services.notifications.types import enabled_notification_types\nfrom ephios.core.widgets import MultiUserProfileWidget\nfrom ephios.extra.crispy import AbortLink\nfrom ephios.extra.permissions import PermissionField, PermissionFormMixin\nfrom ephios.extra.widgets import CustomDateInput\nfrom ephios.modellogging.log import add_log_recorder\nfrom ephios.modellogging.recorders import DerivedFieldsLogRecorder\n\nMANAGEMENT_PERMISSIONS = [\n \"auth.add_group\",\n \"auth.change_group\",\n \"auth.delete_group\",\n \"auth.view_group\",\n \"core.add_userprofile\",\n \"core.change_userprofile\",\n \"core.delete_userprofile\",\n \"core.view_userprofile\",\n \"core.view_event\",\n \"core.add_event\",\n \"core.change_event\",\n \"core.delete_event\",\n \"core.view_eventtype\",\n \"core.add_eventtype\",\n \"core.change_eventtype\",\n \"core.delete_eventtype\",\n \"core.view_qualification\",\n \"core.add_qualification\",\n \"core.change_qualification\",\n \"core.delete_qualification\",\n \"modellogging.view_logentry\",\n]\n\n\ndef get_group_permission_log_fields(group):\n # This lives here because it is closely related to the fields on GroupForm below\n if not group.pk:\n return {}\n perms = set(group.permissions.values_list(\"codename\", flat=True))\n\n return {\n _(\"Can view past events\"): \"view_past_event\" in perms,\n _(\"Can add events\"): \"add_event\" in perms,\n _(\"Can edit users\"): \"change_userprofile\" in perms,\n _(\"Can manage ephios\"): \"change_group\" in perms,\n # force evaluation of querysets\n _(\"Can publish events for groups\"): set(\n get_objects_for_group(group, \"publish_event_for_group\", klass=Group)\n ),\n _(\"Can decide working hours for groups\"): set(\n get_objects_for_group(group, \"decide_workinghours_for_group\", klass=Group)\n ),\n }\n\n\nclass GroupForm(PermissionFormMixin, ModelForm):\n can_view_past_event = PermissionField(\n label=_(\"Can view past events\"), permissions=[\"core.view_past_event\"], required=False\n )\n\n is_planning_group = PermissionField(\n label=_(\"Can add events\"),\n permissions=[\"core.add_event\", \"core.delete_event\"],\n required=False,\n )\n publish_event_for_group = ModelMultipleChoiceField(\n label=_(\"Can publish events for groups\"),\n queryset=Group.objects.all(),\n required=False,\n help_text=_(\"Choose groups that this group can make events visible for.\"),\n widget=Select2MultipleWidget,\n )\n decide_workinghours_for_group = ModelMultipleChoiceField(\n label=_(\"Can decide working hours for groups\"),\n queryset=Group.objects.all(),\n required=False,\n help_text=_(\n \"Choose groups that the group you are currently editing can decide whether to grant working hours for.\"\n ),\n widget=Select2MultipleWidget,\n )\n\n is_hr_group = PermissionField(\n label=_(\"Can edit users\"),\n help_text=_(\n \"If checked, users in this group can view, add, edit and delete users. They can also manage group memberships for their own groups.\"\n ),\n permissions=[\n \"core.add_userprofile\",\n \"core.change_userprofile\",\n \"core.delete_userprofile\",\n \"core.view_userprofile\",\n ],\n required=False,\n )\n is_management_group = PermissionField(\n label=_(\"Can manage ephios\"),\n help_text=_(\n \"If checked, users in this group can manage users, groups, all group memberships, eventtypes and qualifications\"\n ),\n permissions=MANAGEMENT_PERMISSIONS,\n required=False,\n )\n\n users = ModelMultipleChoiceField(\n label=_(\"Users\"), queryset=UserProfile.objects.all(), widget=MultiUserProfileWidget\n )\n\n class Meta:\n model = Group\n fields = [\"name\"]\n\n def __init__(self, **kwargs):\n if (group := kwargs.get(\"instance\", None)) is not None:\n kwargs[\"initial\"] = {\n \"users\": group.user_set.all(),\n \"publish_event_for_group\": get_objects_for_group(\n group, \"publish_event_for_group\", klass=Group\n ),\n \"decide_workinghours_for_group\": get_objects_for_group(\n group, \"decide_workinghours_for_group\", klass=Group\n ),\n **kwargs.get(\"initial\", {}),\n }\n self.permission_target = group\n super().__init__(**kwargs)\n self.helper = FormHelper()\n self.helper.layout = Layout(\n Field(\"name\"),\n Field(\"users\"),\n Field(\"can_view_past_event\"),\n Fieldset(\n _(\"Management\"),\n Field(\"is_hr_group\", title=\"This permission is included with the management role.\"),\n \"is_management_group\",\n ),\n Fieldset(\n _(\"Planning\"),\n Field(\n \"is_planning_group\",\n title=\"This permission is included with the management role.\",\n ),\n Field(\"publish_event_for_group\", wrapper_class=\"publish-select\"),\n \"decide_workinghours_for_group\",\n ),\n FormActions(\n Submit(\"submit\", _(\"Save\"), css_class=\"float-end\"),\n AbortLink(href=reverse(\"core:group_list\")),\n ),\n )\n\n def save(self, commit=True):\n add_log_recorder(self.instance, DerivedFieldsLogRecorder(get_group_permission_log_fields))\n group = super().save(commit)\n\n group.user_set.set(self.cleaned_data[\"users\"])\n\n remove_perm(\"publish_event_for_group\", group, Group.objects.all())\n if group.permissions.filter(codename=\"add_event\").exists():\n assign_perm(\n \"publish_event_for_group\", group, self.cleaned_data[\"publish_event_for_group\"]\n )\n\n if \"decide_workinghours_for_group\" in self.changed_data:\n remove_perm(\"decide_workinghours_for_group\", group, Group.objects.all())\n assign_perm(\n \"decide_workinghours_for_group\",\n group,\n self.cleaned_data[\"decide_workinghours_for_group\"],\n )\n\n group.save() # logging\n return group\n\n\nclass UserProfileForm(ModelForm):\n groups = ModelMultipleChoiceField(\n label=_(\"Groups\"),\n queryset=Group.objects.all(),\n widget=Select2MultipleWidget,\n required=False,\n disabled=True, # explicitly enable for users with `change_group` permission\n )\n\n def __init__(self, *args, **kwargs):\n request = kwargs.pop(\"request\")\n super().__init__(*args, **kwargs)\n self.locked_groups = set()\n if request.user.has_perm(\"auth.change_group\"):\n self.fields[\"groups\"].disabled = False\n elif allowed_groups := request.user.groups:\n self.fields[\"groups\"].disabled = False\n self.fields[\"groups\"].queryset = allowed_groups\n if self.instance.pk:\n self.locked_groups = set(self.instance.groups.exclude(id__in=allowed_groups.all()))\n if self.locked_groups:\n self.fields[\"groups\"].help_text = _(\n \"The user is also member of <b>{groups}</b>, but you are not allowed to manage memberships for those groups.\"\n ).format(groups=\", \".join((group.name for group in self.locked_groups)))\n\n field_order = [\n \"email\",\n \"first_name\",\n \"last_name\",\n \"date_of_birth\",\n \"phone\",\n \"groups\",\n \"is_active\",\n ]\n\n class Meta:\n model = UserProfile\n fields = [\"email\", \"first_name\", \"last_name\", \"date_of_birth\", \"phone\", \"is_active\"]\n widgets = {\"date_of_birth\": CustomDateInput}\n help_texts = {\n \"is_active\": _(\"Inactive users cannot log in and do not get any notifications.\")\n }\n labels = {\"is_active\": _(\"Active user\")}\n\n def save(self, commit=True):\n userprofile = super().save(commit)\n userprofile.groups.set(\n Group.objects.filter(\n Q(id__in=self.cleaned_data[\"groups\"]) | Q(id__in=(g.id for g in self.locked_groups))\n )\n )\n userprofile.save()\n return userprofile\n\n\nclass QualificationGrantForm(ModelForm):\n model = QualificationGrant\n\n class Meta:\n fields = [\"qualification\", \"expires\"]\n widgets = {\"qualification\": Select2Widget}\n\n def __init__(self, *args, **kwargs):\n super().__init__(*args, **kwargs)\n if hasattr(self, \"instance\") and self.instance.pk:\n # Hide the field and simply display the qualification name in the template\n self.fields[\"qualification\"].disabled = True\n self.fields[\"qualification\"].widget = forms.HiddenInput()\n self.fields[\"qualification\"].title = self.instance.qualification.title\n\n\nQualificationGrantFormset = inlineformset_factory(\n UserProfile,\n QualificationGrant,\n form=QualificationGrantForm,\n extra=0,\n)\n\n\nclass QualificationGrantFormsetHelper(FormHelper):\n def __init__(self, *args, **kwargs):\n super().__init__(*args, **kwargs)\n self.label_class = \"col-md-4\"\n self.field_class = \"col-md-8\"\n\n\nclass WorkingHourRequestForm(Form):\n when = DateField(widget=CustomDateInput, label=_(\"Date\"))\n hours = DecimalField(label=_(\"Hours of work\"), min_value=0.5)\n reason = CharField(label=_(\"Occasion\"))\n\n def __init__(self, *args, **kwargs):\n self.request = kwargs.pop(\"request\")\n super().__init__(*args, **kwargs)\n self.helper = FormHelper(self)\n self.helper.layout = Layout(\n Field(\"when\"),\n Field(\"hours\"),\n Field(\"reason\"),\n FormActions(\n Submit(\"submit\", _(\"Send\"), css_class=\"float-end\"),\n AbortLink(href=reverse(\"core:profile\")),\n ),\n )\n\n def create_consequence(self):\n WorkingHoursConsequenceHandler.create(\n user=self.request.user,\n when=self.cleaned_data[\"when\"],\n hours=float(self.cleaned_data[\"hours\"]),\n reason=self.cleaned_data[\"reason\"],\n )\n\n\nclass UserNotificationPreferenceForm(Form):\n def __init__(self, *args, **kwargs):\n self.user = kwargs.pop(\"user\")\n super().__init__(*args, **kwargs)\n\n preferences = self.user.preferences[\"notifications__notifications\"]\n for notification_type in enabled_notification_types():\n if notification_type.unsubscribe_allowed:\n self.fields[notification_type.slug] = MultipleChoiceField(\n label=notification_type.title,\n choices=[\n (backend.slug, backend.title) for backend in enabled_notification_backends()\n ],\n initial=preferences.get(notification_type.slug, {}),\n widget=CheckboxSelectMultiple,\n required=False,\n )\n\n def update_preferences(self):\n self.user.preferences[\"notifications__notifications\"] = self.cleaned_data\n", "path": "ephios/core/forms/users.py"}]}
| 3,987 | 270 |
gh_patches_debug_38572
|
rasdani/github-patches
|
git_diff
|
Pyomo__pyomo-596
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Pyomo crashes when solver returns suffix but no value for variables
When the user requests an irreducibly infeasible set of constraints (IIS) for an infeasible mixed-integer program, cplexamp sometimes returns the IIS but not values for the variables. This causes pyomo to crash while reading the solution. Specifically, `pyomo.opt.plugins.sol` only creates entries in `soln_variable` for variables whose values have been returned by the solver, but then it tries to attach the IIS suffix value to a non-existent item in `soln_variable`, causing an uncaught `KeyError()`.
The code below illustrates this problem:
from pyomo.environ import *
m = ConcreteModel()
m.x1 = Var(within=NonNegativeReals)
m.x2 = Var(within=NonNegativeIntegers)
m.constraint = Constraint(rule=lambda m: m.x1 + m.x2 <= -1)
m.objective = Objective(rule=lambda m: m.x1 + m.x2, sense=minimize)
m.iis = Suffix(direction=Suffix.IMPORT)
solver = SolverFactory('cplexamp')
res = solver.solve(m, options_string='iisfind=1', tee=True)
print("IIS:")
print("\n".join(sorted(c.name for c in m.iis)))
I have added a pull request to fix this: https://github.com/Pyomo/pyomo/pull/596
</issue>
<code>
[start of pyomo/opt/plugins/sol.py]
1 # ___________________________________________________________________________
2 #
3 # Pyomo: Python Optimization Modeling Objects
4 # Copyright 2017 National Technology and Engineering Solutions of Sandia, LLC
5 # Under the terms of Contract DE-NA0003525 with National Technology and
6 # Engineering Solutions of Sandia, LLC, the U.S. Government retains certain
7 # rights in this software.
8 # This software is distributed under the 3-clause BSD License.
9 # ___________________________________________________________________________
10
11 #
12 # Class for reading an AMPL *.sol file
13 #
14
15 import re
16
17 import pyutilib.misc
18
19 from pyomo.common.plugin import alias
20 from pyomo.opt.base import results
21 from pyomo.opt.base.formats import ResultsFormat
22 from pyomo.opt import (SolverResults,
23 SolutionStatus,
24 SolverStatus,
25 TerminationCondition)
26
27 from six.moves import xrange
28
29 class ResultsReader_sol(results.AbstractResultsReader):
30 """
31 Class that reads in a *.sol results file and generates a
32 SolverResults object.
33 """
34
35 alias(str(ResultsFormat.sol))
36
37 def __init__(self, name=None):
38 results.AbstractResultsReader.__init__(self,ResultsFormat.sol)
39 if not name is None:
40 self.name = name
41
42 def __call__(self, filename, res=None, soln=None, suffixes=[]):
43 """
44 Parse a *.sol file
45 """
46 try:
47 with open(filename,"r") as f:
48 return self._load(f, res, soln, suffixes)
49 except ValueError as e:
50 with open(filename,"r") as f:
51 fdata = f.read()
52 raise ValueError(
53 "Error reading '%s': %s.\n"
54 "SOL File Output:\n%s"
55 % (filename, str(e), fdata))
56
57 def _load(self, fin, res, soln, suffixes):
58
59 if res is None:
60 res = SolverResults()
61 #
62 msg = ""
63 line = fin.readline()
64 if line.strip() == "":
65 line = fin.readline()
66 while line:
67 if line[0] == '\n' or (line[0] == '\r' and line[1] == '\n'):
68 break
69 msg += line
70 line = fin.readline()
71 z = []
72 line = fin.readline()
73 if line[:7] == "Options":
74 line = fin.readline()
75 nopts = int(line)
76 need_vbtol = False
77 if nopts > 4: # WEH - when is this true?
78 nopts -= 2
79 need_vbtol = True
80 for i in xrange(nopts + 4):
81 line = fin.readline()
82 z += [int(line)]
83 if need_vbtol: # WEH - when is this true?
84 line = fin.readline()
85 z += [float(line)]
86 else:
87 raise ValueError("no Options line found")
88 n = z[nopts + 3] # variables
89 m = z[nopts + 1] # constraints
90 x = []
91 y = []
92 i = 0
93 while i < m:
94 line = fin.readline()
95 y.append(float(line))
96 i += 1
97 i = 0
98 while i < n:
99 line = fin.readline()
100 x.append(float(line))
101 i += 1
102 objno = [0,0]
103 line = fin.readline()
104 if line: # WEH - when is this true?
105 if line[:5] != "objno": #pragma:nocover
106 raise ValueError("expected 'objno', found '%s'" % (line))
107 t = line.split()
108 if len(t) != 3:
109 raise ValueError("expected two numbers in objno line, "
110 "but found '%s'" % (line))
111 objno = [int(t[1]), int(t[2])]
112 res.solver.message = msg.strip()
113 res.solver.message = res.solver.message.replace("\n","; ")
114 res.solver.message = pyutilib.misc.yaml_fix(res.solver.message)
115 ##res.solver.instanceName = osrl.header.instanceName
116 ##res.solver.systime = osrl.header.time
117 res.solver.status = SolverStatus.ok
118 soln_status = SolutionStatus.unknown
119 if (objno[1] >= 0) and (objno[1] <= 99):
120 objno_message = "OPTIMAL SOLUTION FOUND!"
121 res.solver.termination_condition = TerminationCondition.optimal
122 res.solver.status = SolverStatus.ok
123 soln_status = SolutionStatus.optimal
124 elif (objno[1] >= 100) and (objno[1] <= 199):
125 objno_message = "Optimal solution indicated, but ERROR LIKELY!"
126 res.solver.termination_condition = TerminationCondition.optimal
127 res.solver.status = SolverStatus.warning
128 soln_status = SolutionStatus.optimal
129 elif (objno[1] >= 200) and (objno[1] <= 299):
130 objno_message = "INFEASIBLE SOLUTION: constraints cannot be satisfied!"
131 res.solver.termination_condition = TerminationCondition.infeasible
132 res.solver.status = SolverStatus.warning
133 soln_status = SolutionStatus.infeasible
134 elif (objno[1] >= 300) and (objno[1] <= 399):
135 objno_message = "UNBOUNDED PROBLEM: the objective can be improved without limit!"
136 res.solver.termination_condition = TerminationCondition.unbounded
137 res.solver.status = SolverStatus.warning
138 soln_status = SolutionStatus.unbounded
139 elif (objno[1] >= 400) and (objno[1] <= 499):
140 objno_message = ("EXCEEDED MAXIMUM NUMBER OF ITERATIONS: the solver "
141 "was stopped by a limit that you set!")
142 res.solver.termination_condition = TerminationCondition.maxIterations
143 res.solver.status = SolverStatus.warning
144 soln_status = SolutionStatus.stoppedByLimit
145 elif (objno[1] >= 500) and (objno[1] <= 599):
146 objno_message = ("FAILURE: the solver stopped by an error condition "
147 "in the solver routines!")
148 res.solver.termination_condition = TerminationCondition.internalSolverError
149 res.solver.status = SolverStatus.error
150 soln_status = SolutionStatus.error
151 res.solver.id = objno[1]
152 ##res.problem.name = osrl.header.instanceName
153 if res.solver.termination_condition in [TerminationCondition.unknown,
154 TerminationCondition.maxIterations,
155 TerminationCondition.minFunctionValue,
156 TerminationCondition.minStepLength,
157 TerminationCondition.globallyOptimal,
158 TerminationCondition.locallyOptimal,
159 TerminationCondition.optimal,
160 TerminationCondition.maxEvaluations,
161 TerminationCondition.other,
162 TerminationCondition.infeasible]:
163
164 if soln is None:
165 soln = res.solution.add()
166 res.solution.status = soln_status
167 soln.status_description = objno_message
168 soln.message = msg.strip()
169 soln.message = res.solver.message.replace("\n","; ")
170 soln_variable = soln.variable
171 i = 0
172 for var_value in x:
173 soln_variable["v"+str(i)] = {"Value" : var_value}
174 i = i + 1
175 soln_constraint = soln.constraint
176 if any(re.match(suf,"dual") for suf in suffixes):
177 for i in xrange(0,len(y)):
178 soln_constraint["c"+str(i)] = {"Dual" : y[i]}
179
180 ### Read suffixes ###
181 line = fin.readline()
182 while line:
183 line = line.strip()
184 if line == "":
185 continue
186 line = line.split()
187 if line[0] != 'suffix':
188 # We assume this is the start of a
189 # section like kestrel_option, which
190 # comes after all suffixes.
191 remaining = ""
192 line = fin.readline()
193 while line:
194 remaining += line.strip()+"; "
195 line = fin.readline()
196 res.solver.message += remaining
197 break
198 unmasked_kind = int(line[1])
199 kind = unmasked_kind & 3 # 0-var, 1-con, 2-obj, 3-prob
200 convert_function = int
201 if (unmasked_kind & 4) == 4:
202 convert_function = float
203 nvalues = int(line[2])
204 namelen = int(line[3])
205 tablen = int(line[4])
206 tabline = int(line[5])
207 suffix_name = fin.readline().strip()
208 if any(re.match(suf,suffix_name) for suf in suffixes):
209 # ignore translation of the table number to string value for now,
210 # this information can be obtained from the solver documentation
211 for n in xrange(tabline):
212 fin.readline()
213 if kind == 0: # Var
214 for cnt in xrange(nvalues):
215 suf_line = fin.readline().split()
216 soln_variable["v"+suf_line[0]][suffix_name] = \
217 convert_function(suf_line[1])
218 elif kind == 1: # Con
219 for cnt in xrange(nvalues):
220 suf_line = fin.readline().split()
221 key = "c"+suf_line[0]
222 if key not in soln_constraint:
223 soln_constraint[key] = {}
224 # convert the first letter of the suffix name to upper case,
225 # mainly for pretty-print / output purposes. these are lower-cased
226 # when loaded into real suffixes, so it is largely redundant.
227 translated_suffix_name = suffix_name[0].upper() + suffix_name[1:]
228 soln_constraint[key][translated_suffix_name] = \
229 convert_function(suf_line[1])
230 elif kind == 2: # Obj
231 for cnt in xrange(nvalues):
232 suf_line = fin.readline().split()
233 soln.objective.setdefault("o"+suf_line[0],{})[suffix_name] = \
234 convert_function(suf_line[1])
235 elif kind == 3: # Prob
236 # Skip problem kind suffixes for now. Not sure the
237 # best place to put them in the results object
238 for cnt in xrange(nvalues):
239 suf_line = fin.readline().split()
240 soln.problem[suffix_name] = convert_function(suf_line[1])
241 else:
242 # do not store the suffix in the solution object
243 for cnt in xrange(nvalues):
244 fin.readline()
245 line = fin.readline()
246
247 #
248 # This is a bit of a hack to accommodate PICO. If
249 # the PICO parser has parsed the # of constraints, then
250 # don't try to read it in from the *.sol file. The reason
251 # is that these may be inconsistent values!
252 #
253 if res.problem.number_of_constraints == 0:
254 res.problem.number_of_constraints = m
255 res.problem.number_of_variables = n
256 res.problem.number_of_objectives = 1
257 return res
258
[end of pyomo/opt/plugins/sol.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/pyomo/opt/plugins/sol.py b/pyomo/opt/plugins/sol.py
--- a/pyomo/opt/plugins/sol.py
+++ b/pyomo/opt/plugins/sol.py
@@ -2,8 +2,8 @@
#
# Pyomo: Python Optimization Modeling Objects
# Copyright 2017 National Technology and Engineering Solutions of Sandia, LLC
-# Under the terms of Contract DE-NA0003525 with National Technology and
-# Engineering Solutions of Sandia, LLC, the U.S. Government retains certain
+# Under the terms of Contract DE-NA0003525 with National Technology and
+# Engineering Solutions of Sandia, LLC, the U.S. Government retains certain
# rights in this software.
# This software is distributed under the 3-clause BSD License.
# ___________________________________________________________________________
@@ -213,7 +213,10 @@
if kind == 0: # Var
for cnt in xrange(nvalues):
suf_line = fin.readline().split()
- soln_variable["v"+suf_line[0]][suffix_name] = \
+ key = "v"+suf_line[0]
+ if key not in soln_variable:
+ soln_variable[key] = {}
+ soln_variable[key][suffix_name] = \
convert_function(suf_line[1])
elif kind == 1: # Con
for cnt in xrange(nvalues):
@@ -221,9 +224,14 @@
key = "c"+suf_line[0]
if key not in soln_constraint:
soln_constraint[key] = {}
- # convert the first letter of the suffix name to upper case,
- # mainly for pretty-print / output purposes. these are lower-cased
- # when loaded into real suffixes, so it is largely redundant.
+ # GH: About the comment below: This makes for a
+ # confusing results object and more confusing tests.
+ # We should not muck with the names of suffixes
+ # coming out of the sol file.
+ #
+ # convert the first letter of the suffix name to upper case,
+ # mainly for pretty-print / output purposes. these are lower-cased
+ # when loaded into real suffixes, so it is largely redundant.
translated_suffix_name = suffix_name[0].upper() + suffix_name[1:]
soln_constraint[key][translated_suffix_name] = \
convert_function(suf_line[1])
|
{"golden_diff": "diff --git a/pyomo/opt/plugins/sol.py b/pyomo/opt/plugins/sol.py\n--- a/pyomo/opt/plugins/sol.py\n+++ b/pyomo/opt/plugins/sol.py\n@@ -2,8 +2,8 @@\n #\n # Pyomo: Python Optimization Modeling Objects\n # Copyright 2017 National Technology and Engineering Solutions of Sandia, LLC\n-# Under the terms of Contract DE-NA0003525 with National Technology and \n-# Engineering Solutions of Sandia, LLC, the U.S. Government retains certain \n+# Under the terms of Contract DE-NA0003525 with National Technology and\n+# Engineering Solutions of Sandia, LLC, the U.S. Government retains certain\n # rights in this software.\n # This software is distributed under the 3-clause BSD License.\n # ___________________________________________________________________________\n@@ -213,7 +213,10 @@\n if kind == 0: # Var\n for cnt in xrange(nvalues):\n suf_line = fin.readline().split()\n- soln_variable[\"v\"+suf_line[0]][suffix_name] = \\\n+ key = \"v\"+suf_line[0]\n+ if key not in soln_variable:\n+ soln_variable[key] = {}\n+ soln_variable[key][suffix_name] = \\\n convert_function(suf_line[1])\n elif kind == 1: # Con\n for cnt in xrange(nvalues):\n@@ -221,9 +224,14 @@\n key = \"c\"+suf_line[0]\n if key not in soln_constraint:\n soln_constraint[key] = {}\n- # convert the first letter of the suffix name to upper case,\n- # mainly for pretty-print / output purposes. these are lower-cased\n- # when loaded into real suffixes, so it is largely redundant.\n+ # GH: About the comment below: This makes for a\n+ # confusing results object and more confusing tests.\n+ # We should not muck with the names of suffixes\n+ # coming out of the sol file.\n+ #\n+ # convert the first letter of the suffix name to upper case,\n+ # mainly for pretty-print / output purposes. these are lower-cased\n+ # when loaded into real suffixes, so it is largely redundant.\n translated_suffix_name = suffix_name[0].upper() + suffix_name[1:]\n soln_constraint[key][translated_suffix_name] = \\\n convert_function(suf_line[1])\n", "issue": "Pyomo crashes when solver returns suffix but no value for variables\nWhen the user requests an irreducibly infeasible set of constraints (IIS) for an infeasible mixed-integer program, cplexamp sometimes returns the IIS but not values for the variables. This causes pyomo to crash while reading the solution. Specifically, `pyomo.opt.plugins.sol` only creates entries in `soln_variable` for variables whose values have been returned by the solver, but then it tries to attach the IIS suffix value to a non-existent item in `soln_variable`, causing an uncaught `KeyError()`.\r\n\r\nThe code below illustrates this problem:\r\n\r\n from pyomo.environ import *\r\n m = ConcreteModel()\r\n m.x1 = Var(within=NonNegativeReals)\r\n m.x2 = Var(within=NonNegativeIntegers)\r\n m.constraint = Constraint(rule=lambda m: m.x1 + m.x2 <= -1)\r\n m.objective = Objective(rule=lambda m: m.x1 + m.x2, sense=minimize)\r\n m.iis = Suffix(direction=Suffix.IMPORT)\r\n solver = SolverFactory('cplexamp')\r\n res = solver.solve(m, options_string='iisfind=1', tee=True)\r\n print(\"IIS:\")\r\n print(\"\\n\".join(sorted(c.name for c in m.iis)))\r\n\r\nI have added a pull request to fix this: https://github.com/Pyomo/pyomo/pull/596\n", "before_files": [{"content": "# ___________________________________________________________________________\n#\n# Pyomo: Python Optimization Modeling Objects\n# Copyright 2017 National Technology and Engineering Solutions of Sandia, LLC\n# Under the terms of Contract DE-NA0003525 with National Technology and \n# Engineering Solutions of Sandia, LLC, the U.S. Government retains certain \n# rights in this software.\n# This software is distributed under the 3-clause BSD License.\n# ___________________________________________________________________________\n\n#\n# Class for reading an AMPL *.sol file\n#\n\nimport re\n\nimport pyutilib.misc\n\nfrom pyomo.common.plugin import alias\nfrom pyomo.opt.base import results\nfrom pyomo.opt.base.formats import ResultsFormat\nfrom pyomo.opt import (SolverResults,\n SolutionStatus,\n SolverStatus,\n TerminationCondition)\n\nfrom six.moves import xrange\n\nclass ResultsReader_sol(results.AbstractResultsReader):\n \"\"\"\n Class that reads in a *.sol results file and generates a\n SolverResults object.\n \"\"\"\n\n alias(str(ResultsFormat.sol))\n\n def __init__(self, name=None):\n results.AbstractResultsReader.__init__(self,ResultsFormat.sol)\n if not name is None:\n self.name = name\n\n def __call__(self, filename, res=None, soln=None, suffixes=[]):\n \"\"\"\n Parse a *.sol file\n \"\"\"\n try:\n with open(filename,\"r\") as f:\n return self._load(f, res, soln, suffixes)\n except ValueError as e:\n with open(filename,\"r\") as f:\n fdata = f.read()\n raise ValueError(\n \"Error reading '%s': %s.\\n\"\n \"SOL File Output:\\n%s\"\n % (filename, str(e), fdata))\n\n def _load(self, fin, res, soln, suffixes):\n\n if res is None:\n res = SolverResults()\n #\n msg = \"\"\n line = fin.readline()\n if line.strip() == \"\":\n line = fin.readline()\n while line:\n if line[0] == '\\n' or (line[0] == '\\r' and line[1] == '\\n'):\n break\n msg += line\n line = fin.readline()\n z = []\n line = fin.readline()\n if line[:7] == \"Options\":\n line = fin.readline()\n nopts = int(line)\n need_vbtol = False\n if nopts > 4: # WEH - when is this true?\n nopts -= 2\n need_vbtol = True\n for i in xrange(nopts + 4):\n line = fin.readline()\n z += [int(line)]\n if need_vbtol: # WEH - when is this true?\n line = fin.readline()\n z += [float(line)]\n else:\n raise ValueError(\"no Options line found\")\n n = z[nopts + 3] # variables\n m = z[nopts + 1] # constraints\n x = []\n y = []\n i = 0\n while i < m:\n line = fin.readline()\n y.append(float(line))\n i += 1\n i = 0\n while i < n:\n line = fin.readline()\n x.append(float(line))\n i += 1\n objno = [0,0]\n line = fin.readline()\n if line: # WEH - when is this true?\n if line[:5] != \"objno\": #pragma:nocover\n raise ValueError(\"expected 'objno', found '%s'\" % (line))\n t = line.split()\n if len(t) != 3:\n raise ValueError(\"expected two numbers in objno line, \"\n \"but found '%s'\" % (line))\n objno = [int(t[1]), int(t[2])]\n res.solver.message = msg.strip()\n res.solver.message = res.solver.message.replace(\"\\n\",\"; \")\n res.solver.message = pyutilib.misc.yaml_fix(res.solver.message)\n ##res.solver.instanceName = osrl.header.instanceName\n ##res.solver.systime = osrl.header.time\n res.solver.status = SolverStatus.ok\n soln_status = SolutionStatus.unknown\n if (objno[1] >= 0) and (objno[1] <= 99):\n objno_message = \"OPTIMAL SOLUTION FOUND!\"\n res.solver.termination_condition = TerminationCondition.optimal\n res.solver.status = SolverStatus.ok\n soln_status = SolutionStatus.optimal\n elif (objno[1] >= 100) and (objno[1] <= 199):\n objno_message = \"Optimal solution indicated, but ERROR LIKELY!\"\n res.solver.termination_condition = TerminationCondition.optimal\n res.solver.status = SolverStatus.warning\n soln_status = SolutionStatus.optimal\n elif (objno[1] >= 200) and (objno[1] <= 299):\n objno_message = \"INFEASIBLE SOLUTION: constraints cannot be satisfied!\"\n res.solver.termination_condition = TerminationCondition.infeasible\n res.solver.status = SolverStatus.warning\n soln_status = SolutionStatus.infeasible\n elif (objno[1] >= 300) and (objno[1] <= 399):\n objno_message = \"UNBOUNDED PROBLEM: the objective can be improved without limit!\"\n res.solver.termination_condition = TerminationCondition.unbounded\n res.solver.status = SolverStatus.warning\n soln_status = SolutionStatus.unbounded\n elif (objno[1] >= 400) and (objno[1] <= 499):\n objno_message = (\"EXCEEDED MAXIMUM NUMBER OF ITERATIONS: the solver \"\n \"was stopped by a limit that you set!\")\n res.solver.termination_condition = TerminationCondition.maxIterations\n res.solver.status = SolverStatus.warning\n soln_status = SolutionStatus.stoppedByLimit\n elif (objno[1] >= 500) and (objno[1] <= 599):\n objno_message = (\"FAILURE: the solver stopped by an error condition \"\n \"in the solver routines!\")\n res.solver.termination_condition = TerminationCondition.internalSolverError\n res.solver.status = SolverStatus.error\n soln_status = SolutionStatus.error\n res.solver.id = objno[1]\n ##res.problem.name = osrl.header.instanceName\n if res.solver.termination_condition in [TerminationCondition.unknown,\n TerminationCondition.maxIterations,\n TerminationCondition.minFunctionValue,\n TerminationCondition.minStepLength,\n TerminationCondition.globallyOptimal,\n TerminationCondition.locallyOptimal,\n TerminationCondition.optimal,\n TerminationCondition.maxEvaluations,\n TerminationCondition.other,\n TerminationCondition.infeasible]:\n\n if soln is None:\n soln = res.solution.add()\n res.solution.status = soln_status\n soln.status_description = objno_message\n soln.message = msg.strip()\n soln.message = res.solver.message.replace(\"\\n\",\"; \")\n soln_variable = soln.variable\n i = 0\n for var_value in x:\n soln_variable[\"v\"+str(i)] = {\"Value\" : var_value}\n i = i + 1\n soln_constraint = soln.constraint\n if any(re.match(suf,\"dual\") for suf in suffixes):\n for i in xrange(0,len(y)):\n soln_constraint[\"c\"+str(i)] = {\"Dual\" : y[i]}\n\n ### Read suffixes ###\n line = fin.readline()\n while line:\n line = line.strip()\n if line == \"\":\n continue\n line = line.split()\n if line[0] != 'suffix':\n # We assume this is the start of a\n # section like kestrel_option, which\n # comes after all suffixes.\n remaining = \"\"\n line = fin.readline()\n while line:\n remaining += line.strip()+\"; \"\n line = fin.readline()\n res.solver.message += remaining\n break\n unmasked_kind = int(line[1])\n kind = unmasked_kind & 3 # 0-var, 1-con, 2-obj, 3-prob\n convert_function = int\n if (unmasked_kind & 4) == 4:\n convert_function = float\n nvalues = int(line[2])\n namelen = int(line[3])\n tablen = int(line[4])\n tabline = int(line[5])\n suffix_name = fin.readline().strip()\n if any(re.match(suf,suffix_name) for suf in suffixes):\n # ignore translation of the table number to string value for now,\n # this information can be obtained from the solver documentation\n for n in xrange(tabline):\n fin.readline()\n if kind == 0: # Var\n for cnt in xrange(nvalues):\n suf_line = fin.readline().split()\n soln_variable[\"v\"+suf_line[0]][suffix_name] = \\\n convert_function(suf_line[1])\n elif kind == 1: # Con\n for cnt in xrange(nvalues):\n suf_line = fin.readline().split()\n key = \"c\"+suf_line[0]\n if key not in soln_constraint:\n soln_constraint[key] = {}\n # convert the first letter of the suffix name to upper case,\n # mainly for pretty-print / output purposes. these are lower-cased\n # when loaded into real suffixes, so it is largely redundant.\n translated_suffix_name = suffix_name[0].upper() + suffix_name[1:]\n soln_constraint[key][translated_suffix_name] = \\\n convert_function(suf_line[1])\n elif kind == 2: # Obj\n for cnt in xrange(nvalues):\n suf_line = fin.readline().split()\n soln.objective.setdefault(\"o\"+suf_line[0],{})[suffix_name] = \\\n convert_function(suf_line[1])\n elif kind == 3: # Prob\n # Skip problem kind suffixes for now. Not sure the\n # best place to put them in the results object\n for cnt in xrange(nvalues):\n suf_line = fin.readline().split()\n soln.problem[suffix_name] = convert_function(suf_line[1])\n else:\n # do not store the suffix in the solution object\n for cnt in xrange(nvalues):\n fin.readline()\n line = fin.readline()\n\n #\n # This is a bit of a hack to accommodate PICO. If\n # the PICO parser has parsed the # of constraints, then\n # don't try to read it in from the *.sol file. The reason\n # is that these may be inconsistent values!\n #\n if res.problem.number_of_constraints == 0:\n res.problem.number_of_constraints = m\n res.problem.number_of_variables = n\n res.problem.number_of_objectives = 1\n return res\n", "path": "pyomo/opt/plugins/sol.py"}]}
| 3,944 | 558 |
gh_patches_debug_37742
|
rasdani/github-patches
|
git_diff
|
NVIDIA__NVFlare-196
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
if/elif statement without else clause in `FullModelShareableGenerator`
It would be helpful to add an else statement with a warning message that this DataKind is not supported. I ran into this issue when sending a DataKind.COLLECTION with the shareable by mistake.
See https://github.com/NVIDIA/NVFlare/blob/b3ff7844a9bef746218527ccd07601feb66fd94c/nvflare/app_common/shareablegenerators/full_model_shareable_generator.py#L61
In the same class, when sending a DXO instead of Shareable type, I got this error
```
Traceback (most recent call last):
File "/home/hroth/Code/nvflare/hroth-agglib/nvflare/app_common/workflows/scatter_and_gather.py", line 202, in control_flow
self._global_weights = self.shareable_gen.shareable_to_learnable(aggr_result, fl_ctx)
File "/home/hroth/Code/nvflare/hroth-agglib/nvflare/app_common/shareablegenerators/full_model_shareable_generator.py", line 54, in shareable_to_learnable
dxo = from_shareable(shareable)
File "/home/hroth/Code/nvflare/hroth-agglib/nvflare/apis/dxo.py", line 120, in from_shareable
content_type = s.get_header(ReservedHeaderKey.CONTENT_TYPE)
AttributeError: 'DXO' object has no attribute 'get_header'
```
There should be an instance check here https://github.com/NVIDIA/NVFlare/blob/b3ff7844a9bef746218527ccd07601feb66fd94c/nvflare/app_common/shareablegenerators/full_model_shareable_generator.py#L54
</issue>
<code>
[start of nvflare/app_common/shareablegenerators/full_model_shareable_generator.py]
1 # Copyright (c) 2021-2022, NVIDIA CORPORATION. All rights reserved.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 from nvflare.apis.dxo import DataKind, from_shareable
16 from nvflare.apis.fl_context import FLContext
17 from nvflare.apis.shareable import Shareable
18 from nvflare.app_common.abstract.model import ModelLearnable, ModelLearnableKey, model_learnable_to_dxo
19 from nvflare.app_common.abstract.shareable_generator import ShareableGenerator
20 from nvflare.app_common.app_constant import AppConstants
21
22
23 class FullModelShareableGenerator(ShareableGenerator):
24 def learnable_to_shareable(self, ml: ModelLearnable, fl_ctx: FLContext) -> Shareable:
25 """Convert Learnable to Shareable.
26
27 Args:
28 model (Learnable): model to be converted
29 fl_ctx (FLContext): FL context
30
31 Returns:
32 Shareable: a shareable containing a DXO object,
33 """
34 dxo = model_learnable_to_dxo(ml)
35 return dxo.to_shareable()
36
37 def shareable_to_learnable(self, shareable: Shareable, fl_ctx: FLContext) -> ModelLearnable:
38 """Convert Shareable to Learnable.
39
40 Supporting TYPE == TYPE_WEIGHT_DIFF or TYPE_WEIGHTS
41
42 Args:
43 shareable (Shareable): Shareable that contains a DXO object
44 fl_ctx (FLContext): FL context
45
46 Returns: a ModelLearnable object
47 """
48 base_model = fl_ctx.get_prop(AppConstants.GLOBAL_MODEL)
49 if not base_model:
50 self.system_panic(reason="No global base model!", fl_ctx=fl_ctx)
51 return base_model
52
53 weights = base_model[ModelLearnableKey.WEIGHTS]
54 dxo = from_shareable(shareable)
55
56 if dxo.data_kind == DataKind.WEIGHT_DIFF:
57 if dxo.data is not None:
58 model_diff = dxo.data
59 for v_name, v_value in model_diff.items():
60 weights[v_name] = weights[v_name] + v_value
61 elif dxo.data_kind == DataKind.WEIGHTS:
62 weights = dxo.data
63 if not weights:
64 self.log_info(fl_ctx, "No model weights found. Model will not be updated.")
65 else:
66 base_model[ModelLearnableKey.WEIGHTS] = weights
67
68 base_model[ModelLearnableKey.META] = dxo.get_meta_props()
69 return base_model
70
[end of nvflare/app_common/shareablegenerators/full_model_shareable_generator.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/nvflare/app_common/shareablegenerators/full_model_shareable_generator.py b/nvflare/app_common/shareablegenerators/full_model_shareable_generator.py
--- a/nvflare/app_common/shareablegenerators/full_model_shareable_generator.py
+++ b/nvflare/app_common/shareablegenerators/full_model_shareable_generator.py
@@ -21,21 +21,21 @@
class FullModelShareableGenerator(ShareableGenerator):
- def learnable_to_shareable(self, ml: ModelLearnable, fl_ctx: FLContext) -> Shareable:
- """Convert Learnable to Shareable.
+ def learnable_to_shareable(self, model_learnable: ModelLearnable, fl_ctx: FLContext) -> Shareable:
+ """Convert ModelLearnable to Shareable.
Args:
- model (Learnable): model to be converted
+ model_learnable (ModelLearnable): model to be converted
fl_ctx (FLContext): FL context
Returns:
- Shareable: a shareable containing a DXO object,
+ Shareable: a shareable containing a DXO object.
"""
- dxo = model_learnable_to_dxo(ml)
+ dxo = model_learnable_to_dxo(model_learnable)
return dxo.to_shareable()
def shareable_to_learnable(self, shareable: Shareable, fl_ctx: FLContext) -> ModelLearnable:
- """Convert Shareable to Learnable.
+ """Convert Shareable to ModelLearnable.
