
code
stringlengths 501
5.19M
| package
stringlengths 2
81
| path
stringlengths 9
304
| filename
stringlengths 4
145
|
|---|---|---|---|
from __future__ import annotations
from typing import Callable, Optional, TYPE_CHECKING, Tuple, Type, TypeVar, Union
import inspect
import os
from .item import Item, ItemCallbackType
from ..enums import ButtonStyle, ComponentType
from ..partial_emoji import PartialEmoji, _EmojiTag
from ..components import Button as ButtonComponent
__all__ = (
'Button',
'button',
)
if TYPE_CHECKING:
from .view import View
from ..emoji import Emoji
B = TypeVar('B', bound='Button')
V = TypeVar('V', bound='View', covariant=True)
class Button(Item[V]):
"""Represents a UI button.
.. versionadded:: 2.0
Parameters
------------
style: :class:`discord.ButtonStyle`
The style of the button.
custom_id: Optional[:class:`str`]
The ID of the button that gets received during an interaction.
If this button is for a URL, it does not have a custom ID.
url: Optional[:class:`str`]
The URL this button sends you to.
disabled: :class:`bool`
Whether the button is disabled or not.
label: Optional[:class:`str`]
The label of the button, if any.
emoji: Optional[Union[:class:`.PartialEmoji`, :class:`.Emoji`, :class:`str`]]
The emoji of the button, if available.
row: Optional[:class:`int`]
The relative row this button belongs to. A Discord component can only have 5
rows. By default, items are arranged automatically into those 5 rows. If you'd
like to control the relative positioning of the row then passing an index is advised.
For example, row=1 will show up before row=2. Defaults to ``None``, which is automatic
ordering. The row number must be between 0 and 4 (i.e. zero indexed).
"""
__item_repr_attributes__: Tuple[str, ...] = (
'style',
'url',
'disabled',
'label',
'emoji',
'row',
)
def __init__(
self,
*,
style: ButtonStyle = ButtonStyle.secondary,
label: Optional[str] = None,
disabled: bool = False,
custom_id: Optional[str] = None,
url: Optional[str] = None,
emoji: Optional[Union[str, Emoji, PartialEmoji]] = None,
row: Optional[int] = None,
):
super().__init__()
if custom_id is not None and url is not None:
raise TypeError('cannot mix both url and custom_id with Button')
self._provided_custom_id = custom_id is not None
if url is None and custom_id is None:
custom_id = os.urandom(16).hex()
if url is not None:
style = ButtonStyle.link
if emoji is not None:
if isinstance(emoji, str):
emoji = PartialEmoji.from_str(emoji)
elif isinstance(emoji, _EmojiTag):
emoji = emoji._to_partial()
else:
raise TypeError(f'expected emoji to be str, Emoji, or PartialEmoji not {emoji.__class__}')
self._underlying = ButtonComponent._raw_construct(
type=ComponentType.button,
custom_id=custom_id,
url=url,
disabled=disabled,
label=label,
style=style,
emoji=emoji,
)
self.row = row
@property
def style(self) -> ButtonStyle:
""":class:`discord.ButtonStyle`: The style of the button."""
return self._underlying.style
@style.setter
def style(self, value: ButtonStyle):
self._underlying.style = value
@property
def custom_id(self) -> Optional[str]:
"""Optional[:class:`str`]: The ID of the button that gets received during an interaction.
If this button is for a URL, it does not have a custom ID.
"""
return self._underlying.custom_id
@custom_id.setter
def custom_id(self, value: Optional[str]):
if value is not None and not isinstance(value, str):
raise TypeError('custom_id must be None or str')
self._underlying.custom_id = value
@property
def url(self) -> Optional[str]:
"""Optional[:class:`str`]: The URL this button sends you to."""
return self._underlying.url
@url.setter
def url(self, value: Optional[str]):
if value is not None and not isinstance(value, str):
raise TypeError('url must be None or str')
self._underlying.url = value
@property
def disabled(self) -> bool:
""":class:`bool`: Whether the button is disabled or not."""
return self._underlying.disabled
@disabled.setter
def disabled(self, value: bool):
self._underlying.disabled = bool(value)
@property
def label(self) -> Optional[str]:
"""Optional[:class:`str`]: The label of the button, if available."""
return self._underlying.label
@label.setter
def label(self, value: Optional[str]):
self._underlying.label = str(value) if value is not None else value
@property
def emoji(self) -> Optional[PartialEmoji]:
"""Optional[:class:`.PartialEmoji`]: The emoji of the button, if available."""
return self._underlying.emoji
@emoji.setter
def emoji(self, value: Optional[Union[str, Emoji, PartialEmoji]]): # type: ignore
if value is not None:
if isinstance(value, str):
self._underlying.emoji = PartialEmoji.from_str(value)
elif isinstance(value, _EmojiTag):
self._underlying.emoji = value._to_partial()
else:
raise TypeError(f'expected str, Emoji, or PartialEmoji, received {value.__class__} instead')
else:
self._underlying.emoji = None
@classmethod
def from_component(cls: Type[B], button: ButtonComponent) -> B:
return cls(
style=button.style,
label=button.label,
disabled=button.disabled,
custom_id=button.custom_id,
url=button.url,
emoji=button.emoji,
row=None,
)
@property
def type(self) -> ComponentType:
return self._underlying.type
def to_component_dict(self):
return self._underlying.to_dict()
def is_dispatchable(self) -> bool:
return self.custom_id is not None
def is_persistent(self) -> bool:
if self.style is ButtonStyle.link:
return self.url is not None
return super().is_persistent()
def refresh_component(self, button: ButtonComponent) -> None:
self._underlying = button
def button(
*,
label: Optional[str] = None,
custom_id: Optional[str] = None,
disabled: bool = False,
style: ButtonStyle = ButtonStyle.secondary,
emoji: Optional[Union[str, Emoji, PartialEmoji]] = None,
row: Optional[int] = None,
) -> Callable[[ItemCallbackType], ItemCallbackType]:
"""A decorator that attaches a button to a component.
The function being decorated should have three parameters, ``self`` representing
the :class:`discord.ui.View`, the :class:`discord.ui.Button` being pressed and
the :class:`discord.Interaction` you receive.
.. note::
Buttons with a URL cannot be created with this function.
Consider creating a :class:`Button` manually instead.
This is because buttons with a URL do not have a callback
associated with them since Discord does not do any processing
with it.
Parameters
------------
label: Optional[:class:`str`]
The label of the button, if any.
custom_id: Optional[:class:`str`]
The ID of the button that gets received during an interaction.
It is recommended not to set this parameter to prevent conflicts.
style: :class:`.ButtonStyle`
The style of the button. Defaults to :attr:`.ButtonStyle.grey`.
disabled: :class:`bool`
Whether the button is disabled or not. Defaults to ``False``.
emoji: Optional[Union[:class:`str`, :class:`.Emoji`, :class:`.PartialEmoji`]]
The emoji of the button. This can be in string form or a :class:`.PartialEmoji`
or a full :class:`.Emoji`.
row: Optional[:class:`int`]
The relative row this button belongs to. A Discord component can only have 5
rows. By default, items are arranged automatically into those 5 rows. If you'd
like to control the relative positioning of the row then passing an index is advised.
For example, row=1 will show up before row=2. Defaults to ``None``, which is automatic
ordering. The row number must be between 0 and 4 (i.e. zero indexed).
"""
def decorator(func: ItemCallbackType) -> ItemCallbackType:
if not inspect.iscoroutinefunction(func):
raise TypeError('button function must be a coroutine function')
func.__discord_ui_model_type__ = Button
func.__discord_ui_model_kwargs__ = {
'style': style,
'custom_id': custom_id,
'url': None,
'disabled': disabled,
'label': label,
'emoji': emoji,
'row': row,
}
return func
return decorator | zarenacord.py | /zarenacord.py-2.0.0-py3-none-any.whl/discord/ui/button.py | button.py |
from __future__ import annotations
from typing import List, Optional, TYPE_CHECKING, Tuple, TypeVar, Type, Callable, Union
import inspect
import os
from .item import Item, ItemCallbackType
from ..enums import ComponentType
from ..partial_emoji import PartialEmoji
from ..emoji import Emoji
from ..interactions import Interaction
from ..utils import MISSING
from ..components import (
SelectOption,
SelectMenu,
)
__all__ = (
'Select',
'select',
)
if TYPE_CHECKING:
from .view import View
from ..types.components import SelectMenu as SelectMenuPayload
from ..types.interactions import (
ComponentInteractionData,
)
S = TypeVar('S', bound='Select')
V = TypeVar('V', bound='View', covariant=True)
class Select(Item[V]):
"""Represents a UI select menu.
This is usually represented as a drop down menu.
In order to get the selected items that the user has chosen, use :attr:`Select.values`.
.. versionadded:: 2.0
Parameters
------------
custom_id: :class:`str`
The ID of the select menu that gets received during an interaction.
If not given then one is generated for you.
placeholder: Optional[:class:`str`]
The placeholder text that is shown if nothing is selected, if any.
min_values: :class:`int`
The minimum number of items that must be chosen for this select menu.
Defaults to 1 and must be between 1 and 25.
max_values: :class:`int`
The maximum number of items that must be chosen for this select menu.
Defaults to 1 and must be between 1 and 25.
options: List[:class:`discord.SelectOption`]
A list of options that can be selected in this menu.
disabled: :class:`bool`
Whether the select is disabled or not.
row: Optional[:class:`int`]
The relative row this select menu belongs to. A Discord component can only have 5
rows. By default, items are arranged automatically into those 5 rows. If you'd
like to control the relative positioning of the row then passing an index is advised.
For example, row=1 will show up before row=2. Defaults to ``None``, which is automatic
ordering. The row number must be between 0 and 4 (i.e. zero indexed).
"""
__item_repr_attributes__: Tuple[str, ...] = (
'placeholder',
'min_values',
'max_values',
'options',
'disabled',
)
def __init__(
self,
*,
custom_id: str = MISSING,
placeholder: Optional[str] = None,
min_values: int = 1,
max_values: int = 1,
options: List[SelectOption] = MISSING,
disabled: bool = False,
row: Optional[int] = None,
) -> None:
super().__init__()
self._selected_values: List[str] = []
self._provided_custom_id = custom_id is not MISSING
custom_id = os.urandom(16).hex() if custom_id is MISSING else custom_id
options = [] if options is MISSING else options
self._underlying = SelectMenu._raw_construct(
custom_id=custom_id,
type=ComponentType.select,
placeholder=placeholder,
min_values=min_values,
max_values=max_values,
options=options,
disabled=disabled,
)
self.row = row
@property
def custom_id(self) -> str:
""":class:`str`: The ID of the select menu that gets received during an interaction."""
return self._underlying.custom_id
@custom_id.setter
def custom_id(self, value: str):
if not isinstance(value, str):
raise TypeError('custom_id must be None or str')
self._underlying.custom_id = value
@property
def placeholder(self) -> Optional[str]:
"""Optional[:class:`str`]: The placeholder text that is shown if nothing is selected, if any."""
return self._underlying.placeholder
@placeholder.setter
def placeholder(self, value: Optional[str]):
if value is not None and not isinstance(value, str):
raise TypeError('placeholder must be None or str')
self._underlying.placeholder = value
@property
def min_values(self) -> int:
""":class:`int`: The minimum number of items that must be chosen for this select menu."""
return self._underlying.min_values
@min_values.setter
def min_values(self, value: int):
self._underlying.min_values = int(value)
@property
def max_values(self) -> int:
""":class:`int`: The maximum number of items that must be chosen for this select menu."""
return self._underlying.max_values
@max_values.setter
def max_values(self, value: int):
self._underlying.max_values = int(value)
@property
def options(self) -> List[SelectOption]:
"""List[:class:`discord.SelectOption`]: A list of options that can be selected in this menu."""
return self._underlying.options
@options.setter
def options(self, value: List[SelectOption]):
if not isinstance(value, list):
raise TypeError('options must be a list of SelectOption')
if not all(isinstance(obj, SelectOption) for obj in value):
raise TypeError('all list items must subclass SelectOption')
self._underlying.options = value
def add_option(
self,
*,
label: str,
value: str = MISSING,
description: Optional[str] = None,
emoji: Optional[Union[str, Emoji, PartialEmoji]] = None,
default: bool = False,
):
"""Adds an option to the select menu.
To append a pre-existing :class:`discord.SelectOption` use the
:meth:`append_option` method instead.
Parameters
-----------
label: :class:`str`
The label of the option. This is displayed to users.
Can only be up to 100 characters.
value: :class:`str`
The value of the option. This is not displayed to users.
If not given, defaults to the label. Can only be up to 100 characters.
description: Optional[:class:`str`]
An additional description of the option, if any.
Can only be up to 100 characters.
emoji: Optional[Union[:class:`str`, :class:`.Emoji`, :class:`.PartialEmoji`]]
The emoji of the option, if available. This can either be a string representing
the custom or unicode emoji or an instance of :class:`.PartialEmoji` or :class:`.Emoji`.
default: :class:`bool`
Whether this option is selected by default.
Raises
-------
ValueError
The number of options exceeds 25.
"""
option = SelectOption(
label=label,
value=value,
description=description,
emoji=emoji,
default=default,
)
self.append_option(option)
def append_option(self, option: SelectOption):
"""Appends an option to the select menu.
Parameters
-----------
option: :class:`discord.SelectOption`
The option to append to the select menu.
Raises
-------
ValueError
The number of options exceeds 25.
"""
if len(self._underlying.options) > 25:
raise ValueError('maximum number of options already provided')
self._underlying.options.append(option)
@property
def disabled(self) -> bool:
""":class:`bool`: Whether the select is disabled or not."""
return self._underlying.disabled
@disabled.setter
def disabled(self, value: bool):
self._underlying.disabled = bool(value)
@property
def values(self) -> List[str]:
"""List[:class:`str`]: A list of values that have been selected by the user."""
return self._selected_values
@property
def width(self) -> int:
return 5
def to_component_dict(self) -> SelectMenuPayload:
return self._underlying.to_dict()
def refresh_component(self, component: SelectMenu) -> None:
self._underlying = component
def refresh_state(self, interaction: Interaction) -> None:
data: ComponentInteractionData = interaction.data # type: ignore
self._selected_values = data.get('values', [])
@classmethod
def from_component(cls: Type[S], component: SelectMenu) -> S:
return cls(
custom_id=component.custom_id,
placeholder=component.placeholder,
min_values=component.min_values,
max_values=component.max_values,
options=component.options,
disabled=component.disabled,
row=None,
)
@property
def type(self) -> ComponentType:
return self._underlying.type
def is_dispatchable(self) -> bool:
return True
def select(
*,
placeholder: Optional[str] = None,
custom_id: str = MISSING,
min_values: int = 1,
max_values: int = 1,
options: List[SelectOption] = MISSING,
disabled: bool = False,
row: Optional[int] = None,
) -> Callable[[ItemCallbackType], ItemCallbackType]:
"""A decorator that attaches a select menu to a component.
The function being decorated should have three parameters, ``self`` representing
the :class:`discord.ui.View`, the :class:`discord.ui.Select` being pressed and
the :class:`discord.Interaction` you receive.
In order to get the selected items that the user has chosen within the callback
use :attr:`Select.values`.
Parameters
------------
placeholder: Optional[:class:`str`]
The placeholder text that is shown if nothing is selected, if any.
custom_id: :class:`str`
The ID of the select menu that gets received during an interaction.
It is recommended not to set this parameter to prevent conflicts.
row: Optional[:class:`int`]
The relative row this select menu belongs to. A Discord component can only have 5
rows. By default, items are arranged automatically into those 5 rows. If you'd
like to control the relative positioning of the row then passing an index is advised.
For example, row=1 will show up before row=2. Defaults to ``None``, which is automatic
ordering. The row number must be between 0 and 4 (i.e. zero indexed).
min_values: :class:`int`
The minimum number of items that must be chosen for this select menu.
Defaults to 1 and must be between 1 and 25.
max_values: :class:`int`
The maximum number of items that must be chosen for this select menu.
Defaults to 1 and must be between 1 and 25.
options: List[:class:`discord.SelectOption`]
A list of options that can be selected in this menu.
disabled: :class:`bool`
Whether the select is disabled or not. Defaults to ``False``.
"""
def decorator(func: ItemCallbackType) -> ItemCallbackType:
if not inspect.iscoroutinefunction(func):
raise TypeError('select function must be a coroutine function')
func.__discord_ui_model_type__ = Select
func.__discord_ui_model_kwargs__ = {
'placeholder': placeholder,
'custom_id': custom_id,
'row': row,
'min_values': min_values,
'max_values': max_values,
'options': options,
'disabled': disabled,
}
return func
return decorator | zarenacord.py | /zarenacord.py-2.0.0-py3-none-any.whl/discord/ui/select.py | select.py |
from __future__ import annotations
from typing import Any, Callable, Coroutine, Dict, Generic, Optional, TYPE_CHECKING, Tuple, Type, TypeVar
from ..interactions import Interaction
__all__ = (
'Item',
)
if TYPE_CHECKING:
from ..enums import ComponentType
from .view import View
from ..components import Component
I = TypeVar('I', bound='Item')
V = TypeVar('V', bound='View', covariant=True)
ItemCallbackType = Callable[[Any, I, Interaction], Coroutine[Any, Any, Any]]
class Item(Generic[V]):
"""Represents the base UI item that all UI components inherit from.
The current UI items supported are:
- :class:`discord.ui.Button`
- :class:`discord.ui.Select`
.. versionadded:: 2.0
"""
__item_repr_attributes__: Tuple[str, ...] = ('row',)
def __init__(self):
self._view: Optional[V] = None
self._row: Optional[int] = None
self._rendered_row: Optional[int] = None
# This works mostly well but there is a gotcha with
# the interaction with from_component, since that technically provides
# a custom_id most dispatchable items would get this set to True even though
# it might not be provided by the library user. However, this edge case doesn't
# actually affect the intended purpose of this check because from_component is
# only called upon edit and we're mainly interested during initial creation time.
self._provided_custom_id: bool = False
def to_component_dict(self) -> Dict[str, Any]:
raise NotImplementedError
def refresh_component(self, component: Component) -> None:
return None
def refresh_state(self, interaction: Interaction) -> None:
return None
@classmethod
def from_component(cls: Type[I], component: Component) -> I:
return cls()
@property
def type(self) -> ComponentType:
raise NotImplementedError
def is_dispatchable(self) -> bool:
return False
def is_persistent(self) -> bool:
return self._provided_custom_id
def __repr__(self) -> str:
attrs = ' '.join(f'{key}={getattr(self, key)!r}' for key in self.__item_repr_attributes__)
return f'<{self.__class__.__name__} {attrs}>'
@property
def row(self) -> Optional[int]:
return self._row
@row.setter
def row(self, value: Optional[int]):
if value is None:
self._row = None
elif 5 > value >= 0:
self._row = value
else:
raise ValueError('row cannot be negative or greater than or equal to 5')
@property
def width(self) -> int:
return 1
@property
def view(self) -> Optional[V]:
"""Optional[:class:`View`]: The underlying view for this item."""
return self._view
async def callback(self, interaction: Interaction):
"""|coro|
The callback associated with this UI item.
This can be overriden by subclasses.
Parameters
-----------
interaction: :class:`.Interaction`
The interaction that triggered this UI item.
"""
pass | zarenacord.py | /zarenacord.py-2.0.0-py3-none-any.whl/discord/ui/item.py | item.py |
from __future__ import annotations
import threading
import logging
import json
import time
import re
from urllib.parse import quote as urlquote
from typing import Any, Dict, List, Literal, Optional, TYPE_CHECKING, Tuple, Type, TypeVar, Union, overload
from .. import utils
from ..errors import InvalidArgument, HTTPException, Forbidden, NotFound, DiscordServerError
from ..message import Message
from ..http import Route
from ..channel import PartialMessageable
from .async_ import BaseWebhook, handle_message_parameters, _WebhookState
__all__ = (
'SyncWebhook',
'SyncWebhookMessage',
)
_log = logging.getLogger(__name__)
if TYPE_CHECKING:
from ..file import File
from ..embeds import Embed
from ..mentions import AllowedMentions
from ..types.webhook import (
Webhook as WebhookPayload,
)
from ..abc import Snowflake
try:
from requests import Session, Response
except ModuleNotFoundError:
pass
MISSING = utils.MISSING
class DeferredLock:
def __init__(self, lock: threading.Lock):
self.lock = lock
self.delta: Optional[float] = None
def __enter__(self):
self.lock.acquire()
return self
def delay_by(self, delta: float) -> None:
self.delta = delta
def __exit__(self, type, value, traceback):
if self.delta:
time.sleep(self.delta)
self.lock.release()
class WebhookAdapter:
def __init__(self):
self._locks: Dict[Any, threading.Lock] = {}
def request(
self,
route: Route,
session: Session,
*,
payload: Optional[Dict[str, Any]] = None,
multipart: Optional[List[Dict[str, Any]]] = None,
files: Optional[List[File]] = None,
reason: Optional[str] = None,
auth_token: Optional[str] = None,
params: Optional[Dict[str, Any]] = None,
) -> Any:
headers: Dict[str, str] = {}
files = files or []
to_send: Optional[Union[str, Dict[str, Any]]] = None
bucket = (route.webhook_id, route.webhook_token)
try:
lock = self._locks[bucket]
except KeyError:
self._locks[bucket] = lock = threading.Lock()
if payload is not None:
headers['Content-Type'] = 'application/json'
to_send = utils._to_json(payload)
if auth_token is not None:
headers['Authorization'] = f'Bot {auth_token}'
if reason is not None:
headers['X-Audit-Log-Reason'] = urlquote(reason, safe='/ ')
response: Optional[Response] = None
data: Optional[Union[Dict[str, Any], str]] = None
file_data: Optional[Dict[str, Any]] = None
method = route.method
url = route.url
webhook_id = route.webhook_id
with DeferredLock(lock) as lock:
for attempt in range(5):
for file in files:
file.reset(seek=attempt)
if multipart:
file_data = {}
for p in multipart:
name = p['name']
if name == 'payload_json':
to_send = {'payload_json': p['value']}
else:
file_data[name] = (p['filename'], p['value'], p['content_type'])
try:
with session.request(
method, url, data=to_send, files=file_data, headers=headers, params=params
) as response:
_log.debug(
'Webhook ID %s with %s %s has returned status code %s',
webhook_id,
method,
url,
response.status_code,
)
response.encoding = 'utf-8'
# Compatibility with aiohttp
response.status = response.status_code # type: ignore
data = response.text or None
if data and response.headers['Content-Type'] == 'application/json':
data = json.loads(data)
remaining = response.headers.get('X-Ratelimit-Remaining')
if remaining == '0' and response.status_code != 429:
delta = utils._parse_ratelimit_header(response)
_log.debug(
'Webhook ID %s has been pre-emptively rate limited, waiting %.2f seconds', webhook_id, delta
)
lock.delay_by(delta)
if 300 > response.status_code >= 200:
return data
if response.status_code == 429:
if not response.headers.get('Via'):
raise HTTPException(response, data)
retry_after: float = data['retry_after'] # type: ignore
_log.warning('Webhook ID %s is rate limited. Retrying in %.2f seconds', webhook_id, retry_after)
time.sleep(retry_after)
continue
if response.status_code >= 500:
time.sleep(1 + attempt * 2)
continue
if response.status_code == 403:
raise Forbidden(response, data)
elif response.status_code == 404:
raise NotFound(response, data)
else:
raise HTTPException(response, data)
except OSError as e:
if attempt < 4 and e.errno in (54, 10054):
time.sleep(1 + attempt * 2)
continue
raise
if response:
if response.status_code >= 500:
raise DiscordServerError(response, data)
raise HTTPException(response, data)
raise RuntimeError('Unreachable code in HTTP handling.')
def delete_webhook(
self,
webhook_id: int,
*,
token: Optional[str] = None,
session: Session,
reason: Optional[str] = None,
):
route = Route('DELETE', '/webhooks/{webhook_id}', webhook_id=webhook_id)
return self.request(route, session, reason=reason, auth_token=token)
def delete_webhook_with_token(
self,
webhook_id: int,
token: str,
*,
session: Session,
reason: Optional[str] = None,
):
route = Route('DELETE', '/webhooks/{webhook_id}/{webhook_token}', webhook_id=webhook_id, webhook_token=token)
return self.request(route, session, reason=reason)
def edit_webhook(
self,
webhook_id: int,
token: str,
payload: Dict[str, Any],
*,
session: Session,
reason: Optional[str] = None,
):
route = Route('PATCH', '/webhooks/{webhook_id}', webhook_id=webhook_id)
return self.request(route, session, reason=reason, payload=payload, auth_token=token)
def edit_webhook_with_token(
self,
webhook_id: int,
token: str,
payload: Dict[str, Any],
*,
session: Session,
reason: Optional[str] = None,
):
route = Route('PATCH', '/webhooks/{webhook_id}/{webhook_token}', webhook_id=webhook_id, webhook_token=token)
return self.request(route, session, reason=reason, payload=payload)
def execute_webhook(
self,
webhook_id: int,
token: str,
*,
session: Session,
payload: Optional[Dict[str, Any]] = None,
multipart: Optional[List[Dict[str, Any]]] = None,
files: Optional[List[File]] = None,
thread_id: Optional[int] = None,
wait: bool = False,
):
params = {'wait': int(wait)}
if thread_id:
params['thread_id'] = thread_id
route = Route('POST', '/webhooks/{webhook_id}/{webhook_token}', webhook_id=webhook_id, webhook_token=token)
return self.request(route, session, payload=payload, multipart=multipart, files=files, params=params)
def get_webhook_message(
self,
webhook_id: int,
token: str,
message_id: int,
*,
session: Session,
):
route = Route(
'GET',
'/webhooks/{webhook_id}/{webhook_token}/messages/{message_id}',
webhook_id=webhook_id,
webhook_token=token,
message_id=message_id,
)
return self.request(route, session)
def edit_webhook_message(
self,
webhook_id: int,
token: str,
message_id: int,
*,
session: Session,
payload: Optional[Dict[str, Any]] = None,
multipart: Optional[List[Dict[str, Any]]] = None,
files: Optional[List[File]] = None,
):
route = Route(
'PATCH',
'/webhooks/{webhook_id}/{webhook_token}/messages/{message_id}',
webhook_id=webhook_id,
webhook_token=token,
message_id=message_id,
)
return self.request(route, session, payload=payload, multipart=multipart, files=files)
def delete_webhook_message(
self,
webhook_id: int,
token: str,
message_id: int,
*,
session: Session,
):
route = Route(
'DELETE',
'/webhooks/{webhook_id}/{webhook_token}/messages/{message_id}',
webhook_id=webhook_id,
webhook_token=token,
message_id=message_id,
)
return self.request(route, session)
def fetch_webhook(
self,
webhook_id: int,
token: str,
*,
session: Session,
):
route = Route('GET', '/webhooks/{webhook_id}', webhook_id=webhook_id)
return self.request(route, session=session, auth_token=token)
def fetch_webhook_with_token(
self,
webhook_id: int,
token: str,
*,
session: Session,
):
route = Route('GET', '/webhooks/{webhook_id}/{webhook_token}', webhook_id=webhook_id, webhook_token=token)
return self.request(route, session=session)
class _WebhookContext(threading.local):
adapter: Optional[WebhookAdapter] = None
_context = _WebhookContext()
def _get_webhook_adapter() -> WebhookAdapter:
if _context.adapter is None:
_context.adapter = WebhookAdapter()
return _context.adapter
class SyncWebhookMessage(Message):
"""Represents a message sent from your webhook.
This allows you to edit or delete a message sent by your
webhook.
This inherits from :class:`discord.Message` with changes to
:meth:`edit` and :meth:`delete` to work.
.. versionadded:: 2.0
"""
_state: _WebhookState
def edit(
self,
content: Optional[str] = MISSING,
embeds: List[Embed] = MISSING,
embed: Optional[Embed] = MISSING,
file: File = MISSING,
files: List[File] = MISSING,
allowed_mentions: Optional[AllowedMentions] = None,
) -> SyncWebhookMessage:
"""Edits the message.
Parameters
------------
content: Optional[:class:`str`]
The content to edit the message with or ``None`` to clear it.
embeds: List[:class:`Embed`]
A list of embeds to edit the message with.
embed: Optional[:class:`Embed`]
The embed to edit the message with. ``None`` suppresses the embeds.
This should not be mixed with the ``embeds`` parameter.
file: :class:`File`
The file to upload. This cannot be mixed with ``files`` parameter.
files: List[:class:`File`]
A list of files to send with the content. This cannot be mixed with the
``file`` parameter.
allowed_mentions: :class:`AllowedMentions`
Controls the mentions being processed in this message.
See :meth:`.abc.Messageable.send` for more information.
Raises
-------
HTTPException
Editing the message failed.
Forbidden
Edited a message that is not yours.
TypeError
You specified both ``embed`` and ``embeds`` or ``file`` and ``files``
ValueError
The length of ``embeds`` was invalid
InvalidArgument
There was no token associated with this webhook.
Returns
--------
:class:`SyncWebhookMessage`
The newly edited message.
"""
return self._state._webhook.edit_message(
self.id,
content=content,
embeds=embeds,
embed=embed,
file=file,
files=files,
allowed_mentions=allowed_mentions,
)
def delete(self, *, delay: Optional[float] = None) -> None:
"""Deletes the message.
Parameters
-----------
delay: Optional[:class:`float`]
If provided, the number of seconds to wait before deleting the message.
This blocks the thread.
Raises
------
Forbidden
You do not have proper permissions to delete the message.
NotFound
The message was deleted already.
HTTPException
Deleting the message failed.
"""
if delay is not None:
time.sleep(delay)
self._state._webhook.delete_message(self.id)
class SyncWebhook(BaseWebhook):
"""Represents a synchronous Discord webhook.
For an asynchronous counterpart, see :class:`Webhook`.
.. container:: operations
.. describe:: x == y
Checks if two webhooks are equal.
.. describe:: x != y
Checks if two webhooks are not equal.
.. describe:: hash(x)
Returns the webhooks's hash.
.. versionchanged:: 1.4
Webhooks are now comparable and hashable.
Attributes
------------
id: :class:`int`
The webhook's ID
type: :class:`WebhookType`
The type of the webhook.
.. versionadded:: 1.3
token: Optional[:class:`str`]
The authentication token of the webhook. If this is ``None``
then the webhook cannot be used to make requests.
guild_id: Optional[:class:`int`]
The guild ID this webhook is for.
channel_id: Optional[:class:`int`]
The channel ID this webhook is for.
user: Optional[:class:`abc.User`]
The user this webhook was created by. If the webhook was
received without authentication then this will be ``None``.
name: Optional[:class:`str`]
The default name of the webhook.
source_guild: Optional[:class:`PartialWebhookGuild`]
The guild of the channel that this webhook is following.
Only given if :attr:`type` is :attr:`WebhookType.channel_follower`.
.. versionadded:: 2.0
source_channel: Optional[:class:`PartialWebhookChannel`]
The channel that this webhook is following.
Only given if :attr:`type` is :attr:`WebhookType.channel_follower`.
.. versionadded:: 2.0
"""
__slots__: Tuple[str, ...] = ('session',)
def __init__(self, data: WebhookPayload, session: Session, token: Optional[str] = None, state=None):
super().__init__(data, token, state)
self.session = session
def __repr__(self):
return f'<Webhook id={self.id!r}>'
@property
def url(self) -> str:
""":class:`str` : Returns the webhook's url."""
return f'https://discord.com/api/webhooks/{self.id}/{self.token}'
@classmethod
def partial(cls, id: int, token: str, *, session: Session = MISSING, bot_token: Optional[str] = None) -> SyncWebhook:
"""Creates a partial :class:`Webhook`.
Parameters
-----------
id: :class:`int`
The ID of the webhook.
token: :class:`str`
The authentication token of the webhook.
session: :class:`requests.Session`
The session to use to send requests with. Note
that the library does not manage the session and
will not close it. If not given, the ``requests``
auto session creation functions are used instead.
bot_token: Optional[:class:`str`]
The bot authentication token for authenticated requests
involving the webhook.
Returns
--------
:class:`Webhook`
A partial :class:`Webhook`.
A partial webhook is just a webhook object with an ID and a token.
"""
data: WebhookPayload = {
'id': id,
'type': 1,
'token': token,
}
import requests
if session is not MISSING:
if not isinstance(session, requests.Session):
raise TypeError(f'expected requests.Session not {session.__class__!r}')
else:
session = requests # type: ignore
return cls(data, session, token=bot_token)
@classmethod
def from_url(cls, url: str, *, session: Session = MISSING, bot_token: Optional[str] = None) -> SyncWebhook:
"""Creates a partial :class:`Webhook` from a webhook URL.
Parameters
------------
url: :class:`str`
The URL of the webhook.
session: :class:`requests.Session`
The session to use to send requests with. Note
that the library does not manage the session and
will not close it. If not given, the ``requests``
auto session creation functions are used instead.
bot_token: Optional[:class:`str`]
The bot authentication token for authenticated requests
involving the webhook.
Raises
-------
InvalidArgument
The URL is invalid.
Returns
--------
:class:`Webhook`
A partial :class:`Webhook`.
A partial webhook is just a webhook object with an ID and a token.
"""
m = re.search(r'discord(?:app)?.com/api/webhooks/(?P<id>[0-9]{17,20})/(?P<token>[A-Za-z0-9\.\-\_]{60,68})', url)
if m is None:
raise InvalidArgument('Invalid webhook URL given.')
data: Dict[str, Any] = m.groupdict()
data['type'] = 1
import requests
if session is not MISSING:
if not isinstance(session, requests.Session):
raise TypeError(f'expected requests.Session not {session.__class__!r}')
else:
session = requests # type: ignore
return cls(data, session, token=bot_token) # type: ignore
def fetch(self, *, prefer_auth: bool = True) -> SyncWebhook:
"""Fetches the current webhook.
This could be used to get a full webhook from a partial webhook.
.. note::
When fetching with an unauthenticated webhook, i.e.
:meth:`is_authenticated` returns ``False``, then the
returned webhook does not contain any user information.
Parameters
-----------
prefer_auth: :class:`bool`
Whether to use the bot token over the webhook token
if available. Defaults to ``True``.
Raises
-------
HTTPException
Could not fetch the webhook
NotFound
Could not find the webhook by this ID
InvalidArgument
This webhook does not have a token associated with it.
Returns
--------
:class:`SyncWebhook`
The fetched webhook.
"""
adapter: WebhookAdapter = _get_webhook_adapter()
if prefer_auth and self.auth_token:
data = adapter.fetch_webhook(self.id, self.auth_token, session=self.session)
elif self.token:
data = adapter.fetch_webhook_with_token(self.id, self.token, session=self.session)
else:
raise InvalidArgument('This webhook does not have a token associated with it')
return SyncWebhook(data, self.session, token=self.auth_token, state=self._state)
def delete(self, *, reason: Optional[str] = None, prefer_auth: bool = True) -> None:
"""Deletes this Webhook.
Parameters
------------
reason: Optional[:class:`str`]
The reason for deleting this webhook. Shows up on the audit log.
.. versionadded:: 1.4
prefer_auth: :class:`bool`
Whether to use the bot token over the webhook token
if available. Defaults to ``True``.
Raises
-------
HTTPException
Deleting the webhook failed.
NotFound
This webhook does not exist.
Forbidden
You do not have permissions to delete this webhook.
InvalidArgument
This webhook does not have a token associated with it.
"""
if self.token is None and self.auth_token is None:
raise InvalidArgument('This webhook does not have a token associated with it')
adapter: WebhookAdapter = _get_webhook_adapter()
if prefer_auth and self.auth_token:
adapter.delete_webhook(self.id, token=self.auth_token, session=self.session, reason=reason)
elif self.token:
adapter.delete_webhook_with_token(self.id, self.token, session=self.session, reason=reason)
def edit(
self,
*,
reason: Optional[str] = None,
name: Optional[str] = MISSING,
avatar: Optional[bytes] = MISSING,
channel: Optional[Snowflake] = None,
prefer_auth: bool = True,
) -> SyncWebhook:
"""Edits this Webhook.
Parameters
------------
name: Optional[:class:`str`]
The webhook's new default name.
avatar: Optional[:class:`bytes`]
A :term:`py:bytes-like object` representing the webhook's new default avatar.
channel: Optional[:class:`abc.Snowflake`]
The webhook's new channel. This requires an authenticated webhook.
reason: Optional[:class:`str`]
The reason for editing this webhook. Shows up on the audit log.
.. versionadded:: 1.4
prefer_auth: :class:`bool`
Whether to use the bot token over the webhook token
if available. Defaults to ``True``.
Raises
-------
HTTPException
Editing the webhook failed.
NotFound
This webhook does not exist.
InvalidArgument
This webhook does not have a token associated with it
or it tried editing a channel without authentication.
Returns
--------
:class:`SyncWebhook`
The newly edited webhook.
"""
if self.token is None and self.auth_token is None:
raise InvalidArgument('This webhook does not have a token associated with it')
payload = {}
if name is not MISSING:
payload['name'] = str(name) if name is not None else None
if avatar is not MISSING:
payload['avatar'] = utils._bytes_to_base64_data(avatar) if avatar is not None else None
adapter: WebhookAdapter = _get_webhook_adapter()
data: Optional[WebhookPayload] = None
# If a channel is given, always use the authenticated endpoint
if channel is not None:
if self.auth_token is None:
raise InvalidArgument('Editing channel requires authenticated webhook')
payload['channel_id'] = channel.id
data = adapter.edit_webhook(self.id, self.auth_token, payload=payload, session=self.session, reason=reason)
if prefer_auth and self.auth_token:
data = adapter.edit_webhook(self.id, self.auth_token, payload=payload, session=self.session, reason=reason)
elif self.token:
data = adapter.edit_webhook_with_token(self.id, self.token, payload=payload, session=self.session, reason=reason)
if data is None:
raise RuntimeError('Unreachable code hit: data was not assigned')
return SyncWebhook(data=data, session=self.session, token=self.auth_token, state=self._state)
def _create_message(self, data):
state = _WebhookState(self, parent=self._state)
# state may be artificial (unlikely at this point...)
channel = self.channel or PartialMessageable(state=self._state, id=int(data['channel_id'])) # type: ignore
# state is artificial
return SyncWebhookMessage(data=data, state=state, channel=channel) # type: ignore
@overload
def send(
self,
content: str = MISSING,
*,
username: str = MISSING,
avatar_url: Any = MISSING,
tts: bool = MISSING,
file: File = MISSING,
files: List[File] = MISSING,
embed: Embed = MISSING,
embeds: List[Embed] = MISSING,
allowed_mentions: AllowedMentions = MISSING,
wait: Literal[True],
) -> SyncWebhookMessage:
...
@overload
def send(
self,
content: str = MISSING,
*,
username: str = MISSING,
avatar_url: Any = MISSING,
tts: bool = MISSING,
file: File = MISSING,
files: List[File] = MISSING,
embed: Embed = MISSING,
embeds: List[Embed] = MISSING,
allowed_mentions: AllowedMentions = MISSING,
wait: Literal[False] = ...,
) -> None:
...
def send(
self,
content: str = MISSING,
*,
username: str = MISSING,
avatar_url: Any = MISSING,
tts: bool = False,
file: File = MISSING,
files: List[File] = MISSING,
embed: Embed = MISSING,
embeds: List[Embed] = MISSING,
allowed_mentions: AllowedMentions = MISSING,
thread: Snowflake = MISSING,
wait: bool = False,
) -> Optional[SyncWebhookMessage]:
"""Sends a message using the webhook.
The content must be a type that can convert to a string through ``str(content)``.
To upload a single file, the ``file`` parameter should be used with a
single :class:`File` object.
If the ``embed`` parameter is provided, it must be of type :class:`Embed` and
it must be a rich embed type. You cannot mix the ``embed`` parameter with the
``embeds`` parameter, which must be a :class:`list` of :class:`Embed` objects to send.
Parameters
------------
content: :class:`str`
The content of the message to send.
wait: :class:`bool`
Whether the server should wait before sending a response. This essentially
means that the return type of this function changes from ``None`` to
a :class:`WebhookMessage` if set to ``True``.
username: :class:`str`
The username to send with this message. If no username is provided
then the default username for the webhook is used.
avatar_url: :class:`str`
The avatar URL to send with this message. If no avatar URL is provided
then the default avatar for the webhook is used. If this is not a
string then it is explicitly cast using ``str``.
tts: :class:`bool`
Indicates if the message should be sent using text-to-speech.
file: :class:`File`
The file to upload. This cannot be mixed with ``files`` parameter.
files: List[:class:`File`]
A list of files to send with the content. This cannot be mixed with the
``file`` parameter.
embed: :class:`Embed`
The rich embed for the content to send. This cannot be mixed with
``embeds`` parameter.
embeds: List[:class:`Embed`]
A list of embeds to send with the content. Maximum of 10. This cannot
be mixed with the ``embed`` parameter.
allowed_mentions: :class:`AllowedMentions`
Controls the mentions being processed in this message.
.. versionadded:: 1.4
thread: :class:`~discord.abc.Snowflake`
The thread to send this message to.
.. versionadded:: 2.0
Raises
--------
HTTPException
Sending the message failed.
NotFound
This webhook was not found.
Forbidden
The authorization token for the webhook is incorrect.
TypeError
You specified both ``embed`` and ``embeds`` or ``file`` and ``files``
ValueError
The length of ``embeds`` was invalid
InvalidArgument
There was no token associated with this webhook.
Returns
---------
Optional[:class:`SyncWebhookMessage`]
If ``wait`` is ``True`` then the message that was sent, otherwise ``None``.
"""
if self.token is None:
raise InvalidArgument('This webhook does not have a token associated with it')
previous_mentions: Optional[AllowedMentions] = getattr(self._state, 'allowed_mentions', None)
if content is None:
content = MISSING
params = handle_message_parameters(
content=content,
username=username,
avatar_url=avatar_url,
tts=tts,
file=file,
files=files,
embed=embed,
embeds=embeds,
allowed_mentions=allowed_mentions,
previous_allowed_mentions=previous_mentions,
)
adapter: WebhookAdapter = _get_webhook_adapter()
thread_id: Optional[int] = None
if thread is not MISSING:
thread_id = thread.id
data = adapter.execute_webhook(
self.id,
self.token,
session=self.session,
payload=params.payload,
multipart=params.multipart,
files=params.files,
thread_id=thread_id,
wait=wait,
)
if wait:
return self._create_message(data)
def fetch_message(self, id: int, /) -> SyncWebhookMessage:
"""Retrieves a single :class:`~discord.SyncWebhookMessage` owned by this webhook.
.. versionadded:: 2.0
Parameters
------------
id: :class:`int`
The message ID to look for.
Raises
--------
~discord.NotFound
The specified message was not found.
~discord.Forbidden
You do not have the permissions required to get a message.
~discord.HTTPException
Retrieving the message failed.
InvalidArgument
There was no token associated with this webhook.
Returns
--------
:class:`~discord.SyncWebhookMessage`
The message asked for.
"""
if self.token is None:
raise InvalidArgument('This webhook does not have a token associated with it')
adapter: WebhookAdapter = _get_webhook_adapter()
data = adapter.get_webhook_message(
self.id,
self.token,
id,
session=self.session,
)
return self._create_message(data)
def edit_message(
self,
message_id: int,
*,
content: Optional[str] = MISSING,
embeds: List[Embed] = MISSING,
embed: Optional[Embed] = MISSING,
file: File = MISSING,
files: List[File] = MISSING,
allowed_mentions: Optional[AllowedMentions] = None,
) -> SyncWebhookMessage:
"""Edits a message owned by this webhook.
This is a lower level interface to :meth:`WebhookMessage.edit` in case
you only have an ID.
.. versionadded:: 1.6
Parameters
------------
message_id: :class:`int`
The message ID to edit.
content: Optional[:class:`str`]
The content to edit the message with or ``None`` to clear it.
embeds: List[:class:`Embed`]
A list of embeds to edit the message with.
embed: Optional[:class:`Embed`]
The embed to edit the message with. ``None`` suppresses the embeds.
This should not be mixed with the ``embeds`` parameter.
file: :class:`File`
The file to upload. This cannot be mixed with ``files`` parameter.
files: List[:class:`File`]
A list of files to send with the content. This cannot be mixed with the
``file`` parameter.
allowed_mentions: :class:`AllowedMentions`
Controls the mentions being processed in this message.
See :meth:`.abc.Messageable.send` for more information.
Raises
-------
HTTPException
Editing the message failed.
Forbidden
Edited a message that is not yours.
TypeError
You specified both ``embed`` and ``embeds`` or ``file`` and ``files``
ValueError
The length of ``embeds`` was invalid
InvalidArgument
There was no token associated with this webhook.
"""
if self.token is None:
raise InvalidArgument('This webhook does not have a token associated with it')
previous_mentions: Optional[AllowedMentions] = getattr(self._state, 'allowed_mentions', None)
params = handle_message_parameters(
content=content,
file=file,
files=files,
embed=embed,
embeds=embeds,
allowed_mentions=allowed_mentions,
previous_allowed_mentions=previous_mentions,
)
adapter: WebhookAdapter = _get_webhook_adapter()
data = adapter.edit_webhook_message(
self.id,
self.token,
message_id,
session=self.session,
payload=params.payload,
multipart=params.multipart,
files=params.files,
)
return self._create_message(data)
def delete_message(self, message_id: int, /) -> None:
"""Deletes a message owned by this webhook.
This is a lower level interface to :meth:`WebhookMessage.delete` in case
you only have an ID.
.. versionadded:: 1.6
Parameters
------------
message_id: :class:`int`
The message ID to delete.
Raises
-------
HTTPException
Deleting the message failed.
Forbidden
Deleted a message that is not yours.
"""
if self.token is None:
raise InvalidArgument('This webhook does not have a token associated with it')
adapter: WebhookAdapter = _get_webhook_adapter()
adapter.delete_webhook_message(
self.id,
self.token,
message_id,
session=self.session,
) | zarenacord.py | /zarenacord.py-2.0.0-py3-none-any.whl/discord/webhook/sync.py | sync.py |
from __future__ import annotations
import logging
import asyncio
import json
import re
from urllib.parse import quote as urlquote
from typing import Any, Dict, List, Literal, NamedTuple, Optional, TYPE_CHECKING, Tuple, Union, overload
from contextvars import ContextVar
import aiohttp
from .. import utils
from ..errors import InvalidArgument, HTTPException, Forbidden, NotFound, DiscordServerError
from ..message import Message
from ..enums import try_enum, WebhookType
from ..user import BaseUser, User
from ..asset import Asset
from ..http import Route
from ..mixins import Hashable
from ..channel import PartialMessageable
__all__ = (
'Webhook',
'WebhookMessage',
'PartialWebhookChannel',
'PartialWebhookGuild',
)
_log = logging.getLogger(__name__)
if TYPE_CHECKING:
from ..file import File
from ..embeds import Embed
from ..mentions import AllowedMentions
from ..state import ConnectionState
from ..http import Response
from ..types.webhook import (
Webhook as WebhookPayload,
)
from ..types.message import (
Message as MessagePayload,
)
from ..guild import Guild
from ..channel import TextChannel
from ..abc import Snowflake
from ..ui.view import View
import datetime
MISSING = utils.MISSING
class AsyncDeferredLock:
def __init__(self, lock: asyncio.Lock):
self.lock = lock
self.delta: Optional[float] = None
async def __aenter__(self):
await self.lock.acquire()
return self
def delay_by(self, delta: float) -> None:
self.delta = delta
async def __aexit__(self, type, value, traceback):
if self.delta:
await asyncio.sleep(self.delta)
self.lock.release()
class AsyncWebhookAdapter:
def __init__(self):
self._locks: Dict[Any, asyncio.Lock] = {}
async def request(
self,
route: Route,
session: aiohttp.ClientSession,
*,
payload: Optional[Dict[str, Any]] = None,
multipart: Optional[List[Dict[str, Any]]] = None,
files: Optional[List[File]] = None,
reason: Optional[str] = None,
auth_token: Optional[str] = None,
params: Optional[Dict[str, Any]] = None,
) -> Any:
headers: Dict[str, str] = {}
files = files or []
to_send: Optional[Union[str, aiohttp.FormData]] = None
bucket = (route.webhook_id, route.webhook_token)
try:
lock = self._locks[bucket]
except KeyError:
self._locks[bucket] = lock = asyncio.Lock()
if payload is not None:
headers['Content-Type'] = 'application/json'
to_send = utils._to_json(payload)
if auth_token is not None:
headers['Authorization'] = f'Bot {auth_token}'
if reason is not None:
headers['X-Audit-Log-Reason'] = urlquote(reason, safe='/ ')
response: Optional[aiohttp.ClientResponse] = None
data: Optional[Union[Dict[str, Any], str]] = None
method = route.method
url = route.url
webhook_id = route.webhook_id
async with AsyncDeferredLock(lock) as lock:
for attempt in range(5):
for file in files:
file.reset(seek=attempt)
if multipart:
form_data = aiohttp.FormData()
for p in multipart:
form_data.add_field(**p)
to_send = form_data
try:
async with session.request(method, url, data=to_send, headers=headers, params=params) as response:
_log.debug(
'Webhook ID %s with %s %s has returned status code %s',
webhook_id,
method,
url,
response.status,
)
data = (await response.text(encoding='utf-8')) or None
if data and response.headers['Content-Type'] == 'application/json':
data = json.loads(data)
remaining = response.headers.get('X-Ratelimit-Remaining')
if remaining == '0' and response.status != 429:
delta = utils._parse_ratelimit_header(response)
_log.debug(
'Webhook ID %s has been pre-emptively rate limited, waiting %.2f seconds', webhook_id, delta
)
lock.delay_by(delta)
if 300 > response.status >= 200:
return data
if response.status == 429:
if not response.headers.get('Via'):
raise HTTPException(response, data)
retry_after: float = data['retry_after'] # type: ignore
_log.warning('Webhook ID %s is rate limited. Retrying in %.2f seconds', webhook_id, retry_after)
await asyncio.sleep(retry_after)
continue
if response.status >= 500:
await asyncio.sleep(1 + attempt * 2)
continue
if response.status == 403:
raise Forbidden(response, data)
elif response.status == 404:
raise NotFound(response, data)
else:
raise HTTPException(response, data)
except OSError as e:
if attempt < 4 and e.errno in (54, 10054):
await asyncio.sleep(1 + attempt * 2)
continue
raise
if response:
if response.status >= 500:
raise DiscordServerError(response, data)
raise HTTPException(response, data)
raise RuntimeError('Unreachable code in HTTP handling.')
def delete_webhook(
self,
webhook_id: int,
*,
token: Optional[str] = None,
session: aiohttp.ClientSession,
reason: Optional[str] = None,
) -> Response[None]:
route = Route('DELETE', '/webhooks/{webhook_id}', webhook_id=webhook_id)
return self.request(route, session, reason=reason, auth_token=token)
def delete_webhook_with_token(
self,
webhook_id: int,
token: str,
*,
session: aiohttp.ClientSession,
reason: Optional[str] = None,
) -> Response[None]:
route = Route('DELETE', '/webhooks/{webhook_id}/{webhook_token}', webhook_id=webhook_id, webhook_token=token)
return self.request(route, session, reason=reason)
def edit_webhook(
self,
webhook_id: int,
token: str,
payload: Dict[str, Any],
*,
session: aiohttp.ClientSession,
reason: Optional[str] = None,
) -> Response[WebhookPayload]:
route = Route('PATCH', '/webhooks/{webhook_id}', webhook_id=webhook_id)
return self.request(route, session, reason=reason, payload=payload, auth_token=token)
def edit_webhook_with_token(
self,
webhook_id: int,
token: str,
payload: Dict[str, Any],
*,
session: aiohttp.ClientSession,
reason: Optional[str] = None,
) -> Response[WebhookPayload]:
route = Route('PATCH', '/webhooks/{webhook_id}/{webhook_token}', webhook_id=webhook_id, webhook_token=token)
return self.request(route, session, reason=reason, payload=payload)
def execute_webhook(
self,
webhook_id: int,
token: str,
*,
session: aiohttp.ClientSession,
payload: Optional[Dict[str, Any]] = None,
multipart: Optional[List[Dict[str, Any]]] = None,
files: Optional[List[File]] = None,
thread_id: Optional[int] = None,
wait: bool = False,
) -> Response[Optional[MessagePayload]]:
params = {'wait': int(wait)}
if thread_id:
params['thread_id'] = thread_id
route = Route('POST', '/webhooks/{webhook_id}/{webhook_token}', webhook_id=webhook_id, webhook_token=token)
return self.request(route, session, payload=payload, multipart=multipart, files=files, params=params)
def get_webhook_message(
self,
webhook_id: int,
token: str,
message_id: int,
*,
session: aiohttp.ClientSession,
) -> Response[MessagePayload]:
route = Route(
'GET',
'/webhooks/{webhook_id}/{webhook_token}/messages/{message_id}',
webhook_id=webhook_id,
webhook_token=token,
message_id=message_id,
)
return self.request(route, session)
def edit_webhook_message(
self,
webhook_id: int,
token: str,
message_id: int,
*,
session: aiohttp.ClientSession,
payload: Optional[Dict[str, Any]] = None,
multipart: Optional[List[Dict[str, Any]]] = None,
files: Optional[List[File]] = None,
) -> Response[Message]:
route = Route(
'PATCH',
'/webhooks/{webhook_id}/{webhook_token}/messages/{message_id}',
webhook_id=webhook_id,
webhook_token=token,
message_id=message_id,
)
return self.request(route, session, payload=payload, multipart=multipart, files=files)
def delete_webhook_message(
self,
webhook_id: int,
token: str,
message_id: int,
*,
session: aiohttp.ClientSession,
) -> Response[None]:
route = Route(
'DELETE',
'/webhooks/{webhook_id}/{webhook_token}/messages/{message_id}',
webhook_id=webhook_id,
webhook_token=token,
message_id=message_id,
)
return self.request(route, session)
def fetch_webhook(
self,
webhook_id: int,
token: str,
*,
session: aiohttp.ClientSession,
) -> Response[WebhookPayload]:
route = Route('GET', '/webhooks/{webhook_id}', webhook_id=webhook_id)
return self.request(route, session=session, auth_token=token)
def fetch_webhook_with_token(
self,
webhook_id: int,
token: str,
*,
session: aiohttp.ClientSession,
) -> Response[WebhookPayload]:
route = Route('GET', '/webhooks/{webhook_id}/{webhook_token}', webhook_id=webhook_id, webhook_token=token)
return self.request(route, session=session)
def create_interaction_response(
self,
interaction_id: int,
token: str,
*,
session: aiohttp.ClientSession,
type: int,
data: Optional[Dict[str, Any]] = None,
) -> Response[None]:
payload: Dict[str, Any] = {
'type': type,
}
if data is not None:
payload['data'] = data
route = Route(
'POST',
'/interactions/{webhook_id}/{webhook_token}/callback',
webhook_id=interaction_id,
webhook_token=token,
)
return self.request(route, session=session, payload=payload)
def get_original_interaction_response(
self,
application_id: int,
token: str,
*,
session: aiohttp.ClientSession,
) -> Response[MessagePayload]:
r = Route(
'GET',
'/webhooks/{webhook_id}/{webhook_token}/messages/@original',
webhook_id=application_id,
webhook_token=token,
)
return self.request(r, session=session)
def edit_original_interaction_response(
self,
application_id: int,
token: str,
*,
session: aiohttp.ClientSession,
payload: Optional[Dict[str, Any]] = None,
multipart: Optional[List[Dict[str, Any]]] = None,
files: Optional[List[File]] = None,
) -> Response[MessagePayload]:
r = Route(
'PATCH',
'/webhooks/{webhook_id}/{webhook_token}/messages/@original',
webhook_id=application_id,
webhook_token=token,
)
return self.request(r, session, payload=payload, multipart=multipart, files=files)
def delete_original_interaction_response(
self,
application_id: int,
token: str,
*,
session: aiohttp.ClientSession,
) -> Response[None]:
r = Route(
'DELETE',
'/webhooks/{webhook_id}/{wehook_token}/messages/@original',
webhook_id=application_id,
wehook_token=token,
)
return self.request(r, session=session)
class ExecuteWebhookParameters(NamedTuple):
payload: Optional[Dict[str, Any]]
multipart: Optional[List[Dict[str, Any]]]
files: Optional[List[File]]
def handle_message_parameters(
content: Optional[str] = MISSING,
*,
username: str = MISSING,
avatar_url: Any = MISSING,
tts: bool = False,
ephemeral: bool = False,
file: File = MISSING,
files: List[File] = MISSING,
embed: Optional[Embed] = MISSING,
embeds: List[Embed] = MISSING,
view: Optional[View] = MISSING,
allowed_mentions: Optional[AllowedMentions] = MISSING,
previous_allowed_mentions: Optional[AllowedMentions] = None,
) -> ExecuteWebhookParameters:
if files is not MISSING and file is not MISSING:
raise TypeError('Cannot mix file and files keyword arguments.')
if embeds is not MISSING and embed is not MISSING:
raise TypeError('Cannot mix embed and embeds keyword arguments.')
payload = {}
if embeds is not MISSING:
if len(embeds) > 10:
raise InvalidArgument('embeds has a maximum of 10 elements.')
payload['embeds'] = [e.to_dict() for e in embeds]
if embed is not MISSING:
if embed is None:
payload['embeds'] = []
else:
payload['embeds'] = [embed.to_dict()]
if content is not MISSING:
if content is not None:
payload['content'] = str(content)
else:
payload['content'] = None
if view is not MISSING:
if view is not None:
payload['components'] = view.to_components()
else:
payload['components'] = []
payload['tts'] = tts
if avatar_url:
payload['avatar_url'] = str(avatar_url)
if username:
payload['username'] = username
if ephemeral:
payload['flags'] = 64
if allowed_mentions:
if previous_allowed_mentions is not None:
payload['allowed_mentions'] = previous_allowed_mentions.merge(allowed_mentions).to_dict()
else:
payload['allowed_mentions'] = allowed_mentions.to_dict()
elif previous_allowed_mentions is not None:
payload['allowed_mentions'] = previous_allowed_mentions.to_dict()
multipart = []
if file is not MISSING:
files = [file]
if files:
multipart.append({'name': 'payload_json', 'value': utils._to_json(payload)})
payload = None
if len(files) == 1:
file = files[0]
multipart.append(
{
'name': 'file',
'value': file.fp,
'filename': file.filename,
'content_type': 'application/octet-stream',
}
)
else:
for index, file in enumerate(files):
multipart.append(
{
'name': f'file{index}',
'value': file.fp,
'filename': file.filename,
'content_type': 'application/octet-stream',
}
)
return ExecuteWebhookParameters(payload=payload, multipart=multipart, files=files)
async_context: ContextVar[AsyncWebhookAdapter] = ContextVar('async_webhook_context', default=AsyncWebhookAdapter())
class PartialWebhookChannel(Hashable):
"""Represents a partial channel for webhooks.
These are typically given for channel follower webhooks.
.. versionadded:: 2.0
Attributes
-----------
id: :class:`int`
The partial channel's ID.
name: :class:`str`
The partial channel's name.
"""
__slots__ = ('id', 'name')
def __init__(self, *, data):
self.id = int(data['id'])
self.name = data['name']
def __repr__(self):
return f'<PartialWebhookChannel name={self.name!r} id={self.id}>'
class PartialWebhookGuild(Hashable):
"""Represents a partial guild for webhooks.
These are typically given for channel follower webhooks.
.. versionadded:: 2.0
Attributes
-----------
id: :class:`int`
The partial guild's ID.
name: :class:`str`
The partial guild's name.
"""
__slots__ = ('id', 'name', '_icon', '_state')
def __init__(self, *, data, state):
self._state = state
self.id = int(data['id'])
self.name = data['name']
self._icon = data['icon']
def __repr__(self):
return f'<PartialWebhookGuild name={self.name!r} id={self.id}>'
@property
def icon(self) -> Optional[Asset]:
"""Optional[:class:`Asset`]: Returns the guild's icon asset, if available."""
if self._icon is None:
return None
return Asset._from_guild_icon(self._state, self.id, self._icon)
class _FriendlyHttpAttributeErrorHelper:
__slots__ = ()
def __getattr__(self, attr):
raise AttributeError('PartialWebhookState does not support http methods.')
class _WebhookState:
__slots__ = ('_parent', '_webhook')
def __init__(self, webhook: Any, parent: Optional[Union[ConnectionState, _WebhookState]]):
self._webhook: Any = webhook
self._parent: Optional[ConnectionState]
if isinstance(parent, _WebhookState):
self._parent = None
else:
self._parent = parent
def _get_guild(self, guild_id):
if self._parent is not None:
return self._parent._get_guild(guild_id)
return None
def store_user(self, data):
if self._parent is not None:
return self._parent.store_user(data)
# state parameter is artificial
return BaseUser(state=self, data=data) # type: ignore
def create_user(self, data):
# state parameter is artificial
return BaseUser(state=self, data=data) # type: ignore
@property
def http(self):
if self._parent is not None:
return self._parent.http
# Some data classes assign state.http and that should be kosher
# however, using it should result in a late-binding error.
return _FriendlyHttpAttributeErrorHelper()
def __getattr__(self, attr):
if self._parent is not None:
return getattr(self._parent, attr)
raise AttributeError(f'PartialWebhookState does not support {attr!r}.')
class WebhookMessage(Message):
"""Represents a message sent from your webhook.
This allows you to edit or delete a message sent by your
webhook.
This inherits from :class:`discord.Message` with changes to
:meth:`edit` and :meth:`delete` to work.
.. versionadded:: 1.6
"""
_state: _WebhookState
async def edit(
self,
content: Optional[str] = MISSING,
embeds: List[Embed] = MISSING,
embed: Optional[Embed] = MISSING,
file: File = MISSING,
files: List[File] = MISSING,
view: Optional[View] = MISSING,
allowed_mentions: Optional[AllowedMentions] = None,
) -> WebhookMessage:
"""|coro|
Edits the message.
.. versionadded:: 1.6
.. versionchanged:: 2.0
The edit is no longer in-place, instead the newly edited message is returned.
Parameters
------------
content: Optional[:class:`str`]
The content to edit the message with or ``None`` to clear it.
embeds: List[:class:`Embed`]
A list of embeds to edit the message with.
embed: Optional[:class:`Embed`]
The embed to edit the message with. ``None`` suppresses the embeds.
This should not be mixed with the ``embeds`` parameter.
file: :class:`File`
The file to upload. This cannot be mixed with ``files`` parameter.
.. versionadded:: 2.0
files: List[:class:`File`]
A list of files to send with the content. This cannot be mixed with the
``file`` parameter.
.. versionadded:: 2.0
allowed_mentions: :class:`AllowedMentions`
Controls the mentions being processed in this message.
See :meth:`.abc.Messageable.send` for more information.
view: Optional[:class:`~discord.ui.View`]
The updated view to update this message with. If ``None`` is passed then
the view is removed.
.. versionadded:: 2.0
Raises
-------
HTTPException
Editing the message failed.
Forbidden
Edited a message that is not yours.
TypeError
You specified both ``embed`` and ``embeds`` or ``file`` and ``files``
ValueError
The length of ``embeds`` was invalid
InvalidArgument
There was no token associated with this webhook.
Returns
--------
:class:`WebhookMessage`
The newly edited message.
"""
return await self._state._webhook.edit_message(
self.id,
content=content,
embeds=embeds,
embed=embed,
file=file,
files=files,
view=view,
allowed_mentions=allowed_mentions,
)
async def delete(self, *, delay: Optional[float] = None) -> None:
"""|coro|
Deletes the message.
Parameters
-----------
delay: Optional[:class:`float`]
If provided, the number of seconds to wait before deleting the message.
The waiting is done in the background and deletion failures are ignored.
Raises
------
Forbidden
You do not have proper permissions to delete the message.
NotFound
The message was deleted already.
HTTPException
Deleting the message failed.
"""
if delay is not None:
async def inner_call(delay: float = delay):
await asyncio.sleep(delay)
try:
await self._state._webhook.delete_message(self.id)
except HTTPException:
pass
asyncio.create_task(inner_call())
else:
await self._state._webhook.delete_message(self.id)
class BaseWebhook(Hashable):
__slots__: Tuple[str, ...] = (
'id',
'type',
'guild_id',
'channel_id',
'token',
'auth_token',
'user',
'name',
'_avatar',
'source_channel',
'source_guild',
'_state',
)
def __init__(self, data: WebhookPayload, token: Optional[str] = None, state: Optional[ConnectionState] = None):
self.auth_token: Optional[str] = token
self._state: Union[ConnectionState, _WebhookState] = state or _WebhookState(self, parent=state)
self._update(data)
def _update(self, data: WebhookPayload):
self.id = int(data['id'])
self.type = try_enum(WebhookType, int(data['type']))
self.channel_id = utils._get_as_snowflake(data, 'channel_id')
self.guild_id = utils._get_as_snowflake(data, 'guild_id')
self.name = data.get('name')
self._avatar = data.get('avatar')
self.token = data.get('token')
user = data.get('user')
self.user: Optional[Union[BaseUser, User]] = None
if user is not None:
# state parameter may be _WebhookState
self.user = User(state=self._state, data=user) # type: ignore
source_channel = data.get('source_channel')
if source_channel:
source_channel = PartialWebhookChannel(data=source_channel)
self.source_channel: Optional[PartialWebhookChannel] = source_channel
source_guild = data.get('source_guild')
if source_guild:
source_guild = PartialWebhookGuild(data=source_guild, state=self._state)
self.source_guild: Optional[PartialWebhookGuild] = source_guild
def is_partial(self) -> bool:
""":class:`bool`: Whether the webhook is a "partial" webhook.
.. versionadded:: 2.0"""
return self.channel_id is None
def is_authenticated(self) -> bool:
""":class:`bool`: Whether the webhook is authenticated with a bot token.
.. versionadded:: 2.0
"""
return self.auth_token is not None
@property
def guild(self) -> Optional[Guild]:
"""Optional[:class:`Guild`]: The guild this webhook belongs to.
If this is a partial webhook, then this will always return ``None``.
"""
return self._state and self._state._get_guild(self.guild_id)
@property
def channel(self) -> Optional[TextChannel]:
"""Optional[:class:`TextChannel`]: The text channel this webhook belongs to.
If this is a partial webhook, then this will always return ``None``.
"""
guild = self.guild
return guild and guild.get_channel(self.channel_id) # type: ignore
@property
def created_at(self) -> datetime.datetime:
""":class:`datetime.datetime`: Returns the webhook's creation time in UTC."""
return utils.snowflake_time(self.id)
@property
def avatar(self) -> Asset:
""":class:`Asset`: Returns an :class:`Asset` for the avatar the webhook has.
If the webhook does not have a traditional avatar, an asset for
the default avatar is returned instead.
"""
if self._avatar is None:
# Default is always blurple apparently
return Asset._from_default_avatar(self._state, 0)
return Asset._from_avatar(self._state, self.id, self._avatar)
class Webhook(BaseWebhook):
"""Represents an asynchronous Discord webhook.
Webhooks are a form to send messages to channels in Discord without a
bot user or authentication.
There are two main ways to use Webhooks. The first is through the ones
received by the library such as :meth:`.Guild.webhooks` and
:meth:`.TextChannel.webhooks`. The ones received by the library will
automatically be bound using the library's internal HTTP session.
The second form involves creating a webhook object manually using the
:meth:`~.Webhook.from_url` or :meth:`~.Webhook.partial` classmethods.
For example, creating a webhook from a URL and using :doc:`aiohttp <aio:index>`:
.. code-block:: python3
from discord import Webhook
import aiohttp
async def foo():
async with aiohttp.ClientSession() as session:
webhook = Webhook.from_url('url-here', session=session)
await webhook.send('Hello World', username='Foo')
For a synchronous counterpart, see :class:`SyncWebhook`.
.. container:: operations
.. describe:: x == y
Checks if two webhooks are equal.
.. describe:: x != y
Checks if two webhooks are not equal.
.. describe:: hash(x)
Returns the webhooks's hash.
.. versionchanged:: 1.4
Webhooks are now comparable and hashable.
Attributes
------------
id: :class:`int`
The webhook's ID
type: :class:`WebhookType`
The type of the webhook.
.. versionadded:: 1.3
token: Optional[:class:`str`]
The authentication token of the webhook. If this is ``None``
then the webhook cannot be used to make requests.
guild_id: Optional[:class:`int`]
The guild ID this webhook is for.
channel_id: Optional[:class:`int`]
The channel ID this webhook is for.
user: Optional[:class:`abc.User`]
The user this webhook was created by. If the webhook was
received without authentication then this will be ``None``.
name: Optional[:class:`str`]
The default name of the webhook.
source_guild: Optional[:class:`PartialWebhookGuild`]
The guild of the channel that this webhook is following.
Only given if :attr:`type` is :attr:`WebhookType.channel_follower`.
.. versionadded:: 2.0
source_channel: Optional[:class:`PartialWebhookChannel`]
The channel that this webhook is following.
Only given if :attr:`type` is :attr:`WebhookType.channel_follower`.
.. versionadded:: 2.0
"""
__slots__: Tuple[str, ...] = ('session',)
def __init__(self, data: WebhookPayload, session: aiohttp.ClientSession, token: Optional[str] = None, state=None):
super().__init__(data, token, state)
self.session = session
def __repr__(self):
return f'<Webhook id={self.id!r}>'
@property
def url(self) -> str:
""":class:`str` : Returns the webhook's url."""
return f'https://discord.com/api/webhooks/{self.id}/{self.token}'
@classmethod
def partial(cls, id: int, token: str, *, session: aiohttp.ClientSession, bot_token: Optional[str] = None) -> Webhook:
"""Creates a partial :class:`Webhook`.
Parameters
-----------
id: :class:`int`
The ID of the webhook.
token: :class:`str`
The authentication token of the webhook.
session: :class:`aiohttp.ClientSession`
The session to use to send requests with. Note
that the library does not manage the session and
will not close it.
.. versionadded:: 2.0
bot_token: Optional[:class:`str`]
The bot authentication token for authenticated requests
involving the webhook.
.. versionadded:: 2.0
Returns
--------
:class:`Webhook`
A partial :class:`Webhook`.
A partial webhook is just a webhook object with an ID and a token.
"""
data: WebhookPayload = {
'id': id,
'type': 1,
'token': token,
}
return cls(data, session, token=bot_token)
@classmethod
def from_url(cls, url: str, *, session: aiohttp.ClientSession, bot_token: Optional[str] = None) -> Webhook:
"""Creates a partial :class:`Webhook` from a webhook URL.
Parameters
------------
url: :class:`str`
The URL of the webhook.
session: :class:`aiohttp.ClientSession`
The session to use to send requests with. Note
that the library does not manage the session and
will not close it.
.. versionadded:: 2.0
bot_token: Optional[:class:`str`]
The bot authentication token for authenticated requests
involving the webhook.
.. versionadded:: 2.0
Raises
-------
InvalidArgument
The URL is invalid.
Returns
--------
:class:`Webhook`
A partial :class:`Webhook`.
A partial webhook is just a webhook object with an ID and a token.
"""
m = re.search(r'discord(?:app)?.com/api/webhooks/(?P<id>[0-9]{17,20})/(?P<token>[A-Za-z0-9\.\-\_]{60,68})', url)
if m is None:
raise InvalidArgument('Invalid webhook URL given.')
data: Dict[str, Any] = m.groupdict()
data['type'] = 1
return cls(data, session, token=bot_token) # type: ignore
@classmethod
def _as_follower(cls, data, *, channel, user) -> Webhook:
name = f"{channel.guild} #{channel}"
feed: WebhookPayload = {
'id': data['webhook_id'],
'type': 2,
'name': name,
'channel_id': channel.id,
'guild_id': channel.guild.id,
'user': {'username': user.name, 'discriminator': user.discriminator, 'id': user.id, 'avatar': user._avatar},
}
state = channel._state
session = channel._state.http._HTTPClient__session
return cls(feed, session=session, state=state, token=state.http.token)
@classmethod
def from_state(cls, data, state) -> Webhook:
session = state.http._HTTPClient__session
return cls(data, session=session, state=state, token=state.http.token)
async def fetch(self, *, prefer_auth: bool = True) -> Webhook:
"""|coro|
Fetches the current webhook.
This could be used to get a full webhook from a partial webhook.
.. versionadded:: 2.0
.. note::
When fetching with an unauthenticated webhook, i.e.
:meth:`is_authenticated` returns ``False``, then the
returned webhook does not contain any user information.
Parameters
-----------
prefer_auth: :class:`bool`
Whether to use the bot token over the webhook token
if available. Defaults to ``True``.
Raises
-------
HTTPException
Could not fetch the webhook
NotFound
Could not find the webhook by this ID
InvalidArgument
This webhook does not have a token associated with it.
Returns
--------
:class:`Webhook`
The fetched webhook.
"""
adapter = async_context.get()
if prefer_auth and self.auth_token:
data = await adapter.fetch_webhook(self.id, self.auth_token, session=self.session)
elif self.token:
data = await adapter.fetch_webhook_with_token(self.id, self.token, session=self.session)
else:
raise InvalidArgument('This webhook does not have a token associated with it')
return Webhook(data, self.session, token=self.auth_token, state=self._state)
async def delete(self, *, reason: Optional[str] = None, prefer_auth: bool = True):
"""|coro|
Deletes this Webhook.
Parameters
------------
reason: Optional[:class:`str`]
The reason for deleting this webhook. Shows up on the audit log.
.. versionadded:: 1.4
prefer_auth: :class:`bool`
Whether to use the bot token over the webhook token
if available. Defaults to ``True``.
.. versionadded:: 2.0
Raises
-------
HTTPException
Deleting the webhook failed.
NotFound
This webhook does not exist.
Forbidden
You do not have permissions to delete this webhook.
InvalidArgument
This webhook does not have a token associated with it.
"""
if self.token is None and self.auth_token is None:
raise InvalidArgument('This webhook does not have a token associated with it')
adapter = async_context.get()
if prefer_auth and self.auth_token:
await adapter.delete_webhook(self.id, token=self.auth_token, session=self.session, reason=reason)
elif self.token:
await adapter.delete_webhook_with_token(self.id, self.token, session=self.session, reason=reason)
async def edit(
self,
*,
reason: Optional[str] = None,
name: Optional[str] = MISSING,
avatar: Optional[bytes] = MISSING,
channel: Optional[Snowflake] = None,
prefer_auth: bool = True,
) -> Webhook:
"""|coro|
Edits this Webhook.
Parameters
------------
name: Optional[:class:`str`]
The webhook's new default name.
avatar: Optional[:class:`bytes`]
A :term:`py:bytes-like object` representing the webhook's new default avatar.
channel: Optional[:class:`abc.Snowflake`]
The webhook's new channel. This requires an authenticated webhook.
.. versionadded:: 2.0
reason: Optional[:class:`str`]
The reason for editing this webhook. Shows up on the audit log.
.. versionadded:: 1.4
prefer_auth: :class:`bool`
Whether to use the bot token over the webhook token
if available. Defaults to ``True``.
.. versionadded:: 2.0
Raises
-------
HTTPException
Editing the webhook failed.
NotFound
This webhook does not exist.
InvalidArgument
This webhook does not have a token associated with it
or it tried editing a channel without authentication.
"""
if self.token is None and self.auth_token is None:
raise InvalidArgument('This webhook does not have a token associated with it')
payload = {}
if name is not MISSING:
payload['name'] = str(name) if name is not None else None
if avatar is not MISSING:
payload['avatar'] = utils._bytes_to_base64_data(avatar) if avatar is not None else None
adapter = async_context.get()
data: Optional[WebhookPayload] = None
# If a channel is given, always use the authenticated endpoint
if channel is not None:
if self.auth_token is None:
raise InvalidArgument('Editing channel requires authenticated webhook')
payload['channel_id'] = channel.id
data = await adapter.edit_webhook(self.id, self.auth_token, payload=payload, session=self.session, reason=reason)
if prefer_auth and self.auth_token:
data = await adapter.edit_webhook(self.id, self.auth_token, payload=payload, session=self.session, reason=reason)
elif self.token:
data = await adapter.edit_webhook_with_token(
self.id, self.token, payload=payload, session=self.session, reason=reason
)
if data is None:
raise RuntimeError('Unreachable code hit: data was not assigned')
return Webhook(data=data, session=self.session, token=self.auth_token, state=self._state)
def _create_message(self, data):
state = _WebhookState(self, parent=self._state)
# state may be artificial (unlikely at this point...)
channel = self.channel or PartialMessageable(state=self._state, id=int(data['channel_id'])) # type: ignore
# state is artificial
return WebhookMessage(data=data, state=state, channel=channel) # type: ignore
@overload
async def send(
self,
content: str = MISSING,
*,
username: str = MISSING,
avatar_url: Any = MISSING,
tts: bool = MISSING,
ephemeral: bool = MISSING,
file: File = MISSING,
files: List[File] = MISSING,
embed: Embed = MISSING,
embeds: List[Embed] = MISSING,
allowed_mentions: AllowedMentions = MISSING,
view: View = MISSING,
thread: Snowflake = MISSING,
wait: Literal[True],
) -> WebhookMessage:
...
@overload
async def send(
self,
content: str = MISSING,
*,
username: str = MISSING,
avatar_url: Any = MISSING,
tts: bool = MISSING,
ephemeral: bool = MISSING,
file: File = MISSING,
files: List[File] = MISSING,
embed: Embed = MISSING,
embeds: List[Embed] = MISSING,
allowed_mentions: AllowedMentions = MISSING,
view: View = MISSING,
thread: Snowflake = MISSING,
wait: Literal[False] = ...,
) -> None:
...
async def send(
self,
content: str = MISSING,
*,
username: str = MISSING,
avatar_url: Any = MISSING,
tts: bool = False,
ephemeral: bool = False,
file: File = MISSING,
files: List[File] = MISSING,
embed: Embed = MISSING,
embeds: List[Embed] = MISSING,
allowed_mentions: AllowedMentions = MISSING,
view: View = MISSING,
thread: Snowflake = MISSING,
wait: bool = False,
) -> Optional[WebhookMessage]:
"""|coro|
Sends a message using the webhook.
The content must be a type that can convert to a string through ``str(content)``.
To upload a single file, the ``file`` parameter should be used with a
single :class:`File` object.
If the ``embed`` parameter is provided, it must be of type :class:`Embed` and
it must be a rich embed type. You cannot mix the ``embed`` parameter with the
``embeds`` parameter, which must be a :class:`list` of :class:`Embed` objects to send.
Parameters
------------
content: :class:`str`
The content of the message to send.
wait: :class:`bool`
Whether the server should wait before sending a response. This essentially
means that the return type of this function changes from ``None`` to
a :class:`WebhookMessage` if set to ``True``. If the type of webhook
is :attr:`WebhookType.application` then this is always set to ``True``.
username: :class:`str`
The username to send with this message. If no username is provided
then the default username for the webhook is used.
avatar_url: :class:`str`
The avatar URL to send with this message. If no avatar URL is provided
then the default avatar for the webhook is used. If this is not a
string then it is explicitly cast using ``str``.
tts: :class:`bool`
Indicates if the message should be sent using text-to-speech.
ephemeral: :class:`bool`
Indicates if the message should only be visible to the user.
This is only available to :attr:`WebhookType.application` webhooks.
If a view is sent with an ephemeral message and it has no timeout set
then the timeout is set to 15 minutes.
.. versionadded:: 2.0
file: :class:`File`
The file to upload. This cannot be mixed with ``files`` parameter.
files: List[:class:`File`]
A list of files to send with the content. This cannot be mixed with the
``file`` parameter.
embed: :class:`Embed`
The rich embed for the content to send. This cannot be mixed with
``embeds`` parameter.
embeds: List[:class:`Embed`]
A list of embeds to send with the content. Maximum of 10. This cannot
be mixed with the ``embed`` parameter.
allowed_mentions: :class:`AllowedMentions`
Controls the mentions being processed in this message.
.. versionadded:: 1.4
view: :class:`discord.ui.View`
The view to send with the message. You can only send a view
if this webhook is not partial and has state attached. A
webhook has state attached if the webhook is managed by the
library.
.. versionadded:: 2.0
thread: :class:`~discord.abc.Snowflake`
The thread to send this webhook to.
.. versionadded:: 2.0
Raises
--------
HTTPException
Sending the message failed.
NotFound
This webhook was not found.
Forbidden
The authorization token for the webhook is incorrect.
TypeError
You specified both ``embed`` and ``embeds`` or ``file`` and ``files``.
ValueError
The length of ``embeds`` was invalid.
InvalidArgument
There was no token associated with this webhook or ``ephemeral``
was passed with the improper webhook type or there was no state
attached with this webhook when giving it a view.
Returns
---------
Optional[:class:`WebhookMessage`]
If ``wait`` is ``True`` then the message that was sent, otherwise ``None``.
"""
if self.token is None:
raise InvalidArgument('This webhook does not have a token associated with it')
previous_mentions: Optional[AllowedMentions] = getattr(self._state, 'allowed_mentions', None)
if content is None:
content = MISSING
application_webhook = self.type is WebhookType.application
if ephemeral and not application_webhook:
raise InvalidArgument('ephemeral messages can only be sent from application webhooks')
if application_webhook:
wait = True
if view is not MISSING:
if isinstance(self._state, _WebhookState):
raise InvalidArgument('Webhook views require an associated state with the webhook')
if ephemeral is True and view.timeout is None:
view.timeout = 15 * 60.0
params = handle_message_parameters(
content=content,
username=username,
avatar_url=avatar_url,
tts=tts,
file=file,
files=files,
embed=embed,
embeds=embeds,
ephemeral=ephemeral,
view=view,
allowed_mentions=allowed_mentions,
previous_allowed_mentions=previous_mentions,
)
adapter = async_context.get()
thread_id: Optional[int] = None
if thread is not MISSING:
thread_id = thread.id
data = await adapter.execute_webhook(
self.id,
self.token,
session=self.session,
payload=params.payload,
multipart=params.multipart,
files=params.files,
thread_id=thread_id,
wait=wait,
)
msg = None
if wait:
msg = self._create_message(data)
if view is not MISSING and not view.is_finished():
message_id = None if msg is None else msg.id
self._state.store_view(view, message_id)
return msg
async def fetch_message(self, id: int) -> WebhookMessage:
"""|coro|
Retrieves a single :class:`~discord.WebhookMessage` owned by this webhook.
.. versionadded:: 2.0
Parameters
------------
id: :class:`int`
The message ID to look for.
Raises
--------
~discord.NotFound
The specified message was not found.
~discord.Forbidden
You do not have the permissions required to get a message.
~discord.HTTPException
Retrieving the message failed.
InvalidArgument
There was no token associated with this webhook.
Returns
--------
:class:`~discord.WebhookMessage`
The message asked for.
"""
if self.token is None:
raise InvalidArgument('This webhook does not have a token associated with it')
adapter = async_context.get()
data = await adapter.get_webhook_message(
self.id,
self.token,
id,
session=self.session,
)
return self._create_message(data)
async def edit_message(
self,
message_id: int,
*,
content: Optional[str] = MISSING,
embeds: List[Embed] = MISSING,
embed: Optional[Embed] = MISSING,
file: File = MISSING,
files: List[File] = MISSING,
view: Optional[View] = MISSING,
allowed_mentions: Optional[AllowedMentions] = None,
) -> WebhookMessage:
"""|coro|
Edits a message owned by this webhook.
This is a lower level interface to :meth:`WebhookMessage.edit` in case
you only have an ID.
.. versionadded:: 1.6
.. versionchanged:: 2.0
The edit is no longer in-place, instead the newly edited message is returned.
Parameters
------------
message_id: :class:`int`
The message ID to edit.
content: Optional[:class:`str`]
The content to edit the message with or ``None`` to clear it.
embeds: List[:class:`Embed`]
A list of embeds to edit the message with.
embed: Optional[:class:`Embed`]
The embed to edit the message with. ``None`` suppresses the embeds.
This should not be mixed with the ``embeds`` parameter.
file: :class:`File`
The file to upload. This cannot be mixed with ``files`` parameter.
.. versionadded:: 2.0
files: List[:class:`File`]
A list of files to send with the content. This cannot be mixed with the
``file`` parameter.
.. versionadded:: 2.0
allowed_mentions: :class:`AllowedMentions`
Controls the mentions being processed in this message.
See :meth:`.abc.Messageable.send` for more information.
view: Optional[:class:`~discord.ui.View`]
The updated view to update this message with. If ``None`` is passed then
the view is removed. The webhook must have state attached, similar to
:meth:`send`.
.. versionadded:: 2.0
Raises
-------
HTTPException
Editing the message failed.
Forbidden
Edited a message that is not yours.
TypeError
You specified both ``embed`` and ``embeds`` or ``file`` and ``files``
ValueError
The length of ``embeds`` was invalid
InvalidArgument
There was no token associated with this webhook or the webhook had
no state.
Returns
--------
:class:`WebhookMessage`
The newly edited webhook message.
"""
if self.token is None:
raise InvalidArgument('This webhook does not have a token associated with it')
if view is not MISSING:
if isinstance(self._state, _WebhookState):
raise InvalidArgument('This webhook does not have state associated with it')
self._state.prevent_view_updates_for(message_id)
previous_mentions: Optional[AllowedMentions] = getattr(self._state, 'allowed_mentions', None)
params = handle_message_parameters(
content=content,
file=file,
files=files,
embed=embed,
embeds=embeds,
view=view,
allowed_mentions=allowed_mentions,
previous_allowed_mentions=previous_mentions,
)
adapter = async_context.get()
data = await adapter.edit_webhook_message(
self.id,
self.token,
message_id,
session=self.session,
payload=params.payload,
multipart=params.multipart,
files=params.files,
)
message = self._create_message(data)
if view and not view.is_finished():
self._state.store_view(view, message_id)
return message
async def delete_message(self, message_id: int, /) -> None:
"""|coro|
Deletes a message owned by this webhook.
This is a lower level interface to :meth:`WebhookMessage.delete` in case
you only have an ID.
.. versionadded:: 1.6
Parameters
------------
message_id: :class:`int`
The message ID to delete.
Raises
-------
HTTPException
Deleting the message failed.
Forbidden
Deleted a message that is not yours.
"""
if self.token is None:
raise InvalidArgument('This webhook does not have a token associated with it')
adapter = async_context.get()
await adapter.delete_webhook_message(
self.id,
self.token,
message_id,
session=self.session,
) | zarenacord.py | /zarenacord.py-2.0.0-py3-none-any.whl/discord/webhook/async_.py | async_.py |
from __future__ import annotations
from typing import List, Literal, Optional, TypedDict, Union
from .snowflake import Snowflake, SnowflakeList
from .member import Member, UserWithMember
from .user import User
from .emoji import PartialEmoji
from .embed import Embed
from .channel import ChannelType
from .components import Component
from .interactions import MessageInteraction
from .sticker import StickerItem
class ChannelMention(TypedDict):
id: Snowflake
guild_id: Snowflake
type: ChannelType
name: str
class Reaction(TypedDict):
count: int
me: bool
emoji: PartialEmoji
class _AttachmentOptional(TypedDict, total=False):
height: Optional[int]
width: Optional[int]
content_type: str
spoiler: bool
class Attachment(_AttachmentOptional):
id: Snowflake
filename: str
size: int
url: str
proxy_url: str
MessageActivityType = Literal[1, 2, 3, 5]
class MessageActivity(TypedDict):
type: MessageActivityType
party_id: str
class _MessageApplicationOptional(TypedDict, total=False):
cover_image: str
class MessageApplication(_MessageApplicationOptional):
id: Snowflake
description: str
icon: Optional[str]
name: str
class MessageReference(TypedDict, total=False):
message_id: Snowflake
channel_id: Snowflake
guild_id: Snowflake
fail_if_not_exists: bool
class _MessageOptional(TypedDict, total=False):
guild_id: Snowflake
member: Member
mention_channels: List[ChannelMention]
reactions: List[Reaction]
nonce: Union[int, str]
webhook_id: Snowflake
activity: MessageActivity
application: MessageApplication
application_id: Snowflake
message_reference: MessageReference
flags: int
sticker_items: List[StickerItem]
referenced_message: Optional[Message]
interaction: MessageInteraction
components: List[Component]
MessageType = Literal[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 14, 15, 18, 19, 20, 21]
class Message(_MessageOptional):
id: Snowflake
channel_id: Snowflake
author: User
content: str
timestamp: str
edited_timestamp: Optional[str]
tts: bool
mention_everyone: bool
mentions: List[UserWithMember]
mention_roles: SnowflakeList
attachments: List[Attachment]
embeds: List[Embed]
pinned: bool
type: MessageType
AllowedMentionType = Literal['roles', 'users', 'everyone']
class AllowedMentions(TypedDict):
parse: List[AllowedMentionType]
roles: SnowflakeList
users: SnowflakeList
replied_user: bool | zarenacord.py | /zarenacord.py-2.0.0-py3-none-any.whl/discord/types/message.py | message.py |
from typing import List, Literal, Optional, TypedDict, Union
from .user import PartialUser
from .snowflake import Snowflake
from .threads import ThreadMetadata, ThreadMember, ThreadArchiveDuration
OverwriteType = Literal[0, 1]
class PermissionOverwrite(TypedDict):
id: Snowflake
type: OverwriteType
allow: str
deny: str
ChannelType = Literal[0, 1, 2, 3, 4, 5, 6, 10, 11, 12, 13]
class _BaseChannel(TypedDict):
id: Snowflake
name: str
class _BaseGuildChannel(_BaseChannel):
guild_id: Snowflake
position: int
permission_overwrites: List[PermissionOverwrite]
nsfw: bool
parent_id: Optional[Snowflake]
class PartialChannel(_BaseChannel):
type: ChannelType
class _TextChannelOptional(TypedDict, total=False):
topic: str
last_message_id: Optional[Snowflake]
last_pin_timestamp: str
rate_limit_per_user: int
default_auto_archive_duration: ThreadArchiveDuration
class TextChannel(_BaseGuildChannel, _TextChannelOptional):
type: Literal[0]
class NewsChannel(_BaseGuildChannel, _TextChannelOptional):
type: Literal[5]
VideoQualityMode = Literal[1, 2]
class _VoiceChannelOptional(TypedDict, total=False):
rtc_region: Optional[str]
video_quality_mode: VideoQualityMode
class VoiceChannel(_BaseGuildChannel, _VoiceChannelOptional):
type: Literal[2]
bitrate: int
user_limit: int
class CategoryChannel(_BaseGuildChannel):
type: Literal[4]
class StoreChannel(_BaseGuildChannel):
type: Literal[6]
class _StageChannelOptional(TypedDict, total=False):
rtc_region: Optional[str]
topic: str
class StageChannel(_BaseGuildChannel, _StageChannelOptional):
type: Literal[13]
bitrate: int
user_limit: int
class _ThreadChannelOptional(TypedDict, total=False):
member: ThreadMember
owner_id: Snowflake
rate_limit_per_user: int
last_message_id: Optional[Snowflake]
last_pin_timestamp: str
class ThreadChannel(_BaseChannel, _ThreadChannelOptional):
type: Literal[10, 11, 12]
guild_id: Snowflake
parent_id: Snowflake
owner_id: Snowflake
nsfw: bool
last_message_id: Optional[Snowflake]
rate_limit_per_user: int
message_count: int
member_count: int
thread_metadata: ThreadMetadata
GuildChannel = Union[TextChannel, NewsChannel, VoiceChannel, CategoryChannel, StoreChannel, StageChannel, ThreadChannel]
class DMChannel(_BaseChannel):
type: Literal[1]
last_message_id: Optional[Snowflake]
recipients: List[PartialUser]
class GroupDMChannel(_BaseChannel):
type: Literal[3]
icon: Optional[str]
owner_id: Snowflake
Channel = Union[GuildChannel, DMChannel, GroupDMChannel]
PrivacyLevel = Literal[1, 2]
class StageInstance(TypedDict):
id: Snowflake
guild_id: Snowflake
channel_id: Snowflake
topic: str
privacy_level: PrivacyLevel
discoverable_disabled: bool | zarenacord.py | /zarenacord.py-2.0.0-py3-none-any.whl/discord/types/channel.py | channel.py |
from typing import List, Literal, Optional, TypedDict
from .snowflake import Snowflake
from .channel import GuildChannel
from .voice import GuildVoiceState
from .welcome_screen import WelcomeScreen
from .activity import PartialPresenceUpdate
from .role import Role
from .member import Member
from .emoji import Emoji
from .user import User
from .threads import Thread
class Ban(TypedDict):
reason: Optional[str]
user: User
class _UnavailableGuildOptional(TypedDict, total=False):
unavailable: bool
class UnavailableGuild(_UnavailableGuildOptional):
id: Snowflake
class _GuildOptional(TypedDict, total=False):
icon_hash: Optional[str]
owner: bool
permissions: str
widget_enabled: bool
widget_channel_id: Optional[Snowflake]
joined_at: Optional[str]
large: bool
member_count: int
voice_states: List[GuildVoiceState]
members: List[Member]
channels: List[GuildChannel]
presences: List[PartialPresenceUpdate]
threads: List[Thread]
max_presences: Optional[int]
max_members: int
premium_subscription_count: int
max_video_channel_users: int
DefaultMessageNotificationLevel = Literal[0, 1]
ExplicitContentFilterLevel = Literal[0, 1, 2]
MFALevel = Literal[0, 1]
VerificationLevel = Literal[0, 1, 2, 3, 4]
NSFWLevel = Literal[0, 1, 2, 3]
PremiumTier = Literal[0, 1, 2, 3]
GuildFeature = Literal[
'ANIMATED_ICON',
'BANNER',
'COMMERCE',
'COMMUNITY',
'DISCOVERABLE',
'FEATURABLE',
'INVITE_SPLASH',
'MEMBER_VERIFICATION_GATE_ENABLED',
'MONETIZATION_ENABLED',
'MORE_EMOJI',
'MORE_STICKERS',
'NEWS',
'PARTNERED',
'PREVIEW_ENABLED',
'PRIVATE_THREADS',
'SEVEN_DAY_THREAD_ARCHIVE',
'THREE_DAY_THREAD_ARCHIVE',
'TICKETED_EVENTS_ENABLED',
'VANITY_URL',
'VERIFIED',
'VIP_REGIONS',
'WELCOME_SCREEN_ENABLED',
]
class _BaseGuildPreview(UnavailableGuild):
name: str
icon: Optional[str]
splash: Optional[str]
discovery_splash: Optional[str]
emojis: List[Emoji]
features: List[GuildFeature]
description: Optional[str]
class _GuildPreviewUnique(TypedDict):
approximate_member_count: int
approximate_presence_count: int
class GuildPreview(_BaseGuildPreview, _GuildPreviewUnique):
...
class Guild(_BaseGuildPreview, _GuildOptional):
owner_id: Snowflake
region: str
afk_channel_id: Optional[Snowflake]
afk_timeout: int
verification_level: VerificationLevel
default_message_notifications: DefaultMessageNotificationLevel
explicit_content_filter: ExplicitContentFilterLevel
roles: List[Role]
mfa_level: MFALevel
nsfw_level: NSFWLevel
application_id: Optional[Snowflake]
system_channel_id: Optional[Snowflake]
system_channel_flags: int
rules_channel_id: Optional[Snowflake]
vanity_url_code: Optional[str]
banner: Optional[str]
premium_tier: PremiumTier
preferred_locale: str
public_updates_channel_id: Optional[Snowflake]
class InviteGuild(Guild, total=False):
welcome_screen: WelcomeScreen
class GuildWithCounts(Guild, _GuildPreviewUnique):
...
class GuildPrune(TypedDict):
pruned: Optional[int]
class ChannelPositionUpdate(TypedDict):
id: Snowflake
position: Optional[int]
lock_permissions: Optional[bool]
parent_id: Optional[Snowflake]
class _RolePositionRequired(TypedDict):
id: Snowflake
class RolePositionUpdate(_RolePositionRequired, total=False):
position: Optional[Snowflake] | zarenacord.py | /zarenacord.py-2.0.0-py3-none-any.whl/discord/types/guild.py | guild.py |
from __future__ import annotations
from typing import List, Literal, Optional, TypedDict, Union
from .webhook import Webhook
from .guild import MFALevel, VerificationLevel, ExplicitContentFilterLevel, DefaultMessageNotificationLevel
from .integration import IntegrationExpireBehavior, PartialIntegration
from .user import User
from .snowflake import Snowflake
from .role import Role
from .channel import ChannelType, VideoQualityMode, PermissionOverwrite
from .threads import Thread
AuditLogEvent = Literal[
1,
10,
11,
12,
13,
14,
15,
20,
21,
22,
23,
24,
25,
26,
27,
28,
30,
31,
32,
40,
41,
42,
50,
51,
52,
60,
61,
62,
72,
73,
74,
75,
80,
81,
82,
83,
84,
85,
90,
91,
92,
110,
111,
112,
]
class _AuditLogChange_Str(TypedDict):
key: Literal[
'name', 'description', 'preferred_locale', 'vanity_url_code', 'topic', 'code', 'allow', 'deny', 'permissions', 'tags'
]
new_value: str
old_value: str
class _AuditLogChange_AssetHash(TypedDict):
key: Literal['icon_hash', 'splash_hash', 'discovery_splash_hash', 'banner_hash', 'avatar_hash', 'asset']
new_value: str
old_value: str
class _AuditLogChange_Snowflake(TypedDict):
key: Literal[
'id',
'owner_id',
'afk_channel_id',
'rules_channel_id',
'public_updates_channel_id',
'widget_channel_id',
'system_channel_id',
'application_id',
'channel_id',
'inviter_id',
'guild_id',
]
new_value: Snowflake
old_value: Snowflake
class _AuditLogChange_Bool(TypedDict):
key: Literal[
'widget_enabled',
'nsfw',
'hoist',
'mentionable',
'temporary',
'deaf',
'mute',
'nick',
'enabled_emoticons',
'region',
'rtc_region',
'available',
'archived',
'locked',
]
new_value: bool
old_value: bool
class _AuditLogChange_Int(TypedDict):
key: Literal[
'afk_timeout',
'prune_delete_days',
'position',
'bitrate',
'rate_limit_per_user',
'color',
'max_uses',
'max_age',
'user_limit',
'auto_archive_duration',
'default_auto_archive_duration',
]
new_value: int
old_value: int
class _AuditLogChange_ListRole(TypedDict):
key: Literal['$add', '$remove']
new_value: List[Role]
old_value: List[Role]
class _AuditLogChange_MFALevel(TypedDict):
key: Literal['mfa_level']
new_value: MFALevel
old_value: MFALevel
class _AuditLogChange_VerificationLevel(TypedDict):
key: Literal['verification_level']
new_value: VerificationLevel
old_value: VerificationLevel
class _AuditLogChange_ExplicitContentFilter(TypedDict):
key: Literal['explicit_content_filter']
new_value: ExplicitContentFilterLevel
old_value: ExplicitContentFilterLevel
class _AuditLogChange_DefaultMessageNotificationLevel(TypedDict):
key: Literal['default_message_notifications']
new_value: DefaultMessageNotificationLevel
old_value: DefaultMessageNotificationLevel
class _AuditLogChange_ChannelType(TypedDict):
key: Literal['type']
new_value: ChannelType
old_value: ChannelType
class _AuditLogChange_IntegrationExpireBehaviour(TypedDict):
key: Literal['expire_behavior']
new_value: IntegrationExpireBehavior
old_value: IntegrationExpireBehavior
class _AuditLogChange_VideoQualityMode(TypedDict):
key: Literal['video_quality_mode']
new_value: VideoQualityMode
old_value: VideoQualityMode
class _AuditLogChange_Overwrites(TypedDict):
key: Literal['permission_overwrites']
new_value: List[PermissionOverwrite]
old_value: List[PermissionOverwrite]
AuditLogChange = Union[
_AuditLogChange_Str,
_AuditLogChange_AssetHash,
_AuditLogChange_Snowflake,
_AuditLogChange_Int,
_AuditLogChange_Bool,
_AuditLogChange_ListRole,
_AuditLogChange_MFALevel,
_AuditLogChange_VerificationLevel,
_AuditLogChange_ExplicitContentFilter,
_AuditLogChange_DefaultMessageNotificationLevel,
_AuditLogChange_ChannelType,
_AuditLogChange_IntegrationExpireBehaviour,
_AuditLogChange_VideoQualityMode,
_AuditLogChange_Overwrites,
]
class AuditEntryInfo(TypedDict):
delete_member_days: str
members_removed: str
channel_id: Snowflake
message_id: Snowflake
count: str
id: Snowflake
type: Literal['0', '1']
role_name: str
class _AuditLogEntryOptional(TypedDict, total=False):
changes: List[AuditLogChange]
options: AuditEntryInfo
reason: str
class AuditLogEntry(_AuditLogEntryOptional):
target_id: Optional[str]
user_id: Optional[Snowflake]
id: Snowflake
action_type: AuditLogEvent
class AuditLog(TypedDict):
webhooks: List[Webhook]
users: List[User]
audit_log_entries: List[AuditLogEntry]
integrations: List[PartialIntegration]
threads: List[Thread] | zarenacord.py | /zarenacord.py-2.0.0-py3-none-any.whl/discord/types/audit_log.py | audit_log.py |
from __future__ import annotations
from typing import Optional, TYPE_CHECKING, Dict, TypedDict, Union, List, Literal
from .snowflake import Snowflake
from .components import Component, ComponentType
from .embed import Embed
from .channel import ChannelType
from .member import Member
from .role import Role
from .user import User
if TYPE_CHECKING:
from .message import AllowedMentions, Message
ApplicationCommandType = Literal[1, 2, 3]
class _ApplicationCommandOptional(TypedDict, total=False):
options: List[ApplicationCommandOption]
type: ApplicationCommandType
class ApplicationCommand(_ApplicationCommandOptional):
id: Snowflake
application_id: Snowflake
name: str
description: str
class _ApplicationCommandOptionOptional(TypedDict, total=False):
choices: List[ApplicationCommandOptionChoice]
options: List[ApplicationCommandOption]
ApplicationCommandOptionType = Literal[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
class ApplicationCommandOption(_ApplicationCommandOptionOptional):
type: ApplicationCommandOptionType
name: str
description: str
required: bool
class ApplicationCommandOptionChoice(TypedDict):
name: str
value: Union[str, int]
ApplicationCommandPermissionType = Literal[1, 2]
class ApplicationCommandPermissions(TypedDict):
id: Snowflake
type: ApplicationCommandPermissionType
permission: bool
class BaseGuildApplicationCommandPermissions(TypedDict):
permissions: List[ApplicationCommandPermissions]
class PartialGuildApplicationCommandPermissions(BaseGuildApplicationCommandPermissions):
id: Snowflake
class GuildApplicationCommandPermissions(PartialGuildApplicationCommandPermissions):
application_id: Snowflake
guild_id: Snowflake
InteractionType = Literal[1, 2, 3]
class _ApplicationCommandInteractionDataOption(TypedDict):
name: str
class _ApplicationCommandInteractionDataOptionSubcommand(_ApplicationCommandInteractionDataOption):
type: Literal[1, 2]
options: List[ApplicationCommandInteractionDataOption]
class _ApplicationCommandInteractionDataOptionString(_ApplicationCommandInteractionDataOption):
type: Literal[3]
value: str
class _ApplicationCommandInteractionDataOptionInteger(_ApplicationCommandInteractionDataOption):
type: Literal[4]
value: int
class _ApplicationCommandInteractionDataOptionBoolean(_ApplicationCommandInteractionDataOption):
type: Literal[5]
value: bool
class _ApplicationCommandInteractionDataOptionSnowflake(_ApplicationCommandInteractionDataOption):
type: Literal[6, 7, 8, 9]
value: Snowflake
class _ApplicationCommandInteractionDataOptionNumber(_ApplicationCommandInteractionDataOption):
type: Literal[10]
value: float
ApplicationCommandInteractionDataOption = Union[
_ApplicationCommandInteractionDataOptionString,
_ApplicationCommandInteractionDataOptionInteger,
_ApplicationCommandInteractionDataOptionSubcommand,
_ApplicationCommandInteractionDataOptionBoolean,
_ApplicationCommandInteractionDataOptionSnowflake,
_ApplicationCommandInteractionDataOptionNumber,
]
class ApplicationCommandResolvedPartialChannel(TypedDict):
id: Snowflake
type: ChannelType
permissions: str
name: str
class ApplicationCommandInteractionDataResolved(TypedDict, total=False):
users: Dict[Snowflake, User]
members: Dict[Snowflake, Member]
roles: Dict[Snowflake, Role]
channels: Dict[Snowflake, ApplicationCommandResolvedPartialChannel]
class _ApplicationCommandInteractionDataOptional(TypedDict, total=False):
options: List[ApplicationCommandInteractionDataOption]
resolved: ApplicationCommandInteractionDataResolved
target_id: Snowflake
type: ApplicationCommandType
class ApplicationCommandInteractionData(_ApplicationCommandInteractionDataOptional):
id: Snowflake
name: str
class _ComponentInteractionDataOptional(TypedDict, total=False):
values: List[str]
class ComponentInteractionData(_ComponentInteractionDataOptional):
custom_id: str
component_type: ComponentType
InteractionData = Union[ApplicationCommandInteractionData, ComponentInteractionData]
class _InteractionOptional(TypedDict, total=False):
data: InteractionData
guild_id: Snowflake
channel_id: Snowflake
member: Member
user: User
message: Message
class Interaction(_InteractionOptional):
id: Snowflake
application_id: Snowflake
type: InteractionType
token: str
version: int
class InteractionApplicationCommandCallbackData(TypedDict, total=False):
tts: bool
content: str
embeds: List[Embed]
allowed_mentions: AllowedMentions
flags: int
components: List[Component]
InteractionResponseType = Literal[1, 4, 5, 6, 7]
class _InteractionResponseOptional(TypedDict, total=False):
data: InteractionApplicationCommandCallbackData
class InteractionResponse(_InteractionResponseOptional):
type: InteractionResponseType
class MessageInteraction(TypedDict):
id: Snowflake
type: InteractionType
name: str
user: User
class _EditApplicationCommandOptional(TypedDict, total=False):
description: str
options: Optional[List[ApplicationCommandOption]]
type: ApplicationCommandType
class EditApplicationCommand(_EditApplicationCommandOptional):
name: str
default_permission: bool | zarenacord.py | /zarenacord.py-2.0.0-py3-none-any.whl/discord/types/interactions.py | interactions.py |
from __future__ import annotations
import asyncio
import datetime
from typing import (
Any,
Awaitable,
Callable,
Generic,
List,
Optional,
Type,
TypeVar,
Union,
)
import aiohttp
import discord
import inspect
import sys
import traceback
from collections.abc import Sequence
from discord.backoff import ExponentialBackoff
from discord.utils import MISSING
__all__ = (
'loop',
)
T = TypeVar('T')
_func = Callable[..., Awaitable[Any]]
LF = TypeVar('LF', bound=_func)
FT = TypeVar('FT', bound=_func)
ET = TypeVar('ET', bound=Callable[[Any, BaseException], Awaitable[Any]])
class SleepHandle:
__slots__ = ('future', 'loop', 'handle')
def __init__(self, dt: datetime.datetime, *, loop: asyncio.AbstractEventLoop) -> None:
self.loop = loop
self.future = future = loop.create_future()
relative_delta = discord.utils.compute_timedelta(dt)
self.handle = loop.call_later(relative_delta, future.set_result, True)
def recalculate(self, dt: datetime.datetime) -> None:
self.handle.cancel()
relative_delta = discord.utils.compute_timedelta(dt)
self.handle = self.loop.call_later(relative_delta, self.future.set_result, True)
def wait(self) -> asyncio.Future[Any]:
return self.future
def done(self) -> bool:
return self.future.done()
def cancel(self) -> None:
self.handle.cancel()
self.future.cancel()
class Loop(Generic[LF]):
"""A background task helper that abstracts the loop and reconnection logic for you.
The main interface to create this is through :func:`loop`.
"""
def __init__(
self,
coro: LF,
seconds: float,
hours: float,
minutes: float,
time: Union[datetime.time, Sequence[datetime.time]],
count: Optional[int],
reconnect: bool,
loop: asyncio.AbstractEventLoop,
) -> None:
self.coro: LF = coro
self.reconnect: bool = reconnect
self.loop: asyncio.AbstractEventLoop = loop
self.count: Optional[int] = count
self._current_loop = 0
self._handle: SleepHandle = MISSING
self._task: asyncio.Task[None] = MISSING
self._injected = None
self._valid_exception = (
OSError,
discord.GatewayNotFound,
discord.ConnectionClosed,
aiohttp.ClientError,
asyncio.TimeoutError,
)
self._before_loop = None
self._after_loop = None
self._is_being_cancelled = False
self._has_failed = False
self._stop_next_iteration = False
if self.count is not None and self.count <= 0:
raise ValueError('count must be greater than 0 or None.')
self.change_interval(seconds=seconds, minutes=minutes, hours=hours, time=time)
self._last_iteration_failed = False
self._last_iteration: datetime.datetime = MISSING
self._next_iteration = None
if not inspect.iscoroutinefunction(self.coro):
raise TypeError(f'Expected coroutine function, not {type(self.coro).__name__!r}.')
async def _call_loop_function(self, name: str, *args: Any, **kwargs: Any) -> None:
coro = getattr(self, '_' + name)
if coro is None:
return
if self._injected is not None:
await coro(self._injected, *args, **kwargs)
else:
await coro(*args, **kwargs)
def _try_sleep_until(self, dt: datetime.datetime):
self._handle = SleepHandle(dt=dt, loop=self.loop)
return self._handle.wait()
async def _loop(self, *args: Any, **kwargs: Any) -> None:
backoff = ExponentialBackoff()
await self._call_loop_function('before_loop')
self._last_iteration_failed = False
if self._time is not MISSING:
# the time index should be prepared every time the internal loop is started
self._prepare_time_index()
self._next_iteration = self._get_next_sleep_time()
else:
self._next_iteration = datetime.datetime.now(datetime.timezone.utc)
try:
await self._try_sleep_until(self._next_iteration)
while True:
if not self._last_iteration_failed:
self._last_iteration = self._next_iteration
self._next_iteration = self._get_next_sleep_time()
try:
await self.coro(*args, **kwargs)
self._last_iteration_failed = False
except self._valid_exception:
self._last_iteration_failed = True
if not self.reconnect:
raise
await asyncio.sleep(backoff.delay())
else:
await self._try_sleep_until(self._next_iteration)
if self._stop_next_iteration:
return
now = datetime.datetime.now(datetime.timezone.utc)
if now > self._next_iteration:
self._next_iteration = now
if self._time is not MISSING:
self._prepare_time_index(now)
self._current_loop += 1
if self._current_loop == self.count:
break
except asyncio.CancelledError:
self._is_being_cancelled = True
raise
except Exception as exc:
self._has_failed = True
await self._call_loop_function('error', exc)
raise exc
finally:
await self._call_loop_function('after_loop')
self._handle.cancel()
self._is_being_cancelled = False
self._current_loop = 0
self._stop_next_iteration = False
self._has_failed = False
def __get__(self, obj: T, objtype: Type[T]) -> Loop[LF]:
if obj is None:
return self
copy: Loop[LF] = Loop(
self.coro,
seconds=self._seconds,
hours=self._hours,
minutes=self._minutes,
time=self._time,
count=self.count,
reconnect=self.reconnect,
loop=self.loop,
)
copy._injected = obj
copy._before_loop = self._before_loop
copy._after_loop = self._after_loop
copy._error = self._error
setattr(obj, self.coro.__name__, copy)
return copy
@property
def seconds(self) -> Optional[float]:
"""Optional[:class:`float`]: Read-only value for the number of seconds
between each iteration. ``None`` if an explicit ``time`` value was passed instead.
.. versionadded:: 2.0
"""
if self._seconds is not MISSING:
return self._seconds
@property
def minutes(self) -> Optional[float]:
"""Optional[:class:`float`]: Read-only value for the number of minutes
between each iteration. ``None`` if an explicit ``time`` value was passed instead.
.. versionadded:: 2.0
"""
if self._minutes is not MISSING:
return self._minutes
@property
def hours(self) -> Optional[float]:
"""Optional[:class:`float`]: Read-only value for the number of hours
between each iteration. ``None`` if an explicit ``time`` value was passed instead.
.. versionadded:: 2.0
"""
if self._hours is not MISSING:
return self._hours
@property
def time(self) -> Optional[List[datetime.time]]:
"""Optional[List[:class:`datetime.time`]]: Read-only list for the exact times this loop runs at.
``None`` if relative times were passed instead.
.. versionadded:: 2.0
"""
if self._time is not MISSING:
return self._time.copy()
@property
def current_loop(self) -> int:
""":class:`int`: The current iteration of the loop."""
return self._current_loop
@property
def next_iteration(self) -> Optional[datetime.datetime]:
"""Optional[:class:`datetime.datetime`]: When the next iteration of the loop will occur.
.. versionadded:: 1.3
"""
if self._task is MISSING:
return None
elif self._task and self._task.done() or self._stop_next_iteration:
return None
return self._next_iteration
async def __call__(self, *args: Any, **kwargs: Any) -> Any:
r"""|coro|
Calls the internal callback that the task holds.
.. versionadded:: 1.6
Parameters
------------
\*args
The arguments to use.
\*\*kwargs
The keyword arguments to use.
"""
if self._injected is not None:
args = (self._injected, *args)
return await self.coro(*args, **kwargs)
def start(self, *args: Any, **kwargs: Any) -> asyncio.Task[None]:
r"""Starts the internal task in the event loop.
Parameters
------------
\*args
The arguments to use.
\*\*kwargs
The keyword arguments to use.
Raises
--------
RuntimeError
A task has already been launched and is running.
Returns
---------
:class:`asyncio.Task`
The task that has been created.
"""
if self._task is not MISSING and not self._task.done():
raise RuntimeError('Task is already launched and is not completed.')
if self._injected is not None:
args = (self._injected, *args)
if self.loop is MISSING:
self.loop = asyncio.get_event_loop()
self._task = self.loop.create_task(self._loop(*args, **kwargs))
return self._task
def stop(self) -> None:
r"""Gracefully stops the task from running.
Unlike :meth:`cancel`\, this allows the task to finish its
current iteration before gracefully exiting.
.. note::
If the internal function raises an error that can be
handled before finishing then it will retry until
it succeeds.
If this is undesirable, either remove the error handling
before stopping via :meth:`clear_exception_types` or
use :meth:`cancel` instead.
.. versionadded:: 1.2
"""
if self._task is not MISSING and not self._task.done():
self._stop_next_iteration = True
def _can_be_cancelled(self) -> bool:
return bool(not self._is_being_cancelled and self._task and not self._task.done())
def cancel(self) -> None:
"""Cancels the internal task, if it is running."""
if self._can_be_cancelled():
self._task.cancel()
def restart(self, *args: Any, **kwargs: Any) -> None:
r"""A convenience method to restart the internal task.
.. note::
Due to the way this function works, the task is not
returned like :meth:`start`.
Parameters
------------
\*args
The arguments to use.
\*\*kwargs
The keyword arguments to use.
"""
def restart_when_over(fut: Any, *, args: Any = args, kwargs: Any = kwargs) -> None:
self._task.remove_done_callback(restart_when_over)
self.start(*args, **kwargs)
if self._can_be_cancelled():
self._task.add_done_callback(restart_when_over)
self._task.cancel()
def add_exception_type(self, *exceptions: Type[BaseException]) -> None:
r"""Adds exception types to be handled during the reconnect logic.
By default the exception types handled are those handled by
:meth:`discord.Client.connect`\, which includes a lot of internet disconnection
errors.
This function is useful if you're interacting with a 3rd party library that
raises its own set of exceptions.
Parameters
------------
\*exceptions: Type[:class:`BaseException`]
An argument list of exception classes to handle.
Raises
--------
TypeError
An exception passed is either not a class or not inherited from :class:`BaseException`.
"""
for exc in exceptions:
if not inspect.isclass(exc):
raise TypeError(f'{exc!r} must be a class.')
if not issubclass(exc, BaseException):
raise TypeError(f'{exc!r} must inherit from BaseException.')
self._valid_exception = (*self._valid_exception, *exceptions)
def clear_exception_types(self) -> None:
"""Removes all exception types that are handled.
.. note::
This operation obviously cannot be undone!
"""
self._valid_exception = tuple()
def remove_exception_type(self, *exceptions: Type[BaseException]) -> bool:
r"""Removes exception types from being handled during the reconnect logic.
Parameters
------------
\*exceptions: Type[:class:`BaseException`]
An argument list of exception classes to handle.
Returns
---------
:class:`bool`
Whether all exceptions were successfully removed.
"""
old_length = len(self._valid_exception)
self._valid_exception = tuple(x for x in self._valid_exception if x not in exceptions)
return len(self._valid_exception) == old_length - len(exceptions)
def get_task(self) -> Optional[asyncio.Task[None]]:
"""Optional[:class:`asyncio.Task`]: Fetches the internal task or ``None`` if there isn't one running."""
return self._task if self._task is not MISSING else None
def is_being_cancelled(self) -> bool:
"""Whether the task is being cancelled."""
return self._is_being_cancelled
def failed(self) -> bool:
""":class:`bool`: Whether the internal task has failed.
.. versionadded:: 1.2
"""
return self._has_failed
def is_running(self) -> bool:
""":class:`bool`: Check if the task is currently running.
.. versionadded:: 1.4
"""
return not bool(self._task.done()) if self._task is not MISSING else False
async def _error(self, *args: Any) -> None:
exception: Exception = args[-1]
print(f'Unhandled exception in internal background task {self.coro.__name__!r}.', file=sys.stderr)
traceback.print_exception(type(exception), exception, exception.__traceback__, file=sys.stderr)
def before_loop(self, coro: FT) -> FT:
"""A decorator that registers a coroutine to be called before the loop starts running.
This is useful if you want to wait for some bot state before the loop starts,
such as :meth:`discord.Client.wait_until_ready`.
The coroutine must take no arguments (except ``self`` in a class context).
Parameters
------------
coro: :ref:`coroutine <coroutine>`
The coroutine to register before the loop runs.
Raises
-------
TypeError
The function was not a coroutine.
"""
if not inspect.iscoroutinefunction(coro):
raise TypeError(f'Expected coroutine function, received {coro.__class__.__name__!r}.')
self._before_loop = coro
return coro
def after_loop(self, coro: FT) -> FT:
"""A decorator that register a coroutine to be called after the loop finished running.
The coroutine must take no arguments (except ``self`` in a class context).
.. note::
This coroutine is called even during cancellation. If it is desirable
to tell apart whether something was cancelled or not, check to see
whether :meth:`is_being_cancelled` is ``True`` or not.
Parameters
------------
coro: :ref:`coroutine <coroutine>`
The coroutine to register after the loop finishes.
Raises
-------
TypeError
The function was not a coroutine.
"""
if not inspect.iscoroutinefunction(coro):
raise TypeError(f'Expected coroutine function, received {coro.__class__.__name__!r}.')
self._after_loop = coro
return coro
def error(self, coro: ET) -> ET:
"""A decorator that registers a coroutine to be called if the task encounters an unhandled exception.
The coroutine must take only one argument the exception raised (except ``self`` in a class context).
By default this prints to :data:`sys.stderr` however it could be
overridden to have a different implementation.
.. versionadded:: 1.4
Parameters
------------
coro: :ref:`coroutine <coroutine>`
The coroutine to register in the event of an unhandled exception.
Raises
-------
TypeError
The function was not a coroutine.
"""
if not inspect.iscoroutinefunction(coro):
raise TypeError(f'Expected coroutine function, received {coro.__class__.__name__!r}.')
self._error = coro # type: ignore
return coro
def _get_next_sleep_time(self) -> datetime.datetime:
if self._sleep is not MISSING:
return self._last_iteration + datetime.timedelta(seconds=self._sleep)
if self._time_index >= len(self._time):
self._time_index = 0
if self._current_loop == 0:
# if we're at the last index on the first iteration, we need to sleep until tomorrow
return datetime.datetime.combine(
datetime.datetime.now(datetime.timezone.utc) + datetime.timedelta(days=1), self._time[0]
)
next_time = self._time[self._time_index]
if self._current_loop == 0:
self._time_index += 1
return datetime.datetime.combine(datetime.datetime.now(datetime.timezone.utc), next_time)
next_date = self._last_iteration
if self._time_index == 0:
# we can assume that the earliest time should be scheduled for "tomorrow"
next_date += datetime.timedelta(days=1)
self._time_index += 1
return datetime.datetime.combine(next_date, next_time)
def _prepare_time_index(self, now: datetime.datetime = MISSING) -> None:
# now kwarg should be a datetime.datetime representing the time "now"
# to calculate the next time index from
# pre-condition: self._time is set
time_now = (
now if now is not MISSING else datetime.datetime.now(datetime.timezone.utc).replace(microsecond=0)
).timetz()
for idx, time in enumerate(self._time):
if time >= time_now:
self._time_index = idx
break
else:
self._time_index = 0
def _get_time_parameter(
self,
time: Union[datetime.time, Sequence[datetime.time]],
*,
dt: Type[datetime.time] = datetime.time,
utc: datetime.timezone = datetime.timezone.utc,
) -> List[datetime.time]:
if isinstance(time, dt):
inner = time if time.tzinfo is not None else time.replace(tzinfo=utc)
return [inner]
if not isinstance(time, Sequence):
raise TypeError(
f'Expected datetime.time or a sequence of datetime.time for ``time``, received {type(time)!r} instead.'
)
if not time:
raise ValueError('time parameter must not be an empty sequence.')
ret: List[datetime.time] = []
for index, t in enumerate(time):
if not isinstance(t, dt):
raise TypeError(
f'Expected a sequence of {dt!r} for ``time``, received {type(t).__name__!r} at index {index} instead.'
)
ret.append(t if t.tzinfo is not None else t.replace(tzinfo=utc))
ret = sorted(set(ret)) # de-dupe and sort times
return ret
def change_interval(
self,
*,
seconds: float = 0,
minutes: float = 0,
hours: float = 0,
time: Union[datetime.time, Sequence[datetime.time]] = MISSING,
) -> None:
"""Changes the interval for the sleep time.
.. versionadded:: 1.2
Parameters
------------
seconds: :class:`float`
The number of seconds between every iteration.
minutes: :class:`float`
The number of minutes between every iteration.
hours: :class:`float`
The number of hours between every iteration.
time: Union[:class:`datetime.time`, Sequence[:class:`datetime.time`]]
The exact times to run this loop at. Either a non-empty list or a single
value of :class:`datetime.time` should be passed.
This cannot be used in conjunction with the relative time parameters.
.. versionadded:: 2.0
.. note::
Duplicate times will be ignored, and only run once.
Raises
-------
ValueError
An invalid value was given.
TypeError
An invalid value for the ``time`` parameter was passed, or the
``time`` parameter was passed in conjunction with relative time parameters.
"""
if time is MISSING:
seconds = seconds or 0
minutes = minutes or 0
hours = hours or 0
sleep = seconds + (minutes * 60.0) + (hours * 3600.0)
if sleep < 0:
raise ValueError('Total number of seconds cannot be less than zero.')
self._sleep = sleep
self._seconds = float(seconds)
self._hours = float(hours)
self._minutes = float(minutes)
self._time: List[datetime.time] = MISSING
else:
if any((seconds, minutes, hours)):
raise TypeError('Cannot mix explicit time with relative time')
self._time = self._get_time_parameter(time)
self._sleep = self._seconds = self._minutes = self._hours = MISSING
if self.is_running():
if self._time is not MISSING:
# prepare the next time index starting from after the last iteration
self._prepare_time_index(now=self._last_iteration)
self._next_iteration = self._get_next_sleep_time()
if not self._handle.done():
# the loop is sleeping, recalculate based on new interval
self._handle.recalculate(self._next_iteration)
def loop(
*,
seconds: float = MISSING,
minutes: float = MISSING,
hours: float = MISSING,
time: Union[datetime.time, Sequence[datetime.time]] = MISSING,
count: Optional[int] = None,
reconnect: bool = True,
loop: asyncio.AbstractEventLoop = MISSING,
) -> Callable[[LF], Loop[LF]]:
"""A decorator that schedules a task in the background for you with
optional reconnect logic. The decorator returns a :class:`Loop`.
Parameters
------------
seconds: :class:`float`
The number of seconds between every iteration.
minutes: :class:`float`
The number of minutes between every iteration.
hours: :class:`float`
The number of hours between every iteration.
time: Union[:class:`datetime.time`, Sequence[:class:`datetime.time`]]
The exact times to run this loop at. Either a non-empty list or a single
value of :class:`datetime.time` should be passed. Timezones are supported.
If no timezone is given for the times, it is assumed to represent UTC time.
This cannot be used in conjunction with the relative time parameters.
.. note::
Duplicate times will be ignored, and only run once.
.. versionadded:: 2.0
count: Optional[:class:`int`]
The number of loops to do, ``None`` if it should be an
infinite loop.
reconnect: :class:`bool`
Whether to handle errors and restart the task
using an exponential back-off algorithm similar to the
one used in :meth:`discord.Client.connect`.
loop: :class:`asyncio.AbstractEventLoop`
The loop to use to register the task, if not given
defaults to :func:`asyncio.get_event_loop`.
Raises
--------
ValueError
An invalid value was given.
TypeError
The function was not a coroutine, an invalid value for the ``time`` parameter was passed,
or ``time`` parameter was passed in conjunction with relative time parameters.
"""
def decorator(func: LF) -> Loop[LF]:
return Loop[LF](
func,
seconds=seconds,
minutes=minutes,
hours=hours,
count=count,
time=time,
reconnect=reconnect,
loop=loop,
)
return decorator | zarenacord.py | /zarenacord.py-2.0.0-py3-none-any.whl/discord/ext/tasks/__init__.py | __init__.py |
from .errors import UnexpectedQuoteError, InvalidEndOfQuotedStringError, ExpectedClosingQuoteError
# map from opening quotes to closing quotes
_quotes = {
'"': '"',
"‘": "’",
"‚": "‛",
"“": "”",
"„": "‟",
"⹂": "⹂",
"「": "」",
"『": "』",
"〝": "〞",
"﹁": "﹂",
"﹃": "﹄",
""": """,
"「": "」",
"«": "»",
"‹": "›",
"《": "》",
"〈": "〉",
}
_all_quotes = set(_quotes.keys()) | set(_quotes.values())
class StringView:
def __init__(self, buffer):
self.index = 0
self.buffer = buffer
self.end = len(buffer)
self.previous = 0
@property
def current(self):
return None if self.eof else self.buffer[self.index]
@property
def eof(self):
return self.index >= self.end
def undo(self):
self.index = self.previous
def skip_ws(self):
pos = 0
while not self.eof:
try:
current = self.buffer[self.index + pos]
if not current.isspace():
break
pos += 1
except IndexError:
break
self.previous = self.index
self.index += pos
return self.previous != self.index
def skip_string(self, string):
strlen = len(string)
if self.buffer[self.index:self.index + strlen] == string:
self.previous = self.index
self.index += strlen
return True
return False
def read_rest(self):
result = self.buffer[self.index:]
self.previous = self.index
self.index = self.end
return result
def read(self, n):
result = self.buffer[self.index:self.index + n]
self.previous = self.index
self.index += n
return result
def get(self):
try:
result = self.buffer[self.index + 1]
except IndexError:
result = None
self.previous = self.index
self.index += 1
return result
def get_word(self):
pos = 0
while not self.eof:
try:
current = self.buffer[self.index + pos]
if current.isspace():
break
pos += 1
except IndexError:
break
self.previous = self.index
result = self.buffer[self.index:self.index + pos]
self.index += pos
return result
def get_quoted_word(self):
current = self.current
if current is None:
return None
close_quote = _quotes.get(current)
is_quoted = bool(close_quote)
if is_quoted:
result = []
_escaped_quotes = (current, close_quote)
else:
result = [current]
_escaped_quotes = _all_quotes
while not self.eof:
current = self.get()
if not current:
if is_quoted:
# unexpected EOF
raise ExpectedClosingQuoteError(close_quote)
return ''.join(result)
# currently we accept strings in the format of "hello world"
# to embed a quote inside the string you must escape it: "a \"world\""
if current == '\\':
next_char = self.get()
if not next_char:
# string ends with \ and no character after it
if is_quoted:
# if we're quoted then we're expecting a closing quote
raise ExpectedClosingQuoteError(close_quote)
# if we aren't then we just let it through
return ''.join(result)
if next_char in _escaped_quotes:
# escaped quote
result.append(next_char)
else:
# different escape character, ignore it
self.undo()
result.append(current)
continue
if not is_quoted and current in _all_quotes:
# we aren't quoted
raise UnexpectedQuoteError(current)
# closing quote
if is_quoted and current == close_quote:
next_char = self.get()
valid_eof = not next_char or next_char.isspace()
if not valid_eof:
raise InvalidEndOfQuotedStringError(next_char)
# we're quoted so it's okay
return ''.join(result)
if current.isspace() and not is_quoted:
# end of word found
return ''.join(result)
result.append(current)
def __repr__(self):
return f'<StringView pos: {self.index} prev: {self.previous} end: {self.end} eof: {self.eof}>' | zarenacord.py | /zarenacord.py-2.0.0-py3-none-any.whl/discord/ext/commands/view.py | view.py |
from __future__ import annotations
import inspect
import re
from typing import Any, Dict, Generic, List, Optional, TYPE_CHECKING, TypeVar, Union
import discord.abc
import discord.utils
from discord.message import Message
if TYPE_CHECKING:
from typing_extensions import ParamSpec
from discord.abc import MessageableChannel
from discord.guild import Guild
from discord.member import Member
from discord.state import ConnectionState
from discord.user import ClientUser, User
from discord.voice_client import VoiceProtocol
from .bot import Bot, AutoShardedBot
from .cog import Cog
from .core import Command
from .help import HelpCommand
from .view import StringView
__all__ = (
'Context',
)
MISSING: Any = discord.utils.MISSING
T = TypeVar('T')
BotT = TypeVar('BotT', bound="Union[Bot, AutoShardedBot]")
CogT = TypeVar('CogT', bound="Cog")
if TYPE_CHECKING:
P = ParamSpec('P')
else:
P = TypeVar('P')
class Context(discord.abc.Messageable, Generic[BotT]):
r"""Represents the context in which a command is being invoked under.
This class contains a lot of meta data to help you understand more about
the invocation context. This class is not created manually and is instead
passed around to commands as the first parameter.
This class implements the :class:`~discord.abc.Messageable` ABC.
Attributes
-----------
message: :class:`.Message`
The message that triggered the command being executed.
bot: :class:`.Bot`
The bot that contains the command being executed.
args: :class:`list`
The list of transformed arguments that were passed into the command.
If this is accessed during the :func:`.on_command_error` event
then this list could be incomplete.
kwargs: :class:`dict`
A dictionary of transformed arguments that were passed into the command.
Similar to :attr:`args`\, if this is accessed in the
:func:`.on_command_error` event then this dict could be incomplete.
current_parameter: Optional[:class:`inspect.Parameter`]
The parameter that is currently being inspected and converted.
This is only of use for within converters.
.. versionadded:: 2.0
prefix: Optional[:class:`str`]
The prefix that was used to invoke the command.
command: Optional[:class:`Command`]
The command that is being invoked currently.
invoked_with: Optional[:class:`str`]
The command name that triggered this invocation. Useful for finding out
which alias called the command.
invoked_parents: List[:class:`str`]
The command names of the parents that triggered this invocation. Useful for
finding out which aliases called the command.
For example in commands ``?a b c test``, the invoked parents are ``['a', 'b', 'c']``.
.. versionadded:: 1.7
invoked_subcommand: Optional[:class:`Command`]
The subcommand that was invoked.
If no valid subcommand was invoked then this is equal to ``None``.
subcommand_passed: Optional[:class:`str`]
The string that was attempted to call a subcommand. This does not have
to point to a valid registered subcommand and could just point to a
nonsense string. If nothing was passed to attempt a call to a
subcommand then this is set to ``None``.
command_failed: :class:`bool`
A boolean that indicates if the command failed to be parsed, checked,
or invoked.
"""
def __init__(self,
*,
message: Message,
bot: BotT,
view: StringView,
args: List[Any] = MISSING,
kwargs: Dict[str, Any] = MISSING,
prefix: Optional[str] = None,
command: Optional[Command] = None,
invoked_with: Optional[str] = None,
invoked_parents: List[str] = MISSING,
invoked_subcommand: Optional[Command] = None,
subcommand_passed: Optional[str] = None,
command_failed: bool = False,
current_parameter: Optional[inspect.Parameter] = None,
):
self.message: Message = message
self.bot: BotT = bot
self.args: List[Any] = args or []
self.kwargs: Dict[str, Any] = kwargs or {}
self.prefix: Optional[str] = prefix
self.command: Optional[Command] = command
self.view: StringView = view
self.invoked_with: Optional[str] = invoked_with
self.invoked_parents: List[str] = invoked_parents or []
self.invoked_subcommand: Optional[Command] = invoked_subcommand
self.subcommand_passed: Optional[str] = subcommand_passed
self.command_failed: bool = command_failed
self.current_parameter: Optional[inspect.Parameter] = current_parameter
self._state: ConnectionState = self.message._state
async def invoke(self, command: Command[CogT, P, T], /, *args: P.args, **kwargs: P.kwargs) -> T:
r"""|coro|
Calls a command with the arguments given.
This is useful if you want to just call the callback that a
:class:`.Command` holds internally.
.. note::
This does not handle converters, checks, cooldowns, pre-invoke,
or after-invoke hooks in any matter. It calls the internal callback
directly as-if it was a regular function.
You must take care in passing the proper arguments when
using this function.
Parameters
-----------
command: :class:`.Command`
The command that is going to be called.
\*args
The arguments to use.
\*\*kwargs
The keyword arguments to use.
Raises
-------
TypeError
The command argument to invoke is missing.
"""
return await command(self, *args, **kwargs)
async def reinvoke(self, *, call_hooks: bool = False, restart: bool = True) -> None:
"""|coro|
Calls the command again.
This is similar to :meth:`~.Context.invoke` except that it bypasses
checks, cooldowns, and error handlers.
.. note::
If you want to bypass :exc:`.UserInputError` derived exceptions,
it is recommended to use the regular :meth:`~.Context.invoke`
as it will work more naturally. After all, this will end up
using the old arguments the user has used and will thus just
fail again.
Parameters
------------
call_hooks: :class:`bool`
Whether to call the before and after invoke hooks.
restart: :class:`bool`
Whether to start the call chain from the very beginning
or where we left off (i.e. the command that caused the error).
The default is to start where we left off.
Raises
-------
ValueError
The context to reinvoke is not valid.
"""
cmd = self.command
view = self.view
if cmd is None:
raise ValueError('This context is not valid.')
# some state to revert to when we're done
index, previous = view.index, view.previous
invoked_with = self.invoked_with
invoked_subcommand = self.invoked_subcommand
invoked_parents = self.invoked_parents
subcommand_passed = self.subcommand_passed
if restart:
to_call = cmd.root_parent or cmd
view.index = len(self.prefix or '')
view.previous = 0
self.invoked_parents = []
self.invoked_with = view.get_word() # advance to get the root command
else:
to_call = cmd
try:
await to_call.reinvoke(self, call_hooks=call_hooks)
finally:
self.command = cmd
view.index = index
view.previous = previous
self.invoked_with = invoked_with
self.invoked_subcommand = invoked_subcommand
self.invoked_parents = invoked_parents
self.subcommand_passed = subcommand_passed
@property
def valid(self) -> bool:
""":class:`bool`: Checks if the invocation context is valid to be invoked with."""
return self.prefix is not None and self.command is not None
async def _get_channel(self) -> discord.abc.Messageable:
return self.channel
@property
def clean_prefix(self) -> str:
""":class:`str`: The cleaned up invoke prefix. i.e. mentions are ``@name`` instead of ``<@id>``.
.. versionadded:: 2.0
"""
if self.prefix is None:
return ''
user = self.me
# this breaks if the prefix mention is not the bot itself but I
# consider this to be an *incredibly* strange use case. I'd rather go
# for this common use case rather than waste performance for the
# odd one.
pattern = re.compile(r"<@!?%s>" % user.id)
return pattern.sub("@%s" % user.display_name.replace('\\', r'\\'), self.prefix)
@property
def cog(self) -> Optional[Cog]:
"""Optional[:class:`.Cog`]: Returns the cog associated with this context's command. None if it does not exist."""
if self.command is None:
return None
return self.command.cog
@discord.utils.cached_property
def guild(self) -> Optional[Guild]:
"""Optional[:class:`.Guild`]: Returns the guild associated with this context's command. None if not available."""
return self.message.guild
@discord.utils.cached_property
def channel(self) -> MessageableChannel:
"""Union[:class:`.abc.Messageable`]: Returns the channel associated with this context's command.
Shorthand for :attr:`.Message.channel`.
"""
return self.message.channel
@discord.utils.cached_property
def author(self) -> Union[User, Member]:
"""Union[:class:`~discord.User`, :class:`.Member`]:
Returns the author associated with this context's command. Shorthand for :attr:`.Message.author`
"""
return self.message.author
@discord.utils.cached_property
def me(self) -> Union[Member, ClientUser]:
"""Union[:class:`.Member`, :class:`.ClientUser`]:
Similar to :attr:`.Guild.me` except it may return the :class:`.ClientUser` in private message contexts.
"""
# bot.user will never be None at this point.
return self.guild.me if self.guild is not None else self.bot.user # type: ignore
@property
def voice_client(self) -> Optional[VoiceProtocol]:
r"""Optional[:class:`.VoiceProtocol`]: A shortcut to :attr:`.Guild.voice_client`\, if applicable."""
g = self.guild
return g.voice_client if g else None
async def send_help(self, *args: Any) -> Any:
"""send_help(entity=<bot>)
|coro|
Shows the help command for the specified entity if given.
The entity can be a command or a cog.
If no entity is given, then it'll show help for the
entire bot.
If the entity is a string, then it looks up whether it's a
:class:`Cog` or a :class:`Command`.
.. note::
Due to the way this function works, instead of returning
something similar to :meth:`~.commands.HelpCommand.command_not_found`
this returns :class:`None` on bad input or no help command.
Parameters
------------
entity: Optional[Union[:class:`Command`, :class:`Cog`, :class:`str`]]
The entity to show help for.
Returns
--------
Any
The result of the help command, if any.
"""
from .core import Group, Command, wrap_callback
from .errors import CommandError
bot = self.bot
cmd = bot.help_command
if cmd is None:
return None
cmd = cmd.copy()
cmd.context = self
if len(args) == 0:
await cmd.prepare_help_command(self, None)
mapping = cmd.get_bot_mapping()
injected = wrap_callback(cmd.send_bot_help)
try:
return await injected(mapping)
except CommandError as e:
await cmd.on_help_command_error(self, e)
return None
entity = args[0]
if isinstance(entity, str):
entity = bot.get_cog(entity) or bot.get_command(entity)
if entity is None:
return None
try:
entity.qualified_name
except AttributeError:
# if we're here then it's not a cog, group, or command.
return None
await cmd.prepare_help_command(self, entity.qualified_name)
try:
if hasattr(entity, '__cog_commands__'):
injected = wrap_callback(cmd.send_cog_help)
return await injected(entity)
elif isinstance(entity, Group):
injected = wrap_callback(cmd.send_group_help)
return await injected(entity)
elif isinstance(entity, Command):
injected = wrap_callback(cmd.send_command_help)
return await injected(entity)
else:
return None
except CommandError as e:
await cmd.on_help_command_error(self, e)
@discord.utils.copy_doc(Message.reply)
async def reply(self, content: Optional[str] = None, **kwargs: Any) -> Message:
return await self.message.reply(content, **kwargs) | zarenacord.py | /zarenacord.py-2.0.0-py3-none-any.whl/discord/ext/commands/context.py | context.py |
from __future__ import annotations
import inspect
import discord.utils
from typing import Any, Callable, ClassVar, Dict, Generator, List, Optional, TYPE_CHECKING, Tuple, TypeVar, Type
from ._types import _BaseCommand
if TYPE_CHECKING:
from .bot import BotBase
from .context import Context
from .core import Command
__all__ = (
'CogMeta',
'Cog',
)
CogT = TypeVar('CogT', bound='Cog')
FuncT = TypeVar('FuncT', bound=Callable[..., Any])
MISSING: Any = discord.utils.MISSING
class CogMeta(type):
"""A metaclass for defining a cog.
Note that you should probably not use this directly. It is exposed
purely for documentation purposes along with making custom metaclasses to intermix
with other metaclasses such as the :class:`abc.ABCMeta` metaclass.
For example, to create an abstract cog mixin class, the following would be done.
.. code-block:: python3
import abc
class CogABCMeta(commands.CogMeta, abc.ABCMeta):
pass
class SomeMixin(metaclass=abc.ABCMeta):
pass
class SomeCogMixin(SomeMixin, commands.Cog, metaclass=CogABCMeta):
pass
.. note::
When passing an attribute of a metaclass that is documented below, note
that you must pass it as a keyword-only argument to the class creation
like the following example:
.. code-block:: python3
class MyCog(commands.Cog, name='My Cog'):
pass
Attributes
-----------
name: :class:`str`
The cog name. By default, it is the name of the class with no modification.
description: :class:`str`
The cog description. By default, it is the cleaned docstring of the class.
.. versionadded:: 1.6
command_attrs: :class:`dict`
A list of attributes to apply to every command inside this cog. The dictionary
is passed into the :class:`Command` options at ``__init__``.
If you specify attributes inside the command attribute in the class, it will
override the one specified inside this attribute. For example:
.. code-block:: python3
class MyCog(commands.Cog, command_attrs=dict(hidden=True)):
@commands.command()
async def foo(self, ctx):
pass # hidden -> True
@commands.command(hidden=False)
async def bar(self, ctx):
pass # hidden -> False
"""
__cog_name__: str
__cog_settings__: Dict[str, Any]
__cog_commands__: List[Command]
__cog_listeners__: List[Tuple[str, str]]
def __new__(cls: Type[CogMeta], *args: Any, **kwargs: Any) -> CogMeta:
name, bases, attrs = args
attrs['__cog_name__'] = kwargs.pop('name', name)
attrs['__cog_settings__'] = kwargs.pop('command_attrs', {})
description = kwargs.pop('description', None)
if description is None:
description = inspect.cleandoc(attrs.get('__doc__', ''))
attrs['__cog_description__'] = description
commands = {}
listeners = {}
no_bot_cog = 'Commands or listeners must not start with cog_ or bot_ (in method {0.__name__}.{1})'
new_cls = super().__new__(cls, name, bases, attrs, **kwargs)
for base in reversed(new_cls.__mro__):
for elem, value in base.__dict__.items():
if elem in commands:
del commands[elem]
if elem in listeners:
del listeners[elem]
is_static_method = isinstance(value, staticmethod)
if is_static_method:
value = value.__func__
if isinstance(value, _BaseCommand):
if is_static_method:
raise TypeError(f'Command in method {base}.{elem!r} must not be staticmethod.')
if elem.startswith(('cog_', 'bot_')):
raise TypeError(no_bot_cog.format(base, elem))
commands[elem] = value
elif inspect.iscoroutinefunction(value):
try:
getattr(value, '__cog_listener__')
except AttributeError:
continue
else:
if elem.startswith(('cog_', 'bot_')):
raise TypeError(no_bot_cog.format(base, elem))
listeners[elem] = value
new_cls.__cog_commands__ = list(commands.values()) # this will be copied in Cog.__new__
listeners_as_list = []
for listener in listeners.values():
for listener_name in listener.__cog_listener_names__:
# I use __name__ instead of just storing the value so I can inject
# the self attribute when the time comes to add them to the bot
listeners_as_list.append((listener_name, listener.__name__))
new_cls.__cog_listeners__ = listeners_as_list
return new_cls
def __init__(self, *args: Any, **kwargs: Any) -> None:
super().__init__(*args)
@classmethod
def qualified_name(cls) -> str:
return cls.__cog_name__
def _cog_special_method(func: FuncT) -> FuncT:
func.__cog_special_method__ = None
return func
class Cog(metaclass=CogMeta):
"""The base class that all cogs must inherit from.
A cog is a collection of commands, listeners, and optional state to
help group commands together. More information on them can be found on
the :ref:`ext_commands_cogs` page.
When inheriting from this class, the options shown in :class:`CogMeta`
are equally valid here.
"""
__cog_name__: ClassVar[str]
__cog_settings__: ClassVar[Dict[str, Any]]
__cog_commands__: ClassVar[List[Command]]
__cog_listeners__: ClassVar[List[Tuple[str, str]]]
def __new__(cls: Type[CogT], *args: Any, **kwargs: Any) -> CogT:
# For issue 426, we need to store a copy of the command objects
# since we modify them to inject `self` to them.
# To do this, we need to interfere with the Cog creation process.
self = super().__new__(cls)
cmd_attrs = cls.__cog_settings__
# Either update the command with the cog provided defaults or copy it.
# r.e type ignore, type-checker complains about overriding a ClassVar
self.__cog_commands__ = tuple(c._update_copy(cmd_attrs) for c in cls.__cog_commands__) # type: ignore
lookup = {
cmd.qualified_name: cmd
for cmd in self.__cog_commands__
}
# Update the Command instances dynamically as well
for command in self.__cog_commands__:
setattr(self, command.callback.__name__, command)
parent = command.parent
if parent is not None:
# Get the latest parent reference
parent = lookup[parent.qualified_name] # type: ignore
# Update our parent's reference to our self
parent.remove_command(command.name) # type: ignore
parent.add_command(command) # type: ignore
return self
def get_commands(self) -> List[Command]:
r"""
Returns
--------
List[:class:`.Command`]
A :class:`list` of :class:`.Command`\s that are
defined inside this cog.
.. note::
This does not include subcommands.
"""
return [c for c in self.__cog_commands__ if c.parent is None]
@property
def qualified_name(self) -> str:
""":class:`str`: Returns the cog's specified name, not the class name."""
return self.__cog_name__
@property
def description(self) -> str:
""":class:`str`: Returns the cog's description, typically the cleaned docstring."""
return self.__cog_description__
@description.setter
def description(self, description: str) -> None:
self.__cog_description__ = description
def walk_commands(self) -> Generator[Command, None, None]:
"""An iterator that recursively walks through this cog's commands and subcommands.
Yields
------
Union[:class:`.Command`, :class:`.Group`]
A command or group from the cog.
"""
from .core import GroupMixin
for command in self.__cog_commands__:
if command.parent is None:
yield command
if isinstance(command, GroupMixin):
yield from command.walk_commands()
def get_listeners(self) -> List[Tuple[str, Callable[..., Any]]]:
"""Returns a :class:`list` of (name, function) listener pairs that are defined in this cog.
Returns
--------
List[Tuple[:class:`str`, :ref:`coroutine <coroutine>`]]
The listeners defined in this cog.
"""
return [(name, getattr(self, method_name)) for name, method_name in self.__cog_listeners__]
@classmethod
def _get_overridden_method(cls, method: FuncT) -> Optional[FuncT]:
"""Return None if the method is not overridden. Otherwise returns the overridden method."""
return getattr(method.__func__, '__cog_special_method__', method)
@classmethod
def listener(cls, name: str = MISSING) -> Callable[[FuncT], FuncT]:
"""A decorator that marks a function as a listener.
This is the cog equivalent of :meth:`.Bot.listen`.
Parameters
------------
name: :class:`str`
The name of the event being listened to. If not provided, it
defaults to the function's name.
Raises
--------
TypeError
The function is not a coroutine function or a string was not passed as
the name.
"""
if name is not MISSING and not isinstance(name, str):
raise TypeError(f'Cog.listener expected str but received {name.__class__.__name__!r} instead.')
def decorator(func: FuncT) -> FuncT:
actual = func
if isinstance(actual, staticmethod):
actual = actual.__func__
if not inspect.iscoroutinefunction(actual):
raise TypeError('Listener function must be a coroutine function.')
actual.__cog_listener__ = True
to_assign = name or actual.__name__
try:
actual.__cog_listener_names__.append(to_assign)
except AttributeError:
actual.__cog_listener_names__ = [to_assign]
# we have to return `func` instead of `actual` because
# we need the type to be `staticmethod` for the metaclass
# to pick it up but the metaclass unfurls the function and
# thus the assignments need to be on the actual function
return func
return decorator
def has_error_handler(self) -> bool:
""":class:`bool`: Checks whether the cog has an error handler.
.. versionadded:: 1.7
"""
return not hasattr(self.cog_command_error.__func__, '__cog_special_method__')
@_cog_special_method
def cog_unload(self) -> None:
"""A special method that is called when the cog gets removed.
This function **cannot** be a coroutine. It must be a regular
function.
Subclasses must replace this if they want special unloading behaviour.
"""
pass
@_cog_special_method
def bot_check_once(self, ctx: Context) -> bool:
"""A special method that registers as a :meth:`.Bot.check_once`
check.
This function **can** be a coroutine and must take a sole parameter,
``ctx``, to represent the :class:`.Context`.
"""
return True
@_cog_special_method
def bot_check(self, ctx: Context) -> bool:
"""A special method that registers as a :meth:`.Bot.check`
check.
This function **can** be a coroutine and must take a sole parameter,
``ctx``, to represent the :class:`.Context`.
"""
return True
@_cog_special_method
def cog_check(self, ctx: Context) -> bool:
"""A special method that registers as a :func:`~discord.ext.commands.check`
for every command and subcommand in this cog.
This function **can** be a coroutine and must take a sole parameter,
``ctx``, to represent the :class:`.Context`.
"""
return True
@_cog_special_method
async def cog_command_error(self, ctx: Context, error: Exception) -> None:
"""A special method that is called whenever an error
is dispatched inside this cog.
This is similar to :func:`.on_command_error` except only applying
to the commands inside this cog.
This **must** be a coroutine.
Parameters
-----------
ctx: :class:`.Context`
The invocation context where the error happened.
error: :class:`CommandError`
The error that happened.
"""
pass
@_cog_special_method
async def cog_before_invoke(self, ctx: Context) -> None:
"""A special method that acts as a cog local pre-invoke hook.
This is similar to :meth:`.Command.before_invoke`.
This **must** be a coroutine.
Parameters
-----------
ctx: :class:`.Context`
The invocation context.
"""
pass
@_cog_special_method
async def cog_after_invoke(self, ctx: Context) -> None:
"""A special method that acts as a cog local post-invoke hook.
This is similar to :meth:`.Command.after_invoke`.
This **must** be a coroutine.
Parameters
-----------
ctx: :class:`.Context`
The invocation context.
"""
pass
def _inject(self: CogT, bot: BotBase) -> CogT:
cls = self.__class__
# realistically, the only thing that can cause loading errors
# is essentially just the command loading, which raises if there are
# duplicates. When this condition is met, we want to undo all what
# we've added so far for some form of atomic loading.
for index, command in enumerate(self.__cog_commands__):
command.cog = self
if command.parent is None:
try:
bot.add_command(command)
except Exception as e:
# undo our additions
for to_undo in self.__cog_commands__[:index]:
if to_undo.parent is None:
bot.remove_command(to_undo.name)
raise e
# check if we're overriding the default
if cls.bot_check is not Cog.bot_check:
bot.add_check(self.bot_check)
if cls.bot_check_once is not Cog.bot_check_once:
bot.add_check(self.bot_check_once, call_once=True)
# while Bot.add_listener can raise if it's not a coroutine,
# this precondition is already met by the listener decorator
# already, thus this should never raise.
# Outside of, memory errors and the like...
for name, method_name in self.__cog_listeners__:
bot.add_listener(getattr(self, method_name), name)
return self
def _eject(self, bot: BotBase) -> None:
cls = self.__class__
try:
for command in self.__cog_commands__:
if command.parent is None:
bot.remove_command(command.name)
for _, method_name in self.__cog_listeners__:
bot.remove_listener(getattr(self, method_name))
if cls.bot_check is not Cog.bot_check:
bot.remove_check(self.bot_check)
if cls.bot_check_once is not Cog.bot_check_once:
bot.remove_check(self.bot_check_once, call_once=True)
finally:
try:
self.cog_unload()
except Exception:
pass | zarenacord.py | /zarenacord.py-2.0.0-py3-none-any.whl/discord/ext/commands/cog.py | cog.py |
from __future__ import annotations
import re
import inspect
from typing import (
Any,
Dict,
Generic,
Iterable,
Literal,
Optional,
TYPE_CHECKING,
List,
Protocol,
Type,
TypeVar,
Tuple,
Union,
runtime_checkable,
)
import discord
from .errors import *
if TYPE_CHECKING:
from .context import Context
from discord.message import PartialMessageableChannel
__all__ = (
'Converter',
'ObjectConverter',
'MemberConverter',
'UserConverter',
'MessageConverter',
'PartialMessageConverter',
'TextChannelConverter',
'InviteConverter',
'GuildConverter',
'RoleConverter',
'GameConverter',
'ColourConverter',
'ColorConverter',
'VoiceChannelConverter',
'StageChannelConverter',
'EmojiConverter',
'PartialEmojiConverter',
'CategoryChannelConverter',
'IDConverter',
'StoreChannelConverter',
'ThreadConverter',
'GuildChannelConverter',
'GuildStickerConverter',
'clean_content',
'Greedy',
'run_converters',
)
def _get_from_guilds(bot, getter, argument):
result = None
for guild in bot.guilds:
result = getattr(guild, getter)(argument)
if result:
return result
return result
_utils_get = discord.utils.get
T = TypeVar('T')
T_co = TypeVar('T_co', covariant=True)
CT = TypeVar('CT', bound=discord.abc.GuildChannel)
TT = TypeVar('TT', bound=discord.Thread)
@runtime_checkable
class Converter(Protocol[T_co]):
"""The base class of custom converters that require the :class:`.Context`
to be passed to be useful.
This allows you to implement converters that function similar to the
special cased ``discord`` classes.
Classes that derive from this should override the :meth:`~.Converter.convert`
method to do its conversion logic. This method must be a :ref:`coroutine <coroutine>`.
"""
async def convert(self, ctx: Context, argument: str) -> T_co:
"""|coro|
The method to override to do conversion logic.
If an error is found while converting, it is recommended to
raise a :exc:`.CommandError` derived exception as it will
properly propagate to the error handlers.
Parameters
-----------
ctx: :class:`.Context`
The invocation context that the argument is being used in.
argument: :class:`str`
The argument that is being converted.
Raises
-------
:exc:`.CommandError`
A generic exception occurred when converting the argument.
:exc:`.BadArgument`
The converter failed to convert the argument.
"""
raise NotImplementedError('Derived classes need to implement this.')
_ID_REGEX = re.compile(r'([0-9]{15,20})$')
class IDConverter(Converter[T_co]):
@staticmethod
def _get_id_match(argument):
return _ID_REGEX.match(argument)
class ObjectConverter(IDConverter[discord.Object]):
"""Converts to a :class:`~discord.Object`.
The argument must follow the valid ID or mention formats (e.g. `<@80088516616269824>`).
.. versionadded:: 2.0
The lookup strategy is as follows (in order):
1. Lookup by ID.
2. Lookup by member, role, or channel mention.
"""
async def convert(self, ctx: Context, argument: str) -> discord.Object:
match = self._get_id_match(argument) or re.match(r'<(?:@(?:!|&)?|#)([0-9]{15,20})>$', argument)
if match is None:
raise ObjectNotFound(argument)
result = int(match.group(1))
return discord.Object(id=result)
class MemberConverter(IDConverter[discord.Member]):
"""Converts to a :class:`~discord.Member`.
All lookups are via the local guild. If in a DM context, then the lookup
is done by the global cache.
The lookup strategy is as follows (in order):
1. Lookup by ID.
2. Lookup by mention.
3. Lookup by name#discrim
4. Lookup by name
5. Lookup by nickname
.. versionchanged:: 1.5
Raise :exc:`.MemberNotFound` instead of generic :exc:`.BadArgument`
.. versionchanged:: 1.5.1
This converter now lazily fetches members from the gateway and HTTP APIs,
optionally caching the result if :attr:`.MemberCacheFlags.joined` is enabled.
"""
async def query_member_named(self, guild, argument):
cache = guild._state.member_cache_flags.joined
if len(argument) > 5 and argument[-5] == '#':
username, _, discriminator = argument.rpartition('#')
members = await guild.query_members(username, limit=100, cache=cache)
return discord.utils.get(members, name=username, discriminator=discriminator)
else:
members = await guild.query_members(argument, limit=100, cache=cache)
return discord.utils.find(lambda m: m.name == argument or m.nick == argument, members)
async def query_member_by_id(self, bot, guild, user_id):
ws = bot._get_websocket(shard_id=guild.shard_id)
cache = guild._state.member_cache_flags.joined
if ws.is_ratelimited():
# If we're being rate limited on the WS, then fall back to using the HTTP API
# So we don't have to wait ~60 seconds for the query to finish
try:
member = await guild.fetch_member(user_id)
except discord.HTTPException:
return None
if cache:
guild._add_member(member)
return member
# If we're not being rate limited then we can use the websocket to actually query
members = await guild.query_members(limit=1, user_ids=[user_id], cache=cache)
if not members:
return None
return members[0]
async def convert(self, ctx: Context, argument: str) -> discord.Member:
bot = ctx.bot
match = self._get_id_match(argument) or re.match(r'<@!?([0-9]{15,20})>$', argument)
guild = ctx.guild
result = None
user_id = None
if match is None:
# not a mention...
if guild:
result = guild.get_member_named(argument)
else:
result = _get_from_guilds(bot, 'get_member_named', argument)
else:
user_id = int(match.group(1))
if guild:
result = guild.get_member(user_id) or _utils_get(ctx.message.mentions, id=user_id)
else:
result = _get_from_guilds(bot, 'get_member', user_id)
if result is None:
if guild is None:
raise MemberNotFound(argument)
if user_id is not None:
result = await self.query_member_by_id(bot, guild, user_id)
else:
result = await self.query_member_named(guild, argument)
if not result:
raise MemberNotFound(argument)
return result
class UserConverter(IDConverter[discord.User]):
"""Converts to a :class:`~discord.User`.
All lookups are via the global user cache.
The lookup strategy is as follows (in order):
1. Lookup by ID.
2. Lookup by mention.
3. Lookup by name#discrim
4. Lookup by name
.. versionchanged:: 1.5
Raise :exc:`.UserNotFound` instead of generic :exc:`.BadArgument`
.. versionchanged:: 1.6
This converter now lazily fetches users from the HTTP APIs if an ID is passed
and it's not available in cache.
"""
async def convert(self, ctx: Context, argument: str) -> discord.User:
match = self._get_id_match(argument) or re.match(r'<@!?([0-9]{15,20})>$', argument)
result = None
state = ctx._state
if match is not None:
user_id = int(match.group(1))
result = ctx.bot.get_user(user_id) or _utils_get(ctx.message.mentions, id=user_id)
if result is None:
try:
result = await ctx.bot.fetch_user(user_id)
except discord.HTTPException:
raise UserNotFound(argument) from None
return result
arg = argument
# Remove the '@' character if this is the first character from the argument
if arg[0] == '@':
# Remove first character
arg = arg[1:]
# check for discriminator if it exists,
if len(arg) > 5 and arg[-5] == '#':
discrim = arg[-4:]
name = arg[:-5]
predicate = lambda u: u.name == name and u.discriminator == discrim
result = discord.utils.find(predicate, state._users.values())
if result is not None:
return result
predicate = lambda u: u.name == arg
result = discord.utils.find(predicate, state._users.values())
if result is None:
raise UserNotFound(argument)
return result
class PartialMessageConverter(Converter[discord.PartialMessage]):
"""Converts to a :class:`discord.PartialMessage`.
.. versionadded:: 1.7
The creation strategy is as follows (in order):
1. By "{channel ID}-{message ID}" (retrieved by shift-clicking on "Copy ID")
2. By message ID (The message is assumed to be in the context channel.)
3. By message URL
"""
@staticmethod
def _get_id_matches(ctx, argument):
id_regex = re.compile(r'(?:(?P<channel_id>[0-9]{15,20})-)?(?P<message_id>[0-9]{15,20})$')
link_regex = re.compile(
r'https?://(?:(ptb|canary|www)\.)?discord(?:app)?\.com/channels/'
r'(?P<guild_id>[0-9]{15,20}|@me)'
r'/(?P<channel_id>[0-9]{15,20})/(?P<message_id>[0-9]{15,20})/?$'
)
match = id_regex.match(argument) or link_regex.match(argument)
if not match:
raise MessageNotFound(argument)
data = match.groupdict()
channel_id = discord.utils._get_as_snowflake(data, 'channel_id')
message_id = int(data['message_id'])
guild_id = data.get('guild_id')
if guild_id is None:
guild_id = ctx.guild and ctx.guild.id
elif guild_id == '@me':
guild_id = None
else:
guild_id = int(guild_id)
return guild_id, message_id, channel_id
@staticmethod
def _resolve_channel(ctx, guild_id, channel_id) -> Optional[PartialMessageableChannel]:
if guild_id is not None:
guild = ctx.bot.get_guild(guild_id)
if guild is not None and channel_id is not None:
return guild._resolve_channel(channel_id) # type: ignore
else:
return None
else:
return ctx.bot.get_channel(channel_id) if channel_id else ctx.channel
async def convert(self, ctx: Context, argument: str) -> discord.PartialMessage:
guild_id, message_id, channel_id = self._get_id_matches(ctx, argument)
channel = self._resolve_channel(ctx, guild_id, channel_id)
if not channel:
raise ChannelNotFound(channel_id)
return discord.PartialMessage(channel=channel, id=message_id)
class MessageConverter(IDConverter[discord.Message]):
"""Converts to a :class:`discord.Message`.
.. versionadded:: 1.1
The lookup strategy is as follows (in order):
1. Lookup by "{channel ID}-{message ID}" (retrieved by shift-clicking on "Copy ID")
2. Lookup by message ID (the message **must** be in the context channel)
3. Lookup by message URL
.. versionchanged:: 1.5
Raise :exc:`.ChannelNotFound`, :exc:`.MessageNotFound` or :exc:`.ChannelNotReadable` instead of generic :exc:`.BadArgument`
"""
async def convert(self, ctx: Context, argument: str) -> discord.Message:
guild_id, message_id, channel_id = PartialMessageConverter._get_id_matches(ctx, argument)
message = ctx.bot._connection._get_message(message_id)
if message:
return message
channel = PartialMessageConverter._resolve_channel(ctx, guild_id, channel_id)
if not channel:
raise ChannelNotFound(channel_id)
try:
return await channel.fetch_message(message_id)
except discord.NotFound:
raise MessageNotFound(argument)
except discord.Forbidden:
raise ChannelNotReadable(channel)
class GuildChannelConverter(IDConverter[discord.abc.GuildChannel]):
"""Converts to a :class:`~discord.abc.GuildChannel`.
All lookups are via the local guild. If in a DM context, then the lookup
is done by the global cache.
The lookup strategy is as follows (in order):
1. Lookup by ID.
2. Lookup by mention.
3. Lookup by name.
.. versionadded:: 2.0
"""
async def convert(self, ctx: Context, argument: str) -> discord.abc.GuildChannel:
return self._resolve_channel(ctx, argument, 'channels', discord.abc.GuildChannel)
@staticmethod
def _resolve_channel(ctx: Context, argument: str, attribute: str, type: Type[CT]) -> CT:
bot = ctx.bot
match = IDConverter._get_id_match(argument) or re.match(r'<#([0-9]{15,20})>$', argument)
result = None
guild = ctx.guild
if match is None:
# not a mention
if guild:
iterable: Iterable[CT] = getattr(guild, attribute)
result: Optional[CT] = discord.utils.get(iterable, name=argument)
else:
def check(c):
return isinstance(c, type) and c.name == argument
result = discord.utils.find(check, bot.get_all_channels())
else:
channel_id = int(match.group(1))
if guild:
result = guild.get_channel(channel_id)
else:
result = _get_from_guilds(bot, 'get_channel', channel_id)
if not isinstance(result, type):
raise ChannelNotFound(argument)
return result
@staticmethod
def _resolve_thread(ctx: Context, argument: str, attribute: str, type: Type[TT]) -> TT:
bot = ctx.bot
match = IDConverter._get_id_match(argument) or re.match(r'<#([0-9]{15,20})>$', argument)
result = None
guild = ctx.guild
if match is None:
# not a mention
if guild:
iterable: Iterable[TT] = getattr(guild, attribute)
result: Optional[TT] = discord.utils.get(iterable, name=argument)
else:
thread_id = int(match.group(1))
if guild:
result = guild.get_thread(thread_id)
if not result or not isinstance(result, type):
raise ThreadNotFound(argument)
return result
class TextChannelConverter(IDConverter[discord.TextChannel]):
"""Converts to a :class:`~discord.TextChannel`.
All lookups are via the local guild. If in a DM context, then the lookup
is done by the global cache.
The lookup strategy is as follows (in order):
1. Lookup by ID.
2. Lookup by mention.
3. Lookup by name
.. versionchanged:: 1.5
Raise :exc:`.ChannelNotFound` instead of generic :exc:`.BadArgument`
"""
async def convert(self, ctx: Context, argument: str) -> discord.TextChannel:
return GuildChannelConverter._resolve_channel(ctx, argument, 'text_channels', discord.TextChannel)
class VoiceChannelConverter(IDConverter[discord.VoiceChannel]):
"""Converts to a :class:`~discord.VoiceChannel`.
All lookups are via the local guild. If in a DM context, then the lookup
is done by the global cache.
The lookup strategy is as follows (in order):
1. Lookup by ID.
2. Lookup by mention.
3. Lookup by name
.. versionchanged:: 1.5
Raise :exc:`.ChannelNotFound` instead of generic :exc:`.BadArgument`
"""
async def convert(self, ctx: Context, argument: str) -> discord.VoiceChannel:
return GuildChannelConverter._resolve_channel(ctx, argument, 'voice_channels', discord.VoiceChannel)
class StageChannelConverter(IDConverter[discord.StageChannel]):
"""Converts to a :class:`~discord.StageChannel`.
.. versionadded:: 1.7
All lookups are via the local guild. If in a DM context, then the lookup
is done by the global cache.
The lookup strategy is as follows (in order):
1. Lookup by ID.
2. Lookup by mention.
3. Lookup by name
"""
async def convert(self, ctx: Context, argument: str) -> discord.StageChannel:
return GuildChannelConverter._resolve_channel(ctx, argument, 'stage_channels', discord.StageChannel)
class CategoryChannelConverter(IDConverter[discord.CategoryChannel]):
"""Converts to a :class:`~discord.CategoryChannel`.
All lookups are via the local guild. If in a DM context, then the lookup
is done by the global cache.
The lookup strategy is as follows (in order):
1. Lookup by ID.
2. Lookup by mention.
3. Lookup by name
.. versionchanged:: 1.5
Raise :exc:`.ChannelNotFound` instead of generic :exc:`.BadArgument`
"""
async def convert(self, ctx: Context, argument: str) -> discord.CategoryChannel:
return GuildChannelConverter._resolve_channel(ctx, argument, 'categories', discord.CategoryChannel)
class StoreChannelConverter(IDConverter[discord.StoreChannel]):
"""Converts to a :class:`~discord.StoreChannel`.
All lookups are via the local guild. If in a DM context, then the lookup
is done by the global cache.
The lookup strategy is as follows (in order):
1. Lookup by ID.
2. Lookup by mention.
3. Lookup by name.
.. versionadded:: 1.7
"""
async def convert(self, ctx: Context, argument: str) -> discord.StoreChannel:
return GuildChannelConverter._resolve_channel(ctx, argument, 'channels', discord.StoreChannel)
class ThreadConverter(IDConverter[discord.Thread]):
"""Coverts to a :class:`~discord.Thread`.
All lookups are via the local guild.
The lookup strategy is as follows (in order):
1. Lookup by ID.
2. Lookup by mention.
3. Lookup by name.
.. versionadded: 2.0
"""
async def convert(self, ctx: Context, argument: str) -> discord.Thread:
return GuildChannelConverter._resolve_thread(ctx, argument, 'threads', discord.Thread)
class ColourConverter(Converter[discord.Colour]):
"""Converts to a :class:`~discord.Colour`.
.. versionchanged:: 1.5
Add an alias named ColorConverter
The following formats are accepted:
- ``0x<hex>``
- ``#<hex>``
- ``0x#<hex>``
- ``rgb(<number>, <number>, <number>)``
- Any of the ``classmethod`` in :class:`~discord.Colour`
- The ``_`` in the name can be optionally replaced with spaces.
Like CSS, ``<number>`` can be either 0-255 or 0-100% and ``<hex>`` can be
either a 6 digit hex number or a 3 digit hex shortcut (e.g. #fff).
.. versionchanged:: 1.5
Raise :exc:`.BadColourArgument` instead of generic :exc:`.BadArgument`
.. versionchanged:: 1.7
Added support for ``rgb`` function and 3-digit hex shortcuts
"""
RGB_REGEX = re.compile(r'rgb\s*\((?P<r>[0-9]{1,3}%?)\s*,\s*(?P<g>[0-9]{1,3}%?)\s*,\s*(?P<b>[0-9]{1,3}%?)\s*\)')
def parse_hex_number(self, argument):
arg = ''.join(i * 2 for i in argument) if len(argument) == 3 else argument
try:
value = int(arg, base=16)
if not (0 <= value <= 0xFFFFFF):
raise BadColourArgument(argument)
except ValueError:
raise BadColourArgument(argument)
else:
return discord.Color(value=value)
def parse_rgb_number(self, argument, number):
if number[-1] == '%':
value = int(number[:-1])
if not (0 <= value <= 100):
raise BadColourArgument(argument)
return round(255 * (value / 100))
value = int(number)
if not (0 <= value <= 255):
raise BadColourArgument(argument)
return value
def parse_rgb(self, argument, *, regex=RGB_REGEX):
match = regex.match(argument)
if match is None:
raise BadColourArgument(argument)
red = self.parse_rgb_number(argument, match.group('r'))
green = self.parse_rgb_number(argument, match.group('g'))
blue = self.parse_rgb_number(argument, match.group('b'))
return discord.Color.from_rgb(red, green, blue)
async def convert(self, ctx: Context, argument: str) -> discord.Colour:
if argument[0] == '#':
return self.parse_hex_number(argument[1:])
if argument[0:2] == '0x':
rest = argument[2:]
# Legacy backwards compatible syntax
if rest.startswith('#'):
return self.parse_hex_number(rest[1:])
return self.parse_hex_number(rest)
arg = argument.lower()
if arg[0:3] == 'rgb':
return self.parse_rgb(arg)
arg = arg.replace(' ', '_')
method = getattr(discord.Colour, arg, None)
if arg.startswith('from_') or method is None or not inspect.ismethod(method):
raise BadColourArgument(arg)
return method()
ColorConverter = ColourConverter
class RoleConverter(IDConverter[discord.Role]):
"""Converts to a :class:`~discord.Role`.
All lookups are via the local guild. If in a DM context, the converter raises
:exc:`.NoPrivateMessage` exception.
The lookup strategy is as follows (in order):
1. Lookup by ID.
2. Lookup by mention.
3. Lookup by name
.. versionchanged:: 1.5
Raise :exc:`.RoleNotFound` instead of generic :exc:`.BadArgument`
"""
async def convert(self, ctx: Context, argument: str) -> discord.Role:
guild = ctx.guild
if not guild:
raise NoPrivateMessage()
match = self._get_id_match(argument) or re.match(r'<@&([0-9]{15,20})>$', argument)
if match:
result = guild.get_role(int(match.group(1)))
else:
result = discord.utils.get(guild._roles.values(), name=argument)
if result is None:
raise RoleNotFound(argument)
return result
class GameConverter(Converter[discord.Game]):
"""Converts to :class:`~discord.Game`."""
async def convert(self, ctx: Context, argument: str) -> discord.Game:
return discord.Game(name=argument)
class InviteConverter(Converter[discord.Invite]):
"""Converts to a :class:`~discord.Invite`.
This is done via an HTTP request using :meth:`.Bot.fetch_invite`.
.. versionchanged:: 1.5
Raise :exc:`.BadInviteArgument` instead of generic :exc:`.BadArgument`
"""
async def convert(self, ctx: Context, argument: str) -> discord.Invite:
try:
invite = await ctx.bot.fetch_invite(argument)
return invite
except Exception as exc:
raise BadInviteArgument(argument) from exc
class GuildConverter(IDConverter[discord.Guild]):
"""Converts to a :class:`~discord.Guild`.
The lookup strategy is as follows (in order):
1. Lookup by ID.
2. Lookup by name. (There is no disambiguation for Guilds with multiple matching names).
.. versionadded:: 1.7
"""
async def convert(self, ctx: Context, argument: str) -> discord.Guild:
match = self._get_id_match(argument)
result = None
if match is not None:
guild_id = int(match.group(1))
result = ctx.bot.get_guild(guild_id)
if result is None:
result = discord.utils.get(ctx.bot.guilds, name=argument)
if result is None:
raise GuildNotFound(argument)
return result
class EmojiConverter(IDConverter[discord.Emoji]):
"""Converts to a :class:`~discord.Emoji`.
All lookups are done for the local guild first, if available. If that lookup
fails, then it checks the client's global cache.
The lookup strategy is as follows (in order):
1. Lookup by ID.
2. Lookup by extracting ID from the emoji.
3. Lookup by name
.. versionchanged:: 1.5
Raise :exc:`.EmojiNotFound` instead of generic :exc:`.BadArgument`
"""
async def convert(self, ctx: Context, argument: str) -> discord.Emoji:
match = self._get_id_match(argument) or re.match(r'<a?:[a-zA-Z0-9\_]{1,32}:([0-9]{15,20})>$', argument)
result = None
bot = ctx.bot
guild = ctx.guild
if match is None:
# Try to get the emoji by name. Try local guild first.
if guild:
result = discord.utils.get(guild.emojis, name=argument)
if result is None:
result = discord.utils.get(bot.emojis, name=argument)
else:
emoji_id = int(match.group(1))
# Try to look up emoji by id.
result = bot.get_emoji(emoji_id)
if result is None:
raise EmojiNotFound(argument)
return result
class PartialEmojiConverter(Converter[discord.PartialEmoji]):
"""Converts to a :class:`~discord.PartialEmoji`.
This is done by extracting the animated flag, name and ID from the emoji.
.. versionchanged:: 1.5
Raise :exc:`.PartialEmojiConversionFailure` instead of generic :exc:`.BadArgument`
"""
async def convert(self, ctx: Context, argument: str) -> discord.PartialEmoji:
match = re.match(r'<(a?):([a-zA-Z0-9\_]{1,32}):([0-9]{15,20})>$', argument)
if match:
emoji_animated = bool(match.group(1))
emoji_name = match.group(2)
emoji_id = int(match.group(3))
return discord.PartialEmoji.with_state(
ctx.bot._connection, animated=emoji_animated, name=emoji_name, id=emoji_id
)
raise PartialEmojiConversionFailure(argument)
class GuildStickerConverter(IDConverter[discord.GuildSticker]):
"""Converts to a :class:`~discord.GuildSticker`.
All lookups are done for the local guild first, if available. If that lookup
fails, then it checks the client's global cache.
The lookup strategy is as follows (in order):
1. Lookup by ID.
3. Lookup by name
.. versionadded:: 2.0
"""
async def convert(self, ctx: Context, argument: str) -> discord.GuildSticker:
match = self._get_id_match(argument)
result = None
bot = ctx.bot
guild = ctx.guild
if match is None:
# Try to get the sticker by name. Try local guild first.
if guild:
result = discord.utils.get(guild.stickers, name=argument)
if result is None:
result = discord.utils.get(bot.stickers, name=argument)
else:
sticker_id = int(match.group(1))
# Try to look up sticker by id.
result = bot.get_sticker(sticker_id)
if result is None:
raise GuildStickerNotFound(argument)
return result
class clean_content(Converter[str]):
"""Converts the argument to mention scrubbed version of
said content.
This behaves similarly to :attr:`~discord.Message.clean_content`.
Attributes
------------
fix_channel_mentions: :class:`bool`
Whether to clean channel mentions.
use_nicknames: :class:`bool`
Whether to use nicknames when transforming mentions.
escape_markdown: :class:`bool`
Whether to also escape special markdown characters.
remove_markdown: :class:`bool`
Whether to also remove special markdown characters. This option is not supported with ``escape_markdown``
.. versionadded:: 1.7
"""
def __init__(
self,
*,
fix_channel_mentions: bool = False,
use_nicknames: bool = True,
escape_markdown: bool = False,
remove_markdown: bool = False,
) -> None:
self.fix_channel_mentions = fix_channel_mentions
self.use_nicknames = use_nicknames
self.escape_markdown = escape_markdown
self.remove_markdown = remove_markdown
async def convert(self, ctx: Context, argument: str) -> str:
msg = ctx.message
if ctx.guild:
def resolve_member(id: int) -> str:
m = _utils_get(msg.mentions, id=id) or ctx.guild.get_member(id)
return f'@{m.display_name if self.use_nicknames else m.name}' if m else '@deleted-user'
def resolve_role(id: int) -> str:
r = _utils_get(msg.role_mentions, id=id) or ctx.guild.get_role(id)
return f'@{r.name}' if r else '@deleted-role'
else:
def resolve_member(id: int) -> str:
m = _utils_get(msg.mentions, id=id) or ctx.bot.get_user(id)
return f'@{m.name}' if m else '@deleted-user'
def resolve_role(id: int) -> str:
return '@deleted-role'
if self.fix_channel_mentions and ctx.guild:
def resolve_channel(id: int) -> str:
c = ctx.guild.get_channel(id)
return f'#{c.name}' if c else '#deleted-channel'
else:
def resolve_channel(id: int) -> str:
return f'<#{id}>'
transforms = {
'@': resolve_member,
'@!': resolve_member,
'#': resolve_channel,
'@&': resolve_role,
}
def repl(match: re.Match) -> str:
type = match[1]
id = int(match[2])
transformed = transforms[type](id)
return transformed
result = re.sub(r'<(@[!&]?|#)([0-9]{15,20})>', repl, argument)
if self.escape_markdown:
result = discord.utils.escape_markdown(result)
elif self.remove_markdown:
result = discord.utils.remove_markdown(result)
# Completely ensure no mentions escape:
return discord.utils.escape_mentions(result)
class Greedy(List[T]):
r"""A special converter that greedily consumes arguments until it can't.
As a consequence of this behaviour, most input errors are silently discarded,
since it is used as an indicator of when to stop parsing.
When a parser error is met the greedy converter stops converting, undoes the
internal string parsing routine, and continues parsing regularly.
For example, in the following code:
.. code-block:: python3
@commands.command()
async def test(ctx, numbers: Greedy[int], reason: str):
await ctx.send("numbers: {}, reason: {}".format(numbers, reason))
An invocation of ``[p]test 1 2 3 4 5 6 hello`` would pass ``numbers`` with
``[1, 2, 3, 4, 5, 6]`` and ``reason`` with ``hello``\.
For more information, check :ref:`ext_commands_special_converters`.
"""
__slots__ = ('converter',)
def __init__(self, *, converter: T):
self.converter = converter
def __repr__(self):
converter = getattr(self.converter, '__name__', repr(self.converter))
return f'Greedy[{converter}]'
def __class_getitem__(cls, params: Union[Tuple[T], T]) -> Greedy[T]:
if not isinstance(params, tuple):
params = (params,)
if len(params) != 1:
raise TypeError('Greedy[...] only takes a single argument')
converter = params[0]
origin = getattr(converter, '__origin__', None)
args = getattr(converter, '__args__', ())
if not (callable(converter) or isinstance(converter, Converter) or origin is not None):
raise TypeError('Greedy[...] expects a type or a Converter instance.')
if converter in (str, type(None)) or origin is Greedy:
raise TypeError(f'Greedy[{converter.__name__}] is invalid.')
if origin is Union and type(None) in args:
raise TypeError(f'Greedy[{converter!r}] is invalid.')
return cls(converter=converter)
def _convert_to_bool(argument: str) -> bool:
lowered = argument.lower()
if lowered in ('yes', 'y', 'true', 't', '1', 'enable', 'on'):
return True
elif lowered in ('no', 'n', 'false', 'f', '0', 'disable', 'off'):
return False
else:
raise BadBoolArgument(lowered)
def get_converter(param: inspect.Parameter) -> Any:
converter = param.annotation
if converter is param.empty:
if param.default is not param.empty:
converter = str if param.default is None else type(param.default)
else:
converter = str
return converter
_GenericAlias = type(List[T])
def is_generic_type(tp: Any, *, _GenericAlias: Type = _GenericAlias) -> bool:
return isinstance(tp, type) and issubclass(tp, Generic) or isinstance(tp, _GenericAlias) # type: ignore
CONVERTER_MAPPING: Dict[Type[Any], Any] = {
discord.Object: ObjectConverter,
discord.Member: MemberConverter,
discord.User: UserConverter,
discord.Message: MessageConverter,
discord.PartialMessage: PartialMessageConverter,
discord.TextChannel: TextChannelConverter,
discord.Invite: InviteConverter,
discord.Guild: GuildConverter,
discord.Role: RoleConverter,
discord.Game: GameConverter,
discord.Colour: ColourConverter,
discord.VoiceChannel: VoiceChannelConverter,
discord.StageChannel: StageChannelConverter,
discord.Emoji: EmojiConverter,
discord.PartialEmoji: PartialEmojiConverter,
discord.CategoryChannel: CategoryChannelConverter,
discord.StoreChannel: StoreChannelConverter,
discord.Thread: ThreadConverter,
discord.abc.GuildChannel: GuildChannelConverter,
discord.GuildSticker: GuildStickerConverter,
}
async def _actual_conversion(ctx: Context, converter, argument: str, param: inspect.Parameter):
if converter is bool:
return _convert_to_bool(argument)
try:
module = converter.__module__
except AttributeError:
pass
else:
if module is not None and (module.startswith('discord.') and not module.endswith('converter')):
converter = CONVERTER_MAPPING.get(converter, converter)
try:
if inspect.isclass(converter) and issubclass(converter, Converter):
if inspect.ismethod(converter.convert):
return await converter.convert(ctx, argument)
else:
return await converter().convert(ctx, argument)
elif isinstance(converter, Converter):
return await converter.convert(ctx, argument)
except CommandError:
raise
except Exception as exc:
raise ConversionError(converter, exc) from exc
try:
return converter(argument)
except CommandError:
raise
except Exception as exc:
try:
name = converter.__name__
except AttributeError:
name = converter.__class__.__name__
raise BadArgument(f'Converting to "{name}" failed for parameter "{param.name}".') from exc
async def run_converters(ctx: Context, converter, argument: str, param: inspect.Parameter):
"""|coro|
Runs converters for a given converter, argument, and parameter.
This function does the same work that the library does under the hood.
.. versionadded:: 2.0
Parameters
------------
ctx: :class:`Context`
The invocation context to run the converters under.
converter: Any
The converter to run, this corresponds to the annotation in the function.
argument: :class:`str`
The argument to convert to.
param: :class:`inspect.Parameter`
The parameter being converted. This is mainly for error reporting.
Raises
-------
CommandError
The converter failed to convert.
Returns
--------
Any
The resulting conversion.
"""
origin = getattr(converter, '__origin__', None)
if origin is Union:
errors = []
_NoneType = type(None)
union_args = converter.__args__
for conv in union_args:
# if we got to this part in the code, then the previous conversions have failed
# so we should just undo the view, return the default, and allow parsing to continue
# with the other parameters
if conv is _NoneType and param.kind != param.VAR_POSITIONAL:
ctx.view.undo()
return None if param.default is param.empty else param.default
try:
value = await run_converters(ctx, conv, argument, param)
except CommandError as exc:
errors.append(exc)
else:
return value
# if we're here, then we failed all the converters
raise BadUnionArgument(param, union_args, errors)
if origin is Literal:
errors = []
conversions = {}
literal_args = converter.__args__
for literal in literal_args:
literal_type = type(literal)
try:
value = conversions[literal_type]
except KeyError:
try:
value = await _actual_conversion(ctx, literal_type, argument, param)
except CommandError as exc:
errors.append(exc)
conversions[literal_type] = object()
continue
else:
conversions[literal_type] = value
if value == literal:
return value
# if we're here, then we failed to match all the literals
raise BadLiteralArgument(param, literal_args, errors)
# This must be the last if-clause in the chain of origin checking
# Nearly every type is a generic type within the typing library
# So care must be taken to make sure a more specialised origin handle
# isn't overwritten by the widest if clause
if origin is not None and is_generic_type(converter):
converter = origin
return await _actual_conversion(ctx, converter, argument, param) | zarenacord.py | /zarenacord.py-2.0.0-py3-none-any.whl/discord/ext/commands/converter.py | converter.py |
from __future__ import annotations
from typing import (
Any,
Callable,
Dict,
Generator,
Generic,
Literal,
List,
Optional,
Union,
Set,
Tuple,
TypeVar,
Type,
TYPE_CHECKING,
overload,
)
import asyncio
import functools
import inspect
import datetime
import discord
from .errors import *
from .cooldowns import Cooldown, BucketType, CooldownMapping, MaxConcurrency, DynamicCooldownMapping
from .converter import run_converters, get_converter, Greedy
from ._types import _BaseCommand
from .cog import Cog
from .context import Context
if TYPE_CHECKING:
from typing_extensions import Concatenate, ParamSpec, TypeGuard
from discord.message import Message
from ._types import (
Coro,
CoroFunc,
Check,
Hook,
Error,
)
__all__ = (
'Command',
'Group',
'GroupMixin',
'command',
'group',
'has_role',
'has_permissions',
'has_any_role',
'check',
'check_any',
'before_invoke',
'after_invoke',
'bot_has_role',
'bot_has_permissions',
'bot_has_any_role',
'cooldown',
'dynamic_cooldown',
'max_concurrency',
'dm_only',
'guild_only',
'is_owner',
'is_nsfw',
'has_guild_permissions',
'bot_has_guild_permissions'
)
MISSING: Any = discord.utils.MISSING
T = TypeVar('T')
CogT = TypeVar('CogT', bound='Cog')
CommandT = TypeVar('CommandT', bound='Command')
ContextT = TypeVar('ContextT', bound='Context')
# CHT = TypeVar('CHT', bound='Check')
GroupT = TypeVar('GroupT', bound='Group')
HookT = TypeVar('HookT', bound='Hook')
ErrorT = TypeVar('ErrorT', bound='Error')
if TYPE_CHECKING:
P = ParamSpec('P')
else:
P = TypeVar('P')
def unwrap_function(function: Callable[..., Any]) -> Callable[..., Any]:
partial = functools.partial
while True:
if hasattr(function, '__wrapped__'):
function = function.__wrapped__
elif isinstance(function, partial):
function = function.func
else:
return function
def get_signature_parameters(function: Callable[..., Any], globalns: Dict[str, Any]) -> Dict[str, inspect.Parameter]:
signature = inspect.signature(function)
params = {}
cache: Dict[str, Any] = {}
eval_annotation = discord.utils.evaluate_annotation
for name, parameter in signature.parameters.items():
annotation = parameter.annotation
if annotation is parameter.empty:
params[name] = parameter
continue
if annotation is None:
params[name] = parameter.replace(annotation=type(None))
continue
annotation = eval_annotation(annotation, globalns, globalns, cache)
if annotation is Greedy:
raise TypeError('Unparameterized Greedy[...] is disallowed in signature.')
params[name] = parameter.replace(annotation=annotation)
return params
def wrap_callback(coro):
@functools.wraps(coro)
async def wrapped(*args, **kwargs):
try:
ret = await coro(*args, **kwargs)
except CommandError:
raise
except asyncio.CancelledError:
return
except Exception as exc:
raise CommandInvokeError(exc) from exc
return ret
return wrapped
def hooked_wrapped_callback(command, ctx, coro):
@functools.wraps(coro)
async def wrapped(*args, **kwargs):
try:
ret = await coro(*args, **kwargs)
except CommandError:
ctx.command_failed = True
raise
except asyncio.CancelledError:
ctx.command_failed = True
return
except Exception as exc:
ctx.command_failed = True
raise CommandInvokeError(exc) from exc
finally:
if command._max_concurrency is not None:
await command._max_concurrency.release(ctx)
await command.call_after_hooks(ctx)
return ret
return wrapped
class _CaseInsensitiveDict(dict):
def __contains__(self, k):
return super().__contains__(k.casefold())
def __delitem__(self, k):
return super().__delitem__(k.casefold())
def __getitem__(self, k):
return super().__getitem__(k.casefold())
def get(self, k, default=None):
return super().get(k.casefold(), default)
def pop(self, k, default=None):
return super().pop(k.casefold(), default)
def __setitem__(self, k, v):
super().__setitem__(k.casefold(), v)
class Command(_BaseCommand, Generic[CogT, P, T]):
r"""A class that implements the protocol for a bot text command.
These are not created manually, instead they are created via the
decorator or functional interface.
Attributes
-----------
name: :class:`str`
The name of the command.
callback: :ref:`coroutine <coroutine>`
The coroutine that is executed when the command is called.
help: Optional[:class:`str`]
The long help text for the command.
brief: Optional[:class:`str`]
The short help text for the command.
usage: Optional[:class:`str`]
A replacement for arguments in the default help text.
aliases: Union[List[:class:`str`], Tuple[:class:`str`]]
The list of aliases the command can be invoked under.
enabled: :class:`bool`
A boolean that indicates if the command is currently enabled.
If the command is invoked while it is disabled, then
:exc:`.DisabledCommand` is raised to the :func:`.on_command_error`
event. Defaults to ``True``.
parent: Optional[:class:`Group`]
The parent group that this command belongs to. ``None`` if there
isn't one.
cog: Optional[:class:`Cog`]
The cog that this command belongs to. ``None`` if there isn't one.
checks: List[Callable[[:class:`.Context`], :class:`bool`]]
A list of predicates that verifies if the command could be executed
with the given :class:`.Context` as the sole parameter. If an exception
is necessary to be thrown to signal failure, then one inherited from
:exc:`.CommandError` should be used. Note that if the checks fail then
:exc:`.CheckFailure` exception is raised to the :func:`.on_command_error`
event.
description: :class:`str`
The message prefixed into the default help command.
hidden: :class:`bool`
If ``True``\, the default help command does not show this in the
help output.
rest_is_raw: :class:`bool`
If ``False`` and a keyword-only argument is provided then the keyword
only argument is stripped and handled as if it was a regular argument
that handles :exc:`.MissingRequiredArgument` and default values in a
regular matter rather than passing the rest completely raw. If ``True``
then the keyword-only argument will pass in the rest of the arguments
in a completely raw matter. Defaults to ``False``.
invoked_subcommand: Optional[:class:`Command`]
The subcommand that was invoked, if any.
require_var_positional: :class:`bool`
If ``True`` and a variadic positional argument is specified, requires
the user to specify at least one argument. Defaults to ``False``.
.. versionadded:: 1.5
ignore_extra: :class:`bool`
If ``True``\, ignores extraneous strings passed to a command if all its
requirements are met (e.g. ``?foo a b c`` when only expecting ``a``
and ``b``). Otherwise :func:`.on_command_error` and local error handlers
are called with :exc:`.TooManyArguments`. Defaults to ``True``.
cooldown_after_parsing: :class:`bool`
If ``True``\, cooldown processing is done after argument parsing,
which calls converters. If ``False`` then cooldown processing is done
first and then the converters are called second. Defaults to ``False``.
extras: :class:`dict`
A dict of user provided extras to attach to the Command.
.. note::
This object may be copied by the library.
.. versionadded:: 2.0
"""
__original_kwargs__: Dict[str, Any]
def __new__(cls: Type[CommandT], *args: Any, **kwargs: Any) -> CommandT:
# if you're wondering why this is done, it's because we need to ensure
# we have a complete original copy of **kwargs even for classes that
# mess with it by popping before delegating to the subclass __init__.
# In order to do this, we need to control the instance creation and
# inject the original kwargs through __new__ rather than doing it
# inside __init__.
self = super().__new__(cls)
# we do a shallow copy because it's probably the most common use case.
# this could potentially break if someone modifies a list or something
# while it's in movement, but for now this is the cheapest and
# fastest way to do what we want.
self.__original_kwargs__ = kwargs.copy()
return self
def __init__(self, func: Union[
Callable[Concatenate[CogT, ContextT, P], Coro[T]],
Callable[Concatenate[ContextT, P], Coro[T]],
], **kwargs: Any):
if not asyncio.iscoroutinefunction(func):
raise TypeError('Callback must be a coroutine.')
name = kwargs.get('name') or func.__name__
if not isinstance(name, str):
raise TypeError('Name of a command must be a string.')
self.name: str = name
self.callback = func
self.enabled: bool = kwargs.get('enabled', True)
help_doc = kwargs.get('help')
if help_doc is not None:
help_doc = inspect.cleandoc(help_doc)
else:
help_doc = inspect.getdoc(func)
if isinstance(help_doc, bytes):
help_doc = help_doc.decode('utf-8')
self.help: Optional[str] = help_doc
self.brief: Optional[str] = kwargs.get('brief')
self.usage: Optional[str] = kwargs.get('usage')
self.rest_is_raw: bool = kwargs.get('rest_is_raw', False)
self.aliases: Union[List[str], Tuple[str]] = kwargs.get('aliases', [])
self.extras: Dict[str, Any] = kwargs.get('extras', {})
if not isinstance(self.aliases, (list, tuple)):
raise TypeError("Aliases of a command must be a list or a tuple of strings.")
self.description: str = inspect.cleandoc(kwargs.get('description', ''))
self.hidden: bool = kwargs.get('hidden', False)
try:
checks = func.__commands_checks__
checks.reverse()
except AttributeError:
checks = kwargs.get('checks', [])
self.checks: List[Check] = checks
try:
cooldown = func.__commands_cooldown__
except AttributeError:
cooldown = kwargs.get('cooldown')
if cooldown is None:
buckets = CooldownMapping(cooldown, BucketType.default)
elif isinstance(cooldown, CooldownMapping):
buckets = cooldown
else:
raise TypeError("Cooldown must be a an instance of CooldownMapping or None.")
self._buckets: CooldownMapping = buckets
try:
max_concurrency = func.__commands_max_concurrency__
except AttributeError:
max_concurrency = kwargs.get('max_concurrency')
self._max_concurrency: Optional[MaxConcurrency] = max_concurrency
self.require_var_positional: bool = kwargs.get('require_var_positional', False)
self.ignore_extra: bool = kwargs.get('ignore_extra', True)
self.cooldown_after_parsing: bool = kwargs.get('cooldown_after_parsing', False)
self.cog: Optional[CogT] = None
# bandaid for the fact that sometimes parent can be the bot instance
parent = kwargs.get('parent')
self.parent: Optional[GroupMixin] = parent if isinstance(parent, _BaseCommand) else None # type: ignore
self._before_invoke: Optional[Hook] = None
try:
before_invoke = func.__before_invoke__
except AttributeError:
pass
else:
self.before_invoke(before_invoke)
self._after_invoke: Optional[Hook] = None
try:
after_invoke = func.__after_invoke__
except AttributeError:
pass
else:
self.after_invoke(after_invoke)
@property
def callback(self) -> Union[
Callable[Concatenate[CogT, Context, P], Coro[T]],
Callable[Concatenate[Context, P], Coro[T]],
]:
return self._callback
@callback.setter
def callback(self, function: Union[
Callable[Concatenate[CogT, Context, P], Coro[T]],
Callable[Concatenate[Context, P], Coro[T]],
]) -> None:
self._callback = function
unwrap = unwrap_function(function)
self.module = unwrap.__module__
try:
globalns = unwrap.__globals__
except AttributeError:
globalns = {}
self.params = get_signature_parameters(function, globalns)
def add_check(self, func: Check) -> None:
"""Adds a check to the command.
This is the non-decorator interface to :func:`.check`.
.. versionadded:: 1.3
Parameters
-----------
func
The function that will be used as a check.
"""
self.checks.append(func)
def remove_check(self, func: Check) -> None:
"""Removes a check from the command.
This function is idempotent and will not raise an exception
if the function is not in the command's checks.
.. versionadded:: 1.3
Parameters
-----------
func
The function to remove from the checks.
"""
try:
self.checks.remove(func)
except ValueError:
pass
def update(self, **kwargs: Any) -> None:
"""Updates :class:`Command` instance with updated attribute.
This works similarly to the :func:`.command` decorator in terms
of parameters in that they are passed to the :class:`Command` or
subclass constructors, sans the name and callback.
"""
self.__init__(self.callback, **dict(self.__original_kwargs__, **kwargs))
async def __call__(self, context: Context, *args: P.args, **kwargs: P.kwargs) -> T:
"""|coro|
Calls the internal callback that the command holds.
.. note::
This bypasses all mechanisms -- including checks, converters,
invoke hooks, cooldowns, etc. You must take care to pass
the proper arguments and types to this function.
.. versionadded:: 1.3
"""
if self.cog is not None:
return await self.callback(self.cog, context, *args, **kwargs) # type: ignore
else:
return await self.callback(context, *args, **kwargs) # type: ignore
def _ensure_assignment_on_copy(self, other: CommandT) -> CommandT:
other._before_invoke = self._before_invoke
other._after_invoke = self._after_invoke
if self.checks != other.checks:
other.checks = self.checks.copy()
if self._buckets.valid and not other._buckets.valid:
other._buckets = self._buckets.copy()
if self._max_concurrency != other._max_concurrency:
# _max_concurrency won't be None at this point
other._max_concurrency = self._max_concurrency.copy() # type: ignore
try:
other.on_error = self.on_error
except AttributeError:
pass
return other
def copy(self: CommandT) -> CommandT:
"""Creates a copy of this command.
Returns
--------
:class:`Command`
A new instance of this command.
"""
ret = self.__class__(self.callback, **self.__original_kwargs__)
return self._ensure_assignment_on_copy(ret)
def _update_copy(self: CommandT, kwargs: Dict[str, Any]) -> CommandT:
if kwargs:
kw = kwargs.copy()
kw.update(self.__original_kwargs__)
copy = self.__class__(self.callback, **kw)
return self._ensure_assignment_on_copy(copy)
else:
return self.copy()
async def dispatch_error(self, ctx: Context, error: Exception) -> None:
ctx.command_failed = True
cog = self.cog
try:
coro = self.on_error
except AttributeError:
pass
else:
injected = wrap_callback(coro)
if cog is not None:
await injected(cog, ctx, error)
else:
await injected(ctx, error)
try:
if cog is not None:
local = Cog._get_overridden_method(cog.cog_command_error)
if local is not None:
wrapped = wrap_callback(local)
await wrapped(ctx, error)
finally:
ctx.bot.dispatch('command_error', ctx, error)
async def transform(self, ctx: Context, param: inspect.Parameter) -> Any:
required = param.default is param.empty
converter = get_converter(param)
consume_rest_is_special = param.kind == param.KEYWORD_ONLY and not self.rest_is_raw
view = ctx.view
view.skip_ws()
# The greedy converter is simple -- it keeps going until it fails in which case,
# it undos the view ready for the next parameter to use instead
if isinstance(converter, Greedy):
if param.kind in (param.POSITIONAL_OR_KEYWORD, param.POSITIONAL_ONLY):
return await self._transform_greedy_pos(ctx, param, required, converter.converter)
elif param.kind == param.VAR_POSITIONAL:
return await self._transform_greedy_var_pos(ctx, param, converter.converter)
else:
# if we're here, then it's a KEYWORD_ONLY param type
# since this is mostly useless, we'll helpfully transform Greedy[X]
# into just X and do the parsing that way.
converter = converter.converter
if view.eof:
if param.kind == param.VAR_POSITIONAL:
raise RuntimeError() # break the loop
if required:
if self._is_typing_optional(param.annotation):
return None
if hasattr(converter, '__commands_is_flag__') and converter._can_be_constructible():
return await converter._construct_default(ctx)
raise MissingRequiredArgument(param)
return param.default
previous = view.index
if consume_rest_is_special:
argument = view.read_rest().strip()
else:
try:
argument = view.get_quoted_word()
except ArgumentParsingError as exc:
if self._is_typing_optional(param.annotation):
view.index = previous
return None
else:
raise exc
view.previous = previous
# type-checker fails to narrow argument
return await run_converters(ctx, converter, argument, param) # type: ignore
async def _transform_greedy_pos(self, ctx: Context, param: inspect.Parameter, required: bool, converter: Any) -> Any:
view = ctx.view
result = []
while not view.eof:
# for use with a manual undo
previous = view.index
view.skip_ws()
try:
argument = view.get_quoted_word()
value = await run_converters(ctx, converter, argument, param) # type: ignore
except (CommandError, ArgumentParsingError):
view.index = previous
break
else:
result.append(value)
if not result and not required:
return param.default
return result
async def _transform_greedy_var_pos(self, ctx: Context, param: inspect.Parameter, converter: Any) -> Any:
view = ctx.view
previous = view.index
try:
argument = view.get_quoted_word()
value = await run_converters(ctx, converter, argument, param) # type: ignore
except (CommandError, ArgumentParsingError):
view.index = previous
raise RuntimeError() from None # break loop
else:
return value
@property
def clean_params(self) -> Dict[str, inspect.Parameter]:
"""Dict[:class:`str`, :class:`inspect.Parameter`]:
Retrieves the parameter dictionary without the context or self parameters.
Useful for inspecting signature.
"""
result = self.params.copy()
if self.cog is not None:
# first parameter is self
try:
del result[next(iter(result))]
except StopIteration:
raise ValueError("missing 'self' parameter") from None
try:
# first/second parameter is context
del result[next(iter(result))]
except StopIteration:
raise ValueError("missing 'context' parameter") from None
return result
@property
def full_parent_name(self) -> str:
""":class:`str`: Retrieves the fully qualified parent command name.
This the base command name required to execute it. For example,
in ``?one two three`` the parent name would be ``one two``.
"""
entries = []
command = self
# command.parent is type-hinted as GroupMixin some attributes are resolved via MRO
while command.parent is not None: # type: ignore
command = command.parent # type: ignore
entries.append(command.name) # type: ignore
return ' '.join(reversed(entries))
@property
def parents(self) -> List[Group]:
"""List[:class:`Group`]: Retrieves the parents of this command.
If the command has no parents then it returns an empty :class:`list`.
For example in commands ``?a b c test``, the parents are ``[c, b, a]``.
.. versionadded:: 1.1
"""
entries = []
command = self
while command.parent is not None: # type: ignore
command = command.parent # type: ignore
entries.append(command)
return entries
@property
def root_parent(self) -> Optional[Group]:
"""Optional[:class:`Group`]: Retrieves the root parent of this command.
If the command has no parents then it returns ``None``.
For example in commands ``?a b c test``, the root parent is ``a``.
"""
if not self.parent:
return None
return self.parents[-1]
@property
def qualified_name(self) -> str:
""":class:`str`: Retrieves the fully qualified command name.
This is the full parent name with the command name as well.
For example, in ``?one two three`` the qualified name would be
``one two three``.
"""
parent = self.full_parent_name
if parent:
return parent + ' ' + self.name
else:
return self.name
def __str__(self) -> str:
return self.qualified_name
async def _parse_arguments(self, ctx: Context) -> None:
ctx.args = [ctx] if self.cog is None else [self.cog, ctx]
ctx.kwargs = {}
args = ctx.args
kwargs = ctx.kwargs
view = ctx.view
iterator = iter(self.params.items())
if self.cog is not None:
# we have 'self' as the first parameter so just advance
# the iterator and resume parsing
try:
next(iterator)
except StopIteration:
raise discord.ClientException(f'Callback for {self.name} command is missing "self" parameter.')
