
repo_id
stringlengths 15
86
| file_path
stringlengths 28
180
| content
stringlengths 1
1.75M
| __index_level_0__
int64 0
0
|
|---|---|---|---|
hf_public_repos/transformers/docs/source/en | hf_public_repos/transformers/docs/source/en/model_doc/layoutlm.md | <!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# LayoutLM
<a id='Overview'></a>
## Overview
The LayoutLM model was proposed in the paper [LayoutLM: Pre-training of Text and Layout for Document Image
Understanding](https://arxiv.org/abs/1912.13318) by Yiheng Xu, Minghao Li, Lei Cui, Shaohan Huang, Furu Wei, and
Ming Zhou. It's a simple but effective pretraining method of text and layout for document image understanding and
information extraction tasks, such as form understanding and receipt understanding. It obtains state-of-the-art results
on several downstream tasks:
- form understanding: the [FUNSD](https://guillaumejaume.github.io/FUNSD/) dataset (a collection of 199 annotated
forms comprising more than 30,000 words).
- receipt understanding: the [SROIE](https://rrc.cvc.uab.es/?ch=13) dataset (a collection of 626 receipts for
training and 347 receipts for testing).
- document image classification: the [RVL-CDIP](https://www.cs.cmu.edu/~aharley/rvl-cdip/) dataset (a collection of
400,000 images belonging to one of 16 classes).
The abstract from the paper is the following:
*Pre-training techniques have been verified successfully in a variety of NLP tasks in recent years. Despite the
widespread use of pretraining models for NLP applications, they almost exclusively focus on text-level manipulation,
while neglecting layout and style information that is vital for document image understanding. In this paper, we propose
the LayoutLM to jointly model interactions between text and layout information across scanned document images, which is
beneficial for a great number of real-world document image understanding tasks such as information extraction from
scanned documents. Furthermore, we also leverage image features to incorporate words' visual information into LayoutLM.
To the best of our knowledge, this is the first time that text and layout are jointly learned in a single framework for
document-level pretraining. It achieves new state-of-the-art results in several downstream tasks, including form
understanding (from 70.72 to 79.27), receipt understanding (from 94.02 to 95.24) and document image classification
(from 93.07 to 94.42).*
Tips:
- In addition to *input_ids*, [`~transformers.LayoutLMModel.forward`] also expects the input `bbox`, which are
the bounding boxes (i.e. 2D-positions) of the input tokens. These can be obtained using an external OCR engine such
as Google's [Tesseract](https://github.com/tesseract-ocr/tesseract) (there's a [Python wrapper](https://pypi.org/project/pytesseract/) available). Each bounding box should be in (x0, y0, x1, y1) format, where
(x0, y0) corresponds to the position of the upper left corner in the bounding box, and (x1, y1) represents the
position of the lower right corner. Note that one first needs to normalize the bounding boxes to be on a 0-1000
scale. To normalize, you can use the following function:
```python
def normalize_bbox(bbox, width, height):
return [
int(1000 * (bbox[0] / width)),
int(1000 * (bbox[1] / height)),
int(1000 * (bbox[2] / width)),
int(1000 * (bbox[3] / height)),
]
```
Here, `width` and `height` correspond to the width and height of the original document in which the token
occurs. Those can be obtained using the Python Image Library (PIL) library for example, as follows:
```python
from PIL import Image
# Document can be a png, jpg, etc. PDFs must be converted to images.
image = Image.open(name_of_your_document).convert("RGB")
width, height = image.size
```
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with LayoutLM. If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
<PipelineTag pipeline="document-question-answering" />
- A blog post on [fine-tuning
LayoutLM for document-understanding using Keras & Hugging Face
Transformers](https://www.philschmid.de/fine-tuning-layoutlm-keras).
- A blog post on how to [fine-tune LayoutLM for document-understanding using only Hugging Face Transformers](https://www.philschmid.de/fine-tuning-layoutlm).
- A notebook on how to [fine-tune LayoutLM on the FUNSD dataset with image embeddings](https://colab.research.google.com/github/NielsRogge/Transformers-Tutorials/blob/master/LayoutLM/Add_image_embeddings_to_LayoutLM.ipynb).
- See also: [Document question answering task guide](../tasks/document_question_answering)
<PipelineTag pipeline="text-classification" />
- A notebook on how to [fine-tune LayoutLM for sequence classification on the RVL-CDIP dataset](https://colab.research.google.com/github/NielsRogge/Transformers-Tutorials/blob/master/LayoutLM/Fine_tuning_LayoutLMForSequenceClassification_on_RVL_CDIP.ipynb).
- [Text classification task guide](../tasks/sequence_classification)
<PipelineTag pipeline="token-classification" />
- A notebook on how to [ fine-tune LayoutLM for token classification on the FUNSD dataset](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/LayoutLM/Fine_tuning_LayoutLMForTokenClassification_on_FUNSD.ipynb).
- [Token classification task guide](../tasks/token_classification)
**Other resources**
- [Masked language modeling task guide](../tasks/masked_language_modeling)
🚀 Deploy
- A blog post on how to [Deploy LayoutLM with Hugging Face Inference Endpoints](https://www.philschmid.de/inference-endpoints-layoutlm).
## LayoutLMConfig
[[autodoc]] LayoutLMConfig
## LayoutLMTokenizer
[[autodoc]] LayoutLMTokenizer
## LayoutLMTokenizerFast
[[autodoc]] LayoutLMTokenizerFast
## LayoutLMModel
[[autodoc]] LayoutLMModel
## LayoutLMForMaskedLM
[[autodoc]] LayoutLMForMaskedLM
## LayoutLMForSequenceClassification
[[autodoc]] LayoutLMForSequenceClassification
## LayoutLMForTokenClassification
[[autodoc]] LayoutLMForTokenClassification
## LayoutLMForQuestionAnswering
[[autodoc]] LayoutLMForQuestionAnswering
## TFLayoutLMModel
[[autodoc]] TFLayoutLMModel
## TFLayoutLMForMaskedLM
[[autodoc]] TFLayoutLMForMaskedLM
## TFLayoutLMForSequenceClassification
[[autodoc]] TFLayoutLMForSequenceClassification
## TFLayoutLMForTokenClassification
[[autodoc]] TFLayoutLMForTokenClassification
## TFLayoutLMForQuestionAnswering
[[autodoc]] TFLayoutLMForQuestionAnswering
| 0 |
hf_public_repos/transformers/docs/source/en | hf_public_repos/transformers/docs/source/en/model_doc/flaubert.md | <!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# FlauBERT
<div class="flex flex-wrap space-x-1">
<a href="https://huggingface.co/models?filter=flaubert">
<img alt="Models" src="https://img.shields.io/badge/All_model_pages-flaubert-blueviolet">
</a>
<a href="https://huggingface.co/spaces/docs-demos/flaubert_small_cased">
<img alt="Spaces" src="https://img.shields.io/badge/%F0%9F%A4%97%20Hugging%20Face-Spaces-blue">
</a>
</div>
## Overview
The FlauBERT model was proposed in the paper [FlauBERT: Unsupervised Language Model Pre-training for French](https://arxiv.org/abs/1912.05372) by Hang Le et al. It's a transformer model pretrained using a masked language
modeling (MLM) objective (like BERT).
The abstract from the paper is the following:
*Language models have become a key step to achieve state-of-the art results in many different Natural Language
Processing (NLP) tasks. Leveraging the huge amount of unlabeled texts nowadays available, they provide an efficient way
to pre-train continuous word representations that can be fine-tuned for a downstream task, along with their
contextualization at the sentence level. This has been widely demonstrated for English using contextualized
representations (Dai and Le, 2015; Peters et al., 2018; Howard and Ruder, 2018; Radford et al., 2018; Devlin et al.,
2019; Yang et al., 2019b). In this paper, we introduce and share FlauBERT, a model learned on a very large and
heterogeneous French corpus. Models of different sizes are trained using the new CNRS (French National Centre for
Scientific Research) Jean Zay supercomputer. We apply our French language models to diverse NLP tasks (text
classification, paraphrasing, natural language inference, parsing, word sense disambiguation) and show that most of the
time they outperform other pretraining approaches. Different versions of FlauBERT as well as a unified evaluation
protocol for the downstream tasks, called FLUE (French Language Understanding Evaluation), are shared to the research
community for further reproducible experiments in French NLP.*
This model was contributed by [formiel](https://huggingface.co/formiel). The original code can be found [here](https://github.com/getalp/Flaubert).
Tips:
- Like RoBERTa, without the sentence ordering prediction (so just trained on the MLM objective).
## Documentation resources
- [Text classification task guide](../tasks/sequence_classification)
- [Token classification task guide](../tasks/token_classification)
- [Question answering task guide](../tasks/question_answering)
- [Masked language modeling task guide](../tasks/masked_language_modeling)
- [Multiple choice task guide](../tasks/multiple_choice)
## FlaubertConfig
[[autodoc]] FlaubertConfig
## FlaubertTokenizer
[[autodoc]] FlaubertTokenizer
## FlaubertModel
[[autodoc]] FlaubertModel
- forward
## FlaubertWithLMHeadModel
[[autodoc]] FlaubertWithLMHeadModel
- forward
## FlaubertForSequenceClassification
[[autodoc]] FlaubertForSequenceClassification
- forward
## FlaubertForMultipleChoice
[[autodoc]] FlaubertForMultipleChoice
- forward
## FlaubertForTokenClassification
[[autodoc]] FlaubertForTokenClassification
- forward
## FlaubertForQuestionAnsweringSimple
[[autodoc]] FlaubertForQuestionAnsweringSimple
- forward
## FlaubertForQuestionAnswering
[[autodoc]] FlaubertForQuestionAnswering
- forward
## TFFlaubertModel
[[autodoc]] TFFlaubertModel
- call
## TFFlaubertWithLMHeadModel
[[autodoc]] TFFlaubertWithLMHeadModel
- call
## TFFlaubertForSequenceClassification
[[autodoc]] TFFlaubertForSequenceClassification
- call
## TFFlaubertForMultipleChoice
[[autodoc]] TFFlaubertForMultipleChoice
- call
## TFFlaubertForTokenClassification
[[autodoc]] TFFlaubertForTokenClassification
- call
## TFFlaubertForQuestionAnsweringSimple
[[autodoc]] TFFlaubertForQuestionAnsweringSimple
- call
| 0 |
hf_public_repos/transformers/docs/source/en | hf_public_repos/transformers/docs/source/en/model_doc/prophetnet.md | <!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# ProphetNet
<div class="flex flex-wrap space-x-1">
<a href="https://huggingface.co/models?filter=prophetnet">
<img alt="Models" src="https://img.shields.io/badge/All_model_pages-prophetnet-blueviolet">
</a>
<a href="https://huggingface.co/spaces/docs-demos/prophetnet-large-uncased">
<img alt="Spaces" src="https://img.shields.io/badge/%F0%9F%A4%97%20Hugging%20Face-Spaces-blue">
</a>
</div>
**DISCLAIMER:** If you see something strange, file a [Github Issue](https://github.com/huggingface/transformers/issues/new?assignees=&labels=&template=bug-report.md&title) and assign
@patrickvonplaten
## Overview
The ProphetNet model was proposed in [ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training,](https://arxiv.org/abs/2001.04063) by Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei
Zhang, Ming Zhou on 13 Jan, 2020.
ProphetNet is an encoder-decoder model and can predict n-future tokens for "ngram" language modeling instead of just
the next token.
The abstract from the paper is the following:
*In this paper, we present a new sequence-to-sequence pretraining model called ProphetNet, which introduces a novel
self-supervised objective named future n-gram prediction and the proposed n-stream self-attention mechanism. Instead of
the optimization of one-step ahead prediction in traditional sequence-to-sequence model, the ProphetNet is optimized by
n-step ahead prediction which predicts the next n tokens simultaneously based on previous context tokens at each time
step. The future n-gram prediction explicitly encourages the model to plan for the future tokens and prevent
overfitting on strong local correlations. We pre-train ProphetNet using a base scale dataset (16GB) and a large scale
dataset (160GB) respectively. Then we conduct experiments on CNN/DailyMail, Gigaword, and SQuAD 1.1 benchmarks for
abstractive summarization and question generation tasks. Experimental results show that ProphetNet achieves new
state-of-the-art results on all these datasets compared to the models using the same scale pretraining corpus.*
Tips:
- ProphetNet is a model with absolute position embeddings so it's usually advised to pad the inputs on the right rather than
the left.
- The model architecture is based on the original Transformer, but replaces the “standard” self-attention mechanism in the decoder by a a main self-attention mechanism and a self and n-stream (predict) self-attention mechanism.
The Authors' code can be found [here](https://github.com/microsoft/ProphetNet).
## Documentation resources
- [Causal language modeling task guide](../tasks/language_modeling)
- [Translation task guide](../tasks/translation)
- [Summarization task guide](../tasks/summarization)
## ProphetNetConfig
[[autodoc]] ProphetNetConfig
## ProphetNetTokenizer
[[autodoc]] ProphetNetTokenizer
## ProphetNet specific outputs
[[autodoc]] models.prophetnet.modeling_prophetnet.ProphetNetSeq2SeqLMOutput
[[autodoc]] models.prophetnet.modeling_prophetnet.ProphetNetSeq2SeqModelOutput
[[autodoc]] models.prophetnet.modeling_prophetnet.ProphetNetDecoderModelOutput
[[autodoc]] models.prophetnet.modeling_prophetnet.ProphetNetDecoderLMOutput
## ProphetNetModel
[[autodoc]] ProphetNetModel
- forward
## ProphetNetEncoder
[[autodoc]] ProphetNetEncoder
- forward
## ProphetNetDecoder
[[autodoc]] ProphetNetDecoder
- forward
## ProphetNetForConditionalGeneration
[[autodoc]] ProphetNetForConditionalGeneration
- forward
## ProphetNetForCausalLM
[[autodoc]] ProphetNetForCausalLM
- forward
| 0 |
hf_public_repos/transformers/docs/source/en | hf_public_repos/transformers/docs/source/en/model_doc/pix2struct.md | <!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Pix2Struct
## Overview
The Pix2Struct model was proposed in [Pix2Struct: Screenshot Parsing as Pretraining for Visual Language Understanding](https://arxiv.org/abs/2210.03347) by Kenton Lee, Mandar Joshi, Iulia Turc, Hexiang Hu, Fangyu Liu, Julian Eisenschlos, Urvashi Khandelwal, Peter Shaw, Ming-Wei Chang, Kristina Toutanova.
The abstract from the paper is the following:
> Visually-situated language is ubiquitous -- sources range from textbooks with diagrams to web pages with images and tables, to mobile apps with buttons and forms. Perhaps due to this diversity, previous work has typically relied on domain-specific recipes with limited sharing of the underlying data, model architectures, and objectives. We present Pix2Struct, a pretrained image-to-text model for purely visual language understanding, which can be finetuned on tasks containing visually-situated language. Pix2Struct is pretrained by learning to parse masked screenshots of web pages into simplified HTML. The web, with its richness of visual elements cleanly reflected in the HTML structure, provides a large source of pretraining data well suited to the diversity of downstream tasks. Intuitively, this objective subsumes common pretraining signals such as OCR, language modeling, image captioning. In addition to the novel pretraining strategy, we introduce a variable-resolution input representation and a more flexible integration of language and vision inputs, where language prompts such as questions are rendered directly on top of the input image. For the first time, we show that a single pretrained model can achieve state-of-the-art results in six out of nine tasks across four domains: documents, illustrations, user interfaces, and natural images.
Tips:
Pix2Struct has been fine tuned on a variety of tasks and datasets, ranging from image captioning, visual question answering (VQA) over different inputs (books, charts, science diagrams), captioning UI components etc. The full list can be found in Table 1 of the paper.
We therefore advise you to use these models for the tasks they have been fine tuned on. For instance, if you want to use Pix2Struct for UI captioning, you should use the model fine tuned on the UI dataset. If you want to use Pix2Struct for image captioning, you should use the model fine tuned on the natural images captioning dataset and so on.
If you want to use the model to perform conditional text captioning, make sure to use the processor with `add_special_tokens=False`.
This model was contributed by [ybelkada](https://huggingface.co/ybelkada).
The original code can be found [here](https://github.com/google-research/pix2struct).
## Resources
- [Fine-tuning Notebook](https://github.com/huggingface/notebooks/blob/main/examples/image_captioning_pix2struct.ipynb)
- [All models](https://huggingface.co/models?search=pix2struct)
## Pix2StructConfig
[[autodoc]] Pix2StructConfig
- from_text_vision_configs
## Pix2StructTextConfig
[[autodoc]] Pix2StructTextConfig
## Pix2StructVisionConfig
[[autodoc]] Pix2StructVisionConfig
## Pix2StructProcessor
[[autodoc]] Pix2StructProcessor
## Pix2StructImageProcessor
[[autodoc]] Pix2StructImageProcessor
- preprocess
## Pix2StructTextModel
[[autodoc]] Pix2StructTextModel
- forward
## Pix2StructVisionModel
[[autodoc]] Pix2StructVisionModel
- forward
## Pix2StructForConditionalGeneration
[[autodoc]] Pix2StructForConditionalGeneration
- forward
| 0 |
hf_public_repos/transformers/docs/source/en | hf_public_repos/transformers/docs/source/en/model_doc/pegasus_x.md | <!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# PEGASUS-X
## Overview
The PEGASUS-X model was proposed in [Investigating Efficiently Extending Transformers for Long Input Summarization](https://arxiv.org/abs/2208.04347) by Jason Phang, Yao Zhao and Peter J. Liu.
PEGASUS-X (PEGASUS eXtended) extends the PEGASUS models for long input summarization through additional long input pretraining and using staggered block-local attention with global tokens in the encoder.
The abstract from the paper is the following:
*While large pretrained Transformer models have proven highly capable at tackling natural language tasks, handling long sequence inputs continues to be a significant challenge. One such task is long input summarization, where inputs are longer than the maximum input context of most pretrained models. Through an extensive set of experiments, we investigate what model architectural changes and pretraining paradigms can most efficiently adapt a pretrained Transformer for long input summarization. We find that a staggered, block-local Transformer with global encoder tokens strikes a good balance of performance and efficiency, and that an additional pretraining phase on long sequences meaningfully improves downstream summarization performance. Based on our findings, we introduce PEGASUS-X, an extension of the PEGASUS model with additional long input pretraining to handle inputs of up to 16K tokens. PEGASUS-X achieves strong performance on long input summarization tasks comparable with much larger models while adding few additional parameters and not requiring model parallelism to train.*
Tips:
* PEGASUS-X uses the same tokenizer as PEGASUS.
This model was contributed by [zphang](<https://huggingface.co/zphang). The original code can be found [here](https://github.com/google-research/pegasus).
## Documentation resources
- [Translation task guide](../tasks/translation)
- [Summarization task guide](../tasks/summarization)
## PegasusXConfig
[[autodoc]] PegasusXConfig
## PegasusXModel
[[autodoc]] PegasusXModel
- forward
## PegasusXForConditionalGeneration
[[autodoc]] PegasusXForConditionalGeneration
- forward
| 0 |
hf_public_repos/transformers/docs/source/en | hf_public_repos/transformers/docs/source/en/model_doc/openai-gpt.md | <!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# OpenAI GPT
<div class="flex flex-wrap space-x-1">
<a href="https://huggingface.co/models?filter=openai-gpt">
<img alt="Models" src="https://img.shields.io/badge/All_model_pages-openai--gpt-blueviolet">
</a>
<a href="https://huggingface.co/spaces/docs-demos/openai-gpt">
<img alt="Spaces" src="https://img.shields.io/badge/%F0%9F%A4%97%20Hugging%20Face-Spaces-blue">
</a>
</div>
## Overview
OpenAI GPT model was proposed in [Improving Language Understanding by Generative Pre-Training](https://s3-us-west-2.amazonaws.com/openai-assets/research-covers/language-unsupervised/language_understanding_paper.pdf)
by Alec Radford, Karthik Narasimhan, Tim Salimans and Ilya Sutskever. It's a causal (unidirectional) transformer
pre-trained using language modeling on a large corpus will long range dependencies, the Toronto Book Corpus.
The abstract from the paper is the following:
*Natural language understanding comprises a wide range of diverse tasks such as textual entailment, question answering,
semantic similarity assessment, and document classification. Although large unlabeled text corpora are abundant,
labeled data for learning these specific tasks is scarce, making it challenging for discriminatively trained models to
perform adequately. We demonstrate that large gains on these tasks can be realized by generative pretraining of a
language model on a diverse corpus of unlabeled text, followed by discriminative fine-tuning on each specific task. In
contrast to previous approaches, we make use of task-aware input transformations during fine-tuning to achieve
effective transfer while requiring minimal changes to the model architecture. We demonstrate the effectiveness of our
approach on a wide range of benchmarks for natural language understanding. Our general task-agnostic model outperforms
discriminatively trained models that use architectures specifically crafted for each task, significantly improving upon
the state of the art in 9 out of the 12 tasks studied.*
Tips:
- GPT is a model with absolute position embeddings so it's usually advised to pad the inputs on the right rather than
the left.
- GPT was trained with a causal language modeling (CLM) objective and is therefore powerful at predicting the next
token in a sequence. Leveraging this feature allows GPT-2 to generate syntactically coherent text as it can be
observed in the *run_generation.py* example script.
[Write With Transformer](https://transformer.huggingface.co/doc/gpt) is a webapp created and hosted by Hugging Face
showcasing the generative capabilities of several models. GPT is one of them.
This model was contributed by [thomwolf](https://huggingface.co/thomwolf). The original code can be found [here](https://github.com/openai/finetune-transformer-lm).
Note:
If you want to reproduce the original tokenization process of the *OpenAI GPT* paper, you will need to install `ftfy`
and `SpaCy`:
```bash
pip install spacy ftfy==4.4.3
python -m spacy download en
```
If you don't install `ftfy` and `SpaCy`, the [`OpenAIGPTTokenizer`] will default to tokenize
using BERT's `BasicTokenizer` followed by Byte-Pair Encoding (which should be fine for most usage, don't worry).
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with OpenAI GPT. If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
<PipelineTag pipeline="text-classification"/>
- A blog post on [outperforming OpenAI GPT-3 with SetFit for text-classification](https://www.philschmid.de/getting-started-setfit).
- See also: [Text classification task guide](../tasks/sequence_classification)
<PipelineTag pipeline="text-generation"/>
- A blog on how to [Finetune a non-English GPT-2 Model with Hugging Face](https://www.philschmid.de/fine-tune-a-non-english-gpt-2-model-with-huggingface).
- A blog on [How to generate text: using different decoding methods for language generation with Transformers](https://huggingface.co/blog/how-to-generate) with GPT-2.
- A blog on [Training CodeParrot 🦜 from Scratch](https://huggingface.co/blog/codeparrot), a large GPT-2 model.
- A blog on [Faster Text Generation with TensorFlow and XLA](https://huggingface.co/blog/tf-xla-generate) with GPT-2.
- A blog on [How to train a Language Model with Megatron-LM](https://huggingface.co/blog/megatron-training) with a GPT-2 model.
- A notebook on how to [finetune GPT2 to generate lyrics in the style of your favorite artist](https://colab.research.google.com/github/AlekseyKorshuk/huggingartists/blob/master/huggingartists-demo.ipynb). 🌎
- A notebook on how to [finetune GPT2 to generate tweets in the style of your favorite Twitter user](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb). 🌎
- [Causal language modeling](https://huggingface.co/course/en/chapter7/6?fw=pt#training-a-causal-language-model-from-scratch) chapter of the 🤗 Hugging Face Course.
- [`OpenAIGPTLMHeadModel`] is supported by this [causal language modeling example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/language-modeling#gpt-2gpt-and-causal-language-modeling), [text generation example script](https://github.com/huggingface/transformers/blob/main/examples/pytorch/text-generation/run_generation.py) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/language_modeling.ipynb).
- [`TFOpenAIGPTLMHeadModel`] is supported by this [causal language modeling example script](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/language-modeling#run_clmpy) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/language_modeling-tf.ipynb).
- See also: [Causal language modeling task guide](../tasks/language_modeling)
<PipelineTag pipeline="token-classification"/>
- A course material on [Byte-Pair Encoding tokenization](https://huggingface.co/course/en/chapter6/5).
## OpenAIGPTConfig
[[autodoc]] OpenAIGPTConfig
## OpenAIGPTTokenizer
[[autodoc]] OpenAIGPTTokenizer
- save_vocabulary
## OpenAIGPTTokenizerFast
[[autodoc]] OpenAIGPTTokenizerFast
## OpenAI specific outputs
[[autodoc]] models.openai.modeling_openai.OpenAIGPTDoubleHeadsModelOutput
[[autodoc]] models.openai.modeling_tf_openai.TFOpenAIGPTDoubleHeadsModelOutput
## OpenAIGPTModel
[[autodoc]] OpenAIGPTModel
- forward
## OpenAIGPTLMHeadModel
[[autodoc]] OpenAIGPTLMHeadModel
- forward
## OpenAIGPTDoubleHeadsModel
[[autodoc]] OpenAIGPTDoubleHeadsModel
- forward
## OpenAIGPTForSequenceClassification
[[autodoc]] OpenAIGPTForSequenceClassification
- forward
## TFOpenAIGPTModel
[[autodoc]] TFOpenAIGPTModel
- call
## TFOpenAIGPTLMHeadModel
[[autodoc]] TFOpenAIGPTLMHeadModel
- call
## TFOpenAIGPTDoubleHeadsModel
[[autodoc]] TFOpenAIGPTDoubleHeadsModel
- call
## TFOpenAIGPTForSequenceClassification
[[autodoc]] TFOpenAIGPTForSequenceClassification
- call
| 0 |
hf_public_repos/transformers/docs/source/en | hf_public_repos/transformers/docs/source/en/model_doc/speech_to_text.md | <!--Copyright 2021 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Speech2Text
## Overview
The Speech2Text model was proposed in [fairseq S2T: Fast Speech-to-Text Modeling with fairseq](https://arxiv.org/abs/2010.05171) by Changhan Wang, Yun Tang, Xutai Ma, Anne Wu, Dmytro Okhonko, Juan Pino. It's a
transformer-based seq2seq (encoder-decoder) model designed for end-to-end Automatic Speech Recognition (ASR) and Speech
Translation (ST). It uses a convolutional downsampler to reduce the length of speech inputs by 3/4th before they are
fed into the encoder. The model is trained with standard autoregressive cross-entropy loss and generates the
transcripts/translations autoregressively. Speech2Text has been fine-tuned on several datasets for ASR and ST:
[LibriSpeech](http://www.openslr.org/12), [CoVoST 2](https://github.com/facebookresearch/covost), [MuST-C](https://ict.fbk.eu/must-c/).
This model was contributed by [valhalla](https://huggingface.co/valhalla). The original code can be found [here](https://github.com/pytorch/fairseq/tree/master/examples/speech_to_text).
## Inference
Speech2Text is a speech model that accepts a float tensor of log-mel filter-bank features extracted from the speech
signal. It's a transformer-based seq2seq model, so the transcripts/translations are generated autoregressively. The
`generate()` method can be used for inference.
The [`Speech2TextFeatureExtractor`] class is responsible for extracting the log-mel filter-bank
features. The [`Speech2TextProcessor`] wraps [`Speech2TextFeatureExtractor`] and
[`Speech2TextTokenizer`] into a single instance to both extract the input features and decode the
predicted token ids.
The feature extractor depends on `torchaudio` and the tokenizer depends on `sentencepiece` so be sure to
install those packages before running the examples. You could either install those as extra speech dependencies with
`pip install transformers"[speech, sentencepiece]"` or install the packages separately with `pip install torchaudio sentencepiece`. Also `torchaudio` requires the development version of the [libsndfile](http://www.mega-nerd.com/libsndfile/) package which can be installed via a system package manager. On Ubuntu it can
be installed as follows: `apt install libsndfile1-dev`
- ASR and Speech Translation
```python
>>> import torch
>>> from transformers import Speech2TextProcessor, Speech2TextForConditionalGeneration
>>> from datasets import load_dataset
>>> model = Speech2TextForConditionalGeneration.from_pretrained("facebook/s2t-small-librispeech-asr")
>>> processor = Speech2TextProcessor.from_pretrained("facebook/s2t-small-librispeech-asr")
>>> ds = load_dataset("hf-internal-testing/librispeech_asr_demo", "clean", split="validation")
>>> inputs = processor(ds[0]["audio"]["array"], sampling_rate=ds[0]["audio"]["sampling_rate"], return_tensors="pt")
>>> generated_ids = model.generate(inputs["input_features"], attention_mask=inputs["attention_mask"])
>>> transcription = processor.batch_decode(generated_ids, skip_special_tokens=True)
>>> transcription
['mister quilter is the apostle of the middle classes and we are glad to welcome his gospel']
```
- Multilingual speech translation
For multilingual speech translation models, `eos_token_id` is used as the `decoder_start_token_id` and
the target language id is forced as the first generated token. To force the target language id as the first
generated token, pass the `forced_bos_token_id` parameter to the `generate()` method. The following
example shows how to transate English speech to French text using the *facebook/s2t-medium-mustc-multilingual-st*
checkpoint.
```python
>>> import torch
>>> from transformers import Speech2TextProcessor, Speech2TextForConditionalGeneration
>>> from datasets import load_dataset
>>> model = Speech2TextForConditionalGeneration.from_pretrained("facebook/s2t-medium-mustc-multilingual-st")
>>> processor = Speech2TextProcessor.from_pretrained("facebook/s2t-medium-mustc-multilingual-st")
>>> ds = load_dataset("hf-internal-testing/librispeech_asr_demo", "clean", split="validation")
>>> inputs = processor(ds[0]["audio"]["array"], sampling_rate=ds[0]["audio"]["sampling_rate"], return_tensors="pt")
>>> generated_ids = model.generate(
... inputs["input_features"],
... attention_mask=inputs["attention_mask"],
... forced_bos_token_id=processor.tokenizer.lang_code_to_id["fr"],
... )
>>> translation = processor.batch_decode(generated_ids, skip_special_tokens=True)
>>> translation
["(Vidéo) Si M. Kilder est l'apossible des classes moyennes, et nous sommes heureux d'être accueillis dans son évangile."]
```
See the [model hub](https://huggingface.co/models?filter=speech_to_text) to look for Speech2Text checkpoints.
## Speech2TextConfig
[[autodoc]] Speech2TextConfig
## Speech2TextTokenizer
[[autodoc]] Speech2TextTokenizer
- build_inputs_with_special_tokens
- get_special_tokens_mask
- create_token_type_ids_from_sequences
- save_vocabulary
## Speech2TextFeatureExtractor
[[autodoc]] Speech2TextFeatureExtractor
- __call__
## Speech2TextProcessor
[[autodoc]] Speech2TextProcessor
- __call__
- from_pretrained
- save_pretrained
- batch_decode
- decode
## Speech2TextModel
[[autodoc]] Speech2TextModel
- forward
## Speech2TextForConditionalGeneration
[[autodoc]] Speech2TextForConditionalGeneration
- forward
## TFSpeech2TextModel
[[autodoc]] TFSpeech2TextModel
- call
## TFSpeech2TextForConditionalGeneration
[[autodoc]] TFSpeech2TextForConditionalGeneration
- call
| 0 |
hf_public_repos/transformers/docs/source/en | hf_public_repos/transformers/docs/source/en/model_doc/bert.md | <!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# BERT
<div class="flex flex-wrap space-x-1">
<a href="https://huggingface.co/models?filter=bert">
<img alt="Models" src="https://img.shields.io/badge/All_model_pages-bert-blueviolet">
</a>
<a href="https://huggingface.co/spaces/docs-demos/bert-base-uncased">
<img alt="Spaces" src="https://img.shields.io/badge/%F0%9F%A4%97%20Hugging%20Face-Spaces-blue">
</a>
</div>
## Overview
The BERT model was proposed in [BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding](https://arxiv.org/abs/1810.04805) by Jacob Devlin, Ming-Wei Chang, Kenton Lee and Kristina Toutanova. It's a
bidirectional transformer pretrained using a combination of masked language modeling objective and next sentence
prediction on a large corpus comprising the Toronto Book Corpus and Wikipedia.
The abstract from the paper is the following:
*We introduce a new language representation model called BERT, which stands for Bidirectional Encoder Representations
from Transformers. Unlike recent language representation models, BERT is designed to pre-train deep bidirectional
representations from unlabeled text by jointly conditioning on both left and right context in all layers. As a result,
the pre-trained BERT model can be fine-tuned with just one additional output layer to create state-of-the-art models
for a wide range of tasks, such as question answering and language inference, without substantial task-specific
architecture modifications.*
*BERT is conceptually simple and empirically powerful. It obtains new state-of-the-art results on eleven natural
language processing tasks, including pushing the GLUE score to 80.5% (7.7% point absolute improvement), MultiNLI
accuracy to 86.7% (4.6% absolute improvement), SQuAD v1.1 question answering Test F1 to 93.2 (1.5 point absolute
improvement) and SQuAD v2.0 Test F1 to 83.1 (5.1 point absolute improvement).*
Tips:
- BERT is a model with absolute position embeddings so it's usually advised to pad the inputs on the right rather than
the left.
- BERT was trained with the masked language modeling (MLM) and next sentence prediction (NSP) objectives. It is
efficient at predicting masked tokens and at NLU in general, but is not optimal for text generation.
- Corrupts the inputs by using random masking, more precisely, during pretraining, a given percentage of tokens (usually 15%) is masked by:
* a special mask token with probability 0.8
* a random token different from the one masked with probability 0.1
* the same token with probability 0.1
- The model must predict the original sentence, but has a second objective: inputs are two sentences A and B (with a separation token in between). With probability 50%, the sentences are consecutive in the corpus, in the remaining 50% they are not related. The model has to predict if the sentences are consecutive or not.
This model was contributed by [thomwolf](https://huggingface.co/thomwolf). The original code can be found [here](https://github.com/google-research/bert).
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with BERT. If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
<PipelineTag pipeline="text-classification"/>
- A blog post on [BERT Text Classification in a different language](https://www.philschmid.de/bert-text-classification-in-a-different-language).
- A notebook for [Finetuning BERT (and friends) for multi-label text classification](https://colab.research.google.com/github/NielsRogge/Transformers-Tutorials/blob/master/BERT/Fine_tuning_BERT_(and_friends)_for_multi_label_text_classification.ipynb).
- A notebook on how to [Finetune BERT for multi-label classification using PyTorch](https://colab.research.google.com/github/abhimishra91/transformers-tutorials/blob/master/transformers_multi_label_classification.ipynb). 🌎
- A notebook on how to [warm-start an EncoderDecoder model with BERT for summarization](https://colab.research.google.com/github/patrickvonplaten/notebooks/blob/master/BERT2BERT_for_CNN_Dailymail.ipynb).
- [`BertForSequenceClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/text-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/text_classification.ipynb).
- [`TFBertForSequenceClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/text-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/text_classification-tf.ipynb).
- [`FlaxBertForSequenceClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/flax/text-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/text_classification_flax.ipynb).
- [Text classification task guide](../tasks/sequence_classification)
<PipelineTag pipeline="token-classification"/>
- A blog post on how to use [Hugging Face Transformers with Keras: Fine-tune a non-English BERT for Named Entity Recognition](https://www.philschmid.de/huggingface-transformers-keras-tf).
- A notebook for [Finetuning BERT for named-entity recognition](https://colab.research.google.com/github/NielsRogge/Transformers-Tutorials/blob/master/Custom_Named_Entity_Recognition_with_BERT_only_first_wordpiece.ipynb) using only the first wordpiece of each word in the word label during tokenization. To propagate the label of the word to all wordpieces, see this [version](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/BERT/Custom_Named_Entity_Recognition_with_BERT.ipynb) of the notebook instead.
- [`BertForTokenClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/token-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/token_classification.ipynb).
- [`TFBertForTokenClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/token-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/token_classification-tf.ipynb).
- [`FlaxBertForTokenClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/flax/token-classification).
- [Token classification](https://huggingface.co/course/chapter7/2?fw=pt) chapter of the 🤗 Hugging Face Course.
- [Token classification task guide](../tasks/token_classification)
<PipelineTag pipeline="fill-mask"/>
- [`BertForMaskedLM`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/language-modeling#robertabertdistilbert-and-masked-language-modeling) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/language_modeling.ipynb).
- [`TFBertForMaskedLM`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/language-modeling#run_mlmpy) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/language_modeling-tf.ipynb).
- [`FlaxBertForMaskedLM`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/flax/language-modeling#masked-language-modeling) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/masked_language_modeling_flax.ipynb).
- [Masked language modeling](https://huggingface.co/course/chapter7/3?fw=pt) chapter of the 🤗 Hugging Face Course.
- [Masked language modeling task guide](../tasks/masked_language_modeling)
<PipelineTag pipeline="question-answering"/>
- [`BertForQuestionAnswering`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/question-answering) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/question_answering.ipynb).
- [`TFBertForQuestionAnswering`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/question-answering) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/question_answering-tf.ipynb).
- [`FlaxBertForQuestionAnswering`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/flax/question-answering).
- [Question answering](https://huggingface.co/course/chapter7/7?fw=pt) chapter of the 🤗 Hugging Face Course.
- [Question answering task guide](../tasks/question_answering)
**Multiple choice**
- [`BertForMultipleChoice`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/multiple-choice) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/multiple_choice.ipynb).
- [`TFBertForMultipleChoice`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/multiple-choice) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/multiple_choice-tf.ipynb).
- [Multiple choice task guide](../tasks/multiple_choice)
⚡️ **Inference**
- A blog post on how to [Accelerate BERT inference with Hugging Face Transformers and AWS Inferentia](https://huggingface.co/blog/bert-inferentia-sagemaker).
- A blog post on how to [Accelerate BERT inference with DeepSpeed-Inference on GPUs](https://www.philschmid.de/bert-deepspeed-inference).
⚙️ **Pretraining**
- A blog post on [Pre-Training BERT with Hugging Face Transformers and Habana Gaudi](https://www.philschmid.de/pre-training-bert-habana).
🚀 **Deploy**
- A blog post on how to [Convert Transformers to ONNX with Hugging Face Optimum](https://www.philschmid.de/convert-transformers-to-onnx).
- A blog post on how to [Setup Deep Learning environment for Hugging Face Transformers with Habana Gaudi on AWS](https://www.philschmid.de/getting-started-habana-gaudi#conclusion).
- A blog post on [Autoscaling BERT with Hugging Face Transformers, Amazon SageMaker and Terraform module](https://www.philschmid.de/terraform-huggingface-amazon-sagemaker-advanced).
- A blog post on [Serverless BERT with HuggingFace, AWS Lambda, and Docker](https://www.philschmid.de/serverless-bert-with-huggingface-aws-lambda-docker).
- A blog post on [Hugging Face Transformers BERT fine-tuning using Amazon SageMaker and Training Compiler](https://www.philschmid.de/huggingface-amazon-sagemaker-training-compiler).
- A blog post on [Task-specific knowledge distillation for BERT using Transformers & Amazon SageMaker](https://www.philschmid.de/knowledge-distillation-bert-transformers).
## BertConfig
[[autodoc]] BertConfig
- all
## BertTokenizer
[[autodoc]] BertTokenizer
- build_inputs_with_special_tokens
- get_special_tokens_mask
- create_token_type_ids_from_sequences
- save_vocabulary
## BertTokenizerFast
[[autodoc]] BertTokenizerFast
## TFBertTokenizer
[[autodoc]] TFBertTokenizer
## Bert specific outputs
[[autodoc]] models.bert.modeling_bert.BertForPreTrainingOutput
[[autodoc]] models.bert.modeling_tf_bert.TFBertForPreTrainingOutput
[[autodoc]] models.bert.modeling_flax_bert.FlaxBertForPreTrainingOutput
## BertModel
[[autodoc]] BertModel
- forward
## BertForPreTraining
[[autodoc]] BertForPreTraining
- forward
## BertLMHeadModel
[[autodoc]] BertLMHeadModel
- forward
## BertForMaskedLM
[[autodoc]] BertForMaskedLM
- forward
## BertForNextSentencePrediction
[[autodoc]] BertForNextSentencePrediction
- forward
## BertForSequenceClassification
[[autodoc]] BertForSequenceClassification
- forward
## BertForMultipleChoice
[[autodoc]] BertForMultipleChoice
- forward
## BertForTokenClassification
[[autodoc]] BertForTokenClassification
- forward
## BertForQuestionAnswering
[[autodoc]] BertForQuestionAnswering
- forward
## TFBertModel
[[autodoc]] TFBertModel
- call
## TFBertForPreTraining
[[autodoc]] TFBertForPreTraining
- call
## TFBertModelLMHeadModel
[[autodoc]] TFBertLMHeadModel
- call
## TFBertForMaskedLM
[[autodoc]] TFBertForMaskedLM
- call
## TFBertForNextSentencePrediction
[[autodoc]] TFBertForNextSentencePrediction
- call
## TFBertForSequenceClassification
[[autodoc]] TFBertForSequenceClassification
- call
## TFBertForMultipleChoice
[[autodoc]] TFBertForMultipleChoice
- call
## TFBertForTokenClassification
[[autodoc]] TFBertForTokenClassification
- call
## TFBertForQuestionAnswering
[[autodoc]] TFBertForQuestionAnswering
- call
## FlaxBertModel
[[autodoc]] FlaxBertModel
- __call__
## FlaxBertForPreTraining
[[autodoc]] FlaxBertForPreTraining
- __call__
## FlaxBertForCausalLM
[[autodoc]] FlaxBertForCausalLM
- __call__
## FlaxBertForMaskedLM
[[autodoc]] FlaxBertForMaskedLM
- __call__
## FlaxBertForNextSentencePrediction
[[autodoc]] FlaxBertForNextSentencePrediction
- __call__
## FlaxBertForSequenceClassification
[[autodoc]] FlaxBertForSequenceClassification
- __call__
## FlaxBertForMultipleChoice
[[autodoc]] FlaxBertForMultipleChoice
- __call__
## FlaxBertForTokenClassification
[[autodoc]] FlaxBertForTokenClassification
- __call__
## FlaxBertForQuestionAnswering
[[autodoc]] FlaxBertForQuestionAnswering
- __call__
| 0 |
hf_public_repos/transformers/docs/source/en | hf_public_repos/transformers/docs/source/en/model_doc/bartpho.md | <!--Copyright 2021 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# BARTpho
## Overview
The BARTpho model was proposed in [BARTpho: Pre-trained Sequence-to-Sequence Models for Vietnamese](https://arxiv.org/abs/2109.09701) by Nguyen Luong Tran, Duong Minh Le and Dat Quoc Nguyen.
The abstract from the paper is the following:
*We present BARTpho with two versions -- BARTpho_word and BARTpho_syllable -- the first public large-scale monolingual
sequence-to-sequence models pre-trained for Vietnamese. Our BARTpho uses the "large" architecture and pre-training
scheme of the sequence-to-sequence denoising model BART, thus especially suitable for generative NLP tasks. Experiments
on a downstream task of Vietnamese text summarization show that in both automatic and human evaluations, our BARTpho
outperforms the strong baseline mBART and improves the state-of-the-art. We release BARTpho to facilitate future
research and applications of generative Vietnamese NLP tasks.*
Example of use:
```python
>>> import torch
>>> from transformers import AutoModel, AutoTokenizer
>>> bartpho = AutoModel.from_pretrained("vinai/bartpho-syllable")
>>> tokenizer = AutoTokenizer.from_pretrained("vinai/bartpho-syllable")
>>> line = "Chúng tôi là những nghiên cứu viên."
>>> input_ids = tokenizer(line, return_tensors="pt")
>>> with torch.no_grad():
... features = bartpho(**input_ids) # Models outputs are now tuples
>>> # With TensorFlow 2.0+:
>>> from transformers import TFAutoModel
>>> bartpho = TFAutoModel.from_pretrained("vinai/bartpho-syllable")
>>> input_ids = tokenizer(line, return_tensors="tf")
>>> features = bartpho(**input_ids)
```
Tips:
- Following mBART, BARTpho uses the "large" architecture of BART with an additional layer-normalization layer on top of
both the encoder and decoder. Thus, usage examples in the [documentation of BART](bart), when adapting to use
with BARTpho, should be adjusted by replacing the BART-specialized classes with the mBART-specialized counterparts.
For example:
```python
>>> from transformers import MBartForConditionalGeneration
>>> bartpho = MBartForConditionalGeneration.from_pretrained("vinai/bartpho-syllable")
>>> TXT = "Chúng tôi là <mask> nghiên cứu viên."
>>> input_ids = tokenizer([TXT], return_tensors="pt")["input_ids"]
>>> logits = bartpho(input_ids).logits
>>> masked_index = (input_ids[0] == tokenizer.mask_token_id).nonzero().item()
>>> probs = logits[0, masked_index].softmax(dim=0)
>>> values, predictions = probs.topk(5)
>>> print(tokenizer.decode(predictions).split())
```
- This implementation is only for tokenization: "monolingual_vocab_file" consists of Vietnamese-specialized types
extracted from the pre-trained SentencePiece model "vocab_file" that is available from the multilingual XLM-RoBERTa.
Other languages, if employing this pre-trained multilingual SentencePiece model "vocab_file" for subword
segmentation, can reuse BartphoTokenizer with their own language-specialized "monolingual_vocab_file".
This model was contributed by [dqnguyen](https://huggingface.co/dqnguyen). The original code can be found [here](https://github.com/VinAIResearch/BARTpho).
## BartphoTokenizer
[[autodoc]] BartphoTokenizer
| 0 |
hf_public_repos/transformers/docs/source/en | hf_public_repos/transformers/docs/source/en/model_doc/bort.md | <!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# BORT
<Tip warning={true}>
This model is in maintenance mode only, so we won't accept any new PRs changing its code.
If you run into any issues running this model, please reinstall the last version that supported this model: v4.30.0.
You can do so by running the following command: `pip install -U transformers==4.30.0`.
</Tip>
## Overview
The BORT model was proposed in [Optimal Subarchitecture Extraction for BERT](https://arxiv.org/abs/2010.10499) by
Adrian de Wynter and Daniel J. Perry. It is an optimal subset of architectural parameters for the BERT, which the
authors refer to as "Bort".
The abstract from the paper is the following:
*We extract an optimal subset of architectural parameters for the BERT architecture from Devlin et al. (2018) by
applying recent breakthroughs in algorithms for neural architecture search. This optimal subset, which we refer to as
"Bort", is demonstrably smaller, having an effective (that is, not counting the embedding layer) size of 5.5% the
original BERT-large architecture, and 16% of the net size. Bort is also able to be pretrained in 288 GPU hours, which
is 1.2% of the time required to pretrain the highest-performing BERT parametric architectural variant, RoBERTa-large
(Liu et al., 2019), and about 33% of that of the world-record, in GPU hours, required to train BERT-large on the same
hardware. It is also 7.9x faster on a CPU, as well as being better performing than other compressed variants of the
architecture, and some of the non-compressed variants: it obtains performance improvements of between 0.3% and 31%,
absolute, with respect to BERT-large, on multiple public natural language understanding (NLU) benchmarks.*
Tips:
- BORT's model architecture is based on BERT, so one can refer to [BERT's documentation page](bert) for the
model's API as well as usage examples.
- BORT uses the RoBERTa tokenizer instead of the BERT tokenizer, so one can refer to [RoBERTa's documentation page](roberta) for the tokenizer's API as well as usage examples.
- BORT requires a specific fine-tuning algorithm, called [Agora](https://adewynter.github.io/notes/bort_algorithms_and_applications.html#fine-tuning-with-algebraic-topology) ,
that is sadly not open-sourced yet. It would be very useful for the community, if someone tries to implement the
algorithm to make BORT fine-tuning work.
This model was contributed by [stefan-it](https://huggingface.co/stefan-it). The original code can be found [here](https://github.com/alexa/bort/).
| 0 |
hf_public_repos/transformers/docs/source/en | hf_public_repos/transformers/docs/source/en/model_doc/mask2former.md | <!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Mask2Former
## Overview
The Mask2Former model was proposed in [Masked-attention Mask Transformer for Universal Image Segmentation](https://arxiv.org/abs/2112.01527) by Bowen Cheng, Ishan Misra, Alexander G. Schwing, Alexander Kirillov, Rohit Girdhar. Mask2Former is a unified framework for panoptic, instance and semantic segmentation and features significant performance and efficiency improvements over [MaskFormer](maskformer).
The abstract from the paper is the following:
*Image segmentation groups pixels with different semantics, e.g., category or instance membership. Each choice
of semantics defines a task. While only the semantics of each task differ, current research focuses on designing specialized architectures for each task. We present Masked-attention Mask Transformer (Mask2Former), a new architecture capable of addressing any image segmentation task (panoptic, instance or semantic). Its key components include masked attention, which extracts localized features by constraining cross-attention within predicted mask regions. In addition to reducing the research effort by at least three times, it outperforms the best specialized architectures by a significant margin on four popular datasets. Most notably, Mask2Former sets a new state-of-the-art for panoptic segmentation (57.8 PQ on COCO), instance segmentation (50.1 AP on COCO) and semantic segmentation (57.7 mIoU on ADE20K).*
Tips:
- Mask2Former uses the same preprocessing and postprocessing steps as [MaskFormer](maskformer). Use [`Mask2FormerImageProcessor`] or [`AutoImageProcessor`] to prepare images and optional targets for the model.
- To get the final segmentation, depending on the task, you can call [`~Mask2FormerImageProcessor.post_process_semantic_segmentation`] or [`~Mask2FormerImageProcessor.post_process_instance_segmentation`] or [`~Mask2FormerImageProcessor.post_process_panoptic_segmentation`]. All three tasks can be solved using [`Mask2FormerForUniversalSegmentation`] output, panoptic segmentation accepts an optional `label_ids_to_fuse` argument to fuse instances of the target object/s (e.g. sky) together.
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/model_doc/mask2former_architecture.jpg" alt="drawing" width="600"/>
<small> Mask2Former architecture. Taken from the <a href="https://arxiv.org/abs/2112.01527">original paper.</a> </small>
This model was contributed by [Shivalika Singh](https://huggingface.co/shivi) and [Alara Dirik](https://huggingface.co/adirik). The original code can be found [here](https://github.com/facebookresearch/Mask2Former).
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with Mask2Former.
- Demo notebooks regarding inference + fine-tuning Mask2Former on custom data can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/Mask2Former).
If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we will review it.
The resource should ideally demonstrate something new instead of duplicating an existing resource.
## MaskFormer specific outputs
[[autodoc]] models.mask2former.modeling_mask2former.Mask2FormerModelOutput
[[autodoc]] models.mask2former.modeling_mask2former.Mask2FormerForUniversalSegmentationOutput
## Mask2FormerConfig
[[autodoc]] Mask2FormerConfig
## Mask2FormerModel
[[autodoc]] Mask2FormerModel
- forward
## Mask2FormerForUniversalSegmentation
[[autodoc]] Mask2FormerForUniversalSegmentation
- forward
## Mask2FormerImageProcessor
[[autodoc]] Mask2FormerImageProcessor
- preprocess
- encode_inputs
- post_process_semantic_segmentation
- post_process_instance_segmentation
- post_process_panoptic_segmentation | 0 |
hf_public_repos/transformers/docs/source/en | hf_public_repos/transformers/docs/source/en/model_doc/llama.md | <!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# LLaMA
## Overview
The LLaMA model was proposed in [LLaMA: Open and Efficient Foundation Language Models](https://arxiv.org/abs/2302.13971) by Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, Guillaume Lample. It is a collection of foundation language models ranging from 7B to 65B parameters.
The abstract from the paper is the following:
*We introduce LLaMA, a collection of foundation language models ranging from 7B to 65B parameters. We train our models on trillions of tokens, and show that it is possible to train state-of-the-art models using publicly available datasets exclusively, without resorting to proprietary and inaccessible datasets. In particular, LLaMA-13B outperforms GPT-3 (175B) on most benchmarks, and LLaMA-65B is competitive with the best models, Chinchilla-70B and PaLM-540B. We release all our models to the research community. *
Tips:
- Weights for the LLaMA models can be obtained from by filling out [this form](https://docs.google.com/forms/d/e/1FAIpQLSfqNECQnMkycAp2jP4Z9TFX0cGR4uf7b_fBxjY_OjhJILlKGA/viewform?usp=send_form)
- After downloading the weights, they will need to be converted to the Hugging Face Transformers format using the [conversion script](https://github.com/huggingface/transformers/blob/main/src/transformers/models/llama/convert_llama_weights_to_hf.py). The script can be called with the following (example) command:
```bash
python src/transformers/models/llama/convert_llama_weights_to_hf.py \
--input_dir /path/to/downloaded/llama/weights --model_size 7B --output_dir /output/path
```
- After conversion, the model and tokenizer can be loaded via:
```python
from transformers import LlamaForCausalLM, LlamaTokenizer
tokenizer = LlamaTokenizer.from_pretrained("/output/path")
model = LlamaForCausalLM.from_pretrained("/output/path")
```
Note that executing the script requires enough CPU RAM to host the whole model in float16 precision (even if the biggest versions
come in several checkpoints they each contain a part of each weight of the model, so we need to load them all in RAM). For the 65B model, it's thus 130GB of RAM needed.
- The LLaMA tokenizer is a BPE model based on [sentencepiece](https://github.com/google/sentencepiece). One quirk of sentencepiece is that when decoding a sequence, if the first token is the start of the word (e.g. "Banana"), the tokenizer does not prepend the prefix space to the string.
This model was contributed by [zphang](https://huggingface.co/zphang) with contributions from [BlackSamorez](https://huggingface.co/BlackSamorez). The code of the implementation in Hugging Face is based on GPT-NeoX [here](https://github.com/EleutherAI/gpt-neox). The original code of the authors can be found [here](https://github.com/facebookresearch/llama).
Based on the original LLaMA model, Meta AI has released some follow-up works:
- **Llama2**: Llama2 is an improved version of Llama with some architectural tweaks (Grouped Query Attention), and is pre-trained on 2Trillion tokens. Refer to the documentation of Llama2 which can be found [here](llama2).
## LlamaConfig
[[autodoc]] LlamaConfig
## LlamaTokenizer
[[autodoc]] LlamaTokenizer
- build_inputs_with_special_tokens
- get_special_tokens_mask
- create_token_type_ids_from_sequences
- save_vocabulary
## LlamaTokenizerFast
[[autodoc]] LlamaTokenizerFast
- build_inputs_with_special_tokens
- get_special_tokens_mask
- create_token_type_ids_from_sequences
- update_post_processor
- save_vocabulary
## LlamaModel
[[autodoc]] LlamaModel
- forward
## LlamaForCausalLM
[[autodoc]] LlamaForCausalLM
- forward
## LlamaForSequenceClassification
[[autodoc]] LlamaForSequenceClassification
- forward
| 0 |
hf_public_repos/transformers/docs/source/en | hf_public_repos/transformers/docs/source/en/model_doc/layoutlmv3.md | <!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# LayoutLMv3
## Overview
The LayoutLMv3 model was proposed in [LayoutLMv3: Pre-training for Document AI with Unified Text and Image Masking](https://arxiv.org/abs/2204.08387) by Yupan Huang, Tengchao Lv, Lei Cui, Yutong Lu, Furu Wei.
LayoutLMv3 simplifies [LayoutLMv2](layoutlmv2) by using patch embeddings (as in [ViT](vit)) instead of leveraging a CNN backbone, and pre-trains the model on 3 objectives: masked language modeling (MLM), masked image modeling (MIM)
and word-patch alignment (WPA).
The abstract from the paper is the following:
*Self-supervised pre-training techniques have achieved remarkable progress in Document AI. Most multimodal pre-trained models use a masked language modeling objective to learn bidirectional representations on the text modality, but they differ in pre-training objectives for the image modality. This discrepancy adds difficulty to multimodal representation learning. In this paper, we propose LayoutLMv3 to pre-train multimodal Transformers for Document AI with unified text and image masking. Additionally, LayoutLMv3 is pre-trained with a word-patch alignment objective to learn cross-modal alignment by predicting whether the corresponding image patch of a text word is masked. The simple unified architecture and training objectives make LayoutLMv3 a general-purpose pre-trained model for both text-centric and image-centric Document AI tasks. Experimental results show that LayoutLMv3 achieves state-of-the-art performance not only in text-centric tasks, including form understanding, receipt understanding, and document visual question answering, but also in image-centric tasks such as document image classification and document layout analysis.*
Tips:
- In terms of data processing, LayoutLMv3 is identical to its predecessor [LayoutLMv2](layoutlmv2), except that:
- images need to be resized and normalized with channels in regular RGB format. LayoutLMv2 on the other hand normalizes the images internally and expects the channels in BGR format.
- text is tokenized using byte-pair encoding (BPE), as opposed to WordPiece.
Due to these differences in data preprocessing, one can use [`LayoutLMv3Processor`] which internally combines a [`LayoutLMv3ImageProcessor`] (for the image modality) and a [`LayoutLMv3Tokenizer`]/[`LayoutLMv3TokenizerFast`] (for the text modality) to prepare all data for the model.
- Regarding usage of [`LayoutLMv3Processor`], we refer to the [usage guide](layoutlmv2#usage-layoutlmv2processor) of its predecessor.
- Demo notebooks for LayoutLMv3 can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/LayoutLMv3).
- Demo scripts can be found [here](https://github.com/huggingface/transformers/tree/main/examples/research_projects/layoutlmv3).
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/layoutlmv3_architecture.png"
alt="drawing" width="600"/>
<small> LayoutLMv3 architecture. Taken from the <a href="https://arxiv.org/abs/2204.08387">original paper</a>. </small>
This model was contributed by [nielsr](https://huggingface.co/nielsr). The TensorFlow version of this model was added by [chriskoo](https://huggingface.co/chriskoo), [tokec](https://huggingface.co/tokec), and [lre](https://huggingface.co/lre). The original code can be found [here](https://github.com/microsoft/unilm/tree/master/layoutlmv3).
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with LayoutLMv3. If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
<Tip>
LayoutLMv3 is nearly identical to LayoutLMv2, so we've also included LayoutLMv2 resources you can adapt for LayoutLMv3 tasks. For these notebooks, take care to use [`LayoutLMv2Processor`] instead when preparing data for the model!
</Tip>
<PipelineTag pipeline="text-classification"/>
- [`LayoutLMv2ForSequenceClassification`] is supported by this [notebook](https://colab.research.google.com/github/NielsRogge/Transformers-Tutorials/blob/master/LayoutLMv2/RVL-CDIP/Fine_tuning_LayoutLMv2ForSequenceClassification_on_RVL_CDIP.ipynb).
- [Text classification task guide](../tasks/sequence_classification)
<PipelineTag pipeline="token-classification"/>
- [`LayoutLMv3ForTokenClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/research_projects/layoutlmv3) and [notebook](https://colab.research.google.com/github/NielsRogge/Transformers-Tutorials/blob/master/LayoutLMv3/Fine_tune_LayoutLMv3_on_FUNSD_(HuggingFace_Trainer).ipynb).
- A [notebook](https://colab.research.google.com/github/NielsRogge/Transformers-Tutorials/blob/master/LayoutLMv2/FUNSD/Inference_with_LayoutLMv2ForTokenClassification.ipynb) for how to perform inference with [`LayoutLMv2ForTokenClassification`] and a [notebook](https://colab.research.google.com/github/NielsRogge/Transformers-Tutorials/blob/master/LayoutLMv2/FUNSD/True_inference_with_LayoutLMv2ForTokenClassification_%2B_Gradio_demo.ipynb) for how to perform inference when no labels are available with [`LayoutLMv2ForTokenClassification`].
- A [notebook](https://colab.research.google.com/github/NielsRogge/Transformers-Tutorials/blob/master/LayoutLMv2/FUNSD/Fine_tuning_LayoutLMv2ForTokenClassification_on_FUNSD_using_HuggingFace_Trainer.ipynb) for how to finetune [`LayoutLMv2ForTokenClassification`] with the 🤗 Trainer.
- [Token classification task guide](../tasks/token_classification)
<PipelineTag pipeline="question-answering"/>
- [`LayoutLMv2ForQuestionAnswering`] is supported by this [notebook](https://colab.research.google.com/github/NielsRogge/Transformers-Tutorials/blob/master/LayoutLMv2/DocVQA/Fine_tuning_LayoutLMv2ForQuestionAnswering_on_DocVQA.ipynb).
- [Question answering task guide](../tasks/question_answering)
**Document question answering**
- [Document question answering task guide](../tasks/document_question_answering)
## LayoutLMv3Config
[[autodoc]] LayoutLMv3Config
## LayoutLMv3FeatureExtractor
[[autodoc]] LayoutLMv3FeatureExtractor
- __call__
## LayoutLMv3ImageProcessor
[[autodoc]] LayoutLMv3ImageProcessor
- preprocess
## LayoutLMv3Tokenizer
[[autodoc]] LayoutLMv3Tokenizer
- __call__
- save_vocabulary
## LayoutLMv3TokenizerFast
[[autodoc]] LayoutLMv3TokenizerFast
- __call__
## LayoutLMv3Processor
[[autodoc]] LayoutLMv3Processor
- __call__
## LayoutLMv3Model
[[autodoc]] LayoutLMv3Model
- forward
## LayoutLMv3ForSequenceClassification
[[autodoc]] LayoutLMv3ForSequenceClassification
- forward
## LayoutLMv3ForTokenClassification
[[autodoc]] LayoutLMv3ForTokenClassification
- forward
## LayoutLMv3ForQuestionAnswering
[[autodoc]] LayoutLMv3ForQuestionAnswering
- forward
## TFLayoutLMv3Model
[[autodoc]] TFLayoutLMv3Model
- call
## TFLayoutLMv3ForSequenceClassification
[[autodoc]] TFLayoutLMv3ForSequenceClassification
- call
## TFLayoutLMv3ForTokenClassification
[[autodoc]] TFLayoutLMv3ForTokenClassification
- call
## TFLayoutLMv3ForQuestionAnswering
[[autodoc]] TFLayoutLMv3ForQuestionAnswering
- call
| 0 |
hf_public_repos/transformers/docs/source/en | hf_public_repos/transformers/docs/source/en/model_doc/informer.md | <!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Informer
## Overview
The Informer model was proposed in [Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting ](https://arxiv.org/abs/2012.07436) by Haoyi Zhou, Shanghang Zhang, Jieqi Peng, Shuai Zhang, Jianxin Li, Hui Xiong, and Wancai Zhang.
This method introduces a Probabilistic Attention mechanism to select the "active" queries rather than the "lazy" queries and provides a sparse Transformer thus mitigating the quadratic compute and memory requirements of vanilla attention.
The abstract from the paper is the following:
*Many real-world applications require the prediction of long sequence time-series, such as electricity consumption planning. Long sequence time-series forecasting (LSTF) demands a high prediction capacity of the model, which is the ability to capture precise long-range dependency coupling between output and input efficiently. Recent studies have shown the potential of Transformer to increase the prediction capacity. However, there are several severe issues with Transformer that prevent it from being directly applicable to LSTF, including quadratic time complexity, high memory usage, and inherent limitation of the encoder-decoder architecture. To address these issues, we design an efficient transformer-based model for LSTF, named Informer, with three distinctive characteristics: (i) a ProbSparse self-attention mechanism, which achieves O(L logL) in time complexity and memory usage, and has comparable performance on sequences' dependency alignment. (ii) the self-attention distilling highlights dominating attention by halving cascading layer input, and efficiently handles extreme long input sequences. (iii) the generative style decoder, while conceptually simple, predicts the long time-series sequences at one forward operation rather than a step-by-step way, which drastically improves the inference speed of long-sequence predictions. Extensive experiments on four large-scale datasets demonstrate that Informer significantly outperforms existing methods and provides a new solution to the LSTF problem.*
This model was contributed by [elisim](https://huggingface.co/elisim) and [kashif](https://huggingface.co/kashif).
The original code can be found [here](https://github.com/zhouhaoyi/Informer2020).
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started. If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
- Check out the Informer blog-post in HuggingFace blog: [Multivariate Probabilistic Time Series Forecasting with Informer](https://huggingface.co/blog/informer)
## InformerConfig
[[autodoc]] InformerConfig
## InformerModel
[[autodoc]] InformerModel
- forward
## InformerForPrediction
[[autodoc]] InformerForPrediction
- forward | 0 |
hf_public_repos/transformers/docs/source/en | hf_public_repos/transformers/docs/source/en/model_doc/opt.md | <!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# OPT
## Overview
The OPT model was proposed in [Open Pre-trained Transformer Language Models](https://arxiv.org/pdf/2205.01068) by Meta AI.
OPT is a series of open-sourced large causal language models which perform similar in performance to GPT3.
The abstract from the paper is the following:
*Large language models, which are often trained for hundreds of thousands of compute days, have shown remarkable capabilities for zero- and few-shot learning. Given their computational cost, these models are difficult to replicate without significant capital. For the few that are available through APIs, no access is granted to the full model weights, making them difficult to study. We present Open Pre-trained Transformers (OPT), a suite of decoder-only pre-trained transformers ranging from 125M to 175B parameters, which we aim to fully and responsibly share with interested researchers. We show that OPT-175B is comparable to GPT-3, while requiring only 1/7th the carbon footprint to develop. We are also releasing our logbook detailing the infrastructure challenges we faced, along with code for experimenting with all of the released models.*
Tips:
- OPT has the same architecture as [`BartDecoder`].
- Contrary to GPT2, OPT adds the EOS token `</s>` to the beginning of every prompt.
This model was contributed by [Arthur Zucker](https://huggingface.co/ArthurZ), [Younes Belkada](https://huggingface.co/ybelkada), and [Patrick Von Platen](https://huggingface.co/patrickvonplaten).
The original code can be found [here](https://github.com/facebookresearch/metaseq).
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with OPT. If you're
interested in submitting a resource to be included here, please feel free to open a Pull Request and we will review it.
The resource should ideally demonstrate something new instead of duplicating an existing resource.
<PipelineTag pipeline="text-generation" />
- A notebook on [fine-tuning OPT with PEFT, bitsandbytes, and Transformers](https://colab.research.google.com/drive/1jCkpikz0J2o20FBQmYmAGdiKmJGOMo-o?usp=sharing). 🌎
- A blog post on [decoding strategies with OPT](https://huggingface.co/blog/introducing-csearch#62-example-two---opt).
- [Causal language modeling](https://huggingface.co/course/en/chapter7/6?fw=pt#training-a-causal-language-model-from-scratch) chapter of the 🤗 Hugging Face Course.
- [`OPTForCausalLM`] is supported by this [causal language modeling example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/language-modeling#gpt-2gpt-and-causal-language-modeling) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/language_modeling.ipynb).
- [`TFOPTForCausalLM`] is supported by this [causal language modeling example script](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/language-modeling#run_clmpy) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/language_modeling-tf.ipynb).
- [`FlaxOPTForCausalLM`] is supported by this [causal language modeling example script](https://github.com/huggingface/transformers/tree/main/examples/flax/language-modeling#causal-language-modeling).
<PipelineTag pipeline="text-classification" />
- [Text classification task guide](sequence_classification.md)
- [`OPTForSequenceClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/text-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/text_classification.ipynb).
<PipelineTag pipeline="question-answering" />
- [`OPTForQuestionAnswering`] is supported by this [question answering example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/question-answering) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/question_answering.ipynb).
- [Question answering](https://huggingface.co/course/chapter7/7?fw=pt) chapter
of the 🤗 Hugging Face Course.
⚡️ Inference
- A blog post on [How 🤗 Accelerate runs very large models thanks to PyTorch](https://huggingface.co/blog/accelerate-large-models) with OPT.
## OPTConfig
[[autodoc]] OPTConfig
## OPTModel
[[autodoc]] OPTModel
- forward
## OPTForCausalLM
[[autodoc]] OPTForCausalLM
- forward
## TFOPTModel
[[autodoc]] TFOPTModel
- call
## TFOPTForCausalLM
[[autodoc]] TFOPTForCausalLM
- call
## OPTForSequenceClassification
[[autodoc]] OPTForSequenceClassification
- forward
## OPTForQuestionAnswering
[[autodoc]] OPTForQuestionAnswering
- forward
## FlaxOPTModel
[[autodoc]] FlaxOPTModel
- __call__
## FlaxOPTForCausalLM
[[autodoc]] FlaxOPTForCausalLM
- __call__
| 0 |
hf_public_repos/transformers/docs/source/en | hf_public_repos/transformers/docs/source/en/model_doc/git.md | <!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# GIT
## Overview
The GIT model was proposed in [GIT: A Generative Image-to-text Transformer for Vision and Language](https://arxiv.org/abs/2205.14100) by
Jianfeng Wang, Zhengyuan Yang, Xiaowei Hu, Linjie Li, Kevin Lin, Zhe Gan, Zicheng Liu, Ce Liu, Lijuan Wang. GIT is a decoder-only Transformer
that leverages [CLIP](clip)'s vision encoder to condition the model on vision inputs besides text. The model obtains state-of-the-art results on
image captioning and visual question answering benchmarks.
The abstract from the paper is the following:
*In this paper, we design and train a Generative Image-to-text Transformer, GIT, to unify vision-language tasks such as image/video captioning and question answering. While generative models provide a consistent network architecture between pre-training and fine-tuning, existing work typically contains complex structures (uni/multi-modal encoder/decoder) and depends on external modules such as object detectors/taggers and optical character recognition (OCR). In GIT, we simplify the architecture as one image encoder and one text decoder under a single language modeling task. We also scale up the pre-training data and the model size to boost the model performance. Without bells and whistles, our GIT establishes new state of the arts on 12 challenging benchmarks with a large margin. For instance, our model surpasses the human performance for the first time on TextCaps (138.2 vs. 125.5 in CIDEr). Furthermore, we present a new scheme of generation-based image classification and scene text recognition, achieving decent performance on standard benchmarks.*
Tips:
- GIT is implemented in a very similar way to GPT-2, the only difference being that the model is also conditioned on `pixel_values`.
- One can use [`GitProcessor`] to prepare images for the model, and the `generate` method for autoregressive generation.
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/model_doc/git_architecture.jpg"
alt="drawing" width="600"/>
<small> GIT architecture. Taken from the <a href="https://arxiv.org/abs/2205.14100" target="_blank">original paper</a>. </small>
This model was contributed by [nielsr](https://huggingface.co/nielsr).
The original code can be found [here](https://github.com/microsoft/GenerativeImage2Text).
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with GIT.
- Demo notebooks regarding inference + fine-tuning GIT on custom data can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/GIT).
- See also: [Causal language modeling task guide](../tasks/language_modeling)
If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we will review it.
The resource should ideally demonstrate something new instead of duplicating an existing resource.
## GitVisionConfig
[[autodoc]] GitVisionConfig
## GitVisionModel
[[autodoc]] GitVisionModel
- forward
## GitConfig
[[autodoc]] GitConfig
- all
## GitProcessor
[[autodoc]] GitProcessor
- __call__
## GitModel
[[autodoc]] GitModel
- forward
## GitForCausalLM
[[autodoc]] GitForCausalLM
- forward | 0 |
hf_public_repos/transformers/docs/source/en | hf_public_repos/transformers/docs/source/en/model_doc/mvp.md | <!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# MVP
## Overview
The MVP model was proposed in [MVP: Multi-task Supervised Pre-training for Natural Language Generation](https://arxiv.org/abs/2206.12131) by Tianyi Tang, Junyi Li, Wayne Xin Zhao and Ji-Rong Wen.
According to the abstract,
- MVP follows a standard Transformer encoder-decoder architecture.
- MVP is supervised pre-trained using labeled datasets.
- MVP also has task-specific soft prompts to stimulate the model's capacity in performing a certain task.
- MVP is specially designed for natural language generation and can be adapted to a wide range of generation tasks, including but not limited to summarization, data-to-text generation, open-ended dialogue system, story generation, question answering, question generation, task-oriented dialogue system, commonsense generation, paraphrase generation, text style transfer, and text simplification. Our model can also be adapted to natural language understanding tasks such as sequence classification and (extractive) question answering.
Tips:
- We have released a series of models [here](https://huggingface.co/models?filter=mvp), including MVP, MVP with task-specific prompts, and multi-task pre-trained variants.
- If you want to use a model without prompts (standard Transformer), you can load it through `MvpForConditionalGeneration.from_pretrained('RUCAIBox/mvp')`.
- If you want to use a model with task-specific prompts, such as summarization, you can load it through `MvpForConditionalGeneration.from_pretrained('RUCAIBox/mvp-summarization')`.
- Our model supports lightweight prompt tuning following [Prefix-tuning](https://arxiv.org/abs/2101.00190) with method `set_lightweight_tuning()`.
This model was contributed by [Tianyi Tang](https://huggingface.co/StevenTang). The detailed information and instructions can be found [here](https://github.com/RUCAIBox/MVP).
## Examples
For summarization, it is an example to use MVP and MVP with summarization-specific prompts.
```python
>>> from transformers import MvpTokenizer, MvpForConditionalGeneration
>>> tokenizer = MvpTokenizer.from_pretrained("RUCAIBox/mvp")
>>> model = MvpForConditionalGeneration.from_pretrained("RUCAIBox/mvp")
>>> model_with_prompt = MvpForConditionalGeneration.from_pretrained("RUCAIBox/mvp-summarization")
>>> inputs = tokenizer(
... "Summarize: You may want to stick it to your boss and leave your job, but don't do it if these are your reasons.",
... return_tensors="pt",
... )
>>> generated_ids = model.generate(**inputs)
>>> tokenizer.batch_decode(generated_ids, skip_special_tokens=True)
["Why You Shouldn't Quit Your Job"]
>>> generated_ids = model_with_prompt.generate(**inputs)
>>> tokenizer.batch_decode(generated_ids, skip_special_tokens=True)
["Don't do it if these are your reasons"]
```
For data-to-text generation, it is an example to use MVP and multi-task pre-trained variants.
```python
>>> from transformers import MvpTokenizerFast, MvpForConditionalGeneration
>>> tokenizer = MvpTokenizerFast.from_pretrained("RUCAIBox/mvp")
>>> model = MvpForConditionalGeneration.from_pretrained("RUCAIBox/mvp")
>>> model_with_mtl = MvpForConditionalGeneration.from_pretrained("RUCAIBox/mtl-data-to-text")
>>> inputs = tokenizer(
... "Describe the following data: Iron Man | instance of | Superhero [SEP] Stan Lee | creator | Iron Man",
... return_tensors="pt",
... )
>>> generated_ids = model.generate(**inputs)
>>> tokenizer.batch_decode(generated_ids, skip_special_tokens=True)
['Stan Lee created the character of Iron Man, a fictional superhero appearing in American comic']
>>> generated_ids = model_with_mtl.generate(**inputs)
>>> tokenizer.batch_decode(generated_ids, skip_special_tokens=True)
['Iron Man is a fictional superhero appearing in American comic books published by Marvel Comics.']
```
For lightweight tuning, *i.e.*, fixing the model and only tuning prompts, you can load MVP with randomly initialized prompts or with task-specific prompts. Our code also supports Prefix-tuning with BART following the [original paper](https://arxiv.org/abs/2101.00190).
```python
>>> from transformers import MvpForConditionalGeneration
>>> model = MvpForConditionalGeneration.from_pretrained("RUCAIBox/mvp", use_prompt=True)
>>> # the number of trainable parameters (full tuning)
>>> sum(p.numel() for p in model.parameters() if p.requires_grad)
468116832
>>> # lightweight tuning with randomly initialized prompts
>>> model.set_lightweight_tuning()
>>> # the number of trainable parameters (lightweight tuning)
>>> sum(p.numel() for p in model.parameters() if p.requires_grad)
61823328
>>> # lightweight tuning with task-specific prompts
>>> model = MvpForConditionalGeneration.from_pretrained("RUCAIBox/mtl-data-to-text")
>>> model.set_lightweight_tuning()
>>> # original lightweight Prefix-tuning
>>> model = MvpForConditionalGeneration.from_pretrained("facebook/bart-large", use_prompt=True)
>>> model.set_lightweight_tuning()
```
## Documentation resources
- [Text classification task guide](../tasks/sequence_classification)
- [Question answering task guide](../tasks/question_answering)
- [Causal language modeling task guide](../tasks/language_modeling)
- [Masked language modeling task guide](../tasks/masked_language_modeling)
- [Translation task guide](../tasks/translation)
- [Summarization task guide](../tasks/summarization)
## MvpConfig
[[autodoc]] MvpConfig
## MvpTokenizer
[[autodoc]] MvpTokenizer
## MvpTokenizerFast
[[autodoc]] MvpTokenizerFast
## MvpModel
[[autodoc]] MvpModel
- forward
## MvpForConditionalGeneration
[[autodoc]] MvpForConditionalGeneration
- forward
## MvpForSequenceClassification
[[autodoc]] MvpForSequenceClassification
- forward
## MvpForQuestionAnswering
[[autodoc]] MvpForQuestionAnswering
- forward
## MvpForCausalLM
[[autodoc]] MvpForCausalLM
- forward
| 0 |
hf_public_repos/transformers/docs/source/en | hf_public_repos/transformers/docs/source/en/model_doc/roberta.md | <!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# RoBERTa
<div class="flex flex-wrap space-x-1">
<a href="https://huggingface.co/models?filter=roberta">
<img alt="Models" src="https://img.shields.io/badge/All_model_pages-roberta-blueviolet">
</a>
<a href="https://huggingface.co/spaces/docs-demos/roberta-base">
<img alt="Spaces" src="https://img.shields.io/badge/%F0%9F%A4%97%20Hugging%20Face-Spaces-blue">
</a>
<a href="https://huggingface.co/papers/1907.11692">
<img alt="Paper page" src="https://img.shields.io/badge/Paper%20page-1907.11692-green">
</a>
</div>
## Overview
The RoBERTa model was proposed in [RoBERTa: A Robustly Optimized BERT Pretraining Approach](https://arxiv.org/abs/1907.11692) by Yinhan Liu, [Myle Ott](https://huggingface.co/myleott), Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer
Levy, Mike Lewis, Luke Zettlemoyer, Veselin Stoyanov. It is based on Google's BERT model released in 2018.
It builds on BERT and modifies key hyperparameters, removing the next-sentence pretraining objective and training with
much larger mini-batches and learning rates.
The abstract from the paper is the following:
*Language model pretraining has led to significant performance gains but careful comparison between different
approaches is challenging. Training is computationally expensive, often done on private datasets of different sizes,
and, as we will show, hyperparameter choices have significant impact on the final results. We present a replication
study of BERT pretraining (Devlin et al., 2019) that carefully measures the impact of many key hyperparameters and
training data size. We find that BERT was significantly undertrained, and can match or exceed the performance of every
model published after it. Our best model achieves state-of-the-art results on GLUE, RACE and SQuAD. These results
highlight the importance of previously overlooked design choices, and raise questions about the source of recently
reported improvements. We release our models and code.*
Tips:
- This implementation is the same as [`BertModel`] with a tiny embeddings tweak as well as a setup
for Roberta pretrained models.
- RoBERTa has the same architecture as BERT, but uses a byte-level BPE as a tokenizer (same as GPT-2) and uses a
different pretraining scheme.
- RoBERTa doesn't have `token_type_ids`, you don't need to indicate which token belongs to which segment. Just
separate your segments with the separation token `tokenizer.sep_token` (or `</s>`)
- Same as BERT with better pretraining tricks:
* dynamic masking: tokens are masked differently at each epoch, whereas BERT does it once and for all
* together to reach 512 tokens (so the sentences are in an order than may span several documents)
* train with larger batches
* use BPE with bytes as a subunit and not characters (because of unicode characters)
- [CamemBERT](camembert) is a wrapper around RoBERTa. Refer to this page for usage examples.
This model was contributed by [julien-c](https://huggingface.co/julien-c). The original code can be found [here](https://github.com/pytorch/fairseq/tree/master/examples/roberta).
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with RoBERTa. If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
<PipelineTag pipeline="text-classification"/>
- A blog on [Getting Started with Sentiment Analysis on Twitter](https://huggingface.co/blog/sentiment-analysis-twitter) using RoBERTa and the [Inference API](https://huggingface.co/inference-api).
- A blog on [Opinion Classification with Kili and Hugging Face AutoTrain](https://huggingface.co/blog/opinion-classification-with-kili) using RoBERTa.
- A notebook on how to [finetune RoBERTa for sentiment analysis](https://colab.research.google.com/github/DhavalTaunk08/NLP_scripts/blob/master/sentiment_analysis_using_roberta.ipynb). 🌎
- [`RobertaForSequenceClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/text-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/text_classification.ipynb).
- [`TFRobertaForSequenceClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/text-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/text_classification-tf.ipynb).
- [`FlaxRobertaForSequenceClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/flax/text-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/text_classification_flax.ipynb).
- [Text classification task guide](../tasks/sequence_classification)
<PipelineTag pipeline="token-classification"/>
- [`RobertaForTokenClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/token-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/token_classification.ipynb).
- [`TFRobertaForTokenClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/token-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/token_classification-tf.ipynb).
- [`FlaxRobertaForTokenClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/flax/token-classification).
- [Token classification](https://huggingface.co/course/chapter7/2?fw=pt) chapter of the 🤗 Hugging Face Course.
- [Token classification task guide](../tasks/token_classification)
<PipelineTag pipeline="fill-mask"/>
- A blog on [How to train a new language model from scratch using Transformers and Tokenizers](https://huggingface.co/blog/how-to-train) with RoBERTa.
- [`RobertaForMaskedLM`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/language-modeling#robertabertdistilbert-and-masked-language-modeling) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/language_modeling.ipynb).
- [`TFRobertaForMaskedLM`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/language-modeling#run_mlmpy) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/language_modeling-tf.ipynb).
- [`FlaxRobertaForMaskedLM`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/flax/language-modeling#masked-language-modeling) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/masked_language_modeling_flax.ipynb).
- [Masked language modeling](https://huggingface.co/course/chapter7/3?fw=pt) chapter of the 🤗 Hugging Face Course.
- [Masked language modeling task guide](../tasks/masked_language_modeling)
<PipelineTag pipeline="question-answering"/>
- A blog on [Accelerated Inference with Optimum and Transformers Pipelines](https://huggingface.co/blog/optimum-inference) with RoBERTa for question answering.
- [`RobertaForQuestionAnswering`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/question-answering) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/question_answering.ipynb).
- [`TFRobertaForQuestionAnswering`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/question-answering) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/question_answering-tf.ipynb).
- [`FlaxRobertaForQuestionAnswering`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/flax/question-answering).
- [Question answering](https://huggingface.co/course/chapter7/7?fw=pt) chapter of the 🤗 Hugging Face Course.
- [Question answering task guide](../tasks/question_answering)
**Multiple choice**
- [`RobertaForMultipleChoice`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/multiple-choice) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/multiple_choice.ipynb).
- [`TFRobertaForMultipleChoice`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/multiple-choice) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/multiple_choice-tf.ipynb).
- [Multiple choice task guide](../tasks/multiple_choice)
## RobertaConfig
[[autodoc]] RobertaConfig
## RobertaTokenizer
[[autodoc]] RobertaTokenizer
- build_inputs_with_special_tokens
- get_special_tokens_mask
- create_token_type_ids_from_sequences
- save_vocabulary
## RobertaTokenizerFast
[[autodoc]] RobertaTokenizerFast
- build_inputs_with_special_tokens
## RobertaModel
[[autodoc]] RobertaModel
- forward
## RobertaForCausalLM
[[autodoc]] RobertaForCausalLM
- forward
## RobertaForMaskedLM
[[autodoc]] RobertaForMaskedLM
- forward
## RobertaForSequenceClassification
[[autodoc]] RobertaForSequenceClassification
- forward
## RobertaForMultipleChoice
[[autodoc]] RobertaForMultipleChoice
- forward
## RobertaForTokenClassification
[[autodoc]] RobertaForTokenClassification
- forward
## RobertaForQuestionAnswering
[[autodoc]] RobertaForQuestionAnswering
- forward
## TFRobertaModel
[[autodoc]] TFRobertaModel
- call
## TFRobertaForCausalLM
[[autodoc]] TFRobertaForCausalLM
- call
## TFRobertaForMaskedLM
[[autodoc]] TFRobertaForMaskedLM
- call
## TFRobertaForSequenceClassification
[[autodoc]] TFRobertaForSequenceClassification
- call
## TFRobertaForMultipleChoice
[[autodoc]] TFRobertaForMultipleChoice
- call
## TFRobertaForTokenClassification
[[autodoc]] TFRobertaForTokenClassification
- call
## TFRobertaForQuestionAnswering
[[autodoc]] TFRobertaForQuestionAnswering
- call
## FlaxRobertaModel
[[autodoc]] FlaxRobertaModel
- __call__
## FlaxRobertaForCausalLM
[[autodoc]] FlaxRobertaForCausalLM
- __call__
## FlaxRobertaForMaskedLM
[[autodoc]] FlaxRobertaForMaskedLM
- __call__
## FlaxRobertaForSequenceClassification
[[autodoc]] FlaxRobertaForSequenceClassification
- __call__
## FlaxRobertaForMultipleChoice
[[autodoc]] FlaxRobertaForMultipleChoice
- __call__
## FlaxRobertaForTokenClassification
[[autodoc]] FlaxRobertaForTokenClassification
- __call__
## FlaxRobertaForQuestionAnswering
[[autodoc]] FlaxRobertaForQuestionAnswering
- __call__
| 0 |
hf_public_repos/transformers/docs/source/en | hf_public_repos/transformers/docs/source/en/model_doc/upernet.md | <!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# UPerNet
## Overview
The UPerNet model was proposed in [Unified Perceptual Parsing for Scene Understanding](https://arxiv.org/abs/1807.10221)
by Tete Xiao, Yingcheng Liu, Bolei Zhou, Yuning Jiang, Jian Sun. UPerNet is a general framework to effectively segment
a wide range of concepts from images, leveraging any vision backbone like [ConvNeXt](convnext) or [Swin](swin).
The abstract from the paper is the following:
*Humans recognize the visual world at multiple levels: we effortlessly categorize scenes and detect objects inside, while also identifying the textures and surfaces of the objects along with their different compositional parts. In this paper, we study a new task called Unified Perceptual Parsing, which requires the machine vision systems to recognize as many visual concepts as possible from a given image. A multi-task framework called UPerNet and a training strategy are developed to learn from heterogeneous image annotations. We benchmark our framework on Unified Perceptual Parsing and show that it is able to effectively segment a wide range of concepts from images. The trained networks are further applied to discover visual knowledge in natural scenes.*
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/model_doc/upernet_architecture.jpg"
alt="drawing" width="600"/>
<small> UPerNet framework. Taken from the <a href="https://arxiv.org/abs/1807.10221">original paper</a>. </small>
This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code is based on OpenMMLab's mmsegmentation [here](https://github.com/open-mmlab/mmsegmentation/blob/master/mmseg/models/decode_heads/uper_head.py).
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with UPerNet.
- Demo notebooks for UPerNet can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/UPerNet).
- [`UperNetForSemanticSegmentation`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/semantic-segmentation) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/semantic_segmentation.ipynb).
- See also: [Semantic segmentation task guide](../tasks/semantic_segmentation)
If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
## Usage
UPerNet is a general framework for semantic segmentation. It can be used with any vision backbone, like so:
```py
from transformers import SwinConfig, UperNetConfig, UperNetForSemanticSegmentation
backbone_config = SwinConfig(out_features=["stage1", "stage2", "stage3", "stage4"])
config = UperNetConfig(backbone_config=backbone_config)
model = UperNetForSemanticSegmentation(config)
```
To use another vision backbone, like [ConvNeXt](convnext), simply instantiate the model with the appropriate backbone:
```py
from transformers import ConvNextConfig, UperNetConfig, UperNetForSemanticSegmentation
backbone_config = ConvNextConfig(out_features=["stage1", "stage2", "stage3", "stage4"])
config = UperNetConfig(backbone_config=backbone_config)
model = UperNetForSemanticSegmentation(config)
```
Note that this will randomly initialize all the weights of the model.
## UperNetConfig
[[autodoc]] UperNetConfig
## UperNetForSemanticSegmentation
[[autodoc]] UperNetForSemanticSegmentation
- forward | 0 |
hf_public_repos/transformers/docs/source/en | hf_public_repos/transformers/docs/source/en/model_doc/tapex.md | <!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# TAPEX
<Tip warning={true}>
This model is in maintenance mode only, so we won't accept any new PRs changing its code.
If you run into any issues running this model, please reinstall the last version that supported this model: v4.30.0.
You can do so by running the following command: `pip install -U transformers==4.30.0`.
</Tip>
## Overview
The TAPEX model was proposed in [TAPEX: Table Pre-training via Learning a Neural SQL Executor](https://arxiv.org/abs/2107.07653) by Qian Liu,
Bei Chen, Jiaqi Guo, Morteza Ziyadi, Zeqi Lin, Weizhu Chen, Jian-Guang Lou. TAPEX pre-trains a BART model to solve synthetic SQL queries, after
which it can be fine-tuned to answer natural language questions related to tabular data, as well as performing table fact checking.
TAPEX has been fine-tuned on several datasets:
- [SQA](https://www.microsoft.com/en-us/download/details.aspx?id=54253) (Sequential Question Answering by Microsoft)
- [WTQ](https://github.com/ppasupat/WikiTableQuestions) (Wiki Table Questions by Stanford University)
- [WikiSQL](https://github.com/salesforce/WikiSQL) (by Salesforce)
- [TabFact](https://tabfact.github.io/) (by USCB NLP Lab).
The abstract from the paper is the following:
*Recent progress in language model pre-training has achieved a great success via leveraging large-scale unstructured textual data. However, it is
still a challenge to apply pre-training on structured tabular data due to the absence of large-scale high-quality tabular data. In this paper, we
propose TAPEX to show that table pre-training can be achieved by learning a neural SQL executor over a synthetic corpus, which is obtained by automatically
synthesizing executable SQL queries and their execution outputs. TAPEX addresses the data scarcity challenge via guiding the language model to mimic a SQL
executor on the diverse, large-scale and high-quality synthetic corpus. We evaluate TAPEX on four benchmark datasets. Experimental results demonstrate that
TAPEX outperforms previous table pre-training approaches by a large margin and achieves new state-of-the-art results on all of them. This includes improvements
on the weakly-supervised WikiSQL denotation accuracy to 89.5% (+2.3%), the WikiTableQuestions denotation accuracy to 57.5% (+4.8%), the SQA denotation accuracy
to 74.5% (+3.5%), and the TabFact accuracy to 84.2% (+3.2%). To our knowledge, this is the first work to exploit table pre-training via synthetic executable programs
and to achieve new state-of-the-art results on various downstream tasks.*
Tips:
- TAPEX is a generative (seq2seq) model. One can directly plug in the weights of TAPEX into a BART model.
- TAPEX has checkpoints on the hub that are either pre-trained only, or fine-tuned on WTQ, SQA, WikiSQL and TabFact.
- Sentences + tables are presented to the model as `sentence + " " + linearized table`. The linearized table has the following format:
`col: col1 | col2 | col 3 row 1 : val1 | val2 | val3 row 2 : ...`.
- TAPEX has its own tokenizer, that allows to prepare all data for the model easily. One can pass Pandas DataFrames and strings to the tokenizer,
and it will automatically create the `input_ids` and `attention_mask` (as shown in the usage examples below).
## Usage: inference
Below, we illustrate how to use TAPEX for table question answering. As one can see, one can directly plug in the weights of TAPEX into a BART model.
We use the [Auto API](auto), which will automatically instantiate the appropriate tokenizer ([`TapexTokenizer`]) and model ([`BartForConditionalGeneration`]) for us,
based on the configuration file of the checkpoint on the hub.
```python
>>> from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
>>> import pandas as pd
>>> tokenizer = AutoTokenizer.from_pretrained("microsoft/tapex-large-finetuned-wtq")
>>> model = AutoModelForSeq2SeqLM.from_pretrained("microsoft/tapex-large-finetuned-wtq")
>>> # prepare table + question
>>> data = {"Actors": ["Brad Pitt", "Leonardo Di Caprio", "George Clooney"], "Number of movies": ["87", "53", "69"]}
>>> table = pd.DataFrame.from_dict(data)
>>> question = "how many movies does Leonardo Di Caprio have?"
>>> encoding = tokenizer(table, question, return_tensors="pt")
>>> # let the model generate an answer autoregressively
>>> outputs = model.generate(**encoding)
>>> # decode back to text
>>> predicted_answer = tokenizer.batch_decode(outputs, skip_special_tokens=True)[0]
>>> print(predicted_answer)
53
```
Note that [`TapexTokenizer`] also supports batched inference. Hence, one can provide a batch of different tables/questions, or a batch of a single table
and multiple questions, or a batch of a single query and multiple tables. Let's illustrate this:
```python
>>> # prepare table + question
>>> data = {"Actors": ["Brad Pitt", "Leonardo Di Caprio", "George Clooney"], "Number of movies": ["87", "53", "69"]}
>>> table = pd.DataFrame.from_dict(data)
>>> questions = [
... "how many movies does Leonardo Di Caprio have?",
... "which actor has 69 movies?",
... "what's the first name of the actor who has 87 movies?",
... ]
>>> encoding = tokenizer(table, questions, padding=True, return_tensors="pt")
>>> # let the model generate an answer autoregressively
>>> outputs = model.generate(**encoding)
>>> # decode back to text
>>> tokenizer.batch_decode(outputs, skip_special_tokens=True)
[' 53', ' george clooney', ' brad pitt']
```
In case one wants to do table verification (i.e. the task of determining whether a given sentence is supported or refuted by the contents
of a table), one can instantiate a [`BartForSequenceClassification`] model. TAPEX has checkpoints on the hub fine-tuned on TabFact, an important
benchmark for table fact checking (it achieves 84% accuracy). The code example below again leverages the [Auto API](auto).
```python
>>> from transformers import AutoTokenizer, AutoModelForSequenceClassification
>>> tokenizer = AutoTokenizer.from_pretrained("microsoft/tapex-large-finetuned-tabfact")
>>> model = AutoModelForSequenceClassification.from_pretrained("microsoft/tapex-large-finetuned-tabfact")
>>> # prepare table + sentence
>>> data = {"Actors": ["Brad Pitt", "Leonardo Di Caprio", "George Clooney"], "Number of movies": ["87", "53", "69"]}
>>> table = pd.DataFrame.from_dict(data)
>>> sentence = "George Clooney has 30 movies"
>>> encoding = tokenizer(table, sentence, return_tensors="pt")
>>> # forward pass
>>> outputs = model(**encoding)
>>> # print prediction
>>> predicted_class_idx = outputs.logits[0].argmax(dim=0).item()
>>> print(model.config.id2label[predicted_class_idx])
Refused
```
## TapexTokenizer
[[autodoc]] TapexTokenizer
- __call__
- save_vocabulary | 0 |
hf_public_repos/transformers/docs/source/en | hf_public_repos/transformers/docs/source/en/model_doc/efficientnet.md | <!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# EfficientNet
## Overview
The EfficientNet model was proposed in [EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks](https://arxiv.org/abs/1905.11946)
by Mingxing Tan and Quoc V. Le. EfficientNets are a family of image classification models, which achieve state-of-the-art accuracy, yet being an order-of-magnitude smaller and faster than previous models.
The abstract from the paper is the following:
*Convolutional Neural Networks (ConvNets) are commonly developed at a fixed resource budget, and then scaled up for better accuracy if more resources are available. In this paper, we systematically study model scaling and identify that carefully balancing network depth, width, and resolution can lead to better performance. Based on this observation, we propose a new scaling method that uniformly scales all dimensions of depth/width/resolution using a simple yet highly effective compound coefficient. We demonstrate the effectiveness of this method on scaling up MobileNets and ResNet.
To go even further, we use neural architecture search to design a new baseline network and scale it up to obtain a family of models, called EfficientNets, which achieve much better accuracy and efficiency than previous ConvNets. In particular, our EfficientNet-B7 achieves state-of-the-art 84.3% top-1 accuracy on ImageNet, while being 8.4x smaller and 6.1x faster on inference than the best existing ConvNet. Our EfficientNets also transfer well and achieve state-of-the-art accuracy on CIFAR-100 (91.7%), Flowers (98.8%), and 3 other transfer learning datasets, with an order of magnitude fewer parameters.*
This model was contributed by [adirik](https://huggingface.co/adirik).
The original code can be found [here](https://github.com/tensorflow/tpu/tree/master/models/official/efficientnet).
## EfficientNetConfig
[[autodoc]] EfficientNetConfig
## EfficientNetImageProcessor
[[autodoc]] EfficientNetImageProcessor
- preprocess
## EfficientNetModel
[[autodoc]] EfficientNetModel
- forward
## EfficientNetForImageClassification
[[autodoc]] EfficientNetForImageClassification
- forward
| 0 |
hf_public_repos/transformers/docs/source/en | hf_public_repos/transformers/docs/source/en/model_doc/vit_mae.md | <!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# ViTMAE
## Overview
The ViTMAE model was proposed in [Masked Autoencoders Are Scalable Vision Learners](https://arxiv.org/abs/2111.06377v2) by Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li,
Piotr Dollár, Ross Girshick. The paper shows that, by pre-training a Vision Transformer (ViT) to reconstruct pixel values for masked patches, one can get results after
fine-tuning that outperform supervised pre-training.
The abstract from the paper is the following:
*This paper shows that masked autoencoders (MAE) are scalable self-supervised learners for computer vision. Our MAE approach is simple: we mask random patches of the
input image and reconstruct the missing pixels. It is based on two core designs. First, we develop an asymmetric encoder-decoder architecture, with an encoder that operates
only on the visible subset of patches (without mask tokens), along with a lightweight decoder that reconstructs the original image from the latent representation and mask
tokens. Second, we find that masking a high proportion of the input image, e.g., 75%, yields a nontrivial and meaningful self-supervisory task. Coupling these two designs
enables us to train large models efficiently and effectively: we accelerate training (by 3x or more) and improve accuracy. Our scalable approach allows for learning high-capacity
models that generalize well: e.g., a vanilla ViT-Huge model achieves the best accuracy (87.8%) among methods that use only ImageNet-1K data. Transfer performance in downstream
tasks outperforms supervised pre-training and shows promising scaling behavior.*
Tips:
- MAE (masked auto encoding) is a method for self-supervised pre-training of Vision Transformers (ViTs). The pre-training objective is relatively simple:
by masking a large portion (75%) of the image patches, the model must reconstruct raw pixel values. One can use [`ViTMAEForPreTraining`] for this purpose.
- After pre-training, one "throws away" the decoder used to reconstruct pixels, and one uses the encoder for fine-tuning/linear probing. This means that after
fine-tuning, one can directly plug in the weights into a [`ViTForImageClassification`].
- One can use [`ViTImageProcessor`] to prepare images for the model. See the code examples for more info.
- Note that the encoder of MAE is only used to encode the visual patches. The encoded patches are then concatenated with mask tokens, which the decoder (which also
consists of Transformer blocks) takes as input. Each mask token is a shared, learned vector that indicates the presence of a missing patch to be predicted. Fixed
sin/cos position embeddings are added both to the input of the encoder and the decoder.
- For a visual understanding of how MAEs work you can check out this [post](https://keras.io/examples/vision/masked_image_modeling/).
<img src="https://user-images.githubusercontent.com/11435359/146857310-f258c86c-fde6-48e8-9cee-badd2b21bd2c.png"
alt="drawing" width="600"/>
<small> MAE architecture. Taken from the <a href="https://arxiv.org/abs/2111.06377">original paper.</a> </small>
This model was contributed by [nielsr](https://huggingface.co/nielsr). TensorFlow version of the model was contributed by [sayakpaul](https://github.com/sayakpaul) and
[ariG23498](https://github.com/ariG23498) (equal contribution). The original code can be found [here](https://github.com/facebookresearch/mae).
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with ViTMAE.
- [`ViTMAEForPreTraining`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-pretraining), allowing you to pre-train the model from scratch/further pre-train the model on custom data.
- A notebook that illustrates how to visualize reconstructed pixel values with [`ViTMAEForPreTraining`] can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/ViTMAE/ViT_MAE_visualization_demo.ipynb).
If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
## ViTMAEConfig
[[autodoc]] ViTMAEConfig
## ViTMAEModel
[[autodoc]] ViTMAEModel
- forward
## ViTMAEForPreTraining
[[autodoc]] transformers.ViTMAEForPreTraining
- forward
## TFViTMAEModel
[[autodoc]] TFViTMAEModel
- call
## TFViTMAEForPreTraining
[[autodoc]] transformers.TFViTMAEForPreTraining
- call
| 0 |
hf_public_repos/transformers/docs/source/en | hf_public_repos/transformers/docs/source/en/model_doc/roberta-prelayernorm.md | <!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# RoBERTa-PreLayerNorm
## Overview
The RoBERTa-PreLayerNorm model was proposed in [fairseq: A Fast, Extensible Toolkit for Sequence Modeling](https://arxiv.org/abs/1904.01038) by Myle Ott, Sergey Edunov, Alexei Baevski, Angela Fan, Sam Gross, Nathan Ng, David Grangier, Michael Auli.
It is identical to using the `--encoder-normalize-before` flag in [fairseq](https://fairseq.readthedocs.io/).
The abstract from the paper is the following:
*fairseq is an open-source sequence modeling toolkit that allows researchers and developers to train custom models for translation, summarization, language modeling, and other text generation tasks. The toolkit is based on PyTorch and supports distributed training across multiple GPUs and machines. We also support fast mixed-precision training and inference on modern GPUs.*
Tips:
- The implementation is the same as [Roberta](roberta) except instead of using _Add and Norm_ it does _Norm and Add_. _Add_ and _Norm_ refers to the Addition and LayerNormalization as described in [Attention Is All You Need](https://arxiv.org/abs/1706.03762).
- This is identical to using the `--encoder-normalize-before` flag in [fairseq](https://fairseq.readthedocs.io/).
This model was contributed by [andreasmaden](https://huggingface.co/andreasmaden).
The original code can be found [here](https://github.com/princeton-nlp/DinkyTrain).
## Documentation resources
- [Text classification task guide](../tasks/sequence_classification)
- [Token classification task guide](../tasks/token_classification)
- [Question answering task guide](../tasks/question_answering)
- [Causal language modeling task guide](../tasks/language_modeling)
- [Masked language modeling task guide](../tasks/masked_language_modeling)
- [Multiple choice task guide](../tasks/multiple_choice)
## RobertaPreLayerNormConfig
[[autodoc]] RobertaPreLayerNormConfig
## RobertaPreLayerNormModel
[[autodoc]] RobertaPreLayerNormModel
- forward
## RobertaPreLayerNormForCausalLM
[[autodoc]] RobertaPreLayerNormForCausalLM
- forward
## RobertaPreLayerNormForMaskedLM
[[autodoc]] RobertaPreLayerNormForMaskedLM
- forward
## RobertaPreLayerNormForSequenceClassification
[[autodoc]] RobertaPreLayerNormForSequenceClassification
- forward
## RobertaPreLayerNormForMultipleChoice
[[autodoc]] RobertaPreLayerNormForMultipleChoice
- forward
## RobertaPreLayerNormForTokenClassification
[[autodoc]] RobertaPreLayerNormForTokenClassification
- forward
## RobertaPreLayerNormForQuestionAnswering
[[autodoc]] RobertaPreLayerNormForQuestionAnswering
- forward
## TFRobertaPreLayerNormModel
[[autodoc]] TFRobertaPreLayerNormModel
- call
## TFRobertaPreLayerNormForCausalLM
[[autodoc]] TFRobertaPreLayerNormForCausalLM
- call
## TFRobertaPreLayerNormForMaskedLM
[[autodoc]] TFRobertaPreLayerNormForMaskedLM
- call
## TFRobertaPreLayerNormForSequenceClassification
[[autodoc]] TFRobertaPreLayerNormForSequenceClassification
- call
## TFRobertaPreLayerNormForMultipleChoice
[[autodoc]] TFRobertaPreLayerNormForMultipleChoice
- call
## TFRobertaPreLayerNormForTokenClassification
[[autodoc]] TFRobertaPreLayerNormForTokenClassification
- call
## TFRobertaPreLayerNormForQuestionAnswering
[[autodoc]] TFRobertaPreLayerNormForQuestionAnswering
- call
## FlaxRobertaPreLayerNormModel
[[autodoc]] FlaxRobertaPreLayerNormModel
- __call__
## FlaxRobertaPreLayerNormForCausalLM
[[autodoc]] FlaxRobertaPreLayerNormForCausalLM
- __call__
## FlaxRobertaPreLayerNormForMaskedLM
[[autodoc]] FlaxRobertaPreLayerNormForMaskedLM
- __call__
## FlaxRobertaPreLayerNormForSequenceClassification
[[autodoc]] FlaxRobertaPreLayerNormForSequenceClassification
- __call__
## FlaxRobertaPreLayerNormForMultipleChoice
[[autodoc]] FlaxRobertaPreLayerNormForMultipleChoice
- __call__
## FlaxRobertaPreLayerNormForTokenClassification
[[autodoc]] FlaxRobertaPreLayerNormForTokenClassification
- __call__
## FlaxRobertaPreLayerNormForQuestionAnswering
[[autodoc]] FlaxRobertaPreLayerNormForQuestionAnswering
- __call__
| 0 |
hf_public_repos/transformers/docs/source/en | hf_public_repos/transformers/docs/source/en/model_doc/vit_msn.md | <!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# ViTMSN
## Overview
The ViTMSN model was proposed in [Masked Siamese Networks for Label-Efficient Learning](https://arxiv.org/abs/2204.07141) by Mahmoud Assran, Mathilde Caron, Ishan Misra, Piotr Bojanowski, Florian Bordes,
Pascal Vincent, Armand Joulin, Michael Rabbat, Nicolas Ballas. The paper presents a joint-embedding architecture to match the prototypes
of masked patches with that of the unmasked patches. With this setup, their method yields excellent performance in the low-shot and extreme low-shot
regimes.
The abstract from the paper is the following:
*We propose Masked Siamese Networks (MSN), a self-supervised learning framework for learning image representations. Our
approach matches the representation of an image view containing randomly masked patches to the representation of the original
unmasked image. This self-supervised pre-training strategy is particularly scalable when applied to Vision Transformers since only the
unmasked patches are processed by the network. As a result, MSNs improve the scalability of joint-embedding architectures,
while producing representations of a high semantic level that perform competitively on low-shot image classification. For instance,
on ImageNet-1K, with only 5,000 annotated images, our base MSN model achieves 72.4% top-1 accuracy,
and with 1% of ImageNet-1K labels, we achieve 75.7% top-1 accuracy, setting a new state-of-the-art for self-supervised learning on this benchmark.*
Tips:
- MSN (masked siamese networks) is a method for self-supervised pre-training of Vision Transformers (ViTs). The pre-training
objective is to match the prototypes assigned to the unmasked views of the images to that of the masked views of the same images.
- The authors have only released pre-trained weights of the backbone (ImageNet-1k pre-training). So, to use that on your own image classification dataset,
use the [`ViTMSNForImageClassification`] class which is initialized from [`ViTMSNModel`]. Follow
[this notebook](https://github.com/huggingface/notebooks/blob/main/examples/image_classification.ipynb) for a detailed tutorial on fine-tuning.
- MSN is particularly useful in the low-shot and extreme low-shot regimes. Notably, it achieves 75.7% top-1 accuracy with only 1% of ImageNet-1K
labels when fine-tuned.
<img src="https://i.ibb.co/W6PQMdC/Screenshot-2022-09-13-at-9-08-40-AM.png" alt="drawing" width="600"/>
<small> MSN architecture. Taken from the <a href="https://arxiv.org/abs/2204.07141">original paper.</a> </small>
This model was contributed by [sayakpaul](https://huggingface.co/sayakpaul). The original code can be found [here](https://github.com/facebookresearch/msn).
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with ViT MSN.
<PipelineTag pipeline="image-classification"/>
- [`ViTMSNForImageClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb).
- See also: [Image classification task guide](../tasks/image_classification)
If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
## ViTMSNConfig
[[autodoc]] ViTMSNConfig
## ViTMSNModel
[[autodoc]] ViTMSNModel
- forward
## ViTMSNForImageClassification
[[autodoc]] ViTMSNForImageClassification
- forward
| 0 |
hf_public_repos/transformers/docs/source/en | hf_public_repos/transformers/docs/source/en/model_doc/reformer.md | <!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Reformer
<div class="flex flex-wrap space-x-1">
<a href="https://huggingface.co/models?filter=reformer">
<img alt="Models" src="https://img.shields.io/badge/All_model_pages-reformer-blueviolet">
</a>
<a href="https://huggingface.co/spaces/docs-demos/reformer-crime-and-punishment">
<img alt="Spaces" src="https://img.shields.io/badge/%F0%9F%A4%97%20Hugging%20Face-Spaces-blue">
</a>
</div>
**DISCLAIMER:** This model is still a work in progress, if you see something strange, file a [Github Issue](https://github.com/huggingface/transformers/issues/new?assignees=&labels=&template=bug-report.md&title).
## Overview
The Reformer model was proposed in the paper [Reformer: The Efficient Transformer](https://arxiv.org/abs/2001.04451.pdf) by Nikita Kitaev, Łukasz Kaiser, Anselm Levskaya.
The abstract from the paper is the following:
*Large Transformer models routinely achieve state-of-the-art results on a number of tasks but training these models can
be prohibitively costly, especially on long sequences. We introduce two techniques to improve the efficiency of
Transformers. For one, we replace dot-product attention by one that uses locality-sensitive hashing, changing its
complexity from O(L^2) to O(Llog(L)), where L is the length of the sequence. Furthermore, we use reversible residual
layers instead of the standard residuals, which allows storing activations only once in the training process instead of
N times, where N is the number of layers. The resulting model, the Reformer, performs on par with Transformer models
while being much more memory-efficient and much faster on long sequences.*
This model was contributed by [patrickvonplaten](https://huggingface.co/patrickvonplaten). The Authors' code can be
found [here](https://github.com/google/trax/tree/master/trax/models/reformer).
Tips:
- Reformer does **not** work with *torch.nn.DataParallel* due to a bug in PyTorch, see [issue #36035](https://github.com/pytorch/pytorch/issues/36035).
- Use Axial position encoding (see below for more details). It’s a mechanism to avoid having a huge positional encoding matrix (when the sequence length is very big) by factorizing it into smaller matrices.
- Replace traditional attention by LSH (local-sensitive hashing) attention (see below for more details). It’s a technique to avoid computing the full product query-key in the attention layers.
- Avoid storing the intermediate results of each layer by using reversible transformer layers to obtain them during the backward pass (subtracting the residuals from the input of the next layer gives them back) or recomputing them for results inside a given layer (less efficient than storing them but saves memory).
- Compute the feedforward operations by chunks and not on the whole batch.
## Axial Positional Encodings
Axial Positional Encodings were first implemented in Google's [trax library](https://github.com/google/trax/blob/4d99ad4965bab1deba227539758d59f0df0fef48/trax/layers/research/position_encodings.py#L29)
and developed by the authors of this model's paper. In models that are treating very long input sequences, the
conventional position id encodings store an embedings vector of size \\(d\\) being the `config.hidden_size` for
every position \\(i, \ldots, n_s\\), with \\(n_s\\) being `config.max_embedding_size`. This means that having
a sequence length of \\(n_s = 2^{19} \approx 0.5M\\) and a `config.hidden_size` of \\(d = 2^{10} \approx 1000\\)
would result in a position encoding matrix:
$$X_{i,j}, \text{ with } i \in \left[1,\ldots, d\right] \text{ and } j \in \left[1,\ldots, n_s\right]$$
which alone has over 500M parameters to store. Axial positional encodings factorize \\(X_{i,j}\\) into two matrices:
$$X^{1}_{i,j}, \text{ with } i \in \left[1,\ldots, d^1\right] \text{ and } j \in \left[1,\ldots, n_s^1\right]$$
and
$$X^{2}_{i,j}, \text{ with } i \in \left[1,\ldots, d^2\right] \text{ and } j \in \left[1,\ldots, n_s^2\right]$$
with:
$$d = d^1 + d^2 \text{ and } n_s = n_s^1 \times n_s^2 .$$
Therefore the following holds:
$$X_{i,j} = \begin{cases}
X^{1}_{i, k}, & \text{if }\ i < d^1 \text{ with } k = j \mod n_s^1 \\
X^{2}_{i - d^1, l}, & \text{if } i \ge d^1 \text{ with } l = \lfloor\frac{j}{n_s^1}\rfloor
\end{cases}$$
Intuitively, this means that a position embedding vector \\(x_j \in \mathbb{R}^{d}\\) is now the composition of two
factorized embedding vectors: \\(x^1_{k, l} + x^2_{l, k}\\), where as the `config.max_embedding_size` dimension
\\(j\\) is factorized into \\(k \text{ and } l\\). This design ensures that each position embedding vector
\\(x_j\\) is unique.
Using the above example again, axial position encoding with \\(d^1 = 2^9, d^2 = 2^9, n_s^1 = 2^9, n_s^2 = 2^{10}\\)
can drastically reduced the number of parameters from 500 000 000 to \\(2^{18} + 2^{19} \approx 780 000\\) parameters, this means 85% less memory usage.
In practice, the parameter `config.axial_pos_embds_dim` is set to a tuple \\((d^1, d^2)\\) which sum has to be
equal to `config.hidden_size` and `config.axial_pos_shape` is set to a tuple \\((n_s^1, n_s^2)\\) which
product has to be equal to `config.max_embedding_size`, which during training has to be equal to the *sequence
length* of the `input_ids`.
## LSH Self Attention
In Locality sensitive hashing (LSH) self attention the key and query projection weights are tied. Therefore, the key
query embedding vectors are also tied. LSH self attention uses the locality sensitive hashing mechanism proposed in
[Practical and Optimal LSH for Angular Distance](https://arxiv.org/abs/1509.02897) to assign each of the tied key
query embedding vectors to one of `config.num_buckets` possible buckets. The premise is that the more "similar"
key query embedding vectors (in terms of *cosine similarity*) are to each other, the more likely they are assigned to
the same bucket.
The accuracy of the LSH mechanism can be improved by increasing `config.num_hashes` or directly the argument
`num_hashes` of the forward function so that the output of the LSH self attention better approximates the output
of the "normal" full self attention. The buckets are then sorted and chunked into query key embedding vector chunks
each of length `config.lsh_chunk_length`. For each chunk, the query embedding vectors attend to its key vectors
(which are tied to themselves) and to the key embedding vectors of `config.lsh_num_chunks_before` previous
neighboring chunks and `config.lsh_num_chunks_after` following neighboring chunks.
For more information, see the [original Paper](https://arxiv.org/abs/2001.04451) or this great [blog post](https://www.pragmatic.ml/reformer-deep-dive/).
Note that `config.num_buckets` can also be factorized into a list \\((n_{\text{buckets}}^1,
n_{\text{buckets}}^2)\\). This way instead of assigning the query key embedding vectors to one of \\((1,\ldots,
n_{\text{buckets}})\\) they are assigned to one of \\((1-1,\ldots, n_{\text{buckets}}^1-1, \ldots,
1-n_{\text{buckets}}^2, \ldots, n_{\text{buckets}}^1-n_{\text{buckets}}^2)\\). This is crucial for very long sequences to
save memory.
When training a model from scratch, it is recommended to leave `config.num_buckets=None`, so that depending on the
sequence length a good value for `num_buckets` is calculated on the fly. This value will then automatically be
saved in the config and should be reused for inference.
Using LSH self attention, the memory and time complexity of the query-key matmul operation can be reduced from
\\(\mathcal{O}(n_s \times n_s)\\) to \\(\mathcal{O}(n_s \times \log(n_s))\\), which usually represents the memory
and time bottleneck in a transformer model, with \\(n_s\\) being the sequence length.
## Local Self Attention
Local self attention is essentially a "normal" self attention layer with key, query and value projections, but is
chunked so that in each chunk of length `config.local_chunk_length` the query embedding vectors only attends to
the key embedding vectors in its chunk and to the key embedding vectors of `config.local_num_chunks_before`
previous neighboring chunks and `config.local_num_chunks_after` following neighboring chunks.
Using Local self attention, the memory and time complexity of the query-key matmul operation can be reduced from
\\(\mathcal{O}(n_s \times n_s)\\) to \\(\mathcal{O}(n_s \times \log(n_s))\\), which usually represents the memory
and time bottleneck in a transformer model, with \\(n_s\\) being the sequence length.
## Training
During training, we must ensure that the sequence length is set to a value that can be divided by the least common
multiple of `config.lsh_chunk_length` and `config.local_chunk_length` and that the parameters of the Axial
Positional Encodings are correctly set as described above. Reformer is very memory efficient so that the model can
easily be trained on sequences as long as 64000 tokens.
For training, the [`ReformerModelWithLMHead`] should be used as follows:
```python
input_ids = tokenizer.encode("This is a sentence from the training data", return_tensors="pt")
loss = model(input_ids, labels=input_ids)[0]
```
## Documentation resources
- [Text classification task guide](../tasks/sequence_classification)
- [Question answering task guide](../tasks/question_answering)
- [Causal language modeling task guide](../tasks/language_modeling)
- [Masked language modeling task guide](../tasks/masked_language_modeling)
## ReformerConfig
[[autodoc]] ReformerConfig
## ReformerTokenizer
[[autodoc]] ReformerTokenizer
- save_vocabulary
## ReformerTokenizerFast
[[autodoc]] ReformerTokenizerFast
## ReformerModel
[[autodoc]] ReformerModel
- forward
## ReformerModelWithLMHead
[[autodoc]] ReformerModelWithLMHead
- forward
## ReformerForMaskedLM
[[autodoc]] ReformerForMaskedLM
- forward
## ReformerForSequenceClassification
[[autodoc]] ReformerForSequenceClassification
- forward
## ReformerForQuestionAnswering
[[autodoc]] ReformerForQuestionAnswering
- forward
| 0 |
hf_public_repos/transformers/docs/source/en | hf_public_repos/transformers/docs/source/en/model_doc/biogpt.md | <!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# BioGPT
## Overview
The BioGPT model was proposed in [BioGPT: generative pre-trained transformer for biomedical text generation and mining
](https://academic.oup.com/bib/advance-article/doi/10.1093/bib/bbac409/6713511?guestAccessKey=a66d9b5d-4f83-4017-bb52-405815c907b9) by Renqian Luo, Liai Sun, Yingce Xia, Tao Qin, Sheng Zhang, Hoifung Poon and Tie-Yan Liu. BioGPT is a domain-specific generative pre-trained Transformer language model for biomedical text generation and mining. BioGPT follows the Transformer language model backbone, and is pre-trained on 15M PubMed abstracts from scratch.
The abstract from the paper is the following:
*Pre-trained language models have attracted increasing attention in the biomedical domain, inspired by their great success in the general natural language domain. Among the two main branches of pre-trained language models in the general language domain, i.e. BERT (and its variants) and GPT (and its variants), the first one has been extensively studied in the biomedical domain, such as BioBERT and PubMedBERT. While they have achieved great success on a variety of discriminative downstream biomedical tasks, the lack of generation ability constrains their application scope. In this paper, we propose BioGPT, a domain-specific generative Transformer language model pre-trained on large-scale biomedical literature. We evaluate BioGPT on six biomedical natural language processing tasks and demonstrate that our model outperforms previous models on most tasks. Especially, we get 44.98%, 38.42% and 40.76% F1 score on BC5CDR, KD-DTI and DDI end-to-end relation extraction tasks, respectively, and 78.2% accuracy on PubMedQA, creating a new record. Our case study on text generation further demonstrates the advantage of BioGPT on biomedical literature to generate fluent descriptions for biomedical terms.*
Tips:
- BioGPT is a model with absolute position embeddings so it’s usually advised to pad the inputs on the right rather than the left.
- BioGPT was trained with a causal language modeling (CLM) objective and is therefore powerful at predicting the next token in a sequence. Leveraging this feature allows BioGPT to generate syntactically coherent text as it can be observed in the run_generation.py example script.
- The model can take the `past_key_values` (for PyTorch) as input, which is the previously computed key/value attention pairs. Using this (past_key_values or past) value prevents the model from re-computing pre-computed values in the context of text generation. For PyTorch, see past_key_values argument of the BioGptForCausalLM.forward() method for more information on its usage.
This model was contributed by [kamalkraj](https://huggingface.co/kamalkraj). The original code can be found [here](https://github.com/microsoft/BioGPT).
## Documentation resources
- [Causal language modeling task guide](../tasks/language_modeling)
## BioGptConfig
[[autodoc]] BioGptConfig
## BioGptTokenizer
[[autodoc]] BioGptTokenizer
- save_vocabulary
## BioGptModel
[[autodoc]] BioGptModel
- forward
## BioGptForCausalLM
[[autodoc]] BioGptForCausalLM
- forward
## BioGptForTokenClassification
[[autodoc]] BioGptForTokenClassification
- forward
## BioGptForSequenceClassification
[[autodoc]] BioGptForSequenceClassification
- forward | 0 |
hf_public_repos/transformers/docs/source/en | hf_public_repos/transformers/docs/source/en/model_doc/nllb-moe.md | <!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# NLLB-MOE
## Overview
The NLLB model was presented in [No Language Left Behind: Scaling Human-Centered Machine Translation](https://arxiv.org/abs/2207.04672) by Marta R. Costa-jussà, James Cross, Onur Çelebi,
Maha Elbayad, Kenneth Heafield, Kevin Heffernan, Elahe Kalbassi, Janice Lam, Daniel Licht, Jean Maillard, Anna Sun, Skyler Wang, Guillaume Wenzek, Al Youngblood, Bapi Akula,
Loic Barrault, Gabriel Mejia Gonzalez, Prangthip Hansanti, John Hoffman, Semarley Jarrett, Kaushik Ram Sadagopan, Dirk Rowe, Shannon Spruit, Chau Tran, Pierre Andrews,
Necip Fazil Ayan, Shruti Bhosale, Sergey Edunov, Angela Fan, Cynthia Gao, Vedanuj Goswami, Francisco Guzmán, Philipp Koehn, Alexandre Mourachko, Christophe Ropers,
Safiyyah Saleem, Holger Schwenk, and Jeff Wang.
The abstract of the paper is the following:
*Driven by the goal of eradicating language barriers on a global scale, machine translation has solidified itself as a key focus of artificial intelligence research today.
However, such efforts have coalesced around a small subset of languages, leaving behind the vast majority of mostly low-resource languages. What does it take to break the
200 language barrier while ensuring safe, high quality results, all while keeping ethical considerations in mind? In No Language Left Behind, we took on this challenge by
first contextualizing the need for low-resource language translation support through exploratory interviews with native speakers. Then, we created datasets and models aimed
at narrowing the performance gap between low and high-resource languages. More specifically, we developed a conditional compute model based on Sparsely Gated Mixture of
Experts that is trained on data obtained with novel and effective data mining techniques tailored for low-resource languages. We propose multiple architectural and training
improvements to counteract overfitting while training on thousands of tasks. Critically, we evaluated the performance of over 40,000 different translation directions using
a human-translated benchmark, Flores-200, and combined human evaluation with a novel toxicity benchmark covering all languages in Flores-200 to assess translation safety.
Our model achieves an improvement of 44% BLEU relative to the previous state-of-the-art, laying important groundwork towards realizing a universal translation system.*
Tips:
- M2M100ForConditionalGeneration is the base model for both NLLB and NLLB MoE
- The NLLB-MoE is very similar to the NLLB model, but it's feed forward layer is based on the implementation of SwitchTransformers.
- The tokenizer is the same as the NLLB models.
This model was contributed by [Arthur Zucker](https://huggingface.co/ArtZucker).
The original code can be found [here](https://github.com/facebookresearch/fairseq).
## Implementation differences with SwitchTransformers
The biggest difference is the way the tokens are routed. NLLB-MoE uses a `top-2-gate` which means that for each input, only the top two experts are selected based on the
highest predicted probabilities from the gating network, and the remaining experts are ignored. In `SwitchTransformers`, only the top-1 probabilities are computed,
which means that tokens have less probability of being forwarded. Moreover, if a token is not routed to any expert, `SwitchTransformers` still adds its unmodified hidden
states (kind of like a residual connection) while they are masked in `NLLB`'s top-2 routing mechanism.
## Generating with NLLB-MoE
The avalable checkpoints requires around 350GB of storage. Make sure to use `accelerate` if you do not have enough RAM on your machine.
While generating the target text set the `forced_bos_token_id` to the target language id. The following
example shows how to translate English to French using the *facebook/nllb-200-distilled-600M* model.
Note that we're using the BCP-47 code for French `fra_Latn`. See [here](https://github.com/facebookresearch/flores/blob/main/flores200/README.md#languages-in-flores-200)
for the list of all BCP-47 in the Flores 200 dataset.
```python
>>> from transformers import AutoModelForSeq2SeqLM, AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("facebook/nllb-moe-54b")
>>> model = AutoModelForSeq2SeqLM.from_pretrained("facebook/nllb-moe-54b")
>>> article = "Previously, Ring's CEO, Jamie Siminoff, remarked the company started when his doorbell wasn't audible from his shop in his garage."
>>> inputs = tokenizer(article, return_tensors="pt")
>>> translated_tokens = model.generate(
... **inputs, forced_bos_token_id=tokenizer.lang_code_to_id["fra_Latn"], max_length=50
... )
>>> tokenizer.batch_decode(translated_tokens, skip_special_tokens=True)[0]
"Auparavant, le PDG de Ring, Jamie Siminoff, a fait remarquer que la société avait commencé lorsque sa sonnette n'était pas audible depuis son magasin dans son garage."
```
### Generating from any other language than English
English (`eng_Latn`) is set as the default language from which to translate. In order to specify that you'd like to translate from a different language,
you should specify the BCP-47 code in the `src_lang` keyword argument of the tokenizer initialization.
See example below for a translation from romanian to german:
```python
>>> from transformers import AutoModelForSeq2SeqLM, AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("facebook/nllb-moe-54b", src_lang="ron_Latn")
>>> model = AutoModelForSeq2SeqLM.from_pretrained("facebook/nllb-moe-54b")
>>> article = "Şeful ONU spune că nu există o soluţie militară în Siria"
>>> inputs = tokenizer(article, return_tensors="pt")
>>> translated_tokens = model.generate(
... **inputs, forced_bos_token_id=tokenizer.lang_code_to_id["deu_Latn"], max_length=30
... )
>>> tokenizer.batch_decode(translated_tokens, skip_special_tokens=True)[0]
```
## Documentation resources
- [Translation task guide](../tasks/translation)
- [Summarization task guide](../tasks/summarization)
## NllbMoeConfig
[[autodoc]] NllbMoeConfig
## NllbMoeTop2Router
[[autodoc]] NllbMoeTop2Router
- route_tokens
- forward
## NllbMoeSparseMLP
[[autodoc]] NllbMoeSparseMLP
- forward
## NllbMoeModel
[[autodoc]] NllbMoeModel
- forward
## NllbMoeForConditionalGeneration
[[autodoc]] NllbMoeForConditionalGeneration
- forward
| 0 |
hf_public_repos/transformers/docs/source/en | hf_public_repos/transformers/docs/source/en/model_doc/dinov2.md | <!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# DINOv2
## Overview
The DINOv2 model was proposed in [DINOv2: Learning Robust Visual Features without Supervision](https://arxiv.org/abs/2304.07193) by
Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy Vo, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, Mahmoud Assran, Nicolas Ballas, Wojciech Galuba, Russell Howes, Po-Yao Huang, Shang-Wen Li, Ishan Misra, Michael Rabbat, Vasu Sharma, Gabriel Synnaeve, Hu Xu, Hervé Jegou, Julien Mairal, Patrick Labatut, Armand Joulin, Piotr Bojanowski.
DINOv2 is an upgrade of [DINO](https://arxiv.org/abs/2104.14294), a self-supervised method applied on [Vision Transformers](vit). This method enables all-purpose visual features, i.e., features that work across image distributions and tasks without finetuning.
The abstract from the paper is the following:
*The recent breakthroughs in natural language processing for model pretraining on large quantities of data have opened the way for similar foundation models in computer vision. These models could greatly simplify the use of images in any system by producing all-purpose visual features, i.e., features that work across image distributions and tasks without finetuning. This work shows that existing pretraining methods, especially self-supervised methods, can produce such features if trained on enough curated data from diverse sources. We revisit existing approaches and combine different techniques to scale our pretraining in terms of data and model size. Most of the technical contributions aim at accelerating and stabilizing the training at scale. In terms of data, we propose an automatic pipeline to build a dedicated, diverse, and curated image dataset instead of uncurated data, as typically done in the self-supervised literature. In terms of models, we train a ViT model (Dosovitskiy et al., 2020) with 1B parameters and distill it into a series of smaller models that surpass the best available all-purpose features, OpenCLIP (Ilharco et al., 2021) on most of the benchmarks at image and pixel levels.*
Tips:
- One can use [`AutoImageProcessor`] class to prepare images for the model.
This model was contributed by [nielsr](https://huggingface.co/nielsr).
The original code can be found [here](https://github.com/facebookresearch/dinov2).
## Dinov2Config
[[autodoc]] Dinov2Config
## Dinov2Model
[[autodoc]] Dinov2Model
- forward
## Dinov2ForImageClassification
[[autodoc]] Dinov2ForImageClassification
- forward
| 0 |
hf_public_repos/transformers/docs/source/en | hf_public_repos/transformers/docs/source/en/model_doc/detr.md | <!--Copyright 2021 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# DETR
## Overview
The DETR model was proposed in [End-to-End Object Detection with Transformers](https://arxiv.org/abs/2005.12872) by
Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov and Sergey Zagoruyko. DETR
consists of a convolutional backbone followed by an encoder-decoder Transformer which can be trained end-to-end for
object detection. It greatly simplifies a lot of the complexity of models like Faster-R-CNN and Mask-R-CNN, which use
things like region proposals, non-maximum suppression procedure and anchor generation. Moreover, DETR can also be
naturally extended to perform panoptic segmentation, by simply adding a mask head on top of the decoder outputs.
The abstract from the paper is the following:
*We present a new method that views object detection as a direct set prediction problem. Our approach streamlines the
detection pipeline, effectively removing the need for many hand-designed components like a non-maximum suppression
procedure or anchor generation that explicitly encode our prior knowledge about the task. The main ingredients of the
new framework, called DEtection TRansformer or DETR, are a set-based global loss that forces unique predictions via
bipartite matching, and a transformer encoder-decoder architecture. Given a fixed small set of learned object queries,
DETR reasons about the relations of the objects and the global image context to directly output the final set of
predictions in parallel. The new model is conceptually simple and does not require a specialized library, unlike many
other modern detectors. DETR demonstrates accuracy and run-time performance on par with the well-established and
highly-optimized Faster RCNN baseline on the challenging COCO object detection dataset. Moreover, DETR can be easily
generalized to produce panoptic segmentation in a unified manner. We show that it significantly outperforms competitive
baselines.*
This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be found [here](https://github.com/facebookresearch/detr).
Here's a TLDR explaining how [`~transformers.DetrForObjectDetection`] works:
First, an image is sent through a pre-trained convolutional backbone (in the paper, the authors use
ResNet-50/ResNet-101). Let's assume we also add a batch dimension. This means that the input to the backbone is a
tensor of shape `(batch_size, 3, height, width)`, assuming the image has 3 color channels (RGB). The CNN backbone
outputs a new lower-resolution feature map, typically of shape `(batch_size, 2048, height/32, width/32)`. This is
then projected to match the hidden dimension of the Transformer of DETR, which is `256` by default, using a
`nn.Conv2D` layer. So now, we have a tensor of shape `(batch_size, 256, height/32, width/32).` Next, the
feature map is flattened and transposed to obtain a tensor of shape `(batch_size, seq_len, d_model)` =
`(batch_size, width/32*height/32, 256)`. So a difference with NLP models is that the sequence length is actually
longer than usual, but with a smaller `d_model` (which in NLP is typically 768 or higher).
Next, this is sent through the encoder, outputting `encoder_hidden_states` of the same shape (you can consider
these as image features). Next, so-called **object queries** are sent through the decoder. This is a tensor of shape
`(batch_size, num_queries, d_model)`, with `num_queries` typically set to 100 and initialized with zeros.
These input embeddings are learnt positional encodings that the authors refer to as object queries, and similarly to
the encoder, they are added to the input of each attention layer. Each object query will look for a particular object
in the image. The decoder updates these embeddings through multiple self-attention and encoder-decoder attention layers
to output `decoder_hidden_states` of the same shape: `(batch_size, num_queries, d_model)`. Next, two heads
are added on top for object detection: a linear layer for classifying each object query into one of the objects or "no
object", and a MLP to predict bounding boxes for each query.
The model is trained using a **bipartite matching loss**: so what we actually do is compare the predicted classes +
bounding boxes of each of the N = 100 object queries to the ground truth annotations, padded up to the same length N
(so if an image only contains 4 objects, 96 annotations will just have a "no object" as class and "no bounding box" as
bounding box). The [Hungarian matching algorithm](https://en.wikipedia.org/wiki/Hungarian_algorithm) is used to find
an optimal one-to-one mapping of each of the N queries to each of the N annotations. Next, standard cross-entropy (for
the classes) and a linear combination of the L1 and [generalized IoU loss](https://giou.stanford.edu/) (for the
bounding boxes) are used to optimize the parameters of the model.
DETR can be naturally extended to perform panoptic segmentation (which unifies semantic segmentation and instance
segmentation). [`~transformers.DetrForSegmentation`] adds a segmentation mask head on top of
[`~transformers.DetrForObjectDetection`]. The mask head can be trained either jointly, or in a two steps process,
where one first trains a [`~transformers.DetrForObjectDetection`] model to detect bounding boxes around both
"things" (instances) and "stuff" (background things like trees, roads, sky), then freeze all the weights and train only
the mask head for 25 epochs. Experimentally, these two approaches give similar results. Note that predicting boxes is
required for the training to be possible, since the Hungarian matching is computed using distances between boxes.
Tips:
- DETR uses so-called **object queries** to detect objects in an image. The number of queries determines the maximum
number of objects that can be detected in a single image, and is set to 100 by default (see parameter
`num_queries` of [`~transformers.DetrConfig`]). Note that it's good to have some slack (in COCO, the
authors used 100, while the maximum number of objects in a COCO image is ~70).
- The decoder of DETR updates the query embeddings in parallel. This is different from language models like GPT-2,
which use autoregressive decoding instead of parallel. Hence, no causal attention mask is used.
- DETR adds position embeddings to the hidden states at each self-attention and cross-attention layer before projecting
to queries and keys. For the position embeddings of the image, one can choose between fixed sinusoidal or learned
absolute position embeddings. By default, the parameter `position_embedding_type` of
[`~transformers.DetrConfig`] is set to `"sine"`.
- During training, the authors of DETR did find it helpful to use auxiliary losses in the decoder, especially to help
the model output the correct number of objects of each class. If you set the parameter `auxiliary_loss` of
[`~transformers.DetrConfig`] to `True`, then prediction feedforward neural networks and Hungarian losses
are added after each decoder layer (with the FFNs sharing parameters).
- If you want to train the model in a distributed environment across multiple nodes, then one should update the
_num_boxes_ variable in the _DetrLoss_ class of _modeling_detr.py_. When training on multiple nodes, this should be
set to the average number of target boxes across all nodes, as can be seen in the original implementation [here](https://github.com/facebookresearch/detr/blob/a54b77800eb8e64e3ad0d8237789fcbf2f8350c5/models/detr.py#L227-L232).
- [`~transformers.DetrForObjectDetection`] and [`~transformers.DetrForSegmentation`] can be initialized with
any convolutional backbone available in the [timm library](https://github.com/rwightman/pytorch-image-models).
Initializing with a MobileNet backbone for example can be done by setting the `backbone` attribute of
[`~transformers.DetrConfig`] to `"tf_mobilenetv3_small_075"`, and then initializing the model with that
config.
- DETR resizes the input images such that the shortest side is at least a certain amount of pixels while the longest is
at most 1333 pixels. At training time, scale augmentation is used such that the shortest side is randomly set to at
least 480 and at most 800 pixels. At inference time, the shortest side is set to 800. One can use
[`~transformers.DetrImageProcessor`] to prepare images (and optional annotations in COCO format) for the
model. Due to this resizing, images in a batch can have different sizes. DETR solves this by padding images up to the
largest size in a batch, and by creating a pixel mask that indicates which pixels are real/which are padding.
Alternatively, one can also define a custom `collate_fn` in order to batch images together, using
[`~transformers.DetrImageProcessor.pad_and_create_pixel_mask`].
- The size of the images will determine the amount of memory being used, and will thus determine the `batch_size`.
It is advised to use a batch size of 2 per GPU. See [this Github thread](https://github.com/facebookresearch/detr/issues/150) for more info.
There are three ways to instantiate a DETR model (depending on what you prefer):
Option 1: Instantiate DETR with pre-trained weights for entire model
```py
>>> from transformers import DetrForObjectDetection
>>> model = DetrForObjectDetection.from_pretrained("facebook/detr-resnet-50")
```
Option 2: Instantiate DETR with randomly initialized weights for Transformer, but pre-trained weights for backbone
```py
>>> from transformers import DetrConfig, DetrForObjectDetection
>>> config = DetrConfig()
>>> model = DetrForObjectDetection(config)
```
Option 3: Instantiate DETR with randomly initialized weights for backbone + Transformer
```py
>>> config = DetrConfig(use_pretrained_backbone=False)
>>> model = DetrForObjectDetection(config)
```
As a summary, consider the following table:
| Task | Object detection | Instance segmentation | Panoptic segmentation |
|------|------------------|-----------------------|-----------------------|
| **Description** | Predicting bounding boxes and class labels around objects in an image | Predicting masks around objects (i.e. instances) in an image | Predicting masks around both objects (i.e. instances) as well as "stuff" (i.e. background things like trees and roads) in an image |
| **Model** | [`~transformers.DetrForObjectDetection`] | [`~transformers.DetrForSegmentation`] | [`~transformers.DetrForSegmentation`] |
| **Example dataset** | COCO detection | COCO detection, COCO panoptic | COCO panoptic | |
| **Format of annotations to provide to** [`~transformers.DetrImageProcessor`] | {'image_id': `int`, 'annotations': `List[Dict]`} each Dict being a COCO object annotation | {'image_id': `int`, 'annotations': `List[Dict]`} (in case of COCO detection) or {'file_name': `str`, 'image_id': `int`, 'segments_info': `List[Dict]`} (in case of COCO panoptic) | {'file_name': `str`, 'image_id': `int`, 'segments_info': `List[Dict]`} and masks_path (path to directory containing PNG files of the masks) |
| **Postprocessing** (i.e. converting the output of the model to COCO API) | [`~transformers.DetrImageProcessor.post_process`] | [`~transformers.DetrImageProcessor.post_process_segmentation`] | [`~transformers.DetrImageProcessor.post_process_segmentation`], [`~transformers.DetrImageProcessor.post_process_panoptic`] |
| **evaluators** | `CocoEvaluator` with `iou_types="bbox"` | `CocoEvaluator` with `iou_types="bbox"` or `"segm"` | `CocoEvaluator` with `iou_tupes="bbox"` or `"segm"`, `PanopticEvaluator` |
In short, one should prepare the data either in COCO detection or COCO panoptic format, then use
[`~transformers.DetrImageProcessor`] to create `pixel_values`, `pixel_mask` and optional
`labels`, which can then be used to train (or fine-tune) a model. For evaluation, one should first convert the
outputs of the model using one of the postprocessing methods of [`~transformers.DetrImageProcessor`]. These can
be be provided to either `CocoEvaluator` or `PanopticEvaluator`, which allow you to calculate metrics like
mean Average Precision (mAP) and Panoptic Quality (PQ). The latter objects are implemented in the [original repository](https://github.com/facebookresearch/detr). See the [example notebooks](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/DETR) for more info regarding evaluation.
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with DETR.
<PipelineTag pipeline="object-detection"/>
- All example notebooks illustrating fine-tuning [`DetrForObjectDetection`] and [`DetrForSegmentation`] on a custom dataset an be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/DETR).
- See also: [Object detection task guide](../tasks/object_detection)
If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
## DETR specific outputs
[[autodoc]] models.detr.modeling_detr.DetrModelOutput
[[autodoc]] models.detr.modeling_detr.DetrObjectDetectionOutput
[[autodoc]] models.detr.modeling_detr.DetrSegmentationOutput
## DetrConfig
[[autodoc]] DetrConfig
## DetrImageProcessor
[[autodoc]] DetrImageProcessor
- preprocess
- post_process_object_detection
- post_process_semantic_segmentation
- post_process_instance_segmentation
- post_process_panoptic_segmentation
## DetrFeatureExtractor
[[autodoc]] DetrFeatureExtractor
- __call__
- post_process_object_detection
- post_process_semantic_segmentation
- post_process_instance_segmentation
- post_process_panoptic_segmentation
## DetrModel
[[autodoc]] DetrModel
- forward
## DetrForObjectDetection
[[autodoc]] DetrForObjectDetection
- forward
## DetrForSegmentation
[[autodoc]] DetrForSegmentation
- forward
| 0 |
hf_public_repos/transformers/docs/source/en | hf_public_repos/transformers/docs/source/en/model_doc/lilt.md | <!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# LiLT
## Overview
The LiLT model was proposed in [LiLT: A Simple yet Effective Language-Independent Layout Transformer for Structured Document Understanding](https://arxiv.org/abs/2202.13669) by Jiapeng Wang, Lianwen Jin, Kai Ding.
LiLT allows to combine any pre-trained RoBERTa text encoder with a lightweight Layout Transformer, to enable [LayoutLM](layoutlm)-like document understanding for many
languages.
The abstract from the paper is the following:
*Structured document understanding has attracted considerable attention and made significant progress recently, owing to its crucial role in intelligent document processing. However, most existing related models can only deal with the document data of specific language(s) (typically English) included in the pre-training collection, which is extremely limited. To address this issue, we propose a simple yet effective Language-independent Layout Transformer (LiLT) for structured document understanding. LiLT can be pre-trained on the structured documents of a single language and then directly fine-tuned on other languages with the corresponding off-the-shelf monolingual/multilingual pre-trained textual models. Experimental results on eight languages have shown that LiLT can achieve competitive or even superior performance on diverse widely-used downstream benchmarks, which enables language-independent benefit from the pre-training of document layout structure.*
Tips:
- To combine the Language-Independent Layout Transformer with a new RoBERTa checkpoint from the [hub](https://huggingface.co/models?search=roberta), refer to [this guide](https://github.com/jpWang/LiLT#or-generate-your-own-checkpoint-optional).
The script will result in `config.json` and `pytorch_model.bin` files being stored locally. After doing this, one can do the following (assuming you're logged in with your HuggingFace account):
```
from transformers import LiltModel
model = LiltModel.from_pretrained("path_to_your_files")
model.push_to_hub("name_of_repo_on_the_hub")
```
- When preparing data for the model, make sure to use the token vocabulary that corresponds to the RoBERTa checkpoint you combined with the Layout Transformer.
- As [lilt-roberta-en-base](https://huggingface.co/SCUT-DLVCLab/lilt-roberta-en-base) uses the same vocabulary as [LayoutLMv3](layoutlmv3), one can use [`LayoutLMv3TokenizerFast`] to prepare data for the model.
The same is true for [lilt-roberta-en-base](https://huggingface.co/SCUT-DLVCLab/lilt-infoxlm-base): one can use [`LayoutXLMTokenizerFast`] for that model.
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/model_doc/lilt_architecture.jpg"
alt="drawing" width="600"/>
<small> LiLT architecture. Taken from the <a href="https://arxiv.org/abs/2202.13669">original paper</a>. </small>
This model was contributed by [nielsr](https://huggingface.co/nielsr).
The original code can be found [here](https://github.com/jpwang/lilt).
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with LiLT.
- Demo notebooks for LiLT can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/LiLT).
**Documentation resources**
- [Text classification task guide](../tasks/sequence_classification)
- [Token classification task guide](../tasks/token_classification)
- [Question answering task guide](../tasks/question_answering)
If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
## LiltConfig
[[autodoc]] LiltConfig
## LiltModel
[[autodoc]] LiltModel
- forward
## LiltForSequenceClassification
[[autodoc]] LiltForSequenceClassification
- forward
## LiltForTokenClassification
[[autodoc]] LiltForTokenClassification
- forward
## LiltForQuestionAnswering
[[autodoc]] LiltForQuestionAnswering
- forward
| 0 |
hf_public_repos/transformers/docs/source/en | hf_public_repos/transformers/docs/source/en/model_doc/swiftformer.md | <!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# SwiftFormer
## Overview
The SwiftFormer model was proposed in [SwiftFormer: Efficient Additive Attention for Transformer-based Real-time Mobile Vision Applications](https://arxiv.org/abs/2303.15446) by Abdelrahman Shaker, Muhammad Maaz, Hanoona Rasheed, Salman Khan, Ming-Hsuan Yang, Fahad Shahbaz Khan.
The SwiftFormer paper introduces a novel efficient additive attention mechanism that effectively replaces the quadratic matrix multiplication operations in the self-attention computation with linear element-wise multiplications. A series of models called 'SwiftFormer' is built based on this, which achieves state-of-the-art performance in terms of both accuracy and mobile inference speed. Even their small variant achieves 78.5% top-1 ImageNet1K accuracy with only 0.8 ms latency on iPhone 14, which is more accurate and 2× faster compared to MobileViT-v2.
The abstract from the paper is the following:
*Self-attention has become a defacto choice for capturing global context in various vision applications. However, its quadratic computational complexity with respect to image resolution limits its use in real-time applications, especially for deployment on resource-constrained mobile devices. Although hybrid approaches have been proposed to combine the advantages of convolutions and self-attention for a better speed-accuracy trade-off, the expensive matrix multiplication operations in self-attention remain a bottleneck. In this work, we introduce a novel efficient additive attention mechanism that effectively replaces the quadratic matrix multiplication operations with linear element-wise multiplications. Our design shows that the key-value interaction can be replaced with a linear layer without sacrificing any accuracy. Unlike previous state-of-the-art methods, our efficient formulation of self-attention enables its usage at all stages of the network. Using our proposed efficient additive attention, we build a series of models called "SwiftFormer" which achieves state-of-the-art performance in terms of both accuracy and mobile inference speed. Our small variant achieves 78.5% top-1 ImageNet-1K accuracy with only 0.8 ms latency on iPhone 14, which is more accurate and 2x faster compared to MobileViT-v2.*
Tips:
- One can use the [`ViTImageProcessor`] API to prepare images for the model.
