
code
stringlengths 501
5.19M
| package
stringlengths 2
81
| path
stringlengths 9
304
| filename
stringlengths 4
145
|
|---|---|---|---|
from zeep.utils import get_base_class
from zeep.xsd.types.simple import AnySimpleType
__all__ = ["ListType", "UnionType"]
class ListType(AnySimpleType):
"""Space separated list of simpleType values"""
def __init__(self, item_type):
self.item_type = item_type
super(ListType, self).__init__()
def __call__(self, value):
return value
def render(self, parent, value, xsd_type=None, render_path=None):
parent.text = self.xmlvalue(value)
def resolve(self):
self.item_type = self.item_type.resolve()
self.base_class = self.item_type.__class__
return self
def xmlvalue(self, value):
item_type = self.item_type
return " ".join(item_type.xmlvalue(v) for v in value)
def pythonvalue(self, value):
if not value:
return []
item_type = self.item_type
return [item_type.pythonvalue(v) for v in value.split()]
def signature(self, schema=None, standalone=True):
return self.item_type.signature(schema) + "[]"
class UnionType(AnySimpleType):
"""Simple type existing out of multiple other types"""
def __init__(self, item_types):
self.item_types = item_types
self.item_class = None
assert item_types
super(UnionType, self).__init__(None)
def resolve(self):
self.item_types = [item.resolve() for item in self.item_types]
base_class = get_base_class(self.item_types)
if issubclass(base_class, AnySimpleType) and base_class != AnySimpleType:
self.item_class = base_class
return self
def signature(self, schema=None, standalone=True):
return ""
def parse_xmlelement(
self, xmlelement, schema=None, allow_none=True, context=None, schema_type=None
):
if self.item_class:
return self.item_class().parse_xmlelement(
xmlelement, schema, allow_none, context
)
return xmlelement.text
def pythonvalue(self, value):
if self.item_class:
return self.item_class().pythonvalue(value)
return value
def xmlvalue(self, value):
if self.item_class:
return self.item_class().xmlvalue(value)
return value | zeep-roboticia | /zeep-roboticia-3.4.0.tar.gz/zeep-roboticia-3.4.0/src/zeep/xsd/types/collection.py | collection.py |
import copy
import logging
from collections import OrderedDict, deque
from itertools import chain
from cached_property import threaded_cached_property
from zeep.exceptions import UnexpectedElementError, XMLParseError
from zeep.xsd.const import NotSet, SkipValue, Nil, xsi_ns
from zeep.xsd.elements import (
Any, AnyAttribute, AttributeGroup, Choice, Element, Group, Sequence)
from zeep.xsd.elements.indicators import OrderIndicator
from zeep.xsd.types.any import AnyType
from zeep.xsd.types.simple import AnySimpleType
from zeep.xsd.utils import NamePrefixGenerator
from zeep.xsd.valueobjects import ArrayValue, CompoundValue
logger = logging.getLogger(__name__)
__all__ = ["ComplexType"]
class ComplexType(AnyType):
_xsd_name = None
def __init__(
self,
element=None,
attributes=None,
restriction=None,
extension=None,
qname=None,
is_global=False,
):
if element and type(element) == list:
element = Sequence(element)
self.name = self.__class__.__name__ if qname else None
self._element = element
self._attributes = attributes or []
self._restriction = restriction
self._extension = extension
self._extension_types = tuple()
super(ComplexType, self).__init__(qname=qname, is_global=is_global)
def __call__(self, *args, **kwargs):
if self._array_type:
return self._array_class(*args, **kwargs)
return self._value_class(*args, **kwargs)
@property
def accepted_types(self):
return (self._value_class,) + self._extension_types
@threaded_cached_property
def _array_class(self):
assert self._array_type
return type(
self.__class__.__name__,
(ArrayValue,),
{"_xsd_type": self, "__module__": "zeep.objects"},
)
@threaded_cached_property
def _value_class(self):
return type(
self.__class__.__name__,
(CompoundValue,),
{"_xsd_type": self, "__module__": "zeep.objects"},
)
def __str__(self):
return "%s(%s)" % (self.__class__.__name__, self.signature())
@threaded_cached_property
def attributes(self):
generator = NamePrefixGenerator(prefix="_attr_")
result = []
elm_names = {name for name, elm in self.elements if name is not None}
for attr in self._attributes_unwrapped:
if attr.name is None:
name = generator.get_name()
elif attr.name in elm_names:
name = "attr__%s" % attr.name
else:
name = attr.name
result.append((name, attr))
return result
@threaded_cached_property
def _attributes_unwrapped(self):
attributes = []
for attr in self._attributes:
if isinstance(attr, AttributeGroup):
attributes.extend(attr.attributes)
else:
attributes.append(attr)
return attributes
@threaded_cached_property
def elements(self):
"""List of tuples containing the element name and the element"""
result = []
for name, element in self.elements_nested:
if isinstance(element, Element):
result.append((element.attr_name, element))
else:
result.extend(element.elements)
return result
@threaded_cached_property
def elements_nested(self):
"""List of tuples containing the element name and the element"""
result = []
generator = NamePrefixGenerator()
# Handle wsdl:arrayType objects
if self._array_type:
name = generator.get_name()
if isinstance(self._element, Group):
result = [
(
name,
Sequence(
[
Any(
max_occurs="unbounded",
restrict=self._array_type.array_type,
)
]
),
)
]
else:
result = [(name, self._element)]
else:
# _element is one of All, Choice, Group, Sequence
if self._element:
result.append((generator.get_name(), self._element))
return result
@property
def _array_type(self):
attrs = {attr.qname.text: attr for attr in self._attributes if attr.qname}
array_type = attrs.get("{http://schemas.xmlsoap.org/soap/encoding/}arrayType")
return array_type
def parse_xmlelement(
self, xmlelement, schema=None, allow_none=True, context=None, schema_type=None
):
"""Consume matching xmlelements and call parse() on each
:param xmlelement: XML element objects
:type xmlelement: lxml.etree._Element
:param schema: The parent XML schema
:type schema: zeep.xsd.Schema
:param allow_none: Allow none
:type allow_none: bool
:param context: Optional parsing context (for inline schemas)
:type context: zeep.xsd.context.XmlParserContext
:param schema_type: The original type (not overriden via xsi:type)
:type schema_type: zeep.xsd.types.base.Type
:rtype: dict or None
"""
# If this is an empty complexType (<xsd:complexType name="x"/>)
if not self.attributes and not self.elements:
return None
attributes = xmlelement.attrib
init_kwargs = OrderedDict()
# If this complexType extends a simpleType then we have no nested
# elements. Parse it directly via the type object. This is the case
# for xsd:simpleContent
if isinstance(self._element, Element) and isinstance(
self._element.type, AnySimpleType
):
name, element = self.elements_nested[0]
init_kwargs[name] = element.type.parse_xmlelement(
xmlelement, schema, name, context=context
)
else:
elements = deque(xmlelement.iterchildren())
if allow_none and len(elements) == 0 and len(attributes) == 0:
return
# Parse elements. These are always indicator elements (all, choice,
# group, sequence)
assert len(self.elements_nested) < 2
for name, element in self.elements_nested:
try:
result = element.parse_xmlelements(
elements, schema, name, context=context
)
if result:
init_kwargs.update(result)
except UnexpectedElementError as exc:
raise XMLParseError(exc.message)
# Check if all children are consumed (parsed)
if elements:
if schema.settings.strict:
raise XMLParseError("Unexpected element %r" % elements[0].tag)
else:
init_kwargs["_raw_elements"] = elements
# Parse attributes
if attributes:
attributes = copy.copy(attributes)
for name, attribute in self.attributes:
if attribute.name:
if attribute.qname.text in attributes:
value = attributes.pop(attribute.qname.text)
init_kwargs[name] = attribute.parse(value)
else:
init_kwargs[name] = attribute.parse(attributes)
value = self._value_class(**init_kwargs)
schema_type = schema_type or self
if schema_type and getattr(schema_type, "_array_type", None):
value = schema_type._array_class.from_value_object(value)
return value
def render(self, parent, value, xsd_type=None, render_path=None):
"""Serialize the given value lxml.Element subelements on the parent
element.
:type parent: lxml.etree._Element
:type value: Union[list, dict, zeep.xsd.valueobjects.CompoundValue]
:type xsd_type: zeep.xsd.types.base.Type
:param render_path: list
"""
if not render_path:
render_path = [self.name]
if not self.elements_nested and not self.attributes:
return
# TODO: Implement test case for this
if value is None:
value = {}
if isinstance(value, ArrayValue):
value = value.as_value_object()
# Render attributes
for name, attribute in self.attributes:
attr_value = value[name] if name in value else NotSet
child_path = render_path + [name]
attribute.render(parent, attr_value, child_path)
if (
len(self.elements_nested) == 1
and isinstance(value, self.accepted_types)
and not isinstance(value, (list, dict, CompoundValue))
):
element = self.elements_nested[0][1]
element.type.render(parent, value, None, child_path)
return
# Render sub elements
for name, element in self.elements_nested:
if isinstance(element, Element) or element.accepts_multiple:
element_value = value[name] if name in value else NotSet
child_path = render_path + [name]
else:
element_value = value
child_path = list(render_path)
# We want to explicitly skip this sub-element
if element_value is SkipValue:
continue
if isinstance(element, Element):
element.type.render(parent, element_value, None, child_path)
else:
element.render(parent, element_value, child_path)
if xsd_type:
if xsd_type._xsd_name:
parent.set(xsi_ns("type"), xsd_type._xsd_name)
if xsd_type.qname:
parent.set(xsi_ns("type"), xsd_type.qname)
def parse_kwargs(self, kwargs, name, available_kwargs):
"""Parse the kwargs for this type and return the accepted data as
a dict.
:param kwargs: The kwargs
:type kwargs: dict
:param name: The name as which this type is registered in the parent
:type name: str
:param available_kwargs: The kwargs keys which are still available,
modified in place
:type available_kwargs: set
:rtype: dict
"""
value = None
name = name or self.name
if name in available_kwargs:
value = kwargs[name]
available_kwargs.remove(name)
if value is not Nil:
value = self._create_object(value, name)
return {name: value}
return {}
def _create_object(self, value, name):
"""Return the value as a CompoundValue object
:type value: str
:type value: list, dict, CompoundValue
"""
if value is None:
return None
if isinstance(value, list) and not self._array_type:
return [self._create_object(val, name) for val in value]
if isinstance(value, CompoundValue) or value is SkipValue:
return value
if isinstance(value, dict):
return self(**value)
# Try to automatically create an object. This might fail if there
# are multiple required arguments.
return self(value)
def resolve(self):
"""Resolve all sub elements and types"""
if self._resolved:
return self._resolved
self._resolved = self
resolved = []
for attribute in self._attributes:
value = attribute.resolve()
assert value is not None
if isinstance(value, list):
resolved.extend(value)
else:
resolved.append(value)
self._attributes = resolved
if self._extension:
self._extension = self._extension.resolve()
self._resolved = self.extend(self._extension)
elif self._restriction:
self._restriction = self._restriction.resolve()
self._resolved = self.restrict(self._restriction)
if self._element:
self._element = self._element.resolve()
return self._resolved
def extend(self, base):
"""Create a new ComplexType instance which is the current type
extending the given base type.
Used for handling xsd:extension tags
TODO: Needs a rewrite where the child containers are responsible for
the extend functionality.
:type base: zeep.xsd.types.base.Type
:rtype base: zeep.xsd.types.base.Type
"""
if isinstance(base, ComplexType):
base_attributes = base._attributes_unwrapped
base_element = base._element
else:
base_attributes = []
base_element = None
attributes = base_attributes + self._attributes_unwrapped
# Make sure we don't have duplicate (child is leading)
if base_attributes and self._attributes_unwrapped:
new_attributes = OrderedDict()
for attr in attributes:
if isinstance(attr, AnyAttribute):
new_attributes["##any"] = attr
else:
new_attributes[attr.qname.text] = attr
attributes = new_attributes.values()
# If the base and the current type both have an element defined then
# these need to be merged. The base_element might be empty (or just
# container a placeholder element).
element = []
if self._element and base_element:
self._element = self._element.resolve()
base_element = base_element.resolve()
element = self._element.clone(self._element.name)
if isinstance(base_element, OrderIndicator):
if isinstance(base_element, Choice):
element.insert(0, base_element)
elif isinstance(self._element, Choice):
element = base_element.clone(self._element.name)
element.append(self._element)
elif isinstance(element, OrderIndicator):
for item in reversed(base_element):
element.insert(0, item)
elif isinstance(element, Group):
for item in reversed(base_element):
element.child.insert(0, item)
elif isinstance(self._element, Group):
raise NotImplementedError("TODO")
else:
pass # Element (ignore for now)
elif self._element or base_element:
element = self._element or base_element
else:
element = Element("_value_1", base)
new = self.__class__(
element=element,
attributes=attributes,
qname=self.qname,
is_global=self.is_global,
)
new._extension_types = base.accepted_types
return new
def restrict(self, base):
"""Create a new complextype instance which is the current type
restricted by the base type.
Used for handling xsd:restriction
:type base: zeep.xsd.types.base.Type
:rtype base: zeep.xsd.types.base.Type
"""
attributes = list(chain(base._attributes_unwrapped, self._attributes_unwrapped))
# Make sure we don't have duplicate (self is leading)
if base._attributes_unwrapped and self._attributes_unwrapped:
new_attributes = OrderedDict()
for attr in attributes:
if isinstance(attr, AnyAttribute):
new_attributes["##any"] = attr
else:
new_attributes[attr.qname.text] = attr
attributes = list(new_attributes.values())
if base._element:
base._element.resolve()
new = self.__class__(
element=self._element or base._element,
attributes=attributes,
qname=self.qname,
is_global=self.is_global,
)
return new.resolve()
def signature(self, schema=None, standalone=True):
parts = []
for name, element in self.elements_nested:
part = element.signature(schema, standalone=False)
parts.append(part)
for name, attribute in self.attributes:
part = "%s: %s" % (name, attribute.signature(schema, standalone=False))
parts.append(part)
value = ", ".join(parts)
if standalone:
return "%s(%s)" % (self.get_prefixed_name(schema), value)
else:
return value | zeep-roboticia | /zeep-roboticia-3.4.0.tar.gz/zeep-roboticia-3.4.0/src/zeep/xsd/types/complex.py | complex.py |
import logging
from zeep.utils import qname_attr
from zeep.xsd.const import xsd_ns, xsi_ns
from zeep.xsd.types.base import Type
from zeep.xsd.valueobjects import AnyObject
logger = logging.getLogger(__name__)
__all__ = ["AnyType"]
class AnyType(Type):
_default_qname = xsd_ns("anyType")
_attributes_unwrapped = []
_element = None
def __call__(self, value=None):
return value or ""
def render(self, parent, value, xsd_type=None, render_path=None):
if isinstance(value, AnyObject):
if value.xsd_type is None:
parent.set(xsi_ns("nil"), "true")
else:
value.xsd_type.render(parent, value.value, None, render_path)
parent.set(xsi_ns("type"), value.xsd_type.qname)
elif hasattr(value, "_xsd_elm"):
value._xsd_elm.render(parent, value, render_path)
parent.set(xsi_ns("type"), value._xsd_elm.qname)
else:
parent.text = self.xmlvalue(value)
def parse_xmlelement(
self, xmlelement, schema=None, allow_none=True, context=None, schema_type=None
):
"""Consume matching xmlelements and call parse() on each
:param xmlelement: XML element objects
:type xmlelement: lxml.etree._Element
:param schema: The parent XML schema
:type schema: zeep.xsd.Schema
:param allow_none: Allow none
:type allow_none: bool
:param context: Optional parsing context (for inline schemas)
:type context: zeep.xsd.context.XmlParserContext
:param schema_type: The original type (not overriden via xsi:type)
:type schema_type: zeep.xsd.types.base.Type
:rtype: dict or None
"""
xsi_type = qname_attr(xmlelement, xsi_ns("type"))
xsi_nil = xmlelement.get(xsi_ns("nil"))
children = list(xmlelement)
# Handle xsi:nil attribute
if xsi_nil == "true":
return None
# Check if a xsi:type is defined and try to parse the xml according
# to that type.
if xsi_type and schema:
xsd_type = schema.get_type(xsi_type, fail_silently=True)
# If we were unable to resolve a type for the xsi:type (due to
# buggy soap servers) then we just return the text or lxml element.
if not xsd_type:
logger.debug(
"Unable to resolve type for %r, returning raw data", xsi_type.text
)
if xmlelement.text:
return xmlelement.text
return children
# If the xsd_type is xsd:anyType then we will recurs so ignore
# that.
if isinstance(xsd_type, self.__class__):
return xmlelement.text or None
return xsd_type.parse_xmlelement(xmlelement, schema, context=context)
# If no xsi:type is set and the element has children then there is
# not much we can do. Just return the children
elif children:
return children
elif xmlelement.text is not None:
return self.pythonvalue(xmlelement.text)
return None
def resolve(self):
return self
def xmlvalue(self, value):
"""Guess the xsd:type for the value and use corresponding serializer"""
from zeep.xsd.types import builtins
available_types = [
builtins.String,
builtins.Boolean,
builtins.Decimal,
builtins.Float,
builtins.DateTime,
builtins.Date,
builtins.Time,
]
for xsd_type in available_types:
if isinstance(value, xsd_type.accepted_types):
return xsd_type().xmlvalue(value)
return str(value)
def pythonvalue(self, value, schema=None):
return value
def signature(self, schema=None, standalone=True):
return "xsd:anyType" | zeep-roboticia | /zeep-roboticia-3.4.0.tar.gz/zeep-roboticia-3.4.0/src/zeep/xsd/types/any.py | any.py |
import base64
import datetime
import math
import re
from decimal import Decimal as _Decimal
import isodate
import pytz
import six
from zeep.xsd.const import xsd_ns
from zeep.xsd.types.any import AnyType
from zeep.xsd.types.simple import AnySimpleType
class ParseError(ValueError):
pass
class BuiltinType(object):
def __init__(self, qname=None, is_global=False):
super(BuiltinType, self).__init__(qname, is_global=True)
def check_no_collection(func):
def _wrapper(self, value):
if isinstance(value, (list, dict, set)):
raise ValueError(
"The %s type doesn't accept collections as value"
% (self.__class__.__name__)
)
return func(self, value)
return _wrapper
##
# Primitive types
class String(BuiltinType, AnySimpleType):
_default_qname = xsd_ns("string")
accepted_types = six.string_types
@check_no_collection
def xmlvalue(self, value):
if isinstance(value, bytes):
return value.decode("utf-8")
return six.text_type(value if value is not None else "")
def pythonvalue(self, value):
return value
class Boolean(BuiltinType, AnySimpleType):
_default_qname = xsd_ns("boolean")
accepted_types = (bool,)
@check_no_collection
def xmlvalue(self, value):
return "true" if value and value not in ("false", "0") else "false"
def pythonvalue(self, value):
"""Return True if the 'true' or '1'. 'false' and '0' are legal false
values, but we consider everything not true as false.
"""
return value in ("true", "1")
class Decimal(BuiltinType, AnySimpleType):
_default_qname = xsd_ns("decimal")
accepted_types = (_Decimal, float) + six.string_types
@check_no_collection
def xmlvalue(self, value):
return str(value)
def pythonvalue(self, value):
return _Decimal(value)
class Float(BuiltinType, AnySimpleType):
_default_qname = xsd_ns("float")
accepted_types = (float, _Decimal) + six.string_types
def xmlvalue(self, value):
return str(value).upper()
def pythonvalue(self, value):
return float(value)
class Double(BuiltinType, AnySimpleType):
_default_qname = xsd_ns("double")
accepted_types = (_Decimal, float) + six.string_types
@check_no_collection
def xmlvalue(self, value):
return str(value)
def pythonvalue(self, value):
return float(value)
class Duration(BuiltinType, AnySimpleType):
_default_qname = xsd_ns("duration")
accepted_types = (isodate.duration.Duration,) + six.string_types
@check_no_collection
def xmlvalue(self, value):
return isodate.duration_isoformat(value)
def pythonvalue(self, value):
if value.startswith("PT-"):
value = value.replace("PT-", "PT")
result = isodate.parse_duration(value)
return datetime.timedelta(0 - result.total_seconds())
else:
return isodate.parse_duration(value)
class DateTime(BuiltinType, AnySimpleType):
_default_qname = xsd_ns("dateTime")
accepted_types = (datetime.datetime,) + six.string_types
@check_no_collection
def xmlvalue(self, value):
if isinstance(value, six.string_types):
return value
# Bit of a hack, since datetime is a subclass of date we can't just
# test it with an isinstance(). And actually, we should not really
# care about the type, as long as it has the required attributes
if not all(hasattr(value, attr) for attr in ("hour", "minute", "second")):
value = datetime.datetime.combine(
value,
datetime.time(
getattr(value, "hour", 0),
getattr(value, "minute", 0),
getattr(value, "second", 0),
),
)
if getattr(value, "microsecond", 0):
return isodate.isostrf.strftime(value, "%Y-%m-%dT%H:%M:%S.%f%Z")
return isodate.isostrf.strftime(value, "%Y-%m-%dT%H:%M:%S%Z")
def pythonvalue(self, value):
# Determine based on the length of the value if it only contains a date
# lazy hack ;-)
if len(value) == 10:
value += "T00:00:00"
return isodate.parse_datetime(value)
class Time(BuiltinType, AnySimpleType):
_default_qname = xsd_ns("time")
accepted_types = (datetime.time,) + six.string_types
@check_no_collection
def xmlvalue(self, value):
if isinstance(value, six.string_types):
return value
if value.microsecond:
return isodate.isostrf.strftime(value, "%H:%M:%S.%f%Z")
return isodate.isostrf.strftime(value, "%H:%M:%S%Z")
def pythonvalue(self, value):
return isodate.parse_time(value)
class Date(BuiltinType, AnySimpleType):
_default_qname = xsd_ns("date")
accepted_types = (datetime.date,) + six.string_types
@check_no_collection
def xmlvalue(self, value):
if isinstance(value, six.string_types):
return value
return isodate.isostrf.strftime(value, "%Y-%m-%d")
def pythonvalue(self, value):
return isodate.parse_date(value)
class gYearMonth(BuiltinType, AnySimpleType):
"""gYearMonth represents a specific gregorian month in a specific gregorian
year.
Lexical representation: CCYY-MM
"""
accepted_types = (datetime.date,) + six.string_types
_default_qname = xsd_ns("gYearMonth")
_pattern = re.compile(
r"^(?P<year>-?\d{4,})-(?P<month>\d\d)(?P<timezone>Z|[-+]\d\d:?\d\d)?$"
)
@check_no_collection
def xmlvalue(self, value):
year, month, tzinfo = value
return "%04d-%02d%s" % (year, month, _unparse_timezone(tzinfo))
def pythonvalue(self, value):
match = self._pattern.match(value)
if not match:
raise ParseError()
group = match.groupdict()
return (
int(group["year"]),
int(group["month"]),
_parse_timezone(group["timezone"]),
)
class gYear(BuiltinType, AnySimpleType):
"""gYear represents a gregorian calendar year.
Lexical representation: CCYY
"""
accepted_types = (datetime.date,) + six.string_types
_default_qname = xsd_ns("gYear")
_pattern = re.compile(r"^(?P<year>-?\d{4,})(?P<timezone>Z|[-+]\d\d:?\d\d)?$")
@check_no_collection
def xmlvalue(self, value):
year, tzinfo = value
return "%04d%s" % (year, _unparse_timezone(tzinfo))
def pythonvalue(self, value):
match = self._pattern.match(value)
if not match:
raise ParseError()
group = match.groupdict()
return (int(group["year"]), _parse_timezone(group["timezone"]))
class gMonthDay(BuiltinType, AnySimpleType):
"""gMonthDay is a gregorian date that recurs, specifically a day of the
year such as the third of May.
Lexical representation: --MM-DD
"""
accepted_types = (datetime.date,) + six.string_types
_default_qname = xsd_ns("gMonthDay")
_pattern = re.compile(
r"^--(?P<month>\d\d)-(?P<day>\d\d)(?P<timezone>Z|[-+]\d\d:?\d\d)?$"
)
@check_no_collection
def xmlvalue(self, value):
month, day, tzinfo = value
return "--%02d-%02d%s" % (month, day, _unparse_timezone(tzinfo))
def pythonvalue(self, value):
match = self._pattern.match(value)
if not match:
raise ParseError()
group = match.groupdict()
return (
int(group["month"]),
int(group["day"]),
_parse_timezone(group["timezone"]),
)
class gDay(BuiltinType, AnySimpleType):
"""gDay is a gregorian day that recurs, specifically a day of the month
such as the 5th of the month
Lexical representation: ---DD
"""
accepted_types = (datetime.date,) + six.string_types
_default_qname = xsd_ns("gDay")
_pattern = re.compile(r"^---(?P<day>\d\d)(?P<timezone>Z|[-+]\d\d:?\d\d)?$")
@check_no_collection
def xmlvalue(self, value):
day, tzinfo = value
return "---%02d%s" % (day, _unparse_timezone(tzinfo))
def pythonvalue(self, value):
match = self._pattern.match(value)
if not match:
raise ParseError()
group = match.groupdict()
return (int(group["day"]), _parse_timezone(group["timezone"]))
class gMonth(BuiltinType, AnySimpleType):
"""gMonth is a gregorian month that recurs every year.
Lexical representation: --MM
"""
accepted_types = (datetime.date,) + six.string_types
_default_qname = xsd_ns("gMonth")
_pattern = re.compile(r"^--(?P<month>\d\d)(?P<timezone>Z|[-+]\d\d:?\d\d)?$")
@check_no_collection
def xmlvalue(self, value):
month, tzinfo = value
return "--%d%s" % (month, _unparse_timezone(tzinfo))
def pythonvalue(self, value):
match = self._pattern.match(value)
if not match:
raise ParseError()
group = match.groupdict()
return (int(group["month"]), _parse_timezone(group["timezone"]))
class HexBinary(BuiltinType, AnySimpleType):
accepted_types = six.string_types
_default_qname = xsd_ns("hexBinary")
@check_no_collection
def xmlvalue(self, value):
return value
def pythonvalue(self, value):
return value
class Base64Binary(BuiltinType, AnySimpleType):
accepted_types = six.string_types
_default_qname = xsd_ns("base64Binary")
@check_no_collection
def xmlvalue(self, value):
return base64.b64encode(value)
def pythonvalue(self, value):
return base64.b64decode(value)
class AnyURI(BuiltinType, AnySimpleType):
accepted_types = six.string_types
_default_qname = xsd_ns("anyURI")
@check_no_collection
def xmlvalue(self, value):
return value
def pythonvalue(self, value):
return value
class QName(BuiltinType, AnySimpleType):
accepted_types = six.string_types
_default_qname = xsd_ns("QName")
@check_no_collection
def xmlvalue(self, value):
return value
def pythonvalue(self, value):
return value
class Notation(BuiltinType, AnySimpleType):
accepted_types = six.string_types
_default_qname = xsd_ns("NOTATION")
##
# Derived datatypes
class NormalizedString(String):
_default_qname = xsd_ns("normalizedString")
class Token(NormalizedString):
_default_qname = xsd_ns("token")
class Language(Token):
_default_qname = xsd_ns("language")
class NmToken(Token):
_default_qname = xsd_ns("NMTOKEN")
class NmTokens(NmToken):
_default_qname = xsd_ns("NMTOKENS")
class Name(Token):
_default_qname = xsd_ns("Name")
class NCName(Name):
_default_qname = xsd_ns("NCName")
class ID(NCName):
_default_qname = xsd_ns("ID")
class IDREF(NCName):
_default_qname = xsd_ns("IDREF")
class IDREFS(IDREF):
_default_qname = xsd_ns("IDREFS")
class Entity(NCName):
_default_qname = xsd_ns("ENTITY")
class Entities(Entity):
_default_qname = xsd_ns("ENTITIES")
class Integer(Decimal):
_default_qname = xsd_ns("integer")
accepted_types = (int, float) + six.string_types
def xmlvalue(self, value):
return str(value)
def pythonvalue(self, value):
return int(value)
class NonPositiveInteger(Integer):
_default_qname = xsd_ns("nonPositiveInteger")
class NegativeInteger(Integer):
_default_qname = xsd_ns("negativeInteger")
class Long(Integer):
_default_qname = xsd_ns("long")
def pythonvalue(self, value):
return long(value) if six.PY2 else int(value) # noqa
class Int(Long):
_default_qname = xsd_ns("int")
class Short(Int):
_default_qname = xsd_ns("short")
class Byte(Short):
"""A signed 8-bit integer"""
_default_qname = xsd_ns("byte")
class NonNegativeInteger(Integer):
_default_qname = xsd_ns("nonNegativeInteger")
class UnsignedLong(NonNegativeInteger):
_default_qname = xsd_ns("unsignedLong")
class UnsignedInt(UnsignedLong):
_default_qname = xsd_ns("unsignedInt")
class UnsignedShort(UnsignedInt):
_default_qname = xsd_ns("unsignedShort")
class UnsignedByte(UnsignedShort):
_default_qname = xsd_ns("unsignedByte")
class PositiveInteger(NonNegativeInteger):
_default_qname = xsd_ns("positiveInteger")
##
# Other
def _parse_timezone(val):
"""Return a pytz.tzinfo object"""
if not val:
return
if val == "Z" or val == "+00:00":
return pytz.utc
negative = val.startswith("-")
minutes = int(val[-2:])
minutes += int(val[1:3]) * 60
if negative:
minutes = 0 - minutes
return pytz.FixedOffset(minutes)
def _unparse_timezone(tzinfo):
if not tzinfo:
return ""
if tzinfo == pytz.utc:
return "Z"
hours = math.floor(tzinfo._minutes / 60)
minutes = tzinfo._minutes % 60
if hours > 0:
return "+%02d:%02d" % (hours, minutes)
return "-%02d:%02d" % (abs(hours), minutes)
_types = [
# Primitive
String,
Boolean,
Decimal,
Float,
Double,
Duration,
DateTime,
Time,
Date,
gYearMonth,
gYear,
gMonthDay,
gDay,
gMonth,
HexBinary,
Base64Binary,
AnyURI,
QName,
Notation,
# Derived
NormalizedString,
Token,
Language,
NmToken,
NmTokens,
Name,
NCName,
ID,
IDREF,
IDREFS,
Entity,
Entities,
Integer,
NonPositiveInteger, # noqa
NegativeInteger,
Long,
Int,
Short,
Byte,
NonNegativeInteger, # noqa
UnsignedByte,
UnsignedInt,
UnsignedLong,
UnsignedShort,
PositiveInteger,
# Other
AnyType,
AnySimpleType,
]
default_types = {cls._default_qname: cls(is_global=True) for cls in _types} | zeep-roboticia | /zeep-roboticia-3.4.0.tar.gz/zeep-roboticia-3.4.0/src/zeep/xsd/types/builtins.py | builtins.py |
Authors
=======
* Michael van Tellingen
Contributors
============
* Kateryna Burda
* Alexey Stepanov
* Marco Vellinga
* jaceksnet
* Andrew Serong
* vashek
* Seppo Yli-Olli
* Sam Denton
* Dani Möller
* Julien Delasoie
* Christian González
* bjarnagin
* mcordes
* Joeri Bekker
* Bartek Wójcicki
* jhorman
* fiebiga
* David Baumgold
* Antonio Cuni
* Alexandre de Mari
* Nicolas Evrard
* Eric Wong
* Jason Vertrees
* Falldog
* Matt Grimm (mgrimm)
* Marek Wywiał
* btmanm
* Caleb Salt
* Ondřej Lanč
* Jan Murre
* Stefano Parmesan
* Julien Marechal
* Dave Wapstra
* Mike Fiedler
* Derek Harland
* Bruno Duyé
* Christoph Heuel
* Ben Tucker
* Eric Waller
* Falk Schuetzenmeister
* Jon Jenkins
* OrangGeeGee
* Raymond Piller
* Zoltan Benedek
* Øyvind Heddeland Instefjord
* Pol Sanlorenzo
| zeep | /zeep-4.1.0.tar.gz/zeep-4.1.0/CONTRIBUTORS.rst | CONTRIBUTORS.rst |
========================
Zeep: Python SOAP client
========================
A fast and modern Python SOAP client
Highlights:
* Compatible with Python 3.6, 3.7, 3.8 and PyPy
* Build on top of lxml and requests
* Support for Soap 1.1, Soap 1.2 and HTTP bindings
* Support for WS-Addressing headers
* Support for WSSE (UserNameToken / x.509 signing)
* Support for asyncio using the httpx module
* Experimental support for XOP messages
Please see for more information the documentation at
http://docs.python-zeep.org/
.. start-no-pypi
Status
------
.. image:: https://readthedocs.org/projects/python-zeep/badge/?version=latest
:target: https://readthedocs.org/projects/python-zeep/
.. image:: https://github.com/mvantellingen/python-zeep/workflows/Python%20Tests/badge.svg
:target: https://github.com/mvantellingen/python-zeep/actions?query=workflow%3A%22Python+Tests%22
.. image:: http://codecov.io/github/mvantellingen/python-zeep/coverage.svg?branch=master
:target: http://codecov.io/github/mvantellingen/python-zeep?branch=master
.. image:: https://img.shields.io/pypi/v/zeep.svg
:target: https://pypi.python.org/pypi/zeep/
.. end-no-pypi
Installation
------------
.. code-block:: bash
pip install zeep
Note that the latest version to support Python 2.7, 3.3, 3.4 and 3.5 is Zeep 3.4, install via `pip install zeep==3.4.0`
Zeep uses the lxml library for parsing xml. See https://lxml.de/installation.html for the installation requirements.
Usage
-----
.. code-block:: python
from zeep import Client
client = Client('tests/wsdl_files/example.rst')
client.service.ping()
To quickly inspect a WSDL file use::
python -m zeep <url-to-wsdl>
Please see the documentation at http://docs.python-zeep.org for more
information.
Support
=======
If you want to report a bug then please first read
http://docs.python-zeep.org/en/master/reporting_bugs.html
Please only report bugs and not support requests to the GitHub issue tracker.
| zeep | /zeep-4.1.0.tar.gz/zeep-4.1.0/README.rst | README.rst |
# zeetoo
A collection of various Python scripts created as a help in everyday work in Team II IChO PAS.
- [Geting Started](#getting-started)
- [Running Scripts](#running-scripts)
- [Command Line Interface](#command-line-interface)
- [Python API](#python-api)
- [Graphical User Interface](#graphical-user-interface)
- [Description of modules](#description-of-modules)
- [backuper](#backuper) - simple automated backup tool for Windows
- [confsearch](#confsearch) - find conformers of given molecule using RDKit
- [fixgvmol](#fixgvmol) - correct .mol files created with GaussView software
- [getcdx](#getcdx) - extract all ChemDraw files embedded in .docx file
- [gofproc](#gofproc) - simple script for processing Gaussian output files
- [sdf_to_gjf](#sdf_to_gjf) - save molecules from .sdf file as separate .gjf files
- [Requirements](#requirements)
- [License & Disclaimer](#license--disclaimer)
- [Changelog](#changelog)
## Getting Started
To use this collection of scripts you will need a Python 3 interpreter.
You can download an installer of latest version from [python.org](https://www.python.org)
(a shortcut to direct download for Windows:
[Python 3.7.4 Windows x86 executable installer](https://www.python.org/ftp/python/3.7.4/python-3.7.4.exe)).
The easiest way to get **zeetoo** up and running is to run `pip install zeetoo` in the command line*.
Alternatively, you can download this package as zip file using 'Clone or download' button on this site.
Unzip the package and from the resulting directory run `python setup.py install`
in the command line*.
And that's it, you're ready to go!
* On windows you can reach command line by right-clicking inside the directory
while holding Shift and then choosing "Open PowerShell window here" or "Open command window here".
## Running Scripts
### Command Line Interface
All zeetoo functionality is available from command line.
After installation of the package each module can be accessed with use of
`zeetoo [module_name] [parameters]`.
For more information run `zeetoo --help` to see available modules or
`zeetoo [module_name] --help` to see the help page for specific module.
### Python API
Modules contained in **zeetoo** may also be used directly from python.
This section will be supplemented with details on this topic soon.
### Graphical User Interface
A simple graphical user interface (GUI) is available for backuper script.
Please refer to the [backuper section](#backuper) for details.
GUIs for other modules will probably be available in near future.
## Description of Modules
## backuper
A simple Python script for scheduling and running automated backup.
Essentially, it copies specified files and directories to specified location
with regard to date of last modification of both, source file and existing copy:
- if source file is newer than backup version, the second will be overridden;
- if both files have the same last modification time, file will not be copied;
- if backup version is newer, it will be renamed to "oldname_last-modification-time"
and source file will be copied, preserving both versions.
After creating a specification for backup job (that is, specifying backup destination
and files that should be copied; these information are stored in .ini file),
it may be run manually or scheduled.
Scheduling is currently available only on Windows, as it uses build-in Windows task scheduler.
It is important to remember, that this is not a version control software.
Only lastly copied version is stored.
A minimal graphical user interface for this script is available (see below).
### graphical user interface for backuper module
To start up the graphical user interface (GUI) run `zeetoo backuper_gui` in the command line.
If you've downloaded the whole package manually, you may also double-click on start_gui.bat file.
A window similar to the one below should appear.
Further you'll find description of each element of this window.
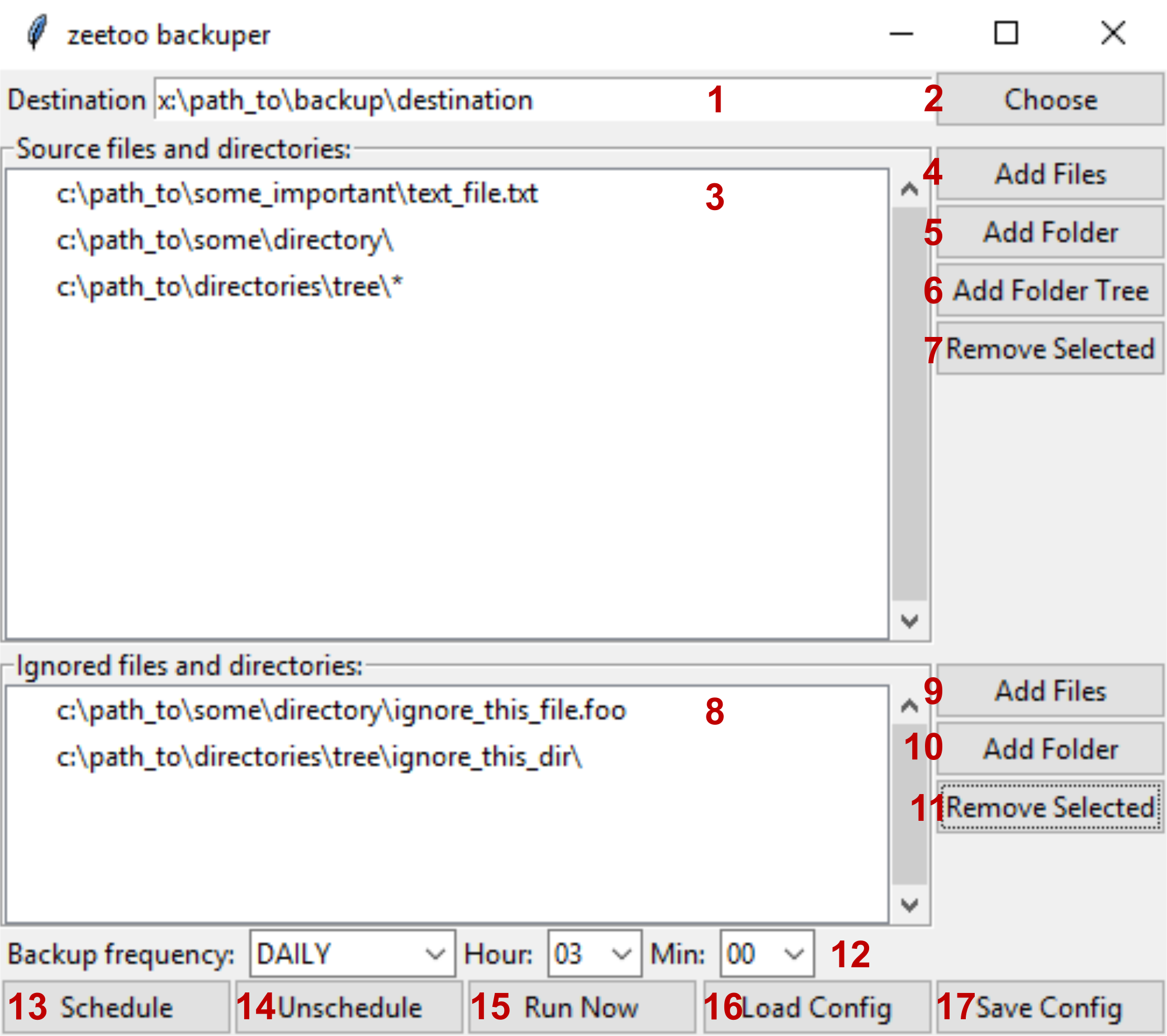
1. This field shows path to backup's main directory. Files will be copied there. You can change this field directly or by clicking 2.
2. Choose backup destination directory using graphical interface.
3. All files and directories that are meant to be backuped are listed here. It will be called 'source' from now on. For more details read 4-7.
4. Add file or files to source. Files will be shown in 3 as line without slash character at the end. Each file will be copied to the directory of the same name as directory it is located in; in example shown above it would be 'x:\path_to\backup\destination\some_important\text_file.text'.
5. Add a directory to source. Directories will be shown in 3 as line with slash character at the end. All files (but not subdirectories!) present in this directory will be copied to directory with same name.
6. Add a directory tree to source. Trees will be shown in 3 as line with slash and star characters at the end. The whole content of chosen directory will be copied, including all files and subdirectories.
7. Remove selected path from source.
8. All files and directories marked as ignored will be shown here. Ignored files and directories won't be copied during backup, even if they are inside source directory or tree, or listed as source.
9. Add file or files to ignored.
10. Add directory to ignored.
11. Remove selected item from list of ignored files and directories.
12. Set how often backup should be run (once a day, once a week or once a month) and at what time.
13. Schedule backup task according to specified guidelines. WARNING: this will also automatically save configuration file.
14. Remove backup task scheduled earlier.
15. Run backup task now, according to specified guidelines. Saving configuration to file not needed.
16. Load configuration from specified file.
17. Save configuration.
Configuration is stored in `[User]/AppData/Local/zeetoo/backuper/config.ini` file.
After scheduling backup task this file should not be moved.
It can be modified though, backup task will be done with this modified guidelines from now on.
Scheduling new backup task, even using different configuration file, will override previous task,
unless task_name in this file is specifically changed.
## confsearch
Performs a conformational search on set of given molecules. Takes a .mol file (or number of them)
as an input and saves a list of generated conformers to specified .sdf file.
Some restriction on this process may be given: a number of conformers to generate,
a minimum RMSD value, a maximum energy difference, a maximum number of optimization cycles,
and a set of constraints for force field optimization.
## fixgvmol
.mol files created with GaussView (GV5 at least) lack some information, namely a mol version and END line.
Without it some programs might not be able to read such files.
This script adds these pieces of information to .mol files missing them.
## getcdx
Extracts all embedded ChemDraw files from a .docx document and saves it in a separate directory
(which might be specified by user), using in-text description of schemes/drawings as file names.
It may be specified if description of the scheme/drawing is located above or underneath it
(the former is default). Finally, It may be specified how long filename should be.
## gofproc
Extracts information about molecule energy and imaginary frequencies from given set of Gaussian
output files with *freq* job performed. Extracted data might be written to terminal (stdout)
or to specified .xlsx file (must not be opened in other programs) at the end of the file or
appended to a row, based on name of the file parsed.
Calculations, that did not converged are reported separately.
## sdf_to_gjf
Writes molecules contained in an .sdf file to a set of .gjf files in accordance with the guidelines
given by user.
# Requirements
- getcdx module requires olefile package
- gofproc module requires openpyxl package
- confsearch module requires RDKit software
Please note, that the RDKit **will not** be installed automatically with this package.
The recommended way to get RDKit software is through use of Anaconda Python distribution.
Please refer to RDKit documentation for more information.
# License & Disclaimer
See the LICENSE.txt file for license rights and limitations (MIT).
# Changelog
## v.0.1.3
- fixed sdf_to_gjf ignoring parameters "charge" and "multiplicity"
- supplemented sdf_to_gjf default values and help message
- fixed typo in sdf_to_gjf CLI ("sufix" -> "suffix")
- enabled specifying coordinates' precision in sdf_to_gjf
- enhanced handling of link0 commands by sdf_to_gjf
- removed filtering of explicitly provided non-.mol files in fixgvmol
## v.0.1.2
- getcdx now changes characters forbidden in file names to "-" instead of raising an exception
- start_gui.bat should now work regardless its location
## v.0.1.1
- fixed import errors when run as module
## v.0.1.0
- initial release | zeetoo | /zeetoo-0.1.3.tar.gz/zeetoo-0.1.3/README.md | README.md |
<div align="center">
<img width="300px" src="https://github.com/zefhub/zefhub-web-assets/blob/main/zef_logo_white.png#gh-dark-mode-only">
<img width="300px" src="https://github.com/zefhub/zefhub-web-assets/blob/main/zef_logo_black.png#gh-light-mode-only">
</div>
<p align="center">
A data-oriented toolkit for graph data
</p>
<p align="center">
<em>versioned graphs + streams + query using Python + GraphQL</em>
</p>
<div align="center">
<a href="https://github.com/zefhub/zef/actions/workflows/on-master-merge.yml">
<img src="https://github.com/zefhub/zef/actions/workflows/on-master-merge.yml/badge.svg" alt="Workflow status badge" loading="lazy" height="20">
</a>
<a href="https://github.com/zefhub/zef/blob/master/LICENSE">
<img src="https://img.shields.io/badge/license-Apache%202.0-teal" />
</a>
<a href="https://twitter.com/zefhub" target="_blank"><img src="https://img.shields.io/twitter/follow/zefhub.svg?style=social&label=Follow"></a>
<br />
<br />
<a href="https://zef.zefhub.io/">Docs</a>
<span> | </span>
<a href="https://zef.zefhub.io/blog">Blog</a>
<span> | </span>
<a href="https://zef.chat/">Chat</a>
<span> | </span>
<a href="https://www.zefhub.io/">ZefHub</a>
</div>
<br />
<br />

<br />
## Description
Zef is an open source, data-oriented toolkit for graph data. It combines the access speed and local development experience of an in-memory data structure with the power of a fully versioned, immutable database (and distributed persistence if needed with ZefHub). Furthermore, Zef includes a library of composable functional operators, effects handling, and native GraphQL support. You can pick and choose what you need for your project.
If any of these apply to you, Zef might help:
- I need a graph database with fast query speeds and hassle-free infra
- I need a graph data model that's more powerful than NetworkX but easier than Neo4j
- I need to "time travel" and access past states easily
- I like Datomic but prefer something open source that feels like working with local data structures
- I would prefer querying and traversing directly in Python, rather than a query language (like Cypher or GSQL)
- I need a GraphQL API that's easy to spin up and close to my data model
<br />
<br />
## Features
- a graph language you can use directly in Python code
- fully versioned graphs
- in-memory access speeds
- free and real-time data persistence (via ZefHub)
- work with graphs like local data structures
- no separate query language
- no ORM
- GraphQL API with low impedance mismatch to data model
- data streams and subscriptions
<br />
<br />
## Status
Zef is currently in Public Alpha.
- [x] Private Alpha: Testing Zef internally and with a closed group of users.
- [x] Public Alpha: Anyone can use Zef but please be patient with very large graphs!
- [ ] Public Beta: Stable enough for most non-enterprise use cases.
- [ ] Public: Stable for all production use cases.
<br />
<br />
## Installation
The platforms we currently support are 64-bit Linux and MacOS. The latest version can be installed via the PyPI repository using:
```bash
pip install zef
```
This will attempt to install a wheel if supported by your system and compile from source otherwise. See INSTALL for more details if compiling from source.
Check out our [installation doc](https://zef.zefhub.io/introduction/installation) for more details about getting up and running once installed.
<br />
<br />
## Using Zef
Here's some quick points to get going. Check out our [Quick Start](https://zef.zefhub.io/introduction/quick-start) and docs for more details.
A quick note, in Zef, we overloaded the "|" pipe so users can chain together values, Zef operators (ZefOps), and functions in sequential, lazy, and executable pipelines where data flow is left to right.
<br />
<div align="center">
<h3>💆 Get started 💆</h3>
</div>
```python
from zef import * # these imports unlock user friendly syntax and powerful Zef operators (ZefOps)
from zef.ops import *
g = Graph() # create an empty graph
```
<br />
<div align="center">
<h3>🌱 Add some data 🌱</h3>
</div>
```python
p1 = ET.Person | g | run # add an entity to the graph
(p1, RT.FirstName, "Yolandi") | g | run # add "fields" via relations triples: (source, relation, target)
```
<br />
<div align="center">
<h3>🐾 Traverse the graph 🐾</h3>
</div>
```python
p1 | Out[RT.FirstName] # one hop: step onto the relation
p1 | out_rel[RT.FirstName] # two hops: step onto the target
```
<br />
<div align="center">
<h3>⏳ Time travel ⌛</h3>
</div>
```python
p1 | time_travel[-2] # move reference frame back two time slices
p1 | time_travel[Time('2021 December 4 15:31:00 (+0100)')] # move to a specific date and time
```
<br />
<div align="center">
<h3>👐 Share with other users (via ZefHub) 👐</h3>
</div>
```python
g | sync[True] | run # save and sync all future changes on ZefHub
# ---------------- Python Session A (You) -----------------
g | uid | to_clipboard | run # copy uid onto local clipboard
# ---------------- Python Session B (Friend) -----------------
graph_uid: str = '...' # uid copied from Slack/WhatsApp/email/etc
g = Graph(graph_uid)
g | now | all[ET] | collect # see all entities in the latest time slice
```
<br />
<div align="center">
<h3>🚣 Choose your own adventure 🚣</h3>
</div>
- [Basic tutorial of Zef](https://zef.zefhub.io/tutorials/basic/employee-database)
- [Build Wordle clone with Zef](https://zef.zefhub.io/blog/wordle-using-zefops)
- [Import data from CSV](https://zef.zefhub.io/how-to/import-csv)
- [Import data from NetworkX](https://zef.zefhub.io/how-to/import-graph-formats)
- [Set up a GraphQL API](https://zef.zefhub.io/how-to/graphql-basic)
- [Use Zef graphs in NetworkX](https://zef.zefhub.io/how-to/use-zef-networkx)
<br />
<div align="center">
<h3>📌 A note on ZefHub 📌</h3>
</div>
Zef is designed so you can use it locally and drop it into any existing project. You have the option of syncing your graphs with ZefHub, a service that persists, syncs, and distributes graphs automatically (and the company behind Zef). ZefHub makes it possible to [share graphs with other users and see changes live](https://zef.zefhub.io/how-to/share-graphs), by memory mapping across machines in real-time!
You can create a ZefHub account for free which gives you full access to storing and sharing graphs forever. For full transparency, our long-term hope is that many users will get value from Zef or Zef + ZefHub for free, while ZefHub power users will pay a fee for added features and services.
<br />
<br />
## Roadmap
We want to make it incredibly easy for developers to build fully distributed, reactive systems with consistent data and cross-language (Python, C++, Julia) support. If there's sufficient interest, we'd be happy to share a public board of items we're working on.
<br />
<br />
## Contributing
Thank you for considering contributing to Zef! We know your time is valuable and your input makes Zef better for all current and future users.
To optimize for feedback speed, please raise bugs or suggest features directly in our community chat [https://zef.chat](https://zef.chat).
Please refer to our [CONTRIBUTING file](https://github.com/zefhub/zef/blob/master/CONTRIBUTING.md) and [CODE_OF_CONDUCT file](https://github.com/zefhub/zef/blob/master/CODE_OF_CONDUCT.md) for more details.
<br />
<br />
## License
Zef is licensed under the Apache License, Version 2.0 (the "License"). You may obtain a copy of the License at
[http://www.apache.org/licenses/LICENSE-2.0](http://www.apache.org/licenses/LICENSE-2.0)
<br />
<br />
## Dependencies
The compiled libraries make use of the following packages:
- `asio` (https://github.com/chriskohlhoff/asio)
- `JWT++` (https://github.com/Thalhammer/jwt-cpp)
- `Curl` (https://github.com/curl/curl)
- `JSON` (https://github.com/nlohmann/json)
- `Parallel hashmap` (https://github.com/greg7mdp/parallel-hashmap)
- `Ranges-v3` (https://github.com/ericniebler/range-v3)
- `Websocket++` (https://github.com/zaphoyd/websocketpp)
- `Zstandard` (https://github.com/facebook/zstd)
- `pybind11` (https://github.com/pybind/pybind11)
- `pybind_json` (https://github.com/pybind/pybind11_json)
| zef | /zef-0.17.0a3.tar.gz/zef-0.17.0a3/README.md | README.md |
# Version: 0.22
"""The Versioneer - like a rocketeer, but for versions.
The Versioneer
==============
* like a rocketeer, but for versions!
* https://github.com/python-versioneer/python-versioneer
* Brian Warner
* License: Public Domain
* Compatible with: Python 3.6, 3.7, 3.8, 3.9, 3.10 and pypy3
* [![Latest Version][pypi-image]][pypi-url]
* [![Build Status][travis-image]][travis-url]
This is a tool for managing a recorded version number in distutils/setuptools-based
python projects. The goal is to remove the tedious and error-prone "update
the embedded version string" step from your release process. Making a new
release should be as easy as recording a new tag in your version-control
system, and maybe making new tarballs.
## Quick Install
* `pip install versioneer` to somewhere in your $PATH
* add a `[versioneer]` section to your setup.cfg (see [Install](INSTALL.md))
* run `versioneer install` in your source tree, commit the results
* Verify version information with `python setup.py version`
## Version Identifiers
Source trees come from a variety of places:
* a version-control system checkout (mostly used by developers)
* a nightly tarball, produced by build automation
* a snapshot tarball, produced by a web-based VCS browser, like github's
"tarball from tag" feature
* a release tarball, produced by "setup.py sdist", distributed through PyPI
Within each source tree, the version identifier (either a string or a number,
this tool is format-agnostic) can come from a variety of places:
* ask the VCS tool itself, e.g. "git describe" (for checkouts), which knows
about recent "tags" and an absolute revision-id
* the name of the directory into which the tarball was unpacked
* an expanded VCS keyword ($Id$, etc)
* a `_version.py` created by some earlier build step
For released software, the version identifier is closely related to a VCS
tag. Some projects use tag names that include more than just the version
string (e.g. "myproject-1.2" instead of just "1.2"), in which case the tool
needs to strip the tag prefix to extract the version identifier. For
unreleased software (between tags), the version identifier should provide
enough information to help developers recreate the same tree, while also
giving them an idea of roughly how old the tree is (after version 1.2, before
version 1.3). Many VCS systems can report a description that captures this,
for example `git describe --tags --dirty --always` reports things like
"0.7-1-g574ab98-dirty" to indicate that the checkout is one revision past the
0.7 tag, has a unique revision id of "574ab98", and is "dirty" (it has
uncommitted changes).
The version identifier is used for multiple purposes:
* to allow the module to self-identify its version: `myproject.__version__`
* to choose a name and prefix for a 'setup.py sdist' tarball
## Theory of Operation
Versioneer works by adding a special `_version.py` file into your source
tree, where your `__init__.py` can import it. This `_version.py` knows how to
dynamically ask the VCS tool for version information at import time.
`_version.py` also contains `$Revision$` markers, and the installation
process marks `_version.py` to have this marker rewritten with a tag name
during the `git archive` command. As a result, generated tarballs will
contain enough information to get the proper version.
To allow `setup.py` to compute a version too, a `versioneer.py` is added to
the top level of your source tree, next to `setup.py` and the `setup.cfg`
that configures it. This overrides several distutils/setuptools commands to
compute the version when invoked, and changes `setup.py build` and `setup.py
sdist` to replace `_version.py` with a small static file that contains just
the generated version data.
## Installation
See [INSTALL.md](./INSTALL.md) for detailed installation instructions.
## Version-String Flavors
Code which uses Versioneer can learn about its version string at runtime by
importing `_version` from your main `__init__.py` file and running the
`get_versions()` function. From the "outside" (e.g. in `setup.py`), you can
import the top-level `versioneer.py` and run `get_versions()`.
Both functions return a dictionary with different flavors of version
information:
* `['version']`: A condensed version string, rendered using the selected
style. This is the most commonly used value for the project's version
string. The default "pep440" style yields strings like `0.11`,
`0.11+2.g1076c97`, or `0.11+2.g1076c97.dirty`. See the "Styles" section
below for alternative styles.
* `['full-revisionid']`: detailed revision identifier. For Git, this is the
full SHA1 commit id, e.g. "1076c978a8d3cfc70f408fe5974aa6c092c949ac".
* `['date']`: Date and time of the latest `HEAD` commit. For Git, it is the
commit date in ISO 8601 format. This will be None if the date is not
available.
* `['dirty']`: a boolean, True if the tree has uncommitted changes. Note that
this is only accurate if run in a VCS checkout, otherwise it is likely to
be False or None
* `['error']`: if the version string could not be computed, this will be set
to a string describing the problem, otherwise it will be None. It may be
useful to throw an exception in setup.py if this is set, to avoid e.g.
creating tarballs with a version string of "unknown".
Some variants are more useful than others. Including `full-revisionid` in a
bug report should allow developers to reconstruct the exact code being tested
(or indicate the presence of local changes that should be shared with the
developers). `version` is suitable for display in an "about" box or a CLI
`--version` output: it can be easily compared against release notes and lists
of bugs fixed in various releases.
The installer adds the following text to your `__init__.py` to place a basic
version in `YOURPROJECT.__version__`:
from ._version import get_versions
__version__ = get_versions()['version']
del get_versions
## Styles
The setup.cfg `style=` configuration controls how the VCS information is
rendered into a version string.
The default style, "pep440", produces a PEP440-compliant string, equal to the
un-prefixed tag name for actual releases, and containing an additional "local
version" section with more detail for in-between builds. For Git, this is
TAG[+DISTANCE.gHEX[.dirty]] , using information from `git describe --tags
--dirty --always`. For example "0.11+2.g1076c97.dirty" indicates that the
tree is like the "1076c97" commit but has uncommitted changes (".dirty"), and
that this commit is two revisions ("+2") beyond the "0.11" tag. For released
software (exactly equal to a known tag), the identifier will only contain the
stripped tag, e.g. "0.11".
Other styles are available. See [details.md](details.md) in the Versioneer
source tree for descriptions.
## Debugging
Versioneer tries to avoid fatal errors: if something goes wrong, it will tend
to return a version of "0+unknown". To investigate the problem, run `setup.py
version`, which will run the version-lookup code in a verbose mode, and will
display the full contents of `get_versions()` (including the `error` string,
which may help identify what went wrong).
## Known Limitations
Some situations are known to cause problems for Versioneer. This details the
most significant ones. More can be found on Github
[issues page](https://github.com/python-versioneer/python-versioneer/issues).
### Subprojects
Versioneer has limited support for source trees in which `setup.py` is not in
the root directory (e.g. `setup.py` and `.git/` are *not* siblings). The are
two common reasons why `setup.py` might not be in the root:
* Source trees which contain multiple subprojects, such as
[Buildbot](https://github.com/buildbot/buildbot), which contains both
"master" and "slave" subprojects, each with their own `setup.py`,
`setup.cfg`, and `tox.ini`. Projects like these produce multiple PyPI
distributions (and upload multiple independently-installable tarballs).
* Source trees whose main purpose is to contain a C library, but which also
provide bindings to Python (and perhaps other languages) in subdirectories.
Versioneer will look for `.git` in parent directories, and most operations
should get the right version string. However `pip` and `setuptools` have bugs
and implementation details which frequently cause `pip install .` from a
subproject directory to fail to find a correct version string (so it usually
defaults to `0+unknown`).
`pip install --editable .` should work correctly. `setup.py install` might
work too.
Pip-8.1.1 is known to have this problem, but hopefully it will get fixed in
some later version.
[Bug #38](https://github.com/python-versioneer/python-versioneer/issues/38) is tracking
this issue. The discussion in
[PR #61](https://github.com/python-versioneer/python-versioneer/pull/61) describes the
issue from the Versioneer side in more detail.
[pip PR#3176](https://github.com/pypa/pip/pull/3176) and
[pip PR#3615](https://github.com/pypa/pip/pull/3615) contain work to improve
pip to let Versioneer work correctly.
Versioneer-0.16 and earlier only looked for a `.git` directory next to the
`setup.cfg`, so subprojects were completely unsupported with those releases.
### Editable installs with setuptools <= 18.5
`setup.py develop` and `pip install --editable .` allow you to install a
project into a virtualenv once, then continue editing the source code (and
test) without re-installing after every change.
"Entry-point scripts" (`setup(entry_points={"console_scripts": ..})`) are a
convenient way to specify executable scripts that should be installed along
with the python package.
These both work as expected when using modern setuptools. When using
setuptools-18.5 or earlier, however, certain operations will cause
`pkg_resources.DistributionNotFound` errors when running the entrypoint
script, which must be resolved by re-installing the package. This happens
when the install happens with one version, then the egg_info data is
regenerated while a different version is checked out. Many setup.py commands
cause egg_info to be rebuilt (including `sdist`, `wheel`, and installing into
a different virtualenv), so this can be surprising.
[Bug #83](https://github.com/python-versioneer/python-versioneer/issues/83) describes
this one, but upgrading to a newer version of setuptools should probably
resolve it.
## Updating Versioneer
To upgrade your project to a new release of Versioneer, do the following:
* install the new Versioneer (`pip install -U versioneer` or equivalent)
* edit `setup.cfg`, if necessary, to include any new configuration settings
indicated by the release notes. See [UPGRADING](./UPGRADING.md) for details.
* re-run `versioneer install` in your source tree, to replace
`SRC/_version.py`
* commit any changed files
## Future Directions
This tool is designed to make it easily extended to other version-control
systems: all VCS-specific components are in separate directories like
src/git/ . The top-level `versioneer.py` script is assembled from these
components by running make-versioneer.py . In the future, make-versioneer.py
will take a VCS name as an argument, and will construct a version of
`versioneer.py` that is specific to the given VCS. It might also take the
configuration arguments that are currently provided manually during
installation by editing setup.py . Alternatively, it might go the other
direction and include code from all supported VCS systems, reducing the
number of intermediate scripts.
## Similar projects
* [setuptools_scm](https://github.com/pypa/setuptools_scm/) - a non-vendored build-time
dependency
* [minver](https://github.com/jbweston/miniver) - a lightweight reimplementation of
versioneer
* [versioningit](https://github.com/jwodder/versioningit) - a PEP 518-based setuptools
plugin
## License
To make Versioneer easier to embed, all its code is dedicated to the public
domain. The `_version.py` that it creates is also in the public domain.
Specifically, both are released under the Creative Commons "Public Domain
Dedication" license (CC0-1.0), as described in
https://creativecommons.org/publicdomain/zero/1.0/ .
[pypi-image]: https://img.shields.io/pypi/v/versioneer.svg
[pypi-url]: https://pypi.python.org/pypi/versioneer/
[travis-image]:
https://img.shields.io/travis/com/python-versioneer/python-versioneer.svg
[travis-url]: https://travis-ci.com/github/python-versioneer/python-versioneer
"""
# pylint:disable=invalid-name,import-outside-toplevel,missing-function-docstring
# pylint:disable=missing-class-docstring,too-many-branches,too-many-statements
# pylint:disable=raise-missing-from,too-many-lines,too-many-locals,import-error
# pylint:disable=too-few-public-methods,redefined-outer-name,consider-using-with
# pylint:disable=attribute-defined-outside-init,too-many-arguments
import configparser
import errno
import json
import os
import re
import subprocess
import sys
from typing import Callable, Dict
import functools
class VersioneerConfig:
"""Container for Versioneer configuration parameters."""
def get_root():
"""Get the project root directory.
We require that all commands are run from the project root, i.e. the
directory that contains setup.py, setup.cfg, and versioneer.py .
"""
root = os.path.realpath(os.path.abspath(os.getcwd()))
setup_py = os.path.join(root, "setup.py")
versioneer_py = os.path.join(root, "versioneer.py")
if not (os.path.exists(setup_py) or os.path.exists(versioneer_py)):
# allow 'python path/to/setup.py COMMAND'
root = os.path.dirname(os.path.realpath(os.path.abspath(sys.argv[0])))
setup_py = os.path.join(root, "setup.py")
versioneer_py = os.path.join(root, "versioneer.py")
if not (os.path.exists(setup_py) or os.path.exists(versioneer_py)):
err = ("Versioneer was unable to run the project root directory. "
"Versioneer requires setup.py to be executed from "
"its immediate directory (like 'python setup.py COMMAND'), "
"or in a way that lets it use sys.argv[0] to find the root "
"(like 'python path/to/setup.py COMMAND').")
raise VersioneerBadRootError(err)
try:
# Certain runtime workflows (setup.py install/develop in a setuptools
# tree) execute all dependencies in a single python process, so
# "versioneer" may be imported multiple times, and python's shared
# module-import table will cache the first one. So we can't use
# os.path.dirname(__file__), as that will find whichever
# versioneer.py was first imported, even in later projects.
my_path = os.path.realpath(os.path.abspath(__file__))
me_dir = os.path.normcase(os.path.splitext(my_path)[0])
vsr_dir = os.path.normcase(os.path.splitext(versioneer_py)[0])
if me_dir != vsr_dir:
print("Warning: build in %s is using versioneer.py from %s"
% (os.path.dirname(my_path), versioneer_py))
except NameError:
pass
return root
def get_config_from_root(root):
"""Read the project setup.cfg file to determine Versioneer config."""
# This might raise OSError (if setup.cfg is missing), or
# configparser.NoSectionError (if it lacks a [versioneer] section), or
# configparser.NoOptionError (if it lacks "VCS="). See the docstring at
# the top of versioneer.py for instructions on writing your setup.cfg .
setup_cfg = os.path.join(root, "setup.cfg")
parser = configparser.ConfigParser()
with open(setup_cfg, "r") as cfg_file:
parser.read_file(cfg_file)
VCS = parser.get("versioneer", "VCS") # mandatory
# Dict-like interface for non-mandatory entries
section = parser["versioneer"]
cfg = VersioneerConfig()
cfg.VCS = VCS
cfg.style = section.get("style", "")
cfg.versionfile_source = section.get("versionfile_source")
cfg.versionfile_build = section.get("versionfile_build")
cfg.tag_prefix = section.get("tag_prefix")
if cfg.tag_prefix in ("''", '""'):
cfg.tag_prefix = ""
cfg.parentdir_prefix = section.get("parentdir_prefix")
cfg.verbose = section.get("verbose")
return cfg
class NotThisMethod(Exception):
"""Exception raised if a method is not valid for the current scenario."""
# these dictionaries contain VCS-specific tools
LONG_VERSION_PY: Dict[str, str] = {}
HANDLERS: Dict[str, Dict[str, Callable]] = {}
def register_vcs_handler(vcs, method): # decorator
"""Create decorator to mark a method as the handler of a VCS."""
def decorate(f):
"""Store f in HANDLERS[vcs][method]."""
HANDLERS.setdefault(vcs, {})[method] = f
return f
return decorate
def run_command(commands, args, cwd=None, verbose=False, hide_stderr=False,
env=None):
"""Call the given command(s)."""
assert isinstance(commands, list)
process = None
popen_kwargs = {}
if sys.platform == "win32":
# This hides the console window if pythonw.exe is used
startupinfo = subprocess.STARTUPINFO()
startupinfo.dwFlags |= subprocess.STARTF_USESHOWWINDOW
popen_kwargs["startupinfo"] = startupinfo
for command in commands:
try:
dispcmd = str([command] + args)
# remember shell=False, so use git.cmd on windows, not just git
process = subprocess.Popen([command] + args, cwd=cwd, env=env,
stdout=subprocess.PIPE,
stderr=(subprocess.PIPE if hide_stderr
else None), **popen_kwargs)
break
except OSError:
e = sys.exc_info()[1]
if e.errno == errno.ENOENT:
continue
if verbose:
print("unable to run %s" % dispcmd)
print(e)
return None, None
else:
if verbose:
print("unable to find command, tried %s" % (commands,))
return None, None
stdout = process.communicate()[0].strip().decode()
if process.returncode != 0:
if verbose:
print("unable to run %s (error)" % dispcmd)
print("stdout was %s" % stdout)
return None, process.returncode
return stdout, process.returncode
LONG_VERSION_PY['git'] = r'''
# This file helps to compute a version number in source trees obtained from
# git-archive tarball (such as those provided by githubs download-from-tag
# feature). Distribution tarballs (built by setup.py sdist) and build
# directories (produced by setup.py build) will contain a much shorter file
# that just contains the computed version number.
# This file is released into the public domain. Generated by
# versioneer-0.22 (https://github.com/python-versioneer/python-versioneer)
"""Git implementation of _version.py."""
import errno
import os
import re
import subprocess
import sys
from typing import Callable, Dict
import functools
def get_keywords():
"""Get the keywords needed to look up the version information."""
# these strings will be replaced by git during git-archive.
# setup.py/versioneer.py will grep for the variable names, so they must
# each be defined on a line of their own. _version.py will just call
# get_keywords().
git_refnames = "%(DOLLAR)sFormat:%%d%(DOLLAR)s"
git_full = "%(DOLLAR)sFormat:%%H%(DOLLAR)s"
git_date = "%(DOLLAR)sFormat:%%ci%(DOLLAR)s"
keywords = {"refnames": git_refnames, "full": git_full, "date": git_date}
return keywords
class VersioneerConfig:
"""Container for Versioneer configuration parameters."""
def get_config():
"""Create, populate and return the VersioneerConfig() object."""
# these strings are filled in when 'setup.py versioneer' creates
# _version.py
cfg = VersioneerConfig()
cfg.VCS = "git"
cfg.style = "%(STYLE)s"
cfg.tag_prefix = "%(TAG_PREFIX)s"
cfg.parentdir_prefix = "%(PARENTDIR_PREFIX)s"
cfg.versionfile_source = "%(VERSIONFILE_SOURCE)s"
cfg.verbose = False
return cfg
class NotThisMethod(Exception):
"""Exception raised if a method is not valid for the current scenario."""
LONG_VERSION_PY: Dict[str, str] = {}
HANDLERS: Dict[str, Dict[str, Callable]] = {}
def register_vcs_handler(vcs, method): # decorator
"""Create decorator to mark a method as the handler of a VCS."""
def decorate(f):
"""Store f in HANDLERS[vcs][method]."""
if vcs not in HANDLERS:
HANDLERS[vcs] = {}
HANDLERS[vcs][method] = f
return f
return decorate
def run_command(commands, args, cwd=None, verbose=False, hide_stderr=False,
env=None):
"""Call the given command(s)."""
assert isinstance(commands, list)
process = None
popen_kwargs = {}
if sys.platform == "win32":
# This hides the console window if pythonw.exe is used
startupinfo = subprocess.STARTUPINFO()
startupinfo.dwFlags |= subprocess.STARTF_USESHOWWINDOW
popen_kwargs["startupinfo"] = startupinfo
for command in commands:
try:
dispcmd = str([command] + args)
# remember shell=False, so use git.cmd on windows, not just git
process = subprocess.Popen([command] + args, cwd=cwd, env=env,
stdout=subprocess.PIPE,
stderr=(subprocess.PIPE if hide_stderr
else None), **popen_kwargs)
break
except OSError:
e = sys.exc_info()[1]
if e.errno == errno.ENOENT:
continue
if verbose:
print("unable to run %%s" %% dispcmd)
print(e)
return None, None
else:
if verbose:
print("unable to find command, tried %%s" %% (commands,))
return None, None
stdout = process.communicate()[0].strip().decode()
if process.returncode != 0:
if verbose:
print("unable to run %%s (error)" %% dispcmd)
print("stdout was %%s" %% stdout)
return None, process.returncode
return stdout, process.returncode
def versions_from_parentdir(parentdir_prefix, root, verbose):
"""Try to determine the version from the parent directory name.
Source tarballs conventionally unpack into a directory that includes both
the project name and a version string. We will also support searching up
two directory levels for an appropriately named parent directory
"""
rootdirs = []
for _ in range(3):
dirname = os.path.basename(root)
if dirname.startswith(parentdir_prefix):
return {"version": dirname[len(parentdir_prefix):],
"full-revisionid": None,
"dirty": False, "error": None, "date": None}
rootdirs.append(root)
root = os.path.dirname(root) # up a level
if verbose:
print("Tried directories %%s but none started with prefix %%s" %%
(str(rootdirs), parentdir_prefix))
raise NotThisMethod("rootdir doesn't start with parentdir_prefix")
@register_vcs_handler("git", "get_keywords")
def git_get_keywords(versionfile_abs):
"""Extract version information from the given file."""
# the code embedded in _version.py can just fetch the value of these
# keywords. When used from setup.py, we don't want to import _version.py,
# so we do it with a regexp instead. This function is not used from
# _version.py.
keywords = {}
try:
with open(versionfile_abs, "r") as fobj:
for line in fobj:
if line.strip().startswith("git_refnames ="):
mo = re.search(r'=\s*"(.*)"', line)
if mo:
keywords["refnames"] = mo.group(1)
if line.strip().startswith("git_full ="):
mo = re.search(r'=\s*"(.*)"', line)
if mo:
keywords["full"] = mo.group(1)
if line.strip().startswith("git_date ="):
mo = re.search(r'=\s*"(.*)"', line)
if mo:
keywords["date"] = mo.group(1)
except OSError:
pass
return keywords
@register_vcs_handler("git", "keywords")
def git_versions_from_keywords(keywords, tag_prefix, verbose):
"""Get version information from git keywords."""
if "refnames" not in keywords:
raise NotThisMethod("Short version file found")
date = keywords.get("date")
if date is not None:
# Use only the last line. Previous lines may contain GPG signature
# information.
date = date.splitlines()[-1]
# git-2.2.0 added "%%cI", which expands to an ISO-8601 -compliant
# datestamp. However we prefer "%%ci" (which expands to an "ISO-8601
# -like" string, which we must then edit to make compliant), because
# it's been around since git-1.5.3, and it's too difficult to
# discover which version we're using, or to work around using an
# older one.
date = date.strip().replace(" ", "T", 1).replace(" ", "", 1)
refnames = keywords["refnames"].strip()
if refnames.startswith("$Format"):
if verbose:
print("keywords are unexpanded, not using")
raise NotThisMethod("unexpanded keywords, not a git-archive tarball")
refs = {r.strip() for r in refnames.strip("()").split(",")}
# starting in git-1.8.3, tags are listed as "tag: foo-1.0" instead of
# just "foo-1.0". If we see a "tag: " prefix, prefer those.
TAG = "tag: "
tags = {r[len(TAG):] for r in refs if r.startswith(TAG)}
if not tags:
# Either we're using git < 1.8.3, or there really are no tags. We use
# a heuristic: assume all version tags have a digit. The old git %%d
# expansion behaves like git log --decorate=short and strips out the
# refs/heads/ and refs/tags/ prefixes that would let us distinguish
# between branches and tags. By ignoring refnames without digits, we
# filter out many common branch names like "release" and
# "stabilization", as well as "HEAD" and "master".
tags = {r for r in refs if re.search(r'\d', r)}
if verbose:
print("discarding '%%s', no digits" %% ",".join(refs - tags))
if verbose:
print("likely tags: %%s" %% ",".join(sorted(tags)))
for ref in sorted(tags):
# sorting will prefer e.g. "2.0" over "2.0rc1"
if ref.startswith(tag_prefix):
r = ref[len(tag_prefix):]
# Filter out refs that exactly match prefix or that don't start
# with a number once the prefix is stripped (mostly a concern
# when prefix is '')
if not re.match(r'\d', r):
continue
if verbose:
print("picking %%s" %% r)
return {"version": r,
"full-revisionid": keywords["full"].strip(),
"dirty": False, "error": None,
"date": date}
# no suitable tags, so version is "0+unknown", but full hex is still there
if verbose:
print("no suitable tags, using unknown + full revision id")
return {"version": "0+unknown",
"full-revisionid": keywords["full"].strip(),
"dirty": False, "error": "no suitable tags", "date": None}
@register_vcs_handler("git", "pieces_from_vcs")
def git_pieces_from_vcs(tag_prefix, root, verbose, runner=run_command):
"""Get version from 'git describe' in the root of the source tree.
This only gets called if the git-archive 'subst' keywords were *not*
expanded, and _version.py hasn't already been rewritten with a short
version string, meaning we're inside a checked out source tree.
"""
GITS = ["git"]
if sys.platform == "win32":
GITS = ["git.cmd", "git.exe"]
# GIT_DIR can interfere with correct operation of Versioneer.
# It may be intended to be passed to the Versioneer-versioned project,
# but that should not change where we get our version from.
env = os.environ.copy()
env.pop("GIT_DIR", None)
runner = functools.partial(runner, env=env)
_, rc = runner(GITS, ["rev-parse", "--git-dir"], cwd=root,
hide_stderr=True)
if rc != 0:
if verbose:
print("Directory %%s not under git control" %% root)
raise NotThisMethod("'git rev-parse --git-dir' returned error")
MATCH_ARGS = ["--match", "%%s*" %% tag_prefix] if tag_prefix else []
# if there is a tag matching tag_prefix, this yields TAG-NUM-gHEX[-dirty]
# if there isn't one, this yields HEX[-dirty] (no NUM)
describe_out, rc = runner(GITS, ["describe", "--tags", "--dirty",
"--always", "--long", *MATCH_ARGS],
cwd=root)
# --long was added in git-1.5.5
if describe_out is None:
raise NotThisMethod("'git describe' failed")
describe_out = describe_out.strip()
full_out, rc = runner(GITS, ["rev-parse", "HEAD"], cwd=root)
if full_out is None:
raise NotThisMethod("'git rev-parse' failed")
full_out = full_out.strip()
pieces = {}
pieces["long"] = full_out
pieces["short"] = full_out[:7] # maybe improved later
pieces["error"] = None
branch_name, rc = runner(GITS, ["rev-parse", "--abbrev-ref", "HEAD"],
cwd=root)
# --abbrev-ref was added in git-1.6.3
if rc != 0 or branch_name is None:
raise NotThisMethod("'git rev-parse --abbrev-ref' returned error")
branch_name = branch_name.strip()
if branch_name == "HEAD":
# If we aren't exactly on a branch, pick a branch which represents
# the current commit. If all else fails, we are on a branchless
# commit.
branches, rc = runner(GITS, ["branch", "--contains"], cwd=root)
# --contains was added in git-1.5.4
if rc != 0 or branches is None:
raise NotThisMethod("'git branch --contains' returned error")
branches = branches.split("\n")
# Remove the first line if we're running detached
if "(" in branches[0]:
branches.pop(0)
# Strip off the leading "* " from the list of branches.
branches = [branch[2:] for branch in branches]
if "master" in branches:
branch_name = "master"
elif not branches:
branch_name = None
else:
# Pick the first branch that is returned. Good or bad.
branch_name = branches[0]
pieces["branch"] = branch_name
# parse describe_out. It will be like TAG-NUM-gHEX[-dirty] or HEX[-dirty]
# TAG might have hyphens.
git_describe = describe_out
# look for -dirty suffix
dirty = git_describe.endswith("-dirty")
pieces["dirty"] = dirty
if dirty:
git_describe = git_describe[:git_describe.rindex("-dirty")]
# now we have TAG-NUM-gHEX or HEX
if "-" in git_describe:
# TAG-NUM-gHEX
mo = re.search(r'^(.+)-(\d+)-g([0-9a-f]+)$', git_describe)
if not mo:
# unparsable. Maybe git-describe is misbehaving?
pieces["error"] = ("unable to parse git-describe output: '%%s'"
%% describe_out)
return pieces
# tag
full_tag = mo.group(1)
if not full_tag.startswith(tag_prefix):
if verbose:
fmt = "tag '%%s' doesn't start with prefix '%%s'"
print(fmt %% (full_tag, tag_prefix))
pieces["error"] = ("tag '%%s' doesn't start with prefix '%%s'"
%% (full_tag, tag_prefix))
return pieces
pieces["closest-tag"] = full_tag[len(tag_prefix):]
# distance: number of commits since tag
pieces["distance"] = int(mo.group(2))
# commit: short hex revision ID
pieces["short"] = mo.group(3)
else:
# HEX: no tags
pieces["closest-tag"] = None
count_out, rc = runner(GITS, ["rev-list", "HEAD", "--count"], cwd=root)
pieces["distance"] = int(count_out) # total number of commits
# commit date: see ISO-8601 comment in git_versions_from_keywords()
date = runner(GITS, ["show", "-s", "--format=%%ci", "HEAD"], cwd=root)[0].strip()
# Use only the last line. Previous lines may contain GPG signature
# information.
date = date.splitlines()[-1]
pieces["date"] = date.strip().replace(" ", "T", 1).replace(" ", "", 1)
return pieces
def plus_or_dot(pieces):
"""Return a + if we don't already have one, else return a ."""
if "+" in pieces.get("closest-tag", ""):
return "."
return "+"
def render_pep440(pieces):
"""Build up version string, with post-release "local version identifier".
Our goal: TAG[+DISTANCE.gHEX[.dirty]] . Note that if you
get a tagged build and then dirty it, you'll get TAG+0.gHEX.dirty
Exceptions:
1: no tags. git_describe was just HEX. 0+untagged.DISTANCE.gHEX[.dirty]
"""
if pieces["closest-tag"]:
rendered = pieces["closest-tag"]
if pieces["distance"] or pieces["dirty"]:
rendered += plus_or_dot(pieces)
rendered += "%%d.g%%s" %% (pieces["distance"], pieces["short"])
if pieces["dirty"]:
rendered += ".dirty"
else:
# exception #1
rendered = "0+untagged.%%d.g%%s" %% (pieces["distance"],
pieces["short"])
if pieces["dirty"]:
rendered += ".dirty"
return rendered
def render_pep440_branch(pieces):
"""TAG[[.dev0]+DISTANCE.gHEX[.dirty]] .
The ".dev0" means not master branch. Note that .dev0 sorts backwards
(a feature branch will appear "older" than the master branch).
Exceptions:
1: no tags. 0[.dev0]+untagged.DISTANCE.gHEX[.dirty]
"""
if pieces["closest-tag"]:
rendered = pieces["closest-tag"]
if pieces["distance"] or pieces["dirty"]:
if pieces["branch"] != "master":
rendered += ".dev0"
rendered += plus_or_dot(pieces)
rendered += "%%d.g%%s" %% (pieces["distance"], pieces["short"])
if pieces["dirty"]:
rendered += ".dirty"
else:
# exception #1
rendered = "0"
if pieces["branch"] != "master":
rendered += ".dev0"
rendered += "+untagged.%%d.g%%s" %% (pieces["distance"],
pieces["short"])
if pieces["dirty"]:
rendered += ".dirty"
return rendered
def pep440_split_post(ver):
"""Split pep440 version string at the post-release segment.
Returns the release segments before the post-release and the
post-release version number (or -1 if no post-release segment is present).
"""
vc = str.split(ver, ".post")
return vc[0], int(vc[1] or 0) if len(vc) == 2 else None
def render_pep440_pre(pieces):
"""TAG[.postN.devDISTANCE] -- No -dirty.
Exceptions:
1: no tags. 0.post0.devDISTANCE
"""
if pieces["closest-tag"]:
if pieces["distance"]:
# update the post release segment
tag_version, post_version = pep440_split_post(pieces["closest-tag"])
rendered = tag_version
if post_version is not None:
rendered += ".post%%d.dev%%d" %% (post_version+1, pieces["distance"])
else:
rendered += ".post0.dev%%d" %% (pieces["distance"])
else:
# no commits, use the tag as the version
rendered = pieces["closest-tag"]
else:
# exception #1
rendered = "0.post0.dev%%d" %% pieces["distance"]
return rendered
def render_pep440_post(pieces):
"""TAG[.postDISTANCE[.dev0]+gHEX] .
The ".dev0" means dirty. Note that .dev0 sorts backwards
(a dirty tree will appear "older" than the corresponding clean one),
but you shouldn't be releasing software with -dirty anyways.
Exceptions:
1: no tags. 0.postDISTANCE[.dev0]
"""
if pieces["closest-tag"]:
rendered = pieces["closest-tag"]
if pieces["distance"] or pieces["dirty"]:
rendered += ".post%%d" %% pieces["distance"]
if pieces["dirty"]:
rendered += ".dev0"
rendered += plus_or_dot(pieces)
rendered += "g%%s" %% pieces["short"]
else:
# exception #1
rendered = "0.post%%d" %% pieces["distance"]
if pieces["dirty"]:
rendered += ".dev0"
rendered += "+g%%s" %% pieces["short"]
return rendered
def render_pep440_post_branch(pieces):
"""TAG[.postDISTANCE[.dev0]+gHEX[.dirty]] .
The ".dev0" means not master branch.
Exceptions:
1: no tags. 0.postDISTANCE[.dev0]+gHEX[.dirty]
"""
if pieces["closest-tag"]:
rendered = pieces["closest-tag"]
if pieces["distance"] or pieces["dirty"]:
rendered += ".post%%d" %% pieces["distance"]
if pieces["branch"] != "master":
rendered += ".dev0"
rendered += plus_or_dot(pieces)
rendered += "g%%s" %% pieces["short"]
if pieces["dirty"]:
rendered += ".dirty"
else:
# exception #1
rendered = "0.post%%d" %% pieces["distance"]
if pieces["branch"] != "master":
rendered += ".dev0"
rendered += "+g%%s" %% pieces["short"]
if pieces["dirty"]:
rendered += ".dirty"
return rendered
def render_pep440_old(pieces):
"""TAG[.postDISTANCE[.dev0]] .
The ".dev0" means dirty.
Exceptions:
1: no tags. 0.postDISTANCE[.dev0]
"""
if pieces["closest-tag"]:
rendered = pieces["closest-tag"]
if pieces["distance"] or pieces["dirty"]:
rendered += ".post%%d" %% pieces["distance"]
if pieces["dirty"]:
rendered += ".dev0"
else:
# exception #1
rendered = "0.post%%d" %% pieces["distance"]
if pieces["dirty"]:
rendered += ".dev0"
return rendered
def render_git_describe(pieces):
"""TAG[-DISTANCE-gHEX][-dirty].
Like 'git describe --tags --dirty --always'.
Exceptions:
1: no tags. HEX[-dirty] (note: no 'g' prefix)
"""
if pieces["closest-tag"]:
rendered = pieces["closest-tag"]
if pieces["distance"]:
rendered += "-%%d-g%%s" %% (pieces["distance"], pieces["short"])
else:
# exception #1
rendered = pieces["short"]
if pieces["dirty"]:
rendered += "-dirty"
return rendered
def render_git_describe_long(pieces):
"""TAG-DISTANCE-gHEX[-dirty].
Like 'git describe --tags --dirty --always -long'.
The distance/hash is unconditional.
Exceptions:
1: no tags. HEX[-dirty] (note: no 'g' prefix)
"""
if pieces["closest-tag"]:
rendered = pieces["closest-tag"]
rendered += "-%%d-g%%s" %% (pieces["distance"], pieces["short"])
else:
# exception #1
rendered = pieces["short"]
if pieces["dirty"]:
rendered += "-dirty"
return rendered
def render(pieces, style):
"""Render the given version pieces into the requested style."""
if pieces["error"]:
return {"version": "unknown",
"full-revisionid": pieces.get("long"),
"dirty": None,
"error": pieces["error"],
"date": None}
if not style or style == "default":
style = "pep440" # the default
if style == "pep440":
rendered = render_pep440(pieces)
elif style == "pep440-branch":
rendered = render_pep440_branch(pieces)
elif style == "pep440-pre":
rendered = render_pep440_pre(pieces)
elif style == "pep440-post":
rendered = render_pep440_post(pieces)
elif style == "pep440-post-branch":
rendered = render_pep440_post_branch(pieces)
elif style == "pep440-old":
rendered = render_pep440_old(pieces)
elif style == "git-describe":
rendered = render_git_describe(pieces)
elif style == "git-describe-long":
rendered = render_git_describe_long(pieces)
else:
raise ValueError("unknown style '%%s'" %% style)
return {"version": rendered, "full-revisionid": pieces["long"],
"dirty": pieces["dirty"], "error": None,
"date": pieces.get("date")}
def get_versions():
"""Get version information or return default if unable to do so."""