# next we have the 'ctx' as the next parameter
try:
next(iterator)
except StopIteration:
raise discord.ClientException(f'Callback for {self.name} command is missing "ctx" parameter.')
for name, param in iterator:
ctx.current_parameter = param
if param.kind in (param.POSITIONAL_OR_KEYWORD, param.POSITIONAL_ONLY):
transformed = await self.transform(ctx, param)
args.append(transformed)
elif param.kind == param.KEYWORD_ONLY:
# kwarg only param denotes "consume rest" semantics
if self.rest_is_raw:
converter = get_converter(param)
argument = view.read_rest()
kwargs[name] = await run_converters(ctx, converter, argument, param)
else:
kwargs[name] = await self.transform(ctx, param)
break
elif param.kind == param.VAR_POSITIONAL:
if view.eof and self.require_var_positional:
raise MissingRequiredArgument(param)
while not view.eof:
try:
transformed = await self.transform(ctx, param)
args.append(transformed)
except RuntimeError:
break
if not self.ignore_extra and not view.eof:
raise TooManyArguments('Too many arguments passed to ' + self.qualified_name)
async def call_before_hooks(self, ctx: Context) -> None:
# now that we're done preparing we can call the pre-command hooks
# first, call the command local hook:
cog = self.cog
if self._before_invoke is not None:
# should be cog if @commands.before_invoke is used
instance = getattr(self._before_invoke, '__self__', cog)
# __self__ only exists for methods, not functions
# however, if @command.before_invoke is used, it will be a function
if instance:
await self._before_invoke(instance, ctx) # type: ignore
else:
await self._before_invoke(ctx) # type: ignore
# call the cog local hook if applicable:
if cog is not None:
hook = Cog._get_overridden_method(cog.cog_before_invoke)
if hook is not None:
await hook(ctx)
# call the bot global hook if necessary
hook = ctx.bot._before_invoke
if hook is not None:
await hook(ctx)
async def call_after_hooks(self, ctx: Context) -> None:
cog = self.cog
if self._after_invoke is not None:
instance = getattr(self._after_invoke, '__self__', cog)
if instance:
await self._after_invoke(instance, ctx) # type: ignore
else:
await self._after_invoke(ctx) # type: ignore
# call the cog local hook if applicable:
if cog is not None:
hook = Cog._get_overridden_method(cog.cog_after_invoke)
if hook is not None:
await hook(ctx)
hook = ctx.bot._after_invoke
if hook is not None:
await hook(ctx)
def _prepare_cooldowns(self, ctx: Context) -> None:
if self._buckets.valid:
dt = ctx.message.edited_at or ctx.message.created_at
current = dt.replace(tzinfo=datetime.timezone.utc).timestamp()
bucket = self._buckets.get_bucket(ctx.message, current)
if bucket is not None:
retry_after = bucket.update_rate_limit(current)
if retry_after:
raise CommandOnCooldown(bucket, retry_after, self._buckets.type) # type: ignore
async def prepare(self, ctx: Context) -> None:
ctx.command = self
if not await self.can_run(ctx):
raise CheckFailure(f'The check functions for command {self.qualified_name} failed.')
if self._max_concurrency is not None:
# For this application, context can be duck-typed as a Message
await self._max_concurrency.acquire(ctx) # type: ignore
try:
if self.cooldown_after_parsing:
await self._parse_arguments(ctx)
self._prepare_cooldowns(ctx)
else:
self._prepare_cooldowns(ctx)
await self._parse_arguments(ctx)
await self.call_before_hooks(ctx)
except:
if self._max_concurrency is not None:
await self._max_concurrency.release(ctx) # type: ignore
raise
def is_on_cooldown(self, ctx: Context) -> bool:
"""Checks whether the command is currently on cooldown.
Parameters
-----------
ctx: :class:`.Context`
The invocation context to use when checking the commands cooldown status.
Returns
--------
:class:`bool`
A boolean indicating if the command is on cooldown.
"""
if not self._buckets.valid:
return False
bucket = self._buckets.get_bucket(ctx.message)
dt = ctx.message.edited_at or ctx.message.created_at
current = dt.replace(tzinfo=datetime.timezone.utc).timestamp()
return bucket.get_tokens(current) == 0
def reset_cooldown(self, ctx: Context) -> None:
"""Resets the cooldown on this command.
Parameters
-----------
ctx: :class:`.Context`
The invocation context to reset the cooldown under.
"""
if self._buckets.valid:
bucket = self._buckets.get_bucket(ctx.message)
bucket.reset()
def get_cooldown_retry_after(self, ctx: Context) -> float:
"""Retrieves the amount of seconds before this command can be tried again.
.. versionadded:: 1.4
Parameters
-----------
ctx: :class:`.Context`
The invocation context to retrieve the cooldown from.
Returns
--------
:class:`float`
The amount of time left on this command's cooldown in seconds.
If this is ``0.0`` then the command isn't on cooldown.
"""
if self._buckets.valid:
bucket = self._buckets.get_bucket(ctx.message)
dt = ctx.message.edited_at or ctx.message.created_at
current = dt.replace(tzinfo=datetime.timezone.utc).timestamp()
return bucket.get_retry_after(current)
return 0.0
async def invoke(self, ctx: Context) -> None:
await self.prepare(ctx)
# terminate the invoked_subcommand chain.
# since we're in a regular command (and not a group) then
# the invoked subcommand is None.
ctx.invoked_subcommand = None
ctx.subcommand_passed = None
injected = hooked_wrapped_callback(self, ctx, self.callback)
await injected(*ctx.args, **ctx.kwargs)
async def reinvoke(self, ctx: Context, *, call_hooks: bool = False) -> None:
ctx.command = self
await self._parse_arguments(ctx)
if call_hooks:
await self.call_before_hooks(ctx)
ctx.invoked_subcommand = None
try:
await self.callback(*ctx.args, **ctx.kwargs) # type: ignore
except:
ctx.command_failed = True
raise
finally:
if call_hooks:
await self.call_after_hooks(ctx)
def error(self, coro: ErrorT) -> ErrorT:
"""A decorator that registers a coroutine as a local error handler.
A local error handler is an :func:`.on_command_error` event limited to
a single command. However, the :func:`.on_command_error` is still
invoked afterwards as the catch-all.
Parameters
-----------
coro: :ref:`coroutine <coroutine>`
The coroutine to register as the local error handler.
Raises
-------
TypeError
The coroutine passed is not actually a coroutine.
"""
if not asyncio.iscoroutinefunction(coro):
raise TypeError('The error handler must be a coroutine.')
self.on_error: Error = coro
return coro
def has_error_handler(self) -> bool:
""":class:`bool`: Checks whether the command has an error handler registered.
.. versionadded:: 1.7
"""
return hasattr(self, 'on_error')
def before_invoke(self, coro: HookT) -> HookT:
"""A decorator that registers a coroutine as a pre-invoke hook.
A pre-invoke hook is called directly before the command is
called. This makes it a useful function to set up database
connections or any type of set up required.
This pre-invoke hook takes a sole parameter, a :class:`.Context`.
See :meth:`.Bot.before_invoke` for more info.
Parameters
-----------
coro: :ref:`coroutine <coroutine>`
The coroutine to register as the pre-invoke hook.
Raises
-------
TypeError
The coroutine passed is not actually a coroutine.
"""
if not asyncio.iscoroutinefunction(coro):
raise TypeError('The pre-invoke hook must be a coroutine.')
self._before_invoke = coro
return coro
def after_invoke(self, coro: HookT) -> HookT:
"""A decorator that registers a coroutine as a post-invoke hook.
A post-invoke hook is called directly after the command is
called. This makes it a useful function to clean-up database
connections or any type of clean up required.
This post-invoke hook takes a sole parameter, a :class:`.Context`.
See :meth:`.Bot.after_invoke` for more info.
Parameters
-----------
coro: :ref:`coroutine <coroutine>`
The coroutine to register as the post-invoke hook.
Raises
-------
TypeError
The coroutine passed is not actually a coroutine.
"""
if not asyncio.iscoroutinefunction(coro):
raise TypeError('The post-invoke hook must be a coroutine.')
self._after_invoke = coro
return coro
@property
def cog_name(self) -> Optional[str]:
"""Optional[:class:`str`]: The name of the cog this command belongs to, if any."""
return type(self.cog).__cog_name__ if self.cog is not None else None
@property
def short_doc(self) -> str:
""":class:`str`: Gets the "short" documentation of a command.
By default, this is the :attr:`.brief` attribute.
If that lookup leads to an empty string then the first line of the
:attr:`.help` attribute is used instead.
"""
if self.brief is not None:
return self.brief
if self.help is not None:
return self.help.split('\n', 1)[0]
return ''
def _is_typing_optional(self, annotation: Union[T, Optional[T]]) -> TypeGuard[Optional[T]]:
return getattr(annotation, '__origin__', None) is Union and type(None) in annotation.__args__ # type: ignore
@property
def signature(self) -> str:
""":class:`str`: Returns a POSIX-like signature useful for help command output."""
if self.usage is not None:
return self.usage
params = self.clean_params
if not params:
return ''
result = []
for name, param in params.items():
greedy = isinstance(param.annotation, Greedy)
optional = False # postpone evaluation of if it's an optional argument
# for typing.Literal[...], typing.Optional[typing.Literal[...]], and Greedy[typing.Literal[...]], the
# parameter signature is a literal list of it's values
annotation = param.annotation.converter if greedy else param.annotation
origin = getattr(annotation, '__origin__', None)
if not greedy and origin is Union:
none_cls = type(None)
union_args = annotation.__args__
optional = union_args[-1] is none_cls
if len(union_args) == 2 and optional:
annotation = union_args[0]
origin = getattr(annotation, '__origin__', None)
if origin is Literal:
name = '|'.join(f'"{v}"' if isinstance(v, str) else str(v) for v in annotation.__args__)
if param.default is not param.empty:
# We don't want None or '' to trigger the [name=value] case and instead it should
# do [name] since [name=None] or [name=] are not exactly useful for the user.
should_print = param.default if isinstance(param.default, str) else param.default is not None
if should_print:
result.append(f'[{name}={param.default}]' if not greedy else
f'[{name}={param.default}]...')
continue
else:
result.append(f'[{name}]')
elif param.kind == param.VAR_POSITIONAL:
if self.require_var_positional:
result.append(f'<{name}...>')
else:
result.append(f'[{name}...]')
elif greedy:
result.append(f'[{name}]...')
elif optional:
result.append(f'[{name}]')
else:
result.append(f'<{name}>')
return ' '.join(result)
async def can_run(self, ctx: Context) -> bool:
"""|coro|
Checks if the command can be executed by checking all the predicates
inside the :attr:`~Command.checks` attribute. This also checks whether the
command is disabled.
.. versionchanged:: 1.3
Checks whether the command is disabled or not
Parameters
-----------
ctx: :class:`.Context`
The ctx of the command currently being invoked.
Raises
-------
:class:`CommandError`
Any command error that was raised during a check call will be propagated
by this function.
Returns
--------
:class:`bool`
A boolean indicating if the command can be invoked.
"""
if not self.enabled:
raise DisabledCommand(f'{self.name} command is disabled')
original = ctx.command
ctx.command = self
try:
if not await ctx.bot.can_run(ctx):
raise CheckFailure(f'The global check functions for command {self.qualified_name} failed.')
cog = self.cog
if cog is not None:
local_check = Cog._get_overridden_method(cog.cog_check)
if local_check is not None:
ret = await discord.utils.maybe_coroutine(local_check, ctx)
if not ret:
return False
predicates = self.checks
if not predicates:
# since we have no checks, then we just return True.
return True
return await discord.utils.async_all(predicate(ctx) for predicate in predicates) # type: ignore
finally:
ctx.command = original
class GroupMixin(Generic[CogT]):
"""A mixin that implements common functionality for classes that behave
similar to :class:`.Group` and are allowed to register commands.
Attributes
-----------
all_commands: :class:`dict`
A mapping of command name to :class:`.Command`
objects.
case_insensitive: :class:`bool`
Whether the commands should be case insensitive. Defaults to ``False``.
"""
def __init__(self, *args: Any, **kwargs: Any) -> None:
case_insensitive = kwargs.get('case_insensitive', False)
self.all_commands: Dict[str, Command[CogT, Any, Any]] = _CaseInsensitiveDict() if case_insensitive else {}
self.case_insensitive: bool = case_insensitive
super().__init__(*args, **kwargs)
@property
def commands(self) -> Set[Command[CogT, Any, Any]]:
"""Set[:class:`.Command`]: A unique set of commands without aliases that are registered."""
return set(self.all_commands.values())
def recursively_remove_all_commands(self) -> None:
for command in self.all_commands.copy().values():
if isinstance(command, GroupMixin):
command.recursively_remove_all_commands()
self.remove_command(command.name)
def add_command(self, command: Command[CogT, Any, Any]) -> None:
"""Adds a :class:`.Command` into the internal list of commands.
This is usually not called, instead the :meth:`~.GroupMixin.command` or
:meth:`~.GroupMixin.group` shortcut decorators are used instead.
.. versionchanged:: 1.4
Raise :exc:`.CommandRegistrationError` instead of generic :exc:`.ClientException`
Parameters
-----------
command: :class:`Command`
The command to add.
Raises
-------
:exc:`.CommandRegistrationError`
If the command or its alias is already registered by different command.
TypeError
If the command passed is not a subclass of :class:`.Command`.
"""
if not isinstance(command, Command):
raise TypeError('The command passed must be a subclass of Command')
if isinstance(self, Command):
command.parent = self
if command.name in self.all_commands:
raise CommandRegistrationError(command.name)
self.all_commands[command.name] = command
for alias in command.aliases:
if alias in self.all_commands:
self.remove_command(command.name)
raise CommandRegistrationError(alias, alias_conflict=True)
self.all_commands[alias] = command
def remove_command(self, name: str) -> Optional[Command[CogT, Any, Any]]:
"""Remove a :class:`.Command` from the internal list
of commands.
This could also be used as a way to remove aliases.
Parameters
-----------
name: :class:`str`
The name of the command to remove.
Returns
--------
Optional[:class:`.Command`]
The command that was removed. If the name is not valid then
``None`` is returned instead.
"""
command = self.all_commands.pop(name, None)
# does not exist
if command is None:
return None
if name in command.aliases:
# we're removing an alias so we don't want to remove the rest
return command
# we're not removing the alias so let's delete the rest of them.
for alias in command.aliases:
cmd = self.all_commands.pop(alias, None)
# in the case of a CommandRegistrationError, an alias might conflict
# with an already existing command. If this is the case, we want to
# make sure the pre-existing command is not removed.
if cmd is not None and cmd != command:
self.all_commands[alias] = cmd
return command
def walk_commands(self) -> Generator[Command[CogT, Any, Any], None, None]:
"""An iterator that recursively walks through all commands and subcommands.
.. versionchanged:: 1.4
Duplicates due to aliases are no longer returned
Yields
------
Union[:class:`.Command`, :class:`.Group`]
A command or group from the internal list of commands.
"""
for command in self.commands:
yield command
if isinstance(command, GroupMixin):
yield from command.walk_commands()
def get_command(self, name: str) -> Optional[Command[CogT, Any, Any]]:
"""Get a :class:`.Command` from the internal list
of commands.
This could also be used as a way to get aliases.
The name could be fully qualified (e.g. ``'foo bar'``) will get
the subcommand ``bar`` of the group command ``foo``. If a
subcommand is not found then ``None`` is returned just as usual.
Parameters
-----------
name: :class:`str`
The name of the command to get.
Returns
--------
Optional[:class:`Command`]
The command that was requested. If not found, returns ``None``.
"""
# fast path, no space in name.
if ' ' not in name:
return self.all_commands.get(name)
names = name.split()
if not names:
return None
obj = self.all_commands.get(names[0])
if not isinstance(obj, GroupMixin):
return obj
for name in names[1:]:
try:
obj = obj.all_commands[name] # type: ignore
except (AttributeError, KeyError):
return None
return obj
@overload
def command(
self,
name: str = ...,
cls: Type[Command[CogT, P, T]] = ...,
*args: Any,
**kwargs: Any,
) -> Callable[
[
Union[
Callable[Concatenate[CogT, ContextT, P], Coro[T]],
Callable[Concatenate[ContextT, P], Coro[T]],
]
], Command[CogT, P, T]]:
...
@overload
def command(
self,
name: str = ...,
cls: Type[CommandT] = ...,
*args: Any,
**kwargs: Any,
) -> Callable[[Callable[Concatenate[ContextT, P], Coro[Any]]], CommandT]:
...
def command(
self,
name: str = MISSING,
cls: Type[CommandT] = MISSING,
*args: Any,
**kwargs: Any,
) -> Callable[[Callable[Concatenate[ContextT, P], Coro[Any]]], CommandT]:
"""A shortcut decorator that invokes :func:`.command` and adds it to
the internal command list via :meth:`~.GroupMixin.add_command`.
Returns
--------
Callable[..., :class:`Command`]
A decorator that converts the provided method into a Command, adds it to the bot, then returns it.
"""
def decorator(func: Callable[Concatenate[ContextT, P], Coro[Any]]) -> CommandT:
kwargs.setdefault('parent', self)
result = command(name=name, cls=cls, *args, **kwargs)(func)
self.add_command(result)
return result
return decorator
@overload
def group(
self,
name: str = ...,
cls: Type[Group[CogT, P, T]] = ...,
*args: Any,
**kwargs: Any,
) -> Callable[[
Union[
Callable[Concatenate[CogT, ContextT, P], Coro[T]],
Callable[Concatenate[ContextT, P], Coro[T]]
]
], Group[CogT, P, T]]:
...
@overload
def group(
self,
name: str = ...,
cls: Type[GroupT] = ...,
*args: Any,
**kwargs: Any,
) -> Callable[[Callable[Concatenate[ContextT, P], Coro[Any]]], GroupT]:
...
def group(
self,
name: str = MISSING,
cls: Type[GroupT] = MISSING,
*args: Any,
**kwargs: Any,
) -> Callable[[Callable[Concatenate[ContextT, P], Coro[Any]]], GroupT]:
"""A shortcut decorator that invokes :func:`.group` and adds it to
the internal command list via :meth:`~.GroupMixin.add_command`.
Returns
--------
Callable[..., :class:`Group`]
A decorator that converts the provided method into a Group, adds it to the bot, then returns it.
"""
def decorator(func: Callable[Concatenate[ContextT, P], Coro[Any]]) -> GroupT:
kwargs.setdefault('parent', self)
result = group(name=name, cls=cls, *args, **kwargs)(func)
self.add_command(result)
return result
return decorator
class Group(GroupMixin[CogT], Command[CogT, P, T]):
"""A class that implements a grouping protocol for commands to be
executed as subcommands.
This class is a subclass of :class:`.Command` and thus all options
valid in :class:`.Command` are valid in here as well.
Attributes
-----------
invoke_without_command: :class:`bool`
Indicates if the group callback should begin parsing and
invocation only if no subcommand was found. Useful for
making it an error handling function to tell the user that
no subcommand was found or to have different functionality
in case no subcommand was found. If this is ``False``, then
the group callback will always be invoked first. This means
that the checks and the parsing dictated by its parameters
will be executed. Defaults to ``False``.
case_insensitive: :class:`bool`
Indicates if the group's commands should be case insensitive.
Defaults to ``False``.
"""
def __init__(self, *args: Any, **attrs: Any) -> None:
self.invoke_without_command: bool = attrs.pop('invoke_without_command', False)
super().__init__(*args, **attrs)
def copy(self: GroupT) -> GroupT:
"""Creates a copy of this :class:`Group`.
Returns
--------
:class:`Group`
A new instance of this group.
"""
ret = super().copy()
for cmd in self.commands:
ret.add_command(cmd.copy())
return ret # type: ignore
async def invoke(self, ctx: Context) -> None:
ctx.invoked_subcommand = None
ctx.subcommand_passed = None
early_invoke = not self.invoke_without_command
if early_invoke:
await self.prepare(ctx)
view = ctx.view
previous = view.index
view.skip_ws()
trigger = view.get_word()
if trigger:
ctx.subcommand_passed = trigger
ctx.invoked_subcommand = self.all_commands.get(trigger, None)
if early_invoke:
injected = hooked_wrapped_callback(self, ctx, self.callback)
await injected(*ctx.args, **ctx.kwargs)
ctx.invoked_parents.append(ctx.invoked_with) # type: ignore
if trigger and ctx.invoked_subcommand:
ctx.invoked_with = trigger
await ctx.invoked_subcommand.invoke(ctx)
elif not early_invoke:
# undo the trigger parsing
view.index = previous
view.previous = previous
await super().invoke(ctx)
async def reinvoke(self, ctx: Context, *, call_hooks: bool = False) -> None:
ctx.invoked_subcommand = None
early_invoke = not self.invoke_without_command
if early_invoke:
ctx.command = self
await self._parse_arguments(ctx)
if call_hooks:
await self.call_before_hooks(ctx)
view = ctx.view
previous = view.index
view.skip_ws()
trigger = view.get_word()
if trigger:
ctx.subcommand_passed = trigger
ctx.invoked_subcommand = self.all_commands.get(trigger, None)
if early_invoke:
try:
await self.callback(*ctx.args, **ctx.kwargs) # type: ignore
except:
ctx.command_failed = True
raise
finally:
if call_hooks:
await self.call_after_hooks(ctx)
ctx.invoked_parents.append(ctx.invoked_with) # type: ignore
if trigger and ctx.invoked_subcommand:
ctx.invoked_with = trigger
await ctx.invoked_subcommand.reinvoke(ctx, call_hooks=call_hooks)
elif not early_invoke:
# undo the trigger parsing
view.index = previous
view.previous = previous
await super().reinvoke(ctx, call_hooks=call_hooks)
# Decorators
@overload
def command(
name: str = ...,
cls: Type[Command[CogT, P, T]] = ...,
**attrs: Any,
) -> Callable[
[
Union[
Callable[Concatenate[CogT, ContextT, P], Coro[T]],
Callable[Concatenate[ContextT, P], Coro[T]],
]
]
, Command[CogT, P, T]]:
...
@overload
def command(
name: str = ...,
cls: Type[CommandT] = ...,
**attrs: Any,
) -> Callable[
[
Union[
Callable[Concatenate[CogT, ContextT, P], Coro[Any]],
Callable[Concatenate[ContextT, P], Coro[Any]],
]
]
, CommandT]:
...
def command(
name: str = MISSING,
cls: Type[CommandT] = MISSING,
**attrs: Any
) -> Callable[
[
Union[
Callable[Concatenate[ContextT, P], Coro[Any]],
Callable[Concatenate[CogT, ContextT, P], Coro[T]],
]
]
, Union[Command[CogT, P, T], CommandT]]:
"""A decorator that transforms a function into a :class:`.Command`
or if called with :func:`.group`, :class:`.Group`.
By default the ``help`` attribute is received automatically from the
docstring of the function and is cleaned up with the use of
``inspect.cleandoc``. If the docstring is ``bytes``, then it is decoded
into :class:`str` using utf-8 encoding.
All checks added using the :func:`.check` & co. decorators are added into
the function. There is no way to supply your own checks through this
decorator.
Parameters
-----------
name: :class:`str`
The name to create the command with. By default this uses the
function name unchanged.
cls
The class to construct with. By default this is :class:`.Command`.
You usually do not change this.
attrs
Keyword arguments to pass into the construction of the class denoted
by ``cls``.
Raises
-------
TypeError
If the function is not a coroutine or is already a command.
"""
if cls is MISSING:
cls = Command # type: ignore
def decorator(func: Union[
Callable[Concatenate[ContextT, P], Coro[Any]],
Callable[Concatenate[CogT, ContextT, P], Coro[Any]],
]) -> CommandT:
if isinstance(func, Command):
raise TypeError('Callback is already a command.')
return cls(func, name=name, **attrs)
return decorator
@overload
def group(
name: str = ...,
cls: Type[Group[CogT, P, T]] = ...,
**attrs: Any,
) -> Callable[
[
Union[
Callable[Concatenate[CogT, ContextT, P], Coro[T]],
Callable[Concatenate[ContextT, P], Coro[T]],
]
]
, Group[CogT, P, T]]:
...
@overload
def group(
name: str = ...,
cls: Type[GroupT] = ...,
**attrs: Any,
) -> Callable[
[
Union[
Callable[Concatenate[CogT, ContextT, P], Coro[Any]],
Callable[Concatenate[ContextT, P], Coro[Any]],
]
]
, GroupT]:
...
def group(
name: str = MISSING,
cls: Type[GroupT] = MISSING,
**attrs: Any,
) -> Callable[
[
Union[
Callable[Concatenate[ContextT, P], Coro[Any]],
Callable[Concatenate[CogT, ContextT, P], Coro[T]],
]
]
, Union[Group[CogT, P, T], GroupT]]:
"""A decorator that transforms a function into a :class:`.Group`.
This is similar to the :func:`.command` decorator but the ``cls``
parameter is set to :class:`Group` by default.
.. versionchanged:: 1.1
The ``cls`` parameter can now be passed.
"""
if cls is MISSING:
cls = Group # type: ignore
return command(name=name, cls=cls, **attrs) # type: ignore
def check(predicate: Check) -> Callable[[T], T]:
r"""A decorator that adds a check to the :class:`.Command` or its
subclasses. These checks could be accessed via :attr:`.Command.checks`.
These checks should be predicates that take in a single parameter taking
a :class:`.Context`. If the check returns a ``False``\-like value then
during invocation a :exc:`.CheckFailure` exception is raised and sent to
the :func:`.on_command_error` event.
If an exception should be thrown in the predicate then it should be a
subclass of :exc:`.CommandError`. Any exception not subclassed from it
will be propagated while those subclassed will be sent to
:func:`.on_command_error`.
A special attribute named ``predicate`` is bound to the value
returned by this decorator to retrieve the predicate passed to the
decorator. This allows the following introspection and chaining to be done:
.. code-block:: python3
def owner_or_permissions(**perms):
original = commands.has_permissions(**perms).predicate
async def extended_check(ctx):
if ctx.guild is None:
return False
return ctx.guild.owner_id == ctx.author.id or await original(ctx)
return commands.check(extended_check)
.. note::
The function returned by ``predicate`` is **always** a coroutine,
even if the original function was not a coroutine.
.. versionchanged:: 1.3
The ``predicate`` attribute was added.
Examples
---------
Creating a basic check to see if the command invoker is you.
.. code-block:: python3
def check_if_it_is_me(ctx):
return ctx.message.author.id == 85309593344815104
@bot.command()
@commands.check(check_if_it_is_me)
async def only_for_me(ctx):
await ctx.send('I know you!')
Transforming common checks into its own decorator:
.. code-block:: python3
def is_me():
def predicate(ctx):
return ctx.message.author.id == 85309593344815104
return commands.check(predicate)
@bot.command()
@is_me()
async def only_me(ctx):
await ctx.send('Only you!')
Parameters
-----------
predicate: Callable[[:class:`Context`], :class:`bool`]
The predicate to check if the command should be invoked.
"""
def decorator(func: Union[Command, CoroFunc]) -> Union[Command, CoroFunc]:
if isinstance(func, Command):
func.checks.append(predicate)
else:
if not hasattr(func, '__commands_checks__'):
func.__commands_checks__ = []
func.__commands_checks__.append(predicate)
return func
if inspect.iscoroutinefunction(predicate):
decorator.predicate = predicate
else:
@functools.wraps(predicate)
async def wrapper(ctx):
return predicate(ctx) # type: ignore
decorator.predicate = wrapper
return decorator # type: ignore
def check_any(*checks: Check) -> Callable[[T], T]:
r"""A :func:`check` that is added that checks if any of the checks passed
will pass, i.e. using logical OR.
If all checks fail then :exc:`.CheckAnyFailure` is raised to signal the failure.
It inherits from :exc:`.CheckFailure`.
.. note::
The ``predicate`` attribute for this function **is** a coroutine.
.. versionadded:: 1.3
Parameters
------------
\*checks: Callable[[:class:`Context`], :class:`bool`]
An argument list of checks that have been decorated with
the :func:`check` decorator.
Raises
-------
TypeError
A check passed has not been decorated with the :func:`check`
decorator.
Examples
---------
Creating a basic check to see if it's the bot owner or
the server owner:
.. code-block:: python3
def is_guild_owner():
def predicate(ctx):
return ctx.guild is not None and ctx.guild.owner_id == ctx.author.id
return commands.check(predicate)
@bot.command()
@commands.check_any(commands.is_owner(), is_guild_owner())
async def only_for_owners(ctx):
await ctx.send('Hello mister owner!')
"""
unwrapped = []
for wrapped in checks:
try:
pred = wrapped.predicate
except AttributeError:
raise TypeError(f'{wrapped!r} must be wrapped by commands.check decorator') from None
else:
unwrapped.append(pred)
async def predicate(ctx: Context) -> bool:
errors = []
for func in unwrapped:
try:
value = await func(ctx)
except CheckFailure as e:
errors.append(e)
else:
if value:
return True
# if we're here, all checks failed
raise CheckAnyFailure(unwrapped, errors)
return check(predicate)
def has_role(item: Union[int, str]) -> Callable[[T], T]:
"""A :func:`.check` that is added that checks if the member invoking the
command has the role specified via the name or ID specified.
If a string is specified, you must give the exact name of the role, including
caps and spelling.
If an integer is specified, you must give the exact snowflake ID of the role.
If the message is invoked in a private message context then the check will
return ``False``.
This check raises one of two special exceptions, :exc:`.MissingRole` if the user
is missing a role, or :exc:`.NoPrivateMessage` if it is used in a private message.
Both inherit from :exc:`.CheckFailure`.
.. versionchanged:: 1.1
Raise :exc:`.MissingRole` or :exc:`.NoPrivateMessage`
instead of generic :exc:`.CheckFailure`
Parameters
-----------
item: Union[:class:`int`, :class:`str`]
The name or ID of the role to check.
"""
def predicate(ctx: Context) -> bool:
if ctx.guild is None:
raise NoPrivateMessage()
# ctx.guild is None doesn't narrow ctx.author to Member
if isinstance(item, int):
role = discord.utils.get(ctx.author.roles, id=item) # type: ignore
else:
role = discord.utils.get(ctx.author.roles, name=item) # type: ignore
if role is None:
raise MissingRole(item)
return True
return check(predicate)
def has_any_role(*items: Union[int, str]) -> Callable[[T], T]:
r"""A :func:`.check` that is added that checks if the member invoking the
command has **any** of the roles specified. This means that if they have
one out of the three roles specified, then this check will return `True`.
Similar to :func:`.has_role`\, the names or IDs passed in must be exact.
This check raises one of two special exceptions, :exc:`.MissingAnyRole` if the user
is missing all roles, or :exc:`.NoPrivateMessage` if it is used in a private message.
Both inherit from :exc:`.CheckFailure`.
.. versionchanged:: 1.1
Raise :exc:`.MissingAnyRole` or :exc:`.NoPrivateMessage`
instead of generic :exc:`.CheckFailure`
Parameters
-----------
items: List[Union[:class:`str`, :class:`int`]]
An argument list of names or IDs to check that the member has roles wise.
Example
--------
.. code-block:: python3
@bot.command()
@commands.has_any_role('Library Devs', 'Moderators', 492212595072434186)
async def cool(ctx):
await ctx.send('You are cool indeed')
"""
def predicate(ctx):
if ctx.guild is None:
raise NoPrivateMessage()
# ctx.guild is None doesn't narrow ctx.author to Member
getter = functools.partial(discord.utils.get, ctx.author.roles) # type: ignore
if any(getter(id=item) is not None if isinstance(item, int) else getter(name=item) is not None for item in items):
return True
raise MissingAnyRole(list(items))
return check(predicate)
def bot_has_role(item: int) -> Callable[[T], T]:
"""Similar to :func:`.has_role` except checks if the bot itself has the
role.
This check raises one of two special exceptions, :exc:`.BotMissingRole` if the bot
is missing the role, or :exc:`.NoPrivateMessage` if it is used in a private message.
Both inherit from :exc:`.CheckFailure`.
.. versionchanged:: 1.1
Raise :exc:`.BotMissingRole` or :exc:`.NoPrivateMessage`
instead of generic :exc:`.CheckFailure`
"""
def predicate(ctx):
if ctx.guild is None:
raise NoPrivateMessage()
me = ctx.me
if isinstance(item, int):
role = discord.utils.get(me.roles, id=item)
else:
role = discord.utils.get(me.roles, name=item)
if role is None:
raise BotMissingRole(item)
return True
return check(predicate)
def bot_has_any_role(*items: int) -> Callable[[T], T]:
"""Similar to :func:`.has_any_role` except checks if the bot itself has
any of the roles listed.
This check raises one of two special exceptions, :exc:`.BotMissingAnyRole` if the bot
is missing all roles, or :exc:`.NoPrivateMessage` if it is used in a private message.
Both inherit from :exc:`.CheckFailure`.
.. versionchanged:: 1.1
Raise :exc:`.BotMissingAnyRole` or :exc:`.NoPrivateMessage`
instead of generic checkfailure
"""
def predicate(ctx):
if ctx.guild is None:
raise NoPrivateMessage()
me = ctx.me
getter = functools.partial(discord.utils.get, me.roles)
if any(getter(id=item) is not None if isinstance(item, int) else getter(name=item) is not None for item in items):
return True
raise BotMissingAnyRole(list(items))
return check(predicate)
def has_permissions(**perms: bool) -> Callable[[T], T]:
"""A :func:`.check` that is added that checks if the member has all of
the permissions necessary.
Note that this check operates on the current channel permissions, not the
guild wide permissions.
The permissions passed in must be exactly like the properties shown under
:class:`.discord.Permissions`.
This check raises a special exception, :exc:`.MissingPermissions`
that is inherited from :exc:`.CheckFailure`.
Parameters
------------
perms
An argument list of permissions to check for.
Example
---------
.. code-block:: python3
@bot.command()
@commands.has_permissions(manage_messages=True)
async def test(ctx):
await ctx.send('You can manage messages.')
"""
invalid = set(perms) - set(discord.Permissions.VALID_FLAGS)
if invalid:
raise TypeError(f"Invalid permission(s): {', '.join(invalid)}")
def predicate(ctx: Context) -> bool:
ch = ctx.channel
permissions = ch.permissions_for(ctx.author) # type: ignore
missing = [perm for perm, value in perms.items() if getattr(permissions, perm) != value]
if not missing:
return True
raise MissingPermissions(missing)
return check(predicate)
def bot_has_permissions(**perms: bool) -> Callable[[T], T]:
"""Similar to :func:`.has_permissions` except checks if the bot itself has
the permissions listed.
This check raises a special exception, :exc:`.BotMissingPermissions`
that is inherited from :exc:`.CheckFailure`.
"""
invalid = set(perms) - set(discord.Permissions.VALID_FLAGS)
if invalid:
raise TypeError(f"Invalid permission(s): {', '.join(invalid)}")
def predicate(ctx: Context) -> bool:
guild = ctx.guild
me = guild.me if guild is not None else ctx.bot.user
permissions = ctx.channel.permissions_for(me) # type: ignore
missing = [perm for perm, value in perms.items() if getattr(permissions, perm) != value]
if not missing:
return True
raise BotMissingPermissions(missing)
return check(predicate)
def has_guild_permissions(**perms: bool) -> Callable[[T], T]:
"""Similar to :func:`.has_permissions`, but operates on guild wide
permissions instead of the current channel permissions.
If this check is called in a DM context, it will raise an
exception, :exc:`.NoPrivateMessage`.
.. versionadded:: 1.3
"""
invalid = set(perms) - set(discord.Permissions.VALID_FLAGS)
if invalid:
raise TypeError(f"Invalid permission(s): {', '.join(invalid)}")
def predicate(ctx: Context) -> bool:
if not ctx.guild:
raise NoPrivateMessage
permissions = ctx.author.guild_permissions # type: ignore
missing = [perm for perm, value in perms.items() if getattr(permissions, perm) != value]
if not missing:
return True
raise MissingPermissions(missing)
return check(predicate)
def bot_has_guild_permissions(**perms: bool) -> Callable[[T], T]:
"""Similar to :func:`.has_guild_permissions`, but checks the bot
members guild permissions.
.. versionadded:: 1.3
"""
invalid = set(perms) - set(discord.Permissions.VALID_FLAGS)
if invalid:
raise TypeError(f"Invalid permission(s): {', '.join(invalid)}")
def predicate(ctx: Context) -> bool:
if not ctx.guild:
raise NoPrivateMessage
permissions = ctx.me.guild_permissions # type: ignore
missing = [perm for perm, value in perms.items() if getattr(permissions, perm) != value]
if not missing:
return True
raise BotMissingPermissions(missing)
return check(predicate)
def dm_only() -> Callable[[T], T]:
"""A :func:`.check` that indicates this command must only be used in a
DM context. Only private messages are allowed when
using the command.
This check raises a special exception, :exc:`.PrivateMessageOnly`
that is inherited from :exc:`.CheckFailure`.
.. versionadded:: 1.1
"""
def predicate(ctx: Context) -> bool:
if ctx.guild is not None:
raise PrivateMessageOnly()
return True
return check(predicate)
def guild_only() -> Callable[[T], T]:
"""A :func:`.check` that indicates this command must only be used in a
guild context only. Basically, no private messages are allowed when
using the command.
This check raises a special exception, :exc:`.NoPrivateMessage`
that is inherited from :exc:`.CheckFailure`.
"""
def predicate(ctx: Context) -> bool:
if ctx.guild is None:
raise NoPrivateMessage()
return True
return check(predicate)
def is_owner() -> Callable[[T], T]:
"""A :func:`.check` that checks if the person invoking this command is the
owner of the bot.
This is powered by :meth:`.Bot.is_owner`.
This check raises a special exception, :exc:`.NotOwner` that is derived
from :exc:`.CheckFailure`.
"""
async def predicate(ctx: Context) -> bool:
if not await ctx.bot.is_owner(ctx.author):
raise NotOwner('You do not own this bot.')
return True
return check(predicate)
def is_nsfw() -> Callable[[T], T]:
"""A :func:`.check` that checks if the channel is a NSFW channel.
This check raises a special exception, :exc:`.NSFWChannelRequired`
that is derived from :exc:`.CheckFailure`.
.. versionchanged:: 1.1
Raise :exc:`.NSFWChannelRequired` instead of generic :exc:`.CheckFailure`.
DM channels will also now pass this check.
"""
def pred(ctx: Context) -> bool:
ch = ctx.channel
if ctx.guild is None or (isinstance(ch, (discord.TextChannel, discord.Thread)) and ch.is_nsfw()):
return True
raise NSFWChannelRequired(ch) # type: ignore
return check(pred)
def cooldown(rate: int, per: float, type: Union[BucketType, Callable[[Message], Any]] = BucketType.default) -> Callable[[T], T]:
"""A decorator that adds a cooldown to a :class:`.Command`
A cooldown allows a command to only be used a specific amount
of times in a specific time frame. These cooldowns can be based
either on a per-guild, per-channel, per-user, per-role or global basis.
Denoted by the third argument of ``type`` which must be of enum
type :class:`.BucketType`.
If a cooldown is triggered, then :exc:`.CommandOnCooldown` is triggered in
:func:`.on_command_error` and the local error handler.
A command can only have a single cooldown.
Parameters
------------
rate: :class:`int`
The number of times a command can be used before triggering a cooldown.
per: :class:`float`
The amount of seconds to wait for a cooldown when it's been triggered.
type: Union[:class:`.BucketType`, Callable[[:class:`.Message`], Any]]
The type of cooldown to have. If callable, should return a key for the mapping.
.. versionchanged:: 1.7
Callables are now supported for custom bucket types.
"""
def decorator(func: Union[Command, CoroFunc]) -> Union[Command, CoroFunc]:
if isinstance(func, Command):
func._buckets = CooldownMapping(Cooldown(rate, per), type)
else:
func.__commands_cooldown__ = CooldownMapping(Cooldown(rate, per), type)
return func
return decorator # type: ignore
def dynamic_cooldown(cooldown: Union[BucketType, Callable[[Message], Any]], type: BucketType = BucketType.default) -> Callable[[T], T]:
"""A decorator that adds a dynamic cooldown to a :class:`.Command`
This differs from :func:`.cooldown` in that it takes a function that
accepts a single parameter of type :class:`.discord.Message` and must
return a :class:`.Cooldown` or ``None``. If ``None`` is returned then
that cooldown is effectively bypassed.
A cooldown allows a command to only be used a specific amount
of times in a specific time frame. These cooldowns can be based
either on a per-guild, per-channel, per-user, per-role or global basis.
Denoted by the third argument of ``type`` which must be of enum
type :class:`.BucketType`.
If a cooldown is triggered, then :exc:`.CommandOnCooldown` is triggered in
:func:`.on_command_error` and the local error handler.
A command can only have a single cooldown.
.. versionadded:: 2.0
Parameters
------------
cooldown: Callable[[:class:`.discord.Message`], Optional[:class:`.Cooldown`]]
A function that takes a message and returns a cooldown that will
apply to this invocation or ``None`` if the cooldown should be bypassed.
type: :class:`.BucketType`
The type of cooldown to have.
"""
if not callable(cooldown):
raise TypeError("A callable must be provided")
def decorator(func: Union[Command, CoroFunc]) -> Union[Command, CoroFunc]:
if isinstance(func, Command):
func._buckets = DynamicCooldownMapping(cooldown, type)
else:
func.__commands_cooldown__ = DynamicCooldownMapping(cooldown, type)
return func
return decorator # type: ignore
def max_concurrency(number: int, per: BucketType = BucketType.default, *, wait: bool = False) -> Callable[[T], T]:
"""A decorator that adds a maximum concurrency to a :class:`.Command` or its subclasses.
This enables you to only allow a certain number of command invocations at the same time,
for example if a command takes too long or if only one user can use it at a time. This
differs from a cooldown in that there is no set waiting period or token bucket -- only
a set number of people can run the command.
.. versionadded:: 1.3
Parameters
-------------
number: :class:`int`
The maximum number of invocations of this command that can be running at the same time.
per: :class:`.BucketType`
The bucket that this concurrency is based on, e.g. ``BucketType.guild`` would allow
it to be used up to ``number`` times per guild.
wait: :class:`bool`
Whether the command should wait for the queue to be over. If this is set to ``False``
then instead of waiting until the command can run again, the command raises
:exc:`.MaxConcurrencyReached` to its error handler. If this is set to ``True``
then the command waits until it can be executed.
"""
def decorator(func: Union[Command, CoroFunc]) -> Union[Command, CoroFunc]:
value = MaxConcurrency(number, per=per, wait=wait)
if isinstance(func, Command):
func._max_concurrency = value
else:
func.__commands_max_concurrency__ = value
return func
return decorator # type: ignore
def before_invoke(coro) -> Callable[[T], T]:
"""A decorator that registers a coroutine as a pre-invoke hook.
This allows you to refer to one before invoke hook for several commands that
do not have to be within the same cog.
.. versionadded:: 1.4
Example
---------
.. code-block:: python3
async def record_usage(ctx):
print(ctx.author, 'used', ctx.command, 'at', ctx.message.created_at)
@bot.command()
@commands.before_invoke(record_usage)
async def who(ctx): # Output: <User> used who at <Time>
await ctx.send('i am a bot')
class What(commands.Cog):
@commands.before_invoke(record_usage)
@commands.command()
async def when(self, ctx): # Output: <User> used when at <Time>
await ctx.send(f'and i have existed since {ctx.bot.user.created_at}')
@commands.command()
async def where(self, ctx): # Output: <Nothing>
await ctx.send('on Discord')
@commands.command()
async def why(self, ctx): # Output: <Nothing>
await ctx.send('because someone made me')
bot.add_cog(What())
"""
def decorator(func: Union[Command, CoroFunc]) -> Union[Command, CoroFunc]:
if isinstance(func, Command):
func.before_invoke(coro)
else:
func.__before_invoke__ = coro
return func
return decorator # type: ignore
def after_invoke(coro) -> Callable[[T], T]:
"""A decorator that registers a coroutine as a post-invoke hook.
This allows you to refer to one after invoke hook for several commands that
do not have to be within the same cog.
.. versionadded:: 1.4
"""
def decorator(func: Union[Command, CoroFunc]) -> Union[Command, CoroFunc]:
if isinstance(func, Command):
func.after_invoke(coro)
else:
func.__after_invoke__ = coro
return func
return decorator # type: ignore | zarenacord.py | /zarenacord.py-2.0.0-py3-none-any.whl/discord/ext/commands/core.py | core.py |
from __future__ import annotations
from typing import Any, Callable, Deque, Dict, Optional, Type, TypeVar, TYPE_CHECKING
from discord.enums import Enum
import time
import asyncio
from collections import deque
from ...abc import PrivateChannel
from .errors import MaxConcurrencyReached
if TYPE_CHECKING:
from ...message import Message
__all__ = (
'BucketType',
'Cooldown',
'CooldownMapping',
'DynamicCooldownMapping',
'MaxConcurrency',
)
C = TypeVar('C', bound='CooldownMapping')
MC = TypeVar('MC', bound='MaxConcurrency')
class BucketType(Enum):
default = 0
user = 1
guild = 2
channel = 3
member = 4
category = 5
role = 6
def get_key(self, msg: Message) -> Any:
if self is BucketType.user:
return msg.author.id
elif self is BucketType.guild:
return (msg.guild or msg.author).id
elif self is BucketType.channel:
return msg.channel.id
elif self is BucketType.member:
return ((msg.guild and msg.guild.id), msg.author.id)
elif self is BucketType.category:
return (msg.channel.category or msg.channel).id # type: ignore
elif self is BucketType.role:
# we return the channel id of a private-channel as there are only roles in guilds
# and that yields the same result as for a guild with only the @everyone role
# NOTE: PrivateChannel doesn't actually have an id attribute but we assume we are
# recieving a DMChannel or GroupChannel which inherit from PrivateChannel and do
return (msg.channel if isinstance(msg.channel, PrivateChannel) else msg.author.top_role).id # type: ignore
def __call__(self, msg: Message) -> Any:
return self.get_key(msg)
class Cooldown:
"""Represents a cooldown for a command.
Attributes
-----------
rate: :class:`int`
The total number of tokens available per :attr:`per` seconds.
per: :class:`float`
The length of the cooldown period in seconds.
"""
__slots__ = ('rate', 'per', '_window', '_tokens', '_last')
def __init__(self, rate: float, per: float) -> None:
self.rate: int = int(rate)
self.per: float = float(per)
self._window: float = 0.0
self._tokens: int = self.rate
self._last: float = 0.0
def get_tokens(self, current: Optional[float] = None) -> int:
"""Returns the number of available tokens before rate limiting is applied.
Parameters
------------
current: Optional[:class:`float`]
The time in seconds since Unix epoch to calculate tokens at.
If not supplied then :func:`time.time()` is used.
Returns
--------
:class:`int`
The number of tokens available before the cooldown is to be applied.
"""
if not current:
current = time.time()
tokens = self._tokens
if current > self._window + self.per:
tokens = self.rate
return tokens
def get_retry_after(self, current: Optional[float] = None) -> float:
"""Returns the time in seconds until the cooldown will be reset.
Parameters
-------------
current: Optional[:class:`float`]
The current time in seconds since Unix epoch.
If not supplied, then :func:`time.time()` is used.
Returns
-------
:class:`float`
The number of seconds to wait before this cooldown will be reset.
"""
current = current or time.time()
tokens = self.get_tokens(current)
if tokens == 0:
return self.per - (current - self._window)
return 0.0
def update_rate_limit(self, current: Optional[float] = None) -> Optional[float]:
"""Updates the cooldown rate limit.
Parameters
-------------
current: Optional[:class:`float`]
The time in seconds since Unix epoch to update the rate limit at.
If not supplied, then :func:`time.time()` is used.
Returns
-------
Optional[:class:`float`]
The retry-after time in seconds if rate limited.
"""
current = current or time.time()
self._last = current
self._tokens = self.get_tokens(current)
# first token used means that we start a new rate limit window
if self._tokens == self.rate:
self._window = current
# check if we are rate limited
if self._tokens == 0:
return self.per - (current - self._window)
# we're not so decrement our tokens
self._tokens -= 1
def reset(self) -> None:
"""Reset the cooldown to its initial state."""
self._tokens = self.rate
self._last = 0.0
def copy(self) -> Cooldown:
"""Creates a copy of this cooldown.
Returns
--------
:class:`Cooldown`
A new instance of this cooldown.
"""
return Cooldown(self.rate, self.per)
def __repr__(self) -> str:
return f'<Cooldown rate: {self.rate} per: {self.per} window: {self._window} tokens: {self._tokens}>'
class CooldownMapping:
def __init__(
self,
original: Optional[Cooldown],
type: Callable[[Message], Any],
) -> None:
if not callable(type):
raise TypeError('Cooldown type must be a BucketType or callable')
self._cache: Dict[Any, Cooldown] = {}
self._cooldown: Optional[Cooldown] = original
self._type: Callable[[Message], Any] = type
def copy(self) -> CooldownMapping:
ret = CooldownMapping(self._cooldown, self._type)
ret._cache = self._cache.copy()
return ret
@property
def valid(self) -> bool:
return self._cooldown is not None
@property
def type(self) -> Callable[[Message], Any]:
return self._type
@classmethod
def from_cooldown(cls: Type[C], rate, per, type) -> C:
return cls(Cooldown(rate, per), type)
def _bucket_key(self, msg: Message) -> Any:
return self._type(msg)
def _verify_cache_integrity(self, current: Optional[float] = None) -> None:
# we want to delete all cache objects that haven't been used
# in a cooldown window. e.g. if we have a command that has a
# cooldown of 60s and it has not been used in 60s then that key should be deleted
current = current or time.time()
dead_keys = [k for k, v in self._cache.items() if current > v._last + v.per]
for k in dead_keys:
del self._cache[k]
def create_bucket(self, message: Message) -> Cooldown:
return self._cooldown.copy() # type: ignore
def get_bucket(self, message: Message, current: Optional[float] = None) -> Cooldown:
if self._type is BucketType.default:
return self._cooldown # type: ignore
self._verify_cache_integrity(current)
key = self._bucket_key(message)
if key not in self._cache:
bucket = self.create_bucket(message)
if bucket is not None:
self._cache[key] = bucket
else:
bucket = self._cache[key]
return bucket
def update_rate_limit(self, message: Message, current: Optional[float] = None) -> Optional[float]:
bucket = self.get_bucket(message, current)
return bucket.update_rate_limit(current)
class DynamicCooldownMapping(CooldownMapping):
def __init__(
self,
factory: Callable[[Message], Cooldown],
type: Callable[[Message], Any]
) -> None:
super().__init__(None, type)
self._factory: Callable[[Message], Cooldown] = factory
def copy(self) -> DynamicCooldownMapping:
ret = DynamicCooldownMapping(self._factory, self._type)
ret._cache = self._cache.copy()
return ret
@property
def valid(self) -> bool:
return True
def create_bucket(self, message: Message) -> Cooldown:
return self._factory(message)
class _Semaphore:
"""This class is a version of a semaphore.
If you're wondering why asyncio.Semaphore isn't being used,
it's because it doesn't expose the internal value. This internal
value is necessary because I need to support both `wait=True` and
`wait=False`.
An asyncio.Queue could have been used to do this as well -- but it is
not as inefficient since internally that uses two queues and is a bit
overkill for what is basically a counter.
"""
__slots__ = ('value', 'loop', '_waiters')
def __init__(self, number: int) -> None:
self.value: int = number
self.loop: asyncio.AbstractEventLoop = asyncio.get_event_loop()
self._waiters: Deque[asyncio.Future] = deque()
def __repr__(self) -> str:
return f'<_Semaphore value={self.value} waiters={len(self._waiters)}>'
def locked(self) -> bool:
return self.value == 0
def is_active(self) -> bool:
return len(self._waiters) > 0
def wake_up(self) -> None:
while self._waiters:
future = self._waiters.popleft()
if not future.done():
future.set_result(None)
return
async def acquire(self, *, wait: bool = False) -> bool:
if not wait and self.value <= 0:
# signal that we're not acquiring
return False
while self.value <= 0:
future = self.loop.create_future()
self._waiters.append(future)
try:
await future
except:
future.cancel()
if self.value > 0 and not future.cancelled():
self.wake_up()
raise
self.value -= 1
return True
def release(self) -> None:
self.value += 1
self.wake_up()
class MaxConcurrency:
__slots__ = ('number', 'per', 'wait', '_mapping')
def __init__(self, number: int, *, per: BucketType, wait: bool) -> None:
self._mapping: Dict[Any, _Semaphore] = {}
self.per: BucketType = per
self.number: int = number
self.wait: bool = wait
if number <= 0:
raise ValueError('max_concurrency \'number\' cannot be less than 1')
if not isinstance(per, BucketType):
raise TypeError(f'max_concurrency \'per\' must be of type BucketType not {type(per)!r}')
def copy(self: MC) -> MC:
return self.__class__(self.number, per=self.per, wait=self.wait)
def __repr__(self) -> str:
return f'<MaxConcurrency per={self.per!r} number={self.number} wait={self.wait}>'
def get_key(self, message: Message) -> Any:
return self.per.get_key(message)
async def acquire(self, message: Message) -> None:
key = self.get_key(message)
try:
sem = self._mapping[key]
except KeyError:
self._mapping[key] = sem = _Semaphore(self.number)
acquired = await sem.acquire(wait=self.wait)
if not acquired:
raise MaxConcurrencyReached(self.number, self.per)
async def release(self, message: Message) -> None:
# Technically there's no reason for this function to be async
# But it might be more useful in the future
key = self.get_key(message)
try:
sem = self._mapping[key]
except KeyError:
# ...? peculiar
return
else:
sem.release()
if sem.value >= self.number and not sem.is_active():
del self._mapping[key] | zarenacord.py | /zarenacord.py-2.0.0-py3-none-any.whl/discord/ext/commands/cooldowns.py | cooldowns.py |
from __future__ import annotations
from typing import Optional, Any, TYPE_CHECKING, List, Callable, Type, Tuple, Union
from discord.errors import ClientException, DiscordException
if TYPE_CHECKING:
from inspect import Parameter
from .converter import Converter
from .context import Context
from .cooldowns import Cooldown, BucketType
from .flags import Flag
from discord.abc import GuildChannel
from discord.threads import Thread
from discord.types.snowflake import Snowflake, SnowflakeList
__all__ = (
'CommandError',
'MissingRequiredArgument',
'BadArgument',
'PrivateMessageOnly',
'NoPrivateMessage',
'CheckFailure',
'CheckAnyFailure',
'CommandNotFound',
'DisabledCommand',
'CommandInvokeError',
'TooManyArguments',
'UserInputError',
'CommandOnCooldown',
'MaxConcurrencyReached',
'NotOwner',
'MessageNotFound',
'ObjectNotFound',
'MemberNotFound',
'GuildNotFound',
'UserNotFound',
'ChannelNotFound',
'ThreadNotFound',
'ChannelNotReadable',
'BadColourArgument',
'BadColorArgument',
'RoleNotFound',
'BadInviteArgument',
'EmojiNotFound',
'GuildStickerNotFound',
'PartialEmojiConversionFailure',
'BadBoolArgument',
'MissingRole',
'BotMissingRole',
'MissingAnyRole',
'BotMissingAnyRole',
'MissingPermissions',
'BotMissingPermissions',
'NSFWChannelRequired',
'ConversionError',
'BadUnionArgument',
'BadLiteralArgument',
'ArgumentParsingError',
'UnexpectedQuoteError',
'InvalidEndOfQuotedStringError',
'ExpectedClosingQuoteError',
'ExtensionError',
'ExtensionAlreadyLoaded',
'ExtensionNotLoaded',
'NoEntryPointError',
'ExtensionFailed',
'ExtensionNotFound',
'CommandRegistrationError',
'FlagError',
'BadFlagArgument',
'MissingFlagArgument',
'TooManyFlags',
'MissingRequiredFlag',
)
class CommandError(DiscordException):
r"""The base exception type for all command related errors.
This inherits from :exc:`discord.DiscordException`.
This exception and exceptions inherited from it are handled
in a special way as they are caught and passed into a special event
from :class:`.Bot`\, :func:`.on_command_error`.
"""
def __init__(self, message: Optional[str] = None, *args: Any) -> None:
if message is not None:
# clean-up @everyone and @here mentions
m = message.replace('@everyone', '@\u200beveryone').replace('@here', '@\u200bhere')
super().__init__(m, *args)
else:
super().__init__(*args)
class ConversionError(CommandError):
"""Exception raised when a Converter class raises non-CommandError.
This inherits from :exc:`CommandError`.
Attributes
----------
converter: :class:`discord.ext.commands.Converter`
The converter that failed.
original: :exc:`Exception`
The original exception that was raised. You can also get this via
the ``__cause__`` attribute.
"""
def __init__(self, converter: Converter, original: Exception) -> None:
self.converter: Converter = converter
self.original: Exception = original
class UserInputError(CommandError):
"""The base exception type for errors that involve errors
regarding user input.
This inherits from :exc:`CommandError`.
"""
pass
class CommandNotFound(CommandError):
"""Exception raised when a command is attempted to be invoked
but no command under that name is found.
This is not raised for invalid subcommands, rather just the
initial main command that is attempted to be invoked.
This inherits from :exc:`CommandError`.
"""
pass
class MissingRequiredArgument(UserInputError):
"""Exception raised when parsing a command and a parameter
that is required is not encountered.
This inherits from :exc:`UserInputError`
Attributes
-----------
param: :class:`inspect.Parameter`
The argument that is missing.
"""
def __init__(self, param: Parameter) -> None:
self.param: Parameter = param
super().__init__(f'{param.name} is a required argument that is missing.')
class TooManyArguments(UserInputError):
"""Exception raised when the command was passed too many arguments and its
:attr:`.Command.ignore_extra` attribute was not set to ``True``.
This inherits from :exc:`UserInputError`
"""
pass
class BadArgument(UserInputError):
"""Exception raised when a parsing or conversion failure is encountered
on an argument to pass into a command.
This inherits from :exc:`UserInputError`
"""
pass
class CheckFailure(CommandError):
"""Exception raised when the predicates in :attr:`.Command.checks` have failed.
This inherits from :exc:`CommandError`
"""
pass
class CheckAnyFailure(CheckFailure):
"""Exception raised when all predicates in :func:`check_any` fail.
This inherits from :exc:`CheckFailure`.
.. versionadded:: 1.3
Attributes
------------
errors: List[:class:`CheckFailure`]
A list of errors that were caught during execution.
checks: List[Callable[[:class:`Context`], :class:`bool`]]
A list of check predicates that failed.
"""
def __init__(self, checks: List[CheckFailure], errors: List[Callable[[Context], bool]]) -> None:
self.checks: List[CheckFailure] = checks
self.errors: List[Callable[[Context], bool]] = errors
super().__init__('You do not have permission to run this command.')
class PrivateMessageOnly(CheckFailure):
"""Exception raised when an operation does not work outside of private
message contexts.
This inherits from :exc:`CheckFailure`
"""
def __init__(self, message: Optional[str] = None) -> None:
super().__init__(message or 'This command can only be used in private messages.')
class NoPrivateMessage(CheckFailure):
"""Exception raised when an operation does not work in private message
contexts.
This inherits from :exc:`CheckFailure`
"""
def __init__(self, message: Optional[str] = None) -> None:
super().__init__(message or 'This command cannot be used in private messages.')
class NotOwner(CheckFailure):
"""Exception raised when the message author is not the owner of the bot.
This inherits from :exc:`CheckFailure`
"""
pass
class ObjectNotFound(BadArgument):
"""Exception raised when the argument provided did not match the format
of an ID or a mention.
This inherits from :exc:`BadArgument`
.. versionadded:: 2.0
Attributes
-----------
argument: :class:`str`
The argument supplied by the caller that was not matched
"""
def __init__(self, argument: str) -> None:
self.argument: str = argument
super().__init__(f'{argument!r} does not follow a valid ID or mention format.')
class MemberNotFound(BadArgument):
"""Exception raised when the member provided was not found in the bot's
cache.
This inherits from :exc:`BadArgument`
.. versionadded:: 1.5
Attributes
-----------
argument: :class:`str`
The member supplied by the caller that was not found
"""
def __init__(self, argument: str) -> None:
self.argument: str = argument
super().__init__(f'Member "{argument}" not found.')
class GuildNotFound(BadArgument):
"""Exception raised when the guild provided was not found in the bot's cache.
This inherits from :exc:`BadArgument`
.. versionadded:: 1.7
Attributes
-----------
argument: :class:`str`
The guild supplied by the called that was not found
"""
def __init__(self, argument: str) -> None:
self.argument: str = argument
super().__init__(f'Guild "{argument}" not found.')
class UserNotFound(BadArgument):
"""Exception raised when the user provided was not found in the bot's
cache.
This inherits from :exc:`BadArgument`
.. versionadded:: 1.5
Attributes
-----------
argument: :class:`str`
The user supplied by the caller that was not found
"""
def __init__(self, argument: str) -> None:
self.argument: str = argument
super().__init__(f'User "{argument}" not found.')
class MessageNotFound(BadArgument):
"""Exception raised when the message provided was not found in the channel.
This inherits from :exc:`BadArgument`
.. versionadded:: 1.5
Attributes
-----------
argument: :class:`str`
The message supplied by the caller that was not found
"""
def __init__(self, argument: str) -> None:
self.argument: str = argument
super().__init__(f'Message "{argument}" not found.')
class ChannelNotReadable(BadArgument):
"""Exception raised when the bot does not have permission to read messages
in the channel.
This inherits from :exc:`BadArgument`
.. versionadded:: 1.5
Attributes
-----------
argument: Union[:class:`.abc.GuildChannel`, :class:`.Thread`]
The channel supplied by the caller that was not readable
"""
def __init__(self, argument: Union[GuildChannel, Thread]) -> None:
self.argument: Union[GuildChannel, Thread] = argument
super().__init__(f"Can't read messages in {argument.mention}.")
class ChannelNotFound(BadArgument):
"""Exception raised when the bot can not find the channel.
This inherits from :exc:`BadArgument`
.. versionadded:: 1.5
Attributes
-----------
argument: :class:`str`
The channel supplied by the caller that was not found
"""
def __init__(self, argument: str) -> None:
self.argument: str = argument
super().__init__(f'Channel "{argument}" not found.')
class ThreadNotFound(BadArgument):
"""Exception raised when the bot can not find the thread.
This inherits from :exc:`BadArgument`
.. versionadded:: 2.0
Attributes
-----------
argument: :class:`str`
The thread supplied by the caller that was not found
"""
def __init__(self, argument: str) -> None:
self.argument: str = argument
super().__init__(f'Thread "{argument}" not found.')
class BadColourArgument(BadArgument):
"""Exception raised when the colour is not valid.
This inherits from :exc:`BadArgument`
.. versionadded:: 1.5
Attributes
-----------
argument: :class:`str`
The colour supplied by the caller that was not valid
"""
def __init__(self, argument: str) -> None:
self.argument: str = argument
super().__init__(f'Colour "{argument}" is invalid.')
BadColorArgument = BadColourArgument
class RoleNotFound(BadArgument):
"""Exception raised when the bot can not find the role.
This inherits from :exc:`BadArgument`
.. versionadded:: 1.5
Attributes
-----------
argument: :class:`str`
The role supplied by the caller that was not found
"""
def __init__(self, argument: str) -> None:
self.argument: str = argument
super().__init__(f'Role "{argument}" not found.')
class BadInviteArgument(BadArgument):
"""Exception raised when the invite is invalid or expired.
This inherits from :exc:`BadArgument`
.. versionadded:: 1.5
"""
def __init__(self, argument: str) -> None:
self.argument: str = argument
super().__init__(f'Invite "{argument}" is invalid or expired.')
class EmojiNotFound(BadArgument):
"""Exception raised when the bot can not find the emoji.
This inherits from :exc:`BadArgument`
.. versionadded:: 1.5
Attributes
-----------
argument: :class:`str`
The emoji supplied by the caller that was not found
"""
def __init__(self, argument: str) -> None:
self.argument: str = argument
super().__init__(f'Emoji "{argument}" not found.')
class PartialEmojiConversionFailure(BadArgument):
"""Exception raised when the emoji provided does not match the correct
format.
This inherits from :exc:`BadArgument`
.. versionadded:: 1.5
Attributes
-----------
argument: :class:`str`
The emoji supplied by the caller that did not match the regex
"""
def __init__(self, argument: str) -> None:
self.argument: str = argument
super().__init__(f'Couldn\'t convert "{argument}" to PartialEmoji.')
class GuildStickerNotFound(BadArgument):
"""Exception raised when the bot can not find the sticker.
This inherits from :exc:`BadArgument`
.. versionadded:: 2.0
Attributes
-----------
argument: :class:`str`
The sticker supplied by the caller that was not found
"""
def __init__(self, argument: str) -> None:
self.argument: str = argument
super().__init__(f'Sticker "{argument}" not found.')
class BadBoolArgument(BadArgument):
"""Exception raised when a boolean argument was not convertable.
This inherits from :exc:`BadArgument`
.. versionadded:: 1.5
Attributes
-----------
argument: :class:`str`
The boolean argument supplied by the caller that is not in the predefined list
"""
def __init__(self, argument: str) -> None:
self.argument: str = argument
super().__init__(f'{argument} is not a recognised boolean option')
class DisabledCommand(CommandError):
"""Exception raised when the command being invoked is disabled.
This inherits from :exc:`CommandError`
"""
pass
class CommandInvokeError(CommandError):
"""Exception raised when the command being invoked raised an exception.
This inherits from :exc:`CommandError`
Attributes
-----------
original: :exc:`Exception`
The original exception that was raised. You can also get this via
the ``__cause__`` attribute.
"""
def __init__(self, e: Exception) -> None:
self.original: Exception = e
super().__init__(f'Command raised an exception: {e.__class__.__name__}: {e}')
class CommandOnCooldown(CommandError):
"""Exception raised when the command being invoked is on cooldown.
This inherits from :exc:`CommandError`
Attributes
-----------
cooldown: :class:`.Cooldown`
A class with attributes ``rate`` and ``per`` similar to the
:func:`.cooldown` decorator.
type: :class:`BucketType`
The type associated with the cooldown.
retry_after: :class:`float`
The amount of seconds to wait before you can retry again.
"""
def __init__(self, cooldown: Cooldown, retry_after: float, type: BucketType) -> None:
self.cooldown: Cooldown = cooldown
self.retry_after: float = retry_after
self.type: BucketType = type
super().__init__(f'You are on cooldown. Try again in {retry_after:.2f}s')
class MaxConcurrencyReached(CommandError):
"""Exception raised when the command being invoked has reached its maximum concurrency.
This inherits from :exc:`CommandError`.
Attributes
------------
number: :class:`int`
The maximum number of concurrent invokers allowed.
per: :class:`.BucketType`
The bucket type passed to the :func:`.max_concurrency` decorator.
"""
def __init__(self, number: int, per: BucketType) -> None:
self.number: int = number
self.per: BucketType = per
name = per.name
suffix = 'per %s' % name if per.name != 'default' else 'globally'
plural = '%s times %s' if number > 1 else '%s time %s'
fmt = plural % (number, suffix)
super().__init__(f'Too many people are using this command. It can only be used {fmt} concurrently.')
class MissingRole(CheckFailure):
"""Exception raised when the command invoker lacks a role to run a command.
This inherits from :exc:`CheckFailure`
.. versionadded:: 1.1
Attributes
-----------
missing_role: Union[:class:`str`, :class:`int`]
The required role that is missing.
This is the parameter passed to :func:`~.commands.has_role`.
"""
def __init__(self, missing_role: Snowflake) -> None:
self.missing_role: Snowflake = missing_role
message = f'Role {missing_role!r} is required to run this command.'
super().__init__(message)
class BotMissingRole(CheckFailure):
"""Exception raised when the bot's member lacks a role to run a command.
This inherits from :exc:`CheckFailure`
.. versionadded:: 1.1
Attributes
-----------
missing_role: Union[:class:`str`, :class:`int`]
The required role that is missing.
This is the parameter passed to :func:`~.commands.has_role`.
"""
def __init__(self, missing_role: Snowflake) -> None:
self.missing_role: Snowflake = missing_role
message = f'Bot requires the role {missing_role!r} to run this command'
super().__init__(message)
class MissingAnyRole(CheckFailure):
"""Exception raised when the command invoker lacks any of
the roles specified to run a command.
This inherits from :exc:`CheckFailure`
.. versionadded:: 1.1
Attributes
-----------
missing_roles: List[Union[:class:`str`, :class:`int`]]
The roles that the invoker is missing.
These are the parameters passed to :func:`~.commands.has_any_role`.
"""
def __init__(self, missing_roles: SnowflakeList) -> None:
self.missing_roles: SnowflakeList = missing_roles
missing = [f"'{role}'" for role in missing_roles]
if len(missing) > 2:
fmt = '{}, or {}'.format(", ".join(missing[:-1]), missing[-1])
else:
fmt = ' or '.join(missing)
message = f"You are missing at least one of the required roles: {fmt}"
super().__init__(message)
class BotMissingAnyRole(CheckFailure):
"""Exception raised when the bot's member lacks any of
the roles specified to run a command.
This inherits from :exc:`CheckFailure`
.. versionadded:: 1.1
Attributes
-----------
missing_roles: List[Union[:class:`str`, :class:`int`]]
The roles that the bot's member is missing.
These are the parameters passed to :func:`~.commands.has_any_role`.
"""
def __init__(self, missing_roles: SnowflakeList) -> None:
self.missing_roles: SnowflakeList = missing_roles
missing = [f"'{role}'" for role in missing_roles]
if len(missing) > 2:
fmt = '{}, or {}'.format(", ".join(missing[:-1]), missing[-1])
else:
fmt = ' or '.join(missing)
message = f"Bot is missing at least one of the required roles: {fmt}"
super().__init__(message)
class NSFWChannelRequired(CheckFailure):
"""Exception raised when a channel does not have the required NSFW setting.
This inherits from :exc:`CheckFailure`.
.. versionadded:: 1.1
Parameters
-----------
channel: Union[:class:`.abc.GuildChannel`, :class:`.Thread`]
The channel that does not have NSFW enabled.
"""
def __init__(self, channel: Union[GuildChannel, Thread]) -> None:
self.channel: Union[GuildChannel, Thread] = channel
super().__init__(f"Channel '{channel}' needs to be NSFW for this command to work.")
class MissingPermissions(CheckFailure):
"""Exception raised when the command invoker lacks permissions to run a
command.
This inherits from :exc:`CheckFailure`
Attributes
-----------
missing_permissions: List[:class:`str`]
The required permissions that are missing.
"""
def __init__(self, missing_permissions: List[str], *args: Any) -> None:
self.missing_permissions: List[str] = missing_permissions
missing = [perm.replace('_', ' ').replace('guild', 'server').title() for perm in missing_permissions]
if len(missing) > 2:
fmt = '{}, and {}'.format(", ".join(missing[:-1]), missing[-1])
else:
fmt = ' and '.join(missing)
message = f'You are missing {fmt} permission(s) to run this command.'
super().__init__(message, *args)
class BotMissingPermissions(CheckFailure):
"""Exception raised when the bot's member lacks permissions to run a
command.
This inherits from :exc:`CheckFailure`
Attributes
-----------
missing_permissions: List[:class:`str`]
The required permissions that are missing.
"""
def __init__(self, missing_permissions: List[str], *args: Any) -> None:
self.missing_permissions: List[str] = missing_permissions
missing = [perm.replace('_', ' ').replace('guild', 'server').title() for perm in missing_permissions]
if len(missing) > 2:
fmt = '{}, and {}'.format(", ".join(missing[:-1]), missing[-1])
else:
fmt = ' and '.join(missing)
message = f'Bot requires {fmt} permission(s) to run this command.'
super().__init__(message, *args)
class BadUnionArgument(UserInputError):
"""Exception raised when a :data:`typing.Union` converter fails for all
its associated types.
This inherits from :exc:`UserInputError`
Attributes
-----------
param: :class:`inspect.Parameter`
The parameter that failed being converted.
converters: Tuple[Type, ``...``]
A tuple of converters attempted in conversion, in order of failure.
errors: List[:class:`CommandError`]
A list of errors that were caught from failing the conversion.
"""
def __init__(self, param: Parameter, converters: Tuple[Type, ...], errors: List[CommandError]) -> None:
self.param: Parameter = param
self.converters: Tuple[Type, ...] = converters
self.errors: List[CommandError] = errors
def _get_name(x):
try:
return x.__name__
except AttributeError:
if hasattr(x, '__origin__'):
return repr(x)
return x.__class__.__name__
to_string = [_get_name(x) for x in converters]
if len(to_string) > 2:
fmt = '{}, or {}'.format(', '.join(to_string[:-1]), to_string[-1])
else:
fmt = ' or '.join(to_string)
super().__init__(f'Could not convert "{param.name}" into {fmt}.')
class BadLiteralArgument(UserInputError):
"""Exception raised when a :data:`typing.Literal` converter fails for all
its associated values.
This inherits from :exc:`UserInputError`
.. versionadded:: 2.0
Attributes
-----------
param: :class:`inspect.Parameter`
The parameter that failed being converted.
literals: Tuple[Any, ``...``]
A tuple of values compared against in conversion, in order of failure.
errors: List[:class:`CommandError`]
A list of errors that were caught from failing the conversion.
"""
def __init__(self, param: Parameter, literals: Tuple[Any, ...], errors: List[CommandError]) -> None:
self.param: Parameter = param
self.literals: Tuple[Any, ...] = literals
self.errors: List[CommandError] = errors
to_string = [repr(l) for l in literals]
if len(to_string) > 2:
fmt = '{}, or {}'.format(', '.join(to_string[:-1]), to_string[-1])
else:
fmt = ' or '.join(to_string)
super().__init__(f'Could not convert "{param.name}" into the literal {fmt}.')
class ArgumentParsingError(UserInputError):
"""An exception raised when the parser fails to parse a user's input.
This inherits from :exc:`UserInputError`.
There are child classes that implement more granular parsing errors for
i18n purposes.
"""
pass
class UnexpectedQuoteError(ArgumentParsingError):
"""An exception raised when the parser encounters a quote mark inside a non-quoted string.
This inherits from :exc:`ArgumentParsingError`.
Attributes
------------
quote: :class:`str`
The quote mark that was found inside the non-quoted string.
"""
def __init__(self, quote: str) -> None:
self.quote: str = quote
super().__init__(f'Unexpected quote mark, {quote!r}, in non-quoted string')
class InvalidEndOfQuotedStringError(ArgumentParsingError):
"""An exception raised when a space is expected after the closing quote in a string
but a different character is found.
This inherits from :exc:`ArgumentParsingError`.
Attributes
-----------
char: :class:`str`
The character found instead of the expected string.
"""
def __init__(self, char: str) -> None:
self.char: str = char
super().__init__(f'Expected space after closing quotation but received {char!r}')
class ExpectedClosingQuoteError(ArgumentParsingError):
"""An exception raised when a quote character is expected but not found.
This inherits from :exc:`ArgumentParsingError`.
Attributes
-----------
close_quote: :class:`str`
The quote character expected.
"""
def __init__(self, close_quote: str) -> None:
self.close_quote: str = close_quote
super().__init__(f'Expected closing {close_quote}.')
class ExtensionError(DiscordException):
"""Base exception for extension related errors.
This inherits from :exc:`~discord.DiscordException`.
Attributes
------------
name: :class:`str`
The extension that had an error.
"""
def __init__(self, message: Optional[str] = None, *args: Any, name: str) -> None:
self.name: str = name
message = message or f'Extension {name!r} had an error.'
# clean-up @everyone and @here mentions
m = message.replace('@everyone', '@\u200beveryone').replace('@here', '@\u200bhere')
super().__init__(m, *args)
class ExtensionAlreadyLoaded(ExtensionError):
"""An exception raised when an extension has already been loaded.
This inherits from :exc:`ExtensionError`
"""
def __init__(self, name: str) -> None:
super().__init__(f'Extension {name!r} is already loaded.', name=name)
class ExtensionNotLoaded(ExtensionError):
"""An exception raised when an extension was not loaded.
This inherits from :exc:`ExtensionError`
"""
def __init__(self, name: str) -> None:
super().__init__(f'Extension {name!r} has not been loaded.', name=name)
class NoEntryPointError(ExtensionError):
"""An exception raised when an extension does not have a ``setup`` entry point function.
This inherits from :exc:`ExtensionError`
"""
def __init__(self, name: str) -> None:
super().__init__(f"Extension {name!r} has no 'setup' function.", name=name)
class ExtensionFailed(ExtensionError):
"""An exception raised when an extension failed to load during execution of the module or ``setup`` entry point.
This inherits from :exc:`ExtensionError`
Attributes
-----------
name: :class:`str`
The extension that had the error.
original: :exc:`Exception`
The original exception that was raised. You can also get this via
the ``__cause__`` attribute.
"""
def __init__(self, name: str, original: Exception) -> None:
self.original: Exception = original
msg = f'Extension {name!r} raised an error: {original.__class__.__name__}: {original}'
super().__init__(msg, name=name)
class ExtensionNotFound(ExtensionError):
"""An exception raised when an extension is not found.
This inherits from :exc:`ExtensionError`
.. versionchanged:: 1.3
Made the ``original`` attribute always None.
Attributes
-----------
name: :class:`str`
The extension that had the error.
"""
def __init__(self, name: str) -> None:
msg = f'Extension {name!r} could not be loaded.'
super().__init__(msg, name=name)
class CommandRegistrationError(ClientException):
"""An exception raised when the command can't be added
because the name is already taken by a different command.
This inherits from :exc:`discord.ClientException`
.. versionadded:: 1.4
Attributes
----------
name: :class:`str`
The command name that had the error.
alias_conflict: :class:`bool`
Whether the name that conflicts is an alias of the command we try to add.
"""
def __init__(self, name: str, *, alias_conflict: bool = False) -> None:
self.name: str = name
self.alias_conflict: bool = alias_conflict
type_ = 'alias' if alias_conflict else 'command'
super().__init__(f'The {type_} {name} is already an existing command or alias.')
class FlagError(BadArgument):
"""The base exception type for all flag parsing related errors.
This inherits from :exc:`BadArgument`.
.. versionadded:: 2.0
"""
pass
class TooManyFlags(FlagError):
"""An exception raised when a flag has received too many values.
This inherits from :exc:`FlagError`.
.. versionadded:: 2.0
Attributes
------------
flag: :class:`~discord.ext.commands.Flag`
The flag that received too many values.
values: List[:class:`str`]
The values that were passed.
"""
def __init__(self, flag: Flag, values: List[str]) -> None:
self.flag: Flag = flag
self.values: List[str] = values
super().__init__(f'Too many flag values, expected {flag.max_args} but received {len(values)}.')
class BadFlagArgument(FlagError):
"""An exception raised when a flag failed to convert a value.
This inherits from :exc:`FlagError`
.. versionadded:: 2.0
Attributes
-----------
flag: :class:`~discord.ext.commands.Flag`
The flag that failed to convert.
"""
def __init__(self, flag: Flag) -> None:
self.flag: Flag = flag
try:
name = flag.annotation.__name__
except AttributeError:
name = flag.annotation.__class__.__name__
super().__init__(f'Could not convert to {name!r} for flag {flag.name!r}')
class MissingRequiredFlag(FlagError):
"""An exception raised when a required flag was not given.
This inherits from :exc:`FlagError`
.. versionadded:: 2.0
Attributes
-----------
flag: :class:`~discord.ext.commands.Flag`
The required flag that was not found.
"""
def __init__(self, flag: Flag) -> None:
self.flag: Flag = flag
super().__init__(f'Flag {flag.name!r} is required and missing')
class MissingFlagArgument(FlagError):
"""An exception raised when a flag did not get a value.
This inherits from :exc:`FlagError`
.. versionadded:: 2.0
Attributes
-----------
flag: :class:`~discord.ext.commands.Flag`
The flag that did not get a value.
"""
def __init__(self, flag: Flag) -> None:
self.flag: Flag = flag
super().__init__(f'Flag {flag.name!r} does not have an argument') | zarenacord.py | /zarenacord.py-2.0.0-py3-none-any.whl/discord/ext/commands/errors.py | errors.py |
from __future__ import annotations
from .errors import (
BadFlagArgument,
CommandError,
MissingFlagArgument,
TooManyFlags,
MissingRequiredFlag,
)
from discord.utils import resolve_annotation
from .view import StringView
from .converter import run_converters
from discord.utils import maybe_coroutine, MISSING
from dataclasses import dataclass, field
from typing import (
Dict,
Iterator,
Literal,
Optional,
Pattern,
Set,
TYPE_CHECKING,
Tuple,
List,
Any,
Type,
TypeVar,
Union,
)
import inspect
import sys
import re
__all__ = (
'Flag',
'flag',
'FlagConverter',
)
if TYPE_CHECKING:
from .context import Context
@dataclass
class Flag:
"""Represents a flag parameter for :class:`FlagConverter`.
The :func:`~discord.ext.commands.flag` function helps
create these flag objects, but it is not necessary to
do so. These cannot be constructed manually.
Attributes
------------
name: :class:`str`
The name of the flag.
aliases: List[:class:`str`]
The aliases of the flag name.
attribute: :class:`str`
The attribute in the class that corresponds to this flag.
default: Any
The default value of the flag, if available.
annotation: Any
The underlying evaluated annotation of the flag.
max_args: :class:`int`
The maximum number of arguments the flag can accept.
A negative value indicates an unlimited amount of arguments.
override: :class:`bool`
Whether multiple given values overrides the previous value.
"""
name: str = MISSING
aliases: List[str] = field(default_factory=list)
attribute: str = MISSING
annotation: Any = MISSING
default: Any = MISSING
max_args: int = MISSING
override: bool = MISSING
cast_to_dict: bool = False
@property
def required(self) -> bool:
""":class:`bool`: Whether the flag is required.
A required flag has no default value.
"""
return self.default is MISSING
def flag(
*,
name: str = MISSING,
aliases: List[str] = MISSING,
default: Any = MISSING,
max_args: int = MISSING,
override: bool = MISSING,
) -> Any:
"""Override default functionality and parameters of the underlying :class:`FlagConverter`
class attributes.
Parameters
------------
name: :class:`str`
The flag name. If not given, defaults to the attribute name.
aliases: List[:class:`str`]
Aliases to the flag name. If not given no aliases are set.
default: Any
The default parameter. This could be either a value or a callable that takes
:class:`Context` as its sole parameter. If not given then it defaults to
the default value given to the attribute.
max_args: :class:`int`
The maximum number of arguments the flag can accept.
A negative value indicates an unlimited amount of arguments.
The default value depends on the annotation given.
override: :class:`bool`
Whether multiple given values overrides the previous value. The default
value depends on the annotation given.
"""
return Flag(name=name, aliases=aliases, default=default, max_args=max_args, override=override)
def validate_flag_name(name: str, forbidden: Set[str]):
if not name:
raise ValueError('flag names should not be empty')
for ch in name:
if ch.isspace():
raise ValueError(f'flag name {name!r} cannot have spaces')
if ch == '\\':
raise ValueError(f'flag name {name!r} cannot have backslashes')
if ch in forbidden:
raise ValueError(f'flag name {name!r} cannot have any of {forbidden!r} within them')
def get_flags(namespace: Dict[str, Any], globals: Dict[str, Any], locals: Dict[str, Any]) -> Dict[str, Flag]:
annotations = namespace.get('__annotations__', {})
case_insensitive = namespace['__commands_flag_case_insensitive__']
flags: Dict[str, Flag] = {}
cache: Dict[str, Any] = {}
names: Set[str] = set()
for name, annotation in annotations.items():
flag = namespace.pop(name, MISSING)
if isinstance(flag, Flag):
flag.annotation = annotation
else:
flag = Flag(name=name, annotation=annotation, default=flag)
flag.attribute = name
if flag.name is MISSING:
flag.name = name
annotation = flag.annotation = resolve_annotation(flag.annotation, globals, locals, cache)
if flag.default is MISSING and hasattr(annotation, '__commands_is_flag__') and annotation._can_be_constructible():
flag.default = annotation._construct_default
if flag.aliases is MISSING:
flag.aliases = []
# Add sensible defaults based off of the type annotation
# <type> -> (max_args=1)
# List[str] -> (max_args=-1)
# Tuple[int, ...] -> (max_args=1)
# Dict[K, V] -> (max_args=-1, override=True)
# Union[str, int] -> (max_args=1)
# Optional[str] -> (default=None, max_args=1)
try:
origin = annotation.__origin__
except AttributeError:
# A regular type hint
if flag.max_args is MISSING:
flag.max_args = 1
else:
if origin is Union:
# typing.Union
if flag.max_args is MISSING:
flag.max_args = 1
if annotation.__args__[-1] is type(None) and flag.default is MISSING:
# typing.Optional
flag.default = None
elif origin is tuple:
# typing.Tuple
# tuple parsing is e.g. `flag: peter 20`
# for Tuple[str, int] would give you flag: ('peter', 20)
if flag.max_args is MISSING:
flag.max_args = 1
elif origin is list:
# typing.List
if flag.max_args is MISSING:
flag.max_args = -1
elif origin is dict:
# typing.Dict[K, V]
# Equivalent to:
# typing.List[typing.Tuple[K, V]]
flag.cast_to_dict = True
if flag.max_args is MISSING:
flag.max_args = -1
if flag.override is MISSING:
flag.override = True
elif origin is Literal:
if flag.max_args is MISSING:
flag.max_args = 1
else:
raise TypeError(f'Unsupported typing annotation {annotation!r} for {flag.name!r} flag')
if flag.override is MISSING:
flag.override = False
# Validate flag names are unique
name = flag.name.casefold() if case_insensitive else flag.name
if name in names:
raise TypeError(f'{flag.name!r} flag conflicts with previous flag or alias.')
else:
names.add(name)
for alias in flag.aliases:
# Validate alias is unique
alias = alias.casefold() if case_insensitive else alias
if alias in names:
raise TypeError(f'{flag.name!r} flag alias {alias!r} conflicts with previous flag or alias.')
else:
names.add(alias)
flags[flag.name] = flag
return flags
class FlagsMeta(type):
if TYPE_CHECKING:
__commands_is_flag__: bool
__commands_flags__: Dict[str, Flag]
__commands_flag_aliases__: Dict[str, str]
__commands_flag_regex__: Pattern[str]
__commands_flag_case_insensitive__: bool
__commands_flag_delimiter__: str
__commands_flag_prefix__: str
def __new__(
cls: Type[type],
name: str,
bases: Tuple[type, ...],
attrs: Dict[str, Any],
*,
case_insensitive: bool = MISSING,
delimiter: str = MISSING,
prefix: str = MISSING,
):
attrs['__commands_is_flag__'] = True
try:
global_ns = sys.modules[attrs['__module__']].__dict__
except KeyError:
global_ns = {}
frame = inspect.currentframe()
try:
if frame is None:
local_ns = {}
else:
if frame.f_back is None:
local_ns = frame.f_locals
else:
local_ns = frame.f_back.f_locals
finally:
del frame
flags: Dict[str, Flag] = {}
aliases: Dict[str, str] = {}
for base in reversed(bases):
if base.__dict__.get('__commands_is_flag__', False):
flags.update(base.__dict__['__commands_flags__'])
aliases.update(base.__dict__['__commands_flag_aliases__'])
if case_insensitive is MISSING:
attrs['__commands_flag_case_insensitive__'] = base.__dict__['__commands_flag_case_insensitive__']
if delimiter is MISSING:
attrs['__commands_flag_delimiter__'] = base.__dict__['__commands_flag_delimiter__']
if prefix is MISSING:
attrs['__commands_flag_prefix__'] = base.__dict__['__commands_flag_prefix__']
if case_insensitive is not MISSING:
attrs['__commands_flag_case_insensitive__'] = case_insensitive
if delimiter is not MISSING:
attrs['__commands_flag_delimiter__'] = delimiter
if prefix is not MISSING:
attrs['__commands_flag_prefix__'] = prefix
case_insensitive = attrs.setdefault('__commands_flag_case_insensitive__', False)
delimiter = attrs.setdefault('__commands_flag_delimiter__', ':')
prefix = attrs.setdefault('__commands_flag_prefix__', '')
for flag_name, flag in get_flags(attrs, global_ns, local_ns).items():
flags[flag_name] = flag
aliases.update({alias_name: flag_name for alias_name in flag.aliases})
forbidden = set(delimiter).union(prefix)
for flag_name in flags:
validate_flag_name(flag_name, forbidden)
for alias_name in aliases:
validate_flag_name(alias_name, forbidden)
regex_flags = 0
if case_insensitive:
flags = {key.casefold(): value for key, value in flags.items()}
aliases = {key.casefold(): value.casefold() for key, value in aliases.items()}
regex_flags = re.IGNORECASE
keys = list(re.escape(k) for k in flags)
keys.extend(re.escape(a) for a in aliases)
keys = sorted(keys, key=lambda t: len(t), reverse=True)
joined = '|'.join(keys)
pattern = re.compile(f'(({re.escape(prefix)})(?P<flag>{joined}){re.escape(delimiter)})', regex_flags)
attrs['__commands_flag_regex__'] = pattern
attrs['__commands_flags__'] = flags
attrs['__commands_flag_aliases__'] = aliases
return type.__new__(cls, name, bases, attrs)
async def tuple_convert_all(ctx: Context, argument: str, flag: Flag, converter: Any) -> Tuple[Any, ...]:
view = StringView(argument)
results = []
param: inspect.Parameter = ctx.current_parameter # type: ignore
while not view.eof:
view.skip_ws()
if view.eof:
break
word = view.get_quoted_word()
if word is None:
break
try:
converted = await run_converters(ctx, converter, word, param)
except CommandError:
raise
except Exception as e:
raise BadFlagArgument(flag) from e
else:
results.append(converted)
return tuple(results)
async def tuple_convert_flag(ctx: Context, argument: str, flag: Flag, converters: Any) -> Tuple[Any, ...]:
view = StringView(argument)
results = []
param: inspect.Parameter = ctx.current_parameter # type: ignore
for converter in converters:
view.skip_ws()
if view.eof:
break
word = view.get_quoted_word()
if word is None:
break
try:
converted = await run_converters(ctx, converter, word, param)
except CommandError:
raise
except Exception as e:
raise BadFlagArgument(flag) from e
else:
results.append(converted)
if len(results) != len(converters):
raise BadFlagArgument(flag)
return tuple(results)
async def convert_flag(ctx, argument: str, flag: Flag, annotation: Any = None) -> Any:
param: inspect.Parameter = ctx.current_parameter # type: ignore
annotation = annotation or flag.annotation
try:
origin = annotation.__origin__
except AttributeError:
pass
else:
if origin is tuple:
if annotation.__args__[-1] is Ellipsis:
return await tuple_convert_all(ctx, argument, flag, annotation.__args__[0])
else:
return await tuple_convert_flag(ctx, argument, flag, annotation.__args__)
elif origin is list:
# typing.List[x]
annotation = annotation.__args__[0]
return await convert_flag(ctx, argument, flag, annotation)
elif origin is Union and annotation.__args__[-1] is type(None):
# typing.Optional[x]
annotation = Union[annotation.__args__[:-1]]
return await run_converters(ctx, annotation, argument, param)
elif origin is dict:
# typing.Dict[K, V] -> typing.Tuple[K, V]
return await tuple_convert_flag(ctx, argument, flag, annotation.__args__)
try:
return await run_converters(ctx, annotation, argument, param)
except CommandError:
raise
except Exception as e:
raise BadFlagArgument(flag) from e
F = TypeVar('F', bound='FlagConverter')
class FlagConverter(metaclass=FlagsMeta):
"""A converter that allows for a user-friendly flag syntax.
The flags are defined using :pep:`526` type annotations similar
to the :mod:`dataclasses` Python module. For more information on
how this converter works, check the appropriate
:ref:`documentation <ext_commands_flag_converter>`.
.. container:: operations
.. describe:: iter(x)
Returns an iterator of ``(flag_name, flag_value)`` pairs. This allows it
to be, for example, constructed as a dict or a list of pairs.
Note that aliases are not shown.
.. versionadded:: 2.0
Parameters
-----------
case_insensitive: :class:`bool`
A class parameter to toggle case insensitivity of the flag parsing.
If ``True`` then flags are parsed in a case insensitive manner.
Defaults to ``False``.
prefix: :class:`str`
The prefix that all flags must be prefixed with. By default
there is no prefix.
delimiter: :class:`str`
The delimiter that separates a flag's argument from the flag's name.
By default this is ``:``.
"""
@classmethod
def get_flags(cls) -> Dict[str, Flag]:
"""Dict[:class:`str`, :class:`Flag`]: A mapping of flag name to flag object this converter has."""
return cls.__commands_flags__.copy()
@classmethod
def _can_be_constructible(cls) -> bool:
return all(not flag.required for flag in cls.__commands_flags__.values())
def __iter__(self) -> Iterator[Tuple[str, Any]]:
for flag in self.__class__.__commands_flags__.values():
yield (flag.name, getattr(self, flag.attribute))
@classmethod
async def _construct_default(cls: Type[F], ctx: Context) -> F:
self: F = cls.__new__(cls)
flags = cls.__commands_flags__
for flag in flags.values():
if callable(flag.default):
default = await maybe_coroutine(flag.default, ctx)
setattr(self, flag.attribute, default)
else:
setattr(self, flag.attribute, flag.default)
return self
def __repr__(self) -> str:
pairs = ' '.join([f'{flag.attribute}={getattr(self, flag.attribute)!r}' for flag in self.get_flags().values()])
return f'<{self.__class__.__name__} {pairs}>'
@classmethod
def parse_flags(cls, argument: str) -> Dict[str, List[str]]:
result: Dict[str, List[str]] = {}
flags = cls.__commands_flags__
aliases = cls.__commands_flag_aliases__
last_position = 0
last_flag: Optional[Flag] = None
case_insensitive = cls.__commands_flag_case_insensitive__
for match in cls.__commands_flag_regex__.finditer(argument):
begin, end = match.span(0)
key = match.group('flag')
if case_insensitive:
key = key.casefold()
if key in aliases:
key = aliases[key]
flag = flags.get(key)
if last_position and last_flag is not None:
value = argument[last_position : begin - 1].lstrip()
if not value:
raise MissingFlagArgument(last_flag)
try:
values = result[last_flag.name]
except KeyError:
result[last_flag.name] = [value]
else:
values.append(value)
last_position = end
last_flag = flag
# Add the remaining string to the last available flag
if last_position and last_flag is not None:
value = argument[last_position:].strip()
if not value:
raise MissingFlagArgument(last_flag)
try:
values = result[last_flag.name]
except KeyError:
result[last_flag.name] = [value]
else:
values.append(value)
# Verification of values will come at a later stage
return result
@classmethod
async def convert(cls: Type[F], ctx: Context, argument: str) -> F:
"""|coro|
The method that actually converters an argument to the flag mapping.
Parameters
----------
cls: Type[:class:`FlagConverter`]
The flag converter class.
ctx: :class:`Context`
The invocation context.
argument: :class:`str`
The argument to convert from.
Raises
--------
FlagError
A flag related parsing error.
CommandError
A command related error.
Returns
--------
:class:`FlagConverter`
The flag converter instance with all flags parsed.
"""
arguments = cls.parse_flags(argument)
flags = cls.__commands_flags__
self: F = cls.__new__(cls)
for name, flag in flags.items():
try:
values = arguments[name]
except KeyError:
if flag.required:
raise MissingRequiredFlag(flag)
else:
if callable(flag.default):
default = await maybe_coroutine(flag.default, ctx)
setattr(self, flag.attribute, default)
else:
setattr(self, flag.attribute, flag.default)
continue
if flag.max_args > 0 and len(values) > flag.max_args:
if flag.override:
values = values[-flag.max_args :]
else:
raise TooManyFlags(flag, values)
# Special case:
if flag.max_args == 1:
value = await convert_flag(ctx, values[0], flag)
setattr(self, flag.attribute, value)
continue
# Another special case, tuple parsing.
# Tuple parsing is basically converting arguments within the flag
# So, given flag: hello 20 as the input and Tuple[str, int] as the type hint
# We would receive ('hello', 20) as the resulting value
# This uses the same whitespace and quoting rules as regular parameters.
values = [await convert_flag(ctx, value, flag) for value in values]
if flag.cast_to_dict:
values = dict(values) # type: ignore
setattr(self, flag.attribute, values)
return self | zarenacord.py | /zarenacord.py-2.0.0-py3-none-any.whl/discord/ext/commands/flags.py | flags.py |
import itertools
import copy
import functools
import inspect
import re
from typing import Optional, TYPE_CHECKING
import discord.utils
from .core import Group, Command
from .errors import CommandError
if TYPE_CHECKING:
from .context import Context
__all__ = (
'Paginator',
'HelpCommand',
'DefaultHelpCommand',
'MinimalHelpCommand',
)
# help -> shows info of bot on top/bottom and lists subcommands
# help command -> shows detailed info of command
# help command <subcommand chain> -> same as above
# <description>
# <command signature with aliases>
# <long doc>
# Cog:
# <command> <shortdoc>
# <command> <shortdoc>
# Other Cog:
# <command> <shortdoc>
# No Category:
# <command> <shortdoc>
# Type <prefix>help command for more info on a command.
# You can also type <prefix>help category for more info on a category.
class Paginator:
"""A class that aids in paginating code blocks for Discord messages.
.. container:: operations
.. describe:: len(x)
Returns the total number of characters in the paginator.
Attributes
-----------
prefix: :class:`str`
The prefix inserted to every page. e.g. three backticks.
suffix: :class:`str`
The suffix appended at the end of every page. e.g. three backticks.
max_size: :class:`int`
The maximum amount of codepoints allowed in a page.
linesep: :class:`str`
The character string inserted between lines. e.g. a newline character.
.. versionadded:: 1.7
"""
def __init__(self, prefix='```', suffix='```', max_size=2000, linesep='\n'):
self.prefix = prefix
self.suffix = suffix
self.max_size = max_size
self.linesep = linesep
self.clear()
def clear(self):
"""Clears the paginator to have no pages."""
if self.prefix is not None:
self._current_page = [self.prefix]
self._count = len(self.prefix) + self._linesep_len # prefix + newline
else:
self._current_page = []
self._count = 0
self._pages = []
@property
def _prefix_len(self):
return len(self.prefix) if self.prefix else 0
@property
def _suffix_len(self):
return len(self.suffix) if self.suffix else 0
@property
def _linesep_len(self):
return len(self.linesep)
def add_line(self, line='', *, empty=False):
"""Adds a line to the current page.
If the line exceeds the :attr:`max_size` then an exception
is raised.
Parameters
-----------
line: :class:`str`
The line to add.
empty: :class:`bool`
Indicates if another empty line should be added.
Raises
------
RuntimeError
The line was too big for the current :attr:`max_size`.
"""
max_page_size = self.max_size - self._prefix_len - self._suffix_len - 2 * self._linesep_len
if len(line) > max_page_size:
raise RuntimeError(f'Line exceeds maximum page size {max_page_size}')
if self._count + len(line) + self._linesep_len > self.max_size - self._suffix_len:
self.close_page()
self._count += len(line) + self._linesep_len
self._current_page.append(line)
if empty:
self._current_page.append('')
self._count += self._linesep_len
def close_page(self):
"""Prematurely terminate a page."""
if self.suffix is not None:
self._current_page.append(self.suffix)
self._pages.append(self.linesep.join(self._current_page))
if self.prefix is not None:
self._current_page = [self.prefix]
self._count = len(self.prefix) + self._linesep_len # prefix + linesep
else:
self._current_page = []
self._count = 0
def __len__(self):
total = sum(len(p) for p in self._pages)
return total + self._count
@property
def pages(self):
"""List[:class:`str`]: Returns the rendered list of pages."""
# we have more than just the prefix in our current page
if len(self._current_page) > (0 if self.prefix is None else 1):
self.close_page()
return self._pages
def __repr__(self):
fmt = '<Paginator prefix: {0.prefix!r} suffix: {0.suffix!r} linesep: {0.linesep!r} max_size: {0.max_size} count: {0._count}>'
return fmt.format(self)
def _not_overriden(f):
f.__help_command_not_overriden__ = True
return f
class _HelpCommandImpl(Command):
def __init__(self, inject, *args, **kwargs):
super().__init__(inject.command_callback, *args, **kwargs)
self._original = inject
self._injected = inject
async def prepare(self, ctx):
self._injected = injected = self._original.copy()
injected.context = ctx
self.callback = injected.command_callback
on_error = injected.on_help_command_error
if not hasattr(on_error, '__help_command_not_overriden__'):
if self.cog is not None:
self.on_error = self._on_error_cog_implementation
else:
self.on_error = on_error
await super().prepare(ctx)
async def _parse_arguments(self, ctx):
# Make the parser think we don't have a cog so it doesn't
# inject the parameter into `ctx.args`.
original_cog = self.cog
self.cog = None
try:
await super()._parse_arguments(ctx)
finally:
self.cog = original_cog
async def _on_error_cog_implementation(self, dummy, ctx, error):
await self._injected.on_help_command_error(ctx, error)
@property
def clean_params(self):
result = self.params.copy()
try:
del result[next(iter(result))]
except StopIteration:
raise ValueError('Missing context parameter') from None
else:
return result
def _inject_into_cog(self, cog):
# Warning: hacky
# Make the cog think that get_commands returns this command
# as well if we inject it without modifying __cog_commands__
# since that's used for the injection and ejection of cogs.
def wrapped_get_commands(*, _original=cog.get_commands):
ret = _original()
ret.append(self)
return ret
# Ditto here
def wrapped_walk_commands(*, _original=cog.walk_commands):
yield from _original()
yield self
functools.update_wrapper(wrapped_get_commands, cog.get_commands)
functools.update_wrapper(wrapped_walk_commands, cog.walk_commands)
cog.get_commands = wrapped_get_commands
cog.walk_commands = wrapped_walk_commands
self.cog = cog
def _eject_cog(self):
if self.cog is None:
return
# revert back into their original methods
cog = self.cog
cog.get_commands = cog.get_commands.__wrapped__
cog.walk_commands = cog.walk_commands.__wrapped__
self.cog = None
class HelpCommand:
r"""The base implementation for help command formatting.
.. note::
Internally instances of this class are deep copied every time
the command itself is invoked to prevent a race condition
mentioned in :issue:`2123`.
This means that relying on the state of this class to be
the same between command invocations would not work as expected.
Attributes
------------
context: Optional[:class:`Context`]
The context that invoked this help formatter. This is generally set after
the help command assigned, :func:`command_callback`\, has been called.
show_hidden: :class:`bool`
Specifies if hidden commands should be shown in the output.
Defaults to ``False``.
verify_checks: Optional[:class:`bool`]
Specifies if commands should have their :attr:`.Command.checks` called
and verified. If ``True``, always calls :attr:`.Command.checks`.
If ``None``, only calls :attr:`.Command.checks` in a guild setting.
If ``False``, never calls :attr:`.Command.checks`. Defaults to ``True``.
.. versionchanged:: 1.7
command_attrs: :class:`dict`
A dictionary of options to pass in for the construction of the help command.
This allows you to change the command behaviour without actually changing
the implementation of the command. The attributes will be the same as the
ones passed in the :class:`.Command` constructor.
"""
MENTION_TRANSFORMS = {
'@everyone': '@\u200beveryone',
'@here': '@\u200bhere',
r'<@!?[0-9]{17,22}>': '@deleted-user',
r'<@&[0-9]{17,22}>': '@deleted-role',
}
MENTION_PATTERN = re.compile('|'.join(MENTION_TRANSFORMS.keys()))
def __new__(cls, *args, **kwargs):
# To prevent race conditions of a single instance while also allowing
# for settings to be passed the original arguments passed must be assigned
# to allow for easier copies (which will be made when the help command is actually called)
# see issue 2123
self = super().__new__(cls)
# Shallow copies cannot be used in this case since it is not unusual to pass
# instances that need state, e.g. Paginator or what have you into the function
# The keys can be safely copied as-is since they're 99.99% certain of being
# string keys
deepcopy = copy.deepcopy
self.__original_kwargs__ = {k: deepcopy(v) for k, v in kwargs.items()}
self.__original_args__ = deepcopy(args)
return self
def __init__(self, **options):
self.show_hidden = options.pop('show_hidden', False)
self.verify_checks = options.pop('verify_checks', True)
self.command_attrs = attrs = options.pop('command_attrs', {})
attrs.setdefault('name', 'help')
attrs.setdefault('help', 'Shows this message')
self.context: Context = discord.utils.MISSING
self._command_impl = _HelpCommandImpl(self, **self.command_attrs)
def copy(self):
obj = self.__class__(*self.__original_args__, **self.__original_kwargs__)
obj._command_impl = self._command_impl
return obj
def _add_to_bot(self, bot):
command = _HelpCommandImpl(self, **self.command_attrs)
bot.add_command(command)
self._command_impl = command
def _remove_from_bot(self, bot):
bot.remove_command(self._command_impl.name)
self._command_impl._eject_cog()
def add_check(self, func):
"""
Adds a check to the help command.
.. versionadded:: 1.4
Parameters
----------
func
The function that will be used as a check.
"""
self._command_impl.add_check(func)
def remove_check(self, func):
"""
Removes a check from the help command.
This function is idempotent and will not raise an exception if
the function is not in the command's checks.
.. versionadded:: 1.4
Parameters
----------
func
The function to remove from the checks.
"""
self._command_impl.remove_check(func)
def get_bot_mapping(self):
"""Retrieves the bot mapping passed to :meth:`send_bot_help`."""
bot = self.context.bot
mapping = {cog: cog.get_commands() for cog in bot.cogs.values()}
mapping[None] = [c for c in bot.commands if c.cog is None]
return mapping
@property
def invoked_with(self):
"""Similar to :attr:`Context.invoked_with` except properly handles
the case where :meth:`Context.send_help` is used.
If the help command was used regularly then this returns
the :attr:`Context.invoked_with` attribute. Otherwise, if
it the help command was called using :meth:`Context.send_help`
then it returns the internal command name of the help command.
Returns
---------
:class:`str`
The command name that triggered this invocation.
"""
command_name = self._command_impl.name
ctx = self.context
if ctx is None or ctx.command is None or ctx.command.qualified_name != command_name:
return command_name
return ctx.invoked_with
def get_command_signature(self, command):
"""Retrieves the signature portion of the help page.
Parameters
------------
command: :class:`Command`
The command to get the signature of.
Returns
--------
:class:`str`
The signature for the command.
"""
parent = command.parent
entries = []
while parent is not None:
if not parent.signature or parent.invoke_without_command:
entries.append(parent.name)
else:
entries.append(parent.name + ' ' + parent.signature)
parent = parent.parent
parent_sig = ' '.join(reversed(entries))
if len(command.aliases) > 0:
aliases = '|'.join(command.aliases)
fmt = f'[{command.name}|{aliases}]'
if parent_sig:
fmt = parent_sig + ' ' + fmt
alias = fmt
else:
alias = command.name if not parent_sig else parent_sig + ' ' + command.name
return f'{self.context.clean_prefix}{alias} {command.signature}'
def remove_mentions(self, string):
"""Removes mentions from the string to prevent abuse.
This includes ``@everyone``, ``@here``, member mentions and role mentions.
Returns
-------
:class:`str`
The string with mentions removed.
"""
def replace(obj, *, transforms=self.MENTION_TRANSFORMS):
return transforms.get(obj.group(0), '@invalid')
return self.MENTION_PATTERN.sub(replace, string)
@property
def cog(self):
"""A property for retrieving or setting the cog for the help command.
When a cog is set for the help command, it is as-if the help command
belongs to that cog. All cog special methods will apply to the help
command and it will be automatically unset on unload.
To unbind the cog from the help command, you can set it to ``None``.
Returns
--------
Optional[:class:`Cog`]
The cog that is currently set for the help command.
"""
return self._command_impl.cog
@cog.setter
def cog(self, cog):
# Remove whatever cog is currently valid, if any
self._command_impl._eject_cog()
# If a new cog is set then inject it.
if cog is not None:
self._command_impl._inject_into_cog(cog)
def command_not_found(self, string):
"""|maybecoro|
A method called when a command is not found in the help command.
This is useful to override for i18n.
Defaults to ``No command called {0} found.``
Parameters
------------
string: :class:`str`
The string that contains the invalid command. Note that this has
had mentions removed to prevent abuse.
Returns
---------
:class:`str`
The string to use when a command has not been found.
"""
return f'No command called "{string}" found.'
def subcommand_not_found(self, command, string):
"""|maybecoro|
A method called when a command did not have a subcommand requested in the help command.
This is useful to override for i18n.
Defaults to either:
- ``'Command "{command.qualified_name}" has no subcommands.'``
- If there is no subcommand in the ``command`` parameter.
- ``'Command "{command.qualified_name}" has no subcommand named {string}'``
- If the ``command`` parameter has subcommands but not one named ``string``.
Parameters
------------
command: :class:`Command`
The command that did not have the subcommand requested.
string: :class:`str`
The string that contains the invalid subcommand. Note that this has
had mentions removed to prevent abuse.
Returns
---------
:class:`str`
The string to use when the command did not have the subcommand requested.
"""
if isinstance(command, Group) and len(command.all_commands) > 0:
return f'Command "{command.qualified_name}" has no subcommand named {string}'
return f'Command "{command.qualified_name}" has no subcommands.'
async def filter_commands(self, commands, *, sort=False, key=None):
"""|coro|
Returns a filtered list of commands and optionally sorts them.
This takes into account the :attr:`verify_checks` and :attr:`show_hidden`
attributes.
Parameters
------------
commands: Iterable[:class:`Command`]
An iterable of commands that are getting filtered.
sort: :class:`bool`
Whether to sort the result.
key: Optional[Callable[:class:`Command`, Any]]
An optional key function to pass to :func:`py:sorted` that
takes a :class:`Command` as its sole parameter. If ``sort`` is
passed as ``True`` then this will default as the command name.
Returns
---------
List[:class:`Command`]
A list of commands that passed the filter.
"""
if sort and key is None:
key = lambda c: c.name
iterator = commands if self.show_hidden else filter(lambda c: not c.hidden, commands)
if self.verify_checks is False:
# if we do not need to verify the checks then we can just
# run it straight through normally without using await.
return sorted(iterator, key=key) if sort else list(iterator)
if self.verify_checks is None and not self.context.guild:
# if verify_checks is None and we're in a DM, don't verify
return sorted(iterator, key=key) if sort else list(iterator)
# if we're here then we need to check every command if it can run
async def predicate(cmd):
try:
return await cmd.can_run(self.context)
except CommandError:
return False
ret = []
for cmd in iterator:
valid = await predicate(cmd)
if valid:
ret.append(cmd)
if sort:
ret.sort(key=key)
return ret
def get_max_size(self, commands):
"""Returns the largest name length of the specified command list.
Parameters
------------
commands: Sequence[:class:`Command`]
A sequence of commands to check for the largest size.
Returns
--------
:class:`int`
The maximum width of the commands.
"""
as_lengths = (discord.utils._string_width(c.name) for c in commands)
return max(as_lengths, default=0)
def get_destination(self):
"""Returns the :class:`~discord.abc.Messageable` where the help command will be output.
You can override this method to customise the behaviour.
By default this returns the context's channel.
Returns
-------
:class:`.abc.Messageable`
The destination where the help command will be output.
"""
return self.context.channel
async def send_error_message(self, error):
"""|coro|
Handles the implementation when an error happens in the help command.
For example, the result of :meth:`command_not_found` will be passed here.
You can override this method to customise the behaviour.
By default, this sends the error message to the destination
specified by :meth:`get_destination`.
.. note::
You can access the invocation context with :attr:`HelpCommand.context`.
Parameters
------------
error: :class:`str`
The error message to display to the user. Note that this has
had mentions removed to prevent abuse.
"""
destination = self.get_destination()
await destination.send(error)
@_not_overriden
async def on_help_command_error(self, ctx, error):
"""|coro|
The help command's error handler, as specified by :ref:`ext_commands_error_handler`.
Useful to override if you need some specific behaviour when the error handler
is called.
By default this method does nothing and just propagates to the default
error handlers.
Parameters
------------
ctx: :class:`Context`
The invocation context.
error: :class:`CommandError`
The error that was raised.
"""
pass
async def send_bot_help(self, mapping):
"""|coro|
Handles the implementation of the bot command page in the help command.
This function is called when the help command is called with no arguments.
It should be noted that this method does not return anything -- rather the
actual message sending should be done inside this method. Well behaved subclasses
should use :meth:`get_destination` to know where to send, as this is a customisation
point for other users.
You can override this method to customise the behaviour.
.. note::
You can access the invocation context with :attr:`HelpCommand.context`.
Also, the commands in the mapping are not filtered. To do the filtering
you will have to call :meth:`filter_commands` yourself.
Parameters
------------
mapping: Mapping[Optional[:class:`Cog`], List[:class:`Command`]]
A mapping of cogs to commands that have been requested by the user for help.
The key of the mapping is the :class:`~.commands.Cog` that the command belongs to, or
``None`` if there isn't one, and the value is a list of commands that belongs to that cog.
"""
return None
async def send_cog_help(self, cog):
"""|coro|
Handles the implementation of the cog page in the help command.
This function is called when the help command is called with a cog as the argument.
It should be noted that this method does not return anything -- rather the
actual message sending should be done inside this method. Well behaved subclasses
should use :meth:`get_destination` to know where to send, as this is a customisation
point for other users.
You can override this method to customise the behaviour.
.. note::
You can access the invocation context with :attr:`HelpCommand.context`.
To get the commands that belong to this cog see :meth:`Cog.get_commands`.
The commands returned not filtered. To do the filtering you will have to call
:meth:`filter_commands` yourself.
Parameters
-----------
cog: :class:`Cog`
The cog that was requested for help.
"""
return None
async def send_group_help(self, group):
"""|coro|
Handles the implementation of the group page in the help command.
This function is called when the help command is called with a group as the argument.
It should be noted that this method does not return anything -- rather the
actual message sending should be done inside this method. Well behaved subclasses
should use :meth:`get_destination` to know where to send, as this is a customisation
point for other users.
You can override this method to customise the behaviour.
.. note::
You can access the invocation context with :attr:`HelpCommand.context`.
To get the commands that belong to this group without aliases see
:attr:`Group.commands`. The commands returned not filtered. To do the
filtering you will have to call :meth:`filter_commands` yourself.
Parameters
-----------
group: :class:`Group`
The group that was requested for help.
"""
return None
async def send_command_help(self, command):
"""|coro|
Handles the implementation of the single command page in the help command.
It should be noted that this method does not return anything -- rather the
actual message sending should be done inside this method. Well behaved subclasses
should use :meth:`get_destination` to know where to send, as this is a customisation
point for other users.
You can override this method to customise the behaviour.
.. note::
You can access the invocation context with :attr:`HelpCommand.context`.
.. admonition:: Showing Help
:class: helpful
There are certain attributes and methods that are helpful for a help command
to show such as the following:
- :attr:`Command.help`
- :attr:`Command.brief`
- :attr:`Command.short_doc`
- :attr:`Command.description`
- :meth:`get_command_signature`
There are more than just these attributes but feel free to play around with
these to help you get started to get the output that you want.
Parameters
-----------
command: :class:`Command`
The command that was requested for help.
"""
return None
async def prepare_help_command(self, ctx, command=None):
"""|coro|
A low level method that can be used to prepare the help command
before it does anything. For example, if you need to prepare
some state in your subclass before the command does its processing
then this would be the place to do it.
The default implementation does nothing.
.. note::
This is called *inside* the help command callback body. So all
the usual rules that happen inside apply here as well.
Parameters
-----------
ctx: :class:`Context`
The invocation context.
command: Optional[:class:`str`]
The argument passed to the help command.
"""
pass
async def command_callback(self, ctx, *, command=None):
"""|coro|
The actual implementation of the help command.
It is not recommended to override this method and instead change
the behaviour through the methods that actually get dispatched.
- :meth:`send_bot_help`
- :meth:`send_cog_help`
- :meth:`send_group_help`
- :meth:`send_command_help`
- :meth:`get_destination`
- :meth:`command_not_found`
- :meth:`subcommand_not_found`
- :meth:`send_error_message`
- :meth:`on_help_command_error`
- :meth:`prepare_help_command`
"""
await self.prepare_help_command(ctx, command)
bot = ctx.bot
if command is None:
mapping = self.get_bot_mapping()
return await self.send_bot_help(mapping)
# Check if it's a cog
cog = bot.get_cog(command)
if cog is not None:
return await self.send_cog_help(cog)
maybe_coro = discord.utils.maybe_coroutine
# If it's not a cog then it's a command.
# Since we want to have detailed errors when someone
# passes an invalid subcommand, we need to walk through
# the command group chain ourselves.
keys = command.split(' ')
cmd = bot.all_commands.get(keys[0])
if cmd is None:
string = await maybe_coro(self.command_not_found, self.remove_mentions(keys[0]))
return await self.send_error_message(string)
for key in keys[1:]:
try:
found = cmd.all_commands.get(key)
except AttributeError:
string = await maybe_coro(self.subcommand_not_found, cmd, self.remove_mentions(key))
return await self.send_error_message(string)
else:
if found is None:
string = await maybe_coro(self.subcommand_not_found, cmd, self.remove_mentions(key))
return await self.send_error_message(string)
cmd = found
if isinstance(cmd, Group):
return await self.send_group_help(cmd)
else:
return await self.send_command_help(cmd)
class DefaultHelpCommand(HelpCommand):
"""The implementation of the default help command.
This inherits from :class:`HelpCommand`.
It extends it with the following attributes.
Attributes
------------
width: :class:`int`
The maximum number of characters that fit in a line.
Defaults to 80.
sort_commands: :class:`bool`
Whether to sort the commands in the output alphabetically. Defaults to ``True``.
dm_help: Optional[:class:`bool`]
A tribool that indicates if the help command should DM the user instead of
sending it to the channel it received it from. If the boolean is set to
``True``, then all help output is DM'd. If ``False``, none of the help
output is DM'd. If ``None``, then the bot will only DM when the help
message becomes too long (dictated by more than :attr:`dm_help_threshold` characters).
Defaults to ``False``.
dm_help_threshold: Optional[:class:`int`]
The number of characters the paginator must accumulate before getting DM'd to the
user if :attr:`dm_help` is set to ``None``. Defaults to 1000.
indent: :class:`int`
How much to indent the commands from a heading. Defaults to ``2``.
commands_heading: :class:`str`
The command list's heading string used when the help command is invoked with a category name.
Useful for i18n. Defaults to ``"Commands:"``
no_category: :class:`str`
The string used when there is a command which does not belong to any category(cog).
Useful for i18n. Defaults to ``"No Category"``
paginator: :class:`Paginator`
The paginator used to paginate the help command output.
"""
def __init__(self, **options):
self.width = options.pop('width', 80)
self.indent = options.pop('indent', 2)
self.sort_commands = options.pop('sort_commands', True)
self.dm_help = options.pop('dm_help', False)
self.dm_help_threshold = options.pop('dm_help_threshold', 1000)
self.commands_heading = options.pop('commands_heading', "Commands:")
self.no_category = options.pop('no_category', 'No Category')
self.paginator = options.pop('paginator', None)
if self.paginator is None:
self.paginator = Paginator()
super().__init__(**options)
def shorten_text(self, text):
""":class:`str`: Shortens text to fit into the :attr:`width`."""
if len(text) > self.width:
return text[:self.width - 3].rstrip() + '...'
return text
def get_ending_note(self):
""":class:`str`: Returns help command's ending note. This is mainly useful to override for i18n purposes."""
command_name = self.invoked_with
return (
f"Type {self.context.clean_prefix}{command_name} command for more info on a command.\n"
f"You can also type {self.context.clean_prefix}{command_name} category for more info on a category."
)
def add_indented_commands(self, commands, *, heading, max_size=None):
"""Indents a list of commands after the specified heading.
The formatting is added to the :attr:`paginator`.
The default implementation is the command name indented by
:attr:`indent` spaces, padded to ``max_size`` followed by
the command's :attr:`Command.short_doc` and then shortened
to fit into the :attr:`width`.
Parameters
-----------
commands: Sequence[:class:`Command`]
A list of commands to indent for output.
heading: :class:`str`
The heading to add to the output. This is only added
if the list of commands is greater than 0.
max_size: Optional[:class:`int`]
The max size to use for the gap between indents.
If unspecified, calls :meth:`~HelpCommand.get_max_size` on the
commands parameter.
"""
if not commands:
return
self.paginator.add_line(heading)
max_size = max_size or self.get_max_size(commands)
get_width = discord.utils._string_width
for command in commands:
name = command.name
width = max_size - (get_width(name) - len(name))
entry = f'{self.indent * " "}{name:<{width}} {command.short_doc}'
self.paginator.add_line(self.shorten_text(entry))
async def send_pages(self):
"""A helper utility to send the page output from :attr:`paginator` to the destination."""
destination = self.get_destination()
for page in self.paginator.pages:
await destination.send(page)
def add_command_formatting(self, command):
"""A utility function to format the non-indented block of commands and groups.
Parameters
------------
command: :class:`Command`
The command to format.
"""
if command.description:
self.paginator.add_line(command.description, empty=True)
signature = self.get_command_signature(command)
self.paginator.add_line(signature, empty=True)
if command.help:
try:
self.paginator.add_line(command.help, empty=True)
except RuntimeError:
for line in command.help.splitlines():
self.paginator.add_line(line)
self.paginator.add_line()
def get_destination(self):
ctx = self.context
if self.dm_help is True:
return ctx.author
elif self.dm_help is None and len(self.paginator) > self.dm_help_threshold:
return ctx.author
else:
return ctx.channel
async def prepare_help_command(self, ctx, command):
self.paginator.clear()
await super().prepare_help_command(ctx, command)
async def send_bot_help(self, mapping):
ctx = self.context
bot = ctx.bot
if bot.description:
# <description> portion
self.paginator.add_line(bot.description, empty=True)
no_category = f'\u200b{self.no_category}:'
def get_category(command, *, no_category=no_category):
cog = command.cog
return cog.qualified_name + ':' if cog is not None else no_category
filtered = await self.filter_commands(bot.commands, sort=True, key=get_category)
max_size = self.get_max_size(filtered)
to_iterate = itertools.groupby(filtered, key=get_category)
# Now we can add the commands to the page.
for category, commands in to_iterate:
commands = sorted(commands, key=lambda c: c.name) if self.sort_commands else list(commands)
self.add_indented_commands(commands, heading=category, max_size=max_size)
note = self.get_ending_note()
if note:
self.paginator.add_line()
self.paginator.add_line(note)
await self.send_pages()
async def send_command_help(self, command):
self.add_command_formatting(command)
self.paginator.close_page()
await self.send_pages()
async def send_group_help(self, group):
self.add_command_formatting(group)
filtered = await self.filter_commands(group.commands, sort=self.sort_commands)
self.add_indented_commands(filtered, heading=self.commands_heading)
if filtered:
note = self.get_ending_note()
if note:
self.paginator.add_line()
self.paginator.add_line(note)
await self.send_pages()
async def send_cog_help(self, cog):
if cog.description:
self.paginator.add_line(cog.description, empty=True)
filtered = await self.filter_commands(cog.get_commands(), sort=self.sort_commands)
self.add_indented_commands(filtered, heading=self.commands_heading)
note = self.get_ending_note()
if note:
self.paginator.add_line()
self.paginator.add_line(note)
await self.send_pages()
class MinimalHelpCommand(HelpCommand):
"""An implementation of a help command with minimal output.
This inherits from :class:`HelpCommand`.
Attributes
------------
sort_commands: :class:`bool`
Whether to sort the commands in the output alphabetically. Defaults to ``True``.
commands_heading: :class:`str`
The command list's heading string used when the help command is invoked with a category name.
Useful for i18n. Defaults to ``"Commands"``
aliases_heading: :class:`str`
The alias list's heading string used to list the aliases of the command. Useful for i18n.
Defaults to ``"Aliases:"``.
dm_help: Optional[:class:`bool`]
A tribool that indicates if the help command should DM the user instead of
sending it to the channel it received it from. If the boolean is set to
``True``, then all help output is DM'd. If ``False``, none of the help
output is DM'd. If ``None``, then the bot will only DM when the help
message becomes too long (dictated by more than :attr:`dm_help_threshold` characters).
Defaults to ``False``.
dm_help_threshold: Optional[:class:`int`]
The number of characters the paginator must accumulate before getting DM'd to the
user if :attr:`dm_help` is set to ``None``. Defaults to 1000.
no_category: :class:`str`
The string used when there is a command which does not belong to any category(cog).
Useful for i18n. Defaults to ``"No Category"``
paginator: :class:`Paginator`
The paginator used to paginate the help command output.
"""
def __init__(self, **options):
self.sort_commands = options.pop('sort_commands', True)
self.commands_heading = options.pop('commands_heading', "Commands")
self.dm_help = options.pop('dm_help', False)
self.dm_help_threshold = options.pop('dm_help_threshold', 1000)
self.aliases_heading = options.pop('aliases_heading', "Aliases:")
self.no_category = options.pop('no_category', 'No Category')
self.paginator = options.pop('paginator', None)
if self.paginator is None:
self.paginator = Paginator(suffix=None, prefix=None)
super().__init__(**options)
async def send_pages(self):
"""A helper utility to send the page output from :attr:`paginator` to the destination."""
destination = self.get_destination()
for page in self.paginator.pages:
await destination.send(page)
def get_opening_note(self):
"""Returns help command's opening note. This is mainly useful to override for i18n purposes.
The default implementation returns ::
Use `{prefix}{command_name} [command]` for more info on a command.
You can also use `{prefix}{command_name} [category]` for more info on a category.
Returns
-------
:class:`str`
The help command opening note.
"""
command_name = self.invoked_with
return (
f"Use `{self.context.clean_prefix}{command_name} [command]` for more info on a command.\n"
f"You can also use `{self.context.clean_prefix}{command_name} [category]` for more info on a category."
)
def get_command_signature(self, command):
return f'{self.context.clean_prefix}{command.qualified_name} {command.signature}'
def get_ending_note(self):
"""Return the help command's ending note. This is mainly useful to override for i18n purposes.
The default implementation does nothing.
Returns
-------
:class:`str`
The help command ending note.
"""
return None
def add_bot_commands_formatting(self, commands, heading):
"""Adds the minified bot heading with commands to the output.
The formatting should be added to the :attr:`paginator`.
The default implementation is a bold underline heading followed
by commands separated by an EN SPACE (U+2002) in the next line.
Parameters
-----------
commands: Sequence[:class:`Command`]
A list of commands that belong to the heading.
heading: :class:`str`
The heading to add to the line.
"""
if commands:
# U+2002 Middle Dot
joined = '\u2002'.join(c.name for c in commands)
self.paginator.add_line(f'__**{heading}**__')
self.paginator.add_line(joined)
def add_subcommand_formatting(self, command):
"""Adds formatting information on a subcommand.
The formatting should be added to the :attr:`paginator`.
The default implementation is the prefix and the :attr:`Command.qualified_name`
optionally followed by an En dash and the command's :attr:`Command.short_doc`.
Parameters
-----------
command: :class:`Command`
The command to show information of.
"""
fmt = '{0}{1} \N{EN DASH} {2}' if command.short_doc else '{0}{1}'
self.paginator.add_line(fmt.format(self.context.clean_prefix, command.qualified_name, command.short_doc))
def add_aliases_formatting(self, aliases):
"""Adds the formatting information on a command's aliases.
The formatting should be added to the :attr:`paginator`.
The default implementation is the :attr:`aliases_heading` bolded
followed by a comma separated list of aliases.
This is not called if there are no aliases to format.
Parameters
-----------
aliases: Sequence[:class:`str`]
A list of aliases to format.
"""
self.paginator.add_line(f'**{self.aliases_heading}** {", ".join(aliases)}', empty=True)
def add_command_formatting(self, command):
"""A utility function to format commands and groups.
Parameters
------------
command: :class:`Command`
The command to format.
"""
if command.description:
self.paginator.add_line(command.description, empty=True)
signature = self.get_command_signature(command)
if command.aliases:
self.paginator.add_line(signature)
self.add_aliases_formatting(command.aliases)
else:
self.paginator.add_line(signature, empty=True)
if command.help:
try:
self.paginator.add_line(command.help, empty=True)
except RuntimeError:
for line in command.help.splitlines():
self.paginator.add_line(line)
self.paginator.add_line()
def get_destination(self):
ctx = self.context
if self.dm_help is True:
return ctx.author
elif self.dm_help is None and len(self.paginator) > self.dm_help_threshold:
return ctx.author
else:
return ctx.channel
async def prepare_help_command(self, ctx, command):
self.paginator.clear()
await super().prepare_help_command(ctx, command)
async def send_bot_help(self, mapping):
ctx = self.context
bot = ctx.bot
if bot.description:
self.paginator.add_line(bot.description, empty=True)
note = self.get_opening_note()
if note:
self.paginator.add_line(note, empty=True)
no_category = f'\u200b{self.no_category}'
def get_category(command, *, no_category=no_category):
cog = command.cog
return cog.qualified_name if cog is not None else no_category
filtered = await self.filter_commands(bot.commands, sort=True, key=get_category)
to_iterate = itertools.groupby(filtered, key=get_category)
for category, commands in to_iterate:
commands = sorted(commands, key=lambda c: c.name) if self.sort_commands else list(commands)
self.add_bot_commands_formatting(commands, category)
note = self.get_ending_note()
if note:
self.paginator.add_line()
self.paginator.add_line(note)
await self.send_pages()
async def send_cog_help(self, cog):
bot = self.context.bot
if bot.description:
self.paginator.add_line(bot.description, empty=True)
note = self.get_opening_note()
if note:
self.paginator.add_line(note, empty=True)
if cog.description:
self.paginator.add_line(cog.description, empty=True)
filtered = await self.filter_commands(cog.get_commands(), sort=self.sort_commands)
if filtered:
self.paginator.add_line(f'**{cog.qualified_name} {self.commands_heading}**')
for command in filtered:
self.add_subcommand_formatting(command)
note = self.get_ending_note()
if note:
self.paginator.add_line()
self.paginator.add_line(note)
await self.send_pages()
async def send_group_help(self, group):
self.add_command_formatting(group)
filtered = await self.filter_commands(group.commands, sort=self.sort_commands)
if filtered:
note = self.get_opening_note()
if note:
self.paginator.add_line(note, empty=True)
self.paginator.add_line(f'**{self.commands_heading}**')
for command in filtered:
self.add_subcommand_formatting(command)
note = self.get_ending_note()
if note:
self.paginator.add_line()
self.paginator.add_line(note)
await self.send_pages()
async def send_command_help(self, command):
self.add_command_formatting(command)
self.paginator.close_page()
await self.send_pages() | zarenacord.py | /zarenacord.py-2.0.0-py3-none-any.whl/discord/ext/commands/help.py | help.py |
from __future__ import annotations
import asyncio
import collections
import collections.abc
import inspect
import importlib.util
import sys
import traceback
import types
from typing import Any, Callable, Mapping, List, Dict, TYPE_CHECKING, Optional, TypeVar, Type, Union
import discord
from .core import GroupMixin
from .view import StringView
from .context import Context
from . import errors
from .help import HelpCommand, DefaultHelpCommand
from .cog import Cog
if TYPE_CHECKING:
import importlib.machinery
from discord.message import Message
from ._types import (
Check,
CoroFunc,
)
__all__ = (
'when_mentioned',
'when_mentioned_or',
'Bot',
'AutoShardedBot',
)
MISSING: Any = discord.utils.MISSING
T = TypeVar('T')
CFT = TypeVar('CFT', bound='CoroFunc')
CXT = TypeVar('CXT', bound='Context')
def when_mentioned(bot: Union[Bot, AutoShardedBot], msg: Message) -> List[str]:
"""A callable that implements a command prefix equivalent to being mentioned.
These are meant to be passed into the :attr:`.Bot.command_prefix` attribute.
"""
# bot.user will never be None when this is called
return [f'<@{bot.user.id}> ', f'<@!{bot.user.id}> '] # type: ignore
def when_mentioned_or(*prefixes: str) -> Callable[[Union[Bot, AutoShardedBot], Message], List[str]]:
"""A callable that implements when mentioned or other prefixes provided.
These are meant to be passed into the :attr:`.Bot.command_prefix` attribute.
Example
--------
.. code-block:: python3
bot = commands.Bot(command_prefix=commands.when_mentioned_or('!'))
.. note::
This callable returns another callable, so if this is done inside a custom
callable, you must call the returned callable, for example:
.. code-block:: python3
async def get_prefix(bot, message):
extras = await prefixes_for(message.guild) # returns a list
return commands.when_mentioned_or(*extras)(bot, message)
See Also
----------
:func:`.when_mentioned`
"""
def inner(bot, msg):
r = list(prefixes)
r = when_mentioned(bot, msg) + r
return r
return inner
def _is_submodule(parent: str, child: str) -> bool:
return parent == child or child.startswith(parent + ".")
class _DefaultRepr:
def __repr__(self):
return '<default-help-command>'
_default = _DefaultRepr()
class BotBase(GroupMixin):
def __init__(self, command_prefix, help_command=_default, description=None, **options):
super().__init__(**options)
self.command_prefix = command_prefix
self.extra_events: Dict[str, List[CoroFunc]] = {}
self.__cogs: Dict[str, Cog] = {}
self.__extensions: Dict[str, types.ModuleType] = {}
self._checks: List[Check] = []
self._check_once = []
self._before_invoke = None
self._after_invoke = None
self._help_command = None
self.description = inspect.cleandoc(description) if description else ''
self.owner_id = options.get('owner_id')
self.owner_ids = options.get('owner_ids', set())
self.strip_after_prefix = options.get('strip_after_prefix', False)
if self.owner_id and self.owner_ids:
raise TypeError('Both owner_id and owner_ids are set.')
if self.owner_ids and not isinstance(self.owner_ids, collections.abc.Collection):
raise TypeError(f'owner_ids must be a collection not {self.owner_ids.__class__!r}')
if help_command is _default:
self.help_command = DefaultHelpCommand()
else:
self.help_command = help_command
# internal helpers
def dispatch(self, event_name: str, *args: Any, **kwargs: Any) -> None:
# super() will resolve to Client
super().dispatch(event_name, *args, **kwargs) # type: ignore
ev = 'on_' + event_name
for event in self.extra_events.get(ev, []):
self._schedule_event(event, ev, *args, **kwargs) # type: ignore
@discord.utils.copy_doc(discord.Client.close)
async def close(self) -> None:
for extension in tuple(self.__extensions):
try:
self.unload_extension(extension)
except Exception:
pass
for cog in tuple(self.__cogs):
try:
self.remove_cog(cog)
except Exception:
pass
await super().close() # type: ignore
async def on_command_error(self, context: Context, exception: errors.CommandError) -> None:
"""|coro|
The default command error handler provided by the bot.
By default this prints to :data:`sys.stderr` however it could be
overridden to have a different implementation.
This only fires if you do not specify any listeners for command error.
"""
if self.extra_events.get('on_command_error', None):
return
command = context.command
if command and command.has_error_handler():
return
cog = context.cog
if cog and cog.has_error_handler():
return
print(f'Ignoring exception in command {context.command}:', file=sys.stderr)
traceback.print_exception(type(exception), exception, exception.__traceback__, file=sys.stderr)
# global check registration
def check(self, func: T) -> T:
r"""A decorator that adds a global check to the bot.
A global check is similar to a :func:`.check` that is applied
on a per command basis except it is run before any command checks
have been verified and applies to every command the bot has.
.. note::
This function can either be a regular function or a coroutine.
Similar to a command :func:`.check`\, this takes a single parameter
of type :class:`.Context` and can only raise exceptions inherited from
:exc:`.CommandError`.
Example
---------
.. code-block:: python3
@bot.check
def check_commands(ctx):
return ctx.command.qualified_name in allowed_commands
"""
# T was used instead of Check to ensure the type matches on return
self.add_check(func) # type: ignore
return func
def add_check(self, func: Check, *, call_once: bool = False) -> None:
"""Adds a global check to the bot.
This is the non-decorator interface to :meth:`.check`
and :meth:`.check_once`.
Parameters
-----------
func
The function that was used as a global check.
call_once: :class:`bool`
If the function should only be called once per
:meth:`.invoke` call.
"""
if call_once:
self._check_once.append(func)
else:
self._checks.append(func)
def remove_check(self, func: Check, *, call_once: bool = False) -> None:
"""Removes a global check from the bot.
This function is idempotent and will not raise an exception
if the function is not in the global checks.
Parameters
-----------
func
The function to remove from the global checks.
call_once: :class:`bool`
If the function was added with ``call_once=True`` in
the :meth:`.Bot.add_check` call or using :meth:`.check_once`.
"""
l = self._check_once if call_once else self._checks
try:
l.remove(func)
except ValueError:
pass
def check_once(self, func: CFT) -> CFT:
r"""A decorator that adds a "call once" global check to the bot.
Unlike regular global checks, this one is called only once
per :meth:`.invoke` call.
Regular global checks are called whenever a command is called
or :meth:`.Command.can_run` is called. This type of check
bypasses that and ensures that it's called only once, even inside
the default help command.
.. note::
When using this function the :class:`.Context` sent to a group subcommand
may only parse the parent command and not the subcommands due to it
being invoked once per :meth:`.Bot.invoke` call.
.. note::
This function can either be a regular function or a coroutine.
Similar to a command :func:`.check`\, this takes a single parameter
of type :class:`.Context` and can only raise exceptions inherited from
:exc:`.CommandError`.
Example
---------
.. code-block:: python3
@bot.check_once
def whitelist(ctx):
return ctx.message.author.id in my_whitelist
"""
self.add_check(func, call_once=True)
return func
async def can_run(self, ctx: Context, *, call_once: bool = False) -> bool:
data = self._check_once if call_once else self._checks
if len(data) == 0:
return True
# type-checker doesn't distinguish between functions and methods
return await discord.utils.async_all(f(ctx) for f in data) # type: ignore
async def is_owner(self, user: discord.User) -> bool:
"""|coro|
Checks if a :class:`~discord.User` or :class:`~discord.Member` is the owner of
this bot.
If an :attr:`owner_id` is not set, it is fetched automatically
through the use of :meth:`~.Bot.application_info`.
.. versionchanged:: 1.3
The function also checks if the application is team-owned if
:attr:`owner_ids` is not set.
Parameters
-----------
user: :class:`.abc.User`
The user to check for.
Returns
--------
:class:`bool`
Whether the user is the owner.
"""
if self.owner_id:
return user.id == self.owner_id
elif self.owner_ids:
return user.id in self.owner_ids
else:
app = await self.application_info() # type: ignore
if app.team:
self.owner_ids = ids = {m.id for m in app.team.members}
return user.id in ids
else:
self.owner_id = owner_id = app.owner.id
return user.id == owner_id
def before_invoke(self, coro: CFT) -> CFT:
"""A decorator that registers a coroutine as a pre-invoke hook.
A pre-invoke hook is called directly before the command is
called. This makes it a useful function to set up database
connections or any type of set up required.
This pre-invoke hook takes a sole parameter, a :class:`.Context`.
.. note::
The :meth:`~.Bot.before_invoke` and :meth:`~.Bot.after_invoke` hooks are
only called if all checks and argument parsing procedures pass
without error. If any check or argument parsing procedures fail
then the hooks are not called.
Parameters
-----------
coro: :ref:`coroutine <coroutine>`
The coroutine to register as the pre-invoke hook.
Raises
-------
TypeError
The coroutine passed is not actually a coroutine.
"""
if not asyncio.iscoroutinefunction(coro):
raise TypeError('The pre-invoke hook must be a coroutine.')
self._before_invoke = coro
return coro
def after_invoke(self, coro: CFT) -> CFT:
r"""A decorator that registers a coroutine as a post-invoke hook.
A post-invoke hook is called directly after the command is
called. This makes it a useful function to clean-up database
connections or any type of clean up required.
This post-invoke hook takes a sole parameter, a :class:`.Context`.
.. note::
Similar to :meth:`~.Bot.before_invoke`\, this is not called unless
checks and argument parsing procedures succeed. This hook is,
however, **always** called regardless of the internal command
callback raising an error (i.e. :exc:`.CommandInvokeError`\).
This makes it ideal for clean-up scenarios.
Parameters
-----------
coro: :ref:`coroutine <coroutine>`
The coroutine to register as the post-invoke hook.
Raises
-------
TypeError
The coroutine passed is not actually a coroutine.
"""
if not asyncio.iscoroutinefunction(coro):
raise TypeError('The post-invoke hook must be a coroutine.')
self._after_invoke = coro
return coro
# listener registration
def add_listener(self, func: CoroFunc, name: str = MISSING) -> None:
"""The non decorator alternative to :meth:`.listen`.
Parameters
-----------
func: :ref:`coroutine <coroutine>`
The function to call.
name: :class:`str`
The name of the event to listen for. Defaults to ``func.__name__``.
Example
--------
.. code-block:: python3
async def on_ready(): pass
async def my_message(message): pass
bot.add_listener(on_ready)
bot.add_listener(my_message, 'on_message')
"""
name = func.__name__ if name is MISSING else name
if not asyncio.iscoroutinefunction(func):
raise TypeError('Listeners must be coroutines')
if name in self.extra_events:
self.extra_events[name].append(func)
else:
self.extra_events[name] = [func]
def remove_listener(self, func: CoroFunc, name: str = MISSING) -> None:
"""Removes a listener from the pool of listeners.
Parameters
-----------
func
The function that was used as a listener to remove.
name: :class:`str`
The name of the event we want to remove. Defaults to
``func.__name__``.
"""
name = func.__name__ if name is MISSING else name
if name in self.extra_events:
try:
self.extra_events[name].remove(func)
except ValueError:
pass
def listen(self, name: str = MISSING) -> Callable[[CFT], CFT]:
"""A decorator that registers another function as an external
event listener. Basically this allows you to listen to multiple
events from different places e.g. such as :func:`.on_ready`
The functions being listened to must be a :ref:`coroutine <coroutine>`.
Example
--------
.. code-block:: python3
@bot.listen()
async def on_message(message):
print('one')
# in some other file...
@bot.listen('on_message')
async def my_message(message):
print('two')
Would print one and two in an unspecified order.
Raises
-------
TypeError
The function being listened to is not a coroutine.
"""
def decorator(func: CFT) -> CFT:
self.add_listener(func, name)
return func
return decorator
# cogs
def add_cog(self, cog: Cog, *, override: bool = False) -> None:
"""Adds a "cog" to the bot.
A cog is a class that has its own event listeners and commands.
.. versionchanged:: 2.0
:exc:`.ClientException` is raised when a cog with the same name
is already loaded.
Parameters
-----------
cog: :class:`.Cog`
The cog to register to the bot.
override: :class:`bool`
If a previously loaded cog with the same name should be ejected
instead of raising an error.
.. versionadded:: 2.0
Raises
-------
TypeError
The cog does not inherit from :class:`.Cog`.
CommandError
An error happened during loading.
.ClientException
A cog with the same name is already loaded.
"""
if not isinstance(cog, Cog):
raise TypeError('cogs must derive from Cog')
cog_name = cog.__cog_name__
existing = self.__cogs.get(cog_name)
if existing is not None:
if not override:
raise discord.ClientException(f'Cog named {cog_name!r} already loaded')
self.remove_cog(cog_name)
cog = cog._inject(self)
self.__cogs[cog_name] = cog
def get_cog(self, name: str) -> Optional[Cog]:
"""Gets the cog instance requested.
If the cog is not found, ``None`` is returned instead.
Parameters
-----------
name: :class:`str`
The name of the cog you are requesting.
This is equivalent to the name passed via keyword
argument in class creation or the class name if unspecified.
Returns
--------
Optional[:class:`Cog`]
The cog that was requested. If not found, returns ``None``.
"""
return self.__cogs.get(name)
def remove_cog(self, name: str) -> Optional[Cog]:
"""Removes a cog from the bot and returns it.
All registered commands and event listeners that the
cog has registered will be removed as well.
If no cog is found then this method has no effect.
Parameters
-----------
name: :class:`str`
The name of the cog to remove.
Returns
-------
Optional[:class:`.Cog`]
The cog that was removed. ``None`` if not found.
"""
cog = self.__cogs.pop(name, None)
if cog is None:
return
help_command = self._help_command
if help_command and help_command.cog is cog:
help_command.cog = None
cog._eject(self)
return cog
@property
def cogs(self) -> Mapping[str, Cog]:
"""Mapping[:class:`str`, :class:`Cog`]: A read-only mapping of cog name to cog."""
return types.MappingProxyType(self.__cogs)
# extensions
def _remove_module_references(self, name: str) -> None:
# find all references to the module
# remove the cogs registered from the module
for cogname, cog in self.__cogs.copy().items():
if _is_submodule(name, cog.__module__):
self.remove_cog(cogname)
# remove all the commands from the module
for cmd in self.all_commands.copy().values():
if cmd.module is not None and _is_submodule(name, cmd.module):
if isinstance(cmd, GroupMixin):
cmd.recursively_remove_all_commands()
self.remove_command(cmd.name)
# remove all the listeners from the module
for event_list in self.extra_events.copy().values():
remove = []
for index, event in enumerate(event_list):
if event.__module__ is not None and _is_submodule(name, event.__module__):
remove.append(index)
for index in reversed(remove):
del event_list[index]
def _call_module_finalizers(self, lib: types.ModuleType, key: str) -> None:
try:
func = getattr(lib, 'teardown')
except AttributeError:
pass
else:
try:
func(self)
except Exception:
pass
finally:
self.__extensions.pop(key, None)
sys.modules.pop(key, None)
name = lib.__name__
for module in list(sys.modules.keys()):
if _is_submodule(name, module):
del sys.modules[module]
def _load_from_module_spec(self, spec: importlib.machinery.ModuleSpec, key: str) -> None:
# precondition: key not in self.__extensions
lib = importlib.util.module_from_spec(spec)
sys.modules[key] = lib
try:
spec.loader.exec_module(lib) # type: ignore
except Exception as e:
del sys.modules[key]
raise errors.ExtensionFailed(key, e) from e
try:
setup = getattr(lib, 'setup')
except AttributeError:
del sys.modules[key]
raise errors.NoEntryPointError(key)
try:
setup(self)
except Exception as e:
del sys.modules[key]
self._remove_module_references(lib.__name__)
self._call_module_finalizers(lib, key)
raise errors.ExtensionFailed(key, e) from e
else:
self.__extensions[key] = lib
def _resolve_name(self, name: str, package: Optional[str]) -> str:
try:
return importlib.util.resolve_name(name, package)
except ImportError:
raise errors.ExtensionNotFound(name)
def load_extension(self, name: str, *, package: Optional[str] = None) -> None:
"""Loads an extension.
An extension is a python module that contains commands, cogs, or
listeners.
An extension must have a global function, ``setup`` defined as
the entry point on what to do when the extension is loaded. This entry
point must have a single argument, the ``bot``.
Parameters
------------
name: :class:`str`
The extension name to load. It must be dot separated like
regular Python imports if accessing a sub-module. e.g.
``foo.test`` if you want to import ``foo/test.py``.
package: Optional[:class:`str`]
The package name to resolve relative imports with.
This is required when loading an extension using a relative path, e.g ``.foo.test``.
Defaults to ``None``.
.. versionadded:: 1.7
Raises
--------
ExtensionNotFound
The extension could not be imported.
This is also raised if the name of the extension could not
be resolved using the provided ``package`` parameter.
ExtensionAlreadyLoaded
The extension is already loaded.
NoEntryPointError
The extension does not have a setup function.
ExtensionFailed
The extension or its setup function had an execution error.
"""
name = self._resolve_name(name, package)
if name in self.__extensions:
raise errors.ExtensionAlreadyLoaded(name)
spec = importlib.util.find_spec(name)
if spec is None:
raise errors.ExtensionNotFound(name)
self._load_from_module_spec(spec, name)
def unload_extension(self, name: str, *, package: Optional[str] = None) -> None:
"""Unloads an extension.
When the extension is unloaded, all commands, listeners, and cogs are
removed from the bot and the module is un-imported.
The extension can provide an optional global function, ``teardown``,
to do miscellaneous clean-up if necessary. This function takes a single
parameter, the ``bot``, similar to ``setup`` from
:meth:`~.Bot.load_extension`.
Parameters
------------
name: :class:`str`
The extension name to unload. It must be dot separated like
regular Python imports if accessing a sub-module. e.g.
``foo.test`` if you want to import ``foo/test.py``.
package: Optional[:class:`str`]
The package name to resolve relative imports with.
This is required when unloading an extension using a relative path, e.g ``.foo.test``.
Defaults to ``None``.
.. versionadded:: 1.7
Raises
-------
ExtensionNotFound
The name of the extension could not
be resolved using the provided ``package`` parameter.
ExtensionNotLoaded
The extension was not loaded.
"""
name = self._resolve_name(name, package)
lib = self.__extensions.get(name)
if lib is None:
raise errors.ExtensionNotLoaded(name)
self._remove_module_references(lib.__name__)
self._call_module_finalizers(lib, name)
def reload_extension(self, name: str, *, package: Optional[str] = None) -> None:
"""Atomically reloads an extension.
This replaces the extension with the same extension, only refreshed. This is
equivalent to a :meth:`unload_extension` followed by a :meth:`load_extension`
except done in an atomic way. That is, if an operation fails mid-reload then
the bot will roll-back to the prior working state.
Parameters
------------
name: :class:`str`
The extension name to reload. It must be dot separated like
regular Python imports if accessing a sub-module. e.g.
``foo.test`` if you want to import ``foo/test.py``.
package: Optional[:class:`str`]
The package name to resolve relative imports with.
This is required when reloading an extension using a relative path, e.g ``.foo.test``.
Defaults to ``None``.
.. versionadded:: 1.7
Raises
-------
ExtensionNotLoaded
The extension was not loaded.
ExtensionNotFound
The extension could not be imported.
This is also raised if the name of the extension could not
be resolved using the provided ``package`` parameter.
NoEntryPointError
The extension does not have a setup function.
ExtensionFailed
The extension setup function had an execution error.
"""
name = self._resolve_name(name, package)
lib = self.__extensions.get(name)
if lib is None:
raise errors.ExtensionNotLoaded(name)
# get the previous module states from sys modules
modules = {
name: module
for name, module in sys.modules.items()
if _is_submodule(lib.__name__, name)
}
try:
# Unload and then load the module...
self._remove_module_references(lib.__name__)
self._call_module_finalizers(lib, name)
self.load_extension(name)
except Exception:
# if the load failed, the remnants should have been
# cleaned from the load_extension function call
# so let's load it from our old compiled library.
lib.setup(self) # type: ignore
self.__extensions[name] = lib
# revert sys.modules back to normal and raise back to caller
sys.modules.update(modules)
raise
@property
def extensions(self) -> Mapping[str, types.ModuleType]:
"""Mapping[:class:`str`, :class:`py:types.ModuleType`]: A read-only mapping of extension name to extension."""
return types.MappingProxyType(self.__extensions)
# help command stuff
@property
def help_command(self) -> Optional[HelpCommand]:
return self._help_command
@help_command.setter
def help_command(self, value: Optional[HelpCommand]) -> None:
if value is not None:
if not isinstance(value, HelpCommand):
raise TypeError('help_command must be a subclass of HelpCommand')
if self._help_command is not None:
self._help_command._remove_from_bot(self)
self._help_command = value
value._add_to_bot(self)
elif self._help_command is not None:
self._help_command._remove_from_bot(self)
self._help_command = None
else:
self._help_command = None
# command processing
async def get_prefix(self, message: Message) -> Union[List[str], str]:
"""|coro|
Retrieves the prefix the bot is listening to
with the message as a context.
Parameters
-----------
message: :class:`discord.Message`
The message context to get the prefix of.
Returns
--------
Union[List[:class:`str`], :class:`str`]
A list of prefixes or a single prefix that the bot is
listening for.
"""
prefix = ret = self.command_prefix
if callable(prefix):
ret = await discord.utils.maybe_coroutine(prefix, self, message)
if not isinstance(ret, str):
try:
ret = list(ret)
except TypeError:
# It's possible that a generator raised this exception. Don't
# replace it with our own error if that's the case.
if isinstance(ret, collections.abc.Iterable):
raise
raise TypeError("command_prefix must be plain string, iterable of strings, or callable "
f"returning either of these, not {ret.__class__.__name__}")
if not ret:
raise ValueError("Iterable command_prefix must contain at least one prefix")
return ret
async def get_context(self, message: Message, *, cls: Type[CXT] = Context) -> CXT:
r"""|coro|
Returns the invocation context from the message.
This is a more low-level counter-part for :meth:`.process_commands`
to allow users more fine grained control over the processing.
The returned context is not guaranteed to be a valid invocation
context, :attr:`.Context.valid` must be checked to make sure it is.
If the context is not valid then it is not a valid candidate to be
invoked under :meth:`~.Bot.invoke`.
Parameters
-----------
message: :class:`discord.Message`
The message to get the invocation context from.
cls
The factory class that will be used to create the context.
By default, this is :class:`.Context`. Should a custom
class be provided, it must be similar enough to :class:`.Context`\'s
interface.
Returns
--------
:class:`.Context`
The invocation context. The type of this can change via the
``cls`` parameter.
"""
view = StringView(message.content)
ctx = cls(prefix=None, view=view, bot=self, message=message)
if message.author.id == self.user.id: # type: ignore
return ctx
prefix = await self.get_prefix(message)
invoked_prefix = prefix
if isinstance(prefix, str):
if not view.skip_string(prefix):
return ctx
else:
try:
# if the context class' __init__ consumes something from the view this
# will be wrong. That seems unreasonable though.
if message.content.startswith(tuple(prefix)):
invoked_prefix = discord.utils.find(view.skip_string, prefix)
else:
return ctx
except TypeError:
if not isinstance(prefix, list):
raise TypeError("get_prefix must return either a string or a list of string, "
f"not {prefix.__class__.__name__}")
# It's possible a bad command_prefix got us here.
for value in prefix:
if not isinstance(value, str):
raise TypeError("Iterable command_prefix or list returned from get_prefix must "
f"contain only strings, not {value.__class__.__name__}")
# Getting here shouldn't happen
raise
if self.strip_after_prefix:
view.skip_ws()
invoker = view.get_word()
ctx.invoked_with = invoker
# type-checker fails to narrow invoked_prefix type.
ctx.prefix = invoked_prefix # type: ignore
ctx.command = self.all_commands.get(invoker)
return ctx
async def invoke(self, ctx: Context) -> None:
"""|coro|
Invokes the command given under the invocation context and
handles all the internal event dispatch mechanisms.
Parameters
-----------
ctx: :class:`.Context`
The invocation context to invoke.
"""
if ctx.command is not None:
self.dispatch('command', ctx)
try:
if await self.can_run(ctx, call_once=True):
await ctx.command.invoke(ctx)
else:
raise errors.CheckFailure('The global check once functions failed.')
except errors.CommandError as exc:
await ctx.command.dispatch_error(ctx, exc)
else:
self.dispatch('command_completion', ctx)
elif ctx.invoked_with:
exc = errors.CommandNotFound(f'Command "{ctx.invoked_with}" is not found')
self.dispatch('command_error', ctx, exc)
async def process_commands(self, message: Message) -> None:
"""|coro|
This function processes the commands that have been registered
to the bot and other groups. Without this coroutine, none of the
commands will be triggered.
By default, this coroutine is called inside the :func:`.on_message`
event. If you choose to override the :func:`.on_message` event, then
you should invoke this coroutine as well.
This is built using other low level tools, and is equivalent to a
call to :meth:`~.Bot.get_context` followed by a call to :meth:`~.Bot.invoke`.
This also checks if the message's author is a bot and doesn't
call :meth:`~.Bot.get_context` or :meth:`~.Bot.invoke` if so.
Parameters
-----------
message: :class:`discord.Message`
The message to process commands for.
"""
if message.author.bot:
return
ctx = await self.get_context(message)
await self.invoke(ctx)
async def on_message(self, message):
await self.process_commands(message)
class Bot(BotBase, discord.Client):
"""Represents a discord bot.
This class is a subclass of :class:`discord.Client` and as a result
anything that you can do with a :class:`discord.Client` you can do with
this bot.
This class also subclasses :class:`.GroupMixin` to provide the functionality
to manage commands.
Attributes
-----------
command_prefix
The command prefix is what the message content must contain initially
to have a command invoked. This prefix could either be a string to
indicate what the prefix should be, or a callable that takes in the bot
as its first parameter and :class:`discord.Message` as its second
parameter and returns the prefix. This is to facilitate "dynamic"
command prefixes. This callable can be either a regular function or
a coroutine.
An empty string as the prefix always matches, enabling prefix-less
command invocation. While this may be useful in DMs it should be avoided
in servers, as it's likely to cause performance issues and unintended
command invocations.
The command prefix could also be an iterable of strings indicating that
multiple checks for the prefix should be used and the first one to
match will be the invocation prefix. You can get this prefix via
:attr:`.Context.prefix`. To avoid confusion empty iterables are not
allowed.
.. note::
When passing multiple prefixes be careful to not pass a prefix
that matches a longer prefix occurring later in the sequence. For
example, if the command prefix is ``('!', '!?')`` the ``'!?'``
prefix will never be matched to any message as the previous one
matches messages starting with ``!?``. This is especially important
when passing an empty string, it should always be last as no prefix
after it will be matched.
case_insensitive: :class:`bool`
Whether the commands should be case insensitive. Defaults to ``False``. This
attribute does not carry over to groups. You must set it to every group if
you require group commands to be case insensitive as well.
description: :class:`str`
The content prefixed into the default help message.
help_command: Optional[:class:`.HelpCommand`]
The help command implementation to use. This can be dynamically
set at runtime. To remove the help command pass ``None``. For more
information on implementing a help command, see :ref:`ext_commands_help_command`.
owner_id: Optional[:class:`int`]
The user ID that owns the bot. If this is not set and is then queried via
:meth:`.is_owner` then it is fetched automatically using
:meth:`~.Bot.application_info`.
owner_ids: Optional[Collection[:class:`int`]]
The user IDs that owns the bot. This is similar to :attr:`owner_id`.
If this is not set and the application is team based, then it is
fetched automatically using :meth:`~.Bot.application_info`.
For performance reasons it is recommended to use a :class:`set`
for the collection. You cannot set both ``owner_id`` and ``owner_ids``.
.. versionadded:: 1.3
strip_after_prefix: :class:`bool`
Whether to strip whitespace characters after encountering the command
prefix. This allows for ``! hello`` and ``!hello`` to both work if
the ``command_prefix`` is set to ``!``. Defaults to ``False``.
.. versionadded:: 1.7
"""
pass
class AutoShardedBot(BotBase, discord.AutoShardedClient):
"""This is similar to :class:`.Bot` except that it is inherited from
:class:`discord.AutoShardedClient` instead.
"""
pass | zarenacord.py | /zarenacord.py-2.0.0-py3-none-any.whl/discord/ext/commands/bot.py | bot.py |
===============================================================
Converter for Zarnegar Encoding and File Format to Unicode Text
===============================================================
Homepage: https://github.com/behnam/python-zarnegar-converter
`Zarnegar`_ (Persian: *زرنگار*, zarnegār, meaning gold-depicting) is a
commercial, stand-alone Persian/Arabic word processor program developed for
MS-DOS and Windows. The first version of Zarnegar (for DOS), was released in
April-May 1991, and Windows versions have been available since 2000.
Zarnegar has employed two different character sets and file formats.
-----------------------
Zarnegar1 Character Set
-----------------------
Zarnegar used an `Iran System`_-based character encoding system, named
*Zarnegar1*, with text file formats for its early versions, up to its "Zarnegar
75" version. *Zarnegar1* character set is a *2-form left-to-right visual
encoding*, meaning the every `Perso-Arabic`_ letter receives different
character codes based on its cursive joining form, but most letters receive
only 2 forms, because of the limited code-points available2 forms, because of
the limited code-points available.
This project has a partial implementation of `Zarnegar1`_ encoding
(`zarnegar_converter/zar1_encoding.py`) and a full implementation of its binary
and text file formats (`zarnegar_converter/zar1_file.py`).
------------------------
Zarnegar75 Character Set
------------------------
With "Zarnegar 75" version of the program, a new character encoding system was
introduced, and the file format was changed to another binary format.
*Zarnegar75* character set is a 4-form bidirectional encoding, meaning that
every `Perso-Arabic`_ letter receives one, two, or four character code,
depending on its cursive joining form, and these letters are stored in the
memory in the semantic order.
Support for *Zarnegar75* file format and encoding is still in progress.
----------
How to Use
----------
.. code:: bash
$ ./src/zarnegar-converter.py unicode_legacy_lro samples/zar1-sample-text-01.zar
ﻡﺎﯾﺧ ﺕﺎﯾﻋﺎﺑﺭ ﻩﺭﺎﺑﺭﺩ |
ﯽﻧﭘﺍﮊ ﺭﻌﺷ ﺭﺩ ﻭﮐﯾﺎﻫ |
-----------------
How to Contribute
-----------------
Please report any issues at
<https://github.com/behnam/python-zarnegar-converter/issues> or submit GitHub
pull requests.
The encoding mappings (both Zarnegar1 and Zarnegar75) can be improved with
access to more sample files. Please write to <[email protected]> if you like to
contribute (private or public) Zarnegar source files to improve this project.
----------------
Acknowledgements
----------------
Thanks to `Cecil H. Green Library`_ of Stanford University, specially John A
Eilts and Behzad Allahyar, for sharing their collection of Zarnegar documents.
Also thanks to `The Official Website of Ahmad Shamlou`_ for sharing their
collection of documents.
------------
Legal Notice
------------
*Zarnegar* is a trademark of *SinaSoft Corporation*. This project is NOT
affiliated with SinaSoft Corporation.
Copyright (C) 2017 Behnam Esfahbod
This program is free software: you can redistribute it and/or modify it under
the terms of the GNU General Public License as published by the Free Software
Foundation, either version 3 of the License, or (at your option) any later
version.
This program is distributed in the hope that it will be useful, but WITHOUT ANY
WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS FOR A
PARTICULAR PURPOSE. See the GNU General Public License for more details.
.. _Zarnegar: https://en.wikipedia.org/wiki/Zarnegar_(word_processor)
.. _Zarnegar1: https://en.wikipedia.org/wiki/Zarnegar1
.. _Iran System: https://en.wikipedia.org/wiki/Iran_System_encoding
.. _Perso-Arabic: https://en.wikipedia.org/wiki/Perso-Arabic
.. _Cecil H. Green Library: https://library.stanford.edu/green
.. _The Official Website of Ahmad Shamlou: http://shamlou.org/
| zarnegar-converter | /zarnegar-converter-0.1.3.tar.gz/zarnegar-converter-0.1.3/README.rst | README.rst |
# Copyright (C) 2017 Behnam Esfahbod
#
# This program is free software: you can redistribute it and/or modify
# it under the terms of the GNU General Public License as published by
# the Free Software Foundation, either version 3 of the License, or
# (at your option) any later version.
#
# This program is distributed in the hope that it will be useful,
# but WITHOUT ANY WARRANTY; without even the implied warranty of
# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
# GNU General Public License for more details.
#
# You should have received a copy of the GNU General Public License
# along with this program. If not, see <http://www.gnu.org/licenses/>.
#
# Author(s): Behnam Esfahbod <[email protected]>
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
from __future__ import unicode_literals
import sys
import os
import logging
from zarnegar_converter.zar_file import ZarFile
"""
Converter for Zarnegar Encoding and File Format to Unicode Text
"""
_USAGE = '''\
Converter for Zarnegar Encoding and File Format to Unicode Text
Usage: %s <output-format> [<input-file> [<output-file> [<log-file>]]]
Arguments:
output-format desired output format (see list below)
input-file path to input file (default: stdin)
output-file path to output file (default: stdout)
log-file path to log file (default: stderr)
Output Formats:
* unicode_rlo Unicode Arabic semantic (standard) encoding, in Right-to-Left Override order
* unicode_lro Unicode Arabic semantic (standard) encoding, in Left-to-Right Override order
* unicode_legacy_lro Legacy Unicoe Arabic Presentation Form encoding, in Right-to-Left Override order
* unicode_legacy_rlo Legacy Unicoe Arabic Presentation Form encoding, in Left-to-Right Override order
* zar1_text Zar1 encoded (text file)
'''
def get_output_bytes(
output_format,
zar_file,
):
# Zar1
if output_format == 'zar1_text':
return zar_file.get_zar1_text_output()
# Unicode Legacy
if output_format == 'unicode_legacy_lro':
return zar_file.get_unicode_legacy_lro_output().encode('utf8')
if output_format == 'unicode_legacy_rlo':
return zar_file.get_unicode_legacy_rlo_output().encode('utf8')
# Unicode Semantic
if output_format == 'unicode_lro':
return zar_file.get_unicode_lro_output().encode('utf8')
if output_format == 'unicode_rlo':
return zar_file.get_unicode_rlo_output().encode('utf8')
raise UsageError("invalid output format: %s" % output_format)
def convert_and_write(
output_format,
in_file,
out_file,
):
zar_file = ZarFile.get(in_file)
out_file.write(get_output_bytes(output_format, zar_file))
def main(
output_format,
in_filename=None,
out_filename=None,
log_filename=None,
):
logging.basicConfig(level=logging.WARNING)
if log_filename:
logging.basicConfig(
filename=log_filename,
level=logging.DEBUG,
filemode='w',
)
in_file = None
out_file = None
try:
in_file = open(in_filename, 'r') if in_filename else sys.stdin
out_file = open(out_filename, 'w') if out_filename else sys.stdout
convert_and_write(output_format, in_file, out_file)
except IOError:
if not in_file:
raise IOError("cannot read from input file: %s" % in_filename)
if not out_file:
raise IOError("cannot write to output file: %s" % out_filename)
finally:
if in_filename and in_file:
in_file.close()
if out_filename and out_file:
out_file.close()
class UsageError (Exception):
pass
def error(err_file, err):
err_file.write("Error: %s%s" % (err, os.linesep))
err_file.write(os.linesep)
def usage(err_file, script_name):
err_file.write(_USAGE % script_name)
if __name__=='__main__':
try:
if len(sys.argv) < 2 or len(sys.argv) > 5:
raise UsageError("invalid arguments")
main(*sys.argv[1:])
except UsageError as err:
error(sys.stderr, err)
usage(sys.stderr, os.path.basename(sys.argv[0]))
exit(1)
except IOError as err:
error(sys.stderr, err)
exit(2) | zarnegar-converter | /zarnegar-converter-0.1.3.tar.gz/zarnegar-converter-0.1.3/src/zarnegar-converter.py | zarnegar-converter.py |
# Copyright (C) 2017 Behnam Esfahbod
#
# This program is free software: you can redistribute it and/or modify
# it under the terms of the GNU General Public License as published by
# the Free Software Foundation, either version 3 of the License, or
# (at your option) any later version.
#
# This program is distributed in the hope that it will be useful,
# but WITHOUT ANY WARRANTY; without even the implied warranty of
# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
# GNU General Public License for more details.
#
# You should have received a copy of the GNU General Public License
# along with this program. If not, see <http://www.gnu.org/licenses/>.
#
# Author(s): Behnam Esfahbod <[email protected]>
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
from __future__ import unicode_literals
from zarnegar_converter import unicode_bidi
from zarnegar_converter.unicode_joining import remove_useless_joining_control_chars, ZWNJ, ZWJ as ZWJ_
"""
Convert Unicode Arabic Presentation Form to semantic Unicode Arabic
"""
# U+ARABIC HAMZA ABOVE U+0654 does not have any presentation form encoded in
# the Unicode, therefore we use a PUA code point here.
#
# See also: http://www.unicode.org/L2/L2017/17149-hamza-above-isolated.pdf
ARABIC_HAMZA_ABOVE_ISOLATED_FORM_PUA = 0xF8FD
_AHAIF = ARABIC_HAMZA_ABOVE_ISOLATED_FORM_PUA
_LEGACY_TO_SEMANTIC_MAP = {
# 1-Shape Letters
0xFB8A: 0x0698, # ARABIC LETTER JEH
0xFE80: 0x0621, # ARABIC LETTER HAMZA
0xFEA9: 0x062F, # ARABIC LETTER DAL
0xFEAB: 0x0630, # ARABIC LETTER THAL
0xFEAD: 0x0631, # ARABIC LETTER REH
0xFEAF: 0x0632, # ARABIC LETTER ZAIN
0xFEC1: 0x0637, # ARABIC LETTER TAH
0xFEC5: 0x0638, # ARABIC LETTER ZAH
0xFEED: 0x0648, # ARABIC LETTER WAW
# 2-Shape Letters: ALEF
0xFE8D: [0x0627, ZWNJ], # ARABIC LETTER ALEF (isolated form)
0xFE8E: [0x0627, ZWJ_], # ARABIC LETTER ALEF (final form)
# 2-Shape Letters: Others
0xFE8F: [ZWNJ, 0x0628], # ARABIC LETTER BEH (final-isolated form)
0xFE91: [ZWJ_, 0x0628], # ARABIC LETTER BEH (initial-medial form)
0xFB56: [ZWNJ, 0x067E], # ARABIC LETTER PEH (final-isolated form)
0xFB58: [ZWJ_, 0x067E], # ARABIC LETTER PEH (initial-medial form)
0xFE95: [ZWNJ, 0x062A], # ARABIC LETTER TEH (final-isolated form)
0xFE97: [ZWJ_, 0x062A], # ARABIC LETTER TEH (initial-medial form)
0xFE99: [ZWNJ, 0x062B], # ARABIC LETTER THEH (final-isolated form)
0xFE9B: [ZWJ_, 0x062B], # ARABIC LETTER THEH (initial-medial form)
0xFE9D: [ZWNJ, 0x062C], # ARABIC LETTER JEEM (final-isolated form)
0xFE9F: [ZWJ_, 0x062C], # ARABIC LETTER JEEM (initial-medial form)
0xFB7A: [ZWNJ, 0x0686], # ARABIC LETTER TCHEH (final-isolated form)
0xFB7C: [ZWJ_, 0x0686], # ARABIC LETTER TCHEH (initial-medial form)
0xFEA1: [ZWNJ, 0x062D], # ARABIC LETTER HAH (final-isolated form)
0xFEA3: [ZWJ_, 0x062D], # ARABIC LETTER HAH (initial-medial form)
0xFEA5: [ZWNJ, 0x062E], # ARABIC LETTER KHAH (final-isolated form)
0xFEA7: [ZWJ_, 0x062E], # ARABIC LETTER KHAH (initial-medial form)
0xFEB1: [ZWNJ, 0x0633], # ARABIC LETTER SEEN (final-isolated form)
0xFEB3: [ZWJ_, 0x0633], # ARABIC LETTER SEEN (initial-medial form)
0xFEB5: [ZWNJ, 0x0634], # ARABIC LETTER SHEEN (final-isolated form)
0xFEB7: [ZWJ_, 0x0634], # ARABIC LETTER SHEEN (initial-medial form)
0xFEB9: [ZWNJ, 0x0635], # ARABIC LETTER SAD (final-isolated form)
0xFEBB: [ZWJ_, 0x0635], # ARABIC LETTER SAD (initial-medial form)
0xFEBD: [ZWNJ, 0x0636], # ARABIC LETTER DAD (final-isolated form)
0xFEBF: [ZWJ_, 0x0636], # ARABIC LETTER DAD (initial-medial form)
0xFED1: [ZWNJ, 0x0641], # ARABIC LETTER FEH (final-isolated form)
0xFED3: [ZWJ_, 0x0641], # ARABIC LETTER FEH (initial-medial form)
0xFED5: [ZWNJ, 0x0642], # ARABIC LETTER QAF (final-isolated form)
0xFED7: [ZWJ_, 0x0642], # ARABIC LETTER QAF (initial-medial form)
0xFB8E: [ZWNJ, 0x06A9], # ARABIC LETTER KEHEH (final-isolated form)
0xFB90: [ZWJ_, 0x06A9], # ARABIC LETTER KEHEH (initial-medial form)
0xFB92: [ZWNJ, 0x06AF], # ARABIC LETTER GAF (final-isolated form)
0xFB94: [ZWJ_, 0x06AF], # ARABIC LETTER GAF (initial-medial form)
0xFEDD: [ZWNJ, 0x0644], # ARABIC LETTER LAM (final-isolated form)
0xFEDF: [ZWJ_, 0x0644], # ARABIC LETTER LAM (initial-medial form)
0xFEE1: [ZWNJ, 0x0645], # ARABIC LETTER MEEM (final-isolated form)
0xFEE3: [ZWJ_, 0x0645], # ARABIC LETTER MEEM (initial-medial form)
0xFEE5: [ZWNJ, 0x0646], # ARABIC LETTER NOON (final-isolated form)
0xFEE7: [ZWJ_, 0x0646], # ARABIC LETTER NOON (initial-medial form)
# 3-Shape Letters
0xFEE9: [ZWNJ, 0x0647], # ARABIC LETTER HEH (final-isolated form)
0xFEEB: [ZWJ_, 0x0647, ZWNJ], # ARABIC LETTER HEH (initial form)
0xFEEC: [ZWJ_, 0x0647, ZWJ_], # ARABIC LETTER HEH (medial form)
0xFBFC: [ZWNJ, 0x06CC, ZWNJ], # ARABIC LETTER FARSI YEH (isolated form)
0xFBFD: [ZWNJ, 0x06CC, ZWJ_], # ARABIC LETTER FARSI YEH (final form)
0xFBFE: [ZWJ_, 0x06CC], # ARABIC LETTER FARSI YEH (initial-medial form)
# 4-Shape Letters
0xFEC9: [ZWNJ, 0x0639, ZWNJ], # ARABIC LETTER AIN (isolated form)
0xFECA: [ZWNJ, 0x0639, ZWJ_], # ARABIC LETTER AIN (final form)
0xFECB: [ZWJ_, 0x0639, ZWNJ], # ARABIC LETTER AIN (initial form)
0xFECC: [ZWJ_, 0x0639, ZWJ_], # ARABIC LETTER AIN (medial form)
0xFECD: [ZWNJ, 0x063A, ZWNJ], # ARABIC LETTER GHAIN (isolated form)
0xFECE: [ZWNJ, 0x063A, ZWJ_], # ARABIC LETTER GHAIN (final form)
0xFECF: [ZWJ_, 0x063A, ZWNJ], # ARABIC LETTER GHAIN (initial form)
0xFED0: [ZWJ_, 0x063A, ZWJ_], # ARABIC LETTER GHAIN (medial form)
# Others Letters
0xFE81: [0x0622, ZWNJ], # ARABIC LETTER ALEF WITH MADDA ABOVE (isolated form)
0xFE8B: [ZWJ_, 0x0626], # ARABIC LETTER YEH WITH HAMZA ABOVE (initial-medial form)
0xFEFB: [0x0627, 0x0644], # ARABIC LIGATURE LAM WITH ALEF
# Diacritics
0xFE70: 0x064B, # ARABIC FATHATAN (mark)
0xFE72: 0x064C, # ARABIC DAMMATAN (mark)
0xFE76: 0x064E, # ARABIC FATHA (mark)
0xFE78: 0x064F, # ARABIC DAMMA (mark)
0xFE7A: 0x0650, # ARABIC KASRA (mark)
0xFE7C: 0x0651, # ARABIC SHADDA (mark)
0xFE7E: 0x0652, # ARABIC SUKUN (mark)
_AHAIF: 0x0654, # ARABIC HAMZA ABOVE (mark)
}
def convert_legacy_char_to_semantic_lro(legacy_char, line_no):
codepoints = _LEGACY_TO_SEMANTIC_MAP.get(ord(legacy_char), ord(legacy_char))
if type(codepoints) is int:
return unichr(codepoints)
if type(codepoints) is list:
return ''.join(map(lambda cp: unichr(cp), codepoints))
raise Error("invalid map value")
def convert_legacy_line_to_semantic_lro(legacy_text, line_no):
semantic_text = ''.join([
convert_legacy_char_to_semantic_lro(legacy_char, line_no)
for legacy_char in legacy_text
])
return remove_useless_joining_control_chars(semantic_text) | zarnegar-converter | /zarnegar-converter-0.1.3.tar.gz/zarnegar-converter-0.1.3/src/zarnegar_converter/unicode_arabic.py | unicode_arabic.py |
# Copyright (C) 2017 Behnam Esfahbod
#
# This program is free software: you can redistribute it and/or modify
# it under the terms of the GNU General Public License as published by
# the Free Software Foundation, either version 3 of the License, or
# (at your option) any later version.
#
# This program is distributed in the hope that it will be useful,
# but WITHOUT ANY WARRANTY; without even the implied warranty of
# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
# GNU General Public License for more details.
#
# You should have received a copy of the GNU General Public License
# along with this program. If not, see <http://www.gnu.org/licenses/>.
#
# Author(s): Behnam Esfahbod <[email protected]>
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
from __future__ import unicode_literals
"""
Unicode Arabic Joining helpers for Zarnegar Encoding
"""
ZWNJ = 0x200C # ZERO-WIDTH NON-JOINER
ZWJ = 0x200D # ZERO-WIDTH JOINER
ZWNJ_CHAR = "\u200C" # ZERO-WIDTH NON-JOINER
ZWJ_CHAR = "\u200D" # ZERO-WIDTH JOINER
LEFT_JOINER = [
0x0626, # ARABIC LETTER YEH WITH HAMZA ABOVE
0x0628, # ARABIC LETTER BEH
0x062A, # ARABIC LETTER TEH
0x062B, # ARABIC LETTER THEH
0x062C, # ARABIC LETTER JEEM
0x062D, # ARABIC LETTER HAH
0x062E, # ARABIC LETTER KHAH
0x0633, # ARABIC LETTER SEEN
0x0634, # ARABIC LETTER SHEEN
0x0635, # ARABIC LETTER SAD
0x0636, # ARABIC LETTER DAD
0x0637, # ARABIC LETTER TAH
0x0638, # ARABIC LETTER ZAH
0x0639, # ARABIC LETTER AIN
0x063A, # ARABIC LETTER GHAIN
0x0640, # ARABIC TATWEEL
0x0641, # ARABIC LETTER FEH
0x0642, # ARABIC LETTER QAF
0x0644, # ARABIC LETTER LAM
0x0645, # ARABIC LETTER MEEM
0x0646, # ARABIC LETTER NOON
0x0647, # ARABIC LETTER HEH
0x067E, # ARABIC LETTER PEH
0x0686, # ARABIC LETTER TCHEH
0x06A9, # ARABIC LETTER KEHEH
0x06AF, # ARABIC LETTER GAF
0x06CC, # ARABIC LETTER FARSI YEH
ZWJ,
]
RIGHT_JOINER = [
0x0622, # ARABIC LETTER ALEF WITH MADDA ABOVE
0x0626, # ARABIC LETTER YEH WITH HAMZA ABOVE
0x0627, # ARABIC LETTER ALEF
0x0628, # ARABIC LETTER BEH
0x062A, # ARABIC LETTER TEH
0x062B, # ARABIC LETTER THEH
0x062C, # ARABIC LETTER JEEM
0x062D, # ARABIC LETTER HAH
0x062E, # ARABIC LETTER KHAH
0x062F, # ARABIC LETTER DAL
0x0630, # ARABIC LETTER THAL
0x0631, # ARABIC LETTER REH
0x0632, # ARABIC LETTER ZAIN
0x0633, # ARABIC LETTER SEEN
0x0634, # ARABIC LETTER SHEEN
0x0635, # ARABIC LETTER SAD
0x0636, # ARABIC LETTER DAD
0x0637, # ARABIC LETTER TAH
0x0638, # ARABIC LETTER ZAH
0x0639, # ARABIC LETTER AIN
0x063A, # ARABIC LETTER GHAIN
0x0640, # ARABIC TATWEEL
0x0641, # ARABIC LETTER FEH
0x0642, # ARABIC LETTER QAF
0x0644, # ARABIC LETTER LAM
0x0645, # ARABIC LETTER MEEM
0x0646, # ARABIC LETTER NOON
0x0647, # ARABIC LETTER HEH
0x0648, # ARABIC LETTER WAW
0x067E, # ARABIC LETTER PEH
0x0686, # ARABIC LETTER TCHEH
0x0698, # ARABIC LETTER JEH
0x06A9, # ARABIC LETTER KEHEH
0x06AF, # ARABIC LETTER GAF
0x06CC, # ARABIC LETTER FARSI YEH
ZWJ,
]
def is_zwnj(char):
return ord(char) == ZWNJ if char is not None else False
def is_zwj(char):
return ord(char) == ZWJ if char is not None else False
def is_left_joiner(char):
return ord(char) in LEFT_JOINER if char is not None else False
def is_right_joiner(char):
return ord(char) in RIGHT_JOINER if char is not None else False
# Applies to a Left-to-Right text
def remove_useless_joining_control_chars(text):
result = ''
text = text.replace(ZWNJ_CHAR + ZWNJ_CHAR, ZWNJ_CHAR)
text = text.replace(ZWJ_CHAR + ZWJ_CHAR, ZWJ_CHAR)
text_len = len(text)
for idx in range(text_len):
chr_on_left = text[idx - 1] if idx > 0 else None
chr_current = text[idx]
chr_on_right = text[idx + 1] if idx < text_len - 1 else None
if is_zwnj(chr_current):
if not (is_right_joiner(chr_on_left) and is_left_joiner(chr_on_right)):
continue
if is_zwj(chr_current):
if is_right_joiner(chr_on_left) and is_left_joiner(chr_on_right):
continue
result += chr_current
return result | zarnegar-converter | /zarnegar-converter-0.1.3.tar.gz/zarnegar-converter-0.1.3/src/zarnegar_converter/unicode_joining.py | unicode_joining.py |
# Copyright (C) 2017 Behnam Esfahbod
#
# This program is free software: you can redistribute it and/or modify
# it under the terms of the GNU General Public License as published by
# the Free Software Foundation, either version 3 of the License, or
# (at your option) any later version.
#
# This program is distributed in the hope that it will be useful,
# but WITHOUT ANY WARRANTY; without even the implied warranty of
# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
# GNU General Public License for more details.
#
# You should have received a copy of the GNU General Public License
# along with this program. If not, see <http://www.gnu.org/licenses/>.
#
# Author(s): Behnam Esfahbod <[email protected]>
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
from __future__ import unicode_literals
import sys
OUTPUT_NEW_LINE = b'\r\n'
class ZarFile(object):
@staticmethod
def get(in_file):
from zarnegar_converter.zar1_file import Zar1File
return Zar1File.get(in_file)
# == DEBUG ==
def get_debug(self):
raise NotImplementedError
# == Zar1, Text ==
def get_zar1_text_output(self):
raise NotImplementedError
def get_zar1_text_lines(self):
raise NotImplementedError
# == Unicode, Legacy ==
def get_unicode_legacy_lro_output(self):
raise NotImplementedError
def get_unicode_legacy_lro_lines(self):
raise NotImplementedError
def get_unicode_legacy_rlo_output(self):
raise NotImplementedError
def get_unicode_legacy_rlo_lines(self):
raise NotImplementedError
# == Unicode, Semantic, Left-to-Right Override ==
def get_unicode_lro_output(self):
raise NotImplementedError
def get_unicode_lro_lines(self):
raise NotImplementedError
# == Unicode, Semantic, Right-to-Left Override ==
def get_unicode_rlo_output(self):
raise NotImplementedError
def get_unicode_rlo_lines(self):
raise NotImplementedError
class ZarFileTypeError(Exception):
pass | zarnegar-converter | /zarnegar-converter-0.1.3.tar.gz/zarnegar-converter-0.1.3/src/zarnegar_converter/zar_file.py | zar_file.py |
# Copyright (C) 2017 Behnam Esfahbod
#
# This program is free software: you can redistribute it and/or modify
# it under the terms of the GNU General Public License as published by
# the Free Software Foundation, either version 3 of the License, or
# (at your option) any later version.
#
# This program is distributed in the hope that it will be useful,
# but WITHOUT ANY WARRANTY; without even the implied warranty of
# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
# GNU General Public License for more details.
#
# You should have received a copy of the GNU General Public License
# along with this program. If not, see <http://www.gnu.org/licenses/>.
#
# Author(s): Behnam Esfahbod <[email protected]>
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
from __future__ import unicode_literals
import logging
from zarnegar_converter import unicode_arabic
from zarnegar_converter import unicode_bidi
"""
Convert Zarnegar Encoding to Unicode Arabic Presentation Form
"""
_AHAIF = unicode_arabic.ARABIC_HAMZA_ABOVE_ISOLATED_FORM_PUA
_IRAN_SYSTEM_MAP = {
# Numerals
0x80: 0x06F0, # EXTENDED ARABIC-INDIC DIGIT ZERO
0x81: 0x06F1, # EXTENDED ARABIC-INDIC DIGIT ONE
0x82: 0x06F2, # EXTENDED ARABIC-INDIC DIGIT TWO
0x83: 0x06F3, # EXTENDED ARABIC-INDIC DIGIT THREE
0x84: 0x06F4, # EXTENDED ARABIC-INDIC DIGIT FOUR
0x85: 0x06F5, # EXTENDED ARABIC-INDIC DIGIT FIVE
0x86: 0x06F6, # EXTENDED ARABIC-INDIC DIGIT SIX
0x87: 0x06F7, # EXTENDED ARABIC-INDIC DIGIT SEVEN
0x88: 0x06F8, # EXTENDED ARABIC-INDIC DIGIT EIGHT
0x89: 0x06F9, # EXTENDED ARABIC-INDIC DIGIT NINE
# Punctuations
0x8A: 0x060C, # ARABIC COMMA
0x8B: 0x0640, # ARABIC TATWEEL
0x8C: 0x061F, # ARABIC QUESTION MARK
# Letters
0x8D: 0xFE81, # ARABIC LETTER ALEF WITH MADDA ABOVE ISOLATED FORM
0x8E: 0xFE8B, # ARABIC LETTER YEH WITH HAMZA ABOVE INITIAL FORM
0x8F: 0xFE80, # ARABIC LETTER HAMZA ISOLATED FORM
0x90: 0xFE8D, # ARABIC LETTER ALEF ISOLATED FORM
0x91: 0xFE8E, # ARABIC LETTER ALEF FINAL FORM
0x92: 0xFE8F, # ARABIC LETTER BEH ISOLATED FORM
0x93: 0xFE91, # ARABIC LETTER BEH INITIAL FORM
0x94: 0xFB56, # ARABIC LETTER PEH ISOLATED FORM
0x95: 0xFB58, # ARABIC LETTER PEH INITIAL FORM
0x96: 0xFE95, # ARABIC LETTER TEH ISOLATED FORM
0x97: 0xFE97, # ARABIC LETTER TEH INITIAL FORM
0x98: 0xFE99, # ARABIC LETTER THEH ISOLATED FORM
0x99: 0xFE9B, # ARABIC LETTER THEH INITIAL FORM
0x9A: 0xFE9D, # ARABIC LETTER JEEM ISOLATED FORM
0x9B: 0xFE9F, # ARABIC LETTER JEEM INITIAL FORM
0x9C: 0xFB7A, # ARABIC LETTER TCHEH ISOLATED FORM
0x9D: 0xFB7C, # ARABIC LETTER TCHEH INITIAL FORM
0x9E: 0xFEA1, # ARABIC LETTER HAH ISOLATED FORM
0x9F: 0xFEA3, # ARABIC LETTER HAH INITIAL FORM
0xA0: 0xFEA5, # ARABIC LETTER KHAH ISOLATED FORM
0xA1: 0xFEA7, # ARABIC LETTER KHAH INITIAL FORM
0xA2: 0xFEA9, # ARABIC LETTER DAL ISOLATED FORM
0xA3: 0xFEAB, # ARABIC LETTER THAL ISOLATED FORM
0xA4: 0xFEAD, # ARABIC LETTER REH ISOLATED FORM
0xA5: 0xFEAF, # ARABIC LETTER ZAIN ISOLATED FORM
0xA6: 0xFB8A, # ARABIC LETTER JEH ISOLATED FORM
0xA7: 0xFEB1, # ARABIC LETTER SEEN ISOLATED FORM
0xA8: 0xFEB3, # ARABIC LETTER SEEN INITIAL FORM
0xA9: 0xFEB5, # ARABIC LETTER SHEEN ISOLATED FORM
0xAA: 0xFEB7, # ARABIC LETTER SHEEN INITIAL FORM
0xAB: 0xFEB9, # ARABIC LETTER SAD ISOLATED FORM
0xAC: 0xFEBB, # ARABIC LETTER SAD INITIAL FORM
0xAD: 0xFEBD, # ARABIC LETTER DAD ISOLATED FORM
0xAE: 0xFEBF, # ARABIC LETTER DAD INITIAL FORM
0xAF: 0xFEC1, # ARABIC LETTER TAH ISOLATED FORM
# Shadows
0xB0: 0x2591, # LIGHT SHADE
0xB1: 0x2592, # MEDIUM SHADE
0xB2: 0x2593, # DARK SHADE
# Box Drawings
0xB3: 0x2502, # BOX DRAWINGS LIGHT VERTICAL
0xB4: 0x2524, # BOX DRAWINGS LIGHT VERTICAL AND LEFT
0xB5: 0x2561, # BOX DRAWINGS VERTICAL SINGLE AND LEFT DOUBLE
0xB6: 0x2562, # BOX DRAWINGS VERTICAL DOUBLE AND LEFT SINGLE
0xB7: 0x2556, # BOX DRAWINGS DOWN DOUBLE AND LEFT SINGLE
0xB8: 0x2555, # BOX DRAWINGS DOWN SINGLE AND LEFT DOUBLE
0xB9: 0x2563, # BOX DRAWINGS DOUBLE VERTICAL AND LEFT
0xBA: 0x2551, # BOX DRAWINGS DOUBLE VERTICAL
0xBB: 0x2557, # BOX DRAWINGS DOUBLE DOWN AND LEFT
0xBC: 0x255D, # BOX DRAWINGS DOUBLE UP AND LEFT
0xBD: 0x255C, # BOX DRAWINGS UP DOUBLE AND LEFT SINGLE
0xBE: 0x255B, # BOX DRAWINGS UP SINGLE AND LEFT DOUBLE
0xBF: 0x2510, # BOX DRAWINGS LIGHT DOWN AND LEFT
0xC0: 0x2514, # BOX DRAWINGS LIGHT UP AND RIGHT
0xC1: 0x2534, # BOX DRAWINGS LIGHT UP AND HORIZONTAL
0xC2: 0x252C, # BOX DRAWINGS LIGHT DOWN AND HORIZONTAL
0xC3: 0x251C, # BOX DRAWINGS LIGHT VERTICAL AND RIGHT
0xC4: 0x2500, # BOX DRAWINGS LIGHT HORIZONTAL
0xC5: 0x253C, # BOX DRAWINGS LIGHT VERTICAL AND HORIZONTAL
0xC6: 0x255E, # BOX DRAWINGS VERTICAL SINGLE AND RIGHT DOUBLE
0xC7: 0x255F, # BOX DRAWINGS VERTICAL DOUBLE AND RIGHT SINGLE
0xC8: 0x255A, # BOX DRAWINGS DOUBLE UP AND RIGHT
0xC9: 0x2554, # BOX DRAWINGS DOUBLE DOWN AND RIGHT
0xCA: 0x2569, # BOX DRAWINGS DOUBLE UP AND HORIZONTAL
0xCB: 0x2566, # BOX DRAWINGS DOUBLE DOWN AND HORIZONTAL
0xCC: 0x2560, # BOX DRAWINGS DOUBLE VERTICAL AND RIGHT
0xCD: 0x2550, # BOX DRAWINGS DOUBLE HORIZONTAL
0xCE: 0x256C, # BOX DRAWINGS DOUBLE VERTICAL AND HORIZONTAL
0xCF: 0x2567, # BOX DRAWINGS UP SINGLE AND HORIZONTAL DOUBLE
0xD0: 0x2568, # BOX DRAWINGS UP DOUBLE AND HORIZONTAL SINGLE
0xD1: 0x2564, # BOX DRAWINGS DOWN SINGLE AND HORIZONTAL DOUBLE
0xD2: 0x2565, # BOX DRAWINGS DOWN DOUBLE AND HORIZONTAL SINGLE
0xD3: 0x2559, # BOX DRAWINGS UP DOUBLE AND RIGHT SINGLE
0xD4: 0x2558, # BOX DRAWINGS UP SINGLE AND RIGHT DOUBLE
0xD5: 0x2552, # BOX DRAWINGS DOWN SINGLE AND RIGHT DOUBLE
0xD6: 0x2553, # BOX DRAWINGS DOWN DOUBLE AND RIGHT SINGLE
0xD7: 0x256B, # BOX DRAWINGS VERTICAL DOUBLE AND HORIZONTAL SINGLE
0xD8: 0x256A, # BOX DRAWINGS VERTICAL SINGLE AND HORIZONTAL DOUBLE
0xD9: 0x2518, # BOX DRAWINGS LIGHT UP AND LEFT
0xDA: 0x250C, # BOX DRAWINGS LIGHT DOWN AND RIGHT
# Shadows
0xDB: 0x2588, # FULL BLOCK
0xDC: 0x2584, # LOWER HALF BLOCK
0xDD: 0x258C, # LEFT HALF BLOCK
0xDE: 0x2590, # RIGHT HALF BLOCK
0xDF: 0x2580, # UPPER HALF BLOCK
# Letters
0xE0: 0xFEC5, # ARABIC LETTER ZAH ISOLATED FORM
0xE1: 0xFEC9, # ARABIC LETTER AIN ISOLATED FORM
0xE2: 0xFECA, # ARABIC LETTER AIN FINAL FORM
0xE3: 0xFECC, # ARABIC LETTER AIN MEDIAL FORM
0xE4: 0xFECB, # ARABIC LETTER AIN INITIAL FORM
0xE5: 0xFECD, # ARABIC LETTER GHAIN ISOLATED FORM
0xE6: 0xFECE, # ARABIC LETTER GHAIN FINAL FORM
0xE7: 0xFED0, # ARABIC LETTER GHAIN MEDIAL FORM
0xE8: 0xFECF, # ARABIC LETTER GHAIN INITIAL FORM
0xE9: 0xFED1, # ARABIC LETTER FEH ISOLATED FORM
0xEA: 0xFED3, # ARABIC LETTER FEH INITIAL FORM
0xEB: 0xFED5, # ARABIC LETTER QAF ISOLATED FORM
0xEC: 0xFED7, # ARABIC LETTER QAF INITIAL FORM
0xED: 0xFB8E, # ARABIC LETTER KEHEH ISOLATED FORM
0xEE: 0xFB90, # ARABIC LETTER KEHEH INITIAL FORM
0xEF: 0xFB92, # ARABIC LETTER GAF ISOLATED FORM
# Letters
0xF0: 0xFB94, # ARABIC LETTER GAF INITIAL FORM
0xF1: 0xFEDD, # ARABIC LETTER LAM ISOLATED FORM
0xF2: 0xFEFB, # ARABIC LIGATURE LAM WITH ALEF ISOLATED FORM
0xF3: 0xFEDF, # ARABIC LETTER LAM INITIAL FORM
0xF4: 0xFEE1, # ARABIC LETTER MEEM ISOLATED FORM
0xF5: 0xFEE3, # ARABIC LETTER MEEM INITIAL FORM
0xF6: 0xFEE5, # ARABIC LETTER NOON ISOLATED FORM
0xF7: 0xFEE7, # ARABIC LETTER NOON INITIAL FORM
0xF8: 0xFEED, # ARABIC LETTER WAW ISOLATED FORM
0xF9: 0xFEE9, # ARABIC LETTER HEH ISOLATED FORM
0xFA: 0xFEEC, # ARABIC LETTER HEH MEDIAL FORM
0xFB: 0xFEEB, # ARABIC LETTER HEH INITIAL FORM
0xFC: 0xFBFD, # ARABIC LETTER FARSI YEH FINAL FORM
0xFD: 0xFBFC, # ARABIC LETTER FARSI YEH ISOLATED FORM
0xFE: 0xFBFE, # ARABIC LETTER FARSI YEH INITIAL FORM
0xFF: 0x00A0, # NO-BREAK SPACE
}
_ZARNEGAR_OVERRIDES_MAP = {
0x00: 0x0000,
0x01: 0x0001,
0x03: 0xFD3E, # ORNATE LEFT PARENTHESIS
0x04: 0xFD3F, # ORNATE RIGHT PARENTHESIS
0x1D: 0x00A0, # NO-BREAK SPACE
0xB0: 0xFE7C, # ARABIC SHADDA ISOLATED FORM
0xB1: 0xFE76, # ARABIC FATHA ISOLATED FORM
0xB2: 0xFE70, # ARABIC FATHATAN ISOLATED FORM
# 0xB3: TODO
0xB4: _AHAIF, # ARABIC HAMZA ABOVE ISOLATED FORM
0xB5: 0xFE78, # ARABIC DAMMA ISOLATED FORM
0xB6: 0xFE72, # ARABIC DAMMATAN ISOLATED FORM
# 0xB7: TODO
# 0xB8: TODO
# 0xB9: TODO
# 0xBA: TODO
# 0xBB: TODO
# 0xBC: TODO
# 0xBD: TODO
0xBE: 0xFE7A, # ARABIC KASRA ISOLATED FORM
# 0xBF: TODO
# 0xC0: TODO
# 0xC1: TODO
# 0xC2: TODO
0xC3: 0x00AB, # LEFT-POINTING DOUBLE ANGLE QUOTATION MARK
0xC4: 0x00BB, # RIGHT-POINTING DOUBLE ANGLE QUOTATION MARK
# 0xC5: TODO
# 0xC6: TODO
0xC7: 0x061B, # ARABIC SEMICOLON
# 0xC8: TODO
# 0xC9: TODO
# 0xCA: TODO
# 0xCB: TODO
# 0xCC: TODO
# 0xCD: TODO
# 0xCE: TODO
# 0xCF: TODO
}
_ZARNEGAR_MAP = dict(enumerate(range(0x80)))
_ZARNEGAR_MAP.update(_IRAN_SYSTEM_MAP)
_ZARNEGAR_MAP.update(_ZARNEGAR_OVERRIDES_MAP)
def _in_zar_override(char_byte):
return ord(char_byte) in _ZARNEGAR_OVERRIDES_MAP
def convert_zar_byte_to_legacy_char(char_byte, line_no):
codepoints = _ZARNEGAR_MAP[ord(char_byte)]
if type(codepoints) is int:
# "U+%04X" % ord(char) if char is not None else "NONE"
#if ord(char_byte) in range(0x00, 0x20):
if ord(char_byte) in range(0x00, 0x20) and not _in_zar_override(char_byte):
logging.error('zar_legacy: ERROR1: Line %4d: 0x%02X', line_no, ord(char_byte))
#if ord(char_byte) in range(0xB0, 0xE0):
if ord(char_byte) in range(0xB0, 0xE0) and not _in_zar_override(char_byte):
logging.error('zar_legacy: ERROR2: Line %4d: 0x%02X', line_no, ord(char_byte))
return unichr(codepoints)
if type(codepoints) is list:
return ''.join(map(lambda cp: unichr(cp), codepoints))
raise Error("invalid map value")
def convert_zar1_line_to_unicode_legacy_lro(zar1_line, line_no):
legacy_text = ''.join([
convert_zar_byte_to_legacy_char(zar_byte, line_no)
for zar_byte in zar1_line
])
return unicode_bidi.LRO_CHAR + legacy_text
def convert_zar1_line_to_semantic_lro(zar_text, line_no):
legacy_text = ''.join([
convert_zar_byte_to_legacy_char(zar_byte, line_no)
for zar_byte in zar_text
])
return unicode_arabic.convert_legacy_line_to_semantic_lro(legacy_text, line_no)
def convert_zar1_line_to_unicode_lro(zar_text, line_no):
lro_text = convert_zar1_line_to_semantic_lro(zar_text, line_no)
return unicode_bidi.LRO_CHAR + lro_text
def convert_zar1_line_to_unicode_rlo(zar_text, line_no):
lro_text = convert_zar1_line_to_semantic_lro(zar_text, line_no)
rlo_text = unicode_bidi.get_reversed(lro_text)
return unicode_bidi.RLO_CHAR + rlo_text | zarnegar-converter | /zarnegar-converter-0.1.3.tar.gz/zarnegar-converter-0.1.3/src/zarnegar_converter/zar1_encoding.py | zar1_encoding.py |
# Copyright (C) 2017 Behnam Esfahbod
#
# This program is free software: you can redistribute it and/or modify
# it under the terms of the GNU General Public License as published by
# the Free Software Foundation, either version 3 of the License, or
# (at your option) any later version.
#
# This program is distributed in the hope that it will be useful,
# but WITHOUT ANY WARRANTY; without even the implied warranty of
# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
# GNU General Public License for more details.
#
# You should have received a copy of the GNU General Public License
# along with this program. If not, see <http://www.gnu.org/licenses/>.
#
# Author(s): Behnam Esfahbod <[email protected]>
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
from __future__ import unicode_literals
import sys
import struct
import logging
from zarnegar_converter import zar1_encoding
from zarnegar_converter.zar_file import ZarFile, ZarFileTypeError, OUTPUT_NEW_LINE
"""
Read-only view on a Zarnegar File
Generates a list of 80-byte-wide lines from a Zarnegar text or binary file.
"""
_LINE_WIDTH = 80
_BINARY_MAGIC = b'\x03\xCA\xB1\xF2'
_BINARY_HEADER_FMT = (
'<' + # Little-Endian
'H' + # Total Lines Count
'H' + # Total Text Length
'10s' # Installation/User Data
)
_binary_header_struct = struct.Struct(_BINARY_HEADER_FMT)
_BINARY_LINE_INFO_FMT = (
'<' + # Little-Endian
'B' + # Line Text Start
'H' + # Cumulative Text Length
'B' # Line Text Length
)
_binary_line_info_struct = struct.Struct(_BINARY_LINE_INFO_FMT)
class Zar1File(ZarFile):
@staticmethod
def get(in_file):
try:
return Zar1BinaryFile(in_file)
except ZarFileTypeError:
return Zar1TextFile(in_file)
def _append_line(self, text):
rest = b' ' * (_LINE_WIDTH - len(text))
self._lines.append(text + rest)
# == Zar1, Text ==
def get_zar1_text_output(self):
return b''.join([
line.rstrip() + OUTPUT_NEW_LINE
for line in self.get_zar1_text_lines()
])
def get_zar1_text_lines(self):
return self._lines
# == Unicode, Legacy ==
def get_unicode_legacy_lro_output(self):
return ''.join([
line.rstrip() + OUTPUT_NEW_LINE
for line in self.get_unicode_legacy_lro_lines()
])
def get_unicode_legacy_lro_lines(self):
return [
zar1_encoding.convert_zar1_line_to_unicode_legacy_lro(zar1_line, line_no)
for line_no, zar1_line in enumerate(self._lines, start=1)
]
# == Unicode, Semantic, Left-to-Right Override ==
def get_unicode_lro_output(self):
return ''.join([
line.rstrip() + OUTPUT_NEW_LINE
for line in self.get_unicode_lro_lines()
])
def get_unicode_lro_lines(self):
return [
zar1_encoding.convert_zar1_line_to_unicode_lro(zar1_line, line_no)
for line_no, zar1_line in enumerate(self._lines, start=1)
]
# == Unicode, Semantic, Right-to-Left Override ==
def get_unicode_rlo_output(self):
return ''.join([
line.rstrip() + OUTPUT_NEW_LINE
for line in self.get_unicode_rlo_lines()
])
def get_unicode_rlo_lines(self):
return [
zar1_encoding.convert_zar1_line_to_unicode_rlo(zar1_line, line_no)
for line_no, zar1_line in enumerate(self._lines, start=1)
]
class Zar1TextFile(Zar1File):
def __init__(self, in_file):
self._file = in_file
self._lines = []
self._read()
def _read(self):
logging.info(b'Reading Zar1 Text file...')
self._file.seek(0)
for line in self._file.readlines():
text = line.rstrip() # Drop CRLF
self._append_line(text)
class Zar1BinaryFile(Zar1File):
def __init__(self, in_file):
self._file = in_file
self._verify_magic_number()
self._lines = []
self._read()
def _verify_magic_number(self):
self._file.seek(0)
magic = self._file.read(len(_BINARY_MAGIC))
if magic != _BINARY_MAGIC:
raise ZarFileTypeError("Not a Zar1 Binary File")
def _read(self):
logging.info(b'Reading Zar1 Binary file...')
self._file.seek(len(_BINARY_MAGIC))
header = _binary_header_struct.unpack(
self._file.read(_binary_header_struct.size),
)
lines_count = header[0]
line_infos = []
for line_idx in range(lines_count):
read_bytes = self._file.read(_binary_line_info_struct.size)
line_info = _binary_line_info_struct.unpack(read_bytes)
line_infos.append(line_info)
for line_info in line_infos:
left_indent = line_info[0]
text_len = line_info[2]
text = b' ' * left_indent + self._file.read(text_len)
self._append_line(text) | zarnegar-converter | /zarnegar-converter-0.1.3.tar.gz/zarnegar-converter-0.1.3/src/zarnegar_converter/zar1_file.py | zar1_file.py |
# Zarnevis : RTL Text for your computer vision projects
## Installation
### The `pip` way
Just run this on your machine:
```
pip install zarnevis
```
### The `git` way
First, clone this repository using this command:
```
git clone https://github.com/prp-e/zarnevis
```
Then run these commands:
```
cd zarnevis && pip install -e .
```
_NOTE_: This method is only suggested for when you're going to do some development and tests on the project. If you want to do something else (such as using this tool in a face tracker drone) just use the `pip` way and don't make trouble for yourself :)
## Example
It is pretty straight-forward. I actually made this because I wanted to do some cool stuff and I didn't want to make it so complex. This is an example code:
```python
import cv2
from zarnevis import Zarnevis
image = cv2.imread('example.jpg')
processor = Zarnevis(image=image, text="اهواز زیبا", font_file='vazir.ttf', font_size=36, text_coords=(200,20), color=(255,0,100))
image = processor.draw_text()
cv2.imwrite('example_zarnevis.jpg', image)
```
### Image - Before

### Image - After

## Special Thanks
- Amin Sharifi - Because he did a great job teaching this method on his [website](https://bigm.ir/persian-character-in-opencv/) and [YouTube channel](https://www.youtube.com/watch?v=RPb1X6Cf-ZU).
- Touhid Arastu - He pointed out in [this issue](https://github.com/prp-e/zarnevis/issues/1) that in new versions of Pillow, we don't really need reshaping and stuff and if we don't want to run our code on many different platforms, it can handle the thing itself. | zarnevis | /zarnevis-0.0.1.tar.gz/zarnevis-0.0.1/README.md | README.md |
<p align="center">
<img src="https://user-images.githubusercontent.com/55444371/126209354-44068bb7-81aa-49a5-af4e-71b8c2475386.png" />
</p>
 [](https://pypi.python.org/pypi/textaugment) [](https://pypi.org/project/textaugment/)
# zarnitsa package
Zarnitsa package with data augmentation tools.