This model was contributed by [shehan97](https://huggingface.co/shehan97).
The original code can be found [here](https://github.com/Amshaker/SwiftFormer).
## SwiftFormerConfig
[[autodoc]] SwiftFormerConfig
## SwiftFormerModel
[[autodoc]] SwiftFormerModel
- forward
## SwiftFormerForImageClassification
[[autodoc]] SwiftFormerForImageClassification
- forward
| 0 |
hf_public_repos/transformers/docs/source/en | hf_public_repos/transformers/docs/source/en/model_doc/xlm-roberta-xl.md | <!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# XLM-RoBERTa-XL
## Overview
The XLM-RoBERTa-XL model was proposed in [Larger-Scale Transformers for Multilingual Masked Language Modeling](https://arxiv.org/abs/2105.00572) by Naman Goyal, Jingfei Du, Myle Ott, Giri Anantharaman, Alexis Conneau.
The abstract from the paper is the following:
*Recent work has demonstrated the effectiveness of cross-lingual language model pretraining for cross-lingual understanding. In this study, we present the results of two larger multilingual masked language models, with 3.5B and 10.7B parameters. Our two new models dubbed XLM-R XL and XLM-R XXL outperform XLM-R by 1.8% and 2.4% average accuracy on XNLI. Our model also outperforms the RoBERTa-Large model on several English tasks of the GLUE benchmark by 0.3% on average while handling 99 more languages. This suggests pretrained models with larger capacity may obtain both strong performance on high-resource languages while greatly improving low-resource languages. We make our code and models publicly available.*
Tips:
- XLM-RoBERTa-XL is a multilingual model trained on 100 different languages. Unlike some XLM multilingual models, it does
not require `lang` tensors to understand which language is used, and should be able to determine the correct
language from the input ids.
This model was contributed by [Soonhwan-Kwon](https://github.com/Soonhwan-Kwon) and [stefan-it](https://huggingface.co/stefan-it). The original code can be found [here](https://github.com/pytorch/fairseq/tree/master/examples/xlmr).
## Documentation resources
- [Text classification task guide](../tasks/sequence_classification)
- [Token classification task guide](../tasks/token_classification)
- [Question answering task guide](../tasks/question_answering)
- [Causal language modeling task guide](../tasks/language_modeling)
- [Masked language modeling task guide](../tasks/masked_language_modeling)
- [Multiple choice task guide](../tasks/multiple_choice)
## XLMRobertaXLConfig
[[autodoc]] XLMRobertaXLConfig
## XLMRobertaXLModel
[[autodoc]] XLMRobertaXLModel
- forward
## XLMRobertaXLForCausalLM
[[autodoc]] XLMRobertaXLForCausalLM
- forward
## XLMRobertaXLForMaskedLM
[[autodoc]] XLMRobertaXLForMaskedLM
- forward
## XLMRobertaXLForSequenceClassification
[[autodoc]] XLMRobertaXLForSequenceClassification
- forward
## XLMRobertaXLForMultipleChoice
[[autodoc]] XLMRobertaXLForMultipleChoice
- forward
## XLMRobertaXLForTokenClassification
[[autodoc]] XLMRobertaXLForTokenClassification
- forward
## XLMRobertaXLForQuestionAnswering
[[autodoc]] XLMRobertaXLForQuestionAnswering
- forward
| 0 |
hf_public_repos/transformers/docs/source/en | hf_public_repos/transformers/docs/source/en/model_doc/gpt_neo.md | <!--Copyright 2021 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# GPT Neo
## Overview
The GPTNeo model was released in the [EleutherAI/gpt-neo](https://github.com/EleutherAI/gpt-neo) repository by Sid
Black, Stella Biderman, Leo Gao, Phil Wang and Connor Leahy. It is a GPT2 like causal language model trained on the
[Pile](https://pile.eleuther.ai/) dataset.
The architecture is similar to GPT2 except that GPT Neo uses local attention in every other layer with a window size of
256 tokens.
This model was contributed by [valhalla](https://huggingface.co/valhalla).
### Generation
The `generate()` method can be used to generate text using GPT Neo model.
```python
>>> from transformers import GPTNeoForCausalLM, GPT2Tokenizer
>>> model = GPTNeoForCausalLM.from_pretrained("EleutherAI/gpt-neo-1.3B")
>>> tokenizer = GPT2Tokenizer.from_pretrained("EleutherAI/gpt-neo-1.3B")
>>> prompt = (
... "In a shocking finding, scientists discovered a herd of unicorns living in a remote, "
... "previously unexplored valley, in the Andes Mountains. Even more surprising to the "
... "researchers was the fact that the unicorns spoke perfect English."
... )
>>> input_ids = tokenizer(prompt, return_tensors="pt").input_ids
>>> gen_tokens = model.generate(
... input_ids,
... do_sample=True,
... temperature=0.9,
... max_length=100,
... )
>>> gen_text = tokenizer.batch_decode(gen_tokens)[0]
```
## Documentation resources
- [Text classification task guide](../tasks/sequence_classification)
- [Causal language modeling task guide](../tasks/language_modeling)
## GPTNeoConfig
[[autodoc]] GPTNeoConfig
## GPTNeoModel
[[autodoc]] GPTNeoModel
- forward
## GPTNeoForCausalLM
[[autodoc]] GPTNeoForCausalLM
- forward
## GPTNeoForQuestionAnswering
[[autodoc]] GPTNeoForQuestionAnswering
- forward
## GPTNeoForSequenceClassification
[[autodoc]] GPTNeoForSequenceClassification
- forward
## GPTNeoForTokenClassification
[[autodoc]] GPTNeoForTokenClassification
- forward
## FlaxGPTNeoModel
[[autodoc]] FlaxGPTNeoModel
- __call__
## FlaxGPTNeoForCausalLM
[[autodoc]] FlaxGPTNeoForCausalLM
- __call__
| 0 |
hf_public_repos/transformers/docs/source/en | hf_public_repos/transformers/docs/source/en/model_doc/mobilebert.md | <!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# MobileBERT
## Overview
The MobileBERT model was proposed in [MobileBERT: a Compact Task-Agnostic BERT for Resource-Limited Devices](https://arxiv.org/abs/2004.02984) by Zhiqing Sun, Hongkun Yu, Xiaodan Song, Renjie Liu, Yiming Yang, and Denny
Zhou. It's a bidirectional transformer based on the BERT model, which is compressed and accelerated using several
approaches.
The abstract from the paper is the following:
*Natural Language Processing (NLP) has recently achieved great success by using huge pre-trained models with hundreds
of millions of parameters. However, these models suffer from heavy model sizes and high latency such that they cannot
be deployed to resource-limited mobile devices. In this paper, we propose MobileBERT for compressing and accelerating
the popular BERT model. Like the original BERT, MobileBERT is task-agnostic, that is, it can be generically applied to
various downstream NLP tasks via simple fine-tuning. Basically, MobileBERT is a thin version of BERT_LARGE, while
equipped with bottleneck structures and a carefully designed balance between self-attentions and feed-forward networks.
To train MobileBERT, we first train a specially designed teacher model, an inverted-bottleneck incorporated BERT_LARGE
model. Then, we conduct knowledge transfer from this teacher to MobileBERT. Empirical studies show that MobileBERT is
4.3x smaller and 5.5x faster than BERT_BASE while achieving competitive results on well-known benchmarks. On the
natural language inference tasks of GLUE, MobileBERT achieves a GLUEscore o 77.7 (0.6 lower than BERT_BASE), and 62 ms
latency on a Pixel 4 phone. On the SQuAD v1.1/v2.0 question answering task, MobileBERT achieves a dev F1 score of
90.0/79.2 (1.5/2.1 higher than BERT_BASE).*
Tips:
- MobileBERT is a model with absolute position embeddings so it's usually advised to pad the inputs on the right rather
than the left.
- MobileBERT is similar to BERT and therefore relies on the masked language modeling (MLM) objective. It is therefore
efficient at predicting masked tokens and at NLU in general, but is not optimal for text generation. Models trained
with a causal language modeling (CLM) objective are better in that regard.
This model was contributed by [vshampor](https://huggingface.co/vshampor). The original code can be found [here](https://github.com/google-research/mobilebert).
## Documentation resources
- [Text classification task guide](../tasks/sequence_classification)
- [Token classification task guide](../tasks/token_classification)
- [Question answering task guide](../tasks/question_answering)
- [Masked language modeling task guide](../tasks/masked_language_modeling)
- [Multiple choice task guide](../tasks/multiple_choice)
## MobileBertConfig
[[autodoc]] MobileBertConfig
## MobileBertTokenizer
[[autodoc]] MobileBertTokenizer
## MobileBertTokenizerFast
[[autodoc]] MobileBertTokenizerFast
## MobileBert specific outputs
[[autodoc]] models.mobilebert.modeling_mobilebert.MobileBertForPreTrainingOutput
[[autodoc]] models.mobilebert.modeling_tf_mobilebert.TFMobileBertForPreTrainingOutput
## MobileBertModel
[[autodoc]] MobileBertModel
- forward
## MobileBertForPreTraining
[[autodoc]] MobileBertForPreTraining
- forward
## MobileBertForMaskedLM
[[autodoc]] MobileBertForMaskedLM
- forward
## MobileBertForNextSentencePrediction
[[autodoc]] MobileBertForNextSentencePrediction
- forward
## MobileBertForSequenceClassification
[[autodoc]] MobileBertForSequenceClassification
- forward
## MobileBertForMultipleChoice
[[autodoc]] MobileBertForMultipleChoice
- forward
## MobileBertForTokenClassification
[[autodoc]] MobileBertForTokenClassification
- forward
## MobileBertForQuestionAnswering
[[autodoc]] MobileBertForQuestionAnswering
- forward
## TFMobileBertModel
[[autodoc]] TFMobileBertModel
- call
## TFMobileBertForPreTraining
[[autodoc]] TFMobileBertForPreTraining
- call
## TFMobileBertForMaskedLM
[[autodoc]] TFMobileBertForMaskedLM
- call
## TFMobileBertForNextSentencePrediction
[[autodoc]] TFMobileBertForNextSentencePrediction
- call
## TFMobileBertForSequenceClassification
[[autodoc]] TFMobileBertForSequenceClassification
- call
## TFMobileBertForMultipleChoice
[[autodoc]] TFMobileBertForMultipleChoice
- call
## TFMobileBertForTokenClassification
[[autodoc]] TFMobileBertForTokenClassification
- call
## TFMobileBertForQuestionAnswering
[[autodoc]] TFMobileBertForQuestionAnswering
- call
| 0 |
hf_public_repos/transformers/docs/source/en | hf_public_repos/transformers/docs/source/en/model_doc/xlm-prophetnet.md | <!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# XLM-ProphetNet
<div class="flex flex-wrap space-x-1">
<a href="https://huggingface.co/models?filter=xprophetnet">
<img alt="Models" src="https://img.shields.io/badge/All_model_pages-xprophetnet-blueviolet">
</a>
<a href="https://huggingface.co/spaces/docs-demos/xprophetnet-large-wiki100-cased-xglue-ntg">
<img alt="Spaces" src="https://img.shields.io/badge/%F0%9F%A4%97%20Hugging%20Face-Spaces-blue">
</a>
</div>
**DISCLAIMER:** If you see something strange, file a [Github Issue](https://github.com/huggingface/transformers/issues/new?assignees=&labels=&template=bug-report.md&title) and assign
@patrickvonplaten
## Overview
The XLM-ProphetNet model was proposed in [ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training,](https://arxiv.org/abs/2001.04063) by Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei
Zhang, Ming Zhou on 13 Jan, 2020.
XLM-ProphetNet is an encoder-decoder model and can predict n-future tokens for "ngram" language modeling instead of
just the next token. Its architecture is identical to ProhpetNet, but the model was trained on the multi-lingual
"wiki100" Wikipedia dump.
The abstract from the paper is the following:
*In this paper, we present a new sequence-to-sequence pretraining model called ProphetNet, which introduces a novel
self-supervised objective named future n-gram prediction and the proposed n-stream self-attention mechanism. Instead of
the optimization of one-step ahead prediction in traditional sequence-to-sequence model, the ProphetNet is optimized by
n-step ahead prediction which predicts the next n tokens simultaneously based on previous context tokens at each time
step. The future n-gram prediction explicitly encourages the model to plan for the future tokens and prevent
overfitting on strong local correlations. We pre-train ProphetNet using a base scale dataset (16GB) and a large scale
dataset (160GB) respectively. Then we conduct experiments on CNN/DailyMail, Gigaword, and SQuAD 1.1 benchmarks for
abstractive summarization and question generation tasks. Experimental results show that ProphetNet achieves new
state-of-the-art results on all these datasets compared to the models using the same scale pretraining corpus.*
The Authors' code can be found [here](https://github.com/microsoft/ProphetNet).
Tips:
- XLM-ProphetNet's model architecture and pretraining objective is same as ProphetNet, but XLM-ProphetNet was pre-trained on the cross-lingual dataset XGLUE.
## Documentation resources
- [Causal language modeling task guide](../tasks/language_modeling)
- [Translation task guide](../tasks/translation)
- [Summarization task guide](../tasks/summarization)
## XLMProphetNetConfig
[[autodoc]] XLMProphetNetConfig
## XLMProphetNetTokenizer
[[autodoc]] XLMProphetNetTokenizer
## XLMProphetNetModel
[[autodoc]] XLMProphetNetModel
## XLMProphetNetEncoder
[[autodoc]] XLMProphetNetEncoder
## XLMProphetNetDecoder
[[autodoc]] XLMProphetNetDecoder
## XLMProphetNetForConditionalGeneration
[[autodoc]] XLMProphetNetForConditionalGeneration
## XLMProphetNetForCausalLM
[[autodoc]] XLMProphetNetForCausalLM
| 0 |
hf_public_repos/transformers/docs/source/en | hf_public_repos/transformers/docs/source/en/model_doc/altclip.md | <!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# AltCLIP
## Overview
The AltCLIP model was proposed in [AltCLIP: Altering the Language Encoder in CLIP for Extended Language Capabilities](https://arxiv.org/abs/2211.06679v2) by Zhongzhi Chen, Guang Liu, Bo-Wen Zhang, Fulong Ye, Qinghong Yang, Ledell Wu. AltCLIP
(Altering the Language Encoder in CLIP) is a neural network trained on a variety of image-text and text-text pairs. By switching CLIP's
text encoder with a pretrained multilingual text encoder XLM-R, we could obtain very close performances with CLIP on almost all tasks, and extended original CLIP's capabilities such as multilingual understanding.
The abstract from the paper is the following:
*In this work, we present a conceptually simple and effective method to train a strong bilingual multimodal representation model.
Starting from the pretrained multimodal representation model CLIP released by OpenAI, we switched its text encoder with a pretrained
multilingual text encoder XLM-R, and aligned both languages and image representations by a two-stage training schema consisting of
teacher learning and contrastive learning. We validate our method through evaluations of a wide range of tasks. We set new state-of-the-art
performances on a bunch of tasks including ImageNet-CN, Flicker30k- CN, and COCO-CN. Further, we obtain very close performances with
CLIP on almost all tasks, suggesting that one can simply alter the text encoder in CLIP for extended capabilities such as multilingual understanding.*
## Usage
The usage of AltCLIP is very similar to the CLIP. the difference between CLIP is the text encoder. Note that we use bidirectional attention instead of casual attention
and we take the [CLS] token in XLM-R to represent text embedding.
AltCLIP is a multi-modal vision and language model. It can be used for image-text similarity and for zero-shot image
classification. AltCLIP uses a ViT like transformer to get visual features and a bidirectional language model to get the text
features. Both the text and visual features are then projected to a latent space with identical dimension. The dot
product between the projected image and text features is then used as a similar score.
To feed images to the Transformer encoder, each image is split into a sequence of fixed-size non-overlapping patches,
which are then linearly embedded. A [CLS] token is added to serve as representation of an entire image. The authors
also add absolute position embeddings, and feed the resulting sequence of vectors to a standard Transformer encoder.
The [`CLIPImageProcessor`] can be used to resize (or rescale) and normalize images for the model.
The [`AltCLIPProcessor`] wraps a [`CLIPImageProcessor`] and a [`XLMRobertaTokenizer`] into a single instance to both
encode the text and prepare the images. The following example shows how to get the image-text similarity scores using
[`AltCLIPProcessor`] and [`AltCLIPModel`].
```python
>>> from PIL import Image
>>> import requests
>>> from transformers import AltCLIPModel, AltCLIPProcessor
>>> model = AltCLIPModel.from_pretrained("BAAI/AltCLIP")
>>> processor = AltCLIPProcessor.from_pretrained("BAAI/AltCLIP")
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> inputs = processor(text=["a photo of a cat", "a photo of a dog"], images=image, return_tensors="pt", padding=True)
>>> outputs = model(**inputs)
>>> logits_per_image = outputs.logits_per_image # this is the image-text similarity score
>>> probs = logits_per_image.softmax(dim=1) # we can take the softmax to get the label probabilities
```
Tips:
This model is build on `CLIPModel`, so use it like a original CLIP.
This model was contributed by [jongjyh](https://huggingface.co/jongjyh).
## AltCLIPConfig
[[autodoc]] AltCLIPConfig
- from_text_vision_configs
## AltCLIPTextConfig
[[autodoc]] AltCLIPTextConfig
## AltCLIPVisionConfig
[[autodoc]] AltCLIPVisionConfig
## AltCLIPProcessor
[[autodoc]] AltCLIPProcessor
## AltCLIPModel
[[autodoc]] AltCLIPModel
- forward
- get_text_features
- get_image_features
## AltCLIPTextModel
[[autodoc]] AltCLIPTextModel
- forward
## AltCLIPVisionModel
[[autodoc]] AltCLIPVisionModel
- forward | 0 |
hf_public_repos/transformers/docs/source/en | hf_public_repos/transformers/docs/source/en/model_doc/blenderbot-small.md | <!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Blenderbot Small
Note that [`BlenderbotSmallModel`] and
[`BlenderbotSmallForConditionalGeneration`] are only used in combination with the checkpoint
[facebook/blenderbot-90M](https://huggingface.co/facebook/blenderbot-90M). Larger Blenderbot checkpoints should
instead be used with [`BlenderbotModel`] and
[`BlenderbotForConditionalGeneration`]
## Overview
The Blender chatbot model was proposed in [Recipes for building an open-domain chatbot](https://arxiv.org/pdf/2004.13637.pdf) Stephen Roller, Emily Dinan, Naman Goyal, Da Ju, Mary Williamson, Yinhan Liu,
Jing Xu, Myle Ott, Kurt Shuster, Eric M. Smith, Y-Lan Boureau, Jason Weston on 30 Apr 2020.
The abstract of the paper is the following:
*Building open-domain chatbots is a challenging area for machine learning research. While prior work has shown that
scaling neural models in the number of parameters and the size of the data they are trained on gives improved results,
we show that other ingredients are important for a high-performing chatbot. Good conversation requires a number of
skills that an expert conversationalist blends in a seamless way: providing engaging talking points and listening to
their partners, and displaying knowledge, empathy and personality appropriately, while maintaining a consistent
persona. We show that large scale models can learn these skills when given appropriate training data and choice of
generation strategy. We build variants of these recipes with 90M, 2.7B and 9.4B parameter models, and make our models
and code publicly available. Human evaluations show our best models are superior to existing approaches in multi-turn
dialogue in terms of engagingness and humanness measurements. We then discuss the limitations of this work by analyzing
failure cases of our models.*
Tips:
- Blenderbot Small is a model with absolute position embeddings so it's usually advised to pad the inputs on the right rather than
the left.
This model was contributed by [patrickvonplaten](https://huggingface.co/patrickvonplaten). The authors' code can be
found [here](https://github.com/facebookresearch/ParlAI).
## Documentation resources
- [Causal language modeling task guide](../tasks/language_modeling)
- [Translation task guide](../tasks/translation)
- [Summarization task guide](../tasks/summarization)
## BlenderbotSmallConfig
[[autodoc]] BlenderbotSmallConfig
## BlenderbotSmallTokenizer
[[autodoc]] BlenderbotSmallTokenizer
- build_inputs_with_special_tokens
- get_special_tokens_mask
- create_token_type_ids_from_sequences
- save_vocabulary
## BlenderbotSmallTokenizerFast
[[autodoc]] BlenderbotSmallTokenizerFast
## BlenderbotSmallModel
[[autodoc]] BlenderbotSmallModel
- forward
## BlenderbotSmallForConditionalGeneration
[[autodoc]] BlenderbotSmallForConditionalGeneration
- forward
## BlenderbotSmallForCausalLM
[[autodoc]] BlenderbotSmallForCausalLM
- forward
## TFBlenderbotSmallModel
[[autodoc]] TFBlenderbotSmallModel
- call
## TFBlenderbotSmallForConditionalGeneration
[[autodoc]] TFBlenderbotSmallForConditionalGeneration
- call
## FlaxBlenderbotSmallModel
[[autodoc]] FlaxBlenderbotSmallModel
- __call__
- encode
- decode
## FlaxBlenderbotForConditionalGeneration
[[autodoc]] FlaxBlenderbotSmallForConditionalGeneration
- __call__
- encode
- decode
| 0 |
hf_public_repos/transformers/docs/source/en | hf_public_repos/transformers/docs/source/en/model_doc/megatron_gpt2.md | <!--Copyright 2021 NVIDIA Corporation and The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# MegatronGPT2
## Overview
The MegatronGPT2 model was proposed in [Megatron-LM: Training Multi-Billion Parameter Language Models Using Model
Parallelism](https://arxiv.org/abs/1909.08053) by Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley,
Jared Casper and Bryan Catanzaro.
The abstract from the paper is the following:
*Recent work in language modeling demonstrates that training large transformer models advances the state of the art in
Natural Language Processing applications. However, very large models can be quite difficult to train due to memory
constraints. In this work, we present our techniques for training very large transformer models and implement a simple,
efficient intra-layer model parallel approach that enables training transformer models with billions of parameters. Our
approach does not require a new compiler or library changes, is orthogonal and complimentary to pipeline model
parallelism, and can be fully implemented with the insertion of a few communication operations in native PyTorch. We
illustrate this approach by converging transformer based models up to 8.3 billion parameters using 512 GPUs. We sustain
15.1 PetaFLOPs across the entire application with 76% scaling efficiency when compared to a strong single GPU baseline
that sustains 39 TeraFLOPs, which is 30% of peak FLOPs. To demonstrate that large language models can further advance
the state of the art (SOTA), we train an 8.3 billion parameter transformer language model similar to GPT-2 and a 3.9
billion parameter model similar to BERT. We show that careful attention to the placement of layer normalization in
BERT-like models is critical to achieving increased performance as the model size grows. Using the GPT-2 model we
achieve SOTA results on the WikiText103 (10.8 compared to SOTA perplexity of 15.8) and LAMBADA (66.5% compared to SOTA
accuracy of 63.2%) datasets. Our BERT model achieves SOTA results on the RACE dataset (90.9% compared to SOTA accuracy
of 89.4%).*
Tips:
We have provided pretrained [GPT2-345M](https://ngc.nvidia.com/catalog/models/nvidia:megatron_lm_345m) checkpoints
for use to evaluate or finetuning downstream tasks.
To access these checkpoints, first [sign up](https://ngc.nvidia.com/signup) for and setup the NVIDIA GPU Cloud (NGC)
Registry CLI. Further documentation for downloading models can be found in the [NGC documentation](https://docs.nvidia.com/dgx/ngc-registry-cli-user-guide/index.html#topic_6_4_1).
Alternatively, you can directly download the checkpoints using:
```bash
wget --content-disposition https://api.ngc.nvidia.com/v2/models/nvidia/megatron_lm_345m/versions/v0.0/zip -O
megatron_gpt2_345m_v0_0.zip
```
Once you have obtained the checkpoint from NVIDIA GPU Cloud (NGC), you have to convert it to a format that will easily
be loaded by Hugging Face Transformers GPT2 implementation.
The following command allows you to do the conversion. We assume that the folder `models/megatron_gpt2` contains
`megatron_gpt2_345m_v0_0.zip` and that the command is run from that folder:
```bash
python3 $PATH_TO_TRANSFORMERS/models/megatron_gpt2/convert_megatron_gpt2_checkpoint.py megatron_gpt2_345m_v0_0.zip
```
This model was contributed by [jdemouth](https://huggingface.co/jdemouth). The original code can be found [here](https://github.com/NVIDIA/Megatron-LM). That repository contains a multi-GPU and multi-node implementation of the
Megatron Language models. In particular, it contains a hybrid model parallel approach using "tensor parallel" and
"pipeline parallel" techniques.
| 0 |
hf_public_repos/transformers/docs/source/en | hf_public_repos/transformers/docs/source/en/model_doc/xmod.md | <!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# X-MOD
## Overview
The X-MOD model was proposed in [Lifting the Curse of Multilinguality by Pre-training Modular Transformers](http://dx.doi.org/10.18653/v1/2022.naacl-main.255) by Jonas Pfeiffer, Naman Goyal, Xi Lin, Xian Li, James Cross, Sebastian Riedel, and Mikel Artetxe.
X-MOD extends multilingual masked language models like [XLM-R](xlm-roberta) to include language-specific modular components (_language adapters_) during pre-training. For fine-tuning, the language adapters in each transformer layer are frozen.
The abstract from the paper is the following:
*Multilingual pre-trained models are known to suffer from the curse of multilinguality, which causes per-language performance to drop as they cover more languages. We address this issue by introducing language-specific modules, which allows us to grow the total capacity of the model, while keeping the total number of trainable parameters per language constant. In contrast with prior work that learns language-specific components post-hoc, we pre-train the modules of our Cross-lingual Modular (X-MOD) models from the start. Our experiments on natural language inference, named entity recognition and question answering show that our approach not only mitigates the negative interference between languages, but also enables positive transfer, resulting in improved monolingual and cross-lingual performance. Furthermore, our approach enables adding languages post-hoc with no measurable drop in performance, no longer limiting the model usage to the set of pre-trained languages.*
Tips:
- X-MOD is similar to [XLM-R](xlm-roberta), but a difference is that the input language needs to be specified so that the correct language adapter can be activated.
- The main models – base and large – have adapters for 81 languages.
This model was contributed by [jvamvas](https://huggingface.co/jvamvas).
The original code can be found [here](https://github.com/facebookresearch/fairseq/tree/58cc6cca18f15e6d56e3f60c959fe4f878960a60/fairseq/models/xmod) and the original documentation is found [here](https://github.com/facebookresearch/fairseq/tree/58cc6cca18f15e6d56e3f60c959fe4f878960a60/examples/xmod).
## Adapter Usage
### Input language
There are two ways to specify the input language:
1. By setting a default language before using the model:
```python
from transformers import XmodModel
model = XmodModel.from_pretrained("facebook/xmod-base")
model.set_default_language("en_XX")
```
2. By explicitly passing the index of the language adapter for each sample:
```python
import torch
input_ids = torch.tensor(
[
[0, 581, 10269, 83, 99942, 136, 60742, 23, 70, 80583, 18276, 2],
[0, 1310, 49083, 443, 269, 71, 5486, 165, 60429, 660, 23, 2],
]
)
lang_ids = torch.LongTensor(
[
0, # en_XX
8, # de_DE
]
)
output = model(input_ids, lang_ids=lang_ids)
```
### Fine-tuning
The paper recommends that the embedding layer and the language adapters are frozen during fine-tuning. A method for doing this is provided:
```python
model.freeze_embeddings_and_language_adapters()
# Fine-tune the model ...
```
### Cross-lingual transfer
After fine-tuning, zero-shot cross-lingual transfer can be tested by activating the language adapter of the target language:
```python
model.set_default_language("de_DE")
# Evaluate the model on German examples ...
```
## Resources
- [Text classification task guide](../tasks/sequence_classification)
- [Token classification task guide](../tasks/token_classification)
- [Question answering task guide](../tasks/question_answering)
- [Causal language modeling task guide](../tasks/language_modeling)
- [Masked language modeling task guide](../tasks/masked_language_modeling)
- [Multiple choice task guide](../tasks/multiple_choice)
## XmodConfig
[[autodoc]] XmodConfig
## XmodModel
[[autodoc]] XmodModel
- forward
## XmodForCausalLM
[[autodoc]] XmodForCausalLM
- forward
## XmodForMaskedLM
[[autodoc]] XmodForMaskedLM
- forward
## XmodForSequenceClassification
[[autodoc]] XmodForSequenceClassification
- forward
## XmodForMultipleChoice
[[autodoc]] XmodForMultipleChoice
- forward
## XmodForTokenClassification
[[autodoc]] XmodForTokenClassification
- forward
## XmodForQuestionAnswering
[[autodoc]] XmodForQuestionAnswering
- forward
| 0 |
hf_public_repos/transformers/docs/source/en | hf_public_repos/transformers/docs/source/en/model_doc/megatron-bert.md | <!--Copyright 2021 NVIDIA Corporation and The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# MegatronBERT
## Overview
The MegatronBERT model was proposed in [Megatron-LM: Training Multi-Billion Parameter Language Models Using Model
Parallelism](https://arxiv.org/abs/1909.08053) by Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley,
Jared Casper and Bryan Catanzaro.
The abstract from the paper is the following:
*Recent work in language modeling demonstrates that training large transformer models advances the state of the art in
Natural Language Processing applications. However, very large models can be quite difficult to train due to memory
constraints. In this work, we present our techniques for training very large transformer models and implement a simple,
efficient intra-layer model parallel approach that enables training transformer models with billions of parameters. Our
approach does not require a new compiler or library changes, is orthogonal and complimentary to pipeline model
parallelism, and can be fully implemented with the insertion of a few communication operations in native PyTorch. We
illustrate this approach by converging transformer based models up to 8.3 billion parameters using 512 GPUs. We sustain
15.1 PetaFLOPs across the entire application with 76% scaling efficiency when compared to a strong single GPU baseline
that sustains 39 TeraFLOPs, which is 30% of peak FLOPs. To demonstrate that large language models can further advance
the state of the art (SOTA), we train an 8.3 billion parameter transformer language model similar to GPT-2 and a 3.9
billion parameter model similar to BERT. We show that careful attention to the placement of layer normalization in
BERT-like models is critical to achieving increased performance as the model size grows. Using the GPT-2 model we
achieve SOTA results on the WikiText103 (10.8 compared to SOTA perplexity of 15.8) and LAMBADA (66.5% compared to SOTA
accuracy of 63.2%) datasets. Our BERT model achieves SOTA results on the RACE dataset (90.9% compared to SOTA accuracy
of 89.4%).*
Tips:
We have provided pretrained [BERT-345M](https://ngc.nvidia.com/catalog/models/nvidia:megatron_bert_345m) checkpoints
for use to evaluate or finetuning downstream tasks.
To access these checkpoints, first [sign up](https://ngc.nvidia.com/signup) for and setup the NVIDIA GPU Cloud (NGC)
Registry CLI. Further documentation for downloading models can be found in the [NGC documentation](https://docs.nvidia.com/dgx/ngc-registry-cli-user-guide/index.html#topic_6_4_1).
Alternatively, you can directly download the checkpoints using:
BERT-345M-uncased:
```bash
wget --content-disposition https://api.ngc.nvidia.com/v2/models/nvidia/megatron_bert_345m/versions/v0.1_uncased/zip
-O megatron_bert_345m_v0_1_uncased.zip
```
BERT-345M-cased:
```bash
wget --content-disposition https://api.ngc.nvidia.com/v2/models/nvidia/megatron_bert_345m/versions/v0.1_cased/zip -O
megatron_bert_345m_v0_1_cased.zip
```
Once you have obtained the checkpoints from NVIDIA GPU Cloud (NGC), you have to convert them to a format that will
easily be loaded by Hugging Face Transformers and our port of the BERT code.
The following commands allow you to do the conversion. We assume that the folder `models/megatron_bert` contains
`megatron_bert_345m_v0_1_{cased, uncased}.zip` and that the commands are run from inside that folder:
```bash
python3 $PATH_TO_TRANSFORMERS/models/megatron_bert/convert_megatron_bert_checkpoint.py megatron_bert_345m_v0_1_uncased.zip
```
```bash
python3 $PATH_TO_TRANSFORMERS/models/megatron_bert/convert_megatron_bert_checkpoint.py megatron_bert_345m_v0_1_cased.zip
```
This model was contributed by [jdemouth](https://huggingface.co/jdemouth). The original code can be found [here](https://github.com/NVIDIA/Megatron-LM). That repository contains a multi-GPU and multi-node implementation of the
Megatron Language models. In particular, it contains a hybrid model parallel approach using "tensor parallel" and
"pipeline parallel" techniques.
## Documentation resources
- [Text classification task guide](../tasks/sequence_classification)
- [Token classification task guide](../tasks/token_classification)
- [Question answering task guide](../tasks/question_answering)
- [Causal language modeling task guide](../tasks/language_modeling)
- [Masked language modeling task guide](../tasks/masked_language_modeling)
- [Multiple choice task guide](../tasks/multiple_choice)
## MegatronBertConfig
[[autodoc]] MegatronBertConfig
## MegatronBertModel
[[autodoc]] MegatronBertModel
- forward
## MegatronBertForMaskedLM
[[autodoc]] MegatronBertForMaskedLM
- forward
## MegatronBertForCausalLM
[[autodoc]] MegatronBertForCausalLM
- forward
## MegatronBertForNextSentencePrediction
[[autodoc]] MegatronBertForNextSentencePrediction
- forward
## MegatronBertForPreTraining
[[autodoc]] MegatronBertForPreTraining
- forward
## MegatronBertForSequenceClassification
[[autodoc]] MegatronBertForSequenceClassification
- forward
## MegatronBertForMultipleChoice
[[autodoc]] MegatronBertForMultipleChoice
- forward
## MegatronBertForTokenClassification
[[autodoc]] MegatronBertForTokenClassification
- forward
## MegatronBertForQuestionAnswering
[[autodoc]] MegatronBertForQuestionAnswering
- forward
| 0 |
hf_public_repos/transformers/docs/source/en | hf_public_repos/transformers/docs/source/en/model_doc/poolformer.md | <!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# PoolFormer
## Overview
The PoolFormer model was proposed in [MetaFormer is Actually What You Need for Vision](https://arxiv.org/abs/2111.11418) by Sea AI Labs. Instead of designing complicated token mixer to achieve SOTA performance, the target of this work is to demonstrate the competence of transformer models largely stem from the general architecture MetaFormer.
The abstract from the paper is the following:
*Transformers have shown great potential in computer vision tasks. A common belief is their attention-based token mixer module contributes most to their competence. However, recent works show the attention-based module in transformers can be replaced by spatial MLPs and the resulted models still perform quite well. Based on this observation, we hypothesize that the general architecture of the transformers, instead of the specific token mixer module, is more essential to the model's performance. To verify this, we deliberately replace the attention module in transformers with an embarrassingly simple spatial pooling operator to conduct only the most basic token mixing. Surprisingly, we observe that the derived model, termed as PoolFormer, achieves competitive performance on multiple computer vision tasks. For example, on ImageNet-1K, PoolFormer achieves 82.1% top-1 accuracy, surpassing well-tuned vision transformer/MLP-like baselines DeiT-B/ResMLP-B24 by 0.3%/1.1% accuracy with 35%/52% fewer parameters and 48%/60% fewer MACs. The effectiveness of PoolFormer verifies our hypothesis and urges us to initiate the concept of "MetaFormer", a general architecture abstracted from transformers without specifying the token mixer. Based on the extensive experiments, we argue that MetaFormer is the key player in achieving superior results for recent transformer and MLP-like models on vision tasks. This work calls for more future research dedicated to improving MetaFormer instead of focusing on the token mixer modules. Additionally, our proposed PoolFormer could serve as a starting baseline for future MetaFormer architecture design.*
The figure below illustrates the architecture of PoolFormer. Taken from the [original paper](https://arxiv.org/abs/2111.11418).
<img width="600" src="https://user-images.githubusercontent.com/15921929/142746124-1ab7635d-2536-4a0e-ad43-b4fe2c5a525d.png"/>
Tips:
- PoolFormer has a hierarchical architecture, where instead of Attention, a simple Average Pooling layer is present. All checkpoints of the model can be found on the [hub](https://huggingface.co/models?other=poolformer).
- One can use [`PoolFormerImageProcessor`] to prepare images for the model.
- As most models, PoolFormer comes in different sizes, the details of which can be found in the table below.
| **Model variant** | **Depths** | **Hidden sizes** | **Params (M)** | **ImageNet-1k Top 1** |
| :---------------: | ------------- | ------------------- | :------------: | :-------------------: |
| s12 | [2, 2, 6, 2] | [64, 128, 320, 512] | 12 | 77.2 |
| s24 | [4, 4, 12, 4] | [64, 128, 320, 512] | 21 | 80.3 |
| s36 | [6, 6, 18, 6] | [64, 128, 320, 512] | 31 | 81.4 |
| m36 | [6, 6, 18, 6] | [96, 192, 384, 768] | 56 | 82.1 |
| m48 | [8, 8, 24, 8] | [96, 192, 384, 768] | 73 | 82.5 |
This model was contributed by [heytanay](https://huggingface.co/heytanay). The original code can be found [here](https://github.com/sail-sg/poolformer).
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with PoolFormer.
<PipelineTag pipeline="image-classification"/>
- [`PoolFormerForImageClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb).
- See also: [Image classification task guide](../tasks/image_classification)
If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
## PoolFormerConfig
[[autodoc]] PoolFormerConfig
## PoolFormerFeatureExtractor
[[autodoc]] PoolFormerFeatureExtractor
- __call__
## PoolFormerImageProcessor
[[autodoc]] PoolFormerImageProcessor
- preprocess
## PoolFormerModel
[[autodoc]] PoolFormerModel
- forward
## PoolFormerForImageClassification
[[autodoc]] PoolFormerForImageClassification
- forward
| 0 |
hf_public_repos/transformers/docs/source/en | hf_public_repos/transformers/docs/source/en/model_doc/mgp-str.md | <!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# MGP-STR
## Overview
The MGP-STR model was proposed in [Multi-Granularity Prediction for Scene Text Recognition](https://arxiv.org/abs/2209.03592) by Peng Wang, Cheng Da, and Cong Yao. MGP-STR is a conceptually **simple** yet **powerful** vision Scene Text Recognition (STR) model, which is built upon the [Vision Transformer (ViT)](vit). To integrate linguistic knowledge, Multi-Granularity Prediction (MGP) strategy is proposed to inject information from the language modality into the model in an implicit way.
The abstract from the paper is the following:
*Scene text recognition (STR) has been an active research topic in computer vision for years. To tackle this challenging problem, numerous innovative methods have been successively proposed and incorporating linguistic knowledge into STR models has recently become a prominent trend. In this work, we first draw inspiration from the recent progress in Vision Transformer (ViT) to construct a conceptually simple yet powerful vision STR model, which is built upon ViT and outperforms previous state-of-the-art models for scene text recognition, including both pure vision models and language-augmented methods. To integrate linguistic knowledge, we further propose a Multi-Granularity Prediction strategy to inject information from the language modality into the model in an implicit way, i.e. , subword representations (BPE and WordPiece) widely-used in NLP are introduced into the output space, in addition to the conventional character level representation, while no independent language model (LM) is adopted. The resultant algorithm (termed MGP-STR) is able to push the performance envelop of STR to an even higher level. Specifically, it achieves an average recognition accuracy of 93.35% on standard benchmarks.*
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/model_doc/mgp_str_architecture.png"
alt="drawing" width="600"/>
<small> MGP-STR architecture. Taken from the <a href="https://arxiv.org/abs/2209.03592">original paper</a>. </small>
Tips:
- MGP-STR is trained on two synthetic datasets [MJSynth]((http://www.robots.ox.ac.uk/~vgg/data/text/)) (MJ) and SynthText(http://www.robots.ox.ac.uk/~vgg/data/scenetext/) (ST) without fine-tuning on other datasets. It achieves state-of-the-art results on six standard Latin scene text benchmarks, including 3 regular text datasets (IC13, SVT, IIIT) and 3 irregular ones (IC15, SVTP, CUTE).
- This model was contributed by [yuekun](https://huggingface.co/yuekun). The original code can be found [here](https://github.com/AlibabaResearch/AdvancedLiterateMachinery/tree/main/OCR/MGP-STR).
## Inference
[`MgpstrModel`] accepts images as input and generates three types of predictions, which represent textual information at different granularities.
The three types of predictions are fused to give the final prediction result.
The [`ViTImageProcessor`] class is responsible for preprocessing the input image and
[`MgpstrTokenizer`] decodes the generated character tokens to the target string. The
[`MgpstrProcessor`] wraps [`ViTImageProcessor`] and [`MgpstrTokenizer`]
into a single instance to both extract the input features and decode the predicted token ids.
- Step-by-step Optical Character Recognition (OCR)
``` py
>>> from transformers import MgpstrProcessor, MgpstrForSceneTextRecognition
>>> import requests
>>> from PIL import Image
>>> processor = MgpstrProcessor.from_pretrained('alibaba-damo/mgp-str-base')
>>> model = MgpstrForSceneTextRecognition.from_pretrained('alibaba-damo/mgp-str-base')
>>> # load image from the IIIT-5k dataset
>>> url = "https://i.postimg.cc/ZKwLg2Gw/367-14.png"
>>> image = Image.open(requests.get(url, stream=True).raw).convert("RGB")
>>> pixel_values = processor(images=image, return_tensors="pt").pixel_values
>>> outputs = model(pixel_values)
>>> generated_text = processor.batch_decode(outputs.logits)['generated_text']
```
## MgpstrConfig
[[autodoc]] MgpstrConfig
## MgpstrTokenizer
[[autodoc]] MgpstrTokenizer
- save_vocabulary
## MgpstrProcessor
[[autodoc]] MgpstrProcessor
- __call__
- batch_decode
## MgpstrModel
[[autodoc]] MgpstrModel
- forward
## MgpstrForSceneTextRecognition
[[autodoc]] MgpstrForSceneTextRecognition
- forward
| 0 |
hf_public_repos/transformers/docs/source/en | hf_public_repos/transformers/docs/source/en/model_doc/bark.md | <!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Bark
## Overview
Bark is a transformer-based text-to-speech model proposed by Suno AI in [suno-ai/bark](https://github.com/suno-ai/bark).
Bark is made of 4 main models:
- [`BarkSemanticModel`] (also referred to as the 'text' model): a causal auto-regressive transformer model that takes as input tokenized text, and predicts semantic text tokens that capture the meaning of the text.
- [`BarkCoarseModel`] (also referred to as the 'coarse acoustics' model): a causal autoregressive transformer, that takes as input the results of the [`BarkSemanticModel`] model. It aims at predicting the first two audio codebooks necessary for EnCodec.
- [`BarkFineModel`] (the 'fine acoustics' model), this time a non-causal autoencoder transformer, which iteratively predicts the last codebooks based on the sum of the previous codebooks embeddings.
- having predicted all the codebook channels from the [`EncodecModel`], Bark uses it to decode the output audio array.
It should be noted that each of the first three modules can support conditional speaker embeddings to condition the output sound according to specific predefined voice.
### Tips:
Suno offers a library of voice presets in a number of languages [here](https://suno-ai.notion.site/8b8e8749ed514b0cbf3f699013548683?v=bc67cff786b04b50b3ceb756fd05f68c).
These presets are also uploaded in the hub [here](https://huggingface.co/suno/bark-small/tree/main/speaker_embeddings) or [here](https://huggingface.co/suno/bark/tree/main/speaker_embeddings).
```python
>>> from transformers import AutoProcessor, BarkModel
>>> processor = AutoProcessor.from_pretrained("suno/bark")
>>> model = BarkModel.from_pretrained("suno/bark")
>>> voice_preset = "v2/en_speaker_6"
>>> inputs = processor("Hello, my dog is cute", voice_preset=voice_preset)
>>> audio_array = model.generate(**inputs)
>>> audio_array = audio_array.cpu().numpy().squeeze()
```
Bark can generate highly realistic, **multilingual** speech as well as other audio - including music, background noise and simple sound effects.
```python
>>> # Multilingual speech - simplified Chinese
>>> inputs = processor("惊人的!我会说中文")
>>> # Multilingual speech - French - let's use a voice_preset as well
>>> inputs = processor("Incroyable! Je peux générer du son.", voice_preset="fr_speaker_5")
>>> # Bark can also generate music. You can help it out by adding music notes around your lyrics.
>>> inputs = processor("♪ Hello, my dog is cute ♪")
>>> audio_array = model.generate(**inputs)
>>> audio_array = audio_array.cpu().numpy().squeeze()
```
The model can also produce **nonverbal communications** like laughing, sighing and crying.
```python
>>> # Adding non-speech cues to the input text
>>> inputs = processor("Hello uh ... [clears throat], my dog is cute [laughter]")
>>> audio_array = model.generate(**inputs)
>>> audio_array = audio_array.cpu().numpy().squeeze()
```
To save the audio, simply take the sample rate from the model config and some scipy utility:
```python
>>> from scipy.io.wavfile import write as write_wav
>>> # save audio to disk, but first take the sample rate from the model config
>>> sample_rate = model.generation_config.sample_rate
>>> write_wav("bark_generation.wav", sample_rate, audio_array)
```
This model was contributed by [Yoach Lacombe (ylacombe)](https://huggingface.co/ylacombe) and [Sanchit Gandhi (sanchit-gandhi)](https://github.com/sanchit-gandhi).
The original code can be found [here](https://github.com/suno-ai/bark).
## BarkConfig
[[autodoc]] BarkConfig
- all
## BarkProcessor
[[autodoc]] BarkProcessor
- all
- __call__
## BarkModel
[[autodoc]] BarkModel
- generate
## BarkSemanticModel
[[autodoc]] BarkSemanticModel
- forward
## BarkCoarseModel
[[autodoc]] BarkCoarseModel
- forward
## BarkFineModel
[[autodoc]] BarkFineModel
- forward
## BarkCausalModel
[[autodoc]] BarkCausalModel
- forward
## BarkCoarseConfig
[[autodoc]] BarkCoarseConfig
- all
## BarkFineConfig
[[autodoc]] BarkFineConfig
- all
## BarkSemanticConfig
[[autodoc]] BarkSemanticConfig
- all
| 0 |
hf_public_repos/transformers/docs/source | hf_public_repos/transformers/docs/source/pt/converting_tensorflow_models.md | <!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Convertendo checkpoints do TensorFlow para Pytorch
Uma interface de linha de comando é fornecida para converter os checkpoints originais Bert/GPT/GPT-2/Transformer-XL/XLNet/XLM em modelos
que podem ser carregados usando os métodos `from_pretrained` da biblioteca.
<Tip>
A partir da versão 2.3.0 o script de conversão agora faz parte do transformers CLI (**transformers-cli**) disponível em qualquer instalação
transformers >= 2.3.0.
A documentação abaixo reflete o formato do comando **transformers-cli convert**.
</Tip>
## BERT
Você pode converter qualquer checkpoint do BERT em TensorFlow (em particular [os modelos pré-treinados lançados pelo Google](https://github.com/google-research/bert#pre-trained-models)) em um arquivo PyTorch usando um
[convert_bert_original_tf_checkpoint_to_pytorch.py](https://github.com/huggingface/transformers/tree/main/src/transformers/models/bert/convert_bert_original_tf_checkpoint_to_pytorch.py) script.
Esta Interface de Linha de Comando (CLI) recebe como entrada um checkpoint do TensorFlow (três arquivos começando com `bert_model.ckpt`) e o
arquivo de configuração (`bert_config.json`), e então cria um modelo PyTorch para esta configuração, carrega os pesos
do checkpoint do TensorFlow no modelo PyTorch e salva o modelo resultante em um arquivo PyTorch que pode
ser importado usando `from_pretrained()` (veja o exemplo em [quicktour](quicktour) , [run_glue.py](https://github.com/huggingface/transformers/tree/main/examples/pytorch/text-classification/run_glue.py) ).
Você só precisa executar este script de conversão **uma vez** para obter um modelo PyTorch. Você pode então desconsiderar o checkpoint em
TensorFlow (os três arquivos começando com `bert_model.ckpt`), mas certifique-se de manter o arquivo de configuração (\
`bert_config.json`) e o arquivo de vocabulário (`vocab.txt`), pois eles também são necessários para o modelo PyTorch.
Para executar este script de conversão específico, você precisará ter o TensorFlow e o PyTorch instalados (`pip install tensorflow`). O resto do repositório requer apenas o PyTorch.
Aqui está um exemplo do processo de conversão para um modelo `BERT-Base Uncased` pré-treinado:
```bash
export BERT_BASE_DIR=/path/to/bert/uncased_L-12_H-768_A-12
transformers-cli convert --model_type bert \
--tf_checkpoint $BERT_BASE_DIR/bert_model.ckpt \
--config $BERT_BASE_DIR/bert_config.json \
--pytorch_dump_output $BERT_BASE_DIR/pytorch_model.bin
```
Você pode baixar os modelos pré-treinados do Google para a conversão [aqui](https://github.com/google-research/bert#pre-trained-models).
## ALBERT
Converta os checkpoints do modelo ALBERT em TensorFlow para PyTorch usando o
[convert_albert_original_tf_checkpoint_to_pytorch.py](https://github.com/huggingface/transformers/tree/main/src/transformers/models/albert/convert_albert_original_tf_checkpoint_to_pytorch.py) script.
A Interface de Linha de Comando (CLI) recebe como entrada um checkpoint do TensorFlow (três arquivos começando com `model.ckpt-best`) e o
arquivo de configuração (`albert_config.json`), então cria e salva um modelo PyTorch. Para executar esta conversão, você
precisa ter o TensorFlow e o PyTorch instalados.
Aqui está um exemplo do processo de conversão para o modelo `ALBERT Base` pré-treinado:
```bash
export ALBERT_BASE_DIR=/path/to/albert/albert_base
transformers-cli convert --model_type albert \
--tf_checkpoint $ALBERT_BASE_DIR/model.ckpt-best \
--config $ALBERT_BASE_DIR/albert_config.json \
--pytorch_dump_output $ALBERT_BASE_DIR/pytorch_model.bin
```
Você pode baixar os modelos pré-treinados do Google para a conversão [aqui](https://github.com/google-research/albert#pre-trained-models).
## OpenAI GPT
Aqui está um exemplo do processo de conversão para um modelo OpenAI GPT pré-treinado, supondo que seu checkpoint NumPy
foi salvo com o mesmo formato do modelo pré-treinado OpenAI (veja [aqui](https://github.com/openai/finetune-transformer-lm)\
)
```bash
export OPENAI_GPT_CHECKPOINT_FOLDER_PATH=/path/to/openai/pretrained/numpy/weights
transformers-cli convert --model_type gpt \
--tf_checkpoint $OPENAI_GPT_CHECKPOINT_FOLDER_PATH \
--pytorch_dump_output $PYTORCH_DUMP_OUTPUT \
[--config OPENAI_GPT_CONFIG] \
[--finetuning_task_name OPENAI_GPT_FINETUNED_TASK] \
```
## OpenAI GPT-2
Aqui está um exemplo do processo de conversão para um modelo OpenAI GPT-2 pré-treinado (consulte [aqui](https://github.com/openai/gpt-2))
```bash
export OPENAI_GPT2_CHECKPOINT_PATH=/path/to/gpt2/pretrained/weights
transformers-cli convert --model_type gpt2 \
--tf_checkpoint $OPENAI_GPT2_CHECKPOINT_PATH \
--pytorch_dump_output $PYTORCH_DUMP_OUTPUT \
[--config OPENAI_GPT2_CONFIG] \
[--finetuning_task_name OPENAI_GPT2_FINETUNED_TASK]
```
## Transformer-XL
Aqui está um exemplo do processo de conversão para um modelo Transformer-XL pré-treinado (consulte [aqui](https://github.com/kimiyoung/transformer-xl/tree/master/tf#obtain-and-evaluate-pretrained-modelos-sota))
```bash
export TRANSFO_XL_CHECKPOINT_FOLDER_PATH=/path/to/transfo/xl/checkpoint
transformers-cli convert --model_type transfo_xl \
--tf_checkpoint $TRANSFO_XL_CHECKPOINT_FOLDER_PATH \
--pytorch_dump_output $PYTORCH_DUMP_OUTPUT \
[--config TRANSFO_XL_CONFIG] \
[--finetuning_task_name TRANSFO_XL_FINETUNED_TASK]
```
## XLNet
Aqui está um exemplo do processo de conversão para um modelo XLNet pré-treinado:
```bash
export TRANSFO_XL_CHECKPOINT_PATH=/path/to/xlnet/checkpoint
export TRANSFO_XL_CONFIG_PATH=/path/to/xlnet/config
transformers-cli convert --model_type xlnet \
--tf_checkpoint $TRANSFO_XL_CHECKPOINT_PATH \
--config $TRANSFO_XL_CONFIG_PATH \
--pytorch_dump_output $PYTORCH_DUMP_OUTPUT \
[--finetuning_task_name XLNET_FINETUNED_TASK] \
```
## XLM
Aqui está um exemplo do processo de conversão para um modelo XLM pré-treinado:
```bash
export XLM_CHECKPOINT_PATH=/path/to/xlm/checkpoint
transformers-cli convert --model_type xlm \
--tf_checkpoint $XLM_CHECKPOINT_PATH \
--pytorch_dump_output $PYTORCH_DUMP_OUTPUT
[--config XML_CONFIG] \
[--finetuning_task_name XML_FINETUNED_TASK]
```
## T5
Aqui está um exemplo do processo de conversão para um modelo T5 pré-treinado:
```bash
export T5=/path/to/t5/uncased_L-12_H-768_A-12
transformers-cli convert --model_type t5 \
--tf_checkpoint $T5/t5_model.ckpt \
--config $T5/t5_config.json \
--pytorch_dump_output $T5/pytorch_model.bin
```
| 0 |
hf_public_repos/transformers/docs/source | hf_public_repos/transformers/docs/source/pt/custom_models.md | <!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Compartilhando modelos customizados
A biblioteca 🤗 Transformers foi projetada para ser facilmente extensível. Cada modelo é totalmente codificado em uma determinada subpasta
do repositório sem abstração, para que você possa copiar facilmente um arquivo de modelagem e ajustá-lo às suas necessidades.
Se você estiver escrevendo um modelo totalmente novo, pode ser mais fácil começar do zero. Neste tutorial, mostraremos
como escrever um modelo customizado e sua configuração para que possa ser usado com Transformers, e como você pode compartilhá-lo
com a comunidade (com o código em que se baseia) para que qualquer pessoa possa usá-lo, mesmo se não estiver presente na biblioteca 🤗 Transformers.
Ilustraremos tudo isso em um modelo ResNet, envolvendo a classe ResNet do
[biblioteca timm](https://github.com/rwightman/pytorch-image-models) em um [`PreTrainedModel`].
## Escrevendo uma configuração customizada
Antes de mergulharmos no modelo, vamos primeiro escrever sua configuração. A configuração de um modelo é um objeto que
terá todas as informações necessárias para construir o modelo. Como veremos na próxima seção, o modelo só pode
ter um `config` para ser inicializado, então realmente precisamos que esse objeto seja o mais completo possível.
Em nosso exemplo, pegaremos alguns argumentos da classe ResNet que podemos querer ajustar. Diferentes
configurações nos dará os diferentes tipos de ResNets que são possíveis. Em seguida, apenas armazenamos esses argumentos,
após verificar a validade de alguns deles.
```python
from transformers import PretrainedConfig
from typing import List
class ResnetConfig(PretrainedConfig):
model_type = "resnet"
def __init__(
self,
block_type="bottleneck",
layers: List[int] = [3, 4, 6, 3],
num_classes: int = 1000,
input_channels: int = 3,
cardinality: int = 1,
base_width: int = 64,
stem_width: int = 64,
stem_type: str = "",
avg_down: bool = False,
**kwargs,
):
if block_type not in ["basic", "bottleneck"]:
raise ValueError(f"`block_type` must be 'basic' or bottleneck', got {block_type}.")
if stem_type not in ["", "deep", "deep-tiered"]:
raise ValueError(f"`stem_type` must be '', 'deep' or 'deep-tiered', got {stem_type}.")
self.block_type = block_type
self.layers = layers
self.num_classes = num_classes
self.input_channels = input_channels
self.cardinality = cardinality
self.base_width = base_width
self.stem_width = stem_width
self.stem_type = stem_type
self.avg_down = avg_down
super().__init__(**kwargs)
```
As três coisas importantes a serem lembradas ao escrever sua própria configuração são:
- você tem que herdar de `PretrainedConfig`,
- o `__init__` do seu `PretrainedConfig` deve aceitar quaisquer kwargs,
- esses `kwargs` precisam ser passados para a superclasse `__init__`.
A herança é para garantir que você obtenha todas as funcionalidades da biblioteca 🤗 Transformers, enquanto as outras duas
restrições vêm do fato de um `PretrainedConfig` ter mais campos do que os que você está configurando. Ao recarregar um
config com o método `from_pretrained`, esses campos precisam ser aceitos pelo seu config e então enviados para a
superclasse.
Definir um `model_type` para sua configuração (aqui `model_type="resnet"`) não é obrigatório, a menos que você queira
registrar seu modelo com as classes automáticas (veja a última seção).
Com isso feito, você pode facilmente criar e salvar sua configuração como faria com qualquer outra configuração de modelo da
biblioteca. Aqui está como podemos criar uma configuração resnet50d e salvá-la:
```py
resnet50d_config = ResnetConfig(block_type="bottleneck", stem_width=32, stem_type="deep", avg_down=True)
resnet50d_config.save_pretrained("custom-resnet")
```
Isso salvará um arquivo chamado `config.json` dentro da pasta `custom-resnet`. Você pode então recarregar sua configuração com o
método `from_pretrained`:
```py
resnet50d_config = ResnetConfig.from_pretrained("custom-resnet")
```
Você também pode usar qualquer outro método da classe [`PretrainedConfig`], como [`~PretrainedConfig.push_to_hub`] para
carregar diretamente sua configuração para o Hub.
## Escrevendo um modelo customizado
Agora que temos nossa configuração ResNet, podemos continuar escrevendo o modelo. Na verdade, escreveremos dois: um que
extrai os recursos ocultos de um lote de imagens (como [`BertModel`]) e um que é adequado para classificação de imagem
(como [`BertForSequenceClassification`]).
Como mencionamos antes, escreveremos apenas um wrapper solto do modelo para mantê-lo simples para este exemplo. A única
coisa que precisamos fazer antes de escrever esta classe é um mapa entre os tipos de bloco e as classes de bloco reais. Então o
modelo é definido a partir da configuração passando tudo para a classe `ResNet`:
```py
from transformers import PreTrainedModel
from timm.models.resnet import BasicBlock, Bottleneck, ResNet
from .configuration_resnet import ResnetConfig
BLOCK_MAPPING = {"basic": BasicBlock, "bottleneck": Bottleneck}
class ResnetModel(PreTrainedModel):
config_class = ResnetConfig
def __init__(self, config):
super().__init__(config)
block_layer = BLOCK_MAPPING[config.block_type]
self.model = ResNet(
block_layer,
config.layers,
num_classes=config.num_classes,
in_chans=config.input_channels,
cardinality=config.cardinality,
base_width=config.base_width,
stem_width=config.stem_width,
stem_type=config.stem_type,
avg_down=config.avg_down,
)
def forward(self, tensor):
return self.model.forward_features(tensor)
```
Para o modelo que irá classificar as imagens, vamos apenas alterar o método forward:
```py
import torch
class ResnetModelForImageClassification(PreTrainedModel):
config_class = ResnetConfig
def __init__(self, config):
super().__init__(config)
block_layer = BLOCK_MAPPING[config.block_type]
self.model = ResNet(
block_layer,
config.layers,
num_classes=config.num_classes,
in_chans=config.input_channels,
cardinality=config.cardinality,
base_width=config.base_width,
stem_width=config.stem_width,
stem_type=config.stem_type,
avg_down=config.avg_down,
)
def forward(self, tensor, labels=None):
logits = self.model(tensor)
if labels is not None:
loss = torch.nn.cross_entropy(logits, labels)
return {"loss": loss, "logits": logits}
return {"logits": logits}
```
Em ambos os casos, observe como herdamos de `PreTrainedModel` e chamamos a inicialização da superclasse com o `config`
(um pouco parecido quando você escreve um `torch.nn.Module`). A linha que define o `config_class` não é obrigatória, a menos que
você deseje registrar seu modelo com as classes automáticas (consulte a última seção).
<Tip>
Se o seu modelo for muito semelhante a um modelo dentro da biblioteca, você poderá reutilizar a mesma configuração desse modelo.
</Tip>
Você pode fazer com que seu modelo retorne o que você quiser,porém retornando um dicionário como fizemos para
`ResnetModelForImageClassification`, com a função de perda incluída quando os rótulos são passados, vai tornar seu modelo diretamente
utilizável dentro da classe [`Trainer`]. Você pode usar outro formato de saída, desde que esteja planejando usar seu próprio
laço de treinamento ou outra biblioteca para treinamento.
Agora que temos nossa classe do modelo, vamos criar uma:
```py
resnet50d = ResnetModelForImageClassification(resnet50d_config)
```
Novamente, você pode usar qualquer um dos métodos do [`PreTrainedModel`], como [`~PreTrainedModel.save_pretrained`] ou
[`~PreTrainedModel.push_to_hub`]. Usaremos o segundo na próxima seção e veremos como enviar os pesos e
o código do nosso modelo. Mas primeiro, vamos carregar alguns pesos pré-treinados dentro do nosso modelo.
Em seu próprio caso de uso, você provavelmente estará treinando seu modelo customizado em seus próprios dados. Para este tutorial ser rápido,
usaremos a versão pré-treinada do resnet50d. Como nosso modelo é apenas um wrapper em torno dele, será
fácil de transferir esses pesos:
```py
import timm
pretrained_model = timm.create_model("resnet50d", pretrained=True)
resnet50d.model.load_state_dict(pretrained_model.state_dict())
```
Agora vamos ver como ter certeza de que quando fazemos [`~PreTrainedModel.save_pretrained`] ou [`~PreTrainedModel.push_to_hub`], o
código do modelo é salvo.
## Enviando o código para o Hub
<Tip warning={true}>
Esta API é experimental e pode ter algumas pequenas alterações nas próximas versões.
</Tip>
Primeiro, certifique-se de que seu modelo esteja totalmente definido em um arquivo `.py`. Ele pode contar com importações relativas para alguns outros arquivos
desde que todos os arquivos estejam no mesmo diretório (ainda não suportamos submódulos para este recurso). Para o nosso exemplo,
vamos definir um arquivo `modeling_resnet.py` e um arquivo `configuration_resnet.py` em uma pasta no
diretório de trabalho atual chamado `resnet_model`. O arquivo de configuração contém o código para `ResnetConfig` e o arquivo de modelagem
contém o código do `ResnetModel` e `ResnetModelForImageClassification`.
```
.
└── resnet_model
├── __init__.py
├── configuration_resnet.py
└── modeling_resnet.py
```
O `__init__.py` pode estar vazio, apenas está lá para que o Python detecte que o `resnet_model` possa ser usado como um módulo.
<Tip warning={true}>
Se estiver copiando arquivos de modelagem da biblioteca, você precisará substituir todas as importações relativas na parte superior do arquivo
para importar do pacote `transformers`.
</Tip>
Observe que você pode reutilizar (ou subclasse) uma configuração/modelo existente.
Para compartilhar seu modelo com a comunidade, siga estas etapas: primeiro importe o modelo ResNet e a configuração do
arquivos criados:
```py
from resnet_model.configuration_resnet import ResnetConfig
from resnet_model.modeling_resnet import ResnetModel, ResnetModelForImageClassification
```
Então você tem que dizer à biblioteca que deseja copiar os arquivos de código desses objetos ao usar o `save_pretrained`
e registrá-los corretamente com uma determinada classe automáticas (especialmente para modelos), basta executar:
```py
ResnetConfig.register_for_auto_class()
ResnetModel.register_for_auto_class("AutoModel")
ResnetModelForImageClassification.register_for_auto_class("AutoModelForImageClassification")
```
Observe que não há necessidade de especificar uma classe automática para a configuração (há apenas uma classe automática,
[`AutoConfig`]), mas é diferente para os modelos. Seu modelo customizado pode ser adequado para muitas tarefas diferentes, então você
tem que especificar qual das classes automáticas é a correta para o seu modelo.
Em seguida, vamos criar a configuração e os modelos como fizemos antes:
```py
resnet50d_config = ResnetConfig(block_type="bottleneck", stem_width=32, stem_type="deep", avg_down=True)
resnet50d = ResnetModelForImageClassification(resnet50d_config)
pretrained_model = timm.create_model("resnet50d", pretrained=True)
resnet50d.model.load_state_dict(pretrained_model.state_dict())
```
Agora para enviar o modelo para o Hub, certifique-se de estar logado. Ou execute no seu terminal:
```bash
huggingface-cli login
```
ou a partir do notebook:
```py
from huggingface_hub import notebook_login
notebook_login()
```
Você pode então enviar para seu próprio namespace (ou uma organização da qual você é membro) assim:
```py
resnet50d.push_to_hub("custom-resnet50d")
```
Além dos pesos do modelo e da configuração no formato json, isso também copiou o modelo e
configuração `.py` na pasta `custom-resnet50d` e carregou o resultado para o Hub. Você pode conferir o resultado
neste [repositório de modelos](https://huggingface.co/sgugger/custom-resnet50d).
Consulte o [tutorial de compartilhamento](model_sharing) para obter mais informações sobre o método push_to_hub.
## Usando um modelo com código customizado
Você pode usar qualquer configuração, modelo ou tokenizador com arquivos de código customizados em seu repositório com as classes automáticas e
o método `from_pretrained`. Todos os arquivos e códigos carregados no Hub são verificados quanto a malware (consulte a documentação de [Segurança do Hub](https://huggingface.co/docs/hub/security#malware-scanning) para obter mais informações), mas você ainda deve
revisar o código do modelo e o autor para evitar a execução de código malicioso em sua máquina. Defina `trust_remote_code=True` para usar
um modelo com código customizado:
```py
from transformers import AutoModelForImageClassification
model = AutoModelForImageClassification.from_pretrained("sgugger/custom-resnet50d", trust_remote_code=True)
```
Também é fortemente recomendado passar um hash de confirmação como uma `revisão` para garantir que o autor dos modelos não
atualize o código com novas linhas maliciosas (a menos que você confie totalmente nos autores dos modelos).
```py
commit_hash = "ed94a7c6247d8aedce4647f00f20de6875b5b292"
model = AutoModelForImageClassification.from_pretrained(
"sgugger/custom-resnet50d", trust_remote_code=True, revision=commit_hash
)
```
Observe que ao navegar no histórico de commits do repositório do modelo no Hub, há um botão para copiar facilmente o commit
hash de qualquer commit.
## Registrando um modelo com código customizado para as classes automáticas
Se você estiver escrevendo uma biblioteca que estende 🤗 Transformers, talvez queira estender as classes automáticas para incluir seus próprios
modelos. Isso é diferente de enviar o código para o Hub no sentido de que os usuários precisarão importar sua biblioteca para
obter os modelos customizados (ao contrário de baixar automaticamente o código do modelo do Hub).
Desde que sua configuração tenha um atributo `model_type` diferente dos tipos de modelo existentes e que as classes do seu modelo
tenha os atributos `config_class` corretos, você pode simplesmente adicioná-los às classes automáticas assim:
```py
from transformers import AutoConfig, AutoModel, AutoModelForImageClassification
AutoConfig.register("resnet", ResnetConfig)
AutoModel.register(ResnetConfig, ResnetModel)
AutoModelForImageClassification.register(ResnetConfig, ResnetModelForImageClassification)
```
Observe que o primeiro argumento usado ao registrar sua configuração customizada para [`AutoConfig`] precisa corresponder ao `model_type`
de sua configuração customizada. E o primeiro argumento usado ao registrar seus modelos customizados, para qualquer necessidade de classe de modelo automático
deve corresponder ao `config_class` desses modelos.
| 0 |
hf_public_repos/transformers/docs/source | hf_public_repos/transformers/docs/source/pt/quicktour.md | <!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Tour rápido
[[open-in-colab]]
Comece a trabalhar com 🤗 Transformers! Comece usando [`pipeline`] para rápida inferência e facilmente carregue um modelo pré-treinado e um tokenizer com [AutoClass](./model_doc/auto) para resolver tarefas de texto, visão ou áudio.
<Tip>
Todos os exemplos de código apresentados na documentação têm um botão no canto superior direito para escolher se você deseja ocultar ou mostrar o código no Pytorch ou no TensorFlow. Caso contrário, é esperado que funcione para ambos back-ends sem nenhuma alteração.
</Tip>
## Pipeline
[`pipeline`] é a maneira mais fácil de usar um modelo pré-treinado para uma dada tarefa.
<Youtube id="tiZFewofSLM"/>
A [`pipeline`] apoia diversas tarefas fora da caixa:
**Texto**:
* Análise sentimental: classifica a polaridade de um texto.
* Geração de texto (em Inglês): gera texto a partir de uma entrada.
* Reconhecimento de entidade mencionada: legenda cada palavra com uma classe que a representa (pessoa, data, local, etc...)
* Respostas: extrai uma resposta dado algum contexto e uma questão
* Máscara de preenchimento: preenche o espaço, dado um texto com máscaras de palavras.
* Sumarização: gera o resumo de um texto longo ou documento.
* Tradução: traduz texto para outra língua.
* Extração de características: cria um tensor que representa o texto.
**Imagem**:
* Classificação de imagens: classifica uma imagem.
* Segmentação de imagem: classifica cada pixel da imagem.
* Detecção de objetos: detecta objetos em uma imagem.
**Audio**:
* Classficação de áudio: legenda um trecho de áudio fornecido.
* Reconhecimento de fala automático: transcreve audio em texto.
<Tip>
Para mais detalhes sobre a [`pipeline`] e tarefas associadas, siga a documentação [aqui](./main_classes/pipelines).
</Tip>
### Uso da pipeline
No exemplo a seguir, você usará [`pipeline`] para análise sentimental.
Instale as seguintes dependências se você ainda não o fez:
<frameworkcontent>
<pt>
```bash
pip install torch
```
</pt>
<tf>
```bash
pip install tensorflow
```
</tf>
</frameworkcontent>
Importe [`pipeline`] e especifique a tarefa que deseja completar:
```py
>>> from transformers import pipeline
>>> classifier = pipeline("sentiment-analysis")
```
A pipeline baixa and armazena um [modelo pré-treinado](https://huggingface.co/distilbert-base-uncased-finetuned-sst-2-english) padrão e tokenizer para análise sentimental. Agora você pode usar `classifier` no texto alvo:
```py
>>> classifier("We are very happy to show you the 🤗 Transformers library.")
[{'label': 'POSITIVE', 'score': 0.9998}]
```
Para mais de uma sentença, passe uma lista para a [`pipeline`], a qual retornará uma lista de dicionários:
```py
>>> results = classifier(["We are very happy to show you the 🤗 Transformers library.", "We hope you don't hate it."])
>>> for result in results:
... print(f"label: {result['label']}, with score: {round(result['score'], 4)}")
label: POSITIVE, with score: 0.9998
label: NEGATIVE, with score: 0.5309
```
A [`pipeline`] também pode iterar sobre um Dataset inteiro. Comece instalando a biblioteca de [🤗 Datasets](https://huggingface.co/docs/datasets/):
```bash
pip install datasets
```
Crie uma [`pipeline`] com a tarefa que deseja resolver e o modelo que deseja usar.
```py
>>> import torch
>>> from transformers import pipeline
>>> speech_recognizer = pipeline("automatic-speech-recognition", model="facebook/wav2vec2-base-960h")
```
A seguir, carregue uma base de dados (confira a 🤗 [Iniciação em Datasets](https://huggingface.co/docs/datasets/quickstart.html) para mais detalhes) que você gostaria de iterar sobre. Por exemplo, vamos carregar o dataset [MInDS-14](https://huggingface.co/datasets/PolyAI/minds14):
```py
>>> from datasets import load_dataset, Audio
>>> dataset = load_dataset("PolyAI/minds14", name="en-US", split="train") # doctest: +IGNORE_RESULT
```
Precisamos garantir que a taxa de amostragem do conjunto de dados corresponda à taxa de amostragem em que o facebook/wav2vec2-base-960h foi treinado.
```py
>>> dataset = dataset.cast_column("audio", Audio(sampling_rate=speech_recognizer.feature_extractor.sampling_rate))
```
Os arquivos de áudio são carregados e re-amostrados automaticamente ao chamar a coluna `"audio"`.
Vamos extrair as arrays de formas de onda originais das primeiras 4 amostras e passá-las como uma lista para o pipeline:
```py
>>> result = speech_recognizer(dataset[:4]["audio"])
>>> print([d["text"] for d in result])
['I WOULD LIKE TO SET UP A JOINT ACCOUNT WITH MY PARTNER HOW DO I PROCEED WITH DOING THAT', "FONDERING HOW I'D SET UP A JOIN TO HET WITH MY WIFE AND WHERE THE AP MIGHT BE", "I I'D LIKE TOY SET UP A JOINT ACCOUNT WITH MY PARTNER I'M NOT SEEING THE OPTION TO DO IT ON THE APSO I CALLED IN TO GET SOME HELP CAN I JUST DO IT OVER THE PHONE WITH YOU AND GIVE YOU THE INFORMATION OR SHOULD I DO IT IN THE AP AND I'M MISSING SOMETHING UQUETTE HAD PREFERRED TO JUST DO IT OVER THE PHONE OF POSSIBLE THINGS", 'HOW DO I TURN A JOIN A COUNT']
```
Para um conjunto de dados maior onde as entradas são maiores (como em fala ou visão), será necessário passar um gerador em vez de uma lista que carregue todas as entradas na memória. Consulte a [documentação do pipeline](./main_classes/pipelines) para mais informações.
### Use outro modelo e tokenizer na pipeline
A [`pipeline`] pode acomodar qualquer modelo do [Model Hub](https://huggingface.co/models), facilitando sua adaptação para outros casos de uso. Por exemplo, se você quiser um modelo capaz de lidar com texto em francês, use as tags no Model Hub para filtrar um modelo apropriado. O principal resultado filtrado retorna um [modelo BERT](https://huggingface.co/nlptown/bert-base-multilingual-uncased-sentiment) bilíngue ajustado para análise de sentimentos. Ótimo, vamos usar este modelo!
```py
>>> model_name = "nlptown/bert-base-multilingual-uncased-sentiment"
```
<frameworkcontent>
<pt>
Use o [`AutoModelForSequenceClassification`] e [`AutoTokenizer`] para carregar o modelo pré-treinado e seu tokenizer associado (mais em `AutoClass` abaixo):
```py
>>> from transformers import AutoTokenizer, AutoModelForSequenceClassification
>>> model = AutoModelForSequenceClassification.from_pretrained(model_name)
>>> tokenizer = AutoTokenizer.from_pretrained(model_name)
```
</pt>
<tf>
Use o [`TFAutoModelForSequenceClassification`] and [`AutoTokenizer`] para carregar o modelo pré-treinado e o tokenizer associado (mais em `TFAutoClass` abaixo):
```py
>>> from transformers import AutoTokenizer, TFAutoModelForSequenceClassification
>>> model = TFAutoModelForSequenceClassification.from_pretrained(model_name)
>>> tokenizer = AutoTokenizer.from_pretrained(model_name)
```
</tf>
</frameworkcontent>
Então você pode especificar o modelo e o tokenizador na [`pipeline`] e aplicar o `classifier` no seu texto alvo:
```py
>>> classifier = pipeline("sentiment-analysis", model=model, tokenizer=tokenizer)
>>> classifier("Nous sommes très heureux de vous présenter la bibliothèque 🤗 Transformers.")
[{'label': '5 stars', 'score': 0.7273}]
```
Se você não conseguir achar um modelo para o seu caso de uso, precisará usar fine-tune em um modelo pré-treinado nos seus dados. Veja nosso [tutorial de fine-tuning](./training) para descobrir como. Finalmente, depois que você tiver usado esse processo em seu modelo, considere compartilhá-lo conosco (veja o tutorial [aqui](./model_sharing)) na plataforma Model Hub afim de democratizar NLP! 🤗
## AutoClass
<Youtube id="AhChOFRegn4"/>
Por baixo dos panos, as classes [`AutoModelForSequenceClassification`] e [`AutoTokenizer`] trabalham juntas para fortificar o [`pipeline`]. Um [AutoClass](./model_doc/auto) é um atalho que automaticamente recupera a arquitetura de um modelo pré-treinado a partir de seu nome ou caminho. Basta selecionar a `AutoClass` apropriada para sua tarefa e seu tokenizer associado com [`AutoTokenizer`].
Vamos voltar ao nosso exemplo e ver como você pode usar a `AutoClass` para replicar os resultados do [`pipeline`].
### AutoTokenizer
Um tokenizer é responsável por pré-processar o texto em um formato que seja compreensível para o modelo. Primeiro, o tokenizer dividirá o texto em palavras chamadas *tokens*. Existem várias regras que regem o processo de tokenização, incluindo como dividir uma palavra e em que nível (saiba mais sobre tokenização [aqui](./tokenizer_summary)). A coisa mais importante a lembrar, porém, é que você precisa instanciar o tokenizer com o mesmo nome do modelo para garantir que está usando as mesmas regras de tokenização com as quais um modelo foi pré-treinado.
Carregue um tokenizer com [`AutoTokenizer`]:
```py
>>> from transformers import AutoTokenizer
>>> model_name = "nlptown/bert-base-multilingual-uncased-sentiment"
>>> tokenizer = AutoTokenizer.from_pretrained(model_name)
```
Em seguida, o tokenizer converte os tokens em números para construir um tensor como entrada para o modelo. Isso é conhecido como o *vocabulário* do modelo.
Passe o texto para o tokenizer:
```py
>>> encoding = tokenizer("We are very happy to show you the 🤗 Transformers library.")
>>> print(encoding)
{'input_ids': [101, 11312, 10320, 12495, 19308, 10114, 11391, 10855, 10103, 100, 58263, 13299, 119, 102],
'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
```
O tokenizer retornará um dicionário contendo:
* [input_ids](./glossary#input-ids): representações numéricas de seus tokens.
* [atttention_mask](.glossary#attention-mask): indica quais tokens devem ser atendidos.
Assim como o [`pipeline`], o tokenizer aceitará uma lista de entradas. Além disso, o tokenizer também pode preencher e truncar o texto para retornar um lote com comprimento uniforme:
<frameworkcontent>
<pt>
```py
>>> pt_batch = tokenizer(
... ["We are very happy to show you the 🤗 transformers library.", "We hope you don't hate it."],
... padding=True,
... truncation=True,
... max_length=512,
... return_tensors="pt",
... )
```
</pt>
<tf>
```py
>>> tf_batch = tokenizer(
... ["We are very happy to show you the 🤗 Transformers library.", "We hope you don't hate it."],
... padding=True,
... truncation=True,
... max_length=512,
... return_tensors="tf",
... )
```
</tf>
</frameworkcontent>
Leia o tutorial de [pré-processamento](./pré-processamento) para obter mais detalhes sobre tokenização.
### AutoModel
<frameworkcontent>
<pt>
🤗 Transformers fornecem uma maneira simples e unificada de carregar instâncias pré-treinadas. Isso significa que você pode carregar um [`AutoModel`] como carregaria um [`AutoTokenizer`]. A única diferença é selecionar o [`AutoModel`] correto para a tarefa. Como você está fazendo classificação de texto ou sequência, carregue [`AutoModelForSequenceClassification`]:
```py
>>> from transformers import AutoModelForSequenceClassification
>>> model_name = "nlptown/bert-base-multilingual-uncased-sentiment"
>>> pt_model = AutoModelForSequenceClassification.from_pretrained(model_name)
```
<Tip>
Veja o [sumário de tarefas](./task_summary) para qual classe de [`AutoModel`] usar para cada tarefa.
</Tip>
Agora você pode passar seu grupo de entradas pré-processadas diretamente para o modelo. Você apenas tem que descompactar o dicionário usando `**`:
```py
>>> pt_outputs = pt_model(**pt_batch)
```
O modelo gera as ativações finais no atributo `logits`. Aplique a função softmax aos `logits` para recuperar as probabilidades:
```py
>>> from torch import nn
>>> pt_predictions = nn.functional.softmax(pt_outputs.logits, dim=-1)
>>> print(pt_predictions)
tensor([[0.0021, 0.0018, 0.0115, 0.2121, 0.7725],
[0.2084, 0.1826, 0.1969, 0.1755, 0.2365]], grad_fn=<SoftmaxBackward0>)
```
</pt>
<tf>
🤗 Transformers fornecem uma maneira simples e unificada de carregar instâncias pré-treinadas. Isso significa que você pode carregar um [`TFAutoModel`] como carregaria um [`AutoTokenizer`]. A única diferença é selecionar o [`TFAutoModel`] correto para a tarefa. Como você está fazendo classificação de texto ou sequência, carregue [`TFAutoModelForSequenceClassification`]:
```py
>>> from transformers import TFAutoModelForSequenceClassification
>>> model_name = "nlptown/bert-base-multilingual-uncased-sentiment"
>>> tf_model = TFAutoModelForSequenceClassification.from_pretrained(model_name)
```
<Tip>
Veja o [sumário de tarefas](./task_summary) para qual classe de [`AutoModel`] usar para cada tarefa.
</Tip>
Agora você pode passar seu grupo de entradas pré-processadas diretamente para o modelo através da passagem de chaves de dicionários ao tensor.
```py
>>> tf_outputs = tf_model(tf_batch)
```
O modelo gera as ativações finais no atributo `logits`. Aplique a função softmax aos `logits` para recuperar as probabilidades:
```py
>>> import tensorflow as tf
>>> tf_predictions = tf.nn.softmax(tf_outputs.logits, axis=-1)
>>> tf_predictions # doctest: +IGNORE_RESULT
```
</tf>
</frameworkcontent>
<Tip>
Todos os modelos de 🤗 Transformers (PyTorch ou TensorFlow) geram tensores *antes* da função de ativação final (como softmax) pois essa função algumas vezes é fundida com a perda.
</Tip>
Os modelos são um standard [`torch.nn.Module`](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) ou um [`tf.keras.Model`](https: //www.tensorflow.org/api_docs/python/tf/keras/Model) para que você possa usá-los em seu loop de treinamento habitual. No entanto, para facilitar as coisas, 🤗 Transformers fornece uma classe [`Trainer`] para PyTorch que adiciona funcionalidade para treinamento distribuído, precisão mista e muito mais. Para o TensorFlow, você pode usar o método `fit` de [Keras](https://keras.io/). Consulte o [tutorial de treinamento](./training) para obter mais detalhes.
<Tip>
As saídas do modelo 🤗 Transformers são classes de dados especiais para que seus atributos sejam preenchidos automaticamente em um IDE.
As saídas do modelo também se comportam como uma tupla ou um dicionário (por exemplo, você pode indexar com um inteiro, uma parte ou uma string), caso em que os atributos `None` são ignorados.
</Tip>
### Salvar um modelo
<frameworkcontent>
<pt>
Uma vez que seu modelo estiver afinado, você pode salvá-lo com seu Tokenizer usando [`PreTrainedModel.save_pretrained`]:
```py
>>> pt_save_directory = "./pt_save_pretrained"
>>> tokenizer.save_pretrained(pt_save_directory) # doctest: +IGNORE_RESULT
>>> pt_model.save_pretrained(pt_save_directory)
```
Quando você estiver pronto para usá-lo novamente, recarregue com [`PreTrainedModel.from_pretrained`]:
```py
>>> pt_model = AutoModelForSequenceClassification.from_pretrained("./pt_save_pretrained")
```
</pt>
<tf>
Uma vez que seu modelo estiver afinado, você pode salvá-lo com seu Tokenizer usando [`TFPreTrainedModel.save_pretrained`]:
```py
>>> tf_save_directory = "./tf_save_pretrained"
>>> tokenizer.save_pretrained(tf_save_directory) # doctest: +IGNORE_RESULT
>>> tf_model.save_pretrained(tf_save_directory)
```
Quando você estiver pronto para usá-lo novamente, recarregue com [`TFPreTrainedModel.from_pretrained`]
```py
>>> tf_model = TFAutoModelForSequenceClassification.from_pretrained("./tf_save_pretrained")
```
</tf>
</frameworkcontent>
Um recurso particularmente interessante dos 🤗 Transformers é a capacidade de salvar um modelo e recarregá-lo como um modelo PyTorch ou TensorFlow. Use `from_pt` ou `from_tf` para converter o modelo de um framework para outro:
<frameworkcontent>
<pt>
```py
>>> from transformers import AutoModel
>>> tokenizer = AutoTokenizer.from_pretrained(tf_save_directory)
>>> pt_model = AutoModelForSequenceClassification.from_pretrained(tf_save_directory, from_tf=True)
```
</pt>
<tf>
```py
>>> from transformers import TFAutoModel
>>> tokenizer = AutoTokenizer.from_pretrained(pt_save_directory)
>>> tf_model = TFAutoModelForSequenceClassification.from_pretrained(pt_save_directory, from_pt=True)
```
</tf>
</frameworkcontent> | 0 |
hf_public_repos/transformers/docs/source | hf_public_repos/transformers/docs/source/pt/run_scripts.md | <!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Treinamento a partir de um script
Junto com os 🤗 Transformers [notebooks](./noteboks/README), também há scripts de exemplo demonstrando como treinar um modelo para uma tarefa com [PyTorch](https://github.com/huggingface/transformers/tree/main/examples/pytorch), [TensorFlow](https://github.com/huggingface/transformers/tree/main/examples/tensorflow) ou [JAX/Flax](https://github.com/huggingface/transformers/tree/main/examples/flax).
Você também encontrará scripts que usamos em nossos [projetos de pesquisa](https://github.com/huggingface/transformers/tree/main/examples/research_projects) e [exemplos legados](https://github.com/huggingface/transformers/tree/main/examples/legacy) que são principalmente contribuições da comunidade. Esses scripts não são mantidos ativamente e exigem uma versão específica de 🤗 Transformers que provavelmente será incompatível com a versão mais recente da biblioteca.
Não se espera que os scripts de exemplo funcionem imediatamente em todos os problemas, você pode precisar adaptar o script ao problema que está tentando resolver. Para ajudá-lo com isso, a maioria dos scripts expõe totalmente como os dados são pré-processados, permitindo que você os edite conforme necessário para seu caso de uso.
Para qualquer recurso que você gostaria de implementar em um script de exemplo, discuta-o no [fórum](https://discuss.huggingface.co/) ou em uma [issue](https://github.com/huggingface/transformers/issues) antes de enviar um Pull Request. Embora recebamos correções de bugs, é improvável que mesclaremos um Pull Request que adicione mais funcionalidades ao custo de legibilidade.
Este guia mostrará como executar um exemplo de script de treinamento de sumarização em [PyTorch](https://github.com/huggingface/transformers/tree/main/examples/pytorch/summarization) e [TensorFlow](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/summarization). Espera-se que todos os exemplos funcionem com ambas as estruturas, a menos que especificado de outra forma.
## Configuração
Para executar com êxito a versão mais recente dos scripts de exemplo, você precisa **instalar o 🤗 Transformers da fonte** em um novo ambiente virtual:
```bash
git clone https://github.com/huggingface/transformers
cd transformers
pip install .
```
Para versões mais antigas dos scripts de exemplo, clique no botão abaixo:
<details>
<summary>Exemplos para versões antigas dos 🤗 Transformers</summary>
<ul>
<li><a href="https://github.com/huggingface/transformers/tree/v4.5.1/examples">v4.5.1</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v4.4.2/examples">v4.4.2</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v4.3.3/examples">v4.3.3</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v4.2.2/examples">v4.2.2</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v4.1.1/examples">v4.1.1</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v4.0.1/examples">v4.0.1</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v3.5.1/examples">v3.5.1</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v3.4.0/examples">v3.4.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v3.3.1/examples">v3.3.1</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v3.2.0/examples">v3.2.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v3.1.0/examples">v3.1.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v3.0.2/examples">v3.0.2</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.11.0/examples">v2.11.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.10.0/examples">v2.10.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.9.1/examples">v2.9.1</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.8.0/examples">v2.8.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.7.0/examples">v2.7.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.6.0/examples">v2.6.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.5.1/examples">v2.5.1</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.4.0/examples">v2.4.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.3.0/examples">v2.3.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.2.0/examples">v2.2.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.1.0/examples">v2.1.1</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.0.0/examples">v2.0.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v1.2.0/examples">v1.2.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v1.1.0/examples">v1.1.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v1.0.0/examples">v1.0.0</a></li>
</ul>
</details>
Em seguida, mude seu clone atual dos 🤗 Transformers para uma versão específica, como v3.5.1, por exemplo:
```bash
git checkout tags/v3.5.1
```
Depois de configurar a versão correta da biblioteca, navegue até a pasta de exemplo de sua escolha e instale os requisitos específicos do exemplo:
```bash
pip install -r requirements.txt
```
## Executando um script
<frameworkcontent>
<pt>
O script de exemplo baixa e pré-processa um conjunto de dados da biblioteca 🤗 [Datasets](https://huggingface.co/docs/datasets/). Em seguida, o script ajusta um conjunto de dados com o [Trainer](https://huggingface.co/docs/transformers/main_classes/trainer) em uma arquitetura que oferece suporte à sumarização. O exemplo a seguir mostra como ajustar [T5-small](https://huggingface.co/t5-small) no conjunto de dados [CNN/DailyMail](https://huggingface.co/datasets/cnn_dailymail). O modelo T5 requer um argumento `source_prefix` adicional devido à forma como foi treinado. Este prompt informa ao T5 que esta é uma tarefa de sumarização.
```bash
python examples/pytorch/summarization/run_summarization.py \
--model_name_or_path t5-small \
--do_train \
--do_eval \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--source_prefix "summarize: " \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--overwrite_output_dir \
--predict_with_generate
```
</pt>
<tf>
Este outro script de exemplo baixa e pré-processa um conjunto de dados da biblioteca 🤗 [Datasets](https://huggingface.co/docs/datasets/). Em seguida, o script ajusta um conjunto de dados usando Keras em uma arquitetura que oferece suporte à sumarização. O exemplo a seguir mostra como ajustar [T5-small](https://huggingface.co/t5-small) no conjunto de dados [CNN/DailyMail](https://huggingface.co/datasets/cnn_dailymail). O modelo T5 requer um argumento `source_prefix` adicional devido à forma como foi treinado. Este prompt informa ao T5 que esta é uma tarefa de sumarização.
```bash
python examples/tensorflow/summarization/run_summarization.py \
--model_name_or_path t5-small \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size 8 \
--per_device_eval_batch_size 16 \
--num_train_epochs 3 \
--do_train \
--do_eval
```
</tf>
</frameworkcontent>
## Treinamento distribuído e precisão mista
O [Trainer](https://huggingface.co/docs/transformers/main_classes/trainer) oferece suporte a treinamento distribuído e precisão mista, o que significa que você também pode usá-lo em um script. Para habilitar esses dois recursos:
- Adicione o argumento `fp16` para habilitar a precisão mista.
- Defina o número de GPUs a serem usadas com o argumento `nproc_per_node`.
```bash
python -m torch.distributed.launch \
--nproc_per_node 8 pytorch/summarization/run_summarization.py \
--fp16 \
--model_name_or_path t5-small \
--do_train \
--do_eval \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--source_prefix "summarize: " \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--overwrite_output_dir \
--predict_with_generate
```
Os scripts do TensorFlow utilizam um [`MirroredStrategy`](https://www.tensorflow.org/guide/distributed_training#mirroredstrategy) para treinamento distribuído, e você não precisa adicionar argumentos adicionais ao script de treinamento. O script do TensorFlow usará várias GPUs por padrão, se estiverem disponíveis.
## Executando um script em uma TPU
<frameworkcontent>
<pt>
As Unidades de Processamento de Tensor (TPUs) são projetadas especificamente para acelerar o desempenho. O PyTorch oferece suporte a TPUs com o compilador de aprendizado profundo [XLA](https://www.tensorflow.org/xla) (consulte [aqui](https://github.com/pytorch/xla/blob/master/README.md) para mais detalhes). Para usar uma TPU, inicie o script `xla_spawn.py` e use o argumento `num_cores` para definir o número de núcleos de TPU que você deseja usar.
```bash
python xla_spawn.py --num_cores 8 \
summarization/run_summarization.py \
--model_name_or_path t5-small \
--do_train \
--do_eval \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--source_prefix "summarize: " \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--overwrite_output_dir \
--predict_with_generate
```
</pt>
<tf>
As Unidades de Processamento de Tensor (TPUs) são projetadas especificamente para acelerar o desempenho. Os scripts do TensorFlow utilizam uma [`TPUStrategy`](https://www.tensorflow.org/guide/distributed_training#tpustrategy) para treinamento em TPUs. Para usar uma TPU, passe o nome do recurso TPU para o argumento `tpu`.
```bash
python run_summarization.py \
--tpu name_of_tpu_resource \
--model_name_or_path t5-small \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size 8 \
--per_device_eval_batch_size 16 \
--num_train_epochs 3 \
--do_train \
--do_eval
```
</tf>
</frameworkcontent>
## Execute um script com 🤗 Accelerate
🤗 [Accelerate](https://huggingface.co/docs/accelerate) é uma biblioteca somente do PyTorch que oferece um método unificado para treinar um modelo em vários tipos de configurações (CPU, multiplas GPUs, TPUs), mantendo visibilidade no loop de treinamento do PyTorch. Certifique-se de ter o 🤗 Accelerate instalado se ainda não o tiver:
> Nota: Como o Accelerate está se desenvolvendo rapidamente, a versão git do Accelerate deve ser instalada para executar os scripts
```bash
pip install git+https://github.com/huggingface/accelerate
```
Em vez do script `run_summarization.py`, você precisa usar o script `run_summarization_no_trainer.py`. Os scripts suportados pelo 🤗 Accelerate terão um arquivo `task_no_trainer.py` na pasta. Comece executando o seguinte comando para criar e salvar um arquivo de configuração:
```bash
accelerate config
```
Teste sua configuração para garantir que ela esteja corretamente configurada :
```bash
accelerate test
```
Agora você está pronto para iniciar o treinamento:
```bash
accelerate launch run_summarization_no_trainer.py \
--model_name_or_path t5-small \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--source_prefix "summarize: " \
--output_dir ~/tmp/tst-summarization
```
## Usando um conjunto de dados personalizado
O script de resumo oferece suporte a conjuntos de dados personalizados, desde que sejam um arquivo CSV ou JSON. Ao usar seu próprio conjunto de dados, você precisa especificar vários argumentos adicionais:
- `train_file` e `validation_file` especificam o caminho para seus arquivos de treinamento e validação respectivamente.
- `text_column` é o texto de entrada para sumarização.
- `summary_column` é o texto de destino para saída.
Um script para sumarização usando um conjunto de dados customizado ficaria assim:
```bash
python examples/pytorch/summarization/run_summarization.py \
--model_name_or_path t5-small \
--do_train \
--do_eval \
--train_file path_to_csv_or_jsonlines_file \
--validation_file path_to_csv_or_jsonlines_file \
--text_column text_column_name \
--summary_column summary_column_name \
--source_prefix "summarize: " \
--output_dir /tmp/tst-summarization \
--overwrite_output_dir \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--predict_with_generate
```
## Testando um script
Geralmente, é uma boa ideia executar seu script em um número menor de exemplos de conjuntos de dados para garantir que tudo funcione conforme o esperado antes de se comprometer com um conjunto de dados inteiro, que pode levar horas para ser concluído. Use os seguintes argumentos para truncar o conjunto de dados para um número máximo de amostras:
- `max_train_samples`
- `max_eval_samples`
- `max_predict_samples`
```bash
python examples/pytorch/summarization/run_summarization.py \
--model_name_or_path t5-small \
--max_train_samples 50 \
--max_eval_samples 50 \
--max_predict_samples 50 \
--do_train \
--do_eval \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--source_prefix "summarize: " \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--overwrite_output_dir \
--predict_with_generate
```
Nem todos os scripts de exemplo suportam o argumento `max_predict_samples`. Se você não tiver certeza se seu script suporta este argumento, adicione o argumento `-h` para verificar:
```bash
examples/pytorch/summarization/run_summarization.py -h
```
## Retomar o treinamento a partir de um checkpoint
Outra opção útil para habilitar é retomar o treinamento de um checkpoint anterior. Isso garantirá que você possa continuar de onde parou sem recomeçar se o seu treinamento for interrompido. Existem dois métodos para retomar o treinamento a partir de um checkpoint.
O primeiro método usa o argumento `output_dir previous_output_dir` para retomar o treinamento do último checkpoint armazenado em `output_dir`. Neste caso, você deve remover `overwrite_output_dir`:
```bash
python examples/pytorch/summarization/run_summarization.py
--model_name_or_path t5-small \
--do_train \
--do_eval \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--source_prefix "summarize: " \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--output_dir previous_output_dir \
--predict_with_generate
```
O segundo método usa o argumento `resume_from_checkpoint path_to_specific_checkpoint` para retomar o treinamento de uma pasta de checkpoint específica.
```bash
python examples/pytorch/summarization/run_summarization.py
--model_name_or_path t5-small \
--do_train \
--do_eval \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--source_prefix "summarize: " \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--overwrite_output_dir \
--resume_from_checkpoint path_to_specific_checkpoint \
--predict_with_generate
```
## Compartilhando seu modelo
Todos os scripts podem enviar seu modelo final para o [Model Hub](https://huggingface.co/models). Certifique-se de estar conectado ao Hugging Face antes de começar:
```bash
huggingface-cli login
```
Em seguida, adicione o argumento `push_to_hub` ao script. Este argumento criará um repositório com seu nome de usuário do Hugging Face e o nome da pasta especificado em `output_dir`.
Para dar um nome específico ao seu repositório, use o argumento `push_to_hub_model_id` para adicioná-lo. O repositório será listado automaticamente em seu namespace.
O exemplo a seguir mostra como fazer upload de um modelo com um nome de repositório específico:
```bash
python examples/pytorch/summarization/run_summarization.py
--model_name_or_path t5-small \
--do_train \
--do_eval \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--source_prefix "summarize: " \
--push_to_hub \
--push_to_hub_model_id finetuned-t5-cnn_dailymail \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--overwrite_output_dir \
--predict_with_generate
```
| 0 |
hf_public_repos/transformers/docs/source | hf_public_repos/transformers/docs/source/pt/index.md | <!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# 🤗 Transformers
Estado da Arte para Aprendizado de Máquina em PyTorch, TensorFlow e JAX.
O 🤗 Transformers disponibiliza APIs para facilmente baixar e treinar modelos pré-treinados de última geração.
O uso de modelos pré-treinados pode diminuir os seus custos de computação, a sua pegada de carbono, além de economizar o
tempo necessário para se treinar um modelo do zero. Os modelos podem ser usados para diversas tarefas:
* 📝 Textos: classificação, extração de informações, perguntas e respostas, resumir, traduzir e gerar textos em mais de 100 idiomas.
* 🖼 Imagens: classificação, deteção de objetos, e segmentação.
* 🗣 Audio: reconhecimento de fala e classificação de áudio.
* 🐙 Multimodal: perguntas tabeladas e respsostas, reconhecimento ótico de charactéres, extração de informação de
documentos escaneados, classificação de vídeo, perguntas e respostas visuais.
Nossa biblioteca aceita integração contínua entre três das bibliotecas mais populares de aprendizado profundo:
Our library supports seamless integration between three of the most popular deep learning libraries:
[PyTorch](https://pytorch.org/), [TensorFlow](https://www.tensorflow.org/) e [JAX](https://jax.readthedocs.io/en/latest/).
Treine seu modelo em três linhas de código em um framework, e carregue-o para execução em outro.
Cada arquitetura 🤗 Transformers é definida em um módulo individual do Python, para que seja facilmente customizável para pesquisa e experimentos.
## Se você estiver procurando suporte do time da Hugging Face, acesse
<a target="_blank" href="https://huggingface.co/support">
<img alt="HuggingFace Expert Acceleration Program" src="https://huggingface.co/front/thumbnails/support.png" style="width: 100%; max-width: 600px; border: 1px solid #eee; border-radius: 4px; box-shadow: 0 1px 2px 0 rgba(0, 0, 0, 0.05);">
</a>
## Conteúdo
A documentação é dividida em cinco partes:
- **INÍCIO** contém um tour rápido de instalação e instruções para te dar um empurrão inicial com os 🤗 Transformers.
- **TUTORIAIS** são perfeitos para começar a aprender sobre a nossa biblioteca. Essa seção irá te ajudar a desenvolver
habilidades básicas necessárias para usar o 🤗 Transformers.
- **GUIAS PRÁTICOS** irão te mostrar como alcançar um certo objetivo, como o fine-tuning de um modelo pré-treinado
para modelamento de idioma, ou como criar um cabeçalho personalizado para um modelo.
- **GUIAS CONCEITUAIS** te darão mais discussões e explicações dos conceitos fundamentais e idéias por trás dos modelos,
tarefas e da filosofia de design por trás do 🤗 Transformers.
- **API** descreve o funcionamento de cada classe e função, agrupada em:
- **CLASSES PRINCIPAIS** para as classes que expõe as APIs importantes da biblioteca.
- **MODELOS** para as classes e funções relacionadas à cada modelo implementado na biblioteca.
- **AUXILIARES INTERNOS** para as classes e funções usadas internamente.
Atualmente a biblioteca contém implementações do PyTorch, TensorFlow e JAX, pesos para modelos pré-treinados e scripts de uso e conversão de utilidades para os seguintes modelos:
### Modelos atuais
<!--This list is updated automatically from the README with _make fix-copies_. Do not update manually! -->
1. **[ALBERT](model_doc/albert)** (from Google Research and the Toyota Technological Institute at Chicago) released with the paper [ALBERT: A Lite BERT for Self-supervised Learning of Language Representations](https://arxiv.org/abs/1909.11942), by Zhenzhong Lan, Mingda Chen, Sebastian Goodman, Kevin Gimpel, Piyush Sharma, Radu Soricut.
1. **[BART](model_doc/bart)** (from Facebook) released with the paper [BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension](https://arxiv.org/abs/1910.13461) by Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Ves Stoyanov and Luke Zettlemoyer.
1. **[BARThez](model_doc/barthez)** (from École polytechnique) released with the paper [BARThez: a Skilled Pretrained French Sequence-to-Sequence Model](https://arxiv.org/abs/2010.12321) by Moussa Kamal Eddine, Antoine J.-P. Tixier, Michalis Vazirgiannis.
1. **[BARTpho](model_doc/bartpho)** (from VinAI Research) released with the paper [BARTpho: Pre-trained Sequence-to-Sequence Models for Vietnamese](https://arxiv.org/abs/2109.09701) by Nguyen Luong Tran, Duong Minh Le and Dat Quoc Nguyen.
1. **[BEiT](model_doc/beit)** (from Microsoft) released with the paper [BEiT: BERT Pre-Training of Image Transformers](https://arxiv.org/abs/2106.08254) by Hangbo Bao, Li Dong, Furu Wei.
1. **[BERT](model_doc/bert)** (from Google) released with the paper [BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding](https://arxiv.org/abs/1810.04805) by Jacob Devlin, Ming-Wei Chang, Kenton Lee and Kristina Toutanova.
1. **[BERTweet](model_doc/bertweet)** (from VinAI Research) released with the paper [BERTweet: A pre-trained language model for English Tweets](https://aclanthology.org/2020.emnlp-demos.2/) by Dat Quoc Nguyen, Thanh Vu and Anh Tuan Nguyen.
1. **[BERT For Sequence Generation](model_doc/bert-generation)** (from Google) released with the paper [Leveraging Pre-trained Checkpoints for Sequence Generation Tasks](https://arxiv.org/abs/1907.12461) by Sascha Rothe, Shashi Narayan, Aliaksei Severyn.
1. **[BigBird-RoBERTa](model_doc/big_bird)** (from Google Research) released with the paper [Big Bird: Transformers for Longer Sequences](https://arxiv.org/abs/2007.14062) by Manzil Zaheer, Guru Guruganesh, Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Ontanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, Amr Ahmed.
1. **[BigBird-Pegasus](model_doc/bigbird_pegasus)** (from Google Research) released with the paper [Big Bird: Transformers for Longer Sequences](https://arxiv.org/abs/2007.14062) by Manzil Zaheer, Guru Guruganesh, Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Ontanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, Amr Ahmed.
1. **[Blenderbot](model_doc/blenderbot)** (from Facebook) released with the paper [Recipes for building an open-domain chatbot](https://arxiv.org/abs/2004.13637) by Stephen Roller, Emily Dinan, Naman Goyal, Da Ju, Mary Williamson, Yinhan Liu, Jing Xu, Myle Ott, Kurt Shuster, Eric M. Smith, Y-Lan Boureau, Jason Weston.
1. **[BlenderbotSmall](model_doc/blenderbot-small)** (from Facebook) released with the paper [Recipes for building an open-domain chatbot](https://arxiv.org/abs/2004.13637) by Stephen Roller, Emily Dinan, Naman Goyal, Da Ju, Mary Williamson, Yinhan Liu, Jing Xu, Myle Ott, Kurt Shuster, Eric M. Smith, Y-Lan Boureau, Jason Weston.
1. **[BORT](model_doc/bort)** (from Alexa) released with the paper [Optimal Subarchitecture Extraction For BERT](https://arxiv.org/abs/2010.10499) by Adrian de Wynter and Daniel J. Perry.
1. **[ByT5](model_doc/byt5)** (from Google Research) released with the paper [ByT5: Towards a token-free future with pre-trained byte-to-byte models](https://arxiv.org/abs/2105.13626) by Linting Xue, Aditya Barua, Noah Constant, Rami Al-Rfou, Sharan Narang, Mihir Kale, Adam Roberts, Colin Raffel.
1. **[CamemBERT](model_doc/camembert)** (from Inria/Facebook/Sorbonne) released with the paper [CamemBERT: a Tasty French Language Model](https://arxiv.org/abs/1911.03894) by Louis Martin*, Benjamin Muller*, Pedro Javier Ortiz Suárez*, Yoann Dupont, Laurent Romary, Éric Villemonte de la Clergerie, Djamé Seddah and Benoît Sagot.
1. **[CANINE](model_doc/canine)** (from Google Research) released with the paper [CANINE: Pre-training an Efficient Tokenization-Free Encoder for Language Representation](https://arxiv.org/abs/2103.06874) by Jonathan H. Clark, Dan Garrette, Iulia Turc, John Wieting.
1. **[ConvNeXT](model_doc/convnext)** (from Facebook AI) released with the paper [A ConvNet for the 2020s](https://arxiv.org/abs/2201.03545) by Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feichtenhofer, Trevor Darrell, Saining Xie.
1. **[ConvNeXTV2](model_doc/convnextv2)** (from Facebook AI) released with the paper [ConvNeXt V2: Co-designing and Scaling ConvNets with Masked Autoencoders](https://arxiv.org/abs/2301.00808) by Sanghyun Woo, Shoubhik Debnath, Ronghang Hu, Xinlei Chen, Zhuang Liu, In So Kweon, Saining Xie.
1. **[CLIP](model_doc/clip)** (from OpenAI) released with the paper [Learning Transferable Visual Models From Natural Language Supervision](https://arxiv.org/abs/2103.00020) by Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, Ilya Sutskever.
1. **[ConvBERT](model_doc/convbert)** (from YituTech) released with the paper [ConvBERT: Improving BERT with Span-based Dynamic Convolution](https://arxiv.org/abs/2008.02496) by Zihang Jiang, Weihao Yu, Daquan Zhou, Yunpeng Chen, Jiashi Feng, Shuicheng Yan.
1. **[CPM](model_doc/cpm)** (from Tsinghua University) released with the paper [CPM: A Large-scale Generative Chinese Pre-trained Language Model](https://arxiv.org/abs/2012.00413) by Zhengyan Zhang, Xu Han, Hao Zhou, Pei Ke, Yuxian Gu, Deming Ye, Yujia Qin, Yusheng Su, Haozhe Ji, Jian Guan, Fanchao Qi, Xiaozhi Wang, Yanan Zheng, Guoyang Zeng, Huanqi Cao, Shengqi Chen, Daixuan Li, Zhenbo Sun, Zhiyuan Liu, Minlie Huang, Wentao Han, Jie Tang, Juanzi Li, Xiaoyan Zhu, Maosong Sun.
1. **[CTRL](model_doc/ctrl)** (from Salesforce) released with the paper [CTRL: A Conditional Transformer Language Model for Controllable Generation](https://arxiv.org/abs/1909.05858) by Nitish Shirish Keskar*, Bryan McCann*, Lav R. Varshney, Caiming Xiong and Richard Socher.
1. **[Data2Vec](model_doc/data2vec)** (from Facebook) released with the paper [Data2Vec: A General Framework for Self-supervised Learning in Speech, Vision and Language](https://arxiv.org/abs/2202.03555) by Alexei Baevski, Wei-Ning Hsu, Qiantong Xu, Arun Babu, Jiatao Gu, Michael Auli.
1. **[DeBERTa](model_doc/deberta)** (from Microsoft) released with the paper [DeBERTa: Decoding-enhanced BERT with Disentangled Attention](https://arxiv.org/abs/2006.03654) by Pengcheng He, Xiaodong Liu, Jianfeng Gao, Weizhu Chen.
1. **[DeBERTa-v2](model_doc/deberta-v2)** (from Microsoft) released with the paper [DeBERTa: Decoding-enhanced BERT with Disentangled Attention](https://arxiv.org/abs/2006.03654) by Pengcheng He, Xiaodong Liu, Jianfeng Gao, Weizhu Chen.
1. **[Decision Transformer](model_doc/decision_transformer)** (from Berkeley/Facebook/Google) released with the paper [Decision Transformer: Reinforcement Learning via Sequence Modeling](https://arxiv.org/abs/2106.01345) by Lili Chen, Kevin Lu, Aravind Rajeswaran, Kimin Lee, Aditya Grover, Michael Laskin, Pieter Abbeel, Aravind Srinivas, Igor Mordatch.
1. **[DiT](model_doc/dit)** (from Microsoft Research) released with the paper [DiT: Self-supervised Pre-training for Document Image Transformer](https://arxiv.org/abs/2203.02378) by Junlong Li, Yiheng Xu, Tengchao Lv, Lei Cui, Cha Zhang, Furu Wei.
1. **[DeiT](model_doc/deit)** (from Facebook) released with the paper [Training data-efficient image transformers & distillation through attention](https://arxiv.org/abs/2012.12877) by Hugo Touvron, Matthieu Cord, Matthijs Douze, Francisco Massa, Alexandre Sablayrolles, Hervé Jégou.
1. **[DETR](model_doc/detr)** (from Facebook) released with the paper [End-to-End Object Detection with Transformers](https://arxiv.org/abs/2005.12872) by Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, Sergey Zagoruyko.
1. **[DialoGPT](model_doc/dialogpt)** (from Microsoft Research) released with the paper [DialoGPT: Large-Scale Generative Pre-training for Conversational Response Generation](https://arxiv.org/abs/1911.00536) by Yizhe Zhang, Siqi Sun, Michel Galley, Yen-Chun Chen, Chris Brockett, Xiang Gao, Jianfeng Gao, Jingjing Liu, Bill Dolan.
1. **[DistilBERT](model_doc/distilbert)** (from HuggingFace), released together with the paper [DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter](https://arxiv.org/abs/1910.01108) by Victor Sanh, Lysandre Debut and Thomas Wolf. The same method has been applied to compress GPT2 into [DistilGPT2](https://github.com/huggingface/transformers/tree/main/examples/research_projects/distillation), RoBERTa into [DistilRoBERTa](https://github.com/huggingface/transformers/tree/main/examples/research_projects/distillation), Multilingual BERT into [DistilmBERT](https://github.com/huggingface/transformers/tree/main/examples/research_projects/distillation) and a German version of DistilBERT.
1. **[DPR](model_doc/dpr)** (from Facebook) released with the paper [Dense Passage Retrieval for Open-Domain Question Answering](https://arxiv.org/abs/2004.04906) by Vladimir Karpukhin, Barlas Oğuz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih.
1. **[DPT](master/model_doc/dpt)** (from Intel Labs) released with the paper [Vision Transformers for Dense Prediction](https://arxiv.org/abs/2103.13413) by René Ranftl, Alexey Bochkovskiy, Vladlen Koltun.
1. **[EfficientNet](model_doc/efficientnet)** (from Google Research) released with the paper [EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks](https://arxiv.org/abs/1905.11946) by Mingxing Tan and Quoc V. Le.
1. **[EncoderDecoder](model_doc/encoder-decoder)** (from Google Research) released with the paper [Leveraging Pre-trained Checkpoints for Sequence Generation Tasks](https://arxiv.org/abs/1907.12461) by Sascha Rothe, Shashi Narayan, Aliaksei Severyn.
1. **[ELECTRA](model_doc/electra)** (from Google Research/Stanford University) released with the paper [ELECTRA: Pre-training text encoders as discriminators rather than generators](https://arxiv.org/abs/2003.10555) by Kevin Clark, Minh-Thang Luong, Quoc V. Le, Christopher D. Manning.
1. **[FlauBERT](model_doc/flaubert)** (from CNRS) released with the paper [FlauBERT: Unsupervised Language Model Pre-training for French](https://arxiv.org/abs/1912.05372) by Hang Le, Loïc Vial, Jibril Frej, Vincent Segonne, Maximin Coavoux, Benjamin Lecouteux, Alexandre Allauzen, Benoît Crabbé, Laurent Besacier, Didier Schwab.
1. **[FNet](model_doc/fnet)** (from Google Research) released with the paper [FNet: Mixing Tokens with Fourier Transforms](https://arxiv.org/abs/2105.03824) by James Lee-Thorp, Joshua Ainslie, Ilya Eckstein, Santiago Ontanon.
1. **[Funnel Transformer](model_doc/funnel)** (from CMU/Google Brain) released with the paper [Funnel-Transformer: Filtering out Sequential Redundancy for Efficient Language Processing](https://arxiv.org/abs/2006.03236) by Zihang Dai, Guokun Lai, Yiming Yang, Quoc V. Le.
1. **[GLPN](model_doc/glpn)** (from KAIST) released with the paper [Global-Local Path Networks for Monocular Depth Estimation with Vertical CutDepth](https://arxiv.org/abs/2201.07436) by Doyeon Kim, Woonghyun Ga, Pyungwhan Ahn, Donggyu Joo, Sehwan Chun, Junmo Kim.
1. **[GPT](model_doc/openai-gpt)** (from OpenAI) released with the paper [Improving Language Understanding by Generative Pre-Training](https://blog.openai.com/language-unsupervised/) by Alec Radford, Karthik Narasimhan, Tim Salimans and Ilya Sutskever.
1. **[GPT-2](model_doc/gpt2)** (from OpenAI) released with the paper [Language Models are Unsupervised Multitask Learners](https://blog.openai.com/better-language-models/) by Alec Radford*, Jeffrey Wu*, Rewon Child, David Luan, Dario Amodei** and Ilya Sutskever**.
1. **[GPT-J](model_doc/gptj)** (from EleutherAI) released in the repository [kingoflolz/mesh-transformer-jax](https://github.com/kingoflolz/mesh-transformer-jax/) by Ben Wang and Aran Komatsuzaki.
1. **[GPT Neo](model_doc/gpt_neo)** (from EleutherAI) released in the repository [EleutherAI/gpt-neo](https://github.com/EleutherAI/gpt-neo) by Sid Black, Stella Biderman, Leo Gao, Phil Wang and Connor Leahy.
1. **[GPTSAN-japanese](model_doc/gptsan-japanese)** released in the repository [tanreinama/GPTSAN](https://github.com/tanreinama/GPTSAN/blob/main/report/model.md) by Toshiyuki Sakamoto(tanreinama).
1. **[Hubert](model_doc/hubert)** (from Facebook) released with the paper [HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units](https://arxiv.org/abs/2106.07447) by Wei-Ning Hsu, Benjamin Bolte, Yao-Hung Hubert Tsai, Kushal Lakhotia, Ruslan Salakhutdinov, Abdelrahman Mohamed.
1. **[I-BERT](model_doc/ibert)** (from Berkeley) released with the paper [I-BERT: Integer-only BERT Quantization](https://arxiv.org/abs/2101.01321) by Sehoon Kim, Amir Gholami, Zhewei Yao, Michael W. Mahoney, Kurt Keutzer.
1. **[ImageGPT](model_doc/imagegpt)** (from OpenAI) released with the paper [Generative Pretraining from Pixels](https://openai.com/blog/image-gpt/) by Mark Chen, Alec Radford, Rewon Child, Jeffrey Wu, Heewoo Jun, David Luan, Ilya Sutskever.
1. **[LayoutLM](model_doc/layoutlm)** (from Microsoft Research Asia) released with the paper [LayoutLM: Pre-training of Text and Layout for Document Image Understanding](https://arxiv.org/abs/1912.13318) by Yiheng Xu, Minghao Li, Lei Cui, Shaohan Huang, Furu Wei, Ming Zhou.
1. **[LayoutLMv2](model_doc/layoutlmv2)** (from Microsoft Research Asia) released with the paper [LayoutLMv2: Multi-modal Pre-training for Visually-Rich Document Understanding](https://arxiv.org/abs/2012.14740) by Yang Xu, Yiheng Xu, Tengchao Lv, Lei Cui, Furu Wei, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha Zhang, Wanxiang Che, Min Zhang, Lidong Zhou.
1. **[LayoutXLM](model_doc/layoutxlm)** (from Microsoft Research Asia) released with the paper [LayoutXLM: Multimodal Pre-training for Multilingual Visually-rich Document Understanding](https://arxiv.org/abs/2104.08836) by Yiheng Xu, Tengchao Lv, Lei Cui, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha Zhang, Furu Wei.
1. **[LED](model_doc/led)** (from AllenAI) released with the paper [Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150) by Iz Beltagy, Matthew E. Peters, Arman Cohan.
1. **[Longformer](model_doc/longformer)** (from AllenAI) released with the paper [Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150) by Iz Beltagy, Matthew E. Peters, Arman Cohan.
1. **[LUKE](model_doc/luke)** (from Studio Ousia) released with the paper [LUKE: Deep Contextualized Entity Representations with Entity-aware Self-attention](https://arxiv.org/abs/2010.01057) by Ikuya Yamada, Akari Asai, Hiroyuki Shindo, Hideaki Takeda, Yuji Matsumoto.
1. **[mLUKE](model_doc/mluke)** (from Studio Ousia) released with the paper [mLUKE: The Power of Entity Representations in Multilingual Pretrained Language Models](https://arxiv.org/abs/2110.08151) by Ryokan Ri, Ikuya Yamada, and Yoshimasa Tsuruoka.
1. **[LXMERT](model_doc/lxmert)** (from UNC Chapel Hill) released with the paper [LXMERT: Learning Cross-Modality Encoder Representations from Transformers for Open-Domain Question Answering](https://arxiv.org/abs/1908.07490) by Hao Tan and Mohit Bansal.
1. **[M2M100](model_doc/m2m_100)** (from Facebook) released with the paper [Beyond English-Centric Multilingual Machine Translation](https://arxiv.org/abs/2010.11125) by Angela Fan, Shruti Bhosale, Holger Schwenk, Zhiyi Ma, Ahmed El-Kishky, Siddharth Goyal, Mandeep Baines, Onur Celebi, Guillaume Wenzek, Vishrav Chaudhary, Naman Goyal, Tom Birch, Vitaliy Liptchinsky, Sergey Edunov, Edouard Grave, Michael Auli, Armand Joulin.
1. **[MarianMT](model_doc/marian)** Machine translation models trained using [OPUS](http://opus.nlpl.eu/) data by Jörg Tiedemann. The [Marian Framework](https://marian-nmt.github.io/) is being developed by the Microsoft Translator Team.
1. **[Mask2Former](model_doc/mask2former)** (from FAIR and UIUC) released with the paper [Masked-attention Mask Transformer for Universal Image Segmentation](https://arxiv.org/abs/2112.01527) by Bowen Cheng, Ishan Misra, Alexander G. Schwing, Alexander Kirillov, Rohit Girdhar.
1. **[MaskFormer](model_doc/maskformer)** (from Meta and UIUC) released with the paper [Per-Pixel Classification is Not All You Need for Semantic Segmentation](https://arxiv.org/abs/2107.06278) by Bowen Cheng, Alexander G. Schwing, Alexander Kirillov.
1. **[MBart](model_doc/mbart)** (from Facebook) released with the paper [Multilingual Denoising Pre-training for Neural Machine Translation](https://arxiv.org/abs/2001.08210) by Yinhan Liu, Jiatao Gu, Naman Goyal, Xian Li, Sergey Edunov, Marjan Ghazvininejad, Mike Lewis, Luke Zettlemoyer.
1. **[MBart-50](model_doc/mbart)** (from Facebook) released with the paper [Multilingual Translation with Extensible Multilingual Pretraining and Finetuning](https://arxiv.org/abs/2008.00401) by Yuqing Tang, Chau Tran, Xian Li, Peng-Jen Chen, Naman Goyal, Vishrav Chaudhary, Jiatao Gu, Angela Fan.
1. **[Megatron-BERT](model_doc/megatron-bert)** (from NVIDIA) released with the paper [Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism](https://arxiv.org/abs/1909.08053) by Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper and Bryan Catanzaro.
1. **[Megatron-GPT2](model_doc/megatron_gpt2)** (from NVIDIA) released with the paper [Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism](https://arxiv.org/abs/1909.08053) by Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper and Bryan Catanzaro.
1. **[MPNet](model_doc/mpnet)** (from Microsoft Research) released with the paper [MPNet: Masked and Permuted Pre-training for Language Understanding](https://arxiv.org/abs/2004.09297) by Kaitao Song, Xu Tan, Tao Qin, Jianfeng Lu, Tie-Yan Liu.
1. **[MT5](model_doc/mt5)** (from Google AI) released with the paper [mT5: A massively multilingual pre-trained text-to-text transformer](https://arxiv.org/abs/2010.11934) by Linting Xue, Noah Constant, Adam Roberts, Mihir Kale, Rami Al-Rfou, Aditya Siddhant, Aditya Barua, Colin Raffel.
1. **[Nyströmformer](model_doc/nystromformer)** (from the University of Wisconsin - Madison) released with the paper [Nyströmformer: A Nyström-Based Algorithm for Approximating Self-Attention](https://arxiv.org/abs/2102.03902) by Yunyang Xiong, Zhanpeng Zeng, Rudrasis Chakraborty, Mingxing Tan, Glenn Fung, Yin Li, Vikas Singh.
1. **[OneFormer](model_doc/oneformer)** (from SHI Labs) released with the paper [OneFormer: One Transformer to Rule Universal Image Segmentation](https://arxiv.org/abs/2211.06220) by Jitesh Jain, Jiachen Li, MangTik Chiu, Ali Hassani, Nikita Orlov, Humphrey Shi.
1. **[Pegasus](model_doc/pegasus)** (from Google) released with the paper [PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization](https://arxiv.org/abs/1912.08777) by Jingqing Zhang, Yao Zhao, Mohammad Saleh and Peter J. Liu.
1. **[Perceiver IO](model_doc/perceiver)** (from Deepmind) released with the paper [Perceiver IO: A General Architecture for Structured Inputs & Outputs](https://arxiv.org/abs/2107.14795) by Andrew Jaegle, Sebastian Borgeaud, Jean-Baptiste Alayrac, Carl Doersch, Catalin Ionescu, David Ding, Skanda Koppula, Daniel Zoran, Andrew Brock, Evan Shelhamer, Olivier Hénaff, Matthew M. Botvinick, Andrew Zisserman, Oriol Vinyals, João Carreira.
1. **[PhoBERT](model_doc/phobert)** (from VinAI Research) released with the paper [PhoBERT: Pre-trained language models for Vietnamese](https://www.aclweb.org/anthology/2020.findings-emnlp.92/) by Dat Quoc Nguyen and Anh Tuan Nguyen.
1. **[PLBart](model_doc/plbart)** (from UCLA NLP) released with the paper [Unified Pre-training for Program Understanding and Generation](https://arxiv.org/abs/2103.06333) by Wasi Uddin Ahmad, Saikat Chakraborty, Baishakhi Ray, Kai-Wei Chang.
1. **[PoolFormer](model_doc/poolformer)** (from Sea AI Labs) released with the paper [MetaFormer is Actually What You Need for Vision](https://arxiv.org/abs/2111.11418) by Yu, Weihao and Luo, Mi and Zhou, Pan and Si, Chenyang and Zhou, Yichen and Wang, Xinchao and Feng, Jiashi and Yan, Shuicheng.
1. **[ProphetNet](model_doc/prophetnet)** (from Microsoft Research) released with the paper [ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training](https://arxiv.org/abs/2001.04063) by Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei Zhang and Ming Zhou.
1. **[QDQBert](model_doc/qdqbert)** (from NVIDIA) released with the paper [Integer Quantization for Deep Learning Inference: Principles and Empirical Evaluation](https://arxiv.org/abs/2004.09602) by Hao Wu, Patrick Judd, Xiaojie Zhang, Mikhail Isaev and Paulius Micikevicius.
1. **[REALM](model_doc/realm.html)** (from Google Research) released with the paper [REALM: Retrieval-Augmented Language Model Pre-Training](https://arxiv.org/abs/2002.08909) by Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat and Ming-Wei Chang.
1. **[Reformer](model_doc/reformer)** (from Google Research) released with the paper [Reformer: The Efficient Transformer](https://arxiv.org/abs/2001.04451) by Nikita Kitaev, Łukasz Kaiser, Anselm Levskaya.
1. **[RemBERT](model_doc/rembert)** (from Google Research) released with the paper [Rethinking embedding coupling in pre-trained language models](https://arxiv.org/abs/2010.12821) by Hyung Won Chung, Thibault Févry, Henry Tsai, M. Johnson, Sebastian Ruder.
1. **[RegNet](model_doc/regnet)** (from META Platforms) released with the paper [Designing Network Design Space](https://arxiv.org/abs/2003.13678) by Ilija Radosavovic, Raj Prateek Kosaraju, Ross Girshick, Kaiming He, Piotr Dollár.
1. **[ResNet](model_doc/resnet)** (from Microsoft Research) released with the paper [Deep Residual Learning for Image Recognition](https://arxiv.org/abs/1512.03385) by Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun.
1. **[RoBERTa](model_doc/roberta)** (from Facebook), released together with the paper [RoBERTa: A Robustly Optimized BERT Pretraining Approach](https://arxiv.org/abs/1907.11692) by Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, Veselin Stoyanov.
1. **[RoFormer](model_doc/roformer)** (from ZhuiyiTechnology), released together with the paper [RoFormer: Enhanced Transformer with Rotary Position Embedding](https://arxiv.org/abs/2104.09864) by Jianlin Su and Yu Lu and Shengfeng Pan and Bo Wen and Yunfeng Liu.
1. **[SegFormer](model_doc/segformer)** (from NVIDIA) released with the paper [SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers](https://arxiv.org/abs/2105.15203) by Enze Xie, Wenhai Wang, Zhiding Yu, Anima Anandkumar, Jose M. Alvarez, Ping Luo.
1. **[SEW](model_doc/sew)** (from ASAPP) released with the paper [Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition](https://arxiv.org/abs/2109.06870) by Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi.
1. **[SEW-D](model_doc/sew_d)** (from ASAPP) released with the paper [Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition](https://arxiv.org/abs/2109.06870) by Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi.
1. **[SpeechToTextTransformer](model_doc/speech_to_text)** (from Facebook), released together with the paper [fairseq S2T: Fast Speech-to-Text Modeling with fairseq](https://arxiv.org/abs/2010.05171) by Changhan Wang, Yun Tang, Xutai Ma, Anne Wu, Dmytro Okhonko, Juan Pino.
1. **[SpeechToTextTransformer2](model_doc/speech_to_text_2)** (from Facebook), released together with the paper [Large-Scale Self- and Semi-Supervised Learning for Speech Translation](https://arxiv.org/abs/2104.06678) by Changhan Wang, Anne Wu, Juan Pino, Alexei Baevski, Michael Auli, Alexis Conneau.
1. **[Splinter](model_doc/splinter)** (from Tel Aviv University), released together with the paper [Few-Shot Question Answering by Pretraining Span Selection](https://arxiv.org/abs/2101.00438) by Ori Ram, Yuval Kirstain, Jonathan Berant, Amir Globerson, Omer Levy.
1. **[SqueezeBert](model_doc/squeezebert)** (from Berkeley) released with the paper [SqueezeBERT: What can computer vision teach NLP about efficient neural networks?](https://arxiv.org/abs/2006.11316) by Forrest N. Iandola, Albert E. Shaw, Ravi Krishna, and Kurt W. Keutzer.
1. **[Swin Transformer](model_doc/swin)** (from Microsoft) released with the paper [Swin Transformer: Hierarchical Vision Transformer using Shifted Windows](https://arxiv.org/abs/2103.14030) by Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, Baining Guo.
1. **[T5](model_doc/t5)** (from Google AI) released with the paper [Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer](https://arxiv.org/abs/1910.10683) by Colin Raffel and Noam Shazeer and Adam Roberts and Katherine Lee and Sharan Narang and Michael Matena and Yanqi Zhou and Wei Li and Peter J. Liu.
1. **[T5v1.1](model_doc/t5v1.1)** (from Google AI) released in the repository [google-research/text-to-text-transfer-transformer](https://github.com/google-research/text-to-text-transfer-transformer/blob/main/released_checkpoints.md#t511) by Colin Raffel and Noam Shazeer and Adam Roberts and Katherine Lee and Sharan Narang and Michael Matena and Yanqi Zhou and Wei Li and Peter J. Liu.
1. **[TAPAS](model_doc/tapas)** (from Google AI) released with the paper [TAPAS: Weakly Supervised Table Parsing via Pre-training](https://arxiv.org/abs/2004.02349) by Jonathan Herzig, Paweł Krzysztof Nowak, Thomas Müller, Francesco Piccinno and Julian Martin Eisenschlos.
1. **[TAPEX](model_doc/tapex)** (from Microsoft Research) released with the paper [TAPEX: Table Pre-training via Learning a Neural SQL Executor](https://arxiv.org/abs/2107.07653) by Qian Liu, Bei Chen, Jiaqi Guo, Morteza Ziyadi, Zeqi Lin, Weizhu Chen, Jian-Guang Lou.
1. **[Transformer-XL](model_doc/transfo-xl)** (from Google/CMU) released with the paper [Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context](https://arxiv.org/abs/1901.02860) by Zihang Dai*, Zhilin Yang*, Yiming Yang, Jaime Carbonell, Quoc V. Le, Ruslan Salakhutdinov.
1. **[TrOCR](model_doc/trocr)** (from Microsoft), released together with the paper [TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models](https://arxiv.org/abs/2109.10282) by Minghao Li, Tengchao Lv, Lei Cui, Yijuan Lu, Dinei Florencio, Cha Zhang, Zhoujun Li, Furu Wei.
1. **[UniSpeech](model_doc/unispeech)** (from Microsoft Research) released with the paper [UniSpeech: Unified Speech Representation Learning with Labeled and Unlabeled Data](https://arxiv.org/abs/2101.07597) by Chengyi Wang, Yu Wu, Yao Qian, Kenichi Kumatani, Shujie Liu, Furu Wei, Michael Zeng, Xuedong Huang.
1. **[UniSpeechSat](model_doc/unispeech-sat)** (from Microsoft Research) released with the paper [UNISPEECH-SAT: UNIVERSAL SPEECH REPRESENTATION LEARNING WITH SPEAKER AWARE PRE-TRAINING](https://arxiv.org/abs/2110.05752) by Sanyuan Chen, Yu Wu, Chengyi Wang, Zhengyang Chen, Zhuo Chen, Shujie Liu, Jian Wu, Yao Qian, Furu Wei, Jinyu Li, Xiangzhan Yu.
1. **[VAN](model_doc/van)** (from Tsinghua University and Nankai University) released with the paper [Visual Attention Network](https://arxiv.org/abs/2202.09741) by Meng-Hao Guo, Cheng-Ze Lu, Zheng-Ning Liu, Ming-Ming Cheng, Shi-Min Hu.
1. **[ViLT](model_doc/vilt)** (from NAVER AI Lab/Kakao Enterprise/Kakao Brain) released with the paper [ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision](https://arxiv.org/abs/2102.03334) by Wonjae Kim, Bokyung Son, Ildoo Kim.
1. **[Vision Transformer (ViT)](model_doc/vit)** (from Google AI) released with the paper [An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale](https://arxiv.org/abs/2010.11929) by Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby.
1. **[ViTMAE](model_doc/vit_mae)** (from Meta AI) released with the paper [Masked Autoencoders Are Scalable Vision Learners](https://arxiv.org/abs/2111.06377) by Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, Ross Girshick.
1. **[VisualBERT](model_doc/visual_bert)** (from UCLA NLP) released with the paper [VisualBERT: A Simple and Performant Baseline for Vision and Language](https://arxiv.org/pdf/1908.03557) by Liunian Harold Li, Mark Yatskar, Da Yin, Cho-Jui Hsieh, Kai-Wei Chang.
1. **[WavLM](model_doc/wavlm)** (from Microsoft Research) released with the paper [WavLM: Large-Scale Self-Supervised Pre-Training for Full Stack Speech Processing](https://arxiv.org/abs/2110.13900) by Sanyuan Chen, Chengyi Wang, Zhengyang Chen, Yu Wu, Shujie Liu, Zhuo Chen, Jinyu Li, Naoyuki Kanda, Takuya Yoshioka, Xiong Xiao, Jian Wu, Long Zhou, Shuo Ren, Yanmin Qian, Yao Qian, Jian Wu, Michael Zeng, Furu Wei.
1. **[Wav2Vec2](model_doc/wav2vec2)** (from Facebook AI) released with the paper [wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations](https://arxiv.org/abs/2006.11477) by Alexei Baevski, Henry Zhou, Abdelrahman Mohamed, Michael Auli.
1. **[Wav2Vec2Phoneme](model_doc/wav2vec2_phoneme)** (from Facebook AI) released with the paper [Simple and Effective Zero-shot Cross-lingual Phoneme Recognition](https://arxiv.org/abs/2109.11680) by Qiantong Xu, Alexei Baevski, Michael Auli.
1. **[XGLM](model_doc/xglm)** (From Facebook AI) released with the paper [Few-shot Learning with Multilingual Language Models](https://arxiv.org/abs/2112.10668) by Xi Victoria Lin, Todor Mihaylov, Mikel Artetxe, Tianlu Wang, Shuohui Chen, Daniel Simig, Myle Ott, Naman Goyal, Shruti Bhosale, Jingfei Du, Ramakanth Pasunuru, Sam Shleifer, Punit Singh Koura, Vishrav Chaudhary, Brian O'Horo, Jeff Wang, Luke Zettlemoyer, Zornitsa Kozareva, Mona Diab, Veselin Stoyanov, Xian Li.
1. **[XLM](model_doc/xlm)** (from Facebook) released together with the paper [Cross-lingual Language Model Pretraining](https://arxiv.org/abs/1901.07291) by Guillaume Lample and Alexis Conneau.
1. **[XLM-ProphetNet](model_doc/xlm-prophetnet)** (from Microsoft Research) released with the paper [ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training](https://arxiv.org/abs/2001.04063) by Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei Zhang and Ming Zhou.
1. **[XLM-RoBERTa](model_doc/xlm-roberta)** (from Facebook AI), released together with the paper [Unsupervised Cross-lingual Representation Learning at Scale](https://arxiv.org/abs/1911.02116) by Alexis Conneau*, Kartikay Khandelwal*, Naman Goyal, Vishrav Chaudhary, Guillaume Wenzek, Francisco Guzmán, Edouard Grave, Myle Ott, Luke Zettlemoyer and Veselin Stoyanov.
1. **[XLM-RoBERTa-XL](model_doc/xlm-roberta-xl)** (from Facebook AI), released together with the paper [Larger-Scale Transformers for Multilingual Masked Language Modeling](https://arxiv.org/abs/2105.00572) by Naman Goyal, Jingfei Du, Myle Ott, Giri Anantharaman, Alexis Conneau.
1. **[XLNet](model_doc/xlnet)** (from Google/CMU) released with the paper [XLNet: Generalized Autoregressive Pretraining for Language Understanding](https://arxiv.org/abs/1906.08237) by Zhilin Yang*, Zihang Dai*, Yiming Yang, Jaime Carbonell, Ruslan Salakhutdinov, Quoc V. Le.
1. **[XLSR-Wav2Vec2](model_doc/xlsr_wav2vec2)** (from Facebook AI) released with the paper [Unsupervised Cross-Lingual Representation Learning For Speech Recognition](https://arxiv.org/abs/2006.13979) by Alexis Conneau, Alexei Baevski, Ronan Collobert, Abdelrahman Mohamed, Michael Auli.
1. **[XLS-R](model_doc/xls_r)** (from Facebook AI) released with the paper [XLS-R: Self-supervised Cross-lingual Speech Representation Learning at Scale](https://arxiv.org/abs/2111.09296) by Arun Babu, Changhan Wang, Andros Tjandra, Kushal Lakhotia, Qiantong Xu, Naman Goyal, Kritika Singh, Patrick von Platen, Yatharth Saraf, Juan Pino, Alexei Baevski, Alexis Conneau, Michael Auli.
1. **[YOSO](model_doc/yoso)** (from the University of Wisconsin - Madison) released with the paper [You Only Sample (Almost) Once: Linear Cost Self-Attention Via Bernoulli Sampling](https://arxiv.org/abs/2111.09714) by Zhanpeng Zeng, Yunyang Xiong, Sathya N. Ravi, Shailesh Acharya, Glenn Fung, Vikas Singh.
### Frameworks aceitos
A tabela abaixo representa a lista de suporte na biblioteca para cada um dos seguintes modelos, caso tenham um tokenizer
do Python (chamado de "slow"), ou um tokenizer construído em cima da biblioteca 🤗 Tokenizers (chamado de "fast"). Além
disso, são diferenciados pelo suporte em diferentes frameworks: JAX (por meio do Flax); PyTorch; e/ou Tensorflow.
<!--This table is updated automatically from the auto modules with _make fix-copies_. Do not update manually!-->
| Model | Tokenizer slow | Tokenizer fast | PyTorch support | TensorFlow support | Flax Support |
|:---------------------------:|:--------------:|:--------------:|:---------------:|:------------------:|:------------:|
| ALBERT | ✅ | ✅ | ✅ | ✅ | ✅ |
| BART | ✅ | ✅ | ✅ | ✅ | ✅ |
| BEiT | ❌ | ❌ | ✅ | ❌ | ✅ |
| BERT | ✅ | ✅ | ✅ | ✅ | ✅ |
| Bert Generation | ✅ | ❌ | ✅ | ❌ | ❌ |
| BigBird | ✅ | ✅ | ✅ | ❌ | ✅ |
| BigBirdPegasus | ❌ | ❌ | ✅ | ❌ | ❌ |
| Blenderbot | ✅ | ✅ | ✅ | ✅ | ✅ |
| BlenderbotSmall | ✅ | ✅ | ✅ | ✅ | ✅ |
| CamemBERT | ✅ | ✅ | ✅ | ✅ | ❌ |
| Canine | ✅ | ❌ | ✅ | ❌ | ❌ |
| CLIP | ✅ | ✅ | ✅ | ✅ | ✅ |
| ConvBERT | ✅ | ✅ | ✅ | ✅ | ❌ |
| ConvNext | ❌ | ❌ | ✅ | ✅ | ❌ |
| CTRL | ✅ | ❌ | ✅ | ✅ | ❌ |
| Data2VecAudio | ❌ | ❌ | ✅ | ❌ | ❌ |
| Data2VecText | ❌ | ❌ | ✅ | ❌ | ❌ |
| Data2VecVision | ❌ | ❌ | ✅ | ❌ | ❌ |
| DeBERTa | ✅ | ✅ | ✅ | ✅ | ❌ |
| DeBERTa-v2 | ✅ | ✅ | ✅ | ✅ | ❌ |
| Decision Transformer | ❌ | ❌ | ✅ | ❌ | ❌ |
| DeiT | ❌ | ❌ | ✅ | ❌ | ❌ |
| DETR | ❌ | ❌ | ✅ | ❌ | ❌ |
| DistilBERT | ✅ | ✅ | ✅ | ✅ | ✅ |
| DPR | ✅ | ✅ | ✅ | ✅ | ❌ |
| DPT | ❌ | ❌ | ✅ | ❌ | ❌ |
| ELECTRA | ✅ | ✅ | ✅ | ✅ | ✅ |
| Encoder decoder | ❌ | ❌ | ✅ | ✅ | ✅ |
| FairSeq Machine-Translation | ✅ | ❌ | ✅ | ❌ | ❌ |
| FlauBERT | ✅ | ❌ | ✅ | ✅ | ❌ |
| FNet | ✅ | ✅ | ✅ | ❌ | ❌ |
| Funnel Transformer | ✅ | ✅ | ✅ | ✅ | ❌ |
| GLPN | ❌ | ❌ | ✅ | ❌ | ❌ |
| GPT Neo | ❌ | ❌ | ✅ | ❌ | ✅ |
| GPT-J | ❌ | ❌ | ✅ | ✅ | ✅ |
| Hubert | ❌ | ❌ | ✅ | ✅ | ❌ |
| I-BERT | ❌ | ❌ | ✅ | ❌ | ❌ |
| ImageGPT | ❌ | ❌ | ✅ | ❌ | ❌ |
| LayoutLM | ✅ | ✅ | ✅ | ✅ | ❌ |
| LayoutLMv2 | ✅ | ✅ | ✅ | ❌ | ❌ |
| LED | ✅ | ✅ | ✅ | ✅ | ❌ |
| Longformer | ✅ | ✅ | ✅ | ✅ | ❌ |
| LUKE | ✅ | ❌ | ✅ | ❌ | ❌ |
| LXMERT | ✅ | ✅ | ✅ | ✅ | ❌ |
| M2M100 | ✅ | ❌ | ✅ | ❌ | ❌ |
| Marian | ✅ | ❌ | ✅ | ✅ | ✅ |
| MaskFormer | ❌ | ❌ | ✅ | ❌ | ❌ |
| mBART | ✅ | ✅ | ✅ | ✅ | ✅ |
| MegatronBert | ❌ | ❌ | ✅ | ❌ | ❌ |
| MobileBERT | ✅ | ✅ | ✅ | ✅ | ❌ |
| MPNet | ✅ | ✅ | ✅ | ✅ | ❌ |
| mT5 | ✅ | ✅ | ✅ | ✅ | ✅ |
| Nystromformer | ❌ | ❌ | ✅ | ❌ | ❌ |
| OpenAI GPT | ✅ | ✅ | ✅ | ✅ | ❌ |
| OpenAI GPT-2 | ✅ | ✅ | ✅ | ✅ | ✅ |
| Pegasus | ✅ | ✅ | ✅ | ✅ | ✅ |
| Perceiver | ✅ | ❌ | ✅ | ❌ | ❌ |
| PLBart | ✅ | ❌ | ✅ | ❌ | ❌ |
| PoolFormer | ❌ | ❌ | ✅ | ❌ | ❌ |
| ProphetNet | ✅ | ❌ | ✅ | ❌ | ❌ |
| QDQBert | ❌ | ❌ | ✅ | ❌ | ❌ |
| RAG | ✅ | ❌ | ✅ | ✅ | ❌ |
| Realm | ✅ | ✅ | ✅ | ❌ | ❌ |
| Reformer | ✅ | ✅ | ✅ | ❌ | ❌ |
| RegNet | ❌ | ❌ | ✅ | ✅ | ✅ |
| RemBERT | ✅ | ✅ | ✅ | ✅ | ❌ |
| ResNet | ❌ | ❌ | ✅ | ❌ | ✅ |
| RetriBERT | ✅ | ✅ | ✅ | ❌ | ❌ |
| RoBERTa | ✅ | ✅ | ✅ | ✅ | ✅ |
| RoFormer | ✅ | ✅ | ✅ | ✅ | ✅ |
| SegFormer | ❌ | ❌ | ✅ | ❌ | ❌ |
| SEW | ❌ | ❌ | ✅ | ❌ | ❌ |
| SEW-D | ❌ | ❌ | ✅ | ❌ | ❌ |
| Speech Encoder decoder | ❌ | ❌ | ✅ | ❌ | ✅ |
| Speech2Text | ✅ | ❌ | ✅ | ✅ | ❌ |
| Speech2Text2 | ✅ | ❌ | ❌ | ❌ | ❌ |
| Splinter | ✅ | ✅ | ✅ | ❌ | ❌ |
| SqueezeBERT | ✅ | ✅ | ✅ | ❌ | ❌ |
| Swin | ❌ | ❌ | ✅ | ❌ | ❌ |
| T5 | ✅ | ✅ | ✅ | ✅ | ✅ |
| TAPAS | ✅ | ❌ | ✅ | ✅ | ❌ |
| TAPEX | ✅ | ✅ | ✅ | ✅ | ✅ |
| Transformer-XL | ✅ | ❌ | ✅ | ✅ | ❌ |
| TrOCR | ❌ | ❌ | ✅ | ❌ | ❌ |
| UniSpeech | ❌ | ❌ | ✅ | ❌ | ❌ |
| UniSpeechSat | ❌ | ❌ | ✅ | ❌ | ❌ |
| VAN | ❌ | ❌ | ✅ | ❌ | ❌ |
| ViLT | ❌ | ❌ | ✅ | ❌ | ❌ |
| Vision Encoder decoder | ❌ | ❌ | ✅ | ✅ | ✅ |
| VisionTextDualEncoder | ❌ | ❌ | ✅ | ❌ | ✅ |
| VisualBert | ❌ | ❌ | ✅ | ❌ | ❌ |
| ViT | ❌ | ❌ | ✅ | ✅ | ✅ |
| ViTMAE | ❌ | ❌ | ✅ | ✅ | ❌ |
| Wav2Vec2 | ✅ | ❌ | ✅ | ✅ | ✅ |
| WavLM | ❌ | ❌ | ✅ | ❌ | ❌ |
| XGLM | ✅ | ✅ | ✅ | ❌ | ✅ |
| XLM | ✅ | ❌ | ✅ | ✅ | ❌ |
| XLM-RoBERTa | ✅ | ✅ | ✅ | ✅ | ✅ |
| XLM-RoBERTa-XL | ❌ | ❌ | ✅ | ❌ | ❌ |
| XLMProphetNet | ✅ | ❌ | ✅ | ❌ | ❌ |
| XLNet | ✅ | ✅ | ✅ | ✅ | ❌ |
| YOSO | ❌ | ❌ | ✅ | ❌ | ❌ |
<!-- End table-->
| 0 |
hf_public_repos/transformers/docs/source | hf_public_repos/transformers/docs/source/pt/installation.md | <!---
Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Guia de Instalação
Neste guia poderá encontrar informações para a instalação do 🤗 Transformers para qualquer biblioteca de
Machine Learning com a qual esteja a trabalhar. Além disso, poderá encontrar informações sobre como gerar cachês e
configurar o 🤗 Transformers para execução em modo offline (opcional).