# I am in _version.py, which lives at ROOT/VERSIONFILE_SOURCE. If we have
# __file__, we can work backwards from there to the root. Some
# py2exe/bbfreeze/non-CPython implementations don't do __file__, in which
# case we can only use expanded keywords.
cfg = get_config()
verbose = cfg.verbose
try:
return git_versions_from_keywords(get_keywords(), cfg.tag_prefix,
verbose)
except NotThisMethod:
pass
try:
root = os.path.realpath(__file__)
# versionfile_source is the relative path from the top of the source
# tree (where the .git directory might live) to this file. Invert
# this to find the root from __file__.
for _ in cfg.versionfile_source.split('/'):
root = os.path.dirname(root)
except NameError:
return {"version": "0+unknown", "full-revisionid": None,
"dirty": None,
"error": "unable to find root of source tree",
"date": None}
try:
pieces = git_pieces_from_vcs(cfg.tag_prefix, root, verbose)
return render(pieces, cfg.style)
except NotThisMethod:
pass
try:
if cfg.parentdir_prefix:
return versions_from_parentdir(cfg.parentdir_prefix, root, verbose)
except NotThisMethod:
pass
return {"version": "0+unknown", "full-revisionid": None,
"dirty": None,
"error": "unable to compute version", "date": None}
'''
@register_vcs_handler("git", "get_keywords")
def git_get_keywords(versionfile_abs):
"""Extract version information from the given file."""
# the code embedded in _version.py can just fetch the value of these
# keywords. When used from setup.py, we don't want to import _version.py,
# so we do it with a regexp instead. This function is not used from
# _version.py.
keywords = {}
try:
with open(versionfile_abs, "r") as fobj:
for line in fobj:
if line.strip().startswith("git_refnames ="):
mo = re.search(r'=\s*"(.*)"', line)
if mo:
keywords["refnames"] = mo.group(1)
if line.strip().startswith("git_full ="):
mo = re.search(r'=\s*"(.*)"', line)
if mo:
keywords["full"] = mo.group(1)
if line.strip().startswith("git_date ="):
mo = re.search(r'=\s*"(.*)"', line)
if mo:
keywords["date"] = mo.group(1)
except OSError:
pass
return keywords
@register_vcs_handler("git", "keywords")
def git_versions_from_keywords(keywords, tag_prefix, verbose):
"""Get version information from git keywords."""
if "refnames" not in keywords:
raise NotThisMethod("Short version file found")
date = keywords.get("date")
if date is not None:
# Use only the last line. Previous lines may contain GPG signature
# information.
date = date.splitlines()[-1]
# git-2.2.0 added "%cI", which expands to an ISO-8601 -compliant
# datestamp. However we prefer "%ci" (which expands to an "ISO-8601
# -like" string, which we must then edit to make compliant), because
# it's been around since git-1.5.3, and it's too difficult to
# discover which version we're using, or to work around using an
# older one.
date = date.strip().replace(" ", "T", 1).replace(" ", "", 1)
refnames = keywords["refnames"].strip()
if refnames.startswith("$Format"):
if verbose:
print("keywords are unexpanded, not using")
raise NotThisMethod("unexpanded keywords, not a git-archive tarball")
refs = {r.strip() for r in refnames.strip("()").split(",")}
# starting in git-1.8.3, tags are listed as "tag: foo-1.0" instead of
# just "foo-1.0". If we see a "tag: " prefix, prefer those.
TAG = "tag: "
tags = {r[len(TAG):] for r in refs if r.startswith(TAG)}
if not tags:
# Either we're using git < 1.8.3, or there really are no tags. We use
# a heuristic: assume all version tags have a digit. The old git %d
# expansion behaves like git log --decorate=short and strips out the
# refs/heads/ and refs/tags/ prefixes that would let us distinguish
# between branches and tags. By ignoring refnames without digits, we
# filter out many common branch names like "release" and
# "stabilization", as well as "HEAD" and "master".
tags = {r for r in refs if re.search(r'\d', r)}
if verbose:
print("discarding '%s', no digits" % ",".join(refs - tags))
if verbose:
print("likely tags: %s" % ",".join(sorted(tags)))
for ref in sorted(tags):
# sorting will prefer e.g. "2.0" over "2.0rc1"
if ref.startswith(tag_prefix):
r = ref[len(tag_prefix):]
# Filter out refs that exactly match prefix or that don't start
# with a number once the prefix is stripped (mostly a concern
# when prefix is '')
if not re.match(r'\d', r):
continue
if verbose:
print("picking %s" % r)
return {"version": r,
"full-revisionid": keywords["full"].strip(),
"dirty": False, "error": None,
"date": date}
# no suitable tags, so version is "0+unknown", but full hex is still there
if verbose:
print("no suitable tags, using unknown + full revision id")
return {"version": "0+unknown",
"full-revisionid": keywords["full"].strip(),
"dirty": False, "error": "no suitable tags", "date": None}
@register_vcs_handler("git", "pieces_from_vcs")
def git_pieces_from_vcs(tag_prefix, root, verbose, runner=run_command):
"""Get version from 'git describe' in the root of the source tree.
This only gets called if the git-archive 'subst' keywords were *not*
expanded, and _version.py hasn't already been rewritten with a short
version string, meaning we're inside a checked out source tree.
"""
GITS = ["git"]
if sys.platform == "win32":
GITS = ["git.cmd", "git.exe"]
# GIT_DIR can interfere with correct operation of Versioneer.
# It may be intended to be passed to the Versioneer-versioned project,
# but that should not change where we get our version from.
env = os.environ.copy()
env.pop("GIT_DIR", None)
runner = functools.partial(runner, env=env)
_, rc = runner(GITS, ["rev-parse", "--git-dir"], cwd=root,
hide_stderr=True)
if rc != 0:
if verbose:
print("Directory %s not under git control" % root)
raise NotThisMethod("'git rev-parse --git-dir' returned error")
MATCH_ARGS = ["--match", "%s*" % tag_prefix] if tag_prefix else []
# if there is a tag matching tag_prefix, this yields TAG-NUM-gHEX[-dirty]
# if there isn't one, this yields HEX[-dirty] (no NUM)
describe_out, rc = runner(GITS, ["describe", "--tags", "--dirty",
"--always", "--long", *MATCH_ARGS],
cwd=root)
# --long was added in git-1.5.5
if describe_out is None:
raise NotThisMethod("'git describe' failed")
describe_out = describe_out.strip()
full_out, rc = runner(GITS, ["rev-parse", "HEAD"], cwd=root)
if full_out is None:
raise NotThisMethod("'git rev-parse' failed")
full_out = full_out.strip()
pieces = {}
pieces["long"] = full_out
pieces["short"] = full_out[:7] # maybe improved later
pieces["error"] = None
branch_name, rc = runner(GITS, ["rev-parse", "--abbrev-ref", "HEAD"],
cwd=root)
# --abbrev-ref was added in git-1.6.3
if rc != 0 or branch_name is None:
raise NotThisMethod("'git rev-parse --abbrev-ref' returned error")
branch_name = branch_name.strip()
if branch_name == "HEAD":
# If we aren't exactly on a branch, pick a branch which represents
# the current commit. If all else fails, we are on a branchless
# commit.
branches, rc = runner(GITS, ["branch", "--contains"], cwd=root)
# --contains was added in git-1.5.4
if rc != 0 or branches is None:
raise NotThisMethod("'git branch --contains' returned error")
branches = branches.split("\n")
# Remove the first line if we're running detached
if "(" in branches[0]:
branches.pop(0)
# Strip off the leading "* " from the list of branches.
branches = [branch[2:] for branch in branches]
if "master" in branches:
branch_name = "master"
elif not branches:
branch_name = None
else:
# Pick the first branch that is returned. Good or bad.
branch_name = branches[0]
pieces["branch"] = branch_name
# parse describe_out. It will be like TAG-NUM-gHEX[-dirty] or HEX[-dirty]
# TAG might have hyphens.
git_describe = describe_out
# look for -dirty suffix
dirty = git_describe.endswith("-dirty")
pieces["dirty"] = dirty
if dirty:
git_describe = git_describe[:git_describe.rindex("-dirty")]
# now we have TAG-NUM-gHEX or HEX
if "-" in git_describe:
# TAG-NUM-gHEX
mo = re.search(r'^(.+)-(\d+)-g([0-9a-f]+)$', git_describe)
if not mo:
# unparsable. Maybe git-describe is misbehaving?
pieces["error"] = ("unable to parse git-describe output: '%s'"
% describe_out)
return pieces
# tag
full_tag = mo.group(1)
if not full_tag.startswith(tag_prefix):
if verbose:
fmt = "tag '%s' doesn't start with prefix '%s'"
print(fmt % (full_tag, tag_prefix))
pieces["error"] = ("tag '%s' doesn't start with prefix '%s'"
% (full_tag, tag_prefix))
return pieces
pieces["closest-tag"] = full_tag[len(tag_prefix):]
# distance: number of commits since tag
pieces["distance"] = int(mo.group(2))
# commit: short hex revision ID
pieces["short"] = mo.group(3)
else:
# HEX: no tags
pieces["closest-tag"] = None
count_out, rc = runner(GITS, ["rev-list", "HEAD", "--count"], cwd=root)
pieces["distance"] = int(count_out) # total number of commits
# commit date: see ISO-8601 comment in git_versions_from_keywords()
date = runner(GITS, ["show", "-s", "--format=%ci", "HEAD"], cwd=root)[0].strip()
# Use only the last line. Previous lines may contain GPG signature
# information.
date = date.splitlines()[-1]
pieces["date"] = date.strip().replace(" ", "T", 1).replace(" ", "", 1)
return pieces
def do_vcs_install(manifest_in, versionfile_source, ipy):
"""Git-specific installation logic for Versioneer.
For Git, this means creating/changing .gitattributes to mark _version.py
for export-subst keyword substitution.
"""
GITS = ["git"]
if sys.platform == "win32":
GITS = ["git.cmd", "git.exe"]
files = [manifest_in, versionfile_source]
if ipy:
files.append(ipy)
try:
my_path = __file__
if my_path.endswith(".pyc") or my_path.endswith(".pyo"):
my_path = os.path.splitext(my_path)[0] + ".py"
versioneer_file = os.path.relpath(my_path)
except NameError:
versioneer_file = "versioneer.py"
files.append(versioneer_file)
present = False
try:
with open(".gitattributes", "r") as fobj:
for line in fobj:
if line.strip().startswith(versionfile_source):
if "export-subst" in line.strip().split()[1:]:
present = True
break
except OSError:
pass
if not present:
with open(".gitattributes", "a+") as fobj:
fobj.write(f"{versionfile_source} export-subst\n")
files.append(".gitattributes")
run_command(GITS, ["add", "--"] + files)
def versions_from_parentdir(parentdir_prefix, root, verbose):
"""Try to determine the version from the parent directory name.
Source tarballs conventionally unpack into a directory that includes both
the project name and a version string. We will also support searching up
two directory levels for an appropriately named parent directory
"""
rootdirs = []
for _ in range(3):
dirname = os.path.basename(root)
if dirname.startswith(parentdir_prefix):
return {"version": dirname[len(parentdir_prefix):],
"full-revisionid": None,
"dirty": False, "error": None, "date": None}
rootdirs.append(root)
root = os.path.dirname(root) # up a level
if verbose:
print("Tried directories %s but none started with prefix %s" %
(str(rootdirs), parentdir_prefix))
raise NotThisMethod("rootdir doesn't start with parentdir_prefix")
SHORT_VERSION_PY = """
# This file was generated by 'versioneer.py' (0.22) from
# revision-control system data, or from the parent directory name of an
# unpacked source archive. Distribution tarballs contain a pre-generated copy
# of this file.
import json
version_json = '''
%s
''' # END VERSION_JSON
def get_versions():
return json.loads(version_json)
"""
def versions_from_file(filename):
"""Try to determine the version from _version.py if present."""
try:
with open(filename) as f:
contents = f.read()
except OSError:
raise NotThisMethod("unable to read _version.py")
mo = re.search(r"version_json = '''\n(.*)''' # END VERSION_JSON",
contents, re.M | re.S)
if not mo:
mo = re.search(r"version_json = '''\r\n(.*)''' # END VERSION_JSON",
contents, re.M | re.S)
if not mo:
raise NotThisMethod("no version_json in _version.py")
return json.loads(mo.group(1))
def write_to_version_file(filename, versions):
"""Write the given version number to the given _version.py file."""
os.unlink(filename)
contents = json.dumps(versions, sort_keys=True,
indent=1, separators=(",", ": "))
with open(filename, "w") as f:
f.write(SHORT_VERSION_PY % contents)
print("set %s to '%s'" % (filename, versions["version"]))
def plus_or_dot(pieces):
"""Return a + if we don't already have one, else return a ."""
if "+" in pieces.get("closest-tag", ""):
return "."
return "+"
def render_pep440(pieces):
"""Build up version string, with post-release "local version identifier".
Our goal: TAG[+DISTANCE.gHEX[.dirty]] . Note that if you
get a tagged build and then dirty it, you'll get TAG+0.gHEX.dirty
Exceptions:
1: no tags. git_describe was just HEX. 0+untagged.DISTANCE.gHEX[.dirty]
"""
if pieces["closest-tag"]:
rendered = pieces["closest-tag"]
if pieces["distance"] or pieces["dirty"]:
rendered += plus_or_dot(pieces)
rendered += "%d.g%s" % (pieces["distance"], pieces["short"])
if pieces["dirty"]:
rendered += ".dirty"
else:
# exception #1
rendered = "0+untagged.%d.g%s" % (pieces["distance"],
pieces["short"])
if pieces["dirty"]:
rendered += ".dirty"
return rendered
def render_pep440_branch(pieces):
"""TAG[[.dev0]+DISTANCE.gHEX[.dirty]] .
The ".dev0" means not master branch. Note that .dev0 sorts backwards
(a feature branch will appear "older" than the master branch).
Exceptions:
1: no tags. 0[.dev0]+untagged.DISTANCE.gHEX[.dirty]
"""
if pieces["closest-tag"]:
rendered = pieces["closest-tag"]
if pieces["distance"] or pieces["dirty"]:
if pieces["branch"] != "master":
rendered += ".dev0"
rendered += plus_or_dot(pieces)
rendered += "%d.g%s" % (pieces["distance"], pieces["short"])
if pieces["dirty"]:
rendered += ".dirty"
else:
# exception #1
rendered = "0"
if pieces["branch"] != "master":
rendered += ".dev0"
rendered += "+untagged.%d.g%s" % (pieces["distance"],
pieces["short"])
if pieces["dirty"]:
rendered += ".dirty"
return rendered
def pep440_split_post(ver):
"""Split pep440 version string at the post-release segment.
Returns the release segments before the post-release and the
post-release version number (or -1 if no post-release segment is present).
"""
vc = str.split(ver, ".post")
return vc[0], int(vc[1] or 0) if len(vc) == 2 else None
def render_pep440_pre(pieces):
"""TAG[.postN.devDISTANCE] -- No -dirty.
Exceptions:
1: no tags. 0.post0.devDISTANCE
"""
if pieces["closest-tag"]:
if pieces["distance"]:
# update the post release segment
tag_version, post_version = pep440_split_post(pieces["closest-tag"])
rendered = tag_version
if post_version is not None:
rendered += ".post%d.dev%d" % (post_version+1, pieces["distance"])
else:
rendered += ".post0.dev%d" % (pieces["distance"])
else:
# no commits, use the tag as the version
rendered = pieces["closest-tag"]
else:
# exception #1
rendered = "0.post0.dev%d" % pieces["distance"]
return rendered
def render_pep440_post(pieces):
"""TAG[.postDISTANCE[.dev0]+gHEX] .
The ".dev0" means dirty. Note that .dev0 sorts backwards
(a dirty tree will appear "older" than the corresponding clean one),
but you shouldn't be releasing software with -dirty anyways.
Exceptions:
1: no tags. 0.postDISTANCE[.dev0]
"""
if pieces["closest-tag"]:
rendered = pieces["closest-tag"]
if pieces["distance"] or pieces["dirty"]:
rendered += ".post%d" % pieces["distance"]
if pieces["dirty"]:
rendered += ".dev0"
rendered += plus_or_dot(pieces)
rendered += "g%s" % pieces["short"]
else:
# exception #1
rendered = "0.post%d" % pieces["distance"]
if pieces["dirty"]:
rendered += ".dev0"
rendered += "+g%s" % pieces["short"]
return rendered
def render_pep440_post_branch(pieces):
"""TAG[.postDISTANCE[.dev0]+gHEX[.dirty]] .
The ".dev0" means not master branch.
Exceptions:
1: no tags. 0.postDISTANCE[.dev0]+gHEX[.dirty]
"""
if pieces["closest-tag"]:
rendered = pieces["closest-tag"]
if pieces["distance"] or pieces["dirty"]:
rendered += ".post%d" % pieces["distance"]
if pieces["branch"] != "master":
rendered += ".dev0"
rendered += plus_or_dot(pieces)
rendered += "g%s" % pieces["short"]
if pieces["dirty"]:
rendered += ".dirty"
else:
# exception #1
rendered = "0.post%d" % pieces["distance"]
if pieces["branch"] != "master":
rendered += ".dev0"
rendered += "+g%s" % pieces["short"]
if pieces["dirty"]:
rendered += ".dirty"
return rendered
def render_pep440_old(pieces):
"""TAG[.postDISTANCE[.dev0]] .
The ".dev0" means dirty.
Exceptions:
1: no tags. 0.postDISTANCE[.dev0]
"""
if pieces["closest-tag"]:
rendered = pieces["closest-tag"]
if pieces["distance"] or pieces["dirty"]:
rendered += ".post%d" % pieces["distance"]
if pieces["dirty"]:
rendered += ".dev0"
else:
# exception #1
rendered = "0.post%d" % pieces["distance"]
if pieces["dirty"]:
rendered += ".dev0"
return rendered
def render_git_describe(pieces):
"""TAG[-DISTANCE-gHEX][-dirty].
Like 'git describe --tags --dirty --always'.
Exceptions:
1: no tags. HEX[-dirty] (note: no 'g' prefix)
"""
if pieces["closest-tag"]:
rendered = pieces["closest-tag"]
if pieces["distance"]:
rendered += "-%d-g%s" % (pieces["distance"], pieces["short"])
else:
# exception #1
rendered = pieces["short"]
if pieces["dirty"]:
rendered += "-dirty"
return rendered
def render_git_describe_long(pieces):
"""TAG-DISTANCE-gHEX[-dirty].
Like 'git describe --tags --dirty --always -long'.
The distance/hash is unconditional.
Exceptions:
1: no tags. HEX[-dirty] (note: no 'g' prefix)
"""
if pieces["closest-tag"]:
rendered = pieces["closest-tag"]
rendered += "-%d-g%s" % (pieces["distance"], pieces["short"])
else:
# exception #1
rendered = pieces["short"]
if pieces["dirty"]:
rendered += "-dirty"
return rendered
def render(pieces, style):
"""Render the given version pieces into the requested style."""
if pieces["error"]:
return {"version": "unknown",
"full-revisionid": pieces.get("long"),
"dirty": None,
"error": pieces["error"],
"date": None}
if not style or style == "default":
style = "pep440" # the default
if style == "pep440":
rendered = render_pep440(pieces)
elif style == "pep440-branch":
rendered = render_pep440_branch(pieces)
elif style == "pep440-pre":
rendered = render_pep440_pre(pieces)
elif style == "pep440-post":
rendered = render_pep440_post(pieces)
elif style == "pep440-post-branch":
rendered = render_pep440_post_branch(pieces)
elif style == "pep440-old":
rendered = render_pep440_old(pieces)
elif style == "git-describe":
rendered = render_git_describe(pieces)
elif style == "git-describe-long":
rendered = render_git_describe_long(pieces)
else:
raise ValueError("unknown style '%s'" % style)
return {"version": rendered, "full-revisionid": pieces["long"],
"dirty": pieces["dirty"], "error": None,
"date": pieces.get("date")}
class VersioneerBadRootError(Exception):
"""The project root directory is unknown or missing key files."""
def get_versions(verbose=False):
"""Get the project version from whatever source is available.
Returns dict with two keys: 'version' and 'full'.
"""
if "versioneer" in sys.modules:
# see the discussion in cmdclass.py:get_cmdclass()
del sys.modules["versioneer"]
root = get_root()
cfg = get_config_from_root(root)
assert cfg.VCS is not None, "please set [versioneer]VCS= in setup.cfg"
handlers = HANDLERS.get(cfg.VCS)
assert handlers, "unrecognized VCS '%s'" % cfg.VCS
verbose = verbose or cfg.verbose
assert cfg.versionfile_source is not None, \
"please set versioneer.versionfile_source"
assert cfg.tag_prefix is not None, "please set versioneer.tag_prefix"
versionfile_abs = os.path.join(root, cfg.versionfile_source)
# extract version from first of: _version.py, VCS command (e.g. 'git
# describe'), parentdir. This is meant to work for developers using a
# source checkout, for users of a tarball created by 'setup.py sdist',
# and for users of a tarball/zipball created by 'git archive' or github's
# download-from-tag feature or the equivalent in other VCSes.
get_keywords_f = handlers.get("get_keywords")
from_keywords_f = handlers.get("keywords")
if get_keywords_f and from_keywords_f:
try:
keywords = get_keywords_f(versionfile_abs)
ver = from_keywords_f(keywords, cfg.tag_prefix, verbose)
if verbose:
print("got version from expanded keyword %s" % ver)
return ver
except NotThisMethod:
pass
try:
ver = versions_from_file(versionfile_abs)
if verbose:
print("got version from file %s %s" % (versionfile_abs, ver))
return ver
except NotThisMethod:
pass
from_vcs_f = handlers.get("pieces_from_vcs")
if from_vcs_f:
try:
pieces = from_vcs_f(cfg.tag_prefix, root, verbose)
ver = render(pieces, cfg.style)
if verbose:
print("got version from VCS %s" % ver)
return ver
except NotThisMethod:
pass
try:
if cfg.parentdir_prefix:
ver = versions_from_parentdir(cfg.parentdir_prefix, root, verbose)
if verbose:
print("got version from parentdir %s" % ver)
return ver
except NotThisMethod:
pass
if verbose:
print("unable to compute version")
return {"version": "0+unknown", "full-revisionid": None,
"dirty": None, "error": "unable to compute version",
"date": None}
def get_version():
"""Get the short version string for this project."""
return get_versions()["version"]
def get_cmdclass(cmdclass=None):
"""Get the custom setuptools/distutils subclasses used by Versioneer.
If the package uses a different cmdclass (e.g. one from numpy), it
should be provide as an argument.
"""
if "versioneer" in sys.modules:
del sys.modules["versioneer"]
# this fixes the "python setup.py develop" case (also 'install' and
# 'easy_install .'), in which subdependencies of the main project are
# built (using setup.py bdist_egg) in the same python process. Assume
# a main project A and a dependency B, which use different versions
# of Versioneer. A's setup.py imports A's Versioneer, leaving it in
# sys.modules by the time B's setup.py is executed, causing B to run
# with the wrong versioneer. Setuptools wraps the sub-dep builds in a
# sandbox that restores sys.modules to it's pre-build state, so the
# parent is protected against the child's "import versioneer". By
# removing ourselves from sys.modules here, before the child build
# happens, we protect the child from the parent's versioneer too.
# Also see https://github.com/python-versioneer/python-versioneer/issues/52
cmds = {} if cmdclass is None else cmdclass.copy()
# we add "version" to both distutils and setuptools
try:
from setuptools import Command
except ImportError:
from distutils.core import Command
class cmd_version(Command):
description = "report generated version string"
user_options = []
boolean_options = []
def initialize_options(self):
pass
def finalize_options(self):
pass
def run(self):
vers = get_versions(verbose=True)
print("Version: %s" % vers["version"])
print(" full-revisionid: %s" % vers.get("full-revisionid"))
print(" dirty: %s" % vers.get("dirty"))
print(" date: %s" % vers.get("date"))
if vers["error"]:
print(" error: %s" % vers["error"])
cmds["version"] = cmd_version
# we override "build_py" in both distutils and setuptools
#
# most invocation pathways end up running build_py:
# distutils/build -> build_py
# distutils/install -> distutils/build ->..
# setuptools/bdist_wheel -> distutils/install ->..
# setuptools/bdist_egg -> distutils/install_lib -> build_py
# setuptools/install -> bdist_egg ->..
# setuptools/develop -> ?
# pip install:
# copies source tree to a tempdir before running egg_info/etc
# if .git isn't copied too, 'git describe' will fail
# then does setup.py bdist_wheel, or sometimes setup.py install
# setup.py egg_info -> ?
# we override different "build_py" commands for both environments
if 'build_py' in cmds:
_build_py = cmds['build_py']
elif "setuptools" in sys.modules:
from setuptools.command.build_py import build_py as _build_py
else:
from distutils.command.build_py import build_py as _build_py
class cmd_build_py(_build_py):
def run(self):
root = get_root()
cfg = get_config_from_root(root)
versions = get_versions()
_build_py.run(self)
# now locate _version.py in the new build/ directory and replace
# it with an updated value
if cfg.versionfile_build:
target_versionfile = os.path.join(self.build_lib,
cfg.versionfile_build)
print("UPDATING %s" % target_versionfile)
write_to_version_file(target_versionfile, versions)
cmds["build_py"] = cmd_build_py
if 'build_ext' in cmds:
_build_ext = cmds['build_ext']
elif "setuptools" in sys.modules:
from setuptools.command.build_ext import build_ext as _build_ext
else:
from distutils.command.build_ext import build_ext as _build_ext
class cmd_build_ext(_build_ext):
def run(self):
root = get_root()
cfg = get_config_from_root(root)
versions = get_versions()
_build_ext.run(self)
if self.inplace:
# build_ext --inplace will only build extensions in
# build/lib<..> dir with no _version.py to write to.
# As in place builds will already have a _version.py
# in the module dir, we do not need to write one.
return
# now locate _version.py in the new build/ directory and replace
# it with an updated value
target_versionfile = os.path.join(self.build_lib,
cfg.versionfile_build)
print("UPDATING %s" % target_versionfile)
write_to_version_file(target_versionfile, versions)
cmds["build_ext"] = cmd_build_ext
if "cx_Freeze" in sys.modules: # cx_freeze enabled?
from cx_Freeze.dist import build_exe as _build_exe
# nczeczulin reports that py2exe won't like the pep440-style string
# as FILEVERSION, but it can be used for PRODUCTVERSION, e.g.
# setup(console=[{
# "version": versioneer.get_version().split("+", 1)[0], # FILEVERSION
# "product_version": versioneer.get_version(),
# ...
class cmd_build_exe(_build_exe):
def run(self):
root = get_root()
cfg = get_config_from_root(root)
versions = get_versions()
target_versionfile = cfg.versionfile_source
print("UPDATING %s" % target_versionfile)
write_to_version_file(target_versionfile, versions)
_build_exe.run(self)
os.unlink(target_versionfile)
with open(cfg.versionfile_source, "w") as f:
LONG = LONG_VERSION_PY[cfg.VCS]
f.write(LONG %
{"DOLLAR": "$",
"STYLE": cfg.style,
"TAG_PREFIX": cfg.tag_prefix,
"PARENTDIR_PREFIX": cfg.parentdir_prefix,
"VERSIONFILE_SOURCE": cfg.versionfile_source,
})
cmds["build_exe"] = cmd_build_exe
del cmds["build_py"]
if 'py2exe' in sys.modules: # py2exe enabled?
from py2exe.distutils_buildexe import py2exe as _py2exe
class cmd_py2exe(_py2exe):
def run(self):
root = get_root()
cfg = get_config_from_root(root)
versions = get_versions()
target_versionfile = cfg.versionfile_source
print("UPDATING %s" % target_versionfile)
write_to_version_file(target_versionfile, versions)
_py2exe.run(self)
os.unlink(target_versionfile)
with open(cfg.versionfile_source, "w") as f:
LONG = LONG_VERSION_PY[cfg.VCS]
f.write(LONG %
{"DOLLAR": "$",
"STYLE": cfg.style,
"TAG_PREFIX": cfg.tag_prefix,
"PARENTDIR_PREFIX": cfg.parentdir_prefix,
"VERSIONFILE_SOURCE": cfg.versionfile_source,
})
cmds["py2exe"] = cmd_py2exe
# we override different "sdist" commands for both environments
if 'sdist' in cmds:
_sdist = cmds['sdist']
elif "setuptools" in sys.modules:
from setuptools.command.sdist import sdist as _sdist
else:
from distutils.command.sdist import sdist as _sdist
class cmd_sdist(_sdist):
def run(self):
versions = get_versions()
self._versioneer_generated_versions = versions
# unless we update this, the command will keep using the old
# version
self.distribution.metadata.version = versions["version"]
return _sdist.run(self)
def make_release_tree(self, base_dir, files):
root = get_root()
cfg = get_config_from_root(root)
_sdist.make_release_tree(self, base_dir, files)
# now locate _version.py in the new base_dir directory
# (remembering that it may be a hardlink) and replace it with an
# updated value
target_versionfile = os.path.join(base_dir, cfg.versionfile_source)
print("UPDATING %s" % target_versionfile)
write_to_version_file(target_versionfile,
self._versioneer_generated_versions)
cmds["sdist"] = cmd_sdist
return cmds
CONFIG_ERROR = """
setup.cfg is missing the necessary Versioneer configuration. You need
a section like:
[versioneer]
VCS = git
style = pep440
versionfile_source = src/myproject/_version.py
versionfile_build = myproject/_version.py
tag_prefix =
parentdir_prefix = myproject-
You will also need to edit your setup.py to use the results:
import versioneer
setup(version=versioneer.get_version(),
cmdclass=versioneer.get_cmdclass(), ...)
Please read the docstring in ./versioneer.py for configuration instructions,
edit setup.cfg, and re-run the installer or 'python versioneer.py setup'.
"""
SAMPLE_CONFIG = """
# See the docstring in versioneer.py for instructions. Note that you must
# re-run 'versioneer.py setup' after changing this section, and commit the
# resulting files.
[versioneer]
#VCS = git
#style = pep440
#versionfile_source =
#versionfile_build =
#tag_prefix =
#parentdir_prefix =
"""
OLD_SNIPPET = """
from ._version import get_versions
__version__ = get_versions()['version']
del get_versions
"""
INIT_PY_SNIPPET = """
from . import {0}
__version__ = {0}.get_versions()['version']
"""
def do_setup():
"""Do main VCS-independent setup function for installing Versioneer."""
root = get_root()
try:
cfg = get_config_from_root(root)
except (OSError, configparser.NoSectionError,
configparser.NoOptionError) as e:
if isinstance(e, (OSError, configparser.NoSectionError)):
print("Adding sample versioneer config to setup.cfg",
file=sys.stderr)
with open(os.path.join(root, "setup.cfg"), "a") as f:
f.write(SAMPLE_CONFIG)
print(CONFIG_ERROR, file=sys.stderr)
return 1
print(" creating %s" % cfg.versionfile_source)
with open(cfg.versionfile_source, "w") as f:
LONG = LONG_VERSION_PY[cfg.VCS]
f.write(LONG % {"DOLLAR": "$",
"STYLE": cfg.style,
"TAG_PREFIX": cfg.tag_prefix,
"PARENTDIR_PREFIX": cfg.parentdir_prefix,
"VERSIONFILE_SOURCE": cfg.versionfile_source,
})
ipy = os.path.join(os.path.dirname(cfg.versionfile_source),
"__init__.py")
if os.path.exists(ipy):
try:
with open(ipy, "r") as f:
old = f.read()
except OSError:
old = ""
module = os.path.splitext(os.path.basename(cfg.versionfile_source))[0]
snippet = INIT_PY_SNIPPET.format(module)
if OLD_SNIPPET in old:
print(" replacing boilerplate in %s" % ipy)
with open(ipy, "w") as f:
f.write(old.replace(OLD_SNIPPET, snippet))
elif snippet not in old:
print(" appending to %s" % ipy)
with open(ipy, "a") as f:
f.write(snippet)
else:
print(" %s unmodified" % ipy)
else:
print(" %s doesn't exist, ok" % ipy)
ipy = None
# Make sure both the top-level "versioneer.py" and versionfile_source
# (PKG/_version.py, used by runtime code) are in MANIFEST.in, so
# they'll be copied into source distributions. Pip won't be able to
# install the package without this.
manifest_in = os.path.join(root, "MANIFEST.in")
simple_includes = set()
try:
with open(manifest_in, "r") as f:
for line in f:
if line.startswith("include "):
for include in line.split()[1:]:
simple_includes.add(include)
except OSError:
pass
# That doesn't cover everything MANIFEST.in can do
# (http://docs.python.org/2/distutils/sourcedist.html#commands), so
# it might give some false negatives. Appending redundant 'include'
# lines is safe, though.
if "versioneer.py" not in simple_includes:
print(" appending 'versioneer.py' to MANIFEST.in")
with open(manifest_in, "a") as f:
f.write("include versioneer.py\n")
else:
print(" 'versioneer.py' already in MANIFEST.in")
if cfg.versionfile_source not in simple_includes:
print(" appending versionfile_source ('%s') to MANIFEST.in" %
cfg.versionfile_source)
with open(manifest_in, "a") as f:
f.write("include %s\n" % cfg.versionfile_source)
else:
print(" versionfile_source already in MANIFEST.in")
# Make VCS-specific changes. For git, this means creating/changing
# .gitattributes to mark _version.py for export-subst keyword
# substitution.
do_vcs_install(manifest_in, cfg.versionfile_source, ipy)
return 0
def scan_setup_py():
"""Validate the contents of setup.py against Versioneer's expectations."""
found = set()
setters = False
errors = 0
with open("setup.py", "r") as f:
for line in f.readlines():
if "import versioneer" in line:
found.add("import")
if "versioneer.get_cmdclass()" in line:
found.add("cmdclass")
if "versioneer.get_version()" in line:
found.add("get_version")
if "versioneer.VCS" in line:
setters = True
if "versioneer.versionfile_source" in line:
setters = True
if len(found) != 3:
print("")
print("Your setup.py appears to be missing some important items")
print("(but I might be wrong). Please make sure it has something")
print("roughly like the following:")
print("")
print(" import versioneer")
print(" setup( version=versioneer.get_version(),")
print(" cmdclass=versioneer.get_cmdclass(), ...)")
print("")
errors += 1
if setters:
print("You should remove lines like 'versioneer.VCS = ' and")
print("'versioneer.versionfile_source = ' . This configuration")
print("now lives in setup.cfg, and should be removed from setup.py")
print("")
errors += 1
return errors
if __name__ == "__main__":
cmd = sys.argv[1]
if cmd == "setup":
errors = do_setup()
errors += scan_setup_py()
if errors:
sys.exit(1) | zef | /zef-0.17.0a3.tar.gz/zef-0.17.0a3/versioneer.py | versioneer.py |
import os
from cogapp import Cog
import sys
search_path = sys.argv[1]
output_path = sys.argv[2]
tokens_path = sys.argv[3]
def find_files_of_type(path, filename_endings, directories_to_exclude={}):
# Returns paths relative to the input path
for dirpath,dirnames,filenames in os.walk(path):
for filename in filenames:
thispath = os.path.join(dirpath, filename)
if os.path.splitext(thispath)[1] in filename_endings:
yield os.path.relpath(thispath, path)
for dirname in directories_to_exclude:
while dirname in dirnames:
dirnames.remove(dirname)
cog = Cog()
cog.options.bReplace = False
cog.options.bDeleteCode = True
cog.options.sPrologue = f"""
import cog
import json
import os
et_filename = os.path.join("{tokens_path}", "zeftypes_ET.json")
with open(et_filename) as F:
et = json.loads(F.read())
rt_filename = os.path.join("{tokens_path}", "zeftypes_RT.json")
with open(rt_filename) as F:
rt = json.loads(F.read())
kw_filename = os.path.join("{tokens_path}", "zeftypes_KW.json")
with open(kw_filename) as F:
kw = json.loads(F.read())
en_filename = os.path.join("{tokens_path}", "zeftypes_EN.json")
with open(en_filename) as F:
en = json.loads(F.read())
def enum_type(x):
return x.split('.')[0]
def enum_val(x):
return x.split('.')[1]
"""
#cog.options.verbosity = 0
for filename in find_files_of_type(path=search_path, filename_endings={'.cog'}):
try:
true_output = os.path.join(output_path, filename[:-len(".cog")] + ".gen")
os.makedirs(os.path.dirname(true_output), exist_ok=True)
cog.options.sOutputName = true_output + ".tmp"
cog.processOneFile(os.path.join(search_path, filename))
if not os.path.exists(true_output) or open(true_output + ".tmp").read() != open(true_output).read():
print(filename, " changed")
os.rename(true_output + ".tmp", true_output)
else:
os.unlink(true_output + ".tmp")
except Exception as exc:
print(f'An exception was raised when processing file "{filename}": {exc}')
# Need this to fail for cmake to not continue on without a care.
raise | zef | /zef-0.17.0a3.tar.gz/zef-0.17.0a3/libzef/scripts/run_cog_gen.py | run_cog_gen.py |
from urllib.request import urlopen
import sys
if len(sys.argv) >= 2:
server = sys.argv[1]
else:
server = "https://hub.zefhub.io"
try:
response = urlopen(f"{server}/REST",
data=b'{"msg_type": "token", "msg_version": 1, "action": "list", "protocol_type": "ZEFDB", "protocol_version": 5}')
b = response.read()
import json
j = json.loads(b)
assert j["msg_type"] == "token_response"
assert j["reason"] == "list"
assert j["success"] == True
except Exception as exc:
print(f"There was an exception when trying to get the tokens from zefhub: {exc}")
print("NOT USING LATEST TOKENS, FALLINBACK BACK TO BOOTSTRAP!!!!")
print("NOT USING LATEST TOKENS, FALLINBACK BACK TO BOOTSTRAP!!!!")
print("NOT USING LATEST TOKENS, FALLINBACK BACK TO BOOTSTRAP!!!!")
print("NOT USING LATEST TOKENS, FALLINBACK BACK TO BOOTSTRAP!!!!")
print("NOT USING LATEST TOKENS, FALLINBACK BACK TO BOOTSTRAP!!!!")
print("NOT USING LATEST TOKENS, FALLINBACK BACK TO BOOTSTRAP!!!!")
print("NOT USING LATEST TOKENS, FALLINBACK BACK TO BOOTSTRAP!!!!")
print("NOT USING LATEST TOKENS, FALLINBACK BACK TO BOOTSTRAP!!!!")
print("NOT USING LATEST TOKENS, FALLINBACK BACK TO BOOTSTRAP!!!!")
print("NOT USING LATEST TOKENS, FALLINBACK BACK TO BOOTSTRAP!!!!")
print("NOT USING LATEST TOKENS, FALLINBACK BACK TO BOOTSTRAP!!!!")
print("NOT USING LATEST TOKENS, FALLINBACK BACK TO BOOTSTRAP!!!!")
import shutil
import os
template_dir = os.path.join(os.path.dirname(__file__), "templates")
shutil.copy(os.path.join(template_dir, "zeftypes_bootstrap_ET.json"), "zeftypes_ET.json")
shutil.copy(os.path.join(template_dir, "zeftypes_bootstrap_RT.json"), "zeftypes_RT.json")
shutil.copy(os.path.join(template_dir, "zeftypes_bootstrap_KW.json"), "zeftypes_KW.json")
shutil.copy(os.path.join(template_dir, "zeftypes_bootstrap_EN.json"), "zeftypes_EN.json")
import sys
sys.exit(0)
et = json.dumps(j["groups"]["ET"])
rt = json.dumps(j["groups"]["RT"])
en = json.dumps(j["groups"]["EN"])
if "KW" in j["groups"]:
kw = json.dumps(j["groups"]["KW"])
else:
with open("zeftypes_bootstrap_KW.json") as file:
kw = file.read()
with open("zeftypes_ET.json", "w") as file:
file.write(et)
print("Successfully wrote ETs to zeftypes_ET.json")
with open("zeftypes_RT.json", "w") as file:
file.write(rt)
print("Successfully wrote RTs to zeftypes_RT.json")
with open("zeftypes_EN.json", "w") as file:
file.write(en)
print("Successfully wrote ENs to zeftypes_EN.json")
with open("zeftypes_KW.json", "w") as file:
file.write(kw)
print("Successfully wrote KWs to zeftypes_KW.json") | zef | /zef-0.17.0a3.tar.gz/zef-0.17.0a3/libzef/scripts/get_zeftypes.py | get_zeftypes.py |
from io import StringIO
from zefactor.api.find_scanner import FindScanner
from zefactor.api.transform import Transform
class FinderRefactor:
def __init__(self, suppress_warnings=False):
self._suppress_warnings = suppress_warnings
def scan_text(self, text, find_tokens):
input_fd = StringIO(text)
for item in self._scan(input_fd, find_tokens):
yield item
def scan_file(self, filepath, find_tokens):
try:
first_char = True
with open(filepath, "r") as input_fd:
for item in self._scan(input_fd, find_tokens):
yield item
except UnicodeDecodeError:
if(not self._suppress_warnings):
print("[WARNING] could not decode: " + filepath + " as utf-8, skipping refactor.")
# Scans files and finds flexible matching patterns to the search tokens.
def _scan(self, input_fd, find_tokens):
find_scanners = []
first_char = True
while True:
find_scanner = FindScanner(find_tokens)
find_scanners.append(find_scanner)
char = input_fd.read(1)
if not char:
break
# A token must match a non-alphanumeric character to start the sequence
# Except for the very first token in a file, so it should be seeded with a fake input.
if(first_char):
find_scanners[0].check_next("")
first_char = False
matched_find_scanners = []
for find_scanner in find_scanners:
match = find_scanner.check_next(char)
if(match):
if(find_scanner.is_done()):
yield find_scanner.get_record()
else:
matched_find_scanners.append(find_scanner)
find_scanners = matched_find_scanners
# If the file terminates, add one empty string to all find_scanners
for find_scanner in find_scanners:
match = find_scanner.check_next("")
if(find_scanner.is_done()):
yield find_scanner.get_record()
# Deterimines the case of a token given the prior casing and the next char
# Cases are either 'upper', 'lower', 'title', or 'none' and if not set Python's None
def resolve_case(self, current_case, next_char):
if(current_case == "none"):
return current_case
if(current_case is None):
if(next_char.isupper()):
return "title"
else:
return "lower"
else:
if(next_char.isupper()):
if(current_case == "title"):
return "upper"
elif(current_case == "lower"):
return "none"
return current_case
else:
if(current_case == "title" or current_case == "lower"):
return current_case
else:
return "none"
# Outputs a list of operations to apply to replace tokens
def classify(self, raw_text, find_tokens):
#print("AE:")
#print(raw_text)
#print(find_tokens)
#print("AE-DONE")
transform = Transform()
case = None
delimiter = ""
find_tokens_index = 0
char_index = 0
first_raw = False
for char in raw_text:
if(first_raw):
if(char.isalnum()):
delimiter = ""
transform.push(case, delimiter)
if(char.isupper()):
case = "title"
else:
case = "lower"
char_index = char_index + 1
else:
delimiter = char
transform.push(case, delimiter)
case = None
# Reset default values
delimiter = ""
first_raw = False
continue
case = self.resolve_case(case, char)
if(char.lower() != find_tokens[find_tokens_index][char_index]):
raise "Classification error"
char_index = char_index + 1
first_raw = False
if(char_index == len(find_tokens[find_tokens_index])):
find_tokens_index = find_tokens_index + 1
char_index = 0
first_raw = True
# The last token always has a null delimiter.
delimiter = ""
transform.push(case, delimiter)
return transform
#def transform_replacement(self, transform, replace_tokens):
# pass
# Computes replacements for the search tokens attempting to follow similar casing and stylistic rules
def compute_replacement(self, raw_text, find_tokens, replace_tokens):
transform = self.classify(raw_text, find_tokens)
return transform.apply(replace_tokens) | zefactor | /api/finder_core.py | finder_core.py |
class ReplaceSemaphore:
def __init__(self):
self._index_scanner = {}
self._index_char = {}
self._index_count = {}
def register_char(self, index, char):
self._index_char[index] = char
def register_scanner(self, index, scanner_key, scanner):
##print("REGISTERING: " + str(index) + "-" + scanner_key)
if(index not in self._index_scanner):
self._index_scanner[index] = {}
self._index_scanner[index][scanner_key] = scanner
# Increase semaphore range by 1 because sequences must contain an extra terminating character
for count in range(index, index + len(scanner_key) + 1):
if(count not in self._index_count):
self._index_count[count] = 1
else:
self._index_count[count] = self._index_count[count] + 1
def get_scanners(self):
scanner_list = []
for index in self._index_scanner:
for scanner_key in self._index_scanner[index]:
scanner_list.append((index, self._index_scanner[index][scanner_key]))
return scanner_list
def unregister_scanner(self, index, scanner_key):
##print("UNREGISTERING: " + str(index) + "-" + scanner_key)
char = ""
self._index_scanner[index].pop(scanner_key)
for count in range(index, index + len(scanner_key) + 1):
self._index_count[count] = self._index_count[count] - 1
if(self._index_count[count] == 0):
if(count in self._index_char):
char = char + self._index_char[count]
self._index_char.pop(count, None)
self._index_count.pop(count, None)
self._index_scanner.pop(count,None)
return char
def mark_done(self, index, find_text, replace_text):
##print("MARK DONE ENTERED: " + str(index) + "-" + replace_text)
for count in range(index, index + len(find_text)):
if(count in self._index_scanner):
for scanner_key in self._index_scanner[count]:
for char_count in range(count, count + len(scanner_key)):
self._index_count[char_count] = self._index_count[char_count] - 1
if(self._index_count[char_count] == 0):
# TODO: Possible bugs - there may be cases where the below is not the full story
self._index_count.pop(char_count, None)
self._index_char.pop(char_count, None)
##if(count in self._index_scanner):
## for scanner_key in self._index_scanner[count]:
## print("DONE REMOVING: " + str(count) + "-" + scanner_key)
self._index_scanner.pop(count, None)
def __str__(self):
indexes = sorted(self._index_char.keys())
content_list = []
for index in indexes:
char = self._index_char[index]
count = self._index_count[index]
content_list.append(str(count) + char)
output_tokens = "tokens [ " + ", ".join(content_list) + " ]"
output_scanners = ""
for index, scanner in self.get_scanners():
output_scanners = output_scanners + str(index) + "-" + scanner.get_find_text() + "\n"
return output_tokens + "\n" + output_scanners | zefactor | /api/replace_semaphore.py | replace_semaphore.py |
from zefactor.api.replace_scanner import ReplaceScanner
from zefactor.api.replace_semaphore import ReplaceSemaphore
import os
from io import StringIO
class ReplacerRefactor:
def __init__(self):
pass
def apply_text(self, text, replacement_map):
input_fd = StringIO(text)
output_fd = StringIO()
self._apply_replacements(input_fd, output_fd, replacement_map)
return output_fd.getvalue()
def _apply_replacements(self, input_fd, output_fd, replacement_map):
replace_semaphore = ReplaceSemaphore()
index = 0
continue_loop = True
while continue_loop:
# if(index > 90):
# print("Exiting early")
# import sys
# sys.exit(0)
# A token must match a non-alphanumeric character to start the sequence
# Except for the very first token in a file, so it should be seeded with a fake input.
char = None
if(index == 0):
char = ""
else:
char = input_fd.read(1)
if index != 0 and not char:
# Scan one more terminating character to represent file end.
continue_loop = False
char = ""
replace_semaphore.register_char(index, char)
for find_text in replacement_map:
replace_text = replacement_map[find_text]
base_replace_scanner = ReplaceScanner(find_text, replace_text, index, char)
replace_semaphore.register_scanner(index, find_text, base_replace_scanner)
##print(replace_semaphore)
done = False
write_chars = ""
for scanner_index, replace_scanner in replace_semaphore.get_scanners():
match = replace_scanner.check_next(char)
if(match):
if(replace_scanner.is_done()):
find_text = replace_scanner.get_find_text()
replace_text = replace_scanner.get_replace_text()
# If a match is done write out the replacement text
output_fd.write(replace_scanner.get_start_symbol())
output_fd.write(replace_text)
replace_semaphore.mark_done(scanner_index, find_text, replace_text)
done = True
else:
write_char = replace_semaphore.unregister_scanner(scanner_index, replace_scanner.get_find_text())
if(len(write_char) > 0):
write_chars = write_chars + write_char
if(len(write_chars) > 0 and done is not True):
output_fd.write(write_chars)
index = index + 1
def apply(self, filepath, replacement_map):
backup_dir = os.path.dirname(filepath)
backup_filepath = backup_dir + os.path.sep + os.path.basename(filepath) + ".rr.backup"
with open(backup_filepath, "r") as input_fd:
with open(filepath, "w") as output_fd:
self._apply_replacements(input_fd, output_fd, replacement_map) | zefactor | /api/replacer_core.py | replacer_core.py |
class Transform:
def __init__(self):
self._transforms = []
pass;
# Add a new transform the list
def push(self, case, delimiter):
transform = (case, delimiter)
self._transforms.append(transform)
# Apply transforms in order to the input replace tokens
def apply(self, replace_tokens):
#print()
#print("Transforms")
#print()
#for case, delimiter in self._transforms:
# print(case + " " + delimiter)
#print()
#print("Replace Tokens")
#print()
#for replace_token in replace_tokens:
# print(replace_token)
#print()
#import sys
#sys.exit(0)
replacement_text = ""
for i in range(min(len(self._transforms), len(replace_tokens))):
case, delimiter = self._transforms[i]
replace_token = replace_tokens[i]
if(case == "upper"):
replace_token = replace_token.upper()
elif(case == "title"):
replace_token = replace_token.title()
elif(case == "lower"):
replace_token = replace_token.lower()
replacement_text = replacement_text + replace_token
if(i < len(replace_tokens) - 1):
replacement_text = replacement_text + delimiter
# If there are more replace tokens than find tokens then use the last case and delimiter to guess how to transform them
diff = len(replace_tokens) - len(self._transforms)
last_delimiter = None
last_case = None
if(diff > 0):
last_delimiter = self._transforms[-2][1]
last_case = self._transforms[-1][0]
for i in range(0, diff):
replace_token = replace_tokens[i + len(self._transforms)]
if(last_case == "upper"):
replace_token = replace_token.upper()
elif(last_case == "title"):
replace_token = replace_token.title()
elif(last_case == "lower"):
replace_token = replace_token.lower()
replacement_text = replacement_text + last_delimiter + replace_token
return replacement_text
def __str__(self):
tokens = []
for case, delimiter in self._transforms:
tokens.append("(" + case + ", '" + delimiter + "')")
return "[" + " ".join(tokens) + "]" | zefactor | /api/transform.py | transform.py |
from zefactor.api.transform.transform import Transform
class TransformManager:
# Deterimines the case of a token given the prior casing and the next char
# Cases are either 'upper', 'lower', 'title', or 'none' and if not set Python's None
def _resolve_case(self, current_case, next_char):
if(current_case == "none"):
return current_case
if(current_case is None):
if(next_char.isupper()):
return "title"
else:
return "lower"
else:
if(next_char.isupper()):
if(current_case == "title"):
return "upper"
elif(current_case == "lower"):
return "none"
return current_case
else:
if(current_case == "title" or current_case == "lower"):
return current_case
else:
return "none"
# Outputs a list of operations to apply to replace tokens
def _classify(self, raw_text, find_tokens):
transform = Transform()
case = None
delimiter = ""
find_tokens_index = 0
char_index = 0
first_raw = False
for char in raw_text:
if(first_raw):
if(char.isalnum()):
delimiter = ""
transform.push(case, delimiter)
if(char.isupper()):
case = "title"
else:
case = "lower"
char_index = char_index + 1
else:
delimiter = char
transform.push(case, delimiter)
case = None
# Reset default values
delimiter = ""
first_raw = False
continue
case = self._resolve_case(case, char)
if(char.lower() != find_tokens[find_tokens_index][char_index]):
raise "Classification error"
char_index = char_index + 1
first_raw = False
if(char_index == len(find_tokens[find_tokens_index])):
find_tokens_index = find_tokens_index + 1
char_index = 0
first_raw = True
# The last token always has a null delimiter.
delimiter = ""
transform.push(case, delimiter)
return transform
# Computes replacements for the search tokens attempting to follow similar casing and stylistic rules
def _compute_replacement(self, raw_text, find_tokens, replace_tokens):
transform = self._classify(raw_text, find_tokens)
return transform.apply(replace_tokens)
def compute_replacement_map(self, input_texts, find_tokens, replace_tokens):
replacement_map = {}
for input_text in input_texts:
replacement = self._compute_replacement(input_text, find_tokens, replace_tokens)
replacement_map[input_text] = replacement
return replacement_map | zefactor | /api/transform/transform_manager.py | transform_manager.py |
==============
zefram package
==============
A convenent, pythnonic way of interacting with data from the [IZA Database of Zeolite Structures](http://www.iza-structure.org/databases/).
Dependencies
============
* SQLAlchemy_
* numpy_
Installation
============
Simplest way to install ``zefram`` is with ``pip``:
.. code-block:: bash
pip install zefram
.. _SQLalchemy: http://www.sqlalchemy.org
.. _numpy: http://www.numpy.org
Usage
=====
The package exposes a simple API to access the database. ``framework`` method
acceps either three letter framework codes such as *AFI* or *MFI* or a list of
such strings returning a ``Framework`` object (or list of objects). The example
below shows also the accessible attributes of the ``Framework`` object
.. code-block:: python
>>> from zefram import framework
>>> afi = framework('AFI')
>>> sorted(list(afi.__dict__.keys()))
['_sa_instance_state',
'_spacegroup_id',
'a',
'accessible_area',
'accessible_area_m2pg',
'accessible_volume',
'accessible_volume_pct',
'alpha',
'atoms',
'b',
'beta',
'c',
'cages',
'channel_dim',
'channels',
'cif',
'code',
'connections',
'framework_density',
'gamma',
'id',
'isdisordered',
'isinterrupted',
'junctions',
'lcd',
'maxdsd_a',
'maxdsd_b',
'maxdsd_c',
'maxdsi',
'name',
'occupiable_area',
'occupiable_area_m2pg',
'occupiable_volume',
'occupiable_volume_pct',
'pld',
'portals',
'rdls',
'sbu',
'specific_accessible_area',
'specific_occupiable_area',
'td10',
'topological_density',
'tpw_abs',
'tpw_pct',
'url_iza',
'url_zeomics']
Data
====
+--------------------------+-------+---------------------------------------------+-------------+
| Attribute | Type | Comment | Data Source |
+==========================+=======+=============================================+=============+
| a | float | *a* unit cell length in Angstroms | [1]_ |
+--------------------------+-------+---------------------------------------------+-------------+
| b | float | *b* unit cell length in Angstroms | [1]_ |
+--------------------------+-------+---------------------------------------------+-------------+
| c | float | *c* unit cell legth in Angstroms | [1]_ |
+--------------------------+-------+---------------------------------------------+-------------+
| alpha | float | *alpha* unit cell angle in degrees | [1]_ |
+--------------------------+-------+---------------------------------------------+-------------+
| beta | float | *c* unit cell angle in degrees | [1]_ |
+--------------------------+-------+---------------------------------------------+-------------+
| gamma | float | *c* unit cell angle in degrees | [1]_ |
+--------------------------+-------+---------------------------------------------+-------------+
| code | str | three letter framework code | [1]_ |
+--------------------------+-------+---------------------------------------------+-------------+
| name | str | name of the framework in english | [1]_ |
+--------------------------+-------+---------------------------------------------+-------------+
| atoms | int | number of atoms in the unit cell | [2]_ |
+--------------------------+-------+---------------------------------------------+-------------+
| portals | int | number of portals in the unit cell | [2]_ |
+--------------------------+-------+---------------------------------------------+-------------+
| cages | int | number of cages in the unit cell | [2]_ |
+--------------------------+-------+---------------------------------------------+-------------+
| channels | int | number of channels in the unit cell | [2]_ |
+--------------------------+-------+---------------------------------------------+-------------+
| junctions | int | number of junctions in the unit cell | [2]_ |
+--------------------------+-------+---------------------------------------------+-------------+
| connections | int | number of connections in the unit cell | [2]_ |
+--------------------------+-------+---------------------------------------------+-------------+
| tpv_abs | float | total pore volume in cm^3/g | [2]_ |
+--------------------------+-------+---------------------------------------------+-------------+
| tpv_rel | float | relative total pore volume in % | [2]_ |
+--------------------------+-------+---------------------------------------------+-------------+
| lcd | float | largest cavity diameter in Angstrom | [2]_ |
+--------------------------+-------+---------------------------------------------+-------------+
| pld | float | pore limiting diameter in Angstrom | [2]_ |
+--------------------------+-------+---------------------------------------------+-------------+
| accessible_area | float | accessible area in Angstrom^2 | [1]_ |
+--------------------------+-------+---------------------------------------------+-------------+
| accessible_area_m2pg | float | accessible area in m^2/g | [1]_ |
+--------------------------+-------+---------------------------------------------+-------------+
| accessible_volume | float | accessible volume in Angstrom^3 | [1]_ |
+--------------------------+-------+---------------------------------------------+-------------+
| accessible_volume_pct | float | accessible volume in % | [1]_ |
+--------------------------+-------+---------------------------------------------+-------------+
| channel_dim | int | channel dimensionality | [1]_ |
+--------------------------+-------+---------------------------------------------+-------------+
| cif | str | cif file contents | [1]_ |
+--------------------------+-------+---------------------------------------------+-------------+
| framework_density | float | number of T-atoms per 1000 Angstrom^3 | [1]_ |
+--------------------------+-------+---------------------------------------------+-------------+
| isinterrrupted | bool | interrrupted framework | [1]_ |
+--------------------------+-------+---------------------------------------------+-------------+
| isdisordered | bool | disordered framework | [1]_ |
+--------------------------+-------+---------------------------------------------+-------------+
| maxdsd_a | float | maximum diameter of a sphere that can | [1]_ |
| | | diffuse along *a* | |
+--------------------------+-------+---------------------------------------------+-------------+
| maxdsd_b | float | maximum diameter of a sphere that can | [1]_ |
| | | diffuse along *b* | |
+--------------------------+-------+---------------------------------------------+-------------+
| maxdsd_c | float | maximum diameter of a sphere that can | [1]_ |
| | | diffuse along *c* | |
+--------------------------+-------+---------------------------------------------+-------------+
| maxdsi | float | maximum diameter of a sphere that can be | [1]_ |
| | | included | |
+--------------------------+-------+---------------------------------------------+-------------+
| occupiable_area | float | occupiable area in Angstrom^2 | [1]_ |
+--------------------------+-------+---------------------------------------------+-------------+
| occupiable_area_m2pg | float | occupiable area in m^2/g | [1]_ |
+--------------------------+-------+---------------------------------------------+-------------+
| occupiable_volume | float | occupiable volume in Angstrom^3 | [1]_ |
+--------------------------+-------+---------------------------------------------+-------------+
| occupiable_volume_pct | float | occupiable volume in % | [1]_ |
+--------------------------+-------+---------------------------------------------+-------------+
| specific_accessible_area | float | accessible area per unit volume in m^2/cm^3 | [1]_ |
+--------------------------+-------+---------------------------------------------+-------------+
| specific_occupiable_area | float | occupiable area per unit volume in m^2/cm^3 | [1]_ |
+--------------------------+-------+---------------------------------------------+-------------+
| td10 | float | approximate topological density | [1]_ |
+--------------------------+-------+---------------------------------------------+-------------+
| topological_density | float | topological density | [1]_ |
+--------------------------+-------+---------------------------------------------+-------------+
| url_iza | str | link to the source [1]_ for this framework | |
+--------------------------+-------+---------------------------------------------+-------------+
| url_zeomics | str | link to the source [2]_ for this framework | |
+--------------------------+-------+---------------------------------------------+-------------+
.. [1] `IZA database of zeolite structures <http://www.iza-structure.org/databases/>`_
.. [2] `ZEOMICS database <http://helios.princeton.edu/zeomics/>`_
License
=======
| The MIT License (MIT)
|
| Copyright (c) 2015 Lukasz Mentel
|
| Permission is hereby granted, free of charge, to any person obtaining a copy
| of this software and associated documentation files (the "Software"), to deal
| in the Software without restriction, including without limitation the rights
| to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
| copies of the Software, and to permit persons to whom the Software is
| furnished to do so, subject to the following conditions:
|
| The above copyright notice and this permission notice shall be included in all
| copies or substantial portions of the Software.
|
| THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
| IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
| FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
| AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
| LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
| OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
| SOFTWARE.
| zefram | /zefram-0.1.3.tar.gz/zefram-0.1.3/README.rst | README.rst |
The MIT License (MIT)
Copyright (c) 2015 Lukasz Mentel
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE.
| zefram | /zefram-0.1.3.tar.gz/zefram-0.1.3/LICENSE.rst | LICENSE.rst |
# zegami-cli
A Command Line Interface for [Zegami](https://www.zegami.com).
Zegami is a visual data exploration tool that makes the analysis of large collections of image rich information quick and simple.
The Zegami cli relies on a combination of yaml files and arguments.
The first step is to create a collection
# Installation
```
pip3 install zegami-cli[sql]
```
# Commands
## Login
The login command promtps for username and password which is then used to retrieve a long-lived API token which can be used for subsequent requests. The token is stored in a file in the currenet users data directory.
Once retrieved all subsequent commands will use the stored token, unless it is specifically overridden with the `--token` option
```
zeg login
```
## Get a collection
Get the details of a collection.
If the `collection id` is excluded then all collections will be listed.
```
zeg get collections [collection id] --project [Project Id]
```
## Create a collection
Create a collection using a combined dataset and imageset config.
```
zeg create collections --project [Project Id] --config [path to configuration yaml]
```
Project id, or workspace id, can be found in the url of a collection or collection listing page. For example:
https://zegami.com/mycollections/66xtfqsk
In the case of this workspace, it's `66xtfqsk`.
The following config properties are supported for file based imageset and datasets.
```
# The name of the collection
name: file based
description: an example collection with a file based imageset and dataset
# The type of data set. For now this needs to be set to 'file'. (optional)
dataset_type: file
# Config for the file data set type
imageset_type: file
# Config for the file image set type
file_config:
# Whether to recursively scan any directories. (optional)
recursive: True
# If provided, the mime-type to use when uploading images. (optional)
mime_type: image/jpeg
# Path to the dataset file. (optional)
path: path/to/file/mydata.csv
# A collection of paths to image files. Paths can be to both images and directories
paths:
- an_image.jpg
- a/directory/path
# Name of the column in the dataset that contains the image name. (optional)
dataset_column: image_name
```
If the `dataset_column` property is not provided, the backend will automatically select the column with the closest match.
To create a collection with only images the `dataset_type` and `path` properties can be omitted.
When providing a `mime_type` property, all files in directories will be uploaded regardless of extension.
If you are creating a url based imageset with a data file use these properties.
The dataset_column property is used to set the column where the url is stored. You will need to include the full image url e.g. https://zegami.com/wp-content/uploads/2018/01/weatherall.svg
```
# The name of the collection
name: url based
# The description of the collection
description: an example collection with a file based dataset where images are to be downloaded from urls
# The type of image set. for now this needs to be set to 'url'
imageset_type: url
# Name of the column in the dataset that contains the image url. (optional)
dataset_column: image_name
# Url pattern - python format string where {} is the values from the dataset_column in data file
url_template: https://example.com/images/{}?accesscode=abc3e20423423497
# Custom headers to add when fetching the image
image_fetch_headers:
Accept: image/png
dataset_type: file
# Config for the file data set type
file_config:
# Path to the dataset file. (optional)
path: path/to/file/mydata.csv
```
If you are creating an imageset on Azure from a private azure bucket with a local file do as follows:
```
# The name of the collection
name: azure bucket based
# The description of the collection
description: an example collection with a file based dataset where images are to be downloaded from an azure bucket
dataset_type: file. (optional)
# Config for the file data set type
file_config:
# Path to the dataset file. (optional)
path: path/to/file/mydata.csv
# The type of image set. for now this needs to be set to 'url'
imageset_type: azure_storage_container
# Name of the container
container_name: my_azure_blobs
# Name of the column in the dataset that contains the image url. (optional)
dataset_column: image_name
# Note that the storage account connection string should also be made available via environment variable AZURE_STORAGE_CONNECTION_STRING
```
If you are using SQL data see below for config
## Create a collection with multiple image sources
```
# The name of the collection
name: file based
description: an example collection with a file based imageset and dataset
collection_version: 2
# The type of data set. For now this needs to be set to 'file'.
dataset_type: file
file_config:
# Path to the dataset file.
path: path/to/file/mydata.csv
image_sources:
# source from file based imageset
- paths:
- a/directory/path
# source_name is a compulsory field. Each source's source_name needs to be unique.
source_name: first_source
# Name of the column in the dataset that contains the image name. (optional)
dataset_column: path
imageset_type: file
# source from url based imageset
- url_template: https://example.com/images/{}?accesscode=abc3e20423423497
image_fetch_headers:
Accept: image/png
source_name: second_source
imageset_type: url
```
## Update a collection
Update a collection - *coming soon*.
## Delete a collection
Delete a collection
```
zeg delete collections [collection id] --project [Project Id]
```
## Publish a collection
```
zeg publish collection [collection id] --project [Project Id] --config [path to configuration yaml]
```
Similarly to the workspace id, the collection id can be found in the url for a given collection. For instance:
https://zegami.com/collections/public-5df0d8c40812cf0001e99945?pan=FILTERS_PANEL&view=grid&info=true
This url is pointing to a collection with a collection id which is 5df0d8c40812cf0001e99945.
The config `yaml` file is used to specify additional configuration for the collection publish.
```
# The type of update. For now this needs to be set to 'publish'
update_type: publish
# Config for the publish update type
publish_config:
# Flag to indicate if the collection should be published or unpublished
publish: true
# The id of the project to publish to
destination_project: public
```
## Get a data set
Get a data set
```
zeg get dataset [dataset id] --project [Project Id]
```
Dataset Ids can be found in the collection information, obtained by running:
```
zeg get collections <collection id> --project <project id>
```
From here `upload_dataset_id` can be obtained. This identifies the dataset that represents the data as it was uploaded. Whereas `dataset_id` identifies the processed dataset delivered to the viewer.
## Update a data set
Update an existing data set with new data.
Note that when using against a collection the dataset id used should be the upload_dataset_id. This is different from the below imageset update which requires the dataset identifier known as dataset_id from the collection.
```
zeg update dataset [dataset id] --project [Project Id] --config [path to configuration yaml]
```
The config `yaml` file is used to specify additional configuration for the data set update. There are *two* supported `dataset_type` supported.
### File
The `file` type is used to update a data set with a file. It can be set up to either specify the fully qualified path to a `.csv.`, `.tsv` or `.xlsx` file to upload using the `path` property *or* the `directory` property can be used to upload the latest file in a directory location.
```
# The type of data set. For now this needs to be set to 'file'
dataset_type: file
# Config for the file data set type
file_config:
# Path to the dataset file
path: path/to/file/mydata.csv
# Or path to a directory that contains data files.
# Only the latest file that matches the accepted extensions (.csv, .tsv, .xlsx)
# will be uploaded. This is useful for creating collections based on
# automated exports from a system, like log files.
directory:
```
### SQL
The `sql` type is used to update a data set based on an `SQL` query.
Uses SQLAlchemy to connect to the database. See http://docs.sqlalchemy.org/en/latest/core/engines.html and https://www.connectionstrings.com/ for the correct connection string format.
```
# The type of data set. For now this needs to be set to 'file'
dataset_type: sql
# Config for the sql data set type
sql_config:
# The connection string.
connection:
# SQL query
query:
```
### PostgreSQL - tested on Linux and windows, up to Python v3.8
Pre-requisites :
1. Standard requirements - code editor, pip package manager, python 3.8.
2. Make sure Zegami CLI latest is installed
```
pip install zegami-cli[sql] --upgrade --no-cache-dir
```
_Note: --no-cache-dir avoids some errors upon install_
Test the install with the login command, which prompts for username and password. This is then used to retrieve a long-lived API token which can be used for subsequent requests. The token is stored in a file in the current users data directory.
Once retrieved all subsequent commands will use the stored token, unless it is specifically overridden with the `--token` option
```
zeg login
```
3. Install pre-requirements for PostgreSQL connection
Psycopg2 - https://pypi.org/project/psycopg2/ , http://initd.org/psycopg/
```
pip install python-psycopg2
```
_libpq-dev was required for linux, not windows_
libpq-dev - https://pypi.org/project/libpq-dev/ , https://github.com/ncbi/python-libpq-dev
```
sudo apt-get install libpq-dev
```
Once these are installed you will need to create a YAML file with the correct connection strings.
*Connection String Example:*
```
# The type of data set. For now this needs to be set to 'file'
dataset_type: sql
# Config for the sql data set type
sql_config:
# The connection string.
connection: "postgresql://postgres:myPassword@localhost:5432/postgres?sslmode=disable"
# SQL query
query: select * from XYZ
```
_Note: Connections strings must have indentation by "connection" and "query"_
If you have already created a collection we can run the update command as above
e.g. zeg update dataset upload_dataset_id --project projectID --config root/psqlconstring.yaml
If successful the following message will appear:
```
=========================================
update dataset with result:
-----------------------------------------
id: datasetID
name: Schema dataset for postgresql test
source:
blob_id: blobID
dataset_id: datasetID
upload:
name: zeg-datasetiop9cbtn.csv
=========================================
```
Useful links:
https://www.npgsql.org/doc/connection-string-parameters.html
https://www.connectionstrings.com/postgresql/ (Standard)
https://docs.sqlalchemy.org/en/13/core/engines.html#postgresql (Specifies pre-reqs for connection)
## Delete a data set
Delete a data set - *coming soon*.
```
zeg delete dataset [dataset id] --project [Project Id]
```
## Get an image set
Get an image set - *coming soon*.
```
zeg get imageset [imageset id] --project [Project Id]
```
## Update an image set
Update an image set with new images.
```
zeg update imageset [imageset id] --project [Project Id] --config [path to configuration yaml]
```
The config `yaml` file is used to specify additional configuration for the image set update. Note that an imageset can only be changed before images are added to it.
### File imageset
The `paths` property is used to specify the location of images to upload and can include both images and directories.
```
# The type of image set. for now this needs to be set to 'file'
imageset_type: file
# Config for the file image set type
file_config:
# A collection of paths. Paths can be to both images and directories
paths:
- an_image.jpg
- a/directory/path
# Unique identifier of the collection
collection_id: 5ad3a99b75f3b30001732f36
# Unique identifier of the collection data set (get this from dataset_id)
dataset_id: 5ad3a99b75f3b30001732f36
# Name of the column in the dataset that contains the image name
dataset_column: image_name
# Only required if this imageset is from a multiple image sources collection
source_name: first_source
```
### URL imageset
The dataset_column property is used to set the column where the url is stored. You will need to include the full image url e.g. https://zegami.com/wp-content/uploads/2018/01/weatherall.svg
```
# The type of image set. for now this needs to be set to 'url'
imageset_type: url
# Unique identifier of the collection
collection_id: 5ad3a99b75f3b30001732f36
# Unique identifier of the collection data set
dataset_id: 5ad3a99b75f3b30001732f36
# Name of the column in the dataset that contains the image url
dataset_column: image_name
# Url pattern - python format string where {} is the name of the image name (from data file)
url_template: https://example.com/images/{}?accesscode=abc3e20423423497
# Optional set of headers to include with the requests to fetch each image,
# e.g. for auth or to specify mime type
image_fetch_headers:
Accept: application/dicom
Authorization: Bearer user:pass
```
### Azure storage imageset
```
# The type of image set.
imageset_type: azure_storage_container
# Name of the container
container_name: my_azure_blobs
# Unique identifier of the collection
collection_id: 5ad3a99b75f3b30001732f36
# Unique identifier of the collection data set
dataset_id: 5ad3a99b75f3b30001732f36
# Name of the column in the dataset that contains the image url
dataset_column: image_name
# Note that the storage account connection string should also be made available via environment variable AZURE_STORAGE_CONNECTION_STRING
```
## Delete an image set
Delete an image set - *coming soon*.
```
zeg delete imageset [imageset id] --project [Project Id]
```
# Developer
## Tests
Setup tests:
```
pip install -r requirements/test.txt
```
Run tests:
```
python3 -m unittest discover .
```
| zegami-cli | /zegami-cli-1.5.1.tar.gz/zegami-cli-1.5.1/README.md | README.md |
"""A command line interface for managing Zegami."""
import sys
from argparse import ArgumentParser, RawDescriptionHelpFormatter
from textwrap import dedent
import jsonschema
import pkg_resources
from . import (
auth,
collections,
datasets,
http,
imagesets,
projects,
log,
)
def main():
"""Zegami command line interface."""
version = pkg_resources.require('zegami-cli')[0].version
description = dedent(r'''
____ _
/_ / ___ ___ ____ ___ _ (_)
/ /_/ -_) _ `/ _ `/ ' \/ /
/___/\__/\_, /\_,_/_/_/_/_/
/___/ v{}
Visual data exploration.
A command line interface for managing Zegami.
'''.format(version))
parser = ArgumentParser(
formatter_class=RawDescriptionHelpFormatter,
description=description,
)
# top level arguments
parser.add_argument(
'--version',
action='version',
version='%(prog)s {}'.format(version),
)
option_mapper = {
'delete': {
'help': 'Delete a resource',
'resources': {
'collections': collections.delete,
'dataset': datasets.delete,
'imageset': imagesets.delete,
}
},
'create': {
'help': 'Create a resource',
'resources': {
'collections': collections.create,
}
},
'list': {
'help': 'Lists entries of a resource',
'resources': {
'projects': projects.enumerate,
}
},
'get': {
'help': 'Get a resource',
'resources': {
'collections': collections.get,
'dataset': datasets.get,
'imageset': imagesets.get,
}
},
'publish': {
'help': 'Publish a resource',
'resources': {
'collection': collections.publish,
}
},
'update': {
'help': 'Update a resource',
'resources': {
'collections': collections.update,
'dataset': datasets.update,
'imageset': imagesets.update,
}
},
}
# option mapper parser
subparsers = parser.add_subparsers()
for action in option_mapper:
action_parser = subparsers.add_parser(
action,
help=option_mapper[action]['help'],
)
# set the action type so we can work out what was chosen
action_parser.set_defaults(action=action)
action_parser.add_argument(
'resource',
choices=option_mapper[action]['resources'].keys(),
help='The name of the resource type.'
)
if action != "create":
action_parser.add_argument(
'id',
default=None,
nargs="?",
help='Resource identifier.',
)
action_parser.add_argument(
'-c',
'--config',
help='Path to command configuration yaml.',
)
action_parser.add_argument(
'-p',
'--project',
help='The id of the project.',
)
_add_standard_args(action_parser)
# login parser
login_parser = subparsers.add_parser(
'login',
help='Authenticate against the API and store a long lived token',
)
login_parser.set_defaults(action='login')
_add_standard_args(login_parser)
try:
args = parser.parse_args()
except jsonschema.exceptions.ValidationError:
sys.exit(1)
if len(sys.argv) == 1:
parser.print_help(sys.stderr)
sys.exit(1)
logger = log.Logger(args.verbose)
token = auth.get_token(args)
session = http.make_session(args.url, token)
if args.action == 'login':
auth.login(
logger,
session,
args,
)
return
try:
option_mapper[args.action]['resources'][args.resource](
logger,
session,
args,
)
except Exception as e:
# unhandled exceptions
if args.verbose:
raise e
logger.error('Unhandled exception: {}'.format(e))
sys.exit(1)
def _add_standard_args(parser):
parser.add_argument(
'-t',
'--token',
default=None,
help='Authentication token.',
)
parser.add_argument(
'-u',
'--url',
default='https://zegami.com',
help='Zegami server address.',
)
parser.add_argument(
'-v',
'--verbose',
action='store_true',
help='Enable verbose logging.',
)
if __name__ == '__main__':
sys.exit(main()) | zegami-cli | /zegami-cli-1.5.1.tar.gz/zegami-cli-1.5.1/zeg/__main__.py | __main__.py |
import requests.auth
import urllib3.util.retry
API_START_FORMAT = "{prefix}/api/v0/project/{project_id}/"
# Max number of api requests to make at once.
CONCURRENCY = 16
class ClientError(Exception):
"""Failure when using http api."""
def __init__(self, response, try_json=True):
self.code = response.status_code
if try_json:
try:
body = response.json()
except ValueError:
body = response.content
else:
body = response.content
self.body = body
def __repr__(self):
return '<{} {} {}>'.format(
self.__class__.__name__, self.code, self.body)
def __str__(self):
return '{} {!r}'.format(self.code, self.body)
class TokenEndpointAuth(requests.auth.AuthBase):
"""Request auth that adds bearer token for specific endpoint only."""
def __init__(self, endpoint, token):
"""Initialise auth helper."""
self.endpoint = endpoint
self.token = token
def __call__(self, request):
"""Call auth helper."""
if request.url.startswith(self.endpoint):
request.headers["Authorization"] = "Bearer {}".format(self.token)
return request
def get_api_url(url_prefix, project_id):
"""Get the formatted API prefix."""
return API_START_FORMAT.format(
prefix=url_prefix,
project_id=project_id)
def make_session(endpoint, token):
"""
Create a session object with optional auth handling and a retry backoff.
See https://www.peterbe.com/plog/best-practice-with-retries-with-requests
"""
session = requests.Session()
# Retry post requests as well as the usual methods.
retry_methods = urllib3.util.retry.Retry.DEFAULT_METHOD_WHITELIST.union(
('POST', 'PUT'))
retry = urllib3.util.retry.Retry(
total=10,
backoff_factor=0.5,
status_forcelist=[(502, 503, 504, 408)],
method_whitelist=retry_methods
)
adapter = requests.adapters.HTTPAdapter(max_retries=retry)
session.mount('http://', adapter)
session.mount('https://', adapter)
if token is not None:
session.auth = TokenEndpointAuth(endpoint, token)
return session
def handle_response(response):
is_204 = response.status_code == 204
is_200 = response.status_code == 200
is_201 = response.status_code == 201
if response.status_code >= 300:
raise ClientError(response)
elif (is_204 or is_201 or is_200 and not response.content):
return None
try:
json = response.json()
except ValueError:
raise ClientError(response, try_json=False)
return json
def get(session, url):
"""Get a json response."""
with session.get(url) as response:
return handle_response(response)
def post_json(session, url, python_obj):
"""Send a json request and decode json response."""
with session.post(url, json=python_obj) as response:
return handle_response(response)
def post_file(session, url, name, filelike, mime):
"""Send a data file."""
details = (name, filelike, mime)
with session.post(url, files={'file': details}) as response:
return handle_response(response)
def delete(session, url):
"""Delete a resource."""
with session.delete(url) as response:
return handle_response(response)
def put_file(session, url, filelike, mimetype):
"""Put binary content and decode json respose."""
headers = {'Content-Type': mimetype}
headers.update(get_platform_headers(url))
with session.put(url, data=filelike, headers=headers) as response:
return handle_response(response)
def put_json(session, url, python_obj):
headers = get_platform_headers(url)
"""Put json content and decode json response."""
with session.put(url, json=python_obj, headers=headers) as response:
return handle_response(response)
def put(session, url, data, content_type):
"""Put data and decode json response."""
headers = {'Content-Type': content_type}
headers.update(get_platform_headers(url))
with session.put(url, data=data, headers=headers) as response:
return handle_response(response)
def get_platform_headers(url):
# Uploading blobs to azure requires us to specify the kind of blob
# Block blobs are typical object storage
# https://docs.microsoft.com/en-us/azure/storage/blobs/storage-blobs-introduction#blobs
if 'windows.net' in url:
return {'x-ms-blob-type': 'BlockBlob'}
return {} | zegami-cli | /zegami-cli-1.5.1.tar.gz/zegami-cli-1.5.1/zeg/http.py | http.py |
import concurrent.futures
import os
import uuid
from urllib.parse import urlparse
import azure.storage.blob
from colorama import Fore, Style
from tqdm import tqdm
from . import (
azure_blobs,
config,
http,
)
MIMES = {
".bmp": "image/bmp",
".jpg": "image/jpeg",
".jpeg": "image/jpeg",
".png": "image/png",
".gif": "image/gif",
".tif": "image/tiff",
".tiff": "image/tiff",
".dcm": "application/dicom",
# TODO add WSI mime types?
}
BLACKLIST = (
".yaml",
".yml",
"thumbs.db",
".ds_store",
".dll",
".sys",
".txt",
".ini",
".tsv",
".csv",
".json"
)
# When a file is larger than 256MB throw up a warning.
# Collection processing may be unreliable when handling files larger than this.
UPLOAD_WARNING_LIMIT = 268435456
def get(log, session, args):
"""Get an image set."""
log('imageset id: {highlight}{id}{reset}',
highlight=Fore.GREEN,
id=args.id,
reset=Style.RESET_ALL)
log.warn('Get imageset command coming soon.')
def _get_chunk_upload_futures(
executor, paths, session, create_url,
complete_url, log, workload_size, offset, mime, use_azure_client
):
"""Return executable tasks with image uploads in batches.
Instead of performing image uploads and updating the imageset
one at a time, we reduce load on the API server by uploading
many images and updating the api server in one go, consequently
making upload faster.
"""
total_work = len(paths)
workloads = []
temp = []
i = 0
while i < total_work:
path = paths[i]
temp.append(path)
i += 1
if len(temp) == workload_size or i == total_work:
workload_info = {
"start": i - len(temp) + offset,
"count": len(temp),
}
workloads.append(executor.submit(
_upload_image_chunked,
temp,
session,
create_url,
complete_url,
log,
workload_info,
mime,
use_azure_client,
))
temp = []
return workloads
def _finish_replace_empty_imageset(session, replace_empty_url):
# this process cleans the imageset by replacing any nulls with placeholders
# sustained network outages during uploads & premautrely aborted uploads may lead to this
http.post_json(session, replace_empty_url, {})
def _upload_image_chunked(paths, session, create_url, complete_url, log, workload_info, mime, use_azure_client=False): # noqa: E501
results = []
# get all signed urls at once
try:
id_set = {"ids": [str(uuid.uuid4()) for path in paths]}
signed_urls = http.post_json(session, create_url, id_set)
except Exception as ex:
log.error("Could not get signed urls for image uploads: {}".format(ex))
return
index = 0
for fpath in paths:
try:
file_name = os.path.basename(fpath)
file_ext = os.path.splitext(fpath)[-1]
if mime is not None:
file_mime = mime
else:
file_mime = MIMES.get(file_ext, MIMES['.jpg'])
except Exception as ex:
log.error("issue with file info: {}".format(ex))
with open(fpath, 'rb') as f:
blob_id = id_set["ids"][index]
info = {
"image": {
"blob_id": blob_id,
"name": file_name,
"size": os.path.getsize(fpath),
"mimetype": file_mime
}
}
index = index + 1
try:
# Post file to storage location
url = signed_urls[blob_id]
if use_azure_client:
url_object = urlparse(url)
# get SAS token from url
sas_token = url_object.query
account_url = url_object.scheme + '://' + url_object.netloc
container_name = url_object.path.split('/')[1]
# upload blob using client
blob_client = azure.storage.blob.ContainerClient(account_url, container_name, credential=sas_token)
blob_client.upload_blob(blob_id, f)
results.append(info["image"])
else:
# TODO fetch project storage location to decide this
is_gcp_storage = url.startswith("/")
if is_gcp_storage:
url = 'https://storage.googleapis.com{}'.format(url)
http.put_file(session, url, f, file_mime)
# pop the info into a temp array, upload only once later
results.append(info["image"])
except Exception as ex:
log.error("File upload failed: {}".format(ex))
# send the chunk of images as a bulk operation rather than per image
try:
url = complete_url + "?start={}".format(workload_info["start"])
log.debug("POSTING TO: {}".format(url))
http.post_json(session, url, {'images': results})
except Exception as ex:
log.error("Failed to complete workload: {}".format(ex))
def _update_file_imageset(log, session, configuration):
bulk_create_url = "{}signed_blob_url".format(
http.get_api_url(configuration["url"], configuration["project"]))
bulk_create_url = bulk_create_url.replace('v0', 'v1')
complete_url = "{}imagesets/{}/images_bulk".format(
http.get_api_url(configuration["url"], configuration["project"]),
configuration["id"])
extend_url = "{}imagesets/{}/extend".format(
http.get_api_url(configuration["url"], configuration["project"]),
configuration["id"])
replace_empty_url = "{}imagesets/{}/replace_empties".format(
http.get_api_url(configuration["url"], configuration["project"]),
configuration["id"])
log.debug('POST: {}'.format(extend_url))
log.debug('POST: {}'.format(bulk_create_url))
log.debug('POST: {}'.format(complete_url))
log.debug('POST: {}'.format(replace_empty_url))
# get image paths
file_config = configuration['file_config']
# check colleciton id, dataset and join column name
recursive = False
mime_type = None
if 'recursive' in file_config:
recursive = file_config["recursive"]
if 'mime_type' in file_config:
mime_type = file_config["mime_type"]
# first extend the imageset by the number of items we have to upload
paths = _resolve_paths(
file_config['paths'], recursive, mime_type is not None, log
)
if len(paths) == 0:
log.warn("No images detected, no images will be uploaded.")
return
extend_response = http.post_json(
session, extend_url, {'delta': len(paths)}
)
add_offset = extend_response['new_size'] - len(paths)
workload_size = optimal_workload_size(len(paths))
# When chunking work, futures could contain as much as 100 images at once.
# If the number of images does not divide cleanly into 10 or 100 (optimal)
# The total may be larger than reality and the image/s speed less accurate.
if workload_size != 1:
log.warn("The progress bar may have reduced accuracy when uploading larger imagesets.") # noqa: E501
use_azure_client = configuration.get('use_wsi', False)
with concurrent.futures.ThreadPoolExecutor(http.CONCURRENCY) as executor:
futures = _get_chunk_upload_futures(
executor,
paths,
session,
bulk_create_url,
complete_url,
log,
workload_size,
add_offset,
mime_type,
use_azure_client,
)
kwargs = {
'total': len(futures),
'unit': 'image',
'unit_scale': workload_size,
'leave': True
}
for f in tqdm(concurrent.futures.as_completed(futures), **kwargs):
pass
_finish_replace_empty_imageset(session, replace_empty_url)
def optimal_workload_size(count):
# Just some sensible values aiming to speed up uploading large imagesets
if count > 2500:
return 100
if count < 100:
return 1
return 10
def _update_join_dataset(
log, configuration, dataset_id, dataset_column, session,
collection_id):
collection_url = "{}collections/{}".format(
http.get_api_url(configuration["url"], configuration["project"]),
collection_id,
)
log.debug('GET (collection): {}'.format(collection_url))
# first need to get the collection object
collection_response = http.get(session, collection_url)
collection = collection_response['collection']
if 'source_name' in configuration:
source_name = configuration['source_name']
for source in collection["image_sources"]:
if source['name'] == source_name:
ims_ds_join_id = source["imageset_dataset_join_id"]
else:
ims_ds_join_id = collection["imageset_dataset_join_id"]
# update the join dataset
join_data = {
'name': 'join dataset',
'source': {
'imageset_id': configuration["id"],
'dataset_id': dataset_id,
'imageset_to_dataset': {
'dataset_column': dataset_column,
},
},
'processing_category': 'join',
'node_groups': ['collection_{}'.format(collection_id)]
}
imageset_dataset_join_url = "{}datasets/{}".format(
http.get_api_url(configuration["url"], configuration["project"]),
ims_ds_join_id
)
log.debug('PUT: {}'.format(imageset_dataset_join_url))
http.put_json(session, imageset_dataset_join_url, join_data)
def get_from_dict(data_dict, maplist):
for k in maplist:
data_dict = data_dict[k]
return data_dict
def check_can_update(ims_type, ims):
features = {
"file": ["source", "upload"],
"url": ["source", "transfer", "url"],
"azure_storage_container": ["source", "transfer", "url"],
}
try:
get_from_dict(ims, features[ims_type])
except KeyError:
if len(ims.get("images", [])) != 0:
raise ValueError(
"Chosen imageset already has images, cannot change type")
def update(log, session, args):
configuration = config.parse_args(args, log)
update_from_dict(log, session, configuration)
def update_from_dict(log, session, configuration):
"""Update an image set."""