Supporting TYPE == TYPE_WEIGHT_DIFF or TYPE_WEIGHTS
@@ -43,8 +43,16 @@
shareable (Shareable): Shareable that contains a DXO object
fl_ctx (FLContext): FL context
- Returns: a ModelLearnable object
+ Returns:
+ A ModelLearnable object
+
+ Raises:
+ TypeError: if shareable is not of type shareable
+ ValueError: if data_kind is not `DataKind.WEIGHTS` and is not `DataKind.WEIGHT_DIFF`
"""
+ if not isinstance(shareable, Shareable):
+ raise TypeError("shareable must be Shareable, but got {}.".format(type(shareable)))
+
base_model = fl_ctx.get_prop(AppConstants.GLOBAL_MODEL)
if not base_model:
self.system_panic(reason="No global base model!", fl_ctx=fl_ctx)
@@ -64,6 +72,10 @@
self.log_info(fl_ctx, "No model weights found. Model will not be updated.")
else:
base_model[ModelLearnableKey.WEIGHTS] = weights
+ else:
+ raise ValueError(
+ "data_kind should be either DataKind.WEIGHTS or DataKind.WEIGHT_DIFF, but got {}".format(dxo.data_kind)
+ )
base_model[ModelLearnableKey.META] = dxo.get_meta_props()
return base_model
|
{"golden_diff": "diff --git a/nvflare/app_common/shareablegenerators/full_model_shareable_generator.py b/nvflare/app_common/shareablegenerators/full_model_shareable_generator.py\n--- a/nvflare/app_common/shareablegenerators/full_model_shareable_generator.py\n+++ b/nvflare/app_common/shareablegenerators/full_model_shareable_generator.py\n@@ -21,21 +21,21 @@\n \n \n class FullModelShareableGenerator(ShareableGenerator):\n- def learnable_to_shareable(self, ml: ModelLearnable, fl_ctx: FLContext) -> Shareable:\n- \"\"\"Convert Learnable to Shareable.\n+ def learnable_to_shareable(self, model_learnable: ModelLearnable, fl_ctx: FLContext) -> Shareable:\n+ \"\"\"Convert ModelLearnable to Shareable.\n \n Args:\n- model (Learnable): model to be converted\n+ model_learnable (ModelLearnable): model to be converted\n fl_ctx (FLContext): FL context\n \n Returns:\n- Shareable: a shareable containing a DXO object,\n+ Shareable: a shareable containing a DXO object.\n \"\"\"\n- dxo = model_learnable_to_dxo(ml)\n+ dxo = model_learnable_to_dxo(model_learnable)\n return dxo.to_shareable()\n \n def shareable_to_learnable(self, shareable: Shareable, fl_ctx: FLContext) -> ModelLearnable:\n- \"\"\"Convert Shareable to Learnable.\n+ \"\"\"Convert Shareable to ModelLearnable.\n \n Supporting TYPE == TYPE_WEIGHT_DIFF or TYPE_WEIGHTS\n \n@@ -43,8 +43,16 @@\n shareable (Shareable): Shareable that contains a DXO object\n fl_ctx (FLContext): FL context\n \n- Returns: a ModelLearnable object\n+ Returns:\n+ A ModelLearnable object\n+\n+ Raises:\n+ TypeError: if shareable is not of type shareable\n+ ValueError: if data_kind is not `DataKind.WEIGHTS` and is not `DataKind.WEIGHT_DIFF`\n \"\"\"\n+ if not isinstance(shareable, Shareable):\n+ raise TypeError(\"shareable must be Shareable, but got {}.\".format(type(shareable)))\n+\n base_model = fl_ctx.get_prop(AppConstants.GLOBAL_MODEL)\n if not base_model:\n self.system_panic(reason=\"No global base model!\", fl_ctx=fl_ctx)\n@@ -64,6 +72,10 @@\n self.log_info(fl_ctx, \"No model weights found. Model will not be updated.\")\n else:\n base_model[ModelLearnableKey.WEIGHTS] = weights\n+ else:\n+ raise ValueError(\n+ \"data_kind should be either DataKind.WEIGHTS or DataKind.WEIGHT_DIFF, but got {}\".format(dxo.data_kind)\n+ )\n \n base_model[ModelLearnableKey.META] = dxo.get_meta_props()\n return base_model\n", "issue": "if/elif statement without else clause in `FullModelShareableGenerator`\nIt would be helpful to add an else statement with a warning message that this DataKind is not supported. I ran into this issue when sending a DataKind.COLLECTION with the shareable by mistake.\r\n\r\nSee https://github.com/NVIDIA/NVFlare/blob/b3ff7844a9bef746218527ccd07601feb66fd94c/nvflare/app_common/shareablegenerators/full_model_shareable_generator.py#L61\r\n\r\nIn the same class, when sending a DXO instead of Shareable type, I got this error\r\n\r\n```\r\nTraceback (most recent call last):\r\n File \"/home/hroth/Code/nvflare/hroth-agglib/nvflare/app_common/workflows/scatter_and_gather.py\", line 202, in control_flow\r\n self._global_weights = self.shareable_gen.shareable_to_learnable(aggr_result, fl_ctx)\r\n File \"/home/hroth/Code/nvflare/hroth-agglib/nvflare/app_common/shareablegenerators/full_model_shareable_generator.py\", line 54, in shareable_to_learnable\r\n dxo = from_shareable(shareable)\r\n File \"/home/hroth/Code/nvflare/hroth-agglib/nvflare/apis/dxo.py\", line 120, in from_shareable\r\n content_type = s.get_header(ReservedHeaderKey.CONTENT_TYPE)\r\nAttributeError: 'DXO' object has no attribute 'get_header'\r\n```\r\nThere should be an instance check here https://github.com/NVIDIA/NVFlare/blob/b3ff7844a9bef746218527ccd07601feb66fd94c/nvflare/app_common/shareablegenerators/full_model_shareable_generator.py#L54\r\n\r\n\r\n\n", "before_files": [{"content": "# Copyright (c) 2021-2022, NVIDIA CORPORATION. All rights reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nfrom nvflare.apis.dxo import DataKind, from_shareable\nfrom nvflare.apis.fl_context import FLContext\nfrom nvflare.apis.shareable import Shareable\nfrom nvflare.app_common.abstract.model import ModelLearnable, ModelLearnableKey, model_learnable_to_dxo\nfrom nvflare.app_common.abstract.shareable_generator import ShareableGenerator\nfrom nvflare.app_common.app_constant import AppConstants\n\n\nclass FullModelShareableGenerator(ShareableGenerator):\n def learnable_to_shareable(self, ml: ModelLearnable, fl_ctx: FLContext) -> Shareable:\n \"\"\"Convert Learnable to Shareable.\n\n Args:\n model (Learnable): model to be converted\n fl_ctx (FLContext): FL context\n\n Returns:\n Shareable: a shareable containing a DXO object,\n \"\"\"\n dxo = model_learnable_to_dxo(ml)\n return dxo.to_shareable()\n\n def shareable_to_learnable(self, shareable: Shareable, fl_ctx: FLContext) -> ModelLearnable:\n \"\"\"Convert Shareable to Learnable.\n\n Supporting TYPE == TYPE_WEIGHT_DIFF or TYPE_WEIGHTS\n\n Args:\n shareable (Shareable): Shareable that contains a DXO object\n fl_ctx (FLContext): FL context\n\n Returns: a ModelLearnable object\n \"\"\"\n base_model = fl_ctx.get_prop(AppConstants.GLOBAL_MODEL)\n if not base_model:\n self.system_panic(reason=\"No global base model!\", fl_ctx=fl_ctx)\n return base_model\n\n weights = base_model[ModelLearnableKey.WEIGHTS]\n dxo = from_shareable(shareable)\n\n if dxo.data_kind == DataKind.WEIGHT_DIFF:\n if dxo.data is not None:\n model_diff = dxo.data\n for v_name, v_value in model_diff.items():\n weights[v_name] = weights[v_name] + v_value\n elif dxo.data_kind == DataKind.WEIGHTS:\n weights = dxo.data\n if not weights:\n self.log_info(fl_ctx, \"No model weights found. Model will not be updated.\")\n else:\n base_model[ModelLearnableKey.WEIGHTS] = weights\n\n base_model[ModelLearnableKey.META] = dxo.get_meta_props()\n return base_model\n", "path": "nvflare/app_common/shareablegenerators/full_model_shareable_generator.py"}]}
| 1,744 | 645 |
gh_patches_debug_36980
|
rasdani/github-patches
|
git_diff
|
svthalia__concrexit-3229
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
N+1 Query on listing memberships due to membership_latest
Sentry Issue: [CONCREXIT-YM](https://thalia.sentry.io/issues/4256012007/?referrer=github_integration)
| | |
| ------------- | --------------- |
| **Offending Spans** | db - SELECT "members_membership"."id", "members...
</issue>
<code>
[start of website/members/api/v2/views.py]
1 """API views of the activemembers app."""
2
3 from django.shortcuts import get_object_or_404
4
5 from oauth2_provider.contrib.rest_framework import IsAuthenticatedOrTokenHasScope
6 from rest_framework import filters as framework_filters
7 from rest_framework.generics import ListAPIView, RetrieveAPIView, UpdateAPIView
8
9 from members.api.v2 import filters
10 from members.api.v2.serializers.member import (
11 MemberCurrentSerializer,
12 MemberListSerializer,
13 MemberSerializer,
14 )
15 from members.models import Member
16 from thaliawebsite.api.openapi import OAuthAutoSchema
17 from thaliawebsite.api.v2.permissions import IsAuthenticatedOrTokenHasScopeForMethod
18 from utils.media.services import fetch_thumbnails_db
19
20
21 class MemberListView(ListAPIView):
22 """Returns an overview of all members."""
23
24 serializer_class = MemberListSerializer
25 queryset = (
26 Member.objects.all()
27 .select_related("profile")
28 .prefetch_related("membership_set")
29 )
30
31 def get_serializer(self, *args, **kwargs):
32 if len(args) > 0:
33 members = args[0]
34 fetch_thumbnails_db([member.profile.photo for member in members])
35 return super().get_serializer(*args, **kwargs)
36
37 permission_classes = [
38 IsAuthenticatedOrTokenHasScope,
39 ]
40 required_scopes = ["members:read"]
41 filter_backends = (
42 framework_filters.OrderingFilter,
43 framework_filters.SearchFilter,
44 filters.MembershipTypeFilter,
45 filters.StartingYearFilter,
46 filters.FormerMemberFilter,
47 )
48 ordering_fields = ("first_name", "last_name", "username")
49 search_fields = (
50 "profile__nickname",
51 "profile__starting_year",
52 "first_name",
53 "last_name",
54 "username",
55 )
56
57
58 class MemberDetailView(RetrieveAPIView):
59 """Returns details of a member."""
60
61 serializer_class = MemberSerializer
62 queryset = Member.objects.all()
63 permission_classes = [
64 IsAuthenticatedOrTokenHasScope,
65 ]
66 required_scopes = ["members:read"]
67
68
69 class MemberCurrentView(MemberDetailView, UpdateAPIView):
70 """Returns details of the authenticated member."""
71
72 serializer_class = MemberCurrentSerializer
73 schema = OAuthAutoSchema(operation_id_base="CurrentMember")
74 permission_classes = [
75 IsAuthenticatedOrTokenHasScopeForMethod,
76 ]
77 required_scopes_per_method = {
78 "GET": ["profile:read"],
79 "PATCH": ["profile:write"],
80 "PUT": ["profile:write"],
81 }
82
83 def get_object(self):
84 return get_object_or_404(Member, pk=self.request.user.pk)
85
[end of website/members/api/v2/views.py]
[start of website/members/models/member.py]
1 import logging
2 import operator
3 from datetime import timedelta
4 from functools import reduce
5
6 from django.contrib.auth.models import User, UserManager
7 from django.db.models import Q
8 from django.urls import reverse
9 from django.utils import timezone
10 from django.utils.translation import gettext_lazy as _
11
12 from activemembers.models import MemberGroup, MemberGroupMembership
13
14 logger = logging.getLogger(__name__)
15
16
17 class MemberManager(UserManager):
18 """Get all members, i.e. all users with a profile."""
19
20 def get_queryset(self):
21 return super().get_queryset().exclude(profile=None)
22
23
24 class ActiveMemberManager(MemberManager):
25 """Get all active members, i.e. who have a committee membership."""
26
27 def get_queryset(self):
28 """Select all committee members."""
29 active_memberships = MemberGroupMembership.active_objects.filter(
30 group__board=None
31 ).filter(group__society=None)
32
33 return (
34 super()
35 .get_queryset()
36 .filter(membergroupmembership__in=active_memberships)
37 .distinct()
38 )
39
40
41 class CurrentMemberManager(MemberManager):
42 """Get all members with an active membership."""
43
44 def get_queryset(self):
45 """Select all members who have a current membership."""
46 return (
47 super()
48 .get_queryset()
49 .exclude(membership=None)
50 .filter(
51 Q(membership__until__isnull=True)
52 | Q(membership__until__gt=timezone.now().date())
53 )
54 .distinct()
55 )
56
57 def with_birthdays_in_range(self, from_date, to_date):
58 """Select all who are currently a Thalia member and have a birthday within the specified range.
59
60 :param from_date: the start of the range (inclusive)
61 :param to_date: the end of the range (inclusive)
62 :paramtype from_date: datetime
63 :paramtype to_date: datetime
64
65 :return: the filtered queryset
66 :rtype: Queryset
67 """
68 queryset = self.get_queryset().filter(profile__birthday__lte=to_date)
69
70 if (to_date - from_date).days >= 366:
71 # 366 is important to also account for leap years
72 # Everyone that's born before to_date has a birthday
73 return queryset
74
75 delta = to_date - from_date
76 dates = [from_date + timedelta(days=i) for i in range(delta.days + 1)]
77 monthdays = [
78 {"profile__birthday__month": d.month, "profile__birthday__day": d.day}
79 for d in dates
80 ]
81 # Don't get me started (basically, we are making a giant OR query with
82 # all days and months that are in the range)
83 query = reduce(operator.or_, [Q(**d) for d in monthdays])
84 return queryset.filter(query)
85
86
87 class Member(User):
88 class Meta:
89 proxy = True
90 ordering = ("first_name", "last_name")
91
92 objects = MemberManager()
93 current_members = CurrentMemberManager()
94 active_members = ActiveMemberManager()
95
96 def __str__(self):
97 return f"{self.get_full_name()} ({self.username})"
98
99 @property
100 def current_membership(self):
101 """Return the currently active membership of the user, one if not active.
102
103 :return: the currently active membership or None
104 :rtype: Membership or None
105 """
106 membership = self.latest_membership
107 if membership and not membership.is_active():
108 return None
109 return membership
110
111 @property
112 def latest_membership(self):
113 """Get the most recent membership of this user."""
114 if not self.membership_set.exists():
115 return None
116 return self.membership_set.latest("since")
117
118 @property
119 def earliest_membership(self):
120 """Get the earliest membership of this user."""
121 if not self.membership_set.exists():
122 return None
123 return self.membership_set.earliest("since")
124
125 def has_been_member(self):
126 """Has this user ever been a member?."""
127 return self.membership_set.filter(type="member").exists()
128
129 def has_been_honorary_member(self):
130 """Has this user ever been an honorary member?."""
131 return self.membership_set.filter(type="honorary").exists()
132
133 def has_active_membership(self):
134 """Is this member currently active.
135
136 Tested by checking if the expiration date has passed.
137 """
138 return self.current_membership is not None
139
140 # Special properties for admin site
141 has_active_membership.boolean = True
142 has_active_membership.short_description = _("Is this user currently active")
143
144 @classmethod
145 def all_with_membership(cls, membership_type):
146 """Get all users who have a specific membership.
147
148 :param membership_type: The membership to select by
149 :return: List of users
150 :rtype: [Member]
151 """
152 return [
153 x
154 for x in cls.objects.all()
155 if x.current_membership and x.current_membership.type == membership_type
156 ]
157
158 @property
159 def can_attend_events(self):
160 """May this user attend events."""
161 if not self.profile:
162 return False
163
164 return (
165 self.profile.event_permissions in ("all", "no_drinks")
166 and self.current_membership is not None
167 )
168
169 @property
170 def can_attend_events_without_membership(self):
171 if not self.profile:
172 return False
173
174 return self.profile.event_permissions in ("all", "no_drinks")
175
176 def get_member_groups(self):
177 """Get the groups this user is a member of."""
178 now = timezone.now()
179 return MemberGroup.objects.filter(
180 Q(membergroupmembership__member=self),
181 Q(membergroupmembership__until=None)
182 | Q(
183 membergroupmembership__since__lte=now,
184 membergroupmembership__until__gte=now,
185 ),
186 active=True,
187 )
188
189 def get_absolute_url(self):
190 return reverse("members:profile", args=[str(self.pk)])
191
[end of website/members/models/member.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/website/members/api/v2/views.py b/website/members/api/v2/views.py
--- a/website/members/api/v2/views.py
+++ b/website/members/api/v2/views.py
@@ -1,5 +1,6 @@
"""API views of the activemembers app."""
+from django.db.models import Prefetch
from django.shortcuts import get_object_or_404
from oauth2_provider.contrib.rest_framework import IsAuthenticatedOrTokenHasScope
@@ -12,7 +13,7 @@
MemberListSerializer,
MemberSerializer,
)
-from members.models import Member
+from members.models import Member, Membership
from thaliawebsite.api.openapi import OAuthAutoSchema
from thaliawebsite.api.v2.permissions import IsAuthenticatedOrTokenHasScopeForMethod
from utils.media.services import fetch_thumbnails_db
@@ -25,7 +26,14 @@
queryset = (
Member.objects.all()
.select_related("profile")
- .prefetch_related("membership_set")
+ .prefetch_related(
+ "membership_set",
+ Prefetch(
+ "membership_set",
+ queryset=Membership.objects.order_by("-since")[:1],
+ to_attr="_latest_membership",
+ ),
+ )
)
def get_serializer(self, *args, **kwargs):
@@ -59,7 +67,9 @@
"""Returns details of a member."""
serializer_class = MemberSerializer
- queryset = Member.objects.all()
+ queryset = Member.objects.all().prefetch_related(
+ "membergroupmembership_set", "mentorship_set"
+ )
permission_classes = [
IsAuthenticatedOrTokenHasScope,
]
@@ -81,4 +91,4 @@
}
def get_object(self):
- return get_object_or_404(Member, pk=self.request.user.pk)
+ return get_object_or_404(self.get_queryset(), pk=self.request.user.pk)
diff --git a/website/members/models/member.py b/website/members/models/member.py
--- a/website/members/models/member.py
+++ b/website/members/models/member.py
@@ -111,6 +111,9 @@
@property
def latest_membership(self):
"""Get the most recent membership of this user."""
+ if hasattr(self, "_latest_membership"):
+ return self._latest_membership[0]
+
if not self.membership_set.exists():
return None
return self.membership_set.latest("since")
|
{"golden_diff": "diff --git a/website/members/api/v2/views.py b/website/members/api/v2/views.py\n--- a/website/members/api/v2/views.py\n+++ b/website/members/api/v2/views.py\n@@ -1,5 +1,6 @@\n \"\"\"API views of the activemembers app.\"\"\"\n \n+from django.db.models import Prefetch\n from django.shortcuts import get_object_or_404\n \n from oauth2_provider.contrib.rest_framework import IsAuthenticatedOrTokenHasScope\n@@ -12,7 +13,7 @@\n MemberListSerializer,\n MemberSerializer,\n )\n-from members.models import Member\n+from members.models import Member, Membership\n from thaliawebsite.api.openapi import OAuthAutoSchema\n from thaliawebsite.api.v2.permissions import IsAuthenticatedOrTokenHasScopeForMethod\n from utils.media.services import fetch_thumbnails_db\n@@ -25,7 +26,14 @@\n queryset = (\n Member.objects.all()\n .select_related(\"profile\")\n- .prefetch_related(\"membership_set\")\n+ .prefetch_related(\n+ \"membership_set\",\n+ Prefetch(\n+ \"membership_set\",\n+ queryset=Membership.objects.order_by(\"-since\")[:1],\n+ to_attr=\"_latest_membership\",\n+ ),\n+ )\n )\n \n def get_serializer(self, *args, **kwargs):\n@@ -59,7 +67,9 @@\n \"\"\"Returns details of a member.\"\"\"\n \n serializer_class = MemberSerializer\n- queryset = Member.objects.all()\n+ queryset = Member.objects.all().prefetch_related(\n+ \"membergroupmembership_set\", \"mentorship_set\"\n+ )\n permission_classes = [\n IsAuthenticatedOrTokenHasScope,\n ]\n@@ -81,4 +91,4 @@\n }\n \n def get_object(self):\n- return get_object_or_404(Member, pk=self.request.user.pk)\n+ return get_object_or_404(self.get_queryset(), pk=self.request.user.pk)\ndiff --git a/website/members/models/member.py b/website/members/models/member.py\n--- a/website/members/models/member.py\n+++ b/website/members/models/member.py\n@@ -111,6 +111,9 @@\n @property\n def latest_membership(self):\n \"\"\"Get the most recent membership of this user.\"\"\"\n+ if hasattr(self, \"_latest_membership\"):\n+ return self._latest_membership[0]\n+\n if not self.membership_set.exists():\n return None\n return self.membership_set.latest(\"since\")\n", "issue": "N+1 Query on listing memberships due to membership_latest\nSentry Issue: [CONCREXIT-YM](https://thalia.sentry.io/issues/4256012007/?referrer=github_integration)\n| | |\n| ------------- | --------------- |\n| **Offending Spans** | db - SELECT \"members_membership\".\"id\", \"members... \n", "before_files": [{"content": "\"\"\"API views of the activemembers app.\"\"\"\n\nfrom django.shortcuts import get_object_or_404\n\nfrom oauth2_provider.contrib.rest_framework import IsAuthenticatedOrTokenHasScope\nfrom rest_framework import filters as framework_filters\nfrom rest_framework.generics import ListAPIView, RetrieveAPIView, UpdateAPIView\n\nfrom members.api.v2 import filters\nfrom members.api.v2.serializers.member import (\n MemberCurrentSerializer,\n MemberListSerializer,\n MemberSerializer,\n)\nfrom members.models import Member\nfrom thaliawebsite.api.openapi import OAuthAutoSchema\nfrom thaliawebsite.api.v2.permissions import IsAuthenticatedOrTokenHasScopeForMethod\nfrom utils.media.services import fetch_thumbnails_db\n\n\nclass MemberListView(ListAPIView):\n \"\"\"Returns an overview of all members.\"\"\"\n\n serializer_class = MemberListSerializer\n queryset = (\n Member.objects.all()\n .select_related(\"profile\")\n .prefetch_related(\"membership_set\")\n )\n\n def get_serializer(self, *args, **kwargs):\n if len(args) > 0:\n members = args[0]\n fetch_thumbnails_db([member.profile.photo for member in members])\n return super().get_serializer(*args, **kwargs)\n\n permission_classes = [\n IsAuthenticatedOrTokenHasScope,\n ]\n required_scopes = [\"members:read\"]\n filter_backends = (\n framework_filters.OrderingFilter,\n framework_filters.SearchFilter,\n filters.MembershipTypeFilter,\n filters.StartingYearFilter,\n filters.FormerMemberFilter,\n )\n ordering_fields = (\"first_name\", \"last_name\", \"username\")\n search_fields = (\n \"profile__nickname\",\n \"profile__starting_year\",\n \"first_name\",\n \"last_name\",\n \"username\",\n )\n\n\nclass MemberDetailView(RetrieveAPIView):\n \"\"\"Returns details of a member.\"\"\"\n\n serializer_class = MemberSerializer\n queryset = Member.objects.all()\n permission_classes = [\n IsAuthenticatedOrTokenHasScope,\n ]\n required_scopes = [\"members:read\"]\n\n\nclass MemberCurrentView(MemberDetailView, UpdateAPIView):\n \"\"\"Returns details of the authenticated member.\"\"\"\n\n serializer_class = MemberCurrentSerializer\n schema = OAuthAutoSchema(operation_id_base=\"CurrentMember\")\n permission_classes = [\n IsAuthenticatedOrTokenHasScopeForMethod,\n ]\n required_scopes_per_method = {\n \"GET\": [\"profile:read\"],\n \"PATCH\": [\"profile:write\"],\n \"PUT\": [\"profile:write\"],\n }\n\n def get_object(self):\n return get_object_or_404(Member, pk=self.request.user.pk)\n", "path": "website/members/api/v2/views.py"}, {"content": "import logging\nimport operator\nfrom datetime import timedelta\nfrom functools import reduce\n\nfrom django.contrib.auth.models import User, UserManager\nfrom django.db.models import Q\nfrom django.urls import reverse\nfrom django.utils import timezone\nfrom django.utils.translation import gettext_lazy as _\n\nfrom activemembers.models import MemberGroup, MemberGroupMembership\n\nlogger = logging.getLogger(__name__)\n\n\nclass MemberManager(UserManager):\n \"\"\"Get all members, i.e. all users with a profile.\"\"\"\n\n def get_queryset(self):\n return super().get_queryset().exclude(profile=None)\n\n\nclass ActiveMemberManager(MemberManager):\n \"\"\"Get all active members, i.e. who have a committee membership.\"\"\"\n\n def get_queryset(self):\n \"\"\"Select all committee members.\"\"\"\n active_memberships = MemberGroupMembership.active_objects.filter(\n group__board=None\n ).filter(group__society=None)\n\n return (\n super()\n .get_queryset()\n .filter(membergroupmembership__in=active_memberships)\n .distinct()\n )\n\n\nclass CurrentMemberManager(MemberManager):\n \"\"\"Get all members with an active membership.\"\"\"\n\n def get_queryset(self):\n \"\"\"Select all members who have a current membership.\"\"\"\n return (\n super()\n .get_queryset()\n .exclude(membership=None)\n .filter(\n Q(membership__until__isnull=True)\n | Q(membership__until__gt=timezone.now().date())\n )\n .distinct()\n )\n\n def with_birthdays_in_range(self, from_date, to_date):\n \"\"\"Select all who are currently a Thalia member and have a birthday within the specified range.\n\n :param from_date: the start of the range (inclusive)\n :param to_date: the end of the range (inclusive)\n :paramtype from_date: datetime\n :paramtype to_date: datetime\n\n :return: the filtered queryset\n :rtype: Queryset\n \"\"\"\n queryset = self.get_queryset().filter(profile__birthday__lte=to_date)\n\n if (to_date - from_date).days >= 366:\n # 366 is important to also account for leap years\n # Everyone that's born before to_date has a birthday\n return queryset\n\n delta = to_date - from_date\n dates = [from_date + timedelta(days=i) for i in range(delta.days + 1)]\n monthdays = [\n {\"profile__birthday__month\": d.month, \"profile__birthday__day\": d.day}\n for d in dates\n ]\n # Don't get me started (basically, we are making a giant OR query with\n # all days and months that are in the range)\n query = reduce(operator.or_, [Q(**d) for d in monthdays])\n return queryset.filter(query)\n\n\nclass Member(User):\n class Meta:\n proxy = True\n ordering = (\"first_name\", \"last_name\")\n\n objects = MemberManager()\n current_members = CurrentMemberManager()\n active_members = ActiveMemberManager()\n\n def __str__(self):\n return f\"{self.get_full_name()} ({self.username})\"\n\n @property\n def current_membership(self):\n \"\"\"Return the currently active membership of the user, one if not active.\n\n :return: the currently active membership or None\n :rtype: Membership or None\n \"\"\"\n membership = self.latest_membership\n if membership and not membership.is_active():\n return None\n return membership\n\n @property\n def latest_membership(self):\n \"\"\"Get the most recent membership of this user.\"\"\"\n if not self.membership_set.exists():\n return None\n return self.membership_set.latest(\"since\")\n\n @property\n def earliest_membership(self):\n \"\"\"Get the earliest membership of this user.\"\"\"\n if not self.membership_set.exists():\n return None\n return self.membership_set.earliest(\"since\")\n\n def has_been_member(self):\n \"\"\"Has this user ever been a member?.\"\"\"\n return self.membership_set.filter(type=\"member\").exists()\n\n def has_been_honorary_member(self):\n \"\"\"Has this user ever been an honorary member?.\"\"\"\n return self.membership_set.filter(type=\"honorary\").exists()\n\n def has_active_membership(self):\n \"\"\"Is this member currently active.\n\n Tested by checking if the expiration date has passed.\n \"\"\"\n return self.current_membership is not None\n\n # Special properties for admin site\n has_active_membership.boolean = True\n has_active_membership.short_description = _(\"Is this user currently active\")\n\n @classmethod\n def all_with_membership(cls, membership_type):\n \"\"\"Get all users who have a specific membership.\n\n :param membership_type: The membership to select by\n :return: List of users\n :rtype: [Member]\n \"\"\"\n return [\n x\n for x in cls.objects.all()\n if x.current_membership and x.current_membership.type == membership_type\n ]\n\n @property\n def can_attend_events(self):\n \"\"\"May this user attend events.\"\"\"\n if not self.profile:\n return False\n\n return (\n self.profile.event_permissions in (\"all\", \"no_drinks\")\n and self.current_membership is not None\n )\n\n @property\n def can_attend_events_without_membership(self):\n if not self.profile:\n return False\n\n return self.profile.event_permissions in (\"all\", \"no_drinks\")\n\n def get_member_groups(self):\n \"\"\"Get the groups this user is a member of.\"\"\"\n now = timezone.now()\n return MemberGroup.objects.filter(\n Q(membergroupmembership__member=self),\n Q(membergroupmembership__until=None)\n | Q(\n membergroupmembership__since__lte=now,\n membergroupmembership__until__gte=now,\n ),\n active=True,\n )\n\n def get_absolute_url(self):\n return reverse(\"members:profile\", args=[str(self.pk)])\n", "path": "website/members/models/member.py"}]}
| 3,083 | 546 |
gh_patches_debug_4572
|
rasdani/github-patches
|
git_diff
|
cltk__cltk-533
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
External punctuation stopped working on Latin sent tokenizer
Recently reviewing the tokenizer, and it is not capturing exclamation points. I'll look to see the NLTK has changed anything.
``` python
In [12]: text = """quam penitus maestas exedit cura medullas! ut tibi tunc toto
...: pectore sollicitae sensibus ereptis mens excidit! at ego certe cognoram
...: a parva virgine magnanimam. Mam. Aemilius ad castra venit."""
In [13]: tokenizer.tokenize_sentences(text)
Out[13]:
['quam penitus maestas exedit cura medullas! ut tibi tunc toto pectore sollicitae sensibus ereptis mens excidit! at ego certe cognoram a parva virgine magnanimam.',
'Mam. Aemilius ad castra venit.']
```
</issue>
<code>
[start of cltk/tokenize/sentence.py]
1 """Tokenize sentences."""
2
3 __author__ = 'Kyle P. Johnson <[email protected]>'
4 __license__ = 'MIT License. See LICENSE.'
5
6
7 from cltk.utils.file_operations import open_pickle
8 from nltk.tokenize.punkt import PunktLanguageVars
9 from nltk.tokenize.punkt import PunktSentenceTokenizer
10 import os
11
12
13 PUNCTUATION = {'greek':
14 {'external': ('.', ';'),
15 'internal': (',', '·'),
16 'file': 'greek.pickle', },
17 'latin':
18 {'external': ('.', '?', ':'),
19 'internal': (',', ';'),
20 'file': 'latin.pickle', }}
21
22
23 class TokenizeSentence(): # pylint: disable=R0903
24 """Tokenize sentences for the language given as argument, e.g.,
25 ``TokenizeSentence('greek')``.
26 """
27
28 def __init__(self: object, language: str):
29 """Lower incoming language name and assemble variables.
30 :type language: str
31 :param language : Language for sentence tokenization.
32 """
33 self.language = language.lower()
34 self.internal_punctuation, self.external_punctuation, self.tokenizer_path = \
35 self._setup_language_variables(self.language)
36
37 def _setup_language_variables(self, lang: str):
38 """Check for language availability and presence of tokenizer file,
39 then read punctuation characters for language and build tokenizer file
40 path.
41 :param lang: The language argument given to the class.
42 :type lang: str
43 :rtype (str, str, str)
44 """
45 assert lang in PUNCTUATION.keys(), \
46 'Sentence tokenizer not available for {0} language.'.format(lang)
47 internal_punctuation = PUNCTUATION[lang]['internal']
48 external_punctuation = PUNCTUATION[lang]['external']
49 file = PUNCTUATION[lang]['file']
50 rel_path = os.path.join('~/cltk_data',
51 lang,
52 'model/' + lang + '_models_cltk/tokenizers/sentence') # pylint: disable=C0301
53 path = os.path.expanduser(rel_path)
54 tokenizer_path = os.path.join(path, file)
55 assert os.path.isfile(tokenizer_path), \
56 'CLTK linguistics data not found for language {0}'.format(lang)
57 return internal_punctuation, external_punctuation, tokenizer_path
58
59 def _setup_tokenizer(self, tokenizer: object):
60 """Add tokenizer and punctuation variables.
61 :type tokenizer: object
62 :param tokenizer : Unpickled tokenizer object.
63 :rtype : object
64 """
65 language_punkt_vars = PunktLanguageVars
66 language_punkt_vars.sent_end_chars = self.external_punctuation
67 language_punkt_vars.internal_punctuation = self.internal_punctuation
68 tokenizer.INCLUDE_ALL_COLLOCS = True
69 tokenizer.INCLUDE_ABBREV_COLLOCS = True
70 params = tokenizer.get_params()
71 return PunktSentenceTokenizer(params)
72
73 def tokenize_sentences(self: object, untokenized_string: str):
74 """Tokenize sentences by reading trained tokenizer and invoking
75 ``PunktSentenceTokenizer()``.
76 :type untokenized_string: str
77 :param untokenized_string: A string containing one of more sentences.
78 :rtype : list of strings
79 """
80 # load tokenizer
81 assert isinstance(untokenized_string, str), \
82 'Incoming argument must be a string.'
83 tokenizer = open_pickle(self.tokenizer_path)
84 tokenizer = self._setup_tokenizer(tokenizer)
85
86 # mk list of tokenized sentences
87 tokenized_sentences = []
88 for sentence in tokenizer.sentences_from_text(untokenized_string, realign_boundaries=True): # pylint: disable=C0301
89 tokenized_sentences.append(sentence)
90 return tokenized_sentences
91
92 def tokenize(self: object, untokenized_string: str):
93 # NLTK's PlaintextCorpusReader needs a function called tokenize
94 # in functions used as a parameter for sentence tokenization.
95 # So this is an alias for tokenize_sentences().
96 return self.tokenize_sentences(untokenized_string)
97
[end of cltk/tokenize/sentence.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/cltk/tokenize/sentence.py b/cltk/tokenize/sentence.py
--- a/cltk/tokenize/sentence.py
+++ b/cltk/tokenize/sentence.py
@@ -15,7 +15,7 @@
'internal': (',', '·'),
'file': 'greek.pickle', },
'latin':
- {'external': ('.', '?', ':'),
+ {'external': ('.', '?', '!', ':'),
'internal': (',', ';'),
'file': 'latin.pickle', }}
|
{"golden_diff": "diff --git a/cltk/tokenize/sentence.py b/cltk/tokenize/sentence.py\n--- a/cltk/tokenize/sentence.py\n+++ b/cltk/tokenize/sentence.py\n@@ -15,7 +15,7 @@\n 'internal': (',', '\u00b7'),\n 'file': 'greek.pickle', },\n 'latin':\n- {'external': ('.', '?', ':'),\n+ {'external': ('.', '?', '!', ':'),\n 'internal': (',', ';'),\n 'file': 'latin.pickle', }}\n", "issue": "External punctuation stopped working on Latin sent tokenizer\nRecently reviewing the tokenizer, and it is not capturing exclamation points. I'll look to see the NLTK has changed anything.\r\n``` python\r\nIn [12]: text = \"\"\"quam penitus maestas exedit cura medullas! ut tibi tunc toto \r\n ...: pectore sollicitae sensibus ereptis mens excidit! at ego certe cognoram\r\n ...: a parva virgine magnanimam. Mam. Aemilius ad castra venit.\"\"\"\r\n\r\nIn [13]: tokenizer.tokenize_sentences(text)\r\nOut[13]: \r\n['quam penitus maestas exedit cura medullas! ut tibi tunc toto pectore sollicitae sensibus ereptis mens excidit! at ego certe cognoram a parva virgine magnanimam.',\r\n 'Mam. Aemilius ad castra venit.']\r\n```\n", "before_files": [{"content": "\"\"\"Tokenize sentences.\"\"\"\n\n__author__ = 'Kyle P. Johnson <[email protected]>'\n__license__ = 'MIT License. See LICENSE.'\n\n\nfrom cltk.utils.file_operations import open_pickle\nfrom nltk.tokenize.punkt import PunktLanguageVars\nfrom nltk.tokenize.punkt import PunktSentenceTokenizer\nimport os\n\n\nPUNCTUATION = {'greek':\n {'external': ('.', ';'),\n 'internal': (',', '\u00b7'),\n 'file': 'greek.pickle', },\n 'latin':\n {'external': ('.', '?', ':'),\n 'internal': (',', ';'),\n 'file': 'latin.pickle', }}\n\n\nclass TokenizeSentence(): # pylint: disable=R0903\n \"\"\"Tokenize sentences for the language given as argument, e.g.,\n ``TokenizeSentence('greek')``.\n \"\"\"\n\n def __init__(self: object, language: str):\n \"\"\"Lower incoming language name and assemble variables.\n :type language: str\n :param language : Language for sentence tokenization.\n \"\"\"\n self.language = language.lower()\n self.internal_punctuation, self.external_punctuation, self.tokenizer_path = \\\n self._setup_language_variables(self.language)\n\n def _setup_language_variables(self, lang: str):\n \"\"\"Check for language availability and presence of tokenizer file,\n then read punctuation characters for language and build tokenizer file\n path.\n :param lang: The language argument given to the class.\n :type lang: str\n :rtype (str, str, str)\n \"\"\"\n assert lang in PUNCTUATION.keys(), \\\n 'Sentence tokenizer not available for {0} language.'.format(lang)\n internal_punctuation = PUNCTUATION[lang]['internal']\n external_punctuation = PUNCTUATION[lang]['external']\n file = PUNCTUATION[lang]['file']\n rel_path = os.path.join('~/cltk_data',\n lang,\n 'model/' + lang + '_models_cltk/tokenizers/sentence') # pylint: disable=C0301\n path = os.path.expanduser(rel_path)\n tokenizer_path = os.path.join(path, file)\n assert os.path.isfile(tokenizer_path), \\\n 'CLTK linguistics data not found for language {0}'.format(lang)\n return internal_punctuation, external_punctuation, tokenizer_path\n\n def _setup_tokenizer(self, tokenizer: object):\n \"\"\"Add tokenizer and punctuation variables.\n :type tokenizer: object\n :param tokenizer : Unpickled tokenizer object.\n :rtype : object\n \"\"\"\n language_punkt_vars = PunktLanguageVars\n language_punkt_vars.sent_end_chars = self.external_punctuation\n language_punkt_vars.internal_punctuation = self.internal_punctuation\n tokenizer.INCLUDE_ALL_COLLOCS = True\n tokenizer.INCLUDE_ABBREV_COLLOCS = True\n params = tokenizer.get_params()\n return PunktSentenceTokenizer(params)\n\n def tokenize_sentences(self: object, untokenized_string: str):\n \"\"\"Tokenize sentences by reading trained tokenizer and invoking\n ``PunktSentenceTokenizer()``.\n :type untokenized_string: str\n :param untokenized_string: A string containing one of more sentences.\n :rtype : list of strings\n \"\"\"\n # load tokenizer\n assert isinstance(untokenized_string, str), \\\n 'Incoming argument must be a string.'\n tokenizer = open_pickle(self.tokenizer_path)\n tokenizer = self._setup_tokenizer(tokenizer)\n\n # mk list of tokenized sentences\n tokenized_sentences = []\n for sentence in tokenizer.sentences_from_text(untokenized_string, realign_boundaries=True): # pylint: disable=C0301\n tokenized_sentences.append(sentence)\n return tokenized_sentences\n \n def tokenize(self: object, untokenized_string: str):\n # NLTK's PlaintextCorpusReader needs a function called tokenize\n # in functions used as a parameter for sentence tokenization.\n # So this is an alias for tokenize_sentences().\n return self.tokenize_sentences(untokenized_string)\n", "path": "cltk/tokenize/sentence.py"}]}
| 1,816 | 118 |
gh_patches_debug_7773
|
rasdani/github-patches
|
git_diff
|
alltheplaces__alltheplaces-3339
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Spider jbhifi is broken
During the global build at 2021-06-16-14-42-20, spider **jbhifi** failed with **78 features** and **1 errors**.
Here's [the log](https://data.alltheplaces.xyz/runs/2021-06-16-14-42-20/logs/jbhifi.txt) and [the output](https://data.alltheplaces.xyz/runs/2021-06-16-14-42-20/output/jbhifi.geojson) ([on a map](https://data.alltheplaces.xyz/map.html?show=https://data.alltheplaces.xyz/runs/2021-06-16-14-42-20/output/jbhifi.geojson))
</issue>
<code>
[start of locations/spiders/jbhifi.py]
1 # -*- coding: utf-8 -*-
2 import scrapy
3 import json
4 from locations.items import GeojsonPointItem
5 from locations.hours import OpeningHours
6
7 DAYS = ['Su', 'Mo', 'Tu', "We", 'Th', 'Fr', 'Sa']
8
9 class JbHifiSpider(scrapy.Spider):
10 name = "jbhifi"
11 allowed_domains = ["algolia.net"]
12
13 def start_requests(self):
14 headers = {"Content-Type": "application/json",
15 "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:81.0) Gecko/20100101 Firefox/81.0",
16 "Origin": "https://www.jbhifi.com.au",
17 "Referer": "https://www.jbhifi.com.au/pages/store-finder",
18 "Accept": "*/*",
19 'Accept-Encoding': 'gzip, deflate'
20
21 }
22 yield scrapy.http.Request(
23 url="https://vtvkm5urpx-dsn.algolia.net/1/indexes/shopify_store_locations/query?x-algolia-agent=Algolia for JavaScript (3.35.1); Browser (lite)&x-algolia-application-id=VTVKM5URPX&x-algolia-api-key=a0c0108d737ad5ab54a0e2da900bf040",
24 method="POST",
25 headers=headers,
26 body='{"params":"query=&hitsPerPage=1000&filters=displayOnWeb%3Ap"}')
27
28 def process_trading_hours(self, store_hours):
29 opening_hours = OpeningHours()
30 for day in store_hours:
31 opening_hours.add_range(DAYS[day['DayOfWeek']], day['OpeningTime'], day['ClosingTime'])
32
33 return opening_hours.as_opening_hours()
34
35 def parse(self, response):
36 stores = json.loads(response.body)
37
38 for store in stores['hits']:
39 properties = {
40 'ref': store['shopId'],
41 'name': store['storeName'],
42 'addr_full': f"{store['storeAddress']['Line1']} {store['storeAddress'].get('Line2','')} {store['storeAddress'].get('Line3','')}".strip(),
43 'city': store['storeAddress']['Suburb'],
44 'state': store['storeAddress']['State'],
45 'postcode': store['storeAddress']['Postcode'],
46 'country': 'AU',
47 'lat': store['_geoloc']['lat'],
48 'lon': store['_geoloc']['lng'],
49 'phone': store['phone'],
50 'opening_hours': self.process_trading_hours(store['normalTradingHours'])
51 }
52
53 yield GeojsonPointItem(**properties)
[end of locations/spiders/jbhifi.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/locations/spiders/jbhifi.py b/locations/spiders/jbhifi.py
--- a/locations/spiders/jbhifi.py
+++ b/locations/spiders/jbhifi.py
@@ -28,7 +28,8 @@
def process_trading_hours(self, store_hours):
opening_hours = OpeningHours()
for day in store_hours:
- opening_hours.add_range(DAYS[day['DayOfWeek']], day['OpeningTime'], day['ClosingTime'])
+ if 'NULL' not in day['OpeningTime'] and 'NULL' not in day['ClosingTime']:
+ opening_hours.add_range(DAYS[day['DayOfWeek']], day['OpeningTime'], day['ClosingTime'])
return opening_hours.as_opening_hours()
|
{"golden_diff": "diff --git a/locations/spiders/jbhifi.py b/locations/spiders/jbhifi.py\n--- a/locations/spiders/jbhifi.py\n+++ b/locations/spiders/jbhifi.py\n@@ -28,7 +28,8 @@\n def process_trading_hours(self, store_hours):\n opening_hours = OpeningHours()\n for day in store_hours:\n- opening_hours.add_range(DAYS[day['DayOfWeek']], day['OpeningTime'], day['ClosingTime'])\n+ if 'NULL' not in day['OpeningTime'] and 'NULL' not in day['ClosingTime']:\n+ opening_hours.add_range(DAYS[day['DayOfWeek']], day['OpeningTime'], day['ClosingTime'])\n \n return opening_hours.as_opening_hours()\n", "issue": "Spider jbhifi is broken\nDuring the global build at 2021-06-16-14-42-20, spider **jbhifi** failed with **78 features** and **1 errors**.\n\nHere's [the log](https://data.alltheplaces.xyz/runs/2021-06-16-14-42-20/logs/jbhifi.txt) and [the output](https://data.alltheplaces.xyz/runs/2021-06-16-14-42-20/output/jbhifi.geojson) ([on a map](https://data.alltheplaces.xyz/map.html?show=https://data.alltheplaces.xyz/runs/2021-06-16-14-42-20/output/jbhifi.geojson))\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\nimport scrapy\nimport json\nfrom locations.items import GeojsonPointItem\nfrom locations.hours import OpeningHours\n\nDAYS = ['Su', 'Mo', 'Tu', \"We\", 'Th', 'Fr', 'Sa']\n\nclass JbHifiSpider(scrapy.Spider):\n name = \"jbhifi\"\n allowed_domains = [\"algolia.net\"]\n \n def start_requests(self):\n headers = {\"Content-Type\": \"application/json\",\n \"User-Agent\": \"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:81.0) Gecko/20100101 Firefox/81.0\",\n \"Origin\": \"https://www.jbhifi.com.au\",\n \"Referer\": \"https://www.jbhifi.com.au/pages/store-finder\",\n \"Accept\": \"*/*\",\n 'Accept-Encoding': 'gzip, deflate'\n\n }\n yield scrapy.http.Request(\n url=\"https://vtvkm5urpx-dsn.algolia.net/1/indexes/shopify_store_locations/query?x-algolia-agent=Algolia for JavaScript (3.35.1); Browser (lite)&x-algolia-application-id=VTVKM5URPX&x-algolia-api-key=a0c0108d737ad5ab54a0e2da900bf040\",\n method=\"POST\",\n headers=headers,\n body='{\"params\":\"query=&hitsPerPage=1000&filters=displayOnWeb%3Ap\"}')\n\n def process_trading_hours(self, store_hours):\n opening_hours = OpeningHours()\n for day in store_hours:\n opening_hours.add_range(DAYS[day['DayOfWeek']], day['OpeningTime'], day['ClosingTime'])\n \n return opening_hours.as_opening_hours()\n\n def parse(self, response):\n stores = json.loads(response.body)\n\n for store in stores['hits']:\n properties = {\n 'ref': store['shopId'],\n 'name': store['storeName'],\n 'addr_full': f\"{store['storeAddress']['Line1']} {store['storeAddress'].get('Line2','')} {store['storeAddress'].get('Line3','')}\".strip(),\n 'city': store['storeAddress']['Suburb'],\n 'state': store['storeAddress']['State'],\n 'postcode': store['storeAddress']['Postcode'],\n 'country': 'AU',\n 'lat': store['_geoloc']['lat'],\n 'lon': store['_geoloc']['lng'],\n 'phone': store['phone'],\n 'opening_hours': self.process_trading_hours(store['normalTradingHours'])\n }\n\n yield GeojsonPointItem(**properties)", "path": "locations/spiders/jbhifi.py"}]}
| 1,416 | 164 |
gh_patches_debug_1878
|
rasdani/github-patches
|
git_diff
|
googleapis__google-cloud-python-5856
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Request to release GCS Python library
Hi,
Is it possible to release the Storage client library for Python?
I'd like the new method `get_service_account_email` to be available. Unless there exist concerns.
</issue>
<code>
[start of storage/setup.py]
1 # Copyright 2018 Google LLC
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 import io
16 import os
17
18 import setuptools
19
20
21 # Package metadata.