🤗 Transformers foi testado com Python 3.6+, PyTorch 1.1.0+, TensorFlow 2.0+, e Flax. Para instalar a biblioteca de
deep learning com que deseja trabalhar, siga as instruções correspondentes listadas a seguir:
* [PyTorch](https://pytorch.org/get-started/locally/)
* [TensorFlow 2.0](https://www.tensorflow.org/install/pip)
* [Flax](https://flax.readthedocs.io/en/latest/)
## Instalação pelo Pip
É sugerido instalar o 🤗 Transformers num [ambiente virtual](https://docs.python.org/3/library/venv.html). Se precisar
de mais informações sobre ambientes virtuais em Python, consulte este [guia](https://packaging.python.org/guides/installing-using-pip-and-virtual-environments/).
Um ambiente virtual facilitará a manipulação e organização de projetos e evita problemas de compatibilidade entre dependências.
Comece criando um ambiente virtual no diretório do seu projeto:
```bash
python -m venv .env
```
E para ativar o ambiente virtual:
```bash
source .env/bin/activate
```
Agora É possível instalar o 🤗 Transformers com o comando a seguir:
```bash
pip install transformers
```
Somente para a CPU, é possível instalar o 🤗 Transformers e a biblioteca de deep learning respectiva apenas numa linha.
Por exemplo, para instalar o 🤗 Transformers e o PyTorch, digite:
```bash
pip install transformers[torch]
```
🤗 Transformers e TensorFlow 2.0:
```bash
pip install transformers[tf-cpu]
```
🤗 Transformers e Flax:
```bash
pip install transformers[flax]
```
Por último, verifique se o 🤗 Transformers foi instalado com sucesso usando o seguinte comando para baixar um modelo pré-treinado:
```bash
python -c "from transformers import pipeline; print(pipeline('sentiment-analysis')('we love you'))"
```
Em seguida, imprima um rótulo e sua pontuação:
```bash
[{'label': 'POSITIVE', 'score': 0.9998704791069031}]
```
## Instalação usando a fonte
Para instalar o 🤗 Transformers a partir da fonte use o seguinte comando:
```bash
pip install git+https://github.com/huggingface/transformers
```
O comando acima instalará a versão `master` mais atual em vez da última versão estável. A versão `master` é útil para
utilizar os últimos updates contidos em 🤗 Transformers. Por exemplo, um erro recente pode ter sido corrigido somente
após a última versão estável, antes que houvesse um novo lançamento. No entanto, há a possibilidade que a versão `master` não esteja estável.
A equipa trata de mantér a versão `master` operacional e a maioria dos erros são resolvidos em poucas horas ou dias.
Se encontrar quaisquer problemas, por favor abra um [Issue](https://github.com/huggingface/transformers/issues) para que o
mesmo possa ser corrigido o mais rápido possível.
Verifique que o 🤗 Transformers está instalado corretamente usando o seguinte comando:
```bash
python -c "from transformers import pipeline; print(pipeline('sentiment-analysis')('I love you'))"
```
## Instalação editável
Uma instalação editável será necessária caso desejas um dos seguintes:
* Usar a versão `master` do código fonte.
* Contribuir ao 🤗 Transformers e precisa testar mudanças ao código.
Para tal, clone o repositório e instale o 🤗 Transformers com os seguintes comandos:
```bash
git clone https://github.com/huggingface/transformers.git
cd transformers
pip install -e .
```
Estes comandos vão ligar o diretório para o qual foi clonado o repositório ao caminho de bibliotecas do Python.
O Python agora buscará dentro dos arquivos que foram clonados além dos caminhos normais da biblioteca.
Por exemplo, se os pacotes do Python se encontram instalados no caminho `~/anaconda3/envs/main/lib/python3.7/site-packages/`,
o Python também buscará módulos no diretório onde clonamos o repositório `~/transformers/`.
<Tip warning={true}>
É necessário manter o diretório `transformers` se desejas continuar usando a biblioteca.
</Tip>
Assim, É possível atualizar sua cópia local para com a última versão do 🤗 Transformers com o seguinte comando:
```bash
cd ~/transformers/
git pull
```
O ambiente de Python que foi criado para a instalação do 🤗 Transformers encontrará a versão `master` em execuções seguintes.
## Instalação usando o Conda
É possível instalar o 🤗 Transformers a partir do canal conda `huggingface` com o seguinte comando:
```bash
conda install -c huggingface transformers
```
## Configuração do Cachê
Os modelos pré-treinados são baixados e armazenados no cachê local, encontrado em `~/.cache/huggingface/transformers/`.
Este é o diretório padrão determinado pela variável `TRANSFORMERS_CACHE` dentro do shell.
No Windows, este diretório pré-definido é dado por `C:\Users\username\.cache\huggingface\transformers`.
É possível mudar as variáveis dentro do shell em ordem de prioridade para especificar um diretório de cachê diferente:
1. Variável de ambiente do shell (por padrão): `TRANSFORMERS_CACHE`.
2. Variável de ambiente do shell:`HF_HOME` + `transformers/`.
3. Variável de ambiente do shell: `XDG_CACHE_HOME` + `/huggingface/transformers`.
<Tip>
O 🤗 Transformers usará as variáveis de ambiente do shell `PYTORCH_TRANSFORMERS_CACHE` ou `PYTORCH_PRETRAINED_BERT_CACHE`
se estiver vindo de uma versão anterior da biblioteca que tenha configurado essas variáveis de ambiente, a menos que
você especifique a variável de ambiente do shell `TRANSFORMERS_CACHE`.
</Tip>
## Modo Offline
O 🤗 Transformers também pode ser executado num ambiente de firewall ou fora da rede (offline) usando arquivos locais.
Para tal, configure a variável de ambiente de modo que `TRANSFORMERS_OFFLINE=1`.
<Tip>
Você pode adicionar o [🤗 Datasets](https://huggingface.co/docs/datasets/) ao pipeline de treinamento offline declarando
a variável de ambiente `HF_DATASETS_OFFLINE=1`.
</Tip>
Segue um exemplo de execução do programa numa rede padrão com firewall para instâncias externas, usando o seguinte comando:
```bash
python examples/pytorch/translation/run_translation.py --model_name_or_path t5-small --dataset_name wmt16 --dataset_config ro-en ...
```
Execute esse mesmo programa numa instância offline com o seguinte comando:
```bash
HF_DATASETS_OFFLINE=1 TRANSFORMERS_OFFLINE=1 \
python examples/pytorch/translation/run_translation.py --model_name_or_path t5-small --dataset_name wmt16 --dataset_config ro-en ...
```
O script agora deve ser executado sem travar ou expirar, pois procurará apenas por arquivos locais.
### Obtendo modelos e tokenizers para uso offline
Outra opção para usar o 🤗 Transformers offline é baixar os arquivos antes e depois apontar para o caminho local onde estão localizados. Existem três maneiras de fazer isso:
* Baixe um arquivo por meio da interface de usuário do [Model Hub](https://huggingface.co/models) clicando no ícone ↓.

* Use o pipeline do [`PreTrainedModel.from_pretrained`] e [`PreTrainedModel.save_pretrained`]:
1. Baixa os arquivos previamente com [`PreTrainedModel.from_pretrained`]:
```py
>>> from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
>>> tokenizer = AutoTokenizer.from_pretrained("bigscience/T0_3B")
>>> model = AutoModelForSeq2SeqLM.from_pretrained("bigscience/T0_3B")
```
2. Salve os arquivos em um diretório específico com [`PreTrainedModel.save_pretrained`]:
```py
>>> tokenizer.save_pretrained("./your/path/bigscience_t0")
>>> model.save_pretrained("./your/path/bigscience_t0")
```
3. Quando estiver offline, acesse os arquivos com [`PreTrainedModel.from_pretrained`] do diretório especificado:
```py
>>> tokenizer = AutoTokenizer.from_pretrained("./your/path/bigscience_t0")
>>> model = AutoModel.from_pretrained("./your/path/bigscience_t0")
```
* Baixando arquivos programaticamente com a biblioteca [huggingface_hub](https://github.com/huggingface/huggingface_hub/tree/main/src/huggingface_hub):
1. Instale a biblioteca [huggingface_hub](https://github.com/huggingface/huggingface_hub/tree/main/src/huggingface_hub) em seu ambiente virtual:
```bash
python -m pip install huggingface_hub
```
2. Utiliza a função [`hf_hub_download`](https://huggingface.co/docs/hub/adding-a-library#download-files-from-the-hub) para baixar um arquivo para um caminho específico. Por exemplo, o comando a seguir baixará o arquivo `config.json` para o modelo [T0](https://huggingface.co/bigscience/T0_3B) no caminho desejado:
```py
>>> from huggingface_hub import hf_hub_download
>>> hf_hub_download(repo_id="bigscience/T0_3B", filename="config.json", cache_dir="./your/path/bigscience_t0")
```
Depois que o arquivo for baixado e armazenado no cachê local, especifique seu caminho local para carregá-lo e usá-lo:
```py
>>> from transformers import AutoConfig
>>> config = AutoConfig.from_pretrained("./your/path/bigscience_t0/config.json")
```
<Tip>
Para obter mais detalhes sobre como baixar arquivos armazenados no Hub, consulte a seção [How to download files from the Hub](https://huggingface.co/docs/hub/how-to-downstream).
</Tip>
| 0 |
hf_public_repos/transformers/docs/source | hf_public_repos/transformers/docs/source/pt/_toctree.yml | - sections:
- local: index
title: 🤗 Transformers
- local: quicktour
title: Tour rápido
- local: installation
title: Instalação
title: Início
- sections:
- local: pipeline_tutorial
title: Pipelines para inferência
- local: training
title: Fine-tuning de um modelo pré-treinado
- local: accelerate
title: Treinamento distribuído com 🤗 Accelerate
title: Tutoriais
- sections:
- local: fast_tokenizers
title: Usando os Tokenizers do 🤗 Tokenizers
- local: create_a_model
title: Criando uma arquitetura customizada
- local: custom_models
title: Compartilhando modelos customizados
- local: run_scripts
title: Treinamento a partir de um script
- local: converting_tensorflow_models
title: Convertendo checkpoints do TensorFlow para Pytorch
- local: serialization
title: Exportando modelos para ONNX
- sections:
- local: tasks/sequence_classification
title: Classificação de texto
- local: tasks/token_classification
title: Classificação de tokens
title: Fine-tuning para tarefas específicas
- local: multilingual
title: Modelos multilinguísticos para inferência
title: Guias práticos
| 0 |
hf_public_repos/transformers/docs/source | hf_public_repos/transformers/docs/source/pt/multilingual.md | <!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Modelos multilinguísticos para inferência
[[open-in-colab]]
Existem vários modelos multilinguísticos no 🤗 Transformers e seus usos para inferência diferem dos modelos monolíngues.
No entanto, nem *todos* os usos dos modelos multilíngues são tão diferentes.
Alguns modelos, como o [bert-base-multilingual-uncased](https://huggingface.co/bert-base-multilingual-uncased),
podem ser usados como se fossem monolíngues. Este guia irá te ajudar a usar modelos multilíngues cujo uso difere
para o propósito de inferência.
## XLM
O XLM tem dez checkpoints diferentes dos quais apenas um é monolíngue.
Os nove checkpoints restantes do modelo são subdivididos em duas categorias:
checkpoints que usam de language embeddings e os que não.
### XLM com language embeddings
Os seguintes modelos de XLM usam language embeddings para especificar a linguagem utilizada para a inferência.
- `xlm-mlm-ende-1024` (Masked language modeling, English-German)
- `xlm-mlm-enfr-1024` (Masked language modeling, English-French)
- `xlm-mlm-enro-1024` (Masked language modeling, English-Romanian)
- `xlm-mlm-xnli15-1024` (Masked language modeling, XNLI languages)
- `xlm-mlm-tlm-xnli15-1024` (Masked language modeling + translation, XNLI languages)
- `xlm-clm-enfr-1024` (Causal language modeling, English-French)
- `xlm-clm-ende-1024` (Causal language modeling, English-German)
Os language embeddings são representados por um tensor de mesma dimensão que os `input_ids` passados ao modelo.
Os valores destes tensores dependem do idioma utilizado e se identificam pelos atributos `lang2id` e `id2lang` do tokenizador.
Neste exemplo, carregamos o checkpoint `xlm-clm-enfr-1024`(Causal language modeling, English-French):
```py
>>> import torch
>>> from transformers import XLMTokenizer, XLMWithLMHeadModel
>>> tokenizer = XLMTokenizer.from_pretrained("xlm-clm-enfr-1024")
>>> model = XLMWithLMHeadModel.from_pretrained("xlm-clm-enfr-1024")
```
O atributo `lang2id` do tokenizador mostra os idiomas deste modelo e seus ids:
```py
>>> print(tokenizer.lang2id)
{'en': 0, 'fr': 1}
```
Em seguida, cria-se um input de exemplo:
```py
>>> input_ids = torch.tensor([tokenizer.encode("Wikipedia was used to")]) # batch size of 1
```
Estabelece-se o id do idioma, por exemplo `"en"`, e utiliza-se o mesmo para definir a language embedding.
A language embedding é um tensor preenchido com `0`, que é o id de idioma para o inglês.
Este tensor deve ser do mesmo tamanho que os `input_ids`.
```py
>>> language_id = tokenizer.lang2id["en"] # 0
>>> langs = torch.tensor([language_id] * input_ids.shape[1]) # torch.tensor([0, 0, 0, ..., 0])
>>> # We reshape it to be of size (batch_size, sequence_length)
>>> langs = langs.view(1, -1) # is now of shape [1, sequence_length] (we have a batch size of 1)
```
Agora você pode passar os `input_ids` e a language embedding ao modelo:
```py
>>> outputs = model(input_ids, langs=langs)
```
O script [run_generation.py](https://github.com/huggingface/transformers/tree/master/examples/pytorch/text-generation/run_generation.py) pode gerar um texto com language embeddings utilizando os checkpoints `xlm-clm`.
### XLM sem language embeddings
Os seguintes modelos XLM não requerem o uso de language embeddings durante a inferência:
- `xlm-mlm-17-1280` (Modelagem de linguagem com máscara, 17 idiomas)
- `xlm-mlm-100-1280` (Modelagem de linguagem com máscara, 100 idiomas)
Estes modelos são utilizados para representações genéricas de frase diferentemente dos checkpoints XLM anteriores.
## BERT
Os seguintes modelos do BERT podem ser utilizados para tarefas multilinguísticas:
- `bert-base-multilingual-uncased` (Modelagem de linguagem com máscara + Previsão de frases, 102 idiomas)
- `bert-base-multilingual-cased` (Modelagem de linguagem com máscara + Previsão de frases, 104 idiomas)
Estes modelos não requerem language embeddings durante a inferência. Devem identificar a linguagem a partir
do contexto e realizar a inferência em sequência.
## XLM-RoBERTa
Os seguintes modelos do XLM-RoBERTa podem ser utilizados para tarefas multilinguísticas:
- `xlm-roberta-base` (Modelagem de linguagem com máscara, 100 idiomas)
- `xlm-roberta-large` Modelagem de linguagem com máscara, 100 idiomas)
O XLM-RoBERTa foi treinado com 2,5 TB de dados do CommonCrawl recém-criados e testados em 100 idiomas.
Proporciona fortes vantagens sobre os modelos multilinguísticos publicados anteriormente como o mBERT e o XLM em tarefas
subsequentes como a classificação, a rotulagem de sequências e à respostas a perguntas.
## M2M100
Os seguintes modelos de M2M100 podem ser utilizados para traduções multilinguísticas:
- `facebook/m2m100_418M` (Tradução)
- `facebook/m2m100_1.2B` (Tradução)
Neste exemplo, o checkpoint `facebook/m2m100_418M` é carregado para traduzir do mandarim ao inglês. É possível
estabelecer o idioma de origem no tokenizador:
```py
>>> from transformers import M2M100ForConditionalGeneration, M2M100Tokenizer
>>> en_text = "Do not meddle in the affairs of wizards, for they are subtle and quick to anger."
>>> chinese_text = "不要插手巫師的事務, 因為他們是微妙的, 很快就會發怒."
>>> tokenizer = M2M100Tokenizer.from_pretrained("facebook/m2m100_418M", src_lang="zh")
>>> model = M2M100ForConditionalGeneration.from_pretrained("facebook/m2m100_418M")
```
Tokenização do texto:
```py
>>> encoded_zh = tokenizer(chinese_text, return_tensors="pt")
```
O M2M100 força o id do idioma de destino como o primeiro token gerado para traduzir ao idioma de destino.
É definido o `forced_bos_token_id` como `en` no método `generate` para traduzir ao inglês.
```py
>>> generated_tokens = model.generate(**encoded_zh, forced_bos_token_id=tokenizer.get_lang_id("en"))
>>> tokenizer.batch_decode(generated_tokens, skip_special_tokens=True)
'Do not interfere with the matters of the witches, because they are delicate and will soon be angry.'
```
## MBart
Os seguintes modelos do MBart podem ser utilizados para tradução multilinguística:
- `facebook/mbart-large-50-one-to-many-mmt` (Tradução automática multilinguística de um a vários, 50 idiomas)
- `facebook/mbart-large-50-many-to-many-mmt` (Tradução automática multilinguística de vários a vários, 50 idiomas)
- `facebook/mbart-large-50-many-to-one-mmt` (Tradução automática multilinguística vários a um, 50 idiomas)
- `facebook/mbart-large-50` (Tradução multilinguística, 50 idiomas)
- `facebook/mbart-large-cc25`
Neste exemplo, carrega-se o checkpoint `facebook/mbart-large-50-many-to-many-mmt` para traduzir do finlandês ao inglês.
Pode-se definir o idioma de origem no tokenizador:
```py
>>> from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
>>> en_text = "Do not meddle in the affairs of wizards, for they are subtle and quick to anger."
>>> fi_text = "Älä sekaannu velhojen asioihin, sillä ne ovat hienovaraisia ja nopeasti vihaisia."
>>> tokenizer = AutoTokenizer.from_pretrained("facebook/mbart-large-50-many-to-many-mmt", src_lang="fi_FI")
>>> model = AutoModelForSeq2SeqLM.from_pretrained("facebook/mbart-large-50-many-to-many-mmt")
```
Tokenizando o texto:
```py
>>> encoded_en = tokenizer(en_text, return_tensors="pt")
```
O MBart força o id do idioma de destino como o primeiro token gerado para traduzir ao idioma de destino.
É definido o `forced_bos_token_id` como `en` no método `generate` para traduzir ao inglês.
```py
>>> generated_tokens = model.generate(**encoded_en, forced_bos_token_id=tokenizer.lang_code_to_id("en_XX"))
>>> tokenizer.batch_decode(generated_tokens, skip_special_tokens=True)
"Don't interfere with the wizard's affairs, because they are subtle, will soon get angry."
```
Se estiver usando o checkpoint `facebook/mbart-large-50-many-to-one-mmt` não será necessário forçar o id do idioma de destino
como sendo o primeiro token generado, caso contrário a usagem é a mesma.
| 0 |
hf_public_repos/transformers/docs/source | hf_public_repos/transformers/docs/source/pt/pipeline_tutorial.md | <!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Pipelines para inferência
Um [pipeline] simplifica o uso dos modelos no [Model Hub](https://huggingface.co/models) para a inferência de uma diversidade de tarefas,
como a geração de texto, a segmentação de imagens e a classificação de áudio.
Inclusive, se não tem experiência com alguma modalidade específica ou não compreende o código que forma os modelos,
pode usar eles mesmo assim com o [pipeline]! Este tutorial te ensinará a:
* Utilizar um [`pipeline`] para inferência.
* Utilizar um tokenizador ou model específico.
* Utilizar um [`pipeline`] para tarefas de áudio e visão computacional.
<Tip>
Acesse a documentação do [`pipeline`] para obter uma lista completa de tarefas possíveis.
</Tip>
## Uso do pipeline
Mesmo que cada tarefa tenha um [`pipeline`] associado, é mais simples usar a abstração geral do [`pipeline`] que
contém todos os pipelines das tarefas mais específicas.
O [`pipeline`] carrega automaticamenta um modelo predeterminado e um tokenizador com capacidade de inferência para sua
tarefa.
1. Comece carregando um [`pipeline`] e especifique uma tarefa de inferência:
```py
>>> from transformers import pipeline
>>> generator = pipeline(task="text-generation")
```
2. Passe seu dado de entrada, no caso um texto, ao [`pipeline`]:
```py
>>> generator("Three Rings for the Elven-kings under the sky, Seven for the Dwarf-lords in their halls of stone")
[{'generated_text': 'Three Rings for the Elven-kings under the sky, Seven for the Dwarf-lords in their halls of stone, Seven for the Iron-priests at the door to the east, and thirteen for the Lord Kings at the end of the mountain'}]
```
Se tiver mais de uma entrada, passe-a como uma lista:
```py
>>> generator(
... [
... "Three Rings for the Elven-kings under the sky, Seven for the Dwarf-lords in their halls of stone",
... "Nine for Mortal Men, doomed to die, One for the Dark Lord on his dark throne",
... ]
... )
```
Qualquer parâmetro adicional para a sua tarefa também pode ser incluído no [`pipeline`]. A tarefa `text-generation` tem um método
[`~generation.GenerationMixin.generate`] com vários parâmetros para controlar a saída.
Por exemplo, se quiser gerar mais de uma saída, defina-a no parâmetro `num_return_sequences`:
```py
>>> generator(
... "Three Rings for the Elven-kings under the sky, Seven for the Dwarf-lords in their halls of stone",
... num_return_sequences=2,
... )
```
### Selecionando um modelo e um tokenizador
O [`pipeline`] aceita qualquer modelo do [Model Hub](https://huggingface.co/models). Há rótulos adicionais no Model Hub
que te permitem filtrar pelo modelo que gostaria de usar para sua tarefa. Uma vez que tiver escolhido o modelo apropriado,
carregue-o com as classes `AutoModelFor` e [`AutoTokenizer'] correspondentes. Por exemplo, carregue a classe [`AutoModelForCausalLM`]
para uma tarefa de modelagem de linguagem causal:
```py
>>> from transformers import AutoTokenizer, AutoModelForCausalLM
>>> tokenizer = AutoTokenizer.from_pretrained("distilgpt2")
>>> model = AutoModelForCausalLM.from_pretrained("distilgpt2")
```
Crie uma [`pipeline`] para a sua tarefa e especifíque o modelo e o tokenizador que foram carregados:
```py
>>> from transformers import pipeline
>>> generator = pipeline(task="text-generation", model=model, tokenizer=tokenizer)
```
Passe seu texto de entrada ao [`pipeline`] para gerar algum texto:
```py
>>> generator("Three Rings for the Elven-kings under the sky, Seven for the Dwarf-lords in their halls of stone")
[{'generated_text': 'Three Rings for the Elven-kings under the sky, Seven for the Dwarf-lords in their halls of stone, Seven for the Dragon-lords (for them to rule in a world ruled by their rulers, and all who live within the realm'}]
```
## Pipeline de audio
A flexibilidade do [`pipeline`] significa que também pode-se extender às tarefas de áudio.
La flexibilidad de [`pipeline`] significa que también se puede extender a tareas de audio.
Por exemplo, classifiquemos a emoção de um breve fragmento do famoso discurso de John F. Kennedy /home/rzimmerdev/dev/transformers/docs/source/pt/pipeline_tutorial.md
Encontre um modelo de [audio classification](https://huggingface.co/models?pipeline_tag=audio-classification) para
reconhecimento de emoções no Model Hub e carregue-o usando o [`pipeline`]:
```py
>>> from transformers import pipeline
>>> audio_classifier = pipeline(
... task="audio-classification", model="ehcalabres/wav2vec2-lg-xlsr-en-speech-emotion-recognition"
... )
```
Passe o arquivo de áudio ao [`pipeline`]:
```py
>>> audio_classifier("jfk_moon_speech.wav")
[{'label': 'calm', 'score': 0.13856211304664612},
{'label': 'disgust', 'score': 0.13148026168346405},
{'label': 'happy', 'score': 0.12635163962841034},
{'label': 'angry', 'score': 0.12439591437578201},
{'label': 'fearful', 'score': 0.12404385954141617}]
```
## Pipeline de visão computacional
Finalmente, utilizar um [`pipeline`] para tarefas de visão é praticamente a mesma coisa.
Especifique a sua tarefa de visão e passe a sua imagem ao classificador.
A imagem pode ser um link ou uma rota local à imagem. Por exemplo, que espécie de gato está presente na imagem?

```py
>>> from transformers import pipeline
>>> vision_classifier = pipeline(task="image-classification")
>>> vision_classifier(
... images="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/pipeline-cat-chonk.jpeg"
... )
[{'label': 'lynx, catamount', 'score': 0.4403027892112732},
{'label': 'cougar, puma, catamount, mountain lion, painter, panther, Felis concolor',
'score': 0.03433405980467796},
{'label': 'snow leopard, ounce, Panthera uncia',
'score': 0.032148055732250214},
{'label': 'Egyptian cat', 'score': 0.02353910356760025},
{'label': 'tiger cat', 'score': 0.023034192621707916}]
```
| 0 |
hf_public_repos/transformers/docs/source | hf_public_repos/transformers/docs/source/pt/fast_tokenizers.md | <!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Usando os Tokenizers do 🤗 Tokenizers
O [`PreTrainedTokenizerFast`] depende da biblioteca [🤗 Tokenizers](https://huggingface.co/docs/tokenizers). O Tokenizer obtido da biblioteca 🤗 Tokenizers pode ser carregado facilmente pelo 🤗 Transformers.
Antes de entrar nos detalhes, vamos começar criando um tokenizer fictício em algumas linhas:
```python
>>> from tokenizers import Tokenizer
>>> from tokenizers.models import BPE
>>> from tokenizers.trainers import BpeTrainer
>>> from tokenizers.pre_tokenizers import Whitespace
>>> tokenizer = Tokenizer(BPE(unk_token="[UNK]"))
>>> trainer = BpeTrainer(special_tokens=["[UNK]", "[CLS]", "[SEP]", "[PAD]", "[MASK]"])
>>> tokenizer.pre_tokenizer = Whitespace()
>>> files = [...]
>>> tokenizer.train(files, trainer)
```
Agora temos um tokenizer treinado nos arquivos que foram definidos. Nós podemos continuar usando nessa execução ou salvar em um arquivo JSON para re-utilizar no futuro.
## Carregando diretamente de um objeto tokenizer
Vamos ver como aproveitar esse objeto tokenizer na biblioteca 🤗 Transformers. A classe [`PreTrainedTokenizerFast`] permite uma instanciação fácil, aceitando o objeto *tokenizer* instanciado como um argumento:
```python
>>> from transformers import PreTrainedTokenizerFast
>>> fast_tokenizer = PreTrainedTokenizerFast(tokenizer_object=tokenizer)
```
Esse objeto pode ser utilizado com todos os métodos compartilhados pelos tokenizers dos 🤗 Transformers! Vá para [a página do tokenizer](main_classes/tokenizer) para mais informações.
## Carregando de um arquivo JSON
Para carregar um tokenizer de um arquivo JSON vamos primeiro começar salvando nosso tokenizer:
```python
>>> tokenizer.save("tokenizer.json")
```
A pasta para qual salvamos esse arquivo pode ser passada para o método de inicialização do [`PreTrainedTokenizerFast`] usando o `tokenizer_file` parâmetro:
```python
>>> from transformers import PreTrainedTokenizerFast
>>> fast_tokenizer = PreTrainedTokenizerFast(tokenizer_file="tokenizer.json")
```
Esse objeto pode ser utilizado com todos os métodos compartilhados pelos tokenizers dos 🤗 Transformers! Vá para [a página do tokenizer](main_classes/tokenizer) para mais informações. | 0 |
hf_public_repos/transformers/docs/source | hf_public_repos/transformers/docs/source/pt/_config.py | # docstyle-ignore
INSTALL_CONTENT = """
# Transformers installation
! pip install transformers datasets
# To install from source instead of the last release, comment the command above and uncomment the following one.
# ! pip install git+https://github.com/huggingface/transformers.git
"""
notebook_first_cells = [{"type": "code", "content": INSTALL_CONTENT}]
black_avoid_patterns = {
"{processor_class}": "FakeProcessorClass",
"{model_class}": "FakeModelClass",
"{object_class}": "FakeObjectClass",
}
| 0 |
hf_public_repos/transformers/docs/source | hf_public_repos/transformers/docs/source/pt/serialization.md | <!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Exportando modelos para ONNX
Se você precisar implantar modelos 🤗 Transformers em ambientes de produção, recomendamos
exporta-los para um formato serializado que pode ser carregado e executado em
tempos de execução e hardware. Neste guia, mostraremos como exportar modelos 🤗 Transformers
para [ONNX (Open Neural Network eXchange)](http://onnx.ai).
<Tip>
Uma vez exportado, um modelo pode ser otimizado para inferência por meio de técnicas como
quantização e poda. Se você estiver interessado em otimizar seus modelos para serem executados com
máxima eficiência, confira a biblioteca [🤗 Optimum
](https://github.com/huggingface/optimum).
</Tip>
ONNX é um padrão aberto que define um conjunto comum de operadores e um formato de arquivo comum
para representar modelos de aprendizado profundo em uma ampla variedade de estruturas, incluindo PyTorch e
TensorFlow. Quando um modelo é exportado para o formato ONNX, esses operadores são usados para
construir um grafo computacional (muitas vezes chamado de _representação intermediária_) que
representa o fluxo de dados através da rede neural.
Ao expor um grafo com operadores e tipos de dados padronizados, o ONNX facilita a
alternar entre os frameworks. Por exemplo, um modelo treinado em PyTorch pode ser exportado para
formato ONNX e depois importado no TensorFlow (e vice-versa).
🤗 Transformers fornece um pacote [`transformers.onnx`](main_classes/onnx) que permite
que você converta os checkpoints do modelo em um grafo ONNX aproveitando os objetos de configuração.
Esses objetos de configuração vêm prontos para várias arquiteturas de modelo e são
projetado para ser facilmente extensível a outras arquiteturas.
As configurações prontas incluem as seguintes arquiteturas:
<!--This table is automatically generated by `make fix-copies`, do not fill manually!-->
- ALBERT
- BART
- BEiT
- BERT
- BigBird
- BigBird-Pegasus
- Blenderbot
- BlenderbotSmall
- BLOOM
- CamemBERT
- CLIP
- CodeGen
- Conditional DETR
- ConvBERT
- ConvNeXT
- ConvNeXTV2
- Data2VecText
- Data2VecVision
- DeBERTa
- DeBERTa-v2
- DeiT
- DETR
- DistilBERT
- ELECTRA
- ERNIE
- FlauBERT
- GPT Neo
- GPT-J
- GroupViT
- I-BERT
- LayoutLM
- LayoutLMv3
- LeViT
- Longformer
- LongT5
- M2M100
- Marian
- mBART
- MobileBERT
- MobileViT
- MT5
- OpenAI GPT-2
- OWL-ViT
- Perceiver
- PLBart
- ResNet
- RoBERTa
- RoFormer
- SegFormer
- SqueezeBERT
- Swin Transformer
- T5
- Table Transformer
- Vision Encoder decoder
- ViT
- XLM
- XLM-RoBERTa
- XLM-RoBERTa-XL
- YOLOS
Nas próximas duas seções, mostraremos como:
* Exportar um modelo suportado usando o pacote `transformers.onnx`.
* Exportar um modelo personalizado para uma arquitetura sem suporte.
## Exportando um modelo para ONNX
Para exportar um modelo 🤗 Transformers para o ONNX, primeiro você precisa instalar algumas
dependências extras:
```bash
pip install transformers[onnx]
```
O pacote `transformers.onnx` pode então ser usado como um módulo Python:
```bash
python -m transformers.onnx --help
usage: Hugging Face Transformers ONNX exporter [-h] -m MODEL [--feature {causal-lm, ...}] [--opset OPSET] [--atol ATOL] output
positional arguments:
output Path indicating where to store generated ONNX model.
optional arguments:
-h, --help show this help message and exit
-m MODEL, --model MODEL
Model ID on huggingface.co or path on disk to load model from.
--feature {causal-lm, ...}
The type of features to export the model with.
--opset OPSET ONNX opset version to export the model with.
--atol ATOL Absolute difference tolerance when validating the model.
```
A exportação de um checkpoint usando uma configuração pronta pode ser feita da seguinte forma:
```bash
python -m transformers.onnx --model=distilbert-base-uncased onnx/
```
Você deve ver os seguintes logs:
```bash
Validating ONNX model...
-[✓] ONNX model output names match reference model ({'last_hidden_state'})
- Validating ONNX Model output "last_hidden_state":
-[✓] (2, 8, 768) matches (2, 8, 768)
-[✓] all values close (atol: 1e-05)
All good, model saved at: onnx/model.onnx
```
Isso exporta um grafo ONNX do ponto de verificação definido pelo argumento `--model`. Nisso
Por exemplo, é `distilbert-base-uncased`, mas pode ser qualquer checkpoint no Hugging
Face Hub ou um armazenado localmente.
O arquivo `model.onnx` resultante pode ser executado em um dos [muitos
aceleradores](https://onnx.ai/supported-tools.html#deployModel) que suportam o ONNX
padrão. Por exemplo, podemos carregar e executar o modelo com [ONNX
Tempo de execução](https://onnxruntime.ai/) da seguinte forma:
```python
>>> from transformers import AutoTokenizer
>>> from onnxruntime import InferenceSession
>>> tokenizer = AutoTokenizer.from_pretrained("distilbert-base-uncased")
>>> session = InferenceSession("onnx/model.onnx")
>>> # ONNX Runtime expects NumPy arrays as input
>>> inputs = tokenizer("Using DistilBERT with ONNX Runtime!", return_tensors="np")
>>> outputs = session.run(output_names=["last_hidden_state"], input_feed=dict(inputs))
```
Os nomes de saída necessários (como `["last_hidden_state"]`) podem ser obtidos pegando uma
configuração ONNX de cada modelo. Por exemplo, para DistilBERT temos:
```python
>>> from transformers.models.distilbert import DistilBertConfig, DistilBertOnnxConfig
>>> config = DistilBertConfig()
>>> onnx_config = DistilBertOnnxConfig(config)
>>> print(list(onnx_config.outputs.keys()))
["last_hidden_state"]
```
O processo é idêntico para os checkpoints do TensorFlow no Hub. Por exemplo, podemos
exportar um checkpoint TensorFlow puro do [Keras
](https://huggingface.co/keras-io) da seguinte forma:
```bash
python -m transformers.onnx --model=keras-io/transformers-qa onnx/
```
Para exportar um modelo armazenado localmente, você precisará ter os pesos e
arquivos tokenizer armazenados em um diretório. Por exemplo, podemos carregar e salvar um checkpoint como:
```python
>>> from transformers import AutoTokenizer, AutoModelForSequenceClassification
>>> # Load tokenizer and PyTorch weights form the Hub
>>> tokenizer = AutoTokenizer.from_pretrained("distilbert-base-uncased")
>>> pt_model = AutoModelForSequenceClassification.from_pretrained("distilbert-base-uncased")
>>> # Save to disk
>>> tokenizer.save_pretrained("local-pt-checkpoint")
>>> pt_model.save_pretrained("local-pt-checkpoint")
```
Uma vez que o checkpoint é salvo, podemos exportá-lo para o ONNX apontando o `--model`
argumento do pacote `transformers.onnx` para o diretório desejado:
```bash
python -m transformers.onnx --model=local-pt-checkpoint onnx/
```
```python
>>> from transformers import AutoTokenizer, TFAutoModelForSequenceClassification
>>> # Load tokenizer and TensorFlow weights from the Hub
>>> tokenizer = AutoTokenizer.from_pretrained("distilbert-base-uncased")
>>> tf_model = TFAutoModelForSequenceClassification.from_pretrained("distilbert-base-uncased")
>>> # Save to disk
>>> tokenizer.save_pretrained("local-tf-checkpoint")
>>> tf_model.save_pretrained("local-tf-checkpoint")
```
Uma vez que o checkpoint é salvo, podemos exportá-lo para o ONNX apontando o `--model`
argumento do pacote `transformers.onnx` para o diretório desejado:
```bash
python -m transformers.onnx --model=local-tf-checkpoint onnx/
```
## Selecionando features para diferentes tarefas do modelo
Cada configuração pronta vem com um conjunto de _features_ que permitem exportar
modelos para diferentes tipos de tarefas. Conforme mostrado na tabela abaixo, cada recurso é
associado a uma `AutoClass` diferente:
| Feature | Auto Class |
| ------------------------------------ | ------------------------------------ |
| `causal-lm`, `causal-lm-with-past` | `AutoModelForCausalLM` |
| `default`, `default-with-past` | `AutoModel` |
| `masked-lm` | `AutoModelForMaskedLM` |
| `question-answering` | `AutoModelForQuestionAnswering` |
| `seq2seq-lm`, `seq2seq-lm-with-past` | `AutoModelForSeq2SeqLM` |
| `sequence-classification` | `AutoModelForSequenceClassification` |
| `token-classification` | `AutoModelForTokenClassification` |
Para cada configuração, você pode encontrar a lista de recursos suportados por meio do
[`~transformers.onnx.FeaturesManager`]. Por exemplo, para DistilBERT temos:
```python
>>> from transformers.onnx.features import FeaturesManager
>>> distilbert_features = list(FeaturesManager.get_supported_features_for_model_type("distilbert").keys())
>>> print(distilbert_features)
["default", "masked-lm", "causal-lm", "sequence-classification", "token-classification", "question-answering"]
```
Você pode então passar um desses recursos para o argumento `--feature` no
pacote `transformers.onnx`. Por exemplo, para exportar um modelo de classificação de texto, podemos
escolher um modelo ajustado no Hub e executar:
```bash
python -m transformers.onnx --model=distilbert-base-uncased-finetuned-sst-2-english \
--feature=sequence-classification onnx/
```
Isso exibe os seguintes logs:
```bash
Validating ONNX model...
-[✓] ONNX model output names match reference model ({'logits'})
- Validating ONNX Model output "logits":
-[✓] (2, 2) matches (2, 2)
-[✓] all values close (atol: 1e-05)
All good, model saved at: onnx/model.onnx
```
Observe que, neste caso, os nomes de saída do modelo ajustado são `logits`
em vez do `last_hidden_state` que vimos com o checkpoint `distilbert-base-uncased`
mais cedo. Isso é esperado, pois o modelo ajustado (fine-tuned) possui uma cabeça de classificação de sequência.
<Tip>
Os recursos que têm um sufixo `with-pass` (como `causal-lm-with-pass`) correspondem a
classes de modelo com estados ocultos pré-computados (chave e valores nos blocos de atenção)
que pode ser usado para decodificação autorregressiva rápida.
</Tip>
<Tip>
Para modelos do tipo `VisionEncoderDecoder`, as partes do codificador e do decodificador são
exportados separadamente como dois arquivos ONNX chamados `encoder_model.onnx` e `decoder_model.onnx` respectivamente.
</Tip>
## Exportando um modelo para uma arquitetura sem suporte
Se você deseja exportar um modelo cuja arquitetura não é suportada nativamente pela
biblioteca, há três etapas principais a seguir:
1. Implemente uma configuração ONNX personalizada.
2. Exporte o modelo para o ONNX.
3. Valide as saídas do PyTorch e dos modelos exportados.
Nesta seção, veremos como o DistilBERT foi implementado para mostrar o que está envolvido
em cada passo.
### Implementando uma configuração ONNX personalizada
Vamos começar com o objeto de configuração ONNX. Fornecemos três classes abstratas que
você deve herdar, dependendo do tipo de arquitetura de modelo que deseja exportar:
* Modelos baseados em codificador herdam de [`~onnx.config.OnnxConfig`]
* Modelos baseados em decodificador herdam de [`~onnx.config.OnnxConfigWithPast`]
* Os modelos codificador-decodificador herdam de [`~onnx.config.OnnxSeq2SeqConfigWithPast`]
<Tip>
Uma boa maneira de implementar uma configuração ONNX personalizada é observar as
implementação no arquivo `configuration_<model_name>.py` de uma arquitetura semelhante.
</Tip>
Como o DistilBERT é um modelo baseado em codificador, sua configuração é herdada de
`OnnxConfig`:
```python
>>> from typing import Mapping, OrderedDict
>>> from transformers.onnx import OnnxConfig
>>> class DistilBertOnnxConfig(OnnxConfig):
... @property
... def inputs(self) -> Mapping[str, Mapping[int, str]]:
... return OrderedDict(
... [
... ("input_ids", {0: "batch", 1: "sequence"}),
... ("attention_mask", {0: "batch", 1: "sequence"}),
... ]
... )
```
Todo objeto de configuração deve implementar a propriedade `inputs` e retornar um mapeamento,
onde cada chave corresponde a uma entrada esperada e cada valor indica o eixo
dessa entrada. Para o DistilBERT, podemos ver que duas entradas são necessárias: `input_ids` e
`attention_mask`. Essas entradas têm a mesma forma de `(batch_size, sequence_length)`
é por isso que vemos os mesmos eixos usados na configuração.
<Tip>
Notice that `inputs` property for `DistilBertOnnxConfig` returns an `OrderedDict`. This
ensures that the inputs are matched with their relative position within the
`PreTrainedModel.forward()` method when tracing the graph. We recommend using an
`OrderedDict` for the `inputs` and `outputs` properties when implementing custom ONNX
configurations.
Observe que a propriedade `inputs` para `DistilBertOnnxConfig` retorna um `OrderedDict`. Este
garante que as entradas sejam combinadas com sua posição relativa dentro do
método `PreTrainedModel.forward()` ao traçar o grafo. Recomendamos o uso de um
`OrderedDict` para as propriedades `inputs` e `outputs` ao implementar configurações personalizadas ONNX.
</Tip>
Depois de implementar uma configuração ONNX, você pode instanciá-la fornecendo a
configuração do modelo base da seguinte forma:
```python
>>> from transformers import AutoConfig
>>> config = AutoConfig.from_pretrained("distilbert-base-uncased")
>>> onnx_config = DistilBertOnnxConfig(config)
```
O objeto resultante tem várias propriedades úteis. Por exemplo, você pode visualizar o conjunto de operadores ONNX
que será usado durante a exportação:
```python
>>> print(onnx_config.default_onnx_opset)
11
```
Você também pode visualizar as saídas associadas ao modelo da seguinte forma:
```python
>>> print(onnx_config.outputs)
OrderedDict([("last_hidden_state", {0: "batch", 1: "sequence"})])
```
Observe que a propriedade outputs segue a mesma estrutura das entradas; ele retorna um
`OrderedDict` de saídas nomeadas e suas formas. A estrutura de saída está ligada a
escolha do recurso com o qual a configuração é inicializada. Por padrão, a configuração do ONNX
é inicializada com o recurso `default` que corresponde à exportação de um
modelo carregado com a classe `AutoModel`. Se você deseja exportar um modelo para outra tarefa,
apenas forneça um recurso diferente para o argumento `task` quando você inicializar a configuração ONNX
. Por exemplo, se quisermos exportar o DistilBERT com uma sequência
de classificação, poderíamos usar:
```python
>>> from transformers import AutoConfig
>>> config = AutoConfig.from_pretrained("distilbert-base-uncased")
>>> onnx_config_for_seq_clf = DistilBertOnnxConfig(config, task="sequence-classification")
>>> print(onnx_config_for_seq_clf.outputs)
OrderedDict([('logits', {0: 'batch'})])
```
<Tip>
Todas as propriedades e métodos básicos associados a [`~onnx.config.OnnxConfig`] e
as outras classes de configuração podem ser substituídas se necessário. Confira [`BartOnnxConfig`]
para um exemplo avançado.
</Tip>
### Exportando um modelo
Depois de ter implementado a configuração do ONNX, o próximo passo é exportar o modelo.
Aqui podemos usar a função `export()` fornecida pelo pacote `transformers.onnx`.
Esta função espera a configuração do ONNX, juntamente com o modelo base e o tokenizer,
e o caminho para salvar o arquivo exportado:
```python
>>> from pathlib import Path
>>> from transformers.onnx import export
>>> from transformers import AutoTokenizer, AutoModel
>>> onnx_path = Path("model.onnx")
>>> model_ckpt = "distilbert-base-uncased"
>>> base_model = AutoModel.from_pretrained(model_ckpt)
>>> tokenizer = AutoTokenizer.from_pretrained(model_ckpt)
>>> onnx_inputs, onnx_outputs = export(tokenizer, base_model, onnx_config, onnx_config.default_onnx_opset, onnx_path)
```
Os `onnx_inputs` e `onnx_outputs` retornados pela função `export()` são listas de
chaves definidas nas propriedades `inputs` e `outputs` da configuração. Uma vez que o
modelo é exportado, você pode testar se o modelo está bem formado da seguinte forma:
```python
>>> import onnx
>>> onnx_model = onnx.load("model.onnx")
>>> onnx.checker.check_model(onnx_model)
```
<Tip>
Se o seu modelo for maior que 2GB, você verá que muitos arquivos adicionais são criados
durante a exportação. Isso é _esperado_ porque o ONNX usa [Protocol
Buffers](https://developers.google.com/protocol-buffers/) para armazenar o modelo e estes
têm um limite de tamanho de 2GB. Veja a [ONNX
documentação](https://github.com/onnx/onnx/blob/master/docs/ExternalData.md) para
instruções sobre como carregar modelos com dados externos.
</Tip>
### Validando a saída dos modelos
A etapa final é validar se as saídas do modelo base e exportado concordam
dentro de alguma tolerância absoluta. Aqui podemos usar a função `validate_model_outputs()`
fornecida pelo pacote `transformers.onnx` da seguinte forma:
```python
>>> from transformers.onnx import validate_model_outputs
>>> validate_model_outputs(
... onnx_config, tokenizer, base_model, onnx_path, onnx_outputs, onnx_config.atol_for_validation
... )
```
Esta função usa o método [`~transformers.onnx.OnnxConfig.generate_dummy_inputs`] para
gerar entradas para o modelo base e o exportado, e a tolerância absoluta pode ser
definida na configuração. Geralmente encontramos concordância numérica em 1e-6 a 1e-4
de alcance, embora qualquer coisa menor que 1e-3 provavelmente esteja OK.
## Contribuindo com uma nova configuração para 🤗 Transformers
Estamos procurando expandir o conjunto de configurações prontas e receber contribuições
da comunidade! Se você gostaria de contribuir para a biblioteca, você
precisará:
* Implemente a configuração do ONNX no arquivo `configuration_<model_name>.py` correspondente
Arquivo
* Incluir a arquitetura do modelo e recursos correspondentes em
[`~onnx.features.FeatureManager`]
* Adicione sua arquitetura de modelo aos testes em `test_onnx_v2.py`
Confira como ficou a configuração do [IBERT
](https://github.com/huggingface/transformers/pull/14868/files) para obter uma
idéia do que está envolvido.
| 0 |
hf_public_repos/transformers/docs/source | hf_public_repos/transformers/docs/source/pt/create_a_model.md | <!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Criar uma arquitetura customizada
Uma [`AutoClass`](model_doc/auto) automaticamente infere a arquitetura do modelo e baixa configurações e pesos pré-treinados. Geralmente, nós recomendamos usar uma `AutoClass` para produzir um código independente de checkpoints. Mas usuários que querem mais contole sobre parâmetros específicos do modelo pode criar um modelo customizado 🤗 Transformers a partir de algumas classes bases. Isso pode ser particulamente útil para alguém que está interessado em estudar, treinar ou fazer experimentos com um modelo 🤗 Transformers. Nesse tutorial, será explicado como criar um modelo customizado sem uma `AutoClass`. Aprenda como:
- Carregar e customizar a configuração de um modelo.
- Criar a arquitetura de um modelo.
- Criar um tokenizer rápido e devagar para textos.
- Criar extrator de features para tarefas envolvendo audio e imagem.
- Criar um processador para tarefas multimodais.
## configuration
A [configuration](main_classes/configuration) refere-se a atributos específicos de um modelo. Cada configuração de modelo tem atributos diferentes; por exemplo, todos modelo de PLN possuem os atributos `hidden_size`, `num_attention_heads`, `num_hidden_layers` e `vocab_size` em comum. Esse atributos especificam o numero de 'attention heads' ou 'hidden layers' para construir um modelo.
Dê uma olhada a mais em [DistilBERT](model_doc/distilbert) acessando [`DistilBertConfig`] para observar esses atributos:
```py
>>> from transformers import DistilBertConfig
>>> config = DistilBertConfig()
>>> print(config)
DistilBertConfig {
"activation": "gelu",
"attention_dropout": 0.1,
"dim": 768,
"dropout": 0.1,
"hidden_dim": 3072,
"initializer_range": 0.02,
"max_position_embeddings": 512,
"model_type": "distilbert",
"n_heads": 12,
"n_layers": 6,
"pad_token_id": 0,
"qa_dropout": 0.1,
"seq_classif_dropout": 0.2,
"sinusoidal_pos_embds": false,
"transformers_version": "4.16.2",
"vocab_size": 30522
}
```
[`DistilBertConfig`] mostra todos os atributos padrões usados para construir um [`DistilBertModel`] base. Todos atributos são customizáveis, o que cria espaço para experimentos. Por exemplo, você pode customizar um modelo padrão para:
- Tentar uma função de ativação diferente com o parâmetro `activation`.
- Usar uma taxa de desistência maior para as probabilidades de 'attention' com o parâmetro `attention_dropout`.
```py
>>> my_config = DistilBertConfig(activation="relu", attention_dropout=0.4)
>>> print(my_config)
DistilBertConfig {
"activation": "relu",
"attention_dropout": 0.4,
"dim": 768,
"dropout": 0.1,
"hidden_dim": 3072,
"initializer_range": 0.02,
"max_position_embeddings": 512,
"model_type": "distilbert",
"n_heads": 12,
"n_layers": 6,
"pad_token_id": 0,
"qa_dropout": 0.1,
"seq_classif_dropout": 0.2,
"sinusoidal_pos_embds": false,
"transformers_version": "4.16.2",
"vocab_size": 30522
}
```
Atributos de um modelo pré-treinado podem ser modificados na função [`~PretrainedConfig.from_pretrained`]:
```py
>>> my_config = DistilBertConfig.from_pretrained("distilbert-base-uncased", activation="relu", attention_dropout=0.4)
```
Uma vez que você está satisfeito com as configurações do seu modelo, você consegue salvar elas com [`~PretrainedConfig.save_pretrained`]. Seu arquivo de configurações está salvo como um arquivo JSON no diretório especificado:
```py
>>> my_config.save_pretrained(save_directory="./your_model_save_path")
```
Para reusar o arquivo de configurações, carregue com [`~PretrainedConfig.from_pretrained`]:
```py
>>> my_config = DistilBertConfig.from_pretrained("./your_model_save_path/my_config.json")
```
<Tip>
Você pode também salvar seu arquivo de configurações como um dicionário ou até mesmo com a diferença entre as seus atributos de configuração customizados e os atributos de configuração padrões! Olhe a documentação [configuration](main_classes/configuration) para mais detalhes.
</Tip>
## Modelo
O próximo passo é criar um [model](main_classes/models). O modelo - também vagamente referido como arquitetura - define o que cada camada está fazendo e quais operações estão acontecendo. Atributos como `num_hidden_layers` das configurações são utilizados para definir a arquitetura. Todo modelo compartilha a classe base [`PreTrainedModel`] e alguns métodos em comum como redimensionar o tamanho dos embeddings de entrada e podar as 'self-attention heads'. Além disso, todos os modelos também são subclasses de [`torch.nn.Module`](https://pytorch.org/docs/stable/generated/torch.nn.Module.html), [`tf.keras.Model`](https://www.tensorflow.org/api_docs/python/tf/keras/Model) ou [`flax.linen.Module`](https://flax.readthedocs.io/en/latest/flax.linen.html#module). Isso significa que os modelos são compatíveis com cada respectivo uso de framework.
<frameworkcontent>
<pt>
Carregar seus atributos de configuração customizados em um modelo:
```py
>>> from transformers import DistilBertModel
>>> my_config = DistilBertConfig.from_pretrained("./your_model_save_path/my_config.json")
>>> model = DistilBertModel(my_config)
```
Isso cria um modelo com valores aleatórios ao invés de pré-treinar os pesos. Você não irá conseguir usar usar esse modelo para nada útil ainda, até você treinar ele. Treino é um processo caro e demorado. Geralmente é melhor utilizar um modelo pré-treinado para obter melhores resultados mais rápido, enquanto usa apenas uma fração dos recursos necessários para treinar.
Criar um modelo pré-treinado com [`~PreTrainedModel.from_pretrained`]:
```py
>>> model = DistilBertModel.from_pretrained("distilbert-base-uncased")
```
Quando você carregar os pesos pré-treinados, a configuração padrão do modelo é automaticamente carregada se o modelo é provido pelo 🤗 Transformers. No entanto, você ainda consegue mudar - alguns ou todos - os atributos padrões de configuração do modelo com os seus próprio atributos, se você preferir:
```py
>>> model = DistilBertModel.from_pretrained("distilbert-base-uncased", config=my_config)
```
</pt>
<tf>
Carregar os seus próprios atributos padrões de contiguração no modelo:
```py
>>> from transformers import TFDistilBertModel
>>> my_config = DistilBertConfig.from_pretrained("./your_model_save_path/my_config.json")
>>> tf_model = TFDistilBertModel(my_config)
```
Isso cria um modelo com valores aleatórios ao invés de pré-treinar os pesos. Você não irá conseguir usar usar esse modelo para nada útil ainda, até você treinar ele. Treino é um processo caro e demorado. Geralmente é melhor utilizar um modelo pré-treinado para obter melhores resultados mais rápido, enquanto usa apenas uma fração dos recursos necessários para treinar.
Criar um modelo pré-treinado com [`~TFPreTrainedModel.from_pretrained`]:
```py
>>> tf_model = TFDistilBertModel.from_pretrained("distilbert-base-uncased")
```
Quando você carregar os pesos pré-treinados, a configuração padrão do modelo é automaticamente carregada se o modelo é provido pelo 🤗 Transformers. No entanto, você ainda consegue mudar - alguns ou todos - os atributos padrões de configuração do modelo com os seus próprio atributos, se você preferir:
```py
>>> tf_model = TFDistilBertModel.from_pretrained("distilbert-base-uncased", config=my_config)
```
</tf>
</frameworkcontent>
### Heads do modelo
Neste ponto, você tem um modelo básico do DistilBERT que gera os *estados ocultos*. Os estados ocultos são passados como entrada para a head do moelo para produzir a saída final. 🤗 Transformers fornece uma head de modelo diferente para cada tarefa desde que o modelo suporte essa tarefa (por exemplo, você não consegue utilizar o modelo DistilBERT para uma tarefa de 'sequence-to-sequence' como tradução).
<frameworkcontent>
<pt>
Por exemplo, [`DistilBertForSequenceClassification`] é um modelo DistilBERT base com uma head de classificação de sequência. A head de calssificação de sequência é uma camada linear no topo das saídas agrupadas.
```py
>>> from transformers import DistilBertForSequenceClassification
>>> model = DistilBertForSequenceClassification.from_pretrained("distilbert-base-uncased")
```
Reutilize facilmente esse ponto de parada para outra tarefe mudando para uma head de modelo diferente. Para uma tarefe de responder questões, você usaria a head do modelo [`DistilBertForQuestionAnswering`]. A head de responder questões é similar com a de classificação de sequências exceto o fato de que ela é uma camada no topo dos estados das saídas ocultas.
```py
>>> from transformers import DistilBertForQuestionAnswering
>>> model = DistilBertForQuestionAnswering.from_pretrained("distilbert-base-uncased")
```
</pt>
<tf>
Por exemplo, [`TFDistilBertForSequenceClassification`] é um modelo DistilBERT base com uma head de classificação de sequência. A head de calssificação de sequência é uma camada linear no topo das saídas agrupadas.
```py
>>> from transformers import TFDistilBertForSequenceClassification
>>> tf_model = TFDistilBertForSequenceClassification.from_pretrained("distilbert-base-uncased")
```
Reutilize facilmente esse ponto de parada para outra tarefe mudando para uma head de modelo diferente. Para uma tarefe de responder questões, você usaria a head do modelo [`TFDistilBertForQuestionAnswering`]. A head de responder questões é similar com a de classificação de sequências exceto o fato de que ela é uma camada no topo dos estados das saídas ocultas.
```py
>>> from transformers import TFDistilBertForQuestionAnswering
>>> tf_model = TFDistilBertForQuestionAnswering.from_pretrained("distilbert-base-uncased")
```
</tf>
</frameworkcontent>
## Tokenizer
A útlima classe base que você precisa antes de usar um modelo para dados textuais é a [tokenizer](main_classes/tokenizer) para converter textos originais para tensores. Existem dois tipos de tokenizers que você pode usar com 🤗 Transformers:
- [`PreTrainedTokenizer`]: uma implementação em Python de um tokenizer.
- [`PreTrainedTokenizerFast`]: um tokenizer da nossa biblioteca [🤗 Tokenizer](https://huggingface.co/docs/tokenizers/python/latest/) baseada em Rust. Esse tipo de tokenizer é significantemente mais rapido - especialmente durante tokenization de codificação - devido a implementação em Rust. O tokenizer rápido tambem oferece métodos adicionais como *offset mapping* que mapeia tokens para suar palavras ou caracteres originais.
Os dois tokenizers suporta métodos comuns como os de codificar e decodificar, adicionar novos tokens, e gerenciar tokens especiais.
<Tip warning={true}>
Nem todo modelo suporta um 'fast tokenizer'. De uma olhada aqui [table](index#supported-frameworks) pra checar se um modelo suporta 'fast tokenizer'.
</Tip>
Se você treinou seu prórpio tokenizer, você pode criar um a partir do seu arquivo *vocabulary*:
```py
>>> from transformers import DistilBertTokenizer
>>> my_tokenizer = DistilBertTokenizer(vocab_file="my_vocab_file.txt", do_lower_case=False, padding_side="left")
```
É importante lembrar que o vocabulário de um tokenizer customizado será diferente de um vocabulário gerado pelo tokenizer de um modelo pré treinado. Você precisa usar o vocabulário de um modelo pré treinado se você estiver usando um modelo pré treinado, caso contrário as entradas não farão sentido. Criando um tokenizer com um vocabulário de um modelo pré treinado com a classe [`DistilBertTokenizer`]:
```py
>>> from transformers import DistilBertTokenizer
>>> slow_tokenizer = DistilBertTokenizer.from_pretrained("distilbert-base-uncased")
```
Criando um 'fast tokenizer' com a classe [`DistilBertTokenizerFast`]:
```py
>>> from transformers import DistilBertTokenizerFast
>>> fast_tokenizer = DistilBertTokenizerFast.from_pretrained("distilbert-base-uncased")
```
<Tip>
Pos padrão, [`AutoTokenizer`] tentará carregar um 'fast tokenizer'. Você pode disabilitar esse comportamento colocando `use_fast=False` no `from_pretrained`.
</Tip>
## Extrator de features
Um extrator de features processa entradas de imagem ou áudio. Ele herda da classe base [`~feature_extraction_utils.FeatureExtractionMixin`], e pode também herdar da classe [`ImageFeatureExtractionMixin`] para processamento de features de imagem ou da classe [`SequenceFeatureExtractor`] para processamento de entradas de áudio.
Dependendo do que você está trabalhando em um audio ou uma tarefa de visão, crie um estrator de features associado com o modelo que você está usando. Por exemplo, crie um [`ViTFeatureExtractor`] padrão se você estiver usando [ViT](model_doc/vit) para classificação de imagens:
```py
>>> from transformers import ViTFeatureExtractor
>>> vit_extractor = ViTFeatureExtractor()
>>> print(vit_extractor)
ViTFeatureExtractor {
"do_normalize": true,
"do_resize": true,
"feature_extractor_type": "ViTFeatureExtractor",
"image_mean": [
0.5,
0.5,
0.5
],
"image_std": [
0.5,
0.5,
0.5
],
"resample": 2,
"size": 224
}
```
<Tip>
Se você não estiver procurando por nenhuma customização, apenas use o método `from_pretrained` para carregar parâmetros do modelo de extrator de features padrão.
</Tip>
Modifique qualquer parâmetro dentre os [`ViTFeatureExtractor`] para criar seu extrator de features customizado.
```py
>>> from transformers import ViTFeatureExtractor
>>> my_vit_extractor = ViTFeatureExtractor(resample="PIL.Image.BOX", do_normalize=False, image_mean=[0.3, 0.3, 0.3])
>>> print(my_vit_extractor)
ViTFeatureExtractor {
"do_normalize": false,
"do_resize": true,
"feature_extractor_type": "ViTFeatureExtractor",
"image_mean": [
0.3,
0.3,
0.3
],
"image_std": [
0.5,
0.5,
0.5
],
"resample": "PIL.Image.BOX",
"size": 224
}
```
Para entradas de áutio, você pode criar um [`Wav2Vec2FeatureExtractor`] e customizar os parâmetros de uma forma similar:
```py
>>> from transformers import Wav2Vec2FeatureExtractor
>>> w2v2_extractor = Wav2Vec2FeatureExtractor()
>>> print(w2v2_extractor)
Wav2Vec2FeatureExtractor {
"do_normalize": true,
"feature_extractor_type": "Wav2Vec2FeatureExtractor",
"feature_size": 1,
"padding_side": "right",
"padding_value": 0.0,
"return_attention_mask": false,
"sampling_rate": 16000
}
```
## Processor
Para modelos que suportam tarefas multimodais, 🤗 Transformers oferece uma classe processadora que convenientemente cobre um extrator de features e tokenizer dentro de um único objeto. Por exemplo, vamos usar o [`Wav2Vec2Processor`] para uma tarefa de reconhecimento de fala automática (ASR). ASR transcreve áudio para texto, então você irá precisar de um extrator de um features e um tokenizer.
Crie um extrator de features para lidar com as entradas de áudio.
```py
>>> from transformers import Wav2Vec2FeatureExtractor
>>> feature_extractor = Wav2Vec2FeatureExtractor(padding_value=1.0, do_normalize=True)
```
Crie um tokenizer para lidar com a entrada de textos:
```py
>>> from transformers import Wav2Vec2CTCTokenizer
>>> tokenizer = Wav2Vec2CTCTokenizer(vocab_file="my_vocab_file.txt")
```
Combine o extrator de features e o tokenizer no [`Wav2Vec2Processor`]:
```py
>>> from transformers import Wav2Vec2Processor
>>> processor = Wav2Vec2Processor(feature_extractor=feature_extractor, tokenizer=tokenizer)
```
Com duas classes básicas - configuração e modelo - e um preprocessamento de classe adicional (tokenizer, extrator de features, ou processador), você pode criar qualquer modelo que suportado por 🤗 Transformers. Qualquer uma dessas classes base são configuráveis, te permitindo usar os atributos específicos que você queira. Você pode facilmente preparar um modelo para treinamento ou modificar um modelo pré-treinado com poucas mudanças. | 0 |
hf_public_repos/transformers/docs/source | hf_public_repos/transformers/docs/source/pt/accelerate.md | <!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Treinamento distribuído com o 🤗 Accelerate
O paralelismo surgiu como uma estratégia para treinar modelos grandes em hardware limitado e aumentar a velocidade
de treinamento em várias órdens de magnitude. Na Hugging Face criamos a biblioteca [🤗 Accelerate](https://huggingface.co/docs/accelerate)
para ajudar os usuários a treinar modelos 🤗 Transformers com qualquer configuração distribuída, seja em uma máquina
com múltiplos GPUs ou em múltiplos GPUs distribuidos entre muitas máquinas. Neste tutorial, você irá aprender como
personalizar seu laço de treinamento de PyTorch para poder treinar em ambientes distribuídos.
## Configuração
De início, instale o 🤗 Accelerate:
```bash
pip install accelerate
```
Logo, devemos importar e criar um objeto [`Accelerator`](https://huggingface.co/docs/accelerate/package_reference/accelerator#accelerate.Accelerator).
O `Accelerator` detectará automáticamente a configuração distribuída disponível e inicializará todos os
componentes necessários para o treinamento. Não há necessidade portanto de especificar o dispositivo onde deve colocar seu modelo.
```py
>>> from accelerate import Accelerator
>>> accelerator = Accelerator()
```
## Preparando a aceleração
Passe todos os objetos relevantes ao treinamento para o método [`prepare`](https://huggingface.co/docs/accelerate/package_reference/accelerator#accelerate.Accelerator.prepare).
Isto inclui os DataLoaders de treino e evaluação, um modelo e um otimizador:
```py
>>> train_dataloader, eval_dataloader, model, optimizer = accelerator.prepare(
... train_dataloader, eval_dataloader, model, optimizer
... )
```
## Backward
Por último, substitua o `loss.backward()` padrão em seu laço de treinamento com o método [`backward`](https://huggingface.co/docs/accelerate/package_reference/accelerator#accelerate.Accelerator.backward) do 🤗 Accelerate:
```py
>>> for epoch in range(num_epochs):
... for batch in train_dataloader:
... outputs = model(**batch)
... loss = outputs.loss
... accelerator.backward(loss)
... optimizer.step()
... lr_scheduler.step()
... optimizer.zero_grad()
... progress_bar.update(1)
```
Como se poder ver no seguinte código, só precisará adicionar quatro linhas de código ao seu laço de treinamento
para habilitar o treinamento distribuído!
```diff
+ from accelerate import Accelerator
from transformers import AdamW, AutoModelForSequenceClassification, get_scheduler
+ accelerator = Accelerator()
model = AutoModelForSequenceClassification.from_pretrained(checkpoint, num_labels=2)
optimizer = AdamW(model.parameters(), lr=3e-5)
- device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
- model.to(device)
+ train_dataloader, eval_dataloader, model, optimizer = accelerator.prepare(
+ train_dataloader, eval_dataloader, model, optimizer
+ )
num_epochs = 3
num_training_steps = num_epochs * len(train_dataloader)
lr_scheduler = get_scheduler(
"linear",
optimizer=optimizer,
num_warmup_steps=0,
num_training_steps=num_training_steps
)
progress_bar = tqdm(range(num_training_steps))
model.train()
for epoch in range(num_epochs):
for batch in train_dataloader:
- batch = {k: v.to(device) for k, v in batch.items()}
outputs = model(**batch)
loss = outputs.loss
- loss.backward()
+ accelerator.backward(loss)
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
progress_bar.update(1)
```
## Treinamento
Quando tiver adicionado as linhas de código relevantes, inicie o treinamento por um script ou notebook como o Colab.
### Treinamento em um Script
Se estiver rodando seu treinamento em um Script, execute o seguinte comando para criar e guardar um arquivo de configuração:
```bash
accelerate config
```
Comece o treinamento com:
```bash
accelerate launch train.py
```
### Treinamento em um Notebook
O 🤗 Accelerate pode rodar em um notebook, por exemplo, se estiver planejando usar as TPUs do Google Colab.
Encapsule o código responsável pelo treinamento de uma função e passe-o ao `notebook_launcher`:
```py
>>> from accelerate import notebook_launcher
>>> notebook_launcher(training_function)
```
Para obter mais informações sobre o 🤗 Accelerate e suas numerosas funções, consulte a [documentación](https://huggingface.co/docs/accelerate/index).
| 0 |
hf_public_repos/transformers/docs/source | hf_public_repos/transformers/docs/source/pt/training.md | <!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Fine-tuning de um modelo pré-treinado
[[open-in-colab]]
O uso de um modelo pré-treinado tem importantes vantagens. Redução do custo computacional, a pegada de carbono, e te
permite utilizar modelos de última geração sem ter que treinar um novo desde o início.
O 🤗 Transformers proporciona acesso a milhares de modelos pré-treinados numa ampla gama de tarefas.
Quando utilizar um modelo pré-treinado, treine-o com um dataset específico para a sua tarefa.
Isto é chamado de fine-tuning, uma técnica de treinamento incrivelmente poderosa. Neste tutorial faremos o fine-tuning
de um modelo pré-treinado com um framework de Deep Learning da sua escolha:
* Fine-tuning de um modelo pré-treinado com o 🤗 Transformers [`Trainer`].
* Fine-tuning de um modelo pré-treinado no TensorFlow com o Keras.
* Fine-tuning de um modelo pré-treinado em PyTorch nativo.
<a id='data-processing'></a>
## Preparando um dataset
<Youtube id="_BZearw7f0w"/>
Antes de aplicar o fine-tuning a um modelo pré-treinado, baixe um dataset e prepare-o para o treinamento.
O tutorial anterior ensinará a processar os dados para o treinamento, e então poderá ter a oportunidade de testar
esse novo conhecimento em algo prático.
Comece carregando o dataset [Yelp Reviews](https://huggingface.co/datasets/yelp_review_full):
```py
>>> from datasets import load_dataset
>>> dataset = load_dataset("yelp_review_full")
>>> dataset[100]
{'label': 0,
'text': 'My expectations for McDonalds are t rarely high. But for one to still fail so spectacularly...that takes something special!\\nThe cashier took my friends\'s order, then promptly ignored me. I had to force myself in front of a cashier who opened his register to wait on the person BEHIND me. I waited over five minutes for a gigantic order that included precisely one kid\'s meal. After watching two people who ordered after me be handed their food, I asked where mine was. The manager started yelling at the cashiers for \\"serving off their orders\\" when they didn\'t have their food. But neither cashier was anywhere near those controls, and the manager was the one serving food to customers and clearing the boards.\\nThe manager was rude when giving me my order. She didn\'t make sure that I had everything ON MY RECEIPT, and never even had the decency to apologize that I felt I was getting poor service.\\nI\'ve eaten at various McDonalds restaurants for over 30 years. I\'ve worked at more than one location. I expect bad days, bad moods, and the occasional mistake. But I have yet to have a decent experience at this store. It will remain a place I avoid unless someone in my party needs to avoid illness from low blood sugar. Perhaps I should go back to the racially biased service of Steak n Shake instead!'}
```
Como já sabe, é necessário ter um tokenizador para processar o texto e incluir uma estratégia de padding e truncamento,
para manejar qualquer tamanho varíavel de sequência. Para processar o seu dataset em apenas um passo, utilize o método de
🤗 Datasets [`map`](https://huggingface.co/docs/datasets/process.html#map) para aplicar uma função de preprocessamento sobre
todo o dataset.
```py
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
>>> def tokenize_function(examples):
... return tokenizer(examples["text"], padding="max_length", truncation=True)
>>> tokenized_datasets = dataset.map(tokenize_function, batched=True)
```
Se desejar, é possível criar um subconjunto menor do dataset completo para aplicar o fine-tuning e assim reduzir o tempo necessário.
```py
>>> small_train_dataset = tokenized_datasets["train"].shuffle(seed=42).select(range(1000))
>>> small_eval_dataset = tokenized_datasets["test"].shuffle(seed=42).select(range(1000))
```
<a id='trainer'></a>
## Fine-tuning com o `Trainer`
<Youtube id="nvBXf7s7vTI"/>
O 🤗 Transformers proporciona uma classe [`Trainer`] otimizada para o treinamento de modelos de 🤗 Transformers,
facilitando os primeiros passos do treinamento sem a necessidade de escrever manualmente o seu próprio ciclo.
A API do [`Trainer`] suporta um grande conjunto de opções de treinamento e funcionalidades, como o logging,
o gradient accumulation e o mixed precision.
Comece carregando seu modelo e especifique o número de labels de previsão.
A partir do [Card Dataset](https://huggingface.co/datasets/yelp_review_full#data-fields) do Yelp Reveiw, que ja
sabemos ter 5 labels usamos o seguinte código:
```py
>>> from transformers import AutoModelForSequenceClassification
>>> model = AutoModelForSequenceClassification.from_pretrained("bert-base-cased", num_labels=5)
```
<Tip>
Você verá um alerta sobre alguns pesos pré-treinados que não estão sendo utilizados e que alguns pesos estão
sendo inicializados aleatoriamente. Não se preocupe, essa mensagem é completamente normal.
O header/cabeçário pré-treinado do modelo BERT é descartado e substitui-se por um header de classificação
inicializado aleatoriamente. Assim, pode aplicar o fine-tuning a este novo header do modelo em sua tarefa
de classificação de sequências fazendo um transfer learning do modelo pré-treinado.
</Tip>
### Hiperparâmetros de treinamento
Em seguida, crie uma classe [`TrainingArguments`] que contenha todos os hiperparâmetros que possam ser ajustados, assim
como os indicadores para ativar as diferentes opções de treinamento. Para este tutorial, você pode começar o treinamento
usando os [hiperparámetros](https://huggingface.co/docs/transformers/main_classes/trainer#transformers.TrainingArguments) padrão,
porém, sinta-se livre para experimentar com eles e encontrar uma configuração ótima.
Especifique onde salvar os checkpoints do treinamento:
```py
>>> from transformers import TrainingArguments
>>> training_args = TrainingArguments(output_dir="test_trainer")
```
### Métricas
O [`Trainer`] não avalia automaticamente o rendimento do modelo durante o treinamento. Será necessário passar ao
[`Trainer`] uma função para calcular e fazer um diagnóstico sobre as métricas. A biblioteca 🤗 Datasets proporciona
uma função de [`accuracy`](https://huggingface.co/metrics/accuracy) simples que pode ser carregada com a função
`load_metric` (ver este [tutorial](https://huggingface.co/docs/datasets/metrics.html) para mais informações):
```py
>>> import numpy as np
>>> from datasets import load_metric
>>> metric = load_metric("accuracy")
```
Defina a função `compute` dentro de `metric` para calcular a precisão das suas predições.
Antes de passar as suas predições ao `compute`, é necessário converter as predições à logits (lembre-se que
todos os modelos de 🤗 Transformers retornam logits).
```py
>>> def compute_metrics(eval_pred):
... logits, labels = eval_pred
... predictions = np.argmax(logits, axis=-1)
... return metric.compute(predictions=predictions, references=labels)
```
Se quiser controlar as suas métricas de avaliação durante o fine-tuning, especifique o parâmetro `evaluation_strategy`
nos seus argumentos de treinamento para que o modelo considere a métrica de avaliação ao final de cada época:
```py
>>> from transformers import TrainingArguments
>>> training_args = TrainingArguments(output_dir="test_trainer", evaluation_strategy="epoch")
```
### Trainer
Crie um objeto [`Trainer`] com o seu modelo, argumentos de treinamento, conjuntos de dados de treinamento e de teste, e a sua função de avaliação:
```py
>>> trainer = Trainer(
... model=model,
... args=training_args,
... train_dataset=small_train_dataset,
... eval_dataset=small_eval_dataset,
... compute_metrics=compute_metrics,
... )
```
Em seguida, aplique o fine-tuning a seu modelo chamado [`~transformers.Trainer.train`]:
```py
>>> trainer.train()
```
<a id='keras'></a>
## Fine-tuning com Keras
<Youtube id="rnTGBy2ax1c"/>
Os modelos de 🤗 Transformers também permitem realizar o treinamento com o TensorFlow com a API do Keras.
Contudo, será necessário fazer algumas mudanças antes de realizar o fine-tuning.
### Conversão do dataset ao formato do TensorFlow
O [`DefaultDataCollator`] junta os tensores em um batch para que o modelo possa ser treinado em cima deles.
Assegure-se de especificar os `return_tensors` para retornar os tensores do TensorFlow:
```py
>>> from transformers import DefaultDataCollator
>>> data_collator = DefaultDataCollator(return_tensors="tf")
```
<Tip>
O [`Trainer`] utiliza [`DataCollatorWithPadding`] por padrão, então você não precisa especificar explicitamente um
colador de dados (data collator).
</Tip>
Em seguida, converta os datasets tokenizados em datasets do TensorFlow com o método
[`to_tf_dataset`](https://huggingface.co/docs/datasets/package_reference/main_classes.html#datasets.Dataset.to_tf_dataset).
Especifique suas entradas em `columns` e seu rótulo em `label_cols`:
```py
>>> tf_train_dataset = small_train_dataset.to_tf_dataset(
... columns=["attention_mask", "input_ids", "token_type_ids"],
... label_cols="labels",
... shuffle=True,
... collate_fn=data_collator,
... batch_size=8,
... )
>>> tf_validation_dataset = small_eval_dataset.to_tf_dataset(
... columns=["attention_mask", "input_ids", "token_type_ids"],
... label_cols="labels",
... shuffle=False,
... collate_fn=data_collator,
... batch_size=8,
... )
```
### Compilação e ajustes
Carregue um modelo do TensorFlow com o número esperado de rótulos:
```py
>>> import tensorflow as tf
>>> from transformers import TFAutoModelForSequenceClassification
>>> model = TFAutoModelForSequenceClassification.from_pretrained("bert-base-cased", num_labels=5)
```
A seguir, compile e ajuste o fine-tuning a seu modelo com [`fit`](https://keras.io/api/models/model_training_apis/) como
faria com qualquer outro modelo do Keras:
```py
>>> model.compile(
... optimizer=tf.keras.optimizers.Adam(learning_rate=5e-5),
... loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
... metrics=tf.metrics.SparseCategoricalAccuracy(),
... )
>>> model.fit(tf_train_dataset, validation_data=tf_validation_dataset, epochs=3)
```
<a id='pytorch_native'></a>
## Fine-tune em PyTorch nativo
<Youtube id="Dh9CL8fyG80"/>
O [`Trainer`] se encarrega do ciclo de treinamento e permite aplicar o fine-tuning a um modelo em uma linha de código apenas.
Para os usuários que preferirem escrever o seu próprio ciclo de treinamento, também é possível aplicar o fine-tuning a um
modelo de 🤗 Transformers em PyTorch nativo.
Neste momento, talvez ocorra a necessidade de reinicar seu notebook ou executar a seguinte linha de código para liberar
memória:
```py
del model
del pytorch_model
del trainer
torch.cuda.empty_cache()
```
Em sequência, faremos um post-processing manual do `tokenized_dataset` e assim prepará-lo para o treinamento.
1. Apague a coluna de `text` porque o modelo não aceita texto cru como entrada:
```py
>>> tokenized_datasets = tokenized_datasets.remove_columns(["text"])
```
2. Troque o nome da coluna `label` para `labels`, pois o modelo espera um argumento de mesmo nome:
```py
>>> tokenized_datasets = tokenized_datasets.rename_column("label", "labels")
```
3. Defina o formato do dataset para retornar tensores do PyTorch no lugar de listas:
```py
>>> tokenized_datasets.set_format("torch")
```
Em sequência, crie um subconjunto menor do dataset, como foi mostrado anteriormente, para acelerá-lo o fine-tuning.
```py
>>> small_train_dataset = tokenized_datasets["train"].shuffle(seed=42).select(range(1000))
>>> small_eval_dataset = tokenized_datasets["test"].shuffle(seed=42).select(range(1000))
```
### DataLoader
Crie um `DataLoader` para os seus datasets de treinamento e de teste para poder iterar sobre batches de dados:
```py
>>> from torch.utils.data import DataLoader
>>> train_dataloader = DataLoader(small_train_dataset, shuffle=True, batch_size=8)
>>> eval_dataloader = DataLoader(small_eval_dataset, batch_size=8)
```
Carregue seu modelo com o número de labels esperados:
```py
>>> from transformers import AutoModelForSequenceClassification
>>> model = AutoModelForSequenceClassification.from_pretrained("bert-base-cased", num_labels=5)
```
### Otimização e configuração do Learning Rate
Crie um otimizador e um learning rate para aplicar o fine-tuning ao modelo.
Iremos utilizar o otimizador [`AdamW`](https://pytorch.org/docs/stable/generated/torch.optim.AdamW.html) do PyTorch:
```py
>>> from torch.optim import AdamW
>>> optimizer = AdamW(model.parameters(), lr=5e-5)
```
Defina o learning rate do [`Trainer`]:
```py
>>> from transformers import get_scheduler
>>> num_epochs = 3
>>> num_training_steps = num_epochs * len(train_dataloader)
>>> lr_scheduler = get_scheduler(
... name="linear", optimizer=optimizer, num_warmup_steps=0, num_training_steps=num_training_steps
... )
```
Por último, especifique o `device` do ambiente para utilizar uma GPU se tiver acesso à alguma. Caso contrário, o treinamento
em uma CPU pode acabar levando várias horas em vez de minutos.
```py
>>> import torch
>>> device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
>>> model.to(device)
```
<Tip>
Se necessário, você pode obter o acesso gratuito a uma GPU na núvem por meio de um notebook no
[Colaboratory](https://colab.research.google.com/) ou [SageMaker StudioLab](https://studiolab.sagemaker.aws/)
se não tiver esse recurso de forma local.
</Tip>
Perfeito, agora estamos prontos para começar o treinamento! 🥳
### Ciclo de treinamento
Para visualizar melhor o processo de treinamento, utilize a biblioteca [tqdm](https://tqdm.github.io/) para adicionar
uma barra de progresso sobre o número de passos percorridos no treinamento atual:
```py
>>> from tqdm.auto import tqdm
>>> progress_bar = tqdm(range(num_training_steps))
>>> model.train()
>>> for epoch in range(num_epochs):
... for batch in train_dataloader:
... batch = {k: v.to(device) for k, v in batch.items()}
... outputs = model(**batch)
... loss = outputs.loss
... loss.backward()
... optimizer.step()
... lr_scheduler.step()
... optimizer.zero_grad()
... progress_bar.update(1)
```
### Métricas
Da mesma forma que é necessário adicionar uma função de avaliação ao [`Trainer`], é necessário fazer o mesmo quando
escrevendo o próprio ciclo de treinamento. Contudo, em vez de calcular e retornar a métrica final de cada época,
você deverá adicionar todos os batches com [`add_batch`](https://huggingface.co/docs/datasets/package_reference/main_classes.html?highlight=add_batch#datasets.Metric.add_batch)
e calcular a métrica apenas no final.
```py
>>> metric = load_metric("accuracy")
>>> model.eval()
>>> for batch in eval_dataloader:
... batch = {k: v.to(device) for k, v in batch.items()}
... with torch.no_grad():
... outputs = model(**batch)
... logits = outputs.logits
... predictions = torch.argmax(logits, dim=-1)
... metric.add_batch(predictions=predictions, references=batch["labels"])
>>> metric.compute()
```
<a id='additional-resources'></a>
## Recursos adicionais
Para mais exemplos de fine-tuning acesse:
- [🤗 Transformers Examples](https://github.com/huggingface/transformers/tree/main/examples) inclui scripts
para treinas tarefas comuns de NLP em PyTorch e TensorFlow.
- [🤗 Transformers Notebooks](notebooks) contém vários notebooks sobre como aplicar o fine-tuning a um modelo
para tarefas específicas no PyTorch e TensorFlow.
| 0 |
hf_public_repos/transformers/docs/source/pt | hf_public_repos/transformers/docs/source/pt/tasks/token_classification.md | <!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Classificação de tokens
<Youtube id="wVHdVlPScxA"/>
A classificação de tokens atribui um rótulo a tokens individuais em uma frase. Uma das tarefas de classificação de tokens mais comuns é o Reconhecimento de Entidade Nomeada, também chamada de NER (sigla em inglês para Named Entity Recognition). O NER tenta encontrar um rótulo para cada entidade em uma frase, como uma pessoa, local ou organização.
Este guia mostrará como realizar o fine-tuning do [DistilBERT](https://huggingface.co/distilbert-base-uncased) no conjunto de dados [WNUT 17](https://huggingface.co/datasets/wnut_17) para detectar novas entidades.
<Tip>
Consulte a [página de tarefas de classificação de tokens](https://huggingface.co/tasks/token-classification) para obter mais informações sobre outras formas de classificação de tokens e seus modelos, conjuntos de dados e métricas associadas.
</Tip>
## Carregando o conjunto de dados WNUT 17
Carregue o conjunto de dados WNUT 17 da biblioteca 🤗 Datasets:
```py
>>> from datasets import load_dataset
>>> wnut = load_dataset("wnut_17")
```
E dê uma olhada em um exemplo:
```py
>>> wnut["train"][0]
{'id': '0',
'ner_tags': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 7, 8, 8, 0, 7, 0, 0, 0, 0, 0, 0, 0, 0],
'tokens': ['@paulwalk', 'It', "'s", 'the', 'view', 'from', 'where', 'I', "'m", 'living', 'for', 'two', 'weeks', '.', 'Empire', 'State', 'Building', '=', 'ESB', '.', 'Pretty', 'bad', 'storm', 'here', 'last', 'evening', '.']
}
```
Cada número em `ner_tags` representa uma entidade. Converta o número em um rótulo para obter mais informações:
```py
>>> label_list = wnut["train"].features[f"ner_tags"].feature.names
>>> label_list
[
"O",
"B-corporation",
"I-corporation",
"B-creative-work",
"I-creative-work",
"B-group",
"I-group",
"B-location",
"I-location",
"B-person",
"I-person",
"B-product",
"I-product",
]
```
O `ner_tag` descreve uma entidade, como uma organização, local ou pessoa. A letra que prefixa cada `ner_tag` indica a posição do token da entidade:
- `B-` indica o início de uma entidade.
- `I-` indica que um token está contido dentro da mesma entidade (por exemplo, o token `State` pode fazer parte de uma entidade como `Empire State Building`).
- `0` indica que o token não corresponde a nenhuma entidade.
## Pré-processamento
<Youtube id="iY2AZYdZAr0"/>
Carregue o tokenizer do DistilBERT para processar os `tokens`:
```py
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("distilbert-base-uncased")
```
Como a entrada já foi dividida em palavras, defina `is_split_into_words=True` para tokenizar as palavras em subpalavras:
```py
>>> tokenized_input = tokenizer(example["tokens"], is_split_into_words=True)
>>> tokens = tokenizer.convert_ids_to_tokens(tokenized_input["input_ids"])
>>> tokens
['[CLS]', '@', 'paul', '##walk', 'it', "'", 's', 'the', 'view', 'from', 'where', 'i', "'", 'm', 'living', 'for', 'two', 'weeks', '.', 'empire', 'state', 'building', '=', 'es', '##b', '.', 'pretty', 'bad', 'storm', 'here', 'last', 'evening', '.', '[SEP]']
```
Ao adicionar os tokens especiais `[CLS]` e `[SEP]` e a tokenização de subpalavras uma incompatibilidade é gerada entre a entrada e os rótulos. Uma única palavra correspondente a um único rótulo pode ser dividida em duas subpalavras. Você precisará realinhar os tokens e os rótulos da seguinte forma:
1. Mapeie todos os tokens para a palavra correspondente com o método [`word_ids`](https://huggingface.co/docs/tokenizers/python/latest/api/reference.html#tokenizers.Encoding.word_ids).
2. Atribuindo o rótulo `-100` aos tokens especiais `[CLS]` e `[SEP]` para que a função de loss do PyTorch ignore eles.
3. Rotular apenas o primeiro token de uma determinada palavra. Atribuindo `-100` a outros subtokens da mesma palavra.
Aqui está como você pode criar uma função para realinhar os tokens e rótulos e truncar sequências para não serem maiores que o comprimento máximo de entrada do DistilBERT:
```py
>>> def tokenize_and_align_labels(examples):
... tokenized_inputs = tokenizer(examples["tokens"], truncation=True, is_split_into_words=True)
... labels = []
... for i, label in enumerate(examples[f"ner_tags"]):
... word_ids = tokenized_inputs.word_ids(batch_index=i) # Map tokens to their respective word.
... previous_word_idx = None
... label_ids = []
... for word_idx in word_ids: # Set the special tokens to -100.
... if word_idx is None:
... label_ids.append(-100)
... elif word_idx != previous_word_idx: # Only label the first token of a given word.
... label_ids.append(label[word_idx])
... else:
... label_ids.append(-100)
... previous_word_idx = word_idx
... labels.append(label_ids)
... tokenized_inputs["labels"] = labels
... return tokenized_inputs
```
Use a função [`map`](https://huggingface.co/docs/datasets/package_reference/main_classes.html#datasets.Dataset.map) do 🤗 Datasets para tokenizar e alinhar os rótulos em todo o conjunto de dados. Você pode acelerar a função `map` configurando `batched=True` para processar vários elementos do conjunto de dados de uma só vez:
```py
>>> tokenized_wnut = wnut.map(tokenize_and_align_labels, batched=True)
```
Use o [`DataCollatorForTokenClassification`] para criar um batch de exemplos. Ele também *preencherá dinamicamente* seu texto e rótulos para o comprimento do elemento mais longo em seu batch, para que tenham um comprimento uniforme. Embora seja possível preencher seu texto na função `tokenizer` configurando `padding=True`, o preenchimento dinâmico é mais eficiente.
<frameworkcontent>
<pt>
```py
>>> from transformers import DataCollatorForTokenClassification
>>> data_collator = DataCollatorForTokenClassification(tokenizer=tokenizer)
```
</pt>
<tf>
```py
>>> from transformers import DataCollatorForTokenClassification
>>> data_collator = DataCollatorForTokenClassification(tokenizer=tokenizer, return_tensors="tf")
```
</tf>
</frameworkcontent>
## Treinamento
<frameworkcontent>
<pt>
Carregue o DistilBERT com o [`AutoModelForTokenClassification`] junto com o número de rótulos esperados:
```py
>>> from transformers import AutoModelForTokenClassification, TrainingArguments, Trainer
>>> model = AutoModelForTokenClassification.from_pretrained("distilbert-base-uncased", num_labels=14)
```
<Tip>
Se você não estiver familiarizado com o fine-tuning de um modelo com o [`Trainer`], dê uma olhada no tutorial básico [aqui](../training#finetune-with-trainer)!
</Tip>
Nesse ponto, restam apenas três passos:
1. Definir seus hiperparâmetros de treinamento em [`TrainingArguments`].
2. Passar os argumentos de treinamento para o [`Trainer`] junto com o modelo, conjunto de dados, tokenizador e o data collator.
3. Chamar a função [`~Trainer.train`] para executar o fine-tuning do seu modelo.
```py
>>> training_args = TrainingArguments(
... output_dir="./results",
... evaluation_strategy="epoch",
... learning_rate=2e-5,
... per_device_train_batch_size=16,
... per_device_eval_batch_size=16,
... num_train_epochs=3,
... weight_decay=0.01,
... )
>>> trainer = Trainer(
... model=model,
... args=training_args,
... train_dataset=tokenized_wnut["train"],
... eval_dataset=tokenized_wnut["test"],
... tokenizer=tokenizer,
... data_collator=data_collator,
... )
>>> trainer.train()
```
</pt>
<tf>
Para executar o fine-tuning de um modelo no TensorFlow, comece convertendo seu conjunto de dados para o formato `tf.data.Dataset` com [`to_tf_dataset`](https://huggingface.co/docs/datasets/package_reference/main_classes.html#datasets.Dataset.to_tf_dataset). Nessa execução você deverá especificar as entradas e rótulos (no parâmetro `columns`), se deseja embaralhar o conjunto de dados, o tamanho do batch e o data collator:
```py
>>> tf_train_set = tokenized_wnut["train"].to_tf_dataset(
... columns=["attention_mask", "input_ids", "labels"],
... shuffle=True,
... batch_size=16,
... collate_fn=data_collator,
... )
>>> tf_validation_set = tokenized_wnut["validation"].to_tf_dataset(
... columns=["attention_mask", "input_ids", "labels"],
... shuffle=False,
... batch_size=16,
... collate_fn=data_collator,
... )
```
<Tip>
Se você não estiver familiarizado com o fine-tuning de um modelo com o Keras, dê uma olhada no tutorial básico [aqui](training#finetune-with-keras)!
</Tip>
Configure o otimizador e alguns hiperparâmetros de treinamento:
```py
>>> from transformers import create_optimizer
>>> batch_size = 16
>>> num_train_epochs = 3
>>> num_train_steps = (len(tokenized_wnut["train"]) // batch_size) * num_train_epochs
>>> optimizer, lr_schedule = create_optimizer(
... init_lr=2e-5,
... num_train_steps=num_train_steps,
... weight_decay_rate=0.01,
... num_warmup_steps=0,
... )
```
Carregue o DistilBERT com o [`TFAutoModelForTokenClassification`] junto com o número de rótulos esperados:
```py
>>> from transformers import TFAutoModelForTokenClassification
>>> model = TFAutoModelForTokenClassification.from_pretrained("distilbert-base-uncased", num_labels=2)
```
Configure o modelo para treinamento com o método [`compile`](https://keras.io/api/models/model_training_apis/#compile-method):
```py
>>> import tensorflow as tf
>>> model.compile(optimizer=optimizer)
```
Chame o método [`fit`](https://keras.io/api/models/model_training_apis/#fit-method) para executar o fine-tuning do modelo:
```py
>>> model.fit(x=tf_train_set, validation_data=tf_validation_set, epochs=3)
```
</tf>
</frameworkcontent>
<Tip>
Para obter um exemplo mais aprofundado de como executar o fine-tuning de um modelo para classificação de tokens, dê uma olhada nesse [notebook utilizando PyTorch](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/token_classification.ipynb) ou nesse [notebook utilizando TensorFlow](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/token_classification-tf.ipynb).
</Tip> | 0 |
hf_public_repos/transformers/docs/source/pt | hf_public_repos/transformers/docs/source/pt/tasks/sequence_classification.md | <!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Classificação de texto
<Youtube id="leNG9fN9FQU"/>
A classificação de texto é uma tarefa comum de NLP que atribui um rótulo ou classe a um texto. Existem muitas aplicações práticas de classificação de texto amplamente utilizadas em produção por algumas das maiores empresas da atualidade. Uma das formas mais populares de classificação de texto é a análise de sentimento, que atribui um rótulo como positivo, negativo ou neutro a um texto.
Este guia mostrará como realizar o fine-tuning do [DistilBERT](https://huggingface.co/distilbert-base-uncased) no conjunto de dados [IMDb](https://huggingface.co/datasets/imdb) para determinar se a crítica de filme é positiva ou negativa.
<Tip>
Consulte a [página de tarefas de classificação de texto](https://huggingface.co/tasks/text-classification) para obter mais informações sobre outras formas de classificação de texto e seus modelos, conjuntos de dados e métricas associados.
</Tip>
## Carregue o conjunto de dados IMDb
Carregue o conjunto de dados IMDb utilizando a biblioteca 🤗 Datasets:
```py
>>> from datasets import load_dataset
>>> imdb = load_dataset("imdb")
```
Em seguida, dê uma olhada em um exemplo:
```py
>>> imdb["test"][0]
{
"label": 0,
"text": "I love sci-fi and am willing to put up with a lot. Sci-fi movies/TV are usually underfunded, under-appreciated and misunderstood. I tried to like this, I really did, but it is to good TV sci-fi as Babylon 5 is to Star Trek (the original). Silly prosthetics, cheap cardboard sets, stilted dialogues, CG that doesn't match the background, and painfully one-dimensional characters cannot be overcome with a 'sci-fi' setting. (I'm sure there are those of you out there who think Babylon 5 is good sci-fi TV. It's not. It's clichéd and uninspiring.) While US viewers might like emotion and character development, sci-fi is a genre that does not take itself seriously (cf. Star Trek). It may treat important issues, yet not as a serious philosophy. It's really difficult to care about the characters here as they are not simply foolish, just missing a spark of life. Their actions and reactions are wooden and predictable, often painful to watch. The makers of Earth KNOW it's rubbish as they have to always say \"Gene Roddenberry's Earth...\" otherwise people would not continue watching. Roddenberry's ashes must be turning in their orbit as this dull, cheap, poorly edited (watching it without advert breaks really brings this home) trudging Trabant of a show lumbers into space. Spoiler. So, kill off a main character. And then bring him back as another actor. Jeeez! Dallas all over again.",
}
```
Existem dois campos neste dataset:
- `text`: uma string contendo o texto da crítica do filme.
- `label`: um valor que pode ser `0` para uma crítica negativa ou `1` para uma crítica positiva.
## Pré-processamento dos dados
Carregue o tokenizador do DistilBERT para processar o campo `text`:
```py
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("distilbert-base-uncased")
```
Crie uma função de pré-processamento para tokenizar o campo `text` e truncar as sequências para que não sejam maiores que o comprimento máximo de entrada do DistilBERT:
```py
>>> def preprocess_function(examples):
... return tokenizer(examples["text"], truncation=True)
```
Use a função [`map`](https://huggingface.co/docs/datasets/package_reference/main_classes.html#datasets.Dataset.map) do 🤗 Datasets para aplicar a função de pré-processamento em todo o conjunto de dados. Você pode acelerar a função `map` definindo `batched=True` para processar vários elementos do conjunto de dados de uma só vez:
```py
tokenized_imdb = imdb.map(preprocess_function, batched=True)
```
Use o [`DataCollatorWithPadding`] para criar um batch de exemplos. Ele também *preencherá dinamicamente* seu texto até o comprimento do elemento mais longo em seu batch, para que os exemplos do batch tenham um comprimento uniforme. Embora seja possível preencher seu texto com a função `tokenizer` definindo `padding=True`, o preenchimento dinâmico utilizando um data collator é mais eficiente.
<frameworkcontent>
<pt>
```py
>>> from transformers import DataCollatorWithPadding
>>> data_collator = DataCollatorWithPadding(tokenizer=tokenizer)
```
</pt>
<tf>
```py
>>> from transformers import DataCollatorWithPadding
>>> data_collator = DataCollatorWithPadding(tokenizer=tokenizer, return_tensors="tf")
```
</tf>
</frameworkcontent>
## Train
<frameworkcontent>
<pt>
Carregue o DistilBERT com [`AutoModelForSequenceClassification`] junto com o número de rótulos esperados:
```py
>>> from transformers import AutoModelForSequenceClassification, TrainingArguments, Trainer
>>> model = AutoModelForSequenceClassification.from_pretrained("distilbert-base-uncased", num_labels=2)
```
<Tip>
Se você não estiver familiarizado com o fine-tuning de um modelo com o [`Trainer`], dê uma olhada no tutorial básico [aqui](../training#finetune-with-trainer)!
</Tip>
Nesse ponto, restam apenas três passos:
1. Definir seus hiperparâmetros de treinamento em [`TrainingArguments`].
2. Passar os argumentos de treinamento para o [`Trainer`] junto com o modelo, conjunto de dados, tokenizador e o data collator.
3. Chamar a função [`~Trainer.train`] para executar o fine-tuning do seu modelo.
```py
>>> training_args = TrainingArguments(
... output_dir="./results",
... learning_rate=2e-5,
... per_device_train_batch_size=16,
... per_device_eval_batch_size=16,
... num_train_epochs=5,
... weight_decay=0.01,
... )
>>> trainer = Trainer(
... model=model,
... args=training_args,
... train_dataset=tokenized_imdb["train"],
... eval_dataset=tokenized_imdb["test"],
... tokenizer=tokenizer,
... data_collator=data_collator,
... )
>>> trainer.train()
```
<Tip>
O [`Trainer`] aplicará o preenchimento dinâmico por padrão quando você definir o argumento `tokenizer` dele. Nesse caso, você não precisa especificar um data collator explicitamente.
</Tip>
</pt>
<tf>
Para executar o fine-tuning de um modelo no TensorFlow, comece convertendo seu conjunto de dados para o formato `tf.data.Dataset` com [`to_tf_dataset`](https://huggingface.co/docs/datasets/package_reference/main_classes.html#datasets.Dataset.to_tf_dataset). Nessa execução você deverá especificar as entradas e rótulos (no parâmetro `columns`), se deseja embaralhar o conjunto de dados, o tamanho do batch e o data collator:
```py
>>> tf_train_set = tokenized_imdb["train"].to_tf_dataset(
... columns=["attention_mask", "input_ids", "label"],
... shuffle=True,
... batch_size=16,
... collate_fn=data_collator,
... )
>>> tf_validation_set = tokenized_imdb["test"].to_tf_dataset(
... columns=["attention_mask", "input_ids", "label"],
... shuffle=False,
... batch_size=16,
... collate_fn=data_collator,
... )
```
<Tip>
Se você não estiver familiarizado com o fine-tuning de um modelo com o Keras, dê uma olhada no tutorial básico [aqui](training#finetune-with-keras)!
</Tip>
Configure o otimizador e alguns hiperparâmetros de treinamento:
```py
>>> from transformers import create_optimizer
>>> import tensorflow as tf
>>> batch_size = 16
>>> num_epochs = 5
>>> batches_per_epoch = len(tokenized_imdb["train"]) // batch_size
>>> total_train_steps = int(batches_per_epoch * num_epochs)
>>> optimizer, schedule = create_optimizer(init_lr=2e-5, num_warmup_steps=0, num_train_steps=total_train_steps)
```
Carregue o DistilBERT com [`TFAutoModelForSequenceClassification`] junto com o número de rótulos esperados:
```py
>>> from transformers import TFAutoModelForSequenceClassification
>>> model = TFAutoModelForSequenceClassification.from_pretrained("distilbert-base-uncased", num_labels=2)
```
Configure o modelo para treinamento com o método [`compile`](https://keras.io/api/models/model_training_apis/#compile-method):
```py
>>> import tensorflow as tf
>>> model.compile(optimizer=optimizer)
```
Chame o método [`fit`](https://keras.io/api/models/model_training_apis/#fit-method) para executar o fine-tuning do modelo:
```py
>>> model.fit(x=tf_train_set, validation_data=tf_validation_set, epochs=3)
```
</tf>
</frameworkcontent>
<Tip>
Para obter um exemplo mais aprofundado de como executar o fine-tuning de um modelo para classificação de texto, dê uma olhada nesse [notebook utilizando PyTorch](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/text_classification.ipynb) ou nesse [notebook utilizando TensorFlow](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/text_classification-tf.ipynb).
</Tip> | 0 |
hf_public_repos/transformers/templates | hf_public_repos/transformers/templates/adding_a_new_model/README.md | <!---
Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
# Adding a new model
This folder contains templates to generate new models that fit the current API and pass all tests. It generates
models in both PyTorch, TensorFlow, and Flax and completes the `__init__.py` and auto-modeling files, and creates the
documentation. Their use is described in the [next section](#cookiecutter-templates).
There is also a CLI tool to generate a new model like an existing one called `transformers-cli add-new-model-like`.
Jump to the [Add new model like section](#add-new-model-like-command) to learn how to use it.
## Cookiecutter Templates
Using the `cookiecutter` utility requires to have all the `dev` dependencies installed. Let's first clone the
repository and install it in our environment:
```shell script
git clone https://github.com/huggingface/transformers
cd transformers
pip install -e ".[dev]"
```
Depending on your OS, and since the number of optional dependencies of Transformers is growing, you might get a
failure with this command. If that's the case make sure to install the Deep Learning framework you are working with
(PyTorch, TensorFlow and/or Flax) then do:
```bash
pip install -e ".[quality]"
```
Once the installation is done, you can use the CLI command `add-new-model` to generate your models:
```shell script
transformers-cli add-new-model
```
This should launch the `cookiecutter` package which should prompt you to fill in the configuration.
The `modelname` should be cased according to the plain text casing, i.e., BERT, RoBERTa, DeBERTa.
```
modelname [<ModelNAME>]:
uppercase_modelname [<MODEL_NAME>]:
lowercase_modelname [<model_name>]:
camelcase_modelname [<ModelName>]:
```
Fill in the `authors` with your team members:
```
authors [The HuggingFace Team]:
```
The checkpoint identifier is the checkpoint that will be used in the examples across the files. Put the name you wish,
as it will appear on the modelhub. Do not forget to include the organisation.
```
checkpoint_identifier [organisation/<model_name>-base-cased]:
```
The tokenizer should either be based on BERT if it behaves exactly like the BERT tokenizer, or a standalone otherwise.
```
Select tokenizer_type:
1 - Based on BERT
2 - Standalone
Choose from 1, 2 [1]:
```
<!---
Choose if your model is an encoder-decoder, or an encoder-only architecture.
If your model is an encoder-only architecture, the generated architecture will be based on the BERT model.
If your model is an encoder-decoder architecture, the generated architecture will be based on the BART model. You can,
of course, edit the files once the generation is complete.
```
Select is_encoder_decoder_model:
1 - True
2 - False
Choose from 1, 2 [1]:
```
-->
Once the command has finished, you should have a total of 7 new files spread across the repository:
```
docs/source/model_doc/<model_name>.md
src/transformers/models/<model_name>/configuration_<model_name>.py
src/transformers/models/<model_name>/modeling_<model_name>.py
src/transformers/models/<model_name>/modeling_tf_<model_name>.py
src/transformers/models/<model_name>/tokenization_<model_name>.py
tests/test_modeling_<model_name>.py
tests/test_modeling_tf_<model_name>.py
```
You can run the tests to ensure that they all pass:
```
python -m pytest ./tests/test_*<model_name>*.py
```
Feel free to modify each file to mimic the behavior of your model.
⚠ You should be careful about the classes preceded by the following line:️
```python
# Copied from transformers.[...]
```
This line ensures that the copy does not diverge from the source. If it *should* diverge, because the implementation
is different, this line needs to be deleted. If you don't delete this line and run `make fix-copies`,
your changes will be overwritten.
Once you have edited the files to fit your architecture, simply re-run the tests (and edit them if a change
is needed!) afterwards to make sure everything works as expected.
Once the files are generated and you are happy with your changes, here's a checklist to ensure that your contribution
will be merged quickly:
- You should run the `make fixup` utility to fix the style of the files and to ensure the code quality meets the
library's standards.
- You should complete the documentation file (`docs/source/model_doc/<model_name>.rst`) so that your model may be
usable.
## Add new model like command
Using the `transformers-cli add-new-model-like` command requires to have all the `dev` dependencies installed. Let's
first clone the repository and install it in our environment:
```shell script
git clone https://github.com/huggingface/transformers
cd transformers
pip install -e ".[dev]"
```
Depending on your OS, and since the number of optional dependencies of Transformers is growing, you might get a
failure with this command. If that's the case make sure to install the Deep Learning framework you are working with
(PyTorch, TensorFlow and/or Flax) then do:
```bash
pip install -e ".[quality]"
```
Once the installation is done, you can use the CLI command `add-new-model-like` to generate your models:
```shell script
transformers-cli add-new-model-like
```
This will start a small questionnaire you have to fill.
```
What identifier would you like to use for the model type of this model?
```
You will have to input the model type of the model you want to clone. The model type can be found in several places:
- inside the configuration of any checkpoint of that model
- the name of the documentation page of that model
For instance the doc page of `BigBirdPegasus` is `https://huggingface.co/docs/transformers/model_doc/bigbird_pegasus`
so its model type is `"bigbird_pegasus"`.
If you make a typo, the command will suggest you the closest model types it can find.
Once this is done, the questionnaire will ask you for the new model name and its various casings:
```
What is the name for your new model?
What identifier would you like to use for the model type of this model?
What name would you like to use for the module of this model?
What prefix (camel-cased) would you like to use for the model classes of this model?
What prefix (upper-cased) would you like to use for the constants relative to this model?
```
From your answer to the first question, defaults will be determined for all others. The first name should be written
as you want your model be named in the doc, with no special casing (like RoBERTa) and from there, you can either stick
with the defaults or change the cased versions.
Next will be the name of the config class to use for this model:
```
What will be the name of the config class for this model?
```
Then, you will be asked for a checkpoint identifier:
```
Please give a checkpoint identifier (on the model Hub) for this new model.
```
This is the checkpoint that will be used in the examples across the files and the integration tests. Put the name you
wish, as it will appear on the Model Hub. Do not forget to include the organisation.
Then you will have to say whether your model re-uses the same processing classes as the model you're cloning:
```
Will your new model use the same processing class as Xxx (XxxTokenizer/XxxFeatureExtractor/XxxImageProcessor)
```
Answer yes if you have no intentions to make any change to the class used for preprocessing. It can use different
files (for instance you can reuse the `BertTokenizer` with a new vocab file).
If you answer no, you will have to give the name of the classes
for the new tokenizer/image processor/feature extractor/processor (depending on the model you're cloning).
Next the questionnaire will ask
```
Should we add # Copied from statements when creating the new modeling file?
```
This is the intenal mechanism used in the library to make sure code copied from various modeling files stay consistent.
If you plan to completely rewrite the modeling file, you should answer no, whereas if you just want to tweak one part
of the model, you should answer yes.
Lastly, the questionnaire will inquire about frameworks:
```
Should we add a version of your new model in all the frameworks implemented by Old Model (xxx)?
```
If you answer yes, the new model will have files for all the frameworks implemented by the model you're cloning.
Otherwise, you will get a new question to select the frameworks you want.
Once the command has finished, you will see a new subfolder in the `src/transformers/models/` folder, with the
necessary files (configuration and modeling files for all frameworks requested, and maybe the processing files,
depending on your choices).
You will also see a doc file and tests for your new models. First you should run
```
make style
make fix-copies
```
and then you can start tweaking your model. You should:
- fill the doc file at `docs/source/model_doc/model_name.md`
- tweak the configuration and modeling files to your need
Once you're done, you can run the tests to ensure that they all pass:
```
python -m pytest ./tests/test_*<model_name>*.py
```
⚠ You should be careful about the classes preceded by the following line:️
```python
# Copied from transformers.[...]
```
This line ensures that the copy does not diverge from the source. If it *should* diverge, because the implementation
is different, this line needs to be deleted. If you don't delete this line and run `make fix-copies`,
your changes will be overwritten.
Once you have edited the files to fit your architecture, simply re-run the tests (and edit them if a change
is needed!) afterwards to make sure everything works as expected.
Once the files are generated and you are happy with your changes, here's a checklist to ensure that your contribution
will be merged quickly:
- You should run the `make fixup` utility to fix the style of the files and to ensure the code quality meets the
library's standards.
- You should add your model to the main README then run `make fix-copies`.
| 0 |
hf_public_repos/transformers/templates | hf_public_repos/transformers/templates/adding_a_new_model/ADD_NEW_MODEL_PROPOSAL_TEMPLATE.md | **TEMPLATE**
=====================================
*search & replace the following keywords, e.g.:*
`:%s/\[name of model\]/brand_new_bert/g`
-[lowercase name of model] # e.g. brand_new_bert
-[camelcase name of model] # e.g. BrandNewBert
-[name of mentor] # e.g. [Peter](https://github.com/peter)
-[link to original repo]
-[start date]
-[end date]
How to add [camelcase name of model] to 🤗 Transformers?
=====================================
Mentor: [name of mentor]
Begin: [start date]
Estimated End: [end date]
Adding a new model is often difficult and requires an in-depth knowledge
of the 🤗 Transformers library and ideally also of the model's original
repository. At Hugging Face, we are trying to empower the community more
and more to add models independently.
The following sections explain in detail how to add [camelcase name of model]
to Transformers. You will work closely with [name of mentor] to
integrate [camelcase name of model] into Transformers. By doing so, you will both gain a
theoretical and deep practical understanding of [camelcase name of model].
But more importantly, you will have made a major
open-source contribution to Transformers. Along the way, you will:
- get insights into open-source best practices
- understand the design principles of one of the most popular NLP
libraries
- learn how to do efficiently test large NLP models
- learn how to integrate Python utilities like `black`, `ruff`,
`make fix-copies` into a library to always ensure clean and readable
code
To start, let's try to get a general overview of the Transformers
library.
General overview of 🤗 Transformers
----------------------------------
First, you should get a general overview of 🤗 Transformers. Transformers
is a very opinionated library, so there is a chance that
you don't agree with some of the library's philosophies or design
choices. From our experience, however, we found that the fundamental
design choices and philosophies of the library are crucial to
efficiently scale Transformers while keeping maintenance costs at a
reasonable level.
A good first starting point to better understand the library is to read
the [documentation of our philosophy](https://huggingface.co/transformers/philosophy.html).
As a result of our way of working, there are some choices that we try to apply to all models:
- Composition is generally favored over abstraction
- Duplicating code is not always bad if it strongly improves the
readability or accessibility of a model
- Model files are as self-contained as possible so that when you read
the code of a specific model, you ideally only have to look into the
respective `modeling_....py` file.
In our opinion, the library's code is not just a means to provide a
product, *e.g.*, the ability to use BERT for inference, but also as the
very product that we want to improve. Hence, when adding a model, the
user is not only the person that will use your model, but also everybody
that will read, try to understand, and possibly tweak your code.
With this in mind, let's go a bit deeper into the general library
design.
### Overview of models
To successfully add a model, it is important to understand the
interaction between your model and its config,
`PreTrainedModel`, and `PretrainedConfig`. For
exemplary purposes, we will call the PyTorch model to be added to 🤗 Transformers
`BrandNewBert`.
Let's take a look:
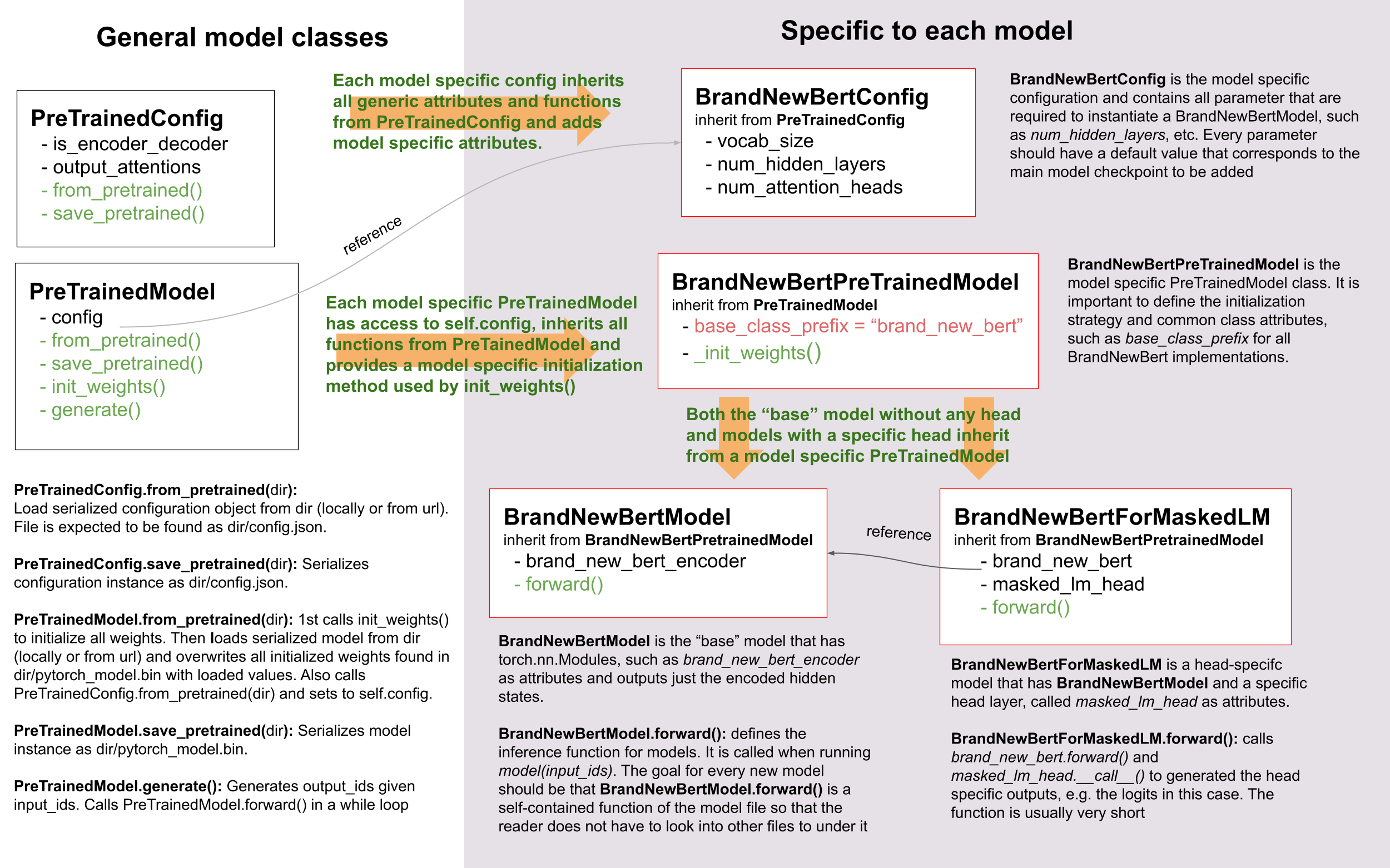
As you can see, we do make use of inheritance in 🤗 Transformers, but we
keep the level of abstraction to an absolute minimum. There are never
more than two levels of abstraction for any model in the library.
`BrandNewBertModel` inherits from
`BrandNewBertPreTrainedModel` which in
turn inherits from `PreTrainedModel` and that's it.
As a general rule, we want to make sure
that a new model only depends on `PreTrainedModel`. The
important functionalities that are automatically provided to every new
model are
`PreTrainedModel.from_pretrained` and `PreTrainedModel.save_pretrained`, which are
used for serialization and deserialization. All
of the other important functionalities, such as
`BrandNewBertModel.forward` should be
completely defined in the new `modeling_brand_new_bert.py` module. Next,
we want to make sure that a model with a specific head layer, such as
`BrandNewBertForMaskedLM` does not inherit
from `BrandNewBertModel`, but rather uses
`BrandNewBertModel` as a component that
can be called in its forward pass to keep the level of abstraction low.
Every new model requires a configuration class, called
`BrandNewBertConfig`. This configuration
is always stored as an attribute in
`PreTrainedModel`, and
thus can be accessed via the `config` attribute for all classes
inheriting from `BrandNewBertPreTrainedModel`
```python
# assuming that `brand_new_bert` belongs to the organization `brandy`
model = BrandNewBertModel.from_pretrained("brandy/brand_new_bert")
model.config # model has access to its config
```
Similar to the model, the configuration inherits basic serialization and
deserialization functionalities from
`PretrainedConfig`. Note
that the configuration and the model are always serialized into two
different formats - the model to a `pytorch_model.bin` file
and the configuration to a `config.json` file. Calling
`PreTrainedModel.save_pretrained` will automatically call
`PretrainedConfig.save_pretrained`, so that both model and configuration are saved.
### Overview of tokenizers
Not quite ready yet :-( This section will be added soon!
Step-by-step recipe to add a model to 🤗 Transformers
----------------------------------------------------
Everyone has different preferences of how to port a model so it can be
very helpful for you to take a look at summaries of how other
contributors ported models to Hugging Face. Here is a list of community
blog posts on how to port a model:
1. [Porting GPT2
Model](https://medium.com/huggingface/from-tensorflow-to-pytorch-265f40ef2a28)
by [Thomas](https://huggingface.co/thomwolf)
2. [Porting WMT19 MT Model](https://huggingface.co/blog/porting-fsmt)
by [Stas](https://huggingface.co/stas)
From experience, we can tell you that the most important things to keep
in mind when adding a model are:
- Don't reinvent the wheel! Most parts of the code you will add for
the new 🤗 Transformers model already exist somewhere in 🤗
Transformers. Take some time to find similar, already existing
models and tokenizers you can copy from.
[grep](https://www.gnu.org/software/grep/) and
[rg](https://github.com/BurntSushi/ripgrep) are your friends. Note
that it might very well happen that your model's tokenizer is based
on one model implementation, and your model's modeling code on
another one. *E.g.*, FSMT's modeling code is based on BART, while
FSMT's tokenizer code is based on XLM.
- It's more of an engineering challenge than a scientific challenge.
You should spend more time on creating an efficient debugging
environment than trying to understand all theoretical aspects of the
model in the paper.
- Ask for help when you're stuck! Models are the core component of 🤗
Transformers so we, at Hugging Face, are more than happy to help
you at every step to add your model. Don't hesitate to ask if you
notice you are not making progress.
In the following, we try to give you a general recipe that we found most
useful when porting a model to 🤗 Transformers.
The following list is a summary of everything that has to be done to add
a model and can be used by you as a To-Do List:
1. [ ] (Optional) Understood theoretical aspects
2. [ ] Prepared transformers dev environment
3. [ ] Set up debugging environment of the original repository
4. [ ] Created script that successfully runs forward pass using
original repository and checkpoint
5. [ ] Successfully opened a PR and added the model skeleton to Transformers
6. [ ] Successfully converted original checkpoint to Transformers
checkpoint
7. [ ] Successfully ran forward pass in Transformers that gives
identical output to original checkpoint
8. [ ] Finished model tests in Transformers
9. [ ] Successfully added Tokenizer in Transformers
10. [ ] Run end-to-end integration tests
11. [ ] Finished docs
12. [ ] Uploaded model weights to the hub
13. [ ] Submitted the pull request for review
14. [ ] (Optional) Added a demo notebook
To begin with, we usually recommend to start by getting a good
theoretical understanding of `[camelcase name of model]`. However, if you prefer to
understand the theoretical aspects of the model *on-the-job*, then it is
totally fine to directly dive into the `[camelcase name of model]`'s code-base. This
option might suit you better, if your engineering skills are better than
your theoretical skill, if you have trouble understanding
`[camelcase name of model]`'s paper, or if you just enjoy programming much more than
reading scientific papers.
### 1. (Optional) Theoretical aspects of [camelcase name of model]
You should take some time to read *[camelcase name of model]'s* paper, if such
descriptive work exists. There might be large sections of the paper that
are difficult to understand. If this is the case, this is fine - don't
worry! The goal is not to get a deep theoretical understanding of the
paper, but to extract the necessary information required to effectively
re-implement the model in 🤗 Transformers. That being said, you don't
have to spend too much time on the theoretical aspects, but rather focus
on the practical ones, namely:
- What type of model is *[camelcase name of model]*? BERT-like encoder-only
model? GPT2-like decoder-only model? BART-like encoder-decoder
model? Look at the `model_summary` if
you're not familiar with the differences between those.
- What are the applications of *[camelcase name of model]*? Text
classification? Text generation? Seq2Seq tasks, *e.g.,*
summarization?
- What is the novel feature of the model making it different from
BERT/GPT-2/BART?
- Which of the already existing [🤗 Transformers
models](https://huggingface.co/transformers/#contents) is most
similar to *[camelcase name of model]*?
- What type of tokenizer is used? A sentencepiece tokenizer? Word
piece tokenizer? Is it the same tokenizer as used for BERT or BART?
After you feel like you have gotten a good overview of the architecture
of the model, you might want to write to [name of mentor] with any
questions you might have. This might include questions regarding the
model's architecture, its attention layer, etc. We will be more than
happy to help you.
#### Additional resources
Before diving into the code, here are some additional resources that might be worth taking a look at:
- [link 1]
- [link 2]
- [link 3]
- ...
#### Make sure you've understood the fundamental aspects of [camelcase name of model]
Alright, now you should be ready to take a closer look into the actual code of [camelcase name of model].
You should have understood the following aspects of [camelcase name of model] by now:
- [characteristic 1 of [camelcase name of model]]
- [characteristic 2 of [camelcase name of model]]
- ...
If any of the mentioned aspects above are **not** clear to you, now is a great time to talk to [name of mentor].
### 2. Next prepare your environment
1. Fork the [repository](https://github.com/huggingface/transformers)
by clicking on the 'Fork' button on the repository's page. This
creates a copy of the code under your GitHub user account.
2. Clone your `transformers` fork to your local disk, and add the base
repository as a remote:
```bash
git clone https://github.com/[your Github handle]/transformers.git
cd transformers
git remote add upstream https://github.com/huggingface/transformers.git
```
3. Set up a development environment, for instance by running the
following command:
```bash
python -m venv .env
source .env/bin/activate
pip install -e ".[dev]"
```
and return to the parent directory
```bash
cd ..
```
4. We recommend adding the PyTorch version of *[camelcase name of model]* to
Transformers. To install PyTorch, please follow the instructions [here](https://pytorch.org/get-started/locally/).
**Note:** You don't need to have CUDA installed. Making the new model
work on CPU is sufficient.
5. To port *[camelcase name of model]*, you will also need access to its
original repository:
```bash
git clone [link to original repo].git
cd [lowercase name of model]
pip install -e .
```
Now you have set up a development environment to port *[camelcase name of model]*
to 🤗 Transformers.
### Run a pretrained checkpoint using the original repository
**3. Set up debugging environment**
At first, you will work on the original *[camelcase name of model]* repository.
Often, the original implementation is very "researchy". Meaning that
documentation might be lacking and the code can be difficult to
understand. But this should be exactly your motivation to reimplement
*[camelcase name of model]*. At Hugging Face, one of our main goals is to *make
people stand on the shoulders of giants* which translates here very well
into taking a working model and rewriting it to make it as **accessible,
user-friendly, and beautiful** as possible. This is the number-one
motivation to re-implement models into 🤗 Transformers - trying to make
complex new NLP technology accessible to **everybody**.
You should start thereby by diving into the [original repository]([link to original repo]).
Successfully running the official pretrained model in the original
repository is often **the most difficult** step. From our experience, it
is very important to spend some time getting familiar with the original
code-base. You need to figure out the following:
- Where to find the pretrained weights?
- How to load the pretrained weights into the corresponding model?
- How to run the tokenizer independently from the model?
- Trace one forward pass so that you know which classes and functions
are required for a simple forward pass. Usually, you only have to
reimplement those functions.
- Be able to locate the important components of the model: Where is
the model's class? Are there model sub-classes, *e.g.*,
EncoderModel, DecoderModel? Where is the self-attention layer? Are
there multiple different attention layers, *e.g.*, *self-attention*,
*cross-attention*...?
- How can you debug the model in the original environment of the repo?
Do you have to add `print` statements, can you work with
an interactive debugger like [ipdb](https://pypi.org/project/ipdb/), or should you use
an efficient IDE to debug the model, like PyCharm?
It is very important that before you start the porting process, that you
can **efficiently** debug code in the original repository! Also,
remember that you are working with an open-source library, so do not
hesitate to open an issue, or even a pull request in the original
repository. The maintainers of this repository are most likely very
happy about someone looking into their code!
At this point, it is really up to you which debugging environment and
strategy you prefer to use to debug the original model. We strongly
advise against setting up a costly GPU environment, but simply work on a
CPU both when starting to dive into the original repository and also
when starting to write the 🤗 Transformers implementation of the model.
Only at the very end, when the model has already been successfully
ported to 🤗 Transformers, one should verify that the model also works as
expected on GPU.
In general, there are two possible debugging environments for running
the original model
- [Jupyter notebooks](https://jupyter.org/) / [google colab](https://colab.research.google.com/notebooks/intro.ipynb)
- Local python scripts.
Jupyter notebooks have the advantage that they allow for cell-by-cell
execution which can be helpful to better split logical components from
one another and to have faster debugging cycles as intermediate results
can be stored. Also, notebooks are often easier to share with other
contributors, which might be very helpful if you want to ask the Hugging
Face team for help. If you are familiar with Jupyter notebooks, we
strongly recommend you to work with them.
The obvious disadvantage of Jupyter notebooks is that if you are not
used to working with them you will have to spend some time adjusting to
the new programming environment and that you might not be able to use
your known debugging tools anymore, like `ipdb`.
**4. Successfully run forward pass**
For each code-base, a good first step is always to load a **small**
pretrained checkpoint and to be able to reproduce a single forward pass
using a dummy integer vector of input IDs as an input. Such a script
could look like this (in pseudocode):
```python
model = [camelcase name of model]Model.load_pretrained_checkpoint("/path/to/checkpoint/")
input_ids = [0, 4, 5, 2, 3, 7, 9] # vector of input ids
original_output = model.predict(input_ids)
```
Next, regarding the debugging strategy, there are generally a few from
which to choose from:
- Decompose the original model into many small testable components and
run a forward pass on each of those for verification
- Decompose the original model only into the original *tokenizer* and
the original *model*, run a forward pass on those, and use
intermediate print statements or breakpoints for verification
Again, it is up to you which strategy to choose. Often, one or the other
is advantageous depending on the original code base.
If the original code-base allows you to decompose the model into smaller
sub-components, *e.g.*, if the original code-base can easily be run in
eager mode, it is usually worth the effort to do so. There are some
important advantages to taking the more difficult road in the beginning:
- at a later stage when comparing the original model to the Hugging
Face implementation, you can verify automatically for each component
individually that the corresponding component of the 🤗 Transformers
implementation matches instead of relying on visual comparison via
print statements
- it can give you some rope to decompose the big problem of porting a
model into smaller problems of just porting individual components
and thus structure your work better
- separating the model into logical meaningful components will help
you to get a better overview of the model's design and thus to
better understand the model
- at a later stage those component-by-component tests help you to
ensure that no regression occurs as you continue changing your code
[Lysandre's](https://gist.github.com/LysandreJik/db4c948f6b4483960de5cbac598ad4ed)
integration checks for ELECTRA gives a nice example of how this can be
done.
However, if the original code-base is very complex or only allows
intermediate components to be run in a compiled mode, it might be too
time-consuming or even impossible to separate the model into smaller
testable sub-components. A good example is [T5's
MeshTensorFlow](https://github.com/tensorflow/mesh/tree/master/mesh_tensorflow)
library which is very complex and does not offer a simple way to
decompose the model into its sub-components. For such libraries, one
often relies on verifying print statements.
No matter which strategy you choose, the recommended procedure is often
the same in that you should start to debug the starting layers first and
the ending layers last.
It is recommended that you retrieve the output, either by print
statements or sub-component functions, of the following layers in the
following order:
1. Retrieve the input IDs passed to the model
2. Retrieve the word embeddings
3. Retrieve the input of the first Transformer layer
4. Retrieve the output of the first Transformer layer
5. Retrieve the output of the following n - 1 Transformer layers
6. Retrieve the output of the whole [camelcase name of model] Model
Input IDs should thereby consists of an array of integers, *e.g.*,
`input_ids = [0, 4, 4, 3, 2, 4, 1, 7, 19]`
The outputs of the following layers often consist of multi-dimensional
float arrays and can look like this:
```bash
[[
[-0.1465, -0.6501, 0.1993, ..., 0.1451, 0.3430, 0.6024],
[-0.4417, -0.5920, 0.3450, ..., -0.3062, 0.6182, 0.7132],
[-0.5009, -0.7122, 0.4548, ..., -0.3662, 0.6091, 0.7648],
...,
[-0.5613, -0.6332, 0.4324, ..., -0.3792, 0.7372, 0.9288],
[-0.5416, -0.6345, 0.4180, ..., -0.3564, 0.6992, 0.9191],
[-0.5334, -0.6403, 0.4271, ..., -0.3339, 0.6533, 0.8694]]],
```
We expect that every model added to 🤗 Transformers passes a couple of
integration tests, meaning that the original model and the reimplemented
version in 🤗 Transformers have to give the exact same output up to a
precision of 0.001! Since it is normal that the exact same model written
in different libraries can give a slightly different output depending on
the library framework, we accept an error tolerance of 1e-3 (0.001). It
is not enough if the model gives nearly the same output, they have to be
the almost identical. Therefore, you will certainly compare the
intermediate outputs of the 🤗 Transformers version multiple times
against the intermediate outputs of the original implementation of
*[camelcase name of model]* in which case an **efficient** debugging environment
of the original repository is absolutely important. Here is some advice
to make your debugging environment as efficient as possible.
- Find the best way of debugging intermediate results. Is the original
repository written in PyTorch? Then you should probably take the
time to write a longer script that decomposes the original model
into smaller sub-components to retrieve intermediate values. Is the
original repository written in Tensorflow 1? Then you might have to
rely on TensorFlow print operations like
[tf.print](https://www.tensorflow.org/api_docs/python/tf/print) to
output intermediate values. Is the original repository written in
Jax? Then make sure that the model is **not jitted** when running
the forward pass, *e.g.*, check-out [this
link](https://github.com/google/jax/issues/196).
- Use the smallest pretrained checkpoint you can find. The smaller the
checkpoint, the faster your debug cycle becomes. It is not efficient
if your pretrained model is so big that your forward pass takes more
than 10 seconds. In case only very large checkpoints are available,
it might make more sense to create a dummy model in the new
environment with randomly initialized weights and save those weights
for comparison with the 🤗 Transformers version of your model
- Make sure you are using the easiest way of calling a forward pass in
the original repository. Ideally, you want to find the function in
the original repository that **only** calls a single forward pass,
*i.e.* that is often called `predict`, `evaluate`, `forward` or
`__call__`. You don't want to debug a function that calls `forward`
multiple times, *e.g.*, to generate text, like
`autoregressive_sample`, `generate`.
- Try to separate the tokenization from the model's
forward pass. If the original repository shows
examples where you have to input a string, then try to find out
where in the forward call the string input is changed to input ids
and start from this point. This might mean that you have to possibly
write a small script yourself or change the original code so that
you can directly input the ids instead of an input string.
- Make sure that the model in your debugging setup is **not** in
training mode, which often causes the model to yield random outputs
due to multiple dropout layers in the model. Make sure that the
forward pass in your debugging environment is **deterministic** so
that the dropout layers are not used. Or use
`transformers.utils.set_seed` if the old and new
implementations are in the same framework.
#### More details on how to create a debugging environment for [camelcase name of model]
[TODO FILL: Here the mentor should add very specific information on what the student should do]
[to set up an efficient environment for the special requirements of this model]
### Port [camelcase name of model] to 🤗 Transformers
Next, you can finally start adding new code to 🤗 Transformers. Go into
the clone of your 🤗 Transformers' fork:
cd transformers
In the special case that you are adding a model whose architecture
exactly matches the model architecture of an existing model you only
have to add a conversion script as described in [this
section](#write-a-conversion-script). In this case, you can just re-use
the whole model architecture of the already existing model.
Otherwise, let's start generating a new model with the amazing
Cookiecutter!
**Use the Cookiecutter to automatically generate the model's code**
To begin with head over to the [🤗 Transformers
templates](https://github.com/huggingface/transformers/tree/main/templates/adding_a_new_model)
to make use of our `cookiecutter` implementation to automatically
generate all the relevant files for your model. Again, we recommend only
adding the PyTorch version of the model at first. Make sure you follow
the instructions of the `README.md` on the [🤗 Transformers
templates](https://github.com/huggingface/transformers/tree/main/templates/adding_a_new_model)
carefully.
**Open a Pull Request on the main huggingface/transformers repo**
Before starting to adapt the automatically generated code, now is the
time to open a "Work in progress (WIP)" pull request, *e.g.*, "\[WIP\]
Add *[camelcase name of model]*", in 🤗 Transformers so that you and the Hugging
Face team can work side-by-side on integrating the model into 🤗
Transformers.
You should do the following:
1. Create a branch with a descriptive name from your main branch
```
git checkout -b add_[lowercase name of model]
```
2. Commit the automatically generated code:
```
git add .
git commit
```
3. Fetch and rebase to current main
```
git fetch upstream
git rebase upstream/main
```
4. Push the changes to your account using:
```
git push -u origin a-descriptive-name-for-my-changes
```
5. Once you are satisfied, go to the webpage of your fork on GitHub.
Click on "Pull request". Make sure to add the GitHub handle of
[name of mentor] as a reviewer, so that the Hugging
Face team gets notified for future changes.
6. Change the PR into a draft by clicking on "Convert to draft" on the
right of the GitHub pull request web page.
In the following, whenever you have done some progress, don't forget to
commit your work and push it to your account so that it shows in the
pull request. Additionally, you should make sure to update your work
with the current main from time to time by doing:
git fetch upstream
git merge upstream/main
In general, all questions you might have regarding the model or your
implementation should be asked in your PR and discussed/solved in the
PR. This way, [name of mentor] will always be notified when you are
committing new code or if you have a question. It is often very helpful
to point [name of mentor] to your added code so that the Hugging
Face team can efficiently understand your problem or question.
To do so, you can go to the "Files changed" tab where you see all of
your changes, go to a line regarding which you want to ask a question,
and click on the "+" symbol to add a comment. Whenever a question or
problem has been solved, you can click on the "Resolve" button of the
created comment.
In the same way, [name of mentor] will open comments when reviewing
your code. We recommend asking most questions on GitHub on your PR. For
some very general questions that are not very useful for the public,
feel free to ping [name of mentor] by Slack or email.
**5. Adapt the generated models code for [camelcase name of model]**
At first, we will focus only on the model itself and not care about the
tokenizer. All the relevant code should be found in the generated files
`src/transformers/models/[lowercase name of model]/modeling_[lowercase name of model].py` and
`src/transformers/models/[lowercase name of model]/configuration_[lowercase name of model].py`.
Now you can finally start coding :). The generated code in
`src/transformers/models/[lowercase name of model]/modeling_[lowercase name of model].py` will
either have the same architecture as BERT if it's an encoder-only model
or BART if it's an encoder-decoder model. At this point, you should
remind yourself what you've learned in the beginning about the
theoretical aspects of the model: *How is the model different from BERT
or BART?*\". Implement those changes which often means to change the
*self-attention* layer, the order of the normalization layer, etc...
Again, it is often useful to look at the similar architecture of already
existing models in Transformers to get a better feeling of how your
model should be implemented.
**Note** that at this point, you don't have to be very sure that your
code is fully correct or clean. Rather, it is advised to add a first
*unclean*, copy-pasted version of the original code to
`src/transformers/models/[lowercase name of model]/modeling_[lowercase name of model].py`
until you feel like all the necessary code is added. From our
experience, it is much more efficient to quickly add a first version of
the required code and improve/correct the code iteratively with the
conversion script as described in the next section. The only thing that
has to work at this point is that you can instantiate the 🤗 Transformers
implementation of *[camelcase name of model]*, *i.e.* the following command
should work:
```python
from transformers import [camelcase name of model]Model, [camelcase name of model]Config
model = [camelcase name of model]Model([camelcase name of model]Config())
```
The above command will create a model according to the default
parameters as defined in `[camelcase name of model]Config()` with random weights,
thus making sure that the `init()` methods of all components works.
[TODO FILL: Here the mentor should add very specific information on what exactly has to be changed for this model]
[...]
[...]
**6. Write a conversion script**
Next, you should write a conversion script that lets you convert the
checkpoint you used to debug *[camelcase name of model]* in the original
repository to a checkpoint compatible with your just created 🤗
Transformers implementation of *[camelcase name of model]*. It is not advised to
write the conversion script from scratch, but rather to look through
already existing conversion scripts in 🤗 Transformers for one that has
been used to convert a similar model that was written in the same
framework as *[camelcase name of model]*. Usually, it is enough to copy an
already existing conversion script and slightly adapt it for your use
case. Don't hesitate to ask [name of mentor] to point you to a
similar already existing conversion script for your model.
- If you are porting a model from TensorFlow to PyTorch, a good
starting point might be BERT's conversion script
[here](https://github.com/huggingface/transformers/blob/7acfa95afb8194f8f9c1f4d2c6028224dbed35a2/src/transformers/models/bert/modeling_bert.py#L91)
- If you are porting a model from PyTorch to PyTorch, a good starting
point might be BART's conversion script
[here](https://github.com/huggingface/transformers/blob/main/src/transformers/models/bart/convert_bart_original_pytorch_checkpoint_to_pytorch.py)
In the following, we'll quickly explain how PyTorch models store layer
weights and define layer names. In PyTorch, the name of a layer is
defined by the name of the class attribute you give the layer. Let's
define a dummy model in PyTorch, called `SimpleModel` as follows:
```python
from torch import nn
class SimpleModel(nn.Module):
def __init__(self):
super().__init__()
self.dense = nn.Linear(10, 10)
self.intermediate = nn.Linear(10, 10)
self.layer_norm = nn.LayerNorm(10)
```
Now we can create an instance of this model definition which will fill
all weights: `dense`, `intermediate`, `layer_norm` with random weights.
We can print the model to see its architecture
```python
model = SimpleModel()
print(model)
```
This will print out the following:
```bash
SimpleModel(
(dense): Linear(in_features=10, out_features=10, bias=True)
(intermediate): Linear(in_features=10, out_features=10, bias=True)
(layer_norm): LayerNorm((10,), eps=1e-05, elementwise_affine=True)
)
```
We can see that the layer names are defined by the name of the class
attribute in PyTorch. You can print out the weight values of a specific
layer:
```python
print(model.dense.weight.data)
```
to see that the weights were randomly initialized
```bash
tensor([[-0.0818, 0.2207, -0.0749, -0.0030, 0.0045, -0.1569, -0.1598, 0.0212,
-0.2077, 0.2157],
[ 0.1044, 0.0201, 0.0990, 0.2482, 0.3116, 0.2509, 0.2866, -0.2190,
0.2166, -0.0212],
[-0.2000, 0.1107, -0.1999, -0.3119, 0.1559, 0.0993, 0.1776, -0.1950,
-0.1023, -0.0447],
[-0.0888, -0.1092, 0.2281, 0.0336, 0.1817, -0.0115, 0.2096, 0.1415,
-0.1876, -0.2467],
[ 0.2208, -0.2352, -0.1426, -0.2636, -0.2889, -0.2061, -0.2849, -0.0465,
0.2577, 0.0402],
[ 0.1502, 0.2465, 0.2566, 0.0693, 0.2352, -0.0530, 0.1859, -0.0604,
0.2132, 0.1680],
[ 0.1733, -0.2407, -0.1721, 0.1484, 0.0358, -0.0633, -0.0721, -0.0090,
0.2707, -0.2509],
[-0.1173, 0.1561, 0.2945, 0.0595, -0.1996, 0.2988, -0.0802, 0.0407,
0.1829, -0.1568],
[-0.1164, -0.2228, -0.0403, 0.0428, 0.1339, 0.0047, 0.1967, 0.2923,
0.0333, -0.0536],
[-0.1492, -0.1616, 0.1057, 0.1950, -0.2807, -0.2710, -0.1586, 0.0739,
0.2220, 0.2358]]).
```
In the conversion script, you should fill those randomly initialized
weights with the exact weights of the corresponding layer in the
checkpoint. *E.g.*,
```python
# retrieve matching layer weights, e.g. by
# recursive algorithm
layer_name = "dense"
pretrained_weight = array_of_dense_layer
model_pointer = getattr(model, "dense")
model_pointer.weight.data = torch.from_numpy(pretrained_weight)
```
While doing so, you must verify that each randomly initialized weight of
your PyTorch model and its corresponding pretrained checkpoint weight
exactly match in both **shape and name**. To do so, it is **necessary**
to add assert statements for the shape and print out the names of the
checkpoints weights. *E.g.*, you should add statements like:
```python
assert (
model_pointer.weight.shape == pretrained_weight.shape
), f"Pointer shape of random weight {model_pointer.shape} and array shape of checkpoint weight {pretrained_weight.shape} mismatched"
```
Besides, you should also print out the names of both weights to make
sure they match, *e.g.*,
```python
logger.info(f"Initialize PyTorch weight {layer_name} from {pretrained_weight.name}")
```
If either the shape or the name doesn't match, you probably assigned
the wrong checkpoint weight to a randomly initialized layer of the 🤗
Transformers implementation.
An incorrect shape is most likely due to an incorrect setting of the
config parameters in `[camelcase name of model]Config()` that do not exactly match
those that were used for the checkpoint you want to convert. However, it
could also be that PyTorch's implementation of a layer requires the
weight to be transposed beforehand.
Finally, you should also check that **all** required weights are
initialized and print out all checkpoint weights that were not used for
initialization to make sure the model is correctly converted. It is
completely normal, that the conversion trials fail with either a wrong
shape statement or wrong name assignment. This is most likely because
either you used incorrect parameters in `[camelcase name of model]Config()`, have a
wrong architecture in the 🤗 Transformers implementation, you have a bug
in the `init()` functions of one of the components of the 🤗 Transformers
implementation or you need to transpose one of the checkpoint weights.
This step should be iterated with the previous step until all weights of
the checkpoint are correctly loaded in the Transformers model. Having
correctly loaded the checkpoint into the 🤗 Transformers implementation,
you can then save the model under a folder of your choice
`/path/to/converted/checkpoint/folder` that should then contain both a
`pytorch_model.bin` file and a `config.json` file:
```python
model.save_pretrained("/path/to/converted/checkpoint/folder")
```
[TODO FILL: Here the mentor should add very specific information on what exactly has to be done for the conversion of this model]
[...]
[...]
**7. Implement the forward pass**
Having managed to correctly load the pretrained weights into the 🤗
Transformers implementation, you should now make sure that the forward
pass is correctly implemented. In [Get familiar with the original
repository](#34-run-a-pretrained-checkpoint-using-the-original-repository),
you have already created a script that runs a forward pass of the model
using the original repository. Now you should write an analogous script
using the 🤗 Transformers implementation instead of the original one. It
should look as follows:
[TODO FILL: Here the model name might have to be adapted, *e.g.*, maybe [camelcase name of model]ForConditionalGeneration instead of [camelcase name of model]Model]
```python
model = [camelcase name of model]Model.from_pretrained("/path/to/converted/checkpoint/folder")
input_ids = [0, 4, 4, 3, 2, 4, 1, 7, 19]
output = model(input_ids).last_hidden_states
```
It is very likely that the 🤗 Transformers implementation and the
original model implementation don't give the exact same output the very
first time or that the forward pass throws an error. Don't be
disappointed - it's expected! First, you should make sure that the
forward pass doesn't throw any errors. It often happens that the wrong
dimensions are used leading to a `"Dimensionality mismatch"`
error or that the wrong data type object is used, *e.g.*, `torch.long`
instead of `torch.float32`. Don't hesitate to ask [name of mentor]
for help, if you don't manage to solve certain errors.