- Internal data augmentation using existed data
- External data augmentation setting known statistical distributions by yourself
- NLP augmentation
## Principal scheme of project (currently)
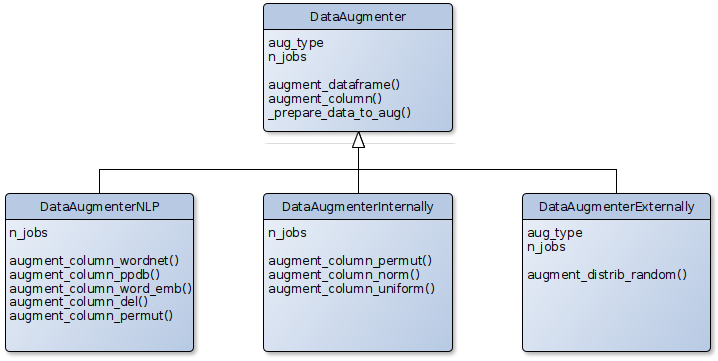
## Requirements
- Python3
- numpy
- pandas
- nlpaug
- wget
- scikt-learn
## Installation
Install package using PyPI:
```
pip install zarnitsa
```
Or using actual github repo:
```
pip install git+https://github.com/AlexKay28/zarnitsa
```
## Usage
Simple usage examples:
### Augmentation internal.
This is type of augmentation which you may use in case of working with numerical features.
```
>>> from zarnitsa.DataAugmenterInternally import DataAugmenterInternally
>>> daug_comb = DataAugmenterInternally()
>>> aug_types = [
>>> "normal",
>>> "uniform",
>>> "permutations",
>>> ]
>>> # pd Series object example
>>> s = pd.Series([1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
>>> for aug_type in aug_types:
>>> print(aug_type)
>>> print(daug_comb.augment_column(s, freq=0.5, return_only_aug=True, aug_type=aug_type))
normal
7 9.958794
3 0.057796
0 -3.135995
6 7.197400
8 13.258087
dtype: float64
uniform
2 10.972232
8 5.335357
9 9.111281
5 5.964971
4 -0.210732
dtype: float64
permutations
4 6
5 4
9 10
3 3
2 5
dtype: int64
```
### Augmentation NLP
This is type of augmentation which you may use in case of working with textual information.
```
>>> from zarnitsa.DataAugmenterNLP import DataAugmenterNLP
>>> daug = DataAugmenterNLP()
>>> text = "This is sentence example to augment. Thank you for interesting"
>>> daug.augment_column_wordnet(text)
'This be sentence example to augment. Thank you for concern'
>>> daug.augment_column_del(text, reps=1)
'This is sentence example to augment. you for interesting'
>>> daug.augment_column_permut(text, reps=1)
'This sentence is example to augment. Thank you for interesting'
```
### Augmentation External
This is type of augmentation which you may use in case of working with distribution modeling
having prior knowlege about it
_Doing df[...] = np.nan we imitate data sparsness or misses which we try to fill up using augmentations_
```
>>> size = 500
>>> serial_was = pd.Series(daug.augment_distrib_random(aug_type='normal', loc=0, scale=1, size=size))
>>> serial_new = copy(serial_was)
>>> serial_new.loc[serial_new.sample(100).index] = None
>>> serial_new = daug.augment_column(serial_new, aug_type='normal', loc=0, scale=1)
>>> plt.figure(figsize=(12, 8))
>>> serial_was.hist(bins=100)
>>> serial_new.hist(bins=100)
```
```
>>> size=50
>>> df = pd.DataFrame({
>>> 'data1': daug.augment_distrib_random(aug_type='normal', loc=0, scale=1, size=size),
>>> 'data2': daug.augment_distrib_random(aug_type='normal', loc=0, scale=1, size=size),
>>> })
>>> for col in df.columns:
>>> df[col].loc[df[col].sample(10).index] = None
>>> plt.figure(figsize=(12, 8))
>>> df.plot()
>>> daug.augment_dataframe(df, aug_type='normal', loc=0, scale=1).plot()
```
| zarnitsa | /zarnitsa-0.0.19.tar.gz/zarnitsa-0.0.19/README.md | README.md |
# ZARP-cli
[![License][badge-license]][badge-url-license]
[![Build_status][badge-build-status]][badge-url-build-status]
[![Docs][badge-docs]][badge-url-docs]
[![Coverage][badge-coverage]][badge-url-coverage]
[![GitHub_tag][badge-github-tag]][badge-url-github-tag]
[![PyPI_release][badge-pypi]][badge-url-pypi]
**_ZARP 'em_** - RNA-Seq analysis made easy!
* Have a bunch of RNA-Seq samples and you wanna know what's in them? **_ZARP
'em!_**
* Barry left you some samples to analyze and then went on vacation, again? **No
problem, _ZARP 'em!_**
* You have an extensive SRA query with hundreds of runs and you don't know
where to start? **Easy - _ZARP 'em!_**
ZARP-cli uses the HTSinfer package to infer missing metadata and then runs the
ZARP RNA-Seq analysis pipeline on your samples. Impress your colleagues with
your sudden productivity boost. Or better yet, use the time saved to go on that
camping trip with Barry. Just make sure to guard your secret! :wink:
:pill: **_ZARP 'em_** - set it up once, benefit for a lifetime! :syringe:
## Basic usage
```sh
zarp [-h] [--init] [--verbosity {DEBUG,INFO,WARN,ERROR,CRITICAL}] [--version]
PATH/ID [PATH/ID ...]
# Examples
zarp --init # set up user defaults for ZARP
zarp sample_1.fq.gz /path/to/sample_2.fq.gz # ZARP two single-end libraries
zarp [email protected] # assign a sample name
zarp mate_1.fq.gz,mate_2.fq.gz # ZARP one paired-end library
zarp table:table.tsv # ZARP all samples from a sample table
zarp SRR0123456789 my_other_sample@SRR0123456789 # ZARP SRA runs
zarp \
sample_1.fq.gz /path/to/sample_2.fq.gz \
[email protected] \
mate_1.fq.gz,mate_2.fq.gz \
table:table.tsv \
SRR0123456789 my_other_sample@SRR0123456789 # ZARP everything at once!
```
## Installation
Clone this repository and traverse into the app directory:
```sh
git clone [email protected]:zavolanlab/zarp-cli.git
cd zarp-cli
```
Install the app:
```sh
pip install .
```
> If you would like to contribute to ZARP-cli development, we recommend
> installing the app in editable mode:
>
> ```sh
> pip install -e .
> ```
Optionally, install required packages for testing and development:
```sh
pip install -r requirements_dev.txt
```
## Contributing
This project lives off your contributions, be it in the form of bug reports,
feature requests, discussions, or fixes and other code changes. Please refer
to the [contributing guidelines](CONTRIBUTING.md) if you are interested to
contribute. Please mind the [code of conduct](CODE_OF_CONDUCT.md) for all
interactions with the community.
## Contact
For questions or suggestions regarding the code, please use the
[issue tracker][issue-tracker]. For any other inquiries, please contact us
by email: <[email protected]>
© 2021 [Zavolab, Biozentrum, University of Basel][contact]
[contact]: <[email protected]>
[badge-build-status]: <https://github.com/zavolanlab/zarp-cli/actions/workflows/ci.yml/badge.svg>
[badge-coverage]: <https://codecov.io/gh/zavolanlab/zarp-cli/branch/dev/graph/badge.svg?branch=dev&token=0KQZYULZ88>
[badge-docs]: <https://readthedocs.org/projects/zarp-cli/badge/?version=latest>
[badge-github-tag]: <https://img.shields.io/github/v/tag/zavolanlab/zarp-cli?color=C39BD3>
[badge-license]: <https://img.shields.io/badge/license-Apache%202.0-blue.svg>
[badge-pypi]: <https://img.shields.io/pypi/v/zarp.svg?style=flat&color=C39BD3>
[badge-url-build-status]: <https://github.com/zavolanlab/zarp-cli/actions/workflows/ci.yml>
[badge-url-coverage]: <https://codecov.io/gh/zavolanlab/zarp-cli?branch=dev>
[badge-url-docs]: <https://zarp-cli.readthedocs.io/en/latest/?badge=latest>
[badge-url-github-tag]: <https://github.com/zavolanlab/zarp-cli/releases>
[badge-url-license]: <http://www.apache.org/licenses/LICENSE-2.0>
[badge-url-pypi]: <https://pypi.python.org/pypi/zarp>
[issue-tracker]: <https://github.com/zavolanlab/zarp-cli/issues>
| zarp | /zarp-0.1.1.tar.gz/zarp-0.1.1/README.md | README.md |
# Guidelines for contributing
## General workflow
We are using [Git][git], [GitHub][github] and [Git Flow][git-flow].
> **Note:** If you are a **beginner** and do not have a lot of experience with
> this sort of workflow, please do not feel overwhelmed. We will guide you
> through the process until you feel comfortable using it. And do not worry
> about mistakes either - everybody does them. Often! Our project layout makes
> it very very hard for anyone to cause irreversible harm, so relax, try things
> out, take your time and enjoy the work! :)
We would kindly ask you to abide by our [Code of Conduct][coc] in all
interactions with the community when contributing to this project, regardless
of the type of contribution. We will not accept any offensive or demeaning
behavior towards others and will take any necessary steps to ensure that
everyone is treated with respect and dignity.
## Issue tracker
Please use each project's GitHub [issue tracker][issue-tracker] to:
- find issues to work on
- report bugs
- propose features
- discuss future directions
## Submitting issues
Please choose a template when submitting an issue: choose the [**bug report**
template][bug-report] only when reporting bugs; for all other issues,
choose the [**feature request** template][bug-report]. Please follow the
instructions in the templates.
You do not need to worry about adding labels or milestones for an issue, the
project maintainers will do that for you. However, it is important that all
issues are written concisely, yet with enough detail and with proper
references (links, screenshots, etc.) to allow other contributors to start
working on them. For bug reports, it is essential that they include all
information required to reproduce the bug.
Please **do not** use the issue tracker to ask usage questions, installation
problems etc., unless they appear to be bugs. For these issues, please use
the [communication channels](#communication) outlined below.
## Communication
Send us an [email][contact] if you want to reach out to us
work on)
## Code style and testing
To make it easier for everyone to maintain, read and contribute to the code,
as well as to ensure that the code base is robust and of high quality, we
would kindly ask you to stick to the following guidelines for code style and
testing.
- Please use a recent version of [Python 3][py] (3.7.4+)
- Please try to conform to the used code, docstring and commenting style within
a project to maintain consistency
- Please use [type hints][py-typing] for all function/method signatures
(exception: tests)
- Please use the following linters (see configuration files in repository root
directory, e.g., `setup.cfg`, for settings):
- [`flake8`][py-flake8]
- [`pylint`][py-pylint] (use available [configuration][py-pylint-conf])
- [`mypy`][py-mypy] OR [`pyright`][py-pyright] to help with type hints
- Please use the following test suites:
- [`pytest`][py-pytest]
- [`coverage`][py-coverage]
## Commit messages
In an effort to increase consistency, simplify maintenance and enable automated
change logs, we would like to kindly ask you to write _semantic commit
messages_, as described in the [Conventional Commits
specification][conv-commits].
The general structure of _Conventional Commits_ is as follows:
```console
<type>[optional scope]: <description>
[optional body]
[optional footer]
```
Depending on the changes, please use one of the following **type** prefixes:
| Type | Description |
| --- | --- |
| build | The build type (formerly known as chore) is used to identify development changes related to the build system (involving scripts, configurations or tools) and package dependencies. |
| ci | The ci type is used to identify development changes related to the continuous integration and deployment system - involving scripts, configurations or tools. |
| docs | The docs type is used to identify documentation changes related to the project - whether intended externally for the end users (in case of a library) or internally for the developers. |
| feat | The feat type is used to identify production changes related to new backward-compatible abilities or functionality. |
| fix | The fix type is used to identify production changes related to backward-compatible bug fixes. |
| perf | The perf type is used to identify production changes related to backward-compatible performance improvements. |
| refactor | The refactor type is used to identify development changes related to modifying the codebase, which neither adds a feature nor fixes a bug - such as removing redundant code, simplifying the code, renaming variables, etc. |
| revert | For commits that revert one or more previous commits. |
| style | The style type is used to identify development changes related to styling the codebase, regardless of the meaning - such as indentations, semi-colons, quotes, trailing commas and so on. |
| test | The test type is used to identify development changes related to tests - such as refactoring existing tests or adding new tests. |
In order to ensure that the format of your commit messages adheres to the
Conventional Commits specification and the defined type vocabulary, you can
use the [dedicated linter][conv-commits-lint]. More information about
_Conventional Commits_ can also be found in this [blog
post][conv-commits-blog].
## Merging your code
Here is a check list that you can follow to make sure that code merges
happen smoothly:
1. [Open an issue](#submitting-issues) _first_ to give other contributors a
chance to discuss the proposed changes (alternatively: assign yourself
to one of the existing issues)
2. Clone the repository, create a feature branch off of the default branch
(never commit changes to protected branches directly) and implement your
code changes
3. If applicable, update relevant sections of the [documentation][docs]
4. Add or update tests; untested code will not be merged; refer to the
[guidelines](#code-style-and-testing) above for details
5. Ensure that your coding style is in line with the
[guidelines](#code-style-and-testing) described above
6. Ensure that all tests and linter checks configured in the [Travis
CI][travis-docs] [continuous integration][ci-cd] (CI) pipeline pass without
issues
7. If necessary, clean up excessive commits with `git rebase`; cherry-pick and
merge commits as you see fit; use concise and descriptive commit messages
8. Push your clean, tested and documented feature branch to the remote; make
sure the [Travis CI][travis-docs] [CI][ci-cd] pipeline passes
9. Issue a pull request against the default branch; follow the instructions in
the [template][pull-request]; importantly, describe your changes in
detail, yet with concise language, and do not forget to indicate which
issue(s) the code changes resolve or refer to; assign a project maintainer
to review your changes
## Becoming a co-maintainer
If you are as interested in the project as we are and have contributed some
code, suggested some features or bug reports and have taken part in
discussions on where to go with the project, we will very likely to have you
on board as a co-maintainer. If you are intersted in that, please let us
know. You can reach us by [email][contact].
[bug-report]: .github/ISSUE_TEMPLATE/bug_report.mdrequest.md
[ci-cd]: <https://en.wikipedia.org/wiki/Continuous_integration>
[coc]: CODE_OF_CONDUCT.md
[contact]: <[email protected]>
[conv-commits]: <https://www.conventionalcommits.org/en/v1.0.0-beta.2/#specification>
[conv-commits-blog]: <https://nitayneeman.com/posts/understanding-semantic-commit-messages-using-git-and-angular/>
[conv-commits-lint]: <https://github.com/conventional-changelog/commitlint>
[docs]: README.md
[git]: <https://git-scm.com/>
[git-flow]: <https://nvie.com/posts/a-successful-git-branching-model/>
[github]: <https://github.com>
[issue-tracker]: <https://github.com/zavolanlab/zarp-cli/issues>
[pull-request]: PULL_REQUEST_TEMPLATE.md
[py]: <https://www.python.org/>
[py-flake8]: <https://gitlab.com/pycqa/flake8>
[py-mypy]: <http://mypy-lang.org/>
[py-pylint]: <https://www.pylint.org/>
[py-pylint-conf]: pylint.cfg
[py-pyright]: <https://github.com/microsoft/pyright>
[py-pytest]: <https://docs.pytest.org/en/latest/>
[py-coverage]: <https://pypi.org/project/coverage/>
[py-typing]: <https://docs.python.org/3/library/typing.html>
[travis-docs]: <https://docs.travis-ci.com/>
| zarp | /zarp-0.1.1.tar.gz/zarp-0.1.1/CONTRIBUTING.md | CONTRIBUTING.md |
# Contributor Covenant Code of Conduct
## Our Pledge
In the interest of fostering an open and welcoming environment, we as
contributors and maintainers pledge to making participation in our project and
our community a harassment-free experience for everyone, regardless of age, body
size, disability, ethnicity, sex characteristics, gender identity and expression,
level of experience, education, socio-economic status, nationality, personal
appearance, race, religion, or sexual identity and orientation.
## Our Standards
Examples of behavior that contributes to creating a positive environment
include:
* Using welcoming and inclusive language
* Being respectful of differing viewpoints and experiences
* Gracefully accepting constructive criticism
* Focusing on what is best for the community
* Showing empathy towards other community members
Examples of unacceptable behavior by participants include:
* The use of sexualized language or imagery and unwelcome sexual attention or
advances
* Trolling, insulting/derogatory comments, and personal or political attacks
* Public or private harassment
* Publishing others' private information, such as a physical or electronic
address, without explicit permission
* Other conduct which could reasonably be considered inappropriate in a
professional setting
## Our Responsibilities
Project maintainers are responsible for clarifying the standards of acceptable
behavior and are expected to take appropriate and fair corrective action in
response to any instances of unacceptable behavior.
Project maintainers have the right and responsibility to remove, edit, or
reject comments, commits, code, wiki edits, issues, and other contributions
that are not aligned to this Code of Conduct, or to ban temporarily or
permanently any contributor for other behaviors that they deem inappropriate,
threatening, offensive, or harmful.
## Scope
This Code of Conduct applies both within project spaces and in public spaces
when an individual is representing the project or its community. Examples of
representing a project or community include using an official project e-mail
address, posting via an official social media account, or acting as an appointed
representative at an online or offline event. Representation of a project may be
further defined and clarified by project maintainers.
## Enforcement
Instances of abusive, harassing, or otherwise unacceptable behavior may be
reported by contacting the [code owners][contact]. All complaints will be
reviewed and investigated and will result in a response that is deemed necessary
and appropriate to the circumstances. The project team is obligated to maintain
confidentiality with regard to the reporter of an incident. Further details of
specific enforcement policies may be posted separately.
Project maintainers who do not follow or enforce the Code of Conduct in good
faith may face temporary or permanent repercussions as determined by other
members of the project's leadership.
## Attribution
This Code of Conduct is adapted from the [Contributor Covenant][homepage], version 1.4,
available at <https://www.contributor-covenant.org/version/1/4/code-of-conduct.html>
[contact]: <[email protected]>
[homepage]: <https://www.contributor-covenant.org>
| zarp | /zarp-0.1.1.tar.gz/zarp-0.1.1/CODE_OF_CONDUCT.md | CODE_OF_CONDUCT.md |
# zarpaint
[](https://github.com/jni/zarpaint/raw/main/LICENSE)
[](https://pypi.org/project/zarpaint)
[](https://python.org)
[](https://github.com/jni/zarpaint/actions)
[](https://codecov.io/gh/jni/zarpaint)
Paint segmentations directly to on-disk/remote zarr arrays
----------------------------------
This [napari] plugin was generated with [Cookiecutter] using with [@napari]'s [cookiecutter-napari-plugin] template.
<!--
Don't miss the full getting started guide to set up your new package:
https://github.com/napari/cookiecutter-napari-plugin#getting-started
and review the napari docs for plugin developers:
https://napari.org/docs/plugins/index.html
-->
## Installation
You can install `zarpaint` via [pip]:
pip install zarpaint
## Contributing
Contributions are very welcome. Tests can be run with [tox], please ensure
the coverage at least stays the same before you submit a pull request.
## License
Distributed under the terms of the [BSD-3] license,
"zarpaint" is free and open source software
## Issues
If you encounter any problems, please [file an issue] along with a detailed description.
[napari]: https://github.com/napari/napari
[Cookiecutter]: https://github.com/audreyr/cookiecutter
[@napari]: https://github.com/napari
[MIT]: http://opensource.org/licenses/MIT
[BSD-3]: http://opensource.org/licenses/BSD-3-Clause
[GNU GPL v3.0]: http://www.gnu.org/licenses/gpl-3.0.txt
[GNU LGPL v3.0]: http://www.gnu.org/licenses/lgpl-3.0.txt
[Apache Software License 2.0]: http://www.apache.org/licenses/LICENSE-2.0
[Mozilla Public License 2.0]: https://www.mozilla.org/media/MPL/2.0/index.txt
[cookiecutter-napari-plugin]: https://github.com/napari/cookiecutter-napari-plugin
[file an issue]: https://github.com/jni/zarpaint/issues
[napari]: https://github.com/napari/napari
[tox]: https://tox.readthedocs.io/en/latest/
[pip]: https://pypi.org/project/pip/
[PyPI]: https://pypi.org/
| zarpaint | /zarpaint-0.2.0.tar.gz/zarpaint-0.2.0/README.md | README.md |
# Zarpy: formally verified biased coin and n-sided die.
See the [paper](https://arxiv.org/abs/2211.06747) (to appear in
PLDI'23) and [Github repository](https://github.com/bagnalla/zar).
## Why use Zarpy?
### Probabilistic choice
A basic operation in randomized algorithms is *probabilistic choice*:
for some `p ∈ [0,1]`, execute action `a1` with probability `p` or
action `a2` with probability `1-p` (i.e., flip a biased coin to
determine the path of execution). A common method for performing
probabilistic choice is as follows:
```python
if random() < p:
execute a1
else:
execute a2
```
where `p` is a float in the range `[0,1]` and `random()` produces a
random float in the range `[0,1)`. While good enough for many
applications, this approach is not always correct due to float
roundoff error. We can only expect `a1` to be executed with
probability `p + ϵ` for some small error term `ϵ`, which technically
invalidates any correctness guarantees of our overall system that
depend on the correctness of its probabilistic choices.
Zarpy provides an alternative that is guaranteed (by formal proof in
Coq) to execute `a1` with probability `p` (where `n` and `d` are
integers such that `p = n/d`):
```python
from zarpy import build_coin, flip
build_coin((n, d)) # Build and cache coin with bias p = n/d
if flip(): # Generate a Boolean value with Pr(True) = p
execute a1
else:
execute a2
```
### Uniform sampling
Another common operation is to randomly draw from a finite collection
of values with equal (uniform) probability of each. An old trick for
drawing an integer uniformly from the range `[0, n)` is to generate a
random integer from `[0, RAND_MAX]` and take the modulus wrt. `n`:
```python
x = rand() % n # Assign x random value from [0,n)
```
but this method suffers from modulo bias when `n` is not a power of 2,
causing some values to occur with higher probability than others (see,
e.g., [this
article](https://research.kudelskisecurity.com/2020/07/28/the-definitive-guide-to-modulo-bias-and-how-to-avoid-it/)
for more information on modulo bias). Zarpy provides a uniform sampler
that is guaranteed for any integer `0 < n` to generate samples from
`[0,n)` with probability `1/n` each:
```python
from zarpy import build_die, roll
build_die(n)
x = roll()
```
Although the Python function `random.randint` is ostensibly free from
modulo bias, our implementation guarantees so by a *formal proof of
correctness* in Coq.
## Trusted Computing Base
The samplers provided by Zarpy have been implemented and verified in
Coq and extracted to OCaml and bundled into Python package via
[pythonlib](https://github.com/janestreet/pythonlib). Validity of the
correctness proofs is thus dependent on the correctness of Coq's
extraction mechanism, the OCaml compiler and runtime, a small amount
of OCaml shim code (viewable
[here](https://github.com/bagnalla/zar/blob/main/python/zar/ocaml/zarpy.ml)),
and the pythonlib library.
## Proofs of correctness
The coin and die samplers are implemented as probabilistic programs in
the [Zar](https://github.com/bagnalla/zar) system and compiled to
[interaction trees](https://github.com/DeepSpec/InteractionTrees)
implementing them via reduction to sequences of fair coin flips. See
Section 3 of the [paper](https://arxiv.org/abs/2211.06747) for details
and the file
[zarpy.v](https://github.com/bagnalla/zar/blob/main/zarpy.v) for their
implementations and proofs of correctness.
Correctness is two-fold. For biased coin with bias `p`, we prove:
*
[coin_itree_correct](https://github.com/bagnalla/zar/blob/main/zarpy.v#L57):
the probability of producing `true` according to the formal probabilistic
semantics of the constructed interaction tree is equal to `p`, and
*
[coin_samples_equidistributed](https://github.com/bagnalla/zar/blob/main/zarpy.v#L75):
when the source of random bits is uniformly distributed, for any
sequence of coin flips the proportion of `true` samples converges to
`p` as the number of samples goes to +∞.
The equidistribution result is dependent on uniform distribution of
the Boolean values generated by OCaml's
[`Random.bool`](https://v2.ocaml.org/api/Random.html) function. See
[the paper](https://arxiv.org/abs/2211.06747) for a more detailed
explanation.
Similarly, the theorem
[die_itree_correct](https://github.com/bagnalla/zar/blob/main/zarpy.v#L136)
proves semantic correctness of the n-sided die, and
[die_samples_equidistributed](https://github.com/bagnalla/zar/blob/main/zarpy.v#L161)
equidistribution of its samples.
## Usage
`seed()` initializes the PRNG via
[Random.self_init](https://v2.ocaml.org/api/Random.html).
### Biased coin
`build_coin((num, denom))` builds and caches a coin with `Pr(True) =
num/denom` for nonnegative integer `num` and positive integer `denom`.
`flip()` produces a single Boolean sample by flipping the cached coin.
`flip_n(n)` produces `n` Boolean samples by flipping the cached coin.
### N-sided die
`build_die(n)` builds and caches an n-sided die with `Pr(m) = 1/n` for
integer `m` where `0 <= m < n`.
`roll()` produces a single sample by rolling the cached die.
`roll_n(n)` produces `n` integer samples by rolling the cached die.
| zarpy | /zarpy-1.0.1.tar.gz/zarpy-1.0.1/README.md | README.md |
# zarr_checksum
Algorithms for calculating a zarr checksum against local or cloud storage
# Install
```
pip install zarr-checksum
```
# Usage
## CLI
To calculate the checksum for a local zarr archive
```
zarrsum local <directory>
```
To calcuate the checksum for a remote (S3) zarr archive
```
zarrsum remote s3://your_bucket/prefix_to_zarr
```
## Python
To calculate the checksum for a local zarr archive
```python
from zarr_checksum import compute_zarr_checksum
from zarr_checksum.generators import yield_files_local, yield_files_s3
# Local
checksum = compute_zarr_checksum(yield_files_local("local_path"))
# Remote
checksum = compute_zarr_checksum(
yield_files_s3(
bucket="your_bucket",
prefix="prefix_to_zarr",
# Credentials can also be passed via environment variables
credentials={
aws_access_key_id: "youraccesskey",
aws_secret_access_key: "yoursecretkey",
region_name: "us-east-1",
}
)
)
```
Access checksum information
```python
>>> checksum.digest
'c228464f432c4376f0de6ddaea32650c-37481--38757151179'
>>> checksum.md5
'c228464f432c4376f0de6ddaea32650c'
>>> checksum.count
37481
>>> checksum.size
38757151179
```
| zarr-checksum | /zarr_checksum-0.2.9.tar.gz/zarr_checksum-0.2.9/README.md | README.md |
from __future__ import annotations
from functools import total_ordering
import hashlib
import re
from typing import List
import pydantic
ZARR_DIGEST_PATTERN = "([0-9a-f]{32})-([0-9]+)--([0-9]+)"
class InvalidZarrChecksum(Exception):
pass
class ZarrDirectoryDigest(pydantic.BaseModel):
"""The data that can be serialized to / deserialized from a checksum string."""
md5: str
count: int
size: int
@classmethod
def parse(cls, checksum: str | None) -> ZarrDirectoryDigest:
if checksum is None:
return cls.parse(EMPTY_CHECKSUM)
match = re.match(ZARR_DIGEST_PATTERN, checksum)
if match is None:
raise InvalidZarrChecksum()
md5, count, size = match.groups()
return cls(md5=md5, count=count, size=size)
def __str__(self) -> str:
return self.digest
@property
def digest(self) -> str:
return f"{self.md5}-{self.count}--{self.size}"
@total_ordering
class ZarrChecksum(pydantic.BaseModel):
"""
A checksum for a single file/directory in a zarr file.
Every file and directory in a zarr archive has a name, digest, and size.
Leaf nodes are created by providing an md5 digest.
Internal nodes (directories) have a digest field that is a zarr directory digest
This class is serialized to JSON, and as such, key order should not be modified.
"""
digest: str
name: str
size: int
# To make this class sortable
def __lt__(self, other: ZarrChecksum):
return self.name < other.name
class ZarrChecksumManifest(pydantic.BaseModel):
"""
A set of file and directory checksums.
This is the data hashed to calculate the checksum of a directory.
"""
directories: List[ZarrChecksum] = pydantic.Field(default_factory=list)
files: List[ZarrChecksum] = pydantic.Field(default_factory=list)
@property
def is_empty(self):
return not (self.files or self.directories)
def generate_digest(self) -> ZarrDirectoryDigest:
"""Generate an aggregated digest for the provided files/directories."""
# Ensure sorted first
self.files.sort()
self.directories.sort()
# Aggregate total file count
count = len(self.files) + sum(
ZarrDirectoryDigest.parse(checksum.digest).count for checksum in self.directories
)
# Aggregate total size
size = sum(file.size for file in self.files) + sum(
directory.size for directory in self.directories
)
# Seralize json without any spacing
json = self.json(separators=(",", ":"))
# Generate digest
md5 = hashlib.md5(json.encode("utf-8")).hexdigest()
# Construct and return
return ZarrDirectoryDigest(md5=md5, count=count, size=size)
# The "null" zarr checksum
EMPTY_CHECKSUM = ZarrChecksumManifest().generate_digest().digest | zarr-checksum | /zarr_checksum-0.2.9.tar.gz/zarr_checksum-0.2.9/zarr_checksum/checksum.py | checksum.py |
from __future__ import annotations
from dataclasses import dataclass
import heapq
from pathlib import Path
from zarr_checksum.checksum import ZarrChecksum, ZarrChecksumManifest, ZarrDirectoryDigest
__all__ = ["ZarrChecksumNode", "ZarrChecksumTree"]
# Pydantic models aren't used for performance reasons
@dataclass
class ZarrChecksumNode:
"""Represents the aggregation of zarr files at a specific path in the tree."""
path: Path
checksums: ZarrChecksumManifest
def __lt__(self, other):
return str(self.path) < str(other.path)
class ZarrChecksumTree:
"""A tree that represents the checksummed files in a zarr."""
def __init__(self) -> None:
self._heap: list[tuple[int, ZarrChecksumNode]] = []
self._path_map: dict[Path, ZarrChecksumNode] = {}
@property
def empty(self):
return len(self._heap) == 0
def _add_path(self, key: Path):
node = ZarrChecksumNode(path=key, checksums=ZarrChecksumManifest())
# Add link to node
self._path_map[key] = node
# Add node to heap with length (negated to representa max heap)
length = len(key.parents)
heapq.heappush(self._heap, (-1 * length, node))
def _get_path(self, key: Path):
if key not in self._path_map:
self._add_path(key)
return self._path_map[key]
def add_leaf(self, path: Path, size: int, digest: str):
"""Add a leaf file to the tree."""
parent_node = self._get_path(path.parent)
parent_node.checksums.files.append(ZarrChecksum(name=path.name, size=size, digest=digest))
def add_node(self, path: Path, size: int, digest: str):
"""Add an internal node to the tree."""
parent_node = self._get_path(path.parent)
parent_node.checksums.directories.append(
ZarrChecksum(
name=path.name,
size=size,
digest=digest,
)
)
def pop_deepest(self) -> ZarrChecksumNode:
"""Find the deepest node in the tree, and return it."""
_, node = heapq.heappop(self._heap)
del self._path_map[node.path]
return node
def process(self) -> ZarrDirectoryDigest:
"""Process the tree, returning the resulting top level digest."""
# Begin with empty root node, so if no files are present, the empty checksum is returned
node = ZarrChecksumNode(path=".", checksums=ZarrChecksumManifest())
while not self.empty:
# Pop the deepest directory available
node = self.pop_deepest()
# If we have reached the root node, then we're done.
if node.path == Path(".") or node.path == Path("/"):
break
# Add the parent of this node to the tree
directory_digest = node.checksums.generate_digest()
self.add_node(
path=node.path,
size=directory_digest.size,
digest=directory_digest.digest,
)
# Return digest
return node.checksums.generate_digest() | zarr-checksum | /zarr_checksum-0.2.9.tar.gz/zarr_checksum-0.2.9/zarr_checksum/tree.py | tree.py |
from __future__ import annotations
from dataclasses import asdict, dataclass
import hashlib
import os
from pathlib import Path
from typing import Iterable
import boto3
from botocore.client import Config
from tqdm import tqdm
from zarr.storage import NestedDirectoryStore
@dataclass
class ZarrArchiveFile:
"""
A file path, size, and md5 checksum, ready to be added to a ZarrChecksumTree.
This class differs from the `ZarrChecksum` class, for the following reasons:
* Field order does not matter
* This class is not serialized in any manner
* The `path` field is relative to the root of the zarr archive, while the `name` field of
`ZarrChecksum` is just the final component of said path
"""
path: Path
size: int
digest: str
FileGenerator = Iterable[ZarrArchiveFile]
@dataclass
class S3ClientOptions:
region_name: str = "us-east-1"
api_version: str | None = None
use_ssl: bool = True
verify: bool | None = None
endpoint_url: str | None = None
aws_access_key_id: str | None = None
aws_secret_access_key: str | None = None
aws_session_token: str | None = None
config: Config | None = None
def yield_files_s3(
bucket: str, prefix: str = "", client_options: S3ClientOptions | None = None
) -> FileGenerator:
if client_options is None:
client_options = S3ClientOptions()
# Construct client
client = boto3.client("s3", **asdict(client_options))
continuation_token = None
options = {"Bucket": bucket, "Prefix": prefix}
print("Retrieving files...")
# Test that url is fully qualified path by appending slash to prefix and listing objects
test_resp = client.list_objects_v2(Bucket=bucket, Prefix=os.path.join(prefix, ""))
if "Contents" not in test_resp:
print(f"Warning: No files found under prefix: {prefix}.")
print("Please check that you have provided the fully qualified path to the zarr root.")
yield from []
return
# Iterate until all files found
while True:
if continuation_token is not None:
options["ContinuationToken"] = continuation_token
# Fetch
res = client.list_objects_v2(**options)
# Fix keys of listing to be relative to zarr root
mapped = (
ZarrArchiveFile(
path=Path(obj["Key"]).relative_to(prefix),
size=obj["Size"],
digest=obj["ETag"].strip('"'),
)
for obj in res.get("Contents", [])
)
# Yield as flat iteratble
yield from mapped
# If all files fetched, end
continuation_token = res.get("NextContinuationToken", None)
if continuation_token is None:
break
def yield_files_local(directory: str | Path) -> FileGenerator:
root_path = Path(os.path.expandvars(directory)).expanduser()
if not root_path.exists():
raise Exception("Path does not exist")
print("Discovering files...")
store = NestedDirectoryStore(root_path)
for file in tqdm(list(store.keys())):
path = Path(file)
absolute_path = root_path / path
size = absolute_path.stat().st_size
# Compute md5sum of file
md5sum = hashlib.md5()
with open(absolute_path, "rb") as f:
for chunk in iter(lambda: f.read(8192), b""):
md5sum.update(chunk)
digest = md5sum.hexdigest()
# Yield file
yield ZarrArchiveFile(path=path, size=size, digest=digest) | zarr-checksum | /zarr_checksum-0.2.9.tar.gz/zarr_checksum-0.2.9/zarr_checksum/generators.py | generators.py |
__all__ = ['to_zarr']
import logging
import os.path as op
import requests
import xml.etree.ElementTree as ElementTree
logger = logging.getLogger(__name__)
# Environment variables
""" Namespaces used in DMRPP XML Files """
NS = {
'dpp': 'http://xml.opendap.org/dap/dmrpp/1.0.0#',
'd': 'http://xml.opendap.org/ns/DAP/4.0#'
}
""" Default compression level """
UNKNOWN_COMPRESSION_LEVEL = 4
""" Data type mappings """
TYPE_INFO = {
'Int8': (int, '|i1'),
'Int16': (int, '<i2'),
'Int32': (int, '<i4'),
'Int64': (int, '<i8'),
'Byte': (int, '|u1'),
'UInt8': (int, '|u1'),
'UInt16': (int, '<u2'),
'UInt32': (int, '<u4'),
'UInt64': (int, '<u8'),
'Float32': (float, '<f4'),
'Float64': (float, '<f8'),
'String': (str, '|s'),
'URI': (str, '|s')
}
def find_child(node, name):
"""Return child node with matching name (this function primarily used for testing)
Args:
node (XML Element): XML Node to search children
name (string): Name of child
Returns:
XML Element: XML Child Element
"""
return node.find(".//d:*[@name='%s']" % (name), NS)
def get_attribute_values(node):
"""Get value for a node
Args:
node (XML Element): An XML Element, presumably of Attribute type
Returns:
str or [str]: Single value or a list
"""
t = TYPE_INFO[node.attrib['type']][0]
vals = [t(val.text) for val in node]
return vals[0] if len(vals) == 1 else vals
def get_attributes(node, exclude=[]):
"""Get all children from a node that are Attributes
Args:
node (XML Element): An XML Element containing Attribute children
exclude (list[str], optional): List of attribute names to exclude. Defaults to [].
Returns:
dict: Dictionary of Atribute values
"""
zattrs = {}
for child in node :
tag = child.tag.split('}')[-1]
if tag == 'Attribute' and child.attrib['name'] not in exclude:
zattrs[child.attrib['name']] = get_attribute_values(child)
return zattrs
def get_dimensions(root, group=None):
"""Get dictionary of dimension info from the root of the DMRPP XML
Args:
root (XML Element): XML Element for the DMRPP root
group (str, optional): Group name to get dimensions from
Returns:
dict: Dictionary containing dimension names, sizes, and full paths
"""
#, group=None): #, path='/'):
if group is None:
group = root
#dimensions = {}
dim_infos = { '/' + dim.attrib['name']: {'size': int(dim.attrib['size'])} for dim in group.findall('d:Dimension', NS)}
for name in dim_infos:
basename = name.split('/')[-1]
dim_node = root.find(".//d:*[@name='%s']/d:Dim[@name='%s']/.." % (basename, name), NS)
if dim_node is None:
logger.warning(f"Could not find details for dimension {name}")
continue
#result = node.find(f"./d:Attribute[@name='{name}']/d:Value", NS)
#return result.text.lstrip('/')
node = dim_node.find(f"./d:Attribute[@name='fullnamepath']/d:Value", NS)
if node:
dim_infos[name]['path'] = node.text
else:
dim_infos[name]['path'] = name
# TODO - HARMONY-530, don't think this works as originally intended. Need test files with nested groups
#for child in group.findall('d:Group', NS):
# dim_infos.update(get_dimensions(root, child)) #, path + child.attrib['name'] + '/'))
return dim_infos
def chunks_to_zarr(node):
"""Convert DMRPP 'Chunks' Element into Zarr metadata
Args:
node (XML Element): XML Element of type dmrpp:chunks
Returns:
dict: Zarr metadata for chunks
"""
chunks = None
zarray = {}
zchunkstore = {}
for child in node:
tag = child.tag.split('}')[-1]
if tag == 'chunkDimensionSizes':
chunks = [int(v) for v in child.text.split(' ')]
elif tag == 'chunk':
offset = int(child.attrib['offset'])
nbytes = int(child.attrib['nBytes'])
positions_in_array = child.get('chunkPositionInArray')
if positions_in_array:
positions_str = positions_in_array[1:-1].split(',')
positions = [int(p) for p in positions_str]
indexes = [ int(p / c) for p, c in zip(positions, chunks) ]
else:
indexes = [0]
key = '.'.join([ str(i) for i in indexes ])
zchunkstore[key] = { 'offset': offset, 'size': nbytes }
zarray['chunks'] = chunks
return {
'zarray': zarray,
'zchunkstore': zchunkstore
}
def array_to_zarr(node, dims, prefix=''):
"""Convert a DMRPP Array into Zarr metadata
Args:
node (XML Element): XML Element of a DMRPP array
dims (dict): Dimension info from DMRPP XML root
prefix (str, optional): Prefix to prepend to array in Zarr metadata. Defaults to ''.
Raises:
Exception: Unrecognized compression type
Returns:
dict: Zarr metadata for this DMRPP array
"""
datatype = node.tag.split('}')[-1]
dtype = TYPE_INFO[datatype][1]
pathnode = node.find(f"./d:Attribute[@name='fullnamepath']/d:Value", NS)
if pathnode is not None:
prefix = op.join(prefix, pathnode.text).lstrip('/')
else:
prefix = op.join(prefix, node.attrib['name']).lstrip('/')
zarray = {
"zarr_format": 2,
"filters": None,
"order": "C",
"dtype": dtype,
"shape": []
}
zattrs = get_attributes(node, exclude=['fullnamepath', 'origname'])
zattrs.update({
"_ARRAY_DIMENSIONS": []
})
zchunkstore = None
for child in node:
tag = child.tag.split('}')[-1]
if tag == 'Dim' and 'name' in child.attrib:
dim = dims[child.attrib['name']]
zattrs['_ARRAY_DIMENSIONS'].append(child.attrib['name'].lstrip('/'))
zarray['shape'].append(dim['size'])
elif tag == 'Dim':
# anonymous Dimensions still have size
zarray['shape'].append(int(child.attrib['size']))
elif tag == 'chunks':
compression = child.attrib.get('compressionType')
if compression == 'deflate':
zarray['compressor'] = { "id": "zlib", "level": UNKNOWN_COMPRESSION_LEVEL }
elif compression == 'deflate shuffle':
zarray['compressor'] = {"id": "zlib", "level": UNKNOWN_COMPRESSION_LEVEL}
size = int(dtype[2:])
zarray['filters'] = [{"id": "shuffle", "elementsize": size}]
elif compression is None:
zarray['compressor'] = None
else:
raise Exception('Unrecognized compressionType: ' + compression)
chunks = chunks_to_zarr(child)
zarray.update(chunks['zarray'])
zchunkstore = chunks['zchunkstore']
# NOTE - this is null in test file
zarray['fill_value'] = zattrs.get('_FillValue')
# HARMONY-896: Automatic scale factor and offset filter. Not yet working with all data types
# if zattrs.get('scale_factor') or zattrs.get('add_offset'):
# zarray['filters'].append({
# 'id': 'fixedscaleoffset',
# 'offset': zattrs.get('add_offset', 0.0),
# 'scale': zattrs.get('scale_factor', 1.0),
# 'dtype': '<f8',
# })
if zarray.get('chunks') is None:
zarray['chunks'] = zarray['shape']
zarr = {
op.join(prefix, '.zarray'): zarray,
op.join(prefix, '.zattrs'): zattrs,
op.join(prefix, '.zchunkstore'): zchunkstore
}
return zarr
def group_to_zarr(node, dims, prefix=''):
"""Convert DMRPP grouping into a Zarr group
Args:
node (XML Element): XML Element representing DMRPP group
dims (dict): Dimension info retrieved from DMRPP root XML
prefix (str, optional): Prefix to prepend to Zarr metadata keys. Defaults to ''.
Returns:
dict: Zarr metadata
"""
zarr = {}
if prefix == '':
zarr['.zgroup'] = {
'zarr_format': 2
}
for child in node:
tag = child.tag.split('}')[-1]
# if this is an array, convert to zarr array
if tag in TYPE_INFO:
zarr_array = array_to_zarr(child, dims, prefix=prefix)
zarr.update(zarr_array)
# otherwise, if this is group or a Container Attribute - this has not been tested
elif tag == 'Group' or (tag == 'Attribute' and child.attrib.get('type', '') == 'Container'):
name = child.attrib['name']
# use for global .zattrs
if name == 'HDF5_GLOBAL':
zarr['.zattrs'] = get_attributes(child)
elif name != 'DODS_EXTRA' and len(child):
zarr_child = group_to_zarr(child, dims, prefix=op.join(prefix, name))
zarr.update(zarr_child)
# if attribute
elif tag == 'Attribute':
# put at current level
key = op.join(prefix, '.zattrs')
if key not in zarr:
zarr[key] = {}
zarr[key][child.attrib['name']] = get_attribute_values(child)
return zarr
def to_zarr(root):
"""Convert DMRPP metadata to Zarr metadata
Args:
root (XML Element): Root XML Element of DMRPP XML
Returns:
dict: Zarr metadata
"""
zarr = {}
dims = get_dimensions(root)
zarr = group_to_zarr(root, dims)
return zarr | zarr-eosdis-store | /zarr_eosdis_store-0.1.3-py3-none-any.whl/eosdis_store/dmrpp.py | dmrpp.py |
import logging
import re
import time
from cachecontrol import CacheController, CacheControlAdapter
import requests
from requests_futures.sessions import FuturesSession
import xml.etree.ElementTree as ElementTree
from .dmrpp import to_zarr
from .version import __version__
from zarr.storage import ConsolidatedMetadataStore
logger = logging.getLogger(__name__)
class ElapsedFuturesSession(FuturesSession):
"""Track start time and elapsed time for all requests in this session
Args:
FuturesSession (FuturesSession): Parent class
"""
def request(self, method, url, hooks={}, *args, **kwargs):
start = time.time()
def timing(r, *args, **kwargs):
r.start = start
r.elapsed = time.time() - start
try:
if isinstance(hooks['response'], (list, tuple)):
# needs to be first so we don't time other hooks execution
hooks['response'].insert(0, timing)
else:
hooks['response'] = [timing, hooks['response']]
except KeyError:
hooks['response'] = timing
return super(ElapsedFuturesSession, self) \
.request(method, url, hooks=hooks, *args, **kwargs)
class HttpByteRangeReader():
"""Perform HTTP range reads on remote files
"""
def __init__(self, url):
"""Create HttpByteRangeRead instance for a single file
Args:
url (str): URL to remote file
"""
self.url = url
self.first_fetch = True
# create futures session
self.session = ElapsedFuturesSession()
cache_adapter = CacheControlAdapter()
cache_adapter.controller = CacheController(
cache=cache_adapter.cache,
status_codes=(200, 203, 300, 301, 303, 307)
)
self.session.mount('http://', cache_adapter)
self.session.mount('https://', cache_adapter)
def read_range(self, offset, size):
"""Read a range of bytes from remote file
Args:
offset (int): Offset, in number of bytes
size (int): Number of bytes to read
Returns:
Bytes: Contents file file over range
"""
return self._async_read(offset, size).result().content
def read_ranges(self, range_iter):
"""Read multiple ranges simultaneously (async)
Args:
range_iter (iterator): List of ranges
Yields:
iterator: Iterator to content of each range
"""
futures = [self._async_read(offset, size) for offset, size in range_iter]
for future in futures:
yield future.result()
def _async_read(self, offset, size):
"""Asynchronous HTTP read
Args:
offset (int): Offset, in number of Bytes
size (int): Number of bytes to read
Returns:
response: Return request response
"""
logger.debug(f"Reading {self.url} [{offset}:{offset+size}] ({size} bytes)")
range_str = '%d-%d' % (offset, offset + size)
request = self.session.get(self.url, headers={
'Range': 'bytes=' + range_str,
'User-Agent': f'zarr-eosdis-store/{__version__}'
})
if self.first_fetch:
self.first_fetch = False
request.result()
return request
class ConsolidatedChunkStore(ConsolidatedMetadataStore):
"""Zarr store for performing range reads on remote HTTP resources in a way that parallelizes
and combines reads.
Args:
ConsolidatedMetadataStore (ConsolidatedMetadataStore): Parent class using single source of metadata
"""
def __init__(self, meta_store, data_url):
"""Instantiate ConsolidatedChunkStore
Args:
meta_store (dict): A Python object with the structure of a consolidated Zarr metadata store
data_url (str): URL to data file
"""
self.meta_store = meta_store
self.chunk_source = HttpByteRangeReader(data_url)
def __getitem__(self, key):
"""Get an item from the store
Args:
key (str): Key of the item to fetch from the store as defined by Zarr
Returns:
The data or metadata value of the item
"""
return self.getitems((key, ))[key]
def getitems(self, keys, **kwargs):
"""Get values for the provided list of keys from the Zarr store
Args:
keys (Array): Array of string keys to fetch from the store
Returns:
An iterator returning tuples of the input keys to their data or metadata values
"""
return dict(self._getitems_generator(keys, **kwargs))
def _getitems_generator(self, keys, **kwargs):
"""Generate results for getitems
"""
ranges = []
for key in keys:
if re.search(r'/\d+(\.\d+)*$', key):
# The key corresponds to a chunk within the file, look up its offset and size
path, name = key.rsplit('/', 1)
chunk_loc = self.meta_store[path + '/.zchunkstore'][name]
ranges.append((key, chunk_loc['offset'], chunk_loc['size']))
else:
# Metadata key, return its value
yield (key, super().__getitem__(key))
# Get all the byte ranges requested
for k, v in self._getranges(ranges).items():
yield (k, v)
def _getranges(self, ranges):
'''Given a set of byte ranges [(key, offset, size), ...], fetches and returns a mapping of keys to bytes
Args:
ranges (Array): Array of desired byte ranges of the form [(key, offset, size), ...]
Returns:
dict-like [(key, bytes), (key, bytes), ...]
'''
reader = self.chunk_source
ranges = sorted(ranges, key=lambda r: r[1])
merged_ranges = self._merge_ranges(ranges)
range_data_offsets = [r[-1] for r in merged_ranges]
logger.debug(f"Merged {len(ranges)} requests into {len(range_data_offsets)}")
range_data = reader.read_ranges([(offset, size) for offset, size, _ in merged_ranges])
self.responses = list(range_data)
range_data = [r.content for r in self.responses]
result = self._split_ranges(zip(range_data_offsets, range_data))
return result
def _split_ranges(self, merged_ranges):
'''Given tuples of range groups as returned by _merge_ranges and corresponding bytes,
returns a map of keys to corresponding bytes.
Args:
merged_ranges (Array): Array of (group, bytes) where group is as returned by _merge_ranges
Returns:
dict-like [(key, bytes), (key, bytes), ...]
'''
result = {}
for ranges, data in merged_ranges:
for key, offset, size in ranges:
result[key] = data[offset:(offset+size)]
return result
def _merge_ranges(self, ranges, max_gap=10000):
'''Group an array of byte ranges that need to be read such that any that are within `max_gap`
of each other are in the same group.
Args:
ranges (Array): An array of tuples of (key, offset, size)
Returns:
An array of groups of near-adjacent ranges
[
[
offset, # The byte offset of the group from the start of the file
size, # The number of bytes that need to be read
[
( # Range within group
key, # The key from the input tuple
sub-offset, # The byte offset of the range from the start of the group
size # The number of bytes for the range
),
(key, sub-offset, size),
...
]
],
...
]
'''
ranges = sorted(ranges, key=lambda r: r[1])
if len(ranges) == 0:
return []
group_offset = ranges[0][1]
prev_offset = ranges[0][1]
group = []
result = []
for key, offset, size in ranges:
if offset - prev_offset > max_gap + 1:
logger.debug("Starting new range due to gap of %d bytes" % (offset - prev_offset,))
result.append((group_offset, prev_offset - group_offset, group))
group_offset = offset
group = []
group.append((key, offset - group_offset, size))
prev_offset = offset + size
result.append((group_offset, prev_offset - group_offset, group))
return result
class EosdisStore(ConsolidatedChunkStore):
"""Store representing a HDF5/NetCDF file accessed over HTTP with zarr metadata derived from a DMR++ file
Args:
ConsolidatedChunkStore (ConsolidatedChunkStore): Parent class is a store for doing byte range reads
"""
def __init__(self, data_url, dmr_url=None):
"""Construct the store
Args:
data_url (String): The URL of the remote data file which should be accessed through Zarr
dmr_url (String): Optional URL to a DMR++ file describing metadata and byte offsets of the
given file. If not provided, the URL is assumed to be the original file with a .dmrpp suffix
"""
if dmr_url is None:
dmr_url = data_url + '.dmrpp'
dmrpp = requests.get(dmr_url).text
tree = ElementTree.fromstring(dmrpp)
meta_store = to_zarr(tree)
super(EosdisStore, self).__init__(meta_store, data_url) | zarr-eosdis-store | /zarr_eosdis_store-0.1.3-py3-none-any.whl/eosdis_store/stores.py | stores.py |
# zarr-swiftstore
openstack swift object storage backend for zarr. It enables direct access to
object storage to read and write zarr datasets.
## Install
```bash
git clone https://github.com/siligam/zarr-swiftstore.git
cd zarr-swiftstore
python setup.py install
```
## Usage
0. Openstack Swift Object Storage auth_v1.0 requires the following keyword arguments for authentication
For initial authentication:
```python
auth = {
"authurl": "...",
"user": "{account}:{user}",
"key": "{password}",
}
```
or if pre-authenticated token is already available:
```python
auth = {
"preauthurl": "...",
"preauthtoken": "...",
}
```
1. using zarr
```python
import os
import zarr
from zarrswift import SwiftStore
auth = {
"preauthurl": os.environ["OS_STORAGE_URL"],
"preauthtoken": os.environ["OS_AUTH_TOKEN"],
}
store = SwiftStore(container='demo', prefix='zarr-demo', storage_options=auth)
root = zarr.group(store=store, overwrite=True)
z = root.zeros('foo/bar', shape=(10, 10), chunks=(5, 5), dtype='i4')
z[:] = 42
```
2. using xarray
```python
import xarray as xr
import numpy as np
from zarrswift import SwiftStore
ds = xr.Dataset(
{"foo": (('x', 'y'), np.random.rand(4, 5))},
coords = {
'x': [10, 20, 30, 40],
'y': [1, 2, 3, 4, 5],
},
}
store = SwiftStore(container='demo', prefix='xarray-demo', storage_options=auth)
ds.to_zarr(store=store, mode='w', consolidated=True)
# load
ds = xr.open_zarr(store=store, consolidated=True)
```
## Test
Test picks up authentication details from the following environment variables.
If pre-authentication token is already available:
```bash
export OS_AUTH_TOKEN="..."
export OS_STORAGE_URL="..."
```
Otherwise:
```bash
export ST_AUTH="..."
export ST_USER="{account}:{user}"
export ST_KEY="{password}"
```
Also set environment variable ZARR_TEST_SWIFT=1
```bash
export ZARR_TEST_SWIFT=1
pytest -v zarrswift
```
| zarr-swiftstore | /zarr-swiftstore-1.2.3.tar.gz/zarr-swiftstore-1.2.3/README.md | README.md |
from collections.abc import MutableMapping
from swiftclient import Connection
from swiftclient.exceptions import ClientException
from zarr.util import normalize_storage_path
from numcodecs.compat import ensure_bytes
class SwiftStore(MutableMapping):
"""Storage class using Openstack Swift Object Store.
Parameters
----------
container: string
swift container to use. It is created if it does not already exists
prefix: string
sub-directory path with in the container to store data
storage_options: dict
authentication information to connect to the swift store.
Examples
--------
>>> import os
>>> from zarrswift import SwiftStore
>>> getenv = os.environ.get
>>> options = {'preauthurl': getenv('OS_STORAGE_URL'),
... 'preauthtoken': getenv('OS_AUTH_TOKEN')}
>>> store = SwiftStore(container="demo", prefix="zarr_demo", storage_options=options)
>>> root = zarr.group(store=store, overwrite=True)
>>> z = root.zeros('foo/bar', shape=(10, 10), chunks=(5, 5), dtype='i4')
>>> z[:] = 42
"""
def __init__(self, container, prefix="", storage_options=None):
self.container = container
self.prefix = normalize_storage_path(prefix)
self.storage_options = storage_options or {}
self.conn = Connection(**self.storage_options)
self._ensure_container()
def __getstate__(self):
state = self.__dict__.copy()
del state["conn"]
return state
def __setstate__(self, state):
self.__dict__.update(state)
self.conn = Connection(**self.storage_options)
def __getitem__(self, name):
name = self._add_prefix(name)
try:
resp, content = self.conn.get_object(self.container, name)
except ClientException:
raise KeyError("Object {} not found".format(name))
return content
def __setitem__(self, name, value):
name = self._add_prefix(name)
value = ensure_bytes(value)
self.conn.put_object(self.container, name, value)
def __delitem__(self, name):
name = self._add_prefix(name)
try:
self.conn.delete_object(self.container, name)
except ClientException:
raise KeyError("Object {} not found".format(name))
def __eq__(self, other):
return (
isinstance(other, SwiftStore)
and self.container == other.container
and self.prefix == other.prefix
)
def __contains__(self, name):
return name in self.keys()
def __iter__(self):
contents = self._list_container(strip_prefix=True)
for entry in contents:
yield entry["name"]
def __len__(self):
return len(self.keys())
def _ensure_container(self):
_, contents = self.conn.get_account()
listings = [item["name"] for item in contents]
if self.container not in listings:
self.conn.put_container(self.container)
def _add_prefix(self, path):
path = normalize_storage_path(path)
path = "/".join([self.prefix, path])
return normalize_storage_path(path)
def _list_container(
self, path=None, delimiter=None, strip_prefix=False, treat_path_as_dir=True
):
path = self.prefix if path is None else self._add_prefix(path)
if path and treat_path_as_dir:
path += "/"
_, contents = self.conn.get_container(
self.container, prefix=path, delimiter=delimiter
)
if strip_prefix:
prefix_size = len(path)
for entry in contents:
name = entry.get('name', entry.get('subdir', ''))
entry["name"] = normalize_storage_path(name[prefix_size:])
for entry in contents:
entry["bytes"] = entry.get("bytes", 0)
return contents
def keys(self):
return list(self.__iter__())
def listdir(self, path=None):
contents = self._list_container(path, delimiter="/", strip_prefix=True)
listings = [entry["name"] for entry in contents]
return sorted(listings)
def getsize(self, path=None):
contents = self._list_container(
path, strip_prefix=True, treat_path_as_dir=False
)
contents = [entry for entry in contents if "/" not in entry["name"]]
return sum([entry["bytes"] for entry in contents])
def rmdir(self, path=None):
contents = self._list_container(path)
for entry in contents:
self.conn.delete_object(self.container, entry["name"])
def clear(self):
self.rmdir()
@property
def url(self):
_url = '/'.join([self.conn.url, self.container, self.prefix])
if not self.prefix:
_url = _url.rstrip('/')
return _url | zarr-swiftstore | /zarr-swiftstore-1.2.3.tar.gz/zarr-swiftstore-1.2.3/zarrswift/storage.py | storage.py |
# zarr-tools
Convert nd2 to zarr
[](https://github.com/BaroudLab/zarr-tools/raw/main/LICENSE)
[](https://pypi.org/project/zarr-tools)
[](https://python.org)
[](https://github.com/BaroudLab/zarr-tools/actions)
[](https://codecov.io/gh/BaroudLab/zarr-tools)
## Installation
```pip install zarr-tools```
## Usage
### As command line
``` python -m zarr-tools file.nd2 ```
This will produce the zarr dataset with default 5 steps of binning for xy dimensions.
### As python module
```python
import nd2
import zarr_tools
data = nd2.ND2File("input.nd2").to_dask()
zarr_tools.convert.to_zarr(
data,
channel_axis=1,
path="output.zarr",
steps=4,
name=['BF','TRITC'],
colormap=['gray','green'],
lut=((1000,30000),(440, 600)),
)
```
| zarr-tools | /zarr-tools-0.4.5.tar.gz/zarr-tools-0.4.5/README.md | README.md |
<div align="center">
<img src="https://raw.githubusercontent.com/zarr-developers/community/main/logos/logo2.png"><br>
</div>
# Zarr
<table>
<tr>
<td>Latest Release</td>
<td>
<a href="https://pypi.org/project/zarr/">
<img src="https://badge.fury.io/py/zarr.svg" alt="latest release" />
</a>
</td>
</tr>
<td></td>
<td>
<a href="https://anaconda.org/anaconda/zarr/">
<img src="https://anaconda.org/conda-forge/zarr/badges/version.svg" alt="latest release" />
</a>
</td>
</tr>
<tr>
<td>Package Status</td>
<td>
<a href="https://pypi.org/project/zarr/">
<img src="https://img.shields.io/pypi/status/zarr.svg" alt="status" />
</a>
</td>
</tr>
<tr>
<td>License</td>
<td>
<a href="https://github.com/zarr-developers/zarr-python/blob/main/LICENSE.txt">
<img src="https://img.shields.io/pypi/l/zarr.svg" alt="license" />
</a>
</td>
</tr>
<tr>
<td>Build Status</td>
<td>
<a href="https://github.com/zarr-developers/zarr-python/blob/main/.github/workflows/python-package.yml">
<img src="https://github.com/zarr-developers/zarr-python/actions/workflows/python-package.yml/badge.svg" alt="build status" />
</a>
</td>
</tr>
<tr>
<td>Pre-commit Status</td>
<td>
<a href=""https://github.com/zarr-developers/zarr-python/blob/main/.pre-commit-config.yaml">
<img src="https://results.pre-commit.ci/badge/github/zarr-developers/zarr-python/main.svg" alt="pre-commit status" />
</a>
</td>
</tr>
<tr>
<td>Coverage</td>
<td>
<a href="https://codecov.io/gh/zarr-developers/zarr-python">
<img src="https://codecov.io/gh/zarr-developers/zarr-python/branch/main/graph/badge.svg"/ alt="coverage">
</a>
</td>
</tr>
<tr>
<td>Downloads</td>
<td>
<a href="https://zarr.readthedocs.io">
<img src="https://pepy.tech/badge/zarr" alt="pypi downloads" />
</a>
</td>
</tr>
<tr>
<td>Gitter</td>
<td>
<a href="https://gitter.im/zarr-developers/community">
<img src="https://badges.gitter.im/zarr-developers/community.svg" />
</a>
</td>
</tr>
<tr>
<td>Citation</td>
<td>
<a href="https://doi.org/10.5281/zenodo.3773450">
<img src="https://zenodo.org/badge/DOI/10.5281/zenodo.3773450.svg" alt="DOI">
</a>
</td>
</tr>
</table>
## What is it?
Zarr is a Python package providing an implementation of compressed, chunked, N-dimensional arrays, designed for use in parallel computing. See the [documentation](https://zarr.readthedocs.io) for more information.
## Main Features
- [**Create**](https://zarr.readthedocs.io/en/stable/tutorial.html#creating-an-array) N-dimensional arrays with any NumPy `dtype`.
- [**Chunk arrays**](https://zarr.readthedocs.io/en/stable/tutorial.html#chunk-optimizations) along any dimension.
- [**Compress**](https://zarr.readthedocs.io/en/stable/tutorial.html#compressors) and/or filter chunks using any NumCodecs codec.
- [**Store arrays**](https://zarr.readthedocs.io/en/stable/tutorial.html#tutorial-storage) in memory, on disk, inside a zip file, on S3, etc...
- [**Read**](https://zarr.readthedocs.io/en/stable/tutorial.html#reading-and-writing-data) an array [**concurrently**](https://zarr.readthedocs.io/en/stable/tutorial.html#parallel-computing-and-synchronization) from multiple threads or processes.
- Write to an array concurrently from multiple threads or processes.
- Organize arrays into hierarchies via [**groups**](https://zarr.readthedocs.io/en/stable/tutorial.html#groups).
## Where to get it
Zarr can be installed from PyPI using `pip`:
```bash
pip install zarr
```
or via `conda`:
```bash
conda install -c conda-forge zarr
```
For more details, including how to install from source, see the [installation documentation](https://zarr.readthedocs.io/en/stable/index.html#installation).
| zarr | /zarr-2.15.0.tar.gz/zarr-2.15.0/README.md | README.md |
# Contributor Covenant Code of Conduct
## Our Pledge
In the interest of fostering an open and welcoming environment, we as contributors and maintainers pledge to making participation in our project and our community a harassment-free experience for everyone, regardless of age, body size, disability, ethnicity, gender identity and expression, level of experience, nationality, personal appearance, race, religion, or sexual identity and orientation.
## Our Standards
Examples of behavior that contributes to creating a positive environment include:
* Using welcoming and inclusive language
* Being respectful of differing viewpoints and experiences
* Gracefully accepting constructive criticism
* Focusing on what is best for the community
* Showing empathy towards other community members
Examples of unacceptable behavior by participants include:
* The use of sexualized language or imagery and unwelcome sexual attention or advances
* Trolling, insulting/derogatory comments, and personal or political attacks
* Public or private harassment
* Publishing others' private information, such as a physical or electronic address, without explicit permission
* Other conduct which could reasonably be considered inappropriate in a professional setting
## Our Responsibilities
Project maintainers are responsible for clarifying the standards of acceptable behavior and are expected to take appropriate and fair corrective action in response to any instances of unacceptable behavior.
Project maintainers have the right and responsibility to remove, edit, or reject comments, commits, code, wiki edits, issues, and other contributions that are not aligned to this Code of Conduct, or to ban temporarily or permanently any contributor for other behaviors that they deem inappropriate, threatening, offensive, or harmful.
## Scope
This Code of Conduct applies both within project spaces and in public spaces when an individual is representing the project or its community. Examples of representing a project or community include using an official project e-mail address, posting via an official social media account, or acting as an appointed representative at an online or offline event. Representation of a project may be further defined and clarified by project maintainers.
## Enforcement
Instances of abusive, harassing, or otherwise unacceptable behavior may be reported by contacting the project team at [email protected]. The project team will review and investigate all complaints, and will respond in a way that it deems appropriate to the circumstances. The project team is obligated to maintain confidentiality with regard to the reporter of an incident. Further details of specific enforcement policies may be posted separately.
Project maintainers who do not follow or enforce the Code of Conduct in good faith may face temporary or permanent repercussions as determined by other members of the project's leadership.
## Attribution
This Code of Conduct is adapted from the [Contributor Covenant][homepage], version 1.4, available at [https://www.contributor-covenant.org/version/1/4][version]
[homepage]: https://www.contributor-covenant.org
[version]: https://www.contributor-covenant.org/version/1/4
| zarr | /zarr-2.15.0.tar.gz/zarr-2.15.0/CODE_OF_CONDUCT.md | CODE_OF_CONDUCT.md |
Getting Started
===============
Zarr is a format for the storage of chunked, compressed, N-dimensional arrays
inspired by `HDF5 <https://www.hdfgroup.org/HDF5/>`_, `h5py
<https://www.h5py.org/>`_ and `bcolz <https://bcolz.readthedocs.io/>`_.
The project is fiscally sponsored by `NumFOCUS <https://numfocus.org/>`_, a US
501(c)(3) public charity, and development is supported by the
`MRC Centre for Genomics and Global Health <https://www.cggh.org>`_
and the `Chan Zuckerberg Initiative <https://chanzuckerberg.com/>`_.
These documents describe the Zarr Python implementation. More information
about the Zarr format can be found on the `main website <https://zarr.dev>`_.
Highlights
----------
* Create N-dimensional arrays with any NumPy dtype.
* Chunk arrays along any dimension.
* Compress and/or filter chunks using any NumCodecs_ codec.
* Store arrays in memory, on disk, inside a Zip file, on S3, ...
* Read an array concurrently from multiple threads or processes.
* Write to an array concurrently from multiple threads or processes.
* Organize arrays into hierarchies via groups.
Contributing
------------
Feedback and bug reports are very welcome, please get in touch via
the `GitHub issue tracker <https://github.com/zarr-developers/zarr-python/issues>`_. See
:doc:`contributing` for further information about contributing to Zarr.
Projects using Zarr
-------------------
If you are using Zarr, we would `love to hear about it
<https://github.com/zarr-developers/community/issues/19>`_.
.. toctree::
:caption: Getting Started
:hidden:
installation
.. _NumCodecs: https://numcodecs.readthedocs.io/
| zarr | /zarr-2.15.0.tar.gz/zarr-2.15.0/docs/getting_started.rst | getting_started.rst |
.. _tutorial:
Tutorial
========
Zarr provides classes and functions for working with N-dimensional arrays that
behave like NumPy arrays but whose data is divided into chunks and each chunk is
compressed. If you are already familiar with HDF5 then Zarr arrays provide
similar functionality, but with some additional flexibility.
.. _tutorial_create:
Creating an array
-----------------
Zarr has several functions for creating arrays. For example::
>>> import zarr
>>> z = zarr.zeros((10000, 10000), chunks=(1000, 1000), dtype='i4')
>>> z
<zarr.core.Array (10000, 10000) int32>
The code above creates a 2-dimensional array of 32-bit integers with 10000 rows
and 10000 columns, divided into chunks where each chunk has 1000 rows and 1000
columns (and so there will be 100 chunks in total).
For a complete list of array creation routines see the :mod:`zarr.creation`
module documentation.
.. _tutorial_array:
Reading and writing data
------------------------
Zarr arrays support a similar interface to NumPy arrays for reading and writing
data. For example, the entire array can be filled with a scalar value::
>>> z[:] = 42
Regions of the array can also be written to, e.g.::
>>> import numpy as np
>>> z[0, :] = np.arange(10000)
>>> z[:, 0] = np.arange(10000)
The contents of the array can be retrieved by slicing, which will load the
requested region into memory as a NumPy array, e.g.::
>>> z[0, 0]
0
>>> z[-1, -1]
42
>>> z[0, :]
array([ 0, 1, 2, ..., 9997, 9998, 9999], dtype=int32)
>>> z[:, 0]
array([ 0, 1, 2, ..., 9997, 9998, 9999], dtype=int32)
>>> z[:]
array([[ 0, 1, 2, ..., 9997, 9998, 9999],
[ 1, 42, 42, ..., 42, 42, 42],
[ 2, 42, 42, ..., 42, 42, 42],
...,
[9997, 42, 42, ..., 42, 42, 42],
[9998, 42, 42, ..., 42, 42, 42],
[9999, 42, 42, ..., 42, 42, 42]], dtype=int32)
.. _tutorial_persist:
Persistent arrays
-----------------
In the examples above, compressed data for each chunk of the array was stored in
main memory. Zarr arrays can also be stored on a file system, enabling
persistence of data between sessions. For example::
>>> z1 = zarr.open('data/example.zarr', mode='w', shape=(10000, 10000),
... chunks=(1000, 1000), dtype='i4')
The array above will store its configuration metadata and all compressed chunk
data in a directory called 'data/example.zarr' relative to the current working
directory. The :func:`zarr.convenience.open` function provides a convenient way
to create a new persistent array or continue working with an existing
array. Note that although the function is called "open", there is no need to
close an array: data are automatically flushed to disk, and files are
automatically closed whenever an array is modified.
Persistent arrays support the same interface for reading and writing data,
e.g.::
>>> z1[:] = 42
>>> z1[0, :] = np.arange(10000)
>>> z1[:, 0] = np.arange(10000)
Check that the data have been written and can be read again::
>>> z2 = zarr.open('data/example.zarr', mode='r')
>>> np.all(z1[:] == z2[:])
True
If you are just looking for a fast and convenient way to save NumPy arrays to
disk then load back into memory later, the functions
:func:`zarr.convenience.save` and :func:`zarr.convenience.load` may be
useful. E.g.::
>>> a = np.arange(10)
>>> zarr.save('data/example.zarr', a)
>>> zarr.load('data/example.zarr')
array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
Please note that there are a number of other options for persistent array
storage, see the section on :ref:`tutorial_storage` below.
.. _tutorial_resize:
Resizing and appending
----------------------
A Zarr array can be resized, which means that any of its dimensions can be
increased or decreased in length. For example::
>>> z = zarr.zeros(shape=(10000, 10000), chunks=(1000, 1000))
>>> z[:] = 42
>>> z.resize(20000, 10000)
>>> z.shape
(20000, 10000)
Note that when an array is resized, the underlying data are not rearranged in
any way. If one or more dimensions are shrunk, any chunks falling outside the
new array shape will be deleted from the underlying store.
For convenience, Zarr arrays also provide an ``append()`` method, which can be
used to append data to any axis. E.g.::
>>> a = np.arange(10000000, dtype='i4').reshape(10000, 1000)
>>> z = zarr.array(a, chunks=(1000, 100))
>>> z.shape
(10000, 1000)
>>> z.append(a)
(20000, 1000)
>>> z.append(np.vstack([a, a]), axis=1)
(20000, 2000)
>>> z.shape
(20000, 2000)
.. _tutorial_compress:
Compressors
-----------
A number of different compressors can be used with Zarr. A separate package
called NumCodecs_ is available which provides a common interface to various
compressor libraries including Blosc, Zstandard, LZ4, Zlib, BZ2 and
LZMA. Different compressors can be provided via the ``compressor`` keyword
argument accepted by all array creation functions. For example::
>>> from numcodecs import Blosc
>>> compressor = Blosc(cname='zstd', clevel=3, shuffle=Blosc.BITSHUFFLE)
>>> data = np.arange(100000000, dtype='i4').reshape(10000, 10000)
>>> z = zarr.array(data, chunks=(1000, 1000), compressor=compressor)
>>> z.compressor
Blosc(cname='zstd', clevel=3, shuffle=BITSHUFFLE, blocksize=0)
This array above will use Blosc as the primary compressor, using the Zstandard
algorithm (compression level 3) internally within Blosc, and with the
bit-shuffle filter applied.
When using a compressor, it can be useful to get some diagnostics on the
compression ratio. Zarr arrays provide a ``info`` property which can be used to
print some diagnostics, e.g.::
>>> z.info
Type : zarr.core.Array
Data type : int32
Shape : (10000, 10000)
Chunk shape : (1000, 1000)
Order : C
Read-only : False
Compressor : Blosc(cname='zstd', clevel=3, shuffle=BITSHUFFLE,
: blocksize=0)
Store type : zarr.storage.KVStore
No. bytes : 400000000 (381.5M)
No. bytes stored : 3379344 (3.2M)
Storage ratio : 118.4
Chunks initialized : 100/100
If you don't specify a compressor, by default Zarr uses the Blosc
compressor. Blosc is generally very fast and can be configured in a variety of
ways to improve the compression ratio for different types of data. Blosc is in
fact a "meta-compressor", which means that it can use a number of different
compression algorithms internally to compress the data. Blosc also provides
highly optimized implementations of byte- and bit-shuffle filters, which can
improve compression ratios for some data. A list of the internal compression
libraries available within Blosc can be obtained via::
>>> from numcodecs import blosc
>>> blosc.list_compressors()
['blosclz', 'lz4', 'lz4hc', 'snappy', 'zlib', 'zstd']
In addition to Blosc, other compression libraries can also be used. For example,
here is an array using Zstandard compression, level 1::
>>> from numcodecs import Zstd
>>> z = zarr.array(np.arange(100000000, dtype='i4').reshape(10000, 10000),
... chunks=(1000, 1000), compressor=Zstd(level=1))
>>> z.compressor
Zstd(level=1)
Here is an example using LZMA with a custom filter pipeline including LZMA's
built-in delta filter::
>>> import lzma
>>> lzma_filters = [dict(id=lzma.FILTER_DELTA, dist=4),
... dict(id=lzma.FILTER_LZMA2, preset=1)]
>>> from numcodecs import LZMA
>>> compressor = LZMA(filters=lzma_filters)
>>> z = zarr.array(np.arange(100000000, dtype='i4').reshape(10000, 10000),
... chunks=(1000, 1000), compressor=compressor)
>>> z.compressor
LZMA(format=1, check=-1, preset=None, filters=[{'dist': 4, 'id': 3}, {'id': 33, 'preset': 1}])
The default compressor can be changed by setting the value of the
``zarr.storage.default_compressor`` variable, e.g.::
>>> import zarr.storage
>>> from numcodecs import Zstd, Blosc
>>> # switch to using Zstandard
... zarr.storage.default_compressor = Zstd(level=1)
>>> z = zarr.zeros(100000000, chunks=1000000)
>>> z.compressor
Zstd(level=1)
>>> # switch back to Blosc defaults
... zarr.storage.default_compressor = Blosc()
To disable compression, set ``compressor=None`` when creating an array, e.g.::
>>> z = zarr.zeros(100000000, chunks=1000000, compressor=None)
>>> z.compressor is None
True
.. _tutorial_filters:
Filters
-------
In some cases, compression can be improved by transforming the data in some
way. For example, if nearby values tend to be correlated, then shuffling the
bytes within each numerical value or storing the difference between adjacent
values may increase compression ratio. Some compressors provide built-in filters
that apply transformations to the data prior to compression. For example, the
Blosc compressor has built-in implementations of byte- and bit-shuffle filters,
and the LZMA compressor has a built-in implementation of a delta
filter. However, to provide additional flexibility for implementing and using
filters in combination with different compressors, Zarr also provides a
mechanism for configuring filters outside of the primary compressor.
Here is an example using a delta filter with the Blosc compressor::
>>> from numcodecs import Blosc, Delta
>>> filters = [Delta(dtype='i4')]
>>> compressor = Blosc(cname='zstd', clevel=1, shuffle=Blosc.SHUFFLE)
>>> data = np.arange(100000000, dtype='i4').reshape(10000, 10000)
>>> z = zarr.array(data, chunks=(1000, 1000), filters=filters, compressor=compressor)
>>> z.info
Type : zarr.core.Array
Data type : int32
Shape : (10000, 10000)
Chunk shape : (1000, 1000)
Order : C
Read-only : False
Filter [0] : Delta(dtype='<i4')
Compressor : Blosc(cname='zstd', clevel=1, shuffle=SHUFFLE, blocksize=0)
Store type : zarr.storage.KVStore
No. bytes : 400000000 (381.5M)
No. bytes stored : 1290562 (1.2M)
Storage ratio : 309.9
Chunks initialized : 100/100
For more information about available filter codecs, see the `Numcodecs
<https://numcodecs.readthedocs.io/>`_ documentation.
.. _tutorial_groups:
Groups
------
Zarr supports hierarchical organization of arrays via groups. As with arrays,
groups can be stored in memory, on disk, or via other storage systems that
support a similar interface.
To create a group, use the :func:`zarr.group` function::
>>> root = zarr.group()
>>> root
<zarr.hierarchy.Group '/'>
Groups have a similar API to the Group class from `h5py
<https://www.h5py.org/>`_. For example, groups can contain other groups::
>>> foo = root.create_group('foo')
>>> bar = foo.create_group('bar')
Groups can also contain arrays, e.g.::
>>> z1 = bar.zeros('baz', shape=(10000, 10000), chunks=(1000, 1000), dtype='i4')
>>> z1
<zarr.core.Array '/foo/bar/baz' (10000, 10000) int32>
Arrays are known as "datasets" in HDF5 terminology. For compatibility with h5py,
Zarr groups also implement the ``create_dataset()`` and ``require_dataset()``
methods, e.g.::
>>> z = bar.create_dataset('quux', shape=(10000, 10000), chunks=(1000, 1000), dtype='i4')
>>> z
<zarr.core.Array '/foo/bar/quux' (10000, 10000) int32>
Members of a group can be accessed via the suffix notation, e.g.::
>>> root['foo']
<zarr.hierarchy.Group '/foo'>
The '/' character can be used to access multiple levels of the hierarchy in one
call, e.g.::
>>> root['foo/bar']
<zarr.hierarchy.Group '/foo/bar'>
>>> root['foo/bar/baz']
<zarr.core.Array '/foo/bar/baz' (10000, 10000) int32>
The :func:`zarr.hierarchy.Group.tree` method can be used to print a tree
representation of the hierarchy, e.g.::
>>> root.tree()
/
└── foo
└── bar
├── baz (10000, 10000) int32
└── quux (10000, 10000) int32
The :func:`zarr.convenience.open` function provides a convenient way to create or
re-open a group stored in a directory on the file-system, with sub-groups stored in
sub-directories, e.g.::
>>> root = zarr.open('data/group.zarr', mode='w')
>>> root
<zarr.hierarchy.Group '/'>
>>> z = root.zeros('foo/bar/baz', shape=(10000, 10000), chunks=(1000, 1000), dtype='i4')
>>> z
<zarr.core.Array '/foo/bar/baz' (10000, 10000) int32>
Groups can be used as context managers (in a ``with`` statement).
If the underlying store has a ``close`` method, it will be called on exit.
For more information on groups see the :mod:`zarr.hierarchy` and
:mod:`zarr.convenience` API docs.
.. _tutorial_diagnostics:
Array and group diagnostics
---------------------------
Diagnostic information about arrays and groups is available via the ``info``
property. E.g.::
>>> root = zarr.group()
>>> foo = root.create_group('foo')
>>> bar = foo.zeros('bar', shape=1000000, chunks=100000, dtype='i8')
>>> bar[:] = 42
>>> baz = foo.zeros('baz', shape=(1000, 1000), chunks=(100, 100), dtype='f4')
>>> baz[:] = 4.2
>>> root.info
Name : /
Type : zarr.hierarchy.Group
Read-only : False
Store type : zarr.storage.MemoryStore
No. members : 1
No. arrays : 0
No. groups : 1
Groups : foo
>>> foo.info
Name : /foo
Type : zarr.hierarchy.Group
Read-only : False
Store type : zarr.storage.MemoryStore
No. members : 2
No. arrays : 2
No. groups : 0
Arrays : bar, baz
>>> bar.info
Name : /foo/bar
Type : zarr.core.Array
Data type : int64
Shape : (1000000,)
Chunk shape : (100000,)
Order : C
Read-only : False
Compressor : Blosc(cname='lz4', clevel=5, shuffle=SHUFFLE, blocksize=0)
Store type : zarr.storage.MemoryStore
No. bytes : 8000000 (7.6M)
No. bytes stored : 33240 (32.5K)
Storage ratio : 240.7
Chunks initialized : 10/10
>>> baz.info
Name : /foo/baz
Type : zarr.core.Array
Data type : float32
Shape : (1000, 1000)
Chunk shape : (100, 100)
Order : C
Read-only : False
Compressor : Blosc(cname='lz4', clevel=5, shuffle=SHUFFLE, blocksize=0)
Store type : zarr.storage.MemoryStore
No. bytes : 4000000 (3.8M)
No. bytes stored : 23943 (23.4K)
Storage ratio : 167.1
Chunks initialized : 100/100
Groups also have the :func:`zarr.hierarchy.Group.tree` method, e.g.::
>>> root.tree()
/
└── foo
├── bar (1000000,) int64
└── baz (1000, 1000) float32
If you're using Zarr within a Jupyter notebook (requires
`ipytree <https://github.com/QuantStack/ipytree>`_), calling ``tree()`` will generate an
interactive tree representation, see the `repr_tree.ipynb notebook
<https://nbviewer.org/github/zarr-developers/zarr-python/blob/main/notebooks/repr_tree.ipynb>`_
for more examples.
.. _tutorial_attrs:
User attributes
---------------
Zarr arrays and groups support custom key/value attributes, which can be useful for
storing application-specific metadata. For example::
>>> root = zarr.group()
>>> root.attrs['foo'] = 'bar'
>>> z = root.zeros('zzz', shape=(10000, 10000))
>>> z.attrs['baz'] = 42
>>> z.attrs['qux'] = [1, 4, 7, 12]
>>> sorted(root.attrs)
['foo']
>>> 'foo' in root.attrs
True
>>> root.attrs['foo']
'bar'
>>> sorted(z.attrs)
['baz', 'qux']
>>> z.attrs['baz']
42
>>> z.attrs['qux']
[1, 4, 7, 12]
Internally Zarr uses JSON to store array attributes, so attribute values must be
JSON serializable.
.. _tutorial_indexing:
Advanced indexing
-----------------
As of version 2.2, Zarr arrays support several methods for advanced or "fancy"
indexing, which enable a subset of data items to be extracted or updated in an
array without loading the entire array into memory.
Note that although this functionality is similar to some of the advanced
indexing capabilities available on NumPy arrays and on h5py datasets, **the Zarr
API for advanced indexing is different from both NumPy and h5py**, so please
read this section carefully. For a complete description of the indexing API,
see the documentation for the :class:`zarr.core.Array` class.
Indexing with coordinate arrays
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
Items from a Zarr array can be extracted by providing an integer array of
coordinates. E.g.::
>>> z = zarr.array(np.arange(10))
>>> z[:]
array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
>>> z.get_coordinate_selection([1, 4])
array([1, 4])
Coordinate arrays can also be used to update data, e.g.::
>>> z.set_coordinate_selection([1, 4], [-1, -2])
>>> z[:]
array([ 0, -1, 2, 3, -2, 5, 6, 7, 8, 9])
For multidimensional arrays, coordinates must be provided for each dimension,
e.g.::
>>> z = zarr.array(np.arange(15).reshape(3, 5))
>>> z[:]
array([[ 0, 1, 2, 3, 4],
[ 5, 6, 7, 8, 9],
[10, 11, 12, 13, 14]])
>>> z.get_coordinate_selection(([0, 2], [1, 3]))
array([ 1, 13])
>>> z.set_coordinate_selection(([0, 2], [1, 3]), [-1, -2])
>>> z[:]
array([[ 0, -1, 2, 3, 4],
[ 5, 6, 7, 8, 9],
[10, 11, 12, -2, 14]])
For convenience, coordinate indexing is also available via the ``vindex``
property, as well as the square bracket operator, e.g.::
>>> z.vindex[[0, 2], [1, 3]]
array([-1, -2])
>>> z.vindex[[0, 2], [1, 3]] = [-3, -4]
>>> z[:]
array([[ 0, -3, 2, 3, 4],
[ 5, 6, 7, 8, 9],
[10, 11, 12, -4, 14]])
>>> z[[0, 2], [1, 3]]
array([-3, -4])
When the indexing arrays have different shapes, they are broadcast together.
That is, the following two calls are equivalent::
>>> z[1, [1, 3]]
array([6, 8])
>>> z[[1, 1], [1, 3]]
array([6, 8])
Indexing with a mask array
~~~~~~~~~~~~~~~~~~~~~~~~~~
Items can also be extracted by providing a Boolean mask. E.g.::
>>> z = zarr.array(np.arange(10))
>>> z[:]
array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
>>> sel = np.zeros_like(z, dtype=bool)
>>> sel[1] = True
>>> sel[4] = True
>>> z.get_mask_selection(sel)
array([1, 4])
>>> z.set_mask_selection(sel, [-1, -2])
>>> z[:]
array([ 0, -1, 2, 3, -2, 5, 6, 7, 8, 9])
Here's a multidimensional example::
>>> z = zarr.array(np.arange(15).reshape(3, 5))
>>> z[:]
array([[ 0, 1, 2, 3, 4],
[ 5, 6, 7, 8, 9],
[10, 11, 12, 13, 14]])
>>> sel = np.zeros_like(z, dtype=bool)
>>> sel[0, 1] = True
>>> sel[2, 3] = True
>>> z.get_mask_selection(sel)
array([ 1, 13])
>>> z.set_mask_selection(sel, [-1, -2])
>>> z[:]
array([[ 0, -1, 2, 3, 4],
[ 5, 6, 7, 8, 9],
[10, 11, 12, -2, 14]])
For convenience, mask indexing is also available via the ``vindex`` property,
e.g.::
>>> z.vindex[sel]
array([-1, -2])
>>> z.vindex[sel] = [-3, -4]
>>> z[:]
array([[ 0, -3, 2, 3, 4],
[ 5, 6, 7, 8, 9],
[10, 11, 12, -4, 14]])
Mask indexing is conceptually the same as coordinate indexing, and is
implemented internally via the same machinery. Both styles of indexing allow
selecting arbitrary items from an array, also known as point selection.
Orthogonal indexing
~~~~~~~~~~~~~~~~~~~
Zarr arrays also support methods for orthogonal indexing, which allows
selections to be made along each dimension of an array independently. For
example, this allows selecting a subset of rows and/or columns from a
2-dimensional array. E.g.::
>>> z = zarr.array(np.arange(15).reshape(3, 5))
>>> z[:]
array([[ 0, 1, 2, 3, 4],
[ 5, 6, 7, 8, 9],
[10, 11, 12, 13, 14]])
>>> z.get_orthogonal_selection(([0, 2], slice(None))) # select first and third rows
array([[ 0, 1, 2, 3, 4],
[10, 11, 12, 13, 14]])
>>> z.get_orthogonal_selection((slice(None), [1, 3])) # select second and fourth columns
array([[ 1, 3],
[ 6, 8],
[11, 13]])
>>> z.get_orthogonal_selection(([0, 2], [1, 3])) # select rows [0, 2] and columns [1, 4]
array([[ 1, 3],
[11, 13]])
Data can also be modified, e.g.::
>>> z.set_orthogonal_selection(([0, 2], [1, 3]), [[-1, -2], [-3, -4]])
>>> z[:]
array([[ 0, -1, 2, -2, 4],
[ 5, 6, 7, 8, 9],
[10, -3, 12, -4, 14]])
For convenience, the orthogonal indexing functionality is also available via the
``oindex`` property, e.g.::
>>> z = zarr.array(np.arange(15).reshape(3, 5))
>>> z.oindex[[0, 2], :] # select first and third rows
array([[ 0, 1, 2, 3, 4],
[10, 11, 12, 13, 14]])
>>> z.oindex[:, [1, 3]] # select second and fourth columns
array([[ 1, 3],
[ 6, 8],
[11, 13]])
>>> z.oindex[[0, 2], [1, 3]] # select rows [0, 2] and columns [1, 4]
array([[ 1, 3],
[11, 13]])
>>> z.oindex[[0, 2], [1, 3]] = [[-1, -2], [-3, -4]]
>>> z[:]
array([[ 0, -1, 2, -2, 4],
[ 5, 6, 7, 8, 9],
[10, -3, 12, -4, 14]])
Any combination of integer, slice, 1D integer array and/or 1D Boolean array can
be used for orthogonal indexing.
If the index contains at most one iterable, and otherwise contains only slices and integers,
orthogonal indexing is also available directly on the array:
>>> z = zarr.array(np.arange(15).reshape(3, 5))
>>> all(z.oindex[[0, 2], :] == z[[0, 2], :])
True
Indexing fields in structured arrays
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
All selection methods support a ``fields`` parameter which allows retrieving or
replacing data for a specific field in an array with a structured dtype. E.g.::
>>> a = np.array([(b'aaa', 1, 4.2),
... (b'bbb', 2, 8.4),
... (b'ccc', 3, 12.6)],
... dtype=[('foo', 'S3'), ('bar', 'i4'), ('baz', 'f8')])
>>> z = zarr.array(a)
>>> z['foo']
array([b'aaa', b'bbb', b'ccc'],
dtype='|S3')
>>> z['baz']
array([ 4.2, 8.4, 12.6])
>>> z.get_basic_selection(slice(0, 2), fields='bar')
array([1, 2], dtype=int32)
>>> z.get_coordinate_selection([0, 2], fields=['foo', 'baz'])
array([(b'aaa', 4.2), (b'ccc', 12.6)],
dtype=[('foo', 'S3'), ('baz', '<f8')])
.. _tutorial_storage:
Storage alternatives
--------------------
Zarr can use any object that implements the ``MutableMapping`` interface from
the :mod:`collections` module in the Python standard library as the store for a
group or an array.
Some pre-defined storage classes are provided in the :mod:`zarr.storage`
module. For example, the :class:`zarr.storage.DirectoryStore` class provides a
``MutableMapping`` interface to a directory on the local file system. This is
used under the hood by the :func:`zarr.convenience.open` function. In other words,
the following code::
>>> z = zarr.open('data/example.zarr', mode='w', shape=1000000, dtype='i4')
...is short-hand for::
>>> store = zarr.DirectoryStore('data/example.zarr')
>>> z = zarr.create(store=store, overwrite=True, shape=1000000, dtype='i4')
...and the following code::
>>> root = zarr.open('data/example.zarr', mode='w')
...is short-hand for::
>>> store = zarr.DirectoryStore('data/example.zarr')
>>> root = zarr.group(store=store, overwrite=True)
Any other compatible storage class could be used in place of
:class:`zarr.storage.DirectoryStore` in the code examples above. For example,
here is an array stored directly into a Zip file, via the
:class:`zarr.storage.ZipStore` class::
>>> store = zarr.ZipStore('data/example.zip', mode='w')
>>> root = zarr.group(store=store)
>>> z = root.zeros('foo/bar', shape=(1000, 1000), chunks=(100, 100), dtype='i4')
>>> z[:] = 42
>>> store.close()
Re-open and check that data have been written::
>>> store = zarr.ZipStore('data/example.zip', mode='r')
>>> root = zarr.group(store=store)
>>> z = root['foo/bar']
>>> z[:]
array([[42, 42, 42, ..., 42, 42, 42],
[42, 42, 42, ..., 42, 42, 42],
[42, 42, 42, ..., 42, 42, 42],
...,
[42, 42, 42, ..., 42, 42, 42],
[42, 42, 42, ..., 42, 42, 42],
[42, 42, 42, ..., 42, 42, 42]], dtype=int32)
>>> store.close()
Note that there are some limitations on how Zip files can be used, because items
within a Zip file cannot be updated in place. This means that data in the array
should only be written once and write operations should be aligned with chunk
boundaries. Note also that the ``close()`` method must be called after writing
any data to the store, otherwise essential records will not be written to the
underlying zip file.
Another storage alternative is the :class:`zarr.storage.DBMStore` class, added
in Zarr version 2.2. This class allows any DBM-style database to be used for
storing an array or group. Here is an example using a Berkeley DB B-tree
database for storage (requires `bsddb3
<https://www.jcea.es/programacion/pybsddb.htm>`_ to be installed)::
>>> import bsddb3
>>> store = zarr.DBMStore('data/example.bdb', open=bsddb3.btopen)
>>> root = zarr.group(store=store, overwrite=True)
>>> z = root.zeros('foo/bar', shape=(1000, 1000), chunks=(100, 100), dtype='i4')
>>> z[:] = 42
>>> store.close()
Also added in Zarr version 2.2 is the :class:`zarr.storage.LMDBStore` class which
enables the lightning memory-mapped database (LMDB) to be used for storing an array or
group (requires `lmdb <https://lmdb.readthedocs.io/>`_ to be installed)::
>>> store = zarr.LMDBStore('data/example.lmdb')
>>> root = zarr.group(store=store, overwrite=True)
>>> z = root.zeros('foo/bar', shape=(1000, 1000), chunks=(100, 100), dtype='i4')
>>> z[:] = 42
>>> store.close()
In Zarr version 2.3 is the :class:`zarr.storage.SQLiteStore` class which
enables the SQLite database to be used for storing an array or group (requires
Python is built with SQLite support)::
>>> store = zarr.SQLiteStore('data/example.sqldb')
>>> root = zarr.group(store=store, overwrite=True)
>>> z = root.zeros('foo/bar', shape=(1000, 1000), chunks=(100, 100), dtype='i4')
>>> z[:] = 42
>>> store.close()
Also added in Zarr version 2.3 are two storage classes for interfacing with server-client
databases. The :class:`zarr.storage.RedisStore` class interfaces `Redis <https://redis.io/>`_
(an in memory data structure store), and the :class:`zarr.storage.MongoDB` class interfaces
with `MongoDB <https://www.mongodb.com/>`_ (an object oriented NoSQL database). These stores
respectively require the `redis-py <https://redis-py.readthedocs.io>`_ and
`pymongo <https://api.mongodb.com/python/current/>`_ packages to be installed.
For compatibility with the `N5 <https://github.com/saalfeldlab/n5>`_ data format, Zarr also provides
an N5 backend (this is currently an experimental feature). Similar to the zip storage class, an
:class:`zarr.n5.N5Store` can be instantiated directly::
>>> store = zarr.N5Store('data/example.n5')
>>> root = zarr.group(store=store)
>>> z = root.zeros('foo/bar', shape=(1000, 1000), chunks=(100, 100), dtype='i4')
>>> z[:] = 42
For convenience, the N5 backend will automatically be chosen when the filename
ends with `.n5`::
>>> root = zarr.open('data/example.n5', mode='w')
Distributed/cloud storage
~~~~~~~~~~~~~~~~~~~~~~~~~
It is also possible to use distributed storage systems. The Dask project has
implementations of the ``MutableMapping`` interface for Amazon S3 (`S3Map
<https://s3fs.readthedocs.io/en/latest/api.html#s3fs.mapping.S3Map>`_), Hadoop
Distributed File System (`HDFSMap
<https://hdfs3.readthedocs.io/en/latest/api.html#hdfs3.mapping.HDFSMap>`_) and
Google Cloud Storage (`GCSMap
<http://gcsfs.readthedocs.io/en/latest/api.html#gcsfs.mapping.GCSMap>`_), which
can be used with Zarr.
Here is an example using S3Map to read an array created previously::
>>> import s3fs
>>> import zarr
>>> s3 = s3fs.S3FileSystem(anon=True, client_kwargs=dict(region_name='eu-west-2'))
>>> store = s3fs.S3Map(root='zarr-demo/store', s3=s3, check=False)
>>> root = zarr.group(store=store)
>>> z = root['foo/bar/baz']
>>> z
<zarr.core.Array '/foo/bar/baz' (21,) |S1>
>>> z.info
Name : /foo/bar/baz
Type : zarr.core.Array
Data type : |S1
Shape : (21,)
Chunk shape : (7,)
Order : C
Read-only : False
Compressor : Blosc(cname='lz4', clevel=5, shuffle=SHUFFLE, blocksize=0)
Store type : zarr.storage.KVStore
No. bytes : 21
No. bytes stored : 382
Storage ratio : 0.1
Chunks initialized : 3/3
>>> z[:]
array([b'H', b'e', b'l', b'l', b'o', b' ', b'f', b'r', b'o', b'm', b' ',
b't', b'h', b'e', b' ', b'c', b'l', b'o', b'u', b'd', b'!'],
dtype='|S1')
>>> z[:].tobytes()
b'Hello from the cloud!'
Zarr now also has a builtin storage backend for Azure Blob Storage.
The class is :class:`zarr.storage.ABSStore` (requires
`azure-storage-blob <https://docs.microsoft.com/en-us/azure/storage/blobs/storage-quickstart-blobs-python>`_
to be installed)::
>>> import azure.storage.blob
>>> container_client = azure.storage.blob.ContainerClient(...) # doctest: +SKIP
>>> store = zarr.ABSStore(client=container_client, prefix='zarr-testing') # doctest: +SKIP
>>> root = zarr.group(store=store, overwrite=True) # doctest: +SKIP
>>> z = root.zeros('foo/bar', shape=(1000, 1000), chunks=(100, 100), dtype='i4') # doctest: +SKIP
>>> z[:] = 42 # doctest: +SKIP
When using an actual storage account, provide ``account_name`` and
``account_key`` arguments to :class:`zarr.storage.ABSStore`, the
above client is just testing against the emulator. Please also note
that this is an experimental feature.
Note that retrieving data from a remote service via the network can be significantly
slower than retrieving data from a local file system, and will depend on network latency
and bandwidth between the client and server systems. If you are experiencing poor
performance, there are several things you can try. One option is to increase the array
chunk size, which will reduce the number of chunks and thus reduce the number of network
round-trips required to retrieve data for an array (and thus reduce the impact of network
latency). Another option is to try to increase the compression ratio by changing
compression options or trying a different compressor (which will reduce the impact of
limited network bandwidth).
As of version 2.2, Zarr also provides the :class:`zarr.storage.LRUStoreCache`
which can be used to implement a local in-memory cache layer over a remote
store. E.g.::
>>> s3 = s3fs.S3FileSystem(anon=True, client_kwargs=dict(region_name='eu-west-2'))
>>> store = s3fs.S3Map(root='zarr-demo/store', s3=s3, check=False)
>>> cache = zarr.LRUStoreCache(store, max_size=2**28)
>>> root = zarr.group(store=cache)
>>> z = root['foo/bar/baz']
>>> from timeit import timeit
>>> # first data access is relatively slow, retrieved from store
... timeit('print(z[:].tobytes())', number=1, globals=globals()) # doctest: +SKIP
b'Hello from the cloud!'
0.1081731989979744
>>> # second data access is faster, uses cache
... timeit('print(z[:].tobytes())', number=1, globals=globals()) # doctest: +SKIP
b'Hello from the cloud!'
0.0009490990014455747
If you are still experiencing poor performance with distributed/cloud storage,
please raise an issue on the GitHub issue tracker with any profiling data you
can provide, as there may be opportunities to optimise further either within
Zarr or within the mapping interface to the storage.
IO with ``fsspec``
~~~~~~~~~~~~~~~~~~
As of version 2.5, zarr supports passing URLs directly to `fsspec`_,
and having it create the "mapping" instance automatically. This means, that
for all of the backend storage implementations `supported by fsspec`_,
you can skip importing and configuring the storage explicitly.
For example::
>>> g = zarr.open_group("s3://zarr-demo/store", storage_options={'anon': True}) # doctest: +SKIP
>>> g['foo/bar/baz'][:].tobytes() # doctest: +SKIP
b'Hello from the cloud!'
The provision of the protocol specifier "s3://" will select the correct backend.
Notice the kwargs ``storage_options``, used to pass parameters to that backend.
As of version 2.6, write mode and complex URLs are also supported, such as::
>>> g = zarr.open_group("simplecache::s3://zarr-demo/store",
... storage_options={"s3": {'anon': True}}) # doctest: +SKIP
>>> g['foo/bar/baz'][:].tobytes() # downloads target file # doctest: +SKIP
b'Hello from the cloud!'
>>> g['foo/bar/baz'][:].tobytes() # uses cached file # doctest: +SKIP
b'Hello from the cloud!'
The second invocation here will be much faster. Note that the ``storage_options``
have become more complex here, to account for the two parts of the supplied
URL.
It is also possible to initialize the filesystem outside of Zarr and then pass
it through. This requires creating an :class:`zarr.storage.FSStore` object
explicitly. For example::
>>> import s3fs * doctest: +SKIP
>>> fs = s3fs.S3FileSystem(anon=True) # doctest: +SKIP
>>> store = zarr.storage.FSStore('/zarr-demo/store', fs=fs) # doctest: +SKIP
>>> g = zarr.open_group(store) # doctest: +SKIP
This is useful in cases where you want to also use the same fsspec filesystem object
separately from Zarr.
.. _fsspec: https://filesystem-spec.readthedocs.io/en/latest/
.. _supported by fsspec: https://filesystem-spec.readthedocs.io/en/latest/api.html#built-in-implementations
.. _tutorial_copy:
Consolidating metadata
~~~~~~~~~~~~~~~~~~~~~~
Since there is a significant overhead for every connection to a cloud object
store such as S3, the pattern described in the previous section may incur
significant latency while scanning the metadata of the array hierarchy, even
though each individual metadata object is small. For cases such as these, once
the data are static and can be regarded as read-only, at least for the
metadata/structure of the array hierarchy, the many metadata objects can be
consolidated into a single one via
:func:`zarr.convenience.consolidate_metadata`. Doing this can greatly increase
the speed of reading the array metadata, e.g.::
>>> zarr.consolidate_metadata(store) # doctest: +SKIP
This creates a special key with a copy of all of the metadata from all of the
metadata objects in the store.
Later, to open a Zarr store with consolidated metadata, use
:func:`zarr.convenience.open_consolidated`, e.g.::
>>> root = zarr.open_consolidated(store) # doctest: +SKIP
This uses the special key to read all of the metadata in a single call to the
backend storage.
Note that, the hierarchy could still be opened in the normal way and altered,
causing the consolidated metadata to become out of sync with the real state of
the array hierarchy. In this case,
:func:`zarr.convenience.consolidate_metadata` would need to be called again.
To protect against consolidated metadata accidentally getting out of sync, the
root group returned by :func:`zarr.convenience.open_consolidated` is read-only
for the metadata, meaning that no new groups or arrays can be created, and
arrays cannot be resized. However, data values with arrays can still be updated.
Copying/migrating data
----------------------
If you have some data in an HDF5 file and would like to copy some or all of it
into a Zarr group, or vice-versa, the :func:`zarr.convenience.copy` and
:func:`zarr.convenience.copy_all` functions can be used. Here's an example
copying a group named 'foo' from an HDF5 file to a Zarr group::
>>> import h5py
>>> import zarr
>>> import numpy as np
>>> source = h5py.File('data/example.h5', mode='w')
>>> foo = source.create_group('foo')
>>> baz = foo.create_dataset('bar/baz', data=np.arange(100), chunks=(50,))
>>> spam = source.create_dataset('spam', data=np.arange(100, 200), chunks=(30,))
>>> zarr.tree(source)
/
├── foo
│ └── bar
│ └── baz (100,) int64
└── spam (100,) int64
>>> dest = zarr.open_group('data/example.zarr', mode='w')
>>> from sys import stdout
>>> zarr.copy(source['foo'], dest, log=stdout)
copy /foo
copy /foo/bar
copy /foo/bar/baz (100,) int64
all done: 3 copied, 0 skipped, 800 bytes copied
(3, 0, 800)
>>> dest.tree() # N.B., no spam
/
└── foo
└── bar
└── baz (100,) int64
>>> source.close()
If rather than copying a single group or array you would like to copy all
groups and arrays, use :func:`zarr.convenience.copy_all`, e.g.::
>>> source = h5py.File('data/example.h5', mode='r')
>>> dest = zarr.open_group('data/example2.zarr', mode='w')
>>> zarr.copy_all(source, dest, log=stdout)
copy /foo
copy /foo/bar
copy /foo/bar/baz (100,) int64
copy /spam (100,) int64
all done: 4 copied, 0 skipped, 1,600 bytes copied
(4, 0, 1600)
>>> dest.tree()
/
├── foo
│ └── bar
│ └── baz (100,) int64
└── spam (100,) int64
If you need to copy data between two Zarr groups, the
:func:`zarr.convenience.copy` and :func:`zarr.convenience.copy_all` functions can
be used and provide the most flexibility. However, if you want to copy data
in the most efficient way possible, without changing any configuration options,
the :func:`zarr.convenience.copy_store` function can be used. This function
copies data directly between the underlying stores, without any decompression or
re-compression, and so should be faster. E.g.::
>>> import zarr
>>> import numpy as np
>>> store1 = zarr.DirectoryStore('data/example.zarr')
>>> root = zarr.group(store1, overwrite=True)
>>> baz = root.create_dataset('foo/bar/baz', data=np.arange(100), chunks=(50,))
>>> spam = root.create_dataset('spam', data=np.arange(100, 200), chunks=(30,))
>>> root.tree()
/
├── foo
│ └── bar
│ └── baz (100,) int64
└── spam (100,) int64
>>> from sys import stdout
>>> store2 = zarr.ZipStore('data/example.zip', mode='w')
>>> zarr.copy_store(store1, store2, log=stdout)
copy .zgroup
copy foo/.zgroup
copy foo/bar/.zgroup
copy foo/bar/baz/.zarray
copy foo/bar/baz/0
copy foo/bar/baz/1
copy spam/.zarray
copy spam/0
copy spam/1
copy spam/2
copy spam/3
all done: 11 copied, 0 skipped, 1,138 bytes copied
(11, 0, 1138)
>>> new_root = zarr.group(store2)
>>> new_root.tree()
/
├── foo
│ └── bar
│ └── baz (100,) int64
└── spam (100,) int64
>>> new_root['foo/bar/baz'][:]
array([ 0, 1, 2, ..., 97, 98, 99])
>>> store2.close() # zip stores need to be closed
.. _tutorial_strings:
String arrays
-------------
There are several options for storing arrays of strings.
If your strings are all ASCII strings, and you know the maximum length of the string in
your array, then you can use an array with a fixed-length bytes dtype. E.g.::
>>> z = zarr.zeros(10, dtype='S6')
>>> z
<zarr.core.Array (10,) |S6>
>>> z[0] = b'Hello'
>>> z[1] = b'world!'
>>> z[:]
array([b'Hello', b'world!', b'', b'', b'', b'', b'', b'', b'', b''],
dtype='|S6')
A fixed-length unicode dtype is also available, e.g.::
>>> greetings = ['¡Hola mundo!', 'Hej Världen!', 'Servus Woid!', 'Hei maailma!',
... 'Xin chào thế giới', 'Njatjeta Botë!', 'Γεια σου κόσμε!',
... 'こんにちは世界', '世界,你好!', 'Helló, világ!', 'Zdravo svete!',
... 'เฮลโลเวิลด์']
>>> text_data = greetings * 10000
>>> z = zarr.array(text_data, dtype='U20')
>>> z
<zarr.core.Array (120000,) <U20>
>>> z[:]
array(['¡Hola mundo!', 'Hej Världen!', 'Servus Woid!', ...,
'Helló, világ!', 'Zdravo svete!', 'เฮลโลเวิลด์'],
dtype='<U20')
For variable-length strings, the ``object`` dtype can be used, but a codec must be
provided to encode the data (see also :ref:`tutorial_objects` below). At the time of
writing there are four codecs available that can encode variable length string
objects: :class:`numcodecs.VLenUTF8`, :class:`numcodecs.JSON`, :class:`numcodecs.MsgPack`.
and :class:`numcodecs.Pickle`. E.g. using ``VLenUTF8``::
>>> import numcodecs
>>> z = zarr.array(text_data, dtype=object, object_codec=numcodecs.VLenUTF8())
>>> z
<zarr.core.Array (120000,) object>
>>> z.filters
[VLenUTF8()]
>>> z[:]
array(['¡Hola mundo!', 'Hej Världen!', 'Servus Woid!', ...,
'Helló, világ!', 'Zdravo svete!', 'เฮลโลเวิลด์'], dtype=object)
As a convenience, ``dtype=str`` (or ``dtype=unicode`` on Python 2.7) can be used, which
is a short-hand for ``dtype=object, object_codec=numcodecs.VLenUTF8()``, e.g.::
>>> z = zarr.array(text_data, dtype=str)
>>> z
<zarr.core.Array (120000,) object>
>>> z.filters
[VLenUTF8()]
>>> z[:]
array(['¡Hola mundo!', 'Hej Världen!', 'Servus Woid!', ...,
'Helló, világ!', 'Zdravo svete!', 'เฮลโลเวิลด์'], dtype=object)
Variable-length byte strings are also supported via ``dtype=object``. Again an
``object_codec`` is required, which can be one of :class:`numcodecs.VLenBytes` or
:class:`numcodecs.Pickle`. For convenience, ``dtype=bytes`` (or ``dtype=str`` on Python
2.7) can be used as a short-hand for ``dtype=object, object_codec=numcodecs.VLenBytes()``,
e.g.::
>>> bytes_data = [g.encode('utf-8') for g in greetings] * 10000
>>> z = zarr.array(bytes_data, dtype=bytes)
>>> z
<zarr.core.Array (120000,) object>
>>> z.filters
[VLenBytes()]
>>> z[:]
array([b'\xc2\xa1Hola mundo!', b'Hej V\xc3\xa4rlden!', b'Servus Woid!',
..., b'Hell\xc3\xb3, vil\xc3\xa1g!', b'Zdravo svete!',
b'\xe0\xb9\x80\xe0\xb8\xae\xe0\xb8\xa5\xe0\xb9\x82\xe0\xb8\xa5\xe0\xb9\x80\xe0\xb8\xa7\xe0\xb8\xb4\xe0\xb8\xa5\xe0\xb8\x94\xe0\xb9\x8c'], dtype=object)
If you know ahead of time all the possible string values that can occur, you could
also use the :class:`numcodecs.Categorize` codec to encode each unique string value as an
integer. E.g.::
>>> categorize = numcodecs.Categorize(greetings, dtype=object)
>>> z = zarr.array(text_data, dtype=object, object_codec=categorize)
>>> z
<zarr.core.Array (120000,) object>
>>> z.filters
[Categorize(dtype='|O', astype='|u1', labels=['¡Hola mundo!', 'Hej Världen!', 'Servus Woid!', ...])]
>>> z[:]
array(['¡Hola mundo!', 'Hej Världen!', 'Servus Woid!', ...,
'Helló, világ!', 'Zdravo svete!', 'เฮลโลเวิลด์'], dtype=object)
.. _tutorial_objects:
Object arrays
-------------
Zarr supports arrays with an "object" dtype. This allows arrays to contain any type of
object, such as variable length unicode strings, or variable length arrays of numbers, or
other possibilities. When creating an object array, a codec must be provided via the
``object_codec`` argument. This codec handles encoding (serialization) of Python objects.
The best codec to use will depend on what type of objects are present in the array.
At the time of writing there are three codecs available that can serve as a general
purpose object codec and support encoding of a mixture of object types:
:class:`numcodecs.JSON`, :class:`numcodecs.MsgPack`. and :class:`numcodecs.Pickle`.
For example, using the JSON codec::
>>> z = zarr.empty(5, dtype=object, object_codec=numcodecs.JSON())
>>> z[0] = 42
>>> z[1] = 'foo'
>>> z[2] = ['bar', 'baz', 'qux']
>>> z[3] = {'a': 1, 'b': 2.2}
>>> z[:]
array([42, 'foo', list(['bar', 'baz', 'qux']), {'a': 1, 'b': 2.2}, None], dtype=object)
Not all codecs support encoding of all object types. The
:class:`numcodecs.Pickle` codec is the most flexible, supporting encoding any type
of Python object. However, if you are sharing data with anyone other than yourself, then
Pickle is not recommended as it is a potential security risk. This is because malicious
code can be embedded within pickled data. The JSON and MsgPack codecs do not have any
security issues and support encoding of unicode strings, lists and dictionaries.
MsgPack is usually faster for both encoding and decoding.
Ragged arrays
~~~~~~~~~~~~~
If you need to store an array of arrays, where each member array can be of any length
and stores the same primitive type (a.k.a. a ragged array), the
:class:`numcodecs.VLenArray` codec can be used, e.g.::
>>> z = zarr.empty(4, dtype=object, object_codec=numcodecs.VLenArray(int))
>>> z
<zarr.core.Array (4,) object>
>>> z.filters
[VLenArray(dtype='<i8')]
>>> z[0] = np.array([1, 3, 5])
>>> z[1] = np.array([4])
>>> z[2] = np.array([7, 9, 14])
>>> z[:]
array([array([1, 3, 5]), array([4]), array([ 7, 9, 14]),
array([], dtype=int64)], dtype=object)
As a convenience, ``dtype='array:T'`` can be used as a short-hand for
``dtype=object, object_codec=numcodecs.VLenArray('T')``, where 'T' can be any NumPy
primitive dtype such as 'i4' or 'f8'. E.g.::
>>> z = zarr.empty(4, dtype='array:i8')
>>> z
<zarr.core.Array (4,) object>
>>> z.filters
[VLenArray(dtype='<i8')]
>>> z[0] = np.array([1, 3, 5])
>>> z[1] = np.array([4])
>>> z[2] = np.array([7, 9, 14])
>>> z[:]
array([array([1, 3, 5]), array([4]), array([ 7, 9, 14]),
array([], dtype=int64)], dtype=object)
.. _tutorial_chunks:
Chunk optimizations
-------------------
.. _tutorial_chunks_shape:
Chunk size and shape
~~~~~~~~~~~~~~~~~~~~
In general, chunks of at least 1 megabyte (1M) uncompressed size seem to provide
better performance, at least when using the Blosc compression library.
The optimal chunk shape will depend on how you want to access the data. E.g.,
for a 2-dimensional array, if you only ever take slices along the first
dimension, then chunk across the second dimenson. If you know you want to chunk
across an entire dimension you can use ``None`` or ``-1`` within the ``chunks``
argument, e.g.::
>>> z1 = zarr.zeros((10000, 10000), chunks=(100, None), dtype='i4')
>>> z1.chunks
(100, 10000)
Alternatively, if you only ever take slices along the second dimension, then
chunk across the first dimension, e.g.::
>>> z2 = zarr.zeros((10000, 10000), chunks=(None, 100), dtype='i4')
>>> z2.chunks
(10000, 100)
If you require reasonable performance for both access patterns then you need to
find a compromise, e.g.::
>>> z3 = zarr.zeros((10000, 10000), chunks=(1000, 1000), dtype='i4')
>>> z3.chunks
(1000, 1000)
If you are feeling lazy, you can let Zarr guess a chunk shape for your data by
providing ``chunks=True``, although please note that the algorithm for guessing
a chunk shape is based on simple heuristics and may be far from optimal. E.g.::
>>> z4 = zarr.zeros((10000, 10000), chunks=True, dtype='i4')
>>> z4.chunks
(625, 625)
If you know you are always going to be loading the entire array into memory, you
can turn off chunks by providing ``chunks=False``, in which case there will be
one single chunk for the array::
>>> z5 = zarr.zeros((10000, 10000), chunks=False, dtype='i4')
>>> z5.chunks
(10000, 10000)
.. _tutorial_chunks_order:
Chunk memory layout
~~~~~~~~~~~~~~~~~~~
The order of bytes **within each chunk** of an array can be changed via the
``order`` keyword argument, to use either C or Fortran layout. For
multi-dimensional arrays, these two layouts may provide different compression
ratios, depending on the correlation structure within the data. E.g.::
>>> a = np.arange(100000000, dtype='i4').reshape(10000, 10000).T
>>> c = zarr.array(a, chunks=(1000, 1000))
>>> c.info
Type : zarr.core.Array
Data type : int32
Shape : (10000, 10000)
Chunk shape : (1000, 1000)
Order : C
Read-only : False
Compressor : Blosc(cname='lz4', clevel=5, shuffle=SHUFFLE, blocksize=0)
Store type : zarr.storage.KVStore
No. bytes : 400000000 (381.5M)
No. bytes stored : 6696010 (6.4M)
Storage ratio : 59.7
Chunks initialized : 100/100
>>> f = zarr.array(a, chunks=(1000, 1000), order='F')
>>> f.info
Type : zarr.core.Array
Data type : int32
Shape : (10000, 10000)
Chunk shape : (1000, 1000)
Order : F
Read-only : False
Compressor : Blosc(cname='lz4', clevel=5, shuffle=SHUFFLE, blocksize=0)
Store type : zarr.storage.KVStore
No. bytes : 400000000 (381.5M)
No. bytes stored : 4684636 (4.5M)
Storage ratio : 85.4
Chunks initialized : 100/100
In the above example, Fortran order gives a better compression ratio. This is an
artificial example but illustrates the general point that changing the order of
bytes within chunks of an array may improve the compression ratio, depending on
the structure of the data, the compression algorithm used, and which compression
filters (e.g., byte-shuffle) have been applied.
.. _tutorial_chunks_empty_chunks:
Empty chunks
~~~~~~~~~~~~
As of version 2.11, it is possible to configure how Zarr handles the storage of
chunks that are "empty" (i.e., every element in the chunk is equal to the array's fill value).
When creating an array with ``write_empty_chunks=False``,
Zarr will check whether a chunk is empty before compression and storage. If a chunk is empty,
then Zarr does not store it, and instead deletes the chunk from storage
if the chunk had been previously stored.
This optimization prevents storing redundant objects and can speed up reads, but the cost is
added computation during array writes, since the contents of
each chunk must be compared to the fill value, and these advantages are contingent on the content of the array.
If you know that your data will form chunks that are almost always non-empty, then there is no advantage to the optimization described above.
In this case, creating an array with ``write_empty_chunks=True`` (the default) will instruct Zarr to write every chunk without checking for emptiness.
The following example illustrates the effect of the ``write_empty_chunks`` flag on
the time required to write an array with different values.::
>>> import zarr
>>> import numpy as np
>>> import time
>>> from tempfile import TemporaryDirectory
>>> def timed_write(write_empty_chunks):
... """
... Measure the time required and number of objects created when writing
... to a Zarr array with random ints or fill value.
... """
... chunks = (8192,)
... shape = (chunks[0] * 1024,)
... data = np.random.randint(0, 255, shape)
... dtype = 'uint8'
...
... with TemporaryDirectory() as store:
... arr = zarr.open(store,
... shape=shape,
... chunks=chunks,
... dtype=dtype,
... write_empty_chunks=write_empty_chunks,
... fill_value=0,
... mode='w')
... # initialize all chunks
... arr[:] = 100
... result = []
... for value in (data, arr.fill_value):
... start = time.time()
... arr[:] = value
... elapsed = time.time() - start
... result.append((elapsed, arr.nchunks_initialized))
...
... return result
>>> for write_empty_chunks in (True, False):
... full, empty = timed_write(write_empty_chunks)
... print(f'\nwrite_empty_chunks={write_empty_chunks}:\n\tRandom Data: {full[0]:.4f}s, {full[1]} objects stored\n\t Empty Data: {empty[0]:.4f}s, {empty[1]} objects stored\n')
write_empty_chunks=True:
Random Data: 0.1252s, 1024 objects stored
Empty Data: 0.1060s, 1024 objects stored
write_empty_chunks=False:
Random Data: 0.1359s, 1024 objects stored
Empty Data: 0.0301s, 0 objects stored
In this example, writing random data is slightly slower with ``write_empty_chunks=True``,
but writing empty data is substantially faster and generates far fewer objects in storage.
.. _tutorial_rechunking:
Changing chunk shapes (rechunking)
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
Sometimes you are not free to choose the initial chunking of your input data, or
you might have data saved with chunking which is not optimal for the analysis you
have planned. In such cases it can be advantageous to re-chunk the data. For small
datasets, or when the mismatch between input and output chunks is small
such that only a few chunks of the input dataset need to be read to create each
chunk in the output array, it is sufficient to simply copy the data to a new array
with the desired chunking, e.g. ::
>>> a = zarr.zeros((10000, 10000), chunks=(100,100), dtype='uint16', store='a.zarr')
>>> b = zarr.array(a, chunks=(100, 200), store='b.zarr')
If the chunk shapes mismatch, however, a simple copy can lead to non-optimal data
access patterns and incur a substantial performance hit when using
file based stores. One of the most pathological examples is
switching from column-based chunking to row-based chunking e.g. ::
>>> a = zarr.zeros((10000,10000), chunks=(10000, 1), dtype='uint16', store='a.zarr')
>>> b = zarr.array(a, chunks=(1,10000), store='b.zarr')
which will require every chunk in the input data set to be repeatedly read when creating
each output chunk. If the entire array will fit within memory, this is simply resolved
by forcing the entire input array into memory as a numpy array before converting
back to zarr with the desired chunking. ::
>>> a = zarr.zeros((10000,10000), chunks=(10000, 1), dtype='uint16', store='a.zarr')
>>> b = a[...]
>>> c = zarr.array(b, chunks=(1,10000), store='c.zarr')
For data sets which have mismatched chunks and which do not fit in memory, a
more sophisticated approach to rechunking, such as offered by the
`rechunker <https://github.com/pangeo-data/rechunker>`_ package and discussed
`here <https://medium.com/pangeo/rechunker-the-missing-link-for-chunked-array-analytics-5b2359e9dc11>`_
may offer a substantial improvement in performance.
.. _tutorial_sync:
Parallel computing and synchronization
--------------------------------------
Zarr arrays have been designed for use as the source or sink for data in
parallel computations. By data source we mean that multiple concurrent read
operations may occur. By data sink we mean that multiple concurrent write
operations may occur, with each writer updating a different region of the
array. Zarr arrays have **not** been designed for situations where multiple
readers and writers are concurrently operating on the same array.
Both multi-threaded and multi-process parallelism are possible. The bottleneck
for most storage and retrieval operations is compression/decompression, and the
Python global interpreter lock (GIL) is released wherever possible during these
operations, so Zarr will generally not block other Python threads from running.
When using a Zarr array as a data sink, some synchronization (locking) may be
required to avoid data loss, depending on how data are being updated. If each
worker in a parallel computation is writing to a separate region of the array,
and if region boundaries are perfectly aligned with chunk boundaries, then no
synchronization is required. However, if region and chunk boundaries are not
perfectly aligned, then synchronization is required to avoid two workers
attempting to modify the same chunk at the same time, which could result in data
loss.
To give a simple example, consider a 1-dimensional array of length 60, ``z``,
divided into three chunks of 20 elements each. If three workers are running and
each attempts to write to a 20 element region (i.e., ``z[0:20]``, ``z[20:40]``
and ``z[40:60]``) then each worker will be writing to a separate chunk and no
synchronization is required. However, if two workers are running and each
attempts to write to a 30 element region (i.e., ``z[0:30]`` and ``z[30:60]``)
then it is possible both workers will attempt to modify the middle chunk at the
same time, and synchronization is required to prevent data loss.
Zarr provides support for chunk-level synchronization. E.g., create an array
with thread synchronization::
>>> z = zarr.zeros((10000, 10000), chunks=(1000, 1000), dtype='i4',
... synchronizer=zarr.ThreadSynchronizer())
>>> z
<zarr.core.Array (10000, 10000) int32>
This array is safe to read or write within a multi-threaded program.
Zarr also provides support for process synchronization via file locking,
provided that all processes have access to a shared file system, and provided
that the underlying file system supports file locking (which is not the case for
some networked file systems). E.g.::
>>> synchronizer = zarr.ProcessSynchronizer('data/example.sync')
>>> z = zarr.open_array('data/example', mode='w', shape=(10000, 10000),
... chunks=(1000, 1000), dtype='i4',
... synchronizer=synchronizer)
>>> z
<zarr.core.Array (10000, 10000) int32>
This array is safe to read or write from multiple processes.
When using multiple processes to parallelize reads or writes on arrays using the Blosc
compression library, it may be necessary to set ``numcodecs.blosc.use_threads = False``,
as otherwise Blosc may share incorrect global state amongst processes causing programs
to hang. See also the section on :ref:`tutorial_tips_blosc` below.
Please note that support for parallel computing is an area of ongoing research
and development. If you are using Zarr for parallel computing, we welcome
feedback, experience, discussion, ideas and advice, particularly about issues
related to data integrity and performance.
.. _tutorial_pickle:
Pickle support
--------------
Zarr arrays and groups can be pickled, as long as the underlying store object can be
pickled. Instances of any of the storage classes provided in the :mod:`zarr.storage`
module can be pickled, as can the built-in ``dict`` class which can also be used for
storage.
Note that if an array or group is backed by an in-memory store like a ``dict`` or
:class:`zarr.storage.MemoryStore`, then when it is pickled all of the store data will be
included in the pickled data. However, if an array or group is backed by a persistent
store like a :class:`zarr.storage.DirectoryStore`, :class:`zarr.storage.ZipStore` or
:class:`zarr.storage.DBMStore` then the store data **are not** pickled. The only thing
that is pickled is the necessary parameters to allow the store to re-open any
underlying files or databases upon being unpickled.
E.g., pickle/unpickle an in-memory array::
>>> import pickle
>>> z1 = zarr.array(np.arange(100000))
>>> s = pickle.dumps(z1)
>>> len(s) > 5000 # relatively large because data have been pickled
True
>>> z2 = pickle.loads(s)
>>> z1 == z2
True
>>> np.all(z1[:] == z2[:])
True
E.g., pickle/unpickle an array stored on disk::
>>> z3 = zarr.open('data/walnuts.zarr', mode='w', shape=100000, dtype='i8')
>>> z3[:] = np.arange(100000)
>>> s = pickle.dumps(z3)
>>> len(s) < 200 # small because no data have been pickled
True
>>> z4 = pickle.loads(s)
>>> z3 == z4
True
>>> np.all(z3[:] == z4[:])
True
.. _tutorial_datetime:
Datetimes and timedeltas
------------------------
NumPy's ``datetime64`` ('M8') and ``timedelta64`` ('m8') dtypes are supported for Zarr
arrays, as long as the units are specified. E.g.::
>>> z = zarr.array(['2007-07-13', '2006-01-13', '2010-08-13'], dtype='M8[D]')
>>> z
<zarr.core.Array (3,) datetime64[D]>
>>> z[:]
array(['2007-07-13', '2006-01-13', '2010-08-13'], dtype='datetime64[D]')
>>> z[0]
numpy.datetime64('2007-07-13')
>>> z[0] = '1999-12-31'
>>> z[:]
array(['1999-12-31', '2006-01-13', '2010-08-13'], dtype='datetime64[D]')
.. _tutorial_tips:
Usage tips
----------
.. _tutorial_tips_copy:
Copying large arrays
~~~~~~~~~~~~~~~~~~~~
Data can be copied between large arrays without needing much memory, e.g.::
>>> z1 = zarr.empty((10000, 10000), chunks=(1000, 1000), dtype='i4')
>>> z1[:] = 42
>>> z2 = zarr.empty_like(z1)
>>> z2[:] = z1
Internally the example above works chunk-by-chunk, extracting only the data from
``z1`` required to fill each chunk in ``z2``. The source of the data (``z1``)
could equally be an h5py Dataset.
.. _tutorial_tips_blosc:
Configuring Blosc
~~~~~~~~~~~~~~~~~
The Blosc compressor is able to use multiple threads internally to accelerate
compression and decompression. By default, Blosc uses up to 8
internal threads. The number of Blosc threads can be changed to increase or
decrease this number, e.g.::
>>> from numcodecs import blosc
>>> blosc.set_nthreads(2) # doctest: +SKIP
8
When a Zarr array is being used within a multi-threaded program, Zarr
automatically switches to using Blosc in a single-threaded
"contextual" mode. This is generally better as it allows multiple
program threads to use Blosc simultaneously and prevents CPU thrashing
from too many active threads. If you want to manually override this
behaviour, set the value of the ``blosc.use_threads`` variable to
``True`` (Blosc always uses multiple internal threads) or ``False``
(Blosc always runs in single-threaded contextual mode). To re-enable
automatic switching, set ``blosc.use_threads`` to ``None``.
Please note that if Zarr is being used within a multi-process program, Blosc may not
be safe to use in multi-threaded mode and may cause the program to hang. If using Blosc
in a multi-process program then it is recommended to set ``blosc.use_threads = False``.
| zarr | /zarr-2.15.0.tar.gz/zarr-2.15.0/docs/tutorial.rst | tutorial.rst |
Contributing to Zarr
====================
Zarr is a community maintained project. We welcome contributions in the form of bug
reports, bug fixes, documentation, enhancement proposals and more. This page provides
information on how best to contribute.
Asking for help
---------------
If you have a question about how to use Zarr, please post your question on
StackOverflow using the `"zarr" tag <https://stackoverflow.com/questions/tagged/zarr>`_.
If you don't get a response within a day or two, feel free to raise a `GitHub issue
<https://github.com/zarr-developers/zarr-python/issues/new>`_ including a link to your StackOverflow
question. We will try to respond to questions as quickly as possible, but please bear
in mind that there may be periods where we have limited time to answer questions
due to other commitments.
Bug reports
-----------
If you find a bug, please raise a `GitHub issue
<https://github.com/zarr-developers/zarr-python/issues/new>`_. Please include the following items in
a bug report:
1. A minimal, self-contained snippet of Python code reproducing the problem. You can
format the code nicely using markdown, e.g.::
```python
import zarr
g = zarr.group()
# etc.
```
2. An explanation of why the current behaviour is wrong/not desired, and what you
expect instead.
3. Information about the version of Zarr, along with versions of dependencies and the
Python interpreter, and installation information. The version of Zarr can be obtained
from the ``zarr.__version__`` property. Please also state how Zarr was installed,
e.g., "installed via pip into a virtual environment", or "installed using conda".
Information about other packages installed can be obtained by executing ``pip freeze``
(if using pip to install packages) or ``conda env export`` (if using conda to install
packages) from the operating system command prompt. The version of the Python
interpreter can be obtained by running a Python interactive session, e.g.::
$ python
Python 3.6.1 (default, Mar 22 2017, 06:17:05)
[GCC 6.3.0 20170321] on linux
Enhancement proposals
---------------------
If you have an idea about a new feature or some other improvement to Zarr, please raise a
`GitHub issue <https://github.com/zarr-developers/zarr-python/issues/new>`_ first to discuss.
We very much welcome ideas and suggestions for how to improve Zarr, but please bear in
mind that we are likely to be conservative in accepting proposals for new features. The
reasons for this are that we would like to keep the Zarr code base lean and focused on
a core set of functionalities, and available time for development, review and maintenance
of new features is limited. But if you have a great idea, please don't let that stop
you from posting it on GitHub, just please don't be offended if we respond cautiously.
Contributing code and/or documentation
--------------------------------------
Forking the repository
~~~~~~~~~~~~~~~~~~~~~~
The Zarr source code is hosted on GitHub at the following location:
* `https://github.com/zarr-developers/zarr-python <https://github.com/zarr-developers/zarr-python>`_
You will need your own fork to work on the code. Go to the link above and hit
the "Fork" button. Then clone your fork to your local machine::
$ git clone [email protected]:your-user-name/zarr-python.git
$ cd zarr-python
$ git remote add upstream [email protected]:zarr-developers/zarr-python.git
Creating a development environment
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
To work with the Zarr source code, it is recommended to set up a Python virtual
environment and install all Zarr dependencies using the same versions as are used by
the core developers and continuous integration services. Assuming you have a Python
3 interpreter already installed, and have also installed the virtualenv package, and
you have cloned the Zarr source code and your current working directory is the root of
the repository, you can do something like the following::
$ mkdir -p ~/pyenv/zarr-dev
$ python -m venv ~/pyenv/zarr-dev
$ source ~/pyenv/zarr-dev/bin/activate
$ pip install -r requirements_dev_minimal.txt -r requirements_dev_numpy.txt -r requirements_rtfd.txt
$ pip install -e .
To verify that your development environment is working, you can run the unit tests::
$ python -m pytest -v zarr
Creating a branch
~~~~~~~~~~~~~~~~~
Before you do any new work or submit a pull request, please open an issue on GitHub to
report the bug or propose the feature you'd like to add.
It's best to synchronize your fork with the upstream repository, then create a
new, separate branch for each piece of work you want to do. E.g.::
git checkout main
git fetch upstream
git rebase upstream/main
git push
git checkout -b shiny-new-feature
git push -u origin shiny-new-feature
This changes your working directory to the 'shiny-new-feature' branch. Keep any changes in
this branch specific to one bug or feature so it is clear what the branch brings to
Zarr.
To update this branch with latest code from Zarr, you can retrieve the changes from
the main branch and perform a rebase::
git fetch upstream
git rebase upstream/main
This will replay your commits on top of the latest Zarr git main. If this leads to
merge conflicts, these need to be resolved before submitting a pull request.
Alternatively, you can merge the changes in from upstream/main instead of rebasing,
which can be simpler::
git fetch upstream
git merge upstream/main
Again, any conflicts need to be resolved before submitting a pull request.
Running the test suite
~~~~~~~~~~~~~~~~~~~~~~
Zarr includes a suite of unit tests, as well as doctests included in
function and class docstrings and in the tutorial and storage
spec. The simplest way to run the unit tests is to activate your
development environment (see `creating a development environment`_ above)
and invoke::
$ python -m pytest -v zarr
Some tests require optional dependencies to be installed, otherwise
the tests will be skipped. To install all optional dependencies, run::
$ pip install -r requirements_dev_optional.txt
To also run the doctests within docstrings (requires optional
dependencies to be installed), run::
$ python -m pytest -v --doctest-plus zarr
To run the doctests within the tutorial and storage spec (requires
optional dependencies to be installed), run::
$ python -m doctest -o NORMALIZE_WHITESPACE -o ELLIPSIS docs/tutorial.rst docs/spec/v2.rst
Note that some tests also require storage services to be running
locally. To run the Azure Blob Service storage tests, run an Azure
storage emulator (e.g., azurite) and set the environment variable
``ZARR_TEST_ABS=1``. If you're using Docker to run azurite, start the service with::
docker run --rm -p 10000:10000 mcr.microsoft.com/azure-storage/azurite azurite-blob --loose --blobHost 0.0.0.0
To run the Mongo DB storage tests, run a Mongo
server locally and set the environment variable ``ZARR_TEST_MONGO=1``.
To run the Redis storage tests, run a Redis server locally on port
6379 and set the environment variable ``ZARR_TEST_REDIS=1``.
All tests are automatically run via GitHub Actions for every pull
request and must pass before code can be accepted. Test coverage is
also collected automatically via the Codecov service, and total
coverage over all builds must be 100% (although individual builds
may be lower due to Python 2/3 or other differences).
Code standards - using pre-commit
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
All code must conform to the PEP8 standard. Regarding line length, lines up to 100
characters are allowed, although please try to keep under 90 wherever possible.
``Zarr`` uses a set of ``pre-commit`` hooks and the ``pre-commit`` bot to format,
type-check, and prettify the codebase. ``pre-commit`` can be installed locally by
running::
$ python -m pip install pre-commit
The hooks can be installed locally by running::
$ pre-commit install
This would run the checks every time a commit is created locally. These checks will also run
on every commit pushed to an open PR, resulting in some automatic styling fixes by the
``pre-commit`` bot. The checks will by default only run on the files modified by a commit,
but the checks can be triggered for all the files by running::
$ pre-commit run --all-files
If you would like to skip the failing checks and push the code for further discussion, use
the ``--no-verify`` option with ``git commit``.
Test coverage
~~~~~~~~~~~~~
Zarr maintains 100% test coverage under the latest Python stable release (currently
Python 3.8). Both unit tests and docstring doctests are included when computing
coverage. Running::
$ python -m pytest -v --cov=zarr --cov-config=pyproject.toml zarr
will automatically run the test suite with coverage and produce a coverage report.
This should be 100% before code can be accepted into the main code base.
When submitting a pull request, coverage will also be collected across all supported
Python versions via the Codecov service, and will be reported back within the pull
request. Codecov coverage must also be 100% before code can be accepted.
Documentation
~~~~~~~~~~~~~
Docstrings for user-facing classes and functions should follow the
`numpydoc
<https://numpydoc.readthedocs.io/en/stable/format.html#docstring-standard>`_
standard, including sections for Parameters and Examples. All examples
should run and pass as doctests under Python 3.8. To run doctests,
activate your development environment, install optional requirements,
and run::
$ python -m pytest -v --doctest-plus zarr
Zarr uses Sphinx for documentation, hosted on readthedocs.org. Documentation is
written in the RestructuredText markup language (.rst files) in the ``docs`` folder.
The documentation consists both of prose and API documentation. All user-facing classes
and functions should be included in the API documentation, under the ``docs/api``
folder. Any new features or important usage information should be included in the
tutorial (``docs/tutorial.rst``). Any changes should also be included in the release
notes (``docs/release.rst``).
The documentation can be built locally by running::
$ cd docs
$ make clean; make html
$ open _build/html/index.html
The resulting built documentation will be available in the ``docs/_build/html`` folder.
Development best practices, policies and procedures
---------------------------------------------------
The following information is mainly for core developers, but may also be of interest to
contributors.
Merging pull requests
~~~~~~~~~~~~~~~~~~~~~
Pull requests submitted by an external contributor should be reviewed and approved by at least
one core developers before being merged. Ideally, pull requests submitted by a core developer
should be reviewed and approved by at least one other core developers before being merged.
Pull requests should not be merged until all CI checks have passed (GitHub Actions
Codecov) against code that has had the latest main merged in.
Compatibility and versioning policies
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
Because Zarr is a data storage library, there are two types of compatibility to
consider: API compatibility and data format compatibility.
API compatibility
"""""""""""""""""
All functions, classes and methods that are included in the API
documentation (files under ``docs/api/*.rst``) are considered as part of the Zarr **public API**,
except if they have been documented as an experimental feature, in which case they are part of
the **experimental API**.
Any change to the public API that does **not** break existing third party
code importing Zarr, or cause third party code to behave in a different way, is a
**backwards-compatible API change**. For example, adding a new function, class or method is usually
a backwards-compatible change. However, removing a function, class or method; removing an argument
to a function or method; adding a required argument to a function or method; or changing the
behaviour of a function or method, are examples of **backwards-incompatible API changes**.
If a release contains no changes to the public API (e.g., contains only bug fixes or
other maintenance work), then the micro version number should be incremented (e.g.,
2.2.0 -> 2.2.1). If a release contains public API changes, but all changes are
backwards-compatible, then the minor version number should be incremented
(e.g., 2.2.1 -> 2.3.0). If a release contains any backwards-incompatible public API changes,
the major version number should be incremented (e.g., 2.3.0 -> 3.0.0).
Backwards-incompatible changes to the experimental API can be included in a minor release,
although this should be minimised if possible. I.e., it would be preferable to save up
backwards-incompatible changes to the experimental API to be included in a major release, and to
stabilise those features at the same time (i.e., move from experimental to public API), rather than
frequently tinkering with the experimental API in minor releases.
Data format compatibility
"""""""""""""""""""""""""
The data format used by Zarr is defined by a specification document, which should be
platform-independent and contain sufficient detail to construct an interoperable
software library to read and/or write Zarr data using any programming language. The
latest version of the specification document is available from the :ref:`spec` page.
Here, **data format compatibility** means that all software libraries that implement a
particular version of the Zarr storage specification are interoperable, in the sense
that data written by any one library can be read by all others. It is obviously
desirable to maintain data format compatibility wherever possible. However, if a change
is needed to the storage specification, and that change would break data format
compatibility in any way, then the storage specification version number should be
incremented (e.g., 2 -> 3).
The versioning of the Zarr software library is related to the versioning of the storage
specification as follows. A particular version of the Zarr library will
implement a particular version of the storage specification. For example, Zarr version
2.2.0 implements the Zarr storage specification version 2. If a release of the Zarr
library implements a different version of the storage specification, then the major
version number of the Zarr library should be incremented. E.g., if Zarr version 2.2.0
implements the storage spec version 2, and the next release of the Zarr library
implements storage spec version 3, then the next library release should have version
number 3.0.0. Note however that the major version number of the Zarr library may not
always correspond to the spec version number. For example, Zarr versions 2.x, 3.x, and
4.x might all implement the same version of the storage spec and thus maintain data
format compatibility, although they will not maintain API compatibility. The version number
of the storage specification that is currently implemented is stored under the
``zarr.meta.ZARR_FORMAT`` variable.
Note that the Zarr test suite includes a data fixture and tests to try and ensure that
data format compatibility is not accidentally broken. See the
:func:`test_format_compatibility` function in the :mod:`zarr.tests.test_storage` module
for details.
When to make a release
~~~~~~~~~~~~~~~~~~~~~~
Ideally, any bug fixes that don't change the public API should be released as soon as
possible. It is fine for a micro release to contain only a single bug fix.
When to make a minor release is at the discretion of the core developers. There are no
hard-and-fast rules, e.g., it is fine to make a minor release to make a single new
feature available; equally, it is fine to make a minor release that includes a number of
changes.
Major releases obviously need to be given careful consideration, and should be done as
infrequently as possible, as they will break existing code and/or affect data
compatibility in some way.
Release procedure
~~~~~~~~~~~~~~~~~
.. note::
Most of the release process is now handled by github workflow which should
automatically push a release to PyPI if a tag is pushed.
Before releasing, make sure that all pull requests which will be
included in the release have been properly documented in
`docs/release.rst`.
To make a new release, go to
https://github.com/zarr-developers/zarr-python/releases and
click "Draft a new release". Choose a version number prefixed
with a `v` (e.g. `v0.0.0`). For pre-releases, include the
appropriate suffix (e.g. `v0.0.0a1` or `v0.0.0rc2`).
Set the description of the release to::
See release notes https://zarr.readthedocs.io/en/stable/release.html#release-0-0-0
replacing the correct version numbers. For pre-release versions,
the URL should omit the pre-release suffix, e.g. "a1" or "rc1".
After creating the release, the documentation will be built on
https://readthedocs.io. Full releases will be available under
`/stable <https://zarr.readthedocs.io/en/stable>`_ while
pre-releases will be available under
`/latest <https://zarr.readthedocs.io/en/latest>`_.
Also review and merge the https://github.com/conda-forge/zarr-feedstock
pull request that will be automatically generated.
| zarr | /zarr-2.15.0.tar.gz/zarr-2.15.0/docs/contributing.rst | contributing.rst |
.. _zarr_docs_mainpage:
***********
Zarr-Python
***********
.. toctree::
:maxdepth: 1
:hidden:
getting_started
tutorial
api
spec
release
license
acknowledgments
contributing
**Version**: |version|
**Download documentation**: `Zipped HTML <https://zarr.readthedocs.io/_/downloads/en/stable/htmlzip/>`_
**Useful links**:
`Installation <installation.html>`_ |
`Source Repository <https://github.com/zarr-developers/zarr-python>`_ |
`Issue Tracker <https://github.com/zarr-developers/zarr-python/issues>`_ |
`Gitter <https://gitter.im/zarr-developers/community>`_
Zarr is a file storage format for chunked, compressed, N-dimensional arrays based on an open-source specification.
.. grid:: 2
.. grid-item-card::
:img-top: _static/index_getting_started.svg
Getting Started
^^^^^^^^^^^^^^^
New to Zarr? Check out the getting started guide. It contains an
introduction to Zarr's main concepts and links to additional tutorials.
+++
.. button-ref:: getting_started
:expand:
:color: dark
:click-parent:
To the getting started guide
.. grid-item-card::
:img-top: _static/index_user_guide.svg
Tutorial
^^^^^^^^
The tutorial provides working examples of Zarr classes and functions.
+++
.. button-ref:: tutorial
:expand:
:color: dark
:click-parent:
To the Tutorial
.. grid-item-card::
:img-top: _static/index_api.svg
API Reference
^^^^^^^^^^^^^
The reference guide contains a detailed description of the functions,
modules, and objects included in Zarr. The reference describes how the
methods work and which parameters can be used. It assumes that you have an
understanding of the key concepts.
+++
.. button-ref:: api
:expand:
:color: dark
:click-parent:
To the api reference guide
.. grid-item-card::
:img-top: _static/index_contribute.svg
Contributor's Guide
^^^^^^^^^^^^^^^^^^^
Want to contribute to Zarr? We welcome contributions in the form of bug reports, bug fixes, documentation, enhancement proposals and more. The contributing guidelines will guide you through the process of improving Zarr.
+++
.. button-ref:: contributing
:expand:
:color: dark
:click-parent:
To the contributor's guide | zarr | /zarr-2.15.0.tar.gz/zarr-2.15.0/docs/index.rst | index.rst |
Release notes
=============
..
# Copy the warning statement _under_ the latest release version
# and unindent for pre-releases.
.. warning::
Pre-release! Use :command:`pip install --pre zarr` to evaluate this release.
..
# Unindent the section between releases in order
# to document your changes. On releases it will be
# re-indented so that it does not show up in the notes.
.. _unreleased:
Unreleased
----------
.. _release_2.15.0:
2.15.0
------
Enhancements
~~~~~~~~~~~~
* Implement more extensive fallback of getitem/setitem for orthogonal indexing.
By :user:`Andreas Albert <AndreasAlbertQC>` :issue:`1029`.
* Getitems supports ``meta_array``.
By :user:`Mads R. B. Kristensen <madsbk>` :issue:`1131`.
* ``open_array()`` now takes the ``meta_array`` argument.
By :user:`Mads R. B. Kristensen <madsbk>` :issue:`1396`.
Maintenance
~~~~~~~~~~~
* Remove ``codecov`` from GitHub actions.
By :user:`John A. Kirkham <jakirkham>` :issue:`1391`.
* Replace ``np.product`` with ``np.prod`` due to deprecation.
By :user:`James Bourbeau <jrbourbeau>` :issue:`1405`.
* Activate Py 3.11 builds.
By :user:`Joe Hamman <jhamman>` :issue:`1415`.
Documentation
~~~~~~~~~~~~~
* Add API reference for V3 Implementation in the docs.
By :user:`Sanket Verma <MSanKeys963>` :issue:`1345`.
Bug fixes
~~~~~~~~~
* Fix the conda-forge error. Read :issue:`1347` for detailed info.
By :user:`Josh Moore <joshmoore>` :issue:`1364` and :issue:`1367`.
* Fix ``ReadOnlyError`` when opening V3 store via fsspec reference file system.
By :user:`Joe Hamman <jhamman>` :issue:`1383`.
* Fix ``normalize_fill_value`` for structured arrays.
By :user:`Alan Du <alanhdu>` :issue:`1397`.
.. _release_2.14.2:
2.14.2
------
Bug fixes
~~~~~~~~~
* Ensure ``zarr.group`` uses writeable mode to fix issue with :issue:`1304`.
By :user:`Brandur Thorgrimsson <swordcat>` :issue:`1354`.
.. _release_2.14.1:
2.14.1
------
Documentation
~~~~~~~~~~~~~
* Fix API links.
By :user:`Josh Moore <joshmoore>` :issue:`1346`.
* Fix unit tests which prevented the conda-forge release.
By :user:`Josh Moore <joshmoore>` :issue:`1348`.
.. _release_2.14.0:
2.14.0
------
Major changes
~~~~~~~~~~~~~
* Improve Zarr V3 support, adding partial store read/write and storage transformers.
Add new features from the `v3 spec <https://zarr-specs.readthedocs.io/en/latest/core/v3.0.html>`_:
* storage transformers
* `get_partial_values` and `set_partial_values`
* efficient `get_partial_values` implementation for `FSStoreV3`
* sharding storage transformer
By :user:`Jonathan Striebel <jstriebel>`; :issue:`1096`, :issue:`1111`.
* N5 nows supports Blosc.
Remove warnings emitted when using N5Store or N5FSStore with a blosc-compressed array.
By :user:`Davis Bennett <d-v-b>`; :issue:`1331`.
Bug fixes
~~~~~~~~~
* Allow reading utf-8 encoded json files
By :user:`Nathan Zimmerberg <nhz2>` :issue:`1308`.
* Ensure contiguous data is give to ``FSStore``. Only copying if needed.
By :user:`Mads R. B. Kristensen <madsbk>` :issue:`1285`.
* NestedDirectoryStore.listdir now returns chunk keys with the correct '/' dimension_separator.
By :user:`Brett Graham <braingram>` :issue:`1334`.
* N5Store/N5FSStore dtype returns zarr Stores readable dtype.
By :user:`Marwan Zouinkhi <mzouink>` :issue:`1339`.
.. _release_2.13.6:
2.13.6
------
Maintenance
~~~~~~~~~~~
* Bump gh-action-pypi-publish to 1.6.4.
By :user:`Josh Moore <joshmoore>` :issue:`1320`.
.. _release_2.13.5:
2.13.5
------
Bug fixes
~~~~~~~~~
* Ensure ``zarr.create`` uses writeable mode to fix issue with :issue:`1304`.
By :user:`James Bourbeau <jrbourbeau>` :issue:`1309`.
.. _release_2.13.4:
2.13.4
------
Appreciation
~~~~~~~~~~~~~
Special thanks to Outreachy participants for contributing to most of the
maintenance PRs. Please read the blog post summarising the contribution phase
and welcoming new Outreachy interns:
https://zarr.dev/blog/welcoming-outreachy-2022-interns/
Enhancements
~~~~~~~~~~~~
* Handle fsspec.FSMap using FSStore store.
By :user:`Rafal Wojdyla <ravwojdyla>` :issue:`1304`.
Bug fixes
~~~~~~~~~
* Fix bug that caused double counting of groups in ``groups()`` and ``group_keys()`` methods with V3 stores.
By :user:`Ryan Abernathey <rabernat>` :issue:`1228`.
* Remove unnecessary calling of `contains_array` for key that ended in `.array.json`.
By :user:`Joe Hamman <jhamman>` :issue:`1149`.
* Fix bug that caused double counting of groups in ``groups()`` and ``group_keys()``
methods with V3 stores.
By :user:`Ryan Abernathey <rabernat>` :issue:`1228`.
Documentation
~~~~~~~~~~~~~
* Fix minor indexing errors in tutorial and specification examples of documentation.
By :user:`Kola Babalola <sprynt001>` :issue:`1277`.
* Add `requirements_rtfd.txt` in `contributing.rst`.
By :user:`AWA BRANDON AWA <DON-BRAN>` :issue:`1243`.
* Add documentation for find/findall using visit.
By :user:`Weddy Gikunda <caviere>` :issue:`1241`.
* Refresh of the main landing page.
By :user:`Josh Moore <joshmoore>` :issue:`1173`.
Maintenance
~~~~~~~~~~~
* Migrate to ``pyproject.toml`` and remove redundant infrastructure.
By :user:`Saransh Chopra <Saransh-cpp>` :issue:`1158`.
* Require ``setuptools`` 64.0.0+
By :user:`Saransh Chopra <Saransh-cpp>` :issue:`1193`.
* Pin action versions (pypi-publish, setup-miniconda) for dependabot
By :user:`Saransh Chopra <Saransh-cpp>` :issue:`1205`.
* Remove ``tox`` support
By :user:`Saransh Chopra <Saransh-cpp>` :issue:`1219`.
* Add workflow to label PRs with "needs release notes".
By :user:`Saransh Chopra <Saransh-cpp>` :issue:`1239`.
* Simplify if/else statement.
By :user:`Dimitri Papadopoulos Orfanos <DimitriPapadopoulos>` :issue:`1227`.
* Get coverage up to 100%.
By :user:`John Kirkham <jakirkham>` :issue:`1264`.
* Migrate coverage to ``pyproject.toml``.
By :user:`John Kirkham <jakirkham>` :issue:`1250`.
* Use ``conda-incubator/[email protected]``.
By :user:`John Kirkham <jakirkham>` :issue:`1263`.
* Delete unused files.
By :user:`John Kirkham <jakirkham>` :issue:`1251`.
* Skip labeller for bot PRs.
By :user:`Saransh Chopra <Saransh-cpp>` :issue:`1271`.
* Restore Flake8 configuration.
By :user:`John Kirkham <jakirkham>` :issue:`1249`.
* Add missing newline at EOF.
By :user:`Dimitri Papadopoulos` :issue:`1253`.
* Add `license_files` to `pyproject.toml`.
By :user:`John Kirkham <jakirkham>` :issue:`1247`.
* Adding `pyupgrade` suggestions.
By :user:`Dimitri Papadopoulos Orfanos <DimitriPapadopoulos>` :issue:`1225`.
* Fixed some linting errors.
By :user:`Weddy Gikunda <caviere>` :issue:`1226`.
* Added the link to main website in readthedocs sidebar.
By :user:`Stephanie_nkwatoh <steph237>` :issue:`1216`.
* Remove redundant wheel dependency in `pyproject.toml`.
By :user:`Dimitri Papadopoulos Orfanos <DimitriPapadopoulos>` :issue:`1233`.
* Turned on `isloated_build` in `tox.ini` file.
By :user:`AWA BRANDON AWA <DON-BRAN>` :issue:`1210`.
* Fixed `flake8` alert and avoid duplication of `Zarr Developers`.
By :user:`Dimitri Papadopoulos Orfanos <DimitriPapadopoulos>` :issue:`1203`.
* Bump to NumPy 1.20+ in `environment.yml`.
By :user:`John Kirkham <jakirkham>` :issue:`1201`.
* Bump to NumPy 1.20 in `pyproject.toml`.
By :user:`Dimitri Papadopoulos Orfanos <DimitriPapadopoulos>` :issue:`1192`.
* Remove LGTM (`.lgtm.yml`) configuration file.
By :user:`Dimitri Papadopoulos Orfanos <DimitriPapadopoulos>` :issue:`1191`.
* Codespell will skip `fixture` in pre-commit.
By :user:`Dimitri Papadopoulos Orfanos <DimitriPapadopoulos>` :issue:`1197`.
* Add msgpack in `requirements_rtfd.txt`.
By :user:`Emmanuel Bolarinwa <GbotemiB>` :issue:`1188`.
* Added license to docs fixed a typo from `_spec_v2` to `_spec_v3`.
By :user:`AWA BRANDON AWA <DON-BRAN>` :issue:`1182`.
* Fixed installation link in `README.md`.
By :user:`AWA BRANDON AWA <DON-BRAN>` :issue:`1177`.
* Fixed typos in `installation.rst` and `release.rst`.
By :user:`Chizoba Nweke <zobbs-git>` :issue:`1178`.
* Set `docs/conf.py` language to `en`.
By :user:`AWA BRANDON AWA <DON-BRAN>` :issue:`1174`.
* Added `installation.rst` to the docs.
By :user:`AWA BRANDON AWA <DON-BRAN>` :issue:`1170`.
* Adjustment of year to `2015-2018` to `2015-2022` in the docs.
By :user:`Emmanuel Bolarinwa <GbotemiB>` :issue:`1165`.
* Updated `Forking the repository` section in `contributing.rst`.
By :user:`AWA BRANDON AWA <DON-BRAN>` :issue:`1171`.
* Updated GitHub actions.
By :user:`Dimitri Papadopoulos Orfanos <DimitriPapadopoulos>` :issue:`1134`.
* Update web links: `http:// → https://`.
By :user:`Dimitri Papadopoulos Orfanos <DimitriPapadopoulos>` :issue:`1313`.
.. _release_2.13.3:
2.13.3
------
* Improve performance of slice selections with steps by omitting chunks with no relevant
data.
By :user:`Richard Shaw <jrs65>` :issue:`843`.
.. _release_2.13.2:
2.13.2
------
* Fix test failure on conda-forge builds (again).
By :user:`Josh Moore <joshmoore>`; see
`zarr-feedstock#65 <https://github.com/conda-forge/zarr-feedstock/pull/65>`_.
.. _release_2.13.1:
2.13.1
------
* Fix test failure on conda-forge builds.
By :user:`Josh Moore <joshmoore>`; see
`zarr-feedstock#65 <https://github.com/conda-forge/zarr-feedstock/pull/65>`_.
.. _release_2.13.0:
2.13.0
------
Major changes
~~~~~~~~~~~~~
* **Support of alternative array classes** by introducing a new argument,
meta_array, that specifies the type/class of the underlying array. The
meta_array argument can be any class instance that can be used as the like
argument in NumPy (see `NEP 35
<https://numpy.org/neps/nep-0035-array-creation-dispatch-with-array-function.html>`_).
enabling support for CuPy through, for example, the creation of a CuPy CPU
compressor.
By :user:`Mads R. B. Kristensen <madsbk>` :issue:`934`.
* **Remove support for Python 3.7** in concert with NumPy dependency.
By :user:`Davis Bennett <d-v-b>` :issue:`1067`.
* **Zarr v3: add support for the default root path** rather than requiring
that all API users pass an explicit path.
By :user:`Gregory R. Lee <grlee77>` :issue:`1085`, :issue:`1142`.
Bug fixes
~~~~~~~~~
* Remove/relax erroneous "meta" path check (**regression**).
By :user:`Gregory R. Lee <grlee77>` :issue:`1123`.
* Cast all attribute keys to strings (and issue deprecation warning).
By :user:`Mattia Almansi <malmans2>` :issue:`1066`.
* Fix bug in N5 storage that prevented arrays located in the root of the hierarchy from
bearing the `n5` keyword. Along with fixing this bug, new tests were added for N5 routines
that had previously been excluded from testing, and type annotations were added to the N5 codebase.
By :user:`Davis Bennett <d-v-b>` :issue:`1092`.
* Fix bug in LRUEStoreCache in which the current size wasn't reset on invalidation.
By :user:`BGCMHou <BGCMHou>` and :user:`Josh Moore <joshmoore>` :issue:`1076`, :issue:`1077`.
* Remove erroneous check that disallowed array keys starting with "meta".
By :user:`Gregory R. Lee <grlee77>` :issue:`1105`.
Documentation
~~~~~~~~~~~~~
* Typo fixes to close quotes. By :user:`Pavithra Eswaramoorthy <pavithraes>`
* Added copy button to documentation.
By :user:`Altay Sansal <tasansal>` :issue:`1124`.
Maintenance
~~~~~~~~~~~
* Simplify release docs.
By :user:`Josh Moore <joshmoore>` :issue:`1119`.
* Pin werkzeug to prevent test hangs.
By :user:`Davis Bennett <d-v-b>` :issue:`1098`.
* Fix a few DeepSource.io alerts
By :user:`Dimitri Papadopoulos Orfanos <DimitriPapadopoulos>` :issue:`1080`.
* Fix URLs.
By :user:`Dimitri Papadopoulos Orfanos <DimitriPapadopoulos>`, :issue:`1074`.
* Fix spelling.
By :user:`Dimitri Papadopoulos Orfanos <DimitriPapadopoulos>`, :issue:`1073`.
* Update GitHub issue templates with `YAML` format.
By :user:`Saransh Chopra <Saransh-cpp>` :issue:`1079`.
* Remove option to return None from _ensure_store.
By :user:`Greggory Lee <grlee77>` :issue:`1068`.
* Fix a typo of "integers".
By :user:`Richard Scott <RichardScottOZ>` :issue:`1056`.
.. _release_2.12.0:
2.12.0
------
Enhancements
~~~~~~~~~~~~
* **Add support for reading and writing Zarr V3.** The new `zarr._store.v3`
package has the necessary classes and functions for evaluating Zarr V3.
Since the format is not yet finalized, the classes and functions are not
automatically imported into the regular `zarr` name space. Setting the
`ZARR_V3_EXPERIMENTAL_API` environment variable will activate them.
By :user:`Greggory Lee <grlee77>`; :issue:`898`, :issue:`1006`, and :issue:`1007`
as well as by :user:`Josh Moore <joshmoore>` :issue:`1032`.
* **Create FSStore from an existing fsspec filesystem**. If you have created
an fsspec filesystem outside of Zarr, you can now pass it as a keyword
argument to ``FSStore``.
By :user:`Ryan Abernathey <rabernat>`; :issue:`911`.
* Add numpy encoder class for json.dumps
By :user:`Eric Prestat <ericpre>`; :issue:`933`.
* Appending performance improvement to Zarr arrays, e.g., when writing to S3.
By :user:`hailiangzhang <hailiangzhang>`; :issue:`1014`.
* Add number encoder for ``json.dumps`` to support numpy integers in
``chunks`` arguments. By :user:`Eric Prestat <ericpre>` :issue:`697`.
Bug fixes
~~~~~~~~~
* Fix bug that made it impossible to create an ``FSStore`` on unlistable filesystems
(e.g. some HTTP servers).
By :user:`Ryan Abernathey <rabernat>`; :issue:`993`.
Documentation
~~~~~~~~~~~~~
* Update resize doc to clarify surprising behavior.
By :user:`hailiangzhang <hailiangzhang>`; :issue:`1022`.
Maintenance
~~~~~~~~~~~
* Added Pre-commit configuration, incl. Yaml Check.
By :user:`Shivank Chaudhary <Alt-Shivam>`; :issue:`1015`, :issue:`1016`.
* Fix URL to renamed file in Blosc repo.
By :user:`Andrew Thomas <amcnicho>` :issue:`1028`.
* Activate Py 3.10 builds.
By :user:`Josh Moore <joshmoore>` :issue:`1027`.
* Make all unignored zarr warnings errors.
By :user:`Josh Moore <joshmoore>` :issue:`1021`.
.. _release_2.11.3:
2.11.3
------
Bug fixes
~~~~~~~~~
* Fix missing case to fully revert change to default write_empty_chunks.
By :user:`Tom White <tomwhite>`; :issue:`1005`.
.. _release_2.11.2:
2.11.2
------
Bug fixes
~~~~~~~~~
* Changes the default value of ``write_empty_chunks`` to ``True`` to prevent
unanticipated data losses when the data types do not have a proper default
value when empty chunks are read back in.
By :user:`Vyas Ramasubramani <vyasr>`; :issue:`965`, :issue:`1001`.
.. _release_2.11.1:
2.11.1
------
Bug fixes
~~~~~~~~~
* Fix bug where indexing with a scalar numpy value returned a single-value array.
By :user:`Ben Jeffery <benjeffery>` :issue:`967`.
* Removed `clobber` argument from `normalize_store_arg`. This enables to change
data within an opened consolidated group using mode `"r+"` (i.e region write).
By :user:`Tobias Kölling <d70-t>` :issue:`975`.
.. _release_2.11.0:
2.11.0
------
Enhancements
~~~~~~~~~~~~
* **Sparse changes with performance impact!** One of the advantages of the Zarr
format is that it is sparse, which means that chunks with no data (more
precisely, with data equal to the fill value, which is usually 0) don't need
to be written to disk at all. They will simply be assumed to be empty at read
time. However, until this release, the Zarr library would write these empty
chunks to disk anyway. This changes in this version: a small performance
penalty at write time leads to significant speedups at read time and in
filesystem operations in the case of sparse arrays. To revert to the old
behavior, pass the argument ``write_empty_chunks=True`` to the array creation
function. By :user:`Juan Nunez-Iglesias <jni>`; :issue:`853` and
:user:`Davis Bennett <d-v-b>`; :issue:`738`.
* **Fancy indexing**. Zarr arrays now support NumPy-style fancy indexing with
arrays of integer coordinates. This is equivalent to using zarr.Array.vindex.
Mixing slices and integer arrays is not supported.
By :user:`Juan Nunez-Iglesias <jni>`; :issue:`725`.
* **New base class**. This release of Zarr Python introduces a new
``BaseStore`` class that all provided store classes implemented in Zarr
Python now inherit from. This is done as part of refactoring to enable future
support of the Zarr version 3 spec. Existing third-party stores that are a
MutableMapping (e.g. dict) can be converted to a new-style key/value store
inheriting from ``BaseStore`` by passing them as the argument to the new
``zarr.storage.KVStore`` class. For backwards compatibility, various
higher-level array creation and convenience functions still accept plain
Python dicts or other mutable mappings for the ``store`` argument, but will
internally convert these to a ``KVStore``.
By :user:`Greggory Lee <grlee77>`; :issue:`839`, :issue:`789`, and :issue:`950`.
* Allow to assign array ``fill_values`` and update metadata accordingly.
By :user:`Ryan Abernathey <rabernat>`, :issue:`662`.
* Allow to update array fill_values
By :user:`Matthias Bussonnier <Carreau>` :issue:`665`.
Bug fixes
~~~~~~~~~
* Fix bug where the checksum of zipfiles is wrong
By :user:`Oren Watson <orenwatson>` :issue:`930`.
* Fix consolidate_metadata with FSStore.
By :user:`Joe Hamman <jhamman>` :issue:`916`.
* Unguarded next inside generator.
By :user:`Dimitri Papadopoulos Orfanos <DimitriPapadopoulos>` :issue:`889`.
Documentation
~~~~~~~~~~~~~
* Update docs creation of dev env.
By :user:`Ray Bell <raybellwaves>` :issue:`921`.
* Update docs to use ``python -m pytest``.
By :user:`Ray Bell <raybellwaves>` :issue:`923`.
* Fix versionadded tag in zarr.core.Array docstring.
By :user:`Juan Nunez-Iglesias <jni>` :issue:`852`.
* Doctest seem to be stricter now, updating tostring() to tobytes().
By :user:`John Kirkham <jakirkham>` :issue:`907`.
* Minor doc fix.
By :user:`Mads R. B. Kristensen <madsbk>` :issue:`937`.
Maintenance
~~~~~~~~~~~
* Upgrade MongoDB in test env.
By :user:`Joe Hamman <jhamman>` :issue:`939`.
* Pass dimension_separator on fixture generation.
By :user:`Josh Moore <joshmoore>` :issue:`858`.
* Activate Python 3.9 in GitHub Actions.
By :user:`Josh Moore <joshmoore>` :issue:`859`.
* Drop shortcut ``fsspec[s3]`` for dependency.
By :user:`Josh Moore <joshmoore>` :issue:`920`.
* and a swath of code-linting improvements by :user:`Dimitri Papadopoulos Orfanos <DimitriPapadopoulos>`:
- Unnecessary comprehension (:issue:`899`)
- Unnecessary ``None`` provided as default (:issue:`900`)
- use an if ``expression`` instead of `and`/`or` (:issue:`888`)
- Remove unnecessary literal (:issue:`891`)
- Decorate a few method with `@staticmethod` (:issue:`885`)
- Drop unneeded ``return`` (:issue:`884`)
- Drop explicit ``object`` inheritance from ``class``-es (:issue:`886`)
- Unnecessary comprehension (:issue:`883`)
- Codespell configuration (:issue:`882`)
- Fix typos found by codespell (:issue:`880`)
- Proper C-style formatting for integer (:issue:`913`)
- Add LGTM.com / DeepSource.io configuration files (:issue:`909`)
.. _release_2.10.3:
2.10.3
------
Bug fixes
~~~~~~~~~
* N5 keywords now emit UserWarning instead of raising a ValueError.
By :user:`Boaz Mohar <boazmohar>`; :issue:`860`.
* blocks_to_decompress not used in read_part function.
By :user:`Boaz Mohar <boazmohar>`; :issue:`861`.
* defines blocksize for array, updates hexdigest values.
By :user:`Andrew Fulton <andrewfulton9>`; :issue:`867`.
* Fix test failure on Debian and conda-forge builds.
By :user:`Josh Moore <joshmoore>`; :issue:`871`.
.. _release_2.10.2:
2.10.2
------
Bug fixes
~~~~~~~~~
* Fix NestedDirectoryStore datasets without dimension_separator metadata.
By :user:`Josh Moore <joshmoore>`; :issue:`850`.
.. _release_2.10.1:
2.10.1
------
Bug fixes
~~~~~~~~~
* Fix regression by setting normalize_keys=False in fsstore constructor.
By :user:`Davis Bennett <d-v-b>`; :issue:`842`.
.. _release_2.10.0:
2.10.0
------
Enhancements
~~~~~~~~~~~~
* Add N5FSStore.
By :user:`Davis Bennett <d-v-b>`; :issue:`793`.
Bug fixes
~~~~~~~~~
* Ignore None dim_separators in save_array.
By :user:`Josh Moore <joshmoore>`; :issue:`831`.
.. _release_2.9.5:
2.9.5
-----
Bug fixes
~~~~~~~~~
* Fix FSStore.listdir behavior for nested directories.
By :user:`Greggory Lee <grlee77>`; :issue:`802`.
.. _release_2.9.4:
2.9.4
-----
Bug fixes
~~~~~~~~~
* Fix structured arrays that contain objects
By :user: `Attila Bergou <abergou>`; :issue: `806`
.. _release_2.9.3:
2.9.3
-----
Maintenance
~~~~~~~~~~~
* Mark the fact that some tests that require ``fsspec``, without compromising the code coverage score.
By :user:`Ben Williams <benjaminhwilliams>`; :issue:`823`.
* Only inspect alternate node type if desired isn't present.
By :user:`Trevor Manz <manzt>`; :issue:`696`.
.. _release_2.9.2:
2.9.2
-----
Maintenance
~~~~~~~~~~~
* Correct conda-forge deployment of Zarr by fixing some Zarr tests.
By :user:`Ben Williams <benjaminhwilliams>`; :issue:`821`.
.. _release_2.9.1:
2.9.1
-----
Maintenance
~~~~~~~~~~~
* Correct conda-forge deployment of Zarr.
By :user:`Josh Moore <joshmoore>`; :issue:`819`.
.. _release_2.9.0:
2.9.0
-----
This release of Zarr Python is the first release of Zarr to not support Python 3.6.
Enhancements
~~~~~~~~~~~~
* Update ABSStore for compatibility with newer `azure.storage.blob`.
By :user:`Tom Augspurger <TomAugspurger>`; :issue:`759`.
* Pathlib support.
By :user:`Chris Barnes <clbarnes>`; :issue:`768`.
Documentation
~~~~~~~~~~~~~
* Clarify that arbitrary key/value pairs are OK for attributes.
By :user:`Stephan Hoyer <shoyer>`; :issue:`751`.
* Clarify how to manually convert a DirectoryStore to a ZipStore.
By :user:`pmav99 <pmav99>`; :issue:`763`.
Bug fixes
~~~~~~~~~
* Fix dimension_separator support.
By :user:`Josh Moore <joshmoore>`; :issue:`775`.
* Extract ABSStore to zarr._storage.absstore.
By :user:`Josh Moore <joshmoore>`; :issue:`781`.
* avoid NumPy 1.21.0 due to https://github.com/numpy/numpy/issues/19325
By :user:`Greggory Lee <grlee77>`; :issue:`791`.
Maintenance
~~~~~~~~~~~
* Drop 3.6 builds.
By :user:`Josh Moore <joshmoore>`; :issue:`774`, :issue:`778`.
* Fix build with Sphinx 4.
By :user:`Elliott Sales de Andrade <QuLogic>`; :issue:`799`.
* TST: add missing assert in test_hexdigest.
By :user:`Greggory Lee <grlee77>`; :issue:`801`.
.. _release_2.8.3:
2.8.3
-----
Bug fixes
~~~~~~~~~
* FSStore: default to normalize_keys=False
By :user:`Josh Moore <joshmoore>`; :issue:`755`.
* ABSStore: compatibility with ``azure.storage.python>=12``
By :user:`Tom Augspurger <tomaugspurger>`; :issue:`618`
.. _release_2.8.2:
2.8.2
-----
Documentation
~~~~~~~~~~~~~
* Add section on rechunking to tutorial
By :user:`David Baddeley <David-Baddeley>`; :issue:`730`.
Bug fixes
~~~~~~~~~
* Expand FSStore tests and fix implementation issues
By :user:`Davis Bennett <d-v-b>`; :issue:`709`.
Maintenance
~~~~~~~~~~~
* Updated ipytree warning for jlab3
By :user:`Ian Hunt-Isaak <ianhi>`; :issue:`721`.
* b170a48a - (issue-728, copy-nested) Updated ipytree warning for jlab3 (#721) (3 weeks ago) <Ian Hunt-Isaak>
* Activate dependabot
By :user:`Josh Moore <joshmoore>`; :issue:`734`.
* Update Python classifiers (Zarr is stable!)
By :user:`Josh Moore <joshmoore>`; :issue:`731`.
.. _release_2.8.1:
2.8.1
-----
Bug fixes
~~~~~~~~~
* raise an error if create_dataset's dimension_separator is inconsistent
By :user:`Gregory R. Lee <grlee77>`; :issue:`724`.
.. _release_2.8.0:
2.8.0
-----
V2 Specification Update
~~~~~~~~~~~~~~~~~~~~~~~
* Introduce optional dimension_separator .zarray key for nested chunks.
By :user:`Josh Moore <joshmoore>`; :issue:`715`, :issue:`716`.
.. _release_2.7.1:
2.7.1
-----
Bug fixes
~~~~~~~~~
* Update Array to respect FSStore's key_separator (#718)
By :user:`Gregory R. Lee <grlee77>`; :issue:`718`.
.. _release_2.7.0:
2.7.0
-----
Enhancements
~~~~~~~~~~~~
* Start stop for iterator (`islice()`)
By :user:`Sebastian Grill <yetyetanotherusername>`; :issue:`621`.
* Add capability to partially read and decompress chunks
By :user:`Andrew Fulton <andrewfulton9>`; :issue:`667`.
Bug fixes
~~~~~~~~~
* Make DirectoryStore __setitem__ resilient against antivirus file locking
By :user:`Eric Younkin <ericgyounkin>`; :issue:`698`.
* Compare test data's content generally
By :user:`John Kirkham <jakirkham>`; :issue:`436`.
* Fix dtype usage in zarr/meta.py
By :user:`Josh Moore <joshmoore>`; :issue:`700`.
* Fix FSStore key_seperator usage
By :user:`Josh Moore <joshmoore>`; :issue:`669`.
* Simplify text handling in DB Store
By :user:`John Kirkham <jakirkham>`; :issue:`670`.
* GitHub Actions migration
By :user:`Matthias Bussonnier <Carreau>`;
:issue:`641`, :issue:`671`, :issue:`674`, :issue:`676`, :issue:`677`, :issue:`678`,
:issue:`679`, :issue:`680`, :issue:`682`, :issue:`684`, :issue:`685`, :issue:`686`,
:issue:`687`, :issue:`695`, :issue:`706`.
.. _release_2.6.1:
2.6.1
-----
* Minor build fix
By :user:`Matthias Bussonnier <Carreau>`; :issue:`666`.
.. _release_2.6.0:
2.6.0
-----
This release of Zarr Python is the first release of Zarr to not support Python 3.5.
* End Python 3.5 support.
By :user:`Chris Barnes <clbarnes>`; :issue:`602`.
* Fix ``open_group/open_array`` to allow opening of read-only store with
``mode='r'`` :issue:`269`
* Add `Array` tests for FSStore.
By :user:`Andrew Fulton <andrewfulton9>`; :issue: `644`.
* fix a bug in which ``attrs`` would not be copied on the root when using ``copy_all``; :issue:`613`
* Fix ``FileNotFoundError`` with dask/s3fs :issue:`649`
* Fix flaky fixture in test_storage.py :issue:`652`
* Fix FSStore getitems fails with arrays that have a 0 length shape dimension :issue:`644`
* Use async to fetch/write result concurrently when possible. :issue:`536`, See `this comment
<https://github.com/zarr-developers/zarr-python/issues/536#issuecomment-721253094>`_ for some performance analysis
showing order of magnitude faster response in some benchmark.
See `this link <https://github.com/zarr-developers/zarr-python/milestone/11?closed=1>`_
for the full list of closed and merged PR tagged with the 2.6 milestone.
* Add ability to partially read and decompress arrays, see :issue:`667`. It is
only available to chunks stored using fsspec and using Blosc as a compressor.
For certain analysis case when only a small portion of chunks is needed it can
be advantageous to only access and decompress part of the chunks. Doing
partial read and decompression add high latency to many of the operation so
should be used only when the subset of the data is small compared to the full
chunks and is stored contiguously (that is to say either last dimensions for C
layout, firsts for F). Pass ``partial_decompress=True`` as argument when
creating an ``Array``, or when using ``open_array``. No option exists yet to
apply partial read and decompress on a per-operation basis.
.. _release_2.5.0:
2.5.0
-----
This release will be the last to support Python 3.5, next version of Zarr will be Python 3.6+.
* `DirectoryStore` now uses `os.scandir`, which should make listing large store
faster, :issue:`563`
* Remove a few remaining Python 2-isms.
By :user:`Poruri Sai Rahul <rahulporuri>`; :issue:`393`.
* Fix minor bug in `N5Store`.
By :user:`gsakkis`, :issue:`550`.
* Improve error message in Jupyter when trying to use the ``ipytree`` widget
without ``ipytree`` installed.
By :user:`Zain Patel <mzjp2>`; :issue:`537`
* Add typing information to many of the core functions :issue:`589`
* Explicitly close stores during testing.
By :user:`Elliott Sales de Andrade <QuLogic>`; :issue:`442`
* Many of the convenience functions to emit errors (``err_*`` from
``zarr.errors`` have been replaced by ``ValueError`` subclasses. The corresponding
``err_*`` function have been removed. :issue:`590`, :issue:`614`)
* Improve consistency of terminology regarding arrays and datasets in the
documentation.
By :user:`Josh Moore <joshmoore>`; :issue:`571`.
* Added support for generic URL opening by ``fsspec``, where the URLs have the
form "protocol://[server]/path" or can be chained URls with "::" separators.
The additional argument ``storage_options`` is passed to the backend, see
the ``fsspec`` docs.
By :user:`Martin Durant <martindurant>`; :issue:`546`
* Added support for fetching multiple items via ``getitems`` method of a
store, if it exists. This allows for concurrent fetching of data blocks
from stores that implement this; presently HTTP, S3, GCS. Currently only
applies to reading.
By :user:`Martin Durant <martindurant>`; :issue:`606`
* Efficient iteration expanded with option to pass start and stop index via
``array.islice``.
By :user:`Sebastian Grill <yetyetanotherusername>`, :issue:`615`.
.. _release_2.4.0:
2.4.0
-----
Enhancements
~~~~~~~~~~~~
* Add key normalization option for ``DirectoryStore``, ``NestedDirectoryStore``,
``TempStore``, and ``N5Store``.
By :user:`James Bourbeau <jrbourbeau>`; :issue:`459`.
* Add ``recurse`` keyword to ``Group.array_keys`` and ``Group.arrays`` methods.
By :user:`James Bourbeau <jrbourbeau>`; :issue:`458`.
* Use uniform chunking for all dimensions when specifying ``chunks`` as an integer.
Also adds support for specifying ``-1`` to chunk across an entire dimension.
By :user:`James Bourbeau <jrbourbeau>`; :issue:`456`.
* Rename ``DictStore`` to ``MemoryStore``.
By :user:`James Bourbeau <jrbourbeau>`; :issue:`455`.
* Rewrite ``.tree()`` pretty representation to use ``ipytree``.
Allows it to work in both the Jupyter Notebook and JupyterLab.
By :user:`John Kirkham <jakirkham>`; :issue:`450`.
* Do not rename Blosc parameters in n5 backend and add `blocksize` parameter,
compatible with n5-blosc. By :user:`axtimwalde`, :issue:`485`.
* Update ``DirectoryStore`` to create files with more permissive permissions.
By :user:`Eduardo Gonzalez <eddienko>` and :user:`James Bourbeau <jrbourbeau>`; :issue:`493`
* Use ``math.ceil`` for scalars.
By :user:`John Kirkham <jakirkham>`; :issue:`500`.
* Ensure contiguous data using ``astype``.
By :user:`John Kirkham <jakirkham>`; :issue:`513`.
* Refactor out ``_tofile``/``_fromfile`` from ``DirectoryStore``.
By :user:`John Kirkham <jakirkham>`; :issue:`503`.
* Add ``__enter__``/``__exit__`` methods to ``Group`` for ``h5py.File`` compatibility.
By :user:`Chris Barnes <clbarnes>`; :issue:`509`.
Bug fixes
~~~~~~~~~
* Fix Sqlite Store Wrong Modification.
By :user:`Tommy Tran <potter420>`; :issue:`440`.
* Add intermediate step (using ``zipfile.ZipInfo`` object) to write
inside ``ZipStore`` to solve too restrictive permission issue.
By :user:`Raphael Dussin <raphaeldussin>`; :issue:`505`.
* Fix '/' prepend bug in ``ABSStore``.
By :user:`Shikhar Goenka <shikharsg>`; :issue:`525`.
Documentation
~~~~~~~~~~~~~
* Fix hyperlink in ``README.md``.
By :user:`Anderson Banihirwe <andersy005>`; :issue:`531`.
* Replace "nuimber" with "number".
By :user:`John Kirkham <jakirkham>`; :issue:`512`.
* Fix azure link rendering in tutorial.
By :user:`James Bourbeau <jrbourbeau>`; :issue:`507`.
* Update ``README`` file to be more detailed.
By :user:`Zain Patel <mzjp2>`; :issue:`495`.
* Import blosc from numcodecs in tutorial.
By :user:`James Bourbeau <jrbourbeau>`; :issue:`491`.
* Adds logo to docs.
By :user:`James Bourbeau <jrbourbeau>`; :issue:`462`.
* Fix N5 link in tutorial.
By :user:`James Bourbeau <jrbourbeau>`; :issue:`480`.
* Fix typo in code snippet.
By :user:`Joe Jevnik <llllllllll>`; :issue:`461`.
* Fix URLs to point to zarr-python
By :user:`John Kirkham <jakirkham>`; :issue:`453`.
Maintenance
~~~~~~~~~~~
* Add documentation build to CI.
By :user:`James Bourbeau <jrbourbeau>`; :issue:`516`.
* Use ``ensure_ndarray`` in a few more places.
By :user:`John Kirkham <jakirkham>`; :issue:`506`.
* Support Python 3.8.
By :user:`John Kirkham <jakirkham>`; :issue:`499`.
* Require Numcodecs 0.6.4+ to use text handling functionality from it.
By :user:`John Kirkham <jakirkham>`; :issue:`497`.
* Updates tests to use ``pytest.importorskip``.
By :user:`James Bourbeau <jrbourbeau>`; :issue:`492`
* Removed support for Python 2.
By :user:`jhamman`; :issue:`393`, :issue:`470`.
* Upgrade dependencies in the test matrices and resolve a
compatibility issue with testing against the Azure Storage
Emulator. By :user:`alimanfoo`; :issue:`468`, :issue:`467`.
* Use ``unittest.mock`` on Python 3.
By :user:`Elliott Sales de Andrade <QuLogic>`; :issue:`426`.
* Drop ``decode`` from ``ConsolidatedMetadataStore``.
By :user:`John Kirkham <jakirkham>`; :issue:`452`.
.. _release_2.3.2:
2.3.2
-----
Enhancements
~~~~~~~~~~~~
* Use ``scandir`` in ``DirectoryStore``'s ``getsize`` method.
By :user:`John Kirkham <jakirkham>`; :issue:`431`.
Bug fixes
~~~~~~~~~
* Add and use utility functions to simplify reading and writing JSON.
By :user:`John Kirkham <jakirkham>`; :issue:`429`, :issue:`430`.
* Fix ``collections``'s ``DeprecationWarning``\ s.
By :user:`John Kirkham <jakirkham>`; :issue:`432`.
* Fix tests on big endian machines.
By :user:`Elliott Sales de Andrade <QuLogic>`; :issue:`427`.
.. _release_2.3.1:
2.3.1
-----
Bug fixes
~~~~~~~~~
* Makes ``azure-storage-blob`` optional for testing.
By :user:`John Kirkham <jakirkham>`; :issue:`419`, :issue:`420`.
.. _release_2.3.0:
2.3.0
-----
Enhancements
~~~~~~~~~~~~
* New storage backend, backed by Azure Blob Storage, class :class:`zarr.storage.ABSStore`.
All data is stored as block blobs. By :user:`Shikhar Goenka <shikarsg>`,
:user:`Tim Crone <tjcrone>` and :user:`Zain Patel <mzjp2>`; :issue:`345`.
* Add "consolidated" metadata as an experimental feature: use
:func:`zarr.convenience.consolidate_metadata` to copy all metadata from the various
metadata keys within a dataset hierarchy under a single key, and
:func:`zarr.convenience.open_consolidated` to use this single key. This can greatly
cut down the number of calls to the storage backend, and so remove a lot of overhead
for reading remote data.
By :user:`Martin Durant <martindurant>`, :user:`Alistair Miles <alimanfoo>`,
:user:`Ryan Abernathey <rabernat>`, :issue:`268`, :issue:`332`, :issue:`338`.
* Support has been added for structured arrays with sub-array shape and/or nested fields. By
:user:`Tarik Onalan <onalant>`, :issue:`111`, :issue:`296`.
* Adds the SQLite-backed :class:`zarr.storage.SQLiteStore` class enabling an
SQLite database to be used as the backing store for an array or group.
By :user:`John Kirkham <jakirkham>`, :issue:`368`, :issue:`365`.
* Efficient iteration over arrays by decompressing chunkwise.
By :user:`Jerome Kelleher <jeromekelleher>`, :issue:`398`, :issue:`399`.
* Adds the Redis-backed :class:`zarr.storage.RedisStore` class enabling a
Redis database to be used as the backing store for an array or group.
By :user:`Joe Hamman <jhamman>`, :issue:`299`, :issue:`372`.
* Adds the MongoDB-backed :class:`zarr.storage.MongoDBStore` class enabling a
MongoDB database to be used as the backing store for an array or group.
By :user:`Noah D Brenowitz <nbren12>`, :user:`Joe Hamman <jhamman>`,
:issue:`299`, :issue:`372`, :issue:`401`.
* **New storage class for N5 containers**. The :class:`zarr.n5.N5Store` has been
added, which uses :class:`zarr.storage.NestedDirectoryStore` to support
reading and writing from and to N5 containers.
By :user:`Jan Funke <funkey>` and :user:`John Kirkham <jakirkham>`.
Bug fixes
~~~~~~~~~
* The implementation of the :class:`zarr.storage.DirectoryStore` class has been modified to
ensure that writes are atomic and there are no race conditions where a chunk might appear
transiently missing during a write operation. By :user:`sbalmer <sbalmer>`, :issue:`327`,
:issue:`263`.
* Avoid raising in :class:`zarr.storage.DirectoryStore`'s ``__setitem__`` when file already exists.
By :user:`Justin Swaney <jmswaney>`, :issue:`272`, :issue:`318`.
* The required version of the `Numcodecs`_ package has been upgraded
to 0.6.2, which has enabled some code simplification and fixes a failing test involving
msgpack encoding. By :user:`John Kirkham <jakirkham>`, :issue:`361`, :issue:`360`, :issue:`352`,
:issue:`355`, :issue:`324`.
* Failing tests related to pickling/unpickling have been fixed. By :user:`Ryan Williams <ryan-williams>`,
:issue:`273`, :issue:`308`.
* Corrects handling of ``NaT`` in ``datetime64`` and ``timedelta64`` in various
compressors (by :user:`John Kirkham <jakirkham>`; :issue:`344`).
* Ensure ``DictStore`` contains only ``bytes`` to facilitate comparisons and protect against writes.
By :user:`John Kirkham <jakirkham>`, :issue:`350`.
* Test and fix an issue (w.r.t. fill values) when storing complex data to ``Array``.
By :user:`John Kirkham <jakirkham>`, :issue:`363`.
* Always use a ``tuple`` when indexing a NumPy ``ndarray``.
By :user:`John Kirkham <jakirkham>`, :issue:`376`.
* Ensure when ``Array`` uses a ``dict``-based chunk store that it only contains
``bytes`` to facilitate comparisons and protect against writes. Drop the copy
for the no filter/compressor case as this handles that case.
By :user:`John Kirkham <jakirkham>`, :issue:`359`.
Maintenance
~~~~~~~~~~~
* Simplify directory creation and removal in ``DirectoryStore.rename``.
By :user:`John Kirkham <jakirkham>`, :issue:`249`.
* CI and test environments have been upgraded to include Python 3.7, drop Python 3.4, and
upgrade all pinned package requirements. :user:`Alistair Miles <alimanfoo>`, :issue:`308`.
* Start using pyup.io to maintain dependencies.
:user:`Alistair Miles <alimanfoo>`, :issue:`326`.
* Configure flake8 line limit generally.
:user:`John Kirkham <jakirkham>`, :issue:`335`.
* Add missing coverage pragmas.
:user:`John Kirkham <jakirkham>`, :issue:`343`, :issue:`355`.
* Fix missing backslash in docs.
:user:`John Kirkham <jakirkham>`, :issue:`254`, :issue:`353`.
* Include tests for stores' ``popitem`` and ``pop`` methods.
By :user:`John Kirkham <jakirkham>`, :issue:`378`, :issue:`380`.
* Include tests for different compressors, endianness, and attributes.
By :user:`John Kirkham <jakirkham>`, :issue:`378`, :issue:`380`.
* Test validity of stores' contents.
By :user:`John Kirkham <jakirkham>`, :issue:`359`, :issue:`408`.
.. _release_2.2.0:
2.2.0
-----
Enhancements
~~~~~~~~~~~~
* **Advanced indexing**. The ``Array`` class has several new methods and
properties that enable a selection of items in an array to be retrieved or
updated. See the :ref:`tutorial_indexing` tutorial section for more
information. There is also a `notebook
<https://github.com/zarr-developers/zarr-python/blob/main/notebooks/advanced_indexing.ipynb>`_
with extended examples and performance benchmarks. :issue:`78`, :issue:`89`,
:issue:`112`, :issue:`172`.
* **New package for compressor and filter codecs**. The classes previously
defined in the :mod:`zarr.codecs` module have been factored out into a
separate package called `Numcodecs`_. The `Numcodecs`_ package also includes
several new codec classes not previously available in Zarr, including
compressor codecs for Zstd and LZ4. This change is backwards-compatible with
existing code, as all codec classes defined by Numcodecs are imported into the
:mod:`zarr.codecs` namespace. However, it is recommended to import codecs from
the new package, see the tutorial sections on :ref:`tutorial_compress` and
:ref:`tutorial_filters` for examples. With contributions by
:user:`John Kirkham <jakirkham>`; :issue:`74`, :issue:`102`, :issue:`120`,
:issue:`123`, :issue:`139`.
* **New storage class for DBM-style databases**. The
:class:`zarr.storage.DBMStore` class enables any DBM-style database such as gdbm,
ndbm or Berkeley DB, to be used as the backing store for an array or group. See the
tutorial section on :ref:`tutorial_storage` for some examples. :issue:`133`,
:issue:`186`.
* **New storage class for LMDB databases**. The :class:`zarr.storage.LMDBStore` class
enables an LMDB "Lightning" database to be used as the backing store for an array or
group. :issue:`192`.
* **New storage class using a nested directory structure for chunk files**. The
:class:`zarr.storage.NestedDirectoryStore` has been added, which is similar to
the existing :class:`zarr.storage.DirectoryStore` class but nests chunk files
for multidimensional arrays into sub-directories. :issue:`155`, :issue:`177`.
* **New tree() method for printing hierarchies**. The ``Group`` class has a new
:func:`zarr.hierarchy.Group.tree` method which enables a tree representation of
a group hierarchy to be printed. Also provides an interactive tree
representation when used within a Jupyter notebook. See the
:ref:`tutorial_diagnostics` tutorial section for examples. By
:user:`John Kirkham <jakirkham>`; :issue:`82`, :issue:`140`, :issue:`184`.
* **Visitor API**. The ``Group`` class now implements the h5py visitor API, see
docs for the :func:`zarr.hierarchy.Group.visit`,
:func:`zarr.hierarchy.Group.visititems` and
:func:`zarr.hierarchy.Group.visitvalues` methods. By
:user:`John Kirkham <jakirkham>`, :issue:`92`, :issue:`122`.
* **Viewing an array as a different dtype**. The ``Array`` class has a new
:func:`zarr.core.Array.astype` method, which is a convenience that enables an
array to be viewed as a different dtype. By :user:`John Kirkham <jakirkham>`,
:issue:`94`, :issue:`96`.
* **New open(), save(), load() convenience functions**. The function
:func:`zarr.convenience.open` provides a convenient way to open a persistent
array or group, using either a ``DirectoryStore`` or ``ZipStore`` as the backing
store. The functions :func:`zarr.convenience.save` and
:func:`zarr.convenience.load` are also available and provide a convenient way to
save an entire NumPy array to disk and load back into memory later. See the
tutorial section :ref:`tutorial_persist` for examples. :issue:`104`,
:issue:`105`, :issue:`141`, :issue:`181`.
* **IPython completions**. The ``Group`` class now implements ``__dir__()`` and
``_ipython_key_completions_()`` which enables tab-completion for group members
to be used in any IPython interactive environment. :issue:`170`.
* **New info property; changes to __repr__**. The ``Group`` and
``Array`` classes have a new ``info`` property which can be used to print
diagnostic information, including compression ratio where available. See the
tutorial section on :ref:`tutorial_diagnostics` for examples. The string
representation (``__repr__``) of these classes has been simplified to ensure
it is cheap and quick to compute in all circumstances. :issue:`83`,
:issue:`115`, :issue:`132`, :issue:`148`.
* **Chunk options**. When creating an array, ``chunks=False`` can be specified,
which will result in an array with a single chunk only. Alternatively,
``chunks=True`` will trigger an automatic chunk shape guess. See
:ref:`tutorial_chunks` for more on the ``chunks`` parameter. :issue:`106`,
:issue:`107`, :issue:`183`.
* **Zero-dimensional arrays** and are now supported; by
:user:`Prakhar Goel <newt0311>`, :issue:`154`, :issue:`161`.
* **Arrays with one or more zero-length dimensions** are now fully supported; by
:user:`Prakhar Goel <newt0311>`, :issue:`150`, :issue:`154`, :issue:`160`.
* **The .zattrs key is now optional** and will now only be created when the first
custom attribute is set; :issue:`121`, :issue:`200`.
* **New Group.move() method** supports moving a sub-group or array to a different
location within the same hierarchy. By :user:`John Kirkham <jakirkham>`,
:issue:`191`, :issue:`193`, :issue:`196`.
* **ZipStore is now thread-safe**; :issue:`194`, :issue:`192`.
* **New Array.hexdigest() method** computes an ``Array``'s hash with ``hashlib``.
By :user:`John Kirkham <jakirkham>`, :issue:`98`, :issue:`203`.
* **Improved support for object arrays**. In previous versions of Zarr,
creating an array with ``dtype=object`` was possible but could under certain
circumstances lead to unexpected errors and/or segmentation faults. To make it easier
to properly configure an object array, a new ``object_codec`` parameter has been
added to array creation functions. See the tutorial section on :ref:`tutorial_objects`
for more information and examples. Also, runtime checks have been added in both Zarr
and Numcodecs so that segmentation faults are no longer possible, even with a badly
configured array. This API change is backwards compatible and previous code that created
an object array and provided an object codec via the ``filters`` parameter will
continue to work, however a warning will be raised to encourage use of the
``object_codec`` parameter. :issue:`208`, :issue:`212`.
* **Added support for datetime64 and timedelta64 data types**;
:issue:`85`, :issue:`215`.
* **Array and group attributes are now cached by default** to improve performance with
slow stores, e.g., stores accessing data via the network; :issue:`220`, :issue:`218`,
:issue:`204`.
* **New LRUStoreCache class**. The class :class:`zarr.storage.LRUStoreCache` has been
added and provides a means to locally cache data in memory from a store that may be
slow, e.g., a store that retrieves data from a remote server via the network;
:issue:`223`.
* **New copy functions**. The new functions :func:`zarr.convenience.copy` and
:func:`zarr.convenience.copy_all` provide a way to copy groups and/or arrays
between HDF5 and Zarr, or between two Zarr groups. The
:func:`zarr.convenience.copy_store` provides a more efficient way to copy
data directly between two Zarr stores. :issue:`87`, :issue:`113`,
:issue:`137`, :issue:`217`.
Bug fixes
~~~~~~~~~
* Fixed bug where ``read_only`` keyword argument was ignored when creating an
array; :issue:`151`, :issue:`179`.
* Fixed bugs when using a ``ZipStore`` opened in 'w' mode; :issue:`158`,
:issue:`182`.
* Fill values can now be provided for fixed-length string arrays; :issue:`165`,
:issue:`176`.
* Fixed a bug where the number of chunks initialized could be counted
incorrectly; :issue:`97`, :issue:`174`.
* Fixed a bug related to the use of an ellipsis (...) in indexing statements;
:issue:`93`, :issue:`168`, :issue:`172`.
* Fixed a bug preventing use of other integer types for indexing; :issue:`143`,
:issue:`147`.
Documentation
~~~~~~~~~~~~~
* Some changes have been made to the :ref:`spec_v2` document to clarify
ambiguities and add some missing information. These changes do not break compatibility
with any of the material as previously implemented, and so the changes have been made
in-place in the document without incrementing the document version number. See the
section on :ref:`spec_v2_changes` in the specification document for more information.
* A new :ref:`tutorial_indexing` section has been added to the tutorial.
* A new :ref:`tutorial_strings` section has been added to the tutorial
(:issue:`135`, :issue:`175`).
* The :ref:`tutorial_chunks` tutorial section has been reorganised and updated.
* The :ref:`tutorial_persist` and :ref:`tutorial_storage` tutorial sections have
been updated with new examples (:issue:`100`, :issue:`101`, :issue:`103`).
* A new tutorial section on :ref:`tutorial_pickle` has been added (:issue:`91`).
* A new tutorial section on :ref:`tutorial_datetime` has been added.
* A new tutorial section on :ref:`tutorial_diagnostics` has been added.
* The tutorial sections on :ref:`tutorial_sync` and :ref:`tutorial_tips_blosc` have been
updated to provide information about how to avoid program hangs when using the Blosc
compressor with multiple processes (:issue:`199`, :issue:`201`).
Maintenance
~~~~~~~~~~~
* A data fixture has been included in the test suite to ensure data format
compatibility is maintained; :issue:`83`, :issue:`146`.
* The test suite has been migrated from nosetests to pytest; :issue:`189`, :issue:`225`.
* Various continuous integration updates and improvements; :issue:`118`, :issue:`124`,
:issue:`125`, :issue:`126`, :issue:`109`, :issue:`114`, :issue:`171`.
* Bump numcodecs dependency to 0.5.3, completely remove nose dependency, :issue:`237`.
* Fix compatibility issues with NumPy 1.14 regarding fill values for structured arrays,
:issue:`222`, :issue:`238`, :issue:`239`.
Acknowledgments
~~~~~~~~~~~~~~~
Code was contributed to this release by :user:`Alistair Miles <alimanfoo>`, :user:`John
Kirkham <jakirkham>` and :user:`Prakhar Goel <newt0311>`.
Documentation was contributed to this release by :user:`Mamy Ratsimbazafy <mratsim>`
and :user:`Charles Noyes <CSNoyes>`.
Thank you to :user:`John Kirkham <jakirkham>`, :user:`Stephan Hoyer <shoyer>`,
:user:`Francesc Alted <FrancescAlted>`, and :user:`Matthew Rocklin <mrocklin>` for code
reviews and/or comments on pull requests.
.. _release_2.1.4:
2.1.4
-----
* Resolved an issue where calling ``hasattr`` on a ``Group`` object erroneously
returned a ``KeyError``. By :user:`Vincent Schut <vincentschut>`; :issue:`88`,
:issue:`95`.
.. _release_2.1.3:
2.1.3
-----
* Resolved an issue with :func:`zarr.creation.array` where dtype was given as
None (:issue:`80`).
.. _release_2.1.2:
2.1.2
-----
* Resolved an issue when no compression is used and chunks are stored in memory
(:issue:`79`).
.. _release_2.1.1:
2.1.1
-----
Various minor improvements, including: ``Group`` objects support member access
via dot notation (``__getattr__``); fixed metadata caching for ``Array.shape``
property and derivatives; added ``Array.ndim`` property; fixed
``Array.__array__`` method arguments; fixed bug in pickling ``Array`` state;
fixed bug in pickling ``ThreadSynchronizer``.
.. _release_2.1.0:
2.1.0
-----
* Group objects now support member deletion via ``del`` statement
(:issue:`65`).
* Added :class:`zarr.storage.TempStore` class for convenience to provide
storage via a temporary directory
(:issue:`59`).
* Fixed performance issues with :class:`zarr.storage.ZipStore` class
(:issue:`66`).
* The Blosc extension has been modified to return bytes instead of array
objects from compress and decompress function calls. This should
improve compatibility and also provides a small performance increase for
compressing high compression ratio data
(:issue:`55`).
* Added ``overwrite`` keyword argument to array and group creation methods
on the :class:`zarr.hierarchy.Group` class
(:issue:`71`).
* Added ``cache_metadata`` keyword argument to array creation methods.
* The functions :func:`zarr.creation.open_array` and
:func:`zarr.hierarchy.open_group` now accept any store as first argument
(:issue:`56`).
.. _release_2.0.1:
2.0.1
-----
The bundled Blosc library has been upgraded to version 1.11.1.
.. _release_2.0.0:
2.0.0
-----
Hierarchies
~~~~~~~~~~~
Support has been added for organizing arrays into hierarchies via groups. See
the tutorial section on :ref:`tutorial_groups` and the :mod:`zarr.hierarchy`
API docs for more information.
Filters
~~~~~~~
Support has been added for configuring filters to preprocess chunk data prior
to compression. See the tutorial section on :ref:`tutorial_filters` and the
:mod:`zarr.codecs` API docs for more information.
Other changes
~~~~~~~~~~~~~
To accommodate support for hierarchies and filters, the Zarr metadata format
has been modified. See the :ref:`spec_v2` for more information. To migrate an
array stored using Zarr version 1.x, use the :func:`zarr.storage.migrate_1to2`
function.
The bundled Blosc library has been upgraded to version 1.11.0.
Acknowledgments
~~~~~~~~~~~~~~~
Thanks to :user:`Matthew Rocklin <mrocklin>`, :user:`Stephan Hoyer <shoyer>` and
:user:`Francesc Alted <FrancescAlted>` for contributions and comments.
.. _release_1.1.0:
1.1.0
-----
* The bundled Blosc library has been upgraded to version 1.10.0. The 'zstd'
internal compression library is now available within Blosc. See the tutorial
section on :ref:`tutorial_compress` for an example.
* When using the Blosc compressor, the default internal compression library
is now 'lz4'.
* The default number of internal threads for the Blosc compressor has been
increased to a maximum of 8 (previously 4).
* Added convenience functions :func:`zarr.blosc.list_compressors` and
:func:`zarr.blosc.get_nthreads`.
.. _release_1.0.0:
1.0.0
-----
This release includes a complete re-organization of the code base. The
major version number has been bumped to indicate that there have been
backwards-incompatible changes to the API and the on-disk storage
format. However, Zarr is still in an early stage of development, so
please do not take the version number as an indicator of maturity.
Storage
~~~~~~~
The main motivation for re-organizing the code was to create an
abstraction layer between the core array logic and data storage (:issue:`21`).
In this release, any
object that implements the ``MutableMapping`` interface can be used as
an array store. See the tutorial sections on :ref:`tutorial_persist`
and :ref:`tutorial_storage`, the :ref:`spec_v1`, and the
:mod:`zarr.storage` module documentation for more information.
Please note also that the file organization and file name conventions
used when storing a Zarr array in a directory on the file system have
changed. Persistent Zarr arrays created using previous versions of the
software will not be compatible with this version. See the
:mod:`zarr.storage` API docs and the :ref:`spec_v1` for more
information.
Compression
~~~~~~~~~~~
An abstraction layer has also been created between the core array
logic and the code for compressing and decompressing array
chunks. This release still bundles the c-blosc library and uses Blosc
as the default compressor, however other compressors including zlib,
BZ2 and LZMA are also now supported via the Python standard
library. New compressors can also be dynamically registered for use
with Zarr. See the tutorial sections on :ref:`tutorial_compress` and
:ref:`tutorial_tips_blosc`, the :ref:`spec_v1`, and the
:mod:`zarr.compressors` module documentation for more information.
Synchronization
~~~~~~~~~~~~~~~
The synchronization code has also been refactored to create a layer of
abstraction, enabling Zarr arrays to be used in parallel computations
with a number of alternative synchronization methods. For more
information see the tutorial section on :ref:`tutorial_sync` and the
:mod:`zarr.sync` module documentation.
Changes to the Blosc extension
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
NumPy is no longer a build dependency for the :mod:`zarr.blosc` Cython
extension, so setup.py will run even if NumPy is not already
installed, and should automatically install NumPy as a runtime
dependency. Manual installation of NumPy prior to installing Zarr is
still recommended, however, as the automatic installation of NumPy may
fail or be sub-optimal on some platforms.
Some optimizations have been made within the :mod:`zarr.blosc`
extension to avoid unnecessary memory copies, giving a ~10-20%
performance improvement for multi-threaded compression operations.