# check for config
ims_type = configuration["imageset_type"]
ims_id = configuration["id"]
ims_url = "{}imagesets/{}".format(
http.get_api_url(configuration["url"], configuration["project"]),
ims_id,
)
preemptive_join = ims_type == "file"
collection_id = configuration['collection_id']
dataset_id = configuration['dataset_id']
dataset_column = configuration.get('dataset_column') if 'dataset_column' in configuration else "__auto_join__"
ims = http.get(session, ims_url)["imageset"]
check_can_update(ims_type, ims)
if ims_type == "url":
_update_to_url_imageset(session, configuration, ims_url)
elif ims_type == "file":
if preemptive_join:
_update_join_dataset(
log, configuration, dataset_id, dataset_column, session, collection_id)
_update_file_imageset(log, session, configuration)
elif ims_type == "azure_storage_container":
if os.environ.get('AZURE_STORAGE_CONNECTION_STRING', None) is None:
log.error(
"The AZURE_STORAGE_CONNECTION_STRING environment variable"
" must be set in order to create an azure storage collection"
)
configuration["url_template"] = azure_blobs.generate_signed_url(
configuration["container_name"])
_update_to_url_imageset(session, configuration, ims_url)
if not preemptive_join:
_update_join_dataset(
log, configuration, dataset_id, dataset_column, session, collection_id)
def _update_to_url_imageset(session, configuration, ims_url):
keys = ["dataset_column", "url_template"]
url_conf = {
key: configuration.get(key)
for key in keys if key in configuration
}
transfer = {
"url": url_conf,
}
if 'image_fetch_headers' in configuration:
transfer['headers'] = configuration['image_fetch_headers']
ims = {
"name": "Imageset created by CLI",
"source": {
"dataset_id": configuration['dataset_id'],
"transfer": transfer
}
}
http.put_json(session, ims_url, ims)
def delete(log, session, args):
"""Delete an image set."""
log('imageset id: {highlight}{id}{reset}',
highlight=Fore.GREEN,
id=args.id,
reset=Style.RESET_ALL)
log.warn('delete imageset command coming soon.')
def _resolve_paths(paths, should_recursive, ignore_mime, log):
"""Resolve all paths to a list of files."""
allowed_ext = tuple(MIMES.keys())
blacklist_ext = BLACKLIST
resolved = []
for path in paths:
whitelisted = (path.lower().endswith(allowed_ext) or ignore_mime)
if os.path.isdir(path):
if should_recursive:
resolved.extend(
_scan_directory_tree(path, allowed_ext, blacklist_ext, ignore_mime, log)
)
else:
resolved.extend(
entry.path for entry in os.scandir(path)
if entry.is_file() and (
entry.name.lower().endswith(allowed_ext) or
(ignore_mime and not entry.name.lower().endswith(blacklist_ext))
)
)
elif os.path.isfile(path) and whitelisted:
resolved.append(path)
total_size = 0
warned = False
for path in resolved:
size = os.path.getsize(path)
total_size += size
if size > UPLOAD_WARNING_LIMIT and not warned:
log.warn("One or more files exceeds 256MB, collection processing may be unreliable.")
warned = True
log.debug("Total upload size: {}".format(format_bytes(total_size)))
return resolved
def format_bytes(size):
power = 1024
n = 0
power_labels = {0: '', 1: 'K', 2: 'M', 3: 'G', 4: 'T'}
while size > power:
size /= power
n += 1
return "{}{}B".format(round(size, 2), power_labels[n])
def _scan_directory_tree(path, allowed_ext, blacklist_ext, ignore_mime, log):
files = []
for entry in os.scandir(path):
whitelisted = entry.name.lower().endswith(allowed_ext)
if ignore_mime and not whitelisted:
whitelisted = True
# Some files should not be uploaded even if we are forcing mime type.
if entry.name.lower().endswith(blacklist_ext):
whitelisted = False
log.debug("Ignoring file due to disallowed extension: {}".format(entry.name))
if entry.is_file() and whitelisted:
files.append(entry.path)
if entry.is_dir():
files.extend(_scan_directory_tree(entry.path, allowed_ext, blacklist_ext, ignore_mime, log))
return files
def _upload_image(path, session, create_url, complete_url, log, mime):
file_name = os.path.basename(path)
file_ext = os.path.splitext(path)[-1]
if mime is not None:
file_mime = mime
else:
file_mime = MIMES.get(file_ext, MIMES['.jpg'])
with open(path, 'rb') as f:
info = {
"image": {
"blob_id": str(uuid.uuid4()),
"name": file_name,
"size": os.path.getsize(path),
"mimetype": file_mime
}
}
try:
# First create file object
create = http.post_json(session, create_url, info)
# Post file to storage location
url = create["url"]
if url.startswith("/"):
url = 'https://storage.googleapis.com{}'.format(url)
http.put_file(session, url, f, file_mime)
# confirm
http.post_json(session, complete_url, info)
except Exception as ex:
log.error("Upload failed: {}".format(ex)) | zegami-cli | /zegami-cli-1.5.1.tar.gz/zegami-cli-1.5.1/zeg/imagesets.py | imagesets.py |
import copy
from colorama import Fore, Style, init
import yaml
class Logger(object):
"""Simplistic output to a stream with verbosity support."""
def __init__(self, verbose=False):
"""Initialise logger."""
init()
self.verbose = verbose
def __call__(self, format_string, **kwargs):
"""Log message to stderr."""
print(format_string.format(**kwargs))
def debug(self, format_string, **kwargs):
"""Log debug message. Only displays if verbose logging turned on."""
if self.verbose:
self.__call__(
Fore.CYAN + format_string + Style.RESET_ALL,
**kwargs)
def warn(self, format_string, **kwargs):
"""Log a warning message."""
self.__call__(
Fore.YELLOW + format_string + Style.RESET_ALL,
**kwargs)
def error(self, format_string, **kwargs):
"""Log an error message."""
self.__call__(
Fore.RED + format_string + Style.RESET_ALL,
**kwargs)
def print_json(self, datadict, typename, verb, shorten=True):
"""Print a JSON file in YAML format."""
output = copy.deepcopy(datadict)
dictdata = self._shorten_arrays(output) if shorten else output
print("=========================================")
print("{} {} with result:".format(verb, typename))
print("-----------------------------------------")
print(yaml.dump(dictdata, default_flow_style=False))
print("=========================================", flush=True)
def _shorten_arrays(self, dictdata):
for key, value in dictdata.items():
if isinstance(value, list):
if len(value) > 3:
restlable = [
"...",
"and {} more...".format(len(value) - 2),
]
dictdata[key] = value[:2] + restlable + value[-1:]
if isinstance(value, dict):
dictdata[key] = self._shorten_arrays(value)
return dictdata | zegami-cli | /zegami-cli-1.5.1.tar.gz/zegami-cli-1.5.1/zeg/log.py | log.py |
"""Collection commands."""
import sys
from datetime import datetime
from colorama import Fore, Style
from . import (
config,
datasets,
imagesets,
http,
)
def get(log, session, args):
"""Get a collection."""
coll_id = args.id if args.id is not None else ""
url = "{}collections/{}".format(
http.get_api_url(args.url, args.project),
coll_id)
log.debug('GET: {}'.format(url))
response_json = http.get(session, url)
log.print_json(response_json, "collection", "get", shorten=False)
def create(log, session, args):
"""Create a collection."""
time_start = datetime.now()
url = "{}collections/".format(
http.get_api_url(args.url, args.project),)
log.debug('POST: {}'.format(url))
# parse config
configuration = config.parse_args(args, log)
if "name" not in configuration:
log.error('Collection name missing from config file')
sys.exit(1)
collection_version = configuration.get('collection_version', 1)
# use name from config
coll = {
"name": configuration["name"],
}
# use description and enable_clustering from config
for key in ["description", "enable_clustering", "enable_image_info", "use_wsi"]:
if key in configuration:
coll[key] = configuration[key]
# replace empty description with an empty string
if 'description' in coll and coll["description"] is None:
coll["description"] = ''
# check multiple image sources config
if collection_version == 2 and 'image_sources' in configuration:
coll['version'] = 2
coll['image_sources'] = []
for source in configuration['image_sources']:
if "source_name" not in source:
log.error('Image source name missing from config file')
sys.exit(1)
if source['source_name'] is None:
log.error('Image source name cannot be empty')
sys.exit(1)
coll['image_sources'].append({'name': source['source_name']})
# create the collection
response_json = http.post_json(session, url, coll)
log.print_json(response_json, "collection", "post", shorten=False)
coll = response_json["collection"]
dataset_config = dict(
configuration, id=coll["upload_dataset_id"]
)
if 'file_config' in dataset_config:
if 'path' in dataset_config['file_config'] or 'directory' in dataset_config['file_config']:
datasets.update_from_dict(log, session, dataset_config)
if collection_version == 2:
for source in configuration['image_sources']:
source_name = source['source_name']
imageset_config = dict(source)
imageset_config["file_config"] = {}
for property in ['paths', 'recursive', 'mime_type']:
if property in source:
imageset_config["file_config"][property] = source[property]
imageset_config["url"] = configuration["url"]
imageset_config["project"] = configuration["project"]
imageset_config["dataset_id"] = coll["dataset_id"]
imageset_config["collection_id"] = coll["id"]
for coll_source in coll["image_sources"]:
if coll_source['name'] == source_name:
imageset_config["id"] = coll_source["imageset_id"]
imagesets.update_from_dict(log, session, imageset_config)
else:
imageset_config = dict(
configuration, id=coll["imageset_id"]
)
imageset_config["dataset_id"] = coll["dataset_id"]
imageset_config["collection_id"] = coll["id"]
imagesets.update_from_dict(log, session, imageset_config)
delta_time = datetime.now() - time_start
log.debug("Collection uploaded in {}".format(delta_time))
return coll
def update(log, session, args):
"""Update a collection."""
log('colection id: {highlight}{id}{reset}',
highlight=Fore.GREEN,
id=args.id,
reset=Style.RESET_ALL)
log.warn('Update collection command coming soon.')
def delete(log, session, args):
"""Delete a collection."""
url = "{}collections/{}".format(
http.get_api_url(args.url, args.project),
args.id)
log.debug('DELETE: {}'.format(url))
http.delete(session, url)
log('collection {highlight}{id}{reset} deleted',
highlight=Fore.GREEN,
id=args.id,
reset=Style.RESET_ALL)
def init(log, session, args):
url = "{}collections/".format(
http.get_api_url(args.url, args.project))
log.debug('INIT: {}'.format(url))
def publish(log, session, args):
"""Publish a collection."""
coll_id = args.id if args.id is not None else ""
# check for config
if 'config' not in args:
log.error('Configuration file path missing')
sys.exit(1)
configuration = config.parse_config(args.config, log)
# get publish details
publish_config = configuration['publish_config']
if publish_config is None:
log.error(
"Missing {highlight}publish_config{reset} parameter".format(
highlight=Fore.YELLOW,
reset=Style.RESET_ALL,
)
)
sys.exit(1)
url = "{}collections/{}/{}".format(
http.get_api_url(args.url, args.project),
coll_id,
'publish' if publish_config['publish'] is True else 'unpublish'
)
log.debug('POST: {}'.format(url))
publish_options = {
"project": publish_config['destination_project'],
}
response_json = http.post_json(session, url, publish_options)
log.print_json(response_json, "collection", "update", shorten=False) | zegami-cli | /zegami-cli-1.5.1.tar.gz/zegami-cli-1.5.1/zeg/collections.py | collections.py |
import os
import sys
from datetime import datetime
from tempfile import mkstemp
import uuid
from colorama import Fore, Style
from . import (
config,
http,
sql,
)
MIMES = {
".tab": "text/tab-separated-values",
".tsv": "text/tab-separated-values",
".csv": "text/csv",
".xlsx": ("application/vnd.openxmlformats-officedocument"
".spreadsheetml.sheet"),
}
def get(log, session, args):
"""Get a data set."""
url = "{}datasets/{}".format(
http.get_api_url(args.url, args.project),
args.id)
log.debug('GET: {}'.format(url))
response_json = http.get(session, url)
log.print_json(response_json, "dataset", "get")
def update(log, session, args):
configuration = config.parse_args(args, log)
update_from_dict(log, session, configuration)
def update_from_dict(log, session, configuration):
"""Update a data set."""
url_url = "{}imagesets/{}/image_url".format(
http.get_api_url(configuration['url'], configuration['project']),
configuration['id'])
replace_url = "{}datasets/{}/".format(
http.get_api_url(configuration['url'], configuration['project']),
configuration['id'])
log.debug('POST: {}'.format(url_url))
# get update config
if 'file_config' in configuration:
(
file_path,
extension,
file_mime
) = _file_type_update(log, configuration['file_config'])
elif 'sql_config' in configuration:
(
file_path,
extension,
file_mime
) = _sql_type_update(log, configuration['sql_config'])
log.debug("File path: {}".format(file_path))
log.debug("File extension: {}".format(extension))
log.debug("File mime: {}".format(file_mime))
file_name = os.path.basename(file_path)
with open(file_path, 'rb') as f:
blob_id = str(uuid.uuid4())
info = {
"image": {
"blob_id": blob_id,
"name": file_name,
"size": os.path.getsize(file_path),
"mimetype": file_mime
}
}
create = http.post_json(session, url_url, info)
# Post file to storage location
url = create["url"]
if url.startswith("/"):
url = 'https://storage.googleapis.com{}'.format(url)
log.debug('PUT (file content): {}'.format(url))
data = f.read()
http.put(session, url, data, file_mime)
# confirm
log.debug('GET (dataset): {}'.format(replace_url))
current = http.get(session, replace_url)["dataset"]
current["source"].pop("schema", None)
current["source"]["upload"] = {
"name": file_name,
}
current["source"]["blob_id"] = blob_id
log.debug('PUT (dataset): {}'.format(replace_url))
http.put_json(session, replace_url, current)
log.print_json(current, "dataset", "update")
def delete(log, args):
"""Delete an data set."""
log('dataset id: {highlight}{id}{reset}',
highlight=Fore.GREEN,
id=args.id,
reset=Style.RESET_ALL)
log.warn('delete dataset command coming soon.')
def _file_type_update(log, file_config):
"""Load file and update data set."""
if 'path' in file_config:
file_path = file_config['path']
elif 'directory' in file_config:
file_path = _get_most_recent_file(file_config['directory'])
if file_path is None:
log.error('Data file not found.')
sys.exit(1)
file_ext = os.path.splitext(file_path)[-1]
file_mime = MIMES.get(file_ext, MIMES['.csv'])
return (file_path, file_ext, file_mime)
def _sql_type_update(log, sql_config):
"""Query database and convert to csv file."""
if not sql.have_driver:
log.error('No sql driver found, is sqlalchemy installed?')
sys.exit(1)
statement = sql.create_statement(sql_config['query'])
engine = sql.create_engine(sql_config['connection'], log.verbose)
mime_type = '.csv'
with engine.connect() as connection:
result = connection.execute(statement)
# write to a comma delimited file
fd, name = mkstemp(suffix=mime_type, prefix='zeg-dataset')
with open(fd, 'w') as output:
# write headers
output.write(str(result.keys())[1:-1] + '\n')
for row in result:
row_as_string = [_handle_sql_types(value) for value in row]
output.write(str(row_as_string)[1:-1] + '\n')
return (name, mime_type, MIMES[mime_type])
def _handle_sql_types(value):
"""Convert types into Zegami friendly string format."""
if type(value) is datetime:
return value.isoformat()
return str(value)
def _newest_ctime(entry):
return -entry.stat().st_ctime, entry.name
def _get_most_recent_file(path):
"""Get the most recent file in a directory."""
allowed_ext = tuple(MIMES.keys())
files_iter = (
entry for entry in os.scandir(path)
if entry.is_file() and entry.name.lower().endswith(allowed_ext)
)
for entry in sorted(files_iter, key=_newest_ctime):
return entry.path
return None | zegami-cli | /zegami-cli-1.5.1.tar.gz/zegami-cli-1.5.1/zeg/datasets.py | datasets.py |
Apache License
Version 2.0, January 2004
http://www.apache.org/licenses/
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
1. Definitions.
"License" shall mean the terms and conditions for use, reproduction,
and distribution as defined by Sections 1 through 9 of this document.
"Licensor" shall mean the copyright owner or entity authorized by
the copyright owner that is granting the License.
"Legal Entity" shall mean the union of the acting entity and all
other entities that control, are controlled by, or are under common
control with that entity. For the purposes of this definition,
"control" means (i) the power, direct or indirect, to cause the
direction or management of such entity, whether by contract or
otherwise, or (ii) ownership of fifty percent (50%) or more of the
outstanding shares, or (iii) beneficial ownership of such entity.
"You" (or "Your") shall mean an individual or Legal Entity
exercising permissions granted by this License.
"Source" form shall mean the preferred form for making modifications,
including but not limited to software source code, documentation
source, and configuration files.
"Object" form shall mean any form resulting from mechanical
transformation or translation of a Source form, including but
not limited to compiled object code, generated documentation,
and conversions to other media types.
"Work" shall mean the work of authorship, whether in Source or
Object form, made available under the License, as indicated by a
copyright notice that is included in or attached to the work
(an example is provided in the Appendix below).
"Derivative Works" shall mean any work, whether in Source or Object
form, that is based on (or derived from) the Work and for which the
editorial revisions, annotations, elaborations, or other modifications
represent, as a whole, an original work of authorship. For the purposes
of this License, Derivative Works shall not include works that remain
separable from, or merely link (or bind by name) to the interfaces of,
the Work and Derivative Works thereof.
"Contribution" shall mean any work of authorship, including
the original version of the Work and any modifications or additions
to that Work or Derivative Works thereof, that is intentionally
submitted to Licensor for inclusion in the Work by the copyright owner
or by an individual or Legal Entity authorized to submit on behalf of
the copyright owner. For the purposes of this definition, "submitted"
means any form of electronic, verbal, or written communication sent
to the Licensor or its representatives, including but not limited to
communication on electronic mailing lists, source code control systems,
and issue tracking systems that are managed by, or on behalf of, the
Licensor for the purpose of discussing and improving the Work, but
excluding communication that is conspicuously marked or otherwise
designated in writing by the copyright owner as "Not a Contribution."
"Contributor" shall mean Licensor and any individual or Legal Entity
on behalf of whom a Contribution has been received by Licensor and
subsequently incorporated within the Work.
2. Grant of Copyright License. Subject to the terms and conditions of
this License, each Contributor hereby grants to You a perpetual,
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
copyright license to reproduce, prepare Derivative Works of,
publicly display, publicly perform, sublicense, and distribute the
Work and such Derivative Works in Source or Object form.
3. Grant of Patent License. Subject to the terms and conditions of
this License, each Contributor hereby grants to You a perpetual,
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
(except as stated in this section) patent license to make, have made,
use, offer to sell, sell, import, and otherwise transfer the Work,
where such license applies only to those patent claims licensable
by such Contributor that are necessarily infringed by their
Contribution(s) alone or by combination of their Contribution(s)
with the Work to which such Contribution(s) was submitted. If You
institute patent litigation against any entity (including a
cross-claim or counterclaim in a lawsuit) alleging that the Work
or a Contribution incorporated within the Work constitutes direct
or contributory patent infringement, then any patent licenses
granted to You under this License for that Work shall terminate
as of the date such litigation is filed.
4. Redistribution. You may reproduce and distribute copies of the
Work or Derivative Works thereof in any medium, with or without
modifications, and in Source or Object form, provided that You
meet the following conditions:
(a) You must give any other recipients of the Work or
Derivative Works a copy of this License; and
(b) You must cause any modified files to carry prominent notices
stating that You changed the files; and
(c) You must retain, in the Source form of any Derivative Works
that You distribute, all copyright, patent, trademark, and
attribution notices from the Source form of the Work,
excluding those notices that do not pertain to any part of
the Derivative Works; and
(d) If the Work includes a "NOTICE" text file as part of its
distribution, then any Derivative Works that You distribute must
include a readable copy of the attribution notices contained
within such NOTICE file, excluding those notices that do not
pertain to any part of the Derivative Works, in at least one
of the following places: within a NOTICE text file distributed
as part of the Derivative Works; within the Source form or
documentation, if provided along with the Derivative Works; or,
within a display generated by the Derivative Works, if and
wherever such third-party notices normally appear. The contents
of the NOTICE file are for informational purposes only and
do not modify the License. You may add Your own attribution
notices within Derivative Works that You distribute, alongside
or as an addendum to the NOTICE text from the Work, provided
that such additional attribution notices cannot be construed
as modifying the License.
You may add Your own copyright statement to Your modifications and
may provide additional or different license terms and conditions
for use, reproduction, or distribution of Your modifications, or
for any such Derivative Works as a whole, provided Your use,
reproduction, and distribution of the Work otherwise complies with
the conditions stated in this License.
5. Submission of Contributions. Unless You explicitly state otherwise,
any Contribution intentionally submitted for inclusion in the Work
by You to the Licensor shall be under the terms and conditions of
this License, without any additional terms or conditions.
Notwithstanding the above, nothing herein shall supersede or modify
the terms of any separate license agreement you may have executed
with Licensor regarding such Contributions.
6. Trademarks. This License does not grant permission to use the trade
names, trademarks, service marks, or product names of the Licensor,
except as required for reasonable and customary use in describing the
origin of the Work and reproducing the content of the NOTICE file.
7. Disclaimer of Warranty. Unless required by applicable law or
agreed to in writing, Licensor provides the Work (and each
Contributor provides its Contributions) on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
implied, including, without limitation, any warranties or conditions
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
PARTICULAR PURPOSE. You are solely responsible for determining the
appropriateness of using or redistributing the Work and assume any
risks associated with Your exercise of permissions under this License.
8. Limitation of Liability. In no event and under no legal theory,
whether in tort (including negligence), contract, or otherwise,
unless required by applicable law (such as deliberate and grossly
negligent acts) or agreed to in writing, shall any Contributor be
liable to You for damages, including any direct, indirect, special,
incidental, or consequential damages of any character arising as a
result of this License or out of the use or inability to use the
Work (including but not limited to damages for loss of goodwill,
work stoppage, computer failure or malfunction, or any and all
other commercial damages or losses), even if such Contributor
has been advised of the possibility of such damages.
9. Accepting Warranty or Additional Liability. While redistributing
the Work or Derivative Works thereof, You may choose to offer,
and charge a fee for, acceptance of support, warranty, indemnity,
or other liability obligations and/or rights consistent with this
License. However, in accepting such obligations, You may act only
on Your own behalf and on Your sole responsibility, not on behalf
of any other Contributor, and only if You agree to indemnify,
defend, and hold each Contributor harmless for any liability
incurred by, or claims asserted against, such Contributor by reason
of your accepting any such warranty or additional liability.
END OF TERMS AND CONDITIONS
APPENDIX: How to apply the Apache License to your work.
To apply the Apache License to your work, attach the following
boilerplate notice, with the fields enclosed by brackets "[]"
replaced with your own identifying information. (Don't include
the brackets!) The text should be enclosed in the appropriate
comment syntax for the file format. We also recommend that a
file or class name and description of purpose be included on the
same "printed page" as the copyright notice for easier
identification within third-party archives.
Copyright [2021] [Zegami Ltd]
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
| zegami-sdk-testrelease | /zegami-sdk-testrelease-0.4.6.tar.gz/zegami-sdk-testrelease-0.4.6/LICENSE.md | LICENSE.md |
# Zegami Python SDK
An SDK and general wrapper for the lower level Zegami API for Python. This package provides higher level collection interaction and data retrieval.
# Getting started
Grab this repo, open the script, and load an instance of ZegamiClient into a variable.
```
from zegami_sdk.client import ZegamiClient
zc = ZegamiClient(username, login)
```
## Credentials
The client operates using a user token. By default, logging in once with a valid username/password will save the acquired token to your home directory as
`zegami.token`. The next time you need to use ZegamiClient, you may call `zc = ZegamiClient()` with no arguments, and it will look for this stored token.
## Example Usage
### Get the metadata and images associated with every dog of the 'beagle' breed in a collection of dogs:
```
zc = ZegamiClient()
```
### Workspaces
To see your available workspaces, use:
```
zc.show_workspaces()
```
You can then ask for a workspace by name, by ID, or just from a list
```
all_workspaces = zc.workspaces
first_workspace = all_workspaces[0]
```
or:
```
zc.show_workspaces()
# Note the ID of a workspace
my_workspace = zc.get_workspace_by_id(id)
```
### Collections
```
my_workspace.show_collections()
# Note the name of a collection
coll = my_workspace.get_collection_by_name(name_of_collection)
```
You can get the metadata in a collection as a Pandas DataFrame using:
```
rows = coll.rows
```
You can get the images of a collection using:
```
first_10_img_urls = coll.get_image_urls(list(range(10)))
imgs = coll.download_image_batch(first_10_img_urls)
```
If your collection supports the new multi-image-source functionality, you can see your available sources using:
```
coll.show_sources()
```
For source 2's (3rd in 0-indexed-list) images, you would use:
```
first_10_source3_img_urls = novo_col.get_image_urls(list(range(10)), source=2)`
# To see the first of these:
coll.download_image(first_10_source3_img_urls[0])
```
### Using with onprem zegami
To use the client with an onprem installation of zegami you have to set the `home` keyword argument when instantiating `ZegamiClient`.
```
zegami_config = {
'username': <user>,
'password': <password>,
'home': <url of onprem zegami>,
'allow_save_token': True,
}
zc = ZegamiClient(**zegami_config)
```
If your onprem installation has self-signed certificates you can disable SSL verification using the environment variable `ALLOW_INSECURE_SSL` before running the python.
```
export ALLOW_INSECURE_SSL=true
python myscript.py
```
or
```
ALLOW_INSECURE_SSL=true python myscript.py
```
WARNING! You should not need to set this when using the SDK for cloud zegami
# In Development
This SDK is in active development, not all features are available yet. Creating/uploading to collections is not supported currently - check back soon!
# Developer Conventions
Keeping the SDK easy and fluent to use externally and internally is crucial. If contributing PRs, some things to consider:
## Relevant
MOST IMPORTANT - Zegami has concepts used internally in its data engine, like 'imageset', 'dataset'. Strive to never require the user to have to know anything about these, or even see them. If the user needs an image, they should ask for an image from a concept they ARE expected to understand like a 'collection' or a 'workspace'. Anything obscure should be hidden, for example: `_get_imageset()`, so that auto-suggestions of a class will always contain relevant and useful methods/attribs/properties.
## Obvious
Avoid ambiguous parameters. Use the best worded, lowest level parameters types for functions/methods. Give them obvious names. Any ambiguity or unobvious parameters MUST be described in detail in the docstring. Avoid parameters like 'target' or 'action', or describe them explicitly. If an instance is needed, describe how/where that instance should come from.
## `assert`
If you expect an RGB image, check that your input is an array, that its len(shape) == 3, that shape[2] == 3. Use a proper message if this is not the case.
## Minimal
Do not ask for more information than is already obtainable. A source knows its parent collection, which knows how to get its own IDs and knows the client. A method never needs to reference a source, the owning collection, and the client all together. Moreover, these chains should have sensible assertions and checks built in, and potentially property/method-based shortcuts (with assertions).
## Helpful
Use sensible defaults wherever possible for minimal effort when using the SDK. V1 collections typically use `source=None`, while V2 collections use `source=0`. This allows a user with an old/new (single source) collection to never even have to know what a source is when fetching images.
| zegami-sdk-testrelease | /zegami-sdk-testrelease-0.4.6.tar.gz/zegami-sdk-testrelease-0.4.6/README.md | README.md |
import io
import os
from urllib.parse import urlparse
from azure.storage.blob import (
ContainerClient,
ContentSettings,
)
import pandas as pd
from .collection import Collection
from .helper import guess_data_mimetype
from .source import UploadableSource
class Workspace():
def __init__(self, client, workspace_dict):
self._client = client
self._data = workspace_dict
self._check_data()
@property
def id():
pass
@id.getter
def id(self):
assert 'id' in self._data.keys(), 'Workspace\'s data didn\'t have an \'id\' key'
return self._data['id']
@property
def client():
pass
@client.getter
def client(self):
return self._client
@property
def name():
pass
@name.getter
def name(self):
assert 'name' in self._data.keys(), 'Workspace\'s data didn\'t have a \'name\' key'
return self._data['name']
@property
def collections():
pass
@collections.getter
def collections(self):
c = self._client
if not c:
raise ValueError('Workspace had no client set when obtaining collections')
url = '{}/{}/project/{}/collections/'.format(c.HOME, c.API_0, self.id)
collection_dicts = c._auth_get(url)
if not collection_dicts:
return []
collection_dicts = collection_dicts['collections']
return [Collection._construct_collection(c, self, d) for d in collection_dicts]
def get_collection_by_name(self, name) -> Collection:
"""Obtains a collection by name (case-insensitive)."""
matches = list(filter(lambda c: c.name.lower() == name.lower(), self.collections))
if len(matches) == 0:
raise IndexError('Couldn\'t find a collection with the name \'{}\''.format(name))
return matches[0]
def get_collection_by_id(self, id) -> Collection:
"""Obtains a collection by ID."""
matches = list(filter(lambda c: c.id == id, self.collections))
if len(matches) == 0:
raise IndexError('Couldn\'t find a collection with the ID \'{}\''.format(id))
return matches[0]
def show_collections(self) -> None:
"""Prints this workspace's available collections."""
cs = self.collections
if not cs:
print('No collections found')
return
print('\nCollections in \'{}\' ({}):'.format(self.name, len(cs)))
for c in cs:
print('{} : {}'.format(c.id, c.name))
def _check_data(self) -> None:
"""This object should have a populated self._data, runs a check."""
if not self._data:
raise ValueError('Workspace has no self._data set')
if type(self._data) is not dict:
raise TypeError('Workspace didn\'t have a dict for its data ({})'.format(type(self._data)))
def get_storage_item(self, storage_id) -> io.BytesIO:
"""Obtains an item in online-storage by its ID."""
c = self._client
url = '{}/{}/project/{}/storage/{}'.format(c.HOME, c.API_1, self.id, storage_id)
resp = c._auth_get(url, return_response=True)
return io.BytesIO(resp.content), resp.headers.get('content-type')
def create_storage_item(self, data, mime_type=None, item_name=None) -> str:
"""Creates and uploads data into online-storage. Returns its storage ID."""
if not mime_type:
mime_type = guess_data_mimetype(data)
# get signed url to use signature
client = self._client
url = '{}/{}/project/{}/storage/signedurl'.format(client.HOME, client.API_1, self.id)
if item_name:
url += '?name={}'.format(item_name)
resp = client._auth_get(url)
blob_id = 'storage/' + resp['id']
url = resp['signedurl']
url_object = urlparse(url)
sas_token = url_object.query
account_url = url_object.scheme + '://' + url_object.netloc
container_name = url_object.path.split('/')[1]
container_client = ContainerClient(account_url, container_name, credential=sas_token)
container_client.upload_blob(
blob_id,
data,
blob_type='BlockBlob',
content_settings=ContentSettings(content_type=mime_type)
)
return resp['id']
def delete_storage_item(self, storage_id) -> bool:
"""Deletes a storage item by ID. Returns the response's OK signal."""
c = self._client
url = '{}/{}/project/{}/storage/{}'.format(c.HOME, c.API_1, self.id, storage_id)
resp = c._auth_delete(url)
return resp.ok
# Version should be used once https://github.com/zegami/zegami-cloud/pull/1103/ is merged
def _create_empty_collection(self, name, uploadable_sources, description='', **kwargs):
"""Create an empty collection, ready for images and data."""
defaults = {
'version': 2,
'dynamic': False,
'upload_dataset': {'source': {'upload': {}}}
}
for k, v in defaults.items():
if k not in kwargs.keys():
kwargs[k] = v
# Don't let the user provide these
reserved = ['name', 'description', 'image_sources']
for k in reserved:
if k in kwargs.keys():
del kwargs[k]
# Data to generate the collection, including sparse sources with no data
post_data = {
'name': name,
'description': description,
'image_sources': [{'name': s.name} for s in uploadable_sources],
**kwargs
}
url = '{}/{}/project/{}/collections'.format(
self.client.HOME, self.client.API_0, self.id)
resp = self.client._auth_post(url, body=None, json=post_data)
return resp['collection']
def create_collection(self, name, uploadable_sources, data=None, description='', **kwargs): # noqa: C901
"""
Create a collection with provided images and data.
A list of image sources (or just one) should be provided, built using
Source.create_uploadable_source(). These instruct the SDK where to
look for images to populate the collection.
- name:
The name of the collection.
- uploadable_sources:
A list of [UploadableSource()] built using:
from zegami_sdk.source import UploadableSource
sources = [ UploadableSource(params_0),
UploadableSource(params_1),
... ]
- data:
Uploading data is optional when uploading a single source, but
required for multi-source collections to match sibling images
together.
Each UploadableSource has a filename_column that should
point to a column in the data. This column should contain the
filename of each image for that source.
Multiple sources may share the same column if all images of
different sources have the same names.
Provide a pandas.DataFrame() a filepath to a .csv.
- description:
A description for the collection.
"""
# Parse for a list of UploadableSources
print('- Parsing uploadable source list')
uploadable_sources = UploadableSource._parse_list(uploadable_sources)
# If using multi-source, must provide data
if data is None and len(uploadable_sources) > 1:
raise ValueError(
'If uploading more than one image source, data '
'is required to correctly join different images from each'
)
# Parse data
if type(data) is str:
if not os.path.exists(data):
raise FileNotFoundError(
'Data file "{}" doesn\'t exist'.format(data))
# Check the file extension
if data.split('.')[-1] == 'tsv':
data = pd.read_csv(data, delimiter='\t')
elif data.split('.')[-1] in ['xls', 'xlsx']:
data = pd.read_excel(data)
else:
data = pd.read_csv(data)
# Check that all source filenames exist in the provided data
if data is not None:
print('- Checking data matches uploadable sources')
for s in uploadable_sources:
s._check_in_data(data)
# Create an empty collection
print('- Creating blank collection "{}"'.format(name))
blank_resp = self._create_empty_collection(
name, uploadable_sources, description=description, **kwargs)
blank_id = blank_resp['id']
blank = self.get_collection_by_id(blank_id)
# If uploading data, do it now from the DataFrame, ignoring fail block
if data is not None:
print('- Uploading data')
blank.replace_data(data, fail_if_not_ready=False)
# Fill in UploadableSource information with empty generated sources
print('- Registering collection sources to uploadable sources')
for i, us in enumerate(uploadable_sources):
us._register_source(i, blank.sources[i])
# Upload source data
for us in uploadable_sources:
us._upload()
# Format output string
plural_str = '' if len(uploadable_sources) < 2 else 's'
data_str = 'no data' if data is None else\
'data of shape {} rows x {} columns'\
.format(len(data), len(data.columns))
print(
'\n- Finished collection "{}" upload using {} image source{} with {}'
.format(name, len(uploadable_sources), plural_str, data_str)
)
def __len__(self):
len(self.collections)
def __repr__(self):
return "<Workspace id={} name={}>".format(self.id, self.name) | zegami-sdk-testrelease | /zegami-sdk-testrelease-0.4.6.tar.gz/zegami-sdk-testrelease-0.4.6/zegami_sdk/workspace.py | workspace.py |
import os
from pathlib import Path
from urllib.parse import urlparse
import uuid
import requests
import urllib3
ALLOW_INSECURE_SSL = os.environ.get('ALLOW_INSECURE_SSL', False)
def __get_retry_adapter():
retry_methods = urllib3.util.retry.Retry.DEFAULT_METHOD_WHITELIST.union(
('POST', 'PUT'))
retry = urllib3.util.retry.Retry(
total=10,
backoff_factor=0.5,
status_forcelist=[(502, 503, 504, 408)],
method_whitelist=retry_methods
)
adapter = requests.adapters.HTTPAdapter(max_retries=retry)
return adapter
def _create_zegami_session(self):
"""Create a session object to centrally handle auth and retry policy."""
s = requests.Session()
if ALLOW_INSECURE_SSL:
s.verify = False
s.headers.update({
'Authorization': 'Bearer {}'.format(self.token),
'Content-Type': 'application/json',
})
# Set up retry policy. Retry post requests as well as the usual methods.
adapter = __get_retry_adapter()
s.mount('http://', adapter)
s.mount('https://', adapter)
self._zegami_session = s
def _create_blobstore_session(self):
"""Session object to centrally handle retry policy."""
s = requests.Session()
if ALLOW_INSECURE_SSL:
s.verify = False
adapter = __get_retry_adapter()
s.mount('http://', adapter)
s.mount('https://', adapter)
self._blobstore_session = s
def _get_token_name(self):
url = urlparse(self.HOME)
netloc = url.netloc
prefix = netloc.replace('.', '_')
return f'{prefix}.zegami.token'
def _ensure_token(self, username, password, token, allow_save_token):
"""Tries the various logical steps to ensure a login token is set.
Will use username/password if given, but will fallback on potentially
saved token files.
"""
# Potential location of locally saved token
local_token_path = os.path.join(Path.home(), self._get_token_name())
if token:
if os.path.exists(token):
with open(token, 'r') as f:
self.token = f.read()
else:
self.token = token
elif username and password:
self.token = self._get_token(username, password)
if allow_save_token:
with open(local_token_path, 'w') as f:
f.write(self.token)
print('Token saved locally to \'{}\'.'.format(local_token_path))
else:
# Potentially use local token
if os.path.exists(local_token_path):
with open(local_token_path, 'r') as f:
self.token = f.read()
print('Used token from \'{}\'.'.format(local_token_path))
else:
raise ValueError('No username & password or token was given, '
'and no locally saved token was found.')
def _get_token(self, username, password):
"""Gets the client's token using a username and password."""
url = '{}/oauth/token/'.format(self.HOME)
data = {'username': username, 'password': password, 'noexpire': True}
r = requests.post(url, json=data, verify=not ALLOW_INSECURE_SSL)
if r.status_code != 200:
raise Exception(f'Couldn\'t set token, bad response ({r.status_code}) Was your username/password correct?')
j = r.json()
return j['token']
def _check_status(response, is_async_request=False):
"""Checks the response for a valid status code.
If allow is set to True, doesn't throw an exception.
"""
if not response.ok:
code = response.status if is_async_request else response.status_code
response_message = 'Bad request response ({}): {}\n\nbody:\n{}'.format(
code, response.reason, response.text
)
raise AssertionError(response_message)
def _auth_get(self, url, return_response=False, **kwargs):
"""Synchronous GET request. Used as standard over async currently.
If return_response == True, the response object is returned rather than
its .json() output.
Any additional kwargs are forwarded onto the requests.get().
"""
r = self._zegami_session.get(url, verify=not ALLOW_INSECURE_SSL, **kwargs)
self._check_status(r, is_async_request=False)
return r if return_response else r.json()
def _auth_delete(self, url, **kwargs):
"""Synchronous DELETE request. Used as standard over async currently.
Any additional kwargs are forwarded onto the requests.delete().
"""
resp = self._zegami_session.delete(
url, verify=not ALLOW_INSECURE_SSL, **kwargs
)
self._check_status(resp, is_async_request=False)
return resp
def _auth_post(self, url, body, return_response=False, **kwargs):
"""Synchronous POST request. Used as standard over async currently.
If return_response == True, the response object is returned rather than
its .json() output.
Any additional kwargs are forwarded onto the requests.post().
"""
r = self._zegami_session.post(
url, body, verify=not ALLOW_INSECURE_SSL, **kwargs
)
self._check_status(r, is_async_request=False)
return r if return_response else r.json()
def _auth_put(self, url, body, return_response=False, **kwargs):
"""Synchronous PUT request. Used as standard over async currently.
If return_response == True, the response object is returned rather than
its .json() output.
Any additional kwargs are forwarded onto the requests.put().
"""
r = self._zegami_session.put(
url, body, verify=not ALLOW_INSECURE_SSL, **kwargs
)
self._check_status(r, is_async_request=False)
return r if return_response and r.ok else r.json()
def _obtain_signed_blob_storage_urls(self, workspace_id, id_count=1, blob_path=None):
"""Obtain a signed blob storage url.
Returns:
[dict]: blob storage urls
[dict]: blob storage ids
"""
blob_url = f'{self.HOME}/{self.API_1}/project/{workspace_id}/signed_blob_url'
if blob_path:
id_set = {"ids": [f'{blob_path}/{str(uuid.uuid4())}' for i in range(id_count)]}
else:
id_set = {"ids": [str(uuid.uuid4()) for i in range(id_count)]}
response = self._auth_post(blob_url, body=None, json=id_set, return_response=True)
data = response.json()
urls = data
return urls, id_set
def _upload_to_signed_blob_storage_url(self, data, url, mime_type, **kwargs):
"""Upload data to an already obtained blob storage url."""
if url.startswith("/"):
url = f'https://storage.googleapis.com{url}'
headers = {'Content-Type': mime_type}
# this header is required for the azure blob storage
# https://docs.microsoft.com/en-us/rest/api/storageservices/put-blob
if 'windows.net' in url:
headers['x-ms-blob-type'] = 'BlockBlob'
response = self._blobstore_session.put(
url, data=data, headers=headers, verify=not ALLOW_INSECURE_SSL, **kwargs
)
assert response.ok | zegami-sdk-testrelease | /zegami-sdk-testrelease-0.4.6.tar.gz/zegami-sdk-testrelease-0.4.6/zegami_sdk/util.py | util.py |
from concurrent.futures import ThreadPoolExecutor
from io import BytesIO
import json
import os
from time import time
import pandas as pd
from PIL import Image, UnidentifiedImageError
from .source import Source, UploadableSource
class Collection():
@staticmethod
def _construct_collection(
client, workspace, collection_dict, allow_caching=True):
"""
Use this to instantiate Collection instances properly.
Requires an instantiated ZegamiClient, a Workspace instance, and the
data describing the collection.
"""
if type(collection_dict) != dict:
raise TypeError(
'Expected collection_dict to be a dict, not {}'
.format(collection_dict))
v = collection_dict['version'] if 'version' in collection_dict.keys()\
else 1
if v == 1:
return Collection(
client, workspace, collection_dict, allow_caching)
elif v == 2:
return CollectionV2(
client, workspace, collection_dict, allow_caching)
else:
raise ValueError('Unsupported collection version: {}'.format(v))
def __init__(self, client, workspace, collection_dict, allow_caching=True):
"""
Represents a Zegami collection, providing controls for data/annotation
read/writing.
User instantiation is not required or recommended, collection instances
can be found in Workspace() objects, and new collections can be created
using workspaces.
"""
self._client = client
self._data = collection_dict
self._workspace = workspace
self._check_data()
self._check_version()
# Caching
self.allow_caching = allow_caching
self.clear_cache()
def clear_cache(self):
self._cached_rows = None
self._cached_image_meta_lookup = None
self._cached_annotations_data = None
@property
def client():
pass
@client.getter
def client(self):
assert self._client, 'Client is not valid'
return self._client
@property
def name():
pass
@name.getter
def name(self) -> str:
self._check_data()
assert 'name' in self._data.keys(),\
'Collection\'s data didn\'t have a \'name\' key'
return self._data['name']
@property
def id():
pass
@id.getter
def id(self):
self._check_data()
assert 'id' in self._data.keys(),\
'Collection\'s data didn\'t have an \'id\' key'
return self._data['id']
@property
def _dataset_id():
pass
@_dataset_id.getter
def _dataset_id(self) -> str:
self._check_data()
assert 'dataset_id' in self._data.keys(),\
'Collection\'s data didn\'t have a \'dataset_id\' key'
return self._data['dataset_id']
@property
def _upload_dataset_id():
pass
@_upload_dataset_id.getter
def _upload_dataset_id(self) -> str:
self._check_data()
assert 'upload_dataset_id' in self._data.keys(),\
'Collection\'s data didn\'t have a \'upload_dataset_id\' key'
return self._data['upload_dataset_id']
@property
def version():
pass
@version.getter
def version(self):
self._check_data()
return self._data['version'] if 'version' in self._data.keys() else 1
@property
def workspace():
pass
@workspace.getter
def workspace(self):
return self._workspace
@property
def workspace_id():
pass
@workspace_id.getter
def workspace_id(self):
assert self.workspace is not None,\
'Tried to get a workspace ID when no workspace was set'
return self.workspace.id
@property
def url():
pass
@url.getter
def url(self):
return '{}/collections/{}-{}'.format(
self.client.HOME, self.workspace_id, self.id)
@property
def sources():
pass
@sources.getter
def sources(self):
"""
Returns all Source() instances belonging to this collection. V1
collections do not use sources, however a single pseudo source with
the correct imageset information is returned.
"""
if self.version < 2:
return [Source(self, self._data)]
if 'image_sources' not in self._data.keys():
raise ValueError(
"Expected to find 'image_sources' in collection but didn't: {}"
.format(self._data))
return [Source(self, s) for s in self._data['image_sources']]
def show_sources(self):
"""Lists the IDs and names of all sources in the collection."""
ss = self.sources
print('\nImage sources ({}):'.format(len(ss)))
for s in ss:
print('{} : {}'.format(s.imageset_id, s.name))
@property
def rows():
pass
@rows.getter
def rows(self):
"""Returns all data rows of the collection as a Pandas DataFrame."""
if self.allow_caching and self._cached_rows is not None:
return self._cached_rows
c = self.client
# Obtain the metadata bytes from Zegami
url = '{}/{}/project/{}/datasets/{}/file'.format(
c.HOME, c.API_0, self.workspace_id, self._dataset_id)
r = c._auth_get(url, return_response=True)
tsv_bytes = BytesIO(r.content)
# Convert into a pd.DataFrame
try:
df = pd.read_csv(tsv_bytes, sep='\t')
except Exception:
try:
df = pd.read_excel(tsv_bytes)
except Exception:
print('Warning - failed to open metadata as a dataframe, '
'returned the tsv bytes instead.')
return tsv_bytes
if self.allow_caching:
self._cached_rows = df
return df
@property
def tags():
pass
@tags.getter
def tags(self):
return self._get_tag_indices()
@property
def status():
pass
@status.getter
def status(self):
"""The current status of this collection."""
url = '{}/{}/project/{}/collections/{}'.format(
self.client.HOME, self.client.API_0, self.workspace_id, self.id)
resp = self.client._auth_get(url)
return resp['collection']['status']
@property
def status_bool():
pass
@status_bool.getter
def status_bool(self) -> bool:
"""The status of this collection as a fully processed or not."""
return self.status['progress'] == 1
def row_index_to_imageset_index(self, row_idx, source=0) -> int:
"""
Turn a row-space index into an imageset-space index. Typically used
in more advanced operations.
"""
row_idx = int(row_idx)
if row_idx < 0:
raise ValueError(
'Use an index above 0, not {}'.format(row_idx))
lookup = self._get_image_meta_lookup(source=source)
try:
return lookup[row_idx]
except IndexError:
raise IndexError(
"Invalid row index {} for this source."
.format(row_idx))
def imageset_index_to_row_index(self, imageset_index, source=0) -> int:
"""
Turn an imageset-space index into a row-space index. Typically used
in more advanced operations.
"""
imageset_index = int(imageset_index)
if imageset_index < 0:
raise ValueError(
'Use an index above 0, not {}'.format(imageset_index))
lookup = self._get_image_meta_lookup(source=source)
try:
return lookup.index(imageset_index)
except ValueError:
raise IndexError(
"Invalid imageset index {} for this source"
.format(imageset_index))
def get_rows_by_filter(self, filters):
"""
Gets rows of metadata in a collection by a flexible filter.
The filter should be a dictionary describing what to permit through
any specified columns.
Example:
row_filter = { 'breed': ['Cairn', 'Dingo'] }
For each filter, OR logic is used ('Cairn' or 'Dingo' would pass)
For multiple filters, AND logic is used (adding an 'age' filter would
require the 'breed' AND 'age' filters to both pass).
"""
if type(filters) != dict:
raise TypeError('Filters should be a dict.')
rows = self.rows.copy()
for fk, fv in filters.items():
if not type(fv) == list:
fv = [fv]
rows = rows[rows[fk].isin(fv)]
return rows
def get_rows_by_tags(self, tag_names):
"""
Gets rows of metadata in a collection by a list of tag_names.
Example:
tag_names = ['name1', 'name2']
This would return rows which has tags in the tag_names.
"""
assert type(tag_names) == list,\
'Expected tag_names to be a list, not a {}'.format(type(tag_names))
row_indices = set()
for tag in tag_names:
if tag in self.tags.keys():
row_indices.update(self.tags[tag])
rows = self.rows.iloc[list(row_indices)]
return rows
def get_image_urls(self, rows, source=0, generate_signed_urls=False,
signed_expiry_days=None, override_imageset_id=None):
"""
Converts rows into their corresponding image URLs.
If generate_signed_urls is false the URLs require a token to download
These urls can be passed to download_image()/download_image_batch().
If generate_signed_urls is true the urls can be used to fetch the
images directly from blob storage, using a temporary access signature
with an optionally specified lifetime.
By default the uploaded images are fetched, but it's possible to fetch
e.g. the thumbnails only, by providing an alternative imageset id.
"""
# Turn the provided 'rows' into a list of ints
if type(rows) == pd.DataFrame:
indices = list(rows.index)
elif type(rows) == list:
indices = [int(r) for r in rows]
elif type(rows) == int:
indices = [rows]
else:
raise ValueError(
'Invalid rows argument, \'{}\' not supported'
.format(type(rows)))
# Convert the row-space indices into imageset-space indices
lookup = self._get_image_meta_lookup(source)
imageset_indices = [lookup[i] for i in indices]
# Convert these into URLs
if override_imageset_id is not None:
imageset_id = override_imageset_id
else:
imageset_id = self._get_imageset_id(source)
c = self.client
if not generate_signed_urls:
return ['{}/{}/project/{}/imagesets/{}/images/{}/data'.format(
c.HOME, c.API_0, self.workspace_id, imageset_id,
i) for i in imageset_indices]
else:
query = ''
if signed_expiry_days is not None:
query = '?expiry_days={}'.format(signed_expiry_days)
get_signed_urls = [
'{}/{}/project/{}/imagesets/{}/images/{}/signed_route{}'
.format(c.HOME, c.API_0, self.workspace_id, imageset_id,
i, query) for i in imageset_indices]
signed_route_urls = []
for url in get_signed_urls:
# Unjoined rows will have None. Possibly better to filter these
# out earlier, but this works
if 'None' in url:
signed_route_urls.append('')
else:
response = c._auth_get(url)
signed_route_urls.append(response['url'])
return signed_route_urls
def download_annotation(self, annotation_id):
"""
Converts an annotation_id into downloaded annotation data.
This will vary in content depending on the annotation type and
format.
"""
zc = self.client
url = '{}/{}/project/{}/annotations/{}'.format(
zc.HOME, zc.API_1, self.workspace.id, annotation_id)
return zc._auth_get(url)
def replace_data(self, data, fail_if_not_ready=True):
"""
Replaces the data in the collection.
The provided input should be a pandas dataframe or a local
csv/json/tsv/txt/xlsx/xls file. If a xlsx/xls file is used only data
from the default sheet will be fetched.
By default, this operation will fail immediately if the collection is
not fully processed to avoid issues.
"""
# If this collection is not fully processed, do not allow data upload
if fail_if_not_ready and not self.status_bool:
raise ValueError(
'Collection has not fully processed. Wait for the collection '
'to finish processing, or force this method with '
'fail_if_not_ready=False (not recommended)\n\n{}'
.format(self.status))
# Prepare data as bytes
if type(data) == pd.DataFrame:
tsv = data.to_csv(sep='\t', index=False)
upload_data = bytes(tsv, 'utf-8')
name = 'provided_as_dataframe.tsv'
else:
name = os.path.split(data)[-1]
if name.split('.')[-1] in ['csv', 'json', 'tsv',
'txt', 'xls', 'xlsx']:
with open(data, 'rb') as f:
upload_data = f.read()
else:
raise ValueError(
'File extension must one of these: csv, json, tsv, txt, '
'xls, xlsx')
# Create blob storage and upload to it
urls, id_set = self.client._obtain_signed_blob_storage_urls(
self.workspace_id,
blob_path='datasets/{}'.format(self._upload_dataset_id)
)
blob_id = id_set['ids'][0]
url = urls[blob_id]
# Upload data to it
self.client._upload_to_signed_blob_storage_url(
upload_data, url, 'application/octet-stream')
# Update the upload dataset details
upload_dataset_url = '{}/{}/project/{}/datasets/{}'.format(
self.client.HOME, self.client.API_0, self.workspace_id,
self._upload_dataset_id)
current_dataset = self.client._auth_get(upload_dataset_url)["dataset"]
current_dataset["source"]["upload"]["name"] = name
current_dataset["source"]["blob_id"] = blob_id
# Returning response is true as otherwise it will try to return json
# but this response is empty
self.client._auth_put(
upload_dataset_url, body=None,
return_response=True, json=current_dataset)
self._cached_rows = None
def save_image(self, url, target_folder_path='./', filename='image',
extension='png'):
"""
Downloads an image and saves to disk.
For input, see Collection.get_image_urls().
"""
if not os.path.exists(target_folder_path):
os.makedirs(target_folder_path)
r = self.client._auth_get(url, return_response=True, stream=True)
with open(target_folder_path + '/' + filename + '.' + extension, 'wb')\
as f:
f.write(r.content)
def save_image_batch(self, urls, target_folder_path='./', extension='png',
max_workers=50, show_time_taken=True):
"""
Downloads a batch of images and saves to disk.
Filenames are the row index followed by the specified extension.
For input, see Collection.get_image_urls().
"""
def save_single(index, url):
self.save_image(url, target_folder_path, filename=str(index),
extension=extension)
return index
t0 = time()
with ThreadPoolExecutor(max_workers=max_workers) as ex:
futures = [ex.submit(save_single, i, u)
for i, u in enumerate(urls)]
ex.shutdown(wait=True)
# Error catch all completed futures
for f in futures:
if f.exception() is not None:
raise Exception(
'Exception in multi-threaded image saving: {}'
.format(f.exception()))
if show_time_taken:
print('\nDownloaded {} images in {:.2f} seconds.'
.format(len(futures), time() - t0))
def download_image(self, url):
"""
Downloads an image into memory as a PIL.Image.
For input, see Collection.get_image_urls().
"""
r = self.client._auth_get(url, return_response=True, stream=True)
r.raw.decode = True
try:
return Image.open(r.raw)
except UnidentifiedImageError:
return Image.open(BytesIO(r.content))
def download_image_batch(self, urls, max_workers=50, show_time_taken=True):
"""
Downloads multiple images into memory (each as a PIL.Image)
concurrently.
Please be aware that these images are being downloaded into memory,
if you download a huge collection of images you may eat up your
RAM!
"""
t0 = time()
with ThreadPoolExecutor(max_workers=max_workers) as ex:
futures = [ex.submit(self.download_image, u) for u in urls]
ex.shutdown(wait=True)
# Error catch all completed futures
for f in futures:
if f.exception() is not None:
raise Exception(
'Exception in multi-threaded image downloading: {}'
.format(f.exception()))
if show_time_taken:
print('\nDownloaded {} images in {:.2f} seconds.'
.format(len(futures), time() - t0))
return [f.result() for f in futures]
def delete_images_with_tag(self, tag='delete'):
"""Delete all the images in the collection with the tag 'delete'.s."""
row_indices = set()
if tag in self.tags.keys():
row_indices.update(self.tags[tag])
lookup = self._get_image_meta_lookup()
imageset_indices = [lookup[int(i)] for i in row_indices]
c = self.client
urls = ['{}/{}/project/{}/imagesets/{}/images/{}'.format(
c.HOME, c.API_0, self.workspace_id, self._get_imageset_id(),
i) for i in imageset_indices]
for url in urls:
c._auth_delete(url)
print(f'\nDeleted {len(urls)} images')
def _get_tag_indices(self):
"""Returns collection tags indices."""
c = self.client
url = '{}/{}/project/{}/collections/{}/tags'.format(
c.HOME, c.API_1, self.workspace_id, self.id)
response = c._auth_get(url)
return self._parse_tags(response['tagRecords'])
def _parse_tags(self, tag_records):
"""
Parses tag indices into a list of tags, each with an list of
indices.
"""
tags = {}
for record in tag_records:
if record['tag'] not in tags.keys():
tags[record['tag']] = []
tags[record['tag']].append(record['key'])
return tags
def get_annotations(self, anno_type='mask') -> dict:
"""
Returns one type of annotations attached to the collection.
Default as mask annotations.
"""
c = self.client
url = '{}/{}/project/{}/annotations/collection/{}?type={}'.format(
c.HOME, c.API_1, self.workspace_id, self.id, anno_type)
return c._auth_get(url)
def get_annotations_for_image(
self, row_index, source=None, anno_type='mask') -> list:
"""
Returns one type of annotations for a single item in the collection.
Default as mask annotations.
"""
if source is not None:
self._source_warning()
assert type(row_index) == int and row_index >= 0,\
'Expected row_index to be a positive int, not {}'.format(row_index)
c = self.client
lookup = self._get_image_meta_lookup()
imageset_index = lookup[row_index]
url = '{}/{}/project/{}/annotations/imageset/{}/images/{}?type={}'\
.format(c.HOME, c.API_1, self.workspace_id,
self._get_imageset_id(), imageset_index, anno_type)
return c._auth_get(url)
def upload_annotation(self, uploadable, row_index=None, image_index=None,
source=None, author=None, debug=False):
"""
Uploads an annotation to Zegami.
Requires uploadable annotation data (see
AnnotationClass.create_uploadable()), the row index of the image the
annotation belongs to, and the source (if using a multi-image-source
collection). If no source is provided, it will be uploaded to the
first source.
Optionally provide an author, which for an inference result should
probably some identifier for the model. If nothing is provided, the
ZegamiClient's .name property will be used.
"""
source = None if self.version == 1 else self._parse_source(source)
imageset_id = self._get_imageset_id(source)
image_meta_lookup = self._get_image_meta_lookup(source)
author = author or self.client.email
if image_index is None:
assert row_index is not None,\
'Must provide either row_index or image_index'
image_index = image_meta_lookup[row_index]
else:
assert row_index is None,\
'Must provide only one or row_index, image_index'
assert type(uploadable) == dict,\
'Expected uploadable data to be a dict, not a {}'\
.format(type(uploadable))
assert 'type' in uploadable.keys(),\
'Expected \'type\' key in uploadable: {}'.format(uploadable)
assert 'annotation' in uploadable.keys(),\
'Expected \'annotation\' key in uploadable: {}'.format(uploadable)
assert type(imageset_id) == str,\
'Expected imageset_id to be a str, not {}'\
.format(type(imageset_id))
# Get the class-specific data to upload
payload = {
'author': author,
'imageset_id': imageset_id,
'image_index': int(image_index),
'annotation': uploadable['annotation'],
'type': uploadable['type'],
'format': uploadable['format'],
'class_id': str(int(uploadable['class_id'])),
}
# Check that there are no missing fields in the payload
for k, v in payload.items():
assert v is not None, 'Empty annotation uploadable data value '
'for \'{}\''.format(k)
# Potentially print for debugging purposes
if debug:
print('\nupload_annotation payload:\n')
for k, v in payload.items():
if k == 'annotation':
print('- annotation:')
for k2, v2 in payload['annotation'].items():
print('\t- {} : {}'.format(k2, v2))
else:
print('- {} : {}'.format(k, v))
print('\nJSON:\n{}'.format(json.dumps(payload)))
# POST
c = self.client
url = '{}/{}/project/{}/annotations'.format(
c.HOME, c.API_1, self.workspace_id)
r = c._auth_post(url, json.dumps(payload), return_response=True)
return r
def delete_annotation(self, annotation_id):
"""
Delete an annotation by its ID. These are obtainable using the
get_annotations...() methods.
"""
c = self.client
url = '{}/{}/project/{}/annotations/{}'\
.format(c.HOME, c.API_1, self.workspace_id, annotation_id)
payload = {
'author': c.email
}
r = c._auth_delete(url, data=json.dumps(payload))
return r
def delete_all_annotations(self, source=0):
"""Deletes all annotations saved to the collection."""
# A list of sources of annotations
anno_sources = self.get_annotations()['sources']
c = 0
for i, source in enumerate(anno_sources):
# A list of annotation objects
annotations = source['annotations']
if len(annotations) == 0:
continue
print('Deleting {} annotations from source {}'
.format(len(annotations), i))
for j, annotation in enumerate(annotations):
self.delete_annotation(annotation['id'])
print('\r{}/{}'.format(j + 1, len(annotations)), end='',
flush=True)
c += 1
print('')
print('\nDeleted {} annotations from collection "{}"'.format(
c, self.name))
@property
def userdata():
pass
@userdata.getter
def userdata(self):
c = self.client
url = '{}/{}/project/{}/collections/{}'.format(
c.HOME, c.API_0, self.workspace_id, self.id)
data = c._auth_get(url)['collection']
userdata = data['userdata'] if 'userdata' in data.keys() else None
return userdata
def set_userdata(self, data):
""" Additively sets userdata. To remove data set its value to None. """
c = self.client
url = '{}/{}/project/{}/collections/{}/userdata'.format(
c.HOME, c.API_0, self.workspace_id, self.id)
userdata = c._auth_post(url, json.dumps(data))
return userdata
@property
def classes():
pass
@classes.getter
def classes(self) -> list:
"""
Property for the class configuration of the collection.
Used in an annotation workflow to tell Zegami how to treat defined
classes.
To set new classes, provide a list of class dictionaries of shape:
collection.classes = [
{
'color' : '#32a852', # A hex color for the class
'name' : 'Dog', # A human-readable identifier
'id' : 0 # The unique integer class ID
},
{
'color' : '#43f821', # A hex color for the class
'name' : 'Cat', # A human-readable identifier
'id' : 1 # The unique integer class ID
}
]
"""
u = self.userdata
return list(u['classes'].values()) if u is not None\
and 'classes' in u.keys() else []
def add_images(self, uploadable_sources, data=None): # noqa: C901
"""
Add more images to a collection, given a set of uploadable_sources and
optional data rows. See workspace.create_collection for details of
these arguments. Note that the images won't appear in the collection
unless rows are provided referencing them.
"""
uploadable_sources = UploadableSource._parse_list(uploadable_sources)
# If using multi-source, must provide data
if data is None and len(uploadable_sources) > 1:
raise ValueError(
'If uploading more than one image source, data '
'is required to correctly join different images from each'
)
# Parse data
if type(data) is str:
if not os.path.exists(data):
raise FileNotFoundError('Data file "{}" doesn\'t exist'
.format(data))
# Check the file extension
if data.split('.')[-1] == 'tsv':
data = pd.read_csv(data, delimiter='\t')
elif data.split('.')[-1] in ['xls', 'xlsx']:
data = pd.read_excel(data)
else:
data = pd.read_csv(data)
# Check that all source filenames exist in the provided data
if data is not None:
print('- Checking data matches uploadable sources')
for s in uploadable_sources:
s._check_in_data(data)
# append rows to data
new_rows = self.rows.append(data)
self.replace_data(new_rows)
# validate and register uploadable sources against existing sources
for s in uploadable_sources:
for i, us in enumerate(uploadable_sources):
us._register_source(i, self.sources[i])
# upload
for us in uploadable_sources:
us._upload()
@classes.setter
def classes(self, classes): # noqa: C901
# Check for a valid classes list
if type(classes) != list:
raise TypeError(
'Expected \'classes\' to be a list, not {}'
.format(type(classes)))
payload = {
'classes': {}
}
for d in classes:
# Check for a sensible class dict
if type(d) != dict:
raise TypeError(
'Expected \'classes\' entry to be a dict, not {}'
.format(type(d)))
if len(d.keys()) != 3:
raise ValueError(
'Expected classes dict to have 3 keys, not {} ({})'
.format(len(d.keys()), d))
for k in ['color', 'name', 'id']:
if k not in d.keys():
raise ValueError('Unexpected class key: {}. Keys must be '
'color | name | id.'.format(k))
# Format as the expected payload
payload['classes'][d['id']] = {
'color': str(d['color']),
'name': str(d['name']),
'id': str(int(d['id']))
}
# POST
c = self.client
url = '{}/{}/project/{}/collections/{}/userdata'.format(
c.HOME, c.API_0, self.workspace_id, self.id)
c._auth_post(url, json.dumps(payload))
print('New classes set:')
for d in self.classes:
print(d)
def _check_data(self) -> None:
if not self._data:
raise ValueError('Collection had no self._data set')
if type(self._data) != dict:
raise TypeError(
'Collection didn\'t have a dict for its data ({})'
.format(type(self._data)))
def _check_version(self) -> None:
v = self.version
class_v = 2 if isinstance(self, CollectionV2) else 1
if v != class_v:
raise ValueError(
'Collection data indicates the class used to construct this '
'collection is the wrong version. v{} class vs v{} data'
.format(class_v, v))
def _get_imageset_id(self, source=0) -> str:
self._check_data()
if 'imageset_id' not in self._data:
raise KeyError(
'Collection\'s data didn\'t have an \'imageset_id\' key')
return self._data['imageset_id']
def _join_id_to_lookup(self, join_id) -> list:
"""
Given a join_id, provides the associated image-meta lookup for
converting between image and row spaces.
"""
# Type-check provided join_id
if type(join_id) != str:
raise TypeError(
'Expected join_id to be str, not: {} ({})'
.format(join_id, type(join_id)))
# Obtain the dataset based on the join_id (dict)
url = '{}/{}/project/{}/datasets/{}'.format(
self.client.HOME, self.client.API_0, self.workspace_id, join_id)
dataset = self.client._auth_get(url)['dataset']
if 'imageset_indices' in dataset.keys():
return dataset['imageset_indices']
else:
# Image only collection. Lookup should be n => n.
# This is a bit of a hack, but works
return {k: k for k in range(100000)}
def _get_image_meta_lookup(self, source=0) -> list:
"""Used to convert between image and row space."""
# If this has already been cached, return that
if self.allow_caching and self._cached_image_meta_lookup:
self._check_data()
return self._cached_image_meta_lookup
key = 'imageset_dataset_join_id'
if key not in self._data.keys():
raise KeyError(
'Collection: Key "{}" not found in self._data'.format(key))
join_id = self._data[key]
lookup = self._join_id_to_lookup(join_id)
# If caching, store it for later
if self.allow_caching:
self._cached_image_meta_lookup = lookup
return lookup
@staticmethod
def _source_warning() -> None:
print(
'Warning - Called with a source when this is not a '
'multi-image-source collection. Treating as if no source '
'was required.')
def __len__(self) -> int:
self._check_data()
key = 'total_data_items'
if key not in self._data.keys():
raise KeyError(
'Collection\'s self._data was missing the key "{}"'
.format(key))
return self._data[key]
def __repr__(self) -> str:
return "<Collection id={} name={}>".format(self.id, self.name)
class CollectionV2(Collection):
def clear_cache(self):
super().clear_cache()
self._cached_image_meta_source_lookups = {}
@property
def sources():
pass
@sources.getter
def sources(self) -> list:
"""Returns all Source() instances belonging to this collection."""
if 'image_sources' not in self._data.keys():
raise KeyError(
'Expected to find \'image_sources\' in collection but '
'didn\'t: {}'.format(self._data))
return [Source(self, s) for s in self._data['image_sources']]
def show_sources(self):
"""Lists the IDs and names of all sources in the collection."""
ss = self.sources
print('\nImage sources ({}):'.format(len(ss)))
for s in ss:
print('{} : {}'.format(s.imageset_id, s.name))
def get_annotations(self, source=0, type='mask') -> list:
"""
Gets one type of annotations for a particular source of a collection.
Defaults to searching for mask-type annotations.
"""
source = self._parse_source(source)
url = '{}/{}/project/{}/annotations/collection/{}/source/{}?type={}'\
.format(self.client.HOME, self.client.API_1, self.workspace_id,
self.id, source.id, type)
return self.client._auth_get(url)
def get_annotations_for_image(
self, row_index, source=0, type='mask') -> list:
"""
Returns one type of annotations for a single item in the collection.
Default to searching for mask-type annotations.
"""
# Parse the source for a valid Source() instance
source = self._parse_source(source)
# Determine the imageset index
imageset_index = self.imageset_index_to_row_index(row_index, source)
# Download and return annotations of the requested type
url = '{}/{}/project/{}/annotations/imageset/{}/images/{}?type={}'\
.format(self.client.HOME, self.client.API_1, self.workspace_id,
self._get_imageset_id(), imageset_index, type)
return self.client._auth_get(url)
def _get_imageset_id(self, source=0) -> str:
"""
Source can be an int or a Source instance associated with this
collection.
"""
self._check_data()
self._check_version()
source = self._parse_source(source)
return source.imageset_id
def _get_image_meta_lookup(self, source=0) -> list:
"""
Returns the image-meta lookup for converting between image and row
space. There is a lookup for each Source in V2 collections, so caching
keeps track of the relevent Source() lookups by join_id.
"""
self._check_data()
self._check_version()
source = self._parse_source(source)
join_id = source._imageset_dataset_join_id
# If already obtained and cached, return that
if self.allow_caching and join_id in\
self._cached_image_meta_source_lookups:
return self._cached_image_meta_source_lookups[join_id]
# No cached lookup, obtain it and potentially cache it
lookup = self._join_id_to_lookup(join_id)
if self.allow_caching:
self._cached_image_meta_source_lookups[join_id] = lookup
return lookup
def _parse_source(self, source):
"""
Accepts an int or a Source instance and always returns a checked
Source instance.
"""
ss = self.sources
# If an index is given, check the index is sensible and return a Source
if type(source) == int:
if source < 0:
raise ValueError(
'Expected source to be a positive int, not {}'
.format(source))
if source >= len(ss):
raise ValueError(
'Source not valid for number of available sources (index '
'{} for list length {})'
.format(source, len(ss)))
return ss[source]
# If a Source is given, check it belongs to this collection and return
if not isinstance(source, Source):
raise TypeError(
'Provided source was neither an int nor a Source instance: {}'
.format(source))
for s in ss:
if s.id == source.id:
return source
raise Exception('Provided source was a Source instance, but didn\'t '
'belong to this collection ({})'.format(self.name))
def __repr__(self) -> str:
return "<Collection V2 id={} name={}>".format(self.id, self.name) | zegami-sdk-testrelease | /zegami-sdk-testrelease-0.4.6.tar.gz/zegami-sdk-testrelease-0.4.6/zegami_sdk/collection.py | collection.py |
import pandas as pd
def calc_num_correlation_matrix(df):
"""Calculates a matrix of correlations for all numerical pairs of columns in a collection."""
# Get the numeric columns
num_cols = [c for c in df.columns if df[c].dtype.kind.lower() in ['f', 'i']]
# Make into reduced frame
df_num = df[num_cols]
# Normalize
df_num_norm = (df_num - df_num.mean(skipna=True)) / df_num.std(skipna=True)
return df_num_norm.cov()
def calc_num_summary(df):
"""Calculates a table to summarise the numeric columns of a collection.
Includes:
- Mean
- Median
- Range
- Standard deviation
"""
# Get the numeric columns
num_cols = [c for c in df.columns if df[c].dtype.kind.lower() in ['f', 'i']]
df = df[num_cols]
# Calculate the means
means = [df[col].mean(skipna=True) for col in df.columns]
# Calculate the medians
medians = [df[col].median(skipna=True) for col in df.columns]
# Calculate the min, max, range
mins = [df[col].min(skipna=True) for col in df.columns]
maxs = [df[col].max(skipna=True) for col in df.columns]
ranges = [maxs[i] - mins[i] for i in range(len(mins))]
# Calculate the standard deviations
stds = [df[col].std(skipna=True) for col in df.columns]
# Construct the results table
df_out = pd.DataFrame(
data=[means, medians, mins, maxs, ranges, stds],
columns=df.columns
)
df_out.index = ['Mean', 'Median', 'Min', 'Max', 'Range',
'Standard Deviation']
return df_out
def calc_cat_representations(df, columns=None, max_cardinality=None):
"""Calculates the 'representation' for a categorical column.
A score closer to zero means that values in the column are more skewed
towards certain classes (some are being under-represented). If closer to
one, there is a more even distribution of possible values.
To specify only certain columns (case sensitive) to analyse, use
columns=['MyColumnA', 'MyColumnB']. Using None will look at all valid
columns.
Columns who's unique values exceed 'max_cardinality' are also excluded to
avoid looking at columns likely containing many mostly unique strings.
If a column should have many classes, increase this number.
To subdue this behaviour entirely, use 'max_cardinality=None'.
Columns whose result is nan are excluded from the output.
"""
# Get all object columns
cat_cols = [col for col in df.columns if df[col].dtype.kind == 'O']
# If filtering to specific columns, exclude any that don't match
if columns is not None:
if not type(columns) is list:
columns = [columns]
cat_cols = [col for col in cat_cols if col in columns]
# Exclude high-cardinality columns
if max_cardinality is not None:
cat_cols = [col for col in cat_cols if len(set(df[col])) <= max_cardinality]
# Build the representation score for each valid column
rep_scores = []
for col in cat_cols:
# The number of unique classes in the column
unique_classes = df[col].nunique()
# The count per unique class in the column
class_counts = df[col].value_counts()
# The total samples (should be ~len(rows))
total_counts = class_counts.sum(skipna=True)
# Ideal count per class
ideal_per_class = total_counts / unique_classes
# Normalized counts per class
norm_class_counts = (class_counts - ideal_per_class).abs() / class_counts.std(skipna=True)
# The representation score
rep_score = 1 - norm_class_counts.std(skipna=True)
rep_scores.append(rep_score)
return {
cat_cols[i]: max(0, rep_scores[i]) for i in range(len(cat_cols)) if not pd.isna(rep_scores[i])
} | zegami-sdk-testrelease | /zegami-sdk-testrelease-0.4.6.tar.gz/zegami-sdk-testrelease-0.4.6/zegami_sdk/stats.py | stats.py |
import base64
import io
import os
import numpy as np
from PIL import Image
import cv2
class _Annotation():
"""Base class for annotations."""
# Define the string annotation TYPE in child classes
TYPE = None
UPLOADABLE_DESCRIPTION = None
def __init__(self, collection, annotation_data, source=None):
"""
Base class for annotations.
Subclasses should call super().__init__ AFTER assignment of members
so that checks can be performed.
If making a new annotation to upload, use collection.upload_annotation
instead.
"""
self._collection = collection # Collection instance
self._source = source # Source instance
# { imageset_id, image_index, type, annotation }
self._data = annotation_data
# Enforce abstract requirement
if self.TYPE is None:
raise TypeError(
'Do not instantiate the base _Annotation class. It is an '
'abstract class, try one of the non-hidden Annotation classes '
'instead.')
@property
def collection():
pass
@collection.getter
def collection(self):
"""The collection this annotation belongs to."""
return self._collection
@property
def source():
pass
@source.getter
def source(self):
"""The source this annotation belongs to in its collection."""
return self._source
@property
def _image_index():
pass
@_image_index.getter
def _image_index(self):
"""The image-space index of this annotation's owner's image."""
if 'image_index' not in self._data.keys():
raise ValueError('Annotation\'s _data did not contain '
'\'image_index\': {}'.format(self._data))
return self._data['image_index']
@property
def row_index():
pass
@row_index.getter
def row_index(self):
return self._row_index
@property
def imageset_index():
pass
@imageset_index.getter
def imageset_index(self):
return self.collection.row_index_to_imageset_index(self.row_index)
@property
def _imageset_id():
pass
@_imageset_id.getter
def _imageset_id(self):
"""Shortcut for the owning collection's (source's) imageset ID."""
return self.collection._get_imageset_id(self.source)
# -- Abstract/virtual, must be implemented in children --
@classmethod
def create_uploadable(cls) -> None:
"""Extend in children to include actual annotation data."""
return {
'type': cls.TYPE,
'format': None,
'annotation': None
}
def view(self):
"""Abstract method to view a representation of the annotation."""
raise NotImplementedError(
'\'view\' method not implemented for annotation type: {}'
.format(self.TYPE))
class AnnotationMask(_Annotation):
"""
An annotation comprising a bitmask and some metadata.
To view the masks an image, use mask.view().
Note: Providing imageset_id and image_index is not mandatory and can be
obtained automatically, but this is slow and can cause unnecessary
re-downloading of data.
"""
TYPE = 'mask'
UPLOADABLE_DESCRIPTION = """
Mask annotation data includes the actual mask (as a base64 encoded
png string), a width and height, bounding box, and score if generated
by a model (else None).
"""
@classmethod
def create_uploadable(cls, bool_mask, class_id):
"""
Creates a data package ready to be uploaded with a collection's
.upload_annotation().
Note: The output of this is NOT an annotation, it is used to upload
annotation data to Zegami, which when retrieved will form an
annotation.
"""
if type(bool_mask) != np.ndarray:
raise TypeError('Expected bool_mask to be a numpy array, not a {}'
.format(type(bool_mask)))
if bool_mask.dtype != bool:
raise TypeError('Expected bool_mask.dtype to be bool, not {}'
.format(bool_mask.dtype))
if len(bool_mask.shape) != 2:
raise ValueError('Expected bool_mask to have a shape of 2 '
'(height, width), not {}'.format(bool_mask.shape))
# Ensure we are working with [h, w]
bool_mask = cls.parse_bool_masks(bool_mask, shape=2)
h, w = bool_mask.shape
# Encode the mask array as a 1 bit PNG encoded as base64
mask_image = Image.fromarray(bool_mask.astype('uint8') * 255).convert('1')
mask_buffer = io.BytesIO()
mask_image.save(mask_buffer, format='PNG')
byte_data = mask_buffer.getvalue()
mask_b64 = base64.b64encode(byte_data)
mask_string = "data:image/png;base64,{}".format(mask_b64.decode("utf-8"))
bounds = cls.find_bool_mask_bounds(bool_mask)
roi = {
'xmin': int(bounds['left']),
'xmax': int(bounds['right']),
'ymin': int(bounds['top']),
'ymax': int(bounds['bottom']),
'width': int(bounds['right'] - bounds['left']),
'height': int(bounds['bottom'] - bounds['top'])
}
data = {
'mask': mask_string,
'width': int(w),
'height': int(h),
'score': None,
'roi': roi
}
uploadable = super().create_uploadable()
uploadable['format'] = '1UC1'
uploadable['annotation'] = data
uploadable['class_id'] = int(class_id)
return uploadable
def view(self):
"""View the mask as an image. """
# NOT TESTED
im = Image.fromarray(self.mask_uint8)
im.show()
@property
def mask_uint8():
pass
@mask_uint8.getter
def mask_uint8(self):
"""Returns mask data as a 0 -> 255 uint8 numpy array, [h, w]."""
return self.mask_bool.astype(np.uint8) * 255
@property
def mask_bool():
pass
@mask_bool.getter
def mask_bool(self):
"""Returns mask data as a False | True bool numpy array, [h, w]."""
raise NotImplementedError('Not implemented, see annotation._data to obtain.')
# return self.parse_bool_masks(self._get_bool_arr(), shape=2)
@staticmethod
def _read_bool_arr(local_fp):
"""
Reads the boolean array from a locally stored file. Useful for
creation of upload package.
"""
# Check for a sensible local file
if not os.path.exists(local_fp):
raise FileNotFoundError('Mask not found: {}'.format(local_fp))
if not os.path.isfile(local_fp):
raise ValueError('Path is not a file: {}'.format(local_fp))
# Convert whatever is found into a [h, w] boolean mask
arr = np.array(Image.open(local_fp), dtype='uint8')
if len(arr.shape) == 3:
N = arr.shape[2]
if N not in [1, 3, 4]:
raise ValueError('Unusable channel count: {}'.format(N))
if N == 1:
arr = arr[:, :, 0]
elif N == 3:
arr = cv2.cvtColor(arr, cv2.COLOR_RGB2GRAY)
elif N == 4:
arr = cv2.cvtColor(arr, cv2.COLOR_RGBA2GRAY)
if arr.any() and arr.max() == 1:
arr *= 255
return arr > 127
@staticmethod
def parse_bool_masks(bool_masks, shape=3):
"""
Checks the masks for correct data types, and ensures a shape of
[h, w, N].
"""
if shape not in [2, 3]:
raise ValueError("Invalid 'shape' - use shape = 2 or 3 for [h, w]"
" or [h, w, N].")
if type(bool_masks) != np.ndarray:
raise TypeError(
'Expected bool_masks to be a numpy array, not {}'
.format(type(bool_masks)))
if bool_masks.dtype != bool:
raise TypeError(
'Expected bool_masks to have dtype == bool, not {}'
.format(bool_masks.dtype))
# If mismatching shape and mode, see if we can unambigously coerce
# into desired shape
if shape == 3 and len(bool_masks.shape) == 2:
bool_masks = np.expand_dims(bool_masks, -1)
elif shape == 2 and len(bool_masks.shape) == 3:
if bool_masks.shape[2] > 1:
raise ValueError(
'Got a multi-layer bool-mask with N > 1 while using shape'
' = 2. In this mode, only [h, w] or [h, w, 1] are '
'permitted, not {}'.format(bool_masks.shape))
bool_masks = bool_masks[:, :, 0]
# Final check
if len(bool_masks.shape) != shape:
raise ValueError(
'Invalid final bool_masks shape. Should be {} but was {}'
.format(shape, bool_masks.shape))
return bool_masks
@classmethod
def find_bool_mask_bounds(cls, bool_mask, fail_on_error=False) -> dict:
"""
Returns a dictionary of { top, bottom, left, right } for the edges
of the given boolmask. If fail_on_error is False, a failed result
returns { 0, 0, 0, 0 }. Set to True for a proper exception.
"""
bool_mask = cls.parse_bool_masks(bool_mask, shape=2)
rows = np.any(bool_mask, axis=1)
cols = np.any(bool_mask, axis=0)
try:
top, bottom = np.where(rows)[0][[0, -1]]
left, right = np.where(cols)[0][[0, -1]]
except Exception:
top, bottom, left, right = 0, 0, 0, 0
if fail_on_error:
raise ValueError(
'Failed to find proper bounds for mask with shape {}'
.format(bool_mask.shape))
return {'top': top, 'bottom': bottom, 'left': left, 'right': right}
@staticmethod
def base64_to_boolmask(b64_data):
"""
Converts str base64 annotation data from Zegami into a boolean
mask.
"""
if type(b64_data) is not str:
raise TypeError(
'b64_data should be a str, not {}'.format(type(b64_data)))
# Remove b64 typical prefix if necessary
if b64_data.startswith('data:'):
b64_data = b64_data.split(',', 1)[-1]
img = Image.open(io.BytesIO(base64.b64decode(b64_data)))
img_arr = np.array(img)
# Correct for potential float->int scale error
premax = img_arr.max()
arr_int = np.array(np.array(img) * 255 if premax < 2 else
np.array(img), dtype='uint8')
return arr_int > 127 | zegami-sdk-testrelease | /zegami-sdk-testrelease-0.4.6.tar.gz/zegami-sdk-testrelease-0.4.6/zegami_sdk/annotation.py | annotation.py |
from .util import (
_auth_delete,
_auth_get,
_auth_post,
_auth_put,
_check_status,
_create_blobstore_session,
_create_zegami_session,
_ensure_token,
_get_token,
_get_token_name,
_obtain_signed_blob_storage_urls,
_upload_to_signed_blob_storage_url
)
from .workspace import Workspace
DEFAULT_HOME = 'https://zegami.com'
class ZegamiClient():
"""This client acts as the root for browsing your Zegami data.
It facilitates making authenticated requests using your token, initially
generated with login credentials. After logging in once, subsequent
credentials should typically not be required, as the token is saved
locally (zegami.token in your root OS folder).
Use zc.show_workspaces() to see your available workspaces. You can access
your workspaces using either zc.get_workspace_by...() or by directly
using workspace = zc.workspaces[0] ([1], [2], ...). These then act as
controllers to browse collections from. Collections in turn act as
controllers to browse data from.
"""
HOME = 'https://zegami.com'
API_0 = 'api/v0'
API_1 = 'api/v1'
_auth_get = _auth_get
_auth_post = _auth_post
_auth_put = _auth_put
_auth_delete = _auth_delete
_create_zegami_session = _create_zegami_session
_create_blobstore_session = _create_blobstore_session
_ensure_token = _ensure_token
_get_token_name = _get_token_name
_get_token = _get_token
_check_status = staticmethod(_check_status)
_obtain_signed_blob_storage_urls = _obtain_signed_blob_storage_urls
_upload_to_signed_blob_storage_url = _upload_to_signed_blob_storage_url
_zegami_session = None
_blobstore_session = None
def __init__(self, username=None, password=None, token=None, allow_save_token=True, home=DEFAULT_HOME):
# Make sure we have a token
self.HOME = home
self._ensure_token(username, password, token, allow_save_token)
# Initialise a requests session
self._create_zegami_session()
self._create_blobstore_session()
# Get user info, workspaces
self._refresh_client()
# Welcome message
try:
print('Client initialized successfully, welcome {}.\n'.format(self.name.split(' ')[0]))
except Exception:
pass
@property
def user_info():
pass
@user_info.getter
def user_info(self):
if not self._user_info:
self._refresh_client()
assert self._user_info, 'user_info not set, even after a client refresh'
return self._user_info
@property
def name():
pass
@name.getter
def name(self):
assert self._user_info, 'Trying to get name from a non-existent user_info'
assert 'name' in self._user_info.keys(),\
'Couldn\'t find \'name\' in user_info: {}'.format(self._user_info)
return self._user_info['name']
@property
def email():
pass
@email.getter
def email(self):
assert self._user_info, 'Trying to get email from a non-existent user_info'
assert 'email' in self._user_info.keys(),\
'Couldn\'t find \'email\' in user_info: {}'.format(self._user_info)
return self._user_info['email']
@property
def workspaces():
pass
@workspaces.getter
def workspaces(self):
if not self._workspaces:
self._refresh_client()
assert self._workspaces, 'workspaces not set, even after a client refresh'
return self._workspaces
def get_workspace_by_name(self, name):
ws = self.workspaces
for w in ws:
if w.name.lower() == name.lower():
return w
raise ValueError('Couldn\'t find a workspace with the name \'{}\''.format(name))
def get_workspace_by_id(self, id):
ws = self.workspaces
for w in ws:
if w.id == id:
return w
raise ValueError('Couldn\'t find a workspace with the ID \'{}\''.format(id))
def show_workspaces(self):
ws = self.workspaces
assert ws, 'Invalid workspaces obtained'
print('\nWorkspaces ({}):'.format(len(ws)))
for w in ws:
print('{} : {}'.format(w.id, w.name))
def _refresh_client(self):
"""Refreshes user_info and workspaces."""
url = '{}/oauth/userinfo/'.format(self.HOME)
self._user_info = self._auth_get(url)
self._workspaces = [Workspace(self, w) for w in self._user_info['projects']]
class _ZegamiStagingClient(ZegamiClient):
def __init__(self, username=None, password=None, token=None, allow_save_token=True,
home='https://staging.zegami.com'):
super().__init__(username, password, token, allow_save_token, home=home) | zegami-sdk-testrelease | /zegami-sdk-testrelease-0.4.6.tar.gz/zegami-sdk-testrelease-0.4.6/zegami_sdk/client.py | client.py |
def add_node(
client,
workspace,
action,
params={},
type="dataset",
dataset_parents=None,
imageset_parents=None,
name="New node",
node_group=None,
processing_category=None
):
"""Create a new processing node."""
assert type in ["dataset", "imageset"]
source = {
action: params,
}
if dataset_parents:
source['dataset_id'] = dataset_parents
if imageset_parents:
source['imageset_id'] = imageset_parents
payload = {
'name': name,
'source': source,
}
if node_group:
payload['node_groups'] = [node_group]
if processing_category:
payload['processing_category'] = processing_category
url = '{}/{}/project/{}/{}'.format(
client.HOME, client.API_0, workspace.id, type + 's'
)
resp = client._auth_post(url, None, json=payload)
new_node_id = resp.get(type).get('id')
print("Created node: {}".format(new_node_id))
return resp
def add_parent(client, workspace, node_id, parent_node_id, type="dataset"):
"""
Add parent_node_id to the list of parents of node_id.