22
23 name = 'google-cloud-storage'
24 description = 'Google Cloud Storage API client library'
25 version = '1.10.0'
26 # Should be one of:
27 # 'Development Status :: 3 - Alpha'
28 # 'Development Status :: 4 - Beta'
29 # 'Development Status :: 5 - Production/Stable'
30 release_status = 'Development Status :: 5 - Production/Stable'
31 dependencies = [
32 'google-cloud-core<0.29dev,>=0.28.0',
33 'google-api-core<2.0.0dev,>=0.1.1',
34 'google-resumable-media>=0.3.1',
35 ]
36 extras = {
37 }
38
39
40 # Setup boilerplate below this line.
41
42 package_root = os.path.abspath(os.path.dirname(__file__))
43
44 readme_filename = os.path.join(package_root, 'README.rst')
45 with io.open(readme_filename, encoding='utf-8') as readme_file:
46 readme = readme_file.read()
47
48 # Only include packages under the 'google' namespace. Do not include tests,
49 # benchmarks, etc.
50 packages = [
51 package for package in setuptools.find_packages()
52 if package.startswith('google')]
53
54 # Determine which namespaces are needed.
55 namespaces = ['google']
56 if 'google.cloud' in packages:
57 namespaces.append('google.cloud')
58
59
60 setuptools.setup(
61 name=name,
62 version=version,
63 description=description,
64 long_description=readme,
65 author='Google LLC',
66 author_email='[email protected]',
67 license='Apache 2.0',
68 url='https://github.com/GoogleCloudPlatform/google-cloud-python',
69 classifiers=[
70 release_status,
71 'Intended Audience :: Developers',
72 'License :: OSI Approved :: Apache Software License',
73 'Programming Language :: Python',
74 'Programming Language :: Python :: 2',
75 'Programming Language :: Python :: 2.7',
76 'Programming Language :: Python :: 3',
77 'Programming Language :: Python :: 3.4',
78 'Programming Language :: Python :: 3.5',
79 'Programming Language :: Python :: 3.6',
80 'Operating System :: OS Independent',
81 'Topic :: Internet',
82 ],
83 platforms='Posix; MacOS X; Windows',
84 packages=packages,
85 namespace_packages=namespaces,
86 install_requires=dependencies,
87 extras_require=extras,
88 include_package_data=True,
89 zip_safe=False,
90 )
91
[end of storage/setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/storage/setup.py b/storage/setup.py
--- a/storage/setup.py
+++ b/storage/setup.py
@@ -22,7 +22,7 @@
name = 'google-cloud-storage'
description = 'Google Cloud Storage API client library'
-version = '1.10.0'
+version = '1.11.0'
# Should be one of:
# 'Development Status :: 3 - Alpha'
# 'Development Status :: 4 - Beta'
|
{"golden_diff": "diff --git a/storage/setup.py b/storage/setup.py\n--- a/storage/setup.py\n+++ b/storage/setup.py\n@@ -22,7 +22,7 @@\n \n name = 'google-cloud-storage'\n description = 'Google Cloud Storage API client library'\n-version = '1.10.0'\n+version = '1.11.0'\n # Should be one of:\n # 'Development Status :: 3 - Alpha'\n # 'Development Status :: 4 - Beta'\n", "issue": "Request to release GCS Python library\nHi,\r\n\r\nIs it possible to release the Storage client library for Python?\r\n\r\nI'd like the new method `get_service_account_email` to be available. Unless there exist concerns.\n", "before_files": [{"content": "# Copyright 2018 Google LLC\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport io\nimport os\n\nimport setuptools\n\n\n# Package metadata.\n\nname = 'google-cloud-storage'\ndescription = 'Google Cloud Storage API client library'\nversion = '1.10.0'\n# Should be one of:\n# 'Development Status :: 3 - Alpha'\n# 'Development Status :: 4 - Beta'\n# 'Development Status :: 5 - Production/Stable'\nrelease_status = 'Development Status :: 5 - Production/Stable'\ndependencies = [\n 'google-cloud-core<0.29dev,>=0.28.0',\n 'google-api-core<2.0.0dev,>=0.1.1',\n 'google-resumable-media>=0.3.1',\n]\nextras = {\n}\n\n\n# Setup boilerplate below this line.\n\npackage_root = os.path.abspath(os.path.dirname(__file__))\n\nreadme_filename = os.path.join(package_root, 'README.rst')\nwith io.open(readme_filename, encoding='utf-8') as readme_file:\n readme = readme_file.read()\n\n# Only include packages under the 'google' namespace. Do not include tests,\n# benchmarks, etc.\npackages = [\n package for package in setuptools.find_packages()\n if package.startswith('google')]\n\n# Determine which namespaces are needed.\nnamespaces = ['google']\nif 'google.cloud' in packages:\n namespaces.append('google.cloud')\n\n\nsetuptools.setup(\n name=name,\n version=version,\n description=description,\n long_description=readme,\n author='Google LLC',\n author_email='[email protected]',\n license='Apache 2.0',\n url='https://github.com/GoogleCloudPlatform/google-cloud-python',\n classifiers=[\n release_status,\n 'Intended Audience :: Developers',\n 'License :: OSI Approved :: Apache Software License',\n 'Programming Language :: Python',\n 'Programming Language :: Python :: 2',\n 'Programming Language :: Python :: 2.7',\n 'Programming Language :: Python :: 3',\n 'Programming Language :: Python :: 3.4',\n 'Programming Language :: Python :: 3.5',\n 'Programming Language :: Python :: 3.6',\n 'Operating System :: OS Independent',\n 'Topic :: Internet',\n ],\n platforms='Posix; MacOS X; Windows',\n packages=packages,\n namespace_packages=namespaces,\n install_requires=dependencies,\n extras_require=extras,\n include_package_data=True,\n zip_safe=False,\n)\n", "path": "storage/setup.py"}]}
| 1,398 | 101 |
gh_patches_debug_25012
|
rasdani/github-patches
|
git_diff
|
frappe__frappe-13240
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Tree DocTypes: Display Group Node 1st in Link Field search list
Presently in Link Fields when you search tree doctype document name you will see that if the document is a group node it is shown last in the list after the child nodes.
Search should generally show the best match first. The current implementation does the opposite.
</issue>
<code>
[start of frappe/desk/search.py]
1 # Copyright (c) 2015, Frappe Technologies Pvt. Ltd. and Contributors
2 # MIT License. See license.txt
3
4 # Search
5 import frappe, json
6 from frappe.utils import cstr, unique, cint
7 from frappe.permissions import has_permission
8 from frappe import _, is_whitelisted
9 import re
10 import wrapt
11
12 UNTRANSLATED_DOCTYPES = ["DocType", "Role"]
13
14 def sanitize_searchfield(searchfield):
15 blacklisted_keywords = ['select', 'delete', 'drop', 'update', 'case', 'and', 'or', 'like']
16
17 def _raise_exception(searchfield):
18 frappe.throw(_('Invalid Search Field {0}').format(searchfield), frappe.DataError)
19
20 if len(searchfield) == 1:
21 # do not allow special characters to pass as searchfields
22 regex = re.compile(r'^.*[=;*,\'"$\-+%#@()_].*')
23 if regex.match(searchfield):
24 _raise_exception(searchfield)
25
26 if len(searchfield) >= 3:
27
28 # to avoid 1=1
29 if '=' in searchfield:
30 _raise_exception(searchfield)
31
32 # in mysql -- is used for commenting the query
33 elif ' --' in searchfield:
34 _raise_exception(searchfield)
35
36 # to avoid and, or and like
37 elif any(' {0} '.format(keyword) in searchfield.split() for keyword in blacklisted_keywords):
38 _raise_exception(searchfield)
39
40 # to avoid select, delete, drop, update and case
41 elif any(keyword in searchfield.split() for keyword in blacklisted_keywords):
42 _raise_exception(searchfield)
43
44 else:
45 regex = re.compile(r'^.*[=;*,\'"$\-+%#@()].*')
46 if any(regex.match(f) for f in searchfield.split()):
47 _raise_exception(searchfield)
48
49 # this is called by the Link Field
50 @frappe.whitelist()
51 def search_link(doctype, txt, query=None, filters=None, page_length=20, searchfield=None, reference_doctype=None, ignore_user_permissions=False):
52 search_widget(doctype, txt.strip(), query, searchfield=searchfield, page_length=page_length, filters=filters, reference_doctype=reference_doctype, ignore_user_permissions=ignore_user_permissions)
53 frappe.response['results'] = build_for_autosuggest(frappe.response["values"])
54 del frappe.response["values"]
55
56 # this is called by the search box
57 @frappe.whitelist()
58 def search_widget(doctype, txt, query=None, searchfield=None, start=0,
59 page_length=20, filters=None, filter_fields=None, as_dict=False, reference_doctype=None, ignore_user_permissions=False):
60
61 start = cint(start)
62
63 if isinstance(filters, str):
64 filters = json.loads(filters)
65
66 if searchfield:
67 sanitize_searchfield(searchfield)
68
69 if not searchfield:
70 searchfield = "name"
71
72 standard_queries = frappe.get_hooks().standard_queries or {}
73
74 if query and query.split()[0].lower()!="select":
75 # by method
76 try:
77 is_whitelisted(frappe.get_attr(query))
78 frappe.response["values"] = frappe.call(query, doctype, txt,
79 searchfield, start, page_length, filters, as_dict=as_dict)
80 except frappe.exceptions.PermissionError as e:
81 if frappe.local.conf.developer_mode:
82 raise e
83 else:
84 frappe.respond_as_web_page(title='Invalid Method', html='Method not found',
85 indicator_color='red', http_status_code=404)
86 return
87 except Exception as e:
88 raise e
89 elif not query and doctype in standard_queries:
90 # from standard queries
91 search_widget(doctype, txt, standard_queries[doctype][0],
92 searchfield, start, page_length, filters)
93 else:
94 meta = frappe.get_meta(doctype)
95
96 if query:
97 frappe.throw(_("This query style is discontinued"))
98 # custom query
99 # frappe.response["values"] = frappe.db.sql(scrub_custom_query(query, searchfield, txt))
100 else:
101 if isinstance(filters, dict):
102 filters_items = filters.items()
103 filters = []
104 for f in filters_items:
105 if isinstance(f[1], (list, tuple)):
106 filters.append([doctype, f[0], f[1][0], f[1][1]])
107 else:
108 filters.append([doctype, f[0], "=", f[1]])
109
110 if filters==None:
111 filters = []
112 or_filters = []
113
114
115 # build from doctype
116 if txt:
117 search_fields = ["name"]
118 if meta.title_field:
119 search_fields.append(meta.title_field)
120
121 if meta.search_fields:
122 search_fields.extend(meta.get_search_fields())
123
124 for f in search_fields:
125 fmeta = meta.get_field(f.strip())
126 if (doctype not in UNTRANSLATED_DOCTYPES) and (f == "name" or (fmeta and fmeta.fieldtype in ["Data", "Text", "Small Text", "Long Text",
127 "Link", "Select", "Read Only", "Text Editor"])):
128 or_filters.append([doctype, f.strip(), "like", "%{0}%".format(txt)])
129
130 if meta.get("fields", {"fieldname":"enabled", "fieldtype":"Check"}):
131 filters.append([doctype, "enabled", "=", 1])
132 if meta.get("fields", {"fieldname":"disabled", "fieldtype":"Check"}):
133 filters.append([doctype, "disabled", "!=", 1])
134
135 # format a list of fields combining search fields and filter fields
136 fields = get_std_fields_list(meta, searchfield or "name")
137 if filter_fields:
138 fields = list(set(fields + json.loads(filter_fields)))
139 formatted_fields = ['`tab%s`.`%s`' % (meta.name, f.strip()) for f in fields]
140
141 # find relevance as location of search term from the beginning of string `name`. used for sorting results.
142 formatted_fields.append("""locate({_txt}, `tab{doctype}`.`name`) as `_relevance`""".format(
143 _txt=frappe.db.escape((txt or "").replace("%", "").replace("@", "")), doctype=doctype))
144
145
146 # In order_by, `idx` gets second priority, because it stores link count
147 from frappe.model.db_query import get_order_by
148 order_by_based_on_meta = get_order_by(doctype, meta)
149 # 2 is the index of _relevance column
150 order_by = "_relevance, {0}, `tab{1}`.idx desc".format(order_by_based_on_meta, doctype)
151
152 ptype = 'select' if frappe.only_has_select_perm(doctype) else 'read'
153 ignore_permissions = True if doctype == "DocType" else (cint(ignore_user_permissions) and has_permission(doctype, ptype=ptype))
154
155 if doctype in UNTRANSLATED_DOCTYPES:
156 page_length = None
157
158 values = frappe.get_list(doctype,
159 filters=filters,
160 fields=formatted_fields,
161 or_filters=or_filters,
162 limit_start=start,
163 limit_page_length=page_length,
164 order_by=order_by,
165 ignore_permissions=ignore_permissions,
166 reference_doctype=reference_doctype,
167 as_list=not as_dict,
168 strict=False)
169
170 if doctype in UNTRANSLATED_DOCTYPES:
171 values = tuple([v for v in list(values) if re.search(re.escape(txt)+".*", (_(v.name) if as_dict else _(v[0])), re.IGNORECASE)])
172
173 # remove _relevance from results
174 if as_dict:
175 for r in values:
176 r.pop("_relevance")
177 frappe.response["values"] = values
178 else:
179 frappe.response["values"] = [r[:-1] for r in values]
180
181 def get_std_fields_list(meta, key):
182 # get additional search fields
183 sflist = ["name"]
184 if meta.search_fields:
185 for d in meta.search_fields.split(","):
186 if d.strip() not in sflist:
187 sflist.append(d.strip())
188
189 if meta.title_field and meta.title_field not in sflist:
190 sflist.append(meta.title_field)
191
192 if key not in sflist:
193 sflist.append(key)
194
195 return sflist
196
197 def build_for_autosuggest(res):
198 results = []
199 for r in res:
200 out = {"value": r[0], "description": ", ".join(unique(cstr(d) for d in r if d)[1:])}
201 results.append(out)
202 return results
203
204 def scrub_custom_query(query, key, txt):
205 if '%(key)s' in query:
206 query = query.replace('%(key)s', key)
207 if '%s' in query:
208 query = query.replace('%s', ((txt or '') + '%'))
209 return query
210
211 @wrapt.decorator
212 def validate_and_sanitize_search_inputs(fn, instance, args, kwargs):
213 kwargs.update(dict(zip(fn.__code__.co_varnames, args)))
214 sanitize_searchfield(kwargs['searchfield'])
215 kwargs['start'] = cint(kwargs['start'])
216 kwargs['page_len'] = cint(kwargs['page_len'])
217
218 if kwargs['doctype'] and not frappe.db.exists('DocType', kwargs['doctype']):
219 return []
220
221 return fn(**kwargs)
222
223
224 @frappe.whitelist()
225 def get_names_for_mentions(search_term):
226 users_for_mentions = frappe.cache().get_value('users_for_mentions', get_users_for_mentions)
227 user_groups = frappe.cache().get_value('user_groups', get_user_groups)
228
229 filtered_mentions = []
230 for mention_data in users_for_mentions + user_groups:
231 if search_term.lower() not in mention_data.value.lower():
232 continue
233
234 mention_data['link'] = frappe.utils.get_url_to_form(
235 'User Group' if mention_data.get('is_group') else 'User Profile',
236 mention_data['id']
237 )
238
239 filtered_mentions.append(mention_data)
240
241 return sorted(filtered_mentions, key=lambda d: d['value'])
242
243 def get_users_for_mentions():
244 return frappe.get_all('User',
245 fields=['name as id', 'full_name as value'],
246 filters={
247 'name': ['not in', ('Administrator', 'Guest')],
248 'allowed_in_mentions': True,
249 'user_type': 'System User',
250 })
251
252 def get_user_groups():
253 return frappe.get_all('User Group', fields=['name as id', 'name as value'], update={
254 'is_group': True
255 })
256
[end of frappe/desk/search.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/frappe/desk/search.py b/frappe/desk/search.py
--- a/frappe/desk/search.py
+++ b/frappe/desk/search.py
@@ -168,7 +168,18 @@
strict=False)
if doctype in UNTRANSLATED_DOCTYPES:
- values = tuple([v for v in list(values) if re.search(re.escape(txt)+".*", (_(v.name) if as_dict else _(v[0])), re.IGNORECASE)])
+ # Filtering the values array so that query is included in very element
+ values = (
+ v for v in values
+ if re.search(
+ f"{re.escape(txt)}.*", _(v.name if as_dict else v[0]), re.IGNORECASE
+ )
+ )
+
+ # Sorting the values array so that relevant results always come first
+ # This will first bring elements on top in which query is a prefix of element
+ # Then it will bring the rest of the elements and sort them in lexicographical order
+ values = sorted(values, key=lambda x: relevance_sorter(x, txt, as_dict))
# remove _relevance from results
if as_dict:
@@ -208,6 +219,13 @@
query = query.replace('%s', ((txt or '') + '%'))
return query
+def relevance_sorter(key, query, as_dict):
+ value = _(key.name if as_dict else key[0])
+ return (
+ value.lower().startswith(query.lower()) is not True,
+ value
+ )
+
@wrapt.decorator
def validate_and_sanitize_search_inputs(fn, instance, args, kwargs):
kwargs.update(dict(zip(fn.__code__.co_varnames, args)))
|
{"golden_diff": "diff --git a/frappe/desk/search.py b/frappe/desk/search.py\n--- a/frappe/desk/search.py\n+++ b/frappe/desk/search.py\n@@ -168,7 +168,18 @@\n \t\t\t\tstrict=False)\n \n \t\t\tif doctype in UNTRANSLATED_DOCTYPES:\n-\t\t\t\tvalues = tuple([v for v in list(values) if re.search(re.escape(txt)+\".*\", (_(v.name) if as_dict else _(v[0])), re.IGNORECASE)])\n+\t\t\t\t# Filtering the values array so that query is included in very element\n+\t\t\t\tvalues = (\n+\t\t\t\t\tv for v in values\n+\t\t\t\t\tif re.search(\n+\t\t\t\t\t\tf\"{re.escape(txt)}.*\", _(v.name if as_dict else v[0]), re.IGNORECASE\n+\t\t\t\t\t)\n+\t\t\t\t)\n+\n+\t\t\t# Sorting the values array so that relevant results always come first\n+\t\t\t# This will first bring elements on top in which query is a prefix of element\n+\t\t\t# Then it will bring the rest of the elements and sort them in lexicographical order\n+\t\t\tvalues = sorted(values, key=lambda x: relevance_sorter(x, txt, as_dict))\n \n \t\t\t# remove _relevance from results\n \t\t\tif as_dict:\n@@ -208,6 +219,13 @@\n \t\tquery = query.replace('%s', ((txt or '') + '%'))\n \treturn query\n \n+def relevance_sorter(key, query, as_dict):\n+\tvalue = _(key.name if as_dict else key[0])\n+\treturn (\n+\t\tvalue.lower().startswith(query.lower()) is not True,\n+\t\tvalue\n+\t)\n+\n @wrapt.decorator\n def validate_and_sanitize_search_inputs(fn, instance, args, kwargs):\n \tkwargs.update(dict(zip(fn.__code__.co_varnames, args)))\n", "issue": "Tree DocTypes: Display Group Node 1st in Link Field search list\nPresently in Link Fields when you search tree doctype document name you will see that if the document is a group node it is shown last in the list after the child nodes.\r\n\r\n\r\n\r\nSearch should generally show the best match first. The current implementation does the opposite.\n", "before_files": [{"content": "# Copyright (c) 2015, Frappe Technologies Pvt. Ltd. and Contributors\n# MIT License. See license.txt\n\n# Search\nimport frappe, json\nfrom frappe.utils import cstr, unique, cint\nfrom frappe.permissions import has_permission\nfrom frappe import _, is_whitelisted\nimport re\nimport wrapt\n\nUNTRANSLATED_DOCTYPES = [\"DocType\", \"Role\"]\n\ndef sanitize_searchfield(searchfield):\n\tblacklisted_keywords = ['select', 'delete', 'drop', 'update', 'case', 'and', 'or', 'like']\n\n\tdef _raise_exception(searchfield):\n\t\tfrappe.throw(_('Invalid Search Field {0}').format(searchfield), frappe.DataError)\n\n\tif len(searchfield) == 1:\n\t\t# do not allow special characters to pass as searchfields\n\t\tregex = re.compile(r'^.*[=;*,\\'\"$\\-+%#@()_].*')\n\t\tif regex.match(searchfield):\n\t\t\t_raise_exception(searchfield)\n\n\tif len(searchfield) >= 3:\n\n\t\t# to avoid 1=1\n\t\tif '=' in searchfield:\n\t\t\t_raise_exception(searchfield)\n\n\t\t# in mysql -- is used for commenting the query\n\t\telif ' --' in searchfield:\n\t\t\t_raise_exception(searchfield)\n\n\t\t# to avoid and, or and like\n\t\telif any(' {0} '.format(keyword) in searchfield.split() for keyword in blacklisted_keywords):\n\t\t\t_raise_exception(searchfield)\n\n\t\t# to avoid select, delete, drop, update and case\n\t\telif any(keyword in searchfield.split() for keyword in blacklisted_keywords):\n\t\t\t_raise_exception(searchfield)\n\n\t\telse:\n\t\t\tregex = re.compile(r'^.*[=;*,\\'\"$\\-+%#@()].*')\n\t\t\tif any(regex.match(f) for f in searchfield.split()):\n\t\t\t\t_raise_exception(searchfield)\n\n# this is called by the Link Field\[email protected]()\ndef search_link(doctype, txt, query=None, filters=None, page_length=20, searchfield=None, reference_doctype=None, ignore_user_permissions=False):\n\tsearch_widget(doctype, txt.strip(), query, searchfield=searchfield, page_length=page_length, filters=filters, reference_doctype=reference_doctype, ignore_user_permissions=ignore_user_permissions)\n\tfrappe.response['results'] = build_for_autosuggest(frappe.response[\"values\"])\n\tdel frappe.response[\"values\"]\n\n# this is called by the search box\[email protected]()\ndef search_widget(doctype, txt, query=None, searchfield=None, start=0,\n\tpage_length=20, filters=None, filter_fields=None, as_dict=False, reference_doctype=None, ignore_user_permissions=False):\n\n\tstart = cint(start)\n\n\tif isinstance(filters, str):\n\t\tfilters = json.loads(filters)\n\n\tif searchfield:\n\t\tsanitize_searchfield(searchfield)\n\n\tif not searchfield:\n\t\tsearchfield = \"name\"\n\n\tstandard_queries = frappe.get_hooks().standard_queries or {}\n\n\tif query and query.split()[0].lower()!=\"select\":\n\t\t# by method\n\t\ttry:\n\t\t\tis_whitelisted(frappe.get_attr(query))\n\t\t\tfrappe.response[\"values\"] = frappe.call(query, doctype, txt,\n\t\t\t\tsearchfield, start, page_length, filters, as_dict=as_dict)\n\t\texcept frappe.exceptions.PermissionError as e:\n\t\t\tif frappe.local.conf.developer_mode:\n\t\t\t\traise e\n\t\t\telse:\n\t\t\t\tfrappe.respond_as_web_page(title='Invalid Method', html='Method not found',\n\t\t\t\tindicator_color='red', http_status_code=404)\n\t\t\treturn\n\t\texcept Exception as e:\n\t\t\traise e\n\telif not query and doctype in standard_queries:\n\t\t# from standard queries\n\t\tsearch_widget(doctype, txt, standard_queries[doctype][0],\n\t\t\tsearchfield, start, page_length, filters)\n\telse:\n\t\tmeta = frappe.get_meta(doctype)\n\n\t\tif query:\n\t\t\tfrappe.throw(_(\"This query style is discontinued\"))\n\t\t\t# custom query\n\t\t\t# frappe.response[\"values\"] = frappe.db.sql(scrub_custom_query(query, searchfield, txt))\n\t\telse:\n\t\t\tif isinstance(filters, dict):\n\t\t\t\tfilters_items = filters.items()\n\t\t\t\tfilters = []\n\t\t\t\tfor f in filters_items:\n\t\t\t\t\tif isinstance(f[1], (list, tuple)):\n\t\t\t\t\t\tfilters.append([doctype, f[0], f[1][0], f[1][1]])\n\t\t\t\t\telse:\n\t\t\t\t\t\tfilters.append([doctype, f[0], \"=\", f[1]])\n\n\t\t\tif filters==None:\n\t\t\t\tfilters = []\n\t\t\tor_filters = []\n\n\n\t\t\t# build from doctype\n\t\t\tif txt:\n\t\t\t\tsearch_fields = [\"name\"]\n\t\t\t\tif meta.title_field:\n\t\t\t\t\tsearch_fields.append(meta.title_field)\n\n\t\t\t\tif meta.search_fields:\n\t\t\t\t\tsearch_fields.extend(meta.get_search_fields())\n\n\t\t\t\tfor f in search_fields:\n\t\t\t\t\tfmeta = meta.get_field(f.strip())\n\t\t\t\t\tif (doctype not in UNTRANSLATED_DOCTYPES) and (f == \"name\" or (fmeta and fmeta.fieldtype in [\"Data\", \"Text\", \"Small Text\", \"Long Text\",\n\t\t\t\t\t\t\"Link\", \"Select\", \"Read Only\", \"Text Editor\"])):\n\t\t\t\t\t\t\tor_filters.append([doctype, f.strip(), \"like\", \"%{0}%\".format(txt)])\n\n\t\t\tif meta.get(\"fields\", {\"fieldname\":\"enabled\", \"fieldtype\":\"Check\"}):\n\t\t\t\tfilters.append([doctype, \"enabled\", \"=\", 1])\n\t\t\tif meta.get(\"fields\", {\"fieldname\":\"disabled\", \"fieldtype\":\"Check\"}):\n\t\t\t\tfilters.append([doctype, \"disabled\", \"!=\", 1])\n\n\t\t\t# format a list of fields combining search fields and filter fields\n\t\t\tfields = get_std_fields_list(meta, searchfield or \"name\")\n\t\t\tif filter_fields:\n\t\t\t\tfields = list(set(fields + json.loads(filter_fields)))\n\t\t\tformatted_fields = ['`tab%s`.`%s`' % (meta.name, f.strip()) for f in fields]\n\n\t\t\t# find relevance as location of search term from the beginning of string `name`. used for sorting results.\n\t\t\tformatted_fields.append(\"\"\"locate({_txt}, `tab{doctype}`.`name`) as `_relevance`\"\"\".format(\n\t\t\t\t_txt=frappe.db.escape((txt or \"\").replace(\"%\", \"\").replace(\"@\", \"\")), doctype=doctype))\n\n\n\t\t\t# In order_by, `idx` gets second priority, because it stores link count\n\t\t\tfrom frappe.model.db_query import get_order_by\n\t\t\torder_by_based_on_meta = get_order_by(doctype, meta)\n\t\t\t# 2 is the index of _relevance column\n\t\t\torder_by = \"_relevance, {0}, `tab{1}`.idx desc\".format(order_by_based_on_meta, doctype)\n\n\t\t\tptype = 'select' if frappe.only_has_select_perm(doctype) else 'read'\n\t\t\tignore_permissions = True if doctype == \"DocType\" else (cint(ignore_user_permissions) and has_permission(doctype, ptype=ptype))\n\n\t\t\tif doctype in UNTRANSLATED_DOCTYPES:\n\t\t\t\tpage_length = None\n\n\t\t\tvalues = frappe.get_list(doctype,\n\t\t\t\tfilters=filters,\n\t\t\t\tfields=formatted_fields,\n\t\t\t\tor_filters=or_filters,\n\t\t\t\tlimit_start=start,\n\t\t\t\tlimit_page_length=page_length,\n\t\t\t\torder_by=order_by,\n\t\t\t\tignore_permissions=ignore_permissions,\n\t\t\t\treference_doctype=reference_doctype,\n\t\t\t\tas_list=not as_dict,\n\t\t\t\tstrict=False)\n\n\t\t\tif doctype in UNTRANSLATED_DOCTYPES:\n\t\t\t\tvalues = tuple([v for v in list(values) if re.search(re.escape(txt)+\".*\", (_(v.name) if as_dict else _(v[0])), re.IGNORECASE)])\n\n\t\t\t# remove _relevance from results\n\t\t\tif as_dict:\n\t\t\t\tfor r in values:\n\t\t\t\t\tr.pop(\"_relevance\")\n\t\t\t\tfrappe.response[\"values\"] = values\n\t\t\telse:\n\t\t\t\tfrappe.response[\"values\"] = [r[:-1] for r in values]\n\ndef get_std_fields_list(meta, key):\n\t# get additional search fields\n\tsflist = [\"name\"]\n\tif meta.search_fields:\n\t\tfor d in meta.search_fields.split(\",\"):\n\t\t\tif d.strip() not in sflist:\n\t\t\t\tsflist.append(d.strip())\n\n\tif meta.title_field and meta.title_field not in sflist:\n\t\tsflist.append(meta.title_field)\n\n\tif key not in sflist:\n\t\tsflist.append(key)\n\n\treturn sflist\n\ndef build_for_autosuggest(res):\n\tresults = []\n\tfor r in res:\n\t\tout = {\"value\": r[0], \"description\": \", \".join(unique(cstr(d) for d in r if d)[1:])}\n\t\tresults.append(out)\n\treturn results\n\ndef scrub_custom_query(query, key, txt):\n\tif '%(key)s' in query:\n\t\tquery = query.replace('%(key)s', key)\n\tif '%s' in query:\n\t\tquery = query.replace('%s', ((txt or '') + '%'))\n\treturn query\n\[email protected]\ndef validate_and_sanitize_search_inputs(fn, instance, args, kwargs):\n\tkwargs.update(dict(zip(fn.__code__.co_varnames, args)))\n\tsanitize_searchfield(kwargs['searchfield'])\n\tkwargs['start'] = cint(kwargs['start'])\n\tkwargs['page_len'] = cint(kwargs['page_len'])\n\n\tif kwargs['doctype'] and not frappe.db.exists('DocType', kwargs['doctype']):\n\t\treturn []\n\n\treturn fn(**kwargs)\n\n\[email protected]()\ndef get_names_for_mentions(search_term):\n\tusers_for_mentions = frappe.cache().get_value('users_for_mentions', get_users_for_mentions)\n\tuser_groups = frappe.cache().get_value('user_groups', get_user_groups)\n\n\tfiltered_mentions = []\n\tfor mention_data in users_for_mentions + user_groups:\n\t\tif search_term.lower() not in mention_data.value.lower():\n\t\t\tcontinue\n\n\t\tmention_data['link'] = frappe.utils.get_url_to_form(\n\t\t\t'User Group' if mention_data.get('is_group') else 'User Profile',\n\t\t\tmention_data['id']\n\t\t)\n\n\t\tfiltered_mentions.append(mention_data)\n\n\treturn sorted(filtered_mentions, key=lambda d: d['value'])\n\ndef get_users_for_mentions():\n\treturn frappe.get_all('User',\n\t\tfields=['name as id', 'full_name as value'],\n\t\tfilters={\n\t\t\t'name': ['not in', ('Administrator', 'Guest')],\n\t\t\t'allowed_in_mentions': True,\n\t\t\t'user_type': 'System User',\n\t\t})\n\ndef get_user_groups():\n\treturn frappe.get_all('User Group', fields=['name as id', 'name as value'], update={\n\t\t'is_group': True\n\t})\n", "path": "frappe/desk/search.py"}]}
| 3,692 | 396 |
gh_patches_debug_10925
|
rasdani/github-patches
|
git_diff
|
pypi__warehouse-12701
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Classifiers: Python version sort order
<!--
NOTE: This issue should be for problems with PyPI itself, including:
* pypi.org
* test.pypi.org
* files.pythonhosted.org
This issue should NOT be for a project installed from PyPI. If you are
having an issue with a specific package, you should reach out to the
maintainers of that project directly instead.
Furthermore, this issue should NOT be for any non-PyPI properties (like
python.org, docs.python.org, etc.)
-->
**Describe the bug**
<!-- A clear and concise description the bug -->
The classifiers "Programming Language :: Python :: 3.X" aren't sorted in the right order on https://pypi.org as well as on https://test.pypi.org
I'm defining the classifiers like this in the `setup.py` file.
```
classifiers=[
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.6",
"Programming Language :: Python :: 3.7",
"Programming Language :: Python :: 3.8",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10"
]
```
In the navigation bar on pypy.org it will then appear like this:

With Python 3.10 at the top instead of at the bottom (after Python 3.9).
To give the visitors of pypi.org a better and faster overview over a project, it would be great if the Python classifiers were sorted by the Python versions.
**Expected behavior**
<!-- A clear and concise description of what you expected to happen -->
Classifiers sorted by Python versions.
Python :: 3
Python :: 3.6
Python :: 3.7
Python :: 3.8
Python :: 3.9
Python :: 3.10
Python :: 3.11
Python :: 3.12
etc.
**To Reproduce**
<!-- Steps to reproduce the bug, or a link to PyPI where the bug is visible -->
It can be seen for example here: https://pypi.org/project/officeextractor/
</issue>
<code>
[start of warehouse/filters.py]
1 # Licensed under the Apache License, Version 2.0 (the "License");
2 # you may not use this file except in compliance with the License.
3 # You may obtain a copy of the License at
4 #
5 # http://www.apache.org/licenses/LICENSE-2.0
6 #
7 # Unless required by applicable law or agreed to in writing, software
8 # distributed under the License is distributed on an "AS IS" BASIS,
9 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
10 # See the License for the specific language governing permissions and
11 # limitations under the License.
12
13 import binascii
14 import collections
15 import datetime
16 import enum
17 import hmac
18 import json
19 import re
20 import urllib.parse
21
22 from email.utils import getaddresses
23
24 import html5lib
25 import html5lib.serializer
26 import html5lib.treewalkers
27 import jinja2
28 import packaging.version
29 import pytz
30
31 from pyramid.threadlocal import get_current_request
32
33 from warehouse.utils.http import is_valid_uri
34
35
36 class PackageType(enum.Enum):
37 bdist_dmg = "OSX Disk Image"
38 bdist_dumb = "Dumb Binary"
39 bdist_egg = "Egg"
40 bdist_msi = "Windows MSI Installer"
41 bdist_rpm = "RPM"
42 bdist_wheel = "Wheel"
43 bdist_wininst = "Windows Installer"
44 sdist = "Source"
45
46
47 def format_package_type(value):
48 try:
49 return PackageType[value].value
50 except KeyError:
51 return value
52
53
54 def _camo_url(request, url):
55 camo_url = request.registry.settings["camo.url"].format(request=request)
56 camo_key = request.registry.settings["camo.key"].encode("utf8")
57 url = url.encode("utf8")
58
59 path = "/".join(
60 [
61 hmac.new(camo_key, url, digestmod="sha1").hexdigest(),
62 binascii.hexlify(url).decode("utf8"),
63 ]
64 )
65
66 return urllib.parse.urljoin(camo_url, path)
67
68
69 @jinja2.pass_context
70 def camoify(ctx, value):
71 request = ctx.get("request") or get_current_request()
72
73 # Parse the rendered output and replace any inline images that don't point
74 # to HTTPS with camouflaged images.
75 tree_builder = html5lib.treebuilders.getTreeBuilder("dom")
76 parser = html5lib.html5parser.HTMLParser(tree=tree_builder)
77 dom = parser.parse(value)
78
79 for element in dom.getElementsByTagName("img"):
80 src = element.getAttribute("src")
81 if src:
82 element.setAttribute("src", request.camo_url(src))
83
84 tree_walker = html5lib.treewalkers.getTreeWalker("dom")
85 html_serializer = html5lib.serializer.HTMLSerializer()
86 camoed = "".join(html_serializer.serialize(tree_walker(dom)))
87
88 return camoed
89
90
91 _SI_SYMBOLS = ["k", "M", "G", "T", "P", "E", "Z", "Y"]
92
93
94 def shorten_number(value):
95 for i, symbol in enumerate(_SI_SYMBOLS):
96 magnitude = value / (1000 ** (i + 1))
97 if magnitude >= 1 and magnitude < 1000:
98 return "{:.3g}{}".format(magnitude, symbol)
99
100 return str(value)
101
102
103 def tojson(value):
104 return json.dumps(value, sort_keys=True, separators=(",", ":"))
105
106
107 def urlparse(value):
108 return urllib.parse.urlparse(value)
109
110
111 def format_tags(tags):
112 # split tags
113 if re.search(r",", tags):
114 split_tags = re.split(r"\s*,\s*", tags)
115 elif re.search(r";", tags):
116 split_tags = re.split(r"\s*;\s*", tags)
117 else:
118 split_tags = re.split(r"\s+", tags)
119
120 # strip whitespace, quotes, double quotes
121 stripped_tags = [re.sub(r'^["\'\s]+|["\'\s]+$', "", t) for t in split_tags]
122
123 # remove any empty tags
124 formatted_tags = [t for t in stripped_tags if t]
125
126 return formatted_tags
127
128
129 def format_classifiers(classifiers):
130 structured = collections.OrderedDict()
131
132 # Split up our classifiers into our data structure
133 for classifier in classifiers:
134 key, *value = classifier.split(" :: ", 1)
135 if value:
136 if key not in structured:
137 structured[key] = []
138 structured[key].append(value[0])
139
140 return structured
141
142
143 def classifier_id(classifier):
144 return classifier.replace(" ", "_").replace("::", ".")
145
146
147 def contains_valid_uris(items):
148 """Returns boolean representing whether the input list contains any valid
149 URIs
150 """
151 return any(is_valid_uri(i) for i in items)
152
153
154 def parse_version(version_str):
155 return packaging.version.parse(version_str)
156
157
158 def localize_datetime(timestamp):
159 return pytz.utc.localize(timestamp)
160
161
162 def ctime(timestamp):
163 return datetime.datetime.fromtimestamp(timestamp)
164
165
166 def is_recent(timestamp):
167 if timestamp:
168 return timestamp + datetime.timedelta(days=30) > datetime.datetime.now()
169 return False
170
171
172 def format_author_email(metadata_email: str) -> tuple[str, str]:
173 """
174 Return the name and email address from a metadata RFC-822 string.
175 Use Jinja's `first` and `last` to access each part in a template.
176 TODO: Support more than one email address, per RFC-822.
177 """
178 author_emails = []
179 for author_name, author_email in getaddresses([metadata_email]):
180 if "@" not in author_email:
181 return author_name, ""
182 author_emails.append((author_name, author_email))
183 return author_emails[0][0], author_emails[0][1]
184
185
186 def includeme(config):
187 config.add_request_method(_camo_url, name="camo_url")
188
[end of warehouse/filters.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/warehouse/filters.py b/warehouse/filters.py
--- a/warehouse/filters.py
+++ b/warehouse/filters.py
@@ -28,6 +28,7 @@
import packaging.version
import pytz
+from natsort import natsorted
from pyramid.threadlocal import get_current_request
from warehouse.utils.http import is_valid_uri
@@ -137,6 +138,10 @@
structured[key] = []
structured[key].append(value[0])
+ # Sort all the values in our data structure
+ for key, value in structured.items():
+ structured[key] = natsorted(value)
+
return structured
|
{"golden_diff": "diff --git a/warehouse/filters.py b/warehouse/filters.py\n--- a/warehouse/filters.py\n+++ b/warehouse/filters.py\n@@ -28,6 +28,7 @@\n import packaging.version\n import pytz\n \n+from natsort import natsorted\n from pyramid.threadlocal import get_current_request\n \n from warehouse.utils.http import is_valid_uri\n@@ -137,6 +138,10 @@\n structured[key] = []\n structured[key].append(value[0])\n \n+ # Sort all the values in our data structure\n+ for key, value in structured.items():\n+ structured[key] = natsorted(value)\n+\n return structured\n", "issue": "Classifiers: Python version sort order\n<!--\r\n NOTE: This issue should be for problems with PyPI itself, including:\r\n * pypi.org\r\n * test.pypi.org\r\n * files.pythonhosted.org\r\n\r\n This issue should NOT be for a project installed from PyPI. If you are\r\n having an issue with a specific package, you should reach out to the\r\n maintainers of that project directly instead.\r\n\r\n Furthermore, this issue should NOT be for any non-PyPI properties (like\r\n python.org, docs.python.org, etc.)\r\n-->\r\n\r\n**Describe the bug**\r\n<!-- A clear and concise description the bug -->\r\n\r\nThe classifiers \"Programming Language :: Python :: 3.X\" aren't sorted in the right order on https://pypi.org as well as on https://test.pypi.org\r\n\r\nI'm defining the classifiers like this in the `setup.py` file.\r\n\r\n```\r\nclassifiers=[\r\n \"Programming Language :: Python :: 3\",\r\n \"Programming Language :: Python :: 3.6\",\r\n \"Programming Language :: Python :: 3.7\",\r\n \"Programming Language :: Python :: 3.8\",\r\n \"Programming Language :: Python :: 3.9\",\r\n \"Programming Language :: Python :: 3.10\"\r\n ]\r\n```\r\n\r\nIn the navigation bar on pypy.org it will then appear like this: \r\n\r\n\r\nWith Python 3.10 at the top instead of at the bottom (after Python 3.9).\r\n\r\n\r\nTo give the visitors of pypi.org a better and faster overview over a project, it would be great if the Python classifiers were sorted by the Python versions.\r\n\r\n\r\n**Expected behavior**\r\n<!-- A clear and concise description of what you expected to happen -->\r\n\r\nClassifiers sorted by Python versions.\r\n\r\nPython :: 3\r\nPython :: 3.6\r\nPython :: 3.7\r\nPython :: 3.8\r\nPython :: 3.9\r\nPython :: 3.10\r\nPython :: 3.11\r\nPython :: 3.12\r\netc.\r\n\r\n**To Reproduce**\r\n<!-- Steps to reproduce the bug, or a link to PyPI where the bug is visible -->\r\n\r\nIt can be seen for example here: https://pypi.org/project/officeextractor/\r\n\n", "before_files": [{"content": "# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport binascii\nimport collections\nimport datetime\nimport enum\nimport hmac\nimport json\nimport re\nimport urllib.parse\n\nfrom email.utils import getaddresses\n\nimport html5lib\nimport html5lib.serializer\nimport html5lib.treewalkers\nimport jinja2\nimport packaging.version\nimport pytz\n\nfrom pyramid.threadlocal import get_current_request\n\nfrom warehouse.utils.http import is_valid_uri\n\n\nclass PackageType(enum.Enum):\n bdist_dmg = \"OSX Disk Image\"\n bdist_dumb = \"Dumb Binary\"\n bdist_egg = \"Egg\"\n bdist_msi = \"Windows MSI Installer\"\n bdist_rpm = \"RPM\"\n bdist_wheel = \"Wheel\"\n bdist_wininst = \"Windows Installer\"\n sdist = \"Source\"\n\n\ndef format_package_type(value):\n try:\n return PackageType[value].value\n except KeyError:\n return value\n\n\ndef _camo_url(request, url):\n camo_url = request.registry.settings[\"camo.url\"].format(request=request)\n camo_key = request.registry.settings[\"camo.key\"].encode(\"utf8\")\n url = url.encode(\"utf8\")\n\n path = \"/\".join(\n [\n hmac.new(camo_key, url, digestmod=\"sha1\").hexdigest(),\n binascii.hexlify(url).decode(\"utf8\"),\n ]\n )\n\n return urllib.parse.urljoin(camo_url, path)\n\n\[email protected]_context\ndef camoify(ctx, value):\n request = ctx.get(\"request\") or get_current_request()\n\n # Parse the rendered output and replace any inline images that don't point\n # to HTTPS with camouflaged images.\n tree_builder = html5lib.treebuilders.getTreeBuilder(\"dom\")\n parser = html5lib.html5parser.HTMLParser(tree=tree_builder)\n dom = parser.parse(value)\n\n for element in dom.getElementsByTagName(\"img\"):\n src = element.getAttribute(\"src\")\n if src:\n element.setAttribute(\"src\", request.camo_url(src))\n\n tree_walker = html5lib.treewalkers.getTreeWalker(\"dom\")\n html_serializer = html5lib.serializer.HTMLSerializer()\n camoed = \"\".join(html_serializer.serialize(tree_walker(dom)))\n\n return camoed\n\n\n_SI_SYMBOLS = [\"k\", \"M\", \"G\", \"T\", \"P\", \"E\", \"Z\", \"Y\"]\n\n\ndef shorten_number(value):\n for i, symbol in enumerate(_SI_SYMBOLS):\n magnitude = value / (1000 ** (i + 1))\n if magnitude >= 1 and magnitude < 1000:\n return \"{:.3g}{}\".format(magnitude, symbol)\n\n return str(value)\n\n\ndef tojson(value):\n return json.dumps(value, sort_keys=True, separators=(\",\", \":\"))\n\n\ndef urlparse(value):\n return urllib.parse.urlparse(value)\n\n\ndef format_tags(tags):\n # split tags\n if re.search(r\",\", tags):\n split_tags = re.split(r\"\\s*,\\s*\", tags)\n elif re.search(r\";\", tags):\n split_tags = re.split(r\"\\s*;\\s*\", tags)\n else:\n split_tags = re.split(r\"\\s+\", tags)\n\n # strip whitespace, quotes, double quotes\n stripped_tags = [re.sub(r'^[\"\\'\\s]+|[\"\\'\\s]+$', \"\", t) for t in split_tags]\n\n # remove any empty tags\n formatted_tags = [t for t in stripped_tags if t]\n\n return formatted_tags\n\n\ndef format_classifiers(classifiers):\n structured = collections.OrderedDict()\n\n # Split up our classifiers into our data structure\n for classifier in classifiers:\n key, *value = classifier.split(\" :: \", 1)\n if value:\n if key not in structured:\n structured[key] = []\n structured[key].append(value[0])\n\n return structured\n\n\ndef classifier_id(classifier):\n return classifier.replace(\" \", \"_\").replace(\"::\", \".\")\n\n\ndef contains_valid_uris(items):\n \"\"\"Returns boolean representing whether the input list contains any valid\n URIs\n \"\"\"\n return any(is_valid_uri(i) for i in items)\n\n\ndef parse_version(version_str):\n return packaging.version.parse(version_str)\n\n\ndef localize_datetime(timestamp):\n return pytz.utc.localize(timestamp)\n\n\ndef ctime(timestamp):\n return datetime.datetime.fromtimestamp(timestamp)\n\n\ndef is_recent(timestamp):\n if timestamp:\n return timestamp + datetime.timedelta(days=30) > datetime.datetime.now()\n return False\n\n\ndef format_author_email(metadata_email: str) -> tuple[str, str]:\n \"\"\"\n Return the name and email address from a metadata RFC-822 string.\n Use Jinja's `first` and `last` to access each part in a template.\n TODO: Support more than one email address, per RFC-822.\n \"\"\"\n author_emails = []\n for author_name, author_email in getaddresses([metadata_email]):\n if \"@\" not in author_email:\n return author_name, \"\"\n author_emails.append((author_name, author_email))\n return author_emails[0][0], author_emails[0][1]\n\n\ndef includeme(config):\n config.add_request_method(_camo_url, name=\"camo_url\")\n", "path": "warehouse/filters.py"}]}
| 2,795 | 149 |
gh_patches_debug_67229
|
rasdani/github-patches
|
git_diff
|
pypi__warehouse-434
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Redirect a slash-less URL to the slashed variant
We have urls like `/project/foobar/`, if someone enters `/project/foobar` we should redirect that to `/project/foobar/`.