The final part to make sure the 🤗 Transformers implementation works
correctly is to ensure that the outputs are equivalent to a precision of
`1e-3`. First, you should ensure that the output shapes are identical,
*i.e.* `outputs.shape` should yield the same value for the script of the
🤗 Transformers implementation and the original implementation. Next, you
should make sure that the output values are identical as well. This one
of the most difficult parts of adding a new model. Common mistakes why
the outputs are not identical are:
- Some layers were not added, *i.e.* an activation layer
was not added, or the residual connection was forgotten
- The word embedding matrix was not tied
- The wrong positional embeddings are used because the original
implementation uses on offset
- Dropout is applied during the forward pass. To fix this make sure
`model.training is False` and that no dropout layer is
falsely activated during the forward pass, *i.e.* pass
`self.training` to [PyTorch's functional
dropout](https://pytorch.org/docs/stable/nn.functional.html?highlight=dropout#torch.nn.functional.dropout)
The best way to fix the problem is usually to look at the forward pass
of the original implementation and the 🤗 Transformers implementation
side-by-side and check if there are any differences. Ideally, you should
debug/print out intermediate outputs of both implementations of the
forward pass to find the exact position in the network where the 🤗
Transformers implementation shows a different output than the original
implementation. First, make sure that the hard-coded `input_ids` in both
scripts are identical. Next, verify that the outputs of the first
transformation of the `input_ids` (usually the word embeddings) are
identical. And then work your way up to the very last layer of the
network. At some point, you will notice a difference between the two
implementations, which should point you to the bug in the 🤗 Transformers
implementation. From our experience, a simple and efficient way is to
add many print statements in both the original implementation and 🤗
Transformers implementation, at the same positions in the network
respectively, and to successively remove print statements showing the
same values for intermediate presentions.
When you're confident that both implementations yield the same output,
verifying the outputs with
`torch.allclose(original_output, output, atol=1e-3)`, you're done with
the most difficult part! Congratulations - the work left to be done
should be a cakewalk 😊.
**8. Adding all necessary model tests**
At this point, you have successfully added a new model. However, it is
very much possible that the model does not yet fully comply with the
required design. To make sure, the implementation is fully compatible
with 🤗 Transformers, all common tests should pass. The Cookiecutter
should have automatically added a test file for your model, probably
under the same `tests/test_modeling_[lowercase name of model].py`. Run this test
file to verify that all common tests pass:
```python
pytest tests/test_modeling_[lowercase name of model].py
```
[TODO FILL: Here the mentor should add very specific information on what tests are likely to fail after having implemented the model
, e.g. given the model, it might be very likely that `test_attention_output` fails]
[...]
[...]
Having fixed all common tests, it is now crucial to ensure that all the
nice work you have done is well tested, so that
- a) The community can easily understand your work by looking at
specific tests of *[camelcase name of model]*
- b) Future changes to your model will not break any important
feature of the model.
At first, integration tests should be added. Those integration tests
essentially do the same as the debugging scripts you used earlier to
implement the model to 🤗 Transformers. A template of those model tests
is already added by the Cookiecutter, called
`[camelcase name of model]ModelIntegrationTests` and only has to be filled out by
you. To ensure that those tests are passing, run
```python
RUN_SLOW=1 pytest -sv tests/test_modeling_[lowercase name of model].py::[camelcase name of model]ModelIntegrationTests
```
**Note:** In case you are using Windows, you should replace `RUN_SLOW=1` with `SET RUN_SLOW=1`
Second, all features that are special to *[camelcase name of model]* should be
tested additionally in a separate test under
`[camelcase name of model]ModelTester`/`[camelcase name of model]ModelTest`. This part is often
forgotten but is extremely useful in two ways:
- It helps to transfer the knowledge you have acquired during the
model addition to the community by showing how the special features
of *[camelcase name of model]* should work.
- Future contributors can quickly test changes to the model by running
those special tests.
[TODO FILL: Here the mentor should add very specific information on what special features of the model should be tested additionally]
[...]
[...]
**9. Implement the tokenizer**
Next, we should add the tokenizer of *[camelcase name of model]*. Usually, the
tokenizer is equivalent or very similar to an already existing tokenizer
of 🤗 Transformers.
[TODO FILL: Here the mentor should add a comment whether a new tokenizer is required or if this is not the case which existing tokenizer closest resembles
[camelcase name of model]'s tokenizer and how the tokenizer should be implemented]
[...]
[...]
It is very important to find/extract the original tokenizer file and to
manage to load this file into the 🤗 Transformers' implementation of the
tokenizer.
For [camelcase name of model], the tokenizer files can be found here:
- [To be filled out by mentor]
and having implemented the 🤗 Transformers' version of the tokenizer can be loaded as follows:
[To be filled out by mentor]
To ensure that the tokenizer works correctly, it is recommended to first
create a script in the original repository that inputs a string and
returns the `input_ids`. It could look similar to this (in pseudo-code):
```bash
input_str = "This is a long example input string containing special characters .$?-, numbers 2872 234 12 and words."
model = [camelcase name of model]Model.load_pretrained_checkpoint("/path/to/checkpoint/")
input_ids = model.tokenize(input_str)
```
You might have to take a deeper look again into the original repository
to find the correct tokenizer function or you might even have to do
changes to your clone of the original repository to only output the
`input_ids`. Having written a functional tokenization script that uses
the original repository, an analogous script for 🤗 Transformers should
be created. It should look similar to this:
```python
from transformers import [camelcase name of model]Tokenizer
input_str = "This is a long example input string containing special characters .$?-, numbers 2872 234 12 and words."
tokenizer = [camelcase name of model]Tokenizer.from_pretrained("/path/to/tokenizer/folder/")
input_ids = tokenizer(input_str).input_ids
```
When both `input_ids` yield the same values, as a final step a tokenizer
test file should also be added.
[TODO FILL: Here mentor should point the student to test files of similar tokenizers]
Analogous to the modeling test files of *[camelcase name of model]*, the
tokenization test files of *[camelcase name of model]* should contain a couple of
hard-coded integration tests.
[TODO FILL: Here mentor should again point to an existing similar test of another model that the student can copy & adapt]
**10. Run End-to-end integration tests**
Having added the tokenizer, you should also add a couple of end-to-end
integration tests using both the model and the tokenizer to
`tests/test_modeling_[lowercase name of model].py` in 🤗 Transformers. Such a test
should show on a meaningful text-to-text sample that the 🤗 Transformers
implementation works as expected. A meaningful text-to-text sample can
include *e.g.* a source-to-target-translation pair, an
article-to-summary pair, a question-to-answer pair, etc... If none of
the ported checkpoints has been fine-tuned on a downstream task it is
enough to simply rely on the model tests. In a final step to ensure that
the model is fully functional, it is advised that you also run all tests
on GPU. It can happen that you forgot to add some `.to(self.device)`
statements to internal tensors of the model, which in such a test would
show in an error. In case you have no access to a GPU, the Hugging Face
team can take care of running those tests for you.
**11. Add Docstring**
Now, all the necessary functionality for *[camelcase name of model]* is added -
you're almost done! The only thing left to add is a nice docstring and
a doc page. The Cookiecutter should have added a template file called
`docs/source/model_doc/[lowercase name of model].rst` that you should fill out.
Users of your model will usually first look at this page before using
your model. Hence, the documentation must be understandable and concise.
It is very useful for the community to add some *Tips* to show how the
model should be used. Don't hesitate to ping [name of mentor]
regarding the docstrings.
Next, make sure that the docstring added to
`src/transformers/models/[lowercase name of model]/modeling_[lowercase name of model].py` is
correct and included all necessary inputs and outputs. It is always to
good to remind oneself that documentation should be treated at least as
carefully as the code in 🤗 Transformers since the documentation is
usually the first contact point of the community with the model.
**Code refactor**
Great, now you have added all the necessary code for *[camelcase name of model]*.
At this point, you should correct some potential incorrect code style by
running:
```bash
make style
```
and verify that your coding style passes the quality check:
```bash
make quality
```
There are a couple of other very strict design tests in 🤗 Transformers
that might still be failing, which shows up in the tests of your pull
request. This is often because of some missing information in the
docstring or some incorrect naming. [name of mentor] will surely
help you if you're stuck here.
Lastly, it is always a good idea to refactor one's code after having
ensured that the code works correctly. With all tests passing, now it's
a good time to go over the added code again and do some refactoring.
You have now finished the coding part, congratulation! 🎉 You are
Awesome! 😎
**12. Upload the models to the model hub**
In this final part, you should convert and upload all checkpoints to the
model hub and add a model card for each uploaded model checkpoint. You
should work alongside [name of mentor] here to decide on a fitting
name for each checkpoint and to get the required access rights to be
able to upload the model under the author's organization of
*[camelcase name of model]*.
It is worth spending some time to create fitting model cards for each
checkpoint. The model cards should highlight the specific
characteristics of this particular checkpoint, *e.g.*, On which dataset
was the checkpoint pretrained/fine-tuned on? On what down-stream task
should the model be used? And also include some code on how to correctly
use the model.
**13. (Optional) Add notebook**
It is very helpful to add a notebook that showcases in-detail how
*[camelcase name of model]* can be used for inference and/or fine-tuned on a
downstream task. This is not mandatory to merge your PR, but very useful
for the community.
**14. Submit your finished PR**
You're done programming now and can move to the last step, which is
getting your PR merged into main. Usually, [name of mentor]
should have helped you already at this point, but it is worth taking
some time to give your finished PR a nice description and eventually add
comments to your code, if you want to point out certain design choices
to your reviewer.
### Share your work!!
Now, it's time to get some credit from the community for your work!
Having completed a model addition is a major contribution to
Transformers and the whole NLP community. Your code and the ported
pre-trained models will certainly be used by hundreds and possibly even
thousands of developers and researchers. You should be proud of your
work and share your achievement with the community.
**You have made another model that is super easy to access for everyone
in the community! 🤯**
| 0 |
hf_public_repos/transformers/templates | hf_public_repos/transformers/templates/adding_a_new_model/cookiecutter.json | {
"modelname": "BrandNewBERT",
"uppercase_modelname": "BRAND_NEW_BERT",
"lowercase_modelname": "brand_new_bert",
"camelcase_modelname": "BrandNewBert",
"authors": "The HuggingFace Team",
"checkpoint_identifier": "brand-new-bert-base-cased",
"tokenizer_type": ["Based on BERT", "Based on BART", "Standalone"],
"generate_tensorflow_pytorch_and_flax": [
"PyTorch, TensorFlow and Flax",
"PyTorch & TensorFlow",
"PyTorch & Flax",
"TensorFlow & Flax",
"PyTorch",
"TensorFlow",
"Flax"
],
"is_encoder_decoder_model": ["True", "False"]
}
| 0 |
hf_public_repos/transformers/templates/adding_a_new_model | hf_public_repos/transformers/templates/adding_a_new_model/tests/tf-seq-2-seq-bart-tokenizer.json | {
"modelname": "NewTFENCDEC",
"uppercase_modelname": "NEW_TF_ENC_DEC",
"lowercase_modelname": "new_tf_enc_dec_template",
"camelcase_modelname": "NewTFEncDec",
"authors": "The HuggingFace Team",
"checkpoint_identifier": "new-tf-enc-dec-base_template",
"tokenizer_type": "Based on BART",
"generate_tensorflow_pytorch_and_flax": "TensorFlow",
"is_encoder_decoder_model": "True"
}
| 0 |
hf_public_repos/transformers/templates/adding_a_new_model | hf_public_repos/transformers/templates/adding_a_new_model/tests/pt-encoder-bert-tokenizer.json | {
"modelname": "TemplatePT",
"uppercase_modelname": "TEMPLATE_PT",
"lowercase_modelname": "template_pt",
"camelcase_modelname": "TemplatePt",
"authors": "The HuggingFace Team",
"checkpoint_identifier": "brand-new-bert-base-cased",
"tokenizer_type": "Based on BERT",
"generate_tensorflow_pytorch_and_flax": "PyTorch",
"is_encoder_decoder_model": "False"
}
| 0 |
hf_public_repos/transformers/templates/adding_a_new_model | hf_public_repos/transformers/templates/adding_a_new_model/tests/encoder-bert-tokenizer.json | {
"modelname": "Template",
"uppercase_modelname": "TEMPLATE",
"lowercase_modelname": "template",
"camelcase_modelname": "Template",
"authors": "The HuggingFace Team",
"checkpoint_identifier": "brand-new-bert-base-cased",
"tokenizer_type": "Based on BERT",
"generate_tensorflow_pytorch_and_flax": "PyTorch, TensorFlow and Flax",
"is_encoder_decoder_model": "False"
}
| 0 |
hf_public_repos/transformers/templates/adding_a_new_model | hf_public_repos/transformers/templates/adding_a_new_model/tests/standalone.json | {
"modelname": "TemplateBI",
"uppercase_modelname": "TEMPLATE_BI",
"lowercase_modelname": "template_bi",
"camelcase_modelname": "TemplateBi",
"authors": "The HuggingFace Team",
"checkpoint_identifier": "bi-brand-new-bert-base-cased",
"tokenizer_type": "Standalone",
"generate_tensorflow_pytorch_and_flax": "PyTorch, TensorFlow and Flax",
"is_encoder_decoder_model": "False"
}
| 0 |
hf_public_repos/transformers/templates/adding_a_new_model | hf_public_repos/transformers/templates/adding_a_new_model/tests/flax-encoder-bert-tokenizer.json | {
"modelname": "TemplateFLAX",
"uppercase_modelname": "TEMPLATE_FLAX",
"lowercase_modelname": "template_flax",
"camelcase_modelname": "TemplateFlax",
"authors": "The HuggingFace Team",
"checkpoint_identifier": "brand-new-bert-base-cased",
"tokenizer_type": "Based on BERT",
"generate_tensorflow_pytorch_and_flax": "Flax",
"is_encoder_decoder_model": "False"
}
| 0 |
hf_public_repos/transformers/templates/adding_a_new_model | hf_public_repos/transformers/templates/adding_a_new_model/tests/pt-seq-2-seq-bart-tokenizer.json | {
"modelname": "PTNewENCDEC",
"uppercase_modelname": "PT_NEW_ENC_DEC",
"lowercase_modelname": "pt_new_enc_dec_template",
"camelcase_modelname": "PtNewEncDec",
"authors": "The HuggingFace Team",
"checkpoint_identifier": "pt-new-enc-dec-base",
"tokenizer_type": "Based on BART",
"generate_tensorflow_pytorch_and_flax": "PyTorch",
"is_encoder_decoder_model": "True"
}
| 0 |
hf_public_repos/transformers/templates/adding_a_new_model | hf_public_repos/transformers/templates/adding_a_new_model/tests/tf-encoder-bert-tokenizer.json | {
"modelname": "TemplateTF",
"uppercase_modelname": "TEMPLATE_TF",
"lowercase_modelname": "template_tf",
"camelcase_modelname": "TemplateTf",
"authors": "The HuggingFace Team",
"checkpoint_identifier": "brand-new-bert-base-cased",
"tokenizer_type": "Based on BERT",
"generate_tensorflow_pytorch_and_flax": "TensorFlow",
"is_encoder_decoder_model": "False"
}
| 0 |
hf_public_repos/transformers/templates/adding_a_new_model | hf_public_repos/transformers/templates/adding_a_new_model/tests/flax-seq-2-seq-bart-tokenizer.json | {
"modelname": "FlaxNewENCDEC",
"uppercase_modelname": "FLAX_NEW_ENC_DEC",
"lowercase_modelname": "flax_new_enc_dec_template",
"camelcase_modelname": "FlaxNewEncDec",
"authors": "The HuggingFace Team",
"checkpoint_identifier": "new-flax-enc-dec-base",
"tokenizer_type": "Based on BART",
"generate_tensorflow_pytorch_and_flax": "Flax",
"is_encoder_decoder_model": "True"
}
| 0 |
hf_public_repos/transformers/templates/adding_a_new_model | hf_public_repos/transformers/templates/adding_a_new_model/cookiecutter-template-{{cookiecutter.modelname}}/configuration.json | {
"modelname": "{{cookiecutter.modelname}}",
"uppercase_modelname": "{{cookiecutter.uppercase_modelname}}",
"lowercase_modelname": "{{cookiecutter.lowercase_modelname}}",
"camelcase_modelname": "{{cookiecutter.camelcase_modelname}}",
"authors": "{{cookiecutter.authors}}",
"checkpoint_identifier": "{{cookiecutter.checkpoint_identifier}}",
"tokenizer_type": "{{cookiecutter.tokenizer_type}}",
"generate_tensorflow_pytorch_and_flax": "{{cookiecutter.generate_tensorflow_pytorch_and_flax}}",
"is_encoder_decoder_model": "{{cookiecutter.is_encoder_decoder_model}}"
}
| 0 |
hf_public_repos/transformers/templates/adding_a_new_model | hf_public_repos/transformers/templates/adding_a_new_model/cookiecutter-template-{{cookiecutter.modelname}}/__init__.py | # Copyright 2020 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
from typing import TYPE_CHECKING
from ...utils import _LazyModule, OptionalDependencyNotAvailable, is_tokenizers_available
{%- if "TensorFlow" in cookiecutter.generate_tensorflow_pytorch_and_flax %}
from ...utils import is_tf_available
{% endif %}
{%- if "PyTorch" in cookiecutter.generate_tensorflow_pytorch_and_flax %}
from ...utils import is_torch_available
{% endif %}
{%- if "Flax" in cookiecutter.generate_tensorflow_pytorch_and_flax %}
from ...utils import is_flax_available
{% endif %}
_import_structure = {
"configuration_{{cookiecutter.lowercase_modelname}}": ["{{cookiecutter.uppercase_modelname}}_PRETRAINED_CONFIG_ARCHIVE_MAP", "{{cookiecutter.camelcase_modelname}}Config"],
"tokenization_{{cookiecutter.lowercase_modelname}}": ["{{cookiecutter.camelcase_modelname}}Tokenizer"],
}
try:
if not is_tokenizers_available():
raise OptionalDependencyNotAvailable()
except OptionalDependencyNotAvailable:
pass
else:
_import_structure["tokenization_{{cookiecutter.lowercase_modelname}}_fast"] = ["{{cookiecutter.camelcase_modelname}}TokenizerFast"]
{%- if "PyTorch" in cookiecutter.generate_tensorflow_pytorch_and_flax %}
{% if cookiecutter.is_encoder_decoder_model == "False" %}
try:
if not is_torch_available():
raise OptionalDependencyNotAvailable()
except OptionalDependencyNotAvailable:
pass
else:
_import_structure["modeling_{{cookiecutter.lowercase_modelname}}"] = [
"{{cookiecutter.uppercase_modelname}}_PRETRAINED_MODEL_ARCHIVE_LIST",
"{{cookiecutter.camelcase_modelname}}ForMaskedLM",
"{{cookiecutter.camelcase_modelname}}ForCausalLM",
"{{cookiecutter.camelcase_modelname}}ForMultipleChoice",
"{{cookiecutter.camelcase_modelname}}ForQuestionAnswering",
"{{cookiecutter.camelcase_modelname}}ForSequenceClassification",
"{{cookiecutter.camelcase_modelname}}ForTokenClassification",
"{{cookiecutter.camelcase_modelname}}Layer",
"{{cookiecutter.camelcase_modelname}}Model",
"{{cookiecutter.camelcase_modelname}}PreTrainedModel",
"load_tf_weights_in_{{cookiecutter.lowercase_modelname}}",
]
{% else %}
try:
if not is_torch_available():
raise OptionalDependencyNotAvailable()
except OptionalDependencyNotAvailable:
pass
else:
_import_structure["modeling_{{cookiecutter.lowercase_modelname}}"] = [
"{{cookiecutter.uppercase_modelname}}_PRETRAINED_MODEL_ARCHIVE_LIST",
"{{cookiecutter.camelcase_modelname}}ForConditionalGeneration",
"{{cookiecutter.camelcase_modelname}}ForQuestionAnswering",
"{{cookiecutter.camelcase_modelname}}ForSequenceClassification",
"{{cookiecutter.camelcase_modelname}}ForCausalLM",
"{{cookiecutter.camelcase_modelname}}Model",
"{{cookiecutter.camelcase_modelname}}PreTrainedModel",
]
{% endif %}
{% endif %}
{%- if "TensorFlow" in cookiecutter.generate_tensorflow_pytorch_and_flax %}
{% if cookiecutter.is_encoder_decoder_model == "False" %}
try:
if not is_tf_available():
raise OptionalDependencyNotAvailable()
except OptionalDependencyNotAvailable:
pass
else:
_import_structure["modeling_tf_{{cookiecutter.lowercase_modelname}}"] = [
"TF_{{cookiecutter.uppercase_modelname}}_PRETRAINED_MODEL_ARCHIVE_LIST",
"TF{{cookiecutter.camelcase_modelname}}ForMaskedLM",
"TF{{cookiecutter.camelcase_modelname}}ForCausalLM",
"TF{{cookiecutter.camelcase_modelname}}ForMultipleChoice",
"TF{{cookiecutter.camelcase_modelname}}ForQuestionAnswering",
"TF{{cookiecutter.camelcase_modelname}}ForSequenceClassification",
"TF{{cookiecutter.camelcase_modelname}}ForTokenClassification",
"TF{{cookiecutter.camelcase_modelname}}Layer",
"TF{{cookiecutter.camelcase_modelname}}Model",
"TF{{cookiecutter.camelcase_modelname}}PreTrainedModel",
]
{% else %}
try:
if not is_tf_available():
raise OptionalDependencyNotAvailable()
except OptionalDependencyNotAvailable:
pass
else:
_import_structure["modeling_tf_{{cookiecutter.lowercase_modelname}}"] = [
"TF{{cookiecutter.camelcase_modelname}}ForConditionalGeneration",
"TF{{cookiecutter.camelcase_modelname}}Model",
"TF{{cookiecutter.camelcase_modelname}}PreTrainedModel",
]
{% endif %}
{% endif %}
{%- if "Flax" in cookiecutter.generate_tensorflow_pytorch_and_flax %}
{% if cookiecutter.is_encoder_decoder_model == "False" %}
try:
if not is_flax_available():
raise OptionalDependencyNotAvailable()
except OptionalDependencyNotAvailable:
pass
else:
_import_structure["modeling_flax_{{cookiecutter.lowercase_modelname}}"] = [
"Flax{{cookiecutter.camelcase_modelname}}ForMaskedLM",
"Flax{{cookiecutter.camelcase_modelname}}ForCausalLM",
"Flax{{cookiecutter.camelcase_modelname}}ForMultipleChoice",
"Flax{{cookiecutter.camelcase_modelname}}ForQuestionAnswering",
"Flax{{cookiecutter.camelcase_modelname}}ForSequenceClassification",
"Flax{{cookiecutter.camelcase_modelname}}ForTokenClassification",
"Flax{{cookiecutter.camelcase_modelname}}Layer",
"Flax{{cookiecutter.camelcase_modelname}}Model",
"Flax{{cookiecutter.camelcase_modelname}}PreTrainedModel",
]
{% else %}
try:
if not is_flax_available():
raise OptionalDependencyNotAvailable()
except OptionalDependencyNotAvailable:
pass
else:
_import_structure["modeling_flax_{{cookiecutter.lowercase_modelname}}"] = [
"Flax{{cookiecutter.camelcase_modelname}}ForConditionalGeneration",
"Flax{{cookiecutter.camelcase_modelname}}ForQuestionAnswering",
"Flax{{cookiecutter.camelcase_modelname}}ForSequenceClassification",
"Flax{{cookiecutter.camelcase_modelname}}Model",
"Flax{{cookiecutter.camelcase_modelname}}PreTrainedModel",
]
{% endif %}
{% endif %}
if TYPE_CHECKING:
from .configuration_{{cookiecutter.lowercase_modelname}} import {{cookiecutter.uppercase_modelname}}_PRETRAINED_CONFIG_ARCHIVE_MAP, {{cookiecutter.camelcase_modelname}}Config
from .tokenization_{{cookiecutter.lowercase_modelname}} import {{cookiecutter.camelcase_modelname}}Tokenizer
try:
if not is_tokenizers_available():
raise OptionalDependencyNotAvailable()
except OptionalDependencyNotAvailable:
pass
else:
from .tokenization_{{cookiecutter.lowercase_modelname}}_fast import {{cookiecutter.camelcase_modelname}}TokenizerFast
{%- if "PyTorch" in cookiecutter.generate_tensorflow_pytorch_and_flax %}
{% if cookiecutter.is_encoder_decoder_model == "False" %}
try:
if not is_torch_available():
raise OptionalDependencyNotAvailable()
except OptionalDependencyNotAvailable:
pass
else:
from .modeling_{{cookiecutter.lowercase_modelname}} import (
{{cookiecutter.uppercase_modelname}}_PRETRAINED_MODEL_ARCHIVE_LIST,
{{cookiecutter.camelcase_modelname}}ForMaskedLM,
{{cookiecutter.camelcase_modelname}}ForCausalLM,
{{cookiecutter.camelcase_modelname}}ForMultipleChoice,
{{cookiecutter.camelcase_modelname}}ForQuestionAnswering,
{{cookiecutter.camelcase_modelname}}ForSequenceClassification,
{{cookiecutter.camelcase_modelname}}ForTokenClassification,
{{cookiecutter.camelcase_modelname}}Layer,
{{cookiecutter.camelcase_modelname}}Model,
{{cookiecutter.camelcase_modelname}}PreTrainedModel,
load_tf_weights_in_{{cookiecutter.lowercase_modelname}},
)
{% else %}
try:
if not is_torch_available():
raise OptionalDependencyNotAvailable()
except OptionalDependencyNotAvailable:
pass
else:
from .modeling_{{cookiecutter.lowercase_modelname}} import (
{{cookiecutter.uppercase_modelname}}_PRETRAINED_MODEL_ARCHIVE_LIST,
{{cookiecutter.camelcase_modelname}}ForConditionalGeneration,
{{cookiecutter.camelcase_modelname}}ForCausalLM,
{{cookiecutter.camelcase_modelname}}ForQuestionAnswering,
{{cookiecutter.camelcase_modelname}}ForSequenceClassification,
{{cookiecutter.camelcase_modelname}}Model,
{{cookiecutter.camelcase_modelname}}PreTrainedModel,
)
{% endif %}
{% endif %}
{%- if "TensorFlow" in cookiecutter.generate_tensorflow_pytorch_and_flax %}
{% if cookiecutter.is_encoder_decoder_model == "False" %}
try:
if not is_tf_available():
raise OptionalDependencyNotAvailable()
except OptionalDependencyNotAvailable:
pass
else:
from .modeling_tf_{{cookiecutter.lowercase_modelname}} import (
TF_{{cookiecutter.uppercase_modelname}}_PRETRAINED_MODEL_ARCHIVE_LIST,
TF{{cookiecutter.camelcase_modelname}}ForMaskedLM,
TF{{cookiecutter.camelcase_modelname}}ForCausalLM,
TF{{cookiecutter.camelcase_modelname}}ForMultipleChoice,
TF{{cookiecutter.camelcase_modelname}}ForQuestionAnswering,
TF{{cookiecutter.camelcase_modelname}}ForSequenceClassification,
TF{{cookiecutter.camelcase_modelname}}ForTokenClassification,
TF{{cookiecutter.camelcase_modelname}}Layer,
TF{{cookiecutter.camelcase_modelname}}Model,
TF{{cookiecutter.camelcase_modelname}}PreTrainedModel,
)
{% else %}
try:
if not is_tf_available():
raise OptionalDependencyNotAvailable()
except OptionalDependencyNotAvailable:
pass
else:
from .modeling_tf_{{cookiecutter.lowercase_modelname}} import (
TF{{cookiecutter.camelcase_modelname}}ForConditionalGeneration,
TF{{cookiecutter.camelcase_modelname}}Model,
TF{{cookiecutter.camelcase_modelname}}PreTrainedModel,
)
{% endif %}
{% endif %}
{%- if "Flax" in cookiecutter.generate_tensorflow_pytorch_and_flax %}
{% if cookiecutter.is_encoder_decoder_model == "False" %}
try:
if not is_flax_available():
raise OptionalDependencyNotAvailable()
except OptionalDependencyNotAvailable:
pass
else:
from .modeling_{{cookiecutter.lowercase_modelname}} import (
Flax{{cookiecutter.camelcase_modelname}}ForMaskedLM,
Flax{{cookiecutter.camelcase_modelname}}ForCausalLM,
Flax{{cookiecutter.camelcase_modelname}}ForMultipleChoice,
Flax{{cookiecutter.camelcase_modelname}}ForQuestionAnswering,
Flax{{cookiecutter.camelcase_modelname}}ForSequenceClassification,
Flax{{cookiecutter.camelcase_modelname}}ForTokenClassification,
Flax{{cookiecutter.camelcase_modelname}}Layer,
Flax{{cookiecutter.camelcase_modelname}}Model,
Flax{{cookiecutter.camelcase_modelname}}PreTrainedModel,
)
{% else %}
try:
if not is_flax_available():
raise OptionalDependencyNotAvailable()
except OptionalDependencyNotAvailable:
pass
else:
from .modeling_{{cookiecutter.lowercase_modelname}} import (
Flax{{cookiecutter.camelcase_modelname}}ForConditionalGeneration,
Flax{{cookiecutter.camelcase_modelname}}ForQuestionAnswering,
Flax{{cookiecutter.camelcase_modelname}}ForSequenceClassification,
Flax{{cookiecutter.camelcase_modelname}}Model,
Flax{{cookiecutter.camelcase_modelname}}PreTrainedModel,
)
{% endif %}
{% endif %}
else:
import sys
sys.modules[__name__] = _LazyModule(__name__, globals()["__file__"], _import_structure, module_spec=__spec__)
| 0 |
hf_public_repos/transformers/templates/adding_a_new_model | hf_public_repos/transformers/templates/adding_a_new_model/cookiecutter-template-{{cookiecutter.modelname}}/modeling_{{cookiecutter.lowercase_modelname}}.py | # coding=utf-8
# Copyright 2022 {{cookiecutter.authors}} The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
""" PyTorch {{cookiecutter.modelname}} model. """
{% if cookiecutter.is_encoder_decoder_model == "False" %}
import math
import os
import torch
import torch.utils.checkpoint
from torch import nn
from torch.nn import BCEWithLogitsLoss, CrossEntropyLoss, MSELoss
from typing import Optional, Tuple, Union
from ...activations import ACT2FN
from ...utils import (
add_code_sample_docstrings,
add_start_docstrings,
add_start_docstrings_to_model_forward,
replace_return_docstrings,
)
from ...modeling_outputs import (
BaseModelOutputWithPastAndCrossAttentions,
CausalLMOutputWithCrossAttentions,
MaskedLMOutput,
MultipleChoiceModelOutput,
QuestionAnsweringModelOutput,
SequenceClassifierOutput,
TokenClassifierOutput,
)
from ...modeling_utils import PreTrainedModel, SequenceSummary
from ...pytorch_utils import (
apply_chunking_to_forward,
find_pruneable_heads_and_indices,
prune_linear_layer,
)
from ...utils import logging
from .configuration_{{cookiecutter.lowercase_modelname}} import {{cookiecutter.camelcase_modelname}}Config
logger = logging.get_logger(__name__)
_CHECKPOINT_FOR_DOC = "{{cookiecutter.checkpoint_identifier}}"
_CONFIG_FOR_DOC = "{{cookiecutter.camelcase_modelname}}Config"
{{cookiecutter.uppercase_modelname}}_PRETRAINED_MODEL_ARCHIVE_LIST = [
"{{cookiecutter.checkpoint_identifier}}",
# See all {{cookiecutter.modelname}} models at https://huggingface.co/models?filter={{cookiecutter.lowercase_modelname}}
]
def load_tf_weights_in_{{cookiecutter.lowercase_modelname}}(model, config, tf_checkpoint_path):
"""Load tf checkpoints in a pytorch model."""
try:
import re
import numpy as np
import tensorflow as tf
except ImportError:
logger.error(
"Loading a TensorFlow model in PyTorch, requires TensorFlow to be installed. Please see "
"https://www.tensorflow.org/install/ for installation instructions."
)
raise
tf_path = os.path.abspath(tf_checkpoint_path)
logger.info(f"Converting TensorFlow checkpoint from {tf_path}")
# Load weights from TF model
init_vars = tf.train.list_variables(tf_path)
names = []
arrays = []
for name, shape in init_vars:
logger.info(f"Loading TF weight {name} with shape {shape}")
array = tf.train.load_variable(tf_path, name)
names.append(name)
arrays.append(array)
for name, array in zip(names, arrays):
name = name.split("/")
# adam_v and adam_m are variables used in AdamWeightDecayOptimizer to calculated m and v
# which are not required for using pretrained model
if any(
n in ["adam_v", "adam_m", "AdamWeightDecayOptimizer", "AdamWeightDecayOptimizer_1", "global_step"]
for n in name
):
logger.info(f"Skipping {'/'.join(name)}")
continue
pointer = model
for m_name in name:
if re.fullmatch(r"[A-Za-z]+_\d+", m_name):
scope_names = re.split(r"_(\d+)", m_name)
else:
scope_names = [m_name]
if scope_names[0] == "kernel" or scope_names[0] == "gamma":
pointer = getattr(pointer, "weight")
elif scope_names[0] == "output_bias" or scope_names[0] == "beta":
pointer = getattr(pointer, "bias")
elif scope_names[0] == "output_weights":
pointer = getattr(pointer, "weight")
elif scope_names[0] == "squad":
pointer = getattr(pointer, "classifier")
else:
try:
pointer = getattr(pointer, scope_names[0])
except AttributeError:
logger.info(f"Skipping {'/'.join(name)}")
continue
if len(scope_names) >= 2:
num = int(scope_names[1])
pointer = pointer[num]
if m_name[-11:] == "_embeddings":
pointer = getattr(pointer, "weight")
elif m_name == "kernel":
array = np.transpose(array)
try:
assert (
pointer.shape == array.shape
), f"Pointer shape {pointer.shape} and array shape {array.shape} mismatched"
except AssertionError as e:
e.args += (pointer.shape, array.shape)
raise
logger.info(f"Initialize PyTorch weight {name}")
pointer.data = torch.from_numpy(array)
return model
# Copied from transformers.models.bert.modeling_bert.BertEmbeddings with Bert->{{cookiecutter.camelcase_modelname}}
class {{cookiecutter.camelcase_modelname}}Embeddings(nn.Module):
"""Construct the embeddings from word, position and token_type embeddings."""
def __init__(self, config):
super().__init__()
self.word_embeddings = nn.Embedding(config.vocab_size, config.hidden_size, padding_idx=config.pad_token_id)
self.position_embeddings = nn.Embedding(config.max_position_embeddings, config.hidden_size)
self.token_type_embeddings = nn.Embedding(config.type_vocab_size, config.hidden_size)
# self.LayerNorm is not snake-cased to stick with TensorFlow model variable name and be able to load
# any TensorFlow checkpoint file
self.LayerNorm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
# position_ids (1, len position emb) is contiguous in memory and exported when serialized
self.register_buffer("position_ids", torch.arange(config.max_position_embeddings).expand((1, -1)))
self.position_embedding_type = getattr(config, "position_embedding_type", "absolute")
self.register_buffer(
"token_type_ids",
torch.zeros(self.position_ids.size(), dtype=torch.long, device=self.position_ids.device),
persistent=False,
)
def forward(
self, input_ids=None, token_type_ids=None, position_ids=None, inputs_embeds=None, past_key_values_length=0
):
if input_ids is not None:
input_shape = input_ids.size()
else:
input_shape = inputs_embeds.size()[:-1]
seq_length = input_shape[1]
if position_ids is None:
position_ids = self.position_ids[:, past_key_values_length : seq_length + past_key_values_length]
# Setting the token_type_ids to the registered buffer in constructor where it is all zeros, which usually occurs
# when its auto-generated, registered buffer helps users when tracing the model without passing token_type_ids, solves
# issue #5664
if token_type_ids is None:
if hasattr(self, "token_type_ids"):
buffered_token_type_ids = self.token_type_ids[:, :seq_length]
buffered_token_type_ids_expanded = buffered_token_type_ids.expand(input_shape[0], seq_length)
token_type_ids = buffered_token_type_ids_expanded
else:
token_type_ids = torch.zeros(input_shape, dtype=torch.long, device=self.position_ids.device)
if inputs_embeds is None:
inputs_embeds = self.word_embeddings(input_ids)
token_type_embeddings = self.token_type_embeddings(token_type_ids)
embeddings = inputs_embeds + token_type_embeddings
if self.position_embedding_type == "absolute":
position_embeddings = self.position_embeddings(position_ids)
embeddings += position_embeddings
embeddings = self.LayerNorm(embeddings)
embeddings = self.dropout(embeddings)
return embeddings
# Copied from transformers.models.bert.modeling_bert.BertSelfAttention with Bert->{{cookiecutter.camelcase_modelname}}
class {{cookiecutter.camelcase_modelname}}SelfAttention(nn.Module):
def __init__(self, config, position_embedding_type=None):
super().__init__()
if config.hidden_size % config.num_attention_heads != 0 and not hasattr(config, "embedding_size"):
raise ValueError(
f"The hidden size ({config.hidden_size}) is not a multiple of the number of attention "
f"heads ({config.num_attention_heads})"
)
self.num_attention_heads = config.num_attention_heads
self.attention_head_size = int(config.hidden_size / config.num_attention_heads)
self.all_head_size = self.num_attention_heads * self.attention_head_size
self.query = nn.Linear(config.hidden_size, self.all_head_size)
self.key = nn.Linear(config.hidden_size, self.all_head_size)
self.value = nn.Linear(config.hidden_size, self.all_head_size)
self.dropout = nn.Dropout(config.attention_probs_dropout_prob)
self.position_embedding_type = position_embedding_type or getattr(config, "position_embedding_type", "absolute")
if self.position_embedding_type == "relative_key" or self.position_embedding_type == "relative_key_query":
self.max_position_embeddings = config.max_position_embeddings
self.distance_embedding = nn.Embedding(2 * config.max_position_embeddings - 1, self.attention_head_size)
self.is_decoder = config.is_decoder
def transpose_for_scores(self, x):
new_x_shape = x.size()[:-1] + (self.num_attention_heads, self.attention_head_size)
x = x.view(*new_x_shape)
return x.permute(0, 2, 1, 3)
def forward(
self,
hidden_states,
attention_mask=None,
head_mask=None,
encoder_hidden_states=None,
encoder_attention_mask=None,
past_key_value=None,
output_attentions=False,
):
mixed_query_layer = self.query(hidden_states)
# If this is instantiated as a cross-attention module, the keys
# and values come from an encoder; the attention mask needs to be
# such that the encoder's padding tokens are not attended to.
is_cross_attention = encoder_hidden_states is not None
if is_cross_attention and past_key_value is not None:
# reuse k,v, cross_attentions
key_layer = past_key_value[0]
value_layer = past_key_value[1]
attention_mask = encoder_attention_mask
elif is_cross_attention:
key_layer = self.transpose_for_scores(self.key(encoder_hidden_states))
value_layer = self.transpose_for_scores(self.value(encoder_hidden_states))
attention_mask = encoder_attention_mask
elif past_key_value is not None:
key_layer = self.transpose_for_scores(self.key(hidden_states))
value_layer = self.transpose_for_scores(self.value(hidden_states))
key_layer = torch.cat([past_key_value[0], key_layer], dim=2)
value_layer = torch.cat([past_key_value[1], value_layer], dim=2)
else:
key_layer = self.transpose_for_scores(self.key(hidden_states))
value_layer = self.transpose_for_scores(self.value(hidden_states))
query_layer = self.transpose_for_scores(mixed_query_layer)
if self.is_decoder:
# if cross_attention save Tuple(torch.Tensor, torch.Tensor) of all cross attention key/value_states.
# Further calls to cross_attention layer can then reuse all cross-attention
# key/value_states (first "if" case)
# if uni-directional self-attention (decoder) save Tuple(torch.Tensor, torch.Tensor) of
# all previous decoder key/value_states. Further calls to uni-directional self-attention
# can concat previous decoder key/value_states to current projected key/value_states (third "elif" case)
# if encoder bi-directional self-attention `past_key_value` is always `None`
past_key_value = (key_layer, value_layer)
# Take the dot product between "query" and "key" to get the raw attention scores.
attention_scores = torch.matmul(query_layer, key_layer.transpose(-1, -2))
if self.position_embedding_type == "relative_key" or self.position_embedding_type == "relative_key_query":
seq_length = hidden_states.size()[1]
position_ids_l = torch.arange(seq_length, dtype=torch.long, device=hidden_states.device).view(-1, 1)
position_ids_r = torch.arange(seq_length, dtype=torch.long, device=hidden_states.device).view(1, -1)
distance = position_ids_l - position_ids_r
positional_embedding = self.distance_embedding(distance + self.max_position_embeddings - 1)
positional_embedding = positional_embedding.to(dtype=query_layer.dtype) # fp16 compatibility
if self.position_embedding_type == "relative_key":
relative_position_scores = torch.einsum("bhld,lrd->bhlr", query_layer, positional_embedding)
attention_scores = attention_scores + relative_position_scores
elif self.position_embedding_type == "relative_key_query":
relative_position_scores_query = torch.einsum("bhld,lrd->bhlr", query_layer, positional_embedding)
relative_position_scores_key = torch.einsum("bhrd,lrd->bhlr", key_layer, positional_embedding)
attention_scores = attention_scores + relative_position_scores_query + relative_position_scores_key
attention_scores = attention_scores / math.sqrt(self.attention_head_size)
if attention_mask is not None:
# Apply the attention mask is (precomputed for all layers in {{cookiecutter.camelcase_modelname}}Model forward() function)
attention_scores = attention_scores + attention_mask
# Normalize the attention scores to probabilities.
attention_probs = nn.functional.softmax(attention_scores, dim=-1)
# This is actually dropping out entire tokens to attend to, which might
# seem a bit unusual, but is taken from the original Transformer paper.
attention_probs = self.dropout(attention_probs)
# Mask heads if we want to
if head_mask is not None:
attention_probs = attention_probs * head_mask
context_layer = torch.matmul(attention_probs, value_layer)
context_layer = context_layer.permute(0, 2, 1, 3).contiguous()
new_context_layer_shape = context_layer.size()[:-2] + (self.all_head_size,)
context_layer = context_layer.view(*new_context_layer_shape)
outputs = (context_layer, attention_probs) if output_attentions else (context_layer,)
if self.is_decoder:
outputs = outputs + (past_key_value,)
return outputs
# Copied from transformers.models.bert.modeling_bert.BertSelfOutput with Bert->{{cookiecutter.camelcase_modelname}}
class {{cookiecutter.camelcase_modelname}}SelfOutput(nn.Module):
def __init__(self, config):
super().__init__()
self.dense = nn.Linear(config.hidden_size, config.hidden_size)
self.LayerNorm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
def forward(self, hidden_states, input_tensor):
hidden_states = self.dense(hidden_states)
hidden_states = self.dropout(hidden_states)
hidden_states = self.LayerNorm(hidden_states + input_tensor)
return hidden_states
# Copied from transformers.models.bert.modeling_bert.BertAttention with Bert->{{cookiecutter.camelcase_modelname}}
class {{cookiecutter.camelcase_modelname}}Attention(nn.Module):
def __init__(self, config, position_embedding_type=None):
super().__init__()
self.self = {{cookiecutter.camelcase_modelname}}SelfAttention(config, position_embedding_type=position_embedding_type)
self.output = {{cookiecutter.camelcase_modelname}}SelfOutput(config)
self.pruned_heads = set()
def prune_heads(self, heads):
if len(heads) == 0:
return
heads, index = find_pruneable_heads_and_indices(
heads, self.self.num_attention_heads, self.self.attention_head_size, self.pruned_heads
)
# Prune linear layers
self.self.query = prune_linear_layer(self.self.query, index)
self.self.key = prune_linear_layer(self.self.key, index)
self.self.value = prune_linear_layer(self.self.value, index)
self.output.dense = prune_linear_layer(self.output.dense, index, dim=1)
# Update hyper params and store pruned heads
self.self.num_attention_heads = self.self.num_attention_heads - len(heads)
self.self.all_head_size = self.self.attention_head_size * self.self.num_attention_heads
self.pruned_heads = self.pruned_heads.union(heads)
def forward(
self,
hidden_states,
attention_mask=None,
head_mask=None,
encoder_hidden_states=None,
encoder_attention_mask=None,
past_key_value=None,
output_attentions=False,
):
self_outputs = self.self(
hidden_states,
attention_mask,
head_mask,
encoder_hidden_states,
encoder_attention_mask,
past_key_value,
output_attentions,
)
attention_output = self.output(self_outputs[0], hidden_states)
outputs = (attention_output,) + self_outputs[1:] # add attentions if we output them
return outputs
# Copied from transformers.models.bert.modeling_bert.BertIntermediate with Bert->{{cookiecutter.camelcase_modelname}}
class {{cookiecutter.camelcase_modelname}}Intermediate(nn.Module):
def __init__(self, config):
super().__init__()
self.dense = nn.Linear(config.hidden_size, config.intermediate_size)
if isinstance(config.hidden_act, str):
self.intermediate_act_fn = ACT2FN[config.hidden_act]
else:
self.intermediate_act_fn = config.hidden_act
def forward(self, hidden_states):
hidden_states = self.dense(hidden_states)
hidden_states = self.intermediate_act_fn(hidden_states)
return hidden_states
# Copied from transformers.models.bert.modeling_bert.BertOutput with Bert->{{cookiecutter.camelcase_modelname}}
class {{cookiecutter.camelcase_modelname}}Output(nn.Module):
def __init__(self, config):
super().__init__()
self.dense = nn.Linear(config.intermediate_size, config.hidden_size)
self.LayerNorm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
def forward(self, hidden_states, input_tensor):
hidden_states = self.dense(hidden_states)
hidden_states = self.dropout(hidden_states)
hidden_states = self.LayerNorm(hidden_states + input_tensor)
return hidden_states
# Copied from transformers.models.bert.modeling_bert.BertLayer with Bert->{{cookiecutter.camelcase_modelname}}
class {{cookiecutter.camelcase_modelname}}Layer(nn.Module):
def __init__(self, config):
super().__init__()
self.chunk_size_feed_forward = config.chunk_size_feed_forward
self.seq_len_dim = 1
self.attention = {{cookiecutter.camelcase_modelname}}Attention(config)
self.is_decoder = config.is_decoder
self.add_cross_attention = config.add_cross_attention
if self.add_cross_attention:
assert self.is_decoder, f"{self} should be used as a decoder model if cross attention is added"
self.crossattention = {{cookiecutter.camelcase_modelname}}Attention(config, position_embedding_type="absolute")
self.intermediate = {{cookiecutter.camelcase_modelname}}Intermediate(config)
self.output = {{cookiecutter.camelcase_modelname}}Output(config)
def forward(
self,
hidden_states,
attention_mask=None,
head_mask=None,
encoder_hidden_states=None,
encoder_attention_mask=None,
past_key_value=None,
output_attentions=False,
):
# decoder uni-directional self-attention cached key/values tuple is at positions 1,2
self_attn_past_key_value = past_key_value[:2] if past_key_value is not None else None
self_attention_outputs = self.attention(
hidden_states,
attention_mask,
head_mask,
output_attentions=output_attentions,
past_key_value=self_attn_past_key_value,
)
attention_output = self_attention_outputs[0]
# if decoder, the last output is tuple of self-attn cache
if self.is_decoder:
outputs = self_attention_outputs[1:-1]
present_key_value = self_attention_outputs[-1]
else:
outputs = self_attention_outputs[1:] # add self attentions if we output attention weights
cross_attn_present_key_value = None
if self.is_decoder and encoder_hidden_states is not None:
assert hasattr(
self, "crossattention"
), f"If `encoder_hidden_states` are passed, {self} has to be instantiated with cross-attention layers by setting `config.add_cross_attention=True`"
# cross_attn cached key/values tuple is at positions 3,4 of past_key_value tuple
cross_attn_past_key_value = past_key_value[-2:] if past_key_value is not None else None
cross_attention_outputs = self.crossattention(
attention_output,
attention_mask,
head_mask,
encoder_hidden_states,
encoder_attention_mask,
cross_attn_past_key_value,
output_attentions,
)
attention_output = cross_attention_outputs[0]
outputs = outputs + cross_attention_outputs[1:-1] # add cross attentions if we output attention weights
# add cross-attn cache to positions 3,4 of present_key_value tuple
cross_attn_present_key_value = cross_attention_outputs[-1]
present_key_value = present_key_value + cross_attn_present_key_value
layer_output = apply_chunking_to_forward(
self.feed_forward_chunk, self.chunk_size_feed_forward, self.seq_len_dim, attention_output
)
outputs = (layer_output,) + outputs
# if decoder, return the attn key/values as the last output
if self.is_decoder:
outputs = outputs + (present_key_value,)
return outputs
def feed_forward_chunk(self, attention_output):
intermediate_output = self.intermediate(attention_output)
layer_output = self.output(intermediate_output, attention_output)
return layer_output
# Copied from transformers.models.bert.modeling_bert.BertEncoder with Bert->{{cookiecutter.camelcase_modelname}}
class {{cookiecutter.camelcase_modelname}}Encoder(nn.Module):
def __init__(self, config):
super().__init__()
self.config = config
self.layer = nn.ModuleList([{{cookiecutter.camelcase_modelname}}Layer(config) for _ in range(config.num_hidden_layers)])
self.gradient_checkpointing = False
def forward(
self,
hidden_states,
attention_mask=None,
head_mask=None,
encoder_hidden_states=None,
encoder_attention_mask=None,
past_key_values=None,
use_cache=None,
output_attentions=False,
output_hidden_states=False,
return_dict=True,
):
if self.gradient_checkpointing and self.training and use_cache:
logger.warning(
"`use_cache=True` is incompatible with gradient checkpointing. Setting `use_cache=False`..."
)
use_cache = False
all_hidden_states = () if output_hidden_states else None
all_self_attentions = () if output_attentions else None
all_cross_attentions = () if output_attentions and self.config.add_cross_attention else None
next_decoder_cache = () if use_cache else None
for i, layer_module in enumerate(self.layer):
if output_hidden_states:
all_hidden_states = all_hidden_states + (hidden_states,)
layer_head_mask = head_mask[i] if head_mask is not None else None
past_key_value = past_key_values[i] if past_key_values is not None else None
if self.gradient_checkpointing and self.training:
def create_custom_forward(module):
def custom_forward(*inputs):
return module(*inputs, past_key_value, output_attentions)
return custom_forward
layer_outputs = torch.utils.checkpoint.checkpoint(
create_custom_forward(layer_module),
hidden_states,
attention_mask,
layer_head_mask,
encoder_hidden_states,
encoder_attention_mask,
)
else:
layer_outputs = layer_module(
hidden_states,
attention_mask,
layer_head_mask,
encoder_hidden_states,
encoder_attention_mask,
past_key_value,
output_attentions,
)
hidden_states = layer_outputs[0]
if use_cache:
next_decoder_cache += (layer_outputs[-1],)
if output_attentions:
all_self_attentions = all_self_attentions + (layer_outputs[1],)
if self.config.add_cross_attention:
all_cross_attentions = all_cross_attentions + (layer_outputs[2],)
if output_hidden_states:
all_hidden_states = all_hidden_states + (hidden_states,)
if not return_dict:
return tuple(
v
for v in [
hidden_states,
next_decoder_cache,
all_hidden_states,
all_self_attentions,
all_cross_attentions,
]
if v is not None
)
return BaseModelOutputWithPastAndCrossAttentions(
last_hidden_state=hidden_states,
past_key_values=next_decoder_cache,
hidden_states=all_hidden_states,
attentions=all_self_attentions,
cross_attentions=all_cross_attentions,
)
# Copied from transformers.models.bert.modeling_bert.BertPredictionHeadTransform with Bert->{{cookiecutter.camelcase_modelname}}
class {{cookiecutter.camelcase_modelname}}PredictionHeadTransform(nn.Module):
def __init__(self, config):
super().__init__()
self.dense = nn.Linear(config.hidden_size, config.hidden_size)
if isinstance(config.hidden_act, str):
self.transform_act_fn = ACT2FN[config.hidden_act]
else:
self.transform_act_fn = config.hidden_act
self.LayerNorm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
def forward(self, hidden_states):
hidden_states = self.dense(hidden_states)
hidden_states = self.transform_act_fn(hidden_states)
hidden_states = self.LayerNorm(hidden_states)
return hidden_states
# Copied from transformers.models.bert.modeling_bert.BertLMPredictionHead with Bert->{{cookiecutter.camelcase_modelname}}
class {{cookiecutter.camelcase_modelname}}LMPredictionHead(nn.Module):
def __init__(self, config):
super().__init__()
self.transform = {{cookiecutter.camelcase_modelname}}PredictionHeadTransform(config)
# The output weights are the same as the input embeddings, but there is
# an output-only bias for each token.
self.decoder = nn.Linear(config.hidden_size, config.vocab_size, bias=False)
self.bias = nn.Parameter(torch.zeros(config.vocab_size))
# Need a link between the two variables so that the bias is correctly resized with `resize_token_embeddings`
self.decoder.bias = self.bias
def forward(self, hidden_states):
hidden_states = self.transform(hidden_states)
hidden_states = self.decoder(hidden_states)
return hidden_states
# Copied from transformers.models.bert.modeling_bert.BertOnlyMLMHead with Bert->{{cookiecutter.camelcase_modelname}}
class {{cookiecutter.camelcase_modelname}}OnlyMLMHead(nn.Module):
def __init__(self, config):
super().__init__()
self.predictions = {{cookiecutter.camelcase_modelname}}LMPredictionHead(config)
def forward(self, sequence_output):
prediction_scores = self.predictions(sequence_output)
return prediction_scores
class {{cookiecutter.camelcase_modelname}}PreTrainedModel(PreTrainedModel):
"""
An abstract class to handle weights initialization and
a simple interface for downloading and loading pretrained models.
"""
config_class = {{cookiecutter.camelcase_modelname}}Config
load_tf_weights = load_tf_weights_in_{{cookiecutter.lowercase_modelname}}
base_model_prefix = "{{cookiecutter.lowercase_modelname}}"
supports_gradient_checkpointing = True
_keys_to_ignore_on_load_missing = [r"position_ids"]
def _init_weights(self, module):
""" Initialize the weights """
if isinstance(module, nn.Linear):
# Slightly different from the TF version which uses truncated_normal for initialization
# cf https://github.com/pytorch/pytorch/pull/5617
module.weight.data.normal_(mean=0.0, std=self.config.initializer_range)
if module.bias is not None:
module.bias.data.zero_()
elif isinstance(module, nn.Embedding):
module.weight.data.normal_(mean=0.0, std=self.config.initializer_range)
if module.padding_idx is not None:
module.weight.data[module.padding_idx].zero_()
elif isinstance(module, nn.LayerNorm):
module.bias.data.zero_()
module.weight.data.fill_(1.0)
def _set_gradient_checkpointing(self, module, value=False):
if isinstance(module, {{cookiecutter.camelcase_modelname}}Encoder):
module.gradient_checkpointing = value
{{cookiecutter.uppercase_modelname}}_START_DOCSTRING = r"""
This model is a PyTorch [torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) sub-class.
Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general
usage and behavior.
Parameters:
config ([`~{{cookiecutter.camelcase_modelname}}Config`]): Model configuration class with all the parameters of the model.
Initializing with a config file does not load the weights associated with the model, only the configuration.
Check out the [`~PreTrainedModel.from_pretrained`] method to load the model weights.
"""
{{cookiecutter.uppercase_modelname}}_INPUTS_DOCSTRING = r"""
Args:
input_ids (`torch.LongTensor` of shape `({0})`):
Indices of input sequence tokens in the vocabulary.
Indices can be obtained using [`{{cookiecutter.camelcase_modelname}}Tokenizer`].
See [`PreTrainedTokenizer.encode`] and
[`PreTrainedTokenizer.__call__`] for details.
[What are input IDs?](../glossary#input-ids)
attention_mask (`torch.FloatTensor` of shape `({0})`, *optional*):
Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
- 1 for tokens that are **not masked**,
- 0 for tokens that are **masked**.
[What are attention masks?](../glossary#attention-mask)
token_type_ids (`torch.LongTensor` of shape `({0})`, *optional*):
Segment token indices to indicate first and second portions of the inputs. Indices are selected in `[0, 1]`:
- 0 corresponds to a *sentence A* token,
- 1 corresponds to a *sentence B* token.
[What are token type IDs?](../glossary#token-type-ids)
position_ids (`torch.LongTensor` of shape `({0})`, *optional*):
Indices of positions of each input sequence tokens in the position embeddings.
Selected in the range `[0, config.max_position_embeddings - 1]`.
[What are position IDs?](../glossary#position-ids)
head_mask (`torch.FloatTensor` of shape `(num_heads,)` or `(num_layers, num_heads)`, *optional*):
Mask to nullify selected heads of the self-attention modules. Mask values selected in `[0, 1]`:
- 1 indicates the head is **not masked**,
- 0 indicates the head is **masked**.
inputs_embeds (`torch.FloatTensor` of shape `({0}, hidden_size)`, *optional*):
Optionally, instead of passing `input_ids` you can choose to directly pass an embedded representation.
This is useful if you want more control over how to convert *input_ids* indices into associated vectors
than the model's internal embedding lookup matrix.
output_attentions (`bool`, *optional*):
Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
tensors for more detail.
output_hidden_states (`bool`, *optional*):
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
more detail.
return_dict (`bool`, *optional*):
Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
"""
@add_start_docstrings(
"The bare {{cookiecutter.modelname}} Model transformer outputting raw hidden-states without any specific head on top.",
{{cookiecutter.uppercase_modelname}}_START_DOCSTRING,
)
class {{cookiecutter.camelcase_modelname}}Model({{cookiecutter.camelcase_modelname}}PreTrainedModel):
"""
The model can behave as an encoder (with only self-attention) as well
as a decoder, in which case a layer of cross-attention is added between
the self-attention layers, following the architecture described in [Attention is
all you need](https://arxiv.org/abs/1706.03762) by Ashish Vaswani,
Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser and Illia Polosukhin.
To behave as an decoder the model needs to be initialized with the
`is_decoder` argument of the configuration set to `True`.
To be used in a Seq2Seq model, the model needs to initialized with both `is_decoder`
argument and `add_cross_attention` set to `True`; an
`encoder_hidden_states` is then expected as an input to the forward pass.
"""
def __init__(self, config):
super().__init__(config)
self.config = config
self.embeddings = {{cookiecutter.camelcase_modelname}}Embeddings(config)
self.encoder = {{cookiecutter.camelcase_modelname}}Encoder(config)
# Initialize weights and apply final processing
self.post_init()
def get_input_embeddings(self):
return self.embeddings.word_embeddings
def set_input_embeddings(self, value):
self.embeddings.word_embeddings = value
def _prune_heads(self, heads_to_prune):
"""Prunes heads of the model.
heads_to_prune: dict of {layer_num: list of heads to prune in this layer}
See base class PreTrainedModel
"""
for layer, heads in heads_to_prune.items():
self.encoder.layer[layer].attention.prune_heads(heads)
@add_start_docstrings_to_model_forward({{cookiecutter.uppercase_modelname}}_INPUTS_DOCSTRING.format("batch_size, sequence_length"))
@add_code_sample_docstrings(
checkpoint=_CHECKPOINT_FOR_DOC,
output_type=BaseModelOutputWithPastAndCrossAttentions,
config_class=_CONFIG_FOR_DOC,
)
def forward(
self,
input_ids=None,
attention_mask=None,
token_type_ids=None,
position_ids=None,
head_mask=None,
inputs_embeds=None,
encoder_hidden_states=None,
encoder_attention_mask=None,
past_key_values=None,
use_cache=None,
output_attentions=None,
output_hidden_states=None,
return_dict=None,
):
r"""
encoder_hidden_states (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`, *optional*):
Sequence of hidden-states at the output of the last layer of the encoder. Used in the cross-attention
if the model is configured as a decoder.
encoder_attention_mask (`torch.FloatTensor` of shape `(batch_size, sequence_length)`, *optional*):
Mask to avoid performing attention on the padding token indices of the encoder input. This mask
is used in the cross-attention if the model is configured as a decoder.
Mask values selected in `[0, 1]`:
- 1 for tokens that are **not masked**,
- 0 for tokens that are **masked**.
past_key_values (`tuple(tuple(torch.FloatTensor))` of length `config.n_layers` with each tuple having 4 tensors of shape `(batch_size, num_heads, sequence_length - 1, embed_size_per_head)`):
Contains precomputed key and value hidden states of the attention blocks. Can be used to speed up decoding.
If `past_key_values` are used, the user can optionally input only the last `decoder_input_ids`
(those that don't have their past key value states given to this model) of shape `(batch_size, 1)`
instead of all `decoder_input_ids` of shape `(batch_size, sequence_length)`.
use_cache (`bool`, *optional*):
If set to `True`, `past_key_values` key value states are returned and can be used to speed up
decoding (see `past_key_values`).
"""
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
output_hidden_states = (
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
)
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
if self.config.is_decoder:
use_cache = use_cache if use_cache is not None else self.config.use_cache
else:
use_cache = False
if input_ids is not None and inputs_embeds is not None:
raise ValueError("You cannot specify both input_ids and inputs_embeds at the same time")
elif input_ids is not None:
input_shape = input_ids.size()
elif inputs_embeds is not None:
input_shape = inputs_embeds.size()[:-1]
else:
raise ValueError("You have to specify either input_ids or inputs_embeds")
batch_size, seq_length = input_shape
device = input_ids.device if input_ids is not None else inputs_embeds.device
# past_key_values_length
past_key_values_length = past_key_values[0][0].shape[2] if past_key_values is not None else 0
if attention_mask is None:
attention_mask = torch.ones(((batch_size, seq_length + past_key_values_length)), device=device)
if token_type_ids is None:
if hasattr(self.embeddings, "token_type_ids"):
buffered_token_type_ids = self.embeddings.token_type_ids[:, :seq_length]
buffered_token_type_ids_expanded = buffered_token_type_ids.expand(batch_size, seq_length)
token_type_ids = buffered_token_type_ids_expanded
else:
token_type_ids = torch.zeros(input_shape, dtype=torch.long, device=device)
# We can provide a self-attention mask of dimensions [batch_size, from_seq_length, to_seq_length]
# ourselves in which case we just need to make it broadcastable to all heads.
extended_attention_mask: torch.Tensor = self.get_extended_attention_mask(attention_mask, input_shape)
# If a 2D or 3D attention mask is provided for the cross-attention
# we need to make broadcastable to [batch_size, num_heads, seq_length, seq_length]
if self.config.is_decoder and encoder_hidden_states is not None:
encoder_batch_size, encoder_sequence_length, _ = encoder_hidden_states.size()
encoder_hidden_shape = (encoder_batch_size, encoder_sequence_length)
if encoder_attention_mask is None:
encoder_attention_mask = torch.ones(encoder_hidden_shape, device=device)
encoder_extended_attention_mask = self.invert_attention_mask(encoder_attention_mask)
else:
encoder_extended_attention_mask = None
# Prepare head mask if needed
# 1.0 in head_mask indicate we keep the head
# attention_probs has shape bsz x n_heads x N x N
# input head_mask has shape [num_heads] or [num_hidden_layers x num_heads]
# and head_mask is converted to shape [num_hidden_layers x batch x num_heads x seq_length x seq_length]
head_mask = self.get_head_mask(head_mask, self.config.num_hidden_layers)
embedding_output = self.embeddings(
input_ids=input_ids,
position_ids=position_ids,
token_type_ids=token_type_ids,
inputs_embeds=inputs_embeds,
past_key_values_length=past_key_values_length,
)
encoder_outputs = self.encoder(
embedding_output,
attention_mask=extended_attention_mask,
head_mask=head_mask,
encoder_hidden_states=encoder_hidden_states,
encoder_attention_mask=encoder_extended_attention_mask,
past_key_values=past_key_values,
use_cache=use_cache,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
sequence_output = encoder_outputs[0]
if not return_dict:
return (sequence_output,) + encoder_outputs[1:]
return BaseModelOutputWithPastAndCrossAttentions(
last_hidden_state=sequence_output,
past_key_values=encoder_outputs.past_key_values,
hidden_states=encoder_outputs.hidden_states,
attentions=encoder_outputs.attentions,
cross_attentions=encoder_outputs.cross_attentions,
)
@add_start_docstrings("""{{cookiecutter.modelname}} Model with a `language modeling` head on top. """, {{cookiecutter.uppercase_modelname}}_START_DOCSTRING)
class {{cookiecutter.camelcase_modelname}}ForMaskedLM({{cookiecutter.camelcase_modelname}}PreTrainedModel):
def __init__(self, config):
super().__init__(config)
if config.is_decoder:
logger.warning(
"If you want to use `{{cookiecutter.camelcase_modelname}}ForMaskedLM` make sure `config.is_decoder=False` for "
"bi-directional self-attention."
)
self.{{cookiecutter.lowercase_modelname}} = {{cookiecutter.camelcase_modelname}}Model(config)
self.cls = {{cookiecutter.camelcase_modelname}}OnlyMLMHead(config)
# Initialize weights and apply final processing
self.post_init()
def get_output_embeddings(self):
return self.cls.predictions.decoder
def set_output_embeddings(self, new_embeddings):
self.cls.predictions.decoder = new_embeddings
@add_start_docstrings_to_model_forward({{cookiecutter.uppercase_modelname}}_INPUTS_DOCSTRING.format("batch_size, sequence_length"))
@add_code_sample_docstrings(
checkpoint=_CHECKPOINT_FOR_DOC,
output_type=MaskedLMOutput,
config_class=_CONFIG_FOR_DOC,
)
def forward(
self,
input_ids=None,
attention_mask=None,
token_type_ids=None,
position_ids=None,
head_mask=None,
inputs_embeds=None,
encoder_hidden_states=None,
encoder_attention_mask=None,
labels=None,
output_attentions=None,
output_hidden_states=None,
return_dict=None,
):
r"""
labels (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
Labels for computing the masked language modeling loss.
Indices should be in `[-100, 0, ..., config.vocab_size]` (see `input_ids` docstring)
Tokens with indices set to `-100` are ignored (masked), the loss is only computed for the tokens with labels
in `[0, ..., config.vocab_size]`.
"""
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
outputs = self.{{cookiecutter.lowercase_modelname}}(
input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
position_ids=position_ids,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
encoder_hidden_states=encoder_hidden_states,
encoder_attention_mask=encoder_attention_mask,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
sequence_output = outputs[0]
prediction_scores = self.cls(sequence_output)
masked_lm_loss = None
if labels is not None:
loss_fct = CrossEntropyLoss() # -100 index = padding token
masked_lm_loss = loss_fct(prediction_scores.view(-1, self.config.vocab_size), labels.view(-1))
if not return_dict:
output = (prediction_scores,) + outputs[1:]
return ((masked_lm_loss,) + output) if masked_lm_loss is not None else output
return MaskedLMOutput(
loss=masked_lm_loss,
logits=prediction_scores,
hidden_states=outputs.hidden_states,
attentions=outputs.attentions,
)
def prepare_inputs_for_generation(self, input_ids, attention_mask=None, **model_kwargs):
input_shape = input_ids.shape
effective_batch_size = input_shape[0]
# add a dummy token
assert self.config.pad_token_id is not None, "The PAD token should be defined for generation"
attention_mask = torch.cat([attention_mask, attention_mask.new_zeros((attention_mask.shape[0], 1))], dim=-1)
dummy_token = torch.full(
(effective_batch_size, 1), self.config.pad_token_id, dtype=torch.long, device=input_ids.device
)
input_ids = torch.cat([input_ids, dummy_token], dim=1)
return {"input_ids": input_ids, "attention_mask": attention_mask}
@add_start_docstrings(
"""{{cookiecutter.modelname}} Model with a `language modeling` head on top for CLM fine-tuning. """, {{cookiecutter.uppercase_modelname}}_START_DOCSTRING
)
class {{cookiecutter.camelcase_modelname}}ForCausalLM({{cookiecutter.camelcase_modelname}}PreTrainedModel):
_keys_to_ignore_on_load_missing = [r"position_ids", r"predictions.decoder.bias"]
def __init__(self, config):
super().__init__(config)
if not config.is_decoder:
logger.warning("If you want to use `{{cookiecutter.camelcase_modelname}}ForCausalLM` as a standalone, add `is_decoder=True.`")
self.{{cookiecutter.lowercase_modelname}} = {{cookiecutter.camelcase_modelname}}Model(config)
self.cls = {{cookiecutter.camelcase_modelname}}OnlyMLMHead(config)
# Initialize weights and apply final processing
self.post_init()
def get_output_embeddings(self):
return self.cls.predictions.decoder
def set_output_embeddings(self, new_embeddings):
self.cls.predictions.decoder = new_embeddings
@add_start_docstrings_to_model_forward({{cookiecutter.uppercase_modelname}}_INPUTS_DOCSTRING.format("batch_size, sequence_length"))
@replace_return_docstrings(output_type=CausalLMOutputWithCrossAttentions, config_class=_CONFIG_FOR_DOC)
def forward(
self,
input_ids=None,
attention_mask=None,
token_type_ids=None,
position_ids=None,
inputs_embeds=None,
encoder_hidden_states=None,
encoder_attention_mask=None,
head_mask=None,
cross_attn_head_mask=None,
past_key_values=None,
labels=None,
use_cache=None,
output_attentions=None,
output_hidden_states=None,
return_dict=None,
):
r"""
encoder_hidden_states (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`, *optional*):
Sequence of hidden-states at the output of the last layer of the encoder. Used in the cross-attention if
the model is configured as a decoder.
encoder_attention_mask (`torch.FloatTensor` of shape `(batch_size, sequence_length)`, *optional*):
Mask to avoid performing attention on the padding token indices of the encoder input. This mask is used in
the cross-attention if the model is configured as a decoder. Mask values selected in `[0, 1]`:
- 1 for tokens that are **not masked**,
- 0 for tokens that are **masked**.
past_key_values (`tuple(tuple(torch.FloatTensor))`, *optional*, returned when `use_cache=True` is passed or when `config.use_cache=True`):
Tuple of `tuple(torch.FloatTensor)` of length `config.n_layers`, with each tuple having 2
tensors of shape `(batch_size, num_heads, sequence_length, embed_size_per_head)`) and 2 additional
tensors of shape `(batch_size, num_heads, encoder_sequence_length, embed_size_per_head)`. The two
additional tensors are only required when the model is used as a decoder in a Sequence to Sequence
model.
Contains pre-computed hidden-states (key and values in the self-attention blocks and in the
cross-attention blocks) that can be used (see `past_key_values` input) to speed up sequential
decoding.
If `past_key_values` are used, the user can optionally input only the last `decoder_input_ids`
(those that don't have their past key value states given to this model) of shape `(batch_size, 1)`
instead of all `decoder_input_ids` of shape `(batch_size, sequence_length)`.
labels (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
Labels for computing the left-to-right language modeling loss (next word prediction). Indices should be in
`[-100, 0, ..., config.vocab_size]` (see `input_ids` docstring) Tokens with indices set to `-100` are
ignored (masked), the loss is only computed for the tokens with labels n `[0, ..., config.vocab_size]`.
use_cache (`bool`, *optional*):
If set to `True`, `past_key_values` key value states are returned and can be used to speed up
decoding (see `past_key_values`).
Returns:
Example:
```python
>>> from transformers import {{cookiecutter.camelcase_modelname}}Tokenizer, {{cookiecutter.camelcase_modelname}}ForCausalLM, {{cookiecutter.camelcase_modelname}}Config
>>> import torch
>>> tokenizer = {{cookiecutter.camelcase_modelname}}Tokenizer.from_pretrained('{{cookiecutter.checkpoint_identifier}}')
>>> config = {{cookiecutter.camelcase_modelname}}Config.from_pretrained("{{cookiecutter.checkpoint_identifier}}")
>>> config.is_decoder = True
>>> model = {{cookiecutter.camelcase_modelname}}ForCausalLM.from_pretrained('{{cookiecutter.checkpoint_identifier}}', config=config)
>>> inputs = tokenizer("Hello, my dog is cute", return_tensors="pt")
>>> outputs = model(**inputs)
>>> prediction_logits = outputs.logits
```
"""
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
outputs = self.{{cookiecutter.lowercase_modelname}}(
input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
position_ids=position_ids,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
encoder_hidden_states=encoder_hidden_states,
encoder_attention_mask=encoder_attention_mask,
past_key_values=past_key_values,
use_cache=use_cache,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
sequence_output = outputs[0]
prediction_scores = self.cls(sequence_output)
lm_loss = None
if labels is not None:
# we are doing next-token prediction; shift prediction scores and input ids by one
shifted_prediction_scores = prediction_scores[:, :-1, :].contiguous()
labels = labels[:, 1:].contiguous()
loss_fct = CrossEntropyLoss()
lm_loss = loss_fct(shifted_prediction_scores.view(-1, self.config.vocab_size), labels.view(-1))
if not return_dict:
output = (prediction_scores,) + outputs[1:]
return ((lm_loss,) + output) if lm_loss is not None else output
return CausalLMOutputWithCrossAttentions(
loss=lm_loss,
logits=prediction_scores,
past_key_values=outputs.past_key_values,
hidden_states=outputs.hidden_states,
attentions=outputs.attentions,
cross_attentions=outputs.cross_attentions,
)
def prepare_inputs_for_generation(self, input_ids, past_key_values=None, attention_mask=None, **model_kwargs):
input_shape = input_ids.shape
# if model is used as a decoder in encoder-decoder model, the decoder attention mask is created on the fly
if attention_mask is None:
attention_mask = input_ids.new_ones(input_shape)
# cut decoder_input_ids if past is used
if past_key_values is not None:
input_ids = input_ids[:, -1:]
return {"input_ids": input_ids, "attention_mask": attention_mask, "past_key_values": past_key_values}
def _reorder_cache(self, past_key_values, beam_idx):
reordered_past = ()
for layer_past in past_key_values:
reordered_past += (tuple(past_state.index_select(0, beam_idx) for past_state in layer_past[:2]) + layer_past[2:],)
return reordered_past
class {{cookiecutter.camelcase_modelname}}ClassificationHead(nn.Module):
"""Head for sentence-level classification tasks."""
def __init__(self, config):
super().__init__()
self.dense = nn.Linear(config.hidden_size, config.hidden_size)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
self.out_proj = nn.Linear(config.hidden_size, config.num_labels)
self.config = config
def forward(self, features, **kwargs):
x = features[:, 0, :] # take <s> token (equiv. to [CLS])
x = self.dropout(x)
x = self.dense(x)
x = ACT2FN[self.config.hidden_act](x)
x = self.dropout(x)
x = self.out_proj(x)
return x
@add_start_docstrings(
"""{{cookiecutter.modelname}} Model transformer with a sequence classification/regression head on top (a linear layer on top of
the pooled output) e.g. for GLUE tasks. """,
{{cookiecutter.uppercase_modelname}}_START_DOCSTRING,
)
class {{cookiecutter.camelcase_modelname}}ForSequenceClassification({{cookiecutter.camelcase_modelname}}PreTrainedModel):
def __init__(self, config):
super().__init__(config)
self.num_labels = config.num_labels
self.{{cookiecutter.lowercase_modelname}} = {{cookiecutter.camelcase_modelname}}Model(config)
self.classifier = {{cookiecutter.camelcase_modelname}}ClassificationHead(config)
# Initialize weights and apply final processing
self.post_init()
@add_start_docstrings_to_model_forward({{cookiecutter.uppercase_modelname}}_INPUTS_DOCSTRING.format("batch_size, sequence_length"))
@add_code_sample_docstrings(
checkpoint=_CHECKPOINT_FOR_DOC,
output_type=SequenceClassifierOutput,
config_class=_CONFIG_FOR_DOC,
)
def forward(
self,
input_ids=None,
attention_mask=None,
token_type_ids=None,
position_ids=None,
head_mask=None,
inputs_embeds=None,
labels=None,
output_attentions=None,
output_hidden_states=None,
return_dict=None,
):
r"""
labels (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
Labels for computing the sequence classification/regression loss.
Indices should be in `[0, ..., config.num_labels - 1]`.
If `config.num_labels == 1` a regression loss is computed (Mean-Square loss),
If `config.num_labels > 1` a classification loss is computed (Cross-Entropy).
"""
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
outputs = self.{{cookiecutter.lowercase_modelname}}(
input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
position_ids=position_ids,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
sequence_output = outputs[0]
logits = self.classifier(sequence_output)
loss = None
if labels is not None:
if self.config.problem_type is None:
if self.num_labels == 1:
self.config.problem_type = "regression"
elif self.num_labels > 1 and (labels.dtype == torch.long or labels.dtype == torch.int):
self.config.problem_type = "single_label_classification"
else:
self.config.problem_type = "multi_label_classification"
if self.config.problem_type == "regression":
loss_fct = MSELoss()
if self.num_labels == 1:
loss = loss_fct(logits.squeeze(), labels.squeeze())
else:
loss = loss_fct(logits, labels)
elif self.config.problem_type == "single_label_classification":
loss_fct = CrossEntropyLoss()
loss = loss_fct(logits.view(-1, self.num_labels), labels.view(-1))
elif self.config.problem_type == "multi_label_classification":
loss_fct = BCEWithLogitsLoss()
loss = loss_fct(logits, labels)
if not return_dict:
output = (logits,) + outputs[1:]
return ((loss,) + output) if loss is not None else output
return SequenceClassifierOutput(
loss=loss,
logits=logits,
hidden_states=outputs.hidden_states,
attentions=outputs.attentions,
)
@add_start_docstrings(
"""{{cookiecutter.modelname}} Model with a multiple choice classification head on top (a linear layer on top of
the pooled output and a softmax) e.g. for RocStories/SWAG tasks. """,
{{cookiecutter.uppercase_modelname}}_START_DOCSTRING,
)
class {{cookiecutter.camelcase_modelname}}ForMultipleChoice({{cookiecutter.camelcase_modelname}}PreTrainedModel):
def __init__(self, config):
super().__init__(config)
self.{{cookiecutter.lowercase_modelname}} = {{cookiecutter.camelcase_modelname}}Model(config)
self.sequence_summary = SequenceSummary(config)
self.classifier = nn.Linear(config.hidden_size, 1)
# Initialize weights and apply final processing
self.post_init()
@add_start_docstrings_to_model_forward({{cookiecutter.uppercase_modelname}}_INPUTS_DOCSTRING.format("batch_size, num_choices, sequence_length"))
@add_code_sample_docstrings(
checkpoint=_CHECKPOINT_FOR_DOC,
output_type=MultipleChoiceModelOutput,
config_class=_CONFIG_FOR_DOC,
)
def forward(
self,
input_ids=None,
attention_mask=None,
token_type_ids=None,
position_ids=None,
head_mask=None,
inputs_embeds=None,
labels=None,
output_attentions=None,
output_hidden_states=None,
return_dict=None,
):
r"""
labels (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
Labels for computing the multiple choice classification loss.
Indices should be in `[0, ..., num_choices-1]` where `num_choices` is the size of the second dimension
of the input tensors. (See `input_ids` above)
"""
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
num_choices = input_ids.shape[1] if input_ids is not None else inputs_embeds.shape[1]
input_ids = input_ids.view(-1, input_ids.size(-1)) if input_ids is not None else None
attention_mask = attention_mask.view(-1, attention_mask.size(-1)) if attention_mask is not None else None
token_type_ids = token_type_ids.view(-1, token_type_ids.size(-1)) if token_type_ids is not None else None
position_ids = position_ids.view(-1, position_ids.size(-1)) if position_ids is not None else None
inputs_embeds = (
inputs_embeds.view(-1, inputs_embeds.size(-2), inputs_embeds.size(-1))
if inputs_embeds is not None
else None
)
outputs = self.{{cookiecutter.lowercase_modelname}}(
input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
position_ids=position_ids,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
sequence_output = outputs[0]
pooled_output = self.sequence_summary(sequence_output)
logits = self.classifier(pooled_output)
reshaped_logits = logits.view(-1, num_choices)
loss = None
if labels is not None:
loss_fct = CrossEntropyLoss()
loss = loss_fct(reshaped_logits, labels)
if not return_dict:
output = (reshaped_logits,) + outputs[1:]
return ((loss,) + output) if loss is not None else output
return MultipleChoiceModelOutput(
loss=loss,
logits=reshaped_logits,
hidden_states=outputs.hidden_states,
attentions=outputs.attentions,
)
@add_start_docstrings(
"""{{cookiecutter.modelname}} Model with a token classification head on top (a linear layer on top of
the hidden-states output) e.g. for Named-Entity-Recognition (NER) tasks. """,
{{cookiecutter.uppercase_modelname}}_START_DOCSTRING,
)
class {{cookiecutter.camelcase_modelname}}ForTokenClassification({{cookiecutter.camelcase_modelname}}PreTrainedModel):
def __init__(self, config):
super().__init__(config)
self.num_labels = config.num_labels
self.{{cookiecutter.lowercase_modelname}} = {{cookiecutter.camelcase_modelname}}Model(config)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
self.classifier = nn.Linear(config.hidden_size, config.num_labels)
# Initialize weights and apply final processing
self.post_init()
@add_start_docstrings_to_model_forward({{cookiecutter.uppercase_modelname}}_INPUTS_DOCSTRING.format("batch_size, sequence_length"))
@add_code_sample_docstrings(
checkpoint=_CHECKPOINT_FOR_DOC,
output_type=TokenClassifierOutput,
config_class=_CONFIG_FOR_DOC,
)
def forward(
self,
input_ids=None,
attention_mask=None,
token_type_ids=None,
position_ids=None,
head_mask=None,
inputs_embeds=None,
labels=None,
output_attentions=None,
output_hidden_states=None,
return_dict=None,
):
r"""
labels (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
Labels for computing the token classification loss.
Indices should be in `[0, ..., config.num_labels - 1]`.
"""
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
outputs = self.{{cookiecutter.lowercase_modelname}}(
input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
position_ids=position_ids,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
sequence_output = outputs[0]
sequence_output = self.dropout(sequence_output)
logits = self.classifier(sequence_output)
loss = None
if labels is not None:
loss_fct = CrossEntropyLoss()
loss = loss_fct(logits.view(-1, self.num_labels), labels.view(-1))
if not return_dict:
output = (logits,) + outputs[1:]
return ((loss,) + output) if loss is not None else output
return TokenClassifierOutput(
loss=loss,
logits=logits,
hidden_states=outputs.hidden_states,
attentions=outputs.attentions,
)
@add_start_docstrings(
"""{{cookiecutter.modelname}} Model with a span classification head on top for extractive question-answering tasks like SQuAD (a linear
layers on top of the hidden-states output to compute `span start logits` and `span end logits`). """,
{{cookiecutter.uppercase_modelname}}_START_DOCSTRING,
)
class {{cookiecutter.camelcase_modelname}}ForQuestionAnswering({{cookiecutter.camelcase_modelname}}PreTrainedModel):
def __init__(self, config):
super().__init__(config)
config.num_labels = 2
self.num_labels = config.num_labels
self.{{cookiecutter.lowercase_modelname}} = {{cookiecutter.camelcase_modelname}}Model(config)
self.qa_outputs = nn.Linear(config.hidden_size, config.num_labels)
# Initialize weights and apply final processing
self.post_init()
@add_start_docstrings_to_model_forward({{cookiecutter.uppercase_modelname}}_INPUTS_DOCSTRING.format("batch_size, sequence_length"))
@add_code_sample_docstrings(
checkpoint=_CHECKPOINT_FOR_DOC,
output_type=QuestionAnsweringModelOutput,
config_class=_CONFIG_FOR_DOC,
)
def forward(
self,
input_ids=None,
attention_mask=None,
token_type_ids=None,
position_ids=None,
head_mask=None,
inputs_embeds=None,
start_positions=None,
end_positions=None,
output_attentions=None,
output_hidden_states=None,
return_dict=None,
):
r"""
start_positions (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
Labels for position (index) of the start of the labelled span for computing the token classification loss.
Positions are clamped to the length of the sequence (`sequence_length`).
Position outside of the sequence are not taken into account for computing the loss.
end_positions (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
Labels for position (index) of the end of the labelled span for computing the token classification loss.
Positions are clamped to the length of the sequence (`sequence_length`).
Position outside of the sequence are not taken into account for computing the loss.
"""
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
outputs = self.{{cookiecutter.lowercase_modelname}}(
input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
position_ids=position_ids,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
sequence_output = outputs[0]
logits = self.qa_outputs(sequence_output)
start_logits, end_logits = logits.split(1, dim=-1)
start_logits = start_logits.squeeze(-1)
end_logits = end_logits.squeeze(-1)
total_loss = None
if start_positions is not None and end_positions is not None:
# If we are on multi-GPU, split add a dimension
if len(start_positions.size()) > 1:
start_positions = start_positions.squeeze(-1)
if len(end_positions.size()) > 1:
end_positions = end_positions.squeeze(-1)
# sometimes the start/end positions are outside our model inputs, we ignore these terms
ignored_index = start_logits.size(1)
start_positions = start_positions.clamp(0, ignored_index)
end_positions = end_positions.clamp(0, ignored_index)
loss_fct = CrossEntropyLoss(ignore_index=ignored_index)
start_loss = loss_fct(start_logits, start_positions)
end_loss = loss_fct(end_logits, end_positions)
total_loss = (start_loss + end_loss) / 2
if not return_dict:
output = (start_logits, end_logits) + outputs[1:]
return ((total_loss,) + output) if total_loss is not None else output
return QuestionAnsweringModelOutput(
loss=total_loss,
start_logits=start_logits,
end_logits=end_logits,
hidden_states=outputs.hidden_states,
attentions=outputs.attentions,
)
{% else %}
import math
import copy
from typing import Optional, Tuple, List, Union
import torch
from torch import nn
from torch.nn import BCEWithLogitsLoss, CrossEntropyLoss, MSELoss
from ...activations import ACT2FN
from ...utils import (
add_code_sample_docstrings,
add_end_docstrings,
add_start_docstrings,
add_start_docstrings_to_model_forward,
replace_return_docstrings,
)
from ...modeling_outputs import (
BaseModelOutput,
BaseModelOutputWithPastAndCrossAttentions,
Seq2SeqLMOutput,
Seq2SeqModelOutput,
Seq2SeqQuestionAnsweringModelOutput,
Seq2SeqSequenceClassifierOutput,
CausalLMOutputWithCrossAttentions
)
from ...modeling_utils import PreTrainedModel
from ...utils import logging
from .configuration_{{cookiecutter.lowercase_modelname}} import {{cookiecutter.camelcase_modelname}}Config
logger = logging.get_logger(__name__)
_CHECKPOINT_FOR_DOC = "{{cookiecutter.checkpoint_identifier}}"
_CONFIG_FOR_DOC = "{{cookiecutter.camelcase_modelname}}Config"
{{cookiecutter.uppercase_modelname}}_PRETRAINED_MODEL_ARCHIVE_LIST = [
"{{cookiecutter.checkpoint_identifier}}",
# See all {{cookiecutter.modelname}} models at https://huggingface.co/models?filter={{cookiecutter.lowercase_modelname}}
]
def shift_tokens_right(input_ids: torch.Tensor, pad_token_id: int, decoder_start_token_id: int):
"""
Shift input ids one token to the right.
"""
shifted_input_ids = input_ids.new_zeros(input_ids.shape)
shifted_input_ids[:, 1:] = input_ids[:, :-1].clone()
shifted_input_ids[:, 0] = decoder_start_token_id
assert pad_token_id is not None, "self.model.config.pad_token_id has to be defined."
# replace possible -100 values in labels by `pad_token_id`
shifted_input_ids.masked_fill_(shifted_input_ids == -100, pad_token_id)
return shifted_input_ids
def _make_causal_mask(input_ids_shape: torch.Size, dtype: torch.dtype, past_key_values_length: int = 0):
"""
Make causal mask used for bi-directional self-attention.
"""
bsz, tgt_len = input_ids_shape
mask = torch.full((tgt_len, tgt_len), torch.finfo(dtype).min)
mask_cond = torch.arange(mask.size(-1))
mask.masked_fill_(mask_cond < (mask_cond + 1).view(mask.size(-1), 1), 0)
mask = mask.to(dtype)
if past_key_values_length > 0:
mask = torch.cat([torch.zeros(tgt_len, past_key_values_length, dtype=dtype), mask], dim=-1)
return mask[None, None, :, :].expand(bsz, 1, tgt_len, tgt_len + past_key_values_length)
def _expand_mask(
mask: torch.Tensor, dtype: torch.dtype, tgt_len: Optional[int] = None
):
"""
Expands attention_mask from `[bsz, seq_len]` to `[bsz, 1, tgt_seq_len, src_seq_len]`.
"""
bsz, src_len = mask.size()
tgt_len = tgt_len if tgt_len is not None else src_len
expanded_mask = mask[:, None, None, :].expand(bsz, 1, tgt_len, src_len).to(dtype)
inverted_mask = 1.0 - expanded_mask
return inverted_mask.masked_fill(inverted_mask.bool(), torch.finfo(dtype).min)
class {{cookiecutter.camelcase_modelname}}LearnedPositionalEmbedding(nn.Embedding):
"""
This module learns positional embeddings up to a fixed maximum size.
"""
def __init__(self, num_embeddings: int, embedding_dim: int):
super().__init__(num_embeddings, embedding_dim)
def forward(self, input_ids_shape: torch.Size, past_key_values_length: int = 0):
"""`input_ids_shape` is expected to be [bsz x seqlen]."""
bsz, seq_len = input_ids_shape[:2]
positions = torch.arange(
past_key_values_length, past_key_values_length + seq_len, dtype=torch.long, device=self.weight.device
)
return super().forward(positions)
class {{cookiecutter.camelcase_modelname}}Attention(nn.Module):
"""Multi-headed attention from 'Attention Is All You Need' paper"""
def __init__(
self,
embed_dim: int,
num_heads: int,
dropout: float = 0.0,
is_decoder: bool = False,
bias: bool = True,
):
super().__init__()
self.embed_dim = embed_dim
self.num_heads = num_heads
self.dropout = dropout
self.head_dim = embed_dim // num_heads
assert (
self.head_dim * num_heads == self.embed_dim
), f"embed_dim must be divisible by num_heads (got `embed_dim`: {self.embed_dim} and `num_heads`: {num_heads})."
self.scaling = self.head_dim ** -0.5
self.is_decoder = is_decoder
self.k_proj = nn.Linear(embed_dim, embed_dim, bias=bias)
self.v_proj = nn.Linear(embed_dim, embed_dim, bias=bias)
self.q_proj = nn.Linear(embed_dim, embed_dim, bias=bias)
self.out_proj = nn.Linear(embed_dim, embed_dim, bias=bias)
def _shape(self, tensor: torch.Tensor, seq_len: int, bsz: int):
return tensor.view(bsz, seq_len, self.num_heads, self.head_dim).transpose(1, 2).contiguous()
def forward(
self,
hidden_states: torch.Tensor,
key_value_states: Optional[torch.Tensor] = None,
past_key_value: Optional[Tuple[torch.Tensor]] = None,
attention_mask: Optional[torch.Tensor] = None,
layer_head_mask: Optional[torch.Tensor] = None,
output_attentions: bool = False,
) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:
"""Input shape: Batch x Time x Channel"""
# if key_value_states are provided this layer is used as a cross-attention layer
# for the decoder
is_cross_attention = key_value_states is not None
bsz, tgt_len, embed_dim = hidden_states.size()
# get query proj
query_states = self.q_proj(hidden_states) * self.scaling
# get key, value proj
if is_cross_attention and past_key_value is not None:
# reuse k,v, cross_attentions
key_states = past_key_value[0]
value_states = past_key_value[1]
elif is_cross_attention:
# cross_attentions
key_states = self._shape(self.k_proj(key_value_states), -1, bsz)
value_states = self._shape(self.v_proj(key_value_states), -1, bsz)
elif past_key_value is not None:
# reuse k, v, self_attention
key_states = self._shape(self.k_proj(hidden_states), -1, bsz)
value_states = self._shape(self.v_proj(hidden_states), -1, bsz)
key_states = torch.cat([past_key_value[0], key_states], dim=2)
value_states = torch.cat([past_key_value[1], value_states], dim=2)
else:
# self_attention
key_states = self._shape(self.k_proj(hidden_states), -1, bsz)
value_states = self._shape(self.v_proj(hidden_states), -1, bsz)
if self.is_decoder:
# if cross_attention save Tuple(torch.Tensor, torch.Tensor) of all cross attention key/value_states.
# Further calls to cross_attention layer can then reuse all cross-attention
# key/value_states (first "if" case)
# if uni-directional self-attention (decoder) save Tuple(torch.Tensor, torch.Tensor) of
# all previous decoder key/value_states. Further calls to uni-directional self-attention
# can concat previous decoder key/value_states to current projected key/value_states (third "elif" case)
# if encoder bi-directional self-attention `past_key_value` is always `None`
past_key_value = (key_states, value_states)
proj_shape = (bsz * self.num_heads, -1, self.head_dim)
query_states = self._shape(query_states, tgt_len, bsz).view(*proj_shape)
key_states = key_states.view(*proj_shape)
value_states = value_states.view(*proj_shape)
src_len = key_states.size(1)
attn_weights = torch.bmm(query_states, key_states.transpose(1, 2))
if attn_weights.size() != (bsz * self.num_heads, tgt_len, src_len):
raise ValueError(
f"Attention weights should be of size {(bsz * self.num_heads, tgt_len, src_len)}, but is {attn_weights.size()}"
)
if attention_mask is not None:
if attention_mask.size() != (bsz, 1, tgt_len, src_len):
raise ValueError(
f"Attention mask should be of size {(bsz, 1, tgt_len, src_len)}, but is {attention_mask.size()}"
)
attn_weights = attn_weights.view(bsz, self.num_heads, tgt_len, src_len) + attention_mask
attn_weights = attn_weights.view(bsz * self.num_heads, tgt_len, src_len)
attn_weights = nn.functional.softmax(attn_weights, dim=-1)
if layer_head_mask is not None:
if layer_head_mask.size() != (self.num_heads,):
raise ValueError(
f"Head mask for a single layer should be of size {(self.num_heads,)}, but is {layer_head_mask.size()}"
)
attn_weights = layer_head_mask.view(1, -1, 1, 1) * attn_weights.view(bsz, self.num_heads, tgt_len, src_len)
attn_weights = attn_weights.view(bsz * self.num_heads, tgt_len, src_len)
if output_attentions:
# this operation is a bit akward, but it's required to
# make sure that attn_weights keeps its gradient.
# In order to do so, attn_weights have to reshaped
# twice and have to be reused in the following
attn_weights_reshaped = attn_weights.view(bsz, self.num_heads, tgt_len, src_len)
attn_weights = attn_weights_reshaped.view(bsz * self.num_heads, tgt_len, src_len)
else:
attn_weights_reshaped = None
attn_probs = nn.functional.dropout(attn_weights, p=self.dropout, training=self.training)
attn_output = torch.bmm(attn_probs, value_states)
if attn_output.size() != (bsz * self.num_heads, tgt_len, self.head_dim):
raise ValueError(
f"`attn_output` should be of size {(bsz, self.num_heads, tgt_len, self.head_dim)}, but is {attn_output.size()}"
)
attn_output = attn_output.view(bsz, self.num_heads, tgt_len, self.head_dim)
attn_output = attn_output.transpose(1, 2)
attn_output = attn_output.reshape(bsz, tgt_len, embed_dim)
attn_output = self.out_proj(attn_output)
return attn_output, attn_weights_reshaped, past_key_value
class {{cookiecutter.camelcase_modelname}}EncoderLayer(nn.Module):
def __init__(self, config: {{cookiecutter.camelcase_modelname}}Config):
super().__init__()
self.embed_dim = config.d_model
self.self_attn = {{cookiecutter.camelcase_modelname}}Attention(
embed_dim=self.embed_dim,
num_heads=config.encoder_attention_heads,
dropout=config.attention_dropout,
)
self.self_attn_layer_norm = nn.LayerNorm(self.embed_dim)
self.dropout = config.dropout
self.activation_fn = ACT2FN[config.activation_function]
self.activation_dropout = config.activation_dropout
self.fc1 = nn.Linear(self.embed_dim, config.encoder_ffn_dim)
self.fc2 = nn.Linear(config.encoder_ffn_dim, self.embed_dim)
self.final_layer_norm = nn.LayerNorm(self.embed_dim)
def forward(
self,
hidden_states: torch.Tensor,
attention_mask: torch.Tensor,
layer_head_mask: torch.Tensor,
output_attentions: bool = False,
):
"""
Args:
hidden_states (`torch.FloatTensor`): input to the layer of shape *(batch, seq_len, embed_dim)*
attention_mask (`torch.FloatTensor`): attention mask of size
*(batch, 1, tgt_len, src_len)* where padding elements are indicated by very large negative values.
layer_head_mask (`torch.FloatTensor`): mask for attention heads in a given layer of size
*(config.encoder_attention_heads,)*.
output_attentions (`bool`, *optional*):
Whether or not to return the attentions tensors of all attention layers. See `attentions` under
returned tensors for more detail.
"""
residual = hidden_states
hidden_states, attn_weights, _ = self.self_attn(
hidden_states=hidden_states,
attention_mask=attention_mask,
layer_head_mask=layer_head_mask,
output_attentions=output_attentions,
)
hidden_states = nn.functional.dropout(hidden_states, p=self.dropout, training=self.training)
hidden_states = residual + hidden_states
hidden_states = self.self_attn_layer_norm(hidden_states)
residual = hidden_states
hidden_states = self.activation_fn(self.fc1(hidden_states))
hidden_states = nn.functional.dropout(hidden_states, p=self.activation_dropout, training=self.training)
hidden_states = self.fc2(hidden_states)
hidden_states = nn.functional.dropout(hidden_states, p=self.dropout, training=self.training)
hidden_states = residual + hidden_states
hidden_states = self.final_layer_norm(hidden_states)
if hidden_states.dtype == torch.float16 and (torch.isinf(hidden_states).any() or torch.isnan(hidden_states).any()):
clamp_value = torch.finfo(hidden_states.dtype).max - 1000
hidden_states = torch.clamp(hidden_states, min=-clamp_value, max=clamp_value)
outputs = (hidden_states,)
if output_attentions:
outputs += (attn_weights,)
return outputs
class {{cookiecutter.camelcase_modelname}}DecoderLayer(nn.Module):
def __init__(self, config: {{cookiecutter.camelcase_modelname}}Config):
super().__init__()
self.embed_dim = config.d_model
self.self_attn = {{cookiecutter.camelcase_modelname}}Attention(
embed_dim=self.embed_dim,
num_heads=config.decoder_attention_heads,
dropout=config.attention_dropout,
is_decoder=True,
)
self.dropout = config.dropout
self.activation_fn = ACT2FN[config.activation_function]
self.activation_dropout = config.activation_dropout
self.self_attn_layer_norm = nn.LayerNorm(self.embed_dim)
self.encoder_attn = {{cookiecutter.camelcase_modelname}}Attention(
self.embed_dim,
config.decoder_attention_heads,
dropout=config.attention_dropout,
is_decoder=True,
)
self.encoder_attn_layer_norm = nn.LayerNorm(self.embed_dim)
self.fc1 = nn.Linear(self.embed_dim, config.decoder_ffn_dim)
self.fc2 = nn.Linear(config.decoder_ffn_dim, self.embed_dim)
self.final_layer_norm = nn.LayerNorm(self.embed_dim)
def forward(
self,
hidden_states: torch.Tensor,
attention_mask: Optional[torch.Tensor] = None,
encoder_hidden_states: Optional[torch.Tensor] = None,
encoder_attention_mask: Optional[torch.Tensor] = None,
layer_head_mask: Optional[torch.Tensor] = None,
cross_layer_head_mask: Optional[torch.Tensor] = None,
past_key_value: Optional[Tuple[torch.Tensor]] = None,
output_attentions: Optional[bool] = False,
use_cache: Optional[bool] = True,
):
"""
Args:
hidden_states (`torch.FloatTensor`): input to the layer of shape *(batch, seq_len, embed_dim)*
attention_mask (`torch.FloatTensor`): attention mask of size
*(batch, 1, tgt_len, src_len)* where padding elements are indicated by very large negative values.
encoder_hidden_states (`torch.FloatTensor`): cross attention input to the layer of shape *(batch, seq_len, embed_dim)*
encoder_attention_mask (`torch.FloatTensor`): encoder attention mask of size
*(batch, 1, tgt_len, src_len)* where padding elements are indicated by very large negative values.
layer_head_mask (`torch.FloatTensor`): mask for attention heads in a given layer of size
*(encoder_attention_heads,)*.
cross_layer_head_mask (`torch.FloatTensor`): mask for cross-attention heads in a given layer of
size *(decoder_attention_heads,)*.
past_key_value (`Tuple(torch.FloatTensor)`): cached past key and value projection states
output_attentions (`bool`, *optional*):
Whether or not to return the attentions tensors of all attention layers. See `attentions` under
returned tensors for more detail.
"""
residual = hidden_states
# Self Attention
# decoder uni-directional self-attention cached key/values tuple is at positions 1,2
self_attn_past_key_value = past_key_value[:2] if past_key_value is not None else None
# add present self-attn cache to positions 1,2 of present_key_value tuple
hidden_states, self_attn_weights, present_key_value = self.self_attn(
hidden_states=hidden_states,
past_key_value=self_attn_past_key_value,
attention_mask=attention_mask,
layer_head_mask=layer_head_mask,
output_attentions=output_attentions,
)
hidden_states = nn.functional.dropout(hidden_states, p=self.dropout, training=self.training)
hidden_states = residual + hidden_states
hidden_states = self.self_attn_layer_norm(hidden_states)
# Cross-Attention Block
cross_attn_present_key_value = None
cross_attn_weights = None
if encoder_hidden_states is not None:
residual = hidden_states
# cross_attn cached key/values tuple is at positions 3,4 of present_key_value tuple
cross_attn_past_key_value = past_key_value[-2:] if past_key_value is not None else None
hidden_states, cross_attn_weights, cross_attn_present_key_value = self.encoder_attn(
hidden_states=hidden_states,
key_value_states=encoder_hidden_states,
attention_mask=encoder_attention_mask,
layer_head_mask=cross_layer_head_mask,
past_key_value=cross_attn_past_key_value,
output_attentions=output_attentions,
)
hidden_states = nn.functional.dropout(hidden_states, p=self.dropout, training=self.training)
hidden_states = residual + hidden_states
hidden_states = self.encoder_attn_layer_norm(hidden_states)
# add cross-attn to positions 3,4 of present_key_value tuple
present_key_value = present_key_value + cross_attn_present_key_value
# Fully Connected
residual = hidden_states
hidden_states = self.activation_fn(self.fc1(hidden_states))
hidden_states = nn.functional.dropout(hidden_states, p=self.activation_dropout, training=self.training)
hidden_states = self.fc2(hidden_states)
hidden_states = nn.functional.dropout(hidden_states, p=self.dropout, training=self.training)
hidden_states = residual + hidden_states
hidden_states = self.final_layer_norm(hidden_states)
outputs = (hidden_states,)
if output_attentions:
outputs += (self_attn_weights, cross_attn_weights)
if use_cache:
outputs += (present_key_value,)
return outputs
# Copied from transformers.models.bart.modeling_bart.BartClassificationHead with Bart->{{cookiecutter.camelcase_modelname}}
class {{cookiecutter.camelcase_modelname}}ClassificationHead(nn.Module):
"""Head for sentence-level classification tasks."""
def __init__(
self,
input_dim: int,
inner_dim: int,
num_classes: int,
pooler_dropout: float,
):
super().__init__()
self.dense = nn.Linear(input_dim, inner_dim)
self.dropout = nn.Dropout(p=pooler_dropout)
self.out_proj = nn.Linear(inner_dim, num_classes)
def forward(self, hidden_states: torch.Tensor):
hidden_states = self.dropout(hidden_states)
hidden_states = self.dense(hidden_states)
hidden_states = torch.tanh(hidden_states)
hidden_states = self.dropout(hidden_states)
hidden_states = self.out_proj(hidden_states)
return hidden_states
class {{cookiecutter.camelcase_modelname}}PreTrainedModel(PreTrainedModel):
config_class = {{cookiecutter.camelcase_modelname}}Config
base_model_prefix = "model"
supports_gradient_checkpointing = True
def _init_weights(self, module):
std = self.config.init_std
if isinstance(module, nn.Linear):
module.weight.data.normal_(mean=0.0, std=std)
if module.bias is not None:
module.bias.data.zero_()
elif isinstance(module, nn.Embedding):
module.weight.data.normal_(mean=0.0, std=std)
if module.padding_idx is not None:
module.weight.data[module.padding_idx].zero_()
def _set_gradient_checkpointing(self, module, value=False):
if isinstance(module, ({{cookiecutter.camelcase_modelname}}Decoder, {{cookiecutter.camelcase_modelname}}Encoder)):
module.gradient_checkpointing = value
{{cookiecutter.uppercase_modelname}}_START_DOCSTRING = r"""
This model inherits from [`PreTrainedModel`]. Check the superclass documentation for the generic
methods the library implements for all its model (such as downloading or saving, resizing the input embeddings,
pruning heads etc.)
This model is also a PyTorch [torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module)
subclass. Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to
general usage and behavior.
Parameters:
config ([`~{{cookiecutter.camelcase_modelname}}Config`]):
Model configuration class with all the parameters of the model.
Initializing with a config file does not load the weights associated with the model, only the
configuration. Check out the [`~PreTrainedModel.from_pretrained`] method to load the model
weights.
"""
{{cookiecutter.uppercase_modelname}}_GENERATION_EXAMPLE = r"""
Summarization example:
```python
>>> from transformers import {{cookiecutter.camelcase_modelname}}Tokenizer, {{cookiecutter.camelcase_modelname}}ForConditionalGeneration
>>> model = {{cookiecutter.camelcase_modelname}}ForConditionalGeneration.from_pretrained('{{cookiecutter.checkpoint_identifier}}')
>>> tokenizer = {{cookiecutter.camelcase_modelname}}Tokenizer.from_pretrained('{{cookiecutter.checkpoint_identifier}}')
>>> ARTICLE_TO_SUMMARIZE = "My friends are cool but they eat too many carbs."
>>> inputs = tokenizer([ARTICLE_TO_SUMMARIZE], max_length=1024, return_tensors='pt')
>>> # Generate Summary
>>> summary_ids = model.generate(inputs['input_ids'], num_beams=4, max_length=5)
>>> print(tokenizer.decode(summary_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False))
```
"""
{{cookiecutter.uppercase_modelname}}_INPUTS_DOCSTRING = r"""
Args:
input_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`):
Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you provide
it.
Indices can be obtained using [`~{{cookiecutter.camelcase_modelname}}Tokenizer`]. See
[`PreTrainedTokenizer.encode`] and [`PreTrainedTokenizer.__call__`] for
details.
[What are input IDs?](../glossary#input-ids)
attention_mask (`torch.Tensor` of shape `(batch_size, sequence_length)`, *optional*):
Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
- 1 for tokens that are **not masked**,
- 0 for tokens that are **masked**.
[What are attention masks?](../glossary#attention-mask)
decoder_input_ids (`torch.LongTensor` of shape `(batch_size, target_sequence_length)`, *optional*):
Provide for translation and summarization training. By default, the model will create this tensor by
shifting the `input_ids` to the right, following the paper.
decoder_attention_mask (`torch.LongTensor` of shape `(batch_size, target_sequence_length)`, *optional*):
Default behavior: generate a tensor that ignores pad tokens in `decoder_input_ids`. Causal mask will
also be used by default.
If you want to change padding behavior, you should read [`modeling_{{cookiecutter.lowercase_modelname}}._prepare_decoder_attention_mask`] and
modify to your needs. See diagram 1 in [the paper](https://arxiv.org/abs/1910.13461) for more
information on the default strategy.
head_mask (`torch.Tensor` of shape `(encoder_layers, encoder_attention_heads)`, *optional*):
Mask to nullify selected heads of the attention modules in the encoder. Mask values selected in `[0, 1]`:
- 1 indicates the head is **not masked**,
- 0 indicates the head is **masked**.
decoder_head_mask (`torch.Tensor` of shape `(decoder_layers, decoder_attention_heads)`, *optional*):
Mask to nullify selected heads of the attention modules in the decoder. Mask values selected in `[0, 1]`:
- 1 indicates the head is **not masked**,
- 0 indicates the head is **masked**.
cross_attn_head_mask (`torch.Tensor` of shape `(decoder_layers, decoder_attention_heads)`, *optional*):
Mask to nullify selected heads of the cross-attention modules. Mask values selected in `[0, 1]`:
- 1 indicates the head is **not masked**,
- 0 indicates the head is **masked**.
encoder_outputs (`tuple(tuple(torch.FloatTensor)`, *optional*):
Tuple consists of (`last_hidden_state`, *optional*: `hidden_states`, *optional*:
`attentions`) `last_hidden_state` of shape `(batch_size, sequence_length, hidden_size)`,
*optional*) is a sequence of hidden-states at the output of the last layer of the encoder. Used in the
cross-attention of the decoder.
past_key_values (`tuple(tuple(torch.FloatTensor))`, *optional*, returned when `use_cache=True` is passed or when `config.use_cache=True`):
Tuple of `tuple(torch.FloatTensor)` of length `config.n_layers`, with each tuple having 2 tensors
of shape `(batch_size, num_heads, sequence_length, embed_size_per_head)`) and 2 additional tensors of
shape `(batch_size, num_heads, encoder_sequence_length, embed_size_per_head)`.
Contains pre-computed hidden-states (key and values in the self-attention blocks and in the cross-attention
blocks) that can be used (see `past_key_values` input) to speed up sequential decoding.
If `past_key_values` are used, the user can optionally input only the last `decoder_input_ids`
(those that don't have their past key value states given to this model) of shape `(batch_size, 1)`
instead of all `decoder_input_ids` of shape `(batch_size, sequence_length)`. inputs_embeds (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`, *optional*): Optionally, instead of passing `input_ids` you can choose to directly pass an embedded representation. This is useful if you want more control over how to convert `input_ids` indices into associated
vectors than the model's internal embedding lookup matrix.
decoder_inputs_embeds (`torch.FloatTensor` of shape `(batch_size, target_sequence_length, hidden_size)`, *optional*):
Optionally, instead of passing `decoder_input_ids` you can choose to directly pass an embedded
representation. If `past_key_values` is used, optionally only the last `decoder_inputs_embeds`
have to be input (see `past_key_values`). This is useful if you want more control over how to convert
`decoder_input_ids` indices into associated vectors than the model's internal embedding lookup matrix.
If `decoder_input_ids` and `decoder_inputs_embeds` are both unset, `decoder_inputs_embeds`
takes the value of `inputs_embeds`.
use_cache (`bool`, *optional*):
If set to `True`, `past_key_values` key value states are returned and can be used to speed up
decoding (see `past_key_values`).
output_attentions (`bool`, *optional*):
Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
tensors for more detail.
output_hidden_states (`bool`, *optional*):
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
more detail.
return_dict (`bool`, *optional*):
Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
"""
{{cookiecutter.uppercase_modelname}}_STANDALONE_INPUTS_DOCSTRING = r"""
Args:
input_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`):
Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you provide
it.
Indices can be obtained using [`ProphetNetTokenizer`]. See
[`PreTrainedTokenizer.encode`] and [`PreTrainedTokenizer.__call__`] for
details.
[What are input IDs?](../glossary#input-ids)
attention_mask (`torch.Tensor` of shape `(batch_size, sequence_length)`, *optional*):
Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
- 1 for tokens that are **not masked**,
- 0 for tokens that are **masked**.
[What are attention masks?](../glossary#attention-mask)
output_attentions (`bool`, *optional*):
Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
tensors for more detail.
output_hidden_states (`bool`, *optional*):
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
more detail.
return_dict (`bool`, *optional*):
Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
"""
class {{cookiecutter.camelcase_modelname}}Encoder({{cookiecutter.camelcase_modelname}}PreTrainedModel):
"""
Transformer encoder consisting of *config.encoder_layers* self attention layers. Each layer is a
[`{{cookiecutter.camelcase_modelname}}EncoderLayer`].
Args:
config: {{cookiecutter.camelcase_modelname}}Config
embed_tokens (nn.Embedding): output embedding
"""
def __init__(self, config: {{cookiecutter.camelcase_modelname}}Config, embed_tokens: Optional[nn.Embedding] = None):
super().__init__(config)
self.dropout = config.dropout
self.layerdrop = config.encoder_layerdrop
embed_dim = config.d_model
self.padding_idx = config.pad_token_id
self.max_source_positions = config.max_position_embeddings
self.embed_scale = math.sqrt(embed_dim) if config.scale_embedding else 1.0
if embed_tokens is not None:
self.embed_tokens = embed_tokens
else:
self.embed_tokens = nn.Embedding(config.vocab_size, embed_dim, self.padding_idx)
self.embed_positions = {{cookiecutter.camelcase_modelname}}LearnedPositionalEmbedding(
config.max_position_embeddings,
embed_dim,
)
self.layers = nn.ModuleList([{{cookiecutter.camelcase_modelname}}EncoderLayer(config) for _ in range(config.encoder_layers)])
self.layernorm_embedding = nn.LayerNorm(embed_dim)
self.gradient_checkpointing = False
# Initialize weights and apply final processing
self.post_init()
def forward(
self,
input_ids=None,
attention_mask=None,
head_mask=None,
inputs_embeds=None,
output_attentions=None,
output_hidden_states=None,
return_dict=None,
):
r"""
Args:
input_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`):
Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you
provide it.
Indices can be obtained using [`~{{cookiecutter.camelcase_modelname}}Tokenizer`]. See
[`PreTrainedTokenizer.encode`] and [`PreTrainedTokenizer.__call__`]
for details.
[What are input IDs?](../glossary#input-ids)
attention_mask (`torch.Tensor` of shape `(batch_size, sequence_length)`, *optional*):
Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
- 1 for tokens that are **not masked**,
- 0 for tokens that are **masked**.
[What are attention masks?](../glossary#attention-mask)
head_mask (`torch.Tensor` of shape `(encoder_layers, encoder_attention_heads)`, *optional*):
Mask to nullify selected heads of the attention modules. Mask values selected in `[0, 1]`:
- 1 indicates the head is **not masked**,
- 0 indicates the head is **masked**.
inputs_embeds (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`, *optional*):
Optionally, instead of passing `input_ids` you can choose to directly pass an embedded
representation. This is useful if you want more control over how to convert `input_ids` indices
into associated vectors than the model's internal embedding lookup matrix.
output_attentions (`bool`, *optional*):
Whether or not to return the attentions tensors of all attention layers. See `attentions` under
returned tensors for more detail.
output_hidden_states (`bool`, *optional*):
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors
for more detail.
return_dict (`bool`, *optional*):
Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
"""
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
output_hidden_states = (
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
)
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
# retrieve input_ids and inputs_embeds
if input_ids is not None and inputs_embeds is not None:
raise ValueError("You cannot specify both input_ids and inputs_embeds at the same time")
elif input_ids is not None:
input_shape = input_ids.size()
input_ids = input_ids.view(-1, input_shape[-1])
elif inputs_embeds is not None:
input_shape = inputs_embeds.size()[:-1]
else:
raise ValueError("You have to specify either input_ids or inputs_embeds")
if inputs_embeds is None:
inputs_embeds = self.embed_tokens(input_ids) * self.embed_scale
embed_pos = self.embed_positions(input_shape)
hidden_states = inputs_embeds + embed_pos
hidden_states = self.layernorm_embedding(hidden_states)
hidden_states = nn.functional.dropout(hidden_states, p=self.dropout, training=self.training)
# expand attention_mask
if attention_mask is not None:
# [bsz, seq_len] -> [bsz, 1, tgt_seq_len, src_seq_len]
attention_mask = _expand_mask(attention_mask, inputs_embeds.dtype)
encoder_states = () if output_hidden_states else None
all_attentions = () if output_attentions else None
# check if head_mask has a correct number of layers specified if desired
if head_mask is not None:
assert head_mask.size()[0] == (
len(self.layers)
), f"The head_mask should be specified for {len(self.layers)} layers, but it is for {head_mask.size()[0]}."
for idx, encoder_layer in enumerate(self.layers):
if output_hidden_states:
encoder_states = encoder_states + (hidden_states,)
# add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
dropout_probability = torch.randn([])
if self.training and (dropout_probability < self.layerdrop): # skip the layer
layer_outputs = (None, None)
else:
if self.gradient_checkpointing and self.training:
def create_custom_forward(module):
def custom_forward(*inputs):
return module(*inputs, output_attentions)
return custom_forward
layer_outputs = torch.utils.checkpoint.checkpoint(
create_custom_forward(encoder_layer),
hidden_states,
attention_mask,
(head_mask[idx] if head_mask is not None else None),
)
else:
layer_outputs = encoder_layer(
hidden_states,
attention_mask,
layer_head_mask=(head_mask[idx] if head_mask is not None else None),
output_attentions=output_attentions,
)
hidden_states = layer_outputs[0]
if output_attentions:
all_attentions = all_attentions + (layer_outputs[1],)
if output_hidden_states:
encoder_states = encoder_states + (hidden_states,)
if not return_dict:
return tuple(v for v in [hidden_states, encoder_states, all_attentions] if v is not None)
return BaseModelOutput(
last_hidden_state=hidden_states, hidden_states=encoder_states, attentions=all_attentions
)
class {{cookiecutter.camelcase_modelname}}Decoder({{cookiecutter.camelcase_modelname}}PreTrainedModel):
"""
Transformer decoder consisting of *config.decoder_layers* layers. Each layer is a [`{{cookiecutter.camelcase_modelname}}DecoderLayer`]
Args:
config: {{cookiecutter.camelcase_modelname}}Config
embed_tokens (nn.Embedding): output embedding
"""
def __init__(self, config: {{cookiecutter.camelcase_modelname}}Config, embed_tokens: Optional[nn.Embedding] = None):
super().__init__(config)
self.dropout = config.dropout
self.layerdrop = config.decoder_layerdrop
self.padding_idx = config.pad_token_id
self.max_target_positions = config.max_position_embeddings
self.embed_scale = math.sqrt(config.d_model) if config.scale_embedding else 1.0
if embed_tokens is not None:
self.embed_tokens = embed_tokens
else:
self.embed_tokens = nn.Embedding(config.vocab_size, config.d_model, self.padding_idx)
self.embed_positions = {{cookiecutter.camelcase_modelname}}LearnedPositionalEmbedding(
config.max_position_embeddings,
config.d_model,
)
self.layers = nn.ModuleList([{{cookiecutter.camelcase_modelname}}DecoderLayer(config) for _ in range(config.decoder_layers)])
self.layernorm_embedding = nn.LayerNorm(config.d_model)
self.gradient_checkpointing = False
# Initialize weights and apply final processing
self.post_init()
def get_input_embeddings(self):
return self.embed_tokens
def set_input_embeddings(self, value):
self.embed_tokens = value
# Copied from transformers.models.bart.modeling_bart.BartDecoder._prepare_decoder_attention_mask
def _prepare_decoder_attention_mask(self, attention_mask, input_shape, inputs_embeds, past_key_values_length):
# create causal mask
# [bsz, seq_len] -> [bsz, 1, tgt_seq_len, src_seq_len]
combined_attention_mask = None
if input_shape[-1] > 1:
combined_attention_mask = _make_causal_mask(
input_shape, inputs_embeds.dtype, past_key_values_length=past_key_values_length
).to(self.device)
if attention_mask is not None:
# [bsz, seq_len] -> [bsz, 1, tgt_seq_len, src_seq_len]
expanded_attn_mask = _expand_mask(attention_mask, inputs_embeds.dtype, tgt_len=input_shape[-1])
combined_attention_mask = (
expanded_attn_mask if combined_attention_mask is None else expanded_attn_mask + combined_attention_mask
)
return combined_attention_mask
def forward(
self,
input_ids=None,
attention_mask=None,
encoder_hidden_states=None,
encoder_attention_mask=None,
head_mask=None,
cross_attn_head_mask=None,
past_key_values=None,
inputs_embeds=None,
use_cache=None,
output_attentions=None,
output_hidden_states=None,
return_dict=None,
):
r"""
Args:
input_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`):
Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you
provide it.
Indices can be obtained using [`~{{cookiecutter.camelcase_modelname}}Tokenizer`]. See
[`PreTrainedTokenizer.encode`] and [`PreTrainedTokenizer.__call__`]
for details.
[What are input IDs?](../glossary#input-ids)
attention_mask (`torch.Tensor` of shape `(batch_size, sequence_length)`, *optional*):
Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
- 1 for tokens that are **not masked**,
- 0 for tokens that are **masked**.
[What are attention masks?](../glossary#attention-mask)
encoder_hidden_states (`torch.FloatTensor` of shape `(batch_size, encoder_sequence_length, hidden_size)`, *optional*):
Sequence of hidden-states at the output of the last layer of the encoder. Used in the cross-attention
of the decoder.
encoder_attention_mask (`torch.LongTensor` of shape `(batch_size, encoder_sequence_length)`, *optional*):
Mask to avoid performing cross-attention on padding tokens indices of encoder input_ids. Mask values
selected in `[0, 1]`:
- 1 for tokens that are **not masked**,
- 0 for tokens that are **masked**.
[What are attention masks?](../glossary#attention-mask)
head_mask (`torch.Tensor` of shape `(decoder_layers, decoder_attention_heads)`, *optional*):
Mask to nullify selected heads of the attention modules. Mask values selected in `[0, 1]`:
- 1 indicates the head is **not masked**,
- 0 indicates the head is **masked**.
cross_attn_head_mask (`torch.Tensor` of shape `(decoder_layers, decoder_attention_heads)`, *optional*):
Mask to nullify selected heads of the cross-attention modules. Mask values selected in `[0, 1]`:
- 1 indicates the head is **not masked**,
- 0 indicates the head is **masked**.
past_key_values (`tuple(tuple(torch.FloatTensor))`, *optional*, returned when `use_cache=True` is passed or when `config.use_cache=True`):
Tuple of `tuple(torch.FloatTensor)` of length `config.n_layers`, with each tuple having 2
tensors of shape `(batch_size, num_heads, sequence_length, embed_size_per_head)`) and 2 additional
tensors of shape `(batch_size, num_heads, encoder_sequence_length, embed_size_per_head)`.
Contains pre-computed hidden-states (key and values in the self-attention blocks and in the
cross-attention blocks) that can be used (see `past_key_values` input) to speed up sequential
decoding.
If `past_key_values` are used, the user can optionally input only the last
`decoder_input_ids` (those that don't have their past key value states given to this model) of
shape `(batch_size, 1)` instead of all `decoder_input_ids` of shape `(batch_size,
sequence_length)`. inputs_embeds (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`, *optional*): Optionally, instead of passing `input_ids` you can choose to directly pass an embedded representation. This is useful if you want more control over how to convert `input_ids` indices
into associated vectors than the model's internal embedding lookup matrix.
output_attentions (`bool`, *optional*):
Whether or not to return the attentions tensors of all attention layers. See `attentions` under
returned tensors for more detail.
output_hidden_states (`bool`, *optional*):
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors
for more detail.
return_dict (`bool`, *optional*):
Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
"""
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
output_hidden_states = (
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
)
use_cache = use_cache if use_cache is not None else self.config.use_cache
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
# retrieve input_ids and inputs_embeds
if input_ids is not None and inputs_embeds is not None:
raise ValueError("You cannot specify both decoder_input_ids and decoder_inputs_embeds at the same time")
elif input_ids is not None:
input_shape = input_ids.size()
input_ids = input_ids.view(-1, input_shape[-1])
elif inputs_embeds is not None:
input_shape = inputs_embeds.size()[:-1]
else:
raise ValueError("You have to specify either decoder_input_ids or decoder_inputs_embeds")
# past_key_values_length
past_key_values_length = past_key_values[0][0].shape[2] if past_key_values is not None else 0
if inputs_embeds is None:
inputs_embeds = self.embed_tokens(input_ids) * self.embed_scale
attention_mask = self._prepare_decoder_attention_mask(attention_mask, input_shape, inputs_embeds, past_key_values_length)
# expand encoder attention mask
if encoder_hidden_states is not None and encoder_attention_mask is not None:
# [bsz, seq_len] -> [bsz, 1, tgt_seq_len, src_seq_len]
encoder_attention_mask = _expand_mask(encoder_attention_mask, inputs_embeds.dtype, tgt_len=input_shape[-1])
# embed positions
positions = self.embed_positions(input_shape, past_key_values_length)
hidden_states = inputs_embeds + positions
hidden_states = self.layernorm_embedding(hidden_states)
hidden_states = nn.functional.dropout(hidden_states, p=self.dropout, training=self.training)
# decoder layers
if self.gradient_checkpointing and self.training and use_cache:
logger.warning("`use_cache = True` is incompatible with gradient checkpointing`. Setting `use_cache = False`...")
use_cache = False
all_hidden_states = () if output_hidden_states else None
all_self_attns = () if output_attentions else None
all_cross_attentions = () if (output_attentions and encoder_hidden_states is not None) else None
next_decoder_cache = () if use_cache else None
# check if head_mask/cross_attn_head_mask has a correct number of layers specified if desired
for attn_mask, mask_name in zip([head_mask, cross_attn_head_mask], ["head_mask", "cross_attn_head_mask"]):
if attn_mask is not None:
assert attn_mask.size()[0] == (
len(self.layers)
), f"The `{mask_name}` should be specified for {len(self.layers)} layers, but it is for {head_mask.size()[0]}."
for idx, decoder_layer in enumerate(self.layers):
# add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
if output_hidden_states:
all_hidden_states += (hidden_states,)
dropout_probability = torch.randn([])
if self.training and (dropout_probability < self.layerdrop):
continue
past_key_value = past_key_values[idx] if past_key_values is not None else None
if self.gradient_checkpointing and self.training:
def create_custom_forward(module):
def custom_forward(*inputs):
# None for past_key_value
return module(*inputs, output_attentions, use_cache)
return custom_forward
layer_outputs = torch.utils.checkpoint.checkpoint(
create_custom_forward(decoder_layer),
hidden_states,
attention_mask,
encoder_hidden_states,
encoder_attention_mask,
head_mask[idx] if head_mask is not None else None,
cross_attn_head_mask[idx] if cross_attn_head_mask is not None else None,
None,
)
else:
layer_outputs = decoder_layer(
hidden_states,
attention_mask=attention_mask,
encoder_hidden_states=encoder_hidden_states,
encoder_attention_mask=encoder_attention_mask,
layer_head_mask=(head_mask[idx] if head_mask is not None else None),
cross_layer_head_mask=(cross_attn_head_mask[idx] if cross_attn_head_mask is not None else None),
past_key_value=past_key_value,
output_attentions=output_attentions,
use_cache=use_cache,
)
hidden_states = layer_outputs[0]
if use_cache:
next_decoder_cache += (layer_outputs[3 if output_attentions else 1],)
if output_attentions:
all_self_attns += (layer_outputs[1],)
if encoder_hidden_states is not None:
all_cross_attentions += (layer_outputs[2],)
# add hidden states from the last decoder layer
if output_hidden_states:
all_hidden_states += (hidden_states,)
next_cache = next_decoder_cache if use_cache else None
if not return_dict:
return tuple(
v
for v in [hidden_states, next_cache, all_hidden_states, all_self_attns, all_cross_attentions]
if v is not None
)
return BaseModelOutputWithPastAndCrossAttentions(
last_hidden_state=hidden_states,
past_key_values=next_cache,
hidden_states=all_hidden_states,
attentions=all_self_attns,
cross_attentions=all_cross_attentions,
)
@add_start_docstrings(
"The bare {{cookiecutter.modelname}} Model outputting raw hidden-states without any specific head on top.",
{{cookiecutter.uppercase_modelname}}_START_DOCSTRING,
)
class {{cookiecutter.camelcase_modelname}}Model({{cookiecutter.camelcase_modelname}}PreTrainedModel):
def __init__(self, config: {{cookiecutter.camelcase_modelname}}Config):
super().__init__(config)
padding_idx, vocab_size = config.pad_token_id, config.vocab_size
self.shared = nn.Embedding(vocab_size, config.d_model, padding_idx)
self.encoder = {{cookiecutter.camelcase_modelname}}Encoder(config, self.shared)
self.decoder = {{cookiecutter.camelcase_modelname}}Decoder(config, self.shared)
# Initialize weights and apply final processing
self.post_init()
def get_input_embeddings(self):
return self.shared
def set_input_embeddings(self, value):
self.shared = value
self.encoder.embed_tokens = self.shared
self.decoder.embed_tokens = self.shared
def get_encoder(self):
return self.encoder
def get_decoder(self):
return self.decoder
@add_start_docstrings_to_model_forward({{cookiecutter.uppercase_modelname}}_INPUTS_DOCSTRING)
@add_code_sample_docstrings(
checkpoint=_CHECKPOINT_FOR_DOC,
output_type=Seq2SeqModelOutput,
config_class=_CONFIG_FOR_DOC,
)
def forward(
self,
input_ids=None,
attention_mask=None,
decoder_input_ids=None,
decoder_attention_mask=None,
head_mask=None,
decoder_head_mask=None,
cross_attn_head_mask=None,
encoder_outputs=None,
past_key_values=None,
inputs_embeds=None,
decoder_inputs_embeds=None,
use_cache=None,
output_attentions=None,
output_hidden_states=None,
return_dict=None,
):
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
output_hidden_states = (
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
)
use_cache = use_cache if use_cache is not None else self.config.use_cache
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
if encoder_outputs is None:
encoder_outputs = self.encoder(
input_ids=input_ids,
attention_mask=attention_mask,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
# If the user passed a tuple for encoder_outputs, we wrap it in a BaseModelOutput when return_dict=True
elif return_dict and not isinstance(encoder_outputs, BaseModelOutput):
encoder_outputs = BaseModelOutput(
last_hidden_state=encoder_outputs[0],
hidden_states=encoder_outputs[1] if len(encoder_outputs) > 1 else None,
attentions=encoder_outputs[2] if len(encoder_outputs) > 2 else None,
)
# decoder outputs consists of (dec_features, past_key_value, dec_hidden, dec_attn)
decoder_outputs = self.decoder(
input_ids=decoder_input_ids,
attention_mask=decoder_attention_mask,
encoder_hidden_states=encoder_outputs[0],
encoder_attention_mask=attention_mask,
head_mask=decoder_head_mask,
cross_attn_head_mask=cross_attn_head_mask,
past_key_values=past_key_values,
inputs_embeds=decoder_inputs_embeds,
use_cache=use_cache,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
if not return_dict:
return decoder_outputs + encoder_outputs
return Seq2SeqModelOutput(
last_hidden_state=decoder_outputs.last_hidden_state,
past_key_values=decoder_outputs.past_key_values,
decoder_hidden_states=decoder_outputs.hidden_states,
decoder_attentions=decoder_outputs.attentions,
cross_attentions=decoder_outputs.cross_attentions,
encoder_last_hidden_state=encoder_outputs.last_hidden_state,
encoder_hidden_states=encoder_outputs.hidden_states,
encoder_attentions=encoder_outputs.attentions,
)
@add_start_docstrings(
"The {{cookiecutter.modelname}} Model with a language modeling head. Can be used for summarization.", {{cookiecutter.uppercase_modelname}}_START_DOCSTRING
)
class {{cookiecutter.camelcase_modelname}}ForConditionalGeneration({{cookiecutter.camelcase_modelname}}PreTrainedModel):
base_model_prefix = "model"
_keys_to_ignore_on_load_missing = [
r"final_logits_bias",
r"encoder\.version",
r"decoder\.version",
r"lm_head\.weight",
]
def __init__(self, config: {{cookiecutter.camelcase_modelname}}Config):
super().__init__(config)
self.model = {{cookiecutter.camelcase_modelname}}Model(config)
self.register_buffer("final_logits_bias", torch.zeros((1, self.model.shared.num_embeddings)))
self.lm_head = nn.Linear(config.d_model, self.model.shared.num_embeddings, bias=False)
# Initialize weights and apply final processing
self.post_init()
def get_encoder(self):
return self.model.get_encoder()
def get_decoder(self):
return self.model.get_decoder()
def resize_token_embeddings(self, new_num_tokens: int) -> nn.Embedding:
new_embeddings = super().resize_token_embeddings(new_num_tokens)
self._resize_final_logits_bias(new_num_tokens)
return new_embeddings
def _resize_final_logits_bias(self, new_num_tokens: int) -> None:
old_num_tokens = self.final_logits_bias.shape[-1]
if new_num_tokens <= old_num_tokens:
new_bias = self.final_logits_bias[:, :new_num_tokens]
else:
extra_bias = torch.zeros((1, new_num_tokens - old_num_tokens), device=self.final_logits_bias.device)
new_bias = torch.cat([self.final_logits_bias, extra_bias], dim=1)
self.register_buffer("final_logits_bias", new_bias)
def get_output_embeddings(self):
return self.lm_head
def set_output_embeddings(self, new_embeddings):
self.lm_head = new_embeddings
@add_start_docstrings_to_model_forward({{cookiecutter.uppercase_modelname}}_INPUTS_DOCSTRING)
@replace_return_docstrings(output_type=Seq2SeqLMOutput, config_class=_CONFIG_FOR_DOC)
@add_end_docstrings({{cookiecutter.uppercase_modelname}}_GENERATION_EXAMPLE)
def forward(
self,
input_ids=None,
attention_mask=None,
decoder_input_ids=None,
decoder_attention_mask=None,
head_mask=None,
decoder_head_mask=None,
cross_attn_head_mask=None,
encoder_outputs=None,
past_key_values=None,
inputs_embeds=None,
decoder_inputs_embeds=None,
labels=None,
use_cache=None,
output_attentions=None,
output_hidden_states=None,
return_dict=None,
):
r"""
labels (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
Labels for computing the masked language modeling loss. Indices should either be in `[0, ..., config.vocab_size]` or -100 (see `input_ids` docstring). Tokens with indices set to `-100` are ignored
(masked), the loss is only computed for the tokens with labels in `[0, ..., config.vocab_size]`.
Returns:
Conditional generation example:
```python
>>> from transformers import {{cookiecutter.camelcase_modelname}}Tokenizer, {{cookiecutter.camelcase_modelname}}ForConditionalGeneration
>>> tokenizer = {{cookiecutter.camelcase_modelname}}Tokenizer.from_pretrained('{{cookiecutter.checkpoint_identifier}}')
>>> TXT = "My friends are <mask> but they eat too many carbs."
>>> model = {{cookiecutter.camelcase_modelname}}ForConditionalGeneration.from_pretrained('{{cookiecutter.checkpoint_identifier}}')
>>> input_ids = tokenizer([TXT], return_tensors='pt')['input_ids']
>>> logits = model(input_ids).logits
>>> masked_index = (input_ids[0] == tokenizer.mask_token_id).nonzero().item()
>>> probs = logits[0, masked_index].softmax(dim=0)
>>> values, predictions = probs.topk(5)
>>> tokenizer.decode(predictions).split()
```
"""
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
if labels is not None:
if use_cache:
logger.warning("The `use_cache` argument is changed to `False` since `labels` is provided.")
use_cache = False
if decoder_input_ids is None and decoder_inputs_embeds is None:
decoder_input_ids = shift_tokens_right(labels, self.config.pad_token_id, self.config.decoder_start_token_id)
outputs = self.model(
input_ids,
attention_mask=attention_mask,
decoder_input_ids=decoder_input_ids,
encoder_outputs=encoder_outputs,
decoder_attention_mask=decoder_attention_mask,
head_mask=head_mask,
decoder_head_mask=decoder_head_mask,
cross_attn_head_mask=cross_attn_head_mask,
past_key_values=past_key_values,
inputs_embeds=inputs_embeds,
decoder_inputs_embeds=decoder_inputs_embeds,
use_cache=use_cache,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
lm_logits = self.lm_head(outputs[0]) + self.final_logits_bias
masked_lm_loss = None
if labels is not None:
loss_fct = CrossEntropyLoss()
masked_lm_loss = loss_fct(lm_logits.view(-1, self.config.vocab_size), labels.view(-1))
if not return_dict:
output = (lm_logits,) + outputs[1:]
return ((masked_lm_loss,) + output) if masked_lm_loss is not None else output
return Seq2SeqLMOutput(
loss=masked_lm_loss,
logits=lm_logits,
past_key_values=outputs.past_key_values,
decoder_hidden_states=outputs.decoder_hidden_states,
decoder_attentions=outputs.decoder_attentions,
cross_attentions=outputs.cross_attentions,
encoder_last_hidden_state=outputs.encoder_last_hidden_state,
encoder_hidden_states=outputs.encoder_hidden_states,
encoder_attentions=outputs.encoder_attentions,
)
def prepare_inputs_for_generation(
self,
decoder_input_ids,
past_key_values=None,
attention_mask=None,
head_mask=None,
decoder_head_mask=None,
cross_attn_head_mask=None,
use_cache=None,
encoder_outputs=None,
**kwargs
):
# cut decoder_input_ids if past is used
if past_key_values is not None:
decoder_input_ids = decoder_input_ids[:, -1:]
return {
"input_ids": None, # encoder_outputs is defined. input_ids not needed
"encoder_outputs": encoder_outputs,
"past_key_values": past_key_values,
"decoder_input_ids": decoder_input_ids,
"attention_mask": attention_mask,
"head_mask": head_mask,
"decoder_head_mask": decoder_head_mask,
"cross_attn_head_mask": cross_attn_head_mask,
"use_cache": use_cache, # change this to avoid caching (presumably for debugging)
}
@staticmethod
def _reorder_cache(past_key_values, beam_idx):
reordered_past = ()
for layer_past in past_key_values:
reordered_past += (tuple(past_state.index_select(0, beam_idx) for past_state in layer_past),)
return reordered_past
@add_start_docstrings(
"""
{{cookiecutter.camelcase_modelname}} model with a sequence classification/head on top (a linear layer on top of the pooled output) e.g. for GLUE
tasks.
""",
{{cookiecutter.uppercase_modelname}}_START_DOCSTRING,
)
class {{cookiecutter.camelcase_modelname}}ForSequenceClassification({{cookiecutter.camelcase_modelname}}PreTrainedModel):
def __init__(self, config: {{cookiecutter.camelcase_modelname}}Config, **kwargs):
super().__init__(config, **kwargs)
self.model = {{cookiecutter.camelcase_modelname}}Model(config)
self.classification_head = {{cookiecutter.camelcase_modelname}}ClassificationHead(
config.d_model,
config.d_model,
config.num_labels,
config.classifier_dropout,
)
self.model._init_weights(self.classification_head.dense)
self.model._init_weights(self.classification_head.out_proj)
@add_start_docstrings_to_model_forward({{cookiecutter.uppercase_modelname}}_INPUTS_DOCSTRING)
@add_code_sample_docstrings(
checkpoint=_CHECKPOINT_FOR_DOC,
output_type=Seq2SeqSequenceClassifierOutput,
config_class=_CONFIG_FOR_DOC,
)
def forward(
self,
input_ids=None,
attention_mask=None,
decoder_input_ids=None,
decoder_attention_mask=None,
encoder_outputs=None,
inputs_embeds=None,
decoder_inputs_embeds=None,
labels=None,
use_cache=None,
output_attentions=None,
output_hidden_states=None,
return_dict=None,
):
r"""
labels (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
Labels for computing the sequence classification/regression loss. Indices should be in `[0, ..., config.num_labels - 1]`. If `config.num_labels > 1` a classification loss is computed (Cross-Entropy).
"""
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
if labels is not None:
use_cache = False
if input_ids is None and inputs_embeds is not None:
raise NotImplementedError(
f"Passing input embeddings is currently not supported for {self.__class__.__name__}"
)
outputs = self.model(
input_ids,
attention_mask=attention_mask,
decoder_input_ids=decoder_input_ids,
decoder_attention_mask=decoder_attention_mask,
encoder_outputs=encoder_outputs,
inputs_embeds=inputs_embeds,
decoder_inputs_embeds=decoder_inputs_embeds,
use_cache=use_cache,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
hidden_states = outputs[0] # last hidden state
eos_mask = input_ids.eq(self.config.eos_token_id).to(hidden_states.device)
if len(torch.unique_consecutive(eos_mask.sum(1))) > 1:
raise ValueError("All examples must have the same number of <eos> tokens.")
sentence_representation = hidden_states[eos_mask, :].view(hidden_states.size(0), -1, hidden_states.size(-1))[
:, -1, :
]
logits = self.classification_head(sentence_representation)
loss = None
if labels is not None:
if self.config.problem_type is None:
if self.config.num_labels == 1:
self.config.problem_type = "regression"
elif self.config.num_labels > 1 and (labels.dtype == torch.long or labels.dtype == torch.int):
self.config.problem_type = "single_label_classification"
else:
self.config.problem_type = "multi_label_classification"
if self.config.problem_type == "regression":
loss_fct = MSELoss()
if self.config.num_labels == 1:
loss = loss_fct(logits.squeeze(), labels.squeeze())
else:
loss = loss_fct(logits, labels)
elif self.config.problem_type == "single_label_classification":
loss_fct = CrossEntropyLoss()
loss = loss_fct(logits.view(-1, self.config.num_labels), labels.view(-1))
elif self.config.problem_type == "multi_label_classification":
loss_fct = BCEWithLogitsLoss()
loss = loss_fct(logits, labels)
if not return_dict:
output = (logits,) + outputs[1:]
return ((loss,) + output) if loss is not None else output
return Seq2SeqSequenceClassifierOutput(
loss=loss,
logits=logits,
past_key_values=outputs.past_key_values,
decoder_hidden_states=outputs.decoder_hidden_states,
decoder_attentions=outputs.decoder_attentions,
cross_attentions=outputs.cross_attentions,
encoder_last_hidden_state=outputs.encoder_last_hidden_state,
encoder_hidden_states=outputs.encoder_hidden_states,
encoder_attentions=outputs.encoder_attentions,
)
@add_start_docstrings(
"""
{{cookiecutter.modelname}} Model with a span classification head on top for extractive question-answering tasks like SQuAD (a linear
layer on top of the hidden-states output to compute `span start logits` and `span end logits`).
""",
{{cookiecutter.uppercase_modelname}}_START_DOCSTRING,
)
class {{cookiecutter.camelcase_modelname}}ForQuestionAnswering({{cookiecutter.camelcase_modelname}}PreTrainedModel):
def __init__(self, config):
super().__init__(config)
config.num_labels = 2
self.num_labels = config.num_labels
self.model = {{cookiecutter.camelcase_modelname}}Model(config)
self.qa_outputs = nn.Linear(config.hidden_size, config.num_labels)
self.model._init_weights(self.qa_outputs)
@add_start_docstrings_to_model_forward({{cookiecutter.uppercase_modelname}}_INPUTS_DOCSTRING)
@add_code_sample_docstrings(
checkpoint=_CHECKPOINT_FOR_DOC,
output_type=Seq2SeqQuestionAnsweringModelOutput,
config_class=_CONFIG_FOR_DOC,
)
def forward(
self,
input_ids=None,
attention_mask=None,
decoder_input_ids=None,
decoder_attention_mask=None,
encoder_outputs=None,
start_positions=None,
end_positions=None,
inputs_embeds=None,
decoder_inputs_embeds=None,
use_cache=None,
output_attentions=None,
output_hidden_states=None,
return_dict=None,
):
r"""
start_positions (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
Labels for position (index) of the start of the labelled span for computing the token classification loss.
Positions are clamped to the length of the sequence (*sequence_length*). Position outside of the sequence
are not taken into account for computing the loss.
end_positions (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
Labels for position (index) of the end of the labelled span for computing the token classification loss.
Positions are clamped to the length of the sequence (*sequence_length*). Position outside of the sequence
are not taken into account for computing the loss.
"""
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
if start_positions is not None and end_positions is not None:
use_cache = False
outputs = self.model(
input_ids,
attention_mask=attention_mask,
decoder_input_ids=decoder_input_ids,
decoder_attention_mask=decoder_attention_mask,
encoder_outputs=encoder_outputs,
inputs_embeds=inputs_embeds,
decoder_inputs_embeds=decoder_inputs_embeds,
use_cache=use_cache,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
sequence_output = outputs[0]
logits = self.qa_outputs(sequence_output)
start_logits, end_logits = logits.split(1, dim=-1)
start_logits = start_logits.squeeze(-1)
end_logits = end_logits.squeeze(-1)
total_loss = None
if start_positions is not None and end_positions is not None:
# If we are on multi-GPU, split add a dimension
if len(start_positions.size()) > 1:
start_positions = start_positions.squeeze(-1)
if len(end_positions.size()) > 1:
end_positions = end_positions.squeeze(-1)
# sometimes the start/end positions are outside our model inputs, we ignore these terms
ignored_index = start_logits.size(1)
start_positions = start_positions.clamp(0, ignored_index)
end_positions = end_positions.clamp(0, ignored_index)
loss_fct = CrossEntropyLoss(ignore_index=ignored_index)
start_loss = loss_fct(start_logits, start_positions)
end_loss = loss_fct(end_logits, end_positions)
total_loss = (start_loss + end_loss) / 2
if not return_dict:
output = (
start_logits,
end_logits,
) + outputs[1:]
return ((total_loss,) + output) if total_loss is not None else output
return Seq2SeqQuestionAnsweringModelOutput(
loss=total_loss,
start_logits=start_logits,
end_logits=end_logits,
past_key_values=outputs.past_key_values,
decoder_hidden_states=outputs.decoder_hidden_states,
decoder_attentions=outputs.decoder_attentions,
cross_attentions=outputs.cross_attentions,
encoder_last_hidden_state=outputs.encoder_last_hidden_state,
encoder_hidden_states=outputs.encoder_hidden_states,
encoder_attentions=outputs.encoder_attentions,
)
# Copied from transformers.models.bart.modeling_bart.BartDecoderWrapper with Bart->{{cookiecutter.camelcase_modelname}}
class {{cookiecutter.camelcase_modelname}}DecoderWrapper({{cookiecutter.camelcase_modelname}}PreTrainedModel):
"""
This wrapper class is a helper class to correctly load pretrained checkpoints when the causal language model is
used in combination with the [`EncoderDecoderModel`] framework.
