
code
stringlengths 501
5.19M
| package
stringlengths 2
81
| path
stringlengths 9
304
| filename
stringlengths 4
145
|
|---|---|---|---|
# zilean
[](https://badge.fury.io/py/zilean) [](https://codecov.io/gh/JohnsonJDDJ/zilean) [](https://zilean.readthedocs.io/en/main/?badge=main)
> _Zilean is a League of Legends character that can drift through past, present and future. The project is borrowing Zilean's temporal magic to foresee the result of a match._
Documentation: [here](https://zilean.readthedocs.io/).
**The project is open to all sorts of contribution and collaboration! Please feel free to clone, fork, PR...anything! If you are interested, contact me!**
Contact: Johnson Du <[email protected]>
[Introduction](#Introduction)\
[Demo](#Demo)
## Introduction
`zilean` is designed to facilitate data analysis of the Riot [MatchTimelineDto](https://developer.riotgames.com/apis#match-v5/GET_getTimeline). The `MatchTimelineDto` is a powerful object that contains information of a specific [League of Legends](https://leagueoflegends.com/) match at **every minute mark**. Naturally, the `MatchTimelineDto` became an **ideal object for various machine learning tasks**. For example, predicting match results using game statistics before the 16 minute mark.
Different from traditional sports, esports such as League of Legends has an innate advantage with respect to the data collection process. Since every play was conducted digitally, it opened up a huge potential to explore and perform all kinds of data analysis. `zilean` hopes to explore the infinite potentials provided by the [Riot Games API](https://developer.riotgames.com/), **and through the power of computing, make our community a better place.**
GL:HF!
## Demo
Here is a quick look of how to do League of Legends data analysis with `zilean`
```python
from zilean import TimelineCrawler, SnapShots, read_api_key
import pandas as pd
# Use the TimelineCrawler to fetch `MatchTimelineDto`s
# from Riot. The `MatchTimelineDto`s have game stats
# at each minute mark.
# We need a API key to fetch data. See the Riot Developer
# Portal for more info.
api_key = read_api_key(you_api_key_here)
# Crawl 2000 Diamond RANKED_SOLO_5x5 timelines from the Korean server.
crawler = TimelineCrawler(api_key, region="kr",
tier="DIAMOND", queue="RANKED_SOLO_5x5")
result = crawler.crawl(2000, match_per_id=30, file="results.json")
# This will take a long time!
# We will look at the player statistics at 10 and 15 minute mark.
snaps = SnapShots(result, frames=[10, 15])
# Store the player statistics using in a pandas DataFrame
player_stats = snaps.summary(per_frame=True)
data = pd.DataFrame(player_stats)
# Look at the distribution of totalGold difference for `player 0` (TOP player)
# at 15 minutes mark.
sns.displot(x="totalGold_0", data=data[data['frame'] == 15], hue="win")
```

Here is an example of some quick machine learning.
```python
# Do some simple modelling
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
# Define X and y for training data
train, test = train_test_split(player_stats, test_size=0.33)
X_train = train.drop(["matchId", "win"], axis=1)
y_train = train["win"].astype(int)
# Build a default random forest classifier
rf = RandomForestClassifier()
rf.fit(X_train, y_train)
y_fitted = rf.predict(X_train)
print(f"Training accuracy: {mean(y_train == y_fitted)}")
``` | zilean | /zilean-0.0.2.tar.gz/zilean-0.0.2/README.md | README.md |
# Notices
This repository incorporates material as listed below or described in the code.
## django-mssql-backend
Please see below for the associated license for the incorporated material from django-mssql-backend (https://github.com/ESSolutions/django-mssql-backend).
### BSD 3-Clause License
Copyright (c) 2019, ES Solutions AB
All rights reserved.
Redistribution and use in source and binary forms, with or without
modification, are permitted provided that the following conditions are met:
* Redistributions of source code must retain the above copyright notice, this
list of conditions and the following disclaimer.
* Redistributions in binary form must reproduce the above copyright notice,
this list of conditions and the following disclaimer in the documentation
and/or other materials provided with the distribution.
* Neither the name of the copyright holder nor the names of its
contributors may be used to endorse or promote products derived from
this software without specific prior written permission.
THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS"
AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE
FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL
DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR
SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER
CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,
OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
| zilian-mssql-django | /zilian-mssql-django-1.1.4.tar.gz/zilian-mssql-django-1.1.4/NOTICE.md | NOTICE.md |
# SQL Server backend for Django
Welcome to the Zilian-MSSQL-Django 3rd party backend project!
*zilian-mssql-django* is a fork of [mssql-django](https://pypi.org/project/mssql-django/). This project provides an enterprise database connectivity option for the Django Web Framework, with support for Microsoft SQL Server and Azure SQL Database.
We'd like to give thanks to the community that made this project possible, with particular recognition of the contributors: OskarPersson, michiya, dlo and the original Google Code django-pyodbc team. Moving forward we encourage partipation in this project from both old and new contributors!
We hope you enjoy using the Zilian-MSSQL-Django 3rd party backend.
## Features
- Supports Django 3.2 and 4.0
- Tested on Microsoft SQL Server 2016, 2017, 2019
- Passes most of the tests of the Django test suite
- Compatible with
[Micosoft ODBC Driver for SQL Server](https://docs.microsoft.com/en-us/sql/connect/odbc/microsoft-odbc-driver-for-sql-server),
[SQL Server Native Client](https://msdn.microsoft.com/en-us/library/ms131321(v=sql.120).aspx),
and [FreeTDS](https://www.freetds.org/) ODBC drivers
- Supports AzureSQL serveless db reconnection
## Dependencies
- pyodbc 3.0 or newer
## Installation
1. Install pyodbc 3.0 (or newer) and Django
2. Install zilian-mssql-django:
pip install zilian-mssql-django
3. Set the `ENGINE` setting in the `settings.py` file used by
your Django application or project to `'mssql'`:
'ENGINE': 'mssql'
## Configuration
### Standard Django settings
The following entries in a database-level settings dictionary
in DATABASES control the behavior of the backend:
- ENGINE
String. It must be `"mssql"`.
- NAME
String. Database name. Required.
- HOST
String. SQL Server instance in `"server\instance"` format.
- PORT
String. Server instance port.
An empty string means the default port.
- USER
String. Database user name in `"user"` format.
If not given then MS Integrated Security will be used.
- PASSWORD
String. Database user password.
- TOKEN
String. Access token fetched as a user or service principal which
has access to the database. E.g. when using `azure.identity`, the
result of `DefaultAzureCredential().get_token('https://database.windows.net/.default')`
can be passed.
- AUTOCOMMIT
Boolean. Set this to `False` if you want to disable
Django's transaction management and implement your own.
- Trusted_Connection
String. Default is `"yes"`. Can be set to `"no"` if required.
and the following entries are also available in the `TEST` dictionary
for any given database-level settings dictionary:
- NAME
String. The name of database to use when running the test suite.
If the default value (`None`) is used, the test database will use
the name `"test_" + NAME`.
- COLLATION
String. The collation order to use when creating the test database.
If the default value (`None`) is used, the test database is assigned
the default collation of the instance of SQL Server.
- DEPENDENCIES
String. The creation-order dependencies of the database.
See the official Django documentation for more details.
- MIRROR
String. The alias of the database that this database should
mirror during testing. Default value is `None`.
See the official Django documentation for more details.
### OPTIONS
Dictionary. Current available keys are:
- driver
String. ODBC Driver to use (`"ODBC Driver 17 for SQL Server"`,
`"SQL Server Native Client 11.0"`, `"FreeTDS"` etc).
Default is `"ODBC Driver 17 for SQL Server"`.
- isolation_level
String. Sets [transaction isolation level](https://docs.microsoft.com/en-us/sql/t-sql/statements/set-transaction-isolation-level-transact-sql)
for each database session. Valid values for this entry are
`READ UNCOMMITTED`, `READ COMMITTED`, `REPEATABLE READ`,
`SNAPSHOT`, and `SERIALIZABLE`. Default is `None` which means
no isolation levei is set to a database session and SQL Server default
will be used.
- dsn
String. A named DSN can be used instead of `HOST`.
- host_is_server
Boolean. Only relevant if using the FreeTDS ODBC driver under
Unix/Linux.
By default, when using the FreeTDS ODBC driver the value specified in
the ``HOST`` setting is used in a ``SERVERNAME`` ODBC connection
string component instead of being used in a ``SERVER`` component;
this means that this value should be the name of a *dataserver*
definition present in the ``freetds.conf`` FreeTDS configuration file
instead of a hostname or an IP address.
But if this option is present and its value is ``True``, this
special behavior is turned off. Instead, connections to the database
server will be established using ``HOST`` and ``PORT`` options, without
requiring ``freetds.conf`` to be configured.
See https://www.freetds.org/userguide/dsnless.html for more information.
- unicode_results
Boolean. If it is set to ``True``, pyodbc's *unicode_results* feature
is activated and strings returned from pyodbc are always Unicode.
Default value is ``False``.
- extra_params
String. Additional parameters for the ODBC connection. The format is
``"param=value;param=value"``, [Azure AD Authentication](https://github.com/microsoft/mssql-django/wiki/Azure-AD-Authentication) (Service Principal, Interactive, Msi) can be added to this field.
- collation
String. Name of the collation to use when performing text field
lookups against the database. Default is ``None``; this means no
collation specifier is added to your lookup SQL (the default
collation of your database will be used). For Chinese language you
can set it to ``"Chinese_PRC_CI_AS"``.
- connection_timeout
Integer. Sets the timeout in seconds for the database connection process.
Default value is ``0`` which disables the timeout.
- connection_retries
Integer. Sets the times to retry the database connection process.
Default value is ``5``.
- connection_retry_backoff_time
Integer. Sets the back off time in seconds for reries of
the database connection process. Default value is ``5``.
- query_timeout
Integer. Sets the timeout in seconds for the database query.
Default value is ``0`` which disables the timeout.
- [setencoding](https://github.com/mkleehammer/pyodbc/wiki/Connection#setencoding) and [setdecoding](https://github.com/mkleehammer/pyodbc/wiki/Connection#setdecoding)
```python
# Example
"OPTIONS": {
"setdecoding": [
{"sqltype": pyodbc.SQL_CHAR, "encoding": 'utf-8'},
{"sqltype": pyodbc.SQL_WCHAR, "encoding": 'utf-8'}],
"setencoding": [
{"encoding": "utf-8"}],
...
},
```
### Backend-specific settings
The following project-level settings also control the behavior of the backend:
- DATABASE_CONNECTION_POOLING
Boolean. If it is set to ``False``, pyodbc's connection pooling feature
won't be activated.
### Example
Here is an example of the database settings:
```python
DATABASES = {
'default': {
'ENGINE': 'mssql',
'NAME': 'mydb',
'USER': 'user@myserver',
'PASSWORD': 'password',
'HOST': 'myserver.database.windows.net',
'PORT': '',
'OPTIONS': {
'driver': 'ODBC Driver 17 for SQL Server',
},
},
}
# set this to False if you want to turn off pyodbc's connection pooling
DATABASE_CONNECTION_POOLING = False
```
## Limitations
The following features are currently not fully supported:
- Altering a model field from or to AutoField at migration
- Django annotate functions have floating point arithmetic problems in some cases
- Annotate function with exists
- Exists function in order_by
- Righthand power and arithmetic with datatimes
- Timezones, timedeltas not fully supported
- Rename field/model with foreign key constraint
- Database level constraints
- Math degrees power or radians
- Bit-shift operators
- Filtered index
- Date extract function
- Hashing functions
JSONField lookups have limitations, more details [here](https://github.com/microsoft/mssql-django/wiki/JSONField).
| zilian-mssql-django | /zilian-mssql-django-1.1.4.tar.gz/zilian-mssql-django-1.1.4/README.md | README.md |
import os
from pathlib import Path
from django import VERSION
BASE_DIR = Path(__file__).resolve().parent.parent
DATABASES = {
"default": {
"ENGINE": "mssql",
"NAME": "default",
"USER": "sa",
"PASSWORD": "MyPassword42",
"HOST": "localhost",
"PORT": "1433",
"OPTIONS": {"driver": "ODBC Driver 17 for SQL Server", },
},
'other': {
"ENGINE": "mssql",
"NAME": "other",
"USER": "sa",
"PASSWORD": "MyPassword42",
"HOST": "localhost",
"PORT": "1433",
"OPTIONS": {"driver": "ODBC Driver 17 for SQL Server", },
},
}
# Django 3.0 and below unit test doesn't handle more than 2 databases in DATABASES correctly
if VERSION >= (3, 1):
DATABASES['sqlite'] = {
"ENGINE": "django.db.backends.sqlite3",
"NAME": str(BASE_DIR / "db.sqlitetest"),
}
# Set to `True` locally if you want SQL queries logged to django_sql.log
DEBUG = False
# Logging
LOG_DIR = os.path.join(os.path.dirname(__file__), '..', 'logs')
os.makedirs(LOG_DIR, exist_ok=True)
LOGGING = {
'version': 1,
'disable_existing_loggers': True,
'formatters': {
'myformatter': {
'format': '%(asctime)s P%(process)05dT%(thread)05d [%(levelname)s] %(name)s: %(message)s',
},
},
'handlers': {
'db_output': {
'level': 'DEBUG',
'class': 'logging.handlers.RotatingFileHandler',
'filename': os.path.join(LOG_DIR, 'django_sql.log'),
'formatter': 'myformatter',
},
'default': {
'level': 'DEBUG',
'class': 'logging.handlers.RotatingFileHandler',
'filename': os.path.join(LOG_DIR, 'default.log'),
'formatter': 'myformatter',
}
},
'loggers': {
'': {
'handlers': ['default'],
'level': 'DEBUG',
'propagate': False,
},
'django.db': {
'handlers': ['db_output'],
'level': 'DEBUG',
'propagate': False,
},
},
}
INSTALLED_APPS = (
'django.contrib.contenttypes',
'django.contrib.staticfiles',
'django.contrib.auth',
'mssql',
'testapp',
)
SECRET_KEY = "django_tests_secret_key"
PASSWORD_HASHERS = [
'django.contrib.auth.hashers.PBKDF2PasswordHasher',
]
DEFAULT_AUTO_FIELD = 'django.db.models.AutoField'
ENABLE_REGEX_TESTS = False
USE_TZ = False
TEST_RUNNER = "testapp.runners.ExcludedTestSuiteRunner"
EXCLUDED_TESTS = [
'aggregation.tests.AggregateTestCase.test_expression_on_aggregation',
'aggregation_regress.tests.AggregationTests.test_annotated_conditional_aggregate',
'aggregation_regress.tests.AggregationTests.test_annotation_with_value',
'aggregation.tests.AggregateTestCase.test_distinct_on_aggregate',
'annotations.tests.NonAggregateAnnotationTestCase.test_annotate_exists',
'custom_lookups.tests.BilateralTransformTests.test_transform_order_by',
'expressions.tests.BasicExpressionsTests.test_filtering_on_annotate_that_uses_q',
'expressions.tests.BasicExpressionsTests.test_order_by_exists',
'expressions.tests.ExpressionOperatorTests.test_righthand_power',
'expressions.tests.FTimeDeltaTests.test_datetime_subtraction_microseconds',
'expressions.tests.FTimeDeltaTests.test_duration_with_datetime_microseconds',
'expressions.tests.IterableLookupInnerExpressionsTests.test_expressions_in_lookups_join_choice',
'expressions_case.tests.CaseExpressionTests.test_annotate_with_in_clause',
'expressions_window.tests.WindowFunctionTests.test_nth_returns_null',
'expressions_window.tests.WindowFunctionTests.test_nthvalue',
'expressions_window.tests.WindowFunctionTests.test_range_n_preceding_and_following',
'field_deconstruction.tests.FieldDeconstructionTests.test_binary_field',
'ordering.tests.OrderingTests.test_orders_nulls_first_on_filtered_subquery',
'get_or_create.tests.UpdateOrCreateTransactionTests.test_creation_in_transaction',
'indexes.tests.PartialIndexTests.test_multiple_conditions',
'introspection.tests.IntrospectionTests.test_get_constraints',
'migrations.test_executor.ExecutorTests.test_alter_id_type_with_fk',
'migrations.test_operations.OperationTests.test_add_constraint_percent_escaping',
'migrations.test_operations.OperationTests.test_alter_field_pk',
'migrations.test_operations.OperationTests.test_alter_field_reloads_state_on_fk_with_to_field_target_changes',
'migrations.test_operations.OperationTests.test_autofield_foreignfield_growth',
'schema.tests.SchemaTests.test_alter_auto_field_to_char_field',
'schema.tests.SchemaTests.test_alter_auto_field_to_integer_field',
'schema.tests.SchemaTests.test_alter_implicit_id_to_explicit',
'schema.tests.SchemaTests.test_alter_int_pk_to_autofield_pk',
'schema.tests.SchemaTests.test_alter_int_pk_to_bigautofield_pk',
'schema.tests.SchemaTests.test_alter_pk_with_self_referential_field',
'schema.tests.SchemaTests.test_no_db_constraint_added_during_primary_key_change',
'schema.tests.SchemaTests.test_remove_field_check_does_not_remove_meta_constraints',
'schema.tests.SchemaTests.test_remove_field_unique_does_not_remove_meta_constraints',
'schema.tests.SchemaTests.test_text_field_with_db_index',
'schema.tests.SchemaTests.test_unique_together_with_fk',
'schema.tests.SchemaTests.test_unique_together_with_fk_with_existing_index',
'aggregation.tests.AggregateTestCase.test_count_star',
'aggregation_regress.tests.AggregationTests.test_values_list_annotation_args_ordering',
'datatypes.tests.DataTypesTestCase.test_error_on_timezone',
'db_functions.math.test_degrees.DegreesTests.test_integer',
'db_functions.math.test_power.PowerTests.test_integer',
'db_functions.math.test_radians.RadiansTests.test_integer',
'db_functions.text.test_pad.PadTests.test_pad',
'db_functions.text.test_replace.ReplaceTests.test_case_sensitive',
'expressions.tests.ExpressionOperatorTests.test_lefthand_bitwise_right_shift_operator',
'expressions.tests.FTimeDeltaTests.test_invalid_operator',
'fixtures_regress.tests.TestFixtures.test_loaddata_raises_error_when_fixture_has_invalid_foreign_key',
'invalid_models_tests.test_ordinary_fields.TextFieldTests.test_max_length_warning',
'model_indexes.tests.IndexesTests.test_db_tablespace',
'ordering.tests.OrderingTests.test_deprecated_values_annotate',
'queries.test_qs_combinators.QuerySetSetOperationTests.test_limits',
'backends.tests.BackendTestCase.test_unicode_password',
'introspection.tests.IntrospectionTests.test_get_table_description_types',
'migrations.test_commands.MigrateTests.test_migrate_syncdb_app_label',
'migrations.test_commands.MigrateTests.test_migrate_syncdb_deferred_sql_executed_with_schemaeditor',
'migrations.test_operations.OperationTests.test_alter_field_pk_fk',
'schema.tests.SchemaTests.test_add_foreign_key_quoted_db_table',
'schema.tests.SchemaTests.test_unique_and_reverse_m2m',
'schema.tests.SchemaTests.test_unique_no_unnecessary_fk_drops',
'select_for_update.tests.SelectForUpdateTests.test_for_update_after_from',
'backends.tests.LastExecutedQueryTest.test_last_executed_query',
'db_functions.datetime.test_now.NowTests.test_basic',
'db_functions.datetime.test_extract_trunc.DateFunctionTests.test_extract_year_exact_lookup',
'db_functions.datetime.test_extract_trunc.DateFunctionTests.test_extract_year_greaterthan_lookup',
'db_functions.datetime.test_extract_trunc.DateFunctionTests.test_extract_year_lessthan_lookup',
'db_functions.datetime.test_extract_trunc.DateFunctionWithTimeZoneTests.test_extract_year_exact_lookup',
'db_functions.datetime.test_extract_trunc.DateFunctionWithTimeZoneTests.test_extract_year_greaterthan_lookup',
'db_functions.datetime.test_extract_trunc.DateFunctionWithTimeZoneTests.test_extract_year_lessthan_lookup',
'db_functions.datetime.test_extract_trunc.DateFunctionWithTimeZoneTests.test_trunc_ambiguous_and_invalid_times',
'delete.tests.DeletionTests.test_only_referenced_fields_selected',
'queries.test_db_returning.ReturningValuesTests.test_insert_returning',
'queries.test_db_returning.ReturningValuesTests.test_insert_returning_non_integer',
'backends.tests.BackendTestCase.test_queries',
'introspection.tests.IntrospectionTests.test_smallautofield',
'schema.tests.SchemaTests.test_inline_fk',
'aggregation.tests.AggregateTestCase.test_aggregation_subquery_annotation_exists',
'aggregation.tests.AggregateTestCase.test_aggregation_subquery_annotation_values_collision',
'db_functions.datetime.test_extract_trunc.DateFunctionWithTimeZoneTests.test_extract_func_with_timezone',
'db_functions.text.test_md5.MD5Tests.test_basic',
'db_functions.text.test_md5.MD5Tests.test_transform',
'db_functions.text.test_sha1.SHA1Tests.test_basic',
'db_functions.text.test_sha1.SHA1Tests.test_transform',
'db_functions.text.test_sha224.SHA224Tests.test_basic',
'db_functions.text.test_sha224.SHA224Tests.test_transform',
'db_functions.text.test_sha256.SHA256Tests.test_basic',
'db_functions.text.test_sha256.SHA256Tests.test_transform',
'db_functions.text.test_sha384.SHA384Tests.test_basic',
'db_functions.text.test_sha384.SHA384Tests.test_transform',
'db_functions.text.test_sha512.SHA512Tests.test_basic',
'db_functions.text.test_sha512.SHA512Tests.test_transform',
'expressions.tests.BasicExpressionsTests.test_case_in_filter_if_boolean_output_field',
'expressions.tests.BasicExpressionsTests.test_subquery_in_filter',
'expressions.tests.FTimeDeltaTests.test_date_subquery_subtraction',
'expressions.tests.FTimeDeltaTests.test_datetime_subquery_subtraction',
'expressions.tests.FTimeDeltaTests.test_time_subquery_subtraction',
'expressions.tests.BasicExpressionsTests.test_filtering_on_q_that_is_boolean',
'migrations.test_operations.OperationTests.test_alter_field_reloads_state_on_fk_with_to_field_target_type_change',
'migrations.test_operations.OperationTests.test_autofield__bigautofield_foreignfield_growth',
'migrations.test_operations.OperationTests.test_smallfield_autofield_foreignfield_growth',
'migrations.test_operations.OperationTests.test_smallfield_bigautofield_foreignfield_growth',
'schema.tests.SchemaTests.test_alter_auto_field_quoted_db_column',
'schema.tests.SchemaTests.test_alter_autofield_pk_to_bigautofield_pk_sequence_owner',
'schema.tests.SchemaTests.test_alter_autofield_pk_to_smallautofield_pk_sequence_owner',
'schema.tests.SchemaTests.test_alter_primary_key_quoted_db_table',
'schema.tests.SchemaTests.test_alter_smallint_pk_to_smallautofield_pk',
'annotations.tests.NonAggregateAnnotationTestCase.test_combined_expression_annotation_with_aggregation',
'db_functions.comparison.test_cast.CastTests.test_cast_to_integer',
'db_functions.datetime.test_extract_trunc.DateFunctionTests.test_extract_func',
'db_functions.datetime.test_extract_trunc.DateFunctionTests.test_extract_iso_weekday_func',
'db_functions.datetime.test_extract_trunc.DateFunctionWithTimeZoneTests.test_extract_func',
'db_functions.datetime.test_extract_trunc.DateFunctionWithTimeZoneTests.test_extract_iso_weekday_func',
'datetimes.tests.DateTimesTests.test_datetimes_ambiguous_and_invalid_times',
'expressions.tests.ExpressionOperatorTests.test_lefthand_bitwise_xor',
'expressions.tests.ExpressionOperatorTests.test_lefthand_bitwise_xor_null',
'inspectdb.tests.InspectDBTestCase.test_number_field_types',
'inspectdb.tests.InspectDBTestCase.test_json_field',
'ordering.tests.OrderingTests.test_default_ordering_by_f_expression',
'ordering.tests.OrderingTests.test_order_by_nulls_first',
'ordering.tests.OrderingTests.test_order_by_nulls_last',
'queries.test_qs_combinators.QuerySetSetOperationTests.test_ordering_by_f_expression_and_alias',
'queries.test_db_returning.ReturningValuesTests.test_insert_returning_multiple',
'dbshell.tests.DbshellCommandTestCase.test_command_missing',
'schema.tests.SchemaTests.test_char_field_pk_to_auto_field',
'datetimes.tests.DateTimesTests.test_21432',
# JSONFields
'model_fields.test_jsonfield.TestQuerying.test_has_key_list',
'model_fields.test_jsonfield.TestQuerying.test_has_key_null_value',
'model_fields.test_jsonfield.TestQuerying.test_key_quoted_string',
'model_fields.test_jsonfield.TestQuerying.test_lookups_with_key_transform',
'model_fields.test_jsonfield.TestQuerying.test_ordering_grouping_by_count',
'model_fields.test_jsonfield.TestQuerying.test_isnull_key',
'model_fields.test_jsonfield.TestQuerying.test_none_key',
'model_fields.test_jsonfield.TestQuerying.test_none_key_and_exact_lookup',
'model_fields.test_jsonfield.TestQuerying.test_key_escape',
'model_fields.test_jsonfield.TestQuerying.test_ordering_by_transform',
'expressions_window.tests.WindowFunctionTests.test_key_transform',
# Django 3.2
'db_functions.datetime.test_extract_trunc.DateFunctionWithTimeZoneTests.test_trunc_func_with_timezone',
'db_functions.datetime.test_extract_trunc.DateFunctionWithTimeZoneTests.test_trunc_timezone_applied_before_truncation',
'expressions.tests.ExistsTests.test_optimizations',
'expressions.tests.FTimeDeltaTests.test_delta_add',
'expressions.tests.FTimeDeltaTests.test_delta_subtract',
'expressions.tests.FTimeDeltaTests.test_delta_update',
'expressions.tests.FTimeDeltaTests.test_exclude',
'expressions.tests.FTimeDeltaTests.test_mixed_comparisons1',
'expressions.tests.FTimeDeltaTests.test_negative_timedelta_update',
'inspectdb.tests.InspectDBTestCase.test_field_types',
'lookup.tests.LookupTests.test_in_ignore_none',
'lookup.tests.LookupTests.test_in_ignore_none_with_unhashable_items',
'queries.test_qs_combinators.QuerySetSetOperationTests.test_exists_union',
'introspection.tests.IntrospectionTests.test_get_constraints_unique_indexes_orders',
'schema.tests.SchemaTests.test_ci_cs_db_collation',
'select_for_update.tests.SelectForUpdateTests.test_unsuported_no_key_raises_error',
# Django 4.0
'aggregation.tests.AggregateTestCase.test_aggregation_default_using_date_from_database',
'aggregation.tests.AggregateTestCase.test_aggregation_default_using_datetime_from_database',
'aggregation.tests.AggregateTestCase.test_aggregation_default_using_time_from_database',
'expressions.tests.FTimeDeltaTests.test_durationfield_multiply_divide',
'lookup.tests.LookupQueryingTests.test_alias',
'lookup.tests.LookupQueryingTests.test_filter_exists_lhs',
'lookup.tests.LookupQueryingTests.test_filter_lookup_lhs',
'lookup.tests.LookupQueryingTests.test_filter_subquery_lhs',
'lookup.tests.LookupQueryingTests.test_filter_wrapped_lookup_lhs',
'lookup.tests.LookupQueryingTests.test_lookup_in_order_by',
'lookup.tests.LookupTests.test_lookup_rhs',
'order_with_respect_to.tests.OrderWithRespectToBaseTests.test_previous_and_next_in_order',
'ordering.tests.OrderingTests.test_default_ordering_does_not_affect_group_by',
'queries.test_explain.ExplainUnsupportedTests.test_message',
'aggregation.tests.AggregateTestCase.test_coalesced_empty_result_set',
'aggregation.tests.AggregateTestCase.test_empty_result_optimization',
'queries.tests.Queries6Tests.test_col_alias_quoted',
'backends.tests.BackendTestCase.test_queries_logger',
'migrations.test_operations.OperationTests.test_alter_field_pk_mti_fk',
'migrations.test_operations.OperationTests.test_run_sql_add_missing_semicolon_on_collect_sql',
'migrations.test_operations.OperationTests.test_alter_field_pk_mti_and_fk_to_base'
]
REGEX_TESTS = [
'lookup.tests.LookupTests.test_regex',
'lookup.tests.LookupTests.test_regex_backreferencing',
'lookup.tests.LookupTests.test_regex_non_ascii',
'lookup.tests.LookupTests.test_regex_non_string',
'lookup.tests.LookupTests.test_regex_null',
'model_fields.test_jsonfield.TestQuerying.test_key_iregex',
'model_fields.test_jsonfield.TestQuerying.test_key_regex',
] | zilian-mssql-django | /zilian-mssql-django-1.1.4.tar.gz/zilian-mssql-django-1.1.4/testapp/settings.py | settings.py |
import datetime
import uuid
from django import VERSION
from django.db import models
from django.db.models import Q
from django.utils import timezone
class Author(models.Model):
name = models.CharField(max_length=100)
class Editor(models.Model):
name = models.CharField(max_length=100)
class Post(models.Model):
title = models.CharField('title', max_length=255)
author = models.ForeignKey(Author, models.CASCADE)
# Optional secondary author
alt_editor = models.ForeignKey(Editor, models.SET_NULL, blank=True, null=True)
class Meta:
unique_together = (
('author', 'title', 'alt_editor'),
)
def __str__(self):
return self.title
class Comment(models.Model):
post = models.ForeignKey(Post, on_delete=models.CASCADE)
text = models.TextField('text')
created_at = models.DateTimeField(default=timezone.now)
def __str__(self):
return self.text
class UUIDModel(models.Model):
id = models.UUIDField(primary_key=True, default=uuid.uuid4, editable=False)
def __str__(self):
return self.pk
class TestUniqueNullableModel(models.Model):
# Issue https://github.com/ESSolutions/django-mssql-backend/issues/38:
# This field started off as unique=True *and* null=True so it is implemented with a filtered unique index
# Then it is made non-nullable by a subsequent migration, to check this is correctly handled (the index
# should be dropped, then a normal unique constraint should be added, now that the column is not nullable)
test_field = models.CharField(max_length=100, unique=True)
# Issue https://github.com/ESSolutions/django-mssql-backend/issues/45 (case 1)
# Field used for testing changing the 'type' of a field that's both unique & nullable
x = models.CharField(max_length=11, null=True, unique=True)
# A variant of Issue https://github.com/microsoft/mssql-django/issues/14 case (b)
# but for a unique index (not db_index)
y_renamed = models.IntegerField(null=True, unique=True)
class TestNullableUniqueTogetherModel(models.Model):
class Meta:
unique_together = (('a', 'b', 'c'),)
# Issue https://github.com/ESSolutions/django-mssql-backend/issues/45 (case 2)
# Fields used for testing changing the type of a field that is in a `unique_together`
a = models.CharField(max_length=51, null=True)
b = models.CharField(max_length=50)
c = models.CharField(max_length=50)
class TestRemoveOneToOneFieldModel(models.Model):
# Issue https://github.com/ESSolutions/django-mssql-backend/pull/51
# Fields used for testing removing OneToOne field. Verifies that delete_unique
# does not try to remove indexes that have already been removed
# b = models.OneToOneField('self', on_delete=models.SET_NULL, null=True)
a = models.CharField(max_length=50)
class TestIndexesRetainedRenamed(models.Model):
# Issue https://github.com/microsoft/mssql-django/issues/14
# In all these cases the column index should still exist afterwards
# case (a) `a` starts out not nullable, but then is changed to be nullable
a = models.IntegerField(db_index=True, null=True)
# case (b) column originally called `b` is renamed
b_renamed = models.IntegerField(db_index=True)
# case (c) this entire model is renamed - this is just a column whose index can be checked afterwards
c = models.IntegerField(db_index=True)
class M2MOtherModel(models.Model):
name = models.CharField(max_length=10)
class TestRenameManyToManyFieldModel(models.Model):
# Issue https://github.com/microsoft/mssql-django/issues/86
others_renamed = models.ManyToManyField(M2MOtherModel)
class Topping(models.Model):
name = models.UUIDField(primary_key=True, default=uuid.uuid4)
class Pizza(models.Model):
name = models.UUIDField(primary_key=True, default=uuid.uuid4)
toppings = models.ManyToManyField(Topping)
def __str__(self):
return "%s (%s)" % (
self.name,
", ".join(topping.name for topping in self.toppings.all()),
)
class TestUnsupportableUniqueConstraint(models.Model):
class Meta:
managed = False
constraints = [
models.UniqueConstraint(
name='or_constraint',
fields=['_type'],
condition=(Q(status='in_progress') | Q(status='needs_changes')),
),
]
_type = models.CharField(max_length=50)
status = models.CharField(max_length=50)
class TestSupportableUniqueConstraint(models.Model):
class Meta:
constraints = [
models.UniqueConstraint(
name='and_constraint',
fields=['_type'],
condition=(
Q(status='in_progress') & Q(status='needs_changes') & Q(status='published')
),
),
models.UniqueConstraint(
name='in_constraint',
fields=['_type'],
condition=(Q(status__in=['in_progress', 'needs_changes'])),
),
]
_type = models.CharField(max_length=50)
status = models.CharField(max_length=50)
class BinaryData(models.Model):
binary = models.BinaryField(null=True)
if VERSION >= (3, 1):
class JSONModel(models.Model):
value = models.JSONField()
class Meta:
required_db_features = {'supports_json_field'}
if VERSION >= (3, 2):
class TestCheckConstraintWithUnicode(models.Model):
name = models.CharField(max_length=100)
class Meta:
required_db_features = {
'supports_table_check_constraints',
}
constraints = [
models.CheckConstraint(
check=~models.Q(name__startswith='\u00f7'),
name='name_does_not_starts_with_\u00f7',
)
]
class Question(models.Model):
question_text = models.CharField(max_length=200)
pub_date = models.DateTimeField('date published')
def __str__(self):
return self.question_text
def was_published_recently(self):
return self.pub_date >= timezone.now() - datetime.timedelta(days=1)
class Choice(models.Model):
question = models.ForeignKey(Question, on_delete=models.CASCADE, null=True)
choice_text = models.CharField(max_length=200)
votes = models.IntegerField(default=0)
class Meta:
unique_together = (('question', 'choice_text'))
class Customer_name(models.Model):
Customer_name = models.CharField(max_length=100)
class Meta:
ordering = ['Customer_name']
class Customer_address(models.Model):
Customer_name = models.ForeignKey(Customer_name, on_delete=models.CASCADE)
Customer_address = models.CharField(max_length=100)
class Meta:
ordering = ['Customer_address'] | zilian-mssql-django | /zilian-mssql-django-1.1.4.tar.gz/zilian-mssql-django-1.1.4/testapp/models.py | models.py |
import uuid
from django.db import migrations, models
import django
class Migration(migrations.Migration):
initial = True
dependencies = [
]
operations = [
migrations.CreateModel(
name='Author',
fields=[
('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),
('name', models.CharField(max_length=100)),
],
),
migrations.CreateModel(
name='Editor',
fields=[
('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),
('name', models.CharField(max_length=100)),
],
),
migrations.CreateModel(
name='Post',
fields=[
('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),
('title', models.CharField(max_length=255, verbose_name='title')),
],
),
migrations.AddField(
model_name='post',
name='alt_editor',
field=models.ForeignKey(blank=True, null=True, on_delete=django.db.models.deletion.SET_NULL, to='testapp.Editor'),
),
migrations.AddField(
model_name='post',
name='author',
field=models.ForeignKey(on_delete=django.db.models.deletion.CASCADE, to='testapp.Author'),
),
migrations.AlterUniqueTogether(
name='post',
unique_together={('author', 'title', 'alt_editor')},
),
migrations.CreateModel(
name='Comment',
fields=[
('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),
('post', models.ForeignKey(on_delete=django.db.models.deletion.CASCADE, to='testapp.Post')),
('text', models.TextField(verbose_name='text')),
('created_at', models.DateTimeField(default=django.utils.timezone.now)),
],
),
migrations.CreateModel(
name='UUIDModel',
fields=[
('id', models.UUIDField(default=uuid.uuid4, editable=False, primary_key=True, serialize=False)),
],
),
] | zilian-mssql-django | /zilian-mssql-django-1.1.4.tar.gz/zilian-mssql-django-1.1.4/testapp/migrations/0001_initial.py | 0001_initial.py |
import binascii
import os
from django.db.utils import InterfaceError
from django.db.backends.base.creation import BaseDatabaseCreation
from django import VERSION as django_version
class DatabaseCreation(BaseDatabaseCreation):
def cursor(self):
if django_version >= (3, 1):
return self.connection._nodb_cursor()
return self.connection._nodb_connection.cursor()
def _create_test_db(self, verbosity, autoclobber, keepdb=False):
"""
Internal implementation - create the test db tables.
"""
# Try to create the test DB, but if we fail due to 28000 (Login failed for user),
# it's probably because the user doesn't have permission to [dbo].[master],
# so we can proceed if we're keeping the DB anyway.
# https://github.com/microsoft/mssql-django/issues/61
try:
return super()._create_test_db(verbosity, autoclobber, keepdb)
except InterfaceError as err:
if err.args[0] == '28000' and keepdb:
self.log('Received error %s, proceeding because keepdb=True' % (
err.args[1],
))
else:
raise err
def _destroy_test_db(self, test_database_name, verbosity):
"""
Internal implementation - remove the test db tables.
"""
# Remove the test database to clean up after
# ourselves. Connect to the previous database (not the test database)
# to do so, because it's not allowed to delete a database while being
# connected to it.
with self.cursor() as cursor:
to_azure_sql_db = self.connection.to_azure_sql_db
if not to_azure_sql_db:
cursor.execute("ALTER DATABASE %s SET SINGLE_USER WITH ROLLBACK IMMEDIATE"
% self.connection.ops.quote_name(test_database_name))
cursor.execute("DROP DATABASE %s"
% self.connection.ops.quote_name(test_database_name))
def sql_table_creation_suffix(self):
suffix = []
collation = self.connection.settings_dict['TEST'].get('COLLATION', None)
if collation:
suffix.append('COLLATE %s' % collation)
return ' '.join(suffix)
# The following code to add regex support in SQLServer is taken from django-mssql
# see https://bitbucket.org/Manfre/django-mssql
def enable_clr(self):
""" Enables clr for server if not already enabled
This function will not fail if current user doesn't have
permissions to enable clr, and clr is already enabled
"""
with self.cursor() as cursor:
# check whether clr is enabled
cursor.execute('''
SELECT value FROM sys.configurations
WHERE name = 'clr enabled'
''')
res = None
try:
res = cursor.fetchone()
except Exception:
pass
if not res or not res[0]:
# if not enabled enable clr
cursor.execute("sp_configure 'clr enabled', 1")
cursor.execute("RECONFIGURE")
cursor.execute("sp_configure 'show advanced options', 1")
cursor.execute("RECONFIGURE")
cursor.execute("sp_configure 'clr strict security', 0")
cursor.execute("RECONFIGURE")
def install_regex_clr(self, database_name):
sql = '''
USE {database_name};
-- Drop and recreate the function if it already exists
IF OBJECT_ID('REGEXP_LIKE') IS NOT NULL
DROP FUNCTION [dbo].[REGEXP_LIKE]
IF EXISTS(select * from sys.assemblies where name like 'regex_clr')
DROP ASSEMBLY regex_clr
;
CREATE ASSEMBLY regex_clr
FROM 0x{assembly_hex}
WITH PERMISSION_SET = SAFE;
create function [dbo].[REGEXP_LIKE]
(
@input nvarchar(max),
@pattern nvarchar(max),
@caseSensitive int
)
RETURNS INT AS
EXTERNAL NAME regex_clr.UserDefinedFunctions.REGEXP_LIKE
'''.format(
database_name=self.connection.ops.quote_name(database_name),
assembly_hex=self.get_regex_clr_assembly_hex(),
).split(';')
self.enable_clr()
with self.cursor() as cursor:
for s in sql:
cursor.execute(s)
def get_regex_clr_assembly_hex(self):
with open(os.path.join(os.path.dirname(__file__), 'regex_clr.dll'), 'rb') as f:
return binascii.hexlify(f.read()).decode('ascii') | zilian-mssql-django | /zilian-mssql-django-1.1.4.tar.gz/zilian-mssql-django-1.1.4/mssql/creation.py | creation.py |
from django.db.backends.base.features import BaseDatabaseFeatures
from django.utils.functional import cached_property
class DatabaseFeatures(BaseDatabaseFeatures):
allow_sliced_subqueries_with_in = False
can_introspect_autofield = True
can_introspect_json_field = False
can_introspect_small_integer_field = True
can_return_columns_from_insert = True
can_return_id_from_insert = True
can_return_rows_from_bulk_insert = True
can_rollback_ddl = True
can_use_chunked_reads = False
for_update_after_from = True
greatest_least_ignores_nulls = True
has_json_object_function = False
has_json_operators = False
has_native_json_field = False
has_native_uuid_field = False
has_real_datatype = True
has_select_for_update = True
has_select_for_update_nowait = True
has_select_for_update_skip_locked = True
ignores_quoted_identifier_case = True
ignores_table_name_case = True
order_by_nulls_first = True
requires_literal_defaults = True
requires_sqlparse_for_splitting = False
supports_boolean_expr_in_select_clause = False
supports_covering_indexes = True
supports_deferrable_unique_constraints = False
supports_expression_indexes = False
supports_ignore_conflicts = False
supports_index_on_text_field = False
supports_json_field_contains = False
supports_order_by_nulls_modifier = False
supports_over_clause = True
supports_paramstyle_pyformat = False
supports_primitives_in_json_field = False
supports_regex_backreferencing = True
supports_sequence_reset = False
supports_subqueries_in_group_by = False
supports_tablespaces = True
supports_temporal_subtraction = True
supports_timezones = False
supports_transactions = True
uses_savepoints = True
has_bulk_insert = True
supports_nullable_unique_constraints = True
supports_partially_nullable_unique_constraints = True
supports_partial_indexes = True
supports_functions_in_partial_indexes = True
@cached_property
def has_zoneinfo_database(self):
with self.connection.cursor() as cursor:
cursor.execute("SELECT TOP 1 1 FROM sys.time_zone_info")
return cursor.fetchone() is not None
@cached_property
def supports_json_field(self):
return self.connection.sql_server_version >= 2016 or self.connection.to_azure_sql_db | zilian-mssql-django | /zilian-mssql-django-1.1.4.tar.gz/zilian-mssql-django-1.1.4/mssql/features.py | features.py |
import datetime
import uuid
import warnings
from django.conf import settings
from django.db.backends.base.operations import BaseDatabaseOperations
from django.db.models.expressions import Exists, ExpressionWrapper, RawSQL
from django.db.models.sql.where import WhereNode
from django.utils import timezone
from django.utils.encoding import force_str
from django import VERSION as django_version
import pytz
class DatabaseOperations(BaseDatabaseOperations):
compiler_module = 'mssql.compiler'
cast_char_field_without_max_length = 'nvarchar(max)'
def max_in_list_size(self):
# The driver might add a few parameters
# chose a reasonable number less than 2100 limit
return 2048
def _convert_field_to_tz(self, field_name, tzname):
if settings.USE_TZ and not tzname == 'UTC':
offset = self._get_utcoffset(tzname)
field_name = 'DATEADD(second, %d, %s)' % (offset, field_name)
return field_name
def _get_utcoffset(self, tzname):
"""
Returns UTC offset for given time zone in seconds
"""
# SQL Server has no built-in support for tz database, see:
# http://blogs.msdn.com/b/sqlprogrammability/archive/2008/03/18/using-time-zone-data-in-sql-server-2008.aspx
zone = pytz.timezone(tzname)
# no way to take DST into account at this point
now = datetime.datetime.now()
delta = zone.localize(now, is_dst=False).utcoffset()
return delta.days * 86400 + delta.seconds - zone.dst(now).seconds
def bulk_batch_size(self, fields, objs):
"""
Returns the maximum allowed batch size for the backend. The fields
are the fields going to be inserted in the batch, the objs contains
all the objects to be inserted.
"""
max_insert_rows = 1000
fields_len = len(fields)
if fields_len == 0:
# Required for empty model
# (bulk_create.tests.BulkCreateTests.test_empty_model)
return max_insert_rows
# MSSQL allows a query to have 2100 parameters but some parameters are
# taken up defining `NVARCHAR` parameters to store the query text and
# query parameters for the `sp_executesql` call. This should only take
# up 2 parameters but I've had this error when sending 2098 parameters.
max_query_params = 2050
# inserts are capped at 1000 rows regardless of number of query params.
# bulk_update CASE...WHEN...THEN statement sometimes takes 2 parameters per field
return min(max_insert_rows, max_query_params // fields_len // 2)
def bulk_insert_sql(self, fields, placeholder_rows):
placeholder_rows_sql = (", ".join(row) for row in placeholder_rows)
values_sql = ", ".join("(%s)" % sql for sql in placeholder_rows_sql)
return "VALUES " + values_sql
def cache_key_culling_sql(self):
"""
Returns a SQL query that retrieves the first cache key greater than the
smallest.
This is used by the 'db' cache backend to determine where to start
culling.
"""
return "SELECT cache_key FROM (SELECT cache_key, " \
"ROW_NUMBER() OVER (ORDER BY cache_key) AS rn FROM %s" \
") cache WHERE rn = %%s + 1"
def combine_duration_expression(self, connector, sub_expressions):
lhs, rhs = sub_expressions
sign = ' * -1' if connector == '-' else ''
if lhs.startswith('DATEADD'):
col, sql = rhs, lhs
else:
col, sql = lhs, rhs
params = [sign for _ in range(sql.count('DATEADD'))]
params.append(col)
return sql % tuple(params)
def combine_expression(self, connector, sub_expressions):
"""
SQL Server requires special cases for some operators in query expressions
"""
if connector == '^':
return 'POWER(%s)' % ','.join(sub_expressions)
elif connector == '<<':
return '%s * (2 * %s)' % tuple(sub_expressions)
elif connector == '>>':
return '%s / (2 * %s)' % tuple(sub_expressions)
return super().combine_expression(connector, sub_expressions)
def convert_datetimefield_value(self, value, expression, connection):
if value is not None:
if settings.USE_TZ:
value = timezone.make_aware(value, self.connection.timezone)
return value
def convert_floatfield_value(self, value, expression, connection):
if value is not None:
value = float(value)
return value
def convert_uuidfield_value(self, value, expression, connection):
if value is not None:
value = uuid.UUID(value)
return value
def convert_booleanfield_value(self, value, expression, connection):
return bool(value) if value in (0, 1) else value
def date_extract_sql(self, lookup_type, field_name):
if lookup_type == 'week_day':
return "DATEPART(weekday, %s)" % field_name
elif lookup_type == 'week':
return "DATEPART(iso_week, %s)" % field_name
elif lookup_type == 'iso_year':
return "YEAR(DATEADD(day, 26 - DATEPART(isoww, %s), %s))" % (field_name, field_name)
else:
return "DATEPART(%s, %s)" % (lookup_type, field_name)
def date_interval_sql(self, timedelta):
"""
implements the interval functionality for expressions
"""
sec = timedelta.seconds + timedelta.days * 86400
sql = 'DATEADD(second, %d%%s, CAST(%%s AS datetime2))' % sec
if timedelta.microseconds:
sql = 'DATEADD(microsecond, %d%%s, CAST(%s AS datetime2))' % (timedelta.microseconds, sql)
return sql
def date_trunc_sql(self, lookup_type, field_name, tzname=''):
CONVERT_YEAR = 'CONVERT(varchar, DATEPART(year, %s))' % field_name
CONVERT_QUARTER = 'CONVERT(varchar, 1+((DATEPART(quarter, %s)-1)*3))' % field_name
CONVERT_MONTH = 'CONVERT(varchar, DATEPART(month, %s))' % field_name
CONVERT_WEEK = "DATEADD(DAY, (DATEPART(weekday, %s) + 5) %%%% 7 * -1, %s)" % (field_name, field_name)
if lookup_type == 'year':
return "CONVERT(datetime2, %s + '/01/01')" % CONVERT_YEAR
if lookup_type == 'quarter':
return "CONVERT(datetime2, %s + '/' + %s + '/01')" % (CONVERT_YEAR, CONVERT_QUARTER)
if lookup_type == 'month':
return "CONVERT(datetime2, %s + '/' + %s + '/01')" % (CONVERT_YEAR, CONVERT_MONTH)
if lookup_type == 'week':
return "CONVERT(datetime2, CONVERT(varchar, %s, 112))" % CONVERT_WEEK
if lookup_type == 'day':
return "CONVERT(datetime2, CONVERT(varchar(12), %s, 112))" % field_name
def datetime_cast_date_sql(self, field_name, tzname):
field_name = self._convert_field_to_tz(field_name, tzname)
sql = 'CAST(%s AS date)' % field_name
return sql
def datetime_cast_time_sql(self, field_name, tzname):
field_name = self._convert_field_to_tz(field_name, tzname)
sql = 'CAST(%s AS time)' % field_name
return sql
def datetime_extract_sql(self, lookup_type, field_name, tzname):
field_name = self._convert_field_to_tz(field_name, tzname)
return self.date_extract_sql(lookup_type, field_name)
def datetime_trunc_sql(self, lookup_type, field_name, tzname):
field_name = self._convert_field_to_tz(field_name, tzname)
sql = ''
if lookup_type in ('year', 'quarter', 'month', 'week', 'day'):
sql = self.date_trunc_sql(lookup_type, field_name)
elif lookup_type == 'hour':
sql = "CONVERT(datetime2, SUBSTRING(CONVERT(varchar, %s, 20), 0, 14) + ':00:00')" % field_name
elif lookup_type == 'minute':
sql = "CONVERT(datetime2, SUBSTRING(CONVERT(varchar, %s, 20), 0, 17) + ':00')" % field_name
elif lookup_type == 'second':
sql = "CONVERT(datetime2, CONVERT(varchar, %s, 20))" % field_name
return sql
def fetch_returned_insert_rows(self, cursor):
"""
Given a cursor object that has just performed an INSERT...OUTPUT INSERTED
statement into a table, return the list of returned data.
"""
return cursor.fetchall()
def return_insert_columns(self, fields):
if not fields:
return '', ()
columns = [
'%s.%s' % (
'INSERTED',
self.quote_name(field.column),
) for field in fields
]
return 'OUTPUT %s' % ', '.join(columns), ()
def for_update_sql(self, nowait=False, skip_locked=False, of=()):
if skip_locked:
return 'WITH (ROWLOCK, UPDLOCK, READPAST)'
elif nowait:
return 'WITH (NOWAIT, ROWLOCK, UPDLOCK)'
else:
return 'WITH (ROWLOCK, UPDLOCK)'
def format_for_duration_arithmetic(self, sql):
if sql == '%s':
# use DATEADD only once because Django prepares only one parameter for this
fmt = 'DATEADD(second, %s / 1000000%%s, CAST(%%s AS datetime2))'
sql = '%%s'
else:
# use DATEADD twice to avoid arithmetic overflow for number part
MICROSECOND = "DATEADD(microsecond, %s %%%%%%%% 1000000%%s, CAST(%%s AS datetime2))"
fmt = 'DATEADD(second, %s / 1000000%%s, {})'.format(MICROSECOND)
sql = (sql, sql)
return fmt % sql
def fulltext_search_sql(self, field_name):
"""
Returns the SQL WHERE clause to use in order to perform a full-text
search of the given field_name. Note that the resulting string should
contain a '%s' placeholder for the value being searched against.
"""
return 'CONTAINS(%s, %%s)' % field_name
def get_db_converters(self, expression):
converters = super().get_db_converters(expression)
internal_type = expression.output_field.get_internal_type()
if internal_type == 'DateTimeField':
converters.append(self.convert_datetimefield_value)
elif internal_type == 'FloatField':
converters.append(self.convert_floatfield_value)
elif internal_type == 'UUIDField':
converters.append(self.convert_uuidfield_value)
elif internal_type in ('BooleanField', 'NullBooleanField'):
converters.append(self.convert_booleanfield_value)
return converters
def last_insert_id(self, cursor, table_name, pk_name):
"""
Given a cursor object that has just performed an INSERT statement into
a table that has an auto-incrementing ID, returns the newly created ID.
This method also receives the table name and the name of the primary-key
column.
"""
# TODO: Check how the `last_insert_id` is being used in the upper layers
# in context of multithreaded access, compare with other backends
# IDENT_CURRENT: http://msdn2.microsoft.com/en-us/library/ms175098.aspx
# SCOPE_IDENTITY: http://msdn2.microsoft.com/en-us/library/ms190315.aspx
# @@IDENTITY: http://msdn2.microsoft.com/en-us/library/ms187342.aspx
# IDENT_CURRENT is not limited by scope and session; it is limited to
# a specified table. IDENT_CURRENT returns the value generated for
# a specific table in any session and any scope.
# SCOPE_IDENTITY and @@IDENTITY return the last identity values that
# are generated in any table in the current session. However,
# SCOPE_IDENTITY returns values inserted only within the current scope;
# @@IDENTITY is not limited to a specific scope.
table_name = self.quote_name(table_name)
cursor.execute("SELECT CAST(IDENT_CURRENT(%s) AS int)", [table_name])
return cursor.fetchone()[0]
def lookup_cast(self, lookup_type, internal_type=None):
if lookup_type in ('iexact', 'icontains', 'istartswith', 'iendswith'):
return "UPPER(%s)"
return "%s"
def max_name_length(self):
return 128
def no_limit_value(self):
return None
def prepare_sql_script(self, sql, _allow_fallback=False):
return [sql]
def quote_name(self, name):
"""
Returns a quoted version of the given table, index or column name. Does
not quote the given name if it's already been quoted.
"""
if name.startswith('[') and name.endswith(']'):
return name # Quoting once is enough.
return '[%s]' % name
def random_function_sql(self):
"""
Returns a SQL expression that returns a random value.
"""
return "RAND()"
def regex_lookup(self, lookup_type):
"""
Returns the string to use in a query when performing regular expression
lookups (using "regex" or "iregex"). The resulting string should
contain a '%s' placeholder for the column being searched against.
If the feature is not supported (or part of it is not supported), a
NotImplementedError exception can be raised.
"""
match_option = {'iregex': 0, 'regex': 1}[lookup_type]
return "dbo.REGEXP_LIKE(%%s, %%s, %s)=1" % (match_option,)
def limit_offset_sql(self, low_mark, high_mark):
"""Return LIMIT/OFFSET SQL clause."""
limit, offset = self._get_limit_offset_params(low_mark, high_mark)
return '%s%s' % (
(' OFFSET %d ROWS' % offset) if offset else '',
(' FETCH FIRST %d ROWS ONLY' % limit) if limit else '',
)
def last_executed_query(self, cursor, sql, params):
"""
Returns a string of the query last executed by the given cursor, with
placeholders replaced with actual values.
`sql` is the raw query containing placeholders, and `params` is the
sequence of parameters. These are used by default, but this method
exists for database backends to provide a better implementation
according to their own quoting schemes.
"""
return super().last_executed_query(cursor, cursor.last_sql, cursor.last_params)
def savepoint_create_sql(self, sid):
"""
Returns the SQL for starting a new savepoint. Only required if the
"uses_savepoints" feature is True. The "sid" parameter is a string
for the savepoint id.
"""
return "SAVE TRANSACTION %s" % sid
def savepoint_rollback_sql(self, sid):
"""
Returns the SQL for rolling back the given savepoint.
"""
return "ROLLBACK TRANSACTION %s" % sid
def _build_sequences(self, sequences, cursor):
seqs = []
for seq in sequences:
cursor.execute("SELECT COUNT(*) FROM %s" % self.quote_name(seq["table"]))
rowcnt = cursor.fetchone()[0]
elem = {}
if rowcnt:
elem['start_id'] = 0
else:
elem['start_id'] = 1
elem.update(seq)
seqs.append(elem)
return seqs
def _sql_flush_new(self, style, tables, *, reset_sequences=False, allow_cascade=False):
if reset_sequences:
return [
sequence
for sequence in self.connection.introspection.sequence_list()
if sequence['table'].lower() in [table.lower() for table in tables]
]
return []
def _sql_flush_old(self, style, tables, sequences, allow_cascade=False):
return sequences
def sql_flush(self, style, tables, *args, **kwargs):
"""
Returns a list of SQL statements required to remove all data from
the given database tables (without actually removing the tables
themselves).
The returned value also includes SQL statements required to reset DB
sequences passed in :param sequences:.
The `style` argument is a Style object as returned by either
color_style() or no_style() in django.core.management.color.
The `allow_cascade` argument determines whether truncation may cascade
to tables with foreign keys pointing the tables being truncated.
"""
if not tables:
return []
if django_version >= (3, 1):
sequences = self._sql_flush_new(style, tables, *args, **kwargs)
else:
sequences = self._sql_flush_old(style, tables, *args, **kwargs)
from django.db import connections
cursor = connections[self.connection.alias].cursor()
seqs = self._build_sequences(sequences, cursor)
COLUMNS = "TABLE_NAME, CONSTRAINT_NAME"
WHERE = "CONSTRAINT_TYPE not in ('PRIMARY KEY','UNIQUE')"
cursor.execute(
"SELECT {} FROM INFORMATION_SCHEMA.TABLE_CONSTRAINTS WHERE {}".format(COLUMNS, WHERE))
fks = cursor.fetchall()
sql_list = ['ALTER TABLE %s NOCHECK CONSTRAINT %s;' %
(self.quote_name(fk[0]), self.quote_name(fk[1])) for fk in fks]
sql_list.extend(['%s %s %s;' % (style.SQL_KEYWORD('DELETE'), style.SQL_KEYWORD('FROM'),
style.SQL_FIELD(self.quote_name(table))) for table in tables])
if self.connection.to_azure_sql_db and self.connection.sql_server_version < 2014:
warnings.warn("Resetting identity columns is not supported "
"on this versios of Azure SQL Database.",
RuntimeWarning)
else:
# Then reset the counters on each table.
sql_list.extend(['%s %s (%s, %s, %s) %s %s;' % (
style.SQL_KEYWORD('DBCC'),
style.SQL_KEYWORD('CHECKIDENT'),
style.SQL_FIELD(self.quote_name(seq["table"])),
style.SQL_KEYWORD('RESEED'),
style.SQL_FIELD('%d' % seq['start_id']),
style.SQL_KEYWORD('WITH'),
style.SQL_KEYWORD('NO_INFOMSGS'),
) for seq in seqs])
sql_list.extend(['ALTER TABLE %s CHECK CONSTRAINT %s;' %
(self.quote_name(fk[0]), self.quote_name(fk[1])) for fk in fks])
return sql_list
def start_transaction_sql(self):
"""
Returns the SQL statement required to start a transaction.
"""
return "BEGIN TRANSACTION"
def subtract_temporals(self, internal_type, lhs, rhs):
lhs_sql, lhs_params = lhs
rhs_sql, rhs_params = rhs
if internal_type == 'DateField':
sql = "CAST(DATEDIFF(day, %(rhs)s, %(lhs)s) AS bigint) * 86400 * 1000000"
params = rhs_params + lhs_params
else:
SECOND = "DATEDIFF(second, %(rhs)s, %(lhs)s)"
MICROSECOND = "DATEPART(microsecond, %(lhs)s) - DATEPART(microsecond, %(rhs)s)"
sql = "CAST({} AS bigint) * 1000000 + {}".format(SECOND, MICROSECOND)
params = rhs_params + lhs_params * 2 + rhs_params
return sql % {'lhs': lhs_sql, 'rhs': rhs_sql}, params
def tablespace_sql(self, tablespace, inline=False):
"""
Returns the SQL that will be appended to tables or rows to define
a tablespace. Returns '' if the backend doesn't use tablespaces.
"""
return "ON %s" % self.quote_name(tablespace)
def prep_for_like_query(self, x):
"""Prepares a value for use in a LIKE query."""
# http://msdn2.microsoft.com/en-us/library/ms179859.aspx
return force_str(x).replace('\\', '\\\\').replace('[', '[[]').replace('%', '[%]').replace('_', '[_]')
def prep_for_iexact_query(self, x):
"""
Same as prep_for_like_query(), but called for "iexact" matches, which
need not necessarily be implemented using "LIKE" in the backend.
"""
return x
def adapt_datetimefield_value(self, value):
"""
Transforms a datetime value to an object compatible with what is expected
by the backend driver for datetime columns.