</issue>
<code>
[start of warehouse/config.py]
1 # Licensed under the Apache License, Version 2.0 (the "License");
2 # you may not use this file except in compliance with the License.
3 # You may obtain a copy of the License at
4 #
5 # http://www.apache.org/licenses/LICENSE-2.0
6 #
7 # Unless required by applicable law or agreed to in writing, software
8 # distributed under the License is distributed on an "AS IS" BASIS,
9 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
10 # See the License for the specific language governing permissions and
11 # limitations under the License.
12
13 import fs.opener
14 import transaction
15
16 from pyramid.config import Configurator
17 from tzf.pyramid_yml import config_defaults
18
19 from warehouse.utils.static import WarehouseCacheBuster
20
21
22 def content_security_policy_tween_factory(handler, registry):
23 policy = registry.settings.get("csp", {})
24 policy = "; ".join([" ".join([k] + v) for k, v in sorted(policy.items())])
25
26 def content_security_policy_tween(request):
27 resp = handler(request)
28
29 # We don't want to apply our Content Security Policy to the debug
30 # toolbar, that's not part of our application and it doesn't work with
31 # our restrictive CSP.
32 if not request.path.startswith("/_debug_toolbar/"):
33 resp.headers["Content-Security-Policy"] = \
34 policy.format(request=request)
35
36 return resp
37
38 return content_security_policy_tween
39
40
41 def configure(settings=None):
42 if settings is None:
43 settings = {}
44
45 config = Configurator(settings=settings)
46
47 # Set our yml.location so that it contains all of our settings files
48 config_defaults(config, ["warehouse:etc"])
49
50 # We want to load configuration from YAML files
51 config.include("tzf.pyramid_yml")
52
53 # We'll want to use Jinja2 as our template system.
54 config.include("pyramid_jinja2")
55
56 # We also want to use Jinja2 for .html templates as well, because we just
57 # assume that all templates will be using Jinja.
58 config.add_jinja2_renderer(".html")
59
60 # We'll want to configure some filters for Jinja2 as well.
61 filters = config.get_settings().setdefault("jinja2.filters", {})
62 filters.setdefault("readme", "warehouse.filters:readme_renderer")
63 filters.setdefault("shorten_number", "warehouse.filters:shorten_number")
64
65 # We also want to register some global functions for Jinja
66 jglobals = config.get_settings().setdefault("jinja2.globals", {})
67 jglobals.setdefault("gravatar", "warehouse.utils.gravatar:gravatar")
68
69 # We'll store all of our templates in one location, warehouse/templates
70 # so we'll go ahead and add that to the Jinja2 search path.
71 config.add_jinja2_search_path("warehouse:templates", name=".html")
72
73 # Configure our transaction handling so that each request gets it's own
74 # transaction handler and the lifetime of the transaction is tied to the
75 # lifetime of the request.
76 config.add_settings({
77 "tm.manager_hook": lambda request: transaction.TransactionManager(),
78 })
79 config.include("pyramid_tm")
80
81 # Register support for services
82 config.include("pyramid_services")
83
84 # Register support for internationalization and localization
85 config.include(".i18n")
86
87 # Register the configuration for the PostgreSQL database.
88 config.include(".db")
89
90 # Register our session support
91 config.include(".sessions")
92
93 # Register our support for http and origin caching
94 config.include(".cache.http")
95 config.include(".cache.origin")
96
97 # Register our CSRF support
98 config.include(".csrf")
99
100 # Register our authentication support.
101 config.include(".accounts")
102
103 # Allow the packaging app to register any services it has.
104 config.include(".packaging")
105
106 # Register all our URL routes for Warehouse.
107 config.include(".routes")
108
109 # Enable a Content Security Policy
110 config.add_settings({
111 "csp": {
112 "default-src": ["'none'"],
113 "frame-ancestors": ["'none'"],
114 "img-src": [
115 "'self'",
116 config.registry.settings["camo.url"],
117 "https://secure.gravatar.com",
118 ],
119 "referrer": ["cross-origin"],
120 "reflected-xss": ["block"],
121 "script-src": ["'self'"],
122 "style-src": ["'self'"],
123 },
124 })
125 config.add_tween("warehouse.config.content_security_policy_tween_factory")
126
127 # Configure the filesystems we use.
128 config.registry["filesystems"] = {}
129 for key, path in {
130 k[5:]: v
131 for k, v in config.registry.settings.items()
132 if k.startswith("dirs.")}.items():
133 config.registry["filesystems"][key] = \
134 fs.opener.fsopendir(path, create_dir=True)
135
136 # Enable Warehouse to service our static files
137 config.add_static_view(
138 name="static",
139 path="warehouse:static",
140 cachebust=WarehouseCacheBuster(
141 "warehouse:static/manifest.json",
142 cache=not config.registry.settings["pyramid.reload_assets"],
143 ),
144 )
145
146 # Scan everything for configuration
147 config.scan(ignore=["warehouse.migrations.env"])
148
149 return config
150
[end of warehouse/config.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/warehouse/config.py b/warehouse/config.py
--- a/warehouse/config.py
+++ b/warehouse/config.py
@@ -124,6 +124,10 @@
})
config.add_tween("warehouse.config.content_security_policy_tween_factory")
+ # If a route matches with a slash appended to it, redirect to that route
+ # instead of returning a HTTPNotFound.
+ config.add_notfound_view(append_slash=True)
+
# Configure the filesystems we use.
config.registry["filesystems"] = {}
for key, path in {
|
{"golden_diff": "diff --git a/warehouse/config.py b/warehouse/config.py\n--- a/warehouse/config.py\n+++ b/warehouse/config.py\n@@ -124,6 +124,10 @@\n })\n config.add_tween(\"warehouse.config.content_security_policy_tween_factory\")\n \n+ # If a route matches with a slash appended to it, redirect to that route\n+ # instead of returning a HTTPNotFound.\n+ config.add_notfound_view(append_slash=True)\n+\n # Configure the filesystems we use.\n config.registry[\"filesystems\"] = {}\n for key, path in {\n", "issue": "Redirect a slash-less URL to the slashed variant\nWe have urls like `/project/foobar/`, if someone enters `/project/foobar` we should redirect that to `/project/foobar/`.\n\n", "before_files": [{"content": "# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport fs.opener\nimport transaction\n\nfrom pyramid.config import Configurator\nfrom tzf.pyramid_yml import config_defaults\n\nfrom warehouse.utils.static import WarehouseCacheBuster\n\n\ndef content_security_policy_tween_factory(handler, registry):\n policy = registry.settings.get(\"csp\", {})\n policy = \"; \".join([\" \".join([k] + v) for k, v in sorted(policy.items())])\n\n def content_security_policy_tween(request):\n resp = handler(request)\n\n # We don't want to apply our Content Security Policy to the debug\n # toolbar, that's not part of our application and it doesn't work with\n # our restrictive CSP.\n if not request.path.startswith(\"/_debug_toolbar/\"):\n resp.headers[\"Content-Security-Policy\"] = \\\n policy.format(request=request)\n\n return resp\n\n return content_security_policy_tween\n\n\ndef configure(settings=None):\n if settings is None:\n settings = {}\n\n config = Configurator(settings=settings)\n\n # Set our yml.location so that it contains all of our settings files\n config_defaults(config, [\"warehouse:etc\"])\n\n # We want to load configuration from YAML files\n config.include(\"tzf.pyramid_yml\")\n\n # We'll want to use Jinja2 as our template system.\n config.include(\"pyramid_jinja2\")\n\n # We also want to use Jinja2 for .html templates as well, because we just\n # assume that all templates will be using Jinja.\n config.add_jinja2_renderer(\".html\")\n\n # We'll want to configure some filters for Jinja2 as well.\n filters = config.get_settings().setdefault(\"jinja2.filters\", {})\n filters.setdefault(\"readme\", \"warehouse.filters:readme_renderer\")\n filters.setdefault(\"shorten_number\", \"warehouse.filters:shorten_number\")\n\n # We also want to register some global functions for Jinja\n jglobals = config.get_settings().setdefault(\"jinja2.globals\", {})\n jglobals.setdefault(\"gravatar\", \"warehouse.utils.gravatar:gravatar\")\n\n # We'll store all of our templates in one location, warehouse/templates\n # so we'll go ahead and add that to the Jinja2 search path.\n config.add_jinja2_search_path(\"warehouse:templates\", name=\".html\")\n\n # Configure our transaction handling so that each request gets it's own\n # transaction handler and the lifetime of the transaction is tied to the\n # lifetime of the request.\n config.add_settings({\n \"tm.manager_hook\": lambda request: transaction.TransactionManager(),\n })\n config.include(\"pyramid_tm\")\n\n # Register support for services\n config.include(\"pyramid_services\")\n\n # Register support for internationalization and localization\n config.include(\".i18n\")\n\n # Register the configuration for the PostgreSQL database.\n config.include(\".db\")\n\n # Register our session support\n config.include(\".sessions\")\n\n # Register our support for http and origin caching\n config.include(\".cache.http\")\n config.include(\".cache.origin\")\n\n # Register our CSRF support\n config.include(\".csrf\")\n\n # Register our authentication support.\n config.include(\".accounts\")\n\n # Allow the packaging app to register any services it has.\n config.include(\".packaging\")\n\n # Register all our URL routes for Warehouse.\n config.include(\".routes\")\n\n # Enable a Content Security Policy\n config.add_settings({\n \"csp\": {\n \"default-src\": [\"'none'\"],\n \"frame-ancestors\": [\"'none'\"],\n \"img-src\": [\n \"'self'\",\n config.registry.settings[\"camo.url\"],\n \"https://secure.gravatar.com\",\n ],\n \"referrer\": [\"cross-origin\"],\n \"reflected-xss\": [\"block\"],\n \"script-src\": [\"'self'\"],\n \"style-src\": [\"'self'\"],\n },\n })\n config.add_tween(\"warehouse.config.content_security_policy_tween_factory\")\n\n # Configure the filesystems we use.\n config.registry[\"filesystems\"] = {}\n for key, path in {\n k[5:]: v\n for k, v in config.registry.settings.items()\n if k.startswith(\"dirs.\")}.items():\n config.registry[\"filesystems\"][key] = \\\n fs.opener.fsopendir(path, create_dir=True)\n\n # Enable Warehouse to service our static files\n config.add_static_view(\n name=\"static\",\n path=\"warehouse:static\",\n cachebust=WarehouseCacheBuster(\n \"warehouse:static/manifest.json\",\n cache=not config.registry.settings[\"pyramid.reload_assets\"],\n ),\n )\n\n # Scan everything for configuration\n config.scan(ignore=[\"warehouse.migrations.env\"])\n\n return config\n", "path": "warehouse/config.py"}]}
| 2,055 | 129 |
gh_patches_debug_34467
|
rasdani/github-patches
|
git_diff
|
numpy__numpy-16879
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
MAINT: ignore `.hypothesis/`
<!-- Please be sure you are following the instructions in the dev guidelines
http://www.numpy.org/devdocs/dev/development_workflow.html
-->
<!-- We'd appreciate it if your commit message is properly formatted
http://www.numpy.org/devdocs/dev/development_workflow.html#writing-the-commit-message
-->
I ran the test using `np.test()`. Then the `.hypothesis` directory was created. This seems to a byproduct of the test.
</issue>
<code>
[start of numpy/conftest.py]
1 """
2 Pytest configuration and fixtures for the Numpy test suite.
3 """
4 import os
5
6 import hypothesis
7 import pytest
8 import numpy
9
10 from numpy.core._multiarray_tests import get_fpu_mode
11
12
13 _old_fpu_mode = None
14 _collect_results = {}
15
16 # See https://hypothesis.readthedocs.io/en/latest/settings.html
17 hypothesis.settings.register_profile(
18 name="numpy-profile", deadline=None, print_blob=True,
19 )
20 hypothesis.settings.load_profile("numpy-profile")
21
22
23 def pytest_configure(config):
24 config.addinivalue_line("markers",
25 "valgrind_error: Tests that are known to error under valgrind.")
26 config.addinivalue_line("markers",
27 "leaks_references: Tests that are known to leak references.")
28 config.addinivalue_line("markers",
29 "slow: Tests that are very slow.")
30 config.addinivalue_line("markers",
31 "slow_pypy: Tests that are very slow on pypy.")
32
33
34 def pytest_addoption(parser):
35 parser.addoption("--available-memory", action="store", default=None,
36 help=("Set amount of memory available for running the "
37 "test suite. This can result to tests requiring "
38 "especially large amounts of memory to be skipped. "
39 "Equivalent to setting environment variable "
40 "NPY_AVAILABLE_MEM. Default: determined"
41 "automatically."))
42
43
44 def pytest_sessionstart(session):
45 available_mem = session.config.getoption('available_memory')
46 if available_mem is not None:
47 os.environ['NPY_AVAILABLE_MEM'] = available_mem
48
49
50 #FIXME when yield tests are gone.
51 @pytest.hookimpl()
52 def pytest_itemcollected(item):
53 """
54 Check FPU precision mode was not changed during test collection.
55
56 The clumsy way we do it here is mainly necessary because numpy
57 still uses yield tests, which can execute code at test collection
58 time.
59 """
60 global _old_fpu_mode
61
62 mode = get_fpu_mode()
63
64 if _old_fpu_mode is None:
65 _old_fpu_mode = mode
66 elif mode != _old_fpu_mode:
67 _collect_results[item] = (_old_fpu_mode, mode)
68 _old_fpu_mode = mode
69
70
71 @pytest.fixture(scope="function", autouse=True)
72 def check_fpu_mode(request):
73 """
74 Check FPU precision mode was not changed during the test.
75 """
76 old_mode = get_fpu_mode()
77 yield
78 new_mode = get_fpu_mode()
79
80 if old_mode != new_mode:
81 raise AssertionError("FPU precision mode changed from {0:#x} to {1:#x}"
82 " during the test".format(old_mode, new_mode))
83
84 collect_result = _collect_results.get(request.node)
85 if collect_result is not None:
86 old_mode, new_mode = collect_result
87 raise AssertionError("FPU precision mode changed from {0:#x} to {1:#x}"
88 " when collecting the test".format(old_mode,
89 new_mode))
90
91
92 @pytest.fixture(autouse=True)
93 def add_np(doctest_namespace):
94 doctest_namespace['np'] = numpy
95
[end of numpy/conftest.py]
[start of numpy/_pytesttester.py]
1 """
2 Pytest test running.
3
4 This module implements the ``test()`` function for NumPy modules. The usual
5 boiler plate for doing that is to put the following in the module
6 ``__init__.py`` file::
7
8 from numpy._pytesttester import PytestTester
9 test = PytestTester(__name__).test
10 del PytestTester
11
12
13 Warnings filtering and other runtime settings should be dealt with in the
14 ``pytest.ini`` file in the numpy repo root. The behavior of the test depends on
15 whether or not that file is found as follows:
16
17 * ``pytest.ini`` is present (develop mode)
18 All warnings except those explicitly filtered out are raised as error.
19 * ``pytest.ini`` is absent (release mode)
20 DeprecationWarnings and PendingDeprecationWarnings are ignored, other
21 warnings are passed through.
22
23 In practice, tests run from the numpy repo are run in develop mode. That
24 includes the standard ``python runtests.py`` invocation.
25
26 This module is imported by every numpy subpackage, so lies at the top level to
27 simplify circular import issues. For the same reason, it contains no numpy
28 imports at module scope, instead importing numpy within function calls.
29 """
30 import sys
31 import os
32
33 __all__ = ['PytestTester']
34
35
36
37 def _show_numpy_info():
38 from numpy.core._multiarray_umath import (
39 __cpu_features__, __cpu_baseline__, __cpu_dispatch__
40 )
41 import numpy as np
42
43 print("NumPy version %s" % np.__version__)
44 relaxed_strides = np.ones((10, 1), order="C").flags.f_contiguous
45 print("NumPy relaxed strides checking option:", relaxed_strides)
46
47 if len(__cpu_baseline__) == 0 and len(__cpu_dispatch__) == 0:
48 enabled_features = "nothing enabled"
49 else:
50 enabled_features = ' '.join(__cpu_baseline__)
51 for feature in __cpu_dispatch__:
52 if __cpu_features__[feature]:
53 enabled_features += " %s*" % feature
54 else:
55 enabled_features += " %s?" % feature
56 print("NumPy CPU features:", enabled_features)
57
58
59
60 class PytestTester:
61 """
62 Pytest test runner.
63
64 A test function is typically added to a package's __init__.py like so::
65
66 from numpy._pytesttester import PytestTester
67 test = PytestTester(__name__).test
68 del PytestTester
69
70 Calling this test function finds and runs all tests associated with the
71 module and all its sub-modules.
72
73 Attributes
74 ----------
75 module_name : str
76 Full path to the package to test.
77
78 Parameters
79 ----------
80 module_name : module name
81 The name of the module to test.
82
83 Notes
84 -----
85 Unlike the previous ``nose``-based implementation, this class is not
86 publicly exposed as it performs some ``numpy``-specific warning
87 suppression.
88
89 """
90 def __init__(self, module_name):
91 self.module_name = module_name
92
93 def __call__(self, label='fast', verbose=1, extra_argv=None,
94 doctests=False, coverage=False, durations=-1, tests=None):
95 """
96 Run tests for module using pytest.
97
98 Parameters
99 ----------
100 label : {'fast', 'full'}, optional
101 Identifies the tests to run. When set to 'fast', tests decorated
102 with `pytest.mark.slow` are skipped, when 'full', the slow marker
103 is ignored.
104 verbose : int, optional
105 Verbosity value for test outputs, in the range 1-3. Default is 1.
106 extra_argv : list, optional
107 List with any extra arguments to pass to pytests.
108 doctests : bool, optional
109 .. note:: Not supported
110 coverage : bool, optional
111 If True, report coverage of NumPy code. Default is False.
112 Requires installation of (pip) pytest-cov.
113 durations : int, optional
114 If < 0, do nothing, If 0, report time of all tests, if > 0,
115 report the time of the slowest `timer` tests. Default is -1.
116 tests : test or list of tests
117 Tests to be executed with pytest '--pyargs'
118
119 Returns
120 -------
121 result : bool
122 Return True on success, false otherwise.
123
124 Notes
125 -----
126 Each NumPy module exposes `test` in its namespace to run all tests for
127 it. For example, to run all tests for numpy.lib:
128
129 >>> np.lib.test() #doctest: +SKIP
130
131 Examples
132 --------
133 >>> result = np.lib.test() #doctest: +SKIP
134 ...
135 1023 passed, 2 skipped, 6 deselected, 1 xfailed in 10.39 seconds
136 >>> result
137 True
138
139 """
140 import pytest
141 import warnings
142
143 module = sys.modules[self.module_name]
144 module_path = os.path.abspath(module.__path__[0])
145
146 # setup the pytest arguments
147 pytest_args = ["-l"]
148
149 # offset verbosity. The "-q" cancels a "-v".
150 pytest_args += ["-q"]
151
152 # Filter out distutils cpu warnings (could be localized to
153 # distutils tests). ASV has problems with top level import,
154 # so fetch module for suppression here.
155 with warnings.catch_warnings():
156 warnings.simplefilter("always")
157 from numpy.distutils import cpuinfo
158
159 # Filter out annoying import messages. Want these in both develop and
160 # release mode.
161 pytest_args += [
162 "-W ignore:Not importing directory",
163 "-W ignore:numpy.dtype size changed",
164 "-W ignore:numpy.ufunc size changed",
165 "-W ignore::UserWarning:cpuinfo",
166 ]
167
168 # When testing matrices, ignore their PendingDeprecationWarnings
169 pytest_args += [
170 "-W ignore:the matrix subclass is not",
171 "-W ignore:Importing from numpy.matlib is",
172 ]
173
174 if doctests:
175 raise ValueError("Doctests not supported")
176
177 if extra_argv:
178 pytest_args += list(extra_argv)
179
180 if verbose > 1:
181 pytest_args += ["-" + "v"*(verbose - 1)]
182
183 if coverage:
184 pytest_args += ["--cov=" + module_path]
185
186 if label == "fast":
187 # not importing at the top level to avoid circular import of module
188 from numpy.testing import IS_PYPY
189 if IS_PYPY:
190 pytest_args += ["-m", "not slow and not slow_pypy"]
191 else:
192 pytest_args += ["-m", "not slow"]
193
194 elif label != "full":
195 pytest_args += ["-m", label]
196
197 if durations >= 0:
198 pytest_args += ["--durations=%s" % durations]
199
200 if tests is None:
201 tests = [self.module_name]
202
203 pytest_args += ["--pyargs"] + list(tests)
204
205
206 # run tests.
207 _show_numpy_info()
208
209 try:
210 code = pytest.main(pytest_args)
211 except SystemExit as exc:
212 code = exc.code
213
214 return code == 0
215
[end of numpy/_pytesttester.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/numpy/_pytesttester.py b/numpy/_pytesttester.py
--- a/numpy/_pytesttester.py
+++ b/numpy/_pytesttester.py
@@ -140,6 +140,9 @@
import pytest
import warnings
+ # Imported after pytest to enable assertion rewriting
+ import hypothesis
+
module = sys.modules[self.module_name]
module_path = os.path.abspath(module.__path__[0])
@@ -202,6 +205,14 @@
pytest_args += ["--pyargs"] + list(tests)
+ # This configuration is picked up by numpy.conftest, and ensures that
+ # running `np.test()` is deterministic and does not write any files.
+ # See https://hypothesis.readthedocs.io/en/latest/settings.html
+ hypothesis.settings.register_profile(
+ name="np.test() profile",
+ deadline=None, print_blob=True, database=None, derandomize=True,
+ suppress_health_check=hypothesis.HealthCheck.all(),
+ )
# run tests.
_show_numpy_info()
diff --git a/numpy/conftest.py b/numpy/conftest.py
--- a/numpy/conftest.py
+++ b/numpy/conftest.py
@@ -2,6 +2,7 @@
Pytest configuration and fixtures for the Numpy test suite.
"""
import os
+import tempfile
import hypothesis
import pytest
@@ -13,11 +14,23 @@
_old_fpu_mode = None
_collect_results = {}
+# Use a known and persistent tmpdir for hypothesis' caches, which
+# can be automatically cleared by the OS or user.
+hypothesis.configuration.set_hypothesis_home_dir(
+ os.path.join(tempfile.gettempdir(), ".hypothesis")
+)
# See https://hypothesis.readthedocs.io/en/latest/settings.html
hypothesis.settings.register_profile(
name="numpy-profile", deadline=None, print_blob=True,
)
-hypothesis.settings.load_profile("numpy-profile")
+# We try loading the profile defined by np.test(), which disables the
+# database and forces determinism, and fall back to the profile defined
+# above if we're running pytest directly. The odd dance is required
+# because np.test() executes this file *after* its own setup code.
+try:
+ hypothesis.settings.load_profile("np.test() profile")
+except hypothesis.errors.InvalidArgument: # profile not found
+ hypothesis.settings.load_profile("numpy-profile")
def pytest_configure(config):
|
{"golden_diff": "diff --git a/numpy/_pytesttester.py b/numpy/_pytesttester.py\n--- a/numpy/_pytesttester.py\n+++ b/numpy/_pytesttester.py\n@@ -140,6 +140,9 @@\n import pytest\n import warnings\n \n+ # Imported after pytest to enable assertion rewriting\n+ import hypothesis\n+\n module = sys.modules[self.module_name]\n module_path = os.path.abspath(module.__path__[0])\n \n@@ -202,6 +205,14 @@\n \n pytest_args += [\"--pyargs\"] + list(tests)\n \n+ # This configuration is picked up by numpy.conftest, and ensures that\n+ # running `np.test()` is deterministic and does not write any files.\n+ # See https://hypothesis.readthedocs.io/en/latest/settings.html\n+ hypothesis.settings.register_profile(\n+ name=\"np.test() profile\",\n+ deadline=None, print_blob=True, database=None, derandomize=True,\n+ suppress_health_check=hypothesis.HealthCheck.all(),\n+ )\n \n # run tests.\n _show_numpy_info()\ndiff --git a/numpy/conftest.py b/numpy/conftest.py\n--- a/numpy/conftest.py\n+++ b/numpy/conftest.py\n@@ -2,6 +2,7 @@\n Pytest configuration and fixtures for the Numpy test suite.\n \"\"\"\n import os\n+import tempfile\n \n import hypothesis\n import pytest\n@@ -13,11 +14,23 @@\n _old_fpu_mode = None\n _collect_results = {}\n \n+# Use a known and persistent tmpdir for hypothesis' caches, which\n+# can be automatically cleared by the OS or user.\n+hypothesis.configuration.set_hypothesis_home_dir(\n+ os.path.join(tempfile.gettempdir(), \".hypothesis\")\n+)\n # See https://hypothesis.readthedocs.io/en/latest/settings.html\n hypothesis.settings.register_profile(\n name=\"numpy-profile\", deadline=None, print_blob=True,\n )\n-hypothesis.settings.load_profile(\"numpy-profile\")\n+# We try loading the profile defined by np.test(), which disables the\n+# database and forces determinism, and fall back to the profile defined\n+# above if we're running pytest directly. The odd dance is required\n+# because np.test() executes this file *after* its own setup code.\n+try:\n+ hypothesis.settings.load_profile(\"np.test() profile\")\n+except hypothesis.errors.InvalidArgument: # profile not found\n+ hypothesis.settings.load_profile(\"numpy-profile\")\n \n \n def pytest_configure(config):\n", "issue": "MAINT: ignore `.hypothesis/`\n<!-- Please be sure you are following the instructions in the dev guidelines\r\nhttp://www.numpy.org/devdocs/dev/development_workflow.html\r\n-->\r\n\r\n<!-- We'd appreciate it if your commit message is properly formatted\r\nhttp://www.numpy.org/devdocs/dev/development_workflow.html#writing-the-commit-message\r\n-->\r\n\r\nI ran the test using `np.test()`. Then the `.hypothesis` directory was created. This seems to a byproduct of the test.\n", "before_files": [{"content": "\"\"\"\nPytest configuration and fixtures for the Numpy test suite.\n\"\"\"\nimport os\n\nimport hypothesis\nimport pytest\nimport numpy\n\nfrom numpy.core._multiarray_tests import get_fpu_mode\n\n\n_old_fpu_mode = None\n_collect_results = {}\n\n# See https://hypothesis.readthedocs.io/en/latest/settings.html\nhypothesis.settings.register_profile(\n name=\"numpy-profile\", deadline=None, print_blob=True,\n)\nhypothesis.settings.load_profile(\"numpy-profile\")\n\n\ndef pytest_configure(config):\n config.addinivalue_line(\"markers\",\n \"valgrind_error: Tests that are known to error under valgrind.\")\n config.addinivalue_line(\"markers\",\n \"leaks_references: Tests that are known to leak references.\")\n config.addinivalue_line(\"markers\",\n \"slow: Tests that are very slow.\")\n config.addinivalue_line(\"markers\",\n \"slow_pypy: Tests that are very slow on pypy.\")\n\n\ndef pytest_addoption(parser):\n parser.addoption(\"--available-memory\", action=\"store\", default=None,\n help=(\"Set amount of memory available for running the \"\n \"test suite. This can result to tests requiring \"\n \"especially large amounts of memory to be skipped. \"\n \"Equivalent to setting environment variable \"\n \"NPY_AVAILABLE_MEM. Default: determined\"\n \"automatically.\"))\n\n\ndef pytest_sessionstart(session):\n available_mem = session.config.getoption('available_memory')\n if available_mem is not None:\n os.environ['NPY_AVAILABLE_MEM'] = available_mem\n\n\n#FIXME when yield tests are gone.\[email protected]()\ndef pytest_itemcollected(item):\n \"\"\"\n Check FPU precision mode was not changed during test collection.\n\n The clumsy way we do it here is mainly necessary because numpy\n still uses yield tests, which can execute code at test collection\n time.\n \"\"\"\n global _old_fpu_mode\n\n mode = get_fpu_mode()\n\n if _old_fpu_mode is None:\n _old_fpu_mode = mode\n elif mode != _old_fpu_mode:\n _collect_results[item] = (_old_fpu_mode, mode)\n _old_fpu_mode = mode\n\n\[email protected](scope=\"function\", autouse=True)\ndef check_fpu_mode(request):\n \"\"\"\n Check FPU precision mode was not changed during the test.\n \"\"\"\n old_mode = get_fpu_mode()\n yield\n new_mode = get_fpu_mode()\n\n if old_mode != new_mode:\n raise AssertionError(\"FPU precision mode changed from {0:#x} to {1:#x}\"\n \" during the test\".format(old_mode, new_mode))\n\n collect_result = _collect_results.get(request.node)\n if collect_result is not None:\n old_mode, new_mode = collect_result\n raise AssertionError(\"FPU precision mode changed from {0:#x} to {1:#x}\"\n \" when collecting the test\".format(old_mode,\n new_mode))\n\n\[email protected](autouse=True)\ndef add_np(doctest_namespace):\n doctest_namespace['np'] = numpy\n", "path": "numpy/conftest.py"}, {"content": "\"\"\"\nPytest test running.\n\nThis module implements the ``test()`` function for NumPy modules. The usual\nboiler plate for doing that is to put the following in the module\n``__init__.py`` file::\n\n from numpy._pytesttester import PytestTester\n test = PytestTester(__name__).test\n del PytestTester\n\n\nWarnings filtering and other runtime settings should be dealt with in the\n``pytest.ini`` file in the numpy repo root. The behavior of the test depends on\nwhether or not that file is found as follows:\n\n* ``pytest.ini`` is present (develop mode)\n All warnings except those explicitly filtered out are raised as error.\n* ``pytest.ini`` is absent (release mode)\n DeprecationWarnings and PendingDeprecationWarnings are ignored, other\n warnings are passed through.\n\nIn practice, tests run from the numpy repo are run in develop mode. That\nincludes the standard ``python runtests.py`` invocation.\n\nThis module is imported by every numpy subpackage, so lies at the top level to\nsimplify circular import issues. For the same reason, it contains no numpy\nimports at module scope, instead importing numpy within function calls.\n\"\"\"\nimport sys\nimport os\n\n__all__ = ['PytestTester']\n\n\n\ndef _show_numpy_info():\n from numpy.core._multiarray_umath import (\n __cpu_features__, __cpu_baseline__, __cpu_dispatch__\n )\n import numpy as np\n\n print(\"NumPy version %s\" % np.__version__)\n relaxed_strides = np.ones((10, 1), order=\"C\").flags.f_contiguous\n print(\"NumPy relaxed strides checking option:\", relaxed_strides)\n\n if len(__cpu_baseline__) == 0 and len(__cpu_dispatch__) == 0:\n enabled_features = \"nothing enabled\"\n else:\n enabled_features = ' '.join(__cpu_baseline__)\n for feature in __cpu_dispatch__:\n if __cpu_features__[feature]:\n enabled_features += \" %s*\" % feature\n else:\n enabled_features += \" %s?\" % feature\n print(\"NumPy CPU features:\", enabled_features)\n\n\n\nclass PytestTester:\n \"\"\"\n Pytest test runner.\n\n A test function is typically added to a package's __init__.py like so::\n\n from numpy._pytesttester import PytestTester\n test = PytestTester(__name__).test\n del PytestTester\n\n Calling this test function finds and runs all tests associated with the\n module and all its sub-modules.\n\n Attributes\n ----------\n module_name : str\n Full path to the package to test.\n\n Parameters\n ----------\n module_name : module name\n The name of the module to test.\n\n Notes\n -----\n Unlike the previous ``nose``-based implementation, this class is not\n publicly exposed as it performs some ``numpy``-specific warning\n suppression.\n\n \"\"\"\n def __init__(self, module_name):\n self.module_name = module_name\n\n def __call__(self, label='fast', verbose=1, extra_argv=None,\n doctests=False, coverage=False, durations=-1, tests=None):\n \"\"\"\n Run tests for module using pytest.\n\n Parameters\n ----------\n label : {'fast', 'full'}, optional\n Identifies the tests to run. When set to 'fast', tests decorated\n with `pytest.mark.slow` are skipped, when 'full', the slow marker\n is ignored.\n verbose : int, optional\n Verbosity value for test outputs, in the range 1-3. Default is 1.\n extra_argv : list, optional\n List with any extra arguments to pass to pytests.\n doctests : bool, optional\n .. note:: Not supported\n coverage : bool, optional\n If True, report coverage of NumPy code. Default is False.\n Requires installation of (pip) pytest-cov.\n durations : int, optional\n If < 0, do nothing, If 0, report time of all tests, if > 0,\n report the time of the slowest `timer` tests. Default is -1.\n tests : test or list of tests\n Tests to be executed with pytest '--pyargs'\n\n Returns\n -------\n result : bool\n Return True on success, false otherwise.\n\n Notes\n -----\n Each NumPy module exposes `test` in its namespace to run all tests for\n it. For example, to run all tests for numpy.lib:\n\n >>> np.lib.test() #doctest: +SKIP\n\n Examples\n --------\n >>> result = np.lib.test() #doctest: +SKIP\n ...\n 1023 passed, 2 skipped, 6 deselected, 1 xfailed in 10.39 seconds\n >>> result\n True\n\n \"\"\"\n import pytest\n import warnings\n\n module = sys.modules[self.module_name]\n module_path = os.path.abspath(module.__path__[0])\n\n # setup the pytest arguments\n pytest_args = [\"-l\"]\n\n # offset verbosity. The \"-q\" cancels a \"-v\".\n pytest_args += [\"-q\"]\n\n # Filter out distutils cpu warnings (could be localized to\n # distutils tests). ASV has problems with top level import,\n # so fetch module for suppression here.\n with warnings.catch_warnings():\n warnings.simplefilter(\"always\")\n from numpy.distutils import cpuinfo\n\n # Filter out annoying import messages. Want these in both develop and\n # release mode.\n pytest_args += [\n \"-W ignore:Not importing directory\",\n \"-W ignore:numpy.dtype size changed\",\n \"-W ignore:numpy.ufunc size changed\",\n \"-W ignore::UserWarning:cpuinfo\",\n ]\n\n # When testing matrices, ignore their PendingDeprecationWarnings\n pytest_args += [\n \"-W ignore:the matrix subclass is not\",\n \"-W ignore:Importing from numpy.matlib is\",\n ]\n\n if doctests:\n raise ValueError(\"Doctests not supported\")\n\n if extra_argv:\n pytest_args += list(extra_argv)\n\n if verbose > 1:\n pytest_args += [\"-\" + \"v\"*(verbose - 1)]\n\n if coverage:\n pytest_args += [\"--cov=\" + module_path]\n\n if label == \"fast\":\n # not importing at the top level to avoid circular import of module\n from numpy.testing import IS_PYPY\n if IS_PYPY:\n pytest_args += [\"-m\", \"not slow and not slow_pypy\"]\n else:\n pytest_args += [\"-m\", \"not slow\"]\n\n elif label != \"full\":\n pytest_args += [\"-m\", label]\n\n if durations >= 0:\n pytest_args += [\"--durations=%s\" % durations]\n\n if tests is None:\n tests = [self.module_name]\n\n pytest_args += [\"--pyargs\"] + list(tests)\n\n\n # run tests.\n _show_numpy_info()\n\n try:\n code = pytest.main(pytest_args)\n except SystemExit as exc:\n code = exc.code\n\n return code == 0\n", "path": "numpy/_pytesttester.py"}]}
| 3,602 | 548 |
gh_patches_debug_1456
|
rasdani/github-patches
|
git_diff
|
arviz-devs__arviz-596
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Installing arviz breaks pymc3 installation
**Describe the bug**
Installing Arviz breaks a pymc3 installation, which is unfortunate because they're built to be compatible. After installation, importing pymc3 throws the following error.
> WARNING (theano.tensor.blas): Using NumPy C-API based implementation for BLAS functions.
The reason is because arviz installation requires numpy==1.15 rather than numpy>=1.15. If you have 1.16, it uninstalls it and re-installs 1.15. It's annoying to fix. I ended up having to scrap the whole virtual environment and start over.
**To Reproduce**
Install arviz if you have any version of numpy other than 1.15, then import pymc3.
**Expected behavior**
Do not force downgrade of numpy.
</issue>
<code>
[start of arviz/__init__.py]
1 # pylint: disable=wildcard-import,invalid-name,wrong-import-position
2 """ArviZ is a library for exploratory analysis of Bayesian models."""
3 __version__ = "0.3.2"
4
5 import os
6 import logging
7 from matplotlib.pyplot import style
8
9 # add ArviZ's styles to matplotlib's styles
10 arviz_style_path = os.path.join(os.path.dirname(__file__), "plots", "styles")
11 style.core.USER_LIBRARY_PATHS.append(arviz_style_path)
12 style.core.reload_library()
13
14 # Configure logging before importing arviz internals
15 _log = logging.getLogger("arviz")
16
17 if not logging.root.handlers:
18 handler = logging.StreamHandler()
19 _log.setLevel(logging.INFO)
20 _log.addHandler(handler)
21
22 from .data import *
23 from .plots import *
24 from .stats import *
25
[end of arviz/__init__.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/arviz/__init__.py b/arviz/__init__.py
--- a/arviz/__init__.py
+++ b/arviz/__init__.py
@@ -1,6 +1,6 @@
# pylint: disable=wildcard-import,invalid-name,wrong-import-position
"""ArviZ is a library for exploratory analysis of Bayesian models."""
-__version__ = "0.3.2"
+__version__ = "0.3.3"
import os
import logging
|
{"golden_diff": "diff --git a/arviz/__init__.py b/arviz/__init__.py\n--- a/arviz/__init__.py\n+++ b/arviz/__init__.py\n@@ -1,6 +1,6 @@\n # pylint: disable=wildcard-import,invalid-name,wrong-import-position\n \"\"\"ArviZ is a library for exploratory analysis of Bayesian models.\"\"\"\n-__version__ = \"0.3.2\"\n+__version__ = \"0.3.3\"\n \n import os\n import logging\n", "issue": "Installing arviz breaks pymc3 installation\n**Describe the bug**\r\nInstalling Arviz breaks a pymc3 installation, which is unfortunate because they're built to be compatible. After installation, importing pymc3 throws the following error. \r\n\r\n> WARNING (theano.tensor.blas): Using NumPy C-API based implementation for BLAS functions.\r\n\r\nThe reason is because arviz installation requires numpy==1.15 rather than numpy>=1.15. If you have 1.16, it uninstalls it and re-installs 1.15. It's annoying to fix. I ended up having to scrap the whole virtual environment and start over.\r\n\r\n**To Reproduce**\r\nInstall arviz if you have any version of numpy other than 1.15, then import pymc3. \r\n\r\n**Expected behavior**\r\nDo not force downgrade of numpy. \n", "before_files": [{"content": "# pylint: disable=wildcard-import,invalid-name,wrong-import-position\n\"\"\"ArviZ is a library for exploratory analysis of Bayesian models.\"\"\"\n__version__ = \"0.3.2\"\n\nimport os\nimport logging\nfrom matplotlib.pyplot import style\n\n# add ArviZ's styles to matplotlib's styles\narviz_style_path = os.path.join(os.path.dirname(__file__), \"plots\", \"styles\")\nstyle.core.USER_LIBRARY_PATHS.append(arviz_style_path)\nstyle.core.reload_library()\n\n# Configure logging before importing arviz internals\n_log = logging.getLogger(\"arviz\")\n\nif not logging.root.handlers:\n handler = logging.StreamHandler()\n _log.setLevel(logging.INFO)\n _log.addHandler(handler)\n\nfrom .data import *\nfrom .plots import *\nfrom .stats import *\n", "path": "arviz/__init__.py"}]}
| 923 | 108 |
gh_patches_debug_1030
|
rasdani/github-patches
|
git_diff
|
scikit-image__scikit-image-1820
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Deprecate Python 2.6 after release of 0.12
</issue>
<code>
[start of skimage/__init__.py]
1 """Image Processing SciKit (Toolbox for SciPy)
2
3 ``scikit-image`` (a.k.a. ``skimage``) is a collection of algorithms for image
4 processing and computer vision.
5
6 The main package of ``skimage`` only provides a few utilities for converting
7 between image data types; for most features, you need to import one of the
8 following subpackages:
9
10 Subpackages
11 -----------
12 color
13 Color space conversion.
14 data
15 Test images and example data.
16 draw
17 Drawing primitives (lines, text, etc.) that operate on NumPy arrays.
18 exposure
19 Image intensity adjustment, e.g., histogram equalization, etc.
20 feature
21 Feature detection and extraction, e.g., texture analysis corners, etc.
22 filters
23 Sharpening, edge finding, rank filters, thresholding, etc.
24 graph
25 Graph-theoretic operations, e.g., shortest paths.
26 io
27 Reading, saving, and displaying images and video.
28 measure
29 Measurement of image properties, e.g., similarity and contours.
30 morphology
31 Morphological operations, e.g., opening or skeletonization.
32 novice
33 Simplified interface for teaching purposes.
34 restoration
35 Restoration algorithms, e.g., deconvolution algorithms, denoising, etc.
36 segmentation
37 Partitioning an image into multiple regions.
38 transform
39 Geometric and other transforms, e.g., rotation or the Radon transform.
40 util
41 Generic utilities.
42 viewer
43 A simple graphical user interface for visualizing results and exploring
44 parameters.
45
46 Utility Functions
47 -----------------
48 img_as_float
49 Convert an image to floating point format, with values in [0, 1].
50 img_as_uint
51 Convert an image to unsigned integer format, with values in [0, 65535].
52 img_as_int
53 Convert an image to signed integer format, with values in [-32768, 32767].
54 img_as_ubyte
55 Convert an image to unsigned byte format, with values in [0, 255].
56
57 """
58
59 import os.path as osp
60 import imp
61 import functools
62 import warnings
63 import sys
64
65 pkg_dir = osp.abspath(osp.dirname(__file__))
66 data_dir = osp.join(pkg_dir, 'data')
67
68 __version__ = '0.12dev'
69
70 try:
71 imp.find_module('nose')
72 except ImportError:
73 def _test(doctest=False, verbose=False):
74 """This would run all unit tests, but nose couldn't be
75 imported so the test suite can not run.
76 """
77 raise ImportError("Could not load nose. Unit tests not available.")
78
79 else:
80 def _test(doctest=False, verbose=False):
81 """Run all unit tests."""
82 import nose
83 args = ['', pkg_dir, '--exe', '--ignore-files=^_test']
84 if verbose:
85 args.extend(['-v', '-s'])
86 if doctest:
87 args.extend(['--with-doctest', '--ignore-files=^\.',
88 '--ignore-files=^setup\.py$$', '--ignore-files=test'])
89 # Make sure warnings do not break the doc tests
90 with warnings.catch_warnings():
91 warnings.simplefilter("ignore")
92 success = nose.run('skimage', argv=args)
93 else:
94 success = nose.run('skimage', argv=args)
95 # Return sys.exit code
96 if success:
97 return 0
98 else:
99 return 1
100
101
102 # do not use `test` as function name as this leads to a recursion problem with
103 # the nose test suite
104 test = _test
105 test_verbose = functools.partial(test, verbose=True)
106 test_verbose.__doc__ = test.__doc__
107 doctest = functools.partial(test, doctest=True)
108 doctest.__doc__ = doctest.__doc__
109 doctest_verbose = functools.partial(test, doctest=True, verbose=True)
110 doctest_verbose.__doc__ = doctest.__doc__
111
112
113 # Logic for checking for improper install and importing while in the source
114 # tree when package has not been installed inplace.
115 # Code adapted from scikit-learn's __check_build module.
116 _INPLACE_MSG = """
117 It appears that you are importing a local scikit-image source tree. For
118 this, you need to have an inplace install. Maybe you are in the source
119 directory and you need to try from another location."""