"""
def __init__(self, config):
super().__init__(config)
self.decoder = {{cookiecutter.camelcase_modelname}}Decoder(config)
def forward(self, *args, **kwargs):
return self.decoder(*args, **kwargs)
# Copied from transformers.models.bart.modeling_bart.BartForCausalLM with Bart->{{cookiecutter.camelcase_modelname}}
class {{cookiecutter.camelcase_modelname}}ForCausalLM({{cookiecutter.camelcase_modelname}}PreTrainedModel):
def __init__(self, config):
config = copy.deepcopy(config)
config.is_decoder = True
config.is_encoder_decoder = False
super().__init__(config)
self.model = {{cookiecutter.camelcase_modelname}}DecoderWrapper(config)
self.lm_head = nn.Linear(config.hidden_size, config.vocab_size, bias=False)
# Initialize weights and apply final processing
self.post_init()
def get_input_embeddings(self):
return self.model.decoder.embed_tokens
def set_input_embeddings(self, value):
self.model.decoder.embed_tokens = value
def get_output_embeddings(self):
return self.lm_head
def set_output_embeddings(self, new_embeddings):
self.lm_head = new_embeddings
def set_decoder(self, decoder):
self.model.decoder = decoder
def get_decoder(self):
return self.model.decoder
@replace_return_docstrings(output_type=CausalLMOutputWithCrossAttentions, config_class=_CONFIG_FOR_DOC)
def forward(
self,
input_ids=None,
attention_mask=None,
encoder_hidden_states=None,
encoder_attention_mask=None,
head_mask=None,
cross_attn_head_mask=None,
past_key_values=None,
inputs_embeds=None,
labels=None,
use_cache=None,
output_attentions=None,
output_hidden_states=None,
return_dict=None,
):
r"""
Args:
input_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`):
Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you
provide it.
Indices can be obtained using [`~{{cookiecutter.camelcase_modelname}}Tokenizer`]. See
[`PreTrainedTokenizer.encode`] and [`PreTrainedTokenizer.__call__`]
for details.
[What are input IDs?](../glossary#input-ids)
attention_mask (`torch.Tensor` of shape `(batch_size, sequence_length)`, *optional*):
Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
- 1 for tokens that are **not masked**,
- 0 for tokens that are **masked**.
[What are attention masks?](../glossary#attention-mask)
encoder_hidden_states (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`, *optional*):
Sequence of hidden-states at the output of the last layer of the encoder. Used in the cross-attention
if the model is configured as a decoder.
encoder_attention_mask (`torch.FloatTensor` of shape `(batch_size, sequence_length)`, *optional*):
Mask to avoid performing attention on the padding token indices of the encoder input. This mask is used
in the cross-attention if the model is configured as a decoder. Mask values selected in `[0, 1]`:
head_mask (`torch.Tensor` of shape `(decoder_layers, decoder_attention_heads)`, *optional*):
Mask to nullify selected heads of the attention modules. Mask values selected in `[0, 1]`:
- 1 indicates the head is **not masked**,
- 0 indicates the head is **masked**.
cross_attn_head_mask (`torch.Tensor` of shape `(decoder_layers, decoder_attention_heads)`, *optional*):
Mask to nullify selected heads of the cross-attention modules. Mask values selected in `[0, 1]`:
- 1 indicates the head is **not masked**,
- 0 indicates the head is **masked**.
past_key_values (`tuple(tuple(torch.FloatTensor))` of length `config.n_layers` with each tuple having 4 tensors of shape `(batch_size, num_heads, sequence_length - 1, embed_size_per_head)`):
Contains precomputed key and value hidden-states of the attention blocks. Can be used to speed up
decoding.
If `past_key_values` are used, the user can optionally input only the last `decoder_input_ids`
(those that don't have their past key value states given to this model) of shape `(batch_size, 1)`
instead of all `decoder_input_ids` of shape `(batch_size, sequence_length)`.
labels (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
Labels for computing the masked language modeling loss. Indices should either be in `[0, ..., config.vocab_size]` or -100 (see `input_ids` docstring). Tokens with indices set to `-100` are
ignored (masked), the loss is only computed for the tokens with labels in `[0, ..., config.vocab_size]`.
use_cache (`bool`, *optional*):
If set to `True`, `past_key_values` key value states are returned and can be used to speed up
decoding (see `past_key_values`).
- 1 for tokens that are **not masked**,
- 0 for tokens that are **masked**.
output_attentions (`bool`, *optional*):
Whether or not to return the attentions tensors of all attention layers. See `attentions` under
returned tensors for more detail.
output_hidden_states (`bool`, *optional*):
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors
for more detail.
return_dict (`bool`, *optional*):
Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
Returns:
Example:
```python
>>> from transformers import {{cookiecutter.camelcase_modelname}}Tokenizer, {{cookiecutter.camelcase_modelname}}ForCausalLM
>>> tokenizer = {{cookiecutter.camelcase_modelname}}Tokenizer.from_pretrained('facebook/bart-large')
>>> model = {{cookiecutter.camelcase_modelname}}ForCausalLM.from_pretrained('facebook/bart-large', add_cross_attention=False)
>>> assert model.config.is_decoder, f"{model.__class__} has to be configured as a decoder."
>>> inputs = tokenizer("Hello, my dog is cute", return_tensors="pt")
>>> outputs = model(**inputs)
>>> logits = outputs.logits
```
"""
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
output_hidden_states = (
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
)
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
# decoder outputs consists of (dec_features, layer_state, dec_hidden, dec_attn)
outputs = self.model.decoder(
input_ids=input_ids,
attention_mask=attention_mask,
encoder_hidden_states=encoder_hidden_states,
encoder_attention_mask=encoder_attention_mask,
head_mask=head_mask,
cross_attn_head_mask=cross_attn_head_mask,
past_key_values=past_key_values,
inputs_embeds=inputs_embeds,
use_cache=use_cache,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
logits = self.lm_head(outputs[0])
loss = None
if labels is not None:
loss_fct = CrossEntropyLoss()
loss = loss_fct(logits.view(-1, self.config.vocab_size), labels.view(-1))
if not return_dict:
output = (logits,) + outputs[1:]
return (loss,) + output if loss is not None else output
return CausalLMOutputWithCrossAttentions(
loss=loss,
logits=logits,
past_key_values=outputs.past_key_values,
hidden_states=outputs.hidden_states,
attentions=outputs.attentions,
cross_attentions=outputs.cross_attentions,
)
def prepare_inputs_for_generation(self, input_ids, past_key_values=None, attention_mask=None, use_cache=None, **kwargs):
# if model is used as a decoder in encoder-decoder model, the decoder attention mask is created on the fly
if attention_mask is None:
attention_mask = input_ids.new_ones(input_ids.shape)
if past_key_values:
input_ids = input_ids[:, -1:]
# first step, decoder_cached_states are empty
return {
"input_ids": input_ids, # encoder_outputs is defined. input_ids not needed
"attention_mask": attention_mask,
"past_key_values": past_key_values,
"use_cache": use_cache,
}
@staticmethod
def _reorder_cache(past_key_values, beam_idx):
reordered_past = ()
for layer_past in past_key_values:
reordered_past += (tuple(past_state.index_select(0, beam_idx) for past_state in layer_past),)
return reordered_past
{% endif -%}
| 0 |
hf_public_repos/transformers/templates/adding_a_new_model | hf_public_repos/transformers/templates/adding_a_new_model/cookiecutter-template-{{cookiecutter.modelname}}/modeling_flax_{{cookiecutter.lowercase_modelname}}.py | # coding=utf-8
# Copyright 2022 {{cookiecutter.authors}} and The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
""" Flax {{cookiecutter.modelname}} model. """
{% if cookiecutter.is_encoder_decoder_model == "False" %}
from typing import Callable, Optional, Tuple
import numpy as np
import flax.linen as nn
import jax
import jax.numpy as jnp
from flax.core.frozen_dict import FrozenDict, unfreeze, freeze
from flax.linen import combine_masks, make_causal_mask
from flax.linen import partitioning as nn_partitioning
from flax.traverse_util import flatten_dict, unflatten_dict
from flax.linen.attention import dot_product_attention_weights
from jax import lax
from ...utils import add_start_docstrings, add_start_docstrings_to_model_forward
from ...modeling_flax_outputs import (
FlaxBaseModelOutputWithPastAndCrossAttentions,
FlaxBaseModelOutputWithPoolingAndCrossAttentions,
FlaxCausalLMOutput,
FlaxCausalLMOutputWithCrossAttentions,
FlaxMaskedLMOutput,
FlaxMultipleChoiceModelOutput,
FlaxQuestionAnsweringModelOutput,
FlaxSequenceClassifierOutput,
FlaxTokenClassifierOutput,
)
from ...modeling_flax_utils import (
ACT2FN,
FlaxPreTrainedModel,
append_call_sample_docstring,
overwrite_call_docstring,
)
from ...utils import logging
from .configuration_{{cookiecutter.lowercase_modelname}} import {{cookiecutter.camelcase_modelname}}Config
logger = logging.get_logger(__name__)
_CHECKPOINT_FOR_DOC = "{{cookiecutter.checkpoint_identifier}}"
_CONFIG_FOR_DOC = "{{cookiecutter.camelcase_modelname}}Config"
_TOKENIZER_FOR_DOC = "{{cookiecutter.camelcase_modelname}}Tokenizer"
{{cookiecutter.uppercase_modelname}}_START_DOCSTRING = r"""
This model inherits from [`FlaxPreTrainedModel`]. Check the superclass documentation for the
generic methods the library implements for all its model (such as downloading, saving and converting weights from
PyTorch models)
This model is also a Flax Linen [flax.linen.Module](https://flax.readthedocs.io/en/latest/flax.linen.html#module) subclass. Use it as a regular Flax linen Module
and refer to the Flax documentation for all matter related to general usage and behavior.
Finally, this model supports inherent JAX features such as:
- [Just-In-Time (JIT) compilation](https://jax.readthedocs.io/en/latest/jax.html#just-in-time-compilation-jit)
- [Automatic Differentiation](https://jax.readthedocs.io/en/latest/jax.html#automatic-differentiation)
- [Vectorization](https://jax.readthedocs.io/en/latest/jax.html#vectorization-vmap)
- [Parallelization](https://jax.readthedocs.io/en/latest/jax.html#parallelization-pmap)
Parameters:
config ([`~{{cookiecutter.uppercase_modelname}}Config`]): Model configuration class with all the parameters of the model.
Initializing with a config file does not load the weights associated with the model, only the
configuration. Check out the [`~FlaxPreTrainedModel.from_pretrained`] method to load the
model weights.
dtype (`jax.numpy.dtype`, *optional*, defaults to `jax.numpy.float32`):
The data type of the computation. Can be one of `jax.numpy.float32`, `jax.numpy.float16` (on
GPUs) and `jax.numpy.bfloat16` (on TPUs).
This can be used to enable mixed-precision training or half-precision inference on GPUs or TPUs. If
specified all the computation will be performed with the given `dtype`.
**Note that this only specifies the dtype of the computation and does not influence the dtype of model
parameters.**
If you wish to change the dtype of the model parameters, see
[`~FlaxPreTrainedModel.to_fp16`] and [`~FlaxPreTrainedModel.to_bf16`].
"""
{{cookiecutter.uppercase_modelname}}_INPUTS_DOCSTRING = r"""
Args:
input_ids (`numpy.ndarray` of shape `({0})`):
Indices of input sequence tokens in the vocabulary.
Indices can be obtained using [`~{{cookiecutter.uppercase_modelname}}ConfiTokenizer`]. See
[`PreTrainedTokenizer.encode`] and [`PreTrainedTokenizer.__call__`] for
details.
[What are input IDs?](../glossary#input-ids)
attention_mask (`numpy.ndarray` of shape `({0})`, *optional*):
Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
- 1 for tokens that are **not masked**,
- 0 for tokens that are **masked**.
[What are attention masks?](../glossary#attention-mask)
token_type_ids (`numpy.ndarray` of shape `({0})`, *optional*):
Segment token indices to indicate first and second portions of the inputs. Indices are selected in `[0, 1]`:
- 0 corresponds to a *sentence A* token,
- 1 corresponds to a *sentence B* token.
[What are token type IDs?](../glossary#token-type-ids)
position_ids (`numpy.ndarray` of shape `({0})`, *optional*):
Indices of positions of each input sequence tokens in the position embeddings. Selected in the range `[0, config.max_position_embeddings - 1]`.
head_mask (`numpy.ndarray` of shape `({0})`, `optional): Mask to nullify selected heads of the attention modules. Mask values selected in `[0, 1]`:
- 1 indicates the head is **not masked**,
- 0 indicates the head is **masked**.
return_dict (`bool`, *optional*):
Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
"""
remat = nn_partitioning.remat
# Copied from transformers.models.bert.modeling_flax_bert.FlaxBertEmbeddings with Bert->{{cookiecutter.camelcase_modelname}}
class Flax{{cookiecutter.camelcase_modelname}}Embeddings(nn.Module):
"""Construct the embeddings from word, position and token_type embeddings."""
config: {{cookiecutter.camelcase_modelname}}Config
dtype: jnp.dtype = jnp.float32 # the dtype of the computation
def setup(self):
self.word_embeddings = nn.Embed(
self.config.vocab_size,
self.config.hidden_size,
embedding_init=jax.nn.initializers.normal(stddev=self.config.initializer_range),
)
self.position_embeddings = nn.Embed(
self.config.max_position_embeddings,
self.config.hidden_size,
embedding_init=jax.nn.initializers.normal(stddev=self.config.initializer_range),
)
self.token_type_embeddings = nn.Embed(
self.config.type_vocab_size,
self.config.hidden_size,
embedding_init=jax.nn.initializers.normal(stddev=self.config.initializer_range),
)
self.LayerNorm = nn.LayerNorm(epsilon=self.config.layer_norm_eps, dtype=self.dtype)
self.dropout = nn.Dropout(rate=self.config.hidden_dropout_prob)
def __call__(self, input_ids, token_type_ids, position_ids, attention_mask, deterministic: bool = True):
# Embed
inputs_embeds = self.word_embeddings(input_ids.astype("i4"))
position_embeds = self.position_embeddings(position_ids.astype("i4"))
token_type_embeddings = self.token_type_embeddings(token_type_ids.astype("i4"))
# Sum all embeddings
hidden_states = inputs_embeds + token_type_embeddings + position_embeds
# Layer Norm
hidden_states = self.LayerNorm(hidden_states)
hidden_states = self.dropout(hidden_states, deterministic=deterministic)
return hidden_states
# Copied from transformers.models.bert.modeling_flax_bert.FlaxBertSelfAttention with Bert->{{cookiecutter.camelcase_modelname}}
class Flax{{cookiecutter.camelcase_modelname}}SelfAttention(nn.Module):
config: {{cookiecutter.camelcase_modelname}}Config
causal: bool = False
dtype: jnp.dtype = jnp.float32 # the dtype of the computation
def setup(self):
self.head_dim = self.config.hidden_size // self.config.num_attention_heads
if self.config.hidden_size % self.config.num_attention_heads != 0:
raise ValueError(
"`config.hidden_size`: {self.config.hidden_size} has to be a multiple of `config.num_attention_heads`\
: {self.config.num_attention_heads}"
)
self.query = nn.Dense(
self.config.hidden_size,
dtype=self.dtype,
kernel_init=jax.nn.initializers.normal(self.config.initializer_range),
)
self.key = nn.Dense(
self.config.hidden_size,
dtype=self.dtype,
kernel_init=jax.nn.initializers.normal(self.config.initializer_range),
)
self.value = nn.Dense(
self.config.hidden_size,
dtype=self.dtype,
kernel_init=jax.nn.initializers.normal(self.config.initializer_range),
)
if self.causal:
self.causal_mask = make_causal_mask(
jnp.ones((1, self.config.max_position_embeddings), dtype="bool"), dtype="bool"
)
def _split_heads(self, hidden_states):
return hidden_states.reshape(hidden_states.shape[:2] + (self.config.num_attention_heads, self.head_dim))
def _merge_heads(self, hidden_states):
return hidden_states.reshape(hidden_states.shape[:2] + (self.config.hidden_size,))
@nn.compact
# Copied from transformers.models.bart.modeling_flax_bart.FlaxBartAttention._concatenate_to_cache
def _concatenate_to_cache(self, key, value, query, attention_mask):
"""
This function takes projected key, value states from a single input token and concatenates the states to cached
states from previous steps. This function is slighly adapted from the official Flax repository:
https://github.com/google/flax/blob/491ce18759622506588784b4fca0e4bf05f8c8cd/flax/linen/attention.py#L252
"""
# detect if we're initializing by absence of existing cache data.
is_initialized = self.has_variable("cache", "cached_key")
cached_key = self.variable("cache", "cached_key", jnp.zeros, key.shape, key.dtype)
cached_value = self.variable("cache", "cached_value", jnp.zeros, value.shape, value.dtype)
cache_index = self.variable("cache", "cache_index", lambda: jnp.array(0, dtype=jnp.int32))
if is_initialized:
*batch_dims, max_length, num_heads, depth_per_head = cached_key.value.shape
# update key, value caches with our new 1d spatial slices
cur_index = cache_index.value
indices = (0,) * len(batch_dims) + (cur_index, 0, 0)
key = lax.dynamic_update_slice(cached_key.value, key, indices)
value = lax.dynamic_update_slice(cached_value.value, value, indices)
cached_key.value = key
cached_value.value = value
num_updated_cache_vectors = query.shape[1]
cache_index.value = cache_index.value + num_updated_cache_vectors
# causal mask for cached decoder self-attention: our single query position should only attend to those key positions that have already been generated and cached, not the remaining zero elements.
pad_mask = jnp.broadcast_to(
jnp.arange(max_length) < cur_index + num_updated_cache_vectors,
tuple(batch_dims) + (1, num_updated_cache_vectors, max_length),
)
attention_mask = combine_masks(pad_mask, attention_mask)
return key, value, attention_mask
def __call__(
self,
hidden_states,
attention_mask,
layer_head_mask,
key_value_states: Optional[jnp.array] = None,
init_cache: bool = False,
deterministic=True,
output_attentions: bool = False,
):
# if key_value_states are provided this layer is used as a cross-attention layer
# for the decoder
is_cross_attention = key_value_states is not None
batch_size = hidden_states.shape[0]
# get query proj
query_states = self.query(hidden_states)
# get key, value proj
if is_cross_attention:
# cross_attentions
key_states = self.key(key_value_states)
value_states = self.value(key_value_states)
else:
# self_attention
key_states = self.key(hidden_states)
value_states = self.value(hidden_states)
query_states = self._split_heads(query_states)
key_states = self._split_heads(key_states)
value_states = self._split_heads(value_states)
# handle cache prepare causal attention mask
if self.causal:
query_length, key_length = query_states.shape[1], key_states.shape[1]
if self.has_variable("cache", "cached_key"):
mask_shift = self.variables["cache"]["cache_index"]
max_decoder_length = self.variables["cache"]["cached_key"].shape[1]
causal_mask = lax.dynamic_slice(
self.causal_mask, (0, 0, mask_shift, 0), (1, 1, query_length, max_decoder_length)
)
else:
causal_mask = self.causal_mask[:, :, :query_length, :key_length]
causal_mask = jnp.broadcast_to(causal_mask, (batch_size,) + causal_mask.shape[1:])
# combine masks if needed
if attention_mask is not None and self.causal:
attention_mask = jnp.broadcast_to(jnp.expand_dims(attention_mask, axis=(-3, -2)), causal_mask.shape)
attention_mask = combine_masks(attention_mask, causal_mask)
elif self.causal:
attention_mask = causal_mask
elif attention_mask is not None:
attention_mask = jnp.expand_dims(attention_mask, axis=(-3, -2))
# During fast autoregressive decoding, we feed one position at a time,
# and cache the keys and values step by step.
if self.causal and (self.has_variable("cache", "cached_key") or init_cache):
key_states, value_states, attention_mask = self._concatenate_to_cache(
key_states, value_states, query_states, attention_mask
)
# Convert the boolean attention mask to an attention bias.
if attention_mask is not None:
# attention mask in the form of attention bias
attention_bias = lax.select(
attention_mask > 0,
jnp.full(attention_mask.shape, 0.0).astype(self.dtype),
jnp.full(attention_mask.shape, jnp.finfo(self.dtype).min).astype(self.dtype),
)
else:
attention_bias = None
dropout_rng = None
if not deterministic and self.config.attention_probs_dropout_prob > 0.0:
dropout_rng = self.make_rng("dropout")
attn_weights = dot_product_attention_weights(
query_states,
key_states,
bias=attention_bias,
dropout_rng=dropout_rng,
dropout_rate=self.config.attention_probs_dropout_prob,
broadcast_dropout=True,
deterministic=deterministic,
dtype=self.dtype,
precision=None,
)
# Mask heads if we want to
if layer_head_mask is not None:
attn_weights = jnp.einsum("...hqk,h->...hqk", attn_weights, layer_head_mask)
attn_output = jnp.einsum("...hqk,...khd->...qhd", attn_weights, value_states)
attn_output = attn_output.reshape(attn_output.shape[:2] + (-1,))
outputs = (attn_output, attn_weights) if output_attentions else (attn_output,)
return outputs
# Copied from transformers.models.bert.modeling_flax_bert.FlaxBertSelfOutput with Bert->{{cookiecutter.camelcase_modelname}}
class Flax{{cookiecutter.camelcase_modelname}}SelfOutput(nn.Module):
config: {{cookiecutter.camelcase_modelname}}Config
dtype: jnp.dtype = jnp.float32 # the dtype of the computation
def setup(self):
self.dense = nn.Dense(
self.config.hidden_size,
kernel_init=jax.nn.initializers.normal(self.config.initializer_range),
dtype=self.dtype,
)
self.LayerNorm = nn.LayerNorm(epsilon=self.config.layer_norm_eps, dtype=self.dtype)
self.dropout = nn.Dropout(rate=self.config.hidden_dropout_prob)
def __call__(self, hidden_states, input_tensor, deterministic: bool = True):
hidden_states = self.dense(hidden_states)
hidden_states = self.dropout(hidden_states, deterministic=deterministic)
hidden_states = self.LayerNorm(hidden_states + input_tensor)
return hidden_states
# Copied from transformers.models.bert.modeling_flax_bert.FlaxBertAttention with Bert->{{cookiecutter.camelcase_modelname}}
class Flax{{cookiecutter.camelcase_modelname}}Attention(nn.Module):
config: {{cookiecutter.camelcase_modelname}}Config
causal: bool = False
dtype: jnp.dtype = jnp.float32
def setup(self):
self.self = Flax{{cookiecutter.camelcase_modelname}}SelfAttention(self.config, dtype=self.dtype)
self.output = Flax{{cookiecutter.camelcase_modelname}}SelfOutput(self.config, dtype=self.dtype)
def __call__(
self,
hidden_states,
attention_mask,
layer_head_mask,
key_value_states=None,
init_cache=False,
deterministic=True,
output_attentions: bool = False,
):
# Attention mask comes in as attention_mask.shape == (*batch_sizes, kv_length)
# FLAX expects: attention_mask.shape == (*batch_sizes, 1, 1, kv_length) such that it is broadcastable
# with attn_weights.shape == (*batch_sizes, num_heads, q_length, kv_length)
attn_outputs = self.self(
hidden_states,
attention_mask,
layer_head_mask=layer_head_mask,
key_value_states=key_value_states,
init_cache=init_cache,
deterministic=deterministic,
output_attentions=output_attentions,
)
attn_output = attn_outputs[0]
hidden_states = self.output(attn_output, hidden_states, deterministic=deterministic)
outputs = (hidden_states,)
if output_attentions:
outputs += (attn_outputs[1],)
return outputs
# Copied from transformers.models.bert.modeling_flax_bert.FlaxBertIntermediate with Bert->{{cookiecutter.camelcase_modelname}}
class Flax{{cookiecutter.camelcase_modelname}}Intermediate(nn.Module):
config: {{cookiecutter.camelcase_modelname}}Config
dtype: jnp.dtype = jnp.float32 # the dtype of the computation
def setup(self):
self.dense = nn.Dense(
self.config.intermediate_size,
kernel_init=jax.nn.initializers.normal(self.config.initializer_range),
dtype=self.dtype,
)
self.activation = ACT2FN[self.config.hidden_act]
def __call__(self, hidden_states):
hidden_states = self.dense(hidden_states)
hidden_states = self.activation(hidden_states)
return hidden_states
# Copied from transformers.models.bert.modeling_flax_bert.FlaxBertOutput with Bert->{{cookiecutter.camelcase_modelname}}
class Flax{{cookiecutter.camelcase_modelname}}Output(nn.Module):
config: {{cookiecutter.camelcase_modelname}}Config
dtype: jnp.dtype = jnp.float32 # the dtype of the computation
def setup(self):
self.dense = nn.Dense(
self.config.hidden_size,
kernel_init=jax.nn.initializers.normal(self.config.initializer_range),
dtype=self.dtype,
)
self.dropout = nn.Dropout(rate=self.config.hidden_dropout_prob)
self.LayerNorm = nn.LayerNorm(epsilon=self.config.layer_norm_eps, dtype=self.dtype)
def __call__(self, hidden_states, attention_output, deterministic: bool = True):
hidden_states = self.dense(hidden_states)
hidden_states = self.dropout(hidden_states, deterministic=deterministic)
hidden_states = self.LayerNorm(hidden_states + attention_output)
return hidden_states
# Copied from transformers.models.bert.modeling_flax_bert.FlaxBertLayer with Bert->{{cookiecutter.camelcase_modelname}}
class Flax{{cookiecutter.camelcase_modelname}}Layer(nn.Module):
config: {{cookiecutter.camelcase_modelname}}Config
dtype: jnp.dtype = jnp.float32 # the dtype of the computation
def setup(self):
self.attention = Flax{{cookiecutter.camelcase_modelname}}Attention(self.config, dtype=self.dtype)
self.intermediate = Flax{{cookiecutter.camelcase_modelname}}Intermediate(self.config, dtype=self.dtype)
self.output = Flax{{cookiecutter.camelcase_modelname}}Output(self.config, dtype=self.dtype)
if self.config.add_cross_attention:
self.crossattention = Flax{{cookiecutter.camelcase_modelname}}Attention(self.config, causal=False, dtype=self.dtype)
def __call__(
self,
hidden_states,
attention_mask,
layer_head_mask,
encoder_hidden_states: Optional[jnp.ndarray] = None,
encoder_attention_mask: Optional[jnp.ndarray] = None,
init_cache: bool = False,
deterministic: bool = True,
output_attentions: bool = False,
):
# Self Attention
attention_outputs = self.attention(
hidden_states,
attention_mask,
layer_head_mask=layer_head_mask,
init_cache=init_cache,
deterministic=deterministic,
output_attentions=output_attentions,
)
attention_output = attention_outputs[0]
# Cross-Attention Block
if encoder_hidden_states is not None:
cross_attention_outputs = self.crossattention(
attention_output,
attention_mask=encoder_attention_mask,
layer_head_mask=layer_head_mask,
key_value_states=encoder_hidden_states,
deterministic=deterministic,
output_attentions=output_attentions,
)
attention_output = cross_attention_outputs[0]
hidden_states = self.intermediate(attention_output)
hidden_states = self.output(hidden_states, attention_output, deterministic=deterministic)
outputs = (hidden_states,)
if output_attentions:
outputs += (attention_outputs[1],)
if encoder_hidden_states is not None:
outputs += (cross_attention_outputs[1],)
return outputs
# Copied from transformers.models.bert.modeling_flax_bert.FlaxBertLayerCollection with Bert->{{cookiecutter.camelcase_modelname}}
class Flax{{cookiecutter.camelcase_modelname}}LayerCollection(nn.Module):
config: {{cookiecutter.camelcase_modelname}}Config
dtype: jnp.dtype = jnp.float32 # the dtype of the computation
gradient_checkpointing: bool = False
def setup(self):
if self.gradient_checkpointing:
Flax{{cookiecutter.camelcase_modelname}}CheckpointLayer = remat(Flax{{cookiecutter.camelcase_modelname}}Layer, static_argnums=(5, 6, 7))
self.layers = [
Flax{{cookiecutter.camelcase_modelname}}CheckpointLayer(self.config, name=str(i), dtype=self.dtype)
for i in range(self.config.num_hidden_layers)
]
else:
self.layers = [
Flax{{cookiecutter.camelcase_modelname}}Layer(self.config, name=str(i), dtype=self.dtype) for i in range(self.config.num_hidden_layers)
]
def __call__(
self,
hidden_states,
attention_mask,
head_mask,
encoder_hidden_states: Optional[jnp.ndarray] = None,
encoder_attention_mask: Optional[jnp.ndarray] = None,
init_cache: bool = False,
deterministic: bool = True,
output_attentions: bool = False,
output_hidden_states: bool = False,
return_dict: bool = True,
):
all_attentions = () if output_attentions else None
all_hidden_states = () if output_hidden_states else None
all_cross_attentions = () if (output_attentions and encoder_hidden_states is not None) else None
# Check if head_mask has a correct number of layers specified if desired
if head_mask is not None:
if head_mask.shape[0] != (len(self.layers)):
raise ValueError(
f"The head_mask should be specified for {len(self.layers)} layers, but it is for \
{head_mask.shape[0]}."
)
for i, layer in enumerate(self.layers):
if output_hidden_states:
all_hidden_states += (hidden_states,)
layer_outputs = layer(
hidden_states,
attention_mask,
head_mask[i] if head_mask is not None else None,
encoder_hidden_states,
encoder_attention_mask,
init_cache,
deterministic,
output_attentions,
)
hidden_states = layer_outputs[0]
if output_attentions:
all_attentions += (layer_outputs[1],)
if encoder_hidden_states is not None:
all_cross_attentions += (layer_outputs[2],)
if output_hidden_states:
all_hidden_states += (hidden_states,)
outputs = (hidden_states,)
if not return_dict:
return tuple(v for v in outputs if v is not None)
return FlaxBaseModelOutputWithPastAndCrossAttentions(
last_hidden_state=hidden_states,
hidden_states=all_hidden_states,
attentions=all_attentions,
cross_attentions=all_cross_attentions,
)
# Copied from transformers.models.bert.modeling_flax_bert.FlaxBertEncoder with Bert->{{cookiecutter.camelcase_modelname}}
class Flax{{cookiecutter.camelcase_modelname}}Encoder(nn.Module):
config: {{cookiecutter.camelcase_modelname}}Config
dtype: jnp.dtype = jnp.float32 # the dtype of the computation
gradient_checkpointing: bool = False
def setup(self):
self.layer = Flax{{cookiecutter.camelcase_modelname}}LayerCollection(self.config, dtype=self.dtype, gradient_checkpointing=self.gradient_checkpointing)
def __call__(
self,
hidden_states,
attention_mask,
head_mask,
encoder_hidden_states: Optional[jnp.ndarray] = None,
encoder_attention_mask: Optional[jnp.ndarray] = None,
init_cache: bool = False,
deterministic: bool = True,
output_attentions: bool = False,
output_hidden_states: bool = False,
return_dict: bool = True,
):
return self.layer(
hidden_states,
attention_mask,
head_mask=head_mask,
encoder_hidden_states=encoder_hidden_states,
encoder_attention_mask=encoder_attention_mask,
init_cache=init_cache,
deterministic=deterministic,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
# Copied from transformers.models.bert.modeling_flax_bert.FlaxBertPooler with Bert->{{cookiecutter.camelcase_modelname}}
class Flax{{cookiecutter.camelcase_modelname}}Pooler(nn.Module):
config: {{cookiecutter.camelcase_modelname}}Config
dtype: jnp.dtype = jnp.float32 # the dtype of the computation
def setup(self):
self.dense = nn.Dense(
self.config.hidden_size,
kernel_init=jax.nn.initializers.normal(self.config.initializer_range),
dtype=self.dtype,
)
def __call__(self, hidden_states):
cls_hidden_state = hidden_states[:, 0]
cls_hidden_state = self.dense(cls_hidden_state)
return nn.tanh(cls_hidden_state)
# Copied from transformers.models.bert.modeling_flax_bert.FlaxBertPredictionHeadTransform with Bert->{{cookiecutter.camelcase_modelname}}
class Flax{{cookiecutter.camelcase_modelname}}PredictionHeadTransform(nn.Module):
config: {{cookiecutter.camelcase_modelname}}Config
dtype: jnp.dtype = jnp.float32
def setup(self):
self.dense = nn.Dense(self.config.hidden_size, dtype=self.dtype)
self.activation = ACT2FN[self.config.hidden_act]
self.LayerNorm = nn.LayerNorm(epsilon=self.config.layer_norm_eps, dtype=self.dtype)
def __call__(self, hidden_states):
hidden_states = self.dense(hidden_states)
hidden_states = self.activation(hidden_states)
return self.LayerNorm(hidden_states)
# Copied from transformers.models.bert.modeling_flax_bert.FlaxBertLMPredictionHead with Bert->{{cookiecutter.camelcase_modelname}}
class Flax{{cookiecutter.camelcase_modelname}}LMPredictionHead(nn.Module):
config: {{cookiecutter.camelcase_modelname}}Config
dtype: jnp.dtype = jnp.float32
bias_init: Callable[..., np.ndarray] = jax.nn.initializers.zeros
def setup(self):
self.transform = Flax{{cookiecutter.camelcase_modelname}}PredictionHeadTransform(self.config, dtype=self.dtype)
self.decoder = nn.Dense(self.config.vocab_size, dtype=self.dtype, use_bias=False)
self.bias = self.param("bias", self.bias_init, (self.config.vocab_size,))
def __call__(self, hidden_states, shared_embedding=None):
hidden_states = self.transform(hidden_states)
if shared_embedding is not None:
hidden_states = self.decoder.apply({"params": {"kernel": shared_embedding.T}}, hidden_states)
else:
hidden_states = self.decoder(hidden_states)
hidden_states += self.bias
return hidden_states
# Copied from transformers.models.bert.modeling_flax_bert.FlaxBertOnlyMLMHead with Bert->{{cookiecutter.camelcase_modelname}}
class Flax{{cookiecutter.camelcase_modelname}}OnlyMLMHead(nn.Module):
config: {{cookiecutter.camelcase_modelname}}Config
dtype: jnp.dtype = jnp.float32
def setup(self):
self.predictions = Flax{{cookiecutter.camelcase_modelname}}LMPredictionHead(self.config, dtype=self.dtype)
def __call__(self, hidden_states, shared_embedding=None):
hidden_states = self.predictions(hidden_states, shared_embedding=shared_embedding)
return hidden_states
# Copied from transformers.models.bert.modeling_flax_bert.FlaxBertOnlyNSPHead with Bert->{{cookiecutter.camelcase_modelname}}
class Flax{{cookiecutter.camelcase_modelname}}OnlyNSPHead(nn.Module):
dtype: jnp.dtype = jnp.float32
def setup(self):
self.seq_relationship = nn.Dense(2, dtype=self.dtype)
def __call__(self, pooled_output):
return self.seq_relationship(pooled_output)
# Copied from transformers.models.bert.modeling_flax_bert.FlaxBertPreTrainingHeads with Bert->{{cookiecutter.camelcase_modelname}}
class Flax{{cookiecutter.camelcase_modelname}}PreTrainingHeads(nn.Module):
config: {{cookiecutter.camelcase_modelname}}Config
dtype: jnp.dtype = jnp.float32
def setup(self):
self.predictions = Flax{{cookiecutter.camelcase_modelname}}LMPredictionHead(self.config, dtype=self.dtype)
self.seq_relationship = nn.Dense(2, dtype=self.dtype)
def __call__(self, hidden_states, pooled_output, shared_embedding=None):
prediction_scores = self.predictions(hidden_states, shared_embedding=shared_embedding)
seq_relationship_score = self.seq_relationship(pooled_output)
return prediction_scores, seq_relationship_score
class Flax{{cookiecutter.camelcase_modelname}}PreTrainedModel(FlaxPreTrainedModel):
"""
An abstract class to handle weights initialization and a simple interface for downloading and loading pretrained
models.
"""
config_class = {{cookiecutter.camelcase_modelname}}Config
base_model_prefix = "{{cookiecutter.lowercase_modelname}}"
module_class: nn.Module = None
def __init__(
self,
config: {{cookiecutter.camelcase_modelname}}Config,
input_shape: Tuple = (1, 1),
seed: int = 0,
dtype: jnp.dtype = jnp.float32,
_do_init: bool = True,
gradient_checkpointing: bool = False,
**kwargs
):
module = self.module_class(config=config, dtype=dtype, gradient_checkpointing=gradient_checkpointing, **kwargs)
super().__init__(config, module, input_shape=input_shape, seed=seed, dtype=dtype, _do_init=_do_init)
# Copied from transformers.models.bert.modeling_flax_bert.FlaxBertPreTrainedModel.enable_gradient_checkpointing
def enable_gradient_checkpointing(self):
self._module = self.module_class(
config=self.config,
dtype=self.dtype,
gradient_checkpointing=True,
)
# Copied from transformers.models.bert.modeling_flax_bert.FlaxBertPreTrainedModel.init_weights with Bert->{{cookiecutter.camelcase_modelname}}
def init_weights(self, rng: jax.random.PRNGKey, input_shape: Tuple, params: FrozenDict = None) -> FrozenDict:
# init input tensors
input_ids = jnp.zeros(input_shape, dtype="i4")
token_type_ids = jnp.zeros_like(input_ids)
position_ids = jnp.broadcast_to(jnp.arange(jnp.atleast_2d(input_ids).shape[-1]), input_shape)
attention_mask = jnp.ones_like(input_ids)
head_mask = jnp.ones((self.config.num_hidden_layers, self.config.num_attention_heads))
params_rng, dropout_rng = jax.random.split(rng)
rngs = {"params": params_rng, "dropout": dropout_rng}
if self.config.add_cross_attention:
encoder_hidden_states = jnp.zeros(input_shape + (self.config.hidden_size,))
encoder_attention_mask = attention_mask
module_init_outputs = self.module.init(
rngs,
input_ids,
attention_mask,
token_type_ids,
position_ids,
head_mask,
encoder_hidden_states,
encoder_attention_mask,
return_dict=False,
)
else:
module_init_outputs = self.module.init(
rngs, input_ids, attention_mask, token_type_ids, position_ids, head_mask, return_dict=False
)
random_params = module_init_outputs["params"]
if params is not None:
random_params = flatten_dict(unfreeze(random_params))
params = flatten_dict(unfreeze(params))
for missing_key in self._missing_keys:
params[missing_key] = random_params[missing_key]
self._missing_keys = set()
return freeze(unflatten_dict(params))
else:
return random_params
# Copied from transformers.models.bert.modeling_flax_bert.FlaxBertPreTrainedModel.init_cache with Bert->{{cookiecutter.camelcase_modelname}}
def init_cache(self, batch_size, max_length):
r"""
Args:
batch_size (`int`):
batch_size used for fast auto-regressive decoding. Defines the batch size of the initialized cache.
max_length (`int`):
maximum possible length for auto-regressive decoding. Defines the sequence length of the initialized
cache.
"""
# init input variables to retrieve cache
input_ids = jnp.ones((batch_size, max_length))
attention_mask = jnp.ones_like(input_ids)
position_ids = jnp.broadcast_to(jnp.arange(jnp.atleast_2d(input_ids).shape[-1]), input_ids.shape)
init_variables = self.module.init(
jax.random.PRNGKey(0), input_ids, attention_mask, position_ids, return_dict=False, init_cache=True
)
return unfreeze(init_variables["cache"])
@add_start_docstrings_to_model_forward({{cookiecutter.uppercase_modelname}}_INPUTS_DOCSTRING.format("batch_size, sequence_length"))
# Copied from transformers.models.bert.modeling_flax_bert.FlaxBertPreTrainedModel.__call__ with Bert->{{cookiecutter.camelcase_modelname}}
def __call__(
self,
input_ids,
attention_mask=None,
token_type_ids=None,
position_ids=None,
head_mask=None,
encoder_hidden_states=None,
encoder_attention_mask=None,
params: dict = None,
dropout_rng: jax.random.PRNGKey = None,
train: bool = False,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
past_key_values: dict = None,
):
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
output_hidden_states = (
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
)
return_dict = return_dict if return_dict is not None else self.config.return_dict
# init input tensors if not passed
if token_type_ids is None:
token_type_ids = jnp.zeros_like(input_ids)
if position_ids is None:
position_ids = jnp.broadcast_to(jnp.arange(jnp.atleast_2d(input_ids).shape[-1]), input_ids.shape)
if attention_mask is None:
attention_mask = jnp.ones_like(input_ids)
if head_mask is None:
head_mask = jnp.ones((self.config.num_hidden_layers, self.config.num_attention_heads))
# Handle any PRNG if needed
rngs = {}
if dropout_rng is not None:
rngs["dropout"] = dropout_rng
inputs = {"params": params or self.params}
if self.config.add_cross_attention:
# if past_key_values are passed then cache is already initialized a private flag init_cache has to be passed
# down to ensure cache is used. It has to be made sure that cache is marked as mutable so that it can be
# changed by FlaxBertAttention module
if past_key_values:
inputs["cache"] = past_key_values
mutable = ["cache"]
else:
mutable = False
outputs = self.module.apply(
inputs,
jnp.array(input_ids, dtype="i4"),
jnp.array(attention_mask, dtype="i4"),
token_type_ids=jnp.array(token_type_ids, dtype="i4"),
position_ids=jnp.array(position_ids, dtype="i4"),
head_mask=jnp.array(head_mask, dtype="i4"),
encoder_hidden_states=encoder_hidden_states,
encoder_attention_mask=encoder_attention_mask,
deterministic=not train,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
rngs=rngs,
mutable=mutable,
)
# add updated cache to model output
if past_key_values is not None and return_dict:
outputs, past_key_values = outputs
outputs["past_key_values"] = unfreeze(past_key_values["cache"])
return outputs
elif past_key_values is not None and not return_dict:
outputs, past_key_values = outputs
outputs = outputs[:1] + (unfreeze(past_key_values["cache"]),) + outputs[1:]
else:
outputs = self.module.apply(
inputs,
jnp.array(input_ids, dtype="i4"),
jnp.array(attention_mask, dtype="i4"),
token_type_ids=jnp.array(token_type_ids, dtype="i4"),
position_ids=jnp.array(position_ids, dtype="i4"),
head_mask=jnp.array(head_mask, dtype="i4"),
deterministic=not train,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
rngs=rngs,
)
return outputs
# Copied from transformers.models.bert.modeling_flax_bert.FlaxBertModule with Bert->{{cookiecutter.camelcase_modelname}}
class Flax{{cookiecutter.camelcase_modelname}}Module(nn.Module):
config: {{cookiecutter.camelcase_modelname}}Config
dtype: jnp.dtype = jnp.float32 # the dtype of the computation
add_pooling_layer: bool = True
gradient_checkpointing: bool = False
def setup(self):
self.embeddings = Flax{{cookiecutter.camelcase_modelname}}Embeddings(self.config, dtype=self.dtype)
self.encoder = Flax{{cookiecutter.camelcase_modelname}}Encoder(self.config, dtype=self.dtype, gradient_checkpointing=self.gradient_checkpointing)
self.pooler = Flax{{cookiecutter.camelcase_modelname}}Pooler(self.config, dtype=self.dtype)
def __call__(
self,
input_ids,
attention_mask,
token_type_ids: Optional[jnp.ndarray] = None,
position_ids: Optional[jnp.ndarray] = None,
head_mask: Optional[jnp.ndarray] = None,
encoder_hidden_states: Optional[jnp.ndarray] = None,
encoder_attention_mask: Optional[jnp.ndarray] = None,
init_cache: bool = False,
deterministic: bool = True,
output_attentions: bool = False,
output_hidden_states: bool = False,
return_dict: bool = True,
):
# make sure `token_type_ids` is correctly initialized when not passed
if token_type_ids is None:
token_type_ids = jnp.zeros_like(input_ids)
# make sure `position_ids` is correctly initialized when not passed
if position_ids is None:
position_ids = jnp.broadcast_to(jnp.arange(jnp.atleast_2d(input_ids).shape[-1]), input_ids.shape)
hidden_states = self.embeddings(
input_ids, token_type_ids, position_ids, attention_mask, deterministic=deterministic
)
outputs = self.encoder(
hidden_states,
attention_mask,
head_mask=head_mask,
deterministic=deterministic,
encoder_hidden_states=encoder_hidden_states,
encoder_attention_mask=encoder_attention_mask,
init_cache=init_cache,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
hidden_states = outputs[0]
pooled = self.pooler(hidden_states) if self.add_pooling_layer else None
if not return_dict:
# if pooled is None, don't return it
if pooled is None:
return (hidden_states,) + outputs[1:]
return (hidden_states, pooled) + outputs[1:]
return FlaxBaseModelOutputWithPoolingAndCrossAttentions(
last_hidden_state=hidden_states,
pooler_output=pooled,
hidden_states=outputs.hidden_states,
attentions=outputs.attentions,
cross_attentions=outputs.cross_attentions,
)
add_start_docstrings(
"The bare {{cookiecutter.camelcase_modelname}} Model transformer outputting raw hidden-states without any specific head on top.",
{{cookiecutter.uppercase_modelname}}_START_DOCSTRING,
)
class Flax{{cookiecutter.camelcase_modelname}}Model(Flax{{cookiecutter.camelcase_modelname}}PreTrainedModel):
module_class = Flax{{cookiecutter.camelcase_modelname}}Module
class Flax{{cookiecutter.camelcase_modelname}}ForMaskedLMModule(nn.Module):
config: {{cookiecutter.camelcase_modelname}}Config
dtype: jnp.dtype = jnp.float32
gradient_checkpointing: bool = False
def setup(self):
self.{{cookiecutter.lowercase_modelname}} = Flax{{cookiecutter.camelcase_modelname}}Module(config=self.config, add_pooling_layer=False, dtype=self.dtype, gradient_checkpointing=self.gradient_checkpointing)
self.cls = Flax{{cookiecutter.camelcase_modelname}}OnlyMLMHead(config=self.config, dtype=self.dtype)
def __call__(
self,
input_ids,
attention_mask,
token_type_ids,
position_ids,
head_mask,
deterministic: bool = True,
output_attentions: bool = False,
output_hidden_states: bool = False,
return_dict: bool = True,
):
# Model
outputs = self.{{cookiecutter.lowercase_modelname}}(
input_ids,
attention_mask,
token_type_ids,
position_ids,
head_mask,
deterministic=deterministic,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
hidden_states = outputs[0]
if self.config.tie_word_embeddings:
shared_embedding = self.{{cookiecutter.lowercase_modelname}}.variables["params"]["embeddings"]["word_embeddings"]["embedding"]
else:
shared_embedding = None
# Compute the prediction scores
logits = self.cls(hidden_states, shared_embedding=shared_embedding)
if not return_dict:
return (logits,) + outputs[1:]
return FlaxCausalLMOutput(
logits=logits,
hidden_states=outputs.hidden_states,
attentions=outputs.attentions,
)
@add_start_docstrings("""{{cookiecutter.camelcase_modelname}} Model with a `language modeling` head on top for MLM training. """, {{cookiecutter.uppercase_modelname}}_START_DOCSTRING)
class Flax{{cookiecutter.camelcase_modelname}}ForMaskedLM(Flax{{cookiecutter.camelcase_modelname}}PreTrainedModel):
module_class = Flax{{cookiecutter.camelcase_modelname}}ForMaskedLMModule
append_call_sample_docstring(
Flax{{cookiecutter.camelcase_modelname}}ForMaskedLM, _TOKENIZER_FOR_DOC, _CHECKPOINT_FOR_DOC, FlaxMaskedLMOutput, _CONFIG_FOR_DOC
)
class Flax{{cookiecutter.camelcase_modelname}}ForCausalLMModule(nn.Module):
config: {{cookiecutter.camelcase_modelname}}Config
dtype: jnp.dtype = jnp.float32
gradient_checkpointing: bool = False
def setup(self):
self.{{cookiecutter.lowercase_modelname}} = Flax{{cookiecutter.camelcase_modelname}}Module(config=self.config, add_pooling_layer=False, dtype=self.dtype, gradient_checkpointing=self.gradient_checkpointing)
self.cls = Flax{{cookiecutter.camelcase_modelname}}OnlyMLMHead(config=self.config, dtype=self.dtype)
def __call__(
self,
input_ids,
attention_mask,
token_type_ids,
position_ids,
head_mask,
deterministic: bool = True,
output_attentions: bool = False,
output_hidden_states: bool = False,
return_dict: bool = True,
):
# Model
outputs = self.{{cookiecutter.lowercase_modelname}}(
input_ids,
attention_mask,
token_type_ids,
position_ids,
head_mask,
deterministic=deterministic,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
hidden_states = outputs[0]
if self.config.tie_word_embeddings:
shared_embedding = self.{{cookiecutter.lowercase_modelname}}.variables["params"]["embeddings"]["word_embeddings"]["embedding"]
else:
shared_embedding = None
# Compute the prediction scores
logits = self.cls(hidden_states, shared_embedding=shared_embedding)
if not return_dict:
return (logits,) + outputs[1:]
return FlaxCausalLMOutput(
logits=logits,
hidden_states=outputs.hidden_states,
attentions=outputs.attentions,
)
@add_start_docstrings("""{{cookiecutter.camelcase_modelname}} Model with a `language modeling` head on top for CLM training. """, {{cookiecutter.uppercase_modelname}}_START_DOCSTRING)
class Flax{{cookiecutter.camelcase_modelname}}ForCausalLM(Flax{{cookiecutter.camelcase_modelname}}PreTrainedModel):
module_class = Flax{{cookiecutter.camelcase_modelname}}ForCausalLMModule
append_call_sample_docstring(
Flax{{cookiecutter.camelcase_modelname}}ForCausalLM, _TOKENIZER_FOR_DOC, _CHECKPOINT_FOR_DOC, FlaxCausalLMOutput, _CONFIG_FOR_DOC
)
class Flax{{cookiecutter.camelcase_modelname}}ForSequenceClassificationModule(nn.Module):
config: {{cookiecutter.camelcase_modelname}}Config
dtype: jnp.dtype = jnp.float32
gradient_checkpointing: bool = False
def setup(self):
self.{{cookiecutter.lowercase_modelname}} = Flax{{cookiecutter.camelcase_modelname}}Module(config=self.config, dtype=self.dtype, gradient_checkpointing=self.gradient_checkpointing)
self.dropout = nn.Dropout(rate=self.config.hidden_dropout_prob)
self.classifier = nn.Dense(
self.config.num_labels,
dtype=self.dtype,
)
def __call__(
self,
input_ids,
attention_mask,
token_type_ids,
position_ids,
head_mask,
deterministic: bool = True,
output_attentions: bool = False,
output_hidden_states: bool = False,
return_dict: bool = True,
):
# Model
outputs = self.{{cookiecutter.lowercase_modelname}}(
input_ids,
attention_mask,
token_type_ids,
position_ids,
head_mask,
deterministic=deterministic,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
pooled_output = outputs[1]
pooled_output = self.dropout(pooled_output, deterministic=deterministic)
logits = self.classifier(pooled_output)
if not return_dict:
return (logits,) + outputs[2:]
return FlaxSequenceClassifierOutput(
logits=logits,
hidden_states=outputs.hidden_states,
attentions=outputs.attentions,
)
@add_start_docstrings(
"""
{{cookiecutter.camelcase_modelname}} Model transformer with a sequence classification/regression head on top (a linear layer on top of the pooled
output) e.g. for GLUE tasks.
""",
{{cookiecutter.uppercase_modelname}}_START_DOCSTRING,
)
class Flax{{cookiecutter.camelcase_modelname}}ForSequenceClassification(Flax{{cookiecutter.camelcase_modelname}}PreTrainedModel):
module_class = Flax{{cookiecutter.camelcase_modelname}}ForSequenceClassificationModule
append_call_sample_docstring(
Flax{{cookiecutter.camelcase_modelname}}ForSequenceClassification,
_TOKENIZER_FOR_DOC,
_CHECKPOINT_FOR_DOC,
FlaxSequenceClassifierOutput,
_CONFIG_FOR_DOC,
)
class Flax{{cookiecutter.camelcase_modelname}}ForMultipleChoiceModule(nn.Module):
config: {{cookiecutter.camelcase_modelname}}Config
dtype: jnp.dtype = jnp.float32
gradient_checkpointing: bool = False
def setup(self):
self.{{cookiecutter.lowercase_modelname}} = Flax{{cookiecutter.camelcase_modelname}}Module(config=self.config, dtype=self.dtype, gradient_checkpointing=self.gradient_checkpointing)
self.dropout = nn.Dropout(rate=self.config.hidden_dropout_prob)
self.classifier = nn.Dense(1, dtype=self.dtype)
def __call__(
self,
input_ids,
attention_mask,
token_type_ids,
position_ids,
head_mask,
deterministic: bool = True,
output_attentions: bool = False,
output_hidden_states: bool = False,
return_dict: bool = True,
):
num_choices = input_ids.shape[1]
input_ids = input_ids.reshape(-1, input_ids.shape[-1]) if input_ids is not None else None
attention_mask = attention_mask.reshape(-1, attention_mask.shape[-1]) if attention_mask is not None else None
token_type_ids = token_type_ids.reshape(-1, token_type_ids.shape[-1]) if token_type_ids is not None else None
position_ids = position_ids.reshape(-1, position_ids.shape[-1]) if position_ids is not None else None
# Model
outputs = self.{{cookiecutter.lowercase_modelname}}(
input_ids,
attention_mask,
token_type_ids,
position_ids,
head_mask,
deterministic=deterministic,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
pooled_output = outputs[1]
pooled_output = self.dropout(pooled_output, deterministic=deterministic)
logits = self.classifier(pooled_output)
reshaped_logits = logits.reshape(-1, num_choices)
if not return_dict:
return (reshaped_logits,) + outputs[2:]
return FlaxMultipleChoiceModelOutput(
logits=reshaped_logits,
hidden_states=outputs.hidden_states,
attentions=outputs.attentions,
)
@add_start_docstrings(
"""
{{cookiecutter.camelcase_modelname}} Model with a multiple choice classification head on top (a linear layer on top of the pooled output and a
softmax) e.g. for RocStories/SWAG tasks.
""",
{{cookiecutter.uppercase_modelname}}_START_DOCSTRING,
)
class Flax{{cookiecutter.camelcase_modelname}}ForMultipleChoice(Flax{{cookiecutter.camelcase_modelname}}PreTrainedModel):
module_class = Flax{{cookiecutter.camelcase_modelname}}ForMultipleChoiceModule
overwrite_call_docstring(
Flax{{cookiecutter.camelcase_modelname}}ForMultipleChoice, {{cookiecutter.uppercase_modelname}}_INPUTS_DOCSTRING.format("batch_size, num_choices, sequence_length")
)
append_call_sample_docstring(
Flax{{cookiecutter.camelcase_modelname}}ForMultipleChoice, _TOKENIZER_FOR_DOC, _CHECKPOINT_FOR_DOC, FlaxMultipleChoiceModelOutput, _CONFIG_FOR_DOC
)
class Flax{{cookiecutter.camelcase_modelname}}ForTokenClassificationModule(nn.Module):
config: {{cookiecutter.camelcase_modelname}}Config
dtype: jnp.dtype = jnp.float32
gradient_checkpointing: bool = False
def setup(self):
self.{{cookiecutter.lowercase_modelname}} = Flax{{cookiecutter.camelcase_modelname}}Module(config=self.config, dtype=self.dtype, add_pooling_layer=False, gradient_checkpointing=self.gradient_checkpointing)
self.dropout = nn.Dropout(rate=self.config.hidden_dropout_prob)
self.classifier = nn.Dense(self.config.num_labels, dtype=self.dtype)
def __call__(
self,
input_ids,
attention_mask,
token_type_ids,
position_ids,
head_mask,
deterministic: bool = True,
output_attentions: bool = False,
output_hidden_states: bool = False,
return_dict: bool = True,
):
# Model
outputs = self.{{cookiecutter.lowercase_modelname}}(
input_ids,
attention_mask,
token_type_ids,
position_ids,
head_mask,
deterministic=deterministic,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
hidden_states = outputs[0]
hidden_states = self.dropout(hidden_states, deterministic=deterministic)
logits = self.classifier(hidden_states)
if not return_dict:
return (logits,) + outputs[1:]
return FlaxTokenClassifierOutput(
logits=logits,
hidden_states=outputs.hidden_states,
attentions=outputs.attentions,
)
@add_start_docstrings(
"""
{{cookiecutter.camelcase_modelname}} Model with a token classification head on top (a linear layer on top of the hidden-states output) e.g. for
Named-Entity-Recognition (NER) tasks.
""",
{{cookiecutter.uppercase_modelname}}_START_DOCSTRING,
)
class Flax{{cookiecutter.camelcase_modelname}}ForTokenClassification(Flax{{cookiecutter.camelcase_modelname}}PreTrainedModel):
module_class = Flax{{cookiecutter.camelcase_modelname}}ForTokenClassificationModule
append_call_sample_docstring(
Flax{{cookiecutter.camelcase_modelname}}ForTokenClassification, _TOKENIZER_FOR_DOC, _CHECKPOINT_FOR_DOC, FlaxTokenClassifierOutput, _CONFIG_FOR_DOC
)
class Flax{{cookiecutter.camelcase_modelname}}ForQuestionAnsweringModule(nn.Module):
config: {{cookiecutter.camelcase_modelname}}Config
dtype: jnp.dtype = jnp.float32
gradient_checkpointing: bool = False
def setup(self):
self.{{cookiecutter.lowercase_modelname}} = Flax{{cookiecutter.camelcase_modelname}}Module(config=self.config, dtype=self.dtype, add_pooling_layer=False, gradient_checkpointing=self.gradient_checkpointing)
self.qa_outputs = nn.Dense(self.config.num_labels, dtype=self.dtype)
def __call__(
self,
input_ids,
attention_mask,
token_type_ids,
position_ids,
head_mask,
deterministic: bool = True,
output_attentions: bool = False,
output_hidden_states: bool = False,
return_dict: bool = True,
):
# Model
outputs = self.{{cookiecutter.lowercase_modelname}}(
input_ids,
attention_mask,
token_type_ids,
position_ids,
head_mask,
deterministic=deterministic,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
hidden_states = outputs[0]
logits = self.qa_outputs(hidden_states)
start_logits, end_logits = logits.split(self.config.num_labels, axis=-1)
start_logits = start_logits.squeeze(-1)
end_logits = end_logits.squeeze(-1)
if not return_dict:
return (start_logits, end_logits) + outputs[1:]
return FlaxQuestionAnsweringModelOutput(
start_logits=start_logits,
end_logits=end_logits,
hidden_states=outputs.hidden_states,
attentions=outputs.attentions,
)
@add_start_docstrings(
"""
{{cookiecutter.camelcase_modelname}} Model with a span classification head on top for extractive question-answering tasks like SQuAD (a linear
layers on top of the hidden-states output to compute `span start logits` and `span end logits`).
""",
{{cookiecutter.uppercase_modelname}}_START_DOCSTRING,
)
class Flax{{cookiecutter.camelcase_modelname}}ForQuestionAnswering(Flax{{cookiecutter.camelcase_modelname}}PreTrainedModel):
module_class = Flax{{cookiecutter.camelcase_modelname}}ForQuestionAnsweringModule
append_call_sample_docstring(
Flax{{cookiecutter.camelcase_modelname}}ForQuestionAnswering,
_TOKENIZER_FOR_DOC,
_CHECKPOINT_FOR_DOC,
FlaxQuestionAnsweringModelOutput,
_CONFIG_FOR_DOC,
)
class Flax{{cookiecutter.camelcase_modelname}}ForCausalLMModule(nn.Module):
config: {{cookiecutter.camelcase_modelname}}Config
dtype: jnp.dtype = jnp.float32
gradient_checkpointing: bool = False
def setup(self):
self.{{cookiecutter.lowercase_modelname}} = Flax{{cookiecutter.camelcase_modelname}}Module(config=self.config, add_pooling_layer=False, dtype=self.dtype, gradient_checkpointing=self.gradient_checkpointing)
self.cls = Flax{{cookiecutter.camelcase_modelname}}OnlyMLMHead(config=self.config, dtype=self.dtype)
def __call__(
self,
input_ids,
attention_mask,
position_ids,
token_type_ids: Optional[jnp.ndarray] = None,
head_mask: Optional[jnp.ndarray] = None,
encoder_hidden_states: Optional[jnp.ndarray] = None,
encoder_attention_mask: Optional[jnp.ndarray] = None,
init_cache: bool = False,
deterministic: bool = True,
output_attentions: bool = False,
output_hidden_states: bool = False,
return_dict: bool = True,
):
# Model
outputs = self.{{cookiecutter.lowercase_modelname}}(
input_ids,
attention_mask,
token_type_ids,
position_ids,
head_mask,
encoder_hidden_states=encoder_hidden_states,
encoder_attention_mask=encoder_attention_mask,
init_cache=init_cache,
deterministic=deterministic,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
hidden_states = outputs[0]
if self.config.tie_word_embeddings:
shared_embedding = self.{{cookiecutter.lowercase_modelname}}.variables["params"]["embeddings"]["word_embeddings"]["embedding"]
else:
shared_embedding = None
# Compute the prediction scores
logits = self.cls(hidden_states, shared_embedding=shared_embedding)
if not return_dict:
return (logits,) + outputs[1:]
return FlaxCausalLMOutputWithCrossAttentions(
logits=logits,
hidden_states=outputs.hidden_states,
attentions=outputs.attentions,
cross_attentions=outputs.cross_attentions,
)
@add_start_docstrings(
"""
{{cookiecutter.camelcase_modelname}} Model with a language modeling head on top (a linear layer on top of the hidden-states output) e.g for
autoregressive tasks.
""",
{{cookiecutter.uppercase_modelname}}_START_DOCSTRING,
)
class Flax{{cookiecutter.camelcase_modelname}}ForCausalLM(Flax{{cookiecutter.camelcase_modelname}}PreTrainedModel):
module_class = Flax{{cookiecutter.camelcase_modelname}}ForCausalLMModule
def prepare_inputs_for_generation(self, input_ids, max_length, attention_mask: Optional[jnp.DeviceArray] = None):
# initializing the cache
batch_size, seq_length = input_ids.shape
past_key_values = self.init_cache(batch_size, max_length)
# Note that usually one would have to put 0's in the attention_mask for x > input_ids.shape[-1] and x < cache_length.
# But since the decoder uses a causal mask, those positions are masked anyway.
# Thus, we can create a single static attention_mask here, which is more efficient for compilation
extended_attention_mask = jnp.ones((batch_size, max_length), dtype="i4")
if attention_mask is not None:
position_ids = attention_mask.cumsum(axis=-1) - 1
extended_attention_mask = lax.dynamic_update_slice(extended_attention_mask, attention_mask, (0, 0))
else:
position_ids = jnp.broadcast_to(jnp.arange(seq_length, dtype="i4")[None, :], (batch_size, seq_length))
return {
"past_key_values": past_key_values,
"attention_mask": extended_attention_mask,
"position_ids": position_ids,
}
def update_inputs_for_generation(self, model_outputs, model_kwargs):
model_kwargs["past_key_values"] = model_outputs.past_key_values
model_kwargs["position_ids"] = model_kwargs["position_ids"][:, -1:] + 1
return model_kwargs
append_call_sample_docstring(
Flax{{cookiecutter.camelcase_modelname}}ForCausalLM,
_TOKENIZER_FOR_DOC,
_CHECKPOINT_FOR_DOC,
FlaxCausalLMOutputWithCrossAttentions,
_CONFIG_FOR_DOC,
)
{# encoder_decoder #}
{% else %}
import math
import random
from functools import partial
from typing import Callable, Optional, Tuple
import flax.linen as nn
import jax
import jax.numpy as jnp
from flax.core.frozen_dict import FrozenDict, unfreeze, freeze
from flax.linen import combine_masks, make_causal_mask
from flax.linen.attention import dot_product_attention_weights
from flax.traverse_util import flatten_dict, unflatten_dict
from jax import lax
from jax.random import PRNGKey
from ...utils import add_start_docstrings, replace_return_docstrings
from ...modeling_flax_outputs import (
FlaxBaseModelOutput,
FlaxBaseModelOutputWithPastAndCrossAttentions,
FlaxCausalLMOutputWithCrossAttentions,
FlaxSeq2SeqLMOutput,
FlaxSeq2SeqModelOutput,
FlaxSeq2SeqQuestionAnsweringModelOutput,
FlaxSeq2SeqSequenceClassifierOutput,
)
from ...modeling_flax_utils import (
ACT2FN,
FlaxPreTrainedModel,
append_call_sample_docstring,
append_replace_return_docstrings,
overwrite_call_docstring,
)
from ...utils import logging
from .configuration_{{cookiecutter.lowercase_modelname}} import {{cookiecutter.camelcase_modelname}}Config
logger = logging.get_logger(__name__)
_CHECKPOINT_FOR_DOC = "{{cookiecutter.checkpoint_identifier}}"
_CONFIG_FOR_DOC = "{{cookiecutter.camelcase_modelname}}Config"
_TOKENIZER_FOR_DOC = "{{cookiecutter.camelcase_modelname}}Tokenizer"
{{cookiecutter.uppercase_modelname}}_START_DOCSTRING = r"""
This model inherits from [`FlaxPreTrainedModel`]. Check the superclass documentation for the
generic methods the library implements for all its model (such as downloading or saving, resizing the input
embeddings, pruning heads etc.)
This model is also a Flax Linen [flax.nn.Module](https://flax.readthedocs.io/en/latest/_autosummary/flax.nn.module.html) subclass. Use it as a regular Flax
Module and refer to the Flax documentation for all matter related to general usage and behavior.
Finally, this model supports inherent JAX features such as:
- [Just-In-Time (JIT) compilation](https://jax.readthedocs.io/en/latest/jax.html#just-in-time-compilation-jit)
- [Automatic Differentiation](https://jax.readthedocs.io/en/latest/jax.html#automatic-differentiation)
- [Vectorization](https://jax.readthedocs.io/en/latest/jax.html#vectorization-vmap)
- [Parallelization](https://jax.readthedocs.io/en/latest/jax.html#parallelization-pmap)
Parameters:
config ([`~{{cookiecutter.camelcase_modelname}}Config`]): Model configuration class with all the parameters of the model.
Initializing with a config file does not load the weights associated with the model, only the
configuration. Check out the [`~FlaxPreTrainedModel.from_pretrained`] method to load the
model weights.
dtype (`jax.numpy.dtype`, *optional*, defaults to `jax.numpy.float32`):
The data type of the computation. Can be one of `jax.numpy.float32`, `jax.numpy.float16` (on
GPUs) and `jax.numpy.bfloat16` (on TPUs).
This can be used to enable mixed-precision training or half-precision inference on GPUs or TPUs. If
specified all the computation will be performed with the given `dtype`.
**Note that this only specifies the dtype of the computation and does not influence the dtype of model
parameters.**
If you wish to change the dtype of the model parameters, see
[`~FlaxPreTrainedModel.to_fp16`] and [`~FlaxPreTrainedModel.to_bf16`].
"""
{{cookiecutter.uppercase_modelname}}_INPUTS_DOCSTRING = r"""
Args:
input_ids (`jnp.ndarray` of shape `(batch_size, sequence_length)`):
Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you provide
it.
Indices can be obtained using [`~{{cookiecutter.camelcase_modelname}}Tokenizer`]. See
[`PreTrainedTokenizer.encode`] and [`PreTrainedTokenizer.__call__`] for
details.
[What are input IDs?](../glossary#input-ids)
attention_mask (`jnp.ndarray` of shape `(batch_size, sequence_length)`, *optional*):
Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
- 1 for tokens that are **not masked**,
- 0 for tokens that are **masked**.
[What are attention masks?](../glossary#attention-mask)
decoder_input_ids (`jnp.ndarray` of shape `(batch_size, target_sequence_length)`, *optional*):
Indices of decoder input sequence tokens in the vocabulary.
Indices can be obtained using [`~{{cookiecutter.camelcase_modelname}}Tokenizer`]. See
[`PreTrainedTokenizer.encode`] and [`PreTrainedTokenizer.__call__`] for
details.
[What are decoder input IDs?](../glossary#decoder-input-ids)
For translation and summarization training, `decoder_input_ids` should be provided. If no
`decoder_input_ids` is provided, the model will create this tensor by shifting the `input_ids` to
the right for denoising pre-training following the paper.
decoder_attention_mask (`jnp.ndarray` of shape `(batch_size, target_sequence_length)`, *optional*):
Default behavior: generate a tensor that ignores pad tokens in `decoder_input_ids`. Causal mask will
also be used by default.
If you want to change padding behavior, you should modify to your needs. See diagram 1 in [the paper](https://arxiv.org/abs/1910.13461) for more information on the default strategy.
position_ids (`numpy.ndarray` of shape `(batch_size, sequence_length)`, *optional*):
Indices of positions of each input sequence tokens in the position embeddings. Selected in the range `[0, config.max_position_embeddings - 1]`.
decoder_position_ids (`numpy.ndarray` of shape `(batch_size, sequence_length)`, *optional*):
Indices of positions of each decoder input sequence tokens in the position embeddings. Selected in the
range `[0, config.max_position_embeddings - 1]`.
output_attentions (`bool`, *optional*):
Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
tensors for more detail.
output_hidden_states (`bool`, *optional*):
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
more detail.
return_dict (`bool`, *optional*):
Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
"""
{{cookiecutter.uppercase_modelname}}_ENCODE_INPUTS_DOCSTRING = r"""
Args:
input_ids (`jnp.ndarray` of shape `(batch_size, sequence_length)`):
Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you provide
it.
Indices can be obtained using [`~{{cookiecutter.camelcase_modelname}}Tokenizer`]. See
[`PreTrainedTokenizer.encode`] and [`PreTrainedTokenizer.__call__`] for
details.
[What are input IDs?](../glossary#input-ids)
attention_mask (`jnp.ndarray` of shape `(batch_size, sequence_length)`, *optional*):
Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
- 1 for tokens that are **not masked**,
- 0 for tokens that are **masked**.
[What are attention masks?](../glossary#attention-mask)
position_ids (`numpy.ndarray` of shape `(batch_size, sequence_length)`, *optional*):
Indices of positions of each input sequence tokens in the position embeddings. Selected in the range `[0, config.max_position_embeddings - 1]`.
output_attentions (`bool`, *optional*):
Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
tensors for more detail.
output_hidden_states (`bool`, *optional*):
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
more detail.
return_dict (`bool`, *optional*):
Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
"""
{{cookiecutter.uppercase_modelname}}_DECODE_INPUTS_DOCSTRING = r"""
Args:
decoder_input_ids (`jnp.ndarray` of shape `(batch_size, target_sequence_length)`):
Indices of decoder input sequence tokens in the vocabulary.
Indices can be obtained using [`~{{cookiecutter.camelcase_modelname}}Tokenizer`]. See
[`PreTrainedTokenizer.encode`] and [`PreTrainedTokenizer.__call__`] for
details.
[What are decoder input IDs?](../glossary#decoder-input-ids)
For translation and summarization training, `decoder_input_ids` should be provided. If no
`decoder_input_ids` is provided, the model will create this tensor by shifting the `input_ids` to
the right for denoising pre-training following the paper.
encoder_outputs (`tuple(tuple(jnp.ndarray)`):
Tuple consists of (`last_hidden_state`, *optional*: `hidden_states`, *optional*:
`attentions`) `last_hidden_state` of shape `(batch_size, sequence_length, hidden_size)`,
*optional*) is a sequence of hidden-states at the output of the last layer of the encoder. Used in the
cross-attention of the decoder.
encoder_attention_mask (`jnp.ndarray` of shape `(batch_size, sequence_length)`, *optional*):
Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
- 1 for tokens that are **not masked**,
- 0 for tokens that are **masked**.
[What are attention masks?](../glossary#attention-mask)
decoder_attention_mask (`jnp.ndarray` of shape `(batch_size, target_sequence_length)`, *optional*):
Default behavior: generate a tensor that ignores pad tokens in `decoder_input_ids`. Causal mask will
also be used by default.
If you want to change padding behavior, you should modify to your needs. See diagram 1 in [the paper](https://arxiv.org/abs/1910.13461) for more information on the default strategy.
decoder_position_ids (`numpy.ndarray` of shape `(batch_size, sequence_length)`, *optional*):
Indices of positions of each decoder input sequence tokens in the position embeddings. Selected in the
range `[0, config.max_position_embeddings - 1]`.
past_key_values (`Dict[str, np.ndarray]`, *optional*, returned by `init_cache` or when passing previous `past_key_values`):
Dictionary of pre-computed hidden-states (key and values in the attention blocks) that can be used for fast
auto-regressive decoding. Pre-computed key and value hidden-states are of shape *[batch_size, max_length]*.
output_attentions (`bool`, *optional*):
Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
tensors for more detail.
output_hidden_states (`bool`, *optional*):
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
more detail.
return_dict (`bool`, *optional*):
Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
"""
def shift_tokens_right(input_ids: jnp.ndarray, pad_token_id: int, decoder_start_token_id: int) -> jnp.ndarray:
"""
Shift input ids one token to the right.
"""
shifted_input_ids = jnp.roll(input_ids, 1, axis=-1)
shifted_input_ids = shifted_input_ids.at[(..., 0)].set(decoder_start_token_id)
# replace possible -100 values in labels by `pad_token_id`
shifted_input_ids = jnp.where(shifted_input_ids == -100, pad_token_id, shifted_input_ids)
return shifted_input_ids
class Flax{{cookiecutter.camelcase_modelname}}Attention(nn.Module):
config: {{cookiecutter.camelcase_modelname}}Config
embed_dim: int
num_heads: int
dropout: float = 0.0
causal: bool = False
bias: bool = True
dtype: jnp.dtype = jnp.float32 # the dtype of the computation
def setup(self) -> None:
self.head_dim = self.embed_dim // self.num_heads
assert (
self.head_dim * self.num_heads == self.embed_dim
), f"embed_dim must be divisible by num_heads (got `embed_dim`: {self.embed_dim} and `num_heads`: {self.num_heads})."
dense = partial(
nn.Dense,
self.embed_dim,
use_bias=self.bias,
dtype=self.dtype,
kernel_init=jax.nn.initializers.normal(self.config.init_std),
)
self.q_proj, self.k_proj, self.v_proj = dense(), dense(), dense()
self.out_proj = dense()
self.dropout_layer = nn.Dropout(rate=self.dropout)
if self.causal:
self.causal_mask = make_causal_mask(
jnp.ones((1, self.config.max_position_embeddings), dtype="bool"), dtype="bool"
)
def _split_heads(self, hidden_states):
return hidden_states.reshape(hidden_states.shape[:2] + (self.num_heads, self.head_dim))
def _merge_heads(self, hidden_states):
return hidden_states.reshape(hidden_states.shape[:2] + (self.embed_dim,))
@nn.compact
def _concatenate_to_cache(self, key, value, query, attention_mask):
"""
This function takes projected key, value states from a single input token and concatenates the states to cached
states from previous steps. This function is slighly adapted from the official Flax repository:
https://github.com/google/flax/blob/491ce18759622506588784b4fca0e4bf05f8c8cd/flax/linen/attention.py#L252
"""
# detect if we're initializing by absence of existing cache data.
is_initialized = self.has_variable("cache", "cached_key")
cached_key = self.variable("cache", "cached_key", jnp.zeros, key.shape, key.dtype)
cached_value = self.variable("cache", "cached_value", jnp.zeros, value.shape, value.dtype)
cache_index = self.variable("cache", "cache_index", lambda: jnp.array(0, dtype=jnp.int32))
if is_initialized:
*batch_dims, max_length, num_heads, depth_per_head = cached_key.value.shape
# update key, value caches with our new 1d spatial slices
cur_index = cache_index.value
indices = (0,) * len(batch_dims) + (cur_index, 0, 0)
key = lax.dynamic_update_slice(cached_key.value, key, indices)
value = lax.dynamic_update_slice(cached_value.value, value, indices)
cached_key.value = key
cached_value.value = value
num_updated_cache_vectors = query.shape[1]
cache_index.value = cache_index.value + num_updated_cache_vectors
# causal mask for cached decoder self-attention: our single query position should only attend to those key positions that have already been generated and cached, not the remaining zero elements.
pad_mask = jnp.broadcast_to(
jnp.arange(max_length) < cur_index + num_updated_cache_vectors,
tuple(batch_dims) + (1, num_updated_cache_vectors, max_length),
)
attention_mask = combine_masks(pad_mask, attention_mask)
return key, value, attention_mask
def __call__(
self,
hidden_states: jnp.ndarray,
key_value_states: Optional[jnp.ndarray] = None,
attention_mask: Optional[jnp.ndarray] = None,
init_cache: bool = False,
deterministic: bool = True,
) -> Tuple[jnp.ndarray]:
"""Input shape: Batch x Time x Channel"""
# if key_value_states are provided this layer is used as a cross-attention layer
# for the decoder
is_cross_attention = key_value_states is not None
batch_size = hidden_states.shape[0]
# get query proj
query_states = self.q_proj(hidden_states)
# get key, value proj
if is_cross_attention:
# cross_attentions
key_states = self.k_proj(key_value_states)
value_states = self.v_proj(key_value_states)
else:
# self_attention
key_states = self.k_proj(hidden_states)
value_states = self.v_proj(hidden_states)
query_states = self._split_heads(query_states)
key_states = self._split_heads(key_states)
value_states = self._split_heads(value_states)
# handle cache prepare causal attention mask
if self.causal:
query_length, key_length = query_states.shape[1], key_states.shape[1]
if self.has_variable("cache", "cached_key"):
mask_shift = self.variables["cache"]["cache_index"]
max_decoder_length = self.variables["cache"]["cached_key"].shape[1]
causal_mask = lax.dynamic_slice(
self.causal_mask, (0, 0, mask_shift, 0), (1, 1, query_length, max_decoder_length)
)
else:
causal_mask = self.causal_mask[:, :, :query_length, :key_length]
causal_mask = jnp.broadcast_to(causal_mask, (batch_size,) + causal_mask.shape[1:])
# combine masks if needed
if attention_mask is not None and self.causal:
attention_mask = jnp.broadcast_to(jnp.expand_dims(attention_mask, axis=(-3, -2)), causal_mask.shape)
attention_mask = combine_masks(attention_mask, causal_mask)
elif self.causal:
attention_mask = causal_mask
elif attention_mask is not None:
attention_mask = jnp.expand_dims(attention_mask, axis=(-3, -2))
# During fast autoregressive decoding, we feed one position at a time,
# and cache the keys and values step by step.
if self.causal and (self.has_variable("cache", "cached_key") or init_cache):
key_states, value_states, attention_mask = self._concatenate_to_cache(
key_states, value_states, query_states, attention_mask
)
# Convert the boolean attention mask to an attention bias.
if attention_mask is not None:
# attention mask in the form of attention bias
attention_bias = lax.select(
attention_mask > 0,
jnp.full(attention_mask.shape, 0.0).astype(self.dtype),
jnp.full(attention_mask.shape, jnp.finfo(self.dtype).min).astype(self.dtype),
)
else:
attention_bias = None
dropout_rng = None
if not deterministic and self.dropout > 0.0:
dropout_rng = self.make_rng("dropout")
attn_weights = dot_product_attention_weights(
query_states,
key_states,
bias=attention_bias,
dropout_rng=dropout_rng,
dropout_rate=self.dropout,
broadcast_dropout=True,
deterministic=deterministic,
dtype=self.dtype,
precision=None,
)
attn_output = jnp.einsum("...hqk,...khd->...qhd", attn_weights, value_states)
attn_output = self._merge_heads(attn_output)
attn_output = self.out_proj(attn_output)
return attn_output, attn_weights
class Flax{{cookiecutter.camelcase_modelname}}EncoderLayer(nn.Module):
config: {{cookiecutter.camelcase_modelname}}Config
dtype: jnp.dtype = jnp.float32
def setup(self) -> None:
self.embed_dim = self.config.d_model
self.self_attn = Flax{{cookiecutter.camelcase_modelname}}Attention(
config=self.config,
embed_dim=self.embed_dim,
num_heads=self.config.encoder_attention_heads,
dropout=self.config.attention_dropout,
dtype=self.dtype
)
self.self_attn_layer_norm = nn.LayerNorm(dtype=self.dtype)
self.dropout_layer = nn.Dropout(rate=self.config.dropout)
self.activation_fn = ACT2FN[self.config.activation_function]
self.activation_dropout_layer = nn.Dropout(rate=self.config.activation_dropout)
self.fc1 = nn.Dense(
self.config.encoder_ffn_dim,
dtype=self.dtype,
kernel_init=jax.nn.initializers.normal(self.config.init_std),
)
self.fc2 = nn.Dense(
self.embed_dim, dtype=self.dtype, kernel_init=jax.nn.initializers.normal(self.config.init_std)
)
self.final_layer_norm = nn.LayerNorm(dtype=self.dtype)
def __call__(
self,
hidden_states: jnp.ndarray,
attention_mask: jnp.ndarray,
output_attentions: bool = True,
deterministic: bool = True,
) -> Tuple[jnp.ndarray]:
residual = hidden_states
hidden_states, attn_weights = self.self_attn(hidden_states=hidden_states, attention_mask=attention_mask)
hidden_states = self.dropout_layer(hidden_states, deterministic=deterministic)
hidden_states = residual + hidden_states
hidden_states = self.self_attn_layer_norm(hidden_states)
residual = hidden_states
hidden_states = self.activation_fn(self.fc1(hidden_states))
hidden_states = self.activation_dropout_layer(hidden_states, deterministic=deterministic)
hidden_states = self.fc2(hidden_states)
hidden_states = self.dropout_layer(hidden_states, deterministic=deterministic)
hidden_states = residual + hidden_states
hidden_states = self.final_layer_norm(hidden_states)
outputs = (hidden_states,)
if output_attentions:
outputs += (attn_weights,)
return outputs
class Flax{{cookiecutter.camelcase_modelname}}EncoderLayerCollection(nn.Module):
config: {{cookiecutter.camelcase_modelname}}Config
dtype: jnp.dtype = jnp.float32 # the dtype of the computation
def setup(self):
self.layers = [
Flax{{cookiecutter.camelcase_modelname}}EncoderLayer(self.config, name=str(i), dtype=self.dtype) for i in range(self.config.encoder_layers)
]
self.layerdrop = self.config.encoder_layerdrop
def __call__(
self,
hidden_states,
attention_mask,
deterministic: bool = True,
output_attentions: bool = False,
output_hidden_states: bool = False,
return_dict: bool = True,
):
all_attentions = () if output_attentions else None
all_hidden_states = () if output_hidden_states else None
for encoder_layer in self.layers:
if output_hidden_states:
all_hidden_states = all_hidden_states + (hidden_states,)
# add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
dropout_probability = random.uniform(0, 1)
if not deterministic and (dropout_probability < self.layerdrop): # skip the layer
layer_outputs = (None, None)
else:
layer_outputs = encoder_layer(
hidden_states,
attention_mask,
output_attentions,
deterministic,
)
hidden_states = layer_outputs[0]
if output_attentions:
all_attentions = all_attentions + (layer_outputs[1],)
if output_hidden_states:
all_hidden_states += (hidden_states,)
outputs = (hidden_states, all_hidden_states, all_attentions)
if not return_dict:
return tuple(v for v in outputs if v is not None)
return FlaxBaseModelOutput(
last_hidden_state=hidden_states, hidden_states=all_hidden_states, attentions=all_attentions
)
class Flax{{cookiecutter.camelcase_modelname}}DecoderLayer(nn.Module):
config: {{cookiecutter.camelcase_modelname}}Config
dtype: jnp.dtype = jnp.float32
def setup(self) -> None:
self.embed_dim = self.config.d_model
self.self_attn = Flax{{cookiecutter.camelcase_modelname}}Attention(
config=self.config,
embed_dim=self.embed_dim,
num_heads=self.config.decoder_attention_heads,
dropout=self.config.attention_dropout,
causal=True,
dtype=self.dtype,
)
self.dropout_layer = nn.Dropout(rate=self.config.dropout)
self.activation_fn = ACT2FN[self.config.activation_function]
self.activation_dropout_layer = nn.Dropout(rate=self.config.activation_dropout)
self.self_attn_layer_norm = nn.LayerNorm(dtype=self.dtype)
self.encoder_attn = Flax{{cookiecutter.camelcase_modelname}}Attention(
config=self.config,
embed_dim=self.embed_dim,
num_heads=self.config.decoder_attention_heads,
dropout=self.config.attention_dropout,
dtype=self.dtype,
)
self.encoder_attn_layer_norm = nn.LayerNorm(dtype=self.dtype)
self.fc1 = nn.Dense(
self.config.decoder_ffn_dim,
dtype=self.dtype,
kernel_init=jax.nn.initializers.normal(self.config.init_std),
)
self.fc2 = nn.Dense(
self.embed_dim, dtype=self.dtype, kernel_init=jax.nn.initializers.normal(self.config.init_std)
)
self.final_layer_norm = nn.LayerNorm(dtype=self.dtype)
def __call__(
self,
hidden_states: jnp.ndarray,
attention_mask: jnp.ndarray,
encoder_hidden_states: Optional[jnp.ndarray] = None,
encoder_attention_mask: Optional[jnp.ndarray] = None,
init_cache: bool = False,
output_attentions: bool = True,
deterministic: bool = True,
) -> Tuple[jnp.ndarray]:
residual = hidden_states
# Self Attention
hidden_states, self_attn_weights = self.self_attn(
hidden_states=hidden_states, attention_mask=attention_mask, init_cache=init_cache
)
hidden_states = self.dropout_layer(hidden_states, deterministic=deterministic)
hidden_states = residual + hidden_states
hidden_states = self.self_attn_layer_norm(hidden_states)
# Cross-Attention Block
cross_attn_weights = None
if encoder_hidden_states is not None:
residual = hidden_states
hidden_states, cross_attn_weights = self.encoder_attn(
hidden_states=hidden_states,
key_value_states=encoder_hidden_states,
attention_mask=encoder_attention_mask,
)
hidden_states = self.dropout_layer(hidden_states, deterministic=deterministic)
hidden_states = residual + hidden_states
hidden_states = self.encoder_attn_layer_norm(hidden_states)
# Fully Connected
residual = hidden_states
hidden_states = self.activation_fn(self.fc1(hidden_states))
hidden_states = self.activation_dropout_layer(hidden_states, deterministic=deterministic)
hidden_states = self.fc2(hidden_states)
hidden_states = self.dropout_layer(hidden_states, deterministic=deterministic)
hidden_states = residual + hidden_states
hidden_states = self.final_layer_norm(hidden_states)
outputs = (hidden_states,)
if output_attentions:
outputs += (self_attn_weights, cross_attn_weights)
return outputs
class Flax{{cookiecutter.camelcase_modelname}}DecoderLayerCollection(nn.Module):
config: {{cookiecutter.camelcase_modelname}}Config
dtype: jnp.dtype = jnp.float32 # the dtype of the computation
def setup(self):
self.layers = [
Flax{{cookiecutter.camelcase_modelname}}DecoderLayer(self.config, name=str(i), dtype=self.dtype) for i in range(self.config.decoder_layers)
]
self.layerdrop = self.config.decoder_layerdrop
def __call__(
self,
hidden_states,
attention_mask,
encoder_hidden_states: Optional[jnp.ndarray] = None,
encoder_attention_mask: Optional[jnp.ndarray] = None,
deterministic: bool = True,
init_cache: bool = False,
output_attentions: bool = False,
output_hidden_states: bool = False,
return_dict: bool = True,
):
# decoder layers
all_hidden_states = () if output_hidden_states else None
all_self_attns = () if output_attentions else None
all_cross_attentions = () if (output_attentions and encoder_hidden_states is not None) else None
for decoder_layer in self.layers:
if output_hidden_states:
all_hidden_states += (hidden_states,)
# add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
dropout_probability = random.uniform(0, 1)
if not deterministic and (dropout_probability < self.layerdrop):
layer_outputs = (None, None, None)
else:
layer_outputs = decoder_layer(
hidden_states,
attention_mask=attention_mask,
encoder_hidden_states=encoder_hidden_states,
encoder_attention_mask=encoder_attention_mask,
init_cache=init_cache,
output_attentions=output_attentions,
deterministic=deterministic,
)
hidden_states = layer_outputs[0]
if output_attentions:
all_self_attns += (layer_outputs[1],)
if encoder_hidden_states is not None:
all_cross_attentions += (layer_outputs[2],)
# add hidden states from the last decoder layer
if output_hidden_states:
all_hidden_states += (hidden_states,)
outputs = [hidden_states, all_hidden_states, all_self_attns, all_cross_attentions]
if not return_dict:
return tuple(v for v in outputs if v is not None)
return FlaxBaseModelOutputWithPastAndCrossAttentions(
last_hidden_state=hidden_states,
hidden_states=all_hidden_states,
attentions=all_self_attns,
cross_attentions=all_cross_attentions,
)
class Flax{{cookiecutter.camelcase_modelname}}ClassificationHead(nn.Module):
"""Head for sentence-level classification tasks."""
config: {{cookiecutter.camelcase_modelname}}Config
inner_dim: int
num_classes: int
pooler_dropout: float
dtype: jnp.dtype = jnp.float32
def setup(self):
self.dense = nn.Dense(
self.inner_dim, dtype=self.dtype, kernel_init=jax.nn.initializers.normal(self.config.init_std)
)
self.dropout = nn.Dropout(rate=self.pooler_dropout)
self.out_proj = nn.Dense(
self.num_classes,
dtype=self.dtype,
kernel_init=jax.nn.initializers.normal(self.config.init_std),
)
def __call__(self, hidden_states: jnp.ndarray, deterministic: bool):
hidden_states = self.dropout(hidden_states, deterministic=deterministic)
hidden_states = self.dense(hidden_states)
hidden_states = jnp.tanh(hidden_states)
hidden_states = self.dropout(hidden_states, deterministic=deterministic)
hidden_states = self.out_proj(hidden_states)
return hidden_states
class Flax{{cookiecutter.camelcase_modelname}}Encoder(nn.Module):
config: {{cookiecutter.camelcase_modelname}}Config
dtype: jnp.dtype = jnp.float32 # the dtype of the computation
embed_tokens: Optional[nn.Embed] = None
def setup(self):
self.dropout_layer = nn.Dropout(rate=self.config.dropout)
embed_dim = self.config.d_model
self.padding_idx = self.config.pad_token_id
self.max_source_positions = self.config.max_position_embeddings
self.embed_scale = math.sqrt(embed_dim) if self.config.scale_embedding else 1.0
if self.embed_tokens is None:
self.embed_tokens = nn.Embed(
self.config.vocab_size,
embed_dim,
embedding_init=jax.nn.initializers.normal(self.config.init_std),
)
# {{cookiecutter.camelcase_modelname}} is set up so that if padding_idx is specified then offset the embedding ids by 2
# and adjust num_embeddings appropriately. Other models don't have this hack
self.offset = 2
self.embed_positions = nn.Embed(
self.config.max_position_embeddings + self.offset,
embed_dim,
embedding_init=jax.nn.initializers.normal(self.config.init_std),
)
self.layers = Flax{{cookiecutter.camelcase_modelname}}EncoderLayerCollection(self.config, self.dtype)
self.layernorm_embedding = nn.LayerNorm(dtype=self.dtype)
def __call__(
self,
input_ids,
attention_mask,
position_ids,
output_attentions: bool = False,
output_hidden_states: bool = False,
return_dict: bool = True,
deterministic: bool = True,
):
input_shape = input_ids.shape
input_ids = input_ids.reshape(-1, input_shape[-1])
inputs_embeds = self.embed_tokens(input_ids) * self.embed_scale
embed_pos = self.embed_positions(position_ids + self.offset)
hidden_states = inputs_embeds + embed_pos
hidden_states = self.layernorm_embedding(hidden_states)
hidden_states = self.dropout_layer(hidden_states, deterministic=deterministic)
outputs = self.layers(
hidden_states,
attention_mask,
deterministic=deterministic,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
if not return_dict:
return outputs
return FlaxBaseModelOutput(
last_hidden_state=outputs.last_hidden_state,
hidden_states=outputs.hidden_states,
attentions=outputs.attentions,
)
class Flax{{cookiecutter.camelcase_modelname}}Decoder(nn.Module):
config: {{cookiecutter.camelcase_modelname}}Config
dtype: jnp.dtype = jnp.float32 # the dtype of the computation
embed_tokens: Optional[nn.Embed] = None
def setup(self):
self.dropout_layer = nn.Dropout(rate=self.config.dropout)
embed_dim = self.config.d_model
self.padding_idx = self.config.pad_token_id
self.max_target_positions = self.config.max_position_embeddings
self.embed_scale = math.sqrt(self.config.d_model) if self.config.scale_embedding else 1.0
if self.embed_tokens is None:
self.embed_tokens = nn.Embed(
self.config.vocab_size,
embed_dim,
embedding_init=jax.nn.initializers.normal(self.config.init_std),
)
# {{cookiecutter.camelcase_modelname}} is set up so that if padding_idx is specified then offset the embedding ids by 2
# and adjust num_embeddings appropriately. Other models don't have this hack
self.offset = 2
self.embed_positions = nn.Embed(
self.config.max_position_embeddings + self.offset,
embed_dim,
embedding_init=jax.nn.initializers.normal(self.config.init_std),
)
self.layers = Flax{{cookiecutter.camelcase_modelname}}DecoderLayerCollection(self.config, self.dtype)
self.layernorm_embedding = nn.LayerNorm(dtype=self.dtype)
def __call__(
self,
input_ids,
attention_mask,
position_ids,
encoder_hidden_states: Optional[jnp.ndarray] = None,
encoder_attention_mask: Optional[jnp.ndarray] = None,
init_cache: bool = False,
output_attentions: bool = False,
output_hidden_states: bool = False,
return_dict: bool = True,
deterministic: bool = True,
):
input_shape = input_ids.shape
input_ids = input_ids.reshape(-1, input_shape[-1])
inputs_embeds = self.embed_tokens(input_ids) * self.embed_scale
# embed positions
positions = self.embed_positions(position_ids + self.offset)
hidden_states = inputs_embeds + positions
hidden_states = self.layernorm_embedding(hidden_states)
hidden_states = self.dropout_layer(hidden_states, deterministic=deterministic)
outputs = self.layers(
hidden_states,
attention_mask,
encoder_hidden_states,
encoder_attention_mask,
deterministic=deterministic,
init_cache=init_cache,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
if not return_dict:
return outputs
return FlaxBaseModelOutputWithPastAndCrossAttentions(
last_hidden_state=outputs.last_hidden_state,
hidden_states=outputs.hidden_states,
attentions=outputs.attentions,
cross_attentions=outputs.cross_attentions,
)
class Flax{{cookiecutter.camelcase_modelname}}Module(nn.Module):
config: {{cookiecutter.camelcase_modelname}}Config
dtype: jnp.dtype = jnp.float32 # the dtype of the computation
def setup(self):
self.shared = nn.Embed(
self.config.vocab_size,
self.config.d_model,
embedding_init=jax.nn.initializers.normal(self.config.init_std),
)
self.encoder = Flax{{cookiecutter.camelcase_modelname}}Encoder(self.config, dtype=self.dtype, embed_tokens=self.shared)
self.decoder = Flax{{cookiecutter.camelcase_modelname}}Decoder(self.config, dtype=self.dtype, embed_tokens=self.shared)
def _get_encoder_module(self):
return self.encoder
def _get_decoder_module(self):
return self.decoder
def __call__(
self,
input_ids,
attention_mask,
decoder_input_ids,
decoder_attention_mask,
position_ids,
decoder_position_ids,
output_attentions: bool = False,
output_hidden_states: bool = False,
return_dict: bool = True,
deterministic: bool = True,
):
encoder_outputs = self.encoder(
input_ids=input_ids,
attention_mask=attention_mask,
position_ids=position_ids,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
deterministic=deterministic,
)
decoder_outputs = self.decoder(
input_ids=decoder_input_ids,
attention_mask=decoder_attention_mask,
position_ids=decoder_position_ids,
encoder_hidden_states=encoder_outputs[0],
encoder_attention_mask=attention_mask,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
deterministic=deterministic,
)
if not return_dict:
return decoder_outputs + encoder_outputs
return FlaxSeq2SeqModelOutput(
last_hidden_state=decoder_outputs.last_hidden_state,
decoder_hidden_states=decoder_outputs.hidden_states,
decoder_attentions=decoder_outputs.attentions,
cross_attentions=decoder_outputs.cross_attentions,
encoder_last_hidden_state=encoder_outputs.last_hidden_state,
encoder_hidden_states=encoder_outputs.hidden_states,
encoder_attentions=encoder_outputs.attentions,
)
class Flax{{cookiecutter.camelcase_modelname}}PreTrainedModel(FlaxPreTrainedModel):
config_class = {{cookiecutter.camelcase_modelname}}Config
base_model_prefix: str = "model"
module_class: nn.Module = None
def __init__(
self,
config: {{cookiecutter.camelcase_modelname}}Config,
input_shape: Tuple[int] = (1, 1),
seed: int = 0,
dtype: jnp.dtype = jnp.float32,
_do_init: bool = True,
**kwargs
):
module = self.module_class(config=config, dtype=dtype, **kwargs)
super().__init__(config, module, input_shape=input_shape, seed=seed, dtype=dtype, _do_init=_do_init)
def init_weights(self, rng: jax.random.PRNGKey, input_shape: Tuple, params: FrozenDict = None) -> FrozenDict:
# init input tensors
input_ids = jnp.zeros(input_shape, dtype="i4")
# make sure initialization pass will work for Flax{{cookiecutter.camelcase_modelname}}ForSequenceClassificationModule
input_ids = input_ids.at[(..., -1)].set(self.config.eos_token_id)
attention_mask = jnp.ones_like(input_ids)
decoder_input_ids = input_ids
decoder_attention_mask = jnp.ones_like(input_ids)
batch_size, sequence_length = input_ids.shape
position_ids = jnp.broadcast_to(jnp.arange(sequence_length)[None, :], (batch_size, sequence_length))
decoder_position_ids = jnp.broadcast_to(jnp.arange(sequence_length)[None, :], (batch_size, sequence_length))
params_rng, dropout_rng = jax.random.split(rng)
rngs = {"params": params_rng, "dropout": dropout_rng}
random_params = self.module.init(
rngs,
input_ids,
attention_mask,
decoder_input_ids,
decoder_attention_mask,
position_ids,
decoder_position_ids,
)["params"]
if params is not None:
random_params = flatten_dict(unfreeze(random_params))
params = flatten_dict(unfreeze(params))
for missing_key in self._missing_keys:
params[missing_key] = random_params[missing_key]
self._missing_keys = set()
return freeze(unflatten_dict(params))
else:
return random_params
def init_cache(self, batch_size, max_length, encoder_outputs):
r"""
Args:
batch_size (`int`):
batch_size used for fast auto-regressive decoding. Defines the batch size of the initialized cache.
max_length (`int`):
maximum possible length for auto-regressive decoding. Defines the sequence length of the initialized
cache.
encoder_outputs (`Union[FlaxBaseModelOutput, tuple(tuple(jnp.ndarray)]`):
`encoder_outputs` consists of (`last_hidden_state`, *optional*: `hidden_states`,
*optional*: `attentions`). `last_hidden_state` of shape `(batch_size, sequence_length, hidden_size)`, *optional*) is a sequence of hidden-states at the output of the last layer of the
encoder. Used in the cross-attention of the decoder.
"""
# init input variables to retrieve cache
decoder_input_ids = jnp.ones((batch_size, max_length), dtype="i4")
decoder_attention_mask = jnp.ones_like(decoder_input_ids)
decoder_position_ids = jnp.broadcast_to(
jnp.arange(jnp.atleast_2d(decoder_input_ids).shape[-1]), decoder_input_ids.shape
)
def _decoder_forward(module, decoder_input_ids, decoder_attention_mask, decoder_position_ids, **kwargs):
decoder_module = module._get_decoder_module()
return decoder_module(
decoder_input_ids,
decoder_attention_mask,
decoder_position_ids,
**kwargs,
)
init_variables = self.module.init(
jax.random.PRNGKey(0),
decoder_input_ids=decoder_input_ids,
decoder_attention_mask=decoder_attention_mask,
decoder_position_ids=decoder_position_ids,
encoder_hidden_states=encoder_outputs[0],
init_cache=True,
method=_decoder_forward, # we only need to call the decoder to init the cache
)
return unfreeze(init_variables["cache"])
@add_start_docstrings({{cookiecutter.uppercase_modelname}}_ENCODE_INPUTS_DOCSTRING)
@replace_return_docstrings(output_type=FlaxBaseModelOutput, config_class={{cookiecutter.camelcase_modelname}}Config)
def encode(
self,
input_ids: jnp.ndarray,
attention_mask: Optional[jnp.ndarray] = None,
position_ids: Optional[jnp.ndarray] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
train: bool = False,
params: dict = None,
dropout_rng: PRNGKey = None,
):
r"""
Returns:
Example:
```python
>>> from transformers import {{cookiecutter.camelcase_modelname}}Tokenizer, Flax{{cookiecutter.camelcase_modelname}}ForConditionalGeneration
>>> model = Flax{{cookiecutter.camelcase_modelname}}ForConditionalGeneration.from_pretrained('{{cookiecutter.checkpoint_identifier}}')
>>> tokenizer = {{cookiecutter.camelcase_modelname}}Tokenizer.from_pretrained('{{cookiecutter.checkpoint_identifier}}')
>>> text = "My friends are cool but they eat too many carbs."
>>> inputs = tokenizer(text, max_length=1024, return_tensors='np')
>>> encoder_outputs = model.encode(**inputs)
```"""
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
output_hidden_states = (
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
)
return_dict = return_dict if return_dict is not None else self.config.return_dict
if attention_mask is None:
attention_mask = jnp.ones_like(input_ids)
if position_ids is None:
batch_size, sequence_length = input_ids.shape
position_ids = jnp.broadcast_to(jnp.arange(sequence_length)[None, :], (batch_size, sequence_length))
# Handle any PRNG if needed
rngs = {}
if dropout_rng is not None:
rngs["dropout"] = dropout_rng
def _encoder_forward(module, input_ids, attention_mask, position_ids, **kwargs):
encode_module = module._get_encoder_module()
return encode_module(input_ids, attention_mask, position_ids, **kwargs)
return self.module.apply(
{"params": params or self.params},
input_ids=jnp.array(input_ids, dtype="i4"),
attention_mask=jnp.array(attention_mask, dtype="i4"),
position_ids=jnp.array(position_ids, dtype="i4"),
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
deterministic=not train,
rngs=rngs,
method=_encoder_forward,
)
@add_start_docstrings({{cookiecutter.uppercase_modelname}}_DECODE_INPUTS_DOCSTRING)
@replace_return_docstrings(output_type=FlaxBaseModelOutputWithPastAndCrossAttentions, config_class={{cookiecutter.camelcase_modelname}}Config)
def decode(
self,
decoder_input_ids,
encoder_outputs,
encoder_attention_mask: Optional[jnp.ndarray] = None,
decoder_attention_mask: Optional[jnp.ndarray] = None,
decoder_position_ids: Optional[jnp.ndarray] = None,
past_key_values: dict = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
train: bool = False,
params: dict = None,
dropout_rng: PRNGKey = None,
):
r"""
Returns:
Example:
```python
>>> import jax.numpy as jnp
>>> from transformers import {{cookiecutter.camelcase_modelname}}Tokenizer, Flax{{cookiecutter.camelcase_modelname}}ForConditionalGeneration
>>> model = Flax{{cookiecutter.camelcase_modelname}}ForConditionalGeneration.from_pretrained('{{cookiecutter.checkpoint_identifier}}')
>>> tokenizer = {{cookiecutter.camelcase_modelname}}Tokenizer.from_pretrained('{{cookiecutter.checkpoint_identifier}}')
>>> text = "My friends are cool but they eat too many carbs."
>>> inputs = tokenizer(text, max_length=1024, return_tensors='np')
>>> encoder_outputs = model.encode(**inputs)
>>> decoder_start_token_id = model.config.decoder_start_token_id
>>> decoder_input_ids = jnp.ones((inputs.input_ids.shape[0], 1), dtype="i4") * decoder_start_token_id
>>> outputs = model.decode(decoder_input_ids, encoder_outputs)
>>> last_decoder_hidden_states = outputs.last_hidden_state
```"""
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
output_hidden_states = (
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
)
return_dict = return_dict if return_dict is not None else self.config.return_dict
encoder_hidden_states = encoder_outputs[0]
if encoder_attention_mask is None:
batch_size, sequence_length = encoder_hidden_states.shape[:2]
encoder_attention_mask = jnp.ones((batch_size, sequence_length))
batch_size, sequence_length = decoder_input_ids.shape
if decoder_attention_mask is None:
decoder_attention_mask = jnp.ones((batch_size, sequence_length))
if decoder_position_ids is None:
if past_key_values is not None:
raise ValueError("Make sure to provide `decoder_position_ids` when passing `past_key_values`.")
decoder_position_ids = jnp.broadcast_to(
jnp.arange(sequence_length)[None, :], (batch_size, sequence_length)
)
# Handle any PRNG if needed
rngs = {}
if dropout_rng is not None:
rngs["dropout"] = dropout_rng
inputs = {"params": params or self.params}
# if past_key_values are passed then cache is already initialized a private flag init_cache has to be
# passed down to ensure cache is used. It has to be made sure that cache is marked as mutable so that
# it can be changed by Flax{{cookiecutter.camelcase_modelname}}Attention module
if past_key_values:
inputs["cache"] = past_key_values
mutable = ["cache"]
else:
mutable = False
def _decoder_forward(module, decoder_input_ids, decoder_attention_mask, decoder_position_ids, **kwargs):
decoder_module = module._get_decoder_module()
return decoder_module(
decoder_input_ids,
decoder_attention_mask,
decoder_position_ids,
**kwargs,
)
outputs = self.module.apply(
inputs,
decoder_input_ids=jnp.array(decoder_input_ids, dtype="i4"),
decoder_attention_mask=jnp.array(decoder_attention_mask, dtype="i4"),
decoder_position_ids=jnp.array(decoder_position_ids, dtype="i4"),
encoder_hidden_states=encoder_hidden_states,
encoder_attention_mask=jnp.array(encoder_attention_mask, dtype="i4"),
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
deterministic=not train,
rngs=rngs,
mutable=mutable,
method=_decoder_forward,
)
# add updated cache to model output
if past_key_values is not None and return_dict:
outputs, past = outputs
outputs["past_key_values"] = unfreeze(past["cache"])
return outputs
elif past_key_values is not None and not return_dict:
outputs, past = outputs
outputs = outputs[:1] + (unfreeze(past["cache"]),) + outputs[1:]
return outputs
def __call__(
self,
input_ids: jnp.ndarray,
attention_mask: Optional[jnp.ndarray] = None,
decoder_input_ids: Optional[jnp.ndarray] = None,
decoder_attention_mask: Optional[jnp.ndarray] = None,
position_ids: Optional[jnp.ndarray] = None,
decoder_position_ids: Optional[jnp.ndarray] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
train: bool = False,
params: dict = None,
dropout_rng: PRNGKey = None,
):
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
output_hidden_states = (
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
)
return_dict = return_dict if return_dict is not None else self.config.return_dict
# prepare encoder inputs
if attention_mask is None:
attention_mask = jnp.ones_like(input_ids)
if position_ids is None:
batch_size, sequence_length = input_ids.shape
position_ids = jnp.broadcast_to(jnp.arange(sequence_length)[None, :], (batch_size, sequence_length))
# prepare decoder inputs
if decoder_input_ids is None:
decoder_input_ids = shift_tokens_right(
input_ids, self.config.pad_token_id, decoder_start_token_id=self.config.decoder_start_token_id
)
if decoder_attention_mask is None:
decoder_attention_mask = jnp.ones_like(decoder_input_ids)
if decoder_position_ids is None:
batch_size, sequence_length = decoder_input_ids.shape
decoder_position_ids = jnp.broadcast_to(
jnp.arange(sequence_length)[None, :], (batch_size, sequence_length)
)
# Handle any PRNG if needed
rngs = {"dropout": dropout_rng} if dropout_rng is not None else {}
return self.module.apply(
{"params": params or self.params},
input_ids=jnp.array(input_ids, dtype="i4"),
attention_mask=jnp.array(attention_mask, dtype="i4"),
position_ids=jnp.array(position_ids, dtype="i4"),
decoder_input_ids=jnp.array(decoder_input_ids, dtype="i4"),
decoder_attention_mask=jnp.array(decoder_attention_mask, dtype="i4"),
decoder_position_ids=jnp.array(decoder_position_ids, dtype="i4"),
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
deterministic=not train,
rngs=rngs,
)
@add_start_docstrings(
"The bare {{cookiecutter.camelcase_modelname}} Model transformer outputting raw hidden-states without any specific head on top.",
{{cookiecutter.uppercase_modelname}}_START_DOCSTRING,
)
class Flax{{cookiecutter.camelcase_modelname}}Model(Flax{{cookiecutter.camelcase_modelname}}PreTrainedModel):
config: {{cookiecutter.camelcase_modelname}}Config
dtype: jnp.dtype = jnp.float32 # the dtype of the computation
module_class = Flax{{cookiecutter.camelcase_modelname}}Module
append_call_sample_docstring(
Flax{{cookiecutter.camelcase_modelname}}Model, _TOKENIZER_FOR_DOC, _CHECKPOINT_FOR_DOC, FlaxSeq2SeqModelOutput, _CONFIG_FOR_DOC
)
class Flax{{cookiecutter.camelcase_modelname}}ForConditionalGenerationModule(nn.Module):
config: {{cookiecutter.camelcase_modelname}}Config
dtype: jnp.dtype = jnp.float32
bias_init: Callable[..., jnp.ndarray] = jax.nn.initializers.zeros
def setup(self):
self.model = Flax{{cookiecutter.camelcase_modelname}}Module(config=self.config, dtype=self.dtype)
self.lm_head = nn.Dense(
self.model.shared.num_embeddings,
use_bias=False,
dtype=self.dtype,
kernel_init=jax.nn.initializers.normal(self.config.init_std),
)
self.final_logits_bias = self.param("final_logits_bias", self.bias_init, (1, self.model.shared.num_embeddings))
def _get_encoder_module(self):
return self.model.encoder
def _get_decoder_module(self):
return self.model.decoder
def __call__(
self,
input_ids,
attention_mask,
decoder_input_ids,
decoder_attention_mask,
position_ids,
decoder_position_ids,
output_attentions: bool = False,
output_hidden_states: bool = False,
return_dict: bool = True,
deterministic: bool = True,
):
outputs = self.model(
input_ids=input_ids,
attention_mask=attention_mask,
decoder_input_ids=decoder_input_ids,
decoder_attention_mask=decoder_attention_mask,
position_ids=position_ids,
decoder_position_ids=decoder_position_ids,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
deterministic=deterministic,
)
hidden_states = outputs[0]
if self.config.tie_word_embeddings:
shared_embedding = self.model.variables["params"]["shared"]["embedding"]
lm_logits = self.lm_head.apply({"params": {"kernel": shared_embedding.T}}, hidden_states)
else:
lm_logits = self.lm_head(hidden_states)
lm_logits += self.final_logits_bias.astype(self.dtype)
if not return_dict:
output = (lm_logits,) + outputs[1:]
return output
return FlaxSeq2SeqLMOutput(
logits=lm_logits,
decoder_hidden_states=outputs.decoder_hidden_states,
decoder_attentions=outputs.decoder_attentions,
cross_attentions=outputs.cross_attentions,
encoder_last_hidden_state=outputs.encoder_last_hidden_state,
encoder_hidden_states=outputs.encoder_hidden_states,
encoder_attentions=outputs.encoder_attentions,
)
@add_start_docstrings(
"The {{cookiecutter.uppercase_modelname}} Model with a language modeling head. Can be used for summarization.", {{cookiecutter.uppercase_modelname}}_START_DOCSTRING
)
class Flax{{cookiecutter.camelcase_modelname}}ForConditionalGeneration(Flax{{cookiecutter.camelcase_modelname}}PreTrainedModel):
module_class = Flax{{cookiecutter.camelcase_modelname}}ForConditionalGenerationModule
dtype: jnp.dtype = jnp.float32
@add_start_docstrings({{cookiecutter.uppercase_modelname}}_DECODE_INPUTS_DOCSTRING)
@replace_return_docstrings(output_type=FlaxCausalLMOutputWithCrossAttentions, config_class={{cookiecutter.camelcase_modelname}}Config)
def decode(
self,
decoder_input_ids,
encoder_outputs,
encoder_attention_mask: Optional[jnp.ndarray] = None,
decoder_attention_mask: Optional[jnp.ndarray] = None,
decoder_position_ids: Optional[jnp.ndarray] = None,
past_key_values: dict = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
deterministic: bool = True,
params: dict = None,
dropout_rng: PRNGKey = None,
):
r"""
Returns:
Example:
```python
>>> import jax.numpy as jnp
>>> from transformers import {{cookiecutter.camelcase_modelname}}Tokenizer, Flax{{cookiecutter.camelcase_modelname}}ForConditionalGeneration
>>> model = Flax{{cookiecutter.camelcase_modelname}}ForConditionalGeneration.from_pretrained('{{cookiecutter.checkpoint_identifier}}')
>>> tokenizer = {{cookiecutter.camelcase_modelname}}Tokenizer.from_pretrained('{{cookiecutter.checkpoint_identifier}}')
>>> text = "My friends are cool but they eat too many carbs."
>>> inputs = tokenizer(text, max_length=1024, return_tensors='np')
>>> encoder_outputs = model.encode(**inputs)
>>> decoder_start_token_id = model.config.decoder_start_token_id
>>> decoder_input_ids = jnp.ones((inputs.input_ids.shape[0], 1), dtype="i4") * decoder_start_token_id
>>> outputs = model.decode(decoder_input_ids, encoder_outputs)
>>> logits = outputs.logits
```"""
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
output_hidden_states = (
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
)
return_dict = return_dict if return_dict is not None else self.config.return_dict
encoder_hidden_states = encoder_outputs[0]
if encoder_attention_mask is None:
batch_size, sequence_length = encoder_hidden_states.shape[:2]
encoder_attention_mask = jnp.ones((batch_size, sequence_length))
batch_size, sequence_length = decoder_input_ids.shape
if decoder_attention_mask is None:
decoder_attention_mask = jnp.ones((batch_size, sequence_length))
if decoder_position_ids is None:
if past_key_values is not None:
raise ValueError("Make sure to provide `decoder_position_ids` when passing `past_key_values`.")
decoder_position_ids = jnp.broadcast_to(
jnp.arange(sequence_length)[None, :], (batch_size, sequence_length)
)
# Handle any PRNG if needed
rngs = {}
if dropout_rng is not None:
rngs["dropout"] = dropout_rng
inputs = {"params": params or self.params}
# if past_key_values are passed then cache is already initialized a private flag init_cache has to be
# passed down to ensure cache is used. It has to be made sure that cache is marked as mutable so that
# it can be changed by Flax{{cookiecutter.camelcase_modelname}}Attention module
if past_key_values:
inputs["cache"] = past_key_values
mutable = ["cache"]
else:
mutable = False
def _decoder_forward(module, decoder_input_ids, decoder_attention_mask, decoder_position_ids, **kwargs):
decoder_module = module._get_decoder_module()
outputs = decoder_module(
decoder_input_ids,
decoder_attention_mask,
decoder_position_ids,
**kwargs,
)
hidden_states = outputs[0]
if self.config.tie_word_embeddings:
shared_embedding = module.model.variables["params"]["shared"]["embedding"]
lm_logits = module.lm_head.apply({"params": {"kernel": shared_embedding.T}}, hidden_states)
else:
lm_logits = module.lm_head(hidden_states)
lm_logits += module.final_logits_bias.astype(self.dtype)
return lm_logits, outputs
outputs = self.module.apply(
inputs,
decoder_input_ids=jnp.array(decoder_input_ids, dtype="i4"),
decoder_attention_mask=jnp.array(decoder_attention_mask, dtype="i4"),
decoder_position_ids=jnp.array(decoder_position_ids, dtype="i4"),
encoder_hidden_states=encoder_hidden_states,
encoder_attention_mask=jnp.array(encoder_attention_mask, dtype="i4"),
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
deterministic=deterministic,
rngs=rngs,
mutable=mutable,
method=_decoder_forward,
)
if past_key_values is None:
lm_logits, decoder_outputs = outputs
else:
(lm_logits, decoder_outputs), past = outputs
if return_dict:
outputs = FlaxCausalLMOutputWithCrossAttentions(
logits=lm_logits,
hidden_states=decoder_outputs.hidden_states,
attentions=decoder_outputs.attentions,
cross_attentions=decoder_outputs.cross_attentions,
)
else:
outputs = (lm_logits,) + decoder_outputs[1:]
# add updated cache to model output
if past_key_values is not None and return_dict:
outputs["past_key_values"] = unfreeze(past["cache"])
return outputs
elif past_key_values is not None and not return_dict:
outputs = outputs[:1] + (unfreeze(past["cache"]),) + outputs[1:]
return outputs
def prepare_inputs_for_generation(
self,
decoder_input_ids,
max_length,
attention_mask: Optional[jnp.DeviceArray] = None,
decoder_attention_mask: Optional[jnp.DeviceArray] = None,
encoder_outputs=None,
**kwargs
):
# initializing the cache
batch_size, seq_length = decoder_input_ids.shape
past_key_values = self.init_cache(batch_size, max_length, encoder_outputs)
# Note that usually one would have to put 0's in the attention_mask for x > input_ids.shape[-1] and x < cache_length.
# But since the decoder uses a causal mask, those positions are masked anyways.
# Thus we can create a single static attention_mask here, which is more efficient for compilation
extended_attention_mask = jnp.ones((batch_size, max_length), dtype="i4")
if decoder_attention_mask is not None:
position_ids = decoder_attention_mask.cumsum(axis=-1) - 1
extended_attention_mask = lax.dynamic_update_slice(extended_attention_mask, decoder_attention_mask, (0, 0))
else:
position_ids = jnp.broadcast_to(jnp.arange(seq_length, dtype="i4")[None, :], (batch_size, seq_length))
return {
"past_key_values": past_key_values,
"encoder_outputs": encoder_outputs,
"encoder_attention_mask": attention_mask,
"decoder_attention_mask": extended_attention_mask,
"decoder_position_ids": position_ids,
}
def update_inputs_for_generation(self, model_outputs, model_kwargs):
model_kwargs["past_key_values"] = model_outputs.past_key_values
model_kwargs["decoder_position_ids"] = model_kwargs["decoder_position_ids"][:, -1:] + 1
return model_kwargs
FLAX_{{cookiecutter.uppercase_modelname}}_CONDITIONAL_GENERATION_DOCSTRING = """
Returns:
Summarization example:
```python
>>> from transformers import {{cookiecutter.camelcase_modelname}}Tokenizer, Flax{{cookiecutter.camelcase_modelname}}ForConditionalGeneration
>>> model = Flax{{cookiecutter.camelcase_modelname}}ForConditionalGeneration.from_pretrained('{{cookiecutter.checkpoint_identifier}}')
>>> tokenizer = {{cookiecutter.camelcase_modelname}}Tokenizer.from_pretrained('{{cookiecutter.checkpoint_identifier}}')
>>> ARTICLE_TO_SUMMARIZE = "My friends are cool but they eat too many carbs."
>>> inputs = tokenizer([ARTICLE_TO_SUMMARIZE], max_length=1024, return_tensors='np')
>>> # Generate Summary
>>> summary_ids = model.generate(inputs['input_ids']).sequences
>>> print(tokenizer.batch_decode(summary_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False))
```
Mask filling example:
```python
>>> import jax
>>> from transformers import {{cookiecutter.camelcase_modelname}}Tokenizer, Flax{{cookiecutter.camelcase_modelname}}ForConditionalGeneration
>>> model = Flax{{cookiecutter.camelcase_modelname}}ForConditionalGeneration.from_pretrained('{{cookiecutter.checkpoint_identifier}}')
>>> tokenizer = {{cookiecutter.camelcase_modelname}}Tokenizer.from_pretrained('{{cookiecutter.checkpoint_identifier}}')
>>> TXT = "My friends are <mask> but they eat too many carbs."
>>> input_ids = tokenizer([TXT], return_tensors='np')['input_ids']
>>> logits = model(input_ids).logits
>>> masked_index = (input_ids[0] == tokenizer.mask_token_id).nonzero().item()
>>> probs = jax.nn.softmax(logits[0, masked_index], axis=0)
>>> values, predictions = jax.lax.top_k(probs, k=1)
>>> tokenizer.decode(predictions).split()
```
"""
overwrite_call_docstring(
Flax{{cookiecutter.camelcase_modelname}}ForConditionalGeneration, {{cookiecutter.uppercase_modelname}}_INPUTS_DOCSTRING + FLAX_{{cookiecutter.uppercase_modelname}}_CONDITIONAL_GENERATION_DOCSTRING
)
append_replace_return_docstrings(
Flax{{cookiecutter.camelcase_modelname}}ForConditionalGeneration, output_type=FlaxSeq2SeqLMOutput, config_class=_CONFIG_FOR_DOC
)
class Flax{{cookiecutter.camelcase_modelname}}ForSequenceClassificationModule(nn.Module):
config: {{cookiecutter.camelcase_modelname}}Config
dtype: jnp.dtype = jnp.float32
num_labels: Optional[int] = None
def setup(self):
self.model = Flax{{cookiecutter.camelcase_modelname}}Module(config=self.config, dtype=self.dtype)
self.classification_head = Flax{{cookiecutter.camelcase_modelname}}ClassificationHead(
config=self.config,
inner_dim=self.config.d_model,
num_classes=self.num_labels if self.num_labels is not None else self.config.num_labels,
pooler_dropout=self.config.classifier_dropout,
)
def _get_encoder_module(self):
return self.model.encoder
def _get_decoder_module(self):
return self.model.decoder
def __call__(
self,
input_ids,
attention_mask,
decoder_input_ids,
decoder_attention_mask,
position_ids,
decoder_position_ids,
output_attentions: bool = False,
output_hidden_states: bool = False,
return_dict: bool = True,
deterministic: bool = True,
):
outputs = self.model(
input_ids=input_ids,
attention_mask=attention_mask,
decoder_input_ids=decoder_input_ids,
decoder_attention_mask=decoder_attention_mask,
position_ids=position_ids,
decoder_position_ids=decoder_position_ids,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
deterministic=deterministic,
)
hidden_states = outputs[0] # last hidden state
eos_mask = jnp.where(input_ids == self.config.eos_token_id, 1, 0)
# The first condition is necessary to overcome jax._src.errors.ConcretizationTypeError during JIT compilation
if type(eos_mask) != jax.interpreters.partial_eval.DynamicJaxprTracer:
if len(jnp.unique(eos_mask.sum(1))) > 1:
raise ValueError("All examples must have the same number of <eos> tokens.")
if any(eos_mask.sum(1) == 0):
raise ValueError("There are missing <eos> tokens in input_ids")
# Ensure to keep 1 only for the last <eos> token for each example
eos_mask_noised = eos_mask + jnp.arange(eos_mask.shape[1]) * 1e-6
eos_mask = jnp.where(eos_mask_noised == eos_mask_noised.max(1).reshape(-1, 1), 1, 0)
sentence_representation = jnp.einsum("ijk, ij -> ijk", hidden_states, eos_mask).sum(1)
logits = self.classification_head(sentence_representation, deterministic=deterministic)
if not return_dict:
output = (logits,) + outputs[1:]
return output
return FlaxSeq2SeqSequenceClassifierOutput(
logits=logits,
decoder_hidden_states=outputs.decoder_hidden_states,
decoder_attentions=outputs.decoder_attentions,
cross_attentions=outputs.cross_attentions,
encoder_last_hidden_state=outputs.encoder_last_hidden_state,
encoder_hidden_states=outputs.encoder_hidden_states,
encoder_attentions=outputs.encoder_attentions,
)
@add_start_docstrings(
"""
{{cookiecutter.camelcase_modelname}} model with a sequence classification/head on top (a linear layer on top of the pooled output) e.g. for GLUE
tasks.
""",
{{cookiecutter.uppercase_modelname}}_START_DOCSTRING,
)
class Flax{{cookiecutter.camelcase_modelname}}ForSequenceClassification(Flax{{cookiecutter.camelcase_modelname}}PreTrainedModel):
module_class = Flax{{cookiecutter.camelcase_modelname}}ForSequenceClassificationModule
dtype = jnp.float32
append_call_sample_docstring(
Flax{{cookiecutter.camelcase_modelname}}ForSequenceClassification,
_TOKENIZER_FOR_DOC,
_CHECKPOINT_FOR_DOC,
FlaxSeq2SeqSequenceClassifierOutput,
_CONFIG_FOR_DOC,
)
class Flax{{cookiecutter.camelcase_modelname}}ForQuestionAnsweringModule(nn.Module):
config: {{cookiecutter.camelcase_modelname}}Config
dtype: jnp.dtype = jnp.float32
num_labels = 2
def setup(self):
self.model = Flax{{cookiecutter.camelcase_modelname}}Module(config=self.config, dtype=self.dtype)
self.qa_outputs = nn.Dense(
self.num_labels, dtype=self.dtype, kernel_init=jax.nn.initializers.normal(self.config.init_std)
)
def _get_encoder_module(self):
return self.model.encoder
def _get_decoder_module(self):
return self.model.decoder
def __call__(
self,
input_ids,
attention_mask,
decoder_input_ids,
decoder_attention_mask,
position_ids,
decoder_position_ids,
output_attentions: bool = False,
output_hidden_states: bool = False,
return_dict: bool = True,
deterministic: bool = True,
):
outputs = self.model(
input_ids=input_ids,
attention_mask=attention_mask,
decoder_input_ids=decoder_input_ids,
decoder_attention_mask=decoder_attention_mask,
position_ids=position_ids,
decoder_position_ids=decoder_position_ids,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
deterministic=deterministic,
)
sequence_output = outputs[0]
logits = self.qa_outputs(sequence_output)
start_logits, end_logits = jnp.split(logits, logits.shape[-1], axis=-1)
start_logits = start_logits.squeeze(-1)
end_logits = end_logits.squeeze(-1)
if not return_dict:
output = (start_logits, end_logits) + outputs[1:]
return output
return FlaxSeq2SeqQuestionAnsweringModelOutput(
start_logits=start_logits,
end_logits=end_logits,
decoder_hidden_states=outputs.decoder_hidden_states,
decoder_attentions=outputs.decoder_attentions,
cross_attentions=outputs.cross_attentions,
encoder_last_hidden_state=outputs.encoder_last_hidden_state,
encoder_hidden_states=outputs.encoder_hidden_states,
encoder_attentions=outputs.encoder_attentions,
)
@add_start_docstrings(
"""
{{cookiecutter.uppercase_modelname}} Model with a span classification head on top for extractive question-answering tasks like SQuAD (a linear
layer on top of the hidden-states output to compute `span start logits` and `span end logits`).
""",
{{cookiecutter.uppercase_modelname}}_START_DOCSTRING,
)
class Flax{{cookiecutter.camelcase_modelname}}ForQuestionAnswering(Flax{{cookiecutter.camelcase_modelname}}PreTrainedModel):
module_class = Flax{{cookiecutter.camelcase_modelname}}ForQuestionAnsweringModule
dtype = jnp.float32
append_call_sample_docstring(
Flax{{cookiecutter.camelcase_modelname}}ForQuestionAnswering,
_TOKENIZER_FOR_DOC,
_CHECKPOINT_FOR_DOC,
FlaxSeq2SeqQuestionAnsweringModelOutput,
_CONFIG_FOR_DOC,
)
{% endif -%}
| 0 |
hf_public_repos/transformers/templates/adding_a_new_model | hf_public_repos/transformers/templates/adding_a_new_model/cookiecutter-template-{{cookiecutter.modelname}}/tokenization_fast_{{cookiecutter.lowercase_modelname}}.py | # coding=utf-8
# Copyright 2022 {{cookiecutter.authors}} and The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""Tokenization classes for {{cookiecutter.modelname}}."""
{%- if cookiecutter.tokenizer_type == "Based on BERT" %}
from ...utils import logging
from ..bert.tokenization_bert_fast import BertTokenizerFast
from .tokenization_{{cookiecutter.lowercase_modelname}} import {{cookiecutter.camelcase_modelname}}Tokenizer
logger = logging.get_logger(__name__)
VOCAB_FILES_NAMES = {"vocab_file": "vocab.txt"}
PRETRAINED_VOCAB_FILES_MAP = {
"vocab_file": {
"{{cookiecutter.checkpoint_identifier}}": "https://huggingface.co/{{cookiecutter.checkpoint_identifier}}/resolve/main/vocab.txt",
}
}
PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
"{{cookiecutter.checkpoint_identifier}}": 512,
}
PRETRAINED_INIT_CONFIGURATION = {
"{{cookiecutter.checkpoint_identifier}}": {"do_lower_case": False},
}
class {{cookiecutter.camelcase_modelname}}TokenizerFast(BertTokenizerFast):
r"""
Construct a "fast" {{cookiecutter.modelname}} tokenizer (backed by HuggingFace's *tokenizers* library).
[`~{{cookiecutter.camelcase_modelname}}TokenizerFast`] is identical to [`BertTokenizerFast`] and runs
end-to-end tokenization: punctuation splitting and wordpiece.
Refer to superclass [`BertTokenizerFast`] for usage examples and documentation concerning
parameters.
"""
vocab_files_names = VOCAB_FILES_NAMES
pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
pretrained_init_configuration = PRETRAINED_INIT_CONFIGURATION
slow_tokenizer_class = {{cookiecutter.camelcase_modelname}}Tokenizer
{%- elif cookiecutter.tokenizer_type == "Based on BART" %}
from ...utils import logging
from ..bart.tokenization_bart_fast import BartTokenizerFast
from .tokenization_{{cookiecutter.lowercase_modelname}} import {{cookiecutter.camelcase_modelname}}Tokenizer
logger = logging.get_logger(__name__)
VOCAB_FILES_NAMES = {"vocab_file": "vocab.json", "merges_file": "merges.txt", "tokenizer_file": "tokenizer.json"}
PRETRAINED_VOCAB_FILES_MAP = {
"vocab_file": {
"{{cookiecutter.checkpoint_identifier}}": "https://huggingface.co/{{cookiecutter.checkpoint_identifier}}/resolve/main/vocab.json",
},
"merges_file": {
"{{cookiecutter.checkpoint_identifier}}": "https://huggingface.co/{{cookiecutter.checkpoint_identifier}}/resolve/main/merges.txt",
},
"tokenizer_file": {
"{{cookiecutter.checkpoint_identifier}}": "https://huggingface.co/{{cookiecutter.checkpoint_identifier}}/resolve/main/tokenizer.json",
},
}
PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
"{{cookiecutter.checkpoint_identifier}}": 1024,
}
class {{cookiecutter.camelcase_modelname}}TokenizerFast(BartTokenizerFast):
r"""
Construct a "fast" {{cookiecutter.modelname}} tokenizer (backed by HuggingFace's *tokenizers* library).
[`~{{cookiecutter.camelcase_modelname}}TokenizerFast`] is identical to [`BartTokenizerFast`] and runs
end-to-end tokenization: punctuation splitting and wordpiece.
Refer to superclass [`BartTokenizerFast`] for usage examples and documentation concerning
parameters.
"""
vocab_files_names = VOCAB_FILES_NAMES
pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
slow_tokenizer_class = {{cookiecutter.camelcase_modelname}}Tokenizer
{%- elif cookiecutter.tokenizer_type == "Standalone" %}
from typing import List, Optional
from tokenizers import ByteLevelBPETokenizer
from ...tokenization_utils_fast import PreTrainedTokenizerFast
from ...utils import logging
from .tokenization_{{cookiecutter.lowercase_modelname}} import {{cookiecutter.camelcase_modelname}}Tokenizer
logger = logging.get_logger(__name__)
VOCAB_FILES_NAMES = {"vocab_file": "vocab.txt", "tokenizer_file": "tokenizer.json"}
PRETRAINED_VOCAB_FILES_MAP = {
"vocab_file": {
"{{cookiecutter.checkpoint_identifier}}": "https://huggingface.co/{{cookiecutter.checkpoint_identifier}}/resolve/main/vocab.txt",
},
"tokenizer_file": {
"{{cookiecutter.checkpoint_identifier}}": "https://huggingface.co/{{cookiecutter.checkpoint_identifier}}/resolve/main/tokenizer.json",
},
}
PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
"{{cookiecutter.checkpoint_identifier}}": 1024,
}
class {{cookiecutter.camelcase_modelname}}TokenizerFast(PreTrainedTokenizerFast):
"""
Construct a "fast" {{cookiecutter.modelname}} tokenizer (backed by HuggingFace's *tokenizers* library).
Args:
vocab_file (`str`):
Path to the vocabulary file.
"""
vocab_files_names = VOCAB_FILES_NAMES
pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
slow_tokenizer_class = {{cookiecutter.camelcase_modelname}}Tokenizer
def __init__(
self,
vocab_file,
merges_file,
unk_token="<|endoftext|>",
bos_token="<|endoftext|>",
eos_token="<|endoftext|>",
add_prefix_space=False,
trim_offsets=True,
**kwargs
):
super().__init__(
ByteLevelBPETokenizer(
vocab_file=vocab_file,
merges_file=merges_file,
add_prefix_space=add_prefix_space,
trim_offsets=trim_offsets,
),
bos_token=bos_token,
eos_token=eos_token,
unk_token=unk_token,
**kwargs,
)
self.add_prefix_space = add_prefix_space
def build_inputs_with_special_tokens(self, token_ids_0, token_ids_1=None):
output = [self.bos_token_id] + token_ids_0 + [self.eos_token_id]
if token_ids_1 is None:
return output
return output + [self.eos_token_id] + token_ids_1 + [self.eos_token_id]
def create_token_type_ids_from_sequences(
self, token_ids_0: List[int], token_ids_1: Optional[List[int]] = None
) -> List[int]:
"""
Create a mask from the two sequences passed to be used in a sequence-pair classification task.
{{cookiecutter.modelname}} does not make use of token type ids, therefore a list of zeros is returned.
Args:
token_ids_0 (`List[int]`):
List of IDs.
token_ids_1 (`List[int]`, *optional*):
Optional second list of IDs for sequence pairs.
Returns:
`List[int]`: List of zeros.