"""
if value is None:
return None
if settings.USE_TZ and timezone.is_aware(value):
# pyodbc donesn't support datetimeoffset
value = value.astimezone(self.connection.timezone).replace(tzinfo=None)
return value
def time_trunc_sql(self, lookup_type, field_name, tzname=''):
# if self.connection.sql_server_version >= 2012:
# fields = {
# 'hour': 'DATEPART(hour, %s)' % field_name,
# 'minute': 'DATEPART(minute, %s)' % field_name if lookup_type != 'hour' else '0',
# 'second': 'DATEPART(second, %s)' % field_name if lookup_type == 'second' else '0',
# }
# sql = 'TIMEFROMPARTS(%(hour)s, %(minute)s, %(second)s, 0, 0)' % fields
if lookup_type == 'hour':
sql = "CONVERT(time, SUBSTRING(CONVERT(varchar, %s, 114), 0, 3) + ':00:00')" % field_name
elif lookup_type == 'minute':
sql = "CONVERT(time, SUBSTRING(CONVERT(varchar, %s, 114), 0, 6) + ':00')" % field_name
elif lookup_type == 'second':
sql = "CONVERT(time, SUBSTRING(CONVERT(varchar, %s, 114), 0, 9))" % field_name
return sql
def conditional_expression_supported_in_where_clause(self, expression):
"""
Following "Moved conditional expression wrapping to the Exact lookup" in django 3.1
https://github.com/django/django/commit/37e6c5b79bd0529a3c85b8c478e4002fd33a2a1d
"""
if isinstance(expression, (Exists, WhereNode)):
return True
if isinstance(expression, ExpressionWrapper) and expression.conditional:
return self.conditional_expression_supported_in_where_clause(expression.expression)
if isinstance(expression, RawSQL) and expression.conditional:
return True
return False | zilian-mssql-django | /zilian-mssql-django-1.1.4.tar.gz/zilian-mssql-django-1.1.4/mssql/operations.py | operations.py |
import os
import re
import time
import struct
from django.core.exceptions import ImproperlyConfigured
try:
import pyodbc as Database
except ImportError as e:
raise ImproperlyConfigured("Error loading pyodbc module: %s" % e)
from django.utils.version import get_version_tuple # noqa
pyodbc_ver = get_version_tuple(Database.version)
if pyodbc_ver < (3, 0):
raise ImproperlyConfigured("pyodbc 3.0 or newer is required; you have %s" % Database.version)
from django.conf import settings # noqa
from django.db import NotSupportedError # noqa
from django.db.backends.base.base import BaseDatabaseWrapper # noqa
from django.utils.encoding import smart_str # noqa
from django.utils.functional import cached_property # noqa
if hasattr(settings, 'DATABASE_CONNECTION_POOLING'):
if not settings.DATABASE_CONNECTION_POOLING:
Database.pooling = False
from .client import DatabaseClient # noqa
from .creation import DatabaseCreation # noqa
from .features import DatabaseFeatures # noqa
from .introspection import DatabaseIntrospection # noqa
from .operations import DatabaseOperations # noqa
from .schema import DatabaseSchemaEditor # noqa
EDITION_AZURE_SQL_DB = 5
def encode_connection_string(fields):
"""Encode dictionary of keys and values as an ODBC connection String.
See [MS-ODBCSTR] document:
https://msdn.microsoft.com/en-us/library/ee208909%28v=sql.105%29.aspx
"""
# As the keys are all provided by us, don't need to encode them as we know
# they are ok.
return ';'.join(
'%s=%s' % (k, encode_value(v))
for k, v in fields.items()
)
def prepare_token_for_odbc(token):
"""
Will prepare token for passing it to the odbc driver, as it expects
bytes and not a string
:param token:
:return: packed binary byte representation of token string
"""
if not isinstance(token, str):
raise TypeError("Invalid token format provided.")
tokenstr = token.encode()
exptoken = b""
for i in tokenstr:
exptoken += bytes({i})
exptoken += bytes(1)
return struct.pack("=i", len(exptoken)) + exptoken
def encode_value(v):
"""If the value contains a semicolon, or starts with a left curly brace,
then enclose it in curly braces and escape all right curly braces.
"""
if ';' in v or v.strip(' ').startswith('{'):
return '{%s}' % (v.replace('}', '}}'),)
return v
class DatabaseWrapper(BaseDatabaseWrapper):
vendor = 'microsoft'
display_name = 'SQL Server'
# This dictionary maps Field objects to their associated MS SQL column
# types, as strings. Column-type strings can contain format strings; they'll
# be interpolated against the values of Field.__dict__ before being output.
# If a column type is set to None, it won't be included in the output.
data_types = {
'AutoField': 'int',
'BigAutoField': 'bigint',
'BigIntegerField': 'bigint',
'BinaryField': 'varbinary(%(max_length)s)',
'BooleanField': 'bit',
'CharField': 'nvarchar(%(max_length)s)',
'DateField': 'date',
'DateTimeField': 'datetime2',
'DecimalField': 'numeric(%(max_digits)s, %(decimal_places)s)',
'DurationField': 'bigint',
'FileField': 'nvarchar(%(max_length)s)',
'FilePathField': 'nvarchar(%(max_length)s)',
'FloatField': 'double precision',
'IntegerField': 'int',
'IPAddressField': 'nvarchar(15)',
'GenericIPAddressField': 'nvarchar(39)',
'JSONField': 'nvarchar(max)',
'NullBooleanField': 'bit',
'OneToOneField': 'int',
'PositiveIntegerField': 'int',
'PositiveSmallIntegerField': 'smallint',
'PositiveBigIntegerField' : 'bigint',
'SlugField': 'nvarchar(%(max_length)s)',
'SmallAutoField': 'smallint',
'SmallIntegerField': 'smallint',
'TextField': 'nvarchar(max)',
'TimeField': 'time',
'UUIDField': 'char(32)',
}
data_types_suffix = {
'AutoField': 'IDENTITY (1, 1)',
'BigAutoField': 'IDENTITY (1, 1)',
'SmallAutoField': 'IDENTITY (1, 1)',
}
data_type_check_constraints = {
'JSONField': '(ISJSON ("%(column)s") = 1)',
'PositiveIntegerField': '[%(column)s] >= 0',
'PositiveSmallIntegerField': '[%(column)s] >= 0',
'PositiveBigIntegerField': '[%(column)s] >= 0',
}
operators = {
# Since '=' is used not only for string comparision there is no way
# to make it case (in)sensitive.
'exact': '= %s',
'iexact': "= UPPER(%s)",
'contains': "LIKE %s ESCAPE '\\'",
'icontains': "LIKE UPPER(%s) ESCAPE '\\'",
'gt': '> %s',
'gte': '>= %s',
'lt': '< %s',
'lte': '<= %s',
'startswith': "LIKE %s ESCAPE '\\'",
'endswith': "LIKE %s ESCAPE '\\'",
'istartswith': "LIKE UPPER(%s) ESCAPE '\\'",
'iendswith': "LIKE UPPER(%s) ESCAPE '\\'",
}
# The patterns below are used to generate SQL pattern lookup clauses when
# the right-hand side of the lookup isn't a raw string (it might be an expression
# or the result of a bilateral transformation).
# In those cases, special characters for LIKE operators (e.g. \, *, _) should be
# escaped on database side.
#
# Note: we use str.format() here for readability as '%' is used as a wildcard for
# the LIKE operator.
pattern_esc = r"REPLACE(REPLACE(REPLACE({}, '\', '[\]'), '%%', '[%%]'), '_', '[_]')"
pattern_ops = {
'contains': "LIKE '%%' + {} + '%%'",
'icontains': "LIKE '%%' + UPPER({}) + '%%'",
'startswith': "LIKE {} + '%%'",
'istartswith': "LIKE UPPER({}) + '%%'",
'endswith': "LIKE '%%' + {}",
'iendswith': "LIKE '%%' + UPPER({})",
}
Database = Database
SchemaEditorClass = DatabaseSchemaEditor
# Classes instantiated in __init__().
client_class = DatabaseClient
creation_class = DatabaseCreation
features_class = DatabaseFeatures
introspection_class = DatabaseIntrospection
ops_class = DatabaseOperations
_codes_for_networkerror = (
'08S01',
'08S02',
)
_sql_server_versions = {
9: 2005,
10: 2008,
11: 2012,
12: 2014,
13: 2016,
14: 2017,
15: 2019,
}
# https://azure.microsoft.com/en-us/documentation/articles/sql-database-develop-csharp-retry-windows/
_transient_error_numbers = (
'4060',
'10928',
'10929',
'40197',
'40501',
'40613',
'49918',
'49919',
'49920',
'[HYT00] [Microsoft][ODBC Driver 17 for SQL Server]Login timeout expired (0) (SQLDriverConnect)',
)
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
opts = self.settings_dict["OPTIONS"]
# capability for multiple result sets or cursors
self.supports_mars = False
# Some drivers need unicode encoded as UTF8. If this is left as
# None, it will be determined based on the driver, namely it'll be
# False if the driver is a windows driver and True otherwise.
#
# However, recent versions of FreeTDS and pyodbc (0.91 and 3.0.6 as
# of writing) are perfectly okay being fed unicode, which is why
# this option is configurable.
if 'driver_needs_utf8' in opts:
self.driver_charset = 'utf-8'
else:
self.driver_charset = opts.get('driver_charset', None)
# interval to wait for recovery from network error
interval = opts.get('connection_recovery_interval_msec', 0.0)
self.connection_recovery_interval_msec = float(interval) / 1000
# make lookup operators to be collation-sensitive if needed
collation = opts.get('collation', None)
if collation:
self.operators = dict(self.__class__.operators)
ops = {}
for op in self.operators:
sql = self.operators[op]
if sql.startswith('LIKE '):
ops[op] = '%s COLLATE %s' % (sql, collation)
self.operators.update(ops)
def create_cursor(self, name=None):
return CursorWrapper(self.connection.cursor(), self)
def _cursor(self):
new_conn = False
if self.connection is None:
new_conn = True
conn = super()._cursor()
if new_conn:
if self.sql_server_version <= 2005:
self.data_types['DateField'] = 'datetime'
self.data_types['DateTimeField'] = 'datetime'
self.data_types['TimeField'] = 'datetime'
return conn
def get_connection_params(self):
settings_dict = self.settings_dict
if settings_dict['NAME'] == '':
raise ImproperlyConfigured(
"settings.DATABASES is improperly configured. "
"Please supply the NAME value.")
conn_params = settings_dict.copy()
if conn_params['NAME'] is None:
conn_params['NAME'] = 'master'
return conn_params
def get_new_connection(self, conn_params):
database = conn_params['NAME']
host = conn_params.get('HOST', 'localhost')
user = conn_params.get('USER', None)
password = conn_params.get('PASSWORD', None)
port = conn_params.get('PORT', None)
trusted_connection = conn_params.get('Trusted_Connection', 'yes')
options = conn_params.get('OPTIONS', {})
driver = options.get('driver', 'ODBC Driver 17 for SQL Server')
dsn = options.get('dsn', None)
options_extra_params = options.get('extra_params', '')
# Microsoft driver names assumed here are:
# * SQL Server Native Client 10.0/11.0
# * ODBC Driver 11/13 for SQL Server
ms_drivers = re.compile('^ODBC Driver .* for SQL Server$|^SQL Server Native Client')
# available ODBC connection string keywords:
# (Microsoft drivers for Windows)
# https://docs.microsoft.com/en-us/sql/relational-databases/native-client/applications/using-connection-string-keywords-with-sql-server-native-client
# (Microsoft drivers for Linux/Mac)
# https://docs.microsoft.com/en-us/sql/connect/odbc/linux-mac/connection-string-keywords-and-data-source-names-dsns
# (FreeTDS)
# http://www.freetds.org/userguide/odbcconnattr.htm
cstr_parts = {}
if dsn:
cstr_parts['DSN'] = dsn
else:
# Only append DRIVER if DATABASE_ODBC_DSN hasn't been set
cstr_parts['DRIVER'] = driver
if ms_drivers.match(driver):
if port:
host = ','.join((host, str(port)))
cstr_parts['SERVER'] = host
elif options.get('host_is_server', False):
if port:
cstr_parts['PORT'] = str(port)
cstr_parts['SERVER'] = host
else:
cstr_parts['SERVERNAME'] = host
if user:
cstr_parts['UID'] = user
if 'Authentication=ActiveDirectoryInteractive' not in options_extra_params:
cstr_parts['PWD'] = password
elif 'TOKEN' not in conn_params:
if ms_drivers.match(driver) and 'Authentication=ActiveDirectoryMsi' not in options_extra_params:
cstr_parts['Trusted_Connection'] = trusted_connection
else:
cstr_parts['Integrated Security'] = 'SSPI'
cstr_parts['DATABASE'] = database
if ms_drivers.match(driver) and os.name == 'nt':
cstr_parts['MARS_Connection'] = 'yes'
connstr = encode_connection_string(cstr_parts)
# extra_params are glued on the end of the string without encoding,
# so it's up to the settings writer to make sure they're appropriate -
# use encode_connection_string if constructing from external input.
if options.get('extra_params', None):
connstr += ';' + options['extra_params']
unicode_results = options.get('unicode_results', False)
timeout = options.get('connection_timeout', 0)
retries = options.get('connection_retries', 5)
backoff_time = options.get('connection_retry_backoff_time', 5)
query_timeout = options.get('query_timeout', 0)
setencoding = options.get('setencoding', None)
setdecoding = options.get('setdecoding', None)
conn = None
retry_count = 0
need_to_retry = False
args = {
'unicode_results': unicode_results,
'timeout': timeout,
}
if 'TOKEN' in conn_params:
args['attrs_before'] = {
1256: prepare_token_for_odbc(conn_params['TOKEN'])
}
while conn is None:
try:
conn = Database.connect(connstr, **args)
except Exception as e:
for error_number in self._transient_error_numbers:
if error_number in e.args[1]:
if error_number in e.args[1] and retry_count < retries:
time.sleep(backoff_time)
need_to_retry = True
retry_count = retry_count + 1
else:
need_to_retry = False
break
if not need_to_retry:
raise
conn.timeout = query_timeout
if setencoding:
for entry in setencoding:
conn.setencoding(**entry)
if setdecoding:
for entry in setdecoding:
conn.setdecoding(**entry)
return conn
def init_connection_state(self):
drv_name = self.connection.getinfo(Database.SQL_DRIVER_NAME).upper()
if drv_name.startswith('LIBTDSODBC'):
try:
drv_ver = self.connection.getinfo(Database.SQL_DRIVER_VER)
ver = get_version_tuple(drv_ver)[:2]
if ver < (0, 95):
raise ImproperlyConfigured(
"FreeTDS 0.95 or newer is required.")
except Exception:
# unknown driver version
pass
ms_drv_names = re.compile('^(LIB)?(SQLNCLI|MSODBCSQL)')
if ms_drv_names.match(drv_name):
self.driver_charset = None
# http://msdn.microsoft.com/en-us/library/ms131686.aspx
self.supports_mars = True
self.features.can_use_chunked_reads = True
settings_dict = self.settings_dict
cursor = self.create_cursor()
options = settings_dict.get('OPTIONS', {})
isolation_level = options.get('isolation_level', None)
if isolation_level:
cursor.execute('SET TRANSACTION ISOLATION LEVEL %s' % isolation_level)
# Set date format for the connection. Also, make sure Sunday is
# considered the first day of the week (to be consistent with the
# Django convention for the 'week_day' Django lookup) if the user
# hasn't told us otherwise
datefirst = options.get('datefirst', 7)
cursor.execute('SET DATEFORMAT ymd; SET DATEFIRST %s' % datefirst)
val = self.get_system_datetime()
if isinstance(val, str):
raise ImproperlyConfigured(
"The database driver doesn't support modern datatime types.")
def is_usable(self):
try:
self.create_cursor().execute("SELECT 1")
except Database.Error:
return False
else:
return True
def get_system_datetime(self):
# http://blogs.msdn.com/b/sqlnativeclient/archive/2008/02/27/microsoft-sql-server-native-client-and-microsoft-sql-server-2008-native-client.aspx
with self.temporary_connection() as cursor:
if self.sql_server_version <= 2005:
return cursor.execute('SELECT GETDATE()').fetchone()[0]
else:
return cursor.execute('SELECT SYSDATETIME()').fetchone()[0]
@cached_property
def sql_server_version(self, _known_versions={}):
"""
Get the SQL server version
The _known_versions default dictionary is created on the class. This is
intentional - it allows us to cache this property's value across instances.
Therefore, when Django creates a new database connection using the same
alias, we won't need query the server again.
"""
if self.alias not in _known_versions:
with self.temporary_connection() as cursor:
cursor.execute("SELECT CAST(SERVERPROPERTY('ProductVersion') AS varchar)")
ver = cursor.fetchone()[0]
ver = int(ver.split('.')[0])
if ver not in self._sql_server_versions:
raise NotSupportedError('SQL Server v%d is not supported.' % ver)
_known_versions[self.alias] = self._sql_server_versions[ver]
return _known_versions[self.alias]
@cached_property
def to_azure_sql_db(self, _known_azures={}):
"""
Whether this connection is to a Microsoft Azure database server
The _known_azures default dictionary is created on the class. This is
intentional - it allows us to cache this property's value across instances.
Therefore, when Django creates a new database connection using the same
alias, we won't need query the server again.
"""
if self.alias not in _known_azures:
with self.temporary_connection() as cursor:
cursor.execute("SELECT CAST(SERVERPROPERTY('EngineEdition') AS integer)")
_known_azures[self.alias] = cursor.fetchone()[0] == EDITION_AZURE_SQL_DB
return _known_azures[self.alias]
def _execute_foreach(self, sql, table_names=None):
cursor = self.cursor()
if table_names is None:
table_names = self.introspection.table_names(cursor)
for table_name in table_names:
cursor.execute(sql % self.ops.quote_name(table_name))
def _get_trancount(self):
with self.connection.cursor() as cursor:
return cursor.execute('SELECT @@TRANCOUNT').fetchone()[0]
def _on_error(self, e):
if e.args[0] in self._codes_for_networkerror:
try:
# close the stale connection
self.close()
# wait a moment for recovery from network error
time.sleep(self.connection_recovery_interval_msec)
except Exception:
pass
self.connection = None
def _savepoint(self, sid):
with self.cursor() as cursor:
cursor.execute('SELECT @@TRANCOUNT')
trancount = cursor.fetchone()[0]
if trancount == 0:
cursor.execute(self.ops.start_transaction_sql())
cursor.execute(self.ops.savepoint_create_sql(sid))
def _savepoint_commit(self, sid):
# SQL Server has no support for partial commit in a transaction
pass
def _savepoint_rollback(self, sid):
with self.cursor() as cursor:
# FreeTDS requires TRANCOUNT that is greater than 0
cursor.execute('SELECT @@TRANCOUNT')
trancount = cursor.fetchone()[0]
if trancount > 0:
cursor.execute(self.ops.savepoint_rollback_sql(sid))
def _set_autocommit(self, autocommit):
with self.wrap_database_errors:
allowed = not autocommit
if not allowed:
# FreeTDS requires TRANCOUNT that is greater than 0
allowed = self._get_trancount() > 0
if allowed:
self.connection.autocommit = autocommit
def check_constraints(self, table_names=None):
self._execute_foreach('ALTER TABLE %s WITH CHECK CHECK CONSTRAINT ALL',
table_names)
def disable_constraint_checking(self):
if not self.needs_rollback:
self._execute_foreach('ALTER TABLE %s NOCHECK CONSTRAINT ALL')
return not self.needs_rollback
def enable_constraint_checking(self):
if not self.needs_rollback:
self._execute_foreach('ALTER TABLE %s WITH NOCHECK CHECK CONSTRAINT ALL')
class CursorWrapper(object):
"""
A wrapper around the pyodbc's cursor that takes in account a) some pyodbc
DB-API 2.0 implementation and b) some common ODBC driver particularities.
"""
def __init__(self, cursor, connection):
self.active = True
self.cursor = cursor
self.connection = connection
self.driver_charset = connection.driver_charset
self.last_sql = ''
self.last_params = ()
def close(self):
if self.active:
self.active = False
self.cursor.close()
def format_sql(self, sql, params):
if self.driver_charset and isinstance(sql, str):
# FreeTDS (and other ODBC drivers?) doesn't support Unicode
# yet, so we need to encode the SQL clause itself in utf-8
sql = smart_str(sql, self.driver_charset)
# pyodbc uses '?' instead of '%s' as parameter placeholder.
if params is not None:
sql = sql % tuple('?' * len(params))
return sql
def format_params(self, params):
fp = []
if params is not None:
for p in params:
if isinstance(p, str):
if self.driver_charset:
# FreeTDS (and other ODBC drivers?) doesn't support Unicode
# yet, so we need to encode parameters in utf-8
fp.append(smart_str(p, self.driver_charset))
else:
fp.append(p)
elif isinstance(p, bytes):
fp.append(p)
elif isinstance(p, type(True)):
if p:
fp.append(1)
else:
fp.append(0)
else:
fp.append(p)
return tuple(fp)
def execute(self, sql, params=None):
self.last_sql = sql
sql = self.format_sql(sql, params)
params = self.format_params(params)
self.last_params = params
try:
return self.cursor.execute(sql, params)
except Database.Error as e:
self.connection._on_error(e)
raise
def executemany(self, sql, params_list=()):
if not params_list:
return None
raw_pll = [p for p in params_list]
sql = self.format_sql(sql, raw_pll[0])
params_list = [self.format_params(p) for p in raw_pll]
try:
return self.cursor.executemany(sql, params_list)
except Database.Error as e:
self.connection._on_error(e)
raise
def format_rows(self, rows):
return list(map(self.format_row, rows))
def format_row(self, row):
"""
Decode data coming from the database if needed and convert rows to tuples
(pyodbc Rows are not hashable).
"""
if self.driver_charset:
for i in range(len(row)):
f = row[i]
# FreeTDS (and other ODBC drivers?) doesn't support Unicode
# yet, so we need to decode utf-8 data coming from the DB
if isinstance(f, bytes):
row[i] = f.decode(self.driver_charset)
return tuple(row)
def fetchone(self):
row = self.cursor.fetchone()
if row is not None:
row = self.format_row(row)
# Any remaining rows in the current set must be discarded
# before changing autocommit mode when you use FreeTDS
if not self.connection.supports_mars:
self.cursor.nextset()
return row
def fetchmany(self, chunk):
return self.format_rows(self.cursor.fetchmany(chunk))
def fetchall(self):
return self.format_rows(self.cursor.fetchall())
def __getattr__(self, attr):
if attr in self.__dict__:
return self.__dict__[attr]
return getattr(self.cursor, attr)
def __iter__(self):
return iter(self.cursor) | zilian-mssql-django | /zilian-mssql-django-1.1.4.tar.gz/zilian-mssql-django-1.1.4/mssql/base.py | base.py |
import binascii
import datetime
from django.db.backends.base.schema import (
BaseDatabaseSchemaEditor,
_is_relevant_relation,
_related_non_m2m_objects,
logger,
)
from django.db.backends.ddl_references import (
Columns,
IndexName,
Statement as DjStatement,
Table,
)
from django import VERSION as django_version
from django.db.models import Index, UniqueConstraint
from django.db.models.fields import AutoField, BigAutoField
from django.db.models.sql.where import AND
from django.db.transaction import TransactionManagementError
from django.utils.encoding import force_str
if django_version >= (4, 0):
from django.db.models.sql import Query
from django.db.backends.ddl_references import Expressions
class Statement(DjStatement):
def __hash__(self):
return hash((self.template, str(self.parts['name'])))
def __eq__(self, other):
return self.template == other.template and str(self.parts['name']) == str(other.parts['name'])
def rename_column_references(self, table, old_column, new_column):
for part in self.parts.values():
if hasattr(part, 'rename_column_references'):
part.rename_column_references(table, old_column, new_column)
condition = self.parts['condition']
if condition:
self.parts['condition'] = condition.replace(f'[{old_column}]', f'[{new_column}]')
class DatabaseSchemaEditor(BaseDatabaseSchemaEditor):
_sql_check_constraint = " CONSTRAINT %(name)s CHECK (%(check)s)"
_sql_select_default_constraint_name = "SELECT" \
" d.name " \
"FROM sys.default_constraints d " \
"INNER JOIN sys.tables t ON" \
" d.parent_object_id = t.object_id " \
"INNER JOIN sys.columns c ON" \
" d.parent_object_id = c.object_id AND" \
" d.parent_column_id = c.column_id " \
"INNER JOIN sys.schemas s ON" \
" t.schema_id = s.schema_id " \
"WHERE" \
" t.name = %(table)s AND" \
" c.name = %(column)s"
sql_alter_column_default = "ADD DEFAULT %(default)s FOR %(column)s"
sql_alter_column_no_default = "DROP CONSTRAINT %(column)s"
sql_alter_column_not_null = "ALTER COLUMN %(column)s %(type)s NOT NULL"
sql_alter_column_null = "ALTER COLUMN %(column)s %(type)s NULL"
sql_alter_column_type = "ALTER COLUMN %(column)s %(type)s"
sql_create_column = "ALTER TABLE %(table)s ADD %(column)s %(definition)s"
sql_delete_column = "ALTER TABLE %(table)s DROP COLUMN %(column)s"
sql_delete_index = "DROP INDEX %(name)s ON %(table)s"
sql_delete_table = """
DECLARE @sql_froeign_constraint_name nvarchar(128)
DECLARE @sql_drop_constraint nvarchar(300)
WHILE EXISTS(SELECT 1
FROM sys.foreign_keys
WHERE referenced_object_id = object_id('%(table)s'))
BEGIN
SELECT TOP 1 @sql_froeign_constraint_name = name
FROM sys.foreign_keys
WHERE referenced_object_id = object_id('%(table)s')
SELECT
@sql_drop_constraint = 'ALTER TABLE [' + OBJECT_NAME(parent_object_id) + '] ' +
'DROP CONSTRAINT [' + @sql_froeign_constraint_name + '] '
FROM sys.foreign_keys
WHERE referenced_object_id = object_id('%(table)s') and name = @sql_froeign_constraint_name
exec sp_executesql @sql_drop_constraint
END
DROP TABLE %(table)s
"""
sql_rename_column = "EXEC sp_rename '%(table)s.%(old_column)s', %(new_column)s, 'COLUMN'"
sql_rename_table = "EXEC sp_rename %(old_table)s, %(new_table)s"
sql_create_unique_null = "CREATE UNIQUE INDEX %(name)s ON %(table)s(%(columns)s) " \
"WHERE %(columns)s IS NOT NULL"
def _alter_column_default_sql(self, model, old_field, new_field, drop=False):
"""
Hook to specialize column default alteration.
Return a (sql, params) fragment to add or drop (depending on the drop
argument) a default to new_field's column.
"""
new_default = self.effective_default(new_field)
default = '%s'
params = [new_default]
column = self.quote_name(new_field.column)
if drop:
params = []
# SQL Server requires the name of the default constraint
result = self.execute(
self._sql_select_default_constraint_name % {
"table": self.quote_value(model._meta.db_table),
"column": self.quote_value(new_field.column),
},
has_result=True
)
if result:
for row in result:
column = self.quote_name(next(iter(row)))
elif self.connection.features.requires_literal_defaults:
# Some databases (Oracle) can't take defaults as a parameter
# If this is the case, the SchemaEditor for that database should
# implement prepare_default().
default = self.prepare_default(new_default)
params = []
new_db_params = new_field.db_parameters(connection=self.connection)
sql = self.sql_alter_column_no_default if drop else self.sql_alter_column_default
return (
sql % {
'column': column,
'type': new_db_params['type'],
'default': default,
},
params,
)
def _alter_column_null_sql(self, model, old_field, new_field):
"""
Hook to specialize column null alteration.
Return a (sql, params) fragment to set a column to null or non-null
as required by new_field, or None if no changes are required.
"""
if (self.connection.features.interprets_empty_strings_as_nulls and
new_field.get_internal_type() in ("CharField", "TextField")):
# The field is nullable in the database anyway, leave it alone.
return
else:
new_db_params = new_field.db_parameters(connection=self.connection)
sql = self.sql_alter_column_null if new_field.null else self.sql_alter_column_not_null
return (
sql % {
'column': self.quote_name(new_field.column),
'type': new_db_params['type'],
},
[],
)
def _alter_column_type_sql(self, model, old_field, new_field, new_type):
new_type = self._set_field_new_type_null_status(old_field, new_type)
return super()._alter_column_type_sql(model, old_field, new_field, new_type)
def alter_unique_together(self, model, old_unique_together, new_unique_together):
"""
Deal with a model changing its unique_together. The input
unique_togethers must be doubly-nested, not the single-nested
["foo", "bar"] format.
"""
olds = {tuple(fields) for fields in old_unique_together}
news = {tuple(fields) for fields in new_unique_together}
# Deleted uniques
for fields in olds.difference(news):
meta_constraint_names = {constraint.name for constraint in model._meta.constraints}
meta_index_names = {constraint.name for constraint in model._meta.indexes}
columns = [model._meta.get_field(field).column for field in fields]
self._delete_unique_constraint_for_columns(
model, columns, exclude=meta_constraint_names | meta_index_names, strict=True)
# Created uniques
if django_version >= (4, 0):
for field_names in news.difference(olds):
fields = [model._meta.get_field(field) for field in field_names]
columns = [model._meta.get_field(field).column for field in field_names]
condition = ' AND '.join(["[%s] IS NOT NULL" % col for col in columns])
sql = self._create_unique_sql(model, fields, condition=condition)
self.execute(sql)
else:
for fields in news.difference(olds):
columns = [model._meta.get_field(field).column for field in fields]
condition = ' AND '.join(["[%s] IS NOT NULL" % col for col in columns])
sql = self._create_unique_sql(model, columns, condition=condition)
self.execute(sql)
def _model_indexes_sql(self, model):
"""
Return a list of all index SQL statements (field indexes,
index_together, Meta.indexes) for the specified model.
"""
if not model._meta.managed or model._meta.proxy or model._meta.swapped:
return []
output = []
for field in model._meta.local_fields:
output.extend(self._field_indexes_sql(model, field))
for field_names in model._meta.index_together:
fields = [model._meta.get_field(field) for field in field_names]
output.append(self._create_index_sql(model, fields, suffix="_idx"))
if django_version >= (4, 0):
for field_names in model._meta.unique_together:
fields = [model._meta.get_field(field) for field in field_names]
columns = [model._meta.get_field(field).column for field in field_names]
condition = ' AND '.join(["[%s] IS NOT NULL" % col for col in columns])
sql = self._create_unique_sql(model, fields, condition=condition)
output.append(sql)
else:
for field_names in model._meta.unique_together:
columns = [model._meta.get_field(field).column for field in field_names]
condition = ' AND '.join(["[%s] IS NOT NULL" % col for col in columns])
sql = self._create_unique_sql(model, columns, condition=condition)
output.append(sql)
for index in model._meta.indexes:
if django_version >= (3, 2) and (
not index.contains_expressions or
self.connection.features.supports_expression_indexes
):
output.append(index.create_sql(model, self))
else:
output.append(index.create_sql(model, self))
return output
def _db_table_constraint_names(self, db_table, column_names=None, column_match_any=False,
unique=None, primary_key=None, index=None, foreign_key=None,
check=None, type_=None, exclude=None, unique_constraint=None):
"""
Return all constraint names matching the columns and conditions. Modified from base `_constraint_names`
`any_column_matches`=False: (default) only return constraints covering exactly `column_names`
`any_column_matches`=True : return any constraints which include at least 1 of `column_names`
"""
if column_names is not None:
column_names = [
self.connection.introspection.identifier_converter(name)
for name in column_names
]
with self.connection.cursor() as cursor:
constraints = self.connection.introspection.get_constraints(cursor, db_table)
result = []
for name, infodict in constraints.items():
if column_names is None or column_names == infodict['columns'] or (
column_match_any and any(col in infodict['columns'] for col in column_names)
):
if unique is not None and infodict['unique'] != unique:
continue
if unique_constraint is not None and infodict['unique_constraint'] != unique_constraint:
continue
if primary_key is not None and infodict['primary_key'] != primary_key:
continue
if index is not None and infodict['index'] != index:
continue
if check is not None and infodict['check'] != check:
continue
if foreign_key is not None and not infodict['foreign_key']:
continue
if type_ is not None and infodict['type'] != type_:
continue
if not exclude or name not in exclude:
result.append(name)
return result
def _db_table_delete_constraint_sql(self, template, db_table, name):
return Statement(
template,
table=Table(db_table, self.quote_name),
name=self.quote_name(name),
include=''
)
def _alter_field(self, model, old_field, new_field, old_type, new_type,
old_db_params, new_db_params, strict=False):
"""Actually perform a "physical" (non-ManyToMany) field update."""
# the backend doesn't support altering from/to (Big)AutoField
# because of the limited capability of SQL Server to edit IDENTITY property
for t in (AutoField, BigAutoField):
if isinstance(old_field, t) or isinstance(new_field, t):
raise NotImplementedError("the backend doesn't support altering from/to %s." % t.__name__)
# Drop any FK constraints, we'll remake them later
fks_dropped = set()
if old_field.remote_field and old_field.db_constraint:
# Drop index, SQL Server requires explicit deletion
if not hasattr(new_field, 'db_constraint') or not new_field.db_constraint:
index_names = self._constraint_names(model, [old_field.column], index=True)
for index_name in index_names:
self.execute(self._delete_constraint_sql(self.sql_delete_index, model, index_name))
fk_names = self._constraint_names(model, [old_field.column], foreign_key=True)
if strict and len(fk_names) != 1:
raise ValueError("Found wrong number (%s) of foreign key constraints for %s.%s" % (
len(fk_names),
model._meta.db_table,
old_field.column,
))
for fk_name in fk_names:
fks_dropped.add((old_field.column,))
self.execute(self._delete_constraint_sql(self.sql_delete_fk, model, fk_name))
# Has unique been removed?
if old_field.unique and (not new_field.unique or self._field_became_primary_key(old_field, new_field)):
self._delete_unique_constraint_for_columns(model, [old_field.column], strict=strict)
# Drop incoming FK constraints if the field is a primary key or unique,
# which might be a to_field target, and things are going to change.
drop_foreign_keys = (
(
(old_field.primary_key and new_field.primary_key) or
(old_field.unique and new_field.unique)
) and old_type != new_type
)
if drop_foreign_keys:
# '_meta.related_field' also contains M2M reverse fields, these
# will be filtered out
for _old_rel, new_rel in _related_non_m2m_objects(old_field, new_field):
rel_fk_names = self._constraint_names(
new_rel.related_model, [new_rel.field.column], foreign_key=True
)
for fk_name in rel_fk_names:
self.execute(self._delete_constraint_sql(self.sql_delete_fk, new_rel.related_model, fk_name))
# Removed an index? (no strict check, as multiple indexes are possible)
# Remove indexes if db_index switched to False or a unique constraint
# will now be used in lieu of an index. The following lines from the
# truth table show all True cases; the rest are False:
#
# old_field.db_index | old_field.unique | new_field.db_index | new_field.unique
# ------------------------------------------------------------------------------
# True | False | False | False
# True | False | False | True
# True | False | True | True
if (old_field.db_index and not old_field.unique and (not new_field.db_index or new_field.unique)) or (
# Drop indexes on nvarchar columns that are changing to a different type
# SQL Server requires explicit deletion
(old_field.db_index or old_field.unique) and (
(old_type.startswith('nvarchar') and not new_type.startswith('nvarchar'))
)):
# Find the index for this field
meta_index_names = {index.name for index in model._meta.indexes}
# Retrieve only BTREE indexes since this is what's created with
# db_index=True.
index_names = self._constraint_names(model, [old_field.column], index=True, type_=Index.suffix)
for index_name in index_names:
if index_name not in meta_index_names:
# The only way to check if an index was created with
# db_index=True or with Index(['field'], name='foo')
# is to look at its name (refs #28053).
self.execute(self._delete_constraint_sql(self.sql_delete_index, model, index_name))
# Change check constraints?
if (old_db_params['check'] != new_db_params['check'] and old_db_params['check']) or (
# SQL Server requires explicit deletion befor altering column type with the same constraint
old_db_params['check'] == new_db_params['check'] and old_db_params['check'] and
old_db_params['type'] != new_db_params['type']
):
constraint_names = self._constraint_names(model, [old_field.column], check=True)
if strict and len(constraint_names) != 1:
raise ValueError("Found wrong number (%s) of check constraints for %s.%s" % (
len(constraint_names),
model._meta.db_table,
old_field.column,
))
for constraint_name in constraint_names:
self.execute(self._delete_constraint_sql(self.sql_delete_check, model, constraint_name))
# Have they renamed the column?
if old_field.column != new_field.column:
sql_restore_index = ''
# Drop any unique indexes which include the column to be renamed
index_names = self._db_table_constraint_names(
db_table=model._meta.db_table, column_names=[old_field.column], column_match_any=True,
index=True, unique=True,
)
for index_name in index_names:
# Before dropping figure out how to recreate it afterwards
with self.connection.cursor() as cursor:
cursor.execute(f"""
SELECT COL_NAME(ic.object_id,ic.column_id) AS column_name,
filter_definition
FROM sys.indexes AS i
INNER JOIN sys.index_columns AS ic
ON i.object_id = ic.object_id AND i.index_id = ic.index_id
WHERE i.object_id = OBJECT_ID('{model._meta.db_table}')
and i.name = '{index_name}'
""")
result = cursor.fetchall()
columns_to_recreate_index = ', '.join(['%s' % self.quote_name(column[0]) for column in result])
filter_definition = result[0][1]
sql_restore_index += f'CREATE UNIQUE INDEX {index_name} ON {model._meta.db_table} ({columns_to_recreate_index}) WHERE {filter_definition};'
self.execute(self._db_table_delete_constraint_sql(
self.sql_delete_index, model._meta.db_table, index_name))
self.execute(self._rename_field_sql(model._meta.db_table, old_field, new_field, new_type))
# Restore index(es) now the column has been renamed
if sql_restore_index:
self.execute(sql_restore_index.replace(f'[{old_field.column}]', f'[{new_field.column}]'))
# Rename all references to the renamed column.
for sql in self.deferred_sql:
if isinstance(sql, DjStatement):
sql.rename_column_references(model._meta.db_table, old_field.column, new_field.column)
# Next, start accumulating actions to do
actions = []
null_actions = []
post_actions = []
# Type change?
if old_type != new_type:
fragment, other_actions = self._alter_column_type_sql(model, old_field, new_field, new_type)
actions.append(fragment)
post_actions.extend(other_actions)
# Drop unique constraint, SQL Server requires explicit deletion
self._delete_unique_constraints(model, old_field, new_field, strict)
# Drop indexes, SQL Server requires explicit deletion
self._delete_indexes(model, old_field, new_field)
# When changing a column NULL constraint to NOT NULL with a given
# default value, we need to perform 4 steps:
# 1. Add a default for new incoming writes
# 2. Update existing NULL rows with new default
# 3. Replace NULL constraint with NOT NULL
# 4. Drop the default again.
# Default change?
old_default = self.effective_default(old_field)
new_default = self.effective_default(new_field)
needs_database_default = (
old_field.null and
not new_field.null and
old_default != new_default and
new_default is not None and
not self.skip_default(new_field)
)
if needs_database_default:
actions.append(self._alter_column_default_sql(model, old_field, new_field))
# Nullability change?
if old_field.null != new_field.null:
fragment = self._alter_column_null_sql(model, old_field, new_field)
if fragment:
null_actions.append(fragment)
# Drop unique constraint, SQL Server requires explicit deletion
self._delete_unique_constraints(model, old_field, new_field, strict)
# Drop indexes, SQL Server requires explicit deletion
indexes_dropped = self._delete_indexes(model, old_field, new_field)
auto_index_names = []
for index_from_meta in model._meta.indexes:
auto_index_names.append(self._create_index_name(model._meta.db_table, index_from_meta.fields))
if (
new_field.get_internal_type() not in ("JSONField", "TextField") and
(old_field.db_index or not new_field.db_index) and
new_field.db_index or
((indexes_dropped and sorted(indexes_dropped) == sorted([index.name for index in model._meta.indexes])) or
(indexes_dropped and sorted(indexes_dropped) == sorted(auto_index_names)))
):
create_index_sql_statement = self._create_index_sql(model, [new_field])
if create_index_sql_statement.__str__() not in [sql.__str__() for sql in self.deferred_sql]:
post_actions.append((create_index_sql_statement, ()))
# Only if we have a default and there is a change from NULL to NOT NULL
four_way_default_alteration = (
new_field.has_default() and
(old_field.null and not new_field.null)
)
if actions or null_actions:
if not four_way_default_alteration:
# If we don't have to do a 4-way default alteration we can
# directly run a (NOT) NULL alteration
actions = actions + null_actions
# Combine actions together if we can (e.g. postgres)
if self.connection.features.supports_combined_alters and actions:
sql, params = tuple(zip(*actions))
actions = [(", ".join(sql), sum(params, []))]
# Apply those actions
for sql, params in actions:
self.execute(
self.sql_alter_column % {
"table": self.quote_name(model._meta.db_table),
"changes": sql,
},
params,
)
if four_way_default_alteration:
# Update existing rows with default value
self.execute(
self.sql_update_with_default % {
"table": self.quote_name(model._meta.db_table),
"column": self.quote_name(new_field.column),
"default": "%s",
},
[new_default],
)
# Since we didn't run a NOT NULL change before we need to do it
# now
for sql, params in null_actions:
self.execute(
self.sql_alter_column % {
"table": self.quote_name(model._meta.db_table),
"changes": sql,
},
params,
)
if post_actions:
for sql, params in post_actions:
self.execute(sql, params)
# If primary_key changed to False, delete the primary key constraint.
if old_field.primary_key and not new_field.primary_key:
self._delete_primary_key(model, strict)
# Added a unique?
if self._unique_should_be_added(old_field, new_field):
if (self.connection.features.supports_nullable_unique_constraints and
not new_field.many_to_many and new_field.null):
self.execute(
self._create_index_sql(
model, [new_field], sql=self.sql_create_unique_null, suffix="_uniq"
)
)
else:
if django_version >= (4, 0):
self.execute(self._create_unique_sql(model, [new_field]))
else:
self.execute(self._create_unique_sql(model, [new_field.column]))
# Added an index?
# constraint will no longer be used in lieu of an index. The following
# lines from the truth table show all True cases; the rest are False:
#
# old_field.db_index | old_field.unique | new_field.db_index | new_field.unique
# ------------------------------------------------------------------------------
# False | False | True | False
# False | True | True | False
# True | True | True | False
if (not old_field.db_index or old_field.unique) and new_field.db_index and not new_field.unique:
self.execute(self._create_index_sql(model, [new_field]))
# Restore indexes & unique constraints deleted above, SQL Server requires explicit restoration
if (old_type != new_type or (old_field.null != new_field.null)) and (
old_field.column == new_field.column
):
# Restore unique constraints
# Note: if nullable they are implemented via an explicit filtered UNIQUE INDEX (not CONSTRAINT)
# in order to get ANSI-compliant NULL behaviour (i.e. NULL != NULL, multiple are allowed)
if old_field.unique and new_field.unique:
if new_field.null:
self.execute(
self._create_index_sql(
model, [old_field], sql=self.sql_create_unique_null, suffix="_uniq"
)
)
else:
if django_version >= (4, 0):
self.execute(self._create_unique_sql(model, [old_field]))
else:
self.execute(self._create_unique_sql(model, columns=[old_field.column]))
else:
if django_version >= (4, 0):
for field_names in model._meta.unique_together:
columns = [model._meta.get_field(field).column for field in field_names]
fields = [model._meta.get_field(field) for field in field_names]
if old_field.column in columns:
condition = ' AND '.join(["[%s] IS NOT NULL" % col for col in columns])
self.execute(self._create_unique_sql(model, fields, condition=condition))
else:
for fields in model._meta.unique_together:
columns = [model._meta.get_field(field).column for field in fields]
if old_field.column in columns:
condition = ' AND '.join(["[%s] IS NOT NULL" % col for col in columns])
self.execute(self._create_unique_sql(model, columns, condition=condition))
# Restore indexes
index_columns = []
if old_field.db_index and new_field.db_index:
index_columns.append([old_field])
else:
for fields in model._meta.index_together:
columns = [model._meta.get_field(field) for field in fields]
if old_field.column in [c.column for c in columns]:
index_columns.append(columns)
if index_columns:
for columns in index_columns:
create_index_sql_statement = self._create_index_sql(model, columns)
if (create_index_sql_statement.__str__()
not in [sql.__str__() for sql in self.deferred_sql] + [statement[0].__str__() for statement in post_actions]
):
self.execute(create_index_sql_statement)
# Type alteration on primary key? Then we need to alter the column
# referring to us.
rels_to_update = []
if old_field.primary_key and new_field.primary_key and old_type != new_type:
rels_to_update.extend(_related_non_m2m_objects(old_field, new_field))
# Changed to become primary key?
if self._field_became_primary_key(old_field, new_field):
# Make the new one
self.execute(
self.sql_create_pk % {
"table": self.quote_name(model._meta.db_table),
"name": self.quote_name(
self._create_index_name(model._meta.db_table, [new_field.column], suffix="_pk")
),
"columns": self.quote_name(new_field.column),
}
)
# Update all referencing columns
rels_to_update.extend(_related_non_m2m_objects(old_field, new_field))
# Handle our type alters on the other end of rels from the PK stuff above
for old_rel, new_rel in rels_to_update:
rel_db_params = new_rel.field.db_parameters(connection=self.connection)
rel_type = rel_db_params['type']
fragment, other_actions = self._alter_column_type_sql(
new_rel.related_model, old_rel.field, new_rel.field, rel_type
)
# Drop related_model indexes, so it can be altered
index_names = self._db_table_constraint_names(old_rel.related_model._meta.db_table, index=True)
for index_name in index_names:
self.execute(self._db_table_delete_constraint_sql(
self.sql_delete_index, old_rel.related_model._meta.db_table, index_name))
self.execute(
self.sql_alter_column % {
"table": self.quote_name(new_rel.related_model._meta.db_table),
"changes": fragment[0],
},
fragment[1],
)
for sql, params in other_actions:
self.execute(sql, params)
# Restore related_model indexes
self.execute(self._create_index_sql(new_rel.related_model, [new_rel.field]))
# Does it have a foreign key?
if (new_field.remote_field and
(fks_dropped or not old_field.remote_field or not old_field.db_constraint) and
new_field.db_constraint):
self.execute(self._create_fk_sql(model, new_field, "_fk_%(to_table)s_%(to_column)s"))
# Rebuild FKs that pointed to us if we previously had to drop them
if drop_foreign_keys:
for rel in new_field.model._meta.related_objects:
if _is_relevant_relation(rel, new_field) and rel.field.db_constraint:
self.execute(self._create_fk_sql(rel.related_model, rel.field, "_fk"))
# Does it have check constraints we need to add?
if (old_db_params['check'] != new_db_params['check'] and new_db_params['check']) or (
# SQL Server requires explicit creation after altering column type with the same constraint
old_db_params['check'] == new_db_params['check'] and new_db_params['check'] and
old_db_params['type'] != new_db_params['type']
):
self.execute(
self.sql_create_check % {
"table": self.quote_name(model._meta.db_table),
"name": self.quote_name(
self._create_index_name(model._meta.db_table, [new_field.column], suffix="_check")
),
"column": self.quote_name(new_field.column),
"check": new_db_params['check'],
}
)
# Drop the default if we need to
# (Django usually does not use in-database defaults)
if needs_database_default:
changes_sql, params = self._alter_column_default_sql(model, old_field, new_field, drop=True)
sql = self.sql_alter_column % {
"table": self.quote_name(model._meta.db_table),
"changes": changes_sql,
}
self.execute(sql, params)
# Reset connection if required
if self.connection.features.connection_persists_old_columns:
self.connection.close()
def _delete_indexes(self, model, old_field, new_field):
index_columns = []
index_names = []
if old_field.db_index and new_field.db_index:
index_columns.append([old_field.column])
elif old_field.null != new_field.null:
index_columns.append([old_field.column])
for fields in model._meta.index_together:
columns = [model._meta.get_field(field).column for field in fields]
if old_field.column in columns:
index_columns.append(columns)
for fields in model._meta.unique_together:
columns = [model._meta.get_field(field).column for field in fields]
if old_field.column in columns:
index_columns.append(columns)
if index_columns:
for columns in index_columns:
index_names = self._constraint_names(model, columns, index=True)
for index_name in index_names:
self.execute(self._delete_constraint_sql(self.sql_delete_index, model, index_name))
return index_names
def _delete_unique_constraints(self, model, old_field, new_field, strict=False):
unique_columns = []
if old_field.unique and new_field.unique:
unique_columns.append([old_field.column])
if unique_columns:
for columns in unique_columns:
self._delete_unique_constraint_for_columns(model, columns, strict=strict)
def _delete_unique_constraint_for_columns(self, model, columns, strict=False, **constraint_names_kwargs):
constraint_names_unique = self._db_table_constraint_names(
model._meta.db_table, columns, unique=True, unique_constraint=True, **constraint_names_kwargs)
constraint_names_primary = self._db_table_constraint_names(
model._meta.db_table, columns, unique=True, primary_key=True, **constraint_names_kwargs)
constraint_names_normal = constraint_names_unique + constraint_names_primary
constraint_names_index = self._db_table_constraint_names(
model._meta.db_table, columns, unique=True, unique_constraint=False, primary_key=False,
**constraint_names_kwargs)
constraint_names = constraint_names_normal + constraint_names_index
if strict and len(constraint_names) != 1:
raise ValueError("Found wrong number (%s) of unique constraints for columns %s" % (
len(constraint_names),
repr(columns),
))
for constraint_name in constraint_names_normal:
self.execute(self._delete_constraint_sql(self.sql_delete_unique, model, constraint_name))
# Unique indexes which are not table constraints must be deleted using the appropriate SQL.
# These may exist for example to enforce ANSI-compliant unique constraints on nullable columns.
for index_name in constraint_names_index:
self.execute(self._delete_constraint_sql(self.sql_delete_index, model, index_name))
def _rename_field_sql(self, table, old_field, new_field, new_type):
new_type = self._set_field_new_type_null_status(old_field, new_type)
return super()._rename_field_sql(table, old_field, new_field, new_type)
def _set_field_new_type_null_status(self, field, new_type):
"""
Keep the null property of the old field. If it has changed, it will be
handled separately.
"""
if field.null:
new_type += " NULL"
else:
new_type += " NOT NULL"
return new_type
def add_field(self, model, field):
"""
Create a field on a model. Usually involves adding a column, but may
involve adding a table instead (for M2M fields).
"""
# Special-case implicit M2M tables
if field.many_to_many and field.remote_field.through._meta.auto_created:
return self.create_model(field.remote_field.through)
# Get the column's definition
definition, params = self.column_sql(model, field, include_default=True)
# It might not actually have a column behind it
if definition is None:
return
if (self.connection.features.supports_nullable_unique_constraints and
not field.many_to_many and field.null and field.unique):
definition = definition.replace(' UNIQUE', '')
self.deferred_sql.append(self._create_index_sql(
model, [field], sql=self.sql_create_unique_null, suffix="_uniq"
))
# Check constraints can go on the column SQL here
db_params = field.db_parameters(connection=self.connection)
if db_params['check']:
definition += " CHECK (%s)" % db_params['check']
# Build the SQL and run it
sql = self.sql_create_column % {
"table": self.quote_name(model._meta.db_table),
"column": self.quote_name(field.column),
"definition": definition,
}
self.execute(sql, params)
# Drop the default if we need to
# (Django usually does not use in-database defaults)
if not self.skip_default(field) and self.effective_default(field) is not None:
changes_sql, params = self._alter_column_default_sql(model, None, field, drop=True)
sql = self.sql_alter_column % {
"table": self.quote_name(model._meta.db_table),
"changes": changes_sql,
}
self.execute(sql, params)
# Add an index, if required
self.deferred_sql.extend(self._field_indexes_sql(model, field))
# Add any FK constraints later
if field.remote_field and self.connection.features.supports_foreign_keys and field.db_constraint:
self.deferred_sql.append(self._create_fk_sql(model, field, "_fk_%(to_table)s_%(to_column)s"))
# Reset connection if required
if self.connection.features.connection_persists_old_columns:
self.connection.close()
if django_version >= (4, 0):
def _create_unique_sql(self, model, fields,
name=None, condition=None, deferrable=None,
include=None, opclasses=None, expressions=None):
if (deferrable and not getattr(self.connection.features, 'supports_deferrable_unique_constraints', False) or
(condition and not self.connection.features.supports_partial_indexes) or
(include and not self.connection.features.supports_covering_indexes) or
(expressions and not self.connection.features.supports_expression_indexes)):
return None
def create_unique_name(*args, **kwargs):
return self.quote_name(self._create_index_name(*args, **kwargs))
compiler = Query(model, alias_cols=False).get_compiler(connection=self.connection)
columns = [field.column for field in fields]
table = model._meta.db_table
if name is None:
name = IndexName(table, columns, '_uniq', create_unique_name)
else:
name = self.quote_name(name)
if columns:
columns = self._index_columns(table, columns, col_suffixes=(), opclasses=opclasses)
else:
columns = Expressions(table, expressions, compiler, self.quote_value)
statement_args = {
"deferrable": self._deferrable_constraint_sql(deferrable)
}
include = self._index_include_sql(model, include)
if condition:
return Statement(
self.sql_create_unique_index,
table=self.quote_name(table),
name=name,
columns=columns,
condition=' WHERE ' + condition,
**statement_args,
include=include,
) if self.connection.features.supports_partial_indexes else None
else:
return Statement(
self.sql_create_unique,
table=self.quote_name(table),
name=name,
columns=columns,
**statement_args,
include=include,
)
else:
def _create_unique_sql(self, model, columns,
name=None, condition=None, deferrable=None,
include=None, opclasses=None, expressions=None):
if (deferrable and not getattr(self.connection.features, 'supports_deferrable_unique_constraints', False) or
(condition and not self.connection.features.supports_partial_indexes) or
(include and not self.connection.features.supports_covering_indexes) or
(expressions and not self.connection.features.supports_expression_indexes)):
return None
def create_unique_name(*args, **kwargs):
return self.quote_name(self._create_index_name(*args, **kwargs))
table = Table(model._meta.db_table, self.quote_name)
if name is None:
name = IndexName(model._meta.db_table, columns, '_uniq', create_unique_name)
else:
name = self.quote_name(name)
columns = Columns(table, columns, self.quote_name)
statement_args = {
"deferrable": self._deferrable_constraint_sql(deferrable)
} if django_version >= (3, 1) else {}
include = self._index_include_sql(model, include) if django_version >= (3, 2) else ''
if condition:
return Statement(
self.sql_create_unique_index,
table=self.quote_name(table) if isinstance(table, str) else table,
name=name,
columns=columns,
condition=' WHERE ' + condition,
**statement_args,
include=include,
) if self.connection.features.supports_partial_indexes else None
else:
return Statement(
self.sql_create_unique,
table=self.quote_name(table) if isinstance(table, str) else table,
name=name,
columns=columns,
**statement_args,
include=include,
)
def _create_index_sql(self, model, fields, *, name=None, suffix='', using='',
db_tablespace=None, col_suffixes=(), sql=None, opclasses=(),
condition=None, include=None, expressions=None):
"""
Return the SQL statement to create the index for one or several fields.
`sql` can be specified if the syntax differs from the standard (GIS
indexes, ...).
"""
if django_version >= (3, 2):
return super()._create_index_sql(
model, fields=fields, name=name, suffix=suffix, using=using,
db_tablespace=db_tablespace, col_suffixes=col_suffixes, sql=sql,
opclasses=opclasses, condition=condition, include=include,
expressions=expressions,
)
return super()._create_index_sql(
model, fields=fields, name=name, suffix=suffix, using=using,
db_tablespace=db_tablespace, col_suffixes=col_suffixes, sql=sql,
opclasses=opclasses, condition=condition,
)
def create_model(self, model):
"""
Takes a model and creates a table for it in the database.
Will also create any accompanying indexes or unique constraints.
"""
# Create column SQL, add FK deferreds if needed
column_sqls = []
params = []
for field in model._meta.local_fields:
# SQL
definition, extra_params = self.column_sql(model, field)
if definition is None:
continue
if (self.connection.features.supports_nullable_unique_constraints and
not field.many_to_many and field.null and field.unique):
definition = definition.replace(' UNIQUE', '')
self.deferred_sql.append(self._create_index_sql(
model, [field], sql=self.sql_create_unique_null, suffix="_uniq"
))
# Check constraints can go on the column SQL here
db_params = field.db_parameters(connection=self.connection)
if db_params['check']:
# SQL Server requires a name for the check constraint
definition += self._sql_check_constraint % {
"name": self._create_index_name(model._meta.db_table, [field.column], suffix="_check"),
"check": db_params['check']
}
# Autoincrement SQL (for backends with inline variant)
col_type_suffix = field.db_type_suffix(connection=self.connection)
if col_type_suffix:
definition += " %s" % col_type_suffix
params.extend(extra_params)
# FK
if field.remote_field and field.db_constraint:
to_table = field.remote_field.model._meta.db_table
to_column = field.remote_field.model._meta.get_field(field.remote_field.field_name).column
if self.sql_create_inline_fk:
definition += " " + self.sql_create_inline_fk % {
"to_table": self.quote_name(to_table),
"to_column": self.quote_name(to_column),
}
elif self.connection.features.supports_foreign_keys:
self.deferred_sql.append(self._create_fk_sql(model, field, "_fk_%(to_table)s_%(to_column)s"))
# Add the SQL to our big list
column_sqls.append("%s %s" % (
self.quote_name(field.column),
definition,
))
# Autoincrement SQL (for backends with post table definition variant)
if field.get_internal_type() in ("AutoField", "BigAutoField", "SmallAutoField"):
autoinc_sql = self.connection.ops.autoinc_sql(model._meta.db_table, field.column)
if autoinc_sql:
self.deferred_sql.extend(autoinc_sql)
# Add any unique_togethers (always deferred, as some fields might be
# created afterwards, like geometry fields with some backends)
for field_names in model._meta.unique_together:
fields = [model._meta.get_field(field) for field in field_names]
columns = [model._meta.get_field(field).column for field in field_names]
condition = ' AND '.join(["[%s] IS NOT NULL" % col for col in columns])
if django_version >= (4, 0):
self.deferred_sql.append(self._create_unique_sql(model, fields, condition=condition))
else:
self.deferred_sql.append(self._create_unique_sql(model, columns, condition=condition))
constraints = [constraint.constraint_sql(model, self) for constraint in model._meta.constraints]
# Make the table
sql = self.sql_create_table % {
"table": self.quote_name(model._meta.db_table),
'definition': ', '.join(constraint for constraint in (*column_sqls, *constraints) if constraint),
}
if model._meta.db_tablespace:
tablespace_sql = self.connection.ops.tablespace_sql(model._meta.db_tablespace)
if tablespace_sql:
sql += ' ' + tablespace_sql
# Prevent using [] as params, in the case a literal '%' is used in the definition
self.execute(sql, params or None)
# Add any field index and index_together's (deferred as SQLite3 _remake_table needs it)
self.deferred_sql.extend(self._model_indexes_sql(model))
self.deferred_sql = list(set(self.deferred_sql))
# Make M2M tables
for field in model._meta.local_many_to_many:
if field.remote_field.through._meta.auto_created:
self.create_model(field.remote_field.through)
def _delete_unique_sql(
self, model, name, condition=None, deferrable=None, include=None,
opclasses=None, expressions=None
):
if (
(
deferrable and
not self.connection.features.supports_deferrable_unique_constraints
) or
(condition and not self.connection.features.supports_partial_indexes) or
(include and not self.connection.features.supports_covering_indexes) or
(expressions and not self.connection.features.supports_expression_indexes)
):
return None
if condition or include or opclasses:
sql = self.sql_delete_index
with self.connection.cursor() as cursor:
cursor.execute(
"SELECT 1 FROM INFORMATION_SCHEMA.CONSTRAINT_COLUMN_USAGE WHERE CONSTRAINT_NAME = '%s'" % name)
row = cursor.fetchone()
if row:
sql = self.sql_delete_unique
else:
sql = self.sql_delete_unique
return self._delete_constraint_sql(sql, model, name)
def delete_model(self, model):
super().delete_model(model)
def execute(self, sql, params=(), has_result=False):
"""
Executes the given SQL statement, with optional parameters.
"""
result = None
# Don't perform the transactional DDL check if SQL is being collected
# as it's not going to be executed anyway.
if not self.collect_sql and self.connection.in_atomic_block and not self.connection.features.can_rollback_ddl:
raise TransactionManagementError(
"Executing DDL statements while in a transaction on databases "
"that can't perform a rollback is prohibited."
)
# Account for non-string statement objects.
sql = str(sql)
# Log the command we're running, then run it
logger.debug("%s; (params %r)", sql, params, extra={'params': params, 'sql': sql})
if self.collect_sql:
ending = "" if sql.endswith(";") else ";"
if params is not None:
self.collected_sql.append((sql % tuple(map(self.quote_value, params))) + ending)
else:
self.collected_sql.append(sql + ending)
else:
cursor = self.connection.cursor()
cursor.execute(sql, params)
if has_result:
result = cursor.fetchall()
# the cursor can be closed only when the driver supports opening
# multiple cursors on a connection because the migration command
# has already opened a cursor outside this method
if self.connection.supports_mars:
cursor.close()
return result
def prepare_default(self, value):
return self.quote_value(value)
def quote_value(self, value):
"""
Returns a quoted version of the value so it's safe to use in an SQL
string. This is not safe against injection from user code; it is
intended only for use in making SQL scripts or preparing default values
for particularly tricky backends (defaults are not user-defined, though,
so this is safe).
"""
if isinstance(value, (datetime.datetime, datetime.date, datetime.time)):
return "'%s'" % value
elif isinstance(value, str):
return "'%s'" % value.replace("'", "''")
elif isinstance(value, (bytes, bytearray, memoryview)):
return "0x%s" % force_str(binascii.hexlify(value))
elif isinstance(value, bool):
return "1" if value else "0"
else:
return str(value)
def remove_field(self, model, field):
"""
Removes a field from a model. Usually involves deleting a column,
but for M2Ms may involve deleting a table.