The :mod:`zarr.blosc` extension now automatically detects whether it
is running within a single-threaded or multi-threaded program and
adapts its internal behaviour accordingly (:issue:`27`). There is no need for
the user to make any API calls to switch Blosc between contextual and
non-contextual (global lock) mode. See also the tutorial section on
:ref:`tutorial_tips_blosc`.
Other changes
~~~~~~~~~~~~~
The internal code for managing chunks has been rewritten to be more
efficient. Now no state is maintained for chunks outside of the array
store, meaning that chunks do not carry any extra memory overhead not
accounted for by the store. This negates the need for the "lazy"
option present in the previous release, and this has been removed.
The memory layout within chunks can now be set as either "C"
(row-major) or "F" (column-major), which can help to provide better
compression for some data (:issue:`7`). See the tutorial
section on :ref:`tutorial_chunks_order` for more information.
A bug has been fixed within the ``__getitem__`` and ``__setitem__``
machinery for slicing arrays, to properly handle getting and setting
partial slices.
Acknowledgments
~~~~~~~~~~~~~~~
Thanks to :user:`Matthew Rocklin <mrocklin>`, :user:`Stephan Hoyer <shoyer>`,
:user:`Francesc Alted <FrancescAlted>`, :user:`Anthony Scopatz <scopatz>` and
:user:`Martin Durant <martindurant>` for contributions and comments.
.. _release_0.4.0:
0.4.0
-----
See `v0.4.0 release notes on GitHub
<https://github.com/zarr-developers/zarr-python/releases/tag/v0.4.0>`_.
.. _release_0.3.0:
0.3.0
-----
See `v0.3.0 release notes on GitHub
<https://github.com/zarr-developers/zarr-python/releases/tag/v0.3.0>`_.
.. _Numcodecs: https://numcodecs.readthedocs.io/
| zarr | /zarr-2.15.0.tar.gz/zarr-2.15.0/docs/release.rst | release.rst |
Installation
============
Zarr depends on NumPy. It is generally best to `install NumPy
<https://numpy.org/doc/stable/user/install.html>`_ first using whatever method is most
appropriate for your operating system and Python distribution. Other dependencies should be
installed automatically if using one of the installation methods below.
Install Zarr from PyPI::
$ pip install zarr
Alternatively, install Zarr via conda::
$ conda install -c conda-forge zarr
To install the latest development version of Zarr, you can use pip with the
latest GitHub main::
$ pip install git+https://github.com/zarr-developers/zarr-python.git
To work with Zarr source code in development, install from GitHub::
$ git clone --recursive https://github.com/zarr-developers/zarr-python.git
$ cd zarr-python
$ python -m pip install -e .
To verify that Zarr has been fully installed, run the test suite::
$ pip install pytest
$ python -m pytest -v --pyargs zarr
| zarr | /zarr-2.15.0.tar.gz/zarr-2.15.0/docs/installation.rst | installation.rst |
Acknowledgments
===============
The following people have contributed to the development of Zarr by contributing code,
documentation, code reviews, comments and/or ideas:
* :user:`Alistair Miles <alimanfoo>`
* :user:`Altay Sansal <tasansal>`
* :user:`Anderson Banihirwe <andersy005>`
* :user:`Andrew Fulton <andrewfulton9>`
* :user:`Andrew Thomas <amcnicho>`
* :user:`Anthony Scopatz <scopatz>`
* :user:`Attila Bergou <abergou>`
* :user:`BGCMHou <BGCMHou>`
* :user:`Ben Jeffery <benjeffery>`
* :user:`Ben Williams <benjaminhwilliams>`
* :user:`Boaz Mohar <boazmohar>`
* :user:`Charles Noyes <CSNoyes>`
* :user:`Chris Barnes <clbarnes>`
* :user:`David Baddeley <David-Baddeley>`
* :user:`Davis Bennett <d-v-b>`
* :user:`Dimitri Papadopoulos Orfanos <DimitriPapadopoulos>`
* :user:`Eduardo Gonzalez <eddienko>`
* :user:`Elliott Sales de Andrade <QuLogic>`
* :user:`Eric Prestat <ericpre>`
* :user:`Eric Younkin <ericgyounkin>`
* :user:`Francesc Alted <FrancescAlted>`
* :user:`Greggory Lee <grlee77>`
* :user:`Gregory R. Lee <grlee77>`
* :user:`Ian Hunt-Isaak <ianhi>`
* :user:`James Bourbeau <jrbourbeau>`
* :user:`Jan Funke <funkey>`
* :user:`Jerome Kelleher <jeromekelleher>`
* :user:`Joe Hamman <jhamman>`
* :user:`Joe Jevnik <llllllllll>`
* :user:`John Kirkham <jakirkham>`
* :user:`Josh Moore <joshmoore>`
* :user:`Juan Nunez-Iglesias <jni>`
* :user:`Justin Swaney <jmswaney>`
* :user:`Mads R. B. Kristensen <madsbk>`
* :user:`Mamy Ratsimbazafy <mratsim>`
* :user:`Martin Durant <martindurant>`
* :user:`Matthew Rocklin <mrocklin>`
* :user:`Matthias Bussonnier <Carreau>`
* :user:`Mattia Almansi <malmans2>`
* :user:`Noah D Brenowitz <nbren12>`
* :user:`Oren Watson <orenwatson>`
* :user:`Pavithra Eswaramoorthy <pavithraes>`
* :user:`Poruri Sai Rahul <rahulporuri>`
* :user:`Prakhar Goel <newt0311>`
* :user:`Raphael Dussin <raphaeldussin>`
* :user:`Ray Bell <raybellwaves>`
* :user:`Richard Scott <RichardScottOZ>`
* :user:`Richard Shaw <jrs65>`
* :user:`Ryan Abernathey <rabernat>`
* :user:`Ryan Williams <ryan-williams>`
* :user:`Saransh Chopra <Saransh-cpp>`
* :user:`Sebastian Grill <yetyetanotherusername>`
* :user:`Shikhar Goenka <shikharsg>`
* :user:`Shivank Chaudhary <Alt-Shivam>`
* :user:`Stephan Hoyer <shoyer>`
* :user:`Stephan Saalfeld <axtimwalde>`
* :user:`Tarik Onalan <onalant>`
* :user:`Tim Crone <tjcrone>`
* :user:`Tobias Kölling <d70-t>`
* :user:`Tom Augspurger <TomAugspurger>`
* :user:`Tom White <tomwhite>`
* :user:`Tommy Tran <potter420>`
* :user:`Trevor Manz <manzt>`
* :user:`Vincent Schut <vincentschut>`
* :user:`Vyas Ramasubramani <vyasr>`
* :user:`Zain Patel <mzjp2>`
* :user:`gsakkis`
* :user:`hailiangzhang <hailiangzhang>`
* :user:`pmav99 <pmav99>`
* :user:`sbalmer <sbalmer>` | zarr | /zarr-2.15.0.tar.gz/zarr-2.15.0/docs/acknowledgments.rst | acknowledgments.rst |
Groups (``zarr.hierarchy``)
===========================
.. module:: zarr.hierarchy
.. autofunction:: group
.. autofunction:: open_group
.. autoclass:: Group
.. automethod:: __len__
.. automethod:: __iter__
.. automethod:: __contains__
.. automethod:: __getitem__
.. automethod:: __enter__
.. automethod:: __exit__
.. automethod:: group_keys
.. automethod:: groups
.. automethod:: array_keys
.. automethod:: arrays
.. automethod:: visit
.. automethod:: visitkeys
.. automethod:: visitvalues
.. automethod:: visititems
.. automethod:: tree
.. automethod:: create_group
.. automethod:: require_group
.. automethod:: create_groups
.. automethod:: require_groups
.. automethod:: create_dataset
.. automethod:: require_dataset
.. automethod:: create
.. automethod:: empty
.. automethod:: zeros
.. automethod:: ones
.. automethod:: full
.. automethod:: array
.. automethod:: empty_like
.. automethod:: zeros_like
.. automethod:: ones_like
.. automethod:: full_like
.. automethod:: move
| zarr | /zarr-2.15.0.tar.gz/zarr-2.15.0/docs/api/hierarchy.rst | hierarchy.rst |
V3 Specification Implementation(``zarr._storage.v3``)
=====================================================
This module contains the implementation of the `Zarr V3 Specification <https://zarr-specs.readthedocs.io/en/latest/v3/core/v3.0.html>`_.
.. warning::
Since Zarr Python 2.12 release, this module provides experimental infrastructure for reading and
writing the upcoming V3 spec of the Zarr format. Users wishing to prepare for the migration can set
the environment variable ``ZARR_V3_EXPERIMENTAL_API=1`` to begin experimenting, however data
written with this API should be expected to become stale, as the implementation will still change.
The new ``zarr._store.v3`` package has the necessary classes and functions for evaluating Zarr V3.
Since the design is not finalised, the classes and functions are not automatically imported into
the regular Zarr namespace.
Code snippet for creating Zarr V3 arrays::
>>> import zarr
>>> z = zarr.create((10000, 10000),
>>> chunks=(100, 100),
>>> dtype='f8',
>>> compressor='default',
>>> path='path-where-you-want-zarr-v3-array',
>>> zarr_version=3)
Further, you can use `z.info` to see details about the array you just created::
>>> z.info
Name : path-where-you-want-zarr-v3-array
Type : zarr.core.Array
Data type : float64
Shape : (10000, 10000)
Chunk shape : (100, 100)
Order : C
Read-only : False
Compressor : Blosc(cname='lz4', clevel=5, shuffle=SHUFFLE, blocksize=0)
Store type : zarr._storage.v3.KVStoreV3
No. bytes : 800000000 (762.9M)
No. bytes stored : 557
Storage ratio : 1436265.7
Chunks initialized : 0/10000
You can also check ``Store type`` here (which indicates Zarr V3).
.. module:: zarr._storage.v3
.. autoclass:: RmdirV3
.. autoclass:: KVStoreV3
.. autoclass:: FSStoreV3
.. autoclass:: MemoryStoreV3
.. autoclass:: DirectoryStoreV3
.. autoclass:: ZipStoreV3
.. autoclass:: RedisStoreV3
.. autoclass:: MongoDBStoreV3
.. autoclass:: DBMStoreV3
.. autoclass:: LMDBStoreV3
.. autoclass:: SQLiteStoreV3
.. autoclass:: LRUStoreCacheV3
.. autoclass:: ConsolidatedMetadataStoreV3
In v3 `storage transformers <https://zarr-specs.readthedocs.io/en/latest/v3/array-storage-transformers/sharding/v1.0.html>`_
can be set via ``zarr.create(…, storage_transformers=[…])``.
The experimental sharding storage transformer can be tested by setting
the environment variable ``ZARR_V3_SHARDING=1``. Data written with this flag
enabled should be expected to become stale until
`ZEP 2 <https://zarr.dev/zeps/draft/ZEP0002.html>`_ is approved
and fully implemented.
.. module:: zarr._storage.v3_storage_transformers
.. autoclass:: ShardingStorageTransformer
The abstract base class for storage transformers is
.. module:: zarr._storage.store
.. autoclass:: StorageTransformer
| zarr | /zarr-2.15.0.tar.gz/zarr-2.15.0/docs/api/v3.rst | v3.rst |
Storage (``zarr.storage``)
==========================
.. automodule:: zarr.storage
.. autoclass:: MemoryStore
.. autoclass:: DirectoryStore
.. autoclass:: TempStore
.. autoclass:: NestedDirectoryStore
.. autoclass:: ZipStore
.. automethod:: close
.. automethod:: flush
.. autoclass:: DBMStore
.. automethod:: close
.. automethod:: flush
.. autoclass:: LMDBStore
.. automethod:: close
.. automethod:: flush
.. autoclass:: SQLiteStore
.. automethod:: close
.. autoclass:: MongoDBStore
.. autoclass:: RedisStore
.. autoclass:: LRUStoreCache
.. automethod:: invalidate
.. automethod:: invalidate_values
.. automethod:: invalidate_keys
.. autoclass:: ABSStore
.. autoclass:: FSStore
.. autoclass:: ConsolidatedMetadataStore
.. autofunction:: init_array
.. autofunction:: init_group
.. autofunction:: contains_array
.. autofunction:: contains_group
.. autofunction:: listdir
.. autofunction:: rmdir
.. autofunction:: getsize
.. autofunction:: rename
.. autofunction:: migrate_1to2
| zarr | /zarr-2.15.0.tar.gz/zarr-2.15.0/docs/api/storage.rst | storage.rst |
Compressors and filters (``zarr.codecs``)
=========================================
.. module:: zarr.codecs
This module contains compressor and filter classes for use with Zarr. Please note that this module
is provided for backwards compatibility with previous versions of Zarr. From Zarr version 2.2
onwards, all codec classes have been moved to a separate package called Numcodecs_. The two
packages (Zarr and Numcodecs_) are designed to be used together. For example, a Numcodecs_ codec
class can be used as a compressor for a Zarr array::
>>> import zarr
>>> from numcodecs import Blosc
>>> z = zarr.zeros(1000000, compressor=Blosc(cname='zstd', clevel=1, shuffle=Blosc.SHUFFLE))
Codec classes can also be used as filters. See the tutorial section on :ref:`tutorial_filters`
for more information.
Please note that it is also relatively straightforward to define and register custom codec
classes. See the Numcodecs `codec API <https://numcodecs.readthedocs.io/en/latest/abc.html>`_ and
`codec registry <https://numcodecs.readthedocs.io/en/latest/registry.html>`_ documentation for more
information.
.. _Numcodecs: https://numcodecs.readthedocs.io/
| zarr | /zarr-2.15.0.tar.gz/zarr-2.15.0/docs/api/codecs.rst | codecs.rst |
The Array class (``zarr.core``)
===============================
.. module:: zarr.core
.. autoclass:: Array
.. automethod:: __getitem__
.. automethod:: __setitem__
.. automethod:: get_basic_selection
.. automethod:: set_basic_selection
.. automethod:: get_mask_selection
.. automethod:: set_mask_selection
.. automethod:: get_coordinate_selection
.. automethod:: set_coordinate_selection
.. automethod:: get_orthogonal_selection
.. automethod:: set_orthogonal_selection
.. automethod:: digest
.. automethod:: hexdigest
.. automethod:: resize
.. automethod:: append
.. automethod:: view
.. automethod:: astype
| zarr | /zarr-2.15.0.tar.gz/zarr-2.15.0/docs/api/core.rst | core.rst |
.. _spec_v1:
Zarr storage specification version 1
====================================
This document provides a technical specification of the protocol and
format used for storing a Zarr array. The key words "MUST", "MUST
NOT", "REQUIRED", "SHALL", "SHALL NOT", "SHOULD", "SHOULD NOT",
"RECOMMENDED", "MAY", and "OPTIONAL" in this document are to be
interpreted as described in `RFC 2119
<https://www.ietf.org/rfc/rfc2119.txt>`_.
Status
------
This specification is deprecated. See :ref:`spec` for the latest version.
Storage
-------
A Zarr array can be stored in any storage system that provides a
key/value interface, where a key is an ASCII string and a value is an
arbitrary sequence of bytes, and the supported operations are read
(get the sequence of bytes associated with a given key), write (set
the sequence of bytes associated with a given key) and delete (remove
a key/value pair).
For example, a directory in a file system can provide this interface,
where keys are file names, values are file contents, and files can be
read, written or deleted via the operating system. Equally, an S3
bucket can provide this interface, where keys are resource names,
values are resource contents, and resources can be read, written or
deleted via HTTP.
Below an "array store" refers to any system implementing this
interface.
Metadata
--------
Each array requires essential configuration metadata to be stored,
enabling correct interpretation of the stored data. This metadata is
encoded using JSON and stored as the value of the 'meta' key within an
array store.
The metadata resource is a JSON object. The following keys MUST be
present within the object:
zarr_format
An integer defining the version of the storage specification to which the
array store adheres.
shape
A list of integers defining the length of each dimension of the array.
chunks
A list of integers defining the length of each dimension of a chunk of the
array. Note that all chunks within a Zarr array have the same shape.
dtype
A string or list defining a valid data type for the array. See also
the subsection below on data type encoding.
compression
A string identifying the primary compression library used to compress
each chunk of the array.
compression_opts
An integer, string or dictionary providing options to the primary
compression library.
fill_value
A scalar value providing the default value to use for uninitialized
portions of the array.
order
Either 'C' or 'F', defining the layout of bytes within each chunk of the
array. 'C' means row-major order, i.e., the last dimension varies fastest;
'F' means column-major order, i.e., the first dimension varies fastest.
Other keys MAY be present within the metadata object however they MUST
NOT alter the interpretation of the required fields defined above.
For example, the JSON object below defines a 2-dimensional array of
64-bit little-endian floating point numbers with 10000 rows and 10000
columns, divided into chunks of 1000 rows and 1000 columns (so there
will be 100 chunks in total arranged in a 10 by 10 grid). Within each
chunk the data are laid out in C contiguous order, and each chunk is
compressed using the Blosc compression library::
{
"chunks": [
1000,
1000
],
"compression": "blosc",
"compression_opts": {
"clevel": 5,
"cname": "lz4",
"shuffle": 1
},
"dtype": "<f8",
"fill_value": null,
"order": "C",
"shape": [
10000,
10000
],
"zarr_format": 1
}
Data type encoding
~~~~~~~~~~~~~~~~~~
Simple data types are encoded within the array metadata resource as a
string, following the `NumPy array protocol type string (typestr)
format
<numpy:arrays.interface>`_. The
format consists of 3 parts: a character describing the byteorder of
the data (``<``: little-endian, ``>``: big-endian, ``|``:
not-relevant), a character code giving the basic type of the array,
and an integer providing the number of bytes the type uses. The byte
order MUST be specified. E.g., ``"<f8"``, ``">i4"``, ``"|b1"`` and
``"|S12"`` are valid data types.
Structure data types (i.e., with multiple named fields) are encoded as
a list of two-element lists, following `NumPy array protocol type
descriptions (descr)
<numpy:arrays.interface>`_.
For example, the JSON list ``[["r", "|u1"], ["g", "|u1"], ["b",
"|u1"]]`` defines a data type composed of three single-byte unsigned
integers labelled 'r', 'g' and 'b'.
Chunks
------
Each chunk of the array is compressed by passing the raw bytes for the
chunk through the primary compression library to obtain a new sequence
of bytes comprising the compressed chunk data. No header is added to
the compressed bytes or any other modification made. The internal
structure of the compressed bytes will depend on which primary
compressor was used. For example, the `Blosc compressor
<https://github.com/Blosc/c-blosc/blob/main/README_HEADER.rst>`_
produces a sequence of bytes that begins with a 16-byte header
followed by compressed data.
The compressed sequence of bytes for each chunk is stored under a key
formed from the index of the chunk within the grid of chunks
representing the array. To form a string key for a chunk, the indices
are converted to strings and concatenated with the period character
('.') separating each index. For example, given an array with shape
(10000, 10000) and chunk shape (1000, 1000) there will be 100 chunks
laid out in a 10 by 10 grid. The chunk with indices (0, 0) provides
data for rows 0-999 and columns 0-999 and is stored under the key
'0.0'; the chunk with indices (2, 4) provides data for rows 2000-2999
and columns 4000-4999 and is stored under the key '2.4'; etc.
There is no need for all chunks to be present within an array
store. If a chunk is not present then it is considered to be in an
uninitialized state. An uninitialized chunk MUST be treated as if it
was uniformly filled with the value of the 'fill_value' field in the
array metadata. If the 'fill_value' field is ``null`` then the
contents of the chunk are undefined.
Note that all chunks in an array have the same shape. If the length of
any array dimension is not exactly divisible by the length of the
corresponding chunk dimension then some chunks will overhang the edge
of the array. The contents of any chunk region falling outside the
array are undefined.
Attributes
----------
Each array can also be associated with custom attributes, which are
simple key/value items with application-specific meaning. Custom
attributes are encoded as a JSON object and stored under the 'attrs'
key within an array store. Even if the attributes are empty, the
'attrs' key MUST be present within an array store.
For example, the JSON object below encodes three attributes named
'foo', 'bar' and 'baz'::
{
"foo": 42,
"bar": "apples",
"baz": [1, 2, 3, 4]
}
Example
-------
Below is an example of storing a Zarr array, using a directory on the
local file system as storage.
Initialize the store::
>>> import zarr
>>> store = zarr.DirectoryStore('example.zarr')
>>> zarr.init_store(store, shape=(20, 20), chunks=(10, 10),
... dtype='i4', fill_value=42, compression='zlib',
... compression_opts=1, overwrite=True)
No chunks are initialized yet, so only the 'meta' and 'attrs' keys
have been set::
>>> import os
>>> sorted(os.listdir('example.zarr'))
['attrs', 'meta']
Inspect the array metadata::
>>> print(open('example.zarr/meta').read())
{
"chunks": [
10,
10
],
"compression": "zlib",
"compression_opts": 1,
"dtype": "<i4",
"fill_value": 42,
"order": "C",
"shape": [
20,
20
],
"zarr_format": 1
}
Inspect the array attributes::
>>> print(open('example.zarr/attrs').read())
{}
Set some data::
>>> z = zarr.Array(store)
>>> z[0:10, 0:10] = 1
>>> sorted(os.listdir('example.zarr'))
['0.0', 'attrs', 'meta']
Set some more data::
>>> z[0:10, 10:20] = 2
>>> z[10:20, :] = 3
>>> sorted(os.listdir('example.zarr'))
['0.0', '0.1', '1.0', '1.1', 'attrs', 'meta']
Manually decompress a single chunk for illustration::
>>> import zlib
>>> b = zlib.decompress(open('example.zarr/0.0', 'rb').read())
>>> import numpy as np
>>> a = np.frombuffer(b, dtype='<i4')
>>> a
array([1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1], dtype=int32)
Modify the array attributes::
>>> z.attrs['foo'] = 42
>>> z.attrs['bar'] = 'apples'
>>> z.attrs['baz'] = [1, 2, 3, 4]
>>> print(open('example.zarr/attrs').read())
{
"bar": "apples",
"baz": [
1,
2,
3,
4
],
"foo": 42
}
| zarr | /zarr-2.15.0.tar.gz/zarr-2.15.0/docs/spec/v1.rst | v1.rst |
.. _spec_v2:
Zarr storage specification version 2
====================================
This document provides a technical specification of the protocol and format
used for storing Zarr arrays. The key words "MUST", "MUST NOT", "REQUIRED",
"SHALL", "SHALL NOT", "SHOULD", "SHOULD NOT", "RECOMMENDED", "MAY", and
"OPTIONAL" in this document are to be interpreted as described in `RFC 2119
<https://www.ietf.org/rfc/rfc2119.txt>`_.
Status
------
This specification is the latest version. See :ref:`spec` for previous
versions.
.. _spec_v2_storage:
Storage
-------
A Zarr array can be stored in any storage system that provides a key/value
interface, where a key is an ASCII string and a value is an arbitrary sequence
of bytes, and the supported operations are read (get the sequence of bytes
associated with a given key), write (set the sequence of bytes associated with
a given key) and delete (remove a key/value pair).
For example, a directory in a file system can provide this interface, where
keys are file names, values are file contents, and files can be read, written
or deleted via the operating system. Equally, an S3 bucket can provide this
interface, where keys are resource names, values are resource contents, and
resources can be read, written or deleted via HTTP.
Below an "array store" refers to any system implementing this interface.
.. _spec_v2_array:
Arrays
------
.. _spec_v2_array_metadata:
Metadata
~~~~~~~~
Each array requires essential configuration metadata to be stored, enabling
correct interpretation of the stored data. This metadata is encoded using JSON
and stored as the value of the ".zarray" key within an array store.
The metadata resource is a JSON object. The following keys MUST be present
within the object:
zarr_format
An integer defining the version of the storage specification to which the
array store adheres.
shape
A list of integers defining the length of each dimension of the array.
chunks
A list of integers defining the length of each dimension of a chunk of the
array. Note that all chunks within a Zarr array have the same shape.
dtype
A string or list defining a valid data type for the array. See also
the subsection below on data type encoding.
compressor
A JSON object identifying the primary compression codec and providing
configuration parameters, or ``null`` if no compressor is to be used.
The object MUST contain an ``"id"`` key identifying the codec to be used.
fill_value
A scalar value providing the default value to use for uninitialized
portions of the array, or ``null`` if no fill_value is to be used.
order
Either "C" or "F", defining the layout of bytes within each chunk of the
array. "C" means row-major order, i.e., the last dimension varies fastest;
"F" means column-major order, i.e., the first dimension varies fastest.
filters
A list of JSON objects providing codec configurations, or ``null`` if no
filters are to be applied. Each codec configuration object MUST contain a
``"id"`` key identifying the codec to be used.
The following keys MAY be present within the object:
dimension_separator
If present, either the string ``"."`` or ``"/""`` defining the separator placed
between the dimensions of a chunk. If the value is not set, then the
default MUST be assumed to be ``"."``, leading to chunk keys of the form "0.0".
Arrays defined with ``"/"`` as the dimension separator can be considered to have
nested, or hierarchical, keys of the form "0/0" that SHOULD where possible
produce a directory-like structure.
Other keys SHOULD NOT be present within the metadata object and SHOULD be
ignored by implementations.
For example, the JSON object below defines a 2-dimensional array of 64-bit
little-endian floating point numbers with 10000 rows and 10000 columns, divided
into chunks of 1000 rows and 1000 columns (so there will be 100 chunks in total
arranged in a 10 by 10 grid). Within each chunk the data are laid out in C
contiguous order. Each chunk is encoded using a delta filter and compressed
using the Blosc compression library prior to storage::
{
"chunks": [
1000,
1000
],
"compressor": {
"id": "blosc",
"cname": "lz4",
"clevel": 5,
"shuffle": 1
},
"dtype": "<f8",
"fill_value": "NaN",
"filters": [
{"id": "delta", "dtype": "<f8", "astype": "<f4"}
],
"order": "C",
"shape": [
10000,
10000
],
"zarr_format": 2
}
.. _spec_v2_array_dtype:
Data type encoding
~~~~~~~~~~~~~~~~~~
Simple data types are encoded within the array metadata as a string,
following the :ref:`NumPy array protocol type string (typestr) format
<numpy:arrays.interface>`. The format
consists of 3 parts:
* One character describing the byteorder of the data (``"<"``: little-endian;
``">"``: big-endian; ``"|"``: not-relevant)
* One character code giving the basic type of the array (``"b"``: Boolean (integer
type where all values are only True or False); ``"i"``: integer; ``"u"``: unsigned
integer; ``"f"``: floating point; ``"c"``: complex floating point; ``"m"``: timedelta;
``"M"``: datetime; ``"S"``: string (fixed-length sequence of char); ``"U"``: unicode
(fixed-length sequence of Py_UNICODE); ``"V"``: other (void * – each item is a
fixed-size chunk of memory))
* An integer specifying the number of bytes the type uses.
The byte order MUST be specified. E.g., ``"<f8"``, ``">i4"``, ``"|b1"`` and
``"|S12"`` are valid data type encodings.
For datetime64 ("M") and timedelta64 ("m") data types, these MUST also include the
units within square brackets. A list of valid units and their definitions are given in
the :ref:`NumPy documentation on Datetimes and Timedeltas
<numpy:arrays.dtypes.dateunits>`.
For example, ``"<M8[ns]"`` specifies a datetime64 data type with nanosecond time units.
Structured data types (i.e., with multiple named fields) are encoded
as a list of lists, following :ref:`NumPy array protocol type descriptions
(descr)
<numpy:arrays.interface>`. Each
sub-list has the form ``[fieldname, datatype, shape]`` where ``shape``
is optional. ``fieldname`` is a string, ``datatype`` is a string
specifying a simple data type (see above), and ``shape`` is a list of
integers specifying subarray shape. For example, the JSON list below
defines a data type composed of three single-byte unsigned integer
fields named "r", "g" and "b"::
[["r", "|u1"], ["g", "|u1"], ["b", "|u1"]]
For example, the JSON list below defines a data type composed of three
fields named "x", "y" and "z", where "x" and "y" each contain 32-bit
floats, and each item in "z" is a 2 by 2 array of floats::
[["x", "<f4"], ["y", "<f4"], ["z", "<f4", [2, 2]]]
Structured data types may also be nested, e.g., the following JSON
list defines a data type with two fields "foo" and "bar", where "bar"
has two sub-fields "baz" and "qux"::
[["foo", "<f4"], ["bar", [["baz", "<f4"], ["qux", "<i4"]]]]
.. _spec_v2_array_fill_value:
Fill value encoding
~~~~~~~~~~~~~~~~~~~
For simple floating point data types, the following table MUST be used to
encode values of the "fill_value" field:
================= ===============
Value JSON encoding
================= ===============
Not a Number ``"NaN"``
Positive Infinity ``"Infinity"``
Negative Infinity ``"-Infinity"``
================= ===============
If an array has a fixed length byte string data type (e.g., ``"|S12"``), or a
structured data type, and if the fill value is not null, then the fill value
MUST be encoded as an ASCII string using the standard Base64 alphabet.
.. _spec_v2_array_chunks:
Chunks
~~~~~~
Each chunk of the array is compressed by passing the raw bytes for the chunk
through the primary compression library to obtain a new sequence of bytes
comprising the compressed chunk data. No header is added to the compressed
bytes or any other modification made. The internal structure of the compressed
bytes will depend on which primary compressor was used. For example, the `Blosc
compressor <https://github.com/Blosc/c-blosc/blob/main/README_CHUNK_FORMAT.rst>`_
produces a sequence of bytes that begins with a 16-byte header followed by
compressed data.
The compressed sequence of bytes for each chunk is stored under a key formed
from the index of the chunk within the grid of chunks representing the array.
To form a string key for a chunk, the indices are converted to strings and
concatenated with the period character (".") separating each index. For
example, given an array with shape (10000, 10000) and chunk shape (1000, 1000)
there will be 100 chunks laid out in a 10 by 10 grid. The chunk with indices
(0, 0) provides data for rows 0-999 and columns 0-999 and is stored under the
key "0.0"; the chunk with indices (2, 4) provides data for rows 2000-2999 and
columns 4000-4999 and is stored under the key "2.4"; etc.
There is no need for all chunks to be present within an array store. If a chunk
is not present then it is considered to be in an uninitialized state. An
uninitialized chunk MUST be treated as if it was uniformly filled with the value
of the "fill_value" field in the array metadata. If the "fill_value" field is
``null`` then the contents of the chunk are undefined.
Note that all chunks in an array have the same shape. If the length of any
array dimension is not exactly divisible by the length of the corresponding
chunk dimension then some chunks will overhang the edge of the array. The
contents of any chunk region falling outside the array are undefined.
.. _spec_v2_array_filters:
Filters
~~~~~~~
Optionally a sequence of one or more filters can be used to transform chunk
data prior to compression. When storing data, filters are applied in the order
specified in array metadata to encode data, then the encoded data are passed to
the primary compressor. When retrieving data, stored chunk data are
decompressed by the primary compressor then decoded using filters in the
reverse order.
.. _spec_v2_hierarchy:
Hierarchies
-----------
.. _spec_v2_hierarchy_paths:
Logical storage paths
~~~~~~~~~~~~~~~~~~~~~
Multiple arrays can be stored in the same array store by associating each array
with a different logical path. A logical path is simply an ASCII string. The
logical path is used to form a prefix for keys used by the array. For example,
if an array is stored at logical path "foo/bar" then the array metadata will be
stored under the key "foo/bar/.zarray", the user-defined attributes will be
stored under the key "foo/bar/.zattrs", and the chunks will be stored under
keys like "foo/bar/0.0", "foo/bar/0.1", etc.
To ensure consistent behaviour across different storage systems, logical paths
MUST be normalized as follows:
* Replace all backward slash characters ("\\\\") with forward slash characters
("/")
* Strip any leading "/" characters
* Strip any trailing "/" characters
* Collapse any sequence of more than one "/" character into a single "/"
character
The key prefix is then obtained by appending a single "/" character to the
normalized logical path.
After normalization, if splitting a logical path by the "/" character results
in any path segment equal to the string "." or the string ".." then an error
MUST be raised.
N.B., how the underlying array store processes requests to store values under
keys containing the "/" character is entirely up to the store implementation
and is not constrained by this specification. E.g., an array store could simply
treat all keys as opaque ASCII strings; equally, an array store could map
logical paths onto some kind of hierarchical storage (e.g., directories on a
file system).
.. _spec_v2_hierarchy_groups:
Groups
~~~~~~
Arrays can be organized into groups which can also contain other groups. A
group is created by storing group metadata under the ".zgroup" key under some
logical path. E.g., a group exists at the root of an array store if the
".zgroup" key exists in the store, and a group exists at logical path "foo/bar"
if the "foo/bar/.zgroup" key exists in the store.
If the user requests a group to be created under some logical path, then groups
MUST also be created at all ancestor paths. E.g., if the user requests group
creation at path "foo/bar" then groups MUST be created at path "foo" and the
root of the store, if they don't already exist.
If the user requests an array to be created under some logical path, then
groups MUST also be created at all ancestor paths. E.g., if the user requests
array creation at path "foo/bar/baz" then groups must be created at path
"foo/bar", path "foo", and the root of the store, if they don't already exist.
The group metadata resource is a JSON object. The following keys MUST be present
within the object:
zarr_format
An integer defining the version of the storage specification to which the
array store adheres.
Other keys MUST NOT be present within the metadata object.
The members of a group are arrays and groups stored under logical paths that
are direct children of the parent group's logical path. E.g., if groups exist
under the logical paths "foo" and "foo/bar" and an array exists at logical path
"foo/baz" then the members of the group at path "foo" are the group at path
"foo/bar" and the array at path "foo/baz".
.. _spec_v2_attrs:
Attributes
----------
An array or group can be associated with custom attributes, which are arbitrary
key/value pairs with application-specific meaning. Custom attributes are encoded
as a JSON object and stored under the ".zattrs" key within an array store. The
".zattrs" key does not have to be present, and if it is absent the attributes
should be treated as empty.
For example, the JSON object below encodes three attributes named
"foo", "bar" and "baz"::
{
"foo": 42,
"bar": "apples",
"baz": [1, 2, 3, 4]
}
.. _spec_v2_examples:
Examples
--------
Storing a single array
~~~~~~~~~~~~~~~~~~~~~~
Below is an example of storing a Zarr array, using a directory on the
local file system as storage.
Create an array::
>>> import zarr
>>> store = zarr.DirectoryStore('data/example.zarr')
>>> a = zarr.create(shape=(20, 20), chunks=(10, 10), dtype='i4',
... fill_value=42, compressor=zarr.Zlib(level=1),
... store=store, overwrite=True)
No chunks are initialized yet, so only the ".zarray" and ".zattrs" keys
have been set in the store::
>>> import os
>>> sorted(os.listdir('data/example.zarr'))
['.zarray']
Inspect the array metadata::
>>> print(open('data/example.zarr/.zarray').read())
{
"chunks": [
10,
10
],
"compressor": {
"id": "zlib",
"level": 1
},
"dtype": "<i4",
"fill_value": 42,
"filters": null,
"order": "C",
"shape": [
20,
20
],
"zarr_format": 2
}
Chunks are initialized on demand. E.g., set some data::
>>> a[0:10, 0:10] = 1
>>> sorted(os.listdir('data/example.zarr'))
['.zarray', '0.0']
Set some more data::
>>> a[0:10, 10:20] = 2
>>> a[10:20, :] = 3
>>> sorted(os.listdir('data/example.zarr'))
['.zarray', '0.0', '0.1', '1.0', '1.1']
Manually decompress a single chunk for illustration::
>>> import zlib
>>> buf = zlib.decompress(open('data/example.zarr/0.0', 'rb').read())
>>> import numpy as np
>>> chunk = np.frombuffer(buf, dtype='<i4')
>>> chunk
array([1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1], dtype=int32)
Modify the array attributes::
>>> a.attrs['foo'] = 42
>>> a.attrs['bar'] = 'apples'
>>> a.attrs['baz'] = [1, 2, 3, 4]
>>> sorted(os.listdir('data/example.zarr'))
['.zarray', '.zattrs', '0.0', '0.1', '1.0', '1.1']
>>> print(open('data/example.zarr/.zattrs').read())
{
"bar": "apples",
"baz": [
1,
2,
3,
4
],
"foo": 42
}
Storing multiple arrays in a hierarchy
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
Below is an example of storing multiple Zarr arrays organized into a group
hierarchy, using a directory on the local file system as storage. This storage
implementation maps logical paths onto directory paths on the file system,
however this is an implementation choice and is not required.
Setup the store::
>>> import zarr
>>> store = zarr.DirectoryStore('data/group.zarr')
Create the root group::
>>> root_grp = zarr.group(store, overwrite=True)
The metadata resource for the root group has been created::
>>> import os
>>> sorted(os.listdir('data/group.zarr'))
['.zgroup']
Inspect the group metadata::
>>> print(open('data/group.zarr/.zgroup').read())
{
"zarr_format": 2
}
Create a sub-group::
>>> sub_grp = root_grp.create_group('foo')
What has been stored::
>>> sorted(os.listdir('data/group.zarr'))
['.zgroup', 'foo']
>>> sorted(os.listdir('data/group.zarr/foo'))
['.zgroup']
Create an array within the sub-group::
>>> a = sub_grp.create_dataset('bar', shape=(20, 20), chunks=(10, 10))
>>> a[:] = 42
Set a custom attributes::
>>> a.attrs['comment'] = 'answer to life, the universe and everything'
What has been stored::
>>> sorted(os.listdir('data/group.zarr'))
['.zgroup', 'foo']
>>> sorted(os.listdir('data/group.zarr/foo'))
['.zgroup', 'bar']
>>> sorted(os.listdir('data/group.zarr/foo/bar'))
['.zarray', '.zattrs', '0.0', '0.1', '1.0', '1.1']
Here is the same example using a Zip file as storage::
>>> store = zarr.ZipStore('data/group.zip', mode='w')
>>> root_grp = zarr.group(store)
>>> sub_grp = root_grp.create_group('foo')
>>> a = sub_grp.create_dataset('bar', shape=(20, 20), chunks=(10, 10))
>>> a[:] = 42
>>> a.attrs['comment'] = 'answer to life, the universe and everything'
>>> store.close()
What has been stored::
>>> import zipfile
>>> zf = zipfile.ZipFile('data/group.zip', mode='r')
>>> for name in sorted(zf.namelist()):
... print(name)
.zgroup
foo/.zgroup
foo/bar/.zarray
foo/bar/.zattrs
foo/bar/0.0
foo/bar/0.1
foo/bar/1.0
foo/bar/1.1
.. _spec_v2_changes:
Changes
-------
Version 2 clarifications
~~~~~~~~~~~~~~~~~~~~~~~~
The following changes have been made to the version 2 specification since it was
initially published to clarify ambiguities and add some missing information.
* The specification now describes how bytes fill values should be encoded and
decoded for arrays with a fixed-length byte string data type (:issue:`165`,
:issue:`176`).
* The specification now clarifies that units must be specified for datetime64 and
timedelta64 data types (:issue:`85`, :issue:`215`).
* The specification now clarifies that the '.zattrs' key does not have to be present for
either arrays or groups, and if absent then custom attributes should be treated as
empty.
* The specification now describes how structured datatypes with
subarray shapes and/or with nested structured data types are encoded
in array metadata (:issue:`111`, :issue:`296`).
* Clarified the key/value pairs of custom attributes as "arbitrary" rather than
"simple".
Changes from version 1 to version 2
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
The following changes were made between version 1 and version 2 of this specification:
* Added support for storing multiple arrays in the same store and organising
arrays into hierarchies using groups.
* Array metadata is now stored under the ".zarray" key instead of the "meta"
key.
* Custom attributes are now stored under the ".zattrs" key instead of the
"attrs" key.
* Added support for filters.
* Changed encoding of "fill_value" field within array metadata.
* Changed encoding of compressor information within array metadata to be
consistent with representation of filter information.
| zarr | /zarr-2.15.0.tar.gz/zarr-2.15.0/docs/spec/v2.rst | v2.rst |
Zarr - scalable storage of tensor data for use in parallel and distributed computing
====================================================================================
SciPy 2019 submission.
Short summary
-------------
Many scientific problems involve computing over large N-dimensional
typed arrays of data, and reading or writing data is often the major
bottleneck limiting speed or scalability. The Zarr project is
developing a simple, scalable approach to storage of such data in a
way that is compatible with a range of approaches to distributed and
parallel computing. We describe the Zarr protocol and data storage
format, and the current state of implementations for various
programming languages including Python. We also describe current uses
of Zarr in malaria genomics, the Human Cell Atlas, and the Pangeo
project.
Abstract
--------
Background
~~~~~~~~~~
Across a broad range of scientific disciplines, data are naturally
represented and stored as N-dimensional typed arrays, also known as
tensors. The volume of data being generated is outstripping our
ability to analyse it, and scientific communities are looking for ways
to leverage modern multi-core CPUs and distributed computing
platforms, including cloud computing. Retrieval and storage of data is
often the major bottleneck, and new approaches to data storage are
needed to accelerate distributed computations and enable them to scale
on a variety of platforms.
Methods
~~~~~~~
We have designed a new storage format and protocol for tensor data
[1_], and have released an open source Python implementation [2_,
3_]. Our approach builds on data storage concepts from HDF5 [4_],
particularly chunking and compression, and hierarchical organisation
of datasets. Key design goals include: a simple protocol and format
that can be implemented in other programming languages; support for
multiple concurrent readers or writers; support for a variety of
parallel computing environments, from multi-threaded execution on a
single CPU to multi-process execution across a multi-node cluster;
pluggable storage subsystem with support for file systems, key-value
databases and cloud object stores; pluggable encoding subsystem with
support for a variety of modern compressors.
Results
~~~~~~~
We illustrate the use of Zarr with examples from several scientific
domains. Zarr is being used within the Pangeo project [5_], which is
building a community platform for big data geoscience. The Pangeo
community have converted a number of existing climate modelling and
satellite observation datasets to Zarr [6_], and have demonstrated
their use in computations using HPC and cloud computing
environments. Within the MalariaGEN project [7_], Zarr is used to
store genome variation data from next-generation sequencing of natural
populations of malaria parasites and mosquitoes [8_] and these data
are used as input to analyses of the evolution of these organisms in
response to selective pressure from anti-malarial drugs and
insecticides. Zarr is being used within the Human Cell Atlas (HCA)
project [9_], which is building a reference atlas of healthy human
cell types. This project hopes to leverage this information to better
understand the dysregulation of cellular states that underly human
disease. The Human Cell Atlas uses Zarr as the output data format
because it enables the project to easily generate matrices containing
user-selected subsets of cells.
Conclusions
~~~~~~~~~~~
Zarr is generating interest across a range of scientific domains, and
work is ongoing to establish a community process to support further
development of the specifications and implementations in other
programming languages [10_, 11_, 12_] and building interoperability
with a similar project called N5 [13_]. Other packages within the
PyData ecosystem, notably Dask [14_], Xarray [15_] and Intake [16_],
have added capability to read and write Zarr, and together these
packages provide a compelling solution for large scale data science
using Python [17_]. Zarr has recently been presented in several
venues, including a webinar for the ESIP Federation tech dive series
[18_], and a talk at the AGU Fall Meeting 2018 [19_].
References
~~~~~~~~~~
.. _1: https://zarr.readthedocs.io/en/stable/spec/v2.html
.. _2: https://github.com/zarr-developers/zarr-python
.. _3: https://github.com/zarr-developers/numcodecs
.. _4: https://www.hdfgroup.org/solutions/hdf5/
.. _5: https://pangeo.io/
.. _6: https://pangeo.io/catalog.html
.. _7: https://www.malariagen.net/
.. _8: http://alimanfoo.github.io/2016/09/21/genotype-compression-benchmark.html
.. _9: https://www.humancellatlas.org/
.. _10: https://github.com/constantinpape/z5
.. _11: https://github.com/lasersonlab/ndarray.scala
.. _12: https://github.com/meggart/ZarrNative.jl
.. _13: https://github.com/saalfeldlab/n5
.. _14: http://docs.dask.org/en/latest/array-creation.html
.. _15: http://xarray.pydata.org/en/stable/io.html
.. _16: https://github.com/ContinuumIO/intake-xarray
.. _17: http://matthewrocklin.com/blog/work/2018/01/22/pangeo-2
.. _18: http://wiki.esipfed.org/index.php/Interoperability_and_Technology/Tech_Dive_Webinar_Series#8_March.2C_2018:_.22Zarr:_A_simple.2C_open.2C_scalable_solution_for_big_NetCDF.2FHDF_data_on_the_Cloud.22:_Alistair_Miles.2C_University_of_Oxford.
.. _19: https://agu.confex.com/agu/fm18/meetingapp.cgi/Paper/390015
Authors
-------
Project contributors are listed in alphabetical order by surname.
* `Ryan Abernathey <https://github.com/rabernat>`_, Columbia University
* `Stephan Balmer <https://github.com/sbalmer>`_, Meteotest
* `Ambrose Carr <https://github.com/ambrosejcarr>`_, Chan Zuckerberg Initiative
* `Tim Crone <https://github.com/tjcrone>`_, Columbia University
* `Martin Durant <https://github.com/martindurant>`_, Anaconda, inc.
* `Jan Funke <https://github.com/funkey>`_, HHMI Janelia
* `Darren Gallagher <https://github.com/dazzag24>`_, Satavia
* `Fabian Gans <https://github.com/meggart>`_, Max Planck Institute for Biogeochemistry
* `Shikhar Goenka <https://github.com/shikharsg>`_, Satavia
* `Joe Hamman <https://github.com/jhamman>`_, NCAR
* `Stephan Hoyer <https://github.com/shoyer>`_, Google
* `Jerome Kelleher <https://github.com/jeromekelleher>`_, University of Oxford
* `John Kirkham <https://github.com/jakirkham>`_, HHMI Janelia
* `Alistair Miles <https://github.com/alimanfoo>`_, University of Oxford
* `Josh Moore <https://github.com/joshmoore>`_, University of Dundee
* `Charles Noyes <https://github.com/CSNoyes>`_, University of Southern California
* `Tarik Onalan <https://github.com/onalant>`_
* `Constantin Pape <https://github.com/constantinpape>`_, University of Heidelberg
* `Zain Patel <https://github.com/mzjp2>`_, University of Cambridge
* `Matthew Rocklin <https://github.com/mrocklin>`_, NVIDIA
* `Stephan Saafeld <https://github.com/axtimwalde>`_, HHMI Janelia
* `Vincent Schut <https://github.com/vincentschut>`_, Satelligence
* `Justin Swaney <https://github.com/jmswaney>`_, MIT
* `Ryan Williams <https://github.com/ryan-williams>`_, Chan Zuckerberg Initiative
| zarr | /zarr-2.15.0.tar.gz/zarr-2.15.0/docs/talks/scipy2019/submission.rst | submission.rst |
This notebook has some profiling of Dask used to make a selection along both first and second axes of a large-ish multidimensional array. The use case is making selections of genotype data, e.g., as required for making a web-browser for genotype data as in www.malariagen.net/apps/ag1000g.
```
import zarr; print('zarr', zarr.__version__)
import dask; print('dask', dask.__version__)
import dask.array as da
import numpy as np
```
## Real data
```
# here's the real data
callset = zarr.open_group('/kwiat/2/coluzzi/ag1000g/data/phase1/release/AR3.1/variation/main/zarr2/zstd/ag1000g.phase1.ar3',
mode='r')
callset
# here's the array we're going to work with
g = callset['3R/calldata/genotype']
g
# wrap as dask array with very simple chunking of first dim only
%time gd = da.from_array(g, chunks=(g.chunks[0], None, None))
gd
# load condition used to make selection on first axis
dim0_condition = callset['3R/variants/FILTER_PASS'][:]
dim0_condition.shape, dim0_condition.dtype, np.count_nonzero(dim0_condition)
# invent a random selection for second axis
dim1_indices = sorted(np.random.choice(765, size=100, replace=False))
# setup the 2D selection - this is the slow bit
%time gd_sel = gd[dim0_condition][:, dim1_indices]
gd_sel
# now load a slice from this new selection - quick!
%time gd_sel[1000000:1100000].compute(optimize_graph=False)
# what's taking so long?
import cProfile
cProfile.run('gd[dim0_condition][:, dim1_indices]', sort='time')
cProfile.run('gd[dim0_condition][:, dim1_indices]', sort='cumtime')
```
## Synthetic data
```
# create a synthetic dataset for profiling
a = zarr.array(np.random.randint(-1, 4, size=(20000000, 200, 2), dtype='i1'),
chunks=(10000, 100, 2), compressor=zarr.Blosc(cname='zstd', clevel=1, shuffle=2))
a
# create a synthetic selection for first axis
c = np.random.randint(0, 2, size=a.shape[0], dtype=bool)
# create a synthetic selection for second axis
s = sorted(np.random.choice(a.shape[1], size=100, replace=False))
%time d = da.from_array(a, chunks=(a.chunks[0], None, None))
d
%time ds = d[c][:, s]
cProfile.run('d[c][:, s]', sort='time')
%time ds[1000000:1100000].compute(optimize_graph=False)
# problem is in fact just the dim0 selection
cProfile.run('d[c]', sort='time')
```
| zarr | /zarr-2.15.0.tar.gz/zarr-2.15.0/notebooks/dask_2d_subset.ipynb | dask_2d_subset.ipynb |
```
import sys
sys.path.insert(0, '..')
import zarr
zarr.__version__
store = zarr.ZipStore('/data/coluzzi/ag1000g/data/phase1/release/AR3.1/haplotypes/main/zarr2/zstd/ag1000g.phase1.ar3.1.haplotypes.zip',
mode='r')
grp = zarr.Group(store)
z = grp['3L/calldata/genotype']
z
import cProfile
cProfile.run('z[:10]', sort='cumtime')
import dask
import dask.array as da
dask.__version__
d = da.from_array(z, chunks=z.chunks)
d
%time d.sum(axis=1).compute()
# compare with same data via directory store
store_dir = zarr.DirectoryStore('/data/coluzzi/ag1000g/data/phase1/release/AR3.1/haplotypes/main/zarr2/zstd/ag1000g.phase1.ar3.1.haplotypes')
grp_dir = zarr.Group(store_dir)
z_dir = grp_dir['3L/calldata/genotype']
z_dir
d_dir = da.from_array(z_dir, chunks=z_dir.chunks)
d_dir
%time d_dir.sum(axis=1).compute()
```
| zarr | /zarr-2.15.0.tar.gz/zarr-2.15.0/notebooks/zip_benchmark.ipynb | zip_benchmark.ipynb |
```
import zarr
zarr.__version__
g1 = zarr.group()
g2 = g1.create_group('foo')
g3 = g1.create_group('bar')
g3.create_group('baz')
g3.create_dataset('xxx', shape=100)
g3.create_dataset('yyy', shape=(100, 100), dtype='i4')
g5 = g3.create_group('quux')
g5.create_dataset('aaa', shape=100)
g5.create_dataset('bbb', shape=(100, 100), dtype='i4')
g7 = g3.create_group('zoo')
```
Generate text (unicode) tree:
```
print(g1.tree())
```
The ``level`` parameter controls how deep the tree is.
```
print(g1.tree(level=1))
print(g1.tree(level=2))
```
Alternative plain ASCII tree:
```
print(bytes(g1.tree()).decode())
```
HTML trees:
```
g1.tree()
```
Use ``expand=True`` to have all groups automatically expanded.
```
g1.tree(expand=True)
g1.tree(expand=True, level=2)
g1.tree(expand=True, level=1)
```
The ``expand`` parameter can also be an integer, giving the depth to expand to.
```
g1.tree(expand=1)
g1.tree(expand=2)
g1.tree(expand=3)
```
| zarr | /zarr-2.15.0.tar.gz/zarr-2.15.0/notebooks/repr_tree.ipynb | repr_tree.ipynb |
# Object arrays
See [#212](https://github.com/alimanfoo/zarr/pull/212) for more information.
```
import numpy as np
import zarr
zarr.__version__
import numcodecs
numcodecs.__version__
```
## API changes in Zarr version 2.2
Creation of an object array requires providing new ``object_codec`` argument:
```
z = zarr.empty(10, chunks=5, dtype=object, object_codec=numcodecs.MsgPack())
z
```
To maintain backwards compatibility with previously-created data, the object codec is treated as a filter and inserted as the first filter in the chain:
```
z.info
z[0] = 'foo'
z[1] = b'bar' # msgpack doesn't support bytes objects correctly
z[2] = 1
z[3] = [2, 4, 6, 'baz']
z[4] = {'a': 'b', 'c': 'd'}
a = z[:]
a
```
If no ``object_codec`` is provided, a ``ValueError`` is raised:
```
z = zarr.empty(10, chunks=5, dtype=object)
```
For API backward-compatibility, if object codec is provided via filters, issue a warning but don't raise an error.
```
z = zarr.empty(10, chunks=5, dtype=object, filters=[numcodecs.MsgPack()])
```
If a user tries to subvert the system and create an object array with no object codec, a runtime check is added to ensure no object arrays are passed down to the compressor (which could lead to nasty errors and/or segfaults):
```
z = zarr.empty(10, chunks=5, dtype=object, object_codec=numcodecs.MsgPack())
z._filters = None # try to live dangerously, manually wipe filters
z[0] = 'foo'
```
Here is another way to subvert the system, wiping filters **after** storing some data. To cover this case a runtime check is added to ensure no object arrays are handled inappropriately during decoding (which could lead to nasty errors and/or segfaults).
```
from numcodecs.tests.common import greetings
z = zarr.array(greetings, chunks=5, dtype=object, object_codec=numcodecs.MsgPack())
z[:]
z._filters = [] # try to live dangerously, manually wipe filters
z[:]
```
| zarr | /zarr-2.15.0.tar.gz/zarr-2.15.0/notebooks/object_arrays.ipynb | object_arrays.ipynb |
There are lies, damn lies and benchmarks...
## Setup
```
import zarr
zarr.__version__
import bsddb3
bsddb3.__version__
import lmdb
lmdb.__version__
import numpy as np
import dbm.gnu
import dbm.ndbm
import os
import shutil
bench_dir = '../data/bench'
def clean():
if os.path.isdir(bench_dir):
shutil.rmtree(bench_dir)
os.makedirs(bench_dir)
def setup(a, name='foo/bar'):
global fdict_z, hdict_z, lmdb_z, gdbm_z, ndbm_z, bdbm_btree_z, bdbm_hash_z, zip_z, dir_z
clean()
fdict_root = zarr.group(store=dict())
hdict_root = zarr.group(store=zarr.DictStore())
lmdb_root = zarr.group(store=zarr.LMDBStore(os.path.join(bench_dir, 'lmdb')))
gdbm_root = zarr.group(store=zarr.DBMStore(os.path.join(bench_dir, 'gdbm'), open=dbm.gnu.open))
ndbm_root = zarr.group(store=zarr.DBMStore(os.path.join(bench_dir, 'ndbm'), open=dbm.ndbm.open))
bdbm_btree_root = zarr.group(store=zarr.DBMStore(os.path.join(bench_dir, 'bdbm_btree'), open=bsddb3.btopen))
bdbm_hash_root = zarr.group(store=zarr.DBMStore(os.path.join(bench_dir, 'bdbm_hash'), open=bsddb3.hashopen))
zip_root = zarr.group(store=zarr.ZipStore(os.path.join(bench_dir, 'zip'), mode='w'))
dir_root = zarr.group(store=zarr.DirectoryStore(os.path.join(bench_dir, 'dir')))
fdict_z = fdict_root.empty_like(name, a)
hdict_z = hdict_root.empty_like(name, a)
lmdb_z = lmdb_root.empty_like(name, a)
gdbm_z = gdbm_root.empty_like(name, a)
ndbm_z = ndbm_root.empty_like(name, a)
bdbm_btree_z = bdbm_btree_root.empty_like(name, a)
bdbm_hash_z = bdbm_hash_root.empty_like(name, a)
zip_z = zip_root.empty_like(name, a)
dir_z = dir_root.empty_like(name, a)
# check compression ratio
fdict_z[:] = a
return fdict_z.info
```
## Main benchmarks
```
def save(a, z):
if isinstance(z.store, zarr.ZipStore):
# needed for zip benchmarks to avoid duplicate entries
z.store.clear()
z[:] = a
if hasattr(z.store, 'flush'):
z.store.flush()
def load(z, a):
z.get_basic_selection(out=a)
```
## arange
```
a = np.arange(500000000)
setup(a)
```
### save
```
%timeit save(a, fdict_z)
%timeit save(a, hdict_z)
%timeit save(a, lmdb_z)
%timeit save(a, gdbm_z)
%timeit save(a, ndbm_z)
%timeit save(a, bdbm_btree_z)
%timeit save(a, bdbm_hash_z)
%timeit save(a, zip_z)
%timeit save(a, dir_z)
```
### load
```
%timeit load(fdict_z, a)
%timeit load(hdict_z, a)
%timeit load(lmdb_z, a)
%timeit load(gdbm_z, a)
%timeit load(ndbm_z, a)
%timeit load(bdbm_btree_z, a)
%timeit load(bdbm_hash_z, a)
%timeit load(zip_z, a)
%timeit load(dir_z, a)
```
## randint
```
np.random.seed(42)
a = np.random.randint(0, 2**30, size=500000000)
setup(a)
```
### save
```
%timeit -r3 save(a, fdict_z)
%timeit -r3 save(a, hdict_z)
%timeit -r3 save(a, lmdb_z)
%timeit -r3 save(a, gdbm_z)
%timeit -r3 save(a, ndbm_z)
%timeit -r3 save(a, bdbm_btree_z)
%timeit -r3 save(a, bdbm_hash_z)
%timeit -r3 save(a, zip_z)
%timeit -r3 save(a, dir_z)
```
### load
```
%timeit -r3 load(fdict_z, a)
%timeit -r3 load(hdict_z, a)
%timeit -r3 load(lmdb_z, a)
%timeit -r3 load(gdbm_z, a)
%timeit -r3 load(ndbm_z, a)
%timeit -r3 load(bdbm_btree_z, a)
%timeit -r3 load(bdbm_hash_z, a)
%timeit -r3 load(zip_z, a)
%timeit -r3 load(dir_z, a)
```
### dask
```
import dask.array as da
def dask_op(source, sink, chunks=None):
if isinstance(sink.store, zarr.ZipStore):
sink.store.clear()
if chunks is None:
try:
chunks = sink.chunks
except AttributeError:
chunks = source.chunks
d = da.from_array(source, chunks=chunks, asarray=False, fancy=False, lock=False)
result = (d // 2) * 2
da.store(result, sink, lock=False)
if hasattr(sink.store, 'flush'):
sink.store.flush()
```
#### Compare sources
```
%time dask_op(fdict_z, fdict_z)
%time dask_op(hdict_z, fdict_z)
%time dask_op(lmdb_z, fdict_z)
%time dask_op(gdbm_z, fdict_z)
%time dask_op(ndbm_z, fdict_z)
%time dask_op(bdbm_btree_z, fdict_z)
%time dask_op(bdbm_hash_z, fdict_z)
%time dask_op(zip_z, fdict_z)
%time dask_op(dir_z, fdict_z)
```
#### Compare sinks
```
%time dask_op(fdict_z, hdict_z)
%time dask_op(fdict_z, lmdb_z)
%time dask_op(fdict_z, gdbm_z)
%time dask_op(fdict_z, ndbm_z)
%time dask_op(fdict_z, bdbm_btree_z)
%time dask_op(fdict_z, bdbm_hash_z)
%time dask_op(fdict_z, zip_z)
%time dask_op(fdict_z, dir_z)
lmdb_z.store.close()
gdbm_z.store.close()
ndbm_z.store.close()
bdbm_btree_z.store.close()
bdbm_hash_z.store.close()
zip_z.store.close()
```
| zarr | /zarr-2.15.0.tar.gz/zarr-2.15.0/notebooks/store_benchmark.ipynb | store_benchmark.ipynb |
```
import numpy as np
import zarr
zarr.__version__
z = zarr.empty(shape=100000000, chunks=200000, dtype='i8')
data = np.arange(100000000, dtype='i8')
%timeit z[:] = data
%timeit z[:]
print(z)
assert np.all(z[:] == data)
z = zarr.empty(shape=100000000, chunks=200000, dtype='f8')
data = np.random.normal(size=100000000)
%timeit z[:] = data
%timeit z[:]
print(z)
assert np.all(z[:] == data)
import numpy as np
import sys
sys.path.insert(0, '..')
import zarr
zarr.__version__
z = zarr.empty(shape=100000000, chunks=200000, dtype='i8')
data = np.arange(100000000, dtype='i8')
%timeit z[:] = data
%timeit z[:]
print(z)
assert np.all(z[:] == data)
z = zarr.empty(shape=100000000, chunks=200000, dtype='f8')
data = np.random.normal(size=100000000)
%timeit z[:] = data
%timeit z[:]
print(z)
assert np.all(z[:] == data)
```
| zarr | /zarr-2.15.0.tar.gz/zarr-2.15.0/notebooks/blosc_microbench.ipynb | blosc_microbench.ipynb |
# Advanced indexing
```
import sys
sys.path.insert(0, '..')
import zarr
import numpy as np
np.random.seed(42)
import cProfile
zarr.__version__
```
## Functionality and API
### Indexing a 1D array with a Boolean (mask) array
Supported via ``get/set_mask_selection()`` and ``.vindex[]``. Also supported via ``get/set_orthogonal_selection()`` and ``.oindex[]``.
```
a = np.arange(10)
za = zarr.array(a, chunks=2)
ix = [False, True, False, True, False, True, False, True, False, True]
# get items
za.vindex[ix]
# get items
za.oindex[ix]
# set items
za.vindex[ix] = a[ix] * 10
za[:]
# set items
za.oindex[ix] = a[ix] * 100
za[:]
# if using .oindex, indexing array can be any array-like, e.g., Zarr array
zix = zarr.array(ix, chunks=2)
za = zarr.array(a, chunks=2)
za.oindex[zix] # will not load all zix into memory
```
### Indexing a 1D array with a 1D integer (coordinate) array
Supported via ``get/set_coordinate_selection()`` and ``.vindex[]``. Also supported via ``get/set_orthogonal_selection()`` and ``.oindex[]``.
```
a = np.arange(10)
za = zarr.array(a, chunks=2)
ix = [1, 3, 5, 7, 9]
# get items
za.vindex[ix]
# get items
za.oindex[ix]
# set items
za.vindex[ix] = a[ix] * 10
za[:]
# set items
za.oindex[ix] = a[ix] * 100
za[:]
```
### Indexing a 1D array with a multi-dimensional integer (coordinate) array
Supported via ``get/set_coordinate_selection()`` and ``.vindex[]``.
```
a = np.arange(10)
za = zarr.array(a, chunks=2)
ix = np.array([[1, 3, 5], [2, 4, 6]])
# get items
za.vindex[ix]
# set items
za.vindex[ix] = a[ix] * 10
za[:]
```
### Slicing a 1D array with step > 1
Slices with step > 1 are supported via ``get/set_basic_selection()``, ``get/set_orthogonal_selection()``, ``__getitem__`` and ``.oindex[]``. Negative steps are not supported.
```
a = np.arange(10)
za = zarr.array(a, chunks=2)
# get items
za[1::2]
# set items
za.oindex[1::2] = a[1::2] * 10
za[:]
```
### Orthogonal (outer) indexing of multi-dimensional arrays
Orthogonal (a.k.a. outer) indexing is supported with either Boolean or integer arrays, in combination with integers and slices. This functionality is provided via the ``get/set_orthogonal_selection()`` methods. For convenience, this functionality is also available via the ``.oindex[]`` property.
```
a = np.arange(15).reshape(5, 3)
za = zarr.array(a, chunks=(3, 2))
za[:]
# orthogonal indexing with Boolean arrays
ix0 = [False, True, False, True, False]
ix1 = [True, False, True]
za.get_orthogonal_selection((ix0, ix1))
# alternative API
za.oindex[ix0, ix1]
# orthogonal indexing with integer arrays
ix0 = [1, 3]
ix1 = [0, 2]
za.get_orthogonal_selection((ix0, ix1))
# alternative API
za.oindex[ix0, ix1]
# combine with slice
za.oindex[[1, 3], :]
# combine with slice
za.oindex[:, [0, 2]]
# set items via Boolean selection
ix0 = [False, True, False, True, False]
ix1 = [True, False, True]
selection = ix0, ix1
value = 42
za.set_orthogonal_selection(selection, value)
za[:]
# alternative API
za.oindex[ix0, ix1] = 44
za[:]
# set items via integer selection
ix0 = [1, 3]
ix1 = [0, 2]
selection = ix0, ix1
value = 46
za.set_orthogonal_selection(selection, value)
za[:]
# alternative API
za.oindex[ix0, ix1] = 48
za[:]
```
### Coordinate indexing of multi-dimensional arrays
Selecting arbitrary points from a multi-dimensional array by indexing with integer (coordinate) arrays is supported. This functionality is provided via the ``get/set_coordinate_selection()`` methods. For convenience, this functionality is also available via the ``.vindex[]`` property.
```
a = np.arange(15).reshape(5, 3)
za = zarr.array(a, chunks=(3, 2))
za[:]
# get items
ix0 = [1, 3]
ix1 = [0, 2]
za.get_coordinate_selection((ix0, ix1))
# alternative API
za.vindex[ix0, ix1]
# set items
za.set_coordinate_selection((ix0, ix1), 42)
za[:]
# alternative API
za.vindex[ix0, ix1] = 44
za[:]
```
### Mask indexing of multi-dimensional arrays
Selecting arbitrary points from a multi-dimensional array by a Boolean array is supported. This functionality is provided via the ``get/set_mask_selection()`` methods. For convenience, this functionality is also available via the ``.vindex[]`` property.
```
a = np.arange(15).reshape(5, 3)
za = zarr.array(a, chunks=(3, 2))
za[:]
ix = np.zeros_like(a, dtype=bool)
ix[1, 0] = True
ix[3, 2] = True
za.get_mask_selection(ix)
za.vindex[ix]
za.set_mask_selection(ix, 42)
za[:]
za.vindex[ix] = 44
za[:]
```
### Selecting fields from arrays with a structured dtype
All ``get/set_selection_...()`` methods support a ``fields`` argument which allows retrieving/replacing data for a specific field or fields. Also h5py-like API is supported where fields can be provided within ``__getitem__``, ``.oindex[]`` and ``.vindex[]``.
```
a = np.array([(b'aaa', 1, 4.2),
(b'bbb', 2, 8.4),
(b'ccc', 3, 12.6)],
dtype=[('foo', 'S3'), ('bar', 'i4'), ('baz', 'f8')])
za = zarr.array(a, chunks=2, fill_value=None)
za[:]
za['foo']
za['foo', 'baz']
za[:2, 'foo']
za[:2, 'foo', 'baz']
za.oindex[[0, 2], 'foo']
za.vindex[[0, 2], 'foo']
za['bar'] = 42
za[:]
za[:2, 'bar'] = 84
za[:]
```
Note that this API differs from numpy when selecting multiple fields. E.g.:
```
a['foo', 'baz']
a[['foo', 'baz']]
za['foo', 'baz']
za[['foo', 'baz']]
```
## 1D Benchmarking
```
c = np.arange(100000000)
c.nbytes
%time zc = zarr.array(c)
zc.info
%timeit c.copy()
%timeit zc[:]
```
### bool dense selection
```
# relatively dense selection - 10%
ix_dense_bool = np.random.binomial(1, 0.1, size=c.shape[0]).astype(bool)
np.count_nonzero(ix_dense_bool)
%timeit c[ix_dense_bool]
%timeit zc.oindex[ix_dense_bool]
%timeit zc.vindex[ix_dense_bool]
import tempfile
import cProfile
import pstats
def profile(statement, sort='time', restrictions=(7,)):
with tempfile.NamedTemporaryFile() as f:
cProfile.run(statement, filename=f.name)
pstats.Stats(f.name).sort_stats(sort).print_stats(*restrictions)
profile('zc.oindex[ix_dense_bool]')
```
Method ``nonzero`` is being called internally within numpy to convert bool to int selections, no way to avoid.
```
profile('zc.vindex[ix_dense_bool]')
```
``.vindex[]`` is a bit slower, possibly because internally it converts to a coordinate array first.
### int dense selection
```
ix_dense_int = np.random.choice(c.shape[0], size=c.shape[0]//10, replace=True)
ix_dense_int_sorted = ix_dense_int.copy()
ix_dense_int_sorted.sort()
len(ix_dense_int)
%timeit c[ix_dense_int_sorted]
%timeit zc.oindex[ix_dense_int_sorted]
%timeit zc.vindex[ix_dense_int_sorted]
%timeit c[ix_dense_int]
%timeit zc.oindex[ix_dense_int]
%timeit zc.vindex[ix_dense_int]
profile('zc.oindex[ix_dense_int_sorted]')
profile('zc.vindex[ix_dense_int_sorted]')
profile('zc.oindex[ix_dense_int]')
profile('zc.vindex[ix_dense_int]')
```
When indices are not sorted, zarr needs to partially sort them so the occur in chunk order, so we only have to visit each chunk once. This sorting dominates the processing time and is unavoidable AFAIK.
### bool sparse selection
```
# relatively sparse selection
ix_sparse_bool = np.random.binomial(1, 0.0001, size=c.shape[0]).astype(bool)
np.count_nonzero(ix_sparse_bool)
%timeit c[ix_sparse_bool]
%timeit zc.oindex[ix_sparse_bool]
%timeit zc.vindex[ix_sparse_bool]
profile('zc.oindex[ix_sparse_bool]')
profile('zc.vindex[ix_sparse_bool]')
```
### int sparse selection
```
ix_sparse_int = np.random.choice(c.shape[0], size=c.shape[0]//10000, replace=True)
ix_sparse_int_sorted = ix_sparse_int.copy()
ix_sparse_int_sorted.sort()
len(ix_sparse_int)
%timeit c[ix_sparse_int_sorted]
%timeit c[ix_sparse_int]
%timeit zc.oindex[ix_sparse_int_sorted]
%timeit zc.vindex[ix_sparse_int_sorted]
%timeit zc.oindex[ix_sparse_int]
%timeit zc.vindex[ix_sparse_int]
profile('zc.oindex[ix_sparse_int]')
profile('zc.vindex[ix_sparse_int]')
```
For sparse selections, processing time is dominated by decompression, so we can't do any better.
### sparse bool selection as zarr array
```
zix_sparse_bool = zarr.array(ix_sparse_bool)
zix_sparse_bool.info
%timeit zc.oindex[zix_sparse_bool]
```
### slice with step
```
%timeit np.array(c[::2])
%timeit zc[::2]
%timeit zc[::10]
%timeit zc[::100]
%timeit zc[::1000]
profile('zc[::2]')
```
## 2D Benchmarking
```
c.shape
d = c.reshape(-1, 1000)
d.shape
zd = zarr.array(d)
zd.info
```
### bool orthogonal selection
```
ix0 = np.random.binomial(1, 0.5, size=d.shape[0]).astype(bool)
ix1 = np.random.binomial(1, 0.5, size=d.shape[1]).astype(bool)
%timeit d[np.ix_(ix0, ix1)]
%timeit zd.oindex[ix0, ix1]
```
### int orthogonal selection
```
ix0 = np.random.choice(d.shape[0], size=int(d.shape[0] * .5), replace=True)
ix1 = np.random.choice(d.shape[1], size=int(d.shape[1] * .5), replace=True)
%timeit d[np.ix_(ix0, ix1)]
%timeit zd.oindex[ix0, ix1]
```
### coordinate (point) selection
```
n = int(d.size * .1)
ix0 = np.random.choice(d.shape[0], size=n, replace=True)
ix1 = np.random.choice(d.shape[1], size=n, replace=True)
n
%timeit d[ix0, ix1]
%timeit zd.vindex[ix0, ix1]
profile('zd.vindex[ix0, ix1]')
```
Points need to be partially sorted so all points in the same chunk are grouped and processed together. This requires ``argsort`` which dominates time.
## h5py comparison
N.B., not really fair because using slower compressor, but for interest...
```
import h5py
import tempfile
h5f = h5py.File(tempfile.mktemp(), driver='core', backing_store=False)
hc = h5f.create_dataset('c', data=c, compression='gzip', compression_opts=1, chunks=zc.chunks, shuffle=True)
hc
%time hc[:]
%time hc[ix_sparse_bool]
# # this is pathological, takes minutes
# %time hc[ix_dense_bool]
# this is pretty slow
%time hc[::1000]
```
| zarr | /zarr-2.15.0.tar.gz/zarr-2.15.0/notebooks/advanced_indexing.ipynb | advanced_indexing.ipynb |
# Zarrita
Zarrita is an experimental implementation of [Zarr v3](https://zarr-specs.readthedocs.io/en/latest/v3/core/v3.0.html) including [sharding](https://zarr.dev/zeps/draft/ZEP0002.html). This is only a technical proof of concept meant for generating sample datasets. Not recommended for production use.
## Setup
```python
import zarrita
import numpy as np
store = zarrita.LocalStore('testdata') # or zarrita.RemoteStore('s3://bucket/test')
```
## Create an array
```python
a = await zarrita.Array.create_async(
store / 'array',
shape=(6, 10),
dtype='int32',
chunk_shape=(2, 5),
codecs=[zarrita.codecs.blosc_codec()],
attributes={'question': 'life', 'answer': 42}
)
await a.async_[:, :].set(np.ones((6, 10), dtype='int32'))
```
## Open an array
```python
a = await zarrita.Array.open_async(store / 'array')
assert np.array_equal(await a.async_[:, :].get(), np.ones((6, 10), dtype='int32'))
```
## Create an array with sharding
```python
a = await zarrita.Array.create_async(
store / 'sharding',
shape=(16, 16),
dtype='int32',
chunk_shape=(16, 16),
chunk_key_encoding=('v2', '.'),
codecs=[
zarrita.codecs.sharding_codec(
chunk_shape=(8, 8),
codecs=[zarrita.codecs.blosc_codec()]
),
],
)
data = np.arange(0, 16 * 16, dtype='int32').reshape((16, 16))
await a.async_[:, :].set(data)
assert np.array_equal(await a.async_[:, :].get(), data)
```
## Create a group
```python
g = await zarrita.Group.create_async(store / 'group')
g2 = await g.create_group_async('group2')
a = await g2.create_array_async(
'array',
shape=(16, 16),
dtype='int32',
chunk_shape=(16, 16),
)
await a.async_[:, :].set(np.arange(0, 16 * 16, dtype='int32').reshape((16, 16)))
```
## Open a group
```python
g = await zarrita.Group.open_async(store / 'group')
g2 = g['group2']
a = g['group2']['array']
assert np.array_equal(await a.asnyc_[:, :].get(), np.arange(0, 16 * 16, dtype='int32').reshape((16, 16)))
```
# Credits
This is a largely-rewritten fork of `zarrita` by [@alimanfoo](https://github.com/alimanfoo). It implements the Zarr v3 draft specification created by [@alimanfoo](https://github.com/alimanfoo), [@jstriebel](https://github.com/jstriebel), [@jbms](https://github.com/jbms) et al.
Licensed under MIT
| zarrita | /zarrita-0.1.0a9.tar.gz/zarrita-0.1.0a9/README.md | README.md |
# zarr-view
PySide or PyQt tree model-view for a Zarr hierarchy
- [Install](#install)
- [Quick start example](#quick-start-example)
- [Path slice](#path-slice)
- [Path slice for N-D arrays of nested ordered groups](#path-slice-for-n-d-arrays-of-nested-ordered-groups)
- [Performance](#performance)
# Install
1. Install either `"PySide6>=6.5.2"`, `"PyQt6>=6.5.2"`, or `PyQt5`. :warning: The Qt6 version requirements are due to a [Qt6.5.1 bug](https://bugreports.qt.io/browse/QTBUG-115136) that causes the tree view to crash on macOS arm64 chipset. If you are using a different OS, then this bug may not apply to you and you may be able to ignore these version requirements. For example:
```
pip install "PySide6>=6.5.2"
```
2. Install `zarrview`:
```
pip install zarrview
```
# Quick start example
The following code is from [quick_start_example.py](/quick_start_example.py):
```python
# Replace PySide6 with PyQt6 or PyQt5 depending on what Qt package you installed.
from PySide6.QtWidgets import QApplication
import sys
import zarr
from zarrview.ZarrViewer import ZarrViewer
# example zarr hierarchy (in-memory vs on-disk should not matter)
root = zarr.group()
foo = root.create_group('foo')
bar = foo.create_dataset('bar', shape=100, chunks=10)
baz = foo.create_group('baz')
quux = baz.create_dataset('quux', shape=200, chunks=20)
# attributes for quux
quux.attrs['a_int'] = 82
quux.attrs['a_float'] = 3.14
quux.attrs['a_bool'] = False
quux.attrs['a_str'] = 'zarr-view is awesome!'
quux.attrs['a_dict'] = {'a_child': 42}
quux.attrs['a_list'] = [8, 4.5, True, 'hello']
# create app
app = QApplication(sys.argv)
# init zarr viewer widget with root of hierarchy
viewer = ZarrViewer(root)
# Here the viewer is shown in its own window.
# However, it can also be inserted int a Qt app just like any QWidget.
viewer.show()
viewer.setWindowTitle('ZarrViewer')
# run app
sys.exit(app.exec())
```
The viewer displays a tree view of the Zaar hierarchy groups and arrays along with a representation of each arrays size and data type.
Selecting a group or array in the tree view of the Zarr hierarchy displays the info for the selected object below the tree:
<img src='images/quick-start-example-info.png' width=400>
The selected object's attributes can also be viewed and edited in their own tree view below the main hierarchy view:
<img src='images/quick-start-example-attrs.png' width=400>
You can insert new attributes or delete attributes via the viewer:
<img src='images/quick-start-example-insert-attr.png' width=400>
Toolbar buttons allow quickly collapsing or expanding the tree to any level:
<img src='images/quick-start-example-collapse-all.png' width=400>
<img src='images/quick-start-example-expand-all.png' width=400>
<img src='images/quick-start-example-expand-1.png' width=400>
You can insert new groups or delete groups or arrays via the viewer:
<img src='images/quick-start-example-insert-group.png' width=400>
You can rename all groups, arrays, and attrs:
<img src='images/quick-start-example-rename.png' width=400>
You can drag and drop groups or arrays to restructure the hierarchy:
<img src='images/quick-start-example-drag.png' width=400>
<img src='images/quick-start-example-drop.png' width=400>
You can specify a specific path or path slice to view only a subset of the hierarchy (see the sections on [path slice](#path-slice) and [path slice for N-D arrays of nested ordered groups](#path-slice-for-n-d-arrays-of-nested-ordered-groups)):
<img src='images/quick-start-example-path.png' width=400>
You can dynamically reset the displayed hierarchy:
```python
viewer.setTree(new_root)
```
# Path slice
It can be useful to view only a subset of a large hierarchy. This can be done in the `ZarrViewer` widget by specifying a path or path slice to view.
All functions for Zarr hierarchy path slices are in `zarr_path_utils.py` which is independent of the Qt model-view classes in `ZarrViewer.py`. Thus, these path utilities may be useful outside of the Qt tree model-view interface. The paths in a slice are found by regex matching paths in the hierarchy.
Consider the following Zarr hierarchy where branches are groups and leaves are either groups or arrays:
```
/
├── foo
│ ├── bar
│ │ ├── baz
│ │ └── quux
│ ├── foo
│ │ ├── bar
│ │ └── baz
│ │ └── quux
│ └── baz
│ ├── quux
│ └── foo
│ └── bar
│ └── baz
│ └── quux
└── bar
├── baz
└── quux
```
The following are examples of specifying a subset of the above hierarchy using a path slice:
`"foo/bar"`:
```
/
└── foo
└── bar
```
`"*/baz"`:
```
/
├── foo
│ └── baz
└── bar
└── baz
```
`"foo/*/baz"`:
```
/
└── foo
├── bar
│ └── baz
└── foo
└── baz
```
`"foo/.../baz"`:
```
/
└── foo
├── bar
│ └── baz
├── foo
│ └── baz
└── baz
└── foo
└── bar
└── baz
```
`".../bar"`:
```
/
├── foo
│ ├── bar
│ ├── foo
│ │ └── bar
│ └── baz
│ └── foo
│ └── bar
└── bar
```
`".../foo/bar/..."`:
```
/
└── foo
├── bar
│ ├── baz
│ └── quux
├── foo
│ └── bar
└── baz
└── foo
└── bar
└── baz
└── quux
```
`".../baz/quux"`:
```
/
└── foo
├── foo
│ └── baz
│ └── quux
└── baz
└── foo
└── bar
└── baz
└── quux
```
Note that the path slice functions actually return only the Zarr objects at the matched paths:
```
".../baz/quux" -> ["foo/foo/baz/quux", "foo/baz/foo/bar/baz/quux"]
```
However, the subtree containing the matched paths as indicated above is easily reconstructed in the viewer.
# Path slice for N-D arrays of nested ordered groups
Consider an example dataset for EEG recordings across 100 trials and 64 probes where each recorded waveform is a time series with 2000 samples. Furthermore, the dataset includes the (x,y,z) location of each probe and the reward probability on each trial. This dataset could be stored as a 3-D array for the EEG waveforms across trials and probes, a 2-D array for the probe (x,y,z) locations, and a 1-D array for the trial reward probabilities:
```
/
eeg_waveforms (100, 64, 2000) float
probe_locations (64, 3) float
trial_reward_probas (100,) float
```
where sample frequency and units are left to metadata.
Alternatively, the dataset could be stored as a nested hierarchy of groups for each trial and probe with leaf 1-D arrays for each individual EEG waveform:
```
/
trial.i/
probe.j/
eeg_waveform (2000,) float
```
where `i` is in 0-99 and `j` is in 0-63 such that the ordering of the trials and probes is contained in the group paths (e.g., `trial.3/probe.42/`). The probe location and trial reward probability are simply stored as attributes of their respective groups.
Why might you want to store your data in such a tree hierarchy rather than a series of N-D arrays?
- **Associated data:** It is trivial to append entire trees of associated data to individual trials or probes within a trial. In contrast, for the 3-D array example you would need to store additional indices along with any associated data to indicate which trials/probes the data belonged with. Although such indices are trivial to provide, they complicate deciphering and maintaining the dataset, and require some metadata conventions to be universally understood. In contrast, the relationships in the tree format are obvious even to a naive program that does not understand the concept of a trial or a probe. For example, consider adding a note to a specific trial indicating that the subject was distracted by something during that trial.
- **Restructure or copy a subset of the data:** It is trivial to simply move, delete, or copy entire subtrees including both primary and the relevant associated data. In contrast, for the 3-D array example you would need to ensure that all associated data arrays were similarly manipulated to reflect the changed or copied subset of the primary data array, which is difficult to automate without strict universal conventions. Note that [Xarray](https://xarray.dev) conventions may suffice for cases where labeled dimensions are sufficient to find matching slices in all arrays in the dataset.
- **Flexibility:** The tree format is more flexible than the array format in that arbitrary associated data can be added at any level and that it is straightforward to represent ragged arrays in the tree.
:bangbang: **If you do decide to go the route of the tree format, one thing you certainly don't want to give up is the ability to slice your dataset as is trivially done for the 3-D array** (e.g., `eeg_waveforms[82,20:22]`).
`zarr_path_utils.py` provides functions for similarly slicing a path hierarchy of nested ordered groups such as `trial.i/probe.j/` using [NumPy](https://numpy.org) slice syntax. The following are examples of such path slices for the EEG dataset above.
`"trial[82]/probe[20:22]/..."`:
```
/
trial.82/
probe.20/
eeg_waveform (2000,) float
probe.21/
eeg_waveform (2000,) float
```
`"trial[:2]/probe[62:]/..."`:
```
/
trial.0/
probe.62/
eeg_waveform (2000,) float
probe.63/
eeg_waveform (2000,) float
trial.1/
probe.62/
eeg_waveform (2000,) float
probe.63/
eeg_waveform (2000,) float
```
`"trial[9]/probe[[1,5]]/..."`:
```
/
trial.9/
probe.1/
eeg_waveform (2000,) float
probe.5/
eeg_waveform (2000,) float
```
`"trial[80:90:2]"`:
```
/
trial.80/
trial.82/
trial.84/
trial.86/
trial.88/
```
You can try these examples out in [eeg_example.py](/eeg_example.py):
<img src='images/eeg-example.png' width=400>
# Performance
The current implementation of the viewer is slow when displaying a large hierarchy with many nodes (e.g., see [eeg_example.py](/eeg_example.py) which has 12,900 rows in the fully expanded tree). You can restrict the view using path slices, which can be enormously helpful in reducing the size of the displayed hierarchy and speeding up the responsiveness of the viewer. Nonetheless, any help in making the viewer more performant would be much appreciated.
| zarrview | /zarrview-0.1.2.tar.gz/zarrview-0.1.2/README.md | README.md |
from datetime import datetime
from decimal import Decimal
from typing import Optional
import requests
class Client:
ISO_8601_DATE_FORMAT = '%Y-%m-%dT%H:%M:%S.%fZ'
def __init__(self, host: str):
self.host = host
def get(self):
return requests.get(f"{self.host}").json()
# leads
def get_lead_by_id(self, lead_id: str):
return requests.get(f"{self.host}/v1/leads/{lead_id}").json()
def find_leads(self, limit: int = 100, skip: int = 0):
return requests.get(f"{self.host}/v1/leads", {'limit': limit, 'skip': skip}).json()
# accounts
def get_account_by_id(self, account_id: str):
return requests.get(f"{self.host}/v1/accounts/{account_id}").json()
def find_accounts(self, limit: int = 100, skip: int = 0):
return requests.get(f"{self.host}/v1/accounts", {'limit': limit, 'skip': skip}).json()
# deposits
def create_deposits(self, account_id: str, amount: Decimal, currency: str, crypto_transaction_reference: str, created: Optional[datetime] = None):
amount = str(amount)
created = None if created is None else created.strftime(Client.ISO_8601_DATE_FORMAT)
return requests.post(f"{self.host}/v1/deposits", json={'accountId': account_id, 'amount': amount, 'currency': currency, 'cryptoTransactionReference': crypto_transaction_reference, 'created': created})
def get_deposit_by_id(self, deposit_id: str):
return requests.get(f"{self.host}/v1/deposits/{deposit_id}").json()
def find_deposits_by_range(self, begin: datetime, end: datetime, limit: int = 100, skip: int = 0):
begin = begin.strftime(Client.ISO_8601_DATE_FORMAT)
end = end.strftime(Client.ISO_8601_DATE_FORMAT)
return requests.get(f"{self.host}/v1/deposits/range", {'begin': begin, 'end': end, 'limit': limit, 'skip': skip}).json()
def find_deposits_by_account_id(self, account_id: str, limit: int = 100, skip: int = 0):
return requests.get(f"{self.host}/v1/deposits/account/{account_id}", {'limit': limit, 'skip': skip}).json()
def find_deposits_by_account_id_and_currency(self, account_id: str, currency: str, limit: int = 100, skip: int = 0):
return requests.get(f"{self.host}/v1/deposits/account/{account_id}/currency/{currency}", {'limit': limit, 'skip': skip}).json()
# withdraws
def create_withdraws(self, account_id: str, amount: Decimal, currency: str, address: str, created: Optional[datetime] = None):
amount = str(amount)
created = None if created is None else created.strftime(Client.ISO_8601_DATE_FORMAT)
return requests.post(f"{self.host}/v1/withdraws", json={'accountId': account_id, 'amount': amount, 'currency': currency, 'address': address, 'created': created})
def get_withdraw_by_id(self, withdraw_id: str):
return requests.get(f"{self.host}/v1/withdraws/{withdraw_id}").json()
def find_withdraws_by_range(self, begin: datetime, end: datetime, limit: int = 100, skip: int = 0):
begin = begin.strftime(Client.ISO_8601_DATE_FORMAT)
end = end.strftime(Client.ISO_8601_DATE_FORMAT)
return requests.get(f"{self.host}/v1/withdraws/range", {'begin': begin, 'end': end, 'limit': limit, 'skip': skip}).json()
def find_withdraws_by_account_id(self, account_id: str, limit: int = 100, skip: int = 0):
return requests.get(f"{self.host}/v1/withdraws/account/{account_id}", {'limit': limit, 'skip': skip}).json()
def find_withdraws_by_account_id_and_currency(self, account_id: str, currency: str, limit: int = 100, skip: int = 0):
return requests.get(f"{self.host}/v1/withdraws/account/{account_id}/currency/{currency}", {'limit': limit, 'skip': skip}).json()
# interests
def create_interests(self, account_id: str, amount: Decimal, currency: str, trading_trade_reference: str, created: Optional[datetime] = None):
amount = str(amount)
created = None if created is None else created.strftime(Client.ISO_8601_DATE_FORMAT)
return requests.post(f"{self.host}/v1/interests", json={'accountId': account_id, 'amount': amount, 'currency': currency, 'tradingTradeReference': trading_trade_reference, 'created': created})
def find_interests_by_range(self, begin: datetime, end: datetime, limit: int = 100, skip: int = 0):
begin = begin.strftime(Client.ISO_8601_DATE_FORMAT)
end = end.strftime(Client.ISO_8601_DATE_FORMAT)
return requests.get(f"{self.host}/v1/interests/range", {'begin': begin, 'end': end, 'limit': limit, 'skip': skip}).json()
def get_interest_by_id(self, interest_id: str):
return requests.get(f"{self.host}/v1/interests/{interest_id}").json()
def find_interests_by_account_id(self, account_id: str, limit: int = 100, skip: int = 0):
return requests.get(f"{self.host}/v1/interests/account/{account_id}", {'limit': limit, 'skip': skip}).json()
def find_interests_by_account_id_and_currency(self, account_id: str, currency: str, limit: int = 100, skip: int = 0):
return requests.get(f"{self.host}/v1/interests/account/{account_id}/currency/{currency}", {'limit': limit, 'skip': skip}).json()
# wallets
def get_wallet_by_id(self, wallet_id: str):
return requests.get(f"{self.host}/v1/wallets/{wallet_id}").json()
def get_wallet_by_account_id_and_currency(self, account_id: str, currency: str, limit: int = 100, skip: int = 0):
return requests.get(f"{self.host}/v1/wallets/account/{account_id}/currency/{currency}", {'limit': limit, 'skip': skip}).json()
def find_wallets(self, limit: int = 100, skip: int = 0):
return requests.get(f"{self.host}/v1/wallets", {'limit': limit, 'skip': skip}).json()
def find_wallets_by_account_id(self, account_id: str, limit: int = 100, skip: int = 0):
return requests.get(f"{self.host}/v1/wallets/account/{account_id}", {'limit': limit, 'skip': skip}).json() | zaruti-account | /zaruti_account-1.0.3-py3-none-any.whl/zaruti/account.py | account.py |
# ZAS-REP-TOOLS
Current Tool was developed in the frame of the linguistics Study/Project *"The Pragmatic Status of Iconic Meaning in Spoken Communication: Gestures, Ideophones, Prosodic Modulations* ([PSIMS](http://www.zas.gwz-berlin.de/psims.html)) as the Bachelor Thesis.
___
* **Project Members:**
- [Susanne Fuchs](mailto:[email protected])
- [Aleksandra Ćwiek](mailto:[email protected])
- [Egor Savin](mailto:[email protected])
- [Cornelia Ebert](mailto:[email protected])
- [Manfred Krifka](mailto:[email protected])
* **Bachelor Thesis Appraisers:**
- [Ulf Leser](mailto:[email protected])
- [Susanne Fuchs](mailto:[email protected])
* **Tool-Developer:**
- [Egor Savin](mailto:[email protected])
---
**ZAS-REP-TOOLS** is a bundle of Tools for automatic extraction and quantification of the repetitions from the unstructured textual Data Collections for different languages with additional Search Engine wrapped around extracted data + on-board supplied Twitter Streamer to collect real-time tweets.
<sub> (This ReadMe still to be in the developing process and still has grammatical errors. Please ignore them=) But if you have any suggestions of improvement please contact [Egor Savin](mailto:[email protected]) ) </sub>
---
**<span style="color:red;">For a quick-start,</span>** first [download and install all dependencies](#dependencies) , then [install the tool](#settingup) and afterwards go to the [Workflow](#workflow) and [Tutorials](#tutorials) section to begin.
___
<br/>
<br/>
<a name="toc"/>
## Table of Contents
1. [Hardware Requirements](#requirements)
2. [Dependencies Installation](#dependencies)
- On Linux
- On Windows
- On MacOS
3. [Setting up](#settingup)
4. [Definitions](#definitions)
- Repetition
- Full Repetitiveness
5. [Functionality](#functionality)
- [CLI-Commands](#cli-commands)
- [CLI-Options](#cli-options)
- [CLI-Usage](#cli-usage)
- [Multiprocessing](#multiprocessing)
- [NLP-Methods](#nlp-methods)
- [InternDataBase-Structure](#db)
- [Additional Features](#additional_features)
- Formatters
- Templates
6. [WorkFlow](#workflow)
7. [Tutorials](#tutorials)
- Python Package Tutorial
- Command line Tutorial
8. [Input/Output](#input/output)
- File Formats
- Columns Explanation in the Output Tables
9. [Restrictions](#restrictions)
10. [Citing ZAS-REP-TOOLS](#citing)
11. [Possible errors and warnings](#errors)
12. [Data-Examples](#data)
13. [Acknowledgements](#acknowledgements)
<br/>
---
---
---
---
<br/>
<a name="requirements"/>
<p style='text-align: right;'> <sub> <a href="#toc">Back to top</a>
</sub> </p>
## 1. Hardware Requirements
|| Minimum: | Average: |
|:--------------: |:----------------: | :----------------: |
| CPU | 2 Core 2 GHz | 4 Core 2.6 GHz |
| RAM | 8 GB | 16 GB |
<br/>
---
---
---
---
<br/>
<a name="dependencies"/>
<p style='text-align: right;'> <sub> <a href="#toc">Back to top</a>
</sub> </p>
## 2. Dependencies
In order to use ZAS-REP-TOOLS you'll need the following installed Dependencies in addition to the source code provided here:
* [Python (both Versions: 2.7 + 3.5 or later)](https://www.python.org/download/releases/2.7.6>)
* [JAVA JDC](https://www.oracle.com/technetwork/java/javase/downloads/java-archive-downloads-javase6-419409.html)
* [GCC, the GNU Compiler Collection](http://gcc.gnu.org/install/download.html)
* [SQLite3](https://www.sqlite.org/download.html)
* [NoseTests](https://nose.readthedocs.io/en/latest/)
* [Pysqlcipher](https://github.com/leapcode/pysqlcipher)
* Git
#### Dependencies Installation
following installation commands should be seeing as just an idea how and could become incorrect with time. Important is, that all above listed Dependencies are installed, before you can start to SetUp the Tool.
<sub>*$ - symbol ensure the begin of the command, which should be copy-pasted into the terminal window.*</sub>
##### On Linux (UbuntuOS 16.04.5 LTS)
0. open Terminal/Bash/Shell
1. Add other repositories
$ sudo add-apt-repository "deb http://archive.canonical.com/ubuntu saucy partner"
$ sudo add-apt-repository "deb http://us.archive.ubuntu.com/ubuntu/ saucy universe multiverse"
$ sudo add-apt-repository "deb http://us.archive.ubuntu.com/ubuntu/ saucy-updates universe multiverse"
2. Upgrade default linux tools
$ sudo apt-get update
$ sudo apt-get upgrade
3. Install additional SW
$ sudo apt-get install python-setuptools python-dev build-essential autoconf libtiff5-dev libjpeg8-dev zlib1g-dev libfreetype6-dev liblcms2-dev libwebp-dev tcl8.6-dev tk8.6-dev python-tk libtool pkg-config python-opengl python-pyrex python-pyside.qtopengl idle-python2.7 qt4-dev-tools qt4-designer libqtgui4 libqtcore4 libqt4-xml libqt4-test libqt4-script libqt4-network libqt4-dbus python-qt4 python-qt4-gl libgle3 python-dev libssl-dev g++ openssl git
2. Python Installation
-> python + pip
$ sudo add-apt-repository ppa:jonathonf/python-3.6
$ sudo apt-get update
$ sudo apt install python2.7 python-pip python3.6 python3-pip virtualenv curl
$ sudo -H pip2 install --upgrade pip setuptools
$ sudo -H pip3 install --upgrade pip setuptools
--- ensure to have python3.6 http://ubuntuhandbook.org/index.php/2017/07/install-python-3-6-1-in-ubuntu-16-04-lts/
$ alias python3=python3.6
-> Additional Python3 packages, which will not be installed automatically
$ sudo -H python3 -m pip install somajo someweta
4. Sqlite + Pysqlcipher
$ sudo apt-get install sqlite3 sqlcipher
$ sudo -H python2 -m pip install pysqlcipher --install-option="--bundled"
5. JAVA
$ sudo add-apt-repository ppa:linuxuprising/java
$ sudo apt-get update
$ sudo apt-get install oracle-java11-installer
6. GIT LFS
$ sudo apt-get install software-properties-common
$ sudo add-apt-repository ppa:git-core/ppa
$ apt-get update
$ curl -s https://packagecloud.io/install/repositories/github/git-lfs/script.deb.sh | sudo bash
$ sudo apt-get install git-lfs
$ git lfs install
<br/>
##### On Windows (Win10)
(this tool could be invoked just up from the Windows10 Version)
1. Microsoft Visual C++ Compiler for Python 2.7
(https://www.microsoft.com/en-us/download/details.aspx?id=44266)
2. Enable in Features - "Windows Subsystem for Linux"
(https://docs.microsoft.com/en-us/windows/wsl/install-win10)
3. Enable in Settings - "Developer Mode"
(https://www.wikihow.com/Enable-Developer-Mode-in-Windows-10)
4. Install Ubuntu 16.04 from the Windows Store
(https://devtidbits.com/2017/11/09/ubuntu-linux-on-windows-10-how-to/)
5. goes to Ubuntu Bash
6. goes now above to the part with instructions for Linux
*** root path to Ubuntu Directory on Windows: C:\Users\<username>\AppData\Local\Packages\CanonicalGroupLimited.UbuntuonWindows_79rhkp1fndgsc\LocalState\rootfs\home
<br/>
##### On macOS (10.13.6)
0. open Terminal
1. Install brew
$ /usr/bin/ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)"
2. Install Python
-> python ( pip (2+3)
$ brew install python2 python3
$ sudo python2 -m ensurepip
$ sudo python3 -m ensurepip
Ensure to have Python3.6 and not later version:
$ brew unlink python3
$ brew install https://raw.githubusercontent.com/Homebrew/homebrew-core/f2a764ef944b1080be64bd88dca9a1d80130c558/Formula/python.rb
$ brew link python3
$ pip2 install --upgrade pip setuptools wheel
$ pip3 install --upgrade pip setuptools wheel
$ pip2 install virtualenv
-> Additional python packages (for Python3)
(which will not be installed automatically)
$ sudo python3 -m pip install somajo someweta
3. Sqlite + Pysqlcipher + Git LFS
$ brew install sqlite openssl sqlcipher git-lfs
$ sudo -H python2 -m pip install pysqlcipher --install-option="--bundled"
$ git lfs install
4. Last Java Version (for TweetNLP Tokenizer and POS Tagger)
$ brew cask install java
<br/>
---
---
---
---
<br/>
<a name="settingup"/>
<p style='text-align: right;'> <sub> <a href="#toc">Back to top</a>
</sub> </p>
## 3. Setting up
<sub>*Set background color of your terminal to dark (ex. black, dark blue etc.)*</sub>
##### 1. Package Installation
0. open Terminal
2. pip install zas-rep-tools
##### 2. User Configuration
<sub> Before you can test and work with this tool you need before to confige it. To make it easy set '.' while setttinh up of the project folder, if you want to user current folder as your project folder.</sub>
$ cd <path_to_the_project_folder>
$ sudo zas-rep-tools configer prjdir print
###### 3. Package Tests
<sub> To be sure if your installation in the current system could work error free please run tests. Be aware that it could take around 10-20 min.</sub>
sudo zas-rep-tools testspath | sudo xargs -I {} nosetests -s -v --rednose {}
<br/>
---
---
---
---
<br/>
<a name="definitions"/>
<p style='text-align: right;'> <sub> <a href="#toc">Back to top</a>
</sub> </p>
## 4. Definitions
- **Repetitions** (rep)
We differentiate between two main types of repetitions:
* **Replications** (repl)
-> every Repetition on the letter level up from 3 repetitions (excluded: web links)
- ex. 'veeeeeerrrry'
(Following letters was replicated: 'e', 'r')
* **Reduplications** (redu)
-> every Repetition on the word level
- ex. 'very very very'
(Following word was reduplicated: 'very' )
And one additional compound repetitions:
* **Replications in Reduplications**
- ex. 'veeeerrrryyy veeery very vvvverryyy'
(Here is to see one reduplication of the word 'very' with the length 4 and also 3 uniq and 6 exhausted replications)
- ****Length****
* **Replications**
-> The Number of the replicated letters
- ex: 'verrrry'
('r' was replicated and has length of 4)
* **Reduplications**
-> The Number of the words in one reduplication
- ex: 'very very very much much much much'
(There is two reduplications: 'very', 'much'. Reduplication of 'very' has length of 3 and the length of the reduplication for 'much' = 4.)
- **Uniq vs. Exhausted Re(du)plication**
<sub>(Every repetitions could be quantified in the uniq or exhausted way)</sub>
* **Replications**
-> Every reduplicated letter will be counted once as exhausted replication and each word contained one or many replications will be counted once as uniq replication.
- ex: 'vvvvveeery'
**Exhausted**
= 2, ('v', 'e' was replicated)
**Uniq**
= 1 (because word 'very' contain any replications, but the word will be counted just once for this category)
* **Reduplications**
-> Every reduplicated word will be counted once as uniq reduplication and the length of the reduplication will be counted as exhausted reduplication.
- ex: 'very very very or not very very but very'
**Uniq**
For 'very' = 2 (not 3)
**Exhausted**
For 'very' = 5 (not 6)
- **Syntagma**
Combination/Group of words according to the rules of syntax for current language (each word could be also combinated with an empty word).
- ex: 'very much', 'very'
- **Scope**
The length of syntagma
- ex: 'very much' = 2; 'very'=1;
<a name="full"/>
- **Full Repetitiveness**
<sub>(Each syntagma with scope > 1 have an additional attribute - full-repetitiveness.)</sub>
- **Replications**
If Every element of an syntagma was replicated, than Full-Repetitiveness for this Syntagma is True.
- ex: 'iiii llllovvveee verrry muuuuch', 'veryyyy verrryy muccchhhh', 'verrrrryyy muchhhhhh'
- **Reduplications**
If every element of an syntagma was reduplicated, than Full-Repetitiveness for this Syntagma is True.
- ex: 'very very very much much', "veeeerrryyy veeerryy mmmuuccc muuucch much "
Current function could be switch on/off in StatsDB with following Options '--full_repetativ_syntagma'. If this option is on, than the just full-repetativ syntagmas will be available/matched with the export function. If it is on, than all syntagmas could be matched/exported, which contain at list one re(du)plication.
<br/>
---
---
---
---
<br/>
<a name="functionality"/>
<p style='text-align: right;'> <sub> <a href="#toc">Back to top</a>
</sub> </p>
## 5. Functionality
<a name="cli-commands"/>
<p style='text-align: right;'> <sub> <a href="#toc">Back to top</a>
</sub> </p>
### 5.1 CLI-Commands
Current CommandLineInterface support interaction for following entry points:
- configer
<sub>Set/Delete/reset all user information</sub>
- corpora
<sub>Working with corpus DataBases</sub>
- stats
<sub>Working with Statistics DataBases</sub>
- streamer
<sub>Stream Twitter Data</sub>
In the following part you can see a small explanation to each entry point:
- $ zas-rep-tools configer
- prjdir
<sub>Folder where all User Data will be saved for current copy of the Tool.</sub>
- clean
- set
- reset
- print
- error_track
<sub>current tool support error tracking and report to the developers</sub>
- set
- reset
- respeak
- print
- twitter
<sub>This function set twitter credentials for the streamer</sub>
- set
- reset
- respeak
- print
- email
<sub>to get error reports from twitter streamer per email, please give your emails</sub>
- set
- reset
- respeak
- print
- user_data
- clean
- location
- print
<br>
- $ zas-rep-tools corpora
- add
<sub>create and add new corpus into project folder from given text collection</sub>
- del
<sub> delete existing corpus via name from project folder</sub>
- names
<sub> print all names from existing corpora in the project folder</sub>
- meta
<sub> print all meta-data for corpus via corp-name</sub>
- basic_stats
<sub> print all general statistics for corpus via corp-name</sub>
- update_attr
<sub> change meta-data for corpus via corp-name</sub>
- export
<sub> export corpus into other file type (xml, csv, json) </sub>
- used_tools
<sub> print all used NLP methods and tools</sub>
- clean_dir
<sub> delete corrupted corpora from project folder </sub>
- cols
<sub> print column names for given table in corpus</sub>
- doc
<sub> print all content for given doc via doc_id </sub>
- ids
<sub> print ids for all docs in corpus via corp-name</sub>
<br>
- $ zas-rep-tools stats
- compute
<sub>create and add compute (from given corpus) new stats-db and locate into project folder</sub>
- del
<sub> delete existing stats-db via name from project folder</sub>
- names
<sub> print all names of existing stats-db in the project folder</sub>
- meta
<sub> print all meta-data for stats-db via name</sub>
- basic_stats
<sub> print all general statistics for stats-db via name</sub>
- update_attr
<sub> change meta-data in stats-db via name</sub>
- export
<sub> export statistics as csv, xml, json </sub>
- clean_dir
<sub> delete corrupted stats-db from project folder </sub>
- recompute
<sub> recompute stats-db with other full-repetativenes marker </sub>
- optimize
<sub> spaces and speed optimization via stats-db freezing </sub>
- recreate_indexes
<sub> recreate indexes in an stats-db for better performance </sub>
- $ zas-rep-tools streamTwitter
- $ zas-rep-tools streamerInfo
- enc
<sub> Supported Encodings </sub>
- lang
<sub> Supported Languages for Streamer </sub>
- nltk_lang
<sub> Supported Languages for NLTK </sub>
- twitter_lang
<sub> Supported Languages for TwitterAPI </sub>
- classiefier_lang
<sub> Supported Languages for Language Classifier </sub>
- stop_words
<sub> Predefined Stopwords </sub>
- platforms
<sub> Supported Platforms </sub>
- $ zas-rep-tools help
---
<br>
<a name="cli-options"/>
<p style='text-align: right;'> <sub> <a href="#toc">Back to top</a>
</sub> </p>
### 5.2 CLI-Options
- ***zas-rep-tools configer --help***
Usage: zas-rep-tools configer [OPTIONS] COMMAND1 COMMAND2
Options:
-m, --mode [error|test|dev|dev+|dev-|prod|free|prod+t|test+s+|test+s-|silent|prod+|prod-|blind]
Set one of the Tool Modus
-ld, --logdir TEXT Choose the name of the Directory for log
data.
--help Show this message and exit.
<br>
- ***zas-rep-tools corpora --help***
Usage: zas-rep-tools corpora [OPTIONS] COMMAND1
Options:
-sb, --status_bar BOOLEAN Enable/Disable the Status Bat
-uefm, --use_end_file_marker BOOLEAN
Enable/Disable usage of endfilemarker to
change the couter unit from rows to files in
the status bar
-tscc, --tok_split_camel_case BOOLEAN
Enable/Disable the option for Tokenizer to
convertion and split of the CamelCase (ex.
'CamelCase')
-backup, --make_backup BOOLEAN Enable/Disable making BackUp of the whole
Corpus before the new Insetions
-lb, --lazyness_border INTEGER Set the number of the border, which ensure
when exactly data collector should save data
on the disk. If you have a big RAM than
select the high number, to ensure the hight
performance.
-rw, --rewrite BOOLEAN Enable/Disable rewrite option, which ensure
the file replacing/rewriting during the
export, if the same filename was found in
the same directory.
-uc, --use_cash BOOLEAN Enable/Disable during the insertion process
write direct on the disk or first into cash.
It is a good performance booster, but just
in the case of the big RAM.
-opt, --optimizer TEXT Enable/Disable DB Optimizer, which makes
current DB much faster, but less safety.
-optps, --optimizer_page_size INTEGER
Setting for DBOptimizer. See more in the
Hell-text for optimizer.
-optcs, --optimizer_cache_size INTEGER
Setting for DBOptimizer. See more in the
Hell-text for optimizer.
-optlm, --optimizer_locking_mode [normal|exclusive]
Setting for DBOptimizer. See more in the
Hell-text for optimizer.
-optsyn, --optimizer_synchronous [1|0|3|2|normal|off|extra|full]
Setting for DBOptimizer. See more in the
Hell-text for optimizer.
-optjm, --optimizer_journal_mode [delete|truncate|persist|memory|wal|off]
Setting for DBOptimizer. See more in the
Hell-text for optimizer.
-optts, --optimizer_temp_store [1|0|2|file|default|memory]
Setting for DBOptimizer. See more in the
Hell-text for optimizer.
-gr, --gready BOOLEAN If False -> Stop Process immediately if
error was returned. If True -> Try to
execute script so long as possible, without
stopping the main process.
-cn, --corp_fname TEXT File Name of the CorpusDB (with or without
extention)
-lang, --language [test|de|en|False]
Give language acronym according to standard
ISO639_2.
-vis, --visibility [extern|intern|False]
Is that an intern or extern Corpus?
-platf, --platform_name TEXT
-encrkey, --encryption_key TEXT
For encryption of the current DB please
given an key. If key is not given, than the
current DB will be not encrypted.
-cname, --corp_intern_dbname TEXT
Intern Name of the DB, which will be saved
as tag inside the DB.
-src, --source TEXT Source of the text collection.
-lic, --license TEXT License, under which this corpus will be
used.
-templ, --template_name [blogger|twitter|False]
Templates are there for initialization of
the preinitialized Document Table in the DB.
Every Columns in the DocumentTable should be
initialized. For this you can use Templates
(which contain preinitialized Information)
or initialize manually those columns
manually with the '--
cols_and_types_in_doc'-Option.
-ver, --version INTEGER Version Number of the DB
-additcols, --cols_and_types_in_doc TEXT
Additional Columns from input text
Collections. Every Columns in the
DocumentTable should be initialized. Every
Document Table has already two default
columns (id, text) if you want to insert
also other columns, please define them here
with the type names. The colnames should
correspond to the colnames in the input text
data and be given in the following form: 'co
lname1:coltype1,colname2:coltype2,colname3:c
oltype3'
-cid, --corpus_id_to_init TEXT Manually given corpid
-tok, --tokenizer [somajo|nltk|False|True]
Select Tokenizer by name
-ptager, --pos_tagger [someweta|tweetnlp|False|True]
Select POS-Tagger by name
-sentim, --sentiment_analyzer [textblob|False|True]
Select Sentiment Analyzer by name
-sentspl, --sent_splitter [pystemmer|False|True]
Select Stemmer by name
-preproc, --preprocession BOOLEAN
Enable/disable Proprocessing of the text
elements.
-langclas, --lang_classification TEXT
Enable/disable Language Classification
-durl, --del_url BOOLEAN Enable/disable Hiding of all URLs
-dpnkt, --del_punkt BOOLEAN Enable/disable Hiding of all Punctuation
-dnum, --del_num BOOLEAN Enable/disable Hiding of all Numbers
-dment, --del_mention BOOLEAN Enable/disable Hiding of all Mentions
-dhash, --del_hashtag BOOLEAN Enable/disable Hiding of all Hashtags
-dhtml, --del_html BOOLEAN Enable/disable cleaning of all not needed
html tags
-case, --case_sensitiv BOOLEAN Enable/disable the case sensitivity in the
Corpus during initialization.
-emojnorm, --emojis_normalization BOOLEAN
Enable/disable restructure of all Emojis.
(could cost much time)
-texname, --text_field_name TEXT
If new input data has different name with
text or id information, than use this
options to ensure correct use of data.
-idname, --id_field_name TEXT If new input data has different name with
text or id information, than use this
options to ensure correct use of data.
-heal, --heal_me_if_possible BOOLEAN
If '--template_name' and '--
cols_and_types_in_doc' wasn't selected, than
with this option ('--heal_me_if_possible')
DB will try to initialize those information
automatically. But be careful with this
option, because it could also return
unexpected errors.
-ptr, --path_to_read TEXT Path to folder with text collection, which
should be collected and transformed into
CorpusDB.
-readtyp, --file_format_to_read [txt|json|xml|csv|False]
File Format which should be read.
-readregextempl, --reader_regex_template [blogger|False]
Name of the template for Reading of the TXT
Files.
-readregexpattern, --reader_regex_for_fname TEXT
Regex Pattern for Extraction of the Columns
from the filenames.
-zipread, --read_from_zip BOOLEAN
Enable/Disable the possibly also to search
and read automatically from *.zip Achieves.
-formatter, --formatter_name [twitterstreamapi|sifter|False]
Give the name of the predefined Formatters
and Preprocessors for different text
collections.
-retweetsignr, --reader_ignore_retweets BOOLEAN
Ignore Retweets, if original JsonTweet was
given.
-minfile, --min_files_pro_stream INTEGER
The Limit, when Multiprocessing will be
start to create a new stream.
-csvd, --csvdelimiter TEXT CSV Files has offten different dialects and
delimiters. With this option, it is
possible, to set an delimiter, which ensure
correct processing of the CSV File Data.
-enc, --encoding [bz2_codec|cp1140|rot_13|cp932|euc_jisx0213|cp037|hex_codec|cp500|uu_codec|big5hkscs|mbcs|euc_jis_2004|iso2022_jp_3|iso2022_jp_2|iso2022_jp_1|gbk|iso2022_jp_2004|quopri_codec|cp424|iso2022_jp|mac_iceland|hp_roman8|iso2022_kr|euc_kr|cp1254|utf_32_be|gb2312|cp850|shift_jis|cp852|cp855|utf_16_le|cp857|cp775|cp1026|mac_latin2|utf_32|mac_cyrillic|base64_codec|ptcp154|euc_jp|hz|utf_8|utf_32_le|mac_greek|utf_7|mac_turkish|cp949|zlib_codec|big5|iso8859_9|iso8859_8|iso8859_5|iso8859_4|iso8859_7|iso8859_6|iso8859_3|iso8859_2|gb18030|shift_jis_2004|mac_roman|cp950|utf_16|iso8859_15|iso8859_14|tis_620|iso8859_16|iso8859_11|iso8859_10|iso8859_13|ascii|cp869|utf-8|cp860|cp861|cp862|cp863|cp864|cp865|cp866|shift_jisx0213|cp1255|latin_1|cp1257|cp1256|cp1251|cp1250|cp1253|cp1252|cp437|cp1258|tactis|koi8_r|utf_16_be|johab|iso2022_jp_ext|cp858]
All Text Files are encoded with help of the
EncodingTables. If you input files are not
unicode-compatible, please give the encoding
name, which was used for encoding the input
data.
-docid, --doc_id TEXT Document ID in the Corpus DB.
-attr, --attr_name TEXT Stats and Corpus DBs has intern Attributes.
For changing of getting them you need to get
the name of this attribute.
-val, --value TEXT For setting of the new Value for one
Attribute.
-exptyp, --type_to_export [sqlite|json|xml|csv|False]
FileType for the export function.
-expdir, --export_dir TEXT Directory where Exports will be saved. If
False, than they will be saved in the
default ProjectDirectory.
-expname, --export_name TEXT FileName for ExportData.
-rowlim, --rows_limit_in_file INTEGER
Number of the Rows Max in the Files to
export.
-sn, --stream_number INTEGER Enable or Disable the Multiprocessing. If
Number > 1, than tool try to compute every
thing parallel. This function could bring
much better performance on the PC with multi
cores and big Operation Memory.
-m, --mode [error|test|dev|dev+|dev-|prod|free|prod+t|test+s+|test+s-|silent|prod+|prod-|blind]
Set one of the Tool Modus. Modi ensure the
communication behavior of this Tool.
-ld, --logdir TEXT Choose the name of the Directory for log
data.
--help Show this message and exit.
<br>
- ***zas-rep-tools stats --help***
Usage: zas-rep-tools stats [OPTIONS] COMMAND1
Options:
-sb, --status_bar BOOLEAN Enable/Disable the Status Bat
-uefm, --use_end_file_marker BOOLEAN
Enable/Disable usage of endfilemarker to
change the couter unit from rows to files in
the status bar
-backup, --make_backup BOOLEAN Enable/Disable making BackUp of the whole
Corpus before the new Insetions
-lb, --lazyness_border INTEGER Set the number of the border, which ensure
when exactly data collector should save data
on the disk. If you have a big RAM than
select the high number, to ensure the hight
performance.
-rw, --rewrite BOOLEAN Enable/Disable rewrite option, which ensure
the file replacing/rewriting during the
export, if the same filename was found in
the same directory.
-uc, --use_cash BOOLEAN Enable/Disable during the insertion process
write direct on the disk or first into cash.
It is a good performance booster, but just
in the case of the big RAM.
-opt, --optimizer TEXT Enable/Disable DB Optimizer, which makes
current DB much faster, but less safety. See
more: https://www.sqlite.org/pragma.html
-optps, --optimizer_page_size INTEGER
Setting for DBOptimizer. See more in the
Hell-text for optimizer.
-optcs, --optimizer_cache_size INTEGER
Setting for DBOptimizer. See more in the
Hell-text for optimizer.
-optlm, --optimizer_locking_mode [normal|exclusive]
Setting for DBOptimizer. See more in the
Hell-text for optimizer.
-optsyn, --optimizer_synchronous [1|0|3|2|normal|off|extra|full]
Setting for DBOptimizer. See more in the
Hell-text for optimizer.
-optjm, --optimizer_journal_mode [delete|truncate|persist|memory|wal|off]
Setting for DBOptimizer. See more in the
Hell-text for optimizer.
-optts, --optimizer_temp_store [1|0|2|file|default|memory]
Setting for DBOptimizer. See more in the
Hell-text for optimizer.
-gr, --gready BOOLEAN If False -> Stop Process immediately if
error was returned. If True -> Try to
execute script so long as possible, without
stopping the main process.
-cn, --corp_fname TEXT File Name of the CorpusDB (with or without
extention)
-sn, --stream_number INTEGER Enable or Disable the Multiprocessing. If
Number > 1, than tool try to compute every
thing parallel. This function could bring
much better performance on the PC with multi
cores and big Operation Memory.
-crtix, --create_indexes BOOLEAN
For better performance it is highly
recommended to create indexes. But their
creation could also cost time once during
their creation and also space.
-freeze, --freeze_db BOOLEAN Freeze current DB and close for all next
possible insertion of the new data. This
option also triggers the DB Optimization
Porcess, which could cost a lost of time,
but make this DB much space and time
efficient. Once this process is done, it is
not possible anymore to decline it.
-optlongsyn, --optimized_for_long_syntagmas BOOLEAN
If you are planing to search in the big
syntagmas, than set this to True. It will
optimize DB to be fast with long syntagmas.
-minfile, --min_files_pro_stream INTEGER
The Limit, when Multiprocessing will be
start to create a new stream.
-basdelim, --baseline_delimiter TEXT
Delimiter for Syntagmas in intern Baseline
Table. Change here if you really know, that
you need it.
-sfn, --stats_fname TEXT File Name of the StatsDB.
-vis, --visibility [extern|intern|False]
Is that an intern or extern Corpus?
-encrkey, --encryption_key TEXT
For encryption of the current DB please
given an key. If key is not given, than the
current DB will be not encrypted.
-ver, --version INTEGER Version Number of the DB
-stats_id, --stats_id TEXT Possibilty to set StatsId manually.
Otherwise it will be setted automatically.
-cname, --stats_intern_dbname TEXT
Intern Name of the DB, which will be saved
as tag inside the DB.
-conlen, --context_lenght INTEGER
This number mean how much tokens left and
right will be also captured and saved for
each found re(du)plication. This number
should be >=3
-fullrep, --full_repetativ_syntagma BOOLEAN
Disable/Enable FullRepetativnes. If it is
True, than just full repetativ syntagmas
would be considered. FullRepetativ syntagma
is those one, where all words was ongoing
either replicated or replicated. (ex.:
FullRepRedu: 'klitze klitze kleine kleine' ,
FullRepRepl: 'kliiitzeee kleeeinee') (See
more about it in Readme -> Definitions)
-ru, --repl_up INTEGER Up this number this tool recognize repetativ
letter as replication.
-ignht, --ignore_hashtag BOOLEAN
Enable/disable Hiding of all Hashtags, if it
wasn't done during CorpusCreationProcess.
-case, --case_sensitiv BOOLEAN Enable/disable the case sensitivity during
Stats Computation Process.
-ignurl, --ignore_url BOOLEAN Enable/disable Hiding of all URLS, if it
wasn't done during CorpusCreationProcess.
-ignment, --ignore_mention BOOLEAN
Enable/disable Hiding of all Mentions, if it
wasn't done during CorpusCreationProcess.
-ignp, --ignore_punkt BOOLEAN Enable/disable Hiding of all Punctuation, if
it wasn't done during CorpusCreationProcess.
-ignnum, --ignore_num BOOLEAN Enable/disable Hiding of all Numbers, if it
wasn't done during CorpusCreationProcess.
-bliti, --baseline_insertion_border INTEGER
Number of the limit, when syntagmas will be
delete from cash and saved on the disk.
-expdir, --export_dir TEXT Set Path to export dir. If it is not given,
than all export will be saved into
ProjectFolder.
-exp_fname, --export_name TEXT Set fname for export files.
-syn, --syntagma_for_export TEXT
Set Syntagmas for search/extract. Default:
'*'-match all syntagmas. Example: 'very|huge
|highly,pitty|hard|happy,man|woman|boy|perso
n' ('|' - as delimiter in paradigm; ',' - as
delimiter of the syntagmas part.) Notice:
Now white space is allow.
-repl, --exp_repl BOOLEAN Disable/Enable Replications Extraction
-redu, --exp_redu BOOLEAN Disable/Enable Reduplications Extraction
-styp, --exp_syntagma_typ [pos|lexem]
Ensure type of the given components in
Syntagma_to_search. It is possible to search
in pos-tags or in lexems.
-sent, --exp_sentiment [neutral|positive|negative|False]
Search in Sentiment tagged data.
-ftyp, --export_file_type [csv|json|xml]
-rowlim, --rows_limit_in_file INTEGER
Number of the Rows Max in the Files to
export.
-exp_encrkey, --encryption_key_corp TEXT
For export additional columns
(--additional_doc_cols) from encrypted
CorpDB or for compution of the new StatsDb
from the encrypted CorpDB
-ott, --output_table_type [exhausted|sum]
-doccols, --additional_doc_cols TEXT
For export of stats with additional columns
from document from CorpDB. Don't forget to
give also the FName of CorpusDB for which
current statsDB was computed. (--corp_fname)
Please give it in the following Form:
'gender,age,' (NO WHITE SPACES ARE ALLOW)
-mscope, --max_scope TEXT Upper Limit of the syntagma length to
search. Example: if max_scope = 1, than tool
will search just in those syntagmas, which
contain just 1 word.
-stemm, --stemmed_search BOOLEAN
Search in lemantisated/stemmed syntagmas. Be
careful and don't give different
conjugations of one lemma, if current
options is True. Because you could get
duplicates.
-conleft, --context_len_left TEXT
The length of context In Output Tables.
Could be also Disabled (False).
-conright, --context_len_right TEXT
The length of context In Output Tables.
Could be also Disabled (False).
-sepsyn, --separator_syn TEXT Separator inside syntagma in baseline.
-wordex, --word_examples_sum_table BOOLEAN
Enable/disable Word Examples in Exported
Output. (Just For SumOutputTables)
-ignsym, --ignore_symbol TEXT Enable/disable Symbols in Exported Outputs.
(Just For SumOutputTables)
-recflag, --recompute_flag TEXT
For 'recompute' command. This command
recompute the FullRepetativnes in given
StatsDB. True - full_repetativnes, False -
no_full_repetativnes/all_syntagmas
-attr, --attr_name TEXT Stats and Corpus DBs has intern Attributes.
For changing of getting them you need to get
the name of this attribute.
-val, --value TEXT For setting of the new Value for one
Attribute.
-m, --mode [error|test|dev|dev+|dev-|prod|free|prod+t|test+s+|test+s-|silent|prod+|prod-|blind]
Set one of the Tool Modus
-ld, --logdir TEXT Choose the name of the Directory for log
data.
--help Show this message and exit.
<br>
- ***zas-rep-tools streamTwitter --help***
Usage: zas-rep-tools streamTwitter [OPTIONS] PATH_TO_SAVE
Options:
-l, --language [en|it|ar|id|es|ru|nl|pt|no|tr|th|pl|fr|de|da|fa|hi|fi|hu|ja|he|ko|sv|ur|False]
-sw, --stop_words TEXT
-t, --terms TEXT
-e, --encoding [bz2_codec|cp1140|rot_13|cp932|euc_jisx0213|cp037|hex_codec|cp500|uu_codec|big5hkscs|mbcs|euc_jis_2004|iso2022_jp_3|iso2022_jp_2|iso2022_jp_1|gbk|iso2022_jp_2004|quopri_codec|cp424|iso2022_jp|mac_iceland|hp_roman8|iso2022_kr|euc_kr|cp1254|utf_32_be|gb2312|cp850|shift_jis|cp852|cp855|utf_16_le|cp857|cp775|cp1026|mac_latin2|utf_32|mac_cyrillic|base64_codec|ptcp154|euc_jp|hz|utf_8|utf_32_le|mac_greek|utf_7|mac_turkish|cp949|zlib_codec|big5|iso8859_9|iso8859_8|iso8859_5|iso8859_4|iso8859_7|iso8859_6|iso8859_3|iso8859_2|gb18030|shift_jis_2004|mac_roman|cp950|utf_16|iso8859_15|iso8859_14|tis_620|iso8859_16|iso8859_11|iso8859_10|iso8859_13|ascii|cp869|cp860|cp861|cp862|cp863|cp864|cp865|cp866|shift_jisx0213|cp1255|latin_1|cp1257|cp1256|cp1251|cp1250|cp1253|cp1252|cp437|cp1258|tactis|koi8_r|utf_16_be|johab|iso2022_jp_ext|cp858]
-irt, --ignore_rt BOOLEAN
-f, --filter_strategie [t|t+l|False]
Set Filter Strategy. 1) 't'-just search for
terms/stop_words; 2) 't+l' - search for
stop_words and language (recomended)
-sut, --save_used_terms BOOLEAN
-m, --mode [error|test|dev|dev+|dev-|prod|free|prod+t|test+s+|test+s-|silent|prod+|prod-|blind]
Set one of the Tool Modus
-ld, --logdir TEXT Choose the name of the Directory for log
data.
--help Show this message and exit.
- ***zas-rep-tools streamerInfo --help***
Usage: zas-rep-tools streamerInfo [OPTIONS] COMMAND
Options:
-m, --mode [error|test|dev|dev+|dev-|prod|free|prod+t|test+s+|test+s-|silent|prod+|prod-|blind]
Set one of the Tool Modus
-ld, --logdir TEXT Choose the name of the Directory for log
data.
--help Show this message and exit.
---
<br>
<a name="cli-usage"/>
<p style='text-align: right;'> <sub> <a href="#toc">Back to top</a>
</sub> </p>
### 5.3 CLI-Usage
<sub> Usage examples for each CLI-Command with belonging to it options.
Notice: this tool is quite user friendly and if something goes wrong this Tool try to predict, what was wrong and try to give the useful information, about how to solve the current problem. </sub>
#### Necessary Options
<sub> List of the minimum/necessary options, which needed to run certain command.</sub>
- $ zas-rep-tools corpora
- **add**
- *\--path_to_read*
- *\--file_format_to_read*
- *\--corp_intern_dbname*
- *\--language*
- *\--visibility*
- *\--platform_name*
- **del**
- *\--corp_fname*
- **names**
<sub>None additional option</sub>
- **meta**
- *\--corp_fname*
- **basic_stats**
- *\--corp_fname*
- **update_attr**
- *\--corp_fname*
- *\--attr_name*
- *\--value*
- **export**
- *\--corp_fname*
- *\--type_to_export*
- **used_tools**
<sub>None additional option</sub>
- **clean_dir**
<sub>None additional option</sub>
- **cols**
- *\--corp_fname*
- **doc**
- *\--corp_fname*
- *\--doc_id*
- **ids**
- *\--corp_fname*
<br>
- $ zas-rep-tools stats
- **compute**
- *\--corp_fname*
- *\--stats_intern_dbname*
- *\--visibility*
- **del**
- *\--stats_fname*
- **names**
<sub>None additional option</sub>
- **meta**
- *\--stats_fname*
- **basic_stats**
- *\--stats_fname*
- **update_attr**
- *\--stats_fname*
- *\--attr_name*
- *\--value*
- **export**
- *\--stats_fname*
- *\--export_file_type*
- **clean_dir**
<sub>None additional option</sub>
- **recompute**
- *\--stats_fname*
- *\--recompute_flag*
- **optimize**
- *\--stats_fname*
- **recreate_indexes**
- *\--stats_fname*
- $ zas-rep-tools streamTwitter
- *\--path_to_save*
- *\--filter_strategie*
<br>
<br>
#### Exhausted Options
<sub> List of the exhausted/additional options, which needed to run certain command. (just for those commands which are different to the category before)</sub>
- $ zas-rep-tools corpora
- **add**
- *\--path_to_read*
- *\--file_format_to_read*
- *\--reader_regex_template*
- *\--reader_regex_for_fname*
- *\--end_file_marker*
- *\--use_end_file_marker*
- *\--stop_process_if_possible*
- *\--formatter_name*
- *\--text_field_name*
- *\--id_field_name*
- *\--reader_ignore_retweets*
- *\--mode*
- *\--status_bar*
- *\--tok_split_camel_case*
- *\--make_backup*
- *\--lazyness_border*
- *\--rewrite*
- *\--stop_if_db_already_exist*
- *\--use_cash*
- *\--optimizer*
- *\--optimizer_page_size*
- *\--optimizer_cache_size*
- *\--optimizer_locking_mode*
- *\--optimizer_synchronous*
- *\--optimizer_journal_mode*
- *\--optimizer_temp_store*
- *\--stop_process_if_possible*
- *\--heal_me_if_possible*
- *\--corp_intern_dbname*
- *\--language*
- *\--visibility*
- *\--encryption_key*
- *\--corp_fname*
- *\--source*
- *\--license*
- *\--template_name*
- *\--version*
- *\--cols_and_types_in_doc*
- *\--corpus_id_to_init*
- *\--tokenizer*
- *\--pos_tagger*
- *\--sentiment_analyzer*
- *\--sent_splitter*
- *\--preprocession*
- *\--lang_classification*
- *\--del_url*
- *\--del_punkt*
- *\--del_num*
- *\--del_mention*
- *\--del_hashtag*
- *\--del_html*
- *\--case_sensitiv*
- *\--emojis_normalization*
- *\--stream_number*
- *\--min_files_pro_stream*
- *\--csvdelimiter*
- *\--encoding*
- *\--del_hashtag*
- *\--del_html*
- *\--case_sensitiv*
- *\--read_from_zip*
- **meta**
- *\--corp_fname*
- *\--encryption_key*
- **basic_stats**
- *\--corp_fname*
- *\--encryption_key*
- **update_attr**
- *\--corp_fname*
- *\--attr_name*
- *\--value*
- *\--encryption_key*
- **export**
- *\--corp_fname*
- *\--type_to_export*
- *\--encryption_key*
- *\--export_dir*
- **cols**
- *\--corp_fname*
- *\--encryption_key*
- **doc**
- *\--corp_fname*
- *\--doc_id*
- *\--encryption_key*
- **ids**
- *\--corp_fname*
- *\--encryption_key*
<br>
- $ zas-rep-tools stats
- **compute**
- *\--corp_fname*
- *\--encryption_key_corp*
- *\--mode*
- *\--status_bar*
- *\--make_backup*
- *\--lazyness_border*
- *\--rewrite*
- *\--stop_if_db_already_exist*
- *\--use_cash*
- *\--optimizer*
- *\--optimizer_page_size*
- *\--optimizer_cache_size*
- *\--optimizer_locking_mode*
- *\--optimizer_synchronous*
- *\--optimizer_journal_mode*
- *\--optimizer_temp_store*
- *\--stats_intern_dbname*
- *\--visibility*
- *\--encryption_key*
- *\--stats_fname*
- *\--gready*
- *\--version*
- *\--context_lenght*
- *\--full_repetativ_syntagma*
- *\--repl_up*
- *\--ignore_hashtag*
- *\--case_sensitiv*
- *\--ignore_url*
- *\--ignore_mention*
- *\--ignore_punkt*
- *\--ignore_num*
- *\--baseline_delimiter*
- *\--min_files_pro_stream*
- *\--create_indexes*
- *\--freeze_db*
- *\--baseline_insertion_border*
- *\--optimized_for_long_syntagmas*
- **meta**
- *\--stats_fname*
- *\--encryption_key*
- **basic_stats**
- *\--stats_fname*
- *\--encryption_key*
- **update_attr**
- *\--stats_fname*
- *\--attr_name*
- *\--value*
- *\--encryption_key*
- **export**
- *\--mode*
- *\--status_bar*
- *\--stats_fname*
- *\--encryption_key*
- *\--export_dir*
- *\--syntagma_for_export*
- *\--exp_repl*
- *\--exp_redu*
- *\--exp_syntagma_typ*
- *\--exp_sentiment*
- *\--encryption_key_corp*
- *\--output_table_type*
- *\--additional_doc_cols*
- *\--path_to_corpdb*
- *\--max_scope*
- *\--stemmed_search*
- *\--context_len_left*
- *\--context_len_right*
- *\--separator_syn*
- *\--word_examples_sum_table*
- *\--ignore_num*
- *\--ignore_symbol*
- **recompute**
- *\--stats_fname*
- *\--recompute_flag*
- *\--encryption_key*
- **optimize**
- *\--stats_fname*
- *\--encryption_key*
- **recreate_indexes**
- *\--stats_fname*
- *\--encryption_key*
<br>
- $ zas-rep-tools streamTwitter <path_to_save>
- *\--language*
- *\--filter_strategie*
- *\--stop_words*
- *\--terms*
- *\--encoding*
- *\--ignore_rt*
- *\--save_used_terms*
- *\--mode*
- *\--logdir*
<br>
---
<a name="multiprocessing"/>
<p style='text-align: right;'> <sub> <a href="#toc">Back to top</a>
</sub> </p>
### 5.4 Multiprocessing
Current Tool support multiprocessing. Just set 'stream_number'-Option to more as 1 to ensure the process to be executed parallel.
<br>
---
<a name="nlp-methods"/>
<p style='text-align: right;'> <sub> <a href="#toc">Back to top</a>
</sub> </p>
### 5.5 NLP-Methods
Used NLP-Methods:
- Tokenization
- Sent-Segmentation
- POS-Tagging
- Sentiment Analysis
- Steaming
- RLE (run length encoding)
<br>
---
<a name="db"/>
<p style='text-align: right;'> <sub> <a href="#toc">Back to top</a>
</sub> </p>
### 5.6 InternDataBase-Structure (SQLite)
- **Corpus**
- Tables:
- Documents
- Info
- Meta-Data:
(id,name,platform_name,template_name,version,language,created_at,source,license,visibility,typ,tokenizer,sent_splitter,pos_tagger,sentiment_analyzer,preprocession,del_url,del_punkt,del_num,del_mention,del_hashtag,del_html,case_sensitiv,lang_classification,emojis_normalization,sent_num,token_num,doc_num,text_field_name,id_field_name,locked)
- **Stats**
- Tables:
- Replications
- Reduplications
- Baseline
- Info
- Meta-Data:
(id, corpus_id, name, version, created_at, visibility, typ, db_frozen, context_lenght, language, repl_up, ignore_hashtag, ignore_url, ignore_mention, ignore_punkt, ignore_num, force_cleaning, case_sensitiv, full_repetativ_syntagma, min_scope_for_indexes, locked, pos_tagger, sentiment_analyzer, baseline_delimiter)
<br>
---
<a name="additional_features"/>
<p style='text-align: right;'> <sub> <a href="#toc">Back to top</a>
</sub> </p>
### 5.7 Additional Features
- **Formatters**
Are there to help for better reading or the unstructured data.
Existing Formatters: ["twitterstreamapi", "sifter"]
- **Templates**
Predefinition of corpus-DB for different exiting projects, which contain information about columns for the documents-table
Existing Templates: ["twitter","blogger"]
<br/>
---
---
---
---
<br/>
<a name="workflow"/>
<p style='text-align: right;'> <sub> <a href="#toc">Back to top</a>
</sub> </p>
## 6. WorkFlow
Step 1: Corpus Data Base Creation
$ zas-rep-tools corpora add
Step 2: Stats DataBase Computation
$ zas-rep-tools stats compute
Step 3: Export of the computed Statistics
$ zas-rep-tools stats export
<br/>
---
---
---
---
<br/>
<a name="tutorials"/>
<p style='text-align: right;'> <sub> <a href="#toc">Back to top</a>
</sub> </p>
## 7. Tutorials
**Notice**
1. Don't use following symbols in the namespaces: '-,;:=)({}¢[];
2. All DataBases will be saves into the given ProjectFolders';
3. To Stop Executions please use 'Ctrl+C';
4. To ensure the fast corpus creation try to use minimum of preprocessing
functions;
5. Following command are just example and have as a goal to inspire the user;
## Python Package Tutorial
***-work_in_progress-*** <sub>(API could be found in the tests-folder. If you interested to use this Tool also as Python Package please contact the developer and ask for better API Explanation.)</sub>
---
---
<br/>
## Command line Tutorial
<br/>
#### Add/Create Corpus
<sub>Following examples ensure corpora creation process from current directory and with maximal preprocessing steps.
</sub>
- From Certain (predefined) Sources
<sub>Predifinition is done through following options:'\--formatter_name','\--reader_regex_template', '\--template_name'</sub>
- [Sifter-Twitter-Data (csv)](https://sifter.texifter.com)
- $ zas-rep-tools corpora add --path_to_read . --file_format_to_read csv --corp_intern_dbname sifter_twitter_2014 --language de --visibility intern --platform_name twitter --read_from_zip True --mode prod --heal_me_if_possible True --formatter_name sifter --sent_splitter True --pos_tagger True --read_from_zip True --version 1 --sentiment_analyzer True --del_url True --del_punkt True --del_num True --del_html True --case_sensitiv False
- [Blogger Autorship Corpus (txt)](http://u.cs.biu.ac.il/~koppel/BlogCorpus.htm)
- $ zas-rep-tools corpora add --path_to_read . --file_format_to_read txt --corp_intern_dbname blogger_txt --language en --visibility extern --platform_name blogger --reader_regex_template blogger --sent_splitter True --pos_tagger True --del_html True --mode prod+ --read_from_zip True --source LanguageGoldMine --version 1 --sentiment_analyzer True --del_url True --del_punkt True --del_num True --del_html True --case_sensitiv False
- [Twitter Stream API (json)](https://developer.twitter.com/en/docs/tweets/filter-realtime/overview.html)
- $ zas-rep-tools corpora add --path_to_read . --file_format_to_read json --corp_intern_dbname twitter_streamed_2019 --language en --visibility extern --platform_name twitter --template_name twitter --stream_number 1 --formatter_name twitterstreamapi --sent_splitter True --pos_tagger True --mode prod+ --read_from_zip True --source TwitterAPI --license Twitter_Developer_Agreement_and_Policy --version 1 --sentiment_analyzer True --del_url True --del_punkt True --del_num True --del_html True --case_sensitiv False
- From Scratch
- txt
<sub>This tool can just work with those TXT-Text-Collections, which have all meta-data in the filename, which could be matched with an regex.</sub>
- $ zas-rep-tools corpora add --path_to_read . --file_format_to_read txt --corp_intern_dbname txt_corp --language en --visibility extern --platform_name blogger --del_html True --reader_regex_for_fname "(?P<id>[\d]*)\.(?P<gender>[\w]*)\.(?P<age>\d*)\.(?P<working_area>.*)\.(?P<star_constellation>[\w]*)" --sent_splitter True --pos_tagger True --mode prod+ --read_from_zip True --source LanguageGoldMine --version 1 --sentiment_analyzer True --del_url True --del_punkt True --del_num True --del_html True --case_sensitiv False
- csv/json/json
- $ zas-rep-tools corpora add --path_to_read . --file_format_to_read json --corp_intern_dbname twitter_streamed_2019 --language en --visibility extern --platform_name twitter --stream_number 1 --sent_splitter True --pos_tagger True --mode prod+ --read_from_zip True --source TwitterAPI --license Twitter_Developer_Agreement_and_Policy --version 1 --sentiment_analyzer True --del_url True --del_punkt True --del_num True --del_html True --case_sensitiv False --heal_me_if_possible False --cols_and_types_in_doc 't_created_at:TEXT,t_language:TEXT,t_used_client:TEXT,u_created_at:TEXT,u_description:TEXT,u_favourites:INTEGER,u_followers:INTEGER,u_friends:INTEGER,u_id:INTEGER'
<sub>or (let tool extract the columns from input text collection automatically (\--heal_me_if_possible True), but if input data is not consistent and every document have different number of columns, than it could ensure unpredictable errors)</sub>
- $ zas-rep-tools corpora add --path_to_read . --file_format_to_read csv --corp_intern_dbname twitter_streamed_2019 --language en --visibility extern --platform_name twitter --stream_number 1 --sent_splitter True --pos_tagger True --mode prod+ --read_from_zip True --source unknown --license Twitter_Developer_Agreement_and_Policy --version 1 --sentiment_analyzer True --del_url True --del_punkt True --del_num True --del_html True --case_sensitiv False --heal_me_if_possible True
---
<br/>
#### Compute StatsDB
- with Preprocessing
$ zas-rep-tools stats compute --corp_fname 7728_corpus_twitter_sifter_de_intern_plaintext.db --stats_intern_dbname sifter --visibility intern --full_repetativ_syntagma True --optimizer True --use_cash True --status_bar True --context_lenght 5 --ignore_url True --ignore_punkt True --ignore_num True
- without Preprocessing
$ zas-rep-tools stats compute --corp_fname 7728_corpus_twitter_sifter_de_intern_plaintext.db --stats_intern_dbname sifter --visibility intern --full_repetativ_syntagma True --optimizer True --use_cash True --status_bar True
- compute for non-full-repetativ syntagmas (see more in definitions)
$ zas-rep-tools stats compute --corp_fname 7728_corpus_twitter_sifter_de_intern_plaintext.db --stats_intern_dbname sifter --visibility intern --full_repetativ_syntagma False --optimizer True --use_cash True --status_bar True
---
<br/>
#### Export Statistics from StatsDB
**Exhausted Output-Tables**
- **For scope = 1** (just those syntagmas which have length/scope = 1)
$ git s
- **For all syntagmas**
$ zas-rep-tools stats export --stats_fname 7614_3497_stats_bloggerCorpus_en_extern_plaintext.db --export_file_type csv --output_table_type exhausted --exp_redu True --exp_repl True
- **With additional columns from CorpusDB**
$ zas-rep-tools stats export --stats_fname 7614_3497_stats_bloggerCorpus_en_extern_plaintext.db --export_file_type csv --exp_redu True --exp_repl True --max_scope 1 --additional_doc_cols 'gender,age' --corp_fname 7614_corpus_blogs_bloggerCorpus_test_extern_plaintext.db
- **Search in certain syntagmas**
<sub> ('|' = 'or'; ',' = 'delimiter between words in syntagma'; )</sub>
- Stemmed-Search (in lexical basic from) <sub>(syntagma_for_export will be first stemmed)</sub>
$ zas-rep-tools stats export --stats_fname 7614_3497_stats_bloggerCorpus_de_extern_plaintext.db --export_file_type csv --exp_repl True --exp_redu True --output_table_type exhausted --syntagma_for_export 'klitze,kleine' --exp_syntagma_typ lexem --stemmed_search True
- POS-search (search in part of speech tags)
$ zas-rep-tools stats export --stats_fname 7614_3497_stats_bloggerCorpus_de_extern_plaintext.db --export_file_type csv --exp_repl True --exp_redu True --max_scope 1 --output_table_type exhausted --syntagma_for_export 'EMOIMG|EMOASC,number' --exp_syntagma_typ pos
- Normal-search (search in non-stemmed lexems)
$ zas-rep-tools stats export --stats_fname 7614_3497_stats_bloggerCorpus_de_extern_plaintext.db --export_file_type csv --exp_repl True --exp_redu True --output_table_type exhausted --syntagma_for_export 'klitze,kleine' --exp_syntagma_typ lexem
- Sentiment Search
<sub> Additional to each export command you can use following options to search just in certain sentiment </sub>
'--exp_sentiment'
There was implemented 3 different sentiment polarity:
["neutral", "positive","negative"]
<br>
**Summary Output-Tables**
- ***Replications*** (Letters)
- Normal search
$ zas-rep-tools stats export --stats_fname 7614_3497_stats_bloggerCorpus_en_extern_plaintext.db --export_file_type csv --output_table_type sum --exp_repl True --word_examples_sum_table True
- POS-search
$ zas-rep-tools stats export --stats_fname 7614_3497_stats_bloggerCorpus_de_extern_plaintext.db --export_file_type csv --exp_redu False --exp_repl True --max_scope 1 --output_table_type sum --syntagma_for_export 'EMOIMG|EMOASC' --exp_syntagma_typ pos
- Stemmed-Search
$ zas-rep-tools stats export --stats_fname 7614_3497_stats_bloggerCorpus_de_extern_plaintext.db --export_file_type csv --exp_repl True --output_table_type sum --syntagma_for_export 'klitze,kleine' --exp_syntagma_typ lexem --stemmed_search True
- Sentiment Search
<sub> See before</sub>
- ***Reduplications*** (Words)
- Normal search
$ zas-rep-tools stats export --stats_fname 7614_3497_stats_bloggerCorpus_en_extern_plaintext.db --export_file_type csv --output_table_type sum --exp_redu True --word_examples_sum_table True
- POS-search + Stemmed-Search + Sentiment Search
<sub> See before </sub>
---
<br/>
#### Stream Twitter
$ zas-rep-tools streamTwitter . --language de --filter_strategie "t+l"
<br/>
---
---
---
---
<br/>
<a name="input/output"/>
<p style='text-align: right;'> <sub> <a href="#toc">Back to top</a>
</sub> </p>
## 8. Input/Output
### Input
- **FileTypes:**
- csv
- xml
- json
- txt
- zip
### Output
- **FileTypes:**
- csv
- xml
- json
- **Columns in the Output Tables**
- **Baseline**
- syntagma
<sub>Search Syntagma</sub>
- stemmed
<sub>stemmed syntagma</sub>
- occur_syntagma_all
<sub>Occurrence Number of the current syntagma in the whole corpus</sub>
- occur_repl_uniq
<sub>Occurrence Number of the uniq replication in the current syntagma</sub>
- occur_repl_exhausted
<sub>Occurrence Number of the exhausted replication in the current syntagma</sub>
- occur_redu_uniq
<sub>Occurrence Number of the uniq reduplication in the current syntagma</sub>
- occur_redu_exhausted
<sub>Occurrence Number of the exhausted reduplication in the current syntagma</sub>
- occur_full_syn_repl
<sub>Occurrence Number of the full-repetativ syntagma according replications</sub>
- occur_full_syn_redu
<sub>Occurrence Number of the full-repetativ syntagma according reduplications</sub>
- **Document**
- doc_id
<sub>ID-Number of the current Document</sub>
- redufree_len
<sub>Length of the current Text Element from the current Document</sub>
- **Word**
- normalized_word
<sub>Repetitions-Free word</sub>
- rle_word
<sub>RunLengthEncoded Word</sub>
- stemmed
<sub>Stemmed Words</sub>
- pos
<sub>Part of Speech Tag</sub>
- polarity
<sub>Polarity/Sentiment of the word context and also word it self.</sub>
- **Repl**
- id
<sub>Replications ID Number</sub>
- index_in_corpus
<sub>Address of the current Word in the corpus.</sub>
- index_in_redufree
<sub>Address of the current Word in the reduplications free text element.</sub>
- repl_letter
<sub>Replicated letter</sub>
- repl_length
<sub>Length of the replication</sub>
- index_of_repl
<sub>Index of the current replicated letter in the current normalized_word started from 0</sub>
- in_redu
<sub>If current word, which contain an replication is also a part of one reduplication, than here will be the Address of this reduplication</sub>
- **Redu**
- id
<sub>Reduplications ID Number</sub>
- index_in_corpus
<sub>Address of the current reduplication in the corpus, which </sub>
- index_in_redufree
<sub>Address of the current reduplications in the reduplications free text element.</sub>
- orig_words
<sub>rle_words and their occurrence number contained in the current reduplication </sub>
- redu_length
<sub>The Length of the current reduplication</sub>
- **context**
- contextL{number}
<sub>Context Word left from the current token</sub>
- context_infoL{number}
<sub>Additional Data for the Context Word left from the current token</sub>
- contextR{number}
<sub>Context Word right from the current token</sub>
- context_infoR{number}
<sub>Additional Data for the Context Word right from the current token</sub>
- **Precomputed Example Tables**
In the Folder 'zas_rep_tools/examples' you could found precomputed examples of the output tables and also the input text collection.
<br/>
---
---
---
---
<br/>
<a name="restrictions"/>
<p style='text-align: right;'> <sub> <a href="#toc">Back to top</a>
</sub> </p>
## 9. Restrictions
**Input:**
- TXT:
currently this tool-set support just those txt-files, which has all meta-data in the filename, which could be matched with an regex expression.
<br/>
---
---
---
---
<br/>
<a name="citing"/>
<p style='text-align: right;'> <sub> <a href="#toc">Back to top</a>
</sub> </p>
## 10. Citing ZAS-REP-TOOLS
### How do I Cite AutoVOT in my articles?
***If possible to cite a program, the following format is recommended (adjusting retrieval dates and versions as necessary):***
* Savin, E., Fuchs, S., Ćwiek, A. (2018). ZAS-VOT-TOOLS: A tool for automatic extraction and quantification of the repetition from the written language. [Computer program]. Version 0.1, retrieved August 2018 from https://github.com/savin-berlin/zas-rep-tools.
<br/>
---
---
---
---
<br/><br/>
<a name="errors"/>
<p style='text-align: right;'> <sub> <a href="#toc">Back to top</a>
</sub> </p>
## 11. Possible errors and warnings
#### 1. Error: 'Too many open files:'
#####Solutions:
1. Increase the max number of open files in system:
###### macOS:
$ sudo launchctl limit maxfiles 3000000 3000000
$ sysctl -a | grep kern.maxfiles
(If still not be worked, that test every component separated)
###### Ubuntu:
$ cat /proc/sys/fs/file-max
$ ulimit -n 300000
$ ulimit -n
#### 2. Error: "MemoryError"
It means that your Computer dont have enought of the RAM or the Swap is to short. Please try to increase Swap on your computer.
###### Ubuntu:
$ size="8G" && file_swap=/swapfile_$size.img && sudo touch $file_swap && sudo fallocate -l $size /$file_swap && sudo mkswap /$file_swap && sudo swapon -p 20 /$file_swap
$ sudo swapon --show
$ free -h
#### 3. Error: In Windows Environment - to long reaction
If during the installation process some commands needs more as 5-10 min than try to push "ENTER" Button to ensure the refreshing of the command line
#### 4. UnicodeDecodeError: 'ascii' codec can't decode byte in position : ordinal not in range(128)
- It could be a Problem with the choiced encoding
- or the input command wasn't recognized in the right way (corrupt syntax).
#### 5. 'Permission Error' or 'UserConfigDBGetterError:'
- execute the command with the admin rights (with following prefix "sudo")
<br/>
---
---
---
---
<br/>
<a name="data"/>
<p style='text-align: right;'> <sub> <a href="#toc">Back to top</a>
</sub> </p>
## 12. Data-Examples
There are also available following examples:
- ***StatdDBs*** and ***CorpusDBs***
<sub> You can copy-paste this data in your project folders and try to work with that. </sub>
- 'zas_rep_tools/data/tests_data/testDBs/testFolder'
- ***Output tables*** (csv)
- 'zas_rep_tools/examples'
<br/>
---
---
---
---
<br/>
<a name="acknowledgements"/>
<p style='text-align: right;'> <sub> <a href="#toc">Back to top</a>
</sub> </p>
## 13. Acknowledgements
#### A big Thank to the following Peoples, who makes this work and current results possible:
- [Susanne Fuchs](mailto:[email protected]) <sup>*(Linguistic & Organization )*</sup>
- [Ulf Leser](mailto:[email protected]) <sup>*(Computer Science & Organization )*</sup>
- [Aleksandra Ćwiek](mailto:[email protected]) <sup>*(Linguistic)*</sup>
- [Bodo Winter](mailto:[email protected]) <sup>*(Statistical & linguistic Expertise)*</sup>
- [Stephanie Solt](mailto:[email protected]) <sup>*(Semantics&Pragmatics)*</sup>
- [Cornelia Ebert](mailto:[email protected]) <sup>*(Phonology&Semantics&Pragmatics)*</sup>
- [Manfred Krifka](mailto:[email protected]) <sup>*(Semantics&Pragmatics)*</sup>
- [Dominik Koeppl](mailto:[email protected]) <sup>*(Combinatorics on Words)*</sup>
- [Tatjana Scheffler](mailto:[email protected]) <sup>*(NLP+Twitter expertise)*</sup>
- [Stefan Thater](mailto:[email protected]) <sup>*(NLP expertise)*</sup>
- [Katarzyna Stoltmann](mailto:[email protected]) <sup>*(Linguistic & NLP&Organisation)*</sup>
- [Christina Beckmann](mailto:[email protected]) <sup>*(Bibliographical Expertise)*</sup>
- [Tomasz Kociumaka](mailto:[email protected]) <sup>*(Combinatorics on Words)*</sup>
- [Frantisek Franek](mailto:[email protected]) <sup>*(Combinatorics on Words)*</sup>
<br/>
<p align="center">
<table style="width:100%">
<tr>
<th><img src="http://www.zas.gwz-berlin.de/uploads/pics/dfg_logo_blau_klein_1a3937.jpg"></th>
<th><img src="http://www.zas.gwz-berlin.de/uploads/pics/xprag_logo_32.jpg"></th>
<th><img src="http://www.zas.gwz-berlin.de/typo3temp/pics/6969c56953.png"></th>
</tr>
<tr>
<td colspan = "3">
<center>
<img src="http://www.zas.gwz-berlin.de/fileadmin/images/logo2011.png">
</center>
</td>
</tr>
<tr>
<td colspan = "3">
<p>
<center>
This research was supported by an DFG and XPRAG.de grants <br/> to the Leibniz-Center General Linguistics.
</center>
</p>
</td>
</tr>
</table>
</p>
| zas-rep-tools | /zas-rep-tools-0.2.tar.gz/zas-rep-tools-0.2/README.md | README.md |
import subprocess
import shlex
import os
import sys
from zas_rep_tools.src.utils.helpers import path_to_zas_rep_tools
from zas_rep_tools.src.utils.debugger import p
# The only relavent source I've found is here:
# http://m1ked.com/post/12304626776/pos-tagger-for-twitter-successfully-implemented-in
# which is a very simple implementation, my implementation is a bit more
# useful (but not much).
# NOTE this command is directly lifted from runTagger.sh
path_to_zas_rep_tools
path_to_jar = os.path.join(path_to_zas_rep_tools, "src/extensions/tweet_nlp/ark_tweet_nlp/ark-tweet-nlp-0.3.2.jar")
RUN_TAGGER_CMD = "java -XX:ParallelGCThreads=2 -Xmx500m -jar {}".format(path_to_jar)
def _split_results(rows):
"""Parse the tab-delimited returned lines, modified from: https://github.com/brendano/ark-tweet-nlp/blob/master/scripts/show.py"""
for line in rows:
line = line.strip() # remove '\n'
if len(line) > 0:
if line.count('\t') == 2:
parts = line.split('\t')
tokens = parts[0]
tags = parts[1]
try:
confidence = float(parts[2])
except ValueError:
confidence = float(parts[2].replace(",", ".") )
yield tokens, tags, confidence
def _call_runtagger(tweets, run_tagger_cmd=RUN_TAGGER_CMD):
"""Call runTagger.sh using a named input file"""
# remove carriage returns as they are tweet separators for the stdin
# interface
tweets_cleaned = [tw.replace('\n', ' ') for tw in tweets]
message = "\n".join(tweets_cleaned)
# force UTF-8 encoding (from internal unicode type) to avoid .communicate encoding error as per:
# http://stackoverflow.com/questions/3040101/python-encoding-for-pipe-communicate
message = message.encode('utf-8')
# build a list of args
args = shlex.split(run_tagger_cmd)
args.append('--output-format')
args.append('conll')
po = subprocess.Popen(args, stdin=subprocess.PIPE, stdout=subprocess.PIPE, stderr=subprocess.PIPE)
# old call - made a direct call to runTagger.sh (not Windows friendly)
#po = subprocess.Popen([run_tagger_cmd, '--output-format', 'conll'], stdin=subprocess.PIPE, stdout=subprocess.PIPE, stderr=subprocess.PIPE)
result = po.communicate(message)
# expect a tuple of 2 items like:
# ('hello\t!\t0.9858\nthere\tR\t0.4168\n\n',
# 'Listening on stdin for input. (-h for help)\nDetected text input format\nTokenized and tagged 1 tweets (2 tokens) in 7.5 seconds: 0.1 tweets/sec, 0.3 tokens/sec\n')
pos_result = result[0].strip('\n\n') # get first line, remove final double carriage return
pos_result = pos_result.split('\n\n') # split messages by double carriage returns
pos_results = [pr.split('\n') for pr in pos_result] # split parts of message by each carriage return
return pos_results
def runtagger_parse(tweets, run_tagger_cmd=RUN_TAGGER_CMD):
"""Call runTagger.sh on a list of tweets, parse the result, return lists of tuples of (term, type, confidence)"""
pos_raw_results = _call_runtagger(tweets, run_tagger_cmd)
#print "tweets=", tweets
#print "pos_raw_results=",pos_raw_results
#sys.exit()
pos_result = []
#print tweets
for pos_raw_result in pos_raw_results:
#p(pos_raw_results, "pos_raw_result")
#sys.exit()
#print "1pos_raw_result=", pos_raw_result
splitted = list(_split_results(pos_raw_result))[0]
#print "splitted=", splitted
#p((len(splitted),splitted), "splitted)")
pos_result.append((splitted[0].decode("utf-8"),splitted[1].decode("utf-8")))
#p(pos_result, "pos_result")
return pos_result
def check_script_is_present(run_tagger_cmd=RUN_TAGGER_CMD):
"""Simple test to make sure we can see the script"""
success = False
try:
args = shlex.split(run_tagger_cmd)
#print args
args.append("--help")
po = subprocess.Popen(args, stdout=subprocess.PIPE)
#print(po.communicate())
# old call - made a direct call to runTagger.sh (not Windows friendly)
#po = subprocess.Popen([run_tagger_cmd, '--help'], stdout=subprocess.PIPE)
#p(po.poll(), "11po.poll()")
i = -1
while not po.poll():
i+= 1
#for answer in po.poll():
#if not answer:
# break
#p(po.poll(), "po.poll()")
#_1 = repr(answer)
#_2 = type(answer)
#print "_1= ", _1, " _2= ", _2
stdout = list(po.stdout)
#p(stdout, "stdout")
if i >= 2: break
if not stdout: break
lines = [l for l in stdout]
return "RunTagger [options]" in lines[0]
#p(lines,"lines")
#print
# we expected the first line of --help to look like the following:
#success = True
except OSError as err:
print "Caught an OSError, have you specified the correct path to runTagger.sh? We are using \"%s\". Exception: %r" % (run_tagger_cmd, repr(err))
return success
if __name__ == "__main__":
print "Checking that we can see \"%s\", this will crash if we can't" % (RUN_TAGGER_CMD)
success = check_script_is_present()
if success:
print "Success."
print "Now pass in two messages, get a list of tuples back:"
tweets = ['this is a message', 'and a second message']
print runtagger_parse(tweets) | zas-rep-tools | /zas-rep-tools-0.2.tar.gz/zas-rep-tools-0.2/zas_rep_tools/src/extensions/tweet_nlp/ark_tweet_nlp/CMUTweetTagger.py | CMUTweetTagger.py |
CMU ARK Twitter Part-of-Speech Tagger v0.3
http://www.ark.cs.cmu.edu/TweetNLP/
Basic usage
===========
Requires Java 6. To run the tagger from a unix shell:
./runTagger.sh examples/example_tweets.txt
The tagger outputs tokens, predicted part-of-speech tags, and confidences.
See:
./runTagger.sh --help
We also include a script that invokes just the tokenizer:
./twokenize.sh examples/example_tweets.txt
You may have to adjust the parameters to "java" depending on your system.
Information
===========
Version 0.3 of the tagger is much faster and more accurate. Please see the
tech report on the website for details.
For the Java API, see src/cmu/arktweetnlp; especially Tagger.java.
See also documentation in docs/ and src/cmu/arktweetnlp/package.html.
This tagger is described in the following two papers, available at the website.
Please cite these if you write a research paper using this software.
Part-of-Speech Tagging for Twitter: Annotation, Features, and Experiments
Kevin Gimpel, Nathan Schneider, Brendan O'Connor, Dipanjan Das, Daniel Mills,
Jacob Eisenstein, Michael Heilman, Dani Yogatama, Jeffrey Flanigan, and
Noah A. Smith
In Proceedings of the Annual Meeting of the Association
for Computational Linguistics, companion volume, Portland, OR, June 2011.
http://www.ark.cs.cmu.edu/TweetNLP/gimpel+etal.acl11.pdf
Part-of-Speech Tagging for Twitter: Word Clusters and Other Advances
Olutobi Owoputi, Brendan O'Connor, Chris Dyer, Kevin Gimpel, and
Nathan Schneider.
Technical Report, Machine Learning Department. CMU-ML-12-107. September 2012.
Contact
=======
Please contact Brendan O'Connor ([email protected]) and Kevin Gimpel
([email protected]) if you encounter any problems.
| zas-rep-tools | /zas-rep-tools-0.2.tar.gz/zas-rep-tools-0.2/zas_rep_tools/src/extensions/tweet_nlp/ark_tweet_nlp/README.txt | README.txt |
These notes were taken by Nathan during Daily 547 annotations. Not all final annotation decisions followed the below.
#### Preposition-y things ####
difficult decision in annotation: preposition-like verb modifiers. preposition, particle, or adverb?
* I am only tagging as particles (T) intransitive prepositions for verbs which can be transitive
(e.g., 'up' in 'wake up'/'wake up his friend'). I do not use T for the rare verbs and adjectives that
can serve as particles (cut *short*, let *go*). 'around' in 'turn around the company/turn the company around'
is also a particle.
* For 41852812245598208 (stick around) I went with P because 'stick around' cannot be transitive
(I think 'stick around the house' is [stick [around the house]], not [[stick around\] \[the house]]).
* For 'turn (a)round' meaning rotate oneself to face another direction, I tagged as R. I guess this feels
right because 'around' in this case indicates a path without relating two (overt or implied) entities. (The path is intrinsic?)
### Nathan's notes from annotation ###
(✓ = added below)
* ✓ proposed rule: titles/forms of address with personal names are ^: Mr., Mrs., Sir, Aunt, President, Captain.-
On their own, they are common nouns, even in the official name of an office: _President/^ Obama/^ said/V_, _the/D president/N said/V_, _he/O is/V president/N of/P the/D U.S./^_
[PTB looks inconsistent, relying too much on capitalization]
* ✓ a big issue with the default tags: 'that' functioning as a pronoun but tagged as D.
- Kevin points out that always tagging 'that' as a determiner follows the PTB (where the distinction can be seen not in the POS tag but in the containing phrase—the pronoun-like use is annotated as a DT which is its own NP).
- I have been tagging that/O but those are easy converted as postprocessing if we want to ensure consistency.
- similarly, I have noticed a couple instances of all/D which could arguably be pronouns (_all who/that VP_), but I haven't changed these.
* ✓ proposed rule: units of measurement are common nouns, even if they come from a person's name (like _Celsius_)
* ✓ proposed rule: cardinal directions (_east_, _NNW_) are common nouns (in all cases?)
Difficult cases:
* 25244937167568896 x2 - emoticon? 2 times?
* 26042601522073600 that one - one tagged as pronoun
* ✓ 26085492428636161 Prime Minister
* 26085492428636161 cash-for-sex
* 28569472516235264 ass clitic
* 30656193286377472 mention of the word "aint" (metalinguistic)
* 30656193286377472 yes, no
* 32189630715535361 you two
* ✓ 32468904269844480 Let's (verbal + nominal)? 38756380194254849 buy'em
* 32942659601440768 (several issues)
* ✓ 36246374219522048 vocative 'dude' (noun? interjection?)
- per below, should be a noun
* 36246374219522048 down there
* 36949436257013760, 37310741828603905 Valentine's Day (^ ^ or Z N?)
* 37935252550860800 up for grabs
* 38756380194254849 All-star Weekend (^ ^ or N N?)
* 41198546862616576 Trueshit (! or N?)
* 43341785887543296 "It kinda feels like a junk food kinda day." - different senses of _kinda_! first one is a hedge; second one is really _kind of_ (like _type of_).
- first tagged as R, second tagged as G
* 49149970200272896 "Xbox Kinect FAIL"
- FAIL as N (because it would be _spectacular FAIL_, not _*spectacularly FAIL_)
* 49559011401531392 "SHM" = shower, hair, makeup
- tagged as N per below...this would be a good example to list
* ✓ 49931213963665408 "mfw" = my face when (not sure I've ever seen an abbreviation ending with a complementizer!)
- tagged as G
* ✓ 51858412669124608 at-mentions @wordpress and @joomla are clearly used within the sentence. cf. 58666191618719744, 65450293604777984
- we still use @ regardless of context (unlike with hashtags)
* ✓ Citizens United? Media Lab? are the nouns here N or ^?
- (clarifying the discussion below) For most proper names, all content words are ^ regardless of whether there is internal syntactic structure. An exception is made for titles of works which have an "internal interpretation" independent of the reference to the work, and which contain non-nouns: for such cases the title is tagged as if it were a normal phrase. Function words are only tagged with ^ if they are not behaving in a normal syntactic fashion, e.g. Ace/^ of/^ Base/^.
* 81421997929795585 "the other person feelings" - SAE would be person's/S, but should this just be N? | zas-rep-tools | /zas-rep-tools-0.2.tar.gz/zas-rep-tools-0.2/zas_rep_tools/src/extensions/tweet_nlp/ark_tweet_nlp/docs/nathan_notes.md | nathan_notes.md |
Annotation Guidelines for Twitter Part-of-Speech Tagging
========================================================
Authors: Kevin Gimpel, Nathan Schneider, Brendan O'Connor
2012-09-20, for the 0.3 data release (http://www.ark.cs.cmu.edu/TweetNLP/)
Introduction
------------
Social media text differs markedly from traditional written genres like newswire,
including in ways that bear on linguistic analysis schemes. Here we describe __a
part-of-speech (POS) tagset used to annotate tweets__, elaborating on
[this ACL 2011 paper with many authors](http://www.cs.cmu.edu/~nasmith/papers/gimpel+etal.acl11.pdf).
That paper discusses design goals, introduces the tagset, and presents experimental
results for a supervised tagger. (The annotated datasets have since been expanded and the
tagger improved.)
Table 1 of the paper provides an overview of the 25 tags. Each is represented with a
single ASCII symbol. In brief:
* __Nominal__
`N` common noun
`O` pronoun (personal/WH; not possessive)
`^` proper noun
`S` nominal + possessive
`Z` proper noun + possessive
* __Other open-class words__
`V` verb incl. copula, auxiliaries
`A` adjective
`R` adverb
`!` interjection
* __Other closed-class words__
`D` determiner
`P` pre- or postposition, or subordinating conjunction
`&` coordinating conjunction
`T` verb particle
`X` existential _there_, predeterminers
* __Twitter/online-specific__
`#` hashtag (indicates topic/category for tweet)
`@` at-mention (indicates another user as a recipient of a tweet)
`~` discourse marker, indications of continuation of a message across multiple tweets
`U` URL or email address
`E` emoticon
* __Miscellaneous__
`$` numeral
`,` punctuation
`G` other abbreviations, foreign words, possessive endings, symbols, garbage
* __Other Compounds__
`L` nominal + verbal (e.g. _i'm_), verbal + nominal (_let's_, _lemme_)
`M` proper noun + verbal
`Y` `X` + verbal
Since our tokenization scheme avoids splitting most surface words, we opt for
complex parts of speech where necessary; for instance, _Noah’s_ would receive the `Z`
(proper noun + possessive) tag.
Tokenization
------------
The __twokenize__ tool included with the ARK TweetNLP package handles tokenization.
It seeks to identify word-external punctuation tokens and emoticons — not an easy task given
Twitter’s lack of orthographic orthodoxy!
When multiple words are written together without spaces, or when there are spaces
between all characters of a word, or when the tokenizer fails to split words,
we tag the resulting tokens as `G`. This is illustrated by the bolded tokens in the
following examples:
* It's Been Coldd :/ __iGuess__ It's Better Than Beingg Hot Tho . Where Do Yuhh Live At ? @iKnow\_YouWantMe
* This yearâs almond crop is a great one . And the crop is being shipped fresh to __youâŠNow__ !
* RT @Mz\_GoHAM Um ..... #TeamHeat ........ wut Happend ?? Haha <== #TeamCeltics showin that ass what's __good...That's__ wat happened !!! LMAO
* \#uWasCoolUntil you unfollowed me ! __R E T W E E T__ if you Hate when people do that for no reason .
<!--
28873458992 L V A E G L A P V A R , R V O V P ,
28899336035 D S N N V D A $ , & D N V V V A P G ,
28847830495 # O V O , G G G G G G G P O V R N V D P D N ,
-->
We decided not to manually fix tokenization errors (like in the third example above)
before POS annotation. We made this decision because we want to be able to run our
tagger on new text that is tokenized automatically, so we need to _train_ the tagger on annotated
data that is tokenized in the same way.
Penn Treebank Conventions
-------------------------
Generally, we followed the Penn Treebank (PTB) WSJ conventions in determining parts of speech.
However, there are many inconsistencies in the PTB annotations. We attempted to follow
the majority convention for a particular use of a word, but in some cases we did not.
Specific cases which caused difficulty for annotators or necessitated a departure from the PTB
approach are discussed below.
Gerunds and Participles
-----------------------
Verb forms are nearly always given a verbal tag in the PTB (VBG for _-ing_ forms,
VBD for _-ed_ forms), so we generally tag them as `V` in our dataset.
However, PTB sometimes tags as nouns or adjectives words such as
_upcoming_, _annoying_, _amazing_, _scared_,
_related_ (as in _the related article_), and _unexpected_.
We follow the PTB in tagging these as adjectives or nouns, appropriately.
Numbers and Values
------------------
* __Cardinal numbers__ are tagged as `$`.
* __Ordinal numbers__ are typically tagged as adjectives, following the PTB, except for cases like
_28th October_, in which _28th_ is tagged as `$`.
* __Times__
Following the Treebank, _A.M._ and _P.M._ are common nouns, while time zones (_EST_, etc.) are proper nouns.
* __Days, months, and seasons__
Like the PTB, days of the week and months of the year are always tagged as proper nouns, while seasons are common nouns.
* __Street addresses__
We follow the PTB convention of tagging numbers (house numbers, street numbers, and zip codes) as `$` and all other words
in the address as proper nouns. Consider the following PTB example:
- 153/CD East/NNP 53rd/CD St./NNP
However, this is not entirely consistent in the PTB. Certain street numbers in the PTB are tagged as proper nouns:
- Fifth/NNP Ave/NNP
Annotators are to use their best judgment in tagging street numbers.
* __Cardinal directions__ (_east_, _NNW_) referred to in isolation (not as a modifier or part of a name) are common nouns
* __Units of measurement__ are common nouns, even if they come from a person’s name (like _Celsius_)
<!-- TODO: inconsistency in the data: °C/N in 95974936845352960 but °F/^ in 28883465935 -->
Time and location nouns modifying verbs
---------------------------------------
In the PTB, time and location nouns (words like _yesterday_/_today_/_tomorrow_, _home_/_outside_, etc.)
that modify verbs are inconsistently labeled.
The words _yesterday_/_today_/_tomorrow_ are nearly always tagged as nouns, even when modifying verbs.
For example, in the PTB _today_ is tagged as NN 336 times and RB once. We note, however, that sometimes
the parse structure can be used to disambiguate the NN tags. When used as an adverb, _today_ is often
the sole child of an NP-TMP, e.g.,
- (NP-SBJ (DT These) (JJ high) (NNS rollers) )
(VP (VBD took)
(NP (DT a) (JJ big) (NN bath) )
(NP-TMP (NN today) )))
When used as a noun, it is often the sole child of an NP, e.g.,
- (PP-TMP (IN until) (NP (NN today) ))
Since we are not annotating parse structure, it is less clear what to do with our data. In attempting
to be consistent with the PTB, we typically tagged _today_ as a noun.
The PTB annotations are less clear for words like _home_. Of the 24 times that _home_ appears as the
sole child under a _DIR_ (direction) nonterminal, it is annotated as
- (ADVP-DIR (NN home) ) 14 times
- (ADVP-DIR (RB home) ) 6 times
- (NP-DIR (NN home) ) 3 times
- (NP-DIR (RB home) ) 1 time
Manual inspection of the 24 occurrences revealed no discernible difference in usage that would
warrant these differences in annotation. As a result of these inconsistencies, we decided to let
annotators use their best judgment when annotating these types of words in tweets,
asking them to refer to the PTB and to previously-annotated data to improve consistency.
<!-- [TODO: examples] [actually, I see at least one PTB example
that is _go home/RB_. Another possibility is to treat these as intransitive prepositions:
_go home/P_, _go outside/P_.] -->
Names
-----
In general, every noun within a proper name should be tagged as a proper noun (`^`):
* Jesse/^ and/& the/D Rippers/^
* the/D California/^ Chamber/^ of/P Commerce/^
Company and web site names (_Twitter_, _Yahoo ! News_) are tagged as proper nouns.
<!-- the/DT California/NNP Chamber/NNP of/IN Commerce/NNP -- this was a PTB example, I have substituted Twitter tags -->
Function words are only ever tagged as proper nouns
if they are not behaving in a normal syntactic fashion, e.g. _Ace/^ of/^ Base/^_.
* __Personal names__
Titles/forms of address with personal names should be tagged as proper nouns:
_Mr._, _Mrs._, _Sir_, _Aunt_, _President_, _Captain_
On their own—not preceding someone’s given name or surname—they are common nouns,
even in the official name of an office: _President/^ Obama/^ said/V_,
_the/D president/N said/V_, _he/O is/V president/N of/P the/D U.S./^_
* __Titles of works__
In PTB, simple titles like _Star Wars_ and _Cheers_ are tagged as proper nouns,
but titles with more extensive phrasal structure are tagged as ordinary phrases:
- A/DT Fish/NN Called/VBN Wanda/NNP
Note that _Fish_ is tagged as NN (common noun). Therefore, we adopt the following
rule: __titles containing only nouns should be tagged as proper nouns, and other titles as ordinary phrases__.
<!--Friday Night Lights = ^^^ ?-->
<!--Justin Bieber's " My World " -- 28867570795-->
Prepositions and Particles
--------------------------
To differentiate between prepositions and verb particles (e.g., _out_ in _take out_), we asked annotators to
use the following test:
- if you can insert an adverb within the phrasal verb, it's probably a preposition rather than a particle:
- turn slowly into/P a monster
- *take slowly out/T the trash
Some other verb particle examples:
* what's going on/T
* check it out/T
* shout out/T
- abbreviations like _s/o_ and _SO_ are tagged as `V`
_this_ and _that_: Demonstratives and Relativizers
------------------------------------
PTB almost always tags demonstrative _this_/_that_ as a determiner, but in cases where it is
used pronominally, it is immediately dominated by a singleton NP, e.g.
* (NP (DT This)) is Japan
For our purposes, since we do not have parse trees and want to straightforwardly use the tags
in POS patterns, we tag such cases as pronouns:
* i just orgasmed over __this/O__
<!-- 28139103509815297 -->
as opposed to
* __this/D__ wind is serious
<!-- 194552682147610625 -->
Words where we were careful about the `D`/`O` distinction include, but are not limited
to: _that, this, these, those, dat, daht, dis, tht_.
When _this_ or _that_ is used as a relativizer, we tag it as `P` (never `O`):
* You should know , __that/P__ if you come any closer ...
* Never cheat on a woman __that/P__ holds you down
<!-- 87519526148780032 115821393559552000 -->
(Version 0.2 of the ACL-2011 data often used this/D for nominal usage, but was somewhat inconsistent.
For the 0.3 release, we changed the tags on the ACL-2011 tweets to conform to the new style; all Daily547 tags conform as well.)
WH-word relativizers are treated differently than the above: they are sometimes tagged as `O`, sometimes as `D`, but never as `P`.
<!-- [TODO: should we normalize them somehow? or another can of worms?] -->
Quantifiers and Referentiality
------------------------------
* A few non-prenominal cases of _some_ are tagged as pronouns (_get some/O_). However, we use _some/D of_, _any/D of_, _all/D of_.
* _someone_, _everyone_, _anyone_, _somebody_, _everybody_, _anybody_, _nobody_, _something_, _everything_, _anything_, and _nothing_ are almost always tagged as nouns
* _one_ is usually tagged as a number, but occasionally as a noun or pronoun when it is referential (inconsistent)
* _none_ is tagged as a noun
* _all_, _any_ are almost always tagged as a (pre)determiner or adverb
* _few_, _several_ are tagged as an adjective when used as a modifier, and as a noun elsewhere
* _many_ is tagged as an adjective
* _lot_, _lots_ (meaning a large amount/degree of something) are tagged as nouns
<!-- TODO: some apparent inconsistencies in the data: someone/O, anyone/O, any1/O, all/O, Everybody/O. many/A in 28914826190, 28897684962 are not prenominal and thus might be reconsidered in light of 'few', 'several', and 'many'. Also, I think most/A in 28905710274 ought to be an adverb. -->
Hashtags and At-mentions
------------------------
As discussed in the [ACL paper](http://www.cs.cmu.edu/~nasmith/papers/gimpel+etal.acl11.pdf),
__hashtags__ used within a phrase or sentence are not
distinguished from normal words. However, when the hashtag is external to the syntax
and merely serves to categorize the tweet, it receives the `#` tag.
__At-mentions__ _always_ receive the `@` tag, even though they occasionally double
as words within a sentence.
Multiword Abbreviations
------------------------
Some of these have natural tag correspondences: _lol_ (laughing out loud) is typically
an exclamation, tagged as `!`; _idk_ or _iono_ (I don’t know) can be tagged as `L`
(nominal + verbal).
Miscellaneous kinds of abbreviations are tagged with `G`:
* _ily_ (I love you)
* _wby_ (what about you)
* _mfw_ (my face when)
<!-- removed let's from list above since we tag it as L. was: _let's_ (let us) -->
<!-- TODO: buy'em should also be tagged as L, but in the data it is V. -->
Metalinguistic Mentions
-----------------------
Mentions of a word (typically in quotes) are tagged as if the word had been used normally:
* RT @HeyKikO Every girl lives for the " unexpected hugs from behind " moments < I wouldn't say " __live__ "... but they r nice
> Here _live_ is tagged as a verb.
Clipping
--------
Due to space constraints, words at the ends of tweets are sometimes cut off.
We attempt to tag the partial word as if it had not been clipped. If the tag is unclear,
we fall back to `G`:
* RT @ucsantabarbara : Tonight's memorial for Lucas Ransom starts at 8:00 p.m. and is being held at the open space at the corner of Del __Pla__ ...
> We infer that _Pla_ is a clipped proper name, and accordingly tag it as `^`.
* RT @BroderickWalton : Usually the people that need our help the most are the ones that are hardest 2 get through 2 . Be patient , love on __t__ ...
> The continuation is unclear, so we fall back to _t/G_.
<!--
28841569916 ~ @ ~ S N P ^ ^ V P $ N & V V V P D A N P D N P ^ ^ ~
28905710274 ~ @ ~ R D N P V D N D A V D N D V R P V P P , V N , V P G ~
-->
<!--Why does the wifi on my boyfriend& #8217 ; s macbook pro have speed ...: We were trying to figure out why download sp ... http://bit.ly/dbpcE1
"sp" is clearly trimmed due to space constraints, so we tag it as G.-->
Symbols, Arrows, etc.
---------------------
<!--
28860873076 ~ @ ~ V O , L A G U
28841534211 U G # $ ^ ^ , A ^ , N D ^ , V
-->
* RT @YourFavWhiteGuy : Helppp meeeee . I'mmm meltiiinngggg --> http://twitpic.com/316cjg
* http://bit.ly/cLRm23 <-- #ICONLOUNGE 257 Trinity Ave , Downtown Atlanta ... Party This Wednesday ! RT
These arrows (_-->_ and _<--_) are tagged as `G`. But see the next section for
Twitter discourse uses of arrows, which receive the `~` tag.
Twitter Discourse Tokens: Retweets, Continuation Markers, and Arrow Deixis
--------------------------------------------------------------------------
A common phenomenon in Twitter is the __“retweet construction”__, shown in the following example:
<!--28841537250 ~ @ ~ ^ V D N P O ,-->
* RT @Solodagod : Miami put a fork in it ...
The _RT_ indicates that what follows is a “retweet” of another tweet. Typically it is
followed by a Twitter username in the form of an at-mention followed by a colon (:). In this
construction, we tag both the _RT_ and _:_ as `~`.
It is often the case that, due to the presence of the retweet header information, there is
not enough space for the entirety of the original tweet:
<!--28841503214-->
<!--~ @ ~ P P D N P ^ , O V R V T D N , O V A N , V O V D N P V D G ~-->
<!--huma = G-->
* RT @donnabrazile : Because of the crisis in Haiti , I must now turn down the volume . We are one people . Let us find a way to show our huma ...
Here, the final _..._ is also tagged as `~` because it is not
intentional punctuation but rather indicates that the tweet has been cut short
due to space limitations. (cf. ["Clipping" above](#clipping))
Aside from retweets, a common phenomenon in tweets is posting a link to a news story or other
item of interest on the Internet. Typically the headline/title and beginning of the article
begins the tweet, followed by _..._ and the URL:
<!--28841540324-->
<!--A ^ N N V N P , R A A N , A N V T P D A N ~ U-->
* New NC Highway Signs Welcome Motorists To " Most Military Friendly State ": New signs going up on the major highways ... http://bit.ly/cPNH6e
> Since the ellipsis indicates that the text in the tweet is continued elsewhere (namely
at the subsequent URL), we tag it as `~`.
Sometimes instead of _..._, the token _cont_ (short for “continued”) is used to indicate
continuation:
<!--28936861036 O V O V V D A N O V P , V ^ ^ N , P P O V L P O ~ @ ~ ^ , ~ , U-->
* I predict I won't win a single game I bet on . Got Cliff Lee today , so if he loses its on me RT @e\_one : Texas ( cont ) http://tl.gd/6meogh
> Here, _cont_ is tagged as `~` and the surrounding parentheses are tagged as punctutation.
Another use of `~` is for tokens that indicate that one part of a tweet is a response to
another part, particularly when used in an RT construction. Consider:
<!--RT @ayy_yoHONEY : . #walesaid dt @its_a_hair_flip should go DOWNTOWN ! Lol !!.. #jammy -->~LMAO !! Man BIANCA !!!-->
<!--28860458956 ~ @ ~ A N V Z N P ^ ~ O V O V P O ,-->
* RT @Love\_JAsh : First time seeing Ye's film on VH1 « -What do you think about it ?
> The _«_ indicates that the text after it is a response to the text before it, and is therefore tagged with `~`.
<!--arrows = ~-->
<!--if a tweet is clearly cut off due to space constraints and ends with "...", we tag the ellipsis as `~`.-->
<!--If the thought appears to be complete and the author merely uses "..." to indicate ordinary ellipsis, we tag it as "," (punctuation).-->
<!--"Audio: \u203a Lupe Fiasco - The show goes on \u203a \u203a 1st Single\u201dOff \u201cLasers\u2019s\u201d Album http:\/\/tumblr.com\/xlnngu9sg"-->
<!--when RT is used as a V, tag it as V-->
<!--RT as verb example -- 28920085623-->
<!--28864005243 for ~ and heart (but wide char)-->
<!--28924724042
RT~ @lilduval@ AD waitressN inP theD stripN clubN ain'tV nothingN but& aD stripperN witP aD apronN <-~ Ha! !, @MayaKisseZ
-->
<!--PublicA and& privateA jobsN |~ Angry^ Bear^ :~ TheD wifeN and& IO usedV toP workV retailN forP theD California^ State^ Parks^ ., IfP ourD paG ...~ http://bit.ly/9EeCmY-->
<!--28849968113 no tilde
compare with 28849968113
-->
<!--
Photo : http://tumblr.com/xohnc4qk5
: is not ~
-->
<!--
RT @Mz_GoHAM Um ..... #TeamHeat ........ wut Happend ?? Haha <== #TeamCeltics showin that ass what's good...That's wat happened !!! LMAO
good...That's is G
also good example for ~
-->
<!--
non-~ ellipsis -- 28841498542
-->
<!--
28851460183
RT~ @ayy_yoHONEY@ :~ ., #walesaid# dtG @its_a_hair_flip@ shouldV goV DOWNTOWNN !, Lol! !!.., #jammy# -->~ LMAO! !!, Man! BIANCA^ !!!,
-->
Nonstandard Spellings
---------------------
We aim to choose tags that reflect what is _meant_ by a token,
even in the face of typographic errors, spelling errors, or intentional nonstandard spellings.
For instance, in
* I'm here are the game! But not with the tickets from your brother. Lol
it is assumed that _at_ was intended instead of _are_, so _are_ is labeled as a preposition
(`P`). Likewise, missing or extraneous apostrophes (e.g., _your_ clearly intended as “you are”)
should not influence the choice of tag.
Direct Address
--------------
Words such as _girl_, _miss_, _man_, and _dude_ are often used vocatively in
tweets directed to another person. They are tagged as nouns in such cases:
<!--
28909766051 ~ @ ~ V P @ N P ^ Z A G V O V O V N , ~ ! ,
28841447123 O V T V N N , V D N O V V , ! ,
-->
* RT @iLoveTaraBriona : Shout-out to @ImLuckyFeCarter definition of lil webbies i-n-d-e-p-e-n-d-e-n-t --> do you know what means __man__ ??? << Ayyye !
* I need to go home __man__ . Got some thangs I wanna try . Lol .
On the other hand, when such words do not refer to an individual but provide general
emphasis, they are tagged as interjections (`!`):
<!--
28851460183 ~ @ ~ , # G @ V V N , ! , # ~ ! , ! ^ ,
28848789014 ^ A N , ! D # V R A ,
28853024982 ! D # V D R A N V P O ,
-->
* RT @ayy\_yoHONEY : . #walesaid dt @its\_a\_hair\_flip should go DOWNTOWN ! Lol !!.. #jammy -->~LMAO !! __Man__ BIANCA !!!
* Bbm yawn face * __Man__ that #napflow felt so refreshing .
* __Man__ da #Lakers have a fucking all-star squad fuck wit it !!