"""
sep = [self.sep_token_id]
cls = [self.cls_token_id]
if token_ids_1 is None:
return len(cls + token_ids_0 + sep) * [0]
return len(cls + token_ids_0 + sep + sep + token_ids_1 + sep) * [0]
{% endif %}
| 0 |
hf_public_repos/transformers/templates/adding_a_new_model | hf_public_repos/transformers/templates/adding_a_new_model/cookiecutter-template-{{cookiecutter.modelname}}/test_modeling_tf_{{cookiecutter.lowercase_modelname}}.py | # coding=utf-8
# Copyright 2022 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
{% if cookiecutter.is_encoder_decoder_model == "False" %}
import unittest
from transformers import is_tf_available, {{cookiecutter.camelcase_modelname}}Config
from transformers.testing_utils import require_tf, slow
from ...test_configuration_common import ConfigTester
from ...test_modeling_tf_common import TFModelTesterMixin, floats_tensor, ids_tensor, random_attention_mask
if is_tf_available():
import tensorflow as tf
from transformers import (
TF{{cookiecutter.camelcase_modelname}}ForCausalLM,
TF{{cookiecutter.camelcase_modelname}}ForMaskedLM,
TF{{cookiecutter.camelcase_modelname}}ForMultipleChoice,
TF{{cookiecutter.camelcase_modelname}}ForQuestionAnswering,
TF{{cookiecutter.camelcase_modelname}}ForSequenceClassification,
TF{{cookiecutter.camelcase_modelname}}ForTokenClassification,
TF{{cookiecutter.camelcase_modelname}}Model,
)
class TF{{cookiecutter.camelcase_modelname}}ModelTester:
def __init__(
self,
parent,
batch_size=13,
seq_length=7,
is_training=True,
use_input_mask=True,
use_token_type_ids=True,
use_labels=True,
vocab_size=99,
hidden_size=32,
num_hidden_layers=5,
num_attention_heads=4,
intermediate_size=37,
hidden_act="gelu",
hidden_dropout_prob=0.1,
attention_probs_dropout_prob=0.1,
max_position_embeddings=512,
type_vocab_size=16,
type_sequence_label_size=2,
initializer_range=0.02,
num_labels=3,
num_choices=4,
scope=None,
):
self.parent = parent
self.batch_size = 13
self.seq_length = 7
self.is_training = True
self.use_input_mask = True
self.use_token_type_ids = True
self.use_labels = True
self.vocab_size = 99
self.hidden_size = 32
self.num_hidden_layers = 5
self.num_attention_heads = 4
self.intermediate_size = 37
self.hidden_act = "gelu"
self.hidden_dropout_prob = 0.1
self.attention_probs_dropout_prob = 0.1
self.max_position_embeddings = 512
self.type_vocab_size = 16
self.type_sequence_label_size = 2
self.initializer_range = 0.02
self.num_labels = 3
self.num_choices = 4
self.scope = None
def prepare_config_and_inputs(self):
input_ids = ids_tensor([self.batch_size, self.seq_length], self.vocab_size)
input_mask = None
if self.use_input_mask:
input_mask = random_attention_mask([self.batch_size, self.seq_length])
token_type_ids = None
if self.use_token_type_ids:
token_type_ids = ids_tensor([self.batch_size, self.seq_length], self.type_vocab_size)
sequence_labels = None
token_labels = None
choice_labels = None
if self.use_labels:
sequence_labels = ids_tensor([self.batch_size], self.type_sequence_label_size)
token_labels = ids_tensor([self.batch_size, self.seq_length], self.num_labels)
choice_labels = ids_tensor([self.batch_size], self.num_choices)
config = {{cookiecutter.camelcase_modelname}}Config(
vocab_size=self.vocab_size,
hidden_size=self.hidden_size,
num_hidden_layers=self.num_hidden_layers,
num_attention_heads=self.num_attention_heads,
intermediate_size=self.intermediate_size,
hidden_act=self.hidden_act,
hidden_dropout_prob=self.hidden_dropout_prob,
attention_probs_dropout_prob=self.attention_probs_dropout_prob,
max_position_embeddings=self.max_position_embeddings,
type_vocab_size=self.type_vocab_size,
initializer_range=self.initializer_range,
return_dict=True,
)
return config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
def prepare_config_and_inputs_for_decoder(self):
(
config,
input_ids,
token_type_ids,
input_mask,
sequence_labels,
token_labels,
choice_labels,
) = self.prepare_config_and_inputs()
config.is_decoder = True
encoder_hidden_states = floats_tensor([self.batch_size, self.seq_length, self.hidden_size])
encoder_attention_mask = ids_tensor([self.batch_size, self.seq_length], vocab_size=2)
return (
config,
input_ids,
token_type_ids,
input_mask,
sequence_labels,
token_labels,
choice_labels,
encoder_hidden_states,
encoder_attention_mask,
)
def create_and_check_model(
self, config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
):
model = TF{{cookiecutter.camelcase_modelname}}Model(config=config)
inputs = {"input_ids": input_ids, "attention_mask": input_mask, "token_type_ids": token_type_ids}
inputs = [input_ids, input_mask]
result = model(inputs)
result = model(input_ids)
self.parent.assertEqual(result.last_hidden_state.shape, (self.batch_size, self.seq_length, self.hidden_size))
def create_and_check_causal_lm_base_model(
self, config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
):
config.is_decoder = True
model = TF{{cookiecutter.camelcase_modelname}}Model(config=config)
inputs = {"input_ids": input_ids, "attention_mask": input_mask, "token_type_ids": token_type_ids}
result = model(inputs)
inputs = [input_ids, input_mask]
result = model(inputs)
result = model(input_ids)
self.parent.assertEqual(result.last_hidden_state.shape, (self.batch_size, self.seq_length, self.hidden_size))
def create_and_check_model_as_decoder(
self,
config,
input_ids,
token_type_ids,
input_mask,
sequence_labels,
token_labels,
choice_labels,
encoder_hidden_states,
encoder_attention_mask,
):
config.add_cross_attention = True
model = TF{{cookiecutter.camelcase_modelname}}Model(config=config)
inputs = {
"input_ids": input_ids,
"attention_mask": input_mask,
"token_type_ids": token_type_ids,
"encoder_hidden_states": encoder_hidden_states,
"encoder_attention_mask": encoder_attention_mask,
}
result = model(inputs)
inputs = [input_ids, input_mask]
result = model(inputs, token_type_ids=token_type_ids, encoder_hidden_states=encoder_hidden_states)
# Also check the case where encoder outputs are not passed
result = model(input_ids, attention_mask=input_mask, token_type_ids=token_type_ids)
self.parent.assertEqual(result.last_hidden_state.shape, (self.batch_size, self.seq_length, self.hidden_size))
def create_and_check_causal_lm_model(
self, config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
):
config.is_decoder = True
model = TF{{cookiecutter.camelcase_modelname}}ForCausalLM(config=config)
inputs = {
"input_ids": input_ids,
"attention_mask": input_mask,
"token_type_ids": token_type_ids,
}
prediction_scores = model(inputs)["logits"]
self.parent.assertListEqual(
list(prediction_scores.numpy().shape), [self.batch_size, self.seq_length, self.vocab_size]
)
def create_and_check_causal_lm_model_as_decoder(
self,
config,
input_ids,
token_type_ids,
input_mask,
sequence_labels,
token_labels,
choice_labels,
encoder_hidden_states,
encoder_attention_mask,
):
config.add_cross_attention = True
model = TF{{cookiecutter.camelcase_modelname}}ForCausalLM(config=config)
inputs = {
"input_ids": input_ids,
"attention_mask": input_mask,
"token_type_ids": token_type_ids,
"encoder_hidden_states": encoder_hidden_states,
"encoder_attention_mask": encoder_attention_mask,
}
result = model(inputs)
inputs = [input_ids, input_mask]
result = model(inputs, token_type_ids=token_type_ids, encoder_hidden_states=encoder_hidden_states)
prediction_scores = result["logits"]
self.parent.assertListEqual(
list(prediction_scores.numpy().shape), [self.batch_size, self.seq_length, self.vocab_size]
)
def create_and_check_causal_lm_model_past(
self,
config,
input_ids,
token_type_ids,
input_mask,
sequence_labels,
token_labels,
choice_labels,
):
config.is_decoder = True
model = TF{{cookiecutter.camelcase_modelname}}ForCausalLM(config=config)
# first forward pass
outputs = model(input_ids, use_cache=True)
outputs_use_cache_conf = model(input_ids)
outputs_no_past = model(input_ids, use_cache=False)
self.parent.assertTrue(len(outputs) == len(outputs_use_cache_conf))
self.parent.assertTrue(len(outputs) == len(outputs_no_past) + 1)
past_key_values = outputs.past_key_values
# create hypothetical next token and extent to next_input_ids
next_tokens = ids_tensor((self.batch_size, 1), config.vocab_size)
# append to next input_ids and attn_mask
next_input_ids = tf.concat([input_ids, next_tokens], axis=-1)
output_from_no_past = model(next_input_ids, output_hidden_states=True).hidden_states[0]
output_from_past = model(
next_tokens, past_key_values=past_key_values, output_hidden_states=True
).hidden_states[0]
# select random slice
random_slice_idx = int(ids_tensor((1,), output_from_past.shape[-1]))
output_from_no_past_slice = output_from_no_past[:, -1, random_slice_idx]
output_from_past_slice = output_from_past[:, 0, random_slice_idx]
# test that outputs are equal for slice
tf.debugging.assert_near(output_from_past_slice, output_from_no_past_slice, rtol=1e-6)
def create_and_check_causal_lm_model_past_with_attn_mask(
self,
config,
input_ids,
token_type_ids,
input_mask,
sequence_labels,
token_labels,
choice_labels,
):
config.is_decoder = True
model = TF{{cookiecutter.camelcase_modelname}}ForCausalLM(config=config)
# create attention mask
half_seq_length = self.seq_length // 2
attn_mask_begin = tf.ones((self.batch_size, half_seq_length), dtype=tf.int32)
attn_mask_end = tf.zeros((self.batch_size, self.seq_length - half_seq_length), dtype=tf.int32)
attn_mask = tf.concat([attn_mask_begin, attn_mask_end], axis=1)
# first forward pass
outputs = model(input_ids, attention_mask=attn_mask, use_cache=True)
# create hypothetical next token and extent to next_input_ids
next_tokens = ids_tensor((self.batch_size, 1), config.vocab_size)
past_key_values = outputs.past_key_values
# change a random masked slice from input_ids
random_seq_idx_to_change = ids_tensor((1,), half_seq_length).numpy() + 1
random_other_next_tokens = ids_tensor((self.batch_size, self.seq_length), config.vocab_size)
vector_condition = tf.range(self.seq_length) == (self.seq_length - random_seq_idx_to_change)
condition = tf.transpose(
tf.broadcast_to(tf.expand_dims(vector_condition, -1), (self.seq_length, self.batch_size))
)
input_ids = tf.where(condition, random_other_next_tokens, input_ids)
# append to next input_ids and
next_input_ids = tf.concat([input_ids, next_tokens], axis=-1)
attn_mask = tf.concat(
[attn_mask, tf.ones((attn_mask.shape[0], 1), dtype=tf.int32)],
axis=1,
)
output_from_no_past = model(
next_input_ids,
attention_mask=attn_mask,
output_hidden_states=True,
).hidden_states[0]
output_from_past = model(
next_tokens, past_key_values=past_key_values, attention_mask=attn_mask, output_hidden_states=True
).hidden_states[0]
# select random slice
random_slice_idx = int(ids_tensor((1,), output_from_past.shape[-1]))
output_from_no_past_slice = output_from_no_past[:, -1, random_slice_idx]
output_from_past_slice = output_from_past[:, 0, random_slice_idx]
# test that outputs are equal for slice
tf.debugging.assert_near(output_from_past_slice, output_from_no_past_slice, rtol=1e-6)
def create_and_check_causal_lm_model_past_large_inputs(
self,
config,
input_ids,
token_type_ids,
input_mask,
sequence_labels,
token_labels,
choice_labels,
):
config.is_decoder = True
model = TF{{cookiecutter.camelcase_modelname}}ForCausalLM(config=config)
input_ids = input_ids[:1, :]
input_mask = input_mask[:1, :]
self.batch_size = 1
# first forward pass
outputs = model(input_ids, attention_mask=input_mask, use_cache=True)
past_key_values = outputs.past_key_values
# create hypothetical next token and extent to next_input_ids
next_tokens = ids_tensor((self.batch_size, 3), config.vocab_size)
next_attn_mask = ids_tensor((self.batch_size, 3), 2)
# append to next input_ids and
next_input_ids = tf.concat([input_ids, next_tokens], axis=-1)
next_attention_mask = tf.concat([input_mask, next_attn_mask], axis=-1)
output_from_no_past = model(
next_input_ids,
attention_mask=next_attention_mask,
output_hidden_states=True,
).hidden_states[0]
output_from_past = model(
next_tokens,
attention_mask=next_attention_mask,
past_key_values=past_key_values,
output_hidden_states=True,
).hidden_states[0]
self.parent.assertEqual(next_tokens.shape[1], output_from_past.shape[1])
# select random slice
random_slice_idx = int(ids_tensor((1,), output_from_past.shape[-1]))
output_from_no_past_slice = output_from_no_past[:, -3:, random_slice_idx]
output_from_past_slice = output_from_past[:, :, random_slice_idx]
# test that outputs are equal for slice
tf.debugging.assert_near(output_from_past_slice, output_from_no_past_slice, rtol=1e-3)
def create_and_check_decoder_model_past_large_inputs(
self,
config,
input_ids,
token_type_ids,
input_mask,
sequence_labels,
token_labels,
choice_labels,
encoder_hidden_states,
encoder_attention_mask,
):
config.add_cross_attention = True
model = TF{{cookiecutter.camelcase_modelname}}ForCausalLM(config=config)
input_ids = input_ids[:1, :]
input_mask = input_mask[:1, :]
encoder_hidden_states = encoder_hidden_states[:1, :, :]
encoder_attention_mask = encoder_attention_mask[:1, :]
self.batch_size = 1
# first forward pass
outputs = model(
input_ids,
attention_mask=input_mask,
encoder_hidden_states=encoder_hidden_states,
encoder_attention_mask=encoder_attention_mask,
use_cache=True,
)
past_key_values = outputs.past_key_values
# create hypothetical next token and extent to next_input_ids
next_tokens = ids_tensor((self.batch_size, 3), config.vocab_size)
next_attn_mask = ids_tensor((self.batch_size, 3), 2)
# append to next input_ids and
next_input_ids = tf.concat([input_ids, next_tokens], axis=-1)
next_attention_mask = tf.concat([input_mask, next_attn_mask], axis=-1)
output_from_no_past = model(
next_input_ids,
attention_mask=next_attention_mask,
encoder_hidden_states=encoder_hidden_states,
encoder_attention_mask=encoder_attention_mask,
output_hidden_states=True,
).hidden_states[0]
output_from_past = model(
next_tokens,
attention_mask=next_attention_mask,
encoder_hidden_states=encoder_hidden_states,
encoder_attention_mask=encoder_attention_mask,
past_key_values=past_key_values,
output_hidden_states=True,
).hidden_states[0]
self.parent.assertEqual(next_tokens.shape[1], output_from_past.shape[1])
# select random slice
random_slice_idx = int(ids_tensor((1,), output_from_past.shape[-1]))
output_from_no_past_slice = output_from_no_past[:, -3:, random_slice_idx]
output_from_past_slice = output_from_past[:, :, random_slice_idx]
# test that outputs are equal for slice
tf.debugging.assert_near(output_from_past_slice, output_from_no_past_slice, rtol=1e-3)
def create_and_check_for_masked_lm(
self, config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
):
model = TF{{cookiecutter.camelcase_modelname}}ForMaskedLM(config=config)
inputs = {
"input_ids": input_ids,
"attention_mask": input_mask,
"token_type_ids": token_type_ids,
}
result = model(inputs)
self.parent.assertEqual(result.logits.shape, (self.batch_size, self.seq_length, self.vocab_size))
def create_and_check_for_sequence_classification(
self, config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
):
config.num_labels = self.num_labels
model = TF{{cookiecutter.camelcase_modelname}}ForSequenceClassification(config=config)
inputs = {
"input_ids": input_ids,
"attention_mask": input_mask,
"token_type_ids": token_type_ids,
}
result = model(inputs)
self.parent.assertEqual(result.logits.shape, (self.batch_size, self.num_labels))
def create_and_check_for_multiple_choice(
self, config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
):
config.num_choices = self.num_choices
model = TF{{cookiecutter.camelcase_modelname}}ForMultipleChoice(config=config)
multiple_choice_inputs_ids = tf.tile(tf.expand_dims(input_ids, 1), (1, self.num_choices, 1))
multiple_choice_input_mask = tf.tile(tf.expand_dims(input_mask, 1), (1, self.num_choices, 1))
multiple_choice_token_type_ids = tf.tile(tf.expand_dims(token_type_ids, 1), (1, self.num_choices, 1))
inputs = {
"input_ids": multiple_choice_inputs_ids,
"attention_mask": multiple_choice_input_mask,
"token_type_ids": multiple_choice_token_type_ids,
}
result = model(inputs)
self.parent.assertEqual(result.logits.shape, (self.batch_size, self.num_choices))
def create_and_check_for_token_classification(
self, config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
):
config.num_labels = self.num_labels
model = TF{{cookiecutter.camelcase_modelname}}ForTokenClassification(config=config)
inputs = {
"input_ids": input_ids,
"attention_mask": input_mask,
"token_type_ids": token_type_ids,
}
result = model(inputs)
self.parent.assertEqual(result.logits.shape, (self.batch_size, self.seq_length, self.num_labels))
def create_and_check_for_question_answering(
self, config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
):
model = TF{{cookiecutter.camelcase_modelname}}ForQuestionAnswering(config=config)
inputs = {
"input_ids": input_ids,
"attention_mask": input_mask,
"token_type_ids": token_type_ids,
}
result = model(inputs)
self.parent.assertEqual(result.start_logits.shape, (self.batch_size, self.seq_length))
self.parent.assertEqual(result.end_logits.shape, (self.batch_size, self.seq_length))
def prepare_config_and_inputs_for_common(self):
config_and_inputs = self.prepare_config_and_inputs()
(
config,
input_ids,
token_type_ids,
input_mask,
sequence_labels,
token_labels,
choice_labels,
) = config_and_inputs
inputs_dict = {"input_ids": input_ids, "token_type_ids": token_type_ids, "attention_mask": input_mask}
return config, inputs_dict
@require_tf
class TF{{cookiecutter.camelcase_modelname}}ModelTest(TFModelTesterMixin, unittest.TestCase):
all_model_classes = (
(
TF{{cookiecutter.camelcase_modelname}}Model,
TF{{cookiecutter.camelcase_modelname}}ForCausalLM,
TF{{cookiecutter.camelcase_modelname}}ForMaskedLM,
TF{{cookiecutter.camelcase_modelname}}ForQuestionAnswering,
TF{{cookiecutter.camelcase_modelname}}ForSequenceClassification,
TF{{cookiecutter.camelcase_modelname}}ForTokenClassification,
TF{{cookiecutter.camelcase_modelname}}ForMultipleChoice,
)
if is_tf_available()
else ()
)
test_head_masking = False
test_onnx = False
def setUp(self):
self.model_tester = TF{{cookiecutter.camelcase_modelname}}ModelTester(self)
self.config_tester = ConfigTester(self, config_class={{cookiecutter.camelcase_modelname}}Config, hidden_size=37)
def test_config(self):
self.config_tester.run_common_tests()
def test_model(self):
"""Test the base model"""
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_model(*config_and_inputs)
@unittest.skip(reason="Template classes interact badly with this test.")
def test_keras_fit(self):
pass
def test_causal_lm_base_model(self):
"""Test the base model of the causal LM model
is_deocder=True, no cross_attention, no encoder outputs
"""
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_causal_lm_base_model(*config_and_inputs)
def test_model_as_decoder(self):
"""Test the base model as a decoder (of an encoder-decoder architecture)
is_deocder=True + cross_attention + pass encoder outputs
"""
config_and_inputs = self.model_tester.prepare_config_and_inputs_for_decoder()
self.model_tester.create_and_check_model_as_decoder(*config_and_inputs)
def test_for_masked_lm(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_for_masked_lm(*config_and_inputs)
def test_for_causal_lm(self):
"""Test the causal LM model"""
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_causal_lm_model(*config_and_inputs)
def test_causal_lm_model_as_decoder(self):
"""Test the causal LM model as a decoder"""
config_and_inputs = self.model_tester.prepare_config_and_inputs_for_decoder()
self.model_tester.create_and_check_causal_lm_model_as_decoder(*config_and_inputs)
def test_causal_lm_model_past(self):
"""Test causal LM model with `past_key_values`"""
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_causal_lm_model_past(*config_and_inputs)
def test_causal_lm_model_past_with_attn_mask(self):
"""Test the causal LM model with `past_key_values` and `attention_mask`"""
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_causal_lm_model_past_with_attn_mask(*config_and_inputs)
def test_causal_lm_model_past_with_large_inputs(self):
"""Test the causal LM model with `past_key_values` and a longer decoder sequence length"""
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_causal_lm_model_past_large_inputs(*config_and_inputs)
def test_decoder_model_past_with_large_inputs(self):
"""Similar to `test_causal_lm_model_past_with_large_inputs` but with cross-attention"""
config_and_inputs = self.model_tester.prepare_config_and_inputs_for_decoder()
self.model_tester.create_and_check_decoder_model_past_large_inputs(*config_and_inputs)
def test_for_multiple_choice(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_for_multiple_choice(*config_and_inputs)
def test_for_question_answering(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_for_question_answering(*config_and_inputs)
def test_for_sequence_classification(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_for_sequence_classification(*config_and_inputs)
def test_for_token_classification(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_for_token_classification(*config_and_inputs)
@slow
def test_model_from_pretrained(self):
model = TF{{cookiecutter.camelcase_modelname}}Model.from_pretrained("{{cookiecutter.checkpoint_identifier}}")
self.assertIsNotNone(model)
@require_tf
class TF{{cookiecutter.camelcase_modelname}}ModelIntegrationTest(unittest.TestCase):
@slow
def test_inference_masked_lm(self):
model = TF{{cookiecutter.camelcase_modelname}}ForMaskedLM.from_pretrained("{{cookiecutter.checkpoint_identifier}}")
input_ids = tf.constant([[0, 1, 2, 3, 4, 5]])
output = model(input_ids)[0]
# TODO Replace vocab size
vocab_size = 32000
expected_shape = [1, 6, vocab_size]
self.assertEqual(output.shape, expected_shape)
print(output[:, :3, :3])
# TODO Replace values below with what was printed above.
expected_slice = tf.constant(
[
[
[-0.05243197, -0.04498899, 0.05512108],
[-0.07444685, -0.01064632, 0.04352357],
[-0.05020351, 0.05530146, 0.00700043],
]
]
)
tf.debugging.assert_near(output[:, :3, :3], expected_slice, atol=1e-4)
{% else %}
import unittest
from transformers import (
is_tf_available,
{{cookiecutter.camelcase_modelname}}Config,
{{cookiecutter.camelcase_modelname}}Tokenizer,
)
from transformers.testing_utils import require_sentencepiece, require_tf, require_tokenizers, slow
from ...test_configuration_common import ConfigTester
from ...test_modeling_tf_common import TFModelTesterMixin, ids_tensor
if is_tf_available():
import tensorflow as tf
from transformers import (
TF{{cookiecutter.camelcase_modelname}}ForConditionalGeneration,
TF{{cookiecutter.camelcase_modelname}}Model,
)
@require_tf
class TF{{cookiecutter.camelcase_modelname}}ModelTester:
config_cls = {{cookiecutter.camelcase_modelname}}Config
config_updates = {}
hidden_act = "gelu"
def __init__(
self,
parent,
batch_size=13,
seq_length=7,
is_training=True,
use_labels=False,
vocab_size=99,
hidden_size=32,
num_hidden_layers=5,
num_attention_heads=4,
intermediate_size=37,
hidden_dropout_prob=0.1,
attention_probs_dropout_prob=0.1,
max_position_embeddings=20,
eos_token_id=2,
pad_token_id=1,
bos_token_id=0,
):
self.parent = parent
self.batch_size = batch_size
self.seq_length = seq_length
self.is_training = is_training
self.use_labels = use_labels
self.vocab_size = vocab_size
self.hidden_size = hidden_size
self.num_hidden_layers = num_hidden_layers
self.num_attention_heads = num_attention_heads
self.intermediate_size = intermediate_size
self.hidden_dropout_prob = hidden_dropout_prob
self.attention_probs_dropout_prob = attention_probs_dropout_prob
self.max_position_embeddings = max_position_embeddings
self.eos_token_id = eos_token_id
self.pad_token_id = pad_token_id
self.bos_token_id = bos_token_id
def prepare_config_and_inputs_for_common(self):
input_ids = ids_tensor([self.batch_size, self.seq_length - 1], self.vocab_size)
eos_tensor = tf.expand_dims(tf.constant([self.eos_token_id] * self.batch_size), 1)
input_ids = tf.concat([input_ids, eos_tensor], axis=1)
decoder_input_ids = ids_tensor([self.batch_size, self.seq_length], self.vocab_size)
config = self.config_cls(
vocab_size=self.vocab_size,
d_model=self.hidden_size,
encoder_layers=self.num_hidden_layers,
decoder_layers=self.num_hidden_layers,
encoder_attention_heads=self.num_attention_heads,
decoder_attention_heads=self.num_attention_heads,
encoder_ffn_dim=self.intermediate_size,
decoder_ffn_dim=self.intermediate_size,
dropout=self.hidden_dropout_prob,
attention_dropout=self.attention_probs_dropout_prob,
max_position_embeddings=self.max_position_embeddings,
eos_token_ids=[2],
bos_token_id=self.bos_token_id,
pad_token_id=self.pad_token_id,
decoder_start_token_id=self.pad_token_id,
**self.config_updates,
)
inputs_dict = prepare_{{cookiecutter.lowercase_modelname}}_inputs_dict(config, input_ids, decoder_input_ids)
return config, inputs_dict
def check_decoder_model_past_large_inputs(self, config, inputs_dict):
model = TF{{cookiecutter.camelcase_modelname}}Model(config=config).get_decoder()
input_ids = inputs_dict["input_ids"]
input_ids = input_ids[:1, :]
attention_mask = inputs_dict["attention_mask"][:1, :]
self.batch_size = 1
# first forward pass
outputs = model(input_ids, attention_mask=attention_mask, use_cache=True)
output, past_key_values = outputs.to_tuple()
# create hypothetical next token and extent to next_input_ids
next_tokens = ids_tensor((self.batch_size, 3), config.vocab_size)
next_attn_mask = ids_tensor((self.batch_size, 3), 2)
# append to next input_ids and
next_input_ids = tf.concat([input_ids, next_tokens], axis=-1)
next_attention_mask = tf.concat([attention_mask, next_attn_mask], axis=-1)
output_from_no_past = model(next_input_ids, attention_mask=next_attention_mask)[0]
output_from_past = model(next_tokens, attention_mask=next_attention_mask, past_key_values=past_key_values)[0]
self.parent.assertEqual(next_tokens.shape[1], output_from_past.shape[1])
# select random slice
random_slice_idx = int(ids_tensor((1,), output_from_past.shape[-1]))
output_from_no_past_slice = output_from_no_past[:, -3:, random_slice_idx]
output_from_past_slice = output_from_past[:, :, random_slice_idx]
# test that outputs are equal for slice
tf.debugging.assert_near(output_from_past_slice, output_from_no_past_slice, rtol=1e-3)
def prepare_{{cookiecutter.lowercase_modelname}}_inputs_dict(
config,
input_ids,
decoder_input_ids,
attention_mask=None,
decoder_attention_mask=None,
):
if attention_mask is None:
attention_mask = tf.cast(tf.math.not_equal(input_ids, config.pad_token_id), tf.int32)
if decoder_attention_mask is None:
decoder_attention_mask = tf.concat([tf.ones(decoder_input_ids[:, :1].shape, dtype=tf.int32), tf.cast(tf.math.not_equal(decoder_input_ids[:, 1:], config.pad_token_id), tf.int32)], axis=-1)
return {
"input_ids": input_ids,
"decoder_input_ids": decoder_input_ids,
"attention_mask": attention_mask,
"decoder_attention_mask": decoder_attention_mask,
}
@require_tf
class TF{{cookiecutter.camelcase_modelname}}ModelTest(TFModelTesterMixin, unittest.TestCase):
all_model_classes = (TF{{cookiecutter.camelcase_modelname}}ForConditionalGeneration, TF{{cookiecutter.camelcase_modelname}}Model) if is_tf_available() else ()
all_generative_model_classes = (TF{{cookiecutter.camelcase_modelname}}ForConditionalGeneration,) if is_tf_available() else ()
is_encoder_decoder = True
test_pruning = False
test_head_masking = False
test_onnx = False
def setUp(self):
self.model_tester = TF{{cookiecutter.camelcase_modelname}}ModelTester(self)
self.config_tester = ConfigTester(self, config_class={{cookiecutter.camelcase_modelname}}Config)
def test_config(self):
self.config_tester.run_common_tests()
def test_decoder_model_past_large_inputs(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs_for_common()
self.model_tester.check_decoder_model_past_large_inputs(*config_and_inputs)
@unittest.skip(reason="Template classes interact badly with this test.")
def test_keras_fit(self):
pass
def _assert_tensors_equal(a, b, atol=1e-12, prefix=""):
"""If tensors not close, or a and b arent both tensors, raise a nice Assertion error."""
if a is None and b is None:
return True
try:
if tf.debugging.assert_near(a, b, atol=atol):
return True
raise
except Exception:
if len(prefix) > 0:
prefix = f"{prefix}: "
raise AssertionError(f"{prefix}{a} != {b}")
def _long_tensor(tok_lst):
return tf.constant(tok_lst, dtype=tf.int32)
TOLERANCE = 1e-4
@slow
@require_sentencepiece
@require_tokenizers
@require_tf
class TF{{cookiecutter.camelcase_modelname}}ModelIntegrationTest(unittest.TestCase):
def test_inference_no_head(self):
model = TF{{cookiecutter.camelcase_modelname}}Model.from_pretrained('{{cookiecutter.checkpoint_identifier}}')
# change to intended input here
input_ids = _long_tensor([[0, 31414, 232, 328, 740, 1140, 12695, 69, 46078, 1588, 2]])
decoder_input_ids = _long_tensor([[0, 31414, 232, 328, 740, 1140, 12695, 69, 46078, 1588, 2]])
inputs_dict = prepare_{{cookiecutter.lowercase_modelname}}_inputs_dict(model.config, input_ids, decoder_input_ids)
output = model(**inputs_dict)[0]
expected_shape = (1, 11, 1024)
self.assertEqual(output.shape, expected_shape)
# change to expected output here
expected_slice = tf.Tensor(
[[0.7144, 0.8143, -1.2813], [0.7144, 0.8143, -1.2813], [-0.0467, 2.5911, -2.1845]],
)
tf.debugging.assert_near(output[:, :3, :3], expected_slice, atol=TOLERANCE)
def test_inference_with_head(self):
model = TF{{cookiecutter.camelcase_modelname}}ForConditionalGeneration.from_pretrained('{{cookiecutter.checkpoint_identifier}}')
# change to intended input here
input_ids = _long_tensor([[0, 31414, 232, 328, 740, 1140, 12695, 69, 46078, 1588, 2]])
decoder_input_ids = _long_tensor([[0, 31414, 232, 328, 740, 1140, 12695, 69, 46078, 1588, 2]])
inputs_dict = prepare_{{cookiecutter.lowercase_modelname}}_inputs_dict(model.config, input_ids, decoder_input_ids)
output = model(**inputs_dict)[0]
expected_shape = (1, 11, 1024)
self.assertEqual(output.shape, expected_shape)
# change to expected output here
expected_slice = tf.Tensor(
[[0.7144, 0.8143, -1.2813], [0.7144, 0.8143, -1.2813], [-0.0467, 2.5911, -2.1845]],
)
tf.debugging.assert_near(output[:, :3, :3], expected_slice, atol=TOLERANCE)
def test_seq_to_seq_generation(self):
hf = TF{{cookiecutter.camelcase_modelname}}ForConditionalGeneration.from_pretrained('{{cookiecutter.checkpoint_identifier}}')
tok = {{cookiecutter.camelcase_modelname}}Tokenizer.from_pretrained('{{cookiecutter.checkpoint_identifier}}')
batch_input = [
# string 1,
# string 2,
# string 3,
# string 4,
]
# The below article tests that we don't add any hypotheses outside of the top n_beams
dct = tok.batch_encode_plus(
batch_input,
max_length=512,
padding="max_length",
truncation_strategy="only_first",
truncation=True,
return_tensors="tf",
)
hypotheses_batch = hf.generate(
input_ids=dct["input_ids"],
attention_mask=dct["attention_mask"],
num_beams=2,
)
EXPECTED = [
# here expected 1,
# here expected 2,
# here expected 3,
# here expected 4,
]
generated = tok.batch_decode(
hypotheses_batch.tolist(), clean_up_tokenization_spaces=True, skip_special_tokens=True
)
assert generated == EXPECTED
{%- endif %}
| 0 |
hf_public_repos/transformers/templates/adding_a_new_model | hf_public_repos/transformers/templates/adding_a_new_model/cookiecutter-template-{{cookiecutter.modelname}}/tokenization_{{cookiecutter.lowercase_modelname}}.py | # coding=utf-8
# Copyright 2022 {{cookiecutter.authors}} and The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""Tokenization classes for {{cookiecutter.modelname}}."""
{%- if cookiecutter.tokenizer_type == "Based on BERT" %}
from ...utils import logging
from ..bert.tokenization_bert import BertTokenizer
logger = logging.get_logger(__name__)
VOCAB_FILES_NAMES = {"vocab_file": "vocab.txt"}
PRETRAINED_VOCAB_FILES_MAP = {
"vocab_file": {
"{{cookiecutter.checkpoint_identifier}}": "https://huggingface.co/{{cookiecutter.checkpoint_identifier}}/resolve/main/vocab.txt",
}
}
PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
"{{cookiecutter.checkpoint_identifier}}": 512,
}
PRETRAINED_INIT_CONFIGURATION = {
"{{cookiecutter.checkpoint_identifier}}": {"do_lower_case": False},
}
class {{cookiecutter.camelcase_modelname}}Tokenizer(BertTokenizer):
r"""
Construct a {{cookiecutter.modelname}} tokenizer.
[`~{{cookiecutter.camelcase_modelname}}Tokenizer`] is identical to [`BertTokenizer`] and runs end-to-end
tokenization: punctuation splitting and wordpiece.
Refer to superclass [`BertTokenizer`] for usage examples and documentation concerning
parameters.
"""
vocab_files_names = VOCAB_FILES_NAMES
pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
pretrained_init_configuration = PRETRAINED_INIT_CONFIGURATION
{%- elif cookiecutter.tokenizer_type == "Based on BART" %}
from ...utils import logging
from ..bart.tokenization_bart import BartTokenizer
logger = logging.get_logger(__name__)
VOCAB_FILES_NAMES = {"vocab_file": "vocab.json", "merges_file": "merges.txt"}
PRETRAINED_VOCAB_FILES_MAP = {
"vocab_file": {
"{{cookiecutter.checkpoint_identifier}}": "https://huggingface.co/{{cookiecutter.checkpoint_identifier}}/resolve/main/vocab.json",
},
"merges_file": {
"{{cookiecutter.checkpoint_identifier}}": "https://huggingface.co/{{cookiecutter.checkpoint_identifier}}/resolve/main/merges.txt",
},
}
PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
"{{cookiecutter.checkpoint_identifier}}": 1024,
}
class {{cookiecutter.camelcase_modelname}}Tokenizer(BartTokenizer):
"""
Construct a {{cookiecutter.modelname}} tokenizer.
[`~{{cookiecutter.camelcase_modelname}}Tokenizer`] is identical to [`BartTokenizer`] and runs end-to-end
tokenization: punctuation splitting and wordpiece.
Refer to superclass [`BartTokenizer`] for usage examples and documentation concerning
parameters.
"""
vocab_files_names = VOCAB_FILES_NAMES
pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
{%- elif cookiecutter.tokenizer_type == "Standalone" %}
from typing import List, Optional
from tokenizers import ByteLevelBPETokenizer
from ...tokenization_utils import AddedToken, PreTrainedTokenizer
from ...tokenization_utils_fast import PreTrainedTokenizerFast
from ...utils import logging
logger = logging.get_logger(__name__)
VOCAB_FILES_NAMES = {"vocab_file": "vocab.txt"}
PRETRAINED_VOCAB_FILES_MAP = {
"vocab_file": {
"{{cookiecutter.checkpoint_identifier}}": "https://huggingface.co/{{cookiecutter.checkpoint_identifier}}/resolve/main/vocab.txt",
},
}
PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
"{{cookiecutter.checkpoint_identifier}}": 1024,
}
class {{cookiecutter.camelcase_modelname}}Tokenizer(PreTrainedTokenizer):
"""
Construct a {{cookiecutter.modelname}} tokenizer. Based on byte-level Byte-Pair-Encoding.
Args:
vocab_file (`str`):
Path to the vocabulary file.
"""
vocab_files_names = VOCAB_FILES_NAMES
pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
model_input_names = ["input_ids", "attention_mask"]
def __init__(
self,
vocab_file,
unk_token="<|endoftext|>",
bos_token="<|endoftext|>",
eos_token="<|endoftext|>",
**kwargs
):
bos_token = AddedToken(bos_token, lstrip=False, rstrip=False) if isinstance(bos_token, str) else bos_token
eos_token = AddedToken(eos_token, lstrip=False, rstrip=False) if isinstance(eos_token, str) else eos_token
unk_token = AddedToken(unk_token, lstrip=False, rstrip=False) if isinstance(unk_token, str) else unk_token
super().__init__(bos_token=bos_token, eos_token=eos_token, unk_token=unk_token, **kwargs)
""" Initialisation """
@property
def vocab_size(self):
""" Returns vocab size """
def get_vocab(self):
""" Returns vocab as a dict """
def _tokenize(self, text):
""" Returns a tokenized string. """
def _convert_token_to_id(self, token):
""" Converts a token (str) in an id using the vocab. """
def _convert_id_to_token(self, index):
"""Converts an index (integer) in a token (str) using the vocab."""
def convert_tokens_to_string(self, tokens):
""" Converts a sequence of tokens (string) in a single string. """
def save_vocabulary(self, save_directory):
"""
Save the vocabulary and special tokens file to a directory.
Args:
save_directory (`str`):
The directory in which to save the vocabulary.
Returns:
`Tuple(str)`: Paths to the files saved.
"""
def build_inputs_with_special_tokens(
self, token_ids_0: List[int], token_ids_1: Optional[List[int]] = None
) -> List[int]:
"""
Build model inputs from a sequence or a pair of sequence for sequence classification tasks
by concatenating and adding special tokens.
A {{cookiecutter.modelname}} sequence has the following format:
- single sequence: `<s> X </s>`
- pair of sequences: `<s> A </s></s> B </s>`
Args:
token_ids_0 (`List[int]`):
List of IDs to which the special tokens will be added.
token_ids_1 (`List[int]`, *optional*):
Optional second list of IDs for sequence pairs.
Returns:
`List[int]`: List of [input IDs](../glossary#input-ids) with the appropriate special tokens.
"""
if token_ids_1 is None:
return [self.cls_token_id] + token_ids_0 + [self.sep_token_id]
cls = [self.cls_token_id]
sep = [self.sep_token_id]
return cls + token_ids_0 + sep + sep + token_ids_1 + sep
def get_special_tokens_mask(
self, token_ids_0: List[int], token_ids_1: Optional[List[int]] = None, already_has_special_tokens: bool = False
) -> List[int]:
"""
Retrieve sequence ids from a token list that has no special tokens added. This method is called when adding
special tokens using the tokenizer `prepare_for_model` method.
Args:
token_ids_0 (`List[int]`):
List of IDs.
token_ids_1 (`List[int]`, *optional*):
Optional second list of IDs for sequence pairs.
already_has_special_tokens (`bool`, *optional*, defaults to `False`):
Whether or not the token list is already formatted with special tokens for the model.
Returns:
`List[int]`: A list of integers in the range [0, 1]: 1 for a special token, 0 for a sequence token.
"""
if already_has_special_tokens:
return super().get_special_tokens_mask(
token_ids_0=token_ids_0, token_ids_1=token_ids_1, already_has_special_tokens=True
)
if token_ids_1 is None:
return [1] + ([0] * len(token_ids_0)) + [1]
return [1] + ([0] * len(token_ids_0)) + [1, 1] + ([0] * len(token_ids_1)) + [1]
def create_token_type_ids_from_sequences(
self, token_ids_0: List[int], token_ids_1: Optional[List[int]] = None
) -> List[int]:
"""
Create a mask from the two sequences passed to be used in a sequence-pair classification task.
{{cookiecutter.modelname}} does not make use of token type ids, therefore a list of zeros is returned.
Args:
token_ids_0 (`List[int]`):
List of IDs.
token_ids_1 (`List[int]`, *optional*):
Optional second list of IDs for sequence pairs.
Returns:
`List[int]`: List of zeros.
"""
sep = [self.sep_token_id]
cls = [self.cls_token_id]
if token_ids_1 is None:
return len(cls + token_ids_0 + sep) * [0]
return len(cls + token_ids_0 + sep + sep + token_ids_1 + sep) * [0]
def prepare_for_tokenization(self, text, is_split_into_words=False, **kwargs):
add_prefix_space = kwargs.pop("add_prefix_space", self.add_prefix_space)
if (is_split_into_words or add_prefix_space) and (len(text) > 0 and not text[0].isspace()):
text = " " + text
return (text, kwargs)
class {{cookiecutter.camelcase_modelname}}TokenizerFast(PreTrainedTokenizerFast):
"""
Construct a "fast" {{cookiecutter.modelname}} tokenizer (backed by HuggingFace's *tokenizers* library).
Args:
vocab_file (`str`):
Path to the vocabulary file.
"""
vocab_files_names = VOCAB_FILES_NAMES
pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
model_input_names = ["input_ids", "attention_mask"]
def __init__(
self,
vocab_file,
merges_file,
unk_token="<|endoftext|>",
bos_token="<|endoftext|>",
eos_token="<|endoftext|>",
add_prefix_space=False,
trim_offsets=True,
**kwargs
):
super().__init__(
ByteLevelBPETokenizer(
vocab_file=vocab_file,
merges_file=merges_file,
add_prefix_space=add_prefix_space,
trim_offsets=trim_offsets,
),
bos_token=bos_token,
eos_token=eos_token,
unk_token=unk_token,
**kwargs,
)
self.add_prefix_space = add_prefix_space
def build_inputs_with_special_tokens(self, token_ids_0, token_ids_1=None):
output = [self.bos_token_id] + token_ids_0 + [self.eos_token_id]
if token_ids_1 is None:
return output
return output + [self.eos_token_id] + token_ids_1 + [self.eos_token_id]
def create_token_type_ids_from_sequences(
self, token_ids_0: List[int], token_ids_1: Optional[List[int]] = None
) -> List[int]:
"""
Create a mask from the two sequences passed to be used in a sequence-pair classification task.
{{cookiecutter.modelname}} does not make use of token type ids, therefore a list of zeros is returned.
Args:
token_ids_0 (`List[int]`):
List of IDs.
token_ids_1 (`List[int]`, *optional*):
Optional second list of IDs for sequence pairs.
Returns:
`List[int]`: List of zeros.
"""
sep = [self.sep_token_id]
cls = [self.cls_token_id]
if token_ids_1 is None:
return len(cls + token_ids_0 + sep) * [0]
return len(cls + token_ids_0 + sep + sep + token_ids_1 + sep) * [0]
{% endif %}
| 0 |
hf_public_repos/transformers/templates/adding_a_new_model | hf_public_repos/transformers/templates/adding_a_new_model/cookiecutter-template-{{cookiecutter.modelname}}/to_replace_{{cookiecutter.lowercase_modelname}}.py | ## Copyright 2022 The HuggingFace Team. All rights reserved.
##
## Licensed under the Apache License, Version 2.0 (the "License");
## you may not use this file except in compliance with the License.
## You may obtain a copy of the License at
##
## http://www.apache.org/licenses/LICENSE-2.0
##
## Unless required by applicable law or agreed to in writing, software
## distributed under the License is distributed on an "AS IS" BASIS,
## WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
## See the License for the specific language governing permissions and
## limitations under the License.
## This file is made so that specific statements may be copied inside existing files. This is useful to copy
## import statements in __init__.py, or to complete model lists in the AUTO files.
##
## It is to be used as such:
## Put '# To replace in: "FILE_PATH"' in order to indicate the contents will be copied in the file at path FILE_PATH
## Put '# Below: "STATEMENT"' in order to copy the contents below **the first occurence** of that line in the file at FILE_PATH
## Put '# Replace with:' followed by the lines containing the content to define the content
## End a statement with '# End.'. If starting a new statement without redefining the FILE_PATH, it will continue pasting
## content in that file.
##
## Put '## COMMENT' to comment on the file.
# To replace in: "src/transformers/__init__.py"
# Below: " # PyTorch models structure" if generating PyTorch
# Replace with:
{% if cookiecutter.is_encoder_decoder_model == "False" %}
_import_structure["models.{{cookiecutter.lowercase_modelname}}"].extend(
[
"{{cookiecutter.uppercase_modelname}}_PRETRAINED_MODEL_ARCHIVE_LIST",
"{{cookiecutter.camelcase_modelname}}ForMaskedLM",
"{{cookiecutter.camelcase_modelname}}ForCausalLM",
"{{cookiecutter.camelcase_modelname}}ForMultipleChoice",
"{{cookiecutter.camelcase_modelname}}ForQuestionAnswering",
"{{cookiecutter.camelcase_modelname}}ForSequenceClassification",
"{{cookiecutter.camelcase_modelname}}ForTokenClassification",
"{{cookiecutter.camelcase_modelname}}Layer",
"{{cookiecutter.camelcase_modelname}}Model",
"{{cookiecutter.camelcase_modelname}}PreTrainedModel",
"load_tf_weights_in_{{cookiecutter.lowercase_modelname}}",
]
)
{% else %}
_import_structure["models.{{cookiecutter.lowercase_modelname}}"].extend(
[
"{{cookiecutter.uppercase_modelname}}_PRETRAINED_MODEL_ARCHIVE_LIST",
"{{cookiecutter.camelcase_modelname}}ForCausalLM",
"{{cookiecutter.camelcase_modelname}}ForConditionalGeneration",
"{{cookiecutter.camelcase_modelname}}ForQuestionAnswering",
"{{cookiecutter.camelcase_modelname}}ForSequenceClassification",
"{{cookiecutter.camelcase_modelname}}Model",
"{{cookiecutter.camelcase_modelname}}PreTrainedModel",
]
)
{% endif -%}
# End.
# Below: " # TensorFlow models structure" if generating TensorFlow
# Replace with:
{% if cookiecutter.is_encoder_decoder_model == "False" %}
_import_structure["models.{{cookiecutter.lowercase_modelname}}"].extend(
[
"TF_{{cookiecutter.uppercase_modelname}}_PRETRAINED_MODEL_ARCHIVE_LIST",
"TF{{cookiecutter.camelcase_modelname}}ForMaskedLM",
"TF{{cookiecutter.camelcase_modelname}}ForCausalLM",
"TF{{cookiecutter.camelcase_modelname}}ForMultipleChoice",
"TF{{cookiecutter.camelcase_modelname}}ForQuestionAnswering",
"TF{{cookiecutter.camelcase_modelname}}ForSequenceClassification",
"TF{{cookiecutter.camelcase_modelname}}ForTokenClassification",
"TF{{cookiecutter.camelcase_modelname}}Layer",
"TF{{cookiecutter.camelcase_modelname}}Model",
"TF{{cookiecutter.camelcase_modelname}}PreTrainedModel",
]
)
{% else %}
_import_structure["models.{{cookiecutter.lowercase_modelname}}"].extend(
[
"TF{{cookiecutter.camelcase_modelname}}ForConditionalGeneration",
"TF{{cookiecutter.camelcase_modelname}}Model",
"TF{{cookiecutter.camelcase_modelname}}PreTrainedModel",
]
)
{% endif -%}
# End.
# Below: " # Flax models structure" if generating Flax
# Replace with:
{% if cookiecutter.is_encoder_decoder_model == "False" %}
_import_structure["models.{{cookiecutter.lowercase_modelname}}"].extend(
[
"Flax{{cookiecutter.camelcase_modelname}}ForMaskedLM",
"Flax{{cookiecutter.camelcase_modelname}}ForCausalLM",
"Flax{{cookiecutter.camelcase_modelname}}ForMultipleChoice",
"Flax{{cookiecutter.camelcase_modelname}}ForQuestionAnswering",
"Flax{{cookiecutter.camelcase_modelname}}ForSequenceClassification",
"Flax{{cookiecutter.camelcase_modelname}}ForTokenClassification",
"Flax{{cookiecutter.camelcase_modelname}}Layer",
"Flax{{cookiecutter.camelcase_modelname}}Model",
"Flax{{cookiecutter.camelcase_modelname}}PreTrainedModel",
]
)
{% else %}
_import_structure["models.{{cookiecutter.lowercase_modelname}}"].extend(
[
"Flax{{cookiecutter.camelcase_modelname}}ForConditionalGeneration",
"Flax{{cookiecutter.camelcase_modelname}}ForQuestionAnswering",
"Flax{{cookiecutter.camelcase_modelname}}ForSequenceClassification",
"Flax{{cookiecutter.camelcase_modelname}}Model",
"Flax{{cookiecutter.camelcase_modelname}}PreTrainedModel",
]
)
{% endif -%}
# End.
# Below: " # Fast tokenizers structure"
# Replace with:
_import_structure["models.{{cookiecutter.lowercase_modelname}}"].append("{{cookiecutter.camelcase_modelname}}TokenizerFast")
# End.
# Below: " # Models"
# Replace with:
"models.{{cookiecutter.lowercase_modelname}}": ["{{cookiecutter.uppercase_modelname}}_PRETRAINED_CONFIG_ARCHIVE_MAP", "{{cookiecutter.camelcase_modelname}}Config", "{{cookiecutter.camelcase_modelname}}Tokenizer"],
# End.
# To replace in: "src/transformers/__init__.py"
# Below: " # PyTorch model imports" if generating PyTorch
# Replace with:
{% if cookiecutter.is_encoder_decoder_model == "False" %}
from .models.{{cookiecutter.lowercase_modelname}} import (
{{cookiecutter.uppercase_modelname}}_PRETRAINED_MODEL_ARCHIVE_LIST,
{{cookiecutter.camelcase_modelname}}ForMaskedLM,
{{cookiecutter.camelcase_modelname}}ForCausalLM,
{{cookiecutter.camelcase_modelname}}ForMultipleChoice,
{{cookiecutter.camelcase_modelname}}ForQuestionAnswering,
{{cookiecutter.camelcase_modelname}}ForSequenceClassification,
{{cookiecutter.camelcase_modelname}}ForTokenClassification,
{{cookiecutter.camelcase_modelname}}Layer,
{{cookiecutter.camelcase_modelname}}Model,
{{cookiecutter.camelcase_modelname}}PreTrainedModel,
load_tf_weights_in_{{cookiecutter.lowercase_modelname}},
)
{% else %}
from .models.{{cookiecutter.lowercase_modelname}} import (
{{cookiecutter.uppercase_modelname}}_PRETRAINED_MODEL_ARCHIVE_LIST,
{{cookiecutter.camelcase_modelname}}ForConditionalGeneration,
{{cookiecutter.camelcase_modelname}}ForCausalLM,
{{cookiecutter.camelcase_modelname}}ForQuestionAnswering,
{{cookiecutter.camelcase_modelname}}ForSequenceClassification,
{{cookiecutter.camelcase_modelname}}Model,
{{cookiecutter.camelcase_modelname}}PreTrainedModel,
)
{% endif -%}
# End.
# Below: " # TensorFlow model imports" if generating TensorFlow
# Replace with:
{% if cookiecutter.is_encoder_decoder_model == "False" %}
from .models.{{cookiecutter.lowercase_modelname}} import (
TF_{{cookiecutter.uppercase_modelname}}_PRETRAINED_MODEL_ARCHIVE_LIST,
TF{{cookiecutter.camelcase_modelname}}ForMaskedLM,
TF{{cookiecutter.camelcase_modelname}}ForCausalLM,
TF{{cookiecutter.camelcase_modelname}}ForMultipleChoice,
TF{{cookiecutter.camelcase_modelname}}ForQuestionAnswering,
TF{{cookiecutter.camelcase_modelname}}ForSequenceClassification,
TF{{cookiecutter.camelcase_modelname}}ForTokenClassification,
TF{{cookiecutter.camelcase_modelname}}Layer,
TF{{cookiecutter.camelcase_modelname}}Model,
TF{{cookiecutter.camelcase_modelname}}PreTrainedModel,
)
{% else %}
from .models.{{cookiecutter.lowercase_modelname}} import (
TF{{cookiecutter.camelcase_modelname}}ForConditionalGeneration,
TF{{cookiecutter.camelcase_modelname}}Model,
TF{{cookiecutter.camelcase_modelname}}PreTrainedModel,
)
{% endif -%}
# End.
# Below: " # Flax model imports" if generating Flax
# Replace with:
{% if cookiecutter.is_encoder_decoder_model == "False" %}
from .models.{{cookiecutter.lowercase_modelname}} import (
Flax{{cookiecutter.camelcase_modelname}}ForMaskedLM,
Flax{{cookiecutter.camelcase_modelname}}ForCausalLM,
Flax{{cookiecutter.camelcase_modelname}}ForMultipleChoice,
Flax{{cookiecutter.camelcase_modelname}}ForQuestionAnswering,
Flax{{cookiecutter.camelcase_modelname}}ForSequenceClassification,
Flax{{cookiecutter.camelcase_modelname}}ForTokenClassification,
Flax{{cookiecutter.camelcase_modelname}}Layer,
Flax{{cookiecutter.camelcase_modelname}}Model,
Flax{{cookiecutter.camelcase_modelname}}PreTrainedModel,
)
{% else %}
from .models.{{cookiecutter.lowercase_modelname}} import (
Flax{{cookiecutter.camelcase_modelname}}ForConditionalGeneration,
Flax{{cookiecutter.camelcase_modelname}}ForQuestionAnswering,
Flax{{cookiecutter.camelcase_modelname}}ForSequenceClassification,
Flax{{cookiecutter.camelcase_modelname}}Model,
Flax{{cookiecutter.camelcase_modelname}}PreTrainedModel,
)
{% endif -%}
# End.
# Below: " # Fast tokenizers imports"
# Replace with:
from .models.{{cookiecutter.lowercase_modelname}} import {{cookiecutter.camelcase_modelname}}TokenizerFast
# End.
# Below: " from .models.albert import ALBERT_PRETRAINED_CONFIG_ARCHIVE_MAP, AlbertConfig"
# Replace with:
from .models.{{cookiecutter.lowercase_modelname}} import {{cookiecutter.uppercase_modelname}}_PRETRAINED_CONFIG_ARCHIVE_MAP, {{cookiecutter.camelcase_modelname}}Config, {{cookiecutter.camelcase_modelname}}Tokenizer
# End.
# To replace in: "src/transformers/models/__init__.py"
# Below: "from . import ("
# Replace with:
{{cookiecutter.lowercase_modelname}},
# End.
# To replace in: "src/transformers/models/auto/configuration_auto.py"
# Below: "# Add configs here"
# Replace with:
("{{cookiecutter.lowercase_modelname}}", "{{cookiecutter.camelcase_modelname}}Config"),
# End.
# Below: "# Add archive maps here"
# Replace with:
("{{cookiecutter.lowercase_modelname}}", "{{cookiecutter.uppercase_modelname}}_PRETRAINED_CONFIG_ARCHIVE_MAP"),
# End.
# Below: "# Add full (and cased) model names here"
# Replace with:
("{{cookiecutter.lowercase_modelname}}", "{{cookiecutter.camelcase_modelname}}"),
# End.
# To replace in: "src/transformers/models/auto/modeling_auto.py" if generating PyTorch
# Below: "# Base model mapping"
# Replace with:
("{{cookiecutter.lowercase_modelname}}", "{{cookiecutter.camelcase_modelname}}Model"),
# End.
# Below: "# Model with LM heads mapping"
# Replace with:
{% if cookiecutter.is_encoder_decoder_model == "False" -%}
("{{cookiecutter.lowercase_modelname}}", "{{cookiecutter.camelcase_modelname}}ForMaskedLM"),
{% else %}
("{{cookiecutter.lowercase_modelname}}", "{{cookiecutter.camelcase_modelname}}ForConditionalGeneration"),
{% endif -%}
# End.
# Below: "# Model for Causal LM mapping"
# Replace with:
("{{cookiecutter.lowercase_modelname}}", "{{cookiecutter.camelcase_modelname}}ForCausalLM"),
# End.
# Below: "# Model for Masked LM mapping"
# Replace with:
{% if cookiecutter.is_encoder_decoder_model == "False" -%}
("{{cookiecutter.lowercase_modelname}}", "{{cookiecutter.camelcase_modelname}}ForMaskedLM"),
{% else -%}
{% endif -%}
# End.
# Below: "# Model for Sequence Classification mapping"
# Replace with:
("{{cookiecutter.lowercase_modelname}}", "{{cookiecutter.camelcase_modelname}}ForSequenceClassification"),
# End.
# Below: "# Model for Question Answering mapping"
# Replace with:
("{{cookiecutter.lowercase_modelname}}", "{{cookiecutter.camelcase_modelname}}ForQuestionAnswering"),
# End.
# Below: "# Model for Token Classification mapping"
# Replace with:
{% if cookiecutter.is_encoder_decoder_model == "False" -%}
("{{cookiecutter.lowercase_modelname}}", "{{cookiecutter.camelcase_modelname}}ForTokenClassification"),
{% else -%}
{% endif -%}
# End.
# Below: "# Model for Multiple Choice mapping"
# Replace with:
{% if cookiecutter.is_encoder_decoder_model == "False" -%}
("{{cookiecutter.lowercase_modelname}}", "{{cookiecutter.camelcase_modelname}}ForMultipleChoice"),
{% else -%}
{% endif -%}
# End.
# Below: "# Model for Seq2Seq Causal LM mapping"
# Replace with:
{% if cookiecutter.is_encoder_decoder_model == "False" -%}
{% else %}
("{{cookiecutter.lowercase_modelname}}", "{{cookiecutter.camelcase_modelname}}ForConditionalGeneration"),
{% endif -%}
# End.
# To replace in: "src/transformers/models/auto/modeling_tf_auto.py" if generating TensorFlow
# Below: "# Base model mapping"
# Replace with:
("{{cookiecutter.lowercase_modelname}}", "TF{{cookiecutter.camelcase_modelname}}Model"),
# End.
# Below: "# Model with LM heads mapping"
# Replace with:
{% if cookiecutter.is_encoder_decoder_model == "False" -%}
("{{cookiecutter.lowercase_modelname}}", "TF{{cookiecutter.camelcase_modelname}}ForMaskedLM"),
{% else %}
("{{cookiecutter.lowercase_modelname}}", "TF{{cookiecutter.camelcase_modelname}}ForConditionalGeneration"),
{% endif -%}
# End.
# Below: "# Model for Causal LM mapping"
# Replace with:
{% if cookiecutter.is_encoder_decoder_model == "False" -%}
("{{cookiecutter.lowercase_modelname}}", "TF{{cookiecutter.camelcase_modelname}}ForCausalLM"),
{% else -%}
{% endif -%}
# End.
# Below: "# Model for Masked LM mapping"
# Replace with:
{% if cookiecutter.is_encoder_decoder_model == "False" -%}
("{{cookiecutter.lowercase_modelname}}", "TF{{cookiecutter.camelcase_modelname}}ForMaskedLM"),
{% else -%}
{% endif -%}
# End.
# Below: "# Model for Sequence Classification mapping"
# Replace with:
{% if cookiecutter.is_encoder_decoder_model == "False" -%}
("{{cookiecutter.lowercase_modelname}}", "TF{{cookiecutter.camelcase_modelname}}ForSequenceClassification"),
{% else -%}
{% endif -%}
# End.
# Below: "# Model for Question Answering mapping"
# Replace with:
{% if cookiecutter.is_encoder_decoder_model == "False" -%}
("{{cookiecutter.lowercase_modelname}}", "TF{{cookiecutter.camelcase_modelname}}ForQuestionAnswering"),
{% else -%}
{% endif -%}
# End.
# Below: "# Model for Token Classification mapping"
# Replace with:
{% if cookiecutter.is_encoder_decoder_model == "False" -%}
("{{cookiecutter.lowercase_modelname}}", "TF{{cookiecutter.camelcase_modelname}}ForTokenClassification"),
{% else -%}
{% endif -%}
# End.
# Below: "# Model for Multiple Choice mapping"
# Replace with:
{% if cookiecutter.is_encoder_decoder_model == "False" -%}
("{{cookiecutter.lowercase_modelname}}", "TF{{cookiecutter.camelcase_modelname}}ForMultipleChoice"),
{% else -%}
{% endif -%}
# End.
# Below: "# Model for Seq2Seq Causal LM mapping"
# Replace with:
{% if cookiecutter.is_encoder_decoder_model == "False" -%}
{% else %}
("{{cookiecutter.lowercase_modelname}}", "TF{{cookiecutter.camelcase_modelname}}ForConditionalGeneration"),
{% endif -%}
# End.
# To replace in: "src/transformers/models/auto/modeling_flax_auto.py" if generating Flax
# Below: "# Base model mapping"
# Replace with:
("{{cookiecutter.lowercase_modelname}}", "Flax{{cookiecutter.camelcase_modelname}}Model"),
# End.
# Below: "# Model for Masked LM mapping"
# Replace with:
{% if cookiecutter.is_encoder_decoder_model == "False" -%}
("{{cookiecutter.lowercase_modelname}}", "Flax{{cookiecutter.camelcase_modelname}}ForMaskedLM"),
{% else %}
("{{cookiecutter.lowercase_modelname}}", "Flax{{cookiecutter.camelcase_modelname}}ForConditionalGeneration"),
{% endif -%}
# End.
# Below: "# Model for Causal LM mapping"
# Replace with:
{% if cookiecutter.is_encoder_decoder_model == "False" -%}
("{{cookiecutter.lowercase_modelname}}", "Flax{{cookiecutter.camelcase_modelname}}ForCausalLM"),
{% else -%}
{% endif -%}
# End.
# Below: "# Model for Masked LM mapping"
# Replace with:
{% if cookiecutter.is_encoder_decoder_model == "False" -%}
("{{cookiecutter.lowercase_modelname}}", "Flax{{cookiecutter.camelcase_modelname}}ForMaskedLM"),
{% else -%}
{% endif -%}
# End.
# Below: "# Model for Sequence Classification mapping"
# Replace with:
{% if cookiecutter.is_encoder_decoder_model == "False" -%}
("{{cookiecutter.lowercase_modelname}}", "Flax{{cookiecutter.camelcase_modelname}}ForSequenceClassification"),
{% else %}
("{{cookiecutter.lowercase_modelname}}", "Flax{{cookiecutter.camelcase_modelname}}ForSequenceClassification"),
{% endif -%}
# End.
# Below: "# Model for Question Answering mapping"
# Replace with:
{% if cookiecutter.is_encoder_decoder_model == "False" -%}
("{{cookiecutter.lowercase_modelname}}", "Flax{{cookiecutter.camelcase_modelname}}ForQuestionAnswering"),
{% else %}
("{{cookiecutter.lowercase_modelname}}", "Flax{{cookiecutter.camelcase_modelname}}ForQuestionAnswering"),
{% endif -%}
# End.
# Below: "# Model for Token Classification mapping"
# Replace with:
{% if cookiecutter.is_encoder_decoder_model == "False" -%}
("{{cookiecutter.lowercase_modelname}}", "Flax{{cookiecutter.camelcase_modelname}}ForTokenClassification"),
{% else -%}
{% endif -%}
# End.
# Below: "# Model for Multiple Choice mapping"
# Replace with:
{% if cookiecutter.is_encoder_decoder_model == "False" -%}
("{{cookiecutter.lowercase_modelname}}", "Flax{{cookiecutter.camelcase_modelname}}ForMultipleChoice"),
{% else -%}
{% endif -%}
# End.
# Below: "# Model for Seq2Seq Causal LM mapping"
# Replace with:
{% if cookiecutter.is_encoder_decoder_model == "False" -%}
{% else %}
("{{cookiecutter.lowercase_modelname}}", "Flax{{cookiecutter.camelcase_modelname}}ForConditionalGeneration"),
{% endif -%}
# End.
# To replace in: "utils/check_repo.py" if generating PyTorch
# Below: "models to ignore for model xxx mapping"
# Replace with:
{% if cookiecutter.is_encoder_decoder_model == "False" -%}
{% else -%}
"{{cookiecutter.camelcase_modelname}}Encoder",
"{{cookiecutter.camelcase_modelname}}Decoder",
"{{cookiecutter.camelcase_modelname}}DecoderWrapper",
{% endif -%}
# End.
# Below: "models to ignore for not tested"
# Replace with:
{% if cookiecutter.is_encoder_decoder_model == "False" -%}
{% else -%}
"{{cookiecutter.camelcase_modelname}}Encoder", # Building part of bigger (tested) model.
"{{cookiecutter.camelcase_modelname}}Decoder", # Building part of bigger (tested) model.
"{{cookiecutter.camelcase_modelname}}DecoderWrapper", # Building part of bigger (tested) model.
{% endif -%}
# End.
| 0 |
hf_public_repos/transformers/templates/adding_a_new_model | hf_public_repos/transformers/templates/adding_a_new_model/cookiecutter-template-{{cookiecutter.modelname}}/{{cookiecutter.lowercase_modelname}}.md | <!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# {{cookiecutter.modelname}}
## Overview
The {{cookiecutter.modelname}} model was proposed in [<INSERT PAPER NAME HERE>](<INSERT PAPER LINK HERE>) by <INSERT AUTHORS HERE>. <INSERT SHORT SUMMARY HERE>
The abstract from the paper is the following:
*<INSERT PAPER ABSTRACT HERE>*
Tips:
<INSERT TIPS ABOUT MODEL HERE>
This model was contributed by [INSERT YOUR HF USERNAME HERE](<https://huggingface.co/<INSERT YOUR HF USERNAME HERE>). The original code can be found [here](<INSERT LINK TO GITHUB REPO HERE>).
## {{cookiecutter.camelcase_modelname}}Config
[[autodoc]] {{cookiecutter.camelcase_modelname}}Config
## {{cookiecutter.camelcase_modelname}}Tokenizer
[[autodoc]] {{cookiecutter.camelcase_modelname}}Tokenizer
- build_inputs_with_special_tokens
- get_special_tokens_mask
- create_token_type_ids_from_sequences
- save_vocabulary
## {{cookiecutter.camelcase_modelname}}TokenizerFast
[[autodoc]] {{cookiecutter.camelcase_modelname}}TokenizerFast
{% if "PyTorch" in cookiecutter.generate_tensorflow_pytorch_and_flax -%}
## {{cookiecutter.camelcase_modelname}}Model
[[autodoc]] {{cookiecutter.camelcase_modelname}}Model
- forward
{% if cookiecutter.is_encoder_decoder_model == "False" %}
## {{cookiecutter.camelcase_modelname}}ForCausalLM
[[autodoc]] {{cookiecutter.camelcase_modelname}}ForCausalLM
- forward
## {{cookiecutter.camelcase_modelname}}ForMaskedLM
[[autodoc]] {{cookiecutter.camelcase_modelname}}ForMaskedLM
- forward
## {{cookiecutter.camelcase_modelname}}ForSequenceClassification
[[autodoc]] transformers.{{cookiecutter.camelcase_modelname}}ForSequenceClassification
- forward
## {{cookiecutter.camelcase_modelname}}ForMultipleChoice
[[autodoc]] transformers.{{cookiecutter.camelcase_modelname}}ForMultipleChoice
- forward
## {{cookiecutter.camelcase_modelname}}ForTokenClassification
[[autodoc]] transformers.{{cookiecutter.camelcase_modelname}}ForTokenClassification
- forward
## {{cookiecutter.camelcase_modelname}}ForQuestionAnswering
[[autodoc]] {{cookiecutter.camelcase_modelname}}ForQuestionAnswering
- forward
{%- else %}
## {{cookiecutter.camelcase_modelname}}ForConditionalGeneration
[[autodoc]] {{cookiecutter.camelcase_modelname}}ForConditionalGeneration
- forward
## {{cookiecutter.camelcase_modelname}}ForSequenceClassification
[[autodoc]] {{cookiecutter.camelcase_modelname}}ForSequenceClassification
- forward
## {{cookiecutter.camelcase_modelname}}ForQuestionAnswering
[[autodoc]] {{cookiecutter.camelcase_modelname}}ForQuestionAnswering
- forward
## {{cookiecutter.camelcase_modelname}}ForCausalLM
[[autodoc]] {{cookiecutter.camelcase_modelname}}ForCausalLM
- forward
{% endif -%}
{% endif -%}
{% if "TensorFlow" in cookiecutter.generate_tensorflow_pytorch_and_flax -%}
## TF{{cookiecutter.camelcase_modelname}}Model
[[autodoc]] TF{{cookiecutter.camelcase_modelname}}Model
- call
{% if cookiecutter.is_encoder_decoder_model == "False" %}
## TF{{cookiecutter.camelcase_modelname}}ForMaskedLM
[[autodoc]] TF{{cookiecutter.camelcase_modelname}}ForMaskedLM
- call
## TF{{cookiecutter.camelcase_modelname}}ForCausalLM
[[autodoc]] TF{{cookiecutter.camelcase_modelname}}ForCausalLM
- call
## TF{{cookiecutter.camelcase_modelname}}ForSequenceClassification
[[autodoc]] TF{{cookiecutter.camelcase_modelname}}ForSequenceClassification
- call
## TF{{cookiecutter.camelcase_modelname}}ForMultipleChoice
[[autodoc]] TF{{cookiecutter.camelcase_modelname}}ForMultipleChoice
- call
## TF{{cookiecutter.camelcase_modelname}}ForTokenClassification
[[autodoc]] TF{{cookiecutter.camelcase_modelname}}ForTokenClassification
- call
## TF{{cookiecutter.camelcase_modelname}}ForQuestionAnswering
[[autodoc]] TF{{cookiecutter.camelcase_modelname}}ForQuestionAnswering
- call
{%- else %}
## TF{{cookiecutter.camelcase_modelname}}ForConditionalGeneration
[[autodoc]] TF{{cookiecutter.camelcase_modelname}}ForConditionalGeneration
- call
{% endif -%}
{% endif -%}
{% if "Flax" in cookiecutter.generate_tensorflow_pytorch_and_flax -%}
## Flax{{cookiecutter.camelcase_modelname}}Model
[[autodoc]] Flax{{cookiecutter.camelcase_modelname}}Model
- call
{% if cookiecutter.is_encoder_decoder_model == "False" %}
## Flax{{cookiecutter.camelcase_modelname}}ForMaskedLM
[[autodoc]] Flax{{cookiecutter.camelcase_modelname}}ForMaskedLM
- call
## Flax{{cookiecutter.camelcase_modelname}}ForCausalLM
[[autodoc]] Flax{{cookiecutter.camelcase_modelname}}ForCausalLM
- call
## Flax{{cookiecutter.camelcase_modelname}}ForSequenceClassification
[[autodoc]] Flax{{cookiecutter.camelcase_modelname}}ForSequenceClassification
- call
## Flax{{cookiecutter.camelcase_modelname}}ForMultipleChoice
[[autodoc]] Flax{{cookiecutter.camelcase_modelname}}ForMultipleChoice
- call
## Flax{{cookiecutter.camelcase_modelname}}ForTokenClassification
[[autodoc]] Flax{{cookiecutter.camelcase_modelname}}ForTokenClassification
- call
## Flax{{cookiecutter.camelcase_modelname}}ForQuestionAnswering
[[autodoc]] Flax{{cookiecutter.camelcase_modelname}}ForQuestionAnswering
- call
{%- else %}
## Flax{{cookiecutter.camelcase_modelname}}ForSequenceClassification
[[autodoc]] Flax{{cookiecutter.camelcase_modelname}}ForSequenceClassification
- call
## Flax{{cookiecutter.camelcase_modelname}}ForQuestionAnswering
[[autodoc]] Flax{{cookiecutter.camelcase_modelname}}ForQuestionAnswering
- call
## Flax{{cookiecutter.camelcase_modelname}}ForConditionalGeneration
[[autodoc]] Flax{{cookiecutter.camelcase_modelname}}ForConditionalGeneration
- call
{% endif -%}
{% endif -%}
| 0 |
hf_public_repos/transformers/templates/adding_a_new_model | hf_public_repos/transformers/templates/adding_a_new_model/cookiecutter-template-{{cookiecutter.modelname}}/test_modeling_{{cookiecutter.lowercase_modelname}}.py | # coding=utf-8
# Copyright 2022 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
""" Testing suite for the PyTorch {{cookiecutter.modelname}} model. """
{% if cookiecutter.is_encoder_decoder_model == "False" -%}
import unittest
from ...test_modeling_common import floats_tensor
from transformers import is_torch_available
from transformers.testing_utils import require_torch, slow, torch_device
from transformers import {{cookiecutter.camelcase_modelname}}Config
from ...test_configuration_common import ConfigTester
from ...test_modeling_common import ModelTesterMixin, ids_tensor, random_attention_mask
if is_torch_available():
import torch
from transformers import (
{{cookiecutter.camelcase_modelname}}ForCausalLM,
{{cookiecutter.camelcase_modelname}}ForMaskedLM,
{{cookiecutter.camelcase_modelname}}ForMultipleChoice,
{{cookiecutter.camelcase_modelname}}ForQuestionAnswering,
{{cookiecutter.camelcase_modelname}}ForSequenceClassification,
{{cookiecutter.camelcase_modelname}}ForTokenClassification,
{{cookiecutter.camelcase_modelname}}Model,
)
from transformers.models.{{cookiecutter.lowercase_modelname}}.modeling_{{cookiecutter.lowercase_modelname}} import (
{{cookiecutter.uppercase_modelname}}_PRETRAINED_MODEL_ARCHIVE_LIST,
)
class {{cookiecutter.camelcase_modelname}}ModelTester:
def __init__(
self,
parent,
batch_size=13,
seq_length=7,
is_training=True,
use_input_mask=True,
use_token_type_ids=True,
use_labels=True,
vocab_size=99,
hidden_size=32,
num_hidden_layers=5,
num_attention_heads=4,
intermediate_size=37,
hidden_act="gelu",
hidden_dropout_prob=0.1,
attention_probs_dropout_prob=0.1,
max_position_embeddings=512,
type_vocab_size=16,
type_sequence_label_size=2,
initializer_range=0.02,
num_labels=3,
num_choices=4,
scope=None,
):
self.parent = parent
self.batch_size = batch_size
self.seq_length = seq_length
self.is_training = is_training
self.use_input_mask = use_input_mask
self.use_token_type_ids = use_token_type_ids
self.use_labels = use_labels
self.vocab_size = vocab_size
self.hidden_size = hidden_size
self.num_hidden_layers = num_hidden_layers
self.num_attention_heads = num_attention_heads
self.intermediate_size = intermediate_size
self.hidden_act = hidden_act
self.hidden_dropout_prob = hidden_dropout_prob
self.attention_probs_dropout_prob = attention_probs_dropout_prob
self.max_position_embeddings = max_position_embeddings
self.type_vocab_size = type_vocab_size
self.type_sequence_label_size = type_sequence_label_size
self.initializer_range = initializer_range
self.num_labels = num_labels
self.num_choices = num_choices
self.scope = scope
def prepare_config_and_inputs(self):
input_ids = ids_tensor([self.batch_size, self.seq_length], self.vocab_size)
input_mask = None
if self.use_input_mask:
input_mask = random_attention_mask([self.batch_size, self.seq_length])
token_type_ids = None
if self.use_token_type_ids:
token_type_ids = ids_tensor([self.batch_size, self.seq_length], self.type_vocab_size)
sequence_labels = None
token_labels = None
choice_labels = None
if self.use_labels:
sequence_labels = ids_tensor([self.batch_size], self.type_sequence_label_size)
token_labels = ids_tensor([self.batch_size, self.seq_length], self.num_labels)
choice_labels = ids_tensor([self.batch_size], self.num_choices)
config = self.get_config()
return config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
def get_config(self):
return {{cookiecutter.camelcase_modelname}}Config(
vocab_size=self.vocab_size,
hidden_size=self.hidden_size,
num_hidden_layers=self.num_hidden_layers,
num_attention_heads=self.num_attention_heads,
intermediate_size=self.intermediate_size,
hidden_act=self.hidden_act,
hidden_dropout_prob=self.hidden_dropout_prob,
attention_probs_dropout_prob=self.attention_probs_dropout_prob,
max_position_embeddings=self.max_position_embeddings,
type_vocab_size=self.type_vocab_size,
is_decoder=False,
initializer_range=self.initializer_range,
)
def prepare_config_and_inputs_for_decoder(self):
(
config,
input_ids,
token_type_ids,
input_mask,
sequence_labels,
token_labels,
choice_labels,
) = self.prepare_config_and_inputs()
config.is_decoder = True
encoder_hidden_states = floats_tensor([self.batch_size, self.seq_length, self.hidden_size])
encoder_attention_mask = ids_tensor([self.batch_size, self.seq_length], vocab_size=2)
return (
config,
input_ids,
token_type_ids,
input_mask,
sequence_labels,
token_labels,
choice_labels,
encoder_hidden_states,
encoder_attention_mask,
)
def create_and_check_model(
self, config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
):
model = {{cookiecutter.camelcase_modelname}}Model(config=config)
model.to(torch_device)
model.eval()
result = model(input_ids, attention_mask=input_mask, token_type_ids=token_type_ids)
result = model(input_ids, token_type_ids=token_type_ids)
result = model(input_ids)
self.parent.assertEqual(result.last_hidden_state.shape, (self.batch_size, self.seq_length, self.hidden_size))
def create_and_check_model_as_decoder(
self,
config,
input_ids,
token_type_ids,
input_mask,
sequence_labels,
token_labels,
choice_labels,
encoder_hidden_states,
encoder_attention_mask,
):
config.add_cross_attention = True
model = {{cookiecutter.camelcase_modelname}}Model(config)
model.to(torch_device)
model.eval()
result = model(
input_ids,
attention_mask=input_mask,
token_type_ids=token_type_ids,
encoder_hidden_states=encoder_hidden_states,
encoder_attention_mask=encoder_attention_mask,
)
result = model(
input_ids,
attention_mask=input_mask,
token_type_ids=token_type_ids,
encoder_hidden_states=encoder_hidden_states,
)
result = model(input_ids, attention_mask=input_mask, token_type_ids=token_type_ids)
self.parent.assertEqual(result.last_hidden_state.shape, (self.batch_size, self.seq_length, self.hidden_size))
def create_and_check_for_causal_lm(
self,
config,
input_ids,
token_type_ids,
input_mask,
sequence_labels,
token_labels,
choice_labels,
encoder_hidden_states,
encoder_attention_mask,
):
model = {{cookiecutter.camelcase_modelname}}ForCausalLM(config=config)
model.to(torch_device)
model.eval()
result = model(input_ids, attention_mask=input_mask, token_type_ids=token_type_ids, labels=token_labels)
self.parent.assertEqual(result.logits.shape, (self.batch_size, self.seq_length, self.vocab_size))
def create_and_check_for_masked_lm(
self, config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
):
model = {{cookiecutter.camelcase_modelname}}ForMaskedLM(config=config)
model.to(torch_device)
model.eval()
result = model(input_ids, attention_mask=input_mask, token_type_ids=token_type_ids, labels=token_labels)
self.parent.assertEqual(result.logits.shape, (self.batch_size, self.seq_length, self.vocab_size))
def create_and_check_decoder_model_past_large_inputs(
self,
config,
input_ids,
token_type_ids,
input_mask,
sequence_labels,
token_labels,
choice_labels,
encoder_hidden_states,
encoder_attention_mask,
):
config.is_decoder = True
config.add_cross_attention = True
model = {{cookiecutter.camelcase_modelname}}ForCausalLM(config=config)
model.to(torch_device)
model.eval()
# first forward pass
outputs = model(
input_ids,
attention_mask=input_mask,
encoder_hidden_states=encoder_hidden_states,
encoder_attention_mask=encoder_attention_mask,
use_cache=True,
)
past_key_values = outputs.past_key_values
# create hypothetical multiple next token and extent to next_input_ids
next_tokens = ids_tensor((self.batch_size, 3), config.vocab_size)
next_mask = ids_tensor((self.batch_size, 3), vocab_size=2)
# append to next input_ids and
next_input_ids = torch.cat([input_ids, next_tokens], dim=-1)
next_attention_mask = torch.cat([input_mask, next_mask], dim=-1)
output_from_no_past = model(
next_input_ids,
attention_mask=next_attention_mask,
encoder_hidden_states=encoder_hidden_states,
encoder_attention_mask=encoder_attention_mask,
output_hidden_states=True,
)["hidden_states"][0]
output_from_past = model(
next_tokens,
attention_mask=next_attention_mask,
encoder_hidden_states=encoder_hidden_states,
encoder_attention_mask=encoder_attention_mask,
past_key_values=past_key_values,
output_hidden_states=True,
)["hidden_states"][0]
# select random slice
random_slice_idx = ids_tensor((1,), output_from_past.shape[-1]).item()
output_from_no_past_slice = output_from_no_past[:, -3:, random_slice_idx].detach()
output_from_past_slice = output_from_past[:, :, random_slice_idx].detach()
self.parent.assertTrue(output_from_past_slice.shape[1] == next_tokens.shape[1])
# test that outputs are equal for slice
self.parent.assertTrue(torch.allclose(output_from_past_slice, output_from_no_past_slice, atol=1e-3))
def create_and_check_for_question_answering(
self, config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
):
model = {{cookiecutter.camelcase_modelname}}ForQuestionAnswering(config=config)
model.to(torch_device)
model.eval()
result = model(
input_ids,
attention_mask=input_mask,
token_type_ids=token_type_ids,
start_positions=sequence_labels,
end_positions=sequence_labels,
)
self.parent.assertEqual(result.start_logits.shape, (self.batch_size, self.seq_length))
self.parent.assertEqual(result.end_logits.shape, (self.batch_size, self.seq_length))
def create_and_check_for_sequence_classification(
self, config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
):
config.num_labels = self.num_labels
model = {{cookiecutter.camelcase_modelname}}ForSequenceClassification(config)
model.to(torch_device)
model.eval()
result = model(input_ids, attention_mask=input_mask, token_type_ids=token_type_ids, labels=sequence_labels)
self.parent.assertEqual(result.logits.shape, (self.batch_size, self.num_labels))
def create_and_check_for_token_classification(
self, config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
):
config.num_labels = self.num_labels
model = {{cookiecutter.camelcase_modelname}}ForTokenClassification(config=config)
model.to(torch_device)
model.eval()
result = model(input_ids, attention_mask=input_mask, token_type_ids=token_type_ids, labels=token_labels)
self.parent.assertEqual(result.logits.shape, (self.batch_size, self.seq_length, self.num_labels))
def create_and_check_for_multiple_choice(
self, config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
):
config.num_choices = self.num_choices
model = {{cookiecutter.camelcase_modelname}}ForMultipleChoice(config=config)
model.to(torch_device)
model.eval()
multiple_choice_inputs_ids = input_ids.unsqueeze(1).expand(-1, self.num_choices, -1).contiguous()
multiple_choice_token_type_ids = token_type_ids.unsqueeze(1).expand(-1, self.num_choices, -1).contiguous()
multiple_choice_input_mask = input_mask.unsqueeze(1).expand(-1, self.num_choices, -1).contiguous()
result = model(
multiple_choice_inputs_ids,
attention_mask=multiple_choice_input_mask,
token_type_ids=multiple_choice_token_type_ids,
labels=choice_labels,
)
self.parent.assertEqual(result.logits.shape, (self.batch_size, self.num_choices))
def prepare_config_and_inputs_for_common(self):
config_and_inputs = self.prepare_config_and_inputs()
(
config,
input_ids,
token_type_ids,
input_mask,
sequence_labels,
token_labels,
choice_labels,
) = config_and_inputs
inputs_dict = {"input_ids": input_ids, "token_type_ids": token_type_ids, "attention_mask": input_mask}
return config, inputs_dict
@require_torch
class {{cookiecutter.camelcase_modelname}}ModelTest(ModelTesterMixin, unittest.TestCase):
all_model_classes = (
(
{{cookiecutter.camelcase_modelname}}Model,
{{cookiecutter.camelcase_modelname}}ForMaskedLM,
{{cookiecutter.camelcase_modelname}}ForCausalLM,
{{cookiecutter.camelcase_modelname}}ForMultipleChoice,
{{cookiecutter.camelcase_modelname}}ForQuestionAnswering,
{{cookiecutter.camelcase_modelname}}ForSequenceClassification,
{{cookiecutter.camelcase_modelname}}ForTokenClassification,
)
if is_torch_available()
else ()
)
all_generative_model_classes = ({{cookiecutter.camelcase_modelname}}ForCausalLM,) if is_torch_available() else ()
def setUp(self):
self.model_tester = {{cookiecutter.camelcase_modelname}}ModelTester(self)
self.config_tester = ConfigTester(self, config_class={{cookiecutter.camelcase_modelname}}Config, hidden_size=37)
def test_config(self):
self.config_tester.run_common_tests()
def test_model(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_model(*config_and_inputs)
def test_model_various_embeddings(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
for type in ["absolute", "relative_key", "relative_key_query"]:
config_and_inputs[0].position_embedding_type = type
self.model_tester.create_and_check_model(*config_and_inputs)
def test_for_masked_lm(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_for_masked_lm(*config_and_inputs)
def test_for_multiple_choice(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_for_multiple_choice(*config_and_inputs)
def test_decoder_model_past_with_large_inputs(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs_for_decoder()
self.model_tester.create_and_check_decoder_model_past_large_inputs(*config_and_inputs)
def test_for_question_answering(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_for_question_answering(*config_and_inputs)
def test_for_sequence_classification(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_for_sequence_classification(*config_and_inputs)
def test_for_token_classification(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_for_token_classification(*config_and_inputs)
def test_model_as_decoder(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs_for_decoder()
self.model_tester.create_and_check_model_as_decoder(*config_and_inputs)
def test_model_as_decoder_with_default_input_mask(self):
# This regression test was failing with PyTorch < 1.3
(
config,
input_ids,
token_type_ids,
input_mask,
sequence_labels,
token_labels,
choice_labels,
encoder_hidden_states,
encoder_attention_mask,
) = self.model_tester.prepare_config_and_inputs_for_decoder()
input_mask = None
self.model_tester.create_and_check_model_as_decoder(
config,
input_ids,
token_type_ids,
input_mask,
sequence_labels,
token_labels,
choice_labels,
encoder_hidden_states,
encoder_attention_mask,
)
@slow
def test_model_from_pretrained(self):
for model_name in {{cookiecutter.uppercase_modelname}}_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
model = {{cookiecutter.camelcase_modelname}}Model.from_pretrained(model_name)
self.assertIsNotNone(model)
@require_torch
class {{cookiecutter.camelcase_modelname}}ModelIntegrationTest(unittest.TestCase):
@slow
def test_inference_masked_lm(self):
model = {{cookiecutter.camelcase_modelname}}ForMaskedLM.from_pretrained("{{cookiecutter.checkpoint_identifier}}")
input_ids = torch.tensor([[0, 1, 2, 3, 4, 5]])
output = model(input_ids)[0]
# TODO Replace vocab size
vocab_size = 32000
expected_shape = torch.Size((1, 6, vocab_size))
self.assertEqual(output.shape, expected_shape)
# TODO Replace values below with what was printed above.
expected_slice = torch.tensor(
[[[-0.0483, 0.1188, -0.0313], [-0.0606, 0.1435, 0.0199], [-0.0235, 0.1519, 0.0175]]]
)
self.assertTrue(torch.allclose(output[:, :3, :3], expected_slice, atol=1e-4))
{% else -%}
import copy
import tempfile
import unittest
from transformers import is_torch_available
from transformers.utils import cached_property
from transformers.testing_utils import require_sentencepiece, require_tokenizers, require_torch, slow, torch_device
from ...test_configuration_common import ConfigTester
from ...generation.test_utils import GenerationTesterMixin
from ...test_modeling_common import ModelTesterMixin, ids_tensor
if is_torch_available():
import torch
from transformers import (
{{cookiecutter.camelcase_modelname}}Config,
{{cookiecutter.camelcase_modelname}}ForConditionalGeneration,
{{cookiecutter.camelcase_modelname}}ForQuestionAnswering,
{{cookiecutter.camelcase_modelname}}ForCausalLM,
{{cookiecutter.camelcase_modelname}}ForSequenceClassification,
{{cookiecutter.camelcase_modelname}}Model,
{{cookiecutter.camelcase_modelname}}Tokenizer,
)
from transformers.models.{{cookiecutter.lowercase_modelname}}.modeling_{{cookiecutter.lowercase_modelname}} import (
{{cookiecutter.camelcase_modelname}}Decoder,
{{cookiecutter.camelcase_modelname}}Encoder,
)
def prepare_{{cookiecutter.lowercase_modelname}}_inputs_dict(
config,
input_ids,
decoder_input_ids,
attention_mask=None,
decoder_attention_mask=None,
):
if attention_mask is None:
attention_mask = input_ids.ne(config.pad_token_id)
if decoder_attention_mask is None:
decoder_attention_mask = decoder_input_ids.ne(config.pad_token_id)
return {
"input_ids": input_ids,
"decoder_input_ids": decoder_input_ids,
"attention_mask": attention_mask,
"decoder_attention_mask": attention_mask,
}
@require_torch
class {{cookiecutter.camelcase_modelname}}ModelTester:
def __init__(
self,
parent,
batch_size=13,
seq_length=7,
is_training=True,
use_labels=False,
vocab_size=99,
hidden_size=16,
num_hidden_layers=2,
num_attention_heads=4,
intermediate_size=4,
hidden_act="gelu",
hidden_dropout_prob=0.1,
attention_probs_dropout_prob=0.1,
max_position_embeddings=20,
eos_token_id=2,
pad_token_id=1,
bos_token_id=0,
):
self.parent = parent
self.batch_size = batch_size
self.seq_length = seq_length
self.is_training = is_training
self.use_labels = use_labels
self.vocab_size = vocab_size
self.hidden_size = hidden_size
self.num_hidden_layers = num_hidden_layers
self.num_attention_heads = num_attention_heads
self.intermediate_size = intermediate_size
self.hidden_act = hidden_act
self.hidden_dropout_prob = hidden_dropout_prob
self.attention_probs_dropout_prob = attention_probs_dropout_prob
self.max_position_embeddings = max_position_embeddings
self.eos_token_id = eos_token_id
self.pad_token_id = pad_token_id
self.bos_token_id = bos_token_id
def prepare_config_and_inputs(self):
input_ids = ids_tensor([self.batch_size, self.seq_length], self.vocab_size)
input_ids = ids_tensor([self.batch_size, self.seq_length], self.vocab_size).clamp(
3,
)
input_ids[:, -1] = self.eos_token_id # Eos Token
decoder_input_ids = ids_tensor([self.batch_size, self.seq_length], self.vocab_size)
config = {{cookiecutter.camelcase_modelname}}Config(
vocab_size=self.vocab_size,
d_model=self.hidden_size,
encoder_layers=self.num_hidden_layers,
decoder_layers=self.num_hidden_layers,
encoder_attention_heads=self.num_attention_heads,
decoder_attention_heads=self.num_attention_heads,
encoder_ffn_dim=self.intermediate_size,
decoder_ffn_dim=self.intermediate_size,
dropout=self.hidden_dropout_prob,
attention_dropout=self.attention_probs_dropout_prob,
max_position_embeddings=self.max_position_embeddings,
eos_token_id=self.eos_token_id,
bos_token_id=self.bos_token_id,
pad_token_id=self.pad_token_id,
)
inputs_dict = prepare_{{cookiecutter.lowercase_modelname}}_inputs_dict(config, input_ids, decoder_input_ids)
return config, inputs_dict
def prepare_config_and_inputs_for_common(self):
config, inputs_dict = self.prepare_config_and_inputs()
return config, inputs_dict
def create_and_check_decoder_model_past_large_inputs(self, config, inputs_dict):
model = {{cookiecutter.camelcase_modelname}}Model(config=config).get_decoder().to(torch_device).eval()
input_ids = inputs_dict["input_ids"]
attention_mask = inputs_dict["attention_mask"]
# first forward pass
outputs = model(input_ids, attention_mask=attention_mask, use_cache=True)
output, past_key_values = outputs.to_tuple()
# create hypothetical multiple next token and extent to next_input_ids
next_tokens = ids_tensor((self.batch_size, 3), config.vocab_size)
next_attn_mask = ids_tensor((self.batch_size, 3), 2)
# append to next input_ids and
next_input_ids = torch.cat([input_ids, next_tokens], dim=-1)
next_attention_mask = torch.cat([attention_mask, next_attn_mask], dim=-1)
output_from_no_past = model(next_input_ids, attention_mask=next_attention_mask)["last_hidden_state"]
output_from_past = model(next_tokens, attention_mask=next_attention_mask, past_key_values=past_key_values)["last_hidden_state"]
# select random slice
random_slice_idx = ids_tensor((1,), output_from_past.shape[-1]).item()
output_from_no_past_slice = output_from_no_past[:, -3:, random_slice_idx].detach()
output_from_past_slice = output_from_past[:, :, random_slice_idx].detach()
self.parent.assertTrue(output_from_past_slice.shape[1] == next_tokens.shape[1])
# test that outputs are equal for slice
self.parent.assertTrue(torch.allclose(output_from_past_slice, output_from_no_past_slice, atol=1e-2))
def check_encoder_decoder_model_standalone(self, config, inputs_dict):
model = {{cookiecutter.camelcase_modelname}}Model(config=config).to(torch_device).eval()
outputs = model(**inputs_dict)
encoder_last_hidden_state = outputs.encoder_last_hidden_state
last_hidden_state = outputs.last_hidden_state
with tempfile.TemporaryDirectory() as tmpdirname:
encoder = model.get_encoder()
encoder.save_pretrained(tmpdirname)
encoder = {{cookiecutter.camelcase_modelname}}Encoder.from_pretrained(tmpdirname).to(torch_device)
encoder_last_hidden_state_2 = encoder(inputs_dict["input_ids"], attention_mask=inputs_dict["attention_mask"])[
0
]
self.parent.assertTrue((encoder_last_hidden_state_2 - encoder_last_hidden_state).abs().max().item() < 1e-3)
with tempfile.TemporaryDirectory() as tmpdirname:
decoder = model.get_decoder()
decoder.save_pretrained(tmpdirname)
decoder = {{cookiecutter.camelcase_modelname}}Decoder.from_pretrained(tmpdirname).to(torch_device)
last_hidden_state_2 = decoder(
input_ids=inputs_dict["decoder_input_ids"],
attention_mask=inputs_dict["decoder_attention_mask"],
encoder_hidden_states=encoder_last_hidden_state,
encoder_attention_mask=inputs_dict["attention_mask"],
)[0]
self.parent.assertTrue((last_hidden_state_2 - last_hidden_state).abs().max().item() < 1e-3)
@require_torch
class {{cookiecutter.camelcase_modelname}}ModelTest(ModelTesterMixin, GenerationTesterMixin, unittest.TestCase):
all_model_classes = (
({{cookiecutter.camelcase_modelname}}Model, {{cookiecutter.camelcase_modelname}}ForConditionalGeneration, {{cookiecutter.camelcase_modelname}}ForSequenceClassification, {{cookiecutter.camelcase_modelname}}ForQuestionAnswering)
if is_torch_available()
else ()
)
all_generative_model_classes = ({{cookiecutter.camelcase_modelname}}ForConditionalGeneration,) if is_torch_available() else ()
is_encoder_decoder = True
test_pruning = False
test_head_masking = False
test_missing_keys = False
def setUp(self):
self.model_tester = {{cookiecutter.camelcase_modelname}}ModelTester(self)
self.config_tester = ConfigTester(self, config_class={{cookiecutter.camelcase_modelname}}Config)
def test_config(self):
self.config_tester.run_common_tests()
def test_save_load_strict(self):
config, inputs_dict = self.model_tester.prepare_config_and_inputs()
for model_class in self.all_model_classes:
model = model_class(config)
with tempfile.TemporaryDirectory() as tmpdirname:
model.save_pretrained(tmpdirname)
model2, info = model_class.from_pretrained(tmpdirname, output_loading_info=True)
self.assertEqual(info["missing_keys"], [])
def test_decoder_model_past_with_large_inputs(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_decoder_model_past_large_inputs(*config_and_inputs)
def test_encoder_decoder_model_standalone(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs_for_common()
self.model_tester.check_encoder_decoder_model_standalone(*config_and_inputs)
# {{cookiecutter.camelcase_modelname}}ForSequenceClassification does not support inputs_embeds
def test_inputs_embeds(self):
config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
for model_class in ({{cookiecutter.camelcase_modelname}}Model, {{cookiecutter.camelcase_modelname}}ForConditionalGeneration, {{cookiecutter.camelcase_modelname}}ForQuestionAnswering):
model = model_class(config)
model.to(torch_device)
model.eval()
inputs = copy.deepcopy(self._prepare_for_class(inputs_dict, model_class))
if not self.is_encoder_decoder:
input_ids = inputs["input_ids"]
del inputs["input_ids"]
else:
encoder_input_ids = inputs["input_ids"]
decoder_input_ids = inputs.get("decoder_input_ids", encoder_input_ids)
del inputs["input_ids"]
inputs.pop("decoder_input_ids", None)
wte = model.get_input_embeddings()
if not self.is_encoder_decoder:
inputs["inputs_embeds"] = wte(input_ids)
else:
inputs["inputs_embeds"] = wte(encoder_input_ids)
inputs["decoder_inputs_embeds"] = wte(decoder_input_ids)
with torch.no_grad():
model(**inputs)[0]
def test_generate_fp16(self):
config, input_dict = self.model_tester.prepare_config_and_inputs()
input_ids = input_dict["input_ids"]
attention_mask = input_ids.ne(1).to(torch_device)
model = {{cookiecutter.camelcase_modelname}}ForConditionalGeneration(config).eval().to(torch_device)
if torch_device == "cuda":
model.half()
model.generate(input_ids, attention_mask=attention_mask)
model.generate(num_beams=4, do_sample=True, early_stopping=False, num_return_sequences=3)
def assert_tensors_close(a, b, atol=1e-12, prefix=""):
"""If tensors have different shapes, different values or a and b are not both tensors, raise a nice Assertion error."""
if a is None and b is None:
return True
try:
if torch.allclose(a, b, atol=atol):
return True
raise
except Exception:
pct_different = (torch.gt((a - b).abs(), atol)).float().mean().item()
if a.numel() > 100:
msg = f"tensor values are {pct_different:.1%} percent different."
else:
msg = f"{a} != {b}"
if prefix:
msg = prefix + ": " + msg
raise AssertionError(msg)
def _long_tensor(tok_lst):
return torch.tensor(tok_lst, dtype=torch.long, device=torch_device)
TOLERANCE = 1e-4
@require_torch
@require_sentencepiece
@require_tokenizers
@slow
class {{cookiecutter.camelcase_modelname}}ModelIntegrationTests(unittest.TestCase):
@cached_property
def default_tokenizer(self):
return {{cookiecutter.camelcase_modelname}}Tokenizer.from_pretrained('{{cookiecutter.checkpoint_identifier}}')
def test_inference_no_head(self):
model = {{cookiecutter.camelcase_modelname}}Model.from_pretrained('{{cookiecutter.checkpoint_identifier}}').to(torch_device)
input_ids = _long_tensor([[0, 31414, 232, 328, 740, 1140, 12695, 69, 46078, 1588, 2]])
decoder_input_ids = _long_tensor([[2, 0, 31414, 232, 328, 740, 1140, 12695, 69, 46078, 1588]])
inputs_dict = prepare_{{cookiecutter.lowercase_modelname}}_inputs_dict(model.config, input_ids, decoder_input_ids)
with torch.no_grad():
output = model(**inputs_dict)[0]
expected_shape = torch.Size((1, 11, 1024))
self.assertEqual(output.shape, expected_shape)
# change to expected output here
expected_slice = torch.tensor(
[[0.7144, 0.8143, -1.2813], [0.7144, 0.8143, -1.2813], [-0.0467, 2.5911, -2.1845]], device=torch_device
)
self.assertTrue(torch.allclose(output[:, :3, :3], expected_slice, atol=TOLERANCE))
def test_inference_head(self):
model = {{cookiecutter.camelcase_modelname}}ForConditionalGeneration.from_pretrained('{{cookiecutter.checkpoint_identifier}}').to(torch_device)
# change to intended input
input_ids = _long_tensor([[0, 31414, 232, 328, 740, 1140, 12695, 69, 46078, 1588, 2]])
decoder_input_ids = _long_tensor([[0, 31414, 232, 328, 740, 1140, 12695, 69, 46078, 1588, 2]])
inputs_dict = prepare_{{cookiecutter.lowercase_modelname}}_inputs_dict(model.config, input_ids, decoder_input_ids)
with torch.no_grad():
output = model(**inputs_dict)[0]
expected_shape = torch.Size((1, 11, model.config.vocab_size))
self.assertEqual(output.shape, expected_shape)
# change to expected output here
expected_slice = torch.tensor(
[[0.7144, 0.8143, -1.2813], [0.7144, 0.8143, -1.2813], [-0.0467, 2.5911, -2.1845]], device=torch_device
)
self.assertTrue(torch.allclose(output[:, :3, :3], expected_slice, atol=TOLERANCE))
def test_seq_to_seq_generation(self):
hf = {{cookiecutter.camelcase_modelname}}ForConditionalGeneration.from_pretrained('{{cookiecutter.checkpoint_identifier}}').to(torch_device)
tok = {{cookiecutter.camelcase_modelname}}Tokenizer.from_pretrained('{{cookiecutter.checkpoint_identifier}}')
batch_input = [
# string 1,
# string 2,
# string 3,
# string 4,
]
# The below article tests that we don't add any hypotheses outside of the top n_beams
dct = tok.batch_encode_plus(
batch_input,
max_length=512,
padding="max_length",
truncation_strategy="only_first",
truncation=True,
return_tensors="pt",
)
hypotheses_batch = hf.generate(
input_ids=dct["input_ids"].to(torch_device),
attention_mask=dct["attention_mask"].to(torch_device),
num_beams=2,
)
EXPECTED = [
# here expected 1,
# here expected 2,
# here expected 3,
# here expected 4,
]
generated = tok.batch_decode(
hypotheses_batch.tolist(), clean_up_tokenization_spaces=True, skip_special_tokens=True
)
assert generated == EXPECTED
class {{cookiecutter.camelcase_modelname}}StandaloneDecoderModelTester:
def __init__(
self,
parent,
vocab_size=99,
batch_size=13,
d_model=16,
decoder_seq_length=7,
is_training=True,
is_decoder=True,
use_attention_mask=True,
use_cache=False,
use_labels=True,
decoder_start_token_id=2,
decoder_ffn_dim=32,
decoder_layers=4,
encoder_attention_heads=4,
decoder_attention_heads=4,
max_position_embeddings=30,
is_encoder_decoder=False,
pad_token_id=0,
bos_token_id=1,
eos_token_id=2,
scope=None,
):
self.parent = parent
self.batch_size = batch_size
self.decoder_seq_length = decoder_seq_length
# For common tests
self.seq_length = self.decoder_seq_length
self.is_training = is_training
self.use_attention_mask = use_attention_mask
self.use_labels = use_labels
self.vocab_size = vocab_size
self.d_model = d_model
self.hidden_size = d_model
self.num_hidden_layers = decoder_layers
self.decoder_layers = decoder_layers
self.decoder_ffn_dim = decoder_ffn_dim
self.encoder_attention_heads = encoder_attention_heads
self.decoder_attention_heads = decoder_attention_heads
self.num_attention_heads = decoder_attention_heads
self.eos_token_id = eos_token_id
self.bos_token_id = bos_token_id
self.pad_token_id = pad_token_id
self.decoder_start_token_id = decoder_start_token_id
self.use_cache = use_cache
self.max_position_embeddings = max_position_embeddings
self.is_encoder_decoder = is_encoder_decoder
self.scope = None
self.decoder_key_length = decoder_seq_length
self.base_model_out_len = 2
self.decoder_attention_idx = 1
def prepare_config_and_inputs(self):
input_ids = ids_tensor([self.batch_size, self.decoder_seq_length], self.vocab_size)
attention_mask = None
if self.use_attention_mask:
attention_mask = ids_tensor([self.batch_size, self.decoder_seq_length], vocab_size=2)
lm_labels = None
if self.use_labels:
lm_labels = ids_tensor([self.batch_size, self.decoder_seq_length], self.vocab_size)
config = {{cookiecutter.camelcase_modelname}}Config(
vocab_size=self.vocab_size,
d_model=self.d_model,
decoder_layers=self.decoder_layers,
decoder_ffn_dim=self.decoder_ffn_dim,
encoder_attention_heads=self.encoder_attention_heads,
decoder_attention_heads=self.decoder_attention_heads,
eos_token_id=self.eos_token_id,
bos_token_id=self.bos_token_id,
use_cache=self.use_cache,
pad_token_id=self.pad_token_id,
decoder_start_token_id=self.decoder_start_token_id,
max_position_embeddings=self.max_position_embeddings,
is_encoder_decoder=self.is_encoder_decoder,
)
return (
config,
input_ids,
attention_mask,
lm_labels,
)
def create_and_check_decoder_model_past(
self,
config,
input_ids,
attention_mask,
lm_labels,
):
config.use_cache = True
model = {{cookiecutter.camelcase_modelname}}Decoder(config=config).to(torch_device).eval()
# first forward pass
outputs = model(input_ids, use_cache=True)
outputs_use_cache_conf = model(input_ids)
outputs_no_past = model(input_ids, use_cache=False)
self.parent.assertTrue(len(outputs) == len(outputs_use_cache_conf))
self.parent.assertTrue(len(outputs) == len(outputs_no_past) + 1)
past_key_values = outputs["past_key_values"]
# create hypothetical next token and extent to next_input_ids
next_tokens = ids_tensor((self.batch_size, 1), config.vocab_size)
# append to next input_ids and
next_input_ids = torch.cat([input_ids, next_tokens], dim=-1)
output_from_no_past = model(next_input_ids)["last_hidden_state"]
output_from_past = model(next_tokens, past_key_values=past_key_values)["last_hidden_state"]
# select random slice
random_slice_idx = ids_tensor((1,), output_from_past.shape[-1]).item()
output_from_no_past_slice = output_from_no_past[:, next_input_ids.shape[-1] - 1, random_slice_idx].detach()
output_from_past_slice = output_from_past[:, 0, random_slice_idx].detach()
# test that outputs are equal for slice
assert torch.allclose(output_from_past_slice, output_from_no_past_slice, atol=1e-3)
def create_and_check_decoder_model_attention_mask_past(
self,
config,
input_ids,
attention_mask,
lm_labels,
):
model = {{cookiecutter.camelcase_modelname}}Decoder(config=config).to(torch_device).eval()
# create attention mask
attn_mask = torch.ones(input_ids.shape, dtype=torch.long, device=torch_device)
half_seq_length = input_ids.shape[-1] // 2
attn_mask[:, half_seq_length:] = 0
# first forward pass
past_key_values = model(input_ids, attention_mask=attn_mask, use_cache=True)["past_key_values"]
# create hypothetical next token and extent to next_input_ids
next_tokens = ids_tensor((self.batch_size, 1), config.vocab_size)
# change a random masked slice from input_ids
random_seq_idx_to_change = ids_tensor((1,), half_seq_length).item() + 1
random_other_next_tokens = ids_tensor((self.batch_size, 1), config.vocab_size).squeeze(-1)
input_ids[:, -random_seq_idx_to_change] = random_other_next_tokens
# append to next input_ids and attn_mask
next_input_ids = torch.cat([input_ids, next_tokens], dim=-1)
attn_mask = torch.cat(
[attn_mask, torch.ones((attn_mask.shape[0], 1), dtype=torch.long, device=torch_device)],
dim=1,
)
# get two different outputs
output_from_no_past = model(next_input_ids)["last_hidden_state"]
output_from_past = model(next_tokens, past_key_values=past_key_values)["last_hidden_state"]
# select random slice
random_slice_idx = ids_tensor((1,), output_from_past.shape[-1]).item()
output_from_no_past_slice = output_from_no_past[:, next_input_ids.shape[-1] - 1, random_slice_idx].detach()
output_from_past_slice = output_from_past[:, 0, random_slice_idx].detach()
# test that outputs are equal for slice
assert torch.allclose(output_from_past_slice, output_from_no_past_slice, atol=1e-2)
def prepare_config_and_inputs_for_common(self):
config_and_inputs = self.prepare_config_and_inputs()
(
config,
input_ids,
attention_mask,
lm_labels,
) = config_and_inputs
inputs_dict = {
"input_ids": input_ids,
"attention_mask": attention_mask,
}
return config, inputs_dict
@require_torch
class {{cookiecutter.camelcase_modelname}}StandaloneDecoderModelTest(ModelTesterMixin, GenerationTesterMixin, unittest.TestCase):
all_model_classes = ({{cookiecutter.camelcase_modelname}}Decoder, {{cookiecutter.camelcase_modelname}}ForCausalLM) if is_torch_available() else ()
all_generative_model_classes = ({{cookiecutter.camelcase_modelname}}ForCausalLM,) if is_torch_available() else ()
test_pruning = False
is_encoder_decoder = False
def setUp(
self,
):
self.model_tester = {{cookiecutter.camelcase_modelname}}StandaloneDecoderModelTester(self, is_training=False)
self.config_tester = ConfigTester(self, config_class={{cookiecutter.camelcase_modelname}}Config)
def test_config(self):
self.config_tester.run_common_tests()
def test_decoder_model_past(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_decoder_model_past(*config_and_inputs)
def test_decoder_model_attn_mask_past(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_decoder_model_attention_mask_past(*config_and_inputs)
def test_retain_grad_hidden_states_attentions(self):
# decoder cannot keep gradients
return
{% endif -%}
| 0 |
hf_public_repos/transformers/templates/adding_a_new_model | hf_public_repos/transformers/templates/adding_a_new_model/cookiecutter-template-{{cookiecutter.modelname}}/configuration_{{cookiecutter.lowercase_modelname}}.py | # coding=utf-8
# Copyright 2022 {{cookiecutter.authors}} and The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
""" {{cookiecutter.modelname}} model configuration """
from ...configuration_utils import PretrainedConfig
from ...utils import logging
logger = logging.get_logger(__name__)
{{cookiecutter.uppercase_modelname}}_PRETRAINED_CONFIG_ARCHIVE_MAP = {
"{{cookiecutter.checkpoint_identifier}}": "https://huggingface.co/{{cookiecutter.checkpoint_identifier}}/resolve/main/config.json",
# See all {{cookiecutter.modelname}} models at https://huggingface.co/models?filter={{cookiecutter.lowercase_modelname}}
}
class {{cookiecutter.camelcase_modelname}}Config(PretrainedConfig):
r"""
This is the configuration class to store the configuration of a [`~{{cookiecutter.camelcase_modelname}}Model`].
It is used to instantiate an {{cookiecutter.modelname}} model according to the specified arguments, defining the model
architecture. Instantiating a configuration with the defaults will yield a similar configuration to that of
the {{cookiecutter.modelname}} [{{cookiecutter.checkpoint_identifier}}](https://huggingface.co/{{cookiecutter.checkpoint_identifier}}) architecture.
Configuration objects inherit from [`PretrainedConfig`] and can be used
to control the model outputs. Read the documentation from [`PretrainedConfig`]
for more information.
Args:
{% if cookiecutter.is_encoder_decoder_model == "False" -%}
vocab_size (`int`, *optional*, defaults to 30522):
Vocabulary size of the {{cookiecutter.modelname}} model. Defines the number of different tokens that can be represented by the
`inputs_ids` passed when calling [`~{{cookiecutter.camelcase_modelname}}Model`] or
[`~TF{{cookiecutter.camelcase_modelname}}Model`].
hidden_size (`int`, *optional*, defaults to 768):
Dimension of the encoder layers and the pooler layer.
num_hidden_layers (`int`, *optional*, defaults to 12):
Number of hidden layers in the Transformer encoder.
num_attention_heads (`int`, *optional*, defaults to 12):
Number of attention heads for each attention layer in the Transformer encoder.
intermediate_size (`int`, *optional*, defaults to 3072):
Dimension of the "intermediate" (i.e., feed-forward) layer in the Transformer encoder.
hidden_act (`str` or `function`, *optional*, defaults to `"gelu"`):
The non-linear activation function (function or string) in the encoder and pooler.
If string, `"gelu"`, `"relu"`, `"selu"` and `"gelu_new"` are supported.
hidden_dropout_prob (`float`, *optional*, defaults to 0.1):
The dropout probabilitiy for all fully connected layers in the embeddings, encoder, and pooler.
attention_probs_dropout_prob (`float`, *optional*, defaults to 0.1):
The dropout ratio for the attention probabilities.
max_position_embeddings (`int`, *optional*, defaults to 512):
The maximum sequence length that this model might ever be used with.
Typically set this to something large just in case (e.g., 512 or 1024 or 2048).
type_vocab_size (`int`, *optional*, defaults to 2):
The vocabulary size of the `token_type_ids` passed when calling [`~{{cookiecutter.camelcase_modelname}}Model`] or
[`~TF{{cookiecutter.camelcase_modelname}}Model`].
initializer_range (`float`, *optional*, defaults to 0.02):
The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
layer_norm_eps (`float`, *optional*, defaults to 1e-12):
The epsilon used by the layer normalization layers.
use_cache (`bool`, *optional*, defaults to `True`):
Whether or not the model should return the last key/values attentions (not used by all models). Only
relevant if `config.is_decoder=True`.
{% else -%}
vocab_size (`int`, *optional*, defaults to 50265):
Vocabulary size of the {{cookiecutter.modelname}} model. Defines the number of different tokens that can be represented by the
`inputs_ids` passed when calling [`~{{cookiecutter.camelcase_modelname}}Model`] or
[`~TF{{cookiecutter.camelcase_modelname}}Model`].
d_model (`int`, *optional*, defaults to 1024):
Dimension of the layers and the pooler layer.
encoder_layers (`int`, *optional*, defaults to 12):
Number of encoder layers.
decoder_layers (`int`, *optional*, defaults to 12):
Number of decoder layers.
encoder_attention_heads (`int`, *optional*, defaults to 16):
Number of attention heads for each attention layer in the Transformer encoder.
decoder_attention_heads (`int`, *optional*, defaults to 16):
Number of attention heads for each attention layer in the Transformer decoder.
decoder_ffn_dim (`int`, *optional*, defaults to 4096):
Dimension of the "intermediate" (often named feed-forward) layer in decoder.
encoder_ffn_dim (`int`, *optional*, defaults to 4096):
Dimension of the "intermediate" (often named feed-forward) layer in decoder.
activation_function (`str` or `function`, *optional*, defaults to `"gelu"`):
The non-linear activation function (function or string) in the encoder and pooler. If string,
`"gelu"`, `"relu"`, `"silu"` and `"gelu_new"` are supported.
dropout (`float`, *optional*, defaults to 0.1):
The dropout probability for all fully connected layers in the embeddings, encoder, and pooler.
attention_dropout (`float`, *optional*, defaults to 0.0):
The dropout ratio for the attention probabilities.
activation_dropout (`float`, *optional*, defaults to 0.0):
The dropout ratio for activations inside the fully connected layer.
classifier_dropout (`float`, *optional*, defaults to 0.0):
The dropout ratio for classifier.
max_position_embeddings (`int`, *optional*, defaults to 1024):
The maximum sequence length that this model might ever be used with. Typically set this to something large
just in case (e.g., 512 or 1024 or 2048).
init_std (`float`, *optional*, defaults to 0.02):
The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
encoder_layerdrop (`float`, *optional*, defaults to 0.0):
The LayerDrop probability for the encoder. See the [LayerDrop paper](see
https://arxiv.org/abs/1909.11556) for more details.
decoder_layerdrop (`float`, *optional*, defaults to 0.0):
The LayerDrop probability for the decoder. See the [LayerDrop paper](see
https://arxiv.org/abs/1909.11556) for more details.
use_cache (`bool`, *optional*, defaults to `True`):
Whether or not the model should return the last key/values attentions (not used by all models).
{% endif -%}
Example:
```python
>>> from transformers import {{cookiecutter.camelcase_modelname}}Model, {{cookiecutter.camelcase_modelname}}Config
>>> # Initializing a {{cookiecutter.modelname}} {{cookiecutter.checkpoint_identifier}} style configuration
>>> configuration = {{cookiecutter.camelcase_modelname}}Config()
>>> # Initializing a model from the {{cookiecutter.checkpoint_identifier}} style configuration
>>> model = {{cookiecutter.camelcase_modelname}}Model(configuration)
>>> # Accessing the model configuration
>>> configuration = model.config
```
"""
model_type = "{{cookiecutter.lowercase_modelname}}"
{% if cookiecutter.is_encoder_decoder_model == "False" -%}
{% else -%}
keys_to_ignore_at_inference = ["past_key_values"]
{% endif -%}
{% if cookiecutter.is_encoder_decoder_model == "False" %}
{%- else %}
attribute_map = {
"num_attention_heads": "encoder_attention_heads",
"hidden_size": "d_model"
}
{%- endif %}
def __init__(
self,
{% if cookiecutter.is_encoder_decoder_model == "False" -%}
vocab_size=30522,
hidden_size=768,
num_hidden_layers=12,
num_attention_heads=12,
intermediate_size=3072,
hidden_act="gelu",
hidden_dropout_prob=0.1,
attention_probs_dropout_prob=0.1,
max_position_embeddings=512,
type_vocab_size=2,
initializer_range=0.02,
layer_norm_eps=1e-12,
use_cache=True,
{% else -%}
vocab_size=50265,
max_position_embeddings=1024,
encoder_layers=12,
encoder_ffn_dim=4096,
encoder_attention_heads=16,
decoder_layers=12,
decoder_ffn_dim=4096,
decoder_attention_heads=16,
encoder_layerdrop=0.0,
decoder_layerdrop=0.0,
use_cache=True,
is_encoder_decoder=True,
activation_function="gelu",
d_model=1024,
dropout=0.1,
attention_dropout=0.0,
activation_dropout=0.0,
init_std=0.02,
decoder_start_token_id=2,
classifier_dropout=0.0,
scale_embedding=False,
{% endif -%}
pad_token_id=1,
bos_token_id=0,
eos_token_id=2,
**kwargs
):
self.vocab_size = vocab_size
self.max_position_embeddings = max_position_embeddings
{% if cookiecutter.is_encoder_decoder_model == "False" -%}
self.hidden_size = hidden_size
self.num_hidden_layers = num_hidden_layers
self.num_attention_heads = num_attention_heads
self.intermediate_size = intermediate_size
self.hidden_act = hidden_act
self.hidden_dropout_prob = hidden_dropout_prob
self.attention_probs_dropout_prob = attention_probs_dropout_prob
self.initializer_range = initializer_range
self.type_vocab_size = type_vocab_size
self.layer_norm_eps = layer_norm_eps
self.use_cache = use_cache
{% else -%}
self.d_model = d_model
self.encoder_ffn_dim = encoder_ffn_dim
self.encoder_layers = encoder_layers
self.encoder_attention_heads = encoder_attention_heads
self.decoder_ffn_dim = decoder_ffn_dim
self.decoder_layers = decoder_layers
self.decoder_attention_heads = decoder_attention_heads
self.dropout = dropout
self.attention_dropout = attention_dropout
self.activation_dropout = activation_dropout
self.activation_function = activation_function
self.init_std = init_std
self.encoder_layerdrop = encoder_layerdrop
self.decoder_layerdrop = decoder_layerdrop
self.classifier_dropout = classifier_dropout
self.use_cache = use_cache
self.num_hidden_layers = encoder_layers
self.scale_embedding = scale_embedding # scale factor will be sqrt(d_model) if True
{% endif -%}
super().__init__(
pad_token_id=pad_token_id,
bos_token_id=bos_token_id,
eos_token_id=eos_token_id,
{% if cookiecutter.is_encoder_decoder_model == "False" -%}
{% else -%}
is_encoder_decoder=is_encoder_decoder,
decoder_start_token_id=decoder_start_token_id,
{% endif -%}
**kwargs
)
| 0 |
hf_public_repos/transformers/templates/adding_a_new_model | hf_public_repos/transformers/templates/adding_a_new_model/cookiecutter-template-{{cookiecutter.modelname}}/test_modeling_flax_{{cookiecutter.lowercase_modelname}}.py | # coding=utf-8
# Copyright 2022 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
{% if cookiecutter.is_encoder_decoder_model == "False" %}
import unittest
from transformers import is_flax_available, {{cookiecutter.camelcase_modelname}}Config
from transformers.testing_utils import require_flax, slow
from ...test_configuration_common import ConfigTester
from ...test_modeling_flax_common import FlaxModelTesterMixin, ids_tensor
if is_flax_available():
import numpy as np
from transformers import (
Flax{{cookiecutter.camelcase_modelname}}ForCausalLM,
Flax{{cookiecutter.camelcase_modelname}}ForMaskedLM,
Flax{{cookiecutter.camelcase_modelname}}ForMultipleChoice,
Flax{{cookiecutter.camelcase_modelname}}ForQuestionAnswering,
Flax{{cookiecutter.camelcase_modelname}}ForSequenceClassification,
Flax{{cookiecutter.camelcase_modelname}}ForTokenClassification,
Flax{{cookiecutter.camelcase_modelname}}Model,
)
class Flax{{cookiecutter.camelcase_modelname}}ModelTester:
def __init__(
self,
parent,
batch_size=13,
seq_length=7,
is_training=True,
use_input_mask=True,
use_token_type_ids=True,
use_labels=True,
vocab_size=99,
hidden_size=32,
num_hidden_layers=5,
num_attention_heads=4,
intermediate_size=37,
hidden_act="gelu",
hidden_dropout_prob=0.1,
attention_probs_dropout_prob=0.1,
max_position_embeddings=512,
type_vocab_size=16,
type_sequence_label_size=2,
initializer_range=0.02,
num_labels=3,
num_choices=4,
scope=None,
):
self.parent = parent
self.batch_size = 13
self.seq_length = 7
self.is_training = True
self.use_input_mask = True
self.use_token_type_ids = True
self.use_labels = True
self.vocab_size = 99
self.hidden_size = 32
self.num_hidden_layers = 5
self.num_attention_heads = 4
self.intermediate_size = 37
self.hidden_act = "gelu"
self.hidden_dropout_prob = 0.1
self.attention_probs_dropout_prob = 0.1
self.max_position_embeddings = 512
self.type_vocab_size = 16
self.type_sequence_label_size = 2
self.initializer_range = 0.02
self.num_labels = 3
self.num_choices = 4
self.scope = None
def prepare_config_and_inputs(self):
input_ids = ids_tensor([self.batch_size, self.seq_length], self.vocab_size)
input_mask = None
if self.use_input_mask:
input_mask = ids_tensor([self.batch_size, self.seq_length], vocab_size=2)
token_type_ids = None
if self.use_token_type_ids:
token_type_ids = ids_tensor([self.batch_size, self.seq_length], self.type_vocab_size)
sequence_labels = None
token_labels = None
choice_labels = None
if self.use_labels:
sequence_labels = ids_tensor([self.batch_size], self.type_sequence_label_size)
token_labels = ids_tensor([self.batch_size, self.seq_length], self.num_labels)
choice_labels = ids_tensor([self.batch_size], self.num_choices)
config = {{cookiecutter.camelcase_modelname}}Config(
vocab_size=self.vocab_size,
hidden_size=self.hidden_size,
num_hidden_layers=self.num_hidden_layers,
num_attention_heads=self.num_attention_heads,
intermediate_size=self.intermediate_size,
hidden_act=self.hidden_act,
hidden_dropout_prob=self.hidden_dropout_prob,
attention_probs_dropout_prob=self.attention_probs_dropout_prob,
max_position_embeddings=self.max_position_embeddings,
type_vocab_size=self.type_vocab_size,
initializer_range=self.initializer_range,
return_dict=True,
)
return config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
def create_and_check_model(
self, config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
):
model = Flax{{cookiecutter.camelcase_modelname}}Model(config=config)
inputs = {"input_ids": input_ids, "attention_mask": input_mask, "token_type_ids": token_type_ids}
inputs = [input_ids, input_mask]
result = model(*inputs)
self.parent.assertEqual(result.last_hidden_state.shape, (self.batch_size, self.seq_length, self.hidden_size))
def create_and_check_lm_head(
self, config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
):
config.is_decoder = True
model = Flax{{cookiecutter.camelcase_modelname}}ForCausalLM(config=config)
inputs = {
"input_ids": input_ids,
"attention_mask": input_mask,
"token_type_ids": token_type_ids,
}
prediction_scores = model(**inputs)["logits"]
self.parent.assertListEqual(
list(prediction_scores.shape), [self.batch_size, self.seq_length, self.vocab_size]
)
def create_and_check_for_masked_lm(
self, config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
):
model = Flax{{cookiecutter.camelcase_modelname}}ForMaskedLM(config=config)
inputs = {
"input_ids": input_ids,
"attention_mask": input_mask,
"token_type_ids": token_type_ids,
}
result = model(**inputs)
self.parent.assertEqual(result.logits.shape, (self.batch_size, self.seq_length, self.vocab_size))
def create_and_check_for_sequence_classification(
self, config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
):
config.num_labels = self.num_labels
model = Flax{{cookiecutter.camelcase_modelname}}ForSequenceClassification(config=config)
inputs = {
"input_ids": input_ids,
"attention_mask": input_mask,
"token_type_ids": token_type_ids,
}
result = model(**inputs)
self.parent.assertEqual(result.logits.shape, (self.batch_size, self.num_labels))
def create_and_check_for_multiple_choice(
self, config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
):
config.num_choices = self.num_choices
model = Flax{{cookiecutter.camelcase_modelname}}ForMultipleChoice(config=config)
multiple_choice_inputs_ids = np.tile(np.expand_dims(input_ids, 1), (1, self.num_choices, 1))
multiple_choice_input_mask = np.tile(np.expand_dims(input_mask, 1), (1, self.num_choices, 1))
multiple_choice_token_type_ids = np.tile(np.expand_dims(token_type_ids, 1), (1, self.num_choices, 1))
inputs = {
"input_ids": multiple_choice_inputs_ids,
"attention_mask": multiple_choice_input_mask,
"token_type_ids": multiple_choice_token_type_ids,
}
result = model(**inputs)
self.parent.assertEqual(result.logits.shape, (self.batch_size, self.num_choices))
def create_and_check_for_token_classification(
self, config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
):
config.num_labels = self.num_labels
model = Flax{{cookiecutter.camelcase_modelname}}ForTokenClassification(config=config)
inputs = {
"input_ids": input_ids,
"attention_mask": input_mask,
"token_type_ids": token_type_ids,
}
result = model(**inputs)
self.parent.assertEqual(result.logits.shape, (self.batch_size, self.seq_length, self.num_labels))
def create_and_check_for_question_answering(
self, config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
):
model = Flax{{cookiecutter.camelcase_modelname}}ForQuestionAnswering(config=config)
inputs = {
"input_ids": input_ids,
"attention_mask": input_mask,
"token_type_ids": token_type_ids,
}
result = model(**inputs)
self.parent.assertEqual(result.start_logits.shape, (self.batch_size, self.seq_length))
self.parent.assertEqual(result.end_logits.shape, (self.batch_size, self.seq_length))
def prepare_config_and_inputs_for_common(self):
config_and_inputs = self.prepare_config_and_inputs()
(
config,
input_ids,
token_type_ids,
input_mask,
sequence_labels,
token_labels,
choice_labels,
) = config_and_inputs
inputs_dict = {"input_ids": input_ids, "token_type_ids": token_type_ids, "attention_mask": input_mask}
return config, inputs_dict
@require_flax
class Flax{{cookiecutter.camelcase_modelname}}ModelTest(FlaxModelTesterMixin, unittest.TestCase):
all_model_classes = (
(
Flax{{cookiecutter.camelcase_modelname}}Model,
Flax{{cookiecutter.camelcase_modelname}}ForCausalLM,
Flax{{cookiecutter.camelcase_modelname}}ForMaskedLM,
Flax{{cookiecutter.camelcase_modelname}}ForQuestionAnswering,
Flax{{cookiecutter.camelcase_modelname}}ForSequenceClassification,
Flax{{cookiecutter.camelcase_modelname}}ForTokenClassification,
Flax{{cookiecutter.camelcase_modelname}}ForMultipleChoice,
)
if is_flax_available()
else ()
)
test_head_masking = False
test_onnx = False
def setUp(self):
self.model_tester = Flax{{cookiecutter.camelcase_modelname}}ModelTester(self)
self.config_tester = ConfigTester(self, config_class={{cookiecutter.camelcase_modelname}}Config, hidden_size=37)
def test_config(self):
self.config_tester.run_common_tests()
def test_model(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_model(*config_and_inputs)
def test_for_masked_lm(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_for_masked_lm(*config_and_inputs)
def test_for_causal_lm(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_lm_head(*config_and_inputs)
def test_for_multiple_choice(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_for_multiple_choice(*config_and_inputs)
def test_for_question_answering(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_for_question_answering(*config_and_inputs)
def test_for_sequence_classification(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_for_sequence_classification(*config_and_inputs)
def test_for_token_classification(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_for_token_classification(*config_and_inputs)
@slow
def test_model_from_pretrained(self):
model = Flax{{cookiecutter.camelcase_modelname}}Model.from_pretrained("{{cookiecutter.checkpoint_identifier}}")
self.assertIsNotNone(model)
def _assert_tensors_equal(a, b, atol=1e-12, prefix=""):
"""If tensors not close, or a and b arent both tensors, raise a nice Assertion error."""
if a is None and b is None:
return True
try:
if _assert_tensors_equal(a, b, atol=atol):
return True
raise
except Exception:
if len(prefix) > 0:
prefix = f"{prefix}: "
raise AssertionError(f"{prefix}{a} != {b}")
@require_flax
class Flax{{cookiecutter.camelcase_modelname}}ModelIntegrationTest(unittest.TestCase):
@slow
def test_inference_masked_lm(self):
model = Flax{{cookiecutter.camelcase_modelname}}ForMaskedLM.from_pretrained("{{cookiecutter.checkpoint_identifier}}")
input_ids = np.array([[0, 1, 2, 3, 4, 5]])
output = model(input_ids)[0]
# TODO Replace vocab size
vocab_size = 32000
expected_shape = [1, 6, vocab_size]
self.assertEqual(output.shape, expected_shape)
print(output[:, :3, :3])
# TODO Replace values below with what was printed above.
expected_slice = np.array(
[
[
[-0.05243197, -0.04498899, 0.05512108],
[-0.07444685, -0.01064632, 0.04352357],
[-0.05020351, 0.05530146, 0.00700043],
]
]
)
_assert_tensors_equal(output[:, :3, :3], expected_slice, atol=1e-4)
{% else %}
import unittest
from transformers import (
is_flax_available,
{{cookiecutter.camelcase_modelname}}Config,
{{cookiecutter.camelcase_modelname}}Tokenizer,
)
from transformers.testing_utils import require_sentencepiece, require_flax, require_tokenizers, slow
from ...test_configuration_common import ConfigTester
from ...test_modeling_flax_common import FlaxModelTesterMixin, ids_tensor
if is_flax_available():
import numpy as np
import jax.numpy as jnp
from transformers import (
Flax{{cookiecutter.camelcase_modelname}}ForConditionalGeneration,
Flax{{cookiecutter.camelcase_modelname}}ForQuestionAnswering,
Flax{{cookiecutter.camelcase_modelname}}ForSequenceClassification,
Flax{{cookiecutter.camelcase_modelname}}Model,
)
@require_flax
class Flax{{cookiecutter.camelcase_modelname}}ModelTester:
config_cls = {{cookiecutter.camelcase_modelname}}Config
config_updates = {}
hidden_act = "gelu"
def __init__(
self,
parent,
batch_size=13,
seq_length=7,
is_training=True,
use_labels=False,
vocab_size=99,
hidden_size=32,
num_hidden_layers=5,
num_attention_heads=4,
intermediate_size=37,
hidden_dropout_prob=0.1,
attention_probs_dropout_prob=0.1,
max_position_embeddings=20,
eos_token_id=2,
pad_token_id=1,
bos_token_id=0,
):
self.parent = parent
self.batch_size = batch_size
self.seq_length = seq_length
self.is_training = is_training
self.use_labels = use_labels
self.vocab_size = vocab_size
self.hidden_size = hidden_size
self.num_hidden_layers = num_hidden_layers
self.num_attention_heads = num_attention_heads
self.intermediate_size = intermediate_size
self.hidden_dropout_prob = hidden_dropout_prob
self.attention_probs_dropout_prob = attention_probs_dropout_prob
self.max_position_embeddings = max_position_embeddings
self.eos_token_id = eos_token_id
self.pad_token_id = pad_token_id
self.bos_token_id = bos_token_id
def prepare_config_and_inputs_for_common(self):
input_ids = ids_tensor([self.batch_size, self.seq_length - 1], self.vocab_size).clip(3, self.vocab_size)
eos_tensor = np.expand_dims(np.array([self.eos_token_id] * self.batch_size), 1)
input_ids = np.concatenate([input_ids, eos_tensor], axis=1)
decoder_input_ids = ids_tensor([self.batch_size, self.seq_length], self.vocab_size)
config = self.config_cls(
vocab_size=self.vocab_size,
d_model=self.hidden_size,
encoder_layers=self.num_hidden_layers,
decoder_layers=self.num_hidden_layers,
encoder_attention_heads=self.num_attention_heads,
decoder_attention_heads=self.num_attention_heads,
encoder_ffn_dim=self.intermediate_size,
decoder_ffn_dim=self.intermediate_size,
dropout=self.hidden_dropout_prob,
attention_dropout=self.attention_probs_dropout_prob,
max_position_embeddings=self.max_position_embeddings,
eos_token_ids=[2],
bos_token_id=self.bos_token_id,
pad_token_id=self.pad_token_id,
decoder_start_token_id=self.pad_token_id,
**self.config_updates,
)
inputs_dict = prepare_{{cookiecutter.lowercase_modelname}}_inputs_dict(config, input_ids, decoder_input_ids)
return config, inputs_dict
def check_use_cache_forward(self, model_class_name, config, inputs_dict):
max_decoder_length = 20
model = model_class_name(config)
encoder_outputs = model.encode(inputs_dict["input_ids"])
decoder_input_ids, decoder_attention_mask = (
inputs_dict["decoder_input_ids"],
inputs_dict["decoder_attention_mask"],
)
past_key_values = model.init_cache(decoder_input_ids.shape[0], max_decoder_length, encoder_outputs)
decoder_attention_mask = jnp.ones((decoder_input_ids.shape[0], max_decoder_length), dtype="i4")
decoder_position_ids = jnp.broadcast_to(
jnp.arange(decoder_input_ids.shape[-1] - 1)[None, :],
(decoder_input_ids.shape[0], decoder_input_ids.shape[-1] - 1),
)
outputs_cache = model.decode(
decoder_input_ids[:, :-1],
encoder_outputs,
decoder_attention_mask=decoder_attention_mask,
past_key_values=past_key_values,
decoder_position_ids=decoder_position_ids,
)
decoder_position_ids = jnp.array(decoder_input_ids.shape[0] * [[decoder_input_ids.shape[-1] - 1]], dtype="i4")
outputs_cache_next = model.decode(
decoder_input_ids[:, -1:],
encoder_outputs,
decoder_attention_mask=decoder_attention_mask,
past_key_values=outputs_cache.past_key_values,
decoder_position_ids=decoder_position_ids,
)
outputs = model.decode(decoder_input_ids, encoder_outputs)
diff = np.max(np.abs((outputs_cache_next[0][:, -1, :5] - outputs[0][:, -1, :5])))
self.parent.assertTrue(diff < 1e-3, msg=f"Max diff is {diff}")
def check_use_cache_forward_with_attn_mask(self, model_class_name, config, inputs_dict):
max_decoder_length = 20
model = model_class_name(config)
encoder_outputs = model.encode(inputs_dict["input_ids"])
decoder_input_ids, decoder_attention_mask = (
inputs_dict["decoder_input_ids"],
inputs_dict["decoder_attention_mask"],
)
decoder_attention_mask_cache = jnp.concatenate(
[
decoder_attention_mask,
jnp.zeros((decoder_attention_mask.shape[0], max_decoder_length - decoder_attention_mask.shape[1])),
],
axis=-1,
)
past_key_values = model.init_cache(decoder_input_ids.shape[0], max_decoder_length, encoder_outputs)
decoder_position_ids = jnp.broadcast_to(
jnp.arange(decoder_input_ids.shape[-1] - 1)[None, :],
(decoder_input_ids.shape[0], decoder_input_ids.shape[-1] - 1),
)
outputs_cache = model.decode(
decoder_input_ids[:, :-1],
encoder_outputs,
decoder_attention_mask=decoder_attention_mask_cache,
past_key_values=past_key_values,
decoder_position_ids=decoder_position_ids,
)
decoder_position_ids = jnp.array(decoder_input_ids.shape[0] * [[decoder_input_ids.shape[-1] - 1]], dtype="i4")
outputs_cache_next = model.decode(
decoder_input_ids[:, -1:],
encoder_outputs,
past_key_values=outputs_cache.past_key_values,
decoder_attention_mask=decoder_attention_mask_cache,
decoder_position_ids=decoder_position_ids,
)
outputs = model.decode(decoder_input_ids, encoder_outputs, decoder_attention_mask=decoder_attention_mask)
diff = np.max(np.abs((outputs_cache_next[0][:, -1, :5] - outputs[0][:, -1, :5])))
self.parent.assertTrue(diff < 1e-3, msg=f"Max diff is {diff}")
def prepare_{{cookiecutter.lowercase_modelname}}_inputs_dict(
config,
input_ids,
decoder_input_ids,
attention_mask=None,
decoder_attention_mask=None,
):
if attention_mask is None:
attention_mask = np.not_equal(input_ids, config.pad_token_id).astype(np.int8)
if decoder_attention_mask is None:
decoder_attention_mask = np.concatenate([np.ones(decoder_input_ids[:, :1].shape, dtype=np.int8), np.not_equal(decoder_input_ids[:, 1:], config.pad_token_id).astype(np.int8)], axis=-1)
return {
"input_ids": input_ids,
"decoder_input_ids": decoder_input_ids,
"attention_mask": attention_mask,
"decoder_attention_mask": decoder_attention_mask,
}
@require_flax
class Flax{{cookiecutter.camelcase_modelname}}ModelTest(FlaxModelTesterMixin, unittest.TestCase):
all_model_classes = (
(
Flax{{cookiecutter.camelcase_modelname}}ForConditionalGeneration,
Flax{{cookiecutter.camelcase_modelname}}ForQuestionAnswering,
Flax{{cookiecutter.camelcase_modelname}}ForSequenceClassification,
Flax{{cookiecutter.camelcase_modelname}}Model,
) if is_flax_available()
else ()
)
all_generative_model_classes = (Flax{{cookiecutter.camelcase_modelname}}ForConditionalGeneration,) if is_flax_available() else ()
is_encoder_decoder = True
test_pruning = False
test_head_masking = False
test_onnx = False
def setUp(self):
self.model_tester = Flax{{cookiecutter.camelcase_modelname}}ModelTester(self)
self.config_tester = ConfigTester(self, config_class={{cookiecutter.camelcase_modelname}}Config)
def test_config(self):
self.config_tester.run_common_tests()
def test_use_cache_forward(self):
config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
for model_class in self.all_model_classes:
self.model_tester.check_use_cache_forward(model_class, config, inputs_dict)
def test_use_cache_forward_with_attn_mask(self):
config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
for model_class in self.all_model_classes:
self.model_tester.check_use_cache_forward_with_attn_mask(model_class, config, inputs_dict)
def _assert_tensors_equal(a, b, atol=1e-12, prefix=""):
"""If tensors not close, or a and b arent both tensors, raise a nice Assertion error."""
if a is None and b is None:
return True
try:
if _assert_tensors_equal(a, b, atol=atol):
return True
raise
except Exception:
if len(prefix) > 0:
prefix = f"{prefix}: "
raise AssertionError(f"{prefix}{a} != {b}")
def _long_tensor(tok_lst):
return np.array(tok_lst, dtype=np.int32)
TOLERANCE = 1e-4
@slow
@require_sentencepiece
@require_tokenizers
@require_flax
class Flax{{cookiecutter.camelcase_modelname}}ModelIntegrationTest(unittest.TestCase):
def test_inference_no_head(self):
model = Flax{{cookiecutter.camelcase_modelname}}Model.from_pretrained('{{cookiecutter.checkpoint_identifier}}')
# change to intended input here
input_ids = _long_tensor([[0, 31414, 232, 328, 740, 1140, 12695, 69, 46078, 1588, 2]])
decoder_input_ids = _long_tensor([[0, 31414, 232, 328, 740, 1140, 12695, 69, 46078, 1588, 2]])
inputs_dict = prepare_{{cookiecutter.lowercase_modelname}}_inputs_dict(model.config, input_ids, decoder_input_ids)
output = model(**inputs_dict)[0]
expected_shape = (1, 11, 1024)
self.assertEqual(output.shape, expected_shape)
# change to expected output here
expected_slice = np.array(
[[0.7144, 0.8143, -1.2813], [0.7144, 0.8143, -1.2813], [-0.0467, 2.5911, -2.1845]],
)
_assert_tensors_equal(output[:, :3, :3], expected_slice, atol=TOLERANCE)
def test_inference_with_head(self):
model = Flax{{cookiecutter.camelcase_modelname}}ForConditionalGeneration.from_pretrained('{{cookiecutter.checkpoint_identifier}}')
# change to intended input here
input_ids = _long_tensor([[0, 31414, 232, 328, 740, 1140, 12695, 69, 46078, 1588, 2]])
decoder_input_ids = _long_tensor([[0, 31414, 232, 328, 740, 1140, 12695, 69, 46078, 1588, 2]])
inputs_dict = prepare_{{cookiecutter.lowercase_modelname}}_inputs_dict(model.config, input_ids, decoder_input_ids)
output = model(**inputs_dict)[0]
expected_shape = (1, 11, 1024)
self.assertEqual(output.shape, expected_shape)
# change to expected output here
expected_slice = np.array(
[[0.7144, 0.8143, -1.2813], [0.7144, 0.8143, -1.2813], [-0.0467, 2.5911, -2.1845]],
)
_assert_tensors_equal(output[:, :3, :3], expected_slice, atol=TOLERANCE)
def test_seq_to_seq_generation(self):
hf = Flax{{cookiecutter.camelcase_modelname}}ForConditionalGeneration.from_pretrained('{{cookiecutter.checkpoint_identifier}}')
tok = {{cookiecutter.camelcase_modelname}}Tokenizer.from_pretrained('{{cookiecutter.checkpoint_identifier}}')
batch_input = [
# string 1,
# string 2,
# string 3,
# string 4,
]
# The below article tests that we don't add any hypotheses outside of the top n_beams
dct = tok.batch_encode_plus(
batch_input,
max_length=512,
padding="max_length",
truncation_strategy="only_first",
truncation=True,
return_tensors="np",
)
hypotheses_batch = hf.generate(
input_ids=dct["input_ids"],
attention_mask=dct["attention_mask"],
num_beams=2,
)
EXPECTED = [
# here expected 1,
# here expected 2,
# here expected 3,
# here expected 4,
]
generated = tok.batch_decode(
hypotheses_batch.tolist(), clean_up_tokenization_spaces=True, skip_special_tokens=True
)
assert generated == EXPECTED
{%- endif %}
| 0 |
hf_public_repos/transformers/templates/adding_a_new_model | hf_public_repos/transformers/templates/adding_a_new_model/cookiecutter-template-{{cookiecutter.modelname}}/modeling_tf_{{cookiecutter.lowercase_modelname}}.py | # coding=utf-8
# Copyright 2022 {{cookiecutter.authors}} and The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
""" TF 2.0 {{cookiecutter.modelname}} model. """
{% if cookiecutter.is_encoder_decoder_model == "False" %}
import math
from typing import Dict, Optional, Tuple, Union
import numpy as np
import tensorflow as tf
from ...activations_tf import get_tf_activation
from ...utils import (
DUMMY_INPUTS,
MULTIPLE_CHOICE_DUMMY_INPUTS,
add_code_sample_docstrings,
add_start_docstrings,
add_start_docstrings_to_model_forward,
)
from ...modeling_tf_outputs import (
TFBaseModelOutputWithPastAndCrossAttentions,
TFCausalLMOutputWithCrossAttentions,
TFMaskedLMOutput,
TFMultipleChoiceModelOutput,
TFQuestionAnsweringModelOutput,
TFSequenceClassifierOutput,
TFTokenClassifierOutput,
)
from ...modeling_tf_utils import (
TFCausalLanguageModelingLoss,
TFMaskedLanguageModelingLoss,
TFModelInputType,
TFMultipleChoiceLoss,
TFPreTrainedModel,
TFQuestionAnsweringLoss,
TFSequenceClassificationLoss,
TFSequenceSummary,
TFTokenClassificationLoss,
get_initializer,
keras_serializable,
unpack_inputs,
)
from ...tf_utils import check_embeddings_within_bounds, shape_list, stable_softmax
from ...utils import logging
from .configuration_{{cookiecutter.lowercase_modelname}} import {{cookiecutter.camelcase_modelname}}Config
logger = logging.get_logger(__name__)
_CHECKPOINT_FOR_DOC = "{{cookiecutter.checkpoint_identifier}}"
_CONFIG_FOR_DOC = "{{cookiecutter.camelcase_modelname}}Config"
TF_{{cookiecutter.uppercase_modelname}}_PRETRAINED_MODEL_ARCHIVE_LIST = [
"{{cookiecutter.checkpoint_identifier}}",
# See all {{cookiecutter.modelname}} models at https://huggingface.co/models?filter={{cookiecutter.lowercase_modelname}}
]
# Copied from transformers.models.bert.modeling_tf_bert.TFBertEmbeddings with Bert->{{cookiecutter.camelcase_modelname}}
class TF{{cookiecutter.camelcase_modelname}}Embeddings(tf.keras.layers.Layer):
"""Construct the embeddings from word, position and token_type embeddings."""
def __init__(self, config: {{cookiecutter.camelcase_modelname}}Config, **kwargs):
super().__init__(**kwargs)
self.vocab_size = config.vocab_size
self.type_vocab_size = config.type_vocab_size
self.hidden_size = config.hidden_size
self.max_position_embeddings = config.max_position_embeddings
self.initializer_range = config.initializer_range
self.LayerNorm = tf.keras.layers.LayerNormalization(epsilon=config.layer_norm_eps, name="LayerNorm")
self.dropout = tf.keras.layers.Dropout(rate=config.hidden_dropout_prob)
def build(self, input_shape: tf.TensorShape):
with tf.name_scope("word_embeddings"):
self.weight = self.add_weight(
name="weight",
shape=[self.vocab_size, self.hidden_size],
initializer=get_initializer(self.initializer_range),
)
with tf.name_scope("token_type_embeddings"):
self.token_type_embeddings = self.add_weight(
name="embeddings",
shape=[self.type_vocab_size, self.hidden_size],
initializer=get_initializer(self.initializer_range),
)
with tf.name_scope("position_embeddings"):
self.position_embeddings = self.add_weight(
name="embeddings",
shape=[self.max_position_embeddings, self.hidden_size],
initializer=get_initializer(self.initializer_range),
)
super().build(input_shape)
def call(
self,
input_ids: tf.Tensor = None,
position_ids: tf.Tensor = None,
token_type_ids: tf.Tensor = None,
inputs_embeds: tf.Tensor = None,
past_key_values_length=0,
training: bool = False,
) -> tf.Tensor:
"""
Applies embedding based on inputs tensor.
Returns:
final_embeddings (`tf.Tensor`): output embedding tensor.