"""
# Special-case implicit M2M tables
if field.many_to_many and field.remote_field.through._meta.auto_created:
return self.delete_model(field.remote_field.through)
# It might not actually have a column behind it
if field.db_parameters(connection=self.connection)['type'] is None:
return
# Drop any FK constraints, SQL Server requires explicit deletion
with self.connection.cursor() as cursor:
constraints = self.connection.introspection.get_constraints(cursor, model._meta.db_table)
for name, infodict in constraints.items():
if field.column in infodict['columns'] and infodict['foreign_key']:
self.execute(self._delete_constraint_sql(self.sql_delete_fk, model, name))
# Drop any indexes, SQL Server requires explicit deletion
for name, infodict in constraints.items():
if field.column in infodict['columns'] and infodict['index']:
self.execute(self.sql_delete_index % {
"table": self.quote_name(model._meta.db_table),
"name": self.quote_name(name),
})
# Drop primary key constraint, SQL Server requires explicit deletion
for name, infodict in constraints.items():
if field.column in infodict['columns'] and infodict['primary_key']:
self.execute(self.sql_delete_pk % {
"table": self.quote_name(model._meta.db_table),
"name": self.quote_name(name),
})
# Drop check constraints, SQL Server requires explicit deletion
for name, infodict in constraints.items():
if field.column in infodict['columns'] and infodict['check']:
self.execute(self.sql_delete_check % {
"table": self.quote_name(model._meta.db_table),
"name": self.quote_name(name),
})
# Drop unique constraints, SQL Server requires explicit deletion
for name, infodict in constraints.items():
if (field.column in infodict['columns'] and infodict['unique'] and
not infodict['primary_key'] and not infodict['index']):
self.execute(self.sql_delete_unique % {
"table": self.quote_name(model._meta.db_table),
"name": self.quote_name(name),
})
# Delete the column
sql = self.sql_delete_column % {
"table": self.quote_name(model._meta.db_table),
"column": self.quote_name(field.column),
}
self.execute(sql)
# Reset connection if required
if self.connection.features.connection_persists_old_columns:
self.connection.close()
# Remove all deferred statements referencing the deleted column.
for sql in list(self.deferred_sql):
if isinstance(sql, Statement) and sql.references_column(model._meta.db_table, field.column):
self.deferred_sql.remove(sql)
def add_constraint(self, model, constraint):
if isinstance(constraint, UniqueConstraint) and constraint.condition and constraint.condition.connector != AND:
raise NotImplementedError("The backend does not support %s conditions on unique constraint %s." %
(constraint.condition.connector, constraint.name))
super().add_constraint(model, constraint)
def _collate_sql(self, collation):
return ' COLLATE ' + collation
def _create_index_name(self, table_name, column_names, suffix=""):
index_name = super()._create_index_name(table_name, column_names, suffix)
# Check if the db_table specified a user-defined schema
if('].[' in index_name):
new_index_name = index_name.replace('[', '').replace(']', '').replace('.', '_')
return new_index_name
return index_name | zilian-mssql-django | /zilian-mssql-django-1.1.4.tar.gz/zilian-mssql-django-1.1.4/mssql/schema.py | schema.py |
import pyodbc as Database
from django import VERSION
from django.db.backends.base.introspection import (
BaseDatabaseIntrospection, FieldInfo, TableInfo,
)
from django.db.models.indexes import Index
from django.conf import settings
SQL_AUTOFIELD = -777555
SQL_BIGAUTOFIELD = -777444
def get_schema_name():
return getattr(settings, 'SCHEMA_TO_INSPECT', 'SCHEMA_NAME()')
class DatabaseIntrospection(BaseDatabaseIntrospection):
# Map type codes to Django Field types.
data_types_reverse = {
SQL_AUTOFIELD: 'AutoField',
SQL_BIGAUTOFIELD: 'BigAutoField',
Database.SQL_BIGINT: 'BigIntegerField',
# Database.SQL_BINARY: ,
Database.SQL_BIT: 'BooleanField',
Database.SQL_CHAR: 'CharField',
Database.SQL_DECIMAL: 'DecimalField',
Database.SQL_DOUBLE: 'FloatField',
Database.SQL_FLOAT: 'FloatField',
Database.SQL_GUID: 'TextField',
Database.SQL_INTEGER: 'IntegerField',
Database.SQL_LONGVARBINARY: 'BinaryField',
# Database.SQL_LONGVARCHAR: ,
Database.SQL_NUMERIC: 'DecimalField',
Database.SQL_REAL: 'FloatField',
Database.SQL_SMALLINT: 'SmallIntegerField',
Database.SQL_SS_TIME2: 'TimeField',
Database.SQL_TINYINT: 'SmallIntegerField',
Database.SQL_TYPE_DATE: 'DateField',
Database.SQL_TYPE_TIME: 'TimeField',
Database.SQL_TYPE_TIMESTAMP: 'DateTimeField',
Database.SQL_VARBINARY: 'BinaryField',
Database.SQL_VARCHAR: 'TextField',
Database.SQL_WCHAR: 'CharField',
Database.SQL_WLONGVARCHAR: 'TextField',
Database.SQL_WVARCHAR: 'TextField',
}
ignored_tables = []
def get_field_type(self, data_type, description):
field_type = super().get_field_type(data_type, description)
# the max nvarchar length is described as 0 or 2**30-1
# (it depends on the driver)
size = description.internal_size
if field_type == 'CharField':
if size == 0 or size >= 2**30 - 1:
field_type = "TextField"
elif field_type == 'TextField':
if size > 0 and size < 2**30 - 1:
field_type = 'CharField'
return field_type
def get_table_list(self, cursor):
"""
Returns a list of table and view names in the current database.
"""
sql = f'SELECT TABLE_NAME, TABLE_TYPE FROM INFORMATION_SCHEMA.TABLES WHERE TABLE_SCHEMA = {get_schema_name()}'
cursor.execute(sql)
types = {'BASE TABLE': 't', 'VIEW': 'v'}
return [TableInfo(row[0], types.get(row[1]))
for row in cursor.fetchall()
if row[0] not in self.ignored_tables]
def _is_auto_field(self, cursor, table_name, column_name):
"""
Checks whether column is Identity
"""
# COLUMNPROPERTY: http://msdn2.microsoft.com/en-us/library/ms174968.aspx
# from django.db import connection
# cursor.execute("SELECT COLUMNPROPERTY(OBJECT_ID(%s), %s, 'IsIdentity')",
# (connection.ops.quote_name(table_name), column_name))
cursor.execute("SELECT COLUMNPROPERTY(OBJECT_ID(%s), %s, 'IsIdentity')",
(self.connection.ops.quote_name(table_name), column_name))
return cursor.fetchall()[0][0]
def get_table_description(self, cursor, table_name, identity_check=True):
"""Returns a description of the table, with DB-API cursor.description interface.
The 'auto_check' parameter has been added to the function argspec.
If set to True, the function will check each of the table's fields for the
IDENTITY property (the IDENTITY property is the MSSQL equivalent to an AutoField).
When an integer field is found with an IDENTITY property, it is given a custom field number
of SQL_AUTOFIELD, which maps to the 'AutoField' value in the DATA_TYPES_REVERSE dict.
When a bigint field is found with an IDENTITY property, it is given a custom field number
of SQL_BIGAUTOFIELD, which maps to the 'BigAutoField' value in the DATA_TYPES_REVERSE dict.
"""
# map pyodbc's cursor.columns to db-api cursor description
columns = [[c[3], c[4], None, c[6], c[6], c[8], c[10], c[12]] for c in cursor.columns(table=table_name)]
items = []
for column in columns:
if VERSION >= (3, 2):
if self.connection.sql_server_version >= 2019:
sql = """SELECT collation_name
FROM sys.columns c
inner join sys.tables t on c.object_id = t.object_id
WHERE t.name = '%s' and c.name = '%s'
""" % (table_name, column[0])
cursor.execute(sql)
collation_name = cursor.fetchone()
column.append(collation_name[0] if collation_name else '')
else:
column.append('')
if identity_check and self._is_auto_field(cursor, table_name, column[0]):
if column[1] == Database.SQL_BIGINT:
column[1] = SQL_BIGAUTOFIELD
else:
column[1] = SQL_AUTOFIELD
if column[1] == Database.SQL_WVARCHAR and column[3] < 4000:
column[1] = Database.SQL_WCHAR
items.append(FieldInfo(*column))
return items
def get_sequences(self, cursor, table_name, table_fields=()):
cursor.execute(f"""
SELECT c.name FROM sys.columns c
INNER JOIN sys.tables t ON c.object_id = t.object_id
WHERE t.schema_id = SCHEMA_ID({get_schema_name()}) AND t.name = %s AND c.is_identity = 1""",
[table_name])
# SQL Server allows only one identity column per table
# https://docs.microsoft.com/en-us/sql/t-sql/statements/create-table-transact-sql-identity-property
row = cursor.fetchone()
return [{'table': table_name, 'column': row[0]}] if row else []
def get_relations(self, cursor, table_name):
"""
Returns a dictionary of {field_name: (field_name_other_table, other_table)}
representing all relationships to the given table.
"""
# CONSTRAINT_COLUMN_USAGE: http://msdn2.microsoft.com/en-us/library/ms174431.aspx
# CONSTRAINT_TABLE_USAGE: http://msdn2.microsoft.com/en-us/library/ms179883.aspx
# REFERENTIAL_CONSTRAINTS: http://msdn2.microsoft.com/en-us/library/ms179987.aspx
# TABLE_CONSTRAINTS: http://msdn2.microsoft.com/en-us/library/ms181757.aspx
sql = f"""
SELECT e.COLUMN_NAME AS column_name,
c.TABLE_NAME AS referenced_table_name,
d.COLUMN_NAME AS referenced_column_name
FROM INFORMATION_SCHEMA.TABLE_CONSTRAINTS AS a
INNER JOIN INFORMATION_SCHEMA.REFERENTIAL_CONSTRAINTS AS b
ON a.CONSTRAINT_NAME = b.CONSTRAINT_NAME AND a.TABLE_SCHEMA = b.CONSTRAINT_SCHEMA
INNER JOIN INFORMATION_SCHEMA.CONSTRAINT_TABLE_USAGE AS c
ON b.UNIQUE_CONSTRAINT_NAME = c.CONSTRAINT_NAME AND b.CONSTRAINT_SCHEMA = c.CONSTRAINT_SCHEMA
INNER JOIN INFORMATION_SCHEMA.CONSTRAINT_COLUMN_USAGE AS d
ON c.CONSTRAINT_NAME = d.CONSTRAINT_NAME AND c.CONSTRAINT_SCHEMA = d.CONSTRAINT_SCHEMA
INNER JOIN INFORMATION_SCHEMA.CONSTRAINT_COLUMN_USAGE AS e
ON a.CONSTRAINT_NAME = e.CONSTRAINT_NAME AND a.TABLE_SCHEMA = e.TABLE_SCHEMA
WHERE a.TABLE_SCHEMA = {get_schema_name()} AND a.TABLE_NAME = %s AND a.CONSTRAINT_TYPE = 'FOREIGN KEY'"""
cursor.execute(sql, (table_name,))
return dict([[item[0], (item[2], item[1])] for item in cursor.fetchall()])
def get_key_columns(self, cursor, table_name):
"""
Returns a list of (column_name, referenced_table_name, referenced_column_name) for all
key columns in given table.
"""
key_columns = []
cursor.execute(f"""
SELECT c.name AS column_name, rt.name AS referenced_table_name, rc.name AS referenced_column_name
FROM sys.foreign_key_columns fk
INNER JOIN sys.tables t ON t.object_id = fk.parent_object_id
INNER JOIN sys.columns c ON c.object_id = t.object_id AND c.column_id = fk.parent_column_id
INNER JOIN sys.tables rt ON rt.object_id = fk.referenced_object_id
INNER JOIN sys.columns rc ON rc.object_id = rt.object_id AND rc.column_id = fk.referenced_column_id
WHERE t.schema_id = SCHEMA_ID({get_schema_name()}) AND t.name = %s""", [table_name])
key_columns.extend([tuple(row) for row in cursor.fetchall()])
return key_columns
def get_constraints(self, cursor, table_name):
"""
Retrieves any constraints or keys (unique, pk, fk, check, index)
across one or more columns.
Returns a dict mapping constraint names to their attributes,
where attributes is a dict with keys:
* columns: List of columns this covers
* primary_key: True if primary key, False otherwise
* unique: True if this is a unique constraint, False otherwise
* foreign_key: (table, column) of target, or None
* check: True if check constraint, False otherwise
* index: True if index, False otherwise.
* orders: The order (ASC/DESC) defined for the columns of indexes
* type: The type of the index (btree, hash, etc.)
"""
constraints = {}
# Loop over the key table, collecting things as constraints
# This will get PKs, FKs, and uniques, but not CHECK
cursor.execute(f"""
SELECT
kc.constraint_name,
kc.column_name,
tc.constraint_type,
fk.referenced_table_name,
fk.referenced_column_name
FROM INFORMATION_SCHEMA.KEY_COLUMN_USAGE AS kc
INNER JOIN INFORMATION_SCHEMA.TABLE_CONSTRAINTS AS tc ON
kc.table_schema = tc.table_schema AND
kc.table_name = tc.table_name AND
kc.constraint_name = tc.constraint_name
LEFT OUTER JOIN (
SELECT
ps.name AS table_schema,
pt.name AS table_name,
pc.name AS column_name,
rt.name AS referenced_table_name,
rc.name AS referenced_column_name
FROM
sys.foreign_key_columns fkc
INNER JOIN sys.tables pt ON
fkc.parent_object_id = pt.object_id
INNER JOIN sys.schemas ps ON
pt.schema_id = ps.schema_id
INNER JOIN sys.columns pc ON
fkc.parent_object_id = pc.object_id AND
fkc.parent_column_id = pc.column_id
INNER JOIN sys.tables rt ON
fkc.referenced_object_id = rt.object_id
INNER JOIN sys.schemas rs ON
rt.schema_id = rs.schema_id
INNER JOIN sys.columns rc ON
fkc.referenced_object_id = rc.object_id AND
fkc.referenced_column_id = rc.column_id
) fk ON
kc.table_schema = fk.table_schema AND
kc.table_name = fk.table_name AND
kc.column_name = fk.column_name
WHERE
kc.table_schema = {get_schema_name()} AND
kc.table_name = %s
ORDER BY
kc.constraint_name ASC,
kc.ordinal_position ASC
""", [table_name])
for constraint, column, kind, ref_table, ref_column in cursor.fetchall():
# If we're the first column, make the record
if constraint not in constraints:
constraints[constraint] = {
"columns": [],
"primary_key": kind.lower() == "primary key",
# In the sys.indexes table, primary key indexes have is_unique_constraint as false,
# but is_unique as true.
"unique": kind.lower() in ["primary key", "unique"],
"unique_constraint": kind.lower() == "unique",
"foreign_key": (ref_table, ref_column) if kind.lower() == "foreign key" else None,
"check": False,
# Potentially misleading: primary key and unique constraints still have indexes attached to them.
# Should probably be updated with the additional info from the sys.indexes table we fetch later on.
"index": False,
}
# Record the details
constraints[constraint]['columns'].append(column)
# Now get CHECK constraint columns
cursor.execute(f"""
SELECT kc.constraint_name, kc.column_name
FROM INFORMATION_SCHEMA.CONSTRAINT_COLUMN_USAGE AS kc
JOIN INFORMATION_SCHEMA.TABLE_CONSTRAINTS AS c ON
kc.table_schema = c.table_schema AND
kc.table_name = c.table_name AND
kc.constraint_name = c.constraint_name
WHERE
c.constraint_type = 'CHECK' AND
kc.table_schema = {get_schema_name()} AND
kc.table_name = %s
""", [table_name])
for constraint, column in cursor.fetchall():
# If we're the first column, make the record
if constraint not in constraints:
constraints[constraint] = {
"columns": [],
"primary_key": False,
"unique": False,
"unique_constraint": False,
"foreign_key": None,
"check": True,
"index": False,
}
# Record the details
constraints[constraint]['columns'].append(column)
# Now get indexes
cursor.execute(f"""
SELECT
i.name AS index_name,
i.is_unique,
i.is_unique_constraint,
i.is_primary_key,
i.type,
i.type_desc,
ic.is_descending_key,
c.name AS column_name
FROM
sys.tables AS t
INNER JOIN sys.schemas AS s ON
t.schema_id = s.schema_id
INNER JOIN sys.indexes AS i ON
t.object_id = i.object_id
INNER JOIN sys.index_columns AS ic ON
i.object_id = ic.object_id AND
i.index_id = ic.index_id
INNER JOIN sys.columns AS c ON
ic.object_id = c.object_id AND
ic.column_id = c.column_id
WHERE
t.schema_id = SCHEMA_ID({get_schema_name()}) AND
t.name = %s
ORDER BY
i.index_id ASC,
ic.index_column_id ASC
""", [table_name])
indexes = {}
for index, unique, unique_constraint, primary, type_, desc, order, column in cursor.fetchall():
if index not in indexes:
indexes[index] = {
"columns": [],
"primary_key": primary,
"unique": unique,
"unique_constraint": unique_constraint,
"foreign_key": None,
"check": False,
"index": True,
"orders": [],
"type": Index.suffix if type_ in (1, 2) else desc.lower(),
}
indexes[index]["columns"].append(column)
indexes[index]["orders"].append("DESC" if order == 1 else "ASC")
for index, constraint in indexes.items():
if index not in constraints:
constraints[index] = constraint
return constraints
def get_primary_key_column(self, cursor, table_name):
cursor.execute("SELECT 1 FROM INFORMATION_SCHEMA.TABLES WHERE TABLE_NAME = N'%s'" % table_name)
row = cursor.fetchone()
if row is None:
raise ValueError("Table %s does not exist" % table_name)
return super().get_primary_key_column(cursor, table_name) | zilian-mssql-django | /zilian-mssql-django-1.1.4.tar.gz/zilian-mssql-django-1.1.4/mssql/introspection.py | introspection.py |
import json
from django import VERSION
from django.core import validators
from django.db import NotSupportedError, connections, transaction
from django.db.models import BooleanField, CheckConstraint, Value
from django.db.models.expressions import Case, Exists, Expression, OrderBy, When, Window
from django.db.models.fields import BinaryField, Field
from django.db.models.functions import Cast, NthValue
from django.db.models.functions.math import ATan2, Ln, Log, Mod, Round
from django.db.models.lookups import In, Lookup
from django.db.models.query import QuerySet
from django.db.models.sql.query import Query
if VERSION >= (3, 1):
from django.db.models.fields.json import (
KeyTransform, KeyTransformIn, KeyTransformExact,
HasKeyLookup, compile_json_path)
if VERSION >= (3, 2):
from django.db.models.functions.math import Random
DJANGO3 = VERSION[0] >= 3
class TryCast(Cast):
function = 'TRY_CAST'
def sqlserver_atan2(self, compiler, connection, **extra_context):
return self.as_sql(compiler, connection, function='ATN2', **extra_context)
def sqlserver_log(self, compiler, connection, **extra_context):
clone = self.copy()
clone.set_source_expressions(self.get_source_expressions()[::-1])
return clone.as_sql(compiler, connection, **extra_context)
def sqlserver_ln(self, compiler, connection, **extra_context):
return self.as_sql(compiler, connection, function='LOG', **extra_context)
def sqlserver_mod(self, compiler, connection):
# MSSQL doesn't have keyword MOD
expr = self.get_source_expressions()
number_a = compiler.compile(expr[0])
number_b = compiler.compile(expr[1])
return self.as_sql(
compiler, connection,
function="",
template='(ABS({a}) - FLOOR(ABS({a}) / ABS({b})) * ABS({b})) * SIGN({a}) * SIGN({b})'.format(
a=number_a[0], b=number_b[0]),
arg_joiner=""
)
def sqlserver_nth_value(self, compiler, connection, **extra_content):
raise NotSupportedError('This backend does not support the NthValue function')
def sqlserver_round(self, compiler, connection, **extra_context):
return self.as_sql(compiler, connection, template='%(function)s(%(expressions)s, 0)', **extra_context)
def sqlserver_random(self, compiler, connection, **extra_context):
return self.as_sql(compiler, connection, function='RAND', **extra_context)
def sqlserver_window(self, compiler, connection, template=None):
# MSSQL window functions require an OVER clause with ORDER BY
if self.order_by is None:
self.order_by = Value('SELECT NULL')
return self.as_sql(compiler, connection, template)
def sqlserver_exists(self, compiler, connection, template=None, **extra_context):
# MS SQL doesn't allow EXISTS() in the SELECT list, so wrap it with a
# CASE WHEN expression. Change the template since the When expression
# requires a left hand side (column) to compare against.
sql, params = self.as_sql(compiler, connection, template, **extra_context)
sql = 'CASE WHEN {} THEN 1 ELSE 0 END'.format(sql)
return sql, params
def sqlserver_lookup(self, compiler, connection):
# MSSQL doesn't allow EXISTS() to be compared to another expression
# unless it's wrapped in a CASE WHEN.
wrapped = False
exprs = []
for expr in (self.lhs, self.rhs):
if isinstance(expr, Exists):
expr = Case(When(expr, then=True), default=False, output_field=BooleanField())
wrapped = True
exprs.append(expr)
lookup = type(self)(*exprs) if wrapped else self
return lookup.as_sql(compiler, connection)
def sqlserver_orderby(self, compiler, connection):
template = None
if self.nulls_last:
template = 'CASE WHEN %(expression)s IS NULL THEN 1 ELSE 0 END, %(expression)s %(ordering)s'
if self.nulls_first:
template = 'CASE WHEN %(expression)s IS NULL THEN 0 ELSE 1 END, %(expression)s %(ordering)s'
copy = self.copy()
# Prevent OrderBy.as_sql() from modifying supplied templates
copy.nulls_first = False
copy.nulls_last = False
# MSSQL doesn't allow ORDER BY EXISTS() unless it's wrapped in a CASE WHEN.
if isinstance(self.expression, Exists):
copy.expression = Case(
When(self.expression, then=True),
default=False,
output_field=BooleanField(),
)
return copy.as_sql(compiler, connection, template=template)
def split_parameter_list_as_sql(self, compiler, connection):
if connection.vendor == 'microsoft':
return mssql_split_parameter_list_as_sql(self, compiler, connection)
else:
return in_split_parameter_list_as_sql(self, compiler, connection)
def mssql_split_parameter_list_as_sql(self, compiler, connection):
# Insert In clause parameters 1000 at a time into a temp table.
lhs, _ = self.process_lhs(compiler, connection)
_, rhs_params = self.batch_process_rhs(compiler, connection)
with connection.cursor() as cursor:
cursor.execute("IF OBJECT_ID('tempdb.dbo.#Temp_params', 'U') IS NOT NULL DROP TABLE #Temp_params; ")
parameter_data_type = self.lhs.field.db_type(connection)
Temp_table_collation = 'COLLATE DATABASE_DEFAULT' if 'char' in parameter_data_type else ''
cursor.execute(f"CREATE TABLE #Temp_params (params {parameter_data_type} {Temp_table_collation})")
for offset in range(0, len(rhs_params), 1000):
sqls_params = rhs_params[offset: offset + 1000]
sqls_params = ", ".join("('{}')".format(item) for item in sqls_params)
cursor.execute("INSERT INTO #Temp_params VALUES %s" % sqls_params)
in_clause = lhs + ' IN ' + '(SELECT params from #Temp_params)'
return in_clause, ()
def unquote_json_rhs(rhs_params):
for value in rhs_params:
value = json.loads(value)
if not isinstance(value, (list, dict)):
rhs_params = [param.replace('"', '') for param in rhs_params]
return rhs_params
def json_KeyTransformExact_process_rhs(self, compiler, connection):
rhs, rhs_params = key_transform_exact_process_rhs(self, compiler, connection)
if connection.vendor == 'microsoft':
rhs_params = unquote_json_rhs(rhs_params)
return rhs, rhs_params
def json_KeyTransformIn(self, compiler, connection):
lhs, _ = super(KeyTransformIn, self).process_lhs(compiler, connection)
rhs, rhs_params = super(KeyTransformIn, self).process_rhs(compiler, connection)
return (lhs + ' IN ' + rhs, unquote_json_rhs(rhs_params))
def json_HasKeyLookup(self, compiler, connection):
# Process JSON path from the left-hand side.
if isinstance(self.lhs, KeyTransform):
lhs, _, lhs_key_transforms = self.lhs.preprocess_lhs(compiler, connection)
lhs_json_path = compile_json_path(lhs_key_transforms)
else:
lhs, _ = self.process_lhs(compiler, connection)
lhs_json_path = '$'
sql = lhs + ' IN (SELECT ' + lhs + ' FROM ' + self.lhs.output_field.model._meta.db_table + \
' CROSS APPLY OPENJSON(' + lhs + ') WITH ( [json_path_value] char(1) \'%s\') WHERE [json_path_value] IS NOT NULL)'
# Process JSON path from the right-hand side.
rhs = self.rhs
rhs_params = []
if not isinstance(rhs, (list, tuple)):
rhs = [rhs]
for key in rhs:
if isinstance(key, KeyTransform):
*_, rhs_key_transforms = key.preprocess_lhs(compiler, connection)
else:
rhs_key_transforms = [key]
rhs_params.append('%s%s' % (
lhs_json_path,
compile_json_path(rhs_key_transforms, include_root=False),
))
# Add condition for each key.
if self.logical_operator:
sql = '(%s)' % self.logical_operator.join([sql] * len(rhs_params))
return sql % tuple(rhs_params), []
def BinaryField_init(self, *args, **kwargs):
# Add max_length option for BinaryField, default to max
kwargs.setdefault('editable', False)
Field.__init__(self, *args, **kwargs)
if self.max_length is not None:
self.validators.append(validators.MaxLengthValidator(self.max_length))
else:
self.max_length = 'max'
def _get_check_sql(self, model, schema_editor):
if VERSION >= (3, 1):
query = Query(model=model, alias_cols=False)
else:
query = Query(model=model)
where = query.build_where(self.check)
compiler = query.get_compiler(connection=schema_editor.connection)
sql, params = where.as_sql(compiler, schema_editor.connection)
if schema_editor.connection.vendor == 'microsoft':
try:
for p in params:
str(p).encode('ascii')
except UnicodeEncodeError:
sql = sql.replace('%s', 'N%s')
return sql % tuple(schema_editor.quote_value(p) for p in params)
def bulk_update_with_default(self, objs, fields, batch_size=None, default=0):
"""
Update the given fields in each of the given objects in the database.
When bulk_update all fields to null,
SQL Server require that at least one of the result expressions in a CASE specification must be an expression other than the NULL constant.
Patched with a default value 0. The user can also pass a custom default value for CASE statement.
"""
if batch_size is not None and batch_size < 0:
raise ValueError('Batch size must be a positive integer.')
if not fields:
raise ValueError('Field names must be given to bulk_update().')
objs = tuple(objs)
if any(obj.pk is None for obj in objs):
raise ValueError('All bulk_update() objects must have a primary key set.')
fields = [self.model._meta.get_field(name) for name in fields]
if any(not f.concrete or f.many_to_many for f in fields):
raise ValueError('bulk_update() can only be used with concrete fields.')
if any(f.primary_key for f in fields):
raise ValueError('bulk_update() cannot be used with primary key fields.')
if not objs:
return 0
# PK is used twice in the resulting update query, once in the filter
# and once in the WHEN. Each field will also have one CAST.
max_batch_size = connections[self.db].ops.bulk_batch_size(['pk', 'pk'] + fields, objs)
batch_size = min(batch_size, max_batch_size) if batch_size else max_batch_size
requires_casting = connections[self.db].features.requires_casted_case_in_updates
batches = (objs[i:i + batch_size] for i in range(0, len(objs), batch_size))
updates = []
for batch_objs in batches:
update_kwargs = {}
for field in fields:
value_none_counter = 0
when_statements = []
for obj in batch_objs:
attr = getattr(obj, field.attname)
if not isinstance(attr, Expression):
if attr is None:
value_none_counter += 1
attr = Value(attr, output_field=field)
when_statements.append(When(pk=obj.pk, then=attr))
if connections[self.db].vendor == 'microsoft' and value_none_counter == len(when_statements):
case_statement = Case(*when_statements, output_field=field, default=Value(default))
else:
case_statement = Case(*when_statements, output_field=field)
if requires_casting:
case_statement = Cast(case_statement, output_field=field)
update_kwargs[field.attname] = case_statement
updates.append(([obj.pk for obj in batch_objs], update_kwargs))
rows_updated = 0
with transaction.atomic(using=self.db, savepoint=False):
for pks, update_kwargs in updates:
rows_updated += self.filter(pk__in=pks).update(**update_kwargs)
return rows_updated
ATan2.as_microsoft = sqlserver_atan2
# Need copy of old In.split_parameter_list_as_sql for other backends to call
in_split_parameter_list_as_sql = In.split_parameter_list_as_sql
In.split_parameter_list_as_sql = split_parameter_list_as_sql
if VERSION >= (3, 1):
KeyTransformIn.as_microsoft = json_KeyTransformIn
# Need copy of old KeyTransformExact.process_rhs to call later
key_transform_exact_process_rhs = KeyTransformExact.process_rhs
KeyTransformExact.process_rhs = json_KeyTransformExact_process_rhs
HasKeyLookup.as_microsoft = json_HasKeyLookup
Ln.as_microsoft = sqlserver_ln
Log.as_microsoft = sqlserver_log
Mod.as_microsoft = sqlserver_mod
NthValue.as_microsoft = sqlserver_nth_value
Round.as_microsoft = sqlserver_round
Window.as_microsoft = sqlserver_window
BinaryField.__init__ = BinaryField_init
CheckConstraint._get_check_sql = _get_check_sql
if VERSION >= (3, 2):
Random.as_microsoft = sqlserver_random
if DJANGO3:
Lookup.as_microsoft = sqlserver_lookup
else:
Exists.as_microsoft = sqlserver_exists
OrderBy.as_microsoft = sqlserver_orderby
QuerySet.bulk_update = bulk_update_with_default | zilian-mssql-django | /zilian-mssql-django-1.1.4.tar.gz/zilian-mssql-django-1.1.4/mssql/functions.py | functions.py |
import types
from itertools import chain
import django
from django.db.models.aggregates import Avg, Count, StdDev, Variance
from django.db.models.expressions import Ref, Subquery, Value
from django.db.models.functions import (
Chr, ConcatPair, Greatest, Least, Length, LPad, Repeat, RPad, StrIndex, Substr, Trim
)
from django.db.models.sql import compiler
from django.db.transaction import TransactionManagementError
from django.db.utils import NotSupportedError
if django.VERSION >= (3, 1):
from django.db.models.fields.json import compile_json_path, KeyTransform as json_KeyTransform
def _as_sql_agv(self, compiler, connection):
return self.as_sql(compiler, connection, template='%(function)s(CONVERT(float, %(field)s))')
def _as_sql_chr(self, compiler, connection):
return self.as_sql(compiler, connection, function='NCHAR')
def _as_sql_concatpair(self, compiler, connection):
if connection.sql_server_version < 2012:
node = self.coalesce()
return node.as_sql(compiler, connection, arg_joiner=' + ', template='%(expressions)s')
else:
return self.as_sql(compiler, connection)
def _as_sql_count(self, compiler, connection):
return self.as_sql(compiler, connection, function='COUNT_BIG')
def _as_sql_greatest(self, compiler, connection):
# SQL Server does not provide GREATEST function,
# so we emulate it with a table value constructor
# https://msdn.microsoft.com/en-us/library/dd776382.aspx
template = '(SELECT MAX(value) FROM (VALUES (%(expressions)s)) AS _%(function)s(value))'
return self.as_sql(compiler, connection, arg_joiner='), (', template=template)
def _as_sql_json_keytransform(self, compiler, connection):
lhs, params, key_transforms = self.preprocess_lhs(compiler, connection)
json_path = compile_json_path(key_transforms)
return (
"COALESCE(JSON_QUERY(%s, '%s'), JSON_VALUE(%s, '%s'))" %
((lhs, json_path) * 2)
), tuple(params) * 2
def _as_sql_least(self, compiler, connection):
# SQL Server does not provide LEAST function,
# so we emulate it with a table value constructor
# https://msdn.microsoft.com/en-us/library/dd776382.aspx
template = '(SELECT MIN(value) FROM (VALUES (%(expressions)s)) AS _%(function)s(value))'
return self.as_sql(compiler, connection, arg_joiner='), (', template=template)
def _as_sql_length(self, compiler, connection):
return self.as_sql(compiler, connection, function='LEN')
def _as_sql_lpad(self, compiler, connection):
i = iter(self.get_source_expressions())
expression, expression_arg = compiler.compile(next(i))
length, length_arg = compiler.compile(next(i))
fill_text, fill_text_arg = compiler.compile(next(i))
params = []
params.extend(fill_text_arg)
params.extend(length_arg)
params.extend(length_arg)
params.extend(expression_arg)
params.extend(length_arg)
params.extend(expression_arg)
params.extend(expression_arg)
template = ('LEFT(REPLICATE(%(fill_text)s, %(length)s), CASE WHEN %(length)s > LEN(%(expression)s) '
'THEN %(length)s - LEN(%(expression)s) ELSE 0 END) + %(expression)s')
return template % {'expression': expression, 'length': length, 'fill_text': fill_text}, params
def _as_sql_repeat(self, compiler, connection):
return self.as_sql(compiler, connection, function='REPLICATE')
def _as_sql_rpad(self, compiler, connection):
i = iter(self.get_source_expressions())
expression, expression_arg = compiler.compile(next(i))
length, length_arg = compiler.compile(next(i))
fill_text, fill_text_arg = compiler.compile(next(i))
params = []
params.extend(expression_arg)
params.extend(fill_text_arg)
params.extend(length_arg)
params.extend(length_arg)
template = 'LEFT(%(expression)s + REPLICATE(%(fill_text)s, %(length)s), %(length)s)'
return template % {'expression': expression, 'length': length, 'fill_text': fill_text}, params
def _as_sql_stddev(self, compiler, connection):
function = 'STDEV'
if self.function == 'STDDEV_POP':
function = '%sP' % function
return self.as_sql(compiler, connection, function=function)
def _as_sql_strindex(self, compiler, connection):
self.source_expressions.reverse()
sql = self.as_sql(compiler, connection, function='CHARINDEX')
self.source_expressions.reverse()
return sql
def _as_sql_substr(self, compiler, connection):
if len(self.get_source_expressions()) < 3:
self.get_source_expressions().append(Value(2**31 - 1))
return self.as_sql(compiler, connection)
def _as_sql_trim(self, compiler, connection):
return self.as_sql(compiler, connection, template='LTRIM(RTRIM(%(expressions)s))')
def _as_sql_variance(self, compiler, connection):
function = 'VAR'
if self.function == 'VAR_POP':
function = '%sP' % function
return self.as_sql(compiler, connection, function=function)
def _cursor_iter(cursor, sentinel, col_count, itersize):
"""
Yields blocks of rows from a cursor and ensures the cursor is closed when
done.
"""
if not hasattr(cursor.db, 'supports_mars') or cursor.db.supports_mars:
# same as the original Django implementation
try:
for rows in iter((lambda: cursor.fetchmany(itersize)), sentinel):
yield rows if col_count is None else [r[:col_count] for r in rows]
finally:
cursor.close()
else:
# retrieve all chunks from the cursor and close it before yielding
# so that we can open an another cursor over an iteration
# (for drivers such as FreeTDS)
chunks = []
try:
for rows in iter((lambda: cursor.fetchmany(itersize)), sentinel):
chunks.append(rows if col_count is None else [r[:col_count] for r in rows])
finally:
cursor.close()
for rows in chunks:
yield rows
compiler.cursor_iter = _cursor_iter
class SQLCompiler(compiler.SQLCompiler):
def as_sql(self, with_limits=True, with_col_aliases=False):
"""
Create the SQL for this query. Return the SQL string and list of
parameters.
If 'with_limits' is False, any limit/offset information is not included
in the query.
"""
refcounts_before = self.query.alias_refcount.copy()
try:
extra_select, order_by, group_by = self.pre_sql_setup()
for_update_part = None
# Is a LIMIT/OFFSET clause needed?
with_limit_offset = with_limits and (self.query.high_mark is not None or self.query.low_mark)
combinator = self.query.combinator
features = self.connection.features
# The do_offset flag indicates whether we need to construct
# the SQL needed to use limit/offset w/SQL Server.
high_mark = self.query.high_mark
low_mark = self.query.low_mark
do_limit = with_limits and high_mark is not None
do_offset = with_limits and low_mark != 0
# SQL Server 2012 or newer supports OFFSET/FETCH clause
supports_offset_clause = self.connection.sql_server_version >= 2012
do_offset_emulation = do_offset and not supports_offset_clause
if combinator:
if not getattr(features, 'supports_select_{}'.format(combinator)):
raise NotSupportedError('{} is not supported on this database backend.'.format(combinator))
result, params = self.get_combinator_sql(combinator, self.query.combinator_all)
else:
distinct_fields, distinct_params = self.get_distinct()
# This must come after 'select', 'ordering', and 'distinct' -- see
# docstring of get_from_clause() for details.
from_, f_params = self.get_from_clause()
where, w_params = self.compile(self.where) if self.where is not None else ("", [])
having, h_params = self.compile(self.having) if self.having is not None else ("", [])
params = []
result = ['SELECT']
if self.query.distinct:
distinct_result, distinct_params = self.connection.ops.distinct_sql(
distinct_fields,
distinct_params,
)
result += distinct_result
params += distinct_params
# SQL Server requires the keword for limitting at the begenning
if do_limit and not do_offset:
result.append('TOP %d' % high_mark)
out_cols = []
col_idx = 1
for _, (s_sql, s_params), alias in self.select + extra_select:
if alias:
s_sql = '%s AS %s' % (s_sql, self.connection.ops.quote_name(alias))
elif with_col_aliases or do_offset_emulation:
s_sql = '%s AS %s' % (s_sql, 'Col%d' % col_idx)
col_idx += 1
params.extend(s_params)
out_cols.append(s_sql)
# SQL Server requires an order-by clause for offsetting
if do_offset:
meta = self.query.get_meta()
qn = self.quote_name_unless_alias
offsetting_order_by = '%s.%s' % (qn(meta.db_table), qn(meta.pk.db_column or meta.pk.column))
if do_offset_emulation:
if order_by:
ordering = []
for expr, (o_sql, o_params, _) in order_by:
# value_expression in OVER clause cannot refer to
# expressions or aliases in the select list. See:
# http://msdn.microsoft.com/en-us/library/ms189461.aspx
src = next(iter(expr.get_source_expressions()))
if isinstance(src, Ref):
src = next(iter(src.get_source_expressions()))
o_sql, _ = src.as_sql(self, self.connection)
odir = 'DESC' if expr.descending else 'ASC'
o_sql = '%s %s' % (o_sql, odir)
ordering.append(o_sql)
params.extend(o_params)
offsetting_order_by = ', '.join(ordering)
order_by = []
out_cols.append('ROW_NUMBER() OVER (ORDER BY %s) AS [rn]' % offsetting_order_by)
elif not order_by:
order_by.append(((None, ('%s ASC' % offsetting_order_by, [], None))))
if self.query.select_for_update and self.connection.features.has_select_for_update:
if self.connection.get_autocommit():
raise TransactionManagementError('select_for_update cannot be used outside of a transaction.')
if with_limit_offset and not self.connection.features.supports_select_for_update_with_limit:
raise NotSupportedError(
'LIMIT/OFFSET is not supported with '
'select_for_update on this database backend.'
)
nowait = self.query.select_for_update_nowait
skip_locked = self.query.select_for_update_skip_locked
of = self.query.select_for_update_of
# If it's a NOWAIT/SKIP LOCKED/OF query but the backend
# doesn't support it, raise NotSupportedError to prevent a
# possible deadlock.
if nowait and not self.connection.features.has_select_for_update_nowait:
raise NotSupportedError('NOWAIT is not supported on this database backend.')
elif skip_locked and not self.connection.features.has_select_for_update_skip_locked:
raise NotSupportedError('SKIP LOCKED is not supported on this database backend.')
elif of and not self.connection.features.has_select_for_update_of:
raise NotSupportedError('FOR UPDATE OF is not supported on this database backend.')
for_update_part = self.connection.ops.for_update_sql(
nowait=nowait,
skip_locked=skip_locked,
of=self.get_select_for_update_of_arguments(),
)
if for_update_part and self.connection.features.for_update_after_from:
from_.insert(1, for_update_part)
result += [', '.join(out_cols), 'FROM', *from_]
params.extend(f_params)
if where:
result.append('WHERE %s' % where)
params.extend(w_params)
grouping = []
for g_sql, g_params in group_by:
grouping.append(g_sql)
params.extend(g_params)
if grouping:
if distinct_fields:
raise NotImplementedError('annotate() + distinct(fields) is not implemented.')
order_by = order_by or self.connection.ops.force_no_ordering()
result.append('GROUP BY %s' % ', '.join(grouping))
if having:
result.append('HAVING %s' % having)
params.extend(h_params)
explain = self.query.explain_info if django.VERSION >= (4, 0) else self.query.explain_query
if explain:
result.insert(0, self.connection.ops.explain_query_prefix(
self.query.explain_format,
**self.query.explain_options
))
if order_by:
ordering = []
for _, (o_sql, o_params, _) in order_by:
ordering.append(o_sql)
params.extend(o_params)
result.append('ORDER BY %s' % ', '.join(ordering))
# For subqueres with an ORDER BY clause, SQL Server also
# requires a TOP or OFFSET clause which is not generated for
# Django 2.x. See https://github.com/microsoft/mssql-django/issues/12
# Add OFFSET for all Django versions.
# https://github.com/microsoft/mssql-django/issues/109
if not (do_offset or do_limit):
result.append("OFFSET 0 ROWS")
# SQL Server requires the backend-specific emulation (2008 or earlier)
# or an offset clause (2012 or newer) for offsetting
if do_offset:
if do_offset_emulation:
# Construct the final SQL clause, using the initial select SQL
# obtained above.
result = ['SELECT * FROM (%s) AS X WHERE X.rn' % ' '.join(result)]
# Place WHERE condition on `rn` for the desired range.
if do_limit:
result.append('BETWEEN %d AND %d' % (low_mark + 1, high_mark))
else:
result.append('>= %d' % (low_mark + 1))
if not self.query.subquery:
result.append('ORDER BY X.rn')
else:
result.append(self.connection.ops.limit_offset_sql(self.query.low_mark, self.query.high_mark))
if self.query.subquery and extra_select:
# If the query is used as a subquery, the extra selects would
# result in more columns than the left-hand side expression is
# expecting. This can happen when a subquery uses a combination
# of order_by() and distinct(), forcing the ordering expressions
# to be selected as well. Wrap the query in another subquery
# to exclude extraneous selects.
sub_selects = []
sub_params = []
for index, (select, _, alias) in enumerate(self.select, start=1):
if not alias and with_col_aliases:
alias = 'col%d' % index
if alias:
sub_selects.append("%s.%s" % (
self.connection.ops.quote_name('subquery'),
self.connection.ops.quote_name(alias),
))
else:
select_clone = select.relabeled_clone({select.alias: 'subquery'})
subselect, subparams = select_clone.as_sql(self, self.connection)
sub_selects.append(subselect)
sub_params.extend(subparams)
return 'SELECT %s FROM (%s) subquery' % (
', '.join(sub_selects),
' '.join(result),
), tuple(sub_params + params)
return ' '.join(result), tuple(params)
finally:
# Finally do cleanup - get rid of the joins we created above.
self.query.reset_refcounts(refcounts_before)
def compile(self, node, *args, **kwargs):
node = self._as_microsoft(node)
return super().compile(node, *args, **kwargs)
def collapse_group_by(self, expressions, having):
expressions = super().collapse_group_by(expressions, having)
return [e for e in expressions if not isinstance(e, Subquery)]
def _as_microsoft(self, node):
as_microsoft = None
if isinstance(node, Avg):
as_microsoft = _as_sql_agv
elif isinstance(node, Chr):
as_microsoft = _as_sql_chr
elif isinstance(node, ConcatPair):
as_microsoft = _as_sql_concatpair
elif isinstance(node, Count):
as_microsoft = _as_sql_count
elif isinstance(node, Greatest):
as_microsoft = _as_sql_greatest
elif isinstance(node, Least):
as_microsoft = _as_sql_least
elif isinstance(node, Length):
as_microsoft = _as_sql_length
elif isinstance(node, RPad):
as_microsoft = _as_sql_rpad
elif isinstance(node, LPad):
as_microsoft = _as_sql_lpad
elif isinstance(node, Repeat):
as_microsoft = _as_sql_repeat
elif isinstance(node, StdDev):
as_microsoft = _as_sql_stddev
elif isinstance(node, StrIndex):
as_microsoft = _as_sql_strindex
elif isinstance(node, Substr):
as_microsoft = _as_sql_substr
elif isinstance(node, Trim):
as_microsoft = _as_sql_trim
elif isinstance(node, Variance):
as_microsoft = _as_sql_variance
if django.VERSION >= (3, 1):
if isinstance(node, json_KeyTransform):
as_microsoft = _as_sql_json_keytransform
if as_microsoft:
node = node.copy()
node.as_microsoft = types.MethodType(as_microsoft, node)
return node
class SQLInsertCompiler(compiler.SQLInsertCompiler, SQLCompiler):
def get_returned_fields(self):
if django.VERSION >= (3, 0, 0):
return self.returning_fields
return self.return_id
def can_return_columns_from_insert(self):
if django.VERSION >= (3, 0, 0):
return self.connection.features.can_return_columns_from_insert
return self.connection.features.can_return_id_from_insert
def can_return_rows_from_bulk_insert(self):
if django.VERSION >= (3, 0, 0):
return self.connection.features.can_return_rows_from_bulk_insert
return self.connection.features.can_return_ids_from_bulk_insert
def fix_auto(self, sql, opts, fields, qn):
if opts.auto_field is not None:
# db_column is None if not explicitly specified by model field
auto_field_column = opts.auto_field.db_column or opts.auto_field.column
columns = [f.column for f in fields]
if auto_field_column in columns:
id_insert_sql = []
table = qn(opts.db_table)
sql_format = 'SET IDENTITY_INSERT %s ON; %s; SET IDENTITY_INSERT %s OFF'
for q, p in sql:
id_insert_sql.append((sql_format % (table, q, table), p))
sql = id_insert_sql
return sql
def bulk_insert_default_values_sql(self, table):
seed_rows_number = 8
cross_join_power = 4 # 8^4 = 4096 > maximum allowed batch size for the backend = 1000
def generate_seed_rows(n):
return " UNION ALL ".join("SELECT 1 AS x" for _ in range(n))
def cross_join(p):
return ", ".join("SEED_ROWS AS _%s" % i for i in range(p))
return """
WITH SEED_ROWS AS (%s)
MERGE INTO %s
USING (
SELECT TOP %s * FROM (SELECT 1 as x FROM %s) FAKE_ROWS
) FAKE_DATA
ON 1 = 0
WHEN NOT MATCHED THEN
INSERT DEFAULT VALUES
""" % (generate_seed_rows(seed_rows_number),
table,
len(self.query.objs),
cross_join(cross_join_power))
def as_sql(self):
# We don't need quote_name_unless_alias() here, since these are all
# going to be column names (so we can avoid the extra overhead).
qn = self.connection.ops.quote_name
opts = self.query.get_meta()
result = ['INSERT INTO %s' % qn(opts.db_table)]
if self.query.fields:
fields = self.query.fields
result.append('(%s)' % ', '.join(qn(f.column) for f in fields))
values_format = 'VALUES (%s)'
value_rows = [
[self.prepare_value(field, self.pre_save_val(field, obj)) for field in fields]
for obj in self.query.objs
]
else:
values_format = '%s VALUES'
# An empty object.
value_rows = [[self.connection.ops.pk_default_value()] for _ in self.query.objs]
fields = [None]
# Currently the backends just accept values when generating bulk
# queries and generate their own placeholders. Doing that isn't
# necessary and it should be possible to use placeholders and
# expressions in bulk inserts too.
can_bulk = (not self.get_returned_fields() and self.connection.features.has_bulk_insert) and self.query.fields
placeholder_rows, param_rows = self.assemble_as_sql(fields, value_rows)
if self.get_returned_fields() and self.can_return_columns_from_insert():
if self.can_return_rows_from_bulk_insert():
if not(self.query.fields):
# There isn't really a single statement to bulk multiple DEFAULT VALUES insertions,
# so we have to use a workaround:
# https://dba.stackexchange.com/questions/254771/insert-multiple-rows-into-a-table-with-only-an-identity-column
result = [self.bulk_insert_default_values_sql(qn(opts.db_table))]
r_sql, self.returning_params = self.connection.ops.return_insert_columns(self.get_returned_fields())
if r_sql:
result.append(r_sql)
sql = " ".join(result) + ";"
return [(sql, None)]
# Regular bulk insert
params = []
r_sql, self.returning_params = self.connection.ops.return_insert_columns(self.get_returned_fields())
if r_sql:
result.append(r_sql)
params += [self.returning_params]
params += param_rows
result.append(self.connection.ops.bulk_insert_sql(fields, placeholder_rows))
else:
result.insert(0, 'SET NOCOUNT ON')
result.append((values_format + ';') % ', '.join(placeholder_rows[0]))
params = [param_rows[0]]
result.append('SELECT CAST(SCOPE_IDENTITY() AS bigint)')
sql = [(" ".join(result), tuple(chain.from_iterable(params)))]
else:
if can_bulk:
result.append(self.connection.ops.bulk_insert_sql(fields, placeholder_rows))
sql = [(" ".join(result), tuple(p for ps in param_rows for p in ps))]
else:
sql = [
(" ".join(result + [values_format % ", ".join(p)]), vals)
for p, vals in zip(placeholder_rows, param_rows)
]
if self.query.fields:
sql = self.fix_auto(sql, opts, fields, qn)
return sql
class SQLDeleteCompiler(compiler.SQLDeleteCompiler, SQLCompiler):
def as_sql(self):
sql, params = super().as_sql()
if sql:
sql = '; '.join(['SET NOCOUNT OFF', sql])
return sql, params
class SQLUpdateCompiler(compiler.SQLUpdateCompiler, SQLCompiler):
def as_sql(self):
sql, params = super().as_sql()
if sql:
sql = '; '.join(['SET NOCOUNT OFF', sql])
return sql, params
class SQLAggregateCompiler(compiler.SQLAggregateCompiler, SQLCompiler):
pass | zilian-mssql-django | /zilian-mssql-django-1.1.4.tar.gz/zilian-mssql-django-1.1.4/mssql/compiler.py | compiler.py |
Zillion: Make sense of it all
=============================
[](https://shields.io/)
[](https://github.com/psf/black)


[](https://pepy.tech/project/zillion)
**Introduction**
----------------
`Zillion` is a data modeling and analytics tool that allows combining and
analyzing data from multiple datasources through a simple API. It writes SQL
so you don't have to, and it easily bolts onto existing database infrastructure
via SQLAlchemy. The `Zillion` NLP extension has experimental support for AI-powered
natural language querying and warehouse configuration.
With `Zillion` you can:
* Define a warehouse that contains a variety of SQL and/or file-like
datasources
* Define or reflect metrics, dimensions, and relationships in your data
* Run multi-datasource reports and combine the results in a DataFrame
* Flexibly aggregate your data with multi-level rollups and table pivots
* Customize or combine fields with formulas
* Apply technical transformations including rolling, cumulative, and rank
statistics
* Apply automatic type conversions - i.e. get a "year" dimension for free
from a "date" column
* Save and share report specifications
* Utilize ad hoc or public datasources, tables, and fields to enrich reports
* Query your warehouse with natural language (NLP extension)
* Leverage AI to bootstrap your warehouse configurations (NLP extension)
**Table of Contents**
---------------------
* [Installation](#installation)
* [Primer](#primer)
* [Metrics and Dimensions](#metrics-and-dimensions)
* [Warehouse Theory](#warehouse-theory)
* [Query Layers](#query-layers)
* [Warehouse Creation](#warehouse-creation)
* [Executing Reports](#executing-reports)
* [Natural Language Querying](#natural-language-querying)
* [Zillion Configuration](#zillion-configuration)
* [Example - Sales Analytics](#example-sales-analytics)
* [Warehouse Configuration](#example-warehouse-config)
* [Reports](#example-reports)
* [Advanced Topics](#advanced-topics)
* [Subreports](#subreports)
* [FormulaMetrics](#formula-metrics)
* [Divisor Metrics](#divisor-metrics)
* [FormulaDimensions](#formula-dimensions)
* [DataSource Formulas](#datasource-formulas)
* [Type Conversions](#type-conversions)
* [AdHocMetrics](#adhoc-metrics)
* [AdHocDimensions](#adhoc-dimensions)
* [AdHocDataTables](#adhoc-data-tables)
* [Technicals](#technicals)
* [Config Variables](#config-variables)
* [DataSource Priority](#datasource-priority)
* [Supported DataSources](#supported-datasources)
* [Multiprocess Considerations](#multiprocess-considerations)
* [Demo UI / Web API](#demo-ui)
* [Docs](#documentation)
* [How to Contribute](#how-to-contribute)
<a name="installation"></a>
**Installation**
----------------
> **Warning**: This project is in an alpha state and is subject to change. Please test carefully for production usage and report any issues.
```shell
$ pip install zillion
or
$ pip install zillion[nlp]
```
---
<a name="primer"></a>
**Primer**
----------
The following is meant to give a quick overview of some theory and
nomenclature used in data warehousing with `Zillion` which will be useful
if you are newer to this area. You can also skip below for a usage [example](#example-sales-analytics) or warehouse/datasource creation [quickstart](#warehouse-creation) options.
In short: `Zillion` writes SQL for you and makes data accessible through a very simple API:
```python
result = warehouse.execute(
metrics=["revenue", "leads"],
dimensions=["date"],
criteria=[
("date", ">", "2020-01-01"),
("partner", "=", "Partner A")
]
)
```
<a name="metrics-and-dimensions"></a>
### **Metrics and Dimensions**
In `Zillion` there are two main types of `Fields` that will be used in
your report requests:
1. `Dimensions`: attributes of data used for labelling, grouping, and filtering
2. `Metrics`: facts and measures that may be broken down along dimensions
A `Field` encapsulates the concept of a column in your data. For example, you
may have a `Field` called "revenue". That `Field` may occur across several
datasources or possibly in multiple tables within a single datasource. `Zillion`
understands that all of those columns represent the same concept, and it can try
to use any of them to satisfy reports requesting "revenue".
Likewise there are two main types of tables used to structure your warehouse:
1. `Dimension Tables`: reference/attribute tables containing only related
dimensions
2. `Metric Tables`: fact tables that may contain metrics and some related
dimensions/attributes
Dimension tables are often static or slowly growing in terms of row count and contain
attributes tied to a primary key. Some common examples would be lists of US Zip Codes or
company/partner directories.
Metric tables are generally more transactional in nature. Some common examples
would be records for web requests, ecommerce sales, or stock market price history.
<a name="warehouse-theory"></a>
### **Warehouse Theory**
If you really want to go deep on dimensional modeling and the drill-across
querying technique `Zillion` employs, I recommend reading Ralph Kimball's
[book](https://www.kimballgroup.com/data-warehouse-business-intelligence-resources/books/data-warehouse-dw-toolkit/) on data warehousing.
To summarize, [drill-across
querying](https://www.kimballgroup.com/data-warehouse-business-intelligence-resources/kimball-techniques/dimensional-modeling-techniques/drilling-across/)
forms one or more queries to satisfy a report request for `metrics` that may
exist across multiple datasources and/or tables at a particular `dimension` grain.
`Zillion` supports flexible warehouse setups such as
[snowflake](https://en.wikipedia.org/wiki/Snowflake_schema) or
[star](https://en.wikipedia.org/wiki/Star_schema) schemas, though it isn't
picky about it. You can specify table relationships through a parent-child
lineage, and `Zillion` can also infer acceptable joins based on the presence
of dimension table primary keys. `Zillion` does not support many-to-many relationships at this time, though most analytics-focused scenarios should be able to work around that by adding views to the model if needed.
<a name="query-layers"></a>
### **Query Layers**
`Zillion` reports can be thought of as running in two layers:
1. `DataSource Layer`: SQL queries against the warehouse's datasources
2. `Combined Layer`: A final SQL query against the combined data from the
DataSource Layer
The Combined Layer is just another SQL database (in-memory SQLite by default)
that is used to tie the datasource data together and apply a few additional
features such as rollups, row filters, row limits, sorting, pivots, and technical computations.
<a name="warehouse-creation"></a>
### **Warehouse Creation**
There are multiple ways to quickly initialize a warehouse from a local or remote file:
```python
# Path/link to a CSV, XLSX, XLS, JSON, HTML, or Google Sheet
# This builds a single-table Warehouse for quick/ad-hoc analysis.
url = "https://raw.githubusercontent.com/totalhack/zillion/master/tests/dma_zip.xlsx"
wh = Warehouse.from_data_file(url, ["Zip_Code"]) # Second arg is primary key
# Path/link to a sqlite database
# This can build a single or multi-table Warehouse
url = "https://github.com/totalhack/zillion/blob/master/tests/testdb1?raw=true"
wh = Warehouse.from_db_file(url)
# Path/link to a WarehouseConfigSchema (or pass a dict)
# This is the recommended production approach!
config = "https://raw.githubusercontent.com/totalhack/zillion/master/examples/example_wh_config.json"
wh = Warehouse(config=config)
```
Zillion also provides a helper script to boostrap a DataSource configuration file for an existing database. See `zillion.scripts.bootstrap_datasource_config.py`. The bootstrap script requires a connection/database url and output file as arguments. See `--help` output for more options, including the optional `--nlp` flag that leverages OpenAI to infer configuration information such as column types, table types, and table relationships. The NLP feature requires the NLP extension to be installed as well as the following set in your `Zillion` config file:
* OPENAI_MODEL
* OPENAI_API_KEY
<a name="executing-reports"></a>
### **Executing Reports**
The main purpose of `Zillion` is to execute reports against a `Warehouse`.
At a high level you will be crafting reports as follows:
```python
result = warehouse.execute(
metrics=["revenue", "leads"],
dimensions=["date"],
criteria=[
("date", ">", "2020-01-01"),
("partner", "=", "Partner A")
]
)
print(result.df) # Pandas DataFrame
```
When comparing to writing SQL, it's helpful to think of the dimensions as the
target columns of a **group by** SQL statement. Think of the metrics as the
columns you are **aggregating**. Think of the criteria as the **where
clause**. Your criteria are applied in the DataSource Layer SQL queries.
The `ReportResult` has a Pandas DataFrame with the dimensions as the index and
the metrics as the columns.
A `Report` is said to have a `grain`, which defines the dimensions each metric
must be able to join to in order to satisfy the `Report` requirements. The
`grain` is a combination of **all** dimensions, including those referenced in
criteria or in metric formulas. In the example above, the `grain` would be
`{date, partner}`. Both "revenue" and "leads" must be able to join to those
dimensions for this report to be possible.
These concepts can take time to sink in and obviously vary with the specifics
of your data model, but you will become more familiar with them as you start
putting together reports against your data warehouses.
<a name="natural-language-querying"></a>
### **Natural Language Querying**
With the NLP extension `Zillion` has experimental support for natural language querying of your data warehouse. For example:
```python
result = warehouse.execute_text("revenue and leads by date last month")
print(result.df) # Pandas DataFrame
```
This NLP feature require a running instance of Qdrant (vector database) and the following values set in your `Zillion` config file:
* QDRANT_HOST
* OPENAI_API_KEY
Embeddings will be produced and stored in both Qdrant and a local cache. The
vector database will be initialized the first time you try to use this by
analyzing all fields in your warehouse. An example docker file to run Qdrant is provided in the root of this repo.
You have some control over how fields get embedded. Namely in the configuration for any field you can choose whether to exclude a field from embeddings or override which embeddings map to that field. All fields are
included by default. The following example would exclude the `net_revenue` field from being embedded and map `revenue` metric requests to the `gross_revenue` field.
```javascript
{
"name": "gross_revenue",
"type": "numeric(10,2)",
"aggregation": "sum",
"rounding": 2,
"meta": {
"nlp": {
// enabled defaults to true
"embedding_text": "revenue" // str or list of str
}
}
},
{
"name": "net_revenue",
"type": "numeric(10,2)",
"aggregation": "sum",
"rounding": 2,
"meta": {
"nlp": {
"enabled": false
}
}
},
```
Additionally you may also exclude fields via the following warehouse-level configuration settings:
```javascript
{
"meta": {
"nlp": {
"field_disabled_patterns": [
// list of regex patterns to exclude
"rpl_ma_5"
],
"field_disabled_groups": [
// list of "groups" to exclude, assuming you have
// set group value in the field's meta dict.
"No NLP"
]
}
},
...
}
```
If a field is disabled at any of the aforementioned levels it will be ignored. This type of control becomes useful as your data model gets more complex and you want to guide the NLP logic in cases where it could confuse similarly named fields. Any time you adjust which fields are excluded you will want to force recreation of your embeddings collection using the `force_recreate` flag on `Warehouse.init_embeddings`.
> *Note:* This feature is in its infancy. It's usefulness will depend on the
quality of both the input query and your data model (i.e. good field names)!
<a name="zillion-configuration"></a>
### **Zillion Configuration**
In addition to configuring the structure of your `Warehouse`, which will be
discussed further below, `Zillion` has a global configuration to control some
basic settings. The `ZILLION_CONFIG` environment var can point to a yaml config file. See `examples/sample_config.yaml` for more details on what values can be set. Environment vars prefixed with ZILLION_ can override config settings (i.e. ZILLION_DB_URL will override DB_URL).
The database used to store Zillion report specs can be configured by setting the DB_URL value in your `Zillion` config to a valid database connection string. By default a SQLite DB in /tmp is used.
---
<a name="example-sales-analytics"></a>
**Example - Sales Analytics**
-----------------------------
Below we will walk through a simple hypothetical sales data model that
demonstrates basic `DataSource` and `Warehouse` configuration and then shows
some sample [reports](#example-reports). The data is a simple SQLite database
that is part of the `Zillion` test code. For reference, the schema is as
follows:
```sql
CREATE TABLE partners (
id INTEGER PRIMARY KEY,
name VARCHAR NOT NULL UNIQUE,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
CREATE TABLE campaigns (
id INTEGER PRIMARY KEY,
name VARCHAR NOT NULL UNIQUE,
category VARCHAR NOT NULL,
partner_id INTEGER NOT NULL,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
CREATE TABLE leads (
id INTEGER PRIMARY KEY,
name VARCHAR NOT NULL,
campaign_id INTEGER NOT NULL,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
CREATE TABLE sales (
id INTEGER PRIMARY KEY,
item VARCHAR NOT NULL,
quantity INTEGER NOT NULL,
revenue DECIMAL(10, 2),
lead_id INTEGER NOT NULL,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
```
<a name="example-warehouse-config"></a>
### **Warehouse Configuration**
A `Warehouse` may be created from a from a JSON or YAML configuration that defines
its fields, datasources, and tables. The code below shows how it can be done in as little as one line of code if you have a pointer to a JSON/YAML `Warehouse` config.