120
121 _STANDARD_MSG = """
122 Your install of scikit-image appears to be broken.
123 Try re-installing the package following the instructions at:
124 http://scikit-image.org/docs/stable/install.html """
125
126
127 def _raise_build_error(e):
128 # Raise a comprehensible error
129 local_dir = osp.split(__file__)[0]
130 msg = _STANDARD_MSG
131 if local_dir == "skimage":
132 # Picking up the local install: this will work only if the
133 # install is an 'inplace build'
134 msg = _INPLACE_MSG
135 raise ImportError("""%s
136 It seems that scikit-image has not been built correctly.
137 %s""" % (e, msg))
138
139 try:
140 # This variable is injected in the __builtins__ by the build
141 # process. It used to enable importing subpackages of skimage when
142 # the binaries are not built
143 __SKIMAGE_SETUP__
144 except NameError:
145 __SKIMAGE_SETUP__ = False
146
147 if __SKIMAGE_SETUP__:
148 sys.stderr.write('Partial import of skimage during the build process.\n')
149 # We are not importing the rest of the scikit during the build
150 # process, as it may not be compiled yet
151 else:
152 try:
153 from ._shared import geometry
154 del geometry
155 except ImportError as e:
156 _raise_build_error(e)
157 from .util.dtype import *
158
159 del warnings, functools, osp, imp, sys
160
[end of skimage/__init__.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/skimage/__init__.py b/skimage/__init__.py
--- a/skimage/__init__.py
+++ b/skimage/__init__.py
@@ -156,4 +156,9 @@
_raise_build_error(e)
from .util.dtype import *
+
+if sys.version.startswith('2.6'):
+ warnings.warn("Python 2.6 is deprecated and will not be supported in scikit-image 0.13+")
+
+
del warnings, functools, osp, imp, sys
|
{"golden_diff": "diff --git a/skimage/__init__.py b/skimage/__init__.py\n--- a/skimage/__init__.py\n+++ b/skimage/__init__.py\n@@ -156,4 +156,9 @@\n _raise_build_error(e)\n from .util.dtype import *\n \n+\n+if sys.version.startswith('2.6'):\n+ warnings.warn(\"Python 2.6 is deprecated and will not be supported in scikit-image 0.13+\")\n+\n+\n del warnings, functools, osp, imp, sys\n", "issue": "Deprecate Python 2.6 after release of 0.12\n\n", "before_files": [{"content": "\"\"\"Image Processing SciKit (Toolbox for SciPy)\n\n``scikit-image`` (a.k.a. ``skimage``) is a collection of algorithms for image\nprocessing and computer vision.\n\nThe main package of ``skimage`` only provides a few utilities for converting\nbetween image data types; for most features, you need to import one of the\nfollowing subpackages:\n\nSubpackages\n-----------\ncolor\n Color space conversion.\ndata\n Test images and example data.\ndraw\n Drawing primitives (lines, text, etc.) that operate on NumPy arrays.\nexposure\n Image intensity adjustment, e.g., histogram equalization, etc.\nfeature\n Feature detection and extraction, e.g., texture analysis corners, etc.\nfilters\n Sharpening, edge finding, rank filters, thresholding, etc.\ngraph\n Graph-theoretic operations, e.g., shortest paths.\nio\n Reading, saving, and displaying images and video.\nmeasure\n Measurement of image properties, e.g., similarity and contours.\nmorphology\n Morphological operations, e.g., opening or skeletonization.\nnovice\n Simplified interface for teaching purposes.\nrestoration\n Restoration algorithms, e.g., deconvolution algorithms, denoising, etc.\nsegmentation\n Partitioning an image into multiple regions.\ntransform\n Geometric and other transforms, e.g., rotation or the Radon transform.\nutil\n Generic utilities.\nviewer\n A simple graphical user interface for visualizing results and exploring\n parameters.\n\nUtility Functions\n-----------------\nimg_as_float\n Convert an image to floating point format, with values in [0, 1].\nimg_as_uint\n Convert an image to unsigned integer format, with values in [0, 65535].\nimg_as_int\n Convert an image to signed integer format, with values in [-32768, 32767].\nimg_as_ubyte\n Convert an image to unsigned byte format, with values in [0, 255].\n\n\"\"\"\n\nimport os.path as osp\nimport imp\nimport functools\nimport warnings\nimport sys\n\npkg_dir = osp.abspath(osp.dirname(__file__))\ndata_dir = osp.join(pkg_dir, 'data')\n\n__version__ = '0.12dev'\n\ntry:\n imp.find_module('nose')\nexcept ImportError:\n def _test(doctest=False, verbose=False):\n \"\"\"This would run all unit tests, but nose couldn't be\n imported so the test suite can not run.\n \"\"\"\n raise ImportError(\"Could not load nose. Unit tests not available.\")\n\nelse:\n def _test(doctest=False, verbose=False):\n \"\"\"Run all unit tests.\"\"\"\n import nose\n args = ['', pkg_dir, '--exe', '--ignore-files=^_test']\n if verbose:\n args.extend(['-v', '-s'])\n if doctest:\n args.extend(['--with-doctest', '--ignore-files=^\\.',\n '--ignore-files=^setup\\.py$$', '--ignore-files=test'])\n # Make sure warnings do not break the doc tests\n with warnings.catch_warnings():\n warnings.simplefilter(\"ignore\")\n success = nose.run('skimage', argv=args)\n else:\n success = nose.run('skimage', argv=args)\n # Return sys.exit code\n if success:\n return 0\n else:\n return 1\n\n\n# do not use `test` as function name as this leads to a recursion problem with\n# the nose test suite\ntest = _test\ntest_verbose = functools.partial(test, verbose=True)\ntest_verbose.__doc__ = test.__doc__\ndoctest = functools.partial(test, doctest=True)\ndoctest.__doc__ = doctest.__doc__\ndoctest_verbose = functools.partial(test, doctest=True, verbose=True)\ndoctest_verbose.__doc__ = doctest.__doc__\n\n\n# Logic for checking for improper install and importing while in the source\n# tree when package has not been installed inplace.\n# Code adapted from scikit-learn's __check_build module.\n_INPLACE_MSG = \"\"\"\nIt appears that you are importing a local scikit-image source tree. For\nthis, you need to have an inplace install. Maybe you are in the source\ndirectory and you need to try from another location.\"\"\"\n\n_STANDARD_MSG = \"\"\"\nYour install of scikit-image appears to be broken.\nTry re-installing the package following the instructions at:\nhttp://scikit-image.org/docs/stable/install.html \"\"\"\n\n\ndef _raise_build_error(e):\n # Raise a comprehensible error\n local_dir = osp.split(__file__)[0]\n msg = _STANDARD_MSG\n if local_dir == \"skimage\":\n # Picking up the local install: this will work only if the\n # install is an 'inplace build'\n msg = _INPLACE_MSG\n raise ImportError(\"\"\"%s\nIt seems that scikit-image has not been built correctly.\n%s\"\"\" % (e, msg))\n\ntry:\n # This variable is injected in the __builtins__ by the build\n # process. It used to enable importing subpackages of skimage when\n # the binaries are not built\n __SKIMAGE_SETUP__\nexcept NameError:\n __SKIMAGE_SETUP__ = False\n\nif __SKIMAGE_SETUP__:\n sys.stderr.write('Partial import of skimage during the build process.\\n')\n # We are not importing the rest of the scikit during the build\n # process, as it may not be compiled yet\nelse:\n try:\n from ._shared import geometry\n del geometry\n except ImportError as e:\n _raise_build_error(e)\n from .util.dtype import *\n\ndel warnings, functools, osp, imp, sys\n", "path": "skimage/__init__.py"}]}
| 2,139 | 121 |
gh_patches_debug_14545
|
rasdani/github-patches
|
git_diff
|
sql-machine-learning__elasticdl-332
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Failed generating cifar10 dataset when building dev image
</issue>
<code>
[start of elasticdl/recordio_ds_gen/cifar10/show_data.py]
1 from recordio import File
2 from elasticdl.recordio_ds_gen.mnist import record
3 import sys
4 import argparse
5
6 # TODO: share code with MNIST dataset.
7 def main(argv):
8 print(argv)
9 parser = argparse.ArgumentParser(
10 description="Show same data from CIFAR10 recordio"
11 )
12 parser.add_argument("file", help="RecordIo file to read")
13 parser.add_argument(
14 "--start", default=0, type=int, help="Start record number"
15 )
16 parser.add_argument("--step", default=1, type=int, help="Step")
17 parser.add_argument(
18 "--n", default=20, type=int, help="How many record to show"
19 )
20 args = parser.parse_args(argv)
21
22 with File(args.file, "r") as f:
23 for i in range(
24 args.start, args.start + (args.n * args.step), args.step
25 ):
26 print("-" * 10)
27 print("record:", i)
28 record.show(*record.decode(f.get(i)))
29
30
31 if __name__ == "__main__":
32 main(sys.argv[1:])
33
[end of elasticdl/recordio_ds_gen/cifar10/show_data.py]
[start of elasticdl/recordio_ds_gen/cifar10/gen_data.py]
1 #!/usr/bin/env python
2
3 """
4 Download and transform CIFAR10 data to RecordIO format.
5 """
6
7 import itertools
8 import argparse
9 import os
10 import sys
11 from recordio import File
12 from tensorflow.python.keras import backend
13 from tensorflow.python.keras.datasets import cifar10
14 from elasticdl.recordio_ds_gen.mnist import record
15
16 # TODO: This function can be shared with MNIST dataset
17 def gen(file_dir, data, label, *, chunk_size, record_per_file):
18 assert len(data) == len(label) and len(data) > 0
19 os.makedirs(file_dir)
20 it = zip(data, label)
21 try:
22 for i in itertools.count():
23 file_name = file_dir + "/data-%04d" % i
24 print("writing:", file_name)
25 with File(file_name, "w", max_chunk_size=chunk_size) as f:
26 for _ in range(record_per_file):
27 row = next(it)
28 f.write(record.encode(row[0], row[1]))
29 except StopIteration:
30 pass
31
32
33 def main(argv):
34 parser = argparse.ArgumentParser(
35 description="Generate CIFAR10 datasets in RecordIO format."
36 )
37 parser.add_argument("dir", help="Output directory")
38 parser.add_argument(
39 "--num_record_per_chunk",
40 default=1024,
41 type=int,
42 help="Approximate number of records in a chunk.",
43 )
44 parser.add_argument(
45 "--num_chunk",
46 default=16,
47 type=int,
48 help="Number of chunks in a RecordIO file",
49 )
50 args = parser.parse_args(argv)
51 # one uncompressed record has size 3 * 32 * 32 + 1 bytes.
52 # Also add some slack for safety.
53 chunk_size = args.num_record_per_chunk * (3 * 32 * 32 + 1) + 100
54 record_per_file = args.num_record_per_chunk * args.num_chunk
55 backend.set_image_data_format("channels_first")
56
57 (x_train, y_train), (x_test, y_test) = cifar10.load_data()
58 gen(
59 args.dir + "/cifar10/train",
60 x_train,
61 y_train,
62 chunk_size=chunk_size,
63 record_per_file=record_per_file,
64 )
65
66 # Work around a bug in cifar10.load_data() where y_test is not converted
67 # to uint8
68 y_test = y_test.astype("uint8")
69 gen(
70 args.dir + "/cifar10/test",
71 x_test,
72 y_test,
73 chunk_size=chunk_size,
74 record_per_file=record_per_file,
75 )
76
77
78 if __name__ == "__main__":
79 main(sys.argv[1:])
80
[end of elasticdl/recordio_ds_gen/cifar10/gen_data.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/elasticdl/recordio_ds_gen/cifar10/gen_data.py b/elasticdl/recordio_ds_gen/cifar10/gen_data.py
--- a/elasticdl/recordio_ds_gen/cifar10/gen_data.py
+++ b/elasticdl/recordio_ds_gen/cifar10/gen_data.py
@@ -11,7 +11,7 @@
from recordio import File
from tensorflow.python.keras import backend
from tensorflow.python.keras.datasets import cifar10
-from elasticdl.recordio_ds_gen.mnist import record
+from elasticdl.recordio_ds_gen.cifar10 import record
# TODO: This function can be shared with MNIST dataset
def gen(file_dir, data, label, *, chunk_size, record_per_file):
diff --git a/elasticdl/recordio_ds_gen/cifar10/show_data.py b/elasticdl/recordio_ds_gen/cifar10/show_data.py
--- a/elasticdl/recordio_ds_gen/cifar10/show_data.py
+++ b/elasticdl/recordio_ds_gen/cifar10/show_data.py
@@ -1,5 +1,5 @@
from recordio import File
-from elasticdl.recordio_ds_gen.mnist import record
+from elasticdl.recordio_ds_gen.cifar10 import record
import sys
import argparse
|
{"golden_diff": "diff --git a/elasticdl/recordio_ds_gen/cifar10/gen_data.py b/elasticdl/recordio_ds_gen/cifar10/gen_data.py\n--- a/elasticdl/recordio_ds_gen/cifar10/gen_data.py\n+++ b/elasticdl/recordio_ds_gen/cifar10/gen_data.py\n@@ -11,7 +11,7 @@\n from recordio import File\n from tensorflow.python.keras import backend\n from tensorflow.python.keras.datasets import cifar10\n-from elasticdl.recordio_ds_gen.mnist import record\n+from elasticdl.recordio_ds_gen.cifar10 import record\n \n # TODO: This function can be shared with MNIST dataset\n def gen(file_dir, data, label, *, chunk_size, record_per_file):\ndiff --git a/elasticdl/recordio_ds_gen/cifar10/show_data.py b/elasticdl/recordio_ds_gen/cifar10/show_data.py\n--- a/elasticdl/recordio_ds_gen/cifar10/show_data.py\n+++ b/elasticdl/recordio_ds_gen/cifar10/show_data.py\n@@ -1,5 +1,5 @@\n from recordio import File\n-from elasticdl.recordio_ds_gen.mnist import record\n+from elasticdl.recordio_ds_gen.cifar10 import record\n import sys\n import argparse\n", "issue": "Failed generating cifar10 dataset when building dev image\n\n", "before_files": [{"content": "from recordio import File\nfrom elasticdl.recordio_ds_gen.mnist import record\nimport sys\nimport argparse\n\n# TODO: share code with MNIST dataset.\ndef main(argv):\n print(argv)\n parser = argparse.ArgumentParser(\n description=\"Show same data from CIFAR10 recordio\"\n )\n parser.add_argument(\"file\", help=\"RecordIo file to read\")\n parser.add_argument(\n \"--start\", default=0, type=int, help=\"Start record number\"\n )\n parser.add_argument(\"--step\", default=1, type=int, help=\"Step\")\n parser.add_argument(\n \"--n\", default=20, type=int, help=\"How many record to show\"\n )\n args = parser.parse_args(argv)\n\n with File(args.file, \"r\") as f:\n for i in range(\n args.start, args.start + (args.n * args.step), args.step\n ):\n print(\"-\" * 10)\n print(\"record:\", i)\n record.show(*record.decode(f.get(i)))\n\n\nif __name__ == \"__main__\":\n main(sys.argv[1:])\n", "path": "elasticdl/recordio_ds_gen/cifar10/show_data.py"}, {"content": "#!/usr/bin/env python\n\n\"\"\"\nDownload and transform CIFAR10 data to RecordIO format.\n\"\"\"\n\nimport itertools\nimport argparse\nimport os\nimport sys\nfrom recordio import File\nfrom tensorflow.python.keras import backend\nfrom tensorflow.python.keras.datasets import cifar10\nfrom elasticdl.recordio_ds_gen.mnist import record\n\n# TODO: This function can be shared with MNIST dataset\ndef gen(file_dir, data, label, *, chunk_size, record_per_file):\n assert len(data) == len(label) and len(data) > 0\n os.makedirs(file_dir)\n it = zip(data, label)\n try:\n for i in itertools.count():\n file_name = file_dir + \"/data-%04d\" % i\n print(\"writing:\", file_name)\n with File(file_name, \"w\", max_chunk_size=chunk_size) as f:\n for _ in range(record_per_file):\n row = next(it)\n f.write(record.encode(row[0], row[1]))\n except StopIteration:\n pass\n\n\ndef main(argv):\n parser = argparse.ArgumentParser(\n description=\"Generate CIFAR10 datasets in RecordIO format.\"\n )\n parser.add_argument(\"dir\", help=\"Output directory\")\n parser.add_argument(\n \"--num_record_per_chunk\",\n default=1024,\n type=int,\n help=\"Approximate number of records in a chunk.\",\n )\n parser.add_argument(\n \"--num_chunk\",\n default=16,\n type=int,\n help=\"Number of chunks in a RecordIO file\",\n )\n args = parser.parse_args(argv)\n # one uncompressed record has size 3 * 32 * 32 + 1 bytes.\n # Also add some slack for safety.\n chunk_size = args.num_record_per_chunk * (3 * 32 * 32 + 1) + 100\n record_per_file = args.num_record_per_chunk * args.num_chunk\n backend.set_image_data_format(\"channels_first\")\n\n (x_train, y_train), (x_test, y_test) = cifar10.load_data()\n gen(\n args.dir + \"/cifar10/train\",\n x_train,\n y_train,\n chunk_size=chunk_size,\n record_per_file=record_per_file,\n )\n\n # Work around a bug in cifar10.load_data() where y_test is not converted\n # to uint8\n y_test = y_test.astype(\"uint8\")\n gen(\n args.dir + \"/cifar10/test\",\n x_test,\n y_test,\n chunk_size=chunk_size,\n record_per_file=record_per_file,\n )\n\n\nif __name__ == \"__main__\":\n main(sys.argv[1:])\n", "path": "elasticdl/recordio_ds_gen/cifar10/gen_data.py"}]}
| 1,636 | 286 |
gh_patches_debug_37990
|
rasdani/github-patches
|
git_diff
|
ansible-collections__community.general-4436
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
ipa_service: Add skip_host_check option
### Summary
Module ipa_service has missing functionality `skip_host_check` to create service without checking if host exist or not.
### Issue Type
Feature Idea
### Component Name
ipa_service.py
### Additional Information
```yaml (paste below)
ipa_service:
name: "http/[email protected]"
state: present
force: True
skip_host_check: True
ipa_host: "{{ freeipa_client_ipa_server }}"
ipa_user: "{{ freeipa_client_ipa_user }}"
ipa_pass: "{{ freeipa_client_ipa_password }}"
```
### Code of Conduct
- [X] I agree to follow the Ansible Code of Conduct
</issue>
<code>
[start of plugins/modules/identity/ipa/ipa_service.py]
1 #!/usr/bin/python
2 # -*- coding: utf-8 -*-
3 # Copyright: (c) 2018, Ansible Project
4 # GNU General Public License v3.0+ (see COPYING or https://www.gnu.org/licenses/gpl-3.0.txt)
5
6 from __future__ import absolute_import, division, print_function
7 __metaclass__ = type
8
9 DOCUMENTATION = r'''
10 ---
11 module: ipa_service
12 author: Cédric Parent (@cprh)
13 short_description: Manage FreeIPA service
14 description:
15 - Add and delete an IPA service using IPA API.
16 options:
17 krbcanonicalname:
18 description:
19 - Principal of the service.
20 - Can not be changed as it is the unique identifier.
21 required: true
22 aliases: ["name"]
23 type: str
24 hosts:
25 description:
26 - Defines the list of 'ManagedBy' hosts.
27 required: false
28 type: list
29 elements: str
30 force:
31 description:
32 - Force principal name even if host is not in DNS.
33 required: false
34 type: bool
35 state:
36 description: State to ensure.
37 required: false
38 default: present
39 choices: ["absent", "present"]
40 type: str
41 extends_documentation_fragment:
42 - community.general.ipa.documentation
43
44 '''
45
46 EXAMPLES = r'''
47 - name: Ensure service is present
48 community.general.ipa_service:
49 name: http/host01.example.com
50 state: present
51 ipa_host: ipa.example.com
52 ipa_user: admin
53 ipa_pass: topsecret
54
55 - name: Ensure service is absent
56 community.general.ipa_service:
57 name: http/host01.example.com
58 state: absent
59 ipa_host: ipa.example.com
60 ipa_user: admin
61 ipa_pass: topsecret
62
63 - name: Changing Managing hosts list
64 community.general.ipa_service:
65 name: http/host01.example.com
66 hosts:
67 - host01.example.com
68 - host02.example.com
69 ipa_host: ipa.example.com
70 ipa_user: admin
71 ipa_pass: topsecret
72 '''
73
74 RETURN = r'''
75 service:
76 description: Service as returned by IPA API.
77 returned: always
78 type: dict
79 '''
80
81 import traceback
82
83 from ansible.module_utils.basic import AnsibleModule
84 from ansible_collections.community.general.plugins.module_utils.ipa import IPAClient, ipa_argument_spec
85 from ansible.module_utils.common.text.converters import to_native
86
87
88 class ServiceIPAClient(IPAClient):
89 def __init__(self, module, host, port, protocol):
90 super(ServiceIPAClient, self).__init__(module, host, port, protocol)
91
92 def service_find(self, name):
93 return self._post_json(method='service_find', name=None, item={'all': True, 'krbcanonicalname': name})
94
95 def service_add(self, name, service):
96 return self._post_json(method='service_add', name=name, item=service)
97
98 def service_mod(self, name, service):
99 return self._post_json(method='service_mod', name=name, item=service)
100
101 def service_del(self, name):
102 return self._post_json(method='service_del', name=name)
103
104 def service_disable(self, name):
105 return self._post_json(method='service_disable', name=name)
106
107 def service_add_host(self, name, item):
108 return self._post_json(method='service_add_host', name=name, item={'host': item})
109
110 def service_remove_host(self, name, item):
111 return self._post_json(method='service_remove_host', name=name, item={'host': item})
112
113
114 def get_service_dict(force=None, krbcanonicalname=None):
115 data = {}
116 if force is not None:
117 data['force'] = force
118 if krbcanonicalname is not None:
119 data['krbcanonicalname'] = krbcanonicalname
120 return data
121
122
123 def get_service_diff(client, ipa_host, module_service):
124 non_updateable_keys = ['force', 'krbcanonicalname']
125 for key in non_updateable_keys:
126 if key in module_service:
127 del module_service[key]
128
129 return client.get_diff(ipa_data=ipa_host, module_data=module_service)
130
131
132 def ensure(module, client):
133 name = module.params['krbcanonicalname']
134 state = module.params['state']
135 hosts = module.params['hosts']
136
137 ipa_service = client.service_find(name=name)
138 module_service = get_service_dict(force=module.params['force'])
139 changed = False
140 if state in ['present', 'enabled', 'disabled']:
141 if not ipa_service:
142 changed = True
143 if not module.check_mode:
144 client.service_add(name=name, service=module_service)
145 else:
146 diff = get_service_diff(client, ipa_service, module_service)
147 if len(diff) > 0:
148 changed = True
149 if not module.check_mode:
150 data = {}
151 for key in diff:
152 data[key] = module_service.get(key)
153 client.service_mod(name=name, service=data)
154 if hosts is not None:
155 if 'managedby_host' in ipa_service:
156 for host in ipa_service['managedby_host']:
157 if host not in hosts:
158 if not module.check_mode:
159 client.service_remove_host(name=name, item=host)
160 changed = True
161 for host in hosts:
162 if host not in ipa_service['managedby_host']:
163 if not module.check_mode:
164 client.service_add_host(name=name, item=host)
165 changed = True
166 else:
167 for host in hosts:
168 if not module.check_mode:
169 client.service_add_host(name=name, item=host)
170 changed = True
171
172 else:
173 if ipa_service:
174 changed = True
175 if not module.check_mode:
176 client.service_del(name=name)
177
178 return changed, client.service_find(name=name)
179
180
181 def main():
182 argument_spec = ipa_argument_spec()
183 argument_spec.update(
184 krbcanonicalname=dict(type='str', required=True, aliases=['name']),
185 force=dict(type='bool', required=False),
186 hosts=dict(type='list', required=False, elements='str'),
187 state=dict(type='str', required=False, default='present',
188 choices=['present', 'absent']))
189
190 module = AnsibleModule(argument_spec=argument_spec,
191 supports_check_mode=True)
192
193 client = ServiceIPAClient(module=module,
194 host=module.params['ipa_host'],
195 port=module.params['ipa_port'],
196 protocol=module.params['ipa_prot'])
197
198 try:
199 client.login(username=module.params['ipa_user'],
200 password=module.params['ipa_pass'])
201 changed, host = ensure(module, client)
202 module.exit_json(changed=changed, host=host)
203 except Exception as e:
204 module.fail_json(msg=to_native(e), exception=traceback.format_exc())
205
206
207 if __name__ == '__main__':
208 main()
209
[end of plugins/modules/identity/ipa/ipa_service.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/plugins/modules/identity/ipa/ipa_service.py b/plugins/modules/identity/ipa/ipa_service.py
--- a/plugins/modules/identity/ipa/ipa_service.py
+++ b/plugins/modules/identity/ipa/ipa_service.py
@@ -32,6 +32,14 @@
- Force principal name even if host is not in DNS.
required: false
type: bool
+ skip_host_check:
+ description:
+ - Force service to be created even when host object does not exist to manage it.
+ - This is only used on creation, not for updating existing services.
+ required: false
+ type: bool
+ default: false
+ version_added: 4.7.0
state:
description: State to ensure.
required: false
@@ -111,17 +119,19 @@
return self._post_json(method='service_remove_host', name=name, item={'host': item})
-def get_service_dict(force=None, krbcanonicalname=None):
+def get_service_dict(force=None, krbcanonicalname=None, skip_host_check=None):
data = {}
if force is not None:
data['force'] = force
if krbcanonicalname is not None:
data['krbcanonicalname'] = krbcanonicalname
+ if skip_host_check is not None:
+ data['skip_host_check'] = skip_host_check
return data
def get_service_diff(client, ipa_host, module_service):
- non_updateable_keys = ['force', 'krbcanonicalname']
+ non_updateable_keys = ['force', 'krbcanonicalname', 'skip_host_check']
for key in non_updateable_keys:
if key in module_service:
del module_service[key]
@@ -135,7 +145,7 @@
hosts = module.params['hosts']
ipa_service = client.service_find(name=name)
- module_service = get_service_dict(force=module.params['force'])
+ module_service = get_service_dict(force=module.params['force'], skip_host_check=module.params['skip_host_check'])
changed = False
if state in ['present', 'enabled', 'disabled']:
if not ipa_service:
@@ -183,6 +193,7 @@
argument_spec.update(
krbcanonicalname=dict(type='str', required=True, aliases=['name']),
force=dict(type='bool', required=False),
+ skip_host_check=dict(type='bool', default=False, required=False),
hosts=dict(type='list', required=False, elements='str'),
state=dict(type='str', required=False, default='present',
choices=['present', 'absent']))
|
{"golden_diff": "diff --git a/plugins/modules/identity/ipa/ipa_service.py b/plugins/modules/identity/ipa/ipa_service.py\n--- a/plugins/modules/identity/ipa/ipa_service.py\n+++ b/plugins/modules/identity/ipa/ipa_service.py\n@@ -32,6 +32,14 @@\n - Force principal name even if host is not in DNS.\n required: false\n type: bool\n+ skip_host_check:\n+ description:\n+ - Force service to be created even when host object does not exist to manage it.\n+ - This is only used on creation, not for updating existing services.\n+ required: false\n+ type: bool\n+ default: false\n+ version_added: 4.7.0\n state:\n description: State to ensure.\n required: false\n@@ -111,17 +119,19 @@\n return self._post_json(method='service_remove_host', name=name, item={'host': item})\n \n \n-def get_service_dict(force=None, krbcanonicalname=None):\n+def get_service_dict(force=None, krbcanonicalname=None, skip_host_check=None):\n data = {}\n if force is not None:\n data['force'] = force\n if krbcanonicalname is not None:\n data['krbcanonicalname'] = krbcanonicalname\n+ if skip_host_check is not None:\n+ data['skip_host_check'] = skip_host_check\n return data\n \n \n def get_service_diff(client, ipa_host, module_service):\n- non_updateable_keys = ['force', 'krbcanonicalname']\n+ non_updateable_keys = ['force', 'krbcanonicalname', 'skip_host_check']\n for key in non_updateable_keys:\n if key in module_service:\n del module_service[key]\n@@ -135,7 +145,7 @@\n hosts = module.params['hosts']\n \n ipa_service = client.service_find(name=name)\n- module_service = get_service_dict(force=module.params['force'])\n+ module_service = get_service_dict(force=module.params['force'], skip_host_check=module.params['skip_host_check'])\n changed = False\n if state in ['present', 'enabled', 'disabled']:\n if not ipa_service:\n@@ -183,6 +193,7 @@\n argument_spec.update(\n krbcanonicalname=dict(type='str', required=True, aliases=['name']),\n force=dict(type='bool', required=False),\n+ skip_host_check=dict(type='bool', default=False, required=False),\n hosts=dict(type='list', required=False, elements='str'),\n state=dict(type='str', required=False, default='present',\n choices=['present', 'absent']))\n", "issue": "ipa_service: Add skip_host_check option\n### Summary\n\nModule ipa_service has missing functionality `skip_host_check` to create service without checking if host exist or not.\n\n### Issue Type\n\nFeature Idea\n\n### Component Name\n\nipa_service.py\n\n### Additional Information\n\n```yaml (paste below)\r\n ipa_service:\r\n name: \"http/[email protected]\"\r\n state: present\r\n force: True\r\n skip_host_check: True\r\n ipa_host: \"{{ freeipa_client_ipa_server }}\"\r\n ipa_user: \"{{ freeipa_client_ipa_user }}\"\r\n ipa_pass: \"{{ freeipa_client_ipa_password }}\"\r\n```\r\n\n\n### Code of Conduct\n\n- [X] I agree to follow the Ansible Code of Conduct\n", "before_files": [{"content": "#!/usr/bin/python\n# -*- coding: utf-8 -*-\n# Copyright: (c) 2018, Ansible Project\n# GNU General Public License v3.0+ (see COPYING or https://www.gnu.org/licenses/gpl-3.0.txt)\n\nfrom __future__ import absolute_import, division, print_function\n__metaclass__ = type\n\nDOCUMENTATION = r'''\n---\nmodule: ipa_service\nauthor: C\u00e9dric Parent (@cprh)\nshort_description: Manage FreeIPA service\ndescription:\n- Add and delete an IPA service using IPA API.\noptions:\n krbcanonicalname:\n description:\n - Principal of the service.\n - Can not be changed as it is the unique identifier.\n required: true\n aliases: [\"name\"]\n type: str\n hosts:\n description:\n - Defines the list of 'ManagedBy' hosts.\n required: false\n type: list\n elements: str\n force:\n description:\n - Force principal name even if host is not in DNS.\n required: false\n type: bool\n state:\n description: State to ensure.\n required: false\n default: present\n choices: [\"absent\", \"present\"]\n type: str\nextends_documentation_fragment:\n- community.general.ipa.documentation\n\n'''\n\nEXAMPLES = r'''\n- name: Ensure service is present\n community.general.ipa_service:\n name: http/host01.example.com\n state: present\n ipa_host: ipa.example.com\n ipa_user: admin\n ipa_pass: topsecret\n\n- name: Ensure service is absent\n community.general.ipa_service:\n name: http/host01.example.com\n state: absent\n ipa_host: ipa.example.com\n ipa_user: admin\n ipa_pass: topsecret\n\n- name: Changing Managing hosts list\n community.general.ipa_service:\n name: http/host01.example.com\n hosts:\n - host01.example.com\n - host02.example.com\n ipa_host: ipa.example.com\n ipa_user: admin\n ipa_pass: topsecret\n'''\n\nRETURN = r'''\nservice:\n description: Service as returned by IPA API.\n returned: always\n type: dict\n'''\n\nimport traceback\n\nfrom ansible.module_utils.basic import AnsibleModule\nfrom ansible_collections.community.general.plugins.module_utils.ipa import IPAClient, ipa_argument_spec\nfrom ansible.module_utils.common.text.converters import to_native\n\n\nclass ServiceIPAClient(IPAClient):\n def __init__(self, module, host, port, protocol):\n super(ServiceIPAClient, self).__init__(module, host, port, protocol)\n\n def service_find(self, name):\n return self._post_json(method='service_find', name=None, item={'all': True, 'krbcanonicalname': name})\n\n def service_add(self, name, service):\n return self._post_json(method='service_add', name=name, item=service)\n\n def service_mod(self, name, service):\n return self._post_json(method='service_mod', name=name, item=service)\n\n def service_del(self, name):\n return self._post_json(method='service_del', name=name)\n\n def service_disable(self, name):\n return self._post_json(method='service_disable', name=name)\n\n def service_add_host(self, name, item):\n return self._post_json(method='service_add_host', name=name, item={'host': item})\n\n def service_remove_host(self, name, item):\n return self._post_json(method='service_remove_host', name=name, item={'host': item})\n\n\ndef get_service_dict(force=None, krbcanonicalname=None):\n data = {}\n if force is not None:\n data['force'] = force\n if krbcanonicalname is not None:\n data['krbcanonicalname'] = krbcanonicalname\n return data\n\n\ndef get_service_diff(client, ipa_host, module_service):\n non_updateable_keys = ['force', 'krbcanonicalname']\n for key in non_updateable_keys:\n if key in module_service:\n del module_service[key]\n\n return client.get_diff(ipa_data=ipa_host, module_data=module_service)\n\n\ndef ensure(module, client):\n name = module.params['krbcanonicalname']\n state = module.params['state']\n hosts = module.params['hosts']\n\n ipa_service = client.service_find(name=name)\n module_service = get_service_dict(force=module.params['force'])\n changed = False\n if state in ['present', 'enabled', 'disabled']:\n if not ipa_service:\n changed = True\n if not module.check_mode:\n client.service_add(name=name, service=module_service)\n else:\n diff = get_service_diff(client, ipa_service, module_service)\n if len(diff) > 0:\n changed = True\n if not module.check_mode:\n data = {}\n for key in diff:\n data[key] = module_service.get(key)\n client.service_mod(name=name, service=data)\n if hosts is not None:\n if 'managedby_host' in ipa_service:\n for host in ipa_service['managedby_host']:\n if host not in hosts:\n if not module.check_mode:\n client.service_remove_host(name=name, item=host)\n changed = True\n for host in hosts:\n if host not in ipa_service['managedby_host']:\n if not module.check_mode:\n client.service_add_host(name=name, item=host)\n changed = True\n else:\n for host in hosts:\n if not module.check_mode:\n client.service_add_host(name=name, item=host)\n changed = True\n\n else:\n if ipa_service:\n changed = True\n if not module.check_mode:\n client.service_del(name=name)\n\n return changed, client.service_find(name=name)\n\n\ndef main():\n argument_spec = ipa_argument_spec()\n argument_spec.update(\n krbcanonicalname=dict(type='str', required=True, aliases=['name']),\n force=dict(type='bool', required=False),\n hosts=dict(type='list', required=False, elements='str'),\n state=dict(type='str', required=False, default='present',\n choices=['present', 'absent']))\n\n module = AnsibleModule(argument_spec=argument_spec,\n supports_check_mode=True)\n\n client = ServiceIPAClient(module=module,\n host=module.params['ipa_host'],\n port=module.params['ipa_port'],\n protocol=module.params['ipa_prot'])\n\n try:\n client.login(username=module.params['ipa_user'],\n password=module.params['ipa_pass'])\n changed, host = ensure(module, client)\n module.exit_json(changed=changed, host=host)\n except Exception as e:\n module.fail_json(msg=to_native(e), exception=traceback.format_exc())\n\n\nif __name__ == '__main__':\n main()\n", "path": "plugins/modules/identity/ipa/ipa_service.py"}]}
| 2,729 | 585 |
gh_patches_debug_11697
|
rasdani/github-patches
|
git_diff
|
wagtail__wagtail-11817
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
`to_python` throws `AttributeError` on `TableBlock` when value is None
### Issue Summary
Similar to: https://github.com/wagtail/wagtail/issues/4822
After upgrading one of our sites to 6.0, attempting to update some of our pages' indices results in a server error.
```
File "/venv/lib/python3.8/site-packages/wagtail/contrib/table_block/blocks.py", line 135, in to_python
if not value.get("table_header_choice", ""):
AttributeError: 'NoneType' object has no attribute 'get'
```
This is because, in Wagtail 6.0, the following code has been added:
https://github.com/wagtail/wagtail/commit/fe1a306285da6c48b66506c589abc2c66b51668a#diff-f058d7a36746222950f678ed6b178205778e4e1e5b85f0299c2a7c3b9d6c8939R129
### Steps to Reproduce
1. Create a page with an empty TableBlock in its body
2. Before Wagtail 6.0, this should save and render OK
3. After upgrading to 6.0, editing the same page will throw an error.
4. Looking at the logs, you should see the error above
A workaround is to identify those pages and remove the empty TableBlocks, but this would prove to be a tedious task if there are many page instances.
A possible fix would be to check if the value is not None first:
```
if value and not value.get("table_header_choice", ""):
```
</issue>
<code>
[start of wagtail/contrib/table_block/blocks.py]
1 import json
2
3 from django import forms
4 from django.core.exceptions import ValidationError
5 from django.forms.fields import Field
6 from django.forms.utils import ErrorList
7 from django.template.loader import render_to_string
8 from django.utils import translation
9 from django.utils.functional import cached_property
10 from django.utils.translation import gettext as _
11
12 from wagtail.admin.staticfiles import versioned_static
13 from wagtail.blocks import FieldBlock
14 from wagtail.telepath import register
15 from wagtail.widget_adapters import WidgetAdapter
16
17 DEFAULT_TABLE_OPTIONS = {
18 "minSpareRows": 0,
19 "startRows": 3,
20 "startCols": 3,
21 "colHeaders": False,
22 "rowHeaders": False,
23 "contextMenu": [
24 "row_above",
25 "row_below",
26 "---------",
27 "col_left",
28 "col_right",
29 "---------",
30 "remove_row",
31 "remove_col",
32 "---------",
33 "undo",
34 "redo",
35 ],
36 "editor": "text",
37 "stretchH": "all",
38 "height": 108,
39 "renderer": "text",
40 "autoColumnSize": False,
41 }
42
43
44 class TableInput(forms.HiddenInput):
45 def __init__(self, table_options=None, attrs=None):
46 self.table_options = table_options
47 super().__init__(attrs=attrs)
48
49 @cached_property
50 def media(self):
51 return forms.Media(
52 css={
53 "all": [
54 versioned_static(
55 "table_block/css/vendor/handsontable-6.2.2.full.min.css"
56 ),
57 ]
58 },
59 js=[
60 versioned_static(
61 "table_block/js/vendor/handsontable-6.2.2.full.min.js"
62 ),
63 versioned_static("table_block/js/table.js"),
64 ],
65 )
66
67
68 class TableInputAdapter(WidgetAdapter):
69 js_constructor = "wagtail.widgets.TableInput"
70
71 def js_args(self, widget):
72 strings = {
73 "Row header": _("Row header"),
74 "Table headers": _("Table headers"),
75 "Display the first row as a header": _("Display the first row as a header"),
76 "Display the first column as a header": _(
77 "Display the first column as a header"
78 ),
79 "Column header": _("Column header"),
80 "Display the first row AND first column as headers": _(
81 "Display the first row AND first column as headers"
82 ),
83 "No headers": _("No headers"),
84 "Which cells should be displayed as headers?": _(
85 "Which cells should be displayed as headers?"
86 ),
87 "Table caption": _("Table caption"),
88 "A heading that identifies the overall topic of the table, and is useful for screen reader users.": _(
89 "A heading that identifies the overall topic of the table, and is useful for screen reader users."
90 ),
91 "Table": _("Table"),
92 }
93
94 return [
95 widget.table_options,
96 strings,
97 ]
98
99
100 register(TableInputAdapter(), TableInput)
101
102
103 class TableBlock(FieldBlock):
104 def __init__(self, required=True, help_text=None, table_options=None, **kwargs):
105 """
106 CharField's 'label' and 'initial' parameters are not exposed, as Block
107 handles that functionality natively (via 'label' and 'default')
108
109 CharField's 'max_length' and 'min_length' parameters are not exposed as table
110 data needs to have arbitrary length
111 """
112 self.table_options = self.get_table_options(table_options=table_options)
113 self.field_options = {"required": required, "help_text": help_text}
114
115 super().__init__(**kwargs)
116
117 @cached_property
118 def field(self):
119 return forms.CharField(
120 widget=TableInput(table_options=self.table_options), **self.field_options
121 )
122
123 def value_from_form(self, value):
124 return json.loads(value)
125
126 def value_for_form(self, value):
127 return json.dumps(value)
128
129 def to_python(self, value):
130 """
131 If value came from a table block stored before Wagtail 6.0, we need to set an appropriate
132 value for the header choice. I would really like to have this default to "" and force the
133 editor to reaffirm they don't want any headers, but that would be a breaking change.
134 """
135 if not value.get("table_header_choice", ""):
136 if value.get("first_row_is_table_header", False) and value.get(
137 "first_col_is_header", False
138 ):
139 value["table_header_choice"] = "both"
140 elif value.get("first_row_is_table_header", False):
141 value["table_header_choice"] = "row"
142 elif value.get("first_col_is_header", False):
143 value["table_header_choice"] = "col"
144 else:
145 value["table_header_choice"] = "neither"
146 return value
147
148 def clean(self, value):
149 if not value:
150 return value
151
152 if value.get("table_header_choice", ""):
153 value["first_row_is_table_header"] = value["table_header_choice"] in [
154 "row",
155 "both",
156 ]
157 value["first_col_is_header"] = value["table_header_choice"] in [
158 "column",
159 "both",
160 ]
161 else:
162 # Ensure we have a choice for the table_header_choice
163 errors = ErrorList(Field.default_error_messages["required"])
164 raise ValidationError("Validation error in TableBlock", params=errors)
165 return self.value_from_form(self.field.clean(self.value_for_form(value)))
166
167 def get_form_state(self, value):
168 # pass state to frontend as a JSON-ish dict - do not serialise to a JSON string
169 return value
170
171 def is_html_renderer(self):
172 return self.table_options["renderer"] == "html"
173
174 def get_searchable_content(self, value):
175 content = []
176 if value:
177 for row in value.get("data", []):
178 content.extend([v for v in row if v])
179 return content
180
181 def render(self, value, context=None):
182 template = getattr(self.meta, "template", None)
183 if template and value:
184 table_header = (
185 value["data"][0]
186 if value.get("data", None)
187 and len(value["data"]) > 0
188 and value.get("first_row_is_table_header", False)
189 else None
190 )
191 first_col_is_header = value.get("first_col_is_header", False)
192
193 if context is None:
194 new_context = {}
195 else:
196 new_context = dict(context)
197
198 new_context.update(
199 {
200 "self": value,
201 self.TEMPLATE_VAR: value,
202 "table_header": table_header,
203 "first_col_is_header": first_col_is_header,
204 "html_renderer": self.is_html_renderer(),
205 "table_caption": value.get("table_caption"),
206 "data": value["data"][1:]
207 if table_header
208 else value.get("data", []),
209 }
210 )
211
212 if value.get("cell"):
213 new_context["classnames"] = {}
214 new_context["hidden"] = {}
215 for meta in value["cell"]:
216 if "className" in meta:
217 new_context["classnames"][(meta["row"], meta["col"])] = meta[
218 "className"
219 ]
220 if "hidden" in meta:
221 new_context["hidden"][(meta["row"], meta["col"])] = meta[
222 "hidden"
223 ]
224
225 if value.get("mergeCells"):
226 new_context["spans"] = {}
227 for merge in value["mergeCells"]:
228 new_context["spans"][(merge["row"], merge["col"])] = {
229 "rowspan": merge["rowspan"],
230 "colspan": merge["colspan"],
231 }
232
233 return render_to_string(template, new_context)
234 else:
235 return self.render_basic(value or "", context=context)
236
237 def get_table_options(self, table_options=None):
238 """
239 Return a dict of table options using the defaults unless custom options provided
240
241 table_options can contain any valid handsontable options:
242 https://handsontable.com/docs/6.2.2/Options.html
243 contextMenu: if value from table_options is True, still use default
244 language: if value is not in table_options, attempt to get from environment
245 """
246
247 collected_table_options = DEFAULT_TABLE_OPTIONS.copy()
248
249 if table_options is not None:
250 if table_options.get("contextMenu", None) is True:
251 # explicitly check for True, as value could also be array
252 # delete to ensure the above default is kept for contextMenu
253 del table_options["contextMenu"]
254 collected_table_options.update(table_options)
255
256 if "language" not in collected_table_options:
257 # attempt to gather the current set language of not provided
258 language = translation.get_language()
259 collected_table_options["language"] = language
260
261 return collected_table_options
262
263 class Meta:
264 default = None
265 template = "table_block/blocks/table.html"
266 icon = "table"
267
[end of wagtail/contrib/table_block/blocks.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/wagtail/contrib/table_block/blocks.py b/wagtail/contrib/table_block/blocks.py
--- a/wagtail/contrib/table_block/blocks.py
+++ b/wagtail/contrib/table_block/blocks.py
@@ -132,7 +132,7 @@
value for the header choice. I would really like to have this default to "" and force the
editor to reaffirm they don't want any headers, but that would be a breaking change.