This should eventually be done via a dedicated API endpoint to avoid the need to fetch and modify the existing node
"""
assert type in ["dataset", "imageset"]
# fetch target node
url = '{}/{}/project/{}/{}/{}'.format(
client.HOME, client.API_0, workspace.id, type + 's', node_id
)
resp = client._auth_get(url)
node = resp.get(type)
# strip irrelevant fields
readonly_fields = ['data_link', 'id', 'parent_versioning_values', 'schema', 'total_rows']
for field in readonly_fields:
if field in node:
node.pop(field)
# add new parent to source
parent_ids = node.get('source').get(type + '_id')
parent_ids.append(parent_node_id)
# update node over API
client._auth_put(url, None, json=node, return_response=True)
def _get_imageset_images(client, workspace, node_id):
"""
Get the list of image info entries for the given node
"""
# fetch target node
url = '{}/{}/project/{}/{}/{}/images'.format(
client.HOME, client.API_1, workspace.id, "nodes", node_id
)
resp = client._auth_get(url)
return resp['images']
def _get_null_imageset_entries(client, workspace, node_id):
"""
Get the indices of all image info entries which are null
"""
images_info = _get_imageset_images(client, workspace, node_id)
indices = [i for i, info in enumerate(images_info) if info is None]
return indices
def _create_tasks_for_null_entries(client, workspace, node_id):
"""
Trigger creation of tasks for any entries in the imageset which are null.
This can happen as a result of failed database writes.
"""
url = '{}/{}/project/{}/{}/{}/create_tasks_for_null'.format(
client.HOME, client.API_1, workspace.id, "nodes", node_id
)
client._auth_post(url, None) | zegami-sdk-testrelease | /zegami-sdk-testrelease-0.4.6.tar.gz/zegami-sdk-testrelease-0.4.6/zegami_sdk/nodes.py | nodes.py |
import base64
import os
import numpy as np
from PIL import Image
def get_annotations_for_collection(self, collection, source=None, type='mask'):
"""
Gets all one type of annotations available for a given collection.
Default as mask annotations.
Optionally, provide a source index (integer) to retrieve only annotations
related to that source.
"""
wid = self._extract_workspace_id(collection)
cid = self._extract_id(collection)
url = '{}/{}/project/{}/annotations/collection/{}'.format(
self.HOME, self.API_1, wid, cid)
# If a source was provided, modify the URL
if source is not None:
assert type(source) == int and source >= 0,\
'Expected provided source to be a positive integer, got {}'\
.format(source)
srcs = self.list_image_sources(collection, return_dicts=True, hide_warning=True)
assert source < len(srcs),\
'Provided source is too high for number of sources available '\
'(index {} in list length {})'.format(source, len(srcs))
url += '/source/{}'.format(source)
url += '?type={}'.format(type)
# Perform the GET
annos = self._auth_get(url)
return annos
def get_annotations_for_image(self, collection, row_index, source=None, type='mask'):
"""
Gets one type of annotations for a single image in a collection.
Default as mask annotations.
Specify the image by giving its data row.
"""
assert source is None or type(source) == int and source >= 0,\
'Expected source to be None or a positive int, not {}'.format(source)
srcs = self.list_image_sources(collection, return_dicts=True, hide_warning=True)
uses_sources = len(srcs) > 0
if uses_sources and source is None:
source = 0
wid = self._extract_workspace_id(collection)
cid = self._extract_id(collection)
# Convert the row index into the
lookup = self._get_image_meta_lookup(collection, source=source)
imageset_index = lookup[row_index]
if uses_sources:
url = '{}/{}/project/{}/annotations/collection/{}/source/{}/images/{}?type={}'\
.format(self.HOME, self.API_1, wid, cid, srcs[source]['source_id'], imageset_index, type)
else:
iid = self._extract_imageset_id(collection)
url = '{}/{}/project/{}/annotations/imageset/{}/images/{}?type={}'\
.format(self.HOME, self.API_1, wid, iid, imageset_index, type)
# Perform the GET
annos = self._auth_get(url)
return annos
def post_annotation(self, collection, row_index, annotation, source=None, return_req=False):
"""Posts an annotation to Zegami, storing it online.
Requires the target collection and the row_index of the item being annotated. If the image
is from a particular source, provide that too.
For the 'annotation', provide the result of zc.create_<type>_annotation().
"""
srcs = self.list_image_sources(collection, return_dicts=True, hide_warning=True)
uses_sources = len(srcs) > 0
if uses_sources:
if source is None:
source = 0
wid = self._extract_workspace_id(collection)
iid = self._extract_imageset_id(collection)
lookup = self._get_image_meta_lookup(collection, source=source)
imageset_index = lookup[row_index]
annotation['imageset_id'] = iid
annotation['image_index'] = imageset_index
url = '{}/{}/project/{}/annotations/'.format(self.HOME, self.API_1, wid)
r = self._auth_post(url, annotation, return_req)
return r
def create_mask_annotation(mask):
"""Creates a mask annotation using a mask.
Accepts either a boolean numpy array, or the path to a mask png image.
Note: 'imageset_id' and 'image_index' keys MUST be added to this before
sending.
"""
if type(mask) == str:
assert os.path.exists(mask),\
'Got type(mask): str but the path \'{}\' did not exist'.format(mask)
mask = np.array(Image.open(mask))
elif type(mask) != np.array:
raise TypeError('Expected mask to be a str (filepath) or a np array, not {}'
.format(type(mask)))
if len(mask.shape) > 2:
mask = mask[:, :, 0]
if mask.dtype is not bool:
mask = mask > 127
h, w = mask.shape
# Encode the single channel boolean mask into a '1' type image, as bytes
mask_bytes = Image.fromarray(mask.astype('uint8') * 255).convert('1').tobytes()
# Encode the mask bytes prior to serialisation
mask_serialised = base64.b64encode(mask_bytes)
return {
'imageset_id': None,
'image_index': None,
'type': 'mask_1UC1',
'annotation': {
'data': mask_serialised,
'width': w,
'height': h,
}
}
def _reconstitute_mask(annotation):
if 'annotation' in annotation.keys():
annotation = annotation['annotation']
data = annotation['data']
w = annotation['width']
h = annotation['height']
decoded_data = base64.b64decode(data)
bool_arr = np.array(Image.frombytes('1', (w, h), decoded_data), dtype=int) > 0
return bool_arr | zegami-sdk-testrelease | /zegami-sdk-testrelease-0.4.6.tar.gz/zegami-sdk-testrelease-0.4.6/zegami_sdk/_annotation_methods.py | _annotation_methods.py |
from concurrent.futures import as_completed, ThreadPoolExecutor
from glob import glob
import json
import os
from tqdm import tqdm
class Source():
def __init__(self, collection, source_dict):
self._collection = collection
self._data = source_dict
@property
def name():
pass
@name.getter
def name(self):
assert self._data, 'Source had no self._data set'
assert 'name' in self._data.keys(), 'Source\'s data didn\'t have a \'name\' key'
return self._data['name']
@property
def collection():
pass
@collection.getter
def collection(self):
return self._collection
@property
def id():
pass
@id.getter
def id(self):
assert self._data, 'Source had no self._data set'
assert 'source_id' in self._data, 'Source\'s data didn\'t have a \'source_id\' key'
return self._data['source_id']
@property
def imageset_id():
pass
@imageset_id.getter
def imageset_id(self):
assert self._data, 'Source had no self._data set'
assert 'imageset_id' in self._data, 'Source\'s data didn\'t have an \'imageset_id\' key'
return self._data['imageset_id']
@property
def _imageset_dataset_join_id():
pass
@_imageset_dataset_join_id.getter
def _imageset_dataset_join_id(self):
k = 'imageset_dataset_join_id'
assert self._data, 'Source had no self._data set'
assert k in self._data, 'Source\'s data didn\'t have an \'{}\' key'.format(k)
return self._data[k]
class UploadableSource():
IMAGE_MIMES = {
".bmp": "image/bmp",
".jpg": "image/jpeg",
".jpeg": "image/jpeg",
".png": "image/png",
".gif": "image/gif",
".tif": "image/tiff",
".tiff": "image/tiff",
".dcm": "application/dicom",
}
BLACKLIST = (
".yaml",
".yml",
"thumbs.db",
".ds_store",
".dll",
".sys",
".txt",
".ini",
".tsv",
".csv",
".json"
)
def __init__(self, name, image_dir, column_filename='Filename', recursive_search=True):
"""Used in conjunction with create_collection().
An UploadableSource() points towards and manages the upload of local files, resulting in the
generation of a true Source() in the collection.
"""
self.name = name
self.image_dir = image_dir
self.column_filename = column_filename
# Set externally once a blank collection has been made
self._source = None
self._index = None
# Check the directory exists
if not os.path.exists(image_dir):
raise FileNotFoundError('image_dir "{}" does not exist'.format(self.image_dir))
if not os.path.isdir(image_dir):
raise TypeError('image_dir "{}" is not a directory'.format(self.image_dir))
# Find all files matching the allowed mime-types
self.filepaths = sum(
[glob('{}/**/*{}'.format(image_dir, ext), recursive=recursive_search)
for ext in self.IMAGE_MIMES.keys()], [])
self.filenames = [os.path.basename(fp) for fp in self.filepaths]
print('UploadableSource "{}" found {} images in "{}"'.format(self.name, len(self), image_dir))
@property
def source():
pass
@source.getter
def source(self) -> Source:
"""An UploadableSource() is the gateway to uploading into a true Zegami collection Source().
Once a collection is created and an empty Source() exists, this reference points to it ready to upload to.
"""
if self._source is None:
raise Exception(
'UploadableSource\'s generated source has not been set yet. This should be done automatically '
'after the blank collection has been generated.'
)
return self._source
@property
def index():
pass
@index.getter
def index(self) -> int:
"""The source index this UploadableSource is for.
Only set after a blank source has been generated ready to be uploaded to.
"""
if self._index is None:
raise Exception('UploadableSource\'s generated source index has '
'not been set yet. This should be done '
'automatically after the blank collection has '
'been generated')
return self._index
@property
def imageset_id():
pass
@imageset_id.getter
def imageset_id(self):
return self.source.imageset_id
def __len__(self):
return len(self.filepaths)
def _register_source(self, index, source):
"""Called to register a new (empty) Source() from a new collection to this, ready for uploading data into."""
if type(index) is not int:
raise TypeError('index should be an int, not {}'.format(type(index)))
if repr(type(source)) != repr(Source):
raise TypeError('source should be a Source(), not {}'.format(type(source)))
self._index = index
self._source = source
if not self.source.name == self.name:
raise Exception(
'UploadableSource "{}" registered to Source "{}" when their names should match'
.format(self.name, self.source.name)
)
def _assign_images_to_smaller_lists(self, file_paths):
"""Create smaller lists based on the number of images in the directory."""
# Recurse and pick up only valid files (either with image extensions, or not on blacklist)
total_work = len(file_paths)
workloads = []
workload = []
start = 0
if total_work > 2500:
size = 100
elif total_work < 100:
size = 1
else:
size = 10
i = 0
while i < total_work:
path = file_paths[i]
workload.append(path)
i += 1
if len(workload) == size or i == total_work:
workloads.append({'paths': workload, 'start': start})
workload = []
start = i
return workloads, total_work, size
def get_threaded_workloads(self, executor, workloads):
threaded_workloads = []
for workload in workloads:
threaded_workloads.append(executor.submit(
self._upload_image_group,
workload['paths'],
workload['start']
))
return threaded_workloads
def _upload(self):
"""Uploads all images by filepath to the collection.
provided a Source() has been generated and designated to this instance.
"""
collection = self.source.collection
c = collection.client
print('- Uploadable source {} "{}" beginning upload'.format(self.index, self.name))
# Tell the server how many uploads are expected for this source
url = '{}/{}/project/{}/imagesets/{}/extend'.format(c.HOME, c.API_0, collection.workspace_id, self.imageset_id)
c._auth_post(url, body=None, json={'delta': len(self)})
(workloads, total_work, group_size) = self._assign_images_to_smaller_lists(self.filepaths)
# Multiprocess upload the images
# divide the filepaths into smaller groups
# with ThreadPoolExecutor() as ex:
CONCURRENCY = 16
with ThreadPoolExecutor(CONCURRENCY) as executor:
threaded_workloads = self.get_threaded_workloads(executor, workloads)
kwargs = {
'total': len(threaded_workloads),
'unit': 'image',
'unit_scale': group_size,
'leave': True
}
for f in tqdm(as_completed(threaded_workloads), **kwargs):
if f.exception():
raise f.exception()
def _upload_image_group(self, paths, start_index):
"""Upload a group of images.
Item is a tuple comprising:
- blob_id
- blob_url
- file path
"""
coll = self.source.collection
c = coll.client
# Obtain blob storage information
blob_storage_urls, id_set = c._obtain_signed_blob_storage_urls(
coll.workspace_id, id_count=len(paths))
# Check that numbers of values are still matching
if not len(paths) == len(blob_storage_urls):
raise Exception(
'Mismatch in blob urls count ({}) to filepath count ({})'
.format(len(blob_storage_urls), len(self))
)
bulk_info = []
for (i, path) in enumerate(paths):
mime_type = self._get_mime_type(path)
blob_id = id_set['ids'][i]
blob_url = blob_storage_urls[blob_id]
bulk_info.append({
'blob_id': blob_id,
'name': os.path.basename(path),
'size': os.path.getsize(path),
'mimetype': mime_type
})
self._upload_image(c, path, blob_url, mime_type)
# Upload bulk image info
url = (
f'{c.HOME}/{c.API_0}/project/{coll.workspace_id}/imagesets/{self.imageset_id}'
f'/images_bulk?start={start_index}'
)
c._auth_post(url, body=None, return_response=True, json={'images': bulk_info})
def _upload_image(self, client, path, blob_url, mime_type):
"""Uploads a single image to the collection."""
try:
with open(path, 'rb') as f:
client._upload_to_signed_blob_storage_url(f, blob_url, mime_type)
except Exception as e:
print('Error uploading "{}" to blob storage:\n{}'.format(path, e))
def _check_in_data(self, data):
cols = list(data.columns)
if self.column_filename not in cols:
raise Exception('Source "{}" had the filename_column "{}" '
'which is not a column of the provided data:\n{}'
.format(self.name, self.column_filename, cols))
@classmethod
def _parse_list(cls, uploadable_sources) -> list:
"""Returns a checked list of instances."""
if isinstance(uploadable_sources, cls):
uploadable_sources = [uploadable_sources]
elif type(uploadable_sources) is not list:
raise TypeError('uploadable_sources should be a list of UploadableSources')
for u in uploadable_sources:
if not isinstance(u, UploadableSource):
raise TypeError('uploadable_sources should be a list of source.UploadableSource() instances')
names = [u.name for u in uploadable_sources]
for name in names:
if names.count(name) > 1:
raise ValueError('Two or more sources share the name "{}"'.format(name))
return uploadable_sources
@classmethod
def _get_mime_type(cls, path) -> str:
"""Gets the mime_type of the path. Raises an error if not a valid image mime_type."""
ext = os.path.splitext(path)[-1]
if ext in cls.IMAGE_MIMES.keys():
return cls.IMAGE_MIMES[ext]
raise TypeError('"{}" is not a supported image mime_type ({})'.format(path, cls.IMAGE_MIMES))
class UrlSource(UploadableSource):
def __init__(self, name, url_template, image_fetch_headers, column_filename='Filename'):
"""Used in conjunction with create_collection().
A UrlSource() fetches the images from the url template given, resulting in the
generation of a true Source() in the collection.
"""
self.name = name
self.url_template = url_template
self.image_fetch_headers = image_fetch_headers
self.column_filename = column_filename
# Set externally once a blank collection has been made
self._source = None
self._index = None
def _upload(self):
"""Update upload imageset to use the provided url template to get the images.
provided a Source() has been generated and designated to this instance.
"""
collection = self.source.collection
c = collection.client
print('- Configuring source {} "{}" to fetch images from url'
.format(self.index, self.name))
upload_ims_url = '{}/{}/project/{}/imagesets/{}'.format(
c.HOME, c.API_0, collection.workspace_id, self.imageset_id)
upload_ims = c._auth_get(upload_ims_url)
new_source = {
"dataset_id": collection._dataset_id,
'transfer': {
'headers': self.image_fetch_headers,
'url': {
'dataset_column': self.column_filename,
'url_template': self.url_template,
}
}
}
upload_ims['imageset']['source'] = new_source
# TODO: remove this when backend fixed transfer imageset to use sql storage
upload_ims['imageset']['imageinfo_storage'] = 'mongodb'
payload = json.dumps(upload_ims['imageset'])
r = c._auth_put(upload_ims_url, payload, return_response=True)
return r | zegami-sdk-testrelease | /zegami-sdk-testrelease-0.4.6.tar.gz/zegami-sdk-testrelease-0.4.6/zegami_sdk/source.py | source.py |
import io
import os
from urllib.parse import urlparse
from azure.storage.blob import (
ContainerClient,
ContentSettings,
)
import pandas as pd
from .collection import Collection
from .helper import guess_data_mimetype
from .source import UploadableSource
class Workspace():
def __init__(self, client, workspace_dict):
self._client = client
self._data = workspace_dict
self._check_data()
@property
def id():
pass
@id.getter
def id(self):
assert 'id' in self._data.keys(), 'Workspace\'s data didn\'t have an \'id\' key'
return self._data['id']
@property
def client():
pass
@client.getter
def client(self):
return self._client
@property
def name():
pass
@name.getter
def name(self):
assert 'name' in self._data.keys(), 'Workspace\'s data didn\'t have a \'name\' key'
return self._data['name']
@property
def collections():
pass
@collections.getter
def collections(self):
c = self._client
if not c:
raise ValueError('Workspace had no client set when obtaining collections')
url = '{}/{}/project/{}/collections/'.format(c.HOME, c.API_0, self.id)
collection_dicts = c._auth_get(url)
if not collection_dicts:
return []
collection_dicts = collection_dicts['collections']
return [Collection(c, self, d) for d in collection_dicts]
def get_collection_by_name(self, name) -> Collection:
"""Obtains a collection by name (case-insensitive)."""
matches = list(filter(lambda c: c.name.lower() == name.lower(), self.collections))
if len(matches) == 0:
raise IndexError('Couldn\'t find a collection with the name \'{}\''.format(name))
return matches[0]
def get_collection_by_id(self, id) -> Collection:
"""Obtains a collection by ID."""
matches = list(filter(lambda c: c.id == id, self.collections))
if len(matches) == 0:
raise IndexError('Couldn\'t find a collection with the ID \'{}\''.format(id))
return matches[0]
def show_collections(self) -> None:
"""Prints this workspace's available collections."""
cs = self.collections
if not cs:
print('No collections found')
return
print('\nCollections in \'{}\' ({}):'.format(self.name, len(cs)))
for c in cs:
print('{} : {}'.format(c.id, c.name))
def _check_data(self) -> None:
"""This object should have a populated self._data, runs a check."""
if not self._data:
raise ValueError('Workspace has no self._data set')
if type(self._data) is not dict:
raise TypeError('Workspace didn\'t have a dict for its data ({})'.format(type(self._data)))
def get_storage_item(self, storage_id) -> io.BytesIO:
"""Obtains an item in online-storage by its ID."""
c = self._client
url = '{}/{}/project/{}/storage/{}'.format(c.HOME, c.API_1, self.id, storage_id)
resp = c._auth_get(url, return_response=True)
return io.BytesIO(resp.content), resp.headers.get('content-type')
def create_storage_item(self, data, mime_type=None, item_name=None) -> str:
"""Creates and uploads data into online-storage. Returns its storage ID."""
if not mime_type:
mime_type = guess_data_mimetype(data)
# get signed url to use signature
client = self._client
url = '{}/{}/project/{}/storage/signedurl'.format(client.HOME, client.API_1, self.id)
if item_name:
url += '?name={}'.format(item_name)
resp = client._auth_get(url)
blob_id = 'storage/' + resp['id']
url = resp['signedurl']
url_object = urlparse(url)
sas_token = url_object.query
account_url = url_object.scheme + '://' + url_object.netloc
container_name = url_object.path.split('/')[1]
container_client = ContainerClient(account_url, container_name, credential=sas_token)
container_client.upload_blob(
blob_id,
data,
blob_type='BlockBlob',
content_settings=ContentSettings(content_type=mime_type)
)
return resp['id']
def delete_storage_item(self, storage_id) -> bool:
"""Deletes a storage item by ID. Returns the response's OK signal."""
c = self._client
url = '{}/{}/project/{}/storage/{}'.format(c.HOME, c.API_1, self.id, storage_id)
resp = c._auth_delete(url)
return resp.ok
def _create_empty_collection(self, name, source_names_and_filename_columns, description='', **kwargs):
"""
Create an empty collection, ready for images and data.
- source_names_and_filename_columns:
A dictionary of { name: filename_column } for incoming sources.
filename columns indicate where to find image filenames
within uploaded data. For non-data collections, the default
uploadable source name is used '__auto_join__', but this could
be 'Filename' if that is the name of your image filename column.
Example: {
'Regular': 'Filename',
'X-Ray': 'XRay Filename',
'Heatmap': 'Heatmap Filename'
}
Sources may share the same filename column (different folders may
contain identical filenames for different sources).
"""
defaults = {
'version': 2,
'dynamic': False,
'upload_dataset': {'source': {'upload': {}}}
}
for k, v in defaults.items():
if k not in kwargs.keys():
kwargs[k] = v
# Don't let the user provide these
reserved = ['name', 'description', 'image_sources']
for k in reserved:
if k in kwargs.keys():
del kwargs[k]
# Display actual kwargs used
for k, v in kwargs.items():
print('- Creation argument used - {} : {}'.format(k, v))
# Data to generate the collection, including sparse sources with no data
post_data = {
'name': name,
'description': description,
'image_sources': [{'name': name, 'dataset_column': col} for name, col
in source_names_and_filename_columns.items()],
**kwargs
}
url = '{}/{}/project/{}/collections'.format(
self.client.HOME, self.client.API_0, self.id)
resp = self.client._auth_post(url, body=None, json=post_data)
return resp['collection']
def create_collection(self, name, uploadable_sources, data=None, description='', **kwargs): # noqa: C901
"""
Create a collection with provided images and data.
A list of image sources (or just one) should be provided, built using
Source.create_uploadable_source(). These instruct the SDK where to
look for images to populate the collection.
- name:
The name of the collection.
- uploadable_sources:
A list of [UploadableSource()] built using:
from zegami_sdk.source import UploadableSource
sources = [ UploadableSource(params_0),
UploadableSource(params_1),
... ]
- data:
Uploading data is optional when uploading a single source, but
required for multi-source collections to match sibling images
together.
Each UploadableSource has a filename_column that should
point to a column in the data. This column should contain the
filename of each image for that source.
Multiple sources may share the same column if all images of
different sources have the same names.
Provide a pandas.DataFrame() a filepath to a .csv.
- description:
A description for the collection.
- kwargs (advanced, default signified in []):
- (bool) enable_clustering: [True]/False
Automatic image clustering. For massive collections this
process can cause memory issues, and clustering may not
even be wanted/necessary for the collection.
- (bool) use_wsi: True/[False]
Whole-slide-image format. If using WSI images, please use this
argument.
"""
# Parse for a list of UploadableSources
print('- Parsing uploadable source list')
uploadable_sources = UploadableSource._parse_list(uploadable_sources)
# If using multi-source, must provide data
if data is None and len(uploadable_sources) > 1:
raise ValueError(
'If uploading more than one image source, data '
'is required to correctly join different images from each'
)
# Parse data
if type(data) is str:
if not os.path.exists(data):
raise FileNotFoundError(
'Data file "{}" doesn\'t exist'.format(data))
# Check the file extension
if data.split('.')[-1] == 'tsv':
data = pd.read_csv(data, delimiter='\t')
elif data.split('.')[-1] in ['xls', 'xlsx']:
data = pd.read_excel(data)
else:
data = pd.read_csv(data)
# Check that all source filenames exist in the provided data
if data is not None:
print('- Checking data matches uploadable sources')
for s in uploadable_sources:
s._check_in_data(data)
# Creating an empty collection requires these parameters
source_names_and_filename_cols = {n: c for n, c in zip(
[us.name for us in uploadable_sources],
[us.column_filename for us in uploadable_sources]
)}
# Create an empty collection
print('- Creating blank collection "{}"'.format(name))
blank_resp = self._create_empty_collection(
name, source_names_and_filename_cols, description=description, **kwargs)
blank_id = blank_resp['id']
blank = self.get_collection_by_id(blank_id)
# If uploading data, do it now from the DataFrame, ignoring fail block
if data is not None:
print('- Uploading data')
blank.replace_data(data, fail_if_not_ready=False)
# Fill in UploadableSource information with empty generated sources
print('- Registering collection sources to uploadable sources')
for i, us in enumerate(uploadable_sources):
us._register_source(i, blank.sources[i])
# Upload source data
for us in uploadable_sources:
us._upload()
# Format output string
plural_str = '' if len(uploadable_sources) < 2 else 's'
data_str = 'no data' if data is None else\
'data of shape {} rows x {} columns'\
.format(len(data), len(data.columns))
print(
'\n- Finished collection "{}" upload using {} image source{} with {}'
.format(name, len(uploadable_sources), plural_str, data_str)
)
return self.get_collection_by_id(blank_id)
def __len__(self):
len(self.collections)
def __repr__(self):
return "<Workspace id={} name={}>".format(self.id, self.name) | zegami-sdk | /zegami_sdk-0.4.9-py3-none-any.whl/zegami_sdk/workspace.py | workspace.py |
import os
from pathlib import Path
from urllib.parse import urlparse
import uuid
import requests
import urllib3
ALLOW_INSECURE_SSL = os.environ.get('ALLOW_INSECURE_SSL', False)
def __get_retry_adapter():
retry_methods = urllib3.util.retry.Retry.DEFAULT_METHOD_WHITELIST.union(
('POST', 'PUT'))
retry = urllib3.util.retry.Retry(
total=10,
backoff_factor=0.5,
status_forcelist=[(502, 503, 504, 408)],
method_whitelist=retry_methods
)
adapter = requests.adapters.HTTPAdapter(max_retries=retry)
return adapter
def _create_zegami_session(self):
"""Create a session object to centrally handle auth and retry policy."""
s = requests.Session()
if ALLOW_INSECURE_SSL:
s.verify = False
s.headers.update({
'Authorization': 'Bearer {}'.format(self.token),
'Content-Type': 'application/json',
})
# Set up retry policy. Retry post requests as well as the usual methods.
adapter = __get_retry_adapter()
s.mount('http://', adapter)
s.mount('https://', adapter)
self._zegami_session = s
def _create_blobstore_session(self):
"""Session object to centrally handle retry policy."""
s = requests.Session()
if ALLOW_INSECURE_SSL:
s.verify = False
adapter = __get_retry_adapter()
s.mount('http://', adapter)
s.mount('https://', adapter)
self._blobstore_session = s
def _get_token_name(self):
url = urlparse(self.HOME)
netloc = url.netloc
prefix = netloc.replace('.', '_')
return f'{prefix}.zegami.token'
def _ensure_token(self, username, password, token, allow_save_token):
"""Tries the various logical steps to ensure a login token is set.
Will use username/password if given, but will fallback on potentially
saved token files.
"""
# Potential location of locally saved token
local_token_path = os.path.join(Path.home(), self._get_token_name())
if token:
if os.path.exists(token):
with open(token, 'r') as f:
self.token = f.read()
else:
self.token = token
elif username and password:
self.token = self._get_token(username, password)
if allow_save_token:
with open(local_token_path, 'w') as f:
f.write(self.token)
print('Token saved locally to \'{}\'.'.format(local_token_path))
else:
# Potentially use local token
if os.path.exists(local_token_path):
with open(local_token_path, 'r') as f:
self.token = f.read()
print('Used token from \'{}\'.'.format(local_token_path))
else:
raise ValueError('No username & password or token was given, '
'and no locally saved token was found.')
def _get_token(self, username, password):
"""Gets the client's token using a username and password."""
url = '{}/oauth/token/'.format(self.HOME)
data = {'username': username, 'password': password, 'noexpire': True}
r = requests.post(url, json=data, verify=not ALLOW_INSECURE_SSL)
if r.status_code != 200:
raise Exception(f'Couldn\'t set token, bad response ({r.status_code}) Was your username/password correct?')
j = r.json()
return j['token']
def _check_status(response, is_async_request=False):
"""Checks the response for a valid status code.
If allow is set to True, doesn't throw an exception.
"""
if not response.ok:
code = response.status if is_async_request else response.status_code
response_message = 'Bad request response ({}): {}\n\nbody:\n{}'.format(
code, response.reason, response.text
)
raise AssertionError(response_message)
def _auth_get(self, url, return_response=False, **kwargs):
"""Synchronous GET request. Used as standard over async currently.
If return_response == True, the response object is returned rather than
its .json() output.
Any additional kwargs are forwarded onto the requests.get().
"""
r = self._zegami_session.get(url, verify=not ALLOW_INSECURE_SSL, **kwargs)
self._check_status(r, is_async_request=False)
return r if return_response else r.json()
def _auth_delete(self, url, **kwargs):
"""Synchronous DELETE request. Used as standard over async currently.
Any additional kwargs are forwarded onto the requests.delete().
"""
resp = self._zegami_session.delete(
url, verify=not ALLOW_INSECURE_SSL, **kwargs
)
self._check_status(resp, is_async_request=False)
return resp
def _auth_post(self, url, body, return_response=False, **kwargs):
"""Synchronous POST request. Used as standard over async currently.
If return_response == True, the response object is returned rather than
its .json() output.
Any additional kwargs are forwarded onto the requests.post().
"""
r = self._zegami_session.post(
url, body, verify=not ALLOW_INSECURE_SSL, **kwargs
)
self._check_status(r, is_async_request=False)
return r if return_response else r.json()
def _auth_put(self, url, body, return_response=False, **kwargs):
"""Synchronous PUT request. Used as standard over async currently.
If return_response == True, the response object is returned rather than
its .json() output.
Any additional kwargs are forwarded onto the requests.put().
"""
r = self._zegami_session.put(
url, body, verify=not ALLOW_INSECURE_SSL, **kwargs
)
self._check_status(r, is_async_request=False)
return r if return_response and r.ok else r.json()
def _obtain_signed_blob_storage_urls(self, workspace_id, id_count=1, blob_path=None):
"""Obtain a signed blob storage url.
Returns:
[dict]: blob storage urls
[dict]: blob storage ids
"""
blob_url = f'{self.HOME}/{self.API_1}/project/{workspace_id}/signed_blob_url'
if blob_path:
id_set = {"ids": [f'{blob_path}/{str(uuid.uuid4())}' for i in range(id_count)]}
else:
id_set = {"ids": [str(uuid.uuid4()) for i in range(id_count)]}
response = self._auth_post(blob_url, body=None, json=id_set, return_response=True)
data = response.json()
urls = data
return urls, id_set
def _upload_to_signed_blob_storage_url(self, data, url, mime_type, **kwargs):
"""Upload data to an already obtained blob storage url."""
if url.startswith("/"):
url = f'https://storage.googleapis.com{url}'
headers = {'Content-Type': mime_type}
# this header is required for the azure blob storage
# https://docs.microsoft.com/en-us/rest/api/storageservices/put-blob
if 'windows.net' in url:
headers['x-ms-blob-type'] = 'BlockBlob'
response = self._blobstore_session.put(
url, data=data, headers=headers, verify=not ALLOW_INSECURE_SSL, **kwargs
)
assert response.ok | zegami-sdk | /zegami_sdk-0.4.9-py3-none-any.whl/zegami_sdk/util.py | util.py |
from concurrent.futures import ThreadPoolExecutor
from io import BytesIO
import json
import os
from time import time
import pandas as pd
from PIL import Image, UnidentifiedImageError
from .source import Source, UploadableSource
from .nodes import add_node, add_parent
class Collection():
def __repr__(self) -> str:
return "<CollectionV{} id={} name={}>".format(
self.version, self.id, self.name)
def __len__(self) -> int:
return int(self._retrieve('total_data_items'))
def __init__(self, client, workspace, collection_dict, allow_caching=True):
"""
Represents a Zegami collection, providing controls for data/annotation
read/writing.
User instantiation is not required or recommended, collection instances
can be found in Workspace() objects, and new collections can be created
using workspaces.
"""
self._client = client
self._data = collection_dict
self._workspace = workspace
self._generate_sources()
# Caching
self.allow_caching = allow_caching
self.clear_cache()
def clear_cache(self):
self._cached_rows = None
self._cached_annotations_data = None
self._cached_image_meta_source_lookups = {}
@property
def client():
pass
@client.getter
def client(self):
if not self._client:
raise ValueError('Collection: Client is not valid')
return self._client
@property
def name():
pass
@name.getter
def name(self) -> str:
return self._retrieve('name')
@property
def id():
pass
@id.getter
def id(self):
return self._retrieve('id')
@property
def _dataset_id():
pass
@_dataset_id.getter
def _dataset_id(self) -> str:
return self._retrieve('dataset_id')
@property
def _upload_dataset_id():
pass
@_upload_dataset_id.getter
def _upload_dataset_id(self) -> str:
return self._retrieve('upload_dataset_id')
@property
def version():
pass
@version.getter
def version(self):
return self._data['version'] if 'version' in self._data.keys() else 1
@property
def workspace():
pass
@workspace.getter
def workspace(self):
return self._workspace
@property
def workspace_id():
pass
@workspace_id.getter
def workspace_id(self):
if self.workspace is None:
raise ValueError('Collection has no assigned workspace')
return self.workspace.id
@property
def url():
pass
@url.getter
def url(self):
return '{}/collections/{}-{}'.format(
self.client.HOME, self.workspace_id, self.id)
def _generate_sources(self):
"""On-construction sets source instances using of collection data."""
if self.version < 2:
source_data = self._data.copy()
source_data['name'] = 'None'
self._sources = [Source(self, source_data)]
else:
self._sources = [
Source(self, s) for s in self._data['image_sources']]
@property
def sources():
pass
@sources.getter
def sources(self) -> list:
"""
All Source() instances belonging to this collection. V1 collections do
not use sources, however a single pseudo source with the correct
imageset information is returned.
"""
return self._sources
def show_sources(self):
"""Lists the IDs and names of all sources in the collection."""
print('\nImage sources ({}):'.format(len(self.sources)))
for s in self.sources:
print(s)
@property
def rows():
pass
@rows.getter
def rows(self) -> pd.DataFrame:
"""All data rows of the collection as a dataframe."""
if self.allow_caching and self._cached_rows is not None:
return self._cached_rows
# Obtain the metadata bytes from Zegami
url = '{}/{}/project/{}/datasets/{}/file'.format(
self.client.HOME, self.client.API_0,
self.workspace_id, self._dataset_id)
r = self.client._auth_get(url, return_response=True)
tsv_bytes = BytesIO(r.content)
# Convert into a pd.DataFrame
try:
df = pd.read_csv(tsv_bytes, sep='\t')
except Exception:
try:
df = pd.read_excel(tsv_bytes)
except Exception:
print('Warning - failed to open metadata as a dataframe, '
'returned the tsv bytes instead.')
return tsv_bytes
if self.allow_caching:
self._cached_rows = df
return df
@property
def tags():
pass
@tags.getter
def tags(self):
return self._get_tag_indices()
@property
def status():
pass
@status.getter
def status(self):
"""The current status of this collection."""
url = '{}/{}/project/{}/collections/{}'.format(
self.client.HOME, self.client.API_0, self.workspace_id, self.id)
resp = self.client._auth_get(url)
return resp['collection']['status']
@property
def status_bool():
pass
@status_bool.getter
def status_bool(self) -> bool:
"""The status of this collection as a fully processed or not."""
return self.status['progress'] == 1
@property
def node_statuses():
pass
@node_statuses.getter
def node_statuses(self):
"""All nodes and statuses that belong to the collection."""
url = '{}/{}/project/{}/collections/{}/node_statuses'.format(
self.client.HOME, self.client.API_0, self.workspace_id, self.id)
resp = self.client._auth_get(url)
return resp
def _move_to_folder(self, folder_name):
"""
Move current collection into a folder. When folder_name is None, the collection will
not belong to any folder.
This feature is still WIP.
"""
url = '{}/{}/project/{}/collections/{}'.format(
self.client.HOME, self.client.API_0, self.workspace_id, self.id)
collection_body = self.client._auth_get(url)['collection']
if folder_name is None:
if 'folder' in collection_body:
del collection_body['folder']
if 'folder' in self._data:
del self._data['folder']
else:
collection_body['folder'] = folder_name
self._data['folder'] = folder_name
if 'projectId' in collection_body:
del collection_body['projectId']
if 'published' in collection_body:
for record in collection_body['published']:
del record['status']
self.client._auth_put(
url, body=None,
return_response=True, json=collection_body)
def duplicate(self, duplicate_name=None):
"""
Creates a completely separate copy of the collection within the workspace
Processed blobs are reused but there is no ongoing link to the original
"""
url = '{}/{}/project/{}/collections/duplicate'.format(
self.client.HOME, self.client.API_0, self.workspace_id)
payload = {
"old_collection_id": self.id,
}
if duplicate_name:
payload["new_collection_name"] = duplicate_name
resp = self.client._auth_post(url, json.dumps(payload))
print('Duplicated collection. New collection id: ', resp['new_collection_id'])
return resp
def row_index_to_imageset_index(self, row_idx, source=0) -> int:
"""
Turn a row-space index into an imageset-space index. Typically used
in more advanced operations.
"""
row_idx = int(row_idx)
if row_idx < 0:
raise ValueError(
'Use an index above 0, not {}'.format(row_idx))
lookup = self._get_image_meta_lookup(source=source)
try:
return lookup[row_idx]
except IndexError:
raise IndexError(
"Invalid row index {} for this source."
.format(row_idx))
def imageset_index_to_row_index(self, imageset_index, source=0) -> int:
"""
Turn an imageset-space index into a row-space index. Typically used
in more advanced operations.
"""
imageset_index = int(imageset_index)
if imageset_index < 0:
raise ValueError(
'Use an index above 0, not {}'.format(imageset_index))
lookup = self._get_image_meta_lookup(source=source)
try:
return lookup.index(imageset_index)
except ValueError:
raise IndexError(
"Invalid imageset index {} for this source"
.format(imageset_index))
def add_snapshot(self, name, desc, snapshot):
url = '{}/{}/project/{}/snapshots/{}/snapshots'.format(
self.client.HOME, self.client.API_0, self.workspace_id, self.id)
payload = {
'name': name,
'description': desc,
'snapshot': snapshot,
'version': 3,
}
r = self.client._auth_post(url, json.dumps(payload), return_response=True)
return r
def add_feature_pipeline(self, pipeline_name, steps, source=0, generate_snapshot=False):
"""
Add mRMR, cluster, mapping nodes and update the merge node for the source.
pipeline_name: self defined name used to derive column ids/titles
source: index or name of the collection source to use
generate_snapshot: whether to generate a snapshot for the new clustering results
steps: list of nodes which would feed one into the other in sequence
- example:
[
{
'action': 'mRMR',
'params': {
'target_column': 'weight',
'K': 20,
'option': 'regression' # another option is classification
},
},
{
'action': 'cluster',
'params': {}
}
}
]
The results from get_feature_pipelines() can be used to passed in here to recreate a pipeline.
"""
# get the source
source = self._parse_source(source)
node_group = [
'source_{}'.format(source.name),
'collection_{}'.format(self.id),
'feature_pipeline_{}'.format(pipeline_name)]
mRMR_params = steps[0]['params']
# find the feature extraction node
source_feature_extraction_node = self.get_feature_extraction_imageset_id(source)
join_dataset_id = source._imageset_dataset_join_id
imageset_parents = [source_feature_extraction_node]
dataset_parents = [self._dataset_id, join_dataset_id]
mRMR_node = add_node(
self.client,
self.workspace,
action=steps[0]['action'],
params=mRMR_params,
type="imageset",
dataset_parents=dataset_parents,
imageset_parents=imageset_parents,
processing_category='image_clustering',
node_group=node_group,
name="{} imageset for {} of {}".format(pipeline_name, source.name, self.name),
)
cluster_params = steps[1]['params']
cluster_params["out_column_title_prefix"] = "{} Image Similarity ({})".format(pipeline_name, source.name)
pipeline_name_stripped = (pipeline_name.lower().
replace(' ', '').replace('_', '').replace('-', '').replace('.', ''))
cluster_params["out_column_name_prefix"] = "image_similarity_{}_{}".format(source.name, pipeline_name_stripped)
cluster_node = add_node(
self.client,
self.workspace,
action=steps[1]['action'],
params=cluster_params,
type="dataset",
dataset_parents=mRMR_node.get('imageset').get('id'),
imageset_parents=None,
processing_category='image_clustering',
node_group=node_group,
name="{} Image clustering dataset for {} of {}".format(pipeline_name, source.name, self.name),
)
# add node to map the output to row space
mapping_node = add_node(
self.client,
self.workspace,
'mapping',
{},
dataset_parents=[cluster_node.get('dataset').get('id'), join_dataset_id],
name=pipeline_name + " mapping",
node_group=node_group,
processing_category='image_clustering'
)
# add to the collection's output node
output_dataset_id = self._data.get('output_dataset_id')
add_parent(
self.client,
self.workspace,
output_dataset_id,
mapping_node.get('dataset').get('id')
)
# generate snapshot
if generate_snapshot:
snapshot_name = '{} Image Similarity View ({})'.format(pipeline_name, source.name)
snapshot_desc = 'Target column is {}, K value is {}'.format(mRMR_params['target_column'], mRMR_params['K'])
source_name_stripped = (source.name.lower().
replace(' ', '').replace('_', '').replace('-', '').replace('.', ''))
snapshot_payload = {
'view': 'scatter',
'sc_h': 'imageSimilarity{}{}0'.format(source_name_stripped, pipeline_name_stripped),
'sc_v': 'imageSimilarity{}{}1'.format(source_name_stripped, pipeline_name_stripped),
'source': source.name,
'pan': 'TYPES_PANEL'
}
self.add_snapshot(snapshot_name, snapshot_desc, snapshot_payload)
def get_feature_pipelines(self): # noqa: C901
"""
Get all feature pipelines in a collection.
Example shape:
feature_pipelines = [
{
name='mRMR20',
source=0,
steps=[ # list of nodes which would feed one into the other in sequence
{
'action': 'mRMR',
'params': {
'target_column': 'weight',
'K': 20,
},
},
{
'action': 'cluster',
'params': {
"out_column_start_order": 1010,
'algorithm_args': {
'algorithm': 'umap',
'n_components': 2,
"n_neighbors": 15,
"min_dist": 0.5,
"spread": 2,
"random_state": 123,
}
}
}
]
},
]
"""
all_nodes = self.node_statuses
source_names = [s.name for s in self.sources]
feature_pipelines = []
# nodes sorted by source and feature pipeline name
feature_pipelines_nodes = {}
for source_name in source_names:
feature_pipelines_nodes[source_name] = {}
for node in all_nodes:
node_groups = node.get('node_groups')
# check if node_groups contain 'feature_pipeline_'
if node_groups and len(node_groups) == 3:
# get the source name after 'source_'
node_source_name = [
group for group in node_groups if group.startswith('source_')
][0][7:]
# get the source name after 'feature_pipeline_'
feature_pipeline_name = [
group for group in node_groups if group.startswith('feature_pipeline_')
][0][17:]
if feature_pipeline_name in feature_pipelines_nodes[node_source_name]:
feature_pipelines_nodes[node_source_name][feature_pipeline_name].append(node)
else:
feature_pipelines_nodes[node_source_name][feature_pipeline_name] = [node]
for source_name in source_names:
source_pipelines = feature_pipelines_nodes[source_name]
for pipeline_name, nodes in source_pipelines.items():
for node in nodes:
if 'cluster' in node['source']:
cluster_params = node['source']['cluster']
# some params should be generated by add_feature_pipeline
unwanted_params = [
'out_column_name_prefix',
'out_column_title_prefix',
'out_column_start_order',
]
for param in unwanted_params:
if param in cluster_params.keys():
cluster_params.pop(param)
if 'mRMR' in node['source']:
mRMR_params = node['source']['mRMR']
feature_pipelines.append({
'pipeline_name': pipeline_name,
'source_name': source_name,
'steps': [
{
'action': 'mRMR',
'params': mRMR_params,
},
{
'action': 'cluster',
'params': cluster_params,
}
]
})
return feature_pipelines
def add_explainability(self, data, parent_source=0):
"""
Add an explainability map node and create a new source with the node.
"""
collection_group_source = [
'source_' + data['NEW_SOURCE_NAME'],
'collection_' + self.id
]
parent_source = self._parse_source(parent_source)
augment_imageset_id = parent_source._data.get('augment_imageset_id')
resp = add_node(
self.client,
self.workspace,
'explainability_map',
data['EXPLAINABILITY_SOURCE'],
'imageset',
imageset_parents=augment_imageset_id,
name="{} explainability map node".format(data['NEW_SOURCE_NAME']),
node_group=collection_group_source,
processing_category='upload'
)
explainability_map_node = resp.get('imageset')
self.add_source(data['NEW_SOURCE_NAME'], explainability_map_node.get('id'))
def add_custom_clustering(self, data, source=0):
"""
Add feature extraction and clustering given an custom model.
"""
source = self._parse_source(source)
collection_group_source = [
'source_' + source.name,
'collection_' + self.id
]
scaled_imageset_id = source._data.get('scaled_imageset_id')
join_dataset_id = source._imageset_dataset_join_id
resp = add_node(
self.client,
self.workspace,
'custom_feature_extraction',
data['FEATURE_EXTRACTION_SOURCE'],
'imageset',
imageset_parents=scaled_imageset_id,
name="custom feature extraction node",
node_group=collection_group_source,
processing_category='image_clustering'
)
custom_feature_extraction_node = resp.get('imageset')
resp = add_node(
self.client,
self.workspace,
'cluster',
data['CLUSTERING_SOURCE'],
dataset_parents=custom_feature_extraction_node.get('id'),
name="custom feature extraction similarity",
node_group=collection_group_source,
processing_category='image_clustering'
)
cluster_node = resp.get('dataset')
resp = add_node(
self.client,
self.workspace,
'mapping',
{},
dataset_parents=[cluster_node.get('id'), join_dataset_id],
name="custom feature extraction mapping",
node_group=collection_group_source,
processing_category='image_clustering'
)
mapping_node = resp.get('dataset')
output_dataset_id = self._data.get('output_dataset_id')
resp = add_parent(
self.client,
self.workspace,
output_dataset_id,
mapping_node.get('id')
)
def get_rows_by_filter(self, filters):
"""
Gets rows of metadata in a collection by a flexible filter.
The filter should be a dictionary describing what to permit through
any specified columns.
Example:
row_filter = { 'breed': ['Cairn', 'Dingo'] }
For each filter, OR logic is used ('Cairn' or 'Dingo' would pass)
For multiple filters, AND logic is used (adding an 'age' filter would
require the 'breed' AND 'age' filters to both pass).
"""
if type(filters) != dict:
raise TypeError('Filters should be a dict.')
rows = self.rows.copy()
for fk, fv in filters.items():
if not type(fv) == list:
fv = [fv]
rows = rows[rows[fk].isin(fv)]
return rows
def get_rows_by_tags(self, tag_names):
"""
Gets rows of metadata in a collection by a list of tag_names.
Example:
tag_names = ['name1', 'name2']
This would return rows which has tags in the tag_names.
"""
if type(tag_names) != list:
raise TypeError('Expected tag_names to be a list, not a {}'
.format(type(tag_names)))
row_indices = set()
for tag in tag_names:
if tag in self.tags.keys():
row_indices.update(self.tags[tag])
rows = self.rows.iloc[list(row_indices)]
return rows
def get_image_urls(self, rows=None, source=0, generate_signed_urls=False,
signed_expiry_days=None, override_imageset_id=None):
"""
Converts rows into their corresponding image URLs.
If generate_signed_urls is false the URLs require a token to download
These urls can be passed to download_image()/download_image_batch().
If generate_signed_urls is true the urls can be used to fetch the
images directly from blob storage, using a temporary access signature
with an optionally specified lifetime.
By default the uploaded images are fetched, but it's possible to fetch
e.g. the thumbnails only, by providing an alternative imageset id.
"""
# Turn the provided 'rows' into a list of ints.
# If 'rows' are not defined, get all rows of collection.
if rows is not None:
if type(rows) == pd.DataFrame:
indices = list(rows.index)
elif type(rows) == list:
indices = [int(r) for r in rows]
elif type(rows) == int:
indices = [rows]
else:
raise ValueError('Invalid rows argument, \'{}\' not supported'
.format(type(rows)))
else:
indices = [i for i in range(len(self))]
# Convert the row-space indices into imageset-space indices
lookup = self._get_image_meta_lookup(source)
imageset_indices = [lookup[i] for i in indices]
# Convert these into URLs
if override_imageset_id is not None:
imageset_id = override_imageset_id
else:
imageset_id = self._get_imageset_id(source)
c = self.client
if not generate_signed_urls:
return ['{}/{}/project/{}/imagesets/{}/images/{}/data'.format(
c.HOME, c.API_0, self.workspace_id, imageset_id,
i) for i in imageset_indices]
else:
query = ''
if signed_expiry_days is not None:
query = '?expiry_days={}'.format(signed_expiry_days)
get_signed_urls = [
'{}/{}/project/{}/imagesets/{}/images/{}/signed_route{}'
.format(c.HOME, c.API_0, self.workspace_id, imageset_id,
i, query) for i in imageset_indices]
signed_route_urls = []
for url in get_signed_urls:
# Unjoined rows will have None. Possibly better to filter these
# out earlier, but this works
if 'None' in url:
signed_route_urls.append('')
else:
response = c._auth_get(url)
signed_route_urls.append(response['url'])
return signed_route_urls
def get_feature_extraction_imageset_id(self, source=0) -> str:
"""Returns the feature extraction imageset id in the given source index."""
source = self._parse_source(source)
source_name = source.name
all_nodes = self.node_statuses
for node in all_nodes:
if ('image_feature_extraction' in node['source'].keys() and
node['node_groups'][0] == 'source_{}'.format(source_name)):
return node["id"]
return None
def download_annotation(self, annotation_id):
"""
Converts an annotation_id into downloaded annotation data.
This will vary in content depending on the annotation type and
format.
"""
url = '{}/{}/project/{}/annotations/{}'.format(
self.client.HOME, self.client.API_1, self.workspace.id,
annotation_id)
return self.client._auth_get(url)
def replace_data(self, data, fail_if_not_ready=True):
"""
Replaces the data in the collection.
The provided input should be a pandas dataframe or a local
csv/json/tsv/txt/xlsx/xls file. If a xlsx/xls file is used only data
from the default sheet will be fetched.
By default, this operation will fail immediately if the collection is
not fully processed to avoid issues.
"""
# If this collection is not fully processed, do not allow data upload
if fail_if_not_ready and not self.status_bool:
raise ValueError(
'Collection has not fully processed. Wait for the collection '
'to finish processing, or force this method with '
'fail_if_not_ready=False (not recommended)\n\n{}'
.format(self.status))
# Prepare data as bytes
if type(data) == pd.DataFrame:
tsv = data.to_csv(sep='\t', index=False)
upload_data = bytes(tsv, 'utf-8')
name = 'provided_as_dataframe.tsv'
else:
name = os.path.split(data)[-1]
if name.split('.')[-1] in ['csv', 'json', 'tsv',
'txt', 'xls', 'xlsx']:
with open(data, 'rb') as f:
upload_data = f.read()
else:
raise ValueError(
'File extension must one of these: csv, json, tsv, txt, '
'xls, xlsx')
# Create blob storage and upload to it
urls, id_set = self.client._obtain_signed_blob_storage_urls(
self.workspace_id,
blob_path='datasets/{}'.format(self._upload_dataset_id)
)
blob_id = id_set['ids'][0]
url = urls[blob_id]
# Upload data to it
self.client._upload_to_signed_blob_storage_url(
upload_data, url, 'application/octet-stream')
# Update the upload dataset details
upload_dataset_url = '{}/{}/project/{}/datasets/{}'.format(
self.client.HOME, self.client.API_0, self.workspace_id,
self._upload_dataset_id)
current_dataset = self.client._auth_get(upload_dataset_url)["dataset"]
current_dataset["source"]["upload"]["name"] = name
current_dataset["source"]["blob_id"] = blob_id
# Returning response is true as otherwise it will try to return json
# but this response is empty
self.client._auth_put(
upload_dataset_url, body=None,
return_response=True, json=current_dataset)
self._cached_rows = None
def save_image(self, url, target_folder_path='./', filename='image',
extension='png'):
"""
Downloads an image and saves to disk.
For input, see Collection.get_image_urls().
"""
if not os.path.exists(target_folder_path):
os.makedirs(target_folder_path)
r = self.client._auth_get(url, return_response=True, stream=True)
with open(target_folder_path + '/' + filename + '.' + extension, 'wb')\
as f:
f.write(r.content)
def save_image_batch(self, urls, target_folder_path='./', extension='png',
max_workers=50, show_time_taken=True):
"""
Downloads a batch of images and saves to disk.
Filenames are the row index followed by the specified extension.
For input, see Collection.get_image_urls().
"""
def save_single(index, url):
self.save_image(url, target_folder_path, filename=str(index),
extension=extension)
return index
t0 = time()
with ThreadPoolExecutor(max_workers=max_workers) as ex:
futures = [ex.submit(save_single, i, u)
for i, u in enumerate(urls)]
ex.shutdown(wait=True)
# Error catch all completed futures
for f in futures:
if f.exception() is not None:
raise Exception(
'Exception in multi-threaded image saving: {}'
.format(f.exception()))
if show_time_taken:
print('\nDownloaded {} images in {:.2f} seconds.'
.format(len(futures), time() - t0))
def download_image(self, url):
"""
Downloads an image into memory as a PIL.Image.
For input, see Collection.get_image_urls().
"""
r = self.client._auth_get(url, return_response=True, stream=True)
r.raw.decode = True
try:
return Image.open(r.raw)
except UnidentifiedImageError:
return Image.open(BytesIO(r.content))
def download_image_batch(self, urls, max_workers=50, show_time_taken=True):
"""
Downloads multiple images into memory (each as a PIL.Image)
concurrently.
Please be aware that these images are being downloaded into memory,
if you download a huge collection of images you may eat up your
RAM!
"""
t0 = time()
with ThreadPoolExecutor(max_workers=max_workers) as ex:
futures = [ex.submit(self.download_image, u) for u in urls]
ex.shutdown(wait=True)
# Error catch all completed futures
for f in futures:
if f.exception() is not None:
raise Exception(
'Exception in multi-threaded image downloading: {}'
.format(f.exception()))
if show_time_taken:
print('\nDownloaded {} images in {:.2f} seconds.'
.format(len(futures), time() - t0))
return [f.result() for f in futures]
def delete_images_with_tag(self, tag='delete'):
"""Delete all the images in the collection with the tag 'delete'.s."""
row_indices = set()
if tag in self.tags.keys():
row_indices.update(self.tags[tag])
lookup = self._get_image_meta_lookup()
imageset_indices = [lookup[int(i)] for i in row_indices]
c = self.client
urls = ['{}/{}/project/{}/imagesets/{}/images/{}'.format(
c.HOME, c.API_0, self.workspace_id, self._get_imageset_id(),
i) for i in imageset_indices]
for url in urls:
c._auth_delete(url)
print(f'\nDeleted {len(urls)} images')
def _get_tag_indices(self):
"""Returns collection tags indices."""
c = self.client
url = '{}/{}/project/{}/collections/{}/tags'.format(
c.HOME, c.API_1, self.workspace_id, self.id)
response = c._auth_get(url)
return self._parse_tags(response['tagRecords'])
def _parse_tags(self, tag_records):
"""
Parses tag indices into a list of tags, each with an list of
indices.
"""
tags = {}
for record in tag_records:
if record['tag'] not in tags.keys():
tags[record['tag']] = []
tags[record['tag']].append(record['key'])
return tags
def get_annotations(self, anno_type=None, source=0) -> dict:
"""
Gets the annotations of a collection.
Defaults to searching for annotations of all types.
In V1 collections, the source argument is ignored.
"""
if self.version < 2:
url = '{}/{}/project/{}/annotations/collection/{}'.format(
self.client.HOME, self.client.API_1, self.workspace_id,
self.id)
else:
source = self._parse_source(source)
url = '{}/{}/project/{}/annotations/collection/{}/source/{}'\
.format(self.client.HOME, self.client.API_1, self.workspace_id,
self.id, source.id)
if anno_type is not None:
url += '?type=' + anno_type
annos = self.client._auth_get(url)
if self.version < 2:
annos = annos['sources'][0]
return annos['annotations']
def get_annotations_for_image(
self, row_index, source=0, anno_type=None) -> list:
"""
Returns annotations for a single item in the collection.
Defaults to searching for annotations of all types.
"""
source = self._parse_source(source)
if type(row_index) != int or row_index < 0:
raise ValueError(
'Expected row_index to be a positive int, not {}'
.format(row_index))
imageset_index = self.row_index_to_imageset_index(
row_index, source=source)
url = '{}/{}/project/{}/annotations/imageset/{}/images/{}'\
.format(self.client.HOME, self.client.API_1, self.workspace_id,
self._get_imageset_id(), imageset_index)
if anno_type is not None:
url += '?type=' + anno_type
return self.client._auth_get(url)
def upload_annotation(self, uploadable, row_index=None, image_index=None,
source=None, author=None, debug=False):
"""
Uploads an annotation to Zegami.
Requires uploadable annotation data (see
AnnotationClass.create_uploadable()), the row index of the image the
annotation belongs to, and the source (if using a multi-image-source
collection). If no source is provided, it will be uploaded to the
first source.
Optionally provide an author, which for an inference result should
probably some identifier for the model. If nothing is provided, the
ZegamiClient's .name property will be used.
"""
source = None if self.version == 1 else self._parse_source(source)
imageset_id = self._get_imageset_id(source)
image_meta_lookup = self._get_image_meta_lookup(source)
author = author or self.client.email
if image_index is None:
assert row_index is not None,\
'Must provide either row_index or image_index'
image_index = image_meta_lookup[row_index]
else:
assert row_index is None,\
'Must provide only one or row_index, image_index'
assert type(uploadable) == dict,\
'Expected uploadable data to be a dict, not a {}'\
.format(type(uploadable))
assert 'type' in uploadable.keys(),\
'Expected \'type\' key in uploadable: {}'.format(uploadable)
assert 'annotation' in uploadable.keys(),\
'Expected \'annotation\' key in uploadable: {}'.format(uploadable)
assert type(imageset_id) == str,\
'Expected imageset_id to be a str, not {}'\
.format(type(imageset_id))
# Get the class-specific data to upload
payload = {
'author': author,
'imageset_id': imageset_id,
'image_index': int(image_index),
'annotation': uploadable['annotation'],
'type': uploadable['type'],
'format': uploadable['format'],
'class_id': str(int(uploadable['class_id'])),
}
# Check that there are no missing fields in the payload
for k, v in payload.items():
assert v is not None, 'Empty annotation uploadable data value '
'for \'{}\''.format(k)
# Potentially print for debugging purposes
if debug:
print('\nupload_annotation payload:\n')
for k, v in payload.items():
if k == 'annotation':
print('- annotation:')
for k2, v2 in payload['annotation'].items():
print('\t- {} : {}'.format(k2, v2))
else:
print('- {} : {}'.format(k, v))
print('\nJSON:\n{}'.format(json.dumps(payload)))
# POST
c = self.client
url = '{}/{}/project/{}/annotations'.format(
c.HOME, c.API_1, self.workspace_id)
r = c._auth_post(url, json.dumps(payload), return_response=True)
return r
def delete_annotation(self, annotation_id):
"""
Delete an annotation by its ID. These are obtainable using the
get_annotations...() methods.
"""
c = self.client
url = '{}/{}/project/{}/annotations/{}'\
.format(c.HOME, c.API_1, self.workspace_id, annotation_id)
payload = {
'author': c.email
}
r = c._auth_delete(url, data=json.dumps(payload))
return r
def delete_all_annotations(self, only_for_source=None):
"""
Deletes all annotations saved to the collection. By default this
operation deletes all annotations from all sources. Provide a
specific source (instance or index) to limit this to a particular
source.
"""
# Get the sources to delete annotations from
scoped_sources = self.sources if only_for_source is None\
else [self._parse_source(only_for_source)]
c = 0
for source in scoped_sources:
annos = self.get_annotations(source=source)
if len(annos) == 0:
continue
print('Deleting {} annotations from source {}'
.format(len(annos), source.name))
for j, anno in enumerate(annos):
self.delete_annotation(anno['id'])
print('\r{}/{}'.format(j + 1, len(annos)), end='',
flush=True)
c += 1
print('')
print('\nDeleted {} annotations from collection "{}"'.format(
c, self.name))
@property
def userdata():
pass
@userdata.getter
def userdata(self):
c = self.client
url = '{}/{}/project/{}/collections/{}'.format(
c.HOME, c.API_0, self.workspace_id, self.id)
data = c._auth_get(url)['collection']
userdata = data['userdata'] if 'userdata' in data.keys() else None
return userdata
def set_userdata(self, data):
""" Additively sets userdata. To remove data set its value to None. """
c = self.client
url = '{}/{}/project/{}/collections/{}/userdata'.format(
c.HOME, c.API_0, self.workspace_id, self.id)
userdata = c._auth_post(url, json.dumps(data))
return userdata
@property
def classes():
pass
@classes.getter
def classes(self) -> list:
"""
Property for the class configuration of the collection.
Used in an annotation workflow to tell Zegami how to treat defined
classes.
To set new classes, provide a list of class dictionaries of shape:
collection.classes = [
{
'color' : '#32a852', # A hex color for the class
'name' : 'Dog', # A human-readable identifier
'id' : 0 # The unique integer class ID
},
{
'color' : '#43f821', # A hex color for the class
'name' : 'Cat', # A human-readable identifier
'id' : 1 # The unique integer class ID
}
]
"""
u = self.userdata
return list(u['classes'].values()) if u is not None\
and 'classes' in u.keys() else []
def add_images(self, uploadable_sources, data=None): # noqa: C901
"""
Add more images to a collection, given a set of uploadable_sources and
optional data rows. See workspace.create_collection for details of
these arguments. Note that the images won't appear in the collection
unless rows are provided referencing them.
"""
uploadable_sources = UploadableSource._parse_list(uploadable_sources)
# If using multi-source, must provide data
if data is None and len(uploadable_sources) > 1:
raise ValueError(
'If uploading more than one image source, data '
'is required to correctly join different images from each'
)
# Parse data
if type(data) is str:
if not os.path.exists(data):
raise FileNotFoundError('Data file "{}" doesn\'t exist'
.format(data))
# Check the file extension
if data.split('.')[-1] == 'tsv':
data = pd.read_csv(data, delimiter='\t')
elif data.split('.')[-1] in ['xls', 'xlsx']:
data = pd.read_excel(data)
else:
data = pd.read_csv(data)
# Check that all source filenames exist in the provided data
if data is not None:
print('- Checking data matches uploadable sources')
for s in uploadable_sources:
s._check_in_data(data)
# append rows to data
new_rows = self.rows.append(data)
self.replace_data(new_rows)
# validate and register uploadable sources against existing sources
for i, us in enumerate(uploadable_sources):
us._register_source(i, self.sources[i])
# upload
for us in uploadable_sources:
us._upload()
@classes.setter
def classes(self, classes): # noqa: C901
# Check for a valid classes list
if type(classes) != list:
raise TypeError(
'Expected \'classes\' to be a list, not {}'
.format(type(classes)))
payload = {
'classes': {}
}
for d in classes:
# Check for a sensible class dict
if type(d) != dict:
raise TypeError(
'Expected \'classes\' entry to be a dict, not {}'
.format(type(d)))
if len(d.keys()) != 3:
raise ValueError(
'Expected classes dict to have 3 keys, not {} ({})'
.format(len(d.keys()), d))
for k in ['color', 'name', 'id']:
if k not in d.keys():
raise ValueError('Unexpected class key: {}. Keys must be '
'color | name | id.'.format(k))
# Format as the expected payload
payload['classes'][d['id']] = {
'color': str(d['color']),
'name': str(d['name']),
'id': str(int(d['id']))
}
# POST
c = self.client
url = '{}/{}/project/{}/collections/{}/userdata'.format(
c.HOME, c.API_0, self.workspace_id, self.id)
c._auth_post(url, json.dumps(payload))
print('New classes set:')
for d in self.classes:
print(d)
def _retrieve(self, key):
"""Retrieve a key from self._data, with a friendly error on failure."""
if key not in self._data:
raise KeyError(
'Collection did not find requested key "{}" in its _data'
.format(key))
return self._data[key]
def _get_imageset_id(self, source=0) -> str:
"""
Returns imageset_id of the collection. If using V2+, can optionally
provide a source for that source's imageset_id instead.
"""
source = self._parse_source(source)
return source.imageset_id
def _join_id_to_lookup(self, join_id) -> list:
"""
Given a join_id, provides the associated image-meta lookup for
converting between image and row spaces.
"""
# Type-check provided join_id
if type(join_id) != str:
raise TypeError(
'Expected join_id to be str, not: {} ({})'
.format(join_id, type(join_id)))
# Obtain the dataset based on the join_id (dict)
url = '{}/{}/project/{}/datasets/{}'.format(
self.client.HOME, self.client.API_0, self.workspace_id, join_id)
dataset = self.client._auth_get(url)['dataset']
if 'imageset_indices' in dataset.keys():
return dataset['imageset_indices']
else:
# Image only collection. Lookup should be n => n.
# This is a bit of a hack, but works
return {k: k for k in range(100000)}
def _get_image_meta_lookup(self, source=0) -> list:
"""
Returns the image-meta lookup for converting between image and row
space. There is a lookup for each Source in V2 collections, so caching
keeps track of the relevent Source() lookups by join_id.
"""
source = self._parse_source(source)
join_id = source._imageset_dataset_join_id
# If already obtained and cached, return that
if self.allow_caching and join_id in\
self._cached_image_meta_source_lookups:
return self._cached_image_meta_source_lookups[join_id]
# No cached lookup, obtain it and potentially cache it
lookup = self._join_id_to_lookup(join_id)
if self.allow_caching:
self._cached_image_meta_source_lookups[join_id] = lookup
return lookup
@staticmethod
def _source_warning() -> None:
print(
'Warning - Called with a source when this is not a '
'multi-image-source collection. Treating as if no source '
'was required.')
def get_annotations_as_dataframe(
self, anno_type=None, source=0) -> pd.DataFrame:
"""
Collects all annotations of a type (or all if anno_type=None) and
returns the information as a dataframe.
"""
source = self._parse_source(source)
annos = self.get_annotations(
anno_type=anno_type, source=source)
classes = self.classes
def to_dict(a):
d = {}
if classes and 'class_id' in a.keys():
c = next(filter(lambda c: int(c['id']) == int(a['class_id']), classes))
d['Class'] = c['name']
d['Class ID'] = int(c['id'])
d['Type'] = a['type']
d['Author'] = a['author']
d['Row Index'] = self.imageset_index_to_row_index(a['image_index'])
d['Imageset Index'] = a['image_index']
d['ID'] = a['id']
if 'metadata' in a.keys():
for k, v in a['metadata'].items():
d[k] = v
return d
df = pd.DataFrame([to_dict(a) for a in annos])
return df
def _parse_source(self, source) -> Source: # noqa: C901
"""
Accepts an int or a Source instance or source name and always returns a checked
Source instance. If a V1 collection, always returns the one and only
first source.
"""
if self.version == 1:
return self.sources[0]
# If an index is given, check the index is sensible and return a Source
if type(source) == int:
if source < 0:
raise ValueError(
'Expected source to be a positive int, not {}'
.format(source))
if source >= len(self.sources):
raise ValueError(
'Source not valid for number of available sources (index '
'{} for list length {})'
.format(source, len(self.sources)))
return self.sources[source]
# If a string is given, check the source name that matches
if type(source) == str:
for s in self.sources:
if s.name == source:
return s
raise ValueError('Cannot find a source with name {}'.format(source))
# If a Source is given, check it belongs to this collection and return
if not isinstance(source, Source):
raise TypeError(
'Provided source was neither an int nor a Source instance: {}'
.format(source))
try:
s = next(filter(lambda s: s.imageset_id == source.imageset_id, self.sources))
except StopIteration:
raise ValueError(
'Provided source with ID "{}" does not match any sources '
'associated with this collection'.format(source.name))
return s
def add_source(self, source_name, root_imageset_id):
"""
Accepts source name and root imageset id to add a source to the collection.
"""
url = '{}/{}/project/{}/collections/{}/sources'.format(
self.client.HOME, self.client.API_0, self.workspace_id, self.id)
payload = {
'name': source_name,
'imageset_id': root_imageset_id
}
self.client._auth_post(url, json.dumps(payload)) | zegami-sdk | /zegami_sdk-0.4.9-py3-none-any.whl/zegami_sdk/collection.py | collection.py |
import pandas as pd
def calc_num_correlation_matrix(df):
"""Calculates a matrix of correlations for all numerical pairs of columns in a collection."""
# Get the numeric columns
num_cols = [c for c in df.columns if df[c].dtype.kind.lower() in ['f', 'i']]
# Make into reduced frame
df_num = df[num_cols]
# Normalize
df_num_norm = (df_num - df_num.mean(skipna=True)) / df_num.std(skipna=True)
return df_num_norm.cov()
def calc_num_summary(df):
"""Calculates a table to summarise the numeric columns of a collection.
Includes:
- Mean
- Median
- Range
- Standard deviation
"""
# Get the numeric columns
num_cols = [c for c in df.columns if df[c].dtype.kind.lower() in ['f', 'i']]
df = df[num_cols]
# Calculate the means
means = [df[col].mean(skipna=True) for col in df.columns]
# Calculate the medians
medians = [df[col].median(skipna=True) for col in df.columns]
# Calculate the min, max, range
mins = [df[col].min(skipna=True) for col in df.columns]
maxs = [df[col].max(skipna=True) for col in df.columns]
ranges = [maxs[i] - mins[i] for i in range(len(mins))]
# Calculate the standard deviations
stds = [df[col].std(skipna=True) for col in df.columns]
# Construct the results table
df_out = pd.DataFrame(
data=[means, medians, mins, maxs, ranges, stds],
columns=df.columns
)
df_out.index = ['Mean', 'Median', 'Min', 'Max', 'Range',
'Standard Deviation']
return df_out
def calc_cat_representations(df, columns=None, max_cardinality=None):
"""Calculates the 'representation' for a categorical column.
A score closer to zero means that values in the column are more skewed
towards certain classes (some are being under-represented). If closer to
one, there is a more even distribution of possible values.
To specify only certain columns (case sensitive) to analyse, use
columns=['MyColumnA', 'MyColumnB']. Using None will look at all valid
columns.
Columns who's unique values exceed 'max_cardinality' are also excluded to
avoid looking at columns likely containing many mostly unique strings.
If a column should have many classes, increase this number.
To subdue this behaviour entirely, use 'max_cardinality=None'.
Columns whose result is nan are excluded from the output.
"""
# Get all object columns
cat_cols = [col for col in df.columns if df[col].dtype.kind == 'O']
# If filtering to specific columns, exclude any that don't match
if columns is not None:
if not type(columns) is list:
columns = [columns]
cat_cols = [col for col in cat_cols if col in columns]
# Exclude high-cardinality columns
if max_cardinality is not None:
cat_cols = [col for col in cat_cols if len(set(df[col])) <= max_cardinality]
# Build the representation score for each valid column
rep_scores = []
for col in cat_cols:
# The number of unique classes in the column
unique_classes = df[col].nunique()
# The count per unique class in the column
class_counts = df[col].value_counts()
# The total samples (should be ~len(rows))
total_counts = class_counts.sum(skipna=True)
# Ideal count per class
ideal_per_class = total_counts / unique_classes
# Normalized counts per class
norm_class_counts = (class_counts - ideal_per_class).abs() / class_counts.std(skipna=True)
# The representation score
rep_score = 1 - norm_class_counts.std(skipna=True)
rep_scores.append(rep_score)
return {
cat_cols[i]: max(0, rep_scores[i]) for i in range(len(cat_cols)) if not pd.isna(rep_scores[i])
} | zegami-sdk | /zegami_sdk-0.4.9-py3-none-any.whl/zegami_sdk/stats.py | stats.py |
import base64
import io
import os
import numpy as np
from PIL import Image
import cv2
class _Annotation():
"""Base class for annotations."""
# Define the string annotation TYPE in child classes
TYPE = None
UPLOADABLE_DESCRIPTION = None
def __init__(self, collection, annotation_data, source=None):
"""
Base class for annotations.
Subclasses should call super().__init__ AFTER assignment of members
so that checks can be performed.
If making a new annotation to upload, use collection.upload_annotation
instead.
"""
self._collection = collection # Collection instance
self._source = source # Source instance
# { imageset_id, image_index, type, annotation }
self._data = annotation_data
# Enforce abstract requirement
if self.TYPE is None:
raise TypeError(
'Do not instantiate the base _Annotation class. It is an '
'abstract class, try one of the non-hidden Annotation classes '
'instead.')
@property
def collection():
pass
@collection.getter
def collection(self):
"""The collection this annotation belongs to."""
return self._collection
@property
def source():
pass
@source.getter
def source(self):
"""The source this annotation belongs to in its collection."""
return self._source
@property
def _image_index():
pass
@_image_index.getter
def _image_index(self):
"""The image-space index of this annotation's owner's image."""
if 'image_index' not in self._data.keys():
raise ValueError('Annotation\'s _data did not contain '
'\'image_index\': {}'.format(self._data))
return self._data['image_index']
@property
def row_index():
pass
@row_index.getter
def row_index(self):
return self._row_index
@property
def imageset_index():
pass
@imageset_index.getter
def imageset_index(self):
return self.collection.row_index_to_imageset_index(self.row_index)
@property
def _imageset_id():
pass
@_imageset_id.getter
def _imageset_id(self):
"""Shortcut for the owning collection's (source's) imageset ID."""
return self.collection._get_imageset_id(self.source)
# -- Abstract/virtual, must be implemented in children --
@classmethod
def create_uploadable(cls) -> None:
"""Extend in children to include actual annotation data."""
return {
'type': cls.TYPE,
'format': None,
'annotation': None
}
def view(self):
"""Abstract method to view a representation of the annotation."""
raise NotImplementedError(
'\'view\' method not implemented for annotation type: {}'
.format(self.TYPE))
class AnnotationMask(_Annotation):
"""
An annotation comprising a bitmask and some metadata.
To view the masks an image, use mask.view().
Note: Providing imageset_id and image_index is not mandatory and can be
obtained automatically, but this is slow and can cause unnecessary
re-downloading of data.
"""
TYPE = 'mask'
UPLOADABLE_DESCRIPTION = """
Mask annotation data includes the actual mask (as a base64 encoded
png string), a width and height, bounding box, and score if generated
by a model (else None).
"""
@classmethod
def create_uploadable(cls, bool_mask, class_id):
"""
Creates a data package ready to be uploaded with a collection's
.upload_annotation().
Note: The output of this is NOT an annotation, it is used to upload
annotation data to Zegami, which when retrieved will form an
annotation.
"""
if type(bool_mask) != np.ndarray:
raise TypeError('Expected bool_mask to be a numpy array, not a {}'
.format(type(bool_mask)))
if bool_mask.dtype != bool:
raise TypeError('Expected bool_mask.dtype to be bool, not {}'
.format(bool_mask.dtype))
if len(bool_mask.shape) != 2:
raise ValueError('Expected bool_mask to have a shape of 2 '
'(height, width), not {}'.format(bool_mask.shape))
# Ensure we are working with [h, w]
bool_mask = cls.parse_bool_masks(bool_mask, shape=2)
h, w = bool_mask.shape
# Encode the mask array as a 1 bit PNG encoded as base64
mask_image = Image.fromarray(bool_mask.astype('uint8') * 255).convert('1')
mask_buffer = io.BytesIO()
mask_image.save(mask_buffer, format='PNG')
byte_data = mask_buffer.getvalue()
mask_b64 = base64.b64encode(byte_data)
mask_string = "data:image/png;base64,{}".format(mask_b64.decode("utf-8"))
bounds = cls.find_bool_mask_bounds(bool_mask)
roi = {
'xmin': int(bounds['left']),
'xmax': int(bounds['right']),
'ymin': int(bounds['top']),
'ymax': int(bounds['bottom']),
'width': int(bounds['right'] - bounds['left']),
'height': int(bounds['bottom'] - bounds['top'])
}
data = {
'mask': mask_string,
'width': int(w),
'height': int(h),
'score': None,
'roi': roi
}
uploadable = super().create_uploadable()
uploadable['format'] = '1UC1'
uploadable['annotation'] = data
uploadable['class_id'] = int(class_id)
return uploadable
def view(self):
"""View the mask as an image. """
# NOT TESTED
im = Image.fromarray(self.mask_uint8)
im.show()
@property
def mask_uint8():
pass
@mask_uint8.getter
def mask_uint8(self):
"""Returns mask data as a 0 -> 255 uint8 numpy array, [h, w]."""
return self.mask_bool.astype(np.uint8) * 255
@property
def mask_bool():
pass
@mask_bool.getter
def mask_bool(self):
"""Returns mask data as a False | True bool numpy array, [h, w]."""
raise NotImplementedError('Not implemented, see annotation._data to obtain.')
# return self.parse_bool_masks(self._get_bool_arr(), shape=2)
@staticmethod
def _read_bool_arr(local_fp):
"""
Reads the boolean array from a locally stored file. Useful for
creation of upload package.
"""
# Check for a sensible local file
if not os.path.exists(local_fp):
raise FileNotFoundError('Mask not found: {}'.format(local_fp))
if not os.path.isfile(local_fp):
raise ValueError('Path is not a file: {}'.format(local_fp))
# Convert whatever is found into a [h, w] boolean mask
arr = np.array(Image.open(local_fp), dtype='uint8')
if len(arr.shape) == 3:
N = arr.shape[2]
if N not in [1, 3, 4]:
raise ValueError('Unusable channel count: {}'.format(N))
if N == 1:
arr = arr[:, :, 0]
elif N == 3:
arr = cv2.cvtColor(arr, cv2.COLOR_RGB2GRAY)
elif N == 4:
arr = cv2.cvtColor(arr, cv2.COLOR_RGBA2GRAY)
if arr.any() and arr.max() == 1:
arr *= 255
return arr > 127
@staticmethod
def parse_bool_masks(bool_masks, shape=3):
"""
Checks the masks for correct data types, and ensures a shape of
[h, w, N].
"""
if shape not in [2, 3]:
raise ValueError("Invalid 'shape' - use shape = 2 or 3 for [h, w]"
" or [h, w, N].")
if type(bool_masks) != np.ndarray:
raise TypeError(
'Expected bool_masks to be a numpy array, not {}'
.format(type(bool_masks)))
if bool_masks.dtype != bool:
raise TypeError(
'Expected bool_masks to have dtype == bool, not {}'
.format(bool_masks.dtype))
# If mismatching shape and mode, see if we can unambigously coerce
# into desired shape
if shape == 3 and len(bool_masks.shape) == 2:
bool_masks = np.expand_dims(bool_masks, -1)
elif shape == 2 and len(bool_masks.shape) == 3:
if bool_masks.shape[2] > 1:
raise ValueError(
'Got a multi-layer bool-mask with N > 1 while using shape'
' = 2. In this mode, only [h, w] or [h, w, 1] are '
'permitted, not {}'.format(bool_masks.shape))
bool_masks = bool_masks[:, :, 0]
# Final check
if len(bool_masks.shape) != shape:
raise ValueError(
'Invalid final bool_masks shape. Should be {} but was {}'
.format(shape, bool_masks.shape))
return bool_masks
@classmethod
def find_bool_mask_bounds(cls, bool_mask, fail_on_error=False) -> dict:
"""
Returns a dictionary of { top, bottom, left, right } for the edges
of the given boolmask. If fail_on_error is False, a failed result
returns { 0, 0, 0, 0 }. Set to True for a proper exception.
"""
bool_mask = cls.parse_bool_masks(bool_mask, shape=2)
rows = np.any(bool_mask, axis=1)
cols = np.any(bool_mask, axis=0)
try:
top, bottom = np.where(rows)[0][[0, -1]]
left, right = np.where(cols)[0][[0, -1]]
except Exception:
top, bottom, left, right = 0, 0, 0, 0
if fail_on_error:
raise ValueError(
'Failed to find proper bounds for mask with shape {}'
.format(bool_mask.shape))
return {'top': top, 'bottom': bottom, 'left': left, 'right': right}
@staticmethod
def base64_to_boolmask(b64_data):
"""
Converts str base64 annotation data from Zegami into a boolean
mask.
"""
if type(b64_data) is not str:
raise TypeError(
'b64_data should be a str, not {}'.format(type(b64_data)))
# Remove b64 typical prefix if necessary
if b64_data.startswith('data:'):
b64_data = b64_data.split(',', 1)[-1]
img = Image.open(io.BytesIO(base64.b64decode(b64_data)))
img_arr = np.array(img)
# Correct for potential float->int scale error
premax = img_arr.max()
arr_int = np.array(np.array(img) * 255 if premax < 2 else
np.array(img), dtype='uint8')
return arr_int > 127
class AnnotationBB(_Annotation):
"""
An annotation comprising a bounding box and some metadata.
Note: Providing imageset_id and image_index is not mandatory and can be
obtained automatically, but this is slow and can cause unnecessary
re-downloading of data.
"""
TYPE = 'zc-boundingbox'
UPLOADABLE_DESCRIPTION = """
Bounding box annotation data includes the bounding box bounds,
a width and height, and score if generated
by a model (else None).
"""
@classmethod
def create_uploadable(cls, bounds: dict, class_id) -> dict:
"""
Creates a data package ready to be uploaded with a collection's
.upload_annotation().
Input 'bounds' is a dictionary of { x, y, width, height }, where x and
y are the coordinates of the top left point of the given bounding box.
Note: The output of this is NOT an annotation, it is used to upload
annotation data to Zegami, which when retrieved will form an
annotation.
"""
data = {
'x': bounds['x'],
'y': bounds['y'],
'w': bounds['width'],
'h': bounds['height'],
'type': cls.TYPE,
'score': None
}
uploadable = super().create_uploadable()
uploadable['format'] = 'BB1'
uploadable['annotation'] = data
uploadable['class_id'] = int(class_id)
return uploadable
class AnnotationPolygon(_Annotation):
"""
An annotation comprising a polygon and some metadata.
Note: Providing imageset_id and image_index is not mandatory and can be
obtained automatically, but this is slow and can cause unnecessary
re-downloading of data.
"""
TYPE = 'zc-polygon'
UPLOADABLE_DESCRIPTION = """
Polygon annotation data includes the coordinates of the
polygon points (vertices), and score if generated
by a model (else None).
"""
@classmethod
def create_uploadable(cls, points: list, class_id) -> dict:
"""
Creates a data package ready to be uploaded with a collection's
.upload_annotation().
Input 'points' is a list of (x, y) coordinates for each vertex of the polygon.
Note: The output of this is NOT an annotation, it is used to upload
annotation data to Zegami, which when retrieved will form an
annotation.
"""
data = {
'points': points,
'type': cls.TYPE,
'score': None
}
uploadable = super().create_uploadable()
uploadable['format'] = 'BB1'
uploadable['annotation'] = data
uploadable['class_id'] = int(class_id)
return uploadable | zegami-sdk | /zegami_sdk-0.4.9-py3-none-any.whl/zegami_sdk/annotation.py | annotation.py |
from .util import (
_auth_delete,
_auth_get,
_auth_post,
_auth_put,
_check_status,
_create_blobstore_session,
_create_zegami_session,
_ensure_token,
_get_token,
_get_token_name,
_obtain_signed_blob_storage_urls,
_upload_to_signed_blob_storage_url
)
from .workspace import Workspace
DEFAULT_HOME = 'https://zegami.com'
class ZegamiClient():
"""This client acts as the root for browsing your Zegami data.
It facilitates making authenticated requests using your token, initially
generated with login credentials. After logging in once, subsequent
credentials should typically not be required, as the token is saved
locally (zegami.token in your root OS folder).
Use zc.show_workspaces() to see your available workspaces. You can access
your workspaces using either zc.get_workspace_by...() or by directly
using workspace = zc.workspaces[0] ([1], [2], ...). These then act as
controllers to browse collections from. Collections in turn act as
controllers to browse data from.
"""
HOME = 'https://zegami.com'
API_0 = 'api/v0'
API_1 = 'api/v1'
_auth_get = _auth_get
_auth_post = _auth_post
_auth_put = _auth_put
_auth_delete = _auth_delete
_create_zegami_session = _create_zegami_session
_create_blobstore_session = _create_blobstore_session
_ensure_token = _ensure_token
_get_token_name = _get_token_name
_get_token = _get_token
_check_status = staticmethod(_check_status)
_obtain_signed_blob_storage_urls = _obtain_signed_blob_storage_urls
_upload_to_signed_blob_storage_url = _upload_to_signed_blob_storage_url
_zegami_session = None
_blobstore_session = None
def __init__(self, username=None, password=None, token=None, allow_save_token=True, home=DEFAULT_HOME):
# Make sure we have a token
self.HOME = home
self._ensure_token(username, password, token, allow_save_token)
# Initialise a requests session
self._create_zegami_session()
self._create_blobstore_session()
# Get user info, workspaces
self._refresh_client()
# Welcome message
try:
print('Client initialized successfully, welcome {}.\n'.format(self.name.split(' ')[0]))
except Exception:
pass
@property
def user_info():
pass
@user_info.getter
def user_info(self):
if not self._user_info:
self._refresh_client()
assert self._user_info, 'user_info not set, even after a client refresh'
return self._user_info
@property
def name():
pass
@name.getter
def name(self):
assert self._user_info, 'Trying to get name from a non-existent user_info'
assert 'name' in self._user_info.keys(),\
'Couldn\'t find \'name\' in user_info: {}'.format(self._user_info)
return self._user_info['name']
@property
def email():
pass
@email.getter
def email(self):
assert self._user_info, 'Trying to get email from a non-existent user_info'
assert 'email' in self._user_info.keys(),\
'Couldn\'t find \'email\' in user_info: {}'.format(self._user_info)
return self._user_info['email']
@property
def workspaces():
pass
@workspaces.getter
def workspaces(self):
if not self._workspaces:
self._refresh_client()
assert self._workspaces, 'workspaces not set, even after a client refresh'
return self._workspaces
def get_workspace_by_name(self, name):
ws = self.workspaces
for w in ws:
if w.name.lower() == name.lower():
return w
raise ValueError('Couldn\'t find a workspace with the name \'{}\''.format(name))
def get_workspace_by_id(self, id):
ws = self.workspaces
for w in ws:
if w.id == id:
return w
raise ValueError('Couldn\'t find a workspace with the ID \'{}\''.format(id))
def show_workspaces(self):
ws = self.workspaces
assert ws, 'Invalid workspaces obtained'
print('\nWorkspaces ({}):'.format(len(ws)))
for w in ws:
print('{} : {}'.format(w.id, w.name))
def _refresh_client(self):
"""Refreshes user_info and workspaces."""
url = '{}/oauth/userinfo/'.format(self.HOME)
self._user_info = self._auth_get(url)
self._workspaces = [Workspace(self, w) for w in self._user_info['projects']]
class _ZegamiStagingClient(ZegamiClient):
def __init__(self, username=None, password=None, token=None, allow_save_token=True,
home='https://staging.zegami.com'):
super().__init__(username, password, token, allow_save_token, home=home) | zegami-sdk | /zegami_sdk-0.4.9-py3-none-any.whl/zegami_sdk/client.py | client.py |
def add_node(
client,
workspace,
action,
params={},
type="dataset",
dataset_parents=None,
imageset_parents=None,
name="New node",
node_group=None,
processing_category=None
):
"""Create a new processing node."""
assert type in ["dataset", "imageset"]
source = {
action: params,
}
if dataset_parents:
source['dataset_id'] = dataset_parents
if imageset_parents:
source['imageset_id'] = imageset_parents
payload = {
'name': name,
'source': source,
}
if node_group:
payload['node_groups'] = node_group
if processing_category:
payload['processing_category'] = processing_category
url = '{}/{}/project/{}/{}'.format(
client.HOME, client.API_0, workspace.id, type + 's'
)
resp = client._auth_post(url, None, json=payload)
new_node_id = resp.get(type).get('id')
print("Created node: {}".format(new_node_id))
return resp
def add_parent(client, workspace, node_id, parent_node_id, type="dataset"):
"""
Add parent_node_id to the list of parents of node_id.