```python
from zillion import Warehouse
wh = Warehouse(config="https://raw.githubusercontent.com/totalhack/zillion/master/examples/example_wh_config.json")
```
This example config uses a `data_url` in its `DataSource` `connect` info that
tells `Zillion` to dynamically download that data and connect to it as a
SQLite database. This is useful for quick examples or analysis, though in most
scenarios you would put a connection string to an existing database like you
see
[here](https://raw.githubusercontent.com/totalhack/zillion/master/tests/test_mysql_ds_config.json)
The basics of `Zillion's` warehouse configuration structure are as follows:
A `Warehouse` config has the following main sections:
* `metrics`: optional list of metric configs for global metrics
* `dimensions`: optional list of dimension configs for global dimensions
* `datasources`: mapping of datasource names to datasource configs or config URLs
A `DataSource` config has the following main sections:
* `connect`: database connection url or dict of connect params
* `metrics`: optional list of metric configs specific to this datasource
* `dimensions`: optional list of dimension configs specific to this datasource
* `tables`: mapping of table names to table configs or config URLs
> Tip: datasource and table configs may also be replaced with a URL that points
to a local or remote config file.
In this example all four tables in our database are included in the config,
two as dimension tables and two as metric tables. The tables are linked
through a parent->child relationship: partners to campaigns, and leads to
sales. Some tables also utilize the `create_fields` flag to automatically
create `Fields` on the datasource from column definitions. Other metrics and
dimensions are defined explicitly.
To view the structure of this `Warehouse` after init you can use the `print_info`
method which shows all metrics, dimensions, tables, and columns that are part
of your data warehouse:
```python
wh.print_info() # Formatted print of the Warehouse structure
```
For a deeper dive of the config schema please see the full
[docs](https://totalhack.github.io/zillion/zillion.configs/).
<a name="example-reports"></a>
### **Reports**
**Example:** Get sales, leads, and revenue by partner:
```python
result = wh.execute(
metrics=["sales", "leads", "revenue"],
dimensions=["partner_name"]
)
print(result.df)
"""
sales leads revenue
partner_name
Partner A 11 4 165.0
Partner B 2 2 19.0
Partner C 5 1 118.5
"""
```
**Example:** Let's limit to Partner A and break down by its campaigns:
```python
result = wh.execute(
metrics=["sales", "leads", "revenue"],
dimensions=["campaign_name"],
criteria=[("partner_name", "=", "Partner A")]
)
print(result.df)
"""
sales leads revenue
campaign_name
Campaign 1A 5 2 83
Campaign 2A 6 2 82
"""
```
**Example:** The output below shows rollups at the campaign level within each
partner, and also a rollup of totals at the partner and campaign level.
> *Note:* the output contains a special character to mark DataFrame rollup rows
that were added to the result. The
[ReportResult](https://totalhack.github.io/zillion/zillion.report/#reportresult)
object contains some helper attributes to automatically access or filter
rollups, as well as a `df_display` attribute that returns the result with
friendlier display values substituted for special characters. The
under-the-hood special character is left here for illustration, but may not
render the same in all scenarios.
```python
from zillion import RollupTypes
result = wh.execute(
metrics=["sales", "leads", "revenue"],
dimensions=["partner_name", "campaign_name"],
rollup=RollupTypes.ALL
)
print(result.df)
"""
sales leads revenue
partner_name campaign_name
Partner A Campaign 1A 5.0 2.0 83.0
Campaign 2A 6.0 2.0 82.0
11.0 4.0 165.0
Partner B Campaign 1B 1.0 1.0 6.0
Campaign 2B 1.0 1.0 13.0
2.0 2.0 19.0
Partner C Campaign 1C 5.0 1.0 118.5
5.0 1.0 118.5
18.0 7.0 302.5
"""
```
See the `Report`
[docs](https://totalhack.github.io/zillion/zillion.report/#report) for more
information on supported rollup behavior.
**Example:** Save a report spec (not the data):
First you must make sure you have saved your `Warehouse`, as saved reports
are scoped to a particular `Warehouse` ID. To save a `Warehouse`
you must provide a URL that points to the complete config.
```python
name = "My Unique Warehouse Name"
config_url = <some url pointing to a complete warehouse config>
wh.save(name, config_url) # wh.id is populated after this
spec_id = wh.save_report(
metrics=["sales", "leads", "revenue"],
dimensions=["partner_name"]
)
```
> *Note*: If you built your `Warehouse` in python from a list of `DataSources`,
or passed in a `dict` for the `config` param on init, there currently is not
a built-in way to output a complete config to a file for reference when saving.
**Example:** Load and run a report from a spec ID:
```python
result = wh.execute_id(spec_id)
```
This assumes you have saved this report ID previously in the database specified by the DB_URL in your `Zillion` yaml configuration.
**Example:** Unsupported Grain
If you attempt an impossible report, you will get an
`UnsupportedGrainException`. The report below is impossible because it
attempts to break down the leads metric by a dimension that only exists
in a child table. Generally speaking, child tables can join back up to
parents (and "siblings" of parents) to find dimensions, but not the other
way around.
```python
# Fails with UnsupportedGrainException
result = wh.execute(
metrics=["leads"],
dimensions=["sale_id"]
)
```
---
<a name="advanced-topics"></a>
**Advanced Topics**
-------------------
<a name="subreports"></a>
### **Subreports**
Sometimes you need subquery-like functionality in order to filter one
report to the results of some other (that perhaps required a different grain).
Zillion provides a simplistic way of doing that by using the `in report` or `not in report`
criteria operations. There are two supported ways to specify the subreport: passing a
report spec ID or passing a dict of report params.
```python
# Assuming you have saved report 1234 and it has "partner" as a dimension:
result = warehouse.execute(
metrics=["revenue", "leads"],
dimensions=["date"],
criteria=[
("date", ">", "2020-01-01"),
("partner", "in report", 1234)
]
)
# Or with a dict:
result = warehouse.execute(
metrics=["revenue", "leads"],
dimensions=["date"],
criteria=[
("date", ">", "2020-01-01"),
("partner", "in report", dict(
metrics=[...],
dimension=["partner"],
criteria=[...]
))
]
)
```
The criteria field used in `in report` or `not in report` must be a dimension
in the subreport. Note that subreports are executed at `Report` object initialization
time instead of during `execute` -- as such they can not be killed using `Report.kill`.
This may change down the road.
<a name="formula-metrics"></a>
### **Formula Metrics**
In our example above our config included a formula-based metric called "rpl",
which is simply `revenue / leads`. A `FormulaMetric` combines other metrics
and/or dimensions to calculate a new metric at the Combined Layer of
querying. The syntax must match your Combined Layer database, which is SQLite
in our example.
```json
{
"name": "rpl",
"aggregation": "mean",
"rounding": 2,
"formula": "{revenue}/{leads}"
}
```
<a name="divisor-metrics"></a>
### **Divisor Metrics**
As a convenience, rather than having to repeatedly define formula metrics for
rate variants of a core metric, you can specify a divisor metric configuration on a non-formula metric. As an example, say you have a `revenue` metric and want to create variants for `revenue_per_lead` and `revenue_per_sale`. You can define your revenue metric as follows:
```json
{
"name": "revenue",
"type": "numeric(10,2)",
"aggregation": "sum",
"rounding": 2,
"divisors": {
"metrics": [
"leads",
"sales"
]
}
}
```
See `zillion.configs.DivisorsConfigSchema` for more details on configuration options, such as overriding naming templates, formula templates, and rounding.
<a name="formula-dimensions"></a>
### **Formula Dimensions**
Experimental support exists for `FormulaDimension` fields as well. A `FormulaDimension` can only use other dimensions as part of its formula, and it also gets evaluated in the Combined Layer database. As an additional restriction, a `FormulaDimension` can not be used in report criteria as those filters are evaluated at the DataSource Layer. The following example assumes a SQLite Combined Layer database:
```json
{
"name": "partner_is_a",
"formula": "{partner_name} = 'Partner A'"
}
```
<a name="datasource-formulas"></a>
### **DataSource Formulas**
Our example also includes a metric "sales" whose value is calculated via
formula at the DataSource Layer of querying. Note the following in the
`fields` list for the "id" param in the "main.sales" table. These formulas are
in the syntax of the particular `DataSource` database technology, which also
happens to be SQLite in our example.
```json
"fields": [
"sale_id",
{"name":"sales", "ds_formula": "COUNT(DISTINCT sales.id)"}
]
```
<a name="type-conversions"></a>
### **Type Conversions**
Our example also automatically created a handful of dimensions from the
"created_at" columns of the leads and sales tables. Support for automatic type
conversions is limited, but for date/datetime columns in supported
`DataSource` technologies you can get a variety of dimensions for free this
way.
The output of `wh.print_info` will show the added dimensions, which are
prefixed with "lead_" or "sale_" as specified by the optional
`type_conversion_prefix` in the config for each table. Some examples of
auto-generated dimensions in our example warehouse include sale_hour,
sale_day_name, sale_month, sale_year, etc.
As an optimization in the where clause of underlying report queries, `Zillion`
will try to apply conversions to criteria values instead of columns. For example,
it is generally more efficient to query as `my_datetime > '2020-01-01' and my_datetime < '2020-01-02'`
instead of `DATE(my_datetime) == '2020-01-01'`, because the latter can prevent index
usage in many database technologies. The ability to apply conversions to values
instead of columns varies by field and `DataSource` technology as well.
To prevent type conversions, set `skip_conversion_fields` to `true` on your
`DataSource` config.
See `zillion.field.TYPE_ALLOWED_CONVERSIONS` and `zillion.field.DIALECT_CONVERSIONS`
for more details on currently supported conversions.
<a name="adhoc-metrics"></a>
### **Ad Hoc Metrics**
You may also define metrics "ad hoc" with each report request. Below is an
example that creates a revenue-per-lead metric on the fly. These only exist
within the scope of the report, and the name can not conflict with any existing
fields:
```python
result = wh.execute(
metrics=[
"leads",
{"formula": "{revenue}/{leads}", "name": "my_rpl"}
],
dimensions=["partner_name"]
)
```
<a name="adhoc-dimensions"></a>
### **Ad Hoc Dimensions**
You may also define dimensions "ad hoc" with each report request. Below is an
example that creates a dimension that partitions on a particular dimension value on the fly. Ad Hoc Dimensions are a subclass of `FormulaDimension`s and therefore have the same restrictions, such as not being able to use a metric as a formula field. These only exist within the scope of the report, and the name can not conflict with any existing fields:
```python
result = wh.execute(
metrics=["leads"],
dimensions=[{"name": "partner_is_a", "formula": "{partner_name} = 'Partner A'"]
)
```
<a name="adhoc-tables"></a>
### **Ad Hoc Tables**
`Zillion` also supports creation or syncing of ad hoc tables in your database
during `DataSource` or `Warehouse` init. An example of a table config that
does this is shown
[here](https://github.com/totalhack/zillion/blob/master/tests/test_adhoc_ds_config.json).
It uses the table config's `data_url` and `if_exists` params to control the
syncing and/or creation of the "main.dma_zip" table from a remote CSV in a
SQLite database. The same can be done in other database types too.
The potential performance drawbacks to such an approach should be obvious,
particularly if you are initializing your warehouse often or if the remote
data file is large. It is often better to sync and create your data ahead of
time so you have complete schema control, but this method can be very useful
in certain scenarios.
> **Warning**: be careful not to overwrite existing tables in your database!
<a name="technicals"></a>
### **Technicals**
There are a variety of technical computations that can be applied to metrics to
compute rolling, cumulative, or rank statistics. For example, to compute a 5-point
moving average on revenue one might define a new metric as follows:
```json
{
"name": "revenue_ma_5",
"type": "numeric(10,2)",
"aggregation": "sum",
"rounding": 2,
"technical": "mean(5)"
}
```
Technical computations are computed at the Combined Layer, whereas the "aggregation"
is done at the DataSource Layer (hence needing to define both above).
For more info on how shorthand technical strings are parsed, see the
[parse_technical_string](https://totalhack.github.io/zillion/zillion.configs/#parse_technical_string)
code. For a full list of supported technical types see
`zillion.core.TechnicalTypes`.
Technicals also support two modes: "group" and "all". The mode controls how to
apply the technical computation across the data's dimensions. In "group" mode,
it computes the technical across the last dimension, whereas in "all" mode in
computes the technical across all data without any regard for dimensions.
The point of this becomes more clear if you try to do a "cumsum" technical
across data broken down by something like ["partner_name", "date"]. If "group"
mode is used (the default in most cases) it will do cumulative sums *within*
each partner over the date ranges. If "all" mode is used, it will do a
cumulative sum across every data row. You can be explicit about the mode by
appending it to the technical string: i.e. "cumsum:all" or "mean(5):group"
---
<a name="config-variables"></a>
### **Config Variables**
If you'd like to avoid putting sensitive connection information directly in
your `DataSource` configs you can leverage config variables. In your `Zillion`
yaml config you can specify a `DATASOURCE_CONTEXTS` section as follows:
```yaml
DATASOURCE_CONTEXTS:
my_ds_name:
user: user123
pass: goodpassword
host: 127.0.0.1
schema: reporting
```
Then when your `DataSource` config for the datasource named "my_ds_name" is
read, it can use this context to populate variables in your connection url:
```json
"datasources": {
"my_ds_name": {
"connect": "mysql+pymysql://{user}:{pass}@{host}/{schema}"
...
}
}
```
<a name="datasource-priority"></a>
### **DataSource Priority**
On `Warehouse` init you can specify a default priority order for datasources
by name. This will come into play when a report could be satisfied by multiple
datasources. `DataSources` earlier in the list will be higher priority. This
would be useful if you wanted to favor a set of faster, aggregate tables that
are grouped in a `DataSource`.
```python
wh = Warehouse(config=config, ds_priority=["aggr_ds", "raw_ds", ...])
```
<a name="supported-datasources"></a>
**Supported DataSources**
-------------------------
`Zillion's` goal is to support any database technology that SQLAlchemy
supports (pictured below). That said the support and testing levels in `Zillion` vary at the
moment. In particular, the ability to do type conversions, database
reflection, and kill running queries all require some database-specific code
for support. The following list summarizes known support levels. Your mileage
may vary with untested database technologies that SQLAlchemy supports (it
might work just fine, just hasn't been tested yet). Please report bugs and
help add more support!
* SQLite: supported
* MySQL: supported
* PostgreSQL: supported
* DuckDB: supported
* BigQuery, Redshift, Snowflake, SingleStore, PlanetScale, etc: not tested but would like to support these
SQLAlchemy has connectors to many popular databases. The barrier to support many of these is likely
pretty low given the simple nature of the sql operations `Zillion` uses.

Note that the above is different than the database support for the Combined Layer
database. Currently only SQLite is supported there; that should be sufficient for
most use cases but more options will be added down the road.
<a name="multiprocess-considerations"></a>
**Multiprocess Considerations**
-------------------------------
If you plan to run `Zillion` in a multiprocess scenario, whether on a single
node or across multiple nodes, there are a couple of things to consider:
* SQLite DataSources do not scale well and may run into locking issues with multiple processes trying to access them on the same node.
* Any file-based database technology that isn't centrally accessible would be challenging when using multiple nodes.
* Ad Hoc DataSource and Ad Hoc Table downloads should be avoided as they may conflict/repeat across each process. Offload this to an external
ETL process that is better suited to manage those data flows in a scalable production scenario.
Note that you can still use the default SQLite in-memory Combined Layer DB without issues, as that is made on the fly with each report request and
requires no coordination/communication with other processes or nodes.
<a name="demo-ui"></a>
**Demo UI / Web API**
--------------------
[Zillion Web UI](https://github.com/totalhack/zillion-web) is a demo UI and web API for Zillion that also includes an experimental ChatGPT plugin. See the README there for more info on installation and project structure. Please note that the code is light on testing and polish, but is expected to work in modern browsers. Also ChatGPT plugins are quite slow at the moment, so currently that is mostly for fun and not that useful.
---
<a name="documentation"></a>
**Documentation**
-----------------
More thorough documentation can be found [here](https://totalhack.github.io/zillion/).
You can supplement your knowledge by perusing the [tests](https://github.com/totalhack/zillion/tree/master/tests) directory
or the [API reference](https://totalhack.github.io/zillion/).
---
<a name="how-to-contribute"></a>
**How to Contribute**
---------------------
Please See the
[contributing](https://github.com/totalhack/zillion/blob/master/CONTRIBUTING.md)
guide for more information. If you are looking for inspiration, adding support and tests for additional database technologies would be a great help.
| zillion | /zillion-0.10.0.tar.gz/zillion-0.10.0/README.md | README.md |
import logging
import os
import sys
import cfg4py
import fire
import omicron
from omicron.models.timeframe import TimeFrame
from pyemit import emit
from sanic import Sanic, response
from backtest.config import endpoint, get_config_dir
from backtest.feed.basefeed import BaseFeed
from backtest.web.accounts import Accounts
from backtest.web.interfaces import bp, ver
application = Sanic("backtest")
logger = logging.getLogger(__name__)
@application.route("/")
async def root(request):
return response.json(
{
"greetings": "欢迎使用大富翁回测系统!",
"version": ver.base_version,
"endpoint": bp.url_prefix,
}
)
@application.listener("before_server_start")
async def application_init(app, *args):
try:
await omicron.init()
except Exception:
logger.warning(
"omicron running in degrade mode, this may cause inaccurate results due to calendar issues"
)
if os.environ.get(cfg4py.envar) in ("DEV", "TEST"):
TimeFrame.service_degrade()
else:
sys.exit(-1)
cfg = cfg4py.get_instance()
await emit.start(emit.Engine.REDIS, start_server=True, dsn=cfg.redis.dsn)
feed = await BaseFeed.create_instance(interface="zillionare")
await feed.init()
app.ctx.feed = feed
app.ctx.accounts = Accounts()
app.ctx.accounts.on_startup()
@application.listener("after_server_stop")
async def application_exit(app, *args):
accounts = app.ctx.accounts
accounts.on_exit()
await omicron.close()
await emit.stop()
def start(port: int):
cfg4py.init(get_config_dir())
ep = endpoint()
logger.info("start backtest server at http://host:%s/%s", port, ep)
bp.url_prefix = ep
# added for gh://zillionare/backtesting/issues/6
application.config.RESPONSE_TIMEOUT = 60 * 10
application.blueprint(bp)
application.run(host="0.0.0.0", port=port, register_sys_signals=True)
logger.info("backtest server stopped")
if __name__ == "__main__":
# important! we use this to mimic start a module as a script
fire.Fire({"start": start}) | zillionare-backtest | /zillionare_backtest-0.4.19-py3-none-any.whl/backtest/app.py | app.py |
import logging
import os
import re
import signal
import subprocess
import sys
import time
import cfg4py
import fire
import httpx
import psutil
from tqdm import tqdm
from backtest.config import endpoint, get_config_dir
logger = logging.getLogger(__name__)
cfg = cfg4py.init(get_config_dir())
def help():
print("backtest")
print("=" * len("backtest"))
print("backtest framework")
def find_backtest_process():
"""查找backtest进程
backtest进程在ps -aux中显示应该包含 backtest.app --port=<port>信息
"""
for p in psutil.process_iter():
cmd = " ".join(p.cmdline())
if "backtest.app start" in cmd:
matched = re.search(r"--port=(\d+)", cmd)
if matched and len(matched.groups()):
return p.pid, int(matched.groups()[0])
return p.pid, None
return None, None
def is_running(port, endpoint):
url = f"http://localhost:{port}/{endpoint}/status"
try:
r = httpx.get(url)
return r.status_code == 200
except Exception:
return False
def status():
"""检查backtest server是否已经启动"""
pid, port = find_backtest_process()
if pid is None:
print("backtest server未启动")
return
if is_running(port, endpoint()):
print("\n=== backtest server is RUNNING ===")
print("pid:", pid)
print("port:", port)
print("endpoint:", endpoint())
print("\n")
else:
print("=== backtest server is DEAD ===")
os.kill(pid, signal.SIGKILL)
def stop():
print("停止backtest server...")
pid, _ = find_backtest_process()
if pid is None:
print("backtest server未启动")
return
p = psutil.Process(pid)
p.terminate()
p.wait()
print("backtest server已停止服务")
def start(port: int = None):
port = port or cfg.server.port
if is_running(port, endpoint()):
status()
return
print("启动backtest server")
process = subprocess.Popen(
[sys.executable, "-m", "backtest.app", "start", f"--port={port}"],
stdout=subprocess.PIPE,
stderr=subprocess.PIPE,
)
for i in tqdm(range(100)):
time.sleep(0.1)
if is_running(port, endpoint()):
status()
return
if process.poll() is not None: # pragma: no cover
# already exit, due to finish or fail
out, err = process.communicate()
logger.warning(
"subprocess exited, %s: %s", process.pid, out.decode("utf-8")
)
raise subprocess.SubprocessError(err.decode("utf-8"))
else:
print("backtest server启动超时或者失败。")
def main():
fire.Fire({"help": help, "start": start, "stop": stop, "status": status})
if __name__ == "__main__":
main() # pragma: no cover | zillionare-backtest | /zillionare_backtest-0.4.19-py3-none-any.whl/backtest/cli.py | cli.py |
import asyncio
import datetime
import logging
import uuid
from typing import Dict, List, Optional, Tuple, Union
import arrow
import cfg4py
import numpy as np
from coretypes import Frame, FrameType
from empyrical import (
annual_return,
annual_volatility,
calmar_ratio,
cum_returns_final,
max_drawdown,
sharpe_ratio,
sortino_ratio,
)
from omicron.extensions import array_math_round, array_price_equal, math_round
from omicron.models.stock import Stock
from omicron.models.timeframe import TimeFrame as tf
from pyemit import emit
from backtest.common.errors import AccountError, BadParameterError, EntrustError
from backtest.common.helper import get_app_context, jsonify, tabulate_numpy_array
from backtest.trade.datatypes import (
E_BACKTEST,
BidType,
Entrust,
EntrustSide,
assets_dtype,
cash_dtype,
daily_position_dtype,
float_ts_dtype,
position_dtype,
rich_assets_dtype,
)
from backtest.trade.trade import Trade
from backtest.trade.transaction import Transaction
cfg = cfg4py.get_instance()
logger = logging.getLogger(__name__)
entrustlog = logging.getLogger("entrust")
tradelog = logging.getLogger("trade")
class Broker:
def __init__(
self,
account_name: str,
principal: float,
commission: float,
bt_start: datetime.date = None,
bt_end: datetime.date = None,
):
"""创建一个Broker对象
Args:
account_name : 账号/策略名
principal : 初始本金
commission : 佣金率
start : 开始日期(回测时使用)
end : 结束日期(回测时使用)
"""
if bt_start is not None and bt_end is not None:
self.mode = "bt"
self.bt_start = bt_start
self.bt_stop = bt_end
# 回测是否终止?
self._bt_stopped = False
else:
self.mode = "mock"
self._bt_stopped = False
self.bt_start = None
self.bt_stop = None
# 最后交易时间
self._last_trade_time: datetime.datetime = None
self._first_trade_time: datetime.datetime = None
self.account_name = account_name
self.commission = commission
# 初始本金
self.principal = principal
# 每日盘后可用资金
self._cash = np.array([], dtype=cash_dtype)
# 每日总资产, 包括本金和持仓资产
self._assets = np.array([], dtype=assets_dtype)
self._positions = np.array([], dtype=daily_position_dtype) # 每日持仓
self._unclosed_trades = {} # 未平仓的交易
# 委托列表,包括废单和未成交委托
self.entrusts = {}
# 所有的成交列表,包括买入和卖出,已关闭和未关闭的
self.trades = {}
# trasaction = buy + sell trade
self.transactions: List[Transaction] = []
self._lock = asyncio.Lock()
def __getstate__(self):
# self._lock is not pickable
state = self.__dict__.copy()
del state["_lock"]
return state
def __setstate__(self, state):
self.__dict__.update(state)
self._lock = asyncio.Lock()
@property
def lock(self):
return self._lock
@property
def cash(self):
if self._cash.size == 0:
return self.principal
return self._cash[-1]["cash"].item()
@property
def account_start_date(self) -> datetime.date:
if self.mode == "bt":
return self.bt_start
else:
return (
None
if self._first_trade_time is None
else self._first_trade_time.date()
)
@property
def account_end_date(self) -> datetime.date:
if self.mode == "bt":
return self.bt_stop
else:
return (
None if self._last_trade_time is None else self._last_trade_time.date()
)
@property
def last_trade_date(self):
return None if self._last_trade_time is None else self._last_trade_time.date()
@property
def first_trade_date(self):
return None if self._first_trade_time is None else self._first_trade_time.date()
def get_cash(self, dt: datetime.date) -> float:
"""获取`dt`当天的可用资金
在查询时,如果`dt`小于首次交易日,则返回空,否则,如果当日无数据,将从上一个有数据之日起,进行补齐填充。
Args:
dt (datetime.date): 日期
Returns:
float: 某日可用资金
"""
if self._cash.size == 0:
return self.principal
if dt > self._cash[-1]["date"]:
return self._cash[-1]["cash"].item()
elif dt < self._cash[0]["date"]:
return self.principal
result = self._cash[self._cash["date"] == dt]["cash"]
if result.size == 0:
raise ValueError(f"{dt} not found")
else:
return result.item()
def get_unclosed_trades(self, dt: datetime.date) -> set:
"""获取`dt`当天未平仓的交易
如果`dt`小于首次交易日,则返回空,否则,如果当日无数据,将从上一个有数据之日起,进行补齐填充。
"""
if len(self._unclosed_trades) == 0:
return set()
result = self._unclosed_trades.get(dt)
if result is None:
start = sorted(self._unclosed_trades.keys())[0]
if dt < start:
return set()
else:
self._fillup_unclosed_trades(dt)
return self._unclosed_trades.get(dt)
def get_position(self, dt: datetime.date, dtype=position_dtype) -> np.ndarray:
"""获取`dt`日持仓
如果传入的`dt`大于持仓数据的最后一天,将返回最后一天的持仓数据,并且所有持仓均为可售状态
如果传入的`dt`小于持仓数据的第一天,将返回空。
Args:
dt : 查询哪一天的持仓
dtype : 返回的数据类型,可为[position_dtype][backtest.trade.datatypes.position_dtype]或[daily_position_dtype][backtest.trade.datatypes.daily_position_dtype],后者用于日志输出
Returns:
返回结果为dtype为`dtype`的一维numpy structured array,其中price为该批持仓的均价。
"""
if self._positions.size == 0:
return np.array([], dtype=dtype)
if dt < self._positions[0]["date"]:
return np.array([], dtype=dtype)
last_date = self._positions[-1]["date"]
if dt > last_date:
result = self._positions[self._positions["date"] == last_date]
result["sellable"] = result["shares"]
return result[list(dtype.names)].astype(dtype)
result = self._positions[self._positions["date"] == dt]
if result.size == 0:
raise ValueError(f"{dt} not found")
return result[list(dtype.names)].astype(dtype)
async def recalc_assets(
self, start: Optional[datetime.date] = None, end: Optional[datetime.date] = None
):
"""重新计算账户的每日资产
计算完成后,资产表将包括从账户开始前一日,到`end`日的资产数据。从账户开始前一日起,是为了方便计算首个交易日的收益。
Args:
end: 计算到哪一天的资产,默认为空,即计算到最后一个交易日(非回测),或者回测结束日。
"""
if end is None:
if self.mode != "bt": # 非回测下计算到当下
end = arrow.now().date()
else: # 回测时计算到bt_stop
end = self.bt_stop
# 把期初资产加进来
if self._assets.size == 0:
start = self.account_start_date
if start is None:
return np.array([], dtype=rich_assets_dtype)
_before_start = tf.day_shift(start, -1)
self._assets = np.array(
[(_before_start, self.principal)], dtype=assets_dtype
)
start = start or tf.day_shift(self._assets[-1]["date"], 1)
if start >= end:
return
# 待补齐的资产日
frames = [tf.int2date(d) for d in tf.get_frames(start, end, FrameType.DAY)]
# 从最后一个资产日到`end`,持仓应都是一样的
position = self.get_position(end, position_dtype)
if position.size == 0:
assets = self._assets[-1]["assets"]
self._assets = np.concatenate(
(
self._assets,
np.array([(frame, assets) for frame in frames], dtype=assets_dtype),
)
)
return
secs = position[position["shares"] != 0]["security"]
shares = {
sec: position[position["security"] == sec]["shares"][0] for sec in secs
}
if len(secs):
feed = get_app_context().feed
closes = await feed.batch_get_close_price_in_range(secs, frames)
for frame in frames:
cash = self.get_cash(frame)
mv = 0
for sec in secs:
if closes.get(sec) is None:
price = position[position["security"] == sec]["price"].item()
mv += shares.get(sec, 0) * price
else:
iclose = self._index_of(closes[sec], frame, "frame")
mv += closes[sec][iclose]["close"] * shares.get(sec, 0)
i = self._index_of(self._assets, frame)
if i is None:
self._assets = np.append(
self._assets,
np.array([(frame, float(cash + mv))], dtype=assets_dtype),
axis=0,
)
else:
self._assets[i]["assets"] = float(cash + mv)
async def info(self, dt: datetime.date = None) -> Dict:
"""`dt`日的账号相关信息
Returns:
Dict: 账号相关信息:
- name: str, 账户名
- principal: float, 初始资金
- assets: float, `dt`日资产
- start: datetime.date, 账户创建时间
- end: 账户结束时间,仅在回测模式下有效
- bt_stopped: 回测是否结束,仅在回测模式下有效。
- last_trade: datetime.datetime, 最后一笔交易时间
- available: float, `dt`日可用资金
- market_value: `dt`日股票市值
- pnl: `dt`盈亏(绝对值)
- ppnl: 盈亏(百分比),即pnl/principal
- positions: 当前持仓,dtype为position_dtype的numpy structured array
"""
dt = dt or self.last_trade_date
cash = self.get_cash(dt)
assets = await self.get_assets(dt)
return {
"name": self.account_name,
"principal": self.principal,
"start": self.account_start_date,
"end": self.bt_stop,
"bt_stopped": self._bt_stopped,
"last_trade": self.last_trade_date,
"assets": assets,
"available": cash,
"market_value": assets - cash,
"pnl": assets - self.principal,
"ppnl": assets / self.principal - 1,
"positions": self.get_position(dt),
}
async def get_returns(
self, start_date: datetime.date = None, end_date: datetime.date = None
) -> np.ndarray:
"""求截止`end_date`时的每日回报
Args:
start_date: 计算回报的起始日期
end_date : 计算回报的结束日期
Returns:
以百分比为单位的每日回报率,索引为对应日期
"""
start = start_date or self.account_start_date
# 当计算[start, end]之间的每日回报时,需要取多一日,即`start`之前一日的总资产
_start = tf.day_shift(start, -1)
end = end_date or self.account_end_date
assert self.account_start_date <= start <= end
assert start <= end <= self.account_end_date
if not self._bt_stopped:
await self.recalc_assets()
assets = self._assets[
(self._assets["date"] >= _start) & (self._assets["date"] <= end)
]
if assets.size == 0:
raise ValueError(f"date range error: {start} - {end} contains no data")
return assets["assets"][1:] / assets["assets"][:-1] - 1
@property
def assets(self) -> float:
"""当前总资产。
如果要获取历史上某天的总资产,请使用`get_assets`方法。
"""
if self._assets.size == 0:
return self.principal
else:
return self._assets[-1]["assets"]
async def get_assets(self, date: datetime.date) -> float:
"""查询某日的总资产
当日总资产 = 当日可用资金 + 持仓市值
Args:
date: 查询哪一天的资产
Returns:
返回某一日的总资产
"""
if self._assets.size == 0:
return self.principal
if date is None:
return self._assets[-1]["assets"]
result = self._assets[self._assets["date"] == date]
if result.size == 1:
return result["assets"].item()
assets, *_ = await self._calc_assets(date)
return assets
def _index_of(
self, arr: np.ndarray, date: datetime.date, index: str = "date"
) -> int:
"""查找`arr`中其`index`字段等于`date`的索引
注意数组中`date`字段取值必须惟一。
Args:
arr: numpy array, 需要存在`index`字段
date: datetime.date, 查找的日期
Returns:
如果存在,返回索引,否则返回None
"""
pos = np.argwhere(arr[index] == date).ravel()
assert len(pos) <= 1, "date should be unique"
if len(pos) == 0:
return None
return pos[0]
async def _calc_assets(self, date: datetime.date) -> Tuple[float]:
"""计算某日的总资产
此函数不更新资产表,以避免资产表中留下空洞。比如:
当前最后交易日为4月10日,4月17日发生一笔委卖,导致cash/position记录更新到4/17,但资产表仍然保持在4月10日,此时如果缓存该记录,将导致资产表中留下空洞。
Args:
date: 计算哪一天的资产
Returns:
返回总资产, 可用资金, 持仓市值
"""
if date < self.account_start_date:
return self.principal, 0, 0
if (self.mode == "bt" and date > self.bt_stop) or date > arrow.now().date():
raise ValueError(
f"wrong date: {date}, date must be before {self.bt_stop} or {arrow.now().date()}"
)
cash = self.get_cash(date)
positions = self.get_position(date)
# this also exclude empty entry (which security is None)
heldings = positions[positions["shares"] > 0]["security"]
market_value = 0
if heldings.size > 0:
feed = get_app_context().feed
for sec in heldings:
shares = positions[positions["security"] == sec]["shares"].item()
price = await feed.get_close_price(sec, date)
if price is not None:
market_value += shares * price
else:
price = positions[positions["security"] == sec]["price"].item()
market_value += shares * price
assets = cash + market_value
return assets, cash, market_value
@property
def position(self) -> np.ndarray:
"""获取当前持仓
如果要获取历史上某天的持仓,请使用`get_position`方法。
如果当天个股曾有持仓,但被清仓,持仓表仍保留entry,但shares将置为空。如果当天没有任何持仓(不包括当天清空的情况),则会留一个`security`字段为None的空entry。
Returns:
返回dtype为[position_dtype][backtest.trade.datatypes.position_dtype]的numpy structure array
"""
if self._positions.size == 0:
return np.array([], dtype=position_dtype)
last_day = self._positions[-1]["date"]
result = self._positions[self._positions["date"] == last_day]
return result[list(position_dtype.names)].astype(position_dtype)
def __str__(self):
s = (
f"账户:{self.account_name}:\n"
+ f" 总资产:{self.assets:,.2f}\n"
+ f" 本金:{self.principal:,.2f}\n"
+ f" 可用资金:{self.cash:,.2f}\n"
+ f" 持仓:{self.position}\n"
)
return s
def __repr__(self) -> str:
return f"<{self.__class__.__name__}>{self}"
async def _calendar_validation(self, bid_time: datetime.datetime):
"""更新和校准交易日期
如果是回测模式,则在进入_bt_stopped状态时,还要完整计算一次assets,此后不再重复计算。
Args:
bid_time : 交易发生的时间
"""
if self.mode == "bt" and self._bt_stopped:
logger.warning("委托时间超过回测结束时间: %s, %s", bid_time, self.bt_stop)
raise AccountError(f"下单时间为{bid_time},而账户已于{self.bt_stop}冻结。")
if self._first_trade_time is None:
self._first_trade_time = bid_time
elif bid_time < self._first_trade_time:
logger.warning("委托时间必须递增出现: %s -> %s", self._first_trade_time, bid_time)
raise EntrustError(
EntrustError.TIME_REWIND,
time=bid_time,
last_trade_time=self._first_trade_time,
)
if self._last_trade_time is None or bid_time >= self._last_trade_time:
self._last_trade_time = bid_time
else:
logger.warning("委托时间必须递增出现:%s -> %s", self._last_trade_time, bid_time)
raise EntrustError(
EntrustError.TIME_REWIND,
time=bid_time,
last_trade_time=self._last_trade_time,
)
if self.mode == "bt" and bid_time.date() > self.bt_stop:
self._bt_stopped = True
await self.recalc_assets()
logger.warning("委托时间超过回测结束时间: %s, %s", bid_time, self.bt_stop)
raise AccountError(f"下单时间为{bid_time},而账户已于{self.bt_stop}冻结。")
async def buy(
self,
security: str,
bid_price: float,
bid_shares: int,
bid_time: datetime.datetime,
) -> Trade:
"""买入委托
买入以尽可能实现委托为目标。如果可用资金不足,但能买入部分股票,则部分买入。
如果bid_price为None,则使用涨停价买入。
Args:
security str: 证券代码
bid_price float: 委托价格。如果为None,则为市价委托
bid_shares int: 询买的股数
bid_time datetime.datetime: 委托时间
Returns:
[Trade][backtest.trade.trade.Trade]对象
"""
# 同一个账户,也可能出现并发的买单和卖单,这些操作必须串行化
async with self.lock:
return await self._buy(security, bid_price, bid_shares, bid_time)
async def _buy(
self,
security: str,
bid_price: float,
bid_shares: int,
bid_time: datetime.datetime,
) -> Trade:
entrustlog.info(
f"{bid_time}\t{security}\t{bid_shares}\t{bid_price}\t{EntrustSide.BUY}"
)
assert (
type(bid_time) is datetime.datetime
), f"{bid_time} is not type of datetime"
await self._before_trade(bid_time)
feed = get_app_context().feed
en = Entrust(
security,
EntrustSide.BUY,
bid_shares,
bid_price,
bid_time,
BidType.LIMIT if bid_price is not None else BidType.MARKET,
)
logger.info(
"买入委托(%s): %s %d %s, 单号:%s",
bid_time,
security,
bid_shares,
bid_price,
en.eid,
)
self.entrusts[en.eid] = en
_, buy_limit_price, _ = await feed.get_trade_price_limits(
security, bid_time.date()
)
bid_price = bid_price or buy_limit_price
# 获取用以撮合的数据
bars = await feed.get_price_for_match(security, bid_time)
if bars.size == 0:
logger.warning("failed to match %s, no data at %s", security, bid_time)
raise EntrustError(
EntrustError.NODATA_FOR_MATCH, security=security, time=bid_time
)
# 移除掉涨停和价格高于委买价的bar后,看还能买多少股
bars = self._remove_for_buy(
security, bid_time, bars, bid_price, buy_limit_price
)
# 将买入数限制在可用资金范围内
shares_to_buy = min(
bid_shares, self.cash // (bid_price * (1 + self.commission))
)
# 必须以手为单位买入,否则委托会失败
shares_to_buy = shares_to_buy // 100 * 100
if shares_to_buy < 100:
logger.info("委买失败:%s(%s), 资金(%s)不足", security, self.cash, en.eid)
raise EntrustError(
EntrustError.NO_CASH,
account=self.account_name,
required=100 * bid_price,
available=self.cash,
)
mean_price, filled, close_time = self._match_buy(bars, shares_to_buy)
if filled == 0:
raise EntrustError(
EntrustError.VOLUME_NOT_ENOUGH, security=security, price=bid_price
)
return await self._fill_buy_order(en, mean_price, filled, close_time)
def _match_buy(
self, bid_queue, shares_to_buy
) -> Tuple[float, float, datetime.datetime]:
"""计算此次买入的成交均价和成交量
Args:
bid_queue : 撮合数据
shares_to_buy : 要买入的股数
Returns:
成交均价、可埋单股数和最后成交时间
"""
c, v = bid_queue["price"], bid_queue["volume"]
cum_v = np.cumsum(v)
# until i the order can be filled
where_total_filled = np.argwhere(cum_v >= shares_to_buy)
if len(where_total_filled) == 0:
i = len(v) - 1
else:
i = np.min(where_total_filled)
# 也许到当天结束,都没有足够的股票
filled = min(cum_v[i], shares_to_buy) // 100 * 100
# 最后一周期,只需要成交剩余的部分
vol = v[: i + 1].copy()
vol[-1] = filled - np.sum(vol[:-1])
money = sum(c[: i + 1] * vol)
mean_price = money / filled
return mean_price, filled, bid_queue["frame"][i]
def _fillup_unclosed_trades(self, dt: datetime.date):
if len(self._unclosed_trades) != 0 and self._unclosed_trades.get(dt) is None:
days = sorted(list(self._unclosed_trades.keys()))
frames = tf.get_frames(days[-1], dt, FrameType.DAY)
for src, dst in zip(frames[:-1], frames[1:]):
src = tf.int2date(src)
dst = tf.int2date(dst)
self._unclosed_trades[dst] = self._unclosed_trades[src].copy()
def _update_unclosed_trades(self, tid, date: datetime.date):
"""记录每日持有的未平仓交易
Args:
trades: 交易列表
"""
unclosed = self._unclosed_trades.get(date, [])
if len(unclosed):
unclosed.append(tid)
return
if len(self._unclosed_trades) == 0:
self._unclosed_trades[date] = [tid]
return
# 记录还未创建,需要复制前一日记录
self._fillup_unclosed_trades(date)
self._unclosed_trades[date].append(tid)
async def _fill_buy_order(
self, en: Entrust, price: float, filled: float, close_time: datetime.datetime
) -> Trade:
"""生成trade,更新交易、持仓和assets
Args:
en : _description_
price : _description_
filled : _description_
close_time : _description_
Returns:
成交记录
"""
money = price * filled
fee = math_round(money * self.commission, 2)
trade = Trade(en.eid, en.security, price, filled, fee, en.side, close_time)
self.trades[trade.tid] = trade
self._update_unclosed_trades(trade.tid, close_time.date())
await self._update_positions(trade, close_time.date())
logger.info(
"买入成交(%s): %s (%d %.2f %.2f),委单号: %s, 成交号: %s",
close_time,
en.security,
filled,
price,
fee,
en.eid,
trade.tid,
)
tradelog.info(
f"{en.bid_time.date()}\t{en.side}\t{en.security}\t{filled}\t{price}\t{fee}"
)
logger.info(
"%s 买入后持仓: \n%s",
close_time.date(),
tabulate_numpy_array(
self.get_position(close_time.date(), daily_position_dtype)
),
)
# 当发生新的买入时,更新资产
cash_change = -1 * (money + fee)
await self._update_assets(cash_change, close_time)
await emit.emit(E_BACKTEST, {"buy": jsonify(trade)})
return trade
async def _before_trade(self, bid_time: datetime.datetime):
"""交易前的准备工作
在每次交易前,补齐每日现金数据和持仓数据到`bid_time`,更新账户生命期等。
Args:
bid_time: 委托时间
Returns:
无
"""
logger.info("bid_time is %s", bid_time)
await self._calendar_validation(bid_time)
# 补齐可用将资金表
if self._cash.size == 0:
start = tf.day_shift(self.account_start_date, -1)
end = bid_time.date()
frames = tf.get_frames(start, end, FrameType.DAY)
_cash = [(tf.int2date(frame), self.principal) for frame in frames]
self._cash = np.array(_cash, dtype=cash_dtype)
else:
prev, cash = self._cash[-1]
frames = tf.get_frames(prev, bid_time, FrameType.DAY)[1:]
if len(frames) > 0:
recs = [(tf.int2date(date), cash) for date in frames]
self._cash = np.concatenate(
(self._cash, np.array(recs, dtype=cash_dtype))
)
await self._fillup_positions(bid_time)
async def _fillup_positions(self, bid_time: datetime.datetime):
# 补齐持仓表(需要处理复权)
feed = get_app_context().feed
if self._positions.size == 0:
return
prev = self._positions[-1]["date"]
logger.info("handling positions fillup from %s to %s", prev, bid_time)
frames = [
tf.int2date(frame) for frame in tf.get_frames(prev, bid_time, FrameType.DAY)
]
if len(frames) == 1:
return
last_day_position = self._positions[self._positions["date"] == prev]
if np.all(last_day_position["security"] is None):
# empty entries, no need to be extended
return
last_held_position = last_day_position[last_day_position["shares"] != 0]
if last_held_position.size == 0:
empty = np.array(
[(frame, None, 0, 0, 0) for frame in frames[1:]],
dtype=daily_position_dtype,
)
self._positions = np.hstack((self._positions, empty))
return
# 已清空股票不需要展仓, issue 9
secs = last_held_position["security"].tolist()
dr_info = await feed.get_dr_factor(secs, frames)
padding_positions = []
for position in last_held_position:
sec = position["security"]
if sec in dr_info:
dr = dr_info[sec]
else:
dr = None
paddings = np.array(
[position.item()] * len(frames), dtype=daily_position_dtype
)
paddings["date"] = frames
if dr is not None:
adjust_shares = array_math_round(
paddings["shares"][1:] * np.diff(dr), 2
)
paddings["shares"] = paddings["shares"] * dr
paddings["price"] = paddings["price"] / dr
# 模拟一笔买单,以便此后卖出时能对应到买单。否则,将卖不出去。
# https://github.com/zillionare/trader-client/issues/10
for i, adjust_share in enumerate(adjust_shares):
if abs(adjust_share) < 1e-5:
continue
order_time = tf.combine_time(frames[i + 1], 15)
trade = Trade(
uuid.uuid4(),
sec,
paddings["price"][i + 1].item(),
adjust_share,
0,
EntrustSide.XDXR,
order_time,
)
self.trades[trade.tid] = trade
self._update_unclosed_trades(trade.tid, bid_time.date())
paddings["sellable"][1:] = paddings["shares"][:-1]
padding_positions.extend(paddings[1:])
if len(padding_positions):
padding_positions.sort(key=lambda x: x[0])
self._positions = np.concatenate((self._positions, padding_positions))
async def _update_positions(self, trade: Trade, bid_date: datetime.date):
"""更新持仓信息
持仓信息为一维numpy数组,其类型为daily_position_dtype。如果某支股票在某日被清空,则当日持仓表保留记录,置shares为零,方便通过持仓表看出股票的进场出场时间,另一方面,如果不保留这条记录(而是删除),则在所有股票都被清空的情况下,会导致持仓表出现空洞,从而导致下一次交易时,误将更早之前的持仓记录复制到当日的持仓表中(在_before_trade中),而这些持仓实际上已经被清空。
Args:
trade: 交易信息
bid_date: 买入/卖出日期
"""
if type(bid_date) == datetime.datetime:
bid_date = bid_date.date()
if self._positions.size == 0:
self._positions = np.array(
[(bid_date, trade.security, trade.shares, 0, trade.price)],
dtype=daily_position_dtype,
)
return
# find if the security is already in the position (same day)
pos = np.argwhere(
(self._positions["security"] == trade.security)
& (self._positions["date"] == bid_date)
)
if pos.size == 0:
self._positions = np.append(
self._positions,
np.array(
[(bid_date, trade.security, trade.shares, 0, trade.price)],
dtype=daily_position_dtype,
),
)
else:
i = pos[0].item()
*_, old_shares, old_sellable, old_price = self._positions[i]
new_shares, new_price = trade.shares, trade.price
if trade.side == EntrustSide.BUY:
self._positions[i] = (
bid_date,
trade.security,
old_shares + trade.shares,
old_sellable,
(old_price * old_shares + new_shares * new_price)
/ (old_shares + new_shares),
)
else:
shares = old_shares - trade.shares
sellable = old_sellable - trade.shares
if shares <= 0.1:
old_price = 0
shares = 0
sellable = 0
self._positions[i] = (
bid_date,
trade.security,
shares,
sellable,
old_price, # 卖出时成本不变,除非已清空
)
return
async def _update_assets(self, cash_change: float, bid_time: datetime.datetime):
"""更新当前资产(含持仓)
在每次资产变动时进行计算和更新,并对之前的资产表进行补全。
Args:
cash_change : 变动的现金
bid_time: 委托时间
"""
logger.info("cash change: %s", cash_change)
# 补齐资产表到上一个交易日
if self._assets.size == 0:
_before_start = tf.day_shift(self.account_start_date, -1)
self._assets = np.array(
[(_before_start, self.principal)], dtype=assets_dtype
)
start = tf.day_shift(self._assets[-1]["date"], 1)
end = tf.day_shift(bid_time, -1)
if start < end:
await self.recalc_assets(start, end)
bid_date = bid_time.date()
# _before_trade应该已经为当日交易准备好了可用资金数据
assert self._cash[-1]["date"] == bid_date
self._cash[-1]["cash"] += cash_change
assets, cash, mv = await self._calc_assets(bid_date)
i = self._index_of(self._assets, bid_date)
if i is None:
self._assets = np.append(
self._assets, np.array([(bid_date, assets)], dtype=assets_dtype)
)
else:
# don't use self._assets[self._assets["date"] == date], this always return copy
self._assets[i]["assets"] = assets
info = np.array(
[(bid_date, assets, cash, mv, cash_change)],
dtype=[
("date", "O"),
("assets", float),
("cash", float),
("market value", float),
("change", float),
],
)
logger.info("\n%s", tabulate_numpy_array(info))
async def _fill_sell_order(
self, en: Entrust, price: float, to_sell: float
) -> List[Trade]:
"""从positions中扣减股票、增加可用现金
Args:
en : 委卖单
price : 成交均价
filled : 回报的卖出数量
Returns:
成交记录列表
"""
dt = en.bid_time.date()
money = price * to_sell
fee = math_round(money * self.commission, 2)
security = en.security
unclosed_trades = self.get_unclosed_trades(dt)
closed_trades = []
exit_trades = []
refund = 0
while to_sell > 0:
for tid in unclosed_trades:
trade: Trade = self.trades[tid]
if trade.security != security:
continue
if trade.time.date() >= dt:
# not T + 1
continue
to_sell, fee, exit_trade, tx = trade.sell(
to_sell, price, fee, en.bid_time
)
logger.info(
"卖出成交(%s): %s (%d %.2f %.2f),委单号: %s, 成交号: %s",
exit_trade.time,
en.security,
exit_trade.shares,
exit_trade.price,
exit_trade.fee,
en.eid,
exit_trade.tid,
)
tradelog.info(
f"{en.bid_time.date()}\t{exit_trade.side}\t{exit_trade.security}\t{exit_trade.shares}\t{exit_trade.price}\t{exit_trade.fee}"
)
await self._update_positions(exit_trade, exit_trade.time)
exit_trades.append(exit_trade)
self.trades[exit_trade.tid] = exit_trade
self.transactions.append(tx)
refund += exit_trade.shares * exit_trade.price - exit_trade.fee
if trade.closed:
closed_trades.append(tid)
if to_sell == 0:
break
else: # no more unclosed trades, even if to_sell > 0
break
unclosed_trades = [tid for tid in unclosed_trades if tid not in closed_trades]
self._unclosed_trades[dt] = unclosed_trades
logger.info(
"%s 卖出后持仓: \n%s",
dt,
tabulate_numpy_array(self.get_position(dt, daily_position_dtype)),
)
await self._update_assets(refund, en.bid_time)
await emit.emit(E_BACKTEST, {"sell": jsonify(exit_trades)})
return exit_trades
async def sell(
self,
security: str,
bid_price: Union[None, float],
bid_shares: float,
bid_time: datetime.datetime,
) -> List[Trade]:
"""卖出委托
Args:
security str: 委托证券代码
bid_price float: 出售价格,如果为None,则为市价委托
bid_shares float: 询卖股数。注意我们不限制必须以100的倍数卖出。
bid_time datetime.datetime: 委托时间
Returns:
成交记录列表,每个元素都是一个[Trade][backtest.trade.trade.Trade]对象
"""
# 同一个账户,也可能出现并发的买单和卖单,这些操作必须串行化
async with self.lock:
return await self._sell(security, bid_price, bid_shares, bid_time)
async def _sell(
self,
security: str,
bid_price: Union[None, float],
bid_shares: float,
bid_time: datetime.datetime,
) -> List[Trade]:
await self._before_trade(bid_time)
feed = get_app_context().feed
entrustlog.info(
f"{bid_time}\t{security}\t{bid_shares}\t{bid_price}\t{EntrustSide.SELL}"
)
logger.info("卖出委托(%s): %s %s %s", bid_time, security, bid_price, bid_shares)
_, _, sell_limit_price = await feed.get_trade_price_limits(
security, bid_time.date()
)
if bid_price is None:
bid_type = BidType.MARKET
bid_price = sell_limit_price
else:
bid_type = BidType.LIMIT
# fill the order, get mean price
bars = await feed.get_price_for_match(security, bid_time)
if bars.size == 0:
logger.warning("failed to match: %s, no data at %s", security, bid_time)
raise EntrustError(
EntrustError.NODATA_FOR_MATCH, security=security, time=bid_time
)
bars = self._remove_for_sell(
security, bid_time, bars, bid_price, sell_limit_price
)
c, v = bars["price"], bars["volume"]
cum_v = np.cumsum(v)
shares_to_sell = self._get_sellable_shares(security, bid_shares, bid_time)
if shares_to_sell == 0:
logger.info("卖出失败: %s %s %s, 可用股数为0", security, bid_shares, bid_time)
logger.info("%s", self.get_unclosed_trades(bid_time.date()))
raise EntrustError(
EntrustError.NO_POSITION, security=security, time=bid_time
)
# until i the order can be filled
where_total_filled = np.argwhere(cum_v >= shares_to_sell)
if len(where_total_filled) == 0:
i = len(v) - 1
else:
i = np.min(where_total_filled)
close_time = bars[i]["frame"]
# 也许到当天结束,都没有足够的股票
filled = min(cum_v[i], shares_to_sell)
# 最后一周期,只需要成交剩余的部分
vol = v[: i + 1].copy()
vol[-1] = filled - np.sum(vol[:-1])
money = sum(c[: i + 1] * vol)
mean_price = money / filled
en = Entrust(
security, EntrustSide.SELL, bid_shares, bid_price, bid_time, bid_type
)
logger.info(
"委卖%s(%s), 成交%s股,均价%.2f, 成交时间%s",
en.security,
en.eid,
filled,
mean_price,
close_time,
)
return await self._fill_sell_order(en, mean_price, filled)
def _get_sellable_shares(
self, security: str, shares_asked: int, bid_time: datetime.datetime
) -> int:
"""获取可卖股数
如果shares_asked与可售之间的差不足1股,则自动加上零头,确保可以卖完。
Args:
security: 证券代码
Returns:
可卖股数
"""
shares = 0
for tid in self.get_unclosed_trades(bid_time.date()):
t = self.trades[tid]
if t.security == security and t.time.date() < bid_time.date():
assert t.closed is False
shares += t._unsell
if shares - shares_asked < 100:
return shares
return min(shares_asked, shares)
def _remove_for_buy(
self,
security: str,
order_time: datetime.datetime,
bars: np.ndarray,
price: float,
limit_price: float,
) -> np.ndarray:
"""
去掉已达到涨停时的分钟线,或者价格高于买入价的bars
"""
reach_limit = array_price_equal(bars["price"], limit_price)
bars = bars[(~reach_limit)]
if bars.size == 0:
raise EntrustError(
EntrustError.REACH_BUY_LIMIT, security=security, time=order_time
)
bars = bars[(bars["price"] <= price)]
if bars.size == 0:
raise EntrustError(
EntrustError.PRICE_NOT_MEET,
security=security,
time=order_time,
entrust=price,
)
return bars
def _remove_for_sell(
self,
security: str,
order_time: datetime.datetime,
bars: np.ndarray,
price: float,
limit_price: float,
) -> np.ndarray:
"""去掉当前价格低于price,或者已经达到跌停时的bars,这些bars上无法成交"""
reach_limit = array_price_equal(bars["price"], limit_price)
bars = bars[(~reach_limit)]
if bars.size == 0:
raise EntrustError(
EntrustError.REACH_SELL_LIMIT, security=security, time=order_time
)
bars = bars[(bars["price"] >= price)]
if bars.size == 0:
raise EntrustError(
EntrustError.PRICE_NOT_MEET, security=security, entrust=price
)
return bars
def freeze(self):
"""冻结账户,停止接收新的委托"""
self._bt_stopped = True
async def metrics(
self,
start: Optional[datetime.date] = None,
end: Optional[datetime.date] = None,
baseline: Optional[str] = "399300.XSHE",
) -> Dict:
"""获取指定时间段的账户指标
Args:
start: 开始时间
end: 结束时间
baseline: 参考标的
Returns:
Dict: 指标字典,其key为
- start 回测起始时间
- end 回测结束时间
- window 资产暴露时间
- total_tx 发生的配对交易次数
- total_profit 总盈亏
- total_profit_rate 总盈亏率
- win_rate 胜率
- mean_return 每笔配对交易平均回报率
- sharpe 夏普比率
- max_drawdown 最大回撤
- sortino
- calmar
- annual_return 年化收益率
- volatility 波动率
- baseline: dict
- win_rate
- sharpe
- max_drawdown
- sortino
- annual_return
- total_profit_rate
- volatility
"""
try:
rf = cfg.metrics.risk_free_rate / cfg.metrics.annual_days
except Exception:
rf = 0
start = min(start or self.account_start_date, self.account_start_date)
end = max(end or self.account_end_date, self.account_end_date)
tx = []
logger.info("%s tx in total", len(self.transactions))
for t in self.transactions:
if t.entry_time.date() >= start and t.exit_time.date() <= end:
tx.append(t)
else:
logger.info(
"tx %s not in range, start: %s, end: %s",
t.sec,
t.entry_time,
t.exit_time,
)
# 资产暴露时间
window = tf.count_day_frames(start, end)
total_tx = len(tx)
if total_tx == 0:
return {
"start": start,
"end": end,
"window": window,
"total_tx": total_tx,
"total_profit": None,
"total_profit_rate": None,
"win_rate": None,
"mean_return": None,
"sharpe": None,
"sortino": None,
"calmar": None,
"max_drawdown": None,
"annual_return": None,
"volatility": None,
"baseline": None,
}
# win_rate
wr = len([t for t in tx if t.profit > 0]) / total_tx
if not self._bt_stopped:
await self.recalc_assets()
# 当计算[start, end]之间的盈亏时,我们实际上要多取一个交易日,即start之前一个交易日的资产数据
_start = tf.day_shift(start, -1)
total_profit = await self.get_assets(end) - await self.get_assets(_start)
returns = await self.get_returns(start, end)
mean_return = np.mean(returns)
sharpe = sharpe_ratio(returns, rf)
sortino = sortino_ratio(returns, rf)
calma = calmar_ratio(returns)
mdd = max_drawdown(returns)
# 年化收益率
ar = annual_return(returns)
# 年化波动率
vr = annual_volatility(returns)
# 计算参考标的的相关指标
if baseline is not None:
ref_bars = await Stock.get_bars_in_range(
baseline, FrameType.DAY, start, end
)
if ref_bars.size < 2:
ref_results = None
else:
returns = ref_bars["close"][1:] / ref_bars["close"][:-1] - 1
ref_results = {
"total_profit_rate": cum_returns_final(returns),
"win_rate": np.count_nonzero(returns > 0) / len(returns),
"mean_return": np.mean(returns).item(),
"sharpe": sharpe_ratio(returns, rf),
"sortino": sortino_ratio(returns, rf),
"calmar": calmar_ratio(returns),
"max_drawdown": max_drawdown(returns),
"annual_return": annual_return(returns),
"volatility": annual_volatility(returns),
}
else:
ref_results = None
return {
"start": start,
"end": end,
"window": window,
"total_tx": total_tx,
"total_profit": total_profit,
"total_profit_rate": total_profit / self.principal,
"win_rate": wr,
"mean_return": mean_return,
"sharpe": sharpe,
"sortino": sortino,
"calmar": calma,
"max_drawdown": mdd,
"annual_return": ar,