"""
- if not value.get("table_header_choice", ""):
+ if value and not value.get("table_header_choice", ""):
if value.get("first_row_is_table_header", False) and value.get(
"first_col_is_header", False
):
|
{"golden_diff": "diff --git a/wagtail/contrib/table_block/blocks.py b/wagtail/contrib/table_block/blocks.py\n--- a/wagtail/contrib/table_block/blocks.py\n+++ b/wagtail/contrib/table_block/blocks.py\n@@ -132,7 +132,7 @@\n value for the header choice. I would really like to have this default to \"\" and force the\n editor to reaffirm they don't want any headers, but that would be a breaking change.\n \"\"\"\n- if not value.get(\"table_header_choice\", \"\"):\n+ if value and not value.get(\"table_header_choice\", \"\"):\n if value.get(\"first_row_is_table_header\", False) and value.get(\n \"first_col_is_header\", False\n ):\n", "issue": "`to_python` throws `AttributeError` on `TableBlock` when value is None\n### Issue Summary\r\n\r\nSimilar to: https://github.com/wagtail/wagtail/issues/4822\r\n\r\nAfter upgrading one of our sites to 6.0, attempting to update some of our pages' indices results in a server error.\r\n\r\n```\r\n File \"/venv/lib/python3.8/site-packages/wagtail/contrib/table_block/blocks.py\", line 135, in to_python\r\n if not value.get(\"table_header_choice\", \"\"):\r\nAttributeError: 'NoneType' object has no attribute 'get'\r\n```\r\n\r\nThis is because, in Wagtail 6.0, the following code has been added:\r\nhttps://github.com/wagtail/wagtail/commit/fe1a306285da6c48b66506c589abc2c66b51668a#diff-f058d7a36746222950f678ed6b178205778e4e1e5b85f0299c2a7c3b9d6c8939R129\r\n\r\n### Steps to Reproduce\r\n\r\n1. Create a page with an empty TableBlock in its body\r\n2. Before Wagtail 6.0, this should save and render OK\r\n3. After upgrading to 6.0, editing the same page will throw an error.\r\n4. Looking at the logs, you should see the error above\r\n\r\nA workaround is to identify those pages and remove the empty TableBlocks, but this would prove to be a tedious task if there are many page instances.\r\n\r\nA possible fix would be to check if the value is not None first:\r\n```\r\nif value and not value.get(\"table_header_choice\", \"\"):\r\n```\n", "before_files": [{"content": "import json\n\nfrom django import forms\nfrom django.core.exceptions import ValidationError\nfrom django.forms.fields import Field\nfrom django.forms.utils import ErrorList\nfrom django.template.loader import render_to_string\nfrom django.utils import translation\nfrom django.utils.functional import cached_property\nfrom django.utils.translation import gettext as _\n\nfrom wagtail.admin.staticfiles import versioned_static\nfrom wagtail.blocks import FieldBlock\nfrom wagtail.telepath import register\nfrom wagtail.widget_adapters import WidgetAdapter\n\nDEFAULT_TABLE_OPTIONS = {\n \"minSpareRows\": 0,\n \"startRows\": 3,\n \"startCols\": 3,\n \"colHeaders\": False,\n \"rowHeaders\": False,\n \"contextMenu\": [\n \"row_above\",\n \"row_below\",\n \"---------\",\n \"col_left\",\n \"col_right\",\n \"---------\",\n \"remove_row\",\n \"remove_col\",\n \"---------\",\n \"undo\",\n \"redo\",\n ],\n \"editor\": \"text\",\n \"stretchH\": \"all\",\n \"height\": 108,\n \"renderer\": \"text\",\n \"autoColumnSize\": False,\n}\n\n\nclass TableInput(forms.HiddenInput):\n def __init__(self, table_options=None, attrs=None):\n self.table_options = table_options\n super().__init__(attrs=attrs)\n\n @cached_property\n def media(self):\n return forms.Media(\n css={\n \"all\": [\n versioned_static(\n \"table_block/css/vendor/handsontable-6.2.2.full.min.css\"\n ),\n ]\n },\n js=[\n versioned_static(\n \"table_block/js/vendor/handsontable-6.2.2.full.min.js\"\n ),\n versioned_static(\"table_block/js/table.js\"),\n ],\n )\n\n\nclass TableInputAdapter(WidgetAdapter):\n js_constructor = \"wagtail.widgets.TableInput\"\n\n def js_args(self, widget):\n strings = {\n \"Row header\": _(\"Row header\"),\n \"Table headers\": _(\"Table headers\"),\n \"Display the first row as a header\": _(\"Display the first row as a header\"),\n \"Display the first column as a header\": _(\n \"Display the first column as a header\"\n ),\n \"Column header\": _(\"Column header\"),\n \"Display the first row AND first column as headers\": _(\n \"Display the first row AND first column as headers\"\n ),\n \"No headers\": _(\"No headers\"),\n \"Which cells should be displayed as headers?\": _(\n \"Which cells should be displayed as headers?\"\n ),\n \"Table caption\": _(\"Table caption\"),\n \"A heading that identifies the overall topic of the table, and is useful for screen reader users.\": _(\n \"A heading that identifies the overall topic of the table, and is useful for screen reader users.\"\n ),\n \"Table\": _(\"Table\"),\n }\n\n return [\n widget.table_options,\n strings,\n ]\n\n\nregister(TableInputAdapter(), TableInput)\n\n\nclass TableBlock(FieldBlock):\n def __init__(self, required=True, help_text=None, table_options=None, **kwargs):\n \"\"\"\n CharField's 'label' and 'initial' parameters are not exposed, as Block\n handles that functionality natively (via 'label' and 'default')\n\n CharField's 'max_length' and 'min_length' parameters are not exposed as table\n data needs to have arbitrary length\n \"\"\"\n self.table_options = self.get_table_options(table_options=table_options)\n self.field_options = {\"required\": required, \"help_text\": help_text}\n\n super().__init__(**kwargs)\n\n @cached_property\n def field(self):\n return forms.CharField(\n widget=TableInput(table_options=self.table_options), **self.field_options\n )\n\n def value_from_form(self, value):\n return json.loads(value)\n\n def value_for_form(self, value):\n return json.dumps(value)\n\n def to_python(self, value):\n \"\"\"\n If value came from a table block stored before Wagtail 6.0, we need to set an appropriate\n value for the header choice. I would really like to have this default to \"\" and force the\n editor to reaffirm they don't want any headers, but that would be a breaking change.\n \"\"\"\n if not value.get(\"table_header_choice\", \"\"):\n if value.get(\"first_row_is_table_header\", False) and value.get(\n \"first_col_is_header\", False\n ):\n value[\"table_header_choice\"] = \"both\"\n elif value.get(\"first_row_is_table_header\", False):\n value[\"table_header_choice\"] = \"row\"\n elif value.get(\"first_col_is_header\", False):\n value[\"table_header_choice\"] = \"col\"\n else:\n value[\"table_header_choice\"] = \"neither\"\n return value\n\n def clean(self, value):\n if not value:\n return value\n\n if value.get(\"table_header_choice\", \"\"):\n value[\"first_row_is_table_header\"] = value[\"table_header_choice\"] in [\n \"row\",\n \"both\",\n ]\n value[\"first_col_is_header\"] = value[\"table_header_choice\"] in [\n \"column\",\n \"both\",\n ]\n else:\n # Ensure we have a choice for the table_header_choice\n errors = ErrorList(Field.default_error_messages[\"required\"])\n raise ValidationError(\"Validation error in TableBlock\", params=errors)\n return self.value_from_form(self.field.clean(self.value_for_form(value)))\n\n def get_form_state(self, value):\n # pass state to frontend as a JSON-ish dict - do not serialise to a JSON string\n return value\n\n def is_html_renderer(self):\n return self.table_options[\"renderer\"] == \"html\"\n\n def get_searchable_content(self, value):\n content = []\n if value:\n for row in value.get(\"data\", []):\n content.extend([v for v in row if v])\n return content\n\n def render(self, value, context=None):\n template = getattr(self.meta, \"template\", None)\n if template and value:\n table_header = (\n value[\"data\"][0]\n if value.get(\"data\", None)\n and len(value[\"data\"]) > 0\n and value.get(\"first_row_is_table_header\", False)\n else None\n )\n first_col_is_header = value.get(\"first_col_is_header\", False)\n\n if context is None:\n new_context = {}\n else:\n new_context = dict(context)\n\n new_context.update(\n {\n \"self\": value,\n self.TEMPLATE_VAR: value,\n \"table_header\": table_header,\n \"first_col_is_header\": first_col_is_header,\n \"html_renderer\": self.is_html_renderer(),\n \"table_caption\": value.get(\"table_caption\"),\n \"data\": value[\"data\"][1:]\n if table_header\n else value.get(\"data\", []),\n }\n )\n\n if value.get(\"cell\"):\n new_context[\"classnames\"] = {}\n new_context[\"hidden\"] = {}\n for meta in value[\"cell\"]:\n if \"className\" in meta:\n new_context[\"classnames\"][(meta[\"row\"], meta[\"col\"])] = meta[\n \"className\"\n ]\n if \"hidden\" in meta:\n new_context[\"hidden\"][(meta[\"row\"], meta[\"col\"])] = meta[\n \"hidden\"\n ]\n\n if value.get(\"mergeCells\"):\n new_context[\"spans\"] = {}\n for merge in value[\"mergeCells\"]:\n new_context[\"spans\"][(merge[\"row\"], merge[\"col\"])] = {\n \"rowspan\": merge[\"rowspan\"],\n \"colspan\": merge[\"colspan\"],\n }\n\n return render_to_string(template, new_context)\n else:\n return self.render_basic(value or \"\", context=context)\n\n def get_table_options(self, table_options=None):\n \"\"\"\n Return a dict of table options using the defaults unless custom options provided\n\n table_options can contain any valid handsontable options:\n https://handsontable.com/docs/6.2.2/Options.html\n contextMenu: if value from table_options is True, still use default\n language: if value is not in table_options, attempt to get from environment\n \"\"\"\n\n collected_table_options = DEFAULT_TABLE_OPTIONS.copy()\n\n if table_options is not None:\n if table_options.get(\"contextMenu\", None) is True:\n # explicitly check for True, as value could also be array\n # delete to ensure the above default is kept for contextMenu\n del table_options[\"contextMenu\"]\n collected_table_options.update(table_options)\n\n if \"language\" not in collected_table_options:\n # attempt to gather the current set language of not provided\n language = translation.get_language()\n collected_table_options[\"language\"] = language\n\n return collected_table_options\n\n class Meta:\n default = None\n template = \"table_block/blocks/table.html\"\n icon = \"table\"\n", "path": "wagtail/contrib/table_block/blocks.py"}]}
| 3,567 | 165 |
gh_patches_debug_29462
|
rasdani/github-patches
|
git_diff
|
akvo__akvo-rsr-2566
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Search in EUTF akvo site
Partner team had a training and workshop with EUTF last week and discovered that search terms in EUTF akvo site returned unrelated results.
Search for tombouctou shows up a project of SNV in EUTF akvo page, which is confusing for the partner as they expect to see their own projects only on their akvo site.
<img width="1070" alt="screen shot 2017-02-06 at 15 56 41" src="https://cloud.githubusercontent.com/assets/21127166/22652066/45bdf606-ec85-11e6-9c05-25d421b329c1.png">
What the partner expects is to see just projects where they are one of the participating partners.
If the search does not match any of their projects, it should then not return anything.
</issue>
<code>
[start of akvo/rest/views/typeahead.py]
1 # -*- coding: utf-8 -*-
2
3 """Akvo RSR is covered by the GNU Affero General Public License.
4 See more details in the license.txt file located at the root folder of the
5 Akvo RSR module. For additional details on the GNU license please
6 see < http://www.gnu.org/licenses/agpl.html >.
7 """
8
9 from akvo.rest.serializers import (TypeaheadCountrySerializer,
10 TypeaheadOrganisationSerializer,
11 TypeaheadProjectSerializer,
12 TypeaheadProjectUpdateSerializer)
13
14 from akvo.codelists.models import Country, Version
15 from akvo.rsr.models import Organisation, Project, ProjectUpdate
16 from akvo.rsr.views.project import _project_directory_coll
17
18 from django.conf import settings
19
20 from rest_framework.decorators import api_view
21 from rest_framework.response import Response
22
23
24 def rejig(queryset, serializer):
25 """Rearrange & add queryset count to the response data."""
26 return {
27 'count': queryset.count(),
28 'results': serializer.data
29 }
30
31
32 @api_view(['GET'])
33 def typeahead_country(request):
34 iati_version = Version.objects.get(code=settings.IATI_VERSION)
35 countries = Country.objects.filter(version=iati_version)
36 return Response(
37 rejig(countries, TypeaheadCountrySerializer(countries, many=True))
38 )
39
40
41 @api_view(['GET'])
42 def typeahead_organisation(request):
43 organisations = Organisation.objects.all()
44 return Response(
45 rejig(organisations, TypeaheadOrganisationSerializer(organisations,
46 many=True))
47 )
48
49
50 @api_view(['GET'])
51 def typeahead_user_organisations(request):
52 user = request.user
53 is_admin = user.is_active and (user.is_superuser or user.is_admin)
54 organisations = user.approved_organisations() if not is_admin else Organisation.objects.all()
55 return Response(
56 rejig(organisations, TypeaheadOrganisationSerializer(organisations,
57 many=True))
58 )
59
60
61 @api_view(['GET'])
62 def typeahead_project(request):
63 """Return the typeaheads for projects.
64
65 Without any query parameters, it returns the info for all the projects in
66 the current context -- changes depending on whether we are on a partner
67 site, or the RSR site.
68
69 If a project query parameter with a project id is passed, the info for all
70 projects associated with partners for the specified project is returned.
71
72 NOTE: The unauthenticated user gets information about all the projects when
73 using this API endpoint. More permission checking will need to be added,
74 if the amount of data being returned is changed.
75
76 """
77 project_id = request.GET.get('project', None)
78 if project_id is None:
79 project = None
80
81 else:
82 try:
83 project = Project.objects.get(id=project_id)
84 except Project.DoesNotExist:
85 project = None
86
87 if project is None:
88 # Search bar - organization projects, published
89 projects = _project_directory_coll(request)
90
91 else:
92 # Project editor - all projects of partners for this project
93 projects = Project.objects.of_partners(project.partners.distinct()).distinct()
94
95 projects = projects.exclude(title='')
96 return Response(
97 rejig(projects, TypeaheadProjectSerializer(projects, many=True))
98 )
99
100
101 @api_view(['GET'])
102 def typeahead_user_projects(request):
103 user = request.user
104 is_admin = user.is_active and (user.is_superuser or user.is_admin)
105 if is_admin:
106 projects = Project.objects.all()
107 else:
108 projects = user.approved_organisations().all_projects()
109 projects = projects.exclude(title='')
110 return Response(
111 rejig(projects, TypeaheadProjectSerializer(projects, many=True))
112 )
113
114
115 @api_view(['GET'])
116 def typeahead_impact_projects(request):
117 user = request.user
118 projects = Project.objects.all() if user.is_admin or user.is_superuser else user.my_projects()
119 projects = projects.published().filter(is_impact_project=True).order_by('title')
120
121 return Response(
122 rejig(projects, TypeaheadProjectSerializer(projects, many=True))
123 )
124
125
126 @api_view(['GET'])
127 def typeahead_projectupdate(request):
128 updates = ProjectUpdate.objects.all()
129 return Response(
130 rejig(updates, TypeaheadProjectUpdateSerializer(updates, many=True))
131 )
132
[end of akvo/rest/views/typeahead.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/akvo/rest/views/typeahead.py b/akvo/rest/views/typeahead.py
--- a/akvo/rest/views/typeahead.py
+++ b/akvo/rest/views/typeahead.py
@@ -66,32 +66,22 @@
the current context -- changes depending on whether we are on a partner
site, or the RSR site.
- If a project query parameter with a project id is passed, the info for all
- projects associated with partners for the specified project is returned.
+ If a published query parameter is passed, only projects that have been
+ published are returned.
NOTE: The unauthenticated user gets information about all the projects when
using this API endpoint. More permission checking will need to be added,
if the amount of data being returned is changed.
"""
- project_id = request.GET.get('project', None)
- if project_id is None:
- project = None
-
+ if request.GET.get('published', '0') == '0':
+ # Project editor - organization projects, all
+ page = request.rsr_page
+ projects = page.organisation.all_projects() if page else Project.objects.all()
else:
- try:
- project = Project.objects.get(id=project_id)
- except Project.DoesNotExist:
- project = None
-
- if project is None:
# Search bar - organization projects, published
projects = _project_directory_coll(request)
- else:
- # Project editor - all projects of partners for this project
- projects = Project.objects.of_partners(project.partners.distinct()).distinct()
-
projects = projects.exclude(title='')
return Response(
rejig(projects, TypeaheadProjectSerializer(projects, many=True))
|
{"golden_diff": "diff --git a/akvo/rest/views/typeahead.py b/akvo/rest/views/typeahead.py\n--- a/akvo/rest/views/typeahead.py\n+++ b/akvo/rest/views/typeahead.py\n@@ -66,32 +66,22 @@\n the current context -- changes depending on whether we are on a partner\n site, or the RSR site.\n \n- If a project query parameter with a project id is passed, the info for all\n- projects associated with partners for the specified project is returned.\n+ If a published query parameter is passed, only projects that have been\n+ published are returned.\n \n NOTE: The unauthenticated user gets information about all the projects when\n using this API endpoint. More permission checking will need to be added,\n if the amount of data being returned is changed.\n \n \"\"\"\n- project_id = request.GET.get('project', None)\n- if project_id is None:\n- project = None\n-\n+ if request.GET.get('published', '0') == '0':\n+ # Project editor - organization projects, all\n+ page = request.rsr_page\n+ projects = page.organisation.all_projects() if page else Project.objects.all()\n else:\n- try:\n- project = Project.objects.get(id=project_id)\n- except Project.DoesNotExist:\n- project = None\n-\n- if project is None:\n # Search bar - organization projects, published\n projects = _project_directory_coll(request)\n \n- else:\n- # Project editor - all projects of partners for this project\n- projects = Project.objects.of_partners(project.partners.distinct()).distinct()\n-\n projects = projects.exclude(title='')\n return Response(\n rejig(projects, TypeaheadProjectSerializer(projects, many=True))\n", "issue": "Search in EUTF akvo site\nPartner team had a training and workshop with EUTF last week and discovered that search terms in EUTF akvo site returned unrelated results.\r\n\r\nSearch for tombouctou shows up a project of SNV in EUTF akvo page, which is confusing for the partner as they expect to see their own projects only on their akvo site. \r\n\r\n<img width=\"1070\" alt=\"screen shot 2017-02-06 at 15 56 41\" src=\"https://cloud.githubusercontent.com/assets/21127166/22652066/45bdf606-ec85-11e6-9c05-25d421b329c1.png\">\r\n\r\nWhat the partner expects is to see just projects where they are one of the participating partners. \r\nIf the search does not match any of their projects, it should then not return anything. \n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\n\"\"\"Akvo RSR is covered by the GNU Affero General Public License.\nSee more details in the license.txt file located at the root folder of the\nAkvo RSR module. For additional details on the GNU license please\nsee < http://www.gnu.org/licenses/agpl.html >.\n\"\"\"\n\nfrom akvo.rest.serializers import (TypeaheadCountrySerializer,\n TypeaheadOrganisationSerializer,\n TypeaheadProjectSerializer,\n TypeaheadProjectUpdateSerializer)\n\nfrom akvo.codelists.models import Country, Version\nfrom akvo.rsr.models import Organisation, Project, ProjectUpdate\nfrom akvo.rsr.views.project import _project_directory_coll\n\nfrom django.conf import settings\n\nfrom rest_framework.decorators import api_view\nfrom rest_framework.response import Response\n\n\ndef rejig(queryset, serializer):\n \"\"\"Rearrange & add queryset count to the response data.\"\"\"\n return {\n 'count': queryset.count(),\n 'results': serializer.data\n }\n\n\n@api_view(['GET'])\ndef typeahead_country(request):\n iati_version = Version.objects.get(code=settings.IATI_VERSION)\n countries = Country.objects.filter(version=iati_version)\n return Response(\n rejig(countries, TypeaheadCountrySerializer(countries, many=True))\n )\n\n\n@api_view(['GET'])\ndef typeahead_organisation(request):\n organisations = Organisation.objects.all()\n return Response(\n rejig(organisations, TypeaheadOrganisationSerializer(organisations,\n many=True))\n )\n\n\n@api_view(['GET'])\ndef typeahead_user_organisations(request):\n user = request.user\n is_admin = user.is_active and (user.is_superuser or user.is_admin)\n organisations = user.approved_organisations() if not is_admin else Organisation.objects.all()\n return Response(\n rejig(organisations, TypeaheadOrganisationSerializer(organisations,\n many=True))\n )\n\n\n@api_view(['GET'])\ndef typeahead_project(request):\n \"\"\"Return the typeaheads for projects.\n\n Without any query parameters, it returns the info for all the projects in\n the current context -- changes depending on whether we are on a partner\n site, or the RSR site.\n\n If a project query parameter with a project id is passed, the info for all\n projects associated with partners for the specified project is returned.\n\n NOTE: The unauthenticated user gets information about all the projects when\n using this API endpoint. More permission checking will need to be added,\n if the amount of data being returned is changed.\n\n \"\"\"\n project_id = request.GET.get('project', None)\n if project_id is None:\n project = None\n\n else:\n try:\n project = Project.objects.get(id=project_id)\n except Project.DoesNotExist:\n project = None\n\n if project is None:\n # Search bar - organization projects, published\n projects = _project_directory_coll(request)\n\n else:\n # Project editor - all projects of partners for this project\n projects = Project.objects.of_partners(project.partners.distinct()).distinct()\n\n projects = projects.exclude(title='')\n return Response(\n rejig(projects, TypeaheadProjectSerializer(projects, many=True))\n )\n\n\n@api_view(['GET'])\ndef typeahead_user_projects(request):\n user = request.user\n is_admin = user.is_active and (user.is_superuser or user.is_admin)\n if is_admin:\n projects = Project.objects.all()\n else:\n projects = user.approved_organisations().all_projects()\n projects = projects.exclude(title='')\n return Response(\n rejig(projects, TypeaheadProjectSerializer(projects, many=True))\n )\n\n\n@api_view(['GET'])\ndef typeahead_impact_projects(request):\n user = request.user\n projects = Project.objects.all() if user.is_admin or user.is_superuser else user.my_projects()\n projects = projects.published().filter(is_impact_project=True).order_by('title')\n\n return Response(\n rejig(projects, TypeaheadProjectSerializer(projects, many=True))\n )\n\n\n@api_view(['GET'])\ndef typeahead_projectupdate(request):\n updates = ProjectUpdate.objects.all()\n return Response(\n rejig(updates, TypeaheadProjectUpdateSerializer(updates, many=True))\n )\n", "path": "akvo/rest/views/typeahead.py"}]}
| 1,952 | 386 |
gh_patches_debug_22979
|
rasdani/github-patches
|
git_diff
|
pyro-ppl__pyro-1246
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
lr scheduler not optimizing params
`svi.step()` is not updating parameters with each optimizer. see #1241
</issue>
<code>
[start of pyro/optim/optim.py]
1 from __future__ import absolute_import, division, print_function
2
3 import torch
4
5 import pyro
6 from pyro.optim.adagrad_rmsprop import AdagradRMSProp as pt_AdagradRMSProp
7 from pyro.optim.clipped_adam import ClippedAdam as pt_ClippedAdam
8 from pyro.params import module_from_param_with_module_name, user_param_name
9
10
11 class PyroOptim(object):
12 """
13 A wrapper for torch.optim.Optimizer objects that helps with managing dynamically generated parameters.
14
15 :param optim_constructor: a torch.optim.Optimizer
16 :param optim_args: a dictionary of learning arguments for the optimizer or a callable that returns
17 such dictionaries
18 """
19 def __init__(self, optim_constructor, optim_args):
20 self.pt_optim_constructor = optim_constructor
21
22 # must be callable or dict
23 assert callable(optim_args) or isinstance(
24 optim_args, dict), "optim_args must be function that returns defaults or a defaults dictionary"
25
26 # hold our args to be called/used
27 self.pt_optim_args = optim_args
28
29 # holds the torch optimizer objects
30 self.optim_objs = {}
31
32 # holds the current epoch
33 self.epoch = None
34
35 # any optimizer state that's waiting to be consumed (because that parameter hasn't been seen before)
36 self._state_waiting_to_be_consumed = {}
37
38 def __call__(self, params, *args, **kwargs):
39 """
40 :param params: a list of parameters
41 :type params: an iterable of strings
42
43 Do an optimization step for each param in params. If a given param has never been seen before,
44 initialize an optimizer for it.
45 """
46 for p in params:
47 # if we have not seen this param before, we instantiate and optim object to deal with it
48 if p not in self.optim_objs:
49 # create a single optim object for that param
50 self.optim_objs[p] = self._get_optim(p)
51 # set state from _state_waiting_to_be_consumed if present
52 param_name = pyro.get_param_store().param_name(p)
53 if param_name in self._state_waiting_to_be_consumed:
54 state = self._state_waiting_to_be_consumed.pop(param_name)
55 self.optim_objs[p].load_state_dict(state)
56
57 # actually perform the step for the optim object
58 self.optim_objs[p].step(*args, **kwargs)
59
60 def get_state(self):
61 """
62 Get state associated with all the optimizers in the form of a dictionary with
63 key-value pairs (parameter name, optim state dicts)
64 """
65 state_dict = {}
66 for param in self.optim_objs:
67 param_name = pyro.get_param_store().param_name(param)
68 state_dict[param_name] = self.optim_objs[param].state_dict()
69 return state_dict
70
71 def set_state(self, state_dict):
72 """
73 Set the state associated with all the optimizers using the state obtained
74 from a previous call to get_state()
75 """
76 self._state_waiting_to_be_consumed = state_dict
77
78 def save(self, filename):
79 """
80 :param filename: file name to save to
81 :type name: str
82
83 Save optimizer state to disk
84 """
85 with open(filename, "wb") as output_file:
86 torch.save(self.get_state(), output_file)
87
88 def load(self, filename):
89 """
90 :param filename: file name to load from
91 :type name: str
92
93 Load optimizer state from disk
94 """
95 with open(filename, "rb") as input_file:
96 state = torch.load(input_file)
97 self.set_state(state)
98
99 def _get_optim(self, param):
100 return self.pt_optim_constructor([param], **self._get_optim_args(param))
101
102 # helper to fetch the optim args if callable (only used internally)
103 def _get_optim_args(self, param):
104 # if we were passed a fct, we call fct with param info
105 # arguments are (module name, param name) e.g. ('mymodule', 'bias')
106 if callable(self.pt_optim_args):
107
108 # get param name
109 param_name = pyro.get_param_store().param_name(param)
110 module_name = module_from_param_with_module_name(param_name)
111 stripped_param_name = user_param_name(param_name)
112
113 # invoke the user-provided callable
114 opt_dict = self.pt_optim_args(module_name, stripped_param_name)
115
116 # must be dictionary
117 assert isinstance(opt_dict, dict), "per-param optim arg must return defaults dictionary"
118 return opt_dict
119 else:
120 return self.pt_optim_args
121
122
123 def AdagradRMSProp(optim_args):
124 """
125 A wrapper for an optimizer that is a mash-up of
126 :class:`~torch.optim.Adagrad` and :class:`~torch.optim.RMSprop`.
127 """
128 return PyroOptim(pt_AdagradRMSProp, optim_args)
129
130
131 def ClippedAdam(optim_args):
132 """
133 A wrapper for a modification of the :class:`~torch.optim.Adam`
134 optimization algorithm that supports gradient clipping.
135 """
136 return PyroOptim(pt_ClippedAdam, optim_args)
137
[end of pyro/optim/optim.py]
[start of pyro/optim/lr_scheduler.py]
1 from __future__ import absolute_import, division, print_function
2
3 from pyro.optim.optim import PyroOptim
4
5
6 class PyroLRScheduler(PyroOptim):
7 """
8 A wrapper for torch.optim.lr_scheduler objects that adjust learning rates
9 for dynamically generated parameters.
10
11 :param optim_constructor: a torch.optim.lr_scheduler
12 :param optim_args: a dictionary of learning arguments for the optimizer or a callable that returns
13 such dictionaries. must contain the key 'optimizer' with pytorch optimizer value
14
15 Example::
16
17 optimizer = torch.optim.SGD
18 pyro_scheduler = pyro.optim.ExponentialLR({'optimizer': optimizer, 'optim_args': {'lr': 0.01}, 'gamma': 0.1})
19 """
20 def __init__(self, scheduler_constructor, optim_args):
21 # pytorch scheduler
22 self.pt_scheduler_constructor = scheduler_constructor
23 # torch optimizer
24 pt_optim_constructor = optim_args.pop('optimizer')
25 # kwargs for the torch optimizer
26 optim_kwargs = optim_args.pop('optim_args')
27 self.kwargs = optim_args
28 # current epoch
29 self.epoch = None
30 super(PyroLRScheduler, self).__init__(pt_optim_constructor, optim_kwargs)
31
32 def __call__(self, params, *args, **kwargs):
33 kwargs['epoch'] = self.epoch
34 super(PyroLRScheduler, self).__call__(params, *args, **kwargs)
35
36 def _get_optim(self, params):
37 optim = super(PyroLRScheduler, self)._get_optim(params)
38 return self.pt_scheduler_constructor(optim, **self.kwargs)
39
40 def set_epoch(self, epoch):
41 self.epoch = epoch
42
[end of pyro/optim/lr_scheduler.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/pyro/optim/lr_scheduler.py b/pyro/optim/lr_scheduler.py
--- a/pyro/optim/lr_scheduler.py
+++ b/pyro/optim/lr_scheduler.py
@@ -16,6 +16,8 @@
optimizer = torch.optim.SGD
pyro_scheduler = pyro.optim.ExponentialLR({'optimizer': optimizer, 'optim_args': {'lr': 0.01}, 'gamma': 0.1})
+ svi = SVI(model, guide, pyro_scheduler, loss=TraceGraph_ELBO())
+ svi.step()
"""
def __init__(self, scheduler_constructor, optim_args):
# pytorch scheduler
diff --git a/pyro/optim/optim.py b/pyro/optim/optim.py
--- a/pyro/optim/optim.py
+++ b/pyro/optim/optim.py
@@ -57,6 +57,12 @@
# actually perform the step for the optim object
self.optim_objs[p].step(*args, **kwargs)
+ # if optim object was a scheduler, perform an actual optim step
+ if isinstance(self.optim_objs[p], torch.optim.lr_scheduler._LRScheduler):
+ optim_kwargs = kwargs.copy()
+ optim_kwargs.pop('epoch', None)
+ self.optim_objs[p].optimizer.step(*args, **optim_kwargs)
+
def get_state(self):
"""
Get state associated with all the optimizers in the form of a dictionary with
|
{"golden_diff": "diff --git a/pyro/optim/lr_scheduler.py b/pyro/optim/lr_scheduler.py\n--- a/pyro/optim/lr_scheduler.py\n+++ b/pyro/optim/lr_scheduler.py\n@@ -16,6 +16,8 @@\n \n optimizer = torch.optim.SGD\n pyro_scheduler = pyro.optim.ExponentialLR({'optimizer': optimizer, 'optim_args': {'lr': 0.01}, 'gamma': 0.1})\n+ svi = SVI(model, guide, pyro_scheduler, loss=TraceGraph_ELBO())\n+ svi.step()\n \"\"\"\n def __init__(self, scheduler_constructor, optim_args):\n # pytorch scheduler\ndiff --git a/pyro/optim/optim.py b/pyro/optim/optim.py\n--- a/pyro/optim/optim.py\n+++ b/pyro/optim/optim.py\n@@ -57,6 +57,12 @@\n # actually perform the step for the optim object\n self.optim_objs[p].step(*args, **kwargs)\n \n+ # if optim object was a scheduler, perform an actual optim step\n+ if isinstance(self.optim_objs[p], torch.optim.lr_scheduler._LRScheduler):\n+ optim_kwargs = kwargs.copy()\n+ optim_kwargs.pop('epoch', None)\n+ self.optim_objs[p].optimizer.step(*args, **optim_kwargs)\n+\n def get_state(self):\n \"\"\"\n Get state associated with all the optimizers in the form of a dictionary with\n", "issue": "lr scheduler not optimizing params\n`svi.step()` is not updating parameters with each optimizer. see #1241\n", "before_files": [{"content": "from __future__ import absolute_import, division, print_function\n\nimport torch\n\nimport pyro\nfrom pyro.optim.adagrad_rmsprop import AdagradRMSProp as pt_AdagradRMSProp\nfrom pyro.optim.clipped_adam import ClippedAdam as pt_ClippedAdam\nfrom pyro.params import module_from_param_with_module_name, user_param_name\n\n\nclass PyroOptim(object):\n \"\"\"\n A wrapper for torch.optim.Optimizer objects that helps with managing dynamically generated parameters.\n\n :param optim_constructor: a torch.optim.Optimizer\n :param optim_args: a dictionary of learning arguments for the optimizer or a callable that returns\n such dictionaries\n \"\"\"\n def __init__(self, optim_constructor, optim_args):\n self.pt_optim_constructor = optim_constructor\n\n # must be callable or dict\n assert callable(optim_args) or isinstance(\n optim_args, dict), \"optim_args must be function that returns defaults or a defaults dictionary\"\n\n # hold our args to be called/used\n self.pt_optim_args = optim_args\n\n # holds the torch optimizer objects\n self.optim_objs = {}\n\n # holds the current epoch\n self.epoch = None\n\n # any optimizer state that's waiting to be consumed (because that parameter hasn't been seen before)\n self._state_waiting_to_be_consumed = {}\n\n def __call__(self, params, *args, **kwargs):\n \"\"\"\n :param params: a list of parameters\n :type params: an iterable of strings\n\n Do an optimization step for each param in params. If a given param has never been seen before,\n initialize an optimizer for it.\n \"\"\"\n for p in params:\n # if we have not seen this param before, we instantiate and optim object to deal with it\n if p not in self.optim_objs:\n # create a single optim object for that param\n self.optim_objs[p] = self._get_optim(p)\n # set state from _state_waiting_to_be_consumed if present\n param_name = pyro.get_param_store().param_name(p)\n if param_name in self._state_waiting_to_be_consumed:\n state = self._state_waiting_to_be_consumed.pop(param_name)\n self.optim_objs[p].load_state_dict(state)\n\n # actually perform the step for the optim object\n self.optim_objs[p].step(*args, **kwargs)\n\n def get_state(self):\n \"\"\"\n Get state associated with all the optimizers in the form of a dictionary with\n key-value pairs (parameter name, optim state dicts)\n \"\"\"\n state_dict = {}\n for param in self.optim_objs:\n param_name = pyro.get_param_store().param_name(param)\n state_dict[param_name] = self.optim_objs[param].state_dict()\n return state_dict\n\n def set_state(self, state_dict):\n \"\"\"\n Set the state associated with all the optimizers using the state obtained\n from a previous call to get_state()\n \"\"\"\n self._state_waiting_to_be_consumed = state_dict\n\n def save(self, filename):\n \"\"\"\n :param filename: file name to save to\n :type name: str\n\n Save optimizer state to disk\n \"\"\"\n with open(filename, \"wb\") as output_file:\n torch.save(self.get_state(), output_file)\n\n def load(self, filename):\n \"\"\"\n :param filename: file name to load from\n :type name: str\n\n Load optimizer state from disk\n \"\"\"\n with open(filename, \"rb\") as input_file:\n state = torch.load(input_file)\n self.set_state(state)\n\n def _get_optim(self, param):\n return self.pt_optim_constructor([param], **self._get_optim_args(param))\n\n # helper to fetch the optim args if callable (only used internally)\n def _get_optim_args(self, param):\n # if we were passed a fct, we call fct with param info\n # arguments are (module name, param name) e.g. ('mymodule', 'bias')\n if callable(self.pt_optim_args):\n\n # get param name\n param_name = pyro.get_param_store().param_name(param)\n module_name = module_from_param_with_module_name(param_name)\n stripped_param_name = user_param_name(param_name)\n\n # invoke the user-provided callable\n opt_dict = self.pt_optim_args(module_name, stripped_param_name)\n\n # must be dictionary\n assert isinstance(opt_dict, dict), \"per-param optim arg must return defaults dictionary\"\n return opt_dict\n else:\n return self.pt_optim_args\n\n\ndef AdagradRMSProp(optim_args):\n \"\"\"\n A wrapper for an optimizer that is a mash-up of\n :class:`~torch.optim.Adagrad` and :class:`~torch.optim.RMSprop`.\n \"\"\"\n return PyroOptim(pt_AdagradRMSProp, optim_args)\n\n\ndef ClippedAdam(optim_args):\n \"\"\"\n A wrapper for a modification of the :class:`~torch.optim.Adam`\n optimization algorithm that supports gradient clipping.\n \"\"\"\n return PyroOptim(pt_ClippedAdam, optim_args)\n", "path": "pyro/optim/optim.py"}, {"content": "from __future__ import absolute_import, division, print_function\n\nfrom pyro.optim.optim import PyroOptim\n\n\nclass PyroLRScheduler(PyroOptim):\n \"\"\"\n A wrapper for torch.optim.lr_scheduler objects that adjust learning rates\n for dynamically generated parameters.\n\n :param optim_constructor: a torch.optim.lr_scheduler\n :param optim_args: a dictionary of learning arguments for the optimizer or a callable that returns\n such dictionaries. must contain the key 'optimizer' with pytorch optimizer value\n\n Example::\n\n optimizer = torch.optim.SGD\n pyro_scheduler = pyro.optim.ExponentialLR({'optimizer': optimizer, 'optim_args': {'lr': 0.01}, 'gamma': 0.1})\n \"\"\"\n def __init__(self, scheduler_constructor, optim_args):\n # pytorch scheduler\n self.pt_scheduler_constructor = scheduler_constructor\n # torch optimizer\n pt_optim_constructor = optim_args.pop('optimizer')\n # kwargs for the torch optimizer\n optim_kwargs = optim_args.pop('optim_args')\n self.kwargs = optim_args\n # current epoch\n self.epoch = None\n super(PyroLRScheduler, self).__init__(pt_optim_constructor, optim_kwargs)\n\n def __call__(self, params, *args, **kwargs):\n kwargs['epoch'] = self.epoch\n super(PyroLRScheduler, self).__call__(params, *args, **kwargs)\n\n def _get_optim(self, params):\n optim = super(PyroLRScheduler, self)._get_optim(params)\n return self.pt_scheduler_constructor(optim, **self.kwargs)\n\n def set_epoch(self, epoch):\n self.epoch = epoch\n", "path": "pyro/optim/lr_scheduler.py"}]}
| 2,452 | 323 |
gh_patches_debug_24894
|
rasdani/github-patches
|
git_diff
|
privacyidea__privacyidea-2130
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Better separation of audit log from privacyidea*
Hi,
python logging may be easily separated using the qualname. However, privacyidea uses the module/class names. Since they all start with "privacyidea.", it is not possible to log the audit to one place and all the rest to a different place (python logging cannot *exclude* qualnames).
To solve this, one could use a custom qualname for the privacyidea audit. I think here:
https://github.com/privacyidea/privacyidea/blob/ea7d9e53d42504288ba3909f7057924fe8d250b0/privacyidea/lib/auditmodules/loggeraudit.py#L62
Best regards,
Henning
</issue>
<code>
[start of privacyidea/lib/auditmodules/loggeraudit.py]
1 # -*- coding: utf-8 -*-
2 #
3 # 2019-11-06 Cornelius Kölbel <[email protected]>
4 # initial code for writing audit information to a file
5 #
6 # This code is free software; you can redistribute it and/or
7 # modify it under the terms of the GNU AFFERO GENERAL PUBLIC LICENSE
8 # License as published by the Free Software Foundation; either
9 # version 3 of the License, or any later version.
10 #
11 # This code is distributed in the hope that it will be useful,
12 # but WITHOUT ANY WARRANTY; without even the implied warranty of
13 # MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
14 # GNU AFFERO GENERAL PUBLIC LICENSE for more details.
15 #
16 # You should have received a copy of the GNU Affero General Public
17 # License along with this program. If not, see <http://www.gnu.org/licenses/>.
18 #
19 #
20 __doc__ = """The Logger Audit Module is used to write audit entries to the Python logging module.
21
22 The Logger Audit Module is configured like this:
23
24 PI_AUDIT_MODULE = "privacyidea.lib.auditmodules.loggeraudit"
25 PI_AUDIT_SERVERNAME = "your choice"
26
27 PI_LOGCONFIG = "/etc/privacyidea/logging.cfg"
28
29 The LoggerAudit Class uses the same PI logging config as you could use anyways.
30 To explicitly write audit logs, you need to add something like the following to
31 the logging.cfg
32
33 Example:
34
35 [handlers]
36 keys=file,audit
37
38 [loggers]
39 keys=root,privacyidea,audit
40
41 ...
42
43 [logger_audit]
44 handlers=audit
45 qualname=privacyidea.lib.auditmodules.loggeraudit
46 level=INFO
47
48 [handler_audit]
49 class=logging.handlers.RotatingFileHandler
50 backupCount=14
51 maxBytes=10000000
52 formatter=detail
53 level=INFO
54 args=('/var/log/privacyidea/audit.log',)
55
56 """
57
58 import logging
59 from privacyidea.lib.auditmodules.base import (Audit as AuditBase)
60 import datetime
61
62 log = logging.getLogger(__name__)
63
64
65 class Audit(AuditBase):
66 """
67 This is the LoggerAudit module, which writes the audit entries
68 to the Python logging
69
70 .. note:: This audit module does not provide a *Read* capability.
71 """
72
73 def __init__(self, config=None):
74 super(Audit, self).__init__(config)
75 self.name = "loggeraudit"
76
77 def finalize_log(self):
78 """
79 This method is used to log the data
80 e.g. write the data to a file.
81 """
82 self.audit_data["policies"] = ",".join(self.audit_data.get("policies", []))
83 self.audit_data["timestamp"] = datetime.datetime.utcnow()
84 log.info(u"{0!s}".format(self.audit_data))
85 self.audit_data = {}
86
87
88
[end of privacyidea/lib/auditmodules/loggeraudit.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/privacyidea/lib/auditmodules/loggeraudit.py b/privacyidea/lib/auditmodules/loggeraudit.py
--- a/privacyidea/lib/auditmodules/loggeraudit.py
+++ b/privacyidea/lib/auditmodules/loggeraudit.py
@@ -56,10 +56,9 @@
"""
import logging
+import json
from privacyidea.lib.auditmodules.base import (Audit as AuditBase)
-import datetime
-
-log = logging.getLogger(__name__)
+from datetime import datetime
class Audit(AuditBase):
@@ -73,6 +72,8 @@
def __init__(self, config=None):
super(Audit, self).__init__(config)
self.name = "loggeraudit"
+ self.qualname = self.config.get('PI_AUDIT_LOGGER_QUALNAME', __name__)
+ self.logger = logging.getLogger(self.qualname)
def finalize_log(self):
"""
@@ -80,8 +81,6 @@
e.g. write the data to a file.