This should eventually be done via a dedicated API endpoint to avoid the need to fetch and modify the existing node
"""
assert type in ["dataset", "imageset"]
# fetch target node
url = '{}/{}/project/{}/{}/{}'.format(
client.HOME, client.API_0, workspace.id, type + 's', node_id
)
resp = client._auth_get(url)
node = resp.get(type)
# strip irrelevant fields
readonly_fields = ['data_link', 'id', 'parent_versioning_values', 'schema', 'total_rows']
for field in readonly_fields:
if field in node:
node.pop(field)
# add new parent to source
parent_ids = node.get('source').get(type + '_id')
parent_ids.append(parent_node_id)
# update node over API
client._auth_put(url, None, json=node, return_response=True)
def _get_imageset_images(client, workspace, node_id):
"""
Get the list of image info entries for the given node
"""
# fetch target node
url = '{}/{}/project/{}/{}/{}/images'.format(
client.HOME, client.API_1, workspace.id, "nodes", node_id
)
resp = client._auth_get(url)
return resp['images']
def _get_null_imageset_entries(client, workspace, node_id):
"""
Get the indices of all image info entries which are null
"""
images_info = _get_imageset_images(client, workspace, node_id)
indices = [i for i, info in enumerate(images_info) if info is None]
return indices
def _create_tasks_for_null_entries(client, workspace, node_id):
"""
Trigger creation of tasks for any entries in the imageset which are null.
This can happen as a result of failed database writes.
"""
url = '{}/{}/project/{}/{}/{}/create_tasks_for_null'.format(
client.HOME, client.API_1, workspace.id, "nodes", node_id
)
client._auth_post(url, None) | zegami-sdk | /zegami_sdk-0.4.9-py3-none-any.whl/zegami_sdk/nodes.py | nodes.py |
import base64
import os
import numpy as np
from PIL import Image
def get_annotations_for_collection(self, collection, source=None, type='mask'):
"""
Gets all one type of annotations available for a given collection.
Default as mask annotations.
Optionally, provide a source index (integer) to retrieve only annotations
related to that source.
"""
wid = self._extract_workspace_id(collection)
cid = self._extract_id(collection)
url = '{}/{}/project/{}/annotations/collection/{}'.format(
self.HOME, self.API_1, wid, cid)
# If a source was provided, modify the URL
if source is not None:
assert type(source) == int and source >= 0,\
'Expected provided source to be a positive integer, got {}'\
.format(source)
srcs = self.list_image_sources(collection, return_dicts=True, hide_warning=True)
assert source < len(srcs),\
'Provided source is too high for number of sources available '\
'(index {} in list length {})'.format(source, len(srcs))
url += '/source/{}'.format(source)
url += '?type={}'.format(type)
# Perform the GET
annos = self._auth_get(url)
return annos
def get_annotations_for_image(self, collection, row_index, source=None, type='mask'):
"""
Gets one type of annotations for a single image in a collection.
Default as mask annotations.
Specify the image by giving its data row.
"""
assert source is None or type(source) == int and source >= 0,\
'Expected source to be None or a positive int, not {}'.format(source)
srcs = self.list_image_sources(collection, return_dicts=True, hide_warning=True)
uses_sources = len(srcs) > 0
if uses_sources and source is None:
source = 0
wid = self._extract_workspace_id(collection)
cid = self._extract_id(collection)
# Convert the row index into the
lookup = self._get_image_meta_lookup(collection, source=source)
imageset_index = lookup[row_index]
if uses_sources:
url = '{}/{}/project/{}/annotations/collection/{}/source/{}/images/{}?type={}'\
.format(self.HOME, self.API_1, wid, cid, srcs[source]['source_id'], imageset_index, type)
else:
iid = self._extract_imageset_id(collection)
url = '{}/{}/project/{}/annotations/imageset/{}/images/{}?type={}'\
.format(self.HOME, self.API_1, wid, iid, imageset_index, type)
# Perform the GET
annos = self._auth_get(url)
return annos
def post_annotation(self, collection, row_index, annotation, source=None, return_req=False):
"""Posts an annotation to Zegami, storing it online.
Requires the target collection and the row_index of the item being annotated. If the image
is from a particular source, provide that too.
For the 'annotation', provide the result of zc.create_<type>_annotation().
"""
srcs = self.list_image_sources(collection, return_dicts=True, hide_warning=True)
uses_sources = len(srcs) > 0
if uses_sources:
if source is None:
source = 0
wid = self._extract_workspace_id(collection)
iid = self._extract_imageset_id(collection)
lookup = self._get_image_meta_lookup(collection, source=source)
imageset_index = lookup[row_index]
annotation['imageset_id'] = iid
annotation['image_index'] = imageset_index
url = '{}/{}/project/{}/annotations/'.format(self.HOME, self.API_1, wid)
r = self._auth_post(url, annotation, return_req)
return r
def create_mask_annotation(mask):
"""Creates a mask annotation using a mask.
Accepts either a boolean numpy array, or the path to a mask png image.
Note: 'imageset_id' and 'image_index' keys MUST be added to this before
sending.
"""
if type(mask) == str:
assert os.path.exists(mask),\
'Got type(mask): str but the path \'{}\' did not exist'.format(mask)
mask = np.array(Image.open(mask))
elif type(mask) != np.array:
raise TypeError('Expected mask to be a str (filepath) or a np array, not {}'
.format(type(mask)))
if len(mask.shape) > 2:
mask = mask[:, :, 0]
if mask.dtype is not bool:
mask = mask > 127
h, w = mask.shape
# Encode the single channel boolean mask into a '1' type image, as bytes
mask_bytes = Image.fromarray(mask.astype('uint8') * 255).convert('1').tobytes()
# Encode the mask bytes prior to serialisation
mask_serialised = base64.b64encode(mask_bytes)
return {
'imageset_id': None,
'image_index': None,
'type': 'mask_1UC1',
'annotation': {
'data': mask_serialised,
'width': w,
'height': h,
}
}
def _reconstitute_mask(annotation):
if 'annotation' in annotation.keys():
annotation = annotation['annotation']
data = annotation['data']
w = annotation['width']
h = annotation['height']
decoded_data = base64.b64decode(data)
bool_arr = np.array(Image.frombytes('1', (w, h), decoded_data), dtype=int) > 0
return bool_arr | zegami-sdk | /zegami_sdk-0.4.9-py3-none-any.whl/zegami_sdk/_annotation_methods.py | _annotation_methods.py |
from concurrent.futures import as_completed, ThreadPoolExecutor
from glob import glob
import json
import os
from tqdm import tqdm
class Source():
"""
A data structure representing information about a subset of a collection.
V1 collections have one source, V2+ can contain multiple each with their
own imagesets.
"""
def __repr__(self):
return '<Source "{}" from Collection "{}", id: "{}"'.format(
self.name, self.collection.name, self.id)
def __init__(self, collection, source_dict):
self._collection = collection
self._data = source_dict
@property
def collection():
pass
@collection.getter
def collection(self):
return self._collection
@property
def name():
pass
@name.getter
def name(self):
return self._retrieve('name')
@property
def id():
pass
@id.getter
def id(self):
"""The .source_id of this Source. Note: Invalid for V1 collections."""
if self.collection.version < 2:
return None
return self._retrieve('source_id')
@property
def imageset_id():
pass
@imageset_id.getter
def imageset_id(self):
return self._retrieve('imageset_id')
@property
def index():
pass
@index.getter
def index(self) -> int:
"""
The index/position of this source in its collection's .sources list.
"""
return self.collection.sources.index(self)
@property
def _imageset_dataset_join_id():
pass
@_imageset_dataset_join_id.getter
def _imageset_dataset_join_id(self):
return self._retrieve('imageset_dataset_join_id')
def _retrieve(self, key):
if key not in self._data:
raise KeyError('Key "{}" not found in Source _data'.format(key))
return self._data[key]
@property
def image_details():
pass
@image_details.getter
def image_details(self):
collection = self.collection
c = collection.client
ims_url = '{}/{}/project/{}/nodes/{}/images'.format(
c.HOME, c.API_1, collection.workspace_id, self.imageset_id)
ims = c._auth_get(ims_url)
return ims
class UploadableSource():
IMAGE_MIMES = {
".bmp": "image/bmp",
".jpg": "image/jpeg",
".jpeg": "image/jpeg",
".png": "image/png",
".gif": "image/gif",
".tif": "image/tiff",
".tiff": "image/tiff",
".dcm": "application/dicom",
}
BLACKLIST = (
".yaml",
".yml",
"thumbs.db",
".ds_store",
".dll",
".sys",
".txt",
".ini",
".tsv",
".csv",
".json"
)
def __init__(self, name, image_dir, column_filename='__auto_join__', recursive_search=True, filename_filter=[],
additional_mimes={}):
"""
Used in conjunction with create_collection().
An UploadableSource() points towards and manages the upload of local
files, resulting in the generation of a true Source() in the
collection.
To limit to an allowed specific list of filenames, provide
'filename_filter'. This filter will check against
os.path.basename(filepath).
Common mime types are inferred from the file extension,
but a dict of additional mime type mappings can be provided eg to
cater for files with no extension.
"""
self.name = name
self.image_dir = image_dir
self.column_filename = column_filename
# Set externally once a blank collection has been made
self._source = None
self._index = None
self.image_mimes = {**UploadableSource.IMAGE_MIMES, **additional_mimes}
# Check the directory exists
if not os.path.exists(image_dir):
raise FileNotFoundError('image_dir "{}" does not exist'.format(self.image_dir))
if not os.path.isdir(image_dir):
raise TypeError('image_dir "{}" is not a directory'.format(self.image_dir))
# Potentially limit paths based on filename_filter.
if filename_filter:
if type(filename_filter) != list:
raise TypeError('filename_filter should be a list')
fps = [os.path.join(image_dir, fp) for fp in filename_filter if os.path.exists(os.path.join(image_dir, fp))]
else:
# Find all files matching the allowed mime-types
fps = sum(
[glob('{}/**/*{}'.format(image_dir, ext), recursive=recursive_search)
for ext in self.IMAGE_MIMES.keys()], [])
self.filepaths = fps
self.filenames = [os.path.basename(fp) for fp in self.filepaths]
print('UploadableSource "{}" found {} images in "{}"'.format(self.name, len(self), image_dir))
@property
def source():
pass
@source.getter
def source(self) -> Source:
"""An UploadableSource() is the gateway to uploading into a true Zegami collection Source().
Once a collection is created and an empty Source() exists, this reference points to it ready to upload to.
"""
if self._source is None:
raise Exception(
'UploadableSource\'s generated source has not been set yet. This should be done automatically '
'after the blank collection has been generated.'
)
return self._source
@property
def index():
pass
@index.getter
def index(self) -> int:
"""The source index this UploadableSource is for.
Only set after a blank source has been generated ready to be uploaded to.
"""
if self._index is None:
raise Exception('UploadableSource\'s generated source index has '
'not been set yet. This should be done '
'automatically after the blank collection has '
'been generated')
return self._index
@property
def imageset_id():
pass
@imageset_id.getter
def imageset_id(self):
return self.source.imageset_id
def __len__(self):
return len(self.filepaths)
def _register_source(self, index, source):
"""Called to register a new (empty) Source() from a new collection to this, ready for uploading data into."""
if type(index) is not int:
raise TypeError('index should be an int, not {}'.format(type(index)))
if repr(type(source)) != repr(Source):
raise TypeError('source should be a Source(), not {}'.format(type(source)))
self._index = index
self._source = source
if not self.source.name == 'None' and not self.source.name == self.name:
raise Exception(
'UploadableSource "{}" registered to Source "{}" when their names should match'
.format(self.name, self.source.name)
)
def _assign_images_to_smaller_lists(self, file_paths, start=0):
"""Create smaller lists based on the number of images in the directory."""
# Recurse and pick up only valid files (either with image extensions, or not on blacklist)
total_work = len(file_paths)
workloads = []
workload = []
workload_start = start
if total_work > 2500:
size = 100
elif total_work < 100:
size = 1
else:
size = 10
i = 0
while i < total_work:
path = file_paths[i]
workload.append(path)
i += 1
if len(workload) == size or i == total_work:
workloads.append({'paths': workload, 'start': workload_start})
workload = []
workload_start = start + i
return workloads, total_work, size
def get_threaded_workloads(self, executor, workloads):
threaded_workloads = []
for workload in workloads:
threaded_workloads.append(executor.submit(
self._upload_image_group,
workload['paths'],
workload['start']
))
return threaded_workloads
def _upload(self):
"""Uploads all images by filepath to the collection.
provided a Source() has been generated and designated to this instance.
"""
collection = self.source.collection
c = collection.client
print('- Uploadable source {} "{}" beginning upload'.format(self.index, self.name))
# Tell the server how many uploads are expected for this source
url = '{}/{}/project/{}/imagesets/{}/extend'.format(c.HOME, c.API_0, collection.workspace_id, self.imageset_id)
delta = len(self)
# If there are no new uploads, ignore.
if delta == 0:
print('No new data to be uploaded.')
return
resp = c._auth_post(url, body=None, json={'delta': delta})
new_size = resp['new_size']
start = new_size - delta
(workloads, total_work, group_size) = self._assign_images_to_smaller_lists(self.filepaths, start=start)
# Multiprocess upload the images
# divide the filepaths into smaller groups
# with ThreadPoolExecutor() as ex:
CONCURRENCY = 16
with ThreadPoolExecutor(CONCURRENCY) as executor:
threaded_workloads = self.get_threaded_workloads(executor, workloads)
kwargs = {
'total': len(threaded_workloads),
'unit': 'image',
'unit_scale': group_size,
'leave': True
}
for f in tqdm(as_completed(threaded_workloads), **kwargs):
if f.exception():
raise f.exception()
def _upload_image_group(self, paths, start_index):
"""Upload a group of images.
Item is a tuple comprising:
- blob_id
- blob_url
- file path
"""
coll = self.source.collection
c = coll.client
# Obtain blob storage information
blob_storage_urls, id_set = c._obtain_signed_blob_storage_urls(
coll.workspace_id, id_count=len(paths), blob_path="imagesets/{}".format(self.imageset_id))
# Check that numbers of values are still matching
if not len(paths) == len(blob_storage_urls):
raise Exception(
'Mismatch in blob urls count ({}) to filepath count ({})'
.format(len(blob_storage_urls), len(self))
)
bulk_info = []
for (i, path) in enumerate(paths):
mime_type = self._get_mime_type(path)
blob_id = id_set['ids'][i]
blob_url = blob_storage_urls[blob_id]
bulk_info.append({
'blob_id': blob_id,
'name': os.path.basename(path),
'size': os.path.getsize(path),
'mimetype': mime_type
})
self._upload_image(c, path, blob_url, mime_type)
# Upload bulk image info
url = (
f'{c.HOME}/{c.API_0}/project/{coll.workspace_id}/imagesets/{self.imageset_id}'
f'/images_bulk?start={start_index}'
)
c._auth_post(url, body=None, return_response=True, json={'images': bulk_info})
def _upload_image(self, client, path, blob_url, mime_type):
"""Uploads a single image to the collection."""
try:
with open(path, 'rb') as f:
client._upload_to_signed_blob_storage_url(f, blob_url, mime_type)
except Exception as e:
print('Error uploading "{}" to blob storage:\n{}'.format(path, e))
def _check_in_data(self, data):
cols = list(data.columns)
if self.column_filename != '__auto_join__' and self.column_filename not in cols:
raise Exception('Source "{}" had the filename_column "{}" '
'which is not a column of the provided data:\n{}'
.format(self.name, self.column_filename, cols))
@classmethod
def _parse_list(cls, uploadable_sources) -> list:
"""Returns a checked list of instances."""
if isinstance(uploadable_sources, cls):
uploadable_sources = [uploadable_sources]
elif type(uploadable_sources) is not list:
raise TypeError('uploadable_sources should be a list of UploadableSources')
for u in uploadable_sources:
if not isinstance(u, UploadableSource):
raise TypeError('uploadable_sources should be a list of source.UploadableSource() instances')
names = [u.name for u in uploadable_sources]
for name in names:
if names.count(name) > 1:
raise ValueError('Two or more sources share the name "{}"'.format(name))
return uploadable_sources
def _get_mime_type(self, path) -> str:
"""Gets the mime_type of the path. Raises an error if not a valid image mime_type."""
if '.' not in path:
return self.image_mimes['']
ext = os.path.splitext(path)[-1]
if ext in self.image_mimes.keys():
return self.image_mimes[ext]
raise TypeError('"{}" is not a supported image mime_type ({})'.format(path, self.image_mimes))
class UrlSource(UploadableSource):
def __init__(self, name, url_template, image_fetch_headers, column_filename=None):
"""Used in conjunction with create_collection().
A UrlSource() fetches the images from the url template given, resulting in the
generation of a true Source() in the collection.
"""
self.name = name
self.url_template = url_template
self.image_fetch_headers = image_fetch_headers
self.column_filename = column_filename
# Set externally once a blank collection has been made
self._source = None
self._index = None
def _upload(self):
"""Update upload imageset to use the provided url template to get the images.
provided a Source() has been generated and designated to this instance.
"""
collection = self.source.collection
c = collection.client
print('- Configuring source {} "{}" to fetch images from url'
.format(self.index, self.name))
upload_ims_url = '{}/{}/project/{}/imagesets/{}'.format(
c.HOME, c.API_0, collection.workspace_id, self.imageset_id)
upload_ims = c._auth_get(upload_ims_url)
new_source = {
"dataset_id": collection._dataset_id,
'fetch': {
'headers': self.image_fetch_headers,
'url': {
'dataset_column': self.column_filename,
'url_template': self.url_template,
}
}
}
upload_ims['imageset']['source'] = new_source
payload = json.dumps(upload_ims['imageset'])
r = c._auth_put(upload_ims_url, payload, return_response=True)
return r | zegami-sdk | /zegami_sdk-0.4.9-py3-none-any.whl/zegami_sdk/source.py | source.py |
Apache License
Version 2.0, January 2004
http://www.apache.org/licenses/
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
1. Definitions.
"License" shall mean the terms and conditions for use, reproduction,
and distribution as defined by Sections 1 through 9 of this document.
"Licensor" shall mean the copyright owner or entity authorized by
the copyright owner that is granting the License.
"Legal Entity" shall mean the union of the acting entity and all
other entities that control, are controlled by, or are under common
control with that entity. For the purposes of this definition,
"control" means (i) the power, direct or indirect, to cause the
direction or management of such entity, whether by contract or
otherwise, or (ii) ownership of fifty percent (50%) or more of the
outstanding shares, or (iii) beneficial ownership of such entity.
"You" (or "Your") shall mean an individual or Legal Entity
exercising permissions granted by this License.
"Source" form shall mean the preferred form for making modifications,
including but not limited to software source code, documentation
source, and configuration files.
"Object" form shall mean any form resulting from mechanical
transformation or translation of a Source form, including but
not limited to compiled object code, generated documentation,
and conversions to other media types.
"Work" shall mean the work of authorship, whether in Source or
Object form, made available under the License, as indicated by a
copyright notice that is included in or attached to the work
(an example is provided in the Appendix below).
"Derivative Works" shall mean any work, whether in Source or Object
form, that is based on (or derived from) the Work and for which the
editorial revisions, annotations, elaborations, or other modifications
represent, as a whole, an original work of authorship. For the purposes
of this License, Derivative Works shall not include works that remain
separable from, or merely link (or bind by name) to the interfaces of,
the Work and Derivative Works thereof.
"Contribution" shall mean any work of authorship, including
the original version of the Work and any modifications or additions
to that Work or Derivative Works thereof, that is intentionally
submitted to Licensor for inclusion in the Work by the copyright owner
or by an individual or Legal Entity authorized to submit on behalf of
the copyright owner. For the purposes of this definition, "submitted"
means any form of electronic, verbal, or written communication sent
to the Licensor or its representatives, including but not limited to
communication on electronic mailing lists, source code control systems,
and issue tracking systems that are managed by, or on behalf of, the
Licensor for the purpose of discussing and improving the Work, but
excluding communication that is conspicuously marked or otherwise
designated in writing by the copyright owner as "Not a Contribution."
"Contributor" shall mean Licensor and any individual or Legal Entity
on behalf of whom a Contribution has been received by Licensor and
subsequently incorporated within the Work.
2. Grant of Copyright License. Subject to the terms and conditions of
this License, each Contributor hereby grants to You a perpetual,
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
copyright license to reproduce, prepare Derivative Works of,
publicly display, publicly perform, sublicense, and distribute the
Work and such Derivative Works in Source or Object form.
3. Grant of Patent License. Subject to the terms and conditions of
this License, each Contributor hereby grants to You a perpetual,
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
(except as stated in this section) patent license to make, have made,
use, offer to sell, sell, import, and otherwise transfer the Work,
where such license applies only to those patent claims licensable
by such Contributor that are necessarily infringed by their
Contribution(s) alone or by combination of their Contribution(s)
with the Work to which such Contribution(s) was submitted. If You
institute patent litigation against any entity (including a
cross-claim or counterclaim in a lawsuit) alleging that the Work
or a Contribution incorporated within the Work constitutes direct
or contributory patent infringement, then any patent licenses
granted to You under this License for that Work shall terminate
as of the date such litigation is filed.
4. Redistribution. You may reproduce and distribute copies of the
Work or Derivative Works thereof in any medium, with or without
modifications, and in Source or Object form, provided that You
meet the following conditions:
(a) You must give any other recipients of the Work or
Derivative Works a copy of this License; and
(b) You must cause any modified files to carry prominent notices
stating that You changed the files; and
(c) You must retain, in the Source form of any Derivative Works
that You distribute, all copyright, patent, trademark, and
attribution notices from the Source form of the Work,
excluding those notices that do not pertain to any part of
the Derivative Works; and
(d) If the Work includes a "NOTICE" text file as part of its
distribution, then any Derivative Works that You distribute must
include a readable copy of the attribution notices contained
within such NOTICE file, excluding those notices that do not
pertain to any part of the Derivative Works, in at least one
of the following places: within a NOTICE text file distributed
as part of the Derivative Works; within the Source form or
documentation, if provided along with the Derivative Works; or,
within a display generated by the Derivative Works, if and
wherever such third-party notices normally appear. The contents
of the NOTICE file are for informational purposes only and
do not modify the License. You may add Your own attribution
notices within Derivative Works that You distribute, alongside
or as an addendum to the NOTICE text from the Work, provided
that such additional attribution notices cannot be construed
as modifying the License.
You may add Your own copyright statement to Your modifications and
may provide additional or different license terms and conditions
for use, reproduction, or distribution of Your modifications, or
for any such Derivative Works as a whole, provided Your use,
reproduction, and distribution of the Work otherwise complies with
the conditions stated in this License.
5. Submission of Contributions. Unless You explicitly state otherwise,
any Contribution intentionally submitted for inclusion in the Work
by You to the Licensor shall be under the terms and conditions of
this License, without any additional terms or conditions.
Notwithstanding the above, nothing herein shall supersede or modify
the terms of any separate license agreement you may have executed
with Licensor regarding such Contributions.
6. Trademarks. This License does not grant permission to use the trade
names, trademarks, service marks, or product names of the Licensor,
except as required for reasonable and customary use in describing the
origin of the Work and reproducing the content of the NOTICE file.
7. Disclaimer of Warranty. Unless required by applicable law or
agreed to in writing, Licensor provides the Work (and each
Contributor provides its Contributions) on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
implied, including, without limitation, any warranties or conditions
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
PARTICULAR PURPOSE. You are solely responsible for determining the
appropriateness of using or redistributing the Work and assume any
risks associated with Your exercise of permissions under this License.
8. Limitation of Liability. In no event and under no legal theory,
whether in tort (including negligence), contract, or otherwise,
unless required by applicable law (such as deliberate and grossly
negligent acts) or agreed to in writing, shall any Contributor be
liable to You for damages, including any direct, indirect, special,
incidental, or consequential damages of any character arising as a
result of this License or out of the use or inability to use the
Work (including but not limited to damages for loss of goodwill,
work stoppage, computer failure or malfunction, or any and all
other commercial damages or losses), even if such Contributor
has been advised of the possibility of such damages.
9. Accepting Warranty or Additional Liability. While redistributing
the Work or Derivative Works thereof, You may choose to offer,
and charge a fee for, acceptance of support, warranty, indemnity,
or other liability obligations and/or rights consistent with this
License. However, in accepting such obligations, You may act only
on Your own behalf and on Your sole responsibility, not on behalf
of any other Contributor, and only if You agree to indemnify,
defend, and hold each Contributor harmless for any liability
incurred by, or claims asserted against, such Contributor by reason
of your accepting any such warranty or additional liability.
END OF TERMS AND CONDITIONS
APPENDIX: How to apply the Apache License to your work.
To apply the Apache License to your work, attach the following
boilerplate notice, with the fields enclosed by brackets "[]"
replaced with your own identifying information. (Don't include
the brackets!) The text should be enclosed in the appropriate
comment syntax for the file format. We also recommend that a
file or class name and description of purpose be included on the
same "printed page" as the copyright notice for easier
identification within third-party archives.
Copyright [2021] [Zegami Ltd]
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
| zegami-sdk | /zegami_sdk-0.4.9-py3-none-any.whl/zegami_sdk-0.4.9.dist-info/LICENSE.md | LICENSE.md |
import functools
import json
import logging
import math
import sys
import urllib.parse
import uuid
from abc import ABC
from abc import abstractmethod
from collections.abc import Iterable
from collections.abc import Iterator
from dataclasses import dataclass
from datetime import date
from typing import Any
from typing import Callable
from typing import Dict
from typing import Generic
from typing import List
from typing import Literal
from typing import Optional
from typing import Tuple
from typing import TypeVar
from typing import Union
from typing import overload
import requests
# tqdm is optional
# Allowed return types for searches. http://search.rcsb.org/#return-type
ReturnType = Literal[
"entry", "assembly", "polymer_entity", "non_polymer_entity", "polymer_instance"
]
TAndOr = Literal["and", "or"]
# All valid types for Terminal values
TValue = Union[
str,
int,
float,
date,
list[str],
list[int],
list[float],
list[date],
tuple[str, ...],
tuple[int, ...],
tuple[float, ...],
tuple[date, ...],
dict[str, Any],
]
# Types valid for numeric operators
TNumberLike = Union[int, float, date, "Value[int]", "Value[float]", "Value[date]"]
class Query(ABC):
"""Base class for all types of queries.
Queries can be combined using set operators:
- `q1 & q2`: Intersection (AND)
- `q1 | q2`: Union (OR)
- `~q1`: Negation (NOT)
- `q1 - q2`: Difference (implemented as `q1 & ~q2`)
- `q1 ^ q2`: Symmetric difference (XOR, implemented as `(q1 & ~q2) | (~q1 & q2)`)
Note that only AND, OR, and negation of terminals are directly supported by
the API, so other operations may be slower.
Queries can be executed by calling them as functions (`list(query())`) or using
the exec function.
Queries are immutable, and all modifying functions return new instances.
"""
@abstractmethod
def to_dict(self) -> dict:
"""Get dictionary representing this query"""
...
def to_json(self) -> str:
"""Get JSON string of this query"""
return json.dumps(self.to_dict(), separators=(",", ":"))
@abstractmethod
def _assign_ids(self, node_id=0) -> tuple["Query", int]:
"""Assign node_ids sequentially for all terminal nodes
This is a helper for the :py:meth:`Query.assign_ids` method
Args:
node_id: Id to assign to the first leaf of this query
Returns:
query: The modified query, with node_ids assigned
node_id: The next available node_id
"""
...
def assign_ids(self) -> "Query":
"""Assign node_ids sequentially for all terminal nodes
Returns:
the modified query, with node_ids assigned sequentially from 0
"""
return self._assign_ids(0)[0]
@abstractmethod
def __invert__(self) -> "Query":
"""Negation: `~a`"""
...
def __and__(self, other: "Query") -> "Query":
"""Intersection: `a & b`"""
assert isinstance(other, Query)
return Group("and", [self, other])
def __or__(self, other: "Query") -> "Query":
"""Union: `a | b`"""
assert isinstance(other, Query)
return Group("or", [self, other])
def __sub__(self, other: "Query") -> "Query":
"""Difference: `a - b`"""
return self & ~other
def __xor__(self, other: "Query") -> "Query":
"""Symmetric difference: `a ^ b`"""
return (self & ~other) | (~self & other)
def exec(self, return_type: ReturnType = "entry", rows: int = 100) -> "Session":
"""Evaluate this query and return an iterator of all result IDs"""
return Session(self, return_type, rows)
def __call__(self, return_type: ReturnType = "entry", rows: int = 100) -> "Session":
"""Evaluate this query and return an iterator of all result IDs"""
return self.exec(return_type, rows)
@overload
def and_(self, other: "Query") -> "Query":
...
@overload
def and_(self, other: Union[str, "Attr"]) -> "PartialQuery":
...
def and_(
self, other: Union[str, "Query", "Attr"]
) -> Union["Query", "PartialQuery"]:
"""Extend this query with an additional attribute via an AND"""
if isinstance(other, Query):
return self & other
elif isinstance(other, Attr):
return PartialQuery(self, "and", other)
elif isinstance(other, str):
return PartialQuery(self, "and", Attr(other))
else:
raise TypeError(f"Expected Query or Attr, got {type(other)}")
@overload
def or_(self, other: "Query") -> "Query":
...
@overload
def or_(self, other: Union[str, "Attr"]) -> "PartialQuery":
...
def or_(self, other: Union[str, "Query", "Attr"]) -> Union["Query", "PartialQuery"]:
"""Extend this query with an additional attribute via an OR"""
if isinstance(other, Query):
return self & other
elif isinstance(other, Attr):
return PartialQuery(self, "or", other)
elif isinstance(other, str):
return PartialQuery(self, "or", Attr(other))
else:
raise TypeError(f"Expected Query or Attr, got {type(other)}")
@dataclass(frozen=True)
class Terminal(Query):
"""A terminal query node.
Terminals are simple predicates comparing some *attribute* of a structure to a
value.
Examples:
>>> Terminal("exptl.method", "exact_match", "X-RAY DIFFRACTION")
>>> Terminal("rcsb_id", "in", ["5T89", "1TIM"])
>>> Terminal(value="tubulin")
A full list of attributes is available in the
`schema <http://search.rcsb.org/rcsbsearch/v2/metadata/schema>`_.
Operators are documented `here <http://search.rcsb.org/#field-queries>`_.
The :py:class:`Attr` class provides a more pythonic way of constructing Terminals.
"""
attribute: Optional[str] = None
operator: Optional[str] = None
value: Optional[TValue] = None
service: str = "text"
negation: Optional[bool] = False
node_id: int = 0
def to_dict(self):
params = dict()
if self.attribute is not None:
params["attribute"] = self.attribute
if self.operator is not None:
params["operator"] = self.operator
if self.value is not None:
params["value"] = self.value
if self.negation is not None:
params["negation"] = self.negation
return dict(
type="terminal",
service=self.service,
parameters=params,
node_id=self.node_id,
)
def __invert__(self):
return Terminal(
self.attribute,
self.operator,
self.value,
self.service,
not self.negation,
self.node_id,
)
def _assign_ids(self, node_id=0) -> tuple[Query, int]:
if self.node_id == node_id:
return (self, node_id + 1)
else:
return (
Terminal(
self.attribute,
self.operator,
self.value,
self.service,
self.negation,
node_id,
),
node_id + 1,
)
def __str__(self):
"""Return a simplified string representation
Examples:
>>> Terminal("attr", "op", "val")
>>> ~Terminal(value="val")
"""
negation = "~" if self.negation else ""
if self.attribute is None and self.operator is None:
# value-only
return f"{negation}Terminal(value={self.value!r})"
else:
return (
f"{negation}Terminal({self.attribute!r}, {self.operator!r}, "
f"{self.value!r})"
)
class TextQuery(Terminal):
"""Special case of a Terminal for free-text queries"""
def __init__(self, value: str):
"""Search for the string value anywhere in the text
Args:
value: free-text query
negation: find structures without the pattern
"""
super().__init__(service="full_text", value=value, negation=None)
@dataclass(frozen=True)
class Group(Query):
"""AND and OR combinations of queries"""
operator: TAndOr
nodes: Iterable[Query] = ()
def to_dict(self):
return dict(
type="group",
logical_operator=self.operator,
nodes=[node.to_dict() for node in self.nodes],
)
def __invert__(self):
if self.operator == "and":
return Group("or", [~node for node in self.nodes])
def __and__(self, other: Query) -> Query:
# Combine nodes if possible
if self.operator == "and":
if isinstance(other, Group):
if other.operator == "and":
return Group("and", (*self.nodes, *other.nodes))
elif isinstance(other, Query):
return Group("and", (*self.nodes, other))
else:
return NotImplemented
return super().__and__(other)
def __or__(self, other: Query) -> Query:
# Combine nodes if possible
if self.operator == "or":
if isinstance(other, Group):
if other.operator == "or":
return Group("or", (*self.nodes, *other.nodes))
elif isinstance(other, Terminal):
return Group("or", (*self.nodes, other))
else:
return NotImplemented
return super().__or__(other)
def _assign_ids(self, node_id=0) -> tuple[Query, int]:
nodes = []
changed = False
for node in self.nodes:
assigned = node._assign_ids(node_id)
nodes.append(assigned[0])
node_id = assigned[1]
# Track whether any nodes were modified
changed = changed or assigned[0] is node
if changed:
return (Group(self.operator, nodes), node_id)
else:
return (self, node_id)
def __str__(self):
"""""" # hide in documentation
if self.operator == "and":
return f"({' & '.join((str(n) for n in self.nodes))})"
elif self.operator == "or":
return f"({' | '.join((str(n) for n in self.nodes))})"
else:
raise ValueError("Illegal Operator")
@dataclass(frozen=True)
class Attr:
"""A search attribute, e.g. "rcsb_entry_container_identifiers.entry_id"
Terminals can be constructed from Attr objects using either a functional syntax,
which mirrors the API operators, or with python operators.
+--------------------+---------------------+
| Fluent Function | Operator |
+====================+=====================+
| exact_match | attr == str |
+--------------------+---------------------+
| contains_words | |
+--------------------+---------------------+
| contains_phrase | |
+--------------------+---------------------+
| greater | attr > date,number |
+--------------------+---------------------+
| less | attr < date,number |
+--------------------+---------------------+
| greater_or_equal | attr >= date,number |
+--------------------+---------------------+
| less_or_equal | attr <= date,number |
+--------------------+---------------------+
| equals | attr == date,number |
+--------------------+---------------------+
| range | dict (keys below)* |
+--------------------+---------------------+
| exists | bool(attr) |
+--------------------+---------------------+
| in\\_ | |
+--------------------+---------------------+
Rather than their normal bool return values, operators return Terminals.
Pre-instantiated attributes are available from the
:py:data:`rcsbsearch.rcsb_attributes` object. These are generally easier to use
than constructing Attr objects by hand. A complete list of valid attributes is
available in the `schema <http://search.rcsb.org/rcsbsearch/v2/metadata/schema>`_.
* The `range` dictionary requires the following keys:
* "from" -> int
* "to" -> int
* "include_lower" -> bool
* "include_upper" -> bool
"""
attribute: str
def exact_match(self, value: Union[str, "Value[str]"]) -> Terminal:
"""Exact match with the value"""
if isinstance(value, Value):
value = value.value
return Terminal(self.attribute, "exact_match", value)
def contains_words(
self, value: Union[str, "Value[str]", list[str], "Value[List[str]]"]
) -> Terminal:
"""Match any word within the string.
Words are split at whitespace. All results which match any word are returned,
with results matching more words sorted first.
"""
if isinstance(value, Value):
value = value.value
if isinstance(value, list):
value = " ".join(value)
return Terminal(self.attribute, "contains_words", value)
def contains_phrase(self, value: Union[str, "Value[str]"]) -> Terminal:
"""Match an exact phrase"""
if isinstance(value, Value):
value = value.value
return Terminal(self.attribute, "contains_phrase", value)
def greater(self, value: TNumberLike) -> Terminal:
"""Attribute > `value`"""
if isinstance(value, Value):
value = value.value
return Terminal(self.attribute, "greater", value)
def less(self, value: TNumberLike) -> Terminal:
"""Attribute < `value`"""
if isinstance(value, Value):
value = value.value
return Terminal(self.attribute, "less", value)
def greater_or_equal(self, value: TNumberLike) -> Terminal:
"""Attribute >= `value`"""
if isinstance(value, Value):
value = value.value
return Terminal(self.attribute, "greater_or_equal", value)
def less_or_equal(self, value: TNumberLike) -> Terminal:
"""Attribute <= `value`"""
if isinstance(value, Value):
value = value.value
return Terminal(self.attribute, "less_or_equal", value)
def equals(self, value: TNumberLike) -> Terminal:
"""Attribute == `value`"""
if isinstance(value, Value):
value = value.value
return Terminal(self.attribute, "equals", value)
def range(self, value: dict[str, Any]) -> Terminal:
"""Attribute is within the specified half-open range
Args:
value: lower and upper bounds `[a, b)`
"""
if isinstance(value, Value):
value = value.value
return Terminal(self.attribute, "range", value)
def exists(self) -> Terminal:
"""Attribute is defined for the structure"""
return Terminal(self.attribute, "exists")
def in_(
self,
value: Union[
list[str],
list[int],
list[float],
list[date],
tuple[str, ...],
tuple[int, ...],
tuple[float, ...],
tuple[date, ...],
"Value[List[str]]",
"Value[List[int]]",
"Value[List[float]]",
"Value[List[date]]",
"Value[Tuple[str, ...]]",
"Value[Tuple[int, ...]]",
"Value[Tuple[float, ...]]",
"Value[Tuple[date, ...]]",
],
) -> Terminal:
"""Attribute is contained in the list of values"""
if isinstance(value, Value):
value = value.value
return Terminal(self.attribute, "in", value)
# Need ignore[override] because typeshed restricts __eq__ return value
# https://github.com/python/mypy/issues/2783
@overload # type: ignore[override]
def __eq__(self, value: "Attr") -> bool:
...
@overload # type: ignore[override]
def __eq__(
self,
value: Union[
str,
int,
float,
date,
"Value[str]",
"Value[int]",
"Value[float]",
"Value[date]",
],
) -> Terminal:
...
def __eq__(
self,
value: Union[
"Attr",
str,
int,
float,
date,
"Value[str]",
"Value[int]",
"Value[float]",
"Value[date]",
],
) -> Union[Terminal, bool]: # type: ignore[override]
if isinstance(value, Attr):
return self.attribute == value.attribute
if isinstance(value, Value):
value = value.value
if isinstance(value, str):
return self.exact_match(value)
elif (
isinstance(value, date)
or isinstance(value, float)
or isinstance(value, int)
):
return self.equals(value)
else:
return NotImplemented
@overload # type: ignore[override]
def __ne__(self, value: "Attr") -> bool:
...
@overload # type: ignore[override]
def __ne__(
self,
value: Union[
str,
int,
float,
date,
"Value[str]",
"Value[int]",
"Value[float]",
"Value[date]",
],
) -> Terminal:
...
def __ne__(
self,
value: Union[
"Attr",
str,
int,
float,
date,
"Value[str]",
"Value[int]",
"Value[float]",
"Value[date]",
],
) -> Union[Terminal, bool]: # type: ignore[override]
if isinstance(value, Attr):
return self.attribute != value.attribute
if isinstance(value, Value):
value = value.value
return ~(self == value)
def __lt__(self, value: TNumberLike) -> Terminal:
if isinstance(value, Value):
value = value.value
return self.less(value)
def __le__(self, value: TNumberLike) -> Terminal:
if isinstance(value, Value):
value = value.value
return self.less_or_equal(value)
def __gt__(self, value: TNumberLike) -> Terminal:
if isinstance(value, Value):
value = value.value
return self.greater(value)
def __ge__(self, value: TNumberLike) -> Terminal:
if isinstance(value, Value):
value = value.value
return self.greater_or_equal(value)
def __bool__(self) -> Terminal:
return self.exists()
def __contains__(
self, value: Union[str, list[str], "Value[str]", "Value[List[str]]"]
) -> Terminal:
"""Maps to contains_words or contains_phrase depending on the value passed.
* `"value" in attr` maps to `attr.contains_phrase("value")` for simple values.
* `["value"] in attr` maps to `attr.contains_words(["value"])` for lists and
tuples.
"""
if isinstance(value, Value):
value = value.value
if isinstance(value, list):
if len(value) == 0 or isinstance(value[0], str):
return self.contains_words(value)
else:
return NotImplemented
else:
return self.contains_phrase(value)
# Type for functions returning Terminal
FTerminal = TypeVar("FTerminal", bound=Callable[..., Terminal])
# Type for functions returning Query
FQuery = TypeVar("FQuery", bound=Callable[..., Query])
def _attr_delegate(attr_func: FTerminal) -> Callable[[FQuery], FQuery]:
"""Decorator for PartialQuery methods. Delegates a function to self.attr.
This reduces boilerplate, especially for classes with lots of dunder methods
(preventing the use of `__getattr__`).
Argument:
- attr_func: A method in the Attr class producing a Terminal
Returns: A function producing a Query according to the PartialQuery's operator
"""
def decorator(partialquery_func: FQuery):
@functools.wraps(partialquery_func)
def wrap(self: "PartialQuery", *args, **kwargs) -> Query:
term: Terminal = attr_func(self.attr, *args, **kwargs)
if self.operator == "and":
return self.query & term
elif self.operator == "or":
return self.query | term
else:
raise ValueError(f"Unknown operator: {self.operator}")
return wrap
return decorator
class PartialQuery:
"""A PartialQuery extends a growing query with an Attr. It is constructed
using the fluent syntax with the `and_` and `or_` methods. It is not usually
necessary to create instances of this class directly.
PartialQuery instances behave like Attr instances in most situations.
"""
attr: Attr
query: Query
operator: TAndOr
def __init__(self, query: Query, operator: TAndOr, attr: Attr):
self.query = query
self.operator = operator
self.attr = attr
@_attr_delegate(Attr.exact_match)
def exact_match(self, value: Union[str, "Value[str]"]) -> Query:
...
@_attr_delegate(Attr.contains_words)
def contains_words(
self, value: Union[str, "Value[str]", list[str], "Value[List[str]]"]
) -> Query:
...
@_attr_delegate(Attr.contains_phrase)
def contains_phrase(self, value: Union[str, "Value[str]"]) -> Query:
...
@_attr_delegate(Attr.greater)
def greater(self, value: TNumberLike) -> Query:
...
@_attr_delegate(Attr.less)
def less(self, value: TNumberLike) -> Query:
...
@_attr_delegate(Attr.greater_or_equal)
def greater_or_equal(self, value: TNumberLike) -> Query:
...
@_attr_delegate(Attr.less_or_equal)
def less_or_equal(self, value: TNumberLike) -> Query:
...
@_attr_delegate(Attr.equals)
def equals(self, value: TNumberLike) -> Query:
...
@_attr_delegate(Attr.range)
def range(self, value: dict[str, Any]) -> Query:
...
@_attr_delegate(Attr.exists)
def exists(self) -> Query:
...
@_attr_delegate(Attr.in_)
def in_(
self,
value: Union[
str,
int,
float,
date,
"Value[str]",
"Value[int]",
"Value[float]",
"Value[date]",
],
) -> Query:
...
@overload # type: ignore[override]
def __eq__(self, value: "PartialQuery") -> bool:
...
@overload # type: ignore[override]
def __eq__(
self,
value: Union[
str,
int,
float,
date,
"Value[str]",
"Value[int]",
"Value[float]",
"Value[date]",
],
) -> Query:
...
def __eq__(
self,
value: Union[
"PartialQuery",
str,
int,
float,
date,
"Value[str]",
"Value[int]",
"Value[float]",
"Value[date]",
],
) -> Union[Query, bool]: # type: ignore[override]
if isinstance(value, PartialQuery):
return (
self.attr == value.attr
and self.query == value.query
and self.operator == value.operator
)
if self.operator == "and":
return self.query & (self.attr == value)
elif self.operator == "or":
return self.query | (self.attr == value)
else:
raise ValueError(f"Unknown operator: {self.operator}")
@overload # type: ignore[override]
def __ne__(self, value: "PartialQuery") -> bool:
...
@overload # type: ignore[override]
def __ne__(
self,
value: Union[
str,
int,
float,
date,
"Value[str]",
"Value[int]",
"Value[float]",
"Value[date]",
],
) -> Query:
...
def __ne__(
self,
value: Union[
"PartialQuery",
str,
int,
float,
date,
"Value[str]",
"Value[int]",
"Value[float]",
"Value[date]",
],
) -> Union[Query, bool]: # type: ignore[override]
if isinstance(value, PartialQuery):
return self.attr != value.attr
return ~(self == value)
@_attr_delegate(Attr.__lt__)
def __lt__(self, value: TNumberLike) -> Query:
...
@_attr_delegate(Attr.__le__)
def __le__(self, value: TNumberLike) -> Query:
...
@_attr_delegate(Attr.__gt__)
def __gt__(self, value: TNumberLike) -> Query:
...
@_attr_delegate(Attr.__ge__)
def __ge__(self, value: TNumberLike) -> Query:
...
@_attr_delegate(Attr.__bool__)
def __bool__(self) -> Query:
...
@_attr_delegate(Attr.__contains__)
def __contains__(
self, value: Union[str, list[str], "Value[str]", "Value[List[str]]"]
) -> Query:
...
T = TypeVar("T", bound="TValue")
@dataclass(frozen=True)
class Value(Generic[T]):
"""Represents a value in a query.
In most cases values are unnecessary and can be replaced directly by the python
value.
Values can also be used if the Attr object appears on the right:
Value("4HHB") == Attr("rcsb_entry_container_identifiers.entry_id")
"""
value: T
@overload # type: ignore[override]
def __eq__(self, attr: "Value") -> bool:
...
@overload # type: ignore[override]
def __eq__(self, attr: Attr) -> Terminal:
...
def __eq__(self, attr: Union["Value", Attr]) -> Union[bool, Terminal]:
# type: ignore[override]
if isinstance(attr, Value):
return self.value == attr.value
if not isinstance(attr, Attr):
return NotImplemented
return attr == self
@overload # type: ignore[override]
def __ne__(self, attr: "Value") -> bool:
...
@overload # type: ignore[override]
def __ne__(self, attr: Attr) -> Terminal:
...
def __ne__(self, attr: Union["Value", Attr]) -> Union[bool, Terminal]:
# type: ignore[override]
if isinstance(attr, Value):
return self.value != attr.value
if not isinstance(attr, Attr):
return NotImplemented
return attr != self.value
def __lt__(self, attr: Attr) -> Terminal:
if not isinstance(attr, Attr):
return NotImplemented
if not (
isinstance(self.value, int)
or isinstance(self.value, float)
or isinstance(self.value, date)
):
return NotImplemented
return attr.greater(self.value)
def __le__(self, attr: Attr) -> Terminal:
if not isinstance(attr, Attr):
return NotImplemented
if not (
isinstance(self.value, int)
or isinstance(self.value, float)
or isinstance(self.value, date)
):
return NotImplemented
return attr.greater_or_equal(self.value)
def __gt__(self, attr: Attr) -> Terminal:
if not isinstance(attr, Attr):
return NotImplemented
if not (
isinstance(self.value, int)
or isinstance(self.value, float)
or isinstance(self.value, date)
):
return NotImplemented
return attr.less(self.value)
def __ge__(self, attr: Attr) -> Terminal:
if not isinstance(attr, Attr):
return NotImplemented
if not (
isinstance(self.value, int)
or isinstance(self.value, float)
or isinstance(self.value, date)
):
return NotImplemented
return attr.less_or_equal(self.value)
class Session(Iterable[str]):
"""A single query session.
Handles paging the query and parsing results
"""
url = "http://search.rcsb.org/rcsbsearch/v2/query"
query_id: str
query: Query
return_type: ReturnType
start: int
rows: int
def __init__(
self, query: Query, return_type: ReturnType = "entry", rows: int = 100
):
self.query_id = Session.make_uuid()
self.query = query.assign_ids()
self.return_type = return_type
self.start = 0
self.rows = rows
@staticmethod
def make_uuid() -> str:
"Create a new UUID to identify a query"
return uuid.uuid4().hex
@staticmethod
def _extract_identifiers(query_json: Optional[dict]) -> list[str]:
"""Extract identifiers from a JSON response"""
if query_json is None:
return []
# total_count = int(query_json["total_count"])
identifiers = [result["identifier"] for result in query_json["result_set"]]
# assert len(identifiers) == total_count, f"{len(identifiers)} != {total_count}"
return identifiers
def _make_params(self, start=0):
"Generate GET parameters as a dict"
return dict(
query=self.query.to_dict(),
return_type=self.return_type,
request_info=dict(query_id=self.query_id, src="ui"), # TODO src deprecated?
request_options=dict(paginate=dict(start=start, rows=self.rows)),
)
def _single_query(self, start=0) -> Optional[dict]:
"Fires a single query"
params = self._make_params(start)
logging.debug(
f"Querying {self.url} for results {start}-{start + self.rows - 1}"
)
response = requests.get(
self.url, {"json": json.dumps(params, separators=(",", ":"))}
)
response.raise_for_status()
if response.status_code == requests.codes.OK:
return response.json()
elif response.status_code == requests.codes.NO_CONTENT:
return None
else:
raise Exception(f"Unexpected status: {response.status_code}")
def __iter__(self) -> Iterator[str]:
"Generator for all results as a list of identifiers"
start = 0
response = self._single_query(start=start)
if response is None:
return # be explicit for mypy
identifiers = self._extract_identifiers(response)
start += self.rows
logging.debug(f"Got {len(identifiers)} ids")
if len(identifiers) == 0:
return
yield from identifiers
total = response["total_count"]
while start < total:
assert len(identifiers) == self.rows
response = self._single_query(start=start)
identifiers = self._extract_identifiers(response)
logging.debug(f"Got {len(identifiers)} ids")
start += self.rows
yield from identifiers
def iquery(self, limit: Optional[int] = None) -> list[str]:
"""Evaluate the query and display an interactive progress bar.
Requires tqdm.
"""
from tqdm import trange # type: ignore
response = self._single_query(start=0)
if response is None:
return []
total = response["total_count"]
identifiers = self._extract_identifiers(response)
if limit is not None and len(identifiers) >= limit:
return identifiers[:limit]
pages = math.ceil((total if limit is None else min(total, limit)) / self.rows)
for page in trange(1, pages, initial=1, total=pages):
response = self._single_query(page * self.rows)
ids = self._extract_identifiers(response)
identifiers.extend(ids)
return identifiers[:limit]
def rcsb_query_editor_url(self) -> str:
"""URL to edit this query in the RCSB query editor"""
data = json.dumps(self._make_params(), separators=(",", ":"))
return (
f"http://search.rcsb.org/query-editor.html?json={urllib.parse.quote(data)}"
)
def rcsb_query_builder_url(self) -> str:
"""URL to view this query on the RCSB website query builder"""
data = json.dumps(self._make_params(), separators=(",", ":"))
return f"http://www.rcsb.org/search?request={urllib.parse.quote(data)}" | zeigen | /zeigen-0.3.0-py3-none-any.whl/rcsbsearch/search.py | search.py |
import json
import logging
import os
import pkgutil
import re
from collections.abc import Iterator
from typing import Any
from typing import List
from typing import Union
import requests
from .search import Attr
METADATA_SCHEMA_URL = "http://search.rcsb.org/rcsbsearch/v2/metadata/schema"
SEARCH_SCHEMA_URL = "http://search.rcsb.org/json-schema-rcsb_search_query.json"
ENV_RCSBSEARCH_DOWNLOAD_SCHEMA = "RCSBSEARCH_DOWNLOAD_SCHEMA"
def _get_json_schema(download=None):
"""Get the JSON schema
The RCSBSEARCH_DOWNLOAD_SCHEMA environmental variable controls whether
to download the schema from the web each time vs using the version shipped
with rcsbsearch
"""
if download is True or (
download is None
and (
os.environ.get(ENV_RCSBSEARCH_DOWNLOAD_SCHEMA, "no").lower()
in ("1", "yes", "y")
)
):
return _download_json_schema()
return _load_json_schema()
def _download_json_schema():
"Get the current JSON schema from the web"
url = METADATA_SCHEMA_URL
logging.info(f"Downloading {url}")
response = requests.get(url)
response.raise_for_status()
return response.json()
def _load_json_schema():
logging.info("Loading schema from file")
latest = pkgutil.get_data(__package__, "resources/metadata_schema.json")
return json.loads(latest)
class SchemaGroup:
"""A non-leaf node in the RCSB schema. Leaves are Attr values."""
def search(self, pattern: Union[str, re.Pattern], flags=0) -> Iterator[Attr]:
"""Find all attributes in the schema matching a regular expression.
Returns:
An iterator supplying Attr objects whose attribute matches.
"""
matcher = re.compile(pattern, flags=flags)
return filter(lambda a: matcher.search(a.attribute), self)
def __iter__(self) -> Iterator[Attr]:
"""Iterate over all leaf nodes
Example:
>>> [a for a in attrs if "stoichiometry" in a.attribute]
[Attr(attribute='rcsb_struct_symmetry.stoichiometry')]
"""
def leaves(self):
for k, v in self.__dict__.items():
if isinstance(v, Attr):
yield v
elif isinstance(v, SchemaGroup):
yield from iter(v)
else:
# Shouldn't happen
raise TypeError(f"Unrecognized member {k!r}: {v!r}")
return leaves(self)
def __str__(self):
return "\n".join(str(c) for c in self.__dict__.values())
def _make_group(fullname: str, node) -> Union[SchemaGroup, Attr]:
"""Represent this node of the schema as a python object
Params:
- name: full dot-separated attribute name
Returns:
An Attr (Leaf nodes) or SchemaGroup (object nodes)
"""
if "anyOf" in node:
children = {_make_group(fullname, n) for n in node["anyOf"]}
# Currently only deal with anyOf in leaf nodes
assert len(children) == 1, f"type of {fullname} couldn't be determined"
return next(iter(children))
if "oneOf" in node:
children = {_make_group(fullname, n) for n in node["oneOf"]}
# Currently only deal with oneOf in leaf nodes
assert len(children) == 1, f"type of {fullname} couldn't be determined"
return next(iter(children))
if "allOf" in node:
children = {_make_group(fullname, n) for n in node["allOf"]}
# Currently only deal with allOf in leaf nodes
assert len(children) == 1, f"type of {fullname} couldn't be determined"
return next(iter(children))
if node["type"] in ("string", "number", "integer", "date"):
return Attr(fullname)
elif node["type"] == "array":
# skip to items
return _make_group(fullname, node["items"])
elif node["type"] == "object":
group = SchemaGroup() # parent, name)
for childname, childnode in node["properties"].items():
fullchildname = f"{fullname}.{childname}" if fullname else childname
childgroup = _make_group(fullchildname, childnode)
setattr(group, childname, childgroup)
return group
else:
raise TypeError(f"Unrecognized node type {node['type']!r} of {fullname}")
def _make_schema() -> SchemaGroup:
json = _get_json_schema()
schema = _make_group("", json)
assert isinstance(schema, SchemaGroup) # for type checking
return schema
rcsb_attributes: SchemaGroup
"""Object with all known RCSB attributes.
This is provided to ease autocompletion as compared to creating Attr objects from
strings. For example,
::
rcsb_attributes.rcsb_nonpolymer_instance_feature_summary.chem_id
is equivalent to
::
Attr('rcsb_nonpolymer_instance_feature_summary.chem_id')
All attributes in `rcsb_attributes` can be iterated over.
>>> [a for a in rcsb_attributes if "stoichiometry" in a.attribute]
[Attr(attribute='rcsb_struct_symmetry.stoichiometry')]
Attributes matching a regular expression can also be filtered:
>>> list(rcsb_attributes.search('rcsb.*stoichiometry'))
[Attr(attribute='rcsb_struct_symmetry.stoichiometry')]a
"""
def __getattr__(name: str) -> Any:
# delay instantiating rcsb_attributes until it is needed
if name == "rcsb_attributes":
if "rcsb_attributes" not in globals():
globals()["rcsb_attributes"] = _make_schema()
return globals()["rcsb_attributes"]
raise AttributeError(f"module {__name__!r} has no attribute {name!r}")
def __dir__() -> list[str]:
return sorted(__all__)
__all__ = [ # noqa: F822
"METADATA_SCHEMA_URL",
"SEARCH_SCHEMA_URL",
"ENV_RCSBSEARCH_DOWNLOAD_SCHEMA",
"rcsb_attributes",
"SchemaGroup",
] | zeigen | /zeigen-0.3.0-py3-none-any.whl/rcsbsearch/schema.py | schema.py |
<div align="center">
<img src="logo.png" alt="Ather logo" width="400" height="auto" />
<h1>aman</h1>
<p> A python library for ensuring the safety and security of ML models and their outputs for the Arabic and Islamic community.</p>
</div>
### Library Mission
- The package includes a module that filters out profane words in Arabic text, using a comprehensive list of swear words and a smart algorithm that can handle variations and misspellings.
- The package also includes a module that detects offensive sentences that insult or mock any of the Abrahamic religions (Islam, Christianity, Judaism), or any person or institution associated with them. The module uses natural language processing and sentiment analysis to identify the tone and intention of the sentences.
- The package further includes a module that detects sexual images, or images that disrespect or ridicule any of the prophets or sacred symbols of the Abrahamic religions. The module uses computer vision and deep learning to classify and flag the images.
<!-- About the Project -->
## ⬇️: Installation
Install using `pip <http://www.pip-installer.org/en/latest/>`__ with:
pip install aman
Or, `download a wheel or source archive from
PyPI <https://pypi.python.org/pypi/aman>`__.
## 🧑🤝🧑: Call for Contributions
<p>We Need Your Help The aman project values your skills and passion!</p>
<p>We appreciate any small enhancements or fixes you can make. If you want to make bigger changes to the source code, please let us know through the mailing list first.</p>
There are many other ways to contribute to NumPy besides writing code. You can also:
- Help us manage new and old issues
- Create tutorials, presentations, and other learning materials
- Evaluate pull requests
| zein | /zein-0.0.4.tar.gz/zein-0.0.4/README.md | README.md |
import pandas as pd
#%%
def facetter(response):
""" takes in the json of a response, returns a time series of the facets"""
time_series = pd.Series()
for a,b in response["facets"]["release_date"].items():
if type(b) != str:
date = pd.to_datetime(a)
count = b
time_series[date] = count
time_series = time_series.sort_index()
return time_series
class BaseClass():
def set_facets(self):
""" add facets to the object, only works if response has facetting activated """
try:
ts = facetter(self.response)
self.time_series = ts
except:
raise Exception("no facets in the response")
def get_facets(self):
""" get facets of the object, needs set_facets called before
returns a pandas time series """
try:
return self.time_series
except:
raise Exception("you forgot to set facets")
def has_facets(self):
"""function to see if object has facets or not
True if it has facets, False if not"""
try:
self.time_series
return True
except:
return False
def get_raw(self):
""" get the pure json of the object"""
return self.response
def get_matches(self):
""" extracts the articles of the object, if there were articles in the initilization
returns a dict in form if {uuid:[title, subtitle, zeitonline link]}
"""
articles = {}
for a in self.matches:
id = a["uuid"]
title = a["title"]
href = a["href"]
sub = a["subtitle"]
articles[id] = [title, sub, href]
return articles
#the simple response class
class Search(BaseClass):
""" class which makes the response of a search prettier and easier to understand"""
def __init__(self, search_term, response,):
self.name = search_term
self.found = response["found"]
self.limit = response["limit"]
self.matches = response["matches"]
self.response = response
def __repr__(self):
string = f" Search for '{self.name}': {self.found} results, limit: {self.limit}, matches : \n \n"
for uri, tuple in self.get_matches().items():
desc = tuple[0]
string += f"{desc}: {uri}\n"
return string
def get_matches(self):
""" get the matches of the search result , returns a dictionary
of type {uri: (description, match_json) }"""
matches = {}
try:
for m in self.matches:
#checks if the matches are articles, which do not have a value field,
#or anything else
desc = m["value"]
uri = m["uri"]
matches[uri] = (desc, m)
return matches
except:
for m in self.matches:
desc = m["title"]
uri = m["uri"]
matches[uri] = (desc, m)
return matches
#the keyword class
class Keyword(BaseClass):
def __init__(self, response):
""" initialize a keyword instance from a json response"""
self.name = response["value"]
self.uri = response["uri"]
self.lexical = response["lexical"]
self.href = response["href"]
self.score = response["score"]
self.type = response["type"]
self.matches = response["matches"]
self.found = response["found"]
#save response for possible later usage
self.response = response
def __repr__(self):
string = f"Keyword: '{self.lexical}' with id '{self.name}', keyword type: '{self.type}' with score {self.score} and {self.found} matches \n\n\
matches: {self.matches}"
return string
#%%
class Department(BaseClass):
def __init__(self, response):
self.uri = response["uri"]
self.name = response["value"]
self.parent = response["parent"]
self.href = response["href"]
self.matches = response["matches"]
self.found = response["found"]
self.response = response
def __repr__(self):
string = f"Department {self.name} \n Articles: {self.found}; \n uri:{self.uri} \n "
if self.has_parent():
string += f"parent : {self.parent}"
else:
string += "no parent"
return string
def has_parent(self):
""" check if the department has a parent department """
if self.parent == "":
return False
return True
#%%
class Client():
def __init__(self, response):
self.name = response["name"]
self.email = response["email"]
self.reset = response["reset"]
self.api_key = response["api_key"]
self.requests = response["requests"]
self.quota = response["quota"]
self.response = response
def __repr__(self):
string = f"Client: Name: {self.name} \n \
Client Key: {self.api_key} "
return string
def requests_left(self):
""" function to get the remaining requests left with your key"""
left = self.quota - self.requests
return left
def reset_time(self):
""" shows the time when the counter will reset"""
date = pd.to_datetime(self.reset, unit = "s")
return date
#%%
#simple article class , todo: web scraper
class Article():
def __init__(self, response):
self.title = response["title"]
self.href = response["href"]
self.text = response["teaser_text"]
self.id = response["uuid"]
self.supertitle = response["supertitle"]
self.uri = response["uri"]
self.response = response
def __repr__(self):
string = f"Article with title '{self.title}' UUID: {self.id}, URI: {self.uri}\
teaser_text: '{self.text}'"
return string
def get_keywords(self):
""" get the keywords linked to the article, returns
a dict of {"uri":"name", "uri":"name"}"""
answer = {}
for i in self.response["keywords"]:
uri, name = i["uri"], i["name"]
answer[uri] = name
return answer
def get_authors(self):
""" get the authors linked to the article, returns
a dict of {uri:name, uri:name}"""
answer = {}
for i in self.response["creators"]:
uri, name = i["uri"], i["name"]
answer[uri] = name
return answer
def get_date(self):
""" get release date of the article, returns a pandas timestamp"""
date = self.response["release_date"]
date = pd.to_datetime(date)
return date
def get_raw(self):
""" get the raw json of the initilazation"""
return self.response | zeit-online | /zeit_online-1.0.0-py3-none-any.whl/zeit/classes.py | classes.py |
import requests
import pandas as pd
#%%
# helpful functions
def facetter(response):
""" takes in the json of a response, returns a time series of the facets"""
time_series = pd.Series()
for a,b in response["facets"]["release_date"].items():
if type(b) != str:
date = pd.to_datetime(a)
count = b
time_series[date] = count
time_series = time_series.sort_index()
return time_series
#%%
#the central API Class
class API():
def __init__(self):
self.base_url = "http://api.zeit.de"
#general check
def get_status(self):
"""checks the status of the connection with the api, takes a API-KEY as input
raises Error when not workin
"""
header = {"X-Authorization":self.token}
url = "http://api.zeit.de/client"
status = requests.get(url, headers = header)
if status:
return "everything ok"
else:
assert f"something gone wrong, code: {status.status_code}"
#definte the token method
def set_token(self, api_key):
""" set the api key, expects key
raises Error when key is not proper"""
#check
check = requests.get(
"http://api.zeit.de/client", headers = {"X-Authorization":api_key})
if check:
self.token = api_key
else:
assert "Not a good key"
#general get function
def get(self, url = "http://api.zeit.de/content", limit = 10, search = False, time_range = False, fields = False, facet_time = False):
""" function to get content from the api, really broadly defined
Arguments:
url: content endpoint, default = api.zeit.de/content is standard content endpoint
limit: number results, default : 10
search: a specific search string
time-range: expects tuple of two datetime objects, default False
fields: return specific fields of the repsonse, expects a list
facetting = the time frame specified, e.g "1year"
Returns:
pure web response in json format
"""
header = {"X-Authorization":self.token}
parameters = {}
parameters["limit"] = limit
if search:
parameters["q"] = search
if fields:
parameters["fields"] = f"{*fields,}"
if time_range:
time1, time2 = time_range[0].isoformat(), time_range[1].isoformat
parameters["q"] = f'"+search+" AND release_date:[{time1.isoformat()} TO {time2.isoformat()}]'
if facet_time:
parameters["facet_date"] = facet_time
response = requests.get(url, params = parameters, headers = header).json()
return response
#specific get functions
def get_article(self, article_id):
""" function to get an article by ist article id"""
url = self.base_url + f"/content/{article_id}"
response = self.get( url, limit=1)
return response
def get_author(self, author_id, limit = 1):
""" get an author by id, expects a valid author id
and optionally a limit on the number of articles"""
if author_id.startswith("http://"):
url = author_id
else:
url = self.base_url + f"/author/{author_id}"
response = self.get( url, limit = limit)
return response
def get_keyword(self, keyword_id, limit = 1, facet_time = False):
""" get information about a keyword, expects keyword id and
optionally a limit on the number of articles returned"""
if keyword_id.startswith("http://"):
url = keyword_id
else:
url = self.base_url + f"/keyword/{keyword_id}"
if facet_time:
response = self.get( url, limit = limit, facet_time=facet_time)
keyword = Keyword(response)
keyword.set_facets()
else:
response = self.get( url, limit = limit)
keyword = Keyword(response)
return keyword
#search functions
def search_for(self, search_string, search_type = "content", limit = 10, time_range = False, facet_time = False):
""" search the API for a specified string, one word only
allowed search types = content, keyword, department, author, product author
allows a time range of the format tuple(time1, time2)
also allows for facetting by setting a facet_time line '1year' etc.
returns a Search Class
"""
string = "*"
string += search_string
string += "*"
url = self.base_url+f"/{search_type}"
if facet_time:
response = self.get( url, limit = limit, search = string, time_range=time_range, facet_time=facet_time)
search = Search(search_string, response)
search.set_facets()
else:
response = self.get( url, limit = limit, search = string, time_range=time_range)
search = Search(search_string, response)
return search
#%%
class BaseClass():
def set_facets(self):
""" add facets to the object, only works if response has facetting activated """
try:
ts = facetter(self.response)
self.time_series = ts
except:
raise Exception("no facets in the response")
def get_facets(self):
""" get facets of the object, needs set_facets called before
returns a pandas time series """
try:
return self.time_series
except:
raise Exception("you forgot to set facets")
def has_facets(self):
"""function to see if object has facets or not
True if it has facets, False if not"""
try:
self.time_series
return True
except:
return False
#%%
#the simple response class
class Search(BaseClass):
""" class which makes the response of a search prettier and easier to understand"""
def __init__(self, search_term, response,):
self.name = search_term
self.found = response["found"]
self.limit = response["limit"]
self.matches = response["matches"]
self.response = response
def __repr__(self):
string = f" Search for '{self.name}': {self.found} results, limit: {self.limit}, matches : \n \n"
for name, match in self.get_matches().items():
uri = match["uri"]
string += f"{name}: {uri}\n"
return string
def get_matches(self):
""" get the matches of the search result , returns a dictionary
of type {title:json}"""
matches = {}
try:
for m in self.matches:
#checks if the matches are articles, which do not have a value field,
#or anything else
value = m["value"]
matches[value] = m
return matches
except:
for m in self.matches:
title = m["title"]
matches[title] = m
return matches
def get_raw(self):
""" get the pure json of the search"""
return self.response
# %%
#the keyword class
class Keyword(BaseClass):
def __init__(self, response):
""" initialize a keyword instance from a json response"""
self.name = response["id"]
self.uri = response["uri"]
self.lexical = response["lexical"]
self.score = response["score"]
self.type = response["type"]
self.matches = response["found"]
#save response for possible later usage
self.response = response
def __repr__(self):
string = f"Keyword: '{self.lexical}' with id '{self.name}',\
keyword type: '{self.type}' with score {self.score} and {self.matches} matches"
return string
def get_raw(self):
""" get raw json response of the keyword"""
return self.response
def get_articles(self):
""" get the articles associated with the response,
only works if there were articles in the initilization
returns a dict of keys : article ids and values : a list of type [title, subtitle, zeitonline link]"""
articles = {}
for a in self.response["matches"]:
id = a["uuid"]
title = a["title"]
href = a["href"]
sub = a["subtitle"]
articles[id] = [title, sub, href]
return articles
#%%
#simple article class , todo: web scraper
class Article():
def __init__(self, response):
self.title = response["title"]
self.href = response["href"]
self.text = response["teaser_text"]
self.id = response["uuid"]
self.supertitle = response["supertitle"]
self.response = response
def get_keywords(self):
""" get the keywords linked to the article, returns
a dict of {"uri":"name", "uri":"name"}"""
answer = {}
for i in self.response["keywords"]:
uri, name = i["uri"], i["name"]
answer[uri] = name
return answer
def get_authors(self):
""" get the authors linked to the article, returns
a dict of {uri:name, uri:name}"""
answer = {}
for i in self.response["creators"]:
uri, name = i["uri"], i["name"]
answer[uri] = name
return answer
def get_date(self):
""" get release date of the article, returns a pandas timestamp"""
date = self.response["release_date"]
date = pd.to_datetime(date)
return date
def get_raw(self):
return self.response
# %% | zeit-online | /zeit_online-1.0.0-py3-none-any.whl/zeit/zeit.py | zeit.py |
import requests
import pandas as pd
from .classes import *
def id_check(id, endpoint = "http://api.zeit.de/content"):
""" check ids, input id and endpoint like "http://api.zeit.de/content", returns url"""
if id.startswith("http://"):
url = id
else:
url = f"{endpoint}/{id}"
return url
#the central API Class
class API():
def __init__(self):
self.base_url = "http://api.zeit.de"
self.token = None
def __repr__(self):
return f"API Object of zeit-online module"
#general check
def get_status(self):
"""checks the status of the connection with the api, takes a API-KEY as input
raises Error when not workin
"""
header = {"X-Authorization":self.token}
url = "http://api.zeit.de/client"
status = requests.get(url, headers = header)
if status:
return "everything ok"
else:
raise Exception(f"something gone wrong, code: {status.status_code}")
def client(self):
""" get the complete client request from the API,
returns a Client Object"""
url = self.base_url + "/client"
response = self.get(url)
cli = Client(response)
return cli
#definte the token method
def set_token(self, api_key):
""" set the api key, expects key
raises Error when key is not proper"""
#check
check = requests.get(
"http://api.zeit.de/client", headers = {"X-Authorization":api_key}
)
if check:
self.token = api_key
else:
raise Exception("Not a good key")
#general get function
def get(self, url = "http://api.zeit.de/content", limit = 10, search = False, time_range = False, fields = False, facet_time = False):
""" function to get content from the api, really broadly defined
Arguments:
url: content endpoint, default = api.zeit.de/content is standard content endpoint
limit: number results, default : 10
search: a specific search string
time-range: expects tuple of two datetime objects, default False
fields: return specific fields of the repsonse, expects a list
facetting = the time frame specified, e.g "1year"
Returns:
pure web response in json format
"""
header = {"X-Authorization":self.token}
parameters = {}
parameters["limit"] = limit
if search:
parameters["q"] = search
if fields:
parameters["fields"] = f"{*fields,}"
if time_range:
time1, time2 = time_range[0].isoformat(), time_range[1].isoformat()
if time1[-1] != "Z":
time1 += "Z"
time2 += "Z"
parameters["q"] = f'"{search}" AND release_date:[{time1} TO {time2}]'
if facet_time:
parameters["facet_date"] = facet_time
response = requests.get(url, params = parameters, headers = header).json()
return response
#specific get functions
def get_article(self, article_id):
""" function to get an article by its article id
returns a Article Object"""
endpoint = self.base_url + "/content"
url = id_check(article_id, endpoint)
response = self.get( url, limit=1)
article = Article(response)
return article
def get_author(self, author_id, limit = 1):
""" get an author by id, expects a valid author id
and optionally a limit on the number of articles"""
endpoint = self.base_url + "/author"
url = id_check(author_id, endpoint)
response = self.get( url, limit = limit)
return response
def get_keyword(self, keyword_id, limit = 1, facet_time = False):
""" get information about a keyword, expects keyword id and
optionally a limit on the number of articles returned"""
endpoint = self.base_url + "/keyword"
url = id_check(keyword_id, endpoint)
if facet_time:
response = self.get( url, limit = limit, facet_time=facet_time)
keyword = Keyword(response)
keyword.set_facets()
else:
response = self.get( url, limit = limit)
keyword = Keyword(response)
return keyword
def get_department(self, department_id, limit = 1):
""" get a department by id, returns a Department object"""
endpoint = self.base_url + "/department"
url = id_check(department_id, endpoint)
response = self.get( url, limit=1)
department = Department(response)
return department
#search functions
def search_for(self, search_string, search_type = "content", limit = 10, time_range = False, facet_time = False):
""" search the API for a specified string, one word only
allowed search types = content, keyword, department, author, product author
allows a time range of the format tuple(time1, time2)
also allows for facetting by setting a facet_time line '1year' etc.
returns a Search Class
"""
string = "*"
string += search_string
string += "*"
url = self.base_url+f"/{search_type}"
if facet_time:
response = self.get( url, limit = limit, search = string, time_range=time_range, facet_time=facet_time)
search = Search(search_string, response)
search.set_facets()
else:
response = self.get( url, limit = limit, search = string, time_range=time_range)
search = Search(search_string, response)
return search | zeit-online | /zeit_online-1.0.0-py3-none-any.whl/zeit/api.py | api.py |
=========
zeit.msal
=========
Helper to authenticate against Microsoft Azure AD and store the resulting tokens for commandline applications.
Usage
=====
1. Run interactively to store a refresh token in the cache
2. Use in e.g. automated tests to retrieve an ID token from the cache (which automatically refreshes it if necessary).
::
$ msal-token --client-id=myclient --client-secret=mysecret \
--cache-url=file:///tmp/msal.json login
Please visit https://login.microsoftonline.com/...
# Perform login via browser
def test_protected_web_ui():
auth = zeit.msal.Authenticator(
'myclient', 'mysecret', 'file:///tmp/msal.json')
http = requests.Session()
http.headers['Authorization'] = 'Bearer %s' % auth.get_id_token()
r = http.get('https://example.zeit.de/')
assert r.status_code == 200
Alternatively, retrieve the refresh token after interactive login, and use that in tests::
auth.login_with_refresh_token('myrefreshtoken')
| zeit.msal | /zeit.msal-1.1.0.tar.gz/zeit.msal-1.1.0/README.rst | README.rst |
from msal.token_cache import decode_id_token
from time import time
from urllib.parse import urlparse, parse_qsl
import msal
import wsgiref.simple_server
import zeit.msal.cache
class Authenticator:
redirect_url = 'http://localhost:4180/oauth2/callback'
tenant_zeitverlag = 'f6fef55b-9aba-48ae-9c6d-7ee8872bd9ed'
def __init__(self, client_id, client_secret, cache, tenant_id=None,
scopes=None):
if isinstance(cache, str):
cache = zeit.msal.cache.from_url(cache)
self.cache = cache
if tenant_id is None:
tenant_id = self.tenant_zeitverlag
self.app = msal.ConfidentialClientApplication(
client_id, client_secret, token_cache=self.cache,
authority='https://login.microsoftonline.com/%s' % tenant_id)
# msal requires this to signify that we want an ID token. It then
# allows specifying no other scopes, but implicitly uses openid,profile
# So I guess we're lucky that we use `upn` and not `mail`, because I
# don't see a way to add the `email` scope here.
if scopes is None:
self.scopes = [client_id]
else:
self.scopes = scopes
def get_id_token(self):
self.cache.load()
accounts = self.app.get_accounts()
if not accounts:
raise RuntimeError('No cached token available')
# XXX The msal cache currently does not handle id tokens, it always
# runs refresh even if the cached data is still valid.
result = self.cache.find(self.cache.CredentialType.ID_TOKEN)
if result:
token = result[0]['secret']
try:
data = decode_id_token(token)
except Exception:
pass
else:
# Like _acquire_token_silent_from_cache_and_possibly_refresh_it
expires_in = data['exp'] - time()
if expires_in > 5 * 60:
return token
result = self.app.acquire_token_silent(self.scopes, accounts[0])
if not result:
raise RuntimeError('Refreshing token failed')
self.cache.save()
return result['id_token']
def get_access_token(self):
self.cache.load()
accounts = self.app.get_accounts()
if not accounts:
raise RuntimeError('No cached token available')
result = self.app.acquire_token_silent(self.scopes, accounts[0])
if not result:
raise RuntimeError('Refreshing token failed')
self.cache.save()
return result['access_token']
def login_with_refresh_token(self, token):
result = self.app.acquire_token_by_refresh_token(token, self.scopes)
if 'error' in result:
raise RuntimeError(result['error'])
self.cache.save()
return result['id_token']
login_result = None
def login_interactively(self):
self.flow = self.app.initiate_auth_code_flow(
self.scopes, self.redirect_url)
print('Please visit %s' % self.flow['auth_uri'])
self.accept_http_callback()
if not self.login_result:
raise RuntimeError('Obtaining token failed')
self.cache.save()
return self.login_result['id_token']
def accept_http_callback(self):
with wsgiref.simple_server.make_server(
'0.0.0.0', urlparse(self.redirect_url).port,
self.http_callback,
handler_class=SilentRequestHandler) as server:
server.handle_request()
def http_callback(self, environ, start_response):
start_response('200 OK', [('Content-type', 'text/plain')])
self.login_result = self.app.acquire_token_by_auth_code_flow(
self.flow, dict(parse_qsl(environ.get('QUERY_STRING', ''))))
return [b'Success, this window can now be closed']
class SilentRequestHandler(wsgiref.simple_server.WSGIRequestHandler):
def log_request(self, *args, **kw):
pass | zeit.msal | /zeit.msal-1.1.0.tar.gz/zeit.msal-1.1.0/src/zeit/msal/authenticate.py | authenticate.py |
.. image:: https://github.com/ZeitOnline/zeit.nightwatch/workflows/Run%20tests/badge.svg
:alt: Test status badge
===============
zeit.nightwatch
===============
pytest helpers for http smoke tests
Making HTTP requests
====================
``zeit.nightwatch.Browser`` wraps a `requests <https://pypi.org/project/requests/>`_ ``Session`` to provide some convenience features:
- Instantiate with a base url, and then only use paths:
``http = Browser('https://example.com'); http.get('/foo')``
will request https://example.com/foo
- A convenience ``http`` fixture is provided, which can be configured via the ``nightwatch_config`` fixture.
- Use call instead of get, because it's just that *little bit* shorter.
(``http('/foo')`` instead of ``http.get('/foo')``)
- Fill and submit forms, powered by `mechanicalsoup <https://pypi.org/project/MechanicalSoup/>`_.
(We've customized this a bit, so that responses are only parsed with beautifulsoup if a feature like forms or links is actually used.)
- Logs request and response headers, so pytest prints these on test failures, to help debugging.
- Use ``sso_login(username, password)`` to log into https://meine.zeit.de.
- See source code for specific API details.
Example usage::
@pytest.fixture(scope='session')
def nightwatch_config():
return dict(browser=dict(
baseurl='https://example.com',
sso_url='https://meine.zeit.de/anmelden',
))
def test_my_site(http):
r = http.get('/something')
assert r.status_code == 200
def test_login(http):
http('/login')
http.select_form()
http.form['username'] = '[email protected]'
http.form['password'] = 'secret'
r = http.submit()
assert '/home' in r.url
def test_meinezeit_redirects_to_konto_after_login(http):
r = http.sso_login('[email protected]', 'secret')
assert r.url == 'https://www.zeit.de/konto'
Examining HTML responses
========================
nightwatch adds two helper methods to the ``requests.Response`` object:
* ``xpath()``: parses the response with ``lxml.html`` and then calls ``xpath()`` on that document
* ``css()``: converts the selector to xpath using `cssselect <https://pypi.org/project/cssselect/>`_ and then calls ``xpath()``
Example usage::
def test_error_page_contains_home_link(http):
r = http('/nonexistent')
assert r.status_code == 404
assert r.css('a.home')
Controlling a browser with Selenium
===================================
``zeit.nightwatch.WebDriverChrome`` inherits from ``selenium.webdriver.Chrome`` to provide some convenience features:
- Instantiate with a base url, and then only use paths:
``browser = WebDriverChrome('https://example.com'); browser.get('/foo')``
- A convenience ``selenium`` fixture is provided, which can be configured via the ``nightwatch_config`` fixture.
- ``wait()`` wraps ``WebDriverWait`` and converts ``TimeoutException` into an ``AssertionError``
- Use ``sso_login(username, password)`` to log into https://meine.zeit.de
- See source code for specific API details.
nightwatch also declares a pytest commandline option ``--selenium-visible`` to help toggling headless mode,
and adds a ``selenium`` mark to all tests that use a ``selenium`` fixture, so you can (de)select them with ``pytest -m selenium`` (or ``-m 'not selenium'``).
Since you'll probably want to set a base url, you have to provide this fixture yourself.
Example usage::
@pytest.fixture(scope='session')
def nightwatch_config():
return dict(selenium=dict(
baseurl='https://example.com',
))
def test_js_based_video_player(selenium):
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
s = selenium
s.get('/my-video')
s.wait(EC.presence_of_element_located((By.CLASS_NAME, 'videoplayer')))
Advanced usecase: To intercept/modify browser requests with `selenium-wire <https://pypi.org/project/selenium-wire/>`_, install that package (e.g. ``pip install selenium-wire``) and set ``driver_class=ProxiedWebDriverChrome`` in the nightwatch ``selenium`` config::
@pytest.fixture(scope='session')
def nightwatch_config():
return dict(selenium=dict(
baseurl='https://example.com',
driver_class='ProxiedWebDriverChrome',
))
def test_inject_authorization_header(selenium):
s = selenium
s.request_interceptor = lambda x: r.headers['authorization'] = 'Bearer MYTOKEN'
s.get('/protected-page')
Controlling a browser with playwright
=====================================
As an alternative to Selenium (above) nightwatch also supports playwright;
mostly by pulling in the ``pytest-playwright`` plugin, so you can use their fixtures, with some convenience features:
- Configure a base url, and then only use paths:
``page.goto('/foo')``
Example usage::
@pytest.fixture(scope='session')
def nightwatch_config():
return dict(selenium=dict(
baseurl='https://example.com',
))
def test_playwright_works(page):
page.goto('/something')
Running against different environments
======================================
To help with running the same tests against e.g. a staging and production environment, nightwatch declares a pytest commandline option ``--nightwatch-environment``.
A pattern we found helpful is using a fixture to provide environment-specific settings, like this::
CONFIG_STAGING = {
'base_url': 'https://staging.example.com',
'username': 'staging_user',
'password': 'secret',
}
CONFIG_PRODUCTION = {
'base_url': 'https://www.example.com',
'username': 'production_user',
'password': 'secret2',
}
@pytest.fixture(scope='session')
def nightwatch_config(nightwatch_environment):
config = globals()['CONFIG_%s' % nightwatch_environment.upper()]
return dict(environment=nightwatch_environment, browser=config)
def test_some_integration_that_has_no_staging(http, nightwatch_config):
if nightwatch_config['environment'] != 'production':
pytest.skip('The xyz integration has no staging')
r = http('/trigger-xyz')
assert r.json()['message'] == 'OK'
Sending test results to prometheus
==================================
Like the medieval night watch people who made the rounds checking that doors were locked,
our use case for this library is continuous black box high-level tests that check that main functional areas of our systems are working.
For this purpose, we want to integrate the test results with our monitoring system, which is based on `Prometheus <https://prometheus.io>`_.
We've taken inspiration from the `pytest-prometheus <https://pypi.org/project/pytest-prometheus/>`_ plugin, and tweaked it a little to use a stable metric name, so we can write a generic alerting rule.
This uses the configured `Pushgateway <https://prometheus.io/docs/practices/pushing/>`_ to record metrics like this (the ``environment`` label is populated from ``--nightwatch-environment``, see above)::
nightwatch_check{test="test_error_page_contains_home_link",environment="staging",job="website"}=1 # pass=1, fail=0
Clients should set the job name, e.g. like this::
def pytest_configure(config):
config.option.prometheus_job_name = 'website'
This functionality is disabled by default, nightwatch declares a pytest commandline option ``--prometheus`` which has to be present to enable pushing the metrics.
There also are commandline options to override the pushgateway url etc., please see the source code for those details.
| zeit.nightwatch | /zeit.nightwatch-1.6.0.tar.gz/zeit.nightwatch-1.6.0/README.rst | README.rst |
import prometheus_client
def addoption(parser):
group = parser.getgroup('terminal reporting')
group.addoption(
'--prometheus', action='store_true', default=False,
help='Send metrics to prometheus')
group.addoption(
'--prometheus-pushgateway-url',
default='https://prometheus-pushgw.ops.zeit.de',
help='Push Gateway URL to send metrics to')
group.addoption(
'--prometheus-metric-name', default='nightwatch_check',
help='Name for prometheus metrics, can contain {funcname} placeholder')
group.addoption(
'--prometheus-extra-labels', action='append',
help='Extra labels to attach to reported metrics')
group.addoption(
'--prometheus-job-name', default='unknown',
help='Value for the "job" key in exported metrics')
def configure(config):
if config.option.prometheus_extra_labels is None:
config.option.prometheus_extra_labels = []
config.option.prometheus_extra_labels.append(
'environment=%s' % config.getoption('--nightwatch-environment'))
config._prometheus = PrometheusReport(config)
config.pluginmanager.register(config._prometheus)
def unconfigure(config):
if getattr(config, '_prometheus', None) is not None:
config.pluginmanager.unregister(config._prometheus)
del config._prometheus
class PrometheusReport:
SUCCESSFUL_OUTCOMES = ['passed', 'skipped']
def __init__(self, config):
self.config = config
self.registry = prometheus_client.CollectorRegistry()
self.metrics = {}
def pytest_runtest_logreport(self, report):
if report.when != 'call':
return
opt = self.config.option
labels = dict(x.split('=') for x in opt.prometheus_extra_labels)
labels['test'] = report.location[2]
name = opt.prometheus_metric_name.format(funcname=report.location[2])
if 'name' not in self.metrics:
self.metrics['name'] = prometheus_client.Gauge(
name, '', labels.keys(), registry=self.registry)
self.metrics['name'].labels(**labels).set(
1 if report.outcome in self.SUCCESSFUL_OUTCOMES else 0)
def pytest_sessionfinish(self, session):
opt = self.config.option
if opt.verbose > 0:
print('\n' + prometheus_client.generate_latest(
self.registry).decode('utf-8'))
if not opt.prometheus:
return
prometheus_client.push_to_gateway(
opt.prometheus_pushgateway_url, job=opt.prometheus_job_name,
registry=self.registry) | zeit.nightwatch | /zeit.nightwatch-1.6.0.tar.gz/zeit.nightwatch-1.6.0/src/zeit/nightwatch/prometheus.py | prometheus.py |
from mechanicalsoup.stateful_browser import _BrowserState
import bs4
import cssselect
import logging
import lxml.html
import mechanicalsoup
import re
import requests
log = logging.getLogger(__name__)
# requests offers no easy way to customize the response class (response_hook
# and copy everything over to a new instance, anyone?), but since we only want
# two simple helper methods, monkey patching them should be quite alright.
def css(self, selector):
xpath = cssselect.HTMLTranslator().css_to_xpath(selector)
return self.xpath(xpath)
def xpath(self, selector):
if not hasattr(self, 'parsed'):
self.parsed = lxml.html.document_fromstring(self.text)
return self.parsed.xpath(selector)
requests.models.Response.css = css
requests.models.Response.xpath = xpath
class Browser(mechanicalsoup.StatefulBrowser):
"""Wraps a requests.Session to add some helpful features.