"volatility": vr,
"baseline": ref_results,
} | zillionare-backtest | /zillionare_backtest-0.4.19-py3-none-any.whl/backtest/trade/broker.py | broker.py |
import datetime
import logging
import uuid
from backtest.trade.datatypes import EntrustSide
from backtest.trade.transaction import Transaction
logger = logging.getLogger(__name__)
class Trade:
"""Trade对象代表了一笔已成功完成的委托。一个委托可能对应多个Trade,特别是当卖出的时候"""
def __init__(
self,
eid: str,
security: str,
price: float,
shares: int,
fee: float,
side: EntrustSide,
time: datetime.datetime,
):
"""Trade对象代表了一笔已成功的委托(即已完成的交易)
Args:
eid: 对应的委托号
security: 证券代码
price: 交易价格
shares: 交易数量
fee: 交易手续费
time: 交易时间
"""
self.eid = eid
self.tid = str(uuid.uuid4())
self.security = security
self.fee = fee
self.price = price
self.shares = shares
self.time = time
self.side = side
# only for buying trade
self._unsell = shares
self._unamortized_fee = fee
self.closed = False
if side == EntrustSide.XDXR:
logger.info("XDXR entrust: %s", self)
def __str__(self):
return f"证券代码: {self.security}\n成交方向: {self.side}\n成交均价: {self.price}\n数量: {self.shares}\n手续费: {self.fee}\n委托号: {self.eid}\n成交号: {self.tid}\n成交时间: {self.time}\n"
def to_dict(self) -> dict:
"""将Trade对象转换为字典格式。
Returns:
Dict: 返回值,其key为
- tid: 交易号
- eid: 委托号
- security: 证券代码
- price: 交易价格
- filled: 居交数量
- trade_fees: 交易手续费
- order_side: 交易方向
- time: 交易时间
"""
return {
"tid": str(self.tid),
"eid": str(self.eid),
"security": self.security,
"order_side": str(self.side),
"price": self.price,
"filled": self.shares,
"time": self.time.isoformat(),
"trade_fees": self.fee,
}
def sell(
self, shares: float, price: float, fee: float, close_time: datetime.datetime
):
"""从当前未售出股中售出。
计算时将根据售出的股数,分摊买入和卖的交易成本。返回未售出的股份和未分摊的成本。
Args:
shares: 待出售股数
price: 出售价格
fee: 交易手续费
close_time: 成交日期
"""
assert self.side in (EntrustSide.BUY, EntrustSide.XDXR)
if not self.closed:
sec = self.security
assert self._unsell > 0, str(self) + "状态错误,无法售出,请检查代码"
sellable = min(shares, self._unsell)
# 计算本次交易的收益,并分摊交易成本
amortized_buy_fee = self.fee * sellable / self.shares
amortized_sell_fee = fee * sellable / shares
self._unsell -= sellable
self._unamortized_fee -= amortized_buy_fee
if self._unsell == 0:
logger.debug("交易%s (%s)已close.", self.security, self.tid)
self.closed = True
trade = Trade(
self.eid,
sec,
price,
sellable,
amortized_sell_fee,
EntrustSide.SELL,
close_time,
)
tx = Transaction(
sec,
self.time,
close_time,
self.price,
price,
sellable,
amortized_buy_fee + amortized_sell_fee,
)
return shares - sellable, fee - amortized_sell_fee, trade, tx | zillionare-backtest | /zillionare_backtest-0.4.19-py3-none-any.whl/backtest/trade/trade.py | trade.py |
import datetime
import uuid
from enum import IntEnum
from typing import Final
import numpy as np
E_BACKTEST: Final = "BACKTEST"
class EntrustSide(IntEnum):
BUY = 1
SELL = -1
XDXR = 0
def __str__(self):
return {
EntrustSide.BUY: "买入",
EntrustSide.SELL: "卖出",
EntrustSide.XDXR: "分红配股",
}[self]
class BidType(IntEnum):
LIMIT = 1
MARKET = 2
def __str__(self):
return {BidType.LIMIT: "限价委托", BidType.MARKET: "市价委托"}.get(self)
class Entrust:
def __init__(
self,
security: str,
side: EntrustSide,
shares: int,
price: float,
bid_time: datetime.datetime,
bid_type: BidType = BidType.MARKET,
):
self.eid = str(uuid.uuid4()) # the contract id
self.security = security
self.side = side
self.bid_type = bid_type
self.bid_shares = shares
self.bid_price = price
self.bid_time = bid_time
def to_json(self):
return {
"eid": self.eid,
"security": self.security,
"side": str(self.side),
"bid_shares": self.bid_shares,
"bid_price": self.bid_price,
"bid_type": str(self.bid_type),
"bid_time": self.bid_time.isoformat(),
}
cash_dtype = np.dtype([("date", "O"), ("cash", "<f8")])
daily_position_dtype = np.dtype(
[
("date", "O"),
("security", "O"),
("shares", "<f8"),
("sellable", "<f8"),
("price", "<f8"),
]
)
"""the position dtype which usually used in backtest server internally:
```
np.dtype(
[
("date", "O"),
("security", "O"),
("shares", "<f8"),
("sellable", "<f8"),
("price", "<f8"),
]
)
```
"""
position_dtype = np.dtype(
[("security", "O"), ("shares", "<f8"), ("sellable", "<f8"), ("price", "<f8")]
)
"""the position dtype which will return back to trader-client
```
np.dtype(
[
("security", "O"),
("shares", "<f8"),
("sellable", "<f8"),
("price", "<f8")
]
)
```
"""
assets_dtype = np.dtype([("date", "O"), ("assets", "<f8")])
"""the assets dtype as the following:
```
np.dtype(
[
("date", "O"),
("assets", "<f8")
]
)
"""
float_ts_dtype = np.dtype([("date", "O"), ("value", "<f8")])
"""generic date-float dtype as the following:
```
np.dtype(
[
("date", "O"),
("value", "<f8")
]
)
"""
rich_assets_dtype = np.dtype(
[("date", "O"), ("assets", "<f8"), ("cash", "<f8"), ("mv", "<f8")]
)
"""the rich assets dtype as the following:
```
np.dtype(
[
("date", "O"),
("assets", "<f8"),
("cash", "<f8"),
("mv", "<f8")
]
)
```
""" | zillionare-backtest | /zillionare_backtest-0.4.19-py3-none-any.whl/backtest/trade/datatypes.py | datatypes.py |
import datetime
from abc import ABCMeta, abstractmethod
from calendar import c
from typing import Dict, List, Tuple, Union
import numpy as np
class BaseFeed(metaclass=ABCMeta):
def __init__(self, *args, **kwargs):
pass
@abstractmethod
async def init(self, *args, **kwargs):
pass
@classmethod
async def create_instance(cls, interface="zillionare", **kwargs):
"""
创建feed实例。当前仅支持zillionare接口。该接口要求使用[zillionare-omicron](https://zillionare.github.io/omicron/)来提供数据。
"""
from backtest.feed.zillionarefeed import ZillionareFeed
if interface == "zillionare":
feed = ZillionareFeed(**kwargs)
await feed.init()
return feed
else:
raise TypeError(f"{interface} is not supported")
@abstractmethod
async def get_price_for_match(
self, security: str, start: datetime.datetime
) -> np.ndarray:
"""获取从`start`之后起当天所有的行情数据,用以撮合
这里没有要求指定行情数据的时间帧类型,理论上无论从tick级到日线级,backtest都能支持。返回的数据至少要包括`frame`、`price`、`volume`三列。
Args:
security : 证券代码
start : 起始时间
Returns:
a numpy array which dtype is `match_data_dtype`
"""
raise NotImplementedError
@abstractmethod
async def get_close_price(self, sec: str, date: datetime.date, fq=False) -> float:
"""
获取证券品种在`date`日期的收盘价
Args:
sec: 证券代码
date: 日期
fq: 是否进行前复权
Returns:
`sec`在`date`日的收盘价
"""
raise NotImplementedError
@abstractmethod
async def batch_get_close_price_in_range(
self, secs: List[str], frames: List[datetime.date], fq=False
) -> Dict[str, np.array]:
"""获取多个证券在多个日期的收盘价
Args:
secs: 证券代码列表
frames: 日期列表, 日期必须是有序且连续
fq: 是否复权。
Returns:
a dict which key is `sec` and value is a numpy array which dtype is `[("frame", "O"), ("close", "f4")]`
"""
raise NotImplementedError
@abstractmethod
async def get_trade_price_limits(self, sec: str, date: datetime.date) -> Tuple:
"""获取证券的交易价格限制
获取证券`sec`在`date`日期的交易价格限制。
Args:
sec : 证券代码
date : 日期
Returns:
交易价格限制,元组,(日期,涨停价,跌停价)
"""
raise NotImplementedError
@abstractmethod
async def get_dr_factor(
self, secs: Union[str, List[str]], frames: List[datetime.date]
) -> Dict[str, np.array]:
"""股票在[start,end]间的每天的复权因子,使用start日进行归一化处理
注意实现者必须保证,复权因子的长度与日期的长度相同且完全对齐。如果遇到停牌的情况,应该进行相应的填充。
Args:
secs: 股票代码
frames: 日期列表
Returns:
返回一个dict
"""
raise NotImplementedError | zillionare-backtest | /zillionare_backtest-0.4.19-py3-none-any.whl/backtest/feed/basefeed.py | basefeed.py |
import datetime
import logging
from typing import Dict, List, Union
import numpy as np
from coretypes import FrameType
from omicron.extensions import array_math_round, fill_nan, math_round
from omicron.models.stock import Stock
from backtest.common.errors import EntrustError
from backtest.feed import match_data_dtype
from backtest.feed.basefeed import BaseFeed
logger = logging.getLogger(__name__)
class ZillionareFeed(BaseFeed):
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
async def init(self, *args, **kwargs):
pass
async def get_price_for_match(
self, security: str, start: datetime.datetime
) -> np.ndarray:
end = datetime.datetime.combine(start.date(), datetime.time(15))
bars = await Stock.get_bars(security, 240, FrameType.MIN1, end)
if start.hour * 60 + start.minute <= 571: # 09:31
bars[0]["close"] = bars[0]["open"]
return bars[bars["frame"] >= start][["frame", "close", "volume"]].astype(
match_data_dtype
)
async def get_close_price(self, sec: str, date: datetime.date, fq=False) -> float:
try:
bars = await Stock.get_bars(sec, 1, FrameType.DAY, date, fq=fq)
if len(bars):
return math_round(bars[-1]["close"].item(), 2)
else:
bars = await Stock.get_bars(sec, 500, FrameType.DAY, date, fq=fq)
return math_round(bars[-1]["close"].item(), 2)
except Exception as e:
logger.exception(e)
logger.warning("get_close_price failed for %s:%s", sec, date)
return None
async def batch_get_close_price_in_range(
self, secs: List[str], frames: List[datetime.date], fq=False
) -> Dict[str, np.array]:
if len(secs) == 0:
raise ValueError("No securities provided")
start = frames[0]
end = frames[-1]
close_dtype = [("frame", "O"), ("close", "<f4")]
result = {}
try:
async for sec, values in Stock.batch_get_day_level_bars_in_range(
secs, FrameType.DAY, start, end, fq=fq
):
closes = values[["frame", "close"]].astype(close_dtype)
if len(closes) == 0:
# 遇到停牌的情况
price = await self.get_close_price(sec, frames[-1], fq=fq)
if price is None:
result[sec] = None
else:
result[sec] = np.array(
[(f, price) for f in frames], dtype=close_dtype
)
continue
closes["close"] = array_math_round(closes["close"], 2)
closes["frame"] = [item.date() for item in closes["frame"]]
# find missed frames, using left fill
missed = np.setdiff1d(frames, closes["frame"])
if len(missed):
missed = np.array(
[(f, np.nan) for f in missed],
dtype=close_dtype,
)
closes = np.concatenate([closes, missed])
closes = np.sort(closes, order="frame")
closes["close"] = fill_nan(closes["close"])
result[sec] = closes
return result
except Exception:
logger.warning("get_close_price failed for %s:%s - %s", secs, start, end)
raise
async def get_trade_price_limits(self, sec: str, date: datetime.date) -> np.ndarray:
prices = await Stock.get_trade_price_limits(sec, date, date)
if len(prices):
return prices[0]
else:
logger.warning("get_trade_price_limits failed for %s:%s", sec, date)
raise EntrustError(EntrustError.NODATA, security=sec, time=date)
async def get_dr_factor(
self, secs: Union[str, List[str]], frames: List[datetime.date]
) -> Dict[str, np.ndarray]:
try:
result = {}
async for sec, bars in Stock.batch_get_day_level_bars_in_range(
secs, FrameType.DAY, frames[0], frames[-1], fq=False
):
factors = bars[["frame", "factor"]].astype(
[("frame", "O"), ("factor", "<f4")]
)
# find missed frames, using left fill
missed = np.setdiff1d(
frames, [item.item().date() for item in bars["frame"]]
)
if len(missed):
missed = np.array(
[(f, np.nan) for f in missed],
dtype=[("frame", "datetime64[s]"), ("factor", "<f4")],
)
factors = np.concatenate([factors, missed])
factors = np.sort(factors, order="frame")
if all(np.isnan(factors["factor"])):
factors["factor"] = [1.0] * len(factors)
else:
factors["factor"] = fill_nan(factors["factor"])
result[sec] = factors["factor"] / factors["factor"][0]
return result
except Exception as e:
logger.exception(e)
logger.warning(
"get_dr_factor failed for %s:%s ~ %s", secs, frames[0], frames[-1]
)
raise | zillionare-backtest | /zillionare_backtest-0.4.19-py3-none-any.whl/backtest/feed/zillionarefeed.py | zillionarefeed.py |
import datetime
import logging
import os
import pickle
import cfg4py
from backtest.common.errors import AccountError
from backtest.config import home_dir
from backtest.trade.broker import Broker
logger = logging.getLogger(__name__)
cfg = cfg4py.get_instance()
class Accounts:
_brokers = {}
def on_startup(self):
token = cfg.auth.admin
self._brokers[token] = Broker("admin", 0, 0.0)
state_file = os.path.join(home_dir(), "state.pkl")
try:
with open(state_file, "rb") as f:
self._brokers = pickle.load(f)
except FileNotFoundError:
pass
except Exception as e:
logger.exception(e)
def on_exit(self):
state_file = os.path.join(home_dir(), "state.pkl")
with open(state_file, "wb") as f:
pickle.dump(self._brokers, f)
def get_broker(self, token):
return self._brokers.get(token)
def is_valid(self, token: str):
return token in self._brokers
def is_admin(self, token: str):
cfg = cfg4py.get_instance()
return token == cfg.auth.admin
def create_account(
self,
name: str,
token: str,
principal: float,
commission: float,
start: datetime.date = None,
end: datetime.date = None,
):
"""创建新账户
一个账户由`name`和`token`的组合惟一确定。如果前述组合已经存在,则创建失败。
Args:
name (str): 账户/策略名称
token (str): 账户token
principal (float): 账户起始资金
commission (float): 账户手续费
start (datetime.date, optional): 回测开始日期,如果是模拟盘,则可为空
end (datetime.date, optional): 回测结束日期,如果是模拟盘,则可为空
"""
if token in self._brokers:
msg = f"账户{name}:{token}已经存在,不能重复创建。"
raise AccountError(msg)
for broker in self._brokers.values():
if broker.account_name == name:
msg = f"账户{name}:{token}已经存在,不能重复创建。"
raise AccountError(msg)
broker = Broker(name, principal, commission, start, end)
self._brokers[token] = broker
logger.info("新建账户:%s, %s", name, token)
return {
"account_name": name,
"token": token,
"account_start_date": broker.account_start_date,
"principal": broker.principal,
}
def list_accounts(self, mode: str):
if mode != "all":
filtered = {
token: broker
for token, broker in self._brokers.items()
if broker.mode == mode and broker.account_name != "admin"
}
else:
filtered = {
token: broker
for token, broker in self._brokers.items()
if broker.account_name != "admin"
}
return [
{
"account_name": broker.account_name,
"token": token,
"account_start_date": broker.account_start_date,
"principal": broker.principal,
}
for token, broker in filtered.items()
]
def delete_accounts(self, account_to_delete: str = None):
if account_to_delete is None:
self._brokers = {}
self._brokers[cfg.auth.admin] = Broker("admin", 0, 0.0)
return 0
else:
for token, broker in self._brokers.items():
if broker.account_name == account_to_delete:
del self._brokers[token]
logger.info("账户:%s已删除", account_to_delete)
return len(self._brokers) - 1
else:
logger.warning("账户%s不存在", account_to_delete)
return len(self._brokers) | zillionare-backtest | /zillionare_backtest-0.4.19-py3-none-any.whl/backtest/web/accounts.py | accounts.py |
import logging
import pickle
import arrow
import numpy as np
import pkg_resources
from numpy.typing import NDArray
from omicron.extensions import numpy_append_fields
from sanic import response
from sanic.blueprints import Blueprint
from backtest.common.errors import AccountError, EntrustError
from backtest.common.helper import jsonify, protected, protected_admin
from backtest.trade.broker import Broker
from backtest.trade.datatypes import cash_dtype, daily_position_dtype, rich_assets_dtype
ver = pkg_resources.get_distribution("zillionare-backtest").parsed_version
bp = Blueprint("backtest")
logger = logging.getLogger(__name__)
@bp.route("status", methods=["GET"])
async def status(request):
return response.json(
{"status": "ok", "listen": request.url, "version": ver.base_version}
)
@bp.route("start_backtest", methods=["POST"])
async def start_backtest(request):
"""启动回测
启动回测时,将为接下来的回测创建一个新的账户。
Args:
request Request: 包含以下字段的请求对象
- name, 账户名称
- token,账户token
- principal,账户初始资金
- commission,账户手续费率
- start,回测开始日期,格式为YYYY-MM-DD
- end,回测结束日期,格式为YYYY-MM-DD
Returns:
json: 包含以下字段的json对象
- account_name, str
- token, str
- account_start_date, str
- principal, float
"""
params = request.json or {}
try:
name = params["name"]
token = params["token"]
start = arrow.get(params["start"]).date()
end = arrow.get(params["end"]).date()
principal = params["principal"]
commission = params["commission"]
except KeyError as e:
logger.warning(f"parameter {e} is required")
return response.text(f"parameter {e} is required", status=499)
except Exception as e:
logger.exception(e)
return response.text(
"parameter error: name, token, start, end, principal, commission",
status=499,
)
accounts = request.app.ctx.accounts
try:
result = accounts.create_account(
name, token, principal, commission, start=start, end=end
)
logger.info("backtest account created:", result)
return response.json(jsonify(result))
except AccountError as e:
return response.text(e.message, status=499)
@bp.route("stop_backtest", methods=["POST"])
@protected
async def stop_backtest(request):
"""结束回测
结束回测后,账户将被冻结,此后将不允许进行任何操作
# todo: 增加持久化操作
"""
broker = request.ctx.broker
if broker.mode != "bt":
raise AccountError("在非回测账户上试图执行不允许的操作")
if not broker._bt_stopped:
broker._bt_stopped = True
await broker.recalc_assets()
return response.text("ok")
@bp.route("accounts", methods=["GET"])
@protected_admin
async def list_accounts(request):
mode = request.args.get("mode", "all")
accounts = request.app.ctx.accounts
result = accounts.list_accounts(mode)
return response.json(jsonify(result))
@bp.route("buy", methods=["POST"])
@protected
async def buy(request):
"""买入
Args:
request Request: 参数以json方式传入, 包含:
- security : 证券代码
- price: 买入价格,如果为None,则意味着以市价买入
- volume: 买入数量
- order_time: 下单时间
Returns:
Response: 买入结果, 字典,包含以下字段:
- tid: str, 交易id
- eid: str, 委托id
- security: str, 证券代码
- order_side: str, 买入/卖出
- price: float, 成交均价
- filled: float, 成交数量
- time: str, 下单时间
- trade_fees: float, 手续费
"""
params = request.json or {}
security = params["security"]
price = params["price"]
volume = params["volume"]
order_time = arrow.get(params["order_time"]).naive
result = await request.ctx.broker.buy(security, price, volume, order_time)
return response.json(jsonify(result))
@bp.route("market_buy", methods=["POST"])
@protected
async def market_buy(request):
"""市价买入
Args:
request Request: 参数以json方式传入, 包含
- security: 证券代码
- volume: 买入数量
- order_time: 下单时间
Returns:
Response: 买入结果, 请参考[backtest.web.interfaces.buy][]
"""
params = request.json or {}
security = params["security"]
volume = params["volume"]
order_time = arrow.get(params["order_time"]).naive
result = await request.ctx.broker.buy(security, None, volume, order_time)
return response.json(jsonify(result))
@bp.route("sell", methods=["POST"])
@protected
async def sell(request):
"""卖出证券
Args:
request: 参数以json方式传入, 包含:
- security : 证券代码
- price: 卖出价格,如果为None,则意味着以市价卖出
- volume: 卖出数量
- order_time: 下单时间
Returns:
Response: 参考[backtest.web.interfaces.buy][]
"""
params = request.json or {}
security = params["security"]
price = params["price"]
volume = params["volume"]
order_time = arrow.get(params["order_time"]).naive
result = await request.ctx.broker.sell(security, price, volume, order_time)
return response.json(jsonify(result))
@bp.route("sell_percent", methods=["POST"])
@protected
async def sell_percent(request):
"""卖出证券
Args:
request Request: 参数以json方式传入, 包含
- security: 证券代码
- percent: 卖出比例
- order_time: 下单时间
- price: 卖出价格,如果为None,则意味着以市价卖出
Returns:
Response: 参考[backtest.web.interfaces.buy][]
"""
params = request.json or {}
security = params["security"]
price = params["price"]
percent = params["percent"]
order_time = arrow.get(params["order_time"]).naive
assert 0 < percent <= 1.0, "percent must be between 0 and 1.0"
broker: Broker = request.ctx.broker
position = broker.get_position(order_time.date())
sellable = position[position["security"] == security]
if sellable.size == 0:
raise EntrustError(EntrustError.NO_POSITION, security=security, time=order_time)
sellable = sellable[0]["sellable"] * percent
result = await request.ctx.broker.sell(security, price, sellable, order_time)
return response.json(jsonify(result))
@bp.route("market_sell", methods=["POST"])
@protected
async def market_sell(request):
"""以市价卖出证券
Args:
request : 以json方式传入,包含以下字段
- security : 证券代码
- volume: 卖出数量
- order_time: 下单时间
Returns:
Response: 参考[backtest.web.interfaces.buy][]
"""
params = request.json or {}
security = params["security"]
volume = params["volume"]
order_time = arrow.get(params["order_time"]).naive
result = await request.ctx.broker.sell(security, None, volume, order_time)
return response.json(jsonify(result))
@bp.route("positions", methods=["GET"])
@protected
async def positions(request) -> NDArray[daily_position_dtype]:
"""获取持仓信息
Args:
request Request:以args方式传入,包含以下字段:
- date: 日期,格式为YYYY-MM-DD,待获取持仓信息的日期
Returns:
Response: 结果以binary方式返回。结果为一个numpy structured array数组,其dtype为[backtest.trade.datatypes.daily_position_dtype][]
"""
date = request.args.get("date")
if date is None:
position = request.ctx.broker.position
else:
date = arrow.get(date).date()
position = request.ctx.broker.get_position(date)
position = position[position["shares"] != 0]
return response.raw(pickle.dumps(position))
@bp.route("info", methods=["GET"])
@protected
async def info(request):
"""获取账户信息
Args:
request Request: 以args方式传入,包含以下字段
- date: 日期,格式为YYYY-MM-DD,待获取账户信息的日期,如果为空,则意味着取当前日期的账户信息
Returns:
Response: 结果以binary方式返回。结果为一个dict,其中包含以下字段:
- name: str, 账户名
- principal: float, 初始资金
- assets: float, 当前资产
- start: datetime.date, 账户创建时间
- last_trade: datetime.date, 最后一笔交易日期
- end: 账户结束时间,仅对回测模式有效
- available: float, 可用资金
- market_value: 股票市值
- pnl: 盈亏(绝对值)
- ppnl: 盈亏(百分比),即pnl/principal
- positions: 当前持仓,dtype为[backtest.trade.datatypes.position_dtype][]的numpy structured array
"""
date = request.args.get("date")
result = await request.ctx.broker.info(date)
return response.raw(pickle.dumps(result))
@bp.route("metrics", methods=["GET"])
@protected
async def metrics(request):
"""获取回测的评估指标信息
Args:
request : 以args方式传入,包含以下字段
- start: 开始时间,格式为YYYY-MM-DD
- end: 结束时间,格式为YYYY-MM-DD
- baseline: str, 用来做对比的证券代码,默认为空,即不做对比
Returns:
Response: 结果以binary方式返回,参考[backtest.trade.broker.Broker.metrics][]
"""
start = request.args.get("start")
end = request.args.get("end")
baseline = request.args.get("baseline")
if start:
start = arrow.get(start).date()
if end:
end = arrow.get(end).date()
metrics = await request.ctx.broker.metrics(start, end, baseline)
return response.raw(pickle.dumps(metrics))
@bp.route("bills", methods=["GET"])
@protected
async def bills(request):
"""获取交易记录
Returns:
Response: 以binary方式返回。结果为一个字典,包括以下字段:
- tx: 配对的交易记录
- trades: 成交记录
- positions: 持仓记录
- assets: 每日市值
"""
results = {}
broker: Broker = request.ctx.broker
results["tx"] = broker.transactions
results["trades"] = broker.trades
results["positions"] = broker._positions
if not (broker.mode == "bt" and broker._bt_stopped):
await broker.recalc_assets()
results["assets"] = broker._assets
return response.json(jsonify(results))
@bp.route("accounts", methods=["DELETE"])
@protected
async def delete_accounts(request):
"""删除账户
当提供了账户名`name`和token(通过headers传递)时,如果name与token能够匹配,则删除`name`账户。
Args:
request Request: 通过params传递以下字段
- name, 待删除的账户名。如果为空,且提供了admin token,则删除全部账户。
"""
account_to_delete = request.args.get("name", None)
accounts = request.app.ctx.accounts
if account_to_delete is None:
if request.ctx.broker.account_name == "admin":
accounts.delete_accounts()
else:
return response.text("admin account required", status=403)
if account_to_delete == request.ctx.broker.account_name:
accounts.delete_accounts(account_to_delete)
@bp.route("assets", methods=["GET"])
@protected
async def get_assets(request):
"""获取账户资产信息
本方法主要为绘制资产收益曲线提供数据。
Args:
request Request: 以args方式传入,包含以下字段
- start: 日期,格式为YYYY-MM-DD,待获取账户信息的日期,如果为空,则取账户起始日
- end: 日期,格式为YYYY-MM-DD,待获取账户信息的日期,如果为空,则取最后交易日
Returns:
Response: 从`start`到`end`期间的账户资产信息,结果以binary方式返回,参考[backtest.trade.datatypes.rich_assets_dtype][]
"""
broker: Broker = request.ctx.broker
start = request.args.get("start")
if start:
start = arrow.get(start).date()
else:
start = broker.account_start_date
end = request.args.get("end")
if end:
end = arrow.get(end).date()
else:
end = broker.account_end_date
if not (broker.mode == "bt" and broker._bt_stopped):
await broker.recalc_assets(end)
if broker._assets.size == 0:
return response.raw(pickle.dump(np.empty(0, dtype=rich_assets_dtype)))
# cash may be shorter than assets
if broker._cash.size == 0:
cash = broker._assets.astype(cash_dtype)
elif broker._cash.size < broker._assets.size:
n = broker._assets.size - broker._cash.size
cash = np.pad(broker._cash, (0, n), "edge")
cash["date"] = broker._assets["date"]
else:
cash = broker._cash
cash = cash[(cash["date"] <= end) & (cash["date"] >= start)]
assets = broker._assets
assets = assets[(assets["date"] <= end) & (assets["date"] >= start)]
mv = assets["assets"] - cash["cash"]
# both _cash and _assets has been moved backward one day
result = numpy_append_fields(
assets, ["cash", "mv"], [cash["cash"], mv], [("cash", "f8"), ("mv", "f8")]
).astype(rich_assets_dtype)
return response.raw(pickle.dumps(result)) | zillionare-backtest | /zillionare_backtest-0.4.19-py3-none-any.whl/backtest/web/interfaces.py | interfaces.py |
import logging
import traceback
from functools import wraps
import cfg4py
import numpy as np
from expiringdict import ExpiringDict
from sanic import Sanic, response
from tabulate import tabulate
from backtest.common.errors import EntrustError
seen_requests = ExpiringDict(max_len=1000, max_age_seconds=10 * 60)
logger = logging.getLogger(__name__)
def get_call_stack(e: Exception) -> str:
"""get exception callstack as a string"""
return "".join(traceback.format_exception(None, e, e.__traceback__))
def get_app_context():
app = Sanic.get_app("backtest")
return app.ctx
def check_token(request):
if not request.token:
return False
app = Sanic.get_app("backtest")
if check_admin_token(request):
return True
if app.ctx.accounts.is_valid(request.token):
request.ctx.broker = app.ctx.accounts.get_broker(request.token)
return True
else:
return False
def check_admin_token(request):
if not request.token:
return False
app = Sanic.get_app("backtest")
if app.ctx.accounts.is_admin(request.token):
cfg = cfg4py.get_instance()
request.ctx.broker = app.ctx.accounts.get_broker(cfg.auth.admin)
return True
else:
return False
def check_duplicated_request(request):
request_id = request.headers.get("Request-ID")
if request_id in seen_requests:
logger.info("duplicated request: [%s]", request_id)
return True
seen_requests[request_id] = True
request.ctx.request_id = request_id
return False
def protected(wrapped):
"""check token and duplicated request"""
def decorator(f):
@wraps(f)
async def decorated_function(request, *args, **kwargs):
is_authenticated = check_token(request)
is_duplicated = check_duplicated_request(request)
params = request.json or request.args
command = request.server_path.split("/")[-1]
if is_authenticated and not is_duplicated:
try:
logger.info("received request: %s, params %s", command, params)
result = await f(request, *args, **kwargs)
logger.info("finished request: %s, params %s", command, params)
return result
except EntrustError as e:
logger.exception(e)
logger.warning("request: %s failed: %s", command, params)
return response.text(
f"{e.status_code} {e.message}\n{get_call_stack(e)}", status=499
)
except Exception as e:
logger.exception(e)
logger.warning("%s error: %s", f.__name__, params)
return response.text(get_call_stack(e), status=499)
elif not is_authenticated:
logger.warning("token is invalid: [%s]", request.token)
return response.json({"msg": "token is invalid"}, 401)
elif is_duplicated:
return response.json({"msg": "duplicated request"}, 200)
return decorated_function
return decorator(wrapped)
def protected_admin(wrapped):
"""check token and duplicated request"""
def decorator(f):
@wraps(f)
async def decorated_function(request, *args, **kwargs):
is_authenticated = check_admin_token(request)
is_duplicated = check_duplicated_request(request)
if is_authenticated and not is_duplicated:
try:
result = await f(request, *args, **kwargs)
return result
except Exception as e:
logger.exception(e)
return response.text(str(e), status=500)
elif not is_authenticated:
logger.warning("admin token is invalid: [%s]", request.token)
return response.text(f"token({request.token}) is invalid", 401)
elif is_duplicated:
return response.text(
f"duplicated request: {request.ctx.request_id}", 200
)
return decorated_function
return decorator(wrapped)
def jsonify(obj) -> dict:
"""将对象`obj`转换成为可以通过json.dumps序列化的字典
本方法可以将str, int, float, bool, datetime.date, datetime.datetime, 或者提供了isoformat方法的其它时间类型, 提供了to_dict方法的对象类型(比如自定义对象),提供了tolist或者__iter__方法的序列对象(比如numpy数组),或者提供了__dict__方法的对象,以及上述对象的复合对象,都可以被正确地转换。
转换中依照以下顺序进行:
1. 简单类型,如str, int, float, bool
2. 提供了to_dict的自定义类型
3. 如果是numpy数组,优先按tolist方法进行转换
4. 如果是提供了isoformat的时间类型,优先转换
5. 如果对象是dict, 按dict进行转换
6. 如果对象提供了__iter__方法,按序列进行转换
7. 如果对象提供了__dict__方法,按dict进行转换
8. 抛出异常
Args:
obj : object to convert
Returns:
A dict able to be json dumps
"""
if obj is None or isinstance(obj, (str, int, float, bool)):
return obj
elif getattr(obj, "to_dict", False):
return jsonify(obj.to_dict())
elif getattr(obj, "tolist", False): # for numpy array
return jsonify(obj.tolist())
elif getattr(obj, "isoformat", False):
return obj.isoformat()
elif isinstance(obj, dict):
return {k: jsonify(v) for k, v in obj.items()}
elif getattr(obj, "__iter__", False): # 注意dict类型也有__iter__
return [jsonify(x) for x in obj]
elif getattr(obj, "__dict__", False):
return {k: jsonify(v) for k, v in obj.__dict__.items()}
else:
raise ValueError(f"{obj} is not jsonable")
def tabulate_numpy_array(arr: np.ndarray) -> str:
"""将numpy structured array 格式化为表格对齐的字符串
Args:
arr : _description_
Returns:
_description_
"""
table = tabulate(arr, headers=arr.dtype.names, tablefmt="fancy_grid")
return table | zillionare-backtest | /zillionare_backtest-0.4.19-py3-none-any.whl/backtest/common/helper.py | helper.py |
# zillionare core types
<p align="center">
<a href="https://pypi.python.org/pypi/zillionare_core_types">
<img src="https://img.shields.io/pypi/v/zillionare_core_types.svg"
alt = "Release Status">
</a>
<a href="#">
<img src="https://github.com/zillionare/core-types/actions/workflows/release.yml/badge.svg" alt="CI status"/>
</a>
</p>
定义了zillionare平台中多数项目/模块需要使用的核心数据类型,比如FrameType, SecuirityType, bars_dtype, BarsArray等。
* Free software: MIT
* Documentation: <https://zillionare-core-types.readthedocs.io>
## Features
* 提供了FrameType, SecurityType, bars_dtype等数据类型
* 提供了BarsArray, BarsPanel, BarsWithLimitArray等type annotation (type hint)类型
* 提供了quote_fetcher接口类。
## Credits
本项目使用[ppw](https://zillionare.github.io/python-project-wizard/)创建,并遵循ppw定义的代码风格和质量规范。
| zillionare-core-types | /zillionare_core_types-0.5.2.tar.gz/zillionare_core_types-0.5.2/README.md | README.md |
# !/usr/bin/env python
# -*- coding: utf-8 -*-
import datetime
from enum import Enum
from typing import Union
import numpy as np
from numpy.typing import NDArray
Frame = Union[datetime.date, datetime.datetime]
"""包含日期date和时间datetime的联合类型"""
class FrameType(Enum):
"""对证券交易中K线周期的封装。提供了以下对应周期:
| 周期 | 字符串 | 类型 | 数值 |
| --------- | --- | ------------------ | -- |
| 年线 | 1Y | FrameType.YEAR | 10 |
| 季线 | 1Q | FrameType.QUARTER | 9 |
| 月线 | 1M | FrameType.MONTH | 8 |
| 周线 | 1W | FrameType.WEEK | 7 |
| 日线 | 1D | FrameType.DAY | 6 |
| 60分钟线 | 60m | FrameType.MIN60 | 5 |
| 30分钟线 | 30m | FrameType.MIN30 | 4 |
| 15分钟线 | 15m | FrameType.MIN15 | 3 |
| 5分钟线 | 5m | FrameType.MIN5 | 2 |
| 分钟线 | 1m | FrameType.MIN1 | 1 |
"""
DAY = "1d"
MIN60 = "60m"
MIN30 = "30m"
MIN15 = "15m"
MIN5 = "5m"
MIN1 = "1m"
WEEK = "1w"
MONTH = "1M"
QUARTER = "1Q"
YEAR = "1Y"
def to_int(self) -> int:
"""转换为整数表示,用于串行化"""
mapping = {
FrameType.MIN1: 1,
FrameType.MIN5: 2,
FrameType.MIN15: 3,
FrameType.MIN30: 4,
FrameType.MIN60: 5,
FrameType.DAY: 6,
FrameType.WEEK: 7,
FrameType.MONTH: 8,
FrameType.QUARTER: 9,
FrameType.YEAR: 10,
}
return mapping[self]
@staticmethod
def from_int(frame_type: int) -> "FrameType":
"""将整数表示的`frame_type`转换为`FrameType`类型"""
mapping = {
1: FrameType.MIN1,
2: FrameType.MIN5,
3: FrameType.MIN15,
4: FrameType.MIN30,
5: FrameType.MIN60,
6: FrameType.DAY,
7: FrameType.WEEK,
8: FrameType.MONTH,
9: FrameType.QUARTER,
10: FrameType.YEAR,
}
return mapping[frame_type]
def __lt__(self, other):
if self.__class__ is other.__class__:
return self.to_int() < other.to_int()
return NotImplemented
def __le__(self, other) -> bool:
if self.__class__ is other.__class__:
return self.to_int() <= other.to_int()
return NotImplemented
def __ge__(self, other) -> bool:
if self.__class__ is other.__class__:
return self.to_int() >= other.to_int()
return NotImplemented
def __gt__(self, other) -> bool:
if self.__class__ is other.__class__:
return self.to_int() > other.to_int()
return NotImplemented
class SecurityType(Enum):
"""支持的证券品种类型定义
| 类型 | 值 | 说明 |
| ------------------------ | --------- | ----- |
| SecurityType.STOCK | stock | 股票类型 |
| SecurityType.INDEX | index | 指数类型 |
| SecurityType.ETF | etf | ETF基金 |
| SecurityType.FUND | fund | 基金 |
| SecurityType.LOF | lof,LOF基金 | |
| SecurityType.FJA | fja | 分级A基金 |
| SecurityType.FJB | fjb | 分级B基金 |
| SecurityType.BOND | bond | 债券基金 |
| SecurityType.STOCK_B | stock_b | B股 |
| SecurityType.UNKNOWN | unknown | 未知品种 |
"""
STOCK = "stock"
INDEX = "index"
ETF = "etf"
FUND = "fund"
LOF = "lof"
FJA = "fja"
FJB = "fjb"
FUTURES = "futures"
BOND = "bond"
STOCK_B = "stock_b"
UNKNOWN = "unknown"
class MarketType(Enum):
"""市场类型。当前支持的类型为上交所`XSHG`和`XSHE`"""
XSHG = "XSHG"
XSHE = "XSHE"
bars_dtype = np.dtype(
[
# use datetime64 may improve performance/memory usage, but it's hard to talk with other modules, like TimeFrame
("frame", "datetime64[s]"),
("open", "f4"),
("high", "f4"),
("low", "f4"),
("close", "f4"),
("volume", "f8"),
("amount", "f8"),
("factor", "f4"),
]
)
"""行情数据元类型"""
bars_dtype_with_code = np.dtype(
[
("code", "O"),
# use datetime64 may improve performance/memory usage, but it's hard to talk with other modules, like TimeFrame
("frame", "datetime64[s]"),
("open", "f4"),
("high", "f4"),
("low", "f4"),
("close", "f4"),
("volume", "f8"),
("amount", "f8"),
("factor", "f4"),
]
)
"""带证券代码的行情数据元类型"""
bars_cols = list(bars_dtype.names)
"""行情数据列名数组,即[frame, open, high, low, close, volume, amount, factor]"""
fields = bars_dtype.descr.copy()
fields.extend([("high_limit", "f4"), ("low_limit", "f4")])
bars_with_limit_dtype = np.dtype(fields)
"""带涨跌停价格的行情数据元类型,包含frame, open, high, low, close, volume, amount, factort high_limit, low_limit"""
bars_with_limit_cols = list(bars_with_limit_dtype.names)
"""带涨跌停价的行情数据列名数组,即[frame, open, high, low, close, volume, amount, factort high_limit, low_limit]"""
BarsArray = NDArray[bars_dtype]
"""行情数据(包含列frame, open, high, low, close, volume, amount, factor)数组"""
BarsWithLimitArray = NDArray[bars_with_limit_dtype]
"""带涨跌停价(high_limit, low_limit)的行情数据数组"""
limit_price_only_dtype = np.dtype(
[("frame", "O"), ("code", "O"), ("high_limit", "f4"), ("low_limit", "f4")]
)
"""只包含涨跌停价的行情数据元类型,即frame, code, high_limit, low_limit"""
LimitPriceOnlyBarsArray = NDArray[limit_price_only_dtype]
"""仅包括日期、代码、涨跌停价的的行情数据数组"""
BarsPanel = NDArray[bars_dtype_with_code]
"""带证券代码的行情数据数组"""
security_db_dtype = [("frame", "O"), ("code", "U16"), ("info", "O")]
security_info_dtype = [
("code", "O"),
("alias", "O"),
("name", "O"),
("ipo", "datetime64[s]"),
("end", "datetime64[s]"),
("type", "O"),
]
xrxd_info_dtype = [
("code", "O"),
("a_xr_date", "datetime64[s]"),
("bonusnote1", "O"),
("bonus_ratio", "<f4"),
("dividend_ratio", "<f4"),
("transfer_ratio", "<f4"),
("at_bonus_ratio", "<f4"),
("report_date", "datetime64[s]"),
("plan_progress", "O"),
("bonusnote2", "O"),
("bonus_cancel_pub_date", "datetime64[s]"),
]
__all__ = [
"Frame",
"FrameType",
"SecurityType",
"MarketType",
"bars_dtype",
"bars_dtype_with_code",
"bars_cols",
"bars_with_limit_dtype",
"bars_with_limit_cols",
"limit_price_only_dtype",
"LimitPriceOnlyBarsArray",
"BarsWithLimitArray",
"BarsArray",
"BarsWithLimitArray",
"BarsPanel",
"security_db_dtype",
"security_info_dtype",
"xrxd_info_dtype",
] | zillionare-core-types | /zillionare_core_types-0.5.2.tar.gz/zillionare_core_types-0.5.2/coretypes/types.py | types.py |
import datetime
from abc import ABC
from typing import Dict, List, Union
import deprecation
import numpy
from coretypes.__version__ import __version__
from coretypes.types import Frame, FrameType
class QuotesFetcher(ABC):
async def get_quota(self) -> int:
"""获取接口当前可用的quota
Raises:
NotImplementedError: [description]
Returns:
int: [description]
"""
raise NotImplementedError
async def get_security_list(self) -> numpy.ndarray:
"""fetch security list from server.
The returned list is a numpy.ndarray, which each elements should look like:
code display_name name start_date end_date type
000001.XSHE 平安银行 PAYH 1991-04-03 2200-01-01 stock
000002.XSHE 万科A WKA 1991-01-29 2200-01-01 stock
all fields are string type
Returns:
numpy.ndarray: [description]
"""
raise NotImplementedError
async def get_bars(
self,
sec: str,
end: Frame,
n_bars: int,
frame_type: FrameType,
allow_unclosed=True,
) -> numpy.ndarray:
"""取n个单位的k线数据。
k线周期由frame_type指定。最后结束周期为end。股票停牌期间的数据会使用None填充。
Args:
sec (str): 证券代码
end (Frame):
n_bars (int):
frame_type (FrameType):
allow_unclosed (bool): 为真时,当前未结束的帧数据也获取
Returns:
a numpy.ndarray, with each element is:
'frame': datetime.date or datetime.datetime, depends on frame_type.
Denotes which time frame the data
belongs .
'open, high, low, close': float
'volume': double
'amount': the buy/sell amount in total, double
'factor': float, may exist or not
"""
raise NotImplementedError
async def get_price(
self,
sec: Union[List, str],
end_at: Union[str, datetime.datetime],
n_bars: int,
frame_type: str,
) -> Dict[str, numpy.recarray]:
raise NotImplementedError
async def create_instance(self, **kwargs):
raise NotImplementedError
async def get_all_trade_days(self):
"""返回交易日历。不同的服务器可能返回的时间跨度不一样,但相同跨度内的时间应该一样。对已
经过去的交易日,可以用上证指数来验证。
"""
raise NotImplementedError
async def get_valuation(
self, code: Union[str, List[str]], day: Frame
) -> numpy.ndarray:
"""读取code指定的股票在date指定日期的市值数据。
返回数据包括:
code: 股票代码
day: 日期
captialization: 总股本
circulating_cap: 流通股本(万股)
market_cap: 总市值(亿元)
circulating_market_cap: 流通市值(亿元)
turnover_ration: 换手率(%)
pe_ratio: 市盈率(PE,TTM)每股市价为每股收益的倍数,反映投资人对每元净利润所愿支付的价
格,用来估计股票的投资报酬和风险
pe_ratio_lyr: 市盈率(PE),以上一年度每股盈利计算的静态市盈率. 股价/最近年度报告EPS
pb_ratio: 市净率(PB)
ps_ratio: 市销率(PS)
pcf_ratio: 市现率(PCF)
Args:
code (Union[str, List[str]]): [description]
day (Frame): [description]
Returns:
numpy.ndarray: [description]
"""
raise NotImplementedError
async def get_fund_list(self, codes: Union[str, List[str]] = None) -> numpy.ndarray:
"""
获取所有的基金基本信息
Args:
codes (Union[str, List[str]]): [description]
Returns:
np.array: [基金的基本信息]
"""
raise NotImplementedError
async def get_fund_portfolio_stock(
self, codes: Union[str, List[str]], pub_date: Union[str, datetime.date] = None
) -> numpy.array:
raise NotImplementedError
async def get_fund_net_value(
self,
codes: Union[str, List[str]],
day: datetime.date = None,
) -> numpy.array:
raise NotImplementedError
async def get_fund_share_daily(
self, codes: Union[str, List[str]] = None, day: datetime.date = None
) -> numpy.array:
raise NotImplementedError
@deprecation.deprecated(
deprecated_in="0.2",
removed_in="0.3",
current_version=__version__,
details="Use get_quota instead",
)
async def get_query_count(self):
"""查询当日剩余可调用数据条数"""
raise NotImplementedError | zillionare-core-types | /zillionare_core_types-0.5.2.tar.gz/zillionare_core_types-0.5.2/coretypes/quote_fetcher.py | quote_fetcher.py |
# em
<p align="center">
<a href="https://pypi.python.org/pypi/em">
<img src="https://img.shields.io/pypi/v/em.svg"
alt = "Release Status">
</a>
<a href="https://github.com/zillionare/em/actions">
<img src="https://github.com/zillionare/em/actions/workflows/main.yml/badge.svg?branch=release" alt="CI Status">
</a>
<a href="https://em.readthedocs.io/en/latest/?badge=latest">
<img src="https://readthedocs.org/projects/em/badge/?version=latest" alt="Documentation Status">
</a>
</p>
* Free software: MIT
* Documentation: <https://em.readthedocs.io>
## Features
* TODO
## Credits
This package was created with [Cookiecutter](https://github.com/audreyr/cookiecutter) and the [zillionare/cookiecutter-pypackage](https://github.com/zillionare/cookiecutter-pypackage) project template.
| zillionare-em | /zillionare-em-0.1.1.tar.gz/zillionare-em-0.1.1/README.md | README.md |
import asyncio
import datetime
import json
import logging
import os
import random
from typing import Any, Union
import arrow
import pyppeteer as pp
from pyppeteer.browser import Browser
from pyppeteer.page import Page
from sanic import request, response
from em.basecrawler import BaseCrawler
from em.errors import FetchPortfolioError, FetchQuotationError, PlaceOrderError
from em.portfolio import Portfolio
from em.quotation import Quotation
from em.selectors import Selectors
from em.util import datetime_as_filename
logger = logging.getLogger(__name__)
class EMTraderWebInterface(BaseCrawler):
def __init__(self, model, screenshot_dir=None):
if screenshot_dir is None:
screenshot_dir = os.path.expanduser("~/em/screenshots")
os.makedirs(screenshot_dir, exist_ok=True)
super().__init__("https://jy.xzsec.com", screenshot_dir)
self._browser: Browser = None
self._decay_retry = 1
self._model = model
self._is_authed = False
self._portfolio = None
self.account = os.getenv("ACCOUNT")
@property
def is_authed(self):
return self._is_authed
@property
def portfolio(self):
return self._portfolio
async def init(self, *args):
await self.start()
await self.login()
await self._get_portfolio()
async def stop(self, *args):
await super().stop()
async def _dismiss_notice(self, page: Page):
notice = await page.xpath(Selectors.notice_btn)
if notice:
await notice[0].click()
async def login(self):
try:
page, _ = await self.goto(self._base_url)
await self._dismiss_notice(page)
img_src = await page.Jeval(Selectors.captcha_img_src, "node => node.src")
code = await self._hack_captcha(img_src)
password = os.environ["PASSWORD"]
await page.Jeval(Selectors.account, f"el => el.value = {self.account}")
await page.Jeval(Selectors.password, f"el => el.value = {password}")
await page.Jeval(Selectors.captcha_txt, f"el => el.value = {code}")
await page.click(Selectors.valid_thru_3h)
await page.waitFor(random.randrange(500, 1000))
# wait until login complete
await asyncio.gather(
*[
# submit the form
page.click(Selectors.login_button),
page.waitForNavigation(),
],
return_exceptions=False,
)
if page.url.find("/Trade/Buy") != -1:
logger.info("login succeeded")
self._is_authed = True
except Exception as e:
logger.exception(e)
dt = datetime.datetime.now()
screenshot = os.path.join(
self.screenshot_dir,
f"login_{dt.year}-{dt.month}-{dt.day}_{dt.hour:02d}{dt.minute:02d}.jpg",
)
await page.screenshot(path=screenshot)
# login failed, simply redo
await asyncio.sleep(self._decay_retry)
self._decay_retry *= 1.2
logger.warning("login failed, retrying...")
await self.login()
async def _hack_captcha(self, img_src: str):
_, response = await self.goto(img_src)
letters, *_ = self._model._learner.predict(await response.buffer())
return "".join(letters)
async def _get_quotation(self, code) -> Quotation:
quotation_url = f"https://hsmarket.eastmoney.com/api/SHSZQuoteSnapshot?id={code}&market=SH&callback="
try:
_, response = await self.goto(quotation_url)
jsonp = await response.text()
quotation = json.loads(jsonp.replace("(", "").replace(");", ""))
return Quotation(**quotation)
except Exception as e:
logger.exception(e)
msg = f"failed to fetch quotation for {code}"
raise FetchQuotationError(msg)
async def _place_order_long(self, code: str, units: int, price: float):
"""[summary]
只实现限价委托方式。限价委托代码为'B'
Args:
code ([type]): 股票代码,6位数字
units (int): 将买入的股票手数(一手=100股)
"""
page, _ = await self.goto("/Trade/Buy")
# 输入股票代码
await page.focus(Selectors.stockcode)
await page.keyboard.type(code)
await page.waitFor(300)
await page.keyboard.press("Enter")
# 输入委托方式:限价委托
control = "div.select_showbox"
option = "div.select_box>ul>li[data-value='B']"
await self.select_from_dropdown(page, control, option)
# 输入买入价
await page.Jeval(Selectors.price, f"el => el.value = {price}")
# 输入购买股票数量
await page.Jeval(Selectors.shares, f"el => el.value = {units * 100}")
logger.info("order %s 手数 %s", units, code)
await page.click(Selectors.confirm_order)
# todo: wait for jump, and take screenshot on failure
def _calc_units(self, money: float, price: float, margin: float = 1.1):
"""计算给定资金量`money`和`price`,能买入多少手股份。
为提高资金利用率,允许超买(由`margin`指定)。举例来说,如果资金为1万,股价为9.3,则不超买的,允许买入1000股,资金余额为7千。允许超买的情况下,将买入1100股,使用资金为10,230元,超出2.3%,在默认的`margin`(10%)以内。
买入股票数还将被限制在可用资金(`portfolio.avail`)以内
Args:
money (float): [description]
price (float): [description]
margin : 允许超买额,介于[1,1.5]之间。1.5意味着允许超买50%,但不会超过当前可用资金。
Returns:
[type]: [description]
"""
assert 1 <= margin <= 1.5
avail = self._portfolio.avail
money = min(money, avail)
units = int(((money / price) // 100))
lower_bound = units * price
upper_bound = (units + 1) * price * 100
if (money - lower_bound >= upper_bound - money) and upper_bound < min(
money * margin, avail
):
# closer to upper_bound
return units + 1
else:
return units
async def buy(self, request: request.Request) -> response.HTTPResponse:
"""[summary]
Args:
request (request.Request): [description]
Returns:
response.HTTPResponse: [description]
"""
args = request.json
money = args.get("money")
units = args.get("units")
price = args.get("price")
code = args.get("code")
if all([money is None, units is None]):
return response.json(body=None, status=400)
try:
quotation = await self._get_quotation(code)
await self._get_portfolio()
# 计算可买手数
price = price or quotation.topprice
units = units or self._calc_units(money, price)
await self._place_order_long(code, units, price)
return response.json(
body={"err": 0, "oder": {"code": code, "price": price, "units": units}}
)
except FetchQuotationError as e:
return response.json(body={"err": -1, "code": code, "desc": e.message})
except FetchPortfolioError as e:
return response.json(body={"err": -1, "desc": e.message})
except PlaceOrderError:
return response.json(
body={
"err": -1,
"desc": "failed to place order",
"order": {"code": code, "units": units, "price": price},
}
)
async def _on_portfolio_response(self, resp: pp.network_manager.Response):
try:
if resp.url.find("queryAssetAndPositionV1") != -1:
result = await resp.json()
if result["Status"] == 0:
return result["Data"][0]
else:
logger.warning("failed to get portfolio: %s", result["Status"])
except Exception as e:
logger.exception(e)
async def _get_portfolio(self):
"""获取资金持仓"""
try:
page, _ = await self.goto(
"Search/Position", self._on_portfolio_response, "position"
)
data = await self.wait_response("position")
self._portfolio = Portfolio(**Portfolio.convert(data))
except Exception as e:
logger.exception(e)
filename = f"portfolio_{datetime_as_filename()}.jpg"
await self.screenshot(page, filename)
raise FetchPortfolioError(account=self.account)
async def get_portfolio(self, request: request.Request) -> response.HTTPResponse:
await self._get_portfolio()
return response.json(self._portfolio.as_dict()) | zillionare-em | /zillionare-em-0.1.1.tar.gz/zillionare-em-0.1.1/em/api.py | api.py |
import asyncio
import logging
import os
from typing import Any, Awaitable, Callable, List, Tuple, Union
import pyppeteer as pp
from numpy import isin
from pyppeteer.browser import Browser
from pyppeteer.network_manager import Response
from pyppeteer.page import Page
logger = logging.getLogger(__name__)
class ResponseInterceptor:
"""
传入response处理回调函数(awaiable)和一个buffer。其中buffer[0]为`event`对象,buffer[1]则存放处理repsone得到的`result`。
通过`event.set`来通知等待者已经获取到对应的response。
Examples:
>>> async def on_response(resp):
... if resp.request.url == "...":
... return await resp.buffer()
>>> await crawler.goto(url, on_response, "test")
>>> data = await crawler.wait_for("test", 2)
"""
def __init__(self, handler: Callable[[int], Awaitable], buffer: List):
self.handler = handler
self.buffer = buffer
async def handle_response(self, resp: Response):
result = await self.handler(resp)
if result is not None:
self.buffer[1] = result
self.buffer[0].set()
class BaseCrawler:
def __init__(self, base_url: str, screenshot_dir: str = None):
self._browser: Browser = None
self._base_url = base_url
self._screenshot_dir = screenshot_dir
# event_name -> (Event, data)
self._events = {}
@property
def base_url(self):
return self._base_url
@property
def screenshot_dir(self):
return self._screenshot_dir
async def start(self):
if self._browser is None:
self._browser = await pp.launch(
{"headless": True, "args": ["--no-sandbox"]}
)
async def stop(self):
await self._browser.close()
async def goto(
self,
url: str,
interceptor: Callable[[int], Awaitable] = None,
name: str = None,
) -> Tuple[Page, Response]:
"""获取url指定的页面,返回Page对象和Response。
本函数返回的`response`直接对应于url。当获取到`url`指定的页面后,可能触发其它网络请求(比如js, ajax等),如果要获取这些网络请求的数据,需要通过`interceptor`机制。
如果需要同步获取该页面触发的其它请求中的某个`response`,请指定`name`值,后续可以使用`crawler.wait_response(name)`来得到等待中的`response`的经处理后的数据。如果只允许异步获取某个`response`中的数据,则可以不传入`name`。此时`interceptor`需要自行保存(或者使用)处理后的数据。
Args:
url (str): [description]
interceptor (Callable[[int], Awaitable], optional): [description]. Defaults to None.
name (str, optional): [description]. Defaults to None.
Returns:
Tuple[Page, Response]: [description]
"""
if not url.startswith("http"):
# url is just a server path, not a full url
url = f"{self._base_url}/{url}"
page: Page = await self._browser.newPage()
if interceptor:
if name:
buffer = [asyncio.Event(), None]
self._events[name] = buffer
ri = ResponseInterceptor(interceptor, buffer)
page.on("response", ri.handle_response)
else:
page.on("response", interceptor)
resp: pp.network_manager.Response = await page.goto(url)
logger.debug("page %s returns %s", page.url, resp.status)
return page, resp
async def wait_response(self, name: str, timeout: int = 10):
"""等待命名为`name`的某个网络请求的`response`处理结果。
Args:
name (str): [description]
timeout (int, optional): [description]. Defaults to 10.
Raises:
ValueError: [description]
Returns:
[type]: [description]
"""
try:
logger.info("waiting for repsone: %s", name)
buffer = self._events.get(name)
event = buffer[0]
if event is None:
raise ValueError(f"Event({name}) not exist")
await asyncio.wait_for(event.wait(), timeout)
logger.info("Got response named as %s, len is %s", name, len(buffer[1]))
return buffer[1]
finally:
if name in self._events:
del self._events[name]
async def select_from_dropdown(self, page: Page, control: str, option: str):
"""模拟dropdown的选择操作。
一些页面的下拉菜单(select控件)是经过包装的,不能直接使用page.select()来完成选择,需要使用模拟操作的方法。
Args:
page (Page): the page object
control (str): selector for the control, for example, `div.select_box>ul>li[data-value='x']`
option (str): selector for the option
"""
await page.Jeval(control, "el => el.click()")
await page.waitFor(100)
await page.screenshot(path="/root/trader/screenshot/select_1.jpg")
await page.Jeval(option, "el => el.click()")
await page.screenshot(path="/root/trader/screenshot/select_2.jpg")
async def screenshot(self, page: Page, filename: str):
if self.screenshot_dir:
await page.screenshot(path=os.path.join(self.screenshot_dir, filename)) | zillionare-em | /zillionare-em-0.1.1.tar.gz/zillionare-em-0.1.1/em/basecrawler.py | basecrawler.py |
__author__ = """Aaron Yang"""
__email__ = "[email protected]"
__version__ = "0.1.1"
# -*- coding: utf-8 -*-
import asyncio
import copy
import datetime
import functools
import logging
import math
from concurrent.futures import ThreadPoolExecutor
from typing import Dict, List, Tuple, Union
import jqdatasdk as jq
import numpy as np
import pandas as pd
import pytz
from coretypes import QuotesFetcher, bars_dtype
from numpy.typing import ArrayLike
from pandas.core.frame import DataFrame
from sqlalchemy import func
logger = logging.getLogger(__name__)
minute_level_frames = ["60m", "30m", "15m", "5m", "1m"]
def async_concurrent(executors):
def decorator(f):
@functools.wraps(f)
async def wrapper(*args, **kwargs):
p = functools.partial(f, *args, **kwargs)
loop = asyncio.get_running_loop()
try:
return await loop.run_in_executor(executors, p)
except Exception as e: # pylint: disable=broad-except
logger.exception(e)
if str(e).find("最大查询限制") != -1:
raise FetcherQuotaError("Exceeded JQDataSDK Quota") from e
elif str(e).find("账号过期") != -1:
logger.warning(
"account %s expired, please contact jqdata", Fetcher.account
)
raise AccountExpiredError(
f"Account {Fetcher.account} expired"
) from e
else:
raise e
return wrapper
return decorator
class FetcherQuotaError(BaseException):
"""quotes fetcher quota exceed"""
pass
class AccountExpiredError(BaseException):
pass
def singleton(cls):
"""Make a class a Singleton class
Examples:
>>> @singleton
... class Foo:
... # this is a singleton class
... pass
"""
instances = {}
@functools.wraps(cls)
def get_instance(*args, **kwargs):
if cls not in instances:
instances[cls] = cls(*args, **kwargs)
return instances[cls]
return get_instance
@singleton
class Fetcher(QuotesFetcher):
"""
JQFetcher is a subclass of QuotesFetcher
"""
connected = False
tz = pytz.timezone("Asia/Shanghai")
executor = ThreadPoolExecutor(1)
account = None
password = None
def __init__(self):
pass
@classmethod
@async_concurrent(executor)
def create_instance(cls, account: str, password: str, **kwargs):
"""创建jq_adaptor实例。 kwargs用来接受多余但不需要的参数。
Args:
account: 聚宽账号
password: 聚宽密码
kwargs: not required
Returns:
None
"""
cls.login(account, password, **kwargs)
@async_concurrent(executor)
def get_bars_batch(
self,
secs: List[str],
end_at: datetime.datetime,
n_bars: int,
frame_type: str,
include_unclosed=True,
) -> Dict[str, np.ndarray]:
"""批量获取多只股票的行情数据
Args:
secs: 股票代码列表
end_at: 查询的结束时间
n_bars: 查询的记录数
frame_type: 查询的周期,比如1m, 5m, 15m, 30m, 60m, 1d, 1w, 1M, 1Q, 1Y等
include_unclosed: 如果`end_at`没有指向`frame_type`的收盘时间,是否只取截止到上一个已收盘的数据。
Returns:
字典,其中key为股票代码,值为对应的行情数据,类型为bars_dtype.
"""
if not self.connected:
logger.warning("not connected.")
return None
if type(end_at) not in [datetime.date, datetime.datetime]:
raise TypeError("end_at must by type of datetime.date or datetime.datetime")
# has to use type rather than isinstance, since the latter always return true
# when check if isinstance(datetime.datetime, datetime.date)
if type(end_at) is datetime.date: # pylint: disable=unidiomatic-typecheck
end_at = datetime.datetime(end_at.year, end_at.month, end_at.day, 15)
resp = jq.get_bars(
secs,
n_bars,
frame_type,
fields=[
"date",
"open",
"high",
"low",
"close",
"volume",
"money",
"factor",
],
end_dt=end_at,
include_now=include_unclosed,
fq_ref_date=end_at,
df=False,
)
return {code: bars.astype(bars_dtype) for code, bars in resp.items()}
@async_concurrent(executor)
def get_bars(
self,
sec: str,
end_at: Union[datetime.date, datetime.datetime],
n_bars: int,
frame_type: str,
include_unclosed=True,
) -> np.ndarray:
"""获取`sec`在`end_at`时刻的`n_bars`个`frame_type`的行情数据
Args:
sec: 股票代码
end_at: 查询的结束时间
n_bars: 查询的记录数
frame_type: 查询的周期,比如1m, 5m, 15m, 30m, 60m, 1d, 1w, 1M, 1Q, 1Y等
include_unclosed: 如果`end_at`没有指向`frame_type`的收盘时间,是否只取截止到上一个已收盘的数据。
Returns:
行情数据,类型为bars_dtype.