"""
assert not (input_ids is None and inputs_embeds is None)
if input_ids is not None:
check_embeddings_within_bounds(input_ids, self.vocab_size)
inputs_embeds = tf.gather(params=self.weight, indices=input_ids)
input_shape = shape_list(inputs_embeds)[:-1]
if token_type_ids is None:
token_type_ids = tf.fill(dims=input_shape, value=0)
if position_ids is None:
position_ids = tf.expand_dims(
tf.range(start=past_key_values_length, limit=input_shape[1] + past_key_values_length), axis=0
)
position_embeds = tf.gather(params=self.position_embeddings, indices=position_ids)
token_type_embeds = tf.gather(params=self.token_type_embeddings, indices=token_type_ids)
final_embeddings = inputs_embeds + position_embeds + token_type_embeds
final_embeddings = self.LayerNorm(inputs=final_embeddings)
final_embeddings = self.dropout(inputs=final_embeddings, training=training)
return final_embeddings
# Copied from transformers.models.bert.modeling_tf_bert.TFBertSelfAttention with Bert->{{cookiecutter.camelcase_modelname}}
class TF{{cookiecutter.camelcase_modelname}}SelfAttention(tf.keras.layers.Layer):
def __init__(self, config: {{cookiecutter.camelcase_modelname}}Config, **kwargs):
super().__init__(**kwargs)
if config.hidden_size % config.num_attention_heads != 0:
raise ValueError(
f"The hidden size ({config.hidden_size}) is not a multiple of the number "
f"of attention heads ({config.num_attention_heads})"
)
self.num_attention_heads = config.num_attention_heads
self.attention_head_size = int(config.hidden_size / config.num_attention_heads)
self.all_head_size = self.num_attention_heads * self.attention_head_size
self.sqrt_att_head_size = math.sqrt(self.attention_head_size)
self.query = tf.keras.layers.Dense(
units=self.all_head_size, kernel_initializer=get_initializer(config.initializer_range), name="query"
)
self.key = tf.keras.layers.Dense(
units=self.all_head_size, kernel_initializer=get_initializer(config.initializer_range), name="key"
)
self.value = tf.keras.layers.Dense(
units=self.all_head_size, kernel_initializer=get_initializer(config.initializer_range), name="value"
)
self.dropout = tf.keras.layers.Dropout(rate=config.attention_probs_dropout_prob)
self.is_decoder = config.is_decoder
def transpose_for_scores(self, tensor: tf.Tensor, batch_size: int) -> tf.Tensor:
# Reshape from [batch_size, seq_length, all_head_size] to [batch_size, seq_length, num_attention_heads, attention_head_size]
tensor = tf.reshape(tensor=tensor, shape=(batch_size, -1, self.num_attention_heads, self.attention_head_size))
# Transpose the tensor from [batch_size, seq_length, num_attention_heads, attention_head_size] to [batch_size, num_attention_heads, seq_length, attention_head_size]
return tf.transpose(tensor, perm=[0, 2, 1, 3])
def call(
self,
hidden_states: tf.Tensor,
attention_mask: tf.Tensor,
head_mask: tf.Tensor,
encoder_hidden_states: tf.Tensor,
encoder_attention_mask: tf.Tensor,
past_key_value: Tuple[tf.Tensor],
output_attentions: bool,
training: bool = False,
) -> Tuple[tf.Tensor]:
batch_size = shape_list(hidden_states)[0]
mixed_query_layer = self.query(inputs=hidden_states)
# If this is instantiated as a cross-attention module, the keys
# and values come from an encoder; the attention mask needs to be
# such that the encoder's padding tokens are not attended to.
is_cross_attention = encoder_hidden_states is not None
if is_cross_attention and past_key_value is not None:
# reuse k,v, cross_attentions
key_layer = past_key_value[0]
value_layer = past_key_value[1]
attention_mask = encoder_attention_mask
elif is_cross_attention:
key_layer = self.transpose_for_scores(self.key(inputs=encoder_hidden_states), batch_size)
value_layer = self.transpose_for_scores(self.value(inputs=encoder_hidden_states), batch_size)
attention_mask = encoder_attention_mask
elif past_key_value is not None:
key_layer = self.transpose_for_scores(self.key(inputs=hidden_states), batch_size)
value_layer = self.transpose_for_scores(self.value(inputs=hidden_states), batch_size)
key_layer = tf.concat([past_key_value[0], key_layer], axis=2)
value_layer = tf.concat([past_key_value[1], value_layer], axis=2)
else:
key_layer = self.transpose_for_scores(self.key(inputs=hidden_states), batch_size)
value_layer = self.transpose_for_scores(self.value(inputs=hidden_states), batch_size)
query_layer = self.transpose_for_scores(mixed_query_layer, batch_size)
if self.is_decoder:
# if cross_attention save Tuple(tf.Tensor, tf.Tensor) of all cross attention key/value_states.
# Further calls to cross_attention layer can then reuse all cross-attention
# key/value_states (first "if" case)
# if uni-directional self-attention (decoder) save Tuple(tf.Tensor, tf.Tensor) of
# all previous decoder key/value_states. Further calls to uni-directional self-attention
# can concat previous decoder key/value_states to current projected key/value_states (third "elif" case)
# if encoder bi-directional self-attention `past_key_value` is always `None`
past_key_value = (key_layer, value_layer)
# Take the dot product between "query" and "key" to get the raw attention scores.
# (batch size, num_heads, seq_len_q, seq_len_k)
attention_scores = tf.matmul(query_layer, key_layer, transpose_b=True)
dk = tf.cast(self.sqrt_att_head_size, dtype=attention_scores.dtype)
attention_scores = tf.divide(attention_scores, dk)
if attention_mask is not None:
# Apply the attention mask is (precomputed for all layers in TF{{cookiecutter.camelcase_modelname}}Model call() function)
attention_scores = tf.add(attention_scores, attention_mask)
# Normalize the attention scores to probabilities.
attention_probs = stable_softmax(logits=attention_scores, axis=-1)
# This is actually dropping out entire tokens to attend to, which might
# seem a bit unusual, but is taken from the original Transformer paper.
attention_probs = self.dropout(inputs=attention_probs, training=training)
# Mask heads if we want to
if head_mask is not None:
attention_probs = tf.multiply(attention_probs, head_mask)
attention_output = tf.matmul(attention_probs, value_layer)
attention_output = tf.transpose(attention_output, perm=[0, 2, 1, 3])
# (batch_size, seq_len_q, all_head_size)
attention_output = tf.reshape(tensor=attention_output, shape=(batch_size, -1, self.all_head_size))
outputs = (attention_output, attention_probs) if output_attentions else (attention_output,)
if self.is_decoder:
outputs = outputs + (past_key_value,)
return outputs
# Copied from transformers.models.bert.modeling_tf_bert.TFBertSelfOutput with Bert->{{cookiecutter.camelcase_modelname}}
class TF{{cookiecutter.camelcase_modelname}}SelfOutput(tf.keras.layers.Layer):
def __init__(self, config: {{cookiecutter.camelcase_modelname}}Config, **kwargs):
super().__init__(**kwargs)
self.dense = tf.keras.layers.Dense(
units=config.hidden_size, kernel_initializer=get_initializer(config.initializer_range), name="dense"
)
self.LayerNorm = tf.keras.layers.LayerNormalization(epsilon=config.layer_norm_eps, name="LayerNorm")
self.dropout = tf.keras.layers.Dropout(rate=config.hidden_dropout_prob)
def call(self, hidden_states: tf.Tensor, input_tensor: tf.Tensor, training: bool = False) -> tf.Tensor:
hidden_states = self.dense(inputs=hidden_states)
hidden_states = self.dropout(inputs=hidden_states, training=training)
hidden_states = self.LayerNorm(inputs=hidden_states + input_tensor)
return hidden_states
# Copied from transformers.models.bert.modeling_tf_bert.TFBertAttention with Bert->{{cookiecutter.camelcase_modelname}}
class TF{{cookiecutter.camelcase_modelname}}Attention(tf.keras.layers.Layer):
def __init__(self, config: {{cookiecutter.camelcase_modelname}}Config, **kwargs):
super().__init__(**kwargs)
self.self_attention = TF{{cookiecutter.camelcase_modelname}}SelfAttention(config, name="self")
self.dense_output = TF{{cookiecutter.camelcase_modelname}}SelfOutput(config, name="output")
def prune_heads(self, heads):
raise NotImplementedError
def call(
self,
input_tensor: tf.Tensor,
attention_mask: tf.Tensor,
head_mask: tf.Tensor,
encoder_hidden_states: tf.Tensor,
encoder_attention_mask: tf.Tensor,
past_key_value: Tuple[tf.Tensor],
output_attentions: bool,
training: bool = False,
) -> Tuple[tf.Tensor]:
self_outputs = self.self_attention(
hidden_states=input_tensor,
attention_mask=attention_mask,
head_mask=head_mask,
encoder_hidden_states=encoder_hidden_states,
encoder_attention_mask=encoder_attention_mask,
past_key_value=past_key_value,
output_attentions=output_attentions,
training=training,
)
attention_output = self.dense_output(
hidden_states=self_outputs[0], input_tensor=input_tensor, training=training
)
# add attentions (possibly with past_key_value) if we output them
outputs = (attention_output,) + self_outputs[1:]
return outputs
# Copied from transformers.models.bert.modeling_tf_bert.TFBertIntermediate with Bert->{{cookiecutter.camelcase_modelname}}
class TF{{cookiecutter.camelcase_modelname}}Intermediate(tf.keras.layers.Layer):
def __init__(self, config: {{cookiecutter.camelcase_modelname}}Config, **kwargs):
super().__init__(**kwargs)
self.dense = tf.keras.layers.Dense(
units=config.intermediate_size, kernel_initializer=get_initializer(config.initializer_range), name="dense"
)
if isinstance(config.hidden_act, str):
self.intermediate_act_fn = get_tf_activation(config.hidden_act)
else:
self.intermediate_act_fn = config.hidden_act
def call(self, hidden_states: tf.Tensor) -> tf.Tensor:
hidden_states = self.dense(inputs=hidden_states)
hidden_states = self.intermediate_act_fn(hidden_states)
return hidden_states
# Copied from transformers.models.bert.modeling_tf_bert.TFBertOutput with Bert->{{cookiecutter.camelcase_modelname}}
class TF{{cookiecutter.camelcase_modelname}}Output(tf.keras.layers.Layer):
def __init__(self, config: {{cookiecutter.camelcase_modelname}}Config, **kwargs):
super().__init__(**kwargs)
self.dense = tf.keras.layers.Dense(
units=config.hidden_size, kernel_initializer=get_initializer(config.initializer_range), name="dense"
)
self.LayerNorm = tf.keras.layers.LayerNormalization(epsilon=config.layer_norm_eps, name="LayerNorm")
self.dropout = tf.keras.layers.Dropout(rate=config.hidden_dropout_prob)
def call(self, hidden_states: tf.Tensor, input_tensor: tf.Tensor, training: bool = False) -> tf.Tensor:
hidden_states = self.dense(inputs=hidden_states)
hidden_states = self.dropout(inputs=hidden_states, training=training)
hidden_states = self.LayerNorm(inputs=hidden_states + input_tensor)
return hidden_states
# Copied from transformers.models.bert.modeling_tf_bert.TFBertLayer with Bert->{{cookiecutter.camelcase_modelname}}
class TF{{cookiecutter.camelcase_modelname}}Layer(tf.keras.layers.Layer):
def __init__(self, config: {{cookiecutter.camelcase_modelname}}Config, **kwargs):
super().__init__(**kwargs)
self.attention = TF{{cookiecutter.camelcase_modelname}}Attention(config, name="attention")
self.is_decoder = config.is_decoder
self.add_cross_attention = config.add_cross_attention
if self.add_cross_attention:
if not self.is_decoder:
raise ValueError(f"{self} should be used as a decoder model if cross attention is added")
self.crossattention = TF{{cookiecutter.camelcase_modelname}}Attention(config, name="crossattention")
self.intermediate = TF{{cookiecutter.camelcase_modelname}}Intermediate(config, name="intermediate")
self.bert_output = TF{{cookiecutter.camelcase_modelname}}Output(config, name="output")
def call(
self,
hidden_states: tf.Tensor,
attention_mask: tf.Tensor,
head_mask: tf.Tensor,
encoder_hidden_states: tf.Tensor | None,
encoder_attention_mask: tf.Tensor | None,
past_key_value: Tuple[tf.Tensor] | None,
output_attentions: bool,
training: bool = False,
) -> Tuple[tf.Tensor]:
# decoder uni-directional self-attention cached key/values tuple is at positions 1,2
self_attn_past_key_value = past_key_value[:2] if past_key_value is not None else None
self_attention_outputs = self.attention(
input_tensor=hidden_states,
attention_mask=attention_mask,
head_mask=head_mask,
encoder_hidden_states=None,
encoder_attention_mask=None,
past_key_value=self_attn_past_key_value,
output_attentions=output_attentions,
training=training,
)
attention_output = self_attention_outputs[0]
# if decoder, the last output is tuple of self-attn cache
if self.is_decoder:
outputs = self_attention_outputs[1:-1]
present_key_value = self_attention_outputs[-1]
else:
outputs = self_attention_outputs[1:] # add self attentions if we output attention weights
cross_attn_present_key_value = None
if self.is_decoder and encoder_hidden_states is not None:
if not hasattr(self, "crossattention"):
raise ValueError(
f"If `encoder_hidden_states` are passed, {self} has to be instantiated with cross-attention layers "
"by setting `config.add_cross_attention=True`"
)
# cross_attn cached key/values tuple is at positions 3,4 of past_key_value tuple
cross_attn_past_key_value = past_key_value[-2:] if past_key_value is not None else None
cross_attention_outputs = self.crossattention(
input_tensor=attention_output,
attention_mask=attention_mask,
head_mask=head_mask,
encoder_hidden_states=encoder_hidden_states,
encoder_attention_mask=encoder_attention_mask,
past_key_value=cross_attn_past_key_value,
output_attentions=output_attentions,
training=training,
)
attention_output = cross_attention_outputs[0]
outputs = outputs + cross_attention_outputs[1:-1] # add cross attentions if we output attention weights
# add cross-attn cache to positions 3,4 of present_key_value tuple
cross_attn_present_key_value = cross_attention_outputs[-1]
present_key_value = present_key_value + cross_attn_present_key_value
intermediate_output = self.intermediate(hidden_states=attention_output)
layer_output = self.bert_output(
hidden_states=intermediate_output, input_tensor=attention_output, training=training
)
outputs = (layer_output,) + outputs # add attentions if we output them
# if decoder, return the attn key/values as the last output
if self.is_decoder:
outputs = outputs + (present_key_value,)
return outputs
# Copied from transformers.models.bert.modeling_tf_bert.TFBertEncoder with Bert->{{cookiecutter.camelcase_modelname}}
class TF{{cookiecutter.camelcase_modelname}}Encoder(tf.keras.layers.Layer):
def __init__(self, config: {{cookiecutter.camelcase_modelname}}Config, **kwargs):
super().__init__(**kwargs)
self.config = config
self.layer = [TF{{cookiecutter.camelcase_modelname}}Layer(config, name=f"layer_._{i}") for i in range(config.num_hidden_layers)]
def call(
self,
hidden_states: tf.Tensor,
attention_mask: tf.Tensor,
head_mask: tf.Tensor,
encoder_hidden_states: tf.Tensor | None,
encoder_attention_mask: tf.Tensor | None,
past_key_values: Tuple[Tuple[tf.Tensor]] | None,
use_cache: Optional[bool],
output_attentions: bool,
output_hidden_states: bool,
return_dict: bool,
training: bool = False,
) -> Union[TFBaseModelOutputWithPastAndCrossAttentions, Tuple[tf.Tensor]]:
all_hidden_states = () if output_hidden_states else None
all_attentions = () if output_attentions else None
all_cross_attentions = () if output_attentions and self.config.add_cross_attention else None
next_decoder_cache = () if use_cache else None
for i, layer_module in enumerate(self.layer):
if output_hidden_states:
all_hidden_states = all_hidden_states + (hidden_states,)
past_key_value = past_key_values[i] if past_key_values is not None else None
layer_outputs = layer_module(
hidden_states=hidden_states,
attention_mask=attention_mask,
head_mask=head_mask[i],
encoder_hidden_states=encoder_hidden_states,
encoder_attention_mask=encoder_attention_mask,
past_key_value=past_key_value,
output_attentions=output_attentions,
training=training,
)
hidden_states = layer_outputs[0]
if use_cache:
next_decoder_cache += (layer_outputs[-1],)
if output_attentions:
all_attentions = all_attentions + (layer_outputs[1],)
if self.config.add_cross_attention and encoder_hidden_states is not None:
all_cross_attentions = all_cross_attentions + (layer_outputs[2],)
# Add last layer
if output_hidden_states:
all_hidden_states = all_hidden_states + (hidden_states,)
if not return_dict:
return tuple(
v for v in [hidden_states, all_hidden_states, all_attentions, all_cross_attentions] if v is not None
)
return TFBaseModelOutputWithPastAndCrossAttentions(
last_hidden_state=hidden_states,
past_key_values=next_decoder_cache,
hidden_states=all_hidden_states,
attentions=all_attentions,
cross_attentions=all_cross_attentions,
)
# Copied from transformers.models.bert.modeling_tf_bert.TFBertPredictionHeadTransform with Bert->{{cookiecutter.camelcase_modelname}}
class TF{{cookiecutter.camelcase_modelname}}PredictionHeadTransform(tf.keras.layers.Layer):
def __init__(self, config: {{cookiecutter.camelcase_modelname}}Config, **kwargs):
super().__init__(**kwargs)
self.dense = tf.keras.layers.Dense(
units=config.hidden_size,
kernel_initializer=get_initializer(config.initializer_range),
name="dense",
)
if isinstance(config.hidden_act, str):
self.transform_act_fn = get_tf_activation(config.hidden_act)
else:
self.transform_act_fn = config.hidden_act
self.LayerNorm = tf.keras.layers.LayerNormalization(epsilon=config.layer_norm_eps, name="LayerNorm")
def call(self, hidden_states: tf.Tensor) -> tf.Tensor:
hidden_states = self.dense(inputs=hidden_states)
hidden_states = self.transform_act_fn(hidden_states)
hidden_states = self.LayerNorm(inputs=hidden_states)
return hidden_states
# Copied from transformers.models.bert.modeling_tf_bert.TFBertLMPredictionHead with Bert->{{cookiecutter.camelcase_modelname}}
class TF{{cookiecutter.camelcase_modelname}}LMPredictionHead(tf.keras.layers.Layer):
def __init__(self, config: {{cookiecutter.camelcase_modelname}}Config, input_embeddings: tf.keras.layers.Layer, **kwargs):
super().__init__(**kwargs)
self.vocab_size = config.vocab_size
self.hidden_size = config.hidden_size
self.transform = TF{{cookiecutter.camelcase_modelname}}PredictionHeadTransform(config, name="transform")
# The output weights are the same as the input embeddings, but there is
# an output-only bias for each token.
self.input_embeddings = input_embeddings
def build(self, input_shape: tf.TensorShape):
self.bias = self.add_weight(shape=(self.vocab_size,), initializer="zeros", trainable=True, name="bias")
super().build(input_shape)
def get_output_embeddings(self) -> tf.keras.layers.Layer:
return self.input_embeddings
def set_output_embeddings(self, value: tf.Variable):
self.input_embeddings.weight = value
self.input_embeddings.vocab_size = shape_list(value)[0]
def get_bias(self) -> Dict[str, tf.Variable]:
return {"bias": self.bias}
def set_bias(self, value: tf.Variable):
self.bias = value["bias"]
self.vocab_size = shape_list(value["bias"])[0]
def call(self, hidden_states: tf.Tensor) -> tf.Tensor:
hidden_states = self.transform(hidden_states=hidden_states)
seq_length = shape_list(hidden_states)[1]
hidden_states = tf.reshape(tensor=hidden_states, shape=[-1, self.hidden_size])
hidden_states = tf.matmul(a=hidden_states, b=self.input_embeddings.weight, transpose_b=True)
hidden_states = tf.reshape(tensor=hidden_states, shape=[-1, seq_length, self.vocab_size])
hidden_states = tf.nn.bias_add(value=hidden_states, bias=self.bias)
return hidden_states
# Copied from transformers.models.bert.modeling_tf_bert.TFBertMLMHead with Bert->{{cookiecutter.camelcase_modelname}}
class TF{{cookiecutter.camelcase_modelname}}MLMHead(tf.keras.layers.Layer):
def __init__(self, config: {{cookiecutter.camelcase_modelname}}Config, input_embeddings: tf.keras.layers.Layer, **kwargs):
super().__init__(**kwargs)
self.predictions = TF{{cookiecutter.camelcase_modelname}}LMPredictionHead(config, input_embeddings, name="predictions")
def call(self, sequence_output: tf.Tensor) -> tf.Tensor:
prediction_scores = self.predictions(hidden_states=sequence_output)
return prediction_scores
@keras_serializable
class TF{{cookiecutter.camelcase_modelname}}MainLayer(tf.keras.layers.Layer):
config_class = {{cookiecutter.camelcase_modelname}}Config
def __init__(self, config: {{cookiecutter.camelcase_modelname}}Config, add_pooling_layer: bool = True, **kwargs):
super().__init__(**kwargs)
self.config = config
self.is_decoder = config.is_decoder
self.embeddings = TF{{cookiecutter.camelcase_modelname}}Embeddings(config, name="embeddings")
self.encoder = TF{{cookiecutter.camelcase_modelname}}Encoder(config, name="encoder")
# Copied from transformers.models.bert.modeling_tf_bert.TFBertMainLayer.get_input_embeddings
def get_input_embeddings(self) -> tf.keras.layers.Layer:
return self.embeddings
# Copied from transformers.models.bert.modeling_tf_bert.TFBertMainLayer.set_input_embeddings
def set_input_embeddings(self, value: tf.Variable):
self.embeddings.weight = value
self.embeddings.vocab_size = shape_list(value)[0]
# Copied from transformers.models.bert.modeling_tf_bert.TFBertMainLayer._prune_heads
def _prune_heads(self, heads_to_prune):
"""
Prunes heads of the model. heads_to_prune: dict of {layer_num: list of heads to prune in this layer} See base
class PreTrainedModel
"""
raise NotImplementedError
@unpack_inputs
def call(
self,
input_ids: TFModelInputType | None = None,
attention_mask: np.ndarray | tf.Tensor | None = None,
token_type_ids: np.ndarray | tf.Tensor | None = None,
position_ids: np.ndarray | tf.Tensor | None = None,
head_mask: np.ndarray | tf.Tensor | None = None,
inputs_embeds: np.ndarray | tf.Tensor | None = None,
encoder_hidden_states: np.ndarray | tf.Tensor | None = None,
encoder_attention_mask: np.ndarray | tf.Tensor | None = None,
past_key_values: Optional[Tuple[Tuple[Union[np.ndarray, tf.Tensor]]]] = None,
use_cache: Optional[bool] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
training: bool = False,
) -> Union[TFBaseModelOutputWithPastAndCrossAttentions, Tuple[tf.Tensor]]:
if not self.config.is_decoder:
use_cache = False
if input_ids is not None and inputs_embeds is not None:
raise ValueError("You cannot specify both input_ids and inputs_embeds at the same time")
elif input_ids is not None:
input_shape = shape_list(input_ids)
elif inputs_embeds is not None:
input_shape = shape_list(inputs_embeds)[:-1]
else:
raise ValueError("You have to specify either input_ids or inputs_embeds")
batch_size, seq_length = input_shape
if past_key_values is None:
past_key_values_length = 0
past_key_values = [None] * len(self.encoder.layer)
else:
past_key_values_length = shape_list(past_key_values[0][0])[-2]
if attention_mask is None:
attention_mask = tf.fill(dims=(batch_size, seq_length + past_key_values_length), value=1)
if token_type_ids is None:
token_type_ids = tf.fill(dims=input_shape, value=0)
embedding_output = self.embeddings(
input_ids=input_ids,
position_ids=position_ids,
token_type_ids=token_type_ids,
inputs_embeds=inputs_embeds,
past_key_values_length=past_key_values_length,
training=training,
)
# We create a 3D attention mask from a 2D tensor mask.
# Sizes are [batch_size, 1, 1, to_seq_length]
# So we can broadcast to [batch_size, num_heads, from_seq_length, to_seq_length]
# this attention mask is more simple than the triangular masking of causal attention
# used in OpenAI GPT, we just need to prepare the broadcast dimension here.
attention_mask_shape = shape_list(attention_mask)
mask_seq_length = seq_length + past_key_values_length
# Copied from `modeling_tf_t5.py`
# Provided a padding mask of dimensions [batch_size, mask_seq_length]
# - if the model is a decoder, apply a causal mask in addition to the padding mask
# - if the model is an encoder, make the mask broadcastable to [batch_size, num_heads, mask_seq_length, mask_seq_length]
if self.is_decoder:
seq_ids = tf.range(mask_seq_length)
causal_mask = tf.less_equal(
tf.tile(seq_ids[None, None, :], (batch_size, mask_seq_length, 1)),
seq_ids[None, :, None],
)
causal_mask = tf.cast(causal_mask, dtype=attention_mask.dtype)
extended_attention_mask = causal_mask * attention_mask[:, None, :]
attention_mask_shape = shape_list(extended_attention_mask)
extended_attention_mask = tf.reshape(
extended_attention_mask, (attention_mask_shape[0], 1, attention_mask_shape[1], attention_mask_shape[2])
)
if past_key_values[0] is not None:
# attention_mask needs to be sliced to the shape `[batch_size, 1, from_seq_length - cached_seq_length, to_seq_length]
extended_attention_mask = extended_attention_mask[:, :, -seq_length:, :]
else:
extended_attention_mask = tf.reshape(
attention_mask, (attention_mask_shape[0], 1, 1, attention_mask_shape[1])
)
# Since attention_mask is 1.0 for positions we want to attend and 0.0 for
# masked positions, this operation will create a tensor which is 0.0 for
# positions we want to attend and -10000.0 for masked positions.
# Since we are adding it to the raw scores before the softmax, this is
# effectively the same as removing these entirely.
extended_attention_mask = tf.cast(extended_attention_mask, dtype=embedding_output.dtype)
one_cst = tf.constant(1.0, dtype=embedding_output.dtype)
ten_thousand_cst = tf.constant(-10000.0, dtype=embedding_output.dtype)
extended_attention_mask = tf.multiply(tf.subtract(one_cst, extended_attention_mask), ten_thousand_cst)
# Copied from `modeling_tf_t5.py` with -1e9 -> -10000
if self.is_decoder and encoder_attention_mask is not None:
# If a 2D ou 3D attention mask is provided for the cross-attention
# we need to make broadcastable to [batch_size, num_heads, mask_seq_length, mask_seq_length]
# we need to make broadcastable to [batch_size, num_heads, seq_length, seq_length]
encoder_attention_mask = tf.cast(
encoder_attention_mask, dtype=extended_attention_mask.dtype
)
num_dims_encoder_attention_mask = len(shape_list(encoder_attention_mask))
if num_dims_encoder_attention_mask == 3:
encoder_extended_attention_mask = encoder_attention_mask[:, None, :, :]
if num_dims_encoder_attention_mask == 2:
encoder_extended_attention_mask = encoder_attention_mask[:, None, None, :]
# T5 has a mask that can compare sequence ids, we can simulate this here with this transposition
# Cf. https://github.com/tensorflow/mesh/blob/8d2465e9bc93129b913b5ccc6a59aa97abd96ec6/mesh_tensorflow/transformer/transformer_layers.py#L270
# encoder_extended_attention_mask = tf.math.equal(encoder_extended_attention_mask,
# tf.transpose(encoder_extended_attention_mask, perm=(-1, -2)))
encoder_extended_attention_mask = (1.0 - encoder_extended_attention_mask) * -10000.0
else:
encoder_extended_attention_mask = None
# Prepare head mask if needed
# 1.0 in head_mask indicate we keep the head
# attention_probs has shape bsz x n_heads x N x N
# input head_mask has shape [num_heads] or [num_hidden_layers x num_heads]
# and head_mask is converted to shape [num_hidden_layers x batch x num_heads x seq_length x seq_length]
if head_mask is not None:
raise NotImplementedError
else:
head_mask = [None] * self.config.num_hidden_layers
encoder_outputs = self.encoder(
hidden_states=embedding_output,
attention_mask=extended_attention_mask,
head_mask=head_mask,
encoder_hidden_states=encoder_hidden_states,
encoder_attention_mask=encoder_extended_attention_mask,
past_key_values=past_key_values,
use_cache=use_cache,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
training=training,
)
sequence_output = encoder_outputs[0]
if not return_dict:
return (
sequence_output,
) + encoder_outputs[1:]
return TFBaseModelOutputWithPastAndCrossAttentions(
last_hidden_state=sequence_output,
past_key_values=encoder_outputs.past_key_values,
hidden_states=encoder_outputs.hidden_states,
attentions=encoder_outputs.attentions,
cross_attentions=encoder_outputs.cross_attentions,
)
class TF{{cookiecutter.camelcase_modelname}}PreTrainedModel(TFPreTrainedModel):
"""An abstract class to handle weights initialization and
a simple interface for downloading and loading pretrained models.
"""
config_class = {{cookiecutter.camelcase_modelname}}Config
base_model_prefix = "{{cookiecutter.lowercase_modelname}}"
{{cookiecutter.uppercase_modelname}}_START_DOCSTRING = r"""
This model inherits from [`TFPreTrainedModel`]. Check the superclass documentation for the
generic methods the library implements for all its model (such as downloading or saving, resizing the input
embeddings, pruning heads etc.)
This model is also a [tf.keras.Model](https://www.tensorflow.org/api_docs/python/tf/keras/Model) subclass.
Use it as a regular TF 2.0 Keras Model and refer to the TF 2.0 documentation for all matter related to general
usage and behavior.
<Tip>
TensorFlow models and layers in `transformers` accept two formats as input:
- having all inputs as keyword arguments (like PyTorch models), or
- having all inputs as a list, tuple or dict in the first positional argument.
The reason the second format is supported is that Keras methods prefer this format when passing inputs to models
and layers. Because of this support, when using methods like `model.fit()` things should "just work" for you - just
pass your inputs and labels in any format that `model.fit()` supports! If, however, you want to use the second format outside of Keras methods like `fit()` and `predict()`, such as when creating
your own layers or models with the Keras `Functional` API, there are three possibilities you
can use to gather all the input Tensors in the first positional argument:
- a single Tensor with `input_ids` only and nothing else: `model(input_ids)`
- a list of varying length with one or several input Tensors IN THE ORDER given in the docstring:
`model([input_ids, attention_mask])` or `model([input_ids, attention_mask, token_type_ids])`
- a dictionary with one or several input Tensors associated to the input names given in the docstring:
`model({"input_ids": input_ids, "token_type_ids": token_type_ids})`
Note that when creating models and layers with (subclassing)[https://keras.io/guides/making_new_layers_and_models_via_subclassing/]
then you don't need to worry about any of this, as you can just pass inputs like you would to any other Python
function!
</Tip>
Args:
config ([`~{{cookiecutter.camelcase_modelname}}Config`]): Model configuration class with all the parameters of the model.
Initializing with a config file does not load the weights associated with the model, only the configuration.
Check out the [`~PreTrainedModel.from_pretrained`] method to load the model weights.
"""
{{cookiecutter.uppercase_modelname}}_INPUTS_DOCSTRING = r"""
Args:
input_ids (`np.ndarray`, `tf.Tensor`, `List[tf.Tensor]`, `Dict[str, tf.Tensor]` or `Dict[str, np.ndarray]` and each example must have the shape `({0})`):
Indices of input sequence tokens in the vocabulary.
Indices can be obtained using [`AutoTokenizer`]. See
[`PreTrainedTokenizer.__call__`] and [`PreTrainedTokenizer.encode`] for
details.
[What are input IDs?](../glossary#input-ids)
attention_mask (`np.ndarray` or `tf.Tensor` of shape `({0})`, *optional*):
Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
- 1 for tokens that are **not masked**,
- 0 for tokens that are **masked**.
[What are attention masks?](../glossary#attention-mask)
token_type_ids (`np.ndarray` or `tf.Tensor` of shape `({0})`, *optional*):
Segment token indices to indicate first and second portions of the inputs. Indices are selected in `[0, 1]`:
- 0 corresponds to a *sentence A* token,
- 1 corresponds to a *sentence B* token.
[What are token type IDs?](../glossary#token-type-ids)
position_ids (`np.ndarray` or `tf.Tensor` of shape `({0})`, *optional*):
Indices of positions of each input sequence tokens in the position embeddings. Selected in the range `[0, config.max_position_embeddings - 1]`.
[What are position IDs?](../glossary#position-ids)
head_mask (`np.ndarray` or `tf.Tensor` of shape `(num_heads,)` or `(num_layers, num_heads)`, *optional*):
Mask to nullify selected heads of the self-attention modules. Mask values selected in `[0, 1]`:
- 1 indicates the head is **not masked**,
- 0 indicates the head is **masked**.
inputs_embeds (`np.ndarray` or `tf.Tensor` of shape `({0}, hidden_size)`, *optional*):
Optionally, instead of passing `input_ids` you can choose to directly pass an embedded representation.
This is useful if you want more control over how to convert `input_ids` indices into associated
vectors than the model's internal embedding lookup matrix.
output_attentions (`bool`, *optional*):
Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
tensors for more detail. This argument can be used only in eager mode, in graph mode the value in the
config will be used instead.
output_hidden_states (`bool`, *optional*):
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
more detail. This argument can be used only in eager mode, in graph mode the value in the config will be
used instead.
return_dict (`bool`, *optional*):
Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple. This
argument can be used in eager mode, in graph mode the value will always be set to True.
training (`bool`, *optional*, defaults to `False`):
Whether or not to use the model in training mode (some modules like dropout modules have different
behaviors between training and evaluation).
"""
@add_start_docstrings(
"The bare {{cookiecutter.modelname}} Model transformer outputing raw hidden-states without any specific head on top.",
{{cookiecutter.uppercase_modelname}}_START_DOCSTRING,
)
class TF{{cookiecutter.camelcase_modelname}}Model(TF{{cookiecutter.camelcase_modelname}}PreTrainedModel):
def __init__(self, config: {{cookiecutter.camelcase_modelname}}Config, *inputs, **kwargs):
super().__init__(config, *inputs, **kwargs)
self.{{cookiecutter.lowercase_modelname}} = TF{{cookiecutter.camelcase_modelname}}MainLayer(config, name="{{cookiecutter.lowercase_modelname}}")
@unpack_inputs
@add_start_docstrings_to_model_forward({{cookiecutter.uppercase_modelname}}_INPUTS_DOCSTRING.format("batch_size, sequence_length"))
@add_code_sample_docstrings(
checkpoint=_CHECKPOINT_FOR_DOC,
output_type=TFBaseModelOutputWithPastAndCrossAttentions,
config_class=_CONFIG_FOR_DOC,
)
def call(
self,
input_ids: TFModelInputType | None = None,
attention_mask: np.ndarray | tf.Tensor | None = None,
token_type_ids: np.ndarray | tf.Tensor | None = None,
position_ids: np.ndarray | tf.Tensor | None = None,
head_mask: np.ndarray | tf.Tensor | None = None,
inputs_embeds: np.ndarray | tf.Tensor | None = None,
encoder_hidden_states: np.ndarray | tf.Tensor | None = None,
encoder_attention_mask: np.ndarray | tf.Tensor | None = None,
past_key_values: Optional[Tuple[Tuple[Union[np.ndarray, tf.Tensor]]]] = None,
use_cache: Optional[bool] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
training: Optional[bool] = False,
) -> Union[TFBaseModelOutputWithPastAndCrossAttentions, Tuple[tf.Tensor]]:
r"""
encoder_hidden_states (`tf.Tensor` of shape `(batch_size, sequence_length, hidden_size)`, *optional*):
Sequence of hidden-states at the output of the last layer of the encoder. Used in the cross-attention if
the model is configured as a decoder.
encoder_attention_mask (`tf.Tensor` of shape `(batch_size, sequence_length)`, *optional*):
Mask to avoid performing attention on the padding token indices of the encoder input. This mask is used in
the cross-attention if the model is configured as a decoder. Mask values selected in `[0, 1]`:
- 1 for tokens that are **not masked**,
- 0 for tokens that are **masked**.
past_key_values (`Tuple[Tuple[tf.Tensor]]` of length `config.n_layers`)
contains precomputed key and value hidden states of the attention blocks. Can be used to speed up decoding.
If `past_key_values` are used, the user can optionally input only the last `decoder_input_ids`
(those that don't have their past key value states given to this model) of shape `(batch_size, 1)`
instead of all `decoder_input_ids` of shape `(batch_size, sequence_length)`.
use_cache (`bool`, *optional*, defaults to `True`):
If set to `True`, `past_key_values` key value states are returned and can be used to speed up
decoding (see `past_key_values`). Set to `False` during training, `True` during generation
"""
outputs = self.{{cookiecutter.lowercase_modelname}}(
input_ids=input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
position_ids=position_ids,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
encoder_hidden_states=encoder_hidden_states,
encoder_attention_mask=encoder_attention_mask,
past_key_values=past_key_values,
use_cache=use_cache,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
training=training,
)
return outputs
@add_start_docstrings("""{{cookiecutter.modelname}} Model with a `language modeling` head on top. """, {{cookiecutter.uppercase_modelname}}_START_DOCSTRING)
class TF{{cookiecutter.camelcase_modelname}}ForMaskedLM(TF{{cookiecutter.camelcase_modelname}}PreTrainedModel, TFMaskedLanguageModelingLoss):
def __init__(self, config: {{cookiecutter.camelcase_modelname}}Config, *inputs, **kwargs):
super().__init__(config, *inputs, **kwargs)
if config.is_decoder:
logger.warning(
"If you want to use `TF{{cookiecutter.camelcase_modelname}}ForMaskedLM` make sure `config.is_decoder=False` for "
"bi-directional self-attention."
)
self.{{cookiecutter.lowercase_modelname}} = TF{{cookiecutter.camelcase_modelname}}MainLayer(config, name="{{cookiecutter.lowercase_modelname}}")
self.mlm = TF{{cookiecutter.camelcase_modelname}}MLMHead(config, input_embeddings=self.{{cookiecutter.lowercase_modelname}}.embeddings, name="mlm___cls")
def get_lm_head(self) -> tf.keras.layers.Layer:
return self.mlm.predictions
@unpack_inputs
@add_start_docstrings_to_model_forward({{cookiecutter.uppercase_modelname}}_INPUTS_DOCSTRING.format("batch_size, sequence_length"))
@add_code_sample_docstrings(
checkpoint=_CHECKPOINT_FOR_DOC,
output_type=TFMaskedLMOutput,
config_class=_CONFIG_FOR_DOC,
)
def call(
self,
input_ids: TFModelInputType | None = None,
attention_mask: np.ndarray | tf.Tensor | None = None,
token_type_ids: np.ndarray | tf.Tensor | None = None,
position_ids: np.ndarray | tf.Tensor | None = None,
head_mask: np.ndarray | tf.Tensor | None = None,
inputs_embeds: np.ndarray | tf.Tensor | None = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
labels: np.ndarray | tf.Tensor | None = None,
training: Optional[bool] = False,
) -> Union[TFMaskedLMOutput, Tuple[tf.Tensor]]:
r"""
labels (`tf.Tensor` or `np.ndarray` of shape `(batch_size, sequence_length)`, *optional*):
Labels for computing the masked language modeling loss. Indices should be in `[-100, 0, ..., config.vocab_size]` (see `input_ids` docstring) Tokens with indices set to `-100` are ignored
(masked), the loss is only computed for the tokens with labels in `[0, ..., config.vocab_size]`
"""
outputs = self.{{cookiecutter.lowercase_modelname}}(
input_ids=input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
position_ids=position_ids,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
training=training,
)
sequence_output = outputs[0]
prediction_scores = self.mlm(sequence_output=sequence_output, training=training)
loss = (
None if labels is None else self.hf_compute_loss(labels=labels, logits=prediction_scores)
)
if not return_dict:
output = (prediction_scores,) + outputs[2:]
return ((loss,) + output) if loss is not None else output
return TFMaskedLMOutput(
loss=loss,
logits=prediction_scores,
hidden_states=outputs.hidden_states,
attentions=outputs.attentions,
)
@add_start_docstrings(
"""{{cookiecutter.modelname}} Model with a `language modeling` head on top for CLM fine-tuning. """, {{cookiecutter.uppercase_modelname}}_START_DOCSTRING
)
class TF{{cookiecutter.camelcase_modelname}}ForCausalLM(TF{{cookiecutter.camelcase_modelname}}PreTrainedModel, TFCausalLanguageModelingLoss):
def __init__(self, config: {{cookiecutter.camelcase_modelname}}Config, *inputs, **kwargs):
super().__init__(config, *inputs, **kwargs)
if not config.is_decoder:
logger.warning("If you want to use `TF{{cookiecutter.camelcase_modelname}}ForCausalLM` as a standalone, add `is_decoder=True.`")
self.{{cookiecutter.lowercase_modelname}} = TF{{cookiecutter.camelcase_modelname}}MainLayer(config, name="{{cookiecutter.lowercase_modelname}}")
self.mlm = TF{{cookiecutter.camelcase_modelname}}MLMHead(config, input_embeddings=self.{{cookiecutter.lowercase_modelname}}.embeddings, name="mlm___cls")
def get_lm_head(self) -> tf.keras.layers.Layer:
return self.mlm.predictions
def prepare_inputs_for_generation(self, inputs, past_key_values=None, attention_mask=None, **model_kwargs):
# cut decoder_input_ids if past is used
if past_key_values:
inputs = tf.expand_dims(inputs[:, -1], -1)
return {
"input_ids": inputs,
"attention_mask": attention_mask,
"past_key_values": past_key_values,
"use_cache": model_kwargs["use_cache"],
}
@unpack_inputs
@add_code_sample_docstrings(
checkpoint=_CHECKPOINT_FOR_DOC,
output_type=TFCausalLMOutputWithCrossAttentions,
config_class=_CONFIG_FOR_DOC,
)
def call(
self,
input_ids: TFModelInputType | None = None,
attention_mask: np.ndarray | tf.Tensor | None = None,
token_type_ids: np.ndarray | tf.Tensor | None = None,
position_ids: np.ndarray | tf.Tensor | None = None,
head_mask: np.ndarray | tf.Tensor | None = None,
inputs_embeds: np.ndarray | tf.Tensor | None = None,
encoder_hidden_states: np.ndarray | tf.Tensor | None = None,
encoder_attention_mask: np.ndarray | tf.Tensor | None = None,
past_key_values: Optional[Tuple[Tuple[Union[np.ndarray, tf.Tensor]]]] = None,
use_cache: Optional[bool] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
labels: np.ndarray | tf.Tensor | None = None,
training: Optional[bool] = False,
) -> Union[TFCausalLMOutputWithCrossAttentions, Tuple[tf.Tensor]]:
r"""
encoder_hidden_states (`tf.Tensor` of shape `(batch_size, sequence_length, hidden_size)`, *optional*):
Sequence of hidden-states at the output of the last layer of the encoder. Used in the cross-attention if
the model is configured as a decoder.
encoder_attention_mask (`tf.Tensor` of shape `(batch_size, sequence_length)`, *optional*):
Mask to avoid performing attention on the padding token indices of the encoder input. This mask is used in
the cross-attention if the model is configured as a decoder. Mask values selected in `[0, 1]`:
- 1 for tokens that are **not masked**,
- 0 for tokens that are **masked**.
past_key_values (`Tuple[Tuple[tf.Tensor]]` of length `config.n_layers`)
contains precomputed key and value hidden states of the attention blocks. Can be used to speed up decoding.
If `past_key_values` are used, the user can optionally input only the last `decoder_input_ids`
(those that don't have their past key value states given to this model) of shape `(batch_size, 1)`
instead of all `decoder_input_ids` of shape `(batch_size, sequence_length)`.
use_cache (`bool`, *optional*, defaults to `True`):
If set to `True`, `past_key_values` key value states are returned and can be used to speed up
decoding (see `past_key_values`). Set to `False` during training, `True` during generation
labels (`tf.Tensor` or `np.ndarray` of shape `(batch_size, sequence_length)`, *optional*):
Labels for computing the cross entropy classification loss. Indices should be in `[0, ..., config.vocab_size - 1]`.
"""
outputs = self.{{cookiecutter.lowercase_modelname}}(
input_ids=input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
position_ids=position_ids,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
encoder_hidden_states=encoder_hidden_states,
encoder_attention_mask=encoder_attention_mask,
past_key_values=past_key_values,
use_cache=use_cache,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
training=training,
)
sequence_output = outputs[0]
logits = self.mlm(sequence_output=sequence_output, training=training)
loss = None
if labels is not None:
# shift labels to the left and cut last logit token
shifted_logits = logits[:, :-1]
labels = labels[:, 1:]
loss = self.hf_compute_loss(labels=labels, logits=shifted_logits)
if not return_dict:
output = (logits,) + outputs[2:]
return ((loss,) + output) if loss is not None else output
return TFCausalLMOutputWithCrossAttentions(
loss=loss,
logits=logits,
past_key_values=outputs.past_key_values,
hidden_states=outputs.hidden_states,
attentions=outputs.attentions,
cross_attentions=outputs.cross_attentions,
)
class TF{{cookiecutter.camelcase_modelname}}ClassificationHead(tf.keras.layers.Layer):
"""Head for sentence-level classification tasks."""
def __init__(self, config: {{cookiecutter.camelcase_modelname}}Config, *inputs, **kwargs):
super().__init__(config, *inputs, **kwargs)
self.dense = tf.keras.layers.Dense(
units=config.hidden_size, kernel_initializer=get_initializer(config.initializer_range), name="dense"
)
self.dropout = tf.keras.layers.Dropout(rate=config.hidden_dropout_prob)
self.out_proj = tf.keras.layers.Dense(
units=config.num_labels, kernel_initializer=get_initializer(config.initializer_range), name="out_proj"
)
if isinstance(config.hidden_act, str):
self.classifier_act_fn = get_tf_activation(config.hidden_act)
else:
self.classifier_act_fn = config.hidden_act
def call(self, hidden_states: tf.Tensor, training: bool = False) -> tf.Tensor:
hidden_states = hidden_states[:, 0, :] # take <s> token (equiv. to [CLS])
hidden_states = self.dropout(inputs=hidden_states, training=training)
hidden_states = self.dense(inputs=hidden_states)
hidden_states = self.classifier_act_fn(hidden_states)
hidden_states = self.dropout(inputs=hidden_states, training=training)
hidden_states = self.out_proj(hidden_states)
return hidden_states
@add_start_docstrings(
"""{{cookiecutter.modelname}} Model transformer with a sequence classification/regression head on top
e.g., for GLUE tasks. """,
{{cookiecutter.uppercase_modelname}}_START_DOCSTRING,
)
class TF{{cookiecutter.camelcase_modelname}}ForSequenceClassification(TF{{cookiecutter.camelcase_modelname}}PreTrainedModel, TFSequenceClassificationLoss):
def __init__(self, config: {{cookiecutter.camelcase_modelname}}Config, *inputs, **kwargs):
super().__init__(config, *inputs, **kwargs)
self.num_labels = config.num_labels
self.{{cookiecutter.lowercase_modelname}} = TF{{cookiecutter.camelcase_modelname}}MainLayer(config, name="{{cookiecutter.lowercase_modelname}}")
self.classifier = TF{{cookiecutter.camelcase_modelname}}ClassificationHead(config, name="classifier")
@unpack_inputs
@add_start_docstrings_to_model_forward({{cookiecutter.uppercase_modelname}}_INPUTS_DOCSTRING.format("batch_size, sequence_length"))
@add_code_sample_docstrings(
checkpoint=_CHECKPOINT_FOR_DOC,
output_type=TFSequenceClassifierOutput,
config_class=_CONFIG_FOR_DOC,
)
def call(
self,
input_ids: TFModelInputType | None = None,
attention_mask: np.ndarray | tf.Tensor | None = None,
token_type_ids: np.ndarray | tf.Tensor | None = None,
position_ids: np.ndarray | tf.Tensor | None = None,
head_mask: np.ndarray | tf.Tensor | None = None,
inputs_embeds: np.ndarray | tf.Tensor | None = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
labels: np.ndarray | tf.Tensor | None = None,
training: Optional[bool] = False,
) -> Union[TFSequenceClassifierOutput, Tuple[tf.Tensor]]:
r"""
labels (`tf.Tensor` or `np.ndarray` of shape `(batch_size,)`, *optional*):
Labels for computing the sequence classification/regression loss. Indices should be in `[0, ..., config.num_labels - 1]`. If `config.num_labels == 1` a regression loss is computed (Mean-Square loss),
If `config.num_labels > 1` a classification loss is computed (Cross-Entropy).
"""
outputs = self.{{cookiecutter.lowercase_modelname}}(
input_ids=input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
position_ids=position_ids,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
training=training,
)
logits = self.classifier(hidden_states=outputs[0], training=training)
loss = None if labels is None else self.hf_compute_loss(labels=labels, logits=logits)
if not return_dict:
output = (logits,) + outputs[1:]
return ((loss,) + output) if loss is not None else output
return TFSequenceClassifierOutput(
loss=loss,
logits=logits,
hidden_states=outputs.hidden_states,
attentions=outputs.attentions,
)
@add_start_docstrings(
"""{{cookiecutter.modelname}} Model with a multiple choice classification head on top (a linear layer on top of
the pooled output and a softmax) e.g. for RocStories/SWAG tasks. """,
{{cookiecutter.uppercase_modelname}}_START_DOCSTRING,
)
class TF{{cookiecutter.camelcase_modelname}}ForMultipleChoice(TF{{cookiecutter.camelcase_modelname}}PreTrainedModel, TFMultipleChoiceLoss):
def __init__(self, config: {{cookiecutter.camelcase_modelname}}Config, *inputs, **kwargs):
super().__init__(config, *inputs, **kwargs)
self.{{cookiecutter.lowercase_modelname}} = TF{{cookiecutter.camelcase_modelname}}MainLayer(config, name="{{cookiecutter.lowercase_modelname}}")
self.sequence_summary = TFSequenceSummary(
config, config.initializer_range, name="sequence_summary"
)
self.classifier = tf.keras.layers.Dense(
units=1, kernel_initializer=get_initializer(config.initializer_range), name="classifier"
)
@unpack_inputs
@add_start_docstrings_to_model_forward({{cookiecutter.uppercase_modelname}}_INPUTS_DOCSTRING.format("batch_size, num_choices, sequence_length"))
@add_code_sample_docstrings(
checkpoint=_CHECKPOINT_FOR_DOC,
output_type=TFMultipleChoiceModelOutput,
config_class=_CONFIG_FOR_DOC,
)
def call(
self,
input_ids: TFModelInputType | None = None,
attention_mask: np.ndarray | tf.Tensor | None = None,
token_type_ids: np.ndarray | tf.Tensor | None = None,
position_ids: np.ndarray | tf.Tensor | None = None,
head_mask: np.ndarray | tf.Tensor | None = None,
inputs_embeds: np.ndarray | tf.Tensor | None = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
labels: np.ndarray | tf.Tensor | None = None,
training: Optional[bool] = False,
) -> Union[TFMultipleChoiceModelOutput, Tuple[tf.Tensor]]:
r"""
labels (`tf.Tensor` or `np.ndarray` of shape `(batch_size,)`, *optional*):
Labels for computing the multiple choice classification loss. Indices should be in `[0, ..., num_choices]` where `num_choices` is the size of the second dimension of the input tensors. (See
`input_ids` above)
"""
if input_ids is not None:
num_choices = shape_list(input_ids)[1]
seq_length = shape_list(input_ids)[2]
else:
num_choices = shape_list(inputs_embeds)[1]
seq_length = shape_list(inputs_embeds)[2]
flat_input_ids = (
tf.reshape(tensor=input_ids, shape=(-1, seq_length)) if input_ids is not None else None
)
flat_attention_mask = (
tf.reshape(tensor=attention_mask, shape=(-1, seq_length))
if attention_mask is not None
else None
)
flat_token_type_ids = (
tf.reshape(tensor=token_type_ids, shape=(-1, seq_length))
if token_type_ids is not None
else None
)
flat_position_ids = (
tf.reshape(tensor=position_ids, shape=(-1, seq_length))
if position_ids is not None
else None
)
flat_inputs_embeds = (
tf.reshape(
tensor=inputs_embeds, shape=(-1, seq_length, shape_list(inputs_embeds)[3])
)
if inputs_embeds is not None
else None
)
outputs = self.{{cookiecutter.lowercase_modelname}}(
input_ids=flat_input_ids,
attention_mask=flat_attention_mask,
token_type_ids=flat_token_type_ids,
position_ids=flat_position_ids,
head_mask=head_mask,
inputs_embeds=flat_inputs_embeds,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
training=training,
)
logits = self.sequence_summary(inputs=outputs[0], training=training)
logits = self.classifier(inputs=logits)
reshaped_logits = tf.reshape(tensor=logits, shape=(-1, num_choices))
loss = None if labels is None else self.hf_compute_loss(labels=labels, logits=reshaped_logits)
if not return_dict:
output = (reshaped_logits,) + outputs[1:]
return ((loss,) + output) if loss is not None else output
return TFMultipleChoiceModelOutput(
loss=loss,
logits=reshaped_logits,
hidden_states=outputs.hidden_states,
attentions=outputs.attentions,
)
@add_start_docstrings(
"""{{cookiecutter.modelname}} Model with a token classification head on top (a linear layer on top of
the hidden-states output) e.g. for Named-Entity-Recognition (NER) tasks. """,
{{cookiecutter.uppercase_modelname}}_START_DOCSTRING,
)
class TF{{cookiecutter.camelcase_modelname}}ForTokenClassification(TF{{cookiecutter.camelcase_modelname}}PreTrainedModel, TFTokenClassificationLoss):
def __init__(self, config: {{cookiecutter.camelcase_modelname}}Config, *inputs, **kwargs):
super().__init__(config, *inputs, **kwargs)
self.num_labels = config.num_labels
self.{{cookiecutter.lowercase_modelname}} = TF{{cookiecutter.camelcase_modelname}}MainLayer(config, name="{{cookiecutter.lowercase_modelname}}")
self.dropout = tf.keras.layers.Dropout(rate=config.hidden_dropout_prob)
self.classifier = tf.keras.layers.Dense(
units=config.num_labels, kernel_initializer=get_initializer(config.initializer_range), name="classifier"
)
@unpack_inputs
@add_start_docstrings_to_model_forward({{cookiecutter.uppercase_modelname}}_INPUTS_DOCSTRING.format("batch_size, sequence_length"))
@add_code_sample_docstrings(
checkpoint=_CHECKPOINT_FOR_DOC,
output_type=TFTokenClassifierOutput,
config_class=_CONFIG_FOR_DOC,
)
def call(
self,
input_ids: TFModelInputType | None = None,
attention_mask: np.ndarray | tf.Tensor | None = None,
token_type_ids: np.ndarray | tf.Tensor | None = None,
position_ids: np.ndarray | tf.Tensor | None = None,
head_mask: np.ndarray | tf.Tensor | None = None,
inputs_embeds: np.ndarray | tf.Tensor | None = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
labels: np.ndarray | tf.Tensor | None = None,
training: Optional[bool] = False,
) -> Union[TFTokenClassifierOutput, Tuple[tf.Tensor]]:
r"""
labels (`tf.Tensor` or `np.ndarray` of shape `(batch_size, sequence_length)`, *optional*):
Labels for computing the token classification loss. Indices should be in `[0, ..., config.num_labels - 1]`.
"""
outputs = self.{{cookiecutter.lowercase_modelname}}(
input_ids=input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
position_ids=position_ids,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
training=training,
)
sequence_output = outputs[0]
sequence_output = self.dropout(inputs=sequence_output, training=training)
logits = self.classifier(inputs=sequence_output)
loss = None if labels is None else self.hf_compute_loss(labels=labels, logits=logits)
if not return_dict:
output = (logits,) + outputs[1:]
return ((loss,) + output) if loss is not None else output
return TFTokenClassifierOutput(
loss=loss,
logits=logits,
hidden_states=outputs.hidden_states,
attentions=outputs.attentions,
)
@add_start_docstrings(
"""{{cookiecutter.modelname}} Model with a span classification head on top for extractive question-answering tasks like SQuAD (a linear
layer on top of the hidden-states output to compute `span start logits` and `span end logits`). """,
{{cookiecutter.uppercase_modelname}}_START_DOCSTRING,
)
class TF{{cookiecutter.camelcase_modelname}}ForQuestionAnswering(TF{{cookiecutter.camelcase_modelname}}PreTrainedModel, TFQuestionAnsweringLoss):
def __init__(self, config: {{cookiecutter.camelcase_modelname}}Config, *inputs, **kwargs):
super().__init__(config, *inputs, **kwargs)
self.num_labels = config.num_labels
self.{{cookiecutter.lowercase_modelname}} = TF{{cookiecutter.camelcase_modelname}}MainLayer(config, name="{{cookiecutter.lowercase_modelname}}")
self.qa_outputs = tf.keras.layers.Dense(
units=config.num_labels, kernel_initializer=get_initializer(config.initializer_range), name="qa_outputs"
)
@unpack_inputs
@add_start_docstrings_to_model_forward({{cookiecutter.uppercase_modelname}}_INPUTS_DOCSTRING.format("batch_size, sequence_length"))
@add_code_sample_docstrings(
checkpoint=_CHECKPOINT_FOR_DOC,
output_type=TFQuestionAnsweringModelOutput,
config_class=_CONFIG_FOR_DOC,
)
def call(
self,
input_ids: TFModelInputType | None = None,
attention_mask: np.ndarray | tf.Tensor | None = None,
token_type_ids: np.ndarray | tf.Tensor | None = None,
position_ids: np.ndarray | tf.Tensor | None = None,
head_mask: np.ndarray | tf.Tensor | None = None,
inputs_embeds: np.ndarray | tf.Tensor | None = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
start_positions: np.ndarray | tf.Tensor | None = None,
end_positions: np.ndarray | tf.Tensor | None = None,
training: Optional[bool] = False,
) -> Union[TFQuestionAnsweringModelOutput, Tuple[tf.Tensor]]:
r"""
start_positions (`tf.Tensor` or `np.ndarray` of shape `(batch_size,)`, *optional*):
Labels for position (index) of the start of the labelled span for computing the token classification loss.
Positions are clamped to the length of the sequence (`sequence_length`). Position outside of the
sequence are not taken into account for computing the loss.
end_positions (`tf.Tensor` or `np.ndarray` of shape `(batch_size,)`, *optional*):
Labels for position (index) of the end of the labelled span for computing the token classification loss.
Positions are clamped to the length of the sequence (`sequence_length`). Position outside of the
sequence are not taken into account for computing the loss.
"""
outputs = self.{{cookiecutter.lowercase_modelname}}(
input_ids=input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
position_ids=position_ids,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
training=training,
)
sequence_output = outputs[0]
logits = self.qa_outputs(inputs=sequence_output)
start_logits, end_logits = tf.split(value=logits, num_or_size_splits=2, axis=-1)
start_logits = tf.squeeze(input=start_logits, axis=-1)
end_logits = tf.squeeze(input=end_logits, axis=-1)
loss = None
if start_positions is not None and end_positions is not None:
labels = {"start_position": start_positions}
labels["end_position"] = end_positions
loss = self.hf_compute_loss(labels=labels, logits=(start_logits, end_logits))
if not return_dict:
output = (start_logits, end_logits) + outputs[2:]
return ((loss,) + output) if loss is not None else output
return TFQuestionAnsweringModelOutput(
loss=loss,
start_logits=start_logits,
end_logits=end_logits,
hidden_states=outputs.hidden_states,
attentions=outputs.attentions,
)
{% else %}
import random
from typing import Optional, Tuple, Union
import tensorflow as tf
from ...activations_tf import get_tf_activation
from ...utils import (
add_code_sample_docstrings,
add_start_docstrings,
add_start_docstrings_to_model_forward,
replace_return_docstrings,
)
from ...modeling_tf_outputs import (
TFBaseModelOutput,
TFBaseModelOutputWithPastAndCrossAttentions,
TFSeq2SeqLMOutput,
TFSeq2SeqModelOutput,
)
# Public API
from ...modeling_tf_utils import (
DUMMY_INPUTS,
TFPreTrainedModel,
keras_serializable,
unpack_inputs,
)
from ...tf_utils import check_embeddings_within_bounds, shape_list, stable_softmax
from ...utils import ContextManagers, logging
from .configuration_{{cookiecutter.lowercase_modelname}} import {{cookiecutter.camelcase_modelname}}Config
logger = logging.get_logger(__name__)
_CHECKPOINT_FOR_DOC = "{{cookiecutter.checkpoint_identifier}}"
_CONFIG_FOR_DOC = "{{cookiecutter.camelcase_modelname}}Config"
_TOKENIZER_FOR_DOC = "{{cookiecutter.camelcase_modelname}}Tokenizer"
LARGE_NEGATIVE = -1e8
# Copied from transformers.models.bart.modeling_tf_bart.shift_tokens_right
def shift_tokens_right(input_ids: tf.Tensor, pad_token_id: int, decoder_start_token_id: int):
pad_token_id = tf.cast(pad_token_id, input_ids.dtype)
decoder_start_token_id = tf.cast(decoder_start_token_id, input_ids.dtype)
start_tokens = tf.fill((shape_list(input_ids)[0], 1), tf.convert_to_tensor(decoder_start_token_id, input_ids.dtype))
shifted_input_ids = tf.concat([start_tokens, input_ids[:, :-1]], -1)
# replace possible -100 values in labels by `pad_token_id`
shifted_input_ids = tf.where(
shifted_input_ids == -100,
tf.fill(shape_list(shifted_input_ids), tf.convert_to_tensor(pad_token_id, input_ids.dtype)),
shifted_input_ids,
)
# "Verify that `labels` has only positive values and -100"
assert_gte0 = tf.debugging.assert_greater_equal(shifted_input_ids, tf.constant(0, dtype=shifted_input_ids.dtype))
# Make sure the assertion op is called by wrapping the result in an identity no-op
with tf.control_dependencies([assert_gte0]):
shifted_input_ids = tf.identity(shifted_input_ids)
return shifted_input_ids
def _make_causal_mask(input_ids_shape: tf.TensorShape, past_key_values_length: int = 0):
"""
Make causal mask used for bi-directional self-attention.
"""
bsz, tgt_len = input_ids_shape
mask = tf.ones((tgt_len, tgt_len)) * LARGE_NEGATIVE
mask_cond = tf.range(shape_list(mask)[-1])
mask = tf.where(mask_cond < tf.reshape(mask_cond + 1, (shape_list(mask)[-1], 1)), 0.0, mask)
if past_key_values_length > 0:
mask = tf.concat([tf.zeros((tgt_len, past_key_values_length)), mask], axis=-1)
return tf.tile(mask[None, None, :, :], (bsz, 1, 1, 1))
def _expand_mask(mask: tf.Tensor, tgt_len: Optional[int] = None):
"""
Expands attention_mask from `[bsz, seq_len]` to `[bsz, 1, tgt_seq_len, src_seq_len]`.
"""
src_len = shape_list(mask)[1]
tgt_len = tgt_len if tgt_len is not None else src_len
one_cst = tf.constant(1.0)
mask = tf.cast(mask, dtype=one_cst.dtype)
expanded_mask = tf.tile(mask[:, None, None, :], (1, 1, tgt_len, 1))
return (one_cst - expanded_mask) * LARGE_NEGATIVE
class TF{{cookiecutter.camelcase_modelname}}LearnedPositionalEmbedding(tf.keras.layers.Embedding):
"""
This module learns positional embeddings up to a fixed maximum size.
"""
def __init__(self, num_embeddings: int, embedding_dim: int, **kwargs):
super().__init__(num_embeddings, embedding_dim, **kwargs)
def call(self, input_shape: tf.TensorShape, past_key_values_length: int = 0):
"""Input is expected to be of size [bsz x seqlen]."""
seq_len = input_shape[1]
position_ids = tf.range(seq_len, delta=1, name="range")
position_ids += past_key_values_length
return super().call(tf.cast(position_ids, dtype=tf.int32))
class TF{{cookiecutter.camelcase_modelname}}Attention(tf.keras.layers.Layer):
"""Multi-headed attention from "Attention Is All You Need"""
def __init__(
self,
embed_dim: int,
num_heads: int,
dropout: float = 0.0,
is_decoder: bool = False,
bias: bool = True,
**kwargs,
):
super().__init__(**kwargs)
self.embed_dim = embed_dim
self.num_heads = num_heads
self.dropout = tf.keras.layers.Dropout(dropout)
self.head_dim = embed_dim // num_heads
assert self.head_dim * num_heads == self.embed_dim, "embed_dim must be divisible by num_heads"
self.scaling = self.head_dim ** -0.5
self.is_decoder = is_decoder
self.k_proj = tf.keras.layers.Dense(embed_dim, use_bias=bias, name="k_proj")
self.q_proj = tf.keras.layers.Dense(embed_dim, use_bias=bias, name="q_proj")
self.v_proj = tf.keras.layers.Dense(embed_dim, use_bias=bias, name="v_proj")
self.out_proj = tf.keras.layers.Dense(embed_dim, use_bias=bias, name="out_proj")
def _shape(self, tensor: tf.Tensor, seq_len: int, bsz: int):
return tf.transpose(tf.reshape(tensor, (bsz, seq_len, self.num_heads, self.head_dim)), (0, 2, 1, 3))
def call(
self,
hidden_states: tf.Tensor,
key_value_states: tf.Tensor | None = None,
past_key_value: Tuple[Tuple[tf.Tensor]] | None = None,
attention_mask: tf.Tensor | None = None,
layer_head_mask: tf.Tensor | None = None,
training=False,
) -> Tuple[tf.Tensor, tf.Tensor | None]:
"""Input shape: Batch x Time x Channel"""
# if key_value_states are provided this layer is used as a cross-attention layer
# for the decoder
is_cross_attention = key_value_states is not None
bsz, tgt_len, embed_dim = shape_list(hidden_states)
# get query proj
query_states = self.q_proj(hidden_states) * self.scaling
# get key, value proj
if is_cross_attention and past_key_value is not None:
# reuse k,v, cross_attentions
key_states = past_key_value[0]
value_states = past_key_value[1]
elif is_cross_attention:
# cross_attentions
key_states = self._shape(self.k_proj(key_value_states), -1, bsz)
value_states = self._shape(self.v_proj(key_value_states), -1, bsz)
elif past_key_value is not None:
# reuse k, v, self_attention
key_states = self._shape(self.k_proj(hidden_states), -1, bsz)
value_states = self._shape(self.v_proj(hidden_states), -1, bsz)
key_states = tf.concat([past_key_value[0], key_states], axis=2)
value_states = tf.concat([past_key_value[1], value_states], axis=2)
else:
# self_attention
key_states = self._shape(self.k_proj(hidden_states), -1, bsz)
value_states = self._shape(self.v_proj(hidden_states), -1, bsz)
if self.is_decoder:
# if cross_attention save Tuple(tf.Tensor, tf.Tensor) of all cross attention key/value_states.
# Further calls to cross_attention layer can then reuse all cross-attention
# key/value_states (first "if" case)
# if uni-directional self-attention (decoder) save Tuple(tf.Tensor, tf.Tensor) of
# all previous decoder key/value_states. Further calls to uni-directional self-attention
# can concat previous decoder key/value_states to current projected key/value_states (third "elif" case)
# if encoder bi-directional self-attention `past_key_value` is always `None`
past_key_value = (key_states, value_states)
proj_shape = (bsz * self.num_heads, -1, self.head_dim)
query_states = tf.reshape(self._shape(query_states, tgt_len, bsz), proj_shape)
key_states = tf.reshape(key_states, proj_shape)
value_states = tf.reshape(value_states, proj_shape)
src_len = shape_list(key_states)[1]
attn_weights = tf.matmul(query_states, key_states, transpose_b=True)
tf.debugging.assert_equal(
shape_list(attn_weights),
[bsz * self.num_heads, tgt_len, src_len],
message=f"Attention weights should be of size {(bsz * self.num_heads, tgt_len, src_len)}, but is {shape_list(attn_weights)}",
)
if attention_mask is not None:
tf.debugging.assert_equal(
shape_list(attention_mask),
[bsz, 1, tgt_len, src_len],
message=f"Attention mask should be of size {(bsz, 1, tgt_len, src_len)}, but is {shape_list(attention_mask)}",
)
attn_weights = tf.reshape(attn_weights, (bsz, self.num_heads, tgt_len, src_len)) + attention_mask
attn_weights = tf.reshape(attn_weights, (bsz * self.num_heads, tgt_len, src_len))
attn_weights = stable_softmax(attn_weights, axis=-1)
if layer_head_mask is not None:
tf.debugging.assert_equal(
shape_list(layer_head_mask),
[self.num_heads],
message=f"Head mask for a single layer should be of size {(self.num_heads)}, but is {shape_list(layer_head_mask)}",
)
attn_weights = tf.reshape(layer_head_mask, (1, -1, 1, 1)) * tf.reshape(
attn_weights, (bsz, self.num_heads, tgt_len, src_len)
)
attn_weights = tf.reshape(attn_weights, (bsz * self.num_heads, tgt_len, src_len))
attn_probs = self.dropout(attn_weights, training=training)
attn_output = tf.matmul(attn_probs, value_states)
tf.debugging.assert_equal(
shape_list(attn_output),
[bsz * self.num_heads, tgt_len, self.head_dim],
message=f"`attn_output` should be of size {(bsz, self.num_heads, tgt_len, self.head_dim)}, but is {shape_list(attn_output)}",
)
attn_output = tf.transpose(
tf.reshape(attn_output, (bsz, self.num_heads, tgt_len, self.head_dim)), (0, 2, 1, 3)
)
attn_output = tf.reshape(attn_output, (bsz, tgt_len, embed_dim))
attn_output = self.out_proj(attn_output)
attn_weights: tf.Tensor = tf.reshape(attn_weights, (bsz, self.num_heads, tgt_len, src_len))
return attn_output, attn_weights, past_key_value
class TF{{cookiecutter.camelcase_modelname}}EncoderLayer(tf.keras.layers.Layer):
def __init__(self, config: {{cookiecutter.camelcase_modelname}}Config, **kwargs):
super().__init__(**kwargs)
self.embed_dim = config.d_model
self.self_attn = TF{{cookiecutter.camelcase_modelname}}Attention(
self.embed_dim, config.encoder_attention_heads, dropout=config.attention_dropout, name="self_attn"
)
self.self_attn_layer_norm = tf.keras.layers.LayerNormalization(epsilon=1e-5, name="self_attn_layer_norm")
self.dropout = tf.keras.layers.Dropout(config.dropout)
self.activation_fn = get_tf_activation(config.activation_function)
self.activation_dropout = tf.keras.layers.Dropout(config.activation_dropout)
self.fc1 = tf.keras.layers.Dense(config.encoder_ffn_dim, name="fc1")
self.fc2 = tf.keras.layers.Dense(self.embed_dim, name="fc2")
self.final_layer_norm = tf.keras.layers.LayerNormalization(epsilon=1e-5, name="final_layer_norm")
def call(self, hidden_states: tf.Tensor, attention_mask: tf.Tensor, layer_head_mask: tf.Tensor, training=False):
"""
Args:
hidden_states (`tf.Tensor`): input to the layer of shape *(batch, seq_len, embed_dim)*
attention_mask (`tf.Tensor`): attention mask of size
*(batch, 1, tgt_len, src_len)* where padding elements are indicated by very large negative values.
layer_head_mask (`tf.Tensor`): mask for attention heads in a given layer of size
*(encoder_attention_heads,)*
"""
residual = hidden_states
hidden_states, self_attn_weights, _ = self.self_attn(
hidden_states=hidden_states, attention_mask=attention_mask, layer_head_mask=layer_head_mask
)
tf.debugging.assert_equal(
shape_list(hidden_states),
shape_list(residual),
message=f"Self attn modified the shape of query {shape_list(residual)} to {shape_list(hidden_states)}",
)
hidden_states = self.dropout(hidden_states, training=training)
hidden_states = residual + hidden_states
hidden_states = self.self_attn_layer_norm(hidden_states)
residual = hidden_states
hidden_states = self.activation_fn(self.fc1(hidden_states))
hidden_states = self.activation_dropout(hidden_states, training=training)
hidden_states = self.fc2(hidden_states)
hidden_states = self.dropout(hidden_states, training=training)
hidden_states = residual + hidden_states
hidden_states = self.final_layer_norm(hidden_states)
return hidden_states, self_attn_weights
class TF{{cookiecutter.camelcase_modelname}}DecoderLayer(tf.keras.layers.Layer):
def __init__(self, config: {{cookiecutter.camelcase_modelname}}Config, **kwargs):
super().__init__(**kwargs)
self.embed_dim = config.d_model
self.self_attn = TF{{cookiecutter.camelcase_modelname}}Attention(
embed_dim=self.embed_dim,
num_heads=config.decoder_attention_heads,
dropout=config.attention_dropout,
name="self_attn",
is_decoder=True,
)
self.dropout = tf.keras.layers.Dropout(config.dropout)
self.activation_fn = get_tf_activation(config.activation_function)
self.activation_dropout = tf.keras.layers.Dropout(config.activation_dropout)
self.self_attn_layer_norm = tf.keras.layers.LayerNormalization(epsilon=1e-5, name="self_attn_layer_norm")
self.encoder_attn = TF{{cookiecutter.camelcase_modelname}}Attention(
self.embed_dim,
config.decoder_attention_heads,
dropout=config.attention_dropout,
name="encoder_attn",
is_decoder=True,
)
self.encoder_attn_layer_norm = tf.keras.layers.LayerNormalization(epsilon=1e-5, name="encoder_attn_layer_norm")
self.fc1 = tf.keras.layers.Dense(config.decoder_ffn_dim, name="fc1")
self.fc2 = tf.keras.layers.Dense(self.embed_dim, name="fc2")
self.final_layer_norm = tf.keras.layers.LayerNormalization(epsilon=1e-5, name="final_layer_norm")
def call(
self,
hidden_states,
attention_mask: tf.Tensor | None = None,
encoder_hidden_states: tf.Tensor | None = None,
encoder_attention_mask: tf.Tensor | None = None,
layer_head_mask: tf.Tensor | None = None,
cross_attn_layer_head_mask: tf.Tensor | None = None,
past_key_value: Tuple[tf.Tensor] | None = None,
training=False,
) -> Tuple[tf.Tensor, tf.Tensor, Tuple[Tuple[tf.Tensor]]]:
"""
Args:
hidden_states (`tf.Tensor`): input to the layer of shape *(batch, seq_len, embed_dim)*
attention_mask (`tf.Tensor`): attention mask of size
*(batch, 1, tgt_len, src_len)* where padding elements are indicated by very large negative values.
encoder_hidden_states (`tf.Tensor`): cross attention input to the layer of shape *(batch, seq_len, embed_dim)*
encoder_attention_mask (`tf.Tensor`): encoder attention mask of size
*(batch, 1, tgt_len, src_len)* where padding elements are indicated by very large negative values.
layer_head_mask (`tf.Tensor`): mask for attention heads in a given layer of size
*(decoder_attention_heads,)*
cross_attn_layer_head_mask (`tf.Tensor`): mask for heads of the cross-attention module.
*(decoder_attention_heads,)*
past_key_value (`Tuple(tf.Tensor)`): cached past key and value projection states
"""
residual = hidden_states
# Self Attention
# decoder uni-directional self-attention cached key/values tuple is at positions 1,2
self_attn_past_key_value = past_key_value[:2] if past_key_value is not None else None
# add present self-attn cache to positions 1,2 of present_key_value tuple
hidden_states, self_attn_weights, present_key_value = self.self_attn(
hidden_states=hidden_states,
past_key_value=self_attn_past_key_value,
attention_mask=attention_mask,
layer_head_mask=layer_head_mask,
)
hidden_states = self.dropout(hidden_states, training=training)
hidden_states = residual + hidden_states
hidden_states = self.self_attn_layer_norm(hidden_states)
# Cross-Attention Block
cross_attn_present_key_value = None
cross_attn_weights = None
if encoder_hidden_states is not None:
residual = hidden_states
# cross_attn cached key/values tuple is at positions 3,4 of present_key_value tuple
cross_attn_past_key_value = past_key_value[-2:] if past_key_value is not None else None
hidden_states, cross_attn_weights, cross_attn_present_key_value = self.encoder_attn(
hidden_states=hidden_states,
key_value_states=encoder_hidden_states,
attention_mask=encoder_attention_mask,
layer_head_mask=cross_attn_layer_head_mask,
past_key_value=cross_attn_past_key_value,
)
hidden_states = self.dropout(hidden_states, training=training)
hidden_states = residual + hidden_states
hidden_states = self.encoder_attn_layer_norm(hidden_states)
# add cross-attn to positions 3,4 of present_key_value tuple
present_key_value = present_key_value + cross_attn_present_key_value
# Fully Connected
residual = hidden_states
hidden_states = self.activation_fn(self.fc1(hidden_states))
hidden_states = self.activation_dropout(hidden_states, training=training)
hidden_states = self.fc2(hidden_states)
hidden_states = self.dropout(hidden_states, training=training)
hidden_states = residual + hidden_states
hidden_states = self.final_layer_norm(hidden_states)
return (
hidden_states,
self_attn_weights,
cross_attn_weights,
present_key_value,
)
class TF{{cookiecutter.camelcase_modelname}}PreTrainedModel(TFPreTrainedModel):
config_class = {{cookiecutter.camelcase_modelname}}Config
base_model_prefix = "model"
{{cookiecutter.uppercase_modelname}}_START_DOCSTRING = r"""
This model inherits from [`TFPreTrainedModel`]. Check the superclass documentation for the
generic methods the library implements for all its model (such as downloading or saving, resizing the input
embeddings, pruning heads etc.)
This model is also a [tf.keras.Model](https://www.tensorflow.org/api_docs/python/tf/keras/Model) subclass. Use
it as a regular TF 2.0 Keras Model and refer to the TF 2.0 documentation for all matter related to general usage
and behavior.
<Tip>
TensorFlow models and layers in `transformers` accept two formats as input:
- having all inputs as keyword arguments (like PyTorch models), or
- having all inputs as a list, tuple or dict in the first positional argument.
The reason the second format is supported is that Keras methods prefer this format when passing inputs to models
and layers. Because of this support, when using methods like `model.fit()` things should "just work" for you - just
pass your inputs and labels in any format that `model.fit()` supports! If, however, you want to use the second format outside of Keras methods like `fit()` and `predict()`, such as when creating
your own layers or models with the Keras `Functional` API, there are three possibilities you
can use to gather all the input Tensors in the first positional argument:
- a single Tensor with `input_ids` only and nothing else: `model(input_ids)`
- a list of varying length with one or several input Tensors IN THE ORDER given in the docstring:
`model([input_ids, attention_mask])` or `model([input_ids, attention_mask, token_type_ids])`
- a dictionary with one or several input Tensors associated to the input names given in the docstring:
`model({"input_ids": input_ids, "token_type_ids": token_type_ids})`
Note that when creating models and layers with (subclassing)[https://keras.io/guides/making_new_layers_and_models_via_subclassing/]
then you don't need to worry about any of this, as you can just pass inputs like you would to any other Python
function!
</Tip>
Args:
config ([`~{{cookiecutter.camelcase_modelname}}Config`]): Model configuration class with all the parameters of the model.
Initializing with a config file does not load the weights associated with the model, only the
configuration. Check out the [`~TFPreTrainedModel.from_pretrained`] method to load the
model weights.
"""
{{cookiecutter.uppercase_modelname}}_INPUTS_DOCSTRING = r"""
Args:
input_ids (`tf.Tensor` of shape `({0})`):
Indices of input sequence tokens in the vocabulary.
Indices can be obtained using [`~{{cookiecutter.camelcase_modelname}}Tokenizer`]. See
[`PreTrainedTokenizer.encode`] and [`PreTrainedTokenizer.__call__`] for
details.
[What are input IDs?](../glossary#input-ids)
attention_mask (`tf.Tensor` of shape `({0})`, *optional*):
Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
- 1 for tokens that are **not masked**,
- 0 for tokens that are **masked**.
[What are attention masks?](../glossary#attention-mask)
decoder_input_ids (`tf.Tensor` of shape `(batch_size, target_sequence_length)`, *optional*):
Indices of decoder input sequence tokens in the vocabulary.
Indices can be obtained using [`~{{cookiecutter.camelcase_modelname}}Tokenizer`]. See
[`PreTrainedTokenizer.encode`] and [`PreTrainedTokenizer.__call__`] for
details.
[What are input IDs?](../glossary#input-ids)
{{cookiecutter.camelcase_modelname}} uses the `eos_token_id` as the starting token for
`decoder_input_ids` generation. If `past_key_values` is used, optionally only the last
`decoder_input_ids` have to be input (see `past_key_values`).
For translation and summarization training, `decoder_input_ids` should be provided. If no
`decoder_input_ids` is provided, the model will create this tensor by shifting the `input_ids` to
the right for denoising pre-training following the paper.
decoder_attention_mask (`tf.Tensor` of shape `(batch_size, target_sequence_length)`, *optional*):
will be made by default and ignore pad tokens. It is not recommended to set this for most use cases.
head_mask (`tf.Tensor` of shape `(encoder_layers, encoder_attention_heads)`, *optional*):
Mask to nullify selected heads of the attention modules in the encoder. Mask values selected in `[0, 1]`:
- 1 indicates the head is **not masked**,
- 0 indicates the head is **masked**.
decoder_head_mask (`tf.Tensor` of shape `(decoder_layers, decoder_attention_heads)`, *optional*):
Mask to nullify selected heads of the attention modules in the decoder. Mask values selected in `[0, 1]`:
- 1 indicates the head is **not masked**,
- 0 indicates the head is **masked**.
cross_attn_head_mask (`tf.Tensor` of shape `(decoder_layers, decoder_attention_heads)`, *optional*):
Mask to nullify selected heads of the cross-attention modules. Mask values selected in `[0, 1]`:
- 1 indicates the head is **not masked**,
- 0 indicates the head is **masked**.
encoder_outputs (`tf.FloatTensor`, *optional*):
hidden states at the output of the last layer of the encoder. Used in the cross-attention of the decoder.
of shape `(batch_size, sequence_length, hidden_size)` is a sequence of
past_key_values (`Tuple[Tuple[tf.Tensor]]` of length `config.n_layers`)
contains precomputed key and value hidden states of the attention blocks. Can be used to speed up decoding.
If `past_key_values` are used, the user can optionally input only the last `decoder_input_ids`
(those that don't have their past key value states given to this model) of shape `(batch_size, 1)`
instead of all `decoder_input_ids` of shape `(batch_size, sequence_length)`.
use_cache (`bool`, *optional*, defaults to `True`):
If set to `True`, `past_key_values` key value states are returned and can be used to speed up
decoding (see `past_key_values`). Set to `False` during training, `True` during generation
output_attentions (`bool`, *optional*):
Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
tensors for more detail. This argument can be used only in eager mode, in graph mode the value in the
config will be used instead.
output_hidden_states (`bool`, *optional*):
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
more detail. This argument can be used only in eager mode, in graph mode the value in the config will be
used instead.
return_dict (`bool`, *optional*):
Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple. This
argument can be used in eager mode, in graph mode the value will always be set to True.
training (`bool`, *optional*, defaults to `False`):
Whether or not to use the model in training mode (some modules like dropout modules have different
behaviors between training and evaluation).
"""
@keras_serializable
class TF{{cookiecutter.camelcase_modelname}}Encoder(tf.keras.layers.Layer):
config_class = {{cookiecutter.camelcase_modelname}}Config
"""
Transformer encoder consisting of *config.encoder_layers* self attention layers. Each layer is a
[`TF{{cookiecutter.camelcase_modelname}}EncoderLayer`].
Args:
config: {{cookiecutter.camelcase_modelname}}Config
"""
def __init__(self, config: {{cookiecutter.camelcase_modelname}}Config, embed_tokens: Optional[tf.keras.layers.Embedding] = None, **kwargs):
super().__init__(**kwargs)
self.config = config
self.dropout = tf.keras.layers.Dropout(config.dropout)
self.layerdrop = config.encoder_layerdrop
self.padding_idx = config.pad_token_id
self.max_source_positions = config.max_position_embeddings
self.embed_scale = tf.math.sqrt(float(config.d_model)) if config.scale_embedding else 1.0
self.embed_tokens = embed_tokens
self.embed_positions = TF{{cookiecutter.camelcase_modelname}}LearnedPositionalEmbedding(
config.max_position_embeddings,
config.d_model,
name="embed_positions",
)
self.layers = [TF{{cookiecutter.camelcase_modelname}}EncoderLayer(config, name=f"layers.{i}") for i in range(config.encoder_layers)]
self.layernorm_embedding = tf.keras.layers.LayerNormalization(epsilon=1e-5, name="layernorm_embedding")
def get_embed_tokens(self):
return self.embed_tokens
def set_embed_tokens(self, embed_tokens):
self.embed_tokens = embed_tokens
@unpack_inputs
def call(
self,
input_ids=None,
inputs_embeds=None,
attention_mask=None,
head_mask=None,
output_attentions=None,
output_hidden_states=None,
return_dict=None,
training=False,
):
"""
Args:
input_ids (`tf.Tensor` of shape `(batch_size, sequence_length)`):
Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you
provide it.
Indices can be obtained using [`~{{cookiecutter.camelcase_modelname}}Tokenizer`]. See
[`PreTrainedTokenizer.encode`] and [`PreTrainedTokenizer.__call__`]
for details.
[What are input IDs?](../glossary#input-ids)
attention_mask (`tf.Tensor` of shape `(batch_size, sequence_length)`, *optional*):
Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
- 1 for tokens that are **not masked**,
- 0 for tokens that are **masked**.
[What are attention masks?](../glossary#attention-mask)
head_mask (`tf.Tensor` of shape `(encoder_layers, encoder_attention_heads)`, `optional): Mask to nullify selected heads of the attention modules. Mask values selected in `[0, 1]`:
- 1 indicates the head is **not masked**,
- 0 indicates the head is **masked**.
inputs_embeds (`tf.Tensor` of shape `(batch_size, sequence_length, hidden_size)`, *optional*):
Optionally, instead of passing `input_ids` you can choose to directly pass an embedded
representation. This is useful if you want more control over how to convert `input_ids` indices
into associated vectors than the model's internal embedding lookup matrix.
output_attentions (`bool`, *optional*):
Whether or not to return the attentions tensors of all attention layers. See `attentions` under
returned tensors for more detail. This argument can be used only in eager mode, in graph mode the value
in the config will be used instead.
output_hidden_states (`bool`, *optional*):
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors
for more detail. This argument can be used only in eager mode, in graph mode the value in the config
will be used instead.
return_dict (`bool`, *optional*):
Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple. This
argument can be used in eager mode, in graph mode the value will always be set to True.
training (`bool`, *optional*, defaults to `False`):
Whether or not to use the model in training mode (some modules like dropout modules have different
behaviors between training and evaluation).
"""
if input_ids is not None and inputs_embeds is not None:
raise ValueError("You cannot specify both input_ids and inputs_embeds at the same time")
elif input_ids is not None:
input_shape = shape_list(input_ids)
elif inputs_embeds is not None:
input_shape = shape_list(inputs_embeds)[:-1]
else:
raise ValueError("You have to specify either input_ids or inputs_embeds")
if inputs_embeds is None:
# if `self.embed_tokens.load_weight_prefix` is set, runs the embedding operation with the correct name
# scope, so that its weights are registered with the desired name for loading/storing. When `tf.name_scope`
# is used with a name ending in `/`, that name replaces the current name scope.
# (embeddings with tf.name_scope: self.embed_tokens.load_weight_prefix/self.embed_tokens.name/embeddings:0)
context = []
if hasattr(self.embed_tokens, "load_weight_prefix"):
context.append(tf.name_scope(self.embed_tokens.load_weight_prefix + "/"))
with ContextManagers(context):
check_embeddings_within_bounds(input_ids, self.embed_tokens.input_dim)
inputs_embeds = self.embed_tokens(input_ids) * self.embed_scale
embed_pos = self.embed_positions(input_shape)
hidden_states = inputs_embeds + embed_pos
hidden_states = self.layernorm_embedding(hidden_states)
hidden_states = self.dropout(hidden_states, training=training)
# check attention mask and invert
if attention_mask is not None:
# [bsz, seq_len] -> [bsz, 1, tgt_seq_len, src_seq_len]
attention_mask = _expand_mask(attention_mask)
encoder_states = () if output_hidden_states else None
all_attentions = () if output_attentions else None
# check if head_mask has a correct number of layers specified if desired
if head_mask is not None:
tf.debugging.assert_equal(
shape_list(head_mask)[0],
len(self.layers),
message=f"The head_mask should be specified for {len(self.layers)} layers, but it is for {shape_list(head_mask)[0]}.",
)
# encoder layers
for idx, encoder_layer in enumerate(self.layers):
if output_hidden_states:
encoder_states = encoder_states + (hidden_states,)
# add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
dropout_probability = random.uniform(0, 1)
if training and (dropout_probability < self.layerdrop): # skip the layer
continue
hidden_states, attn = encoder_layer(
hidden_states,
attention_mask,
head_mask[idx] if head_mask is not None else None,
)
if output_attentions:
all_attentions += (attn,)
if output_hidden_states:
encoder_states = encoder_states + (hidden_states,)
if not return_dict:
return tuple(v for v in [hidden_states, encoder_states, all_attentions] if v is not None)
return TFBaseModelOutput(
last_hidden_state=hidden_states, hidden_states=encoder_states, attentions=all_attentions
)
@keras_serializable
class TF{{cookiecutter.camelcase_modelname}}Decoder(tf.keras.layers.Layer):
config_class = {{cookiecutter.camelcase_modelname}}Config
"""
Transformer decoder consisting of *config.decoder_layers* layers. Each layer is a [`TF{{cookiecutter.camelcase_modelname}}DecoderLayer`]
Args:
config: {{cookiecutter.camelcase_modelname}}Config
embed_tokens: output embedding
"""
def __init__(self, config: {{cookiecutter.camelcase_modelname}}Config, embed_tokens: Optional[tf.keras.layers.Embedding] = None, **kwargs):
super().__init__(**kwargs)
self.config = config
self.padding_idx = config.pad_token_id
self.embed_tokens = embed_tokens
self.layerdrop = config.decoder_layerdrop
self.embed_positions = TF{{cookiecutter.camelcase_modelname}}LearnedPositionalEmbedding(
config.max_position_embeddings,
config.d_model,
name="embed_positions",
)
self.embed_scale = tf.math.sqrt(float(config.d_model)) if config.scale_embedding else 1.0
self.layers = [TF{{cookiecutter.camelcase_modelname}}DecoderLayer(config, name=f"layers.{i}") for i in range(config.decoder_layers)]
self.layernorm_embedding = tf.keras.layers.LayerNormalization(epsilon=1e-5, name="layernorm_embedding")
self.dropout = tf.keras.layers.Dropout(config.dropout)
def get_embed_tokens(self):
return self.embed_tokens
def set_embed_tokens(self, embed_tokens):
self.embed_tokens = embed_tokens
@unpack_inputs
def call(
self,
input_ids=None,
inputs_embeds=None,
attention_mask=None,
encoder_hidden_states=None,
encoder_attention_mask=None,
head_mask=None,
cross_attn_head_mask=None,
past_key_values=None,
use_cache=None,
output_attentions=None,
output_hidden_states=None,
return_dict=None,
training=False,
):
r"""
Args:
input_ids (`tf.Tensor` of shape `(batch_size, sequence_length)`):
Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you
provide it.
Indices can be obtained using [`~{{cookiecutter.camelcase_modelname}}Tokenizer`]. See
[`PreTrainedTokenizer.encode`] and [`PreTrainedTokenizer.__call__`]
for details.
[What are input IDs?](../glossary#input-ids)
attention_mask (`tf.Tensor` of shape `(batch_size, sequence_length)`, *optional*):
Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
- 1 for tokens that are **not masked**,
- 0 for tokens that are **masked**.
[What are attention masks?](../glossary#attention-mask)
encoder_hidden_states (`tf.Tensor` of shape `(batch_size, encoder_sequence_length, hidden_size)`, *optional*):
Sequence of hidden-states at the output of the last layer of the encoder. Used in the cross-attention
of the decoder.
encoder_attention_mask (`tf.Tensor` of shape `(batch_size, encoder_sequence_length)`, *optional*):
Mask to avoid performing cross-attention on padding tokens indices of encoder input_ids. Mask values
selected in `[0, 1]`:
- 1 for tokens that are **not masked**,
- 0 for tokens that are **masked**.
[What are attention masks?](../glossary#attention-mask)
head_mask (`tf.Tensor` of shape `(decoder_layers, decoder_attention_heads)`, *optional*):
Mask to nullify selected heads of the attention modules. Mask values selected in `[0, 1]`:
- 1 indicates the head is **not masked**,
- 0 indicates the head is **masked**.
cross_attn_head_mask (`tf.Tensor` of shape `(decoder_layers, decoder_attention_heads)`, *optional*):
Mask to nullify selected heads of the cross-attention modules. Mask values selected in `[0, 1]`:
- 1 indicates the head is **not masked**,
- 0 indicates the head is **masked**.
past_key_values (`Tuple[Tuple[tf.Tensor]]` of length `config.n_layers` with each tuple having 2 tuples each of which has 2 tensors of shape `(batch_size, num_heads, sequence_length - 1, embed_size_per_head)`):
Contains precomputed key and value hidden-states of the attention blocks. Can be used to speed up
decoding.
If `past_key_values` are used, the user can optionally input only the last
`decoder_input_ids` (those that don't have their past key value states given to this model) of
shape `(batch_size, 1)` instead of all `decoder_input_ids` of shape `(batch_size,
sequence_length)`.
inputs_embeds (`tf.Tensor` of shape `(batch_size, sequence_length, hidden_size)`, *optional*):
Optionally, instead of passing `input_ids` you can choose to directly pass an embedded representation.
This is useful if you want more control over how to convert `input_ids` indices
into associated vectors than the model's internal embedding lookup matrix.
output_attentions (`bool`, *optional*):
Whether or not to return the attentions tensors of all attention layers. See `attentions` under
returned tensors for more detail. This argument can be used only in eager mode, in graph mode the value
in the config will be used instead.
output_hidden_states (`bool`, *optional*):
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors
for more detail. This argument can be used only in eager mode, in graph mode the value in the config
will be used instead.
return_dict (`bool`, *optional*):
Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple. This
argument can be used in eager mode, in graph mode the value will always be set to True.
training (`bool`, *optional*, defaults to `False`):
Whether or not to use the model in training mode (some modules like dropout modules have different
behaviors between training and evaluation).
"""
if input_ids is not None and inputs_embeds is not None:
raise ValueError("You cannot specify both decoder_input_ids and decoder_inputs_embeds at the same time")
elif input_ids is not None:
input_shape = shape_list(input_ids)
elif inputs_embeds is not None:
input_shape = shape_list(inputs_embeds)[:-1]
else:
raise ValueError("You have to specify either decoder_input_ids or decoder_inputs_embeds")
past_key_values_length = (
shape_list(past_key_values[0][0])[2] if past_key_values is not None else 0
)
# embed positions
positions = self.embed_positions(input_shape, past_key_values_length)
if inputs_embeds is None:
# if `self.embed_tokens.load_weight_prefix` is set, runs the embedding operation with the correct name
# scope, so that its weights are registered with the desired name for loading/storing. When `tf.name_scope`
# is used with a name ending in `/`, that name replaces the current name scope.
# (embeddings with tf.name_scope: self.embed_tokens.load_weight_prefix/self.embed_tokens.name/embeddings:0)
context = []
if hasattr(self.embed_tokens, "load_weight_prefix"):
context.append(tf.name_scope(self.embed_tokens.load_weight_prefix + "/"))
with ContextManagers(context):
check_embeddings_within_bounds(input_ids, self.embed_tokens.input_dim)
inputs_embeds = self.embed_tokens(input_ids)
hidden_states = inputs_embeds
attention_mask, combined_attention_mask = self.compute_combined_attns_mask(
input_ids, attention_mask, input_shape, past_key_values_length
)
if encoder_hidden_states is not None and encoder_attention_mask is not None:
# [bsz, seq_len] -> [bsz, 1, tgt_seq_len, src_seq_len]
encoder_attention_mask = _expand_mask(encoder_attention_mask, tgt_len=input_shape[-1])
hidden_states = self.layernorm_embedding(hidden_states + positions)
hidden_states = self.dropout(hidden_states, training=training)
# decoder layers
all_hidden_states = () if output_hidden_states else None
all_self_attns = () if output_attentions else None
all_cross_attns = () if (output_attentions and encoder_hidden_states is not None) else None
present_key_values = () if use_cache else None
# check if head_mask and cross_attn_head_mask have a correct number of layers specified if desired
for attn_mask_name, attn_mask in [("head_mask", head_mask), ("cross_attn_head_mask", cross_attn_head_mask)]:
if attn_mask is not None:
tf.debugging.assert_equal(
shape_list(attn_mask)[0],
len(self.layers),
message=f"The {attn_mask_name} should be specified for {len(self.layers)} layers, but it is for {shape_list(attn_mask)[0]}.",
)
for idx, decoder_layer in enumerate(self.layers):
# add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
if output_hidden_states:
all_hidden_states += (hidden_states,)
dropout_probability = random.uniform(0, 1)
if training and (dropout_probability < self.layerdrop):
continue
past_key_value = past_key_values[idx] if past_key_values is not None else None
hidden_states, layer_self_attn, layer_cross_attn, present_key_value = decoder_layer(
hidden_states,
attention_mask=combined_attention_mask,
encoder_hidden_states=encoder_hidden_states,
encoder_attention_mask=encoder_attention_mask,
layer_head_mask=head_mask[idx] if head_mask is not None else None,
cross_attn_layer_head_mask=cross_attn_head_mask[idx]
if cross_attn_head_mask is not None
else None,
past_key_value=past_key_value,
)
if use_cache:
present_key_values += (present_key_value,)
if output_attentions:
all_self_attns += (layer_self_attn,)
if encoder_hidden_states is not None:
all_cross_attns += (layer_cross_attn,)
if output_hidden_states:
all_hidden_states += (hidden_states,)
if not return_dict:
return hidden_states, present_key_values, all_hidden_states, all_self_attns, all_cross_attns
else:
return TFBaseModelOutputWithPastAndCrossAttentions(
last_hidden_state=hidden_states,
past_key_values=present_key_values,
hidden_states=all_hidden_states,
attentions=all_self_attns,
cross_attentions=all_cross_attns,
)
@tf.function
def compute_combined_attns_mask(self, input_ids, attention_mask, input_shape, past_key_values_length):
# [bsz, seq_len] -> [bsz, 1, tgt_seq_len, src_seq_len]
combined_attention_mask = None
if input_shape[-1] > 1:
combined_attention_mask = _make_causal_mask(input_shape, past_key_values_length=past_key_values_length)
else:
combined_attention_mask = _expand_mask(
tf.ones((input_shape[0], input_shape[1] + past_key_values_length)), tgt_len=input_shape[-1]
)
if attention_mask is None and input_ids is not None and input_shape[-1] > 1:
attention_mask = tf.cast(
tf.math.not_equal(input_ids, self.config.pad_token_id), input_ids.dtype
)
attention_mask = tf.concat(
[
tf.ones((input_shape[0], past_key_values_length), dtype=attention_mask.dtype),
attention_mask,
],
axis=-1,
)
else:
attention_mask = tf.ones((input_shape[0], input_shape[1] + past_key_values_length))
return attention_mask, combined_attention_mask
@keras_serializable
class TF{{cookiecutter.camelcase_modelname}}MainLayer(tf.keras.layers.Layer):
config_class = {{cookiecutter.camelcase_modelname}}Config
def __init__(self, config: {{cookiecutter.camelcase_modelname}}Config, **kwargs):
super().__init__(**kwargs)
self.config = config
self.shared = tf.keras.layers.Embedding(
input_dim=config.vocab_size,
output_dim=config.d_model,
embeddings_initializer=tf.keras.initializers.TruncatedNormal(stddev=self.config.init_std),
name="model.shared"
)
# Additional attribute to specify the expected name scope of the layer (for loading/storing weights)
self.shared.load_weight_prefix = "model.shared"
self.encoder = TF{{cookiecutter.camelcase_modelname}}Encoder(config, self.shared, name="encoder")
self.decoder = TF{{cookiecutter.camelcase_modelname}}Decoder(config, self.shared, name="decoder")
def get_input_embeddings(self):
return self.shared
def set_input_embeddings(self, new_embeddings):
self.shared = new_embeddings
self.encoder.embed_tokens = self.shared
self.decoder.embed_tokens = self.shared
@unpack_inputs
def call(
self,
input_ids=None,
attention_mask=None,
decoder_input_ids=None,
decoder_attention_mask=None,
head_mask=None,
decoder_head_mask=None,
cross_attn_head_mask=None,
encoder_outputs: Optional[Union[Tuple, TFBaseModelOutput]] = None,
past_key_values=None,
inputs_embeds=None,
decoder_inputs_embeds=None,
use_cache=None,
output_attentions=None,
output_hidden_states=None,
return_dict=None,
training=False,
**kwargs
):
if decoder_input_ids is None and decoder_inputs_embeds is None:
use_cache = False
if encoder_outputs is None:
encoder_outputs = self.encoder(
input_ids=input_ids,
attention_mask=attention_mask,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
training=training,
)
# If the user passed a tuple for encoder_outputs, we wrap it in a TFBaseModelOutput when return_dict=True
elif return_dict and not isinstance(encoder_outputs, TFBaseModelOutput):
encoder_outputs = TFBaseModelOutput(
last_hidden_state=encoder_outputs[0],
hidden_states=encoder_outputs[1] if len(encoder_outputs) > 1 else None,
attentions=encoder_outputs[2] if len(encoder_outputs) > 2 else None,
)
# If the user passed a TFBaseModelOutput for encoder_outputs, we wrap it in a tuple when return_dict=False
elif not return_dict and not isinstance(encoder_outputs, tuple):
encoder_outputs = encoder_outputs.to_tuple()
decoder_outputs = self.decoder(
decoder_input_ids,
attention_mask=decoder_attention_mask,
encoder_hidden_states=encoder_outputs[0],
encoder_attention_mask=attention_mask,
head_mask=decoder_head_mask,
cross_attn_head_mask=cross_attn_head_mask,
past_key_values=past_key_values,
inputs_embeds=decoder_inputs_embeds,
use_cache=use_cache,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
training=training,
)
if not return_dict:
return decoder_outputs + encoder_outputs
return TFSeq2SeqModelOutput(
last_hidden_state=decoder_outputs.last_hidden_state,
past_key_values=decoder_outputs.past_key_values,
decoder_hidden_states=decoder_outputs.hidden_states,
decoder_attentions=decoder_outputs.attentions,
cross_attentions=decoder_outputs.cross_attentions,
encoder_last_hidden_state=encoder_outputs.last_hidden_state,
encoder_hidden_states=encoder_outputs.hidden_states,
encoder_attentions=encoder_outputs.attentions,
)
@add_start_docstrings(
"The bare {{cookiecutter.uppercase_modelname}} Model outputting raw hidden-states without any specific head on top.",
{{cookiecutter.uppercase_modelname}}_START_DOCSTRING,
)
class TF{{cookiecutter.camelcase_modelname}}Model(TF{{cookiecutter.camelcase_modelname}}PreTrainedModel):
def __init__(self, config: {{cookiecutter.camelcase_modelname}}Config, *inputs, **kwargs):
super().__init__(config, *inputs, **kwargs)
self.model = TF{{cookiecutter.camelcase_modelname}}MainLayer(config, name="model")
def get_encoder(self):
return self.model.encoder
def get_decoder(self):
return self.model.decoder
@unpack_inputs
@add_start_docstrings_to_model_forward({{cookiecutter.uppercase_modelname}}_INPUTS_DOCSTRING.format("batch_size, sequence_length"))
@add_code_sample_docstrings(
checkpoint=_CHECKPOINT_FOR_DOC,
output_type=TFSeq2SeqModelOutput,
config_class=_CONFIG_FOR_DOC,
)
def call(
self,
input_ids=None,
attention_mask=None,
decoder_input_ids=None,
decoder_attention_mask=None,
head_mask=None,
decoder_head_mask=None,
cross_attn_head_mask=None,
encoder_outputs: Optional[Union[Tuple, TFBaseModelOutput]] = None,
past_key_values=None,
inputs_embeds=None,
decoder_inputs_embeds=None,
use_cache=None,
output_attentions=None,
output_hidden_states=None,
return_dict=None,
training=False,
**kwargs
):
outputs = self.model(
input_ids=input_ids,
attention_mask=attention_mask,
decoder_input_ids=decoder_input_ids,
decoder_attention_mask=decoder_attention_mask,
head_mask=head_mask,
decoder_head_mask=decoder_head_mask,
cross_attn_head_mask=cross_attn_head_mask,
encoder_outputs=encoder_outputs,
past_key_values=past_key_values,
inputs_embeds=inputs_embeds,
decoder_inputs_embeds=decoder_inputs_embeds,
use_cache=use_cache,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
training=training,
)
return outputs
# Copied from transformers.models.bart.modeling_tf_bart.BiasLayer
class BiasLayer(tf.keras.layers.Layer):
"""
Bias as a layer. It is used for serialization purposes: `tf.keras.Model.save_weights` stores on a per-layer basis,
so all weights have to be registered in a layer.
"""
def __init__(self, shape, initializer, trainable, name, **kwargs):
super().__init__(name=name, **kwargs)
# Note: the name of this variable will NOT be scoped when serialized, i.e. it will not be in the format of
# "outer_layer/inner_layer/.../name:0". Instead, it will be "name:0". For further details, see:
# https://github.com/huggingface/transformers/pull/18833#issuecomment-1233090214
self.bias = self.add_weight(name=name, shape=shape, initializer=initializer, trainable=trainable)
def call(self, x):
return x + self.bias
@add_start_docstrings(
"The {{cookiecutter.uppercase_modelname}} Model with a language modeling head. Can be used for summarization.",
{{cookiecutter.uppercase_modelname}}_START_DOCSTRING,
)
class TF{{cookiecutter.camelcase_modelname}}ForConditionalGeneration(TF{{cookiecutter.camelcase_modelname}}PreTrainedModel):
_keys_to_ignore_on_load_unexpected = [
r"model.encoder.embed_tokens.weight",
r"model.decoder.embed_tokens.weight",
]
def __init__(self, config, *inputs, **kwargs):
super().__init__(config, *inputs, **kwargs)
self.model = TF{{cookiecutter.camelcase_modelname}}MainLayer(config, name="model")
self.use_cache = config.use_cache
# final_bias_logits is registered as a buffer in pytorch, so not trainable for the sake of consistency.
self.bias_layer = BiasLayer(
name="final_logits_bias", shape=[1, config.vocab_size], initializer="zeros", trainable=False
)
def get_decoder(self):
return self.model.decoder
def get_encoder(self):
return self.model.encoder
def get_bias(self):
return {"final_logits_bias": self.bias_layer.bias}
def set_bias(self, value):
# Replaces the existing layers containing bias for correct (de)serialization.
vocab_size = value["final_logits_bias"].shape[-1]
self.bias_layer = BiasLayer(
name="final_logits_bias", shape=[1, vocab_size], initializer="zeros", trainable=False
)
self.bias_layer.bias.assign(value["final_logits_bias"])
def get_output_embeddings(self):
return self.get_input_embeddings()
def set_output_embeddings(self, value):
self.set_input_embeddings(value)
@unpack_inputs
@add_start_docstrings_to_model_forward({{cookiecutter.uppercase_modelname}}_INPUTS_DOCSTRING)
@replace_return_docstrings(output_type=TFSeq2SeqLMOutput, config_class=_CONFIG_FOR_DOC)
def call(
self,
input_ids=None,
attention_mask=None,
decoder_input_ids=None,
decoder_attention_mask=None,
head_mask=None,
decoder_head_mask=None,
cross_attn_head_mask=None,
encoder_outputs: Optional[TFBaseModelOutput] = None,
past_key_values=None,
inputs_embeds=None,
decoder_inputs_embeds=None,
use_cache=None,
output_attentions=None,
output_hidden_states=None,
return_dict=None,
labels=None,
training=False,
):
"""
Returns:
Examples:
```python
>>> from transformers import {{cookiecutter.camelcase_modelname}}Tokenizer, TF{{cookiecutter.camelcase_modelname}}ForConditionalGeneration
>>> import tensorflow as tf
>>> mname = '{{cookiecutter.checkpoint_identifier}}'
>>> tokenizer = {{cookiecutter.camelcase_modelname}}Tokenizer.from_pretrained(mname)
>>> TXT = "My friends are <mask> but they eat too many carbs."
>>> model = TF{{cookiecutter.camelcase_modelname}}ForConditionalGeneration.from_pretrained(mname)
>>> batch = tokenizer([TXT], return_tensors='tf')
>>> logits = model(inputs=batch.input_ids).logits
>>> probs = tf.nn.softmax(logits[0])
>>> # probs[5] is associated with the mask token
```"""
if labels is not None:
use_cache = False
if decoder_input_ids is None and decoder_inputs_embeds is None:
decoder_input_ids = shift_tokens_right(
labels, self.config.pad_token_id, self.config.decoder_start_token_id
)
outputs = self.model(
input_ids,
attention_mask=attention_mask,
decoder_input_ids=decoder_input_ids,
encoder_outputs=encoder_outputs,
decoder_attention_mask=decoder_attention_mask,
head_mask=head_mask,
decoder_head_mask=decoder_head_mask,
cross_attn_head_mask=cross_attn_head_mask,
past_key_values=past_key_values,
inputs_embeds=inputs_embeds,
decoder_inputs_embeds=decoder_inputs_embeds,
use_cache=use_cache,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
training=training
)
lm_logits = tf.matmul(outputs[0], self.model.shared.weights, transpose_b=True)
lm_logits = self.bias_layer(lm_logits)
masked_lm_loss = None if labels is None else self.hf_compute_loss(labels, lm_logits)
if not return_dict:
output = (lm_logits,) + outputs[1:]
return ((masked_lm_loss,) + output) if masked_lm_loss is not None else output
return TFSeq2SeqLMOutput(
loss=masked_lm_loss,
logits=lm_logits,
past_key_values=outputs.past_key_values, # index 1 of d outputs
decoder_hidden_states=outputs.decoder_hidden_states, # index 2 of d outputs
decoder_attentions=outputs.decoder_attentions, # index 3 of d outputs
cross_attentions=outputs.cross_attentions, # index 4 of d outputs
encoder_last_hidden_state=outputs.encoder_last_hidden_state, # index 0 of encoder outputs
encoder_hidden_states=outputs.encoder_hidden_states, # 1 of e out
encoder_attentions=outputs.encoder_attentions, # 2 of e out
)
def prepare_inputs_for_generation(
self,
decoder_input_ids,
past_key_values=None,
attention_mask=None,
head_mask=None,
decoder_head_mask=None,
cross_attn_head_mask=None,
use_cache=None,
encoder_outputs=None,
**kwargs
):
# cut decoder_input_ids if past is used
if past_key_values is not None:
decoder_input_ids = decoder_input_ids[:, -1:]
return {
"input_ids": None, # needs to be passed to make Keras.layer.__call__ happy
"encoder_outputs": encoder_outputs,
"past_key_values": past_key_values,
"decoder_input_ids": decoder_input_ids,
"attention_mask": attention_mask,
"head_mask": head_mask,
"decoder_head_mask": decoder_head_mask,
"cross_attn_head_mask": cross_attn_head_mask,
"use_cache": use_cache, # change this to avoid caching (presumably for debugging)
}
def hf_compute_loss(self, labels, logits):
"""CrossEntropyLoss that ignores pad tokens"""
loss_fn = tf.keras.losses.SparseCategoricalCrossentropy(
from_logits=True,
reduction=tf.keras.losses.Reduction.NONE,
)
melted_labels = tf.reshape(labels, (-1,))
active_loss = tf.not_equal(melted_labels, self.config.pad_token_id)
reduced_logits = tf.boolean_mask(tf.reshape(logits, (-1, shape_list(logits)[2])), active_loss)
labels = tf.boolean_mask(melted_labels, active_loss)
return loss_fn(labels, reduced_logits)
{% endif -%}
| 0 |
hf_public_repos/transformers/templates/adding_a_new_model | hf_public_repos/transformers/templates/adding_a_new_model/open_model_proposals/ADD_BIG_BIRD.md | How to add BigBird to 🤗 Transformers?
=====================================
Mentor: [Patrick](https://github.com/patrickvonplaten)
Begin: 12.02.2020
Estimated End: 19.03.2020
Contributor: [Vasudev](https://github.com/vasudevgupta7)
Adding a new model is often difficult and requires an in-depth knowledge
of the 🤗 Transformers library and ideally also of the model's original
repository. At Hugging Face, we are trying to empower the community more
and more to add models independently.
The following sections explain in detail how to add BigBird
to Transformers. You will work closely with Patrick to
integrate BigBird into Transformers. By doing so, you will both gain a
theoretical and deep practical understanding of BigBird.
But more importantly, you will have made a major
open-source contribution to Transformers. Along the way, you will:
- get insights into open-source best practices
- understand the design principles of one of the most popular NLP
libraries
- learn how to do efficiently test large NLP models
- learn how to integrate Python utilities like `black`, `ruff`,
`make fix-copies` into a library to always ensure clean and readable
code
To start, let's try to get a general overview of the Transformers
library.
General overview of 🤗 Transformers
----------------------------------
First, you should get a general overview of 🤗 Transformers. Transformers
is a very opinionated library, so there is a chance that
you don't agree with some of the library's philosophies or design
choices. From our experience, however, we found that the fundamental
design choices and philosophies of the library are crucial to
efficiently scale Transformers while keeping maintenance costs at a
reasonable level.
A good first starting point to better understand the library is to read
the [documentation of our philosophy](https://huggingface.co/transformers/philosophy.html).
As a result of our way of working, there are some choices that we try to apply to all models:
- Composition is generally favored over abstraction
- Duplicating code is not always bad if it strongly improves the
readability or accessibility of a model
- Model files are as self-contained as possible so that when you read
the code of a specific model, you ideally only have to look into the
respective `modeling_....py` file.
In our opinion, the library's code is not just a means to provide a
product, *e.g.*, the ability to use BERT for inference, but also as the
very product that we want to improve. Hence, when adding a model, the
user is not only the person that will use your model, but also everybody
that will read, try to understand, and possibly tweak your code.
With this in mind, let's go a bit deeper into the general library
design.
### Overview of models
To successfully add a model, it is important to understand the
interaction between your model and its config,
`PreTrainedModel`, and `PretrainedConfig`. For
exemplary purposes, we will call the PyTorch model to be added to 🤗 Transformers
`BrandNewBert`.
Let's take a look:

As you can see, we do make use of inheritance in 🤗 Transformers, but we
keep the level of abstraction to an absolute minimum. There are never
more than two levels of abstraction for any model in the library.
`BrandNewBertModel` inherits from
`BrandNewBertPreTrainedModel` which in
turn inherits from `PreTrainedModel` and that's it.
As a general rule, we want to make sure
that a new model only depends on `PreTrainedModel`. The
important functionalities that are automatically provided to every new
model are
`PreTrainedModel.from_pretrained` and `PreTrainedModel.save_pretrained`, which are
used for serialization and deserialization. All
of the other important functionalities, such as
`BrandNewBertModel.forward` should be
completely defined in the new `modeling_brand_new_bert.py` module. Next,
we want to make sure that a model with a specific head layer, such as
`BrandNewBertForMaskedLM` does not inherit
from `BrandNewBertModel`, but rather uses
`BrandNewBertModel` as a component that
can be called in its forward pass to keep the level of abstraction low.
Every new model requires a configuration class, called
`BrandNewBertConfig`. This configuration
is always stored as an attribute in
`PreTrainedModel`, and
thus can be accessed via the `config` attribute for all classes
inheriting from `BrandNewBertPreTrainedModel`
```python
# assuming that `brand_new_bert` belongs to the organization `brandy`
model = BrandNewBertModel.from_pretrained("brandy/brand_new_bert")
model.config # model has access to its config
```
Similar to the model, the configuration inherits basic serialization and
deserialization functionalities from
`PretrainedConfig`. Note
that the configuration and the model are always serialized into two
different formats - the model to a `pytorch_model.bin` file
and the configuration to a `config.json` file. Calling
`PreTrainedModel.save_pretrained` will automatically call
`PretrainedConfig.save_pretrained`, so that both model and configuration are saved.
### Overview of tokenizers
Not quite ready yet :-( This section will be added soon!
Step-by-step recipe to add a model to 🤗 Transformers
----------------------------------------------------
Everyone has different preferences of how to port a model so it can be
very helpful for you to take a look at summaries of how other
contributors ported models to Hugging Face. Here is a list of community
blog posts on how to port a model:
1. [Porting GPT2
Model](https://medium.com/huggingface/from-tensorflow-to-pytorch-265f40ef2a28)
by [Thomas](https://huggingface.co/thomwolf)
2. [Porting WMT19 MT Model](https://huggingface.co/blog/porting-fsmt)
by [Stas](https://huggingface.co/stas)
From experience, we can tell you that the most important things to keep
in mind when adding a model are:
- Don't reinvent the wheel! Most parts of the code you will add for
the new 🤗 Transformers model already exist somewhere in 🤗
Transformers. Take some time to find similar, already existing
models and tokenizers you can copy from.
[grep](https://www.gnu.org/software/grep/) and
[rg](https://github.com/BurntSushi/ripgrep) are your friends. Note
that it might very well happen that your model's tokenizer is based
on one model implementation, and your model's modeling code on
another one. *E.g.*, FSMT's modeling code is based on BART, while
FSMT's tokenizer code is based on XLM.
- It's more of an engineering challenge than a scientific challenge.
You should spend more time on creating an efficient debugging
environment than trying to understand all theoretical aspects of the
model in the paper.
- Ask for help when you're stuck! Models are the core component of 🤗
Transformers so we, at Hugging Face, are more than happy to help
you at every step to add your model. Don't hesitate to ask if you
notice you are not making progress.
In the following, we try to give you a general recipe that we found most
useful when porting a model to 🤗 Transformers.
The following list is a summary of everything that has to be done to add
a model and can be used by you as a To-Do List:
1. [ ] (Optional) Understood theoretical aspects
2. [ ] Prepared transformers dev environment
3. [ ] Set up debugging environment of the original repository
4. [ ] Created script that successfully runs forward pass using
original repository and checkpoint
5. [ ] Successfully opened a PR and added the model skeleton to Transformers
6. [ ] Successfully converted original checkpoint to Transformers
checkpoint
7. [ ] Successfully ran forward pass in Transformers that gives
identical output to original checkpoint
8. [ ] Finished model tests in Transformers
9. [ ] Successfully added Tokenizer in Transformers
10. [ ] Run end-to-end integration tests
11. [ ] Finished docs
12. [ ] Uploaded model weights to the hub
13. [ ] Submitted the pull request for review
14. [ ] (Optional) Added a demo notebook
To begin with, we usually recommend to start by getting a good
theoretical understanding of `BigBird`. However, if you prefer to
understand the theoretical aspects of the model *on-the-job*, then it is
totally fine to directly dive into the `BigBird`'s code-base. This
option might suit you better, if your engineering skills are better than
your theoretical skill, if you have trouble understanding
`BigBird`'s paper, or if you just enjoy programming much more than
reading scientific papers.
### 1. (Optional) Theoretical aspects of BigBird
You should take some time to read *BigBird's* paper, if such
descriptive work exists. There might be large sections of the paper that
are difficult to understand. If this is the case, this is fine - don't
worry! The goal is not to get a deep theoretical understanding of the
paper, but to extract the necessary information required to effectively
re-implement the model in 🤗 Transformers. That being said, you don't
have to spend too much time on the theoretical aspects, but rather focus
on the practical ones, namely:
- What type of model is *BigBird*? BERT-like encoder-only
model? GPT2-like decoder-only model? BART-like encoder-decoder
model? Look at the `model_summary` if
you're not familiar with the differences between those.
- What are the applications of *BigBird*? Text
classification? Text generation? Seq2Seq tasks, *e.g.,*
summarization?
- What is the novel feature of the model making it different from
BERT/GPT-2/BART?
- Which of the already existing [🤗 Transformers
models](https://huggingface.co/transformers/#contents) is most
similar to *BigBird*?
- What type of tokenizer is used? A sentencepiece tokenizer? Word
piece tokenizer? Is it the same tokenizer as used for BERT or BART?
After you feel like you have gotten a good overview of the architecture
of the model, you might want to write to Patrick with any
questions you might have. This might include questions regarding the
model's architecture, its attention layer, etc. We will be more than
happy to help you.
#### Additional resources
Before diving into the code, here are some additional resources that might be worth taking a look at:
- [Yannic Kilcher's paper summary](https://www.youtube.com/watch?v=WVPE62Gk3EM&ab_channel=YannicKilcher)
- [Yannic Kilcher's summary of Longformer](https://www.youtube.com/watch?v=_8KNb5iqblE&ab_channel=YannicKilcher) - Longformer and BigBird are **very** similar models. Since Longformer has already been ported to 🤗 Transformers, it is useful to understand the differences between the two models
- [Blog post](https://medium.com/dsc-msit/is-google-bigbird-gonna-be-the-new-leader-in-nlp-domain-8c95cecc30f8) - A relatively superficial blog post about BigBird. Might be a good starting point to understand BigBird
#### Make sure you've understood the fundamental aspects of BigBird
Alright, now you should be ready to take a closer look into the actual code of BigBird.
You should have understood the following aspects of BigBird by now:
- BigBird provides a new attention layer for long-range sequence modelling that can be used
as a drop-in replacement for already existing architectures. This means that every transformer-based model architecture can replace its [Self-attention layer](https://towardsdatascience.com/illustrated-self-attention-2d627e33b20a) with BigBird's self-attention layer.
- BigBird's self-attention layer is composed of three mechanisms: block sparse (local) self-attention, global self-attention, random self-attention
- BigBird's block sparse (local) self-attention is different from Longformer's local self-attention. How so? Why does that matter? => Can be deployed on TPU much easier this way
- BigBird can be implemented for both an encoder-only model **and**
for an encoder-decoder model, which means that we can reuse lots of [code from RoBERTa](https://github.com/huggingface/transformers/blob/main/src/transformers/models/roberta/modeling_roberta.py) and [from PEGASUS](https://github.com/huggingface/transformers/blob/main/src/transformers/models/pegasus/modeling_pegasus.py) at a later stage.
If any of the mentioned aspects above are **not** clear to you, now is a great time to talk to Patrick.
### 2. Next prepare your environment
1. Fork the [repository](https://github.com/huggingface/transformers)
by clicking on the 'Fork' button on the repository's page. This
creates a copy of the code under your GitHub user account.
2. Clone your `transformers` fork to your local disk, and add the base
repository as a remote:
```bash
git clone https://github.com/[your Github handle]/transformers.git
cd transformers
git remote add upstream https://github.com/huggingface/transformers.git
```
3. Set up a development environment, for instance by running the
following command:
```bash
python -m venv .env
source .env/bin/activate
pip install -e ".[dev]"
```
and return to the parent directory
```bash
cd ..
```
4. We recommend adding the PyTorch version of *BigBird* to
Transformers. To install PyTorch, please follow the instructions [here](https://pytorch.org/get-started/locally/).
**Note:** You don't need to have CUDA installed. Making the new model
work on CPU is sufficient.
5. To port *BigBird*, you will also need access to its
original repository:
```bash
git clone https://github.com/google-research/bigbird.git
cd big_bird
pip install -e .
```
Now you have set up a development environment to port *BigBird*
to 🤗 Transformers.
### Run a pretrained checkpoint using the original repository
**3. Set up debugging environment**
At first, you will work on the original *BigBird* repository.
Often, the original implementation is very "researchy". Meaning that
documentation might be lacking and the code can be difficult to
understand. But this should be exactly your motivation to reimplement
*BigBird*. At Hugging Face, one of our main goals is to *make
people stand on the shoulders of giants* which translates here very well
into taking a working model and rewriting it to make it as **accessible,
user-friendly, and beautiful** as possible. This is the number-one
motivation to re-implement models into 🤗 Transformers - trying to make
complex new NLP technology accessible to **everybody**.
You should start thereby by diving into the [original repository](https://github.com/google-research/bigbird).
Successfully running the official pretrained model in the original
repository is often **the most difficult** step. From our experience, it
is very important to spend some time getting familiar with the original
code-base. You need to figure out the following:
- Where to find the pretrained weights?
- How to load the pretrained weights into the corresponding model?
- How to run the tokenizer independently from the model?
- Trace one forward pass so that you know which classes and functions
are required for a simple forward pass. Usually, you only have to
reimplement those functions.
- Be able to locate the important components of the model: Where is
the model's class? Are there model sub-classes, *e.g.*,
EncoderModel, DecoderModel? Where is the self-attention layer? Are
there multiple different attention layers, *e.g.*, *self-attention*,
*cross-attention*...?
- How can you debug the model in the original environment of the repo?
Do you have to add `print` statements, can you work with
an interactive debugger like [ipdb](https://pypi.org/project/ipdb/), or should you use
an efficient IDE to debug the model, like PyCharm?
It is very important that before you start the porting process, that you
can **efficiently** debug code in the original repository! Also,
remember that you are working with an open-source library, so do not
hesitate to open an issue, or even a pull request in the original
repository. The maintainers of this repository are most likely very
happy about someone looking into their code!
At this point, it is really up to you which debugging environment and
strategy you prefer to use to debug the original model. We strongly
advise against setting up a costly GPU environment, but simply work on a
CPU both when starting to dive into the original repository and also
when starting to write the 🤗 Transformers implementation of the model.
Only at the very end, when the model has already been successfully
ported to 🤗 Transformers, one should verify that the model also works as
expected on GPU.
In general, there are two possible debugging environments for running
the original model
- [Jupyter notebooks](https://jupyter.org/) / [google colab](https://colab.research.google.com/notebooks/intro.ipynb)
- Local python scripts.
Jupyter notebooks have the advantage that they allow for cell-by-cell
execution which can be helpful to better split logical components from
one another and to have faster debugging cycles as intermediate results
can be stored. Also, notebooks are often easier to share with other
contributors, which might be very helpful if you want to ask the Hugging
Face team for help. If you are familiar with Jupyter notebooks, we
strongly recommend you to work with them.
The obvious disadvantage of Jupyter notebooks is that if you are not
used to working with them you will have to spend some time adjusting to
the new programming environment and that you might not be able to use
your known debugging tools anymore, like `ipdb`.
**4. Successfully run forward pass**
For each code-base, a good first step is always to load a **small**
pretrained checkpoint and to be able to reproduce a single forward pass
using a dummy integer vector of input IDs as an input. Such a script
could look something like this:
```python
from bigbird.core import modeling
model = modeling.BertModel(bert_config)
from bigbird.core import utils
params = utils.BigBirdConfig(vocab_size=32000, hidden_size=512,
num_hidden_layers=8, num_attention_heads=6, intermediate_size=1024)
ckpt_path = 'gs://bigbird-transformer/pretrain/bigbr_base/model.ckpt-0'
ckpt_reader = tf.compat.v1.train.NewCheckpointReader(ckpt_path)
model.set_weights([ckpt_reader.get_tensor(v.name[:-2]) for v in tqdm(model.trainable_weights, position=0)])
input_ids = tf.constant([[31, 51, 99], [15, 5, 0]])
_, pooled_output = model(input_ids=input_ids, token_type_ids=token_type_ids)
...
```
Next, regarding the debugging strategy, there are generally a few from
which to choose from:
- Decompose the original model into many small testable components and
run a forward pass on each of those for verification
- Decompose the original model only into the original *tokenizer* and
the original *model*, run a forward pass on those, and use
intermediate print statements or breakpoints for verification
Again, it is up to you which strategy to choose. Often, one or the other
is advantageous depending on the original code base.
If the original code-base allows you to decompose the model into smaller
sub-components, *e.g.*, if the original code-base can easily be run in
eager mode, it is usually worth the effort to do so. There are some
important advantages to taking the more difficult road in the beginning:
- at a later stage when comparing the original model to the Hugging
Face implementation, you can verify automatically for each component
individually that the corresponding component of the 🤗 Transformers
implementation matches instead of relying on visual comparison via
print statements
- it can give you some rope to decompose the big problem of porting a
model into smaller problems of just porting individual components
and thus structure your work better
- separating the model into logical meaningful components will help
you to get a better overview of the model's design and thus to
better understand the model
- at a later stage those component-by-component tests help you to
ensure that no regression occurs as you continue changing your code
[Lysandre's](https://gist.github.com/LysandreJik/db4c948f6b4483960de5cbac598ad4ed)
integration checks for ELECTRA gives a nice example of how this can be
done.
However, if the original code-base is very complex or only allows
intermediate components to be run in a compiled mode, it might be too
time-consuming or even impossible to separate the model into smaller
testable sub-components. A good example is [T5's
MeshTensorFlow](https://github.com/tensorflow/mesh/tree/master/mesh_tensorflow)
library which is very complex and does not offer a simple way to
decompose the model into its sub-components. For such libraries, one
often relies on verifying print statements.
No matter which strategy you choose, the recommended procedure is often
the same in that you should start to debug the starting layers first and
the ending layers last.
It is recommended that you retrieve the output, either by print
statements or sub-component functions, of the following layers in the
following order:
1. Retrieve the input IDs passed to the model
2. Retrieve the word embeddings
3. Retrieve the input of the first Transformer layer
4. Retrieve the output of the first Transformer layer
5. Retrieve the output of the following n - 1 Transformer layers
6. Retrieve the output of the whole BigBird Model
Input IDs should thereby consists of an array of integers, *e.g.*,
`input_ids = [0, 4, 4, 3, 2, 4, 1, 7, 19]`
The outputs of the following layers often consist of multi-dimensional
float arrays and can look like this:
```bash
[[
[-0.1465, -0.6501, 0.1993, ..., 0.1451, 0.3430, 0.6024],
[-0.4417, -0.5920, 0.3450, ..., -0.3062, 0.6182, 0.7132],
[-0.5009, -0.7122, 0.4548, ..., -0.3662, 0.6091, 0.7648],
...,
[-0.5613, -0.6332, 0.4324, ..., -0.3792, 0.7372, 0.9288],
[-0.5416, -0.6345, 0.4180, ..., -0.3564, 0.6992, 0.9191],
[-0.5334, -0.6403, 0.4271, ..., -0.3339, 0.6533, 0.8694]]],
```
We expect that every model added to 🤗 Transformers passes a couple of
integration tests, meaning that the original model and the reimplemented
version in 🤗 Transformers have to give the exact same output up to a
precision of 0.001! Since it is normal that the exact same model written
in different libraries can give a slightly different output depending on
the library framework, we accept an error tolerance of 1e-3 (0.001). It
is not enough if the model gives nearly the same output, they have to be
the almost identical. Therefore, you will certainly compare the
intermediate outputs of the 🤗 Transformers version multiple times
against the intermediate outputs of the original implementation of
*BigBird* in which case an **efficient** debugging environment
of the original repository is absolutely important. Here is some advice
to make your debugging environment as efficient as possible.
- Find the best way of debugging intermediate results. Is the original
repository written in PyTorch? Then you should probably take the
time to write a longer script that decomposes the original model
into smaller sub-components to retrieve intermediate values. Is the
original repository written in Tensorflow 1? Then you might have to
rely on TensorFlow print operations like
[tf.print](https://www.tensorflow.org/api_docs/python/tf/print) to
output intermediate values. Is the original repository written in
Jax? Then make sure that the model is **not jitted** when running
the forward pass, *e.g.*, check-out [this
link](https://github.com/google/jax/issues/196).
- Use the smallest pretrained checkpoint you can find. The smaller the
checkpoint, the faster your debug cycle becomes. It is not efficient
if your pretrained model is so big that your forward pass takes more
than 10 seconds. In case only very large checkpoints are available,
it might make more sense to create a dummy model in the new
environment with randomly initialized weights and save those weights
for comparison with the 🤗 Transformers version of your model
- Make sure you are using the easiest way of calling a forward pass in
the original repository. Ideally, you want to find the function in
the original repository that **only** calls a single forward pass,
*i.e.* that is often called `predict`, `evaluate`, `forward` or
`__call__`. You don't want to debug a function that calls `forward`
multiple times, *e.g.*, to generate text, like
`autoregressive_sample`, `generate`.
- Try to separate the tokenization from the model's
forward pass. If the original repository shows
examples where you have to input a string, then try to find out
where in the forward call the string input is changed to input ids
and start from this point. This might mean that you have to possibly
write a small script yourself or change the original code so that
you can directly input the ids instead of an input string.
- Make sure that the model in your debugging setup is **not** in
training mode, which often causes the model to yield random outputs
due to multiple dropout layers in the model. Make sure that the
forward pass in your debugging environment is **deterministic** so
that the dropout layers are not used. Or use
`transformers.utils.set_seed` if the old and new
implementations are in the same framework.
#### (Important) More details on how to create a debugging environment for BigBird
- BigBird has multiple pretrained checkpoints that should eventually all be ported to
🤗 Transformers. The pretrained checkpoints can be found [here](https://console.cloud.google.com/storage/browser/bigbird-transformer/pretrain;tab=objects?prefix=&forceOnObjectsSortingFiltering=false).
Those checkpoints include both pretrained weights for encoder-only (BERT/RoBERTa) under the folder `bigbr_base` and encoder-decoder (PEGASUS) under the folder `bigbp_large`.
You should start by porting the `bigbr_base` model. The encoder-decoder model
can be ported afterward.
for an encoder-decoder architecture as well as an encoder-only architecture.
- BigBird was written in tf.compat meaning that a mixture of a TensorFlow 1 and
TensorFlow 2 API was used.
- The most important part of the BigBird code-base is [bigbird.bigbird.core](https://github.com/google-research/bigbird/tree/master/bigbird/core) which includes all logic necessary
to implement BigBird.
- The first goal should be to successfully run a forward pass using the RoBERTa checkpoint `bigbr_base/model.ckpt-0.data-00000-of-00001` and `bigbr_base/model.ckpt-0.index`.
### Port BigBird to 🤗 Transformers
Next, you can finally start adding new code to 🤗 Transformers. Go into
the clone of your 🤗 Transformers' fork:
cd transformers
In the special case that you are adding a model whose architecture
exactly matches the model architecture of an existing model you only
have to add a conversion script as described in [this
section](#write-a-conversion-script). In this case, you can just re-use
the whole model architecture of the already existing model.
Otherwise, let's start generating a new model with the amazing
Cookiecutter!
**Use the Cookiecutter to automatically generate the model's code**
To begin with head over to the [🤗 Transformers
templates](https://github.com/huggingface/transformers/tree/main/templates/adding_a_new_model)
to make use of our `cookiecutter` implementation to automatically
generate all the relevant files for your model. Again, we recommend only
adding the PyTorch version of the model at first. Make sure you follow
the instructions of the `README.md` on the [🤗 Transformers
templates](https://github.com/huggingface/transformers/tree/main/templates/adding_a_new_model)
carefully.
Since you will first implement the Encoder-only/RoBERTa-like version of BigBird you should
select the `is_encoder_decoder_model = False` option in the cookiecutter. Also, it is recommended
that you implement the model only in PyTorch in the beginning and select "Standalone" as the
tokenizer type for now.
**Open a Pull Request on the main huggingface/transformers repo**
Before starting to adapt the automatically generated code, now is the
time to open a "Work in progress (WIP)" pull request, *e.g.*, "\[WIP\]
Add *BigBird*", in 🤗 Transformers so that you and the Hugging
Face team can work side-by-side on integrating the model into 🤗
Transformers.
You should do the following:
1. Create a branch with a descriptive name from your main branch
```
git checkout -b add_big_bird
```
2. Commit the automatically generated code:
```
git add .
git commit
```
3. Fetch and rebase to current main
```
git fetch upstream
git rebase upstream/main
```
4. Push the changes to your account using:
```
git push -u origin a-descriptive-name-for-my-changes
```
5. Once you are satisfied, go to the webpage of your fork on GitHub.
Click on "Pull request". Make sure to add the GitHub handle of Patrick
as one reviewer, so that the Hugging Face team gets notified for future changes.
6. Change the PR into a draft by clicking on "Convert to draft" on the
right of the GitHub pull request web page.
In the following, whenever you have done some progress, don't forget to
commit your work and push it to your account so that it shows in the
pull request. Additionally, you should make sure to update your work
with the current main from time to time by doing:
git fetch upstream
git merge upstream/main
In general, all questions you might have regarding the model or your
implementation should be asked in your PR and discussed/solved in the
PR. This way, Patrick will always be notified when you are
committing new code or if you have a question. It is often very helpful
to point Patrick to your added code so that the Hugging
Face team can efficiently understand your problem or question.
To do so, you can go to the "Files changed" tab where you see all of
your changes, go to a line regarding which you want to ask a question,
and click on the "+" symbol to add a comment. Whenever a question or
problem has been solved, you can click on the "Resolve" button of the
created comment.
In the same way, Patrick will open comments when reviewing
your code. We recommend asking most questions on GitHub on your PR. For
some very general questions that are not very useful for the public,
feel free to ping Patrick by Slack or email.
**5. Adapt the generated models code for BigBird**
At first, we will focus only on the model itself and not care about the
tokenizer. All the relevant code should be found in the generated files
`src/transformers/models/big_bird/modeling_big_bird.py` and
`src/transformers/models/big_bird/configuration_big_bird.py`.
Now you can finally start coding :). The generated code in
`src/transformers/models/big_bird/modeling_big_bird.py` will
either have the same architecture as BERT if it's an encoder-only model
or BART if it's an encoder-decoder model. At this point, you should
remind yourself what you've learned in the beginning about the
theoretical aspects of the model: *How is the model different from BERT
or BART?*\". Implement those changes which often means to change the
*self-attention* layer, the order of the normalization layer, etc...
Again, it is often useful to look at the similar architecture of already
existing models in Transformers to get a better feeling of how your
model should be implemented.
**Note** that at this point, you don't have to be very sure that your
code is fully correct or clean. Rather, it is advised to add a first
*unclean*, copy-pasted version of the original code to
`src/transformers/models/big_bird/modeling_big_bird.py`
until you feel like all the necessary code is added. From our
experience, it is much more efficient to quickly add a first version of
the required code and improve/correct the code iteratively with the
conversion script as described in the next section. The only thing that
has to work at this point is that you can instantiate the 🤗 Transformers
implementation of *BigBird*, *i.e.* the following command
should work:
```python
from transformers import BigBirdModel, BigBirdConfig
model = BigBirdModel(BigBirdConfig())
```
The above command will create a model according to the default
parameters as defined in `BigBirdConfig()` with random weights,
thus making sure that the `init()` methods of all components works.
Note that for BigBird you have to change the attention layer. BigBird's attention
layer is quite complex as you can see [here](https://github.com/google-research/bigbird/blob/103a3345f94bf6364749b51189ed93024ca5ef26/bigbird/core/attention.py#L560). Don't
feel discouraged by this! In a first step you should simply make sure that
the layer `BigBirdAttention` has the correct weights as can be found in the
pretrained checkpoints. This means that you have to make sure that in the
`__init__(self, ...)` function of `BigBirdAttention`, all submodules include all
necessary `nn.Module` layers. Only at a later stage do we need to fully rewrite
the complex attention function.
**6. Write a conversion script**
Next, you should write a conversion script that lets you convert the
checkpoint you used to debug *BigBird* in the original
repository to a checkpoint compatible with your just created 🤗
Transformers implementation of *BigBird*. It is not advised to
write the conversion script from scratch, but rather to look through
already existing conversion scripts in 🤗 Transformers for one that has
been used to convert a similar model that was written in the same
framework as *BigBird*. Usually, it is enough to copy an
already existing conversion script and slightly adapt it for your use
case. Don't hesitate to ask Patrick to point you to a
similar already existing conversion script for your model.
- A good starting point to convert the original TF BigBird implementation to the PT Hugging Face implementation is probably BERT's conversion script
[here](https://github.com/huggingface/transformers/blob/7acfa95afb8194f8f9c1f4d2c6028224dbed35a2/src/transformers/models/bert/modeling_bert.py#L91)
You can copy paste the conversion function into `modeling_big_bird.py` and then adapt it
to your needs.
In the following, we'll quickly explain how PyTorch models store layer
weights and define layer names. In PyTorch, the name of a layer is
defined by the name of the class attribute you give the layer. Let's
define a dummy model in PyTorch, called `SimpleModel` as follows:
```python
from torch import nn
class SimpleModel(nn.Module):
def __init__(self):
super().__init__()
self.dense = nn.Linear(10, 10)
self.intermediate = nn.Linear(10, 10)
self.layer_norm = nn.LayerNorm(10)
```
Now we can create an instance of this model definition which will fill
all weights: `dense`, `intermediate`, `layer_norm` with random weights.
We can print the model to see its architecture
```python
model = SimpleModel()
print(model)
```
This will print out the following:
```bash
SimpleModel(
(dense): Linear(in_features=10, out_features=10, bias=True)
(intermediate): Linear(in_features=10, out_features=10, bias=True)
(layer_norm): LayerNorm((10,), eps=1e-05, elementwise_affine=True)
)
```
We can see that the layer names are defined by the name of the class
attribute in PyTorch. You can print out the weight values of a specific
layer:
```python
print(model.dense.weight.data)
```
to see that the weights were randomly initialized
```bash
tensor([[-0.0818, 0.2207, -0.0749, -0.0030, 0.0045, -0.1569, -0.1598, 0.0212,
-0.2077, 0.2157],
[ 0.1044, 0.0201, 0.0990, 0.2482, 0.3116, 0.2509, 0.2866, -0.2190,
0.2166, -0.0212],
[-0.2000, 0.1107, -0.1999, -0.3119, 0.1559, 0.0993, 0.1776, -0.1950,
-0.1023, -0.0447],
[-0.0888, -0.1092, 0.2281, 0.0336, 0.1817, -0.0115, 0.2096, 0.1415,
-0.1876, -0.2467],
[ 0.2208, -0.2352, -0.1426, -0.2636, -0.2889, -0.2061, -0.2849, -0.0465,
0.2577, 0.0402],
[ 0.1502, 0.2465, 0.2566, 0.0693, 0.2352, -0.0530, 0.1859, -0.0604,
0.2132, 0.1680],
[ 0.1733, -0.2407, -0.1721, 0.1484, 0.0358, -0.0633, -0.0721, -0.0090,
0.2707, -0.2509],
[-0.1173, 0.1561, 0.2945, 0.0595, -0.1996, 0.2988, -0.0802, 0.0407,
0.1829, -0.1568],
[-0.1164, -0.2228, -0.0403, 0.0428, 0.1339, 0.0047, 0.1967, 0.2923,
0.0333, -0.0536],
[-0.1492, -0.1616, 0.1057, 0.1950, -0.2807, -0.2710, -0.1586, 0.0739,
0.2220, 0.2358]]).
```
In the conversion script, you should fill those randomly initialized
weights with the exact weights of the corresponding layer in the
checkpoint. *E.g.*,
```python
# retrieve matching layer weights, e.g. by
# recursive algorithm
layer_name = "dense"
pretrained_weight = array_of_dense_layer
model_pointer = getattr(model, "dense")
model_pointer.weight.data = torch.from_numpy(pretrained_weight)
```
While doing so, you must verify that each randomly initialized weight of
your PyTorch model and its corresponding pretrained checkpoint weight
exactly match in both **shape and name**. To do so, it is **necessary**
to add assert statements for the shape and print out the names of the
checkpoints weights. *E.g.*, you should add statements like:
```python
assert (
model_pointer.weight.shape == pretrained_weight.shape
), f"Pointer shape of random weight {model_pointer.shape} and array shape of checkpoint weight {pretrained_weight.shape} mismatched"
```
Besides, you should also print out the names of both weights to make
sure they match, *e.g.*,
```python
logger.info(f"Initialize PyTorch weight {layer_name} from {pretrained_weight.name}")
```
If either the shape or the name doesn't match, you probably assigned
the wrong checkpoint weight to a randomly initialized layer of the 🤗
Transformers implementation.
An incorrect shape is most likely due to an incorrect setting of the
config parameters in `BigBirdConfig()` that do not exactly match
those that were used for the checkpoint you want to convert. However, it
could also be that PyTorch's implementation of a layer requires the
weight to be transposed beforehand.
Finally, you should also check that **all** required weights are
initialized and print out all checkpoint weights that were not used for
initialization to make sure the model is correctly converted. It is
completely normal, that the conversion trials fail with either a wrong
shape statement or wrong name assignment. This is most likely because
either you used incorrect parameters in `BigBirdConfig()`, have a
wrong architecture in the 🤗 Transformers implementation, you have a bug
in the `init()` functions of one of the components of the 🤗 Transformers
implementation or you need to transpose one of the checkpoint weights.
This step should be iterated with the previous step until all weights of
the checkpoint are correctly loaded in the Transformers model. Having
correctly loaded the checkpoint into the 🤗 Transformers implementation,
you can then save the model under a folder of your choice
`/path/to/converted/checkpoint/folder` that should then contain both a
`pytorch_model.bin` file and a `config.json` file:
```python
model.save_pretrained("/path/to/converted/checkpoint/folder")
```
**7. Implement the forward pass**
Having managed to correctly load the pretrained weights into the 🤗
Transformers implementation, you should now make sure that the forward
pass is correctly implemented. In [Get familiar with the original
repository](#run-a-pretrained-checkpoint-using-the-original-repository),
you have already created a script that runs a forward pass of the model
using the original repository. Now you should write an analogous script
using the 🤗 Transformers implementation instead of the original one. It
should look as follows:
[Here the model name might have to be adapted, *e.g.*, maybe BigBirdForConditionalGeneration instead of BigBirdModel]
```python
model = BigBirdModel.from_pretrained("/path/to/converted/checkpoint/folder")
input_ids = [0, 4, 4, 3, 2, 4, 1, 7, 19]
output = model(input_ids).last_hidden_states
```
It is very likely that the 🤗 Transformers implementation and the
original model implementation don't give the exact same output the very
first time or that the forward pass throws an error. Don't be
disappointed - it's expected! First, you should make sure that the
forward pass doesn't throw any errors. It often happens that the wrong
dimensions are used leading to a `"Dimensionality mismatch"`
error or that the wrong data type object is used, *e.g.*, `torch.long`
instead of `torch.float32`. Don't hesitate to ask Patrick
for help, if you don't manage to solve certain errors.
The final part to make sure the 🤗 Transformers implementation works
correctly is to ensure that the outputs are equivalent to a precision of
`1e-3`. First, you should ensure that the output shapes are identical,
*i.e.* `outputs.shape` should yield the same value for the script of the
🤗 Transformers implementation and the original implementation. Next, you
should make sure that the output values are identical as well. This one
of the most difficult parts of adding a new model. Common mistakes why
the outputs are not identical are:
- Some layers were not added, *i.e.* an activation layer
was not added, or the residual connection was forgotten
- The word embedding matrix was not tied
- The wrong positional embeddings are used because the original
implementation uses on offset
- Dropout is applied during the forward pass. To fix this make sure
`model.training is False` and that no dropout layer is
falsely activated during the forward pass, *i.e.* pass
`self.training` to [PyTorch's functional
dropout](https://pytorch.org/docs/stable/nn.functional.html?highlight=dropout#torch.nn.functional.dropout)
The best way to fix the problem is usually to look at the forward pass
of the original implementation and the 🤗 Transformers implementation
side-by-side and check if there are any differences. Ideally, you should
debug/print out intermediate outputs of both implementations of the
forward pass to find the exact position in the network where the 🤗
Transformers implementation shows a different output than the original
implementation. First, make sure that the hard-coded `input_ids` in both
scripts are identical. Next, verify that the outputs of the first
transformation of the `input_ids` (usually the word embeddings) are
identical. And then work your way up to the very last layer of the
network. At some point, you will notice a difference between the two
implementations, which should point you to the bug in the 🤗 Transformers
implementation. From our experience, a simple and efficient way is to
add many print statements in both the original implementation and 🤗
Transformers implementation, at the same positions in the network
respectively, and to successively remove print statements showing the
same values for intermediate presentions.
When you're confident that both implementations yield the same output,
verifying the outputs with
`torch.allclose(original_output, output, atol=1e-3)`, you're done with
the most difficult part! Congratulations - the work left to be done
should be a cakewalk 😊.
**8. Adding all necessary model tests**
At this point, you have successfully added a new model. However, it is
very much possible that the model does not yet fully comply with the
required design. To make sure, the implementation is fully compatible
with 🤗 Transformers, all common tests should pass. The Cookiecutter
should have automatically added a test file for your model, probably
under the same `tests/test_modeling_big_bird.py`. Run this test
file to verify that all common tests pass:
```python
pytest tests/test_modeling_big_bird.py
```
Having fixed all common tests, it is now crucial to ensure that all the
nice work you have done is well tested, so that
- a) The community can easily understand your work by looking at
specific tests of *BigBird*
- b) Future changes to your model will not break any important
feature of the model.
At first, integration tests should be added. Those integration tests
essentially do the same as the debugging scripts you used earlier to
implement the model to 🤗 Transformers. A template of those model tests
is already added by the Cookiecutter, called
`BigBirdModelIntegrationTests` and only has to be filled out by
you. To ensure that those tests are passing, run
```python
RUN_SLOW=1 pytest -sv tests/test_modeling_big_bird.py::BigBirdModelIntegrationTests
```
**Note**: In case you are using Windows, you should replace `RUN_SLOW=1` with
`SET RUN_SLOW=1`
Second, all features that are special to *BigBird* should be
tested additionally in a separate test under
`BigBirdModelTester`/`BigBirdModelTest`. This part is often
forgotten but is extremely useful in two ways:
- It helps to transfer the knowledge you have acquired during the
model addition to the community by showing how the special features
of *BigBird* should work.
- Future contributors can quickly test changes to the model by running
those special tests.
BigBird has quite a complex attention layer, so it is very important
to add more tests verifying the all parts of BigBird's self-attention layer
works as expected. This means that there should be at least 3 additional tests:
- 1. Verify that the sparse attention works correctly
- 2. Verify that the global attention works correctly
- 3. Verify that the random attention works correctly
**9. Implement the tokenizer**
Next, we should add the tokenizer of *BigBird*. Usually, the
tokenizer is equivalent or very similar to an already existing tokenizer
of 🤗 Transformers.
In the case of BigBird you should be able to just rely on an already existing tokenizer.
If not mistaken, BigBird uses the same tokenizer that was used for `BertGenerationTokenizer`,
which is based on `sentencepiece`. So you should be able to just set the config parameter
`tokenizer_class` to `BertGenerationTokenizer` without having to implement any new tokenizer.
It is very important to find/extract the original tokenizer file and to
manage to load this file into the 🤗 Transformers' implementation of the
tokenizer.
For BigBird, the tokenizer (sentencepiece) files can be found [here](https://github.com/google-research/bigbird/blob/master/bigbird/vocab/gpt2.model), which you should be able to load
as easily as:
```python
from transformers import BertGenerationTokenizer
tokenizer = BertGenerationTokenizer("/path/to/gpt2.model/file")
```
To ensure that the tokenizer works correctly, it is recommended to first
create a script in the original repository that inputs a string and
returns the `input_ids`. It could look similar to this (in pseudo-code):
```bash
input_str = "This is a long example input string containing special characters .$?-, numbers 2872 234 12 and words."
model = BigBirdModel.load_pretrained_checkpoint("/path/to/checkpoint/")
input_ids = model.tokenize(input_str)
```
You might have to take a deeper look again into the original repository
to find the correct tokenizer function or you might even have to do
changes to your clone of the original repository to only output the
`input_ids`. Having written a functional tokenization script that uses
the original repository, an analogous script for 🤗 Transformers should
be created. It should look similar to this:
```python
from transformers import BertGenerationTokenizer
input_str = "This is a long example input string containing special characters .$?-, numbers 2872 234 12 and words."
tokenizer = BertGenerationTokenizer.from_pretrained("/path/big/bird/folder")
input_ids = tokenizer(input_str).input_ids
```
When both `input_ids` yield the same values, as a final step a tokenizer
test file should also be added.
Since BigBird is most likely fully based on `BertGenerationTokenizer`,
you should only add a couple of "slow" integration tests. However, in this
case you do **not** need to add any `BigBirdTokenizationTest`.
**10. Run End-to-end integration tests**
Having added the tokenizer, you should also add a couple of end-to-end
integration tests using both the model and the tokenizer to
`tests/test_modeling_big_bird.py` in 🤗 Transformers. Such a test
should show on a meaningful text-to-text sample that the 🤗 Transformers
implementation works as expected. A meaningful text-to-text sample can
include, *e.g.*, a source-to-target-translation pair, an
article-to-summary pair, a question-to-answer pair, etc... If none of
the ported checkpoints has been fine-tuned on a downstream task it is
enough to simply rely on the model tests. In a final step to ensure that
the model is fully functional, it is advised that you also run all tests
on GPU. It can happen that you forgot to add some `.to(self.device)`
statements to internal tensors of the model, which in such a test would
show in an error. In case you have no access to a GPU, the Hugging Face
team can take care of running those tests for you.
**11. Add Docstring**
Now, all the necessary functionality for *BigBird* is added -
you're almost done! The only thing left to add is a nice docstring and
a doc page. The Cookiecutter should have added a template file called
`docs/source/model_doc/big_bird.rst` that you should fill out.
Users of your model will usually first look at this page before using
your model. Hence, the documentation must be understandable and concise.
It is very useful for the community to add some *Tips* to show how the
model should be used. Don't hesitate to ping Patrick
regarding the docstrings.
Next, make sure that the docstring added to
`src/transformers/models/big_bird/modeling_big_bird.py` is
correct and included all necessary inputs and outputs. It is always to
good to remind oneself that documentation should be treated at least as
carefully as the code in 🤗 Transformers since the documentation is
usually the first contact point of the community with the model.
**Code refactor**
Great, now you have added all the necessary code for *BigBird*.
At this point, you should correct some potential incorrect code style by
running:
```bash
make style
```
and verify that your coding style passes the quality check:
```bash
make quality
```
There are a couple of other very strict design tests in 🤗 Transformers
that might still be failing, which shows up in the tests of your pull
request. This is often because of some missing information in the
docstring or some incorrect naming. Patrick will surely
help you if you're stuck here.
Lastly, it is always a good idea to refactor one's code after having
ensured that the code works correctly. With all tests passing, now it's
a good time to go over the added code again and do some refactoring.
You have now finished the coding part, congratulation! 🎉 You are
Awesome! 😎
**12. Upload the models to the model hub**
In this final part, you should convert and upload all checkpoints to the
model hub and add a model card for each uploaded model checkpoint. You
should work alongside Patrick here to decide on a fitting
name for each checkpoint and to get the required access rights to be
able to upload the model under the author's organization of
*BigBird*.
It is worth spending some time to create fitting model cards for each
checkpoint. The model cards should highlight the specific
characteristics of this particular checkpoint, *e.g.*, On which dataset
was the checkpoint pretrained/fine-tuned on? On what down-stream task
should the model be used? And also include some code on how to correctly
use the model.
**13. (Optional) Add notebook**
It is very helpful to add a notebook that showcases in-detail how
*BigBird* can be used for inference and/or fine-tuned on a
downstream task. This is not mandatory to merge your PR, but very useful
for the community.
**14. Submit your finished PR**
You're done programming now and can move to the last step, which is
getting your PR merged into main. Usually, Patrick
should have helped you already at this point, but it is worth taking
some time to give your finished PR a nice description and eventually add
comments to your code, if you want to point out certain design choices
to your reviewer.
### Share your work!!
Now, it's time to get some credit from the community for your work!
Having completed a model addition is a major contribution to
Transformers and the whole NLP community. Your code and the ported
pre-trained models will certainly be used by hundreds and possibly even
thousands of developers and researchers. You should be proud of your
work and share your achievement with the community.