"""
self.audit_data["policies"] = ",".join(self.audit_data.get("policies", []))
- self.audit_data["timestamp"] = datetime.datetime.utcnow()
- log.info(u"{0!s}".format(self.audit_data))
+ self.audit_data["timestamp"] = datetime.utcnow().isoformat()
+ self.logger.info("{0!s}".format(json.dumps(self.audit_data, sort_keys=True)))
self.audit_data = {}
-
-
|
{"golden_diff": "diff --git a/privacyidea/lib/auditmodules/loggeraudit.py b/privacyidea/lib/auditmodules/loggeraudit.py\n--- a/privacyidea/lib/auditmodules/loggeraudit.py\n+++ b/privacyidea/lib/auditmodules/loggeraudit.py\n@@ -56,10 +56,9 @@\n \"\"\"\n \n import logging\n+import json\n from privacyidea.lib.auditmodules.base import (Audit as AuditBase)\n-import datetime\n-\n-log = logging.getLogger(__name__)\n+from datetime import datetime\n \n \n class Audit(AuditBase):\n@@ -73,6 +72,8 @@\n def __init__(self, config=None):\n super(Audit, self).__init__(config)\n self.name = \"loggeraudit\"\n+ self.qualname = self.config.get('PI_AUDIT_LOGGER_QUALNAME', __name__)\n+ self.logger = logging.getLogger(self.qualname)\n \n def finalize_log(self):\n \"\"\"\n@@ -80,8 +81,6 @@\n e.g. write the data to a file.\n \"\"\"\n self.audit_data[\"policies\"] = \",\".join(self.audit_data.get(\"policies\", []))\n- self.audit_data[\"timestamp\"] = datetime.datetime.utcnow()\n- log.info(u\"{0!s}\".format(self.audit_data))\n+ self.audit_data[\"timestamp\"] = datetime.utcnow().isoformat()\n+ self.logger.info(\"{0!s}\".format(json.dumps(self.audit_data, sort_keys=True)))\n self.audit_data = {}\n-\n-\n", "issue": "Better separation of audit log from privacyidea*\nHi,\r\n\r\npython logging may be easily separated using the qualname. However, privacyidea uses the module/class names. Since they all start with \"privacyidea.\", it is not possible to log the audit to one place and all the rest to a different place (python logging cannot *exclude* qualnames).\r\n\r\nTo solve this, one could use a custom qualname for the privacyidea audit. I think here:\r\nhttps://github.com/privacyidea/privacyidea/blob/ea7d9e53d42504288ba3909f7057924fe8d250b0/privacyidea/lib/auditmodules/loggeraudit.py#L62\r\n\r\nBest regards,\r\n\r\nHenning\r\n\r\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n#\n# 2019-11-06 Cornelius K\u00f6lbel <[email protected]>\n# initial code for writing audit information to a file\n#\n# This code is free software; you can redistribute it and/or\n# modify it under the terms of the GNU AFFERO GENERAL PUBLIC LICENSE\n# License as published by the Free Software Foundation; either\n# version 3 of the License, or any later version.\n#\n# This code is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU AFFERO GENERAL PUBLIC LICENSE for more details.\n#\n# You should have received a copy of the GNU Affero General Public\n# License along with this program. If not, see <http://www.gnu.org/licenses/>.\n#\n#\n__doc__ = \"\"\"The Logger Audit Module is used to write audit entries to the Python logging module.\n\nThe Logger Audit Module is configured like this:\n\n PI_AUDIT_MODULE = \"privacyidea.lib.auditmodules.loggeraudit\"\n PI_AUDIT_SERVERNAME = \"your choice\"\n\n PI_LOGCONFIG = \"/etc/privacyidea/logging.cfg\"\n\nThe LoggerAudit Class uses the same PI logging config as you could use anyways.\nTo explicitly write audit logs, you need to add something like the following to\nthe logging.cfg\n\nExample:\n\n[handlers]\nkeys=file,audit\n\n[loggers]\nkeys=root,privacyidea,audit\n\n...\n\n[logger_audit]\nhandlers=audit\nqualname=privacyidea.lib.auditmodules.loggeraudit\nlevel=INFO\n\n[handler_audit]\nclass=logging.handlers.RotatingFileHandler\nbackupCount=14\nmaxBytes=10000000\nformatter=detail\nlevel=INFO\nargs=('/var/log/privacyidea/audit.log',)\n\n\"\"\"\n\nimport logging\nfrom privacyidea.lib.auditmodules.base import (Audit as AuditBase)\nimport datetime\n\nlog = logging.getLogger(__name__)\n\n\nclass Audit(AuditBase):\n \"\"\"\n This is the LoggerAudit module, which writes the audit entries\n to the Python logging\n\n .. note:: This audit module does not provide a *Read* capability.\n \"\"\"\n\n def __init__(self, config=None):\n super(Audit, self).__init__(config)\n self.name = \"loggeraudit\"\n\n def finalize_log(self):\n \"\"\"\n This method is used to log the data\n e.g. write the data to a file.\n \"\"\"\n self.audit_data[\"policies\"] = \",\".join(self.audit_data.get(\"policies\", []))\n self.audit_data[\"timestamp\"] = datetime.datetime.utcnow()\n log.info(u\"{0!s}\".format(self.audit_data))\n self.audit_data = {}\n\n\n", "path": "privacyidea/lib/auditmodules/loggeraudit.py"}]}
| 1,489 | 320 |
gh_patches_debug_1290
|
rasdani/github-patches
|
git_diff
|
weecology__retriever-950
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Check MySQL and Postgres credential files
In addition to allowing users to directly provide their MySQL and PostgreSQL credentials, it should also be possible for them to store these credentials in the usual places.
We should check information given by the user to the retriever first, and then fall back on the configuration files for usernames and passwords if they are not provided.
For PostgreSQL this is `~/.pgpass` with the format:
```
hostname:port:database:username:password
```
See: https://wiki.postgresql.org/wiki/Pgpass. `*`s can be used in place of any of the `:` separated values.
For MySQL this is `~/.my.cnf` with the format:
```
[client]
user = root
password = yourpassword
```
See: https://dev.mysql.com/doc/refman/5.5/en/option-files.html. `.my.cnf` can contain a lot of additional configuration information so we'll need to look explicitly for `user =` and `password =`.
</issue>
<code>
[start of retriever/engines/mysql.py]
1 from __future__ import print_function
2 from builtins import str
3 import os
4 from retriever.lib.models import Engine, no_cleanup
5 from retriever import ENCODING
6
7
8 class engine(Engine):
9 """Engine instance for MySQL."""
10 name = "MySQL"
11 abbreviation = "mysql"
12 datatypes = {
13 "auto": "INT(5) NOT NULL AUTO_INCREMENT",
14 "int": "INT",
15 "bigint": "BIGINT",
16 "double": "DOUBLE",
17 "decimal": "DECIMAL",
18 "char": ("TEXT", "VARCHAR"),
19 "bool": "BOOL",
20 }
21 max_int = 4294967295
22 placeholder = "%s"
23 required_opts = [("user",
24 "Enter your MySQL username",
25 "root"),
26 ("password",
27 "Enter your password",
28 ""),
29 ("host",
30 "Enter your MySQL host",
31 "localhost"),
32 ("port",
33 "Enter your MySQL port",
34 3306),
35 ("database_name",
36 "Format of database name",
37 "{db}"),
38 ("table_name",
39 "Format of table name",
40 "{db}.{table}"),
41 ]
42
43 def create_db_statement(self):
44 """Returns a SQL statement to create a database."""
45 createstatement = "CREATE DATABASE IF NOT EXISTS " + self.database_name()
46 return createstatement
47
48 def insert_data_from_file(self, filename):
49 """Calls MySQL "LOAD DATA LOCAL INFILE" statement to perform a bulk
50 insert."""
51
52 mysql_set_autocommit_off = """SET autocommit=0; SET UNIQUE_CHECKS=0; SET FOREIGN_KEY_CHECKS=0; SET sql_log_bin=0;"""
53 mysql_set_autocommit_on = """SET GLOBAL innodb_flush_log_at_trx_commit=1; COMMIT; SET autocommit=1; SET unique_checks=1; SET foreign_key_checks=1;"""
54
55 self.get_cursor()
56 ct = len([True for c in self.table.columns if c[1][0][:3] == "ct-"]) != 0
57 if (self.table.cleanup.function == no_cleanup and
58 not self.table.fixed_width and
59 not ct and
60 (not hasattr(self.table, "do_not_bulk_insert") or not self.table.do_not_bulk_insert)):
61
62 print ("Inserting data from " + os.path.basename(filename) + "...")
63
64 columns = self.table.get_insert_columns()
65 statement = """
66 LOAD DATA LOCAL INFILE '""" + filename.replace("\\", "\\\\") + """'
67 INTO TABLE """ + self.table_name() + """
68 FIELDS TERMINATED BY '""" + self.table.delimiter + """'
69 OPTIONALLY ENCLOSED BY '"'
70 LINES TERMINATED BY '\\n'
71 IGNORE """ + str(self.table.header_rows) + """ LINES
72 (""" + columns + ")"
73 try:
74 self.cursor.execute(mysql_set_autocommit_off)
75 self.cursor.execute(statement)
76
77 self.cursor.execute(mysql_set_autocommit_on)
78 except Exception as e:
79 self.disconnect() # If the execute fails the database connection can get hung up
80 self.cursor.execute(mysql_set_autocommit_on)
81 return Engine.insert_data_from_file(self, filename)
82 else:
83 return Engine.insert_data_from_file(self, filename)
84
85 def table_exists(self, dbname, tablename):
86 """Checks to see if the given table exists"""
87 if not hasattr(self, 'existing_table_names'):
88 self.cursor.execute(
89 "SELECT table_schema, table_name "
90 "FROM information_schema.tables WHERE table_schema NOT IN "
91 "('mysql', 'information_schema', 'performance_schema');")
92 self.existing_table_names = set()
93 for schema, table in self.cursor:
94 self.existing_table_names.add((schema.lower(), table.lower()))
95 return (dbname.lower(), tablename.lower()) in self.existing_table_names
96
97 def set_engine_encoding(self):
98 """Set MySQL database encoding to match data encoding
99
100 Please update the encoding lookup table if the required encoding is not present.
101 """
102 encoding = ENCODING.lower()
103 if self.script.encoding:
104 encoding = self.script.encoding.lower()
105 encoding_lookup = {'iso-8859-1': 'latin1', 'latin-1': 'latin1', 'utf-8': 'utf8'}
106 db_encoding = encoding_lookup.get(encoding)
107 self.execute("SET NAMES '{0}';".format(db_encoding))
108
109 def get_connection(self):
110 """Gets the db connection."""
111 args = {'host': self.opts['host'],
112 'port': int(self.opts['port']),
113 'user': self.opts['user'],
114 'passwd': self.opts['password']}
115 import pymysql as dbapi
116 import pymysql.constants.CLIENT as client
117 args['client_flag'] = client.LOCAL_FILES
118 self.get_input()
119 return dbapi.connect(**args)
120
[end of retriever/engines/mysql.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/retriever/engines/mysql.py b/retriever/engines/mysql.py
--- a/retriever/engines/mysql.py
+++ b/retriever/engines/mysql.py
@@ -116,4 +116,4 @@
import pymysql.constants.CLIENT as client
args['client_flag'] = client.LOCAL_FILES
self.get_input()
- return dbapi.connect(**args)
+ return dbapi.connect(read_default_file='~/.my.cnf', **args)
|
{"golden_diff": "diff --git a/retriever/engines/mysql.py b/retriever/engines/mysql.py\n--- a/retriever/engines/mysql.py\n+++ b/retriever/engines/mysql.py\n@@ -116,4 +116,4 @@\n import pymysql.constants.CLIENT as client\n args['client_flag'] = client.LOCAL_FILES\n self.get_input()\n- return dbapi.connect(**args)\n+ return dbapi.connect(read_default_file='~/.my.cnf', **args)\n", "issue": "Check MySQL and Postgres credential files\nIn addition to allowing users to directly provide their MySQL and PostgreSQL credentials, it should also be possible for them to store these credentials in the usual places.\n\nWe should check information given by the user to the retriever first, and then fall back on the configuration files for usernames and passwords if they are not provided.\n\nFor PostgreSQL this is `~/.pgpass` with the format:\n\n```\nhostname:port:database:username:password \n```\n\nSee: https://wiki.postgresql.org/wiki/Pgpass. `*`s can be used in place of any of the `:` separated values.\n\nFor MySQL this is `~/.my.cnf` with the format:\n\n```\n[client]\nuser = root\npassword = yourpassword\n```\n\nSee: https://dev.mysql.com/doc/refman/5.5/en/option-files.html. `.my.cnf` can contain a lot of additional configuration information so we'll need to look explicitly for `user =` and `password =`.\n\n", "before_files": [{"content": "from __future__ import print_function\nfrom builtins import str\nimport os\nfrom retriever.lib.models import Engine, no_cleanup\nfrom retriever import ENCODING\n\n\nclass engine(Engine):\n \"\"\"Engine instance for MySQL.\"\"\"\n name = \"MySQL\"\n abbreviation = \"mysql\"\n datatypes = {\n \"auto\": \"INT(5) NOT NULL AUTO_INCREMENT\",\n \"int\": \"INT\",\n \"bigint\": \"BIGINT\",\n \"double\": \"DOUBLE\",\n \"decimal\": \"DECIMAL\",\n \"char\": (\"TEXT\", \"VARCHAR\"),\n \"bool\": \"BOOL\",\n }\n max_int = 4294967295\n placeholder = \"%s\"\n required_opts = [(\"user\",\n \"Enter your MySQL username\",\n \"root\"),\n (\"password\",\n \"Enter your password\",\n \"\"),\n (\"host\",\n \"Enter your MySQL host\",\n \"localhost\"),\n (\"port\",\n \"Enter your MySQL port\",\n 3306),\n (\"database_name\",\n \"Format of database name\",\n \"{db}\"),\n (\"table_name\",\n \"Format of table name\",\n \"{db}.{table}\"),\n ]\n\n def create_db_statement(self):\n \"\"\"Returns a SQL statement to create a database.\"\"\"\n createstatement = \"CREATE DATABASE IF NOT EXISTS \" + self.database_name()\n return createstatement\n\n def insert_data_from_file(self, filename):\n \"\"\"Calls MySQL \"LOAD DATA LOCAL INFILE\" statement to perform a bulk\n insert.\"\"\"\n\n mysql_set_autocommit_off = \"\"\"SET autocommit=0; SET UNIQUE_CHECKS=0; SET FOREIGN_KEY_CHECKS=0; SET sql_log_bin=0;\"\"\"\n mysql_set_autocommit_on = \"\"\"SET GLOBAL innodb_flush_log_at_trx_commit=1; COMMIT; SET autocommit=1; SET unique_checks=1; SET foreign_key_checks=1;\"\"\"\n \n self.get_cursor()\n ct = len([True for c in self.table.columns if c[1][0][:3] == \"ct-\"]) != 0\n if (self.table.cleanup.function == no_cleanup and\n not self.table.fixed_width and\n not ct and\n (not hasattr(self.table, \"do_not_bulk_insert\") or not self.table.do_not_bulk_insert)):\n\n print (\"Inserting data from \" + os.path.basename(filename) + \"...\")\n\n columns = self.table.get_insert_columns()\n statement = \"\"\"\nLOAD DATA LOCAL INFILE '\"\"\" + filename.replace(\"\\\\\", \"\\\\\\\\\") + \"\"\"'\nINTO TABLE \"\"\" + self.table_name() + \"\"\"\nFIELDS TERMINATED BY '\"\"\" + self.table.delimiter + \"\"\"'\nOPTIONALLY ENCLOSED BY '\"'\nLINES TERMINATED BY '\\\\n'\nIGNORE \"\"\" + str(self.table.header_rows) + \"\"\" LINES\n(\"\"\" + columns + \")\"\n try:\n self.cursor.execute(mysql_set_autocommit_off)\n self.cursor.execute(statement)\n\n self.cursor.execute(mysql_set_autocommit_on)\n except Exception as e:\n self.disconnect() # If the execute fails the database connection can get hung up\n self.cursor.execute(mysql_set_autocommit_on)\n return Engine.insert_data_from_file(self, filename)\n else:\n return Engine.insert_data_from_file(self, filename)\n\n def table_exists(self, dbname, tablename):\n \"\"\"Checks to see if the given table exists\"\"\"\n if not hasattr(self, 'existing_table_names'):\n self.cursor.execute(\n \"SELECT table_schema, table_name \"\n \"FROM information_schema.tables WHERE table_schema NOT IN \"\n \"('mysql', 'information_schema', 'performance_schema');\")\n self.existing_table_names = set()\n for schema, table in self.cursor:\n self.existing_table_names.add((schema.lower(), table.lower()))\n return (dbname.lower(), tablename.lower()) in self.existing_table_names\n\n def set_engine_encoding(self):\n \"\"\"Set MySQL database encoding to match data encoding\n\n Please update the encoding lookup table if the required encoding is not present.\n \"\"\"\n encoding = ENCODING.lower()\n if self.script.encoding:\n encoding = self.script.encoding.lower()\n encoding_lookup = {'iso-8859-1': 'latin1', 'latin-1': 'latin1', 'utf-8': 'utf8'}\n db_encoding = encoding_lookup.get(encoding)\n self.execute(\"SET NAMES '{0}';\".format(db_encoding))\n\n def get_connection(self):\n \"\"\"Gets the db connection.\"\"\"\n args = {'host': self.opts['host'],\n 'port': int(self.opts['port']),\n 'user': self.opts['user'],\n 'passwd': self.opts['password']}\n import pymysql as dbapi\n import pymysql.constants.CLIENT as client\n args['client_flag'] = client.LOCAL_FILES\n self.get_input()\n return dbapi.connect(**args)\n", "path": "retriever/engines/mysql.py"}]}
| 2,029 | 111 |
gh_patches_debug_3942
|
rasdani/github-patches
|
git_diff
|
pre-commit__pre-commit-2979
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
CPU count logic does not distinguish "usable" CPUs inside cgroup'd containers (e.g. inside k8s)
### search you tried in the issue tracker
multiprocessing, k8s, usable, cpu
### describe your issue
When invoking pre-commit from within a container environment with cgroup cpu enforcement, pre-commit fans out more than expected (based on the total number of CPUs rather than the number of _usable_ CPUs). This ends up causing unexpected behaviour and makes it hard to optimise for performance when running hooks in CI inside containers (since [pre-commit's parallelism is non-configurable](https://github.com/pre-commit/pre-commit/issues/1710)), which leaves us with either "shard using too many CPUs" or `require_serial: true`, both of which aren't ideal.
The cause is seemingly due to the implementation in xargs.py: https://github.com/pre-commit/pre-commit/blob/bde292b51078357384602ebe6b9b27b1906987e5/pre_commit/xargs.py#L28 which uses `multiprocessing.cpu_count()`, which is documented to [not [be] equivalent to the number of CPUs the current process can use](https://docs.python.org/3/library/multiprocessing.html#:~:text=This%20number%20is%20not%20equivalent%20to%20the%20number%20of%20CPUs%20the%20current%20process%20can%20use.%20The%20number%20of%20usable%20CPUs%20can%20be%20obtained%20with%20len(os.sched_getaffinity(0))). This is confirmed by running `python3 -c 'import multiprocessing; print(multiprocessing.cpu_count())'` inside the container environment: the number is higher than expected.
From the docs, it looks like a cgroup-compatible way of grabbing the number of usable CPUs would be to use `len(os.sched_getaffinity(0))`, but I don't know if that has undesirable downsides. I also don't know if this would be a disruptive breaking change to anyone relying on the old behaviour, so I wanted to make this issue first to get your thoughts.
### pre-commit --version
pre-commit 2.19.0
### .pre-commit-config.yaml
```yaml
n/a - can provide a dummy config invoking `python3 -c 'import multiprocessing; print(multiprocessing.cpu_count())'` if more info needed, but this isn't specific to any one hook or config option
```
### ~/.cache/pre-commit/pre-commit.log (if present)
_No response_
</issue>
<code>
[start of pre_commit/xargs.py]
1 from __future__ import annotations
2
3 import concurrent.futures
4 import contextlib
5 import math
6 import multiprocessing
7 import os
8 import subprocess
9 import sys
10 from typing import Any
11 from typing import Callable
12 from typing import Generator
13 from typing import Iterable
14 from typing import MutableMapping
15 from typing import Sequence
16 from typing import TypeVar
17
18 from pre_commit import parse_shebang
19 from pre_commit.util import cmd_output_b
20 from pre_commit.util import cmd_output_p
21
22 TArg = TypeVar('TArg')
23 TRet = TypeVar('TRet')
24
25
26 def cpu_count() -> int:
27 try:
28 return multiprocessing.cpu_count()
29 except NotImplementedError:
30 return 1
31
32
33 def _environ_size(_env: MutableMapping[str, str] | None = None) -> int:
34 environ = _env if _env is not None else getattr(os, 'environb', os.environ)
35 size = 8 * len(environ) # number of pointers in `envp`
36 for k, v in environ.items():
37 size += len(k) + len(v) + 2 # c strings in `envp`
38 return size
39
40
41 def _get_platform_max_length() -> int: # pragma: no cover (platform specific)
42 if os.name == 'posix':
43 maximum = os.sysconf('SC_ARG_MAX') - 2048 - _environ_size()
44 maximum = max(min(maximum, 2 ** 17), 2 ** 12)
45 return maximum
46 elif os.name == 'nt':
47 return 2 ** 15 - 2048 # UNICODE_STRING max - headroom
48 else:
49 # posix minimum
50 return 2 ** 12
51
52
53 def _command_length(*cmd: str) -> int:
54 full_cmd = ' '.join(cmd)
55
56 # win32 uses the amount of characters, more details at:
57 # https://github.com/pre-commit/pre-commit/pull/839
58 if sys.platform == 'win32':
59 return len(full_cmd.encode('utf-16le')) // 2
60 else:
61 return len(full_cmd.encode(sys.getfilesystemencoding()))
62
63
64 class ArgumentTooLongError(RuntimeError):
65 pass
66
67
68 def partition(
69 cmd: Sequence[str],
70 varargs: Sequence[str],
71 target_concurrency: int,
72 _max_length: int | None = None,
73 ) -> tuple[tuple[str, ...], ...]:
74 _max_length = _max_length or _get_platform_max_length()
75
76 # Generally, we try to partition evenly into at least `target_concurrency`
77 # partitions, but we don't want a bunch of tiny partitions.
78 max_args = max(4, math.ceil(len(varargs) / target_concurrency))
79
80 cmd = tuple(cmd)
81 ret = []
82
83 ret_cmd: list[str] = []
84 # Reversed so arguments are in order
85 varargs = list(reversed(varargs))
86
87 total_length = _command_length(*cmd) + 1
88 while varargs:
89 arg = varargs.pop()
90
91 arg_length = _command_length(arg) + 1
92 if (
93 total_length + arg_length <= _max_length and
94 len(ret_cmd) < max_args
95 ):
96 ret_cmd.append(arg)
97 total_length += arg_length
98 elif not ret_cmd:
99 raise ArgumentTooLongError(arg)
100 else:
101 # We've exceeded the length, yield a command
102 ret.append(cmd + tuple(ret_cmd))
103 ret_cmd = []
104 total_length = _command_length(*cmd) + 1
105 varargs.append(arg)
106
107 ret.append(cmd + tuple(ret_cmd))
108
109 return tuple(ret)
110
111
112 @contextlib.contextmanager
113 def _thread_mapper(maxsize: int) -> Generator[
114 Callable[[Callable[[TArg], TRet], Iterable[TArg]], Iterable[TRet]],
115 None, None,
116 ]:
117 if maxsize == 1:
118 yield map
119 else:
120 with concurrent.futures.ThreadPoolExecutor(maxsize) as ex:
121 yield ex.map
122
123
124 def xargs(
125 cmd: tuple[str, ...],
126 varargs: Sequence[str],
127 *,
128 color: bool = False,
129 target_concurrency: int = 1,
130 _max_length: int = _get_platform_max_length(),
131 **kwargs: Any,
132 ) -> tuple[int, bytes]:
133 """A simplified implementation of xargs.
134
135 color: Make a pty if on a platform that supports it
136 target_concurrency: Target number of partitions to run concurrently
137 """
138 cmd_fn = cmd_output_p if color else cmd_output_b
139 retcode = 0
140 stdout = b''
141
142 try:
143 cmd = parse_shebang.normalize_cmd(cmd)
144 except parse_shebang.ExecutableNotFoundError as e:
145 return e.to_output()[:2]
146
147 # on windows, batch files have a separate length limit than windows itself
148 if (
149 sys.platform == 'win32' and
150 cmd[0].lower().endswith(('.bat', '.cmd'))
151 ): # pragma: win32 cover
152 # this is implementation details but the command gets translated into
153 # full/path/to/cmd.exe /c *cmd
154 cmd_exe = parse_shebang.find_executable('cmd.exe')
155 # 1024 is additionally subtracted to give headroom for further
156 # expansion inside the batch file
157 _max_length = 8192 - len(cmd_exe) - len(' /c ') - 1024
158
159 partitions = partition(cmd, varargs, target_concurrency, _max_length)
160
161 def run_cmd_partition(
162 run_cmd: tuple[str, ...],
163 ) -> tuple[int, bytes, bytes | None]:
164 return cmd_fn(
165 *run_cmd, check=False, stderr=subprocess.STDOUT, **kwargs,
166 )
167
168 threads = min(len(partitions), target_concurrency)
169 with _thread_mapper(threads) as thread_map:
170 results = thread_map(run_cmd_partition, partitions)
171
172 for proc_retcode, proc_out, _ in results:
173 if abs(proc_retcode) > abs(retcode):
174 retcode = proc_retcode
175 stdout += proc_out
176
177 return retcode, stdout
178
[end of pre_commit/xargs.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/pre_commit/xargs.py b/pre_commit/xargs.py
--- a/pre_commit/xargs.py
+++ b/pre_commit/xargs.py
@@ -24,6 +24,14 @@
def cpu_count() -> int:
+ try:
+ # On systems that support it, this will return a more accurate count of
+ # usable CPUs for the current process, which will take into account
+ # cgroup limits
+ return len(os.sched_getaffinity(0))
+ except AttributeError:
+ pass
+
try:
return multiprocessing.cpu_count()
except NotImplementedError:
|
{"golden_diff": "diff --git a/pre_commit/xargs.py b/pre_commit/xargs.py\n--- a/pre_commit/xargs.py\n+++ b/pre_commit/xargs.py\n@@ -24,6 +24,14 @@\n \n \n def cpu_count() -> int:\n+ try:\n+ # On systems that support it, this will return a more accurate count of\n+ # usable CPUs for the current process, which will take into account\n+ # cgroup limits\n+ return len(os.sched_getaffinity(0))\n+ except AttributeError:\n+ pass\n+\n try:\n return multiprocessing.cpu_count()\n except NotImplementedError:\n", "issue": "CPU count logic does not distinguish \"usable\" CPUs inside cgroup'd containers (e.g. inside k8s)\n### search you tried in the issue tracker\r\n\r\nmultiprocessing, k8s, usable, cpu\r\n\r\n### describe your issue\r\n\r\nWhen invoking pre-commit from within a container environment with cgroup cpu enforcement, pre-commit fans out more than expected (based on the total number of CPUs rather than the number of _usable_ CPUs). This ends up causing unexpected behaviour and makes it hard to optimise for performance when running hooks in CI inside containers (since [pre-commit's parallelism is non-configurable](https://github.com/pre-commit/pre-commit/issues/1710)), which leaves us with either \"shard using too many CPUs\" or `require_serial: true`, both of which aren't ideal.\r\n\r\nThe cause is seemingly due to the implementation in xargs.py: https://github.com/pre-commit/pre-commit/blob/bde292b51078357384602ebe6b9b27b1906987e5/pre_commit/xargs.py#L28 which uses `multiprocessing.cpu_count()`, which is documented to [not [be] equivalent to the number of CPUs the current process can use](https://docs.python.org/3/library/multiprocessing.html#:~:text=This%20number%20is%20not%20equivalent%20to%20the%20number%20of%20CPUs%20the%20current%20process%20can%20use.%20The%20number%20of%20usable%20CPUs%20can%20be%20obtained%20with%20len(os.sched_getaffinity(0))). This is confirmed by running `python3 -c 'import multiprocessing; print(multiprocessing.cpu_count())'` inside the container environment: the number is higher than expected.\r\n\r\nFrom the docs, it looks like a cgroup-compatible way of grabbing the number of usable CPUs would be to use `len(os.sched_getaffinity(0))`, but I don't know if that has undesirable downsides. I also don't know if this would be a disruptive breaking change to anyone relying on the old behaviour, so I wanted to make this issue first to get your thoughts.\r\n\r\n### pre-commit --version\r\n\r\npre-commit 2.19.0\r\n\r\n### .pre-commit-config.yaml\r\n\r\n```yaml\r\nn/a - can provide a dummy config invoking `python3 -c 'import multiprocessing; print(multiprocessing.cpu_count())'` if more info needed, but this isn't specific to any one hook or config option\r\n```\r\n\r\n\r\n### ~/.cache/pre-commit/pre-commit.log (if present)\r\n\r\n_No response_\n", "before_files": [{"content": "from __future__ import annotations\n\nimport concurrent.futures\nimport contextlib\nimport math\nimport multiprocessing\nimport os\nimport subprocess\nimport sys\nfrom typing import Any\nfrom typing import Callable\nfrom typing import Generator\nfrom typing import Iterable\nfrom typing import MutableMapping\nfrom typing import Sequence\nfrom typing import TypeVar\n\nfrom pre_commit import parse_shebang\nfrom pre_commit.util import cmd_output_b\nfrom pre_commit.util import cmd_output_p\n\nTArg = TypeVar('TArg')\nTRet = TypeVar('TRet')\n\n\ndef cpu_count() -> int:\n try:\n return multiprocessing.cpu_count()\n except NotImplementedError:\n return 1\n\n\ndef _environ_size(_env: MutableMapping[str, str] | None = None) -> int:\n environ = _env if _env is not None else getattr(os, 'environb', os.environ)\n size = 8 * len(environ) # number of pointers in `envp`\n for k, v in environ.items():\n size += len(k) + len(v) + 2 # c strings in `envp`\n return size\n\n\ndef _get_platform_max_length() -> int: # pragma: no cover (platform specific)\n if os.name == 'posix':\n maximum = os.sysconf('SC_ARG_MAX') - 2048 - _environ_size()\n maximum = max(min(maximum, 2 ** 17), 2 ** 12)\n return maximum\n elif os.name == 'nt':\n return 2 ** 15 - 2048 # UNICODE_STRING max - headroom\n else:\n # posix minimum\n return 2 ** 12\n\n\ndef _command_length(*cmd: str) -> int:\n full_cmd = ' '.join(cmd)\n\n # win32 uses the amount of characters, more details at:\n # https://github.com/pre-commit/pre-commit/pull/839\n if sys.platform == 'win32':\n return len(full_cmd.encode('utf-16le')) // 2\n else:\n return len(full_cmd.encode(sys.getfilesystemencoding()))\n\n\nclass ArgumentTooLongError(RuntimeError):\n pass\n\n\ndef partition(\n cmd: Sequence[str],\n varargs: Sequence[str],\n target_concurrency: int,\n _max_length: int | None = None,\n) -> tuple[tuple[str, ...], ...]:\n _max_length = _max_length or _get_platform_max_length()\n\n # Generally, we try to partition evenly into at least `target_concurrency`\n # partitions, but we don't want a bunch of tiny partitions.\n max_args = max(4, math.ceil(len(varargs) / target_concurrency))\n\n cmd = tuple(cmd)\n ret = []\n\n ret_cmd: list[str] = []\n # Reversed so arguments are in order\n varargs = list(reversed(varargs))\n\n total_length = _command_length(*cmd) + 1\n while varargs:\n arg = varargs.pop()\n\n arg_length = _command_length(arg) + 1\n if (\n total_length + arg_length <= _max_length and\n len(ret_cmd) < max_args\n ):\n ret_cmd.append(arg)\n total_length += arg_length\n elif not ret_cmd:\n raise ArgumentTooLongError(arg)\n else:\n # We've exceeded the length, yield a command\n ret.append(cmd + tuple(ret_cmd))\n ret_cmd = []\n total_length = _command_length(*cmd) + 1\n varargs.append(arg)\n\n ret.append(cmd + tuple(ret_cmd))\n\n return tuple(ret)\n\n\[email protected]\ndef _thread_mapper(maxsize: int) -> Generator[\n Callable[[Callable[[TArg], TRet], Iterable[TArg]], Iterable[TRet]],\n None, None,\n]:\n if maxsize == 1:\n yield map\n else:\n with concurrent.futures.ThreadPoolExecutor(maxsize) as ex:\n yield ex.map\n\n\ndef xargs(\n cmd: tuple[str, ...],\n varargs: Sequence[str],\n *,\n color: bool = False,\n target_concurrency: int = 1,\n _max_length: int = _get_platform_max_length(),\n **kwargs: Any,\n) -> tuple[int, bytes]:\n \"\"\"A simplified implementation of xargs.\n\n color: Make a pty if on a platform that supports it\n target_concurrency: Target number of partitions to run concurrently\n \"\"\"\n cmd_fn = cmd_output_p if color else cmd_output_b\n retcode = 0\n stdout = b''\n\n try:\n cmd = parse_shebang.normalize_cmd(cmd)\n except parse_shebang.ExecutableNotFoundError as e:\n return e.to_output()[:2]\n\n # on windows, batch files have a separate length limit than windows itself\n if (\n sys.platform == 'win32' and\n cmd[0].lower().endswith(('.bat', '.cmd'))\n ): # pragma: win32 cover\n # this is implementation details but the command gets translated into\n # full/path/to/cmd.exe /c *cmd\n cmd_exe = parse_shebang.find_executable('cmd.exe')\n # 1024 is additionally subtracted to give headroom for further\n # expansion inside the batch file\n _max_length = 8192 - len(cmd_exe) - len(' /c ') - 1024\n\n partitions = partition(cmd, varargs, target_concurrency, _max_length)\n\n def run_cmd_partition(\n run_cmd: tuple[str, ...],\n ) -> tuple[int, bytes, bytes | None]:\n return cmd_fn(\n *run_cmd, check=False, stderr=subprocess.STDOUT, **kwargs,\n )\n\n threads = min(len(partitions), target_concurrency)\n with _thread_mapper(threads) as thread_map:\n results = thread_map(run_cmd_partition, partitions)\n\n for proc_retcode, proc_out, _ in results:\n if abs(proc_retcode) > abs(retcode):\n retcode = proc_retcode\n stdout += proc_out\n\n return retcode, stdout\n", "path": "pre_commit/xargs.py"}]}
| 2,909 | 134 |
gh_patches_debug_2231
|
rasdani/github-patches
|
git_diff
|
pytorch__ignite-751
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
correct the type hints of this function
https://github.com/pytorch/ignite/blob/ca738d8f3f106093aa04b6bce9506129a1059df8/ignite/engine/events.py#L81
this really should read
` def wrapper(engine, event: int) -> bool:`
</issue>
<code>
[start of ignite/engine/events.py]
1
2 from typing import Callable, Optional, Union, Any
3
4 from enum import Enum
5 import numbers
6 import weakref
7
8 from ignite.engine.utils import _check_signature
9
10
11 __all__ = [
12 'Events',
13 'State'
14 ]
15
16
17 class EventWithFilter:
18
19 def __init__(self, event: Any, filter: Callable):
20 if not callable(filter):
21 raise TypeError("Argument filter should be callable")
22 self.event = event
23 self.filter = filter
24
25 def __str__(self) -> str:
26 return "<%s event=%s, filter=%r>" % (self.__class__.__name__, self.event, self.filter)
27
28
29 class CallableEvents:
30 """Base class for Events implementing call operator and storing event filter. This class should be inherited
31 for any custom events with event filtering feature:
32
33 .. code-block:: python
34
35 from ignite.engine.engine import CallableEvents
36
37 class CustomEvents(CallableEvents, Enum):
38 TEST_EVENT = "test_event"
39
40 engine = ...
41 engine.register_events(*CustomEvents, event_to_attr={CustomEvents.TEST_EVENT: "test_event"})
42
43 @engine.on(CustomEvents.TEST_EVENT(every=5))
44 def call_on_test_event_every(engine):
45 # do something
46
47 """
48
49 def __call__(self, event_filter: Optional[Callable] = None,
50 every: Optional[int] = None, once: Optional[int] = None):
51
52 if not ((event_filter is not None) ^ (every is not None) ^ (once is not None)):
53 raise ValueError("Only one of the input arguments should be specified")
54
55 if (event_filter is not None) and not callable(event_filter):
56 raise TypeError("Argument event_filter should be a callable")
57
58 if (every is not None) and not (isinstance(every, numbers.Integral) and every > 0):
59 raise ValueError("Argument every should be integer and greater than zero")
60
61 if (once is not None) and not (isinstance(once, numbers.Integral) and once > 0):
62 raise ValueError("Argument every should be integer and positive")
63
64 if every is not None:
65 if every == 1:
66 # Just return the event itself
67 return self
68 event_filter = CallableEvents.every_event_filter(every)
69
70 if once is not None:
71 event_filter = CallableEvents.once_event_filter(once)
72
73 # check signature:
74 _check_signature("engine", event_filter, "event_filter", "event")
75
76 return EventWithFilter(self, event_filter)
77
78 @staticmethod
79 def every_event_filter(every: int) -> Callable:
80 def wrapper(engine, event: bool):
81 if event % every == 0:
82 return True
83 return False
84
85 return wrapper
86
87 @staticmethod
88 def once_event_filter(once: int) -> Callable:
89 def wrapper(engine, event: int) -> bool:
90 if event == once:
91 return True
92 return False
93
94 return wrapper
95
96
97 class Events(CallableEvents, Enum):
98 """Events that are fired by the :class:`~ignite.engine.Engine` during execution.
99
100 Since v0.3.0, Events become more flexible and allow to pass an event filter to the Engine:
101
102 .. code-block:: python
103
104 engine = Engine()
105
106 # a) custom event filter
107 def custom_event_filter(engine, event):
108 if event in [1, 2, 5, 10, 50, 100]:
109 return True
110 return False
111
112 @engine.on(Events.ITERATION_STARTED(event_filter=custom_event_filter))
113 def call_on_special_event(engine):
114 # do something on 1, 2, 5, 10, 50, 100 iterations
115
116 # b) "every" event filter
117 @engine.on(Events.ITERATION_STARTED(every=10))
118 def call_every(engine):
119 # do something every 10th iteration
120
121 # c) "once" event filter
122 @engine.on(Events.ITERATION_STARTED(once=50))
123 def call_once(engine):
124 # do something on 50th iteration
125
126 Event filter function `event_filter` accepts as input `engine` and `event` and should return True/False.
127 Argument `event` is the value of iteration or epoch, depending on which type of Events the function is passed.
128
129 """
130 EPOCH_STARTED = "epoch_started"
131 EPOCH_COMPLETED = "epoch_completed"
132 STARTED = "started"
133 COMPLETED = "completed"
134 ITERATION_STARTED = "iteration_started"
135 ITERATION_COMPLETED = "iteration_completed"
136 EXCEPTION_RAISED = "exception_raised"
137
138 GET_BATCH_STARTED = "get_batch_started"
139 GET_BATCH_COMPLETED = "get_batch_completed"
140
141
142 class State:
143 """An object that is used to pass internal and user-defined state between event handlers. By default, state
144 contains the following attributes:
145
146 .. code-block:: python
147
148 state.iteration # 1-based, the first iteration is 1
149 state.epoch # 1-based, the first epoch is 1
150 state.seed # seed to set at each epoch
151 state.dataloader # data passed to engine
152 state.epoch_length # optional length of an epoch
153 state.max_epochs # number of epochs to run
154 state.batch # batch passed to `process_function`
155 state.output # output of `process_function` after a single iteration
156 state.metrics # dictionary with defined metrics if any
157
158 """
159
160 event_to_attr = {
161 Events.GET_BATCH_STARTED: "iteration",
162 Events.GET_BATCH_COMPLETED: "iteration",
163 Events.ITERATION_STARTED: "iteration",
164 Events.ITERATION_COMPLETED: "iteration",
165 Events.EPOCH_STARTED: "epoch",
166 Events.EPOCH_COMPLETED: "epoch",
167 Events.STARTED: "epoch",
168 Events.COMPLETED: "epoch",
169 }
170
171 def __init__(self, **kwargs):
172 self.iteration = 0
173 self.epoch = 0
174 self.epoch_length = None
175 self.max_epochs = None
176 self.output = None
177 self.batch = None
178 self.metrics = {}
179 self.dataloader = None
180 self.seed = None
181
182 for k, v in kwargs.items():
183 setattr(self, k, v)
184
185 for value in self.event_to_attr.values():
186 if not hasattr(self, value):
187 setattr(self, value, 0)
188
189 def get_event_attrib_value(self, event_name: Union[EventWithFilter, CallableEvents, Enum]) -> int:
190 if isinstance(event_name, EventWithFilter):
191 event_name = event_name.event
192 if event_name not in State.event_to_attr:
193 raise RuntimeError("Unknown event name '{}'".format(event_name))
194 return getattr(self, State.event_to_attr[event_name])
195
196 def __repr__(self) -> str:
197 s = "State:\n"
198 for attr, value in self.__dict__.items():
199 if not isinstance(value, (numbers.Number, str)):
200 value = type(value)
201 s += "\t{}: {}\n".format(attr, value)
202 return s
203
204
205 class RemovableEventHandle:
206 """A weakref handle to remove a registered event.
207
208 A handle that may be used to remove a registered event handler via the
209 remove method, with-statement, or context manager protocol. Returned from
210 :meth:`~ignite.engine.Engine.add_event_handler`.
211
212
213 Args:
214 event_name: Registered event name.
215 handler: Registered event handler, stored as weakref.
216 engine: Target engine, stored as weakref.
217
218 Example usage:
219
220 .. code-block:: python
221
222 engine = Engine()
223
224 def print_epoch(engine):
225 print("Epoch: {}".format(engine.state.epoch))
226
227 with engine.add_event_handler(Events.EPOCH_COMPLETED, print_epoch):
228 # print_epoch handler registered for a single run
229 engine.run(data)
230
231 # print_epoch handler is now unregistered
232 """
233
234 def __init__(self, event_name: Union[EventWithFilter, CallableEvents, Enum], handler: Callable, engine):
235 self.event_name = event_name
236 self.handler = weakref.ref(handler)
237 self.engine = weakref.ref(engine)
238
239 def remove(self) -> None:
240 """Remove handler from engine."""
241 handler = self.handler()
242 engine = self.engine()
243
244 if handler is None or engine is None:
245 return
246
247 if engine.has_event_handler(handler, self.event_name):
248 engine.remove_event_handler(handler, self.event_name)
249
250 def __enter__(self):
251 return self
252
253 def __exit__(self, *args, **kwargs) -> None:
254 self.remove()
255
[end of ignite/engine/events.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/ignite/engine/events.py b/ignite/engine/events.py
--- a/ignite/engine/events.py
+++ b/ignite/engine/events.py
@@ -77,7 +77,7 @@
@staticmethod
def every_event_filter(every: int) -> Callable:
- def wrapper(engine, event: bool):
+ def wrapper(engine, event: int) -> bool:
if event % every == 0:
return True
return False
|
{"golden_diff": "diff --git a/ignite/engine/events.py b/ignite/engine/events.py\n--- a/ignite/engine/events.py\n+++ b/ignite/engine/events.py\n@@ -77,7 +77,7 @@\n \n @staticmethod\n def every_event_filter(every: int) -> Callable:\n- def wrapper(engine, event: bool):\n+ def wrapper(engine, event: int) -> bool:\n if event % every == 0:\n return True\n return False\n", "issue": "correct the type hints of this function\nhttps://github.com/pytorch/ignite/blob/ca738d8f3f106093aa04b6bce9506129a1059df8/ignite/engine/events.py#L81\r\n\r\nthis really should read\r\n\r\n` def wrapper(engine, event: int) -> bool:`\n", "before_files": [{"content": "\nfrom typing import Callable, Optional, Union, Any\n\nfrom enum import Enum\nimport numbers\nimport weakref\n\nfrom ignite.engine.utils import _check_signature\n\n\n__all__ = [\n 'Events',\n 'State'\n]\n\n\nclass EventWithFilter:\n\n def __init__(self, event: Any, filter: Callable):\n if not callable(filter):\n raise TypeError(\"Argument filter should be callable\")\n self.event = event\n self.filter = filter\n\n def __str__(self) -> str:\n return \"<%s event=%s, filter=%r>\" % (self.__class__.__name__, self.event, self.filter)\n\n\nclass CallableEvents:\n \"\"\"Base class for Events implementing call operator and storing event filter. This class should be inherited\n for any custom events with event filtering feature:\n\n .. code-block:: python\n\n from ignite.engine.engine import CallableEvents\n\n class CustomEvents(CallableEvents, Enum):\n TEST_EVENT = \"test_event\"\n\n engine = ...\n engine.register_events(*CustomEvents, event_to_attr={CustomEvents.TEST_EVENT: \"test_event\"})\n\n @engine.on(CustomEvents.TEST_EVENT(every=5))\n def call_on_test_event_every(engine):\n # do something\n\n \"\"\"\n\n def __call__(self, event_filter: Optional[Callable] = None,\n every: Optional[int] = None, once: Optional[int] = None):\n\n if not ((event_filter is not None) ^ (every is not None) ^ (once is not None)):\n raise ValueError(\"Only one of the input arguments should be specified\")\n\n if (event_filter is not None) and not callable(event_filter):\n raise TypeError(\"Argument event_filter should be a callable\")\n\n if (every is not None) and not (isinstance(every, numbers.Integral) and every > 0):\n raise ValueError(\"Argument every should be integer and greater than zero\")\n\n if (once is not None) and not (isinstance(once, numbers.Integral) and once > 0):\n raise ValueError(\"Argument every should be integer and positive\")\n\n if every is not None:\n if every == 1:\n # Just return the event itself\n return self\n event_filter = CallableEvents.every_event_filter(every)\n\n if once is not None:\n event_filter = CallableEvents.once_event_filter(once)\n\n # check signature:\n _check_signature(\"engine\", event_filter, \"event_filter\", \"event\")\n\n return EventWithFilter(self, event_filter)\n\n @staticmethod\n def every_event_filter(every: int) -> Callable:\n def wrapper(engine, event: bool):\n if event % every == 0:\n return True\n return False\n\n return wrapper\n\n @staticmethod\n def once_event_filter(once: int) -> Callable:\n def wrapper(engine, event: int) -> bool:\n if event == once:\n return True\n return False\n\n return wrapper\n\n\nclass Events(CallableEvents, Enum):\n \"\"\"Events that are fired by the :class:`~ignite.engine.Engine` during execution.\n\n Since v0.3.0, Events become more flexible and allow to pass an event filter to the Engine:\n\n .. code-block:: python\n\n engine = Engine()\n\n # a) custom event filter\n def custom_event_filter(engine, event):\n if event in [1, 2, 5, 10, 50, 100]:\n return True\n return False\n\n @engine.on(Events.ITERATION_STARTED(event_filter=custom_event_filter))\n def call_on_special_event(engine):\n # do something on 1, 2, 5, 10, 50, 100 iterations\n\n # b) \"every\" event filter\n @engine.on(Events.ITERATION_STARTED(every=10))\n def call_every(engine):\n # do something every 10th iteration\n\n # c) \"once\" event filter\n @engine.on(Events.ITERATION_STARTED(once=50))\n def call_once(engine):\n # do something on 50th iteration\n\n Event filter function `event_filter` accepts as input `engine` and `event` and should return True/False.\n Argument `event` is the value of iteration or epoch, depending on which type of Events the function is passed.\n\n \"\"\"\n EPOCH_STARTED = \"epoch_started\"\n EPOCH_COMPLETED = \"epoch_completed\"\n STARTED = \"started\"\n COMPLETED = \"completed\"\n ITERATION_STARTED = \"iteration_started\"\n ITERATION_COMPLETED = \"iteration_completed\"\n EXCEPTION_RAISED = \"exception_raised\"\n\n GET_BATCH_STARTED = \"get_batch_started\"\n GET_BATCH_COMPLETED = \"get_batch_completed\"\n\n\nclass State:\n \"\"\"An object that is used to pass internal and user-defined state between event handlers. By default, state\n contains the following attributes:\n\n .. code-block:: python\n\n state.iteration # 1-based, the first iteration is 1\n state.epoch # 1-based, the first epoch is 1\n state.seed # seed to set at each epoch\n state.dataloader # data passed to engine\n state.epoch_length # optional length of an epoch\n state.max_epochs # number of epochs to run\n state.batch # batch passed to `process_function`\n state.output # output of `process_function` after a single iteration\n state.metrics # dictionary with defined metrics if any\n\n \"\"\"\n\n event_to_attr = {\n Events.GET_BATCH_STARTED: \"iteration\",\n Events.GET_BATCH_COMPLETED: \"iteration\",\n Events.ITERATION_STARTED: \"iteration\",\n Events.ITERATION_COMPLETED: \"iteration\",\n Events.EPOCH_STARTED: \"epoch\",\n Events.EPOCH_COMPLETED: \"epoch\",\n Events.STARTED: \"epoch\",\n Events.COMPLETED: \"epoch\",\n }\n\n def __init__(self, **kwargs):\n self.iteration = 0\n self.epoch = 0\n self.epoch_length = None\n self.max_epochs = None\n self.output = None\n self.batch = None\n self.metrics = {}\n self.dataloader = None\n self.seed = None\n\n for k, v in kwargs.items():\n setattr(self, k, v)\n\n for value in self.event_to_attr.values():\n if not hasattr(self, value):\n setattr(self, value, 0)\n\n def get_event_attrib_value(self, event_name: Union[EventWithFilter, CallableEvents, Enum]) -> int:\n if isinstance(event_name, EventWithFilter):\n event_name = event_name.event\n if event_name not in State.event_to_attr:\n raise RuntimeError(\"Unknown event name '{}'\".format(event_name))\n return getattr(self, State.event_to_attr[event_name])\n\n def __repr__(self) -> str:\n s = \"State:\\n\"\n for attr, value in self.__dict__.items():\n if not isinstance(value, (numbers.Number, str)):\n value = type(value)\n s += \"\\t{}: {}\\n\".format(attr, value)\n return s\n\n\nclass RemovableEventHandle:\n \"\"\"A weakref handle to remove a registered event.\n\n A handle that may be used to remove a registered event handler via the\n remove method, with-statement, or context manager protocol. Returned from\n :meth:`~ignite.engine.Engine.add_event_handler`.\n\n\n Args:\n event_name: Registered event name.\n handler: Registered event handler, stored as weakref.\n engine: Target engine, stored as weakref.\n\n Example usage:\n\n .. code-block:: python\n\n engine = Engine()\n\n def print_epoch(engine):\n print(\"Epoch: {}\".format(engine.state.epoch))\n\n with engine.add_event_handler(Events.EPOCH_COMPLETED, print_epoch):\n # print_epoch handler registered for a single run\n engine.run(data)\n\n # print_epoch handler is now unregistered\n \"\"\"\n\n def __init__(self, event_name: Union[EventWithFilter, CallableEvents, Enum], handler: Callable, engine):\n self.event_name = event_name\n self.handler = weakref.ref(handler)\n self.engine = weakref.ref(engine)\n\n def remove(self) -> None:\n \"\"\"Remove handler from engine.\"\"\"\n handler = self.handler()\n engine = self.engine()\n\n if handler is None or engine is None:\n return\n\n if engine.has_event_handler(handler, self.event_name):\n engine.remove_event_handler(handler, self.event_name)\n\n def __enter__(self):\n return self\n\n def __exit__(self, *args, **kwargs) -> None:\n self.remove()\n", "path": "ignite/engine/events.py"}]}
| 3,157 | 102 |
gh_patches_debug_28027
|
rasdani/github-patches
|
git_diff
|
StackStorm__st2-1766
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Reinstalling mmonit pack fails as the venv is being used
Im sure this is due the sensor being run, so you cant create the virtualenv again as its being used.