- instantiate with a base url, and then only use paths:
`http = Browser('https://example.com'); http.get('/foo')`
will request https://example.com/foo
- can use call instead of get, because it's just that little bit shorter
(`http('/foo')` instead of `http.get('/foo')`)
- fill and submit forms, powered by mechanicalsoup
(note that we override the "state" mechanics so beautifulsoup parsing
is only performed when it's actually needed)
"""
def __init__(self, baseurl=None, sso_url=None, *args, **kw):
self.baseurl = baseurl
self.sso_url = sso_url
kw.setdefault('session', HeaderPrintingSession())
super().__init__(*args, **kw)
@property
def headers(self):
return self.session.headers
def get(self, *args, **kw):
return self.request('get', *args, **kw)
def __call__(self, *args, **kw):
return self.get(*args, **kw)
def open(self, url, *args, **kw):
return self.request('get', url, *args, **kw)
def head(self, *args, **kw):
kw.setdefault('allow_redirects', False)
return self.request('head', *args, **kw)
def patch(self, *args, **kw):
return self.request('patch', *args, **kw)
def put(self, *args, **kw):
return self.request('put', *args, **kw)
def post(self, *args, **kw):
return self.request('post', *args, **kw)
def delete(self, *args, **kw):
return self.request('delete', *args, **kw)
def request(self, method, url, *args, **kw):
if url.startswith('/') and self.baseurl:
url = self.baseurl + url
r = self.session.request(method, url, *args, **kw)
# Taken from StatefulBrowser.open()
self._StatefulBrowser__state = LazySoupBrowserState(
r, self.soup_config, url=r.url, request=r.request)
return r
def submit(self, form=None, url=None, submit=None, **kw):
# This combines StatefulBrowser.submit_selected() and Browser.submit()
# and bases it all on self.request()
if form is None:
form = self.form
url = self._StatefulBrowser__state.url
self.form.choose_submit(submit)
if isinstance(form, mechanicalsoup.Form):
form = form.form
return self.request(**self.get_request_kwargs(form, url, **kw))
submit_selected = NotImplemented # Use our customized submit() instead
def links(self, url_regex=None, link_text=None, exact_text=False,
*args, **kw):
"""Enhanced to support contains instead of equals for link_text."""
links = self.page.find_all('a', href=True, *args, **kw)
if url_regex is not None:
return [a for a in links if re.search(url_regex, a['href'])]
if link_text is not None:
if exact_text:
return [a for a in links if a.text == link_text]
else:
return [a for a in links if link_text in a.text]
return []
def sso_login(self, username, password, url=None):
"""Performs login on meine.zeit.de. Opens either the configured sso_url,
or the given one (useful if e.g. it contains a return `?url` parameter)
and fills in and submits the form.
"""
if url is None:
url = self.sso_url
if url is None:
raise ValueError('No url given and no sso_url configured')
self.get(url)
self.select_form()
self.form['email'] = username
self.form['pass'] = password
return self.submit(headers={"referer": url})
class LazySoupBrowserState(_BrowserState):
"""Only parse with beautifulsoup if a client wants to use features that
need it (form filling, link selection)."""
def __init__(self, response, soup_config, **kw):
self.soup_config = soup_config
self.response = response
self._page = None
super().__init__(**kw)
@property
def page(self):
if self._page is None:
# Taken from mechanicalsoup.Browser.add_soup()
self._page = bs4.BeautifulSoup(
self.response.content, **self.soup_config)
return self._page
@page.setter
def page(self, value):
pass
class HeaderPrintingSession(requests.Session):
"""Prints request+response headers, to help understanding test failures."""
def request(self, method, url, *args, **kw):
log.info('> %s %s', method.upper(), url)
response = super().request(method, url, *args, **kw)
request = response.request
lines = ['< %s %s' % (request.method, request.url)]
lines.extend(['> %s: %s' % x for x in request.headers.items()])
lines.append('---')
resp = {'Status': response.status_code}
resp.update(response.headers)
lines.extend(['< %s: %s' % x for x in resp.items()])
log.info('\n'.join(lines))
return response | zeit.nightwatch | /zeit.nightwatch-1.6.0.tar.gz/zeit.nightwatch-1.6.0/src/zeit/nightwatch/requests.py | requests.py |
from selenium.common.exceptions import TimeoutException
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
import selenium.webdriver
class Convenience:
default_options = [
'disable-gpu',
]
def __init__(
self, baseurl, timeout=30, sso_url=None, headless=True,
window='1200x800', user_agent='Mozilla/ZONFrontendMonitoring',
*args, **kw):
self.baseurl = baseurl
self.sso_url = sso_url
self.timeout = timeout
opts = Options()
for x in self.default_options:
opts.add_argument(x)
if headless:
opts.add_argument('headless')
opts.add_argument('user-agent=[%s]' % user_agent)
opts.add_argument('window-size=%s' % window)
kw['options'] = opts
super().__init__(*args, **kw)
def get(self, url):
if url.startswith('/'):
url = self.baseurl + url
super().get(url)
def wait(self, condition, timeout=None):
if timeout is None:
timeout = self.timeout
try:
return WebDriverWait(self, timeout).until(condition)
except TimeoutException as e:
raise AssertionError() from e
def sso_login(self, username, password, url=None):
if url is None:
url = self.sso_url
if url is None:
raise ValueError('No url given and no sso_url configured')
self.get(url)
self.find_element(By.ID, 'login_email').send_keys(username)
self.find_element(By.ID, 'login_pass').send_keys(password)
self.find_element(By.CSS_SELECTOR, 'input.submit-button.log').click()
class WebDriverChrome(Convenience, selenium.webdriver.Chrome):
pass
try:
import seleniumwire.webdriver
class ProxiedWebDriverChrome(Convenience, seleniumwire.webdriver.Chrome):
pass
except ImportError: # soft dependency
class ProxiedWebDriverChrome:
def __init__(self, *args, **kw):
raise RuntimeError(
'Could not import `seleniumwire`, maybe run '
'`pip install selenium-wire`?') | zeit.nightwatch | /zeit.nightwatch-1.6.0.tar.gz/zeit.nightwatch-1.6.0/src/zeit/nightwatch/selenium.py | selenium.py |
import os
import tomli
from .utils import bump_version, cmd, find_basedir
class ReleaseOnlyPackage:
def __init__(self, name, where):
self.name = name
self.basedir = find_basedir(where)
# init convenience properties:
self.k8s_dir = self.basedir
self.fs_pyprojecttoml = os.path.join(self.basedir, "pyproject.toml")
self.release_version = self._get_release_version()
self.component = None
def release(self, version=None, rebuild=False, draft=False):
print("Releasing")
if not draft:
self.assert_clean_checkout()
self.preflight(rebuild=rebuild, draft=draft)
if not draft:
self.set_version(rebuild=rebuild)
self.run_skaffold_build(draft=draft)
if not draft:
self.postflight()
def run_skaffold_build(self, draft=False):
if self.component:
k8s = f"cd {self.k8s_dir}; skaffold build -m {self.component} --tag={self.release_version}" # noqa
else:
k8s = f"cd {self.k8s_dir}; skaffold build --tag={self.release_version}"
if draft:
k8s = "%s --dry-run=true" % k8s
status = os.system(k8s)
if status != 0:
raise SystemExit(1)
def preflight(self, rebuild=False, draft=False):
""" performs sanity checks but otherwise has no side effects, except exiting on failure
"""
towncrier_output = cmd(
f"towncrier --draft --config {self.fs_pyprojecttoml} --version {self.release_version}",
cwd=os.path.join(self.basedir),
)
if draft:
print(towncrier_output)
elif not rebuild and "No significant changes" in towncrier_output:
print("No changes to release found. Check output of ``towncrier --draft``")
raise SystemExit(1)
def postflight(self):
new_version = bump_version(self.release_version)
self._write_release_version(new_version)
cmd('git commit -am "Bump %s version"' % self.name)
cmd("git push")
def set_version(self, version=None, rebuild=False):
""" Sets the new release version, by either using the supplied version
or otherwise by finalizing the current development version.
Commits the version in git and creates a tag from it and pushes the change.
"""
if version is None:
version = self.release_version
if version is None:
print("Failed to calculate new version")
return
# sanitize version from dev suffix
version = version.split(".dev")[0].split("dev")[0]
tag = self.compute_tag(version)
if self._tag_exists(tag):
if rebuild:
print('Warning! Tag "%s" already exists. Reusing existing.' % tag)
# TODO: we should probably check out that tag, then, ey?
return tag
else:
print('Tag "%s" already exists. Aborting' % tag)
raise SystemExit(1)
self._write_release_version(version)
if self.component:
cmd(
f"towncrier --yes --config {self.fs_pyprojecttoml} --version {version}",
cwd=os.path.join(self.basedir, self.component),
)
else:
cmd(
f"towncrier --yes --config {self.fs_pyprojecttoml} --version {version}",
cwd=self.basedir,
)
self._write_deployment_version(version)
cmd('git commit -am "Release %s"' % tag)
cmd('git tag %s -m "%s"' % (tag, tag))
cmd("git push")
cmd("git push --tags")
return tag
def compute_tag(self, version):
""" hook to allow subclasses to customize tag generation"""
return version
# helpers you probably won't need to customize
def assert_clean_checkout(self):
if cmd("git status --short --untracked-files=no", cwd=self.basedir):
print("This is NOT a clean checkout. Aborting.")
raise SystemExit(1)
def _tag_exists(self, tag):
return cmd(
"git rev-parse --verify --quiet %s" % tag,
cwd=self.basedir,
acceptable_returncodes=[0, 1],
)
def _get_release_version(self):
with open(self.fs_pyprojecttoml) as fp:
toml_dict = tomli.load(fp)
try:
return toml_dict["tool"]["poetry"]["version"]
except KeyError:
raise RuntimeError("Unable to find own version string")
def _write_release_version(self, version):
# to preserve the pyproject.toml as much as possible we
# let poetry write the version instead of writing back the parsed
# dict
cmd(f"poetry version {version}", cwd=self.basedir)
self.release_version = version
def _write_deployment_version(self, version):
pass
class Package(ReleaseOnlyPackage):
environments = ["devel", "staging", "production"]
run_environments = ["devel"]
def __init__(self, name, where, component=None):
super().__init__(name, where)
self.component = component
self.k8s_dir = os.path.join(self.basedir, "k8s")
self.deployment_version = self._get_deployment_version()
def deploy(self, environment, version=None):
if environment not in self.environments:
print(
f"Cannot deploy to {environment} environment (must be one of {self.environments})"
)
raise SystemExit(1)
print(f"deploying to {environment}")
if version is None:
version = self.deployment_version
if self.component:
k8s = f"cd {self.k8s_dir}; skaffold deploy -m {self.component} --tag={version} --kube-context={environment}" # noqa
else:
k8s = f"cd {self.k8s_dir}; skaffold deploy --tag={version} --kube-context={environment}" # noqa
status = os.system(k8s)
if status != 0:
raise SystemExit(1)
def run_skaffold_run(self, environment):
if environment not in self.run_environments:
print(
f"Refusing to run against {environment} environment (must be {self.run_environments})" # noqa
)
raise SystemExit(1)
k8s = f"cd {self.basedir}/k8s; skaffold run --kube-context={environment}"
status = os.system(k8s)
if status != 0:
raise SystemExit(1)
def _deployment_versions_path(self):
if self.component:
return os.path.join(self.k8s_dir, self.component, "version")
else:
return os.path.join(self.k8s_dir, "version")
def _get_deployment_version(self):
return open(self._deployment_versions_path()).readline().split()[0]
def _write_deployment_version(self, version):
with open(self._deployment_versions_path(), "w") as v_f:
v_f.write(version)
self.deployment_version = version | zeit.shipit | /zeit.shipit-0.1.10.tar.gz/zeit.shipit-0.1.10/src/zeit/shipit/package.py | package.py |
GNU AFFERO GENERAL PUBLIC LICENSE
Version 3, 19 November 2007
Copyright (C) 2007 Free Software Foundation, Inc. <https://fsf.org/>
Everyone is permitted to copy and distribute verbatim copies
of this license document, but changing it is not allowed.
Preamble
The GNU Affero General Public License is a free, copyleft license for
software and other kinds of works, specifically designed to ensure
cooperation with the community in the case of network server software.
The licenses for most software and other practical works are designed
to take away your freedom to share and change the works. By contrast,
our General Public Licenses are intended to guarantee your freedom to
share and change all versions of a program--to make sure it remains free
software for all its users.
When we speak of free software, we are referring to freedom, not
price. Our General Public Licenses are designed to make sure that you
have the freedom to distribute copies of free software (and charge for
them if you wish), that you receive source code or can get it if you
want it, that you can change the software or use pieces of it in new
free programs, and that you know you can do these things.
Developers that use our General Public Licenses protect your rights
with two steps: (1) assert copyright on the software, and (2) offer
you this License which gives you legal permission to copy, distribute
and/or modify the software.
A secondary benefit of defending all users' freedom is that
improvements made in alternate versions of the program, if they
receive widespread use, become available for other developers to
incorporate. Many developers of free software are heartened and
encouraged by the resulting cooperation. However, in the case of
software used on network servers, this result may fail to come about.
The GNU General Public License permits making a modified version and
letting the public access it on a server without ever releasing its
source code to the public.
The GNU Affero General Public License is designed specifically to
ensure that, in such cases, the modified source code becomes available
to the community. It requires the operator of a network server to
provide the source code of the modified version running there to the
users of that server. Therefore, public use of a modified version, on
a publicly accessible server, gives the public access to the source
code of the modified version.
An older license, called the Affero General Public License and
published by Affero, was designed to accomplish similar goals. This is
a different license, not a version of the Affero GPL, but Affero has
released a new version of the Affero GPL which permits relicensing under
this license.
The precise terms and conditions for copying, distribution and
modification follow.
TERMS AND CONDITIONS
0. Definitions.
"This License" refers to version 3 of the GNU Affero General Public License.
"Copyright" also means copyright-like laws that apply to other kinds of
works, such as semiconductor masks.
"The Program" refers to any copyrightable work licensed under this
License. Each licensee is addressed as "you". "Licensees" and
"recipients" may be individuals or organizations.
To "modify" a work means to copy from or adapt all or part of the work
in a fashion requiring copyright permission, other than the making of an
exact copy. The resulting work is called a "modified version" of the
earlier work or a work "based on" the earlier work.
A "covered work" means either the unmodified Program or a work based
on the Program.
To "propagate" a work means to do anything with it that, without
permission, would make you directly or secondarily liable for
infringement under applicable copyright law, except executing it on a
computer or modifying a private copy. Propagation includes copying,
distribution (with or without modification), making available to the
public, and in some countries other activities as well.
To "convey" a work means any kind of propagation that enables other
parties to make or receive copies. Mere interaction with a user through
a computer network, with no transfer of a copy, is not conveying.
An interactive user interface displays "Appropriate Legal Notices"
to the extent that it includes a convenient and prominently visible
feature that (1) displays an appropriate copyright notice, and (2)
tells the user that there is no warranty for the work (except to the
extent that warranties are provided), that licensees may convey the
work under this License, and how to view a copy of this License. If
the interface presents a list of user commands or options, such as a
menu, a prominent item in the list meets this criterion.
1. Source Code.
The "source code" for a work means the preferred form of the work
for making modifications to it. "Object code" means any non-source
form of a work.
A "Standard Interface" means an interface that either is an official
standard defined by a recognized standards body, or, in the case of
interfaces specified for a particular programming language, one that
is widely used among developers working in that language.
The "System Libraries" of an executable work include anything, other
than the work as a whole, that (a) is included in the normal form of
packaging a Major Component, but which is not part of that Major
Component, and (b) serves only to enable use of the work with that
Major Component, or to implement a Standard Interface for which an
implementation is available to the public in source code form. A
"Major Component", in this context, means a major essential component
(kernel, window system, and so on) of the specific operating system
(if any) on which the executable work runs, or a compiler used to
produce the work, or an object code interpreter used to run it.
The "Corresponding Source" for a work in object code form means all
the source code needed to generate, install, and (for an executable
work) run the object code and to modify the work, including scripts to
control those activities. However, it does not include the work's
System Libraries, or general-purpose tools or generally available free
programs which are used unmodified in performing those activities but
which are not part of the work. For example, Corresponding Source
includes interface definition files associated with source files for
the work, and the source code for shared libraries and dynamically
linked subprograms that the work is specifically designed to require,
such as by intimate data communication or control flow between those
subprograms and other parts of the work.
The Corresponding Source need not include anything that users
can regenerate automatically from other parts of the Corresponding
Source.
The Corresponding Source for a work in source code form is that
same work.
2. Basic Permissions.
All rights granted under this License are granted for the term of
copyright on the Program, and are irrevocable provided the stated
conditions are met. This License explicitly affirms your unlimited
permission to run the unmodified Program. The output from running a
covered work is covered by this License only if the output, given its
content, constitutes a covered work. This License acknowledges your
rights of fair use or other equivalent, as provided by copyright law.
You may make, run and propagate covered works that you do not
convey, without conditions so long as your license otherwise remains
in force. You may convey covered works to others for the sole purpose
of having them make modifications exclusively for you, or provide you
with facilities for running those works, provided that you comply with
the terms of this License in conveying all material for which you do
not control copyright. Those thus making or running the covered works
for you must do so exclusively on your behalf, under your direction
and control, on terms that prohibit them from making any copies of
your copyrighted material outside their relationship with you.
Conveying under any other circumstances is permitted solely under
the conditions stated below. Sublicensing is not allowed; section 10
makes it unnecessary.
3. Protecting Users' Legal Rights From Anti-Circumvention Law.
No covered work shall be deemed part of an effective technological
measure under any applicable law fulfilling obligations under article
11 of the WIPO copyright treaty adopted on 20 December 1996, or
similar laws prohibiting or restricting circumvention of such
measures.
When you convey a covered work, you waive any legal power to forbid
circumvention of technological measures to the extent such circumvention
is effected by exercising rights under this License with respect to
the covered work, and you disclaim any intention to limit operation or
modification of the work as a means of enforcing, against the work's
users, your or third parties' legal rights to forbid circumvention of
technological measures.
4. Conveying Verbatim Copies.
You may convey verbatim copies of the Program's source code as you
receive it, in any medium, provided that you conspicuously and
appropriately publish on each copy an appropriate copyright notice;
keep intact all notices stating that this License and any
non-permissive terms added in accord with section 7 apply to the code;
keep intact all notices of the absence of any warranty; and give all
recipients a copy of this License along with the Program.
You may charge any price or no price for each copy that you convey,
and you may offer support or warranty protection for a fee.
5. Conveying Modified Source Versions.
You may convey a work based on the Program, or the modifications to
produce it from the Program, in the form of source code under the
terms of section 4, provided that you also meet all of these conditions:
a) The work must carry prominent notices stating that you modified
it, and giving a relevant date.
b) The work must carry prominent notices stating that it is
released under this License and any conditions added under section
7. This requirement modifies the requirement in section 4 to
"keep intact all notices".
c) You must license the entire work, as a whole, under this
License to anyone who comes into possession of a copy. This
License will therefore apply, along with any applicable section 7
additional terms, to the whole of the work, and all its parts,
regardless of how they are packaged. This License gives no
permission to license the work in any other way, but it does not
invalidate such permission if you have separately received it.
d) If the work has interactive user interfaces, each must display
Appropriate Legal Notices; however, if the Program has interactive
interfaces that do not display Appropriate Legal Notices, your
work need not make them do so.
A compilation of a covered work with other separate and independent
works, which are not by their nature extensions of the covered work,
and which are not combined with it such as to form a larger program,
in or on a volume of a storage or distribution medium, is called an
"aggregate" if the compilation and its resulting copyright are not
used to limit the access or legal rights of the compilation's users
beyond what the individual works permit. Inclusion of a covered work
in an aggregate does not cause this License to apply to the other
parts of the aggregate.
6. Conveying Non-Source Forms.
You may convey a covered work in object code form under the terms
of sections 4 and 5, provided that you also convey the
machine-readable Corresponding Source under the terms of this License,
in one of these ways:
a) Convey the object code in, or embodied in, a physical product
(including a physical distribution medium), accompanied by the
Corresponding Source fixed on a durable physical medium
customarily used for software interchange.
b) Convey the object code in, or embodied in, a physical product
(including a physical distribution medium), accompanied by a
written offer, valid for at least three years and valid for as
long as you offer spare parts or customer support for that product
model, to give anyone who possesses the object code either (1) a
copy of the Corresponding Source for all the software in the
product that is covered by this License, on a durable physical
medium customarily used for software interchange, for a price no
more than your reasonable cost of physically performing this
conveying of source, or (2) access to copy the
Corresponding Source from a network server at no charge.
c) Convey individual copies of the object code with a copy of the
written offer to provide the Corresponding Source. This
alternative is allowed only occasionally and noncommercially, and
only if you received the object code with such an offer, in accord
with subsection 6b.
d) Convey the object code by offering access from a designated
place (gratis or for a charge), and offer equivalent access to the
Corresponding Source in the same way through the same place at no
further charge. You need not require recipients to copy the
Corresponding Source along with the object code. If the place to
copy the object code is a network server, the Corresponding Source
may be on a different server (operated by you or a third party)
that supports equivalent copying facilities, provided you maintain
clear directions next to the object code saying where to find the
Corresponding Source. Regardless of what server hosts the
Corresponding Source, you remain obligated to ensure that it is
available for as long as needed to satisfy these requirements.
e) Convey the object code using peer-to-peer transmission, provided
you inform other peers where the object code and Corresponding
Source of the work are being offered to the general public at no
charge under subsection 6d.
A separable portion of the object code, whose source code is excluded
from the Corresponding Source as a System Library, need not be
included in conveying the object code work.
A "User Product" is either (1) a "consumer product", which means any
tangible personal property which is normally used for personal, family,
or household purposes, or (2) anything designed or sold for incorporation
into a dwelling. In determining whether a product is a consumer product,
doubtful cases shall be resolved in favor of coverage. For a particular
product received by a particular user, "normally used" refers to a
typical or common use of that class of product, regardless of the status
of the particular user or of the way in which the particular user
actually uses, or expects or is expected to use, the product. A product
is a consumer product regardless of whether the product has substantial
commercial, industrial or non-consumer uses, unless such uses represent
the only significant mode of use of the product.
"Installation Information" for a User Product means any methods,
procedures, authorization keys, or other information required to install
and execute modified versions of a covered work in that User Product from
a modified version of its Corresponding Source. The information must
suffice to ensure that the continued functioning of the modified object
code is in no case prevented or interfered with solely because
modification has been made.
If you convey an object code work under this section in, or with, or
specifically for use in, a User Product, and the conveying occurs as
part of a transaction in which the right of possession and use of the
User Product is transferred to the recipient in perpetuity or for a
fixed term (regardless of how the transaction is characterized), the
Corresponding Source conveyed under this section must be accompanied
by the Installation Information. But this requirement does not apply
if neither you nor any third party retains the ability to install
modified object code on the User Product (for example, the work has
been installed in ROM).
The requirement to provide Installation Information does not include a
requirement to continue to provide support service, warranty, or updates
for a work that has been modified or installed by the recipient, or for
the User Product in which it has been modified or installed. Access to a
network may be denied when the modification itself materially and
adversely affects the operation of the network or violates the rules and
protocols for communication across the network.
Corresponding Source conveyed, and Installation Information provided,
in accord with this section must be in a format that is publicly
documented (and with an implementation available to the public in
source code form), and must require no special password or key for
unpacking, reading or copying.
7. Additional Terms.
"Additional permissions" are terms that supplement the terms of this
License by making exceptions from one or more of its conditions.
Additional permissions that are applicable to the entire Program shall
be treated as though they were included in this License, to the extent
that they are valid under applicable law. If additional permissions
apply only to part of the Program, that part may be used separately
under those permissions, but the entire Program remains governed by
this License without regard to the additional permissions.
When you convey a copy of a covered work, you may at your option
remove any additional permissions from that copy, or from any part of
it. (Additional permissions may be written to require their own
removal in certain cases when you modify the work.) You may place
additional permissions on material, added by you to a covered work,
for which you have or can give appropriate copyright permission.
Notwithstanding any other provision of this License, for material you
add to a covered work, you may (if authorized by the copyright holders of
that material) supplement the terms of this License with terms:
a) Disclaiming warranty or limiting liability differently from the
terms of sections 15 and 16 of this License; or
b) Requiring preservation of specified reasonable legal notices or
author attributions in that material or in the Appropriate Legal
Notices displayed by works containing it; or
c) Prohibiting misrepresentation of the origin of that material, or
requiring that modified versions of such material be marked in
reasonable ways as different from the original version; or
d) Limiting the use for publicity purposes of names of licensors or
authors of the material; or
e) Declining to grant rights under trademark law for use of some
trade names, trademarks, or service marks; or
f) Requiring indemnification of licensors and authors of that
material by anyone who conveys the material (or modified versions of
it) with contractual assumptions of liability to the recipient, for
any liability that these contractual assumptions directly impose on
those licensors and authors.
All other non-permissive additional terms are considered "further
restrictions" within the meaning of section 10. If the Program as you
received it, or any part of it, contains a notice stating that it is
governed by this License along with a term that is a further
restriction, you may remove that term. If a license document contains
a further restriction but permits relicensing or conveying under this
License, you may add to a covered work material governed by the terms
of that license document, provided that the further restriction does
not survive such relicensing or conveying.
If you add terms to a covered work in accord with this section, you
must place, in the relevant source files, a statement of the
additional terms that apply to those files, or a notice indicating
where to find the applicable terms.
Additional terms, permissive or non-permissive, may be stated in the
form of a separately written license, or stated as exceptions;
the above requirements apply either way.
8. Termination.
You may not propagate or modify a covered work except as expressly
provided under this License. Any attempt otherwise to propagate or
modify it is void, and will automatically terminate your rights under
this License (including any patent licenses granted under the third
paragraph of section 11).
However, if you cease all violation of this License, then your
license from a particular copyright holder is reinstated (a)
provisionally, unless and until the copyright holder explicitly and
finally terminates your license, and (b) permanently, if the copyright
holder fails to notify you of the violation by some reasonable means
prior to 60 days after the cessation.
Moreover, your license from a particular copyright holder is
reinstated permanently if the copyright holder notifies you of the
violation by some reasonable means, this is the first time you have
received notice of violation of this License (for any work) from that
copyright holder, and you cure the violation prior to 30 days after
your receipt of the notice.
Termination of your rights under this section does not terminate the
licenses of parties who have received copies or rights from you under
this License. If your rights have been terminated and not permanently
reinstated, you do not qualify to receive new licenses for the same
material under section 10.
9. Acceptance Not Required for Having Copies.
You are not required to accept this License in order to receive or
run a copy of the Program. Ancillary propagation of a covered work
occurring solely as a consequence of using peer-to-peer transmission
to receive a copy likewise does not require acceptance. However,
nothing other than this License grants you permission to propagate or
modify any covered work. These actions infringe copyright if you do
not accept this License. Therefore, by modifying or propagating a
covered work, you indicate your acceptance of this License to do so.
10. Automatic Licensing of Downstream Recipients.
Each time you convey a covered work, the recipient automatically
receives a license from the original licensors, to run, modify and
propagate that work, subject to this License. You are not responsible
for enforcing compliance by third parties with this License.
An "entity transaction" is a transaction transferring control of an
organization, or substantially all assets of one, or subdividing an
organization, or merging organizations. If propagation of a covered
work results from an entity transaction, each party to that
transaction who receives a copy of the work also receives whatever
licenses to the work the party's predecessor in interest had or could
give under the previous paragraph, plus a right to possession of the
Corresponding Source of the work from the predecessor in interest, if
the predecessor has it or can get it with reasonable efforts.
You may not impose any further restrictions on the exercise of the
rights granted or affirmed under this License. For example, you may
not impose a license fee, royalty, or other charge for exercise of
rights granted under this License, and you may not initiate litigation
(including a cross-claim or counterclaim in a lawsuit) alleging that
any patent claim is infringed by making, using, selling, offering for
sale, or importing the Program or any portion of it.
11. Patents.
A "contributor" is a copyright holder who authorizes use under this
License of the Program or a work on which the Program is based. The
work thus licensed is called the contributor's "contributor version".
A contributor's "essential patent claims" are all patent claims
owned or controlled by the contributor, whether already acquired or
hereafter acquired, that would be infringed by some manner, permitted
by this License, of making, using, or selling its contributor version,
but do not include claims that would be infringed only as a
consequence of further modification of the contributor version. For
purposes of this definition, "control" includes the right to grant
patent sublicenses in a manner consistent with the requirements of
this License.
Each contributor grants you a non-exclusive, worldwide, royalty-free
patent license under the contributor's essential patent claims, to
make, use, sell, offer for sale, import and otherwise run, modify and
propagate the contents of its contributor version.
In the following three paragraphs, a "patent license" is any express
agreement or commitment, however denominated, not to enforce a patent
(such as an express permission to practice a patent or covenant not to
sue for patent infringement). To "grant" such a patent license to a
party means to make such an agreement or commitment not to enforce a
patent against the party.
If you convey a covered work, knowingly relying on a patent license,
and the Corresponding Source of the work is not available for anyone
to copy, free of charge and under the terms of this License, through a
publicly available network server or other readily accessible means,
then you must either (1) cause the Corresponding Source to be so
available, or (2) arrange to deprive yourself of the benefit of the
patent license for this particular work, or (3) arrange, in a manner
consistent with the requirements of this License, to extend the patent
license to downstream recipients. "Knowingly relying" means you have
actual knowledge that, but for the patent license, your conveying the
covered work in a country, or your recipient's use of the covered work
in a country, would infringe one or more identifiable patents in that
country that you have reason to believe are valid.
If, pursuant to or in connection with a single transaction or
arrangement, you convey, or propagate by procuring conveyance of, a
covered work, and grant a patent license to some of the parties
receiving the covered work authorizing them to use, propagate, modify
or convey a specific copy of the covered work, then the patent license
you grant is automatically extended to all recipients of the covered
work and works based on it.
A patent license is "discriminatory" if it does not include within
the scope of its coverage, prohibits the exercise of, or is
conditioned on the non-exercise of one or more of the rights that are
specifically granted under this License. You may not convey a covered
work if you are a party to an arrangement with a third party that is
in the business of distributing software, under which you make payment
to the third party based on the extent of your activity of conveying
the work, and under which the third party grants, to any of the
parties who would receive the covered work from you, a discriminatory
patent license (a) in connection with copies of the covered work
conveyed by you (or copies made from those copies), or (b) primarily
for and in connection with specific products or compilations that
contain the covered work, unless you entered into that arrangement,
or that patent license was granted, prior to 28 March 2007.
Nothing in this License shall be construed as excluding or limiting
any implied license or other defenses to infringement that may
otherwise be available to you under applicable patent law.
12. No Surrender of Others' Freedom.
If conditions are imposed on you (whether by court order, agreement or
otherwise) that contradict the conditions of this License, they do not
excuse you from the conditions of this License. If you cannot convey a
covered work so as to satisfy simultaneously your obligations under this
License and any other pertinent obligations, then as a consequence you may
not convey it at all. For example, if you agree to terms that obligate you
to collect a royalty for further conveying from those to whom you convey
the Program, the only way you could satisfy both those terms and this
License would be to refrain entirely from conveying the Program.
13. Remote Network Interaction; Use with the GNU General Public License.
Notwithstanding any other provision of this License, if you modify the
Program, your modified version must prominently offer all users
interacting with it remotely through a computer network (if your version
supports such interaction) an opportunity to receive the Corresponding
Source of your version by providing access to the Corresponding Source
from a network server at no charge, through some standard or customary
means of facilitating copying of software. This Corresponding Source
shall include the Corresponding Source for any work covered by version 3
of the GNU General Public License that is incorporated pursuant to the
following paragraph.
Notwithstanding any other provision of this License, you have
permission to link or combine any covered work with a work licensed
under version 3 of the GNU General Public License into a single
combined work, and to convey the resulting work. The terms of this
License will continue to apply to the part which is the covered work,
but the work with which it is combined will remain governed by version
3 of the GNU General Public License.
14. Revised Versions of this License.
The Free Software Foundation may publish revised and/or new versions of
the GNU Affero General Public License from time to time. Such new versions
will be similar in spirit to the present version, but may differ in detail to
address new problems or concerns.
Each version is given a distinguishing version number. If the
Program specifies that a certain numbered version of the GNU Affero General
Public License "or any later version" applies to it, you have the
option of following the terms and conditions either of that numbered
version or of any later version published by the Free Software
Foundation. If the Program does not specify a version number of the
GNU Affero General Public License, you may choose any version ever published
by the Free Software Foundation.
If the Program specifies that a proxy can decide which future
versions of the GNU Affero General Public License can be used, that proxy's
public statement of acceptance of a version permanently authorizes you
to choose that version for the Program.
Later license versions may give you additional or different
permissions. However, no additional obligations are imposed on any
author or copyright holder as a result of your choosing to follow a
later version.
15. Disclaimer of Warranty.
THERE IS NO WARRANTY FOR THE PROGRAM, TO THE EXTENT PERMITTED BY
APPLICABLE LAW. EXCEPT WHEN OTHERWISE STATED IN WRITING THE COPYRIGHT
HOLDERS AND/OR OTHER PARTIES PROVIDE THE PROGRAM "AS IS" WITHOUT WARRANTY
OF ANY KIND, EITHER EXPRESSED OR IMPLIED, INCLUDING, BUT NOT LIMITED TO,
THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR
PURPOSE. THE ENTIRE RISK AS TO THE QUALITY AND PERFORMANCE OF THE PROGRAM
IS WITH YOU. SHOULD THE PROGRAM PROVE DEFECTIVE, YOU ASSUME THE COST OF
ALL NECESSARY SERVICING, REPAIR OR CORRECTION.
16. Limitation of Liability.
IN NO EVENT UNLESS REQUIRED BY APPLICABLE LAW OR AGREED TO IN WRITING
WILL ANY COPYRIGHT HOLDER, OR ANY OTHER PARTY WHO MODIFIES AND/OR CONVEYS
THE PROGRAM AS PERMITTED ABOVE, BE LIABLE TO YOU FOR DAMAGES, INCLUDING ANY
GENERAL, SPECIAL, INCIDENTAL OR CONSEQUENTIAL DAMAGES ARISING OUT OF THE
USE OR INABILITY TO USE THE PROGRAM (INCLUDING BUT NOT LIMITED TO LOSS OF
DATA OR DATA BEING RENDERED INACCURATE OR LOSSES SUSTAINED BY YOU OR THIRD
PARTIES OR A FAILURE OF THE PROGRAM TO OPERATE WITH ANY OTHER PROGRAMS),
EVEN IF SUCH HOLDER OR OTHER PARTY HAS BEEN ADVISED OF THE POSSIBILITY OF
SUCH DAMAGES.
17. Interpretation of Sections 15 and 16.
If the disclaimer of warranty and limitation of liability provided
above cannot be given local legal effect according to their terms,
reviewing courts shall apply local law that most closely approximates
an absolute waiver of all civil liability in connection with the
Program, unless a warranty or assumption of liability accompanies a
copy of the Program in return for a fee.
END OF TERMS AND CONDITIONS
How to Apply These Terms to Your New Programs
If you develop a new program, and you want it to be of the greatest
possible use to the public, the best way to achieve this is to make it
free software which everyone can redistribute and change under these terms.
To do so, attach the following notices to the program. It is safest
to attach them to the start of each source file to most effectively
state the exclusion of warranty; and each file should have at least
the "copyright" line and a pointer to where the full notice is found.
<one line to give the program's name and a brief idea of what it does.>
Copyright (C) <year> <name of author>
This program is free software: you can redistribute it and/or modify
it under the terms of the GNU Affero General Public License as published
by the Free Software Foundation, either version 3 of the License, or
(at your option) any later version.
This program is distributed in the hope that it will be useful,
but WITHOUT ANY WARRANTY; without even the implied warranty of
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
GNU Affero General Public License for more details.
You should have received a copy of the GNU Affero General Public License
along with this program. If not, see <https://www.gnu.org/licenses/>.
Also add information on how to contact you by electronic and paper mail.
If your software can interact with users remotely through a computer
network, you should also make sure that it provides a way for users to
get its source. For example, if your program is a web application, its
interface could display a "Source" link that leads users to an archive
of the code. There are many ways you could offer source, and different
solutions will be better for different programs; see section 13 for the
specific requirements.
You should also get your employer (if you work as a programmer) or school,
if any, to sign a "copyright disclaimer" for the program, if necessary.
For more information on this, and how to apply and follow the GNU AGPL, see
<https://www.gnu.org/licenses/>.
| zeitgitterd | /zeitgitterd-1.1.3-py3-none-any.whl/zeitgitterd-1.1.3.dist-info/LICENSE.md | LICENSE.md |
# Committing to git and obtaining timestamps
import datetime
import logging as _logging
import subprocess
import sys
import threading
import time
import traceback
import pygit2 as git
import autoblockchainify.config
import autoblockchainify.mail
logging = _logging.getLogger('commit')
def push_upstream(repo, to, branches):
logging.info("Pushing to %s" % (['git', 'push', to] + branches))
ret = subprocess.run(['git', 'push', to] + branches,
cwd=repo)
if ret.returncode != 0:
logging.error("'git push %s %s' failed" % (to, branches))
def cross_timestamp(repo, branch, server):
ret = subprocess.run(['git', 'timestamp',
'--branch', branch, '--server', server],
cwd=repo)
if ret.returncode != 0:
sys.stderr.write("git timestamp --branch %s --server %s failed"
% (branch, server))
def has_changes(repo):
"""Check whether there are uncommitted changes, i.e., whether
`git status -z` has any output."""
ret = subprocess.run(['git', 'status', '-z'],
cwd=repo, capture_output=True, check=True)
return len(ret.stdout) > 0
def commit_current_state(repo):
"""Force a commit; will be called only if a commit has to be made.
I.e., if there really are changes or the force duration has expired."""
now = datetime.datetime.now(datetime.timezone.utc)
nowstr = now.strftime('%Y-%m-%d %H:%M:%S UTC')
subprocess.run(['git', 'add', '.'],
cwd=repo, check=True)
subprocess.run(['git', 'commit', '--allow-empty',
'-m', ":link: Autoblockchainify data as of " + nowstr],
cwd=repo, check=True)
def head_older_than(repo, duration):
"""Check whether the last commit is older than `duration`.
Unborn HEAD is *NOT* considered to be older; as a result,
the first commit will be done only after the first change."""
r = git.Repository(repo)
if r.head_is_unborn:
return False
now = datetime.datetime.utcnow()
if datetime.datetime.utcfromtimestamp(r.head.peel().commit_time) + duration < now:
return True
def do_commit():
"""To be called in a non-daemon thread to reduce possibilities of
early termination.
1. Commit if
* there is anything uncommitted, or
* more than FORCE_AFTER_INTERVALS intervals have passed since the
most recent commit.
2. Timestamp using HTTPS (synchronous)
3. (Optionally) push
4. (Optionally) cross-timestamp using email (asynchronous), if the previous
email has been sent more than FORCE_AFTER_INTERVALS ago. The response
will be added to a future commit."""
# Allow 5% of an interval tolerance, such that small timing differences
# will not lead to lengthening the duration by one commit_interval
force_interval = (autoblockchainify.config.arg.commit_interval
* (autoblockchainify.config.arg.force_after_intervals - 0.05))
try:
repo = autoblockchainify.config.arg.repository
if has_changes(repo) or head_older_than(repo, force_interval):
# 1. Commit
commit_current_state(repo)
# 2. Timestamp using Zeitgitter
repositories = autoblockchainify.config.arg.push_repository
branches = autoblockchainify.config.arg.push_branch
for r in autoblockchainify.config.arg.zeitgitter_servers:
logging.info("Cross-timestamping %s" % r)
(branch, server) = r.split('=', 1)
cross_timestamp(repo, branch, server)
# 3. Push
for r in repositories:
logging.info("Pushing upstream to %s" % r)
push_upstream(repo, r, branches)
# 4. Timestamp by mail (asynchronous)
if autoblockchainify.config.arg.stamper_own_address:
logging.info("cross-timestamping by mail")
autoblockchainify.mail.async_email_timestamp()
logging.info("do_commit done")
except Exception as e:
logging.error("Unhandled exception in do_commit() thread: %s: %s" %
(e, ''.join(traceback.format_tb(sys.exc_info()[2]))))
def loop():
"""Run at given interval and offset"""
interval = autoblockchainify.config.arg.commit_interval.total_seconds()
offset = autoblockchainify.config.arg.commit_offset.total_seconds()
while True:
now = time.time()
until = now - (now % interval) + offset
if until <= now:
until += interval
time.sleep(until - now)
threading.Thread(target=do_commit, daemon=False).start() | zeitgitterd | /zeitgitterd-1.1.3-py3-none-any.whl/autoblockchainify/commit.py | commit.py |
# Configuration handling
import argparse
import configargparse
import datetime
import logging as _logging
import os
import sys
import random
import autoblockchainify.deltat
import autoblockchainify.version
logging = _logging.getLogger('config')
def get_args(args=None, config_file_contents=None):
global arg
# Config file in /etc or the program directory
parser = configargparse.ArgumentParser(
auto_env_var_prefix="autoblockchainify_",
formatter_class=argparse.ArgumentDefaultsHelpFormatter,
description="autoblockchainify — Turn any directory into a GIT Blockchain.",
default_config_files=['/etc/autoblockchainify.conf',
os.path.join(os.getenv('HOME'), 'autoblockchainify.conf')])
# General
parser.add_argument('--config-file', '-c',
is_config_file=True,
help="config file path")
parser.add_argument('--debug-level',
default='INFO',
help="""amount of debug output: WARN, INFO, or DEBUG.
Debug levels for specific loggers can also be
specified using 'name=level'. Valid logger names:
`config`, `daemon`, `commit` (incl. requesting
timestamps), `gnupg`, `mail` (interfacing with PGP
Timestamping Server). Example: `DEBUG,gnupg=INFO`
sets the default debug level to DEBUG, except for
`gnupg`.""")
parser.add_argument('--version',
action='version', version=autoblockchainify.version.VERSION)
# Identity
# Default is applied in daemon.py:finish_setup()
parser.add_argument('--identity',
help="""'Full Name <email@address>' for tagging
GIT commits.
Default (will only be applied to new repositories):
'Autoblockchainify <autoblockchainify@localhost>'.
An explicit value (non-default) will always update
the current GIT config.""")
# Stamping
parser.add_argument('--commit-interval',
default='1h',
help="how often to commit")
parser.add_argument('--commit-offset',
help="""when to commit within that interval; e.g. after
37m19.3s. Default: Random choice in the interval.
For a production server, please fix a value in
the config file to avoid it jumping after every
restart.""")
parser.add_argument('--force-after-intervals',
type=int,
default=6,
help="""After how many intervals to force a commit (and
request a timestamp by email, if configured).""")
parser.add_argument('--repository',
default='.',
help="""path to the GIT repository (default '.')""")
parser.add_argument('--zeitgitter-servers',
default=
'diversity-timestamps=https://diversity.zeitgitter.net'
' gitta-timestamps=https://gitta.zeitgitter.net',
help="""any number of <branch>=<URL> tuples of
Zeitgitter timestampers""")
# Pushing
parser.add_argument('--push-repository',
default='',
help="""Space-separated list of repositores to push to;
setting this enables automatic push""")
parser.add_argument('--push-branch',
default='',
help="Space-separated list of branches to push")
# PGP Digital Timestamper interface
parser.add_argument('--stamper-own-address', '--mail-address', '--email-address',
help="""our email address; enables
cross-timestamping from the PGP timestamper""")
parser.add_argument('--stamper-keyid', '--external-pgp-timestamper-keyid',
default="70B61F81",
help="PGP key ID to obtain email cross-timestamps from")
parser.add_argument('--stamper-to', '--external-pgp-timestamper-to',
default="[email protected]",
help="""destination email address
to obtain email cross-timestamps from""")
parser.add_argument('--stamper-from', '--external-pgp-timestamper-from',
default="[email protected]",
help="""email address used by PGP timestamper
in its replies""")
parser.add_argument('--stamper-smtp-server', '--smtp-server',
help="""SMTP server to use for
sending mail to PGP Timestamper""")
parser.add_argument('--stamper-imap-server', '--imap-server',
help="""IMAP server to use for
receiving mail from PGP Timestamper""")
parser.add_argument('--stamper-username', '--mail-username',
help="""username to use for IMAP and SMTP
(default from `--stamper-own-address`)""")
parser.add_argument('--stamper-password', '--mail-password',
help="password to use for IMAP and SMTP")
parser.add_argument('--no-dovecot-bug-workaround', action='store_true',
help="""Some Dovecot mail server seem unable to match
the last char of an email address in an IMAP
SEARCH, so this cuts off the last char from
`stamper-from`. Should not impact other mail
servers.""")
arg = parser.parse_args(args=args, config_file_contents=config_file_contents)
_logging.basicConfig()
for level in str(arg.debug_level).split(','):
if '=' in level:
(logger, lvl) = level.split('=', 1)
else:
logger = None # Root logger
lvl = level
try:
lvl = int(lvl)
lvl = _logging.WARN - lvl * (_logging.WARN - _logging.INFO)
except ValueError:
# Does not work in Python 3.4.0 and 3.4.1
# See note in https://docs.python.org/3/library/logging.html#logging.getLevelName
lvl = _logging.getLevelName(lvl.upper())
_logging.getLogger(logger).setLevel(lvl)
if arg.stamper_username is None:
arg.stamper_username = arg.stamper_own_address
if arg.force_after_intervals < 2:
sys.exit("--force-after-intervals must be >= 2")
arg.commit_interval = autoblockchainify.deltat.parse_time(arg.commit_interval)
if arg.stamper_own_address is None:
if arg.commit_interval < datetime.timedelta(minutes=1):
sys.exit("--commit-interval may not be shorter than 1m")
else:
if arg.commit_interval*arg.force_after_intervals < datetime.timedelta(minutes=10):
sys.exit("--commit-interval times --force-after-intervals may "
"not be shorter than 10m when using the (mail-based) "
"PGP Digital Timestamping Service")
if arg.commit_offset is None:
# Avoid the seconds around the full interval, to avoid clustering
# with other system activity.
arg.commit_offset = arg.commit_interval * random.uniform(0.05, 0.95)
logging.info("Chose --commit-offset %s" % arg.commit_offset)
else:
arg.commit_offset = autoblockchainify.deltat.parse_time(arg.commit_offset)
if arg.commit_offset < datetime.timedelta(seconds=0):
sys.exit("--commit-offset must be positive")
if arg.commit_offset >= arg.commit_interval:
sys.exit("--commit-offset must be less than --commit-interval")
# Work around ConfigArgParse list bugs by implementing lists ourselves
arg.zeitgitter_servers = arg.zeitgitter_servers.split()
arg.push_repository = arg.push_repository.split()
arg.push_branch = arg.push_branch.split()
for i in arg.zeitgitter_servers:
if not '=' in i:
sys.exit("--upstream-timestamp requires (space-separated list of)"
" <branch>=<url> arguments")
if not arg.no_dovecot_bug_workaround:
arg.stamper_from = arg.stamper_from[:-1] # See help text
logging.debug("Settings applied: %s" % str(arg))
return arg | zeitgitterd | /zeitgitterd-1.1.3-py3-none-any.whl/autoblockchainify/config.py | config.py |
# Sending and receiving mail
import logging as _logging
import os
import re
import subprocess
import threading
import time
from datetime import datetime, timedelta
from imaplib import IMAP4
from pathlib import Path
from smtplib import SMTP
from time import gmtime, strftime
import pygit2 as git
import autoblockchainify.config
logging = _logging.getLogger('mail')
def split_host_port(host, default_port):
if ':' in host:
host, port = host.split(':', 1)
return (host, int(port))
else:
return (host, default_port)
def send(body, subject='Stamping request', to=None):
# Does not work in unittests if assigned in function header
# (are bound too early? At load time instead of at call time?)
if to is None:
to = autoblockchainify.config.arg.stamper_to
logging.debug('SMTP server %s' % autoblockchainify.config.arg.stamper_smtp_server)
(host, port) = split_host_port(autoblockchainify.config.arg.stamper_smtp_server, 587)
with SMTP(host, port=port) as smtp:
smtp.starttls()
smtp.login(autoblockchainify.config.arg.stamper_username,
autoblockchainify.config.arg.stamper_password)
frm = autoblockchainify.config.arg.stamper_own_address
date = strftime("%a, %d %b %Y %H:%M:%S +0000", gmtime())
msg = """From: %s
To: %s
Date: %s
Subject: %s
%s""" % (frm, to, date, subject, body)
smtp.sendmail(frm, to, msg)
def extract_pgp_body(body):
try:
body = str(body, 'ASCII')
except TypeError as t:
logging.warning("Conversion error for message body: %s" % t)
return None
lines = body.splitlines()
start = None
for i in range(0, len(lines)):
if lines[i] == '-----BEGIN PGP SIGNED MESSAGE-----':
logging.debug("Found start at %d: %s" % (i, lines[i]))
start = i
break
else:
return None
end = None
for i in range(start, len(lines)):
if lines[i] == '-----END PGP SIGNATURE-----':
logging.debug("Found end at %d: %s" % (i, lines[i]))
end = i
break
else:
return None
return lines[start:end + 1]
def save_signature(bodylines, logfile):
repo = autoblockchainify.config.arg.repository
ascfile = Path(repo, 'pgp-timestamp.sig')
with ascfile.open(mode='w') as f:
f.write('\n'.join(bodylines) + '\n')
# Change will be picked up by next check for directory modification
logfile.unlink() # Mark as reply received, no need for resumption
def maybe_decode(s):
"""Decode, if it is not `None`"""
if s is None:
return s
else:
return s.decode('ASCII')
def body_signature_correct(bodylines, stat):
body = '\n'.join(bodylines)
logging.debug("Bodylines: %s" % body)
# Cannot use Python gnupg wrapper: Requires GPG 1.x to verify
# Copy env for gnupg without locale
env = {}
for k in os.environ:
if not k.startswith('LC_'):
env[k] = os.environ[k]
env['LANG'] = 'C'
env['TZ'] = 'UTC'
res = subprocess.run(['gpg1', '--pgp2', '--verify'],
env=env, input=body.encode('ASCII'),
stderr=subprocess.PIPE)
stderr = maybe_decode(res.stderr)
logging.debug(stderr)
if res.returncode != 0:
logging.warning("gpg1 return code %d (%r)" % (res.returncode, stderr))
return False
if '\ngpg: Good signature' not in stderr:
logging.warning("Not good signature (%r)" % stderr)
return False
if not stderr.startswith('gpg: Signature made '):
logging.warning("Signature not made (%r)" % stderr)
return False
if not ((' key ID %s\n' % autoblockchainify.config.arg.stamper_keyid)
in stderr):
logging.warning("Wrong KeyID (%r)" % stderr)
return False
try:
logging.debug(stderr[24:48])
sigtime = datetime.strptime(stderr[24:48], "%b %d %H:%M:%S %Y %Z")
logging.debug(sigtime)
except ValueError:
logging.warning("Illegal date (%r)" % stderr)
return False
if sigtime > datetime.utcnow() + timedelta(seconds=30):
logging.warning("Signature time %s lies more than 30 seconds in the future"
% sigtime)
return False
modtime = datetime.utcfromtimestamp(stat.st_mtime)
if sigtime < modtime - timedelta(seconds=30):
logging.warning("Signature time %s is more than 30 seconds before\n"
"file modification time %s"
% (sigtime, modtime))
return False
return True
def verify_body_and_save_signature(body, stat, logfile, msgno):
bodylines = extract_pgp_body(body)
if bodylines is None:
logging.warning("No body lines")
return False
res = body_contains_file(bodylines, logfile)
if res is None:
logging.warning("File contents not in message %s" % msgno)
return False
else:
(before, after) = res
logging.debug("before %d, after %d" % (before, after))
if before > 20 or after > 20:
logging.warning("Too many lines added by the PGP Timestamping Server"
" before (%d)/after (%d) our contents" % (before, after))
return False
if not body_signature_correct(bodylines, stat):
logging.warning("Body signature incorrect")
return False
save_signature(bodylines, logfile)
return True
def body_contains_file(bodylines, logfile):
if bodylines is None:
return None
linesbefore = 0
with logfile.open(mode='r') as f:
# A few empty/comment lines at the beginning
firstline = f.readline().rstrip()
for i in range(len(bodylines)):
if bodylines[i] == firstline:
break
elif bodylines[i] == '' or bodylines[i][0] in '#-':
linesbefore += 1
else:
return None
# Now should be contiguous
i += 1
for line in f:
if bodylines[i] != line.rstrip():
return None
i += 1
# Now there should only be empty lines and a PGP signature
linesafter = len(bodylines) - i
i += 1
while bodylines[i] == '':
i += 1
if bodylines[i] != '-----BEGIN PGP SIGNATURE-----':
return None
# No further line starting with '-'
for i in range(i + 1, len(bodylines) - 1):
if bodylines[i] != '' and bodylines[i][0] == '-':
return None
return (linesbefore, linesafter)
def file_unchanged(stat, logfile):
try:
cur_stat = logfile.stat()
return (cur_stat.st_mtime == stat.st_mtime
and cur_stat.st_ino == stat.st_ino)
except FileNotFoundError:
return False
def imap_idle(imap, stat, logfile):
while True:
imap.send(b'%s IDLE\r\n' % (imap._new_tag()))
logging.info("IMAP waiting for IDLE response")
line = imap.readline().strip()
logging.debug("IMAP IDLE → %s" % line)
if line != b'+ idling':
logging.info("IMAP IDLE unsuccessful")
return False
# Wait for new message
while file_unchanged(stat, logfile):
line = imap.readline().strip()
if line == b'' or line.startswith(b'* BYE '):
return False
match = re.match(r'^\* ([0-9]+) EXISTS$', str(line, 'ASCII'))
if match:
logging.info("You have new mail %s!"
% match.group(1).encode('ASCII'))
# Stop idling
imap.send(b'DONE\r\n')
if check_for_stamper_mail(imap, stat, logfile) is True:
return False
break # Restart IDLE command
# Otherwise: Uninteresting untagged response, continue idling
logging.error("Next mail sent, giving up waiting on now-old reply")
def check_for_stamper_mail(imap, stat, logfile):
# See `--no-dovecot-bug-workaround`:
query = ('FROM', '"%s"' % autoblockchainify.config.arg.stamper_from,
'UNSEEN',
'LARGER', str(stat.st_size),
'SMALLER', str(stat.st_size + 16384))
logging.debug("IMAP SEARCH " + (' '.join(query)))
(typ, msgs) = imap.search(None, *query)
logging.info("IMAP SEARCH → %s, %s" % (typ, msgs))
if len(msgs) == 1 and len(msgs[0]) > 0:
mseq = msgs[0].replace(b' ', b',')
(typ, contents) = imap.fetch(mseq, 'BODY[TEXT]')
logging.debug("IMAP FETCH → %s (%d)" % (typ, len(contents)))
remaining_msgids = mseq.split(b',')
for m in contents:
if m != b')':
msgid = remaining_msgids[0]
remaining_msgids = remaining_msgids[1:]
logging.debug("IMAP FETCH BODY (%s) → %s…" % (msgid, m[1][:20]))
if verify_body_and_save_signature(m[1], stat, logfile, msgid):
logging.info("Verify_body() succeeded; deleting %s" % msgid)
imap.store(msgid, '+FLAGS', '\\Deleted')
return True
return False
def wait_for_receive(logfile):
stat = logfile.stat() # Should always succeed
logging.debug("Timestamp revision file is from %d" % stat.st_mtime)
(host, port) = split_host_port(autoblockchainify.config.arg.stamper_imap_server, 143)
with IMAP4(host=host, port=port) as imap:
imap.starttls()
imap.login(autoblockchainify.config.arg.stamper_username,
autoblockchainify.config.arg.stamper_password)
imap.select('INBOX')
if not check_for_stamper_mail(imap, stat, logfile):
# No existing message found, wait for more incoming messages
# and process them until definitely okay or giving up for good
if 'IDLE' in imap.capabilities:
imap_idle(imap, stat, logfile)
else:
logging.warning("IMAP server does not support IDLE")
# Poll every minute, for 10 minutes
for i in range(10):
time.sleep(60)
if check_for_stamper_mail(imap, stat, logfile):
return
logging.error("No response received, giving up")
def async_email_timestamp(resume=False):
"""If called with `resume=True`, tries to resume waiting for the mail"""
path = autoblockchainify.config.arg.repository
repo = git.Repository(path)
head = repo.head
logfile = Path(path, 'pgp-timestamp.tmp')
if repo.head_is_unborn:
logging.error("Cannot timestamp by email in repository without commits")
return
if resume:
if not logfile.is_file():
logging.info("Not resuming mail timestamp: No pending mail reply")
return
with logfile.open() as f:
contents = f.read()
if len(contents) < 40:
logging.info("Not resuming mail timestamp: No revision info")
return
else: # Fresh request
new_rev = ("Timestamp requested for\ngit commit %s\nat %s\n" %
(head.target.hex,
strftime("%a, %d %b %Y %H:%M:%S +0000", gmtime())))
with logfile.open('w') as f:
f.write(new_rev)
send(new_rev)
threading.Thread(target=wait_for_receive, args=(logfile,),
daemon=True).start() | zeitgitterd | /zeitgitterd-1.1.3-py3-none-any.whl/autoblockchainify/mail.py | mail.py |
# Committing to git and obtaining upstream timestamps
#
# The state machine used is described in ../doc/StateMachine.md
import datetime
import logging as _logging
import os
import subprocess
import sys
import threading
import time
import traceback
from pathlib import Path
import zeitgitter.config
import zeitgitter.mail
import zeitgitter.stamper
logging = _logging.getLogger('commit')
# To serialize all commit-related operations
# - writing commit entries in order (that includes obtaining the timestamp)
# - rotating files
# - performing other operations in the repository
serialize = threading.Lock()
def commit_to_git(repo, log, preserve=None, msg="Newly timestamped commits"):
subprocess.run(['git', 'add', log.as_posix()],
cwd=repo, check=True)
env = os.environ.copy()
env['GNUPGHOME'] = zeitgitter.config.arg.gnupg_home
subprocess.run(['git', 'commit', '-m', msg, '--allow-empty',
'--gpg-sign=' + zeitgitter.config.arg.keyid],
cwd=repo, env=env, check=True)
# Mark as processed; use only while locked!
if preserve is None:
log.unlink()
else:
log.rename(preserve)
with preserve.open('r') as p:
for line in p:
logging.debug('%s: %s' % (preserve, line))
def commit_dangling(repo, log):
"""If there is still a hashes.log hanging around, commit it now"""
# `subprocess.run(['git', …], …)` (called from `commit_to_git()`) may also
# raise FileNotFoundError. This, we do not want to be hidden by the `pass`.
# Therefore, this weird construct.
stat = None
try:
stat = log.stat()
except FileNotFoundError:
pass
if stat is not None:
d = datetime.datetime.utcfromtimestamp(stat.st_mtime)
dstr = d.strftime('%Y-%m-%d %H:%M:%S UTC')
# Do not preserve for PGP Timestamper, as another commit will follow
# immediately
commit_to_git(repo, log, None,
"Found uncommitted data from " + dstr)
def rotate_log_file(tmp, log):
tmp.rename(log)
def push_upstream(repo, to, branches):
logging.info("Pushing to %s" % (['git', 'push', to] + branches))
ret = subprocess.run(['git', 'push', to] + branches,
cwd=repo)
if ret.returncode != 0:
logging.error("'git push %s %s' failed" % (to, ' '.join(branches)))
def cross_timestamp(repo, options, delete_fake_time=False):
# Servers specified by servername only always use wallclock for the
# timestamps. Servers specified as `branch=server` tuples will
# allow wallclock to be overridden by `ZEITGITTER_FAKE_TIME`.
# This is needed for testing only, so that both reproducible
# signatures can be generated (with ourselves as timestamper
# and `ZEITGITTER_FAKE_TIME`) as well as remote Zeitgitter
# servers can be used.
if delete_fake_time and 'ZEITGITTER_FAKE_TIME' in os.environ:
env = os.environ.copy()
del env['ZEITGITTER_FAKE_TIME']
else:
env = os.environ
ret = subprocess.run(['git', 'timestamp'] + options, cwd=repo, env=env)
if ret.returncode != 0:
sys.stderr.write("git timestamp " + ' '.join(options) + " failed")
def do_commit():
"""To be called in a non-daemon thread to reduce possibilities of
early termination.
0. Check if there is anything uncommitted
1. Rotate log file
2. Commit to git
3. (Optionally) cross-timestamp using HTTPS (synchronous)
4. (Optionally) push
5. (Optionally) cross-timestamp using email (asynchronous)"""
try:
repo = zeitgitter.config.arg.repository
tmp = Path(repo, 'hashes.work')
log = Path(repo, 'hashes.log')
preserve = Path(repo, 'hashes.stamp')
with serialize:
commit_dangling(repo, log)
# See comment in `commit_dangling`
stat = None
try:
stat = tmp.stat()
except FileNotFoundError:
logging.info("Nothing to rotate")
if stat is not None:
rotate_log_file(tmp, log)
d = datetime.datetime.utcfromtimestamp(stat.st_mtime)
dstr = d.strftime('%Y-%m-%d %H:%M:%S UTC')
commit_to_git(repo, log, preserve,
"Newly timestamped commits up to " + dstr)
with tmp.open(mode='ab'):
pass # Recreate hashes.work
repositories = zeitgitter.config.arg.push_repository
branches = zeitgitter.config.arg.push_branch
for r in zeitgitter.config.arg.upstream_timestamp:
logging.info("Cross-timestamping %s" % r)
if '=' in r:
(branch, server) = r.split('=', 1)
cross_timestamp(repo, ['--branch', branch, '--server', server])
else:
cross_timestamp(repo, ['--server', r], delete_fake_time=True)
time.sleep(zeitgitter.config.arg.upstream_sleep.total_seconds())
for r in repositories:
logging.info("Pushing upstream to %s" % r)
push_upstream(repo, r, branches)
if zeitgitter.config.arg.stamper_own_address:
logging.info("cross-timestamping by mail")
zeitgitter.mail.async_email_timestamp(preserve)
logging.info("do_commit done")
except Exception as e:
logging.error("Unhandled exception in do_commit() thread: %s: %s" %
(e, ''.join(traceback.format_tb(sys.exc_info()[2]))))
def wait_until():
"""Run at given interval and offset"""
interval = zeitgitter.config.arg.commit_interval.total_seconds()
offset = zeitgitter.config.arg.commit_offset.total_seconds()
while True:
now = time.time()
until = now - (now % interval) + offset
if until <= now:
until += interval
time.sleep(until - now)
threading.Thread(target=do_commit, daemon=False).start()
def run():
"""Start background thread to wait for given time"""
threading.Thread(target=wait_until, daemon=True).start() | zeitgitterd | /zeitgitterd-1.1.3-py3-none-any.whl/zeitgitter/commit.py | commit.py |
# Configuration handling
import argparse
import datetime
import logging as _logging
import os
import random
import sys
import configargparse
import zeitgitter.deltat
import zeitgitter.version
logging = _logging.getLogger('config')
def print_sample_config():
from zeitgitter import moddir
from pathlib import Path
try:
with Path(moddir(), 'sample.conf').open(mode='r') as f:
print(f.read())
except IOError:
import importlib.resources
print(importlib.resources.read_text('zeitgitter', 'sample.conf'))
sys.exit(0)
def get_args(args=None, config_file_contents=None):
global arg
writeback = {}
# Config file in /etc or the program directory
parser = configargparse.ArgumentParser(
auto_env_var_prefix="zeitgitter_",
formatter_class=argparse.ArgumentDefaultsHelpFormatter,
description="zeitgitterd.py — The Independent git Timestamping server.",
default_config_files=['/etc/zeitgitter.conf',
os.path.join(os.getenv('HOME'), 'zeitgitter.conf')])
# General
parser.add_argument('--config-file', '-c',
is_config_file=True,
help="config file path")
parser.add_argument('--print-sample-config',
action='store_true',
help="""output sample configuration file from package
and exit""")
parser.add_argument('--debug-level',
default='INFO',
help="""amount of debug output: WARN, INFO, or DEBUG.
Debug levels for specific loggers can also be
specified using 'name=level'. Valid logger names:
`config`, `server`, `stamper`, `commit` (incl.
requesting cross-timestamps), `gnupg`, `mail`
(interfacing with PGP Timestamping Server).
Example: `DEBUG,gnupg=INFO` sets the default
debug level to DEBUG, except for `gnupg`.""")
parser.add_argument('--version',
action='version', version=zeitgitter.version.VERSION)
# Identity
parser.add_argument('--keyid',
help="""the PGP key ID to timestamp with, creating
this key first if necessary.""")
parser.add_argument('--own-url',
help="the URL of this service (REQUIRED)")
parser.add_argument('--domain',
help="the domain name, for HTML substitution and SMTP greeting. "
"Defaults to host part of --own-url")
parser.add_argument('--country',
help="the jurisdiction this falls under,"
" for HTML substitution (REQUIRED)")
parser.add_argument('--owner',
help="owner and operator of this instance,"
" for HTML substitution (REQUIRED)")
parser.add_argument('--contact',
help="contact for this instance,"
" for HTML substitution (REQUIRED)")
# Server
parser.add_argument('--webroot',
help="path to the webroot (fallback: in-module files)")
parser.add_argument('--listen-address',
default='127.0.0.1', # Still not all machines support ::1
help="IP address to listen on")
parser.add_argument('--listen-port',
default=15177, type=int,
help="port number to listen on")
parser.add_argument('--cache-control-static',
default="max-age=86400,"
" stale-while-revalidate=86400,"
" stale-if-error=86400",
help="The value of the `Cache-Control` HTTP header"
" returned for static pages")
# GnuPG
parser.add_argument('--max-parallel-signatures',
default=2, type=int,
help="""maximum number of parallel timestamping operations.
Please note that GnuPG serializes all operations through
the gpg-agent, so parallelism helps very little""")
parser.add_argument('--max-parallel-timeout',
type=float,
help="""number of seconds to wait for a timestamping thread
before failing (default: wait forever)""")
parser.add_argument('--number-of-gpg-agents',
default=1, type=int,
help="number of gpg-agents to run")
parser.add_argument('--gnupg-home',
default=os.getenv('GNUPGHOME',
os.getenv('HOME', '/var/lib/zeitgitter') + '/.gnupg'),
help="""GnuPG Home Dir to use (default from $GNUPGHOME
or $HOME/.gnupg or /var/lib/zeitgitter/.gnupg)""")
# Stamping
parser.add_argument('--commit-interval',
default='1h',
help="how often to commit")
parser.add_argument('--commit-offset',
help="""when to commit within that interval; e.g. after
37m19.3s. Default: Random choice in the interval.
For a production server, please fix a value in
the config file to avoid it jumping after every
restart.""")
parser.add_argument('--repository',
default=os.path.join(
os.getenv('HOME', '/var/lib/zeitgitter'), 'repo'),
help="""path to the GIT repository (default from
$HOME/repo or /var/lib/zeitgitter/repo)""")
parser.add_argument('--upstream-timestamp',
default='diversity gitta',
help="""any number of space-separated upstream
Zeitgitter servers of the form
`[<branch>=]<server>`. The server name will
be passed with `--server` to `git timestamp`,
the (optional) branch name with `--branch`.""")
parser.add_argument('--upstream-sleep',
default='0s',
help="""Delay between cross-timestamping for the
different timestampers""")
# Pushing
parser.add_argument('--push-repository',
default='',
help="""Space-separated list of repositores to push to;
setting this enables automatic push""")
parser.add_argument('--push-branch',
default='*',
help="""Space-separated list of branches to push.
`*` means all, as `--all` is eaten by ConfigArgParse""")
# PGP Digital Timestamper interface
parser.add_argument('--stamper-own-address', '--mail-address', '--email-address',
help="""our email address; enables
cross-timestamping from the PGP timestamper""")
parser.add_argument('--stamper-keyid', '--external-pgp-timestamper-keyid',
default="70B61F81",
help="PGP key ID to obtain email cross-timestamps from")
parser.add_argument('--stamper-to', '--external-pgp-timestamper-to',
default="[email protected]",
help="""destination email address
to obtain email cross-timestamps from""")
parser.add_argument('--stamper-from', '--external-pgp-timestamper-from',
default="[email protected]",
help="""email address used by PGP timestamper
in its replies""")
parser.add_argument('--stamper-smtp-server', '--smtp-server',
help="""SMTP server to use for
sending mail to PGP Timestamper""")
parser.add_argument('--stamper-imap-server', '--imap-server',
help="""IMAP server to use for
receiving mail from PGP Timestamper""")
parser.add_argument('--stamper-username', '--mail-username',
help="""username to use for IMAP and SMTP
(default from `--stamper-own-address`)""")
parser.add_argument('--stamper-password', '--mail-password',
help="password to use for IMAP and SMTP")
parser.add_argument('--no-dovecot-bug-workaround', action='store_true',
help="""Some Dovecot mail server seem unable to match
the last char of an email address in an IMAP
SEARCH, so this cuts off the last char from
`stamper-from`. Should not impact other mail
servers.""")
arg = parser.parse_args(
args=args, config_file_contents=config_file_contents)
if arg.print_sample_config:
print_sample_config()
sys.exit(0)
# To be able to support `--print-sample-config`, we need to handle
# `required` attributes ourselves
missing = []
if arg.owner is None:
missing.append("--owner")
if arg.contact is None:
missing.append("--contact")
if arg.country is None:
missing.append("--country")
if arg.own_url is None:
missing.append("--own-url")
if len(missing):
parser.print_help()
sys.exit("Required arguments missing: " + ", ".join(missing))
_logging.basicConfig()
for level in str(arg.debug_level).split(','):
if '=' in level:
(logger, lvl) = level.split('=', 1)
else:
logger = None # Root logger
lvl = level
try:
lvl = int(lvl)
lvl = _logging.WARN - lvl * (_logging.WARN - _logging.INFO)
except ValueError:
# Does not work in Python 3.4.0 and 3.4.1
# See note in https://docs.python.org/3/library/logging.html#logging.getLevelName
lvl = _logging.getLevelName(lvl.upper())
_logging.getLogger(logger).setLevel(lvl)
if arg.stamper_username is None:
arg.stamper_username = arg.stamper_own_address
arg.commit_interval = zeitgitter.deltat.parse_time(arg.commit_interval)
if arg.stamper_own_address is None:
if arg.commit_interval < datetime.timedelta(minutes=1):
sys.exit("--commit-interval may not be shorter than 1m")
else:
if arg.commit_interval < datetime.timedelta(minutes=10):
sys.exit("--commit-interval may not be shorter than 10m when "
"using the PGP Digital Timestamper")
if arg.commit_offset is None:
# Avoid the seconds around the full interval, to avoid clustering
# with other system activity.
arg.commit_offset = arg.commit_interval * random.uniform(0.05, 0.95)
logging.info("Chose --commit-offset %s" % arg.commit_offset)
else:
arg.commit_offset = zeitgitter.deltat.parse_time(arg.commit_offset)
if arg.commit_offset < datetime.timedelta(seconds=0):
sys.exit("--commit-offset must be positive")
if arg.commit_offset >= arg.commit_interval:
sys.exit("--commit-offset must be less than --commit-interval")
arg.upstream_sleep = zeitgitter.deltat.parse_time(arg.upstream_sleep)
if arg.domain is None:
arg.domain = arg.own_url.replace('https://', '')
# Work around ConfigArgParse list bugs by implementing lists ourselves
# and working around the problem that values cannot start with `-`.
arg.upstream_timestamp = arg.upstream_timestamp.split()
arg.push_repository = arg.push_repository.split()
if arg.push_branch == '*':
arg.push_branch = ['--all']
else:
arg.push_branch = arg.push_branch.split()
if not arg.no_dovecot_bug_workaround:
arg.stamper_from = arg.stamper_from[:-1] # See help text
return arg | zeitgitterd | /zeitgitterd-1.1.3-py3-none-any.whl/zeitgitter/config.py | config.py |
# Timestamp creation
import logging as _logging
import os
import re
import shutil
import sys
import threading
import time
from pathlib import Path
import gnupg
import zeitgitter.commit
import zeitgitter.config
logging = _logging.getLogger('stamper')
def get_nick(domain):
fields = domain.split('.')
for i in fields:
if i != '' and i != 'igitt' and i != 'zeitgitter' and 'stamp' not in i:
return i
sys.exit("Please specify a keyid")
def create_key(gpg, keyid):
name, mail = keyid.split(' <')
mail = mail[:-1]
gki = gpg.gen_key_input(name_real=name, name_email=mail,
key_type='eddsa', key_curve='Ed25519', key_usage='sign')
# Force to not ask (non-existant) user for passphrase
gki = '%no-protection\n' + gki
key = gpg.gen_key(gki)
if key.fingerprint is None:
sys.exit("Cannot create PGP key for %s: %s" % (keyid, key.stderr))
logging.info("Created PGP key %s" % key.fingerprint)
return key.fingerprint
def get_keyid(keyid, domain, gnupg_home):
"""Find (and possibly create) a key ID by trying the following, in order:
1. `keyid` is not `None`:
1. `keyid` matches exactly one secret key: return the hexadecimal
key ID of that key.
2. `keyid` does not match any existing key, but matches the pattern
"Name <email>": Create an ed25519 key and return its ID.
3. Else fail.
2. `keyid` is `None`:
1. If there is exactly one secret key in the keyring, return that one.
2. If there are no secret keys in the keyring, create an ed25519 key
named "Nickname Timestamping Service <domain-to-email>", where
"Nickname" is the capitalized first dot-separated part of `domain`
which is not "zeitgitter", "igitt", or "*stamp*"; and
"domain-to-email" is `domain` with its first dot is replaced by an @.
3. Else fail.
Design decision: The key is only created if the next start would chose that
key (this obviates the need to monkey-patch the config file).
All these operations must be done before round-robin operations (and
copying the "original" GnuPG "home" directory) start."""
gpg = gnupg.GPG(gnupghome=gnupg_home)
if keyid is not None:
keyinfo = gpg.list_keys(secret=True, keys=keyid)
if len(keyinfo) == 1:
return keyinfo[0]['keyid']
elif re.match("^[A-Z][A-Za-z0-9 ]+ <[-_a-z0-9.]+@[-a-z0-9.]+>$",
keyid) and len(keyinfo) == 0:
return create_key(gpg, keyid)
else:
if len(keyinfo) > 0:
sys.exit("Too many secret keys matching key '%s'" % keyid)
else:
sys.exit("No secret keys match keyid '%s', "
"use the form 'Description <email>' if zeitgitterd "
"should create one automatically with that name" % keyid)
else:
keyinfo = gpg.list_keys(secret=True)
if len(keyinfo) == 1:
return keyinfo[0]['keyid']
elif len(keyinfo) == 0:
nick = get_nick(domain)
maildomain = domain.replace('.', '@', 1)
return create_key(gpg, "%s Timestamping Service <%s>"
% (nick.capitalize(), maildomain))
else:
sys.exit("Please specify a keyid in the configuration file")
class Stamper:
def __init__(self):
self.sem = threading.BoundedSemaphore(
zeitgitter.config.arg.max_parallel_signatures)
self.gpg_serialize = threading.Lock()
self.timeout = zeitgitter.config.arg.max_parallel_timeout
self.url = zeitgitter.config.arg.own_url
self.keyid = zeitgitter.config.arg.keyid
self.gpgs = [gnupg.GPG(gnupghome=zeitgitter.config.arg.gnupg_home)]
self.max_threads = 1 # Start single-threaded
self.keyinfo = self.gpg().list_keys(True, keys=self.keyid)
if len(self.keyinfo) == 0:
raise ValueError("No keys found")
self.fullid = self.keyinfo[0]['uids'][0]
self.pubkey = self.gpg().export_keys(self.keyid)
self.extra_delay = None
def start_multi_threaded(self):
self.max_threads = zeitgitter.config.arg.number_of_gpg_agents
def gpg(self):
"""Return the next GnuPG object, in round robin order.
Create one, if less than `number-of-gpg-agents` are available."""
with self.gpg_serialize:
if len(self.gpgs) < self.max_threads:
home = Path('%s-%d' % (zeitgitter.config.arg.gnupg_home, len(self.gpgs)))
# Create copy if needed; to trick an additional gpg-agent
# being started for the same directory
if home.exists():
if home.is_symlink():
logging.info("Creating GnuPG key copy %s→%s"
", replacing old symlink"
% (zeitgitter.config.arg.gnupg_home, home))
home.unlink()
# Ignore sockets (must) and backups (may) on copy
shutil.copytree(zeitgitter.config.arg.gnupg_home,
home, ignore=shutil.ignore_patterns("S.*", "*~"))
else:
logging.info("Creating GnuPG key copy %s→%s"
% (zeitgitter.config.arg.gnupg_home, home))
shutil.copytree(zeitgitter.config.arg.gnupg_home,
home, ignore=shutil.ignore_patterns("S.*", "*~"))
nextgpg = gnupg.GPG(gnupghome=home.as_posix())
self.gpgs.append(nextgpg)
logging.debug("Returning new %r (gnupghome=%s)" % (nextgpg, nextgpg.gnupghome))
return nextgpg
else:
# Rotate list left and return element wrapped around (if the list
# just became full, this is the one least recently used)
nextgpg = self.gpgs[0]
self.gpgs = self.gpgs[1:]
self.gpgs.append(nextgpg)
logging.debug("Returning old %r (gnupghome=%s)" % (nextgpg, nextgpg.gnupghome))
return nextgpg
def sig_time(self):
"""Current time, unless in test mode"""
return int(os.getenv('ZEITGITTER_FAKE_TIME', time.time()))
def get_public_key(self):
return self.pubkey
def valid_tag(self, tag):
"""Tag validity defined in doc/Protocol.md
Switching to `pygit2.reference_is_valid_name()` should be considered
when this function is widely availabe in installations
(was only added on 2018-10-17)"""
# '$' always matches '\n' as well. Don't want this here.
return (re.match('^[_a-z][-._a-z0-9]{,99}$', tag, re.IGNORECASE)
and ".." not in tag and not '\n' in tag)
def valid_commit(self, commit):
# '$' always matches '\n' as well. Don't want this here.
if '\n' in commit:
return False
return re.match('^[0-9a-f]{40}$', commit)
def limited_sign(self, now, commit, data):
"""Sign, but allow at most <max-parallel-timeout> executions.
Requests exceeding this limit will return None after <timeout> s,
or wait indefinitely, if `--max-parallel-timeout` has not been
given (i.e., is None). It logs any commit ID to stable storage
before attempting to even create a signature. It also makes sure
that the GnuPG signature time matches the GIT timestamps."""
if self.sem.acquire(timeout=self.timeout):
ret = None
try:
if self.extra_delay:
time.sleep(self.extra_delay)
ret = self.gpg().sign(data, keyid=self.keyid, binary=False,
clearsign=False, detach=True,
extra_args=('--faked-system-time',
str(now) + '!'))
finally:
self.sem.release()
return ret
else: # Timeout
return None
def log_commit(self, commit):
with Path(zeitgitter.config.arg.repository,
'hashes.work').open(mode='ab', buffering=0) as f:
f.write(bytes(commit + '\n', 'ASCII'))
os.fsync(f.fileno())
def stamp_tag(self, commit, tagname):
if self.valid_commit(commit) and self.valid_tag(tagname):
with zeitgitter.commit.serialize:
now = int(self.sig_time())
self.log_commit(commit)
isonow = time.strftime("%Y-%m-%d %H:%M:%S UTC", time.gmtime(now))
tagobj = """object %s
type commit
tag %s
tagger %s %d +0000
:watch: %s tag timestamp
""" % (commit, tagname, self.fullid, now,
self.url)
sig = self.limited_sign(now, commit, tagobj)
if sig == None:
return None
else:
return tagobj + str(sig)
else:
return 406
def stamp_branch(self, commit, parent, tree):
if (self.valid_commit(commit) and self.valid_commit(tree)
and (parent == None or self.valid_commit(parent))):
with zeitgitter.commit.serialize:
now = int(self.sig_time())
self.log_commit(commit)
isonow = time.strftime("%Y-%m-%d %H:%M:%S UTC", time.gmtime(now))
if parent == None:
commitobj1 = """tree %s
parent %s
author %s %d +0000
committer %s %d +0000
""" % (tree, commit, self.fullid, now, self.fullid, now)
else:
commitobj1 = """tree %s
parent %s
parent %s
author %s %d +0000
committer %s %d +0000
""" % (tree, parent, commit, self.fullid, now, self.fullid, now)
commitobj2 = """
:watch: %s branch timestamp %s
""" % (self.url, isonow)
sig = self.limited_sign(now, commit, commitobj1 + commitobj2)
if sig == None:
return None
else:
# Replace all inner '\n' with '\n '
gpgsig = 'gpgsig ' + str(sig).replace('\n', '\n ')[:-1]
assert gpgsig[-1] == '\n'
return commitobj1 + gpgsig + commitobj2
else:
return 406 | zeitgitterd | /zeitgitterd-1.1.3-py3-none-any.whl/zeitgitter/stamper.py | stamper.py |
# Sending and receiving mail
import logging as _logging
import os
import re
import subprocess
import threading
import time
from datetime import datetime, timedelta
from imaplib import IMAP4
from pathlib import Path
from smtplib import SMTP
from time import gmtime, strftime
import pygit2 as git
import zeitgitter.config
logging = _logging.getLogger('mail')
def split_host_port(host, default_port):
if ':' in host:
host, port = host.split(':', 1)
return (host, int(port))
else:
return (host, default_port)
nth_mail_being_sent = 0
def send(body, subject='Stamping request', to=None):
global nth_mail_being_sent
# Does not work in unittests if assigned in function header
# (are bound too early? At load time instead of at call time?)
if to is None:
to = zeitgitter.config.arg.stamper_to
logging.debug('SMTP server %s' % zeitgitter.config.arg.stamper_smtp_server)
(host, port) = split_host_port(zeitgitter.config.arg.stamper_smtp_server, 587)
# Race conditions should not happen (and will eventually be recognized)
nth_mail_being_sent += 1
our_sending = nth_mail_being_sent
# Retry only until the next send request goes out
# Synchronous waiting, as we are called asynchronously to the stamping
# process and IMAP reception should start only after we succeed here
while nth_mail_being_sent == our_sending:
try:
with SMTP(host, port=port,
local_hostname=zeitgitter.config.arg.domain) as smtp:
smtp.starttls()
smtp.login(zeitgitter.config.arg.stamper_username,
zeitgitter.config.arg.stamper_password)
frm = zeitgitter.config.arg.stamper_own_address
date = strftime("%a, %d %b %Y %H:%M:%S +0000", gmtime())
msg = """From: %s
To: %s
Date: %s
Subject: %s
%s""" % (frm, to, date, subject, body)
smtp.sendmail(frm, to, msg)
return True # Success, end loop
except ConnectionError as e:
logging.error(f"Error connecting to SMTP server"
" {zeitgitter.config.arg.stamper_smtp_server}:"
" {e.strerror}, will try again in 60 seconds")
logging.debug(e)
time.sleep(60)
except TimeoutError as e:
logging.error(f"Timeout connecting to SMTP server"
" {zeitgitter.config.arg.stamper_smtp_server},"
" will try again in 60 seconds")
logging.debug(e)
time.sleep(60)
except OSError as e:
logging.error(f"{e.strerror} talking to the SMTP server,"
" will try again in 60 seconds")
logging.debug(e)
time.sleep(60)
except SMTP.Error as e:
logging.error(f"{str(e)} while talking to the SMTP server,"
" will try again in 60 seconds")
logging.debug(e)
time.sleep(60)
except Exception as e:
logging.error(
"Unhandled exception, aborting SMTP receiving\n" + str(e))
return False
def extract_pgp_body(body):
try:
body = str(body, 'ASCII')
except TypeError as t:
logging.warning("Conversion error for message body: %s" % t)
return None
lines = body.splitlines()
start = None
for i in range(0, len(lines)):
if lines[i] == '-----BEGIN PGP SIGNED MESSAGE-----':
logging.debug("Found start at %d: %s" % (i, lines[i]))
start = i
break
else:
return None
end = None
for i in range(start, len(lines)):
if lines[i] == '-----END PGP SIGNATURE-----':
logging.debug("Found end at %d: %s" % (i, lines[i]))
end = i
break
else:
return None
return lines[start:end + 1]
def save_signature(bodylines):
repo = zeitgitter.config.arg.repository
ascfile = Path(repo, 'hashes.asc')
with ascfile.open(mode='w') as f:
f.write('\n'.join(bodylines) + '\n')
res = subprocess.run(['git', 'add', ascfile], cwd=repo)
if res.returncode != 0:
logging.warning("git add %s in %s failed: %d"
% (ascfile, repo, res.returncode))
def maybe_decode(str):
"""Decode, if it is not `None`"""
if str is None:
return str
else:
return str.decode('ASCII')
def body_signature_correct(bodylines, stat):
body = '\n'.join(bodylines)
logging.debug("Bodylines: %s" % body)
# Cannot use Python gnupg wrapper: Requires GPG 1.x to verify
# Copy env for gnupg without locale
env = {}
for k in os.environ:
if not k.startswith('LC_'):
env[k] = os.environ[k]
env['LANG'] = 'C'
env['TZ'] = 'UTC'
res = subprocess.run(['gpg1', '--pgp2', '--verify'],
env=env, input=body.encode('ASCII'),
stderr=subprocess.PIPE)
stderr = maybe_decode(res.stderr)
stdout = maybe_decode(res.stdout)
logging.debug(stderr)
if res.returncode != 0:
logging.warning("gpg1 return code %d (%r)" % (res.returncode, stderr))
return False
if not '\ngpg: Good signature' in stderr:
logging.warning("Not good signature (%r)" % stderr)
return False
if not stderr.startswith('gpg: Signature made '):
logging.warning("Signature not made (%r)" % stderr)
return False
if not ((' key ID %s\n' % zeitgitter.config.arg.stamper_keyid)
in stderr):
logging.warning("Wrong KeyID (%r)" % stderr)
return False
try:
logging.debug(stderr[24:48])
sigtime = datetime.strptime(stderr[24:48], "%b %d %H:%M:%S %Y %Z")
logging.debug(sigtime)
except ValueError:
logging.warning("Illegal date (%r)" % stderr)
return False
if sigtime > datetime.utcnow() + timedelta(seconds=30):
logging.warning("Signature time %s lies more than 30 seconds in the future"
% sigtime)
return False
modtime = datetime.utcfromtimestamp(stat.st_mtime)
if sigtime < modtime - timedelta(seconds=30):
logging.warning("Signature time %s is more than 30 seconds before\n"
"file modification time %s"
% (sigtime, modtime))
return False
return True
def verify_body_and_save_signature(body, stat, logfile, msgno):
bodylines = extract_pgp_body(body)
if bodylines is None:
logging.warning("No body lines")
return False
res = body_contains_file(bodylines, logfile)
if res is None:
logging.warning("File contents not in message %s" % msgno)
return False
else:
(before, after) = res
logging.debug("before %d, after %d" % (before, after))
if before > 20 or after > 20:
logging.warning("Too many lines added by the PGP Timestamping Server"
" before (%d)/after (%d) our contents" % (before, after))
return False
if not body_signature_correct(bodylines, stat):
logging.warning("Body signature incorrect")
return False
save_signature(bodylines)
return True
def body_contains_file(bodylines, logfile):
if bodylines is None:
return None
linesbefore = 0
with logfile.open(mode='r') as f:
# A few empty/comment lines at the beginning
firstline = f.readline().rstrip()
for i in range(len(bodylines)):
if bodylines[i] == firstline:
break
elif bodylines[i] == '' or bodylines[i][0] in '#-':
linesbefore += 1
else:
return None
# Now should be contiguous
i += 1
for l in f:
if bodylines[i] != l.rstrip():
return None
i += 1
# Now there should only be empty lines and a PGP signature
linesafter = len(bodylines) - i
i += 1
while bodylines[i] == '':
i += 1
if bodylines[i] != '-----BEGIN PGP SIGNATURE-----':
return None
# No further line starting with '-'
for i in range(i + 1, len(bodylines) - 1):
if bodylines[i] != '' and bodylines[i][0] == '-':
return None
return (linesbefore, linesafter)
def imap_idle(imap, stat, repo, initial_head, logfile):
while still_same_head(repo, initial_head):
imap.send(b'%s IDLE\r\n' % (imap._new_tag()))
logging.info("IMAP waiting for IDLE response")
line = imap.readline().strip()
logging.debug("IMAP IDLE → %s" % line)
if line != b'+ idling':
logging.info("IMAP IDLE unsuccessful")
return False
# Wait for new message
while True:
line = imap.readline().strip()
if line == b'' or line.startswith(b'* BYE '):
return False
if re.match(r'^\* [0-9]+ EXISTS$', str(line, 'ASCII')):
logging.info("You have new mail!")