"""
if not self.connected:
logger.warning("not connected")
return None
logger.debug("fetching %s bars for %s until %s", n_bars, sec, end_at)
if type(end_at) not in [datetime.date, datetime.datetime]:
raise TypeError("end_at must by type of datetime.date or datetime.datetime")
if type(end_at) is datetime.date: # noqa
end_at = datetime.datetime(end_at.year, end_at.month, end_at.day, 15)
bars = jq.get_bars(
sec,
n_bars,
unit=frame_type,
end_dt=end_at,
fq_ref_date=None,
df=False,
fields=[
"date",
"open",
"high",
"low",
"close",
"volume",
"money",
"factor",
],
include_now=include_unclosed,
)
# convert to omega supported format
bars = bars.astype(bars_dtype)
if len(bars) == 0:
logger.warning(
"fetching %s(%s,%s) returns empty result", sec, n_bars, end_at
)
return bars
return bars
@async_concurrent(executor)
def get_price(
self,
sec: Union[List, str],
end_date: Union[str, datetime.datetime],
n_bars: int,
frame_type: str,
) -> Dict[str, np.ndarray]:
"""获取一支或者多支股票的价格数据
一般我们使用`get_bars`来获取股票的行情数据。这个方法用以数据校验。
Args:
sec: 股票代码或者股票代码列表
end_date: 查询的结束时间
n_bars: 查询的记录数
frame_type: 查询的周期,比如1m, 5m, 15m, 30m, 60m, 1d, 1w, 1M, 1Q, 1Y等
Returns:
字典,其中key为股票代码,值为对应的行情数据,类型为bars_dtype.
"""
if type(end_date) not in (str, datetime.date, datetime.datetime):
raise TypeError(
"end_at must by type of datetime.date or datetime.datetime or str"
)
if type(sec) not in (list, str):
raise TypeError("sec must by type of list or str")
fields = [
"open",
"high",
"low",
"close",
"volume",
"money",
"factor",
]
params = {
"security": sec,
"end_date": end_date,
"fields": fields,
"fq": None,
"fill_paused": False,
"frequency": frame_type,
"count": n_bars,
"skip_paused": True,
}
df = jq.get_price(**params)
# 处理时间 转换成datetime
temp_bars_dtype = copy.deepcopy(bars_dtype)
temp_bars_dtype.insert(1, ("code", "O"))
ret = {}
for code, group in df.groupby("code"):
df = group[
[
"time", # python object either of Frame type
"code",
"open",
"high",
"low",
"close",
"volume",
"money",
"factor",
]
].sort_values("time")
bars = df.to_records(index=False).astype(temp_bars_dtype)
bars["frame"] = [x.to_pydatetime() for x in df["time"]]
ret[code] = bars.view(np.ndarray)
return ret
@async_concurrent(executor)
def get_finance_xrxd_info(
self, dt_start: datetime.date, dt_end: datetime.date
) -> list:
"""上市公司分红送股(除权除息)数据 / 2005至今,8:00更新
聚宽提供的数据是按季组织的。这里的`dt_start`和`dt_end`是指实际季报/年报的时间,而不是实际除权除息的时间。
Args:
dt_start: 开始日期
dt_end: 结束日期
Returns:
分红送股数据,其每一个元素是一个元组,形如:('002589.XSHE', datetime.date(2022, 7, 22), '10派0.09元(含税)', 0.09, 0.0, 0.0, 0.09, datetime.date(2021, 12, 31), '实施方案', '10派0.09元(含税)', datetime.date(2099, 1, 1))
"""
if not self.connected:
logger.warning("not connected")
return None
# dt_end一般为当天,dt_start一般为dt_end-366天
if dt_start is None or dt_end is None:
return None
q_for_count = jq.query(func.count(jq.finance.STK_XR_XD.id))
q_for_count = q_for_count.filter(
jq.finance.STK_XR_XD.a_xr_date.isnot(None),
jq.finance.STK_XR_XD.report_date >= dt_start,
jq.finance.STK_XR_XD.report_date <= dt_end,
)
q = jq.query(jq.finance.STK_XR_XD).filter(
jq.finance.STK_XR_XD.a_xr_date.isnot(None),
jq.finance.STK_XR_XD.report_date >= dt_start,
jq.finance.STK_XR_XD.report_date <= dt_end,
)
reports_count = jq.finance.run_query(q_for_count)["count_1"][0]
page = 0
dfs: List[pd.DataFrame] = []
while page * 3000 < reports_count:
df1 = jq.finance.run_query(q.offset(page * 3000).limit(3000))
dfs.append(df1)
page += 1
if len(dfs) == 0:
return None
df = pd.concat(dfs)
reports = []
for _, row in df.iterrows():
a_xr_date = row["a_xr_date"]
if a_xr_date is None: # 还未确定的方案不登记
continue
code = row["code"]
# company_name = row['company_name'] # 暂时不存公司名字,没实际意义
report_date = row["report_date"]
board_plan_bonusnote = row["board_plan_bonusnote"]
implementation_bonusnote = row["implementation_bonusnote"] # 有实施才有公告
bonus_cancel_pub_date = row["bonus_cancel_pub_date"]
if bonus_cancel_pub_date is None: # 如果不是2099.1.1,即发生了取消事件
bonus_cancel_pub_date = datetime.date(2099, 1, 1)
bonus_ratio_rmb = row["bonus_ratio_rmb"]
if bonus_ratio_rmb is None or math.isnan(bonus_ratio_rmb):
bonus_ratio_rmb = 0.0
dividend_ratio = row["dividend_ratio"]
if dividend_ratio is None or math.isnan(dividend_ratio):
dividend_ratio = 0.0
transfer_ratio = row["transfer_ratio"]
if transfer_ratio is None or math.isnan(transfer_ratio):
transfer_ratio = 0.0
at_bonus_ratio_rmb = row["at_bonus_ratio_rmb"]
if at_bonus_ratio_rmb is None or math.isnan(at_bonus_ratio_rmb):
at_bonus_ratio_rmb = 0.0
plan_progress = row["plan_progress"]
record = (
code,
a_xr_date,
board_plan_bonusnote,
bonus_ratio_rmb,
dividend_ratio,
transfer_ratio,
at_bonus_ratio_rmb,
report_date,
plan_progress,
implementation_bonusnote,
bonus_cancel_pub_date,
)
reports.append(record)
return reports
@async_concurrent(executor)
def get_security_list(self, date: datetime.date = None) -> np.ndarray:
"""获取`date`日的证券列表
Args:
date: 日期。如果为None,则取当前日期的证券列表
Returns:
证券列表, dtype为[('code', 'O'), ('display_name', 'O'), ('name', 'O'), ('start_date', 'O'), ('end_date', 'O'), ('type', 'O')]的structured array
"""
if not self.connected:
logger.warning("not connected")
return None
types = ["stock", "fund", "index", "etf", "lof"]
securities = jq.get_all_securities(types, date)
securities.insert(0, "code", securities.index)
# remove client dependency of pandas
securities["start_date"] = securities["start_date"].apply(
lambda s: f"{s.year:04}-{s.month:02}-{s.day:02}"
)
securities["end_date"] = securities["end_date"].apply(
lambda s: f"{s.year:04}-{s.month:02}-{s.day:02}"
)
return securities.to_records(index=False)
@async_concurrent(executor)
def get_all_trade_days(self) -> np.ndarray:
"""获取所有交易日的日历
Returns:
交易日日历, dtype为datetime.date的numpy array
"""
if not self.connected:
logger.warning("not connected")
return None
return jq.get_all_trade_days()
def _to_numpy(self, df: pd.DataFrame) -> np.ndarray:
df["date"] = pd.to_datetime(df["day"]).dt.date
# translate joinquant definition to zillionare definition
fields = {
"code": "code",
"pe_ratio": "pe",
"turnover_ratio": "turnover",
"pb_ratio": "pb",
"ps_ratio": "ps",
"pcf_ratio": "pcf",
"capitalization": "capital",
"market_cap": "market_cap",
"circulating_cap": "circulating_cap",
"circulating_market_cap": "circulating_market_cap",
"pe_ratio_lyr": "pe_lyr",
"date": "frame",
}
df = df[fields.keys()]
dtypes = [
(fields[_name], _type) for _name, _type in zip(df.dtypes.index, df.dtypes)
]
# the following line will return a np.recarray, which is slightly slow than
# structured array, so it's commented out
# return np.rec.fromrecords(valuation.values, names=valuation.columns.tolist())
# to get a structued array
return np.array([tuple(x) for x in df.to_numpy()], dtype=dtypes)
@async_concurrent(executor)
def get_valuation(
self, codes: Union[str, List[str]], day: datetime.date, n: int = 1
) -> np.ndarray:
if not self.connected:
logger.warning("not connected")
return None
"""get `n` of `code`'s valuation records, end at day.
对同一证券,返回的数据按升序排列(但取决于上游数据源)
Args:
code (str): [description]
day (datetime.date): [description]
n (int): [description]
Returns:
np.array: [description]
"""
if isinstance(codes, str):
codes = [codes]
if codes is None:
q = jq.query(jq.valuation)
else:
q = jq.query(jq.valuation).filter(jq.valuation.code.in_(codes))
records = jq.get_fundamentals_continuously(
q, count=n, end_date=day, panel=False
)
return self._to_numpy(records)
@staticmethod
def __dataframe_to_structured_array(
df: pd.DataFrame, dtypes: List[Tuple] = None
) -> ArrayLike:
"""convert dataframe (with all columns, and index possibly) to numpy structured arrays
`len(dtypes)` should be either equal to `len(df.columns)` or `len(df.columns) + 1`. In the later case, it implies to include `df.index` into converted array.
Args:
df: the one needs to be converted
dtypes: Defaults to None. If it's `None`, then dtypes of `df` is used, in such case, the `index` of `df` will not be converted.
Returns:
ArrayLike: [description]
"""
v = df
if dtypes is not None:
dtypes_in_dict = {key: value for key, value in dtypes}
col_len = len(df.columns)
if len(dtypes) == col_len + 1:
v = df.reset_index()
rename_index_to = set(dtypes_in_dict.keys()).difference(set(df.columns))
v.rename(columns={"index": list(rename_index_to)[0]}, inplace=True)
elif col_len != len(dtypes):
raise ValueError(
f"length of dtypes should be either {col_len} or {col_len + 1}, is {len(dtypes)}"
)
# re-arrange order of dtypes, in order to align with df.columns
dtypes = []
for name in v.columns:
dtypes.append((name, dtypes_in_dict[name]))
else:
dtypes = df.dtypes
return np.array(np.rec.fromrecords(v.values), dtype=dtypes)
@async_concurrent(executor)
def get_trade_price_limits(
self, sec: Union[List, str], dt: Union[str, datetime.datetime, datetime.date]
) -> np.ndarray:
"""获取某个时间点的交易价格限制,即涨停价和跌停价
Returns:
an numpy structured array which dtype is:
[('frame', 'O'), ('code', 'O'), ('high_limit', '<f4'), ('low_limit', '<f4')]
the frame is python datetime.date object
"""
if type(dt) not in (str, datetime.date, datetime.datetime):
raise TypeError(
"end_at must by type of datetime.date or datetime.datetime or str"
)
if type(sec) not in (list, str):
raise TypeError("sec must by type of list or str")
fields = ["high_limit", "low_limit"]
params = {
"security": sec,
"end_date": dt,
"fields": fields,
"fq": None,
"fill_paused": False,
"frequency": "1d",
"count": 1,
"skip_paused": True,
}
df = jq.get_price(**params)
dtype = [
("frame", "O"),
("code", "O"),
("high_limit", "<f4"),
("low_limit", "<f4"),
]
if len(df) == 0:
return None
bars = df.to_records(index=False).astype(dtype)
bars["frame"] = df["time"].apply(lambda x: x.to_pydatetime().date())
return bars
def _to_fund_numpy(self, df: pd.DataFrame) -> np.array:
df["start_date"] = pd.to_datetime(df["start_date"]).dt.date
df["end_date"] = pd.to_datetime(df["end_date"]).dt.date
fields = {
"main_code": "code",
"name": "name",
"advisor": "advisor",
"trustee": "trustee",
"operate_mode_id": "operate_mode_id",
"operate_mode": "operate_mode",
"start_date": "start_date",
"end_date": "end_date",
"underlying_asset_type_id": "underlying_asset_type_id",
"underlying_asset_type": "underlying_asset_type",
}
df = df[fields.keys()]
dtypes = [
(fields[_name], _type) for _name, _type in zip(df.dtypes.index, df.dtypes)
]
return np.array([tuple(x) for x in df.to_numpy()], dtype=dtypes)
@async_concurrent(executor)
def get_fund_list(self, codes: Union[str, List[str]] = None) -> np.ndarray:
"""获取所有的基金基本信息
Args:
codes: 可以是一个基金代码,或者是一个列表,如果为空,则获取所有的基金
Returns:
np.array: [基金的基本信息]
"""
if not self.connected:
logger.warning("not connected")
return None
if codes and isinstance(codes, str):
codes = [codes]
fund_count_q = jq.query(func.count(jq.finance.FUND_MAIN_INFO.id))
fund_q = jq.query(jq.finance.FUND_MAIN_INFO).order_by(
jq.finance.FUND_MAIN_INFO.id.asc()
)
if codes:
fund_count_q = fund_count_q.filter(
jq.finance.FUND_MAIN_INFO.main_code.in_(codes)
)
fund_q = fund_q.filter(jq.finance.FUND_MAIN_INFO.main_code.in_(codes))
fund_count = jq.finance.run_query(fund_count_q)["count_1"][0]
dfs: List[pd.DataFrame] = []
page = 0
while page * 3000 < fund_count:
df1 = jq.finance.run_query(fund_q.offset(page * 3000).limit(3000))
dfs.append(df1)
page += 1
funds: DataFrame = (
pd.concat(dfs)
if dfs
else pd.DataFrame(
columns=[
"main_code",
"name",
"advisor",
"trustee",
"operate_mode_id",
"operate_mode",
"start_date",
"end_date",
"underlying_asset_type_id",
"underlying_asset_type",
]
)
)
funds["start_date"] = funds["start_date"].apply(
lambda s: f"{s.year:04}-{s.month:02}-{s.day:02}" if s else "2099-01-01"
)
funds["end_date"] = funds["end_date"].apply(
lambda s: f"{s.year:04}-{s.month:02}-{s.day:02}" if s else "2099-01-01"
)
return self._to_fund_numpy(funds)
def _to_fund_portfolio_stock_numpy(self, df: pd.DataFrame) -> np.array:
fields = {
"code": "code",
"period_start": "period_start",
"period_end": "period_end",
"pub_date": "pub_date",
"report_type_id": "report_type_id",
"report_type": "report_type",
"rank": "rank",
"symbol": "symbol",
"name": "name",
"shares": "shares",
"market_cap": "market_cap",
"proportion": "proportion",
"deadline": "deadline",
}
df = df[fields.keys()]
dtypes = [
(fields[_name], _type) for _name, _type in zip(df.dtypes.index, df.dtypes)
]
return np.array([tuple(x) for x in df.to_numpy()], dtype=dtypes)
@async_concurrent(executor)
def get_fund_portfolio_stock(
self, codes: Union[str, List[str]], pub_date: Union[str, datetime.date] = None
) -> np.array:
if not self.connected:
logger.warning("not connected")
return None
if codes and isinstance(codes, str):
codes = [codes]
fund_count_q = jq.query(func.count(jq.finance.FUND_PORTFOLIO_STOCK.id))
q = jq.query(jq.finance.FUND_PORTFOLIO_STOCK)
if codes:
q = q.filter(jq.finance.FUND_PORTFOLIO_STOCK.code.in_(codes))
fund_count_q = fund_count_q.filter(
jq.finance.FUND_PORTFOLIO_STOCK.code.in_(codes)
)
if pub_date:
q = q.filter(jq.finance.FUND_PORTFOLIO_STOCK.pub_date == pub_date)
fund_count_q = fund_count_q.filter(
jq.finance.FUND_PORTFOLIO_STOCK.pub_date == pub_date
)
fund_count = jq.finance.run_query(fund_count_q)["count_1"][0]
dfs: List[pd.DataFrame] = []
page = 0
while page * 3000 < fund_count:
df1 = jq.finance.run_query(q.offset(page * 3000).limit(3000))
dfs.append(df1)
page += 1
df: DataFrame = (
pd.concat(dfs)
if dfs
else pd.DataFrame(
columns=[
"code",
"period_start",
"period_end",
"pub_date",
"report_type_id",
"report_type",
"rank",
"symbol",
"name",
"shares",
"market_cap",
"proportion",
"deadline",
]
)
)
df["deadline"] = df["pub_date"].map(
lambda x: (
x
+ pd.tseries.offsets.DateOffset(
months=-((x.month - 1) % 3), days=1 - x.day
)
- datetime.timedelta(days=1)
).date()
)
df = df.sort_values(
by=["code", "pub_date", "symbol", "report_type", "period_end"],
ascending=[False, False, False, False, False],
).drop_duplicates(
subset=[
"code",
"pub_date",
"symbol",
"report_type",
],
keep="first",
)
if df.empty:
df = pd.DataFrame(
columns=[
"code",
"period_start",
"period_end",
"pub_date",
"report_type_id",
"report_type",
"rank",
"symbol",
"name",
"shares",
"market_cap",
"proportion",
"deadline",
]
)
else:
df = df.groupby(by="code").apply(lambda x: x.nlargest(10, "shares"))
return self._to_fund_portfolio_stock_numpy(df)
def _to_fund_net_value_numpy(self, df: pd.DataFrame) -> np.ndarray:
df["day"] = pd.to_datetime(df["day"]).dt.date
fields = {
"code": "code",
"net_value": "net_value",
"sum_value": "sum_value",
"factor": "factor",
"acc_factor": "acc_factor",
"refactor_net_value": "refactor_net_value",
"day": "day",
}
df = df[fields.keys()]
dtypes = [
(fields[_name], _type) for _name, _type in zip(df.dtypes.index, df.dtypes)
]
return np.array([tuple(x) for x in df.to_numpy()], dtype=dtypes)
@async_concurrent(executor)
def get_fund_net_value(
self,
codes: Union[str, List[str]],
day: datetime.date = None,
) -> np.ndarray:
if not self.connected:
logger.warning("not connected")
return None
if codes and isinstance(codes, str):
codes = [codes]
day = day or (datetime.datetime.now().date() - datetime.timedelta(days=1))
q = jq.query(jq.finance.FUND_NET_VALUE).filter(
jq.finance.FUND_NET_VALUE.day == day
)
q_count = jq.query(func.count(jq.finance.FUND_NET_VALUE.id)).filter(
jq.finance.FUND_NET_VALUE.day == day
)
if codes:
q = q.filter(jq.finance.FUND_NET_VALUE.code.in_(codes))
q_count = q_count.filter(jq.finance.FUND_NET_VALUE.code.in_(codes))
fund_count = jq.finance.run_query(q_count)["count_1"][0]
dfs: List[pd.DataFrame] = []
page = 0
while page * 3000 < fund_count:
df1: DataFrame = jq.finance.run_query(q.offset(page * 3000).limit(3000))
if not df1.empty:
dfs.append(df1)
page += 1
df = (
pd.concat(dfs)
if dfs
else pd.DataFrame(
columns=[
"code",
"net_value",
"sum_value",
"factor",
"acc_factor",
"refactor_net_value",
"day",
]
)
)
return self._to_fund_net_value_numpy(df)
def _to_fund_share_daily_numpy(self, df: pd.DataFrame) -> np.ndarray:
df["day"] = pd.to_datetime(df["pub_date"]).dt.date
fields = {
"code": "code",
"total_tna": "total_tna",
"day": "date",
"name": "name",
}
df = df[fields.keys()]
dtypes = [
(fields[_name], _type) for _name, _type in zip(df.dtypes.index, df.dtypes)
]
return np.array([tuple(x) for x in df.to_numpy()], dtype=dtypes)
@async_concurrent(executor)
def get_fund_share_daily(
self, codes: Union[str, List[str]] = None, day: datetime.date = None
) -> np.ndarray:
if not self.connected:
logger.warning("not connected")
return None
if codes and isinstance(codes, str):
codes = [codes]
day = day or (datetime.datetime.now().date() - datetime.timedelta(days=1))
q_fund_fin_indicator = jq.query(jq.finance.FUND_FIN_INDICATOR).filter(
jq.finance.FUND_FIN_INDICATOR.pub_date == day
)
if codes:
q_fund_fin_indicator = q_fund_fin_indicator.filter(
jq.finance.FUND_FIN_INDICATOR.code.in_(codes)
)
df: DataFrame = jq.finance.run_query(q_fund_fin_indicator)
df = df.drop_duplicates(subset=["code", "pub_date"], keep="first")
df["total_tna"] = df["total_tna"].fillna(0)
return self._to_fund_share_daily_numpy(df)
@async_concurrent(executor)
def get_quota(self) -> Dict[str, int]:
"""查询quota使用情况
返回值为一个dict, key为"total","spare"
Returns:
dict: quota
"""
quota = jq.get_query_count()
assert "total" in quota
assert "spare" in quota
return quota
@classmethod
def login(cls, account, password, **kwargs):
"""登录"""
account = str(account)
password = str(password)
logger.info(
"login jqdatasdk with account %s, password: %s",
account[: min(4, len(account))].ljust(7, "*"),
password[:2],
)
try:
jq.auth(account, password)
cls.connected = True
cls.account = account
cls.password = password
logger.info("jqdatasdk login success")
except Exception as e:
cls.connected = False
logger.exception(e)
logger.warning("jqdatasdk login failed")
@classmethod
def logout(cls):
"""退出登录"""
return jq.logout()
@classmethod
def reconnect(cls):
cls.logout()
cls.login(cls.account, cls.password)
@classmethod
def result_size_limit(cls, op) -> int:
"""单次查询允许返回的最大记录数"""
return {}.get(op, 3000) | zillionare-omega-adaptors-jq | /zillionare_omega_adaptors_jq-1.1.0-py3-none-any.whl/jqadaptor/fetcher.py | fetcher.py |

[](https://pypi.python.org/pypi/zillionare-omega)
[](https://github.com/zillionare/omega)
[](https://app.codecov.io/gh/zillionare/omega)
[](https://omega.readthedocs.io/en/latest/?badge=latest)
[](https://pepy.tech/project/zillionare-omega)
[](https://opensource.org/licenses/MIT)
[](https://github.com/psf/black)
高速分布式本地行情服务器
# 简介
Omega为大富翁(Zillionare)智能量化交易平台提供数据服务。它是一个分布式、高性能的行情服务器,核心功能有:
1. 并发对接多个上游数据源,如果数据源还支持多账户和多个并发会话的话,Omega也能充分利用这种能力,从而享受到最快的实时行情。目前官方已提供JoinQuant的数据源适配。
2. 高性能和层次化的数据本地化存储,在最佳性能和存储空间上巧妙平衡。在需要被高频调用的行情数据部分,Omega直接使用Redis存储数据;财务数据一个季度才会变动一次,因而读取频率也不会太高,所以存放在关系型数据库中。这种安排为各种交易风格都提供了最佳计算性能。
3. 优秀的可伸缩部署(scalability)特性。Omega可以根据您对数据吞吐量的需求,按需部署在单机或者多台机器上,从而满足个人、工作室到大型团队的数据需求。
4. 自带数据(Battery included)。我们提供了从2015年以来的30分钟k线以上数据,并且通过CDN进行高速分发。安装好Omega之后,您可以最快在十多分钟内将这样巨量的数据同步到本地数据库。
[帮助文档](https://zillionare-omega.readthedocs.io)
鸣谢
=========
Zillionare-Omega采用以下技术构建:
[Pycharm开源项目支持计划](https://www.jetbrains.com/?from=zillionare-omega)

| zillionare-omega | /zillionare-omega-1.1.0.1.tar.gz/zillionare-omega-1.1.0.1/README.md | README.md |
# 版本历史
## 0.1.0 (2020-04-28)
* First release on PyPI.
## 0.5.0 (2020-11-09)
* 增加市值数据
* Update omicron to 0.2.0
* Update jq-adaptor to 0.2.1
## 0.6.0 (2020-11-25)
* 重构了[omega.app.start][]接口,允许从父进程继承`cfg`设置
* web interface增加[omega.app.get_version][]接口。此接口也可以用来判断Omega服务器是否在线
* 本版本适配zillionare-omicron 0.3和zillionare-omega-adaptors-jq 0.2.4
## 1.0 (2020-?)
first stable release
* 可导入从2015年以来的A股30分钟及以上股票数据。
* 高速行情同步。支持多账号、多session、多进程。
* 向外提供服务时,支持load-balance(需要配置http网关,如nginx)。
* 自动实时行情同步。
* 仅支持JoinQuant作为上游数据源
| zillionare-omega | /zillionare-omega-1.1.0.1.tar.gz/zillionare-omega-1.1.0.1/HISTORY.md | HISTORY.md |
# 1. 系统要求
## 1.1. 硬件清单
### 1.1.1. 内存
Zillionare-Omega(以下简称Omega)将行情数据保存在内存数据库中(redis-server)。根据实测结果,每存储1000条A股全市场日线数据(只包括股票数据,按5000支计),大概需要0.75GB的内存。这相当于存储了4年多的A股全市场数据。
以下是推算的物理内存需求表:
| 行情数据 | 记录数(每品种) | 时长(年) | 物理内存(GB) |
| ----- | -------- | ----- | -------- |
| 日线 | 1000 | 4 | 0.75 |
| 月线 | 120 | 10 | 0.09 |
| 年线 | 10 | 10 | 0.0075 |
| 小时线 | 1000 | 1 | 0.75 |
| 30分钟线 | 1000 | 0.5 | 0.75 |
| 15分钟线 | 1000 | 0.25 | 0.75 |
| 5分钟线 | 960 | 0.08 | 0.72 |
| 1分钟线 | 960 | 0.016 | 0.72 |
| 合计 | | | 3.7875 |
对于绝大多数动量策略的研究而言,每支品种有1000条记录用于机器学习基本上是足够的。更多的行情数据,可能也一些pattern的自重复而已。当然Omega也允许您根据自己的需求和硬件环境,来选择保存哪些证券品种,以及每个证券品种保存多长的数据(包括周期)。
如果您的学习模型需要结合基本面(财务数据),从而可能需要相应更长周期的行情数据。在这种情况下,建议您只保存日线及以上级别的数据。公司基本面的数据,对日线以下级别的股价波动是没有影响的。保存全市场10年的日线数据,也只要2GB左右的内存。
Omega社区版被设计为支持从个人到小型团队的AI量化研究。如果您需要保存tick级的数据,或者较长时间范围的分钟级别数据,请使用企业版。
###CPU
Omega被设计为能运行在从台式机到多台服务器集群上。由于Python本身的限制,Python程序一般无法有效地使用机器的多个CPU(内核)。为了避免这一限制,Omega设计成异步多进程协作模式,从而可以最大限度地利用您机器的CPU。因此,在您配置机器时,CPU仍然是越多越好。
###硬盘
Omega对硬盘的性能和容量几乎没有要求。一般而言,在安装Omega之前,系统最好至少还有50GB磁盘空间。
### 1.1.2. 网络
如果您使用分布式部署,建议Zillionare各服务都运行在同一个千兆局域网内。
## 1.2. 软件清单
???+ note
Omega不适合部署在Windows操作系统上。Omega的各个版本均只在Ubuntu 18, Ubuntu 20上进行测试。因此,即使Omega能在Windows上运行起来,我们也不推荐您这样使用。
如果您是个人研究使用,只有Windows机器,建议您启用Windows的WSL平台,这样就可以在同一台机器上,同时使用Ubuntu和Windows了。关于如何在Windows上启用WSL,您可以参考这篇文章[Windows下如何构建Python开发环境](https://zhuanlan.zhihu.com/p/138005979)
Omega使用Python 3.8开发,理论上可以部署在任何类Unix的机器上。但只在Ubuntu上经过严格的测试。以下为软件环境类清单:
| 软件类别 | 软件 | 版本 | 说明 |
| ----- | --------- | ----- | -- |
| 操作系统 | Ubuntu | 18/20 | |
| 运行时 | Python | >=3.8 | |
| 内存数据库 | Redis | >=4.0 | |
| 数据库 | Postgres | >=10 | 选装 |
| 负载均衡 | Nginx | | 选装 |
| 行情服务 | jqdatasdk | >=1.8 | |
| 编译工具 | gcc | latest | jqdatasdk使用了thrift2,需要gcc进行编译|
如果您的模型中不打算使用财务数据,则可以不安装Postgres。但是,即使是在动量策略研究中,您也可能使用财务数据。因为流通股本属于财务数据,所以在换手率的计算中,还必须使用财务数据。即便如此,如果您对性能没有太高要求的话,仍然可以不安装Postgres数据库。当您需要使用这些财务数据时,Omega会从上游数据服务器获取相关数据用于计算(但这些数据不会在本地保存)。在这种情况下,计算性能的强弱,可能主要取决于上游行情服务器的数据服务能力和响应速度。
尽管Omega被设计成支持分布式部署(即可以运行在多台机器上,并且相互协作),但自己只实现了简单的任务管理。负载均衡的实现,目前是由Nginx这样的代理在HTTP层完成的。您可以根据需要来选择是否这样进行部署。
# 2. 推荐的部署模式
Omega的部署全景图如下,您可以根据自己的需要进行定制。

## 2.1. 个人研究
对于个人研究,我们推荐可以在单台笔记本、台式机上进行部署。您可以将Omega, redis和Postgres安装在同一台机器上。如果您只做动量研究,也可以不安装Postgres。
如果您的操作系统是Windows的话,建议您按照 [这篇文章](http://blog.jieyu.ai/blog_2020/%E5%A6%82%E4%BD%95%E6%9E%84%E5%BB%BAPython%E5%BC%80%E5%8F%91%E7%8E%AF%E5%A2%83/) 来安装WSL,以获得Omega安装需要的Ubuntu操作系统环境。
如果您使用Mac机器的话,应该可以直接安装Omega。但您可能需要自行研究如何将rsyslog服务配置成功。
## 2.2. 团队使用
如果您有一个团队需要使用Omega提供的行情服务,非常棒!Omega完全适合这种场景下的应用。建议您根据团队使用数据的频度、量级和人数,来决定需要多少台机器安装Omega,以及安装Nginx作为Omega的前置代理。
# 3. 安装步骤
## 3.1. 创建Python虚拟环境
为避免与其它Python程序产生冲突,推荐您为Omega创建专属的运行环境。您可以使用[conda](https://docs.conda.io/en/latest/miniconda.html) 或者venv来创建专属运行环境。这里以conda为例:
1. 从 [这里](https://docs.conda.io/en/latest/miniconda.html)下载miniconda到本地,并运行安装。下载页面提供了多个版本,请下载Python3.8的Linux installer版本(假定您使用Ubuntu。如果使用windows,请参考 [这篇文章](http://blog.jieyu.ai/blog_2020/%E5%A6%82%E4%BD%95%E6%9E%84%E5%BB%BAPython%E5%BC%80%E5%8F%91%E7%8E%AF%E5%A2%83/) 在Windows上启用WSL和Ubuntu。
2. 运行下面的命令以创建Omega运行环境:
```
conda create -n omega python=3.8
conda activate omega
```
## 3.2. 设置服务器角色
Omega使用cfg4py来解析和管理配置。作为最佳实践,cfg4py要求您设置服务器角色,以便为您加载正确的配置。在开始安装之前,您需要通过环境变量来设置服务器角色。
您可以在/etc/profile,或者~/.bashrc中加上这样一行:
```bash
# 可选项包括 PRODUCTION, TEST, DEV
export __cfg4py_server_role__ = PRODUCTION
```
如果您只是普通用户,那么一般来说,应该设置为PRODUCTION。
## 3.3. 安装第三方软件
请参照Redis和Postgres的安装指南,分别完成Redis和Postgres的安装。
???+ Note
如果您的机器上已经有其它程序在使用Redis服务,为避免冲突,请在本机上启动第二个Redis实例,
独立为Omega提供服务。这个实例应该使用不同的端口。
您可以为Omega安装一个全新的Postgres数据库服务器,也重复使用现有的Postgres数据库服务器,
只要为Omega准备一个单独的数据库即可。Omega将在该数据库中创建一系列表(table)。
安装完成Postgres后,请为Zillionare创建数据库,推荐使用zillionare作为数据库名称:
```bash
# 使用psql,本地以postgres账户登录进来
sudo su - Postgres
psql
# 进入数据库以后
create user zillionare with password 'your_secret';
create database zillionare;
grant all privileges on database 'zillionare' to zillionare;
```
记下这里使用的用户名和口令,在安装Omega时需要使用。
Omega使用了rsyslog来收集和输出生产环境下的日志。请使用下面的命令安装:
```bash
sudo apt install rsyslog
```
## 3.4. 安装Omega
### 3.4.1. 从pip安装Omega
请运行以下命令来从pip安装zillionare-omega(以下称为Omega):
```bash
$ pip install zillionare-omega
```
### 3.4.2. 从源代码安装Omega
Omega的源代码可以从 [github](https://github.com/zillionare/omega)下载:
你可以clone代码库:
```
$ git clone git://github.com/zillionare/omega
```
或者下载 [源码包](https://github.com/zillionare/omega/tarball/master):
```
$ curl -OJL https://github.com/zillionare/omega/tarball/master
```
一旦源代码复制到本地,可以执行以下命令进行安装:
```
$ python setup.py install
```
除非您是Omega的协同开发者,或者遇到紧急修复的bug,否则都应该通过``pip``的方式来安装稳定版,而不应该从源代码安装。
## 3.5. 初始化
通过Pip安装的Python包,如果是wheel格式安装,是无法在安装过程中向用户进行交互式提示的,并不适合制作复杂的初始化程序,所以Omega选择在安装之后,再通过`setup`命令来完成安装定制部分。
初始化主要完成以下任务:
1. 检测安装环境。
2. 配置行情服务器
3. 配置Redis数据库
4. 配置Postgres数据库
5. 其它设置(如日志等)
### 3.5.1. 初始化前的检查
现在,请确认您已经准备好:
1. 设置好了服务器角色
2. 已切换至专门为Omega创建的虚拟运行环境
3. Redis服务、Postgres服务和rsyslog已安装好,并且都已经启动。
4. zillionare数据库已经创建,并且已得到数据库账户。
5. 已安装了Omega
现在,您就可以开始进入到启动Omega前的最后一步了。请使用以下命令来进行初始化:
```
omega setup
```
### 3.5.2. 检测安装环境
作为一种最佳实践,Omega推荐您为Omega创建专属虚拟运行环境,并始终在该虚拟环境中运行Omega。安装程序也会检测当前是否在虚拟环境中运行。
Omega使用 cfg4py_ 来管理配置。Cfg4py要求您为部署机器设置场景(开发、测试、生产环境),以便根据对应的场景来应用配置。因此,在Omega安装时,也会检测当前机器是否正确地设置了场景。

### 3.5.3. 配置行情服务器
Omega通过插件来从上游服务器获取行情数据。当前支持的数据提供源有聚宽(JoinQuant)。
在使用聚宽之前,您需要在 聚宽_ 官网上申请 `jqdatasdk` 的使用权限。在安装过程中,将需要您提供这些信息。每个聚宽账号最多允许3个并发连接。在安装时,Omega需要您为每个账号决定同时允许的最大会话(连接)数。

Omega支持多个数据源同时工作(但当前只提供了对聚宽的接口适配),并且支持在同一数据源下,配置多个账号,多个会话(如果您这样做,请确保得到了服务提供商的许可),从而可以最快速获取实时行情。所以在上面的安装过程中,将提示您输入并发会话数,以及是否配置多个账号。
???+ tip
Omega通过HTTP微服务向Zillionare的其它组件提供行情数据,因此Omega本身也是一种行情服务器。默认地,Omega的服务端口从3181开始,如果您有多个数据源,或者多个账号,那么Omega将为不同的数据源、或者同一数据源的不同账号,启用新的端口。
比如,如果您拥有两个jqdatasdk的账号,并配置在Omega中使用,那么,Omega将启动两个HTTP服务器,一个监听在3181端口,另一个监听在3182端口。
安装程序没有提供端口定制的功能。但是,您可以在配置文件中找到它们并进行修改:
```yaml
omega:
urls:
quotes_server: http://localhost:3181
quotes_fetchers:
- impl: jqadaptor # there must be a create_instance method in this module
workers:
- account: ${jq_account}
password: ${jq_password}
port: 3181
sessions: 2
```
这里有几点需要注意:
1. Omega使用Sanic作为HTTP服务器。可能是由于Sanic的原因,如果您需要Omega与上游服务器同时建立3个并发会话,那么会话设置应该设置为2,而不是3,即您得到的会话数,总会比设置值大1。
2. 在上面的配置示例中,出现了${jq_account}这样的宏,这是 cfg4py_ 支持的功能,如果您设置了同名的环境变量,则 cfg4py_ 将会将其替换成为环境变量确定的值。建议Omega的协作开发者始终使用这一语法,以避免误将账号和口令公开的互联网上。
3. Omega作为本地行情服务器,其它组件在访问它时,需要得到服务地址。安装程序没有提供配置项,默认地,它被配置在 http://localhost:3181 上,这个配置是供独立研究者使用的,但无法使用多账号、多数据源功能,也没有负载均衡功能。为实现负载均衡,您需要自行安装nginx做代理,并将nginx的代理地址配置在下面的配置当中:
```
omega:
urls:
quotes_fetchers: http://your_nginx_address
```
这些配置看上去比较复杂,但实际上,在您一开始的时候,可以完全按默认设置来使用。您甚至可以直接跳过这一步--如果您通过环境变量配置了聚宽的账号和密码的话。
### 3.5.4. 配置Redis服务器
行情数据都存放在Redis数据库里。您需要事先安装好Redis服务器,并告诉Omega如何连接:

### 3.5.5. 配置Postgres数据库
如果您急于开始使用Omega,您可以略过Postgres的安装和配置。但是配置数据库将使得您访问财务数据时,能获得更好的性能。因为如果您没有配置Postgres数据库的话,这些数据都将从上游服务器去实时获取。

### 3.5.6. 配置系统日志
在生产环境下,Omega使用rsyslog来收集日志文件,并写入同一个omega.log文件中。为了实现这一功能,Omega需要将一些配置文件拷入/etc/rsyslog.d/文件夹下。在这个过程中,可能需要您提供相关权限。
最后,安装全部结束,Omega将为您启动服务,并显示服务状态:

| zillionare-omega | /zillionare-omega-1.1.0.1.tar.gz/zillionare-omega-1.1.0.1/docs/deployment.md | deployment.md |
# 1. 配置文件
对普通用户而言,Omega会从~/zillionare/omega/config下加载配置。
!!! Note
如果您是Omega的开发者,应该将环境变量```__cfg4py_server_role__```设置为DEV,这样Omega会
从源代码所在文件夹下面的omega/config下读取配置。
如果您是Omega的测试者,建议您将环境变量```__cfg4py_server_role__```设置为TEST,这样Omega
会从~/.zillionare/omega/config下加载配置。
上述设置并非必须,如果您不懂得这种设置的意义,您完全可以使用默认的位置,即~/zillionare/omega/config
配置文件使用YAML文件格式,并支持环境变量。比如,如果您通过环境变量``POSTGRES_USER``来设置了数据库
账号,则可以在配置文件中这样使用它:
```YAML
postgres:
dsn: postgres://${POSTGRES_USER}:${POSTGRES_PASSWORD}@localhost/zillionare
```
上述环境变量的扩展是通过[cfg4py](https://pypi.org/project/cfg4py/)来支持的。
# 2. 数据同步
数据同步是Omega最核心的工作之一。Omega专门配置了一个Jobs进程来管理数据同步及其它工作。Jobs通过
读取配置文件来确定应该如何进行同步,并向Omega Fetcher进程发出数据同步请求。
对于日历、证券列表等少量数据的同步,这些请求通常只会发给一个Omega Fetcher进程,而对K线这样的大
批量数据,这些请求则会发给所有在线的Omega Fetcher进程,因此,使用Omega可以得到极为优秀的数据同
步性能。
## 2.1. 数据同步发生的时间
对日历和证券列表等数据,Omega每天进行一次,具体同步时间默认为午夜2点,您可以在配置文件中进行修改:
```yaml
omega: # omega服务自身相关的配置
sync: # 同步相关的配置都在sync节下
security_list: 02:00
calendar: 02:00
```
建议在每个交易日盘前进行同步。如无特别需求,请保持默认值就好。
K线数据会在每个Frame结束时间进行同步。比如,对60分钟k线,会分别在10:30, 11:30, 14:00和15:00
各进行一次同步;对日线数据,会在15:00时进行同步,这样确保您始终可以得到最新的数据。
您的上游数据服务提供者可能没来得及在每个Frame结束时,就刚好把所有的数据准备好。因此,您可以通过
设置delay来稍稍延迟同步时间。如果您没有设置delay,而上游数据服务提供者又不能在Frame刚好结束时
提供数据的话,数据同步仍然会触发,只不过您只能得到上一帧的数据。您可以根据您应用的实时性要求和上
游数据提供者的服务能力来设置这个延时,系统默认是5秒钟。
关于``delay``的设置,我们在下一节中介绍。
## 2.2. 如何同步K线数据
Omega控制K线数据同步的配置格式如下(注意其中包括了上一节已经提到的``delay``参数):
```yaml
omega:
sync: # 同步相关的配置都在sync节下
bars: # K线数据同步配置都在bars节下
- frame: '1d' # k线帧类型
start: '2005-1-1' # 可以不指定,系统会从当前日期倒推到1000个数据记录前的时间
stop: 2020-12-30 # 可以不指定,以便同步到最新的日期
include: 000001.XSHG 399001.XSHE
exclude: 000001.XSHE 600001.XSHG
delay: 5
cat: # 证券分类,如股票(stock), 指数(index)等
- stock
- frame: '1m'
start: '2005-1-1'
cat:
- stock
```
上述配置格式提供了要同步的证券标的、K线的帧类型(比如,是30分钟线还是日线),起始时间和延迟等关键
信息。其中证券标的又是由``cat``、``exclude``和``include``共同决定的。
上述配置中,每种K线都有自己的设置,它们构成了一个数组。
``frame``键表明k线的帧类型。Omega支持的帧类型如下(注意区分大小写):
| K线类型 | 标识 | 说明 |
| ----- | --- | ------------------ |
| 年线 | 1Y | 每年一条记录,当年停牌的除外,下同 |
| 季线 | 1Q | 每年产生4条记录 |
| 月线 | 1M | 每月产生1条记录 |
| 周线 | 1W | 每周产生1条记录 |
| 日线 | 1d | 每天产生1条记录,全年约250条记录 |
| 60分钟线 | 60m | 每天产生4条记录 |
| 30分钟线 | 30m | 每天产生8条记录 |
| 15分钟线 | 15m | 每天产生16条记录 |
| 5分钟线 | 5m | 每天产生48条记录 |
| 1分钟线 | 1m | 每天产生240条记录 |
``start``指定该种k线获取数据的起点时间。如果不指定,则系统会从当前日期倒推1000个数据记录。您无
须指定精确的时间,比如对30分钟线指定精确到2020年1月3日10:00开始,或者担心2020年1月4日是否刚好是
周线的结束日。对于同步数据来说,多取一个帧的数据并不会增加什么负担,所以系统会取到一个最合适的起
始时间,刚好保证您要求的数据都能被同步。
``stop``指定该种k线获取数据的终点。通常您无须进行设置,系统应该自动为您同步到最新时间。但
如果您设置了,则系统将**不会为您获取在``stop``之后的任何数据**。实际效果是,在首次同步完成后,禁
止了今后的数据同步。
待同步证券的标的由``cat``、``include``和``exclude``共同决定。系统先根据``cat``选出一些标的,
然后排除在``exclude``中的标的,再加入``include``中的标的。
如果``cat``为空,则根据上述规则,将只有``include``中的标的被加入。如果一支标的在``exclude``和
``include``中同时存在,则``include``拥有更高的优选级。
根据上述规则,如果您有以下同步需求:同步除了银行股以外的所有股票的日线数据,并且包括上证指数和深
成指,则可以使用以下的配置:
```yaml
omega:
sync:
bars:
- frame: 1d # 要求同步日线数据
include: 000001.XSHG 399001.XSHE # 使用空格分隔
exclude: 600001.XSHG 000001.XSHE ...
cat:
- stock # 仅包含股票
```
# 3. 管理omega
1. 要启动Omega的行情服务,请在命令行下输入:
```bash
omega start
```
1. 行情同步等任务是由jobs进程管理的,所以您还需要启动jobs进程
```bash
omega start jobs
```
3. 要查看当前有哪些fetcher和jobs进程在运行,使用下面的命令:
```bash
omega status
```
4. 此外,Omega还提供了stop和restart命令:
```bash
omega stop jobs
omega stop
omega restart jobs
omega restart
```
# 4. 使用行情数据
虽然Omega提供了HTTP接口,但因为性能优化的原因,其通过HTTP接口提供的数据,都是二进制的。
使用行情数据的正确方式是通过Omicron SDK来访问数据。请跳转至 [Omicron帮助文档](https://zillionare-omicron.readthedocs.io) 继续阅读。
| zillionare-omega | /zillionare-omega-1.1.0.1.tar.gz/zillionare-omega-1.1.0.1/docs/usage.md | usage.md |
import logging
import os
import time
from time import timezone
from typing import List
import cfg4py
import fire
import omicron
from apscheduler.schedulers.asyncio import AsyncIOScheduler
from pyemit import emit
from sanic import Blueprint, Sanic
from sanic.websocket import WebSocketProtocol
from omega.config import get_config_dir
from omega.core.events import Events
from omega.fetcher.abstract_quotes_fetcher import AbstractQuotesFetcher as aq
from omega.interfaces import jobs, quotes, sys
from omega.jobs import syncjobs
cfg = cfg4py.get_instance()
app = Sanic("Omega")
logger = logging.getLogger(__name__)
class Omega(object):
def __init__(self, fetcher_impl: str, cfg: dict = None, **kwargs):
self.port = kwargs.get("port")
self.gid = kwargs.get("account")
self.fetcher_impl = fetcher_impl
self.params = kwargs
self.inherit_cfg = cfg or {}
self.scheduler = AsyncIOScheduler(timezone="Asia/Shanghai")
async def init(self, *args):
logger.info("init %s", self.__class__.__name__)
cfg4py.init(get_config_dir(), False)
cfg4py.update_config(self.inherit_cfg)
await aq.create_instance(self.fetcher_impl, **self.params)
await omicron.init(aq)
interfaces = Blueprint.group(jobs.bp, quotes.bp, sys.bp)
app.blueprint(interfaces)
# listen on omega events
emit.register(Events.OMEGA_DO_SYNC, syncjobs.sync_bars)
await emit.start(emit.Engine.REDIS, dsn=cfg.redis.dsn)
await self.heart_beat()
self.scheduler.add_job(self.heart_beat, trigger="interval", seconds=3)
self.scheduler.start()
logger.info("<<< init %s process done", self.__class__.__name__)
async def heart_beat(self):
pid = os.getpid()
key = f"process.fetchers.{pid}"
logger.debug("send heartbeat from omega fetcher: %s", pid)
await omicron.cache.sys.hmset(
key,
"impl", self.fetcher_impl,
"gid", self.gid,
"port", self.port,
"pid", pid,
"heartbeat", time.time(),
)
def get_fetcher_info(fetchers: List, impl: str):
for fetcher_info in fetchers:
if fetcher_info.get("impl") == impl:
return fetcher_info
return None
def start(impl: str, cfg: dict = None, **fetcher_params):
"""启动一个Omega fetcher进程
使用本函数来启动一个Omega fetcher进程。该进程可能与其它进程一样,使用相同的impl和账号,因此构成一组进程。
通过多次调用本方法,传入不同的quotes fetcher impl参数,即可启动多组Omega服务。
如果指定了`fetcher_params`,则`start`将使用impl, fetcher_params来启动单个Omega服务,使
用impl指定的fetcher。否则,将使用`cfg.quotes_fetcher`中提供的信息来创建Omega.
如果`cfg`不为None,则应该指定为合法的json string,其内容将覆盖本地cfg。这个设置目前的主要
要作用是方便单元测试。
Args:
impl (str): quotes fetcher implementor
cfg: the cfg in json string
fetcher_params: contains info required by creating quotes fetcher
"""
port = fetcher_params.get("port", 3181)
omega = Omega(impl, cfg, **fetcher_params)
app.register_listener(omega.init, "before_server_start")
logger.info("starting sanic group listen on %s with %s workers", port, 1)
app.run(
host="0.0.0.0",
port=port,
workers=1,
register_sys_signals=True,
protocol=WebSocketProtocol,
)
logger.info("sanic stopped.")
if __name__ == "__main__":
fire.Fire({"start": start}) | zillionare-omega | /zillionare-omega-1.1.0.1.tar.gz/zillionare-omega-1.1.0.1/omega/app.py | app.py |
import asyncio
import itertools
import logging
import os
import random
import re
import signal
import subprocess
import sys
import time
from pathlib import Path
from typing import Any, Callable, List, Union
import aiohttp
import aioredis
import asyncpg
import cfg4py
import fire
import omicron
import psutil
import sh
from omicron.core.timeframe import tf
from omicron.core.types import FrameType
from pyemit import emit
from ruamel.yaml import YAML
from termcolor import colored
import omega
from omega.config import get_config_dir
from omega.fetcher import archive
from omega.fetcher.abstract_quotes_fetcher import AbstractQuotesFetcher
from omega.jobs import syncjobs
logger = logging.getLogger(__name__)
cfg = cfg4py.get_instance()
class CancelError(BaseException):
pass
def load_factory_settings():
config_file = os.path.join(factory_config_dir(), "defaults.yaml")
with open(config_file, "r") as f:
parser = YAML()
_cfg = parser.load(f)
return _cfg
def factory_config_dir():
module_dir = os.path.dirname(omega.__file__)
return os.path.join(module_dir, "config")
def format_msg(msg: str):
"""格式化msg并显示在控制台上
本函数允许在写代码时按格式要求进行缩进和排版,但在输出时,这些格式都会被移除;对较长的文本,
按每80个字符为一行进行输出。
如果需要在msg中插入换行或者制表符,使用`\\n`和`\\t`。
args:
msg:
returns:
"""
msg = re.sub(r"\n\s+", "", msg)
msg = re.sub(r"[\t\n]", "", msg)
msg = msg.replace("\\t", "\t").replace("\\n", "\n")
lines = msg.split("\n")
msg = []
for line in lines:
for i in range(int(len(line) / 80 + 1)):
msg.append(line[i * 80 : min(len(line), (i + 1) * 80)])
return "\n".join(msg)
def update_config(settings: dict, root_key: str, conf: Any):
keys = root_key.split(".")
current_item = settings
for key in keys[:-1]:
v = current_item.get(key, {})
current_item[key] = v
current_item = current_item[key]
if isinstance(conf, dict):
if current_item.get(keys[-1]):
current_item[keys[-1]].update(conf)
else:
current_item[keys[-1]] = conf
else:
current_item[keys[-1]] = conf
def append_fetcher(settings: dict, worker):
qf = settings.get("quotes_fetchers", [])
settings["quotes_fetchers"] = qf
qf.append(worker)
def is_in_venv():
# 是否为virtual env
is_venv = hasattr(sys, "real_prefix") or (
hasattr(sys, "base_prefix") and sys.base_prefix != sys.prefix
)
if is_venv:
return True
# 是否为conda
return os.environ.get("CONDA_DEFAULT_ENV") is not None
def is_valid_port(port):
try:
port = int(port)
if 1000 < port < 65535:
return True
except (ValueError, Exception):
return False
async def check_postgres(dsn: str):
try:
conn = await asyncpg.connect(dsn=dsn)
print("连接成功,正在初始化数据库...")
script_file = os.path.join(factory_config_dir(), "sql/init.sql")
with open(script_file, "r") as f:
script = "".join(f.readlines())
await conn.execute(script)
return True
except asyncpg.InvalidCatalogNameError:
print("数据库<zillionare>不存在,请联系管理员创建后,再运行本程序")
except asyncpg.InvalidPasswordError:
print("账号或者密码错误,请重新输入!")
return False
except OSError:
print("无效的地址或者端口")
return False
except Exception as e:
print("出现未知错误。")
logger.exception(e)
return False
async def config_postgres(settings):
"""配置数据连接并进行测试"""
msg = """
配置数据库并非必须。如果您仅限于在某些场景下使用Zillionare-omega,也可以不配置
数据库更多信息,\\n请参阅https://readthedocs.org/projects/zillionare-omega/
\\n跳过此项[S], 任意键继续:
"""
choice = input(format_msg(msg))
if choice.upper() == "S":
return
action = "R"
while action == "R":
host = get_input(
"请输入服务器地址,", None, os.environ.get("POSTGRES_HOST") or "localhost"
)
port = get_input(
"请输入服务器端口,", is_valid_port, os.environ.get("POSTGRES_PORT") or 5432
)
account = get_input("请输入账号,", None, os.environ.get("POSTGRES_USER"))
password = get_input("请输入密码,", None, os.environ.get("POSTGRES_PASSWORD"))
dbname = get_input(
"请输入数据库名,", None, os.environ.get("POSTGRES_DB") or "zillionare"
)
print("正在测试Postgres连接...")
dsn = f"postgres://{account}:{password}@{host}:{port}/{dbname}"
if await check_postgres(dsn):
update_config(settings, "postgres.dsn", dsn)
update_config(settings, "postgres.enabled", True)
print(f"[{colored('PASS', 'green')}] 数据库连接成功,并成功初始化!")
return True
else:
hint = f"[{colored('FAIL', 'red')}] 忽略错误[C],重新输入[R],退出[Q]"
action = choose_action(hint)
def choose_action(prompt: str, actions: tuple = None, default_action="R"):
print(format_msg(prompt))
actions = ("C", "R", "Q")
answer = input().upper()
while answer not in actions:
print(f"请在{actions}中进行选择")
answer = input().upper()
if answer == "Q":
print("您选择了放弃安装。安装程序即将退出")
sys.exit(0)
if answer == "C":
print("您选择了忽略本项。您可以在此后重新运行安装程序,或者手动修改配置文件")
return answer
def config_logging(settings):
msg = """
请指定日志文件存放位置:
"""
action = "R"
while action == "R":
try:
folder = get_input(msg, None, "/var/log/zillionare")
folder = Path(folder).expanduser()
if not os.path.exists(folder):
try:
os.makedirs(folder, exist_ok=True)
except PermissionError:
print("正在创建日志目录,需要您的授权:")
sh.contrib.sudo.mkdir(folder, "-p")
sh.contrib.sudo.chmod(777, folder)
logfile = os.path.join(folder, "omega.log")
update_config(settings, "logreceiver.filename", logfile)
action = None
except Exception as e:
print(e)
prompt = "创建日志目录失败,请排除错误重试,或者重新指定目录"
action = choose_action(prompt)
# activate file logging now
root_logger = logging.getLogger()
logfile = os.path.join(folder, "omega.log")
handler = logging.handlers.RotatingFileHandler(logfile)
fmt_str = "%(asctime)s %(levelname)-1.1s %(process)d %(name)s:%(funcName)s:%(lineno)s | %(message)s"
fmt = logging.Formatter(fmt_str)
handler.setFormatter(fmt)
root_logger.addHandler(handler)
logger.info("logging output is written to %s now", logfile)
def config_fetcher(settings):
"""配置jq_fetcher
为Omega安装jqdatasdk, zillionare-omega-adaptors-jq, 配置jqdata访问账号
"""
msg = """
Omega需要配置上游行情服务器。当前支持的上游服务器有:\\n
[1] 聚宽`<joinquant>`\\n
"""
print(format_msg(msg))
more_account = True
workers = []
port = 3181
while more_account:
account = get_input("请输入账号:", None, os.environ.get("JQ_ACCOUNT") or "")
password = get_input("请输入密码:", None, os.environ.get("JQ_PASSWORD") or "")
sessions = get_input("请输入并发会话数", None, 1, "默认值[1]")
workers.append(
{
"account": account,
"password": password,
"sessions": sessions,
"port": port,
}
)
port += 1
more_account = input("继续配置新的账号[y|N]?\n").upper() == "Y"
settings["quotes_fetchers"] = []
append_fetcher(settings, {"impl": "jqadaptor", "workers": workers})
def get_input(
prompt: str,
validation: Union[None, List, Callable],
default: Any,
op_hint: str = None,
):
if op_hint is None:
op_hint = f"忽略此项(C),退出(Q),回车选择默认值[{default}]:"
value = input(format_msg(prompt + op_hint))
while True:
if isinstance(validation, List) and value.upper() in validation:
is_valid_input = True
elif validation is None:
is_valid_input = True
elif isinstance(validation, Callable):
is_valid_input = validation(value)
else:
is_valid_input = True
if value.upper() == "C":
return None
elif value == "":
return default
elif value.upper() == "Q":
print("您选择了退出")
sys.exit(-1)
elif is_valid_input:
if isinstance(default, int):
return int(value)
return value
else:
value = input(prompt + op_hint)
async def check_redis(dsn: str):
redis = await aioredis.create_redis(dsn)
await redis.set("omega-test", "delete me on sight")
redis.close()
await redis.wait_closed()
async def config_redis(settings):
msg = """
Zillionare-omega使用Redis作为其数据库。请确认系统中已安装好redis。\\n请根据提示输入
Redis服务器连接信息。
"""
print(format_msg(msg))
action = "R"
while action == "R":
host = get_input(
"请输入Reids服务器,", None, os.environ.get("REDIS_HOST") or "localhost"
)
port = get_input(
"请输入Redis服务器端口,", is_valid_port, os.environ.get("REDIS_PORT") or 6379
)
password = get_input(
"请输入Redis服务器密码,", None, os.environ.get("REDIS_PASSWORD") or ""
)
logger.info("give redis configurations are: %s, %s, %s", host, port, password)
try:
if password:
dsn = f"redis://{password}@{host}:{port}"
else:
dsn = f"redis://{host}:{port}"
await check_redis(dsn)
print(f"[{colored('PASS', 'green')}] redis连接成功: {dsn}")
update_config(settings, "redis.dsn", dsn)
update_config(settings, "logreceiver.dsn", dsn)
update_config(settings, "logging.handlers.redis.host", host)
update_config(settings, "logging.handlers.redis.port", port)
update_config(settings, "logging.handlers.redis.password", password)
action = None
except Exception as e:
logger.exception(e)
action = choose_action(
f"[{colored('FAIL', 'red')}]连接失败。忽略错误[C]," f"重输入[R],放弃安装[Q]"
)
def print_title(msg):
print(colored(msg, "green"))
print(colored("".join(["-"] * len(msg)), "green"))
async def setup(reset_factory=False, force=False):
"""安装初始化入口
Args:
reset_factory: reset to factory settings
force: if true, force setup no matter if run already
Returns:
"""
msg = """
Zillionare-omega (大富翁)\\n
-------------------------\\n
感谢使用Zillionare-omega -- 高速分布式行情服务器!\\n
"""
print(format_msg(msg))
if not force:
config_file = os.path.join(get_config_dir(), "defaults.yaml")
if os.path.exists(config_file):
print(f"{colored('[PASS]', 'green')} 安装程序已在本机上成功运行")
sys.exit(0)
if reset_factory:
import sh
dst = get_config_dir()
os.makedirs(dst, exist_ok=True)
src = os.path.join(factory_config_dir(), "defaults.yaml")
dst = os.path.join(get_config_dir(), "defaults.yaml")
sh.cp("-r", src, dst)
print_title("Step 1. 检测安装环境...")
settings = load_factory_settings()
if not check_environment():
sys.exit(-1)
print_title("Step 2. 配置日志")
config_logging(settings)
print_title("Step 3. 配置上游服务器")
config_fetcher(settings)
print_title("Step 4. 配置Redis服务器")
await config_redis(settings)
print_title("Step 5. 配置Postgres服务器")
await config_postgres(settings)
save_config(settings)
print_title("Step 6. 下载历史数据")
config_dir = get_config_dir()
cfg4py.init(config_dir, False)
remove_console_log_handler()
await start("fetcher")
await download_archive(None)
print_title("配置已完成。现在为您启动Omega,开启财富之旅!")
await start("jobs")
await status()
def save_config(settings):
os.makedirs(get_config_dir(), exist_ok=True)
config_file = os.path.join(get_config_dir(), "defaults.yaml")
settings["version"] = omega.__version__
try:
with open(config_file, "w", encoding="utf-8") as f:
parser = YAML()
parser.indent(sequence=4, offset=2)
parser.dump(settings, f)
except Exception as e: # noqa
# restore the backup
logger.exception(e)
logger.warning("failed to save config:\n%s", settings)
print(f"[{colored('FAIL', 'green')}] 无法保存文件。安装失败。")
sys.exit(-1)
def check_environment():
if not is_in_venv():
msg = """
检测到当前未处于任何虚拟环境中。\\n运行Zillionare的正确方式是为其创建单独的虚拟运行环境。\\n
建议您通过conda或者venv来为Zillionare-omega创建单独的运行环境。
"""
hint = "按任意键忽略错误继续安装,退出安装[Q]:\n"
prompt = f"[{colored('FAIL','green')}] {msg} \\n{hint}"
print(format_msg(prompt))
if input().upper() == "Q":
print("您选择了终止安装程序")
sys.exit(0)
else:
print(f"[{colored('PASS', 'green')}] 当前运行在虚拟环境下")
# create /var/log/zillionare for logging
if not os.path.exists("/var/log/zillionare"):
sh.contrib.sudo.mkdir("/var/log/zillionare", "-m", "777")
return True
def find_fetcher_processes():
"""查找所有的omega(fetcher)进程
Omega进程在ps -aux中显示应该包含 omega.app --impl=<fetcher> --port=<port>信息
"""
result = {}
for p in psutil.process_iter():
cmd = " ".join(p.cmdline())
if "omega.app start" in cmd and "--impl" in cmd and "--port" in cmd:
m = re.search(r"--impl=([^\s]+)", cmd)
impl = m.group(1) if m else ""
m = re.search(r"--port=(\d+)", cmd)
port = m.group(1) if m else ""
group = f"{impl}:{port}"
pids = result.get(group, [])
pids.append(p.pid)
result[group] = pids
return result
async def start(service: str = ""):
"""启动omega主进程或者任务管理进程
Args:
service: if service is '', then starts fetcher processes.