Should the packs action check if there is sensors and try to stop them before reinstalling a pack?
```
"stderr": "st2.actions.python.SetupVirtualEnvironmentAction: DEBUG Setting up virtualenv for pack \"mmonit\"\nst2.actions.python.SetupVirtualEnvironmentAction: DEBUG Creating virtualenv for pack \"mmonit\" in \"/opt/stackstorm/virtualenvs/mmonit\"\nst2.actions.python.SetupVirtualEnvironmentAction: DEBUG Creating virtualenv in \"/opt/stackstorm/virtualenvs/mmonit\" using Python binary \"/usr/bin/python2.7\"\nTraceback (most recent call last):\n File \"/usr/lib/python2.7/dist-packages/st2actions/runners/python_action_wrapper.py\", line 116, in <module>\n obj.run()\n File \"/usr/lib/python2.7/dist-packages/st2actions/runners/python_action_wrapper.py\", line 61, in run\n output = action.run(**self._parameters)\n File \"/opt/stackstorm/packs/packs/actions/pack_mgmt/setup_virtualenv.py\", line 52, in run\n self._setup_pack_virtualenv(pack_name=pack_name)\n File \"/opt/stackstorm/packs/packs/actions/pack_mgmt/setup_virtualenv.py\", line 89, in _setup_pack_virtualenv\n self._create_virtualenv(virtualenv_path=virtualenv_path)\n File \"/opt/stackstorm/packs/packs/actions/pack_mgmt/setup_virtualenv.py\", line 125, in _create_virtualenv\n (virtualenv_path, stderr))\nException: Failed to create virtualenv in \"/opt/stackstorm/virtualenvs/mmonit\": Traceback (most recent call last):\n File \"/usr/local/lib/python2.7/dist-packages/virtualenv.py\", line 2363, in <module>\n main()\n File \"/usr/local/lib/python2.7/dist-packages/virtualenv.py\", line 832, in main\n symlink=options.symlink)\n File \"/usr/local/lib/python2.7/dist-packages/virtualenv.py\", line 994, in create_environment\n site_packages=site_packages, clear=clear, symlink=symlink))\n File \"/usr/local/lib/python2.7/dist-packages/virtualenv.py\", line 1288, in install_python\n shutil.copyfile(executable, py_executable)\n File \"/usr/lib/python2.7/shutil.py\", line 83, in copyfile\n with open(dst, 'wb') as fdst:\nIOError: [Errno 26] Text file busy: '/opt/stackstorm/virtualenvs/mmonit/bin/python2.7'\n\n",
```
</issue>
<code>
[start of contrib/packs/actions/pack_mgmt/setup_virtualenv.py]
1 # Licensed to the StackStorm, Inc ('StackStorm') under one or more
2 # contributor license agreements. See the NOTICE file distributed with
3 # this work for additional information regarding copyright ownership.
4 # The ASF licenses this file to You under the Apache License, Version 2.0
5 # (the "License"); you may not use this file except in compliance with
6 # the License. You may obtain a copy of the License at
7 #
8 # http://www.apache.org/licenses/LICENSE-2.0
9 #
10 # Unless required by applicable law or agreed to in writing, software
11 # distributed under the License is distributed on an "AS IS" BASIS,
12 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
13 # See the License for the specific language governing permissions and
14 # limitations under the License.
15
16 import os
17 import re
18
19 from oslo_config import cfg
20
21 from st2common.util.shell import run_command
22 from st2actions.runners.pythonrunner import Action
23 from st2common.constants.pack import PACK_NAME_WHITELIST
24 from st2common.constants.pack import BASE_PACK_REQUIREMENTS
25 from st2common.content.utils import get_packs_base_paths
26 from st2common.content.utils import get_pack_directory
27 from st2common.util.shell import quote_unix
28
29
30 class SetupVirtualEnvironmentAction(Action):
31 """
32 Action which sets up virtual environment for the provided packs.
33
34 Setup consists of the following step:
35
36 1. Create virtual environment for the pack
37 2. Install base requirements which are common to all the packs
38 3. Install pack-specific requirements (if any)
39 """
40
41 def __init__(self, config=None):
42 super(SetupVirtualEnvironmentAction, self).__init__(config=config)
43 self._base_virtualenvs_path = os.path.join(cfg.CONF.system.base_path,
44 'virtualenvs/')
45
46 def run(self, packs):
47 """
48 :param packs: A list of packs to create the environment for.
49 :type: packs: ``list``
50 """
51 for pack_name in packs:
52 self._setup_pack_virtualenv(pack_name=pack_name)
53
54 message = ('Successfuly set up virtualenv for the following packs: %s' %
55 (', '.join(packs)))
56 return message
57
58 def _setup_pack_virtualenv(self, pack_name):
59 """
60 Setup virtual environment for the provided pack.
61
62 :param pack_name: Pack name.
63 :type pack_name: ``str``
64 """
65 # Prevent directory traversal by whitelisting allowed characters in the
66 # pack name
67 if not re.match(PACK_NAME_WHITELIST, pack_name):
68 raise ValueError('Invalid pack name "%s"' % (pack_name))
69
70 self.logger.debug('Setting up virtualenv for pack "%s"' % (pack_name))
71
72 virtualenv_path = os.path.join(self._base_virtualenvs_path, quote_unix(pack_name))
73
74 # Ensure pack directory exists in one of the search paths
75 pack_path = get_pack_directory(pack_name=pack_name)
76
77 if not pack_path:
78 packs_base_paths = get_packs_base_paths()
79 search_paths = ', '.join(packs_base_paths)
80 msg = 'Pack "%s" is not installed. Looked in: %s' % (pack_name, search_paths)
81 raise Exception(msg)
82
83 if not os.path.exists(self._base_virtualenvs_path):
84 os.makedirs(self._base_virtualenvs_path)
85
86 # 1. Create virtual environment
87 self.logger.debug('Creating virtualenv for pack "%s" in "%s"' %
88 (pack_name, virtualenv_path))
89 self._create_virtualenv(virtualenv_path=virtualenv_path)
90
91 # 2. Install base requirements which are common to all the packs
92 self.logger.debug('Installing base requirements')
93 for requirement in BASE_PACK_REQUIREMENTS:
94 self._install_requirement(virtualenv_path=virtualenv_path,
95 requirement=requirement)
96
97 # 3. Install pack-specific requirements
98 requirements_file_path = os.path.join(pack_path, 'requirements.txt')
99 has_requirements = os.path.isfile(requirements_file_path)
100
101 if has_requirements:
102 self.logger.debug('Installing pack specific requirements from "%s"' %
103 (requirements_file_path))
104 self._install_requirements(virtualenv_path, requirements_file_path)
105 else:
106 self.logger.debug('No pack specific requirements found')
107
108 self.logger.debug('Virtualenv for pack "%s" successfully created in "%s"' %
109 (pack_name, virtualenv_path))
110
111 def _create_virtualenv(self, virtualenv_path):
112 python_binary = cfg.CONF.actionrunner.python_binary
113
114 if not os.path.isfile(python_binary):
115 raise Exception('Python binary "%s" doesn\'t exist' % (python_binary))
116
117 self.logger.debug('Creating virtualenv in "%s" using Python binary "%s"' %
118 (virtualenv_path, python_binary))
119
120 cmd = ['virtualenv', '-p', python_binary, '--system-site-packages', virtualenv_path]
121 exit_code, _, stderr = run_command(cmd=cmd)
122
123 if exit_code != 0:
124 raise Exception('Failed to create virtualenv in "%s": %s' %
125 (virtualenv_path, stderr))
126
127 return True
128
129 def _install_requirements(self, virtualenv_path, requirements_file_path):
130 """
131 Install requirements from a file.
132 """
133 pip_path = os.path.join(virtualenv_path, 'bin/pip')
134 cmd = [pip_path, 'install', '-U', '-r', requirements_file_path]
135 env = self._get_env_for_subprocess_command()
136 exit_code, stdout, stderr = run_command(cmd=cmd, env=env)
137
138 if exit_code != 0:
139 raise Exception('Failed to install requirements from "%s": %s' %
140 (requirements_file_path, stdout))
141
142 return True
143
144 def _install_requirement(self, virtualenv_path, requirement):
145 """
146 Install a single requirement.
147 """
148 pip_path = os.path.join(virtualenv_path, 'bin/pip')
149 cmd = [pip_path, 'install', requirement]
150 env = self._get_env_for_subprocess_command()
151 exit_code, stdout, stderr = run_command(cmd=cmd, env=env)
152
153 if exit_code != 0:
154 raise Exception('Failed to install requirement "%s": %s' %
155 (requirement, stdout))
156
157 return True
158
159 def _get_env_for_subprocess_command(self):
160 """
161 Retrieve environment to be used with the subprocess command.
162
163 Note: We remove PYTHONPATH from the environment so the command works
164 correctly with the newely created virtualenv.
165 """
166 env = os.environ.copy()
167
168 if 'PYTHONPATH' in env:
169 del env['PYTHONPATH']
170
171 return env
172
[end of contrib/packs/actions/pack_mgmt/setup_virtualenv.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/contrib/packs/actions/pack_mgmt/setup_virtualenv.py b/contrib/packs/actions/pack_mgmt/setup_virtualenv.py
--- a/contrib/packs/actions/pack_mgmt/setup_virtualenv.py
+++ b/contrib/packs/actions/pack_mgmt/setup_virtualenv.py
@@ -15,6 +15,7 @@
import os
import re
+import shutil
from oslo_config import cfg
@@ -83,6 +84,9 @@
if not os.path.exists(self._base_virtualenvs_path):
os.makedirs(self._base_virtualenvs_path)
+ # 0. Delete virtual environment if it exists
+ self._remove_virtualenv(virtualenv_path=virtualenv_path)
+
# 1. Create virtual environment
self.logger.debug('Creating virtualenv for pack "%s" in "%s"' %
(pack_name, virtualenv_path))
@@ -126,6 +130,20 @@
return True
+ def _remove_virtualenv(self, virtualenv_path):
+ if not os.path.exists(virtualenv_path):
+ self.logger.info('Virtualenv path "%s" doesn\'t exist' % virtualenv_path)
+ return True
+
+ self.logger.debug('Removing virtualenv in "%s"' % virtualenv_path)
+ try:
+ shutil.rmtree(virtualenv_path)
+ except Exception as error:
+ self.logger.error('Error while removing virtualenv at "%s": "%s"' %
+ (virtualenv_path, error))
+ raise
+ return True
+
def _install_requirements(self, virtualenv_path, requirements_file_path):
"""
Install requirements from a file.
|
{"golden_diff": "diff --git a/contrib/packs/actions/pack_mgmt/setup_virtualenv.py b/contrib/packs/actions/pack_mgmt/setup_virtualenv.py\n--- a/contrib/packs/actions/pack_mgmt/setup_virtualenv.py\n+++ b/contrib/packs/actions/pack_mgmt/setup_virtualenv.py\n@@ -15,6 +15,7 @@\n \n import os\n import re\n+import shutil\n \n from oslo_config import cfg\n \n@@ -83,6 +84,9 @@\n if not os.path.exists(self._base_virtualenvs_path):\n os.makedirs(self._base_virtualenvs_path)\n \n+ # 0. Delete virtual environment if it exists\n+ self._remove_virtualenv(virtualenv_path=virtualenv_path)\n+\n # 1. Create virtual environment\n self.logger.debug('Creating virtualenv for pack \"%s\" in \"%s\"' %\n (pack_name, virtualenv_path))\n@@ -126,6 +130,20 @@\n \n return True\n \n+ def _remove_virtualenv(self, virtualenv_path):\n+ if not os.path.exists(virtualenv_path):\n+ self.logger.info('Virtualenv path \"%s\" doesn\\'t exist' % virtualenv_path)\n+ return True\n+\n+ self.logger.debug('Removing virtualenv in \"%s\"' % virtualenv_path)\n+ try:\n+ shutil.rmtree(virtualenv_path)\n+ except Exception as error:\n+ self.logger.error('Error while removing virtualenv at \"%s\": \"%s\"' %\n+ (virtualenv_path, error))\n+ raise\n+ return True\n+\n def _install_requirements(self, virtualenv_path, requirements_file_path):\n \"\"\"\n Install requirements from a file.\n", "issue": "Reinstalling mmonit pack fails as the venv is being used\nIm sure this is due the sensor being run, so you cant create the virtualenv again as its being used.\n\nShould the packs action check if there is sensors and try to stop them before reinstalling a pack?\n\n```\n \"stderr\": \"st2.actions.python.SetupVirtualEnvironmentAction: DEBUG Setting up virtualenv for pack \\\"mmonit\\\"\\nst2.actions.python.SetupVirtualEnvironmentAction: DEBUG Creating virtualenv for pack \\\"mmonit\\\" in \\\"/opt/stackstorm/virtualenvs/mmonit\\\"\\nst2.actions.python.SetupVirtualEnvironmentAction: DEBUG Creating virtualenv in \\\"/opt/stackstorm/virtualenvs/mmonit\\\" using Python binary \\\"/usr/bin/python2.7\\\"\\nTraceback (most recent call last):\\n File \\\"/usr/lib/python2.7/dist-packages/st2actions/runners/python_action_wrapper.py\\\", line 116, in <module>\\n obj.run()\\n File \\\"/usr/lib/python2.7/dist-packages/st2actions/runners/python_action_wrapper.py\\\", line 61, in run\\n output = action.run(**self._parameters)\\n File \\\"/opt/stackstorm/packs/packs/actions/pack_mgmt/setup_virtualenv.py\\\", line 52, in run\\n self._setup_pack_virtualenv(pack_name=pack_name)\\n File \\\"/opt/stackstorm/packs/packs/actions/pack_mgmt/setup_virtualenv.py\\\", line 89, in _setup_pack_virtualenv\\n self._create_virtualenv(virtualenv_path=virtualenv_path)\\n File \\\"/opt/stackstorm/packs/packs/actions/pack_mgmt/setup_virtualenv.py\\\", line 125, in _create_virtualenv\\n (virtualenv_path, stderr))\\nException: Failed to create virtualenv in \\\"/opt/stackstorm/virtualenvs/mmonit\\\": Traceback (most recent call last):\\n File \\\"/usr/local/lib/python2.7/dist-packages/virtualenv.py\\\", line 2363, in <module>\\n main()\\n File \\\"/usr/local/lib/python2.7/dist-packages/virtualenv.py\\\", line 832, in main\\n symlink=options.symlink)\\n File \\\"/usr/local/lib/python2.7/dist-packages/virtualenv.py\\\", line 994, in create_environment\\n site_packages=site_packages, clear=clear, symlink=symlink))\\n File \\\"/usr/local/lib/python2.7/dist-packages/virtualenv.py\\\", line 1288, in install_python\\n shutil.copyfile(executable, py_executable)\\n File \\\"/usr/lib/python2.7/shutil.py\\\", line 83, in copyfile\\n with open(dst, 'wb') as fdst:\\nIOError: [Errno 26] Text file busy: '/opt/stackstorm/virtualenvs/mmonit/bin/python2.7'\\n\\n\",\n```\n\n", "before_files": [{"content": "# Licensed to the StackStorm, Inc ('StackStorm') under one or more\n# contributor license agreements. See the NOTICE file distributed with\n# this work for additional information regarding copyright ownership.\n# The ASF licenses this file to You under the Apache License, Version 2.0\n# (the \"License\"); you may not use this file except in compliance with\n# the License. You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport os\nimport re\n\nfrom oslo_config import cfg\n\nfrom st2common.util.shell import run_command\nfrom st2actions.runners.pythonrunner import Action\nfrom st2common.constants.pack import PACK_NAME_WHITELIST\nfrom st2common.constants.pack import BASE_PACK_REQUIREMENTS\nfrom st2common.content.utils import get_packs_base_paths\nfrom st2common.content.utils import get_pack_directory\nfrom st2common.util.shell import quote_unix\n\n\nclass SetupVirtualEnvironmentAction(Action):\n \"\"\"\n Action which sets up virtual environment for the provided packs.\n\n Setup consists of the following step:\n\n 1. Create virtual environment for the pack\n 2. Install base requirements which are common to all the packs\n 3. Install pack-specific requirements (if any)\n \"\"\"\n\n def __init__(self, config=None):\n super(SetupVirtualEnvironmentAction, self).__init__(config=config)\n self._base_virtualenvs_path = os.path.join(cfg.CONF.system.base_path,\n 'virtualenvs/')\n\n def run(self, packs):\n \"\"\"\n :param packs: A list of packs to create the environment for.\n :type: packs: ``list``\n \"\"\"\n for pack_name in packs:\n self._setup_pack_virtualenv(pack_name=pack_name)\n\n message = ('Successfuly set up virtualenv for the following packs: %s' %\n (', '.join(packs)))\n return message\n\n def _setup_pack_virtualenv(self, pack_name):\n \"\"\"\n Setup virtual environment for the provided pack.\n\n :param pack_name: Pack name.\n :type pack_name: ``str``\n \"\"\"\n # Prevent directory traversal by whitelisting allowed characters in the\n # pack name\n if not re.match(PACK_NAME_WHITELIST, pack_name):\n raise ValueError('Invalid pack name \"%s\"' % (pack_name))\n\n self.logger.debug('Setting up virtualenv for pack \"%s\"' % (pack_name))\n\n virtualenv_path = os.path.join(self._base_virtualenvs_path, quote_unix(pack_name))\n\n # Ensure pack directory exists in one of the search paths\n pack_path = get_pack_directory(pack_name=pack_name)\n\n if not pack_path:\n packs_base_paths = get_packs_base_paths()\n search_paths = ', '.join(packs_base_paths)\n msg = 'Pack \"%s\" is not installed. Looked in: %s' % (pack_name, search_paths)\n raise Exception(msg)\n\n if not os.path.exists(self._base_virtualenvs_path):\n os.makedirs(self._base_virtualenvs_path)\n\n # 1. Create virtual environment\n self.logger.debug('Creating virtualenv for pack \"%s\" in \"%s\"' %\n (pack_name, virtualenv_path))\n self._create_virtualenv(virtualenv_path=virtualenv_path)\n\n # 2. Install base requirements which are common to all the packs\n self.logger.debug('Installing base requirements')\n for requirement in BASE_PACK_REQUIREMENTS:\n self._install_requirement(virtualenv_path=virtualenv_path,\n requirement=requirement)\n\n # 3. Install pack-specific requirements\n requirements_file_path = os.path.join(pack_path, 'requirements.txt')\n has_requirements = os.path.isfile(requirements_file_path)\n\n if has_requirements:\n self.logger.debug('Installing pack specific requirements from \"%s\"' %\n (requirements_file_path))\n self._install_requirements(virtualenv_path, requirements_file_path)\n else:\n self.logger.debug('No pack specific requirements found')\n\n self.logger.debug('Virtualenv for pack \"%s\" successfully created in \"%s\"' %\n (pack_name, virtualenv_path))\n\n def _create_virtualenv(self, virtualenv_path):\n python_binary = cfg.CONF.actionrunner.python_binary\n\n if not os.path.isfile(python_binary):\n raise Exception('Python binary \"%s\" doesn\\'t exist' % (python_binary))\n\n self.logger.debug('Creating virtualenv in \"%s\" using Python binary \"%s\"' %\n (virtualenv_path, python_binary))\n\n cmd = ['virtualenv', '-p', python_binary, '--system-site-packages', virtualenv_path]\n exit_code, _, stderr = run_command(cmd=cmd)\n\n if exit_code != 0:\n raise Exception('Failed to create virtualenv in \"%s\": %s' %\n (virtualenv_path, stderr))\n\n return True\n\n def _install_requirements(self, virtualenv_path, requirements_file_path):\n \"\"\"\n Install requirements from a file.\n \"\"\"\n pip_path = os.path.join(virtualenv_path, 'bin/pip')\n cmd = [pip_path, 'install', '-U', '-r', requirements_file_path]\n env = self._get_env_for_subprocess_command()\n exit_code, stdout, stderr = run_command(cmd=cmd, env=env)\n\n if exit_code != 0:\n raise Exception('Failed to install requirements from \"%s\": %s' %\n (requirements_file_path, stdout))\n\n return True\n\n def _install_requirement(self, virtualenv_path, requirement):\n \"\"\"\n Install a single requirement.\n \"\"\"\n pip_path = os.path.join(virtualenv_path, 'bin/pip')\n cmd = [pip_path, 'install', requirement]\n env = self._get_env_for_subprocess_command()\n exit_code, stdout, stderr = run_command(cmd=cmd, env=env)\n\n if exit_code != 0:\n raise Exception('Failed to install requirement \"%s\": %s' %\n (requirement, stdout))\n\n return True\n\n def _get_env_for_subprocess_command(self):\n \"\"\"\n Retrieve environment to be used with the subprocess command.\n\n Note: We remove PYTHONPATH from the environment so the command works\n correctly with the newely created virtualenv.\n \"\"\"\n env = os.environ.copy()\n\n if 'PYTHONPATH' in env:\n del env['PYTHONPATH']\n\n return env\n", "path": "contrib/packs/actions/pack_mgmt/setup_virtualenv.py"}]}
| 3,051 | 366 |
gh_patches_debug_38936
|
rasdani/github-patches
|
git_diff
|
fedora-infra__bodhi-1335
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
The docs on readthedocs are missing the Python bindings
Our RTD page is missing the Python bindings:
http://bodhi.readthedocs.io/en/latest/python_bindings.html
Very likely this is due to our ```docs/conf.py``` file not injecting the root of our repo into sys.path.
</issue>
<code>
[start of setup.py]
1 import __main__
2 __requires__ = __main__.__requires__ = 'WebOb>=1.4.1'
3 import pkg_resources
4
5 # The following two imports are required to shut up an
6 # atexit error when running tests with python 2.7
7 import logging
8 import multiprocessing
9
10 import os
11 import sys
12
13 from setuptools import setup, find_packages
14 import setuptools.command.egg_info
15
16
17 here = os.path.abspath(os.path.dirname(__file__))
18 README = open(os.path.join(here, 'README.rst')).read()
19 VERSION = '2.4.0'
20 # Possible options are at https://pypi.python.org/pypi?%3Aaction=list_classifiers
21 CLASSIFIERS = [
22 'Development Status :: 5 - Production/Stable',
23 'Intended Audience :: Developers',
24 'Intended Audience :: System Administrators',
25 'License :: OSI Approved :: GNU General Public License v2 or later (GPLv2+)',
26 'Operating System :: POSIX :: Linux',
27 'Programming Language :: Python :: 2.7',
28 'Topic :: System :: Software Distribution']
29 LICENSE = 'GPLv2+'
30 MAINTAINER = 'Fedora Infrastructure Team'
31 MAINTAINER_EMAIL = '[email protected]'
32 PLATFORMS = ['Fedora', 'GNU/Linux']
33 URL = 'https://github.com/fedora-infra/bodhi'
34
35 server_requires = [
36 # push.py uses click
37 'click',
38 'pyramid',
39 'pyramid_mako',
40 'pyramid_tm',
41 'waitress',
42 'colander',
43 'cornice<2',
44
45 'python-openid',
46 'pyramid_fas_openid',
47 'packagedb-cli',
48
49 'sqlalchemy',
50 'zope.sqlalchemy',
51
52 'webhelpers',
53 'progressbar',
54
55 'bunch',
56
57 # for captchas
58 'cryptography',
59 'Pillow',
60
61 # Useful tools
62 'kitchen',
63 'python-fedora',
64 'pylibravatar',
65 'pyDNS',
66 'dogpile.cache',
67 'arrow',
68 'markdown',
69
70 # i18n, that we're not actually doing yet.
71 #'Babel',
72 #'lingua',
73
74 # External resources
75 'python-bugzilla',
76 'simplemediawiki',
77
78 # "python setup.py test" needs one of fedmsg's setup.py extra_requires
79 'fedmsg[consumers]',
80 # The masher needs fedmsg-atomic-composer
81 'fedmsg-atomic-composer >= 2016.3',
82
83 'WebOb>=1.4.1',
84 ]
85
86 if sys.version_info[:3] < (2,7,0):
87 server_requires.append('importlib')
88
89 if sys.version_info[:3] < (2,5,0):
90 server_requires.append('pysqlite')
91
92
93 setuptools.command.egg_info.manifest_maker.template = 'BODHI_MANIFEST.in'
94
95
96 setup(name='bodhi',
97 version=VERSION,
98 description='bodhi common package',
99 long_description=README,
100 classifiers=CLASSIFIERS,
101 license=LICENSE,
102 maintainer=MAINTAINER,
103 maintainer_email=MAINTAINER_EMAIL,
104 platforms=PLATFORMS,
105 url=URL,
106 keywords='fedora',
107 packages=['bodhi'],
108 include_package_data=True,
109 zip_safe=False,
110 install_requires = [],
111 tests_require = [
112 'flake8',
113 'nose',
114 'nose-cov',
115 'webtest',
116 'mock'
117 ],
118 test_suite="nose.collector",
119 )
120
121
122 setuptools.command.egg_info.manifest_maker.template = 'CLIENT_MANIFEST.in'
123
124
125 setup(name='bodhi-client',
126 version=VERSION,
127 description='bodhi client',
128 long_description=README,
129 classifiers=CLASSIFIERS,
130 license=LICENSE,
131 maintainer=MAINTAINER,
132 maintainer_email=MAINTAINER_EMAIL,
133 platforms=PLATFORMS,
134 url=URL,
135 keywords='fedora',
136 packages=['bodhi.client'],
137 include_package_data=False,
138 zip_safe=False,
139 install_requires = ['click', 'six'],
140 entry_points = """\
141 [console_scripts]
142 bodhi = bodhi.client:cli
143 """,
144 )
145
146
147 setuptools.command.egg_info.manifest_maker.template = 'SERVER_MANIFEST.in'
148 # Due to https://github.com/pypa/setuptools/issues/808, we need to include the bodhi superpackage
149 # and then remove it if we want find_packages() to find the bodhi.server package and its
150 # subpackages without including the bodhi top level package.
151 server_packages = find_packages(
152 exclude=['bodhi.client', 'bodhi.client.*', 'bodhi.tests', 'bodhi.tests.*'])
153 server_packages.remove('bodhi')
154
155
156 setup(name='bodhi-server',
157 version=VERSION,
158 description='bodhi server',
159 long_description=README,
160 classifiers=CLASSIFIERS + [
161 "Framework :: Pyramid",
162 'Programming Language :: JavaScript',
163 "Topic :: Internet :: WWW/HTTP",
164 "Topic :: Internet :: WWW/HTTP :: WSGI :: Application"],
165 license=LICENSE,
166 maintainer=MAINTAINER,
167 maintainer_email=MAINTAINER_EMAIL,
168 platforms=PLATFORMS,
169 url=URL,
170 keywords='web fedora pyramid',
171 packages=server_packages,
172 include_package_data=True,
173 # script_args=sys.argv.extend(['--template', 'TEST']),
174 zip_safe=False,
175 install_requires = server_requires,
176 message_extractors = { '.': [
177 #('**.py', 'lingua_python', None),
178 #('**.mak', 'lingua_xml', None),
179 ]},
180 entry_points = """\
181 [paste.app_factory]
182 main = bodhi.server:main
183 [console_scripts]
184 initialize_bodhi_db = bodhi.server.scripts.initializedb:main
185 bodhi-clean-old-mashes = bodhi.server.scripts.clean_old_mashes:clean_up
186 bodhi-push = bodhi.server.push:push
187 bodhi-expire-overrides = bodhi.server.scripts.expire_overrides:main
188 bodhi-untag-branched = bodhi.server.scripts.untag_branched:main
189 bodhi-approve-testing = bodhi.server.scripts.approve_testing:main
190 bodhi-manage-releases = bodhi.server.scripts.manage_releases:main
191 [moksha.consumer]
192 masher = bodhi.server.consumers.masher:Masher
193 updates = bodhi.server.consumers.updates:UpdatesHandler
194 signed = bodhi.server.consumers.signed:SignedHandler
195 """,
196 paster_plugins=['pyramid'],
197 )
198
[end of setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -14,6 +14,38 @@
import setuptools.command.egg_info
+def get_requirements(requirements_file='requirements.txt'):
+ """
+ Get the contents of a file listing the requirements.
+
+ Args:
+ requirements_file (str): path to a requirements file
+
+ Returns:
+ list: the list of requirements, or an empty list if
+ `requirements_file` could not be opened or read
+ """
+ lines = open(requirements_file).readlines()
+ dependencies = []
+ for line in lines:
+ maybe_dep = line.strip()
+ if maybe_dep.startswith('#'):
+ # Skip pure comment lines
+ continue
+ if maybe_dep.startswith('git+'):
+ # VCS reference for dev purposes, expect a trailing comment
+ # with the normal requirement
+ __, __, maybe_dep = maybe_dep.rpartition('#')
+ else:
+ # Ignore any trailing comment
+ maybe_dep, __, __ = maybe_dep.partition('#')
+ # Remove any whitespace and assume non-empty results are dependencies
+ maybe_dep = maybe_dep.strip()
+ if maybe_dep:
+ dependencies.append(maybe_dep)
+ return dependencies
+
+
here = os.path.abspath(os.path.dirname(__file__))
README = open(os.path.join(here, 'README.rst')).read()
VERSION = '2.4.0'
@@ -32,63 +64,6 @@
PLATFORMS = ['Fedora', 'GNU/Linux']
URL = 'https://github.com/fedora-infra/bodhi'
-server_requires = [
- # push.py uses click
- 'click',
- 'pyramid',
- 'pyramid_mako',
- 'pyramid_tm',
- 'waitress',
- 'colander',
- 'cornice<2',
-
- 'python-openid',
- 'pyramid_fas_openid',
- 'packagedb-cli',
-
- 'sqlalchemy',
- 'zope.sqlalchemy',
-
- 'webhelpers',
- 'progressbar',
-
- 'bunch',
-
- # for captchas
- 'cryptography',
- 'Pillow',
-
- # Useful tools
- 'kitchen',
- 'python-fedora',
- 'pylibravatar',
- 'pyDNS',
- 'dogpile.cache',
- 'arrow',
- 'markdown',
-
- # i18n, that we're not actually doing yet.
- #'Babel',
- #'lingua',
-
- # External resources
- 'python-bugzilla',
- 'simplemediawiki',
-
- # "python setup.py test" needs one of fedmsg's setup.py extra_requires
- 'fedmsg[consumers]',
- # The masher needs fedmsg-atomic-composer
- 'fedmsg-atomic-composer >= 2016.3',
-
- 'WebOb>=1.4.1',
- ]
-
-if sys.version_info[:3] < (2,7,0):
- server_requires.append('importlib')
-
-if sys.version_info[:3] < (2,5,0):
- server_requires.append('pysqlite')
-
setuptools.command.egg_info.manifest_maker.template = 'BODHI_MANIFEST.in'
@@ -172,7 +147,7 @@
include_package_data=True,
# script_args=sys.argv.extend(['--template', 'TEST']),
zip_safe=False,
- install_requires = server_requires,
+ install_requires=get_requirements(),
message_extractors = { '.': [
#('**.py', 'lingua_python', None),
#('**.mak', 'lingua_xml', None),
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -14,6 +14,38 @@\n import setuptools.command.egg_info\n \n \n+def get_requirements(requirements_file='requirements.txt'):\n+ \"\"\"\n+ Get the contents of a file listing the requirements.\n+\n+ Args:\n+ requirements_file (str): path to a requirements file\n+\n+ Returns:\n+ list: the list of requirements, or an empty list if\n+ `requirements_file` could not be opened or read\n+ \"\"\"\n+ lines = open(requirements_file).readlines()\n+ dependencies = []\n+ for line in lines:\n+ maybe_dep = line.strip()\n+ if maybe_dep.startswith('#'):\n+ # Skip pure comment lines\n+ continue\n+ if maybe_dep.startswith('git+'):\n+ # VCS reference for dev purposes, expect a trailing comment\n+ # with the normal requirement\n+ __, __, maybe_dep = maybe_dep.rpartition('#')\n+ else:\n+ # Ignore any trailing comment\n+ maybe_dep, __, __ = maybe_dep.partition('#')\n+ # Remove any whitespace and assume non-empty results are dependencies\n+ maybe_dep = maybe_dep.strip()\n+ if maybe_dep:\n+ dependencies.append(maybe_dep)\n+ return dependencies\n+\n+\n here = os.path.abspath(os.path.dirname(__file__))\n README = open(os.path.join(here, 'README.rst')).read()\n VERSION = '2.4.0'\n@@ -32,63 +64,6 @@\n PLATFORMS = ['Fedora', 'GNU/Linux']\n URL = 'https://github.com/fedora-infra/bodhi'\n \n-server_requires = [\n- # push.py uses click\n- 'click',\n- 'pyramid',\n- 'pyramid_mako',\n- 'pyramid_tm',\n- 'waitress',\n- 'colander',\n- 'cornice<2',\n-\n- 'python-openid',\n- 'pyramid_fas_openid',\n- 'packagedb-cli',\n-\n- 'sqlalchemy',\n- 'zope.sqlalchemy',\n-\n- 'webhelpers',\n- 'progressbar',\n-\n- 'bunch',\n-\n- # for captchas\n- 'cryptography',\n- 'Pillow',\n-\n- # Useful tools\n- 'kitchen',\n- 'python-fedora',\n- 'pylibravatar',\n- 'pyDNS',\n- 'dogpile.cache',\n- 'arrow',\n- 'markdown',\n-\n- # i18n, that we're not actually doing yet.\n- #'Babel',\n- #'lingua',\n-\n- # External resources\n- 'python-bugzilla',\n- 'simplemediawiki',\n-\n- # \"python setup.py test\" needs one of fedmsg's setup.py extra_requires\n- 'fedmsg[consumers]',\n- # The masher needs fedmsg-atomic-composer\n- 'fedmsg-atomic-composer >= 2016.3',\n-\n- 'WebOb>=1.4.1',\n- ]\n-\n-if sys.version_info[:3] < (2,7,0):\n- server_requires.append('importlib')\n-\n-if sys.version_info[:3] < (2,5,0):\n- server_requires.append('pysqlite')\n-\n \n setuptools.command.egg_info.manifest_maker.template = 'BODHI_MANIFEST.in'\n \n@@ -172,7 +147,7 @@\n include_package_data=True,\n # script_args=sys.argv.extend(['--template', 'TEST']),\n zip_safe=False,\n- install_requires = server_requires,\n+ install_requires=get_requirements(),\n message_extractors = { '.': [\n #('**.py', 'lingua_python', None),\n #('**.mak', 'lingua_xml', None),\n", "issue": "The docs on readthedocs are missing the Python bindings\nOur RTD page is missing the Python bindings:\r\n\r\nhttp://bodhi.readthedocs.io/en/latest/python_bindings.html\r\n\r\nVery likely this is due to our ```docs/conf.py``` file not injecting the root of our repo into sys.path.\n", "before_files": [{"content": "import __main__\n__requires__ = __main__.__requires__ = 'WebOb>=1.4.1'\nimport pkg_resources\n\n# The following two imports are required to shut up an\n# atexit error when running tests with python 2.7\nimport logging\nimport multiprocessing\n\nimport os\nimport sys\n\nfrom setuptools import setup, find_packages\nimport setuptools.command.egg_info\n\n\nhere = os.path.abspath(os.path.dirname(__file__))\nREADME = open(os.path.join(here, 'README.rst')).read()\nVERSION = '2.4.0'\n# Possible options are at https://pypi.python.org/pypi?%3Aaction=list_classifiers\nCLASSIFIERS = [\n 'Development Status :: 5 - Production/Stable',\n 'Intended Audience :: Developers',\n 'Intended Audience :: System Administrators',\n 'License :: OSI Approved :: GNU General Public License v2 or later (GPLv2+)',\n 'Operating System :: POSIX :: Linux',\n 'Programming Language :: Python :: 2.7',\n 'Topic :: System :: Software Distribution']\nLICENSE = 'GPLv2+'\nMAINTAINER = 'Fedora Infrastructure Team'\nMAINTAINER_EMAIL = '[email protected]'\nPLATFORMS = ['Fedora', 'GNU/Linux']\nURL = 'https://github.com/fedora-infra/bodhi'\n\nserver_requires = [\n # push.py uses click\n 'click',\n 'pyramid',\n 'pyramid_mako',\n 'pyramid_tm',\n 'waitress',\n 'colander',\n 'cornice<2',\n\n 'python-openid',\n 'pyramid_fas_openid',\n 'packagedb-cli',\n\n 'sqlalchemy',\n 'zope.sqlalchemy',\n\n 'webhelpers',\n 'progressbar',\n\n 'bunch',\n\n # for captchas\n 'cryptography',\n 'Pillow',\n\n # Useful tools\n 'kitchen',\n 'python-fedora',\n 'pylibravatar',\n 'pyDNS',\n 'dogpile.cache',\n 'arrow',\n 'markdown',\n\n # i18n, that we're not actually doing yet.\n #'Babel',\n #'lingua',\n\n # External resources\n 'python-bugzilla',\n 'simplemediawiki',\n\n # \"python setup.py test\" needs one of fedmsg's setup.py extra_requires\n 'fedmsg[consumers]',\n # The masher needs fedmsg-atomic-composer\n 'fedmsg-atomic-composer >= 2016.3',\n\n 'WebOb>=1.4.1',\n ]\n\nif sys.version_info[:3] < (2,7,0):\n server_requires.append('importlib')\n\nif sys.version_info[:3] < (2,5,0):\n server_requires.append('pysqlite')\n\n\nsetuptools.command.egg_info.manifest_maker.template = 'BODHI_MANIFEST.in'\n\n\nsetup(name='bodhi',\n version=VERSION,\n description='bodhi common package',\n long_description=README,\n classifiers=CLASSIFIERS,\n license=LICENSE,\n maintainer=MAINTAINER,\n maintainer_email=MAINTAINER_EMAIL,\n platforms=PLATFORMS,\n url=URL,\n keywords='fedora',\n packages=['bodhi'],\n include_package_data=True,\n zip_safe=False,\n install_requires = [],\n tests_require = [\n 'flake8',\n 'nose',\n 'nose-cov',\n 'webtest',\n 'mock'\n ],\n test_suite=\"nose.collector\",\n )\n\n\nsetuptools.command.egg_info.manifest_maker.template = 'CLIENT_MANIFEST.in'\n\n\nsetup(name='bodhi-client',\n version=VERSION,\n description='bodhi client',\n long_description=README,\n classifiers=CLASSIFIERS,\n license=LICENSE,\n maintainer=MAINTAINER,\n maintainer_email=MAINTAINER_EMAIL,\n platforms=PLATFORMS,\n url=URL,\n keywords='fedora',\n packages=['bodhi.client'],\n include_package_data=False,\n zip_safe=False,\n install_requires = ['click', 'six'],\n entry_points = \"\"\"\\\n [console_scripts]\n bodhi = bodhi.client:cli\n \"\"\",\n )\n\n\nsetuptools.command.egg_info.manifest_maker.template = 'SERVER_MANIFEST.in'\n# Due to https://github.com/pypa/setuptools/issues/808, we need to include the bodhi superpackage\n# and then remove it if we want find_packages() to find the bodhi.server package and its\n# subpackages without including the bodhi top level package.\nserver_packages = find_packages(\n exclude=['bodhi.client', 'bodhi.client.*', 'bodhi.tests', 'bodhi.tests.*'])\nserver_packages.remove('bodhi')\n\n\nsetup(name='bodhi-server',\n version=VERSION,\n description='bodhi server',\n long_description=README,\n classifiers=CLASSIFIERS + [\n \"Framework :: Pyramid\",\n 'Programming Language :: JavaScript',\n \"Topic :: Internet :: WWW/HTTP\",\n \"Topic :: Internet :: WWW/HTTP :: WSGI :: Application\"],\n license=LICENSE,\n maintainer=MAINTAINER,\n maintainer_email=MAINTAINER_EMAIL,\n platforms=PLATFORMS,\n url=URL,\n keywords='web fedora pyramid',\n packages=server_packages,\n include_package_data=True,\n# script_args=sys.argv.extend(['--template', 'TEST']),\n zip_safe=False,\n install_requires = server_requires,\n message_extractors = { '.': [\n #('**.py', 'lingua_python', None),\n #('**.mak', 'lingua_xml', None),\n ]},\n entry_points = \"\"\"\\\n [paste.app_factory]\n main = bodhi.server:main\n [console_scripts]\n initialize_bodhi_db = bodhi.server.scripts.initializedb:main\n bodhi-clean-old-mashes = bodhi.server.scripts.clean_old_mashes:clean_up\n bodhi-push = bodhi.server.push:push\n bodhi-expire-overrides = bodhi.server.scripts.expire_overrides:main\n bodhi-untag-branched = bodhi.server.scripts.untag_branched:main\n bodhi-approve-testing = bodhi.server.scripts.approve_testing:main\n bodhi-manage-releases = bodhi.server.scripts.manage_releases:main\n [moksha.consumer]\n masher = bodhi.server.consumers.masher:Masher\n updates = bodhi.server.consumers.updates:UpdatesHandler\n signed = bodhi.server.consumers.signed:SignedHandler\n \"\"\",\n paster_plugins=['pyramid'],\n )\n", "path": "setup.py"}]}
| 2,549 | 850 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.