# Stop idling
imap.send(b'DONE\r\n')
if check_for_stamper_mail(imap, stat, logfile) is True:
return False
break # Restart IDLE command
# Otherwise: Seen untagged response we don't care for, continue idling
def check_for_stamper_mail(imap, stat, logfile):
# See `--no-dovecot-bug-workaround`:
query = ('FROM', '"%s"' % zeitgitter.config.arg.stamper_from,
'UNSEEN',
'LARGER', str(stat.st_size),
'SMALLER', str(stat.st_size + 16384))
logging.debug("IMAP SEARCH " + (' '.join(query)))
(typ, msgs) = imap.search(None, *query)
logging.info("IMAP SEARCH → %s, %s" % (typ, msgs))
if len(msgs) == 1 and len(msgs[0]) > 0:
mseq = msgs[0].replace(b' ', b',')
(typ, contents) = imap.fetch(mseq, 'BODY[TEXT]')
logging.debug("IMAP FETCH → %s (%d)" % (typ, len(contents)))
remaining_msgids = mseq.split(b',')
for m in contents:
if m != b')':
msgid = remaining_msgids[0]
remaining_msgids = remaining_msgids[1:]
logging.debug("IMAP FETCH BODY (%s) → %s…" %
(msgid, m[1][:20]))
if verify_body_and_save_signature(m[1], stat, logfile, msgid):
logging.info(
"Verify_body() succeeded; deleting %s" % msgid)
imap.store(msgid, '+FLAGS', '\\Deleted')
return True
return False
def still_same_head(repo, initial_head):
if repo.head.target.hex == initial_head.target.hex:
return True
else:
logging.warning("No valid email answer before next commit (%s->%s)"
% (initial_head.target.hex, repo.head.target.hex))
return False
def wait_for_receive(repo, initial_head, logfile):
while True:
try:
try:
stat = logfile.stat()
logging.debug("File is from %d" % stat.st_mtime)
except FileNotFoundError:
return
(host, port) = split_host_port(
zeitgitter.config.arg.stamper_imap_server, 143)
with IMAP4(host=host, port=port) as imap:
imap.starttls()
imap.login(zeitgitter.config.arg.stamper_username,
zeitgitter.config.arg.stamper_password)
imap.select('INBOX')
if (check_for_stamper_mail(imap, stat, logfile) == False
and still_same_head(repo, initial_head)):
# No existing message found, wait for more incoming messages
# and process them until definitely okay or giving up for good
if 'IDLE' in imap.capabilities:
imap_idle(imap, stat, repo, initial_head, logfile)
else:
logging.warning("IMAP server does not support IDLE")
for i in range(10):
time.sleep(60)
if not still_same_head(repo, initial_head):
return
if check_for_stamper_mail(imap, stat, logfile):
return
# Do not loop on normal operation
return
except ConnectionError as e:
logging.error("Error connecting to IMAP server"
f" {zeitgitter.config.arg.stamper_imap_server}:"
f" {e.strerror}, will try again in 60 seconds")
logging.debug(e)
time.sleep(60)
except TimeoutError as e:
logging.error("Timeout connecting to IMAP server"
f" {zeitgitter.config.arg.stamper_imap_server},"
" will try again in 60 seconds")
logging.debug(e)
time.sleep(60)
except OSError as e:
logging.error(f"{e.strerror} talking to the IMAP server,"
" will try again in 60 seconds")
logging.debug(e)
time.sleep(60)
except IMAP4.Error as e:
logging.error(f"{str(e)} while talking to the IMAP server,"
" will try again in 60 seconds")
logging.debug(e)
time.sleep(60)
except Exception as e:
logging.error(
"Unhandled exception, aborting IMAP receiving\n" + str(e))
return
def async_email_timestamp(logfile, resume=False):
"""If called with `resume=True`, tries to resume waiting for the mail"""
repo = git.Repository(zeitgitter.config.arg.repository)
if repo.head_is_unborn:
logging.error(
"Cannot timestamp by email in repository without commits")
return
head = repo.head
with logfile.open() as f:
contents = f.read()
if contents == "":
logging.info("Not trying to timestamp empty log")
return
if not (resume or '\ngit commit: ' in contents):
append = '\ngit commit: %s\n' % head.target.hex
with logfile.open('a') as f:
f.write(append)
contents = contents + append
if not resume:
if not send(contents):
logging.info("Mail not sent, not waiting for reply (obviously)")
return
threading.Thread(target=wait_for_receive, args=(repo, head, logfile),
daemon=True).start() | zeitgitterd | /zeitgitterd-1.1.3-py3-none-any.whl/zeitgitter/mail.py | mail.py |
# HTTP request handling
import cgi
import importlib.resources
import logging as _logging
import os
import re
import socket
import socketserver
import subprocess
import urllib
from http.server import BaseHTTPRequestHandler, HTTPServer
from pathlib import Path
import zeitgitter.commit
import zeitgitter.config
import zeitgitter.stamper
import zeitgitter.version
from zeitgitter import moddir
logging = _logging.getLogger('server')
class SocketActivationMixin:
"""Use systemd provided socket, if available.
When socket activation is used, exactly one socket needs to be passed."""
def server_bind(self):
nfds = 0
if os.environ.get('LISTEN_PID', None) == str(os.getpid()):
nfds = int(os.environ.get('LISTEN_FDS', 0))
if nfds == 1:
self.socket = socket.socket(fileno=3)
else:
logging.error(
"Socket activation must provide exactly one socket (for now)\n")
exit(1)
else:
super().server_bind()
class ThreadingHTTPServer(socketserver.ThreadingMixIn, HTTPServer):
"""Replacement for http.server.ThreadingHTTPServer for Python < 3.7"""
pass
class SocketActivationHTTPServer(SocketActivationMixin, ThreadingHTTPServer):
pass
class FlatFileRequestHandler(BaseHTTPRequestHandler):
def send_file(self, content_type, filename, replace={}):
try:
webroot = zeitgitter.config.arg.webroot
if webroot is None:
webroot = moddir('web')
if webroot and os.path.isdir(webroot):
with Path(webroot, filename).open(mode='rb') as f:
contents = f.read()
else:
contents = importlib.resources.read_binary(
'zeitgitter', filename)
for k, v in replace.items():
contents = contents.replace(k, v)
self.send_response(200)
self.send_header(
'Cache-Control', zeitgitter.config.arg.cache_control_static)
if content_type.startswith('text/'):
self.send_header(
'Content-Type', content_type + '; charset=UTF-8')
else:
self.send_header('Content-Type', content_type)
self.send_header('Content-Length', len(contents))
self.end_headers()
self.wfile.write(contents)
except IOError as e:
self.send_bodyerr(404, "File not found",
"This file was not found on this server")
def send_bodyerr(self, status, title, body):
explain = """<html><head><title>%s</title></head>
<body><h1>%s</h1>%s
<p><a href="/">Go home</a></p></body></html>
""" % (title, title, body)
explain = bytes(explain, 'UTF-8')
self.send_response(status)
self.send_header('Content-Type', 'text/html; charset=UTF-8')
self.send_header('Content-Length', len(explain))
self.end_headers()
self.wfile.write(explain)
def do_GET(self):
subst = {b'ZEITGITTER_DOMAIN': bytes(zeitgitter.config.arg.domain, 'UTF-8'),
b'ZEITGITTER_OWNER': bytes(zeitgitter.config.arg.owner, 'UTF-8'),
b'ZEITGITTER_CONTACT': bytes(zeitgitter.config.arg.contact, 'UTF-8'),
b'ZEITGITTER_COUNTRY': bytes(zeitgitter.config.arg.country, 'UTF-8')}
if self.path == '/':
self.path = '/index.html'
match = re.match(r'^/([a-z0-9][-_.a-z0-9]*)\.([a-z]*)$',
self.path, re.IGNORECASE)
mimemap = {
'html': 'text/html',
'txt': 'text/plain',
'xml': 'text/xml',
'css': 'text/css',
'js': 'text/javascript',
'png': 'image/png',
'ico': 'image/png',
'svg': 'image/svg+xml',
'jpg': 'image/jpeg',
'jpeg': 'image/jpeg'}
if match and match.group(2) in mimemap:
mime = mimemap[match.group(2)]
if mime.startswith('text/'):
self.send_file(mime, self.path[1:], replace=subst)
else:
self.send_file(mime, self.path[1:])
else:
self.send_bodyerr(406, "Illegal file name",
"<p>This type of file/path is not served here.</p>")
stamper = None
public_key = None
def ensure_stamper(start_multi_threaded=False):
global stamper
if stamper is None:
stamper = zeitgitter.stamper.Stamper()
if start_multi_threaded:
stamper.start_multi_threaded()
class StamperRequestHandler(FlatFileRequestHandler):
def __init__(self, *args, **kwargs):
ensure_stamper()
self.protocol_version = 'HTTP/1.1'
super().__init__(*args, **kwargs)
def version_string(self):
return "zeitgitter/" + zeitgitter.version.VERSION
def send_public_key(self):
global stamper, public_key
if public_key == None:
public_key = stamper.get_public_key()
if public_key == None:
self.send_bodyerr(500, "Internal server error",
"<p>No public key found</p>")
else:
pk = bytes(public_key, 'ASCII')
self.send_response(200)
self.send_header(
'Cache-Control', zeitgitter.config.arg.cache_control_static)
self.send_header('Content-Type', 'application/pgp-keys')
self.send_header('Content-Length', len(pk))
self.end_headers()
self.wfile.write(pk)
def handle_signature(self, params):
global stamper
if 'request' in params:
if (params['request'][0] == 'stamp-tag-v1'
and 'commit' in params and 'tagname' in params):
return stamper.stamp_tag(params['commit'][0],
params['tagname'][0])
elif (params['request'][0] == 'stamp-branch-v1'
and 'commit' in params and 'tree' in params):
if 'parent' in params:
return stamper.stamp_branch(params['commit'][0],
params['parent'][0],
params['tree'][0])
else:
return stamper.stamp_branch(params['commit'][0],
None,
params['tree'][0])
else:
return 406
def handle_request(self, params):
sig = self.handle_signature(params)
if sig == 406:
self.send_bodyerr(406, "Unsupported timestamping request",
"<p>See the documentation for the accepted requests</p>")
elif sig == None:
self.send_bodyerr(429, "Too many requests",
"<p>The server is currently overloaded</p>")
else:
sig = bytes(sig, 'ASCII')
self.send_response(200)
self.send_header('Cache-Control', 'no-cache, no-store')
self.send_header('Content-Type', 'application/x-git-object')
self.send_header('Content-Length', len(sig))
self.end_headers()
self.wfile.write(sig)
def do_POST(self):
self.method = 'POST'
ctype, pdict = cgi.parse_header(self.headers['Content-Type'])
try:
clen = self.headers['Content-Length']
clen = int(clen)
except:
self.send_bodyerr(411, "Length required",
"<p>Your request did not contain a valid length</p>")
return
if clen > 1000 or clen < 0:
self.send_bodyerr(413, "Request too long",
"<p>Your request is too long</p>")
return
if ctype == 'multipart/form-data':
params = cgi.parse_multipart(self.rfile, pdict)
self.handle_request(params)
elif ctype == 'application/x-www-form-urlencoded':
contents = self.rfile.read(clen)
contents = contents.decode('UTF-8')
params = urllib.parse.parse_qs(contents)
self.handle_request(params)
else:
self.send_bodyerr(415, "Unsupported media type",
"<p>Need form data input</p>")
def do_GET(self):
self.method = 'GET'
if self.path.startswith('/?'):
params = urllib.parse.parse_qs(self.path[2:])
if 'request' in params and params['request'][0] == 'get-public-key-v1':
self.send_public_key()
else:
self.send_bodyerr(406, "Bad parameters",
"<p>Need a valid `request` parameter</p>")
else:
super().do_GET()
def send_response(self, code, message=None):
try:
if code != 200 and self.method == 'HEAD':
self.method = self.method + '+error'
except AttributeError:
self.method = '[UNKNOWN]'
super().send_response(code, message)
def end_headers(self):
"""If it is a successful HEAD request, drop the body.
Evil hack for minimal HEAD support."""
super().end_headers()
if self.method == 'HEAD':
self.wfile.close()
self.rfile.close()
def do_HEAD(self):
self.method = 'HEAD'
self.do_GET()
def finish_setup(arg):
# 1. Determine or create key, if possible
# (Not yet ready to use global stamper)
arg.keyid = zeitgitter.stamper.get_keyid(arg.keyid,
arg.domain, arg.gnupg_home)
# Now, we're ready
ensure_stamper()
# 2. Create git repository, if necessary
# and set user name/email
repo = zeitgitter.config.arg.repository
Path(repo).mkdir(parents=True, exist_ok=True)
if not Path(repo, '.git').is_dir():
logging.info("Initializing new repo with user info")
subprocess.run(['git', 'init'], cwd=repo, check=True)
(name, mail) = stamper.fullid[:-1].split(' <')
subprocess.run(['git', 'config', 'user.name', name],
cwd=repo, check=True)
subprocess.run(['git', 'config', 'user.email', mail],
cwd=repo, check=True)
# 3. Create initial files in repo, when needed
# (`hashes.work` will be created on demand).
# Will be committed with first commit.
pubkey = Path(repo, 'pubkey.asc')
if not pubkey.is_file():
logging.info("Storing pubkey.asc in repository")
with pubkey.open('w') as f:
f.write(stamper.get_public_key())
subprocess.run(['git', 'add', 'pubkey.asc'],
cwd=repo, check=True)
subprocess.run(['git', 'commit', '-m', 'Started timestamping'],
cwd=repo, check=True)
def run():
zeitgitter.config.get_args()
finish_setup(zeitgitter.config.arg)
zeitgitter.commit.run()
httpd = SocketActivationHTTPServer(
(zeitgitter.config.arg.listen_address,
zeitgitter.config.arg.listen_port),
StamperRequestHandler)
logging.info("Start serving")
ensure_stamper(start_multi_threaded=True)
# Try to resume a waiting for a PGP Timestamping Server reply, if any
if zeitgitter.config.arg.stamper_own_address:
repo = zeitgitter.config.arg.repository
preserve = Path(repo, 'hashes.stamp')
if preserve.exists():
logging.info("possibly resuming cross-timestamping by mail")
zeitgitter.mail.async_email_timestamp(preserve)
try:
httpd.serve_forever()
except KeyboardInterrupt:
logging.info("Received Ctrl-C, shutting down...")
httpd.server_close() | zeitgitterd | /zeitgitterd-1.1.3-py3-none-any.whl/zeitgitter/server.py | server.py |
=======
History
=======
0.1.1 (2021-10-02)
------------------
* Adjust URLs to GitHub account due to renaming @munterfinger to @munterfi.
* Note: zeitsprung.fm has moved to geschichte.fm, therefore this project no longer is maintained.
0.1.0 (2020-09-22)
------------------
* First release on PyPI.
* Scraper class to download the meta data and audio files of all episodes.
* Database class to setup and access the SQLite database containing the meta data of the episodes.
* Documentation using readthedocs: https://zeitsprung.readthedocs.io/en/latest/
* Github action for building and testing the package.
* Coverage tests using codecov.io.
| zeitsprung | /zeitsprung-0.1.1.tar.gz/zeitsprung-0.1.1/HISTORY.rst | HISTORY.rst |
.. image:: https://raw.githubusercontent.com/munterfi/zeitsprung/master/docs/_static/logo.svg
:width: 120 px
:alt: zeitsprung.fm
:align: right
==========
zeitsprung
==========
.. image:: https://img.shields.io/pypi/v/zeitsprung.svg
:target: https://pypi.python.org/pypi/zeitsprung
.. image:: https://github.com/munterfi/zeitsprung/workflows/build/badge.svg
:target: https://github.com/munterfi/zeitsprung/actions?query=workflow%3Abuild
.. image:: https://readthedocs.org/projects/zeitsprung/badge/?version=latest
:target: https://zeitsprung.readthedocs.io/en/latest/?badge=latest
:alt: Documentation Status
.. image:: https://pyup.io/repos/github/munterfi/zeitsprung/shield.svg
:target: https://pyup.io/repos/github/munterfi/zeitsprung/
:alt: Updates
.. image:: https://codecov.io/gh/munterfi/zeitsprung/branch/master/graph/badge.svg
:target: https://codecov.io/gh/munterfi/zeitsprung
Note: zeitsprung.fm has moved to geschichte.fm, therefore this project is no longer maintained.
This package provides a scraper for www.zeitsprung.fm, a great history podcast.
To get the metadata of all episodes from the website, simply start the scraper::
from zeitsprung.scraping import Scraper
s = Scraper('path/to/folder/for/database')
s.run()
The scraper then downloads the all episode metadata and audio files. The metadata is written to the 'meta' table in the
database. The audio files are converted to '.wav' files and saved separately to a folder, while a link to the file is
stored in the 'audio' table in the database.
To access the data, create a SQLiteEngine::
from zeitsprung.database import SQLiteEngine
db = SQLiteEngine('path/to/folder/for/database/zeitsprung.db')
Query the meta data from the database::
db.query_all_meta()
And the audio file paths and meta data::
db.query_all_audio()
Now have fun with analysing the episodes of zeitsprung!
Features
--------
* Scraper class to download the meta data and audio files of all episodes.
* Database class to setup and access the SQLite database containing the meta data of the episodes.
To Do
-----
* Processing class to conduct speech recognition on the audio files and build an index for clustering the topics.
* Visualize up to date statistics.
References
----------
* https://www.zeitsprung.fm, check it out!
* This package is licensed under MIT, see the LICENSE file for details.
| zeitsprung | /zeitsprung-0.1.1.tar.gz/zeitsprung-0.1.1/README.rst | README.rst |
.. highlight:: shell
============
Contributing
============
Contributions are welcome, and they are greatly appreciated! Every little bit
helps, and credit will always be given.
You can contribute in many ways:
Types of Contributions
----------------------
Report Bugs
~~~~~~~~~~~
Report bugs at https://github.com/munterfi/zeitsprung/issues.
If you are reporting a bug, please include:
* Your operating system name and version.
* Any details about your local setup that might be helpful in troubleshooting.
* Detailed steps to reproduce the bug.
Fix Bugs
~~~~~~~~
Look through the GitHub issues for bugs. Anything tagged with "bug" and "help
wanted" is open to whoever wants to implement it.
Implement Features
~~~~~~~~~~~~~~~~~~
Look through the GitHub issues for features. Anything tagged with "enhancement"
and "help wanted" is open to whoever wants to implement it.
Write Documentation
~~~~~~~~~~~~~~~~~~~
zeitsprung could always use more documentation, whether as part of the
official zeitsprung docs, in docstrings, or even on the web in blog posts,
articles, and such.
Submit Feedback
~~~~~~~~~~~~~~~
The best way to send feedback is to file an issue at https://github.com/munterfi/zeitsprung/issues.
If you are proposing a feature:
* Explain in detail how it would work.
* Keep the scope as narrow as possible, to make it easier to implement.
* Remember that this is a volunteer-driven project, and that contributions
are welcome :)
Get Started!
------------
Ready to contribute? Here's how to set up `zeitsprung` for local development.
1. Fork the `zeitsprung` repo on GitHub.
2. Clone your fork locally::
$ git clone [email protected]:your_name_here/zeitsprung.git
3. Install your local copy into a virtualenv. Assuming you have virtualenvwrapper installed, this is how you set up your fork for local development::
$ mkvirtualenv zeitsprung
$ cd zeitsprung/
$ python setup.py develop
4. Create a branch for local development::
$ git checkout -b name-of-your-bugfix-or-feature
Now you can make your changes locally.
5. When you're done making changes, check that your changes pass flake8 and the
tests, including testing other Python versions with tox::
$ flake8 zeitsprung tests
$ python setup.py test or pytest
$ tox
To get flake8 and tox, just pip install them into your virtualenv.
6. Commit your changes and push your branch to GitHub::
$ git add .
$ git commit -m "Your detailed description of your changes."
$ git push origin name-of-your-bugfix-or-feature
7. Submit a pull request through the GitHub website.
Pull Request Guidelines
-----------------------
Before you submit a pull request, check that it meets these guidelines:
1. The pull request should include tests.
2. If the pull request adds functionality, the docs should be updated. Put
your new functionality into a function with a docstring, and add the
feature to the list in README.rst.
3. The pull request should work for Python 3.5, 3.6, 3.7 and 3.8, and for PyPy. Check
https://travis-ci.com/munterfi/zeitsprung/pull_requests
and make sure that the tests pass for all supported Python versions.
Tips
----
To run a subset of tests::
$ pytest tests.test_zeitsprung
Deploying
---------
A reminder for the maintainers on how to deploy.
Make sure all your changes are committed (including an entry in HISTORY.rst).
Then run::
$ bump2version patch # possible: major / minor / patch
$ git push
$ git push --tags
Travis will then deploy to PyPI if tests pass.
| zeitsprung | /zeitsprung-0.1.1.tar.gz/zeitsprung-0.1.1/CONTRIBUTING.rst | CONTRIBUTING.rst |
=====
Usage
=====
To get the metadata of all episodes from the website, simply start the scraper::
from zeitsprung.scraping import Scraper
s = Scraper('path/to/folder/for/database')
s.run()
The scraper then downloads the all episode metadata and audio files. The metadata is written to the 'meta' table in the
database. The audio files are converted to '.wav' files and saved separately to a folder, while a link to the file is
stored in the 'audio' table in the database.
To access the data, create a SQLiteEngine::
from zeitsprung.database import SQLiteEngine
db = SQLiteEngine('path/to/folder/for/database/zeitsprung.db')
Query the meta data from the database::
db.query_all_meta()
And the audio file paths and meta data::
db.query_all_audio()
Now have fun with analysing the episodes of zeitsprung!
| zeitsprung | /zeitsprung-0.1.1.tar.gz/zeitsprung-0.1.1/docs/usage.rst | usage.rst |
.. highlight:: shell
============
Installation
============
System dependencies
-------------------
The zeitsprung package depends on the pydub package, which needs ffmpeg to be installed on the system.
macOS (using homebrew):
.. code-block:: console
$ brew install ffmpeg
Linux (using aptitude):
.. code-block:: console
$ apt-get install ffmpeg libavcodec-extra
Stable release
--------------
To install zeitsprung, run this command in your terminal:
.. code-block:: console
$ pip install zeitsprung
This is the preferred method to install zeitsprung, as it will always install the most recent stable release.
If you don't have `pip`_ installed, this `Python installation guide`_ can guide
you through the process.
.. _pip: https://pip.pypa.io
.. _Python installation guide: http://docs.python-guide.org/en/latest/starting/installation/
From sources
------------
The sources for zeitsprung can be downloaded from the `Github repo`_.
You can either clone the public repository:
.. code-block:: console
$ git clone git://github.com/munterfi/zeitsprung
Or download the `tarball`_:
.. code-block:: console
$ curl -OJL https://github.com/munterfi/zeitsprung/tarball/master
Once you have a copy of the source, you can install it with:
.. code-block:: console
$ python setup.py install
.. _Github repo: https://github.com/munterfi/zeitsprung
.. _tarball: https://github.com/munterfi/zeitsprung/tarball/master
| zeitsprung | /zeitsprung-0.1.1.tar.gz/zeitsprung-0.1.1/docs/installation.rst | installation.rst |
zeitsprung package
==================
Submodules
----------
zeitsprung.base module
----------------------
.. automodule:: zeitsprung.base
:members:
:undoc-members:
:show-inheritance:
zeitsprung.database module
--------------------------
.. automodule:: zeitsprung.database
:members:
:undoc-members:
:show-inheritance:
zeitsprung.scraping module
--------------------------
.. automodule:: zeitsprung.scraping
:members:
:undoc-members:
:show-inheritance:
Module contents
---------------
.. automodule:: zeitsprung
:members:
:undoc-members:
:show-inheritance:
| zeitsprung | /zeitsprung-0.1.1.tar.gz/zeitsprung-0.1.1/docs/zeitsprung.rst | zeitsprung.rst |
import collections
import json
from .ZeitzonoCity import ZeitzonoCity
import copy
class ZeitzonoCities:
"a city list object"
def __init__(self, cities=None):
if cities is None:
self.cities = []
else:
self.cities = cities
self.undo_stack = []
self.redo_stack = []
def save_state(self):
city_copy = copy.copy(self.cities)
self.undo_stack.append(city_copy)
self.redo_stack = []
if len(self.undo_stack) > 10:
self.undo_stack.pop(0)
def undo(self):
if len(self.undo_stack) > 0:
old_state = self.undo_stack.pop()
self.redo_stack.append(self.cities)
self.cities = old_state
def redo(self):
if len(self.redo_stack) > 0:
new_state = self.redo_stack.pop()
self.undo_stack.append(self.cities)
self.cities = new_state
def numcities(self):
return len(self.cities)
def isempty(self):
return self.numcities() == 0
def addcity(self, city):
self.save_state()
self.cities.insert(0, city)
def addcities(self, hcities):
self.save_state()
self.cities = hcities.cities + self.cities
def clear(self):
self.save_state()
self.cities = []
self.nresults = None
def del_first(self):
return self.del_index(0)
def del_last(self):
self.save_state()
if self.cities:
return self.cities.pop()
def del_index(self, index):
self.save_state()
if self.cities:
return self.cities.pop(index)
def _rotate(self, n):
if self.cities:
self.save_state()
deck = collections.deque(self.cities)
deck.rotate(n)
self.cities = list(deck)
def rotate_right(self):
self._rotate(1)
def rotate_left(self):
self._rotate(-1)
def roll_4(self):
if self.numcities() >= 4:
self.save_state()
city1 = self.del_first()
city2 = self.del_first()
city3 = self.del_first()
city4 = self.del_first()
self.addcity(city1)
self.addcity(city4)
self.addcity(city3)
self.addcity(city2)
def roll_3(self):
if self.numcities() >= 3:
self.save_state()
city1 = self.del_first()
city2 = self.del_first()
city3 = self.del_first()
self.addcity(city1)
self.addcity(city3)
self.addcity(city2)
def roll_2(self):
if self.numcities() >= 2:
self.save_state()
city1 = self.del_first()
city2 = self.del_first()
self.addcity(city1)
self.addcity(city2)
def sort_utc_offset(self, reverse=False):
self.save_state()
self.cities.sort(
key=lambda city: city.utc_offset(), reverse=not reverse
)
def __iter__(self):
return iter(self.cities)
def _hcity_to_dict(self, c):
# used by self.toJSON() to serialize
return c.__dict__
def toJSON(self, filehandle):
return json.dump(
self.cities, filehandle, default=self._hcity_to_dict, indent=4
)
def fromJSON(self, filehandle):
string_cities = json.load(filehandle)
self.cities = []
for sc in string_cities:
hc = ZeitzonoCity(**sc)
self.cities.append(hc)
class ZeitzonoCitySearch(ZeitzonoCities):
"this is basically ZeitzonoCities with search results"
def __init__(self, cities=None, results=0):
super().__init__(cities=cities)
self.results = results
def numresults(self):
return self.results
def clear(self):
super.clear()
self.results = 0 | zeitzono | /zeitzono-0.8.0-py3-none-any.whl/Zeitzono/ZeitzonoCities.py | ZeitzonoCities.py |
import lzma
import pkg_resources
import random
DB_FILE = "data/zeitzono.db"
# if a search returns more than MAX_LIMIT_AMT results
# only return at most MAX_LIMIT_AMT
MAX_LIMIT_AMT = 100
class ZeitzonoDB:
# search types
SEARCH_CITY_ALL = 0 # used to search all city fields
SEARCH_CITY_NAME = 1 # used to search city names only
SEARCH_CADMIN = 2 # used to search against country/admin codes
def __init__(self):
dbfile = pkg_resources.resource_filename("Zeitzono", DB_FILE)
# - db contains a list of dictionaries,
# each dictionary has the following keys:
#
# name - the name of the city (lower case)
# ascii - the ascii name of the city
# asciil - the ascii name of the city (lower case)
# alt - alternate names for the city (lower case)
# cc - the country that the city is inc
# ccl - the country that the city is in (lower case)
# admin1 - city's admin1 code
# admin1l - city's admin1 code (lower case)
# admin2 - city's admin2 code
# admin2l - city's admin2 code (lower case)
# pop - the population of the city (used for sorting)
# tz - the city's timezone
#
# - for stuff we don't display and only search against, we store
# only the lower case version
#
# - for stuff we both display and search against, we store both
#
self.db = self._db_load(dbfile)
# this is set by db_search
# it contains the number of matches returned by a search
self.matches = []
# - this is set by db_search
# - it contains the number of matches returned by a search
# - note that count may not match len(self.matches)
# because we truncate at MAX_LIMIT_AMT matches
self.numresults = 0
def _db_load(self, dbfile):
# the Zeitzono db is just a compressed TSV file that we open and return
# as a list of dictionaries
dbfh = lzma.open(dbfile, mode="rt")
db = []
for line in dbfh:
db.append(self._tsv_line_2_dict(line.strip()))
return db
def _tsv_line_2_dict(self, tsvline):
# given a city entry
# return a dict that contains things we need to search or display later
city = tsvline.strip().split("\t")
cityd = {}
cityd["name"] = city[0].lower()
cityd["ascii"] = city[1]
cityd["asciil"] = cityd["ascii"].lower()
cityd["alt"] = city[2].lower()
cityd["cc"] = city[3]
cityd["ccl"] = cityd["cc"].lower()
cityd["admin1"] = city[4]
cityd["admin1l"] = cityd["admin1"].lower()
cityd["admin2"] = city[5]
cityd["admin2l"] = cityd["admin2"].lower()
cityd["pop"] = int(city[6])
cityd["tz"] = city[7]
# some null admin1/admin2 listings are labeled like this,
# so we have to null them out manually
if cityd["admin1"] == "00":
cityd["admin1"] = ""
cityd["admin1l"] = ""
if cityd["admin2"] == "00":
cityd["admin2"] = ""
cityd["admin2l"] = ""
return cityd
def _search_parser(self, search):
# given a search string, will tokenize and return a list of tuples
#
# (pattern, SEARCH_TYPE) - pattern to search for
# and search type const
#
patterns = []
tokens = search.strip().split()
for tok in tokens:
if tok.startswith(":"):
if len(tok) > 1:
patterns.append((tok[1:].lower(), self.SEARCH_CADMIN))
elif tok.startswith("'"):
if len(tok) > 1:
patterns.append((tok[1:].lower(), self.SEARCH_CITY_NAME))
else:
patterns.append((tok.lower(), self.SEARCH_CITY_ALL))
return patterns
def _city_name_only_search_match(self, pattern, city):
# return True if pattern matches city name only
if pattern in city["name"]:
return True
elif pattern in city["asciil"]:
return True
return False
def _city_search_match(self, pattern, city):
# return True if pattern matches city name of altname
if self._city_name_only_search_match(pattern, city):
return True
elif pattern in city["alt"]:
return True
return False
def _cadmin_search_match(self, pattern, city):
# return True if pattern matches cc or admin
if pattern in city["ccl"]:
return True
elif pattern in city["admin1l"]:
return True
elif pattern in city["admin2l"]:
return True
return False
def _sort_matches(self, matches, limit=None):
# given a list of matches (indexes into the database)
# return a sorted list of cities
#
# will always truncate to MAX_LIMIT_AMT searches
smatches = sorted(matches, key=lambda i: self.db[i]["pop"])
maxresults = MAX_LIMIT_AMT
if (limit is not None) and (limit < MAX_LIMIT_AMT):
maxresults = limit
if (limit is not None) and (limit < MAX_LIMIT_AMT):
maxresults = limit
self.numresults = len(matches)
if self.numresults > maxresults:
smatches = smatches[-maxresults:]
self.matches = smatches
def db_search(self, search, limit=None):
# will return: list, boolean
# list contains numbers, which correspond to cities in db
# if boolean is true, max limit was reached
#
# if list is empty, no cities were found
self._reset_search()
# tokenize search string
patterns = self._search_parser(search)
# need at least one city to search for
if not patterns:
return [], False
matched = range(len(self.db))
# search through with patterns
for pattern, search_type in patterns:
newmatched = []
for match in matched:
if search_type == self.SEARCH_CITY_ALL:
if self._city_search_match(pattern, self.db[match]):
newmatched.append(match)
elif search_type == self.SEARCH_CITY_NAME:
if self._city_name_only_search_match(
pattern, self.db[match]
):
newmatched.append(match)
elif search_type == self.SEARCH_CADMIN:
if self._cadmin_search_match(pattern, self.db[match]):
newmatched.append(match)
if not newmatched:
return [], False
matched = newmatched
self._sort_matches(matched, limit)
def _reset_search(self):
self.matches = []
self.numresults = 0
def random_cities(self, count):
numrand = count if count < MAX_LIMIT_AMT else MAX_LIMIT_AMT
population = range(len(self.db))
randmatches = random.choices(population, k=numrand)
self._sort_matches(randmatches)
def match_cities(self):
# generator that prints returns matched cities
for m in self.matches:
yield self.db[m] | zeitzono | /zeitzono-0.8.0-py3-none-any.whl/Zeitzono/ZeitzonoDB.py | ZeitzonoDB.py |
class ZeitzonoUrwidPalette:
palette = """
main_zeitzono, light red, default
main_version, light cyan, default
main_base_time, yellow, default
main_base_time_current, light magenta, default
main_basezc, yellow, default
main_helpline, light green, default
main_index, light red, default
search_prompt, light red, default
splash_url, yellow, default
splash_main, light red, default
splash_main_clock, dark green, default
splash_version, light cyan, default
splash_presskey, white, default
splash_author, light blue, default
numresults_str, yellow, default
numresults_num, light magenta, default
"""
palette_lightbg = """
main_zeitzono, dark red, default
main_version, dark cyan, default
main_base_time, brown, default
main_base_time_current, dark magenta, default
main_basezc, brown, default
main_helpline, dark green, default
main_index, dark red, default
search_prompt, dark red, default
splash_url, brown, default
splash_main, dark red, default
splash_main_clock, brown, default
splash_version, dark cyan, default
splash_presskey, black, default
splash_author, dark blue, default
numresults_str, brown, default
numresults_num, dark magenta, default
"""
palette_nocolor = """
main_zeitzono, default, default
main_version, default, default
main_base_time_current, default, default
main_base_time, default, default
main_basezc, default, default
main_helpline, default, default
main_index, default, default
search_prompt, default, default
splash_url, default, default
splash_main, default, default
splash_main_clock, default, default
splash_version, default, default
splash_presskey, default, default
splash_author, default, default
numresults_str, default, default
numresults_num, default, default
"""
def __init__(self, no_color=False, lightbg=False):
palette = self.palette
if lightbg:
palette = self.palette_lightbg
if no_color:
palette = self.palette_nocolor
mypalette = palette.strip().splitlines()
mypalette = [p.strip() for p in mypalette if p.strip()]
mypalette = [p.split(",") for p in mypalette]
mypalette = [[i.strip() for i in p] for p in mypalette]
self.palette = mypalette
def get_palette(self):
return self.palette | zeitzono | /zeitzono-0.8.0-py3-none-any.whl/Zeitzono/ZeitzonoUrwidPalette.py | ZeitzonoUrwidPalette.py |
import urwid
from .ZeitzonoTime import ZeitzonoTime
from .ZeitzonoCities import ZeitzonoCities
from .ZeitzonoUrwidSearch import ZeitzonoUrwidSearch
from .ZeitzonoSearch import ZeitzonoSearch
from .ZeitzonoDB import ZeitzonoDB
class ZeitzonoUrwidMain(urwid.WidgetWrap):
_selectable = True
def __init__(self, loop, zeitzonowidgetswitcher, cache, version):
self.zeitzonotime = ZeitzonoTime()
self.zeitzonocities = ZeitzonoCities()
self.zeitzonodb = ZeitzonoDB()
self.footerpile = None
self.nlp_mode = (
False # if set, we are parsing keyboard input differently
)
self.clock_mode = True # if set, we update the base clock in realtime
self.loop = loop # this is needed call set_alarm_in()
self.index_mode = False # if set, we are picking an item in list
self.screen = urwid.raw_display.Screen()
# if we are caching, read HoronoCities from cache
self.cache = cache
if cache is not None:
try:
with open(self.cache) as cachefile:
self.zeitzonocities.fromJSON(cachefile)
except Exception:
pass
self.baset = urwid.Text("", wrap="clip", align="left")
basetmap = urwid.AttrMap(self.baset, "main_base_time")
self.basezc = urwid.Text("", wrap="clip", align="right")
basezcmap = urwid.AttrMap(self.basezc, "main_basezc")
self.basezc_is_c = False
self.basezc_city = None
self.baset_update()
self.basezc_update()
htext = "zeitzono "
htext_len = len(htext)
zeitzono_ut = urwid.Text(htext, wrap="clip", align="right")
zeitzono_ut_am = urwid.AttrMap(zeitzono_ut, "main_zeitzono")
self.version = version
version_len = len(version)
version_ut = urwid.Text(version, wrap="clip", align="right")
version_ut_am = urwid.AttrMap(version_ut, "main_version")
blank = urwid.Text("", align="right")
versioncols = urwid.Columns(
[
("weight", 99, blank),
(htext_len, zeitzono_ut_am),
(version_len, version_ut_am),
]
)
self.bodypile = urwid.Pile(self.body_gen())
self.bodyfill = urwid.Filler(self.bodypile, valign="bottom")
self.zeitzonowidgetswitcher = zeitzonowidgetswitcher
cols = urwid.Columns([basetmap, basezcmap])
blankline = urwid.Text("", wrap="clip")
helpline = (
"? - help, c - add cities, n - display current time, Q - quit"
)
helpline = urwid.Text(helpline, wrap="clip")
helpline_attr = urwid.AttrMap(helpline, "main_helpline")
self.footer = [blankline, helpline_attr, cols]
self.footerpile = urwid.Pile(
self.footer, focus_item=len(self.footer) - 1
)
self.footer_bak = [(x, ("pack", None)) for x in self.footer]
# ---------------------------------
# create a footer pile for nlp mode
helpline_nlp = "enter a human-readable date/time string:"
helpline_nlp = urwid.Text(helpline_nlp, wrap="clip", align="left")
helpline_nlp_attr = urwid.AttrMap(helpline_nlp, "main_helpline")
self.nlp_prompt = urwid.Edit(caption="(NLP) zeitzono> ", align="left")
nlp_prompt_attr = urwid.AttrMap(self.nlp_prompt, "search_prompt")
nlp_pilelist = [blankline, helpline_nlp_attr, nlp_prompt_attr]
self.nlp_pilelist = [(x, ("pack", None)) for x in nlp_pilelist]
# ---------------------------------
frame = urwid.Frame(
self.bodyfill,
header=versioncols,
footer=self.footerpile,
focus_part="footer",
)
super().__init__(frame)
def _list_is_max_capacity(self, fakecap=None):
cols, rows = self.screen.get_cols_rows()
maxrows = rows - 4
cap = self.zeitzonocities.numcities()
if fakecap is not None:
cap = cap + fakecap - 1
if cap >= maxrows:
return True
return False
def time_adjust(self, key): # noqa
if key in "SsMmHhXxFfDdWwOoYy0":
self.clock_mode = False
if key in ("S"):
self.zeitzonotime.sub_sec()
if key in ("s"):
self.zeitzonotime.add_sec()
if key in ("M"):
self.zeitzonotime.sub_min()
if key in ("m"):
self.zeitzonotime.add_min()
if key in ("H"):
self.zeitzonotime.sub_hour()
if key in ("h"):
self.zeitzonotime.add_hour()
if key in ("X"):
self.zeitzonotime.sub_qday()
if key in ("x"):
self.zeitzonotime.add_qday()
if key in ("F"):
self.zeitzonotime.sub_qhour()
if key in ("f"):
self.zeitzonotime.add_qhour()
if key in ("D"):
self.zeitzonotime.sub_day()
if key in ("d"):
self.zeitzonotime.add_day()
if key in ("W"):
self.zeitzonotime.sub_week()
if key in ("w"):
self.zeitzonotime.add_week()
if key in ("O"):
self.zeitzonotime.sub_month()
if key in ("o"):
self.zeitzonotime.add_month()
if key in ("Y"):
self.zeitzonotime.sub_year()
if key in ("y"):
self.zeitzonotime.add_year()
if key in ("0"):
self.zeitzonotime.zero_sec()
self.zeitzonotime.zero_min()
if key in ("n"):
self.zeitzonotime.set_time_now()
self.clock_mode = True
self.clock_update(self.loop, None)
self.body_render()
self.baset_update()
return True
def keypress(self, size, key): # noqa
if self.index_mode:
index = self.label2index(key)
if index is None:
self.index_mode_off()
return True
else:
if self.index_mode_type == "zone":
city = self.zeitzonocities.cities[index]
self.basezc_is_c = True
self.basezc_city = city.name
self.zeitzonotime.set_tz(city.tz)
self.basezc_update()
if self.index_mode_type == "pop":
self.zeitzonocities.del_index(index)
self.index_mode_off()
return True
if self.nlp_mode:
self.nlp_prompt.keypress((size[0],), key)
if key == "enter":
x = self.nlp_prompt.get_edit_text()
# exit if nothing entered
if not x.strip():
self.nlp_prompt.set_edit_text("")
self.nlp_mode = False
self.footerpile.contents[:] = self.footer_bak
# try and set time
success = self.zeitzonotime.set_time_nlp(x)
# if it doesn't work, try again
if not success:
self.nlp_prompt.set_edit_text("")
return
# if it does work, set clock and exit
self.nlp_prompt.set_edit_text("")
self.nlp_mode = False
self.footerpile.contents[:] = self.footer_bak
self.body_render()
self.baset_update()
return True
return
if key.lower() in ("q"):
# if we are caching, write HoronoCities to cache before exiting
if self.cache is not None:
with open(self.cache, "w") as cachefile:
self.zeitzonocities.toJSON(cachefile)
raise urwid.ExitMainLoop()
if key in ("N"):
self.clock_mode = False
self.nlp_mode = True
self.footerpile.contents[:] = self.nlp_pilelist
if key == ("?"):
self.zeitzonowidgetswitcher.switch_widget_help_main()
if key in ("C"):
self.zeitzonocities.clear()
if key in ("c") and not self._list_is_max_capacity():
zeitzonourwidsearch = ZeitzonoUrwidSearch(
self.zeitzonowidgetswitcher,
self.zeitzonocities,
self.version,
self.zeitzonodb,
self.screen,
)
self.zeitzonowidgetswitcher.set_widget(
"search", zeitzonourwidsearch
)
self.zeitzonowidgetswitcher.switch_widget_search()
if key in ("L"):
self.zeitzonotime.set_tz_local()
self.basezc_is_c = False
self.basezc_update()
return True
if key in ("p"):
self.zeitzonocities.del_first()
self.body_render()
return True
if key in ("P"):
if self.zeitzonocities.numcities() > 0:
self.index_mode_on(mode="pop")
return True
if key in ("."):
self.zeitzonocities.rotate_right()
self.body_render()
return True
if key in (","):
self.zeitzonocities.rotate_left()
self.body_render()
return True
if key in ("/"):
self.zeitzonocities.roll_2()
self.body_render()
return True
if key in ("'"):
self.zeitzonocities.roll_3()
self.body_render()
return True
if key in (";"):
self.zeitzonocities.roll_4()
self.body_render()
return True
if key in ("]"):
self.zeitzonocities.sort_utc_offset()
self.body_render()
return True
if key in ("["):
self.zeitzonocities.sort_utc_offset(reverse=True)
self.body_render()
return True
if key in ("z"):
if self.zeitzonocities.numcities() > 0:
city = self.zeitzonocities.cities[0]
self.basezc_is_c = True
self.basezc_city = city.name
self.zeitzonotime.set_tz(city.tz)
self.basezc_update()
return True
if key in ("Z"):
if self.zeitzonocities.numcities() > 0:
self.index_mode_on(mode="zone")
return True
if key in ("u"):
self.zeitzonocities.undo()
if key in ("r"):
self.zeitzonocities.redo()
if key in ("-"):
if self._list_is_max_capacity():
return True
zsearch = ZeitzonoSearch(db=self.zeitzonodb)
rcities = zsearch.random1()
self.zeitzonocities.addcities(rcities)
self.body_render()
return True
if key in ("="):
if self._list_is_max_capacity(fakecap=10):
return True
zsearch = ZeitzonoSearch(db=self.zeitzonodb)
rcities = zsearch.random10()
self.zeitzonocities.addcities(rcities)
self.body_render()
return True
self.time_adjust(key)
self.body_render()
def baset_update(self):
# If we have a terminal that is sized ~80 columns wide (eg. 80x25),
# adding the [C] in wall clock mode will truncate part of the base
# time.
#
# So to get around that awkwardness, if we are smaller than some
# arbitrary number of columns, we don't print the "base time: " string.
cols, _ = self.screen.get_cols_rows()
newstr = "base time: "
if cols < 95:
newstr = ""
newstr = newstr + "%s" % self.zeitzonotime.get_time_str()
newstr = [("main_base_time", newstr)]
if self.clock_mode:
newstr = newstr + [("main_base_time_current", " [C]")]
self.baset.set_text(newstr)
def basezc_update(self):
newstr = "base zone: %s" % str(self.zeitzonotime.get_tz())
if self.basezc_is_c:
newstr = "base city: %s" % self.basezc_city
self.basezc.set_text(newstr)
self.baset_update()
def body_gen(self, update=False, nourwid=False):
bodylist = []
for index, city in enumerate(self.zeitzonocities.cities):
bodytext = str(self.zeitzonotime.get_time_tz_str(city.get_tz()))
bodytext = bodytext + " "
bodytext = bodytext + str(city)
# if we are in indexmode, prepend a 0-9a-zA-Z to
# the bottom 62 items on stack
if self.index_mode:
if index < 62:
index_label = self.index2label(index) + ": "
else:
index_label = " "
# index_label_u = urwid.Text(index_label, wrap="clip", align="left")
# index_label_a = urwid.AttrMap(index_label_u, "main_index")
# nourwid is true when in --list-cached mode
if nourwid:
rawtext = bodytext
else:
if self.index_mode:
rawtext = urwid.Text(
[("main_index", index_label), ("default", bodytext)],
wrap="clip",
align="left",
)
else:
rawtext = urwid.Text(bodytext, wrap="clip", align="left")
if nourwid:
content = rawtext
else:
if update:
content = (rawtext, ("pack", None))
else:
content = rawtext
bodylist.append(content)
bodylist.reverse()
return bodylist
def body_render(self):
self.bodypile.contents = self.body_gen(update=True)
def clock_update(self, loop, user_date=None):
# we only update in clock mode
if not self.clock_mode:
return
# update to current time
self.zeitzonotime.set_time_now()
# update clock
self.baset_update()
# update body
self.body_render()
# how long to wait between refreshes, in seconds
sleeptime = 1
# set alarm for next refresh
self.loop.set_alarm_in(sleeptime, self.clock_update)
def index_mode_on(self, mode=None):
self.index_mode_type = mode
self.index_mode = True
self.body_render()
def index_mode_off(self):
self.index_mode = False
self.body_render()
def index2label(self, num):
"given a stack number, return the index 0-9a-zA-Z, or None"
nums = "0123456789"
alpha_lower = "abcdefghijklmnopqrstuvwxyz"
alpha_upper = "ABCDEFGHIJKLMNOPQRSTUVWXYZ"
code = nums + alpha_lower + alpha_upper
if num < len(code):
return code[num]
return None
def label2index(self, label):
nums = "0123456789"
alpha_lower = "abcdefghijklmnopqrstuvwxyz"
alpha_upper = "ABCDEFGHIJKLMNOPQRSTUVWXYZ"
code = nums + alpha_lower + alpha_upper
if label not in code:
# a valid label was not entered
return None
index = code.index(label)
if index >= len(self.zeitzonocities.cities):
# a valid label was entered
# but our list is not that long
return None
return index | zeitzono | /zeitzono-0.8.0-py3-none-any.whl/Zeitzono/ZeitzonoUrwidMain.py | ZeitzonoUrwidMain.py |
import urwid
import base64
import bz2
import re
class ZeitzonoUrwidSplashScreen(urwid.WidgetWrap):
_selectable = True
def __init__(self, zeitzonowidgetswitcher, version, dbversion):
self.zeitzonowidgetswitcher = zeitzonowidgetswitcher
b64 = """
QlpoOTFBWSZTWZTfzlIAACH/gDoQIQBQjoBAAAJAIPQAAAQwAMMCREJ6kZMmmEKD
Ro0GQGgkJE1HqZGjRk4oM2tgesad9SYwCDSCUQn2UrOVS38KX5rcZ6eGFO1OMxy0
L2yZjG83yvza0wxsIyI5ZFk2uiOXCmy86IhXumSUcPJkgbOr5+Wwjhgmw7QacRrz
dBuc3lEDqbD9u2TJKr0iDd07LfQgMIEvAa6UuFjDN21xYf7zVBcNktFVhkYzEZR/
F3JFOFCQlN/OUg==
"""
urltext = "zeitzono.org"
bz2bin = base64.b64decode(b64)
splashtext = bz2.decompress(bz2bin)
splashtext = splashtext.decode("ascii")
splashtext_lines = splashtext.splitlines()
splash = []
# import sys
# sys.exit(splashtext_lines)
splash_regex = re.compile(r"[+|\-/]")
for line in splashtext_lines:
if splash_regex.search(line):
line_array = []
for char in line:
ut = urwid.Text(char, wrap="clip")
if splash_regex.search(char):
attmap = urwid.AttrMap(ut, "splash_main_clock")
else:
attmap = urwid.AttrMap(ut, "splash_main")
line_array.append(attmap)
line_col = urwid.Columns(line_array)
splash.append(line_col)
else:
ut = urwid.Text(line, wrap="clip")
attmap = urwid.AttrMap(ut, "splash_main")
splash.append(attmap)
splashpile = urwid.Pile(splash)
presskeytext = "[Press any key to continue]\n"
presskey = urwid.Text(presskeytext, wrap="clip", align="center")
presskeymap = urwid.AttrMap(presskey, "splash_presskey")
authortext = "by N.J. Thomas"
author = urwid.Text(authortext, wrap="clip", align="right")
authormap = urwid.AttrMap(author, "splash_author")
url = urwid.Text(urltext, wrap="clip")
urlmap = urwid.AttrMap(url, "splash_url")
version_ut = urwid.Text(version, wrap="clip", align="right")
versionmap = urwid.AttrMap(version_ut, "splash_version")
dbversion_ut = urwid.Text(dbversion, wrap="clip", align="right")
dbversionmap = urwid.AttrMap(dbversion_ut, "splash_version")
topcols = urwid.Columns([urlmap, authormap])
mainpile = urwid.Pile([topcols, splashpile, versionmap, dbversionmap])
mainpad = urwid.Padding(mainpile, align="center", width=77)
f = urwid.Filler(mainpad)
frame = urwid.Frame(body=f, footer=presskeymap)
super().__init__(frame)
def keypress(self, size, key):
self.zeitzonowidgetswitcher.switch_widget_main() | zeitzono | /zeitzono-0.8.0-py3-none-any.whl/Zeitzono/ZeitzonoUrwidSplashScreen.py | ZeitzonoUrwidSplashScreen.py |
import datetime
import pytz
import tzlocal
from dateutil.relativedelta import relativedelta
from parsedatetime import parsedatetime
import warnings
class ZeitzonoTime:
"""
a time object
- basically keeps a time (datetime.datetime) and a timezone
- initalized with local time and local timezone
- can update time with new time (will be treated as utc)
"""
def __init__(self):
self.time = self._get_utc_now()
self.set_tz_local()
def set_tz(self, tz):
tz = self._tz_to_pytz(tz)
self.time = self.time.astimezone(tz)
def set_tz_local(self):
localtz = self._get_local_tz()
self.time = self.time.astimezone(localtz)
def set_time_now(self):
tz = self.get_tz()
self.time = self._get_utc_now().astimezone(tz)
def set_time_nlp(self, englishtime):
pdt_version = parsedatetime.VERSION_CONTEXT_STYLE
pdt_cal = parsedatetime.Calendar(version=pdt_version)
tzinfo = self.time.tzinfo
# remove this after python 3.9 because supported minimum
# and parsedatetime code is switched to use
# zoneinfo instead localize
warnings.filterwarnings("ignore")
parsed_dtresult, errno = pdt_cal.parseDT(englishtime, tzinfo=tzinfo)
warnings.filterwarnings("default")
# parsedatetime docs are confusing, errno is supposed to be an int,
# but in recent testing, we get some other object returned
#
# so we try and do the right thing no matter what we get
if not isinstance(errno, int):
errno = errno.dateTimeFlag
if errno == 0:
return False
self.time = parsed_dtresult
return True
def get_time_utc(self):
return self.time.astimezone(pytz.utc)
def get_time(self):
return self.time
def get_time_str(self):
return self._time_to_str(self.time)
def get_tz(self):
return self.time.tzinfo
def get_time_tz_str(self, tz):
return self._time_to_str(self.get_time_tz(tz))
def get_time_tz(self, tz):
return self.time.astimezone(self._tz_to_pytz(tz))
def zero_sec(self):
self.time = self.time.replace(second=0)
def zero_min(self):
self.time = self.time.replace(minute=0)
def add_sec(self):
self.time = self.time + datetime.timedelta(seconds=1)
def sub_sec(self):
self.time = self.time - datetime.timedelta(seconds=1)
def add_min(self):
self.time = self.time + datetime.timedelta(seconds=60)
def sub_min(self):
self.time = self.time - datetime.timedelta(seconds=60)
def add_hour(self):
self.time = self.time + datetime.timedelta(seconds=3600)
def sub_hour(self):
self.time = self.time - datetime.timedelta(seconds=3600)
def add_qhour(self):
self.time = self.time + datetime.timedelta(seconds=900)
def sub_qhour(self):
self.time = self.time - datetime.timedelta(seconds=900)
def add_day(self):
self.time = self.time + datetime.timedelta(days=1)
def sub_day(self):
self.time = self.time - datetime.timedelta(days=1)
def add_qday(self):
self.time = self.time + datetime.timedelta(hours=6)
def sub_qday(self):
self.time = self.time - datetime.timedelta(hours=6)
def add_week(self):
self.time = self.time + datetime.timedelta(days=7)
def sub_week(self):
self.time = self.time - datetime.timedelta(days=7)
def add_month(self):
self.time = self.time + relativedelta(months=1)
def sub_month(self):
self.time = self.time - relativedelta(months=1)
def add_year(self):
self.time = self.time + relativedelta(years=1)
def sub_year(self):
self.time = self.time - relativedelta(years=1)
def __str__(self):
return self._time_to_str(self.time)
def _time_to_str(self, time):
return time.strftime("%a") + " " + str(time)
def _get_utc_now(self):
now = datetime.datetime.utcnow()
now = now.replace(microsecond=0)
nowutc = now.replace(tzinfo=pytz.utc)
return nowutc
def _get_local_tz(self):
# if tzlocal.get_localzone() cannot determine the local machine's time
# zone, it returns UTC, but throws a warning
#
# we want to handle the warning gracefully, so we convert it to an
# exception and catch it and return UTC ourselves
warnings.simplefilter("error")
try:
localzone = tzlocal.get_localzone()
except UserWarning:
return pytz.utc
return localzone
def _tz_to_pytz(self, tz):
if isinstance(tz, str):
return pytz.timezone(tz)
else:
return tz | zeitzono | /zeitzono-0.8.0-py3-none-any.whl/Zeitzono/ZeitzonoTime.py | ZeitzonoTime.py |
import urwid
import pkg_resources
import os
class ZeitzonoUrwidHelp(urwid.WidgetWrap):
_selectable = True
def __init__(self, zeitzonowidgetswitcher, helpfile, prev_is_main):
self.zeitzonowidgetswitcher = zeitzonowidgetswitcher
self.prev_is_main = prev_is_main
helpfilepath = os.path.join("data", helpfile)
helpmaintext_file = pkg_resources.resource_stream(
"Zeitzono", helpfilepath
)
helpmaintext = helpmaintext_file.read().decode("latin-1").strip()
helpmaintext_file.close()
helpmaintext = helpmaintext.split("\n")
helpmaintext_u = [
urwid.Text(line, wrap="clip") for line in helpmaintext
]
self.listwalker = urwid.SimpleListWalker(helpmaintext_u)
self.listbox = urwid.ListBox(self.listwalker)
frame = urwid.Frame(self.listbox, focus_part="body")
super().__init__(frame)
def go_previous_screen(self):
if self.prev_is_main:
self.zeitzonowidgetswitcher.switch_widget_main()
else:
self.zeitzonowidgetswitcher.switch_widget_search()
def keypress(self, size, key):
self.listbox.keypress(size, key)
if isinstance(key, str):
if key.isalpha():
if key.lower() == "k":
self.listbox.keypress(size, "up")
return True
if key.lower() == "j":
self.listbox.keypress(size, "down")
return True
if key == "G":
self.listbox.keypress(size, "end")
return True
if key == "g":
self.listbox.keypress(size, "home")
return True
if (key.lower() == "q") or (key == "esc"):
self.go_previous_screen()
return True
if (key == "backspace") or (key == "delete"):
self.listbox.keypress(size, "page up")
return True
if key == " ":
self.listbox.keypress(size, "page down")
return True
class ZeitzonoUrwidHelpMain(ZeitzonoUrwidHelp):
def __init__(self, zeitzonowidgetswitcher):
helpfile = "helpmain.txt"
prev_is_main = True
super().__init__(zeitzonowidgetswitcher, helpfile, prev_is_main)
class ZeitzonoUrwidHelpSearch(ZeitzonoUrwidHelp):
def __init__(self, zeitzonowidgetswitcher):
helpfile = "helpsearch.txt"
prev_is_main = False
super().__init__(zeitzonowidgetswitcher, helpfile, prev_is_main) | zeitzono | /zeitzono-0.8.0-py3-none-any.whl/Zeitzono/ZeitzonoUrwidHelp.py | ZeitzonoUrwidHelp.py |
import urwid
from .ZeitzonoSearch import ZeitzonoSearch
class ZeitzonoUrwidSearch(urwid.WidgetWrap):
_selectable = True
def __init__(
self, zeitzonowidgetswitcher, maincities, version, db, screen
):
self.zeitzonowidgetswitcher = zeitzonowidgetswitcher
self.bodypile = urwid.Pile([])
self.hsearch = ZeitzonoSearch(db)
self.maincities = maincities
self.screen = screen
self.results = None
self.prompt = urwid.Edit(caption="zeitzono> ", align="left")
prompt_attr = urwid.AttrMap(self.prompt, "search_prompt")
self.search2pile("")
blankline = urwid.Text("", wrap="clip")
helpline = "? - help, 0-9: add city, Enter - add bottom city, Esc - return to main"
helpline = urwid.Text(helpline, wrap="clip")
helpline_attr = urwid.AttrMap(helpline, "main_helpline")
footer = [blankline, helpline_attr, prompt_attr]
footerpile = urwid.Pile(footer)
htext = "zeitzono "
htext_len = len(htext)
zeitzono_ut = urwid.Text(htext, wrap="clip", align="right")
zeitzono_ut_am = urwid.AttrMap(zeitzono_ut, "main_zeitzono")
version_len = len(version)
version_ut = urwid.Text(version, wrap="clip", align="right")
version_ut_am = urwid.AttrMap(version_ut, "main_version")
blank = urwid.Text("", align="right")
versioncols = urwid.Columns(
[
("weight", 99, blank),
(htext_len, zeitzono_ut_am),
(version_len, version_ut_am),
]
)
self.bodypilefiller = urwid.Filler(self.bodypile, valign="bottom")
self.frame = urwid.Frame(
self.bodypilefiller,
header=versioncols,
footer=footerpile,
focus_part="footer",
)
urwid.connect_signal(self.prompt, "change", self.input_handler)
super().__init__(self.frame)
def input_handler(self, widget, newtext):
if newtext:
lastchar = newtext[-1]
if lastchar == "?":
return False
if lastchar.isdigit():
lastint = int(lastchar)
num = self.results.numcities()
if (num > 0) and (lastint + 1 <= num):
index = -1 - lastint
self.maincities.addcity(self.results.cities[index])
self.zeitzonowidgetswitcher.switch_widget_main()
self.search2pile(newtext)
def keypress(self, size, key):
self.prompt.keypress((size[0],), key)
if isinstance(key, str):
if key == "ctrl g":
self.prompt.set_edit_text("")
if key == "?":
self.prompt.set_edit_text("")
self.zeitzonowidgetswitcher.switch_widget_help_search()
if key == "enter":
if self.results is not None:
if self.results.numcities() >= 1:
self.maincities.addcity(self.results.cities[-1])
self.zeitzonowidgetswitcher.switch_widget_main()
if key == "esc":
self.results.clear()
self.zeitzonowidgetswitcher.switch_widget_main()
def _item2pileitem(self, item):
options = ("weight", 1)
pitem = (item, options)
return pitem
def _get_max_capacity(self):
# this is kludgy because Urwid doesn't give us a really great way to
# get the size of some widget
cols, rows = self.screen.get_cols_rows()
maxrows = rows - 6
return maxrows
def search2pile(self, terms):
newlist = []
terms = terms.strip()
hcities = self.hsearch.search(terms, limit=self._get_max_capacity())
numresults = hcities.numresults()
numresults_t = urwid.Text("NUMRESULTS: ")
numresultst_map = urwid.AttrMap(numresults_t, "numresults_str")
numresults_num_t = urwid.Text("%s" % str(numresults))
numresults_num_map = urwid.AttrMap(numresults_num_t, "numresults_num")
numresultscols = urwid.Columns(
[("pack", numresultst_map), ("pack", numresults_num_map)]
)
for idx, city in enumerate(hcities):
stacknum = hcities.numcities() - idx - 1
citys = str(city)
if stacknum > 9:
cityt = urwid.Text(" " + citys, wrap="clip", align="left")
else:
cityt = urwid.Text(
str(stacknum) + ": " + citys, wrap="clip", align="left"
)
newlist.append(cityt)
newlist.append(urwid.Text("", align="right"))
newlist.append(numresultscols)
newlist = [self._item2pileitem(item) for item in newlist]
self.bodypile.contents[:] = newlist
self.results = hcities | zeitzono | /zeitzono-0.8.0-py3-none-any.whl/Zeitzono/ZeitzonoUrwidSearch.py | ZeitzonoUrwidSearch.py |
# Zelda
> an nlp training framework,基础架构基于allennlp
## 目前支持模型
text classifier:
1. [average_pooling_text_classifier](https://github.com/whu-SpongeBob/spongenlp/blob/master/spongenlp/models/text_classifier/aver_pooling_text_classifier.py)
2. [bert_text_classifier](https://github.com/whu-SpongeBob/spongenlp/blob/master/spongenlp/models/text_classifier/bert_text_classifier_model.py)
3. [cnn_text_classifier](https://github.com/whu-SpongeBob/spongenlp/blob/master/spongenlp/models/text_classifier/cnn_test_classifier.py)
intent slot multitask:
1. [sf_id](https://github.com/whu-SpongeBob/spongenlp/blob/master/spongenlp/models/intent_slot/sf_id_intent_slot_model.py)
## 论文复现
1. [A Novel Bi-directional Interrelated Model for Joint Intent Detection and
Slot Filling
](https://github.com/whu-SpongeBob/spongenlp/blob/master/spongenlp/models/intent_slot/sf_id_intent_slot_model.py) | zelda | /zelda-0.0.1rc1.tar.gz/zelda-0.0.1rc1/README.md | README.md |
# Licence
## General licence
The following licence applies to all the files in this repository unless stated otherwise
Copyright 2021 Loïc Grobol <[email protected]>
Permission is hereby granted, free of charge, to any person obtaining a copy of this software and
associated documentation files (the "Software"), to deal in the Software without restriction,
including without limitation the rights to use, copy, modify, merge, publish, distribute,
sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all copies or substantial
portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT
NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND
NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES
OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN
CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
## Licence exceptions
- [`tests/fixtures/raw.txt`](tests/fixtures/raw.txt) is a mashup including the following [CC-BY-SA
4.0](https://creativecommons.org/licenses/by-sa/4.0/) licenced texts
- [*Rayons émis par les composés de l’uranium et du
thorium*](https://fr.wikisource.org/wiki/Rayons_%C3%A9mis_par_les_compos%C3%A9s_de_l%E2%80%99uranium_et_du_thorium),
Maria Skłodowska Curie
- [*Les maîtres sonneurs*](https://fr.wikisource.org/wiki/Les_Ma%C3%AEtres_sonneurs), George Sand | zeldarose | /zeldarose-0.7.3.tar.gz/zeldarose-0.7.3/LICENCE.md | LICENCE.md |
Zelda Rose
==========
[](https://pypi.org/project/zeldarose)
[](https://github.com/LoicGrobol/zeldarose/actions?query=workflow%3ACI)
[](https://github.com/psf/black)
[](https://zeldarose.readthedocs.io/en/latest/?badge=latest)
A straightforward trainer for transformer-based models.
## Installation
Simply install with pipx
```bash
pipx install zeldarose
```
## Train MLM models
Here is a short example of training first a tokenizer, then a transformer MLM model:
```bash
TOKENIZERS_PARALLELISM=true zeldarose tokenizer --vocab-size 4096 --out-path local/tokenizer --model-name "my-muppet" tests/fixtures/raw.txt
zeldarose
transformer --tokenizer local/tokenizer --pretrained-model flaubert/flaubert_small_cased --out-dir local/muppet --val-text tests/fixtures/raw.txt tests/fixtures/raw.txt
```
The `.txt` files are meant to be raw text files, with one sample (e.g. sentence) per line.
There are other parameters (see `zeldarose transformer --help` for a comprehensive list), the one
you are probably mostly interested in is `--config`, giving the path to a training config (for which
we have [`examples/`](examples)).
The parameters `--pretrained-models`, `--tokenizer` and `--model-config` are all fed directly to
[Huggingface's `transformers`](https://huggingface.co/transformers) and can be [pretrained
models](https://huggingface.co/transformers/pretrained_models.html) names or local path.
## Distributed training
This is somewhat tricky, you have several options
- If you are running in a SLURM cluster use `--strategy ddp` and invoke via `srun`
- You might want to preprocess your data first outside of the main compute allocation. The
`--profile` option might be abused for that purpose, since it won't run a full training, but
will run any data preprocessing you ask for. It might also be beneficial at this step to load a
placeholder model such as
[RoBERTa-minuscule](https://huggingface.co/lgrobol/roberta-minuscule/tree/main) to avoid runnin
out of memory, since the only thing that matter for this preprocessing is the tokenizer.
- Otherwise you have two options
- Run with `--strategy ddp_spawn`, which uses `multiprocessing.spawn` to start the process
swarm (tested, but possibly slower and more limited, see `pytorch-lightning` doc)
- Run with `--strategy ddp` and start with `torch.distributed.launch` with `--use_env` and
`--no_python` (untested)
## Other hints
- Data management relies on 🤗 datasets and use their cache management system. To run in a clear
environment, you might have to check the cache directory pointed to by the`HF_DATASETS_CACHE`
environment variable.
## Inspirations
- <https://github.com/shoarora/lmtuners>
- <https://github.com/huggingface/transformers/blob/243e687be6cd701722cce050005a2181e78a08a8/examples/run_language_modeling.py>
| zeldarose | /zeldarose-0.7.3.tar.gz/zeldarose-0.7.3/README.md | README.md |
from string import Formatter
from typing import Callable
from typing import Tuple
from typing import Union
from selenium.webdriver.remote.webdriver import WebDriver
from selenium.webdriver.support.wait import WebDriverWait
from zelenium import expected_conditions as EC
from zelenium.base.config import Config
class FormatTuple(tuple):
def __getitem__(self, key):
if key + 1 > len(self):
return "{}"
return tuple.__getitem__(self, key)
class FormatDict(dict):
def __missing__(self, key):
return "{" + key + "}"
def f(string, *args, **kwargs):
formatter = Formatter()
args_mapping = FormatTuple(args)
mapping = FormatDict(kwargs)
return formatter.vformat(string, args_mapping, mapping)
class Base:
conf: Config = None
def __init__(self, conf: Config = None):
self.conf = conf or Config.get_instance()
def wait(self, parent: WebDriver = None):
return WebDriverWait(
parent or self.conf.d, self.conf.dwt, self.conf.dpf
)
def until(self, method: Callable, message: str = "", **kwargs):
return self.wait(**kwargs).until(method, message)
def until_not(self, method: Callable, message: str = "", **kwargs):
return self.wait(**kwargs).until_not(method, message)
def find(
self,
selector: Union[Tuple[str, str], "BaseElement"],
parent: WebDriver = None,
):
if isinstance(selector, BaseElement):
selector = selector.selector
return self.until(self.conf.dec(selector), parent=parent)
def find_all(
self,
selector: Union[Tuple[str, str], "BaseElement"],
parent: WebDriver = None,
):
if isinstance(selector, BaseElement):
selector = selector.selector
return self.until(
EC.presence_of_all_elements_located(selector), parent=parent
)
class BaseElement(Base):
by: str
value: str
selector: Tuple[str, str]
_suffix: str = ""
def __init__(self, by: str, value: str):
super().__init__()
self.by = by
self.value = value
def __call__(self):
return self.find(self.selector)
def __repr__(self):
return "Element {1} ({0})".format(*self.selector)
@property
def selector(self):
return self.by, f(self.value, s=self._suffix)
def set_suffix(self, value):
self._suffix = value
def format(self, *args, **kwargs):
el = BaseElement(self.by, f(self.value, *args, **kwargs))
el.set_suffix(self._suffix)
return el
def child(self, value: Union[Tuple[str, str], "BaseElement"]):
return self.find(value, self())
def child_all(self, value: Union[Tuple[str, str], "BaseElement"]):
return self.find_all(value, self())
def all(self):
return self.find_all(self.selector) | zelenium | /base/__init__.py | __init__.py |
<!-- @Author: Thomas Firmin <ThomasFirmin> -->
<!-- @Date: 2022-05-03T15:41:48+02:00 -->
<!-- @Email: [email protected] -->
<!-- @Project: Zellij -->
<!-- @Last modified by: ThomasFirmin -->
<!-- @Last modified time: 2022-05-03T15:44:11+02:00 -->
<!-- @License: CeCILL-C (http://www.cecill.info/index.fr.html) -->
<!-- @Copyright: Copyright (C) 2022 Thomas Firmin -->

[](https://pypi.org/project/zellij/)
[](https://pypi.org/project/zellij/)
[](https://zellij.readthedocs.io/en/latest/?badge=latest)
[](https://github.com/ThomasFirmin/zellij/commit/)

**Zellij** is an open source Python framework for *HyperParameter Optimization* (HPO) which was orginally dedicated to *Fractal Decomposition based algorithms* [[1]](#1) [[2]](#2).
It includes tools to define mixed search space, manage objective functions, and a few algorithms.
To implements metaheuristics and other optimization methods, **Zellij** uses [DEAP](https://deap.readthedocs.io/)[[3]](#3) for the *Evolutionary Algorithms* part
and [BoTorch](https://botorch.org/) [[4]](#4) for *Bayesian Optimization*.
**Zellij** is defined as an easy to use and modular framework, based on Python object oriented paradigm.
See [documentation](https://zellij.readthedocs.io/en/latest/).
## Install Zellij
#### Original version
```
$ pip install zellij
```
#### Distributed Zellij
This version requires a MPI library, such as [MPICH](https://www.mpich.org/) or [Open MPI](https://www.open-mpi.org/).
It is based on [mpi4py](https://mpi4py.readthedocs.io/en/stable/intro.html#what-is-mpi)
```
$ pip install zellij[mpi]
```
User will then be able to use the `MPI` option of the `Loss` decorator.
```python
@Loss(MPI=True)
```
Then the python script must be executed using `mpiexec`:
```python
$ mpiexec -machinefile <path/to/hostfile> -n <number of processes> python3 <path/to/python/script>
```
## Dependencies
#### Original version
* **Python** >=3.6
* [numpy](https://numpy.org/)=>1.21.4
* [DEAP](https://deap.readthedocs.io/en/master/)>=1.3.1
* [botorch](https://botorch.org/)>=0.6.3.1
* [gpytorch](https://gpytorch.ai/)>=1.6.0
* [pandas](https://pandas.pydata.org/)>=1.3.4
* [enlighten](https://python-enlighten.readthedocs.io/en/stable/)>=1.10.2
#### MPI version
* **Python** >=3.6
* [numpy](https://numpy.org/)=>1.21.4
* [DEAP](https://deap.readthedocs.io/en/master/)>=1.3.1
* [botorch](https://botorch.org/)>=0.6.3.1
* [gpytorch](https://gpytorch.ai/)>=1.6.0
* [pandas](https://pandas.pydata.org/)>=1.3.4
* [enlighten](https://python-enlighten.readthedocs.io/en/stable/)>=1.10.2
* [mpi4py](https://mpi4py.readthedocs.io/en/stable/)>=3.1.2
## Contributors
### Design
* Thomas Firmin: [email protected]
* El-Ghazali Talbi: [email protected]
## References
<a id="1">[1]</a>
Nakib, A., Ouchraa, S., Shvai, N., Souquet, L. & Talbi, E.-G. Deterministic metaheuristic based on fractal decomposition for large-scale optimization. Applied Soft Computing 61, 468–485 (2017).
<a id="2">[2]</a>
Demirhan, M., Özdamar, L., Helvacıoğlu, L. & Birbil, Ş. I. FRACTOP: A Geometric Partitioning Metaheuristic for Global Optimization. Journal of Global Optimization 14, 415–436 (1999).
<a id="3">[3]</a>
Félix-Antoine Fortin, François-Michel De Rainville, Marc-André Gardner, Marc Parizeau and Christian Gagné, "DEAP: Evolutionary Algorithms Made Easy", Journal of Machine Learning Research, vol. 13, pp. 2171-2175, jul 2012.
<a id="4">[4]</a>
M. Balandat, B. Karrer, D. R. Jiang, S. Daulton, B. Letham, A. G. Wilson, and E. Bakshy. BoTorch: A Framework for Efficient Monte-Carlo Bayesian Optimization. Advances in Neural Information Processing Systems 33, 2020.
| zellij | /zellij-1.0.1.tar.gz/zellij-1.0.1/README.md | README.md |
# Zelos CrasHD Plugin
A plugin for [Zelos](https://github.com/zeropointdynamics/zelos) to enhance crash triaging by performing dataflow & root cause analysis.
## Optional Prerequisites
This plugin has an optional dependency on the [graphviz](https://pypi.org/project/graphviz/) package to render control flow graphs to png. The graphviz python package can be installed normally via `pip install graphviz`, but will also require [Graphviz](https://www.graphviz.org/) itself to be installed locally as well. Instructions for installing Graphviz locally can be found [here](https://graphviz.org/download/).
If you do not wish to install the graphviz package or Graphviz, you can safely ignore this optional dependency and zelos-crashd will still work as intended, but control flow graphs will not be rendered to png.
## Installation
Install from pypi
```console
$ pip install zelos-crashd
```
Or install directly from the repo
```console
$ git clone https://github.com/zeropointdynamics/zelos-crashd.git
$ cd zelos-crashd
$ pip install .
```
Alternatively, install an _editable_ version for development
```console
$ git clone https://github.com/zeropointdynamics/zelos-crashd.git
$ cd zelos-crashd
$ pip install -e '.[dev]'
```
## Related Resources
[CrasHD Visualizer](https://github.com/zeropointdynamics/vscode-crashd) is a VS Code extension for visualizing the results & output of this plugin that features:
- Contextual source code highlighting
- Interactive graph of data flow
- Additional context & runtime information
[CrasHD Examples](https://github.com/zeropointdynamics/examples-crashd) is a collection of reproducible crashes that can be used with this plugin.
## Usage
The following snippets use the example from [examples-crashd/afl_training/vulnerable.c](https://github.com/zeropointdynamics/examples-crashd/tree/master/afl_training)
After compiling the above example (`vulnerable.c`) you can emulate the binary using zelos:
```console
$ zelos vulnerable < inputs/crashing_input
```
To gain a more information on the crashing program, use the `--taint` and `--taint_output` flags in order to keep track of dataflow leading from the crash. When the `--taint` flag is used, Zelos will calculate the dataflow and taint information related to the crash. `--taint_output terminal` is used to specify that the output of `--taint` will be to stdout.
```console
$ zelos --taint --taint_output terminal vulnerable < inputs/crashing_input
```
| zelos-crashd | /zelos-crashd-0.0.2.tar.gz/zelos-crashd-0.0.2/README.md | README.md |
# Changelog
All notable changes to this project will be documented in this file.
The format is based on [Keep a Changelog](https://keepachangelog.com/en/1.0.0/),
and this project adheres to [Semantic Versioning](https://semver.org/spec/v2.0.0.html).
## [Version 0.0.2] - 2020-08-06
Remove graphviz as a required dependency, add the taint_output flag.
### Added
- taint_output flag
### Changed
- N/A
### Removed
- Dependency on graphviz package
[0.0.2]: https://github.com/zeropointdynamics/zelos-crashd/releases/tag/v0.0.2
## [Version 0.0.1] - 2020-08-05
Initial public release.
### Added
- Initial open source commit.
### Changed
- N/A
### Removed
- N/A
[0.0.1]: https://github.com/zeropointdynamics/zelos-crashd/releases/tag/v0.0.1 | zelos-crashd | /zelos-crashd-0.0.2.tar.gz/zelos-crashd-0.0.2/CHANGELOG.md | CHANGELOG.md |
# This program is free software: you can redistribute it and/or modify
# it under the terms of the GNU Affero General Public License as
# published by the Free Software Foundation, either version 3 of the
# License, or (at your option) any later version.
# This program is distributed in the hope that it will be useful,
# but WITHOUT ANY WARRANTY; without even the implied warranty of
# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
# GNU Affero General Public License for more details.
# You should have received a copy of the GNU Affero General Public
# License along with this program. If not, see
# <http://www.gnu.org/licenses/>.
# ======================================================================
from collections import defaultdict
import os
from pathlib import Path
from typing import Optional
from elftools.dwarf.descriptions import describe_form_class
from elftools.elf.elffile import ELFFile
class AddressEntry:
def __init__(self, low, high, file, line_num):
self.low = low
self.high = high
self.file = file
self.line_num = line_num
def __str__(self):
return f"(0x{self.low:x}-0x{self.high:x}: {self.file}:{self.line_num})"
class AddressMap:
def __init__(self):
self._address_low_high = []
self._cache = {}
self._source2addr_range = {}
def __str__(self):
return [entry.__str__() for entry in self._address_low_high].__str__()
def files(self):
return {entry.file for entry in self._address_low_high}
def get_addr_range_from_source(self, file, line_num):
return self._source2addr_range.get(f"{file}{line_num}", (None, None))
def _add_cache(self, addr, file, line):
self._cache[addr] = (file, line - 1)
def add(self, low, high, file, line):
file = file.decode()
self._add_cache(low, file, line)
self._source2addr_range[f"{file}{line}"] = (low, high)
for addr in range(low, high):
self._add_cache(addr, file, line)
entry = AddressEntry(low, high, file, line)
self._address_low_high.append(entry)
self._address_low_high.sort(key=lambda x: x.low)
def get(self, addr: int, default=(None, None)):
cached_val = self._cache.get(addr, None)
if cached_val is not None:
return cached_val
idx = self.binary_search(addr)
if idx is not None:
entry = self._address_low_high[idx]
retval = (entry.file, entry.line_num - 1)
self._cache[addr] = retval
return retval
return default
def _attach_src_to_external_addrs(self, trace, dwarf_data):
"""
Certain addresses in the trace are not associated with source
code because they are in external modules. We associate those
addresses with source code from the last line that occurred
before moving to the external module.
"""
# External modules can call each other. This means that the same
# address could have multiple candidates for what address should
# be associated with them.
file_lines = dwarf_data._file_lines
current_source = None
current_file = None
current_line = None
smeared = {}
for addr in trace:
file, line_num = self.get(addr)
if file in file_lines and addr not in smeared:
dwarf_data._addr2source[addr] = file_lines[file][line_num]
current_source = file_lines[file][line_num]
current_file = file
current_line = line_num
elif current_source is not None:
dwarf_data._addr2source[addr] = "within " + current_source
self._add_cache(addr, current_file, current_line + 1)
smeared[addr] = current_source
def binary_search(self, x):
low = 0
mid = 0
high = len(self._address_low_high) - 1
while low <= high:
mid = (high + low) // 2
entry = self._address_low_high[mid]
if entry.low <= x < entry.high:
return mid
if entry.low == entry.high and entry.low == x:
return mid
# Check if x is present at mid
if entry.low < x:
low = mid + 1
# If x is greater, ignore left half
elif entry.low > x:
high = mid - 1
# If we reach here, then the element was not present
return None
class DwarfData:
"""
Class to parse and hold relevant Dwarf information from binary
"""
def __init__(self, binary_path, source_path, rebased_module_base=None):
self._binary_path = binary_path
self._source_path = source_path
self._rebased_module_base = rebased_module_base
self._fp = None
self._elf = None
self._dwarfinfo = None
self._offset = 0
self._file_lines = {}
self._file_to_syspath = {}
self._addr2source = {}
self._address_map = None
self._function_map = {}
self.__load_elf_and_dwarf(binary_path)
self.__calculate_offset(rebased_module_base)
self.__set_address_map()
self.__setup_file_lines()
self.__build_function_map()
def __del__(self):
if hasattr(self._fp, "close"):
self._fp.close()
def get_source(self, addr: int) -> Optional[str]:
return self._addr2source.get(addr, None)
def get_function_info(self, taint_graph):
function_map = self._function_map
addr2func = {}
for addr in taint_graph._reduced_path.keys():
for f, ranges in function_map.items():
for r in ranges:
(low, high) = r
if low <= addr <= high:
addr2func[addr] = f
return addr2func
def attach_src_to_external_addrs(self, trace):
if self._address_map is None:
return
self._address_map._attach_src_to_external_addrs(trace, self)
def __get_elf_module_base(self, elf):
# This function DOES NOT WORK for static binaries.
# It gets lucky on binaries where the main module is loaded at 0,
# which is what this function normally returns. Have to find a way
# to get the desired load address of binaries. Maybe one way to get
# around is always return 0 for dynamic binaries.
segment_addrs = [s.header.p_vaddr for s in elf.iter_segments()]
# print(f"Segment_addrs: {segment_addrs}")
return min(segment_addrs)
def __load_elf_and_dwarf(self, binary_path):
if os.path.exists(binary_path) and os.path.isfile(binary_path):
self._fp = open(binary_path, "rb")
self._elf = ELFFile(self._fp)
try:
self._dwarfinfo = self._elf.get_dwarf_info()
self._elf_module_base = self.__get_elf_module_base(self._elf)
except:
pass
def __calculate_offset(self, rebased_module_base):
if rebased_module_base is None:
return
symbols_module_base = self._elf_module_base
offset = rebased_module_base - symbols_module_base
# TODO: TEMP for static binaries
if offset != 0x10000:
offset = 0
# print("Got offset: ", offset)
self._offset = offset
def __set_address_map(self):
if self._dwarfinfo is None:
return
dwarfinfo = self._dwarfinfo
offset = self._offset
address_map = AddressMap()
# Go over all the line programs in the DWARF information, looking for
# one that describes the given address.
for CU in dwarfinfo.iter_CUs():
# First, look at line programs to find the file/line for the addr
lineprog = dwarfinfo.line_program_for_CU(CU)
prevstate = None
for entry in lineprog.get_entries():
# We're interested in entries where a new state is assigned
if entry.state is None:
continue
if entry.state.end_sequence:
# if the line number sequence ends, clear prevstate.
prevstate = None
continue
# Looking for a range of addresses in two consecutive states
# that contain the required address.
if prevstate:
filename = lineprog["file_entry"][prevstate.file - 1].name
line = prevstate.line
address_map.add(
prevstate.address + offset,
entry.state.address + offset,
filename,
line,
)
prevstate = entry.state
self._address_map = address_map
def __resolve_filepath(self, path):
"""
First checks the current directory for the path.
Then checks recursively in the source code folder for the path
"""
if os.path.exists(path):
return path
matching_files = [path for path in Path(self._source_path).rglob(path)]
if len(matching_files) == 0:
# print(
# f"Could not find source code file {path} within"
# f" {source_code_path}"
# )
return None
if len(matching_files) > 1:
# print(
# f"There is more than one matching file for {path}:"
# f" {matching_files}. Picking {matching_files[0]}"
# )
pass
return matching_files[0]
def __setup_file_lines(self):
for filename in self._address_map.files():
resolved_filename = self.__resolve_filepath(filename)
if resolved_filename is None:
continue
f = open(resolved_filename, "r")
self._file_to_syspath[filename] = resolved_filename
# Keep this keyed by the original file name so that later on we
# can find these lines
self._file_lines[filename] = list(f.readlines())
def __build_function_map(self):
"""
Builds the mapping of function names to
list of tuples: [(low, high), ...]
"""
dwarfinfo = self._dwarfinfo
offset = self._offset
if dwarfinfo is None:
return
functions = defaultdict(list)
entries = []
for CU in dwarfinfo.iter_CUs():
for DIE in CU.iter_DIEs():
die_info = self.__handle_DIE(DIE)
if die_info is not None:
entries.append(die_info)
for entry in entries:
func_name = entry["name"]
low, high = entry["range"]
functions[func_name].append((low + offset, high + offset))
self._function_map = functions
def __handle_DIE(self, DIE):
def __extract_value(attr, key, default):
if key in attr.keys():
return attr[key].value
return default
# we are interested in two things: name and address range
tag = DIE.tag
attr = DIE.attributes
# ignore compile unit info
if tag == "DW_TAG_compile_unit":
return None
# check for low_pc
lowpc = __extract_value(attr, "DW_AT_low_pc", -1)
# we don't care if DIE holds no address
if lowpc == -1:
return None
elif "DW_AT_high_pc" in attr.keys():
highpc_attr = attr["DW_AT_high_pc"]
highpc_attr_class = describe_form_class(highpc_attr.form)
if highpc_attr_class == "address":
highpc = highpc_attr.value
elif highpc_attr_class == "constant":
highpc = lowpc + highpc_attr.value
else:
highpc = lowpc
# recursive search for name
current_die = DIE
while True:
name = __extract_value(attr, "DW_AT_name", b"")
if name and current_die.tag == "DW_TAG_subprogram":
return {"name": name.decode(), "range": (lowpc, highpc)}
origin = __extract_value(attr, "DW_AT_abstract_origin", -1)
if origin == -1:
break
current_die = current_die.get_DIE_from_attribute(
"DW_AT_abstract_origin"
)
attr = current_die.attributes
return None | zelos-crashd | /zelos-crashd-0.0.2.tar.gz/zelos-crashd-0.0.2/src/crashd/dwarf/dwarf_data.py | dwarf_data.py |
# This program is free software: you can redistribute it and/or modify
# it under the terms of the GNU Affero General Public License as
# published by the Free Software Foundation, either version 3 of the
# License, or (at your option) any later version.
# This program is distributed in the hope that it will be useful,
# but WITHOUT ANY WARRANTY; without even the implied warranty of
# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
# GNU Affero General Public License for more details.
# You should have received a copy of the GNU Affero General Public
# License along with this program. If not, see
# <http://www.gnu.org/licenses/>.
# ======================================================================
from collections import defaultdict
from termcolor import colored
import os
import html
from pathlib import Path
from typing import Optional
from elftools.dwarf.descriptions import describe_form_class
from elftools.elf.elffile import ELFFile
def find_file(path, source_code_path):
"""
First checks the current directory for the path.