<!--
asian european greek -- all A
So have to get it all in. all is D
So = P when used in beginning of sentence
28887923159, 28913460489, 28917281684 = good examples for why this is hard
good example: 28841534211
--> | zas-rep-tools | /zas-rep-tools-0.2.tar.gz/zas-rep-tools-0.2/zas_rep_tools/src/extensions/tweet_nlp/ark_tweet_nlp/docs/annot_guidelines.md | annot_guidelines.md |
(function(A,w){function ma(){if(!c.isReady){try{s.documentElement.doScroll("left")}catch(a){setTimeout(ma,1);return}c.ready()}}function Qa(a,b){b.src?c.ajax({url:b.src,async:false,dataType:"script"}):c.globalEval(b.text||b.textContent||b.innerHTML||"");b.parentNode&&b.parentNode.removeChild(b)}function X(a,b,d,f,e,j){var i=a.length;if(typeof b==="object"){for(var o in b)X(a,o,b[o],f,e,d);return a}if(d!==w){f=!j&&f&&c.isFunction(d);for(o=0;o<i;o++)e(a[o],b,f?d.call(a[o],o,e(a[o],b)):d,j);return a}return i?
e(a[0],b):w}function J(){return(new Date).getTime()}function Y(){return false}function Z(){return true}function na(a,b,d){d[0].type=a;return c.event.handle.apply(b,d)}function oa(a){var b,d=[],f=[],e=arguments,j,i,o,k,n,r;i=c.data(this,"events");if(!(a.liveFired===this||!i||!i.live||a.button&&a.type==="click")){a.liveFired=this;var u=i.live.slice(0);for(k=0;k<u.length;k++){i=u[k];i.origType.replace(O,"")===a.type?f.push(i.selector):u.splice(k--,1)}j=c(a.target).closest(f,a.currentTarget);n=0;for(r=
j.length;n<r;n++)for(k=0;k<u.length;k++){i=u[k];if(j[n].selector===i.selector){o=j[n].elem;f=null;if(i.preType==="mouseenter"||i.preType==="mouseleave")f=c(a.relatedTarget).closest(i.selector)[0];if(!f||f!==o)d.push({elem:o,handleObj:i})}}n=0;for(r=d.length;n<r;n++){j=d[n];a.currentTarget=j.elem;a.data=j.handleObj.data;a.handleObj=j.handleObj;if(j.handleObj.origHandler.apply(j.elem,e)===false){b=false;break}}return b}}function pa(a,b){return"live."+(a&&a!=="*"?a+".":"")+b.replace(/\./g,"`").replace(/ /g,
"&")}function qa(a){return!a||!a.parentNode||a.parentNode.nodeType===11}function ra(a,b){var d=0;b.each(function(){if(this.nodeName===(a[d]&&a[d].nodeName)){var f=c.data(a[d++]),e=c.data(this,f);if(f=f&&f.events){delete e.handle;e.events={};for(var j in f)for(var i in f[j])c.event.add(this,j,f[j][i],f[j][i].data)}}})}function sa(a,b,d){var f,e,j;b=b&&b[0]?b[0].ownerDocument||b[0]:s;if(a.length===1&&typeof a[0]==="string"&&a[0].length<512&&b===s&&!ta.test(a[0])&&(c.support.checkClone||!ua.test(a[0]))){e=
true;if(j=c.fragments[a[0]])if(j!==1)f=j}if(!f){f=b.createDocumentFragment();c.clean(a,b,f,d)}if(e)c.fragments[a[0]]=j?f:1;return{fragment:f,cacheable:e}}function K(a,b){var d={};c.each(va.concat.apply([],va.slice(0,b)),function(){d[this]=a});return d}function wa(a){return"scrollTo"in a&&a.document?a:a.nodeType===9?a.defaultView||a.parentWindow:false}var c=function(a,b){return new c.fn.init(a,b)},Ra=A.jQuery,Sa=A.$,s=A.document,T,Ta=/^[^<]*(<[\w\W]+>)[^>]*$|^#([\w-]+)$/,Ua=/^.[^:#\[\.,]*$/,Va=/\S/,
Wa=/^(\s|\u00A0)+|(\s|\u00A0)+$/g,Xa=/^<(\w+)\s*\/?>(?:<\/\1>)?$/,P=navigator.userAgent,xa=false,Q=[],L,$=Object.prototype.toString,aa=Object.prototype.hasOwnProperty,ba=Array.prototype.push,R=Array.prototype.slice,ya=Array.prototype.indexOf;c.fn=c.prototype={init:function(a,b){var d,f;if(!a)return this;if(a.nodeType){this.context=this[0]=a;this.length=1;return this}if(a==="body"&&!b){this.context=s;this[0]=s.body;this.selector="body";this.length=1;return this}if(typeof a==="string")if((d=Ta.exec(a))&&
(d[1]||!b))if(d[1]){f=b?b.ownerDocument||b:s;if(a=Xa.exec(a))if(c.isPlainObject(b)){a=[s.createElement(a[1])];c.fn.attr.call(a,b,true)}else a=[f.createElement(a[1])];else{a=sa([d[1]],[f]);a=(a.cacheable?a.fragment.cloneNode(true):a.fragment).childNodes}return c.merge(this,a)}else{if(b=s.getElementById(d[2])){if(b.id!==d[2])return T.find(a);this.length=1;this[0]=b}this.context=s;this.selector=a;return this}else if(!b&&/^\w+$/.test(a)){this.selector=a;this.context=s;a=s.getElementsByTagName(a);return c.merge(this,
a)}else return!b||b.jquery?(b||T).find(a):c(b).find(a);else if(c.isFunction(a))return T.ready(a);if(a.selector!==w){this.selector=a.selector;this.context=a.context}return c.makeArray(a,this)},selector:"",jquery:"1.4.2",length:0,size:function(){return this.length},toArray:function(){return R.call(this,0)},get:function(a){return a==null?this.toArray():a<0?this.slice(a)[0]:this[a]},pushStack:function(a,b,d){var f=c();c.isArray(a)?ba.apply(f,a):c.merge(f,a);f.prevObject=this;f.context=this.context;if(b===
"find")f.selector=this.selector+(this.selector?" ":"")+d;else if(b)f.selector=this.selector+"."+b+"("+d+")";return f},each:function(a,b){return c.each(this,a,b)},ready:function(a){c.bindReady();if(c.isReady)a.call(s,c);else Q&&Q.push(a);return this},eq:function(a){return a===-1?this.slice(a):this.slice(a,+a+1)},first:function(){return this.eq(0)},last:function(){return this.eq(-1)},slice:function(){return this.pushStack(R.apply(this,arguments),"slice",R.call(arguments).join(","))},map:function(a){return this.pushStack(c.map(this,
function(b,d){return a.call(b,d,b)}))},end:function(){return this.prevObject||c(null)},push:ba,sort:[].sort,splice:[].splice};c.fn.init.prototype=c.fn;c.extend=c.fn.extend=function(){var a=arguments[0]||{},b=1,d=arguments.length,f=false,e,j,i,o;if(typeof a==="boolean"){f=a;a=arguments[1]||{};b=2}if(typeof a!=="object"&&!c.isFunction(a))a={};if(d===b){a=this;--b}for(;b<d;b++)if((e=arguments[b])!=null)for(j in e){i=a[j];o=e[j];if(a!==o)if(f&&o&&(c.isPlainObject(o)||c.isArray(o))){i=i&&(c.isPlainObject(i)||
c.isArray(i))?i:c.isArray(o)?[]:{};a[j]=c.extend(f,i,o)}else if(o!==w)a[j]=o}return a};c.extend({noConflict:function(a){A.$=Sa;if(a)A.jQuery=Ra;return c},isReady:false,ready:function(){if(!c.isReady){if(!s.body)return setTimeout(c.ready,13);c.isReady=true;if(Q){for(var a,b=0;a=Q[b++];)a.call(s,c);Q=null}c.fn.triggerHandler&&c(s).triggerHandler("ready")}},bindReady:function(){if(!xa){xa=true;if(s.readyState==="complete")return c.ready();if(s.addEventListener){s.addEventListener("DOMContentLoaded",
L,false);A.addEventListener("load",c.ready,false)}else if(s.attachEvent){s.attachEvent("onreadystatechange",L);A.attachEvent("onload",c.ready);var a=false;try{a=A.frameElement==null}catch(b){}s.documentElement.doScroll&&a&&ma()}}},isFunction:function(a){return $.call(a)==="[object Function]"},isArray:function(a){return $.call(a)==="[object Array]"},isPlainObject:function(a){if(!a||$.call(a)!=="[object Object]"||a.nodeType||a.setInterval)return false;if(a.constructor&&!aa.call(a,"constructor")&&!aa.call(a.constructor.prototype,
"isPrototypeOf"))return false;var b;for(b in a);return b===w||aa.call(a,b)},isEmptyObject:function(a){for(var b in a)return false;return true},error:function(a){throw a;},parseJSON:function(a){if(typeof a!=="string"||!a)return null;a=c.trim(a);if(/^[\],:{}\s]*$/.test(a.replace(/\\(?:["\\\/bfnrt]|u[0-9a-fA-F]{4})/g,"@").replace(/"[^"\\\n\r]*"|true|false|null|-?\d+(?:\.\d*)?(?:[eE][+\-]?\d+)?/g,"]").replace(/(?:^|:|,)(?:\s*\[)+/g,"")))return A.JSON&&A.JSON.parse?A.JSON.parse(a):(new Function("return "+
a))();else c.error("Invalid JSON: "+a)},noop:function(){},globalEval:function(a){if(a&&Va.test(a)){var b=s.getElementsByTagName("head")[0]||s.documentElement,d=s.createElement("script");d.type="text/javascript";if(c.support.scriptEval)d.appendChild(s.createTextNode(a));else d.text=a;b.insertBefore(d,b.firstChild);b.removeChild(d)}},nodeName:function(a,b){return a.nodeName&&a.nodeName.toUpperCase()===b.toUpperCase()},each:function(a,b,d){var f,e=0,j=a.length,i=j===w||c.isFunction(a);if(d)if(i)for(f in a){if(b.apply(a[f],
d)===false)break}else for(;e<j;){if(b.apply(a[e++],d)===false)break}else if(i)for(f in a){if(b.call(a[f],f,a[f])===false)break}else for(d=a[0];e<j&&b.call(d,e,d)!==false;d=a[++e]);return a},trim:function(a){return(a||"").replace(Wa,"")},makeArray:function(a,b){b=b||[];if(a!=null)a.length==null||typeof a==="string"||c.isFunction(a)||typeof a!=="function"&&a.setInterval?ba.call(b,a):c.merge(b,a);return b},inArray:function(a,b){if(b.indexOf)return b.indexOf(a);for(var d=0,f=b.length;d<f;d++)if(b[d]===
a)return d;return-1},merge:function(a,b){var d=a.length,f=0;if(typeof b.length==="number")for(var e=b.length;f<e;f++)a[d++]=b[f];else for(;b[f]!==w;)a[d++]=b[f++];a.length=d;return a},grep:function(a,b,d){for(var f=[],e=0,j=a.length;e<j;e++)!d!==!b(a[e],e)&&f.push(a[e]);return f},map:function(a,b,d){for(var f=[],e,j=0,i=a.length;j<i;j++){e=b(a[j],j,d);if(e!=null)f[f.length]=e}return f.concat.apply([],f)},guid:1,proxy:function(a,b,d){if(arguments.length===2)if(typeof b==="string"){d=a;a=d[b];b=w}else if(b&&
!c.isFunction(b)){d=b;b=w}if(!b&&a)b=function(){return a.apply(d||this,arguments)};if(a)b.guid=a.guid=a.guid||b.guid||c.guid++;return b},uaMatch:function(a){a=a.toLowerCase();a=/(webkit)[ \/]([\w.]+)/.exec(a)||/(opera)(?:.*version)?[ \/]([\w.]+)/.exec(a)||/(msie) ([\w.]+)/.exec(a)||!/compatible/.test(a)&&/(mozilla)(?:.*? rv:([\w.]+))?/.exec(a)||[];return{browser:a[1]||"",version:a[2]||"0"}},browser:{}});P=c.uaMatch(P);if(P.browser){c.browser[P.browser]=true;c.browser.version=P.version}if(c.browser.webkit)c.browser.safari=
true;if(ya)c.inArray=function(a,b){return ya.call(b,a)};T=c(s);if(s.addEventListener)L=function(){s.removeEventListener("DOMContentLoaded",L,false);c.ready()};else if(s.attachEvent)L=function(){if(s.readyState==="complete"){s.detachEvent("onreadystatechange",L);c.ready()}};(function(){c.support={};var a=s.documentElement,b=s.createElement("script"),d=s.createElement("div"),f="script"+J();d.style.display="none";d.innerHTML=" <link/><table></table><a href='/a' style='color:red;float:left;opacity:.55;'>a</a><input type='checkbox'/>";
var e=d.getElementsByTagName("*"),j=d.getElementsByTagName("a")[0];if(!(!e||!e.length||!j)){c.support={leadingWhitespace:d.firstChild.nodeType===3,tbody:!d.getElementsByTagName("tbody").length,htmlSerialize:!!d.getElementsByTagName("link").length,style:/red/.test(j.getAttribute("style")),hrefNormalized:j.getAttribute("href")==="/a",opacity:/^0.55$/.test(j.style.opacity),cssFloat:!!j.style.cssFloat,checkOn:d.getElementsByTagName("input")[0].value==="on",optSelected:s.createElement("select").appendChild(s.createElement("option")).selected,
parentNode:d.removeChild(d.appendChild(s.createElement("div"))).parentNode===null,deleteExpando:true,checkClone:false,scriptEval:false,noCloneEvent:true,boxModel:null};b.type="text/javascript";try{b.appendChild(s.createTextNode("window."+f+"=1;"))}catch(i){}a.insertBefore(b,a.firstChild);if(A[f]){c.support.scriptEval=true;delete A[f]}try{delete b.test}catch(o){c.support.deleteExpando=false}a.removeChild(b);if(d.attachEvent&&d.fireEvent){d.attachEvent("onclick",function k(){c.support.noCloneEvent=
false;d.detachEvent("onclick",k)});d.cloneNode(true).fireEvent("onclick")}d=s.createElement("div");d.innerHTML="<input type='radio' name='radiotest' checked='checked'/>";a=s.createDocumentFragment();a.appendChild(d.firstChild);c.support.checkClone=a.cloneNode(true).cloneNode(true).lastChild.checked;c(function(){var k=s.createElement("div");k.style.width=k.style.paddingLeft="1px";s.body.appendChild(k);c.boxModel=c.support.boxModel=k.offsetWidth===2;s.body.removeChild(k).style.display="none"});a=function(k){var n=
s.createElement("div");k="on"+k;var r=k in n;if(!r){n.setAttribute(k,"return;");r=typeof n[k]==="function"}return r};c.support.submitBubbles=a("submit");c.support.changeBubbles=a("change");a=b=d=e=j=null}})();c.props={"for":"htmlFor","class":"className",readonly:"readOnly",maxlength:"maxLength",cellspacing:"cellSpacing",rowspan:"rowSpan",colspan:"colSpan",tabindex:"tabIndex",usemap:"useMap",frameborder:"frameBorder"};var G="jQuery"+J(),Ya=0,za={};c.extend({cache:{},expando:G,noData:{embed:true,object:true,
applet:true},data:function(a,b,d){if(!(a.nodeName&&c.noData[a.nodeName.toLowerCase()])){a=a==A?za:a;var f=a[G],e=c.cache;if(!f&&typeof b==="string"&&d===w)return null;f||(f=++Ya);if(typeof b==="object"){a[G]=f;e[f]=c.extend(true,{},b)}else if(!e[f]){a[G]=f;e[f]={}}a=e[f];if(d!==w)a[b]=d;return typeof b==="string"?a[b]:a}},removeData:function(a,b){if(!(a.nodeName&&c.noData[a.nodeName.toLowerCase()])){a=a==A?za:a;var d=a[G],f=c.cache,e=f[d];if(b){if(e){delete e[b];c.isEmptyObject(e)&&c.removeData(a)}}else{if(c.support.deleteExpando)delete a[c.expando];
else a.removeAttribute&&a.removeAttribute(c.expando);delete f[d]}}}});c.fn.extend({data:function(a,b){if(typeof a==="undefined"&&this.length)return c.data(this[0]);else if(typeof a==="object")return this.each(function(){c.data(this,a)});var d=a.split(".");d[1]=d[1]?"."+d[1]:"";if(b===w){var f=this.triggerHandler("getData"+d[1]+"!",[d[0]]);if(f===w&&this.length)f=c.data(this[0],a);return f===w&&d[1]?this.data(d[0]):f}else return this.trigger("setData"+d[1]+"!",[d[0],b]).each(function(){c.data(this,
a,b)})},removeData:function(a){return this.each(function(){c.removeData(this,a)})}});c.extend({queue:function(a,b,d){if(a){b=(b||"fx")+"queue";var f=c.data(a,b);if(!d)return f||[];if(!f||c.isArray(d))f=c.data(a,b,c.makeArray(d));else f.push(d);return f}},dequeue:function(a,b){b=b||"fx";var d=c.queue(a,b),f=d.shift();if(f==="inprogress")f=d.shift();if(f){b==="fx"&&d.unshift("inprogress");f.call(a,function(){c.dequeue(a,b)})}}});c.fn.extend({queue:function(a,b){if(typeof a!=="string"){b=a;a="fx"}if(b===
w)return c.queue(this[0],a);return this.each(function(){var d=c.queue(this,a,b);a==="fx"&&d[0]!=="inprogress"&&c.dequeue(this,a)})},dequeue:function(a){return this.each(function(){c.dequeue(this,a)})},delay:function(a,b){a=c.fx?c.fx.speeds[a]||a:a;b=b||"fx";return this.queue(b,function(){var d=this;setTimeout(function(){c.dequeue(d,b)},a)})},clearQueue:function(a){return this.queue(a||"fx",[])}});var Aa=/[\n\t]/g,ca=/\s+/,Za=/\r/g,$a=/href|src|style/,ab=/(button|input)/i,bb=/(button|input|object|select|textarea)/i,
cb=/^(a|area)$/i,Ba=/radio|checkbox/;c.fn.extend({attr:function(a,b){return X(this,a,b,true,c.attr)},removeAttr:function(a){return this.each(function(){c.attr(this,a,"");this.nodeType===1&&this.removeAttribute(a)})},addClass:function(a){if(c.isFunction(a))return this.each(function(n){var r=c(this);r.addClass(a.call(this,n,r.attr("class")))});if(a&&typeof a==="string")for(var b=(a||"").split(ca),d=0,f=this.length;d<f;d++){var e=this[d];if(e.nodeType===1)if(e.className){for(var j=" "+e.className+" ",
i=e.className,o=0,k=b.length;o<k;o++)if(j.indexOf(" "+b[o]+" ")<0)i+=" "+b[o];e.className=c.trim(i)}else e.className=a}return this},removeClass:function(a){if(c.isFunction(a))return this.each(function(k){var n=c(this);n.removeClass(a.call(this,k,n.attr("class")))});if(a&&typeof a==="string"||a===w)for(var b=(a||"").split(ca),d=0,f=this.length;d<f;d++){var e=this[d];if(e.nodeType===1&&e.className)if(a){for(var j=(" "+e.className+" ").replace(Aa," "),i=0,o=b.length;i<o;i++)j=j.replace(" "+b[i]+" ",
" ");e.className=c.trim(j)}else e.className=""}return this},toggleClass:function(a,b){var d=typeof a,f=typeof b==="boolean";if(c.isFunction(a))return this.each(function(e){var j=c(this);j.toggleClass(a.call(this,e,j.attr("class"),b),b)});return this.each(function(){if(d==="string")for(var e,j=0,i=c(this),o=b,k=a.split(ca);e=k[j++];){o=f?o:!i.hasClass(e);i[o?"addClass":"removeClass"](e)}else if(d==="undefined"||d==="boolean"){this.className&&c.data(this,"__className__",this.className);this.className=
this.className||a===false?"":c.data(this,"__className__")||""}})},hasClass:function(a){a=" "+a+" ";for(var b=0,d=this.length;b<d;b++)if((" "+this[b].className+" ").replace(Aa," ").indexOf(a)>-1)return true;return false},val:function(a){if(a===w){var b=this[0];if(b){if(c.nodeName(b,"option"))return(b.attributes.value||{}).specified?b.value:b.text;if(c.nodeName(b,"select")){var d=b.selectedIndex,f=[],e=b.options;b=b.type==="select-one";if(d<0)return null;var j=b?d:0;for(d=b?d+1:e.length;j<d;j++){var i=
e[j];if(i.selected){a=c(i).val();if(b)return a;f.push(a)}}return f}if(Ba.test(b.type)&&!c.support.checkOn)return b.getAttribute("value")===null?"on":b.value;return(b.value||"").replace(Za,"")}return w}var o=c.isFunction(a);return this.each(function(k){var n=c(this),r=a;if(this.nodeType===1){if(o)r=a.call(this,k,n.val());if(typeof r==="number")r+="";if(c.isArray(r)&&Ba.test(this.type))this.checked=c.inArray(n.val(),r)>=0;else if(c.nodeName(this,"select")){var u=c.makeArray(r);c("option",this).each(function(){this.selected=
c.inArray(c(this).val(),u)>=0});if(!u.length)this.selectedIndex=-1}else this.value=r}})}});c.extend({attrFn:{val:true,css:true,html:true,text:true,data:true,width:true,height:true,offset:true},attr:function(a,b,d,f){if(!a||a.nodeType===3||a.nodeType===8)return w;if(f&&b in c.attrFn)return c(a)[b](d);f=a.nodeType!==1||!c.isXMLDoc(a);var e=d!==w;b=f&&c.props[b]||b;if(a.nodeType===1){var j=$a.test(b);if(b in a&&f&&!j){if(e){b==="type"&&ab.test(a.nodeName)&&a.parentNode&&c.error("type property can't be changed");
a[b]=d}if(c.nodeName(a,"form")&&a.getAttributeNode(b))return a.getAttributeNode(b).nodeValue;if(b==="tabIndex")return(b=a.getAttributeNode("tabIndex"))&&b.specified?b.value:bb.test(a.nodeName)||cb.test(a.nodeName)&&a.href?0:w;return a[b]}if(!c.support.style&&f&&b==="style"){if(e)a.style.cssText=""+d;return a.style.cssText}e&&a.setAttribute(b,""+d);a=!c.support.hrefNormalized&&f&&j?a.getAttribute(b,2):a.getAttribute(b);return a===null?w:a}return c.style(a,b,d)}});var O=/\.(.*)$/,db=function(a){return a.replace(/[^\w\s\.\|`]/g,
function(b){return"\\"+b})};c.event={add:function(a,b,d,f){if(!(a.nodeType===3||a.nodeType===8)){if(a.setInterval&&a!==A&&!a.frameElement)a=A;var e,j;if(d.handler){e=d;d=e.handler}if(!d.guid)d.guid=c.guid++;if(j=c.data(a)){var i=j.events=j.events||{},o=j.handle;if(!o)j.handle=o=function(){return typeof c!=="undefined"&&!c.event.triggered?c.event.handle.apply(o.elem,arguments):w};o.elem=a;b=b.split(" ");for(var k,n=0,r;k=b[n++];){j=e?c.extend({},e):{handler:d,data:f};if(k.indexOf(".")>-1){r=k.split(".");
k=r.shift();j.namespace=r.slice(0).sort().join(".")}else{r=[];j.namespace=""}j.type=k;j.guid=d.guid;var u=i[k],z=c.event.special[k]||{};if(!u){u=i[k]=[];if(!z.setup||z.setup.call(a,f,r,o)===false)if(a.addEventListener)a.addEventListener(k,o,false);else a.attachEvent&&a.attachEvent("on"+k,o)}if(z.add){z.add.call(a,j);if(!j.handler.guid)j.handler.guid=d.guid}u.push(j);c.event.global[k]=true}a=null}}},global:{},remove:function(a,b,d,f){if(!(a.nodeType===3||a.nodeType===8)){var e,j=0,i,o,k,n,r,u,z=c.data(a),
C=z&&z.events;if(z&&C){if(b&&b.type){d=b.handler;b=b.type}if(!b||typeof b==="string"&&b.charAt(0)==="."){b=b||"";for(e in C)c.event.remove(a,e+b)}else{for(b=b.split(" ");e=b[j++];){n=e;i=e.indexOf(".")<0;o=[];if(!i){o=e.split(".");e=o.shift();k=new RegExp("(^|\\.)"+c.map(o.slice(0).sort(),db).join("\\.(?:.*\\.)?")+"(\\.|$)")}if(r=C[e])if(d){n=c.event.special[e]||{};for(B=f||0;B<r.length;B++){u=r[B];if(d.guid===u.guid){if(i||k.test(u.namespace)){f==null&&r.splice(B--,1);n.remove&&n.remove.call(a,u)}if(f!=
null)break}}if(r.length===0||f!=null&&r.length===1){if(!n.teardown||n.teardown.call(a,o)===false)Ca(a,e,z.handle);delete C[e]}}else for(var B=0;B<r.length;B++){u=r[B];if(i||k.test(u.namespace)){c.event.remove(a,n,u.handler,B);r.splice(B--,1)}}}if(c.isEmptyObject(C)){if(b=z.handle)b.elem=null;delete z.events;delete z.handle;c.isEmptyObject(z)&&c.removeData(a)}}}}},trigger:function(a,b,d,f){var e=a.type||a;if(!f){a=typeof a==="object"?a[G]?a:c.extend(c.Event(e),a):c.Event(e);if(e.indexOf("!")>=0){a.type=
e=e.slice(0,-1);a.exclusive=true}if(!d){a.stopPropagation();c.event.global[e]&&c.each(c.cache,function(){this.events&&this.events[e]&&c.event.trigger(a,b,this.handle.elem)})}if(!d||d.nodeType===3||d.nodeType===8)return w;a.result=w;a.target=d;b=c.makeArray(b);b.unshift(a)}a.currentTarget=d;(f=c.data(d,"handle"))&&f.apply(d,b);f=d.parentNode||d.ownerDocument;try{if(!(d&&d.nodeName&&c.noData[d.nodeName.toLowerCase()]))if(d["on"+e]&&d["on"+e].apply(d,b)===false)a.result=false}catch(j){}if(!a.isPropagationStopped()&&
f)c.event.trigger(a,b,f,true);else if(!a.isDefaultPrevented()){f=a.target;var i,o=c.nodeName(f,"a")&&e==="click",k=c.event.special[e]||{};if((!k._default||k._default.call(d,a)===false)&&!o&&!(f&&f.nodeName&&c.noData[f.nodeName.toLowerCase()])){try{if(f[e]){if(i=f["on"+e])f["on"+e]=null;c.event.triggered=true;f[e]()}}catch(n){}if(i)f["on"+e]=i;c.event.triggered=false}}},handle:function(a){var b,d,f,e;a=arguments[0]=c.event.fix(a||A.event);a.currentTarget=this;b=a.type.indexOf(".")<0&&!a.exclusive;
if(!b){d=a.type.split(".");a.type=d.shift();f=new RegExp("(^|\\.)"+d.slice(0).sort().join("\\.(?:.*\\.)?")+"(\\.|$)")}e=c.data(this,"events");d=e[a.type];if(e&&d){d=d.slice(0);e=0;for(var j=d.length;e<j;e++){var i=d[e];if(b||f.test(i.namespace)){a.handler=i.handler;a.data=i.data;a.handleObj=i;i=i.handler.apply(this,arguments);if(i!==w){a.result=i;if(i===false){a.preventDefault();a.stopPropagation()}}if(a.isImmediatePropagationStopped())break}}}return a.result},props:"altKey attrChange attrName bubbles button cancelable charCode clientX clientY ctrlKey currentTarget data detail eventPhase fromElement handler keyCode layerX layerY metaKey newValue offsetX offsetY originalTarget pageX pageY prevValue relatedNode relatedTarget screenX screenY shiftKey srcElement target toElement view wheelDelta which".split(" "),
fix:function(a){if(a[G])return a;var b=a;a=c.Event(b);for(var d=this.props.length,f;d;){f=this.props[--d];a[f]=b[f]}if(!a.target)a.target=a.srcElement||s;if(a.target.nodeType===3)a.target=a.target.parentNode;if(!a.relatedTarget&&a.fromElement)a.relatedTarget=a.fromElement===a.target?a.toElement:a.fromElement;if(a.pageX==null&&a.clientX!=null){b=s.documentElement;d=s.body;a.pageX=a.clientX+(b&&b.scrollLeft||d&&d.scrollLeft||0)-(b&&b.clientLeft||d&&d.clientLeft||0);a.pageY=a.clientY+(b&&b.scrollTop||
d&&d.scrollTop||0)-(b&&b.clientTop||d&&d.clientTop||0)}if(!a.which&&(a.charCode||a.charCode===0?a.charCode:a.keyCode))a.which=a.charCode||a.keyCode;if(!a.metaKey&&a.ctrlKey)a.metaKey=a.ctrlKey;if(!a.which&&a.button!==w)a.which=a.button&1?1:a.button&2?3:a.button&4?2:0;return a},guid:1E8,proxy:c.proxy,special:{ready:{setup:c.bindReady,teardown:c.noop},live:{add:function(a){c.event.add(this,a.origType,c.extend({},a,{handler:oa}))},remove:function(a){var b=true,d=a.origType.replace(O,"");c.each(c.data(this,
"events").live||[],function(){if(d===this.origType.replace(O,""))return b=false});b&&c.event.remove(this,a.origType,oa)}},beforeunload:{setup:function(a,b,d){if(this.setInterval)this.onbeforeunload=d;return false},teardown:function(a,b){if(this.onbeforeunload===b)this.onbeforeunload=null}}}};var Ca=s.removeEventListener?function(a,b,d){a.removeEventListener(b,d,false)}:function(a,b,d){a.detachEvent("on"+b,d)};c.Event=function(a){if(!this.preventDefault)return new c.Event(a);if(a&&a.type){this.originalEvent=
a;this.type=a.type}else this.type=a;this.timeStamp=J();this[G]=true};c.Event.prototype={preventDefault:function(){this.isDefaultPrevented=Z;var a=this.originalEvent;if(a){a.preventDefault&&a.preventDefault();a.returnValue=false}},stopPropagation:function(){this.isPropagationStopped=Z;var a=this.originalEvent;if(a){a.stopPropagation&&a.stopPropagation();a.cancelBubble=true}},stopImmediatePropagation:function(){this.isImmediatePropagationStopped=Z;this.stopPropagation()},isDefaultPrevented:Y,isPropagationStopped:Y,
isImmediatePropagationStopped:Y};var Da=function(a){var b=a.relatedTarget;try{for(;b&&b!==this;)b=b.parentNode;if(b!==this){a.type=a.data;c.event.handle.apply(this,arguments)}}catch(d){}},Ea=function(a){a.type=a.data;c.event.handle.apply(this,arguments)};c.each({mouseenter:"mouseover",mouseleave:"mouseout"},function(a,b){c.event.special[a]={setup:function(d){c.event.add(this,b,d&&d.selector?Ea:Da,a)},teardown:function(d){c.event.remove(this,b,d&&d.selector?Ea:Da)}}});if(!c.support.submitBubbles)c.event.special.submit=
{setup:function(){if(this.nodeName.toLowerCase()!=="form"){c.event.add(this,"click.specialSubmit",function(a){var b=a.target,d=b.type;if((d==="submit"||d==="image")&&c(b).closest("form").length)return na("submit",this,arguments)});c.event.add(this,"keypress.specialSubmit",function(a){var b=a.target,d=b.type;if((d==="text"||d==="password")&&c(b).closest("form").length&&a.keyCode===13)return na("submit",this,arguments)})}else return false},teardown:function(){c.event.remove(this,".specialSubmit")}};
if(!c.support.changeBubbles){var da=/textarea|input|select/i,ea,Fa=function(a){var b=a.type,d=a.value;if(b==="radio"||b==="checkbox")d=a.checked;else if(b==="select-multiple")d=a.selectedIndex>-1?c.map(a.options,function(f){return f.selected}).join("-"):"";else if(a.nodeName.toLowerCase()==="select")d=a.selectedIndex;return d},fa=function(a,b){var d=a.target,f,e;if(!(!da.test(d.nodeName)||d.readOnly)){f=c.data(d,"_change_data");e=Fa(d);if(a.type!=="focusout"||d.type!=="radio")c.data(d,"_change_data",
e);if(!(f===w||e===f))if(f!=null||e){a.type="change";return c.event.trigger(a,b,d)}}};c.event.special.change={filters:{focusout:fa,click:function(a){var b=a.target,d=b.type;if(d==="radio"||d==="checkbox"||b.nodeName.toLowerCase()==="select")return fa.call(this,a)},keydown:function(a){var b=a.target,d=b.type;if(a.keyCode===13&&b.nodeName.toLowerCase()!=="textarea"||a.keyCode===32&&(d==="checkbox"||d==="radio")||d==="select-multiple")return fa.call(this,a)},beforeactivate:function(a){a=a.target;c.data(a,
"_change_data",Fa(a))}},setup:function(){if(this.type==="file")return false;for(var a in ea)c.event.add(this,a+".specialChange",ea[a]);return da.test(this.nodeName)},teardown:function(){c.event.remove(this,".specialChange");return da.test(this.nodeName)}};ea=c.event.special.change.filters}s.addEventListener&&c.each({focus:"focusin",blur:"focusout"},function(a,b){function d(f){f=c.event.fix(f);f.type=b;return c.event.handle.call(this,f)}c.event.special[b]={setup:function(){this.addEventListener(a,
d,true)},teardown:function(){this.removeEventListener(a,d,true)}}});c.each(["bind","one"],function(a,b){c.fn[b]=function(d,f,e){if(typeof d==="object"){for(var j in d)this[b](j,f,d[j],e);return this}if(c.isFunction(f)){e=f;f=w}var i=b==="one"?c.proxy(e,function(k){c(this).unbind(k,i);return e.apply(this,arguments)}):e;if(d==="unload"&&b!=="one")this.one(d,f,e);else{j=0;for(var o=this.length;j<o;j++)c.event.add(this[j],d,i,f)}return this}});c.fn.extend({unbind:function(a,b){if(typeof a==="object"&&
!a.preventDefault)for(var d in a)this.unbind(d,a[d]);else{d=0;for(var f=this.length;d<f;d++)c.event.remove(this[d],a,b)}return this},delegate:function(a,b,d,f){return this.live(b,d,f,a)},undelegate:function(a,b,d){return arguments.length===0?this.unbind("live"):this.die(b,null,d,a)},trigger:function(a,b){return this.each(function(){c.event.trigger(a,b,this)})},triggerHandler:function(a,b){if(this[0]){a=c.Event(a);a.preventDefault();a.stopPropagation();c.event.trigger(a,b,this[0]);return a.result}},
toggle:function(a){for(var b=arguments,d=1;d<b.length;)c.proxy(a,b[d++]);return this.click(c.proxy(a,function(f){var e=(c.data(this,"lastToggle"+a.guid)||0)%d;c.data(this,"lastToggle"+a.guid,e+1);f.preventDefault();return b[e].apply(this,arguments)||false}))},hover:function(a,b){return this.mouseenter(a).mouseleave(b||a)}});var Ga={focus:"focusin",blur:"focusout",mouseenter:"mouseover",mouseleave:"mouseout"};c.each(["live","die"],function(a,b){c.fn[b]=function(d,f,e,j){var i,o=0,k,n,r=j||this.selector,
u=j?this:c(this.context);if(c.isFunction(f)){e=f;f=w}for(d=(d||"").split(" ");(i=d[o++])!=null;){j=O.exec(i);k="";if(j){k=j[0];i=i.replace(O,"")}if(i==="hover")d.push("mouseenter"+k,"mouseleave"+k);else{n=i;if(i==="focus"||i==="blur"){d.push(Ga[i]+k);i+=k}else i=(Ga[i]||i)+k;b==="live"?u.each(function(){c.event.add(this,pa(i,r),{data:f,selector:r,handler:e,origType:i,origHandler:e,preType:n})}):u.unbind(pa(i,r),e)}}return this}});c.each("blur focus focusin focusout load resize scroll unload click dblclick mousedown mouseup mousemove mouseover mouseout mouseenter mouseleave change select submit keydown keypress keyup error".split(" "),
function(a,b){c.fn[b]=function(d){return d?this.bind(b,d):this.trigger(b)};if(c.attrFn)c.attrFn[b]=true});A.attachEvent&&!A.addEventListener&&A.attachEvent("onunload",function(){for(var a in c.cache)if(c.cache[a].handle)try{c.event.remove(c.cache[a].handle.elem)}catch(b){}});(function(){function a(g){for(var h="",l,m=0;g[m];m++){l=g[m];if(l.nodeType===3||l.nodeType===4)h+=l.nodeValue;else if(l.nodeType!==8)h+=a(l.childNodes)}return h}function b(g,h,l,m,q,p){q=0;for(var v=m.length;q<v;q++){var t=m[q];
if(t){t=t[g];for(var y=false;t;){if(t.sizcache===l){y=m[t.sizset];break}if(t.nodeType===1&&!p){t.sizcache=l;t.sizset=q}if(t.nodeName.toLowerCase()===h){y=t;break}t=t[g]}m[q]=y}}}function d(g,h,l,m,q,p){q=0;for(var v=m.length;q<v;q++){var t=m[q];if(t){t=t[g];for(var y=false;t;){if(t.sizcache===l){y=m[t.sizset];break}if(t.nodeType===1){if(!p){t.sizcache=l;t.sizset=q}if(typeof h!=="string"){if(t===h){y=true;break}}else if(k.filter(h,[t]).length>0){y=t;break}}t=t[g]}m[q]=y}}}var f=/((?:\((?:\([^()]+\)|[^()]+)+\)|\[(?:\[[^[\]]*\]|['"][^'"]*['"]|[^[\]'"]+)+\]|\\.|[^ >+~,(\[\\]+)+|[>+~])(\s*,\s*)?((?:.|\r|\n)*)/g,
e=0,j=Object.prototype.toString,i=false,o=true;[0,0].sort(function(){o=false;return 0});var k=function(g,h,l,m){l=l||[];var q=h=h||s;if(h.nodeType!==1&&h.nodeType!==9)return[];if(!g||typeof g!=="string")return l;for(var p=[],v,t,y,S,H=true,M=x(h),I=g;(f.exec(""),v=f.exec(I))!==null;){I=v[3];p.push(v[1]);if(v[2]){S=v[3];break}}if(p.length>1&&r.exec(g))if(p.length===2&&n.relative[p[0]])t=ga(p[0]+p[1],h);else for(t=n.relative[p[0]]?[h]:k(p.shift(),h);p.length;){g=p.shift();if(n.relative[g])g+=p.shift();
t=ga(g,t)}else{if(!m&&p.length>1&&h.nodeType===9&&!M&&n.match.ID.test(p[0])&&!n.match.ID.test(p[p.length-1])){v=k.find(p.shift(),h,M);h=v.expr?k.filter(v.expr,v.set)[0]:v.set[0]}if(h){v=m?{expr:p.pop(),set:z(m)}:k.find(p.pop(),p.length===1&&(p[0]==="~"||p[0]==="+")&&h.parentNode?h.parentNode:h,M);t=v.expr?k.filter(v.expr,v.set):v.set;if(p.length>0)y=z(t);else H=false;for(;p.length;){var D=p.pop();v=D;if(n.relative[D])v=p.pop();else D="";if(v==null)v=h;n.relative[D](y,v,M)}}else y=[]}y||(y=t);y||k.error(D||
g);if(j.call(y)==="[object Array]")if(H)if(h&&h.nodeType===1)for(g=0;y[g]!=null;g++){if(y[g]&&(y[g]===true||y[g].nodeType===1&&E(h,y[g])))l.push(t[g])}else for(g=0;y[g]!=null;g++)y[g]&&y[g].nodeType===1&&l.push(t[g]);else l.push.apply(l,y);else z(y,l);if(S){k(S,q,l,m);k.uniqueSort(l)}return l};k.uniqueSort=function(g){if(B){i=o;g.sort(B);if(i)for(var h=1;h<g.length;h++)g[h]===g[h-1]&&g.splice(h--,1)}return g};k.matches=function(g,h){return k(g,null,null,h)};k.find=function(g,h,l){var m,q;if(!g)return[];
for(var p=0,v=n.order.length;p<v;p++){var t=n.order[p];if(q=n.leftMatch[t].exec(g)){var y=q[1];q.splice(1,1);if(y.substr(y.length-1)!=="\\"){q[1]=(q[1]||"").replace(/\\/g,"");m=n.find[t](q,h,l);if(m!=null){g=g.replace(n.match[t],"");break}}}}m||(m=h.getElementsByTagName("*"));return{set:m,expr:g}};k.filter=function(g,h,l,m){for(var q=g,p=[],v=h,t,y,S=h&&h[0]&&x(h[0]);g&&h.length;){for(var H in n.filter)if((t=n.leftMatch[H].exec(g))!=null&&t[2]){var M=n.filter[H],I,D;D=t[1];y=false;t.splice(1,1);if(D.substr(D.length-
1)!=="\\"){if(v===p)p=[];if(n.preFilter[H])if(t=n.preFilter[H](t,v,l,p,m,S)){if(t===true)continue}else y=I=true;if(t)for(var U=0;(D=v[U])!=null;U++)if(D){I=M(D,t,U,v);var Ha=m^!!I;if(l&&I!=null)if(Ha)y=true;else v[U]=false;else if(Ha){p.push(D);y=true}}if(I!==w){l||(v=p);g=g.replace(n.match[H],"");if(!y)return[];break}}}if(g===q)if(y==null)k.error(g);else break;q=g}return v};k.error=function(g){throw"Syntax error, unrecognized expression: "+g;};var n=k.selectors={order:["ID","NAME","TAG"],match:{ID:/#((?:[\w\u00c0-\uFFFF-]|\\.)+)/,
CLASS:/\.((?:[\w\u00c0-\uFFFF-]|\\.)+)/,NAME:/\[name=['"]*((?:[\w\u00c0-\uFFFF-]|\\.)+)['"]*\]/,ATTR:/\[\s*((?:[\w\u00c0-\uFFFF-]|\\.)+)\s*(?:(\S?=)\s*(['"]*)(.*?)\3|)\s*\]/,TAG:/^((?:[\w\u00c0-\uFFFF\*-]|\\.)+)/,CHILD:/:(only|nth|last|first)-child(?:\((even|odd|[\dn+-]*)\))?/,POS:/:(nth|eq|gt|lt|first|last|even|odd)(?:\((\d*)\))?(?=[^-]|$)/,PSEUDO:/:((?:[\w\u00c0-\uFFFF-]|\\.)+)(?:\((['"]?)((?:\([^\)]+\)|[^\(\)]*)+)\2\))?/},leftMatch:{},attrMap:{"class":"className","for":"htmlFor"},attrHandle:{href:function(g){return g.getAttribute("href")}},
relative:{"+":function(g,h){var l=typeof h==="string",m=l&&!/\W/.test(h);l=l&&!m;if(m)h=h.toLowerCase();m=0;for(var q=g.length,p;m<q;m++)if(p=g[m]){for(;(p=p.previousSibling)&&p.nodeType!==1;);g[m]=l||p&&p.nodeName.toLowerCase()===h?p||false:p===h}l&&k.filter(h,g,true)},">":function(g,h){var l=typeof h==="string";if(l&&!/\W/.test(h)){h=h.toLowerCase();for(var m=0,q=g.length;m<q;m++){var p=g[m];if(p){l=p.parentNode;g[m]=l.nodeName.toLowerCase()===h?l:false}}}else{m=0;for(q=g.length;m<q;m++)if(p=g[m])g[m]=
l?p.parentNode:p.parentNode===h;l&&k.filter(h,g,true)}},"":function(g,h,l){var m=e++,q=d;if(typeof h==="string"&&!/\W/.test(h)){var p=h=h.toLowerCase();q=b}q("parentNode",h,m,g,p,l)},"~":function(g,h,l){var m=e++,q=d;if(typeof h==="string"&&!/\W/.test(h)){var p=h=h.toLowerCase();q=b}q("previousSibling",h,m,g,p,l)}},find:{ID:function(g,h,l){if(typeof h.getElementById!=="undefined"&&!l)return(g=h.getElementById(g[1]))?[g]:[]},NAME:function(g,h){if(typeof h.getElementsByName!=="undefined"){var l=[];
h=h.getElementsByName(g[1]);for(var m=0,q=h.length;m<q;m++)h[m].getAttribute("name")===g[1]&&l.push(h[m]);return l.length===0?null:l}},TAG:function(g,h){return h.getElementsByTagName(g[1])}},preFilter:{CLASS:function(g,h,l,m,q,p){g=" "+g[1].replace(/\\/g,"")+" ";if(p)return g;p=0;for(var v;(v=h[p])!=null;p++)if(v)if(q^(v.className&&(" "+v.className+" ").replace(/[\t\n]/g," ").indexOf(g)>=0))l||m.push(v);else if(l)h[p]=false;return false},ID:function(g){return g[1].replace(/\\/g,"")},TAG:function(g){return g[1].toLowerCase()},
CHILD:function(g){if(g[1]==="nth"){var h=/(-?)(\d*)n((?:\+|-)?\d*)/.exec(g[2]==="even"&&"2n"||g[2]==="odd"&&"2n+1"||!/\D/.test(g[2])&&"0n+"+g[2]||g[2]);g[2]=h[1]+(h[2]||1)-0;g[3]=h[3]-0}g[0]=e++;return g},ATTR:function(g,h,l,m,q,p){h=g[1].replace(/\\/g,"");if(!p&&n.attrMap[h])g[1]=n.attrMap[h];if(g[2]==="~=")g[4]=" "+g[4]+" ";return g},PSEUDO:function(g,h,l,m,q){if(g[1]==="not")if((f.exec(g[3])||"").length>1||/^\w/.test(g[3]))g[3]=k(g[3],null,null,h);else{g=k.filter(g[3],h,l,true^q);l||m.push.apply(m,
g);return false}else if(n.match.POS.test(g[0])||n.match.CHILD.test(g[0]))return true;return g},POS:function(g){g.unshift(true);return g}},filters:{enabled:function(g){return g.disabled===false&&g.type!=="hidden"},disabled:function(g){return g.disabled===true},checked:function(g){return g.checked===true},selected:function(g){return g.selected===true},parent:function(g){return!!g.firstChild},empty:function(g){return!g.firstChild},has:function(g,h,l){return!!k(l[3],g).length},header:function(g){return/h\d/i.test(g.nodeName)},
text:function(g){return"text"===g.type},radio:function(g){return"radio"===g.type},checkbox:function(g){return"checkbox"===g.type},file:function(g){return"file"===g.type},password:function(g){return"password"===g.type},submit:function(g){return"submit"===g.type},image:function(g){return"image"===g.type},reset:function(g){return"reset"===g.type},button:function(g){return"button"===g.type||g.nodeName.toLowerCase()==="button"},input:function(g){return/input|select|textarea|button/i.test(g.nodeName)}},
setFilters:{first:function(g,h){return h===0},last:function(g,h,l,m){return h===m.length-1},even:function(g,h){return h%2===0},odd:function(g,h){return h%2===1},lt:function(g,h,l){return h<l[3]-0},gt:function(g,h,l){return h>l[3]-0},nth:function(g,h,l){return l[3]-0===h},eq:function(g,h,l){return l[3]-0===h}},filter:{PSEUDO:function(g,h,l,m){var q=h[1],p=n.filters[q];if(p)return p(g,l,h,m);else if(q==="contains")return(g.textContent||g.innerText||a([g])||"").indexOf(h[3])>=0;else if(q==="not"){h=
h[3];l=0;for(m=h.length;l<m;l++)if(h[l]===g)return false;return true}else k.error("Syntax error, unrecognized expression: "+q)},CHILD:function(g,h){var l=h[1],m=g;switch(l){case "only":case "first":for(;m=m.previousSibling;)if(m.nodeType===1)return false;if(l==="first")return true;m=g;case "last":for(;m=m.nextSibling;)if(m.nodeType===1)return false;return true;case "nth":l=h[2];var q=h[3];if(l===1&&q===0)return true;h=h[0];var p=g.parentNode;if(p&&(p.sizcache!==h||!g.nodeIndex)){var v=0;for(m=p.firstChild;m;m=
m.nextSibling)if(m.nodeType===1)m.nodeIndex=++v;p.sizcache=h}g=g.nodeIndex-q;return l===0?g===0:g%l===0&&g/l>=0}},ID:function(g,h){return g.nodeType===1&&g.getAttribute("id")===h},TAG:function(g,h){return h==="*"&&g.nodeType===1||g.nodeName.toLowerCase()===h},CLASS:function(g,h){return(" "+(g.className||g.getAttribute("class"))+" ").indexOf(h)>-1},ATTR:function(g,h){var l=h[1];g=n.attrHandle[l]?n.attrHandle[l](g):g[l]!=null?g[l]:g.getAttribute(l);l=g+"";var m=h[2];h=h[4];return g==null?m==="!=":m===
"="?l===h:m==="*="?l.indexOf(h)>=0:m==="~="?(" "+l+" ").indexOf(h)>=0:!h?l&&g!==false:m==="!="?l!==h:m==="^="?l.indexOf(h)===0:m==="$="?l.substr(l.length-h.length)===h:m==="|="?l===h||l.substr(0,h.length+1)===h+"-":false},POS:function(g,h,l,m){var q=n.setFilters[h[2]];if(q)return q(g,l,h,m)}}},r=n.match.POS;for(var u in n.match){n.match[u]=new RegExp(n.match[u].source+/(?![^\[]*\])(?![^\(]*\))/.source);n.leftMatch[u]=new RegExp(/(^(?:.|\r|\n)*?)/.source+n.match[u].source.replace(/\\(\d+)/g,function(g,
h){return"\\"+(h-0+1)}))}var z=function(g,h){g=Array.prototype.slice.call(g,0);if(h){h.push.apply(h,g);return h}return g};try{Array.prototype.slice.call(s.documentElement.childNodes,0)}catch(C){z=function(g,h){h=h||[];if(j.call(g)==="[object Array]")Array.prototype.push.apply(h,g);else if(typeof g.length==="number")for(var l=0,m=g.length;l<m;l++)h.push(g[l]);else for(l=0;g[l];l++)h.push(g[l]);return h}}var B;if(s.documentElement.compareDocumentPosition)B=function(g,h){if(!g.compareDocumentPosition||
!h.compareDocumentPosition){if(g==h)i=true;return g.compareDocumentPosition?-1:1}g=g.compareDocumentPosition(h)&4?-1:g===h?0:1;if(g===0)i=true;return g};else if("sourceIndex"in s.documentElement)B=function(g,h){if(!g.sourceIndex||!h.sourceIndex){if(g==h)i=true;return g.sourceIndex?-1:1}g=g.sourceIndex-h.sourceIndex;if(g===0)i=true;return g};else if(s.createRange)B=function(g,h){if(!g.ownerDocument||!h.ownerDocument){if(g==h)i=true;return g.ownerDocument?-1:1}var l=g.ownerDocument.createRange(),m=
h.ownerDocument.createRange();l.setStart(g,0);l.setEnd(g,0);m.setStart(h,0);m.setEnd(h,0);g=l.compareBoundaryPoints(Range.START_TO_END,m);if(g===0)i=true;return g};(function(){var g=s.createElement("div"),h="script"+(new Date).getTime();g.innerHTML="<a name='"+h+"'/>";var l=s.documentElement;l.insertBefore(g,l.firstChild);if(s.getElementById(h)){n.find.ID=function(m,q,p){if(typeof q.getElementById!=="undefined"&&!p)return(q=q.getElementById(m[1]))?q.id===m[1]||typeof q.getAttributeNode!=="undefined"&&
q.getAttributeNode("id").nodeValue===m[1]?[q]:w:[]};n.filter.ID=function(m,q){var p=typeof m.getAttributeNode!=="undefined"&&m.getAttributeNode("id");return m.nodeType===1&&p&&p.nodeValue===q}}l.removeChild(g);l=g=null})();(function(){var g=s.createElement("div");g.appendChild(s.createComment(""));if(g.getElementsByTagName("*").length>0)n.find.TAG=function(h,l){l=l.getElementsByTagName(h[1]);if(h[1]==="*"){h=[];for(var m=0;l[m];m++)l[m].nodeType===1&&h.push(l[m]);l=h}return l};g.innerHTML="<a href='#'></a>";
if(g.firstChild&&typeof g.firstChild.getAttribute!=="undefined"&&g.firstChild.getAttribute("href")!=="#")n.attrHandle.href=function(h){return h.getAttribute("href",2)};g=null})();s.querySelectorAll&&function(){var g=k,h=s.createElement("div");h.innerHTML="<p class='TEST'></p>";if(!(h.querySelectorAll&&h.querySelectorAll(".TEST").length===0)){k=function(m,q,p,v){q=q||s;if(!v&&q.nodeType===9&&!x(q))try{return z(q.querySelectorAll(m),p)}catch(t){}return g(m,q,p,v)};for(var l in g)k[l]=g[l];h=null}}();
(function(){var g=s.createElement("div");g.innerHTML="<div class='test e'></div><div class='test'></div>";if(!(!g.getElementsByClassName||g.getElementsByClassName("e").length===0)){g.lastChild.className="e";if(g.getElementsByClassName("e").length!==1){n.order.splice(1,0,"CLASS");n.find.CLASS=function(h,l,m){if(typeof l.getElementsByClassName!=="undefined"&&!m)return l.getElementsByClassName(h[1])};g=null}}})();var E=s.compareDocumentPosition?function(g,h){return!!(g.compareDocumentPosition(h)&16)}:
function(g,h){return g!==h&&(g.contains?g.contains(h):true)},x=function(g){return(g=(g?g.ownerDocument||g:0).documentElement)?g.nodeName!=="HTML":false},ga=function(g,h){var l=[],m="",q;for(h=h.nodeType?[h]:h;q=n.match.PSEUDO.exec(g);){m+=q[0];g=g.replace(n.match.PSEUDO,"")}g=n.relative[g]?g+"*":g;q=0;for(var p=h.length;q<p;q++)k(g,h[q],l);return k.filter(m,l)};c.find=k;c.expr=k.selectors;c.expr[":"]=c.expr.filters;c.unique=k.uniqueSort;c.text=a;c.isXMLDoc=x;c.contains=E})();var eb=/Until$/,fb=/^(?:parents|prevUntil|prevAll)/,
gb=/,/;R=Array.prototype.slice;var Ia=function(a,b,d){if(c.isFunction(b))return c.grep(a,function(e,j){return!!b.call(e,j,e)===d});else if(b.nodeType)return c.grep(a,function(e){return e===b===d});else if(typeof b==="string"){var f=c.grep(a,function(e){return e.nodeType===1});if(Ua.test(b))return c.filter(b,f,!d);else b=c.filter(b,f)}return c.grep(a,function(e){return c.inArray(e,b)>=0===d})};c.fn.extend({find:function(a){for(var b=this.pushStack("","find",a),d=0,f=0,e=this.length;f<e;f++){d=b.length;
c.find(a,this[f],b);if(f>0)for(var j=d;j<b.length;j++)for(var i=0;i<d;i++)if(b[i]===b[j]){b.splice(j--,1);break}}return b},has:function(a){var b=c(a);return this.filter(function(){for(var d=0,f=b.length;d<f;d++)if(c.contains(this,b[d]))return true})},not:function(a){return this.pushStack(Ia(this,a,false),"not",a)},filter:function(a){return this.pushStack(Ia(this,a,true),"filter",a)},is:function(a){return!!a&&c.filter(a,this).length>0},closest:function(a,b){if(c.isArray(a)){var d=[],f=this[0],e,j=
{},i;if(f&&a.length){e=0;for(var o=a.length;e<o;e++){i=a[e];j[i]||(j[i]=c.expr.match.POS.test(i)?c(i,b||this.context):i)}for(;f&&f.ownerDocument&&f!==b;){for(i in j){e=j[i];if(e.jquery?e.index(f)>-1:c(f).is(e)){d.push({selector:i,elem:f});delete j[i]}}f=f.parentNode}}return d}var k=c.expr.match.POS.test(a)?c(a,b||this.context):null;return this.map(function(n,r){for(;r&&r.ownerDocument&&r!==b;){if(k?k.index(r)>-1:c(r).is(a))return r;r=r.parentNode}return null})},index:function(a){if(!a||typeof a===
"string")return c.inArray(this[0],a?c(a):this.parent().children());return c.inArray(a.jquery?a[0]:a,this)},add:function(a,b){a=typeof a==="string"?c(a,b||this.context):c.makeArray(a);b=c.merge(this.get(),a);return this.pushStack(qa(a[0])||qa(b[0])?b:c.unique(b))},andSelf:function(){return this.add(this.prevObject)}});c.each({parent:function(a){return(a=a.parentNode)&&a.nodeType!==11?a:null},parents:function(a){return c.dir(a,"parentNode")},parentsUntil:function(a,b,d){return c.dir(a,"parentNode",
d)},next:function(a){return c.nth(a,2,"nextSibling")},prev:function(a){return c.nth(a,2,"previousSibling")},nextAll:function(a){return c.dir(a,"nextSibling")},prevAll:function(a){return c.dir(a,"previousSibling")},nextUntil:function(a,b,d){return c.dir(a,"nextSibling",d)},prevUntil:function(a,b,d){return c.dir(a,"previousSibling",d)},siblings:function(a){return c.sibling(a.parentNode.firstChild,a)},children:function(a){return c.sibling(a.firstChild)},contents:function(a){return c.nodeName(a,"iframe")?
a.contentDocument||a.contentWindow.document:c.makeArray(a.childNodes)}},function(a,b){c.fn[a]=function(d,f){var e=c.map(this,b,d);eb.test(a)||(f=d);if(f&&typeof f==="string")e=c.filter(f,e);e=this.length>1?c.unique(e):e;if((this.length>1||gb.test(f))&&fb.test(a))e=e.reverse();return this.pushStack(e,a,R.call(arguments).join(","))}});c.extend({filter:function(a,b,d){if(d)a=":not("+a+")";return c.find.matches(a,b)},dir:function(a,b,d){var f=[];for(a=a[b];a&&a.nodeType!==9&&(d===w||a.nodeType!==1||!c(a).is(d));){a.nodeType===
1&&f.push(a);a=a[b]}return f},nth:function(a,b,d){b=b||1;for(var f=0;a;a=a[d])if(a.nodeType===1&&++f===b)break;return a},sibling:function(a,b){for(var d=[];a;a=a.nextSibling)a.nodeType===1&&a!==b&&d.push(a);return d}});var Ja=/ jQuery\d+="(?:\d+|null)"/g,V=/^\s+/,Ka=/(<([\w:]+)[^>]*?)\/>/g,hb=/^(?:area|br|col|embed|hr|img|input|link|meta|param)$/i,La=/<([\w:]+)/,ib=/<tbody/i,jb=/<|&#?\w+;/,ta=/<script|<object|<embed|<option|<style/i,ua=/checked\s*(?:[^=]|=\s*.checked.)/i,Ma=function(a,b,d){return hb.test(d)?
a:b+"></"+d+">"},F={option:[1,"<select multiple='multiple'>","</select>"],legend:[1,"<fieldset>","</fieldset>"],thead:[1,"<table>","</table>"],tr:[2,"<table><tbody>","</tbody></table>"],td:[3,"<table><tbody><tr>","</tr></tbody></table>"],col:[2,"<table><tbody></tbody><colgroup>","</colgroup></table>"],area:[1,"<map>","</map>"],_default:[0,"",""]};F.optgroup=F.option;F.tbody=F.tfoot=F.colgroup=F.caption=F.thead;F.th=F.td;if(!c.support.htmlSerialize)F._default=[1,"div<div>","</div>"];c.fn.extend({text:function(a){if(c.isFunction(a))return this.each(function(b){var d=
c(this);d.text(a.call(this,b,d.text()))});if(typeof a!=="object"&&a!==w)return this.empty().append((this[0]&&this[0].ownerDocument||s).createTextNode(a));return c.text(this)},wrapAll:function(a){if(c.isFunction(a))return this.each(function(d){c(this).wrapAll(a.call(this,d))});if(this[0]){var b=c(a,this[0].ownerDocument).eq(0).clone(true);this[0].parentNode&&b.insertBefore(this[0]);b.map(function(){for(var d=this;d.firstChild&&d.firstChild.nodeType===1;)d=d.firstChild;return d}).append(this)}return this},
wrapInner:function(a){if(c.isFunction(a))return this.each(function(b){c(this).wrapInner(a.call(this,b))});return this.each(function(){var b=c(this),d=b.contents();d.length?d.wrapAll(a):b.append(a)})},wrap:function(a){return this.each(function(){c(this).wrapAll(a)})},unwrap:function(){return this.parent().each(function(){c.nodeName(this,"body")||c(this).replaceWith(this.childNodes)}).end()},append:function(){return this.domManip(arguments,true,function(a){this.nodeType===1&&this.appendChild(a)})},
prepend:function(){return this.domManip(arguments,true,function(a){this.nodeType===1&&this.insertBefore(a,this.firstChild)})},before:function(){if(this[0]&&this[0].parentNode)return this.domManip(arguments,false,function(b){this.parentNode.insertBefore(b,this)});else if(arguments.length){var a=c(arguments[0]);a.push.apply(a,this.toArray());return this.pushStack(a,"before",arguments)}},after:function(){if(this[0]&&this[0].parentNode)return this.domManip(arguments,false,function(b){this.parentNode.insertBefore(b,
this.nextSibling)});else if(arguments.length){var a=this.pushStack(this,"after",arguments);a.push.apply(a,c(arguments[0]).toArray());return a}},remove:function(a,b){for(var d=0,f;(f=this[d])!=null;d++)if(!a||c.filter(a,[f]).length){if(!b&&f.nodeType===1){c.cleanData(f.getElementsByTagName("*"));c.cleanData([f])}f.parentNode&&f.parentNode.removeChild(f)}return this},empty:function(){for(var a=0,b;(b=this[a])!=null;a++)for(b.nodeType===1&&c.cleanData(b.getElementsByTagName("*"));b.firstChild;)b.removeChild(b.firstChild);
return this},clone:function(a){var b=this.map(function(){if(!c.support.noCloneEvent&&!c.isXMLDoc(this)){var d=this.outerHTML,f=this.ownerDocument;if(!d){d=f.createElement("div");d.appendChild(this.cloneNode(true));d=d.innerHTML}return c.clean([d.replace(Ja,"").replace(/=([^="'>\s]+\/)>/g,'="$1">').replace(V,"")],f)[0]}else return this.cloneNode(true)});if(a===true){ra(this,b);ra(this.find("*"),b.find("*"))}return b},html:function(a){if(a===w)return this[0]&&this[0].nodeType===1?this[0].innerHTML.replace(Ja,
""):null;else if(typeof a==="string"&&!ta.test(a)&&(c.support.leadingWhitespace||!V.test(a))&&!F[(La.exec(a)||["",""])[1].toLowerCase()]){a=a.replace(Ka,Ma);try{for(var b=0,d=this.length;b<d;b++)if(this[b].nodeType===1){c.cleanData(this[b].getElementsByTagName("*"));this[b].innerHTML=a}}catch(f){this.empty().append(a)}}else c.isFunction(a)?this.each(function(e){var j=c(this),i=j.html();j.empty().append(function(){return a.call(this,e,i)})}):this.empty().append(a);return this},replaceWith:function(a){if(this[0]&&
this[0].parentNode){if(c.isFunction(a))return this.each(function(b){var d=c(this),f=d.html();d.replaceWith(a.call(this,b,f))});if(typeof a!=="string")a=c(a).detach();return this.each(function(){var b=this.nextSibling,d=this.parentNode;c(this).remove();b?c(b).before(a):c(d).append(a)})}else return this.pushStack(c(c.isFunction(a)?a():a),"replaceWith",a)},detach:function(a){return this.remove(a,true)},domManip:function(a,b,d){function f(u){return c.nodeName(u,"table")?u.getElementsByTagName("tbody")[0]||
u.appendChild(u.ownerDocument.createElement("tbody")):u}var e,j,i=a[0],o=[],k;if(!c.support.checkClone&&arguments.length===3&&typeof i==="string"&&ua.test(i))return this.each(function(){c(this).domManip(a,b,d,true)});if(c.isFunction(i))return this.each(function(u){var z=c(this);a[0]=i.call(this,u,b?z.html():w);z.domManip(a,b,d)});if(this[0]){e=i&&i.parentNode;e=c.support.parentNode&&e&&e.nodeType===11&&e.childNodes.length===this.length?{fragment:e}:sa(a,this,o);k=e.fragment;if(j=k.childNodes.length===
1?(k=k.firstChild):k.firstChild){b=b&&c.nodeName(j,"tr");for(var n=0,r=this.length;n<r;n++)d.call(b?f(this[n],j):this[n],n>0||e.cacheable||this.length>1?k.cloneNode(true):k)}o.length&&c.each(o,Qa)}return this}});c.fragments={};c.each({appendTo:"append",prependTo:"prepend",insertBefore:"before",insertAfter:"after",replaceAll:"replaceWith"},function(a,b){c.fn[a]=function(d){var f=[];d=c(d);var e=this.length===1&&this[0].parentNode;if(e&&e.nodeType===11&&e.childNodes.length===1&&d.length===1){d[b](this[0]);
return this}else{e=0;for(var j=d.length;e<j;e++){var i=(e>0?this.clone(true):this).get();c.fn[b].apply(c(d[e]),i);f=f.concat(i)}return this.pushStack(f,a,d.selector)}}});c.extend({clean:function(a,b,d,f){b=b||s;if(typeof b.createElement==="undefined")b=b.ownerDocument||b[0]&&b[0].ownerDocument||s;for(var e=[],j=0,i;(i=a[j])!=null;j++){if(typeof i==="number")i+="";if(i){if(typeof i==="string"&&!jb.test(i))i=b.createTextNode(i);else if(typeof i==="string"){i=i.replace(Ka,Ma);var o=(La.exec(i)||["",
""])[1].toLowerCase(),k=F[o]||F._default,n=k[0],r=b.createElement("div");for(r.innerHTML=k[1]+i+k[2];n--;)r=r.lastChild;if(!c.support.tbody){n=ib.test(i);o=o==="table"&&!n?r.firstChild&&r.firstChild.childNodes:k[1]==="<table>"&&!n?r.childNodes:[];for(k=o.length-1;k>=0;--k)c.nodeName(o[k],"tbody")&&!o[k].childNodes.length&&o[k].parentNode.removeChild(o[k])}!c.support.leadingWhitespace&&V.test(i)&&r.insertBefore(b.createTextNode(V.exec(i)[0]),r.firstChild);i=r.childNodes}if(i.nodeType)e.push(i);else e=
c.merge(e,i)}}if(d)for(j=0;e[j];j++)if(f&&c.nodeName(e[j],"script")&&(!e[j].type||e[j].type.toLowerCase()==="text/javascript"))f.push(e[j].parentNode?e[j].parentNode.removeChild(e[j]):e[j]);else{e[j].nodeType===1&&e.splice.apply(e,[j+1,0].concat(c.makeArray(e[j].getElementsByTagName("script"))));d.appendChild(e[j])}return e},cleanData:function(a){for(var b,d,f=c.cache,e=c.event.special,j=c.support.deleteExpando,i=0,o;(o=a[i])!=null;i++)if(d=o[c.expando]){b=f[d];if(b.events)for(var k in b.events)e[k]?
c.event.remove(o,k):Ca(o,k,b.handle);if(j)delete o[c.expando];else o.removeAttribute&&o.removeAttribute(c.expando);delete f[d]}}});var kb=/z-?index|font-?weight|opacity|zoom|line-?height/i,Na=/alpha\([^)]*\)/,Oa=/opacity=([^)]*)/,ha=/float/i,ia=/-([a-z])/ig,lb=/([A-Z])/g,mb=/^-?\d+(?:px)?$/i,nb=/^-?\d/,ob={position:"absolute",visibility:"hidden",display:"block"},pb=["Left","Right"],qb=["Top","Bottom"],rb=s.defaultView&&s.defaultView.getComputedStyle,Pa=c.support.cssFloat?"cssFloat":"styleFloat",ja=
function(a,b){return b.toUpperCase()};c.fn.css=function(a,b){return X(this,a,b,true,function(d,f,e){if(e===w)return c.curCSS(d,f);if(typeof e==="number"&&!kb.test(f))e+="px";c.style(d,f,e)})};c.extend({style:function(a,b,d){if(!a||a.nodeType===3||a.nodeType===8)return w;if((b==="width"||b==="height")&&parseFloat(d)<0)d=w;var f=a.style||a,e=d!==w;if(!c.support.opacity&&b==="opacity"){if(e){f.zoom=1;b=parseInt(d,10)+""==="NaN"?"":"alpha(opacity="+d*100+")";a=f.filter||c.curCSS(a,"filter")||"";f.filter=
Na.test(a)?a.replace(Na,b):b}return f.filter&&f.filter.indexOf("opacity=")>=0?parseFloat(Oa.exec(f.filter)[1])/100+"":""}if(ha.test(b))b=Pa;b=b.replace(ia,ja);if(e)f[b]=d;return f[b]},css:function(a,b,d,f){if(b==="width"||b==="height"){var e,j=b==="width"?pb:qb;function i(){e=b==="width"?a.offsetWidth:a.offsetHeight;f!=="border"&&c.each(j,function(){f||(e-=parseFloat(c.curCSS(a,"padding"+this,true))||0);if(f==="margin")e+=parseFloat(c.curCSS(a,"margin"+this,true))||0;else e-=parseFloat(c.curCSS(a,
"border"+this+"Width",true))||0})}a.offsetWidth!==0?i():c.swap(a,ob,i);return Math.max(0,Math.round(e))}return c.curCSS(a,b,d)},curCSS:function(a,b,d){var f,e=a.style;if(!c.support.opacity&&b==="opacity"&&a.currentStyle){f=Oa.test(a.currentStyle.filter||"")?parseFloat(RegExp.$1)/100+"":"";return f===""?"1":f}if(ha.test(b))b=Pa;if(!d&&e&&e[b])f=e[b];else if(rb){if(ha.test(b))b="float";b=b.replace(lb,"-$1").toLowerCase();e=a.ownerDocument.defaultView;if(!e)return null;if(a=e.getComputedStyle(a,null))f=
a.getPropertyValue(b);if(b==="opacity"&&f==="")f="1"}else if(a.currentStyle){d=b.replace(ia,ja);f=a.currentStyle[b]||a.currentStyle[d];if(!mb.test(f)&&nb.test(f)){b=e.left;var j=a.runtimeStyle.left;a.runtimeStyle.left=a.currentStyle.left;e.left=d==="fontSize"?"1em":f||0;f=e.pixelLeft+"px";e.left=b;a.runtimeStyle.left=j}}return f},swap:function(a,b,d){var f={};for(var e in b){f[e]=a.style[e];a.style[e]=b[e]}d.call(a);for(e in b)a.style[e]=f[e]}});if(c.expr&&c.expr.filters){c.expr.filters.hidden=function(a){var b=
a.offsetWidth,d=a.offsetHeight,f=a.nodeName.toLowerCase()==="tr";return b===0&&d===0&&!f?true:b>0&&d>0&&!f?false:c.curCSS(a,"display")==="none"};c.expr.filters.visible=function(a){return!c.expr.filters.hidden(a)}}var sb=J(),tb=/<script(.|\s)*?\/script>/gi,ub=/select|textarea/i,vb=/color|date|datetime|email|hidden|month|number|password|range|search|tel|text|time|url|week/i,N=/=\?(&|$)/,ka=/\?/,wb=/(\?|&)_=.*?(&|$)/,xb=/^(\w+:)?\/\/([^\/?#]+)/,yb=/%20/g,zb=c.fn.load;c.fn.extend({load:function(a,b,d){if(typeof a!==
"string")return zb.call(this,a);else if(!this.length)return this;var f=a.indexOf(" ");if(f>=0){var e=a.slice(f,a.length);a=a.slice(0,f)}f="GET";if(b)if(c.isFunction(b)){d=b;b=null}else if(typeof b==="object"){b=c.param(b,c.ajaxSettings.traditional);f="POST"}var j=this;c.ajax({url:a,type:f,dataType:"html",data:b,complete:function(i,o){if(o==="success"||o==="notmodified")j.html(e?c("<div />").append(i.responseText.replace(tb,"")).find(e):i.responseText);d&&j.each(d,[i.responseText,o,i])}});return this},
serialize:function(){return c.param(this.serializeArray())},serializeArray:function(){return this.map(function(){return this.elements?c.makeArray(this.elements):this}).filter(function(){return this.name&&!this.disabled&&(this.checked||ub.test(this.nodeName)||vb.test(this.type))}).map(function(a,b){a=c(this).val();return a==null?null:c.isArray(a)?c.map(a,function(d){return{name:b.name,value:d}}):{name:b.name,value:a}}).get()}});c.each("ajaxStart ajaxStop ajaxComplete ajaxError ajaxSuccess ajaxSend".split(" "),
function(a,b){c.fn[b]=function(d){return this.bind(b,d)}});c.extend({get:function(a,b,d,f){if(c.isFunction(b)){f=f||d;d=b;b=null}return c.ajax({type:"GET",url:a,data:b,success:d,dataType:f})},getScript:function(a,b){return c.get(a,null,b,"script")},getJSON:function(a,b,d){return c.get(a,b,d,"json")},post:function(a,b,d,f){if(c.isFunction(b)){f=f||d;d=b;b={}}return c.ajax({type:"POST",url:a,data:b,success:d,dataType:f})},ajaxSetup:function(a){c.extend(c.ajaxSettings,a)},ajaxSettings:{url:location.href,
global:true,type:"GET",contentType:"application/x-www-form-urlencoded",processData:true,async:true,xhr:A.XMLHttpRequest&&(A.location.protocol!=="file:"||!A.ActiveXObject)?function(){return new A.XMLHttpRequest}:function(){try{return new A.ActiveXObject("Microsoft.XMLHTTP")}catch(a){}},accepts:{xml:"application/xml, text/xml",html:"text/html",script:"text/javascript, application/javascript",json:"application/json, text/javascript",text:"text/plain",_default:"*/*"}},lastModified:{},etag:{},ajax:function(a){function b(){e.success&&
e.success.call(k,o,i,x);e.global&&f("ajaxSuccess",[x,e])}function d(){e.complete&&e.complete.call(k,x,i);e.global&&f("ajaxComplete",[x,e]);e.global&&!--c.active&&c.event.trigger("ajaxStop")}function f(q,p){(e.context?c(e.context):c.event).trigger(q,p)}var e=c.extend(true,{},c.ajaxSettings,a),j,i,o,k=a&&a.context||e,n=e.type.toUpperCase();if(e.data&&e.processData&&typeof e.data!=="string")e.data=c.param(e.data,e.traditional);if(e.dataType==="jsonp"){if(n==="GET")N.test(e.url)||(e.url+=(ka.test(e.url)?
"&":"?")+(e.jsonp||"callback")+"=?");else if(!e.data||!N.test(e.data))e.data=(e.data?e.data+"&":"")+(e.jsonp||"callback")+"=?";e.dataType="json"}if(e.dataType==="json"&&(e.data&&N.test(e.data)||N.test(e.url))){j=e.jsonpCallback||"jsonp"+sb++;if(e.data)e.data=(e.data+"").replace(N,"="+j+"$1");e.url=e.url.replace(N,"="+j+"$1");e.dataType="script";A[j]=A[j]||function(q){o=q;b();d();A[j]=w;try{delete A[j]}catch(p){}z&&z.removeChild(C)}}if(e.dataType==="script"&&e.cache===null)e.cache=false;if(e.cache===
false&&n==="GET"){var r=J(),u=e.url.replace(wb,"$1_="+r+"$2");e.url=u+(u===e.url?(ka.test(e.url)?"&":"?")+"_="+r:"")}if(e.data&&n==="GET")e.url+=(ka.test(e.url)?"&":"?")+e.data;e.global&&!c.active++&&c.event.trigger("ajaxStart");r=(r=xb.exec(e.url))&&(r[1]&&r[1]!==location.protocol||r[2]!==location.host);if(e.dataType==="script"&&n==="GET"&&r){var z=s.getElementsByTagName("head")[0]||s.documentElement,C=s.createElement("script");C.src=e.url;if(e.scriptCharset)C.charset=e.scriptCharset;if(!j){var B=
false;C.onload=C.onreadystatechange=function(){if(!B&&(!this.readyState||this.readyState==="loaded"||this.readyState==="complete")){B=true;b();d();C.onload=C.onreadystatechange=null;z&&C.parentNode&&z.removeChild(C)}}}z.insertBefore(C,z.firstChild);return w}var E=false,x=e.xhr();if(x){e.username?x.open(n,e.url,e.async,e.username,e.password):x.open(n,e.url,e.async);try{if(e.data||a&&a.contentType)x.setRequestHeader("Content-Type",e.contentType);if(e.ifModified){c.lastModified[e.url]&&x.setRequestHeader("If-Modified-Since",
c.lastModified[e.url]);c.etag[e.url]&&x.setRequestHeader("If-None-Match",c.etag[e.url])}r||x.setRequestHeader("X-Requested-With","XMLHttpRequest");x.setRequestHeader("Accept",e.dataType&&e.accepts[e.dataType]?e.accepts[e.dataType]+", */*":e.accepts._default)}catch(ga){}if(e.beforeSend&&e.beforeSend.call(k,x,e)===false){e.global&&!--c.active&&c.event.trigger("ajaxStop");x.abort();return false}e.global&&f("ajaxSend",[x,e]);var g=x.onreadystatechange=function(q){if(!x||x.readyState===0||q==="abort"){E||
d();E=true;if(x)x.onreadystatechange=c.noop}else if(!E&&x&&(x.readyState===4||q==="timeout")){E=true;x.onreadystatechange=c.noop;i=q==="timeout"?"timeout":!c.httpSuccess(x)?"error":e.ifModified&&c.httpNotModified(x,e.url)?"notmodified":"success";var p;if(i==="success")try{o=c.httpData(x,e.dataType,e)}catch(v){i="parsererror";p=v}if(i==="success"||i==="notmodified")j||b();else c.handleError(e,x,i,p);d();q==="timeout"&&x.abort();if(e.async)x=null}};try{var h=x.abort;x.abort=function(){x&&h.call(x);
g("abort")}}catch(l){}e.async&&e.timeout>0&&setTimeout(function(){x&&!E&&g("timeout")},e.timeout);try{x.send(n==="POST"||n==="PUT"||n==="DELETE"?e.data:null)}catch(m){c.handleError(e,x,null,m);d()}e.async||g();return x}},handleError:function(a,b,d,f){if(a.error)a.error.call(a.context||a,b,d,f);if(a.global)(a.context?c(a.context):c.event).trigger("ajaxError",[b,a,f])},active:0,httpSuccess:function(a){try{return!a.status&&location.protocol==="file:"||a.status>=200&&a.status<300||a.status===304||a.status===
1223||a.status===0}catch(b){}return false},httpNotModified:function(a,b){var d=a.getResponseHeader("Last-Modified"),f=a.getResponseHeader("Etag");if(d)c.lastModified[b]=d;if(f)c.etag[b]=f;return a.status===304||a.status===0},httpData:function(a,b,d){var f=a.getResponseHeader("content-type")||"",e=b==="xml"||!b&&f.indexOf("xml")>=0;a=e?a.responseXML:a.responseText;e&&a.documentElement.nodeName==="parsererror"&&c.error("parsererror");if(d&&d.dataFilter)a=d.dataFilter(a,b);if(typeof a==="string")if(b===
"json"||!b&&f.indexOf("json")>=0)a=c.parseJSON(a);else if(b==="script"||!b&&f.indexOf("javascript")>=0)c.globalEval(a);return a},param:function(a,b){function d(i,o){if(c.isArray(o))c.each(o,function(k,n){b||/\[\]$/.test(i)?f(i,n):d(i+"["+(typeof n==="object"||c.isArray(n)?k:"")+"]",n)});else!b&&o!=null&&typeof o==="object"?c.each(o,function(k,n){d(i+"["+k+"]",n)}):f(i,o)}function f(i,o){o=c.isFunction(o)?o():o;e[e.length]=encodeURIComponent(i)+"="+encodeURIComponent(o)}var e=[];if(b===w)b=c.ajaxSettings.traditional;
if(c.isArray(a)||a.jquery)c.each(a,function(){f(this.name,this.value)});else for(var j in a)d(j,a[j]);return e.join("&").replace(yb,"+")}});var la={},Ab=/toggle|show|hide/,Bb=/^([+-]=)?([\d+-.]+)(.*)$/,W,va=[["height","marginTop","marginBottom","paddingTop","paddingBottom"],["width","marginLeft","marginRight","paddingLeft","paddingRight"],["opacity"]];c.fn.extend({show:function(a,b){if(a||a===0)return this.animate(K("show",3),a,b);else{a=0;for(b=this.length;a<b;a++){var d=c.data(this[a],"olddisplay");
this[a].style.display=d||"";if(c.css(this[a],"display")==="none"){d=this[a].nodeName;var f;if(la[d])f=la[d];else{var e=c("<"+d+" />").appendTo("body");f=e.css("display");if(f==="none")f="block";e.remove();la[d]=f}c.data(this[a],"olddisplay",f)}}a=0;for(b=this.length;a<b;a++)this[a].style.display=c.data(this[a],"olddisplay")||"";return this}},hide:function(a,b){if(a||a===0)return this.animate(K("hide",3),a,b);else{a=0;for(b=this.length;a<b;a++){var d=c.data(this[a],"olddisplay");!d&&d!=="none"&&c.data(this[a],
"olddisplay",c.css(this[a],"display"))}a=0;for(b=this.length;a<b;a++)this[a].style.display="none";return this}},_toggle:c.fn.toggle,toggle:function(a,b){var d=typeof a==="boolean";if(c.isFunction(a)&&c.isFunction(b))this._toggle.apply(this,arguments);else a==null||d?this.each(function(){var f=d?a:c(this).is(":hidden");c(this)[f?"show":"hide"]()}):this.animate(K("toggle",3),a,b);return this},fadeTo:function(a,b,d){return this.filter(":hidden").css("opacity",0).show().end().animate({opacity:b},a,d)},
animate:function(a,b,d,f){var e=c.speed(b,d,f);if(c.isEmptyObject(a))return this.each(e.complete);return this[e.queue===false?"each":"queue"](function(){var j=c.extend({},e),i,o=this.nodeType===1&&c(this).is(":hidden"),k=this;for(i in a){var n=i.replace(ia,ja);if(i!==n){a[n]=a[i];delete a[i];i=n}if(a[i]==="hide"&&o||a[i]==="show"&&!o)return j.complete.call(this);if((i==="height"||i==="width")&&this.style){j.display=c.css(this,"display");j.overflow=this.style.overflow}if(c.isArray(a[i])){(j.specialEasing=
j.specialEasing||{})[i]=a[i][1];a[i]=a[i][0]}}if(j.overflow!=null)this.style.overflow="hidden";j.curAnim=c.extend({},a);c.each(a,function(r,u){var z=new c.fx(k,j,r);if(Ab.test(u))z[u==="toggle"?o?"show":"hide":u](a);else{var C=Bb.exec(u),B=z.cur(true)||0;if(C){u=parseFloat(C[2]);var E=C[3]||"px";if(E!=="px"){k.style[r]=(u||1)+E;B=(u||1)/z.cur(true)*B;k.style[r]=B+E}if(C[1])u=(C[1]==="-="?-1:1)*u+B;z.custom(B,u,E)}else z.custom(B,u,"")}});return true})},stop:function(a,b){var d=c.timers;a&&this.queue([]);
this.each(function(){for(var f=d.length-1;f>=0;f--)if(d[f].elem===this){b&&d[f](true);d.splice(f,1)}});b||this.dequeue();return this}});c.each({slideDown:K("show",1),slideUp:K("hide",1),slideToggle:K("toggle",1),fadeIn:{opacity:"show"},fadeOut:{opacity:"hide"}},function(a,b){c.fn[a]=function(d,f){return this.animate(b,d,f)}});c.extend({speed:function(a,b,d){var f=a&&typeof a==="object"?a:{complete:d||!d&&b||c.isFunction(a)&&a,duration:a,easing:d&&b||b&&!c.isFunction(b)&&b};f.duration=c.fx.off?0:typeof f.duration===
"number"?f.duration:c.fx.speeds[f.duration]||c.fx.speeds._default;f.old=f.complete;f.complete=function(){f.queue!==false&&c(this).dequeue();c.isFunction(f.old)&&f.old.call(this)};return f},easing:{linear:function(a,b,d,f){return d+f*a},swing:function(a,b,d,f){return(-Math.cos(a*Math.PI)/2+0.5)*f+d}},timers:[],fx:function(a,b,d){this.options=b;this.elem=a;this.prop=d;if(!b.orig)b.orig={}}});c.fx.prototype={update:function(){this.options.step&&this.options.step.call(this.elem,this.now,this);(c.fx.step[this.prop]||
c.fx.step._default)(this);if((this.prop==="height"||this.prop==="width")&&this.elem.style)this.elem.style.display="block"},cur:function(a){if(this.elem[this.prop]!=null&&(!this.elem.style||this.elem.style[this.prop]==null))return this.elem[this.prop];return(a=parseFloat(c.css(this.elem,this.prop,a)))&&a>-10000?a:parseFloat(c.curCSS(this.elem,this.prop))||0},custom:function(a,b,d){function f(j){return e.step(j)}this.startTime=J();this.start=a;this.end=b;this.unit=d||this.unit||"px";this.now=this.start;
this.pos=this.state=0;var e=this;f.elem=this.elem;if(f()&&c.timers.push(f)&&!W)W=setInterval(c.fx.tick,13)},show:function(){this.options.orig[this.prop]=c.style(this.elem,this.prop);this.options.show=true;this.custom(this.prop==="width"||this.prop==="height"?1:0,this.cur());c(this.elem).show()},hide:function(){this.options.orig[this.prop]=c.style(this.elem,this.prop);this.options.hide=true;this.custom(this.cur(),0)},step:function(a){var b=J(),d=true;if(a||b>=this.options.duration+this.startTime){this.now=
this.end;this.pos=this.state=1;this.update();this.options.curAnim[this.prop]=true;for(var f in this.options.curAnim)if(this.options.curAnim[f]!==true)d=false;if(d){if(this.options.display!=null){this.elem.style.overflow=this.options.overflow;a=c.data(this.elem,"olddisplay");this.elem.style.display=a?a:this.options.display;if(c.css(this.elem,"display")==="none")this.elem.style.display="block"}this.options.hide&&c(this.elem).hide();if(this.options.hide||this.options.show)for(var e in this.options.curAnim)c.style(this.elem,
e,this.options.orig[e]);this.options.complete.call(this.elem)}return false}else{e=b-this.startTime;this.state=e/this.options.duration;a=this.options.easing||(c.easing.swing?"swing":"linear");this.pos=c.easing[this.options.specialEasing&&this.options.specialEasing[this.prop]||a](this.state,e,0,1,this.options.duration);this.now=this.start+(this.end-this.start)*this.pos;this.update()}return true}};c.extend(c.fx,{tick:function(){for(var a=c.timers,b=0;b<a.length;b++)a[b]()||a.splice(b--,1);a.length||
c.fx.stop()},stop:function(){clearInterval(W);W=null},speeds:{slow:600,fast:200,_default:400},step:{opacity:function(a){c.style(a.elem,"opacity",a.now)},_default:function(a){if(a.elem.style&&a.elem.style[a.prop]!=null)a.elem.style[a.prop]=(a.prop==="width"||a.prop==="height"?Math.max(0,a.now):a.now)+a.unit;else a.elem[a.prop]=a.now}}});if(c.expr&&c.expr.filters)c.expr.filters.animated=function(a){return c.grep(c.timers,function(b){return a===b.elem}).length};c.fn.offset="getBoundingClientRect"in s.documentElement?
function(a){var b=this[0];if(a)return this.each(function(e){c.offset.setOffset(this,a,e)});if(!b||!b.ownerDocument)return null;if(b===b.ownerDocument.body)return c.offset.bodyOffset(b);var d=b.getBoundingClientRect(),f=b.ownerDocument;b=f.body;f=f.documentElement;return{top:d.top+(self.pageYOffset||c.support.boxModel&&f.scrollTop||b.scrollTop)-(f.clientTop||b.clientTop||0),left:d.left+(self.pageXOffset||c.support.boxModel&&f.scrollLeft||b.scrollLeft)-(f.clientLeft||b.clientLeft||0)}}:function(a){var b=
this[0];if(a)return this.each(function(r){c.offset.setOffset(this,a,r)});if(!b||!b.ownerDocument)return null;if(b===b.ownerDocument.body)return c.offset.bodyOffset(b);c.offset.initialize();var d=b.offsetParent,f=b,e=b.ownerDocument,j,i=e.documentElement,o=e.body;f=(e=e.defaultView)?e.getComputedStyle(b,null):b.currentStyle;for(var k=b.offsetTop,n=b.offsetLeft;(b=b.parentNode)&&b!==o&&b!==i;){if(c.offset.supportsFixedPosition&&f.position==="fixed")break;j=e?e.getComputedStyle(b,null):b.currentStyle;
k-=b.scrollTop;n-=b.scrollLeft;if(b===d){k+=b.offsetTop;n+=b.offsetLeft;if(c.offset.doesNotAddBorder&&!(c.offset.doesAddBorderForTableAndCells&&/^t(able|d|h)$/i.test(b.nodeName))){k+=parseFloat(j.borderTopWidth)||0;n+=parseFloat(j.borderLeftWidth)||0}f=d;d=b.offsetParent}if(c.offset.subtractsBorderForOverflowNotVisible&&j.overflow!=="visible"){k+=parseFloat(j.borderTopWidth)||0;n+=parseFloat(j.borderLeftWidth)||0}f=j}if(f.position==="relative"||f.position==="static"){k+=o.offsetTop;n+=o.offsetLeft}if(c.offset.supportsFixedPosition&&
f.position==="fixed"){k+=Math.max(i.scrollTop,o.scrollTop);n+=Math.max(i.scrollLeft,o.scrollLeft)}return{top:k,left:n}};c.offset={initialize:function(){var a=s.body,b=s.createElement("div"),d,f,e,j=parseFloat(c.curCSS(a,"marginTop",true))||0;c.extend(b.style,{position:"absolute",top:0,left:0,margin:0,border:0,width:"1px",height:"1px",visibility:"hidden"});b.innerHTML="<div style='position:absolute;top:0;left:0;margin:0;border:5px solid #000;padding:0;width:1px;height:1px;'><div></div></div><table style='position:absolute;top:0;left:0;margin:0;border:5px solid #000;padding:0;width:1px;height:1px;' cellpadding='0' cellspacing='0'><tr><td></td></tr></table>";
a.insertBefore(b,a.firstChild);d=b.firstChild;f=d.firstChild;e=d.nextSibling.firstChild.firstChild;this.doesNotAddBorder=f.offsetTop!==5;this.doesAddBorderForTableAndCells=e.offsetTop===5;f.style.position="fixed";f.style.top="20px";this.supportsFixedPosition=f.offsetTop===20||f.offsetTop===15;f.style.position=f.style.top="";d.style.overflow="hidden";d.style.position="relative";this.subtractsBorderForOverflowNotVisible=f.offsetTop===-5;this.doesNotIncludeMarginInBodyOffset=a.offsetTop!==j;a.removeChild(b);
c.offset.initialize=c.noop},bodyOffset:function(a){var b=a.offsetTop,d=a.offsetLeft;c.offset.initialize();if(c.offset.doesNotIncludeMarginInBodyOffset){b+=parseFloat(c.curCSS(a,"marginTop",true))||0;d+=parseFloat(c.curCSS(a,"marginLeft",true))||0}return{top:b,left:d}},setOffset:function(a,b,d){if(/static/.test(c.curCSS(a,"position")))a.style.position="relative";var f=c(a),e=f.offset(),j=parseInt(c.curCSS(a,"top",true),10)||0,i=parseInt(c.curCSS(a,"left",true),10)||0;if(c.isFunction(b))b=b.call(a,
d,e);d={top:b.top-e.top+j,left:b.left-e.left+i};"using"in b?b.using.call(a,d):f.css(d)}};c.fn.extend({position:function(){if(!this[0])return null;var a=this[0],b=this.offsetParent(),d=this.offset(),f=/^body|html$/i.test(b[0].nodeName)?{top:0,left:0}:b.offset();d.top-=parseFloat(c.curCSS(a,"marginTop",true))||0;d.left-=parseFloat(c.curCSS(a,"marginLeft",true))||0;f.top+=parseFloat(c.curCSS(b[0],"borderTopWidth",true))||0;f.left+=parseFloat(c.curCSS(b[0],"borderLeftWidth",true))||0;return{top:d.top-
f.top,left:d.left-f.left}},offsetParent:function(){return this.map(function(){for(var a=this.offsetParent||s.body;a&&!/^body|html$/i.test(a.nodeName)&&c.css(a,"position")==="static";)a=a.offsetParent;return a})}});c.each(["Left","Top"],function(a,b){var d="scroll"+b;c.fn[d]=function(f){var e=this[0],j;if(!e)return null;if(f!==w)return this.each(function(){if(j=wa(this))j.scrollTo(!a?f:c(j).scrollLeft(),a?f:c(j).scrollTop());else this[d]=f});else return(j=wa(e))?"pageXOffset"in j?j[a?"pageYOffset":
"pageXOffset"]:c.support.boxModel&&j.document.documentElement[d]||j.document.body[d]:e[d]}});c.each(["Height","Width"],function(a,b){var d=b.toLowerCase();c.fn["inner"+b]=function(){return this[0]?c.css(this[0],d,false,"padding"):null};c.fn["outer"+b]=function(f){return this[0]?c.css(this[0],d,false,f?"margin":"border"):null};c.fn[d]=function(f){var e=this[0];if(!e)return f==null?null:this;if(c.isFunction(f))return this.each(function(j){var i=c(this);i[d](f.call(this,j,i[d]()))});return"scrollTo"in
e&&e.document?e.document.compatMode==="CSS1Compat"&&e.document.documentElement["client"+b]||e.document.body["client"+b]:e.nodeType===9?Math.max(e.documentElement["client"+b],e.body["scroll"+b],e.documentElement["scroll"+b],e.body["offset"+b],e.documentElement["offset"+b]):f===w?c.css(e,d):this.css(d,typeof f==="string"?f:f+"px")}});A.jQuery=A.$=c})(window); | zas-rep-tools | /zas-rep-tools-0.2.tar.gz/zas-rep-tools-0.2/zas_rep_tools/src/extensions/tweet_nlp/ark_tweet_nlp/data/twpos-annotator-v0.1/lib/jquery-1.4.2.min.js | jquery-1.4.2.min.js |
============================================================================
Twitter Part-of-Speech Annotated Data
Carnegie Mellon University
http://www.ark.cs.cmu.edu/TweetNLP
=============================================================================
Description:
This is release v0.3 of a data set of tweets manually annotated with
coarse part- of-speech tags. The annotated data is divided into two
groups:
* "Oct27": 1827 tweets from 2010-10-27
* "Daily547": 547 tweets, one per day from 2011-01-01 through 2012-06-30
The "Oct27" dataset is further split into "train", "dev", and "test" subsets
(the same splits in Gimpel et al. 2011).
We distribute two data formats. The "conll" format has one token per
line, and a blank line to indicate a tweet boundary. The "supertsv"
format includes additional metainformation about tweets (and has a
different column ordering).
See the Owoputi and O'Connor (2012) tech report for more information.
Available at http://www.ark.cs.cmu.edu/TweetNLP
Also see the annotation guidelines, currently at:
https://github.com/brendano/ark-tweet-nlp/blob/master/docs/annot_guidelines.md
Contact:
Please contact Brendan O'Connor ([email protected], http://brenocon.com)
and Kevin Gimpel ([email protected]) with any questions about this
release.
Changes:
Version 0.3 (2012-09-19): Added new Daily547 data, fixed inconsistencies
in Oct27 data (see anno_changes/). Documented in the 2012 tech report.
Version 0.2.1 (2012-08-01): License changed from GPL to CC-BY.
Version 0.2 (2011-08-15): Based on an improved Twitter tokenizer. After
the new tokenizer was run, tweets with differing tokenizations were
reannotated following the same guidelines as the initial release.
Version 0.1 (2011-04-26): First release.
References:
The following papers describe this dataset. If you use this data in a
research publication, we ask that you cite this (the original paper):
Kevin Gimpel, Nathan Schneider, Brendan O'Connor, Dipanjan Das,
Daniel Mills, Jacob Eisenstein, Michael Heilman, Dani Yogatama, Jeffrey
Flanigan, and Noah A. Smith.
Part-of-Speech Tagging for Twitter: Annotation, Features, and Experiments.
In Proceedings of the Annual Meeting of the Association for Computational
Linguistics, companion volume, Portland, OR, June 2011.
Changes to the 0.3 version are described in
Part-of-Speech Tagging for Twitter: Word Clusters and Other Advances
Olutobi Owoputi, Brendan O'Connor, Chris Dyer, Kevin Gimpel, and
Nathan Schneider.
Technical Report, Machine Learning Department. CMU-ML-12-107.
September 2012.
============================================================================
Copyright (C) 2011-2012
Kevin Gimpel, Nathan Schneider, Brendan O'Connor, Dipanjan Das, Daniel
Mills, Jacob Eisenstein, Michael Heilman, Dani Yogatama, Jeffrey Flanigan,
and Noah A. Smith
Language Technologies Institute, Carnegie Mellon University
This data is made available under the terms of the Creative Commons
Attribution 3.0 Unported license ("CC-BY"):
http://creativecommons.org/licenses/by/3.0/
| zas-rep-tools | /zas-rep-tools-0.2.tar.gz/zas-rep-tools-0.2/zas_rep_tools/src/extensions/tweet_nlp/ark_tweet_nlp/data/twpos-data-v0.3/README.txt | README.txt |
import subprocess
import shlex
# The only relavent source I've found is here:
# http://m1ked.com/post/12304626776/pos-tagger-for-twitter-successfully-implemented-in
# which is a very simple implementation, my implementation is a bit more
# useful (but not much).
# NOTE this command is directly lifted from runTagger.sh
RUN_TAGGER_CMD = "java -XX:ParallelGCThreads=2 -Xmx500m -jar ../ark_tweet_nlp/ark-tweet-nlp-0.3.2.jar"
def _split_results(rows):
"""Parse the tab-delimited returned lines, modified from: https://github.com/brendano/ark-tweet-nlp/blob/master/scripts/show.py"""
for line in rows:
line = line.strip() # remove '\n'
if len(line) > 0:
if line.count('\t') == 2:
parts = line.split('\t')
tokens = parts[0]
tags = parts[1]
confidence = float(parts[2])
yield tokens, tags, confidence
def _call_runtagger(tweets, run_tagger_cmd=RUN_TAGGER_CMD):
"""Call runTagger.sh using a named input file"""
# remove carriage returns as they are tweet separators for the stdin
# interface
tweets_cleaned = [tw.replace('\n', ' ') for tw in tweets]
message = "\n".join(tweets_cleaned)
# force UTF-8 encoding (from internal unicode type) to avoid .communicate encoding error as per:
# http://stackoverflow.com/questions/3040101/python-encoding-for-pipe-communicate
message = message.encode('utf-8')
# build a list of args
args = shlex.split(run_tagger_cmd)
args.append('--output-format')
args.append('conll')
po = subprocess.Popen(args, stdin=subprocess.PIPE, stdout=subprocess.PIPE, stderr=subprocess.PIPE)
# old call - made a direct call to runTagger.sh (not Windows friendly)
#po = subprocess.Popen([run_tagger_cmd, '--output-format', 'conll'], stdin=subprocess.PIPE, stdout=subprocess.PIPE, stderr=subprocess.PIPE)
result = po.communicate(message)
# expect a tuple of 2 items like:
# ('hello\t!\t0.9858\nthere\tR\t0.4168\n\n',
# 'Listening on stdin for input. (-h for help)\nDetected text input format\nTokenized and tagged 1 tweets (2 tokens) in 7.5 seconds: 0.1 tweets/sec, 0.3 tokens/sec\n')
pos_result = result[0].strip('\n\n') # get first line, remove final double carriage return
pos_result = pos_result.split('\n\n') # split messages by double carriage returns
pos_results = [pr.split('\n') for pr in pos_result] # split parts of message by each carriage return
return pos_results
def runtagger_parse(tweets, run_tagger_cmd=RUN_TAGGER_CMD):
"""Call runTagger.sh on a list of tweets, parse the result, return lists of tuples of (term, type, confidence)"""
pos_raw_results = _call_runtagger(tweets, run_tagger_cmd)
pos_result = []
for pos_raw_result in pos_raw_results:
pos_result.append([x for x in _split_results(pos_raw_result)])
return pos_result
def check_script_is_present(run_tagger_cmd=RUN_TAGGER_CMD):
"""Simple test to make sure we can see the script"""
success = False
try:
args = shlex.split(run_tagger_cmd)
print args
args.append("--help")
po = subprocess.Popen(args, stdout=subprocess.PIPE)
# old call - made a direct call to runTagger.sh (not Windows friendly)
#po = subprocess.Popen([run_tagger_cmd, '--help'], stdout=subprocess.PIPE)
while not po.poll():
lines = [l for l in po.stdout]
# we expected the first line of --help to look like the following:
assert "RunTagger [options]" in lines[0]
success = True
except OSError as err:
print "Caught an OSError, have you specified the correct path to runTagger.sh? We are using \"%s\". Exception: %r" % (run_tagger_cmd, repr(err))
return success
if __name__ == "__main__":
print "Checking that we can see \"%s\", this will crash if we can't" % (RUN_TAGGER_CMD)
success = check_script_is_present()
if success:
print "Success."
print "Now pass in two messages, get a list of tuples back:"
tweets = ['this is a message', 'and a second message']
print runtagger_parse(tweets) | zas-rep-tools | /zas-rep-tools-0.2.tar.gz/zas-rep-tools-0.2/zas_rep_tools/src/extensions/tweet_nlp/ark_tweet_nlp_python/CMUTweetTagger.py | CMUTweetTagger.py |
ark-tweet-nlp-python [no longer supported by Ian]
=================================================
**Note** this is _no longer supported_ by Ian Ozsvald, sorry, you're most welcome to fork this. If you are running a living fork then I'd be happy to point users at your repo.
Simple Python wrapper around runTagger.sh of ark-tweet-nlp. It passes a list of tweets to runTagger.sh and parses the result into a list of lists of tuples, each tuple represents the (token, type, confidence).
Wraps up:
* https://github.com/brendano/ark-tweet-nlp
* http://www.ark.cs.cmu.edu/TweetNLP/
Lives here:
* https://github.com/ianozsvald/ark-tweet-nlp-python
Usage:
-----
>>> import CMUTweetTagger
>>> print CMUTweetTagger.runtagger_parse(['example tweet 1', 'example tweet 2'])
>>> [[('example', 'N', 0.979), ('tweet', 'V', 0.7763), ('1', '$', 0.9916)], [('example', 'N', 0.979), ('tweet', 'V', 0.7713), ('2', '$', 0.5832)]]
Note, if you receive:
>>> Error: Unable to access jarfile ark-tweet-nlp-0.3.2.jar
Make sure you pass in the correct path to the jar file, e.g. if this script is cloned into a subdirectory of ark-tweet-nlp then you may need to use:
>>> print CMUTweetTagger.runtagger_parse(['example tweet 1', 'example tweet 2'], run_tagger_cmd="java -XX:ParallelGCThreads=2 -Xmx500m -jar ../ark-tweet-nlp-0.3.2.jar")
Notes and possible improvements:
-------------------------------
* This wrapper calls runTagger.sh's contents via command line, Java takes a few seconds to start - you should send in a list of tweets rather than doing them one at a time
* Communicating once the shell process is opened rather than closing comms would be more sensible
* _call_runtagger replaces new-lines in the tweet with a space (as new-lines signify tweet separators in runTagger.sh), this might not be appropriate if you need to maintain new-lines
* It would probably be awfully nicer if somebody wrapped up a py4J interface so we didn't have to start java at the command line each time (or maybe I shouldn't use .communicate which closes the process and instead keep the process open?)
* _split_results could do with a unittest, probably the module should turn into a class so you only have to set runTagger.sh's path location once (and it should assert if it can't find the script on initialisation)
* Really the script should be in a class so it can be initialised with runTagger.sh
License:
-------
*MIT*
Copyright (c) 2013 Ian Ozsvald.
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in
all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN
THE SOFTWARE.
Copyright (c) 2013 Ian Ozsvald
| zas-rep-tools | /zas-rep-tools-0.2.tar.gz/zas-rep-tools-0.2/zas_rep_tools/src/extensions/tweet_nlp/ark_tweet_nlp_python/README.md | README.md |
from __future__ import (absolute_import,
division,
print_function,
unicode_literals)
from unicodedata import east_asian_width
from .breaking import boundaries, break_units
from .codepoint import ord, unichr, code_point, code_points
from .db import line_break as _line_break
__all__ = [
'line_break',
'line_break_breakables',
'line_break_boundaries',
'line_break_units',
]
BK = 'BK' # Mandatory Break
CR = 'CR' # Carriage Return
LF = 'LF' # Line Feed
CM = 'CM' # Combining Mark
NL = 'NL' # Next Line
SG = 'SG' # Surrogate
WJ = 'WJ' # Word Joiner
ZW = 'ZW' # Zero Width Space
GL = 'GL' # Non-breaking ("Glue")
SP = 'SP' # Space
B2 = 'B2' # Break Opportunity Before and After
BA = 'BA' # Break After
BB = 'BB' # Break Before
HY = 'HY' # Hyphen
CB = 'CB' # Contingent Break Opportunity
CL = 'CL' # Close Punctuation
CP = 'CP' # Close Parenthesis
EX = 'EX' # Exclamation/Interrogation
IN = 'IN' # Inseparable
NS = 'NS' # Nonstarter
OP = 'OP' # Open Punctuation
QU = 'QU' # Quotation
IS = 'IS' # Infix Numeric Separator
NU = 'NU' # Numeric
PO = 'PO' # Postfix Numeric
PR = 'PR' # Prefix Numeric
SY = 'SY' # Symbols Allowing Break After
AI = 'AI' # Ambiguous (Alphabetic or Ideographic)
AL = 'AL' # Alphabetic
CJ = 'CJ' # Conditional Japanese Starter
H2 = 'H2' # Hangul LV Syllable
H3 = 'H3' # Hangul LVT Syllable
HL = 'HL' # Hebrew Letter
ID = 'ID' # Ideographic
JL = 'JL' # Hangul L Jamo
JV = 'JV' # Hangul V Jamo
JT = 'JT' # Hangul T Jamo
RI = 'RI' # Regional Indicator
SA = 'SA' # Complex Context Dependent (South East Asian)
XX = 'XX' # Unknown
# Pair table based on UAX #14.
# cf. http://www.unicode.org/reports/tr14/#ExampleTable
# The table is extended to handle CBs.
pair_table = {
OP: {OP: '^', CL: '^', CP: '^', QU: '^', GL: '^', NS: '^',
EX: '^', SY: '^', IS: '^', PR: '^', PO: '^', NU: '^',
AL: '^', ID: '^', IN: '^', HY: '^', BA: '^', BB: '^',
B2: '^', ZW: '^', CM: '@', WJ: '^', H2: '^', H3: '^',
JL: '^', JV: '^', JT: '^', CB: '^'},
CL: {OP: '_', CL: '^', CP: '^', QU: '%', GL: '%', NS: '^',
EX: '^', SY: '^', IS: '^', PR: '%', PO: '%', NU: '_',
AL: '_', ID: '_', IN: '_', HY: '%', BA: '%', BB: '_',
B2: '_', ZW: '^', CM: '#', WJ: '^', H2: '_', H3: '_',
JL: '_', JV: '_', JT: '_', CB: '_'},
CP: {OP: '_', CL: '^', CP: '^', QU: '%', GL: '%', NS: '^',
EX: '^', SY: '^', IS: '^', PR: '%', PO: '%', NU: '%',
AL: '%', ID: '_', IN: '_', HY: '%', BA: '%', BB: '_',
B2: '_', ZW: '^', CM: '#', WJ: '^', H2: '_', H3: '_',
JL: '_', JV: '_', JT: '_', CB: '_'},
QU: {OP: '^', CL: '^', CP: '^', QU: '%', GL: '%', NS: '%',
EX: '^', SY: '^', IS: '^', PR: '%', PO: '%', NU: '%',
AL: '%', ID: '%', IN: '%', HY: '%', BA: '%', BB: '%',
B2: '%', ZW: '^', CM: '#', WJ: '^', H2: '%', H3: '%',
JL: '%', JV: '%', JT: '%', CB: '%'},
GL: {OP: '%', CL: '^', CP: '^', QU: '%', GL: '%', NS: '%',
EX: '^', SY: '^', IS: '^', PR: '%', PO: '%', NU: '%',
AL: '%', ID: '%', IN: '%', HY: '%', BA: '%', BB: '%',
B2: '%', ZW: '^', CM: '#', WJ: '^', H2: '%', H3: '%',
JL: '%', JV: '%', JT: '%', CB: '%'},
NS: {OP: '_', CL: '^', CP: '^', QU: '%', GL: '%', NS: '%',
EX: '^', SY: '^', IS: '^', PR: '_', PO: '_', NU: '_',
AL: '_', ID: '_', IN: '_', HY: '%', BA: '%', BB: '_',
B2: '_', ZW: '^', CM: '#', WJ: '^', H2: '_', H3: '_',
JL: '_', JV: '_', JT: '_', CB: '_'},
EX: {OP: '_', CL: '^', CP: '^', QU: '%', GL: '%', NS: '%',
EX: '^', SY: '^', IS: '^', PR: '_', PO: '_', NU: '_',
AL: '_', ID: '_', IN: '_', HY: '%', BA: '%', BB: '_',
B2: '_', ZW: '^', CM: '#', WJ: '^', H2: '_', H3: '_',
JL: '_', JV: '_', JT: '_', CB: '_'},
SY: {OP: '_', CL: '^', CP: '^', QU: '%', GL: '%', NS: '%',
EX: '^', SY: '^', IS: '^', PR: '_', PO: '_', NU: '%',
AL: '_', ID: '_', IN: '_', HY: '%', BA: '%', BB: '_',
B2: '_', ZW: '^', CM: '#', WJ: '^', H2: '_', H3: '_',
JL: '_', JV: '_', JT: '_', CB: '_'},
IS: {OP: '_', CL: '^', CP: '^', QU: '%', GL: '%', NS: '%',
EX: '^', SY: '^', IS: '^', PR: '_', PO: '_', NU: '%',
AL: '%', ID: '_', IN: '_', HY: '%', BA: '%', BB: '_',
B2: '_', ZW: '^', CM: '#', WJ: '^', H2: '_', H3: '_',
JL: '_', JV: '_', JT: '_', CB: '_'},
PR: {OP: '%', CL: '^', CP: '^', QU: '%', GL: '%', NS: '%',
EX: '^', SY: '^', IS: '^', PR: '_', PO: '_', NU: '%',
AL: '%', ID: '%', IN: '_', HY: '%', BA: '%', BB: '_',
B2: '_', ZW: '^', CM: '#', WJ: '^', H2: '%', H3: '%',
JL: '%', JV: '%', JT: '%', CB: '_'},
PO: {OP: '%', CL: '^', CP: '^', QU: '%', GL: '%', NS: '%',
EX: '^', SY: '^', IS: '^', PR: '_', PO: '_', NU: '%',
AL: '%', ID: '_', IN: '_', HY: '%', BA: '%', BB: '_',
B2: '_', ZW: '^', CM: '#', WJ: '^', H2: '_', H3: '_',
JL: '_', JV: '_', JT: '_', CB: '_'},
NU: {OP: '%', CL: '^', CP: '^', QU: '%', GL: '%', NS: '%',
EX: '^', SY: '^', IS: '^', PR: '%', PO: '%', NU: '%',
AL: '%', ID: '_', IN: '%', HY: '%', BA: '%', BB: '_',
B2: '_', ZW: '^', CM: '#', WJ: '^', H2: '_', H3: '_',
JL: '_', JV: '_', JT: '_', CB: '_'},
AL: {OP: '%', CL: '^', CP: '^', QU: '%', GL: '%', NS: '%',
EX: '^', SY: '^', IS: '^', PR: '_', PO: '_', NU: '%',
AL: '%', ID: '_', IN: '%', HY: '%', BA: '%', BB: '_',
B2: '_', ZW: '^', CM: '#', WJ: '^', H2: '_', H3: '_',
JL: '_', JV: '_', JT: '_', CB: '_'},
ID: {OP: '_', CL: '^', CP: '^', QU: '%', GL: '%', NS: '%',
EX: '^', SY: '^', IS: '^', PR: '_', PO: '%', NU: '_',
AL: '_', ID: '_', IN: '%', HY: '%', BA: '%', BB: '_',
B2: '_', ZW: '^', CM: '#', WJ: '^', H2: '_', H3: '_',
JL: '_', JV: '_', JT: '_', CB: '_'},
IN: {OP: '_', CL: '^', CP: '^', QU: '%', GL: '%', NS: '%',
EX: '^', SY: '^', IS: '^', PR: '_', PO: '_', NU: '_',
AL: '_', ID: '_', IN: '%', HY: '%', BA: '%', BB: '_',
B2: '_', ZW: '^', CM: '#', WJ: '^', H2: '_', H3: '_',
JL: '_', JV: '_', JT: '_', CB: '_'},
HY: {OP: '_', CL: '^', CP: '^', QU: '%', GL: '_', NS: '%',
EX: '^', SY: '^', IS: '^', PR: '_', PO: '_', NU: '%',
AL: '_', ID: '_', IN: '_', HY: '%', BA: '%', BB: '_',
B2: '_', ZW: '^', CM: '#', WJ: '^', H2: '_', H3: '_',
JL: '_', JV: '_', JT: '_', CB: '_'},
BA: {OP: '_', CL: '^', CP: '^', QU: '%', GL: '_', NS: '%',
EX: '^', SY: '^', IS: '^', PR: '_', PO: '_', NU: '_',
AL: '_', ID: '_', IN: '_', HY: '%', BA: '%', BB: '_',
B2: '_', ZW: '^', CM: '#', WJ: '^', H2: '_', H3: '_',
JL: '_', JV: '_', JT: '_', CB: '_'},
BB: {OP: '%', CL: '^', CP: '^', QU: '%', GL: '%', NS: '%',
EX: '^', SY: '^', IS: '^', PR: '%', PO: '%', NU: '%',
AL: '%', ID: '%', IN: '%', HY: '%', BA: '%', BB: '%',
B2: '%', ZW: '^', CM: '#', WJ: '^', H2: '%', H3: '%',
JL: '%', JV: '%', JT: '%', CB: '_'},
B2: {OP: '_', CL: '^', CP: '^', QU: '%', GL: '%', NS: '%',
EX: '^', SY: '^', IS: '^', PR: '_', PO: '_', NU: '_',
AL: '_', ID: '_', IN: '_', HY: '%', BA: '%', BB: '_',
B2: '^', ZW: '^', CM: '#', WJ: '^', H2: '_', H3: '_',
JL: '_', JV: '_', JT: '_', CB: '_'},
ZW: {OP: '_', CL: '_', CP: '_', QU: '_', GL: '_', NS: '_',
EX: '_', SY: '_', IS: '_', PR: '_', PO: '_', NU: '_',
AL: '_', ID: '_', IN: '_', HY: '_', BA: '_', BB: '_',
B2: '_', ZW: '^', CM: '_', WJ: '_', H2: '_', H3: '_',
JL: '_', JV: '_', JT: '_', CB: '_'},
CM: {OP: '%', CL: '^', CP: '^', QU: '%', GL: '%', NS: '%',
EX: '^', SY: '^', IS: '^', PR: '_', PO: '_', NU: '%',
AL: '%', ID: '_', IN: '%', HY: '%', BA: '%', BB: '_',
B2: '_', ZW: '^', CM: '#', WJ: '^', H2: '_', H3: '_',
JL: '_', JV: '_', JT: '_', CB: '_'},
WJ: {OP: '%', CL: '^', CP: '^', QU: '%', GL: '%', NS: '%',
EX: '^', SY: '^', IS: '^', PR: '%', PO: '%', NU: '%',
AL: '%', ID: '%', IN: '%', HY: '%', BA: '%', BB: '%',
B2: '%', ZW: '^', CM: '#', WJ: '^', H2: '%', H3: '%',
JL: '%', JV: '%', JT: '%', CB: '%'},
H2: {OP: '_', CL: '^', CP: '^', QU: '%', GL: '%', NS: '%',
EX: '^', SY: '^', IS: '^', PR: '_', PO: '%', NU: '_',
AL: '_', ID: '_', IN: '%', HY: '%', BA: '%', BB: '_',
B2: '_', ZW: '^', CM: '#', WJ: '^', H2: '_', H3: '_',
JL: '_', JV: '%', JT: '%', CB: '_'},
H3: {OP: '_', CL: '^', CP: '^', QU: '%', GL: '%', NS: '%',
EX: '^', SY: '^', IS: '^', PR: '_', PO: '%', NU: '_',
AL: '_', ID: '_', IN: '%', HY: '%', BA: '%', BB: '_',
B2: '_', ZW: '^', CM: '#', WJ: '^', H2: '_', H3: '_',
JL: '_', JV: '_', JT: '%', CB: '_'},
JL: {OP: '_', CL: '^', CP: '^', QU: '%', GL: '%', NS: '%',
EX: '^', SY: '^', IS: '^', PR: '_', PO: '%', NU: '_',
AL: '_', ID: '_', IN: '%', HY: '%', BA: '%', BB: '_',
B2: '_', ZW: '^', CM: '#', WJ: '^', H2: '%', H3: '%',
JL: '%', JV: '%', JT: '_', CB: '_'},
JV: {OP: '_', CL: '^', CP: '^', QU: '%', GL: '%', NS: '%',
EX: '^', SY: '^', IS: '^', PR: '_', PO: '%', NU: '_',
AL: '_', ID: '_', IN: '%', HY: '%', BA: '%', BB: '_',
B2: '_', ZW: '^', CM: '#', WJ: '^', H2: '_', H3: '_',
JL: '_', JV: '%', JT: '%', CB: '_'},
JT: {OP: '_', CL: '^', CP: '^', QU: '%', GL: '%', NS: '%',
EX: '^', SY: '^', IS: '^', PR: '_', PO: '%', NU: '_',
AL: '_', ID: '_', IN: '%', HY: '%', BA: '%', BB: '_',
B2: '_', ZW: '^', CM: '#', WJ: '^', H2: '_', H3: '_',
JL: '_', JV: '_', JT: '%', CB: '_'},
CB: {OP: '_', CL: '^', CP: '^', QU: '%', GL: '%', NS: '_',
EX: '^', SY: '^', IS: '^', PR: '_', PO: '_', NU: '_',
AL: '_', ID: '_', IN: '_', HY: '_', BA: '_', BB: '_',
B2: '_', ZW: '^', CM: '#', WJ: '^', H2: '_', H3: '_',
JL: '_', JV: '_', JT: '_', CB: '_'},
}
def line_break(c, index=0):
r"""Return the Line_Break property of `c`
`c` must be a single Unicode code point string.
>>> print(line_break('\x0d'))
CR
>>> print(line_break(' '))
SP
>>> print(line_break('1'))
NU
If `index` is specified, this function consider `c` as a unicode
string and return Line_Break property of the code point at
c[index].
>>> print(line_break(u'a\x0d', 1))
CR
"""
return _line_break(code_point(c, index))
def _preprocess_boundaries(s):
r"""(internal) Preprocess LB9: X CM* -> X
Where X is not in (BK, CR, LF, NL, SP, ZW)
>>> list(_preprocess_boundaries(u'\r\n')) == [(0, 'CR'), (1, 'LF')]
True
>>> list(_preprocess_boundaries(u'A\x01A')) == [(0, 'AL'), (2, 'AL')]
True
>>> list(_preprocess_boundaries(u'\n\x01')) == [(0, 'LF'), (1, 'CM')]
True
>>> list(_preprocess_boundaries(u'\n A')) == [(0, 'LF'), (1, 'SP'), (2, 'SP'), (3, 'AL')]
True
"""
prev_prop = None
i = 0
for c in code_points(s):
prop = line_break(c)
if prop in (BK, CR, LF, SP, NL, ZW):
yield (i, prop)
prev_prop = None
elif prop == CM:
if prev_prop is None:
yield (i, prop)
prev_prop = prop
else:
yield (i, prop)
prev_prop = prop
i += len(c)
def line_break_breakables(s, legacy=False):
"""Iterate line breaking opportunities for every position of `s`
1 means "break" and 0 means "do not break" BEFORE the postion.
The length of iteration will be the same as ``len(s)``.
>>> list(line_break_breakables('ABC'))
[0, 0, 0]
>>> list(line_break_breakables('Hello, world.'))
[0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0]
>>> list(line_break_breakables(u''))
[]
"""
if not s:
return
primitive_boundaries = list(_preprocess_boundaries(s))
prev_prev_lb = None
prev_lb = None
for i, (pos, lb) in enumerate(primitive_boundaries):
next_pos, __ = (primitive_boundaries[i+1]
if i<len(primitive_boundaries)-1 else (len(s), None))
if legacy:
if lb == AL:
cp = unichr(ord(s, pos))
lb = ID if east_asian_width(cp) == 'A' else AL
elif lb == AI:
lb = ID
else:
if lb == AI:
lb = AL
if lb == CJ:
lb = NS
if lb in (CM, XX, SA):
lb = AL
# LB4
if pos == 0:
do_break = False
elif prev_lb == BK:
do_break = True
# LB5
elif prev_lb in (CR, LF, NL):
do_break = not (prev_lb == CR and lb == LF)
# LB6
elif lb in (BK, CR, LF, NL):
do_break = False
# LB7
elif lb in (SP, ZW):
do_break = False
# LB8
elif ((prev_prev_lb == ZW and prev_lb == SP) or (prev_lb == ZW)):
do_break = True
# LB11
elif lb == WJ or prev_lb == WJ:
do_break = False
# LB12
elif prev_lb == GL:
do_break = False
# LB12a
elif prev_lb not in (SP, BA, HY) and lb == GL:
do_break = False
# LB13
elif lb in (CL, CP, EX, IS, SY):
do_break = False
# LB14
elif (prev_prev_lb == OP and prev_lb == SP) or prev_lb == OP:
do_break = False
# LB15
elif ((prev_prev_lb == QU and prev_lb == SP and lb == OP)
or (prev_lb == QU and lb == OP)):
do_break = False
# LB16
elif ((prev_prev_lb in (CL, CP) and prev_lb == SP and lb == NS)
or (prev_lb in (CL, CP) and lb == NS)):
do_break = False
# LB17
elif ((prev_prev_lb == B2 and prev_lb == SP and lb == B2)
or (prev_lb == B2 and lb == B2)):
do_break = False
# LB18
elif prev_lb == SP:
do_break = True
# LB19
elif lb == QU or prev_lb == QU:
do_break = False
# LB20
elif lb == CB or prev_lb == CB:
do_break = True
# LB21
elif lb in (BA, HY, NS) or prev_lb == BB:
do_break = False
# LB22
elif prev_lb in (AL, HL, ID, IN, NU) and lb == IN:
do_break = False
# LB23
elif ((prev_lb == ID and lb == PO)
or (prev_lb in (AL, HL) and lb == NU)
or (prev_lb == NU and lb in (AL, HL))):
do_break = False
# LB24
elif ((prev_lb == PR and lb == ID)
or (prev_lb == PR and lb in (AL, HL))
or (prev_lb == PO and lb in (AL, HL))):
do_break = False
# LB25
elif ((prev_lb == CL and lb == PO)
or (prev_lb == CP and lb == PO)
or (prev_lb == CL and lb == PR)
or (prev_lb == CP and lb == PR)
or (prev_lb == NU and lb == PO)
or (prev_lb == NU and lb == PR)
or (prev_lb == PO and lb == OP)
or (prev_lb == PO and lb == NU)
or (prev_lb == PR and lb == OP)
or (prev_lb == PR and lb == NU)
or (prev_lb == HY and lb == NU)
or (prev_lb == IS and lb == NU)
or (prev_lb == NU and lb == NU)
or (prev_lb == SY and lb == NU)):
do_break = False
# LB26
elif ((prev_lb == JL and lb in (JL, JV, H2, H3))
or (prev_lb in (JV, H2) and lb in (JV, JT))
or (prev_lb in (JT, H3) and lb == JT)):
do_break = False
# LB27
elif ((prev_lb in (JL, JV, JT, H2, H3) and lb in (IN, PO))
or (prev_lb == PR and lb in (JL, JV, JT, H2, H3))):
do_break = False
# LB28
elif prev_lb in (AL, HL) and lb in (AL, HL):
do_break = False
# LB29
elif prev_lb == IS and lb in (AL, HL):
do_break = False
# LB30
elif ((prev_lb in (AL, HL, NU) and lb == OP)
or (prev_lb == CP and lb in (AL, HL, NU))):
do_break = False
# LB30a
elif prev_lb == lb == RI:
do_break = False
else:
do_break = True
for j in range(next_pos-pos):
yield int(j==0 and do_break)
prev_prev_lb = prev_lb
prev_lb = lb
def line_break_boundaries(s, legacy=False, tailor=None):
"""Iterate indices of the line breaking boundaries of `s`
This function yields from 0 to the end of the string (== len(s)).
"""
breakables = line_break_breakables(s, legacy)
if tailor is not None:
breakables = tailor(s, breakables)
return boundaries(breakables)
def line_break_units(s, legacy=False, tailor=None):
r"""Iterate every line breaking token of `s`
>>> s = 'The quick (\u201cbrown\u201d) fox can\u2019t jump 32.3 feet, right?'
>>> '|'.join(line_break_units(s)) == 'The |quick |(\u201cbrown\u201d) |fox |can\u2019t |jump |32.3 |feet, |right?'
True
>>> list(line_break_units(u''))
[]
>>> list(line_break_units('\u03b1\u03b1')) == [u'\u03b1\u03b1']
True
>>> list(line_break_units(u'\u03b1\u03b1', True)) == [u'\u03b1', u'\u03b1']
True
"""
breakables = line_break_breakables(s, legacy)
if tailor is not None:
breakables = tailor(s, breakables)
return break_units(s, breakables)
if __name__ == '__main__':
import doctest
doctest.testmod() | zas-rep-tools | /zas-rep-tools-0.2.tar.gz/zas-rep-tools-0.2/zas_rep_tools/src/extensions/uniseg/linebreak.py | linebreak.py |
from __future__ import (absolute_import,
division,
print_function,
unicode_literals)
from .breaking import boundaries, break_units
from .codepoint import ord, code_point, code_points
from .db import sentence_break as _sentence_break
__all__ = [
'sentence_break',
'sentence_breakables',
'sentence_boundaries',
'sentences',
]
CR = 'CR'
LF = 'LF'
Extend = 'Extend'
Sep = 'Sep'
Format = 'Format'
Sp = 'Sp'
Lower = 'Lower'
Upper = 'Upper'
OLetter = 'OLetter'
Numeric = 'Numeric'
ATerm = 'ATerm'
SContinue = 'SContinue'
STerm = 'STerm'
Close = 'Close'
def sentence_break(c, index=0):
r"""Return Sentence_Break property value of `c`
`c` must be a single Unicode code point string.
>>> print(sentence_break(u'\x0d'))
CR
>>> print(sentence_break(u' '))
Sp
>>> print(sentence_break(u'a'))
Lower
If `index` is specified, this function consider `c` as a unicode
string and return Sentence_Break property of the code point at
c[index].
>>> print(sentence_break(u'a\x0d', 1))
CR
"""
return _sentence_break(code_point(c, index))
def _preprocess_boundaries(s):
r"""(internal)
>>> list(_preprocess_boundaries('Aa')) == [(0, 'Upper'), (1, 'Lower')]
True
>>> list(_preprocess_boundaries('A a')) == [(0, 'Upper'), (1, 'Sp'), (2, 'Lower')]
True
>>> list(_preprocess_boundaries('A" a')) == [(0, 'Upper'), (1, 'Close'), (2, 'Sp'), (3, 'Lower')]
True
>>> list(_preprocess_boundaries('A\xad "')) == [(0, 'Upper'), (2, 'Sp'), (3, 'Close')]
True
>>> list(_preprocess_boundaries('\r\rA')) == [(0, 'CR'), (1, 'CR'), (2, 'Upper')]
True
"""
prev_prop = None
i = 0
for c in code_points(s):
prop = sentence_break(c)
if prop in (Sep, CR, LF):
yield (i, prop)
prev_prop = None
elif prop in (Extend, Format):
if prev_prop is None:
yield (i, prop)
prev_prop = prop
elif prev_prop != prop:
yield (i, prop)
prev_prop = prop
i += len(c)
def _next_break(primitive_boundaries, pos, expects):
"""(internal)
"""
for i in xrange(pos, len(primitive_boundaries)):
sb = primitive_boundaries[i][1]
if sb in expects:
return sb
return None
def sentence_breakables(s):
r"""Iterate sentence breaking opportunities for every position of
`s`
1 for "break" and 0 for "do not break". The length of iteration
will be the same as ``len(s)``.
>>> s = 'He said, \u201cAre you going?\u201d John shook his head.'
>>> list(sentence_breakables(s))
[1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
"""
primitive_boundaries = list(_preprocess_boundaries(s))
prev_prev_prev_prev_sb = None
prev_prev_prev_sb = None
prev_prev_sb = None
prev_sb = None
pos = 0
for i, (pos, sb) in enumerate(primitive_boundaries):
next_pos, next_sb = (primitive_boundaries[i+1]
if i<len(primitive_boundaries)-1 else (len(s), None))
if pos == 0:
do_break = True
# SB3
elif prev_sb == CR and sb == LF:
do_break = False
# SB4
elif prev_sb in (Sep, CR, LF):
do_break = True
# SB6
elif prev_sb == ATerm and sb == Numeric:
do_break = False
# SB7
elif prev_prev_sb == Upper and prev_sb == ATerm and sb == Upper:
do_break = False
# SB8
elif (((prev_sb == ATerm)
or (prev_prev_sb == ATerm
and prev_sb == Close)
or (prev_prev_sb == ATerm
and prev_sb == Sp)
or (prev_prev_prev_sb == ATerm
and prev_prev_sb == Close
and prev_sb == Sp))
and _next_break(primitive_boundaries, i,
[OLetter, Upper, Lower, Sep, CR, LF,
STerm, ATerm]) == Lower):
do_break = False
# SB8a
elif (((prev_sb in (STerm, ATerm))
or (prev_prev_sb in (STerm, ATerm)
and prev_sb == Close)
or (prev_prev_sb in (STerm, ATerm)
and prev_sb == Sp)
or (prev_prev_prev_sb in (STerm, ATerm)
and prev_prev_sb == Close
and prev_sb == Sp))
and sb in (SContinue, STerm, ATerm)):
do_break = False
# SB9
elif (((prev_sb in (STerm, ATerm))
or (prev_prev_sb in (STerm, ATerm)
and prev_sb == Close))
and sb in (Close, Sp, Sep, CR, LF)):
do_break = False
# SB10
elif (((prev_sb in (STerm, ATerm))
or (prev_prev_sb in (STerm, ATerm)
and prev_sb == Close)
or (prev_prev_sb in (STerm, ATerm)
and prev_sb == Sp)
or (prev_prev_prev_sb in (STerm, ATerm)
and prev_prev_sb == Close
and prev_sb == Sp))
and sb in (Sp, Sep, CR, LF)):
do_break = False
# SB11
elif ((prev_sb in (STerm, ATerm))
or (prev_prev_sb in (STerm, ATerm)
and prev_sb == Close)
or (prev_prev_sb in (STerm, ATerm)
and prev_sb == Sp)
or (prev_prev_sb in (STerm, ATerm)
and prev_sb in (Sep, CR, LF))
or (prev_prev_prev_sb in (STerm, ATerm)
and prev_prev_sb == Close
and prev_sb == Sp)
or (prev_prev_prev_sb in (STerm, ATerm)
and prev_prev_sb == Close
and prev_sb in (Sep, CR, LF))
or (prev_prev_prev_sb in (STerm, ATerm)
and prev_prev_sb == Sp
and prev_sb in (Sep, CR, LF))
or (prev_prev_prev_prev_sb in (STerm, ATerm)
and prev_prev_prev_sb == Close
and prev_prev_sb == Sp
and prev_sb in (Sep, CR, LF))):
do_break = True
else:
do_break = False
for j in range(next_pos-pos):
yield int(j==0 and do_break)
prev_prev_prev_prev_sb = prev_prev_prev_sb
prev_prev_prev_sb = prev_prev_sb
prev_prev_sb = prev_sb
prev_sb = sb
pos = next_pos
def sentence_boundaries(s, tailor=None):
"""Iterate indices of the sentence boundaries of `s`
This function yields from 0 to the end of the string (== len(s)).
>>> list(sentence_boundaries(u'ABC'))
[0, 3]
>>> s = 'He said, \u201cAre you going?\u201d John shook his head.'
>>> list(sentence_boundaries(s))
[0, 26, 46]
>>> list(sentence_boundaries(u''))
[]
"""
breakables = sentence_breakables(s)
if tailor is not None:
breakables = tailor(s, breakables)
return boundaries(breakables)
def sentences(s, tailor=None):
"""Iterate every sentence of `s`
>>> s = 'He said, \u201cAre you going?\u201d John shook his head.'
>>> list(sentences(s)) == ['He said, \u201cAre you going?\u201d ', 'John shook his head.']
True
"""
breakables = sentence_breakables(s)
if tailor is not None:
breakables = tailor(s, breakables)
return list(break_units(s, breakables))
if __name__ == '__main__':
import doctest
doctest.testmod() | zas-rep-tools | /zas-rep-tools-0.2.tar.gz/zas-rep-tools-0.2/zas_rep_tools/src/extensions/uniseg/sentencebreak.py | sentencebreak.py |
from __future__ import (absolute_import,
division,
print_function,
unicode_literals)
import re
import sys
if sys.version_info >= (3, 0):
from builtins import ord as _ord, chr as _chr
else:
from __builtin__ import ord as _ord, unichr as _chr
__all__ = [
'ord',
'unichr',
'code_points'
]
if sys.maxunicode < 0x10000:
# narrow unicode build
def ord_impl(c, index):
if isinstance(c, str):
return _ord(c[index or 0])
if not isinstance(c, unicode):
raise TypeError('must be unicode, not %s' % type(c).__name__)
i = index or 0
len_s = len(c)-i
if len_s:
value = hi = _ord(c[i])
i += 1
if 0xd800 <= hi < 0xdc00:
if len_s > 1:
lo = _ord(c[i])
i += 1
if 0xdc00 <= lo < 0xe000:
value = (hi-0xd800)*0x400+(lo-0xdc00)+0x10000
if index is not None or i == len_s:
return value
raise TypeError('need a single Unicode code point as parameter')
def unichr_impl(cp):
if not isinstance(cp, int):
raise TypeError('must be int, not %s' % type(c).__name__)
if cp < 0x10000:
return _chr(cp)
hi, lo = divmod(cp-0x10000, 0x400)
hi += 0xd800
lo += 0xdc00
if 0xd800 <= hi < 0xdc00 and 0xdc00 <= lo < 0xe000:
return _chr(hi)+_chr(lo)
raise ValueError('illeagal code point')
rx_codepoints = re.compile(r'[\ud800-\udbff][\udc00-\udfff]|.', re.DOTALL)
def code_point_impl(s, index):
L = rx_codepoints.findall(s)
return L[index]
def code_points_impl(s):
return rx_codepoints.findall(s)
else:
# wide unicode build
def ord_impl(c, index):
return _ord(c if index is None else c[index])
def unichr_impl(cp):
return _chr(cp)
def code_point_impl(s, index):
return s[index or 0]
def code_points_impl(s):
return list(s)
def ord(c, index=None):
"""Return the integer value of the Unicode code point `c`
NOTE: Some Unicode code points may be expressed with a couple of
other code points ("surrogate pair"). This function treats
surrogate pairs as representations of original code points; e.g.
``ord(u'\\ud842\\udf9f')`` returns ``134047`` (``0x20b9f``).
``u'\\ud842\\udf9f'`` is a surrogate pair expression which means
``u'\\U00020b9f'``.
>>> ord('a')
97
>>> ord('\\u3042')
12354
>>> ord('\\U00020b9f')
134047
>>> ord('abc')
Traceback (most recent call last):
...
TypeError: need a single Unicode code point as parameter
It returns the result of built-in ord() when `c` is a single str
object for compatibility:
>>> ord('a')
97
When `index` argument is specified (to not ``None``), this function
treats `c` as a Unicode string and returns integer value of code
point at ``c[index]`` (or may be ``c[index:index+2]``):
>>> ord('hello', 0)
104
>>> ord('hello', 1)
101
>>> ord('a\\U00020b9f', 1)
134047
"""
return ord_impl(c, index)
def unichr(cp):
"""Return the unicode object represents the code point integer `cp`
>>> unichr(0x61) == 'a'
True
Notice that some Unicode code points may be expressed with a
couple of other code points ("surrogate pair") in narrow-build
Python. In those cases, this function will return a unicode
object of which length is more than one; e.g. ``unichr(0x20b9f)``
returns ``u'\\U00020b9f'`` while built-in ``unichr()`` may raise
ValueError.
>>> unichr(0x20b9f) == '\\U00020b9f'
True
"""
return unichr_impl(cp)
def code_point(s, index=0):
"""Return code point at s[index]
>>> code_point('ABC') == 'A'
True
>>> code_point('ABC', 1) == 'B'
True
>>> code_point('\\U00020b9f\\u3042') == '\\U00020b9f'
True
>>> code_point('\\U00020b9f\u3042', 1) == '\\u3042'
True
"""
return code_point_impl(s, index)
def code_points(s):
"""Iterate every Unicode code points of the unicode string `s`
>>> s = 'hello'
>>> list(code_points(s)) == ['h', 'e', 'l', 'l', 'o']
True
The number of iteration may differ from the ``len(s)``, because some
code points may be represented as a couple of other code points
("surrogate pair") in narrow-build Python.
>>> s = 'abc\\U00020b9f\\u3042'
>>> list(code_points(s)) == ['a', 'b', 'c', '\\U00020b9f', '\\u3042']
True
"""
return code_points_impl(s)
if __name__ == '__main__':
import doctest
doctest.testmod(optionflags=doctest.IGNORE_EXCEPTION_DETAIL) | zas-rep-tools | /zas-rep-tools-0.2.tar.gz/zas-rep-tools-0.2/zas_rep_tools/src/extensions/uniseg/codepoint.py | codepoint.py |
from __future__ import (absolute_import,
division,
print_function,
unicode_literals)
import re
from unicodedata import east_asian_width
from .codepoint import ord, code_point, code_points
from .graphemecluster import grapheme_clusters, grapheme_cluster_boundaries
from .linebreak import line_break_boundaries
__all__ = [
'Wrapper',
'wrap',
'Formatter',
'TTFormatter',
'tt_width',
'tt_text_extents',
'tt_wrap'
]
class Wrapper(object):
""" Text wrapping engine
Usually, you don't need to create an instance of the class directly. Use
:func:`wrap` instead.
"""
def wrap(self, formatter, s, cur=0, offset=0, char_wrap=None):
"""Wrap string `s` with `formatter` and invoke its handlers
The optional arguments, `cur` is the starting position of the string
in logical length, and `offset` means left-side offset of the wrapping
area in logical length --- this parameter is only used for calculating
tab-stopping positions for now.
If `char_wrap` is set to ``True``, the text will be warpped with its
grapheme cluster boundaries instead of its line break boundaries.
This may be helpful when you don't want the word wrapping feature in
your application.
This function returns the total count of wrapped lines.
- *Changed in version 0.7:* The order of the parameters are changed.
- *Changed in version 0.7.1:* It returns the count of lines now.
"""
partial_extents = self._partial_extents
if char_wrap:
iter_boundaries = grapheme_cluster_boundaries
else:
iter_boundaries = line_break_boundaries
iline = 0
for para in s.splitlines(True):
for field in re.split('(\\t)', para):
if field == '\t':
tw = formatter.tab_width
field_extents = [tw - (offset + cur) % tw]
else:
field_extents = formatter.text_extents(field)
prev_boundary = 0
prev_extent = 0
breakpoint = 0
for boundary in iter_boundaries(field):
extent = field_extents[boundary-1]
w = extent - prev_extent
wrap_width = formatter.wrap_width
if wrap_width is not None and cur + w > wrap_width:
line = field[breakpoint:prev_boundary]
line_extents = partial_extents(field_extents,
breakpoint,
prev_boundary)
formatter.handle_text(line, line_extents)
formatter.handle_new_line(); iline += 1
cur = 0
breakpoint = prev_boundary
cur += w
prev_boundary = boundary
prev_extent = extent
line = field[breakpoint:]
line_extents = partial_extents(field_extents, breakpoint)
formatter.handle_text(line, line_extents)
formatter.handle_new_line(); iline += 1
cur = 0
return iline
@staticmethod
def _partial_extents(extents, start, stop=None):
"""(internal) return partial extents of `extents[start:end]` """
if stop is None:
stop = len(extents)
extent_offset = extents[start-1] if start > 0 else 0
return [extents[x] - extent_offset for x in range(start, stop)]
### static objects
__wrapper__ = Wrapper()
def wrap(formatter, s, cur=0, offset=0, char_wrap=None):
"""Wrap string `s` with `formatter` using the module's static
:class:`Wrapper` instance
See :meth:`Wrapper.wrap` for further details of the parameters.
- *Changed in version 0.7.1:* It returns the count of lines now.
"""
return __wrapper__.wrap(formatter, s, cur, offset, char_wrap)
class Formatter(object):
"""The abstruct base class for formatters invoked by a :class:`Wrapper`
object
This class is implemented only for convinience sake and does nothing
itself. You don't have to design your own formatter as a subclass of it,
while it is not deprecated either.
**Your formatters should have the methods and properties this class has.**
They are invoked by a :class:`Wrapper` object to determin *logical widths*
of texts and to give you the ways to handle them, such as to render them.
"""
@property
def wrap_width(self):
"""The logical width of text wrapping
Note that returning ``None`` (which is the default) means *"do not
wrap"* while returning ``0`` means *"wrap as narrowly as possible."*
"""
return None
@property
def tab_width(self):
"""The logical width of tab forwarding
This property value is used by a :class:`Wrapper` object to determin
the actual forwarding extents of tabs in each of the positions.
"""
return 0
def reset(self):
"""Reset all states of the formatter """
pass
def text_extents(self, s):
"""Return a list of logical lengths from start of the string to
each of characters in `s`
"""
pass
def handle_text(self, text, extents):
"""The handler method which is invoked when `text` should be put
on the current position with `extents`
"""
pass
def handle_new_line(self):
"""The handler method which is invoked when the current line is
over and a new line begins
"""
pass
### TT
class TTFormatter(object):
"""A Fixed-width text wrapping formatter """
def __init__(self, wrap_width,
tab_width=8, tab_char=' ', ambiguous_as_wide=False):
self._lines = ['']
self.wrap_width = wrap_width
self.tab_width = tab_width
self.ambiguous_as_wide = ambiguous_as_wide
self.tab_char = tab_char
@property
def wrap_width(self):
"""Wrapping width """
return self._wrap_width
@wrap_width.setter
def wrap_width(self, value):
self._wrap_width = value
@property
def tab_width(self):
"""forwarding size of tabs """
return self._tab_width
@tab_width.setter
def tab_width(self, value):
self._tab_width = value
@property
def tab_char(self):
"""Character to fill tab spaces with """
return self._tab_char
@tab_char.setter
def tab_char(self, value):
if (east_asian_width(value) not in ('N', 'Na', 'H')):
raise ValueError("""only a narrow code point is available for
tab_char""")
self._tab_char = value
@property
def ambiguous_as_wide(self):
"""Treat code points with its East_Easian_Width property is 'A' as
those with 'W'; having double width as alpha-numerics
"""
return self._ambiguous_as_wide
@ambiguous_as_wide.setter
def ambiguous_as_wide(self, value):
self._ambiguous_as_wide = value
def reset(self):
"""Reset all states of the formatter
"""
del self._lines[:]
def text_extents(self, s):
"""Return a list of logical lengths from start of the string to
each of characters in `s`
"""
return tt_text_extents(s, self.ambiguous_as_wide)
def handle_text(self, text, extents):
"""The handler which is invoked when a text should be put on the
current position
"""
if text == '\t':
text = self.tab_char * extents[0]
self._lines[-1] += text
def handle_new_line(self):
"""The handler which is invoked when the current line is over and a
new line begins
"""
self._lines.append('')
def lines(self):
"""Iterate every wrapped line strings
"""
if not self._lines[-1]:
self._lines.pop()
return iter(self._lines)
def tt_width(s, index=0, ambiguous_as_wide=False):
"""Return logical width of the grapheme cluster at `s[index]` on
fixed-width typography
Return value will be ``1`` (halfwidth) or ``2`` (fullwidth).
Generally, the width of a grapheme cluster is determined by its leading
code point.
>>> tt_width('A')
1
>>> tt_width('\\u8240') # U+8240: CJK UNIFIED IDEOGRAPH-8240
2
>>> tt_width('g\\u0308') # U+0308: COMBINING DIAERESIS
1
>>> tt_width('\\U00029e3d') # U+29E3D: CJK UNIFIED IDEOGRAPH-29E3D
2
If `ambiguous_as_wide` is specified to ``True``, some characters such as
greek alphabets are treated as they have fullwidth as well as ideographics
does.
>>> tt_width('\\u03b1') # U+03B1: GREEK SMALL LETTER ALPHA
1
>>> tt_width('\\u03b1', ambiguous_as_wide=True)
2
"""
cp = code_point(s, index)
eaw = east_asian_width(cp)
if eaw in ('W', 'F') or (eaw == 'A' and ambiguous_as_wide):
return 2
return 1
def tt_text_extents(s, ambiguous_as_wide=False):
"""Return a list of logical widths from the start of `s` to each of
characters *(not of code points)* on fixed-width typography
>>> tt_text_extents('')
[]
>>> tt_text_extents('abc')
[1, 2, 3]
>>> tt_text_extents('\\u3042\\u3044\\u3046')
[2, 4, 6]
>>> import sys
>>> s = '\\U00029e3d' # test a code point out of BMP
>>> actual = tt_text_extents(s)
>>> expect = [2] if sys.maxunicode > 0xffff else [2, 2]
>>> len(s) == len(expect)
True
>>> actual == expect
True
The meaning of `ambiguous_as_wide` is the same as that of
:func:`tt_width`.
"""
widths = []
total_width = 0
for gc in grapheme_clusters(s):
total_width += tt_width(gc, ambiguous_as_wide)
widths.extend(total_width for __ in gc)
return widths
def tt_wrap(s, wrap_width, tab_width=8, tab_char=' ', ambiguous_as_wide=False,
cur=0, offset=0, char_wrap=False):
"""Wrap `s` with given parameters and return a list of wrapped lines
See :class:`TTFormatter` for `wrap_width`, `tab_width` and `tab_char`, and
:func:`tt_wrap` for `cur`, `offset` and `char_wrap`.
"""
formatter = TTFormatter(wrap_width, tab_width, tab_char,
ambiguous_as_wide)
__wrapper__.wrap(formatter, s, cur, offset, char_wrap)
return formatter.lines()
### Main
if __name__ == '__main__':
import doctest
doctest.testmod() | zas-rep-tools | /zas-rep-tools-0.2.tar.gz/zas-rep-tools-0.2/zas_rep_tools/src/extensions/uniseg/wrap.py | wrap.py |
from __future__ import (absolute_import,
division,
print_function,
unicode_literals)
from .breaking import boundaries, break_units
from .codepoint import code_point, code_points
from .db import word_break as _word_break
__all__ = [
'word_break',
'word_breakables',
'word_boundaries',
'words',
]
Other = 'Other'
CR = 'CR'
LF = 'LF'
Newline = 'Newline'
Extend = 'Extend'
Regional_Indicator = 'Regional_Indicator'
Format = 'Format'
Katakana = 'Katakana'
ALetter = 'ALetter'
MidNumLet = 'MidNumLet'
MidLetter = 'MidLetter'
MidNum = 'MidNum'
Numeric = 'Numeric'
ExtendNumLet = 'ExtendNumLet'
ALetter_FormatFE = 'ALetter_FormatFE'
ALetter_MidLetter = 'ALetter_MidLetter'
ALetter_MidNumLet = 'ALetter_MidNumLet'
ALetter_MidNumLet_FormatFE = 'ALetter_MidNumLet_FormatFE'
ALetter_MidNum = 'ALetter_MidNum'
Numeric_MidLetter = 'Numeric_MidLetter'
Numeric_MidNumLet = 'Numeric_MidNumLet'
Numeric_MidNum = 'Numeric_MidNum'
Numeric_MidNumLet_FormatFE = 'Numeric_MidNumLet_FormatFE'
break_table_index = [
Other,
CR,
LF,
Newline,
Katakana,
ALetter,
MidLetter,
MidNum,
MidNumLet,
Numeric,
ExtendNumLet,
Regional_Indicator,
Format,
Extend,
ALetter_FormatFE,
ALetter_MidLetter,
ALetter_MidNumLet,
ALetter_MidNumLet_FormatFE,
ALetter_MidNum,
Numeric_MidLetter,
Numeric_MidNumLet,
Numeric_MidNum,
Numeric_MidNumLet_FormatFE,
]
# cf. http://www.unicode.org/Public/6.2.0/ucd/auxiliary/WordBreakTest.html
break_table = [
#### 0 1 2 3 4 5 6 7 8 9 10 11 12 13 ###
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0], # 0 Other
[1, 1, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], # 1 CR
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], # 2 LF
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], # 3 Newline
[1, 1, 1, 1, 0, 1, 1, 1, 1, 1, 0, 1, 0, 0], # 4 Katakana
[1, 1, 1, 1, 1, 0, 1, 1, 1, 0, 0, 1, 0, 0], # 5 ALetter
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0], # 6 MidLetter
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0], # 7 MidNum
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0], # 8 MidNumLet
[1, 1, 1, 1, 1, 0, 1, 1, 1, 0, 0, 1, 0, 0], # 9 Numeric
[1, 1, 1, 1, 0, 0, 1, 1, 1, 0, 0, 1, 0, 0], # 10 ExtendNumLet
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0], # 11 Regional_Indicator
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0], # 12 Format_FE
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0], # 13 Extend_FE
# ========================================= #
[1, 1, 1, 1, 1, 0, 1, 1, 1, 0, 0, 1, 0, 0], # 14 ALetter Format_FE
[1, 1, 1, 1, 1, 0, 1, 1, 1, 1, 1, 1, 0, 0], # 15 ALetter MidLetter
[1, 1, 1, 1, 1, 0, 1, 1, 1, 1, 1, 1, 0, 0], # 16 ALetter MidNumLet
[1, 1, 1, 1, 1, 0, 1, 1, 1, 1, 1, 1, 0, 0], # 17 ALetter MidNumLet Format_FE
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0], # 18 ALetter MidNum
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0], # 19 Numeric MidLetter
[1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 1, 1, 0, 0], # 20 Numeric MidNumLet
[1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 1, 1, 0, 0], # 21 Numeric MidNum
[1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 1, 1, 0, 0], # 22 Numeric MidNumLet Format_FE
]
def word_break(c, index=0):
r"""Return the Word_Break property of `c`
`c` must be a single Unicode code point string.
>>> print(word_break('\x0d'))
CR
>>> print(word_break('\x0b'))
Newline
>>> print(word_break('\u30a2'))
Katakana
If `index` is specified, this function consider `c` as a unicode
string and return Word_Break property of the code point at
c[index].
>>> print(word_break('A\u30a2', 1))
Katakana
"""
return _word_break(code_point(c, index))
def _preprocess_boundaries(s):
r"""(internal) Preprocess WB4; X [Extend Format]* -> X
>>> result = list(_preprocess_boundaries('\r\n'))
>>> result == [(0, 'CR'), (1, 'LF')]
True
>>> result = list(_preprocess_boundaries('A\u0308A'))
>>> result == [(0, 'ALetter'), (2, 'ALetter')]
True
>>> result = list(_preprocess_boundaries('\n\u2060'))
>>> result == [(0, 'LF'), (1, 'Format')]
True
>>> result = list(_preprocess_boundaries('\x01\u0308\x01'))
>>> result == [(0, 'Other'), (2, 'Other')]
True
"""
prev_prop = None
i = 0
for c in code_points(s):
prop = word_break(c)
if prop in (Newline, CR, LF):
yield (i, prop)
prev_prop = None
elif prop in (Extend, Format):
if prev_prop is None:
yield (i, prop)
prev_prop = prop
else:
yield (i, prop)
prev_prop = prop
i += len(c)
def word_breakables(s):
r"""Iterate word breaking opportunities for every position of `s`
1 for "break" and 0 for "do not break". The length of iteration
will be the same as ``len(s)``.
>>> list(word_breakables(u'ABC'))
[1, 0, 0]
>>> list(word_breakables(u'Hello, world.'))
[1, 0, 0, 0, 0, 1, 1, 1, 0, 0, 0, 0, 1]
>>> list(word_breakables(u'\x01\u0308\x01'))
[1, 0, 1]
"""
if not s:
return
primitive_boundaries = list(_preprocess_boundaries(s))
prev_prev_wb = None
prev_wb = None
prev_pos = 0
for i, (pos, wb) in enumerate(primitive_boundaries):
next_pos, next_wb = (primitive_boundaries[i+1]
if i<len(primitive_boundaries)-1 else (len(s), None))
#print pos, prev_wb, wb
if prev_wb in (Newline, CR, LF) or wb in (Newline, CR, LF):
do_break = not (prev_wb == CR and wb == LF)
# WB5.
elif prev_wb == wb == ALetter:
do_break = False
# WB6.
elif (prev_wb == next_wb == ALetter
and wb in (MidLetter, MidNumLet)):
do_break = False
# WB7.
elif (prev_prev_wb == wb == ALetter
and prev_wb in (MidLetter, MidNumLet)):
do_break = False
# WB8.
elif prev_wb == wb == Numeric:
do_break = False
# WB9.
elif prev_wb == ALetter and wb == Numeric:
do_break = False
# WB10.
elif prev_wb == Numeric and wb == ALetter:
do_break = False
# WB11.
elif (prev_prev_wb == wb == Numeric
and prev_wb in (MidNum, MidNumLet)):
do_break = False
# WB12.
elif (prev_wb == next_wb == Numeric
and wb in (MidNum, MidNumLet)):
do_break = False
# WB13. WB13a. WB13b.
elif (prev_wb == wb == Katakana
or (prev_wb in (ALetter, Numeric, Katakana, ExtendNumLet)
and wb == ExtendNumLet)
or (prev_wb == ExtendNumLet
and wb in ((ALetter, Numeric, Katakana)))
):
do_break = False
# WB13c.
elif prev_wb == wb == Regional_Indicator:
do_break = False
# WB14.
else:
do_break = True
for j in range(next_pos-pos):
yield int(j==0 and do_break)
prev_pos = pos
prev_prev_wb = prev_wb
prev_wb = wb
def word_boundaries(s, tailor=None):
"""Iterate indices of the word boundaries of `s`
This function yields indices from the first boundary position (> 0)
to the end of the string (== len(s)).
"""
breakables = word_breakables(s)
if tailor is not None:
breakables = tailor(s, breakables)
return boundaries(breakables)
def words(s, tailor=None):
"""Iterate *user-perceived* words of `s`
These examples bellow is from
http://www.unicode.org/reports/tr29/tr29-15.html#Word_Boundaries
>>> s = 'The quick (“brown”) fox can’t jump 32.3 feet, right?'
>>> print('|'.join(words(s)))
The| |quick| |(|“|brown|”|)| |fox| |can’t| |jump| |32.3| |feet|,| |right|?
>>> list(words(u''))
[]
"""
breakables = word_breakables(s)
if tailor is not None:
breakables = tailor(s, breakables)
return break_units(s, breakables)
if __name__ == '__main__':
import doctest
doctest.testmod() | zas-rep-tools | /zas-rep-tools-0.2.tar.gz/zas-rep-tools-0.2/zas_rep_tools/src/extensions/uniseg/wordbreak.py | wordbreak.py |
from __future__ import (absolute_import,
division,
print_function,
unicode_literals)
import errno
import os
import sqlite3
import sys
import time
import threading
from .codepoint import ord
def print_dbpath():
"""Print the path of the database file. """
print(os.path.abspath(_dbpath))
def find_dbpath():
"""Find the database file in the specified order and return its path.
The search paths (in the order of priority) are:
1. The directory of the package,
2. that of the executable
3. and the current directory.
"""
dbname = 'ucd.sqlite3'
dbpath = os.path.join(os.path.dirname(__file__), dbname)
if (os.path.exists(dbpath)):
return dbpath
dbpath = os.path.join(os.path.dirname(sys.executable), dbname)
if (os.path.exists(dbpath)):
return dbpath
dbpath = os.path.join(os.getcwd(), dbname)
if (os.path.exists(dbpath)):
return dbpath
return None
#print(str(repr(threading.current_thread))+" IMPORT")
#time.sleep(3)
_dbpath = find_dbpath()
if _dbpath:
_conn = sqlite3.connect(_dbpath, check_same_thread=False)
else:
_conn = None
def grapheme_cluster_break(u):
cur = _conn.cursor()
cur.execute('select value from GraphemeClusterBreak where cp = ?',
(ord(u),))
for value, in cur:
return str(value)
return 'Other'
def iter_grapheme_cluster_break_tests():
cur = _conn.cursor()
cur.execute('select name, pattern, comment from GraphemeClusterBreakTest')
return iter(cur)
def word_break(u):
cur = _conn.cursor()
cur.execute('select value from WordBreak where cp = ?',
(ord(u),))
for value, in cur:
return str(value)
return 'Other'
def iter_word_break_tests():
cur = _conn.cursor()
cur.execute('select name, pattern, comment from WordBreakTest')
return iter(cur)
def sentence_break(u):
cur = _conn.cursor()
cur.execute('select value from SentenceBreak where cp = ?',
(ord(u),))
for value, in cur:
return str(value)
return 'Other'
def iter_sentence_break_tests():
cur = _conn.cursor()
cur.execute('select name, pattern, comment from SentenceBreakTest')
return iter(cur)
def line_break(u):
cur = _conn.cursor()
cur.execute('select value from LineBreak where cp = ?',
(ord(u),))
for value, in cur:
return str(value)
return 'Other'
def iter_line_break_tests():
cur = _conn.cursor()
cur.execute('select name, pattern, comment from LineBreakTest')
return iter(cur) | zas-rep-tools | /zas-rep-tools-0.2.tar.gz/zas-rep-tools-0.2/zas_rep_tools/src/extensions/uniseg/db.py | db.py |
from __future__ import (absolute_import,
division,
print_function,
unicode_literals)
from .breaking import boundaries, break_units
from .codepoint import code_point, code_points
from .db import grapheme_cluster_break as _grapheme_cluster_break
__all__ = [
'grapheme_cluster_break',
'grapheme_cluster_breakables',
'grapheme_cluster_boundaries',
'grapheme_clusters',
]
Other = 0
CR = 1
LF = 2
Control = 3
Extend = 4
SpacingMark = 5
L = 6
V = 7
T = 8
LV = 9
LVT = 10
Regional_Indicator = 11
names = [
'Other', # 0
'CR', # 1
'LF', # 2
'Control', # 3
'Extend', # 4
'SpacingMark', # 5
'L', # 6
'V', # 7
'T', # 8
'LV', # 9
'LVT', # 10
'Regional_Indicator', # 11
]
# cf. http://www.unicode.org/Public/6.2.0/ucd/auxiliary/GraphemeBreakTest.html
# 0: not break, 1: break
break_table = [
[1, 1, 1, 1, 0, 0, 1, 1, 1, 1, 1, 1],
[1, 1, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 0, 0, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 0, 0, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 0, 0, 0, 0, 1, 0, 0, 1],
[1, 1, 1, 1, 0, 0, 1, 0, 0, 1, 1, 1],
[1, 1, 1, 1, 0, 0, 1, 1, 0, 1, 1, 1],
[1, 1, 1, 1, 0, 0, 1, 0, 0, 1, 1, 1],
[1, 1, 1, 1, 0, 0, 1, 1, 0, 1, 1, 1],
[1, 1, 1, 1, 0, 0, 1, 1, 1, 1, 1, 0],
]
def grapheme_cluster_break(c, index=0):
r"""Return the Grapheme_Cluster_Break property of `c`
`c` must be a single Unicode code point string.
>>> print(grapheme_cluster_break('\x0d'))
CR
>>> print(grapheme_cluster_break('\x0a'))
LF
>>> print(grapheme_cluster_break('a'))
Other
If `index` is specified, this function consider `c` as a unicode
string and return Grapheme_Cluster_Break property of the code
point at c[index].
>>> print(grapheme_cluster_break(u'a\x0d', 1))
CR
"""
return _grapheme_cluster_break(code_point(c, index))
def grapheme_cluster_breakables(s):
"""Iterate grapheme cluster breaking opportunities for every
position of `s`
1 for "break" and 0 for "do not break". The length of iteration
will be the same as ``len(s)``.
>>> list(grapheme_cluster_breakables(u'ABC'))
[1, 1, 1]
>>> list(grapheme_cluster_breakables(u'\x67\u0308'))
[1, 0]
>>> list(grapheme_cluster_breakables(u''))
[]
"""
if not s:
return
prev_gcbi = 0
i = 0
for c in code_points(s):
gcb = grapheme_cluster_break(c)
gcbi = names.index(gcb)
if i > 0:
breakable = break_table[prev_gcbi][gcbi]
else:
breakable = 1
for j in range(len(c)):
yield int(j==0 and breakable)
prev_gcbi = gcbi
i += len(c)
def grapheme_cluster_boundaries(s, tailor=None):
"""Iterate indices of the grapheme cluster boundaries of `s`
This function yields from 0 to the end of the string (== len(s)).
>>> list(grapheme_cluster_boundaries('ABC'))
[0, 1, 2, 3]
>>> list(grapheme_cluster_boundaries('\x67\u0308'))
[0, 2]
>>> list(grapheme_cluster_boundaries(''))
[]
"""
breakables = grapheme_cluster_breakables(s)
if tailor is not None:
breakables = tailor(s, breakables)
return boundaries(breakables)
def grapheme_clusters(s, tailor=None):
r"""Iterate every grapheme cluster token of `s`
Grapheme clusters (both legacy and extended):
>>> list(grapheme_clusters('g\u0308')) == ['g\u0308']
True
>>> list(grapheme_clusters('\uac01')) == ['\uac01']
True
>>> list(grapheme_clusters('\u1100\u1161\u11a8')) == ['\u1100\u1161\u11a8']
True
Extended grapheme clusters:
>>> list(grapheme_clusters('\u0ba8\u0bbf')) == ['\u0ba8\u0bbf']
True
>>> list(grapheme_clusters('\u0937\u093f')) == ['\u0937\u093f']
True
Empty string leads the result of empty sequence:
>>> list(grapheme_clusters('')) == []
True
You can customize the default breaking behavior by modifying
breakable table so as to fit the specific locale in `tailor`
function. It receives `s` and its default breaking sequence
(iterator) as its arguments and returns the sequence of customized
breaking opportunities:
>>> def tailor_grapheme_cluster_breakables(s, breakables):
...
... for i, breakable in enumerate(breakables):
... # don't break between 'c' and 'h'
... if s.endswith('c', 0, i) and s.startswith('h', i):
... yield 0
... else:
... yield breakable
...
>>> s = 'Czech'
>>> list(grapheme_clusters(s)) == ['C', 'z', 'e', 'c', 'h']
True
>>> list(grapheme_clusters(s, tailor_grapheme_cluster_breakables)) == ['C', 'z', 'e', 'ch']
True
"""
breakables = grapheme_cluster_breakables(s)
if tailor is not None:
breakables = tailor(s, breakables)
return break_units(s, breakables)
if __name__ == '__main__':
import doctest
doctest.testmod() | zas-rep-tools | /zas-rep-tools-0.2.tar.gz/zas-rep-tools-0.2/zas_rep_tools/src/extensions/uniseg/graphemecluster.py | graphemecluster.py |
"""Text wrapping demo on uniseg + wxPython """
from __future__ import (absolute_import,
division,
print_function,
unicode_literals)
from locale import getpreferredencoding
import wx
from uniseg.wrap import wrap, Formatter
default_text = """The quick (\u201cbrown\u201d) fox \
can\u2019t jump 32.3 feet, right?
Alice was beginning to get very tired of sitting by her \
sister on the bank, and of having nothing to do: once or \
twice she had peeped into the book her sister was reading, \
but it had no pictures or conversations in it, 'and what is \
the use of a book,' thought Alice 'without pictures or \
conversation?'
\u864e\u68b5\u540d\u30f4\u30a3\u30e4\u30b0\u30e9\u3001\u4eca\
\u306e\u30a4\u30f3\u30c9\u8a9e\u3067\u30d0\u30b0\u3001\u5357\
\u30a4\u30f3\u30c9\u306e\u30bf\u30df\u30eb\u8a9e\u3067\u30d4\
\u30ea\u3001\u30b8\u30e3\u30ef\u540d\u30de\u30c1\u30e3\u30e0\
\u3001\u30de\u30ec\u30fc\u540d\u30ea\u30de\u30a6\u3001\u30a2\
\u30e9\u30d6\u540d\u30cb\u30e0\u30eb\u3001\u82f1\u8a9e\u3067\
\u30bf\u30a4\u30ac\u30fc\u3001\u305d\u306e\u4ed6\u6b27\u5dde\
\u8af8\u56fd\u5927\u62b5\u3053\u308c\u306b\u4f3c\u304a\u308a\
\u3001\u3044\u305a\u308c\u3082\u30ae\u30ea\u30b7\u30a2\u3084\
\u30e9\u30c6\u30f3\u306e\u30c1\u30b0\u30ea\u30b9\u306b\u57fa\
\u3065\u304f\u3002\u305d\u306e\u30c1\u30b0\u30ea\u30b9\u306a\
\u308b\u540d\u306f\u53e4\u30da\u30eb\u30b7\u30a2\u8a9e\u306e\
\u30c1\u30b0\u30ea\uff08\u7bad\uff09\u3088\u308a\u51fa\u3067\
\u3001\u864e\u306e\u99db\u304f\u8d70\u308b\u3092\u7bad\u306e\
\u98db\u3076\u306b\u6bd4\u3079\u305f\u308b\u306b\u56e0\u308b\
\u306a\u3089\u3093\u3068\u3044\u3046\u3002\u308f\u304c\u56fd\
\u3067\u3082\u53e4\u6765\u864e\u3092\u5b9f\u969b\u898b\u305a\
\u306b\u5343\u91cc\u3092\u8d70\u308b\u3068\u4fe1\u3058\u3001\
\u622f\u66f2\u306b\u6e05\u6b63\u306e\u6377\u75be\u3092\u8cde\
\u3057\u3066\u5343\u91cc\u4e00\u8df3\u864e\u4e4b\u52a9\u306a\
\u3069\u3068\u6d12\u843d\u3066\u5c45\u308b\u3002\u30d7\u30ea\
\u30cb\u306e\u300e\u535a\u7269\u5fd7\u300f\u306b\u62e0\u308c\
\u3070\u751f\u304d\u305f\u864e\u3092\u30ed\u30fc\u30de\u4eba\
\u304c\u521d\u3081\u3066\u898b\u305f\u306e\u306f\u30a2\u30a6\
\u30b0\u30b9\u30c3\u30b9\u5e1d\u306e\u4ee3\u3060\u3063\u305f\
\u3002
"""
_preferredencoding = getpreferredencoding()
class SampleWxFormatter(Formatter):
def __init__(self, dc, log_width):
self._dc = dc
self._log_width = log_width
self._log_cur_x = 0
self._log_cur_y = 0
@property
def wrap_width(self):
return self._log_width
def reset(self):
self._log_cur_x = 0
self._log_cur_y = 0
def text_extents(self, s):
dc = self._dc
return dc.GetPartialTextExtents(s)
def handle_text(self, text, extents):
if not text or not extents:
return
dc = self._dc
dc.DrawText(text, self._log_cur_x, self._log_cur_y)
self._log_cur_x += extents[-1]
def handle_new_line(self):
dc = self._dc
log_line_height = dc.GetCharHeight()
self._log_cur_y += log_line_height
self._log_cur_x = 0
class App(wx.App):
def OnInit(self):
frame = Frame(None, wx.ID_ANY, __file__)
self.SetTopWindow(frame)
frame.Show()
return True
class Frame(wx.Frame):
ID_FONT = wx.NewId()
def __init__(self, parent, id_, title,
pos=wx.DefaultPosition,
size=wx.DefaultSize,
style=wx.DEFAULT_FRAME_STYLE,
name='frame'):
wx.Frame.__init__(self, parent, id_, title, pos, size, style, name)
self.Bind(wx.EVT_MENU, self.OnCmdOpen, id=wx.ID_OPEN)
self.Bind(wx.EVT_MENU, self.OnCmdExit, id=wx.ID_EXIT)
self.Bind(wx.EVT_MENU, self.OnCmdFont, id=self.ID_FONT)
menubar = wx.MenuBar()
menu = wx.Menu()
menu.Append(wx.ID_OPEN, '&Open')
menu.AppendSeparator()
menu.Append(wx.ID_EXIT, '&Exit')
menubar.Append(menu, '&File')
menu = wx.Menu()
menu.Append(self.ID_FONT, '&Font...')
menubar.Append(menu, 'F&ormat')
self.SetMenuBar(menubar)
self.wrap_window = WrapWindow(self, wx.ID_ANY)
def OnCmdOpen(self, evt):
filename = wx.FileSelector('Open')
if not filename:
return
raw_text = open(filename, 'rU').read()
for enc in {'utf-8', _preferredencoding}:
try:
text = raw_text.decode(enc)
except UnicodeDecodeError:
continue
else:
break
else:
wx.MessageBox('Couldn\'t open this file.', 'Open', wx.ICON_ERROR)
return
self.wrap_window.SetText(text)
self.wrap_window.Refresh()
def OnCmdExit(self, evt):
self.Close()
def OnCmdFont(self, evt):
data = wx.FontData()
font = self.wrap_window.GetFont()
data.SetInitialFont(font)
dlg = wx.FontDialog(self, data)
if dlg.ShowModal() == wx.ID_OK:
ret_data = dlg.GetFontData()
ret_font = ret_data.GetChosenFont()
self.wrap_window.SetFont(ret_font)
self.wrap_window.Refresh()
class WrapWindow(wx.Window):
_text = default_text
_default_fontface = 'Times New Roman'
_default_fontsize = 18
def __init__(self, parent, id_,
pos=wx.DefaultPosition, size=wx.DefaultSize,
style=0, name=wx.PanelNameStr):
wx.Window.__init__(self, parent, id_, pos, size, style, name)
self.SetBackgroundStyle(wx.BG_STYLE_CUSTOM)
self.Bind(wx.EVT_PAINT, self.OnPaint)
self.Bind(wx.EVT_SIZE, self.OnSize)
self.SetBackgroundColour(wx.WHITE)
self.SetForegroundColour(wx.BLACK)
font = wx.Font(self._default_fontsize,
wx.FONTFAMILY_DEFAULT,
wx.FONTSTYLE_NORMAL,
wx.FONTWEIGHT_NORMAL,
False,
self._default_fontface)
self.SetFont(font)
def GetText(self, value):
return _text
def SetText(self, value):
self._text = value
def OnPaint(self, evt):
dc = wx.AutoBufferedPaintDC(self)
dc.Clear()
font = self.GetFont()
dc.SetFont(font)
dev_width, dev_height = self.GetClientSize()
log_width = dc.DeviceToLogicalX(dev_width)
log_height = dc.DeviceToLogicalY(dev_height)
formatter = SampleWxFormatter(dc, log_width)
wrap(formatter, self._text)
def OnSize(self, evt):
self.Refresh()
def main():
app = App(0)
app.MainLoop()
if __name__ == '__main__':
main() | zas-rep-tools | /zas-rep-tools-0.2.tar.gz/zas-rep-tools-0.2/zas_rep_tools/src/extensions/uniseg/samples/wxwrapdemo.py | wxwrapdemo.py |
from __future__ import (absolute_import,
division,
print_function,
unicode_literals)
import argparse
import io
import sys
from locale import getpreferredencoding
from uniseg.wrap import tt_wrap
def argopen(file, mode, encoding=None, errors=None):
closefd = True
if file == '-':
closefd = False
if 'r' in mode:
file = sys.stdin.fileno()
else:
file = sys.stdout.fileno()
return io.open(file, mode, encoding=encoding, errors=errors,
closefd=closefd)
def main():
encoding = getpreferredencoding()
parser = argparse.ArgumentParser()
parser.add_argument('-e', '--encoding',
default=encoding,
help='file encoding (%(default)s)')
parser.add_argument('-r', '--ruler',
action='store_true',
help='show ruler')
parser.add_argument('-t', '--tab-width',
type=int,
default=8,
help='tab width (%(default)d)')
parser.add_argument('-l', '--legacy',
action='store_true',
help='treat ambiguous-width letters as wide')
parser.add_argument('-o', '--output',
default='-',
help='leave output to specified file')
parser.add_argument('-w', '--wrap-width',
type=int,
default=60,
help='wrap width (%(default)s)')
parser.add_argument('-c', '--char-wrap',
action='store_true',
help="""wrap on grapheme boundaries instead of
line break boundaries""")
parser.add_argument('file',
nargs='?',
default='-',
help='input file')
args = parser.parse_args()
ruler = args.ruler
tab_width = args.tab_width
wrap_width = args.wrap_width
char_wrap = args.char_wrap
legacy = args.legacy
encoding = args.encoding
fin = argopen(args.file, 'r', encoding)
fout = argopen(args.output, 'w', encoding)
if ruler:
if tab_width:
ruler = ('+'+'-'*(tab_width-1)) * (wrap_width//tab_width+1)
ruler = ruler[:wrap_width]
else:
ruler = '-' * wrap_width
print(ruler, file=fout)
for para in fin:
for line in tt_wrap(para, wrap_width, tab_width,
ambiguous_as_wide=legacy, char_wrap=char_wrap):
print(line.rstrip('\n'), file=fout)
if __name__ == '__main__':
main() | zas-rep-tools | /zas-rep-tools-0.2.tar.gz/zas-rep-tools-0.2/zas_rep_tools/src/extensions/uniseg/samples/uniwrap.py | uniwrap.py |
from __future__ import (absolute_import,
division,
print_function,
unicode_literals)
import io
import sys
from uniseg.codepoint import code_points
from uniseg.graphemecluster import grapheme_clusters
from uniseg.wordbreak import words
from uniseg.sentencebreak import sentences
from uniseg.linebreak import line_break_units
def argopen(file, mode, encoding=None, errors=None):
closefd = True
if file == '-':
closefd = False
if 'r' in mode:
file = sys.stdin.fileno()
else:
file = sys.stdout.fileno()
return io.open(file, mode, encoding=encoding, errors=errors,
closefd=closefd)
def main():
import argparse
from locale import getpreferredencoding
parser = argparse.ArgumentParser()
parser.add_argument('-e', '--encoding',
default=getpreferredencoding(),
help="""text encoding of the input (%(default)s)""")
parser.add_argument('-l', '--legacy',
action='store_true',
help="""legacy mode (makes sense only with
'--mode l')""")
parser.add_argument('-m', '--mode',
choices=['c', 'g', 'l', 's', 'w'],
default='w',
help="""breaking algorithm (%(default)s)
(c: code points, g: grapheme clusters,
s: sentences l: line breaking units, w: words)""")
parser.add_argument('-o', '--output',
default='-',
help="""leave output to specified file""")
parser.add_argument('file',
nargs='?',
default='-',
help="""input text file""")
args = parser.parse_args()
encoding = args.encoding
fin = argopen(args.file, 'r', encoding)
fout = argopen(args.output, 'w', encoding)
_words = {'c': code_points,
'g': grapheme_clusters,
'l': lambda x: line_break_units(x, args.legacy),
's': sentences,
'w': words,
}[args.mode]
for line in fin:
for w in _words(line):
print(w, file=fout)
if __name__ == '__main__':
main() | zas-rep-tools | /zas-rep-tools-0.2.tar.gz/zas-rep-tools-0.2/zas_rep_tools/src/extensions/uniseg/samples/unibreak.py | unibreak.py |
# ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
# : XXX{Information about this code}XXX
# Author:
# c(Developer) -> {'Egor Savin'}
# ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
###Programm Info######
#
#
#
#
#
import os
#import copy
import sys
#import regex
import logging
import sys
#import signal
import platform
import shutil
import io
import inspect
import time
from datetime import date
import tweepy
import langid
import unicodecsv as csv
import codecs
import json
#from collections import defaultdict
from raven import Client
#from cached_property import cached_property
from encodings.aliases import aliases
import nltk
from nltk.corpus import stopwords
import threading
#import multiprocessing
try:
nltk.data.find('corpora/stopwords')
except:
nltk.download("stopwords")
if platform.uname()[0].lower() !="windows":
from blessings import Terminal
if platform.uname()[0].lower() !="windows":
import colored_traceback
colored_traceback.add_hook()
else:
import colorama
from zas_rep_tools_data.utils import path_to_data_folder, path_to_models, path_to_someweta_models, path_to_stop_words
from zas_rep_tools.src.utils.zaslogger import ZASLogger
#from zas_rep_tools.src.utils.logger import main_logger
from zas_rep_tools.src.utils.debugger import p
from zas_rep_tools.src.utils.error_tracking import initialisation
from zas_rep_tools.src.utils.helpers import write_data_to_json, paste_new_line, send_email, set_class_mode, print_mode_name, path_to_zas_rep_tools, instance_info
from zas_rep_tools.src.utils.traceback_helpers import print_exc_plus
from zas_rep_tools.src.classes.basecontent import BaseContent
#from zas_rep_tools.src.classes.configer import Configer
abs_paths_to_stop_words = path_to_stop_words
global last_error
last_error = ""
#### initialize all counters
num_tweets_all_saved_for_this_session = 0
num_tweets_all_getted_for_one_day = 0
num_tweets_saved_on_the_disk_for_one_day = 0
num_tweets_selected_for_one_day = 0 # selected language, contain tweets and retweets
num_tweets_outsorted_for_one_day = 0
num_tweets_undelivered_for_one_day = 0
num_retweets_for_one_day = 0
num_original_tweets_for_one_day = 0
#runing_theards = []
class Streamer(BaseContent):
supported_languages_by_langid = [u'af', u'am', u'an', u'ar', u'as', u'az', u'be', u'bg', u'bn', u'br', u'bs', u'ca', u'cs', u'cy', u'da', u'de', u'dz', u'el', u'en', u'eo', u'es', u'et', u'eu', u'fa', u'fi', u'fo', u'fr', u'ga', u'gl', u'gu', u'he', u'hi', u'hr', u'ht', u'hu', u'hy', u'id', u'is', u'it', u'ja', u'jv', u'ka', u'kk', u'km', u'kn', u'ko', u'ku', u'ky', u'la', u'lb', u'lo', u'lt', u'lv', u'mg', u'mk', u'ml', u'mn', u'mr', u'ms', u'mt', u'nb', u'ne', u'nl', u'nn', u'no', u'oc', u'or', u'pa', u'pl', u'ps', u'pt', u'qu', u'ro', u'ru', u'rw', u'se', u'si', u'sk', u'sl', u'sq', u'sr', u'sv', u'sw', u'ta', u'te', u'th', u'tl', u'tr', u'ug', u'uk', u'ur', u'vi', u'vo', u'wa', u'xh', u'zh', u'zu']
supported_languages_by_twitter = [u'fr', u'en', u'ar', u'ja', u'es', u'de', u'it', u'id', u'pt', u'ko', u'tr', u'ru', u'nl', u'fil', u'msa', u'zh-tw', u'zh-cn', u'hi', u'no', u'sv', u'fi', u'da', u'pl', u'hu', u'fa', u'he', u'ur', u'th', u'en-gb']
NLTKlanguages= {u'ru': u'russian', u'fr': u'french', u'en': u'english', u'nl': u'dutch', u'pt': u'portuguese', u'no': u'norwegian', u'sv': u'swedish', u'de': u'german', u'tr': u'turkish', u'it': u'italian', u'hu': u'hungarian', u'fi': u'finnish', u'da': u'danish', u'es': u'spanish'}
supported_languages = set(supported_languages_by_langid) & set(supported_languages_by_twitter )
supported_encodings_types = set(aliases.values())
supported_filter_strategies = ['t', 't+l']
stop_words_collection = {k:stopwords.words(v) for k,v in NLTKlanguages.iteritems()}
stop_words_collection.update({u"de":os.path.join(abs_paths_to_stop_words, u"de.txt")}) # add my own set for german lang
supported_stop_words = [k for k in stop_words_collection] # language naming should be the same as in this module "langid.classify(data["text"])[0]""
supported_platforms= ["twitter"]
#p(path_to_zas_rep_tools)
def __init__(self, consumer_key, consumer_secret, access_token, access_token_secret, storage_path,
platfrom="twitter", language=False, terms=False, stop_words=False, encoding="utf_8",
email_addresse=False, ignore_rt=False, save_used_terms=False, filterStrat=False, **kwargs):
#super(Streamer, self).__init__(**kwargs)
super(type(self), self).__init__(**kwargs)
#super(BaseContent, self).__init__(**kwargs)
global num_tweets_all_saved_for_this_session
global num_tweets_all_getted_for_one_day
global num_tweets_saved_on_the_disk_for_one_day
global num_tweets_selected_for_one_day
global num_tweets_outsorted_for_one_day
global num_tweets_undelivered_for_one_day
global num_retweets_for_one_day
global num_original_tweets_for_one_day
#Input: Instance Encapsulation:
self._consumer_key = consumer_key
self._consumer_secret = consumer_secret
self._access_token = access_token
self._access_token_secret = access_token_secret
self._storage_path = storage_path
self._platfrom = platfrom
self._language = language #
self._terms = terms
self._stop_words = stop_words
self._encoding = encoding
self._email_addresse = email_addresse
self._ignore_retweets = ignore_rt
self._save_used_terms = save_used_terms
self._filterStrat = filterStrat
self._streamer_settings = {"language":self._language,
"terms":True if self._terms else False,
"stop_words":True if self._stop_words else False ,
"filter":self._filterStrat }
# make Variable global for tweepy
if platform.uname()[0].lower() !="windows":
self.t = Terminal()
else:
self.t = False
# Validation
self._validate_input()
self.logger.debug('Intern InstanceAttributes was initialized')
self.logger.debug('An instance of Streamer() was created ')
if platfrom not in Streamer.supported_platforms:
self.logger.error("Given Platform({}) is not supported. Please choice one of the following platforms: {}".format(platfrom,Streamer.supported_platforms), exc_info=self._logger_traceback)
sys.exit()
## Log Settings of the Instance
self._log_settings(attr_to_flag = False,attr_to_len = False)
def __del__(self):
super(type(self), self).__del__()
def _get_stop_words(self):
#p(Streamer.stop_words_collection[self._language], c="m")
# to ensure the possibility to get intern stop_words_set
# if not self._language:
# language = str(self._language)
# else:
# language = self._language
if self._stop_words and not self._language:
self.logger.error("ToolRestriction: Stop-words cannot be given as stand-alone parameter. It should be given together with the any languages. If you want to give stop-words alone, please use for it parameter with the name 'terms'. ", exc_info=self._logger_traceback)
sys.exit()
elif not self._stop_words and self._language:
if self._language in Streamer.stop_words_collection:
if isinstance(Streamer.stop_words_collection[self._language], (str,unicode)):
if os.path.isfile(Streamer.stop_words_collection[self._language]):
stop_words = [line.strip() for line in codecs.open(Streamer.stop_words_collection[self._language], encoding=self._encoding)]
self.logger.debug("Stop words was read from a file")
else:
self.logger.error("StopWordsGetterError: Given path to stop_words is not exist", exc_info=self._logger_traceback)
sys.exit()
elif isinstance(Streamer.stop_words_collection[self._language], list):
stop_words = Streamer.stop_words_collection[self._language]
self.logger.debug("Stop words was read from a given list")
else:
self.logger.error("StopWordsGetterError: Not supported format of stop-words. Please give them as path of as a list.", exc_info=self._logger_traceback)
sys.exit()
self._streamer_settings["stop_words"] = True
self.logger.info("Stop-words was took from the intern-set for the '{}' language.".format(self._language))
else:
self.logger.error("StopWordsGetterError: Stop-words for given language ('{}') wasn't found in the intern set of stop-words. Please import them into the Streamer using 'stop_words' parameter ".format(language) , exc_info=self._logger_traceback)
sys.exit()
#self.logger.error("TwitterRestriction: Language cannot be given as stand-alone parameter. It should be given together with the stop-words or terms.", exc_info=self._logger_traceback)
#sys.exit()
elif self._stop_words and self._language:
#Streamer.stop_words_collection[self._language] =
if isinstance(self._stop_words, (str,unicode)):
if self._stop_words in Streamer.stop_words_collection:
if isinstance(Streamer.stop_words_collection[self._stop_words], (str,unicode)):
if os.path.isfile(Streamer.stop_words_collection[self._stop_words]):
stop_words = [line.strip() for line in codecs.open(Streamer.stop_words_collection[self._stop_words], encoding=self._encoding)]
self.logger.debug("Stop words was read from a file")
else:
self.logger.error("StopWordsGetterError: Given path to stop_words is not exist", exc_info=self._logger_traceback)
sys.exit()
elif isinstance(Streamer.stop_words_collection[self._stop_words], list):
stop_words = Streamer.stop_words_collection[self._stop_words]
self.logger.debug("Stop words was read from a given list")
else:
self.logger.error("StopWordsGetterError: Given path to stop_words or stop-words in the intern collection is not exist", exc_info=self._logger_traceback)
sys.exit()
self.logger.info("Stop-words was took from the intern-set for the '{}' language.".format(self._stop_words))
elif os.path.isfile(self._stop_words):
stop_words = [line.strip() for line in codecs.open(self._stop_words, encoding=self._encoding)]
self.logger.debug("Stop words was read from a file")
else:
self.logger.error("StopWordsGetterError: Not supported format of stop-words. Please give them as path or as a list. (or check, if given path to file exist)", exc_info=self._logger_traceback)
sys.exit()
elif isinstance(self._stop_words, list):
stop_words = self._stop_words
self.logger.debug("Stop words was read from a given list")
else:
self.logger.error("StopWordsGetterError: Not supported format of stop-words. Please give them as path of as a list.", exc_info=self._logger_traceback)
sys.exit()
elif not self._stop_words and not self._language and not self._terms:
self.logger.error("InputError: No filtering parameters was given.", exc_info=self._logger_traceback)
sys.exit()
else:
self.logger.error("StopWordsGetterError: Something was wrong!", exc_info=self._logger_traceback)
sys.exit()
return stop_words
def cleaned_instance_attributes(self):
#p(self.__dict__)
exclude = ["_consumer_key","_consumer_secret","_access_token", "_access_token_secret", "client", "logger"]
return {k:v for k,v in self.__dict__.iteritems() if k not in exclude}
def _validate_input(self):
self._validate_given_language()
if not self._stop_words:
if self._language:
if not self._terms and self._language not in Streamer.supported_stop_words:
self.logger.error("InputError: Terms or/and stop-words wasn't given. According the Twitter 'Developer Agreement and Policy' - 'terms' or/and 'stop-words' should be given. A Language is just an option and not obligatory for the Streamer. ", exc_info=self._logger_traceback)
sys.exit()
else:
if not self._terms:
self.logger.error("InputError: Nothing was given. Streamer need some input to initialize the Filtering. (Please give any terms/stop-words/language) ", exc_info=self._logger_traceback)
sys.exit()
self._evaluate_stop_words()
self._evaluate_terms()
self._validate_filter_strat()
self._validate_storage_path()
self._validate_given_encoding()
def _validate_storage_path(self):
if not os.path.isdir(self._storage_path):
try:
os.makedirs(self._storage_path)
self.logger.info("Following storage directory was created: '{}'. There you will find all streamed data.".format(os.path.join(os.getcwd(),self._storage_path)))
except:
self.logger.error("PathError: It wasn't possible to create following directory: '{}' ".format(os.path.join(os.getcwd(),self._storage_path)), exc_info=self._logger_traceback)
sys.exit()
def _validate_filter_strat(self):
if self._filterStrat:
if self._filterStrat not in Streamer.supported_filter_strategies:
self.logger.error("Given filter-strategies ('{}') is not supported. Please use one of the possible: {}".format(self._filterStrat,Streamer.supported_filter_strategies), exc_info=self._logger_traceback)
sys.exit()
elif not self._filterStrat:
if self._language:
self._filterStrat = "t+l"
self._streamer_settings['filter'] = self._filterStrat
self.logger.info("FilterStrategie was automatically set to: '{}'.".format(self._filterStrat))
elif not self._language:
self._filterStrat = "t"
self._streamer_settings['filter'] = self._filterStrat
self.logger.info("FilterStrategie was automatically set to: '{}'.".format(self._filterStrat))
def _validate_given_language(self):
if self._language:
if self._language not in Streamer.supported_languages:
self.logger.error("Given Language ('{}'') is not supported. Please use one of the following languages: {}".format(self._language, Streamer.supported_languages), exc_info=self._logger_traceback)
sys.exit()
# if not self._stop_words:
# self.logger.error("TwitterRestriction: Language cannot be given as stand-alone parameter. It should be given together with the stop-words or terms. ", exc_info=self._logger_traceback)
# sys.exit()
def get_track_terms(self):
all_terms_to_track = []
if self._terms:
if self._stop_words:
all_terms_to_track = self._get_stop_words() + self._terms
elif not self._stop_words:
all_terms_to_track = self._terms
elif not self._terms:
if self._stop_words:
all_terms_to_track = self._get_stop_words()
elif not self._stop_words:
if not self._language:
self.logger.error("InputError: Don't found any 'stop_words/terms/language'. It is not allow to stream Twitter without any stop_words/terms." , exc_info=self._logger_traceback )
sys.exit()
all_terms_to_track = self._get_stop_words()
if len(all_terms_to_track) > 400:
self.logger.error("InputError: The Number of given stop_word/terms are exceeded (Twitter-API restriction). It is allow to track not more as 400 words. It was given '{}' words together. Please give less number of stop_word/terms.\n\n Following words was given: \n{} ".format(len(all_terms_to_track), all_terms_to_track) , exc_info=self._logger_traceback)
sys.exit()
elif len(all_terms_to_track) == 0:
self.logger.error("InputError: Not terms/stop_words for tracking was given.", exc_info=self._logger_traceback)
sys.exit()
#p(all_terms_to_track)
return all_terms_to_track
def _evaluate_terms(self):
if self._terms:
if isinstance(self._terms, (str,unicode)):
if os.path.isfile(self._terms):
self._terms = [line.strip() for line in codecs.open(self._terms, encoding=self._encoding)]
else:
self.logger.error("PathError: Given Path ({}) to terms are not exist".format(self._terms), exc_info=self._logger_traceback)
sys.exit()
elif isinstance(self._terms, list):
for term in self._terms:
if not isinstance(term, (str,unicode)):
self.logger.error("TypeError: Some of the given terms in the list is not string/unicode.", exc_info=self._logger_traceback)
sys.exit()
else:
self.logger.error("InputError: Not supported format of terms. Please give them as path of as a list.", exc_info=self._logger_traceback)
sys.exit()
def _evaluate_stop_words(self):
# change setting, if was toked intern stop_words set
# if self._language and not self._stop_words and not self._terms:
# if self._language in Streamer.supported_stop_words:
# self._streamer_settings["stop_words"] = True
if self._stop_words and not self._language:
self.logger.error("ToolRestriction: Stop-words cannot be given as stand-alone parameter. It should be given together with the any languages. If you want to give stop-words alone, please use for it parameter with the name 'terms'. ", exc_info=self._logger_traceback)
sys.exit()
elif not self._stop_words and self._language:
pass
elif self._stop_words and self._language:
pass
elif not self._stop_words and not self._language and not self._terms:
self.logger.error("InputError: No filtering parameters was given.", exc_info=self._logger_traceback)
sys.exit()
# else:
# self.logger.error("StopWordsGetterError: Something was wrong!", exc_info=self._logger_traceback)
# sys.exit()
def _validate_given_encoding(self):
if self._encoding not in Streamer.supported_encodings_types:
self.logger.error("Given encoding ({}) is not supported. Choice one of the following encodings: {}".format(self._encoding, Streamer.supported_encodings_types), exc_info=self._logger_traceback)
sys.exit()
def get_supported_platforms(self):
return Streamer.supported_platforms
def get_supported_languages(self):
return Streamer.supported_languages
def get_exist_stop_words(self):
return Streamer.supported_languages
def _create_main_log_message(self):
msg_to_log = " >>>Streaming was started<<< "
if self._language:
msg_to_log = "{} for '{}' language".format(msg_to_log, self._language)
if self._terms and self._language:
msg_to_log = "{} and for given terms".format(msg_to_log)
elif self._terms and not self._language:
msg_to_log = "{} for given terms".format(msg_to_log)
if (self._stop_words and self._language) or (self._stop_words and self._terms):
msg_to_log = "{} and for given stop_words".format(msg_to_log)
elif self._stop_words and not self._language and not self._terms:
msg_to_log = "{} for given stop_words".format(msg_to_log)
return msg_to_log
def _initialize_status_bar(self):
if platform.uname()[0].lower() !="windows":
if self._language:
sys.stdout.write("\n Status: {startW} totalSaved {stop} = {startW}{selected:^8}{stop} + {startW}{retweets:^8}{stop} + {startW}other_lang{stop} {startW}|undelivered|{stop} \n".format(selected=self._name_in_the_status_bar_original_tweets, retweets= self._name_in_the_status_bar_retweets, startW=self.t.bold_black_on_bright_white, stop=self.t.normal))
print " {startW}{total:^13d}{stop} {startW}{original:^8d}{stop} {startW}{retweets:^8}{stop} {startW}{outsorted:^10d}{stop} {startW}|{undelivered:^11d}|{stop} ".format(total=0, original=0, retweets= 0, outsorted=0, undelivered=0 ,startW=self.t.bold_black_on_bright_white, stop=self.t.normal)
else:
sys.stdout.write("\n Status: {startW} totalSaved {stop} {startW}|undelivered|{stop} \n".format( startW=self.t.bold_black_on_bright_white, stop=self.t.normal))
print " {startW}{total:^13d}{stop} {startW}|{undelivered:^11d}|{stop} ".format(total=0, undelivered=0 ,startW=self.t.bold_black_on_bright_white, stop=self.t.normal)
else:
if self._language:
sys.stdout.write("\n Status: totalSaved = {selected:^8} + {retweets:^8} + other_lang |undelivered| \n".format(selected=self._name_in_the_status_bar_original_tweets, retweets= self._name_in_the_status_bar_retweets))
print " {total:^13d} {original:^8d} {retweets:^8} {outsorted:^10d} |{undelivered:^11d}| ".format(total=0, original=0, retweets= 0, outsorted=0, undelivered=0 )
else:
sys.stdout.write("\n Status: totalSaved |undelivered| \n")
print " {total:^13d} |{undelivered:^11d}| ".format(total=0, undelivered=0)
def stream_twitter(self):
global old_date
global logfile
global storage_path
global email_addresse
global file_selected
global file_outsorted
global file_undelivered
global file_retweets
global path_to_the_jsons
global last_error
global num_tweets_all_saved_for_this_session
global num_tweets_saved_on_the_disk_for_one_day
#global runing_theards
#global last_error
# initialize it once
langid.classify("test")
email_addresse= self._email_addresse
storage_path = self._storage_path
old_date = date.today()
path_to_the_day = os.path.join(storage_path, str(old_date))
#last_error = ""
file_selected, file_outsorted, file_undelivered, file_retweets, path_to_the_jsons = create_new_files_for_new_day(str(old_date), storage_path, self._language)
auth = tweepy.OAuthHandler(self._consumer_key, self._consumer_secret)
auth.set_access_token(self._access_token, self._access_token_secret)
api = tweepy.API(auth, parser=tweepy.parsers.JSONParser(),timeout=5)
global logfile
logfile = codecs.open(os.path.join(self._storage_path,"streaming.log"), 'a', encoding="utf-8")
#localtime = time.asctime( time.localtime(time.time()) )
# longer timeout to keep SSL connection open even when few tweets are coming in
stream = tweepy.streaming.Stream(auth, CustomStreamListener(streamer_settings=self._streamer_settings,language=self._language, ignore_retweets=self._ignore_retweets, logger_level=self._logger_level, logger_folder_to_save=self._logger_folder_to_save, logger_usage=self._logger_usage, logger_save_logs=self._logger_save_logs, ext_tb=self._ext_tb), timeout=1000.0)
terms = self.get_track_terms()
self.logger.info("{} terms/stop_words used for tacking.".format(len(terms)))
#p(terms)
if self._save_used_terms:
#p(os.path.join(path_to_the_day, "used_terms.log"))
output_file_used_terms = codecs.open(os.path.join(path_to_the_day, "used_terms.log"), "a", encoding="utf-8")
output_file_used_terms.write("{}:::{}:::{}\n\n\n".format(old_date, len(terms), terms))
output_file_used_terms.close()
#p(terms)
# open output file
#non_stop = True
last_5_error = []
self._name_in_the_status_bar_original_tweets = "orig_{}".format(self._language) if self._language else "original"
self._name_in_the_status_bar_retweets = "rt_{}".format(self._language) if self._language else "retweets"
# stall_warnings - will inform you if you're falling behind. Falling behind means that you're unable to process tweets as quickly as the Twitter API is sending them to you.
while True:
#send_email("[email protected]", "Error", "Some error ")
try:
msg_to_log = self._create_main_log_message()
#log_msg = "\n{} Starting stream for '{}' language.\n"
logfile.write( "{} {} \n".format(time.asctime( time.localtime(time.time()) ) , msg_to_log) )
msg_settings = "StreamerFilterSetting: {}".format(self._streamer_settings)
if self._filterStrat == "t+l":
if not self._language:
self.logger.error("FilterStrategieError: Language is not given! But selected Strategy ('{}') requires an language. Please select another Strategy or give an language. ".format(self._filterStrat), exc_info=self._logger_traceback)
sys.exit()
else:
log_msg_settings = "{} (l+t)".format(msg_settings)
logfile.write( " {} \n".format(log_msg_settings) )
self.logger.info(log_msg_settings)
self.logger.info(msg_to_log)
self._initialize_status_bar()
#stream = tweepy.streaming.Stream(auth, CustomStreamListener(), timeout=30)
stream.filter(languages=[self._language], track=terms, stall_warnings=True)
#streamer_arguments = "languages=['{}'], track={}, stall_warnings=True".format(self._language, terms)
elif self._filterStrat == "t":
log_msg_settings = "{} (t)".format(msg_settings)
logfile.write( " {} \n".format(log_msg_settings) )
self.logger.info(log_msg_settings)
self.logger.info(msg_to_log)
self._initialize_status_bar()
#stream = tweepy.streaming.Stream(auth, CustomStreamListener(), timeout=30)
stream.filter(track=terms, stall_warnings=True) # , async=True
except KeyboardInterrupt:
print_exc_plus() if self._ext_tb else ""
paste_new_line()
self.logger.info("Streaming was aborted. stopping all processes.....")
log_msg = " {} Stream was aborted by user 'KeyboardInterrupt' \n"
logfile.write( log_msg.format(time.asctime(time.localtime(time.time()))) )
stream.disconnect() # that should wait until next tweet, so let's delete it
del stream
num_tweets_all_saved_for_this_session += num_tweets_saved_on_the_disk_for_one_day
stats_cli = generate_status_msg_after_one_day(self._language,cl=True)
stats_logfile = generate_status_msg_after_one_day(self._language)
msg = "Short Conclusion:\n {}".format( stats_cli)
self.logger.info(msg)
logfile.write(" Short Conclusion for the last day ({}):\n{}".format(old_date, stats_logfile))
logfile.close()
file_selected.close()
file_outsorted.close()
file_undelivered.close()
file_retweets.close()
# for theard in runing_theards:
# if theard.isAlive():
# theard.do_run = False
# theard.daemon = True
# self.logger.info("'{}'-Theard was stopped!!!".format(theard.name))
self.logger.info("All processes was correctly closed.")
sys.exit(1)
#os._exit(1)
except Exception, e:
print_exc_plus() if self._ext_tb else ""
if "Failed to establish a new connection" in str(e):
log_msg = " {} No Internet Connection. Wait 15 sec..... \n"
logfile.write( log_msg.format(time.asctime(time.localtime(time.time()))) )
paste_new_line()
self.logger.critical("No Internet Connection. Wait 15 sec.....")
time.sleep(5)
else:
log_msg = " {} Stream get an Error: '{}' \n"
logfile.write( log_msg.format(time.asctime(time.localtime(time.time())),e) )
paste_new_line()
self.logger.critical("Streaming get an Error......‘{}‘".format(e))
if "IncompleteRead" not in str(e):
last_5_error.append(str(e))
if len(last_5_error) >= 5:
if len(set(last_5_error)) ==1 :
log_msg = " {} Stream was stopped after 5 same errors in stack: '{}' \n"
logfile.write( log_msg.format(time.asctime(time.localtime(time.time())),e) )
msg = 'Hey,</br></br> Something was Wrong! Streamer throw the following error-message and the Streaming Process was stopped:</br> <p style="margin-left: 50px;"><strong><font color="red">{}</strong> </font> </p> Please check if everything is fine with this Process. </br></br> Greeting, </br>Your Streamer'.format(e)
last_error = str(e)
subject = "TwitterStreamer was stopped (Reason: last 5 errors are same)"
paste_new_line()
send_email(email_addresse, subject, msg)
self.logger.error("Stream was stopped after 5 same errors in stack")
#os._exit(1)
sys.exit()
else:
last_5_error = []
if last_error != str(e):
msg = "Hey,</br></br> Something was Wrong! Streamer throw the following error-message:</br> <p style='margin-left: 50px;''><strong><font color='red'>{}</strong> </font> </p> Please check if everything is fine with this Process. </br></br> Greeting, </br>Your Streamer".format(e)
last_error = str(e)
paste_new_line()
send_email(email_addresse, 'Error: '+str(e), msg)
# except tweepy.TweepError, e:
# paste_new_line()
# self.logger.info("Streaming geted an error: '{}'".format(e))
# log_msg = " Streaming geted an error: {} \n"
# logfile.write( log_msg.format(e) )
class CustomStreamListener(tweepy.StreamListener):
def __init__(self, streamer_settings=False, language=False, ignore_retweets = False,
logger_level=logging.INFO, logger_folder_to_save="logs", logger_usage=True,
logger_traceback=False,logger_save_logs=False,
ext_tb=False ):
global logfile
global num_tweets_all_saved_for_this_session
global num_tweets_saved_on_the_disk_for_one_day
global num_tweets_all_getted_for_one_day
global num_tweets_selected_for_one_day
global num_tweets_outsorted_for_one_day
global num_tweets_undelivered_for_one_day
global num_retweets_for_one_day
global num_original_tweets_for_one_day
#global runing_theards
## Developing Mode: Part 1
# self._devmode = devmode
# self._logger_level = logger_level
# if self._devmode:
# self._logger_level = logging.DEBUG
# logger_traceback = True
## Logger Initialisation
self._logger_traceback =logger_traceback
self._logger_folder_to_save = logger_folder_to_save
self._logger_usage = logger_usage
self._logger_save_logs = logger_save_logs
self._logger_level = logger_level
self.L = ZASLogger(self.__class__.__name__, level=self._logger_level,
folder_for_log=self._logger_folder_to_save,
logger_usage=self._logger_usage,
save_logs=self._logger_save_logs)
self.logger = self.L.getLogger()
self._ignore_retweets = ignore_retweets
self.restart_all_counters()
self._language = language
self._streamer_settings = streamer_settings
self._ignore_retweets = ignore_retweets
self._ext_tb = ext_tb
if platform.uname()[0].lower() !="windows":
self.t = Terminal()
else:
self.t =False
if self._ignore_retweets:
num_retweets_for_one_day = ">ignore<"
#sys.stdout.write("\r {startW}{total:^13d}{stop} {startW}{original:^8d}{stop} {startW}{retweets:^8}{stop} {startW}{outsorted:^9d}{stop} {startW}{undelivered:^11d}{stop} ".format(total=num_tweets_all_getted_for_one_day, original=num_original_tweets_for_one_day, retweets= num_retweets_for_one_day, outsorted=num_tweets_outsorted_for_one_day, undelivered=num_tweets_undelivered_for_one_day ,startW=self.t.bold_black_on_bright_white, startG=self.t.bold_black_on_bright_green, startY=self.t.bold_black_on_bright_yellow, startB=self.t.bold_black_on_bright_blue, startR=self.t.bold_black_on_bright_red, stop=self.t.normal))
def on_connect(self):
sys.stdout.write("\033[A") # “Move the cursor up (1 line up)”
#pass
def archive_jsons(self,path_to_the_jsons):
## Step 1: Find the best right name
f_base_name = "jsons"
extenstion = ".zip"
full_fname = f_base_name+extenstion
i=0
while True:
i+=1
if os.path.isfile(os.path.join(os.path.dirname(path_to_the_jsons),full_fname)):
f_base_name = f_base_name + "_"+ str(i)
full_fname = f_base_name+extenstion
else:
break
# Step 2: if in the current folder alredy exist an Archive, than remove it
if os.path.isfile(os.path.join(os.getcwd(),full_fname)):
os.remove(os.path.join(os.getcwd(),full_fname))
#sys.exit()
make_zipfile(full_fname, path_to_the_jsons)
#p(ziparch)
shutil.move(os.path.join(os.getcwd(),full_fname), os.path.dirname(path_to_the_jsons))
shutil.rmtree(path_to_the_jsons, ignore_errors=True)
self.logger.debug("All JSONS was moved and orig (not archived) folder was deleted.")
paste_new_line()
self.logger.info("All JSONS was archived and moved.")
paste_new_line()
self._initialize_status_bar()
def _initialize_status_bar(self):
self._name_in_the_status_bar_original_tweets = "orig_{}".format(self._language) if self._language else "original"
self._name_in_the_status_bar_retweets = "rt_{}".format(self._language) if self._language else "retweets"
if platform.uname()[0].lower() !="windows":
if self._language:
sys.stdout.write("\n Status: {startW} totalSaved {stop} = {startW}{selected:^8}{stop} + {startW}{retweets:^8}{stop} + {startW}other_lang{stop} {startW}|undelivered|{stop} \n".format(selected=self._name_in_the_status_bar_original_tweets, retweets= self._name_in_the_status_bar_retweets, startW=self.t.bold_black_on_bright_white, stop=self.t.normal))
#print " {startW}{total:^13d}{stop} {startW}{original:^8d}{stop} {startW}{retweets:^8}{stop} {startW}{outsorted:^10d}{stop} {startW}|{undelivered:^11d}|{stop} ".format(total=0, original=0, retweets= 0, outsorted=0, undelivered=0 ,startW=self.t.bold_black_on_bright_white, stop=self.t.normal)
else:
sys.stdout.write("\n Status: {startW} totalSaved {stop} {startW}|undelivered|{stop} \n".format( startW=self.t.bold_black_on_bright_white, stop=self.t.normal))
#print " {startW}{total:^13d}{stop} {startW}|{undelivered:^11d}|{stop} ".format(total=0, undelivered=0 ,startW=self.t.bold_black_on_bright_white, stop=self.t.normal)
else:
if self._language:
sys.stdout.write("\n Status: totalSaved = {selected:^8} + {retweets:^8} + other_lang |undelivered| \n".format(selected=self._name_in_the_status_bar_original_tweets, retweets= self._name_in_the_status_bar_retweets))
#print " {total:^13d} {original:^8d} {retweets:^8} {outsorted:^10d} |{undelivered:^11d}| ".format(total=0, original=0, retweets= 0, outsorted=0, undelivered=0 )
else:
sys.stdout.write("\n Status: totalSaved |undelivered| \n")
#print " {total:^13d} |{undelivered:^11d}| ".format(total=0, undelivered=0)
def restart_all_counters(self):
global num_tweets_all_saved_for_this_session
global num_tweets_all_getted_for_one_day
global num_tweets_saved_on_the_disk_for_one_day
global num_tweets_selected_for_one_day
global num_tweets_outsorted_for_one_day
global num_tweets_undelivered_for_one_day
global num_retweets_for_one_day
global num_original_tweets_for_one_day
num_tweets_all_getted_for_one_day = 0
num_tweets_saved_on_the_disk_for_one_day = 0
num_tweets_selected_for_one_day = 0 # selected language, contain tweets and retweets
num_tweets_outsorted_for_one_day = 0
num_tweets_undelivered_for_one_day = 0
num_retweets_for_one_day = ">ignore<" if self._ignore_retweets else 0
num_original_tweets_for_one_day = 0
def on_data(self, data):
global old_date
global file_selected
global file_outsorted
global file_undelivered
global file_retweets
global logfile
global path_to_the_jsons
global email_addresse
global num_tweets_all_saved_for_this_session
global num_tweets_all_getted_for_one_day
global num_tweets_saved_on_the_disk_for_one_day
global num_tweets_selected_for_one_day
global num_tweets_outsorted_for_one_day
global num_tweets_undelivered_for_one_day
global num_retweets_for_one_day
global num_original_tweets_for_one_day
#global runing_theards
new_date = date.today()
# new day was started
if not new_date == old_date:
# Preparation for the last day
file_selected.close()
file_outsorted.close()
file_undelivered.close()
file_retweets.close()
paste_new_line()
# #clean closed theards
# for theard in runing_theards:
# if not theard.isAlive():
# self.runing_theards.remove(theard)
processThread = threading.Thread(target=self.archive_jsons, args=(path_to_the_jsons,), name="archive_jsons")
processThread.setDaemon(True)
processThread.start()
#runing_theards.append(processThread)
# self.archive_jsons(path_to_the_jsons)
file_selected, file_outsorted, file_undelivered, file_retweets, path_to_the_jsons = create_new_files_for_new_day(str(new_date), storage_path, self._language)
# file_selected.write('[\n') # start a new json array
# file_outsorted.write('[\n') # start a new json array
num_tweets_all_saved_for_this_session += num_tweets_saved_on_the_disk_for_one_day
paste_new_line()
stats_cli = generate_status_msg_after_one_day(self._language,cl=True)
stats_logfile = generate_status_msg_after_one_day(self._language)
msg = "Short Conclusion for day ({}):\n {}".format(old_date, stats_cli)
self.logger.info(msg)
logfile.write(" End of The day -> {}\n".format(old_date))
logfile.write(" Short Conclusion for the day ({}):\n{}".format(old_date, stats_logfile))
# Send Email
streamer_settings_str_html = streamer_settings_to_str(self._streamer_settings).replace("\n", "</br>")
stats_cli_to_html = stats_cli.replace("\n", "</br>")
#p(stats_cli_to_html, c="m")
msg = 'Hey,</br></br> Yeeeeeap, News Day was started! </br></br>See Stats for the last Day "{}" below: </br> <p style="margin-left: 50px;"><strong><font color="green">{}</strong> </font> </p> </br></br> </br> Streamer Settings: <p style="margin-left: 50px;"><strong><font color="blue">{}</strong> </font> </p> With love, </br>Your Streamer'.format(old_date, stats_cli.replace("\n", "</br>"), streamer_settings_str_html)
subject = "TwitterStreamer started New Day ({})".format(new_date)
send_email(email_addresse, subject, msg)
# Start new day
old_date = new_date
self.restart_all_counters()
#p(num_tweets_saved_on_the_disk_for_one_day)
self.logger.info("New day was started! ({})".format(old_date))
logfile.write(" New day was started! -> {}\n".format(new_date))
paste_new_line()
self._initialize_status_bar()
data = json.loads(data)
### Print Status of downloaded Tweets
num_tweets_all_getted_for_one_day += 1
try:
tId = data["id"]
# if tweets longer as 140 characters
if "extended_tweet" in data:
text = data["extended_tweet"]["full_text"].replace('\n', ' ').replace('\r', ' ')
else:
text = data["text"].replace('\n', ' ').replace('\r', ' ')
# filter out all retweets
lang = langid.classify(text)[0]
# if len(data) ==2:
# p(data)
if lang == self._language:
num_tweets_selected_for_one_day += 1
if self._ignore_retweets:
if "retweeted_status" not in data:
num_original_tweets_for_one_day += 1
file_selected.write(u"{} <t>{}</t>\n".format(unicode(tId), text))
write_data_to_json(os.path.join(path_to_the_jsons, "{}.json".format(tId)), data)
num_tweets_saved_on_the_disk_for_one_day += 1
else:
if "retweeted_status" in data:
num_retweets_for_one_day += 1
file_retweets.write(u"{} \n".format(unicode(tId)))
else:
num_original_tweets_for_one_day += 1
file_selected.write(u"{} <t>{}</t>\n".format(unicode(tId), text))
write_data_to_json(os.path.join(path_to_the_jsons, "{}.json".format(tId)), data)
num_tweets_saved_on_the_disk_for_one_day += 1
else:
if self._ignore_retweets:
if "retweeted_status" not in data:
num_tweets_outsorted_for_one_day +=1
file_outsorted.write(u"{} <t>{}</t> <l>{}</l>\n".format(unicode(tId), text, lang))
write_data_to_json(os.path.join(path_to_the_jsons, "{}.json".format(tId)), data)
num_tweets_saved_on_the_disk_for_one_day += 1
else:
num_tweets_outsorted_for_one_day +=1
file_outsorted.write(u"{} <t>{}</t> <l>{}</l>\n".format(unicode(tId), text, lang))
write_data_to_json(os.path.join(path_to_the_jsons, "{}.json".format(tId)), data)
num_tweets_saved_on_the_disk_for_one_day += 1
self._update_status_bar()
#self._output_file_other_tweets.write( data["created_at"]+ data["id_str"]+ data["text"] + "\n" )
except KeyError, ke:
print_exc_plus() if self._ext_tb else ""
#p(data)
if "limit" in str(data):
#{u'limit': {u'track': 233, u'timestamp_ms': u'1527958183844'}}
#p(data)
if data["limit"]["track"] > num_tweets_undelivered_for_one_day:
num_tweets_undelivered_for_one_day = data["limit"]["track"]
#pattern = r""
time_now = time.asctime( time.localtime(time.time()) )
file_undelivered.write(u"{} {} \n".format( time_now, data) )
else:
paste_new_line()
self.logger.critical(str(repr(ke)))
except Exception, e:
print_exc_plus() if self._ext_tb else ""
log_msg = "Encountered error with status code: '{}' \n"
logfile.write( log_msg.format(time.asctime(time.localtime(time.time())),e) )
paste_new_line()
self.logger.critical(log_msg.format(e))
def _update_status_bar(self):
if platform.uname()[0].lower() !="windows":
if self._language:
sys.stdout.write("\r {startW}{total:^13d}{stop} {startW}{original:^8d}{stop} {startW}{retweets:^8}{stop} {startW}{outsorted:^10d}{stop} {startW}|{undelivered:^11d}|{stop} ".format(total=num_tweets_saved_on_the_disk_for_one_day, original=num_original_tweets_for_one_day, retweets= num_retweets_for_one_day, outsorted=num_tweets_outsorted_for_one_day, undelivered=num_tweets_undelivered_for_one_day ,startW=self.t.bold_black_on_bright_white, stop=self.t.normal))
sys.stdout.flush()
else:
sys.stdout.write("\r {startW}{total:^13d}{stop} {startW}|{undelivered:^11d}|{stop} ".format(total=num_tweets_saved_on_the_disk_for_one_day, undelivered=num_tweets_undelivered_for_one_day ,startW=self.t.bold_black_on_bright_white, stop=self.t.normal))
sys.stdout.flush()
else:
if self._language:
sys.stdout.write("\r {total:^13d} {original:^8d} {retweets:^8} {outsorted:^10d} |{undelivered:^11d}| ".format(total=num_tweets_saved_on_the_disk_for_one_day, original=num_original_tweets_for_one_day, retweets= num_retweets_for_one_day, outsorted=num_tweets_outsorted_for_one_day, undelivered=num_tweets_undelivered_for_one_day ))
sys.stdout.flush()
else:
sys.stdout.write("\r {total:^13d} |{undelivered:^11d}| ".format(total=num_tweets_saved_on_the_disk_for_one_day, undelivered=num_tweets_undelivered_for_one_day ))
sys.stdout.flush()
def on_error(self, status_code):
"""Called when a non-200 status code is returned"""
log_msg = " {} Encountered error with status code (Streamer still be on): '{}' \n"
logfile.write( log_msg.format(time.asctime(time.localtime(time.time())),status_code) )
#return True # Don't kill the stream
if status_code == 401:
#print status_code
logger_msg = "UnauthorizedError401: Your credentials are invalid or your system time is wrong.\nTry re-creating the credentials correctly again following the instructions here (https://developer.twitter.com/en/docs/basics/authentication/guides/access-tokens). \nAfter recreation you need to retype your data. Use: $ zas-rep-tools retypeTwitterData"
paste_new_line()
self.logger.error(logger_msg, exc_info=self._logger_traceback)
#return False
#os._exit(1)
msg = 'Hey,</br></br> Something was Wrong! Streamer throw the following error-message and the Streaming Process was stopped:</br> <p style="margin-left: 50px;"><strong><font color="red">{}</strong> </font> </p> Please check if everything is fine with this Process. </br></br> Greeting, </br>Your Streamer'.format(logger_msg)
subject = "TwitterStreamer was stopped (Reason: UnauthorizedError401)"
send_email(email_addresse, subject, msg)
sys.exit()
else:
paste_new_line()
self.logger.critical(log_msg.format(time.asctime(time.localtime(time.time())),status_code))
return True
def on_timeout(self):
"""Called when stream connection times out"""
logfile.write(" "+str(time.asctime( time.localtime(time.time()) )) + ' Timeout...' + "\n")
paste_new_line()
self.logger.warning(" Timeout...")
time.sleep(5)
return True # Don't kill the stream
def on_disconnect(self, notice):
"""Called when twitter sends a disconnect notice
Disconnect codes are listed here:
https://dev.twitter.com/docs/streaming-apis/messages#Disconnect_messages_disconnect
"""
logfile.write(" "+str(time.asctime( time.localtime(time.time()) )) + ' Disconnected from twitter...' + "\n")
paste_new_line()
self.logger.warning("OnDisconnect: Twitter sends a disconnect notice ('{}')".format(notice))
time.sleep(5)
return True
def on_limit(self, track):
"""Called when a limitation notice arrives"""
logfile.write(" "+str(time.asctime( time.localtime(time.time()) )) + ' Disconnected from twitter...' + "\n")
paste_new_line()
self.logger.warning("OnLimit: Limitation notice arrives ('{}')".format(track))
time.sleep(5)
return True
def on_warning(self, notice):
"""Called when a disconnection warning message arrives"""
logfile.write(" "+str(time.asctime( time.localtime(time.time()) )) + ' Disconnected from twitter...' + "\n")
paste_new_line()
self.logger.warning("OnWarning: disconnection warning message arrives ('{}')".format(notice))
time.sleep(5)
return True
def create_new_files_for_new_day(current_data, storage_path, language):
#p("new day")
language = language if language else "none"
path_to_the_day = os.path.join(storage_path, str(current_data))
#p(path_to_the_day)
path_to_the_jsons = os.path.join(path_to_the_day, "jsons")
if not os.path.isdir(path_to_the_day):
os.mkdir(path_to_the_day)
if not os.path.isdir(path_to_the_jsons):
os.mkdir(path_to_the_jsons)
outfile_name = "tweets-" + current_data
outfile_full_name = outfile_name + ".txt"
language_outfile_name = "{}_{}".format( language,outfile_full_name)
other_outfile_name = "outsorted_{}".format(outfile_full_name)
retweets_id_name = "{}_retweets_{}".format(language,outfile_full_name)
file_retweets = codecs.open(os.path.join(path_to_the_day, retweets_id_name), "a", encoding="utf-8")
output_file_selected_tweets = codecs.open(os.path.join(path_to_the_day, language_outfile_name), "a", encoding="utf-8")
output_file_outsorted_tweets = codecs.open(os.path.join(path_to_the_day,other_outfile_name), "a", encoding="utf-8")
output_file_undelivered_tweets = codecs.open(os.path.join(path_to_the_day,"undelivered_"+outfile_name+ ".log"), "a", encoding="utf-8")
return output_file_selected_tweets, output_file_outsorted_tweets, output_file_undelivered_tweets , file_retweets, path_to_the_jsons
def generate_status_msg_after_one_day(language, cl=False):
#p(self._language)
if cl:
if language:
msg = "TotalSavedThisSession: {session}\n TotalSavedThisDay: {total}\n Original-{lang}-Tweets: {original}\n Original-{lang}-Retweets: {retweets}\n Other languages: {outsorted}\n Undelivered: {undelivered} ".format(session=num_tweets_all_saved_for_this_session, total=num_tweets_saved_on_the_disk_for_one_day, original=num_original_tweets_for_one_day, retweets= num_retweets_for_one_day, outsorted=num_tweets_outsorted_for_one_day, undelivered=num_tweets_undelivered_for_one_day, lang=language )
else:
msg = "TotalSavedThisSession: {session}\n TotalSavedThisDay: {total}\n Undelivered: {undelivered}".format(session=num_tweets_all_saved_for_this_session,total=num_tweets_saved_on_the_disk_for_one_day, undelivered=num_tweets_undelivered_for_one_day )
else:
if language:
msg = " TotalSavedThisSession: {session}\n TotalSavedThisDay: {total}\n Original-{lang}-Tweets: {original}\n Original-{lang}-Retweets: {retweets}\n Other languages: {outsorted}\n Undelivered: {undelivered} \n".format(session=num_tweets_all_saved_for_this_session, total=num_tweets_saved_on_the_disk_for_one_day, original=num_original_tweets_for_one_day, retweets= num_retweets_for_one_day, outsorted=num_tweets_outsorted_for_one_day, undelivered=num_tweets_undelivered_for_one_day, lang=language )
else:
msg = " TotalSavedThisSession: {session}\n TotalSavedThisDay: {total}\n Undelivered: {undelivered}\n".format(session=num_tweets_all_saved_for_this_session,total=num_tweets_saved_on_the_disk_for_one_day, undelivered=num_tweets_undelivered_for_one_day )
#p(msg)
return msg
def streamer_settings_to_str(settings):
output = ""
for setting_name, value in settings.iteritems():
output += "'{}' = '{}'\n".format(setting_name,value)
return output | zas-rep-tools | /zas-rep-tools-0.2.tar.gz/zas-rep-tools-0.2/zas_rep_tools/src/classes/streamer.py | streamer.py |
# ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
# : XXX{Information about this code}XXX
# Author:
# c(Developer) -> {'Egor Savin'}
# ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
###Programm Info######
#
#
#
#
#Info:
# SQLite will easily do 50,000 or more INSERT statements per second on an average desktop computer.
# But it will only do a few dozen transactions per second.
# avoid cursore.executescript() becuase it makes commit first
# By default, the sqlite module opens transactions implicitly before a Data Modification Language (DML) statement (i.e. INSERT/UPDATE/DELETE/REPLACE), and commits transactions implicitly before a non-DML, non-query statement (i. e. anything other than SELECT or the aforementioned).
from __future__ import absolute_import
import os
import copy
import sys
import time
import logging
import json
import traceback
import threading
import gc
import inspect
import threading
import subprocess
from collections import defaultdict, OrderedDict
from raven import Client
from time import gmtime, strftime
import random
from shutil import copyfile
#import sqlite3 as sqlite
#from pysqlcipher import dbapi2 as sqlite
#import zas_rep_tools.src.classes.sql.singlethreadsinglecursor as sqlite
#import zas_rep_tools.src.classes.sql.MultiThreadMultiCursor as sqlite
from zas_rep_tools.src.utils.zaslogger import ZASLogger
from zas_rep_tools.src.utils.custom_exceptions import ZASCursorError, ZASConnectionError,DBHandlerError,ProcessError,ErrorInsertion,ThreadsCrash
import zas_rep_tools.src.utils.db_helper as db_helper
from zas_rep_tools.src.utils.helpers import set_class_mode, print_mode_name, path_to_zas_rep_tools, instance_info, Status,function_name, SharedCounterExtern, SharedCounterIntern, statusesTstring
from zas_rep_tools.src.utils.debugger import p
from zas_rep_tools.src.classes.basecontent import BaseContent, BaseDB
from zas_rep_tools.src.utils.error_tracking import initialisation
from zas_rep_tools.src.utils.traceback_helpers import print_exc_plus
import platform
if platform.uname()[0].lower() !="windows":
import colored_traceback
colored_traceback.add_hook()
else:
import colorama
#"pclsjt"
# optimizer_names= {
# "p":"page_size",
# "c":"cache_size", #When you change the cache size using the cache_size pragma, the change only endures for the current session. The cache size reverts to the default value when the database is closed and reopened.