Returns:
"""
print(f"正在启动zillionare-omega {colored(service, 'green')}...")
config_dir = get_config_dir()
cfg4py.init(config_dir, False)
if service == "":
await _start_jobs()
await _start_fetcher_processes()
elif service == "jobs":
return await _start_jobs()
elif service == "fetcher":
return await _start_fetcher_processes()
else:
print("不支持的服务")
async def _start_fetcher_processes():
procs = find_fetcher_processes()
# fetcher processes are started by groups
cfg = cfg4py.get_instance()
for fetcher in cfg.quotes_fetchers:
impl = fetcher.get("impl")
workers = fetcher.get("workers")
ports = [3181 + i for i in range(len(workers))]
for group in workers:
sessions = group.get("sessions", 1)
port = group.get("port") or ports.pop()
account = group.get("account")
password = group.get("password")
started_sessions = procs.get(f"{impl}:{port}", [])
if sessions - len(started_sessions) > 0:
print(f"启动的{impl}实例少于配置要求(或尚未启动),正在启动中。。。")
# sanic manages sessions, so we have to restart it as a whole
for pid in started_sessions:
try:
os.kill(pid, signal.SIGTERM)
except Exception:
pass
_start_fetcher(impl, account, password, port, sessions)
await asyncio.sleep(1)
await asyncio.sleep(3)
show_fetcher_processes()
def show_fetcher_processes():
print(f"正在运行中的omega-fetchers进程:\n{'=' * 40}")
procs = find_fetcher_processes()
if len(procs):
print(" impl | port | pids")
for group, pids in procs.items():
impl, port = group.split(":")
print(f"{impl:10}|{' ':5}{port:2}{' ':3}| {pids}")
else:
print("None")
def _start_fetcher(
impl: str, account: str, password: str, port: int, sessions: int = 1
):
subprocess.Popen(
[
sys.executable,
"-m",
"omega.app",
"start",
f"--impl={impl}",
f"--account={account}",
f"--password={password}",
f"--port={port}",
f"--sessions={sessions}",
],
stdout=subprocess.DEVNULL,
)
async def _start_jobs():
subprocess.Popen(
[
sys.executable,
"-m",
"omega.jobs",
"start",
f"--port={cfg.omega.jobs.port}",
]
)
retry = 0
while _find_jobs_process() is None and retry < 5:
print("等待omega.jobs启动中")
retry += 1
await asyncio.sleep(1)
if retry < 5:
print("omega.jobs启动成功。")
else:
print("omega.jobs启动失败。")
return
_show_jobs_process()
def _restart_jobs():
pid = _find_jobs_process()
if pid is None:
print("omega.jobs未运行。正在启动中...")
_start_jobs()
else:
# 如果omega.jobs已经运行
_stop_jobs()
_start_jobs()
async def _stop_jobs():
pid = _find_jobs_process()
retry = 0
while pid is not None and retry < 5:
retry += 1
try:
os.kill(pid, signal.SIGTERM)
await asyncio.sleep(0.5)
except Exception:
pass
pid = _find_jobs_process()
if retry >= 5:
print("未能停止omega.jobs")
def _show_jobs_process():
print(f"正在运行中的jobs进程:\n{'=' * 40}")
pid = _find_jobs_process()
if pid:
print(pid)
else:
print("None")
def _find_jobs_process():
for p in psutil.process_iter():
try:
cmd = " ".join(p.cmdline())
if cmd.find("omega.jobs") != -1:
return p.pid
except (PermissionError, ProcessLookupError):
pass
return None
async def _stop_fetcher_processes():
retry = 0
while retry < 5:
procs = find_fetcher_processes()
retry += 1
if len(procs) == 0:
return
for group, pids in procs.items():
for pid in pids:
try:
os.kill(pid, signal.SIGTERM)
except Exception:
pass
await asyncio.sleep(1)
if retry >= 5:
print("未能终止fetcher进程")
async def status():
show_fetcher_processes()
print("\n")
_show_jobs_process()
async def stop(service: str = ""):
if service == "":
await _stop_jobs()
await _stop_fetcher_processes()
elif service == "jobs":
return await _stop_jobs()
else:
await _stop_fetcher_processes()
async def restart(service: str = ""):
print("正在重启动服务...")
await _init()
if service == "":
await _stop_jobs()
await _stop_fetcher_processes()
await _start_jobs()
await _start_fetcher_processes()
elif service == "jobs":
return await _restart_jobs()
else:
await _stop_fetcher_processes()
await _start_fetcher_processes()
async def sync_sec_list():
"""发起同步证券列表请求"""
await _init()
await syncjobs.trigger_single_worker_sync("security_list")
async def sync_calendar():
"""发起同步交易日历请求"""
await _init()
await syncjobs.trigger_single_worker_sync("calendar")
async def sync_bars(frame: str = None, codes: str = None):
"""立即同步行情数据
如果`frame`, `codes`没有提供,则从配置文件中读取相关信息
Args:
frame:
codes:
Returns:
"""
await _init()
if frame:
frame_type = FrameType(frame)
params = syncjobs.load_sync_params(frame_type)
if codes:
params["cat"] = None
params["include"] = codes
await syncjobs.trigger_bars_sync(params, force=True)
logger.info("request %s,%s send to workers.", params, codes)
else:
for frame_type in itertools.chain(tf.day_level_frames, tf.minute_level_frames):
params = syncjobs.load_sync_params(frame_type)
if not params:
continue
if codes:
params["cat"] = None
params["include"] = codes
await syncjobs.trigger_bars_sync(params, force=True)
logger.info("request %s,%s send to workers.", params, codes)
async def http_get(url, content_type: str = "json"):
try:
async with aiohttp.ClientSession() as client:
async with client.get(url) as resp:
if resp.status == 200:
if content_type == "json":
return await resp.json()
elif content_type == "text":
return await resp.text()
else:
return await resp.content.read(-1)
except Exception as e:
logger.exception(e)
return None
async def get_archive_index():
url = cfg.omega.urls.archive + f"/index.yml?{random.random()}"
content = await http_get(url, "text")
if content is None:
print("当前没有历史数据可供下载")
return
return archive.parse_index(content)
def bin_cut(arr: list, n: int):
"""将数组arr切分成n份
Args:
arr ([type]): [description]
n ([type]): [description]
Returns:
[type]: [description]
"""
result = [[] for i in range(n)]
for i, e in enumerate(arr):
result[i % n].append(e)
return [e for e in result if len(e)]
async def show_subprocess_output(stream):
while True:
try:
line = await stream.readline()
line = line.decode("utf-8")
if not line:
break
# this is logger output
if line.find(" I ") != -1:
continue
print(line)
except Exception:
pass
async def download_archive(n: Union[str, int] = None):
await omicron.init()
await archive.clear_range()
index = await get_archive_index()
avail_months = [int(m) for m in index.get("stock")]
avail_months.sort()
if avail_months is None:
print("当前没有历史数据可供下载")
return
else:
prompt = f"现有截止到{avail_months[-1]}的{len(avail_months)}个月的数据可供下载。"
if n is None:
op_hint = "请输入要下载的数据的月数,0表示不下载:"
def is_valid(x):
try:
return 0 < int(x) <= len(avail_months)
except Exception:
return False
n = int(get_input(prompt, is_valid, None, op_hint=op_hint))
else:
n = int(n)
if n is None or n <= 0:
return
t0 = time.time()
n = min(n, len(avail_months))
# months = ",".join([str(x) for x in avail_months[-n:]])
cats = "stock"
cpus = psutil.cpu_count()
months_groups = bin_cut(avail_months[-n:], cpus)
tasks = []
print(f"共启动{len(months_groups)}个进程,正在下载中...")
for m in months_groups:
if len(m) == 0:
break
months = ",".join([str(x) for x in m])
proc = await asyncio.create_subprocess_exec(
sys.executable,
"-m",
"omega.fetcher.archive",
"main",
f"'{months}'",
f"'{cats}'",
cfg.omega.urls.archive,
stdout=asyncio.subprocess.PIPE,
stderr=asyncio.subprocess.PIPE,
)
tasks.append(show_subprocess_output(proc.stdout))
tasks.append(show_subprocess_output(proc.stderr))
await asyncio.gather(*tasks)
await archive.adjust_range()
print(f"数据导入共费时{int(time.time() - t0)}秒")
def remove_console_log_handler():
root_logger = logging.getLogger()
for h in root_logger.handlers:
if isinstance(h, logging.StreamHandler):
root_logger.removeHandler(h)
async def _init():
config_dir = get_config_dir()
cfg = cfg4py.init(config_dir, False)
# remove console log, so the output message will looks prettier
remove_console_log_handler()
try:
await emit.start(emit.Engine.REDIS, dsn=cfg.redis.dsn)
except Exception:
print(f"dsn is {cfg.redis.dsn}")
impl = cfg.quotes_fetchers[0]["impl"]
params = cfg.quotes_fetchers[0]["workers"][0]
await AbstractQuotesFetcher.create_instance(impl, **params)
await omicron.init(AbstractQuotesFetcher)
def run_with_init(func):
def wrapper(*args, **kwargs):
async def init_and_run(*args, **kwargs):
try:
await _init()
# os.system("clear")
await func(*args, **kwargs)
except CancelError:
pass
finally:
await omicron.cache.close()
asyncio.run(init_and_run(*args, **kwargs))
return wrapper
def run(func):
def wrapper(*args, **kwargs):
asyncio.run(func(*args, **kwargs))
return wrapper
def main():
import warnings
warnings.simplefilter("ignore")
fire.Fire(
{
"start": run(start),
"setup": run(setup),
"stop": run(stop),
"status": run(status),
"restart": run(restart),
"sync_sec_list": run_with_init(sync_sec_list),
"sync_calendar": run_with_init(sync_calendar),
"sync_bars": run_with_init(sync_bars),
"download": run_with_init(download_archive),
}
)
if __name__ == "__main__":
main() | zillionare-omega | /zillionare-omega-1.1.0.1.tar.gz/zillionare-omega-1.1.0.1/omega/cli.py | cli.py |
import logging
import pickle
import arrow
import cfg4py
from omicron.core.timeframe import tf
from omicron.core.types import FrameType
from sanic import Blueprint, response
from omega.fetcher.abstract_quotes_fetcher import AbstractQuotesFetcher as aq
bp = Blueprint("quotes", url_prefix="/quotes/")
logger = logging.getLogger(__name__)
cfg = cfg4py.get_instance()
@bp.route("valuation")
async def get_valuation(request):
try:
secs = request.json.get("secs")
date = arrow.get(request.json.get("date")).date()
fields = request.json.get("fields")
n = request.json.get("n", 1)
except Exception as e:
logger.exception(e)
logger.error("problem params:%s", request.json)
return response.empty(status=400)
try:
valuation = await aq.get_valuation(secs, date, fields, n)
body = pickle.dumps(valuation, protocol=cfg.pickle.ver)
return response.raw(body)
except Exception as e:
logger.exception(e)
return response.raw(pickle.dumps(None, protocol=cfg.pickle.ver))
@bp.route("security_list")
async def get_security_list_handler(request):
secs = await aq.get_security_list()
body = pickle.dumps(secs, protocol=cfg.pickle.ver)
return response.raw(body)
@bp.route("bars_batch")
async def get_bars_batch_handler(request):
try:
secs = request.json.get("secs")
frame_type = FrameType(request.json.get("frame_type"))
end = arrow.get(request.json.get("end"), tzinfo=cfg.tz)
end = end.date() if frame_type in tf.day_level_frames else end.datetime
n_bars = request.json.get("n_bars")
include_unclosed = request.json.get("include_unclosed", False)
bars = await aq.get_bars_batch(secs, end, n_bars, frame_type, include_unclosed)
body = pickle.dumps(bars, protocol=cfg.pickle.ver)
return response.raw(body)
except Exception as e:
logger.exception(e)
return response.raw(pickle.dumps(None, protocol=cfg.pickle.ver))
@bp.route("bars")
async def get_bars_handler(request):
try:
sec = request.json.get("sec")
frame_type = FrameType(request.json.get("frame_type"))
end = arrow.get(request.json.get("end"), tzinfo=cfg.tz)
end = end.date() if frame_type in tf.day_level_frames else end.datetime
n_bars = request.json.get("n_bars")
include_unclosed = request.json.get("include_unclosed", False)
bars = await aq.get_bars(sec, end, n_bars, frame_type, include_unclosed)
body = pickle.dumps(bars, protocol=cfg.pickle.ver)
return response.raw(body)
except Exception as e:
logger.exception(e)
return response.raw(pickle.dumps(None, protocol=cfg.pickle.ver))
@bp.route("all_trade_days")
async def get_all_trade_days_handler(request):
days = await aq.get_all_trade_days()
body = pickle.dumps(days, protocol=cfg.pickle.ver)
return response.raw(body) | zillionare-omega | /zillionare-omega-1.1.0.1.tar.gz/zillionare-omega-1.1.0.1/omega/interfaces/quotes.py | quotes.py |
import asyncio
import datetime
import json
import os
import re
from typing import Union
import aioredis
class RedisLogReceiver:
def __init__(
self,
dsn: str,
channel_name: str,
filename: str,
backup_count: int = 7,
max_bytes: Union[str, int] = 10 * 1024 * 1024,
fmt: str = None,
):
self._dsn = dsn
self._channel_name = channel_name
self._backup_count = backup_count
self._max_bytes = self.parse_max_bytes(max_bytes)
self._dir = os.path.dirname(filename)
if not os.path.exists(self._dir):
try:
os.makedirs(self._dir)
except Exception as e:
print(e)
print("创建日志目录失败,已将日志目录更改为:/tmp/omega.log")
filename = "/tmp/omega.log"
self._filename = os.path.split(filename)[-1]
self._fmt = (
fmt
or "%(asctime)s %(levelname)-1.1s %(process)d %(name)s:%(funcName)s:%(lineno)s | %(message)s"
)
# the file handler to save log messages
self._fh = open(filename, mode="a", encoding="utf-8", buffering=1)
# bytes written. to decide when to rotate files
self._written_bytes = os.path.getsize(filename)
# the redis connection
self._redis = None
# the channel returned by redis.subscribe
self._channel = None
# the loop for listen and dump log
self._reader_task = None
def rotate(self):
self._fh.flush()
self._fh.close()
self._fh = None
err_msg = None
try:
files = []
for file in os.listdir(self._dir):
if file.startswith(self._filename):
files.append(file)
files.sort()
for file in files[::-1]:
old_file = os.path.join(self._dir, file)
matched = re.match(fr"{self._filename}\.(\d+)", file)
if matched:
seq = int(matched.group(1))
if seq + 1 > self._backup_count:
continue
else:
seq = 0
new_file = os.path.join(self._dir, f"{self._filename}.{seq+1}")
if os.path.exists(new_file):
os.remove(new_file)
os.rename(old_file, new_file)
except Exception as e:
err_msg = str(e)
filename = os.path.join(self._dir, self._filename)
self._fh = open(filename, mode="a", encoding="utf-8", buffering=1)
self._written_bytes = 0
if err_msg:
self._fh.write(err_msg)
def _write(self, msg: str):
self._written_bytes += len(msg)
if (1 + self._written_bytes) % 4096 == 0:
self._fh.flush()
if self._written_bytes > self._max_bytes:
self.rotate()
if self._fh is None:
print(msg)
else:
self._fh.write(msg)
self._fh.write("\n")
async def stop(self):
self._fh.flush()
self._fh.close()
self._fh = None
await self._redis.unsubscribe(self._channel_name)
await self._reader_task
self._redis.close()
async def start(self):
self._redis = await aioredis.create_redis(self._dsn)
res = await self._redis.subscribe(self._channel_name)
self._channel = res[0]
self._reader_task = asyncio.create_task(self.reader())
async def reader(self):
while await self._channel.wait_message():
msg = (await self._channel.get()).decode("utf-8")
self._write(msg)
@staticmethod
def parse_max_bytes(max_bytes: Union[str, int]):
if isinstance(max_bytes, str):
size, unit = re.match(r"([.\d]+)([MK])", max_bytes.upper()).groups()
if unit == "M":
max_bytes = float(size) * 1024 * 1024
elif unit == "K":
max_bytes = float(size) * 1024
else: # pragma: no cover
raise ValueError(f"{max_bytes} is not parsable")
elif isinstance(max_bytes, int):
pass
else: # pragma: no cover
raise ValueError(f"type of max_bytes({type(max_bytes)}) is not supported.")
return max_bytes | zillionare-omega | /zillionare-omega-1.1.0.1.tar.gz/zillionare-omega-1.1.0.1/omega/logreceivers/redis.py | redis.py |
import asyncio
import functools
import itertools
import logging
import os
import time
from typing import Optional
import arrow
import cfg4py
import fire
import omicron
from apscheduler.schedulers.asyncio import AsyncIOScheduler
from omicron import cache
from omicron.core.timeframe import tf
from pyemit import emit
from sanic import Sanic, response
import omega.jobs.syncjobs as syncjobs
from omega.config import get_config_dir
from omega.logreceivers.redis import RedisLogReceiver
app = Sanic("Omega-jobs")
logger = logging.getLogger(__name__)
cfg = cfg4py.get_instance()
scheduler: Optional[AsyncIOScheduler] = None
receiver: RedisLogReceiver = None
async def start_logging():
global receiver
if getattr(cfg, "logreceiver") is None:
return
if cfg.logreceiver.klass == "omega.logging.receiver.redis.RedisLogReceiver":
dsn = cfg.logreceiver.dsn
channel = cfg.logreceiver.channel
filename = cfg.logreceiver.filename
backup_count = cfg.logreceiver.backup_count
max_bytes = cfg.logreceiver.max_bytes
receiver = RedisLogReceiver(dsn, channel, filename, backup_count, max_bytes)
await receiver.start()
logger.info("%s is working now", cfg.logreceiver.klass)
async def heartbeat():
global scheduler
pid = os.getpid()
key = "process.jobs"
await omicron.cache.sys.hmset(key, "pid", pid, "heartbeat", time.time())
async def init(app, loop): # noqa
global scheduler
config_dir = get_config_dir()
cfg4py.init(get_config_dir(), False)
await start_logging()
logger.info("init omega-jobs process with config at %s", config_dir)
await omicron.init()
await emit.start(emit.Engine.REDIS, dsn=cfg.redis.dsn)
scheduler = AsyncIOScheduler(timezone=cfg.tz)
await heartbeat()
scheduler.add_job(heartbeat, "interval", seconds=5)
# sync securities daily
h, m = map(int, cfg.omega.sync.security_list.split(":"))
scheduler.add_job(
syncjobs.trigger_single_worker_sync,
"cron",
hour=h,
minute=m,
args=("calendar",),
name="sync_calendar",
)
scheduler.add_job(
syncjobs.trigger_single_worker_sync,
"cron",
args=("security_list",),
name="sync_security_list",
hour=h,
minute=m,
)
syncjobs.load_bars_sync_jobs(scheduler)
# sync bars at startup
last_sync = await cache.sys.get("jobs.bars_sync.stop")
if last_sync:
try:
last_sync = arrow.get(last_sync, tzinfo=cfg.tz).timestamp
except ValueError:
logger.warning("failed to parse last_sync: %s", last_sync)
last_sync = None
if not last_sync or time.time() - last_sync >= 24 * 3600:
next_run_time = arrow.now(cfg.tz).shift(minutes=5).datetime
logger.info("start catch-up quotes sync at %s", next_run_time)
for frame_type in itertools.chain(tf.day_level_frames, tf.minute_level_frames):
params = syncjobs.load_sync_params(frame_type)
if params:
scheduler.add_job(
syncjobs.trigger_bars_sync,
args=(params, True),
name=f"catch-up sync for {frame_type}",
next_run_time=next_run_time,
)
else:
logger.info("%s: less than 24 hours since last sync", last_sync)
scheduler.start()
logger.info("omega jobs finished initialization")
@app.route("/jobs/sync_bars")
async def start_sync(request): # pragma: no cover :they're in another process
logger.info("received http command sync_bars")
sync_params = request.json
app.add_task(syncjobs.trigger_bars_sync(sync_params, True))
return response.text("sync task scheduled")
@app.route("/jobs/status") # pragma: no cover
async def get_status(request):
return response.empty(status=200)
@app.listener("after_server_stop")
async def on_shutdown(app, loop): # pragma: no cover
global receiver
logger.info("omega jobs is shutting down...")
try:
if receiver:
await receiver.stop()
except Exception:
pass
await omicron.shutdown()
def start(host: str = "0.0.0.0", port: int = 3180): # pragma: no cover
logger.info("starting omega jobs ...")
app.register_listener(init, "before_server_start")
app.run(host=host, port=port, register_sys_signals=True)
logger.info("omega jobs exited.")
if __name__ == "__main__":
fire.Fire({"start": start}) | zillionare-omega | /zillionare-omega-1.1.0.1.tar.gz/zillionare-omega-1.1.0.1/omega/jobs/__main__.py | __main__.py |
import asyncio
import datetime
import logging
import os
from typing import List, Optional, Tuple, Union
import aiohttp
import arrow
import cfg4py
from dateutil import tz
from omicron import cache
from omicron.core.errors import FetcherQuotaError
from omicron.core.timeframe import tf
from omicron.core.types import Frame, FrameType
from omicron.models.securities import Securities
from pyemit import emit
from omega.core.events import Events
from omega.fetcher.abstract_quotes_fetcher import AbstractQuotesFetcher as aq
logger = logging.getLogger(__name__)
cfg = cfg4py.get_instance()
async def _start_job_timer(job_name: str):
key_start = f"jobs.bars_{job_name}.start"
pl = cache.sys.pipeline()
pl.delete(f"jobs.bars_{job_name}.*")
pl.set(key_start, arrow.now(tz=cfg.tz).format("YYYY-MM-DD HH:mm:ss"))
await pl.execute()
async def _stop_job_timer(job_name: str) -> int:
key_start = f"jobs.bars_{job_name}.start"
key_stop = f"jobs.bars_{job_name}.stop"
key_elapsed = f"jobs.bars_{job_name}.elapsed"
start = arrow.get(await cache.sys.get(key_start), tzinfo=cfg.tz)
stop = arrow.now(tz=cfg.tz)
elapsed = (stop - start).seconds
pl = cache.sys.pipeline()
pl.set(key_stop, stop.format("YYYY-MM-DD HH:mm:ss"))
pl.set(key_elapsed, elapsed)
await pl.execute()
return elapsed
def load_sync_params(frame_type: FrameType) -> dict:
"""根据指定的frame_type,从配置文件中加载同步参数
Args:
frame_type (FrameType): [description]
Returns:
dict: see @[omega.jobs.syncjobs.parse_sync_params]
"""
for item in cfg.omega.sync.bars:
if item.get("frame") == frame_type.value:
try:
secs, frame_type, start, stop, delay = parse_sync_params(**item)
return item
except Exception as e:
logger.exception(e)
logger.warning("failed to parse %s", item)
return None
return None
async def trigger_bars_sync(sync_params: dict = None, force=False):
"""初始化bars_sync的任务,发信号给各quotes_fetcher进程以启动同步。
Args:
frame_type (FrameType): 要同步的帧类型
sync_params (dict): 同步参数
```
{
start: 起始帧
stop: 截止帧
frame: 帧类型
delay: 延迟启动时间,以秒为单位
cat: 证券分类,如stock, index等
delay: seconds for sync to wait.
}
```
see more @[omega.jobs.syncjobs.parse_sync_params][]
force: 即使当前不是交易日,是否也强行进行同步。
Returns:
"""
if not force and not tf.is_trade_day(arrow.now()):
return
codes, frame_type, start, stop, delay = parse_sync_params(**sync_params)
key_scope = f"jobs.bars_sync.scope.{frame_type.value}"
if len(codes) == 0:
logger.warning("no securities are specified for sync %s", frame_type)
return
fmt_str = "sync from %s to %s in frame_type(%s) for %s secs"
logger.info(fmt_str, start, stop, frame_type, len(codes))
# secs are stored into cache, so each fetcher can polling it
pl = cache.sys.pipeline()
pl.delete(key_scope)
pl.lpush(key_scope, *codes)
await pl.execute()
await asyncio.sleep(delay)
await _start_job_timer("sync")
await emit.emit(
Events.OMEGA_DO_SYNC, {"frame_type": frame_type, "start": start, "stop": stop}
)
fmt_str = "send trigger sync event to fetchers: from %s to %s in frame_type(%s) for %s secs"
logger.info(fmt_str, start, stop, frame_type, len(codes))
def parse_sync_params(
frame: Union[str, Frame],
cat: List[str] = None,
start: Union[str, datetime.date] = None,
stop: Union[str, Frame] = None,
delay: int = 0,
include: str = "",
exclude: str = "",
) -> Tuple:
"""按照[使用手册](usage.md#22-如何同步K线数据)中的规则,解析和补全同步参数。
如果`frame_type`为分钟级,则当`start`指定为`date`类型时,自动更正为对应交易日的起始帧;
当`stop`为`date`类型时,自动更正为对应交易日的最后一帧。
Args:
frame (Union[str, Frame]): frame type to be sync. The word ``frame`` is used
here for easy understand by end user. It actually implies "FrameType".
cat (List[str]): which catetories is about to be synced. Should be one of
['stock', 'index']. Defaults to None.
start (Union[str, datetime.date], optional): [description]. Defaults to None.
stop (Union[str, Frame], optional): [description]. Defaults to None.
delay (int, optional): [description]. Defaults to 5.
include (str, optional): which securities should be included, seperated by
space, for example, "000001.XSHE 000004.XSHE". Defaults to empty string.
exclude (str, optional): which securities should be excluded, seperated by
a space. Defaults to empty string.
Returns:
- codes (List[str]): 待同步证券列表
- frame_type (FrameType):
- start (Frame):
- stop (Frame):
- delay (int):
"""
frame_type = FrameType(frame)
if frame_type in tf.minute_level_frames:
if stop:
stop = arrow.get(stop, tzinfo=cfg.tz)
if stop.hour == 0: # 未指定有效的时间帧,使用当日结束帧
stop = tf.last_min_frame(tf.day_shift(stop.date(), 0), frame_type)
else:
stop = tf.floor(stop, frame_type)
else:
stop = tf.floor(arrow.now(tz=cfg.tz).datetime, frame_type)
if stop > arrow.now(tz=cfg.tz):
raise ValueError(f"请勿将同步截止时间设置在未来: {stop}")
if start:
start = arrow.get(start, tzinfo=cfg.tz)
if start.hour == 0: # 未指定有效的交易帧,使用当日的起始帧
start = tf.first_min_frame(tf.day_shift(start.date(), 0), frame_type)
else:
start = tf.floor(start, frame_type)
else:
start = tf.shift(stop, -999, frame_type)
else:
stop = (stop and arrow.get(stop).date()) or arrow.now().date()
if stop == arrow.now().date():
stop = arrow.now(tz=cfg.tz)
stop = tf.floor(stop, frame_type)
start = tf.floor((start and arrow.get(start).date()), frame_type) or tf.shift(
stop, -1000, frame_type
)
secs = Securities()
codes = secs.choose(cat or [])
exclude = map(lambda x: x, exclude.split(" "))
codes = list(set(codes) - set(exclude))
include = list(filter(lambda x: x, include.split(" ")))
codes.extend(include)
return codes, frame_type, start, stop, int(delay)
async def sync_bars(params: dict):
"""sync bars on signal OMEGA_DO_SYNC received
Args:
params (dict): composed of the following:
```
{
secs (List[str]): 待同步的证券标的.如果为None或者为空,则从数据库中轮询
frame_type (FrameType):k线的帧类型
start (Frame): k线起始时间
stop (Frame): k线结束时间
}
```
Returns:
[type]: [description]
"""
secs, frame_type, start, stop = (
params.get("secs"),
params.get("frame_type"),
params.get("start"),
params.get("stop"),
)
if secs is not None:
logger.info(
"sync bars with %s(%s ~ %s) for given %s secs",
frame_type,
start,
stop,
len(secs),
)
async def get_sec():
return secs.pop() if len(secs) else None
else:
logger.info(
"sync bars with %s(%s ~ %s) in polling mode", frame_type, start, stop
)
async def get_sec():
return await cache.sys.lpop(key_scope)
key_scope = f"jobs.bars_sync.scope.{frame_type.value}"
if start is None or frame_type is None:
raise ValueError("you must specify a start date/frame_type for sync")
if stop is None:
stop = tf.floor(arrow.now(tz=cfg.tz), frame_type)
while code := await get_sec():
try:
await sync_bars_for_security(code, frame_type, start, stop)
except FetcherQuotaError as e:
logger.warning("Quota exceeded when syncing %s. Sync aborted.", code)
logger.exception(e)
return # stop the sync
except Exception as e:
logger.warning("Failed to sync %s", code)
logger.exception(e)
elapsed = await _stop_job_timer("sync")
logger.info("%s finished quotes sync in %s seconds", os.getpid(), elapsed)
async def sync_bars_for_security(
code: str,
frame_type: FrameType,
start: Union[datetime.date, datetime.datetime],
stop: Union[None, datetime.date, datetime.datetime],
):
counters = 0
# 取数据库中该frame_type下该code的k线起始点
head, tail = await cache.get_bars_range(code, frame_type)
if not all([head, tail]):
await cache.clear_bars_range(code, frame_type)
n_bars = tf.count_frames(start, stop, frame_type)
bars = await aq.get_bars(code, stop, n_bars, frame_type)
if bars is not None and len(bars):
logger.debug(
"sync %s(%s), from %s to %s: actual got %s ~ %s (%s)",
code,
frame_type,
start,
head,
bars[0]["frame"],
bars[-1]["frame"],
len(bars),
)
counters = len(bars)
return
if start < head:
n = tf.count_frames(start, head, frame_type) - 1
if n > 0:
_end_at = tf.shift(head, -1, frame_type)
bars = await aq.get_bars(code, _end_at, n, frame_type)
if bars is not None and len(bars):
counters += len(bars)
logger.debug(
"sync %s(%s), from %s to %s: actual got %s ~ %s (%s)",
code,
frame_type,
start,
head,
bars[0]["frame"],
bars[-1]["frame"],
len(bars),
)
if bars["frame"][-1] != _end_at:
logger.warning(
"discrete frames found:%s, bars[-1](%s), " "head(%s)",
code,
bars["frame"][-1],
head,
)
if stop > tail:
n = tf.count_frames(tail, stop, frame_type) - 1
if n > 0:
bars = await aq.get_bars(code, stop, n, frame_type)
if bars is not None and len(bars):
logger.debug(
"sync %s(%s), from %s to %s: actual got %s ~ %s (%s)",
code,
frame_type,
tail,
stop,
bars[0]["frame"],
bars[-1]["frame"],
len(bars),
)
counters += len(bars)
if bars["frame"][0] != tf.shift(tail, 1, frame_type):
logger.warning(
"discrete frames found: %s, tail(%s), bars[0](" "%s)",
code,
tail,
bars["frame"][0],
)
async def trigger_single_worker_sync(_type: str, params: dict = None):
"""启动只需要单个quotes fetcher进程来完成的数据同步任务
比如交易日历、证券列表等如果需要同时启动多个quotes fetcher进程来完成数据同步任务,应该通过
pyemit来发送广播消息。
Args:
_type: the type of data to be synced, either ``calendar`` or ``ecurity_list``
"""
url = cfg.omega.urls.quotes_server
if _type == "calendar":
url += "/jobs/sync_calendar"
elif _type == "security_list":
url += "/jobs/sync_security_list"
else:
raise ValueError(f"{_type} is not supported sync type.")
async with aiohttp.ClientSession() as client:
try:
async with client.post(url, data=params) as resp:
if resp.status != 200:
logger.warning("failed to trigger %s sync", _type)
else:
return await resp.json()
except Exception as e:
logger.exception(e)
async def sync_calendar():
"""从上游服务器获取所有交易日,并计算出周线帧和月线帧
Returns:
"""
trade_days = await aq.get_all_trade_days()
if trade_days is None or len(trade_days) == 0:
logger.warning("failed to fetch trade days.")
return None
tf.day_frames = [tf.date2int(x) for x in trade_days]
weeks = []
last = trade_days[0]
for cur in trade_days:
if cur.weekday() < last.weekday() or (cur - last).days >= 7:
weeks.append(last)
last = cur
if weeks[-1] < last:
weeks.append(last)
tf.week_frames = [tf.date2int(x) for x in weeks]
await cache.save_calendar("week_frames", map(tf.date2int, weeks))
months = []
last = trade_days[0]
for cur in trade_days:
if cur.day < last.day:
months.append(last)
last = cur
months.append(last)
tf.month_frames = [tf.date2int(x) for x in months]
await cache.save_calendar("month_frames", map(tf.date2int, months))
logger.info("trade_days is updated to %s", trade_days[-1])
async def sync_security_list():
"""更新证券列表
注意证券列表在AbstractQuotesServer取得时就已保存,此处只是触发
"""
secs = await aq.get_security_list()
logger.info("%s secs are fetched and saved.", len(secs))
async def reset_tail(codes: [], frame_type: FrameType, days=-1):
"""
重置tail的值,来同步数据
Args:
days: 需要重置到多少天之前
codes:
frame_type:
Returns:
"""
now = arrow.now()
_day = tf.day_shift(now, days)
if frame_type in [
FrameType.MIN1,
FrameType.MIN5,
FrameType.MIN15,
FrameType.MIN30,
FrameType.MIN60]:
date = datetime.datetime(_day.year, _day.month, _day.day, 15)
tail = tf.time2int(date)
elif frame_type == FrameType.DAY:
date = _day
tail = tf.date2int(date)
elif frame_type == FrameType.WEEK:
date = tf.shift(now, days, FrameType.WEEK)
tail = tf.date2int(date)
elif frame_type == FrameType.MONTH:
date = tf.shift(now, days, FrameType.MONTH)
tail = tf.date2int(date)
else:
raise Exception("不支持的frame_type")
# print(f"reset tail to[m:{m}, day:{day}, week:{week}, month:{month}] ")
for code in codes:
key = f"{code}:{frame_type.value}"
resp = await cache.security.hget(key, "tail")
if resp is None:
continue
_tail = int(resp)
print(_tail)
if _tail > tail: # 只有数据库里的时间大于tail 才可以
await cache.security.hset(key, 'tail', tail)
return date.strftime('%Y-%m-%d')
async def closing_quotation_sync_bars(all_params):
"""
收盘之后从新同步今天的分钟线数据和日周月
Returns:
{
"frame": "1m",
"start": "2020-01-02",
"stop": "2020-01-02",
"delay": 3,
"cat": [],
"include": "000001.XSHE",
"exclude": "000001.XSHG",
},
"""
logger.info("正在同步今天的分钟线数据和日周月")
for params in all_params:
codes, frame_type, start, stop, delay = parse_sync_params(**params)
start_date = await reset_tail(codes, frame_type)
params["start"] = start_date
logger.info(params)
await trigger_bars_sync(params)
def load_bars_sync_jobs(scheduler):
all_params = []
frame_type = FrameType.MIN1
params = load_sync_params(frame_type)
if params:
all_params.append(params)
params["delay"] = params.get("delay") or 5
scheduler.add_job(
trigger_bars_sync,
"cron",
hour=9,
minute="31-59",
args=(params,),
name=f"{frame_type.value}:9:31-59",
)
scheduler.add_job(
trigger_bars_sync,
"cron",
hour=10,
minute="*",
args=(params,),
name=f"{frame_type.value}:10:*",
)
scheduler.add_job(
trigger_bars_sync,
"cron",
hour=11,
minute="0-30",
args=(params,),
name=f"{frame_type.value}:11:0-30",
)
scheduler.add_job(
trigger_bars_sync,
"cron",
hour="13-14",
minute="*",
args=(params,),
name=f"{frame_type.value}:13-14:*",
)
scheduler.add_job(
trigger_bars_sync,
"cron",
hour="15",
args=(params,),
name=f"{frame_type.value}:15:00",
)
frame_type = FrameType.MIN5
params = load_sync_params(frame_type)
if params:
all_params.append(params)
params["delay"] = params.get("delay") or 60
scheduler.add_job(
trigger_bars_sync,
"cron",
hour=9,
minute="35-55/5",
args=(params,),
name=f"{frame_type.value}:9:35-55/5",
)
scheduler.add_job(
trigger_bars_sync,
"cron",
hour=10,
minute="*/5",
args=(params,),
name=f"{frame_type.value}:10:*/5",
)
scheduler.add_job(
trigger_bars_sync,
"cron",
hour=11,
minute="0-30/5",
args=(params,),
name=f"{frame_type.value}:11:0-30/5",
)
scheduler.add_job(
trigger_bars_sync,
"cron",
hour="13-14",
minute="*/5",
args=(params,),
name=f"{frame_type.value}:13-14:*/5",
)
scheduler.add_job(
trigger_bars_sync,
"cron",
hour="15",
args=(params,),
name=f"{frame_type.value}:15:00",
)
frame_type = FrameType.MIN15
params = load_sync_params(frame_type)
if params:
all_params.append(params)
params["delay"] = params.get("delay") or 60
scheduler.add_job(
trigger_bars_sync,
"cron",
hour=9,
minute="45",
args=(params,),
name=f"{frame_type.value}:9:45",
)
scheduler.add_job(
trigger_bars_sync,
"cron",
hour=10,
minute="*/15",
args=(params,),
name=f"{frame_type.value}:10:*/5",
)
scheduler.add_job(
trigger_bars_sync,
"cron",
hour=11,
minute="15,30",
args=(params,),
name=f"{frame_type.value}:11:15,30",
)
scheduler.add_job(
trigger_bars_sync,
"cron",
hour="13-14",
minute="*/15",
args=(params,),
name=f"{frame_type.value}:13-14:*/15",
)
scheduler.add_job(
trigger_bars_sync,
"cron",
hour="15",
args=(params,),
name=f"{frame_type.value}:15:00",
)
frame_type = FrameType.MIN30
params = load_sync_params(frame_type)
if params:
all_params.append(params)
params["delay"] = params.get("delay") or 60
scheduler.add_job(
trigger_bars_sync,
"cron",
hour="10-11",
minute="*/30",
args=(params,),
name=f"{frame_type.value}:10-11:*/30",
)
scheduler.add_job(
trigger_bars_sync,
"cron",
hour="13",
minute="30",
args=(params,),
name=f"{frame_type.value}:13:30",
)
scheduler.add_job(
trigger_bars_sync,
"cron",
hour="14-15",
minute="*/30",
args=(params,),
name=f"{frame_type.value}:14-15:*/30",
)
frame_type = FrameType.MIN60
params = load_sync_params(frame_type)
if params:
all_params.append(params)
params["delay"] = params.get("delay") or 60
scheduler.add_job(
trigger_bars_sync,
"cron",
hour="10",
minute="30",
args=(params,),
name=f"{frame_type.value}:10:30",
)
scheduler.add_job(
trigger_bars_sync,
"cron",
hour="11",
minute="30",
args=(params,),
name=f"{frame_type.value}:11:30",
)
scheduler.add_job(
trigger_bars_sync,
"cron",
hour="14-15",
minute=0,
args=(params,),
name=f"{frame_type.value}:14-15:00",
)
for frame_type in tf.day_level_frames:
params = load_sync_params(frame_type)
if params:
all_params.append(params)
params["delay"] = params.get("delay") or 60
scheduler.add_job(
trigger_bars_sync,
"cron",
hour=15,
args=(params,),
name=f"{frame_type.value}:15:00",
)
scheduler.add_job(
closing_quotation_sync_bars,
"cron",
hour=15,
minute=5,
args=(all_params, ),
name="closing_quotation_sync_bars",
) | zillionare-omega | /zillionare-omega-1.1.0.1.tar.gz/zillionare-omega-1.1.0.1/omega/jobs/syncjobs.py | syncjobs.py |
import datetime
from abc import ABC
from typing import List, Union, Optional
import numpy
from omicron.core.types import Frame, FrameType
class QuotesFetcher(ABC):
async def get_security_list(self) -> numpy.ndarray:
"""
fetch security list from server. The returned list is a numpy.ndarray,
which each elements
should look like:
code display_name name start_date end_date type
000001.XSHE 平安银行 PAYH 1991-04-03 2200-01-01 stock
000002.XSHE 万科A WKA 1991-01-29 2200-01-01 stock
all fields are string type
Returns:
"""
raise NotImplementedError
async def get_bars(
self,
sec: str,
end: Frame,
n_bars: int,
frame_type: FrameType,
allow_unclosed=True,
) -> numpy.ndarray:
"""取n个单位的k线数据。
k线周期由frame_type指定。最后结束周期为end。股票停牌期间的数据会使用None填充。
Args:
sec (str): 证券代码
end (Frame):
n_bars (int):
frame_type (FrameType):
allow_unclosed (bool): 为真时,当前未结束的帧数据也获取
Returns:
a numpy.ndarray, with each element is:
'frame': datetime.date or datetime.datetime, depends on frame_type.
Denotes which time frame the data
belongs .
'open, high, low, close': float
'volume': double
'amount': the buy/sell amount in total, double
'factor': float, may exist or not
"""
raise NotImplementedError
async def get_price(
self,
sec: Union[List, str],
end_date: Union[str, datetime.datetime],
n_bars: Optional[int],
start_date: Optional[Union[str, datetime.datetime]] = None,
) -> numpy.ndarray:
raise NotImplementedError
async def create_instance(self, **kwargs):
raise NotImplementedError
async def get_all_trade_days(self):
"""
返回交易日历。不同的服务器可能返回的时间跨度不一样,但相同跨度内的时间应该一样。对已
经过去的交易日,可以用上证指数来验证。
"""
raise NotImplementedError
async def get_valuation(
self, code: Union[str, List[str]], day: Frame
) -> numpy.ndarray:
"""读取code指定的股票在date指定日期的市值数据。
返回数据包括:
code: 股票代码
day: 日期
captialization: 总股本
circulating_cap: 流通股本(万股)
market_cap: 总市值(亿元)
circulating_market_cap: 流通市值(亿元)
turnover_ration: 换手率(%)
pe_ratio: 市盈率(PE,TTM)每股市价为每股收益的倍数,反映投资人对每元净利润所愿支付的价
格,用来估计股票的投资报酬和风险
pe_ratio_lyr: 市盈率(PE),以上一年度每股盈利计算的静态市盈率. 股价/最近年度报告EPS
pb_ratio: 市净率(PB)
ps_ratio: 市销率(PS)
pcf_ratio: 市现率(PCF)
Args:
code (Union[str, List[str]]): [description]
day (Frame): [description]
Returns:
numpy.ndarray: [description]
"""
raise NotImplementedError | zillionare-omega | /zillionare-omega-1.1.0.1.tar.gz/zillionare-omega-1.1.0.1/omega/fetcher/quotes_fetcher.py | quotes_fetcher.py |
"""This is a awesome
python script!"""
import datetime
import importlib
import logging
from typing import List, Union, Optional
import arrow
import cfg4py
import numpy as np
from numpy.lib import recfunctions as rfn
from omicron import cache
from omicron.core.lang import static_vars
from omicron.core.timeframe import tf
from omicron.core.types import Frame, FrameType
from omicron.models.valuation import Valuation
from omega.core.accelerate import merge
from omega.fetcher.quotes_fetcher import QuotesFetcher
logger = logging.getLogger(__file__)
cfg = cfg4py.get_instance()
class AbstractQuotesFetcher(QuotesFetcher):
_instances = []
@classmethod
async def create_instance(cls, module_name, **kwargs):
# todo: check if implementor has implemented all the required methods
# todo: check duplicates
module = importlib.import_module(module_name)
factory_method = getattr(module, "create_instance")
if not callable(factory_method):
raise TypeError(f"Bad omega adaptor implementation {module_name}")
impl: QuotesFetcher = await factory_method(**kwargs)
cls._instances.append(impl)
logger.info("add one quotes fetcher implementor: %s", module_name)
@classmethod
@static_vars(i=0)
def get_instance(cls):
if len(cls._instances) == 0:
raise IndexError("No fetchers available")
i = (cls.get_instance.i + 1) % len(cls._instances)
return cls._instances[i]
@classmethod
async def get_security_list(cls) -> Union[None, np.ndarray]:
"""按如下格式返回证券列表。
code display_name name start_date end_date type
000001.XSHE 平安银行 PAYH 1991-04-03 2200-01-01 stock
Returns:
Union[None, np.ndarray]: [description]
"""
securities = await cls.get_instance().get_security_list()
if securities is None or len(securities) == 0:
logger.warning("failed to update securities. %s is returned.", securities)
return securities
key = "securities"
pipeline = cache.security.pipeline()
pipeline.delete(key)
for code, display_name, name, start, end, _type in securities:
pipeline.rpush(
key, f"{code},{display_name},{name},{start}," f"{end},{_type}"
)
await pipeline.execute()
return securities
@classmethod
async def get_bars_batch(
cls,
secs: List[str],
end: Frame,
n_bars: int,
frame_type: FrameType,
include_unclosed=True,
) -> np.ndarray:
return await cls.get_instance().get_bars_batch(
secs, end, n_bars, frame_type.value, include_unclosed
)
@classmethod
async def get_bars(
cls,
sec: str,
end: Frame,
n_bars: int,
frame_type: FrameType,
include_unclosed=True,
) -> np.ndarray:
"""获取行情数据,并将已结束的周期数据存入缓存。
各种情况:
1. 假设现在时间是2021-2-24日,盘中。此时请求上证指数日线,且`include_unclosed`为
`True`:
```python
get_bars("000001.XSHE", None, 1, FrameType.DAY)
```
得到的数据可能如下:
```
[(datetime.date(2021, 2, 24), 3638.9358, 3645.5288, 3617.44, 3620.3542, ...)]
```
在收盘前不同时间调用,得到的数据除开盘价外,其它都实时在变动。
2. 假设现在时间是2021-2-23日,盘后,此时请求上证指数日线,将得到收盘后固定的价格。
3. 上述请求中,`include_unclosed`参数使用默认值(`True`)。如果取为`False`,仍以示例1
指定的场景为例,则:
```python
get_bars("000001.XSHG", None, 1, FrameType.DAY, False)
```
因为2021-2-24日未收盘,所以获取的最后一条数据是2021-2-23日的。
4. 同样假设现在时间是2021-2-24日盘中,周三。此时获取周K线。在`include_unclosed`分别为
`True`和`False`的情况下:
```
[(datetime.date(2021, 2, 24), 3707.19, 3717.27, 3591.3647, 3592.3977, ...)]
[(datetime.date(2021, 2, 19), 3721.09, 3731.69, 3634.01, 3696.17, ...)]
```
注意这里当`include_unclosed`为True时,返回的周K线是以2021-2-24为Frame的。同样,在盘中
的不同时间取这个数据,除了`open`数值之外,其它都是实时变化的。
5. 如果在已结束的周期中,包含停牌数据,则会对停牌期间的数据进行nan填充,以方便数据使用
者可以较容易地分辨出数据不连贯的原因:哪些是停牌造成的,哪些是非交易日造成的。这种处理
会略微降低数据获取速度,并增加存储空间。
比如下面的请求:
```python
get_bars("000029.XSHE", datetime.date(2020,8,18), 10, FrameType.DAY)
```
将获取到2020-8-5到2020-8-18间共10条数据。但由于期间000029这支股票处于停牌期,所以返回
的10条数据中,数值部分全部填充为np.nan。
注意如果取周线和月线数据,如果当天停牌,但只要周线有数据,则仍能取到。周线(或者月线)的
`frame`将是停牌前一交易日。比如,
```python
sec = "600721.XSHG"
frame_type = FrameType.WEEK
end = arrow.get("2020-4-29 15:00").datetime
bars = await aq.get_bars(sec, end, 3, FrameType.WEEK)
print(bars)
```
2020年4月30日是该周的最后一个交易日。股票600721在4月29日停牌一天。上述请求将得到如下数
据:
```
[(datetime.date(2020, 4, 17), 6.02, 6.69, 5.84, 6.58, ...)
(datetime.date(2020, 4, 24), 6.51, 6.57, 5.68, 5.72, ...)
(datetime.date(2020, 4, 28), 5.7, 5.71, 5.17, 5.36, ...)]
```
停牌发生在日线级别上,但我们的请求发生在周线级别上,所以不会对4/29日进行填充,而是返回
截止到4月29日的数据。
args:
sec: 证券代码
end: 数据截止日
n_bars: 待获取的数据条数
frame_type: 数据所属的周期
include_unclosed: 如果为真,则会包含当end所处的那个Frame的数据,即使当前它还未结束
"""
now = arrow.now(tz=cfg.tz)
end = end or now.datetime
# 如果end超出当前时间,则认为是不合法的。如果用户想取到最新的数据,应该传入None
if type(end) == datetime.date:
if end > now.date():
return None
elif type(end) == datetime.datetime:
if end > now:
return None
bars = await cls.get_instance().get_bars(
sec, end, n_bars, frame_type.value, include_unclosed
)
if len(bars) == 0:
return
# 根据指定的end,计算结束时的frame
last_closed_frame = tf.floor(end, frame_type)
last_frame = bars[-1]["frame"]
# 计算有多少根k线是已结束的
n_closed = n_bars - 1
if frame_type == FrameType.DAY:
# 盘后取日线,返回的一定是全部都已closed的数据
# 盘中取日线,返回的last_frame会是当天的日期,但该日线并未结束
if now.datetime.hour >= 15 or last_frame < now.date():
n_closed = n_bars
else:
# 如果last_frame <= end的上限,则返回的也一定是全部都closed的数据
if last_frame <= tf.floor(end, frame_type):
n_closed = n_bars
remainder = [bars[-1]] if n_closed < n_bars else None
closed_bars = cls._fill_na(bars, n_closed, last_closed_frame, frame_type)
# 只保存已结束的bar
await cache.save_bars(sec, closed_bars, frame_type)
if remainder is None:
return closed_bars
else:
return np.concatenate([closed_bars, remainder])
@classmethod
def _fill_na(cls, bars: np.array, n: int, end: Frame, frame_type) -> np.ndarray:
if frame_type in tf.minute_level_frames:
convert = tf.int2time
else:
convert = tf.int2date
frames = [convert(x) for x in tf.get_frames_by_count(end, n, frame_type)]
filled = np.empty(n, dtype=bars.dtype)
filled[:] = np.nan
filled["frame"] = frames
return merge(filled, bars, "frame")
@classmethod
async def get_all_trade_days(cls):
days = await cls.get_instance().get_all_trade_days()
await cache.save_calendar("day_frames", map(tf.date2int, days))
return days
@classmethod
async def get_valuation(
cls,
code: Union[str, List[str]],
day: datetime.date,
fields: List[str] = None,
n: int = 1,
) -> np.ndarray:
valuation = await cls.get_instance().get_valuation(code, day, n)
await Valuation.save(valuation)
if fields is None:
return valuation
if isinstance(fields, str):
fields = [fields]
mapping = dict(valuation.dtype.descr)
fields = [(name, mapping[name]) for name in fields]
return rfn.require_fields(valuation, fields)
@classmethod
async def get_price(
cls,
sec: Union[List, str],
end_date: Union[str, datetime.datetime],
n_bars: Optional[int],
start_date: Optional[Union[str, datetime.datetime]] = None,
) -> np.ndarray:
fields = ['open', 'close', 'high', 'low', 'volume', 'money', 'high_limit', 'low_limit', 'avg', 'factor']
params = {
"security": sec,
"end_date": end_date,
"fields": fields,
"fq": None,
"fill_paused": False,
"frequency": FrameType.MIN1.value,
}
if start_date:
params.update({"start_date": start_date})
if n_bars is not None:
params.update({"count": start_date})
if "start_date" in params and "count" in params:
raise ValueError("start_date and count cannot appear at the same time")
bars = await cls.get_instance().get_price(**params)
if len(bars) == 0:
return | zillionare-omega | /zillionare-omega-1.1.0.1.tar.gz/zillionare-omega-1.1.0.1/omega/fetcher/abstract_quotes_fetcher.py | abstract_quotes_fetcher.py |
import asyncio
import glob
import io
import logging
import os
import random
import shutil
import tarfile
import tempfile
from typing import List, Tuple
import aiohttp
import cfg4py
import fire
import omicron
import pandas as pd
from omicron import cache
from omicron.core.types import FrameType
from ruamel.yaml import YAML
from ruamel.yaml.error import YAMLError
from ruamel.yaml.main import parse
from omega.config import get_config_dir
logger = logging.getLogger(__name__)
cfg = cfg4py.get_instance()
class FileHandler:
async def process(self, stream):
raise NotImplementedError
class ArchivedBarsHandler(FileHandler):
def __init__(self, url: str):
self.url = url
async def process(self, file_content):
extract_to = tempfile.mkdtemp(prefix="omega-archive-")
try:
_, (year, month, cat) = parse_url(self.url)
fileobj = io.BytesIO(file_content)
tar = tarfile.open(fileobj=fileobj, mode="r")
logger.info("extracting %s into %s", self.url, extract_to)
tar.extractall(extract_to)
pattern = os.path.join(extract_to, "**/*.XSH?")
for file in glob.glob(pattern, recursive=True):
await self.save(file)
logger.info("%s数据导入完成", self.url)
except Exception as e:
logger.exception(e)
return self.url, f"500 导入数据{year}/{month}:{cat}失败"
try:
shutil.rmtree(extract_to)
except Exception as e:
logger.exception(e)
logger.warning("failed to remove temp dir %s", extract_to)
return self.url, f"200 成功导入{year}年{month}月的{cat}数据"
async def save(self, file: str):
try:
logger.debug("saving file %s", file)
df = pd.read_parquet(file)
code = os.path.split(file)[-1]
pipeline = cache.security.pipeline()
range_pl = cache.sys.pipeline()
for frame, (o, h, l, c, v, a, fq, frame_type) in df.iterrows():
key = f"{code}:{FrameType.from_int(frame_type).value}"
pipeline.hset(
key, frame, f"{o:.2f} {h:.2f} {l:.2f} {c:.2f} {v} {a:.2f} {fq:.2f}"
)
range_pl.lpush(f"archive.ranges.{key}", int(frame))
await pipeline.execute()
await range_pl.execute()
except Exception as e:
logger.info("导入%s失败", file)
logger.exception(e)
def parse_url(url: str):
if url.find("index.yml") != -1:
return True, (url, None, None)
return False, url.split("/")[-1].split(".")[0].split("-")
async def get_file(url: str, timeout: int = 1200, handler: FileHandler = None):
timeout = aiohttp.ClientTimeout(total=timeout)
logger.info("downloading file from %s", url)
is_index, (year, month, cat) = parse_url(url)
try:
async with aiohttp.ClientSession(timeout=timeout) as client:
async with client.get(url) as response:
if response.status == 200:
logger.info("file %s downloaded", url)
content = await response.read()
if handler is None:
return url, content
else:
return await handler.process(content)
elif response.status == 404:
if is_index:
return url, "404 未找到索引文件"
else:
return url, f"404 服务器上没有{year}年{month}月的{cat}数据"
except aiohttp.ServerTimeoutError as e:
logger.warning("downloading %s failed", url)
logger.exception(e)
if is_index:
return url, "500 下载索引文件超时"
else:
return url, f"500 {year}/{month}的{cat}数据下载超时"
except Exception as e:
logger.warning("downloading %s failed", url)
logger.exception(e)
if is_index:
return url, "500 下载索引文件失败"
else:
return url, f"500 {year}/{month}的{cat}数据下载失败"
def parse_index(text):
yaml = YAML(typ="safe")
index = yaml.load(text)
parsed = {}
for key in ["index", "stock"]:
files = index.get(key) or []
parsed[key] = {}
for file in files:
month = "".join(os.path.basename(file).split("-")[:2])
parsed[key].update({int(month): file})
return parsed
async def _load_index(url: str):
"""load and parse index.yml
Args:
url (str): [description]
Returns:
[type]: [description]
"""
try:
url, content = await get_file(url)
if content is not None:
return 200, parse_index(content)
except aiohttp.ClientConnectionError as e:
logger.exception(e)
return 500, f"无法建立与服务器{url}的连接"
except YAMLError as e:
logger.exception(e)
return 500, "无法解析索引文件"
except Exception as e:
logger.exception(e)
return 500, "未知错误"
async def get_bars(server, months: List[int], cats: List[str]) -> Tuple[int, str]:
if not server.endswith("/"):
server += "/"
status, response = await _load_index(server + f"index.yml?{random.random()}")
if status != 200:
yield status, response
yield 500, "读取索引失败,无法下载历史数据"
return
else:
yield 200, "读取索引成功"
index = response
files = []
for month in months:
for cat in cats:
file = index.get(cat, {}).get(month)
if file is None:
yield 404, f"服务器没有{month}的{cat}数据"
continue
else:
files.append(server + file)
if len(files) == 0:
yield 200, "没有可以下载的数据"
yield 200, "DONE"
return
tasks = [get_file(file, handler=ArchivedBarsHandler(file)) for file in files]
for task in asyncio.as_completed(tasks):
url, result = await task
if result is not None:
status, desc = result.split(" ")
yield int(status), desc
yield 200, "DONE"
async def get_index(server):
if not server.endswith("/"):
server += "/"
status, index = await _load_index(server + f"/index.yml?{random.random()}")
if status != 200 or (index is None):
return 500, None
return 200, {cat: list(index[cat].keys()) for cat in index.keys()}
async def clear_range():
"""clear cached secs's range before/after import archive bars"""
key = "archive.ranges.*"
keys = await cache.sys.keys(key)
if keys:
await cache.sys.delete(*keys)
async def adjust_range(batch: int = 500):
"""adjust secs's range after archive bars imported"""
cur = b"0"
key = "archive.ranges.*"
logger.info("start adjust range")
while cur:
cur, keys = await cache.sys.scan(cur, match=key, count=batch)
if not keys:
continue
pl = cache.security.pipeline()
for item in keys:
try:
values = [int(v) for v in await cache.sys.lrange(item, 0, -1)]
values.sort()
arc_head, arc_tail = values[0], values[-1]
code_frame_key = item.replace("archive.ranges.", "")
head, tail = await cache.security.hmget(code_frame_key, "head", "tail")
head = int(head) if head is not None else None
tail = int(tail) if tail is not None else None
# head, tail, arc_head, arc_tail should be all frame-aligned
if head is None or tail is None:
head, tail = arc_head, arc_tail
elif arc_tail < head or arc_head > tail:
head, tail = arc_head, arc_tail
else:
head = min(arc_head, head)
tail = max(arc_tail, tail)
pl.hset(code_frame_key, "head", head)
pl.hset(code_frame_key, "tail", tail)
except Exception as e:
logger.exception(e)
logger.warning("failed to set range for %s", code_frame_key)
await pl.execute()
async def _main(months: list, cats: list):
await omicron.init()
try:
async for status, desc in get_bars(cfg.omega.urls.archive, months, cats):
print(status, desc)
finally:
await omicron.shutdown()
def main(months: str, cats: str, archive_server: str = None):
"""允许将本模块以独立进程运行,以支持多进程
Args:
months (str): 逗号分隔的月列表。格式如202012
cats (str): 逗号分隔的类别列表,如"stock,index"
"""
config_dir = get_config_dir()
cfg = cfg4py.init(config_dir, False)
if archive_server:
cfg.omega.urls.archive = archive_server
months = str(months)
months = [int(x) for x in months.split(",") if x]
cats = [x for x in cats.split(",")]
asyncio.run(_main(months, cats))
if __name__ == "__main__":
fire.Fire({"main": main}) | zillionare-omega | /zillionare-omega-1.1.0.1.tar.gz/zillionare-omega-1.1.0.1/omega/fetcher/archive.py | archive.py |
import asyncio
import datetime
import json
import logging
import os
import signal
import subprocess
import sys
import time
from pathlib import Path
from typing import List, Optional
import aiohttp
import arrow
import cfg4py
import omicron
import psutil
import xxhash
from aiocache import cached
from aiohttp import ClientError
from dateutil import tz
from omicron import cache
from omicron.core.timeframe import tf
from omicron.core.types import FrameType
from omicron.models.securities import Securities
from omicron.models.security import Security
from pyemit import emit
from omega.config import get_config_dir
from omega.core.events import Events, ValidationError
validation_errors = []
cfg = cfg4py.get_instance()
logger = logging.getLogger(__name__)
async def calc_checksums(day: datetime.date, codes: List) -> dict:
"""
Args:
day:
codes:
Returns:
返回值为以code为键,该证券对应的{周期:checksum}的集合为值的集合
"""
end_time = arrow.get(day, tzinfo=cfg.tz).replace(hour=15)
checksums = {}
for i, code in enumerate(codes):
try:
checksum = {}
d = await cache.get_bars_raw_data(code, day, 1, FrameType.DAY)
if d:
checksum[f"{FrameType.DAY.value}"] = xxhash.xxh32_hexdigest(d)
d = await cache.get_bars_raw_data(code, end_time, 240, FrameType.MIN1)
if d:
checksum[f"{FrameType.MIN1.value}"] = xxhash.xxh32_hexdigest(d)
d = await cache.get_bars_raw_data(code, end_time, 48, FrameType.MIN5)
if d:
checksum[f"{FrameType.MIN5.value}"] = xxhash.xxh32_hexdigest(d)
d = await cache.get_bars_raw_data(code, end_time, 16, FrameType.MIN15)
if d:
checksum[f"{FrameType.MIN15.value}"] = xxhash.xxh32_hexdigest(d)
d = await cache.get_bars_raw_data(code, end_time, 8, FrameType.MIN30)
if d:
checksum[f"{FrameType.MIN30.value}"] = xxhash.xxh32_hexdigest(d)
d = await cache.get_bars_raw_data(code, end_time, 4, FrameType.MIN60)
if d:
checksum[f"{FrameType.MIN60.value}"] = xxhash.xxh32_hexdigest(d)
checksums[code] = checksum
except Exception as e:
logger.exception(e)
if (i + 1) % 500 == 0:
logger.info("calc checksum progress: %s/%s", i + 1, len(codes))
return checksums
@cached(ttl=3600)
async def get_checksum(day: int) -> Optional[List]:
save_to = (Path(cfg.omega.home) / "data/chksum").expanduser()
chksum_file = os.path.join(save_to, f"chksum-{day}.json")
try:
with open(chksum_file, "r") as f:
return json.load(f)
except (FileNotFoundError, Exception):
pass
url = cfg.omega.urls.checksum + f"/chksum-{day}.json"
async with aiohttp.ClientSession() as client:
for i in range(3):
try:
async with client.get(url) as resp:
if resp.status != 200:
logger.warning("failed to fetch checksum from %s", url)
return None
checksum = await resp.json(encoding="utf-8")
with open(chksum_file, "w+") as f:
json.dump(checksum, f, indent=2)
return checksum
except ClientError:
continue
def do_validation_process_entry():
try:
t0 = time.time()
asyncio.run(do_validation())
logger.info("validation finished in %s seconds", time.time() - t0)
return 0
except Exception as e:
logger.warning("validation exit due to exception:")
logger.exception(e)
return -1
async def do_validation(secs: List[str] = None, start: str = None, end: str = None):
"""对列表secs中指定的证券行情数据按start到end指定的时间范围进行校验
Args:
secs (List[str], optional): [description]. Defaults to None.
start (str, optional): [description]. Defaults to None.
end (str, optional): [description]. Defaults to None.