Then checks recursively in the source code folder for the path
"""
if os.path.exists(path):
return path
matching_files = [path for path in Path(source_code_path).rglob(path)]
if len(matching_files) == 0:
# print(
# f"Could not find source code file {path} within {source_code_path}"
# )
return None
if len(matching_files) > 1:
# print(
# f"There is more than one matching file for {path}: {matching_files}. Picking {matching_files[0]}"
# )
pass
return matching_files[0]
def _construct_zcov_files(
taint_path, address_map, trace, edges, files, file_to_syspath, src_path
):
from pathlib import Path
import json
crash_line = None
crash_file = None
zcov_files = defaultdict(dict)
# Merge values used for each source code line of dataflow
for k, v in taint_path.reduced_path.items():
k_addr = k
file, line_num = address_map.get(k_addr, (None, None))
if file not in files:
continue
# Get absolute paths, resolve any symbolic links, etc.
parent_path = os.path.realpath(src_path)
child_path = os.path.realpath(file_to_syspath[file])
# Ensure file path is actually rooted in the src parent path
# (i.e. ignore system libc headers, etc.)
if os.path.commonpath([parent_path]) != os.path.commonpath(
[parent_path, child_path]
):
continue
line_num += 1
assembly = taint_path._assembly.get(k_addr, "Missing Assembly")
if crash_line is None:
kind = "FLOW_END"
crash_line = line_num
crash_file = file
# if taint_path._dataflow.zelos.config.asan:
# crash_summary = (
# taint_path._dataflow.zelos.plugins.asan.get_crash_summary()
# )
# crash_summary_comments = "".join(
# [f";{line}\n" for line in crash_summary.split("\n")]
# )
# assembly = crash_summary_comments + assembly
else:
kind = "FLOW_THROUGH"
vals_used = list(set([str(rtd[1].val) for rtd in v.items()]))
# print(file, line_num, kind, vals_used)
if int(line_num) in zcov_files[file]:
existing_vals = zcov_files[file][int(line_num)]["meta"]
zcov_files[file][int(line_num)]["meta"] = list(
set(existing_vals + vals_used)
)
else:
zcov_files[file][int(line_num)] = {
"kind": kind,
"meta": vals_used,
"asm": [],
}
zcov_files[file][int(line_num)]["asm"].append((k_addr, assembly))
# print(" zcov merge values")
# Add lines-executed information
count = 0
after_dataflow = True
addrs = set()
for addr in reversed(trace):
file, line_num = address_map.get(addr, (None, None))
if file not in zcov_files:
continue
# Get absolute paths, resolve any symbolic links, etc.
parent_path = os.path.realpath(src_path)
child_path = os.path.realpath(file)
# Ensure file path is actually rooted in the src parent path
# (i.e. ignore system libc headers, etc.)
if os.path.commonpath([parent_path]) != os.path.commonpath(
[parent_path, child_path]
):
continue
line_num += 1
if line_num == crash_line:
after_dataflow = False
if int(line_num) not in zcov_files[file]:
if after_dataflow:
zcov_files[file][int(line_num)] = {
"kind": "EXEC_AFTER_FLOW_END",
"asm": [],
}
else:
zcov_files[file][int(line_num)] = {"kind": "EXEC", "asm": []}
if addr in addrs:
continue
addrs.add(addr)
assembly = taint_path._assembly.get(addr, None)
if assembly is None:
assembly = taint_path.get_assembly_for_range(addr, addr + 20)[addr]
zcov_files[file][int(line_num)]["asm"].append((addr, assembly))
count += 1
# Add annotation of where asan guarded memory was triggered.
# if taint_path._dataflow.zelos.plugins.asan._asan_guard_triggered:
# addr = (
# taint_path._dataflow.zelos.plugins.asan.crash_alloc_info.inst_address
# )
# file, line_num = address_map.get(addr, (None, None))
# line_num += 1
# if file in zcov_files:
# zcov_files[file][line_num]["kind"] = "ALLOC"
# print(" zcov added lines executed")
# Add data flow line edge information
for src, dests in edges.items():
srcfile, srcline_num = address_map.get(src, (None, None))
if srcfile not in zcov_files:
continue
srcline_num += 1
for dest in dests:
destfile, destline_num = address_map.get(dest, (None, None))
if destfile not in zcov_files:
continue
destline_num += 1
# print(f" {destfile}{destline_num} -> {srcfile}{srcline_num}")
if destfile not in zcov_files or srcfile not in zcov_files:
continue
if "data_from" not in zcov_files[destfile][int(destline_num)]:
zcov_files[destfile][int(destline_num)]["data_from"] = list()
if "data_to" not in zcov_files[srcfile][int(srcline_num)]:
zcov_files[srcfile][int(srcline_num)]["data_to"] = list()
zcov_files[destfile][int(destline_num)]["data_from"].append(
{"file": srcfile, "line_number": srcline_num}
)
zcov_files[srcfile][int(srcline_num)]["data_to"].append(
{"file": destfile, "line_number": destline_num}
)
# print(f"{destfile}{destline_num} -> {srcfile}{srcline_num}")
# print(" zcov add data flow edges")
# Generate zcov-formatted JSON
single_json = {"files": list(), "graphs": list()}
for file, zcov_content in zcov_files.items():
if file not in file_to_syspath:
continue
zcov_file = Path(file_to_syspath[file]).with_suffix(".zcov")
zcov_json = defaultdict(dict)
zcov_json["file"] = file
lines = []
for line_num, line_info in zcov_content.items():
line = {}
line["line_number"] = line_num
line["kind"] = line_info["kind"]
if "data_to" in line_info:
line["data_from"] = line_info["data_to"]
if "data_from" in line_info:
line["data_to"] = line_info["data_from"]
if "meta" in line_info:
# Convert vals list to short string
vals_used = line_info["meta"]
vals_used = sorted(
vals_used, key=lambda x: 0 if "=" in x else 1
)
elipsis = ""
if len(vals_used) > 5:
elipsis = f",(+{len(vals_used)-5} more)"
vals_used = vals_used[:5]
info_str = "Vals: " + ",".join(vals_used) + elipsis
line["meta"] = info_str
if "asm" in line_info:
# sorted_lines = sorted(line_info["asm"], key=lambda x: x[0])
# line["asm"] = [x[1] for x in sorted_lines]
line["asm"] = [x[1] for x in reversed(line_info["asm"])]
lines.append(line)
zcov_json["lines"] = lines
# json_str = json.dumps(zcov_json, indent=2, sort_keys=True)
single_json["files"].append(zcov_json)
# print(f"==== {zcov_file} ====")
# print(json_str)
# with open(zcov_file, "w") as f:
# f.write(json_str)
(
src_graph,
ordering,
wave_order,
child2parents,
parent2children,
) = export_source_graph(taint_path, address_map, files)
num_waves = max(wave_order.values()) + 1
wave_ordering = [[] for _ in range(num_waves)]
for key, wave_num in wave_order.items():
wave_ordering[wave_num].append(key)
graph_json = {
"name": "source_graph",
"data": src_graph,
"crashpoint": f"{crash_file}{str(crash_line - 1)}",
"ordering": ordering,
"wave_ordering": wave_ordering,
"child2parents": child2parents,
"parent2children": parent2children,
}
single_json["graphs"].append(graph_json)
with open(os.path.join(src_path, "crashd.zcov"), "w") as f:
f.write(json.dumps(single_json, indent=2, sort_keys=True))
_cwd = os.path.dirname(os.path.realpath(__file__))
with open(os.path.join(_cwd, "template.html"), "r") as inf:
with open(os.path.join(src_path, "crashd.graph.html"), "w") as outf:
data = inf.read()
data = data.replace(
"@@ZPD_GRAPH@@", json.dumps(single_json["graphs"])
)
outf.write(data)
def annotate_with_dwarf_data(zelos, binary_path, trace, taint_path):
zelos_module_base = zelos.internal_engine.memory.get_module_base(
binary_path
)
address_map = process_file(binary_path, zelos_module_base)
dwarf_data = DwarfData(address_map, zelos.config.source_code_path)
# TODO: The following uses the updated DwarfData
# dwarf_data = DwarfData(
# binary_path, zelos.config.source_code_path, zelos_module_base
# )
taint_path._dwarf_data = dwarf_data
def get_nodes_and_edges(taint_graph, address_map):
# print("Setting up source graph")
# tuples containing source code addr and next addr to check
open_paths = [(taint_graph._start_addr, taint_graph._start_addr)]
# No need to analyze an address that has already been analyzed.
analyzed_addrs = set()
# use to defines
edges = defaultdict(list)
nodes = set()
while len(open_paths) > 0:
child, next_ancestor = open_paths.pop()
if next_ancestor in analyzed_addrs:
continue
analyzed_addrs.add(next_ancestor)
parents = taint_graph._reduced_path_parents.get(next_ancestor, [])
for parent in parents:
if address_map.get(parent, None) is not None:
edges[child].append(parent)
nodes.add(child)
nodes.add(parent)
if parent not in analyzed_addrs:
open_paths.append((parent, parent))
else:
if parent not in analyzed_addrs:
open_paths.append((child, parent))
return (nodes, edges)
def show_tainted_source(zelos, binary_path, trace, taint_path):
dwarf_data = taint_path._dwarf_data
files = dwarf_data._file_lines
file_to_syspath = dwarf_data._file_to_syspath
address_map = dwarf_data._address_map
address_map._attach_src_to_external_addrs(trace, dwarf_data)
from crashd.taint.render.graphviz import render_source_graph
render_source_graph(taint_path, address_map, files)
(nodes, edges) = get_nodes_and_edges(taint_path, address_map)
if len(file_to_syspath) > 0:
_construct_zcov_files(
taint_path,
address_map,
trace,
edges,
files,
file_to_syspath,
zelos.config.source_code_path,
)
if not zelos.config.taint_output == "terminal":
return
# print("generated .zcov file")
crash_line = None
source_path = {}
changed_file_lines = defaultdict(list)
for k, v in taint_path.reduced_path.items():
k_addr = k
file, line = address_map.get(k_addr, (None, None))
source_path[(file, line)] = v
if file in files:
if crash_line is None:
files[file][line] = colored(
# f"!0x{k:x}" +
files[file][line] + str(v) + "\n",
color="red",
)
crash_line = line
changed_file_lines[file].append(line)
else:
files[file][line] = colored(
# f"*0x{k:x}" +
files[file][line] + str(v) + "\n",
color="white",
attrs=["bold"],
)
changed_file_lines[file].append(line)
# print("Updated source lines with data flow")
count = 0
# Get first trace line that is in the source
for addr in reversed(trace):
file, line = address_map.get(addr, (None, None))
if file not in files:
continue
if line == crash_line:
break
files[file][line] = colored(
files[file][line] + f" Count: {count}\n",
color="green",
attrs=["bold"],
)
changed_file_lines[file].append(line)
count += 1
# print("Updated source lines with trace to crash")
if len(changed_file_lines) == 0:
print(
"There are no lines in source that correspond to the taint path."
" There may have been a bug."
)
for path, lines in files.items():
if path not in changed_file_lines:
continue
idxes = changed_file_lines[path]
# print(path, idxes)
lines_to_print = []
indices_chosen = set()
context = 3
for idx in reversed(idxes):
i = idx - context
while i < idx + context + 1:
if i < 0 or i >= len(lines):
i += 1
continue
if i in indices_chosen:
i += 1
continue
if i > idx and i in idxes:
idx = i
lines_to_print.append(lines[i])
indices_chosen.add(i)
i += 1
if lines_to_print[-1] != "...\n":
lines_to_print.append("...\n")
print("".join(lines_to_print))
# print("Changed lines: ")
# print(changed_file_lines)
# print("Num lines: ", len(changed_file_lines))
def process_file(filename, zelos_module_base):
"""
Returns a dictionary containing addr -> (file, 0-indexed source code line)
Returns 0 indexed results, while ElfFile gives 1 indexed results
"""
# print("Processing file:", filename)
with open(filename, "rb") as f:
elffile = ELFFile(f)
if not elffile.has_dwarf_info():
# print(" file has no DWARF info")
return
symbols_module_base = _get_module_base(elffile)
offset = zelos_module_base - symbols_module_base
if offset != 0x1000: # TODO TEMP for static binaries
offset = 0
# print("Got offset: ", offset)
total_address_map = {}
dwarfinfo = elffile.get_dwarf_info()
return decode_file_lines(dwarfinfo, offset)
def __extract_value(attr, key, default):
if key in attr.keys():
return attr[key].value
return default
def __handle_DIE(DIE):
# we are interested in two things: name and address range
tag = DIE.tag
attr = DIE.attributes
# ignore compile unit info
if tag == "DW_TAG_compile_unit":
return None
# check for low_pc
lowpc = __extract_value(attr, "DW_AT_low_pc", -1)
# we don't care if DIE holds no address
if lowpc == -1:
return None
elif "DW_AT_high_pc" in attr.keys():
highpc_attr = attr["DW_AT_high_pc"]
highpc_attr_class = describe_form_class(highpc_attr.form)
if highpc_attr_class == "address":
highpc = highpc_attr.value
elif highpc_attr_class == "constant":
highpc = lowpc + highpc_attr.value
else:
highpc = lowpc
# recursive search for name
current_die = DIE
while True:
name = __extract_value(attr, "DW_AT_name", b"")
if name and current_die.tag == "DW_TAG_subprogram":
return {"name": name.decode(), "range": (lowpc, highpc)}
origin = __extract_value(attr, "DW_AT_abstract_origin", -1)
if origin == -1:
break
current_die = current_die.get_DIE_from_attribute(
"DW_AT_abstract_origin"
)
attr = current_die.attributes
return None
def get_function_info(filename, taint_graph, zelos_module_base):
"""
Returns mapping of function names to tuple (low addr, high addr)
"""
# print("Parsing DWARF info")
with open(filename, "rb") as f:
elffile = ELFFile(f)
if not elffile.has_dwarf_info():
# print(" file has no DWARF info")
return
symbols_module_base = _get_module_base(elffile)
offset = zelos_module_base - symbols_module_base
if offset != 0x1000: # TODO TEMP for static binaries
offset = 0
# print("Got offset: ", offset)
dwarfinfo = elffile.get_dwarf_info()
functions = defaultdict(list)
entries = []
for CU in dwarfinfo.iter_CUs():
for DIE in CU.iter_DIEs():
die_info = __handle_DIE(DIE)
if die_info is not None:
entries.append(die_info)
for entry in entries:
func_name = entry["name"]
low, high = entry["range"]
functions[func_name].append((low + offset, high + offset))
# print(" Constructing addr2func")
addr2func = {}
for addr in taint_graph._reduced_path.keys():
for f, ranges in functions.items():
for r in ranges:
(low, high) = r
if low <= addr <= high:
addr2func[addr] = f
# print("Done parsing dwarf info")
return addr2func
class AddressEntry:
def __init__(self, low, high, file, line_num):
self.low = low
self.high = high
self.file = file
self.line_num = line_num
def __str__(self):
return f"(0x{self.low:x}-0x{self.high:x}: {self.file}:{self.line_num})"
class AddressMap:
def __init__(self):
self._address_low_high = []
self._cache = {}
self._source2addr_range = {}
def __str__(self):
return [entry.__str__() for entry in self._address_low_high].__str__()
def files(self):
return {entry.file for entry in self._address_low_high}
def get_addr_range_from_source(self, file, line_num):
return self._source2addr_range.get(f"{file}{line_num}", (None, None))
def _add_cache(self, addr, file, line):
self._cache[addr] = (file, line - 1)
def add(self, low, high, file, line):
file = file.decode()
self._add_cache(low, file, line)
self._source2addr_range[f"{file}{line}"] = (low, high)
for addr in range(low, high):
self._add_cache(addr, file, line)
entry = AddressEntry(low, high, file, line)
self._address_low_high.append(entry)
self._address_low_high.sort(key=lambda x: x.low)
def get(self, addr: int, default=(None, None)):
cached_val = self._cache.get(addr, None)
if cached_val is not None:
return cached_val
idx = self.binary_search(addr)
if idx is not None:
entry = self._address_low_high[idx]
retval = (entry.file, entry.line_num - 1)
self._cache[addr] = retval
return retval
return default
def _attach_src_to_external_addrs(self, trace, dwarf_data):
"""
Certain addresses in the trace are not associated with source
code because they are in external modules. We associate those
addresses with source code from the last line that occurred
before moving to the external module.
"""
# External modules can call each other. This means that the same
# address could have multiple candidates for what address should
# be associated with them.
files = dwarf_data._file_lines
current_source = None
current_file = None
current_line = None
smeared = {}
for addr in trace:
file, line_num = self.get(addr)
if file in files and addr not in smeared:
dwarf_data._addr2source[addr] = files[file][line_num]
current_source = files[file][line_num]
current_file = file
current_line = line_num
elif current_source is not None:
dwarf_data._addr2source[addr] = "within " + current_source
self._add_cache(addr, current_file, current_line + 1)
smeared[addr] = current_source
def binary_search(self, x):
low = 0
mid = 0
high = len(self._address_low_high) - 1
while low <= high:
mid = (high + low) // 2
entry = self._address_low_high[mid]
if entry.low <= x < entry.high:
return mid
if entry.low == entry.high and entry.low == x:
return mid
# Check if x is present at mid
if entry.low < x:
low = mid + 1
# If x is greater, ignore left half
elif entry.low > x:
high = mid - 1
# If we reach here, then the element was not present
return None
class DwarfData:
def __init__(self, address_map, source_code_path):
self._address_map = address_map
self._file_lines = {}
self._file_to_syspath = {}
self._addr2source = {}
self.setup_file_lines(source_code_path)
def setup_file_lines(self, source_code_path):
for filename in self._address_map.files():
located_filename = find_file(filename, source_code_path)
if located_filename is None:
continue
f = open(located_filename, "r")
self._file_to_syspath[filename] = located_filename
# Keep this keyed by the original file name so that later on we
# can find these lines
self._file_lines[filename] = list(f.readlines())
def get_source(self, addr: int) -> Optional[str]:
return self._addr2source.get(addr, None)
def decode_file_lines(dwarfinfo, offset):
address_map = AddressMap()
# Go over all the line programs in the DWARF information, looking for
# one that describes the given address.
for CU in dwarfinfo.iter_CUs():
# First, look at line programs to find the file/line for the address
lineprog = dwarfinfo.line_program_for_CU(CU)
prevstate = None
for entry in lineprog.get_entries():
# We're interested in those entries where a new state is assigned
if entry.state is None:
continue
if entry.state.end_sequence:
# if the line number sequence ends, clear prevstate.
prevstate = None
continue
# Looking for a range of addresses in two consecutive states that
# contain the required address.
if prevstate:
filename = lineprog["file_entry"][prevstate.file - 1].name
line = prevstate.line
address_map.add(
prevstate.address + offset,
entry.state.address + offset,
filename,
line,
)
prevstate = entry.state
return address_map
def _get_module_base(elf_file):
# This function DOES NOT WORK for static binaries.
# It gets lucky on binaries where the main module is loaded at 0,
# which is what this function normally returns. Have to find a way
# to get the desired load address of binaries. Maybe one way to get
# around is always return 0 for dynamic binaries.
segment_addrs = [s.header.p_vaddr for s in elf_file.iter_segments()]
# print(f"Segment_addrs: {segment_addrs}")
return min(segment_addrs)
# ELK Graph Functions
def _calc_width(text):
return len(text) * 8 + 20
def _create_node(_file, _line, _text):
_id = f"{_file}{_line}"
node = {
"id": _id,
"labels": [{"id": f"{_id}_label", "text": _text, "x": 10, "y": 4,}],
"width": _calc_width(_text),
"height": 24,
"file": f"{_file}",
"line": _line,
}
return node
def _create_group(_id, label=None):
group = {
"id": f"group_{_id}",
"children": [],
"edges": [],
"layoutOptions": {"elk.direction": "DOWN"},
}
if label:
group["labels"] = [
{
"id": f"group_{_id}_label",
"text": f"{html.escape(label)}",
"width": _calc_width(label),
"height": 24,
}
]
return group
def _create_edge(srcfile, srcline, destfile, destline):
_src = f"{srcfile}{srcline}"
_dest = f"{destfile}{destline}"
_id = f"edge_{_src}{_dest}"
edge = {
"id": _id,
"source": _dest,
"target": _src,
"sourceFile": destfile,
"targetFile": srcfile,
"sourceLine": destline,
"targetLine": srcline,
}
return edge
def _find_group(edge, groups):
# Given an edge, search for a function-group
# that contains both it's source and target
# nodes.
src_group = None
dest_group = None
for fn, g in groups.items():
for c in g.get("children", []):
if edge["sourceFile"] == c.get("file", None) and edge[
"sourceLine"
] == c.get("line", None):
src_group = fn
if edge["targetFile"] == c.get("file", None) and edge[
"targetLine"
] == c.get("line", None):
dest_group = fn
if src_group is not None and dest_group is not None:
if src_group == dest_group:
return src_group
return None
return None
def _find_fn(file, line, groups):
# Given a file and line number, search for
# it's containing function-group
for fn, g in groups.items():
for c in g.get("children", []):
if file == c.get("file", None) and line == c.get("line", None):
return fn
return None
def _find_edges(node, groups):
# Given a node that is not part of a group,
# search for a function-group that contains
# edges to or from it.
for fn, g in groups.items():
for e in g.get("edges", []):
if (
node["file"] == e["sourceFile"]
or node["file"] == e["targetFile"]
) and (
node["line"] == e["sourceLine"]
or node["line"] == e["targetLine"]
):
return fn
return None
def export_source_graph(taint_path, address_map, files):
# Helper function for getting id for the source graph
def get_node_id(address_map, addr):
(file, line_num) = address_map.get(addr, (None, None))
if file is None:
return None
return f"{file}{line_num}"
graph_boy = {
"id": "root",
"layoutOptions": {
"algorithm": "layered",
"elk.direction": "DOWN",
"hierarchyHandling": "INCLUDE_CHILDREN",
},
"children": [],
"edges": [],
}
# tuples containing source code addr and next addr to check
open_paths = [(taint_path._start_addr, taint_path._start_addr)]
# No need to analyze an address that has already been analyzed.
analyzed_addrs = set()
# use to defines
edges = defaultdict(list)
nodes = set()
# The order of nodes
ordering = []
# Wave order is broken if you do analysis in depth first search.
# The algorithm for calculating wave order only works if you use
# breadth first.
wave_order = {get_node_id(address_map, taint_path._start_addr): 0}
child2parents = defaultdict(list)
parent2children = defaultdict(list)
while len(open_paths) > 0:
child, next_ancestor = open_paths.pop()
if next_ancestor in analyzed_addrs:
continue
if child not in taint_path._addr2func:
if taint_path._dataflow.zelos.config.link_ida is not None:
taint_path._addr2func[
child
] = taint_path._dataflow._get_ida_func_name(child)
analyzed_addrs.add(next_ancestor)
ancestor_id = get_node_id(address_map, next_ancestor)
if ancestor_id not in ordering:
ordering.append(ancestor_id)
parents = taint_path._reduced_path_parents.get(next_ancestor, [])
for parent in parents:
(file, line_num) = address_map.get(parent, (None, None))
if file is None:
if parent not in analyzed_addrs:
open_paths.append((child, parent))
continue
edges[child].append(parent)
nodes.add(child)
nodes.add(parent)
child_id = get_node_id(address_map, child)
parent_id = get_node_id(address_map, parent)
if parent_id not in wave_order:
wave_order[parent_id] = wave_order[child_id] + 1
if parent not in analyzed_addrs:
open_paths.append((parent, parent))
groups = dict()
added_nodes = set()
function_map = taint_path._addr2func
line2func = defaultdict(lambda: defaultdict(None))
for n in nodes:
file, line_num = address_map.get(n, (None, None))
if file not in files:
continue
function = function_map.get(n, None)
if function is not None:
if function and function not in groups.keys():
fn_label = f"{file}::{function}"
groups[function] = _create_group(function, label=fn_label)
if file and line_num:
line2func[file][line_num] = function
src_line = files[file][line_num].strip()
fline = f"{file}{line_num}"
if fline in added_nodes:
continue
added_nodes.add(fline)
# add node
node = _create_node(file, line_num, " ".join(src_line.split()))
if function:
groups[function]["children"].append(node)
else:
graph_boy["children"].append(node)
added_edges = set()
for src, dests in edges.items():
srcfile, srcline_num = address_map.get(src, (None, None))
srcfn = function_map.get(src, None)
if srcfn is None:
srcfn = line2func[srcfile].get(srcline_num, None)
for dest in dests:
destfile, destline_num = address_map.get(dest, (None, None))
destfn = function_map.get(dest, None)
if destfn is None:
destfn = line2func[destfile].get(destline_num, None)
src = f"{srcfile}{srcline_num}"
dest = f"{destfile}{destline_num}"
if src == "NoneNone" or dest == "NoneNone":
continue
edge_name = f"edge_{src}{dest}"
if edge_name in added_edges:
continue
if src not in added_nodes or dest not in added_nodes:
continue
child2parents[src].append((edge_name, dest))
parent2children[dest].append((edge_name, src))
added_edges.add(edge_name)
edge = _create_edge(srcfile, srcline_num, destfile, destline_num)
fn = _find_group(edge, groups)
if fn is not None:
groups[fn]["edges"].append(edge)
# Same function
elif srcfn and srcfn == destfn:
groups[srcfn]["edges"].append(edge)
# Different function
elif srcfn and destfn and srcfn != destfn:
graph_boy["edges"].append(edge)
# could be either
else:
# if a sourcefile is known and the same
if (srcfile or destfile) and srcfile == destfile:
# if the line number same
if (
srcline_num or destline_num
) and srcline_num == destline_num:
# If line num same and one is mapped to a fn
# it's safe to assume same fn
if srcfn is not None and destfn is None:
groups[srcfn]["edges"].append(edge)
elif srcfn is None and destfn is not None:
groups[destfn]["edges"].append(edge)
else:
# If line num is same but neither mapped to a fn
# Check if we've seen this address mapped to a fn
# previously.
fn = _find_fn(srcfile, srcline_num, groups)
if fn is not None:
groups[fn]["edges"].append(edge)
else:
graph_boy["edges"].append(edge)
else:
# if different line number, check that we've seen both previously
sfn = _find_fn(srcfile, srcline_num, groups)
dfn = _find_fn(destfile, destline_num, groups)
if (sfn or dfn) and sfn == dfn:
groups[sfn]["edges"].append(edge)
else:
graph_boy["edges"].append(edge)
else:
graph_boy["edges"].append(edge)
# Take care of any incorrect func mappings
tmp = []
for c in graph_boy["children"]:
if c.get("file", None) and c.get("line", None):
fn = _find_edges(c, groups)
if fn is not None:
groups[fn]["children"].append(c)
else:
tmp.append(c)
graph_boy["children"] = tmp
# Take care of any incorrect edges
tmp = []
for e in graph_boy["edges"]:
fn = _find_group(e, groups)
if fn is not None:
groups[fn]["edges"].append(e)
else:
tmp.append(e)
graph_boy["edges"] = tmp
for fn in groups.keys():
graph_boy["children"].append(groups[fn])
# import json
# with open("output.json", "w") as fp:
# json.dump(graph_boy, fp)
return graph_boy, ordering, wave_order, child2parents, parent2children | zelos-crashd | /zelos-crashd-0.0.2.tar.gz/zelos-crashd-0.0.2/src/crashd/dwarf/dwarf_source_code.py | dwarf_source_code.py |
# This program is free software: you can redistribute it and/or modify
# it under the terms of the GNU Affero General Public License as
# published by the Free Software Foundation, either version 3 of the
# License, or (at your option) any later version.
# This program is distributed in the hope that it will be useful,
# but WITHOUT ANY WARRANTY; without even the implied warranty of
# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
# GNU Affero General Public License for more details.
# You should have received a copy of the GNU Affero General Public
# License along with this program. If not, see
# <http://www.gnu.org/licenses/>.
# ======================================================================
from collections import defaultdict
from zelos import Zelos, IPlugin, CommandLineOption, HookType
import hexdump
CommandLineOption("asan", action="store_true", help="ASAN-like capabilities")
class WriteRecord:
def __init__(self, ip_addr, mem_addr, value):
self.ip_addr = ip_addr
self.mem_addr = mem_addr
self.value = value
def __repr__(self):
return f"(ip 0x{self.ip_addr:x}: {self.value} -> 0x{self.mem_addr:x})"
class AllocInfo:
def __init__(self, addr, size, inst_addr, desc, is_free=False):
# Address of the corresponding heap buffer allocation
self.address = addr
# Size of the corresponding heap buffer allocation
self.size = size
# Address of the corresponding heap buffer allocation inst.
self.inst_address = inst_addr
# Short string describing the allocation site,
# e.g. "malloc(0x100)"
self.description = desc
# True if the corresponding allocation had been free'd
self.is_free = is_free
self.writes = defaultdict(list)
def __str__(self):
return f"Origin Inst: 0x{self.inst_address:x} {self.description}"
def _record_write(self, ip_addr: int, mem_addr: int, value: int):
self.writes[mem_addr].append(WriteRecord(ip_addr, mem_addr, value))
def get_writes(self, mem_addr: int, size: int):
"""
Returns all addresses that wrote to this memory region
"""
accessors = []
for addr in range(mem_addr, mem_addr + size):
accessors.extend(self.writes[addr])
return accessors
def summarize_buffer(self, memory) -> str:
"""
Returns a string summarizing the memory buffer.
"""
memory_buffer = memory.read(self.address, self.size)
chunk_size = 16
chunks = [
memory_buffer[i : i + chunk_size]
for i in range(0, len(memory_buffer), chunk_size)
]
lines = []
current_chunk = None
duplicate_line_count = 0
for i, chunk in enumerate(chunks):
if current_chunk == chunk:
if lines[-1] != "...":
lines.append("...")
duplicate_line_count += 1
continue
elif len(lines) > 0 and lines[-1] == "...":
lines[
-1
] = f"... omitting {duplicate_line_count} duplicate lines"
duplicate_line_count = 0
current_chunk = chunk
line = hexdump.hexdump(chunk, result="return")
offset, rest = line.split(":", 1)
offset = int(offset, 16) + i * chunk_size
writes = self.get_writes(self.address + offset, chunk_size)
line = f"{offset:08x}:{rest} {writes}"
lines.append(line)
if len(lines) > 20:
lines = (
["First ten lines:"]
+ lines[:10]
+ [f"Last ten lines:"]
+ lines[-10:]
)
return " Buffer Contents:\n" + "\n".join(lines)
class CrashInfo:
def __init__(
self,
reason: str = "",
operation: str = "",
inst_address=None,
mem_address=None,
mem_access_size=None,
alloc_info=None,
):
# Short description of the crash problem
self.reason = reason
# Either READ, WRITE or the empty string
self.operation = operation
# Address of the crashing instruction
self.inst_address = inst_address
# Address of the memory location causing the crash
self.mem_address = mem_address
# Number of bytes read starting at the mem_address
self.mem_access_size = mem_access_size
# Information about the buffer of origin for the crash
self.alloc_info = alloc_info
@property
def exploitability(self):
"""
An estimate on whether the crash is exploitable
"""
reason = self.reason
operation = self.operation
addr = self.mem_address
near_zero = False
if addr > 0 and addr < 0x1000:
near_zero = True
if reason in ["double-free", "bad-free"]:
return "EXPLOITABLE"
if reason == "heap-use-after-free":
return "EXPLOITABLE"
if reason == "heap-overflow":
if operation == "READ":
if near_zero:
return "PROBABLY_NOT_EXPLOITABLE"
else:
return "UNKNOWN"
if operation == "WRITE":
if near_zero:
return "PROBABLY_EXPLOITABLE"
else:
return "EXPLOITABLE"
return "UNKNOWN"
def get_summary(self, memory):
s = f"\nCrash Summary:\n"
s += f" Exploitable: {self.exploitability}\n"
s += f" Reason: {self.reason}\n"
s += f" Crashing Instruction: 0x{self.inst_address:x}\n"
if self.mem_address is not None:
s += f" Crashing Access: {self.operation} 0x{self.mem_address:x}"
if self.alloc_info is not None:
if self.mem_address:
s += f" (buf + 0x{(self.mem_address-self.alloc_info.address):x})"
s += f" size: {self.mem_access_size:x} byte(s)\n"
else:
s += "\n"
s += " " + str(self.alloc_info) + "\n"
s += self.alloc_info.summarize_buffer(memory)
else:
s += "\n"
return s
class Asan(IPlugin):
"""
Implements heap sanitization similar to ASAN or libdislocator.
Specifically:
- Creates a GUARD_SIZE region of protected memory:
- Immediately following malloc'd buffers
"""
def __init__(self, zelos: Zelos):
super().__init__(zelos)
self._allocs = {}
self._guard_size = 0x10
self._crash_info = None
if not zelos.config.asan:
return
# Used to correct invalid crashing address for runs with
# INST.EXEC hook.
self._inst_hook_triggered = False
self._add_hooks()
def _add_hooks(self):
""" Add linux memory allocator hooks and generic invalid
memory access hook.
"""
hooks = {
"malloc": ([("void*", "ptr")], self._malloc),
"calloc": ([("size_t", "num"), ("size_t", "size")], self._calloc),
"realloc": (
[("void*", "ptr"), ("size_t", "new_size")],
self._realloc,
),
"free": ([("void*", "ptr")], self._free),
}
for fn_name, fn_hook in hooks.items():
self.zelos.internal_engine.hook_manager.register_func_hook(
fn_name, fn_hook[1]
)
self.zelos.hook_memory(HookType.MEMORY.INVALID, self._invalid_hook)
def _invalid_hook(self, zelos, access, address, size, value):
""" Hook invoked any time an invalid memory access is triggered.
"""
if self._crash_info is None:
operation = "READ"
if access == 20:
operation = "WRITE"
self._crash_info = CrashInfo(
reason="unknown-crash",
operation=operation,
inst_address=self.zelos.thread.getIP(),
mem_address=address,
mem_access_size=size,
alloc_info=None,
)
self.logger.warning(self._crash_info.get_summary(zelos.memory))
@property
def asan_guard_triggered(self) -> bool:
return self.get_crash_alloc_info() is not None
def get_crash_alloc_info(self) -> AllocInfo:
if self._crash_info is None:
return None
return self._crash_info.alloc_info
def set_inst_hook(self):
def inst_hook(z, addr, size):
pass
return self.zelos.hook_execution(HookType.EXEC.INST, inst_hook)
def _add_memory_guard(self, start: int, end: int, alloc_info: AllocInfo):
def guard_access(zelos, access, addr, size, value):
if addr + size <= start:
return
if not self._inst_hook_triggered:
# If you are running zelos without an EXEC.INST hook,
# the crash at the memory guard page will not return
# the proper instruction address. We set the
# instruction hook and run again to get the correct
# address.
zelos.internal_engine.scheduler.stop_and_exec(
"pre-crash inst hook", self.set_inst_hook
)
self._inst_hook_triggered = True
return
if alloc_info.is_free:
reason = "heap-use-after-free"
else:
reason = "heap-overflow"
operation = "READ"
if access == 22:
operation = "WRITE"
self._crash_info = CrashInfo(
reason=reason,
operation=operation,
inst_address=self.zelos.thread.getIP(),
mem_address=addr,
mem_access_size=size,
alloc_info=alloc_info,
)
self.logger.warning(self._crash_info.get_summary(zelos.memory))
def crash():
# Now make the underlying page a guard page so zelos
# will fault and end execution.
zelos.memory._memory.protect(
start, max(0x1000, end - start), 0
)
zelos.internal_engine.scheduler.stop_and_exec("Crash", crash)
return self.zelos.hook_memory(
HookType.MEMORY.VALID,
guard_access,
mem_low=start - 7,
mem_high=end,
end_condition=lambda: self.asan_guard_triggered,
)
def _safe_alloc(self, size: int, desc: str = "") -> int:
"""
Allocates memory and ensures that a crash will happen if memory
is written outside of the boundaries.
"""
addr = self.zelos.memory._memory.heap.alloc(
size + self._guard_size, name="safe_malloc"
)
alloc_info = AllocInfo(addr, size, self.zelos.thread.getIP(), desc)
self._record_writes(alloc_info)
high_hook = self._add_memory_guard(
addr + size, addr + size + self._guard_size - 1, alloc_info
)
self._allocs[addr] = (size, high_hook)
return addr
def _record_writes(self, alloc_info: AllocInfo):
def record_write(zelos, access, addr, size, value):
alloc_info._record_write(
zelos.thread.getIP(),
addr,
zelos.memory.pack(value, bytes=size),
)
return self.zelos.hook_memory(
HookType.MEMORY.WRITE,
record_write,
mem_low=alloc_info.address,
mem_high=alloc_info.address + alloc_info.size,
)
def _handle_return(self, retval: int):
if retval is not None:
self.zelos.internal_engine.kernel.set_return_value(retval)
dfa = self.zelos.plugins.dataflow
if dfa.dataflow_enabled:
dfa.trace.add_define(
self.zelos.internal_engine.kernel._REG_RETURN,
retval,
label_override="Memory API",
)
thread = self.zelos.thread
# FIXME: this line only works on architectures with stack-based
# return addresses.
retaddr = thread.popstack()
def set_ip():
thread.setIP(retaddr)
self.zelos.internal_engine.scheduler.stop_and_exec(
"syscall_ip_change", set_ip
)
def _get_args(self, args):
return self.zelos.internal_engine.kernel.get_args(args)
def _malloc(self, zelos):
""" Add a GUARD_SIZE guard immediately following the buffer.
"""
args = self._get_args([("int", "size")])
retval = self._safe_alloc(args.size, f"malloc(size=0x{args.size:x})")
self._handle_return(retval)
def _calloc(self, zelos):
""" Add a GUARD_SIZE guard immediately following the buffer.
"""
args = self._get_args([("size_t", "num"), ("size_t", "size")])
size = args.num * args.size
if size <= 0:
self._handle_return(0)
retval = self._safe_alloc(
size, f"calloc(num=0x{args.num:x}, size=0x{args.size:x})"
)
self.zelos.memory.write(retval, b"\x00" * size)
self._handle_return(retval)
def _realloc(self, zelos):
""" Add a GUARD_SIZE guard immediately following the buffer.
"""
args = self._get_args([("void*", "ptr"), ("size_t", "new_size")])
if args.ptr == 0:
retval = self._safe_alloc(
args.new_size,
f"realloc(ptr=0x{args.ptr:x}, new_size=0x{args.new_size:x})",
)
else:
retval = self._safe_alloc(
args.new_size,
f"realloc(ptr=0x{args.ptr:x}, new_size=0x{args.new_size:x})",
)
self._handle_return(retval)
def _free(self, zelos):
""" Add guard in the entirety of the free'd buffer space.
"""
args = self._get_args([("void*", "ptr")])
if args.ptr == 0:
return
# TODO: double-free and bad-free checks
# self.crash_reason = "double-free"
# self.crash_reason = "bad-free"
# if so, end execution
# Delete the previous GUARD_SIZE guard
size, high_hook = self._allocs.pop(args.ptr)
self.zelos.delete_hook(high_hook)
# Add guard in the free'd space
alloc_info = AllocInfo(
args.ptr,
size,
self.zelos.thread.getIP(),
f"free(f{args.ptr:x})",
is_free=True,
)
self._add_memory_guard(
args.ptr - self._guard_size,
args.ptr + size + self._guard_size - 1,
alloc_info,
)
self._handle_return(None) | zelos-crashd | /zelos-crashd-0.0.2.tar.gz/zelos-crashd-0.0.2/src/crashd/asan/asan.py | asan.py |
# This program is free software: you can redistribute it and/or modify
# it under the terms of the GNU Affero General Public License as
# published by the Free Software Foundation, either version 3 of the
# License, or (at your option) any later version.
# This program is distributed in the hope that it will be useful,
# but WITHOUT ANY WARRANTY; without even the implied warranty of
# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
# GNU Affero General Public License for more details.
# You should have received a copy of the GNU Affero General Public
# License along with this program. If not, see
# <http://www.gnu.org/licenses/>.
# ======================================================================
from typing import List, Set, Optional
import ctypes
ARITHMETIC_TCG_INSTS = [
"add",
"sub",
"shr",
"shl",
"sar",
"rotl",
"rotr",
"and",
"nand",
"xor",
"or",
"rem",
"div",
"mul",
]
IGNORED_TCG_INSTS = [
"goto_tb",
"exit_tb",
"set_label",
"end",
"nop",
"deposit", # Not sure what this one does
"discard",
]
def _decode_env_registers(offset):
"""
Converts registers that are of the form env_$
"""
reg = {
"$0x328": "xmm1",
"$0x330": "xmm1",
"$0x338": "xmm2",
"$0x340": "xmm2",
"$0x348": "xmm3",
"$0x350": "xmm3",
"$0x358": "xmm4",
"$0x360": "xmm4",
"$0x368": "xmm5",
"$0x370": "xmm5",
}.get(offset, None)
if reg is None:
return set()
return set([reg])
class TCGInst:
"""
Represents Qemu TCG instruction-level uses and defines.
"""
def __init__(self, inst_str: str):
"""
Example `inst_str`s:
1) "movi_i64 tmp3,$0x18f8d"
2) "st_i64 tmp3,env,$0x80"
"""
args = ""
if " " in inst_str:
self.name, args = inst_str.split(" ", 1)
else:
self.name = inst_str
self.args = args.split(",")
def __str__(self):
return (
f"({self.name}, {self.args}, def:{self.defines()},"
f" use:{self.uses()})"
)
def __repr__(self):
return self.__str__()
def defines(self) -> Set[str]:
"""
Returns the name of registers/temporaries that are defined
by this instruction.
"""
if self.is_type(["movcond_"]):
return set([self.args[1]])
if self.is_type(["st_i64"]):
if self.args[1] == "env":
return _decode_env_registers(self.args[2])
if self.is_type(
ARITHMETIC_TCG_INSTS
+ ["mov", "qemu_ld_", "ld", "ext", "neg", "not"]
):
return set([self.args[0]])
if self.is_type(
IGNORED_TCG_INSTS + ["call", "br", "brcond", "setcond"]
):
return set()
if self.is_type(["qemu_st_", "st32_i64"]):
# Do something with these?
return set()
print(
"[TCGInst] `defines` not parsed:", self.name, ",".join(self.args)
)
return set()
def uses(self) -> Set[str]:
"""
Returns that name of registers/temporaries that are used
by this instruction
"""
if self.is_type(["ld_i64"]):
if self.args[1] == "env":
return _decode_env_registers(self.args[2])
if self.is_type(["movcond"]):
return set(self.args[2:])
if self.is_type(["neg", "not"]):
return set([self.args[0]])
if self.is_type(["qemu_st_", "st"]):
return set(self.args[0:2])
if self.is_type(["call"]):
return set(self.args[3:])
if self.is_type(["mov_", "qemu_ld_", "brcond_", "ld", "ext"]):
return set([self.args[1]])
if self.is_type(["setcond_"]):
return set(self.args[0:3])
if self.is_type(ARITHMETIC_TCG_INSTS):
return set(self.args[1:3])
if self.is_type(IGNORED_TCG_INSTS + ["movi_", "br"]):
return set()
print(f"[TCGInst] `uses` not parsed: {self.name}", ",".join(self.args))
return set()
def is_type(self, list_of_types: List[str]) -> bool:
"""
This takes a list of prefixes, and ensures that this inst is
one of them
"""
return any([self.name.startswith(t) for t in list_of_types])
class TargetInst:
"""
Represents a group of TCGinsts that were generated from a single
target architecture instruction.
"""
def __init__(self, address, header_insts, tcginst_list):
self.address = address
self.header_insts = header_insts
self.tcg_insts = tcginst_list
# self._validate_tmps() # For debugging purposes
def __str__(self):
inst_string = "\n ".join([str(i) for i in self.tcg_insts])
return (
f"(Address: 0x{self.address:x}"
+ "\n "
+ inst_string
+ "\n"
+ f"Defs: {self.defines()} Uses: {self.uses()})"
+ "\n"
)
def __repr__(self):
return self.__str__()
def uses(self) -> Set[str]:
"""
Iterates over all the TCGInst's representing this instruction
and accumulates all their uses.
"""
use_strings = set()
for inst in self.tcg_insts:
use_strings.update(
[
u
for u in inst.uses()
if not (u.startswith("tmp") or u.startswith("loc"))
]
)
return use_strings
def defines(self) -> Set[str]:
"""
Iterates over all the TCGInst's representing this instruction
and accumulates all their defines.
"""
def_strings = set()
for inst in self.tcg_insts:
def_strings.update(
[
d
for d in inst.defines()
if not (d.startswith("tmp") or d.startswith("loc"))
]
)
return def_strings
def _validate_tmps(self):
"""
Ensure that every tmp variable has
* > 0 def and > 0 uses
* the def happens before the uses
"""
defined = set()
used = set()
for inst in self.tcg_insts:
defs = [d for d in inst.defines() if d.startswith("tmp")]
defined.update(defs)
uses = [u for u in inst.uses() if u.startswith("tmp")]
for u in uses:
assert u in defined, (self, u)
used.add(u)
assert used == defined, (self, used, defined)
class TCGParse:
def __init__(self):
pass
def get_tcg(self, zelos):
uc = zelos.internal_engine.emu._uc
# TODO: Need to get the number of bytes that were written to
# the buffer so that we can ensure that we got the full tcg
# string from unicorn. For now, we just pick a big number and
# use that.
size = 1000000
buffer = ctypes.create_string_buffer(size)
uc.get_tcg_x86_64(buffer, size)
insts = buffer.value.decode().split("\n")
tcg_insts = [TCGInst(i.strip()) for i in insts if i != ""]
assert tcg_insts[-1].name == "end"
target_insts = self._split_into_target_insts(tcg_insts)
return target_insts
def _split_into_target_insts(self, tcg_list):
""""""
target_insts = None
target_inst_grouping = []
for i in tcg_list:
target_inst_grouping.append(i)
if i.name == "call" and i.args[0] == "uc_tracecode":
if target_insts is None:
target_insts = []
target_inst_grouping = target_inst_grouping[-5:]
else:
target_inst_grouping, new_inst_grouping = (
target_inst_grouping[:-5],
target_inst_grouping[-5:],
)
target_inst = self._make_target_inst(target_inst_grouping)
if target_inst is not None:
target_insts.append(target_inst)
target_inst_grouping = new_inst_grouping
if len(target_inst_grouping) > 0:
target_inst = self._make_target_inst(target_inst_grouping)
if target_inst is not None:
target_insts.append(target_inst)
return target_insts
def _make_target_inst(self, tcg_list) -> Optional[TargetInst]:
"""
Cleanup tcg_list by removing some patterns that don't seem to
contribute to the understanding of the original code
"""
new_tcg_list = []
i = 0
while i < len(tcg_list):
inst = tcg_list[i]
if inst.name in ["nopn", "nop"]:
i += 1
continue
new_tcg_list.append(inst)
i += 1
tcg_list = new_tcg_list
addr = "????"
call_inst = tcg_list[4]
if call_inst.name == "call" and call_inst.args[0] == "uc_tracecode":
# Unsure why this is, but in x86_64, I found that the first
# instruction seems to be repeated, but with tmps instead of
# the actual registers. It also seems like the second
# argument to tracecode is 3 for the first call and 2 for
# the others. I'll assume that 3's are always bad, and not
# include those in the output
if tcg_list[1].args[1] == "$0x3":
return None
addr_str = tcg_list[3].args[1]
assert addr_str.startswith("$")
addr = int(addr_str[1:], base=16)
return TargetInst(addr, tcg_list[:5], tcg_list[5:])
return TargetInst(addr, [], tcg_list) | zelos-crashd | /zelos-crashd-0.0.2.tar.gz/zelos-crashd-0.0.2/src/crashd/taint/tcg.py | tcg.py |
# This program is free software: you can redistribute it and/or modify
# it under the terms of the GNU Affero General Public License as
# published by the Free Software Foundation, either version 3 of the
# License, or (at your option) any later version.
# This program is distributed in the hope that it will be useful,
# but WITHOUT ANY WARRANTY; without even the implied warranty of
# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
# GNU Affero General Public License for more details.
# You should have received a copy of the GNU Affero General Public
# License along with this program. If not, see
# <http://www.gnu.org/licenses/>.
# ======================================================================
from zelos import Zelos, HookType, IPlugin, CommandLineOption
from zelos.exceptions import InvalidRegException
from typing import List, Dict, Union
from collections import defaultdict
import functools
import os
from crashd.taint.tcg import TCGParse
from crashd.taint.taint_graph import TaintGraph
from crashd.dwarf.dwarf_source_code import (
show_tainted_source,
annotate_with_dwarf_data,
get_function_info,
)
from zelos.ext.plugins.trace import Trace
_ = Trace
CommandLineOption(
"taint",
action="store_true",
help=(
"Enables collection of data that allows for taint tracking."
" Collection will slow down overall run."
),
)
CommandLineOption(
"taint_when",
action="append",
nargs="?",
default=[],
const="",
metavar="ZML_STRING",
help="Starts taint tracking when the specified ZML condition is met.",
)
CommandLineOption(
"taint_output", default="", help="Specify taint output location.",
)
CommandLineOption(
"source_code_path", default="", help="path to search for source code files"
)
class DataFlowException(Exception):
pass
class TraceInfo:
def __init__(self):
self._trace: List[int] = []
self._addr_comment: Dict[int, str] = {}
"""Map of idx to {memory_addr|reg: last_define_idx}"""
self.uses = defaultdict(dict)
"""Map of idx -> {memory_addr|reg: value}"""
self.defines = defaultdict(dict)
""" Map of memory_addr|reg to last write idx"""
self.last_write = {}
self.label_overrides = {}
@property
def current_idx(self) -> int:
return len(self._trace) - 1
@property
def last_addr(self) -> int:
return self._trace[-1]
def len(self) -> int:
return len(self._trace)
def add_address(self, addr: int):
self._trace.append(addr)
def add_use(
self, addr_or_reg: Union[int, str], idx=None, label_override=None
):
if idx is None:
idx = self.current_idx
self.uses[idx][addr_or_reg] = self.last_write.get(addr_or_reg, None)
if label_override is not None:
self.label_overrides[self.last_addr] = label_override
def get_uses(self, idx: int) -> Dict[Union[int, str], int]:
return self.uses[idx]
def add_define(
self,
addr_or_reg: Union[int, str],
value,
idx=None,
label_override=None,
):
if idx is None:
idx = self.current_idx
if isinstance(value, int):
value = hex(value)
self.defines[idx][addr_or_reg] = value
self.last_write[addr_or_reg] = idx
if label_override is not None:
self.label_overrides[self.last_addr] = label_override
def get_defines(self, idx: int) -> Dict[Union[int, str], str]:
return self.defines[idx]
def _last_idx_of_address(self, address: int) -> int:
# Find the last use of that address
for idx in reversed(range(self.len())):
if self._trace[idx] == address:
return idx
raise DataFlowException(f"Did not find target address {address:x}")
class DataFlow(IPlugin):
"""
A collection of TargetInst. Dataflow techniques can be used on this
collection to identify relationships between instructions
TODO: Some instructions are conditional (movcond), meaning that even
in this dynamic run, it may be unclear where each definition came
from. We can deal with this multiple ways
* Identify all possible sources it could have came from
* Use the actual value that was given in order to give a guess on
where the value came from.
"""
def __init__(self, zelos: Zelos):
super().__init__(zelos)
self.dataflow_enabled = False
if not zelos.config.taint and len(zelos.config.taint_when) == 0:
return
for zml_string in zelos.config.taint_when:
zelos.internal_engine.zml_parser.trigger_on_zml(
functools.partial(self.enable, zelos), zml_string,
)
if len(zelos.config.taint_when) == 0 and zelos.config.taint:
self.enable(zelos)
def enable(self, zelos: Zelos):
"""
After calling this function, all dataflow in the target program
will be tracked globally. The resulting flow is accessible
through:
- Dataflow.trace
- Dataflow.ud_chain()
"""
if self.dataflow_enabled:
return
self.dataflow_enabled = True
self.trace = TraceInfo()
self.define_use_map = {}
self.reaching_defs: List[Dict[str, int]] = []
def trace_inst(z, addr, size):
self.trace.add_address(addr)
# Sometimes the block hook doesn't work because the
# definition of a block in tcg doesn't match up with the
# size of the block. Need to look more into this.
if addr not in self.define_use_map:
self._update_tcg()
# Delay adding register uses one address so that we can
# get the value of the register after the instruction has
# run.
if self.trace.len() < 2:
return
last_addr = self.trace._trace[-2]
(defs, _) = self.define_use_map[last_addr]
idx = self.trace.len() - 2
for register in defs:
try:
reg_val = z.thread.get_reg(register)
self.trace.add_define(register, reg_val, idx=idx)
except InvalidRegException:
# "uses" like "env" aren't registers, we may need
# To track them in the future though
pass
def record_comments(z, addr, cmt):
self.trace._addr_comment[addr] = cmt
# This assumes memory hooks always run after instruction hooks.
def trace_read(z, access, address, size, value):
""" Add memory `use` to the trace """
self.trace.add_use(address)
def trace_write(z, access, address, size, value):
""" Add memory `define` to the trace """
self.trace.add_define(address, value)
def trace_internal_read(z, access, address, size, value):
"""Add memory `use` to the trace originating from a zelos
syscall emulation.
"""
current_syscall = z.internal_engine.kernel._current_syscall
if current_syscall is None:
return
for address in range(address, address + size):
self.trace.add_use(address, label_override=current_syscall)
def trace_internal_write(z, access, address, size, value):
"""Add memory `define` to the trace originating from a zelos
syscall emulation.
"""
current_syscall = z.internal_engine.kernel._current_syscall
if current_syscall is None:
return
for i, address in enumerate(range(address, address + size)):
self.trace.add_define(
address, value[i : i + 4], label_override=current_syscall
)
def trace_syscall(z, name, args, retval):
"""Add syscall arguments and return value uses and defines."""
# FIXME: stack-based arguments will not be properly tracked
# here. For those, their addresses should be added. For
# example, syscalls with many arguments may put the
# overflow arguments on the stack. Uncommon.
uses = set(z.internal_engine.kernel._REG_ARGS[: len(args._args)])
defines = set([z.internal_engine.kernel._REG_RETURN])
self.define_use_map[z.thread.getIP()] = (defines, uses)
def trace_invalid_mem_access(z, access, address, size, value):
"""
Handle invalid memory access violation by building a
reverse taint graph from the crash site.
"""
analyze_crash(self.zelos, self, self.trace.last_addr, address)
return False
zelos.plugins.trace.hook_comments(record_comments)
zelos.hook_execution(HookType.EXEC.INST, trace_inst)
zelos.hook_memory(HookType.MEMORY.READ, trace_read)
zelos.hook_memory(HookType.MEMORY.WRITE, trace_write)
zelos.hook_memory(HookType.MEMORY.INTERNAL_READ, trace_internal_read)
zelos.hook_memory(HookType.MEMORY.INTERNAL_WRITE, trace_internal_write)
zelos.hook_memory(HookType.MEMORY.INVALID, trace_invalid_mem_access)
zelos.hook_syscalls(HookType.SYSCALL.AFTER, trace_syscall)
def _update_tcg(self):
"""
Attempts to get the tcg from the current address.
"""
addr = self.zelos.thread.getIP()
if addr in self.define_use_map:
return
insts = TCGParse().get_tcg(self.zelos)
for i in insts:
if self.state.arch == "x86":
defines = self._adjust_x86_64_registers(i.defines())
uses = self._adjust_x86_64_registers(i.uses())
else:
defines = i.defines()
uses = i.uses()
self.define_use_map[i.address] = (defines, uses)
def _adjust_x86_64_registers(self, registers):
return {
"e" + reg[1:] if reg.startswith("r") else reg for reg in registers
}
def reverse_taint(self, start_addr: int):
""" For testing """
tg = TaintGraph(self, start_addr)
return tg
def _get_ida_func_name(self, address: int) -> str:
if not hasattr(self, "names"):
self.names = {
n: a for a, n in self.zelos.plugins.ida.utils.Names()
}
return self.zelos.plugins.ida.idc.get_func_name(address)
def _compute_defs(self):
previous_dict = {}
reaching_defs = [0] * len(self.trace._trace)
for idx, addr in enumerate(self.trace._trace):
(defs, _) = self.define_use_map.get(addr, ([], []))
previous_dict.update({d: idx for d in defs})
reaching_defs[idx] = previous_dict
previous_dict = previous_dict.copy()
self.reaching_defs = reaching_defs
def ud_chain(self, target_idx: int) -> Dict[str, List[int]]:
"""
Identifies the definition that reaches the current use.
Returns:
Dict of uses to the address of a potential definition.
"""
if len(self.reaching_defs) == 0:
self._compute_defs()
ud_chain = defaultdict(list)
target_address = self.trace._trace[target_idx]
reaching_defs = self.reaching_defs[target_idx]
(_, uses) = self.define_use_map.get(target_address, ([], []))
uses = set(uses) # we want a copy
for u in uses:
if u in ["env"]:
continue
reaching_def_idx = reaching_defs.get(u, None)
if reaching_def_idx == target_idx:
reaching_defs = self.reaching_defs[target_idx - 1]
reaching_def_idx = reaching_defs.get(u, None)
ud_chain[str(u)].append(reaching_def_idx)
return ud_chain
def analyze_crash(z, dataflow, inst_address, mem_address):
"""
Build a reverse taint graph from the crash site.
"""
logger = dataflow.logger
trace = dataflow.trace
logger.notice("Execution finished.")
taint_path = TaintGraph(dataflow, inst_address, mem_address)
zelos_module_base = z.internal_engine.memory.get_module_base(
z.target_binary_path
)
logger.info("Parsing DWARF info")
annotate_with_dwarf_data(z, z.target_binary_path, trace._trace, taint_path)
taint_path._addr2func = get_function_info(
z.target_binary_path, taint_path, zelos_module_base
)
try:
logger.info("Creating source taint graph")
show_tainted_source(z, z.target_binary_path, trace._trace, taint_path)
zcovPath = os.path.abspath(
os.path.join(z.config.source_code_path, "crashd.zcov")
)
logger.notice(f"Wrote file: {zcovPath}")
except Exception:
logger.exception("Unable to show source code")
if True:
# This is all png graph generation
from .render.graphviz import (
render_reduced_path_taint_graph,
render_path_taint_graph,
)
render_reduced_path_taint_graph(logger, taint_path)
render_path_taint_graph(logger, taint_path, trace)
# self.get_ida_taint_overlay(
# z.internal_engine.main_module.EntryPoint,
# trace,
# taint_path,
# open(crash_trace_file_name, "w"),
# )
return False | zelos-crashd | /zelos-crashd-0.0.2.tar.gz/zelos-crashd-0.0.2/src/crashd/taint/taint.py | taint.py |
# This program is free software: you can redistribute it and/or modify
# it under the terms of the GNU Affero General Public License as
# published by the Free Software Foundation, either version 3 of the
# License, or (at your option) any later version.
# This program is distributed in the hope that it will be useful,
# but WITHOUT ANY WARRANTY; without even the implied warranty of
# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
# GNU Affero General Public License for more details.
# You should have received a copy of the GNU Affero General Public
# License along with this program. If not, see
# <http://www.gnu.org/licenses/>.
# ======================================================================
from zelos.exceptions import MemoryReadUnmapped
from typing import List, Dict
from collections import defaultdict
import math
import re
class TaintNode:
"""
TODO
"""
def __init__(self, taint_graph, idx, use, val):
self.idx = idx
self.use = use
self.val = val
self._taint_graph = taint_graph
try:
potential_addr = int(val, 0)
self._taint_graph._dataflow.zelos.memory.read_int(potential_addr)
self.val = "*" + self.val
except Exception:
# Not a valid memory address
pass
def addr(self) -> int:
return self._taint_graph._dataflow.trace._trace[self.idx]
def use_string(self) -> str:
if isinstance(self.use, int):
return f"Use: 0x{self.use:x} Value: {self.val}"
else:
return f"Use: {self.use} Value: {self.val}"
def __str__(self):
return f"(Addr: 0x{self.addr():x} {self.use_string()})"
def __repr__(self):
return self.__str__()
class ReducedTaintNode:
"""
TODO
"""
def __init__(self, taint_graph, taint_node):
self._taint_graph = taint_graph
self._taint_nodes = [taint_node]
@property
def idx(self):
return self._taint_nodes[0].idx
@property
def use(self):
return self._taint_nodes[0].use
@property
def val(self):
return self._taint_nodes[0].val
def addr(self) -> int:
return self._taint_graph._dataflow.trace._trace[self.idx]
def use_string(self) -> str:
if isinstance(self.use, int):
return (
f"Use: 0x{self.use:x} Value: {self.val} Iter:"
f" {len(self._taint_nodes)}"
)
else:
return (
f"Use: {self.use} Value: {self.val} Iter:"
f" {len(self._taint_nodes)}"
)
def add_node(self, taint_node):
self._taint_nodes.append(taint_node)
def __str__(self):
return f"(Addr: 0x{self.addr():x} {self.use_string()})"
def __repr__(self):
return self.__str__()
class TaintGraph:
"""
TODO
"""
def __init__(self, dataflow, start_addr, crashing_address=None):
self.logger = dataflow.logger
self._dataflow = dataflow
"Keys are the index in the trace"
self._path: Dict[int, Dict[int, TaintNode]] = defaultdict(dict)
self._path_parents = defaultdict(list)
"""Keys are the address. This is an optimization to
reduce the size of the graph."""
self._reduced_path: Dict[
int, Dict[int, ReducedTaintNode]
] = defaultdict(dict)
self._reduced_path_parents = defaultdict(set)
self._start_addr = start_addr
self._assembly = defaultdict(str)
self._addr2func = {}
self._dwarf_data = None
self.reverse_taint(start_addr, crashing_address)
def __str__(self):
s = ""
count = 100
if len(self._reduced_path) > 0:
for addr, defines in self._reduced_path.items():
s += f"0x{addr:x} {defines}\n"
s += f" assembly: {self._assembly[addr]}\n"
funcname = self._addr2func.get(addr, None)
if funcname is not None:
s += f" func: {funcname}\n"
srccode = self.get_source(addr)
if srccode is not None:
s += f" src: {srccode}\n"
count -= 1
if count == 0:
break
return s
for idx, defines in self._path.items():
addr = self._dataflow.trace._trace[idx]
s += f"0x{addr:x} {defines}\n"
return s
@property
def reduced_path(self):
return self._reduced_path
def get_source(self, addr: int):
if self._dwarf_data is None:
return None
return self._dwarf_data.get_source(addr)
def get_assembly_from_source(self, file, line_num):
address_map = self._dwarf_data._address_map
(addr_low, addr_high) = address_map.get_addr_range_from_source(
file, line_num
)
if addr_low is None or addr_high is None:
return None
return self.get_assembly_for_range(addr_low, addr_high)
def _reduce(self):
"""
Creates the reduced path which ensures that uses the address as
the key instead of the index
"""
if len(self._reduced_path) > 0:
return # Already reduced
for idx, taint_nodes in self._path.items():
addr = self._dataflow.trace._trace[idx]
for taint_node in taint_nodes.values():
node_addr = self._dataflow.trace._trace[taint_node.idx]
if node_addr in self._reduced_path[addr]:
self._reduced_path[addr][node_addr].add_node(taint_node)
else:
self._reduced_path[addr][node_addr] = ReducedTaintNode(
self, taint_node
)
self._reduced_path_parents[node_addr].add(addr)
# Add information about the assembly instructions
if addr not in self._assembly:
inst_strings = self.get_assembly_for_range(addr, addr + 20)
self._assembly[addr] = inst_strings[addr]
# Filter out adjacent push-pop pairs
for addr, taint_nodes in list(self._reduced_path.items()):
if " push " not in self._assembly.get(addr, ""):
continue
if len(taint_nodes) != 1:
continue
child_addr = list(taint_nodes.keys())[0]
node = taint_nodes[child_addr]
if " pop " not in self._assembly[child_addr]:
continue
grand_children = {
k: v
for k, v in self._reduced_path[child_addr].items()
if "push" not in self._assembly[k]
}
grand_parents = [
x
for x in self._reduced_path_parents[addr]
if "pop" not in self._assembly[x]
]
# print("Beginning Deletion")
# for gp in grand_parents:
# print(f" grand parent 0x{gp:x} {self._assembly[gp]}")
# print(f" children: {self._reduced_path[gp]}")
# print(f" parent: {addr:x} {self._assembly[addr]}")
# print(f" child: {child_addr:x} {self._assembly[child_addr]}")
# for gc_addr in grand_children.keys():
# print(
# f" grand_children {gc_addr:x} {self._assembly[gc_addr]}"
# )
for gp in grand_parents:
del self._reduced_path[gp][addr]
del self._reduced_path[addr]
del self._reduced_path[child_addr]
del self._reduced_path_parents[addr]
del self._reduced_path_parents[child_addr]
# print(
# f" Deleted push-pop pair {self._assembly[addr]} and {self._assembly[child_addr]}"
# )
for grand_child_addr, grand_child in grand_children.items():
# print(f" adding grand child 0x{grand_child_addr:x}")
self._reduced_path_parents[grand_child_addr].remove(child_addr)
self._reduced_path_parents[grand_child_addr].update(
grand_parents
)
for gp in grand_parents:
self._reduced_path[gp][grand_child_addr] = grand_child
# print("After:")
# for gp in grand_parents:
# print(" ", [hex(k) for k in self._reduced_path[gp].keys()])
# for gc in grand_children.keys():
# print(f" Grand child {gc:x}",)
# print(
# f" grand parents: {[hex(x) for x in self._reduced_path_parents[gc]]}"
# )
def get_assembly_for_range(self, addr_low, addr_high):
try:
code = self._dataflow.memory.read(addr_low, addr_high - addr_low)
except MemoryReadUnmapped:
print(f"Error trying to read 0x{addr_low:x}-0x{addr_high:x}")
return {}
if self._dataflow.zelos.config.link_ida is not None:
try:
ida_disasm = self._dataflow.zelos.plugins.ida.idc.GetDisasm(
addr_low
)
if ida_disasm is not None and ida_disasm != "":
self._annotate_variables_in_path(addr_low, ida_disasm)
return {
addr_low: (
f"0x{addr_low:x}: {ida_disasm} ;"
f" {self._dataflow.trace._addr_comment.get(addr_low, '')}"
)
}
except Exception as e:
print("Ida address exception: ", e)
# raise e
pass
inst_list = list(
self._dataflow.zelos.internal_engine.cs.disasm(code, addr_low)
)
return {
i.address: (
f"0x{i.address:x}: {i.mnemonic} {i.op_str} ;"
f" {self._dataflow.trace._addr_comment.get(i.address, '')}"
)
for i in inst_list
}
def _annotate_variables_in_path(self, addr: int, ida_disasm: str):
if ida_disasm is None:
return
if "mov" not in ida_disasm and "lea" not in ida_disasm:
return
cmd, args = ida_disasm.split(maxsplit=1)
if cmd not in ["mov", "lea"]:
return
dest, src = args.split(",", maxsplit=1)
var_name = None
if "[" in dest and "[" not in src:
var_name = self._get_ida_variable(dest)
if "[" in src and "[" not in dest:
var_name = self._get_ida_variable(src)
if var_name is None:
return
if cmd == "lea":
var_name = "&" + var_name
for reduced_nodes in self._reduced_path[addr].values():
for node in reduced_nodes._taint_nodes:
node.val = f"{var_name}={node.val}"
def _get_ida_variable(self, s):
"""
Get the variable name from Ida disassembly if it exists.
"""
match = re.search(r"\[.bp\+(\w+)\]", s)
if match is not None:
return match.group(1)
match = re.search(
r"\[.sp\+[0-9A-Fa-f]+h\+([A-Za-z][A-Za-z0-9.]*)\]", s
)
if match is None:
return None
return match.group(1)
def reverse_taint(self, start_addr: int, crashing_addr: int):
"""
Returns a list of addresses.
Each address also contains what address tainted them and why.
"""
start_idx = self._dataflow.trace._last_idx_of_address(start_addr)
self._path[start_idx][-1] = TaintNode(self, -1, -1, -1)
indices_to_analyze = []
has_been_analyzed = set()
self._add_uses(
start_idx, indices_to_analyze, restrict_to_value=crashing_addr
)
while len(indices_to_analyze) > 0:
current_idx = indices_to_analyze.pop()
# Print how long the path on occasion
self._maybe_log(current_idx, indices_to_analyze)
self._add_uses(current_idx, indices_to_analyze)
self._reduce()
def _add_uses(
self,
current_idx: int,
indices_to_analyze: List[int],
restrict_to_value=None,
):
reg_uses = self._dataflow.ud_chain(current_idx)
for use, define_idxs in reg_uses.items():
if use in [
"ebp",
"esp",
"rbp",
"rsp",
"cc_src",
"cc_src2",
"cc_dst",
"cc_op",
"eq",
"ne",
"ltu",
"leu",
"gtu",
"geu",
]:
continue
for define_idx in define_idxs:
defines = self._dataflow.trace.get_defines(define_idx)
val = defines[use]
if (
restrict_to_value is not None
and hex(restrict_to_value) != val
):
continue
if define_idx not in self._path:
indices_to_analyze.append(define_idx)
self.create_taint_node(
define_idx, current_idx, use, val,
)
mem_uses = self._dataflow.trace.get_uses(current_idx)
for use, define_idx in mem_uses.items():
if define_idx is None:
inst_addr = self._dataflow.trace._trace[current_idx]
self.logger.warning(
"Memory use has not been defined "
f"inst addr: {inst_addr:x} mem_addr: {use:x}"
)
continue
defines = self._dataflow.trace.get_defines(define_idx)
val = defines[use]
if restrict_to_value is not None and hex(restrict_to_value) != val:
continue
if define_idx not in self._path:
indices_to_analyze.append(define_idx)
self.create_taint_node(
define_idx, current_idx, use, val,
)
def _maybe_log(self, current_idx: int, indices_to_analyze: List[int]):
path_len = len(self._path)
order_of_magnitude = 10 ** math.floor(math.log10(path_len))
if path_len % max(100, order_of_magnitude) == 0:
self.logger.info(
f"Path size: {path_len}, Analyzing idx {current_idx}"
f" left:{len(indices_to_analyze)}"
)
def create_taint_node(self, define_idx, current_idx, use, val):
self._path[define_idx][current_idx] = TaintNode(
self, current_idx, use, val
)
self._path_parents[current_idx].append(define_idx)
def _addr_label(self, key: int):
if len(self._reduced_path) > 0:
address = key
else:
address = self._dataflow.trace._trace[key]
if self._dataflow.zelos.config.link_ida is not None:
name = self._dataflow._get_ida_func_name(address)
func_addr = self._dataflow.names.get(name, None)
else:
func_addr = None
s = self._assembly[address]
region = self._dataflow.zelos.memory.get_region(address)
label_override = self._dataflow.trace.label_overrides.get(
address, None
)
if label_override is not None:
label = label_override
elif func_addr is None:
label = f"0x{address:x} {region.name} {region.module_name}"
else:
label = f"{name}+0x{address-func_addr:x}"
s = f"{label}\n{s}\n"
source_code = self.get_source(address)
if source_code is not None:
s += source_code + "\n"
return s | zelos-crashd | /zelos-crashd-0.0.2.tar.gz/zelos-crashd-0.0.2/src/crashd/taint/taint_graph.py | taint_graph.py |
# This program is free software: you can redistribute it and/or modify
# it under the terms of the GNU Affero General Public License as
# published by the Free Software Foundation, either version 3 of the
# License, or (at your option) any later version.
# This program is distributed in the hope that it will be useful,
# but WITHOUT ANY WARRANTY; without even the implied warranty of
# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
# GNU Affero General Public License for more details.
# You should have received a copy of the GNU Affero General Public
# License along with this program. If not, see
# <http://www.gnu.org/licenses/>.
# ======================================================================
from collections import defaultdict
import html
def render_path_taint_graph(logger, taint_graph, trace, max_nodes=50):
try:
from graphviz import Digraph
except Exception as e:
return
logger.info("Creating full taint graphviz")
graph = Digraph(filename="cfg", format="png")
included_keys = set()
to_process = [trace._last_idx_of_address(taint_graph._start_addr)]
while len(included_keys) < max_nodes and len(to_process) > 0:
idx = to_process.pop(0)
if idx in included_keys:
continue
graph.node(
f"{idx:x}",
taint_graph._addr_label(trace._trace[idx]),
style="filled",
)
parents = taint_graph._path_parents.get(idx, [])
to_process.extend(parents)
included_keys.add(idx)
for key, srcs in taint_graph._path.items():
for src_key, src in srcs.items():
if key not in included_keys or src_key not in included_keys:
continue
graph.edge(f"{key:x}", f"{src_key:x}", label=src.use_string())
graph.render()
def render_reduced_path_taint_graph(logger, taint_graph, max_nodes=50):
try:
from graphviz import Digraph
except Exception as e:
return
logger.info("Creating reduced taint graphviz")
graph = Digraph(filename="reduced_cfg", format="png")
included_keys = set()
to_process = [taint_graph._start_addr]
while len(included_keys) < max_nodes and len(to_process) > 0:
addr = to_process.pop(0)
if addr in included_keys:
continue
graph.node(
f"{addr:x}", taint_graph._addr_label(addr), style="filled",
)
parents = taint_graph._reduced_path_parents.get(addr, [])
to_process.extend(parents)
included_keys.add(addr)
for key, srcs in taint_graph._reduced_path.items():
for src_key, src in srcs.items():
if key not in included_keys or src_key not in included_keys:
continue
graph.edge(f"{key:x}", f"{src_key:x}", label=src.use_string())
graph.render()
def get_nodes_and_edges(taint_graph, address_map):
# print("Setting up source graph")
# tuples containing source code addr and next addr to check
open_paths = [(taint_graph._start_addr, taint_graph._start_addr)]
# No need to analyze an address that has already been analyzed.
analyzed_addrs = set()
# use to defines
edges = defaultdict(list)
nodes = set()
while len(open_paths) > 0:
child, next_ancestor = open_paths.pop()
if next_ancestor in analyzed_addrs:
continue
analyzed_addrs.add(next_ancestor)
parents = taint_graph._reduced_path_parents.get(next_ancestor, [])
for parent in parents:
if address_map.get(parent, None) is not None:
edges[child].append(parent)
nodes.add(child)
nodes.add(parent)
if parent not in analyzed_addrs:
open_paths.append((parent, parent))
else:
if parent not in analyzed_addrs:
open_paths.append((child, parent))
return (nodes, edges)
def render_source_graph(taint_graph, address_map, files):
try:
from graphviz import Digraph
except Exception as e:
return
(nodes, edges) = get_nodes_and_edges(taint_graph, address_map)
graph = Digraph(filename="source_cfg", format="png")
graph.node_attr["shape"] = "box"
node_ids = set()
for n in nodes:
file, line_num = address_map.get(n, (None, None))
node_id = f"{file}{line_num}"
if node_id in node_ids:
continue
node_ids.add(node_id)
# Make the taint graph structure have source information
values = list(taint_graph._reduced_path[n].values())
if file not in files:
src_line = f"0x{n:x}"
else:
context = 3
src_lines = []
for i in range(line_num - context, line_num + context + 1):
if i < 0 or i >= len(files[file]):
continue
line = html.escape(files[file][i].strip())
if i == line_num and len(values) > 0:
line = (
f"<u>{line} /*val ="
f" {html.escape(str(values[0].val))}*/</u>"
)
line += f'<br align="left"/>'
src_lines.append(line)
text = "".join(src_lines)
src_line = f"<{text}>"
node_id = f"{file}{line_num}"
if node_id in node_ids:
continue
node_ids.add(node_id)
# Make the taint graph structure have source information
values = list(taint_graph._reduced_path[n].values())
if file not in files:
src_line = f"0x{n:x}"
else:
context = 3
src_lines = []
for i in range(line_num - context, line_num + context + 1):
if i < 0 or i >= len(files[file]):
continue
line = html.escape(files[file][i].strip())
if i == line_num:
line = (
f"<u>{line} /*val = {html.escape(values[0].val)}*/</u>"
)
line += f'<br align="left"/>'
src_lines.append(line)
text = "".join(src_lines)
src_line = f"<{text}>"
graph.node(node_id, label=src_line, style="filled")
for src, dests in edges.items():
srcfile, srcline_num = address_map.get(src, (None, None))
for dest in dests:
destfile, destline_num = address_map.get(dest, (None, None))
graph.edge(
f"{destfile}{destline_num}",
f"{srcfile}{srcline_num}",
label="",
)
graph.render() | zelos-crashd | /zelos-crashd-0.0.2.tar.gz/zelos-crashd-0.0.2/src/crashd/taint/render/graphviz.py | graphviz.py |
# This program is free software: you can redistribute it and/or modify
# it under the terms of the GNU Affero General Public License as
# published by the Free Software Foundation, either version 3 of the
# License, or (at your option) any later version.
# This program is distributed in the hope that it will be useful,
# but WITHOUT ANY WARRANTY; without even the implied warranty of
# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
# GNU Affero General Public License for more details.
# You should have received a copy of the GNU Affero General Public
# License along with this program. If not, see
# <http://www.gnu.org/licenses/>.
# ======================================================================
import subprocess
import pickle
import base64
import os
import os.path as path
import tempfile
from zelos import IPlugin, CommandLineOption
CommandLineOption(
"link_ida",
type=str,
default=None,
help="Absolute path to an instance of IDA Pro",
)
class Ida(IPlugin):
def __init__(self, zelos):
super().__init__(zelos)
self.initialized = False
if zelos.config.link_ida is None:
return
ida_path = zelos.config.link_ida
if not os.path.exists(ida_path):
self.logger.error(f"Cannot resolve path to IDA executable.")
return
server_path = path.join(
path.dirname(path.abspath(__file__)), "ida_server.py"
)
self.temp_dir = tempfile.TemporaryDirectory()
ida_input_path = path.join(self.temp_dir.name, "ida_input")
os.mkfifo(ida_input_path)
ida_output_path = path.join(self.temp_dir.name, "ida_output")
os.mkfifo(ida_output_path)
p = subprocess.Popen(
[
ida_path,
"-c",
"-A",
f'-S""{server_path} {ida_input_path} {ida_output_path}"" ',
zelos.target_binary_path,
]
)
self.ida_input = open(ida_input_path, "w")
self.ida_output = open(ida_output_path, "rb")
def cleanup_proc():
p.terminate()
p.wait()
self.temp_dir.cleanup()
zelos.hook_close(cleanup_proc)
self.initialized = True
self.rebased = False
def _auto_rebase(self):
if self.rebased:
return
zelos = self.zelos
zelos_base = zelos.internal_engine.files.get_module_base_by_name(
zelos.target_binary_path
)
ida_base = self._raw_exec("idaapi.get_imagebase()")
print(f"Adjusting imagebase from: {ida_base:x} to {zelos_base}")
delta = zelos_base - ida_base
# 8 == ida_segment.MSF_FIXONCE
self._raw_exec(f"ida_segment.rebase_program({delta}, 8)")
self.rebased = True
def __getattr__(self, module_name):
if self.initialized:
return FauxModule(self, f"{module_name}")
return super().__getattr__(self, module_name)
@property
def api(self):
return FauxModule(self, f"idaapi")
@property
def utils(self):
return FauxModule(self, f"idautils")
@property
def idc(self):
return FauxModule(self, f"idc")
def _exec(self, cmd: str) -> str:
if not self.rebased:
self._auto_rebase()
return self._raw_exec(cmd)
def _raw_exec(self, cmd: str) -> str:
"""
Sends a command to IDA for execution
"""
self.ida_input.write(f"{cmd}\n")
self.ida_input.flush()
data = self.ida_output.readline()
data = base64.b64decode(data.strip())
return pickle.loads(data, encoding="latin1")
class FauxModule:
"""
This is a class used to identify what methods are being called on
ida so that they can be passed as a string to the IdaServer
"""
def __init__(self, ida_server_plugin, field_name):
self._ida_server_plugin = ida_server_plugin
self.name = field_name
def __getattr__(self, field_name):
return FauxModule(
self._ida_server_plugin, self.name + "." + field_name
)
def _stringify(self, val):
if type(val) == str:
return '"' + val + '"'
return str(val)
def __call__(self, *args, **kwargs):
arguments = [self._stringify(x) for x in args] + [
f"{k}={self._stringify(v)}" for k, v in kwargs
]
return self._ida_server_plugin._exec(
self.name + "(" + ",".join(arguments) + ")"
) | zelos-crashd | /zelos-crashd-0.0.2.tar.gz/zelos-crashd-0.0.2/src/crashd/static_analysis/ida_plugin.py | ida_plugin.py |
# Readme
## Introduction
This repository is an uniswap v3 backtest framework for LP provider.It is
inspired by [gammaStrategy](https://github.com/GammaStrategies/active-strategy-framework) and backtrader.
with following features:
1. backtrader style
2. better abstraction and well-organised
3. tested
Feel free to make an issue or pr to help this repository.
## Design rationale
### data
Evm's event is better than graphQL.
Event approach is cheaper and easier to use than subgraph approach.
It is found that official subgraph had some bugs in some corner cases.
We provide a bigquery downloader to produce daily pool csv files. Data downloading is an independent step for backtesting .You can download and clean it on you your ownself.
More info about download can be found in [here](https://zelos-demeter.readthedocs.io/en/latest/download_tutorial.html).
### abstraction
Strategy: quote/base price.
Broker: storage user asset and trade data.
pool: no state. just calculation. deal with tick, token0,decimal, total L.
### plot and strategy performance
User may have different choices about plot and metrics of strategy performance.
So we did not make such decisions for you. We provide some examples in strategy-example.Hope it can help you to write your own strategy.
We plan to improve metrics in recent.
## how to use
try quickstart in our [docs](https://zelos-demeter.readthedocs.io/en/latest/quickstart.html)
## license
MIT | zelos-demeter | /zelos-demeter-0.2.1.tar.gz/zelos-demeter-0.2.1/README.md | README.md |
from decimal import Decimal
from enum import Enum
from typing import NamedTuple
DECIMAL_0 = Decimal(0)
DECIMAL_1 = Decimal(1)
class TimeUnitEnum(Enum):
"""
time unit for moving average,
* minute
* hour
* day
"""
minute = 1
hour = 60
day = 60 * 24
class UnitDecimal(Decimal):
"""
Decimal with unit, such a 1 eth.
It's inherit from Decimal, but considering performance issues, calculate function is not override,
so if you do calculate on this object, return type will be Decimal
:param number: number to keep
:type number: Decimal
:param unit: unit of the number, eg: eth
:type _unit: str
:param output_format: output format, follow the document here: https://python-reference.readthedocs.io/en/latest/docs/functions/format.html
:type output_format: str
"""
__integral = Decimal(1)
default_output_format = ".8g"
def __new__(cls, value, unit: str = "", output_format=None):
obj = Decimal.__new__(cls, value)
obj._unit = unit
obj.output_format: str = output_format if output_format is not None else UnitDecimal.default_output_format
return obj
def to_str(self):
"""
get formatted string of this decimal. format is defined in self.output_format and unit will be append.
:return: formatted string
:rtype: str
"""
dec = self.quantize(DECIMAL_1) if (self == self.to_integral() and self < 1e+29) else self.normalize()
return "{:{}} {}".format(dec, self.output_format, self._unit)
@property
def unit(self):
return self._unit
@unit.setter
def unit(self, value):
self._unit = value
class EvaluatorEnum(Enum):
ALL = 0
ANNUALIZED_RETURNS = 1
BENCHMARK_RETURNS = 2
MAX_DRAW_DOWN = 3
def __str__(self):
return self.name
class TokenInfo(NamedTuple):
"""
token info
:param name: token symbol, will be set as unit of a token value, usdc
:type name: str
:param decimal: decimal of this token, 6
:type decimal: int
"""
name: str
decimal: int
class PositionInfo(NamedTuple):
"""
position information, including tick range and liquidity. It's the immute properties of a position
:param lower_tick: lower tick
:type lower_tick: int
:param upper_tick: upper tick
:type upper_tick: int
"""
lower_tick: int
upper_tick: int
def __str__(self):
return f"""tick:{self.lower_tick},{self.upper_tick}"""
class DemeterError(Exception):
def __init__(self, message):
self.message = message
class EthError(Exception):
def __init__(self, code, message):
self.code = code
self.message = message | zelos-demeter | /zelos-demeter-0.2.1.tar.gz/zelos-demeter-0.2.1/demeter/_typing.py | _typing.py |
import os
import sys
from datetime import datetime
import toml
from .download import ChainType, DataSource, downloader, DownloadParam
from .utils.application import get_enum_by_name, dict_to_object
class Downloader:
def __init__(self, config):
self.config: DownloadParam = self.convert_config(config)
@staticmethod
def convert_config(config: dict):
param = DownloadParam()
if hasattr(config, "chain"):
param.chain = get_enum_by_name(ChainType, config.chain)
if hasattr(config, "source"):
param.source = get_enum_by_name(DataSource, config.source)
if hasattr(config, "save_path"):
param.save_path = config.save_path
if not param.save_path.endswith("/"):
param.save_path += "/"
if not os.path.exists(param.save_path):
os.makedirs(param.save_path)
if hasattr(config, "pool_address"):
param.pool_address = config.pool_address
else:
raise RuntimeError("you must set pool contract address")
if param.source == DataSource.BigQuery:
if not hasattr(config, "big_query"):
raise RuntimeError("must set big_query parameters")
if hasattr(config.big_query, "auth_file"):
param.big_query.auth_file = config.big_query.auth_file
if not os.path.exists(param.big_query.auth_file):
raise RuntimeError("google auth file not found")
else:
raise RuntimeError("you must set google auth file")
if hasattr(config.big_query, "start"):
param.big_query.start = config.big_query.start
else:
raise RuntimeError("you must set start date, eg: 2022-10-1")
if hasattr(config.big_query, "end"):
param.big_query.end = config.big_query.end
elif param.source == DataSource.RPC:
if not hasattr(config, "rpc"):
raise RuntimeError("must set rpc parameters")
if hasattr(config.rpc, "end_point"):
param.rpc.end_point = config.rpc.end_point
else:
raise RuntimeError("you must set end_point")
if hasattr(config.rpc, "start_height"):
param.rpc.start_height = config.rpc.start_height
else:
raise RuntimeError("you must set start_height")
if hasattr(config.rpc, "end_height"):
param.rpc.end_height = config.rpc.end_height
else:
raise RuntimeError("you must set end_height")
if hasattr(config.rpc, "auth_string"):
param.rpc.auth_string = config.rpc.auth_string
if hasattr(config.rpc, "proxy"):
param.rpc.proxy = config.rpc.proxy
if hasattr(config.rpc, "batch_size"):
param.rpc.batch_size = config.rpc.batch_size
return param
def do_download(self):
if self.config.source == DataSource.BigQuery:
start_date = datetime.strptime(self.config.big_query.start, "%Y-%m-%d").date()
end_date = datetime.strptime(self.config.big_query.end, "%Y-%m-%d").date()
os.environ['GOOGLE_APPLICATION_CREDENTIALS'] = self.config.big_query.auth_file
downloader.download_from_bigquery(self.config.chain,
self.config.pool_address,
start_date,
end_date,
self.config.save_path,
save_raw_file=True)
elif self.config.source == DataSource.RPC:
downloader.download_from_rpc(self.config)
print("download complete, check your files in " + self.config.save_path)
if __name__ == '__main__':
if len(sys.argv) == 1:
print("please set a config file. in toml format. eg: 'python -m demeter.downloader config.toml'.")
exit(1)
if not os.path.exists(sys.argv[1]):
print("config file not found,")
exit(1)
config_file = toml.load(sys.argv[1])
try:
download_entity = Downloader(dict_to_object(config_file))
except RuntimeError as e:
print(e)
exit(1)
print(download_entity.config)
download_entity.do_download() | zelos-demeter | /zelos-demeter-0.2.1.tar.gz/zelos-demeter-0.2.1/demeter/downloader.py | downloader.py |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.