# "l":"locking_mode",
# "s":"synchronous",
# "j":"journal_mode",
# "t":"temp_store",
# }
class DBHandler(BaseContent, BaseDB):
__metaclass__ = db_helper.DBErrorCatcher
#DBErrorCatcher = True
templates = {
"twitter":db_helper.default_tables["corpus"]["documents"]["twitter"],
"blogger":db_helper.default_tables["corpus"]["documents"]["blogger"]
}
supported_db_typs = ["stats", "corpus"]
path_to_json1 = os.path.join(path_to_zas_rep_tools, "src/extensions/json1/json1")
default_optimizer_flags = "lj"
mapped_states = {
"synchronous":{
"0":"off",
"1":"normal",
"2":"full",
"3":"extra",
},
"temp_store":{
"0":"default",
"1":"file",
"2":"memory"
}
}
non_mapped_states= {
"journal_mode":["delete" , "truncate" , "persist" , "memory" , "wal" , "off"],
"locking_mode": ["normal" , "exclusive"],
}
def __init__(self, **kwargs):
super(type(self), self).__init__(**kwargs)
global sqlite
#p(self._optimizer, "11self._optimizer")
if self._thread_safe:
import zas_rep_tools.src.classes.sql.MultiThreadMultiCursor as sqlite
self._check_same_thread = False
#DBHandler.default_optimizer_flags
if not self._optimizer:
self._optimizer = DBHandler.default_optimizer_flags
#self._optimizer = "l"
else:
from pysqlcipher import dbapi2 as sqlite
self._check_same_thread = True
#p(self._optimizer, "22self._optimizer")
self._arguments_for_connection = self._get_arguments_for_conn()
self.locker = threading.Lock()
self._double_items = "or REPLACE" if self._replace_double_items else "or IGNORE"
if self._thread_safe:
self.logger.info("DBHandler was started in ThreadSafeMode.")
else:
self.logger.warning("DBHandler was started in Thread-UNSAFE-Mode. (If you will use current Object in MultiThread Environment, than it could due to crash and all your data will be gone. But for using in the One-Thread Environment it speed-up the process about 10%.)")
#InstanceAttributes: Initialization
self._init_instance_variables()
#p(int(self.number_of_new_inserts_after_last_commit), "self.number_of_new_inserts_after_last_commit")
self.logger.debug('An instance of DB() was created ')
## Log Settings of the Instance
attr_to_flag = ["files_from_zips_to_read_orig", "files_from_zips_to_read_left_over", ]
attr_to_len = ["files_to_read_orig", "files_to_read_leftover", "zips_to_read", ]
self._log_settings(attr_to_flag =attr_to_flag,attr_to_len =attr_to_len)
############################################################
############################################################
####################__init__end#############################
############################################################
def __del__(self):
#import psutil
#for proc in psutil.process_iter():
# p("<<<")
# for f in proc.open_files():
# print f
# p(">>>")
# #p( proc.open_files() )
if self._db:
if self._use_cash:
self._write_cashed_insertion_to_disc()
if int(self.number_of_new_inserts_after_last_commit):
self.logger.info("Connection with DB was closed without commits. {} new inserts wasn't committed/saved_on_the_disk. (Notice: All not-committed changes in the DB wasn't saved on the disk!!! Please use 'db.close()' to commit all changes into DB and save them on the disk before exit the script.".format( int(self.number_of_new_inserts_after_last_commit) ) )
else:
self.logger.info("Connection with DB was closed without commits. ({} insertion was waiting for commit)".format( int(self.number_of_new_inserts_after_last_commit) ) )
if self._created_backups:
for dbname in copy.deepcopy(self._created_backups):
self._del_backup(dbname)
try:
self._db.close()
del self._threads_cursors
except:
pass
if int(self.error_insertion_counter) > 0:
self.logger.error("'{}'-ErrorInsertion(s) was done.".format(int(self.error_insertion_counter)))
raise ErrorInsertion, "'{}'-ErrorInsertion was processed. See additional Information in the logs.".format(int(self.error_insertion_counter))
del self._db
self._db = False
self.logger.debug("DB-Instance was destructed")
#self.logger.newline(1)
super(type(self), self).__del__()
def _get_arguments_for_conn(self):
_arguments_for_connection = {"check_same_thread":self._check_same_thread}
if not (self._isolation_level == False): #https://www.quora.com/What-is-the-purpose-of-an-SQLite3-transaction-if-it-is-not-exclusive
'''
DEFERRED #Acquire and release the appropriate lock(s) for each SQL operation automatically. The operative philosophy here is Just-In-Time; no lock is held for longer than needed, and BEGIN itself doesn’t try to grab any locks at all.
IMMEDIATE # Immediately try to acquire and hold RESERVED locks on all databases opened by this connection. This instantly blocks out all other writers for the duration of this transaction. BEGIN IMMEDIATE TRANSACTION will block or fail if another connection has a RESERVED or EXCLUSIVE lock on any of this connection’s open DBs.
EXCLUSIVE #Immediately acquire and hold EXCLUSIVE locks on all databases opened by this connection. This instantly blocks out all other connections for the duration of this transaction. BEGIN EXCLUSIVE TRANSACTION will block or fail if another connection has any kind of lock on any of this connection’s open DBs.
'''
_arguments_for_connection["isolation_level"] = self._isolation_level
if self._thread_safe:
_arguments_for_connection["logger_usage"] = self._logger_usage
_arguments_for_connection["logger_level"] = self._logger_level
_arguments_for_connection["logger_save_logs"] = self._logger_save_logs
_arguments_for_connection["logger_traceback"] = self._logger_traceback
_arguments_for_connection["save_status"] = self._save_status
_arguments_for_connection["save_settings"] = self._save_settings
_arguments_for_connection["ext_tb"] = self._ext_tb
_arguments_for_connection["mode"] = self._mode
_arguments_for_connection["error_tracking"] = self._error_tracking
#p(_arguments_for_connection)
return _arguments_for_connection
####################################################################################
####################################################################################
####################################################################################
####################################################################################
####################################################################################
####################################################################################
######################################Extern########################################
####################################################################################
####################################################################################
####################################################################################
####################################################################################
####################################################################################
###########################DB-Initialization#############################
def init(self, typ, prjFolder, DBname, language, visibility,
platform_name=False, encryption_key=False, fileName=False,
source=False, license=False, template_name=False, version=False,
cols_and_types_in_doc=False, corpus_id=False,
stats_id=False, retrival_template_automat = True, thread_name="Thread0", db_frozen=False,
context_lenght=None):
cols_and_types_in_doc = copy.deepcopy(cols_and_types_in_doc)
supported_typs = DBHandler.supported_db_typs
typ = typ.lower()
if typ == "corpus":
if not platform_name:
self.logger.error("'Platform_name' wasn't given. 'Corpus' initialization need 'platform_name'.", exc_info=self._logger_traceback)
return Status(status=False, track_id=self._error_track_id.incr(), func_name=function_name(-2))
status = self.init_corpus(prjFolder, DBname, language, visibility, platform_name, encryption_key=encryption_key,fileName=fileName, source=source, license=license, template_name=template_name, version=version, corpus_id=corpus_id, cols_and_types_in_doc=cols_and_types_in_doc, retrival_template_automat=retrival_template_automat, thread_name=thread_name)
if not status["status"]:
return status
return Status(status=True)
elif typ == "stats":
#if not corpus_id:
# self.logger.error("'Corpus_id' wasn't given. 'Stats' initialization need Corpus_id.", exc_info=self._logger_traceback)
# return Status(status=False, track_id=self._error_track_id.incr(), func_name=function_name(-2))
status = self.init_stats(prjFolder, DBname, language, visibility, corpus_id, encryption_key=encryption_key,fileName=fileName, version=version, stats_id=stats_id, thread_name=thread_name, db_frozen=db_frozen, context_lenght=context_lenght)
if not status["status"]:
return status
return Status(status=True)
else:
self.logger.error("Given DB-Typ is not supported! Please one of the following types: '{}'.".format(typ, supported_typs), exc_info=self._logger_traceback)
return Status(status=False, track_id=self._error_track_id.incr(), func_name=function_name(-2))
def init_corpus(self, prjFolder, DBname, language, visibility, platform_name,
encryption_key=False,fileName=False, source=False, license=False,
template_name=False, version=False, thread_name="Thread0",
cols_and_types_in_doc=False, corpus_id=False, retrival_template_automat = True):
### Preprocessing: Create File_Name
#p(template_name, "-3template_name")
cols_and_types_in_doc =copy.deepcopy(cols_and_types_in_doc)
# if retrival_template_automat:
# if not template_name:
# if platform_name in DBHandler.templates:
# template_name = platform_name
# self.logger.debug("For given '{}'-Platform was found an '{}'-Template. (since 'retrival_template_automat'-Option set to True, found Template will be automatically used for Corpus Initialization. If you don't want it than set this Option to False)".format(platform_name, template_name))
self._encryption_key = encryption_key
source="NULL" if not source else source
license = "NULL" if not license else license
version = "NULL" if not "NULL" else version
#p(template_name, "-2template_name")
template_name = "NULL" if not template_name else template_name
typ= "corpus"
#p(template_name, "-1template_name")
if not corpus_id:
corpus_id= db_helper.create_id(DBname,language, typ, visibility)
#p((self._rewrite, self._stop_if_db_already_exist))
fileName,path_to_db = db_helper.get_file_name(prjFolder,corpus_id,DBname,
language,visibility, typ,fileName, platform_name,
encrypted= True if encryption_key else False,
rewrite=self._rewrite,
stop_if_db_already_exist=self._stop_if_db_already_exist)
if path_to_db is None:
self.logger.info("InitCorpusDBProblem: DB with the same Name '{}' is already exist. InitProcess was stopped.".format(fileName))
return Status(status=False, track_id=self._error_track_id.incr(), func_name=function_name(-2))
### Initialisation of DB
if not self._check_db_should_not_exist()["status"]:
return self._check_db_should_not_exist()
if os.path.isdir(prjFolder):
path_to_db =":memory:" if self._in_memory else path_to_db
self._db = sqlite.connect(path_to_db, **self._arguments_for_connection)
#p(self._arguments_for_connection,"self._arguments_for_connection")
self._init_threads_cursors_obj()
if self._optimizer:
self._optimize(thread_name=thread_name)
#self._threads_cursors[thread_name] = self._db.cursor()
self._check_db_compilation_options(self._db)
if self._encryption_key:
try:
#c = self._db.cursor()
self._threads_cursors[thread_name].execute("PRAGMA key='{}'".format(self._encryption_key))
self._commit()
self.is_encrypted = True
except Exception as exception:
print_exc_plus() if self._ext_tb else ""
self.logger.error("Something happens while initialization of Corpus '{}'".format( exception), exc_info=self._logger_traceback)
return Status(status=False, track_id=self._error_track_id.incr(), func_name=function_name(-2))
self._update_database_pragma_list(thread_name=thread_name)
self._update_temp_list_with_dbnames_in_instance(thread_name=thread_name)
created_at = strftime("%Y-%m-%d %H:%M:%S", gmtime())
attributs_list = db_helper.default_tables[typ]["info"]
values = [corpus_id, DBname, platform_name, template_name, version, language, created_at, source,license,visibility,typ]
status = self._init_info_table(attributs_list)
if not status["status"]:
self.logger.error("CorpusInitialisatioError: Corpus wasn't initialized because info Table wasn't initialized. ", exc_info=self._logger_traceback)
self._close()
os.remove(path_to_db)
return status
#sys.exit()
#p(self.tables(), "tables")
#p(dict(zip([attr[0] for attr in attributs_list],values)))
status = self.add_attributs(dict(zip([attr[0] for attr in attributs_list],values)))
if not status["status"]:
self.logger.error("CorpusInitialisatioError: Corpus wasn't initialized because attributes wasn't added into info Table. ", exc_info=self._logger_traceback)
self._close()
os.remove(path_to_db)
return status
#p(template_name, "000template_name")
status = self._init_default_tables("corpus", template=template_name, cols_and_types_in_doc=cols_and_types_in_doc)
if not status["status"] :
self.logger.error("CorpusInitialisatioError: Corpus wasn't initialized because default Tables wasn't initialized. ", exc_info=self._logger_traceback)
self._close()
os.remove(path_to_db)
return status
#self._init_documents_table_in_corpus()
self._commit()
#p(self.tables(), "tables")
self._update_temp_indexesList_in_instance(thread_name=thread_name)
#self._update_database_pragma_list(thread_name=thread_name)
self._update_pragma_table_info(thread_name=thread_name)
#p(self.col("documents"))
#sys.exit()
self.logger.info("Corpus-DB ({}) was initialized and saved on the disk: '{}'. ".format(fileName, path_to_db))
#self.logger.info("Corpus-DB ({}) was connected.".format(fileName))
self._mainDB_was_initialized = True
return Status(status=True)
else:
self.logger.error("Given Project Folder is not exist: '{}'. ".format(prjFolder), exc_info=self._logger_traceback)
return Status(status=False, track_id=self._error_track_id.incr(), func_name=function_name(-2))
def init_stats(self, prjFolder, DBname, language, visibility, corpus_id, thread_name="Thread0",
encryption_key=False,fileName=False, version=False, stats_id=False, db_frozen=False,
context_lenght=None):
self._encryption_key = encryption_key
### Preprocessing: Create File_Name
version = "NULL" if not version else version
typ= "stats"
if not stats_id:
stats_id= db_helper.create_id(DBname,language, typ, visibility)
if not stats_id:
self.logger.error("Id wasn't created. Stats-ID was given without Corpus-ID. This is an illegal input.", exc_info=self._logger_traceback)
return Status(status=False, track_id=self._error_track_id.incr(), func_name=function_name(-2))
fileName,path_to_db = db_helper.get_file_name(prjFolder,corpus_id,DBname,
language,visibility, typ, fileName, second_id=stats_id,
encrypted= True if encryption_key else False,
rewrite=self._rewrite, stop_if_db_already_exist=self._stop_if_db_already_exist)
if path_to_db is None:
self.logger.info("InitStatsDBProblem: DB with the same Name '{}' is already exist. InitProcess was stopped.".format(fileName))
return Status(status=False, track_id=self._error_track_id.incr(), func_name=function_name(-2))
### Initialisation of DB
if not self._check_db_should_not_exist()["status"]:
return self._check_db_should_not_exist()
if os.path.isdir(prjFolder):
path_to_db =":memory:" if self._in_memory else path_to_db
self._db = sqlite.connect(path_to_db, **self._arguments_for_connection)
if self._optimizer:
self._optimize(thread_name=thread_name)
self._init_threads_cursors_obj()
#self._threads_cursors[thread_name] = self._db.cursor()
self._check_db_compilation_options(self._db)
if self._encryption_key:
try:
#c = self._db.cursor()
self._threads_cursors[thread_name].execute("PRAGMA key='{}'".format(self._encryption_key))
self._commit()
self.is_encrypted = True
except Exception as exception:
print_exc_plus() if self._ext_tb else ""
self.logger.error("Something happens while initialization of Stats '{}'".format( exception), exc_info=self._logger_traceback)
return Status(status=False, track_id=self._error_track_id.incr(), func_name=function_name(-2))
self._update_database_pragma_list(thread_name=thread_name)
self._update_temp_list_with_dbnames_in_instance(thread_name=thread_name)
if not stats_id:
stats_id= db_helper.create_id(DBname,language, typ, visibility,corpus_id=corpus_id)
created_at = strftime("%Y-%m-%d %H:%M:%S", gmtime())
attributs_list = db_helper.default_tables[typ]["info"]
#p(attributs_list, "attributs_list")
values = [stats_id,corpus_id, DBname, version, created_at, visibility,typ,db_frozen,context_lenght]
#p(values, "values")
status = self._init_info_table(attributs_list)
#p(dict(zip([attr[0] for attr in attributs_list],values)))
if not status["status"]:
self.logger.error("StatsInitialisatioError: Stats wasn't initialized because info Table wasn't initialized. ", exc_info=self._logger_traceback)
self._close()
os.remove(path_to_db)
return status
status = self.add_attributs(dict(zip([attr[0] for attr in attributs_list],values)))
if not status["status"]:
self.logger.error("StatsInitialisatioError: Stats wasn't initialized because attributes wasn't added into info Table. ", exc_info=self._logger_traceback)
self._close()
os.remove(path_to_db)
return status
status = self._init_default_tables("stats")
if not status["status"]:
self.logger.error("StatsInitialisatioError: Corpus wasn't initialized because default Tables wasn't initialized. ", exc_info=self._logger_traceback)
self._close()
os.remove(path_to_db)
return status
self._commit()
#self.dbnames.append("main")
self._update_temp_indexesList_in_instance(thread_name=thread_name)
#self._update_database_pragma_list(thread_name=thread_name)
self._update_pragma_table_info(thread_name=thread_name)
self.logger.info("Stats-DB ({}) was initialized and saved on the disk: '{}'. ".format(fileName, path_to_db))
#self.logger.info("Stats-DB ({}) was connected.".format(fileName))
self._mainDB_was_initialized = True
return Status(status=True)
else:
self.logger.error("Given Project Folder is not exist: '{}'. ".format(prjFolder), exc_info=self._logger_traceback)
return Status(status=False, track_id=self._error_track_id.incr(), func_name=function_name(-2))
def initempty(self, prjFolder, DBname, encryption_key=False, thread_name="Thread0"):
### Preprocessing: Create File_Name
self._encryption_key = encryption_key
fileName,path_to_db = db_helper.get_file_name_for_empty_DB(prjFolder,DBname,
encrypted= True if encryption_key else False,
rewrite=self._rewrite, stop_if_db_already_exist=self._stop_if_db_already_exist)
if path_to_db is None:
self.logger.info("InitEmptyDBProblem: DB with the same Name '{}' is already exist. InitProcess was stopped.".format(fileName))
return Status(status=False, track_id=self._error_track_id.incr(), func_name=function_name(-2))
if not self._check_db_should_not_exist()["status"]:
return self._check_db_should_not_exist()
if os.path.isdir(prjFolder):
path_to_db =":memory:" if self._in_memory else path_to_db
self._db = sqlite.connect(path_to_db, **self._arguments_for_connection)
if self._optimizer:
self._optimize(thread_name=thread_name)
self._init_threads_cursors_obj()
#self._threads_cursors[thread_name] = self._db.cursor()
self._check_db_compilation_options(self._db)
if self._encryption_key:
try:
#c = self._db.cursor()
self._threads_cursors[thread_name].execute("PRAGMA key='{}'".format(self._encryption_key))
self._commit()
self.is_encrypted = True
except Exception as exception:
print_exc_plus() if self._ext_tb else ""
self.logger.error("Something happens while initialization of Corpus '{}'".format( exception), exc_info=self._logger_traceback)
return Status(status=False, track_id=self._error_track_id.incr(), func_name=function_name(-2))
self._update_database_pragma_list(thread_name=thread_name)
self._update_temp_list_with_dbnames_in_instance(thread_name=thread_name)
self._update_temp_indexesList_in_instance(thread_name=thread_name)
#self._update_database_pragma_list(thread_name=thread_name)
self._update_pragma_table_info(thread_name=thread_name)
#p(self._db)
self.logger.info("Empty-DB ({}) was initialized and saved on the disk: '{}'. ".format(fileName, path_to_db))
#self.logger.info("Empty-DB ({}) was connected.".format(fileName))
self._mainDB_was_initialized = True
return Status(status=True)
else:
self.logger.error("Given Project Folder is not exist: '{}'. ".format(prjFolder), exc_info=self._logger_traceback)
return Status(status=False, track_id=self._error_track_id.incr(), func_name=function_name(-2))
def init_default_indexes(self, thread_name="Thread0"):
s = self._check_db_should_exist()
if not s["status"]:
return s
try:
for table_name, index_query_list in db_helper.default_indexes[self.typ()].iteritems():
for index_query in index_query_list:
#p(index_query)
#c = self._db.cursor()
self._threads_cursors[thread_name].execute(index_query)
self.logger.debug("Index for '{}'-DB, '{}'-Table was initialized.".format(self.typ(), table_name))
self._update_temp_indexesList_in_instance(thread_name=thread_name)
except Exception, e:
print_exc_plus() if self._ext_tb else ""
self.logger.error("IndexesInitError: Following Exception was throw: '{}'".format(e), exc_info=self._logger_traceback)
return Status(status=False, track_id=self._error_track_id.incr(), func_name=function_name(-2))
# ##########################DB-Connection#############################
def dump(self, file_name):
s = self._check_db_should_exist()
if not s["status"]:
return s
with open(file_name, 'w') as f:
for line in self._db.iterdump():
f.write('%s\n' % line)
def connect(self,path_to_db, encryption_key=False, reconnection=False, logger_debug=False, thread_name="Thread0"):
#p(logger_debug, "logger_debug")
if not self._check_file_existens(path_to_db):
return Status(status=False, track_id=self._error_track_id.incr(), func_name=function_name(-2))
if not self._check_db_should_not_exist()["status"]:
return self._check_db_should_not_exist()
self._encryption_key = encryption_key
dbName = os.path.splitext(os.path.basename(path_to_db))[0]
status = self._validation_DBfile(path_to_db, encryption_key=encryption_key)
if not status["status"]:
self.logger.debug("ValidationError: DB cannot be connected!", exc_info=self._logger_traceback)
return status
else:
self._db = status["out_obj"]
self._init_threads_cursors_obj()
#self._threads_cursors[thread_name] = self._db.cursor()
if encryption_key:
self.is_encrypted = True
try:
self._update_database_pragma_list(thread_name=thread_name)
self._update_temp_list_with_dbnames_in_instance(thread_name=thread_name)
self._update_temp_tablesList_in_instance(thread_name=thread_name)
#self._update_database_pragma_list(thread_name=thread_name)
self._update_pragma_table_info(thread_name=thread_name)
self._update_temp_attributsList_in_instance(thread_name=thread_name)
self._update_temp_indexesList_in_instance(thread_name=thread_name)
self.not_initialized_dbs.append("main")
except sqlite.DatabaseError, e:
print_exc_plus() if self._ext_tb else ""
self.logger.error("DatabaseError: {}".format(e), exc_info=self._logger_traceback)
return Status(status=False, track_id=self._error_track_id.incr(), func_name=function_name(-2))
except Exception, e:
print_exc_plus() if self._ext_tb else ""
self.logger.error("ConnectionError: {}".format(e), exc_info=self._logger_traceback)
return Status(status=False, track_id=self._error_track_id.incr(), func_name=function_name(-2))
if reconnection:
msg= "DB ('{}') was RE-connected".format(dbName)
else:
msg= "DB ('{}') was connected.".format(dbName)
if logger_debug:
self.logger.debug(msg)
else:
self.logger.info(msg)
return Status(status=True)
def _backup(self, dbname="main"):
s = self._check_db_should_exist()
if not s["status"]:
return s
if dbname not in self.dbnames:
self.logger.error(" '{}'-DB is not exist in the instance.".format(dbname))
return Status(status=False, track_id=self._error_track_id.incr(), func_name=function_name(-2))
fname = os.path.splitext(self.fname(dbname=dbname))
new_fname = fname[0]+"_backup"+fname[1]
dirname = self.dirname(dbname=dbname)
path = self.path(dbname=dbname)
copyfile(path, os.path.join(dirname, new_fname))
self._created_backups[dbname] = os.path.join(dirname, new_fname)
self.logger.info("Temporary-Backup of '{}'-DB was created in '{}'.".format(fname[0]+fname[1], dirname))
def attach(self,path_to_db, encryption_key=False, reattaching=False, db_name=False,thread_name="Thread0"):
#p((path_to_db, encryption_key), c="m")
status = self._check_file_existens(path_to_db)
if not status["status"]:
return Status(status=False, track_id=self._error_track_id.incr(), func_name=function_name(-2))
s = self._check_db_should_exist()
if not s["status"]:
return s
status = self._validation_DBfile( path_to_db, encryption_key=encryption_key)
#self._reinitialize_logger()
if not status["status"]:
self.logger.error("ValidationError: DB cannot be attached!", exc_info=self._logger_traceback)
return status
else:
del status["out_obj"]
gc.collect()
dbName = db_name if db_name else "_" + os.path.splitext(os.path.basename(path_to_db))[0]
if self._encryption_key:
if encryption_key:
query = "ATTACH DATABASE '{path_to_db}' AS {dbName} KEY '{key}';".format(path_to_db=path_to_db, dbName=dbName, key=encryption_key)
else:
query = "ATTACH DATABASE '{path_to_db}' AS {dbName} KEY '';".format(path_to_db=path_to_db, dbName=dbName)
else:
if encryption_key:
query = "ATTACH DATABASE '{path_to_db}' AS {dbName} KEY '{key}';".format(path_to_db=path_to_db, dbName=dbName, key=encryption_key)
else:
query = "ATTACH DATABASE '{path_to_db}' AS {dbName};".format(path_to_db=path_to_db, dbName=dbName)
#p(query)
#p(self._attachedDBs_config,"1self._attachedDBs_config", c="r")
if dbName not in self.dbnames:
try:
#cursor = self._db.cursor()
self._threads_cursors[thread_name].execute(query)
except Exception as exception:
print_exc_plus() if self._ext_tb else ""
if "unrecognized token" in str(exception):
self.logger.error("DBAttachError: While attaching of the '{}'-DB attacher get an following error: '{}'. Probably you used not allowed characters in the db or file name. (e.g. '.' not allowed).".format(dbName, repr(exception) ), exc_info=self._logger_traceback)
else:
self.logger.error("DBAttachError: Something happens while attaching of '{}'-DB: '{}'".format(dbName, repr(exception) ), exc_info=self._logger_traceback)
return Status(status=False, track_id=self._error_track_id.incr(), func_name=function_name(-2))
#p(self._attachedDBs_config,"2self._attachedDBs_config", c="r")
self._attachedDBs_config.append((path_to_db, dbName, encryption_key))
self._update_database_pragma_list(thread_name=thread_name)
self._update_temp_list_with_dbnames_in_instance(thread_name=thread_name)
self._update_temp_tablesList_in_instance(thread_name=thread_name)
#self._update_database_pragma_list(thread_name=thread_name)
self._update_pragma_table_info(thread_name=thread_name)
self._update_temp_attributsList_in_instance(thread_name=thread_name)
self.not_initialized_dbs.append(dbName)
if reattaching:
self.logger.info("DB ('{}') was Reattached".format(dbName))
else:
self.logger.info("DB ('{}') was attached".format(dbName))
return Status(status=True)
else:
self.logger.error("DB '{}' is already attached. You can not attached same DB more as 1 time!".format(dbName), exc_info=self._logger_traceback)
return Status(status=False, track_id=self._error_track_id.incr(), func_name=function_name(-2))
def reattach(self, dbname="main", thread_name="Thread0"):
s = self._check_db_should_exist()
if not s["status"]:
return s
self._commit_if_inserts_was_did()
list_to_reattach =[]
if dbname and dbname!="main":
list_to_reattach.append(dbname)
else:
list_to_reattach = [attacheddb[1] for attacheddb in self._attachedDBs_config]
#p(list_to_reattach,"list_to_reattach",c="m")
for attached_db_name in list_to_reattach:
if attached_db_name in self.dbnames:
configs_list_of_detached_dbs =self.detach(attached_db_name, thread_name=thread_name)
#p(configs_list_of_detached_dbs )
if configs_list_of_detached_dbs:
path_to_db = configs_list_of_detached_dbs[0][0]
encryption_key = configs_list_of_detached_dbs[0][2]
dbname_to_retach = configs_list_of_detached_dbs[0][1]
status = self.attach(path_to_db, encryption_key=encryption_key, thread_name=thread_name)
#p(status,"status")
if not status["status"]:
self.logger.error("'{}' DB wasn't re-attached".format(dbname_to_retach), exc_info=self._logger_traceback)
return status
else:
self.logger.error("'{}' DB wasn't detached.".format(attached_db_name), exc_info=self._logger_traceback)
return Status(status=False, track_id=self._error_track_id.incr(), func_name=function_name(-2))
else:
self.logger.error("Given dbName ('{}') is not exist in the current DB-Structure.".format(attached_db_name), exc_info=self._logger_traceback)
return Status(status=False, track_id=self._error_track_id.incr(), func_name=function_name(-2))
return Status(status=True)
def detach(self, dbname="main", thread_name="Thread0"):
s = self._check_db_should_exist()
if not s["status"]:
return s
self._commit_if_inserts_was_did()
list_to_detach =[]
detached_dbs = []
if dbname and dbname!="main":
list_to_detach.append(dbname)
else:
list_to_detach = [attacheddb[1] for attacheddb in self._attachedDBs_config]
#p(list_to_detach,"list_to_detach", c="r")
for attached_db_name in list_to_detach:
if attached_db_name in self.dbnames:
configs = self._get_configs_from_attached_DBList(attached_db_name)
if configs:
#p(configs, c="m")
self._del_attached_db_from_a_config_list(attached_db_name)
query = "DETACH DATABASE '{}';".format( attached_db_name)
try:
#cursor = self._db.cursor()
self._threads_cursors[thread_name].execute(query)
self.logger.debug("'{}'-DB was detached.".format(attached_db_name))
detached_dbs.append(configs[0])
self.not_initialized_dbs.remove(attached_db_name)
if attached_db_name in self._created_backups:
self._del_backup(attached_db_name)
except Exception as exception:
print_exc_plus() if self._ext_tb else ""
self.logger.error("Something happens while detaching of '{}'-DB: '{}'".format(attached_db_name, repr(exception) ), exc_info=self._logger_traceback)
else:
self.logger.error("Given Attached DB '{}' is not in the Config-List of AttachedDBs. ".format(attached_db_name), exc_info=self._logger_traceback)
return Status(status=False, track_id=self._error_track_id.incr(), func_name=function_name(-2))
else:
self.logger.error("Given dbName ('{}') is not exist in the current DB-Structure".format(attached_db_name), exc_info=self._logger_traceback)
return Status(status=False, track_id=self._error_track_id.incr(), func_name=function_name(-2))
self._update_database_pragma_list(thread_name=thread_name)
self._update_temp_list_with_dbnames_in_instance(thread_name=thread_name)
self._update_temp_tablesList_in_instance(thread_name=thread_name)
#self._update_database_pragma_list(thread_name=thread_name)
self._update_pragma_table_info(thread_name=thread_name)
self._update_temp_attributsList_in_instance(thread_name=thread_name)
return detached_dbs
##########################DB-Attributes#####################
def add_attributs(self,inp_dict, dbname="main", thread_name="Thread0"):
s = self._check_db_should_exist()
if not s["status"]:
return s
self._commit_if_inserts_was_did()
status = self.insertdict("info", inp_dict, dbname=dbname, thread_name=thread_name)
if status["status"]:
self._update_temp_attributsList_in_instance(thread_name=thread_name)
#self._update_pragma_table_info(thread_name=thread_name)
return status
else:
self.logger.error("Attributes wasn't added into InfoTable (dbName:{})".format(dbname), exc_info=self._logger_traceback)
return Status(status=False, track_id=self._error_track_id.incr(), func_name=function_name(-2))
def update_attr(self,attribut_name, value, dbname="main", thread_name="Thread0"):
### Exception Handling
s = self._check_db_should_exist()
if not s["status"]:
return s
self._commit_if_inserts_was_did()
# Check if attributes and values have the same length
if not isinstance(attribut_name, (str, unicode)):
self.logger.error("Given AttributName should be an string or unicode object.", exc_info=self._logger_traceback)
return Status(status=None, track_id=self._error_track_id.incr(), func_name=function_name(-2))
# if given attribute exist in the Info_Table
if attribut_name not in self.col("info", dbname=dbname):
self.logger.error("Given Attribute ('{}') is not exist in this DataBase.".format(attribut_name), exc_info=self._logger_traceback)
return Status(status=None, track_id=self._error_track_id.incr(), func_name=function_name(-2))
if dbname in self.dbnames:
query = 'UPDATE {}.info \nSET {}="{}";'.format(dbname,attribut_name,value)
else:
self.logger.error("Given dbName ('{}') is not exist in the current DB-Structure".format(dbname), exc_info=self._logger_traceback)
return Status(status=None, track_id=self._error_track_id.incr(), func_name=function_name(-2))
### Update Attribute
if "info" in self.tables(dbname=dbname):
try:
#cursor = self._db.cursor()
self._threads_cursors[thread_name].execute(query)
self._commit()
self._update_temp_attributsList_in_instance(thread_name=thread_name)
return Status(status=True)
except Exception as exception:
print_exc_plus() if self._ext_tb else ""
self.logger.error("Something happens while detaching of '{}'-DB: '{}'".format(attached_db_name, repr(exception) ), exc_info=self._logger_traceback)
return Status(status=False, track_id=self._error_track_id.incr(), func_name=function_name(-2))
else:
self.logger.error("Info-Table is wasn't found or not exist. Please initialize the Info Table, bevor you may add any attributes.", exc_info=self._logger_traceback)
return Status(status=False, track_id=self._error_track_id.incr(), func_name=function_name(-2))
def update_attrs(self, inp_dict, dbname="main", thread_name="Thread0"):
### Exception Handling
s = self._check_db_should_exist()
if not s["status"]:
return s
self._commit_if_inserts_was_did()
# Check if attributes and values have the same length
# Check if attributes and values have the same length
if not isinstance(inp_dict, dict):
self.logger.error("UpdateAttributes: InputDict is not an 'dict'.", exc_info=self._logger_traceback)
return Status(status=False, track_id=self._error_track_id.incr(), func_name=function_name(-2))
inp_dict = copy.deepcopy(inp_dict)
# if given attribute exist in the Info_Table
col_in_info_table = self.col("info", dbname=dbname)
if not all(elem in col_in_info_table for elem in inp_dict.keys()):
average = list(set(inp_dict.keys())-set(col_in_info_table))
self.logger.error("Some of the given Attributes ('{}') is not exist in this DataBase. ".format(average ), exc_info=self._logger_traceback)
return Status(status=None, track_id=self._error_track_id.incr(), func_name=function_name(-2))
attrib_to_str = ",".join(["{}='{}'".format(k,v) for k,v in inp_dict.iteritems()])
if dbname in self.dbnames:
query = 'UPDATE {}.info \nSET {};'.format(dbname,attrib_to_str)
else:
self.logger.error("Given dbName ('{}') is not exist in the current DB-Structure".format(dbname), exc_info=self._logger_traceback)
return Status(status=None, track_id=self._error_track_id.incr(), func_name=function_name(-2))
### Update Attribute
if "info" in self.tables(dbname=dbname):
try:
#cursor = self._db.cursor()
self._threads_cursors[thread_name].execute(query)
self._commit()
self._update_temp_attributsList_in_instance(thread_name=thread_name)
return Status(status=True)
except Exception as exception:
print_exc_plus() if self._ext_tb else ""
self.logger.error("Something happens while detaching of '{}'-DB: '{}'".format(attached_db_name, repr(exception) ), exc_info=self._logger_traceback)
return Status(status=False, track_id=self._error_track_id.incr(), func_name=function_name(-2))
else:
self.logger.error("Info-Table is wasn't found or not exist. Please initialize the Info Table, bevor you may add any attributes.", exc_info=self._logger_traceback)
return Status(status=False, track_id=self._error_track_id.incr(), func_name=function_name(-2))
def get_attr(self,attributName, dbname="main"):
s = self._check_db_should_exist()
if not s["status"]:
return s
if not isinstance(attributName, (str, unicode)):
self.logger.error("Given AttributName should be an string or unicode object.", exc_info=self._logger_traceback)
#return Status(status=None, track_id=self._error_track_id.incr(), func_name=function_name(-2))
return None
if not self._attributs_dict:
self.logger.warning("Temporary AttributesList is empty")
#return Status(status=None, track_id=self._error_track_id.incr(), func_name=function_name(-2))
return None
# if given attribute exist in the Info_Table
#p((attributName, self._attributs_dict,dbname))
try:
if attributName not in self._attributs_dict[dbname]:
self.logger.error("Given Attribute ('{}') is not exist in the '{}'-DB.".format(attributName,dbname), exc_info=self._logger_traceback)
#return Status(status=None, track_id=self._error_track_id.incr(), func_name=function_name(-2))
return None
except KeyError:
self.logger.error("'{}'-DB is not found.".format(dbname))
return None
if dbname in self.dbnames:
try:
return self._attributs_dict.get(dbname, None).get(attributName, None)
except:
return None
#[dbname][attributName]
else:
self.logger.error("Given dbName ('{}') is not exist in the current DB-Structure".format(dbname), exc_info=self._logger_traceback)
#return Status(status=None, track_id=self._error_track_id.incr(), func_name=function_name(-2))
return None
def get_all_attr(self, dbname="main"):
s = self._check_db_should_exist()
if not s["status"]:
return s
if u"info" in self.tables(dbname=dbname):
if dbname in self.dbnames:
return self._attributs_dict[dbname]
else:
self.logger.error("Given dbName ('{}') is not exist in the current DB-Structure".format(dbname), exc_info=self._logger_traceback)
return Status(status=None, track_id=self._error_track_id.incr(), func_name=function_name(-2))
else:
self.logger.error("Info-Table wasn't found or not exist. Please initialize the Info Table, bevor you may add any attributes.", exc_info=self._logger_traceback)
return Status(status=None, track_id=self._error_track_id.incr(), func_name=function_name(-2))
##########################DB-Execute Commands#####################
def execute(self, query, values=False, dbname="main", thread_name="Thread0"):
s = self._check_db_should_exist()
if not s["status"]:
return s
self._commit_if_inserts_was_did()
try:
#c =
s = self._execute(query, values=values, dbname=dbname, thread_name=thread_name, new_cursor=True)
#p(s, c="r")
if not s["status"]:
return False
else:
cur = s["out_obj"]
#p(cur, "cur")
self._update_temp_tablesList_in_instance(thread_name=thread_name)
self._update_temp_indexesList_in_instance(thread_name=thread_name)
self._update_database_pragma_list(thread_name=thread_name)
self._update_pragma_table_info(thread_name=thread_name)
return cur
except Exception as exception:
print_exc_plus() if self._ext_tb else ""
self.logger.error("Something happens while execution of the following query: '{}'. See following Exception: '{}'. ".format(query,str(exception)), exc_info=self._logger_traceback)
return Status(status=False, track_id=self._error_track_id.incr(), func_name=function_name(-2))
def executescript(self, query, thread_name="Thread0", dbname="main"):
s = self._check_db_should_exist()
if not s["status"]:
return s
self._commit_if_inserts_was_did()
try:
#cur = self._db.cursor()
self._threads_cursors[thread_name].executescript(query)
self._update_temp_tablesList_in_instance(thread_name=thread_name)
self._update_temp_indexesList_in_instance(thread_name=thread_name)
self._update_database_pragma_list(thread_name=thread_name)
self._update_pragma_table_info(thread_name=thread_name)
return cur
except Exception as exception:
print_exc_plus() if self._ext_tb else ""
self.logger.error("Something happens while execution of the following query: '{}'. See following Exception: '{}'. ".format(query,str(exception)), exc_info=self._logger_traceback)
return Status(status=False, track_id=self._error_track_id.incr(), func_name=function_name(-2))
def executemany(self, query, argument, thread_name="Thread0", dbname="main"):
s = self._check_db_should_exist()
if not s["status"]:
return s
self._commit_if_inserts_was_did()
try:
s = self._executemany(query, values=argument, dbname=dbname, thread_name=thread_name, new_cursor=True)
if not s["status"]:
return s
else:
cur = s["out_obj"]
self._update_temp_tablesList_in_instance(thread_name=thread_name)
self._update_temp_indexesList_in_instance(thread_name=thread_name)
self._update_database_pragma_list(thread_name=thread_name)
self._update_pragma_table_info(thread_name=thread_name)
return cur
except Exception as exception:
print_exc_plus() if self._ext_tb else ""
self.logger.error("Something happens while execution of the following query: '{}'. See following Exception: '{}'. ".format(query,str(exception)), exc_info=self._logger_traceback)
return Status(status=False, track_id=self._error_track_id.incr(), func_name=function_name(-2))
def _executemany(self, query, values=False, dbname="main", thread_name="Thread0", new_cursor = False):
return self._execution(query, values=values, dbname=dbname, many=True, thread_name=thread_name, new_cursor=new_cursor)
def _execute(self, query, values=False, dbname="main", thread_name="Thread0", new_cursor = False):
return self._execution(query, values=values, dbname=dbname, many=False,thread_name=thread_name, new_cursor=new_cursor)
def _execution(self,query, values=False, dbname="main", many=False, thread_name="Thread0", new_cursor = False):
#p("EXECUTION")
try:
try:
cursor = self._threads_cursors[thread_name]
except:
self._threads_cursors[thread_name] = self._db.cursor()
cursor = self._threads_cursors[thread_name]
cursor = self._db.cursor() if new_cursor else cursor
#p(type(cursor))
#p(query,"query")
if many:
if values:
cursor.executemany(query, values)
else:
cursor.executemany(query)
else:
if values:
cursor.execute(query, values)
else:
cursor.execute(query)
if self._thread_safe:
cursor.join()
#time.sleep(5)
return Status(status=True, out_obj=cursor)
except (sqlite.OperationalError, sqlite.IntegrityError) as exception:
track_id = self._error_track_id.incr()
l_query = query if self._log_content else "!!LogContentDisable!!"
l_values = values if self._log_content else "!!LogContentDisable!!"
if "UNIQUE constraint failed:" in str(exception):
msg = "UniquenessERROR: Redundant row was get and was out-sorted. |ErrorTrackID:'{}'| See Exception: '{}'. InpQuery: '{}'. InpValues: '{}'. ".format( track_id, repr(exception), l_query, l_values)
#self.logger.outsorted_corpus()
if self.typ(dbname=dbname) == "corpus":
level_name = "outsorted_corpus"
self.logger.outsorted_corpus(msg)
elif self.typ(dbname=dbname) == "stats":
level_name = "outsorted_stats"
self.logger.outsorted_stats(msg)
else:
level_name = "error_insertion"
self.logger.error_insertion(msg)
self.error_insertion_counter.incr()
return Status(status=False, track_id=track_id,
desc="Redundant row was get.",
level=level_name, action="outsorted",
inp_obj= (query, values,dbname),
error_name="{} (UniquenessERROR)".format(exception.__class__.__name__), exception=exception)
elif "SQL logic error" in str(exception):
msg = "SQL logic error (ThreadsCrash): Probably it is the result of ThreadsCrash. Please use option 'thread_safe' to ensure ThreadSafety and run script again. (Attention: Executed insertions could be inconsistent!) |ErrorTrackID:'{}'| See Exception: '{}'. InpQuery: '{}'. InpValues: '{}'. ".format( track_id, repr(exception), l_query, l_values)
#self.logger.outsorted_corpus()
level_name = "error_insertion"
self.logger.error_insertion(msg)
self.error_insertion_counter.incr()
#if self._raise_exceptions:
# raise ThreadsCrash,
# "SQL logic error: Probably it is the result of ThreadsCrash. Please use option 'thread_safe' to ensure ThreadSafety and run script again. |ErrorTrackID:'{}'| (Attention: Executed insertions could be inconsistent!) ".format(track_id)
return Status(status=False, track_id=track_id,
desc="SQL logic error. ",
level=level_name, action="ThreadsCrash",
inp_obj= (query, values,dbname),
error_name="{} (ErrorBindingParameter)".format(exception.__class__.__name__), exception=exception)
else:
msg = "ExecutionError: '{}'. (current Execution was ignored) |ErrorTrackID:'{}'|".format( repr(exception),track_id )
if "has no column named" in str(exception):
msg = "ExecutionError: '{}'. (current Execution was ignored) Possible Solution: 'Insert failed columns into SQL-DataBase or use Reader-Template to format and outsorte not needed columns. ' |ErrorTrackID:'{}'|".format( repr(exception),track_id )
self.logger.error_insertion(msg, exc_info=self._logger_traceback)
self.error_insertion_counter.incr()
return Status(status=False, track_id=track_id,
desc="It is not possible to insert all got columns into CorpDB. Possible Explanation: 1. Current DB was initialized with wrong and not full number of columns, please reinitialize current CorpusDB with right column names and types. Or use also option precomputed corp types. For this use option 'template_name' on the Corpus Level ( while Initialization) (ex:template_name='twitter',or template_name='blogger' ) or also on the Reader Level 'reader_formatter_name='twitter'.",
level="error_insertion", action="stop_execution",
inp_obj= (query, values,dbname), func_name=function_name(-3),
error_name=exception.__class__.__name__, exception=repr(exception))
except sqlite.InterfaceError as exception:
#p((query, values))
track_id = self._error_track_id.incr()
l_query = query if self._log_content else "!!LogContentDisable!!"
l_values = values if self._log_content else "!!LogContentDisable!!"
#self.error_insertion_counter.incr()
if "Error binding parameter " in str(exception):
msg = "Error binding parameter(ThreadsCrash): Probably it is the result of ThreadsCrash. Please use option 'thread_safe' to ensure ThreadSafety and run script again. (Attention: Executed insertions could be inconsistent!) |ErrorTrackID:'{}'| See Exception: '{}'. InpQuery: '{}'. InpValues: '{}'. ".format( track_id, repr(exception), l_query, l_values)
#self.logger.outsorted_corpus()
level_name = "error_insertion"
self.logger.error_insertion(msg)
#if self._raise_exceptions:
# raise ThreadsCrash, "Error binding parameter: Probably it is the result of ThreadsCrash. Please use option 'thread_safe' to ensure ThreadSafety and run script again. |ErrorTrackID:'{}'| (Attention: Executed insertions could be inconsistent!) ".format(track_id)
self.error_insertion_counter.incr()
return Status(status=False, track_id=track_id,
desc="Error binding parameter",
level=level_name, action="ThreadsCrash",
inp_obj= (query, values,dbname),
error_name="{} (ErrorBindingParameter)".format(exception.__class__.__name__), exception=exception)
else:
self.logger.error_insertion("ExecutionError: '{}'. (current Execution was ignored) |ErrorTrackID:'{}'|".format( repr(exception),track_id ), exc_info=self._logger_traceback)
self.error_insertion_counter.incr()
return Status(status=False, track_id=track_id,
desc=repr(exception),
level="error_insertion", action="ignored",
inp_obj= (query, values,dbname), func_name=function_name(-3),
error_name=exception.__class__.__name__, exception=exception)
except Exception as exception:
track_id = self._error_track_id.incr()
print_exc_plus() if self._ext_tb else ""
self.logger.low_debug("ExecutionError: |ErrorTrackID:'{}'| Following Query could have an Error: '{}'. Track the error in the 'error_insertion'-Level. ".format(track_id, query, ))
l_query = query if self._log_content else "!!LogContentDisable!!"
l_values = values if self._log_content else "!!LogContentDisable!!"
self.error_insertion_counter.incr()
if "has no column named" in str(exception):
self.logger.error_insertion("ExecutionError: One of the columns is not in the Table. See Exception: '{}'. (current Execution was ignored) |ErrorTrackID:'{}'| InpQuery: '{}'. InpValues: '{}'.".format( repr(exception),track_id ,l_query, l_values ), exc_info=self._logger_traceback)
self.error_insertion_counter.incr()
return Status(status=False, track_id=track_id,
desc="One of the columns is not in the Table.",
inp_obj= (query, values,dbname), func_name=function_name(-3),
level="error_insertion", action="ignored",
error_name=exception.__class__.__name__, exception=exception)
else:
l_query = query if self._log_content else "!!LogContentDisable!!"
l_values = values if self._log_content else "!!LogContentDisable!!"
self.logger.error_insertion("ExecutionError: Something happens. '{}'. (current Execution was ignored) |ErrorTrackID:'{}'| InpQuery: '{}'. InpValues: '{}'. ".format(repr(exception),track_id,l_query, l_values ), exc_info=self._logger_traceback)
self.error_insertion_counter.incr()
return Status(status=False, track_id=track_id,
desc="Something happens",
inp_obj= (query, values,dbname), func_name=function_name(-3),
level="error_insertion", action="ignored",
error_name=exception.__class__.__name__, exception=exception)
##########################DB-Info######################
def exist(self):
return Status(status=True) if self._db else False
def typ(self, dbname="main"):
return self.get_attr("typ", dbname="main")
def name(self, dbname="main"):
return self.get_attr("name", dbname="main")
def visibility(self, dbname="main"):
return self.get_attr("visibility", dbname="main")
def version(self, dbname="main"):
return self.get_attr("version", dbname="main")
def id(self, dbname="main"):
return self.get_attr("id", dbname="main")
def encryption(self):
if self.is_encrypted:
return "encrypted"
else:
return "plaintext"
def status(self):
if self._db:
if self._attachedDBs_config:
return "manyDB"
else:
return "oneDB"
else:
return "noDB"
def tables(self,dbname="main"):
s = self._check_db_should_exist()
if not s["status"]:
return s
if dbname in self.dbnames:
#self.logger.low_debug("Table names was returned (dbname: '{}')".format(dbname))
if len(self._tables_dict)>0:
return self._tables_dict[dbname]
else:
self.logger.debug("Temporary TableList is empty! Probably current DB has no Tables or there is an logical error in the Implementation!")
return []
else:
self.logger.error("Given dbName ('{}') is not exist in the current DB-Structure".format(dbname), exc_info=self._logger_traceback)
return []
def indexes(self,dbname="main"):
s = self._check_db_should_exist()
if not s["status"]:
return s
if dbname in self.dbnames:
#self.logger.low_debug("Indexes names was returned (dbname: '{}')".format(dbname))
if len(self._indexes_dict)>0:
return self._indexes_dict[dbname]
else:
self.logger.critical("Temporary IndexList is empty!")
return []
else:
self.logger.error("Given dbName ('{}') is not exist in the current DB-Structure".format(dbname), exc_info=self._logger_traceback)
return []
def fname(self,dbname="main"):
s = self._check_db_should_exist()
if not s["status"]:
return s
if dbname in self.dbnames:
for row in self._database_pragma_list:
if row[1] == dbname:
return os.path.basename(row[2])
else:
self.logger.error("Given dbName ('{}') is not exist in the current DB-Structure".format(dbname), exc_info=self._logger_traceback)
return Status(status=None, track_id=self._error_track_id.incr(), func_name=function_name(-2))
def path(self, dbname="main"):
s = self._check_db_should_exist()
if not s["status"]:
return s
if dbname in self.dbnames:
for row in self._database_pragma_list:
if row[1] == dbname:
return row[2]
else:
self.logger.error("Given dbName ('{}') is not exist in the current DB-Structure".format(dbname), exc_info=self._logger_traceback)
return Status(status=None, track_id=self._error_track_id.incr(), func_name=function_name(-2))
def dirname(self, dbname="main"):
s = self._check_db_should_exist()
if not s["status"]:
return s
## check existents of the dbName
if dbname in self.dbnames:
for row in self._database_pragma_list:
if row[1] == dbname:
return os.path.dirname(row[2])
else:
self.logger.error("Given dbName ('{}') is not exist in the current DB-Structure".format(dbname), exc_info=self._logger_traceback)
return Status(status=None, track_id=self._error_track_id.incr(), func_name=function_name(-2))
def pathAttachedDBs(self):
s = self._check_db_should_exist()
if not s["status"]:
return s
return [row[2] for row in self._database_pragma_list if row[1]!= "main"]
def fnameAttachedDBs(self):
s = self._check_db_should_exist()
if not s["status"]:
return s
return [ os.path.basename(row[2]) for row in self._database_pragma_list if row[1]!= "main"]
def attached(self):
s = self._check_db_should_exist()
if not s["status"]:
return s
return [ row[1] for row in self._database_pragma_list if row[1]!= "main"]
def col(self, tableName,dbname="main"):
s = self._check_db_should_exist()
if not s["status"]:
return s
if tableName not in self.tables(dbname=dbname):
self.logger.error("'{}'-Table not exist in the '{}'-DB.".format(tableName, dbname))
return Status(status=False, track_id=self._error_track_id.incr(), func_name=function_name(-2))
#self.logger.low_debug("Columns for Table '{}' was returned (dbName:'{}')".format(tableName,dbname))
return [column[1] for column in self._pragma_table_info[dbname][tableName]]
def colt(self, tableName,dbname="main"):
s = self._check_db_should_exist()
if not s["status"]:
return s
if tableName not in self.tables(dbname=dbname):
self.logger.error("'{}'-Table not exist in the '{}'-DB.".format(tableName, dbname))
return Status(status=False, track_id=self._error_track_id.incr(), func_name=function_name(-2))
return [(column[1],column[2]) for column in self._pragma_table_info[dbname][tableName]]
def rownum(self, tableName,dbname="main", thread_name="Thread0", where=False, connector_where="AND"):
s = self._check_db_should_exist()
if not s["status"]:
return s
self._commit_if_inserts_was_did()
## check existents of the tableName
if tableName not in self.tables(dbname=dbname):
return Status(status=None, track_id=self._error_track_id.incr(), func_name=function_name(-2))
if where:
where_cond_as_str = db_helper.where_condition_to_str(where, connector=connector_where)
#p(where_cond_as_str)
if not where_cond_as_str:
self.logger.error("GetRowNum: Where-Condition(s) wasn't compiled to String!", exc_info=self._logger_traceback)
return Status(status=False, track_id=self._error_track_id.incr(), func_name=function_name(-2))
## check existents of the dbName
if dbname in self.dbnames:
if where:
query = "select count(*) from {dbname}.{table_name} WHERE {where} ; ".format(table_name=tableName, dbname=dbname,where=where_cond_as_str)
else:
query = "select count(*) from {dbname}.{table_name}; ".format(table_name=tableName, dbname=dbname)
else:
self.logger.error("Given dbName ('{}') is not exist in the current DB-Structure".format(dbname), exc_info=self._logger_traceback)
return Status(status=None, track_id=self._error_track_id.incr(), func_name=function_name(-2))
try:
#cursor = self._db.cursor()
self._threads_cursors[thread_name].execute(query)
number = self._threads_cursors[thread_name].fetchone()
except Exception as exception:
print_exc_plus() if self._ext_tb else ""
self.logger.error("Something happens while getting of RowsNumber for '{}'-Table: '{}'.".format(tableName, repr(exception) ), exc_info=self._logger_traceback)
return Status(status=False, track_id=self._error_track_id.incr(), func_name=function_name(-2))
#self.logger.debug("Number of Rows was returned")
return number[0]
#return [(column[1],column[2]) for column in columns]
##########################DB--Getters######################
def getall(self, tableName, columns=False, select=False, dbname="main", where=False, connector_where="AND", limit=-1, offset=-1, thread_name="Thread0", case_sensitiv=True, distinct=False):
s = self._intern_getter(tableName, columns=columns, select=select, dbname=dbname, where=where, connector_where=connector_where,limit=limit, offset=offset, thread_name=thread_name, case_sensitiv=case_sensitiv, distinct=distinct)
#p(s["out_obj"])
if s["status"]:
return s["out_obj"].fetchall()
else:
self.logger.error("GetterError: Nor Cursor Element was passed from intern getter.")
return []
def getone(self, tableName, columns=False, select=False, dbname="main", where=False, connector_where="AND", limit=-1, offset=-1, thread_name="Thread0", case_sensitiv=True, distinct=False):
#p(dbname, "dbname")
s = self._intern_getter(tableName, columns=columns, select=select, dbname=dbname, where=where, connector_where=connector_where,limit=limit, offset=offset, thread_name=thread_name, case_sensitiv=case_sensitiv, distinct=distinct)
#p(s["out_obj"])
if s["status"]:
return s["out_obj"].fetchone()
else:
self.logger.error("GetterError: Nor Cursor Element was passed from intern getter.")
return []
def lazyget(self, tableName, columns=False, select=False, dbname="main", where=False, connector_where="AND", size_to_fetch=1000, output="list", limit=-1, offset=-1, thread_name="Thread0", case_sensitiv=True, just_check_existence=False, distinct=False):
#self.logger.low_debug("LazyGet was invoked.")
if output == "list":
for row in self.getlistlazy(tableName, columns=columns, select=select, dbname=dbname, where=where, connector_where=connector_where, size_to_fetch=size_to_fetch,limit=limit, offset=offset, thread_name=thread_name, case_sensitiv=case_sensitiv, just_check_existence=just_check_existence, distinct=distinct):
yield row
elif output == "dict":
for getted_dict in self.getdictlazy( tableName, columns=columns, select=select, dbname=dbname, where=where, connector_where=connector_where, size_to_fetch=size_to_fetch,limit=limit, offset=offset, thread_name=thread_name, case_sensitiv=case_sensitiv,just_check_existence=just_check_existence, distinct=distinct):
yield getted_dict
else:
self.logger.error("LazyGetter: '{}'-OutputFormat is not supported. Please use one of the following: '['list','dict']' ".format(output), exc_info=self._logger_traceback)
yield False
return
def getdictlazy(self, tableName, columns=False, select=False, dbname="main", where=False, connector_where="AND", size_to_fetch=1000, limit=-1, offset=-1, thread_name="Thread0", case_sensitiv=True,just_check_existence=False, distinct=False):
#self.logger.low_debug("GetDictLazy was invoked.")
list_with_keys = []
if columns:
if isinstance(columns, (unicode, str)):
columns = [columns]
list_with_keys += columns
if not columns:
#columns = self.col(tableName, dbname=dbname)
list_with_keys += self.col(tableName, dbname=dbname)
if select:
if isinstance(select, (unicode, str)):
select = [select]
list_with_keys += select
#p(list(self.getlistlazy( tableName, columns=columns, select=select, dbname=dbname, where=where, connector_where=connector_where, size_to_fetch=size_to_fetch,limit=limit, offset=offset)))
generator = self.getlistlazy(tableName, columns=columns, select=select, dbname=dbname, where=where, connector_where=connector_where, size_to_fetch=size_to_fetch,limit=limit, offset=offset, thread_name=thread_name, case_sensitiv=case_sensitiv,just_check_existence=just_check_existence, distinct=distinct)
if just_check_existence:
if next(generator):
yield True
else:
yield False
return
for row in generator:
yield {k:v for k,v in zip(list_with_keys,row)}
def getlistlazy(self, tableName, columns=False, select=False, dbname="main", where=False, connector_where="AND", size_to_fetch=1000, limit=-1, offset=-1, thread_name="Thread0", case_sensitiv=True,just_check_existence=False, distinct=False):
#self.logger.low_debug("GetListLazy was invoked.")
cursor = self._intern_getter(tableName, columns=columns, select=select, dbname=dbname, where=where, connector_where=connector_where,limit=limit, offset=offset, thread_name=thread_name,case_sensitiv=case_sensitiv, distinct=distinct)
try:
if cursor["status"]:
#try:
if just_check_existence:
#p(cursor["out_obj"].fetchone())
if cursor["out_obj"].fetchone():
yield True
else:
yield False
return
else:
while True:
#p(cursor, "cursor")
results = cursor["out_obj"].fetchmany(size_to_fetch)
#p(results, "results")
results = list(results)
if not results:
break
for row in results:
yield row
else:
self.logger.error("GetterError: Nor Cursor Element was passed from intern getter.")
yield []
return
except Exception as e:
self.logger.error("Exception was throw: '{}'. (cursor_obj='{}',tableName='{}', columns='{}', select='{}', where='{}', ) ".format(repr(e), cursor["out_obj"], tableName, columns, select, where))
yield []
return
def _intern_getter(self, tableName, columns=False, select=False, dbname="main", where=False,
connector_where="AND", limit=-1, offset=-1, thread_name="Thread0",
case_sensitiv=True, distinct=False):
# return cursor object
#p((columns, select, where))
#p(dbname, "2dbname")
#self.logger.low_debug("InternGetter was invoked.")
s = self._check_db_should_exist()
if not s["status"]:
return s
tab_exist = self._check_if_table_exist(tableName, dbname=dbname)
if not tab_exist["status"]:
return tab_exist
self._commit_if_inserts_was_did()
if columns:
#p((repr(columns), type(columns)))
if isinstance(columns, (str, unicode)):
columns = (columns,)
#p((repr(columns), type(columns)))
columns_existens = self._check_if_given_columns_exist(tableName, columns, dbname=dbname)
if not columns_existens["status"]:
return columns_existens
if select:
if isinstance(select, (str, unicode)):
select = (select,)
else:
select = ()
#p((columns,select))
try:
select_conditions = db_helper.list_of_select_objects_to_str(columns+select)
except TypeError:
select_conditions = db_helper.list_of_select_objects_to_str(tuple(columns)+tuple(select))
elif select:
if isinstance(select, (str, unicode)):
select = (select,)
select_conditions = db_helper.list_of_select_objects_to_str(select)
else:
select_conditions = '*'
#p(select_conditions, "select_conditions")
if not select_conditions:
self.logger.error("TypeError: Select columns is not given in the right way! '{}' was given. ".format(type(columns)), exc_info=self._logger_traceback)
return Status(status=None, track_id=self._error_track_id.incr(), func_name=function_name(-2))
if where:
where_cond_as_str = db_helper.where_condition_to_str(where, connector=connector_where)
#p(where_cond_as_str)
if not where_cond_as_str:
self.logger.error("GetAllError: Where-Condition(s) wasn't compiled to String!", exc_info=self._logger_traceback)
return Status(status=False, track_id=self._error_track_id.incr(), func_name=function_name(-2))
if dbname not in self.dbnames:
self.logger.error("Given dbName ('{}') is not exist in the current DB-Structure".format(dbname), exc_info=self._logger_traceback)
return Status(status=None, track_id=self._error_track_id.incr(), func_name=function_name(-2))
distinct_tag = "DISTINCT" if distinct else ""
if where:
query = u'SELECT {} {} FROM {}.{} \nWHERE {} LIMIT {} OFFSET {}'.format(distinct_tag,select_conditions, dbname, tableName, where_cond_as_str, limit, offset)
else:
query = u'SELECT {} {} FROM {}.{} LIMIT {} OFFSET {}'.format(distinct_tag, select_conditions, dbname, tableName, limit, offset)
if not case_sensitiv:
query = query + " COLLATE NOCASE"
query = query+";"
#p(query, c="m")
#sys.exit()
try:
#cursor = self._db.cursor()
self._threads_cursors[thread_name].execute(query)
#p((self._threads_cursors[thread_name]), c="r")
#return Status(status=True, out_obj=self._threads_cursors[thread_name])
return Status(status=True, out_obj=self._threads_cursors[thread_name])
except Exception as exception:
print_exc_plus() if self._ext_tb else ""
q = query.replace("\n", " ")
try:
q = q.decode("utf-8")
except:
pass
self.logger.error(u"Exception was throw: '{}' for following query: '{}'".format( repr(exception), q ), exc_info=self._logger_traceback)
return Status(status=False, track_id=self._error_track_id.incr(), func_name=function_name(-2))
##########################SQLITE Settings################
def set_journal(self,mode_to_set, thread_name="Thread0",):
modi = ["delete", "truncate", "persist", "memory", "wal", "off"]
if mode_to_set.lower() in modi:
return self._threads_cursors[thread_name].execute("PRAGMA journal_mode = {};".format(mode_to_set)).fetchall()
else:
self.logger.error("'{}'-Mode is not supported. Use one of the following: '{}'. ".format(mode_to_set, modi))
return Status(status=False, track_id=self._error_track_id.incr(), func_name=function_name(-2))
def get_journal(self,thread_name="Thread0",):
return self._threads_cursors[thread_name].execute("PRAGMA journal_mode;").fetchall()
def set_synch(self,num, dbname="main",thread_name="Thread0",):
#https://www.sqlite.org/pragma.html#pragma_synchronous
if dbname not in self.dbnames:
self.logger.error("'{}'-DB wasn't found in the current Instance. ".format(dbname))
return Status(status=False, track_id=self._error_track_id.incr(), func_name=function_name(-2))
if num <= 3 and num >= 0:
return self._threads_cursors[thread_name].execute("PRAGMA {}.synchronous={};".format(dbname,num)).fetchall()
else:
self.logger.error("'{}'-ModeNummer is not supported. ".format(num))
return Status(status=False, track_id=self._error_track_id.incr(), func_name=function_name(-2))
def get_synch(self, dbname="main",thread_name="Thread0",):
if dbname not in self.dbnames:
self.logger.error("'{}'-DB wasn't found in the current Instance. ".format(dbname))
return Status(status=False, track_id=self._error_track_id.incr(), func_name=function_name(-2))
return self._threads_cursors[thread_name].execute("PRAGMA {}.synchronous;".format(dbname)).fetchall()
#self._cashed_list = defaultdict(lambda: defaultdict(lambda: defaultdict(list)))
#self._cashed_dict = defaultdict(lambda: defaultdict(lambda: defaultdict(dict)))
# def _is_many_values(self, values):
# values
# inp_obj = inp_obj if self._log_content else "RowContentLogger is Off."
# track_id = self._error_track_id.incr()
# self.logger.error_insertion("Throw Exception: '{}'. |ErrorTrackID:'{}'| InpObj:'{}'.".format(exception, track_id,inp_obj), exc_info=self._logger_traceback)
# self.error_insertion_counter.incr()
# return Status(status=False, track_id=track_id,
# desc=str(exception),
# inp_obj= (table_name, inp_obj), func_name=function_name(-2),
# level="error_insertion", action="ignored",
# error_name=exception.__class__.__name__,
# exception=exception)
def _dict_to_cash(self,table_name, inp_obj, dbname, commit_number,thread_name="Thread0"):
if len(inp_obj) < 1:
track_id = self._error_track_id.incr()
msg = "DictTOCashError: Given Dict is empty! |ErrorTrackID:'{}'|".format(track_id)
inp_obj = inp_obj if self._log_content else "RowContentLogger is Off."
self.logger.outsorted_corpus("{} InpObj:'{}'.".format(msg,inp_obj), exc_info=self._logger_traceback)
#self.error_insertion_counter.incr()
return Status(status=False, track_id=track_id,
desc=msg, func_name=function_name(-2),
level="outsorted_corpus", action="outsorted")
## Step 1: Type Recognition (many or unig elem pro key)
try:
#### Is it an list?
new_val_list = []
### Many Values
for item in inp_obj.values():
new_val_list.append([]+item)
length = [len(item) for item in new_val_list]
if len(set(length)) >1:
track_id = self._error_track_id.incr()
msg = "DictTOCashError: Given Dict Values has inconsistent length! This insertion was ignored! |ErrorTrackID:'{}'|".format(track_id)
inp_obj = inp_obj if self._log_content else "RowContentLogger is Off."
self.logger.error_insertion("{} InpObj:'{}'.".format(msg,inp_obj), exc_info=self._logger_traceback)
self.error_insertion_counter.incr()
return Status(status=False, track_id=track_id,
desc=msg, func_name=function_name(-2),
level="error_insertion", action="ignored")
except TypeError:
try:
### Is there tuples?
new_val_list = []
### Many Values
#p(21111)
for item in inp_obj.values():
new_val_list.append(list(()+item))
#p(2222)
length = [len(item) for item in new_val_list ]
#p(set(length), "length")
if len(set(length)) >1:
#p(set(length), "length")
track_id = self._error_track_id.incr()
msg = "DictTOCashError: Given Dict Values has inconsistent length! This insertion was ignored! |ErrorTrackID:'{}'|".format(track_id)
inp_obj = inp_obj if self._log_content else "RowContentLogger is Off."
self.logger.error_insertion("{} InpObj:'{}'.".format(msg,inp_obj), exc_info=self._logger_traceback)
self.error_insertion_counter.incr()
return Status(status=False, track_id=track_id,
desc=msg, func_name=function_name(-2),
level="error_insertion", action="ignored")
except TypeError:
new_val_list = []
for item in inp_obj.values():
new_val_list.append([item])
except Exception as exception:
#p(repr(exception))
track_id = self._error_track_id.incr()
msg = "DictTOCashError: Exception was encountered! This insertion was ignored! |ErrorTrackID:'{}'|".format(track_id)
inp_obj = inp_obj if self._log_content else "RowContentLogger is Off."
self.logger.error_insertion("{} Exception: '{}'. InpObj:'{}'.".format(msg,exception,inp_obj), exc_info=self._logger_traceback)
self.error_insertion_counter.incr()
return Status(status=False,
desc=str(exception),
level="error_insertion", action="ignored",
error_name=exception.__class__.__name__,
exception=exception)
keys_in_cashed_dict = self._cashed_dict[commit_number][thread_name][dbname][table_name].keys()
if keys_in_cashed_dict:
values_length_in_cashed_dict = len(self._cashed_dict[commit_number][thread_name][dbname][table_name][keys_in_cashed_dict[0]])
values_length_in_inp_dict = len(new_val_list[0])
for key, val in zip(inp_obj.keys(), new_val_list):
try:
keys_in_cashed_dict.remove(key)
self._cashed_dict[commit_number][thread_name][dbname][table_name][key] += val
except ValueError:
## following key wasn't before in the cashed dict
### add None-Items, to ensure dict consistence
self._cashed_dict[commit_number][thread_name][dbname][table_name][key] += [None for i in xrange(values_length_in_cashed_dict)]
self._cashed_dict[commit_number][thread_name][dbname][table_name][key] += val
else:## if cashed dict is empty
for key, val in zip(inp_obj.keys(), new_val_list):
self._cashed_dict[commit_number][thread_name][dbname][table_name][key] += val
# Step 3: if keys in cashed dict exist, which wasn't found in inp_dict, that insert empty values, to make cash_dict consistent
if keys_in_cashed_dict:
### if keys from key dict stay exist, after compare them with keys from input_dict, that insert empty items
values_length_in_inp_dict = len(new_val_list[0])
for key in keys_in_cashed_dict:
self._cashed_dict[commit_number][thread_name][dbname][table_name][key] += [None for i in xrange(values_length_in_inp_dict)]
return Status(status=True, out_obj=0)
def _list_to_cash(self,table_name, inp_obj, dbname, commit_number,thread_name="Thread0"):
if len(inp_obj) < 1:
track_id = self._error_track_id.incr()
msg = "ListTOCashError: Given List is empty! |ErrorTrackID:'{}'|".format(track_id)
inp_obj = inp_obj if self._log_content else "RowContentLogger is Off."
self.logger.outsorted_corpus("{} InpObj:'{}'.".format(msg,inp_obj), exc_info=self._logger_traceback)
#self.error_insertion_counter.incr()
return Status(status=False, track_id=track_id,
desc=msg, func_name=function_name(-2),
level="outsorted_corpus", action="outsorted")
#p(inp_obj)
#self._cashed_list[commit_number][thread_name][dbname][table_name]
## Step 1: Type Recognition (many or unig elem pro key)
try:
#### Is it an list?
new_val_list = []
### Many Values
for item in inp_obj:
new_val_list.append([]+item)
length = [len(item) for item in new_val_list ]
if len(set(length)) >1:
track_id = self._error_track_id.incr()
msg = "ListTOCashError: Given List Values has inconsistent length! This insertion was ignored! |ErrorTrackID:'{}'|".format(track_id)
inp_obj = inp_obj if self._log_content else "RowContentLogger is Off."
self.logger.error_insertion("{} InpObj:'{}'.".format(msg,inp_obj), exc_info=self._logger_traceback)
self.error_insertion_counter.incr()
return Status(status=False, track_id=track_id,
desc=msg, func_name=function_name(-2),
level="error_insertion", action="ignored")
#p(new_val_list, "1new_val_list")
except TypeError:
try:
### Is there tuples?
new_val_list = []
### Many Values
#p(21111)
for item in inp_obj:
new_val_list.append(list(()+item))
#p(2222)
length = [len(item) for item in new_val_list ]
#p(set(length), "length")
if len(set(length)) >1:
#p(set(length), "length")
track_id = self._error_track_id.incr()
msg = "ListTOCashError: Given List Values has inconsistent length! This insertion was ignored! |ErrorTrackID:'{}'|".format(track_id)
inp_obj = inp_obj if self._log_content else "RowContentLogger is Off."
self.logger.error_insertion("{} InpObj:'{}'.".format(msg,inp_obj), exc_info=self._logger_traceback)
self.error_insertion_counter.incr()
return Status(status=False, track_id=track_id,
desc=msg, func_name=function_name(-2),
level="error_insertion", action="ignored")
#p(new_val_list, "2new_val_list")
except TypeError:
new_val_list = [inp_obj]
# for item in inp_obj:
# new_val_list.append([item])
#p(new_val_list, "3new_val_list")
except Exception as exception:
#p(repr(exception))
track_id = self._error_track_id.incr()
msg = "ListTOCashError: Exception was encountered! This insertion was ignored! |ErrorTrackID:'{}'|".format(track_id)
inp_obj = inp_obj if self._log_content else "RowContentLogger is Off."
self.logger.error_insertion("{} Exception: '{}'. InpObj:'{}'.".format(msg,exception,inp_obj), exc_info=self._logger_traceback)
self.error_insertion_counter.incr()
return Status(status=False,
desc=str(exception),
level="error_insertion", action="ignored",
error_name=exception.__class__.__name__,
exception=exception)
#self._cashed_list[] = new_val_list
self._cashed_list[commit_number][thread_name][dbname][table_name] += new_val_list
return Status(status=True, out_obj=0)
def _write_cashed_insertion_to_disc(self, write_just_this_commit_number=False, thread_name="Thread0", with_commit=False):
#p("_write_cashed_insertion_to_disc")
with self.locker:
temp_insertion_counter = 0
temp_outsorting_counter = 0
if len(self._cashed_dict)>0:
if write_just_this_commit_number:
if write_just_this_commit_number not in self._cashed_dict:
msg = "CashedWriterError: Given CommitNumber'{}' is not exist. It wasn't possible to write cashed Insertion into DB. ".format(write_just_this_commit_number)
self.logger.debug(msg)
return Status(status=True)
#temp_cashed_dict = self._cashed_dict[write_just_this_commit_number]
if write_just_this_commit_number:
dict_to_work = {write_just_this_commit_number:self._cashed_dict[write_just_this_commit_number]}
else:
dict_to_work = self._cashed_dict
dict_to_delete = []
for commit_number, commit_number_data in dict_to_work.iteritems():
for current_thread_name, thread_data in commit_number_data.iteritems():
for dbname, db_data in thread_data.iteritems():
for table_name, inp_dict in db_data.iteritems():
status = self.insertdict(table_name, inp_dict, dbname, thread_name=thread_name)
if not status["status"]:
#print status
#if status["action"
#self.logger.error("CashedInsertionErr(DICT): '{}'".format(status["desc"]))
return status
else:
temp_insertion_counter += status["out_obj"]
temp_outsorting_counter += status["outsort"]
#del self._cashed_dict[commit_number][current_thread_name][dbname][table_name]
dict_to_delete.append((commit_number,current_thread_name,dbname,table_name))
# else:
# del self._cashed_dict[write_just_this_commit_number]
# #del self._cashed_dict
# #self._cashed_dict = defaultdict(lambda: defaultdict(lambda: defaultdict(lambda: defaultdict(lambda: defaultdict(list)))))
if dict_to_delete:
for item in dict_to_delete:
del self._cashed_dict[item[0]][item[1]][item[2]][item[3]]
if len(self._cashed_list)>0:
if write_just_this_commit_number:
if write_just_this_commit_number not in self._cashed_list:
msg = "CashedWriterError: Given CommitNumber'{}' is not exist. It wasn't possible to write cashed Insertion into DB. ".format(write_just_this_commit_number)
self.logger.debug(msg)
return Status(status=True, desc=msg)
#temp_cashed_list = self._cashed_list[write_just_this_commit_number]
if write_just_this_commit_number:
dict_to_work = {write_just_this_commit_number:self._cashed_list[write_just_this_commit_number]}
else:
dict_to_work = self._cashed_list
list_to_delete = []
for commit_number, commit_number_data in dict_to_work.iteritems():
for current_thread_name, thread_data in commit_number_data.iteritems():
for dbname, db_data in thread_data.iteritems():
for table_name, inp_dict in db_data.iteritems():
status = self.insertlist(table_name, inp_dict, dbname, thread_name=thread_name)
if not status["status"]:
#print status
#if status["action"
#self.logger.error("CashedInsertionErr(DICT): '{}'".format(status["desc"]))
return status
else:
temp_insertion_counter += status["out_obj"]
temp_outsorting_counter += status["outsort"]
#del self._cashed_list[commit_number][current_thread_name][dbname][table_name]
list_to_delete.append((commit_number,current_thread_name,dbname,table_name))
if list_to_delete:
for item in list_to_delete:
del self._cashed_list[item[0]][item[1]][item[2]][item[3]]
# if write_just_this_commit_number:
# del self._cashed_list[write_just_this_commit_number]
# else:
# del self._cashed_list
# self._cashed_list = defaultdict(lambda: defaultdict(lambda: defaultdict(lambda: defaultdict(list))))
if with_commit:
self._commits_with_lazy_writer.incr()
self.commit
return Status(status=True, out_obj=temp_insertion_counter, outsort=temp_outsorting_counter)
#return Status(status=True, out_obj=temp_insertion_counter)
##########################DB-Setters##################
def lazyinsert(self, table_name, inp_obj, dbname="main", thread_name="Thread0", dict_to_list=False):
#p(self._use_cash, "self._use_cash")
# p((self._lazy_writer_number_inserts_after_last_commit, self._lazyness_border))
try:
#p((table_name, inp_obj))
s = self._check_db_should_exist()
if not s["status"]:
return s
if dict_to_list:
if isinstance(inp_obj, dict):
inp_obj = db_helper.dict_to_list(inp_obj, self.col(table_name, dbname=dbname))
if isinstance(inp_obj, dict):
if self._use_cash:
status = self._dict_to_cash(table_name, inp_obj, dbname, int(self._commits_with_lazy_writer),thread_name=thread_name)
else:
status = self.insertdict(table_name, inp_obj, dbname, thread_name=thread_name)
elif isinstance(inp_obj, list):
if self._use_cash:
status = self._list_to_cash(table_name, inp_obj, dbname, int(self._commits_with_lazy_writer),thread_name=thread_name)
else:
status = self.insertlist(table_name, inp_obj, dbname, thread_name=thread_name)
else:
track_id = self._error_track_id.incr()
typ = type(inp_obj)
self.logger.error("Not Supported type of lazy_writer. This type was given: '{}'. Please use one of the supported types: ['dict','list',]. |ErrorTrackID:'{}'|".format(typ, track_id), exc_info=self._logger_traceback)
self.error_insertion_counter.incr()
return Status(status=False, track_id=track_id,
desc="Not Supported type of lazy_writer.",
inp_obj= inp_obj, func_name=function_name(-2),
level="error", action="ignored",)
if not status["status"]:
return status
self._lazy_writer_number_inserts_after_last_commit.incr()
with self.locker:
if int(self._lazy_writer_number_inserts_after_last_commit) >= self._lazyness_border:
#p("DBHANDLER: CASH WILL BE INSERTED!!!!")
temp_counter_insertion_after_last_commit = int(self._lazy_writer_number_inserts_after_last_commit)
self._lazy_writer_all_inserts_counter.incr(temp_counter_insertion_after_last_commit)
self._lazy_writer_number_inserts_after_last_commit.clear()
self._commits_with_lazy_writer.incr()
self._who_will_proceed_commit[thread_name] = int(self._commits_with_lazy_writer)
#p("DBHANDLER:CASH WAS INSERTED!!!!")
if thread_name in self._who_will_proceed_commit:
temp_commit_number = self._who_will_proceed_commit[thread_name]
del self._who_will_proceed_commit[thread_name]
if self._use_cash:
status = self._write_cashed_insertion_to_disc(write_just_this_commit_number=temp_commit_number, thread_name=thread_name)
if not status["status"]:
return status
self._commit()
self.logger.info("LazyWriter: Last {} inserts was committed in the DB. ".format(temp_counter_insertion_after_last_commit))
return status
except Exception as exception:
print_exc_plus() if self._ext_tb else ""
inp_obj = inp_obj if self._log_content else "RowContentLogger is Off."
track_id = self._error_track_id.incr()
self.logger.error_insertion("Throw Exception: '{}'. |ErrorTrackID:'{}'| InpObj:'{}'.".format(exception, track_id,inp_obj), exc_info=self._logger_traceback)
self.error_insertion_counter.incr()
return Status(status=False, track_id=track_id,
desc=str(exception),
inp_obj= (table_name, inp_obj), func_name=function_name(-2),
level="error_insertion", action="ignored",
error_name=exception.__class__.__name__,
exception=exception)
def insertdict(self,table_name, inp_dict, dbname="main", thread_name="Thread0"):
if not isinstance(inp_dict, dict):
track_id = self._error_track_id.incr()
self.logger.error("InsertDictError: Given object in not an dict! |ErrorTrackID:'{}'|".format(track_id), exc_info=self._logger_traceback)
self.error_insertion_counter.incr()
return Status(status=False, track_id=track_id,
desc="InsertDictError: Given object in not an dict!",
inp_obj= inp_dict, func_name=function_name(-2),
level="error", action="ignored")
try:
if self._make_backup:
if dbname in self.not_initialized_dbs:
self._backup(dbname)
random_value = random.choice(inp_dict.values())
type_mask = [type(value) for value in inp_dict.values()]
if len(set(type_mask)) == 1:
if isinstance(random_value, (list,tuple)):
#self.logger.low_debug("InsertDict: Many rows was found in the given dict. ")
return self._insertdict_with_many_rows(table_name, inp_dict, dbname=dbname, thread_name=thread_name)
else:
#self.logger.low_debug("InsertDict: One unique row was found in the given dict. ")
return self._insertdict_with_one_row(table_name, inp_dict, dbname=dbname, thread_name=thread_name)
else:
#self.logger.low_debug("InsertDict: One unique row was found in the given dict. ")
return self._insertdict_with_one_row(table_name, inp_dict, dbname=dbname, thread_name=thread_name)
#p(self._log_content,"self._log_content")
except Exception as exception:
print_exc_plus() if self._ext_tb else ""
track_id = self._error_track_id.incr()
inp_dict = inp_dict if self._log_content else "RowContentLogger is Off."
self.logger.error_insertion("InsertDictError: Following Exception was throw: '{}'. |ErrorTrackID:'{}'| Current Row: '{}'.".format(exception,track_id,inp_dict), exc_info=self._logger_traceback)
self.error_insertion_counter.incr()
return Status(status=False, track_id=track_id,
desc=str(exception),
inp_obj= inp_dict, func_name=function_name(-2),
level="error_insertion", action="ignored",
error_name=exception.__class__.__name__,
exception=exception)
def insertlist(self,table_name, inp_list, dbname="main", thread_name="Thread0", ):
if not isinstance(inp_list, list):
track_id = self._error_track_id.incr()
self.logger.error("InsertDictError: Given object in not an list! |ErrorTrackID:'{}'|".format(track_id), exc_info=self._logger_traceback)
self.error_insertion_counter.incr()
return Status(status=False, track_id=track_id,
desc="InsertDictError: Given object in not an list!",
inp_obj= inp_list, func_name=function_name(-2),
level="error", action="ignored")
try:
if self._make_backup:
if dbname in self.not_initialized_dbs:
self._backup(dbname)
random_value = random.choice(inp_list)
type_mask = [type(value) for value in inp_list]
if len(set(type_mask)) == 1:
if isinstance(random_value, (list,tuple)):
# self.logger.low_debug("InsertList: Many rows was found in the given list. ")
return self._insertlist_with_many_rows(table_name, inp_list, dbname=dbname, thread_name=thread_name)
else:
# self.logger.low_debug("InsertList: One unique row was found in the given list. ")
return self._insertlist_with_one_row(table_name, inp_list, dbname=dbname, thread_name=thread_name)
else:
# self.logger.low_debug("InsertList: One unique row was found in the given list. ")
return self._insertlist_with_one_row(table_name, inp_list, dbname=dbname, thread_name=thread_name)
except Exception as exception:
print_exc_plus() if self._ext_tb else ""
track_id = self._error_track_id.incr()
inp_list = inp_list if self._log_content else "RowContentLogger is Off."
self.logger.error_insertion("InsertListError: Following Exception was throw: '{}'. |ErrorTrackID:'{}'| Current Row: '{}'.".format(exception,track_id,inp_list), exc_info=self._logger_traceback)
self.error_insertion_counter.incr()
return Status(status=False, track_id=track_id,
desc=str(exception),
inp_obj= inp_list, func_name=function_name(-2),
level="error_insertion", action="ignored",
error_name=exception.__class__.__name__,
exception=exception)
def _insertdict_with_many_rows(self,table_name, inp_dict, dbname="main", thread_name="Thread0"):
s = self._check_db_should_exist()
if not s["status"]:
return s
# Check if attributes and values have the same length
if not isinstance(inp_dict, dict):
inp_dict = inp_dict if self._log_content else "RowContentLogger is Off."
self.logger.error_insertion("InsertDictError: InputDict is not an 'dict'.", exc_info=self._logger_traceback)
self.error_insertion_counter.incr()
return Status(status=False, track_id=self._error_track_id.incr(), func_name=function_name(-2))
inp_dict = copy.deepcopy(inp_dict)
status = self._dict_preprocessing_bevore_inserting(inp_dict, "many")
if not status["status"]:
return status
columns = ', '.join(inp_dict.keys())
placeholders = db_helper.values_to_placeholder(len(inp_dict))
number_of_values = len(random.choice(inp_dict.values()))
#p((number_of_values))
data = self._dict_values_to_list_of_tuples(inp_dict)
#p(data)
if not data:
inp_dict = inp_dict if self._log_content else "RowContentLogger is Off."
self.logger.error_insertion("Insertion: Insertion was failed! Current Raw: '{}'.".format(inp_dict ), exc_info=self._logger_traceback)
self.error_insertion_counter.incr()
return Status(status=False, track_id=self._error_track_id.incr(), func_name=function_name(-2))
if dbname not in self.dbnames:
self.logger.error("Given dbName ('{}') is not exist in the current DB-Structure".format(dbname), exc_info=self._logger_traceback)
self.error_insertion_counter.incr()
return Status(status=None, track_id=self._error_track_id.incr(), func_name=function_name(-2))
query = 'INSERT {} INTO {}.{} ({}) VALUES ({})'.format(self._double_items,dbname,table_name, columns, placeholders)
#p(query, c="r")
if table_name in self.tables(dbname=dbname):
status = self._executemany(query, values=data, dbname=dbname, thread_name=thread_name)
if not status["status"]:
status["inp_obj"] = data
return status
num=status["out_obj"].rowcount
outsorted = number_of_values-num
if table_name != "info":
self.all_inserts_counter.incr(n=num)
self.number_of_new_inserts_after_last_commit.incr(num)
# self.logger.low_debug("Insertion: Many rows was inserted into '{}.{}'-Table. ".format(table_name, dbname))
#p(status["out_obj"].rowcount)
if outsorted:
track_id = self._error_track_id.incr()
l_query = query if self._log_content else "!!LogContentDisable!!"
l_values = data if self._log_content else "!!LogContentDisable!!"
self.logger.outsorted_corpus("'{}'-rows was outsorted/ignored while insertion process. (probably that was redundant rows.) |ErrorTrackID:'{}'| InpQuery: '{}'. InpValues: '{}'. ".format(outsorted,track_id, l_query, l_values))
return Status(status=True, out_obj=num, outsort=outsorted)
else:
track_id = self._error_track_id.incr()
inp_dict = inp_dict if self._log_content else "RowContentLogger is Off."
self.logger.error_insertion("Insertion: Table ('{}') wasn't found or not exist. Please initialize the Info Table, before you may add any attributes. |ErrorTrackID:'{}'| CurrentRow: '{}'.".format(table_name, track_id ,inp_dict ), exc_info=self._logger_traceback)
self.error_insertion_counter.incr()
return Status(status=False, track_id=track_id,
desc="Table ('{}') wasn't found or not exist.".format(table_name),
inp_obj= inp_dict,
level="error_insertion", action="ignored")
def _insertdict_with_one_row(self,table_name, inp_dict, dbname="main", thread_name="Thread0"):
s = self._check_db_should_exist()
if not s["status"]:
return s
# Check if attributes and values have the same length
if not isinstance(inp_dict, dict):
self.logger.error_insertion("InsertDictError: InputDict is not form 'dict' Format.", exc_info=self._logger_traceback)
self.error_insertion_counter.incr()
return Status(status=False, track_id=self._error_track_id.incr(), func_name=function_name(-2))
inp_dict = copy.deepcopy(inp_dict)
status = self._dict_preprocessing_bevore_inserting(inp_dict, "one")
if not status["status"]:
return status
columns = ', '.join(inp_dict.keys())
placeholders = ':'+', :'.join(inp_dict.keys())
if dbname not in self.dbnames:
self.logger.error_insertion("Given dbName ('{}') is not exist in the current DB-Structure".format(dbname), exc_info=self._logger_traceback)
self.error_insertion_counter.incr()
return Status(status=None, track_id=self._error_track_id.incr(), func_name=function_name(-2))
main_query = 'INSERT {} INTO {}.{} (%s) VALUES (%s)'.format(self._double_items,dbname,table_name)
query = main_query % (columns, placeholders)
if table_name in self.tables(dbname=dbname):
status = self._execute(query, values=inp_dict, dbname=dbname, thread_name=thread_name)
if not status["status"]:
status["inp_obj"] = inp_dict
return status
num=status["out_obj"].rowcount
outsorted = 1-num
if table_name != "info":
self.all_inserts_counter.incr(n=num)
self.number_of_new_inserts_after_last_commit.incr(num)
if outsorted:
track_id = self._error_track_id.incr()
l_query = query if self._log_content else "!!LogContentDisable!!"
l_values = inp_dict if self._log_content else "!!LogContentDisable!!"
self.logger.outsorted_corpus("'{}'-rows was outsorted/ignored while insertion process. (probably that was redundant rows.) |ErrorTrackID:'{}'| InpQuery: '{}'. InpValues: '{}'. ".format(outsorted,track_id, l_query, l_values))
# self.logger.low_debug("Insertion: One row was inserted into '{}.{}'-Table. ".format(table_name, dbname))
#p(status["out_obj"].rowcount)
return Status(status=True, out_obj=num, outsort=outsorted)
else:
track_id = self._error_track_id.incr()
inp_dict = inp_dict if self._log_content else "RowContentLogger is Off."
self.logger.error_insertion("Insertion: Table ('{}') wasn't found or not exist. Please initialize the Info Table, before you may add any attributes. |ErrorTrackID:'{}'| CurrentRow: '{}'.".format(table_name, track_id ,inp_dict ), exc_info=self._logger_traceback)
self.error_insertion_counter.incr()
return Status(status=False, track_id=track_id,
desc="Table ('{}') wasn't found or not exist.".format(table_name),
inp_obj= inp_dict,
level="error_insertion", action="ignored")
def _insertlist_with_many_rows(self,table_name, inp_list, dbname="main", thread_name="Thread0"):
s = self._check_db_should_exist()
if not s["status"]:
return s
if dbname not in self.dbnames:
self.logger.error_insertion("Given dbName ('{}') is not exist in the current DB-Structure".format(dbname), exc_info=self._logger_traceback)
self.error_insertion_counter.incr()
return Status(status=None, track_id=self._error_track_id.incr(), func_name=function_name(-2))
number = len(inp_list[0])
#values_as_tuple = db_helper.values_to_tuple(inp_list, "many")
values_as_list = db_helper.values_to_list(inp_list, "many")
#
if not values_as_list:
self.logger.error_insertion("Given Values wasn't packet into the list.", exc_info=self._logger_traceback)
self.error_insertion_counter.incr()
return Status(status=False, track_id=self._error_track_id.incr(), func_name=function_name(-2))
query = 'INSERT {} INTO {}.{} \nVALUES ({});'.format(self._double_items,dbname,table_name, db_helper.values_to_placeholder(number))
if table_name in self.tables(dbname=dbname):
status = self._executemany(query, values=values_as_list, dbname=dbname, thread_name=thread_name)
if not status["status"]:
status["inp_obj"] = inp_list
return status
num=status["out_obj"].rowcount
outsorted = len(inp_list)-num
if table_name != "info":
self.all_inserts_counter.incr(num)
self.number_of_new_inserts_after_last_commit.incr(num)
if outsorted:
track_id = self._error_track_id.incr()
l_query = query if self._log_content else "!!LogContentDisable!!"
l_values = values_as_list if self._log_content else "!!LogContentDisable!!"
self.logger.outsorted_corpus("'{}'-rows was outsorted/ignored while insertion process. (probably that was redundant rows.) |ErrorTrackID:'{}'| InpQuery: '{}'. InpValues: '{}'. ".format(outsorted,track_id, l_query, l_values))
# self.logger.low_debug("Insertion: Many row was inserted into '{}.{}'-Table. ".format(table_name, dbname))
#p(status["out_obj"].rowcount)
return Status(status=True, out_obj=num, outsort=outsorted)
else:
track_id = self._error_track_id.incr()
inp_list = inp_list if self._log_content else "RowContentLogger is Off."
self.logger.error_insertion("Insertion: Table ('{}') wasn't found or not exist. Please initialize the Info Table, before you may add any attributes. |ErrorTrackID:'{}'| CurrentRow: '{}'.".format(table_name, track_id ,inp_list ), exc_info=self._logger_traceback)
self.error_insertion_counter.incr()
return Status(status=False, track_id=track_id,
desc="Table ('{}') wasn't found or not exist.".format(table_name),
inp_obj= inp_list,
level="error_insertion", action="ignored")
def _insertlist_with_one_row(self,table_name, inp_list, dbname="main", thread_name="Thread0"):
s = self._check_db_should_exist()
if not s["status"]:
return s
if not isinstance(inp_list, (list, tuple)):
self.logger.error_insertion("insertVError: Given Obj is not a list!", exc_info=self._logger_traceback)
self.error_insertion_counter.incr()
return Status(status=False, track_id=self._error_track_id.incr(), func_name=function_name(-2))
#values_as_tuple = db_helper.values_to_tuple(inp_list, "one")
values_as_list = db_helper.values_to_list(inp_list, "one")
number = len(inp_list)
#p(self.colt("documents"))
if not values_as_list:
self.logger.error_insertion("Given Values wasn't packet into the list.", exc_info=self._logger_traceback)
self.error_insertion_counter.incr()
return Status(status=False, track_id=self._error_track_id.incr(), func_name=function_name(-2))
if dbname not in self.dbnames:
self.logger.error_insertion("Given dbName ('{}') is not exist in the current DB-Structure".format(dbname), exc_info=self._logger_traceback)
self.error_insertion_counter.incr()
return Status(status=None, track_id=self._error_track_id.incr(), func_name=function_name(-2))
#p(values_as_list, c="m")
query = 'INSERT {} INTO {}.{} \nVALUES ({});'.format(self._double_items, dbname,table_name, db_helper.values_to_placeholder(number))
#p((query, values_as_list), c="b")
if table_name in self.tables(dbname=dbname):
status = self._execute(query, values=values_as_list, dbname=dbname, thread_name=thread_name)
if not status["status"]:
status["inp_obj"] = inp_list
return status
num=status["out_obj"].rowcount
outsorted = 1-num
if table_name != "info":
self.all_inserts_counter.incr(num)
self.number_of_new_inserts_after_last_commit.incr(num)
if outsorted:
track_id = self._error_track_id.incr()
l_query = query if self._log_content else "!!LogContentDisable!!"
l_values = values_as_list if self._log_content else "!!LogContentDisable!!"
self.logger.outsorted_corpus("'{}'-rows was outsorted/ignored while insertion process. (probably that was redundant rows.) |ErrorTrackID:'{}'| InpQuery: '{}'. InpValues: '{}'. ".format(outsorted,track_id, l_query, l_values))
# self.logger.low_debug("Insertion: One row was inserted into '{}.{}'-Table. ".format(table_name, dbname))
#p(status["out_obj"].rowcount)
return Status(status=True, out_obj=num, outsort=outsorted)
else:
track_id = self._error_track_id.incr()
inp_list = inp_list if self._log_content else "RowContentLogger is Off."
self.logger.error_insertion("Insertion: Table ('{}') wasn't found or not exist. Please initialize the Info Table, before you may add any attributes. |ErrorTrackID:'{}'| CurrentRow: '{}'.".format(table_name, track_id ,inp_list ), exc_info=self._logger_traceback)
self.error_insertion_counter.incr()
return Status(status=False, track_id=track_id,
desc="Table ('{}') wasn't found or not exist.".format(table_name),
inp_obj= inp_list,
level="error_insertion", action="ignored")
def _dict_values_to_list_of_tuples(self,inp_dict):
dict_as_list = []
for rows in inp_dict.itervalues():
#p(rows, c="b")
#p(tuple(rows), c="b")
dict_as_list.append(tuple(rows))
#p(dict_as_list, "111")
output = zip(*dict_as_list)
#p(output, "222")
return output
def _dict_preprocessing_bevore_inserting(self, inp_dict, mode):
try:
for k,v in inp_dict.iteritems():
if mode == "one":
if isinstance(v, (dict,tuple,list)):
inp_dict[k] = json.dumps(v)
else:
values_list = []
for item in v:
if isinstance(item, (dict,tuple,list)):
values_list.append(json.dumps(item))
else:
values_list.append(item)
inp_dict[k] = values_list
return Status(status=True)
except Exception, e:
print_exc_plus() if self._ext_tb else ""
self.logger.error("DictPreprocessig: '{}' ".format(e), exc_info=self._logger_traceback)
return Status(status=False, track_id=self._error_track_id.incr(), func_name=function_name(-2))
##########################DB-Other Functions###############
#c.execute("alter table linksauthor add column '%s' 'float'" % author)
def add_col(self, table_name, colname, typ, dbname="main", thread_name="Thread0"):
s = self._check_db_should_exist()
if not s["status"]:
return s
self._commit_if_inserts_was_did()
if dbname not in self.dbnames:
self.logger.error("Given dbName ('{}') is not exist in the current DB-Structure".format(dbname), exc_info=self._logger_traceback)
return Status(status=False, track_id=self._error_track_id.incr(), func_name=function_name(-2))
if table_name not in self.tables():
self.logger.error("'{}'-Table is not exist in the current DB. New Columns wasn't inserted.".format(table_name))
return False
if colname in self.col(table_name):
self.logger.error("'{}'-Column is already exist in the current DB. New Columns wasn't inserted.".format(table_name))
return False
query = "ALTER TABLE {}.{} ADD COLUMN {} {} ".format(dbname,table_name,colname,typ)
#p(query)
try:
#cursor = self._db.cursor()
self._threads_cursors[thread_name].execute(query)
#tables_exist = cursor.fetchall()
except Exception as exception:
print_exc_plus() if self._ext_tb else ""
self.logger.error("Something happens while inserting new columns into '{}'-Table: Exception: '{}'.".format(table_name, repr(exception) ), exc_info=self._logger_traceback)
return Status(status=False, track_id=self._error_track_id.incr(), func_name=function_name(-2))
self._update_pragma_table_info(thread_name=thread_name)
self._commit()
self.logger.debug("'{}'-Column(s) was inserted into the '{}'-Table in '{}'-DB.".format(table_name,table_name,dbname))
#self._update_temp_tablesList_in_instance(thread_name=thread_name)
return Status(status=True)
def get_db(self):
return self._db
def drop_table(self, table_name, dbname="main", thread_name="Thread0"):
s = self._check_db_should_exist()
if not s["status"]:
return s
self._commit_if_inserts_was_did()
if dbname in self.dbnames:
query = "DROP TABLE {}.{};".format(dbname,table_name)
else:
self.logger.error("Given dbName ('{}') is not exist in the current DB-Structure".format(dbname), exc_info=self._logger_traceback)
return Status(status=None, track_id=self._error_track_id.incr(), func_name=function_name(-2))
#p(query)
try:
#cursor = self._db.cursor()
self._threads_cursors[thread_name].execute(query)
#tables_exist = cursor.fetchall()
except Exception as exception:
print_exc_plus() if self._ext_tb else ""
self.logger.error("Something happens while dropping the '{}'-Table: '{}'.".format(table_name, repr(exception) ), exc_info=self._logger_traceback)
return Status(status=False, track_id=self._error_track_id.incr(), func_name=function_name(-2))
self._commit()
self.logger.debug("'{}'-Table was deleted from the DB (dbname: '{}')".format(table_name,dbname))
self._update_temp_tablesList_in_instance(thread_name=thread_name)
return Status(status=True)
def update(self,table_name,columns_names,values, dbname="main", where=False, connector_where="AND", thread_name="Thread0"):
# UPDATE COMPANY SET ADDRESS = 'Texas' WHERE ID = 6;
s = self._check_db_should_exist()
if not s["status"]:
return s
self._commit_if_inserts_was_did()
# Check if attributes and values have the same length
if len(columns_names) != len(values):
self.logger.error("Length of given columns_names and values is not equal.", exc_info=self._logger_traceback)
return Status(status=False, track_id=self._error_track_id.incr(), func_name=function_name(-2))
columns_and_values_as_str = db_helper.columns_and_values_to_str(columns_names,values)
if where:
where_cond_as_str = db_helper.where_condition_to_str(where, connector=connector_where)
if not where_cond_as_str:
self.logger.error("GetAllError: Where-Condition(s) wasn't compiled to String!", exc_info=self._logger_traceback)
return Status(status=False, track_id=self._error_track_id.incr(), func_name=function_name(-2))
if dbname in self.dbnames:
if where:
query = 'UPDATE {dbname}.{tableName} \nSET {col_and_val} WHERE {where};'.format(col_and_val=columns_and_values_as_str, dbname=dbname, tableName=table_name, where=where_cond_as_str)
else:
query = 'UPDATE {dbname}.{tableName} \nSET {col_and_val};'.format(col_and_val=columns_and_values_as_str, dbname=dbname, tableName=table_name)
else:
self.logger.error("Given dbName ('{}') is not exist in the current DB-Structure".format(dbname), exc_info=self._logger_traceback)
return Status(status=None, track_id=self._error_track_id.incr(), func_name=function_name(-2))
if table_name in self.tables(dbname=dbname):
try:
#cursor = self._db.cursor()
#p(query)
self._threads_cursors[thread_name].execute(query)
self._commit()
return Status(status=True)
except Exception as exception:
print_exc_plus() if self._ext_tb else ""
self.logger.error("Something happens while updating the '{}'-Table: '{}'.".format(table_name, repr(exception) ), exc_info=self._logger_traceback)
return Status(status=False, track_id=self._error_track_id.incr(), func_name=function_name(-2))
else:
self.logger.error("Table ('{}') wasn't found or not exist. Please initialize the Info Table, before you may add any attributes.".format(table_name), exc_info=self._logger_traceback)
return Status(status=False, track_id=self._error_track_id.incr(), func_name=function_name(-2))
def rollback(self):
'''
-> rollback to roll back any change to the database since the last call to commit.
-> Please remember to always call commit to save the changes. If you close the connection using close or the connection to the file is lost (maybe the program finishes unexpectedly), not committed changes will be lost
'''
s = self._check_db_should_exist()
if not s["status"]:
return s
temp_number_of_new_insertion_after_last_commit = int(self.number_of_new_inserts_after_last_commit)
self._db.rollback()
self.logger.info("ExternRollBack: '{}' insertions was rolled back.".format(temp_number_of_new_insertion_after_last_commit))
self.number_of_new_inserts_after_last_commit.clear()
return temp_number_of_new_insertion_after_last_commit
def commit(self):
s = self._check_db_should_exist()
if not s["status"]:
return s
if self._use_cash:
self._write_cashed_insertion_to_disc()
#self._lazy_writer_counter = 0
temp_number_of_new_insertion_after_last_commit = int(self.number_of_new_inserts_after_last_commit)
#p(temp_number_of_new_insertion_after_last_commit, "temp_number_of_new_insertion_after_last_commit")
self._db.commit()
self.logger.info("ExternCommitter: DB was committed ({} last inserts was wrote on the disk)".format( int(self.number_of_new_inserts_after_last_commit) ) )
self.inserts_was_committed.incr(int(self.number_of_new_inserts_after_last_commit))
self.number_of_new_inserts_after_last_commit.clear()
return temp_number_of_new_insertion_after_last_commit
def _commit(self):
s = self._check_db_should_exist()
if not s["status"]:
return s
if self._use_cash:
self._write_cashed_insertion_to_disc()
temp_number_of_new_insertion_after_last_commit = int(self.number_of_new_inserts_after_last_commit)
self._db.commit()
self.logger.debug("InternCommitter: DB was committed ({} last insert(s) was wrote on the disk)".format( int(self.number_of_new_inserts_after_last_commit) ) )
self.inserts_was_committed.incr(int(self.number_of_new_inserts_after_last_commit))
self.number_of_new_inserts_after_last_commit.clear()
return temp_number_of_new_insertion_after_last_commit
def _default_db_closer(self, for_encryption=False):
try:
self._commit()
if self._db:
del self._threads_cursors
gc.collect()
self._db.close()
self._init_instance_variables()
else:
msg = "No activ DB was found. There is nothing to close!"
self.logger.error(msg)
return Status(status=False, desc=msg)
if for_encryption:
msg = "DBExit: Current DB was closed! En-/Decryption Process will reopen the current DB."
else:
msg = "DBExit: DB was committed and closed. (all changes was saved on the disk)"
return Status(status=True, desc=msg)
except Exception,e:
print_exc_plus() if self._ext_tb else ""
msg = "ClossingError: DB-Closing return an Error: '{}' ".format(e)
self.logger.error(msg, exc_info=self._logger_traceback)
return Status(status=False, desc=msg)
def close(self, for_encryption=False):
s = self._default_db_closer(for_encryption=for_encryption)
if s["status"]:
self.logger.info(s['desc'])
else:
return s
def _close(self, for_encryption=False):
s = self._default_db_closer(for_encryption=for_encryption)
if s["status"]:
self.logger.debug(s['desc'])
else:
return s
def addtable(self, table_name, attributs_names_with_types_as_list_with_tuples,dbname="main", constraints=False, thread_name="Thread0"):
s = self._check_db_should_exist()
if not s["status"]:
return s
self._commit_if_inserts_was_did()
#sys.exit()
if table_name not in self.tables(dbname=dbname):
#sys.exit()
attributs_names_with_types_as_str = db_helper.columns_and_types_in_tuples_to_str(attributs_names_with_types_as_list_with_tuples)
if not attributs_names_with_types_as_str:
self.logger.error("Something was wrong by Converting attributes into string. Program was stoped!", exc_info=self._logger_traceback)
return Status(status=False, track_id=self._error_track_id.incr(), func_name=function_name(-2))
if constraints:
if dbname:
if dbname in self.dbnames:
query = 'CREATE TABLE {}.{} ({}\n{});'.format(dbname,table_name,attributs_names_with_types_as_str, constraints)
else:
self.logger.error("Given dbName ('{}') is not exist in the current DB-Structure".format(dbname), exc_info=self._logger_traceback)
return Status(status=False, track_id=self._error_track_id.incr(), func_name=function_name(-2))
else:
query = 'CREATE TABLE {} ({}\n{});'.format(table_name,attributs_names_with_types_as_str, constraints)
else:
if dbname:
if dbname in self.dbnames:
query = 'CREATE TABLE {}.{} ({});'.format(dbname,table_name,attributs_names_with_types_as_str)
else:
self.logger.error("Given dbName ('{}') is not exist in the current DB-Structure".format(dbname), exc_info=self._logger_traceback)
return Status(status=False, track_id=self._error_track_id.incr(), func_name=function_name(-2))
else:
query = 'CREATE TABLE {} ({});'.format(table_name,attributs_names_with_types_as_str)
#p( query)
try:
#cursor = self._db.cursor()
self._threads_cursors[thread_name].execute(query)
self._commit()
self.logger.debug("'{}'-Table was added into '{}'-DB. ".format(table_name,dbname))
self._update_temp_tablesList_in_instance(thread_name=thread_name)
self._update_pragma_table_info(thread_name=thread_name)
return Status(status=True)
except sqlite.OperationalError, e:
print_exc_plus() if self._ext_tb else ""
if 'near "-"' in str(e):
self.logger.error("AddTableOperationalError: While adding Table-'{}'. Problem: '{}'. (It may be a Problem with using not allowed Symbols in the column name. e.g.'-')\nProblem was found in the following query: '{}'.".format(table_name,e, query.replace("\n", " ")), exc_info=self._logger_traceback)
else:
self.logger.error("AddTableOperationalError: While adding Table-'{}'. Problem: '{}'. \nProblem was found in the following query: '{}'.".format(table_name,e, query.replace("\n", " ")), exc_info=self._logger_traceback)
return Status(status=False, track_id=self._error_track_id.incr(), func_name=function_name(-2))
else:
self.logger.error("'{}'-Table is already exist in the given DB. You can not initialize it one more time!".format(table_name), exc_info=self._logger_traceback)
return Status(status=False, track_id=self._error_track_id.incr(), func_name=function_name(-2))
def change_key(self, new_key_to_encryption, thread_name="Thread0"):
s = self._check_db_should_exist()
if not s["status"]:
return s
if not self._check_should_be_str_or_unicode(new_key_to_encryption)["status"]:
return self._check_should_be_str_or_unicode(new_key_to_encryption)["status"]
if self._encryption_key:
try:
#cursor = self._db.cursor()
self._threads_cursors[thread_name].execute("PRAGMA rekey = '{}';".format(new_key_to_encryption))
self._commit()
self._encryption_key = new_key_to_encryption
self.logger.info("Encryption Key was changed!")
return Status(status=True)
except Exception as exception:
print_exc_plus() if self._ext_tb else ""
self.logger.error("Something happens while changing of the encryption key: '{}'.".format(repr(exception)), exc_info=self._logger_traceback)
return Status(status=False, track_id=self._error_track_id.incr(), func_name=function_name(-2))
else:
self.logger.warning("You cant change encryption key, because the current DataBase wasn't encrypted. You need first to encrypt the current DB and than you can change the encryption key.")
return Status(status=False, track_id=self._error_track_id.incr(), func_name=function_name(-2))
def encrypte(self, key_to_encryption, dbname="main", thread_name="Thread0"):
'''
set key
'''
if dbname != "main":
self.logger.error("Decryption could be done just for the main DataBase.")
return Status(status=False)
s = self._check_db_should_exist()
if not s["status"]:
return s
status= self._check_should_be_str_or_unicode(key_to_encryption)
if not status["status"]:
return status["status"]
#p(status)
if self._encryption_key:
self.logger.critical("You can not encrypte the current DB, because it is already encrypted. What you can, it is just to change already setted key of encryption.")
return Status(status=False, track_id=self._error_track_id.incr(), func_name=function_name(-2))
path_to_temp_db = os.path.join(self.dirname(), "temp_encrypted.db")
path_to_current_db = self.path()
path_to_dir_with_current_db = self.dirname()
fname_of_the_current_db = self.fname()
new_fname_of_encrypted_db= os.path.splitext(fname_of_the_current_db)[0]+"_encrypted"+os.path.splitext(fname_of_the_current_db)[1]
new_path_to_current_encrypted_db = os.path.join(path_to_dir_with_current_db, new_fname_of_encrypted_db)
#p(new_fname_of_encrypted_db)
#p(self.dbnames, "1self.dbnames")
try:
#cursor = self._db.cursor()
self._threads_cursors[thread_name].execute("ATTACH DATABASE '{}' AS temp_encrypted KEY '{}';".format(path_to_temp_db, key_to_encryption))
self._threads_cursors[thread_name].execute("SELECT sqlcipher_export('temp_encrypted');")
self._threads_cursors[thread_name].execute("DETACH DATABASE temp_encrypted;")
except Exception as exception:
print_exc_plus() if self._ext_tb else ""
self.logger.error("Something happens while Encryption: '{}'.".format(repr(exception)), exc_info=self._logger_traceback)
return Status(status=False, track_id=self._error_track_id.incr(), func_name=function_name(-2))
#p(self.dbnames, "2self.dbnames")
if os.path.isfile(path_to_temp_db):
self._close(for_encryption=True)
os.rename(path_to_current_db, path_to_current_db+".temp")
os.rename(path_to_temp_db, new_path_to_current_encrypted_db)
s = self.connect(new_path_to_current_encrypted_db, encryption_key=key_to_encryption, reconnection=True, logger_debug=True)
if os.path.isfile(new_path_to_current_encrypted_db) and s["status"]:
os.remove(path_to_current_db+".temp")
self.logger.debug("Temporary saved (old) DB was removed.")
if self._attachedDBs_config_from_the_last_session:
s_reattach = self._reattach_dbs_after_closing_of_the_main_db()
if not s_reattach["status"]:
return s_reattach
#p(self.dbnames, "7self.dbnames")
#self.logger.info("DB-Encryption end with success!")
self.logger.info("Current DB was encrypted. NewName: {}; NewPath:'{}'.".format(new_fname_of_encrypted_db,new_path_to_current_encrypted_db))
#p(self._db, c="m")
return Status(status=True)
else:
self.logger.error("Encrypted DB wasn't found/connected. Encryption is fail! Roled back to non-encrypted DB.", exc_info=self._logger_traceback)
os.rename(path_to_current_db+".temp", path_to_current_db)
self.connect(path_to_current_db,reconnection=True, logger_debug=True)
return s
else:
self.logger.error("ENCRYPTION: TempDB wasn't found. Encryption is failed! Roled back to non-encrypted DB.", exc_info=self._logger_traceback)
return Status(status=False, track_id=self._error_track_id.incr(), func_name=function_name(-2))
def decrypte(self, thread_name="Thread0"):
'''
delete key
'''
s = self._check_db_should_exist()
if not s["status"]:
return s
if not self._encryption_key:
self.logger.critical("You can not decrypte the current DB, because it wasn't encrypted before.")
return Status(status=False, track_id=self._error_track_id.incr(), func_name=function_name(-2))
path_to_temp_db = os.path.join(self.dirname(), "temp_decrypted.db")
path_to_current_db = self.path()
path_to_dir_with_current_db = self.dirname()
fname_of_the_current_db = self.fname()
new_fname_of_encrypted_db= os.path.splitext(fname_of_the_current_db)[0]+"_decrypted"+os.path.splitext(fname_of_the_current_db)[1]
new_path_to_current_encrypted_db = os.path.join(path_to_dir_with_current_db, new_fname_of_encrypted_db)
#p(new_fname_of_encrypted_db)
try:
#cursor = self._db.cursor()
self._threads_cursors[thread_name].execute("ATTACH DATABASE '{}' AS temp_decrypted KEY '';".format(path_to_temp_db))
self._threads_cursors[thread_name].execute("SELECT sqlcipher_export('temp_decrypted');")
#self.
self._threads_cursors[thread_name].execute("DETACH DATABASE temp_decrypted;")
if os.path.isfile(path_to_temp_db):
self._close(for_encryption=True)
#p(self._db, "conn5555")
os.rename(path_to_current_db, path_to_current_db+".temp")
os.rename(path_to_temp_db, new_path_to_current_encrypted_db)
if os.path.isfile(new_path_to_current_encrypted_db) and self.connect(new_path_to_current_encrypted_db, reconnection=True, encryption_key=False, logger_debug=True)["status"]:
self.logger.info("Current DB was decrypted. NewName: {}; NewPath:'{}'.".format(new_fname_of_encrypted_db,new_path_to_current_encrypted_db))
#self._reinitialize_logger(self, level=self._logger_level)
os.remove(path_to_current_db+".temp")
self.logger.debug("Temporary saved (old) DB was removed.")
if self._attachedDBs_config_from_the_last_session:
s_reattach = self._reattach_dbs_after_closing_of_the_main_db()
if not s_reattach["status"]:
return s_reattach
self.logger.debug("DB-Decryption was end with success!")
#p(self._db, c="m")
return Status(status=True)
else:
self.logger.error("Decrypted DB wasn't found/connected. Decryption is fail! Roled back to encrypted DB.", exc_info=self._logger_traceback)
os.rename(path_to_current_db+".temp", path_to_current_db)
self.connect(path_to_current_db,reconnection=True, logger_debug=True)
return Status(status=False, track_id=self._error_track_id.incr(), func_name=function_name(-2))
else:
self.logger.error("DECRYPTION: TempDB wasn't found. Encryption is failed! Roled back to encrypted DB.", exc_info=self._logger_traceback)
return Status(status=False, track_id=self._error_track_id.incr(), func_name=function_name(-2))
except Exception as exception:
print_exc_plus() if self._ext_tb else ""
self.logger.error("Something happens while Decryption: '{}'.".format(repr(exception)), exc_info=self._logger_traceback)
return Status(status=False, track_id=self._error_track_id.incr(), func_name=function_name(-2))
####################################################################################
####################################################################################
####################################################################################
####################################################################################
####################################################################################
####################################################################################
######################################INTERN########################################
####################################################################################
####################################################################################
####################################################################################
####################################################################################
####################################################################################
###########################DB-Checker#########################
def _check_should_be_str_or_unicode(self, giv_obj):
if not isinstance(giv_obj, (str, unicode)):
self.logger.error("Given Object is not from following type: (str, unicode).", exc_info=self._logger_traceback)
return Status(status=False,
desc="Given Object is not from following type: (str, unicode).",
func_name=function_name(-3))
else:
return Status(status=True)
def _check_if_given_columns_exist(self, tableName,columns, dbname="main"):
#p((tableName,columns))
# self.logger.low_debug("Check_if_given_columns_exist was invoke.")
columns_from_db = self.col(tableName,dbname=dbname)
for column in columns:
if column not in columns_from_db:
if "json_extract" not in column:
msg = "Given Column '{}' is not exist in the following Table '{}' (dbname='{}') ".format(column,tableName,dbname)
self.logger.error(msg, exc_info=self._logger_traceback)
return Status(status=False,
desc=msg,
func_name=function_name(-3))
# self.logger.low_debug("All Given Columns ({}) exist in the '{}'-table.".format(columns,tableName,))
return Status(status=True)
def _check_if_table_exist(self,tableName, dbname="main"):
if tableName not in self.tables(dbname=dbname):
self.logger.error("Given Table '{}' is not exist (dbname='{}')) ".format(tableName,dbname), exc_info=self._logger_traceback)
return Status(status=False,
desc="Given Table '{}' is not exist (dbname='{}')) ".format(tableName,dbname),
func_name=function_name(-3))
else:
return Status(status=True)
def _check_db_should_exist(self):
#p("333")
if not self._db:
#p("33----")
self.logger.error("No active DB was found. You need to connect or initialize a DB first, before you can make any operation on the DB.", exc_info=self._logger_traceback)
return Status(status=False,
desc="No active DB was found.",
func_name=function_name(-3))
else:
return Status(status=True)
def _check_db_should_not_exist(self):
if self._db:
msg = "An active DB was found. You need to initialize new empty Instance of DB before you can do this operation."
self.logger.error(msg, exc_info=self._logger_traceback)
s = Status(status=False,
desc=msg,
func_name=function_name(-3))
return s
else:
return Status(status=True)
def _db_should_be_a_corpus(self):
s = self._check_db_should_exist()
if not s["status"]:
return s
db_typ = self.get_attr(attributName="typ")
if db_typ != "corpus":
track_id = self._error_track_id.incr()
self.logger.error("Active DB is from typ '{}'. But it should be from typ 'corpus'. |ErrorTrackID:'{}'|".format(db_typ, track_id), exc_info=self._logger_traceback)
return Status(status=False, track_id=track_id,
desc="Active DB is from typ '{}'. But it should be from typ 'corpus'. ".format(db_typ),
func_name=function_name(-3))
return Status(status=True)
def _db_should_be_stats(self):
s = self._check_db_should_exist()
if not s["status"]:
return s
db_typ = self.get_attr(attributName="typ")
if db_typ != "stats":
track_id = self._error_track_id.incr()
self.logger.error("Active DB is from typ '{}'. But it should be from typ 'stats'. ".format(db_typ), exc_info=self._logger_traceback)
return Status(status=False, track_id=track_id,
desc="Active DB is from typ '{}'. But it should be from typ 'stats'. ".format(db_typ),
func_name=function_name(-3))
return Status(status=True)
def _check_file_existens(self, path_to_file):
if not os.path.isfile(path_to_file):
track_id = self._error_track_id.incr()
self.logger.error("DB-File wasn't found: ('{}').".format(path_to_file), exc_info=self._logger_traceback)
return Status(status=False, track_id=track_id,
desc="DB-File wasn't found: ('{}').".format(path_to_file),
func_name=function_name(-3))
else:
return Status(status=True)
def _get_compile_options(self, db):
try:
db.cursor
except:
self.logger.error("ExtensionLoaderError: Passed Obj is not an Sqlite-DB.", exc_info=self._logger_traceback)
sys.exit()
try:
output_dict = defaultdict(list)
c = db.cursor()
c.execute("PRAGMA compile_options;")
fetched_data = c.fetchall()
#p(fetched_data)
for option in fetched_data:
if "=" in option[0]:
#p(option[0])
splitted_option = option[0].split("=")
output_dict[splitted_option[0]] = splitted_option[1]
else:
#p(option[0],c="b")
output_dict["parameters"].append(option[0])
return output_dict
except Exception, e:
print_exc_plus() if self._ext_tb else ""
self.logger.error("CompilerOptionsGetterError: Something wrong is happens.See following Exception: '{}' ".format(e), exc_info=self._logger_traceback)
sys.exit()
def _check_if_threads_safe(self):
if not self.compile_options:
self.logger.error("DB-Compile Options wasn't found.")
return Status(status=False, track_id=self._error_track_id.incr(), func_name=function_name(-2))
try:
if int(self.compile_options["THREADSAFE"]) == 0:
self.logger.error("ThreadSafeCheckerError: Given Compilation of SQLITE3 Environment is unsafe to use SQLite in a multithreaded program. Following Tool (zas-rep-tool) was designed to work in multithreaded/multiprocessored Mode and requiring ThreadSafe (1 or 2) compilation of SQLITE3. Please recompile your SQLITE with one of the following options ['SQLITE_CONFIG_MULTITHREAD','SQLITE_CONFIG_SERIALIZED'). Read more here. 'https://www.sqlite.org/compile.html#threadsafe'. ")
sys.exit()
elif int(self.compile_options["THREADSAFE"]) == 1:
self.logger.debug("ThreadSafeChecker(1): This SQLITE Compilation is safe for use in a multithreaded environment. Mode: Serialized (THREADSAFE=1). In serialized mode, SQLite can be safely used by multiple threads with no restriction. Read more: https://www.sqlite.org/threadsafe.html")
elif int(self.compile_options["THREADSAFE"]) == 2:
#self.logger.debug("ThreadSafeChecker: This SQLITE Compilation is safe for use in a multithreaded environment. Mode: Multi-thread (THREADSAFE=2). In this mode, SQLite can be safely used by multiple threads provided that no single database connection is used simultaneously in two or more threads. Read more: https://www.sqlite.org/threadsafe.html")
self.logger.warning("ThreadSafeChecker(2): This SQLITE Compilation is safe for use in a multithreaded environment. Mode: Multi-thread (THREADSAFE=2) can be safely used by multiple threads provided that no single database connection is used simultaneously in two or more threads. Read more: https://www.sqlite.org/threadsafe.html")
except Exception, e:
print_exc_plus() if self._ext_tb else ""
self.logger.error("ThreadSafeCheckerError: Something wrong is happens. See following Exception: '{}' ".format(e), exc_info=self._logger_traceback)
sys.exit()
def _check_db_compilation_options(self, db):
self.compile_options = self._get_compile_options(db)
self._check_if_threads_safe()
self._load_json1_extention_if_needed(db)
def _load_json1_extention(self,db):
try:
db.cursor
except:
self.logger.error("ExtensionLoaderError: Passed Obj is not an Sqlite-DB.", exc_info=self._logger_traceback)
sys.exit()
i = 0
while True:
i += 1
try:
db.enable_load_extension(True)
db.load_extension(DBHandler.path_to_json1)
self.logger.debug("ExtensionLoader: 'json1'-Extension was loaded into SQLite.")
return Status(status=True)
except sqlite.OperationalError,e:
if i == 2:
self.logger.error("It wasn't possible to compile json1 for SQLITE. Please compile 'JSON1'-C-Extension into '{}' manually.".format(DBHandler.path_to_json1))
sys.exit()
if os.path.isfile(DBHandler.path_to_json1+".c"):
print_exc_plus() if self._ext_tb else ""
self.logger.debug("ExtensionLoaderError: 'json1'-Extension wasn't found in '{}'. Probably it wasn't compiled. Please compile this extension before you can use it.".format(DBHandler.path_to_json1), exc_info=self._logger_traceback)
#command_str = "gcc -g -fPIC -shared {} -o {}".format(DBHandler.path_to_json1+".c", DBHandler.path_to_json1+".so")
#command = os.popen(command_str)
#execute = command.read()
#close = command.close()
#if mac "gcc -g -fPIC -dynamiclib YourCode.c -o YourCode.dylib"
args2 = ['gcc', '-g', '-fPIC', '-shared',DBHandler.path_to_json1+".c",'-o',DBHandler.path_to_json1]
answer = subprocess.Popen(args2).communicate()
self.logger.info("Compiled json1 wasn't found. Compilation process was started: ProcessDebug: '{}'. ".format(answer))
#self.logger.info("Compiled json1 wasn't found. Compilation process was started: ProcessDebug: '{}', '{}' ".format(execute, close))
files = os.listdir(os.path.join(path_to_zas_rep_tools, "src/extensions/json1"))
#self.logger.critical("FILES::::: {}".format(files))
#sys.exit()
else:
print_exc_plus() if self._ext_tb else ""
self.logger.error("ExtensionLoaderError: 'json1'-Extension and 'json' C-Source files wasn't found in '{}'. Please give the right path to json1.c File.".format(DBHandler.path_to_json1), exc_info=self._logger_traceback)
sys.exit()
except Exception, e:
print_exc_plus() if self._ext_tb else ""
self.logger.error("ExtensionLoaderError: Something wrong is happens. 'json1'-Extension wasn't loaded. See following Exception: '{}' ".format(e), exc_info=self._logger_traceback)
return Status(status=False, track_id=self._error_track_id.incr(), func_name=function_name(-2))
def _load_json1_extention_if_needed(self, db):
if not self.compile_options:
self.logger.error("DB-Compile Options wasn't found.")
return Status(status=False, track_id=self._error_track_id.incr(), func_name=function_name(-2))
try:
if "ENABLE_JSON1" in self.compile_options["parameters"]:
self.logger.debug("JSONExtentionChecker: Given Compilation of SQLITE3 Environment hat already enabled JSON Extension.")
return Status(status=True)
else:
status = self._load_json1_extention(db)
if "ENABLE_LOAD_EXTENSION" in self.compile_options["parameters"] or "OMIT_LOAD_EXTENSION" in self.compile_options["parameters"]:
if not status["status"]:
return status
else:
self.logger.critical("ExtensionLoaderError: It seems like current Compilation of the SQLITE don't support loading of additional extension. But we will try to force it. ('ZAS-REP-TOOLS' requires loaded 'JSON1' extention. Please recompile your Version of SQLITE with following flags: 'SQLITE_OMIT_LOAD_EXTENSION' or 'SQLITE_ENABLE_JSON1'. See more here: https://www.sqlite.org/compile.html#threadsafe) ")
if not status["status"]:
return status
return Status(status=True)
except Exception, e:
print_exc_plus() if self._ext_tb else ""
self.logger.error("ThreadSafeCheckerError: Something wrong is happens. See following Exception: '{}' ".format(e), exc_info=self._logger_traceback)
sys.exit()
##############################################################################
###########################DB-Validation#######################
##############################################################################
def _validation_DBfile(self, path_to_db, encryption_key=False, thread_name="Thread0"):
if os.path.isfile(path_to_db):
try:
_db = sqlite.connect(path_to_db, **self._arguments_for_connection)
c = _db.cursor()
self._check_db_compilation_options(_db)
if encryption_key:
c.execute("PRAGMA key='{}';".format(encryption_key))
#self.is_encrypted = True
c.execute("SELECT name FROM sqlite_master WHERE type='table';")
tables = c.fetchall()
except sqlite.DatabaseError, e:
print_exc_plus() if self._ext_tb else ""
if encryption_key:
self.logger.error("ValidationError: '{}'. Or maybe a given Key is incorrect. Please give another one. PathToDB: '{}'. ".format( e, path_to_db), exc_info=self._logger_traceback)
else:
self.logger.error("ValidationError: '{}'. PathToDB: '{}'. ".format( e, path_to_db), exc_info=self._logger_traceback)
return Status(status=False, track_id=self._error_track_id.incr(), func_name=function_name(-2))
except Exception as exception:
print_exc_plus() if self._ext_tb else ""
self.logger.error("Something wrong happens while Validation '{}'. PathToDB: '{}'. ".format( repr(exception), path_to_db), exc_info=self._logger_traceback)
return Status(status=False, track_id=self._error_track_id.incr(), func_name=function_name(-2))
try:
#c = _db.cursor()
c.execute("SELECT name FROM sqlite_master WHERE type='table';")
tables = c.fetchall()
#c = _db.cursor()
# p(c)
# p((c.cursor, c.connection))
## check Row Numbers
c.execute("select count(*) from info;")
rowNumbes = c.fetchone()[0]
#sys.exit()
if rowNumbes > 1:
self.logger.error("ValidationError: Info-Table has more as 1 row. It is incorrect!", exc_info=self._logger_traceback)
return Status(status=False, track_id=self._error_track_id.incr(), func_name=function_name(-2))
elif rowNumbes ==0:
self.logger.error("ValidationError: Info-Table is empty. It is incorrect!", exc_info=self._logger_traceback)
return Status(status=False, track_id=self._error_track_id.incr(), func_name=function_name(-2))
try:
## Check existents of attribute typ
get_typ= c.execute("SELECT typ FROM info; ")
get_typ = c.fetchone()
if get_typ[0] == "stats":
stat_val_status = self._validate_statsDB(_db)
if not stat_val_status["status"]:
self.logger.warning("Validator is failed! Connected/Attached DB can not be used. Please choice another one.")
return stat_val_status
elif get_typ[0] == "corpus":
corp_val_status = self._validate_corpusDB(_db)
if not corp_val_status["status"]:
self.logger.warning("Validator is failed! Connected/Attached DB can not be used. Please choice another one.")
return corp_val_status
else:
self.logger.error("ValidationError: Unsupported DB-Type '{}' was found.".format(get_typ[0]), exc_info=self._logger_traceback)
return Status(status=False, track_id=self._error_track_id.incr(), func_name=function_name(-2))
except sqlite.OperationalError, e:
print_exc_plus() if self._ext_tb else ""
self.logger.error("ValidationError: '{}'. Impossible to get DB-Typ. PathToDB: '{}'. ".format( e, path_to_db), exc_info=self._logger_traceback)
return Status(status=False, track_id=self._error_track_id.incr(), func_name=function_name(-2))
except Exception as exception:
print_exc_plus() if self._ext_tb else ""
self.logger.error("ValidationError: Something wrong happens while Validation '{}'. PathToDB: '{}'. ".format( repr(exception), path_to_db), exc_info=self._logger_traceback)
return Status(status=False, track_id=self._error_track_id.incr(), func_name=function_name(-2))
return Status(status=True)
else:
self.logger.error("Given DB-File is not exist: '{}'. ".format(path_to_db), exc_info=self._logger_traceback)
return Status(status=False, track_id=self._error_track_id.incr(), func_name=function_name(-2))
def _validate_corpusDB(self, db):
### Step 1: Attributes
attributs_and_types = [(attr[0], attr[1].split(' ', 1 )[0]) for attr in db_helper.default_tables["corpus"]["info"]]
c = db.cursor()
c.execute("PRAGMA table_info('info'); ")
columns_and_types = c.fetchall()
columns_and_types = [(col[1], col[2])for col in columns_and_types]
if set(columns_and_types) !=set(attributs_and_types):
self.logger.error("CorpusDBValidationError: Given Stats-DB contain not correct attributes. Following col_and_types was extracted: '{}' and they are incorrect. Please use following data as golden standard: '{}'. ".format(columns_and_types, attributs_and_types), exc_info=self._logger_traceback)
return Status(status=False, track_id=self._error_track_id.incr(), func_name=function_name(-2))
## Step 2: Table Names
c.execute("SELECT name FROM sqlite_master WHERE type='table';")
tables = c.fetchall()
default_tables = ["documents"]
extracted_tnames = [table_name[0] for table_name in tables]
for defaultTable in default_tables:
if defaultTable not in extracted_tnames:
self.logger.error("CorpusDBValidationError: '{}'-default-Table wasn't found in the given Corpus-DB.".format(defaultTable), exc_info=self._logger_traceback)
return Status(status=False, track_id=self._error_track_id.incr(), func_name=function_name(-2))
return Status(status=True, out_obj=db)
def _validate_statsDB(self, db):
### Step 1: Attributes
attributs_and_types = [(attr[0], attr[1].split(' ', 1 )[0]) for attr in db_helper.default_tables["stats"]["info"]]
c = db.cursor()
c.execute("PRAGMA table_info('info'); ")
columns_and_types = c.fetchall()
columns_and_types = [(col[1], col[2])for col in columns_and_types]
#p(set(columns_and_types), "set(columns_and_types)")
#p(set(attributs_and_types), "set(attributs_and_types)")
if set(columns_and_types) !=set(attributs_and_types):
self.logger.error("StatsDBValidationError: Given Stats-DB contain not correct attributes. Following col_and_types was extracted: '{}' and they are incorrect. Please use following data as golden standard: '{}'. ".format(columns_and_types, attributs_and_types), exc_info=self._logger_traceback)
return Status(status=False, track_id=self._error_track_id.incr(), func_name=function_name(-2))
## Step 2: Table Names
c.execute("SELECT name FROM sqlite_master WHERE type='table';")
tables = c.fetchall()
default_tables = db_helper.default_tables["stats"].keys()
#["repl_baseline", "redu_baseline","replications", "reduplications", "info"]
extracted_tnames = [table_name[0] for table_name in tables]
for defaultTable in default_tables:
if defaultTable not in extracted_tnames:
self.logger.error("StatsDBValidationError: '{}'-default-Table wasn't found in the given Stats-DB.".format(defaultTable), exc_info=self._logger_traceback)
return Status(status=False, track_id=self._error_track_id.incr(), func_name=function_name(-2))
return Status(status=True, out_obj=db)
##############################################################################
###########################DB-OtherHelpers################
##############################################################################
def _reinitialize_logger(self, level=False):
level = level if level else self._logger_level
## Logger Reinitialisation
self.l = ZASLogger(self.__class__.__name__ ,level=level, folder_for_log=self._logger_folder_to_save, logger_usage=self._logger_usage, save_logs=self._logger_save_logs)
self.logger = self.l.getLogger()
#self.logger = main_logger(self.__class__.__name__, level=level, folder_for_log=self._logger_folder_to_save, logger_usage=self._logger_usage, save_logs=self._logger_save_logs)
self.logger.debug("Logger was reinitialized.")
def _init_default_tables(self,typ, template=False, cols_and_types_in_doc=False):
#p(template, "template")
if template and template!="NULL":
if template in DBHandler.templates:
if cols_and_types_in_doc:
cols_and_types_in_doc += DBHandler.templates[template]
else:
cols_and_types_in_doc = DBHandler.templates[template]
else:
self.logger.error("Given Template ('{}') is not exist".format(template), exc_info=self._logger_traceback)
return Status(status=False, track_id=self._error_track_id.incr(), func_name=function_name(-2))
#p(cols_and_types_in_doc)
if typ == "corpus":
#p(db_helper.default_tables["corpus"]["documents"]["basic"])
#p(cols_and_types_in_doc)
status= self._init_default_table("corpus", "documents", db_helper.default_tables["corpus"]["documents"]["basic"], addit_cols_and_types_in_doc=cols_and_types_in_doc, constraints=db_helper.default_constraints["corpus"]["documents"])
if not status["status"]:
return status
elif typ == "stats":
for table_name, columns in db_helper.default_tables[typ].iteritems(): #foo = data.get("a",{}).get("b",{}).get("c",False)
if table_name == "info":
continue
status = self._init_default_table(typ, table_name, columns, constraints=db_helper.default_constraints.get(typ, False).get(table_name, False))
if not status["status"]:
return status
else:
self.logger.error("Given typ of DB ('{}') is not exist.".format(typ), exc_info=self._logger_traceback)
return Status(status=False, track_id=self._error_track_id.incr(), func_name=function_name(-2))
return Status(status=True)
def _init_default_table(self, typ, tableName , default_collumns_with_types, addit_cols_and_types_in_doc=False, constraints=False):
if typ.lower()=="corpus":
if not self._db_should_be_a_corpus()["status"]:
return self._db_should_be_a_corpus()
elif typ.lower()=="stats":
if not self._db_should_be_stats()["status"]:
return self._db_should_be_stats()
else:
self.logger.error("Not supported typ ('{}') of DB. Please use one of the following DB-Types: '{}'. ".format(typ, DBHandler.supported_db_typs), exc_info=self._logger_traceback)
return Status(status=False, track_id=self._error_track_id.incr(), func_name=function_name(-2))
if addit_cols_and_types_in_doc:
columns_and_types = default_collumns_with_types + addit_cols_and_types_in_doc
else:
columns_and_types = default_collumns_with_types
constraints_in_str = db_helper.constraints_list_to_str(constraints)
#attributs_names_with_types_as_str = db_helper.columns_and_types_in_tuples_to_str(columns_and_types)
status = self.addtable( tableName, columns_and_types,constraints=constraints_in_str)
if not status["status"]:
self.logger.error("InitDefaultTableError: '{}'-Table wasn't added into the {}-DB.".format(tableName, typ), exc_info=self._logger_traceback)
return status
self.logger.debug("{}-Table in {} was initialized".format(tableName, typ))
return Status(status=True)
def _commit_if_inserts_was_did(self):
if int(self.number_of_new_inserts_after_last_commit) >0:
self._commit()
def _init_info_table(self, attributs_names):
#str_attributs_names = db_helper.columns_and_types_in_tuples_to_str(attributs_names)
status = self.addtable("info", attributs_names)
if not status["status"]:
return status
self.logger.debug("Info-Table was initialized")
return Status(status=True)
def _del_attached_db_from_a_config_list(self, dbname):
i=0
found = False
if self._attachedDBs_config:
if dbname not in self.dbnames:
self.logger.warning("Given AttachedDataBaseName is not exist: '{}'.".format(dbname))
return Status(status=False, track_id=self._error_track_id.incr(), func_name=function_name(-2))
configs = self._get_configs_from_attached_DBList(dbname)
if configs:
self._attachedDBs_config.pop(configs[1])
self.logger.debug("Given AttachedDB '{}' was successfully deleted from the configs-list. ".format(dbname))
return Status(status=True)
else:
self.logger.warning("Given AttachedDB '{}' wasn't deleted from the configs-liss. ".format(dbname))
return Status(status=False, track_id=self._error_track_id.incr(), func_name=function_name(-2))
else:
self.logger.warning("List with attached DBs is already empty. You can not delete anything!")
return Status(status=False, track_id=self._error_track_id.incr(), func_name=function_name(-2))
def _convert_if_needed_attr_to_bool(self, attributes):
try:
for attr_name, attr_value in attributes.iteritems():
#attributes[]
if isinstance(attr_value, (int, float)):
attr_value = str(attr_value)
if attr_value is None:
#attr_value = False
attributes[attr_name] = False
elif attr_value.lower() in self.bool_conv:
attributes[attr_name] = self.bool_conv[attr_value.lower()]
except Exception, e:
self.logger.error("Exception was encountered: '{}'. ".format(e))
#p(dict(attributes.iteritems()))
#sys.exit()
def _reattach_dbs_after_closing_of_the_main_db(self):
#p(repr(self._attachedDBs_config_from_the_last_session), "self._attachedDBs_config_from_the_last_session")
#sys.exit()
#p("22")
#p(self.dbnames, "dbnames11")
s = self._check_db_should_exist()
#p("666")
if not s["status"]:
return s
#p(self._attachedDBs_config_from_the_last_session, "self._attachedDBs_config_from_the_last_session")
if self._attachedDBs_config_from_the_last_session:
for attached_db in self._attachedDBs_config_from_the_last_session:
#p(attached_db, c="r")
self.attach(attached_db[0], encryption_key=attached_db[2], reattaching=True)
self.logger.debug("All attached DB was re-attached in the new connected Database")
#p(self.dbnames, "dbnames22")
return Status(status=True)
else:
self.logger.debug("There is no DBs to reattach (after closing of the main DB).")
return Status(status=False, track_id=self._error_track_id.incr(), func_name=function_name(-2), desc="There is no DBs to reattach (after closing of the main DB)")
##############################################################################
##########################Directly AttrGetterFromDB#(for updaters)##########
##############################################################################
def _get_tables_from_db(self,dbname="main", thread_name="Thread0"):
s = self._check_db_should_exist()
if not s["status"]:
return s
self._commit_if_inserts_was_did()
if dbname in self.dbnames:
query = "SELECT name FROM {}.sqlite_master WHERE type='table';".format(dbname)
else:
self.logger.error("Given dbName ('{}') is not exist in the current DB-Structure".format(dbname), exc_info=self._logger_traceback)
return Status(status=None, track_id=self._error_track_id.incr(), func_name=function_name(-2))
try:
#cursor = self._db.cursor()
self._threads_cursors[thread_name].execute(query)
tables_exist = self._threads_cursors[thread_name].fetchall()
self._commit()
except Exception as exception:
print_exc_plus() if self._ext_tb else ""
self.logger.error("Something happens while Getting Tables: '{}'.".format(repr(exception)), exc_info=self._logger_traceback)
return Status(status=False, track_id=self._error_track_id.incr(), func_name=function_name(-2))
self.logger.low_debug("TableNames was get directly from DB. (dbname: '{}')".format(dbname))
return [table_name[0] for table_name in tables_exist]
def _get_indexes_from_db(self,dbname="main", thread_name="Thread0"):
s = self._check_db_should_exist()
if not s["status"]:
return s
self._commit_if_inserts_was_did()
if dbname in self.dbnames:
query = "SELECT * FROM {}.sqlite_master WHERE type='index';".format(dbname)
else:
self.logger.error("Given dbName ('{}') is not exist in the current DB-Structure".format(dbname), exc_info=self._logger_traceback)
return Status(status=None, track_id=self._error_track_id.incr(), func_name=function_name(-2))
try:
#cursor = self._db.cursor()
self._threads_cursors[thread_name].execute(query)
indexes_exist = self._threads_cursors[thread_name].fetchall()
self._commit()
except Exception as exception:
print_exc_plus() if self._ext_tb else ""
self.logger.error("Something happens while Getting Indexes: '{}'.".format(repr(exception)), exc_info=self._logger_traceback)
return Status(status=False, track_id=self._error_track_id.incr(), func_name=function_name(-2))
self.logger.low_debug("IndexesNames was get directly from DB. (dbname: '{}')".format(dbname))
#return [index_name[0] for index_name in indexes_exist]
#p(indexes_exist, c="r")
return indexes_exist
# def _get_db_names_from_main_db(self, thread_name="Thread0"):
# s = self._check_db_should_exist()
# if not s["status"]:
# return s
# self._commit_if_inserts_was_did()
# try:
# #cur = self._db.cursor()
# self._threads_cursors[thread_name].execute("PRAGMA database_list")
# rows = self._threads_cursors[thread_name].fetchall()
# except Exception as exception:
# print_exc_plus() if self._ext_tb else ""
# self.logger.error("Something happens while Getting DBNames: '{}'.".format(repr(exception)), exc_info=self._logger_traceback)
# return Status(status=False, track_id=self._error_track_id.incr(), func_name=function_name(-2))
# self.logger.debug("All DB-Names was taked directly from a Database.")
# if rows:
# return [ row[1] for row in rows]
# else:
# self.logger.critical("DBNamesGetter: No DB Names was returned from a DB")
# return []
def _get_configs_from_attached_DBList(self, dbname):
i=0
found = False
if self._attachedDBs_config:
if dbname not in self.dbnames:
self.logger.warning("Given AttachedDataBaseName is not exist: '{}'.".format(dbname))
return Status(status=False, track_id=self._error_track_id.incr(), func_name=function_name(-2))
for attachedDB in self._attachedDBs_config:
if attachedDB[1] == dbname:
#p((attachedDB[1], i))
found = i
break
i=+1
if isinstance(found, int):
#self._attachedDBs_config.pop(found)
self.logger.debug("Configs for '{}' was successfully found in the config-list of attached DBs. ".format(dbname))
return (attachedDB, found)
else:
self.logger.warning("Configs for '{}' wasn't found!".format(dbname))
return Status(status=False, track_id=self._error_track_id.incr(), func_name=function_name(-2))
else:
self.logger.warning("Configs-List with attached DBs is already empty. ")
return Status(status=False, track_id=self._error_track_id.incr(), func_name=function_name(-2))
def _get_all_attr_from_db(self,dbname="main", thread_name="Thread0"):
s = self._check_db_should_exist()
if not s["status"]:
return s
self._commit_if_inserts_was_did()
if dbname in self.dbnames:
query = 'SELECT * FROM {}.info;'.format( dbname)
else:
self.logger.error("Given dbName ('{}') is not exist in the current DB-Structure".format(dbname), exc_info=self._logger_traceback)
return Status(status=None, track_id=self._error_track_id.incr(), func_name=function_name(-2))
try:
#cursor = self._db.cursor()
self._threads_cursors[thread_name].execute(query)
attribut = self._threads_cursors[thread_name].fetchall()[0]
#p(attribut, "attribut")
except Exception as exception:
print_exc_plus() if self._ext_tb else ""
self.logger.error("Something happens while Getting all Attributes from InfoTable of '{}'-DB: '{}'".format(dbname, exception), exc_info=self._logger_traceback)
return Status(status=False, track_id=self._error_track_id.incr(), func_name=function_name(-2))
number_of_rows_info_table = self.rownum("info",dbname="main")
if number_of_rows_info_table ==1:
columns = self.col("info", dbname=dbname)
return dict(zip(columns, list(attribut)))
elif number_of_rows_info_table ==0:
self.logger.error("Table 'info' is empty. Please set attributes bevor!", exc_info=self._logger_traceback)
return Status(status=None, track_id=self._error_track_id.incr(), func_name=function_name(-2))
else:
self.logger.error("Table 'info' has more as 1 row. It's not correct. Please delete not needed rows.", exc_info=self._logger_traceback)
return Status(status=None, track_id=self._error_track_id.incr(), func_name=function_name(-2))
##############################################################################
###########################Instance-Updater+###################
##############################################################################
def _update_temp_tablesList_in_instance(self, thread_name="Thread0"):
s = self._check_db_should_exist()
if not s["status"]:
return s
#p(self.dbnames, c="r")
self._tables_dict = {}
#if self.dbnames:
for DBName in self.dbnames:
self._tables_dict[DBName] = self._get_tables_from_db(dbname=DBName, thread_name=thread_name)
#else:
# self._tables_dict['main'] = self._get_tables_from_db(dbname='main', thread_name=thread_name)
self.logger.debug("Temporary TableList in the DB-Instance was updated!")
def _update_temp_indexesList_in_instance(self, thread_name="Thread0"):
s = self._check_db_should_exist()
if not s["status"]:
return s
#p(self.dbnames, c="r")
self._indexes_dict = {}
#if self.dbnames:
for DBName in self.dbnames:
self._indexes_dict[DBName] = self._get_indexes_from_db(dbname=DBName, thread_name=thread_name)
#else:
# self._indexes_dict['main'] = self._get_indexes_from_db(dbname='main')
self.logger.debug("Temporary IndexesList in the DB-Instance was updated!")
def _update_temp_attributsList_in_instance(self, thread_name="Thread0"):
s = self._check_db_should_exist()
if not s["status"]:
return s
#p(self.dbnames, c="r")
self._attributs_dict = {}
#if self.dbnames:
for DBName in self.dbnames:
attributes = self._get_all_attr_from_db(dbname=DBName, thread_name=thread_name)
#p((DBName,attributes))
#sys.exit()
if attributes:
self._convert_if_needed_attr_to_bool(attributes)
self._attributs_dict[DBName] = attributes
else:
self.logger.error("Attributes wasn't updated!!!", exc_info=self._logger_traceback)
return Status(status=False, track_id=self._error_track_id.incr(), func_name=function_name(-2))
#else:
# self._attributs_dict['main'] = self._get_all_attr_from_db(dbname='main')
self.logger.debug("Temporary List with all Attributes in the DB-Instance was updated!")
def _update_temp_list_with_dbnames_in_instance(self,thread_name="Thread0"):
s = self._check_db_should_exist()
if not s["status"]:
return s
#if not self._database_pragma_list:
#p(self.dbnames, c="r")
#self._database_pragma_list
self.dbnames = [ row[1] for row in self._database_pragma_list]
#self._get_db_names_from_main_db(thread_name=thread_name)
#p(self.dbnames, c="m")
if self.dbnames:
self.logger.debug("Temporary List with DB-Names in the DB-Instance was updated!")
return Status(status=True)
else:
self.logger.error("Empty List was returned.", exc_info=self._logger_traceback)
return Status(status=False, track_id=self._error_track_id.incr(), func_name=function_name(-2))
def _update_database_pragma_list(self, thread_name="Thread0"):
s = self._check_db_should_exist()
if not s["status"]:
return s
self._commit_if_inserts_was_did()
try:
#cur = self._db.cursor()
self._threads_cursors[thread_name].execute("PRAGMA database_list;")
rows = self._threads_cursors[thread_name].fetchall()
self._database_pragma_list = rows
if not self._database_pragma_list:
self.logger.critical("DBNamesGetter: No DB Names was returned from a DB")
self.logger.debug("DatabasePragmaList was updated in the current instance. (got directly from the DB)")
except Exception as exception:
print_exc_plus() if self._ext_tb else ""
self.logger.error("Something happens while getting DB-FileName: '{}'.".format( repr(exception) ), exc_info=self._logger_traceback)
return Status(status=False, track_id=self._error_track_id.incr(), func_name=function_name(-2))
#self._update_pragma_table_info(thread_name=thread_name)
def _update_pragma_table_info(self, thread_name="Thread0"):
try:
s = self._check_db_should_exist()
if not s["status"]:
return s
self._commit_if_inserts_was_did()
for dbname in self.dbnames:
for table in self.tables(dbname=dbname):
query = "PRAGMA {}.table_info('{}'); ".format(dbname, table)
#cursor = self._db.cursor()
self._threads_cursors[thread_name].execute(query)
data = self._threads_cursors[thread_name].fetchall()
self._pragma_table_info[dbname][table] = data
self.logger.debug("PragmaTableInfo was updated in the current instance. (got directly from the DB)")
except Exception as exception:
print_exc_plus() if self._ext_tb else ""
self.logger.error("Encountered Exception: '{}' ".format(repr(exception) ), exc_info=self._logger_traceback)
return Status(status=False, track_id=self._error_track_id.incr(), func_name=function_name(-2))
##############################################################################
###########################DB-Optimizer #########################
##############################################################################
def _optimize(self, thread_name="Thread0", dbname="main"):
pragma_pattern = "PRAGMA {}.{{}}".format(dbname)
#"pclsjt"
optimizer_names= {
"p":"page_size",
"c":"cache_size", #When you change the cache size using the cache_size pragma, the change only endures for the current session. The cache size reverts to the default value when the database is closed and reopened.
"l":"locking_mode",
"s":"synchronous",
"j":"journal_mode",
"t":"temp_store",
}
#p(self._optimizer_synchronous, "self._optimizer_synchronous")
statement_setting = {
"p":self._optimizer_page_size,
"c":self._optimizer_cache_size,
"l":self._optimizer_locking_mode,
"s":self._optimizer_synchronous,
"j":self._optimizer_journal_mode,
"t":self._optimizer_temp_store
}
s = self._check_db_should_exist()
if not s["status"]:
return s
#"c"
#p((self._optimizer))
#self._optimizer = "jlstc"
extracted_optimizer_flags = []
if self._optimizer:
if self._optimizer != True:
extracted_optimizer_flags = list(self._optimizer)
if len(extracted_optimizer_flags)==0:
extracted_optimizer_flags = optimizer_names.keys()
t= type(self._optimizer)
#p((self._optimizer, t,extracted_optimizer_flags))
executed_statements = []
cur = self._db.cursor()
for flag in extracted_optimizer_flags:
if flag in optimizer_names:
#if optimizer_names[flag]
current_optimizer_name = optimizer_names[flag]
current_optimizer_setting = str(statement_setting[flag]).lower()
optimizer_statement = pragma_pattern.format(current_optimizer_name)
query = "{} = {};".format(optimizer_statement, current_optimizer_setting)
cur.execute(query)
state = str(cur.execute(optimizer_statement+";").fetchall()[0][0]).lower()
#p((query,state))
executed_statements.append("Query: '{}'; Answer: '{}'. ".format(query,state))
if current_optimizer_name in DBHandler.mapped_states:
#pass
mapped_states_k_by_v= DBHandler.mapped_states[current_optimizer_name]
mapped_states_v_by_k = {v: k for k, v in DBHandler.mapped_states[current_optimizer_name].iteritems()}
current_optimizer_setting = str(current_optimizer_setting).lower()
if current_optimizer_setting in mapped_states_k_by_v:
if current_optimizer_setting != state:
self.logger.warning("OptimizerWarning: '{}' wasn't changed. (option_to_set:'{}'; getted_option_from_db:'{}')".format(current_optimizer_name,current_optimizer_setting,state))
elif current_optimizer_setting in mapped_states_v_by_k:
if mapped_states_v_by_k[current_optimizer_setting] != state:
self.logger.warning("OptimizerWarning: '{}' wasn't changed. (option_to_set:'{}'; getted_option_from_db:'{}')".format(current_optimizer_name,mapped_states_v_by_k[current_optimizer_setting],state))
else:
self.logger.error("OptimizerError: Wrong Argument! '{}'-Argument can not be set by '{}'. Use one of the following options: '{}'. ".format(current_optimizer_name, current_optimizer_setting, mapped_states_k_by_v.values()))
elif current_optimizer_name in DBHandler.non_mapped_states:
if current_optimizer_setting in DBHandler.non_mapped_states[current_optimizer_name]:
if state != current_optimizer_setting:
self.logger.warning("OptimizerWarning: '{}' wasn't changed. (option_to_set:'{}'; getted_option_from_db:'{}')".format(current_optimizer_name,current_optimizer_setting,state))
else:
self.logger.error("OptimizerError: Wrong Argument! '{}'-Argument can not be set by '{}'. Use one of the following options: '{}'. ".format(current_optimizer_name, current_optimizer_setting, DBHandler.non_mapped_states[current_optimizer_name]))
else:
self.logger.error("Current Optimization-Flag ('{}') wasn't recognized and selected.".format(flag))
if self._save_settings:
executed_statements_as_str = "\n".join(executed_statements)
self.logger.settings("Following Optimization Settings was selected: \n{}".format(executed_statements_as_str ))
if len(executed_statements)>0:
self.logger.info("Optimizer: '{}'-OptimizationStatements was executed!".format(len(executed_statements)))
##############################################################################
###########################Instance Cleaner##############
##############################################################################
def _init_instance_variables(self):
#InstanceAttributes: Initialization
#dict()
self._db = False
self._encryption_key = False
self.is_encrypted = False
self.compile_options = False
#p(self._attachedDBs_config_from_the_last_session,"self._attachedDBs_config_from_the_last_session")
try:
str(self._attachedDBs_config)
self._attachedDBs_config_from_the_last_session = self._attachedDBs_config
except AttributeError:
self._attachedDBs_config = []
self._attachedDBs_config_from_the_last_session = []
#p(self._attachedDBs_config, "self._attachedDBs_config")
self._attachedDBs_config = []
self._tables_dict = {}
self._indexes_dict = {}
self._attributs_dict = {}
self.dbnames = []
self._created_backups = {}
self._database_pragma_list = []
self._pragma_table_info = defaultdict(lambda: defaultdict(list))
self.not_initialized_dbs = []
self._mainDB_was_initialized = None
#self.lock = threading.Lock()
self._cashed_list = defaultdict(lambda: defaultdict(lambda: defaultdict(lambda: defaultdict(list))))
self._cashed_dict = defaultdict(lambda: defaultdict(lambda: defaultdict(lambda: defaultdict(lambda: defaultdict(list)))))
self._who_will_proceed_commit = {}
self._lazy_writer_all_inserts_counter = SharedCounterIntern()
self._lazy_writer_number_inserts_after_last_commit = SharedCounterIntern()
self._commits_with_lazy_writer = SharedCounterIntern()
self.all_inserts_counter = SharedCounterIntern()
self.number_of_new_inserts_after_last_commit = SharedCounterIntern()
self.inserts_was_committed = SharedCounterIntern()
self.error_insertion_counter = SharedCounterIntern()
self.bool_conv = {'true': True, 'null': None,
'false': False, }
self._error_track_id = SharedCounterExtern()
self.logger.low_debug('Intern InstanceAttributes was (re)-initialized')
def _init_threads_cursors_obj(self):
self._threads_cursors = defaultdict(self._db.cursor)
def _del_backup(self, dbname):
try:
#p(self._created_backups,"self._created_backups", c="r")
if dbname in self._created_backups:
path_to_current_db = self._created_backups[dbname]
#p(path_to_current_db, "path_to_current_db")
#p(os.listdir(os.path.split(path_to_current_db)[0]), "os.listdir(self.tempdir_testdbs)")
if os.path.isfile(path_to_current_db):
os.remove(path_to_current_db)
del self._created_backups[dbname]
self.logger.debug("BackUPRemover: Temporary BackUp for '{}'-DB was deleted. Path:'{}'.".format(dbname, path_to_current_db))
return Status(status=True)
else:
self.logger.error("BackUPRemover: Following BackUp wasn't found on the disk: '{}'. (was ignored) ".format(path_to_current_db))
return Status(status=False, track_id=self._error_track_id.incr(), func_name=function_name(-2))
else:
self.logger.debug("For '{}'-DB any BackUps wasn't created.")
return Status(status=False, track_id=self._error_track_id.incr(), func_name=function_name(-2))
except Exception, e:
self.logger.error("BackupRemover: Encountered Exception: '{}' ".format(e))
return Status(status=False, track_id=self._error_track_id.incr(), func_name=function_name(-2)) | zas-rep-tools | /zas-rep-tools-0.2.tar.gz/zas-rep-tools-0.2/zas_rep_tools/src/classes/dbhandler.py | dbhandler.py |
# ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
# : XXX{Information about this code}XXX
# Author:
# c(Developer) -> {'Egor Savin'}
# ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
###Programm Info######
#
#
#
#
#
import os
import sys
from raven import Client
import types
import Queue
import enlighten
import json
from collections import defaultdict,Counter,OrderedDict
import copy
import threading
import time
from itertools import izip
import re
import Stemmer
from zas_rep_tools.src.utils.helpers import set_class_mode, print_mode_name, path_to_zas_rep_tools, Rle, categorize_token_list, get_categories, instance_info, SharedCounterExtern, SharedCounterIntern, Status,function_name,statusesTstring, ngrams,nextLowest, get_number_of_streams_adjust_cpu,LenGen,DefaultOrderedDict, from_ISO639_2, to_ISO639_2,MyThread
from zas_rep_tools.src.classes.dbhandler import DBHandler
from zas_rep_tools.src.classes.reader import Reader
from zas_rep_tools.src.classes.corpus import Corpus
from zas_rep_tools.src.classes.exporter import Exporter
from zas_rep_tools.src.utils.zaslogger import ZASLogger
from zas_rep_tools.src.utils.debugger import p
from zas_rep_tools.src.utils.error_tracking import initialisation
from zas_rep_tools.src.utils.traceback_helpers import print_exc_plus
from zas_rep_tools.src.classes.basecontent import BaseContent, BaseDB
import zas_rep_tools.src.utils.db_helper as db_helper
from zas_rep_tools.src.utils.custom_exceptions import ZASCursorError, ZASConnectionError,DBHandlerError,ProcessError,ErrorInsertion,ThreadsCrash
#from sortedcontainers import SortedDict
import platform
if platform.uname()[0].lower() !="windows":
import colored_traceback
colored_traceback.add_hook()
else:
import colorama
class Stats(BaseContent,BaseDB):
phenomena_table_map = {
"repl":"replications",
"redu":"reduplications",
"baseline":"baseline",
}
supported_rep_type = set(("repl", "redu"))
supported_phanomena_to_export = supported_rep_type.union(set(("baseline",)))
supported_syntagma_type= set(("lexem", "pos"))
supported_sentiment = set(("negative","positive","neutral"))
output_tables_types = set(("sum", "exhausted"))
output_tables_col_names = {
"baseline":{
"all":"occur_syntagma_all",
"repl":{
"uniq":"occur_repl_uniq",
"exhausted":"occur_repl_exhausted",
},
"redu":{
"uniq":"occur_redu_uniq",
"exhausted":"occur_redu_exhausted",
}
}
}
min_col = {
"repl":('id','doc_id', "redufree_len",'index_in_corpus','index_in_redufree','normalized_word', 'stemmed',"in_redu"),
"redu":('id','doc_id', "redufree_len",'index_in_corpus', 'index_in_redufree',"redu_length",'normalized_word','stemmed'),
"baseline":["syntagma", "occur_syntagma_all", "scope",'stemmed'],
}
_non_pos_tags = set(["EMOIMG", "EMOASC", "number", "symbol", "hashtag", "mention","regular"])
header_order_to_export = ("baseline", "document", "word", "repl", "redu", "context")
def __init__(self, status_bar=True,log_ignored=True,**kwargs):
super(type(self), self).__init__(**kwargs)
#Input: Encapsulation:
self._status_bar = status_bar
self._log_ignored= log_ignored
#self._preprocession = preprocession
self.locker = threading.Lock()
#InstanceAttributes: Initialization
self.statsdb = False
self.corp = False
self._corp_info = False
self.corpdb_defaultname = "corpus"
self.attached_corpdb_name = False
self._doc_id_tag = db_helper.doc_id_tag
#self._baseline_delimiter = baseline_delimiter
#self._init_compution_variables()
self.preprocessors = defaultdict(dict)
self._init_preprocessors(thread_name="Thread0")
self.logger.debug('Intern InstanceAttributes was initialized')
self.logger.debug('An instance of Stats() was created ')
## Log Settings of the Instance
attr_to_flag = False
attr_to_len = False
self._log_settings(attr_to_flag =attr_to_flag,attr_to_len =attr_to_len)
############################################################
####################__init__end#############################
############################################################
def __del__(self):
super(type(self), self).__del__()
####################################################################################
####################################################################################
####################################################################################
####################################################################################
####################################################################################
####################################################################################
######################################Extern########################################
####################################################################################
####################################################################################
####################################################################################
####################################################################################
####################################################################################
def _init_compution_variables(self):
self.threads_error_bucket = Queue.Queue()
self.threads_status_bucket = Queue.Queue()
self.threads_success_exit = []
self.threads_unsuccess_exit = []
self._threads_num = 0
self.status_bars_manager = self._get_status_bars_manager()
self.preprocessors = defaultdict(dict)
#self.baseline_replication = defaultdict(lambda:defaultdict(lambda: 0) )
#self.baseline_reduplication = defaultdict(lambda:defaultdict(lambda: 0) )
self._terminated = False
#self.baseline_ngramm_lenght = self._context_left + 1 +self._context_lenght
self.temporized_baseline = defaultdict(int)
self.active_threads = []
self.main_status_bar_of_insertions = False
self._timer_on_main_status_bar_was_reset = False
self._start_time_of_the_last_insertion = False
self._end_time_of_the_last_insertion = False
self._last_insertion_was_successfull = False
self.counters_attrs = defaultdict(lambda:defaultdict(dict))
#self._avaliable_scope = self._context_lenght+1
self.force_cleaning_flags = set()
self.ignored_pos = set(["URL", "U"])
self.baseline_insrt_process = False
self._text_field_name = "text"
self._id_field_name = "id"
self.temporized_repl = defaultdict(list)
self.temporized_redu = defaultdict(list)
self._repls_cols = self.statsdb.col("replications")
self._redus_cols = self.statsdb.col("reduplications")
self._cleaned_tags = {
"number":":number:",
"URL":":URL:",
"symbol":":symbol:",
"mention":":mention:",
"hashtag":":hashtag:",
}
###########################INITS + Open##########################
def _init_column_index_variables(self):
self.col_index_orig = {
"repl":{colname:index for index,colname in enumerate(self.statsdb.col("replications") )},
"redu":{colname:index for index,colname in enumerate(self.statsdb.col("reduplications") )},
"baseline":{colname:index for index,colname in enumerate(self.statsdb.col("baseline") )},
}
self.col_index_min = {
"repl":{colname:index for index,colname in enumerate(Stats.min_col["repl"])},
"redu":{colname:index for index,colname in enumerate(Stats.min_col["redu"])},
"baseline":{colname:index for index,colname in enumerate(Stats.min_col["baseline"] )},
#"baseline":{colname:index for index,colname in enumerate(self.statsdb.col("baseline") )},
}
# self.col_index_repl = {colname:index for index,colname in enumerate(self.statsdb.col("replications") )}
# self.col_index_redu = {colname:index for index,colname in enumerate(self.statsdb.col("reduplications") )}
# self.col_index_baseline = {colname:index for index,colname in enumerate(self.statsdb.col("baseline") )}
# self._contextR1index = {
# "repl":self._get_col_index("contextR1", "replications"),
# "redu":self._get_col_index("contextR1", "reduplications")
# }
# self._normalized_word_index = {
# "repl":self._get_col_index("normalized_word", "replications"),
# "redu":self._get_col_index("normalized_word", "reduplications")
# }
# self._doc_id_index = {
# "repl":self._get_col_index("doc_id", "replications"),
# "redu":self._get_col_index("doc_id", "reduplications")
# }
# self._adress_index = {
# "repl":self._get_col_index("token_index", "replications"),
# "redu":self._get_col_index("start_index", "reduplications")
# }
# self._rep_id = {
# "repl":self._get_col_index("repl_id", "replications"),
# "redu":self._get_col_index("redu_id", "reduplications")
# }
def additional_attr(self, repl_up,ignore_hashtag,ignore_url,
ignore_mention,ignore_punkt,ignore_num,force_cleaning,
case_sensitiv,full_repetativ_syntagma,
min_scope_for_indexes,baseline_delimiter):
additional_attributes = {
"repl_up":repl_up,
#"log_ignored":log_ignored,
"ignore_hashtag":ignore_hashtag,
"ignore_url":ignore_url,
"ignore_mention":ignore_mention,
"ignore_punkt":ignore_punkt,
"ignore_num":ignore_num,
"force_cleaning":force_cleaning ,
"case_sensitiv":case_sensitiv,
"full_repetativ_syntagma":full_repetativ_syntagma,
"full_repetativ_syntagma": full_repetativ_syntagma,
"min_scope_for_indexes":min_scope_for_indexes,
"baseline_delimiter":baseline_delimiter,
}
return additional_attributes
def init(self, prjFolder, DBname, language, visibility, corpus_id=None,
encryption_key=False,fileName=False, version=False, stats_id=False,
context_lenght=5, full_repetativ_syntagma=False, min_scope_for_indexes=2,
repl_up=3, ignore_hashtag=False, force_cleaning=False,baseline_delimiter="|+|",
case_sensitiv=False,ignore_url=False, ignore_mention=False, ignore_punkt=False, ignore_num=False):
if self.statsdb:
self.logger.error("StatsInitError: An active Stats Instance was found. Please close already initialized/opened Stats, before new initialization.", exc_info=self._logger_traceback)
return False
if context_lenght < 3:
self.logger.error("Given Context-Length is lower as an allow minimum, which is 3.")
return False
self.statsdb = DBHandler( **self._init_attributesfor_dbhandler())
was_initialized = self.statsdb.init("stats", prjFolder, DBname, language, visibility, corpus_id=corpus_id,
encryption_key=encryption_key,fileName=fileName, version=version,
stats_id=stats_id, db_frozen=False, context_lenght=context_lenght )
if not was_initialized:
self.logger.error("StatsInit: Current Stats for following attributes wasn't initialized: 'dbtype='{}'; 'dbname'='{}; corp_id='{}'; 'stats_id'='{}'; encryption_key='{}'; .".format("stats", DBname,corpus_id, stats_id,encryption_key))
return False
if self.statsdb.exist():
self.add_context_columns( context_lenght)
additional_attributes = self.additional_attr(repl_up,ignore_hashtag,ignore_url,
ignore_mention,ignore_punkt,ignore_num,force_cleaning,
case_sensitiv,full_repetativ_syntagma,min_scope_for_indexes,baseline_delimiter)
self.statsdb.update_attrs(additional_attributes)
self.statsdb.update_attr("locked", False)
self.set_all_intern_attributes_from_db()
self.logger.settings("InitStatsDBAttributes: {}".format( instance_info(self.statsdb.get_all_attr(), attr_to_len=False, attr_to_flag=False, as_str=True)))
self.logger.debug("StatsInit: '{}'-Stats was successful initialized.".format(DBname))
self._init_column_index_variables()
self.baseline_ngramm_lenght = 1 +self._context_lenght
return True
else:
self.logger.error("StatsInit: '{}'-Stats wasn't initialized.".format(DBname), exc_info=self._logger_traceback)
return False
def close(self):
self.statsdb.close()
self.statsdb = False
self.corp = False
self._corp_info = False
self.attached_corpdb_name = False
def _close(self):
self.statsdb._close()
self.statsdb = False
self.corp = False
self._corp_info = False
self.attached_corpdb_name = False
def open(self, path_to_stats_db, encryption_key=False):
if self.statsdb:
self.logger.error("StatsInitError: An active Stats Instance was found. Please close already initialized/opened Stats, before new initialization.", exc_info=self._logger_traceback)
return False
self.statsdb = DBHandler( **self._init_attributesfor_dbhandler())
self.statsdb.connect(path_to_stats_db, encryption_key=encryption_key)
if self.statsdb.exist():
if self.statsdb.typ() != "stats":
self.logger.error("Current DB is not an StatsDB.")
self._close()
return False
self.logger.debug("StatsOpener: '{}'-Stats was successful opened.".format(os.path.basename(path_to_stats_db)))
self.set_all_intern_attributes_from_db()
self.logger.settings("OpenedStatsDBAttributes: {}".format( instance_info(self.statsdb.get_all_attr(), attr_to_len=False, attr_to_flag=False, as_str=True)))
self._init_column_index_variables()
self.baseline_ngramm_lenght = 1 +self._context_lenght
self._init_stemmer(self._language)
return True
else:
self.logger.error("StatsOpener: Unfortunately '{}'-Stats wasn't opened.".format(os.path.basename(path_to_stats_db)), exc_info=self._logger_traceback)
return False
def set_all_intern_attributes_from_db(self):
#{u'name': u'bloggerCorpus', u'created_at': u'2018-07-26 17:49:11', u'visibility': u'extern', u'version': u'1', u'corpus_id': 7614, u'typ': u'stats', u'id': 3497}
info_dict = self.info()
self._name = info_dict["name"]
self._created_at = info_dict["created_at"]
self._visibility = info_dict["visibility"]
self._version = info_dict["version"]
self._corpus_id = info_dict["corpus_id"]
self._typ = info_dict["typ"]
self._id = info_dict["id"]
self._db_frozen = info_dict["db_frozen"]
self._context_lenght = info_dict["context_lenght"]
self._language = info_dict["language"]
#self._context_lenght = info_dict["context_right"]
self._avaliable_scope = self._context_lenght+1
self._repl_up = info_dict["repl_up"]
#self._log_ignored = info_dict["log_ignored"]
self._ignore_hashtag = info_dict["ignore_hashtag"]
self._ignore_url = info_dict["ignore_url"]
self._ignore_mention = info_dict["ignore_mention"]
self._ignore_punkt = info_dict["ignore_punkt"]
self._ignore_num = info_dict["ignore_num"]
self._force_cleaning = info_dict["force_cleaning"]
self._case_sensitiv = info_dict["case_sensitiv"]
self._full_repetativ_syntagma = info_dict["full_repetativ_syntagma"]
# self._text_field_name = info_dict["text_field_name"]
# self._id_field_name = info_dict["id_field_name"]
self._min_scope_for_indexes = info_dict["min_scope_for_indexes"]
self._pos_tagger = info_dict["pos_tagger"]
self._sentiment_analyzer = info_dict["sentiment_analyzer"]
self._baseline_delimiter = info_dict["baseline_delimiter"]
#self._id_field_name = None
#self._text_field_name = None
def _get_col_index(self, col_name, table_name):
try:
return self.statsdb.col(table_name).index(col_name)
except ValueError, e:
self.logger.error("'{}'-Colum is not in the '{}'-Table.".fromat(col_name, table_name))
return False
def _init_attributesfor_dbhandler(self):
init_attributes_db_handler = {
"stop_if_db_already_exist":self._stop_if_db_already_exist,
"rewrite":self._rewrite,
"logger_level":self._logger_level,
"optimizer":self._optimizer,
"in_memory":self._in_memory,
"logger_traceback":self._logger_traceback,
"logger_folder_to_save":self._logger_folder_to_save,
"logger_usage":self._logger_usage,
"logger_save_logs":self._logger_save_logs,
"thread_safe":self._thread_safe,
"mode":self._mode,
"error_tracking":self._error_tracking,
"ext_tb":self._ext_tb,
"isolation_level":self._isolation_level,
"optimizer_page_size":self._optimizer_page_size,
"optimizer_cache_size":self._optimizer_cache_size,
"optimizer_locking_mode":self._optimizer_locking_mode,
"optimizer_synchronous":self._optimizer_synchronous,
"optimizer_journal_mode":self._optimizer_journal_mode,
"optimizer_temp_store":self._optimizer_temp_store,
"use_cash":self._use_cash,
"replace_double_items":True,
"stop_process_if_possible":self._stop_process_if_possible,
"make_backup": self._make_backup,
"lazyness_border": self._lazyness_border,
"save_settings": self._save_settings,
"save_status": self._save_status,
"log_content": self._log_content,
"clear_logger": self._clear_logger,
#_replace_double_items
}
return init_attributes_db_handler
def _init_stemmer(self, language):
if language not in Corpus.stemmer_for_languages:
self.logger.error("StemmerINIT: is failed. '{}'-language is not supported.")
return False
lan = from_ISO639_2[language]
self.stemmer = Stemmer.Stemmer(lan)
return True
def stemm(self, word):
#p(word, "word")
try:
word.decode
return self.stemmer.stemWord(word)
except:
return self.stemmer.stemWord(word[0])
def add_context_columns(self, context_lenght):
self._add_context_columns("replications", context_lenght)
self._add_context_columns("reduplications", context_lenght)
def _add_context_columns(self, table_name, context_lenght):
#p("ghjkl")
exist_columns = self.statsdb.col(table_name)
#p(exist_columns,"exist_columns", c="r")
## context left
for context_number in reversed(range(1,context_lenght+1)):
### WordCell####
name = "contextL{}".format(context_number)
exist_columns = self.statsdb.col(table_name)
if name not in exist_columns:
if self.statsdb.add_col(table_name, name, "JSON"):
self.logger.debug("'{}'-Columns was inserted into '{}'-Table. ".format(name, table_name))
else:
return False
else:
self.logger.error("'{}'-Column is already exist in the '{}'-Table. ColumnInsertion was aborted. ".format(name, table_name))
#yield False
return False
### Additional Info Col ####
name = "context_infoL{}".format(context_number)
exist_columns = self.statsdb.col(table_name)
if name not in exist_columns:
if self.statsdb.add_col(table_name, name, "JSON"):
self.logger.debug("'{}'-Columns was inserted into '{}'-Table. ".format(name, table_name))
else:
return False
else:
self.logger.error("'{}'-Column is already exist in the '{}'-Table. ColumnInsertion was aborted. ".format(name, table_name))
#yield False
return False
# context right
for context_number in range(1,context_lenght+1):
### WordCell####
name = "contextR{}".format(context_number)
if name not in exist_columns:
self.statsdb.add_col(table_name, name, "JSON")
self.logger.debug("'{}'-Columns was inserted into '{}'-Table. ".format(name, table_name))
#yield True
else:
self.logger.error("'{}'-Column is already exist in the '{}'-Table. ColumnInsertion was aborted. ".format(name, table_name))
return False
#return
### Additional Info Col ####
name = "context_infoR{}".format(context_number)
if name not in exist_columns:
self.statsdb.add_col(table_name, name, "JSON")
self.logger.debug("'{}'-Columns was inserted into '{}'-Table. ".format(name, table_name))
#yield True
else:
self.logger.error("'{}'-Column is already exist in the '{}'-Table. ColumnInsertion was aborted. ".format(name, table_name))
return False
#return
exist_columns = self.statsdb.col(table_name)
#p(exist_columns,"exist_columns", c="r")
return True
#sys.exit()
def info(self):
if not self._check_stats_db_should_exist():
return False
if not self._check_db_should_be_an_stats():
return False
return self.statsdb.get_all_attr()
# def get_streams_from_corpus(self,inp_corp,stream_number,datatyp="dict"):
# row_num = inp_corp.corpdb.rownum("documents")
# rows_pro_stream = row_num/stream_number
# streams = []
# num_of_getted_items = 0
# for i in range(stream_number):
# thread_name = "Thread{}".format(i)
# if i < (stream_number-1): # for gens in between
# gen = inp_corp.corpdb.lazyget("documents",limit=rows_pro_stream, offset=num_of_getted_items,thread_name=thread_name, output=datatyp)
# num_of_getted_items += rows_pro_stream
# streams.append((thread_name,LenGen(gen, rows_pro_stream)))
# else: # for the last generator
# gen = inp_corp.corpdb.lazyget("documents",limit=-1, offset=num_of_getted_items,thread_name=thread_name, output=datatyp)
# streams.append((thread_name,LenGen(gen, row_num-num_of_getted_items)))
# return streams
def get_streams_from_corpus(self,inp_corp,stream_number,datatyp="dict", size_to_fetch=1000):
row_num = inp_corp.corpdb.rownum("documents")
rows_pro_stream = row_num/stream_number
streams = []
num_of_getted_items = 0
#p((self._id_field_name, self._text_field_name))
def intern_gen(limit, offset):
#p((limit, offset))
query = u'SELECT {}, {} FROM main.documents LIMIT {} OFFSET {};'.format(self._id_field_name, self._text_field_name,limit, offset)
cur = inp_corp.corpdb._threads_cursors[thread_name].execute(query)
while True:
res = list(cur.fetchmany(size_to_fetch))
if not res:
break
for row in res:
#yield {self._id_field_name:row[0], self._text_field_name:row[1]}
yield row
#p(num_of_getted_items,"num_of_getted_items")
for i in range(stream_number):
thread_name = "Thread{}".format(i)
if i < (stream_number-1): # for gens in between
#gen = inp_corp.corpdb.lazyget("documents",limit=rows_pro_stream, offset=num_of_getted_items,thread_name=thread_name, output=datatyp)
#gen = inp_corp.corpdb.lazyget("documents",limit=rows_pro_stream, offset=num_of_getted_items,thread_name=thread_name, output=datatyp)
#p((rows_pro_stream, num_of_getted_items))
streams.append((thread_name,LenGen(intern_gen(rows_pro_stream, num_of_getted_items), rows_pro_stream)))
num_of_getted_items += rows_pro_stream
#print num_of_getted_items, rows_pro_stream
else: # for the last generator
#gen = inp_corp.corpdb.lazyget("documents",limit=-1, offset=num_of_getted_items,thread_name=thread_name, output=datatyp)
#p((-1, num_of_getted_items))
streams.append((thread_name,LenGen(intern_gen(-1, num_of_getted_items), row_num-num_of_getted_items)))
num_of_getted_items += rows_pro_stream
return streams
# query = u'SELECT {}, {} FROM main.documents LIMIT {} OFFSET {};'.format(self._id_field_name, self._text_field_name,rows_pro_stream, num_of_getted_items)
# while True:
# #p(cursor, "cursor")
# results = cursor["out_obj"].fetchmany(size_to_fetch)
# #p(results, "results")
# results = list(results)
# #p(results, "results")
# if not results:
# break
# for row in results:
# #p(row,"row")
# yield row
def _get_export_phanomena(self,repl=False, redu=False, baseline=False):
to_export = []
if repl:
to_export.append("repl")
if redu:
to_export.append("redu")
if baseline:
to_export.append("baseline")
return to_export
def _get_exporter_flags(self,repl=False, redu=False, baseline=False):
flags = []
if redu:
flags.append(True)
if repl:
flags.append(True)
if baseline:
flags.append(True)
return flags
# def _get_header(self, flags, repl=False, redu=False, baseline=False, output_table_type="exhausted", embedded_baseline=True, max_scope=False, additional_doc_cols=False):
# header_main = []
# header_additional = []
# baseline_col_names = Stats.output_tables_col_names["baseline"]
# extracted_colnames_for_repl = [item[0] for item in db_helper.default_tables["stats"]["replications"]]
# extracted_colnames_for_redu = [item[0] for item in db_helper.default_tables["stats"]["reduplications"]]
# baseline_col_names_repl = [baseline_col_names["all"],baseline_col_names["repl"]["uniq"],baseline_col_names["repl"]["exhausted"]]
# baseline_col_names_redu = [baseline_col_names["all"],baseline_col_names["redu"]["uniq"],baseline_col_names["redu"]["exhausted"]]
# #db_helper.get
# if max_scope and max_scope >1:
# header_main.append("syntagma")
# header_additional.append("syntagma")
# if len(flags) == 1:
# if repl:
# header_main = [item[0] for item in db_helper.default_tables["stats"]["replications"]]
# elif redu:
# header_main = [item[0] for item in db_helper.default_tables["stats"]["reduplications"]]
# elif baseline:
# header_main = [item[0] for item in db_helper.default_tables["stats"]["baseline"]]
# elif len(flags) == 2:
# if output_table_type == "sum":
# pass
# else:
# if repl and baseline:
# if embedded_baseline:
# #header_main.append(db_helper.tag_normalized_word)
# #extracted_colnames_for_repl.remove(db_helper.tag_normalized_word)
# extracted_colnames_for_repl.remove(db_helper.tag_normalized_word)
# header_main.append(db_helper.tag_normalized_word)
# header_main += baseline_col_names_repl
# header_main += extracted_colnames_for_repl
# else:
# header_main += extracted_colnames_for_repl
# baseline_col_names_repl.insert(0,db_helper.tag_normalized_word)
# header_additional += baseline_col_names_repl
# elif redu and baseline:
# if embedded_baseline:
# #header_main.append(db_helper.tag_normalized_word)
# extracted_colnames_for_redu.remove(db_helper.tag_normalized_word)
# header_main.append(db_helper.tag_normalized_word)
# header_main += baseline_col_names_redu
# header_main += extracted_colnames_for_redu
# else:
# header_main += extracted_colnames_for_redu
# baseline_col_names_redu.insert(0,db_helper.tag_normalized_word)
# header_additional += baseline_col_names_redu
# elif redu and repl:
# extracted_colnames_for_repl.remove(db_helper.tag_normalized_word)
# extracted_colnames_for_redu.remove(db_helper.tag_normalized_word)
# #header_main.append(db_helper.tag_normalized_word)
# header_main.append(db_helper.tag_normalized_word)
# #if embedded_baseline:
# #header_main.append(db_helper.tag_normalized_word)
# uniq_for_redu = [item for item in extracted_colnames_for_redu if item not in extracted_colnames_for_repl]
# header_main += extracted_colnames_for_repl+uniq_for_redu
# elif len(flags) == 3:
# if embedded_baseline:
# extracted_colnames_for_repl.remove(db_helper.tag_normalized_word)
# extracted_colnames_for_redu.remove(db_helper.tag_normalized_word)
# header_main.append(db_helper.tag_normalized_word)
# header_additional.append(db_helper.tag_normalized_word)
# header_additional += baseline_col_names_repl
# baseline_col_names_redu.remove(baseline_col_names["all"])
# header_additional += baseline_col_names_redu
# header_main += extracted_colnames_for_repl
# uniq_for_redu = [item for item in extracted_colnames_for_redu if item not in extracted_colnames_for_repl]
# header_main += uniq_for_redu
# else:
# extracted_colnames_for_repl.remove(db_helper.tag_normalized_word)
# extracted_colnames_for_redu.remove(db_helper.tag_normalized_word)
# header_main.append(db_helper.tag_normalized_word)
# header_main += baseline_col_names_repl
# baseline_col_names_redu.remove(baseline_col_names["all"])
# header_main += baseline_col_names_redu
# header_main += extracted_colnames_for_repl
# uniq_for_redu = [item for item in extracted_colnames_for_redu if item not in extracted_colnames_for_repl]
# header_main += uniq_for_redu
# #self.logger.error("Simultan Export for 3 Phenomena at the same time is not implemented.")
# if len(header_additional)==1:
# header_additional = []
# if header_main and header_additional:
# return header_main, header_additional
# elif header_main:
# return header_main
def _add_context_columns(self, table_name, context_lenght):
#p("ghjkl")
exist_columns = self.statsdb.col(table_name)
#p(exist_columns,"exist_columns", c="r")
## context left
for context_number in reversed(range(1,context_lenght+1)):
### WordCell####
name = "contextL{}".format(context_number)
exist_columns = self.statsdb.col(table_name)
if name not in exist_columns:
if self.statsdb.add_col(table_name, name, "JSON"):
self.logger.debug("'{}'-Columns was inserted into '{}'-Table. ".format(name, table_name))
else:
return False
else:
self.logger.error("'{}'-Column is already exist in the '{}'-Table. ColumnInsertion was aborted. ".format(name, table_name))
#yield False
return False
### Additional Info Col ####
name = "context_infoL{}".format(context_number)
exist_columns = self.statsdb.col(table_name)
if name not in exist_columns:
if self.statsdb.add_col(table_name, name, "JSON"):
self.logger.debug("'{}'-Columns was inserted into '{}'-Table. ".format(name, table_name))
else:
return False
else:
self.logger.error("'{}'-Column is already exist in the '{}'-Table. ColumnInsertion was aborted. ".format(name, table_name))
#yield False
return False
# context right
for context_number in range(1,context_lenght+1):
### WordCell####
name = "contextR{}".format(context_number)
if name not in exist_columns:
self.statsdb.add_col(table_name, name, "JSON")
self.logger.debug("'{}'-Columns was inserted into '{}'-Table. ".format(name, table_name))
#yield True
else:
self.logger.error("'{}'-Column is already exist in the '{}'-Table. ColumnInsertion was aborted. ".format(name, table_name))
return False
#return
### Additional Info Col ####
name = "context_infoR{}".format(context_number)
if name not in exist_columns:
self.statsdb.add_col(table_name, name, "JSON")
self.logger.debug("'{}'-Columns was inserted into '{}'-Table. ".format(name, table_name))
#yield True
else:
self.logger.error("'{}'-Column is already exist in the '{}'-Table. ColumnInsertion was aborted. ".format(name, table_name))
return False
#return
exist_columns = self.statsdb.col(table_name)
#p(exist_columns,"exist_columns", c="r")
return True
#sys.exit()
def attached_corpdb_number(self):
if not self._check_stats_db_should_exist():
return False
return len(self.statsdb.dbnames)-1
def attach_corpdb(self, path_to_corpdb, encryption_key=False):
if not self._check_stats_db_should_exist():
return False
#p(path_to_corpdb, "path_to_corpdb")
if not self.statsdb.attach(path_to_corpdb, encryption_key=encryption_key, db_name=self.corpdb_defaultname)["status"]:
self.logger.error("'{}' wasn't attached.".format(path_to_corpdb))
return False
id_from_attached_corp = self.statsdb.get_attr("id",dbname=self.corpdb_defaultname)
corp_id = self.statsdb.get_attr("corpus_id",dbname="main")
#p(())
if id_from_attached_corp != corp_id:
self.logger.error("Attached CorpDB (id='{}') is not suitable with the current StatsDB. Current StatsDB is suitable with CorpDB with id='{}'.".format(id_from_attached_corp, corp_id))
self.statsdb.detach(dbname=self.corpdb_defaultname)
return False
self.attached_corpdb_name = self.corpdb_defaultname
return True
def _get_context_cols(self, direction, context_lenght):
output = ()
if direction == "left":
for context_number in reversed(range(1,context_lenght+1)):
### WordCell####
output += ("contextL{}".format(context_number),)
### Additional Info Col ####
output += ("context_infoL{}".format(context_number),)
else:
# context right
for context_number in range(1,context_lenght+1):
### WordCell####
output += ("contextR{}".format(context_number),)
### Additional Info Col ####
output += ("context_infoR{}".format(context_number),)
return output
def _get_header(self, repl=False, redu=False, baseline=False, output_table_type="exhausted", max_scope=False, additional_doc_cols=False, context_len_left=True, context_len_right=True,word_examples_sum_table=True):
if not self._check_stats_db_should_exist():
return False
if output_table_type == "exhausted":
return self._get_header_exhausted( repl=repl, redu=redu, baseline=baseline, additional_doc_cols=additional_doc_cols, context_len_left=context_len_left, context_len_right=context_len_right)
else:
return self._get_header_sum(repl=repl, redu=redu,word_examples_sum_table=word_examples_sum_table)
def _get_header_sum(self, repl=False, redu=False, word_examples_sum_table=True):
if repl and redu:
self.logger.error("GetSummeryHeaderError: Repl and Redu was selected in the same time. Summery Header could be created just for one Phenomen each time.")
return False
output = False
col_repls_core = ("letter", "NrOfRepl", "Occur")
col_redus_core = ("word", "ReduLength", "Occur")
if repl:
col_repls_core = col_repls_core+("Examples",) if word_examples_sum_table else col_repls_core
output = col_repls_core
if redu:
#col_redus_core = col_redus_core+("Examples",) if word_examples_sum_table else col_redus_core
output = col_redus_core
return output
def _get_header_exhausted(self, repl=False, redu=False, baseline=False, additional_doc_cols=False, context_len_left=True, context_len_right=True):
if (repl and not baseline) or (redu and not baseline):
self.logger.error("Export is possible just with selected baseline. Please select also baseline to start the export process.")
return False
if baseline:
baseline = ()
baseline += db_helper.default_col_baseline_main
baseline += db_helper.default_col_baseline_repls_core if repl else ()
baseline += db_helper.default_col_baseline_redus_core if redu else ()
baseline += db_helper.default_col_baseline_repls_addit if repl else ()
baseline += db_helper.default_col_baseline_redus_addit if redu else ()
baseline = tuple(item[0] for item in baseline)
if repl:
repl = ()
repl += db_helper.default_col_for_rep_core
repl += db_helper.default_col_for_rep_indexes
repl += db_helper.default_col_for_rep_repl_data
repl = tuple(item[0] for item in repl)
if redu:
redu = ()
redu += db_helper.default_col_for_rep_core
redu += db_helper.default_col_for_rep_indexes
redu += db_helper.default_col_for_rep_redu_data
redu = tuple(item[0] for item in redu)
word = ()
if repl and not redu:
word += db_helper.default_col_for_repl_word_info
word += db_helper.default_col_for_rep_addit_info_word
elif not repl and redu:
word += db_helper.default_col_for_redu_word_info
word += db_helper.default_col_for_rep_addit_info_word
elif repl and redu:
word += db_helper.default_col_for_repl_word_info
word += db_helper.default_col_for_rep_addit_info_word
word = tuple(item[0] for item in word) if word else ()
document = ()
context = ()
if repl or redu:
document += (tuple(item[0] for item in db_helper.default_col_for_rep_doc_info) ,)
if additional_doc_cols:
document += (tuple(additional_doc_cols),)
else:
document += (None,)
## context left
#context += ()
avalible_context_num_in_stats = self.statsdb.get_attr("context_lenght")
if context_len_left:
context_len_left = avalible_context_num_in_stats if context_len_left is True else context_len_left
if context_len_left > avalible_context_num_in_stats:
self.logger.error("Given ContextLeft Number is higher as possible. Current StatsDB was computed for '{}'-context number. Please use one number, which are not higher as computed context number for current StatsDB.".format(context_len_left,avalible_context_num_in_stats))
return False
context += self._get_context_cols("left", context_len_left)
if context_len_right:
context_len_right = avalible_context_num_in_stats if context_len_right is True else context_len_right
if context_len_right > avalible_context_num_in_stats:
self.logger.error("Given ContextRight Number is higher as possible. Current StatsDB was computed for '{}'-context number. Please use one number, which are not higher as computed context number for current StatsDB.".format(context_len_right,avalible_context_num_in_stats))
return False
context += self._get_context_cols("right", context_len_right)
if not repl and not redu and not baseline:
return {}
else:
return {"baseline":baseline, "document":document, "word":word, "repl":repl, "redu":redu, "context":context}
def cols_exists_in_corpb(self, cols_to_check):
if not self._check_stats_db_should_exist():
return False
if not self.attached_corpdb_name:
self.logger.error("'{}' wasn't attached.".format(path_to_corpdb))
return False
cols_in_doc_tables_in_attached_corp = self.statsdb.col("documents", dbname=self.attached_corpdb_name)
for col in cols_to_check:
if col not in cols_in_doc_tables_in_attached_corp:
self.logger.error("'{}'-ColumnName wasn't found in CorpDB. Please use one of the following additional ColNames: '{}'.".format(col, cols_in_doc_tables_in_attached_corp))
return False
return True
def order_header(self,header, additional_doc_cols,export_file_type):
#p(header, "header")
if export_file_type == "csv":
wrapped_tag_pattern = "[{}]."
else:
wrapped_tag_pattern = "{}."
ordered_header = []
for table_part in Stats.header_order_to_export:
if table_part == "document":
#p(header[table_part], "header[table_part]")
try:
temp_list = list(header[table_part][0])
except:
temp_list = []
wrapped_tag = wrapped_tag_pattern.format(table_part)
ordered_header += ["{}{}".format(wrapped_tag,col) for col in temp_list ]
if additional_doc_cols:
if header[table_part][1]:
temp_list = list(header[table_part][1])
wrapped_tag = wrapped_tag_pattern.format(table_part)
ordered_header += ["{}{}".format(wrapped_tag,col) for col in temp_list ]
#p(ordered_header, "ordered_header")
else:
if header[table_part]:
for col in header[table_part]:
#p(col, "col " )
wrapped_tag = wrapped_tag_pattern.format(table_part)
ordered_header.append("{}{}".format(wrapped_tag,col))
return ordered_header
#Stats._non_pos_tags = set(["EMOIMG", "EMOASC", "number", "symbol", "hashtag", "mention","regular"])
def export(self,path_to_export_dir, syntagma="*", repl=False, redu=False,
baseline=True, syntagma_type="lexem", sentiment=False,
fname=False, export_file_type="csv", rows_limit_in_file=1000000,
encryption_key_corp=False, output_table_type="exhausted",
additional_doc_cols=False, encryption_key_for_exported_db=False,
path_to_corpdb=False, max_scope=False, stemmed_search=False,rewrite=False,
context_len_left=True, context_len_right=True, separator_syn=" || ",
word_examples_sum_table=True,ignore_num=False,ignore_symbol=False,):
#p(locals())
#p((path_to_export_dir,syntagma,repl,redu,syntagma_type,max_scope))
export_file_type = export_file_type.lower()
fname =fname if fname else "export_{}".format(time.time())
if self.statsdb.get_attr("locked"):
self.logger.error("Current DB is still be locked. Possibly it is right now in-use from other process or the last computation-process is failed.")
return False
if export_file_type not in Exporter.supported_file_formats:
self.logger.error("ExportError: '{}'-FileType is not supported. Please use one of the following file type: '{}'.".format(export_file_type, Exporter.supported_file_formats))
return False
if output_table_type not in Stats.output_tables_types:
self.logger.error("Given Type for the outputTable ('{}') is not supported. Please select one of the following types: '{}'. ".format(output_table_type, Stats.output_tables_types))
return False
if sentiment:
if not self._sentiment_analyzer:
self.logger.error("GetterError: Sentiment wasn't computed for current CorpusDB thats why it is not possible to export Data with sentiment.")
return False
if syntagma_type == "pos":
if not self._pos_tagger:
if syntagma != "*":
try:
syntagma[0].decode
for word in syntagma:
if word not in Stats._non_pos_tags:
self.logger.error(u"POSGetterError: Additional POS-Tag was found in Syntagma. ('{}') Current CorpusDB contain just default meta tags. ('{}') If you want to search in additional POS, than recompute CorpusDB with POS-Tagger.".format(word,Stats._non_pos_tags))
return False
except:
try:
syntagma[0][0].decode
for syn in syntagma:
for word in syn:
if word not in Stats._non_pos_tags:
self.logger.error(u"POSGetterError: Additional POS-Tag was found in Syntagma. ('{}') Current CorpusDB contain just default meta tags. ('{}') If you want to search in additional POS, than recompute CorpusDB with POS-Tagger.".format(word,Stats._non_pos_tags))
return False
except:
self.logger.error("SyntagmaError: Given Syntagma has incorrect structure.")
return False
#if repl and redu and baseline:
# self.logger.critical("It is not possible to get repls and redus parallel. Please select one option at the same moment.")