**You have made another model that is super easy to access for everyone
in the community! 🤯**
| 0 |
hf_public_repos/transformers/templates/adding_a_new_model | hf_public_repos/transformers/templates/adding_a_new_model/open_model_proposals/README.md | Currently the following model proposals are available:
- <s>[BigBird (Google)](./ADD_BIG_BIRD.md)</s>
| 0 |
hf_public_repos/transformers/templates | hf_public_repos/transformers/templates/adding_a_new_example_script/README.md | <!---
Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
# How to add a new example script in 🤗 Transformers
This folder provide a template for adding a new example script implementing a training or inference task with the
models in the 🤗 Transformers library. To use it, you will need to install cookiecutter:
```
pip install cookiecutter
```
or refer to the installation page of the [cookiecutter documentation](https://cookiecutter.readthedocs.io/).
You can then run the following command inside the `examples` folder of the transformers repo:
```
cookiecutter ../templates/adding_a_new_example_script/
```
and answer the questions asked, which will generate a new folder where you will find a pre-filled template for your
example following the best practices we recommend for them.
Adjust the way the data is preprocessed, the model is loaded or the Trainer is instantiated then when you're happy, add
a `README.md` in the folder (or complete the existing one if you added a script to an existing folder) telling a user
how to run your script.
Make a PR to the 🤗 Transformers repo. Don't forget to tweet about your new example with a carbon screenshot of how to
run it and tag @huggingface!
| 0 |
hf_public_repos/transformers/templates | hf_public_repos/transformers/templates/adding_a_new_example_script/cookiecutter.json | {
"example_name": "text classification",
"directory_name": "{{cookiecutter.example_name|lower|replace(' ', '-')}}",
"example_shortcut": "{{cookiecutter.directory_name}}",
"model_class": "AutoModel",
"authors": "The HuggingFace Team",
"can_train_from_scratch": ["True", "False"],
"with_trainer": ["True", "False"]
} | 0 |
hf_public_repos/transformers/templates/adding_a_new_example_script | hf_public_repos/transformers/templates/adding_a_new_example_script/{{cookiecutter.directory_name}}/run_{{cookiecutter.example_shortcut}}.py | #!/usr/bin/env python
# coding=utf-8
# Copyright 2022 {{cookiecutter.authors}} and The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""
Fine-tuning a 🤗 Transformers model on {{cookiecutter.example_name}}.
"""
# You can also adapt this script on your own {{cookiecutter.example_name}} task. Pointers for this are left as comments.
{%- if cookiecutter.with_trainer == "True" %}
import logging
import math
import os
import sys
from dataclasses import dataclass, field
from typing import Optional, List
import datasets
import torch
from datasets import load_dataset
import transformers
from transformers import (
CONFIG_MAPPING,
MODEL_MAPPING,
AutoConfig,
{{cookiecutter.model_class}},
AutoTokenizer,
DataCollatorWithPadding,
HfArgumentParser,
Trainer,
TrainingArguments,
default_data_collator,
set_seed,
)
from transformers.trainer_utils import get_last_checkpoint
from transformers.utils import send_example_telemetry
logger = logging.getLogger(__name__)
{%- if cookiecutter.can_train_from_scratch == "True" %}
# You should update this to your particular problem to have better documentation of `model_type`
MODEL_CONFIG_CLASSES = list(MODEL_MAPPING.keys())
MODEL_TYPES = tuple(conf.model_type for conf in MODEL_CONFIG_CLASSES)
@dataclass
class ModelArguments:
"""
Arguments pertaining to which model/config/tokenizer we are going to fine-tune, or train from scratch.
"""
model_name_or_path: Optional[str] = field(
default=None,
metadata={
"help": "The model checkpoint for weights initialization."
"Don't set if you want to train a model from scratch."
},
)
model_type: Optional[str] = field(
default=None,
metadata={"help": "If training from scratch, pass a model type from the list: " + ", ".join(MODEL_TYPES)},
)
config_name: Optional[str] = field(
default=None, metadata={"help": "Pretrained config name or path if not the same as model_name"}
)
tokenizer_name: Optional[str] = field(
default=None, metadata={"help": "Pretrained tokenizer name or path if not the same as model_name"}
)
cache_dir: Optional[str] = field(
default=None, metadata={"help": "Where do you want to store the pretrained models downloaded from huggingface.co"}
)
use_fast_tokenizer: bool = field(
default=True,
metadata={"help": "Whether to use one of the fast tokenizer (backed by the tokenizers library) or not."},
)
{%- elif cookiecutter.can_train_from_scratch == "False" %}
@dataclass
class ModelArguments:
"""
Arguments pertaining to which model/config/tokenizer we are going to fine-tune from.
"""
model_name_or_path: str = field(
metadata={"help": "Path to pretrained model or model identifier from huggingface.co/models"}
)
config_name: Optional[str] = field(
default=None, metadata={"help": "Pretrained config name or path if not the same as model_name"}
)
tokenizer_name: Optional[str] = field(
default=None, metadata={"help": "Pretrained tokenizer name or path if not the same as model_name"}
)
cache_dir: Optional[str] = field(
default=None, metadata={"help": "Where do you want to store the pretrained models downloaded from huggingface.co"}
)
use_fast_tokenizer: bool = field(
default=True,
metadata={"help": "Whether to use one of the fast tokenizer (backed by the tokenizers library) or not."},
)
model_revision: str = field(
default="main",
metadata={"help": "The specific model version to use (can be a branch name, tag name or commit id)."},
)
token: bool = field(
default=False,
metadata={
"help": "Will use the token generated when running `huggingface-cli login` (necessary to use this script "
"with private models)."
},
)
{% endif %}
@dataclass
class DataTrainingArguments:
"""
Arguments pertaining to what data we are going to input our model for training and eval.
"""
dataset_name: Optional[str] = field(
default=None, metadata={"help": "The name of the dataset to use (via the datasets library)."}
)
dataset_config_name: Optional[str] = field(
default=None, metadata={"help": "The configuration name of the dataset to use (via the datasets library)."}
)
train_file: Optional[str] = field(default=None, metadata={"help": "The input training data file (a text file)."})
validation_file: Optional[str] = field(
default=None,
metadata={"help": "An optional input evaluation data file to evaluate the perplexity on (a text file)."},
)
test_file: Optional[str] = field(
default=None,
metadata={"help": "An optional input test data file to predict the label on (a text file)."},
)
overwrite_cache: bool = field(
default=False, metadata={"help": "Overwrite the cached training and evaluation sets"}
)
preprocessing_num_workers: Optional[int] = field(
default=None,
metadata={"help": "The number of processes to use for the preprocessing."},
)
max_train_samples: Optional[int] = field(
default=None,
metadata={
"help": "For debugging purposes or quicker training, truncate the number of training examples to this "
"value if set."
},
)
max_eval_samples: Optional[int] = field(
default=None,
metadata={
"help": "For debugging purposes or quicker training, truncate the number of evaluation examples to this "
"value if set."
},
)
max_predict_samples: Optional[int] = field(
default=None,
metadata={
"help": "For debugging purposes or quicker training, truncate the number of prediction examples to this "
"value if set."
},
)
def __post_init__(self):
if (
self.dataset_name is None
and self.train_file is None
and self.validation_file is None
and self.test_file is None
):
raise ValueError("Need either a dataset name or a training/validation/test file.")
else:
if self.train_file is not None:
extension = self.train_file.split(".")[-1]
assert extension in ["csv", "json", "txt"], "`train_file` should be a csv, a json or a txt file."
if self.validation_file is not None:
extension = self.validation_file.split(".")[-1]
assert extension in ["csv", "json", "txt"], "`validation_file` should be a csv, a json or a txt file."
if self.test_file is not None:
extension = self.test_file.split(".")[-1]
assert extension in ["csv", "json", "txt"], "`test_file` should be a csv, a json or a txt file."
def main():
# See all possible arguments in src/transformers/training_args.py
# or by passing the --help flag to this script.
# We now keep distinct sets of args, for a cleaner separation of concerns.
parser = HfArgumentParser((ModelArguments, DataTrainingArguments, TrainingArguments))
if len(sys.argv) == 2 and sys.argv[1].endswith(".json"):
# If we pass only one argument to the script and it's the path to a json file,
# let's parse it to get our arguments.
model_args, data_args, training_args = parser.parse_json_file(json_file=os.path.abspath(sys.argv[1]))
else:
model_args, data_args, training_args = parser.parse_args_into_dataclasses()
# Sending telemetry. Tracking the example usage helps us better allocate resources to maintain them. The
# information sent is the one passed as arguments along with your Python/PyTorch versions.
send_example_telemetry("run_{{cookiecutter.example_shortcut}}", model_args, data_args)
# Detecting last checkpoint.
last_checkpoint = None
if os.path.isdir(training_args.output_dir) and training_args.do_train and not training_args.overwrite_output_dir:
last_checkpoint = get_last_checkpoint(training_args.output_dir)
if last_checkpoint is None and len(os.listdir(training_args.output_dir)) > 0:
raise ValueError(
f"Output directory ({training_args.output_dir}) already exists and is not empty. "
"Use --overwrite_output_dir to overcome."
)
elif last_checkpoint is not None:
logger.info(
f"Checkpoint detected, resuming training at {last_checkpoint}. To avoid this behavior, change "
"the `--output_dir` or add `--overwrite_output_dir` to train from scratch."
)
# Setup logging
logging.basicConfig(
format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
datefmt="%m/%d/%Y %H:%M:%S",
handlers=[logging.StreamHandler(sys.stdout)],
)
log_level = training_args.get_process_log_level()
logger.setLevel(log_level)
datasets.utils.logging.set_verbosity(log_level)
transformers.utils.logging.set_verbosity(log_level)
transformers.utils.logging.enable_default_handler()
transformers.utils.logging.enable_explicit_format()
# Log on each process the small summary:
logger.warning(
f"Process rank: {training_args.local_rank}, device: {training_args.device}, n_gpu: {training_args.n_gpu}"
+ f"distributed training: {bool(training_args.local_rank != -1)}, 16-bits training: {training_args.fp16}"
)
logger.info(f"Training/evaluation parameters {training_args}")
# Set seed before initializing model.
set_seed(training_args.seed)
# Get the datasets: you can either provide your own CSV/JSON/TXT training and evaluation files (see below)
# or just provide the name of one of the public datasets available on the hub at https://huggingface.co/datasets/
# (the dataset will be downloaded automatically from the datasets Hub).
#
# For CSV/JSON files, this script will use the column called 'text' or the first column if no column called
# 'text' is found. You can easily tweak this behavior (see below).
#
# In distributed training, the load_dataset function guarantee that only one local process can concurrently
# download the dataset.
if data_args.dataset_name is not None:
# Downloading and loading a dataset from the hub.
raw_datasets = load_dataset(data_args.dataset_name, data_args.dataset_config_name)
else:
data_files = {}
if data_args.train_file is not None:
data_files["train"] = data_args.train_file
extension = data_args.train_file.split(".")[-1]
if data_args.validation_file is not None:
data_files["validation"] = data_args.validation_file
extension = data_args.validation_file.split(".")[-1]
if data_args.test_file is not None:
data_files["test"] = data_args.test_file
extension = data_args.test_file.split(".")[-1]
if extension == "txt":
extension = "text"
raw_datasets = load_dataset(extension, data_files=data_files)
# See more about loading any type of standard or custom dataset (from files, python dict, pandas DataFrame, etc) at
# https://huggingface.co/docs/datasets/loading_datasets.html.
# Load pretrained model and tokenizer
#
# Distributed training:
# The .from_pretrained methods guarantee that only one local process can concurrently
# download model & vocab.
{%- if cookiecutter.can_train_from_scratch == "True" %}
config_kwargs = {
"cache_dir": model_args.cache_dir,
"revision": model_args.model_revision,
"token": True if model_args.token else None,
}
if model_args.config_name:
config = AutoConfig.from_pretrained(model_args.config_name, **config_kwargs)
elif model_args.model_name_or_path:
config = AutoConfig.from_pretrained(model_args.model_name_or_path, **config_kwargs)
else:
config = CONFIG_MAPPING[model_args.model_type]()
logger.warning("You are instantiating a new config instance from scratch.")
tokenizer_kwargs = {
"cache_dir": model_args.cache_dir,
"use_fast": model_args.use_fast_tokenizer,
"revision": model_args.model_revision,
"token": True if model_args.token else None,
}
if model_args.tokenizer_name:
tokenizer = AutoTokenizer.from_pretrained(model_args.tokenizer_name, **tokenizer_kwargs)
elif model_args.model_name_or_path:
tokenizer = AutoTokenizer.from_pretrained(model_args.model_name_or_path, **tokenizer_kwargs)
else:
raise ValueError(
"You are instantiating a new tokenizer from scratch. This is not supported by this script."
"You can do it from another script, save it, and load it from here, using --tokenizer_name."
)
if model_args.model_name_or_path:
model = {{cookiecutter.model_class}}.from_pretrained(
model_args.model_name_or_path,
from_tf=bool(".ckpt" in model_args.model_name_or_path),
config=config,
cache_dir=model_args.cache_dir,
revision=model_args.model_revision,
token=True if model_args.token else None,
)
else:
logger.info("Training new model from scratch")
model = {{cookiecutter.model_class}}.from_config(config)
model.resize_token_embeddings(len(tokenizer))
{%- elif cookiecutter.can_train_from_scratch == "False" %}
config = AutoConfig.from_pretrained(
model_args.config_name if model_args.config_name else model_args.model_name_or_path,
# num_labels=num_labels, Uncomment if you have a certain number of labels
finetuning_task=data_args.task_name,
cache_dir=model_args.cache_dir,
revision=model_args.model_revision,
token=True if model_args.token else None,
)
tokenizer = AutoTokenizer.from_pretrained(
model_args.tokenizer_name if model_args.tokenizer_name else model_args.model_name_or_path,
cache_dir=model_args.cache_dir,
use_fast=model_args.use_fast_tokenizer,
revision=model_args.model_revision,
token=True if model_args.token else None,
)
model = AutoModelForSequenceClassification.from_pretrained(
model_args.model_name_or_path,
from_tf=bool(".ckpt" in model_args.model_name_or_path),
config=config,
cache_dir=model_args.cache_dir,
revision=model_args.model_revision,
token=True if model_args.token else None,
)
{% endif %}
# Preprocessing the datasets.
# First we tokenize all the texts.
if training_args.do_train:
column_names = raw_datasets["train"].column_names
elif training_args.do_eval:
column_names = raw_datasets["validation"].column_names
elif training_args.do_predict:
column_names = raw_datasets["test"].column_names
text_column_name = "text" if "text" in column_names else column_names[0]
def tokenize_function(examples):
return tokenizer(examples[text_column_name], padding="max_length", truncation=True)
if training_args.do_train:
if "train" not in raw_datasets:
raise ValueError("--do_train requires a train dataset")
train_dataset = raw_datasets["train"]
if data_args.max_train_samples is not None:
# Select Sample from Dataset
train_dataset = train_dataset.select(range(data_args.max_train_samples))
# tokenize train dataset in batch
with training_args.main_process_first(desc="train dataset map tokenization"):
train_dataset = train_dataset.map(
tokenize_function,
batched=True,
num_proc=data_args.preprocessing_num_workers,
remove_columns=[text_column_name],
load_from_cache_file=not data_args.overwrite_cache,
)
if training_args.do_eval:
if "validation" not in raw_datasets:
raise ValueError("--do_eval requires a validation dataset")
eval_dataset = raw_datasets["validation"]
# Selecting samples from dataset
if data_args.max_eval_samples is not None:
eval_dataset = eval_dataset.select(range(data_args.max_eval_samples))
# tokenize validation dataset
with training_args.main_process_first(desc="validation dataset map tokenization"):
eval_dataset = eval_dataset.map(
tokenize_function,
batched=True,
num_proc=data_args.preprocessing_num_workers,
remove_columns=[text_column_name],
load_from_cache_file=not data_args.overwrite_cache,
)
if training_args.do_predict:
if "test" not in raw_datasets:
raise ValueError("--do_predict requires a test dataset")
predict_dataset = raw_datasets["test"]
# Selecting samples from dataset
if data_args.max_predict_samples is not None:
predict_dataset = predict_dataset.select(range(data_args.max_predict_samples))
# tokenize predict dataset
with training_args.main_process_first(desc="prediction dataset map tokenization"):
predict_dataset = predict_dataset.map(
tokenize_function,
batched=True,
num_proc=data_args.preprocessing_num_workers,
remove_columns=[text_column_name],
load_from_cache_file=not data_args.overwrite_cache,
)
# Data collator
data_collator=default_data_collator if not training_args.fp16 else DataCollatorWithPadding(tokenizer, pad_to_multiple_of=8)
# Initialize our Trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset if training_args.do_train else None,
eval_dataset=eval_dataset if training_args.do_eval else None,
tokenizer=tokenizer,
data_collator=data_collator,
)
# Training
if training_args.do_train:
{%- if cookiecutter.can_train_from_scratch == "False" %}
if last_checkpoint is not None:
checkpoint = last_checkpoint
elif os.path.isdir(model_args.model_name_or_path):
checkpoint = model_args.model_name_or_path
else:
checkpoint = None
{%- elif cookiecutter.can_train_from_scratch == "True" %}
if last_checkpoint is not None:
checkpoint = last_checkpoint
elif model_args.model_name_or_path is not None and os.path.isdir(model_args.model_name_or_path):
checkpoint = model_args.model_name_or_path
else:
checkpoint = None
{% endif %}
train_result = trainer.train(resume_from_checkpoint=checkpoint)
trainer.save_model() # Saves the tokenizer too for easy upload
metrics = train_result.metrics
max_train_samples = (
data_args.max_train_samples if data_args.max_train_samples is not None else len(train_dataset)
)
metrics["train_samples"] = min(max_train_samples, len(train_dataset))
trainer.log_metrics("train", metrics)
trainer.save_metrics("train", metrics)
trainer.save_state()
# Evaluation
if training_args.do_eval:
logger.info("*** Evaluate ***")
metrics = trainer.evaluate()
max_eval_samples = data_args.max_eval_samples if data_args.max_eval_samples is not None else len(eval_dataset)
metrics["eval_samples"] = min(max_eval_samples, len(eval_dataset))
trainer.log_metrics("eval", metrics)
trainer.save_metrics("eval", metrics)
# Prediction
if training_args.do_predict:
logger.info("*** Predict ***")
predictions, labels, metrics = trainer.predict(predict_dataset)
max_predict_samples = data_args.max_predict_samples if data_args.max_predict_samples is not None else len(predict_dataset)
metrics["predict_samples"] = min(max_predict_samples, len(predict_dataset))
trainer.log_metrics("predict", metrics)
trainer.save_metrics("predict", metrics)
# write custom code for saving predictions according to task
def _mp_fn(index):
# For xla_spawn (TPUs)
main()
if __name__ == "__main__":
main()
{%- elif cookiecutter.with_trainer == "False" %}
import argparse
import logging
import math
import os
import random
import datasets
from datasets import load_dataset, load_metric
from torch.utils.data import DataLoader
from tqdm.auto import tqdm
import transformers
from accelerate import Accelerator
from transformers import (
CONFIG_MAPPING,
MODEL_MAPPING,
AdamW,
AutoConfig,
{{cookiecutter.model_class}},
AutoTokenizer,
DataCollatorWithPadding,
PretrainedConfig,
SchedulerType,
default_data_collator,
get_scheduler,
set_seed,
)
from transformers.utils import send_example_telemetry
logger = logging.getLogger(__name__)
{%- if cookiecutter.can_train_from_scratch == "True" %}
# You should update this to your particular problem to have better documentation of `model_type`
MODEL_CONFIG_CLASSES = list(MODEL_MAPPING.keys())
MODEL_TYPES = tuple(conf.model_type for conf in MODEL_CONFIG_CLASSES)
{% endif %}
def parse_args():
parser = argparse.ArgumentParser(description="Finetune a transformers model on a text classification task")
parser.add_argument(
"--dataset_name",
type=str,
default=None,
help="The name of the dataset to use (via the datasets library).",
)
parser.add_argument(
"--dataset_config_name",
type=str,
default=None,
help= "The configuration name of the dataset to use (via the datasets library).",
)
parser.add_argument(
"--train_file", type=str, default=None, help="A csv or a json file containing the training data."
)
parser.add_argument(
"--validation_file", type=str, default=None, help="A csv or a json file containing the validation data."
)
parser.add_argument(
"--max_length",
type=int,
default=128,
help=(
"The maximum total input sequence length after tokenization. Sequences longer than this will be truncated,"
" sequences shorter will be padded if `--pad_to_max_lengh` is passed."
),
)
parser.add_argument(
"--pad_to_max_length",
action="store_true",
help="If passed, pad all samples to `max_length`. Otherwise, dynamic padding is used.",
)
parser.add_argument(
"--model_name_or_path",
type=str,
help="Path to pretrained model or model identifier from huggingface.co/models.",
required=True,
)
parser.add_argument(
"--config_name",
type=str,
default=None,
help="Pretrained config name or path if not the same as model_name",
)
parser.add_argument(
"--tokenizer_name",
type=str,
default=None,
help="Pretrained tokenizer name or path if not the same as model_name",
)
parser.add_argument(
"--use_slow_tokenizer",
action="store_true",
help="If passed, will use a slow tokenizer (not backed by the 🤗 Tokenizers library).",
)
parser.add_argument(
"--per_device_train_batch_size",
type=int,
default=8,
help="Batch size (per device) for the training dataloader.",
)
parser.add_argument(
"--per_device_eval_batch_size",
type=int,
default=8,
help="Batch size (per device) for the evaluation dataloader.",
)
parser.add_argument(
"--learning_rate",
type=float,
default=5e-5,
help="Initial learning rate (after the potential warmup period) to use.",
)
parser.add_argument("--weight_decay", type=float, default=0.0, help="Weight decay to use.")
parser.add_argument("--num_train_epochs", type=int, default=3, help="Total number of training epochs to perform.")
parser.add_argument(
"--max_train_steps",
type=int,
default=None,
help="Total number of training steps to perform. If provided, overrides num_train_epochs.",
)
parser.add_argument(
"--gradient_accumulation_steps",
type=int,
default=1,
help="Number of updates steps to accumulate before performing a backward/update pass.",
)
parser.add_argument(
"--lr_scheduler_type",
type=SchedulerType,
default="linear",
help="The scheduler type to use.",
choices=["linear", "cosine", "cosine_with_restarts", "polynomial", "constant", "constant_with_warmup"],
)
parser.add_argument(
"--num_warmup_steps", type=int, default=0, help="Number of steps for the warmup in the lr scheduler."
)
parser.add_argument("--output_dir", type=str, default=None, help="Where to store the final model.")
parser.add_argument("--seed", type=int, default=None, help="A seed for reproducible training.")
{%- if cookiecutter.can_train_from_scratch == "True" %}
parser.add_argument(
"--model_type",
type=str,
default=None,
help="Model type to use if training from scratch.",
choices=MODEL_TYPES,
)
{% endif %}
args = parser.parse_args()
# Sanity checks
if args.task_name is None and args.train_file is None and args.validation_file is None:
raise ValueError("Need either a task name or a training/validation file.")
else:
if args.train_file is not None:
extension = args.train_file.split(".")[-1]
assert extension in ["csv", "json"], "`train_file` should be a csv or a json file."
if args.validation_file is not None:
extension = args.validation_file.split(".")[-1]
assert extension in ["csv", "json"], "`validation_file` should be a csv or a json file."
if args.output_dir is not None:
os.makedirs(args.output_dir, exist_ok=True)
return args
def main():
args = parse_args()
# Sending telemetry. Tracking the example usage helps us better allocate resources to maintain them. The
# information sent is the one passed as arguments along with your Python/PyTorch versions.
send_example_telemetry("run_{{cookiecutter.example_shortcut}", args)
# Initialize the accelerator. We will let the accelerator handle device placement for us in this example.
accelerator = Accelerator()
# Make one log on every process with the configuration for debugging.
logging.basicConfig(
format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
datefmt="%m/%d/%Y %H:%M:%S",
level=logging.INFO,
)
logger.info(accelerator.state)
# Setup logging, we only want one process per machine to log things on the screen.
# accelerator.is_local_main_process is only True for one process per machine.
logger.setLevel(logging.INFO if accelerator.is_local_main_process else logging.ERROR)
if accelerator.is_local_main_process:
datasets.utils.logging.set_verbosity_warning()
transformers.utils.logging.set_verbosity_info()
else:
datasets.utils.logging.set_verbosity_error()
transformers.utils.logging.set_verbosity_error()
# If passed along, set the training seed now.
if args.seed is not None:
set_seed(args.seed)
# Get the datasets: you can either provide your own CSV/JSON/TXT training and evaluation files (see below)
# or just provide the name of one of the public datasets available on the hub at https://huggingface.co/datasets/
# (the dataset will be downloaded automatically from the datasets Hub).
#
# For CSV/JSON files, this script will use the column called 'text' or the first column if no column called
# 'text' is found. You can easily tweak this behavior (see below).
#
# In distributed training, the load_dataset function guarantee that only one local process can concurrently
# download the dataset.
if args.dataset_name is not None:
# Downloading and loading a dataset from the hub.
raw_datasets = load_dataset(args.dataset_name, args.dataset_config_name)
else:
data_files = {}
if args.train_file is not None:
data_files["train"] = args.train_file
if args.validation_file is not None:
data_files["validation"] = args.validation_file
extension = args.train_file.split(".")[-1]
raw_datasets = load_dataset(extension, data_files=data_files)
# See more about loading any type of standard or custom dataset (from files, python dict, pandas DataFrame, etc) at
# https://huggingface.co/docs/datasets/loading_datasets.html.
# Load pretrained model and tokenizer
#
# In distributed training, the .from_pretrained methods guarantee that only one local process can concurrently
# download model & vocab.
{%- if cookiecutter.can_train_from_scratch == "True" %}
if model_args.config_name:
config = AutoConfig.from_pretrained(args.model_name_or_path)
elif model_args.model_name_or_path:
config = AutoConfig.from_pretrained(args.model_name_or_path)
else:
config = CONFIG_MAPPING[args.model_type]()
logger.warning("You are instantiating a new config instance from scratch.")
if model_args.tokenizer_name:
tokenizer = AutoTokenizer.from_pretrained(model_args.tokenizer_name, use_fast=not args.use_slow_tokenizer)
elif model_args.model_name_or_path:
tokenizer = AutoTokenizer.from_pretrained(model_args.model_name_or_path, use_fast=not args.use_slow_tokenizer)
else:
raise ValueError(
"You are instantiating a new tokenizer from scratch. This is not supported by this script."
"You can do it from another script, save it, and load it from here, using --tokenizer_name."
)
if model_args.model_name_or_path:
model = {{cookiecutter.model_class}}.from_pretrained(
model_args.model_name_or_path,
from_tf=bool(".ckpt" in model_args.model_name_or_path),
config=config,
)
else:
logger.info("Training new model from scratch")
model = {{cookiecutter.model_class}}.from_config(config)
model.resize_token_embeddings(len(tokenizer))
{%- elif cookiecutter.can_train_from_scratch == "False" %}
config = AutoConfig.from_pretrained(
args.config_name if model_args.config_name else args.model_name_or_path,
# num_labels=num_labels, Uncomment if you have a certain number of labels
finetuning_task=data_args.task_name,
)
tokenizer = AutoTokenizer.from_pretrained(
args.tokenizer_name if model_args.tokenizer_name else args.model_name_or_path,
use_fast=not args.use_slow_tokenizer,
)
model = AutoModelForSequenceClassification.from_pretrained(
model_args.model_name_or_path,
from_tf=bool(".ckpt" in model_args.model_name_or_path),
config=config,
)
{% endif %}
# Preprocessing the datasets.
# First we tokenize all the texts.
column_names = raw_datasets["train"].column_names
text_column_name = "text" if "text" in column_names else column_names[0]
padding = "max_length" if args.pad_to_max_length else False
def tokenize_function(examples):
result = tokenizer(examples[text_column_name], padding=padding, max_length=args.max_length, truncation=True)
if "label" in examples:
result["labels"] = examples["label"]
return result
processed_datasets = raw_datasets.map(
preprocess_function, batched=True, remove_columns=raw_datasets["train"].column_names
)
train_dataset = processed_datasets["train"]
eval_dataset = processed_datasets["validation"]
# Log a few random samples from the training set:
for index in random.sample(range(len(train_dataset)), 3):
logger.info(f"Sample {index} of the training set: {train_dataset[index]}.")
# DataLoaders creation:
if args.pad_to_max_length:
# If padding was already done ot max length, we use the default data collator that will just convert everything
# to tensors.
data_collator = default_data_collator
else:
# Otherwise, `DataCollatorWithPadding` will apply dynamic padding for us (by padding to the maximum length of
# the samples passed). When using mixed precision, we add `pad_to_multiple_of=8` to pad all tensors to multiple
# of 8s, which will enable the use of Tensor Cores on NVIDIA hardware with compute capability >= 7.5 (Volta).
data_collator = DataCollatorWithPadding(tokenizer, pad_to_multiple_of=(8 if accelerator.use_fp16 else None))
train_dataloader = DataLoader(
train_dataset, shuffle=True, collate_fn=data_collator, batch_size=args.per_device_train_batch_size
)
eval_dataloader = DataLoader(eval_dataset, collate_fn=data_collator, batch_size=args.per_device_eval_batch_size)
# Optimizer
# Split weights in two groups, one with weight decay and the other not.
no_decay = ["bias", "LayerNorm.weight"]
optimizer_grouped_parameters = [
{
"params": [p for n, p in model.named_parameters() if not any(nd in n for nd in no_decay)],
"weight_decay": args.weight_decay,
},
{
"params": [p for n, p in model.named_parameters() if any(nd in n for nd in no_decay)],
"weight_decay": 0.0,
},
]
optimizer = AdamW(optimizer_grouped_parameters, lr=args.learning_rate)
# Prepare everything with our `accelerator`.
model, optimizer, train_dataloader, eval_dataloader = accelerator.prepare(
model, optimizer, train_dataloader, eval_dataloader
)
# Note -> the training dataloader needs to be prepared before we grab his length below (cause its length will be
# shorter in multiprocess)
# Scheduler and math around the number of training steps.
num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
if args.max_train_steps is None:
args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
else:
args.num_train_epochs = math.ceil(args.max_train_steps / num_update_steps_per_epoch)
lr_scheduler = get_scheduler(
name=args.lr_scheduler_type,
optimizer=optimizer,
num_warmup_steps=args.num_warmup_steps,
num_training_steps=args.max_train_steps,
)
# TODO Get the proper metric function
# metric = load_metric(xxx)
# Train!
total_batch_size = args.per_device_train_batch_size * accelerator.num_processes * args.gradient_accumulation_steps
logger.info("***** Running training *****")
logger.info(f" Num examples = {len(train_dataset)}")
logger.info(f" Num Epochs = {args.num_train_epochs}")
logger.info(f" Instantaneous batch size per device = {args.per_device_train_batch_size}")
logger.info(f" Total train batch size (w. parallel, distributed & accumulation) = {total_batch_size}")
logger.info(f" Gradient Accumulation steps = {args.gradient_accumulation_steps}")
logger.info(f" Total optimization steps = {args.max_train_steps}")
# Only show the progress bar once on each machine.
progress_bar = tqdm(range(args.max_train_steps), disable=not accelerator.is_local_main_process)
completed_steps = 0
for epoch in range(args.num_train_epochs):
model.train()
for step, batch in enumerate(train_dataloader):
outputs = model(**batch)
loss = outputs.loss
loss = loss / args.gradient_accumulation_steps
accelerator.backward(loss)
if step % args.gradient_accumulation_steps == 0 or step == len(train_dataloader) - 1:
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
progress_bar.update(1)
completed_steps += 1
if completed_steps >= args.max_train_steps:
break
model.eval()
for step, batch in enumerate(eval_dataloader):
with torch.no_grad():
outputs = model(**batch)
predictions = outputs.logits.argmax(dim=-1)
metric.add_batch(
predictions=accelerator.gather(predictions),
references=accelerator.gather(batch["labels"]),
)
eval_metric = metric.compute()
logger.info(f"epoch {epoch}: {eval_metric}")
if args.output_dir is not None:
accelerator.wait_for_everyone()
unwrapped_model = accelerator.unwrap_model(model)
unwrapped_model.save_pretrained(args.output_dir, save_function=accelerator.save)
if __name__ == "__main__":
main()
{% endif %}
| 0 |
hf_public_repos/transformers/templates | hf_public_repos/transformers/templates/adding_a_missing_tokenization_test/README.md | <!---
Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
This folder contains a template to add a tokenization test.
## Usage
Using the `cookiecutter` utility requires to have all the `dev` dependencies installed.
Let's first [fork](https://docs.github.com/en/get-started/quickstart/fork-a-repo) the `transformers` repo on github. Once it's done you can clone your fork and install `transformers` in our environment:
```shell script
git clone https://github.com/YOUR-USERNAME/transformers
cd transformers
pip install -e ".[dev]"
```
Once the installation is done, you can generate the template by running the following command. Be careful, the template will be generated inside a new folder in your current working directory.
```shell script
cookiecutter path-to-the folder/adding_a_missing_tokenization_test/
```
You will then have to answer some questions about the tokenizer for which you want to add tests. The `modelname` should be cased according to the plain text casing, i.e., BERT, RoBERTa, DeBERTa.
Once the command has finished, you should have a one new file inside the newly created folder named `test_tokenization_Xxx.py`. At this point the template is finished and you can move it to the sub-folder of the corresponding model in the test folder.
| 0 |
hf_public_repos/transformers/templates | hf_public_repos/transformers/templates/adding_a_missing_tokenization_test/cookiecutter.json | {
"modelname": "BrandNewBERT",
"uppercase_modelname": "BRAND_NEW_BERT",
"lowercase_modelname": "brand_new_bert",
"camelcase_modelname": "BrandNewBert",
"has_slow_class": ["True", "False"],
"has_fast_class": ["True", "False"],
"slow_tokenizer_use_sentencepiece": ["True", "False"],
"authors": "The HuggingFace Team"
}
| 0 |
hf_public_repos/transformers/templates/adding_a_missing_tokenization_test | hf_public_repos/transformers/templates/adding_a_missing_tokenization_test/cookiecutter-template-{{cookiecutter.modelname}}/test_tokenization_{{cookiecutter.lowercase_modelname}}.py | # coding=utf-8
# Copyright 2022 {{cookiecutter.authors}}. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
""" Testing suite for the {{cookiecutter.modelname}} tokenizer. """
import unittest
{% if cookiecutter.has_slow_class == "True" and cookiecutter.has_fast_class == "True" -%}
from transformers import {{cookiecutter.camelcase_modelname}}Tokenizer, {{cookiecutter.camelcase_modelname}}TokenizerFast
{% elif cookiecutter.has_slow_class == "True" -%}
from transformers import {{cookiecutter.camelcase_modelname}}Tokenizer
{% elif cookiecutter.has_fast_class == "True" -%}
from transformers import {{cookiecutter.camelcase_modelname}}TokenizerFast
{% endif -%}
{% if cookiecutter.has_fast_class == "True" and cookiecutter.slow_tokenizer_use_sentencepiece == "True" -%}
from transformers.testing_utils import require_sentencepiece, require_tokenizers
from ...test_tokenization_common import TokenizerTesterMixin
@require_sentencepiece
@require_tokenizers
{% elif cookiecutter.slow_tokenizer_use_sentencepiece == "True" -%}
from transformers.testing_utils import require_sentencepiece
from ...test_tokenization_common import TokenizerTesterMixin
@require_sentencepiece
{% elif cookiecutter.has_fast_class == "True" -%}
from transformers.testing_utils import require_tokenizers
from ...test_tokenization_common import TokenizerTesterMixin
@require_tokenizers
{% else -%}
from ...test_tokenization_common import TokenizerTesterMixin
{% endif -%}
class {{cookiecutter.camelcase_modelname}}TokenizationTest(TokenizerTesterMixin, unittest.TestCase):
{% if cookiecutter.has_slow_class == "True" -%}
tokenizer_class = {{cookiecutter.camelcase_modelname}}Tokenizer
test_slow_tokenizer = True
{% else -%}
tokenizer_class = None
test_slow_tokenizer = False
{% endif -%}
{% if cookiecutter.has_fast_class == "True" -%}
rust_tokenizer_class = {{cookiecutter.camelcase_modelname}}TokenizerFast
test_rust_tokenizer = True
{% else -%}
rust_tokenizer_class = None
test_rust_tokenizer = False
{% endif -%}
{% if cookiecutter.slow_tokenizer_use_sentencepiece == "True" -%}
test_sentencepiece = True
{% endif -%}
# TODO: Check in `TokenizerTesterMixin` if other attributes need to be changed
def setUp(self):
super().setUp()
raise NotImplementedError(
"Here you have to implement the saving of a toy tokenizer in "
"`self.tmpdirname`."
)
# TODO: add tests with hard-coded target values | 0 |
hf_public_repos/transformers | hf_public_repos/transformers/utils/check_self_hosted_runner.py | import argparse
import json
import subprocess
def get_runner_status(target_runners, token):
offline_runners = []
cmd = (
f'curl -H "Accept: application/vnd.github+json" -H "Authorization: Bearer {token}"'
" https://api.github.com/repos/huggingface/transformers/actions/runners"
)
output = subprocess.run(cmd, shell=True, stdout=subprocess.PIPE)
o = output.stdout.decode("utf-8")
status = json.loads(o)
runners = status["runners"]
for runner in runners:
if runner["name"] in target_runners:
if runner["status"] == "offline":
offline_runners.append(runner)
# save the result so we can report them on Slack
with open("offline_runners.txt", "w") as fp:
fp.write(json.dumps(offline_runners))
if len(offline_runners) > 0:
failed = "\n".join([x["name"] for x in offline_runners])
raise ValueError(f"The following runners are offline:\n{failed}")
if __name__ == "__main__":
def list_str(values):
return values.split(",")
parser = argparse.ArgumentParser()
# Required parameters
parser.add_argument(
"--target_runners",
default=None,
type=list_str,
required=True,
help="Comma-separated list of runners to check status.",
)
parser.add_argument(
"--token", default=None, type=str, required=True, help="A token that has actions:read permission."
)
args = parser.parse_args()
get_runner_status(args.target_runners, args.token)
| 0 |
hf_public_repos/transformers | hf_public_repos/transformers/utils/check_config_attributes.py | # coding=utf-8
# Copyright 2023 The HuggingFace Inc. team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import inspect
import os
import re
from transformers.configuration_utils import PretrainedConfig
from transformers.utils import direct_transformers_import
# All paths are set with the intent you should run this script from the root of the repo with the command
# python utils/check_config_docstrings.py
PATH_TO_TRANSFORMERS = "src/transformers"
# This is to make sure the transformers module imported is the one in the repo.
transformers = direct_transformers_import(PATH_TO_TRANSFORMERS)
CONFIG_MAPPING = transformers.models.auto.configuration_auto.CONFIG_MAPPING
SPECIAL_CASES_TO_ALLOW = {
# used to compute the property `self.chunk_length`
"EncodecConfig": ["overlap"],
# used as `self.bert_model = BertModel(config, ...)`
"DPRConfig": True,
# not used in modeling files, but it's an important information
"FSMTConfig": ["langs"],
# used internally in the configuration class file
"GPTNeoConfig": ["attention_types"],
# used internally in the configuration class file
"EsmConfig": ["is_folding_model"],
# used during training (despite we don't have training script for these models yet)
"Mask2FormerConfig": ["ignore_value"],
# `ignore_value` used during training (despite we don't have training script for these models yet)
# `norm` used in conversion script (despite not using in the modeling file)
"OneFormerConfig": ["ignore_value", "norm"],
# used during preprocessing and collation, see `collating_graphormer.py`
"GraphormerConfig": ["spatial_pos_max"],
# used internally in the configuration class file
"T5Config": ["feed_forward_proj"],
# used internally in the configuration class file
# `tokenizer_class` get default value `T5Tokenizer` intentionally
"MT5Config": ["feed_forward_proj", "tokenizer_class"],
"UMT5Config": ["feed_forward_proj", "tokenizer_class"],
# used internally in the configuration class file
"LongT5Config": ["feed_forward_proj"],
# used internally in the configuration class file
"SwitchTransformersConfig": ["feed_forward_proj"],
# having default values other than `1e-5` - we can't fix them without breaking
"BioGptConfig": ["layer_norm_eps"],
# having default values other than `1e-5` - we can't fix them without breaking
"GLPNConfig": ["layer_norm_eps"],
# having default values other than `1e-5` - we can't fix them without breaking
"SegformerConfig": ["layer_norm_eps"],
# having default values other than `1e-5` - we can't fix them without breaking
"CvtConfig": ["layer_norm_eps"],
# having default values other than `1e-5` - we can't fix them without breaking
"PerceiverConfig": ["layer_norm_eps"],
# used internally to calculate the feature size
"InformerConfig": ["num_static_real_features", "num_time_features"],
# used internally to calculate the feature size
"TimeSeriesTransformerConfig": ["num_static_real_features", "num_time_features"],
# used internally to calculate the feature size
"AutoformerConfig": ["num_static_real_features", "num_time_features"],
# used internally to calculate `mlp_dim`
"SamVisionConfig": ["mlp_ratio"],
# For (head) training, but so far not implemented
"ClapAudioConfig": ["num_classes"],
# Not used, but providing useful information to users
"SpeechT5HifiGanConfig": ["sampling_rate"],
}
# TODO (ydshieh): Check the failing cases, try to fix them or move some cases to the above block once we are sure
SPECIAL_CASES_TO_ALLOW.update(
{
"CLIPSegConfig": True,
"DeformableDetrConfig": True,
"DetaConfig": True,
"DinatConfig": True,
"DonutSwinConfig": True,
"EfficientFormerConfig": True,
"FSMTConfig": True,
"JukeboxConfig": True,
"LayoutLMv2Config": True,
"MaskFormerSwinConfig": True,
"MT5Config": True,
# For backward compatibility with trust remote code models
"MptConfig": True,
"MptAttentionConfig": True,
"NatConfig": True,
"OneFormerConfig": True,
"PerceiverConfig": True,
"RagConfig": True,
"SpeechT5Config": True,
"SwinConfig": True,
"Swin2SRConfig": True,
"Swinv2Config": True,
"SwitchTransformersConfig": True,
"TableTransformerConfig": True,
"TapasConfig": True,
"TransfoXLConfig": True,
"UniSpeechConfig": True,
"UniSpeechSatConfig": True,
"WavLMConfig": True,
"WhisperConfig": True,
# TODO: @Arthur (for `alignment_head` and `alignment_layer`)
"JukeboxPriorConfig": True,
# TODO: @Younes (for `is_decoder`)
"Pix2StructTextConfig": True,
}
)
def check_attribute_being_used(config_class, attributes, default_value, source_strings):
"""Check if any name in `attributes` is used in one of the strings in `source_strings`
Args:
config_class (`type`):
The configuration class for which the arguments in its `__init__` will be checked.
attributes (`List[str]`):
The name of an argument (or attribute) and its variant names if any.
default_value (`Any`):
A default value for the attribute in `attributes` assigned in the `__init__` of `config_class`.
source_strings (`List[str]`):
The python source code strings in the same modeling directory where `config_class` is defined. The file
containing the definition of `config_class` should be excluded.
"""
attribute_used = False
for attribute in attributes:
for modeling_source in source_strings:
# check if we can find `config.xxx`, `getattr(config, "xxx", ...)` or `getattr(self.config, "xxx", ...)`
if (
f"config.{attribute}" in modeling_source
or f'getattr(config, "{attribute}"' in modeling_source
or f'getattr(self.config, "{attribute}"' in modeling_source
):
attribute_used = True
# Deal with multi-line cases
elif (
re.search(
rf'getattr[ \t\v\n\r\f]*\([ \t\v\n\r\f]*(self\.)?config,[ \t\v\n\r\f]*"{attribute}"',
modeling_source,
)
is not None
):
attribute_used = True
# `SequenceSummary` is called with `SequenceSummary(config)`
elif attribute in [
"summary_type",
"summary_use_proj",
"summary_activation",
"summary_last_dropout",
"summary_proj_to_labels",
"summary_first_dropout",
]:
if "SequenceSummary" in modeling_source:
attribute_used = True
if attribute_used:
break
if attribute_used:
break
# common and important attributes, even if they do not always appear in the modeling files
attributes_to_allow = [
"bos_index",
"eos_index",
"pad_index",
"unk_index",
"mask_index",
"image_size",
"use_cache",
"out_features",
"out_indices",
]
attributes_used_in_generation = ["encoder_no_repeat_ngram_size"]
# Special cases to be allowed
case_allowed = True
if not attribute_used:
case_allowed = False
for attribute in attributes:
# Allow if the default value in the configuration class is different from the one in `PretrainedConfig`
if attribute in ["is_encoder_decoder"] and default_value is True:
case_allowed = True
elif attribute in ["tie_word_embeddings"] and default_value is False:
case_allowed = True
# Allow cases without checking the default value in the configuration class
elif attribute in attributes_to_allow + attributes_used_in_generation:
case_allowed = True
elif attribute.endswith("_token_id"):
case_allowed = True
# configuration class specific cases
if not case_allowed:
allowed_cases = SPECIAL_CASES_TO_ALLOW.get(config_class.__name__, [])
case_allowed = allowed_cases is True or attribute in allowed_cases
return attribute_used or case_allowed
def check_config_attributes_being_used(config_class):
"""Check the arguments in `__init__` of `config_class` are used in the modeling files in the same directory
Args:
config_class (`type`):
The configuration class for which the arguments in its `__init__` will be checked.
"""
# Get the parameters in `__init__` of the configuration class, and the default values if any
signature = dict(inspect.signature(config_class.__init__).parameters)
parameter_names = [x for x in list(signature.keys()) if x not in ["self", "kwargs"]]
parameter_defaults = [signature[param].default for param in parameter_names]
# If `attribute_map` exists, an attribute can have different names to be used in the modeling files, and as long
# as one variant is used, the test should pass
reversed_attribute_map = {}
if len(config_class.attribute_map) > 0:
reversed_attribute_map = {v: k for k, v in config_class.attribute_map.items()}
# Get the path to modeling source files
config_source_file = inspect.getsourcefile(config_class)
model_dir = os.path.dirname(config_source_file)
# Let's check against all frameworks: as long as one framework uses an attribute, we are good.
modeling_paths = [os.path.join(model_dir, fn) for fn in os.listdir(model_dir) if fn.startswith("modeling_")]
# Get the source code strings
modeling_sources = []
for path in modeling_paths:
if os.path.isfile(path):
with open(path, encoding="utf8") as fp:
modeling_sources.append(fp.read())
unused_attributes = []
for config_param, default_value in zip(parameter_names, parameter_defaults):
# `attributes` here is all the variant names for `config_param`
attributes = [config_param]
# some configuration classes have non-empty `attribute_map`, and both names could be used in the
# corresponding modeling files. As long as one of them appears, it is fine.
if config_param in reversed_attribute_map:
attributes.append(reversed_attribute_map[config_param])
if not check_attribute_being_used(config_class, attributes, default_value, modeling_sources):
unused_attributes.append(attributes[0])
return sorted(unused_attributes)
def check_config_attributes():
"""Check the arguments in `__init__` of all configuration classes are used in python files"""
configs_with_unused_attributes = {}
for _config_class in list(CONFIG_MAPPING.values()):
# Skip deprecated models
if "models.deprecated" in _config_class.__module__:
continue
# Some config classes are not in `CONFIG_MAPPING` (e.g. `CLIPVisionConfig`, `Blip2VisionConfig`, etc.)
config_classes_in_module = [
cls
for name, cls in inspect.getmembers(
inspect.getmodule(_config_class),
lambda x: inspect.isclass(x)
and issubclass(x, PretrainedConfig)
and inspect.getmodule(x) == inspect.getmodule(_config_class),
)
]
for config_class in config_classes_in_module:
unused_attributes = check_config_attributes_being_used(config_class)
if len(unused_attributes) > 0:
configs_with_unused_attributes[config_class.__name__] = unused_attributes
if len(configs_with_unused_attributes) > 0:
error = "The following configuration classes contain unused attributes in the corresponding modeling files:\n"
for name, attributes in configs_with_unused_attributes.items():
error += f"{name}: {attributes}\n"
raise ValueError(error)
if __name__ == "__main__":
check_config_attributes()
| 0 |
hf_public_repos/transformers | hf_public_repos/transformers/utils/get_ci_error_statistics.py | import argparse
import json
import math
import os
import time
import traceback
import zipfile
from collections import Counter
import requests
def get_job_links(workflow_run_id, token=None):
"""Extract job names and their job links in a GitHub Actions workflow run"""
headers = None
if token is not None:
headers = {"Accept": "application/vnd.github+json", "Authorization": f"Bearer {token}"}
url = f"https://api.github.com/repos/huggingface/transformers/actions/runs/{workflow_run_id}/jobs?per_page=100"
result = requests.get(url, headers=headers).json()
job_links = {}
try:
job_links.update({job["name"]: job["html_url"] for job in result["jobs"]})
pages_to_iterate_over = math.ceil((result["total_count"] - 100) / 100)
for i in range(pages_to_iterate_over):
result = requests.get(url + f"&page={i + 2}", headers=headers).json()
job_links.update({job["name"]: job["html_url"] for job in result["jobs"]})
return job_links
except Exception:
print(f"Unknown error, could not fetch links:\n{traceback.format_exc()}")
return {}
def get_artifacts_links(worflow_run_id, token=None):
"""Get all artifact links from a workflow run"""
headers = None
if token is not None:
headers = {"Accept": "application/vnd.github+json", "Authorization": f"Bearer {token}"}
url = f"https://api.github.com/repos/huggingface/transformers/actions/runs/{worflow_run_id}/artifacts?per_page=100"
result = requests.get(url, headers=headers).json()
artifacts = {}
try:
artifacts.update({artifact["name"]: artifact["archive_download_url"] for artifact in result["artifacts"]})
pages_to_iterate_over = math.ceil((result["total_count"] - 100) / 100)
for i in range(pages_to_iterate_over):
result = requests.get(url + f"&page={i + 2}", headers=headers).json()
artifacts.update({artifact["name"]: artifact["archive_download_url"] for artifact in result["artifacts"]})
return artifacts
except Exception:
print(f"Unknown error, could not fetch links:\n{traceback.format_exc()}")
return {}
def download_artifact(artifact_name, artifact_url, output_dir, token):
"""Download a GitHub Action artifact from a URL.
The URL is of the form `https://api.github.com/repos/huggingface/transformers/actions/artifacts/{ARTIFACT_ID}/zip`,
but it can't be used to download directly. We need to get a redirect URL first.
See https://docs.github.com/en/rest/actions/artifacts#download-an-artifact
"""
headers = None
if token is not None:
headers = {"Accept": "application/vnd.github+json", "Authorization": f"Bearer {token}"}
result = requests.get(artifact_url, headers=headers, allow_redirects=False)
download_url = result.headers["Location"]
response = requests.get(download_url, allow_redirects=True)
file_path = os.path.join(output_dir, f"{artifact_name}.zip")
with open(file_path, "wb") as fp:
fp.write(response.content)
def get_errors_from_single_artifact(artifact_zip_path, job_links=None):
"""Extract errors from a downloaded artifact (in .zip format)"""
errors = []
failed_tests = []
job_name = None
with zipfile.ZipFile(artifact_zip_path) as z:
for filename in z.namelist():
if not os.path.isdir(filename):
# read the file
if filename in ["failures_line.txt", "summary_short.txt", "job_name.txt"]:
with z.open(filename) as f:
for line in f:
line = line.decode("UTF-8").strip()
if filename == "failures_line.txt":
try:
# `error_line` is the place where `error` occurs
error_line = line[: line.index(": ")]
error = line[line.index(": ") + len(": ") :]
errors.append([error_line, error])
except Exception:
# skip un-related lines
pass
elif filename == "summary_short.txt" and line.startswith("FAILED "):
# `test` is the test method that failed
test = line[len("FAILED ") :]
failed_tests.append(test)
elif filename == "job_name.txt":
job_name = line
if len(errors) != len(failed_tests):
raise ValueError(
f"`errors` and `failed_tests` should have the same number of elements. Got {len(errors)} for `errors` "
f"and {len(failed_tests)} for `failed_tests` instead. The test reports in {artifact_zip_path} have some"
" problem."
)
job_link = None
if job_name and job_links:
job_link = job_links.get(job_name, None)
# A list with elements of the form (line of error, error, failed test)
result = [x + [y] + [job_link] for x, y in zip(errors, failed_tests)]
return result
def get_all_errors(artifact_dir, job_links=None):
"""Extract errors from all artifact files"""
errors = []
paths = [os.path.join(artifact_dir, p) for p in os.listdir(artifact_dir) if p.endswith(".zip")]
for p in paths:
errors.extend(get_errors_from_single_artifact(p, job_links=job_links))
return errors
def reduce_by_error(logs, error_filter=None):
"""count each error"""
counter = Counter()
counter.update([x[1] for x in logs])
counts = counter.most_common()
r = {}
for error, count in counts:
if error_filter is None or error not in error_filter:
r[error] = {"count": count, "failed_tests": [(x[2], x[0]) for x in logs if x[1] == error]}
r = dict(sorted(r.items(), key=lambda item: item[1]["count"], reverse=True))
return r
def get_model(test):
"""Get the model name from a test method"""
test = test.split("::")[0]
if test.startswith("tests/models/"):
test = test.split("/")[2]
else:
test = None
return test
def reduce_by_model(logs, error_filter=None):
"""count each error per model"""
logs = [(x[0], x[1], get_model(x[2])) for x in logs]
logs = [x for x in logs if x[2] is not None]
tests = {x[2] for x in logs}
r = {}
for test in tests:
counter = Counter()
# count by errors in `test`
counter.update([x[1] for x in logs if x[2] == test])
counts = counter.most_common()
error_counts = {error: count for error, count in counts if (error_filter is None or error not in error_filter)}
n_errors = sum(error_counts.values())
if n_errors > 0:
r[test] = {"count": n_errors, "errors": error_counts}
r = dict(sorted(r.items(), key=lambda item: item[1]["count"], reverse=True))
return r
def make_github_table(reduced_by_error):
header = "| no. | error | status |"
sep = "|-:|:-|:-|"
lines = [header, sep]
for error in reduced_by_error:
count = reduced_by_error[error]["count"]
line = f"| {count} | {error[:100]} | |"
lines.append(line)
return "\n".join(lines)
def make_github_table_per_model(reduced_by_model):
header = "| model | no. of errors | major error | count |"
sep = "|-:|-:|-:|-:|"
lines = [header, sep]
for model in reduced_by_model:
count = reduced_by_model[model]["count"]
error, _count = list(reduced_by_model[model]["errors"].items())[0]
line = f"| {model} | {count} | {error[:60]} | {_count} |"
lines.append(line)
return "\n".join(lines)
if __name__ == "__main__":
parser = argparse.ArgumentParser()
# Required parameters
parser.add_argument("--workflow_run_id", type=str, required=True, help="A GitHub Actions workflow run id.")
parser.add_argument(
"--output_dir",
type=str,
required=True,
help="Where to store the downloaded artifacts and other result files.",
)
parser.add_argument("--token", default=None, type=str, help="A token that has actions:read permission.")
args = parser.parse_args()
os.makedirs(args.output_dir, exist_ok=True)
_job_links = get_job_links(args.workflow_run_id, token=args.token)
job_links = {}
# To deal with `workflow_call` event, where a job name is the combination of the job names in the caller and callee.
# For example, `PyTorch 1.11 / Model tests (models/albert, single-gpu)`.
if _job_links:
for k, v in _job_links.items():
# This is how GitHub actions combine job names.
if " / " in k:
index = k.find(" / ")
k = k[index + len(" / ") :]
job_links[k] = v
with open(os.path.join(args.output_dir, "job_links.json"), "w", encoding="UTF-8") as fp:
json.dump(job_links, fp, ensure_ascii=False, indent=4)
artifacts = get_artifacts_links(args.workflow_run_id, token=args.token)
with open(os.path.join(args.output_dir, "artifacts.json"), "w", encoding="UTF-8") as fp:
json.dump(artifacts, fp, ensure_ascii=False, indent=4)
for idx, (name, url) in enumerate(artifacts.items()):
download_artifact(name, url, args.output_dir, args.token)
# Be gentle to GitHub
time.sleep(1)
errors = get_all_errors(args.output_dir, job_links=job_links)
# `e[1]` is the error
counter = Counter()
counter.update([e[1] for e in errors])
# print the top 30 most common test errors
most_common = counter.most_common(30)
for item in most_common:
print(item)
with open(os.path.join(args.output_dir, "errors.json"), "w", encoding="UTF-8") as fp:
json.dump(errors, fp, ensure_ascii=False, indent=4)
reduced_by_error = reduce_by_error(errors)
reduced_by_model = reduce_by_model(errors)
s1 = make_github_table(reduced_by_error)
s2 = make_github_table_per_model(reduced_by_model)
with open(os.path.join(args.output_dir, "reduced_by_error.txt"), "w", encoding="UTF-8") as fp:
fp.write(s1)
with open(os.path.join(args.output_dir, "reduced_by_model.txt"), "w", encoding="UTF-8") as fp:
fp.write(s2)
| 0 |
hf_public_repos/transformers | hf_public_repos/transformers/utils/create_dummy_models.py | # coding=utf-8
# Copyright 2022 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import argparse
import collections.abc
import copy
import inspect
import json
import multiprocessing
import os
import shutil
import tempfile
import traceback
from pathlib import Path
from check_config_docstrings import get_checkpoint_from_config_class
from datasets import load_dataset
from get_test_info import get_model_to_tester_mapping, get_tester_classes_for_model
from huggingface_hub import Repository, create_repo, hf_api, upload_folder
from transformers import (
CONFIG_MAPPING,
FEATURE_EXTRACTOR_MAPPING,
IMAGE_PROCESSOR_MAPPING,
PROCESSOR_MAPPING,
TOKENIZER_MAPPING,
AutoTokenizer,
LayoutLMv3TokenizerFast,
PreTrainedTokenizer,
PreTrainedTokenizerFast,
logging,
)
from transformers.feature_extraction_utils import FeatureExtractionMixin
from transformers.file_utils import is_tf_available, is_torch_available
from transformers.image_processing_utils import BaseImageProcessor
from transformers.models.auto.configuration_auto import AutoConfig, model_type_to_module_name
from transformers.models.fsmt import configuration_fsmt
from transformers.processing_utils import ProcessorMixin, transformers_module
from transformers.tokenization_utils_base import PreTrainedTokenizerBase
# make sure tokenizer plays nice with multiprocessing
os.environ["TOKENIZERS_PARALLELISM"] = "false"
logging.set_verbosity_error()
logging.disable_progress_bar()
logger = logging.get_logger(__name__)
os.environ["TF_CPP_MIN_LOG_LEVEL"] = "3"
if not is_torch_available():
raise ValueError("Please install PyTorch.")
if not is_tf_available():
raise ValueError("Please install TensorFlow.")
FRAMEWORKS = ["pytorch", "tensorflow"]
INVALID_ARCH = []
TARGET_VOCAB_SIZE = 1024
data = {"training_ds": None, "testing_ds": None}
COMPOSITE_MODELS = {
"EncoderDecoderModel": "EncoderDecoderModel-bert-bert",
"SpeechEncoderDecoderModel": "SpeechEncoderDecoderModel-wav2vec2-bert",
"VisionEncoderDecoderModel": "VisionEncoderDecoderModel-vit-gpt2",
"VisionTextDualEncoderModel": "VisionTextDualEncoderModel-vit-bert",
}
# This list contains the model architectures for which a tiny version could not be created.
# Avoid to add new architectures here - unless we have verified carefully that it's (almost) impossible to create them.
# One such case is: no model tester class is implemented for a model type (like `MT5`) because its architecture is
# identical to another one (`MT5` is based on `T5`), but trained on different datasets or with different techniques.
UNCONVERTIBLE_MODEL_ARCHITECTURES = {
"BertGenerationEncoder",
"BertGenerationDecoder",
"CamembertForSequenceClassification",
"CamembertForMultipleChoice",
"CamembertForMaskedLM",
"CamembertForCausalLM",
"CamembertForTokenClassification",
"CamembertForQuestionAnswering",
"CamembertModel",
"TFCamembertForMultipleChoice",
"TFCamembertForTokenClassification",
"TFCamembertForQuestionAnswering",
"TFCamembertForSequenceClassification",
"TFCamembertForMaskedLM",
"TFCamembertModel",
"TFCamembertForCausalLM",
"DecisionTransformerModel",
"GraphormerModel",
"InformerModel",
"JukeboxModel",
"MarianForCausalLM",
"MaskFormerSwinModel",
"MaskFormerSwinBackbone",
"MT5Model",
"MT5ForConditionalGeneration",
"UMT5ForConditionalGeneration",
"TFMT5ForConditionalGeneration",
"TFMT5Model",
"QDQBertForSequenceClassification",
"QDQBertForMaskedLM",
"QDQBertModel",
"QDQBertForTokenClassification",
"QDQBertLMHeadModel",
"QDQBertForMultipleChoice",
"QDQBertForQuestionAnswering",
"QDQBertForNextSentencePrediction",
"ReformerModelWithLMHead",
"RetriBertModel",
"Speech2Text2ForCausalLM",
"TimeSeriesTransformerModel",
"TrajectoryTransformerModel",
"TrOCRForCausalLM",
"XLMProphetNetForConditionalGeneration",
"XLMProphetNetForCausalLM",
"XLMProphetNetModel",
"XLMRobertaModel",
"XLMRobertaForTokenClassification",
"XLMRobertaForMultipleChoice",
"XLMRobertaForMaskedLM",
"XLMRobertaForCausalLM",
"XLMRobertaForSequenceClassification",
"XLMRobertaForQuestionAnswering",
"TFXLMRobertaForSequenceClassification",
"TFXLMRobertaForMaskedLM",
"TFXLMRobertaForCausalLM",
"TFXLMRobertaForQuestionAnswering",
"TFXLMRobertaModel",
"TFXLMRobertaForMultipleChoice",
"TFXLMRobertaForTokenClassification",
}
def get_processor_types_from_config_class(config_class, allowed_mappings=None):
"""Return a tuple of processors for `config_class`.
We use `tuple` here to include (potentially) both slow & fast tokenizers.
"""
# To make a uniform return type
def _to_tuple(x):
if not isinstance(x, collections.abc.Sequence):
x = (x,)
else:
x = tuple(x)
return x
if allowed_mappings is None:
allowed_mappings = ["processor", "tokenizer", "image_processor", "feature_extractor"]
processor_types = ()
# Check first if a model has `ProcessorMixin`. Otherwise, check if it has tokenizers, and/or an image processor or
# a feature extractor
if config_class in PROCESSOR_MAPPING and "processor" in allowed_mappings:
processor_types = _to_tuple(PROCESSOR_MAPPING[config_class])
else:
if config_class in TOKENIZER_MAPPING and "tokenizer" in allowed_mappings:
processor_types = TOKENIZER_MAPPING[config_class]
if config_class in IMAGE_PROCESSOR_MAPPING and "image_processor" in allowed_mappings:
processor_types += _to_tuple(IMAGE_PROCESSOR_MAPPING[config_class])
elif config_class in FEATURE_EXTRACTOR_MAPPING and "feature_extractor" in allowed_mappings:
processor_types += _to_tuple(FEATURE_EXTRACTOR_MAPPING[config_class])
# Remark: some configurations have no processor at all. For example, generic composite models like
# `EncoderDecoderModel` is used for any (compatible) text models. Also, `DecisionTransformer` doesn't
# require any processor.
# We might get `None` for some tokenizers - remove them here.
processor_types = tuple(p for p in processor_types if p is not None)
return processor_types
def get_architectures_from_config_class(config_class, arch_mappings, models_to_skip=None):
"""Return a tuple of all possible architectures attributed to a configuration class `config_class`.
For example, BertConfig -> [BertModel, BertForMaskedLM, ..., BertForQuestionAnswering].
"""
# A model architecture could appear in several mappings. For example, `BartForConditionalGeneration` is in
# - MODEL_FOR_PRETRAINING_MAPPING_NAMES
# - MODEL_WITH_LM_HEAD_MAPPING_NAMES
# - MODEL_FOR_MASKED_LM_MAPPING_NAMES
# - MODEL_FOR_SEQ_TO_SEQ_CAUSAL_LM_MAPPING_NAMES
# We avoid the duplication.
architectures = set()
if models_to_skip is None:
models_to_skip = []
models_to_skip = UNCONVERTIBLE_MODEL_ARCHITECTURES.union(models_to_skip)
for mapping in arch_mappings:
if config_class in mapping:
models = mapping[config_class]
models = tuple(models) if isinstance(models, collections.abc.Sequence) else (models,)
for model in models:
if model.__name__ not in models_to_skip:
architectures.add(model)
architectures = tuple(architectures)
return architectures
def get_config_class_from_processor_class(processor_class):
"""Get the config class from a processor class.
Some config/model classes use tokenizers/feature_extractors from other models. For example, `GPT-J` uses
`GPT2Tokenizer`. If no checkpoint is found for a config class, or a checkpoint is found without necessary file(s) to
create the processor for `processor_class`, we get the config class that corresponds to `processor_class` and use it
to find a checkpoint in order to create the processor.
"""
processor_prefix = processor_class.__name__
for postfix in ["TokenizerFast", "Tokenizer", "ImageProcessor", "FeatureExtractor", "Processor"]:
processor_prefix = processor_prefix.replace(postfix, "")
# `Wav2Vec2CTCTokenizer` -> `Wav2Vec2Config`
if processor_prefix == "Wav2Vec2CTC":
processor_prefix = "Wav2Vec2"
# Find the new configuration class
new_config_name = f"{processor_prefix}Config"
new_config_class = getattr(transformers_module, new_config_name)
return new_config_class
def build_processor(config_class, processor_class, allow_no_checkpoint=False):
"""Create a processor for `processor_class`.
If a processor is not able to be built with the original arguments, this method tries to change the arguments and
call itself recursively, by inferring a new `config_class` or a new `processor_class` from another one, in order to
find a checkpoint containing the necessary files to build a processor.
The processor is not saved here. Instead, it will be saved in `convert_processors` after further changes in
`convert_processors`. For each model architecture`, a copy will be created and saved along the built model.
"""
# Currently, this solely uses the docstring in the source file of `config_class` to find a checkpoint.
checkpoint = get_checkpoint_from_config_class(config_class)
if checkpoint is None:
# try to get the checkpoint from the config class for `processor_class`.
# This helps cases like `XCLIPConfig` and `VideoMAEFeatureExtractor` to find a checkpoint from `VideoMAEConfig`.
config_class_from_processor_class = get_config_class_from_processor_class(processor_class)
checkpoint = get_checkpoint_from_config_class(config_class_from_processor_class)
processor = None
try:
processor = processor_class.from_pretrained(checkpoint)
except Exception as e:
logger.error(f"{e.__class__.__name__}: {e}")
# Try to get a new processor class from checkpoint. This is helpful for a checkpoint without necessary file to load
# processor while `processor_class` is an Auto class. For example, `sew` has `Wav2Vec2Processor` in
# `PROCESSOR_MAPPING_NAMES`, its `tokenizer_class` is `AutoTokenizer`, and the checkpoint
# `https://huggingface.co/asapp/sew-tiny-100k` has no tokenizer file, but we can get
# `tokenizer_class: Wav2Vec2CTCTokenizer` from the config file. (The new processor class won't be able to load from
# `checkpoint`, but it helps this recursive method to find a way to build a processor).
if (
processor is None
and checkpoint is not None
and issubclass(processor_class, (PreTrainedTokenizerBase, AutoTokenizer))
):
try:
config = AutoConfig.from_pretrained(checkpoint)
except Exception as e:
logger.error(f"{e.__class__.__name__}: {e}")
config = None
if config is not None:
if not isinstance(config, config_class):
raise ValueError(
f"`config` (which is of type {config.__class__.__name__}) should be an instance of `config_class`"
f" ({config_class.__name__})!"
)
tokenizer_class = config.tokenizer_class
new_processor_class = None
if tokenizer_class is not None:
new_processor_class = getattr(transformers_module, tokenizer_class)
if new_processor_class != processor_class:
processor = build_processor(config_class, new_processor_class)
# If `tokenizer_class` is not specified in `config`, let's use `config` to get the process class via auto
# mappings, but only allow the tokenizer mapping being used. This is to make `Wav2Vec2Conformer` build
if processor is None:
new_processor_classes = get_processor_types_from_config_class(
config.__class__, allowed_mappings=["tokenizer"]
)
# Used to avoid infinite recursion between a pair of fast/slow tokenizer types
names = [
x.__name__.replace("Fast", "") for x in [processor_class, new_processor_class] if x is not None
]
new_processor_classes = [
x for x in new_processor_classes if x is not None and x.__name__.replace("Fast", "") not in names
]
if len(new_processor_classes) > 0:
new_processor_class = new_processor_classes[0]
# Let's use fast tokenizer if there is any
for x in new_processor_classes:
if x.__name__.endswith("Fast"):
new_processor_class = x
break
processor = build_processor(config_class, new_processor_class)
if processor is None:
# Try to build each component (tokenizer & feature extractor) of a `ProcessorMixin`.
if issubclass(processor_class, ProcessorMixin):
attrs = {}
for attr_name in processor_class.attributes:
attrs[attr_name] = []
# This could be a tuple (for tokenizers). For example, `CLIPProcessor` has
# - feature_extractor_class = "CLIPFeatureExtractor"
# - tokenizer_class = ("CLIPTokenizer", "CLIPTokenizerFast")
attr_class_names = getattr(processor_class, f"{attr_name}_class")
if not isinstance(attr_class_names, tuple):
attr_class_names = (attr_class_names,)
for name in attr_class_names:
attr_class = getattr(transformers_module, name)
attr = build_processor(config_class, attr_class)
if attr is not None:
attrs[attr_name].append(attr)
# try to build a `ProcessorMixin`, so we can return a single value
if all(len(v) > 0 for v in attrs.values()):
try:
processor = processor_class(**{k: v[0] for k, v in attrs.items()})
except Exception as e:
logger.error(f"{e.__class__.__name__}: {e}")
else:
# `checkpoint` might lack some file(s) to load a processor. For example, `facebook/hubert-base-ls960`
# has no tokenizer file to load `Wav2Vec2CTCTokenizer`. In this case, we try to build a processor
# with the configuration class (for example, `Wav2Vec2Config`) corresponding to `processor_class`.
config_class_from_processor_class = get_config_class_from_processor_class(processor_class)
if config_class_from_processor_class != config_class:
processor = build_processor(config_class_from_processor_class, processor_class)
# Try to create an image processor or a feature extractor without any checkpoint
if (
processor is None
and allow_no_checkpoint
and (issubclass(processor_class, BaseImageProcessor) or issubclass(processor_class, FeatureExtractionMixin))
):
try:
processor = processor_class()
except Exception as e:
logger.error(f"{e.__class__.__name__}: {e}")
# validation
if processor is not None:
if not (isinstance(processor, processor_class) or processor_class.__name__.startswith("Auto")):
raise ValueError(
f"`processor` (which is of type {processor.__class__.__name__}) should be an instance of"
f" {processor_class.__name__} or an Auto class!"
)
return processor
def get_tiny_config(config_class, model_class=None, **model_tester_kwargs):
"""Retrieve a tiny configuration from `config_class` using each model's `ModelTester`.
Args:
config_class: Subclass of `PreTrainedConfig`.
Returns:
An instance of `config_class` with tiny hyperparameters
"""
model_type = config_class.model_type
# For model type like `data2vec-vision` and `donut-swin`, we can't get the config/model file name directly via
# `model_type` as it would be sth. like `configuration_data2vec_vision.py`.
# A simple way is to use `inspect.getsourcefile(config_class)`.
config_source_file = inspect.getsourcefile(config_class)
# The modeling file name without prefix (`modeling_`) and postfix (`.py`)
modeling_name = config_source_file.split(os.path.sep)[-1].replace("configuration_", "").replace(".py", "")
try:
print("Importing", model_type_to_module_name(model_type))
module_name = model_type_to_module_name(model_type)
if not modeling_name.startswith(module_name):
raise ValueError(f"{modeling_name} doesn't start with {module_name}!")
test_file = os.path.join("tests", "models", module_name, f"test_modeling_{modeling_name}.py")
models_to_model_testers = get_model_to_tester_mapping(test_file)
# Find the model tester class
model_tester_class = None
tester_classes = []
if model_class is not None:
tester_classes = get_tester_classes_for_model(test_file, model_class)
else:
for _tester_classes in models_to_model_testers.values():
tester_classes.extend(_tester_classes)
if len(tester_classes) > 0:
# sort with the length of the class names first, then the alphabetical order
# This is to avoid `T5EncoderOnlyModelTest` is used instead of `T5ModelTest`, which has
# `is_encoder_decoder=False` and causes some pipeline tests failing (also failures in `Optimum` CI).
# TODO: More fine grained control of the desired tester class.
model_tester_class = sorted(tester_classes, key=lambda x: (len(x.__name__), x.__name__))[0]
except ModuleNotFoundError:
error = f"Tiny config not created for {model_type} - cannot find the testing module from the model name."
raise ValueError(error)
if model_tester_class is None:
error = f"Tiny config not created for {model_type} - no model tester is found in the testing module."
raise ValueError(error)
# `parent` is an instance of `unittest.TestCase`, but we don't need it here.
model_tester = model_tester_class(parent=None, **model_tester_kwargs)
if hasattr(model_tester, "get_pipeline_config"):
return model_tester.get_pipeline_config()
elif hasattr(model_tester, "prepare_config_and_inputs"):
# `PoolFormer` has no `get_config` defined. Furthermore, it's better to use `prepare_config_and_inputs` even if
# `get_config` is defined, since there might be some extra changes in `prepare_config_and_inputs`.
return model_tester.prepare_config_and_inputs()[0]
elif hasattr(model_tester, "get_config"):
return model_tester.get_config()
else:
error = (
f"Tiny config not created for {model_type} - the model tester {model_tester_class.__name__} lacks"
" necessary method to create config."
)
raise ValueError(error)
def convert_tokenizer(tokenizer_fast: PreTrainedTokenizerFast):
new_tokenizer = tokenizer_fast.train_new_from_iterator(
data["training_ds"]["text"], TARGET_VOCAB_SIZE, show_progress=False
)
# Make sure it at least runs
if not isinstance(new_tokenizer, LayoutLMv3TokenizerFast):
new_tokenizer(data["testing_ds"]["text"])
return new_tokenizer
def convert_feature_extractor(feature_extractor, tiny_config):
to_convert = False
kwargs = {}
if hasattr(tiny_config, "image_size"):
kwargs["size"] = tiny_config.image_size
kwargs["crop_size"] = tiny_config.image_size
to_convert = True
elif (
hasattr(tiny_config, "vision_config")
and tiny_config.vision_config is not None
and hasattr(tiny_config.vision_config, "image_size")
):
kwargs["size"] = tiny_config.vision_config.image_size
kwargs["crop_size"] = tiny_config.vision_config.image_size
to_convert = True
# Speech2TextModel specific.
if hasattr(tiny_config, "input_feat_per_channel"):
kwargs["feature_size"] = tiny_config.input_feat_per_channel
kwargs["num_mel_bins"] = tiny_config.input_feat_per_channel
to_convert = True
if to_convert:
feature_extractor = feature_extractor.__class__(**kwargs)
return feature_extractor
def convert_processors(processors, tiny_config, output_folder, result):
"""Change a processor to work with smaller inputs.
For tokenizers, we try to reduce their vocabulary size.
For feature extractor, we use smaller image size or change
other attributes using the values from `tiny_config`. See `convert_feature_extractor`.
This method should not fail: we catch the errors and put them in `result["warnings"]` with descriptive messages.
"""
def _sanity_check(fast_tokenizer, slow_tokenizer, keep_fast_tokenizer=False):
"""Set tokenizer(s) to `None` if the fast/slow tokenizers have different values for `vocab_size` or `length`.
If `keep_fast_tokenizer=True`, the fast tokenizer will be kept.
"""
# sanity check 1: fast and slow tokenizers should be compatible (vocab_size)
if fast_tokenizer is not None and slow_tokenizer is not None:
if fast_tokenizer.vocab_size != slow_tokenizer.vocab_size:
warning_messagae = (
"The fast/slow tokenizers "
f"({fast_tokenizer.__class__.__name__}/{slow_tokenizer.__class__.__name__}) have different "
"vocabulary size: "
f"fast_tokenizer.vocab_size = {fast_tokenizer.vocab_size} and "
f"slow_tokenizer.vocab_size = {slow_tokenizer.vocab_size}."
)
result["warnings"].append(warning_messagae)
if not keep_fast_tokenizer:
fast_tokenizer = None
slow_tokenizer = None
# sanity check 2: fast and slow tokenizers should be compatible (length)
if fast_tokenizer is not None and slow_tokenizer is not None:
if len(fast_tokenizer) != len(slow_tokenizer):
warning_messagae = (
f"The fast/slow tokenizers () have different length: "
f"len(fast_tokenizer) = {len(fast_tokenizer)} and "
f"len(slow_tokenizer) = {len(slow_tokenizer)}."
)
result["warnings"].append(warning_messagae)
if not keep_fast_tokenizer:
fast_tokenizer = None
slow_tokenizer = None
return fast_tokenizer, slow_tokenizer
tokenizers = []
feature_extractors = []
for processor in processors:
if isinstance(processor, PreTrainedTokenizerBase):
if processor.__class__.__name__ not in {x.__class__.__name__ for x in tokenizers}:
tokenizers.append(processor)
elif isinstance(processor, BaseImageProcessor):
if processor.__class__.__name__ not in {x.__class__.__name__ for x in feature_extractors}:
feature_extractors.append(processor)
elif isinstance(processor, FeatureExtractionMixin):
if processor.__class__.__name__ not in {x.__class__.__name__ for x in feature_extractors}:
feature_extractors.append(processor)
elif isinstance(processor, ProcessorMixin):
if hasattr(processor, "tokenizer"):
if processor.tokenizer.__class__.__name__ not in {x.__class__.__name__ for x in tokenizers}:
tokenizers.append(processor.tokenizer)
# Currently, we only have these 2 possibilities
if hasattr(processor, "image_processor"):
if processor.image_processor.__class__.__name__ not in {
x.__class__.__name__ for x in feature_extractors
}:
feature_extractors.append(processor.image_processor)
elif hasattr(processor, "feature_extractor"):
if processor.feature_extractor.__class__.__name__ not in {
x.__class__.__name__ for x in feature_extractors
}:
feature_extractors.append(processor.feature_extractor)
# check the built processors have the unique type
num_types = len({x.__class__.__name__ for x in feature_extractors})
if num_types >= 2:
raise ValueError(f"`feature_extractors` should contain at most 1 type, but it contains {num_types} types!")
num_types = len({x.__class__.__name__.replace("Fast", "") for x in tokenizers})
if num_types >= 2:
raise ValueError(f"`tokenizers` should contain at most 1 tokenizer type, but it contains {num_types} types!")
fast_tokenizer = None
slow_tokenizer = None
for tokenizer in tokenizers:
if isinstance(tokenizer, PreTrainedTokenizerFast):
fast_tokenizer = tokenizer
else:
slow_tokenizer = tokenizer
# If the (original) fast/slow tokenizers don't correspond, keep only the fast tokenizer.
# This doesn't necessarily imply the fast/slow tokenizers in a single Hub repo. has issues.
# It's more of an issue in `build_processor` which tries to get a checkpoint with as much effort as possible.
# For `YosoModel` (which uses `AlbertTokenizer(Fast)`), its real (Hub) checkpoint doesn't contain valid files to
# load the slower tokenizer (`AlbertTokenizer`), and it ends up finding the (canonical) checkpoint of `AlbertModel`,
# which has different vocabulary.
# TODO: Try to improve `build_processor`'s definition and/or usage to avoid the above situation in the first place.
fast_tokenizer, slow_tokenizer = _sanity_check(fast_tokenizer, slow_tokenizer, keep_fast_tokenizer=True)
original_fast_tokenizer, original_slow_tokenizer = fast_tokenizer, slow_tokenizer
if fast_tokenizer:
try:
# Wav2Vec2ForCTC , ByT5Tokenizer etc. all are already small enough and have no fast version that can
# be retrained
if fast_tokenizer.vocab_size > TARGET_VOCAB_SIZE:
fast_tokenizer = convert_tokenizer(fast_tokenizer)
except Exception:
result["warnings"].append(
(
f"Failed to convert the fast tokenizer for {fast_tokenizer.__class__.__name__}.",
traceback.format_exc(),
)
)
# If `fast_tokenizer` exists, `slow_tokenizer` should correspond to it.
if fast_tokenizer:
# Make sure the fast tokenizer can be saved
try:
# We don't save it to `output_folder` at this moment - only at the end of this function.
with tempfile.TemporaryDirectory() as tmpdir:
fast_tokenizer.save_pretrained(tmpdir)
try:
slow_tokenizer = AutoTokenizer.from_pretrained(tmpdir, use_fast=False)
except Exception:
result["warnings"].append(
(
f"Failed to load the slow tokenizer saved from {fast_tokenizer.__class__.__name__}.",
traceback.format_exc(),
)
)
# Let's just keep the fast version
slow_tokenizer = None
except Exception:
result["warnings"].append(
(
f"Failed to save the fast tokenizer for {fast_tokenizer.__class__.__name__}.",
traceback.format_exc(),
)
)
fast_tokenizer = None
# If the (possibly converted) fast/slow tokenizers don't correspond, set them to `None`, and use the original
# tokenizers.
fast_tokenizer, slow_tokenizer = _sanity_check(fast_tokenizer, slow_tokenizer, keep_fast_tokenizer=False)
# If there is any conversion failed, we keep the original tokenizers.
if (original_fast_tokenizer is not None and fast_tokenizer is None) or (
original_slow_tokenizer is not None and slow_tokenizer is None
):
warning_messagae = (
"There are some issues when converting the fast/slow tokenizers. The original tokenizers from the Hub "
" will be used instead."
)
result["warnings"].append(warning_messagae)
# Let's use the original version at the end (`original_fast_tokenizer` and `original_slow_tokenizer`)
fast_tokenizer = original_fast_tokenizer
slow_tokenizer = original_slow_tokenizer
# Make sure the fast tokenizer can be saved
if fast_tokenizer:
# We don't save it to `output_folder` at this moment - only at the end of this function.
with tempfile.TemporaryDirectory() as tmpdir:
try:
fast_tokenizer.save_pretrained(tmpdir)
except Exception:
result["warnings"].append(
(
f"Failed to save the fast tokenizer for {fast_tokenizer.__class__.__name__}.",
traceback.format_exc(),
)
)
fast_tokenizer = None
# Make sure the slow tokenizer can be saved
if slow_tokenizer:
# We don't save it to `output_folder` at this moment - only at the end of this function.
with tempfile.TemporaryDirectory() as tmpdir:
try:
slow_tokenizer.save_pretrained(tmpdir)
except Exception:
result["warnings"].append(
(
f"Failed to save the slow tokenizer for {slow_tokenizer.__class__.__name__}.",
traceback.format_exc(),
)
)
slow_tokenizer = None
# update feature extractors using the tiny config
try:
feature_extractors = [convert_feature_extractor(p, tiny_config) for p in feature_extractors]
except Exception:
result["warnings"].append(
(
"Failed to convert feature extractors.",
traceback.format_exc(),
)
)
feature_extractors = []
if hasattr(tiny_config, "max_position_embeddings") and tiny_config.max_position_embeddings > 0:
if fast_tokenizer is not None:
if fast_tokenizer.__class__.__name__ in [
"RobertaTokenizerFast",
"XLMRobertaTokenizerFast",
"LongformerTokenizerFast",
"MPNetTokenizerFast",
]:
fast_tokenizer.model_max_length = tiny_config.max_position_embeddings - 2
else:
fast_tokenizer.model_max_length = tiny_config.max_position_embeddings
if slow_tokenizer is not None:
if slow_tokenizer.__class__.__name__ in [
"RobertaTokenizer",
"XLMRobertaTokenizer",
"LongformerTokenizer",
"MPNetTokenizer",
]:
slow_tokenizer.model_max_length = tiny_config.max_position_embeddings - 2
else:
slow_tokenizer.model_max_length = tiny_config.max_position_embeddings
processors = [fast_tokenizer, slow_tokenizer] + feature_extractors
processors = [p for p in processors if p is not None]
for p in processors:
p.save_pretrained(output_folder)
return processors
def get_checkpoint_dir(output_dir, model_arch):
"""Get framework-agnostic architecture name. Used to save all PT/TF/Flax models into the same directory."""
arch_name = model_arch.__name__
if arch_name.startswith("TF"):
arch_name = arch_name[2:]
elif arch_name.startswith("Flax"):
arch_name = arch_name[4:]
return os.path.join(output_dir, arch_name)
def build_model(model_arch, tiny_config, output_dir):
"""Create and save a model for `model_arch`.
Also copy the set of processors to each model (under the same model type) output folder.
"""
checkpoint_dir = get_checkpoint_dir(output_dir, model_arch)
processor_output_dir = os.path.join(output_dir, "processors")
# copy the (same set of) processors (for a model type) to the model arch. specific folder
if os.path.isdir(processor_output_dir):
shutil.copytree(processor_output_dir, checkpoint_dir, dirs_exist_ok=True)
tiny_config = copy.deepcopy(tiny_config)
if any(model_arch.__name__.endswith(x) for x in ["ForCausalLM", "LMHeadModel"]):
tiny_config.is_encoder_decoder = False
tiny_config.is_decoder = True
model = model_arch(config=tiny_config)
model.save_pretrained(checkpoint_dir)
model.from_pretrained(checkpoint_dir)
return model
def fill_result_with_error(result, error, trace, models_to_create):
"""Fill `result` with errors for all target model arch if we can't build processor"""
error = (error, trace)
result["error"] = error
for framework in FRAMEWORKS:
if framework in models_to_create:
result[framework] = {}
for model_arch in models_to_create[framework]:
result[framework][model_arch.__name__] = {"model": None, "checkpoint": None, "error": error}
result["processor"] = {p.__class__.__name__: p.__class__.__name__ for p in result["processor"].values()}
def upload_model(model_dir, organization, token):
"""Upload the tiny models"""
arch_name = model_dir.split(os.path.sep)[-1]
repo_name = f"tiny-random-{arch_name}"
repo_id = f"{organization}/{repo_name}"
repo_exist = False
error = None
try:
create_repo(repo_id=repo_id, exist_ok=False, repo_type="model", token=token)
except Exception as e:
error = e
if "You already created" in str(e):
error = None
logger.warning("Remote repository exists and will be cloned.")
repo_exist = True
try:
create_repo(repo_id=repo_id, exist_ok=True, repo_type="model", token=token)
except Exception as e:
error = e
if error is not None:
raise error
with tempfile.TemporaryDirectory() as tmpdir:
repo = Repository(local_dir=tmpdir, clone_from=repo_id, token=token)
repo.git_pull()
shutil.copytree(model_dir, tmpdir, dirs_exist_ok=True)
if repo_exist:
# Open a PR on the existing Hub repo.
hub_pr_url = upload_folder(
folder_path=model_dir,
repo_id=repo_id,
repo_type="model",
commit_message=f"Update tiny models for {arch_name}",
commit_description=f"Upload tiny models for {arch_name}",
create_pr=True,
token=token,
)
logger.warning(f"PR open in {hub_pr_url}.")
# TODO: We need this information?
else:
# Push to Hub repo directly
repo.git_add(auto_lfs_track=True)
repo.git_commit(f"Upload tiny models for {arch_name}")
repo.git_push(blocking=True) # this prints a progress bar with the upload
logger.warning(f"Tiny models {arch_name} pushed to {repo_id}.")
def build_composite_models(config_class, output_dir):
import tempfile
from transformers import (
BertConfig,
BertLMHeadModel,
BertModel,
BertTokenizer,
BertTokenizerFast,
EncoderDecoderModel,
GPT2Config,
GPT2LMHeadModel,
GPT2Tokenizer,
GPT2TokenizerFast,
SpeechEncoderDecoderModel,
TFEncoderDecoderModel,
TFVisionEncoderDecoderModel,
TFVisionTextDualEncoderModel,
VisionEncoderDecoderModel,
VisionTextDualEncoderModel,
ViTConfig,
ViTFeatureExtractor,
ViTModel,
Wav2Vec2Config,
Wav2Vec2Model,
Wav2Vec2Processor,
)
# These will be removed at the end if they are empty
result = {"error": None, "warnings": []}
if config_class.model_type == "encoder-decoder":
encoder_config_class = BertConfig
decoder_config_class = BertConfig
encoder_processor = (BertTokenizerFast, BertTokenizer)
decoder_processor = (BertTokenizerFast, BertTokenizer)
encoder_class = BertModel
decoder_class = BertLMHeadModel
model_class = EncoderDecoderModel
tf_model_class = TFEncoderDecoderModel
elif config_class.model_type == "vision-encoder-decoder":
encoder_config_class = ViTConfig
decoder_config_class = GPT2Config
encoder_processor = (ViTFeatureExtractor,)
decoder_processor = (GPT2TokenizerFast, GPT2Tokenizer)
encoder_class = ViTModel
decoder_class = GPT2LMHeadModel
model_class = VisionEncoderDecoderModel
tf_model_class = TFVisionEncoderDecoderModel
elif config_class.model_type == "speech-encoder-decoder":
encoder_config_class = Wav2Vec2Config
decoder_config_class = BertConfig
encoder_processor = (Wav2Vec2Processor,)
decoder_processor = (BertTokenizerFast, BertTokenizer)
encoder_class = Wav2Vec2Model
decoder_class = BertLMHeadModel
model_class = SpeechEncoderDecoderModel
tf_model_class = None
elif config_class.model_type == "vision-text-dual-encoder":
# Not encoder-decoder, but encoder-encoder. We just keep the same name as above to make code easier
encoder_config_class = ViTConfig
decoder_config_class = BertConfig
encoder_processor = (ViTFeatureExtractor,)
decoder_processor = (BertTokenizerFast, BertTokenizer)
encoder_class = ViTModel
decoder_class = BertModel
model_class = VisionTextDualEncoderModel
tf_model_class = TFVisionTextDualEncoderModel
with tempfile.TemporaryDirectory() as tmpdir:
try:
# build encoder
models_to_create = {"processor": encoder_processor, "pytorch": (encoder_class,), "tensorflow": []}
encoder_output_dir = os.path.join(tmpdir, "encoder")
build(encoder_config_class, models_to_create, encoder_output_dir)
# build decoder
models_to_create = {"processor": decoder_processor, "pytorch": (decoder_class,), "tensorflow": []}
decoder_output_dir = os.path.join(tmpdir, "decoder")
build(decoder_config_class, models_to_create, decoder_output_dir)
# build encoder-decoder
encoder_path = os.path.join(encoder_output_dir, encoder_class.__name__)
decoder_path = os.path.join(decoder_output_dir, decoder_class.__name__)
if config_class.model_type != "vision-text-dual-encoder":
# Specify these explicitly for encoder-decoder like models, but not for `vision-text-dual-encoder` as it
# has no decoder.
decoder_config = decoder_config_class.from_pretrained(decoder_path)
decoder_config.is_decoder = True
decoder_config.add_cross_attention = True
model = model_class.from_encoder_decoder_pretrained(
encoder_path,
decoder_path,
decoder_config=decoder_config,
)
elif config_class.model_type == "vision-text-dual-encoder":
model = model_class.from_vision_text_pretrained(encoder_path, decoder_path)
model_path = os.path.join(
output_dir,
f"{model_class.__name__}-{encoder_config_class.model_type}-{decoder_config_class.model_type}",
)
model.save_pretrained(model_path)
if tf_model_class is not None:
model = tf_model_class.from_pretrained(model_path, from_pt=True)
model.save_pretrained(model_path)
# copy the processors
encoder_processor_path = os.path.join(encoder_output_dir, "processors")
decoder_processor_path = os.path.join(decoder_output_dir, "processors")
if os.path.isdir(encoder_processor_path):
shutil.copytree(encoder_processor_path, model_path, dirs_exist_ok=True)
if os.path.isdir(decoder_processor_path):
shutil.copytree(decoder_processor_path, model_path, dirs_exist_ok=True)
# fill `result`
result["processor"] = {x.__name__: x.__name__ for x in encoder_processor + decoder_processor}
result["pytorch"] = {model_class.__name__: {"model": model_class.__name__, "checkpoint": model_path}}
result["tensorflow"] = {}
if tf_model_class is not None:
result["tensorflow"] = {
tf_model_class.__name__: {"model": tf_model_class.__name__, "checkpoint": model_path}
}
except Exception:
result["error"] = (
f"Failed to build models for {config_class.__name__}.",
traceback.format_exc(),
)
if not result["error"]:
del result["error"]
if not result["warnings"]:
del result["warnings"]
return result
def get_token_id_from_tokenizer(token_id_name, tokenizer, original_token_id):
"""Use `tokenizer` to get the values of `bos_token_id`, `eos_token_ids`, etc.
The argument `token_id_name` should be a string ending with `_token_id`, and `original_token_id` should be an
integer that will be return if `tokenizer` has no token corresponding to `token_id_name`.
"""
token_id = original_token_id
if not token_id_name.endswith("_token_id"):
raise ValueError(f"`token_id_name` is {token_id_name}, which doesn't end with `_token_id`!")
token = getattr(tokenizer, token_id_name.replace("_token_id", "_token"), None)
if token is not None:
if isinstance(tokenizer, PreTrainedTokenizerFast):
token_id = tokenizer._convert_token_to_id_with_added_voc(token)
else:
token_id = tokenizer._convert_token_to_id(token)
return token_id
def get_config_overrides(config_class, processors):
config_overrides = {}
# Check if there is any tokenizer (prefer fast version if any)
tokenizer = None
for processor in processors:
if isinstance(processor, PreTrainedTokenizerFast):
tokenizer = processor
break
elif isinstance(processor, PreTrainedTokenizer):
tokenizer = processor
if tokenizer is None:
return config_overrides
# Get some properties of the (already converted) tokenizer (smaller vocab size, special token ids, etc.)
# We use `len(tokenizer)` instead of `tokenizer.vocab_size` to avoid potential issues for tokenizers with non-empty
# `added_tokens_encoder`. One example is the `DebertaV2Tokenizer` where the mask token is the extra token.
vocab_size = len(tokenizer)
# The original checkpoint has length `35998`, but it doesn't have ids `30400` and `30514` but instead `35998` and
# `35999`.
if config_class.__name__ == "GPTSanJapaneseConfig":
vocab_size += 2
config_overrides["vocab_size"] = vocab_size
# Used to create a new model tester with `tokenizer.vocab_size` in order to get the (updated) special token ids.
model_tester_kwargs = {"vocab_size": vocab_size}
# CLIP-like models have `text_model_tester` and `vision_model_tester`, and we need to pass `vocab_size` to
# `text_model_tester` via `text_kwargs`. The same trick is also necessary for `Flava`.
if config_class.__name__ in [
"AlignConfig",
"AltCLIPConfig",
"ChineseCLIPConfig",
"CLIPSegConfig",
"ClapConfig",
"CLIPConfig",
"GroupViTConfig",
"OwlViTConfig",
"XCLIPConfig",
"FlavaConfig",
"BlipConfig",
"Blip2Config",
]:
del model_tester_kwargs["vocab_size"]
model_tester_kwargs["text_kwargs"] = {"vocab_size": vocab_size}
# `FSMTModelTester` accepts `src_vocab_size` and `tgt_vocab_size` but not `vocab_size`.
elif config_class.__name__ == "FSMTConfig":
del model_tester_kwargs["vocab_size"]
model_tester_kwargs["src_vocab_size"] = tokenizer.src_vocab_size
model_tester_kwargs["tgt_vocab_size"] = tokenizer.tgt_vocab_size
_tiny_config = get_tiny_config(config_class, **model_tester_kwargs)
# handle the possibility of `text_config` inside `_tiny_config` for clip-like models (`owlvit`, `groupvit`, etc.)
if hasattr(_tiny_config, "text_config"):
_tiny_config = _tiny_config.text_config
# Collect values of some special token ids
for attr in dir(_tiny_config):
if attr.endswith("_token_id"):
token_id = getattr(_tiny_config, attr)
if token_id is not None:
# Using the token id values from `tokenizer` instead of from `_tiny_config`.
token_id = get_token_id_from_tokenizer(attr, tokenizer, original_token_id=token_id)
config_overrides[attr] = token_id
if config_class.__name__ == "FSMTConfig":
config_overrides["src_vocab_size"] = tokenizer.src_vocab_size
config_overrides["tgt_vocab_size"] = tokenizer.tgt_vocab_size
# `FSMTConfig` has `DecoderConfig` as `decoder` attribute.
config_overrides["decoder"] = configuration_fsmt.DecoderConfig(
vocab_size=tokenizer.tgt_vocab_size, bos_token_id=config_overrides["eos_token_id"]
)
return config_overrides
def build(config_class, models_to_create, output_dir):
"""Create all models for a certain model type.
Args:
config_class (`PretrainedConfig`):
A subclass of `PretrainedConfig` that is used to determine `models_to_create`.
models_to_create (`dict`):
A dictionary containing the processor/model classes that we want to create the instances. These models are
of the same model type which is associated to `config_class`.
output_dir (`str`):
The directory to save all the checkpoints. Each model architecture will be saved in a subdirectory under
it. Models in different frameworks with the same architecture will be saved in the same subdirectory.
"""
if data["training_ds"] is None or data["testing_ds"] is None:
ds = load_dataset("wikitext", "wikitext-2-raw-v1")
data["training_ds"] = ds["train"]
data["testing_ds"] = ds["test"]
if config_class.model_type in [
"encoder-decoder",
"vision-encoder-decoder",
"speech-encoder-decoder",
"vision-text-dual-encoder",
]:
return build_composite_models(config_class, output_dir)
result = {k: {} for k in models_to_create}
# These will be removed at the end if they are empty
result["error"] = None
result["warnings"] = []
# Build processors
processor_classes = models_to_create["processor"]
if len(processor_classes) == 0:
error = f"No processor class could be found in {config_class.__name__}."
fill_result_with_error(result, error, None, models_to_create)
logger.error(result["error"][0])
return result
for processor_class in processor_classes:
try:
processor = build_processor(config_class, processor_class, allow_no_checkpoint=True)
if processor is not None:
result["processor"][processor_class] = processor
except Exception:
error = f"Failed to build processor for {processor_class.__name__}."
trace = traceback.format_exc()
fill_result_with_error(result, error, trace, models_to_create)
logger.error(result["error"][0])
return result
if len(result["processor"]) == 0:
error = f"No processor could be built for {config_class.__name__}."
fill_result_with_error(result, error, None, models_to_create)
logger.error(result["error"][0])
return result
try:
tiny_config = get_tiny_config(config_class)
except Exception as e:
error = f"Failed to get tiny config for {config_class.__name__}: {e}"
trace = traceback.format_exc()
fill_result_with_error(result, error, trace, models_to_create)
logger.error(result["error"][0])
return result
# Convert the processors (reduce vocabulary size, smaller image size, etc.)
processors = list(result["processor"].values())
processor_output_folder = os.path.join(output_dir, "processors")
try:
processors = convert_processors(processors, tiny_config, processor_output_folder, result)
except Exception:
error = "Failed to convert the processors."
trace = traceback.format_exc()
result["warnings"].append((error, trace))
if len(processors) == 0:
error = f"No processor is returned by `convert_processors` for {config_class.__name__}."
fill_result_with_error(result, error, None, models_to_create)
logger.error(result["error"][0])
return result
try:
config_overrides = get_config_overrides(config_class, processors)
except Exception as e:
error = f"Failure occurs while calling `get_config_overrides`: {e}"
trace = traceback.format_exc()
fill_result_with_error(result, error, trace, models_to_create)
logger.error(result["error"][0])
return result
# Just for us to see this easily in the report
if "vocab_size" in config_overrides:
result["vocab_size"] = config_overrides["vocab_size"]
# Update attributes that `vocab_size` involves
for k, v in config_overrides.items():
if hasattr(tiny_config, k):
setattr(tiny_config, k, v)
# So far, we only have to deal with `text_config`, as `config_overrides` contains text-related attributes only.
elif (
hasattr(tiny_config, "text_config")
and tiny_config.text_config is not None
and hasattr(tiny_config.text_config, k)
):
setattr(tiny_config.text_config, k, v)
# If `text_config_dict` exists, we need to update its value here too in order to # make
# `save_pretrained -> from_pretrained` work.
if hasattr(tiny_config, "text_config_dict"):
tiny_config.text_config_dict[k] = v
if result["warnings"]:
logger.warning(result["warnings"][0][0])
# update `result["processor"]`
result["processor"] = {type(p).__name__: p.__class__.__name__ for p in processors}
for pytorch_arch in models_to_create["pytorch"]:
result["pytorch"][pytorch_arch.__name__] = {}
error = None
try:
model = build_model(pytorch_arch, tiny_config, output_dir=output_dir)
except Exception as e:
model = None
error = f"Failed to create the pytorch model for {pytorch_arch}: {e}"
trace = traceback.format_exc()
result["pytorch"][pytorch_arch.__name__]["model"] = model.__class__.__name__ if model is not None else None
result["pytorch"][pytorch_arch.__name__]["checkpoint"] = (
get_checkpoint_dir(output_dir, pytorch_arch) if model is not None else None
)
if error is not None:
result["pytorch"][pytorch_arch.__name__]["error"] = (error, trace)
logger.error(f"{pytorch_arch.__name__}: {error}")
for tensorflow_arch in models_to_create["tensorflow"]:
# Make PT/TF weights compatible
pt_arch_name = tensorflow_arch.__name__[2:] # Remove `TF`
pt_arch = getattr(transformers_module, pt_arch_name)
result["tensorflow"][tensorflow_arch.__name__] = {}
error = None
if pt_arch.__name__ in result["pytorch"] and result["pytorch"][pt_arch.__name__]["checkpoint"] is not None:
ckpt = get_checkpoint_dir(output_dir, pt_arch)
# Use the same weights from PyTorch.
try:
model = tensorflow_arch.from_pretrained(ckpt, from_pt=True)
model.save_pretrained(ckpt)
except Exception as e:
# Conversion may fail. Let's not create a model with different weights to avoid confusion (for now).
model = None
error = f"Failed to convert the pytorch model to the tensorflow model for {pt_arch}: {e}"
trace = traceback.format_exc()
else:
try:
model = build_model(tensorflow_arch, tiny_config, output_dir=output_dir)
except Exception as e:
model = None
error = f"Failed to create the tensorflow model for {tensorflow_arch}: {e}"
trace = traceback.format_exc()
result["tensorflow"][tensorflow_arch.__name__]["model"] = (
model.__class__.__name__ if model is not None else None
)
result["tensorflow"][tensorflow_arch.__name__]["checkpoint"] = (
get_checkpoint_dir(output_dir, tensorflow_arch) if model is not None else None
)
if error is not None:
result["tensorflow"][tensorflow_arch.__name__]["error"] = (error, trace)
logger.error(f"{tensorflow_arch.__name__}: {error}")
if not result["error"]:
del result["error"]
if not result["warnings"]:
del result["warnings"]
return result
def build_tiny_model_summary(results, organization=None, token=None):
"""Build a summary: a dictionary of the form
{
model architecture name:
{
"tokenizer_classes": [...],
"processor_classes": [...],
"model_classes": [...],
}
..
}
"""
tiny_model_summary = {}
for config_name in results:
processors = [key for key, value in results[config_name]["processor"].items()]
tokenizer_classes = sorted([x for x in processors if x.endswith("TokenizerFast") or x.endswith("Tokenizer")])
processor_classes = sorted([x for x in processors if x not in tokenizer_classes])
for framework in FRAMEWORKS:
if framework not in results[config_name]:
continue
for arch_name in results[config_name][framework]:
model_classes = [arch_name]
base_arch_name = arch_name[2:] if arch_name.startswith("TF") else arch_name
# tiny model is not created for `arch_name`
if results[config_name][framework][arch_name]["model"] is None:
model_classes = []
if base_arch_name not in tiny_model_summary:
tiny_model_summary[base_arch_name] = {}
tiny_model_summary[base_arch_name].update(
{
"tokenizer_classes": tokenizer_classes,
"processor_classes": processor_classes,
}
)
tiny_model_summary[base_arch_name]["model_classes"] = sorted(
tiny_model_summary[base_arch_name].get("model_classes", []) + model_classes
)
if organization is not None:
repo_name = f"tiny-random-{base_arch_name}"
# composite models' checkpoints have more precise repo. names on the Hub.
if base_arch_name in COMPOSITE_MODELS:
repo_name = f"tiny-random-{COMPOSITE_MODELS[base_arch_name]}"
repo_id = f"{organization}/{repo_name}"
try:
commit_hash = hf_api.repo_info(repo_id, token=token).sha
except Exception:
# The directory is not created, but processor(s) is/are included in `results`.
logger.warning(f"Failed to get information for {repo_id}.\n{traceback.format_exc()}")
del tiny_model_summary[base_arch_name]
continue
tiny_model_summary[base_arch_name]["sha"] = commit_hash
return tiny_model_summary
def build_failed_report(results, include_warning=True):
failed_results = {}
for config_name in results:
if "error" in results[config_name]:
if config_name not in failed_results:
failed_results[config_name] = {}
failed_results[config_name] = {"error": results[config_name]["error"]}
if include_warning and "warnings" in results[config_name]:
if config_name not in failed_results:
failed_results[config_name] = {}
failed_results[config_name]["warnings"] = results[config_name]["warnings"]
for framework in FRAMEWORKS:
if framework not in results[config_name]:
continue
for arch_name in results[config_name][framework]:
if "error" in results[config_name][framework][arch_name]:
if config_name not in failed_results:
failed_results[config_name] = {}
if framework not in failed_results[config_name]:
failed_results[config_name][framework] = {}
if arch_name not in failed_results[config_name][framework]:
failed_results[config_name][framework][arch_name] = {}
error = results[config_name][framework][arch_name]["error"]
failed_results[config_name][framework][arch_name]["error"] = error
return failed_results
def build_simple_report(results):
text = ""
failed_text = ""
for config_name in results:
for framework in FRAMEWORKS:
if framework not in results[config_name]:
continue
for arch_name in results[config_name][framework]:
if "error" in results[config_name][framework][arch_name]:
result = results[config_name][framework][arch_name]["error"]
failed_text += f"{arch_name}: {result[0]}\n"
else:
result = ("OK",)
text += f"{arch_name}: {result[0]}\n"
return text, failed_text
def update_tiny_model_summary_file(report_path):
with open(os.path.join(report_path, "tiny_model_summary.json")) as fp:
new_data = json.load(fp)
with open("tests/utils/tiny_model_summary.json") as fp:
data = json.load(fp)
for key, value in new_data.items():
if key not in data:
data[key] = value
else:
for attr in ["tokenizer_classes", "processor_classes", "model_classes"]:
# we might get duplication here. We will remove them below when creating `updated_data`.
data[key][attr].extend(value[attr])
new_sha = value.get("sha", None)
if new_sha is not None:
data[key]["sha"] = new_sha
updated_data = {}
for key in sorted(data.keys()):
updated_data[key] = {}
for attr, value in data[key].items():
# deduplication and sort
updated_data[key][attr] = sorted(set(value)) if attr != "sha" else value
with open(os.path.join(report_path, "updated_tiny_model_summary.json"), "w") as fp:
json.dump(updated_data, fp, indent=4, ensure_ascii=False)
def create_tiny_models(
output_path,
all,
model_types,
models_to_skip,
no_check,
upload,
organization,
token,
num_workers=1,
):
clone_path = os.path.abspath(os.path.dirname(os.path.dirname(__file__)))
if os.getcwd() != clone_path:
raise ValueError(f"This script should be run from the root of the clone of `transformers` {clone_path}")
report_path = os.path.join(output_path, "reports")
os.makedirs(report_path)
_pytorch_arch_mappings = [
x
for x in dir(transformers_module)
if x.startswith("MODEL_") and x.endswith("_MAPPING") and x != "MODEL_NAMES_MAPPING"
]
_tensorflow_arch_mappings = [
x for x in dir(transformers_module) if x.startswith("TF_MODEL_") and x.endswith("_MAPPING")
]
pytorch_arch_mappings = [getattr(transformers_module, x) for x in _pytorch_arch_mappings]
tensorflow_arch_mappings = [getattr(transformers_module, x) for x in _tensorflow_arch_mappings]
config_classes = CONFIG_MAPPING.values()
if not all:
config_classes = [CONFIG_MAPPING[model_type] for model_type in model_types]
# A map from config classes to tuples of processors (tokenizer, feature extractor, processor) classes
processor_type_map = {c: get_processor_types_from_config_class(c) for c in config_classes}
to_create = {}
for c in config_classes:
processors = processor_type_map[c]
models = get_architectures_from_config_class(c, pytorch_arch_mappings, models_to_skip)
tf_models = get_architectures_from_config_class(c, tensorflow_arch_mappings, models_to_skip)
if len(models) + len(tf_models) > 0:
to_create[c] = {"processor": processors, "pytorch": models, "tensorflow": tf_models}
results = {}
if num_workers <= 1:
for c, models_to_create in list(to_create.items()):
print(f"Create models for {c.__name__} ...")
result = build(c, models_to_create, output_dir=os.path.join(output_path, c.model_type))
results[c.__name__] = result
print("=" * 40)
else:
all_build_args = []
for c, models_to_create in list(to_create.items()):
all_build_args.append((c, models_to_create, os.path.join(output_path, c.model_type)))
with multiprocessing.Pool() as pool:
results = pool.starmap(build, all_build_args)
results = {buid_args[0].__name__: result for buid_args, result in zip(all_build_args, results)}
if upload:
if organization is None:
raise ValueError("The argument `organization` could not be `None`. No model is uploaded")
to_upload = []
for model_type in os.listdir(output_path):
# This is the directory containing the reports
if model_type == "reports":
continue
for arch in os.listdir(os.path.join(output_path, model_type)):
if arch == "processors":
continue
to_upload.append(os.path.join(output_path, model_type, arch))
to_upload = sorted(to_upload)
upload_results = {}
if len(to_upload) > 0:
for model_dir in to_upload:
try:
upload_model(model_dir, organization, token)
except Exception as e:
error = f"Failed to upload {model_dir}. {e.__class__.__name__}: {e}"
logger.error(error)
upload_results[model_dir] = error
with open(os.path.join(report_path, "failed_uploads.json"), "w") as fp:
json.dump(upload_results, fp, indent=4)
# Build the tiny model summary file. The `tokenizer_classes` and `processor_classes` could be both empty lists.
# When using the items in this file to update the file `tests/utils/tiny_model_summary.json`, the model
# architectures with `tokenizer_classes` and `processor_classes` being both empty should **NOT** be added to
# `tests/utils/tiny_model_summary.json`.
tiny_model_summary = build_tiny_model_summary(results, organization=organization, token=token)
with open(os.path.join(report_path, "tiny_model_summary.json"), "w") as fp:
json.dump(tiny_model_summary, fp, indent=4)
with open(os.path.join(report_path, "tiny_model_creation_report.json"), "w") as fp:
json.dump(results, fp, indent=4)
# Build the warning/failure report (json format): same format as the complete `results` except this contains only
# warnings or errors.
failed_results = build_failed_report(results)
with open(os.path.join(report_path, "failed_report.json"), "w") as fp:
json.dump(failed_results, fp, indent=4)
simple_report, failed_report = build_simple_report(results)
# The simplified report: a .txt file with each line of format:
# {model architecture name}: {OK or error message}
with open(os.path.join(report_path, "simple_report.txt"), "w") as fp:
fp.write(simple_report)
# The simplified failure report: same above except this only contains line with errors
with open(os.path.join(report_path, "simple_failed_report.txt"), "w") as fp:
fp.write(failed_report)
update_tiny_model_summary_file(report_path=os.path.join(output_path, "reports"))
if __name__ == "__main__":
# This has to be `spawn` to avoid hanging forever!
multiprocessing.set_start_method("spawn")
def list_str(values):
return values.split(",")
parser = argparse.ArgumentParser()
parser.add_argument("--all", action="store_true", help="Will create all tiny models.")
parser.add_argument(
"--no_check",
action="store_true",
help="If set, will not check the validity of architectures. Use with caution.",
)
parser.add_argument(
"-m",
"--model_types",
type=list_str,
help="Comma-separated list of model type(s) from which the tiny models will be created.",
)
parser.add_argument(
"--models_to_skip",
type=list_str,
help=(
"Comma-separated list of model class names(s) from which the tiny models won't be created.\nThis is usually"
"the list of model classes that have their tiny versions already uploaded to the Hub."
),
)
parser.add_argument("--upload", action="store_true", help="If to upload the created tiny models to the Hub.")
parser.add_argument(
"--organization",
default=None,
type=str,
help="The organization on the Hub to which the tiny models will be uploaded.",
)
parser.add_argument(
"--token", default=None, type=str, help="A valid authentication token for HuggingFace Hub with write access."
)
parser.add_argument("output_path", type=Path, help="Path indicating where to store generated model.")
parser.add_argument("--num_workers", default=1, type=int, help="The number of workers to run.")
args = parser.parse_args()
if not args.all and not args.model_types:
raise ValueError("Please provide at least one model type or pass `--all` to export all architectures.")
create_tiny_models(
args.output_path,
args.all,
args.model_types,
args.models_to_skip,
args.no_check,
args.upload,
args.organization,
args.token,
args.num_workers,
)
| 0 |
hf_public_repos/transformers | hf_public_repos/transformers/utils/add_pipeline_model_mapping_to_test.py | # coding=utf-8
# Copyright 2023 The HuggingFace Inc. team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""A script to add and/or update the attribute `pipeline_model_mapping` in model test files.
This script will be (mostly) used in the following 2 situations:
- run within a (scheduled) CI job to:
- check if model test files in the library have updated `pipeline_model_mapping`,
- and/or update test files and (possibly) open a GitHub pull request automatically
- being run by a `transformers` member to quickly check and update some particular test file(s)
This script is **NOT** intended to be run (manually) by community contributors.
"""
import argparse
import glob
import inspect
import os
import re
import unittest
from get_test_info import get_test_classes
from tests.test_pipeline_mixin import pipeline_test_mapping
PIPELINE_TEST_MAPPING = {}
for task, _ in pipeline_test_mapping.items():
PIPELINE_TEST_MAPPING[task] = {"pt": None, "tf": None}
# DO **NOT** add item to this set (unless the reason is approved)
TEST_FILE_TO_IGNORE = {
"tests/models/esm/test_modeling_esmfold.py", # The pipeline test mapping is added to `test_modeling_esm.py`
}
def get_framework(test_class):
"""Infer the framework from the test class `test_class`."""
if "ModelTesterMixin" in [x.__name__ for x in test_class.__bases__]:
return "pt"
elif "TFModelTesterMixin" in [x.__name__ for x in test_class.__bases__]:
return "tf"
elif "FlaxModelTesterMixin" in [x.__name__ for x in test_class.__bases__]:
return "flax"
else:
return None
def get_mapping_for_task(task, framework):
"""Get mappings defined in `XXXPipelineTests` for the task `task`."""
# Use the cached results
if PIPELINE_TEST_MAPPING[task].get(framework, None) is not None:
return PIPELINE_TEST_MAPPING[task][framework]
pipeline_test_class = pipeline_test_mapping[task]["test"]
mapping = None
if framework == "pt":
mapping = getattr(pipeline_test_class, "model_mapping", None)
elif framework == "tf":
mapping = getattr(pipeline_test_class, "tf_model_mapping", None)
if mapping is not None:
mapping = dict(mapping.items())
# cache the results
PIPELINE_TEST_MAPPING[task][framework] = mapping
return mapping
def get_model_for_pipeline_test(test_class, task):
"""Get the model architecture(s) related to the test class `test_class` for a pipeline `task`."""
framework = get_framework(test_class)
if framework is None:
return None
mapping = get_mapping_for_task(task, framework)
if mapping is None:
return None
config_classes = list({model_class.config_class for model_class in test_class.all_model_classes})
if len(config_classes) != 1:
raise ValueError("There should be exactly one configuration class from `test_class.all_model_classes`.")
# This could be a list/tuple of model classes, but it's rare.
model_class = mapping.get(config_classes[0], None)
if isinstance(model_class, (tuple, list)):
model_class = sorted(model_class, key=lambda x: x.__name__)
return model_class
def get_pipeline_model_mapping(test_class):
"""Get `pipeline_model_mapping` for `test_class`."""
mapping = [(task, get_model_for_pipeline_test(test_class, task)) for task in pipeline_test_mapping]
mapping = sorted([(task, model) for task, model in mapping if model is not None], key=lambda x: x[0])
return dict(mapping)
def get_pipeline_model_mapping_string(test_class):
"""Get `pipeline_model_mapping` for `test_class` as a string (to be added to the test file).
This will be a 1-line string. After this is added to a test file, `make style` will format it beautifully.
"""
framework = get_framework(test_class)
if framework == "pt":
framework = "torch"
default_value = "{}"
mapping = get_pipeline_model_mapping(test_class)
if len(mapping) == 0:
return ""
texts = []
for task, model_classes in mapping.items():
if isinstance(model_classes, (tuple, list)):
# A list/tuple of model classes
value = "(" + ", ".join([x.__name__ for x in model_classes]) + ")"
else:
# A single model class
value = model_classes.__name__
texts.append(f'"{task}": {value}')
text = "{" + ", ".join(texts) + "}"
text = f"pipeline_model_mapping = {text} if is_{framework}_available() else {default_value}"
return text
def is_valid_test_class(test_class):
"""Restrict to `XXXModelTesterMixin` and should be a subclass of `unittest.TestCase`."""
base_class_names = {"ModelTesterMixin", "TFModelTesterMixin", "FlaxModelTesterMixin"}
if not issubclass(test_class, unittest.TestCase):
return False
return len(base_class_names.intersection([x.__name__ for x in test_class.__bases__])) > 0
def find_test_class(test_file):
"""Find a test class in `test_file` to which we will add `pipeline_model_mapping`."""
test_classes = [x for x in get_test_classes(test_file) if is_valid_test_class(x)]
target_test_class = None
for test_class in test_classes:
# If a test class has defined `pipeline_model_mapping`, let's take it
if getattr(test_class, "pipeline_model_mapping", None) is not None:
target_test_class = test_class
break
# Take the test class with the shortest name (just a heuristic)
if target_test_class is None and len(test_classes) > 0:
target_test_class = sorted(test_classes, key=lambda x: (len(x.__name__), x.__name__))[0]
return target_test_class
def find_block_ending(lines, start_idx, indent_level):
end_idx = start_idx
for idx, line in enumerate(lines[start_idx:]):
indent = len(line) - len(line.lstrip())
if idx == 0 or indent > indent_level or (indent == indent_level and line.strip() == ")"):
end_idx = start_idx + idx
elif idx > 0 and indent <= indent_level:
# Outside the definition block of `pipeline_model_mapping`
break
return end_idx
def add_pipeline_model_mapping(test_class, overwrite=False):
"""Add `pipeline_model_mapping` to `test_class`."""
if getattr(test_class, "pipeline_model_mapping", None) is not None:
if not overwrite:
return "", -1
line_to_add = get_pipeline_model_mapping_string(test_class)
if len(line_to_add) == 0:
return "", -1
line_to_add = line_to_add + "\n"
# The code defined the class `test_class`
class_lines, class_start_line_no = inspect.getsourcelines(test_class)
# `inspect` gives the code for an object, including decorator(s) if any.
# We (only) need the exact line of the class definition.
for idx, line in enumerate(class_lines):
if line.lstrip().startswith("class "):
class_lines = class_lines[idx:]
class_start_line_no += idx
break
class_end_line_no = class_start_line_no + len(class_lines) - 1
# The index in `class_lines` that starts the definition of `all_model_classes`, `all_generative_model_classes` or
# `pipeline_model_mapping`. This assumes they are defined in such order, and we take the start index of the last
# block that appears in a `test_class`.
start_idx = None
# The indent level of the line at `class_lines[start_idx]` (if defined)
indent_level = 0
# To record if `pipeline_model_mapping` is found in `test_class`.
def_line = None
for idx, line in enumerate(class_lines):
if line.strip().startswith("all_model_classes = "):
indent_level = len(line) - len(line.lstrip())
start_idx = idx
elif line.strip().startswith("all_generative_model_classes = "):
indent_level = len(line) - len(line.lstrip())
start_idx = idx
elif line.strip().startswith("pipeline_model_mapping = "):
indent_level = len(line) - len(line.lstrip())
start_idx = idx
def_line = line
break
if start_idx is None:
return "", -1
# Find the ending index (inclusive) of the above found block.
end_idx = find_block_ending(class_lines, start_idx, indent_level)
# Extract `is_xxx_available()` from existing blocks: some models require specific libraries like `timm` and use
# `is_timm_available()` instead of `is_torch_available()`.
# Keep leading and trailing whitespaces
r = re.compile(r"\s(is_\S+?_available\(\))\s")
for line in class_lines[start_idx : end_idx + 1]:
backend_condition = r.search(line)
if backend_condition is not None:
# replace the leading and trailing whitespaces to the space character " ".
target = " " + backend_condition[0][1:-1] + " "
line_to_add = r.sub(target, line_to_add)
break
if def_line is None:
# `pipeline_model_mapping` is not defined. The target index is set to the ending index (inclusive) of
# `all_model_classes` or `all_generative_model_classes`.
target_idx = end_idx
else:
# `pipeline_model_mapping` is defined. The target index is set to be one **BEFORE** its start index.
target_idx = start_idx - 1
# mark the lines of the currently existing `pipeline_model_mapping` to be removed.
for idx in range(start_idx, end_idx + 1):
# These lines are going to be removed before writing to the test file.
class_lines[idx] = None # noqa
# Make sure the test class is a subclass of `PipelineTesterMixin`.
parent_classes = [x.__name__ for x in test_class.__bases__]
if "PipelineTesterMixin" not in parent_classes:
# Put `PipelineTesterMixin` just before `unittest.TestCase`
_parent_classes = [x for x in parent_classes if x != "TestCase"] + ["PipelineTesterMixin"]
if "TestCase" in parent_classes:
# Here we **assume** the original string is always with `unittest.TestCase`.
_parent_classes.append("unittest.TestCase")
parent_classes = ", ".join(_parent_classes)
for idx, line in enumerate(class_lines):
# Find the ending of the declaration of `test_class`
if line.strip().endswith("):"):
# mark the lines of the declaration of `test_class` to be removed
for _idx in range(idx + 1):
class_lines[_idx] = None # noqa
break
# Add the new, one-line, class declaration for `test_class`
class_lines[0] = f"class {test_class.__name__}({parent_classes}):\n"
# Add indentation
line_to_add = " " * indent_level + line_to_add
# Insert `pipeline_model_mapping` to `class_lines`.
# (The line at `target_idx` should be kept by definition!)
class_lines = class_lines[: target_idx + 1] + [line_to_add] + class_lines[target_idx + 1 :]
# Remove the lines that are marked to be removed
class_lines = [x for x in class_lines if x is not None]
# Move from test class to module (in order to write to the test file)
module_lines = inspect.getsourcelines(inspect.getmodule(test_class))[0]
# Be careful with the 1-off between line numbers and array indices
module_lines = module_lines[: class_start_line_no - 1] + class_lines + module_lines[class_end_line_no:]
code = "".join(module_lines)
moddule_file = inspect.getsourcefile(test_class)
with open(moddule_file, "w", encoding="UTF-8", newline="\n") as fp:
fp.write(code)
return line_to_add
def add_pipeline_model_mapping_to_test_file(test_file, overwrite=False):
"""Add `pipeline_model_mapping` to `test_file`."""
test_class = find_test_class(test_file)
if test_class:
add_pipeline_model_mapping(test_class, overwrite=overwrite)
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument(
"--test_file", type=str, help="A path to the test file, starting with the repository's `tests` directory."
)
parser.add_argument(
"--all",
action="store_true",
help="If to check and modify all test files.",
)
parser.add_argument(
"--overwrite",
action="store_true",
help="If to overwrite a test class if it has already defined `pipeline_model_mapping`.",
)
args = parser.parse_args()
if not args.all and not args.test_file:
raise ValueError("Please specify either `test_file` or pass `--all` to check/modify all test files.")
elif args.all and args.test_file:
raise ValueError("Only one of `--test_file` and `--all` could be specified.")
test_files = []
if args.test_file:
test_files = [args.test_file]
else:
pattern = os.path.join("tests", "models", "**", "test_modeling_*.py")
for test_file in glob.glob(pattern):
# `Flax` is not concerned at this moment
if not test_file.startswith("test_modeling_flax_"):
test_files.append(test_file)
for test_file in test_files:
if test_file in TEST_FILE_TO_IGNORE:
print(f"[SKIPPED] {test_file} is skipped as it is in `TEST_FILE_TO_IGNORE` in the file {__file__}.")
continue
add_pipeline_model_mapping_to_test_file(test_file, overwrite=args.overwrite)
| 0 |
hf_public_repos/transformers | hf_public_repos/transformers/utils/update_tiny_models.py | # coding=utf-8
# Copyright 2023 The HuggingFace Inc. team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""A script running `create_dummy_models.py` with a pre-defined set of arguments.
This file is intended to be used in a CI workflow file without the need of specifying arguments. It creates and uploads
tiny models for all model classes (if their tiny versions are not on the Hub yet), as well as produces an updated
version of `tests/utils/tiny_model_summary.json`. That updated file should be merged into the `main` branch of
`transformers` so the pipeline testing will use the latest created/updated tiny models.
"""
import argparse
import copy
import json
import multiprocessing
import os
import time
from create_dummy_models import COMPOSITE_MODELS, create_tiny_models
from huggingface_hub import ModelFilter, hf_api
import transformers
from transformers import AutoFeatureExtractor, AutoImageProcessor, AutoTokenizer
from transformers.image_processing_utils import BaseImageProcessor
def get_all_model_names():
model_names = set()
# Each auto modeling files contains multiple mappings. Let's get them in a dynamic way.
for module_name in ["modeling_auto", "modeling_tf_auto", "modeling_flax_auto"]:
module = getattr(transformers.models.auto, module_name, None)
if module is None:
continue
# all mappings in a single auto modeling file
mapping_names = [
x
for x in dir(module)
if x.endswith("_MAPPING_NAMES")
and (x.startswith("MODEL_") or x.startswith("TF_MODEL_") or x.startswith("FLAX_MODEL_"))
]
for name in mapping_names:
mapping = getattr(module, name)
if mapping is not None:
for v in mapping.values():
if isinstance(v, (list, tuple)):
model_names.update(v)
elif isinstance(v, str):
model_names.add(v)
return sorted(model_names)
def get_tiny_model_names_from_repo():
# All model names defined in auto mappings
model_names = set(get_all_model_names())
with open("tests/utils/tiny_model_summary.json") as fp:
tiny_model_info = json.load(fp)
tiny_models_names = set()
for model_base_name in tiny_model_info:
tiny_models_names.update(tiny_model_info[model_base_name]["model_classes"])
# Remove a tiny model name if one of its framework implementation hasn't yet a tiny version on the Hub.
not_on_hub = model_names.difference(tiny_models_names)
for model_name in copy.copy(tiny_models_names):
if not model_name.startswith("TF") and f"TF{model_name}" in not_on_hub:
tiny_models_names.remove(model_name)
elif model_name.startswith("TF") and model_name[2:] in not_on_hub:
tiny_models_names.remove(model_name)
return sorted(tiny_models_names)
def get_tiny_model_summary_from_hub(output_path):
special_models = COMPOSITE_MODELS.values()
# All tiny model base names on Hub
model_names = get_all_model_names()
models = hf_api.list_models(
filter=ModelFilter(
author="hf-internal-testing",
)
)
_models = set()
for x in models:
model = x.modelId
org, model = model.split("/")
if not model.startswith("tiny-random-"):
continue
model = model.replace("tiny-random-", "")
if not model[0].isupper():
continue
if model not in model_names and model not in special_models:
continue
_models.add(model)
models = sorted(_models)
# All tiny model names on Hub
summary = {}
for model in models:
repo_id = f"hf-internal-testing/tiny-random-{model}"
model = model.split("-")[0]
try:
repo_info = hf_api.repo_info(repo_id)
content = {
"tokenizer_classes": set(),
"processor_classes": set(),
"model_classes": set(),
"sha": repo_info.sha,
}
except Exception:
continue
try:
time.sleep(1)
tokenizer_fast = AutoTokenizer.from_pretrained(repo_id)
content["tokenizer_classes"].add(tokenizer_fast.__class__.__name__)
except Exception:
pass
try:
time.sleep(1)
tokenizer_slow = AutoTokenizer.from_pretrained(repo_id, use_fast=False)
content["tokenizer_classes"].add(tokenizer_slow.__class__.__name__)
except Exception:
pass
try:
time.sleep(1)
img_p = AutoImageProcessor.from_pretrained(repo_id)
content["processor_classes"].add(img_p.__class__.__name__)
except Exception:
pass
try:
time.sleep(1)
feat_p = AutoFeatureExtractor.from_pretrained(repo_id)
if not isinstance(feat_p, BaseImageProcessor):
content["processor_classes"].add(feat_p.__class__.__name__)
except Exception:
pass
try:
time.sleep(1)
model_class = getattr(transformers, model)
m = model_class.from_pretrained(repo_id)
content["model_classes"].add(m.__class__.__name__)
except Exception:
pass
try:
time.sleep(1)
model_class = getattr(transformers, f"TF{model}")
m = model_class.from_pretrained(repo_id)
content["model_classes"].add(m.__class__.__name__)
except Exception:
pass
content["tokenizer_classes"] = sorted(content["tokenizer_classes"])
content["processor_classes"] = sorted(content["processor_classes"])
content["model_classes"] = sorted(content["model_classes"])
summary[model] = content
with open(os.path.join(output_path, "hub_tiny_model_summary.json"), "w") as fp:
json.dump(summary, fp, ensure_ascii=False, indent=4)
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("--num_workers", default=1, type=int, help="The number of workers to run.")
args = parser.parse_args()
# This has to be `spawn` to avoid hanging forever!
multiprocessing.set_start_method("spawn")
output_path = "tiny_models"
all = True
model_types = None
models_to_skip = get_tiny_model_names_from_repo()
no_check = True
upload = True
organization = "hf-internal-testing"
create_tiny_models(
output_path,
all,
model_types,
models_to_skip,
no_check,
upload,
organization,
token=os.environ.get("TOKEN", None),
num_workers=args.num_workers,
)
| 0 |
hf_public_repos/transformers | hf_public_repos/transformers/utils/check_inits.py | # coding=utf-8
# Copyright 2020 The HuggingFace Inc. team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import collections
import os
import re
from pathlib import Path
PATH_TO_TRANSFORMERS = "src/transformers"
# Matches is_xxx_available()
_re_backend = re.compile(r"is\_([a-z_]*)_available()")
# Catches a one-line _import_struct = {xxx}
_re_one_line_import_struct = re.compile(r"^_import_structure\s+=\s+\{([^\}]+)\}")
# Catches a line with a key-values pattern: "bla": ["foo", "bar"]
_re_import_struct_key_value = re.compile(r'\s+"\S*":\s+\[([^\]]*)\]')
# Catches a line if not is_foo_available
_re_test_backend = re.compile(r"^\s*if\s+not\s+is\_[a-z_]*\_available\(\)")
# Catches a line _import_struct["bla"].append("foo")
_re_import_struct_add_one = re.compile(r'^\s*_import_structure\["\S*"\]\.append\("(\S*)"\)')
# Catches a line _import_struct["bla"].extend(["foo", "bar"]) or _import_struct["bla"] = ["foo", "bar"]
_re_import_struct_add_many = re.compile(r"^\s*_import_structure\[\S*\](?:\.extend\(|\s*=\s+)\[([^\]]*)\]")
# Catches a line with an object between quotes and a comma: "MyModel",
_re_quote_object = re.compile(r'^\s+"([^"]+)",')
# Catches a line with objects between brackets only: ["foo", "bar"],
_re_between_brackets = re.compile(r"^\s+\[([^\]]+)\]")
# Catches a line with from foo import bar, bla, boo
_re_import = re.compile(r"\s+from\s+\S*\s+import\s+([^\(\s].*)\n")
# Catches a line with try:
_re_try = re.compile(r"^\s*try:")
# Catches a line with else:
_re_else = re.compile(r"^\s*else:")
def find_backend(line):
"""Find one (or multiple) backend in a code line of the init."""
if _re_test_backend.search(line) is None:
return None
backends = [b[0] for b in _re_backend.findall(line)]
backends.sort()
return "_and_".join(backends)
def parse_init(init_file):
"""
Read an init_file and parse (per backend) the _import_structure objects defined and the TYPE_CHECKING objects
defined
"""
with open(init_file, "r", encoding="utf-8", newline="\n") as f:
lines = f.readlines()
line_index = 0
while line_index < len(lines) and not lines[line_index].startswith("_import_structure = {"):
line_index += 1
# If this is a traditional init, just return.
if line_index >= len(lines):
return None
# First grab the objects without a specific backend in _import_structure
objects = []
while not lines[line_index].startswith("if TYPE_CHECKING") and find_backend(lines[line_index]) is None:
line = lines[line_index]
# If we have everything on a single line, let's deal with it.
if _re_one_line_import_struct.search(line):
content = _re_one_line_import_struct.search(line).groups()[0]
imports = re.findall(r"\[([^\]]+)\]", content)
for imp in imports:
objects.extend([obj[1:-1] for obj in imp.split(", ")])
line_index += 1
continue
single_line_import_search = _re_import_struct_key_value.search(line)
if single_line_import_search is not None:
imports = [obj[1:-1] for obj in single_line_import_search.groups()[0].split(", ") if len(obj) > 0]
objects.extend(imports)
elif line.startswith(" " * 8 + '"'):
objects.append(line[9:-3])
line_index += 1
import_dict_objects = {"none": objects}
# Let's continue with backend-specific objects in _import_structure
while not lines[line_index].startswith("if TYPE_CHECKING"):
# If the line is an if not is_backend_available, we grab all objects associated.
backend = find_backend(lines[line_index])
# Check if the backend declaration is inside a try block:
if _re_try.search(lines[line_index - 1]) is None:
backend = None
if backend is not None:
line_index += 1
# Scroll until we hit the else block of try-except-else
while _re_else.search(lines[line_index]) is None:
line_index += 1
line_index += 1
objects = []
# Until we unindent, add backend objects to the list
while len(lines[line_index]) <= 1 or lines[line_index].startswith(" " * 4):
line = lines[line_index]
if _re_import_struct_add_one.search(line) is not None:
objects.append(_re_import_struct_add_one.search(line).groups()[0])
elif _re_import_struct_add_many.search(line) is not None:
imports = _re_import_struct_add_many.search(line).groups()[0].split(", ")
imports = [obj[1:-1] for obj in imports if len(obj) > 0]
objects.extend(imports)
elif _re_between_brackets.search(line) is not None:
imports = _re_between_brackets.search(line).groups()[0].split(", ")
imports = [obj[1:-1] for obj in imports if len(obj) > 0]
objects.extend(imports)
elif _re_quote_object.search(line) is not None:
objects.append(_re_quote_object.search(line).groups()[0])
elif line.startswith(" " * 8 + '"'):
objects.append(line[9:-3])
elif line.startswith(" " * 12 + '"'):
objects.append(line[13:-3])
line_index += 1
import_dict_objects[backend] = objects
else:
line_index += 1
# At this stage we are in the TYPE_CHECKING part, first grab the objects without a specific backend
objects = []
while (
line_index < len(lines)
and find_backend(lines[line_index]) is None
and not lines[line_index].startswith("else")
):
line = lines[line_index]
single_line_import_search = _re_import.search(line)
if single_line_import_search is not None:
objects.extend(single_line_import_search.groups()[0].split(", "))
elif line.startswith(" " * 8):
objects.append(line[8:-2])
line_index += 1
type_hint_objects = {"none": objects}
# Let's continue with backend-specific objects
while line_index < len(lines):
# If the line is an if is_backend_available, we grab all objects associated.
backend = find_backend(lines[line_index])
# Check if the backend declaration is inside a try block:
if _re_try.search(lines[line_index - 1]) is None:
backend = None
if backend is not None:
line_index += 1
# Scroll until we hit the else block of try-except-else
while _re_else.search(lines[line_index]) is None:
line_index += 1
line_index += 1
objects = []
# Until we unindent, add backend objects to the list
while len(lines[line_index]) <= 1 or lines[line_index].startswith(" " * 8):
line = lines[line_index]
single_line_import_search = _re_import.search(line)
if single_line_import_search is not None:
objects.extend(single_line_import_search.groups()[0].split(", "))
elif line.startswith(" " * 12):
objects.append(line[12:-2])
line_index += 1
type_hint_objects[backend] = objects
else:
line_index += 1
return import_dict_objects, type_hint_objects
def analyze_results(import_dict_objects, type_hint_objects):
"""
Analyze the differences between _import_structure objects and TYPE_CHECKING objects found in an init.
"""
def find_duplicates(seq):
return [k for k, v in collections.Counter(seq).items() if v > 1]
if list(import_dict_objects.keys()) != list(type_hint_objects.keys()):
return ["Both sides of the init do not have the same backends!"]
errors = []
for key in import_dict_objects.keys():
duplicate_imports = find_duplicates(import_dict_objects[key])
if duplicate_imports:
errors.append(f"Duplicate _import_structure definitions for: {duplicate_imports}")
duplicate_type_hints = find_duplicates(type_hint_objects[key])
if duplicate_type_hints:
errors.append(f"Duplicate TYPE_CHECKING objects for: {duplicate_type_hints}")
if sorted(set(import_dict_objects[key])) != sorted(set(type_hint_objects[key])):
name = "base imports" if key == "none" else f"{key} backend"
errors.append(f"Differences for {name}:")
for a in type_hint_objects[key]:
if a not in import_dict_objects[key]:
errors.append(f" {a} in TYPE_HINT but not in _import_structure.")
for a in import_dict_objects[key]:
if a not in type_hint_objects[key]:
errors.append(f" {a} in _import_structure but not in TYPE_HINT.")
return errors
def check_all_inits():
"""
Check all inits in the transformers repo and raise an error if at least one does not define the same objects in
both halves.
"""
failures = []
for root, _, files in os.walk(PATH_TO_TRANSFORMERS):
if "__init__.py" in files:
fname = os.path.join(root, "__init__.py")
objects = parse_init(fname)
if objects is not None:
errors = analyze_results(*objects)
if len(errors) > 0:
errors[0] = f"Problem in {fname}, both halves do not define the same objects.\n{errors[0]}"
failures.append("\n".join(errors))
if len(failures) > 0:
raise ValueError("\n\n".join(failures))
def get_transformers_submodules():
"""
Returns the list of Transformers submodules.
"""
submodules = []
for path, directories, files in os.walk(PATH_TO_TRANSFORMERS):
for folder in directories:
# Ignore private modules
if folder.startswith("_"):
directories.remove(folder)
continue
# Ignore leftovers from branches (empty folders apart from pycache)
if len(list((Path(path) / folder).glob("*.py"))) == 0:
continue
short_path = str((Path(path) / folder).relative_to(PATH_TO_TRANSFORMERS))
submodule = short_path.replace(os.path.sep, ".")
submodules.append(submodule)
for fname in files:
if fname == "__init__.py":
continue
short_path = str((Path(path) / fname).relative_to(PATH_TO_TRANSFORMERS))
submodule = short_path.replace(".py", "").replace(os.path.sep, ".")
if len(submodule.split(".")) == 1:
submodules.append(submodule)
return submodules
IGNORE_SUBMODULES = [
"convert_pytorch_checkpoint_to_tf2",
"modeling_flax_pytorch_utils",
"models.esm.openfold_utils",
]
def check_submodules():
# This is to make sure the transformers module imported is the one in the repo.
from transformers.utils import direct_transformers_import
transformers = direct_transformers_import(PATH_TO_TRANSFORMERS)
import_structure_keys = set(transformers._import_structure.keys())
# This contains all the base keys of the _import_structure object defined in the init, but if the user is missing
# some optional dependencies, they may not have all of them. Thus we read the init to read all additions and
# (potentiall re-) add them.
with open(os.path.join(PATH_TO_TRANSFORMERS, "__init__.py"), "r") as f:
init_content = f.read()
import_structure_keys.update(set(re.findall(r"import_structure\[\"([^\"]*)\"\]", init_content)))
module_not_registered = [
module
for module in get_transformers_submodules()
if module not in IGNORE_SUBMODULES and module not in import_structure_keys
]
if len(module_not_registered) > 0:
list_of_modules = "\n".join(f"- {module}" for module in module_not_registered)
raise ValueError(
"The following submodules are not properly registed in the main init of Transformers:\n"
f"{list_of_modules}\n"
"Make sure they appear somewhere in the keys of `_import_structure` with an empty list as value."
)
if __name__ == "__main__":
check_all_inits()
check_submodules()
| 0 |
hf_public_repos/transformers | hf_public_repos/transformers/utils/past_ci_versions.py | import argparse
import os
past_versions_testing = {
"pytorch": {
"1.13": {
"torch": "1.13.1",
"torchvision": "0.14.1",
"torchaudio": "0.13.1",
"python": 3.9,
"cuda": "cu116",
"install": (
"python3 -m pip install --no-cache-dir -U torch==1.13.1 torchvision==0.14.1 torchaudio==0.13.1"
" --extra-index-url https://download.pytorch.org/whl/cu116"
),
"base_image": "nvidia/cuda:11.6.2-cudnn8-devel-ubuntu20.04",
},
"1.12": {
"torch": "1.12.1",
"torchvision": "0.13.1",
"torchaudio": "0.12.1",
"python": 3.9,
"cuda": "cu113",
"install": (
"python3 -m pip install --no-cache-dir -U torch==1.12.1 torchvision==0.13.1 torchaudio==0.12.1"
" --extra-index-url https://download.pytorch.org/whl/cu113"
),
"base_image": "nvidia/cuda:11.2.2-cudnn8-devel-ubuntu20.04",
},
"1.11": {
"torch": "1.11.0",
"torchvision": "0.12.0",
"torchaudio": "0.11.0",
"python": 3.9,
"cuda": "cu113",
"install": (
"python3 -m pip install --no-cache-dir -U torch==1.11.0 torchvision==0.12.0 torchaudio==0.11.0"
" --extra-index-url https://download.pytorch.org/whl/cu113"
),
"base_image": "nvidia/cuda:11.2.2-cudnn8-devel-ubuntu20.04",
},
"1.10": {
"torch": "1.10.2",
"torchvision": "0.11.3",
"torchaudio": "0.10.2",
"python": 3.9,
"cuda": "cu113",
"install": (
"python3 -m pip install --no-cache-dir -U torch==1.10.2 torchvision==0.11.3 torchaudio==0.10.2"
" --extra-index-url https://download.pytorch.org/whl/cu113"
),
"base_image": "nvidia/cuda:11.2.2-cudnn8-devel-ubuntu20.04",
},
# torchaudio < 0.10 has no CUDA-enabled binary distributions
"1.9": {
"torch": "1.9.1",
"torchvision": "0.10.1",
"torchaudio": "0.9.1",
"python": 3.9,
"cuda": "cu111",
"install": (
"python3 -m pip install --no-cache-dir -U torch==1.9.1 torchvision==0.10.1 torchaudio==0.9.1"
" --extra-index-url https://download.pytorch.org/whl/cu111"
),
"base_image": "nvidia/cuda:11.2.2-cudnn8-devel-ubuntu20.04",
},
},
"tensorflow": {
"2.11": {
"tensorflow": "2.11.1",
"install": "python3 -m pip install --no-cache-dir -U tensorflow==2.11.1",
"base_image": "nvidia/cuda:11.2.2-cudnn8-devel-ubuntu20.04",
},
"2.10": {
"tensorflow": "2.10.1",
"install": "python3 -m pip install --no-cache-dir -U tensorflow==2.10.1",
"base_image": "nvidia/cuda:11.2.2-cudnn8-devel-ubuntu20.04",
},
"2.9": {
"tensorflow": "2.9.3",
"install": "python3 -m pip install --no-cache-dir -U tensorflow==2.9.3",
"base_image": "nvidia/cuda:11.2.2-cudnn8-devel-ubuntu20.04",
},
"2.8": {
"tensorflow": "2.8.2",
"install": "python3 -m pip install --no-cache-dir -U tensorflow==2.8.2",
"base_image": "nvidia/cuda:11.2.2-cudnn8-devel-ubuntu20.04",
},
"2.7": {
"tensorflow": "2.7.3",
"install": "python3 -m pip install --no-cache-dir -U tensorflow==2.7.3",
"base_image": "nvidia/cuda:11.2.2-cudnn8-devel-ubuntu20.04",
},
"2.6": {
"tensorflow": "2.6.5",
"install": "python3 -m pip install --no-cache-dir -U tensorflow==2.6.5",
"base_image": "nvidia/cuda:11.2.2-cudnn8-devel-ubuntu20.04",
},
"2.5": {
"tensorflow": "2.5.3",
"install": "python3 -m pip install --no-cache-dir -U tensorflow==2.5.3",
"base_image": "nvidia/cuda:11.2.2-cudnn8-devel-ubuntu20.04",
},
},
}
if __name__ == "__main__":
parser = argparse.ArgumentParser("Choose the framework and version to install")
parser.add_argument(
"--framework", help="The framework to install. Should be `torch` or `tensorflow`", type=str, required=True
)
parser.add_argument("--version", help="The version of the framework to install.", type=str, required=True)
args = parser.parse_args()
info = past_versions_testing[args.framework][args.version]
os.system(f'echo "export INSTALL_CMD=\'{info["install"]}\'" >> ~/.profile')
print(f'echo "export INSTALL_CMD=\'{info["install"]}\'" >> ~/.profile')
cuda = ""
if args.framework == "pytorch":
cuda = info["cuda"]
os.system(f"echo \"export CUDA='{cuda}'\" >> ~/.profile")
print(f"echo \"export CUDA='{cuda}'\" >> ~/.profile")
| 0 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.