# return False
flags = self._get_exporter_flags(repl=repl, redu=redu, baseline=baseline)
if len(flags) == 0:
self.logger.error("No One Phenomena to Export was selected")
return False
if path_to_corpdb:
if not self.attach_corpdb(path_to_corpdb):
self.logger.debug("Given CorpDB '{}' either not exist or not suitable with the current StatsDB.".format(path_to_corpdb))
return False
if not path_to_corpdb and additional_doc_cols:
self.logger.error("Additional Columns from CorpusDB was given, but the path to CorpDB wasn't given. Please give also the path to CorpDB.")
return False
if additional_doc_cols:
if not self.cols_exists_in_corpb(additional_doc_cols):
return False
if output_table_type == "sum":
reptype_sum_table = "repl" if repl else "redu"
else:
reptype_sum_table = False
# p(locals())
#p(max_scope, "max_scope")
header = self._get_header( repl=repl, redu=redu, baseline=True, output_table_type=output_table_type, max_scope=max_scope, additional_doc_cols=additional_doc_cols, context_len_left=context_len_left, context_len_right=context_len_right,word_examples_sum_table=word_examples_sum_table)
if not header:
return False
rows_generator = self._export_generator(header,inp_syntagma=syntagma, reptype_sum_table=reptype_sum_table,
syntagma_type=syntagma_type, sentiment=sentiment, separator_syn=separator_syn,
output_table_type=output_table_type,max_scope=max_scope,
ignore_num=ignore_num,ignore_symbol=ignore_symbol,
word_examples_sum_table=word_examples_sum_table,stemmed_search=stemmed_search)
if not rows_generator:
self.logger.error("RowGenerator is failed.")
return False
if output_table_type == "sum":
ordered_header = header
else:
ordered_header = self.order_header(header, additional_doc_cols,export_file_type)
#p(ordered_header, "ordered_header")
def intern_gen():
# p("111")
for row in rows_generator:
# p("222")
if row:
yield {k:v for k,v in zip(ordered_header,row)}
exporter = Exporter(intern_gen(),rewrite=rewrite,silent_ignore=False )
if export_file_type == "csv":
exporter.tocsv(path_to_export_dir, fname, ordered_header, rows_limit_in_file=rows_limit_in_file)
elif export_file_type == "xml":
exporter.toxml(path_to_export_dir, fname, rows_limit_in_file=rows_limit_in_file, root_elem_name="export", row_elem_name="line")
#elif export_file_type == "sqlite":
# exporter.tosqlite(path_to_export_dir, fname, ordered_header, encryption_key=encryption_key_for_exported_db, table_name="Export")
elif export_file_type == "json":
exporter.tojson(path_to_export_dir, fname, rows_limit_in_file=rows_limit_in_file,)
else:
self.logger.error("'{}'-FileType is not supported..".format(export_file_type))
return False
def _get_values_from_doc(self, doc_id, cols_to_get):
if not self.attached_corpdb_name:
self.logger.error("No One CorpDB was attached. To get additional Columns from corpus, you need attach the right CorpDB before.")
return False
#p((doc_id, cols_to_get), c="m")
#p(self.statsdb.getall("documents", columns=cols_to_get, dbname=self.attached_corpdb_name, where="{}={}".format(self._doc_id_tag, doc_id)), c="r")
return self.statsdb.getone("documents", columns=cols_to_get, dbname=self.attached_corpdb_name, where="{}={}".format(self._doc_id_tag, doc_id))
def _export_generator(self,header,inp_syntagma="*", syntagma_type="lexem", sentiment=False,
output_table_type="exhausted", reptype_sum_table=False, separator_syn=" || ",
thread_name="Thread0",ignore_num=False,ignore_symbol=False,
word_examples_sum_table=True,max_scope=False,stemmed_search=False):
if not separator_syn:
self.logger.error("No Separator for Syntagma was selected.")
yield False
return
# p((inp_syntagma, max_scope),c="r")
#p(locals())
def redu_constr(single_redu):
temp_row = []
for table_part in Stats.header_order_to_export:
if table_part == "baseline":
temp_row += current_ordered_baseline_row
#p(temp_row, "temp_row")
elif table_part == "document":
#p(header["document"])
temp_row += [single_redu[ix_redu[col_name]] for col_name in header["document"][0]]
doc_id = single_redu[ix_doc_id_redu]
col_from_corp = header["document"][1]
#p(col_from_corp, "col_from_corp", c="g")
if col_from_corp:
values_from_corp = self._get_values_from_doc(doc_id, col_from_corp)
#p(values_from_corp, "values_from_corp")
if values_from_corp:
temp_row += list(values_from_corp)
else:
self.logger.error("No values from Corpus was returned")
yield False
return
elif table_part == "word":
temp_row += [None if col_name == 'rle_word' else single_redu[ix_redu[col_name]] for col_name in header["word"]]
elif table_part == "repl":
temp_row += [None for col_name in header["repl"]]
elif table_part == "redu":
temp_row += [single_redu[ix_redu[col_name]] for col_name in header["redu"]]
#extracted_redus.append(single_redu[ix_redu_id])
elif table_part == "context":
temp_row += [single_redu[ix_redu[col_name]] for col_name in header["context"]]
#exported_rows_count += 1
#p(temp_row, "2121temp_row",c="m")
#exported_rows_count += 1
yield temp_row
return
# p("!99999")
if output_table_type == "sum":
if reptype_sum_table not in ("repl", "redu"):
self.logger.error("Wrong RepType ('{}') was selected.".format(reptype_sum_table))
yield False
return
if self._status_bar:
try:
if not self.status_bars_manager.enabled:
self.status_bars_manager = self._get_status_bars_manager()
except:
self.status_bars_manager = self._get_status_bars_manager()
status_bar_start = self._get_new_status_bar(None, self.status_bars_manager.term.center("Exporter (sum)") , "", counter_format=self.status_bars_manager.term.bold_white_on_green("{fill}{desc}{fill}"))
status_bar_start.refresh()
data = self.compute_rep_sum(inp_syntagma, reptype_sum_table, syntagma_type=syntagma_type, sentiment=sentiment,
stemmed_search=stemmed_search, thread_name=thread_name, ignore_num=ignore_num,
ignore_symbol=ignore_symbol, word_examples_sum_table=word_examples_sum_table)
#p(data, "data")
exported_rows_count = 0
if reptype_sum_table == "redu":
tag = "Words"
if self._status_bar:
status_bar_current = self._get_new_status_bar(len(data), "Exporting:", "word")
for word, word_data in dict(sorted(data.items())).items():
if self._status_bar:
status_bar_current.update(incr=1)
for redu_length, occur in dict(sorted(word_data.items())).items():
exported_rows_count += 1
yield (word, redu_length,occur)
#pass
else:
tag = "Letters"
if self._status_bar:
status_bar_current = self._get_new_status_bar(len(data), "Exporting:", "letter")
for letter, letter_data in dict(sorted(data.items())).items():
if self._status_bar:
status_bar_current.update(incr=1)
for NrOfRepl, repl_data in dict(sorted(letter_data.items())).items():
exported_rows_count += 1
occur = repl_data[0]
temp_row = (letter, NrOfRepl, occur)
if word_examples_sum_table:
examples = dict(repl_data[1])
temp_row += (examples, )
yield temp_row
if self._status_bar:
#i += 1
#print status_bar_current.total, i
#if status_bar_current.total != i:
# status_bar_current.total = i
status_bar_total_summary = self._get_new_status_bar(None, self.status_bars_manager.term.center("Exported: {}:'{}'; Rows: '{}'; ".format(tag, status_bar_current.count,exported_rows_count) ), "", counter_format=self.status_bars_manager.term.bold_white_on_green('{fill}{desc}{fill}\n'))
status_bar_total_summary.refresh()
self.status_bars_manager.stop()
else:
# p("!88888")
if not header:
self.logger.error("Header is empty. Please give non-empty header.")
yield False
return
try:
repl = True if header["repl"] else False
redu = True if header["redu"] else False
baseline = True if header["baseline"] else False
except:
self.logger.error("Header has wrong structure. Please give header with the right structure. Probably was selected not correct 'output_table_type'. ")
yield False
return
#p((header, repl, redu, baseline))
#Stats.header_order_to_export
# p("!7777")
data = self.get_data(inp_syntagma=inp_syntagma,repl=repl, redu=redu, baseline=baseline, syntagma_type=syntagma_type,
sentiment=sentiment,thread_name=thread_name, max_scope=max_scope, stemmed_search=stemmed_search,send_empty_marker=True,
minimum_columns=False,order_output_by_syntagma_order=False, return_full_tuple=False,delete_duplicates=True,
get_columns_repl=False,get_columns_redu=False,get_columns_baseline=False,if_type_pos_return_lexem_syn=True)
#p(len(data), "dd")
# p((inp_syntagma, repl, redu,baseline, syntagma_type, sentiment, thread_name,max_scope, stemmed_search,), c="r")
if not data:
self.logger.error("Current Generator wasn't initialized. Because No Data was found in the current StatsDB for current settings. Please try to change the settings.")
yield False
return
if self._status_bar:
try:
if not self.status_bars_manager.enabled:
self.status_bars_manager = self._get_status_bars_manager()
except:
self.status_bars_manager = self._get_status_bars_manager()
status_bar_start = self._get_new_status_bar(None, self.status_bars_manager.term.center("Exporter (exhausted)") , "", counter_format=self.status_bars_manager.term.bold_white_on_green("{fill}{desc}{fill}"))
status_bar_start.refresh()
status_bar_current_all = self._get_new_status_bar(self.statsdb.rownum("baseline"), "All:", "syntagma")
#p(len(data), "dd")
status_bar_current_right = self._get_new_status_bar(len(data), "Qualified:", "syntagma")
status_bar_current_all.refresh()
status_bar_current_right.refresh()
# p("!666")
ix_baseline = self.col_index_orig["baseline"]
ix_repl = self.col_index_orig["repl"]
ix_redu = self.col_index_orig["redu"]
ix_repl_in_redu = ix_repl["in_redu"]
ix_redu_in_redufree = ix_redu["index_in_redufree"]
ix_doc_id_repl = ix_repl["doc_id"]
ix_doc_id_redu = ix_redu["doc_id"]
ix_redu_id = ix_redu["id"]
i = 0
exported_rows_count = 0
# p("!555")
# p(data, "data")
count = 0
for i, item in enumerate(data):
if item == None:
count += 1
# p((i,count))
#p((i, item))
# p(item, "item")
if not item:
if self._status_bar:
status_bar_current_all.update(incr=1)
continue
i += 1
# p("!444")
if self._status_bar:
status_bar_current_all.update(incr=1)
status_bar_current_right.update(incr=1)
#if inp_syntagma == ["klitze, kleine"]:
# p(item, "item")
#p(item , "item")
#temp_rows = []
#### Prepare Baseline
vals_bas = item["baseline"]
if not vals_bas:
self.logger.error("'baseline'-Element is empty. (syntagma: '{}')".format(item["syntagma"]))
yield False
break
#ret
#p(vals_bas, "vals_bas")
#p(header["baseline"],'header["baseline"]')
if len(vals_bas)> 1:
#p(vals_bas, "vals_bas")
self.logger.error( "Baseline Element has more as 1 item. If you searching in 'pos' and you got this error, please select 'if_type_pos_return_lexem_syn'-option to ensure right work. ")
yield False
return
vals_bas = vals_bas[0]
#p(vals_bas,"vals_bas")
#current_ordered_baseline_row = [ " || ".join(vals_bas[ix_baseline[col_name]]) if col_name in ["syntagma", "stemmed"] else vals_bas[ix_baseline[col_name]] for col_name in header["baseline"]]
current_ordered_baseline_row = []
for col_name in header["baseline"]:
if col_name == "syntagma":
current_ordered_baseline_row.append(separator_syn.join(vals_bas[ix_baseline[col_name]]))
elif col_name == "stemmed":
current_ordered_baseline_row.append(separator_syn.join(vals_bas[ix_baseline[col_name]].split(self._baseline_delimiter)))
else:
current_ordered_baseline_row.append(vals_bas[ix_baseline[col_name]])
#p(current_ordered_baseline_row, "current_ordered_baseline_row")
### Prepare Other Data
if repl:
#temp_row = []
vals_repl = item["repl"]
if not vals_repl:
if redu:
vals_redu = item["redu"]
if vals_redu: # if just redus was found, but not repls for current syntagma, than extract just redus
for single_redu in vals_redu:
exported_rows_count += 1
yield tuple(redu_constr(single_redu))[0]
#vals_redu_dict = {singl_redu[ix_doc_id_redu]:{} for singl_redu in vals_redu}
#return
if redu:
vals_redu = item["redu"]
vals_redu_dict = defaultdict(lambda:defaultdict(None))
redu_ids = defaultdict(dict)
for singl_redu in vals_redu:
redu_doc_id = singl_redu[ix_doc_id_redu]
redu_index = singl_redu[ix_redu_in_redufree]
redu_ids[singl_redu[ix_redu_id]] = (singl_redu[ix_doc_id_redu], singl_redu[ix_redu_in_redufree])
vals_redu_dict[redu_doc_id][redu_index] = singl_redu
#vals_redu_dict = {singl_redu[ix_doc_id_redu]:{} for singl_redu in vals_redu}
#temp_data = []
extracted_redus= set()
for single_repl in vals_repl:
temp_row = []
#p(single_repl, "single_repl", c="r")
#for
for table_part in Stats.header_order_to_export:
if table_part == "baseline":
temp_row += current_ordered_baseline_row
elif table_part == "document":
#p(header["document"])
temp_row += [single_repl[ix_repl[col_name]] for col_name in header["document"][0]]
doc_id = single_repl[ix_doc_id_repl]
col_from_corp = header["document"][1]
#p(col_from_corp, "col_from_corp", c="g")
if col_from_corp:
values_from_corp = self._get_values_from_doc(doc_id, col_from_corp)
#p(values_from_corp, "values_from_corp")
if values_from_corp:
temp_row += list(values_from_corp)
else:
self.logger.error("No values from Corpus was returned")
yield False
return
elif table_part == "word":
temp_row += [single_repl[ix_repl[col_name]] for col_name in header["word"]]
elif table_part == "repl":
temp_row += [single_repl[ix_repl[col_name]] for col_name in header["repl"]]
elif table_part == "redu":
if redu:
in_redu = single_repl[ix_repl_in_redu]
if in_redu:
if not vals_redu: # if wasn't found - than re-exctract with other flag
current_syntagma = vals_bas[ix_baseline["syntagma"]]
#p((in_redu,single_repl, vals_redu,current_syntagma))
vals_redu = self._get_data_for_one_syntagma(current_syntagma,redu=True, repl=False, baseline=False,get_also_non_full_repetativ_result=True)["redu"]
#p(vals_redu, "22vals_redu")
vals_redu_dict = defaultdict(lambda:defaultdict(None))
for singl_redu in vals_redu:
vals_redu_dict[singl_redu[ix_doc_id_redu]][singl_redu[ix_redu_in_redufree]] = singl_redu
if not vals_redu:
self.logger.error("ImplementationError: No redus was extracted for '{}'-syntagma. ".format(current_syntagma))
yield False
return
repl_doc_id = single_repl[ix_doc_id_repl]
#p((single_repl))
#p(vals_redu_dict[repl_doc_id].keys(), "111redu_ixs")
try:
redu_for_current_repl = vals_redu_dict[repl_doc_id][in_redu]
except KeyError:
current_syntagma = vals_bas[ix_baseline["syntagma"]]
#!!!!!!!p((in_redu,single_repl, vals_redu,current_syntagma))
vals_redu = self._get_data_for_one_syntagma(current_syntagma,redu=True, repl=False, baseline=False,get_also_non_full_repetativ_result=True)["redu"]
#p(vals_redu, "22vals_redu")
vals_redu_dict = defaultdict(lambda:defaultdict(None))
for singl_redu in vals_redu:
vals_redu_dict[singl_redu[ix_doc_id_redu]][singl_redu[ix_redu_in_redufree]] = singl_redu
if not vals_redu:
self.logger.error("ImplementationError: No redus was extracted for '{}'-syntagma. ".format(current_syntagma))
yield False
return
#p((single_repl))
#p(vals_redu_dict[repl_doc_id].keys(), "222redu_ixs")
redu_for_current_repl = vals_redu_dict[repl_doc_id][in_redu]
if not redu_for_current_repl: # if wasn't found - than re-exctract with other flag
self.logger.error("DB-Inconsistence or ImplementationError: For Current Repl ('{}') in Redu ('{}') wasn't found any redu in the StatsDB.".format(single_repl, in_redu))
yield False
return
temp_row += [redu_for_current_repl[ix_redu[col_name]] for col_name in header["redu"]]
extracted_redus.add(redu_for_current_repl[ix_redu_id])
else:
temp_row += [None for col_name in header["redu"]]
elif table_part == "context":
temp_row += [single_repl[ix_repl[col_name]] for col_name in header["context"]]
exported_rows_count += 1
#p(temp_row, "temp_row")
yield temp_row
## for redus, which still be not extracted
if redu:
for r_id, data in redu_ids.items():
if r_id not in extracted_redus:
redu_to_extract = vals_redu_dict[data[0]][data[1]]
exported_rows_count += 1
#p(tuple(redu_constr(redu_to_extract))[0], c="r")
yield tuple(redu_constr(redu_to_extract))[0]
elif not repl and redu:
temp_row = []
vals_redu = item["redu"]
if not vals_redu:
self.logger.error("'redu'-Element is empty. (syntagma: '{}')".format(item["syntagma"]))
yield False
#return
for single_redu in vals_redu:
temp_row = []
for table_part in Stats.header_order_to_export:
if table_part == "baseline":
temp_row += current_ordered_baseline_row
elif table_part == "document":
#p(header["document"])
temp_row += [single_redu[ix_redu[col_name]] for col_name in header["document"][0]]
col_from_corp = header["document"][1]
doc_id = single_redu[ix_doc_id_redu]
if col_from_corp:
values_from_corp = self._get_values_from_doc(doc_id, col_from_corp)
if values_from_corp:
temp_row += list(values_from_corp)
else:
self.logger.error("No values from Corpus was returned")
yield False
return
elif table_part == "word":
temp_row += [single_redu[ix_redu[col_name]] for col_name in header["word"]]
elif table_part == "redu":
temp_row += [single_redu[ix_redu[col_name]] for col_name in header["redu"]]
elif table_part == "context":
temp_row += [single_redu[ix_redu[col_name]] for col_name in header["context"]]
exported_rows_count += 1
yield temp_row
elif not redu and not repl:
self.logger.error("No one Phanomena was selected. Please select Redu or Repls to export.")
yield False
return
if self._status_bar:
# i += 1
# print status_bar_current_right.total, count, i
# if status_bar_current_right.total != count:
# status_bar_current_right.total = i
# status_bar_current_right.refresh()
#p((status_bar_current_all.total, status_bar_current_all.count))
if status_bar_current_all.total != status_bar_current_all.count:
status_bar_current_all.count = status_bar_current_all.total #= status_bar_current_all.count
status_bar_current_all.refresh()
status_bar_total_summary = self._get_new_status_bar(None, self.status_bars_manager.term.center("Exported: Syntagmas:'{}'; Rows: '{}'; ".format(status_bar_current_right.count,exported_rows_count) ), "", counter_format=self.status_bars_manager.term.bold_white_on_green('{fill}{desc}{fill}\n'))
status_bar_total_summary.refresh()
self.status_bars_manager.stop()
#p(i, "i")
if i == 0:
self.logger.critical("No Data was found for current settings. Please try to change the settings.")
yield False
return
def _check_exist_columns_to_get(self, get_columns_repl, get_columns_redu,get_columns_baseline):
status = True
if get_columns_repl:
columns_from_db = self.statsdb.col("replications")
for col in get_columns_repl:
if col not in columns_from_db:
self.logger.error("'{}'-column is not exist in 'replications'-Table. ".format(col) )
status = False
if get_columns_redu:
columns_from_db = self.statsdb.col("reduplications")
for col in get_columns_redu:
if col not in columns_from_db:
self.logger.error("'{}'-column is not exist in 'reduplications'-Table. ".format(col) )
status = False
if get_columns_baseline:
columns_from_db = self.statsdb.col("baseline")
for col in get_columns_baseline:
if col not in columns_from_db:
self.logger.error("'{}'-column is not exist in 'baseline'-Table. ".format(col) )
status = False
return status
def _convert_cols_to_indexes(self, get_columns_repl,get_columns_redu,get_columns_baseline,indexes):
indexes_to_get_repl = []
indexes_to_get_redu = []
indexes_to_get_baseline = []
if get_columns_repl:
ix = indexes["repl"]
for col in get_columns_repl:
indexes_to_get_repl.append(ix[col])
if get_columns_redu:
ix = indexes["redu"]
for col in get_columns_redu:
indexes_to_get_redu.append(ix[col])
if get_columns_baseline:
ix = indexes["baseline"]
for col in get_columns_baseline:
indexes_to_get_baseline.append(ix[col])
return indexes_to_get_repl,indexes_to_get_redu,indexes_to_get_baseline
#return ""
def _extract_certain_columns(self,data, indexes_to_get_repl,indexes_to_get_redu,indexes_to_get_baseline):
#pass
#indexes = self.col_index_min if minimum_columns else self.col_index_orig
if indexes_to_get_repl:
repls = data["repl"]
if repls:
new_repls = []
for repl in repls:
new_repls.append([repl[i] for i in indexes_to_get_repl])
data["repl"] = new_repls
if indexes_to_get_redu:
redus = data["redu"]
if redus:
new_redus = []
for redu in redus:
new_redus.append([redu[i] for i in indexes_to_get_redu])
data["redu"] = new_redus
if indexes_to_get_baseline:
baseline = data["baseline"]
if baseline:
new_baseline = []
for b in baseline:
new_baseline.append([b[i] for i in indexes_to_get_baseline])
data["baseline"] = new_baseline
return data
def compute_rep_sum(self,syntagma_to_search, reptype, syntagma_type="lexem",sentiment=False,
stemmed_search=False, thread_name="Thread0", ignore_num=False,ignore_symbol=False, word_examples_sum_table=True):
max_scope = 1
if reptype == "repl":
repl = True
redu = False
else:
repl = False
redu = True
num = self._get_row_num_in_baseline_with_rep(redu=redu, repl=repl, max_scope=max_scope)
if self._status_bar:
try:
if not self.status_bars_manager.enabled:
self.status_bars_manager = self._get_status_bars_manager()
except:
self.status_bars_manager = self._get_status_bars_manager()
status_bar_current = self._get_new_status_bar(num, "Summarizing:", "syntagma")
#minimum_columns = True
if reptype == "repl":
collected_repls_from_corp = defaultdict(lambda:defaultdict(lambda: [[],None]))
get_columns_repl = ("doc_id","index_in_corpus","repl_letter", "repl_length", "rle_word", "pos")
### Step 1: Collect Data From Corpus
i = 0
for item in self.get_data(syntagma_to_search, repl=True, redu=False, baseline=False, get_columns_repl=get_columns_repl,
max_scope=max_scope,sentiment=sentiment,syntagma_type=syntagma_type,
stemmed_search=stemmed_search):
if self._status_bar:
status_bar_current.update(incr=1)
i+= 1
#p(item, "item")
#repls = item["repl"]
for repl in item["repl"]:
if ignore_num:
if repl[5] == "number":
continue
if ignore_symbol:
if repl[5] == "symbol":
continue
#p(repl, "repl")
collected_repls_from_corp[repl[0]][repl[1]][0].append((repl[2], repl[3]))
if word_examples_sum_table:
collected_repls_from_corp[repl[0]][repl[1]][1] = repl[4]
### Step 1: Compute Summ
if word_examples_sum_table:
summery = defaultdict(lambda:defaultdict(lambda:[0,defaultdict(lambda: 0) ]))
else:
summery = defaultdict(lambda:defaultdict(lambda:[0]))
for doc_id, doc_data in collected_repls_from_corp.iteritems():
for index_in_corpus , repl_container in doc_data.iteritems():
for repl in repl_container[0]:
#p(repl, "repl")
summery[repl[0]][repl[1]][0] += 1
if word_examples_sum_table:
summery[repl[0]][repl[1]][1][repl_container[1]] += 1
#p(word_examples_sum_table, "word_examples_sum_table")
if self._status_bar:
if status_bar_current.total != i:
#raise Exception, "PREDICED LEN IS NOT CORRECT IN SUM COMPUTER"
status_bar_current.total = i
if i == 0:
self.logger.error("('{}'-sum) Nothing was extracted for '{}'-syntagma. No Data was found for given settings.".format(reptype,syntagma_to_search))
return summery
else:
get_columns_redu = (db_helper.tag_normalized_word,"redu_length", "pos")
collected_redus_from_corp = defaultdict(lambda: defaultdict(lambda:0))
i = 0
#p((syntagma_to_search,max_scope, sentiment, syntagma_type, stemmed_search))
for item in self.get_data(syntagma_to_search, redu=True, repl=False, baseline=False, get_columns_redu=get_columns_redu, max_scope=max_scope,
sentiment=sentiment,syntagma_type=syntagma_type,stemmed_search=stemmed_search):
#p(item,"item")
i += 1
if self._status_bar:
status_bar_current.update(incr=1)
for redu in item["redu"]:
if ignore_num:
if redu[3] == "number":
continue
if ignore_symbol:
if redu[3] == "symbol":
continue
#p(redu)
collected_redus_from_corp[redu[0]][redu[1]] += 1
if self._status_bar:
if status_bar_current.total != i:
#raise Exception, "PREDICED LEN IS NOT CORRECT IN SUM COMPUTER"
status_bar_current.total = i
if i == 0:
self.logger.error("('{}'-sum) Nothing was extracted for '{}'-syntagma. No Data was found for given settings.".format(reptype,syntagma_to_search))
return collected_redus_from_corp
#p(collected_redus_from_corp, "collected_redus_from_corp")
def _get_row_num_in_baseline_with_rep(self, redu=False, repl=False, max_scope=False):
#p((redu, repl, max_scope))
if repl or redu:
rep_w_list = []
if repl:
w_repl = " occur_repl_uniq IS NOT NULL "
if self._full_repetativ_syntagma:
w_repl = "({} AND occur_full_syn_repl IS NOT NULL )".format(w_repl )
rep_w_list.append(w_repl)
if redu:
w_redu = " occur_redu_uniq IS NOT NULL "
if self._full_repetativ_syntagma:
w_redu = "({} AND occur_full_syn_redu IS NOT NULL )".format(w_redu)
rep_w_list.append(w_redu)
#if redu: rep_w_list.append(" occur_redu_uniq IS NOT NULL ")
where_str = "OR".join(rep_w_list)
where_str = "({})".format(where_str) if len(rep_w_list)>1 else where_str
if max_scope: where_str += " AND scope<={} ".format(max_scope)
where_str = where_str if where_str else False
#p(where_str,"where_str")
num= self.statsdb.rownum("baseline", where=where_str,connector_where="OR")
else:
num = 0
return num
def get_data(self,inp_syntagma="*",repl=False, redu=False, baseline=False, syntagma_type="lexem",
sentiment=False,thread_name="Thread0", max_scope=False, stemmed_search=False,send_empty_marker=False,
minimum_columns=False,order_output_by_syntagma_order=False, return_full_tuple=False,delete_duplicates=True,
get_columns_repl=False,get_columns_redu=False,get_columns_baseline=False,
if_type_pos_return_lexem_syn=False):
#p(inp_syntagma, "0inp_syntagma")
# p((inp_syntagma,repl,redu,baseline))
# p("..9999")
#p(locals())
if inp_syntagma == "*":
#p("..888")
return self._get_data(inp_syntagma=inp_syntagma,repl=repl, redu=redu, baseline=baseline, syntagma_type=syntagma_type,
sentiment=sentiment,thread_name=thread_name, max_scope=max_scope, stemmed_search=stemmed_search,
minimum_columns=minimum_columns,order_output_by_syntagma_order=order_output_by_syntagma_order,send_empty_marker=send_empty_marker,
return_full_tuple=return_full_tuple,delete_duplicates=delete_duplicates, if_type_pos_return_lexem_syn=if_type_pos_return_lexem_syn,
get_columns_repl=get_columns_repl,get_columns_redu=get_columns_redu,get_columns_baseline=get_columns_baseline)
else:
if thread_name not in self.preprocessors:
if not self._init_preprocessors(thread_name=thread_name):
self.logger.error("Error during Preprocessors initialization. Thread '{}' was stopped.".format(thread_name), exc_info=self._logger_traceback)
self.threads_status_bucket.put({"name":thread_name, "status":"failed", "info":"Error during Preprocessors initialization"})
self._terminated = True
return False
# p("..7777")
try:
inp_syntagma[0].decode # if iterator with just one syntagma
extract_type = 1
except AttributeError:
try:
inp_syntagma[0][0].decode #if iterator with just many different syntagma
extract_type = 2
except AttributeError as e:
self.logger.error("Given Syntagma '{}' has not correct format. Exception: '{}'.".format(inp_syntagma, repr(e)))
return False
except Exception as e:
self.logger.error(" Exception was throw: '{}'.".format( repr(e)))
return False
# p("..666")
if extract_type == 1:
#p("..555")
#p(inp_syntagma, "999999inp_syntagma")
gen = self._get_data(inp_syntagma=inp_syntagma,repl=repl, redu=redu, baseline=baseline, syntagma_type=syntagma_type,
sentiment=sentiment,thread_name=thread_name, max_scope=max_scope, stemmed_search=stemmed_search,
minimum_columns=minimum_columns,order_output_by_syntagma_order=order_output_by_syntagma_order,send_empty_marker=send_empty_marker,
return_full_tuple=return_full_tuple,delete_duplicates=delete_duplicates,if_type_pos_return_lexem_syn=if_type_pos_return_lexem_syn,
get_columns_repl=get_columns_repl,get_columns_redu=get_columns_redu,get_columns_baseline=get_columns_baseline)
#p(len(gen), "num")
if not gen:
self.logger.error("Current Generator wasn't created")
return False
return gen
else:
#p("..444")
generators = []
#p(inp_syntagma, "1999999inp_syntagma")
#p(inp_syntagma, "2inp_syntagma")
not_init_gens = -1
for counter, inp_syn in enumerate(inp_syntagma):
gen = self._get_data(inp_syntagma=inp_syn,repl=repl, redu=redu, baseline=baseline, syntagma_type=syntagma_type,
sentiment=sentiment,thread_name=thread_name, max_scope=max_scope, stemmed_search=stemmed_search,send_empty_marker=send_empty_marker,
minimum_columns=minimum_columns,order_output_by_syntagma_order=order_output_by_syntagma_order,
return_full_tuple=return_full_tuple,delete_duplicates=delete_duplicates, if_type_pos_return_lexem_syn=if_type_pos_return_lexem_syn,
get_columns_repl=get_columns_repl,get_columns_redu=get_columns_redu,get_columns_baseline=get_columns_baseline)
if not gen:
not_init_gens += 1
else:
#self.logger.error("Current Generator wasn't created")
#return False
generators.append(gen)
if counter == not_init_gens:
#p(not_init_gens)
self.logger.error("Not one generator was created!")
return False
#p(generators, "generators")
# p("..333")
num = sum([len(gen) for gen in generators])
#p(num, "num")
def intern_gen():
# p("..222")
for gen in generators:
if not gen:
yield False
return
for item in gen:
yield item
return LenGen(intern_gen(), num)
def _lexem_syn_extractor_from_pos(self, inp_syntagma, inpdata, repl=False, redu=False, baseline=False,
sentiment=False, minimum_columns=False,order_output_by_syntagma_order=False,
return_full_tuple=False,delete_duplicates=True,#send_empty_marker=False,
get_columns_repl=False,get_columns_redu=False,get_columns_baseline=False):
max_scope=False
stemmed_search=False
inpdata = list(inpdata)
if len(inpdata) > 1:
self.logger.error("The Length of given generator is more as 1.")
return False
elif len(inpdata) == 0:
self.logger.error("The Length of given generator is 0.")
return False
inpdata = inpdata[0]
if not inpdata:
return False
syn_len = len(inp_syntagma)
exctracted_baseline = [b for b in inpdata["baseline"] if len(b[0])==syn_len]
def intern_gen():
already_exported_syntagma = set()
for b in exctracted_baseline:
lexem_syn = b[0]
#p(lexem_syn, "1111lexem_syn", c="r")
data = self._get_data_for_one_syntagma(lexem_syn, repl=repl, redu=redu, baseline=baseline, syntagma_type="lexem", additional_pos_where=inp_syntagma,
sentiment=sentiment, max_scope=False,
for_optimization=False, stemmed_search=False, get_also_non_full_repetativ_result=False,
order_output_by_syntagma_order=order_output_by_syntagma_order, return_full_tuple=return_full_tuple,
minimum_columns=minimum_columns, delete_duplicates=delete_duplicates,)
#p(data,">>>>data", c="c")
s = tuple(data["syntagma"])
if s in already_exported_syntagma:
continue
else:
already_exported_syntagma.add(s)
yield data
return LenGen(intern_gen(), len(exctracted_baseline))
def _get_data(self,inp_syntagma="*",repl=False, redu=False, baseline=False, syntagma_type="lexem",
sentiment=False,thread_name="Thread0", max_scope=False, stemmed_search=False, send_empty_marker=False,
minimum_columns=False,order_output_by_syntagma_order=False, return_full_tuple=False,delete_duplicates=True,
get_columns_repl=False,get_columns_redu=False,get_columns_baseline=False,if_type_pos_return_lexem_syn=False):
#print "111"
# p("---9999")
#p(inp_syntagma, "11inp_syntagma")
if not self._check_stats_db_should_exist():
return False
#if not isinstance(inp_syntagma, (list,tuple))
if syntagma_type not in Stats.supported_syntagma_type:
self.logger.error("Given SyntagmaType '{}' is not supported. Please select one of the following types: '{}'.".format(syntagma_type, Stats.supported_syntagma_type))
return False
if not inp_syntagma:
self.logger.error("NO InpSyntagma was given.")
return False
if sentiment and sentiment not in Stats.supported_sentiment:
self.logger.error("Given SentimentType '{}' is not supported. Please select one of the following types: '{}'. (!should be given in lower case!)".format(sentiment, Stats.supported_sentiment))
return False
indexes = self.col_index_min if minimum_columns else self.col_index_orig
if get_columns_repl or get_columns_redu or get_columns_baseline:
if not self._check_exist_columns_to_get( get_columns_repl, get_columns_redu,get_columns_baseline):
self.logger.error("Some given columns_to_get is not exist.")
return False
indexes_to_get_repl,indexes_to_get_redu,indexes_to_get_baseline = self._convert_cols_to_indexes(get_columns_repl,get_columns_redu,get_columns_baseline,indexes)
#print "2222"
# p("---888")
if not repl and not redu and not baseline:
self.logger.error("No Phenomena to export was selected. Please choice phenomena to export from the following list: '{}'. ".format(Stats.supported_phanomena_to_export))
return False
# p("---777")
if inp_syntagma == "*":
# p("---6666")
#print "333"
#p(inp_syntagma,"0000inp_syntagma")
num = self._get_row_num_in_baseline_with_rep(redu=redu, repl=repl, max_scope=max_scope)
#p(num, "num")
def intern_gen_all():
# p("---555")
for baseline_container in self._baseline("*",max_scope=max_scope):
#inp_syntagma = self._preprocess_syntagma(inp_syntagma,thread_name=thread_name, syntagma_type=syntagma_type)
# p(max_scope, "max_scope")
# p(("---4444", baseline_container))
data = self._get_data_for_one_syntagma(baseline_container[0],repl=repl, redu=redu, baseline=False,
syntagma_type=syntagma_type, sentiment=sentiment,thread_name=thread_name, stemmed_search=False,
max_scope=max_scope, order_output_by_syntagma_order=order_output_by_syntagma_order,
return_full_tuple=return_full_tuple,delete_duplicates=delete_duplicates,
minimum_columns=minimum_columns,indexes=indexes)
# p(("--333", data))
#if data:
# sys.exit()
if data:
if baseline:
data["baseline"] = (baseline_container,)
if get_columns_repl or get_columns_redu or get_columns_baseline:
data = self._extract_certain_columns(data, indexes_to_get_repl,indexes_to_get_redu,indexes_to_get_baseline)
yield data
else:
if data is False:
yield False
return
if send_empty_marker:
yield None
continue
return LenGen(intern_gen_all(), num)
#self._empty_marker = None
else:
# p("---222")
#print "444"
inp_syntagma = self._preprocess_syntagma(inp_syntagma,thread_name=thread_name, syntagma_type=syntagma_type, stemmed_search=stemmed_search)
if not inp_syntagma:
self.logger.error("Error by preprocessing of the InpSyntagma.")
return False
#p(inp_syntagma, "555inp_syntagma")
if stemmed_search:
#print "555"
#p(temp_syntagma, "temp_syntagma")
where_num = "stemmed='{}'".format(self._baseline_delimiter.join(inp_syntagma) )
num = self.statsdb.rownum("baseline", where=where_num)
def intern_gen_2():
scope = len(inp_syntagma)
where = tuple(self._get_where_statement(inp_syntagma,scope=scope,thread_name=thread_name, with_context=False,syntagma_type="lexem", sentiment=sentiment, stemmed_search=True))#, splitted_syntagma=splitted_syntagma)
if not where:
yield False
return
for baseline_container in self._baseline(inp_syntagma,where=where, minimum_columns=minimum_columns,max_scope=max_scope,split_syntagma=True):
#p(baseline_container, "baseline_container")
data = self._get_data_for_one_syntagma(baseline_container[0],repl=repl, redu=redu, baseline=False, syntagma_type=syntagma_type,
sentiment=sentiment,thread_name=thread_name, max_scope=False, stemmed_search=False,
order_output_by_syntagma_order=order_output_by_syntagma_order,minimum_columns=minimum_columns,
return_full_tuple=return_full_tuple,delete_duplicates=delete_duplicates,indexes=indexes)
#p(data, "data")
if data:
data["baseline"] = (baseline_container,)
data["stem_syn"] = inp_syntagma
if get_columns_repl or get_columns_redu or get_columns_baseline:
data = self._extract_certain_columns(data, indexes_to_get_repl,indexes_to_get_redu,indexes_to_get_baseline)
#p(data, "data")
yield data
else:
if send_empty_marker:
yield None
#else:
# yield {}
if if_type_pos_return_lexem_syn and syntagma_type=="pos":
#p("if_type_pos_return_lexem_syn")
return self._lexem_syn_extractor_from_pos(inp_syntagma, intern_gen_all(),
repl=repl, redu=redu, baseline=baseline,
sentiment=sentiment,
minimum_columns=minimum_columns,order_output_by_syntagma_order=order_output_by_syntagma_order, return_full_tuple=return_full_tuple,delete_duplicates=delete_duplicates,
get_columns_repl=get_columns_repl,get_columns_redu=get_columns_redu,get_columns_baseline=get_columns_baseline)
else:
return LenGen(intern_gen_2(), num)
else:
#print "666"
def inter_gen_3():
data = self._get_data_for_one_syntagma(inp_syntagma,repl=repl, redu=redu, baseline=baseline, syntagma_type=syntagma_type,
sentiment=sentiment,thread_name=thread_name, max_scope=max_scope, stemmed_search=False,
order_output_by_syntagma_order=order_output_by_syntagma_order,minimum_columns=minimum_columns,
return_full_tuple=return_full_tuple,delete_duplicates=delete_duplicates,indexes=indexes)
if data:
if get_columns_repl or get_columns_redu or get_columns_baseline:
data = self._extract_certain_columns(data, indexes_to_get_repl,indexes_to_get_redu,indexes_to_get_baseline)
#p(data, "data")
yield data
else:
if send_empty_marker:
yield None
if if_type_pos_return_lexem_syn and syntagma_type=="pos":
#p("if_type_pos_return_lexem_syn")
return self._lexem_syn_extractor_from_pos(inp_syntagma,inter_gen_3(),
repl=repl, redu=redu, baseline=baseline,
sentiment=sentiment,
minimum_columns=minimum_columns,order_output_by_syntagma_order=order_output_by_syntagma_order, return_full_tuple=return_full_tuple,delete_duplicates=delete_duplicates,
get_columns_repl=get_columns_repl,get_columns_redu=get_columns_redu,get_columns_baseline=get_columns_baseline)
else:
return LenGen(inter_gen_3(), 1)
def _get_data_for_one_syntagma(self,inp_syntagma_splitted, inp_syntagma_unsplitted=False,
repl=False, redu=False, baseline=False, syntagma_type="lexem", additional_pos_where=False,
sentiment=False,thread_name="Thread0", max_scope=False,
for_optimization=False, stemmed_search=False, get_also_non_full_repetativ_result=False,
#get_columns_repl=False, get_columns_redu=False,get_columns_baseline=False,
order_output_by_syntagma_order=False, return_full_tuple=False, output_type="list",
minimum_columns=False, delete_duplicates=True, indexes=False, ):#,splitted_syntagma=True):
#p((inp_syntagma_splitted, repl, redu, baseline,stemmed_search,additional_pos_where))
#p(locals())
scope = len(inp_syntagma_splitted)
if not self._is_syntagma_scope_right(scope):
#self.logger.error("The Length ('{}') of Given SyntagmaToSearch ('{}') is bigger as allow ('{}'). Please recompute StatsDB with the bigger ContextNumber.".format(scope, inp_syntagma_splitted,self._avaliable_scope))
#if isinstance()
return None
if stemmed_search:
inp_syntagma_splitted = self._preprocess_syntagma(inp_syntagma_splitted,thread_name=thread_name, syntagma_type=syntagma_type, stemmed_search=stemmed_search)
if inp_syntagma_unsplitted:
inp_syntagma_unsplitted = self._baseline_delimiter.join(inp_syntagma_splitted)
if not indexes:
indexes = self.col_index_min if minimum_columns else self.col_index_orig
#p(indexes, "indexes")
_repl = []
_redu = []
_baseline = []
#p(syntagma_type, "syntagma_type")
#p(scope,"scope2")
where1 = False
if repl:
if not where1:
where1 = tuple(self._get_where_statement(inp_syntagma_splitted,scope=scope,thread_name=thread_name,
with_context=True,syntagma_type=syntagma_type, sentiment=sentiment,
inp_syntagma_unsplitted=inp_syntagma_unsplitted,stemmed_search=stemmed_search,
additional_pos_where=additional_pos_where))#, splitted_syntagma=splitted_syntagma)
if not where1: return False
#p(where1,"where1_repl", c="b")
_repl = self.get_reps("repl",inp_syntagma_splitted,scope,where1,indexes,thread_name=thread_name, minimum_columns=minimum_columns,
order_output_by_syntagma_order=order_output_by_syntagma_order, return_full_tuple=return_full_tuple,stemmed_search=False,
output_type=output_type,delete_duplicates=delete_duplicates,
syntagma_type=syntagma_type, for_optimization=for_optimization, get_also_non_full_repetativ_result=get_also_non_full_repetativ_result)
#p(_repl, "_repl")
# if get_columns_repl:
# if minimum_columns:
# self.logger.error("IllegalState: 'minimum_columns'-Option is True. It is not allow to get certain columns, if this option is true. Please switch off this option.")
# return {}
if redu:
if not where1:
where1 = tuple(self._get_where_statement(inp_syntagma_splitted,scope=scope,thread_name=thread_name, with_context=True,
syntagma_type=syntagma_type, sentiment=sentiment, inp_syntagma_unsplitted=inp_syntagma_unsplitted,
stemmed_search=stemmed_search,additional_pos_where=additional_pos_where))#, splitted_syntagma=splitted_syntagma)
if not where1: return False
#p(where1,"where1_redu", c="b")
_redu = self.get_reps("redu",inp_syntagma_splitted,scope,where1,indexes,thread_name=thread_name, minimum_columns=minimum_columns,
order_output_by_syntagma_order=order_output_by_syntagma_order, return_full_tuple=return_full_tuple,stemmed_search=False,
output_type=output_type,delete_duplicates=delete_duplicates,
syntagma_type=syntagma_type, for_optimization=for_optimization, get_also_non_full_repetativ_result=get_also_non_full_repetativ_result)
#p((repl,_repl, redu, _redu))
if baseline:
if syntagma_type == "lexem":
where2 = tuple(self._get_where_statement(inp_syntagma_splitted,scope=scope,thread_name=thread_name, with_context=False,syntagma_type=syntagma_type, sentiment=sentiment, inp_syntagma_unsplitted=inp_syntagma_unsplitted,stemmed_search=stemmed_search, additional_pos_where=additional_pos_where))#, splitted_syntagma=splitted_syntagma)
if not where2: return False
_baseline = tuple(self._baseline(inp_syntagma_splitted,where=where2,minimum_columns=minimum_columns, thread_name=thread_name))
else:
all_syntagmas = []
if _repl:
all_syntagmas += self._extract_all_syntagmas(_repl, "repl", ordered_output_by_syntagma_order=order_output_by_syntagma_order,minimum_columns=minimum_columns)
if _redu:
all_syntagmas += self._extract_all_syntagmas(_redu, "redu", ordered_output_by_syntagma_order=order_output_by_syntagma_order,minimum_columns=minimum_columns)
#p(all_syntagmas,"all_syntagmas")
for temp_syntagma in set(all_syntagmas):
#p(temp_syntagma, "temp_syntagma")
where2 = tuple(self._get_where_statement(temp_syntagma,scope=scope,thread_name=thread_name, with_context=False,syntagma_type="lexem", sentiment=sentiment,
inp_syntagma_unsplitted=inp_syntagma_unsplitted,stemmed_search=stemmed_search,
additional_pos_where=False))#, splitted_syntagma=splitted_syntagma)
if not where2: return False
_baseline += tuple(self._baseline(temp_syntagma,where=where2, minimum_columns=minimum_columns,thread_name=thread_name))
#p((inp_syntagma_splitted,_repl, _redu, _baseline,))
if not _repl and not _redu and not _baseline:
return {}
if return_full_tuple:
#p((_repl, _redu,_baseline))
if not _repl[0] and not _redu[0] and not _baseline:
return {}
return {"repl":_repl, "redu":_redu, "baseline":_baseline,"syntagma":inp_syntagma_splitted}
def get_reps(self, rep_type,inp_syntagma_splitted,scope,where,indexes,thread_name="Thread0",
order_output_by_syntagma_order=False, return_full_tuple=False, stemmed_search=False,
output_type="list", minimum_columns=False,
delete_duplicates=True, syntagma_type="lexem", for_optimization=False,
get_also_non_full_repetativ_result=False):
#p((rep_type,inp_syntagma_splitted,scope),"get_reps_BEGINN", c="r")
### Step 1: Variables Initialization
_rep = []
is_full_repetativ = True
#if for_optimization:
# col_to_get = "id"
#else:
col_to_get = Stats.min_col[rep_type] if minimum_columns else False
#p((rep_type, inp_syntagma_splitted, get_also_non_full_repetativ_result, for_optimization, scope,where))
# p((where), "where_by_get_reps")
### Step 2:
if order_output_by_syntagma_order:
for word,w in izip(inp_syntagma_splitted,where):
current_reps = tuple(self._rep_getter_from_db(rep_type,inp_syntagma_splitted,scope=scope,where=w,thread_name=thread_name,columns=col_to_get, output_type=output_type, for_optimization=for_optimization))
#if not current_reps:
# return False
#p( current_reps, " current_reps")
# p((current_reps, w))
#for
if current_reps:
if for_optimization: return True # if match, than return True
else:
if for_optimization: continue
is_full_repetativ = False
if self._full_repetativ_syntagma:
if not get_also_non_full_repetativ_result:
_rep = ()
break
_rep.append( (word,current_reps))
if for_optimization: return False # if here, it means, that not one match was found till now.
### Check, if reps in containers are empty
i = 0
for container in _rep:
if not container[1]:
i += 1
if len(_rep) == i:
_rep = ()
else:
for w in where:
#p(w, "w_in_rep", c="c")
#print 1111
current_reps = tuple(self._rep_getter_from_db(rep_type,inp_syntagma_splitted,scope=scope,where=w,thread_name=thread_name,columns=col_to_get, output_type=output_type, for_optimization=for_optimization))
#print "current_reps= ", current_reps
if current_reps:
#print 22222
if for_optimization: return True # if match, than return True
else:
#print 3333
if for_optimization: continue
is_full_repetativ = False
if self._full_repetativ_syntagma:
if not get_also_non_full_repetativ_result:
_rep = ()
break
#print 4444
_rep += current_reps
if for_optimization: return False # if here, it means, that not one match was found till now.
#print 555
if _rep:
## Step 5:
if get_also_non_full_repetativ_result: return _rep
id_ix = indexes[rep_type]["id"]
if self._full_repetativ_syntagma and scope > 1 and is_full_repetativ:
reconstructed,length = self._reconstruct_syntagma(rep_type, _rep, order_output_by_syntagma_order,indexes,syntagma_type=syntagma_type,stemmed_search=stemmed_search)
full_syntagmas, allowed_ids = self._exctract_full_syntagmas(reconstructed,scope,length,inp_syntagma_splitted,syntagma_type=syntagma_type)
_rep = self._filter_full_rep_syn(rep_type,_rep, allowed_ids,order_output_by_syntagma_order ,id_ix) #
if delete_duplicates:
_rep = self._delete_dublicats_in_reps( _rep, order_output_by_syntagma_order,id_ix)
### Step 6:
if return_full_tuple:
try:
full_syn_sum = len(full_syntagmas) if _rep else 0
except:
full_syn_sum = None
if _rep:
return (_rep, is_full_repetativ, full_syn_sum)
else:
_rep
else:
return _rep
def _reconstruct_syntagma(self,rep_type, reps, order_output_by_syntagma_order,indexes,syntagma_type="lexem",stemmed_search=False,):
#p((rep_type, reps, inp_syntagma_splitted, scope,minimum_columns,order_output_by_syntagma_order))
#p(indexes)
reconstr_tree = defaultdict(lambda: defaultdict(lambda: defaultdict(lambda:[None,tuple()])))
#reconstr_tree = defaultdict(lambda: defaultdict(lambda: defaultdict(tuple)))
length = {}
indexes = indexes[rep_type]
word_tag = "stemmed" if stemmed_search else 'normalized_word'
syn_ix = indexes[word_tag] if syntagma_type == "lexem" else indexes['pos']
#p(syn_ix,"syn_ix")
#p(indexes['normalized_word'], "indexes['normalized_word']")
#p(indexes['pos'],"indexes['pos']")
if order_output_by_syntagma_order:
for word, reps_bunch in reps:
#word = reps_container[0]
#reps_bunch = reps_container[1]
for i, rep in enumerate(reps_bunch):
#p((i, rep))
#p(rep[syn_ix])
doc_id = rep[indexes["doc_id"]]
index_in_redufree = json.loads(rep[indexes["index_in_redufree"]])
if doc_id not in length:
length[doc_id] = json.loads(rep[indexes["redufree_len"]])
reconstr_tree[doc_id][index_in_redufree[0]][index_in_redufree[1]][1] += (rep[indexes["id"]],)
if not reconstr_tree[doc_id][index_in_redufree[0]][index_in_redufree[1]][0]:
reconstr_tree[doc_id][index_in_redufree[0]][index_in_redufree[1]][0] = rep[syn_ix]
#+= (rep[indexes["id"]],)
else:
for i,rep in enumerate(reps):
#p((i, rep))
doc_id = rep[indexes["doc_id"]]
index_in_redufree = json.loads(rep[indexes["index_in_redufree"]])
if doc_id not in length:
length[doc_id] = json.loads(rep[indexes["redufree_len"]])
reconstr_tree[doc_id][index_in_redufree[0]][index_in_redufree[1]][1] += (rep[indexes["id"]],)
if not reconstr_tree[doc_id][index_in_redufree[0]][index_in_redufree[1]][0]:
reconstr_tree[doc_id][index_in_redufree[0]][index_in_redufree[1]][0] = rep[syn_ix]
#p({ d:{s:{t:ids for t, ids in s_data.iteritems()} for s, s_data in doc_data.iteritems()} for d, doc_data in reconstr_tree.iteritems()})
return reconstr_tree,length
def _exctract_full_syntagmas(self,reconstr_tree, scope, redu_free_elem_length,inp_syntagma_splitted,syntagma_type="lexem"):
#p((reconstr_tree, scope, redu_free_elem_length,inp_syntagma_splitted,syntagma_type))
try:
#if syntagma_type == "pos":
output_ix = ()
allowed_ids = ()
start_new = False
incr = False
cont = False
orig_first_word = inp_syntagma_splitted[0]
#pos = True if syntagma_type=="pos" else False
for doc_id, doc_data in dict(sorted(reconstr_tree.items())).iteritems():
redu_free_length = [l-1 for l in redu_free_elem_length[doc_id]] # convert length to index
current_syn_ixs = ()
syn_start_word = None
start_tok = None
temp_tok = None
last_token = None
last_sent = None
temp_ids = ()
counter_full_syn = 0
for current_sent, sents_data in dict(sorted(doc_data.items())).iteritems():
for current_tok in sorted(sents_data.keys()):
# p((doc_id,current_sent,current_tok,start_tok, current_syn_ixs),c="m")
if temp_tok:
# print ",,,,,,"
tok_to_use = temp_tok
else:
# print "...."
tok_to_use = start_tok
if not start_tok:
# print "111"
last_token = current_tok
start_tok = (current_sent,current_tok)
start_new = True
counter_full_syn = 1
else:
# print "2222"
# print tok_to_use, counter_full_syn,current_tok
if (tok_to_use[1]+counter_full_syn) == current_tok:
# print "222+++"
counter_full_syn += 1
incr = True
else:#
# print "222---"
#print current_tok, (current_sent,last_sent), (last_token,redu_free_length[last_sent])
if current_tok==0 and ((current_sent-last_sent) == 1) and (last_token==redu_free_length[last_sent]): # if the first token of the next sent build full_syntagma with the last token of the last sent
# print "222!!!"
temp_tok = (current_sent, current_tok)
counter_full_syn = 1
incr = True
else:
# print "222???"
start_new = True
#i = 0
while True:
#i+=1
#if i >3: break
if start_new:
# p("STARTED",c="m")
start_new = False
incr = True
# p(len(current_syn_ixs),"len(current_syn_ixs)")
if len(current_syn_ixs) == scope:
# p("SAVED",c="m")
output_ix += (current_syn_ixs,)
#output_words += ((current_syn_words),)
#output_doc_id += (doc_id,)
allowed_ids += temp_ids
# Clean old vars
current_syn_ixs=()
syn_start_word = sents_data[current_tok][0]
# print orig_first_word, syn_start_word
if orig_first_word not in syn_start_word:
# print "NOT ORIG AS START"
cont = True
break
#syn_start_word = None
temp_ids = ()
temp_tok = None
start_tok = (current_sent,current_tok)
counter_full_syn = 1
# print "+++", counter_full_syn,syn_start_word
if incr:
incr = False
# p("INCR_START",c="m")
# print "!!!!!!!", syn_start_word, sents_data[current_tok]
if syn_start_word:
# p((syn_start_word,sents_data[current_tok][0], counter_full_syn, current_syn_ixs,current_tok,sents_data[current_tok]),c="r")
#if syn_start_word == sents_data[current_tok][0] and counter_full_syn>1 and not pos:
# # p("START NEW",c="m")
# start_new = True
# continue
if len(current_syn_ixs)==scope:
start_new = True
continue
current_syn_ixs += ((current_sent,current_tok),)
curr_rep = sents_data[current_tok]
#current_syn_words += (curr_rep[0],)
#syn_start_word = curr_rep[0]
temp_ids += tuple(curr_rep[1])
# p("INCR_DONE",c="m")
break
if cont:
cont = False
continue
last_token = current_tok
last_sent = current_sent
if len(current_syn_ixs) == scope:
output_ix += (current_syn_ixs,)
allowed_ids += temp_ids
#p((output_ix, set(allowed_ids)))
return output_ix, set(allowed_ids)
except Exception as e:
self.logger.error("Exception was throwed: '{}'.".format(repr(e)) ,exc_info=self._logger_traceback)
return False, False
def _delete_dublicats_in_reps(self,reps,order_output_by_syntagma_order,id_ix):
new_reps = []
used_id = set()
if order_output_by_syntagma_order:
for word, reps in reps[::-1]:
temp_reps = ()
for rep in reps:
rep_id = rep[id_ix]
if rep_id not in used_id:
used_id.add(rep_id)
temp_reps += (rep,)
if temp_reps:
new_reps.append( (word,temp_reps) )
else:
if self._full_repetativ_syntagma:
new_reps = ()
break
else:
new_reps.append( (word,temp_reps) )
new_reps = new_reps[::-1]
else:
#new_reps = ()
for rep in reps:
rep_id = rep[id_ix]
if rep_id not in used_id:
used_id.add(rep_id)
new_reps.append( rep)
return new_reps
def _filter_full_rep_syn(self,rep_type,_rep, allowed_ids,order_output_by_syntagma_order, id_index):
#p((rep_type,_rep, allowed_ids,order_output_by_syntagma_order), c="r")
new_reps = []
if order_output_by_syntagma_order:
for word, reps in _rep:
temp_reps = ()
for rep in reps:
if rep[id_index] in allowed_ids:
temp_reps += (rep,)
if temp_reps:
new_reps.append((word,temp_reps))
else:
new_reps = ()
break
else:
#new_reps = ()
for rep in _rep:
if rep[id_index] in allowed_ids:
new_reps.append(rep)
if not new_reps:
new_reps = ()
#break
return new_reps
def _rep_getter_from_db(self, rep_type,inp_syntagma="*", scope=False,
where=False, output_type="list", size_to_get=1000,
columns=False,thread_name="Thread0",
for_optimization=False,):
if inp_syntagma != "*":
if not where:
self.logger.error("Where wasn't given.")
#yield False
return
try:
table_name = Stats.phenomena_table_map[rep_type]
except:
self.logger.error("Given RepType ('{}') is not exist.".format(rep_type))
#yield False
return
generator = self.statsdb.lazyget(table_name, columns=columns, where=where, connector_where="AND", output=output_type, case_sensitiv=self._case_sensitiv,thread_name=thread_name)
if for_optimization:
try:
next(generator)
yield True
return
except StopIteration:
#pass
return
for row in generator:
yield row
def _extract_all_syntagmas(self, entry, typ, ordered_output_by_syntagma_order=False,minimum_columns=False):
#p(ordered_output_by_syntagma_order, "ordered_output_by_syntagma_order")
all_syntagmas = set()
#p(entry, "entry")
if ordered_output_by_syntagma_order:
for word_container in entry:
for rep in word_container[1]:
done = False
for index in xrange(1, self._avaliable_scope+1):
temp_syntagma = []
for i in xrange(index):
#p(self._get_index_by_codepoint(i, typ), "self._get_index_by_codepoint(i, typ)")
word = rep[self._get_index_by_codepoint(i, typ,minimum_columns)]
#temp_syntagma.append(word)
if word:
temp_syntagma.append(word)
else:
#break
done=True
if done: break
#p(temp_syntagma,"{}temp_syntagma".format(typ))
all_syntagmas.add(tuple(temp_syntagma))
#all_syntagmas.add(temp_syntagma)
if done: break
else:
#p(entry, "entry", c="r")
for rep in entry:
#p(rep,"rep", c="r")
done = False
for index in xrange(1, self._avaliable_scope+1):
temp_syntagma = []
for i in xrange(index):
#p(self._get_index_by_codepoint(i, typ), "self._get_index_by_codepoint(i, typ)")
word = rep[self._get_index_by_codepoint(i, typ,minimum_columns)]
#temp_syntagma.append(word)
#p(word, "word", c="m")
if word:
temp_syntagma.append(word)
else:
#break
done=True
if done: break
#p(temp_syntagma,"{}temp_syntagma".format(typ))
all_syntagmas.add(tuple(temp_syntagma))
#all_syntagmas.add(temp_syntagma)
if done: break
#all_syntagmas.append(temp_syntagma)
#p(all_syntagmas,"set_all_syntagmas")
return all_syntagmas
def _baseline(self, inp_syntagma="*", max_scope=False, where=False, connector_where="AND", output="list", size_to_fetch=1000, thread_name="Thread0", split_syntagma=True,minimum_columns=False ,limit=-1, offset=0):
#temp_cols_to_get = Stats.min_col["baseline"] if minimum_columns else False
#columns = columns if columns else temp_cols_to_get
columns = Stats.min_col["baseline"] if minimum_columns else False
#p((where, inp_syntagma,max_scope))
# p(locals())
if inp_syntagma == "*":
if max_scope is not False:
w = "scope <= {}".format(max_scope)
if where:
if isinstance(where, (list, tuple)):
#answer = None
ix = None
for index, tw in enumerate(where):
if "scope" in tw:
ix = index
if ix:
where[ix] = w
else:
where.append(w)
if connector_where != "AND":
self.logger.error("PossibleWrongData: ConnectorWhere is 'OR' but should be 'AND'")
else:
temp_where = [where]
if "scope" not in where:
temp_where.append(w)
else:
temp_where = [w]
else:
where = w
#baseline_num = len(list(self.statsdb.lazyget("baseline", columns=columns, where=where, connector_where=connector_where, output=output, case_sensitiv=self._case_sensitiv,thread_name=thread_name+"BSGET",limit=limit, offset=offset, size_to_fetch=size_to_fetch)))
# p((where,max_scope,baseline_num), "where")
# print 000
for row in self.statsdb.lazyget("baseline", columns=columns, where=where, connector_where=connector_where, output=output, case_sensitiv=self._case_sensitiv,thread_name=thread_name+"BSGET",limit=limit, offset=offset, size_to_fetch=size_to_fetch):
# p(row, "row")
# print 111
if split_syntagma and row:
# print 222
#temp_row = list(row)
#row = list(row)
splitted_syntagma = row[0].split(self._baseline_delimiter)
#row[0] = splitted_syntagma
r = (splitted_syntagma,) + row[1:]
# p((r, split_syntagma))
yield (splitted_syntagma,) + row[1:]
#yield splitted_syntagma
else:
# p((row, split_syntagma))
yield row
else:
if not where:
self.logger.error("Where wasn't given.")
yield False
return
for row in self.statsdb.lazyget("baseline", columns=columns, where=where, connector_where="AND", output=output, case_sensitiv=self._case_sensitiv,limit=limit, offset=offset):
#p(row, "row")
if split_syntagma and row:
row = list(row)
row[0] = row[0].split(self._baseline_delimiter)
yield row
#sys.exit()
def _get_index_by_codepoint(self, codepoint, typ,minimum_columns):
indexes = self.col_index_min[typ] if minimum_columns else self.col_index_orig[typ]
if codepoint == 0:
return indexes["normalized_word"]
elif codepoint == 1:
return indexes["contextR1"]
else:
return indexes["contextR1"] + (2* (codepoint-1))
def _get_where_statement(self,inp_syntagma_splitted, inp_syntagma_unsplitted=False,
scope=False, syntagma_type="lexem", sentiment=False,thread_name="Thread0",
with_context=True,stemmed_search=False, additional_pos_where=False):#, splitted_syntagma=True):
### Syntagma Preprocessing
#o = type(inp_syntagma_splitted)
#p((inp_syntagma_splitted, o))
status= True
convert = False
if syntagma_type != "pos":
try:
if not inp_syntagma_unsplitted:
try:
inp_syntagma_unsplitted = self._baseline_delimiter.join(inp_syntagma_splitted)
except TypeError:
inp_syntagma_unsplitted = self._baseline_delimiter.join([unicode(syntagma) for syntagma in inp_syntagma_splitted])
except (UnicodeDecodeError, UnicodeEncodeError):
convert = True
while status:
if convert:
#p( inp_syntagma_splitted, "1 inp_syntagma_splitted")
try:
inp_syntagma_splitted = [word.decode("utf-8") for word in inp_syntagma_splitted]
except (UnicodeDecodeError, UnicodeEncodeError):
pass
try:
if inp_syntagma_unsplitted:
try:
inp_syntagma_unsplitted = inp_syntagma_unsplitted.decode("utf-8")
except (UnicodeDecodeError, UnicodeEncodeError):
pass
else:
inp_syntagma_unsplitted = self._baseline_delimiter.join(inp_syntagma_splitted)
#p(repr(inp_syntagma_unsplitted), "inp_syntagma_unsplitted")
except (UnicodeDecodeError, UnicodeEncodeError):
inp_syntagma_unsplitted = self._baseline_delimiter.join([unicode(t) for t in inp_syntagma_splitted])
#p(repr(inp_syntagma_unsplitted), "2 inp_syntagma_unsplitted")
try:
additional_pos_where = [word.decode("utf-8") for word in additional_pos_where]
except:
pass
#p(inp_syntagma_splitted, "inp_syntagma_splitted")
try:
#wheres = []
if with_context: # for repl and redu
if syntagma_type == "lexem":
if stemmed_search:
normalized_word_tag_name = "stemmed"
else:
normalized_word_tag_name = "normalized_word"
else:
normalized_word_tag_name = "pos"
#normalized_word_tag_name = "normalized_word" if syntagma_type == "lexem" else "pos"
if stemmed_search:
context_tag_name_r = "context_infoR"
context_tag_name_l = "context_infoL"
word_index = 2
else:
context_tag_name_r = "contextR" if syntagma_type == "lexem" else "context_infoR"
context_tag_name_l = "contextL" if syntagma_type == "lexem" else "context_infoL"
word_index = 0
# splitted_syntagma = inp_syntagma_splitted if splitted_syntagma else inp_syntagma_splitted.split(self._baseline_delimiter)
# unsplitted_syntagma = inp_syntagma_splitted if splitted_syntagma else inp_syntagma_splitted.split(self._baseline_delimiter)
if scope > self.baseline_ngramm_lenght:
self.logger.error("WhereGetter: Given Scope ('{}') is higher as allow ('{}'). (given syntagma:'{}'). ".format(scope, self.baseline_ngramm_lenght, inp_syntagma_splitted))
#yield False
return
for token_index in xrange(scope):
last_token_index = scope-1
where = []
for i, token in zip(range(scope),inp_syntagma_splitted):
#p(token, "token")
#token = token.replace("'", '"') if "'" in token else token
if i < token_index:
#ix = token_index -1
#json_extract("text", "$[1]")
col_name = u"{}{}".format(context_tag_name_l,token_index-i)
search_pattern = u"{}='{}'".format(col_name,token) if syntagma_type == "lexem" and not stemmed_search else u'json_extract("{}", "$[{}]") = "{}"'.format(col_name,word_index,token)
#search_pattern = u"='{}'".format(token) if syntagma_type == "lexem" else u"LIKE '%{}%'".format(token)
where.append(search_pattern)
if additional_pos_where and syntagma_type!="pos":
col_name = u"{}{}".format("context_infoL",token_index-i)
search_pattern = u'json_extract("{}", "$[0]") = "{}"'.format(col_name,additional_pos_where[i])
where.append(search_pattern)
#where.append(u"{}{} {} ".format(context_tag_name_l,token_index-i,search_pattern))
elif i == token_index:
where.append(u"{}='{}' ".format(normalized_word_tag_name,token))
if additional_pos_where and syntagma_type!="pos":
where.append(u" pos = '{}' ".format(additional_pos_where[i]))
elif i > token_index:
col_name = u"{}{}".format(context_tag_name_r,i-token_index)
search_pattern = u"{}='{}'".format(col_name,token) if syntagma_type == "lexem" and not stemmed_search else u'json_extract("{}", "$[{}]") = "{}"'.format(col_name,word_index,token)
#search_pattern = u"='{}'".format(token) if syntagma_type == "lexem" else u"LIKE '%{}%'".format(token)
where.append(search_pattern)
if additional_pos_where and syntagma_type!="pos":
col_name = u"{}{}".format("context_infoR",i-token_index)
search_pattern = u'json_extract("{}", "$[0]") = "{}"'.format(col_name,additional_pos_where[i])
where.append(search_pattern)
if sentiment:
where.append(u"polarity LIKE '%{}%'".format(sentiment))
yield where
return
else:
if syntagma_type == "pos":
#p((inp_syntagma_splitted, inp_syntagma_unsplitted))
self.logger.error("To get Where Expression without context for SyntagmaType='pos' is not possible. ")
#return False
#yield False
return
syntagma_tag ='stemmed' if stemmed_search else "syntagma"
syntagma_qeary = u"{}= '{}'".format(syntagma_tag,inp_syntagma_unsplitted)
#p([syntagma_qeary], "[syntagma_qeary]")
#return [syntagma_qeary]
yield syntagma_qeary
return
except (UnicodeDecodeError, UnicodeEncodeError):
convert = True
def _is_syntagma_scope_right(self, scope_num):
#self._context_left
#self._context_lenght
if scope_num > self._avaliable_scope:
#self.logger.error("")
return False
else:
return True
def _preprocess_syntagma(self, inp_syntagma,thread_name="Thread0", syntagma_type="lexem",stemmed_search=False):
#p(inp_syntagma,"inp_syntagma")
#p((inp_syntagma), "11")
try:
inp_syntagma = [token.decode("utf-8") for token in inp_syntagma]
except:
pass
#p((inp_syntagma), "22")
if not isinstance(inp_syntagma, (list,tuple)):
self.logger.error("Given inp_syntagma ('{}') is from an un-support type ('{}')".format(inp_syntagma, type(inp_syntagma)))
return False
if syntagma_type == "lexem":
#p((self._case_sensitiv),"self._case_sensitiv")
if not self._case_sensitiv:
inp_syntagma = [token.lower() for token in inp_syntagma]
inp_syntagma = [self.preprocessors[thread_name]["rle"].del_rep(token) for token in inp_syntagma]
#p((inp_syntagma))
if stemmed_search:
inp_syntagma = [self.stemm(word) for word in inp_syntagma]
return inp_syntagma
#p(inp_syntagma,"inp_syntagma")
#if not self._case_sensitiv:
# inp_syntagma = [token.lower() for token in inp_syntagma]
def _check_settings_for_force_cleaning(self):
temp_force_cleaning = False
if self._corp_info["case_sensitiv"] is True and self._case_sensitiv is False:
temp_force_cleaning = True
elif self._corp_info["case_sensitiv"] is False and self._case_sensitiv is True:
self.logger.error("Current CorpDB was lower_cased. And StatdDB was initialized with sensitive case. Because tt is not possible any more to reconstruct the case back, this operation is illegal. Please change setting and try one more time.")
return False
if self._corp_info["del_url"] is False and self._ignore_url is True:
temp_force_cleaning = True
if self._corp_info["del_punkt"] is False and self._ignore_punkt is True:
temp_force_cleaning = True
if self._corp_info["del_num"] is False and self._ignore_num is True:
temp_force_cleaning = True
if self._corp_info["del_mention"] is False and self._ignore_mention is True:
temp_force_cleaning = True
if self._corp_info["del_hashtag"] is False and self._ignore_hashtag is True:
temp_force_cleaning = True
if temp_force_cleaning:
self.statsdb.update_attr("force_cleaning", True)
self.set_all_intern_attributes_from_db()
if self._force_cleaning is not True:
self.logger.error("Force_cleaning-Option wasn't activated.")
return False
else:
self.statsdb.update_attr("force_cleaning", False)
self.set_all_intern_attributes_from_db()
return True
###########################Setters####################
#_drop_created_indexes
def compute(self,inp_corp, stream_number=1, datatyp="dict",
adjust_to_cpu=True,min_files_pro_stream=1000,cpu_percent_to_get=50,
thread_name="Thread0", create_indexes=True, freeze_db=False,
drop_indexes=True,optimized_for_long_syntagmas=True,
baseline_insertion_border=1000000):
if not self._check_stats_db_should_exist():
return False
#p(stream_number, "stream_number")
if not self._check_db_should_be_an_stats():
return False
#self._baseline_intime_insertion_till = baseline_intime_insertion_till
try:
if not isinstance(inp_corp, Corpus):
self.logger.error("Given InpObject is not from Corpus type. Insert was aborted!")
return False
if self.statsdb.get_attr("locked"):
self.logger.error("Current DB is still be locked. Possibly it in ht now fr in-useom other process or la thest computation process is failed.")
return False
self.statsdb.update_attr("locked", True)
self._init_compution_variables()
if self._db_frozen: ## insert "db_frozen" as attribute to the StatsDB!!!
msg = "Current StatsDB is closed for new Insertions because it was already SizeOptimized and all temporary Data was deleted"
self.logger.error(msg)
self.threads_status_bucket.put({"name":thread_name, "status":"failed", "info":msg})
self._terminated = True
return False
if drop_indexes:
self._drop_created_indexes()
self._init_compution_variables()
self.corp = inp_corp
self._corp_info = self.corp.info()
self._text_field_name = self._corp_info["text_field_name"]
self._id_field_name = self._corp_info["id_field_name"]
self.statsdb.update_attr("pos_tagger",self._corp_info["pos_tagger"])
self.statsdb.update_attr("sentiment_analyzer",self._corp_info["sentiment_analyzer"])
self._pos_tagger = self._corp_info["pos_tagger"]
self._sentiment_analyzer = self._corp_info["sentiment_analyzer"]
self._compute_cleaning_flags()
#p(self.force_cleaning_flags, "self.force_cleaning_flags")
#p(self._force_cleaning, "self._force_cleaning")
if not self._check_settings_for_force_cleaning():
return False
#p(self._force_cleaning, "self._force_cleaning")
if not self._language:
self.statsdb.update_attr("language",self._corp_info["language"])
else:
if self._language != self._corp_info["language"]:
self.logger.error("StatsDB language ('{}') is not equal to the inserting CorpDB ('{}'). Those meta data should be equal for staring the insertion process. Please select other corpus, which you want to insert to the current statsDB or initialize a new StatsDB with right language.".format(self._language, self._corp_info["language"]))
return False
#p(self._corpus_id, "self._corpus_id")
if not self._corpus_id:
self.statsdb.update_attr("corpus_id", self._corp_info["id"])
self.set_all_intern_attributes_from_db()
else:
if self._corpus_id != self._corp_info["id"]:
self.logger.error("Current StatdDb was already computed/initialized for Corpus with id '{}'. Now you try to insert Corpus with id '{}' and it is not allow.".format(self._corpus_id,self._corp_info["id"]))
#p(self._corpus_id, "self._corpus_id")
self._init_stemmer(self._corp_info["language"])
#self.status_bars_manager = self._get_status_bars_manager()
##### Status-Bar - Name of the processed DB
if self._status_bar:
# print "\n"
if self._in_memory:
dbname = ":::IN-MEMORY-DB:::"
else:
dbname = '{}'.format(self.statsdb.fname())
status_bar_starting_corpus_insertion = self._get_new_status_bar(None, self.status_bars_manager.term.center( dbname) , "", counter_format=self.status_bars_manager.term.bold_white_on_blue("{fill}{desc}{fill}"))
status_bar_starting_corpus_insertion.refresh()
if adjust_to_cpu:
stream_number= get_number_of_streams_adjust_cpu( min_files_pro_stream, inp_corp.corpdb.rownum("documents"), stream_number, cpu_percent_to_get=cpu_percent_to_get)
if stream_number is None or stream_number==0:
#p((self._get_number_of_left_over_files(),self.counter_lazy_getted),"self._get_number_of_left_over_files()")
self.logger.error("Number of input files is 0. Not generators could be returned.", exc_info=self._logger_traceback)
return []
streams= self.get_streams_from_corpus(inp_corp, stream_number, datatyp=datatyp)
#p(streams, "streams")
## threads
if self._status_bar:
status_bar_threads_init = self._get_new_status_bar(len(streams), "ThreadsStarted", "threads")
#p((stream_number, len(streams)))
#i=1
self._threads_num = len(streams)
if self._threads_num>1:
if self._status_bar:
unit = "rows"
self.main_status_bar_of_insertions = self._get_new_status_bar(0, "AllThreadsTotalInsertions", unit)
self.main_status_bar_of_insertions.refresh()
#self.main_status_bar_of_insertions.total = 0
else:
self.main_status_bar_of_insertions = False
for stream in streams:
gen = stream[1]
if not self._isrighttype(gen):
self.logger.error("StatsComputationalError: Given InpData not from right type. Please give an list or an generator.", exc_info=self._logger_traceback)
return False
#p(gen)
thread_name = stream[0]
processThread = threading.Thread(target=self._compute, args=(gen,datatyp, thread_name,baseline_insertion_border), name=thread_name)
processThread.setDaemon(True)
processThread.start()
self.active_threads.append(processThread)
if self._status_bar:
status_bar_threads_init.update(incr=1)
#i+=1
time.sleep(1)
self.logger.info("'{}'-thread(s) was started. ".format(len(self.active_threads)))
time.sleep(3)
if not self._wait_till_all_threads_are_completed("Compute"):
return False
self.statsdb._write_cashed_insertion_to_disc(with_commit=True)
## save attributes from the main counter
if self._status_bar:
if self.main_status_bar_of_insertions:
self.counters_attrs["compute"]["start"] = self.main_status_bar_of_insertions.start
self.counters_attrs["compute"]["end"] = self.main_status_bar_of_insertions.last_update
self.counters_attrs["compute"]["total"] = self.main_status_bar_of_insertions.total
self.counters_attrs["compute"]["desc"] = self.main_status_bar_of_insertions.desc
else:
self.counters_attrs["compute"] = False
#self._print_summary_status()
inserted_repl = self.statsdb.rownum("replications")
inserted_redu = self.statsdb.rownum("reduplications")
uniq_syntagma_in_baseline = self.statsdb.rownum("baseline")
if self._status_bar:
status_bar_total_summary = self._get_new_status_bar(None, self.status_bars_manager.term.center("Repl:'{}'; Redu:'{}'; UniqSyntagmaBaseline: '{}'.".format(inserted_repl, inserted_redu,uniq_syntagma_in_baseline ) ), "", counter_format=self.status_bars_manager.term.bold_white_on_blue('{fill}{desc}{fill}\n'))
status_bar_total_summary.refresh()
self.status_bars_manager.stop()
#print "\n"
if not self._status_bar:
self.logger.info("Current StatsDB has '{}' rows in the Replications Table; '{}' rows in the Reduplications Table;'{}' rows in the Baseline Table; ".format(inserted_repl,inserted_redu,uniq_syntagma_in_baseline))
else:
self.logger.debug("Current StatsDB has '{}' rows in the Replications Table; '{}' rows in the Reduplications Table;'{}' rows in the Baseline Table; ".format(inserted_repl,inserted_redu,uniq_syntagma_in_baseline))
#self.logger.info("Current StatsDB has '{}' rows in the Reduplications Table.".format(inserted_redu))
#self.logger.info("Current StatsDB has '{}' rows in the Baseline Table.".format(uniq_syntagma_in_baseline))
self._last_insertion_was_successfull = True
self._end_time_of_the_last_insertion = time.time()
self.statsdb._commit()
if create_indexes:
self.statsdb.init_default_indexes(thread_name=thread_name)
self.create_additional_indexes(optimized_for_long_syntagmas=optimized_for_long_syntagmas)
self.statsdb._commit()
if not self._check_baseline_consistency():
self.logger.error("StatsDBCorrupt: Current StatsDB is inconsistent.")
return False
if freeze_db:
self.optimize_db(stream_number=stream_number, min_row_pro_sream=min_files_pro_stream)
self.statsdb._commit()
self._compute_baseline_sum()
if not self._check_statsdb_consistency():
self.logger.error("StatsDBCorrupt: Current StatsDB is inconsistent.")
return False
if len(self.threads_unsuccess_exit) >0:
self.logger.error("StatsComputational process is failed. (some thread end with error)")
raise ProcessError, "'{}'-Threads end with an Error.".format(len(self.threads_unsuccess_exit))
#self.statsdb.update_attr("locked", False)
return False
else:
self.logger.info("StatsComputational process end successful!!!")
self.statsdb.update_attr("locked", False)
self.statsdb._commit()
return True
except Exception, e:
print_exc_plus() if self._ext_tb else ""
self.logger.error("ComputeError: See Exception: '{}'. ".format(e), exc_info=self._logger_traceback)
self.threads_status_bucket.put({"name":thread_name, "status":"failed"})
except KeyboardInterrupt:
self.logger.warning("KeyboardInterrupt: Process was stopped from User. Some inconsistence in the current DB may situated.")
sys.exit()
def _compute(self, inp_data, datatyp="dict", thread_name="Thread0", baseline_insertion_border=1000000,add_also_repeted_redu_to_baseline=True):
try:
if not self._check_corp_should_exist():
self._terminated = True
msg = "StatsObj wasn't found."
self.logger.error(msg)
self.threads_status_bucket.put({"name":thread_name, "status":"failed", "info":msg})
return False
if not self._corp_info:
self._terminated = True
msg = "CorpInfo wasn't found."
self.logger.error(msg)
self.threads_status_bucket.put({"name":thread_name, "status":"failed", "info":msg})
return False
status_bar_insertion_in_the_current_thread = self._initialisation_computation_process( inp_data, thread_name=thread_name, )
if self._status_bar:
if not status_bar_insertion_in_the_current_thread: return False
self.logger.debug("_ComputationalProcess: Was started for '{}'-Thread. ".format(thread_name))
i = 0
for doc_elem in inp_data:
self._check_termination(thread_name=thread_name)
i+= 1
if self._status_bar:
status_bar_insertion_in_the_current_thread.update(incr=1)
if self.main_status_bar_of_insertions:
self.main_status_bar_of_insertions.update(incr=1)
text_elem = json.loads(doc_elem[1])
#p((sum([len(s[0]) for s in text_elem]), "doc_elem"))
if self._force_cleaning:
text_elem = self._preprocess(text_elem,thread_name=thread_name)
#p(text_elem, c="m")
### Extraction
extracted_repl_in_text_container, repl_free_text_container, rle_for_repl_in_text_container = self.extract_replications(text_elem, thread_name=thread_name)
#p((extracted_repl_in_text_container, repl_free_text_container, rle_for_repl_in_text_container), "REPLS")
extracted_redu_in_text_container, redu_free_text_container, mapping_redu = self.extract_reduplications(repl_free_text_container, rle_for_repl_in_text_container, thread_name=thread_name)
#p((extracted_redu_in_text_container, redu_free_text_container, mapping_redu), "REDUS")
computed_baseline = self.compute_baseline(redu_free_text_container,extracted_redu_in_text_container)
stemmed_text_container = [[self.stemm(token) for token in sent] for sent in redu_free_text_container]
#p(stemmed_text_container, "stemmed_text_container")
### Insertion
self.insert_repl_into_db(doc_elem,text_elem,extracted_repl_in_text_container, repl_free_text_container,rle_for_repl_in_text_container,redu_free_text_container,mapping_redu,stemmed_text_container, thread_name=thread_name)
self.insert_redu_into_db(doc_elem,text_elem,extracted_redu_in_text_container, redu_free_text_container, rle_for_repl_in_text_container, repl_free_text_container, mapping_redu,stemmed_text_container,thread_name=thread_name)
#if "@ronetejaye" in [t for sent in redu_free_text_container for t in sent]:
# p((doc_elem,redu_free_text_container,repl_free_text_container), "doc_elem")
with self.locker:
self.baseline_lazyinsertion_into_db(computed_baseline,extracted_redu_in_text_container,baseline_insertion_border=baseline_insertion_border,thread_name=thread_name)
self._write_repl_into_db(thread_name=thread_name)
self._write_redu_into_db(thread_name=thread_name)
with self.locker:
self.baseline_insert_left_over_data(thread_name=thread_name)
if self._status_bar:
status_bar_insertion_in_the_current_thread.refresh()
self.counters_attrs["_compute"][thread_name]["start"] = status_bar_insertion_in_the_current_thread.start
self.counters_attrs["_compute"][thread_name]["end"] = status_bar_insertion_in_the_current_thread.last_update
self.counters_attrs["_compute"][thread_name]["total"] = status_bar_insertion_in_the_current_thread.total
self.counters_attrs["_compute"][thread_name]["desc"] = status_bar_insertion_in_the_current_thread.desc
status_bar_insertion_in_the_current_thread.close(clear=False)
self.threads_status_bucket.put({"name":thread_name, "status":"done"})
self.logger.debug("_Compute: '{}'-Thread is done and was stopped.".format(thread_name))
return True
except Exception, e:
print_exc_plus() if self._ext_tb else ""
msg = "_ComputeError: See Exception: '{}'. ".format(e)
self.logger.error(msg, exc_info=self._logger_traceback)
self.threads_status_bucket.put({"name":thread_name, "status":"failed", "info":msg})
self.statsdb.rollback()
return False
def _check_termination(self, thread_name="Thread0"):
if self._terminated:
self.logger.critical("'{}'-Thread was terminated.".format(thread_name))
self.threads_status_bucket.put({"name":thread_name, "status":"terminated"})
sys.exit()
def _get_occur(self,counted_rep, scope=1,splitted_syntagma=False):
if scope>1:
#if
occur_uniq = defaultdict(lambda:0)
occur_rep_exhausted = defaultdict(lambda:0)
for word, word_data in counted_rep.iteritems():
for doc_id, doc_data in word_data.iteritems():
for rep_count in doc_data.values():
occur_uniq[word] += 1
occur_rep_exhausted[word] += rep_count
if splitted_syntagma:
occur_uniq_output = ()
occur_e_output = ()
#tuple(occur_uniq[word] for word in splitted_syntagma )
for word in splitted_syntagma:
occur_uniq_output += (occur_uniq[word],)
occur_uniq[word] = "IGNOR"
occur_e_output += (occur_rep_exhausted[word],)
occur_rep_exhausted[word] = "IGNOR"
return (occur_uniq_output,occur_e_output)
else:
return (sum(occur_uniq.values()),sum(occur_rep_exhausted.values()) )
else:
occur_uniq = 0
occur_rep_exhausted = 0
for doc_id, doc_data in counted_rep.iteritems():
for rep_count in doc_data.values():
occur_uniq += 1
occur_rep_exhausted += rep_count
return (occur_uniq,occur_rep_exhausted)
def _insert_temporized_sum_into_baseline_table_in_db(self,temporized_sum,tables_name, ):
placeholders = " ,".join(["?" for i in range(len(temporized_sum[0]))])
qeary = """
INSERT OR REPLACE INTO {} VALUES ({});
"""
self.statsdb._threads_cursors["sum_inserter"].executemany(qeary.format(tables_name,placeholders), temporized_sum)
def recompute_syntagma_repetativity_scope(self, full_repetativ_syntagma,_check_statsdb_consistency=True):
values_from_db = self.statsdb.get_attr("full_repetativ_syntagma")
if full_repetativ_syntagma not in [True, False]:
self.logger.error("A non-boolean symbol ('{}') was given as full_repetativ_syntagma-Option. ".format(full_repetativ_syntagma))
return False
if full_repetativ_syntagma == values_from_db:
self.logger.warning("There is nothing to recompute. Values for 'full_repetativ_syntagma' was given: '{}' and values in StatsDB is '{}'.".format(full_repetativ_syntagma, values_from_db))
return False
# if self._full_repetativ_syntagma and self._db_frozen and full_repetativ_syntagma == False:
# self.logger.warning("Recomputing from True->False is failed!!! Because this StatsDB was already optimized and all not-full-repetativ-syntagmas was already deleted during this process.")
# return False
if self.statsdb.get_attr("locked"):
self.logger.error("Current DB is still be locked. Possibly it in ht now fr in-useom other process or la thest computation process is failed.")
return False
self.statsdb.update_attr("locked", True)
self.statsdb.update_attr("full_repetativ_syntagma", full_repetativ_syntagma)
self.set_all_intern_attributes_from_db()
if self._compute_baseline_sum():
self.logger.info("StatsDB FullSyntagmaRepetativnes was recompute with success.")
if _check_statsdb_consistency:
if not self._check_baseline_consistency():
self.logger.error("StatsDBCorrupt: Current StatsDB is inconsistent.")
return False
if not self._check_statsdb_consistency():
self.logger.error("StatsDBCorrupt: Current StatsDB is inconsistent.")
return False
else:
self.logger.error("FullRepetativnes wasn't recompute.")
return False
self.statsdb.update_attr("locked", False)
return True
#self.statsdb.update_attr("full_repetativ_syntagma", full_repetativ_syntagma)
def _compute_baseline_sum(self, insertion_border=10000, thread_name="Thread0",size_to_fetch=10000, ):
if not self._check_stats_db_should_exist():
return False
if self._status_bar:
try:
if not self.status_bars_manager.enabled:
self.status_bars_manager = self._get_status_bars_manager()
except:
self.status_bars_manager = self._get_status_bars_manager()
status_bar_start = self._get_new_status_bar(None, self.status_bars_manager.term.center("RepetitionSummarizing") , "", counter_format=self.status_bars_manager.term.bold_white_on_cyan("{fill}{desc}{fill}"))
status_bar_start.refresh()
status_bar_current = self._get_new_status_bar(self.statsdb.rownum("baseline"), "Processed:", "syntagma")
# ### compute syntagmas to delete
counter_summerized = 0
temporized_sum = []
temp_rep = defaultdict()
minimum_columns = False
syntagma_type = "lexem"
indexes = self.col_index_min if minimum_columns else self.col_index_orig
#### Compute indexes
ix_repl = indexes["repl"]
ix_redu = indexes["redu"]
ix_word_redu = ix_redu['normalized_word']
ix_word_repl = ix_repl['normalized_word']
ix_token_redu = ix_redu["index_in_corpus"]
ix_token_repl = ix_repl["index_in_corpus"]
ix_length_redu = ix_redu["redu_length"]
#ix_in_redu_repl = ix_repl["in_redu"]
ix_doc_id_redu = ix_redu["doc_id"]
ix_doc_id_repl = ix_repl["doc_id"]
row_num_bevore = self.statsdb.rownum("baseline") +1000
#for i, baseline_container in enumerate(self._baseline("*",max_scope=False, split_syntagma=False,thread_name="baseline_getter")):
#gen = self.statsdb.lazyget("baseline", thread_name="baseline_sum")
# def intern_gen():
# gen = self.statsdb._threads_cursors["baseline_getter"].execute("SELECT * FROM baseline;") #lazyget("baseline", thread_name="baseline_sum")
# while True:
# results = gen.fetchmany(size_to_fetch)
# results = list(results)
# if not results:
# break
# for row in results:
# yield row
### create_temp_table
#self.statsdb._threads_cursors["baseline_creater"].execute("CREATE TABLE 'temp_baseline' AS SELECT sql FROM sqlite_master WHERE type='table' AND name='baseline'" ).fetchall()
self.statsdb._commit()
self._temp_baseline_name = "_baseline"
status = self.statsdb.addtable(self._temp_baseline_name, db_helper.default_columns_and_types_for_stats_baseline ,constraints= db_helper.default_constraints_for_stats_baseline)
self.statsdb._commit()
for i, baseline_container in enumerate(self.statsdb.lazyget("baseline", thread_name="baseline_sum")):
if i >row_num_bevore:
self.logger.error("InvalidState: BaselineGetter send more items as need. Script is failed! ( Probably an ImplementationsError. Please contact Egor Savin: [email protected]) ")
sys.exit()
#return
#p(baseline_container, "baseline_container")
if self._status_bar:
status_bar_current.update(incr=1)
#inp_syntagma = self._preprocess_syntagma(inp_syntagma,thread_name=thread_name, syntagma_type=syntagma_type)
unsplitted_syntagma = baseline_container[0]
splitted_syntagma = unsplitted_syntagma.split(self._baseline_delimiter)
#p(baseline_container,"baseline_container")
scope = len(splitted_syntagma)
where = tuple(self._get_where_statement(splitted_syntagma,scope=scope,thread_name=thread_name,
with_context=True,syntagma_type="lexem"))#, splitted_syntagma=splitted_syntagma)
if not where: return False
repls_container = self.get_reps("repl",splitted_syntagma,scope,where,indexes,thread_name=thread_name,return_full_tuple=True,
delete_duplicates=False,syntagma_type=syntagma_type, minimum_columns=minimum_columns)
redus_container = self.get_reps("redu",splitted_syntagma,scope,where,indexes,thread_name=thread_name,return_full_tuple=True,
delete_duplicates=False,syntagma_type=syntagma_type, minimum_columns=minimum_columns)
temp_baseline_row = baseline_container[:4]
#p((repls_container, redus_container, temp_baseline_row))
if repls_container or redus_container:
counter_summerized += 1
occur_full_syn_repl = None
occur_full_syn_redu = None
if scope==1:
if repls_container:
repls =repls_container[0]
temp_repl = defaultdict(lambda:defaultdict(int))
for repl in repls:
temp_repl[repl[ix_doc_id_repl]][repl[ix_token_repl]] += 1
occur = self._get_occur(temp_repl)
temp_baseline_row += occur
occur_full_syn_repl = occur[0]
else:
temp_baseline_row += (None,None)
if redus_container:
redus = redus_container[0]
temp_redu = defaultdict(lambda:defaultdict(int))
for redu in redus:
temp_redu[redu[ix_doc_id_redu]][redu[ix_token_redu]] += redu[ix_length_redu]
occur = self._get_occur(temp_redu)
temp_baseline_row += occur
occur_full_syn_redu = occur[0]
else:
temp_baseline_row += (None,None)
temp_baseline_row += (occur_full_syn_repl,occur_full_syn_redu)
else:
occur_full_syn_repl = None
occur_full_syn_redu = None
#p((baseline_container[0],data),"data")
if repls_container:
repls =repls_container[0]
#p(repls_container, "repls_container")
counted_repls = defaultdict(lambda:defaultdict(lambda:defaultdict(int)))
for repl in repls:
#p(repl[3], "repl[3]")
counted_repls[repl[ix_word_repl]][repl[ix_doc_id_repl]][repl[ix_token_repl]] += 1 #. if not in_redu, that each repl will be counted
#p(counted_repls,"counted_repls")
temp_baseline_row += self._get_occur(counted_repls,scope=scope,splitted_syntagma=splitted_syntagma)
occur_full_syn_repl = repls_container[2] if repls_container[1] else None
else:
temp_baseline_row += (None,None)
if redus_container:
redus = redus_container[0]
counted_redus = defaultdict(lambda:defaultdict(lambda:defaultdict(int)))
for redu in redus:
counted_redus[redu[ix_word_redu]][redu[ix_doc_id_redu]][redu[ix_token_redu]] += redu[ix_length_redu]
#p(counted_redus, "counted_redus")
temp_baseline_row += self._get_occur(counted_redus,scope=scope,splitted_syntagma=splitted_syntagma)
occur_full_syn_redu = redus_container[2] if redus_container[1] else None
else:
temp_baseline_row += (None,None)
temp_baseline_row += (occur_full_syn_repl, occur_full_syn_redu)
temporized_sum.append(db_helper.values_to_list( temp_baseline_row, "one"))
#self.statsdb._threads_cursors["sum_inserter"].execute(qeary.format(self._temp_baseline_name,placeholders), db_helper.values_to_list( temp_baseline_row, "one") )
if len(temporized_sum) > self._lazyness_border:
self._insert_temporized_sum_into_baseline_table_in_db(temporized_sum,self._temp_baseline_name)
temporized_sum = []
if len(temporized_sum) > 0:
self._insert_temporized_sum_into_baseline_table_in_db(temporized_sum,self._temp_baseline_name)
temporized_sum = []
self.statsdb._threads_cursors["baseline_creater"].execute("DROP TABLE {};".format("baseline") )
self.statsdb._commit()
self.statsdb._threads_cursors["baseline_creater"].execute("ALTER TABLE {} RENAME TO baseline;".format(self._temp_baseline_name) ) # #
self.statsdb._commit()
self.statsdb._update_temp_indexesList_in_instance(thread_name=thread_name)
#self.statsdb._update_database_pragma_list(thread_name=thread_name)
self.statsdb._update_pragma_table_info(thread_name=thread_name)
self.statsdb._update_temp_tablesList_in_instance(thread_name=thread_name)
if self._status_bar:
status_bar_total_summary = self._get_new_status_bar(None, self.status_bars_manager.term.center("Syntagmas: Processed:'{}'; Summerized:'{}';".format(status_bar_current.count, counter_summerized) ), "", counter_format=self.status_bars_manager.term.bold_white_on_cyan('{fill}{desc}{fill}\n'))
status_bar_total_summary.refresh()
self.status_bars_manager.stop()
if counter_summerized > 0:
self.logger.info("All Syntagmas was counted and summerized.")
return counter_summerized
else:
self.logger.info("No one Syntagmas summerized.")
return False
def _set_rle(self, thread_name="Thread0"):
try:
self.logger.debug("INIT-RLE: Start the initialization of Run_length_encoder for '{}'-Thread.".format(thread_name))
self.preprocessors[thread_name]["rle"] = Rle(self.logger)
self.logger.debug("INIT-RLE: Run_length_encoder for '{}'-Thread was initialized.".format(thread_name))
return True
except Exception, e:
self.logger.error("Exception was encountered: '{}'. ".format(e), exc_info=self._logger_traceback)
return False
def _init_preprocessors(self, thread_name="Thread0"):
try:
if not self._set_rle(thread_name):
self.logger.error("RLE in '{}'-Thread wasn't initialized. Script will be aborted.".format(thread_name), exc_info=self._logger_traceback)
self.threads_status_bucket.put({"name":thread_name, "status":"failed"})
return False
# if self._status_bar:
# status_bar_preprocessors_init = self._get_new_status_bar(1, "{}:PreprocessorsInit".format(thread_name), "unit")
# if self._set_rle(thread_name):
# if self._status_bar:
# status_bar_preprocessors_init.update(incr=1)
# status_bar_preprocessors_init.refresh()
# else:
# status_bar_preprocessors_init.total -= 1
# self.logger.error("RLE in '{}'-Thread wasn't initialized. Script will be aborted.".format(thread_name), exc_info=self._logger_traceback)
# self.threads_status_bucket.put({"name":thread_name, "status":"failed"})
# return False
# if self._status_bar:
# self.counters_attrs["_init_preprocessors"][thread_name]["start"] = status_bar_preprocessors_init.start
# self.counters_attrs["_init_preprocessors"][thread_name]["end"] = status_bar_preprocessors_init.last_update
# self.counters_attrs["_init_preprocessors"][thread_name]["total"] = status_bar_preprocessors_init.total
# self.counters_attrs["_init_preprocessors"][thread_name]["desc"] = status_bar_preprocessors_init.desc
self.logger.debug("PreprocessorsInit: All Preprocessors for '{}'-Thread was initialized.".format(thread_name))
return True
except Exception, e:
print_exc_plus() if self._ext_tb else ""
self.logger.error("PreprocessorsInitError: See Exception: '{}'. ".format(e), exc_info=self._logger_traceback)
return False
def _compute_cleaning_flags(self):
if not self.force_cleaning_flags:
if not self._corp_info["del_url"]:
if self._ignore_url:
self.force_cleaning_flags.add("URL")
if not self._corp_info["del_hashtag"]:
if self._ignore_hashtag:
self.force_cleaning_flags.add("hashtag")
if not self._corp_info["del_mention"]:
if self._ignore_mention:
self.force_cleaning_flags.add("mention")
if not self._corp_info["del_punkt"]:
if self._ignore_punkt:
self.force_cleaning_flags.add("symbol")
if not self._corp_info["del_num"]:
if self._ignore_num:
self.force_cleaning_flags.add("number")
# = {
# "number":":number:",
# "URL":":URL:",
# "symbol":":symbol:",
# "mention":":mention:",
# "hashtag":":hashtag:",
# }
def _preprocess(self, text_elem,thread_name="Thread0"):
#p(text_elem, "text_elem", c="r")
#time.sleep(3)
#p(text_elem, "text_elem")
new_text_elem = []
for sent_container in text_elem:
#p(sent_container, "sent_container")
sent = sent_container[0]
#p(sent, "sent")
sentiment = sent_container[1]
#categories = get_categories([token[0] for token in sent])
#p(categories, "categories")
temp_sent = []
#i = -1å
for token_container in sent:
#p(token_container, "token_container")
#i+=1
categorie = token_container[1]
if categorie in self.force_cleaning_flags:
if self._log_ignored:
self.logger.outsorted_stats("Following Token was ignored: '{}'. Reason: 'It is an URL'.".format(token_container))
#indexes_to_del.append((index_level_1, index_level_2, index_level_3))
temp_sent.append((None,self._cleaned_tags[categorie]))
continue
#p(token_container)
if not self._case_sensitiv:
temp_sent.append((token_container[0].lower(), token_container[1]))
else:
temp_sent.append(token_container)
#p([token_container[0],token_container[1], i])
#p(temp_sent, "temp_sent")
new_text_elem.append((temp_sent, sentiment))
#p((temp_sent), "temp_sent", c="r")
self.logger.debug("Text-Cleaning for current text_elem is done.")
#p(new_text_elem, "new_text_elem",c="r")
#sys.exit()
return new_text_elem
def extract_reduplications(self,repl_free_text_container,rle_for_repl_in_text_container, thread_name="Thread0"):
#self.logger.low_debug("ReduExtraction was started")
extracted_redu_in_text_container = []
redu_free_text_container = []
text_elem_mapping = []
mapping_redu = []
#p(text_elem, "text_elem")
#p(repl_free_text_container, "repl_free_text_container")
sent_index = -1
#total_sent_number = len(repl_free_text_container)
#p(total_sent_number,"total_sent_number")
for sent in repl_free_text_container:
########### SENTENCE LEVEL ##################
sent_index+= 1
#p(sent, "sent")
repl_in_tuples, mapped = self.preprocessors[thread_name]["rle"].encode_to_tuples(sent,mapping=True)
#p(repl_in_tuples, "repl_in_tuples")
extracted_reps, rep_free_sent = self.preprocessors[thread_name]["rle"].rep_extraction_sent(repl_in_tuples,mapped)
#redu_free_index = -1
for rep in extracted_reps:
#redu_free_index += 1
start_index = rep['start_index_in_orig']
length = rep['length']
i_redu_free = rep["index_in_redu_free"]
repl_free_range = repl_free_text_container[sent_index][start_index:start_index+length]
rle_range = rle_for_repl_in_text_container[sent_index][start_index:start_index+length]
addit_info = []
#p((, ))
#p(repl_free_range, "repl_free_range")
#p(rle_range, "rle_range")
addit_info = [r if r else o for o,r in zip(repl_free_range,rle_range)]
#addit_info = [r if (r,o[1]) else o for o,r in zip(orig_range,rle_range)]
#p(addit_info, "addit_info", c="r")
counts = Counter(addit_info)
#p(counts, "counts")
rep_free_sent[i_redu_free] = (rep_free_sent[i_redu_free], dict(counts))
#p((extracted_reps, rep_free_sent), c="r")
#p(rep_free_sent, "rep_free_sent")
extracted_redu_in_text_container.append(extracted_reps)
redu_free_text_container.append(rep_free_sent)
mapping_redu.append(mapped)
#sys.exit()
#self.logger.low_debug("ReduExtraction was finished")
return extracted_redu_in_text_container, redu_free_text_container, mapping_redu
def extract_replications(self, text_elem, thread_name="Thread0"):
#self.logger.low_debug("ReplExtraction was started")
repl_free_text_container = []
rle_for_repl_in_text_container = []
extracted_repl_in_text_container = []
#p(text_elem)
sent_index = -1
total_sent_number = len(text_elem)
for sent_container in text_elem:
########### SENTENCE LEVEL ##################
repl_free_text_container.append([])
rle_for_repl_in_text_container.append([])
extracted_repl_in_text_container.append([])
sent_index+= 1
#p((type(sent_container),sent_container), "sent_container_in_repl_extr")
try:
sent = sent_container[0]
sentiment = sent_container[1]
except Exception as e:
#p(sent_container, "sent_container")
self._terminated = True
msg = "Given SentContainer has wrong structure! SentContainer: '{}'; Exception: '{}'.".format(sent_container,e)
self.logger.error(msg)
self.threads_status_bucket.put({"name":thread_name, "status":"failed", "info":msg})
return False
if not self._case_sensitiv:
sent = [[token_container[0].lower(), token_container[1]] if token_container[0] else token_container for token_container in sent ]
temp_sent = []
token_index = -1
for token_container in sent:
token_index+=1
try:
token = token_container[0]
pos = token_container[1]
#nr_of_token_in_sent = token_index
except Exception, e:
#p(sent_container, "sent_container")
self._terminated = True
msg = "Given TokenContainer has wrong structure! '{}'.".format(token_container)
self.logger.error(msg)
self.threads_status_bucket.put({"name":thread_name, "status":"failed", "info":msg})
return False
if pos not in self.ignored_pos:
if token:
repl_in_tuples = self.preprocessors[thread_name]["rle"].encode_to_tuples(token)
extracted_reps, rep_free_word,rle_word = self.preprocessors[thread_name]["rle"].rep_extraction_word(repl_in_tuples, get_rle_as_str=True)
#p((repl_in_tuples,extracted_reps, rep_free_word,rle_word))
else:
#p((pos, token))
rep_free_word = pos
extracted_reps = None
repl_free_text_container[sent_index].append(rep_free_word)
if extracted_reps:
#p((extracted_reps, rep_free_word,rle_word),c="r")
rle_for_repl_in_text_container[sent_index].append(rle_word)
extracted_repl_in_text_container[sent_index].append(extracted_reps)
else:
rle_for_repl_in_text_container[sent_index].append("")
extracted_repl_in_text_container[sent_index].append("")
else:
repl_free_text_container[sent_index].append(token)
rle_for_repl_in_text_container[sent_index].append("")
extracted_repl_in_text_container[sent_index].append("")
#p((sent_index,token_index, repl_free_text_container[sent_index][token_index],rle_for_repl_in_text_container[sent_index][token_index] ,extracted_repl_in_text_container[sent_index][token_index]))
#p(repl_free_text_container, "repl_free_text_container")
#self.logger.low_debug("ReplExtraction was finished")
return extracted_repl_in_text_container, repl_free_text_container, rle_for_repl_in_text_container
def _get_cleaned_redu_free(self, redu_free_text_container):
inp_token_list = []
for sent in redu_free_text_container:
for token in sent:
try:
token[1].values
inp_token_list.append(token[0])
except (IndexError,AttributeError):
inp_token_list.append(token)
return inp_token_list
def compute_baseline(self, redu_free_text_container,extracted_redu_in_text_container):
#self.logger.low_debug("Baseline Computation for current text-element was started")
## Step 1: Extract ngramm from redu and repl free text element
inp_token_list = self._get_cleaned_redu_free(redu_free_text_container)
computed_baseline = []
for n in xrange(1,self.baseline_ngramm_lenght+1):
computed_baseline += [tuple(inp_token_list[i:i+n]) for i in xrange(len(inp_token_list)-n+1)]
## Step 2: Add reduplicated unigramms
#self.logger.low_debug("Baseline Computation was finished.")
return computed_baseline
def baseline_insert_temporized_data(self,temporized_baseline,thread_name="Thread0"):
try:
#self.logger.low_debug("Insertion Process of temporized Baseline was started")
qeary = """
INSERT OR REPLACE INTO baseline VALUES (
:0,
:1,
:2,
COALESCE((SELECT occur_syntagma_all FROM baseline WHERE syntagma=:0), 0) + :3,
NULL,NULL,NULL,NULL,NULL,NULL
);"""
cursor = self.statsdb._db.cursor()
def intern_gen():
for syntag, count in temporized_baseline.iteritems():
#print syntag
#self.logger.error("{}".format(syntag))
#sys.exit()
yield (
self._baseline_delimiter.join(syntag).strip(),
self._baseline_delimiter.join([self.stemm(w) for w in syntag]).strip(),
len(syntag),
count,
)
cursor.executemany(qeary, intern_gen() )
self.logger.low_debug("Temporized Baseline was inserted into DB.")
return True
except Exception as e:
self.logger.error("INsertionError: {}".format(repr(e)), exc_info=self._logger_traceback)
self.terminated = True
return False
# def baseline_intime_insertion_into_db(self,thread_name="Thread0"):
# temporized_baseline_to_insert = self.temporized_baseline
# self.temporized_baseline = defaultdict(int)
# thread_name = "basinsrt"
# if self.baseline_insrt_process:
# try:
# i = 0
# while True:
# #a = self.baseline_insrt_process.isAlive()
# #p(a, "isalive")
# i += 1
# if not self.baseline_insrt_process.isAlive():
# self.logger.debug("Waiting is finished -> (BaselineInsertion will be start)")
# break
# else:
# if i >= 50:
# self.logger.error("Timeout limit was reached. Probably something goes wrong!!!!")
# self.terminated = True
# sys.exit()
# self.logger.debug("Wait till BaselineInsertion is done.")
# time.sleep(1)
# except AttributeError:
# pass
# #p("5555")
# self.baseline_insrt_process = threading.Thread(target=self.baseline_insert_temporized_data, args=(temporized_baseline_to_insert, thread_name), name=thread_name)
# self.baseline_insrt_process.setDaemon(True)
# self.baseline_insrt_process.start()
# #time.sleep(5)
# def baseline_insert_left_over_data(self,thread_name="Thread0"):
# thread_name = "basinsrt"
# # p("111")
# if self.baseline_insrt_process:
# # p("222")
# i = 0
# try:
# while True:
# i += 1
# #a = self.baseline_insrt_process.isAlive()
# #p(a, "isalive")
# if not self.baseline_insrt_process.isAlive():
# self.logger.debug("Waiting is finished -> (BaselineInsertion will be start)")
# break
# else:
# if i >= 50:
# self.logger.error("Timeout limit was reached. Probably something goes wrong!!!!")
# self.logger.debug("Wait till BaselineInsertion is done.")
# time.sleep(1)
# except AttributeError:
# pass
# #p("5555")
# self.baseline_insert_temporized_data(self.temporized_baseline,thread_name=thread_name)
def temporize_baseline(self, computed_baseline,extracted_redu_in_text_container):
#self.temporized_baseline = defaultdict(int)
#p(computed_baseline, "computed_baseline")
for syntagma in computed_baseline:
#p(syntagma)
#if "@ronetejaye" in syntagma:
# p(syntagma, "syntagma")
self.temporized_baseline[syntagma] += 1
#if add_also_repeted_redu:
for sent in extracted_redu_in_text_container:
for redu in sent:
if redu:
#p((redu["word"],),"re_wo")
self.temporized_baseline[(redu["word"],)] += redu["length"]-1
#computed_baseline += [(redu["word"],)]*(redu["length"]-1) # -1, because 1 occur of this unigramm is already in the baseline
self.logger.low_debug("BaselineStats for current text-element was temporized.")
def baseline_intime_insertion_into_db(self,thread_name="Thread0"):
thread_name = "baseline_insrt"
self.baseline_insert_temporized_data(self.temporized_baseline,thread_name=thread_name)
self.temporized_baseline= defaultdict(int)
def baseline_insert_left_over_data(self,thread_name="Thread0"):
thread_name = "baseline_insrt"
self.baseline_insert_temporized_data(self.temporized_baseline,thread_name=thread_name)
self.temporized_baseline= defaultdict(int)
def baseline_lazyinsertion_into_db(self,computed_baseline,extracted_redu_in_text_container, baseline_insertion_border=100000,thread_name="Thread0", ):
#l = len(self.temporized_baseline)
#p((l, baseline_insertion_border))
if len(self.temporized_baseline) > baseline_insertion_border:
self.temporize_baseline(computed_baseline, extracted_redu_in_text_container)
self.baseline_intime_insertion_into_db()
else:
self.temporize_baseline(computed_baseline,extracted_redu_in_text_container)
#self.insert_temporized_baseline_into_db()
def insert_repl_into_db(self,doc_elem,text_elem,extracted_repl_in_text_container, repl_free_text_container,rle_for_repl_in_text_container, redu_free_text_container,mapping_redu,stemmed_text_container, thread_name="Thread0"):
#self.logger.low_debug("Insertion of current ReplsIntoDB was started")
sent_index = -1
redufree_len = tuple(len(sent) for sent in redu_free_text_container)
#p((redu_free_text_container,redufree_len, ))
#p(mapping_redu, "mapping_redu")
for sent in extracted_repl_in_text_container:
#p(sent, "sent")
sent_index += 1
token_index = -1
#temp_next_left_index_in_orig_t_elem = mapping_redu[sent_index][temp_index]
#p((doc_elem))
for repls_for_current_token in sent:
token_index += 1
if repls_for_current_token:
#p(repls_for_current_token, "repls_for_current_token")
for repl_container in repls_for_current_token:
#p(repl_container, "repl_container")
if repl_container:
try:
#p((sent_index, token_index), c="c")
current_sent_from_map = mapping_redu[sent_index]
next_left_index_in_orig_t_elem = token_index if token_index in current_sent_from_map else nextLowest(current_sent_from_map,token_index)
token_index_in_redu_free = current_sent_from_map.index(next_left_index_in_orig_t_elem)
it_is_redu = self._is_redu(sent_index,token_index_in_redu_free,redu_free_text_container)
input_dict = {
"doc_id": doc_elem[0],
# "doc_id": doc_elem[self._id_field_name],
'redufree_len':redufree_len,
"index_in_corpus": (sent_index,token_index),
"index_in_redufree": (sent_index,token_index_in_redu_free),
"rle_word": rle_for_repl_in_text_container[sent_index][token_index],
"pos":text_elem[sent_index][0][next_left_index_in_orig_t_elem][1] if it_is_redu else text_elem[sent_index][0][token_index][1],
"normalized_word": repl_free_text_container[sent_index][token_index],
"stemmed":stemmed_text_container[sent_index][token_index_in_redu_free],
"polarity":text_elem[sent_index][1],
"repl_letter": repl_container[0],
"repl_length": repl_container[1],
"index_of_repl": repl_container[2],
"in_redu": (sent_index,token_index_in_redu_free) if it_is_redu else None
}
except Exception as e:
#p(sent_container, "sent_container")
self._terminated = True
msg = "Given ReplContainer has wrong structure! '{}'. ('{}')".format(repl_container, repr(e))
self.logger.error(msg)
self.threads_status_bucket.put({"name":thread_name, "status":"failed", "info":msg})
return False
#p(((sent_index, token_index),repl_free_text_container[sent_index][token_index], ), "GET KONTEXT FueR DAS WORD")
#input_dict =
self._get_context_left_for_repl(input_dict, text_elem, token_index_in_redu_free, mapping_redu, redu_free_text_container, sent_index,stemmed_text_container,)
#input_dict =
self._get_context_right_for_repl(input_dict, text_elem, token_index_in_redu_free, mapping_redu, redu_free_text_container, sent_index,stemmed_text_container,)
self._repl_inserter(input_dict, thread_name=thread_name)
#p(input_dict, "input_dict")
#self.statsdb.lazyinsert("replications", input_dict, thread_name=thread_name)
#self.logger.low_debug("Insertion of current ReplsIntoDB was finished")
def _repl_inserter(self, inp_dict, thread_name="Thread0"):
if len(self.temporized_repl[thread_name]) > self._lazyness_border:
self._temporize_repl(inp_dict, thread_name=thread_name)
self._write_repl_into_db(thread_name=thread_name)
else:
self._temporize_repl(inp_dict, thread_name=thread_name)
def _temporize_repl(self, inp_dict,thread_name="Thread0"):
temp_list = []
for col in self._repls_cols:
temp_list.append(inp_dict.get(col,None))
#temp_list.append()
self.temporized_repl[thread_name].append(db_helper.values_to_list(temp_list, "one"))
def _write_repl_into_db(self,thread_name="Thread0"):
#thread_name =
placeholders = ', '.join('?'*len(self._repls_cols))
query = "INSERT or IGNORE INTO main.replications VALUES ({});".format(placeholders)
#p((query,placeholders),"query")
#p(self.temporized_repl[thread_name][0])
#p(len(self.temporized_repl[thread_name][0]))
self.statsdb._threads_cursors[thread_name].executemany(query,self.temporized_repl[thread_name] )
self.temporized_repl[thread_name] = []
def _redu_inserter(self, inp_dict, thread_name="Thread0"):
if len(self.temporized_redu[thread_name]) > self._lazyness_border:
self._temporize_redu(inp_dict, thread_name=thread_name)
self._write_redu_into_db(thread_name=thread_name)
else:
self._temporize_redu(inp_dict, thread_name=thread_name)
def _temporize_redu(self, inp_dict,thread_name="Thread0"):
temp_list = []
for col in self._redus_cols:
temp_list.append(inp_dict.get(col,None))
#temp_list.append()
self.temporized_redu[thread_name].append(db_helper.values_to_list(temp_list, "one"))
def _write_redu_into_db(self,thread_name="Thread0"):
#thread_name =
placeholders = ', '.join('?'*len(self._redus_cols))
query = "INSERT or IGNORE INTO main.reduplications VALUES ({});".format(placeholders)
#p((query,placeholders),"query")
#p(self.temporized_redu[thread_name][0])
#p(len(self.temporized_redu[thread_name][0]))
self.statsdb._threads_cursors[thread_name].executemany(query,self.temporized_redu[thread_name] )
self.temporized_redu[thread_name] = []
def insert_redu_into_db(self,doc_elem,text_elem,extracted_redu_in_text_container, redu_free_text_container, rle_for_repl_in_text_container, repl_free_text_container, mapping_redu,stemmed_text_container,thread_name="Thread0"):
#self.logger.low_debug("Insertion of current RedusIntoDB was started")
sent_index = -1
#p(extracted_redu_in_text_container, "extracted_redu_in_text_container")
redufree_len = tuple(len(sent) for sent in redu_free_text_container)
for redu_in_sent in extracted_redu_in_text_container:
sent_index += 1
for redu in redu_in_sent:
#p(redu, c="r")
#if redu:
#p(redu_in_sent, "redu_in_sent")
#p(redu_free_text_container, "redu_free_text_container")
try:
rle_word = rle_for_repl_in_text_container[sent_index][redu['start_index_in_orig']]
#p((redu['start_index_in_orig'],rle_for_repl_in_text_container[sent_index][redu['start_index_in_orig']]), "redu['start_index_in_orig']", c="m")
#p(redu_free_text_container[sent_index][redu['index_in_redu_free']], "orig_words")
index_in_redu_free = redu["index_in_redu_free"]
input_dict = {
"doc_id": doc_elem[0],
# "doc_id": doc_elem[self._id_field_name],
'redufree_len':redufree_len,
"index_in_corpus": (sent_index,redu['start_index_in_orig']),
"index_in_redufree": (sent_index,index_in_redu_free),
#"rle_word": rle_word if rle_word else repl_free_text_container[sent_index][redu['start_index_in_orig']],
"pos":text_elem[sent_index][0][redu['start_index_in_orig']][1],
"normalized_word": repl_free_text_container[sent_index][redu['start_index_in_orig']],
"stemmed":stemmed_text_container[sent_index][index_in_redu_free],
'orig_words':redu_free_text_container[sent_index][index_in_redu_free][1],
"redu_length": redu['length'],
"polarity":text_elem[sent_index][1],
#"repl_letter": repl_container[0],
#"index_of_repl": repl_container[2],
}
except Exception as e:
#p(sent_container, "sent_container")
self._terminated = True
msg = "Given ReduContainer has wrong structure! '{}'. ('{}')".format(redu, e)
self.logger.error(msg)
self.threads_status_bucket.put({"name":thread_name, "status":"failed", "info":msg})
return False
#sent =
start_index = redu['start_index_in_orig']
#redu_length = redu['length']
#input_dict =
self._get_context_left_for_redu(input_dict, text_elem, mapping_redu, redu_free_text_container,sent_index , redu,stemmed_text_container,)
#input_dict =
self._get_context_right_for_redu(input_dict, text_elem, mapping_redu, redu_free_text_container, sent_index,redu,stemmed_text_container,)
#p("RIGHT STOP ---------------------\n", c="c")
#self.statsdb.lazyinsert("reduplications", input_dict, thread_name=thread_name)
self._redu_inserter(input_dict, thread_name=thread_name)
#p(input_dict, "input_dict")
#self.logger.low_debug("Insertion of current RedusIntoDB was finished")
def _get_context_left_for_repl(self, input_dict, text_elem, token_index_in_redu_free, mapping_redu, redu_free_text_container, sent_index,stemmed_text_container,):
### context left
#p(token_index_in_redu_free, "1token_index_in_redu_free")
for context_number in range(1,self._context_lenght+1):
col_name_context = "contextL{}".format(context_number)
col_name_info = "context_infoL{}".format(context_number)
#p(token_index_in_redu_free, "2token_index_in_redu_free")
temp_index = token_index_in_redu_free - context_number
## if needed context_item in the current sent
#p((context_number,sent_index,temp_index))
if temp_index >= 0:
temp_next_left_index_in_orig_t_elem = mapping_redu[sent_index][temp_index]
try:
#p((redu_free_text_container,sent_index, temp_index), "redu_free_text_container")
redu_free_text_container[sent_index][temp_index][1].items
item = redu_free_text_container[sent_index][temp_index][0]
info = (text_elem[sent_index][0][temp_next_left_index_in_orig_t_elem][1],
redu_free_text_container[sent_index][temp_index][1],
stemmed_text_container[sent_index][temp_index])
#info = text_elem[sent_index][0][temp_index][1]
except :
#p(repr(e), "E1")
item = redu_free_text_container[sent_index][temp_index]
info = (text_elem[sent_index][0][temp_next_left_index_in_orig_t_elem][1],
None,
stemmed_text_container[sent_index][temp_index])
else: ## if needed context_item not in the current sent
#leftover_contextnumber = context_number - token_index # left over times to go to the left
leftover_contextnumber = context_number - token_index_in_redu_free # left over times to go to the left
if not context_number: # if the not time to go to the left
#p("WrongContextNumber. It should be >0", c="r")
raise Exception, "WrongContextNumber. It should be >0"
number_of_loops = 0
while True:
number_of_loops += 1
temp_sent_index = sent_index - number_of_loops
if temp_sent_index < 0:
item = None
info = None
break
last_sent = redu_free_text_container[temp_sent_index+1]
current_sent = redu_free_text_container[temp_sent_index]
leftover_contextnumber = leftover_contextnumber if number_of_loops == 1 else leftover_contextnumber-(len(last_sent))
if leftover_contextnumber <= len(current_sent) and leftover_contextnumber >= 0:
temp_index = -leftover_contextnumber
temp_next_left_index_in_orig_t_elem = mapping_redu[temp_sent_index][temp_index]
current_sent_from_map = mapping_redu[temp_sent_index]
temp_token_index_in_redu_free = current_sent_from_map.index(temp_next_left_index_in_orig_t_elem)
try:
redu_free_text_container[temp_sent_index][temp_index][1].items
item = redu_free_text_container[temp_sent_index][temp_index][0]
info = (
text_elem[temp_sent_index][0][temp_next_left_index_in_orig_t_elem][1],
redu_free_text_container[temp_sent_index][temp_index][1],
stemmed_text_container[temp_sent_index][temp_token_index_in_redu_free])
#info = text_elem[temp_sent_index][0][temp_index][1]
except :
#p(e, "E2")
item = redu_free_text_container[temp_sent_index][temp_index]
info = (text_elem[temp_sent_index][0][temp_next_left_index_in_orig_t_elem][1],
None,
stemmed_text_container[temp_sent_index][temp_token_index_in_redu_free])
break
#text_elem[sent_index][0][token_index][1]
#item = json.dumps(item)
input_dict.update({col_name_context: item, col_name_info:info})
return input_dict
def _get_context_right_for_repl(self, input_dict, text_elem, token_index_in_redu_free, mapping_redu, redu_free_text_container, sent_index,stemmed_text_container,):
#context right
for context_number in range(1,self._context_lenght+1):
col_name_context = "contextR{}".format(context_number)
col_name_info = "context_infoR{}".format(context_number)
#while True:
#temp_index = token_index + context_number
temp_index = token_index_in_redu_free + context_number
## if needed context_item in the current sent
if temp_index < len(redu_free_text_container[sent_index]):
####p((sent_index, temp_index, len(mapping_redu[sent_index])), "temp_next_left_index_in_orig_t_elem")
temp_next_left_index_in_orig_t_elem = mapping_redu[sent_index][temp_index]
try:
redu_free_text_container[sent_index][temp_index][1].items
item = redu_free_text_container[sent_index][temp_index][0]
info = (text_elem[sent_index][0][temp_next_left_index_in_orig_t_elem][1],
redu_free_text_container[sent_index][temp_index][1],
stemmed_text_container[sent_index][temp_index])
#info = text_elem[sent_index][0][temp_index][1]
except :
item = redu_free_text_container[sent_index][temp_index]
info = (text_elem[sent_index][0][temp_next_left_index_in_orig_t_elem][1],
None,
stemmed_text_container[sent_index][temp_index])
else: ## if needed context_item not in the current sent
#leftover_contextnumber = context_number - (len(sent) - (token_index+1)) # left over times to go to the left
leftover_contextnumber = context_number - (len(redu_free_text_container[sent_index]) - (token_index_in_redu_free+1)) # left over times to go to the left
if not leftover_contextnumber: # if the not time to go to the left
raise Exception, "1. WrongContextNumber. It should be >0"
number_of_loops = 0
while True:
number_of_loops += 1
temp_sent_index = sent_index + number_of_loops
if temp_sent_index >= len(redu_free_text_container):
item = None
info = None
break
last_sent = redu_free_text_container[temp_sent_index-1]
current_sent = redu_free_text_container[temp_sent_index]
leftover_contextnumber = leftover_contextnumber if number_of_loops == 1 else leftover_contextnumber-(len(last_sent))
if leftover_contextnumber <= 0 :
raise Exception, "2. WrongLeftoverContextNumber. It should be >0"
if leftover_contextnumber <= len(current_sent) and leftover_contextnumber > 0:
temp_index =leftover_contextnumber-1
temp_next_left_index_in_orig_t_elem = mapping_redu[temp_sent_index][temp_index]
current_sent_from_map = mapping_redu[temp_sent_index]
temp_token_index_in_redu_free = current_sent_from_map.index(temp_next_left_index_in_orig_t_elem)
try:
redu_free_text_container[temp_sent_index][temp_index][1].items
item = redu_free_text_container[temp_sent_index][temp_index][0]
info = (text_elem[temp_sent_index][0][temp_next_left_index_in_orig_t_elem][1],
redu_free_text_container[temp_sent_index][temp_index][1],
stemmed_text_container[temp_sent_index][temp_token_index_in_redu_free])
except :
#p("444")
item = redu_free_text_container[temp_sent_index][temp_index]
info = (text_elem[temp_sent_index][0][temp_next_left_index_in_orig_t_elem][1],
None,
stemmed_text_container[temp_sent_index][temp_token_index_in_redu_free])
break
#item = json.dumps(item)
input_dict.update({col_name_context: item, col_name_info:info})
return input_dict
def _get_context_right_for_redu(self, input_dict, text_elem, mapping_redu, redu_free_text_container, sent_index,redu,stemmed_text_container,):
## context right
#p("---------------------\nRIGHT START", c="c")
for context_number in range(1,self._context_lenght+1):
col_name_context = "contextR{}".format(context_number)
col_name_info = "context_infoR{}".format(context_number)
#while True:
temp_index = redu['index_in_redu_free'] + context_number
#p((context_number,sent_index,temp_index,len(redu_in_sent)), "context_number,sent_index,temp_index,len(redu_in_sent)")
## if needed context_item in the current sent
if temp_index < len(redu_free_text_container[sent_index]):
#item = redu_free_text_container[sent_index][temp_index]
token_index_in_orig_t_elem = mapping_redu[sent_index][temp_index]
#p((sent_index,temp_index, token_index_in_orig_t_elem), "sent_index,temp_index, token_index_in_orig_t_elem")
try:
#p("111")
redu_free_text_container[sent_index][temp_index][1].items
item = redu_free_text_container[sent_index][temp_index][0]
info = (text_elem[sent_index][0][token_index_in_orig_t_elem][1],
redu_free_text_container[sent_index][temp_index][1],
stemmed_text_container[sent_index][temp_index])
#info = text_elem[sent_index][0][temp_index][1]
except:
#p("222")
item = redu_free_text_container[sent_index][temp_index]
info = (text_elem[sent_index][0][token_index_in_orig_t_elem][1],
None,
stemmed_text_container[sent_index][temp_index])
#p((item, info), c="b")
#info = rle_for_repl_in_text_container[sent_index][start_index:start_index+redu['length']]
#info = text_elem[sent_index][0][temp_index][1]
#p((col_name_context,item, info), "item", c="m")
else: ## if needed context_item not in the current sent
leftover_contextnumber = context_number - (len(redu_free_text_container[sent_index]) - (redu['index_in_redu_free']+1)) # left over times to go to the left
if not leftover_contextnumber: # if the not time to go to the left
raise Exception, "1. WrongContextNumber. It should be >0"
number_of_loops = 0
while True:
number_of_loops += 1
temp_sent_index = sent_index + number_of_loops
if temp_sent_index >= len(redu_free_text_container):
item = None
info = None
#p((item, info), c="b")
break
last_sent = redu_free_text_container[temp_sent_index-1]
current_sent = redu_free_text_container[temp_sent_index]
leftover_contextnumber = leftover_contextnumber if number_of_loops == 1 else leftover_contextnumber-(len(last_sent))
if leftover_contextnumber <= 0 :
raise Exception, "2. WrongLeftoverContextNumber. It should be >0"
if leftover_contextnumber <= len(current_sent) and leftover_contextnumber > 0:
temp_index = leftover_contextnumber-1
token_index_in_orig_t_elem = mapping_redu[temp_sent_index][temp_index]
#p((temp_sent_index,temp_index, token_index_in_orig_t_elem), "sent_index,temp_index, token_index_in_orig_t_elem")
try:
#p("333")
redu_free_text_container[temp_sent_index][temp_index][1].items
item = redu_free_text_container[temp_sent_index][temp_index][0]
info = (text_elem[temp_sent_index][0][token_index_in_orig_t_elem][1],
redu_free_text_container[temp_sent_index][temp_index][1],
stemmed_text_container[temp_sent_index][temp_index])
#info = text_elem[temp_sent_index][0][temp_index][1]
except:
#p("444")
item = redu_free_text_container[temp_sent_index][temp_index]
info = (text_elem[temp_sent_index][0][token_index_in_orig_t_elem][1],
None,
stemmed_text_container[temp_sent_index][temp_index])
#p((item, info), c="b")
#info = [number_of_loops, temp_sent_index, leftover_contextnumber]
#item = current_sent[temp_index]
#info = text_elem[temp_sent_index][0][temp_index][1]
#p((col_name_context,item,info), c="r")
break
#item = json.dumps(item)
input_dict.update({col_name_context: item, col_name_info:info})
return input_dict
def _get_context_left_for_redu(self, input_dict, text_elem, mapping_redu, redu_free_text_container, sent_index,redu,stemmed_text_container,):
### context Left
for context_number in range(1,self._context_lenght+1):
col_name_context = "contextL{}".format(context_number)
col_name_info = "context_infoL{}".format(context_number)
#while True:
temp_index = redu['index_in_redu_free'] - context_number
## if needed context_item in the current sent
if (temp_index) >= 0:
token_index_in_orig_t_elem = mapping_redu[sent_index][temp_index]
try:
redu_free_text_container[sent_index][temp_index][1].items
item = redu_free_text_container[sent_index][temp_index][0]
info = (text_elem[sent_index][0][token_index_in_orig_t_elem][1],
redu_free_text_container[sent_index][temp_index][1],
stemmed_text_container[sent_index][temp_index])
#info = text_elem[sent_index][0][temp_index][1]
except:
item = redu_free_text_container[sent_index][temp_index]
info = (text_elem[sent_index][0][token_index_in_orig_t_elem][1],
None,
stemmed_text_container[sent_index][temp_index])
#'start_index_in_orig'
#p((col_name_context,item, info), "item", c="m")
else: ## if needed context_item not in the current sent
leftover_contextnumber = context_number - redu['index_in_redu_free'] # left over times to go to the left
if not context_number: # if the not time to go to the left
raise Exception, "WrongContextNumber. It should be >0"
number_of_loops = 0
while True:
number_of_loops += 1
temp_sent_index = sent_index - number_of_loops
if temp_sent_index < 0:
item = None #[number_of_loops, temp_sent_index, leftover_contextnumber]
info = None
break
last_sent = redu_free_text_container[temp_sent_index+1]
current_sent = redu_free_text_container[temp_sent_index]
leftover_contextnumber = leftover_contextnumber if number_of_loops == 1 else leftover_contextnumber-(len(last_sent))
if leftover_contextnumber <= len(current_sent) and leftover_contextnumber >= 0:
#item = current_sent[-leftover_contextnumber]
#p(leftover_contextnumber, "leftover_contextnumber")
#info = text_elem[temp_sent_index][0][-leftover_contextnumber][1]
#info = rle_for_repl_in_text_container[sent_index][start_index:start_index+redu['length']]
temp_index = -leftover_contextnumber
token_index_in_orig_t_elem = mapping_redu[temp_sent_index][temp_index]
try:
redu_free_text_container[temp_sent_index][temp_index][1].items
item = redu_free_text_container[temp_sent_index][temp_index][0]
info = (text_elem[temp_sent_index][0][token_index_in_orig_t_elem][1],
redu_free_text_container[temp_sent_index][temp_index][1],
stemmed_text_container[temp_sent_index][temp_index])
#info = text_elem[temp_sent_index][0][temp_index][1]
except:
item = redu_free_text_container[temp_sent_index][temp_index]
info = (text_elem[temp_sent_index][0][token_index_in_orig_t_elem][1],
None,
stemmed_text_container[temp_sent_index][temp_index])
break
#text_elem[sent_index][0][redu['index_in_redu_free']][1]
#item = json.dumps(item)
input_dict.update({col_name_context: item, col_name_info:info})
return input_dict
###################Optimizators########################
def get_streams_from_baseline(self,stream_number, max_scope=False,size_to_fetch=1, split_syntagma=False):
row_num = self.statsdb.rownum("baseline")
rows_pro_stream = row_num/stream_number
streams = []
num_of_getted_items = 0
for i in range(stream_number):
thread_name = "BSThread{}".format(i)
# p((i,thread_name ), "get_streams_from_baseline")
if i < (stream_number-1): # for gens in between
gen = self._baseline("*",max_scope=False,thread_name=thread_name,limit=rows_pro_stream, offset=num_of_getted_items,size_to_fetch=size_to_fetch, split_syntagma=split_syntagma)
num_of_getted_items += rows_pro_stream
streams.append((thread_name,LenGen(gen, rows_pro_stream)))
else: # for the last generator
gen = self._baseline("*",max_scope=False,thread_name=thread_name,limit=-1, offset=num_of_getted_items,size_to_fetch=size_to_fetch, split_syntagma=split_syntagma)
streams.append((thread_name,LenGen(gen, row_num-num_of_getted_items)))
return streams
def _check_termination(self, thread_name="Thread0"):
if self._terminated:
self.logger.critical("'{}'-Thread was terminated.".format(thread_name))
self.threads_status_bucket.put({"name":thread_name, "status":"terminated"})
sys.exit()
def clean_baseline_table(self,stream_number=1, min_row_pro_sream=1000, cpu_percent_to_get=50, adjust_to_cpu=True):
#p(self.statsdb.rownum("baseline"))
if adjust_to_cpu:
stream_number= get_number_of_streams_adjust_cpu( min_row_pro_sream, self.statsdb.rownum("baseline"), stream_number, cpu_percent_to_get=cpu_percent_to_get)
if stream_number is None or stream_number==0:
#p((self._get_number_of_left_over_files(),self.counter_lazy_getted),"self._get_number_of_left_over_files()")
self.logger.error("StreamNumber is 0. Not generators could be returned.", exc_info=self._logger_traceback)
return []
self._init_compution_variables()
streams= self.get_streams_from_baseline(stream_number, split_syntagma=False)
self._terminated = False
if self._status_bar:
try:
if not self.status_bars_manager.enabled:
self.status_bars_manager = self._get_status_bars_manager()
except:
self.status_bars_manager = self._get_status_bars_manager()
status_bar_start = self._get_new_status_bar(None, self.status_bars_manager.term.center("StatsDB-Optimization") , "", counter_format=self.status_bars_manager.term.bold_white_on_cyan("{fill}{desc}{fill}"))
status_bar_start.refresh()
status_bar_threads_init = self._get_new_status_bar(len(streams), "ThreadsStarted", "threads")
#status_bar_current = self._get_new_status_bar(self.statsdb.rownum("baseline"), "{}:BaselineOptimization".format(thread_name), "syntagma")
#if self._status_bar:
self._threads_num = len(streams)
row_num_bevore = self.statsdb.rownum("baseline")
if self._threads_num>1:
if self._status_bar:
unit = "rows"
self.main_status_bar = self._get_new_status_bar(row_num_bevore, "AllThreadsTotalInsertions", unit)
self.main_status_bar.refresh()
else:
self.main_status_bar = False
syntagmas_to_delete = []
#p(len(syntagmas_to_delete), "syntagmas_to_delete")
for stream in streams:
gen = stream[1]
if not self._isrighttype(gen):
self.logger.error("StatsBaselineCleanError: Given InpData not from right type. Please give an list or an generator.", exc_info=self._logger_traceback)
return False
#p(gen)
thread_name = stream[0]
processThread = threading.Thread(target=self._clean_baseline_table, args=(gen,syntagmas_to_delete, thread_name), name=thread_name)
processThread.setDaemon(True)
processThread.start()
self.active_threads.append(processThread)
if self._status_bar:
status_bar_threads_init.update(incr=1)
#i+=1
time.sleep(1)
if not self._wait_till_all_threads_are_completed("Compute"):
return False
#row_num_bevore = self.statsdb.rownum("baseline")
##### delete syntagmas from baseline-table
qeary = "DELETE FROM baseline WHERE syntagma = ?;"
#p(len(syntagmas_to_delete), "syntagmas_to_delete")
if syntagmas_to_delete:
self.statsdb.executemany(qeary,syntagmas_to_delete)
row_num_after = self.statsdb.rownum("baseline")
self.statsdb._commit()
if self._status_bar:
status_bar_total_summary = self._get_new_status_bar(None, self.status_bars_manager.term.center("Syntagmas: Bevore:'{}'; After:'{}'; Removed: '{}'.".format(row_num_bevore, row_num_after, row_num_bevore-row_num_after ) ), "", counter_format=self.status_bars_manager.term.bold_white_on_cyan('{fill}{desc}{fill}\n'))
status_bar_total_summary.refresh()
self.status_bars_manager.stop()
#p(len(syntagmas_to_delete), "syntagmas_to_delete")
#syntagmas_to_delete = []
if (row_num_bevore-row_num_after) == len(syntagmas_to_delete):
if self._status_bar:
self.logger.info("Baseline-Table was cleaned.")
else:
self.logger.info("Baseline-Table was cleaned.")
return True
else:
False
def _clean_baseline_table(self, gen,syntagmas_to_delete, thread_name="Thread0"):
try:
if not self._check_stats_db_should_exist():
return False
#return
### compute syntagmas to delete
if self._status_bar:
status_bar_current = self._get_new_status_bar(len(gen), "{}:".format(thread_name), "syntagma")
minimum_columns = False
indexes = self.col_index_min if minimum_columns else self.col_index_orig
#indexes = self.col_index_min
case = "" if self._case_sensitiv else " COLLATE NOCASE "
for baseline_container in gen:
was_found = False
if self._status_bar:
status_bar_current.update(incr=1)
if self.main_status_bar:
self.main_status_bar.update(incr=1)
#self._check_termination(thread_name=thread_name)
inp_syntagma_splitted = baseline_container[0].split(self._baseline_delimiter)
scope = len(inp_syntagma_splitted)
syntagma_type = "lexem"
where = self._get_where_statement(inp_syntagma_splitted,scope=scope,thread_name=thread_name,
with_context=True,syntagma_type=syntagma_type)
collected_w = ()
for w in where:
#p(w, "w")
#_threads_cursors["Thread0"].execute("SELECT id FROM replications WHERE {} ;".format(" AND ".join(w)))
if w:
current_reps = self.statsdb._threads_cursors[thread_name].execute(u"SELECT id FROM replications WHERE {} {};".format(u" AND ".join(w), case)).fetchone()
#current_reps = self.statsdb.getone("replications", where=w,connector_where="AND",case_sensitiv=self._case_sensitiv,thread_name=thread_name)
#tuple(self._rep_getter_from_db("repl",inp_syntagma_splitted,scope=scope,where=w,thread_name=thread_name, for_optimization=True))
if current_reps:
#p("REPL was found")
was_found = True
break
collected_w += (w,)
else:
self.logger.error("No where Statements was given. Probably an ImplementationsError.")
return False
#else:
## Step 2: If no one repls was found, than search for redus
if was_found:
continue
for w in collected_w:
#collected_w.append(w)
if w:
current_reps = self.statsdb._threads_cursors[thread_name].execute(u"SELECT id FROM reduplications WHERE {} {};".format(u" AND ".join(w), case)).fetchone()
#current_reps = current_reps = self.statsdb.getone("reduplications", where=w,connector_where="AND",case_sensitiv=self._case_sensitiv,thread_name=thread_name)
#tuple(self._rep_getter_from_db("redu",inp_syntagma_splitted,scope=scope,where=w,thread_name=thread_name, for_optimization=True))
if current_reps:
#p("REDU was found")
was_found = True
break
else:
self.logger.error("No where Statements was given. Probably an ImplementationsError.")
return False
if was_found:
continue
syntagmas_to_delete.append((baseline_container[0],))
self.threads_status_bucket.put({"name":thread_name, "status":"done"})
return True
except Exception, e:
print_exc_plus() if self._ext_tb else ""
msg = "_CleanBaselineTableError: See Exception: '{}'. ".format(e)
self.logger.error(msg, exc_info=self._logger_traceback)
self.threads_status_bucket.put({"name":thread_name, "status":"failed", "info":msg})
self._terminated = True
self.statsdb.rollback()
return False
def _check_baseline_consistency(self):
try:
#p(baseline, "baseline")
if self._status_bar:
try:
if not self.status_bars_manager.enabled:
self.status_bars_manager = self._get_status_bars_manager()
except:
self.status_bars_manager = self._get_status_bars_manager()
status_bar_start = self._get_new_status_bar(None, self.status_bars_manager.term.center("Baseline-ConsistencyTest") , "", counter_format=self.status_bars_manager.term.bold_white_on_cyan("{fill}{desc}{fill}"))
status_bar_start.refresh()
normalized_word_tag = db_helper.tag_normalized_word
consistency = True
# counter_inconsistency = 0
###############################
num = self.statsdb.rownum("baseline")
if self._status_bar:
status_bar_current = self._get_new_status_bar(num, "BaselineCheck:", "syntagma")
#indexes = self.col_index_min if minimum_columns else self.col_index_orig
indexes = self.col_index_orig
ix_syntagma = indexes["baseline"]["syntagma"]
ix_scope = indexes["baseline"]["scope"]
ix_stemmed = indexes["baseline"]["stemmed"]
for r in self.statsdb.lazyget("baseline"):
if self._status_bar:
status_bar_current.update(incr=1)
syntagma = r[ix_syntagma].split(self._baseline_delimiter)
stemmed = r[ix_stemmed].split(self._baseline_delimiter)
scope = r[ix_scope]
if (len(syntagma) != scope) or (len(stemmed) != scope):
#p((len(syntagma) != len(stemmed) != 10),c="r")
consistency = False
self.logger.error("BaselineInvalidEntry: syntagma : '{}'; stemmed: '{}'; scope: '{}'; ".format(syntagma, stemmed, scope))
if self._status_bar:
if status_bar_current.count != status_bar_current.total:
status_bar_current.count = status_bar_current.total
status_bar_current.refresh()
if consistency:
status_bar_total_summary = self._get_new_status_bar(None, self.status_bars_manager.term.center("Baseline is consistent."), "", counter_format=self.status_bars_manager.term.bold_white_on_cyan('{fill}{desc}{fill}\n'))
else:
status_bar_total_summary = self._get_new_status_bar(None, self.status_bars_manager.term.center("ERROR!!! Baseline is INCONSISTENT."), "", counter_format=self.status_bars_manager.term.bold_white_on_red('{fill}{desc}{fill}\n'))
status_bar_total_summary.refresh()
self.status_bars_manager.stop()
if consistency:
return True
else:
#inconsistent_words
#inconsistent_words = inconsistent_words if self._log_content else ":HIDDED_CONTENT:"
self.logger.error("StatsDB is inconsistence. Try to set other 'baseline_delimiter' (used now: '{}') And if after that action your Baseline still stay broken than it could be an ImplementationsError. If you have this Problem, please contact Egor Savin ([email protected]).".format(self._baseline_delimiter))
return False
except Exception as e:
self.logger.error("ConsistencyTestError: '{}' ".format(repr(e)))
return False
def _check_statsdb_consistency(self):
try:
baseline = self.statsdb.lazyget("baseline", columns="syntagma", where="scope=1")
if baseline:
baseline = set([b[0] for b in baseline if b])
else:
self.logger.error("BaselineTableErorr: No one syntagma with scope 1 was found. It could mean, that this StatsDB is corrupt or inconsistent")
return False
#p(baseline, "baseline")
if self._status_bar:
try:
if not self.status_bars_manager.enabled:
self.status_bars_manager = self._get_status_bars_manager()
except:
self.status_bars_manager = self._get_status_bars_manager()
status_bar_start = self._get_new_status_bar(None, self.status_bars_manager.term.center("StatsDB-ConsistencyTest") , "", counter_format=self.status_bars_manager.term.bold_white_on_cyan("{fill}{desc}{fill}"))
status_bar_start.refresh()
normalized_word_tag = db_helper.tag_normalized_word
consistency = True
# counter_inconsistency = 0
inconsistent_words = []
##############################
########## REPLS ###########
###############################
num_repl = self.statsdb.execute("SELECT count(DISTINCT {}) FROM replications;".format(normalized_word_tag))
if num_repl:
num_repl = num_repl.fetchone()[0]
else:
self.logger.error("ERROR by getting ReplRowNumber. consistencyTest is failed.")
return False
if self._status_bar:
status_bar_repl = self._get_new_status_bar(num_repl, "ReplsCheck:", "syntagma")
for r in self.statsdb.getall("replications", columns=normalized_word_tag, distinct=True):
if self._status_bar:
status_bar_repl.update(incr=1)
#p(r[0],"r[0]")
if r[0] not in baseline:
consistency = False
# counter_inconsistency += 1
try:
word = r[0].decode()
except:
pass
inconsistent_words.append(word)
self.logger.debug(u"StatsDB is inconsistence. There Exist NO-Baseline-Entry for '{}'-word ".format(word))
##############################
########## REDUS ###########
##############################
num_redu = self.statsdb.execute("SELECT count(DISTINCT {}) FROM reduplications;".format(normalized_word_tag))
if num_redu:
num_redu = num_redu.fetchone()[0]
else:
self.logger.error("ERROR by getting ReduRowNumber. consistencyTest is failed.")
return False
#p("555")
if self._status_bar:
status_bar_redu = self._get_new_status_bar(num_redu, "RedusCheck:", "syntagma")
for r in self.statsdb.getall("reduplications", columns=normalized_word_tag, distinct=True):
if self._status_bar:
status_bar_redu.update(incr=1)
#p(r[0],"r[0]")
if r[0] not in baseline:
consistency = False
# counter_inconsistency += 1
try:
word = r[0].decode()
except:
pass
inconsistent_words.append(word)
self.logger.debug(u"StatsDB is inconsistence. There Exist NO-Baseline-Entry for '{}'-word ".format(word))
if self._status_bar:
#p((num_repl, num_redu))
#p((status_bar_repl.count, status_bar_repl.total, status_bar_redu.count, status_bar_redu.total))
if status_bar_repl.count != status_bar_repl.total:
status_bar_repl.count = status_bar_repl.total
status_bar_repl.refresh()
if status_bar_redu.count != status_bar_redu.total:
status_bar_redu.count = status_bar_redu.total
status_bar_redu.refresh()
if consistency:
status_bar_total_summary = self._get_new_status_bar(None, self.status_bars_manager.term.center("StatsDB is consistent."), "", counter_format=self.status_bars_manager.term.bold_white_on_cyan('{fill}{desc}{fill}\n'))
else:
status_bar_total_summary = self._get_new_status_bar(None, self.status_bars_manager.term.center("ERROR!!! StatsDB is INCONSISTENT."), "", counter_format=self.status_bars_manager.term.bold_white_on_red('{fill}{desc}{fill}\n'))
status_bar_total_summary.refresh()
self.status_bars_manager.stop()
if consistency:
return True
else:
#inconsistent_words
inconsistent_words = inconsistent_words if self._log_content else ":HIDDED_CONTENT:"
self.logger.error("StatsDB is inconsistence. '{}'-words don't have any entry in BaselineTable. It could be an ImplementationsError. If you have this Problem, please contact Egor Savin ([email protected]).\n InconsistentWords: '{}'. ".format(len(inconsistent_words), inconsistent_words))
return False
except Exception as e:
self.logger.error("ConsistencyTestError: '{}' ".format(repr(e)))
return False
def optimize_db(self,stream_number=1,thread_name="Thread0",optimized_for_long_syntagmas=False,min_row_pro_sream=1000, cpu_percent_to_get=50, adjust_to_cpu=True):
if not self._db_frozen:
if self.clean_baseline_table(stream_number=stream_number,min_row_pro_sream=min_row_pro_sream, cpu_percent_to_get=cpu_percent_to_get, adjust_to_cpu=adjust_to_cpu):
#p(self._db_frozen,"self._db_frozen")
self.statsdb.update_attr("db_frozen", True)
self.set_all_intern_attributes_from_db()
self.statsdb._commit()
if self._db_frozen:
self.logger.info("Current StatsDB was successfully optimized.")
return True
else:
return False
else:
self.logger.info("OptimizationError: StatsDB wasn't space optimized.")
return False
else:
self.logger.warning("Current StatsDB was already optimized!")
return False
def _get_number_created_indexes(self):
all_indexes = self.statsdb._get_indexes_from_db()
created_indexes_raw = [item for item in all_indexes if "autoindex" not in item[1] ]
return len(created_indexes_raw)
def _get_created_indexes(self):
all_indexes = self.statsdb._get_indexes_from_db()
#p(all_indexes, "all_indexes")
pattern = re.compile(r"create.+index(.+)on\s.*\((.+)\)", re.IGNORECASE)
pattern_index_columns = re.compile(r"\((.+)\)")
created_indexes_raw = [(item[2],pattern.findall(item[4])[0]) for item in all_indexes if "autoindex" not in item[1]]
created_indexes = defaultdict(list)
for index in created_indexes_raw:
created_indexes[index[0]].append((index[1][0].strip(" ").strip("'").strip('"'),index[1][1].strip("'").strip('"').split(",")))
return created_indexes
def _drop_created_indexes(self, table_name="*"):
indexes = self._get_created_indexes()
if table_name == "*":
for table_name, data in indexes.iteritems():
for created_index_container in data:
self.statsdb.execute("DROP INDEX {};".format(created_index_container[0]))
else:
if table_name not in self.statsdb.tables():
self.logger.error("'{}'-Tables not exist in the given Stats-DB. ".format(table_name))
return False
def _get_column_pairs_for_indexes(self,scope=False,optimized_for_long_syntagmas=False):
columns_to_index = defaultdict(list)
if optimized_for_long_syntagmas:
scope = self.baseline_ngramm_lenght
#if scope > 5:
# scope == 4
#pass
else:
scope = scope if scope else self._min_scope_for_indexes
#scope = 0
if scope > self.baseline_ngramm_lenght:
scope = self.baseline_ngramm_lenght
for syntagma_type in ["lexem","pos"]:
normalized_word_tag_name = "normalized_word" if syntagma_type == "lexem" else "pos"
context_tag_name_r = "contextR" if syntagma_type == "lexem" else "context_infoR"
context_tag_name_l = "contextL" if syntagma_type == "lexem" else "context_infoL"
for step in xrange(scope+1):
for token_index in xrange(step):
temp_columns = []
for i in xrange(step):
if i < token_index:
col_name = u"{}{}".format(context_tag_name_l,token_index-i)
temp_columns.append(col_name)
elif i == token_index:
col_name = u"{}".format(normalized_word_tag_name)
temp_columns.append(col_name)
elif i > token_index:
col_name = u"{}{}".format(context_tag_name_r,i-token_index)
temp_columns.append(col_name)
columns_to_index[syntagma_type].append(temp_columns)
return columns_to_index
def _get_biggest_column_pairs_for_indexes(self, raw_columns_to_index):
#p(raw_columns_to_index, "raw_columns_to_index")
for syntagma_type, column_pairs in raw_columns_to_index.iteritems():
temp_pairs_for_current_syntagma_type = {}
for column_pair in column_pairs:
if column_pair[0] not in temp_pairs_for_current_syntagma_type:
temp_pairs_for_current_syntagma_type[column_pair[0]] = column_pair
else:
if len(temp_pairs_for_current_syntagma_type[column_pair[0]]) < len(column_pair):
temp_pairs_for_current_syntagma_type[column_pair[0]] = column_pair
raw_columns_to_index[syntagma_type] = temp_pairs_for_current_syntagma_type.values()
#p(raw_columns_to_index, "raw_columns_to_index")
return raw_columns_to_index
def _get_not_exists_indexes(self,raw_columns_to_index,tables_to_index,created_indexes):
indexes_optimizes = defaultdict(list,{table_name:[col[1] for col in data] for table_name, data in created_indexes.iteritems() })
columns_to_index = defaultdict(lambda:defaultdict(list))
for table_name in tables_to_index:
for syntagma_type, data in raw_columns_to_index.iteritems():
for columns_bunch in data:
if columns_bunch not in indexes_optimizes[table_name]:
columns_to_index[table_name][syntagma_type].append(columns_bunch)
#p(columns_to_index, "columns_to_index")
return columns_to_index
def create_additional_indexes(self,thread_name="Thread0", scope=False, optimized_for_long_syntagmas=False):
tables_to_index = ["replications", "reduplications"]
### Step 0: Init Status Bar
if self._status_bar:
try:
if not self.status_bars_manager.enabled:
self.status_bars_manager = self._get_status_bars_manager()
except:
self.status_bars_manager = self._get_status_bars_manager()
status_bar_start = self._get_new_status_bar(None, self.status_bars_manager.term.center("StatsDB-Indexing") , "", counter_format=self.status_bars_manager.term.bold_white_on_cyan("{fill}{desc}{fill}"))
status_bar_start.refresh()
#status_bar_current = self._get_new_status_bar(self.statsdb.rownum("baseline"), "BaselineOptimization", "syntagma")
### compute syntagmas to delete
#### Step 1: Extract exist indexes
indexes = self._get_created_indexes()
number_indexes_bevore = self._get_number_created_indexes()
#qeary = "CREATE UNIQUE INDEX {} ON {} ({});"
#qeary = "CREATE UNIQUE INDEX IF NOT EXISTS {} ON {} ({});"
qeary = "CREATE INDEX {} ON {} ({});"
### Step 2: Compute needed indexes to create
raw_columns_to_index = self._get_column_pairs_for_indexes(scope=scope,optimized_for_long_syntagmas=optimized_for_long_syntagmas)
raw_columns_to_index = self._get_biggest_column_pairs_for_indexes(raw_columns_to_index)
#p(raw_columns_to_index, "raw_columns_to_index")
#### Step3: Delete those columns_pairs, which exists in the StatsDB
columns_to_index = self._get_not_exists_indexes(raw_columns_to_index, tables_to_index,indexes)
number_to_create = len([col for table_name, data in columns_to_index.iteritems() for syntagma_type, columns in data.iteritems() for col in columns ])
### Step 4: Delete those indexes from StatsDB, which will be not needed after creation a new indexes
#index_names_to_delete_from_db = self._get_indexes_which_are_smaller_than_new_one(indexes, columns_to_index)
### Step 5: Create Indexes
if self._status_bar:
status_bar_current = self._get_new_status_bar(number_to_create, "IndexCreation:", "index")
i = 0
for table_name, data in columns_to_index.iteritems():
for syntagma_type, columns in data.iteritems():
for columns_bunch in columns:
if self._status_bar:
status_bar_current.update(incr=1)
i += 1
#p(columns_bunch, "columns_bunch")
index_name = "ix_{}_{}_scope_{}_nr_{}".format(table_name[:4],syntagma_type, len(columns_bunch),i)
prepared_qeary = qeary.format(index_name, table_name, ",".join(columns_bunch))
#p(prepared_qeary, "prepared_qeary")
self.statsdb.execute(prepared_qeary)
self.statsdb._commit()
### Step 6: Print Status
if self._status_bar:
#bevore = i
#after = self.statsdb.rownum("baseline")
number_indexes_after = self._get_number_created_indexes()
status_bar_total_summary = self._get_new_status_bar(None, self.status_bars_manager.term.center("Indexes: NumBevore:'{}'; NumAfter:'{}'; WasCreated: '{}'.".format(number_indexes_bevore, number_indexes_after, number_indexes_after-number_indexes_bevore ) ), "", counter_format=self.status_bars_manager.term.bold_white_on_cyan('{fill}{desc}{fill}\n'))
status_bar_total_summary.refresh()
self.status_bars_manager.stop()
#print "\n"
return number_to_create
###########################Other Methods##################
def exist(self):
return True if self.statsdb else False
def db(self):
if not self._check_stats_db_should_exist():
return False
self.logger.debug("DBConnection was passed.")
return self.statsdb
####################################################################################
####################################################################################
####################################################################################
####################################################################################
####################################################################################
####################################################################################
######################################INTERN########################################
####################################################################################
####################################################################################
####################################################################################
####################################################################################
####################################################################################
#######################Status Bars##############
def _get_new_status_bar(self, total, desc, unit, counter_format=False):
#counter_format
try:
self.status_bars_manager
except AttributeError:
self.status_bars_manager = self._get_status_bars_manager()
if counter_format:
counter = self.status_bars_manager.counter(total=total, desc=desc, unit=unit, leave=True, counter_format=counter_format)
else:
counter = self.status_bars_manager.counter(total=total, desc=desc, unit=unit, leave=True)
return counter
def _get_status_bars_manager(self):
config_status_bar = {'stream': sys.stdout,
'useCounter': True,
"set_scroll": True,
"resize_lock": True
}
enableCounter_status_bar = config_status_bar['useCounter'] and config_status_bar['stream'].isatty()
return enlighten.Manager(stream=config_status_bar['stream'], enabled=enableCounter_status_bar, set_scroll=config_status_bar['set_scroll'], resize_lock=config_status_bar['resize_lock'])
def _status_bars(self):
if self.status_bars_manager:
return self.status_bars_manager.counters
else:
self.logger.error("No activ Status Bar Managers was found.", exc_info=self._logger_traceback)
return False
#################################
def _check_db_should_be_an_stats(self):
if self.statsdb.typ() != "stats":
self.logger.error("No active DB was found. You need to connect or initialize a DB first, before you can make any operation on the DB.", exc_info=self._logger_traceback)
return False
else:
return True
def _wait_till_all_threads_are_completed(self, waitername, sec_to_wait=3, sec_to_log = 15):
time_counter = sec_to_log
while not ( (len(self.threads_success_exit) >= len(self.active_threads)) or (len(self.threads_unsuccess_exit) != 0)):
#while len(self.threads_unsuccess_exit) == 0
#p(((len(self.threads_success_exit) <= len(self.active_threads))), "(len(self.threads_success_exit) < len(self.active_threads))")
#p((len(self.threads_unsuccess_exit) == 0), "(len(self.threads_unsuccess_exit) == 0)")
if time_counter >= sec_to_log:
time_counter = 0
self.logger.low_debug("'{}'-Waiter: {}sec was gone.".format(waitername, sec_to_log))
if not self.threads_status_bucket.empty():
answer = self.threads_status_bucket.get()
thread_name = answer["name"]
status = answer["status"]
if status == "done":
if thread_name not in self.threads_success_exit:
self.threads_success_exit.append(answer)
elif status in ["failed", "terminated"]:
if thread_name not in self.threads_unsuccess_exit:
self.threads_unsuccess_exit.append(answer)
elif status == "ThreadsCrash":
if thread_name not in self.threads_unsuccess_exit:
self.threads_unsuccess_exit.append(answer)
self.terminate_all("ThreadsCrash", thread_name=thread_name)
self.logger.critical("'{}'-Thread returned ThreadCrash-Error. |ErrorTrackID:'{}'| (To see more about it track ErrorID in the logs)".format(thread_name,answer["track_id"]))
return False
else:
self.logger.error("ThreadsWaiter: Unknown Status was send: '{}'. Break the execution! ".format(status), exc_info=self._logger_traceback)
sys.exit()
self.threads_status_bucket.task_done()
time.sleep(sec_to_wait)
time_counter += sec_to_wait
#self._check_threads()
self._check_buckets()
self.logger.debug("Waiter '{}' was stopped. ".format(waitername))
return True
def _initialisation_computation_process(self, inp_data, thread_name="Thread0"):
if self._status_bar:
if self._threads_num>1:
if self._status_bar:
unit = "rows"
self.main_status_bar_of_insertions.unit = unit
self.main_status_bar_of_insertions.total += len(inp_data)
### Preprocessors Initialization
if thread_name not in self.preprocessors:
if not self._init_preprocessors(thread_name=thread_name):
self.logger.error("Error during Preprocessors initialization. Thread '{}' was stopped.".format(thread_name), exc_info=self._logger_traceback)
self.threads_status_bucket.put({"name":thread_name, "status":"failed", "info":"Error during Preprocessors initialization"})
self._terminated = True
return False
self.logger.debug("_InitComputationalProcess: Was initialized for '{}'-Thread. ".format(thread_name))
if self._status_bar:
if self._threads_num>1:
if not self._timer_on_main_status_bar_was_reset:
#p(self.main_status_bar_of_insertions.start, "start1")
self.main_status_bar_of_insertions.start= time.time()
#p(self.main_status_bar_of_insertions.start, "start2")
self._timer_on_main_status_bar_was_reset = True
unit = "rows"
status_bar_insertion_in_the_current_thread = self._get_new_status_bar(len(inp_data), "{}:Insertion".format(thread_name), unit)
self._check_termination(thread_name=thread_name)
if self._status_bar:
return status_bar_insertion_in_the_current_thread
else:
False
def _is_redu(self, sent_index, token_index,redu_free_text_container):
try:
redu_free_text_container[sent_index][token_index][1].items
return True
except:
return False
def _check_buckets(self):
status = False
if not self.threads_error_bucket.empty():
while not self.threads_error_bucket.empty():
e = self.threads_error_bucket.get()
self.threads_error_bucket.task_done()
self.logger.error("InsertionError(in_thread_error_bucket): '{}'-Thread throw following Exception: '{}'. ".format(e[0], e[1]), exc_info=self._logger_traceback)
status = True
# if not self.channels_error_bucket.empty():
# while not self.channels_error_bucket.empty():
# e = self.channels_error_bucket.get()
# self.channels_error_bucket.task_done()
# self.logger.error("InsertionError(in_channel_error_bucket): '{}'-Thread ('{}') throw following Exception: '{}'. ".format(e[0], e[1],e[2]), exc_info=self._logger_traceback)
# status = True
if status:
self.logger.error("BucketChecker: Some threads/channels throw exception(s). Program can not be executed. ".format(), exc_info=self._logger_traceback)
sys.exit()
def _check_termination(self, thread_name="Thread0"):
if self._terminated:
self.logger.critical("'{}'-Thread was terminated.".format(thread_name))
self.threads_status_bucket.put({"name":thread_name, "status":"terminated"})
sys.exit()
def _isrighttype(self, inp_data):
#p(inp_data)
check = (isinstance(inp_data, list), isinstance(inp_data, LenGen))
#p(check, "check")
if True not in check:
self.logger.error("InputValidationError: Given 'inpdata' is not iterable. ", exc_info=self._logger_traceback)
return False
return True
# def _isrighttype(self, inp_data):
# check = (isinstance(inp_data, list), isinstance(inp_data, types.GeneratorType))
# if True not in check:
# self.logger.error("InputValidationError: Given 'inpdata' is not iterable. ", exc_info=self._logger_traceback)
# return False
# return True
def _check_corp_should_exist(self):
if not self.corp:
self.logger.error("No active CorpusObj was found. You need to connect or initialize a Corpus first, before you can make any operation with Stats.", exc_info=self._logger_traceback)
return False
else:
return True
def _check_stats_db_should_exist(self):
if not self.statsdb:
self.logger.error("No active DB was found. You need to connect or initialize a DB first, before you can make any operation with Stats.", exc_info=self._logger_traceback)
return False
else:
return True
def _check_stats_db_should_not_exist(self):
if self.statsdb:
self.logger.error("An active DB was found. You need to initialize new empty Instance of DB before you can do this operation.", exc_info=self._logger_traceback)
return False
else:
return True
####################################################################################
####################################################################################
####################################################################################
####################################################################################
####################################################################################
####################################################################################
###################################Other Classes#####################################
####################################################################################
####################################################################################
####################################################################################
####################################################################################
#################################################################################### | zas-rep-tools | /zas-rep-tools-0.2.tar.gz/zas-rep-tools-0.2/zas_rep_tools/src/classes/stats.py | stats.py |
# ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
# : XXX{Information about this code}XXX
# Author:
# c(Developer) -> {'Egor Savin'}
# ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
###Programm Info######
#
#
#
#
#
from __future__ import absolute_import
import os
#import copy
import sys
#import regex
import logging
#import collections
#import types
import csv
#import unicodecsv as csv
import codecs
from lxml import etree as ET
import json
import inspect
import traceback
import re
import gc
from collections import defaultdict
from raven import Client
from zas_rep_tools.src.utils.helpers import set_class_mode, print_mode_name, LenGen, path_to_zas_rep_tools,instance_info, SharedCounterExtern, SharedCounterIntern, Status, function_name
from zas_rep_tools.src.classes.dbhandler import DBHandler
from zas_rep_tools.src.utils.zaslogger import ZASLogger
from zas_rep_tools.src.utils.debugger import p
from zas_rep_tools.src.utils.error_tracking import initialisation
from zas_rep_tools.src.utils.traceback_helpers import print_exc_plus
from zas_rep_tools.src.classes.basecontent import BaseContent
import platform
if platform.uname()[0].lower() !="windows":
import colored_traceback
colored_traceback.add_hook()
else:
import colorama
class Exporter(BaseContent):
supported_file_formats = ["csv", "json", "sqlite", "xml"]
unsupported_file_formats = ["txt",]
def __init__(self, inpdata, rewrite=False, silent_ignore=False,**kwargs):
super(type(self), self).__init__(**kwargs)
#Input: Encapsulation:
self._inpdata = inpdata
self._rewrite = rewrite
self._silent_ignore = silent_ignore
#InstanceAttributes: Initialization
self._used_fnames = {}
self.sqlite_db = False
self._numbers_of_alredy_created_files = defaultdict(lambda: defaultdict(lambda: defaultdict(int)))
self._number_of_inserts_in_the_current_file = 0
self.logger.debug('Intern InstanceAttributes was initialized')
if not self._eval_input_data():
sys.exit()
self.logger.debug('An instance of Exporter() was created ')
## Log Settings of the Instance
self._log_settings(attr_to_flag = False,attr_to_len = False)
############################################################
####################__init__end#############################
############################################################
# def __del__(self):
# super(type(self), self).__del__()
####################################################################################
####################################################################################
####################################################################################
####################################################################################
####################################################################################
####################################################################################
######################################Extern########################################
####################################################################################
####################################################################################
####################################################################################
####################################################################################
####################################################################################
###########################+++++++++############################
def tocsv(self, path_to_export_dir , fname, fieldnames, rows_limit_in_file=50000, encoding="utf-8"):
self.current_csvfile = False
rows_was_exported = 0
#p((len(self._inpdata), self._inpdata))
#p("NEW\n\n", "NEW", c="r")
#if
#p((path_to_export_dir , fname, fieldnames, rows_limit_in_file))
#p(self._inpdata)
for row in self._inpdata:
#p("333")
if not row:
continue
#p(row, "row")
if row == -1:
continue
#p(row)
try:
if not self._write_to_csv_files(row, fieldnames, path_to_export_dir, fname, rows_limit_in_file=rows_limit_in_file, encoding=encoding):
if self._silent_ignore:
self.logger.debug("toCSV: File is already exist and extraction was aborted. ('silent_ignore' is 'on')")
else:
self.logger.info("toCSV: Test Files are already exist. Extraction to_csv was stopped. Please remove those files or use 'rewrite' option. ")
return False
rows_was_exported += 1
except Exception, e:
print_exc_plus() if self._ext_tb else ""
self.logger.error("CSVWriterError: Not possible to Export into CSV. Following Exception was throw: '{}'.".format(e), exc_info=self._logger_traceback)
return False
#p(self.current_csvfile, "000self.current_csvfile")
if self.current_csvfile:
self.current_csvfile.close()
del self.current_csvfile
self.logger.info("CSVWriter: '{}' rows was exported into CSV File(s) in '{}'.".format(rows_was_exported,path_to_export_dir))
#p(self.current_csvfile, "11self.current_csvfile")
return True
else:
self.logger.error("No File was exported. Probably Data for export was empty.")
#p(self.current_csvfile, "22self.current_csvfile")
return False
def toxml(self, path_to_export_dir , fname, rows_limit_in_file=50000, encoding="utf-8", root_elem_name="Docs", row_elem_name="Doc"):
self.current_xmlfile = False
rows_was_exported = 0
for row in self._inpdata:
if row == -1:
continue
try:
if not self._write_to_xml_files(row, path_to_export_dir, fname, rows_limit_in_file=rows_limit_in_file, encoding=encoding, root_elem_name=root_elem_name, row_elem_name=row_elem_name):
if self._silent_ignore:
self.logger.debug("toXML: File is already exist and extraction was aborted. ('silent_ignore' is 'on')")
else:
self.logger.info("toXML: Test Files are already exist. Extraction to_json was stopped. Please remove those files or use 'rewrite' option. ")
#p("ghjkl")
return False
rows_was_exported += 1
except Exception, e:
print_exc_plus() if self._ext_tb else ""
self.logger.error("XMLWriterError: Not possible to Export into XML. Following Exception was throw: '{}'.".format(e), exc_info=self._logger_traceback)
return False
#to save all last data
self._save_output_into_current_xml_file()
self.logger.info("XMLWriter: '{}' rows was exported into XML File(s) in '{}'.".format(rows_was_exported,path_to_export_dir))
return True
def tojson(self, path_to_export_dir , fname, rows_limit_in_file=50000, encoding="utf-8", unicode_encode=True):
self.current_jsonfile = False
rows_was_exported = 0
for row in self._inpdata:
if row == -1:
continue
try:
#p((row, path_to_export_dir, fname))
if not self._write_to_json_files(row, path_to_export_dir, fname, rows_limit_in_file=rows_limit_in_file, encoding=encoding, unicode_encode=unicode_encode):
if self._silent_ignore:
self.logger.debug("toJSON: File is already exist and extraction was aborted. ('silent_ignore' is 'on')")
else:
self.logger.info("toJSON: Test Files are already exist. Extraction to_json was stopped. Please remove those files or use 'rewrite' option. ")
return False
rows_was_exported += 1
except Exception, e:
print_exc_plus() if self._ext_tb else ""
self.logger.error("JSONWriterError: Not possible to Export into JSON. Following Exception was throw: '{}'.".format(e), exc_info=self._logger_traceback)
return False
if self.current_jsonfile:
self.current_jsonfile.seek(-1, os.SEEK_END)
self.current_jsonfile.write("\n\n ]")
self.current_jsonfile.close()
del self.current_jsonfile
self.logger.info("JSONWriter: '{}' rows was exported into JSONS File(s) in '{}'.".format(rows_was_exported,path_to_export_dir))
return True
else:#
self.logger.error("No File was exported. Probably Data for export was empty.")
return False
def tosqlite(self, path_to_export_dir, dbname, fieldnames, encoding="utf-8", encryption_key=False, table_name= "Documents", attributs_names_with_types_as_str=False):
self.current_jsonfile = False
rows_was_exported = 0
#p("fghjkl")
if not attributs_names_with_types_as_str:
attributs_names_with_types_as_str = self._create_list_with_columns_and_types_for_sqlite(fieldnames)
#p(attributs_names_with_types_as_str)
if not os.path.isdir(path_to_export_dir):
os.makedirs(path_to_export_dir)
if not self.sqlite_db:
self.sqlite_db = DBHandler( rewrite=self._rewrite, stop_if_db_already_exist=True, logger_level= self._logger_level,logger_traceback=self._logger_traceback, logger_folder_to_save=self._logger_folder_to_save,logger_usage=self._logger_usage, logger_save_logs= self._logger_save_logs, mode=self._mode , error_tracking=self._error_tracking, ext_tb= self._ext_tb)
if not self.sqlite_db.initempty(path_to_export_dir, dbname, encryption_key=encryption_key)["status"]:
if self._silent_ignore:
self.logger.debug("toSQLLITE: File is already exist and extraction was aborted. ('silent_ignore' is 'on')")
else:
self.logger.info("toSQLITE: Test Files are already exist. Extraction to_json was stopped. Please remove those files or use 'rewrite' option. ")
return False
self.sqlite_db.addtable(table_name, attributs_names_with_types_as_str)
for row in self._inpdata:
if row == -1:
continue
#p(row)
#try:
self._write_to_sqliteDB(row, path_to_export_dir, table_name, encoding=encoding)
rows_was_exported += 1
# except Exception, e:
# self.logger.error("SQLITEWriterError: Not possible to Export into SQLITE-DB. Following Exception was throw: '{}'.".format(e), exc_info=self._logger_traceback)
# return False
try:
self.sqlite_db.close()
del self.sqlite_db
except Exception, e:
print_exc_plus() if self._ext_tb else ""
self.logger.error("SQLITEWriterError: Following Exception was throw: '{}'. ".format(e), exc_info=self._logger_traceback)
self.logger.info("SQLITEWriter: '{}' rows was exported into SQLITE-DB in '{}'.".format(rows_was_exported,path_to_export_dir))
return True
def totxt(self):
self.logger.error("TXTReader is not implemented!", exc_info=self._logger_traceback)
sys.exit()
####################################################################################
####################################################################################
####################################################################################
####################################################################################
####################################################################################
####################################################################################
######################################INTERN########################################
####################################################################################
####################################################################################
####################################################################################
####################################################################################
####################################################################################
def _write_to_json_files(self,row_as_dict, path_to_dir, fname, rows_limit_in_file=50000, encoding="utf-8",unicode_encode=True):
# check if current file has not more row as given rows limits
if self.current_jsonfile:
if self._number_of_inserts_in_the_current_file >= rows_limit_in_file:
self.current_jsonfile.seek(-1, os.SEEK_END)
self.current_jsonfile.write("\n\n ]")
self.current_jsonfile.close()
self._number_of_inserts_in_the_current_file = 0
try:
self.current_jsonfile.close()
del self.current_jsonfile
except:
pass
self.current_jsonfile = self._get_new_file(path_to_dir , fname, "json", encoding=encoding, file_flag="a+", open_file_with_codecs=unicode_encode)
if not self.current_jsonfile:
return False
self.current_jsonfile.write("[ \n\n")
else:
self.current_jsonfile = self._get_new_file(path_to_dir , fname, "json", encoding=encoding, file_flag="a+", open_file_with_codecs=unicode_encode)
#p(self.current_jsonfile, c="m")
if not self.current_jsonfile:
return False
self.current_jsonfile.write("[ \n\n")
#json.dump(row_as_dict, self.current_jsonfile,indent=4)
json.dump(row_as_dict, self.current_jsonfile,indent=4, ensure_ascii=False)
self.current_jsonfile.write(",")
self._number_of_inserts_in_the_current_file += 1
return True
def _get_new_file(self, path_to_dir, fname, file_extention, encoding="utf-8", file_flag="w", open_file_with_codecs=False):
#p(fname, "fname")
if file_extention not in Exporter.supported_file_formats:
self.logger.error("NewFileGetterError: Given file_format '{}' is not supported. Please use one of the following file formats: '{}'. ".format(file_extention,Exporter.supported_file_formats ), exc_info=self._logger_traceback)
sys.exit()
pattern = re.compile("^(.+)_\d{,4}\..+")
matched_fname_current = pattern.findall(fname)
#p(matched_fname_current, "matched_fname_current")
matched_fname_current = matched_fname_current[0] if matched_fname_current else fname
count_of_existing_files = self._numbers_of_alredy_created_files[path_to_dir][file_extention][matched_fname_current]
new_fname_without_extention = fname+ "_{}".format(count_of_existing_files)
new_fname_with_extention =new_fname_without_extention+ "." + file_extention
path_to_file = os.path.join(path_to_dir, new_fname_with_extention)
if not os.path.isdir(path_to_dir):
os.makedirs(path_to_dir)
self.logger.warning("NewFileGetterProblem: '{}' Folder are not exist. It was created.".format(path_to_file))
else:
if count_of_existing_files == 0:
exist_fnames_in_dir = os.listdir(path_to_dir)
exist_fnames_in_dir = set([pattern.findall(fname)[0] if pattern.findall(fname) else fname for fname in exist_fnames_in_dir])
#p((fname,new_fname_without_extention,exist_fnames_in_dir),"fname")
for exist_fname in exist_fnames_in_dir:
matched_fname_from_listdir = pattern.findall(exist_fname)
matched_fname_from_listdir = matched_fname_from_listdir[0] if matched_fname_from_listdir else exist_fname
#if fname != "export":
if matched_fname_current == matched_fname_from_listdir:
if self._rewrite:
exist_fnames_in_dir = os.listdir(path_to_dir)
#for
for exist_fname in exist_fnames_in_dir:
matched = pattern.findall(exist_fname)
if matched:
matched = matched[0]
if matched == matched_fname_current:
os.remove(os.path.join(path_to_dir, exist_fname))
#os.remove(os.path.join(path_to_dir, exist_fname))
self.logger.debug("NewFileRewriter: '{}' File is already exist and was removed from '{}'. ('rewrite'-option is enabled.)".format(exist_fname, path_to_dir))
else:
if not self._silent_ignore:
self.logger.error("NewFileGetterProblem: '*{}*' NamePattern is already exist in '{}'-directory. Please delete those files or give other fname, before you can process Export.".format(matched_fname_current, path_to_dir))
return False
else:
self.logger.debug("NewFileGetter: '{}' NamePattern is already exist in '{}'-directory and was silent ignored.".format(matched_fname_current, path_to_file))
return False
if open_file_with_codecs:
current_file = codecs.open(path_to_file, 'w', encoding)
else:
current_file = open(path_to_file, file_flag)
#p(current_file, c="r")
self._numbers_of_alredy_created_files[path_to_dir][file_extention][matched_fname_current] += 1
# if file_extention == "csv":
# p(self._numbers_of_alredy_created_files,"222self._numbers_of_alredy_created_files")
self.logger.debug("NewFileGetter: New File '{}' was created in '{}'.".format(new_fname_with_extention, path_to_dir))
return current_file
def _write_to_csv_files(self, row_as_dict, fieldnames, path_to_dir , fname, rows_limit_in_file=50000, encoding="utf-8"):
# check if current file has not more row as given rows limits
if self.current_csvfile:
if self._number_of_inserts_in_the_current_file >= rows_limit_in_file:
#self.current_csvfile.close()
self._number_of_inserts_in_the_current_file = 0
try:
self.current_csvfile.close()
del self.current_csvfile
except:
pass
self.current_csvfile = self._get_new_file(path_to_dir , fname, "csv", encoding=encoding)
#p(self.current_csvfile, "self.current_csvfile")
if not self.current_csvfile:
return False
#p((self.current_csvfile, fieldnames))
#self.current_csv_writer = csv.DictWriter(self.current_csvfile, fieldnames=fieldnames, encoding=encoding)
self.current_csv_writer = csv.DictWriter(self.current_csvfile, fieldnames=fieldnames)
self.current_csv_writer.writeheader()
else:
self.current_csvfile = self._get_new_file(path_to_dir , fname, "csv", encoding=encoding)
#p(self.current_csvfile, "self.current_csvfile")
if not self.current_csvfile:
return False
#self.current_csv_writer = csv.DictWriter(self.current_csvfile, fieldnames=fieldnames, encoding=encoding)
self.current_csv_writer = csv.DictWriter(self.current_csvfile, fieldnames=fieldnames)
self.current_csv_writer.writeheader()
encoded_into_str = {}
for k,v in row_as_dict.iteritems():
if isinstance(k, unicode):
k = k.encode(encoding)
if isinstance(v, unicode):
v = v.encode(encoding)
encoded_into_str[k] = v
#encoded_into_str = {k.encode(encoding): v.encode(encoding) for k,v in row_as_dict.iteritems()}
#p(encoded_into_str)
self.current_csv_writer.writerow(encoded_into_str)
#self.current_csv_writer.close()
#self.current_csv_writer.writerow(row_as_dict)
self._number_of_inserts_in_the_current_file += 1
return True
def _write_row_to_xml(self,root_elem, row_as_dict, row_elem_name="Doc"):
try:
row_element = ET.SubElement(root_elem, row_elem_name)
for col_name, value in row_as_dict.iteritems():
# if "324114" in str(value):
# p((repr(value),col_name), c="r")
tag = ET.SubElement(row_element, col_name)
tag.text = unicode(value)
except Exception as e:
print_exc_plus() if self._ext_tb else ""
self.logger.error("WriterRowIntoXMLError: Following Exception was throw: '{}'. ".format(repr(e)), exc_info=self._logger_traceback)
return False
return True
def _save_output_into_current_xml_file(self):
if self.current_xmlfile:
tree = ET.ElementTree(self.current_xml_root_elem)
output_xml = ET.tostring(tree, pretty_print=True, xml_declaration=True, encoding="utf-8")
#p(output_xml)
self.current_xmlfile.write(output_xml)
self.current_xmlfile.close()
del self.current_xmlfile
self.current_xmlfile = False
else:
self.logger.error("SaveOutputIntoXMLError: There is not activ XML-Files", exc_info=self._logger_traceback)
return False
return True
def _write_to_xml_files(self,row_as_dict, path_to_dir, fname, rows_limit_in_file=50000, encoding="utf-8", root_elem_name="Docs", row_elem_name="Doc"):
# check if current file has not more row as given rows limits
#p(self.current_xmlfile)
if self.current_xmlfile:
if self._number_of_inserts_in_the_current_file >= rows_limit_in_file:
self._save_output_into_current_xml_file()
self._number_of_inserts_in_the_current_file = 0
try:
self.current_xmlfile.close()
del self.current_xmlfile
except:
pass
self.current_xmlfile = self._get_new_file(path_to_dir , fname, "xml", encoding=encoding)
if not self.current_xmlfile:
return False
self.current_xml_root_elem = ET.Element(root_elem_name)
else:
self.current_xmlfile = self._get_new_file(path_to_dir , fname, "xml", encoding=encoding)
if not self.current_xmlfile:
return False
self.current_xml_root_elem = ET.Element(root_elem_name)
self._write_row_to_xml(self.current_xml_root_elem, row_as_dict,row_elem_name=row_elem_name)
#self.current_xml_root_elem.writerow(row_as_dict)
self._number_of_inserts_in_the_current_file += 1
return True
def _write_to_sqliteDB(self,row_as_dict, path_to_export_dir, tablename, encoding="utf-8"):
if not self.sqlite_db:
self.logger.error("SQLITEWriterError: No Active DB to write in exist! Please Initialize first an Empty DB.", exc_info=self._logger_traceback)
sys.exit()
# col=[]
# val=[]
# for k, v in row_as_dict.iteritems():
# col.append(k)
# val.append(v)
self.sqlite_db.lazyinsert(tablename, row_as_dict)
return True
def _create_list_with_columns_and_types_for_sqlite(self, fieldnames):
outputlist = []
if isinstance(fieldnames, list):
for colname in fieldnames:
outputlist.append((colname,"TEXT"))
return outputlist
else:
self.logger.error("SQLITECreaterError: Given Fieldnames are not from List Type.", exc_info=self._logger_traceback)
return False
def _eval_input_data(self):
#p((isinstance(self._inpdata, list), isinstance(self._inpdata, types.GeneratorType)))
import types
check = (isinstance(self._inpdata, list), isinstance(self._inpdata, LenGen),isinstance(self._inpdata, types.GeneratorType))
if True not in check:
self.logger.error("InputValidationError: Given 'inpdata' is not iterable. ", exc_info=self._logger_traceback)
return False
return True | zas-rep-tools | /zas-rep-tools-0.2.tar.gz/zas-rep-tools-0.2/zas_rep_tools/src/classes/exporter.py | exporter.py |
# ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
# : XXX{Information about this code}XXX
# Author:
# c(Developer) -> {'Egor Savin'}
# ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
###Programm Info######
#
#
#
#
#
from __future__ import absolute_import
import os
import copy
import sys
import logging
import threading
import time
import Queue
import json
import traceback
from textblob import TextBlob
from textblob_fr import PatternTagger, PatternAnalyzer
from textblob_de import TextBlobDE
import langid
from decimal import Decimal, ROUND_HALF_UP, ROUND_UP, ROUND_HALF_DOWN, ROUND_DOWN
from collections import defaultdict
from raven import Client
import execnet
from nltk.tokenize import TweetTokenizer
import enlighten
import multiprocessing as mp
# db_helper
from zas_rep_tools_data.utils import path_to_data_folder, path_to_models, path_to_someweta_models, path_to_stop_words
from zas_rep_tools.src.extensions.tweet_nlp.ark_tweet_nlp.CMUTweetTagger import check_script_is_present, runtagger_parse
from zas_rep_tools.src.utils.helpers import set_class_mode, print_mode_name, LenGen, path_to_zas_rep_tools, is_emoji, text_has_emoji, char_is_punkt, text_has_punkt, text_is_punkt, text_is_emoji, categorize_token_list, recognize_emoticons_types,removetags, remove_html_codded_chars, get_number_of_streams_adjust_cpu, Rle, instance_info, MyThread, SharedCounterExtern, SharedCounterIntern, Status,function_name,statusesTstring,rle,from_ISO639_2, to_ISO639_2
from zas_rep_tools.src.utils.traceback_helpers import print_exc_plus
from zas_rep_tools.src.classes.dbhandler import DBHandler
from zas_rep_tools.src.classes.reader import Reader
from zas_rep_tools.src.utils.zaslogger import ZASLogger
from zas_rep_tools.src.utils.debugger import p
import zas_rep_tools.src.utils.db_helper as db_helper
from zas_rep_tools.src.utils.error_tracking import initialisation
from zas_rep_tools.src.classes.basecontent import BaseContent, BaseDB
from zas_rep_tools.src.utils.corpus_helpers import CorpusData
from zas_rep_tools.src.utils.custom_exceptions import ZASCursorError, ZASConnectionError,DBHandlerError,ProcessError,ErrorInsertion,ThreadsCrash
import nltk
from nltk.corpus import stopwords
import gc
try:
nltk.data.find('corpora/stopwords')
except:
nltk.download("stopwords")
try:
nltk.data.find('tokenizers/punkt')
except:
nltk.download("punkt")
import platform
if platform.uname()[0].lower() !="windows":
#p("hjklhjk")
import colored_traceback
colored_traceback.add_hook()
#os.system('setterm -back black -fore white -store -clear')
#os.system('setterm -term linux -back 0b2f39 -fore a3bcbf -store -clear')
else:
import colorama
os.system('color 09252d') # change background colore of the terminal
class Corpus(BaseContent,BaseDB,CorpusData):
def __init__(self, use_test_pos_tagger=False, tok_split_camel_case=True, end_file_marker = -1,
use_end_file_marker = False, status_bar= True, heal_me_if_possible=False,**kwargs):
super(type(self), self).__init__(**kwargs)
#p(heal_me_if_possible, "heal_me_if_possible")
#Input: Encapsulation:
self._end_file_marker = end_file_marker
self._use_end_file_marker = use_end_file_marker
self._status_bar = status_bar
self._tok_split_camel_case = tok_split_camel_case
self._raise_exception_if_error_insertion = True if "test" in self._mode else False
self._use_test_pos_tagger = use_test_pos_tagger
self._heal_me_if_possible = heal_me_if_possible
#self._diff_emoticons = diff_emoticons
#InstanceAttributes: Initialization
self.corpdb = False
self.offshoot = defaultdict(list)
self.runcount = 0
self.locker = threading.Lock()
self._emo_sym = set(["-", ':', '=','(',')', ";"])
self.em_start = set([":","-",";","="])
self.em_end = set(["(",")"])
self.logger.low_debug('Intern InstanceAttributes was initialized')
self.logger.debug('An instance of Corpus() was created ')
## Log Settings of the Instance
attr_to_flag = False
attr_to_len = False
self._log_settings(attr_to_flag =attr_to_flag,attr_to_len =attr_to_len)
############################################################
####################__init__end#############################
############################################################
def __del__(self):
super(type(self), self).__del__()
try:
self.status_bars_manager.stop()
except:
pass
####################################################################################
####################################################################################
####################################################################################
####################################################################################
####################################################################################
####################################################################################
######################################Extern########################################
####################################################################################
####################################################################################
####################################################################################
####################################################################################
####################################################################################
def additional_attr(self, language, tokenizer,pos_tagger,sentiment_analyzer,
sent_splitter,preprocession, lang_classification,del_url,
del_punkt,del_num,del_mention,del_hashtag,del_html,case_sensitiv,
emojis_normalization,text_field_name,id_field_name):
additional_attributes = {
"language":language,
"tokenizer":tokenizer,
"pos_tagger":pos_tagger,
"sentiment_analyzer":sentiment_analyzer,
"sent_splitter":sent_splitter,
"preprocession":preprocession,
"lang_classification":lang_classification if language != "test" else False,
"del_url":del_url,
"del_punkt":del_punkt,
"del_num":del_num,
"del_mention":del_mention,
"del_hashtag": del_hashtag,
"del_html":del_html,
"case_sensitiv":case_sensitiv,
"emojis_normalization":emojis_normalization,
"text_field_name":text_field_name,
"id_field_name":id_field_name,
}
return additional_attributes
###########################INITS + Open##########################
def init(self, prjFolder, DBname, language, visibility, platform_name,
encryption_key=False,fileName=False, source=False, license=False,
template_name=False, version=False, cols_and_types_in_doc=False, corpus_id=False,
tokenizer=True,pos_tagger=False,sentiment_analyzer=False,
sent_splitter=False,preprocession=True, lang_classification=False,del_url=False,
del_punkt=False,del_num=False,del_mention=False,del_hashtag=False,del_html=False,case_sensitiv=False,
emojis_normalization=True,text_field_name="text",id_field_name="id"):
if self.corpdb:
self.logger.error("CorpusInitError: An active Corpus Instance was found. Please close already initialized/opened Corpus, before new initialization.", exc_info=self._logger_traceback)
return False
#p((text_field_name,id_field_name))
#p((locals()))
#sys.exit()
# Validate Input variables
valid_answer = list(self._valid_input(language, preprocession, tokenizer, sent_splitter, pos_tagger, sentiment_analyzer))
if False in valid_answer[:-1]:
self.logger.error("InputValidationError: Corpus Instance can not be initialized!", exc_info=self._logger_traceback)
return False
setted_options = valid_answer[-1]
#p(setted_options,"setted_options")
if not isinstance(setted_options, dict):
self.logger.error("Setted Options after Validation wasn't given.")
return False
tokenizer = setted_options["tokenizer"]
sent_splitter = setted_options["sent_splitter"]
pos_tagger = setted_options["pos_tagger"]
sentiment_analyzer = setted_options["sentiment_analyzer"]
#p(self._logger_level,"!!self._logger_level")
#p(self._logger_save_logs, "!!self._logger_save_logs")
self.corpdb = DBHandler( **self._init_attributesfor_dbhandler())
was_initialized = self.corpdb.init("corpus", prjFolder, DBname, language, visibility,
platform_name=platform_name,encryption_key=encryption_key, fileName=fileName,
source=source, license=license, template_name=template_name, version=version,
cols_and_types_in_doc=cols_and_types_in_doc,
corpus_id=corpus_id)
#p(was_initialized, "was_initialized")
if not was_initialized:
self.logger.critical("CorpInit: Current Corpus for following attributes wasn't initialized: 'dbtype='{}'; 'dbname'='{}; id='{}'; encryption_key='{}'; template_name='{}'; language='{}'.".format("corpus", DBname,corpus_id, encryption_key, template_name, language))
return False
#self.corpdb.add_attributs()
self.corpdb.update_attrs(self.additional_attr(language, tokenizer,pos_tagger,sentiment_analyzer,
sent_splitter,preprocession, lang_classification,del_url,
del_punkt,del_num,del_mention,del_hashtag,del_html,case_sensitiv,
emojis_normalization,text_field_name,id_field_name))
self.set_all_intern_attributes_from_db()
self.corpdb.update_attr("locked", False)
#p((tokenizer, pos_tagger, sentiment_analyzer, lang_classification, sent_splitter))
#p((type(tokenizer), type(pos_tagger), type(sentiment_analyzer), type(lang_classification), type(sent_splitter)))
if self._save_settings:
self.logger.settings("InitCorpusDBAttributes: {}".format( instance_info(self.corpdb.get_all_attr(), attr_to_len=False, attr_to_flag=False, as_str=True)))
if self.corpdb.exist():
self.logger.debug("CorpusInit: '{}'-Corpus was successful initialized.".format(DBname))
return True
else:
self.logger.error("CorpusInit: '{}'-Corpus wasn't initialized.".format(DBname), exc_info=self._logger_traceback)
return False
#self.logger.settings("InitializationAttributes: {}".format( instance_info(inp_dict, attr_to_len=attr_to_len, attr_to_flag=attr_to_flag, as_str=True)))
def close(self):
self.corpdb.close()
self.corpdb = False
def _close(self):
self.corpdb._close()
self.corpdb = False
def open(self, path_to_corp_db, encryption_key=False):
if self.corpdb:
self.logger.error("CorpusOpenerError: An active Corpus Instance was found. Please close already initialized/opened Corpus, before new initialization.", exc_info=self._logger_traceback)
return False
self.corpdb = DBHandler(**self._init_attributesfor_dbhandler())
self.corpdb.connect(path_to_corp_db, encryption_key=encryption_key)
if self.corpdb.exist():
#p(self.corpdb.typ())
if self.corpdb.typ() != "corpus":
self.logger.error("Current DB is not an Corpus.")
self._close()
return False
self.logger.info("CorpusOpener: '{}'-Corpus was successful opened.".format(os.path.basename(path_to_corp_db)))
self.set_all_intern_attributes_from_db()
self.logger.settings("OpenedCorpusDBAttributes: {}".format( instance_info(self.corpdb.get_all_attr(), attr_to_len=False, attr_to_flag=False, as_str=True)))
return True
else:
self.logger.warning("CorpusOpener: Unfortunately '{}'-Corpus wasn't opened.".format(os.path.basename(path_to_corp_db)), exc_info=self._logger_traceback)
return False
def set_all_intern_attributes_from_db(self):
info_dict = self.info()
self._del_url = info_dict["del_url"]
self._tokenizer = info_dict["tokenizer"]
self._template_name = info_dict["template_name"]
self._sentiment_analyzer = info_dict["sentiment_analyzer"]
self._preprocession = info_dict["preprocession"]
self._text_field_name = info_dict["text_field_name"]
self._id_field_name = info_dict["id_field_name"]
self._id = info_dict["id"]
self._pos_tagger = info_dict["pos_tagger"]
self._del_hashtag = info_dict["del_hashtag"]
self._lang_classification = info_dict["lang_classification"]
self._source = info_dict["source"]
self._version = info_dict["version"]
self._del_html = info_dict["del_html"]
self._del_punkt = info_dict["del_punkt"]
self._sent_splitter = info_dict["sent_splitter"]
self._visibility = info_dict["visibility"]
self._language = info_dict["language"]
self._typ = info_dict["typ"]
self._del_url = info_dict["del_url"]
self._case_sensitiv = info_dict["case_sensitiv"]
self._name = info_dict["name"]
self._license = info_dict["license"]
self._created_at = info_dict["created_at"]
self._platform_name = info_dict["platform_name"]
self._del_num = info_dict["del_num"]
self._del_mention = info_dict["del_mention"]
self._emojis_normalization = info_dict["emojis_normalization"]
def _init_attributesfor_dbhandler(self):
init_attributes_db_handler = {
"stop_if_db_already_exist":self._stop_if_db_already_exist,
"rewrite":self._rewrite,
"logger_level":self._logger_level,
"optimizer":self._optimizer,
"in_memory":self._in_memory,
"logger_traceback":self._logger_traceback,
"logger_folder_to_save":self._logger_folder_to_save,
"logger_usage":self._logger_usage,
"logger_save_logs":self._logger_save_logs,
"thread_safe":self._thread_safe,
"mode":self._mode,
"error_tracking":self._error_tracking,
"ext_tb":self._ext_tb,
"isolation_level":self._isolation_level,
"optimizer_page_size":self._optimizer_page_size,
"optimizer_cache_size":self._optimizer_cache_size,
"optimizer_locking_mode":self._optimizer_locking_mode,
"optimizer_synchronous":self._optimizer_synchronous,
"optimizer_journal_mode":self._optimizer_journal_mode,
"optimizer_temp_store":self._optimizer_temp_store,
"use_cash":self._use_cash,
"replace_double_items":True,
"stop_process_if_possible":self._stop_process_if_possible,
"make_backup": self._make_backup,
"lazyness_border": self._lazyness_border,
"replace_double_items": self._replace_double_items,
"save_settings": self._save_settings,
"save_status": self._save_status,
"log_content": self._log_content,
"clear_logger": self._clear_logger,
}
return init_attributes_db_handler
def info(self):
if not self._check_db_should_exist():
return False
if not self._check_db_should_be_an_corpus():
return False
return copy.deepcopy(self.corpdb.get_all_attr())
###########################Setters######################
def _init_insertions_variables(self):
self.insertion_status_extended = defaultdict(lambda:lambda:0)
self.inserted_insertion_status_general = defaultdict(lambda:0)
self.error_insertion_status_general = defaultdict(lambda:0)
self.outsorted_insertion_status_general = defaultdict(lambda:0)
self._terminated = False
self._threads_num = False
self.main_status_bar_of_insertions = False
self.preprocessors = defaultdict(dict)
self.active_threads = []
self.KeyboardInterrupt = 0
self.status_bars_manager = False
execnet.set_execmodel("eventlet", "thread")
self.opened_gateways = execnet.Group()
self.threads_error_bucket = Queue.Queue()
# self.threads_success_bucket = Queue.Queue()
self.threads_status_bucket = Queue.Queue()
self.threads_success_exit = []
self.threads_unsuccess_exit = []
self.channels_error_bucket = Queue.Queue()
self.status_bars_bucket = Queue.Queue()
#self.counter = SharedCounterIntern()
#self.total_ignored_last_insertion = 0
self.total_inserted_during_last_insert= 0
self.total_ignored_last_insertion = 0
self.total_outsorted_insertion_during_last_insertion_process = 0
self.total_error_insertion_during_last_insertion_process = 0
self._timer_on_main_status_bar_was_reset = False
self._start_time_of_the_last_insertion = False
self._end_time_of_the_last_insertion = False
self._last_insertion_was_successfull = False
self.counters_attrs = defaultdict(lambda:defaultdict(dict))
self.status_bars_manager = self._get_status_bars_manager()
#self._cleaned_token = (None, u":DEL:")
self._colnames_in_doc_wasnt_checked = False
self._tags_to_delete = self._compute_tags_to_delete()
self._cleaned_tags = {
"number":":number:",
"URL":":URL:",
"symbol":":symbol:",
"mention":":mention:",
"hashtag":":hashtag:",
}
def insert_duration(self):
if not self._last_insertion_was_successfull:
self.logger.error("Last insertion wasn't successfully end -> It is not possible to return this Duration.")
return None
if not self._start_time_of_the_last_insertion and not self._end_time_of_the_last_insertion:
self.logger.error("Start or End Time for last insertion wasn't saved. -> It is not possible to return this Duration.")
return None
return self._end_time_of_the_last_insertion-self._start_time_of_the_last_insertion
def _check_termination(self, thread_name="Thread0"):
if self._terminated:
self.logger.critical("'{}'-Thread was terminated.".format(thread_name))
self.threads_status_bucket.put({"name":thread_name, "status":"terminated"})
sys.exit()
def _initialisation_of_insertion_process(self, inp_data, tablename="documents", thread_name="Thread0", log_ignored=True, dict_to_list=False):
if self._status_bar:
if self._threads_num>1:
if self._status_bar:
unit = "files" if self._use_end_file_marker else "rows"
self.main_status_bar_of_insertions.unit = unit
self.main_status_bar_of_insertions.total += len(inp_data)
### Preprocessors Initialization
if self._preprocession:
if thread_name not in self.preprocessors:
if not self._init_preprocessors(thread_name=thread_name)["status"]:
self.logger.error("Error during Preprocessors initialization. Thread '{}' was stopped.".format(thread_name), exc_info=self._logger_traceback)
self.threads_status_bucket.put({"name":thread_name, "status":"failed", "info":"Error during Preprocessors initialization"})
self._terminated = True
return False
self.logger.debug("_InsertionProcess: Was started for '{}'-Thread. ".format(thread_name))
if self._status_bar:
if self._threads_num>1:
if not self._timer_on_main_status_bar_was_reset:
#p(self.main_status_bar_of_insertions.start, "start1")
self.main_status_bar_of_insertions.start= time.time()
#p(self.main_status_bar_of_insertions.start, "start2")
self._timer_on_main_status_bar_was_reset = True
unit = "files" if self._use_end_file_marker else "rows"
status_bar_insertion_in_the_current_thread = self._get_new_status_bar(len(inp_data), "{}:Insertion".format(thread_name), unit)
return status_bar_insertion_in_the_current_thread
self._check_termination(thread_name=thread_name)
return None
def count_basic_stats(self):
if not self._check_db_should_exist():
return False
sent_num = 0
token_num = 0
doc_num = self.corpdb.rownum("documents")
if self._status_bar:
try:
if not self.status_bars_manager.enabled:
self.status_bars_manager = self._get_status_bars_manager()
except:
self.status_bars_manager = self._get_status_bars_manager()
status_bar_start = self._get_new_status_bar(None, self.status_bars_manager.term.center("CorpSummarizing") , "", counter_format=self.status_bars_manager.term.bold_white_on_magenta("{fill}{desc}{fill}"))
status_bar_start.refresh()
status_bar_current = self._get_new_status_bar(doc_num, "Processed:", "document(s)")
#if doc_num["status"]
#p((sent_num, token_num,doc_num))
#p(list(self.docs()))
if self._preprocession:
for text_elem in self.docs(columns=self._text_field_name):
#p((type(text_elem),repr(text_elem)))
text_elem = json.loads(text_elem[0])
#p(text_elem)
for sent_cont in text_elem:
sent_num += 1
#p(sent_cont[0], "sent_cont")
token_num += len(sent_cont[0])
if self._status_bar:
status_bar_current.update(incr=1)
self.corpdb.update_attr("sent_num", sent_num)
self.corpdb.update_attr("token_num", token_num)
self.corpdb.update_attr("doc_num", doc_num)
self.corpdb.commit()
else:
self.logger.info("Basic Statistics can not be computed, because current Corpus wasn't preprocessed.")
if self._status_bar:
status_bar_total_summary = self._get_new_status_bar(None, self.status_bars_manager.term.center("DocNum: '{}'; SentNum: '{}'; TokenNum: '{}'; ".format(doc_num, sent_num, token_num) ), "", counter_format=self.status_bars_manager.term.bold_white_on_magenta('{fill}{desc}{fill}\n'))
status_bar_total_summary.refresh()
self.status_bars_manager.stop()
def _is_colnames_in_doctable(self, cols_to_check, debug=False):
cols_in_doc_table = self.corpdb.col("documents")
for colname in cols_to_check:
if colname not in cols_in_doc_table:
if debug:
self.logger.debug("'{}'-Colname wasn't found in the DocumentTable. ".format(colname, cols_in_doc_table))
else:
self.logger.error("'{}'-Colname wasn't found in the DocumentTable. ".format(colname, cols_in_doc_table))
return False
#self.logger.error("ALLES SUPPI")
return True
def _insert(self, inp_data, tablename="documents", thread_name="Thread0", log_ignored=True, dict_to_list=False):
try:
self._check_termination(thread_name=thread_name)
time.sleep(2) #
############################################################
####################INITIALISATION####################
############################################################
status_bar_insertion_in_the_current_thread = self._initialisation_of_insertion_process( inp_data, tablename=tablename, thread_name=thread_name, log_ignored=log_ignored, dict_to_list=dict_to_list)
if self._status_bar:
if not status_bar_insertion_in_the_current_thread: return False
#
############################################################
#################### MAIN INSERTION PROCESS ####################
############################################################
to_update = True
self._colnames_in_doc_wasnt_checked = True
#p((self.corpdb.col("documents")))
for row_as_dict in inp_data:
#self._check_termination(thread_name=thread_name)
#p(row_as_dict.keys(), "row_as_dict.keys")
#p(row_as_dict, "row_as_dict")
#sys.exit()
if self._colnames_in_doc_wasnt_checked:
if row_as_dict:
with self.locker:
if self._colnames_in_doc_wasnt_checked:
#p("----1111")
if self._terminated:
self.threads_status_bucket.put({"name":thread_name, "status":"terminated"})
return False
return_error = False
#p("0000")
#invalid_symbols_in_colnames = "{}[]:,;-()°^<>="
is_invalid = False
for colname in row_as_dict.keys():
try:
colname = colname.decode("utf-8")
except:
pass
for invalid_symbol in Corpus.invalid_symbols_in_colnames:
#p((colname, invalid_symbol, ))
#p((type(colname),type(invalid_symbol)))
if invalid_symbol in colname:
if invalid_symbol == " ":
invalid_symbol = "WHITE_SPACE"
self.logger.error("InvalidColNamesError: '{}'-ColumnName contain minimum one invalid Symbol, and that is: '{}'. ".format(colname, invalid_symbol))
is_invalid = True
#self._terminated = True
if is_invalid:
self.logger.error("In the input Data (ColNames) was found minimum one invalid symbol. Please clean Data from the invalid symbols and start this process one more time. Please consult logs for more Information.\n Please ensure that all ColNames in you input Data don't contain following symbols: '{}'.".format(Corpus.invalid_symbols_in_colnames))
self._terminated = True
self.threads_status_bucket.put({"name":thread_name, "status":"failed"})
return False
if not self._is_colnames_in_doctable(row_as_dict.keys(), debug=self._heal_me_if_possible):
#p("1111")
if self.corpdb.rownum("documents") == 0:
#p("22222")
if self._heal_me_if_possible:
#p("22222´´´´´´´")
cursor_name = thread_name+"_temp"
old_cols_in_doc = self.corpdb.col("documents")
drop_status = self.corpdb.drop_table("documents", dbname="main", thread_name=cursor_name)
if not drop_status["status"]:
self.logger.error("HealingError: Tables 'Documents' wasn't deleted. ")
self._terminated = True
self._colnames_in_doc_wasnt_checked = False
self.threads_status_bucket.put({"name":thread_name, "status":"failed"})
return False
temp_cols_and_types_in_doc = [(colname, "TEXT") for colname in row_as_dict.keys()]
init_table_status= self.corpdb._init_default_table("corpus", "documents", temp_cols_and_types_in_doc, constraints=db_helper.default_constraints["corpus"]["documents"])
if not init_table_status["status"]:
self.logger.error("HealingError: Reinitialisation of the ColNames is failed:\n Status_Information:\n ColNamesFromDocTablesBevoreHealing='{}';\n DefaultColNames='{}';\n ColnamesWhichWasFoundInCurrentDocItem='{}'.".format(old_cols_in_doc, db_helper.default_tables["corpus"]["documents"]["basic"].keys(), row_as_dict.keys()))
self._terminated = True
self._colnames_in_doc_wasnt_checked = False
self.threads_status_bucket.put({"name":thread_name, "status":"failed"})
return False
self.corpdb._update_temp_indexesList_in_instance(thread_name=cursor_name)
#self._update_database_pragma_list(thread_name=thread_name)
self.corpdb._update_pragma_table_info(thread_name=cursor_name)
else:
#p("2222______")
#return_error = False
if self._log_content:
cols_in_elem = row_as_dict.keys()
cols_in_doc = self.corpdb.col("documents")
diff = set(cols_in_elem).symmetric_difference(set(cols_in_doc))
else:
cols_in_elem = ":HIDDEN:"
cols_in_doc = ":HIDDEN:"
diff = ":HIDDEN:"
self.logger.error("InputColNamesDifference: Current DocItem contain also not initialized colnames.\n Info_about_the_current_State:\n ColsFromTheCurrentDocItem: '{}';\n InitilizedColsInTheDocumentsTable: '{}';\n ColsDifferenz: '{}'\n Solution:\n 1) Use 'template_name'-Option in Corpus to use preinitialised colnames (ex:{});\n 2) Use 'cols_and_types_in_doc'-Option and predefine your own colnames and types (example for API: [('gender', 'TEXT'), ('age','INTEGER')]; example for command_line_interface: 'gender:TEXT,age:INTEGER') ;\n 3) Set 'heal_me_if_possible'-Option to give the DB permission to repair some broken data if it is possible. But be carefully with that option because, it could create unexpected errors.\n".format(cols_in_elem, cols_in_doc, diff,DBHandler.templates.keys() ))
self.threads_status_bucket.put({"name":thread_name, "status":"failed"})
self._terminated = True
self._colnames_in_doc_wasnt_checked = False
return False
self._colnames_in_doc_wasnt_checked = False
self.logger.info("Cols from given Text Collections was extracted and the documentsTables was hield.")
#p((self.corpdb.col("documents")))
else:
#p("3333")
#return_error = False
if self._log_content:
cols_in_elem = row_as_dict.keys()
cols_in_doc = self.corpdb.col("documents")
diff = set(cols_in_elem).symmetric_difference(set(cols_in_doc))
else:
cols_in_elem = ":HIDDEN:"
cols_in_doc = ":HIDDEN:"
diff = ":HIDDEN:"
if self._heal_me_if_possible:
self.logger.error("InputColNamesDifference: Current DocItem contain also not initialized colnames. And it wasn't possible to repair it.\n Info_about_the_current_State:\n ColsFromTheCurrentDocItem: '{}';\n InitilizedColsInTheDocumentsTable: '{}';\n ColsDifferenz: '{}' \n Solution:\n 1) Use 'template_name'-Option in Corpus to use preinitialised colnames (ex:{});\n 2) Use 'cols_and_types_in_doc'-Option and predefine your own colnames and types (example for API: [('gender', 'TEXT'), ('age','INTEGER')]; example for command_line_interface: 'gender:TEXT,age:INTEGER') ;".format(cols_in_elem, cols_in_doc, diff,DBHandler.templates.keys() ))
else:
self.logger.error("InputColNamesDifference: Current DocItem contain also not initialized colnames.\n Info_about_the_current_State:\n ColsFromTheCurrentDocItem: '{}';\n InitilizedColsInTheDocumentsTable: '{}';\n ColsDifferenz: '{}' \n Solution:\n 1) Use 'template_name'-Option in Corpus to use preinitialised colnames (ex:{});\n 2) Use 'cols_and_types_in_doc'-Option and predefine your own colnames and types (example for API: [('gender', 'TEXT'), ('age','INTEGER')]; example for command_line_interface: 'gender:TEXT,age:INTEGER') ;\n 3) Set 'heal_me_if_possible'-Option to give the DB permission to repair some broken data if it is possible. But be carefully with that option because, it could create unexpected errors.".format(cols_in_elem, cols_in_doc, diff,DBHandler.templates.keys() ))
self.threads_status_bucket.put({"name":thread_name, "status":"failed"})
self._terminated = True
self._colnames_in_doc_wasnt_checked = False
return False
self._colnames_in_doc_wasnt_checked = False
#p(row_as_dict ,"rw_as_dict ")
#self.offshoot[self.runcount].append(row_as_dict)
self._check_termination(thread_name=thread_name)
#p(status_bar_insertion_in_the_current_thread, "status_bar_insertion_in_the_current_thread")
if row_as_dict == self._end_file_marker:
#f.write("{}\n".format(row_as_dict))
if self._status_bar:
if self._use_end_file_marker:
status_bar_insertion_in_the_current_thread.update(incr=1)
if self._threads_num>1:
self.main_status_bar_of_insertions.update(incr=1)
continue
else:
if self._status_bar:
if not self._use_end_file_marker:
status_bar_insertion_in_the_current_thread.update(incr=1)
if self._threads_num>1:
self.main_status_bar_of_insertions.update(incr=1)
else:
if to_update:
to_update = False
counter = status_bar_insertion_in_the_current_thread.count
status_bar_insertion_in_the_current_thread.count = counter + 1
#p(status_bar_insertion_in_the_current_thread.count, "1status_bar_insertion_in_the_current_thread.count")
status_bar_insertion_in_the_current_thread.refresh()
status_bar_insertion_in_the_current_thread.count == counter
#p(status_bar_insertion_in_the_current_thread.count, "2status_bar_insertion_in_the_current_thread.count")
status_bar_insertion_in_the_current_thread.refresh()
#p(status_bar_insertion_in_the_current_thread, "status_bar_insertion_in_the_current_thread")
# for empty insertions
if not row_as_dict:
#f.write("{}\n".format(row_as_dict))
self.outsorted_insertion_status_general[thread_name] +=1
continue
############################################################
#################### TEXT PREPROSSESION ###################
############################################################
if self._preprocession:
text_preprocessed = False
try:
preproc = self._preprocessing(row_as_dict[self._text_field_name],thread_name=thread_name, log_ignored=log_ignored, row=row_as_dict)
if preproc:
if preproc == "terminated":
self.logger.critical("{} got an Termination Command!! and was terminated.".format(thread_name))
self.threads_status_bucket.put({"name":thread_name, "status":"terminated"})
self._terminated = True
return False
text_preprocessed = json.dumps(preproc)
else:
text_preprocessed = preproc
#p(text_preprocessed, "text_preprocessed")
except KeyError, e:
print_exc_plus() if self._ext_tb else ""
msg = "PreprocessingError: (KeyError) See Exception: '{}'. Probably text_field wasn't matched. Possible Explanations: 1. The wrong text_field name was given or 2. matched file has not right structure (every text file should have min an text_element and an id_element) or 3. ImplemenationError, where row was given as list and not as dict. Possible Solution: 1. Check if given file has an id and text element, if not, than you can sort this file out, to be sure, that every thing going right. And than create CorpusDB one more time. ".format(e)
#self.logger.error(msg, exc_info=self._logger_traceback)
self.threads_status_bucket.put({"name":thread_name, "status":"failed"})
if log_ignored:
self.logger.error_insertion(msg, exc_info=self._logger_traceback)
#return False
except Exception, e:
self.logger.error("PreprocessingError: See Exception: '{}'. ".format(e), exc_info=self._logger_traceback)
self.threads_status_bucket.put({"name":thread_name, "status":"failed"})
return False
if text_preprocessed:
row_as_dict[self._text_field_name] = text_preprocessed
else:
#self._check_termination(thread_name=thread_name)
#self.logger.warning("Text in the current DictRow (id='{}') wasn't preprocessed. This Row was ignored.".format(row_as_dict["id"]))
self.outsorted_insertion_status_general[thread_name] +=1
continue
#else:
# row_as_dict[self._text_field_name] = (row_as_dict[self._text_field_name], None)
############################################################
####################INSERTION INTO DB ####################
############################################################
# #return "outsorted"
self._check_termination(thread_name=thread_name)
insertion_status = self.corpdb.lazyinsert( tablename, row_as_dict, thread_name=thread_name, dict_to_list=dict_to_list)
if insertion_status["status"]:
self.inserted_insertion_status_general[thread_name] += insertion_status["out_obj"]
self.outsorted_insertion_status_general[thread_name] += insertion_status["outsort"]
#self.logger.low_debug("Row was inserted into DB.")
elif insertion_status["action"] == "outsorted":
self.outsorted_insertion_status_general[thread_name] +=1
elif insertion_status["action"] == "ThreadsCrash":
msg = "ThreadsCrash: Please use option 'thread_safe' to ensure ThreadSafety and run script again. |ErrorTrackID:'{}'| (To see more use search logs with TrackID)".format(insertion_status["track_id"])
self.logger.error(msg)
if log_ignored:
self.logger.error_insertion("IgnoredRow: |ErrorTrackID:'{}'| Current Row: '{}' wasn't inserted (by dbhandler.lazyinsert()) into DB. Consult logs to find the reason.".format(insertion_status["track_id"],row_as_dict))
self.threads_status_bucket.put({"name":thread_name, "status":"ThreadsCrash", "track_id":insertion_status["track_id"]})
self._terminated = True
raise ThreadsCrash, msg
sys.exit()
elif insertion_status["action"] in ["failed", "ignored"]:
self.error_insertion_status_general[thread_name] +=1
if log_ignored:
self.logger.error_insertion("IgnoredRow: |ErrorTrackID:'{}'| Current Row: '{}' wasn't inserted (by dbhandler.lazyinsert()) into DB. Consult logs to find the reason.".format(insertion_status["track_id"],row_as_dict))
continue
elif insertion_status["action"] == "stop_execution":
self.error_insertion_status_general[thread_name] +=1
if log_ignored:
self.logger.error_insertion("IgnoredRow: |ErrorTrackID:'{}'| Current Row: '{}' wasn't inserted (by dbhandler.lazyinsert()) into DB. Consult logs to find the reason.".format(insertion_status["track_id"],row_as_dict))
self.logger.error(insertion_status["desc"])
self._terminated = True
else:
self.error_insertion_status_general[thread_name] +=1
if log_ignored:
self.logger.error_insertion("IgnoredRow: |ErrorTrackID:'{}'| Current Row: '{}' wasn't inserted (by dbhandler.lazyinsert()) into DB. Consult logs to find the reason.".format(insertion_status["track_id"],row_as_dict))
continue
############################################################
####################FINISCHING ####################
############################################################
self._check_termination(thread_name=thread_name)
if self._status_bar:
status_bar_insertion_in_the_current_thread.refresh()
self.counters_attrs["_insert"][thread_name]["start"] = status_bar_insertion_in_the_current_thread.start
self.counters_attrs["_insert"][thread_name]["end"] = status_bar_insertion_in_the_current_thread.last_update
self.counters_attrs["_insert"][thread_name]["total"] = status_bar_insertion_in_the_current_thread.total
self.counters_attrs["_insert"][thread_name]["desc"] = status_bar_insertion_in_the_current_thread.desc
status_bar_insertion_in_the_current_thread.close(clear=False)
self.threads_status_bucket.put({"name":thread_name, "status":"done"})
self.logger.debug("_Insert: '{}'-Thread is done and was stopped.".format(thread_name))
return True
except KeyboardInterrupt:
self.logger.critical("{} get an KeyboardInterruption.".format(thread_name))
self.threads_status_bucket.put({"name":thread_name, "status":"terminated"})
self._terminated = True
#self.terminate_all("KeyboardInterrupt")
return False
except Exception, e:
print_exc_plus() if self._ext_tb else ""
self.logger.error("_InsertError: See Exception: '{}'. ".format(e), exc_info=self._logger_traceback)
self.threads_status_bucket.put({"name":thread_name, "status":"failed"})
return False
def insert(self, inp_data, tablename="documents", thread_name="Thread0", allow_big_number_of_streams=False, number_of_allow_streams=8, log_ignored=True, dict_to_list=False, create_def_indexes=True):
try:
if not self._check_db_should_exist():
return False
if self.corpdb.get_attr("locked"):
self.logger.error("Current DB ('{}') is still be locked. Possibly it in ht now fr in-useom other process or la thest computation process is failed.".format(self.corpdb.fname()))
return False
self.corpdb.update_attr("locked", True)
self._init_insertions_variables()
self._start_time_of_the_last_insertion = time.time()
self.runcount += 1
if isinstance(inp_data, LenGen):
inp_data= [inp_data]
elif isinstance(inp_data, list):
if isinstance(inp_data[0], dict):
inp_data = [inp_data]
#elif isinstance(inp_data[0], LenGen)
# pass
else:
self.logger.critical("Possibly not right type of data was given. It could be messed up the process.")
#return True
#self.status_bars_manager = self._get_status_bars_manager()
#Manager.term
#self.status_bars_manager.term print(t.bold_red_on_bright_green('It hurts my eyes!'))
if self._status_bar:
print "\n"
if self._in_memory:
dbname = ":::IN-MEMORY-DB:::"
else:
dbname = '{}'.format(self.corpdb.fname())
status_bar_starting_corpus_insertion = self._get_new_status_bar(None, self.status_bars_manager.term.center( dbname) , "", counter_format=self.status_bars_manager.term.bold_white_on_red("{fill}{desc}{fill}"))
status_bar_starting_corpus_insertion.refresh()
## threads
if self._status_bar:
status_bar_threads_init = self._get_new_status_bar(len(inp_data), "ThreadsStarted", "threads")
i=1
if len(inp_data)>=number_of_allow_streams:
if not allow_big_number_of_streams:
self.logger.critical("Number of given streams is to big ('{}'). It it allow to have not more as {} streams/threads parallel. If you want to ignore this border set 'allow_big_number_of_streams' to True. But it also could mean, that the type of data_to_insert is not correct. Please check inserted data. It should be generator/list of rows (packed as dict).".format(len(inp_data),number_of_allow_streams))
return False
self._threads_num = len(inp_data)
if self._threads_num>1:
if self._status_bar:
unit = "files" if self._use_end_file_marker else "rows"
#self.main_status_bar_of_insertions = self._get_new_status_bar(0, "AllThreadsTotalInsertions", unit,
# bar_format= self.status_bars_manager.term.bright_magenta( u'{desc}{desc_pad}{percentage:3.0f}%|{bar}| {count:{len_total}d}/{total:d} [{elapsed}<{eta}, {rate:.2f}{unit_pad}{unit}/s]\t\t\t\t'))
self.main_status_bar_of_insertions = self._get_new_status_bar(0, "AllThreadsTotalInsertions", unit)
self.main_status_bar_of_insertions.refresh()
#self.main_status_bar_of_insertions.total = 0
for gen in inp_data:
#p(gen, "gen")
#self.logger.critical(("3", type(gen), gen ))
if not self._isrighttype(gen):
self.logger.error("InsertionError: Given InpData not from right type. Please given an list or an generator.", exc_info=self._logger_traceback)
return False
thread_name = "Thread{}".format(i)
processThread = MyThread(target=self._insert, args=(gen, tablename, thread_name, log_ignored, dict_to_list), name=thread_name)
#processThread = mp.Process(target=self._insert, args=(gen, tablename, thread_name, log_ignored, dict_to_list), name=thread_name )
#processThread.setDaemon(True)
processThread.start()
self.active_threads.append(processThread)
if self._status_bar:
status_bar_threads_init.update(incr=1)
i+=1
time.sleep(1)
#p("All Threads was initialized", "insertparallel")
self.logger.info("'{}'-thread(s) was started. ".format(len(self.active_threads)))
time.sleep(3)
if not self._wait_till_all_threads_are_completed("Insert"):
return False
status = self.corpdb._write_cashed_insertion_to_disc(with_commit=True)
if status["status"]:
self.inserted_insertion_status_general[thread_name] += status["out_obj"]
self.outsorted_insertion_status_general[thread_name] += status["outsort"]
else:
return status
## save attributes from the main counter
if self._status_bar:
if self.main_status_bar_of_insertions:
self.counters_attrs["insert"]["start"] = self.main_status_bar_of_insertions.start
self.counters_attrs["insert"]["end"] = self.main_status_bar_of_insertions.last_update
self.counters_attrs["insert"]["total"] = self.main_status_bar_of_insertions.total
self.counters_attrs["insert"]["desc"] = self.main_status_bar_of_insertions.desc
else:
self.counters_attrs["insert"] = False
self._print_summary_status()
self.opened_gateways.terminate()
del self.opened_gateways
gc.collect()
#self.corpdb.commit()
if self._status_bar:
was_inserted = sum(self.inserted_insertion_status_general.values())
error_insertion = sum(self.error_insertion_status_general.values())
empty_insertion = sum(self.outsorted_insertion_status_general.values())
was_ignored = error_insertion + empty_insertion
status_bar_total_summary = self._get_new_status_bar(None, self.status_bars_manager.term.center("TotalRowInserted:'{}'; TotalIgnored:'{}' ('{}'-error, '{}'-outsorted)".format(was_inserted, was_ignored,error_insertion,empty_insertion ) ), "", counter_format=self.status_bars_manager.term.bold_white_on_red('{fill}{desc}{fill}\n'))
status_bar_total_summary.refresh()
self.status_bars_manager.stop()
self.corpdb._commit()
rownum = self.corpdb.rownum("documents")
if rownum >0:
self.logger.info("Current CorpusDB has '{}' rows in the Documents Table.".format(rownum))
self.corpdb.update_attr("locked", False)
else:
self.logger.error("InsertionProcessFailed: No one Document was added into CorpDB.")
return False
if create_def_indexes:
self.corpdb.init_default_indexes(thread_name=thread_name)
self.corpdb._commit()
self._last_insertion_was_successfull = True
self._end_time_of_the_last_insertion = time.time()
self.count_basic_stats()
if len(self.threads_unsuccess_exit) >0:
self.logger.error("Insertion process is failed. (some thread end with error)")
raise ProcessError, "'{}'-Threads end with an Error.".format(len(self.threads_unsuccess_exit))
return False
else:
self.logger.info("Insertion process end successful!!!")
self.corpdb._commit()
return True
except KeyboardInterrupt:
#self.logger.warning("KeyboardInterrupt: Process was stopped from User. Some inconsistence in the current DB may situated.")
self.terminate_all("KeyboardInterrupt", thread_name=thread_name)
#self.logger.critical("KeyboardInterrupt: All Instances was successful aborted!!!")
#sys.exit()
except Exception, e:
self.logger.error(" See Exception: '{}'. ".format(e), exc_info=self._logger_traceback)
return False
def terminate_all(self, reason, thread_name="Thread0"):
try:
self.logger.critical("Termination Process was initialized. Reason: '{}'.".format(reason))
self._terminated = True
time.sleep(2)
if self.status_bars_manager:
self.status_bars_manager.stop()
if self.opened_gateways:
self.opened_gateways.terminate()
self._wait_till_all_threads_are_completed("TerminateAll",sec_to_wait=0, sec_to_log = 1)
self._print_summary_status()
self.logger.critical("All active Threads was successful terminated!!!")
if reason == "KeyboardInterrupt":
self.logger.critical("Corpus was Terminated ({}). (For more information please consult logs)".format(reason))
else:
raise ProcessError, "Corpus was Terminated ({}). (For more information please consult logs)".format(reason)
return True
except KeyboardInterrupt:
self.logger.critical("Process was killed un-properly!!!")
sys.exit()
#self.KeyboardInterrupt
# def _terminated_all_activ_threads(self):
# for t in self.active_threads:
# if t.isAlive():
# t.terminate()
# t.join()
# self.logger.info("'{}'-Thread was terminated".format(t.name))
# else:
# self.logger.info("'{}'-Thread can not be terminated, because it is already died.".format(t.name))
###########################Getters#######################
def _intern_docs_getter(self, columns=False, select=False, where=False, connector_where="AND", output="list", size_to_fetch=1000, limit=-1, offset=-1):
if not self._check_db_should_exist():
yield False
return
for row in self.corpdb.lazyget("documents", columns=columns, select=select, where=where, connector_where=connector_where, output=output, size_to_fetch=size_to_fetch, limit=limit, offset=offset):
yield row
def docs(self, columns=False, select=False, where=False, connector_where="AND", output="list", size_to_fetch=1000, limit=-1, offset=-1, stream_number=1, adjust_to_cpu=True, min_files_pro_stream=1000):
row_number = self.corpdb.rownum("documents")
#p((row_number))
if self.corpdb.get_attr("locked"):
self.logger.error("Current DB is still be locked. Possibly it is right now in-use from other process or the last insertion-process is failed.")
return False
wish_stream_number = stream_number
if stream_number <1:
stream_number = 1000000
adjust_to_cpu = True
self.logger.debug("StreamNumber is less as 1. Automatic computing of stream number according cpu was enabled.")
if adjust_to_cpu:
stream_number= get_number_of_streams_adjust_cpu( min_files_pro_stream, row_number, stream_number)
if stream_number is None:
self.logger.error("Number of docs in the table is 0. No one generator could be returned.")
return []
list_with_generators = []
number_of_files_per_stream = int(Decimal(float(row_number)/stream_number).quantize(Decimal('1.'), rounding=ROUND_UP))
if stream_number > row_number:
self.logger.error("StreamNumber is higher as number of the files to read. This is not allowed.")
return False
current_index = 0
for i in range(stream_number):
#p(i, "i")
if i < (stream_number-1): # for gens in between
new_index = current_index+number_of_files_per_stream
gen = self._intern_docs_getter( columns=columns, select=select, where=where, connector_where=connector_where, output=output, size_to_fetch=size_to_fetch, limit=number_of_files_per_stream, offset=current_index)
lengen = LenGen(gen, number_of_files_per_stream)
current_index = new_index
else: # for the last generator
gen = self._intern_docs_getter( columns=columns, select=select, where=where, connector_where=connector_where, output=output, size_to_fetch=size_to_fetch, limit=-1, offset=current_index)
lengen = LenGen(gen, row_number-current_index)
if stream_number == 1:
if wish_stream_number > 1 or wish_stream_number<=0:
#p((stream_number,wish_stream_number))
return [lengen]
else:
return lengen
list_with_generators.append(lengen)
self.logger.debug(" '{}'-streams was created.".format(stream_number))
return list_with_generators
# ###########################Attributes####################
# def update_attr(self,attribut_name, value):
# if not self._check_db_should_exist():
# return False
# if not self.corpdb.update_attr(attribut_name, value, dbname="main"):
# self.logger.error("AttrUpdate: Bot possible. ", exc_info=self._logger_traceback)
# return False
# def add_attributs(self,attributs_names, values):
# if not self._check_db_should_exist():
# return False
# if not self.corpdb.add_attributs(attributs_names, values, dbname="main"):
# self.logger.error("AttrUpdate: Bot possible. ", exc_info=self._logger_traceback)
# return False
# def get_attr(self,attributName, dbname=False):
# if not self._check_db_should_exist():
# return False
# return self.corpdb.get_attr(attributName, dbname="main")
# def get_all_attr(self):
# if not self._check_db_should_exist():
# return False
# #p(self.corpdb.get_all_attr("main"))
# return self.corpdb.get_all_attr(dbname="main")
###########################Other Methods##################
def exist(self):
return True if self.corpdb else False
def db(self):
if not self._check_db_should_exist():
return False
self.logger.debug("DBConnection was passed.")
return self.corpdb
####################################################################################
####################################################################################
####################################################################################
####################################################################################
####################################################################################
####################################################################################
######################################INTERN########################################
####################################################################################
####################################################################################
####################################################################################
####################################################################################
####################################################################################
###########################Input-Validation#############
def _init_preprocessors(self, thread_name="Thread0"):
if not self._check_db_should_exist():
return False
try:
#p(self._preprocession, "self._preprocession", c="r")
#print self._preprocession
if self._preprocession:
### Step 1: Init Status Bar
if not self._terminated:
p_list = [self._sent_splitter, self._pos_tagger, self._lang_classification, self._tokenizer, self._sentiment_analyzer] #,self._stemmer
#p(p_list, "p_list")
preprocessors_number = sum([True for pp in p_list if pp ])
if self._status_bar:
status_bar_preprocessors_init = self._get_new_status_bar(preprocessors_number, "{}:PreprocessorsInit".format(thread_name), "unit")
#p(p_list, "p_list")
### Step 2.
if not self._terminated:
if not self._set_tokenizer(split_camel_case=self._tok_split_camel_case, language=self._language, thread_name=thread_name):
#return False
return Status(status=False, desc="SetTokenizerFailed")
if self._status_bar:
status_bar_preprocessors_init.update(incr=1)
status_bar_preprocessors_init.refresh()
# if not self._terminated:
# if not self._set_stemmer(thread_name=thread_name):
# #return False
# return Status(status=False, desc="SetStemmerFailed")
# if self._status_bar:
# status_bar_preprocessors_init.update(incr=1)
# status_bar_preprocessors_init.refresh()
if not self._terminated:
if self._sent_splitter:
#is_tuple = True if True in [self._tok_token_classes,self._tok_extra_info] else False
if not self._set_sent_splitter( thread_name=thread_name):
return Status(status=False, desc="SetSentSplitterFailed")
if self._status_bar:
status_bar_preprocessors_init.update(incr=1)
status_bar_preprocessors_init.refresh()
#status_bar_preprocessors_init.update(incr=1)
if self._sentiment_analyzer:
if self._status_bar:
status_bar_preprocessors_init.update(incr=1)
status_bar_preprocessors_init.refresh()
if not self._terminated:
if self._pos_tagger:
if not self._set_pos_tagger(thread_name=thread_name):
return Status(status=False, desc="SetPOSTaggerFailed")
if self._status_bar:
status_bar_preprocessors_init.update(incr=1)
status_bar_preprocessors_init.refresh()
if not self._terminated:
if self._lang_classification:
if self._set_rle(thread_name):
if self._status_bar:
status_bar_preprocessors_init.update(incr=1)
status_bar_preprocessors_init.refresh()
else:
self.logger.error("RLE in '{}'-Thread wasn't initialized. Script was aborted.".format(thread_name), exc_info=self._logger_traceback)
#self.threads_status_bucket.put({"name":thread_name, "status":"failed"})
return Status(status=False, desc="SetRLEFailed")
if not self._terminated:
self.logger.debug("PreprocessorsInit: All Preprocessors for '{}'-Thread was initialized.".format(thread_name))
return Status(status=True, desc=preprocessors_number)
if self._terminated:
self.logger.critical("{} was terminated!!!".format(thread_name))
self.threads_status_bucket.put({"name":thread_name, "status":"terminated"})
self._terminated = True
return Status(status=False, desc="WasTerminated")
if self._status_bar:
self.counters_attrs["_init_preprocessors"][thread_name]["start"] = status_bar_preprocessors_init.start
self.counters_attrs["_init_preprocessors"][thread_name]["end"] = status_bar_preprocessors_init.last_update
self.counters_attrs["_init_preprocessors"][thread_name]["total"] = status_bar_preprocessors_init.total
self.counters_attrs["_init_preprocessors"][thread_name]["desc"] = status_bar_preprocessors_init.desc
else:
return Status(status=False, desc="PreprocessorsWasDisabled")
except Exception, e:
print_exc_plus() if self._ext_tb else ""
msg = "PreprocessorsInitError: See Exception: '{}'. ".format(e)
self.logger.error(msg, exc_info=self._logger_traceback)
return Status(status=False, desc=msg)
def _get_status_bars_manager(self):
config_status_bar = {'stream': sys.stdout,
'useCounter': True,
"set_scroll": True,
"resize_lock": True
}
enableCounter_status_bar = config_status_bar['useCounter'] and config_status_bar['stream'].isatty()
return enlighten.Manager(stream=config_status_bar['stream'], enabled=enableCounter_status_bar, set_scroll=config_status_bar['set_scroll'], resize_lock=config_status_bar['resize_lock'])
def _set_rle(self, thread_name="Thread0"):
try:
self.logger.low_debug("INIT-RLE: Start the initialization of Run_length_encoder for '{}'-Thread.".format(thread_name))
self.preprocessors[thread_name]["rle"] = Rle(self.logger)
#p(("RLE_INIT",thread_name))
self.logger.debug("INIT-RLE: Run_length_encoder for '{}'-Thread was initialized.".format(thread_name))
return True
except Exception, e:
self.logger.error("Exception was encountered: '{}'. ".format(e), exc_info=self._logger_traceback)
return False
def _status_bars(self):
if self.status_bars_manager:
return self.status_bars_manager.counters
else:
self.logger.error("No activ Status Bar Managers was found.", exc_info=self._logger_traceback)
return False
def _wait_till_all_threads_are_completed(self, waitername, sec_to_wait=3, sec_to_log = 15):
time_counter = sec_to_log
while not ( (len(self.threads_success_exit) >= len(self.active_threads)) or (len(self.threads_unsuccess_exit) != 0)):
#while len(self.threads_unsuccess_exit) == 0
#p(((len(self.threads_success_exit) <= len(self.active_threads))), "(len(self.threads_success_exit) < len(self.active_threads))")
#p((len(self.threads_unsuccess_exit) == 0), "(len(self.threads_unsuccess_exit) == 0)")
if time_counter >= sec_to_log:
time_counter = 0
self.logger.low_debug("'{}'-Waiter: {}sec was gone.".format(waitername, sec_to_log))
if not self.threads_status_bucket.empty():
answer = self.threads_status_bucket.get()
thread_name = answer["name"]
status = answer["status"]
if status == "done":
if thread_name not in self.threads_success_exit:
self.threads_success_exit.append(answer)
elif status in ["failed", "terminated"]:
if thread_name not in self.threads_unsuccess_exit:
self.threads_unsuccess_exit.append(answer)
elif status == "ThreadsCrash":
if thread_name not in self.threads_unsuccess_exit:
self.threads_unsuccess_exit.append(answer)
self.terminate_all("ThreadsCrash", thread_name=thread_name)
self.logger.critical("'{}'-Thread returned ThreadCrash-Error. |ErrorTrackID:'{}'| (To see more about it track ErrorID in the logs)".format(thread_name,answer["track_id"]))
return False
else:
self.logger.error("ThreadsWaiter: Unknown Status was send: '{}'. Break the execution! ".format(status), exc_info=self._logger_traceback)
sys.exit()
self.threads_status_bucket.task_done()
time.sleep(sec_to_wait)
time_counter += sec_to_wait
#self._check_threads()
self._check_buckets()
self.logger.debug("Waiter '{}' was stopped. ".format(waitername))
return True
def _get_new_status_bar(self, total, desc, unit, counter_format=False, bar_format=False):
#counter_format
if counter_format:
if bar_format:
counter = self.status_bars_manager.counter(total=total, desc=desc, unit=unit, leave=True, counter_format=counter_format, bar_format=bar_format)
else:
counter = self.status_bars_manager.counter(total=total, desc=desc, unit=unit, leave=True, counter_format=counter_format)
else:
if bar_format:
counter = self.status_bars_manager.counter(total=total, desc=desc, unit=unit, leave=True, bar_format=bar_format)
else:
counter = self.status_bars_manager.counter(total=total, desc=desc, unit=unit, leave=True)
return counter
def _check_if_threads_still_alive(self):
for thread in self.active_threads:
if not thread.isAlive():
yield False
yield True
def _check_buckets(self, thread_name="Thread0"):
status = False
if not self.threads_error_bucket.empty():
while not self.threads_error_bucket.empty():
e = self.threads_error_bucket.get()
self.threads_error_bucket.task_done()
self.logger.error("InsertionError(in_thread_error_bucket): '{}'-Thread throw following Exception: '{}'. ".format(e[0], e[1]), exc_info=self._logger_traceback)
status = True
if not self.channels_error_bucket.empty():
while not self.channels_error_bucket.empty():
e = self.channels_error_bucket.get()
self.channels_error_bucket.task_done()
self.logger.error("InsertionError(in_channel_error_bucket): '{}'-Thread ('{}') throw following Exception: '{}'. ".format(e[0], e[1],e[2]), exc_info=self._logger_traceback)
status = True
if status:
self.logger.error("BucketChecker: Some threads/channels throw exception(s). Program can not be executed. ".format(), exc_info=self._logger_traceback)
self.threads_status_bucket.put({"name":thread_name, "status":"terminated"})
self._terminated = True
#sys.exit()
def _print_summary_status(self):
for thread in self.active_threads:
thread_name = thread.getName()
self.total_inserted_during_last_insert += self.inserted_insertion_status_general[thread_name]
self.total_outsorted_insertion_during_last_insertion_process += self.outsorted_insertion_status_general[thread_name]
self.total_error_insertion_during_last_insertion_process += self.error_insertion_status_general[thread_name]
self.total_ignored_last_insertion += (self.total_outsorted_insertion_during_last_insertion_process+self.total_error_insertion_during_last_insertion_process)
#self.logger.info("Summary for {}:\n Total inserted: {} rows; Total ignored: {} rows, from that was {} was error insertions and {} was out-sorted insertions (exp: cleaned tweets/texts, ignored retweets, etc.).".format(thread_name, self.inserted_insertion_status_general[thread_name], self.error_insertion_status_general[thread_name]+ self.outsorted_insertion_status_general[thread_name], self.error_insertion_status_general[thread_name], self.outsorted_insertion_status_general[thread_name]))
self.logger.info(">>>Summary<<< Total inserted: {} rows; Total ignored: {} rows, from that {} was error insertions and {} was out-sorted insertions (exp: cleaned tweets/texts, ignored retweets, ignored files with wrong structure etc.). If you want to see all ignored data than set 'mode'-option to 'prod+' and consult logs which contain following pattern '*outsorted*'. ".format(self.total_inserted_during_last_insert, self.total_ignored_last_insertion, self.total_error_insertion_during_last_insertion_process, self.total_outsorted_insertion_during_last_insertion_process))
if self.total_error_insertion_during_last_insertion_process >0:
msg = "'{}'-ErrorInsertion was processed.".format(self.total_error_insertion_during_last_insertion_process)
if self._raise_exception_if_error_insertion:
raise ErrorInsertion, msg
else:
self.logger.error(msg)
def _valid_input(self, language, preprocession, tokenizer, sent_splitter, pos_tagger, sentiment_analyzer):
# if not self._decoding_to_unicode:
# self.logger.warning("InputValidation: Automaticly Decoding Input byte string to unicode string is deactivated. This could lead to wrong work of this tool. (ex. Emojis will not recognized in the right way, etc.). To ensure correct work of this Tool, please switch on following option -> 'decoding_to_unicode'.")
if language not in from_ISO639_2 and language != "test":
self.logger.error("InputValidationError: Given Language '{}' is not valid code by ISO639_2. Please use the valid language code by ISO639_2.".format(language), exc_info=self._logger_traceback)
yield False
return
if language not in Corpus.supported_languages_tokenizer:
self.logger.error("InputValidationError: Given Language '{}' is not supported by tokenizer.".format(language), exc_info=self._logger_traceback)
yield False
return
if preprocession:
## Choice Tokenizer
if tokenizer is False:
tokenizer = True
self.logger.critical("Tokenizer was automatically activated. For Text-Preprocessing tokenizer should be activate. ")
#yield False
#return
if tokenizer is True:
try:
tokenizer = Corpus.tokenizer_for_languages[language][0]
except:
self.logger.critical("Tokenized for '{}' is not implemented. Please switch off this function or select other language.".format(language))
yield False
return
else:
if tokenizer not in Corpus.supported_tokenizer:
self.logger.error("InputValidationError: Given Tokenizer '{}' is not supported.".format(tokenizer), exc_info=self._logger_traceback)
yield False
if tokenizer not in Corpus.tokenizer_for_languages[language]:
self.logger.critical("InputValidationError: '{}'-tokenizer is not support '{}'-language. Please use another one. For this session the default one will be used. ".format(tokenizer, language))
tokenizer = Corpus.tokenizer_for_languages[language][0]
#yield False
self.logger.debug("'{}'-Tokenizer was chosen.".format(tokenizer))
# ## Choice Stemmer
# if stemmer is False:
# stemmer = True
# self.logger.critical("Stemmer was automatically activated. For Text-Preprocessing tokenizer should be activate.")
# if stemmer is True:
# try:
# stemmer = Corpus.stemmer_for_languages[language][0]
# except:
# self.logger.critical("Stemmer for '{}' is not implemented. Please switch off this function or select other language.".format(language))
# yield False
# return
# else:
# if stemmer not in Corpus.supported_languages_stemmer:
# self.logger.error("InputValidationError: Given Stemmer '{}' is not supported.".format(stemmer), exc_info=self._logger_traceback)
# yield False
# if stemmer not in Corpus.stemmer_for_languages[language]:
# self.logger.critical("InputValidationError: '{}'-stemmer is not support '{}'-language. Please use another one. For this session the default one will be used. ".format(stemmer, language))
# stemmer = Corpus.stemmer_for_languages[language][0]
# #yield False
# self.logger.debug("'{}'-Stemmer was chosen.".format(stemmer))
## Choice Sent Splitter
if sent_splitter:
if language not in Corpus.supported_languages_sent_splitter:
self.logger.error("InputValidationError: Given Language '{}' is not supported by Sentences Splitter.".format(language), exc_info=self._logger_traceback)
yield False
if sent_splitter is True:
sent_splitter = Corpus.sent_splitter_for_languages[language][0]
else:
if sent_splitter not in Corpus.supported_sent_splitter:
self.logger.error("InputValidationError: Given SentenceSplitter '{}' is not supported.".format(sent_splitter), exc_info=self._logger_traceback)
yield False
if sent_splitter not in Corpus.sent_splitter_for_languages[language]:
self.logger.critical("InputValidationError: '{}'-SentenceSplitter is not support '{}'-language. Please use another one. For this session the default one will be used. ".format(sent_splitter, language))
sent_splitter = Corpus.sent_splitter_for_languages[language][0]
self.logger.debug("'{}'-SentSplitter was chosen.".format(sent_splitter))
## Choice POS Tagger
if pos_tagger:
if language not in Corpus.supported_languages_pos_tagger:
self.logger.error("InputValidationError: Given Language '{}' is not supported by POS-Tagger.".format(language), exc_info=self._logger_traceback)
yield False
if pos_tagger is True:
try:
pos_tagger = Corpus.pos_tagger_for_languages[language][0]
except:
self.logger.critical("POS-Tagger for '{}' is not imlemented. Please switch off this function or select other language.".format(language))
yield False
return
else:
if pos_tagger not in Corpus.supported_pos_tagger:
self.logger.error("InputValidationError: Given POS-Tagger '{}' is not supported.".format(pos_tagger), exc_info=self._logger_traceback)
yield False
if not self._use_test_pos_tagger:
if pos_tagger not in Corpus.pos_tagger_for_languages[language]:
self.logger.critical("InputValidationError: '{}'-POS-Tagger is not support '{}'-language. Please use another one. For this session the default one will be used. ".format(pos_tagger, language))
pos_tagger = Corpus.pos_tagger_for_languages[language][0]
#yield True
if not sent_splitter:
self.logger.error("InputError: POS-Tagging require sentence splitter. Please use an option to activate it!", exc_info=self._logger_traceback)
yield False
if self._use_test_pos_tagger:
pos_tagger = "tweetnlp"
self.logger.debug("'{}'-POS-Tagger was chosen.".format(pos_tagger))
if sentiment_analyzer:
if language not in Corpus.supported_languages_sentiment_analyzer:
self.logger.error("InputValidationError: Given Language '{}' is not supported by SentimentAnalyzer.".format(language), exc_info=self._logger_traceback)
yield False
if sentiment_analyzer is True:
try:
sentiment_analyzer = Corpus.sentiment_analyzer_for_languages[language][0]
except:
self.logger.critical("SentimentAnalyzer for '{}' is not imlemented. Please switch off this function or select other language.".format(language))
yield False
return
else:
if sentiment_analyzer not in Corpus.supported_sentiment_analyzer:
self.logger.error("InputValidationError: Given SentimentAnalyzer '{}' is not supported.".format(sentiment_analyzer), exc_info=self._logger_traceback)
yield False
self.logger.debug("'{}'-SentimentAnalyzer was chosen.".format(sentiment_analyzer))
else:
self.logger.warning("Preprocessing is disable. -> it will be not possible to compute statistics for it. Please enable preprocessing, if you want to compute statistics later.")
#yield False
yield True
yield {
"tokenizer": tokenizer,
"sent_splitter": sent_splitter,
"pos_tagger": pos_tagger,
"sentiment_analyzer": sentiment_analyzer,
}
return
def _compute_tags_to_delete(self):
#p((del_url, self._del_punkt, self._del_num, self._del_mention, ))
tags_to_delete = set()
if self._del_url:
tags_to_delete.add("URL")
if self._del_punkt:
tags_to_delete.add("symbol")
if self._del_num:
tags_to_delete.add("number")
if self._del_mention:
tags_to_delete.add("mention")
if self._del_hashtag:
tags_to_delete.add("hashtag")
return tags_to_delete
def _clean_sents_list(self, inp_sent_list):
#p(self._tags_to_delete, "self._tags_to_delete")
cleaned = []
for sents in inp_sent_list:
cleaned_sent = []
for token in sents:
#p(token, "token")
if token[1] not in self._tags_to_delete:
cleaned_sent.append(token)
else:
cleaned_sent.append((None, self._cleaned_tags[token[1]]))
cleaned.append(cleaned_sent)
return cleaned
# for sent in inp_sent_list:
# #print token
# if token[1] in tags_to_delete:
# #p(token, c="r")
# continue
# cleaned.append(token)
# return cleaned
# def _categorize_token_list(self, inp_token_list):
# if self._tokenizer != "somajo":
# return categorize_token_list(inp_token_list)
def _lower_case_sents(self, inpsents):
lower_cased = []
for sents in inpsents:
lower_cased_sent = []
for token in sents:
#p(token[0].lower(), c="m")
tok = token[0]
if tok:
lower_cased_sent.append((tok.lower(), token[1]))
else:
lower_cased_sent.append(token)
lower_cased.append(lower_cased_sent)
return lower_cased
def _re_recognize_complex_clustered_emojis(self,inp_list):
#p(inp_list,"inp_list")
pattern = ['EMOIMG',"emoticon",]
prev_pos = ""
collected_elem = ()
new_output_list = []
#p(inp_list, "111inp_list")
#### Step 1: collect all EMOIMG in neibourghood in one token
for token_container in inp_list:
#p(token_container, "token_container", c="r")
if token_container[1] in pattern:
if prev_pos:
#p((prev_pos, token_container), c="m")
if prev_pos == token_container[1]:
new_text_elem = u"{}{}".format(collected_elem[0], token_container[0])
collected_elem = (new_text_elem, collected_elem[1])
#continue
else:
new_output_list.append(collected_elem)
prev_pos = token_container[1]
collected_elem = token_container
#continue
else:
prev_pos = token_container[1]
collected_elem = token_container
#continue
else:
if prev_pos:
new_output_list.append(collected_elem)
new_output_list.append(token_container)
collected_elem = ()
prev_pos = ""
else:
new_output_list.append(token_container)
#p(inp_list, "222inp_list")
return inp_list
def _normalize_emojis(self,inp_list):
#p(inp_list,"inp_list")
pattern = ['EMOIMG',"emoticon",]
prev = ""
collected_elem = ()
new_output_list = []
for token_container in inp_list:
#p(token_container, "token_container", c="r")
if token_container[1] in pattern:
if prev:
#p((prev, token_container), c="m")
if prev == token_container[0]:
new_text_elem = u"{}{}".format(collected_elem[0], token_container[0])
collected_elem = (new_text_elem, collected_elem[1])
#continue
else:
new_output_list.append(collected_elem)
prev = token_container[0]
collected_elem = token_container
#continue
else:
prev = token_container[0]
collected_elem = token_container
#continue
else:
if prev:
new_output_list.append(collected_elem)
new_output_list.append(token_container)
collected_elem = ()
prev = ""
else:
new_output_list.append(token_container)
if prev:
new_output_list.append(collected_elem)
collected_elem = ()
prev = ""
#p(new_output_list, "new_output_list",c="r")
return new_output_list
def _error_correction_after_somajo_tokenization(self,output):
new_output = []
token_index = -1
ignore_next_step = False
e = ("_","-")
try:
output[1]
except:
return output
#p(output,"11output")
### ReCategorize Symbols
output = [(token_cont[0], u"symbol") if text_is_punkt(token_cont[0]) and token_cont[1]!= "symbol" else token_cont for token_cont in output ]
#p(output,"22output",c="m")
for i,tok in zip(xrange(len(output)),output):
if i == 0:
new_output.append(tok)
elif i > 0:
last_elem = new_output[-1]
#p((last_elem,tok))
#if last_elem[1] ==
#p((last_elem[1], tok[1]))
if last_elem[1] == "emoticon" and tok[1] == 'regular':
if last_elem[0][-1] == tok[0][0]:
new_output[-1] = (last_elem[0]+tok[0], last_elem[1])
else:
new_output.append(tok)
elif last_elem[1] in ("symbol", "regular", 'EMOASC','emoticon') and tok[1] == 'symbol':
if last_elem[0][-1] == tok[0][0]:
new_output[-1] = (last_elem[0]+tok[0], last_elem[1])
#new_output[-1] = (last_elem[0]+tok[0], "FUCK")
elif last_elem[0][-1] in self._emo_sym and tok[0][0] in self._emo_sym:
#p((tok, last_elem))
if (last_elem[0][0] in self.em_start and last_elem[0][-1]in self.em_end) or (last_elem[0][-1] in self.em_start and last_elem[0][0]in self.em_end):
new_output.append(tok)
else:
new_output[-1] = (last_elem[0]+tok[0], "EMOASC")
else:
new_output.append(tok)
elif last_elem[1] == "mention" and tok[1] == 'regular':
#print last_elem[0][-1],tok[0][0]
if tok[0][0] in e:
new_output[-1] = (last_elem[0]+tok[0], last_elem[1])
#new_output[-1] = (last_elem[0]+tok[0], "FUCK")
else:
new_output.append(tok)
else:
new_output.append(tok)
## check if last two elements possibly are same
if len(new_output)>1:
last_item = new_output[-1]
bevore_the_last_item = new_output[-2]
if last_item[0][0] == bevore_the_last_item[0][0]:
if len(rle.del_rep(last_item[0])) and len(rle.del_rep(bevore_the_last_item[0])) == 1 :
#p(new_output, "111new_output", c="r")
if last_item[1] == "symbol" and bevore_the_last_item[1] == "symbol":
poped = new_output.pop()
new_output[-1] = (last_item[0]+poped[0], poped[1])
#p(new_output, "22new_output", c="r")
return new_output
###########################Preprocessing###############
def _preprocessing(self, inp_str, thread_name="Thread0", log_ignored=True, row=False):
#self.logger.debug("Preprocessing: '{}'-Thread do preprocessing.".format( thread_name ))
### convert to unicode, if needed!!!=)
## it is important, fo right works of further preprocessing steps
try:
output = inp_str.decode("utf-8")
except:
output = inp_str
# p(type(output), "output")
#p(self.preprocessors)
#time.sleep(5)
# Preprocessing woth Python !!! (gut) https://www.kdnuggets.com/2018/03/text-data-preprocessing-walkthrough-python.html
# python code: https://de.dariah.eu/tatom/preprocessing.html
#############Step 0 ########################
# Step 0: Noise Removal (https://www.kdnuggets.com/2017/12/general-approach-preprocessing-text-data.html)
# remove text file headers, footers
# remove HTML, XML, etc. markup and metadata
# extract valuable data from other formats, such as JSON, or from within databases
# if you fear regular expressions, this could potentially be the part of text preprocessing in which your worst fears are realized
#was_found= False
# if 1111 == row["id"] or "1111" == row["id"]:
# self.logger.critical(("start",output))
# was_found = True
if self._del_html:
output = removetags(output)
output = remove_html_codded_chars(output) # delete html-codded characters sets
#if was_found:
# self.logger.critical(("del_html",output))
#p(output, "html_deleted")
#if self._del_rep:
############Step 1 ########################
##### Step 1: Language Classification
#self.logger.critical("LANGPREPROC in {}".format(thread_name))
#### time.sleep(10)
if self._lang_classification:
output_with_deleted_repetitions = self.preprocessors[thread_name]["rle"].del_rep(output) #output #self._rle.del_rep(output)
#self.logger.critical(output_with_deleted_repetitions)
lang = langid.classify(output_with_deleted_repetitions)[0]
if lang != self._language:
#p(output_with_deleted_repetitions, "lan_outsorted")
try:
if log_ignored:
row = row if row else ":ORIG_ROW_WASNT_GIVEN:"
self.logger.outsorted_corpus(u"LangClassification: Following row was out-sorted and ignored. Reason: Given language not equal to recognized language ('{}'!='{}'); TextElement: '{}'; FullRow: '{}'. ".format(self._language, lang, output, row))
except Exception, e:
#p(str(e),"e")
self.logger.error(u"LangClassificationResultsStdOut: See Exception: '{}'. ".format(e))
return None
#############Step 2 ########################
# Step 2.1: Tokenization & (https://www.kdnuggets.com/2017/12/general-approach-preprocessing-text-data.html)
#p(inp_str, "inp_str")
output = self.tokenize(output, thread_name=thread_name)
output = [(token[0].replace("'", '"'), token[1]) if "'" in token[0] else token for token in output ]
#if not output:
# return "terminated"
#if was_found:
# self.logger.critical(("tokenize",output))
#p((len(output),output), "tokenized")
#time.time(3)
# Step 2.2
if self._tokenizer == "somajo":
output = self._error_correction_after_somajo_tokenization(output)
#p((len(output),output), "error_corrected")
else:
#############Step 3 ########################
# Step 3: Categorization (if wasn't done before)
#if self._tokenizer != "somajo":
output = categorize_token_list(output)
#p(categorize_token_list, "categorize_token_list")
#############Step 4 ########################
# Step 4: Categorization (if wasn't done before)
#if self._tokenizer == "somajo": #self._diff_emoticons and
output = recognize_emoticons_types(output)
#p(output, "recognize_emoticons_types")
#sys.exit()
#############Step 5 ########################
# Step 5: normalization - Part0
#### Normalisation Emojis
if self._emojis_normalization:
#output = self._re_recognize_complex_clustered_emojis(output)
output = self._normalize_emojis(output)
#p(output, "emojis_normalization")
#############Step 6 ########################
#Step 6: Segmentation
if self._sent_splitter:
output = self.split_sentences(output, thread_name=thread_name)
#p(output, c="r")
#if output
if not output:
return "terminated"
#p((len(sentences),sentences), "sentences", c="r")
#p(len(output), "splitted")
#p(output, "splitted")
#p((len(output),output), "splitted")
else:
output = [output]
#if was_found:
# self.logger.critical(("sent_splitter",output))
#p(output, "sent_splitted")
#############Step 8 ########################
# Step 8: Tagging
#output, cutted_ =
#p(output, "output")
if self._pos_tagger: #u'EMOASC', 'EMOIMG'
non_regular_tokens = self._backup_non_regular_tokens(output)
#p(non_regular_tokens, "non_regular_tokens")
output = [self.tag_pos([token[0] for token in sent ], thread_name=thread_name) for sent in output]
if not output[0]:
return "terminated"
output = self._rebuild_non_regular_tokens(non_regular_tokens, output)
#p(output, "tagged")
#if was_found:
# self.logger.critical(("pos",output))
#############Step ########################
# Step : WDS
#############Step 7 ########################
# Step 7: normalization - Part1
#> Stemming or Lemmatization (https://www.kdnuggets.com/2017/12/general-approach-preprocessing-text-data.html)
#remove numbers (or convert numbers to textual representations)
#remove punctuation (generally part of tokenization, but still worth keeping in mind at this stage, even as confirmation)
output = self._clean_sents_list(output)
#if was_found:
# self.logger.critical(("cleaned",output))
#p(output, "cleaned")
#############Step 9 ########################
# Step 9: normalization
#> Stemming or Lemmatization (https://www.kdnuggets.com/2017/12/general-approach-preprocessing-text-data.html)
#> case normalisation (lower case)
#(NO)remove default stop words (general English stop words)
if not self._case_sensitiv:
output = self._lower_case_sents(output)
#p(output, "lowercased")
#if was_found:
# self.logger.critical(("lowercased",output))
#############Step 10 ########################
# Step 10: Emotikons? werden die durch den Tokenizer zu einer Entität?
#############Step 11 ########################
# Step 11: Sentiment Analysis
output_with_sentiment = []
#p(output, "output")
for sent in output:
#p(" ".join([token[0] for token in sent]), c="m")
#p(sent)
if self._sentiment_analyzer:
polarity = self.get_sentiment(" ".join([token[0] for token in sent if token[0]]))
#p(polarity, "polarity", c="r")
else:
polarity = (None, None)
output_with_sentiment.append((sent, polarity))
#for
output = output_with_sentiment
#if was_found:
# self.logger.critical(("sentiment",output))
#p(output, "sentiment")
#was_found =False
return output
def _backup_non_regular_tokens(self,output):
#["url", "emoji", "emoticon", "symbol", "mention", "hashtag"]
#"regular"
non_regular_tokens = []
sent_index = -1
for sent in output:
sent_index += 1
token_index = -1
for token in sent:
token_index += 1
if token[1] != "regular":
#if token[1] != "emoticon":
non_regular_tokens.append((sent_index, token_index, token[1]))
return non_regular_tokens
def _rebuild_non_regular_tokens(self, non_regular_tokens, output):
for backup_data in non_regular_tokens:
#p(backup_data,"backup_data")
#p(output,"output")
output[backup_data[0]][backup_data[1]] = (output[backup_data[0]][backup_data[1]][0], backup_data[2])
return output
############Tokenization#############
def tokenize(self,inp_str, thread_name="Thread0"):
try:
#self.logger.low_debug("'{}'-Tokenizer: Tokenizer was called from '{}'-Thread.".format(self._tokenizer, thread_name))
if self._tokenizer == "somajo":
return self._tokenize_with_somajo(inp_str, thread_name=thread_name)
elif self._tokenizer == "nltk":
return self._tokenize_with_nltk(inp_str, thread_name=thread_name)
else:
self.logger.error("TokenizationError: No one Tokenizer was chooses.", exc_info=self._logger_traceback)
return False
except KeyboardInterrupt:
self.logger.critical("TokenizerError: in '{}'-Thread get an KeyboardInterruption.".format(thread_name))
self.threads_status_bucket.put({"name":thread_name, "status":"terminated"})
self._terminated = True
#self.terminate_all("KeyboardInterrupt")
return False
except Exception, e:
self.logger.error("TokenizerError: in '{}'-Thread. See Exception '{}'.".format(thread_name,e))
self.terminate = True
return False
#sys.exit()
#return [("",""),("","")]
def _set_tokenizer(self, split_camel_case=True, language="de", thread_name="Thread0"):
token_classes=True
extra_info=False
self.logger.low_debug("INIT-Tokenizer: Start the initialization of '{}'-Tokenizer for '{}'-Thread.".format(self._tokenizer,thread_name))
if self._tokenizer == "somajo":
tokenizer_obj = self._get_somajo_tokenizer( split_camel_case=split_camel_case, token_classes=token_classes, extra_info=extra_info, language=language,thread_name=thread_name)
if not tokenizer_obj:
self.logger.error("Tokenizer for '{}'-Thread wasn't initialized.".format(thread_name), exc_info=self._logger_traceback)
return False
elif self._tokenizer == "nltk":
#from nltk import word_tokenize
#word_tokenize(tweet)
tokenizer_obj = TweetTokenizer()
else:
self.logger.error("INIT-TokenizerError '{}'-tokenizer is not supported. ".format(self._tokenizer), exc_info=self._logger_traceback)
return False
self.preprocessors[thread_name]["tokenizer"] = tokenizer_obj
self.logger.debug("INIT-Tokenizer: '{}'-Tokenizer for '{}'-Thread was initialized.".format(self._tokenizer,thread_name))
return True
def _tokenize_with_somajo(self,inp_str, thread_name="Thread0"):
#p(self.preprocessors)
#self.logger.exception(self.preprocessors)
#self.logger.exception(self.preprocessors[thread_name]["tokenizer"])
self.preprocessors[thread_name]["tokenizer"].send(inp_str)
return self.preprocessors[thread_name]["tokenizer"].receive()
def _tokenize_with_nltk(self, inp_str, thread_name="Thread0"):
return self.preprocessors[thread_name]["tokenizer"].tokenize(inp_str)
def _get_somajo_tokenizer(self, split_camel_case=True, token_classes=True, extra_info=False, language="de", thread_name="Thread0"):
self.logger.low_debug("Start the initialisation of the SoMaJo-Tokenizer.")
try:
args = 'split_camel_case={}, token_classes={}, extra_info={}, language="{}" '.format(split_camel_case, token_classes, extra_info, language)
gw_id = "tokenizer_{}".format(thread_name)
#p(gw_id, "gw_id")
#p(self.opened_gateways, "self.opened_gateways")
gw = self.opened_gateways.makegateway("popen//python=python3//id={}".format(gw_id))
channel = gw.remote_exec("""
import sys, gc
from somajo import Tokenizer
#print "hhh"
tokenizer = Tokenizer({2})
channel.send("ready")
while True:
received = channel.receive()
if received == -1:
del tokenizer
gc.collect()
channel.send("stopped")
break
channel.send(tokenizer.tokenize(received))
sys.exit()
""".format(self._logger_level, gw_id,args))
#channel_error_bucket = pickle.dumps(self.channels_error_bucket)
#channel.send(channel_error_bucket)
answer = channel.receive()
#p( answer, "answer")
if answer == "ready":
self.logger.low_debug("ChannelReady: Channel for Somajo tokenizer ('{}') is open and ready. ".format(thread_name))
return channel
else:
self.logger.error("SomajoTokenizerGetterError: Channel wasn't opended properly. Got following answer: '{}'. and was aborted!!! ".format(answer))
self._terminated = True
self.threads_status_bucket.put({"name":thread_name, "status":"failed"})
return False
except Exception, e:
print_exc_plus() if self._ext_tb else ""
self.channels_error_bucket.put((thread_name,"Tokenizer",e))
self.logger.error("SomajoTokenizerGetterError: '{}'-Thread throw following exception: '{}'. ".format(thread_name, e), exc_info=self._logger_traceback)
#T, V, TB = sys.exc_info()
self.threads_status_bucket.put({"name":thread_name, "status":"failed", "exception":e})
#sys.exit()
return False
# ###########Word Stemmer###########
# def stemm(self,inp_str, thread_name="Thread0"):
# try:
# self.logger.low_debug("'{}'-Stemmer: Stemmer was called from '{}'-Thread.".format(self._tokenizer, thread_name))
# if self._stemmer == "pystemmer":
# return self._stemm_with_pystemmer(inp_str, thread_name=thread_name)
# else:
# self.logger.error("StemmError: selected stemmer '{}' is not supported.".format(self._stemmer), exc_info=self._logger_traceback)
# return False
# except KeyboardInterrupt:
# self.logger.critical("StemmerError: in '{}'-Thread get an KeyboardInterruption.".format(thread_name))
# self.threads_status_bucket.put({"name":thread_name, "status":"terminated"})
# self._terminated = True
# #self.terminate_all("KeyboardInterrupt")
# return False
# except Exception, e:
# self.logger.error("StemmerError: in '{}'-Thread. See Exception '{}'.".format(thread_name,e))
# self.terminate = True
# return False
# #sys.exit()
# #return [("",""),("","")]
# def _set_stemmer(self, thread_name="Thread0"):
# self.logger.low_debug("INIT-Stemmer: Start the initialization of '{}'-Stemmer for '{}'-Thread.".format(self._stemmer,thread_name))
# if self._stemmer == "pystemmer":
# try:
# tokenizer_obj = Stemmer.Stemmer(from_ISO639_2[self._language])
# except Exception as e:
# self.logger.error("Stemmer for '{}'-Thread wasn't initialized.".format(thread_name), exc_info=self._logger_traceback)
# return False
# else:
# self.logger.error("INIT-StemmerError '{}'-stemmer is not supported. ".format(self._stemmer), exc_info=self._logger_traceback)
# return False
# self.preprocessors[thread_name]["stemmer"] = stemmer_obj
# self.logger.debug("INIT-Stemmer: '{}'-Stemmer for '{}'-Thread was initialized.".format(self._stemmer,thread_name))
# return True
# def _stemm_with_pystemmer(self,word, thread_name="Thread0"):
# #p(self.preprocessors)
# #self.logger.exception(self.preprocessors)
# #self.logger.exception(self.preprocessors[thread_name]["stemmer"])
# return self.preprocessors[thread_name]["stemmer"].stemWord(word)
############Sentence Splitting############
def split_sentences(self,inp_list, thread_name="Thread0"):
try:
#self.logger.low_debug("'{}'-SentSplitter: SentSplitter was called from '{}'-Thread.".format(self._sent_splitter, thread_name))
if self._sent_splitter == "somajo":
return self._split_sentences_with_somajo(inp_list,thread_name=thread_name)
except KeyboardInterrupt:
self.logger.critical("SentSplitterError: in '{}'-Thread get an KeyboardInterruption.".format(thread_name))
self.threads_status_bucket.put({"name":thread_name, "status":"terminated"})
self._terminated = True
#self.terminate_all("KeyboardInterrupt")
return False
except Exception, e:
self.logger.error("SentSplitterError: in '{}'-Thread. See Exception '{}'.".format(thread_name,e))
self.terminate = True
#return [[("",""),("","")],[("",""),("","")]]
#sys.exit()
return False
def _set_sent_splitter(self, is_tuple=True,thread_name="Thread0"):
#is_tuple -means, that input tokens are tuples with additonal information about their type (ex: URLS, Emoticons etc.)
self.logger.low_debug("INITSentSplitter: Start the initialization of '{}'-SentSplitter for '{}'-Thread.".format(self._sent_splitter,thread_name))
#p(self._sent_splitter)
if self._sent_splitter == "somajo":
sent_splitter_obj = self._get_somajo_sent_splitter( is_tuple=is_tuple, thread_name=thread_name)
if not sent_splitter_obj:
self.logger.error("SentSplitter for '{}'-Thread wasn't initialized.".format(thread_name))
return False
self.preprocessors[thread_name]["sent_splitter"] = sent_splitter_obj
self.logger.debug("INITSentSplitter: '{}'-SentSplitter for '{}'-Thread was initialized.".format(self._sent_splitter,thread_name))
return True
def _split_sentences_with_somajo(self,inp_list, thread_name="Thread0"):
#self.logger.low_debug("SoMaJo-SentSpliter: Start splitting into sentences.")
self.preprocessors[thread_name]["sent_splitter"].send(inp_list)
return self.preprocessors[thread_name]["sent_splitter"].receive()
def _get_somajo_sent_splitter(self, is_tuple=True, thread_name="Thread0"):
try:
args = 'is_tuple="{}" '.format(is_tuple)
gw = self.opened_gateways.makegateway("popen//python=python3//id=sent_splitter_{}".format(thread_name))
#self.opened_gateways.append(gw)
channel = gw.remote_exec("""
import sys,gc
from somajo import SentenceSplitter
sentence_splitter = SentenceSplitter({})
channel.send("ready")
while True:
received = channel.receive()
if received == -1:
del sentence_splitter
gc.collect()
channel.send("stopped")
break
channel.send(sentence_splitter.split(received))
sys.exit()
""".format(args))
answer = channel.receive()
if answer == "ready":
self.logger.low_debug("ChannelReady: Channel for SentSplitter ('{}') is open and ready. ".format(thread_name))
return channel
else:
self.logger.error("SomajoSentSplitterGetterError: Channel wasn't opended properly. Got following answer: '{}'. and was aborted!!! ".format(answer))
self._terminated = True
self.threads_status_bucket.put({"name":thread_name, "status":"failed"})
return False
except Exception, e:
print_exc_plus() if self._ext_tb else ""
self.logger.error("SomajoSentSplitterGetterError: '{}'-Thread throw following exception: '{}'. ".format(thread_name, e), exc_info=self._logger_traceback)
self.channels_error_bucket.put((thread_name,"SentSplitter",e))
#T, V, TB = sys.exc_info()
self.threads_status_bucket.put({"name":thread_name, "status":"failed", "exception":e})
return False
###########PoS-Tagging###########
def tag_pos(self,inp_list, thread_name="Thread0"):
try:
#self.logger.low_debug("'{}'-POSTagger: POS-tagger was called from '{}'-Thread.".format(self._sent_splitter, thread_name))
if self._pos_tagger == "someweta":
#p("someweta")
return self._tag_pos_with_someweta(inp_list, thread_name=thread_name)
elif self._pos_tagger == "tweetnlp":
#p("tweetnlp")
return self._tag_pos_with_tweetnlp(inp_list)
except KeyboardInterrupt:
self.logger.critical("POSTaggerError: in '{}'-Thread get an KeyboardInterruption.".format(thread_name))
self.threads_status_bucket.put({"name":thread_name, "status":"terminated"})
self._terminated = True
#self.terminate_all("KeyboardInterrupt")
return False
except Exception, e:
#p((inp_list,self._pos_tagger, self.preprocessors[thread_name]["pos-tagger"]))
self.logger.error("POSTaggerError: in '{}'-Thread. See Exception '{}'.".format(thread_name,e))
self.terminate = True
#return [[("",""),("","")],[("",""),("","")]]
#sys.exit()
return False
def _set_pos_tagger(self, thread_name="Thread0"):
#p(self._pos_tagger)
self.logger.low_debug("INIT-POS-Tagger: Start the initialization of '{}'-pos-tagger for '{}'-Thread.".format(self._pos_tagger,thread_name))
if self._pos_tagger == "someweta":
model_name = Corpus.pos_tagger_models[self._pos_tagger][self._language][0]
path_to_model = os.path.join(path_to_someweta_models,model_name)
if not os.path.isfile(path_to_model):
self.logger.error("Current Model wasn't found: '{}'. ".format(path_to_model))
return False
#p((model_name, path_to_model))
#self.logger.critical("{}, {}".format(model_name, path_to_model))
pos_tagger_obj = self._get_someweta_pos_tagger(path_to_model,thread_name=thread_name)
if not pos_tagger_obj:
self.logger.error("POS-Tagger for '{}'-Thread wasn't initialized.".format(thread_name), exc_info=self._logger_traceback)
return False
#p(pos_tagger_obj)
#sys.exit()
elif self._pos_tagger == "tweetnlp":
try:
if not check_script_is_present():
self.logger.error("TweetNLP Java-Script File wasn't found", exc_info=self._logger_traceback)
return False
except Exception as e:
self.logger.error("TweetNLP_tagger wasn't initialized. Please check if JAVA was installed on your PC. Exception: '{}'.".format(repr(e)) )
self.threads_status_bucket.put({"name":thread_name, "status":"failed"})
self.terminate = True
return False
pos_tagger_obj = None
self.preprocessors[thread_name]["pos-tagger"] = pos_tagger_obj
self.logger.debug("INIT-POS-Tagger: '{}'-pos-tagger for '{}'-Thread was initialized.".format(self._pos_tagger,thread_name))
return True
def _tag_pos_with_someweta(self,inp_list, thread_name="Thread0"):
self.preprocessors[thread_name]["pos-tagger"].send(inp_list)
tagged = self.preprocessors[thread_name]["pos-tagger"].receive()
#p(tagged, "tagged_with_someweta")
return tagged
def _tag_pos_with_tweetnlp(self,inp_list):
#CMUTweetTagger.runtagger_parse(['example tweet 1', 'example tweet 2'])
#p(runtagger_parse(inp_list), "tagged_with_tweet_nlp")
return runtagger_parse(inp_list)
def _get_someweta_pos_tagger(self, path_to_model, thread_name="Thread0"):
try:
gw = self.opened_gateways.makegateway("popen//python=python3//id=pos_{}".format(thread_name))
#self.opened_gateways.append(gw)
channel = gw.remote_exec("""
import sys, gc
from someweta import ASPTagger
asptagger = ASPTagger(5, 10)
asptagger.load('{}')
channel.send("ready")
while True:
received = channel.receive()
if received == -1:
del asptagger
gc.collect()
channel.send("stopped")
break
channel.send(asptagger.tag_sentence(received))
sys.exit()
""".format(path_to_model))
answer = channel.receive()
if answer == "ready":
self.logger.low_debug("ChannelReady: Channel for SeMeWeTa-POSTagger ('{}') is open and ready. ".format(thread_name))
return channel
else:
self.logger.error("SoMeWeTaPOSTaggerGetterError: Channel wasn't opended properly. Got following answer: '{}'. and was aborted!!! ".format(answer))
self._terminated = True
self.threads_status_bucket.put({"name":thread_name, "status":"failed"})
return False
except Exception, e:
print_exc_plus() if self._ext_tb else ""
self.logger.error("SoMeWeTaPOSTaggerGetterError: '{}'-Thread throw following exception: '{}'. ".format(thread_name,e), exc_info=self._logger_traceback)
self.channels_error_bucket.put((thread_name,"POSTagger",e))
#T, V, TB = sys.exc_info()
self.threads_status_bucket.put({"name":thread_name, "status":"failed", "exception":e})
return False
###########Sentiment###########
def get_sentiment(self,inp_str, thread_name="Thread0"):
#self.logger.low_debug("'{}'-SentimentAnalyzer: was called from '{}'-Thread.".format(self._sent_splitter, thread_name))
if self._sentiment_analyzer == "textblob":
return self._get_sentiment_with_textblob(inp_str, thread_name=thread_name)
# elif self._pos_tagger == "tweetnlp":
# return self._tag_pos_with_tweetnlp(inp_str)
# def _set_sentiment_analyzer(self, thread_name="Thread0"):
# #p(self._pos_tagger)
# self.logger.debug("INIT-SentimentAnalyzer: Start the initialization of '{}'-sentiment analyzer for '{}'-Thread.".format(self._sentiment_analyzer,thread_name))
# if self._sentiment_analyzer == "textblob":
# if self._language == "fr":
# sentiment_analyser_obj =
# elif self._language =="de":
# sentiment_analyser_obj =
# elif self._language == "en":
# sentiment_analyser_obj=
# if not sentiment_analyser_obj:
# self.logger.error("SentimentAnalyzer for '{}'-Thread wasn't initialized.".format(thread_name))
# return False
# self.preprocessors[thread_name]["sentiment_analyser"] = sentiment_analyser_obj
# self.logger.debug("INIT-SentimentAnalyzer: '{}'-pos-tagger for '{}'-Thread was initialized.".format(self._sentiment_analyzer,thread_name))
# return True
def get_sent_sentiment_with_textblob_for_en(self, sent_as_str):
'''
Utility function to classify sentiment of passed sent_as_str
using textblob's sentiment method
'''
# create TextBlob object of passed sent_as_str text
analysis = TextBlob(sent_as_str)
# set sentiment
polarity = analysis.sentiment.polarity
if polarity > 0:
return ('positive', polarity)
elif polarity == 0:
return ('neutral',polarity)
else:
return ('negative',polarity)
def get_sent_sentiment_with_textblob_for_de(self, sent_as_str):
'''
# https://media.readthedocs.org/pdf/textblob-de/latest/textblob-de.pdf
Utility function to classify sentiment of passed sent_as_str
using textblob's sentiment method
'''
# create TextBlob object of passed sent_as_str text
analysis = TextBlobDE(sent_as_str)
# blob.tags # [('Der', 'DT'), ('Blob', 'NN'), ('macht', 'VB'),
# # ('in', 'IN'), ('seiner', 'PRP$'), ...]
# blob.noun_phrases # WordList(['Der Blob', 'seiner unbekümmert-naiven Weise',
# # 'den gewissen Charme', 'hölzerne Regie',
# # 'konfuse Drehbuch'])
# set sentiment
#for sentence in blob.sentences: print(sentence.sentiment.polarity):
# 1.0 # 0.0
polarity = analysis.sentiment.polarity
if polarity > 0:
return ('positive', polarity)
elif polarity == 0:
return ('neutral',polarity)
else:
return ('negative',polarity)
def get_sent_sentiment_with_textblob_for_fr(self, sent_as_str):
'''
#https://github.com/sloria/textblob-fr
# https://media.readthedocs.org/pdf/textblob-de/latest/textblob-de.pdf
Utility function to classify sentiment of passed sent_as_str
using textblob's sentiment method
'''
# create TextBlob object of passed sent_as_str text
tb = Blobber(pos_tagger=PatternTagger(), analyzer=PatternAnalyzer())
analysis = tb(sent_as_str)
#analysis.sentiment
# blob.tags # [('Der', 'DT'), ('Blob', 'NN'), ('macht', 'VB'),
# # ('in', 'IN'), ('seiner', 'PRP$'), ...]
# blob.noun_phrases # WordList(['Der Blob', 'seiner unbekümmert-naiven Weise',
# # 'den gewissen Charme', 'hölzerne Regie',
# # 'konfuse Drehbuch'])
# set sentiment
polarity = analysis.sentiment[0]
if polarity > 0:
return ('positive', polarity)
elif polarity == 0:
return ('neutral',polarity)
else:
return ('negative',polarity)
def _get_sentiment_with_textblob(self,inp_str, thread_name="Thread0"):
if self._language == "de":
return self.get_sent_sentiment_with_textblob_for_de(inp_str)
elif self._language in ["en", "test"]:
return self.get_sent_sentiment_with_textblob_for_en(inp_str)
elif self._language == "fr":
return self.get_sent_sentiment_with_textblob_for_fr(inp_str)
else:
self.logger.error("SentimentGetterwithTextBlob: Given Language '{}' is not supported. Please use one of the following languages: '{}'. ".format(self._language, Corpus.supported_languages_sentiment_analyzer))
return False
def _check_db_should_be_an_corpus(self):
if self.corpdb.typ() != "corpus":
self.logger.error("No active DB was found. You need to connect or initialize a DB first, before you can make any operation on the DB.", exc_info=self._logger_traceback)
return False
else:
return True
def _isrighttype(self, inp_data):
#p(inp_data)
check = (isinstance(inp_data, list), isinstance(inp_data, LenGen))
#p(check, "check")
if True not in check:
self.logger.error("InputValidationError: Given 'inpdata' is not iterable. ", exc_info=self._logger_traceback)
return False
return True
def _check_db_should_exist(self):
if not self.corpdb:
self.logger.error("No active DB was found. You need to connect or initialize a DB first, before you can make any operation on the DB.", exc_info=self._logger_traceback)
return False
else:
return True
def _check_db_should_not_exist(self):
if self.corpdb:
self.logger.error("An active DB was found. You need to initialize new empty Instance of DB before you can do this operation.", exc_info=self._logger_traceback)
return False
else:
return True
def check_status_gateways(self):
status= []
try:
for gw in self.opened_gateways:
status.append(gw.remote_status())
except Exception,e:
print_exc_plus() if self._ext_tb else ""
self.logger.error("GateWaysStatusCheckerError: Throw following Exception '{}'.".format(e), exc_info=self._logger_traceback)
self.logger.info("GateWaysStatusChecker: '{}'-Gateways was asked for their status..".format(len(status)))
return status
def close_all_gateways(self):
closed=0
try:
for gw in self.opened_gateways:
gw.exit()
closed +=1
except Exception,e:
print_exc_plus() if self._ext_tb else ""
self.logger.error("GateWaysCloserError: Throw following Exception '{}'.".format(e), exc_info=self._logger_traceback)
self.logger.info("GateWaysCloser: '{}'-Gateways was closed.".format(closed))
####################################################################################
####################################################################################
####################################################################################
####################################################################################
####################################################################################
####################################################################################
###################################Other Classes#####################################
####################################################################################
####################################################################################
####################################################################################
####################################################################################
#################################################################################### | zas-rep-tools | /zas-rep-tools-0.2.tar.gz/zas-rep-tools-0.2/zas_rep_tools/src/classes/corpus.py | corpus.py |
# ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
# : XXX{Information about this code}XXX
# Author:
# c(Developer) -> {'Egor Savin'}
# ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
###Programm Info######
#
#
#
import gc
import logging
import psutil
from zas_rep_tools.src.utils.error_tracking import initialisation
from zas_rep_tools.src.utils.traceback_helpers import print_exc_plus
from zas_rep_tools.src.utils.zaslogger import ZASLogger
from zas_rep_tools.src.utils.helpers import set_class_mode, print_mode_name, instance_info, Status,function_name, statusesTstring
from zas_rep_tools.src.utils.debugger import p
class BaseContent(object):
def __init__(self, mode="error", save_settings=False, save_status=False,
logger_folder_to_save=False, logger_usage=True,
logger_level=logging.INFO, log_content=False,
logger_save_logs=False, logger_traceback=False,
error_tracking=True, ext_tb=False, clear_logger=True,
raise_exceptions=True,**kwargs):
## Set Mode: Part 1 (Set Parameters)
self._mode = mode
if mode != "free":
_logger_level, _logger_traceback, _logger_save_logs, _save_status, _log_content, _save_settings, _logger_usage, _ext_tb= set_class_mode(self._mode)
logger_level = _logger_level if _logger_level!=None else logger_level
logger_traceback = _logger_traceback if _logger_traceback!=None else logger_traceback
logger_save_logs = _logger_save_logs if _logger_save_logs!=None else logger_save_logs
save_status = _save_status if _save_status!=None else save_status
log_content = _log_content if _log_content!=None else log_content
save_settings = _save_settings if _save_settings!=None else save_settings
logger_usage = _logger_usage if _logger_usage!=None else logger_usage
ext_tb = _ext_tb if _ext_tb!=None else ext_tb
## Step 2: Instance Encapsulation
## 2.General Parameters
self._save_settings = save_settings
self._save_status = save_status
self._error_tracking = error_tracking
self._ext_tb = ext_tb
## 2.2 Logger Parameters
self._logger_level = logger_level
self._logger_traceback =logger_traceback
self._logger_save_logs = logger_save_logs
self._logger_folder_to_save = logger_folder_to_save
self._logger_usage = logger_usage
self._log_content = log_content
self._clear_logger = clear_logger
self._raise_exceptions = raise_exceptions
self._is_destructed = False
self.class_name = self.__class__.__name__
## Logger Initialisation
self.L = ZASLogger(self.class_name, level=self._logger_level,
folder_for_log=self._logger_folder_to_save,
logger_usage=self._logger_usage,
save_logs=self._logger_save_logs)
self.logger = self.L.getLogger()
self.logger.debug('Beginn of creating an instance of {}()'.format(self.__class__.__name__))
## Set Mode: Part 2 (Print setted Mode)
print_mode_name(self._mode, self.logger)
## Error-Tracking:Initialization #1
if self._error_tracking:
self.client = initialisation()
self.client.context.merge({'InstanceAttributes': self.__dict__})
self.logger.debug('All Base-Parameters was initialized.')
super(BaseContent, self).__init__(**kwargs)
def __del__(self):
# from collections import defaultdict
# import os, sys
# #proc = psutil.Process()
# #p( proc.open_files() )
# from blessings import Terminal
# self.t = Terminal()
# print "\n\n"
# p("<<<", c="r")
# d = defaultdict(lambda: [0, []])
# for proc in psutil.process_iter():
# if proc:
# try:
# for pr in proc.open_files():
# if pr:
# #print type(pr.path)
# #print pr.path
# root = str(pr.path).split("/")
# #print root
# if len(root) <= 1:
# continue
# if root[1] in ["Applications","System","Library","usr",".Spotlight-V100",".DocumentRevisions-V100"]:
# pattern = "{}/{}".format(root[1], root[2])
# d[pattern][0] += 1
# d[pattern][1].append(root[-1])
# continue
# elif root[1] in ["private","Volumes","Users"]:
# pattern = "{}/{}/{}".format(root[1], root[2],root[3])
# d[pattern][0] += 1
# d[pattern][1].append(root[-1])
# continue
# #else:
# if len(root) >= 5:
# pattern = "{}/{}/{}/{}".format(root[1], root[2],root[3],root[4])
# d[pattern][0] += 1
# d[pattern][1].append(root[-1])
# elif len(root) >= 4:
# pattern = "{}/{}/{}".format(root[1], root[2],root[3])
# d[pattern][0] += 1
# d[pattern][1].append(root[-1])
# elif len(root) >= 3:
# pattern = "{}/{}".format(root[1], root[2])
# d[pattern][0] += 1
# d[pattern][1].append(root[-1])
# else:
# d[root[1]][0] += 1
# d[root[1]][1].append(root[-1])
# except:
# pass
# #print sum([num[0] for num in d.values])
# print self.t.bold_black_on_bright_magenta + "\n\n\n\nall_Process ({})".format(sum([num[0] for num in d.values()])) + self.t.normal
# #print d
# #filename, file_extension = os.path.splitext('/path/to/somefile.ext')
# for key in sorted(d.keys()):
# value = d[key]
# #value[0]
# extentions = defaultdict(lambda: [0, []])
# #if isinstance( value[1], int ) :
# # sys.exit()
# for fname in value[1]:
# #if isinstance( fname, int ) :
# # sys.exit()
# #print repr(fname)
# filename, file_extension = os.path.splitext(fname)
# extentions[file_extension][0] += 1
# extentions[file_extension][1].append(filename)
# print " {}{} {} {}".format(self.t.bold_black_on_bright_white,value[0], key, self.t.normal)
# for ext in sorted(extentions.keys()):
# #print " {} {} ({})".format(ext, extentions[ext][0], set(extentions[ext][1]))
# print " {} {} ".format(ext, extentions[ext][0])
# p(">>>", c="r")
# print "\n\n\n\n"
#p( proc.open_files() )
if not self._is_destructed:
if self._logger_usage:
if self._save_settings:
#p(self.__class__.__name__)
inp_dict = { k:v if isinstance(v, (str, unicode, bool, int)) else str(v) for k,v in self.__dict__.iteritems()}
self.logger.settings("InstanceDestructionAttributes: {}".format( instance_info(inp_dict, attr_to_len=False, attr_to_flag=False, as_str=True)))
#p(inp_dict)
if self._save_status:
statuses_as_str = statusesTstring(str(self.__class__.__name__).lower())
if statuses_as_str:
self.logger.status(statuses_as_str)
try:
self.L._close_handlers()
del self.L
gc.collect()
except:
pass
self._is_destructed = True
def _log_settings(self,attr_to_flag=False,attr_to_len=False):
if self._save_settings:
if self._logger_save_logs:
attr_to_flag = attr_to_flag
attr_to_len = attr_to_len
inp_dict = { k:v if isinstance(v, (str, unicode, bool, int)) else str(v) for k,v in self.__dict__.iteritems()}
self.logger.settings("InstanceInitializationAttributes: {}".format( instance_info(inp_dict, attr_to_len=attr_to_len, attr_to_flag=attr_to_flag, as_str=True)))
# def _destruct_instance(self):
# #del self
# gc.collect()
class BaseDB(object):
def __init__(self, optimizer=False, make_backup=True, lazyness_border=100000,
isolation_level=False, in_memory=False,thread_safe=True,
rewrite=False, stop_if_db_already_exist=False, replace_double_items=True,
use_cash=False, stop_process_if_possible=True,
optimizer_page_size = 4096,
optimizer_cache_size=1000000, # The cache_size pragma can get or temporarily set the maximum size of the in-memory page cache.
optimizer_locking_mode="EXCLUSIVE",
optimizer_synchronous="OFF",
optimizer_journal_mode="MEMORY",
optimizer_temp_store="MEMORY",
#backup_bevore_first_insert=True,
**kwargs):
#Input: Encapsulation:
self._rewrite = rewrite
self._stop_if_db_already_exist = stop_if_db_already_exist
self._make_backup = make_backup
#self._backup_bevore_first_insert = backup_bevore_first_insert
self._lazyness_border = lazyness_border
self._optimizer = optimizer
self._in_memory = in_memory
self._thread_safe = thread_safe
self._use_cash = use_cash
self._isolation_level = isolation_level # None, "EXCLUSIVE", "DEFERRED", "IMMEDIATE"
self._optimizer_page_size = optimizer_page_size
self._optimizer_cache_size = optimizer_cache_size
self._optimizer_locking_mode = optimizer_locking_mode
self._optimizer_synchronous = optimizer_synchronous
self._optimizer_journal_mode = optimizer_journal_mode
self._optimizer_temp_store = optimizer_temp_store
self._replace_double_items = replace_double_items
self._stop_process_if_possible = stop_process_if_possible
super(BaseDB, self).__init__(**kwargs) | zas-rep-tools | /zas-rep-tools-0.2.tar.gz/zas-rep-tools-0.2/zas_rep_tools/src/classes/basecontent.py | basecontent.py |
# ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
# : XXX{Information about this code}XXX
# Author:
# c(Developer) -> {'Egor Savin'}
# ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
###Programm Info######
#
#
#
#
#
from __future__ import absolute_import
import os
import copy
import sys
import logging
import inspect
import shutil
import traceback
#import shelve
import time
import json
from collections import defaultdict
from raven import Client
from cached_property import cached_property
import inspect
from consolemenu import *
from consolemenu.items import *
from validate_email import validate_email
import urllib2
import twitter
from nltk.tokenize import TweetTokenizer
from nose.tools import nottest
from zas_rep_tools_data.utils import path_to_data_folder, path_to_models, path_to_someweta_models, path_to_stop_words
from zas_rep_tools.src.utils.debugger import p
from zas_rep_tools.src.utils.helpers import set_class_mode, print_mode_name, MyZODB,transaction, path_to_zas_rep_tools, internet_on, make_zipfile, instance_info, SharedCounterExtern, SharedCounterIntern, Status, function_name,statusesTstring
import zas_rep_tools.src.utils.db_helper as db_helper
from zas_rep_tools.src.utils.error_tracking import initialisation
from zas_rep_tools.src.utils.traceback_helpers import print_exc_plus
from zas_rep_tools.src.classes.exporter import Exporter
from zas_rep_tools.src.classes.reader import Reader
from zas_rep_tools.src.classes.dbhandler import DBHandler
from zas_rep_tools.src.classes.corpus import Corpus
from zas_rep_tools.src.classes.stats import Stats
from zas_rep_tools.src.utils.zaslogger import ZASLogger
from zas_rep_tools.src.classes.basecontent import BaseContent
from zas_rep_tools.src.utils.configer_helpers import ConfigerData
@nottest
class TestsConfiger(BaseContent,ConfigerData):
def __init__(self, rewrite=False,stop_if_db_already_exist = True,**kwargs):
super(type(self), self).__init__(**kwargs)
#Input: Encapsulation:
self._rewrite = rewrite
self._stop_if_db_already_exist = stop_if_db_already_exist
#InstanceAttributes: Initialization
self._path_to_zas_rep_tools = path_to_zas_rep_tools
self._path_to_user_config_data = os.path.join(self._path_to_zas_rep_tools, "user_config/user_data.fs")
self._path_to_zas_rep_tools_data = path_to_data_folder
self._path_to_zas_rep_tools_someweta_models = path_to_someweta_models
self._path_to_zas_rep_tools_stop_words = path_to_stop_words
#self._get_user_config_db()
if not self._check_correctness_of_the_test_data():
self.logger.error("TestDataCorruption: Please check test data.", exc_info=self._logger_traceback)
sys.exit()
self.logger.debug('Intern InstanceAttributes was initialized')
self.logger.debug('An instance of {}() was created '.format(self.__class__.__name__))
## Log Settings of the Instance
attr_to_flag = ["_types_folder_names_of_testsets","_test_dbs", "_init_info_data", "_columns_in_doc_table", "_columns_in_info_tabel", "_columns_in_stats_tables", "_text_elements_collection"]
attr_to_len = False
self._log_settings(attr_to_flag =attr_to_flag,attr_to_len =attr_to_len)
############################################################
####################__init__end#############################
############################################################
def __del__(self):
pass
#super(type(self), self).__del__()
####################################################################################
####################################################################################
####################################################################################
####################################################################################
####################################################################################
####################################################################################
######################################Extern########################################
####################################################################################
####################################################################################
####################################################################################
####################################################################################
####################################################################################
def row_text_elements(self, lang="all"):
return copy.deepcopy(self._row_text_elements(lang=lang))
def text_elements(self, token=True, unicode_str=True,lang="all"):
return copy.deepcopy(self._text_elements(token=token, unicode_str=unicode_str, lang=lang))
def docs_row_values(self,token=True, unicode_str=True, lang="all"):
return copy.deepcopy(self._docs_row_values(token=token,unicode_str=unicode_str, lang=lang))
def docs_row_dict(self, token=True, unicode_str=True, all_values=False, lang="all"):
'''
just one dict with colums as key and list of all values as values for each columns()key
'''
return copy.deepcopy(self._docs_row_dict(token=token, unicode_str=unicode_str, all_values=all_values, lang=lang))
def docs_row_dicts(self, token=True, unicode_str=True, lang="all"):
'''
list of dicts with colums and values for each row
'''
return copy.deepcopy(self._docs_row_dicts(token=token, unicode_str=unicode_str, lang=lang))
###########################Config Values#######################
@cached_property
def path_to_zas_rep_tools(self):
return copy.deepcopy(self._path_to_zas_rep_tools)
@cached_property
def path_to_zas_rep_tools_data(self):
return copy.deepcopy(self._path_to_zas_rep_tools_data)
@nottest
@cached_property
def path_to_testdbs(self):
return copy.deepcopy(self._path_to_testdbs)
@nottest
@cached_property
def test_dbs(self):
return copy.deepcopy(self._test_dbs)
@cached_property
def init_info_data(self):
return copy.deepcopy(self._init_info_data)
@cached_property
def columns_in_doc_table(self):
return copy.deepcopy(self._columns_in_doc_table)
@cached_property
def columns_in_info_tabel(self):
return copy.deepcopy(self._columns_in_info_tabel)
@cached_property
def columns_in_stats_tables(self):
return copy.deepcopy(self._columns_in_stats_tables)
@nottest
@cached_property
def path_to_testsets(self):
return copy.deepcopy(self._path_to_testsets)
@cached_property
def types_folder_names_of_testsets(self):
return copy.deepcopy(self._types_folder_names_of_testsets)
# def clean_user_data(self):
# if self._user_data.clean():
# return True
# else:
# return False
# def get_data_from_user(self, user_info_to_get=False, rewrite=False):
# if not rewrite:
# rewrite = self._rewrite
# if user_info_to_get:
# if isinstance(user_info_to_get, (unicode, str)):
# user_info_to_get = [user_info_to_get]
# else:
# user_info_to_get = self._suported_user_info
# for user_info_name in user_info_to_get:
# if user_info_name not in self._suported_user_info:
# self.logger.error("UserDataGetterError: '{}' - data not supported. ".format(user_info_name), exc_info=self._logger_traceback)
# continue
# if user_info_name == "error_tracking":
# if rewrite:
# self._cli_menu_error_agreement()
# continue
# if "error_tracking" not in self._user_data:
# self._cli_menu_error_agreement()
# elif user_info_name == "project_folder":
# if rewrite:
# self._cli_menu_get_from_user_project_folder()
# continue
# if "project_folder" not in self._user_data:
# self._cli_menu_get_from_user_project_folder()
# elif user_info_name == "twitter_creditials":
# if rewrite:
# self._cli_menu_get_from_user_twitter_credentials()
# continue
# if "twitter_creditials" not in self._user_data:
# self._cli_menu_get_from_user_twitter_credentials()
# elif user_info_name == "email":
# if rewrite:
# self._cli_menu_get_from_user_emails()
# continue
# if "email" not in self._user_data:
# self._cli_menu_get_from_user_emails()
# else:
# self.logger.critical("Not supported user_data_getter ('{}').".format(user_info_name))
@nottest
def create_test_data(self, abs_path_to_storage_place=False, use_original_classes = True, corp_lang_classification=False,
corp_pos_tagger=True, corp_sent_splitter=True, corp_sentiment_analyzer=True, status_bar=True,
corp_log_ignored=False, use_test_pos_tagger=False,rewrite=False):
self.create_testsets(rewrite=rewrite,abs_path_to_storage_place=abs_path_to_storage_place,silent_ignore = True)
if not self.create_test_dbs(rewrite=rewrite, abs_path_to_storage_place=abs_path_to_storage_place, use_original_classes=use_original_classes,
corp_lang_classification=corp_lang_classification, corp_log_ignored=corp_log_ignored,
corp_pos_tagger=corp_pos_tagger, corp_sent_splitter=corp_sent_splitter,
corp_sentiment_analyzer=corp_sentiment_analyzer, status_bar=status_bar,
use_test_pos_tagger=use_test_pos_tagger):
return False
self.logger.info("Test Data was initialized.")
return True
@nottest
def create_test_dbs(self, rewrite=False, abs_path_to_storage_place = False,corp_log_ignored=False,
use_original_classes = True, corp_lang_classification=True, use_test_pos_tagger=False,
corp_pos_tagger=True, corp_sent_splitter=True, corp_sentiment_analyzer=True, status_bar=True):
try:
if not abs_path_to_storage_place:
abs_path_to_storage_place = os.path.join(self._path_to_zas_rep_tools, self._path_to_testdbs)
### clean journal files
exist_fnames_in_dir = os.listdir(abs_path_to_storage_place)
exist_fnames_in_dir = [fname for fname in exist_fnames_in_dir if ".db-journal" in fname]
if exist_fnames_in_dir:
for fname in exist_fnames_in_dir:
os.remove(os.path.join(abs_path_to_storage_place, fname))
msg = "'{}' '.db-journal' files was deleted. ".format(len(exist_fnames_in_dir))
self.logger.critical(msg)
#p(msg, "CRITICAL", c="r")
if not rewrite:
rewrite = self._rewrite
#for
exist_fnames_in_dir = os.listdir(abs_path_to_storage_place)
num = len(exist_fnames_in_dir)
#p((num, exist_fnames_in_dir), "exist_fnames_in_dir")
exist_fnames_in_dir = [fname for fname in exist_fnames_in_dir if (".db" in fname) and (".db-journal" not in fname)]
fnames_test_db = [fname for encr, encr_data in self._test_dbs.items() for template_name, template_name_data in encr_data.items() for lang, lang_data in template_name_data.items() for db_type, fname in lang_data.items()]
test_db_num = len(fnames_test_db)
#p((fnames_test_db,exist_fnames_in_dir,test_db_num), "fnames_test_db")
clean = False
if len(exist_fnames_in_dir) != len(fnames_test_db):
clean = True
self.logger.critical("Some TestDB are missing. There was found '{}'-DBs. But it should be '{}'. Process of TestDB Creation will be started. ".format(len(exist_fnames_in_dir), len(fnames_test_db)))
else:
for fname in fnames_test_db:
if fname not in exist_fnames_in_dir:
msg = "Some TestDB are missing. (eg: '{}') Process of TestDB Creation will be started. ".format(fname)
self.logger.critical(msg)
#p(msg, "CRITICAL", c="r")
clean = True
break
if clean:
clean = False
for fname in exist_fnames_in_dir:
os.remove(os.path.join(abs_path_to_storage_place, fname))
exist_fnames_in_dir = os.listdir(abs_path_to_storage_place)
exist_fnames_in_dir = [fname for fname in exist_fnames_in_dir if ".db-journal" in fname]
for fname in exist_fnames_in_dir:
os.remove(os.path.join(abs_path_to_storage_place, fname))
activ_corp_dbs = defaultdict(lambda: defaultdict(lambda: defaultdict(lambda: defaultdict(dict))) )
for template_name, init_data in self._init_info_data.iteritems():
#p(template_name)
for encryption in ["plaintext", "encrypted"]:
for dbtype in ["corpus", "stats"]:
# if exist and rewrite=True -> remove existed db
#p(self._columns_in_info_tabel[dbtype])
dbname = self._init_info_data[template_name]["name"]
#language = self._init_info_data[template_name]["language"]
visibility = self._init_info_data[template_name]["visibility"]
platform_name = self._init_info_data[template_name]["platform_name"]
license = self._init_info_data[template_name]["license"]
template_name = self._init_info_data[template_name]["template_name"]
version = self._init_info_data[template_name]["version"]
source = self._init_info_data[template_name]["source"]
encryption_key = self._init_info_data[template_name]["encryption_key"][dbtype] if encryption=="encrypted" else False
corpus_id = self._init_info_data[template_name]["id"]["corpus"]
stats_id = self._init_info_data[template_name]["id"]["stats"]
#p((dbtype, encryption_key))
# for which languages create
if encryption == "encrypted":
if template_name == "twitter":
languages = ["de"]
elif template_name == "blogger":
continue
#languages = ["en"]
elif encryption == "plaintext":
if template_name == "twitter":
continue
#languages = ["de"]
elif template_name == "blogger":
languages = ["de", "en", "test"]
for language in languages:
# If Rewrite is on, delete db for current attributes. if this exist in the 'self._test_dbs'. If not, than ignore.
try:
path_to_db = os.path.join(abs_path_to_storage_place, self._test_dbs[encryption][template_name][language][dbtype])
if rewrite:
if os.path.isfile(path_to_db):
os.remove(path_to_db)
self.logger.debug("RewriteOptionIsON: Following DB was deleted from TestDBFolder: '{}'. TestDBCreationScript will try to created this DB.".format(path_to_db))
else:
#self.logger.debug("11111{}:{}:{}:{}".format(dbname, language, platform_name, dbtype))
self.logger.debug("RewriteOptionIsON: Following DB wasn't found in the TestDBFolder and wasn't deleted: '{}'. TestDBCreationScript will try to created this DB.".format(path_to_db))
else:
if os.path.isfile(path_to_db):
self.logger.debug("RewriteOptionIsOFF: '{}'-DB exist and will not be rewrited/recreated.".format(path_to_db))
continue
except KeyError, k:
self.logger.debug("KeyError: DBName for '{}:{}:{}:{}' is not exist in the 'self._test_dbs'. TestDBCreationScript will try to created this DB. ".format(encryption,template_name,language,dbtype))
continue
except Exception, e:
self.logger.error("See Exception: '{}'. (line 703). Creation of the TestDBs was aborted.".format(e), exc_info=self._logger_traceback)
sy.exit()
#self.logger.debug("2222{}:{}:{}:{}".format(dbname, language, platform_name, dbtype))
db_id = corpus_id if dbtype == "corpus" else stats_id
self.logger.info("TestDBCreationProcess: Was started for DB with following attributes: 'dbtype='{}'; id='{}'; encryption='{}'; template_name='{}'; language='{}'. ".format(dbtype, db_id,encryption,template_name,language ))
if dbtype=="corpus":
#self.logger.debug("3333{}:{}:{}:{}".format(dbname, language, platform_name, dbtype))
if not use_original_classes:
db = DBHandler(logger_level=logging.ERROR,logger_traceback=self._logger_traceback,
logger_folder_to_save=self._logger_folder_to_save,logger_usage=self._logger_usage,
logger_save_logs= self._logger_save_logs, mode=self._mode,
error_tracking=self._error_tracking, ext_tb= self._ext_tb,
stop_if_db_already_exist=self._stop_if_db_already_exist, rewrite=self._rewrite)
was_initialized = db.init(dbtype, abs_path_to_storage_place, dbname, language, visibility, platform_name=platform_name, license=license , template_name=template_name, version=version , source=source, corpus_id=corpus_id, stats_id=stats_id, encryption_key=encryption_key)["status"]
# self.logger.critical("was_initialized={}".format(was_initialized))
# sys.exit()
#!!!!
#self.logger.debug("444{}:{}:{}:{}".format(dbname, language, platform_name, dbtype))
if not was_initialized:
if self._stop_if_db_already_exist:
self.logger.debug("DBInitialisation: DBName for '{}:{}:{}:{}' wasn't initialized. Since 'self._stop_if_db_already_exist'-Option is on, current Script will ignore current DB and will try to create next one.".format(encryption,template_name,language,dbtype))
continue
else:
self.logger.error("DBInitialisationError: DBName for '{}:{}:{}:{}' wasn't initialized. TestDBCreation was aborted.".format(encryption,template_name,language,dbtype))
return False
#self.logger.debug("5555{}:{}:{}:{}".format(dbname, language, platform_name, dbtype))
rows_to_insert = self.docs_row_values(token=True, unicode_str=True)[template_name]
path_to_db = db.path()
#self.logger.debug("6666{}:{}:{}:{}".format(dbname, language, platform_name, dbtype))
if not path_to_db:
self.logger.error("Path for current DB wasn't getted. Probably current corpus has InitializationError. TestDBCreation was aborted.")
sys.exit()
db.lazyinsert("documents",rows_to_insert)
#self.logger.debug("77777{}:{}:{}:{}".format(dbname, language, platform_name, dbtype))
#p(( len(db.getall("documents")), len(rows_to_insert)))
if "Connection" not in str(type(db)):
pass
#p((len(db.getall("documents")) , len(rows_to_insert)), c="r")
if len(db.getall("documents")) != len(rows_to_insert):
#db.close()
#p(db._db)
os.remove(path_to_db)
#shutil.rmtree(path_to_db)
self.logger.error("TestDBsCreation(InsertionError): Not all rows was correctly inserted into DB. This db was ignored and not created.", exc_info=self._logger_traceback)
#sys.exit()
sys.exit()
continue
db.commit()
db.close()
else:
#if use_test_pos_tagger and language == "en":
# corp_pos_tagger = "tweetnlp" if corp_pos_tagger else corp_pos_tagger
#else:
# corp_pos_tagger = True if corp_pos_tagger else False
#if corp_language:
# language = corp_language
#p((corp_pos_tagger,language), "pos_tagger")
corp = Corpus(logger_level=logging.ERROR, logger_traceback=self._logger_traceback,
logger_folder_to_save=self._logger_folder_to_save, use_test_pos_tagger=use_test_pos_tagger,
logger_usage=self._logger_usage, logger_save_logs= self._logger_save_logs,
mode=self._mode , error_tracking=self._error_tracking, ext_tb= self._ext_tb,
stop_if_db_already_exist=self._stop_if_db_already_exist, status_bar=status_bar,
rewrite=self._rewrite)
#p(corp.info())
#self.logger.debug("444{}:{}:{}:{}".format(dbname, language, platform_name, dbtype))
was_initialized = corp.init(abs_path_to_storage_place,dbname, language, visibility,platform_name,
license=license , template_name=template_name, version=version, source=source,
corpus_id=corpus_id, encryption_key=encryption_key,
lang_classification=corp_lang_classification,
pos_tagger=corp_pos_tagger, sent_splitter=corp_sent_splitter,
sentiment_analyzer=corp_sentiment_analyzer,)
#self.logger.debug("555{}:{}:{}:{}".format(dbname, language, platform_name, dbtype))
#self.logger.critical("was_initialized={}".format(was_initialized))
#p(corp.info())
if not was_initialized:
if self._stop_if_db_already_exist:
self.logger.debug("DBInitialisation: DBName for '{}:{}:{}:{}' wasn't initialized. Since 'self._stop_if_db_already_exist'-Option is on, current Script will ignore current DB and will try to create next one.".format(encryption,template_name,language,dbtype))
continue
else:
self.logger.error("DBInitialisationError: DB for '{}:{}:{}:{}' wasn't initialized. TestDBCreation was aborted.".format(encryption,template_name,language,dbtype))
return False
rows_as_dict_to_insert = self.docs_row_dicts(token=False, unicode_str=True)[template_name]
path_to_db = corp.corpdb.path()
fname_db = corp.corpdb.fname()
#self.logger.debug("777{}:{}:{}:{}".format(dbname, language, platform_name, dbtype))
if not path_to_db or not fname_db:
self.logger.error("Path or FileName for current CorpusDB wasn't getted. (lang='{}', dbname='{}', id='{}',platform_name='{}', visibility='{}', encryption_key='{}') Probably current corpus has InitializationError. TestDBCreation was aborted.".format(language, dbname,corpus_id, platform_name, visibility, encryption_key))
sys.exit()
#p((path_to_db,fname_db))
was_inserted = corp.insert(rows_as_dict_to_insert, log_ignored=corp_log_ignored)
if not was_inserted:
os.remove(path_to_db)
msg = "Rows wasn't inserted into the '{}'-DB. This DB was deleted and script of creating testDBs was aborted.".format(fname_db)
self.logger.error(msg)
raise Exception, msg
sys.exit()
return False
#continue
else:
if not corp_lang_classification:
if len(corp.docs()) != len(rows_as_dict_to_insert):
os.remove(path_to_db)
#shutil.rmtree(path_to_db)
msg = "TestDBsCreation(InsertionError): Not all rows was correctly inserted into DB. This DB was deleted and script of creating testDBs was aborted."
self.logger.error(msg, exc_info=self._logger_traceback)
#sys.exit()
raise Exception, msg
#continue
if corp.total_error_insertion_during_last_insertion_process:
msg = "TestDBsCreation(InsertionError): '{}'-ErrorInsertion was found!!! Not all rows was correctly inserted into DB. This DB was deleted and script of creating testDBs was aborted.".format(corp.total_error_insertion_during_last_insertion_process)
self.logger.error(msg, exc_info=self._logger_traceback)
raise Exception, msg
return False
else:
self.logger.debug("'{}'-TestDB was created. Path: '{}'.".format(fname_db,path_to_db))
#corp.commit()
self.logger.debug("'{}': Following rows was inserted:\n '{}'. \n\n".format(fname_db, '\n'.join("--->"+str(v) for v in list(corp.docs()) ) ))
activ_corp_dbs[template_name][encryption][dbtype][language] = corp
### get SENTS
# corp.corpdb.commit()
# if language== "de":
# p(list(corp.docs()), "de", c="r")
# elif language== "en":
# p(list(corp.docs()), "en", c="m")
# time.sleep(15)
#else:
# time.sleep(15)
elif dbtype=="stats":
## here insert all rows into stats dbs
if not use_original_classes:
stats = DBHandler(logger_level=logging.ERROR,logger_traceback=self._logger_traceback, logger_folder_to_save=self._logger_folder_to_save,logger_usage=self._logger_usage, logger_save_logs= self._logger_save_logs, mode=self._mode , error_tracking=self._error_tracking, ext_tb= self._ext_tb, stop_if_db_already_exist=self._stop_if_db_already_exist, rewrite=self._rewrite)
stats.init(dbtype, abs_path_to_storage_place, dbname, language, visibility, platform_name=platform_name, license=license , template_name=template_name, version=version , source=source, corpus_id=corpus_id, stats_id=stats_id, encryption_key=encryption_key)
stats.close()
else:
#p(activ_corp_dbs, "activ_corp_dbs")
#p((template_name,encryption,dbtype,language))
stats = Stats(logger_level=logging.ERROR, logger_traceback=self._logger_traceback,
logger_folder_to_save=self._logger_folder_to_save, logger_usage=self._logger_usage,
logger_save_logs= self._logger_save_logs, mode=self._mode, error_tracking=self._error_tracking,
ext_tb= self._ext_tb, stop_if_db_already_exist=self._stop_if_db_already_exist,
status_bar=status_bar,rewrite=self._rewrite)
#p(corp.info())
was_initialized = stats.init(abs_path_to_storage_place,dbname, language, visibility,
version=version, corpus_id=corpus_id, stats_id=stats_id,
encryption_key=encryption_key,case_sensitiv=False,
full_repetativ_syntagma=True,baseline_delimiter="++")
#p((encryption_key,dbtype,dbname,language,visibility,platform_name ), "encryption_key____stats")
corp = activ_corp_dbs[template_name][encryption]["corpus"][language]
#p(corp, "corp")
if isinstance(corp, Corpus):
stats.compute(corp)
corp.corpdb.commit()
stats.statsdb.commit()
corp.close()
stats.close()
else:
self.logger.error("Given CorpObj ('{}') is invalid".format(corp))
return False
#### check if db was created
exist_fnames_in_dir = os.listdir(abs_path_to_storage_place)
exist_fnames_in_dir = [fname for fname in exist_fnames_in_dir if (".db" in fname) and (".db-journal" not in fname)]
if len(fnames_test_db) != len(exist_fnames_in_dir):
self.logger.error("TestDBs wasn't initialized correctly. There was found '{}' testDBs in the TestDBFolder, but it should be '{}'. ".format(len(exist_fnames_in_dir), len(fnames_test_db)))
return False
for fname in fnames_test_db:
if fname not in exist_fnames_in_dir:
self.logger.error("'{}'-testDB wasn't found in the TestDB-Folder. End with Error.".format(fname))
return False
self.logger.info("TestDBs was initialized.")
return True
except KeyboardInterrupt:
exist_fnames_in_dir = os.listdir(abs_path_to_storage_place)
exist_fnames_in_dir = [fname for fname in exist_fnames_in_dir if ".db" in fname]
for fname in exist_fnames_in_dir:
os.remove(os.path.join(abs_path_to_storage_place, fname))
sys.exit()
return False
@nottest
def create_testsets(self, rewrite=False, abs_path_to_storage_place=False, silent_ignore = True):
return list(self.create_testsets_in_diff_file_formats(rewrite=rewrite, abs_path_to_storage_place=abs_path_to_storage_place,silent_ignore=silent_ignore))
@nottest
def create_testsets_in_diff_file_formats(self, rewrite=False, abs_path_to_storage_place=False, silent_ignore = True):
#p(abs_path_to_storage_place)
#sys.exit()
if not rewrite:
rewrite = self._rewrite
if not abs_path_to_storage_place:
abs_path_to_storage_place = self._path_to_zas_rep_tools
#p("fghjk")
created_sets = []
if not abs_path_to_storage_place:
sys.exit()
try:
# make test_sets for Blogger Corp
for file_format, test_sets in self._types_folder_names_of_testsets.iteritems():
for name_of_test_set, folder_for_test_set in test_sets.iteritems():
if file_format == "txt":
continue
abs_path_to_current_test_case = os.path.join(abs_path_to_storage_place, self._path_to_testsets["blogger"], folder_for_test_set)
# p((file_format, name_of_test_set))
# p(abs_path_to_current_test_case)
if rewrite:
if os.path.isdir(abs_path_to_current_test_case):
shutil.rmtree(abs_path_to_current_test_case)
#os.remove(abs_path_to_current_test_case)
if not os.path.isdir(abs_path_to_current_test_case):
os.makedirs(abs_path_to_current_test_case)
path_to_txt_corpus = os.path.join(self.path_to_zas_rep_tools,self._path_to_testsets["blogger"] , self._types_folder_names_of_testsets["txt"][name_of_test_set] )
reader = Reader(path_to_txt_corpus, "txt", regex_template="blogger",logger_level= self._logger_level,logger_traceback=self._logger_traceback, logger_folder_to_save=self._logger_folder_to_save,logger_usage=self._logger_usage, logger_save_logs= self._logger_save_logs, mode=self._mode , error_tracking=self._error_tracking, ext_tb= self._ext_tb)
exporter = Exporter(reader.getlazy(), rewrite=rewrite, silent_ignore=silent_ignore, logger_level= self._logger_level,logger_traceback=self._logger_traceback, logger_folder_to_save=self._logger_folder_to_save,logger_usage=self._logger_usage, logger_save_logs= self._logger_save_logs, mode=self._mode , error_tracking=self._error_tracking, ext_tb= self._ext_tb)
if file_format == "csv":
if name_of_test_set == "small":
flag = exporter.tocsv(abs_path_to_current_test_case, "blogger_corpus",self._columns_in_doc_table["blogger"], rows_limit_in_file=5)
if not flag:
yield False
else:
created_sets.append("csv")
yield True
else:
flag= exporter.tocsv(abs_path_to_current_test_case, "blogger_corpus",self._columns_in_doc_table["blogger"], rows_limit_in_file=2)
if not flag:
yield False
else:
created_sets.append("csv")
yield True
elif file_format == "xml":
if name_of_test_set == "small":
flag = exporter.toxml(abs_path_to_current_test_case, "blogger_corpus", rows_limit_in_file=5)
if not flag:
yield False
else:
created_sets.append("xml")
yield True
else:
flag = exporter.toxml(abs_path_to_current_test_case, "blogger_corpus", rows_limit_in_file=2)
if not flag:
yield False
else:
created_sets.append("xml")
yield True
elif file_format == "json":
if name_of_test_set == "small":
flag = exporter.tojson(abs_path_to_current_test_case, "blogger_corpus", rows_limit_in_file=5)
if not flag:
yield False
else:
created_sets.append("json")
yield True
else:
flag = exporter.tojson(abs_path_to_current_test_case, "blogger_corpus", rows_limit_in_file=2)
if not flag:
yield False
else:
created_sets.append("json")
yield True
elif file_format == "sqlite":
flag = exporter.tosqlite(abs_path_to_current_test_case, "blogger_corpus",self._columns_in_doc_table["blogger"])
if not flag:
yield False
else:
created_sets.append("sqlite")
yield True
#p(created_sets, "created_sets")
for created_set in set(created_sets):
path_to_set = os.path.join(abs_path_to_storage_place, self._path_to_testsets["blogger"], created_set)
#p(path_to_set)
#p(os.path.join(os.path.split(path_to_set)[0], created_set+".zip"))
make_zipfile(os.path.join(os.path.split(path_to_set)[0], created_set+".zip"), path_to_set)
self.logger.info("TestSets (diff file formats) was initialized.")
except Exception, e:
print_exc_plus() if self._ext_tb else ""
self.logger.error("SubsetsCreaterError: Throw following Exception: '{}'. ".format(e), exc_info=self._logger_traceback)
####################################################################################
####################################################################################
####################################################################################
####################################################################################
####################################################################################
####################################################################################
######################################INTERN########################################
####################################################################################
####################################################################################
####################################################################################
####################################################################################
####################################################################################
def _check_correctness_of_the_test_data(self):
## Check mapping of columns and values
try:
for template, data_columns in self._columns_in_doc_table.iteritems():
for data_values in self.docs_row_values(token=True, unicode_str=True)[template]:
#p((len(data_columns), len(data_values)))
if len(data_columns) != len(data_values):
self.logger.error("TestDataCorruption: Not same number of columns and values.", exc_info=self._logger_traceback)
return False
except Exception, e:
#p([(k,v) for k,v in self._columns_in_doc_table.iteritems()])
#p(self.docs_row_values(token=True, unicode_str=True))
self.logger.error("TestDataCorruption: Test Data in Configer is inconsistent. Probably - Not same template_names in columns and rows. See Exception: '{}'. ".format(e), exc_info=self._logger_traceback)
return False
return True
#sys.exit()
# ##### Encrypted #######
###########################Preprocessing###############
####################################################################################
####################################################################################
####################################################################################
####################################################################################
####################################################################################
####################################################################################
###################################Other Classes#####################################
####################################################################################
####################################################################################
####################################################################################
####################################################################################
#################################################################################### | zas-rep-tools | /zas-rep-tools-0.2.tar.gz/zas-rep-tools-0.2/zas_rep_tools/src/classes/TestsConfiger.py | TestsConfiger.py |
# ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
# : XXX{Information about this code}XXX
# Author:
# c(Developer) -> {'Egor Savin'}
# ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
###Programm Info######
#
#
#
#
#
from __future__ import absolute_import
import os
import copy
import sys
import logging
import inspect
import shutil
import traceback
#import shelve
import time
import json
from collections import defaultdict
from raven import Client
from cached_property import cached_property
import inspect
from consolemenu import *
from consolemenu.items import *
from validate_email import validate_email
import urllib2
import twitter
from nltk.tokenize import TweetTokenizer
from nose.tools import nottest
from zas_rep_tools_data.utils import path_to_data_folder, path_to_models, path_to_someweta_models, path_to_stop_words
from zas_rep_tools.src.utils.debugger import p
from zas_rep_tools.src.utils.helpers import set_class_mode, print_mode_name, MyZODB,transaction, path_to_zas_rep_tools, internet_on, make_zipfile, instance_info, SharedCounterExtern, SharedCounterIntern, Status, function_name,statusesTstring
import zas_rep_tools.src.utils.db_helper as db_helper
from zas_rep_tools.src.utils.error_tracking import initialisation
from zas_rep_tools.src.utils.traceback_helpers import print_exc_plus
#from zas_rep_tools.src.classes.exporter import Exporter
#from zas_rep_tools.src.classes.reader import Reader
#from zas_rep_tools.src.classes.dbhandler import DBHandler
#from zas_rep_tools.src.classes.corpus import Corpus
#from zas_rep_tools.src.classes.stats import Stats
#from zas_rep_tools.src.utils.zaslogger import ZASLogger
from zas_rep_tools.src.classes.basecontent import BaseContent
from zas_rep_tools.src.utils.configer_helpers import ConfigerData
class ToolConfiger(BaseContent,ConfigerData):
def __init__(self, rewrite=False,stop_if_db_already_exist = True,**kwargs):
super(type(self), self).__init__(**kwargs)
#p((self._mode,self._logger_save_logs), "self._logger_save_logs", c="b")
#Input: Encapsulation:
self._rewrite = rewrite
self._stop_if_db_already_exist = stop_if_db_already_exist
#InstanceAttributes: Initialization
self._path_to_zas_rep_tools = path_to_zas_rep_tools
self._path_to_user_config_data = os.path.join(self._path_to_zas_rep_tools, "user_config/user_data.fs")
self._path_to_zas_rep_tools_data = path_to_data_folder
self._path_to_zas_rep_tools_someweta_models = path_to_someweta_models
self._path_to_zas_rep_tools_stop_words = path_to_stop_words
self._user_data= self._get_user_config_db()
if not self._user_data:
self.logger.error("UserConfigData wasn't found or wasn't created. Execution was stopped!")
sys.exit()
#self._get_user_config_db()
# if not self._check_correctness_of_the_test_data():
# self.logger.error("TestDataCorruption: Please check test data.", exc_info=self._logger_traceback)
# sys.exit()
self.logger.debug('Intern InstanceAttributes was initialized')
self.logger.debug('An instance of {}() was created '.format(self.__class__.__name__))
## Log Settings of the Instance
attr_to_flag = ["_types_folder_names_of_testsets","_test_dbs", "_init_info_data", "_columns_in_doc_table", "_columns_in_info_tabel", "_columns_in_stats_tables", "_text_elements_collection"]
attr_to_len = False
self._log_settings(attr_to_flag =attr_to_flag,attr_to_len =attr_to_len)
############################################################
####################__init__end#############################
############################################################
def __del__(self):
super(type(self), self).__del__()
####################################################################################
####################################################################################
####################################################################################
####################################################################################
####################################################################################
####################################################################################
######################################Extern########################################
####################################################################################
####################################################################################
####################################################################################
####################################################################################
####################################################################################
# def row_text_elements(self, lang="all"):
# return copy.deepcopy(self._row_text_elements(lang=lang))
# def text_elements(self, token=True, unicode_str=True,lang="all"):
# return copy.deepcopy(self._text_elements(token=token, unicode_str=unicode_str, lang=lang))
# def docs_row_values(self,token=True, unicode_str=True, lang="all"):
# return copy.deepcopy(self._docs_row_values(token=token,unicode_str=unicode_str, lang=lang))
# def docs_row_dict(self, token=True, unicode_str=True, all_values=False, lang="all"):
# '''
# just one dict with colums as key and list of all values as values for each columns()key
# '''
# return copy.deepcopy(self._docs_row_dict(token=token, unicode_str=unicode_str, all_values=all_values, lang=lang))
# def docs_row_dicts(self, token=True, unicode_str=True, lang="all"):
# '''
# list of dicts with colums and values for each row
# '''
# return copy.deepcopy(self._docs_row_dicts(token=token, unicode_str=unicode_str, lang=lang))
###########################Config Values#######################
@cached_property
def path_to_zas_rep_tools(self):
return copy.deepcopy(self._path_to_zas_rep_tools)
@nottest
@cached_property
def path_to_tests(self):
#p(self._path_to_zas_rep_tools)
return os.path.join(self._path_to_zas_rep_tools, "tests/")
# @cached_property
# def path_to_testdbs(self):
# return copy.deepcopy(self._path_to_testdbs)
# @cached_property
# def test_dbs(self):
# return copy.deepcopy(self._test_dbs)
# @cached_property
# def init_info_data(self):
# return copy.deepcopy(self._init_info_data)
# @cached_property
# def columns_in_doc_table(self):
# return copy.deepcopy(self._columns_in_doc_table)
# @cached_property
# def columns_in_info_tabel(self):
# return copy.deepcopy(self._columns_in_info_tabel)
# @cached_property
# def columns_in_stats_tables(self):
# return copy.deepcopy(self._columns_in_stats_tables)
# @cached_property
# def path_to_testsets(self):
# return copy.deepcopy(self._path_to_testsets)
# @cached_property
# def types_folder_names_of_testsets(self):
# return copy.deepcopy(self._types_folder_names_of_testsets)
def clean_user_data(self):
if self._user_data.clean():
return True
else:
return False
def get_data_from_user(self, user_info_to_get=False, rewrite=False):
if not rewrite:
rewrite = self._rewrite
if user_info_to_get:
if isinstance(user_info_to_get, (unicode, str)):
user_info_to_get = [user_info_to_get]
else:
user_info_to_get = self._suported_user_info
for user_info_name in user_info_to_get:
if user_info_name not in self._suported_user_info:
self.logger.error("UserDataGetterError: '{}' - data not supported. ".format(user_info_name), exc_info=self._logger_traceback)
continue
if user_info_name == "error_tracking":
if rewrite:
self._cli_menu_error_agreement()
continue
if self._user_data["error_tracking"] is None:
self._cli_menu_error_agreement()
elif user_info_name == "project_folder":
if rewrite:
self._cli_menu_get_from_user_project_folder()
continue
if self._user_data["project_folder"] is None:
self._cli_menu_get_from_user_project_folder()
elif user_info_name == "twitter_creditials":
if rewrite:
self._cli_menu_get_from_user_twitter_credentials()
continue
if self._user_data["twitter_creditials"] is None:
self._cli_menu_get_from_user_twitter_credentials()
elif user_info_name == "email":
if rewrite:
self._cli_menu_get_from_user_emails()
continue
if self._user_data["email"] is None:
self._cli_menu_get_from_user_emails()
else:
self.logger.critical("Not supported user_data_getter ('{}').".format(user_info_name))
####################################################################################
####################################################################################
####################################################################################
####################################################################################
####################################################################################
####################################################################################
######################################INTERN########################################
####################################################################################
####################################################################################
####################################################################################
####################################################################################
####################################################################################
def _get_user_config_db(self):
#try:
try:
if not os.path.isdir(os.path.split(self._path_to_user_config_data)[0]):
self.logger.debug(" 'user_config' folder was created in '{}' ".format(os.path.split(self._path_to_user_config_data)[0]))
os.mkdir(os.path.split(self._path_to_user_config_data)[0])
db = MyZODB(self._path_to_user_config_data)
db["permission"] = True
db["twitter_creditials"] = None
db["email"] = None
db["project_folder"] = None
db["error_tracking"] = None
else:
db = MyZODB(self._path_to_user_config_data)
db["permission"] = True
return db
except Exception, e:
print_exc_plus() if self._ext_tb else ""
if "permission" in str(e).lower():
self.logger.error("UserConfigDBGetterError: Problem with permission. Probably solution. Please execute same command with 'sudo'-Prefix and enter your admin password. Exception: '{}'. ".format(e) ,exc_info=self._logger_traceback)
else:
self.logger.error("UserConfigDBGetterError: '{}'. ".format(e) ,exc_info=self._logger_traceback)
return False
def _cli_menu_get_from_user_project_folder(self):
getted_project_folder = False
def _get_input(args):
getted_input = input(args)
return str(getted_input)
# Create the menu
menu1 = SelectionMenu(["No", "Yes"],
title="Set Project Folder.",
#subtitle="(via Email)",
prologue_text="Every created database will be saved in the project folder. Before you can work with this tool you need to set up an Project Folder. Do you want to do it now? (if you want to use current directory as project folder just type an dot. exp: '.' )",
#epilogue_text="222"
)
menu1.show()
menu1.join()
selection1 = menu1.selected_option
#print selection1
if selection1 == 1:
status = True
while status:
prj_fldr = raw_input("Enter Project Folder: ")
if os.path.isdir(prj_fldr):
abs_path = os.path.abspath(prj_fldr)
getted_project_folder = abs_path
status = False
else:
self.logger.critical("DirValidation: Given project Folder is not exist. Please retype it. (or type 'Ctrl+D' or 'Ctrl+C' to interrupt this process.)")
#print
if getted_project_folder:
if getted_project_folder ==".":
getted_project_folder = os.getcwd()
self._user_data["project_folder"] = getted_project_folder
#else:
# self._user_data["email"] = False
# return
return getted_project_folder
def _cli_menu_get_from_user_emails(self):
getted_emails = []
# Create the menu
menu1 = SelectionMenu(["No", "Yes"],
title="User Notification.",
subtitle="(via Email)",
prologue_text="This package can send to the users some important information. For example some day statistics for Twitter-Streamer or if some error occurs. Do you want to use this possibility? (Your email adress will stay on you Computer and will not be send anywhere.)",
#epilogue_text="222"
)
menu1.show()
menu1.join()
selection1 = menu1.selected_option
#print selection1
if selection1 == 1:
# Part 1: Get number of emails
status = True
while status:
menu2 = ConsoleMenu(
title="Number of email addresses.",
#subtitle="(via Email)",
prologue_text="How much email addresses do you want to set?",
#epilogue_text="222"
)
one_email = SelectionItem("one", 0)
number_of_emails = FunctionItem("many", function=raw_input, args=["Enter a number: "], should_exit=True)
menu2.append_item(one_email)
menu2.append_item(number_of_emails)
menu2.show()
menu2.join()
getted_number = number_of_emails.return_value
selection2 = menu2.selected_option
#print selection2, getted_number
if selection2 == 0:
status = False
number = 1
else:
try:
if unicode(getted_number).isnumeric() or isinstance(getted_number, int):
number = int(getted_number)
status = False
else:
self.logger.error("InputErr: Given Object is not an integer. Please retype your input! (in 5 seconds...)", exc_info=self._logger_traceback)
time.sleep(3)
except Exception, e:
self.logger.critical("EmailNumberGetterError: '{}'. ".format(e))
## Part2 : Get Email
getted_emails = []
i=0
while i < number:
email = str(raw_input("(#{} from {}) Enter Email: ".format(i+1, number)))
is_valid = validate_email(email)
if is_valid:
getted_emails.append(email)
i+= 1
else:
self.logger.warning( "EmailValidationError: Given Email is not valid. Please retype it.")
else:
self._user_data["email"] = False
return
self._user_data["email"] = getted_emails
return getted_emails
def _cli_menu_error_agreement(self):
menu = SelectionMenu(["No", "Yes"],
title="Error-Tracking Agreement.",
#subtitle="(agreement)",
prologue_text="This package use a nice possibility of the online error tracking.\n It means, if you will get an error than the developers could get an notice about it in the real time. Are you agree to send information about errors directly to developers?",
#epilogue_text="222"
)
menu.show()
selection = menu.selected_option
self._user_data["error_tracking"] = False if selection==0 else True
return selection
def _cli_menu_get_from_user_twitter_credentials(self):
if not internet_on():
self.logger.critical("InternetConnectionError: No Internet connection was found. Please check your connection to Internet and repeat this step. (Internet Connection is needed to validate your Twitter Credentials.)")
sys.exit()
#return []
getted_credentials = []
def _get_input(args):
getted_input = input(args)
return str(getted_input)
# Create the menu
menu1 = SelectionMenu(["No", "Yes"],
title="Twitter API Credentials.",
#subtitle="",
prologue_text="If you want to stream Twitter via official Twitter API than you need to enter your account Credentials. To get more information about it - please consult a README File of this package (https://github.com/savin-berlin/zas-rep-tools). Under 'Start to use streamer' you can see how you can exactly get this data. Do you want to enter this data now?",
#epilogue_text="222"
)
menu1.show()
menu1.join()
selection1 = menu1.selected_option
#print selection1
if selection1 == 1:
# Part 1: Get number of emails
status = True
while status:
menu2 = ConsoleMenu(
title="Number of twitter accounts.",
#subtitle="(via Email)",
prologue_text="How much twitter accounts do you want to set up?",
#epilogue_text="222"
)
one_email = SelectionItem("one", 0)
number_of_emails = FunctionItem("many", function=raw_input, args=["Enter a number: "], should_exit=True)
menu2.append_item(one_email)
menu2.append_item(number_of_emails)
menu2.show()
menu2.join()
getted_number = number_of_emails.return_value
selection2 = menu2.selected_option
#print selection2, getted_number
if selection2 == 0:
status = False
number = 1
else:
try:
if unicode(getted_number).isnumeric() or isinstance(getted_number, int):
number = int(getted_number)
status = False
else:
self.logger.error("InputErr: Given Object is not an integer. Please retype your input! (in 5 seconds...)", exc_info=self._logger_traceback)
#print "InputErr: Given Object is not an integer. Please retype your input! (in 5 seconds...)"
time.sleep(3)
except Exception, e:
self.logger.error("EmailNumberGetterError: '{}'. ".format(e), exc_info=self._logger_traceback)
## Part2 : Get Email
i=0
while i < number:
print "\n\n(#{} from {}) Enter Twitter Credentials: ".format(i+1, number)
consumer_key = raw_input("Enter consumer_key: ")
consumer_secret = raw_input("Enter consumer_secret: ")
access_token = raw_input("Enter access_token: ")
access_token_secret = raw_input("Enter access_token_secret: ")
if internet_on():
api = twitter.Api(consumer_key=consumer_key,
consumer_secret=consumer_secret,
access_token_key=access_token,
access_token_secret=access_token_secret)
try:
if api.VerifyCredentials():
getted_credentials.append({"consumer_key":consumer_key,
"consumer_secret":consumer_secret,
"access_token":access_token,
"access_token_secret":access_token_secret
})
i +=1
else:
print "InvalidCredential: Please retype them."
except Exception, e:
if "Invalid or expired token" in str(e):
self.logger.critical("InvalidCredential: Please retype them.")
elif "Failed to establish a new connection" in str(e):
self.logger.critical("InternetConnectionFailed: '{}' ".format(e))
else:
self.logger.critical("TwitterCredentialsCheckerError: '{}' ".format(e))
else:
self.logger.critical("InternetConnectionError: No Internet connection was found. Please check your connection to Internet and repeat this step. (Internet Connection is needed to validate your Twitter Credentials.)")
sys.exit()
else:
self._user_data["twitter_creditials"] = False
return
self._user_data["twitter_creditials"] = getted_credentials
return getted_credentials
def _check_correctness_of_the_test_data(self):
## Check mapping of columns and values
try:
for template, data_columns in self._columns_in_doc_table.iteritems():
for data_values in self.docs_row_values(token=True, unicode_str=True)[template]:
#p((len(data_columns), len(data_values)))
if len(data_columns) != len(data_values):
self.logger.error("TestDataCorruption: Not same number of columns and values.", exc_info=self._logger_traceback)
return False
except Exception, e:
#p([(k,v) for k,v in self._columns_in_doc_table.iteritems()])
#p(self.docs_row_values(token=True, unicode_str=True))
self.logger.error("TestDataCorruption: Test Data in Configer is inconsistent. Probably - Not same template_names in columns and rows. See Exception: '{}'. ".format(e), exc_info=self._logger_traceback)
return False
return True
#sys.exit()
# ##### Encrypted #######
###########################Preprocessing###############
####################################################################################
####################################################################################
####################################################################################
####################################################################################
####################################################################################
####################################################################################
###################################Other Classes#####################################
####################################################################################
####################################################################################
####################################################################################
####################################################################################
#################################################################################### | zas-rep-tools | /zas-rep-tools-0.2.tar.gz/zas-rep-tools-0.2/zas_rep_tools/src/classes/ToolConfiger.py | ToolConfiger.py |
# ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
# : XXX{Information about this code}XXX
# Author:
# c(Developer) -> {'Egor Savin'}
# ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
###Programm Info######
#
#
#
#
#
from __future__ import division
from __future__ import absolute_import
import os
import copy
import sys
import regex
import logging
import codecs
import json
import csv
import unicodecsv as unicodecsv
from lxml import etree as ET
import psutil
import zipfile
import cStringIO
import json
import StringIO
#zipfile.ZipExtFile
from collections import defaultdict
from raven import Client
#from cached_property import cached_property
from encodings.aliases import aliases
from decimal import Decimal, ROUND_HALF_UP, ROUND_UP, ROUND_HALF_DOWN, ROUND_DOWN
#from zas_rep_tools.src.utils.db_helper import *
#from zas_rep_tools.src.classes.configer import Configer
from zas_rep_tools.src.utils.helpers import set_class_mode, print_mode_name, LenGen, path_to_zas_rep_tools, get_number_of_streams_adjust_cpu, instance_info, SharedCounterExtern, SharedCounterIntern, Status, function_name,statusesTstring
#from zas_rep_tools.src.utils.logger import *
from zas_rep_tools.src.utils.zaslogger import ZASLogger
from zas_rep_tools.src.utils.debugger import p
from zas_rep_tools.src.utils.error_tracking import initialisation
from zas_rep_tools.src.utils.helpers import get_file_list
from zas_rep_tools.src.utils.traceback_helpers import print_exc_plus
from zas_rep_tools.src.classes.basecontent import BaseContent
import platform
if platform.uname()[0].lower() !="windows":
import colored_traceback
colored_traceback.add_hook()
else:
import colorama
csv.field_size_limit(sys.maxsize)
class Reader(BaseContent):
#supported_encodings_types = ["utf-8"]
supported_encodings_types = set(aliases.values())
supported_encodings_types.add("utf-8")
supported_file_types = ["txt", "json", "xml", "csv"]
supported_file_types_to_export = ["sqlite", "json", "xml", "csv"]
regex_templates = {
"blogger":r"(?P<id>[\d]*)\.(?P<gender>[\w]*)\.(?P<age>\d*)\.(?P<working_area>.*)\.(?P<star_constellation>[\w]*)",
}
reader_supported_formatter = {
"json":["TwitterStreamAPI".lower()],
"csv":["Sifter".lower()],
}
def __init__(self, inp_path, file_format, regex_template=False,
regex_for_fname=False, read_from_zip=False,
end_file_marker = -1, send_end_file_marker=False,
formatter_name=False, text_field_name = "text", id_field_name="id",
ignore_retweets=True,stop_process_if_possible=True,
**kwargs):
#p(read_from_zip, "read_from_zip")
super(type(self), self).__init__(**kwargs)
#super(BaseContent, self).__init__(**kwargs)
#p((regex_for_fname , regex_template))
#Input: Encapsulation:
self._inp_path = inp_path
self._file_format = file_format.lower()
#self._columns_source = columns_source
self._regex_for_fname = regex_for_fname
self._regex_template =regex_template
#p((self._regex_for_fname,self._regex_template))
self._formatter_name = formatter_name.lower() if formatter_name else formatter_name
self._text_field_name = text_field_name
self._id_field_name = id_field_name
self._ignore_retweets = ignore_retweets
self._read_from_zip = read_from_zip
self._end_file_marker = end_file_marker
self._send_end_file_marker = send_end_file_marker
self._stop_process_if_possible = stop_process_if_possible
#InstanceAttributes: Initialization
self._created_streams = 0
self._stream_done = 0
self.xmlroottag = False
self.xmlchildetag = False
self.retweet_counter = SharedCounterIntern()
self.files_to_read_orig = []
self.files_to_read_leftover = None
self.files_at_all_was_found = 0
self.zips_to_read = []
self.files_from_zips_to_read_orig = defaultdict(list)
self.files_from_zips_to_read_left_over = None
self.files_number_in_zips = 0
self.counter_lazy_getted = 0
self.logger.debug('Intern InstanceAttributes was initialized')
## Validation
if not self._validate_given_file_format():
sys.exit()
if self._end_file_marker == -10:
self.logger.error("Illegal value of the 'end_file_marker'. Please use another one.")
#return False
sys.exit()
if not self._validation_given_path():
sys.exit()
if not self._validation_regex_treatment():
sys.exit()
self.logger.low_debug('Input was validated')
# Extract Files from the given File Structure
#p(self._inp_path)
self._extract_all_files_according_given_file_format()
self.logger.debug('An instance of Reader() was created ')
#self.inp_obj = StringIO.StringIO()
#self.inp_obj.write('{"id":123456}')
## Log Settings of the Instance
attr_to_flag = ["files_from_zips_to_read_orig", "files_from_zips_to_read_left_over", ]
attr_to_len = ["files_to_read_orig", "files_to_read_leftover", "zips_to_read", ]
self._log_settings(attr_to_flag =attr_to_flag,attr_to_len =attr_to_len)
############################################################
####################__init__end#############################
############################################################
def __del__(self):
super(type(self), self).__del__()
####################################################################################
####################################################################################
####################################################################################
####################################################################################
####################################################################################
####################################################################################
######################################Extern########################################
####################################################################################
####################################################################################
####################################################################################
####################################################################################
####################################################################################
###########################+++++++++############################
def _generator_helper(self, inp_obj, colnames=False, encoding="utf-8", csvdelimiter=',',f_name=False ):
#try:
#output.write('{"id":123456}')
if self._file_format == "txt":
row = self._readTXT(inp_obj, encoding=encoding, columns_extract_from_fname=True, colnames=colnames)
yield row
if self._send_end_file_marker:
yield self._end_file_marker
elif self._file_format == "json":
for row in self._readJSON(inp_obj, encoding=encoding, colnames=colnames,):
if row == -10:
yield -10
self.logger.error("ReaderError: Probably Invalid InputData. Please check logs for more information.")
return
yield row
if self._send_end_file_marker:
yield self._end_file_marker
elif self._file_format == "xml":
for row in self._readXML(inp_obj, encoding=encoding, colnames=colnames):
if row == -10:
yield -10
self.logger.error("ReaderError: Probably Invalid InputData. Please check logs for more information.")
return
yield row
if self._send_end_file_marker:
yield self._end_file_marker
elif self._file_format == "csv":
for row in self._readCSV(inp_obj, encoding=encoding, colnames=colnames, delimiter=csvdelimiter,f_name=f_name):
if row == -10:
self.logger.error("ReaderError: Probably Invalid InputData. Please check logs for more information.")
yield -10
return
yield row
if self._send_end_file_marker:
yield self._end_file_marker
else:
self.logger.error("'{}'-Format not supported.".format(self._file_format), exc_info=self._logger_traceback)
yield False
return
def getgenerator(self, colnames=False, encoding="utf-8", csvdelimiter=',', input_path_list=False, input_zip_file_list = False):
if not input_path_list and not input_zip_file_list:
self.logger.warning("Given Generator is empty.")
yield False
if input_path_list:
for path_to_file in input_path_list:
for row in self._generator_helper(path_to_file, colnames=colnames, encoding=encoding, csvdelimiter=csvdelimiter):
if row == -10:
yield {}
return
yield row
if self._read_from_zip:
if input_zip_file_list:
for path_to_zip, list_with_path_to_files in input_zip_file_list.iteritems():
archive = zipfile.ZipFile(path_to_zip, 'r')
for path_to_file in list_with_path_to_files:
f = archive.open(path_to_file)
for row in self._generator_helper(f, colnames=colnames, encoding=encoding, csvdelimiter=csvdelimiter, f_name=f.name):
if row == -10:
yield {}
return
yield row
self._stream_done += 1
self._print_once_ignore_retweets_counter()
def getlazy(self,colnames=False, encoding="utf-8", csvdelimiter=',', stream_number=1, adjust_to_cpu=True, min_files_pro_stream=1000, restart=True, cpu_percent_to_get=50):
self._stream_done = 0
self.retweet_counter.clear()
wish_stream_number = stream_number
if self.counter_lazy_getted>0 and restart:
self.files_from_zips_to_read_left_over = copy.deepcopy(self.files_from_zips_to_read_orig)
self.files_to_read_leftover = copy.deepcopy(self.files_to_read_orig)
self.counter_lazy_getted +=1
if stream_number <1:
stream_number = 10000
adjust_to_cpu = True
self.logger.debug("StreamNumber is less as 1. Automatic computing of strem number according cpu was enabled.")
#p(stream_number, "stream_number")
if self._get_number_of_left_over_files() == 0:
self.logger.error("No one file was found in the given path ('{}'). Please check the correctness of the given path or give other (correct one) path to the text data.".format(self._inp_path))
return []
if adjust_to_cpu:
stream_number= get_number_of_streams_adjust_cpu( min_files_pro_stream, self._get_number_of_left_over_files(), stream_number, cpu_percent_to_get=cpu_percent_to_get)
if stream_number is None:
#p((self._get_number_of_left_over_files(),self.counter_lazy_getted),"self._get_number_of_left_over_files()")
self.logger.error("Number of input files is 0. Not generators could be returned.", exc_info=self._logger_traceback)
return []
#p(stream_number, "stream_number")
if stream_number > self._get_number_of_left_over_files():
self.logger.error("StreamNumber is higher as number of the files to read. This is not allowed.", exc_info=self._logger_traceback)
return False
list_with_generators = []
number_of_files_per_stream = int(Decimal(float(self._get_number_of_left_over_files()/stream_number)).quantize(Decimal('1.'), rounding=ROUND_DOWN))
#p((stream_number, number_of_files_per_stream), c="m")
#self.files_from_zips_to_read_orig
for i in range(stream_number):
if i < (stream_number-1): # for gens in between
files_to_read_non_zip, files_from_zips_to_read_orig = self._get_files_for_stream(number_of_files_per_stream)
else: # for the last generator
files_to_read_non_zip, files_from_zips_to_read_orig = self._get_files_for_stream(-1)
input_path_list= files_to_read_non_zip if files_to_read_non_zip else False
input_zip_file_list = files_from_zips_to_read_orig if files_from_zips_to_read_orig else False
gen = self._getlazy_single(input_path_list=input_path_list, input_zip_file_list=input_zip_file_list,colnames= colnames, encoding=encoding, csvdelimiter=csvdelimiter)
if stream_number == 1:
#p(wish_stream_number)
if wish_stream_number > 1:
return [gen]
else:
return gen
list_with_generators.append(gen)
self._created_streams = stream_number
self.logger.info(" '{}'-streams was created. (adjust_to_cpu='{}')".format(stream_number, adjust_to_cpu))
return list_with_generators
def _print_once_ignore_retweets_counter(self):
if int(self.retweet_counter) > 0:
if self._stream_done >= self._created_streams:
self.logger.info("'{}'-retweets in total was ignored.".format(int(self.retweet_counter)))
def _get_number_of_left_over_files(self):
#p(len(self.files_to_read_leftover), c="m")
#p(sum([len(v) for v in self.files_from_zips_to_read_left_over.values() ]), c="m")
return len(self.files_to_read_leftover) + sum([len(v) for v in self.files_from_zips_to_read_left_over.values() ])
def _get_files_for_stream(self,number_to_get):
number_files_leftover = self._get_number_of_left_over_files()
if number_to_get == -1:
number_to_get = number_files_leftover
if not (number_to_get <= number_files_leftover):
self.logger.error("Given Number '{}' is higher than number of leftover '{}' files to get.".format(number_to_get, number_files_leftover), exc_info=self._logger_traceback)
return False, False
files_to_read_non_zip = []
files_from_zips_to_read_orig = defaultdict(list)
getted_number = 0
while getted_number< number_to_get:
try:
files_to_read_non_zip.append(self.files_to_read_leftover.pop())
getted_number += 1
except IndexError:
try:
for k in self.files_from_zips_to_read_left_over.keys():
#if len(l[k]) != 0:
files_from_zips_to_read_orig[k].append( self.files_from_zips_to_read_left_over[k].pop() )
getted_number += 1
break
except IndexError:
del self.files_from_zips_to_read_left_over[k]
return files_to_read_non_zip, files_from_zips_to_read_orig
def _getlazy_single(self,colnames=False, encoding="utf-8", csvdelimiter=',', input_path_list=False, input_zip_file_list=False):
len_unzipped_files = len(input_path_list) if input_path_list else 0
len_zipped_files = sum([len(v) for v in input_zip_file_list.values() ]) if input_zip_file_list else 0
length = len_unzipped_files + len_zipped_files
gen = self.getgenerator(colnames=colnames, encoding=encoding, csvdelimiter=csvdelimiter, input_path_list=input_path_list, input_zip_file_list=input_zip_file_list)
#p(type(gen))
return LenGen(gen, length)
##################################################################################
####################################################################################
####################################################################################
####################################################################################
####################################################################################
####################################################################################
######################################INTERN########################################
####################################################################################
####################################################################################
####################################################################################
####################################################################################
####################################################################################
def _get_col_and_values_from_fname(self, fname, compiled_regex_for_fname):
try:
col_and_values_dicts = {}
try:
for m in compiled_regex_for_fname.finditer(fname):
for k,v in m.groupdict().iteritems():
if v.isdigit():
col_and_values_dicts[unicode(k)]= int(v)
elif isinstance(v, (int, float)):
col_and_values_dicts[unicode(k)]= v
else:
col_and_values_dicts[unicode(k)]= unicode(v)
#p(col_and_values_dicts)
#col_and_values_dicts = [{unicode(k): unicode(v) for k,v in m.groupdict().iteritems()} for m in compiled_regex_for_fname.finditer(fname)]
except Exception, e:
print_exc_plus() if self._ext_tb else ""
self.logger.error("RegexError: RegexDictExtractor throw following Error: '{}'. ".format(e), exc_info=self._logger_traceback)
return False
#col_and_values_dicts = [m.groupdict() for m in compiled_regex_for_fname.finditer(fname)]
#p(col_and_values_dicts)
if len(col_and_values_dicts)==0:
self.logger.critical("ColumnsExctractionFromFileNameError: Some of the columns in the given Fname '{}' wasn't detected. Following RegEx-Expression was used: '{}'. ".format(fname,self._regex_for_fname))
return False
return col_and_values_dicts
except Exception as exception:
print_exc_plus() if self._ext_tb else ""
self.logger.critical("ColumnsExctractionFromFileNameError: Following Error was raised: '{}'. ".format(repr(exception)))
return False
def _validation_regex_treatment(self):
if self._regex_template and self._regex_for_fname:
self.logger.error("InputValidationError: Template for Regex and Regex_for_Fname was given parallel. Please give just one of them.", exc_info=self._logger_traceback)
return False
if self._file_format == "txt":
if not self._regex_template and not self._regex_for_fname:
self.logger.error("InputValidationError: Template_for_Regex or Regex_for_Fname wasn't given. Please give one of them.", exc_info=self._logger_traceback)
return False
if self._regex_template and ( self._regex_template.lower() not in Reader.regex_templates):
self.logger.error("InputValidationError: Given RegexTemplateName '{}' is not supporting! ".format(self._regex_template.lower()), exc_info=self._logger_traceback)
return False
if self._regex_for_fname and not isinstance(self._regex_for_fname, (str, unicode)):
self.logger.error("InputValidationError: RegexForFname should be an str or unicode object. Given: '{}'.".format(self._regex_for_fname), exc_info=self._logger_traceback)
return False
if self._regex_template and not self._regex_for_fname:
try:
self._regex_for_fname = Reader.regex_templates[self._regex_template]
### set given id_field_name
self._regex_for_fname = self._regex_for_fname.replace("id", self._id_field_name)
self._compiled_regex_for_fname = regex.compile(self._regex_for_fname, regex.UNICODE)
except Exception, e:
print_exc_plus() if self._ext_tb else ""
self.logger.error("InputValidationError: Given RegEx-Template '{}' is not exist or it wasn't possible to compile it. Check this Exception: '{}'. ".format(self._regex_template, e), exc_info=self._logger_traceback)
return False
elif not self._regex_template and self._regex_for_fname:
try:
self._compiled_regex_for_fname = regex.compile(self._regex_for_fname, regex.UNICODE)
except Exception, e:
print_exc_plus() if self._ext_tb else ""
self.logger.error("InputValidationError: Given RegEx-Template '{}' is not exist or it wasn't possible to compile it. Check this Exception: '{}'.".format(self._regex_template, e), exc_info=self._logger_traceback)
return False
return True
# def _extract_colnames_from_regex(self, regex_for_fname):
# p(repr(regex_for_fname), c="m")
# columns_name = regex.findall(regex_for_fname, fname.strip())
# p(columns_name, c="r")
# if not isinstance(columns_name, list) or len(columns_name)==0 or len(columns_name[0])<5:
# self.logger.critical("ColumnsExctractionFromFileNameError: Some of the columns in the given Fname '{}' wasn't detected. Following RegEx-Expression was used: '{}'. ".format(fname,regex_for_fname))
# return False
# return columns_name
def _get_data_from_dic_for_given_keys(self, colnames_to_extract, given_row_data ):
if isinstance(colnames_to_extract, list):
outputdict = {}
if given_row_data:
for col in colnames_to_extract:
if col in given_row_data:
outputdict[col] =given_row_data[col]
#p(outputdict)
else:
self.logger.critical("ColumnsGetter: '{}'-Column wasn't found in the given Structure and was ignored.".format(col))
return outputdict
else:
self.logger.error("ColumnsGetterError: Given 'colnames_to_extract' are not from type 'list' ", exc_info=self._logger_traceback)
return {}
def _readTXT(self, inp_object,encoding="utf-8", columns_extract_from_fname=True, colnames=False, string_was_given=False):
try:
if isinstance(inp_object, (unicode,str)):
if not os.path.isfile(inp_object):
self.logger.error("TXTFileNotExistError: Following File wasn't found: '{}'. ".format(inp_object), exc_info=self._logger_traceback)
return False
else:
f = open(inp_object, "r")
as_file_handler = False
else:
f = inp_object
as_file_handler = True
#data = json.load(f)
if columns_extract_from_fname:
#file = open(inp_object, "r")
#f = codecs.open(inp_object, "r", encoding=encoding)
fname = os.path.splitext(os.path.basename(f.name))
output_data = self._get_col_and_values_from_fname(fname[0],self._compiled_regex_for_fname)
#p(output_data)
if not output_data or not isinstance(output_data, dict):
self.logger.critical("ReadTXTError: '{}' wasn't readed.".format(fname))
return {}
file_data = f.read().decode(encoding)
output_data.update({self._text_field_name:file_data})
try:
f.close()
del f
except:
pass
if colnames:
return self._get_data_from_dic_for_given_keys(colnames, output_data)
else:
return output_data
else:
self.logger.error("ReadTXTError: Other sources of Columns as from FName are not implemented!", exc_info=self._logger_traceback)
return False
except Exception, e:
print_exc_plus() if self._ext_tb else ""
self.logger.error("TXTReaderError: Following Exception was throw: '{}'. ".format(e), exc_info=self._logger_traceback)
return False
#return
def _readCSV(self, inp_object,encoding="utf_8", delimiter=',', colnames=False, string_was_given=False,f_name=False):
try:
if isinstance(inp_object, (unicode,str)):
if not os.path.isfile(inp_object):
self.logger.error("CSVFileNotExistError: Following File wasn't found: '{}'. ".format(inp_object), exc_info=self._logger_traceback)
yield False
return
else:
f = open(inp_object, "r")
as_file_handler = False
f_name = f_name if f_name else f.name
else:
f = inp_object
try:
f_name = f_name if f_name else f.name
except:
f_name = None
as_file_handler = True
delimiter = str(delimiter)
readCSV = unicodecsv.DictReader(f, delimiter=delimiter, encoding=encoding)
if self._formatter_name == "sifter":
#readCSV.fieldnames = [col.lower() for col in readCSV.fieldnames]
#p(readCSV.fieldnames, "readCSV.fieldnames")
fieldnames = readCSV.fieldnames if readCSV.fieldnames else readCSV.unicode_fieldnames
cleaned = [col.lower().replace("[m]", " ").strip().strip(":").strip("_") for col in fieldnames]
readCSV.unicode_fieldnames = cleaned
#readCSV.renew_fieldnames()
#sys.exit()
#p(dict(readCSV), "readCSV")
to_check = True
for row_dict in readCSV:
if self._formatter_name:
if self._formatter_name in Reader.reader_supported_formatter["csv"]:
#readCSV.fieldnames = [col.lower() for col in readCSV.fieldnames]
#p(readCSV.fieldnames, "readCSV.fieldnames")
#fieldnames = readCSV.fieldnames if readCSV.fieldnames else readCSV.unicode_fieldnames
#cleaned = [col.lower().replace("[m]", " ").strip().strip(":").strip("_") for col in fieldnames]
#readCSV.unicode_fieldnames = cleaned
row_dict = self._csv_sifter_formatter(row_dict,f_name=f_name)
if row_dict == -10:
yield -10
return
else:
self.logger.critical("CSVReaderError: Given '{}'-FormatterName is invalid for CSVFiles. Please choice one of the following: '{}'. Execution of the Program was stopped. (fname: '{}')".format(self._formatter_name, Reader.reader_supported_formatter["csv"], f_name))
yield -10
return
try:
if to_check:
to_check = False
if None in row_dict.keys():
#raise Exception
self.logger.error("CSVReaderError: The structure of the given File is invalid. Probably wrong 'csvdelimiter' was given. Please try other one. (given csvdelimiter: '{}') (fname: '{}') ".format(delimiter,f_name))
yield -10
return
if len(row_dict) <=2 or row_dict.keys()<=2:
self.logger.critical("CSVReaderError: Probably the structure of the given File is wrong or File contain just few items. Probably wrong 'csvdelimiter' was given. Please check the correctness of the given CSV File and give right csvdelimiter. (given csvdelimiter: '{}') (fname: '{}') ".format(delimiter, f_name))
except AttributeError as e:
self.logger.error("Returned Row is not an Dict. Probably Wrongs Structure of the current CSVFileName: '{}'".format(f_name), exc_info=self._logger_traceback)
yield -10
return
#p(row_dict, "row_dict")
if row_dict:
if (self._text_field_name not in row_dict) or (self._id_field_name not in row_dict):
if not self._log_content:
keys = ":HidedContent:"
else:
keys = row_dict.keys()
#p(self._formatter_name, "self._formatter_name")
if self._formatter_name:
self.logger.error("CSVReader: Given CSV '{}' has wrong structure. Text or Id element wasn't found.\n Reasons:\n 1) Probably wrong 'text_field_name' and 'id_field_name' was given. (text_field_name: '{}'; id_field_name: '{}'); If this tags are wrong please use options and set right tags name.\n\n Following columns was found: '{}'.".format(f.name,self._text_field_name,self._id_field_name, keys ))
else:
self.logger.error("CSVReader: Given CSV '{}' has wrong structure. Text or Id element wasn't found.\n Reasons:\n 1) Probably wrong 'text_field_name' and 'id_field_name' was given. (text_field_name: '{}'; id_field_name: '{}'); If this tags are wrong please use options and set right tags name.\n 2) 'formatter_name'-Option wasn't given. If this CSV has contain Tweets, which comes from Sifter/TextDiscovery-Services than please set 'sifter' to 'formatter_name'-Option. \n\n Following columns was found: '{}'.".format(f.name,self._text_field_name,self._id_field_name, keys ))
#self.logger.error()
yield -10
return
if colnames:
yield self._get_data_from_dic_for_given_keys(colnames, row_dict)
else:
yield row_dict
try:
f.close()
del f
except:
pass
except Exception, e:
print_exc_plus() if self._ext_tb else ""
self.logger.error("CSVReaderError: Following Exception was throw: '{}'. For following File: '{}'.".format(e, f_name), exc_info=self._logger_traceback)
yield False
return
def _csv_sifter_formatter(self, dict_row,f_name=False):
#self.logger.info(repr(dict_row))
try:
### Step 1: Variables Initialization
is_extended = None
is_retweet = None
is_answer = None
t_id = dict_row["twitter_id"]
t_created_at = dict_row["posted_time"]
t_language = dict_row["language"]
t_used_client = dict_row["source"]
t_text = dict_row["text"]
u_created_at = None
u_description = dict_row["user_bio_summary"]
u_favourites = dict_row["favorites_count"]
u_followers = dict_row["followers_count"]
u_friends = dict_row["friends_count"]
u_id = dict_row["user_id"].split(":")[-1]
u_lang = dict_row["actor_languages"]
u_given_name = dict_row["real_name"]
u_username = dict_row["username"]
u_verified = dict_row["user_is_verified"]
u_location = dict_row["user_location"]
try:
t_id = int(t_id)
u_id = int(u_id)
except:
self.logger.error("CSVIDConverter: It wasn't possible to convert IDs into integer. Probably illegal CSV Structure.")
return -10
### Initialization fron new Tweet-Dict
new_structure = {}
## main paarameters
new_structure[self._id_field_name] = t_id
new_structure["t_created_at"] = t_created_at if t_created_at else None
new_structure["t_language"] = t_language
new_structure["t_used_client"] = t_used_client
new_structure[self._text_field_name] = t_text
new_structure["u_created_at"] = u_created_at
new_structure["u_description"] = u_description if u_description else None
new_structure["u_favourites"] = u_favourites
new_structure["u_followers"] = u_followers
new_structure["u_friends"] = u_friends
new_structure["u_id"] = u_id
new_structure["u_lang"] = u_lang
new_structure["u_given_name"] = u_given_name
new_structure["u_username"] = u_username
new_structure["u_verified"] = u_verified
new_structure["u_location"] = u_location if u_location else None
# additional parameters
new_structure["is_extended"] = is_extended
new_structure["is_retweet"] = is_retweet
new_structure["is_answer"] = is_answer
return new_structure
except KeyError as e:
if not self._log_content:
#data = data
dict_row = ":HidedContent:"
self.logger.error("CSVReaderKeyError: Current CsvFile was ignored '{}', probably because it is not valid/original SifterCSVFile. Or the wrong delimiter was given. See Exception: '{}'.\n ContentOfTheCsvElement: '{}' ".format(f_name, repr(e), dict_row), exc_info=self._logger_traceback)
#p(dict_row.items(), "dict_row")
#sys.exit()
return -10
except Exception as e:
#p(dict_row.items(), "dict_row")
if not self._log_content:
dict_row = ":HidedContent:"
self.logger.error_insertion("CSVReaderError: For current File '{}' following Exception was throw: '{}'. DataContent: '{}' ".format(f_name, repr(e), dict_row), exc_info=self._logger_traceback)
#p(dict_row.items(), "dict_row")
#sys.exit()
return -10
def _readXML(self, inp_object,encoding="utf_8", colnames=False, string_was_given=False):
try:
if isinstance(inp_object, (unicode,str)):
if not os.path.isfile(inp_object):
self.logger.error("XMLFileNotExistError: Following File wasn't found: '{}'. ".format(inp_object), exc_info=self._logger_traceback)
yield False
return
else:
f = open(inp_object, "r")
as_file_handler = False
else:
f = inp_object
as_file_handler = True
tree = ET.parse(inp_object)
root = tree.getroot()
self.xmlroottag = root.tag
#root.attrib
for child in root:
row_dict = {}
if not self.xmlchildetag:
self.xmlchildetag = child.tag
if self.xmlchildetag != child.tag:
self.logger.critical("XMLReaderError: Child Tags in the the XML-root are different and was ignored. ('{}'!='{}')".format(self.xmlchildetag, child.tag))
break
# collect all columns into dict from the current child
for column in child:
row_dict[column.tag] = column.text
if row_dict:
if (self._text_field_name not in row_dict) or self._id_field_name not in row_dict:
self.logger.outsorted_reader("XMLReader: Given XML '{}' has wrong structure. Not one text or id element was found.".format(f.name))
yield -10
return
if colnames:
yield self._get_data_from_dic_for_given_keys(colnames, row_dict)
else:
yield row_dict
try:
f.close()
del f
except:
pass
except Exception, e:
print_exc_plus() if self._ext_tb else ""
self.logger.error("XMLReaderError: Following Exception was throw: '{}'. For following File: '{}'.".format(e, f.name), exc_info=self._logger_traceback)
yield False
return
def _json_tweets_preprocessing(self, data,f_name=False):
try:
if isinstance(data, dict):
data = [data]
output_json_list = []
if isinstance(data, (list, tuple)):
for json in data:
#p(json.keys())
output_json_list.append(self._clean_json_tweet(json))
return output_json_list
else:
self.logger.critical("JsonTweetsPreparationError: Given '{}'-JSON-Type is from not right type.".format(type(data)))
return {}
#return
except KeyError as e:
if not self._log_content:
#data = data
json = ":HidedContent:"
self.logger.outsorted_reader("JSONReaderKeyError: Current JsonFile was ignored '{}', probably because it is not valid/original TwitterJSONFile. See Exception: '{}'. ContentOfTheJsonElement: '{}' ".format(f_name, repr(e), json), exc_info=self._logger_traceback)
return {}
except Exception as e:
if self._log_content:
data = data
else:
data = ":HidedContent:"
self.logger.error_insertion("JSONReaderError: For current File '{}' following Exception was throw: '{}'. DataContent: '{}' ".format(f_name, repr(e), data), exc_info=self._logger_traceback)
return {}
def _clean_json_tweet(self, json_tweet):
#self.logger.info(repr(json_tweet))
#sys.exit()
### Step 1: Variables Initialization
is_extended = False
is_retweet = False
is_answer = False
t_id = json_tweet["id"]
t_created_at = json_tweet["created_at"]
t_language = json_tweet["lang"]
t_used_client = json_tweet["source"]
t_text = json_tweet["text"]
u_created_at = json_tweet["user"]["created_at"]
u_description = json_tweet["user"]["description"]
u_favourites = json_tweet["user"]["favourites_count"]
u_followers = json_tweet["user"]["followers_count"]
u_friends = json_tweet["user"]["friends_count"]
u_id = json_tweet["user"]["id"]
u_lang = json_tweet["user"]["lang"]
u_given_name = json_tweet["user"]["name"]
u_username = json_tweet["user"]["screen_name"]
u_verified = json_tweet["user"]["verified"]
u_location = json_tweet["user"]["location"]
### Initialization fron new Tweet-Dict
new_structure = {}
# Step 2: Extraction of the additional Information
# "extended_tweet"."full_text" ( 280>len(text)>140)
if "extended_tweet" in json_tweet:
t_text = json_tweet["extended_tweet"]["full_text"]
#p(json_tweet["extended_tweet"])
is_extended = True
if "retweeted_status" in json_tweet:
#p(json_tweet)
#p(json_tweet["retweeted_status"])
is_retweet = True
if self._ignore_retweets:
self.retweet_counter.incr()
self.logger.outsorted_reader("RetweetIgnoring: Retweet with ID:'{}' was ignored. ".format(json_tweet["id"]))
#self.logger.warning("RetweenIgnoring: Current RETweet with ID='{}' was ignored. (for allowing retweets please use 'ignore_retweets' option.)".format(json_tweet["id"]))
return {}
if "quoted_status" in json_tweet:
#p(json_tweet)
#p(json_tweet["quoted_status"])
is_answer = True
# Step 3: Write into new Object
## main paarameters
new_structure[self._id_field_name] = t_id
new_structure["t_created_at"] = t_created_at
new_structure["t_language"] = t_language
new_structure["t_used_client"] = t_used_client
new_structure[self._text_field_name] = t_text
new_structure["u_created_at"] = u_created_at
new_structure["u_description"] = u_description
new_structure["u_favourites"] = u_favourites
new_structure["u_followers"] = u_followers
new_structure["u_friends"] = u_friends
new_structure["u_id"] = u_id
new_structure["u_lang"] = u_lang
new_structure["u_given_name"] = u_given_name
new_structure["u_username"] = u_username
new_structure["u_verified"] = u_verified
new_structure["u_location"] = u_location
# additional parameters
new_structure["is_extended"] = is_extended
new_structure["is_retweet"] = is_retweet
new_structure["is_answer"] = is_answer
return new_structure
# except Exception, e:
# p(json_tweet.keys())
# self.logger.error(str(repr(e)), exc_info=self._logger_traceback)
# sys.exit()
# #p(json_tweet)
def _readJSON(self, inp_object, encoding="utf_8", colnames=False, str_to_reread=False ):
try:
#p(inp_object, "inp_object")
#p(raw_str, "raw_str")
if not str_to_reread:
if isinstance(inp_object, (str,unicode)):
if not os.path.isfile(inp_object):
self.logger.error("JSONFileNotExistError: Following File wasn't found: '{}'. This File was ignored.".format(inp_object), exc_info=self._logger_traceback)
yield {}
return
#return
else:
f = open(inp_object, "r")
as_file_handler = False
raw_str = f.read()
f_name = f.name
else:
f = inp_object
raw_str = f.read()
as_file_handler = True
f_name = str(f)
else:
raw_str = str_to_reread
f_name = None
#inp_object + {}
#del data
temp_json_data = json.loads(raw_str)
if len(temp_json_data) == 0:
self.logger.outsorted_reader("JSONReader: Given JSON '{}' is empty.".format(f.name))
yield {}
return
if self._formatter_name:
if self._formatter_name in Reader.reader_supported_formatter["json"]:
try:
temp_json_data = self._json_tweets_preprocessing(temp_json_data,f_name=f_name)
if len(temp_json_data) == 0:
self.logger.debug("TweetsPreprocessing out-sorted current file: '{}' .".format(f.name))
yield {}
return
except Exception, e:
self.logger.error("JSONReader: Exception encountered during cleaning Twitter-JSON. This File was ignoren. Exception: '{}'.".format(repr(e)))
yield {}
return
else:
self.logger.critical("JSONReaderError: Given '{}'-FormatterName is not supported for JSONFormat. Please choice one of the following: '{}'. Execution of the Program was stopped- ".format(self._formatter_name, Reader.reader_supported_formatter["json"]))
yield -10
return
if isinstance(temp_json_data, dict):
temp_json_data = [temp_json_data]
for row_dict in temp_json_data:
if row_dict:
if (self._text_field_name not in row_dict) or self._id_field_name not in row_dict:
self.logger.outsorted_reader("JSONReader: Given JSON '{}' has wrong structure. Not one text or id element was found.".format(f.name))
yield -10
return
if colnames:
yield self._get_data_from_dic_for_given_keys(colnames, row_dict)
else:
yield row_dict
try:
f.close()
del f
except:
pass
except ValueError, e: # this was implemented, because twitter streamer send sometimes inconsistent tweets, where json is not correct
print_exc_plus() if self._ext_tb else ""
if not str_to_reread:
try:
splitted = raw_str.split("}{")
if len(splitted) > 1:
temp_items = []
for item in splitted:
if item[0] != "{":
item= "{{{}".format(item)
if item[-1]!= "}":
item= "{}}}".format(item)
temp_items.append(json.loads(item))
json_str = json.dumps(temp_items)
#self.logger.critical(temp_items)
#self.logger.critical(json_str)
#sys.exit()
for row in self._readJSON(inp_object, encoding=encoding, colnames=colnames, str_to_reread=json_str):
yield row
self.logger.healed("JSONDoktorSuccess: 'not-valid'-JSON File was getted: '{}'. It was possible to heal it up. ".format(f.name))
except Exception, e:
self.logger.error("JSONDoktorError: It wasn't possible to heal up current 'not-valid'-JSON File: '{}' (was ignored)\n --->See Exception: '{}';\n --->DataFromFile:'{}'; \n".format(f.name, e, raw_str), exc_info=self._logger_traceback)
else:
raw_str= raw_str if self._log_content else "log_content is disable. Switch on this Option, if you want see file data here"
if "Expecting , delimiter" in str(e) or "No JSON object could be decoded" in str(e):
self.logger.error_insertion("JSONReaderError: Current File is not valid JSON: ('{}' was ignored)\n --->See Exception: '{}';\n --->DataFromFile:'{}'; \n".format(f.name, e, raw_str), exc_info=self._logger_traceback)
elif "Extra data" in str(e):
self.logger.error_insertion("JSONReaderError: Probably inconsistent JSON File. ('{}' was ignored)\n --->See Exception: '{}';\n --->DataFromFile:'{}'; \n".format(f.name, e, raw_str), exc_info=self._logger_traceback)
else:
self.logger.error_insertion("JSONReaderError: ('{}' was ignored)\n --->See Exception: '{}';\n --->DataFromFile:'{}'; \n".format(f.name, e, raw_str), exc_info=self._logger_traceback)
#except AttributeError,e:
except Exception, e:
#p(f,"f")
try:
if isinstance(f, (unicode, str)):
fname = f
else:
fname = f.name
except AttributeError:
fname = f
print_exc_plus() if self._ext_tb else ""
self.logger.error("JSONReaderError: For current File '{}' following Exception was throw: '{}'. ".format(fname, e), exc_info=self._logger_traceback)
def _validation_given_path(self):
if not os.path.isdir(self._inp_path):
self.logger.error("ValidationError: Given PathToCorpus is not exist: '{}'. ".format(self._inp_path), exc_info=self._logger_traceback)
return False
return True
def _validate_given_file_format(self):
if self._file_format.lower() not in Reader.supported_file_types:
self.logger.error("ValidationError: Given FileFormat '{}' is not supported by this Reader.".format(self._file_format.lower()), exc_info=self._logger_traceback)
return False
return True
def _extract_all_files_according_given_file_format(self):
#p(self._read_from_zip, "read_from_zip")
try:
output_path_to_file = []
#self.files_to_read_orig = []
#self.zips_to_read = []
for root, dirs, files in os.walk(self._inp_path, topdown=False):
for name in files:
#p( name)
if "."+self._file_format in name.lower():
self.files_to_read_orig.append(os.path.join(root, name))
#print root, name
if self._read_from_zip:
if ".zip" in name.lower():
self.zips_to_read.append(os.path.join(root, name))
#print root, name
if len(self.files_to_read_orig)==0 and len(self.zips_to_read)==0:
#p((self._inp_path))
self.logger.warning("FilesExtractionProblem: No '{}'-Files or ZIPs was found. (check given FileFormat or given path to text collection).".format(self._file_format))
#return self.files_to_read_orig
self.files_to_read_leftover = copy.deepcopy(self.files_to_read_orig)
#p(read_from_zip, "444read_from_zip")
#p(self._read_from_zip, "read_from_zip")
if self._read_from_zip:
for path_to_zip in self.zips_to_read:
archive = zipfile.ZipFile(path_to_zip, 'r')
for name in archive.namelist():
if "."+self._file_format in name:
#f = archive.open(name)
self.files_from_zips_to_read_orig[path_to_zip].append(name)
self.files_from_zips_to_read_left_over = copy.deepcopy(self.files_from_zips_to_read_orig)
self.logger.info("FilesExtraction: '{}' '{}'-Files (unzipped) was found in the given folder Structure: '{}'. ".format(len(self.files_to_read_orig),self._file_format, self._inp_path))
#p(repr(self._read_from_zip), "------1-1-1-1-read_from_zip")
if self._read_from_zip:
if self.zips_to_read:
self.files_number_in_zips = sum([len(v) for v in self.files_from_zips_to_read_orig.values() ])
self.logger.info("ZIPsExtraction: Additional it was found '{}' ZIP-Archives, where '{}' '{}'-Files was found.".format(len(self.zips_to_read), self.files_number_in_zips,self._file_format))
self.files_at_all_was_found = len(self.files_to_read_orig) + self.files_number_in_zips
self.files_from_zips_to_read_left_over = copy.deepcopy(self.files_from_zips_to_read_orig)
self.files_to_read_leftover = copy.deepcopy(self.files_to_read_orig)
except Exception, e:
self.logger.error("FilesExtractionError: Encountered Exception '{}'. ".format(e), exc_info=self._logger_traceback)
return False
####################################################################################
####################################################################################
####################################################################################
####################################################################################
####################################################################################
####################################################################################
###################################Other Classes#####################################
####################################################################################
####################################################################################
####################################################################################
####################################################################################
#################################################################################### | zas-rep-tools | /zas-rep-tools-0.2.tar.gz/zas-rep-tools-0.2/zas_rep_tools/src/classes/reader.py | reader.py |
# ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
# : XXX{Information about this code}XXX
# Author:
# c(Developer) -> {'Egor Savin'}
# ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
###Programm Info######
#
#
#
#
#
from __future__ import absolute_import
import os
import copy
import sys
import logging
import inspect
import shutil
import traceback
import shelve
import time
import json
from collections import defaultdict
from raven import Client
from cached_property import cached_property
import inspect
from consolemenu import *
from consolemenu.items import *
from validate_email import validate_email
import urllib2
import twitter
from nltk.tokenize import TweetTokenizer
from zas_rep_tools.src.utils.debugger import p
from zas_rep_tools.src.utils.helpers import set_class_mode, print_mode_name, MyZODB,transaction, path_to_zas_rep_tools, internet_on, make_zipfile, instance_info, SharedCounterExtern, SharedCounterIntern, Status, function_name,statusesTstring
import zas_rep_tools.src.utils.db_helper as db_helper
from zas_rep_tools.src.utils.error_tracking import initialisation
from zas_rep_tools.src.utils.traceback_helpers import print_exc_plus
from zas_rep_tools.src.classes.exporter import Exporter
from zas_rep_tools.src.classes.reader import Reader
from zas_rep_tools.src.classes.dbhandler import DBHandler
from zas_rep_tools.src.classes.corpus import Corpus
from zas_rep_tools.src.classes.stats import Stats
from zas_rep_tools.src.utils.zaslogger import ZASLogger
from zas_rep_tools.src.classes.basecontent import BaseContent
from zas_rep_tools.src.utils.configer_helpers import ConfigerData
class ToolConfiger(BaseContent,ConfigerData):
def __init__(self, rewrite=False,stop_if_db_already_exist = True,**kwargs):
super(type(self), self).__init__(**kwargs)
#p((self._mode,self._logger_save_logs), "self._logger_save_logs", c="b")
#Input: Encapsulation:
self._rewrite = rewrite
self._stop_if_db_already_exist = stop_if_db_already_exist
#InstanceAttributes: Initialization
self._path_to_zas_rep_tools = path_to_zas_rep_tools
self._path_to_user_config_data = os.path.join(self._path_to_zas_rep_tools, "user_config/user_data.fs")
self._user_data= self._get_user_config_db()
if not self._user_data:
sys.exit()
self._get_user_config_db()
if not self._check_correctness_of_the_test_data():
self.logger.error("TestDataCorruption: Please check test data.", exc_info=self._logger_traceback)
sys.exit()
self.logger.debug('Intern InstanceAttributes was initialized')
self.logger.debug('An instance of {}() was created '.format(self.__class__.__name__))
## Log Settings of the Instance
attr_to_flag = ["_types_folder_names_of_testsets","_test_dbs", "_init_info_data", "_columns_in_doc_table", "_columns_in_info_tabel", "_columns_in_stats_tables", "_text_elements_collection"]
attr_to_len = False
self._log_settings(attr_to_flag =attr_to_flag,attr_to_len =attr_to_len)
############################################################
####################__init__end#############################
############################################################
def __del__(self):
super(type(self), self).__del__()
####################################################################################
####################################################################################
####################################################################################
####################################################################################
####################################################################################
####################################################################################
######################################Extern########################################
####################################################################################
####################################################################################
####################################################################################
####################################################################################
####################################################################################
# def row_text_elements(self, lang="all"):
# return copy.deepcopy(self._row_text_elements(lang=lang))
# def text_elements(self, token=True, unicode_str=True,lang="all"):
# return copy.deepcopy(self._text_elements(token=token, unicode_str=unicode_str, lang=lang))
# def docs_row_values(self,token=True, unicode_str=True, lang="all"):
# return copy.deepcopy(self._docs_row_values(token=token,unicode_str=unicode_str, lang=lang))
# def docs_row_dict(self, token=True, unicode_str=True, all_values=False, lang="all"):
# '''
# just one dict with colums as key and list of all values as values for each columns()key
# '''
# return copy.deepcopy(self._docs_row_dict(token=token, unicode_str=unicode_str, all_values=all_values, lang=lang))
# def docs_row_dicts(self, token=True, unicode_str=True, lang="all"):
# '''
# list of dicts with colums and values for each row
# '''
# return copy.deepcopy(self._docs_row_dicts(token=token, unicode_str=unicode_str, lang=lang))
###########################Config Values#######################
@cached_property
def path_to_zas_rep_tools(self):
return copy.deepcopy(self._path_to_zas_rep_tools)
# @cached_property
# def path_to_testdbs(self):
# return copy.deepcopy(self._path_to_testdbs)
# @cached_property
# def test_dbs(self):
# return copy.deepcopy(self._test_dbs)
# @cached_property
# def init_info_data(self):
# return copy.deepcopy(self._init_info_data)
# @cached_property
# def columns_in_doc_table(self):
# return copy.deepcopy(self._columns_in_doc_table)
# @cached_property
# def columns_in_info_tabel(self):
# return copy.deepcopy(self._columns_in_info_tabel)
# @cached_property
# def columns_in_stats_tables(self):
# return copy.deepcopy(self._columns_in_stats_tables)
# @cached_property
# def path_to_testsets(self):
# return copy.deepcopy(self._path_to_testsets)
# @cached_property
# def types_folder_names_of_testsets(self):
# return copy.deepcopy(self._types_folder_names_of_testsets)
def clean_user_data(self):
if self._user_data.clean():
return True
else:
return False
def get_data_from_user(self, user_info_to_get=False, rewrite=False):
if not rewrite:
rewrite = self._rewrite
if user_info_to_get:
if isinstance(user_info_to_get, (unicode, str)):
user_info_to_get = [user_info_to_get]
else:
user_info_to_get = self._suported_user_info
for user_info_name in user_info_to_get:
if user_info_name not in self._suported_user_info:
self.logger.error("UserDataGetterError: '{}' - data not supported. ".format(user_info_name), exc_info=self._logger_traceback)
continue
if user_info_name == "error_tracking":
if rewrite:
self._cli_menu_error_agreement()
continue
if "error_tracking" not in self._user_data:
self._cli_menu_error_agreement()
elif user_info_name == "project_folder":
if rewrite:
self._cli_menu_get_from_user_project_folder()
continue
if "project_folder" not in self._user_data:
self._cli_menu_get_from_user_project_folder()
elif user_info_name == "twitter_creditials":
if rewrite:
self._cli_menu_get_from_user_twitter_credentials()
continue
if "twitter_creditials" not in self._user_data:
self._cli_menu_get_from_user_twitter_credentials()
elif user_info_name == "email":
if rewrite:
self._cli_menu_get_from_user_emails()
continue
if "email" not in self._user_data:
self._cli_menu_get_from_user_emails()
else:
self.logger.critical("Not supported user_data_getter ('{}').".format(user_info_name))
# def create_test_data(self, abs_path_to_storage_place=False, use_original_classes = True, corp_lang_classification=False,
# corp_pos_tagger=True, corp_sent_splitter=True, corp_sentiment_analyzer=True, corp_status_bar=True,
# corp_log_ignored=False, use_test_pos_tagger=False,rewrite=False):
# #if not corp_language:
# # corp_language = "de"
# self.create_testsets(rewrite=rewrite,abs_path_to_storage_place=abs_path_to_storage_place,silent_ignore = True)
# if not self.create_test_dbs(rewrite=rewrite, abs_path_to_storage_place=abs_path_to_storage_place, use_original_classes=use_original_classes,
# corp_lang_classification=corp_lang_classification, corp_log_ignored=corp_log_ignored,
# corp_pos_tagger=corp_pos_tagger, corp_sent_splitter=corp_sent_splitter,
# corp_sentiment_analyzer=corp_sentiment_analyzer, corp_status_bar=corp_status_bar,
# use_test_pos_tagger=use_test_pos_tagger):
# return False
# self.logger.info("Test Data was initialized.")
# return True
# def create_test_dbs(self, rewrite=False, abs_path_to_storage_place = False,corp_log_ignored=False,
# use_original_classes = True, corp_lang_classification=True, use_test_pos_tagger=False,
# corp_pos_tagger=True, corp_sent_splitter=True, corp_sentiment_analyzer=True, corp_status_bar=True):
# #p(abs_path_to_storage_place, "abs_path_to_storage_place")
# try:
# if not abs_path_to_storage_place:
# abs_path_to_storage_place = os.path.join(self._path_to_zas_rep_tools, self._path_to_testdbs)
# #p(abs_path_to_storage_place, "abs_path_to_storage_place")
# #sys.exit()
# ### clean journal files
# exist_fnames_in_dir = os.listdir(abs_path_to_storage_place)
# exist_fnames_in_dir = [fname for fname in exist_fnames_in_dir if ".db-journal" in fname]
# if exist_fnames_in_dir:
# for fname in exist_fnames_in_dir:
# os.remove(os.path.join(abs_path_to_storage_place, fname))
# msg = "'{}' '.db-journal' files was deleted. ".format(len(exist_fnames_in_dir))
# self.logger.critical(msg)
# p(msg, "CRITICAL", c="r")
# if not rewrite:
# rewrite = self._rewrite
# #for
# exist_fnames_in_dir = os.listdir(abs_path_to_storage_place)
# num = len(exist_fnames_in_dir)
# #p((num, exist_fnames_in_dir), "exist_fnames_in_dir")
# exist_fnames_in_dir = [fname for fname in exist_fnames_in_dir if (".db" in fname) and (".db-journal" not in fname)]
# fnames_test_db = [fname for encr, encr_data in self._test_dbs.items() for template_name, template_name_data in encr_data.items() for lang, lang_data in template_name_data.items() for db_type, fname in lang_data.items()]
# test_db_num = len(fnames_test_db)
# #p((fnames_test_db,exist_fnames_in_dir,test_db_num), "fnames_test_db")
# clean = False
# if len(exist_fnames_in_dir) != len(fnames_test_db):
# clean = True
# self.logger.critical("Some TestDB are missing. There was found '{}'-DBs. But it should be '{}'. Process of TestDB Creation will be started. ".format(len(exist_fnames_in_dir), len(fnames_test_db)))
# else:
# for fname in fnames_test_db:
# if fname not in exist_fnames_in_dir:
# msg = "Some TestDB are missing. (eg: '{}') Process of TestDB Creation will be started. ".format(fname)
# self.logger.critical(msg)
# p(msg, "CRITICAL", c="r")
# clean = True
# break
# if clean:
# clean = False
# for fname in exist_fnames_in_dir:
# os.remove(os.path.join(abs_path_to_storage_place, fname))
# exist_fnames_in_dir = os.listdir(abs_path_to_storage_place)
# exist_fnames_in_dir = [fname for fname in exist_fnames_in_dir if ".db-journal" in fname]
# for fname in exist_fnames_in_dir:
# os.remove(os.path.join(abs_path_to_storage_place, fname))
# activ_corp_dbs = defaultdict(lambda: defaultdict(lambda: defaultdict(lambda: defaultdict(dict))) )
# for template_name, init_data in self._init_info_data.iteritems():
# #p(template_name)
# for encryption in ["plaintext", "encrypted"]:
# for dbtype in ["corpus", "stats"]:
# # if exist and rewrite=True -> remove existed db
# #p(self._columns_in_info_tabel[dbtype])
# dbname = self._init_info_data[template_name]["name"]
# #language = self._init_info_data[template_name]["language"]
# visibility = self._init_info_data[template_name]["visibility"]
# platform_name = self._init_info_data[template_name]["platform_name"]
# license = self._init_info_data[template_name]["license"]
# template_name = self._init_info_data[template_name]["template_name"]
# version = self._init_info_data[template_name]["version"]
# source = self._init_info_data[template_name]["source"]
# encryption_key = self._init_info_data[template_name]["encryption_key"][dbtype] if encryption=="encrypted" else False
# corpus_id = self._init_info_data[template_name]["id"]["corpus"]
# stats_id = self._init_info_data[template_name]["id"]["stats"]
# #p((dbtype, encryption_key))
# # for which languages create
# if encryption == "encrypted":
# if template_name == "twitter":
# languages = ["de"]
# elif template_name == "blogger":
# continue
# #languages = ["en"]
# elif encryption == "plaintext":
# if template_name == "twitter":
# continue
# #languages = ["de"]
# elif template_name == "blogger":
# languages = ["de", "en", "test"]
# for language in languages:
# # If Rewrite is on, delete db for current attributes. if this exist in the 'self._test_dbs'. If not, than ignore.
# try:
# path_to_db = os.path.join(abs_path_to_storage_place, self._test_dbs[encryption][template_name][language][dbtype])
# if rewrite:
# if os.path.isfile(path_to_db):
# os.remove(path_to_db)
# self.logger.debug("RewriteOptionIsON: Following DB was deleted from TestDBFolder: '{}'. TestDBCreationScript will try to created this DB.".format(path_to_db))
# else:
# #self.logger.debug("11111{}:{}:{}:{}".format(dbname, language, platform_name, dbtype))
# self.logger.debug("RewriteOptionIsON: Following DB wasn't found in the TestDBFolder and wasn't deleted: '{}'. TestDBCreationScript will try to created this DB.".format(path_to_db))
# else:
# if os.path.isfile(path_to_db):
# self.logger.debug("RewriteOptionIsOFF: '{}'-DB exist and will not be rewrited/recreated.".format(path_to_db))
# continue
# except KeyError, k:
# self.logger.debug("KeyError: DBName for '{}:{}:{}:{}' is not exist in the 'self._test_dbs'. TestDBCreationScript will try to created this DB. ".format(encryption,template_name,language,dbtype))
# continue
# except Exception, e:
# self.logger.error("See Exception: '{}'. (line 703). Creation of the TestDBs was aborted.".format(e), exc_info=self._logger_traceback)
# sy.exit()
# #self.logger.debug("2222{}:{}:{}:{}".format(dbname, language, platform_name, dbtype))
# db_id = corpus_id if dbtype == "corpus" else stats_id
# self.logger.info("TestDBCreationProcess: Was started for DB with following attributes: 'dbtype='{}'; id='{}'; encryption='{}'; template_name='{}'; language='{}'. ".format(dbtype, db_id,encryption,template_name,language ))
# if dbtype=="corpus":
# #self.logger.debug("3333{}:{}:{}:{}".format(dbname, language, platform_name, dbtype))
# if not use_original_classes:
# db = DBHandler(logger_level=logging.ERROR,logger_traceback=self._logger_traceback,
# logger_folder_to_save=self._logger_folder_to_save,logger_usage=self._logger_usage,
# logger_save_logs= self._logger_save_logs, mode=self._mode,
# error_tracking=self._error_tracking, ext_tb= self._ext_tb,
# stop_if_db_already_exist=self._stop_if_db_already_exist, rewrite=self._rewrite)
# was_initialized = db.init(dbtype, abs_path_to_storage_place, dbname, language, visibility, platform_name=platform_name, license=license , template_name=template_name, version=version , source=source, corpus_id=corpus_id, stats_id=stats_id, encryption_key=encryption_key)["status"]
# # self.logger.critical("was_initialized={}".format(was_initialized))
# # sys.exit()
# #!!!!
# #self.logger.debug("444{}:{}:{}:{}".format(dbname, language, platform_name, dbtype))
# if not was_initialized:
# if self._stop_if_db_already_exist:
# self.logger.debug("DBInitialisation: DBName for '{}:{}:{}:{}' wasn't initialized. Since 'self._stop_if_db_already_exist'-Option is on, current Script will ignore current DB and will try to create next one.".format(encryption,template_name,language,dbtype))
# continue
# else:
# self.logger.error("DBInitialisationError: DBName for '{}:{}:{}:{}' wasn't initialized. TestDBCreation was aborted.".format(encryption,template_name,language,dbtype))
# return False
# #self.logger.debug("5555{}:{}:{}:{}".format(dbname, language, platform_name, dbtype))
# rows_to_insert = self.docs_row_values(token=True, unicode_str=True)[template_name]
# path_to_db = db.path()
# #self.logger.debug("6666{}:{}:{}:{}".format(dbname, language, platform_name, dbtype))
# if not path_to_db:
# self.logger.error("Path for current DB wasn't getted. Probably current corpus has InitializationError. TestDBCreation was aborted.")
# sys.exit()
# db.lazyinsert("documents",rows_to_insert)
# #self.logger.debug("77777{}:{}:{}:{}".format(dbname, language, platform_name, dbtype))
# #p(( len(db.getall("documents")), len(rows_to_insert)))
# if "Connection" not in str(type(db)):
# pass
# #p((len(db.getall("documents")) , len(rows_to_insert)), c="r")
# if len(db.getall("documents")) != len(rows_to_insert):
# #db.close()
# #p(db._db)
# os.remove(path_to_db)
# #shutil.rmtree(path_to_db)
# self.logger.error("TestDBsCreation(InsertionError): Not all rows was correctly inserted into DB. This db was ignored and not created.", exc_info=self._logger_traceback)
# #sys.exit()
# sys.exit()
# continue
# db.commit()
# db.close()
# else:
# #if use_test_pos_tagger and language == "en":
# # corp_pos_tagger = "tweetnlp" if corp_pos_tagger else corp_pos_tagger
# #else:
# # corp_pos_tagger = True if corp_pos_tagger else False
# #if corp_language:
# # language = corp_language
# #p((corp_pos_tagger,language), "pos_tagger")
# corp = Corpus(logger_level=logging.ERROR, logger_traceback=self._logger_traceback,
# logger_folder_to_save=self._logger_folder_to_save, use_test_pos_tagger=use_test_pos_tagger,
# logger_usage=self._logger_usage, logger_save_logs= self._logger_save_logs,
# mode=self._mode , error_tracking=self._error_tracking, ext_tb= self._ext_tb,
# stop_if_db_already_exist=self._stop_if_db_already_exist, status_bar=corp_status_bar,
# rewrite=self._rewrite)
# #p(corp.info())
# #self.logger.debug("444{}:{}:{}:{}".format(dbname, language, platform_name, dbtype))
# was_initialized = corp.init(abs_path_to_storage_place,dbname, language, visibility,platform_name,
# license=license , template_name=template_name, version=version, source=source,
# corpus_id=corpus_id, encryption_key=encryption_key,
# lang_classification=corp_lang_classification,
# pos_tagger=corp_pos_tagger, sent_splitter=corp_sent_splitter,
# sentiment_analyzer=corp_sentiment_analyzer,)
# #self.logger.debug("555{}:{}:{}:{}".format(dbname, language, platform_name, dbtype))
# #self.logger.critical("was_initialized={}".format(was_initialized))
# #p(corp.info())
# if not was_initialized:
# if self._stop_if_db_already_exist:
# self.logger.debug("DBInitialisation: DBName for '{}:{}:{}:{}' wasn't initialized. Since 'self._stop_if_db_already_exist'-Option is on, current Script will ignore current DB and will try to create next one.".format(encryption,template_name,language,dbtype))
# continue
# else:
# self.logger.error("DBInitialisationError: DB for '{}:{}:{}:{}' wasn't initialized. TestDBCreation was aborted.".format(encryption,template_name,language,dbtype))
# return False
# rows_as_dict_to_insert = self.docs_row_dicts(token=False, unicode_str=True)[template_name]
# path_to_db = corp.corpdb.path()
# fname_db = corp.corpdb.fname()
# #self.logger.debug("777{}:{}:{}:{}".format(dbname, language, platform_name, dbtype))
# if not path_to_db or not fname_db:
# self.logger.error("Path or FileName for current CorpusDB wasn't getted. (lang='{}', dbname='{}', id='{}',platform_name='{}', visibility='{}', encryption_key='{}') Probably current corpus has InitializationError. TestDBCreation was aborted.".format(language, dbname,corpus_id, platform_name, visibility, encryption_key))
# sys.exit()
# #p((path_to_db,fname_db))
# was_inserted = corp.insert(rows_as_dict_to_insert, log_ignored=corp_log_ignored)
# if not was_inserted:
# os.remove(path_to_db)
# msg = "Rows wasn't inserted into the '{}'-DB. This DB was deleted and script of creating testDBs was aborted.".format(fname_db)
# self.logger.error(msg)
# raise Exception, msg
# sys.exit()
# return False
# #continue
# else:
# if not corp_lang_classification:
# if len(corp.docs()) != len(rows_as_dict_to_insert):
# os.remove(path_to_db)
# #shutil.rmtree(path_to_db)
# msg = "TestDBsCreation(InsertionError): Not all rows was correctly inserted into DB. This DB was deleted and script of creating testDBs was aborted."
# self.logger.error(msg, exc_info=self._logger_traceback)
# #sys.exit()
# raise Exception, msg
# #continue
# if corp.total_error_insertion_during_last_insertion_process:
# msg = "TestDBsCreation(InsertionError): '{}'-ErrorInsertion was found!!! Not all rows was correctly inserted into DB. This DB was deleted and script of creating testDBs was aborted.".format(corp.total_error_insertion_during_last_insertion_process)
# self.logger.error(msg, exc_info=self._logger_traceback)
# raise Exception, msg
# return False
# else:
# self.logger.debug("'{}'-TestDB was created. Path: '{}'.".format(fname_db,path_to_db))
# #corp.commit()
# self.logger.debug("'{}': Following rows was inserted:\n '{}'. \n\n".format(fname_db, '\n'.join("--->"+str(v) for v in list(corp.docs()) ) ))
# activ_corp_dbs[template_name][encryption][dbtype][language] = corp
# ### get SENTS
# # corp.corpdb.commit()
# # if language== "de":
# # p(list(corp.docs()), "de", c="r")
# # elif language== "en":
# # p(list(corp.docs()), "en", c="m")
# # time.sleep(15)
# #else:
# # time.sleep(15)
# elif dbtype=="stats":
# ## here insert all rows into stats dbs
# if not use_original_classes:
# stats = DBHandler(logger_level=logging.ERROR,logger_traceback=self._logger_traceback, logger_folder_to_save=self._logger_folder_to_save,logger_usage=self._logger_usage, logger_save_logs= self._logger_save_logs, mode=self._mode , error_tracking=self._error_tracking, ext_tb= self._ext_tb, stop_if_db_already_exist=self._stop_if_db_already_exist, rewrite=self._rewrite)
# stats.init(dbtype, abs_path_to_storage_place, dbname, language, visibility, platform_name=platform_name, license=license , template_name=template_name, version=version , source=source, corpus_id=corpus_id, stats_id=stats_id, encryption_key=encryption_key)
# stats.close()
# else:
# #p(activ_corp_dbs, "activ_corp_dbs")
# #p((template_name,encryption,dbtype,language))
# stats = Stats(logger_level=logging.ERROR, logger_traceback=self._logger_traceback,
# logger_folder_to_save=self._logger_folder_to_save, logger_usage=self._logger_usage,
# logger_save_logs= self._logger_save_logs, mode=self._mode, error_tracking=self._error_tracking,
# ext_tb= self._ext_tb, stop_if_db_already_exist=self._stop_if_db_already_exist,
# status_bar=corp_status_bar,rewrite=self._rewrite)
# #p(corp.info())
# was_initialized = stats.init(abs_path_to_storage_place,dbname, language, visibility,
# version=version, corpus_id=corpus_id, stats_id=stats_id,
# encryption_key=encryption_key,case_sensitiv=False,
# full_repetativ_syntagma=True)
# #p((encryption_key,dbtype,dbname,language,visibility,platform_name ), "encryption_key____stats")
# corp = activ_corp_dbs[template_name][encryption]["corpus"][language]
# #p(corp, "corp")
# if isinstance(corp, Corpus):
# stats.compute(corp)
# corp.corpdb.commit()
# stats.statsdb.commit()
# corp.close()
# stats.close()
# else:
# self.logger.error("Given CorpObj ('{}') is invalid".format(corp))
# return False
# #### check if db was created
# exist_fnames_in_dir = os.listdir(abs_path_to_storage_place)
# exist_fnames_in_dir = [fname for fname in exist_fnames_in_dir if (".db" in fname) and (".db-journal" not in fname)]
# if len(fnames_test_db) != len(exist_fnames_in_dir):
# self.logger.error("TestDBs wasn't initialized correctly. There was found '{}' testDBs in the TestDBFolder, but it should be '{}'. ".format(len(exist_fnames_in_dir), len(fnames_test_db)))
# return False
# for fname in fnames_test_db:
# if fname not in exist_fnames_in_dir:
# self.logger.error("'{}'-testDB wasn't found in the TestDB-Folder. End with Error.".format(fname))
# return False
# self.logger.info("TestDBs was initialized.")
# return True
# except KeyboardInterrupt:
# exist_fnames_in_dir = os.listdir(abs_path_to_storage_place)
# exist_fnames_in_dir = [fname for fname in exist_fnames_in_dir if ".db" in fname]
# for fname in exist_fnames_in_dir:
# os.remove(os.path.join(abs_path_to_storage_place, fname))
# sys.exit()
# return False
# def create_testsets(self, rewrite=False, abs_path_to_storage_place=False, silent_ignore = True):
# return list(self.create_testsets_in_diff_file_formats(rewrite=rewrite, abs_path_to_storage_place=abs_path_to_storage_place,silent_ignore=silent_ignore))
# def create_testsets_in_diff_file_formats(self, rewrite=False, abs_path_to_storage_place=False, silent_ignore = True):
# #p(abs_path_to_storage_place)
# #sys.exit()
# if not rewrite:
# rewrite = self._rewrite
# if not abs_path_to_storage_place:
# abs_path_to_storage_place = self._path_to_zas_rep_tools
# #p("fghjk")
# created_sets = []
# try:
# # make test_sets for Blogger Corp
# for file_format, test_sets in self._types_folder_names_of_testsets.iteritems():
# for name_of_test_set, folder_for_test_set in test_sets.iteritems():
# if file_format == "txt":
# continue
# abs_path_to_current_test_case = os.path.join(abs_path_to_storage_place, self._path_to_testsets["blogger"], folder_for_test_set)
# # p((file_format, name_of_test_set))
# # p(abs_path_to_current_test_case)
# if rewrite:
# if os.path.isdir(abs_path_to_current_test_case):
# shutil.rmtree(abs_path_to_current_test_case)
# #os.remove(abs_path_to_current_test_case)
# if not os.path.isdir(abs_path_to_current_test_case):
# os.makedirs(abs_path_to_current_test_case)
# path_to_txt_corpus = os.path.join(self.path_to_zas_rep_tools,self._path_to_testsets["blogger"] , self._types_folder_names_of_testsets["txt"][name_of_test_set] )
# reader = Reader(path_to_txt_corpus, "txt", regex_template="blogger",logger_level= self._logger_level,logger_traceback=self._logger_traceback, logger_folder_to_save=self._logger_folder_to_save,logger_usage=self._logger_usage, logger_save_logs= self._logger_save_logs, mode=self._mode , error_tracking=self._error_tracking, ext_tb= self._ext_tb)
# exporter = Exporter(reader.getlazy(), rewrite=rewrite, silent_ignore=silent_ignore, logger_level= self._logger_level,logger_traceback=self._logger_traceback, logger_folder_to_save=self._logger_folder_to_save,logger_usage=self._logger_usage, logger_save_logs= self._logger_save_logs, mode=self._mode , error_tracking=self._error_tracking, ext_tb= self._ext_tb)
# if file_format == "csv":
# if name_of_test_set == "small":
# flag = exporter.tocsv(abs_path_to_current_test_case, "blogger_corpus",self._columns_in_doc_table["blogger"], rows_limit_in_file=5)
# if not flag:
# yield False
# else:
# created_sets.append("csv")
# yield True
# else:
# flag= exporter.tocsv(abs_path_to_current_test_case, "blogger_corpus",self._columns_in_doc_table["blogger"], rows_limit_in_file=2)
# if not flag:
# yield False
# else:
# created_sets.append("csv")
# yield True
# elif file_format == "xml":
# if name_of_test_set == "small":
# flag = exporter.toxml(abs_path_to_current_test_case, "blogger_corpus", rows_limit_in_file=5)
# if not flag:
# yield False
# else:
# created_sets.append("xml")
# yield True
# else:
# flag = exporter.toxml(abs_path_to_current_test_case, "blogger_corpus", rows_limit_in_file=2)
# if not flag:
# yield False
# else:
# created_sets.append("xml")
# yield True
# elif file_format == "json":
# if name_of_test_set == "small":
# flag = exporter.tojson(abs_path_to_current_test_case, "blogger_corpus", rows_limit_in_file=5)
# if not flag:
# yield False
# else:
# created_sets.append("json")
# yield True
# else:
# flag = exporter.tojson(abs_path_to_current_test_case, "blogger_corpus", rows_limit_in_file=2)
# if not flag:
# yield False
# else:
# created_sets.append("json")
# yield True
# elif file_format == "sqlite":
# flag = exporter.tosqlite(abs_path_to_current_test_case, "blogger_corpus",self._columns_in_doc_table["blogger"])
# if not flag:
# yield False
# else:
# created_sets.append("sqlite")
# yield True
# #p(created_sets, "created_sets")
# for created_set in set(created_sets):
# path_to_set = os.path.join(abs_path_to_storage_place, self._path_to_testsets["blogger"], created_set)
# #p(path_to_set)
# #p(os.path.join(os.path.split(path_to_set)[0], created_set+".zip"))
# make_zipfile(os.path.join(os.path.split(path_to_set)[0], created_set+".zip"), path_to_set)
# self.logger.info("TestSets (diff file formats) was initialized.")
# except Exception, e:
# print_exc_plus() if self._ext_tb else ""
# self.logger.error("SubsetsCreaterError: Throw following Exception: '{}'. ".format(e), exc_info=self._logger_traceback)
####################################################################################
####################################################################################
####################################################################################
####################################################################################
####################################################################################
####################################################################################
######################################INTERN########################################
####################################################################################
####################################################################################
####################################################################################
####################################################################################
####################################################################################
def _get_user_config_db(self):
#try:
try:
if not os.path.isdir(os.path.split(self._path_to_user_config_data)[0]):
self.logger.debug(" 'user_config' folder was created in '{}' ".format(os.path.split(self._path_to_user_config_data)[0]))
os.mkdir(os.path.split(self._path_to_user_config_data)[0])
db = MyZODB(self._path_to_user_config_data)
db["permission"] = True
return db
except Exception, e:
print_exc_plus() if self._ext_tb else ""
if "permission" in str(e).lower():
self.logger.error("UserConfigDBGetterError: Problem with permission. Probably solution. Please execute same command with 'sudo'-Prefix and enter your admin password. Exception: '{}'. ".format(e) ,exc_info=self._logger_traceback)
else:
self.logger.error("UserConfigDBGetterError: '{}'. ".format(e) ,exc_info=self._logger_traceback)
return False
def _cli_menu_get_from_user_project_folder(self):
getted_project_folder = False
def _get_input(args):
getted_input = input(args)
return str(getted_input)
# Create the menu
menu1 = SelectionMenu(["No", "Yes"],
title="Set Project Folder.",
#subtitle="(via Email)",
prologue_text="Every created database will be saved in the project folder. Before you can work with this tool you need to set up an Project Folder. Do you want to do it now? (if you want to use current directory as project folder just type an dot. exp: '.' )",
#epilogue_text="222"
)
menu1.show()
menu1.join()
selection1 = menu1.selected_option
#print selection1
if selection1 == 1:
status = True
while status:
prj_fldr = raw_input("Enter Project Folder: ")
if os.path.isdir(prj_fldr):
getted_project_folder = prj_fldr
status = False
else:
self.logger.critical("DirValidation: Given project Folder is not exist. Please retype it. (or type 'Ctrl+D' or 'Ctrl+C' to interrupt this process.)")
#print
if getted_project_folder:
if getted_project_folder ==".":
getted_project_folder = os.getcwd()
self._user_data["project_folder"] = getted_project_folder
return getted_project_folder
def _cli_menu_get_from_user_emails(self):
getted_emails = []
# Create the menu
menu1 = SelectionMenu(["No", "Yes"],
title="User Notification.",
subtitle="(via Email)",
prologue_text="This package can send to the users some important information. For example some day statistics for Twitter-Streamer or if some error occurs. Do you want to use this possibility? (Your email adress will stay on you Computer and will not be send anywhere.)",
#epilogue_text="222"
)
menu1.show()
menu1.join()
selection1 = menu1.selected_option
#print selection1
if selection1 == 1:
# Part 1: Get number of emails
status = True
while status:
menu2 = ConsoleMenu(
title="Number of email addresses.",
#subtitle="(via Email)",
prologue_text="How much email addresses do you want to set?",
#epilogue_text="222"
)
one_email = SelectionItem("one", 0)
number_of_emails = FunctionItem("many", function=raw_input, args=["Enter a number: "], should_exit=True)
menu2.append_item(one_email)
menu2.append_item(number_of_emails)
menu2.show()
menu2.join()
getted_number = number_of_emails.return_value
selection2 = menu2.selected_option
#print selection2, getted_number
if selection2 == 0:
status = False
number = 1
else:
try:
if unicode(getted_number).isnumeric() or isinstance(getted_number, int):
number = int(getted_number)
status = False
else:
self.logger.error("InputErr: Given Object is not an integer. Please retype your input! (in 5 seconds...)", exc_info=self._logger_traceback)
time.sleep(3)
except Exception, e:
self.logger.critical("EmailNumberGetterError: '{}'. ".format(e))
## Part2 : Get Email
getted_emails = []
i=0
while i < number:
email = str(raw_input("(#{} from {}) Enter Email: ".format(i+1, number)))
is_valid = validate_email(email)
if is_valid:
getted_emails.append(email)
i+= 1
else:
self.logger.warning( "EmailValidationError: Given Email is not valid. Please retype it.")
else:
pass
self._user_data["email"] = getted_emails
return getted_emails
def _cli_menu_error_agreement(self):
menu = SelectionMenu(["No", "Yes"],
title="Error-Tracking Agreement.",
#subtitle="(agreement)",
prologue_text="This package use a nice possibility of the online error tracking.\n It means, if you will get an error than the developers could get an notice about it in the real time. Are you agree to send information about errors directly to developers?",
#epilogue_text="222"
)
menu.show()
selection = menu.selected_option
self._user_data["error_tracking"] = False if selection==0 else True
return selection
def _cli_menu_get_from_user_twitter_credentials(self):
if not internet_on():
self.logger.critical("InternetConnectionError: No Internet connection was found. Please check your connection to Internet and repeat this step. (Internet Connection is needed to validate your Twitter Credentials.)")
sys.exit()
#return []
getted_credentials = []
def _get_input(args):
getted_input = input(args)
return str(getted_input)
# Create the menu
menu1 = SelectionMenu(["No", "Yes"],
title="Twitter API Credentials.",
#subtitle="",
prologue_text="If you want to stream Twitter via official Twitter API than you need to enter your account Credentials. To get more information about it - please consult a README File of this package (https://github.com/savin-berlin/zas-rep-tools). Under 'Start to use streamer' you can see how you can exactly get this data. Do you want to enter this data now?",
#epilogue_text="222"
)
menu1.show()
menu1.join()
selection1 = menu1.selected_option
#print selection1
if selection1 == 1:
# Part 1: Get number of emails
status = True
while status:
menu2 = ConsoleMenu(
title="Number of twitter accounts.",
#subtitle="(via Email)",
prologue_text="How much twitter accounts do you want to set up?",
#epilogue_text="222"
)
one_email = SelectionItem("one", 0)
number_of_emails = FunctionItem("many", function=raw_input, args=["Enter a number: "], should_exit=True)
menu2.append_item(one_email)
menu2.append_item(number_of_emails)
menu2.show()
menu2.join()
getted_number = number_of_emails.return_value
selection2 = menu2.selected_option
#print selection2, getted_number
if selection2 == 0:
status = False
number = 1
else:
try:
if unicode(getted_number).isnumeric() or isinstance(getted_number, int):
number = int(getted_number)
status = False
else:
self.logger.error("InputErr: Given Object is not an integer. Please retype your input! (in 5 seconds...)", exc_info=self._logger_traceback)
#print "InputErr: Given Object is not an integer. Please retype your input! (in 5 seconds...)"
time.sleep(3)
except Exception, e:
self.logger.error("EmailNumberGetterError: '{}'. ".format(e), exc_info=self._logger_traceback)
## Part2 : Get Email
i=0
while i < number:
print "\n\n(#{} from {}) Enter Twitter Credentials: ".format(i+1, number)
consumer_key = raw_input("Enter consumer_key: ")
consumer_secret = raw_input("Enter consumer_secret: ")
access_token = raw_input("Enter access_token: ")
access_token_secret = raw_input("Enter access_token_secret: ")
if internet_on():
api = twitter.Api(consumer_key=consumer_key,
consumer_secret=consumer_secret,
access_token_key=access_token,
access_token_secret=access_token_secret)
try:
if api.VerifyCredentials():
getted_credentials.append({"consumer_key":consumer_key,
"consumer_secret":consumer_secret,
"access_token":access_token,
"access_token_secret":access_token_secret
})
i +=1
else:
print "InvalidCredential: Please retype them."
except Exception, e:
if "Invalid or expired token" in str(e):
self.logger.critical("InvalidCredential: Please retype them.")
elif "Failed to establish a new connection" in str(e):
self.logger.critical("InternetConnectionFailed: '{}' ".format(e))
else:
self.logger.critical("TwitterCredentialsCheckerError: '{}' ".format(e))
else:
self.logger.critical("InternetConnectionError: No Internet connection was found. Please check your connection to Internet and repeat this step. (Internet Connection is needed to validate your Twitter Credentials.)")
sys.exit()
else:
pass
self._user_data["twitter_creditials"] = getted_credentials
return getted_credentials
def _check_correctness_of_the_test_data(self):
## Check mapping of columns and values
try:
for template, data_columns in self._columns_in_doc_table.iteritems():
for data_values in self.docs_row_values(token=True, unicode_str=True)[template]:
#p((len(data_columns), len(data_values)))
if len(data_columns) != len(data_values):
self.logger.error("TestDataCorruption: Not same number of columns and values.", exc_info=self._logger_traceback)
return False
except Exception, e:
#p([(k,v) for k,v in self._columns_in_doc_table.iteritems()])
#p(self.docs_row_values(token=True, unicode_str=True))
self.logger.error("TestDataCorruption: Test Data in Configer is inconsistent. Probably - Not same template_names in columns and rows. See Exception: '{}'. ".format(e), exc_info=self._logger_traceback)
return False
return True
#sys.exit()
# ##### Encrypted #######
###########################Preprocessing###############
####################################################################################
####################################################################################
####################################################################################
####################################################################################
####################################################################################
####################################################################################
###################################Other Classes#####################################
####################################################################################
####################################################################################
####################################################################################
####################################################################################
#################################################################################### | zas-rep-tools | /zas-rep-tools-0.2.tar.gz/zas-rep-tools-0.2/zas_rep_tools/src/classes/configer.py | configer.py |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.