Returns:
[type]: [description]
"""
logger.info("start validation...")
report = logging.getLogger("validation_report")
cfg = cfg4py.init(get_config_dir(), False)
await emit.start(engine=emit.Engine.REDIS, dsn=cfg.redis.dsn, start_server=True)
await omicron.init()
start = int(start or await cache.sys.get("jobs.bars_validation.range.start"))
if end is None:
end = tf.date2int(arrow.now().date())
else:
end = int(end or await cache.sys.get("jobs.bars_validation.range.stop"))
if secs is None:
async def get_sec():
return await cache.sys.lpop("jobs.bars_validation.scope")
else:
async def get_sec():
return secs.pop() if len(secs) else None
errors = 0
while code := await get_sec():
try:
for day in tf.day_frames[(tf.day_frames >= start) & (tf.day_frames <= end)]:
expected = await get_checksum(day)
if expected and expected.get(code):
actual = await calc_checksums(tf.int2date(day), [code])
d1 = actual.get(code)
d2 = expected.get(code)
missing1 = d2.keys() - d1 # local has no checksum
missing2 = d1.keys() - d2 # remote has no checksum
mismatch = {k for k in d1.keys() & d2 if d1[k] != d2[k]}
for k in missing1:
info = (
ValidationError.LOCAL_MISS,
day,
code,
k,
d1.get(k),
d2.get(k),
)
report.info("%s,%s,%s,%s,%s,%s", *info)
await emit.emit(Events.OMEGA_VALIDATION_ERROR, info)
for k in missing2:
info = (
ValidationError.REMOTE_MISS,
day,
code,
k,
d1.get(k),
d2.get(k),
)
report.info("%s,%s,%s,%s,%s,%s", *info)
await emit.emit(Events.OMEGA_VALIDATION_ERROR, info)
for k in mismatch:
info = (
ValidationError.MISMATCH,
day,
code,
k,
d1.get(k),
d2.get(k),
)
report.info("%s,%s,%s,%s,%s,%s", *info)
await emit.emit(Events.OMEGA_VALIDATION_ERROR, info)
else:
logger.error("checksum for %s not found.", day)
info = (ValidationError.NO_CHECKSUM, day, None, None, None, None)
report.info("%s,%s,%s,%s,%s,%s", *info)
await emit.emit(Events.OMEGA_VALIDATION_ERROR, info)
except Exception as e:
logger.exception(e)
errors += 1
await emit.emit(Events.OMEGA_VALIDATION_ERROR, (ValidationError.UNKNOWN, errors))
logger.warning("do_validation meet %s unknown errors", errors)
async def on_validation_error(report: tuple):
"""
Args:
report: object like ::(reason, day, code, frame, local, remote)
Returns:
"""
global validation_errors, no_validation_error_days
# todo: raise no checksum issue
if report[0] == ValidationError.UNKNOWN:
no_validation_error_days = set()
else:
validation_errors.append(report)
if report[1] is not None:
no_validation_error_days -= {report[1]}
async def start_validation():
"""
将待校验的证券按CPU个数均匀划分,创建与CPU个数相同的子进程来执行校验。校验的起始时间由数据
库中jobs.bars_validation.range.start和jobs.bars_validation.range.stop来决定,每次校验
结束后,将jobs.bars_validation.range.start更新为校验截止的最后交易日。如果各个子进程报告
的截止交易日不一样(比如发生了异常),则使用最小的交易日。
"""
global validation_errors, no_validation_error_days
validation_errors = []
secs = Securities()
cpu_count = psutil.cpu_count()
# to check if the range is right
pl = cache.sys.pipeline()
pl.get("jobs.bars_validation.range.start")
pl.get("jobs.bars_validation.range.end")
start, end = await pl.execute()
if start is None:
if cfg.omega.validation.start is None:
logger.warning("start of validation is not specified, validation aborted.")
return
else:
start = tf.date2int(arrow.get(cfg.omega.validation.start))
else:
start = int(start)
if end is None:
end = tf.date2int(tf.floor(arrow.now().date(), FrameType.DAY))
else:
end = int(end)
assert start <= end
no_validation_error_days = set(
tf.day_frames[(tf.day_frames >= start) & (tf.day_frames <= end)]
)
# fixme: do validation per frame_type
# fixme: test fail. Rewrite this before 0.6 releases
codes = secs.choose(cfg.omega.sync)
await cache.sys.delete("jobs.bars_validation.scope")
await cache.sys.lpush("jobs.bars_validation.scope", *codes)
logger.info("start validation %s secs from %s to %s.", len(codes), start, end)
emit.register(Events.OMEGA_VALIDATION_ERROR, on_validation_error)
t0 = time.time()
code = (
"from omega.core.sanity import do_validation_process_entry; "
"do_validation_process_entry()"
)
procs = []
for i in range(cpu_count):
proc = subprocess.Popen([sys.executable, "-c", code], env=os.environ)
procs.append(proc)
timeout = 3600
while timeout > 0:
await asyncio.sleep(2)
timeout -= 2
for proc in procs:
proc.poll()
if all([proc.returncode is not None for proc in procs]):
break
if timeout <= 0:
for proc in procs:
try:
os.kill(proc.pid, signal.SIGTERM)
except Exception:
pass
# set next start point
validation_days = set(
tf.day_frames[(tf.day_frames >= start) & (tf.day_frames <= end)]
)
diff = validation_days - no_validation_error_days
if len(diff):
last_no_error_day = min(diff)
else:
last_no_error_day = end
await cache.sys.set("jobs.bars_validation.range.start", last_no_error_day)
elapsed = time.time() - t0
logger.info(
"Validation cost %s seconds, validation will start at %s next time",
elapsed,
last_no_error_day,
)
async def quick_scan():
# fixme
secs = Securities()
report = logging.getLogger("quickscan")
counters = {}
for sync_config in cfg.omega.sync.bars:
frame = sync_config.get("frame")
start = sync_config.get("start")
if frame is None or start is None:
logger.warning(
"skipped %s: required fields are [frame, start]", sync_config
)
continue
frame_type = FrameType(frame)
start = arrow.get(start).date()
start = tf.floor(start, FrameType.DAY)
stop = sync_config.get("stop") or arrow.now().date()
if frame_type in tf.minute_level_frames:
minutes = tf.ticks[frame_type][0]
h, m = minutes // 60, minutes % 60
start = datetime.datetime(
start.year, start.month, start.day, h, m, tzinfo=tz.gettz(cfg.tz)
)
stop = datetime.datetime(
stop.year, stop.month, stop.day, 15, tzinfo=tz.gettz(cfg.tz)
)
counters[frame] = [0, 0]
codes = secs.choose(sync_config.get("type"))
include = filter(lambda x: x, sync_config.get("include", "").split(","))
include = map(lambda x: x.strip(" "), include)
codes.extend(include)
exclude = sync_config.get("exclude", "")
exclude = map(lambda x: x.strip(" "), exclude)
codes = set(codes) - set(exclude)
counters[frame][1] = len(codes)
for code in codes:
head, tail = await cache.get_bars_range(code, frame_type)
if head is None or tail is None:
report.info("ENOSYNC,%s,%s", code, frame)
counters[frame][0] = counters[frame][0] + 1
continue
expected = tf.count_frames(head, tail, frame_type)
# 'head', 'tail' should be excluded
actual = (await cache.security.hlen(f"{code}:{frame_type.value}")) - 2
if actual != expected:
report.info(
"ELEN,%s,%s,%s,%s,%s,%s", code, frame, expected, actual, head, tail
)
counters[frame][0] = counters[frame][0] + 1
continue
sec = Security(code)
if start != head:
if (
type(start) == datetime.date
and start > sec.ipo_date
or (
type(start) == datetime.datetime and start.date() > sec.ipo_date
)
):
report.info(
"ESTART,%s,%s,%s,%s,%s", code, frame, start, head, sec.ipo_date
)
counters[frame][0] = counters[frame][0] + 1
continue
if tail != stop:
report.info("EEND,%s,%s,%s,%s", code, frame, stop, tail)
counters[frame][0] = counters[frame][0] + 1
return counters | zillionare-omega | /zillionare-omega-1.1.0.1.tar.gz/zillionare-omega-1.1.0.1/omega/core/sanity.py | sanity.py |

<h1 align="center">Omicron - Core Library for Zillionare</h1>
[](https://pypi.python.org/pypi/zillionare-omicron)
[](https://github.com/zillionare/omicron)
[](https://app.codecov.io/gh/zillionare/omicron)
<<<<<<< HEAD
=======
[](https://omicron.readthedocs.io/en/latest/?badge=latest)
>>>>>>> master
[](https://pepy.tech/project/zillionare-omicron)
[](https://opensource.org/licenses/MIT)
[](https://github.com/psf/black)
# Contents
## 简介
Omicron是Zillionare的核心公共模块,向其它模块提供行情数据、交易日历、证券列表、时间操作及Trigger等功能。
Omicron是大富翁量化框架的一部分。您必须至少安装并运行[Omega](https://zillionare.github.io/omega),然后才能利用omicron来访问上述数据。
[使用文档](https://zillionare.github.io/omicron)
## Credits
<<<<<<< HEAD
Zillionare-Omicron采用[Python Project Wizard](https://zillionare.github.io/python-project-wizard)构建。
=======
* [Cookiecutter](https://github.com/audreyr/cookiecutter)
* [Cookiecutter-pypackage](https://github.com/zillionare/cookiecutter-pypackage)
*  [Pycharm开源项目支持计划](https://www.jetbrains.com/?from=zillionare-omega)
>>>>>>> master
| zillionare-omicron | /zillionare_omicron-2.0.0a59-py3-none-any.whl/README.md | README.md |
# History
## 2.0.0-alpha.49 (2022-09-16)
* 修订了安装文档。
* 移除了windows下对ta-lib的依赖。请参考[安装指南](docs/installation.md)以获取在windows下安装ta-lib的方法。
* 更新了poetry.lock文件。在上一版中,该文件与pyproject.toml不同步,导致安装时进行版本锁定,延长了安装时间。
* 修复了k线图标记顶和底时,标记离被标注的点太远的问题。
## 2.0.0-alpha.46 (2022-09-10)
* [#40](https://github.com/zillionare/omicron/issues/40) 增加k线图绘制功能。
* 本次修订增加了对plotly, ckwrap, ta-lib的依赖。
* 将原属于omicron.talib包中的bars_since, find_runs等跟数组相关的操作,移入omicron.extensions.np中。
## 2.0.0-alpha.45 (2022-09-08)
* [#39](https://github.com/zillionare/omicron/issues/39) fixed.
* removed dependency of postgres
* removed funds
* update arrow's version to be great than 1.2
* lock aiohttp's version to >3.8, <4.0>
## 2.0.0-alpha.35 (2022-07-13)
* fix issue in security exit date comparison, Security.eval().
## 2.0.0-alpha.34 (2022-07-13)
* change to sync call for Security.select()
* date parameter of Security.select(): if date >= today, it will use the data in cache, otherwise, query from database.
## 0.3.1 (2020-12-11)
this version introduced no features, just a internal amendment release, we're migrating to poetry build system.
## 0.3.0 (2020-11-22)
* Calendar, Triggers and time frame calculation
* Security list
* Bars with turnover
* Valuation
## 0.1.0 (2020-04-28)
* First release on PyPI.
| zillionare-omicron | /zillionare_omicron-2.0.0a59-py3-none-any.whl/HISTORY.md | HISTORY.md |
from __future__ import annotations
import datetime
import math
from itertools import compress
from typing import List, Sequence, Tuple, Union
import numpy as np
from deprecation import deprecated
from numpy.lib.stride_tricks import sliding_window_view
from numpy.typing import ArrayLike
from pandas import DataFrame
import omicron.extensions.decimals as decimals
def dict_to_numpy_array(d: dict, dtype: List[Tuple]) -> np.array:
"""convert dictionary to numpy array
Examples:
>>> d = {"aaron": 5, "jack": 6}
>>> dtype = [("name", "S8"), ("score", "<i4")]
>>> dict_to_numpy_array(d, dtype)
array([(b'aaron', 5), (b'jack', 6)],
dtype=[('name', 'S8'), ('score', '<i4')])
Args:
d (dict): [description]
dtype (List[Tuple]): [description]
Returns:
np.array: [description]
"""
return np.fromiter(d.items(), dtype=dtype, count=len(d))
def dataframe_to_structured_array(
df: DataFrame, dtypes: List[Tuple] = None
) -> ArrayLike:
"""convert dataframe (with all columns, and index possibly) to numpy structured arrays
`len(dtypes)` should be either equal to `len(df.columns)` or `len(df.columns) + 1`. In the later case, it implies to include `df.index` into converted array.
Args:
df: the one needs to be converted
dtypes: Defaults to None. If it's `None`, then dtypes of `df` is used, in such case, the `index` of `df` will not be converted.
Returns:
ArrayLike: [description]
"""
v = df
if dtypes is not None:
dtypes_in_dict = {key: value for key, value in dtypes}
col_len = len(df.columns)
if len(dtypes) == col_len + 1:
v = df.reset_index()
rename_index_to = set(dtypes_in_dict.keys()).difference(set(df.columns))
v.rename(columns={"index": list(rename_index_to)[0]}, inplace=True)
elif col_len != len(dtypes):
raise ValueError(
f"length of dtypes should be either {col_len} or {col_len + 1}, is {len(dtypes)}"
)
# re-arrange order of dtypes, in order to align with df.columns
dtypes = []
for name in v.columns:
dtypes.append((name, dtypes_in_dict[name]))
else:
dtypes = df.dtypes
return np.array(np.rec.fromrecords(v.values), dtype=dtypes)
def numpy_array_to_dict(arr: np.array, key: str, value: str) -> dict:
return {item[key]: item[value] for item in arr}
def count_between(arr, start, end):
"""计算数组中,`start`元素与`end`元素之间共有多少个元素
要求arr必须是已排序。计算结果会包含区间边界点。
Examples:
>>> arr = [20050104, 20050105, 20050106, 20050107, 20050110, 20050111]
>>> count_between(arr, 20050104, 20050111)
6
>>> count_between(arr, 20050104, 20050109)
4
"""
pos_start = np.searchsorted(arr, start, side="right")
pos_end = np.searchsorted(arr, end, side="right")
counter = pos_end - pos_start + 1
if start < arr[0]:
counter -= 1
if end > arr[-1]:
counter -= 1
return counter
def shift(arr, start, offset):
"""在numpy数组arr中,找到start(或者最接近的一个),取offset对应的元素。
要求`arr`已排序。`offset`为正,表明向后移位;`offset`为负,表明向前移位
Examples:
>>> arr = [20050104, 20050105, 20050106, 20050107, 20050110, 20050111]
>>> shift(arr, 20050104, 1)
20050105
>>> shift(arr, 20050105, -1)
20050104
>>> # 起始点已右越界,且向右shift,返回起始点
>>> shift(arr, 20050120, 1)
20050120
Args:
arr : 已排序的数组
start : numpy可接受的数据类型
offset (int): [description]
Returns:
移位后得到的元素值
"""
pos = np.searchsorted(arr, start, side="right")
if pos + offset - 1 >= len(arr):
return start
else:
return arr[pos + offset - 1]
def floor(arr, item):
"""
在数据arr中,找到小于等于item的那一个值。如果item小于所有arr元素的值,返回arr[0];如果item
大于所有arr元素的值,返回arr[-1]
与`minute_frames_floor`不同的是,本函数不做回绕与进位.
Examples:
>>> a = [3, 6, 9]
>>> floor(a, -1)
3
>>> floor(a, 9)
9
>>> floor(a, 10)
9
>>> floor(a, 4)
3
>>> floor(a,10)
9
Args:
arr:
item:
Returns:
"""
if item < arr[0]:
return arr[0]
index = np.searchsorted(arr, item, side="right")
return arr[index - 1]
def join_by_left(key, r1, r2, mask=True):
"""左连接 `r1`, `r2` by `key`
如果`r1`中存在`r2`中没有的行,则该行对应的`r2`中的那些字段将被mask,或者填充随机数。
same as numpy.lib.recfunctions.join_by(key, r1, r2, jointype='leftouter'), but allows r1 have duplicate keys
[Reference: stackoverflow](https://stackoverflow.com/a/53261882/13395693)
Examples:
>>> # to join the following
>>> # [[ 1, 2],
>>> # [ 1, 3], x [[1, 5],
>>> # [ 2, 3]] [4, 7]]
>>> # only first two rows in left will be joined
>>> r1 = np.array([(1, 2), (1,3), (2,3)], dtype=[('seq', 'i4'), ('score', 'i4')])
>>> r2 = np.array([(1, 5), (4,7)], dtype=[('seq', 'i4'), ('age', 'i4')])
>>> joined = join_by_left('seq', r1, r2)
>>> print(joined)
[(1, 2, 5) (1, 3, 5) (2, 3, --)]
>>> print(joined.dtype)
(numpy.record, [('seq', '<i4'), ('score', '<i4'), ('age', '<i4')])
>>> joined[2][2]
masked
>>> joined.tolist()[2][2] == None
True
Args:
key : join关键字
r1 : 数据集1
r2 : 数据集2
Returns:
a numpy array
"""
# figure out the dtype of the result array
descr1 = r1.dtype.descr
descr2 = [d for d in r2.dtype.descr if d[0] not in r1.dtype.names]
descrm = descr1 + descr2
# figure out the fields we'll need from each array
f1 = [d[0] for d in descr1]
f2 = [d[0] for d in descr2]
# cache the number of columns in f1
ncol1 = len(f1)
# get a dict of the rows of r2 grouped by key
rows2 = {}
for row2 in r2:
rows2.setdefault(row2[key], []).append(row2)
# figure out how many rows will be in the result
nrowm = 0
for k1 in r1[key]:
if k1 in rows2:
nrowm += len(rows2[k1])
else:
nrowm += 1
# allocate the return array
# ret = np.full((nrowm, ), fill, dtype=descrm)
_ret = np.recarray(nrowm, dtype=descrm)
if mask:
ret = np.ma.array(_ret, mask=True)
else:
ret = _ret
# merge the data into the return array
i = 0
for row1 in r1:
if row1[key] in rows2:
for row2 in rows2[row1[key]]:
ret[i] = tuple(row1[f1]) + tuple(row2[f2])
i += 1
else:
for j in range(ncol1):
ret[i][j] = row1[j]
i += 1
return ret
def numpy_append_fields(
base: np.ndarray, names: Union[str, List[str]], data: List, dtypes: List
) -> np.ndarray:
"""给现有的数组`base`增加新的字段
实现了`numpy.lib.recfunctions.rec_append_fields`的功能。提供这个功能,是因为`rec_append_fields`不能处理`data`元素的类型为Object的情况。
新增的数据列将顺序排列在其它列的右边。
Example:
>>> # 新增单个字段
>>> import numpy
>>> old = np.array([i for i in range(3)], dtype=[('col1', '<f4')])
>>> new_list = [2 * i for i in range(3)]
>>> res = numpy_append_fields(old, 'new_col', new_list, [('new_col', '<f4')])
>>> print(res)
... # doctest: +NORMALIZE_WHITESPACE
[(0., 0.) (1., 2.) (2., 4.)]
>>> # 新增多个字段
>>> data = [res['col1'].tolist(), res['new_col'].tolist()]
>>> print(numpy_append_fields(old, ('col3', 'col4'), data, [('col3', '<f4'), ('col4', '<f4')]))
... # doctest: +NORMALIZE_WHITESPACE
[(0., 0., 0.) (1., 1., 2.) (2., 2., 4.)]
Args:
base ([numpy.array]): 基础数组
names ([type]): 新增字段的名字,可以是字符串(单字段的情况),也可以是字符串列表
data (list): 增加的字段的数据,list类型
dtypes ([type]): 新增字段的dtype
"""
if isinstance(names, str):
names = [names]
data = [data]
result = np.empty(base.shape, dtype=base.dtype.descr + dtypes)
for col in base.dtype.names:
result[col] = base[col]
for i in range(len(names)):
result[names[i]] = data[i]
return result
def remove_nan(ts: np.ndarray) -> np.ndarray:
"""从`ts`中去除NaN
Args:
ts (np.array): [description]
Returns:
np.array: [description]
"""
return ts[~np.isnan(ts.astype(float))]
def fill_nan(ts: np.ndarray):
"""将ts中的NaN替换为其前值
如果ts起头的元素为NaN,则用第一个非NaN元素替换。
如果所有元素都为NaN,则无法替换。
Example:
>>> arr = np.arange(6, dtype=np.float32)
>>> arr[3:5] = np.NaN
>>> fill_nan(arr)
... # doctest: +NORMALIZE_WHITESPACE
array([0., 1., 2., 2., 2., 5.], dtype=float32)
>>> arr = np.arange(6, dtype=np.float32)
>>> arr[0:2] = np.nan
>>> fill_nan(arr)
... # doctest: +NORMALIZE_WHITESPACE
array([2., 2., 2., 3., 4., 5.], dtype=float32)
Args:
ts (np.array): [description]
"""
if np.all(np.isnan(ts)):
raise ValueError("all of ts are NaN")
if ts[0] is None or math.isnan(ts[0]):
idx = np.argwhere(~np.isnan(ts))[0]
ts[0] = ts[idx]
mask = np.isnan(ts)
idx = np.where(~mask, np.arange(mask.size), 0)
np.maximum.accumulate(idx, out=idx)
return ts[idx]
def replace_zero(ts: np.ndarray, replacement=None) -> np.ndarray:
"""将ts中的0替换为前值, 处理volume数据时常用用到
如果提供了replacement, 则替换为replacement
"""
if replacement is not None:
return np.where(ts == 0, replacement, ts)
if np.all(ts == 0):
raise ValueError("all of ts are 0")
if ts[0] == 0:
idx = np.argwhere(ts != 0)[0]
ts[0] = ts[idx]
mask = ts == 0
idx = np.where(~mask, np.arange(mask.size), 0)
np.maximum.accumulate(idx, out=idx)
return ts[idx]
def rolling(x, win, func):
"""对序列`x`进行窗口滑动计算。
如果`func`要实现的功能是argmax, argmin, max, mean, median, min, rank, std, sum, var等,move_argmax,请使用bottleneck中的move_argmin, move_max, move_mean, move_median, move_min move_rank, move_std, move_sum, move_var。这些函数的性能更好。
Args:
x ([type]): [description]
win ([type]): [description]
func ([type]): [description]
Returns:
[type]: [description]
"""
results = []
for subarray in sliding_window_view(x, window_shape=win):
results.append(func(subarray))
return np.array(results)
def bin_cut(arr: list, n: int):
"""将数组arr切分成n份
todo: use padding + reshape to boost performance
Args:
arr ([type]): [description]
n ([type]): [description]
Returns:
[type]: [description]
"""
result = [[] for i in range(n)]
for i, e in enumerate(arr):
result[i % n].append(e)
return [e for e in result if len(e)]
def array_math_round(arr: Union[float, ArrayLike], digits: int) -> np.ndarray:
"""将一维数组arr的数据进行四舍五入
numpy.around的函数并不是数学上的四舍五入,对1.5和2.5进行round的结果都会变成2,在金融领域计算中,我们必须使用数学意义上的四舍五入。
Args:
arr (ArrayLike): 输入数组
digits (int):
Returns:
np.ndarray: 四舍五入后的一维数组
"""
# 如果是单个元素,则直接返回
if isinstance(arr, float):
return decimals.math_round(arr, digits)
f = np.vectorize(lambda x: decimals.math_round(x, digits))
return f(arr)
def array_price_equal(price1: ArrayLike, price2: ArrayLike) -> np.ndarray:
"""判断两个价格数组是否相等
Args:
price1 (ArrayLike): 价格数组
price2 (ArrayLike): 价格数组
Returns:
np.ndarray: 判断结果
"""
price1 = array_math_round(price1, 2)
price2 = array_math_round(price2, 2)
return abs(price1 - price2) < 1e-2
@deprecated("2.0.0", details="use `tm.item()` instead")
def to_pydatetime(tm: np.datetime64) -> datetime.datetime:
"""将numpy.datetime64对象转换成为python的datetime对象
numpy.ndarray.item()方法可用以将任何numpy对象转换成python对象,推荐在任何适用的地方使用.item()方法,而不是本方法。示例:
```
arr = np.array(['2022-09-08', '2022-09-09'], dtype='datetime64[s]')
arr.item(0) # output is datetime.datetime(2022, 9, 8, 0, 0)
arr[1].item() # output is datetime.datetime(2022, 9, 9, 0, 0)
```
Args:
tm : the input numpy datetime object
Returns:
python datetime object
"""
unix_epoch = np.datetime64(0, "s")
one_second = np.timedelta64(1, "s")
seconds_since_epoch = (tm - unix_epoch) / one_second
return datetime.datetime.utcfromtimestamp(seconds_since_epoch)
def bars_since(condition: Sequence[bool], default=None) -> int:
"""
Return the number of bars since `condition` sequence was last `True`,
or if never, return `default`.
>>> condition = [True, True, False]
>>> bars_since(condition)
1
"""
return next(compress(range(len(condition)), reversed(condition)), default)
def find_runs(x: ArrayLike) -> Tuple[np.ndarray, np.ndarray, np.ndarray]:
"""Find runs of consecutive items in an array.
Args:
x: the sequence to find runs in
Returns:
A tuple of unique values, start indices, and length of runs
"""
# ensure array
x = np.asanyarray(x)
if x.ndim != 1:
raise ValueError("only 1D array supported")
n = x.shape[0]
# handle empty array
if n == 0:
return np.array([]), np.array([]), np.array([])
else:
# find run starts
loc_run_start = np.empty(n, dtype=bool)
loc_run_start[0] = True
np.not_equal(x[:-1], x[1:], out=loc_run_start[1:])
run_starts = np.nonzero(loc_run_start)[0]
# find run values
run_values = x[loc_run_start]
# find run lengths
run_lengths = np.diff(np.append(run_starts, n))
return run_values, run_starts, run_lengths
def top_n_argpos(ts: np.array, n: int) -> np.array:
"""get top n (max->min) elements and return argpos which its value ordered in descent
Example:
>>> top_n_argpos([np.nan, 4, 3, 9, 8, 5, 2, 1, 0, 6, 7], 2)
array([3, 4])
Args:
ts (np.array): [description]
n (int): [description]
Returns:
np.array: [description]
"""
ts_ = np.copy(ts)
ts_[np.isnan(ts_)] = -np.inf
return np.argsort(ts_)[-n:][::-1]
def smallest_n_argpos(ts: np.array, n: int) -> np.array:
"""get smallest n (min->max) elements and return argpos which its value ordered in ascent
Example:
>>> smallest_n_argpos([np.nan, 4, 3, 9, 8, 5, 2, 1, 0, 6, 7], 2)
array([8, 7])
Args:
ts (np.array): 输入的数组
n (int): 取最小的n个元素
Returns:
np.array: [description]
"""
return np.argsort(ts)[:n] | zillionare-omicron | /zillionare_omicron-2.0.0a59-py3-none-any.whl/omicron/extensions/np.py | np.py |
import datetime
import logging
import re
from typing import Dict, List, Tuple
import arrow
import cfg4py
import numpy as np
from coretypes import SecurityType, security_info_dtype
from numpy.typing import NDArray
from omicron.core.errors import DataNotReadyError
from omicron.dal import cache
from omicron.dal.influx.flux import Flux
from omicron.dal.influx.serialize import DataframeDeserializer
from omicron.models import get_influx_client
from omicron.models.timeframe import TimeFrame as tf
from omicron.notify.dingtalk import ding
logger = logging.getLogger(__name__)
cfg = cfg4py.get_instance()
security_db_dtype = [("frame", "O"), ("code", "U16"), ("info", "O")]
xrxd_info_dtype = [
("code", "O"),
("a_xr_date", "datetime64[s]"),
("bonusnote1", "O"),
("bonus_ratio", "<f4"),
("dividend_ratio", "<f4"),
("transfer_ratio", "<f4"),
("at_bonus_ratio", "<f4"),
("report_date", "datetime64[s]"),
("plan_progress", "O"),
("bonusnote2", "O"),
("bonus_cancel_pub_date", "datetime64[s]"),
]
_delta = np.timedelta64(1, "s")
_start = np.datetime64("1970-01-01 00:00:00")
def convert_nptime_to_datetime(x):
# force using CST timezone
ts = (x - _start) / _delta
# tz=datetime.timezone.utc --> UTC string
_t = datetime.datetime.fromtimestamp(ts, tz=datetime.timezone.utc)
return datetime.datetime(_t.year, _t.month, _t.day, _t.hour, _t.minute, _t.second)
class Query:
"""
["code", "alias(display_name)", "name", "ipo", "end", "type"]
"""
def __init__(self, target_date: datetime.date = None):
if target_date is None:
# 聚宽不一定会及时更新数据,因此db中不存放当天的数据,如果传空,查cache
self.target_date = None
else:
# 如果是交易日,取当天,否则取前一天
self.target_date = tf.day_shift(target_date, 0)
# 名字,显示名,类型过滤器
self._name_pattern = None # 字母名字
self._alias_pattern = None # 显示名
self._type_pattern = None # 不指定则默认为全部,如果传入空值则只选择股票和指数
# 开关选项
self._exclude_kcb = False # 科创板
self._exclude_cyb = False # 创业板
self._exclude_st = False # ST
self._include_exit = False # 是否包含已退市证券(默认不包括当天退市的)
# 下列开关优先级高于上面的
self._only_kcb = False
self._only_cyb = False
self._only_st = False
def only_cyb(self) -> "Query":
"""返回结果中只包含创业板股票"""
self._only_cyb = True # 高优先级
self._exclude_cyb = False
self._only_kcb = False
self._only_st = False
return self
def only_st(self) -> "Query":
"""返回结果中只包含ST类型的证券"""
self._only_st = True # 高优先级
self._exclude_st = False
self._only_kcb = False
self._only_cyb = False
return self
def only_kcb(self) -> "Query":
"""返回结果中只包含科创板股票"""
self._only_kcb = True # 高优先级
self._exclude_kcb = False
self._only_cyb = False
self._only_st = False
return self
def exclude_st(self) -> "Query":
"""从返回结果中排除ST类型的股票"""
self._exclude_st = True
self._only_st = False
return self
def exclude_cyb(self) -> "Query":
"""从返回结果中排除创业板类型的股票"""
self._exclude_cyb = True
self._only_cyb = False
return self
def exclude_kcb(self) -> "Query":
"""从返回结果中排除科创板类型的股票"""
self._exclude_kcb = True
self._only_kcb = False
return self
def include_exit(self) -> "Query":
"""从返回结果中包含已退市的证券"""
self._include_exit = True
return self
def types(self, types: List[str]) -> "Query":
"""选择类型在`types`中的证券品种
Args:
types: 有效的类型包括: 对股票指数而言是('index', 'stock'),对基金而言则是('etf', 'fjb', 'mmf', 'reits', 'fja', 'fjm', 'lof')
"""
if types is None or isinstance(types, List) is False:
return self
if len(types) == 0:
self._type_pattern = ["index", "stock"]
else:
tmp = set(types)
self._type_pattern = list(tmp)
return self
def name_like(self, name: str) -> "Query":
"""查找股票/证券名称中出现`name`的品种
注意这里的证券名称并不是其显示名。比如对中国平安000001.XSHE来说,它的名称是ZGPA,而不是“中国平安”。
Args:
name: 待查找的名字,比如"ZGPA"
"""
if name is None or len(name) == 0:
self._name_pattern = None
else:
self._name_pattern = name
return self
def alias_like(self, display_name: str) -> "Query":
"""查找股票/证券显示名中出现`display_name的品种
Args:
display_name: 显示名,比如“中国平安"
"""
if display_name is None or len(display_name) == 0:
self._alias_pattern = None
else:
self._alias_pattern = display_name
return self
async def eval(self) -> List[str]:
"""对查询结果进行求值,返回code列表
Returns:
代码列表
"""
logger.debug("eval, date: %s", self.target_date)
logger.debug(
"eval, names and types: %s, %s, %s",
self._name_pattern,
self._alias_pattern,
self._type_pattern,
)
logger.debug(
"eval, exclude and include: %s, %s, %s, %s",
self._exclude_cyb,
self._exclude_st,
self._exclude_kcb,
self._include_exit,
)
logger.debug(
"eval, only: %s, %s, %s ", self._only_cyb, self._only_st, self._only_kcb
)
date_in_cache = await cache.security.get("security:latest_date")
if date_in_cache: # 无此数据说明omega有某些问题,不处理
_date = arrow.get(date_in_cache).date()
else:
now = datetime.datetime.now()
_date = tf.day_shift(now, 0)
# 确定数据源,cache为当天8点之后获取的数据,数据库存放前一日和更早的数据
if not self.target_date or self.target_date >= _date:
self.target_date = _date
records = None
if self.target_date == _date: # 从内存中查找,如果缓存中的数据已更新,重新加载到内存
secs = await cache.security.lrange("security:all", 0, -1)
if len(secs) != 0:
# using np.datetime64[s]
records = np.array(
[tuple(x.split(",")) for x in secs], dtype=security_info_dtype
)
else:
records = await Security.load_securities_from_db(self.target_date)
if records is None:
return None
results = []
for record in records:
if self._type_pattern is not None:
if record["type"] not in self._type_pattern:
continue
if self._name_pattern is not None:
if record["name"].find(self._name_pattern) == -1:
continue
if self._alias_pattern is not None:
if record["alias"].find(self._alias_pattern) == -1:
continue
# 创业板,科创板,ST暂时限定为股票类型
if self._only_cyb:
if (
record["type"] != "stock"
or record["code"].startswith("300") is False
):
continue
if self._only_kcb:
if (
record["type"] != "stock"
or record["code"].startswith("688") is False
):
continue
if self._only_st:
if record["type"] != "stock" or record["alias"].find("ST") == -1:
continue
if self._exclude_cyb:
if record["type"] == "stock" and record["code"].startswith("300"):
continue
if self._exclude_st:
if record["type"] == "stock" and record["alias"].find("ST") != -1:
continue
if self._exclude_kcb:
if record["type"] == "stock" and record["code"].startswith("688"):
continue
# 退市暂不限定是否为股票
if self._include_exit is False:
d1 = convert_nptime_to_datetime(record["end"]).date()
if d1 < self.target_date:
continue
results.append(record["code"])
# 返回所有查询到的结果
return results
class Security:
_securities = []
_securities_date = None
_security_types = set()
_stocks = []
@classmethod
async def init(cls):
"""初始化Security.
一般而言,omicron的使用者无须调用此方法,它会在omicron初始化(通过`omicron.init`)时,被自动调用。
Raises:
DataNotReadyError: 如果omicron未初始化,或者cache中未加载最新证券列表,则抛出此异常。
"""
# read all securities from redis, 7111 records now
# {'index', 'stock'}
# {'fjb', 'mmf', 'reits', 'fja', 'fjm'}
# {'etf', 'lof'}
if len(cls._securities) > 100:
return True
secs = await cls.load_securities()
if secs is None or len(secs) == 0: # pragma: no cover
raise DataNotReadyError(
"No securities in cache, make sure you have called omicron.init() first."
)
print("init securities done")
return True
@classmethod
async def load_securities(cls):
"""加载所有证券的信息,并缓存到内存中
一般而言,omicron的使用者无须调用此方法,它会在omicron初始化(通过`omicron.init`)时,被自动调用。
"""
secs = await cache.security.lrange("security:all", 0, -1)
if len(secs) != 0:
# using np.datetime64[s]
_securities = np.array(
[tuple(x.split(",")) for x in secs], dtype=security_info_dtype
)
# 更新证券类型列表
cls._securities = _securities
cls._security_types = set(_securities["type"])
cls._stocks = _securities[
(_securities["type"] == "stock") | (_securities["type"] == "index")
]
logger.info(
"%d securities loaded, types: %s", len(_securities), cls._security_types
)
date_in_cache = await cache.security.get("security:latest_date")
if date_in_cache is not None:
cls._securities_date = arrow.get(date_in_cache).date()
else:
cls._securities_date = datetime.date.today()
return _securities
else: # pragma: no cover
return None
@classmethod
async def get_security_types(cls):
if cls._security_types:
return list(cls._security_types)
else:
return None
@classmethod
def get_stock(cls, code) -> NDArray[security_info_dtype]:
"""根据`code`来查找对应的股票(含指数)对象信息。
如果您只有股票代码,想知道该代码对应的股票名称、别名(显示名)、上市日期等信息,就可以使用此方法来获取相关信息。
返回类型为`security_info_dtype`的numpy数组,但仅包含一个元素。您可以象字典一样存取它,比如
```python
item = Security.get_stock("000001.XSHE")
print(item["alias"])
```
显示为"平安银行"
Args:
code: 待查询的股票/指数代码
Returns:
类型为`security_info_dtype`的numpy数组,但仅包含一个元素
"""
if len(cls._securities) == 0:
return None
tmp = cls._securities[cls._securities["code"] == code]
if len(tmp) > 0:
if tmp["type"] in ["stock", "index"]:
return tmp[0]
return None
@classmethod
def fuzzy_match_ex(cls, query: str) -> Dict[str, Tuple]:
# fixme: 此方法与Stock.fuzzy_match重复,并且进行了类型限制,使得其不适合放在Security里,以及作为一个通用方法
query = query.upper()
if re.match(r"\d+", query):
return {
sec["code"]: sec.tolist()
for sec in cls._securities
if sec["code"].find(query) != -1 and sec["type"] == "stock"
}
elif re.match(r"[A-Z]+", query):
return {
sec["code"]: sec.tolist()
for sec in cls._securities
if sec["name"].startswith(query) and sec["type"] == "stock"
}
else:
return {
sec["code"]: sec.tolist()
for sec in cls._securities
if sec["alias"].find(query) != -1 and sec["type"] == "stock"
}
@classmethod
async def info(cls, code, date=None):
_obj = await cls.query_security_via_date(code, date)
if _obj is None:
return None
# "_time", "code", "type", "alias", "end", "ipo", "name"
d1 = convert_nptime_to_datetime(_obj["ipo"]).date()
d2 = convert_nptime_to_datetime(_obj["end"]).date()
return {
"type": _obj["type"],
"display_name": _obj["alias"],
"alias": _obj["alias"],
"end": d2,
"start": d1,
"name": _obj["name"],
}
@classmethod
async def name(cls, code, date=None):
_security = await cls.query_security_via_date(code, date)
if _security is None:
return None
return _security["name"]
@classmethod
async def alias(cls, code, date=None):
return await cls.display_name(code, date)
@classmethod
async def display_name(cls, code, date=None):
_security = await cls.query_security_via_date(code, date)
if _security is None:
return None
return _security["alias"]
@classmethod
async def start_date(cls, code, date=None):
_security = await cls.query_security_via_date(code, date)
if _security is None:
return None
return convert_nptime_to_datetime(_security["ipo"]).date()
@classmethod
async def end_date(cls, code, date=None):
_security = await cls.query_security_via_date(code, date)
if _security is None:
return None
return convert_nptime_to_datetime(_security["end"]).date()
@classmethod
async def security_type(cls, code, date=None) -> SecurityType:
_security = await cls.query_security_via_date(code, date)
if _security is None:
return None
return _security["type"]
@classmethod
async def query_security_via_date(cls, code: str, date: datetime.date = None):
if date is None: # 从内存中查找,如果缓存中的数据已更新,重新加载到内存
date_in_cache = await cache.security.get("security:latest_date")
if date_in_cache is not None:
date = arrow.get(date_in_cache).date()
if date > cls._securities_date:
await cls.load_securities()
results = cls._securities[cls._securities["code"] == code]
else: # 从influxdb查找
date = tf.day_shift(date, 0)
results = await cls.load_securities_from_db(date, code)
if results is not None and len(results) > 0:
return results[0]
else:
return None
@classmethod
def select(cls, date: datetime.date = None) -> Query:
if date is None:
return Query(target_date=None)
else:
return Query(target_date=date)
@classmethod
async def update_secs_cache(cls, dt: datetime.date, securities: List[Tuple]):
"""更新证券列表到缓存数据库中
Args:
dt: 证券列表归属的日期
securities: 证券列表, 元素为元组,分别为代码、别名、名称、IPO日期、退市日和证券类型
"""
# stock: {'index', 'stock'}
# funds: {'fjb', 'mmf', 'reits', 'fja', 'fjm'}
# {'etf', 'lof'}
key = "security:all"
pipeline = cache.security.pipeline()
pipeline.delete(key)
for code, alias, name, start, end, _type in securities:
pipeline.rpush(key, f"{code},{alias},{name},{start}," f"{end},{_type}")
await pipeline.execute()
logger.info("all securities saved to cache %s, %d secs", key, len(securities))
# update latest date info
await cache.security.set("security:latest_date", dt.strftime("%Y-%m-%d"))
@classmethod
async def save_securities(cls, securities: List[str], dt: datetime.date):
"""保存指定的证券信息到缓存中,并且存入influxdb,定时job调用本接口
Args:
securities: 证券代码列表。
"""
# stock: {'index', 'stock'}
# funds: {'fjb', 'mmf', 'reits', 'fja', 'fjm'}
# {'etf', 'lof'}
if dt is None or len(securities) == 0:
return
measurement = "security_list"
client = get_influx_client()
# code, alias, name, start, end, type
security_list = np.array(
[
(dt, x[0], f"{x[0]},{x[1]},{x[2]},{x[3]},{x[4]},{x[5]}")
for x in securities
],
dtype=security_db_dtype,
)
await client.save(
security_list, measurement, time_key="frame", tag_keys=["code"]
)
@classmethod
async def load_securities_from_db(
cls, target_date: datetime.date, code: str = None
):
if target_date is None:
return None
client = get_influx_client()
measurement = "security_list"
flux = (
Flux()
.measurement(measurement)
.range(target_date, target_date)
.bucket(client._bucket)
.fields(["info"])
)
if code is not None and len(code) > 0:
flux.tags({"code": code})
data = await client.query(flux)
if len(data) == 2: # \r\n
return None
ds = DataframeDeserializer(
sort_values="_time",
usecols=["_time", "code", "info"],
time_col="_time",
engine="c",
)
actual = ds(data)
secs = actual.to_records(index=False)
if len(secs) != 0:
# "_time", "code", "code, alias, name, start, end, type"
_securities = np.array(
[tuple(x["info"].split(",")) for x in secs], dtype=security_info_dtype
)
return _securities
else:
return None
@classmethod
async def get_datescope_from_db(cls):
# fixme: 函数名无法反映用途,需要增加文档注释,说明该函数的作用,或者不应该出现在此类中?
client = get_influx_client()
measurement = "security_list"
date1 = arrow.get("2005-01-01").date()
date2 = arrow.now().naive.date()
flux = (
Flux()
.measurement(measurement)
.range(date1, date2)
.bucket(client._bucket)
.tags({"code": "000001.XSHE"})
)
data = await client.query(flux)
if len(data) == 2: # \r\n
return None, None
ds = DataframeDeserializer(
sort_values="_time", usecols=["_time"], time_col="_time", engine="c"
)
actual = ds(data)
secs = actual.to_records(index=False)
if len(secs) != 0:
d1 = convert_nptime_to_datetime(secs[0]["_time"])
d2 = convert_nptime_to_datetime(secs[len(secs) - 1]["_time"])
return d1.date(), d2.date()
else:
return None, None
@classmethod
async def _notify_special_bonusnote(cls, code, note, cancel_date):
# fixme: 这个函数应该出现在omega中?
default_cancel_date = datetime.date(2099, 1, 1) # 默认无取消公告
# report this special event to notify user
if cancel_date != default_cancel_date:
ding("security %s, bonus_cancel_pub_date %s" % (code, cancel_date))
if note.find("流通") != -1: # 检查是否有“流通股”文字
ding("security %s, special xrxd note: %s" % (code, note))
@classmethod
async def save_xrxd_reports(cls, reports: List[str], dt: datetime.date):
# fixme: 此函数应该属于omega?
"""保存1年内的分红送股信息,并且存入influxdb,定时job调用本接口
Args:
reports: 分红送股公告
"""
# code(0), a_xr_date, board_plan_bonusnote, bonus_ratio_rmb(3), dividend_ratio, transfer_ratio(5),
# at_bonus_ratio_rmb(6), report_date, plan_progress, implementation_bonusnote, bonus_cancel_pub_date(10)
if len(reports) == 0 or dt is None:
return
# read reports from db and convert to dict map
reports_in_db = {}
dt_start = dt - datetime.timedelta(days=366) # 往前回溯366天
dt_end = dt + datetime.timedelta(days=366) # 往后延长366天
existing_records = await cls._load_xrxd_from_db(None, dt_start, dt_end)
for record in existing_records:
code = record[0]
if code not in reports_in_db:
reports_in_db[code] = [record]
else:
reports_in_db[code].append(record)
records = [] # 准备写入db
for x in reports:
code = x[0]
note = x[2]
cancel_date = x[10]
existing_items = reports_in_db.get(code, None)
if existing_items is None: # 新记录
record = (
x[1],
x[0],
f"{x[0]}|{x[1]}|{x[2]}|{x[3]}|{x[4]}|{x[5]}|{x[6]}|{x[7]}|{x[8]}|{x[9]}|{x[10]}",
)
records.append(record)
await cls._notify_special_bonusnote(code, note, cancel_date)
else:
new_record = True
for item in existing_items:
existing_date = convert_nptime_to_datetime(item[1]).date()
if existing_date == x[1]: # 如果xr_date相同,不更新
new_record = False
continue
if new_record:
record = (
x[1],
x[0],
f"{x[0]}|{x[1]}|{x[2]}|{x[3]}|{x[4]}|{x[5]}|{x[6]}|{x[7]}|{x[8]}|{x[9]}|{x[10]}",
)
records.append(record)
await cls._notify_special_bonusnote(code, note, cancel_date)
logger.info("save_xrxd_reports, %d records to be saved", len(records))
if len(records) == 0:
return
measurement = "security_xrxd_reports"
client = get_influx_client()
# a_xr_date(_time), code(tag), info
report_list = np.array(records, dtype=security_db_dtype)
await client.save(report_list, measurement, time_key="frame", tag_keys=["code"])
@classmethod
async def _load_xrxd_from_db(
cls, code, dt_start: datetime.date, dt_end: datetime.date
):
if dt_start is None or dt_end is None:
return []
client = get_influx_client()
measurement = "security_xrxd_reports"
flux = (
Flux()
.measurement(measurement)
.range(dt_start, dt_end)
.bucket(client._bucket)
.fields(["info"])
)
if code is not None and len(code) > 0:
flux.tags({"code": code})
data = await client.query(flux)
if len(data) == 2: # \r\n
return []
ds = DataframeDeserializer(
sort_values="_time",
usecols=["_time", "code", "info"],
time_col="_time",
engine="c",
)
actual = ds(data)
secs = actual.to_records(index=False)
if len(secs) != 0:
_reports = np.array(
[tuple(x["info"].split("|")) for x in secs], dtype=xrxd_info_dtype
)
return _reports
else:
return []
@classmethod
async def get_xrxd_info(cls, dt: datetime.date, code: str = None):
if dt is None:
return None
# code(0), a_xr_date, board_plan_bonusnote, bonus_ratio_rmb(3), dividend_ratio, transfer_ratio(5),
# at_bonus_ratio_rmb(6), report_date, plan_progress, implementation_bonusnote, bonus_cancel_pub_date(10)
reports = await cls._load_xrxd_from_db(code, dt, dt)
if len(reports) == 0:
return None
readable_reports = []
for report in reports:
xr_date = convert_nptime_to_datetime(report[1]).date()
readable_reports.append(
{
"code": report[0],
"xr_date": xr_date,
"bonus": report[3],
"dividend": report[4],
"transfer": report[5],
"bonusnote": report[2],
}
)
return readable_reports | zillionare-omicron | /zillionare_omicron-2.0.0a59-py3-none-any.whl/omicron/models/security.py | security.py |
from __future__ import annotations
import datetime
import itertools
import json
import logging
import os
from typing import TYPE_CHECKING, Iterable, List, Tuple, Union
import arrow
if TYPE_CHECKING:
from arrow import Arrow
import numpy as np
from coretypes import Frame, FrameType
from omicron import extensions as ext
from omicron.core.errors import DataNotReadyError
logger = logging.getLogger(__file__)
EPOCH = datetime.datetime(1970, 1, 1, 0, 0, 0)
CALENDAR_START = datetime.date(2005, 1, 4)
def datetime_to_utc_timestamp(tm: datetime.datetime) -> int:
return (tm - EPOCH).total_seconds()
def date_to_utc_timestamp(dt: datetime.date) -> int:
tm = datetime.datetime(*dt.timetuple()[:-4])
return datetime_to_utc_timestamp(tm)
class TimeFrame:
minute_level_frames = [
FrameType.MIN1,
FrameType.MIN5,
FrameType.MIN15,
FrameType.MIN30,
FrameType.MIN60,
]
day_level_frames = [
FrameType.DAY,
FrameType.WEEK,
FrameType.MONTH,
FrameType.QUARTER,
FrameType.YEAR,
]
ticks = {
FrameType.MIN1: [i for i in itertools.chain(range(571, 691), range(781, 901))],
FrameType.MIN5: [
i for i in itertools.chain(range(575, 695, 5), range(785, 905, 5))
],
FrameType.MIN15: [
i for i in itertools.chain(range(585, 705, 15), range(795, 915, 15))
],
FrameType.MIN30: [
int(s[:2]) * 60 + int(s[2:])
for s in ["1000", "1030", "1100", "1130", "1330", "1400", "1430", "1500"]
],
FrameType.MIN60: [
int(s[:2]) * 60 + int(s[2:]) for s in ["1030", "1130", "1400", "1500"]
],
}
day_frames = None
week_frames = None
month_frames = None
quarter_frames = None
year_frames = None
@classmethod
def service_degrade(cls):
"""当cache中不存在日历时,启用随omicron版本一起发行时自带的日历。
注意:随omicron版本一起发行时自带的日历很可能不是最新的,并且可能包含错误。比如,存在这样的情况,在本版本的omicron发行时,日历更新到了2021年12月31日,在这之前的日历都是准确的,但在此之后的日历,则有可能出现错误。因此,只应该在特殊的情况下(比如测试)调用此方法,以获得一个降级的服务。
"""
_dir = os.path.dirname(__file__)
file = os.path.join(_dir, "..", "config", "calendar.json")
with open(file, "r") as f:
data = json.load(f)
for k, v in data.items():
setattr(cls, k, np.array(v))
@classmethod
async def _load_calendar(cls):
"""从数据缓存中加载更新日历"""
from omicron import cache
names = [
"day_frames",
"week_frames",
"month_frames",
"quarter_frames",
"year_frames",
]
for name, frame_type in zip(names, cls.day_level_frames):
key = f"calendar:{frame_type.value}"
result = await cache.security.lrange(key, 0, -1)
if result is not None and len(result):
frames = [int(x) for x in result]
setattr(cls, name, np.array(frames))
else: # pragma: no cover
raise DataNotReadyError(f"calendar data is not ready: {name} missed")
@classmethod
async def init(cls):
"""初始化日历"""
await cls._load_calendar()
@classmethod
def int2time(cls, tm: int) -> datetime.datetime:
"""将整数表示的时间转换为`datetime`类型表示
examples:
>>> TimeFrame.int2time(202005011500)
datetime.datetime(2020, 5, 1, 15, 0)
Args:
tm: time in YYYYMMDDHHmm format
Returns:
转换后的时间
"""
s = str(tm)
# its 8 times faster than arrow.get()
return datetime.datetime(
int(s[:4]), int(s[4:6]), int(s[6:8]), int(s[8:10]), int(s[10:12])
)
@classmethod
def time2int(cls, tm: Union[datetime.datetime, Arrow]) -> int:
"""将时间类型转换为整数类型
tm可以是Arrow类型,也可以是datetime.datetime或者任何其它类型,只要它有year,month...等
属性
Examples:
>>> TimeFrame.time2int(datetime.datetime(2020, 5, 1, 15))
202005011500
Args:
tm:
Returns:
转换后的整数,比如2020050115
"""
return int(f"{tm.year:04}{tm.month:02}{tm.day:02}{tm.hour:02}{tm.minute:02}")
@classmethod
def date2int(cls, d: Union[datetime.datetime, datetime.date, Arrow]) -> int:
"""将日期转换为整数表示
在zillionare中,如果要对时间和日期进行持久化操作,我们一般将其转换为int类型
Examples:
>>> TimeFrame.date2int(datetime.date(2020,5,1))
20200501
Args:
d: date
Returns:
日期的整数表示,比如20220211
"""
return int(f"{d.year:04}{d.month:02}{d.day:02}")
@classmethod
def int2date(cls, d: Union[int, str]) -> datetime.date:
"""将数字表示的日期转换成为日期格式
Examples:
>>> TimeFrame.int2date(20200501)
datetime.date(2020, 5, 1)
Args:
d: YYYYMMDD表示的日期
Returns:
转换后的日期
"""
s = str(d)
# it's 8 times faster than arrow.get
return datetime.date(int(s[:4]), int(s[4:6]), int(s[6:]))
@classmethod
def day_shift(cls, start: datetime.date, offset: int) -> datetime.date:
"""对指定日期进行前后移位操作
如果 n == 0,则返回d对应的交易日(如果是非交易日,则返回刚结束的一个交易日)
如果 n > 0,则返回d对应的交易日后第 n 个交易日
如果 n < 0,则返回d对应的交易日前第 n 个交易日
Examples:
>>> TimeFrame.day_frames = [20191212, 20191213, 20191216, 20191217,20191218, 20191219]
>>> TimeFrame.day_shift(datetime.date(2019,12,13), 0)
datetime.date(2019, 12, 13)
>>> TimeFrame.day_shift(datetime.date(2019, 12, 15), 0)
datetime.date(2019, 12, 13)
>>> TimeFrame.day_shift(datetime.date(2019, 12, 15), 1)
datetime.date(2019, 12, 16)
>>> TimeFrame.day_shift(datetime.date(2019, 12, 13), 1)
datetime.date(2019, 12, 16)
Args:
start: the origin day
offset: days to shift, can be negative
Returns:
移位后的日期
"""
# accelerated from 0.12 to 0.07, per 10000 loop, type conversion time included
start = cls.date2int(start)
return cls.int2date(ext.shift(cls.day_frames, start, offset))
@classmethod
def week_shift(cls, start: datetime.date, offset: int) -> datetime.date:
"""对指定日期按周线帧进行前后移位操作
参考 [omicron.models.timeframe.TimeFrame.day_shift][]
Examples:
>>> TimeFrame.week_frames = np.array([20200103, 20200110, 20200117, 20200123,20200207, 20200214])
>>> moment = arrow.get('2020-1-21').date()
>>> TimeFrame.week_shift(moment, 1)
datetime.date(2020, 1, 23)
>>> TimeFrame.week_shift(moment, 0)
datetime.date(2020, 1, 17)
>>> TimeFrame.week_shift(moment, -1)
datetime.date(2020, 1, 10)
Returns:
移位后的日期
"""
start = cls.date2int(start)
return cls.int2date(ext.shift(cls.week_frames, start, offset))
@classmethod
def month_shift(cls, start: datetime.date, offset: int) -> datetime.date:
"""求`start`所在的月移位后的frame
本函数首先将`start`对齐,然后进行移位。
Examples:
>>> TimeFrame.month_frames = np.array([20150130, 20150227, 20150331, 20150430])
>>> TimeFrame.month_shift(arrow.get('2015-2-26').date(), 0)
datetime.date(2015, 1, 30)
>>> TimeFrame.month_shift(arrow.get('2015-2-27').date(), 0)
datetime.date(2015, 2, 27)
>>> TimeFrame.month_shift(arrow.get('2015-3-1').date(), 0)
datetime.date(2015, 2, 27)
>>> TimeFrame.month_shift(arrow.get('2015-3-1').date(), 1)
datetime.date(2015, 3, 31)
Returns:
移位后的日期
"""
start = cls.date2int(start)
return cls.int2date(ext.shift(cls.month_frames, start, offset))
@classmethod
def get_ticks(cls, frame_type: FrameType) -> Union[List, np.array]:
"""取月线、周线、日线及各分钟线对应的frame
对分钟线,返回值仅包含时间,不包含日期(均为整数表示)
Examples:
>>> TimeFrame.month_frames = np.array([20050131, 20050228, 20050331])
>>> TimeFrame.get_ticks(FrameType.MONTH)[:3]
array([20050131, 20050228, 20050331])
Args:
frame_type : [description]
Raises:
ValueError: [description]
Returns:
月线、周线、日线及各分钟线对应的frame
"""
if frame_type in cls.minute_level_frames:
return cls.ticks[frame_type]
if frame_type == FrameType.DAY:
return cls.day_frames
elif frame_type == FrameType.WEEK:
return cls.week_frames
elif frame_type == FrameType.MONTH:
return cls.month_frames
else: # pragma: no cover
raise ValueError(f"{frame_type} not supported!")
@classmethod
def shift(
cls,
moment: Union[Arrow, datetime.date, datetime.datetime],
n: int,
frame_type: FrameType,
) -> Union[datetime.date, datetime.datetime]:
"""将指定的moment移动N个`frame_type`位置。
当N为负数时,意味着向前移动;当N为正数时,意味着向后移动。如果n为零,意味着移动到最接近
的一个已结束的frame。
如果moment没有对齐到frame_type对应的时间,将首先进行对齐。
See also:
- [day_shift][omicron.models.timeframe.TimeFrame.day_shift]
- [week_shift][omicron.models.timeframe.TimeFrame.week_shift]
- [month_shift][omicron.models.timeframe.TimeFrame.month_shift]
Examples:
>>> TimeFrame.shift(datetime.date(2020, 1, 3), 1, FrameType.DAY)
datetime.date(2020, 1, 6)
>>> TimeFrame.shift(datetime.datetime(2020, 1, 6, 11), 1, FrameType.MIN30)
datetime.datetime(2020, 1, 6, 11, 30)
Args:
moment:
n:
frame_type:
Returns:
移位后的Frame
"""
if frame_type == FrameType.DAY:
return cls.day_shift(moment, n)
elif frame_type == FrameType.WEEK:
return cls.week_shift(moment, n)
elif frame_type == FrameType.MONTH:
return cls.month_shift(moment, n)
elif frame_type in [
FrameType.MIN1,
FrameType.MIN5,
FrameType.MIN15,
FrameType.MIN30,
FrameType.MIN60,
]:
tm = moment.hour * 60 + moment.minute
new_tick_pos = cls.ticks[frame_type].index(tm) + n
days = new_tick_pos // len(cls.ticks[frame_type])
min_part = new_tick_pos % len(cls.ticks[frame_type])
date_part = cls.day_shift(moment.date(), days)
minutes = cls.ticks[frame_type][min_part]
h, m = minutes // 60, minutes % 60
return datetime.datetime(
date_part.year,
date_part.month,
date_part.day,
h,
m,
tzinfo=moment.tzinfo,
)
else: # pragma: no cover
raise ValueError(f"{frame_type} is not supported.")
@classmethod
def count_day_frames(
cls, start: Union[datetime.date, Arrow], end: Union[datetime.date, Arrow]
) -> int:
"""calc trade days between start and end in close-to-close way.
if start == end, this will returns 1. Both start/end will be aligned to open
trade day before calculation.
Examples:
>>> start = datetime.date(2019, 12, 21)
>>> end = datetime.date(2019, 12, 21)
>>> TimeFrame.day_frames = [20191219, 20191220, 20191223, 20191224, 20191225]
>>> TimeFrame.count_day_frames(start, end)
1
>>> # non-trade days are removed
>>> TimeFrame.day_frames = [20200121, 20200122, 20200123, 20200203, 20200204, 20200205]
>>> start = datetime.date(2020, 1, 23)
>>> end = datetime.date(2020, 2, 4)
>>> TimeFrame.count_day_frames(start, end)
3
args:
start:
end:
returns:
count of days
"""
start = cls.date2int(start)
end = cls.date2int(end)
return int(ext.count_between(cls.day_frames, start, end))
@classmethod
def count_week_frames(cls, start: datetime.date, end: datetime.date) -> int:
"""
calc trade weeks between start and end in close-to-close way. Both start and
end will be aligned to open trade day before calculation. After that, if start
== end, this will returns 1
for examples, please refer to [count_day_frames][omicron.models.timeframe.TimeFrame.count_day_frames]
args:
start:
end:
returns:
count of weeks
"""
start = cls.date2int(start)
end = cls.date2int(end)
return int(ext.count_between(cls.week_frames, start, end))
@classmethod
def count_month_frames(cls, start: datetime.date, end: datetime.date) -> int:
"""calc trade months between start and end date in close-to-close way
Both start and end will be aligned to open trade day before calculation. After
that, if start == end, this will returns 1.
For examples, please refer to [count_day_frames][omicron.models.timeframe.TimeFrame.count_day_frames]
Args:
start:
end:
Returns:
months between start and end
"""
start = cls.date2int(start)
end = cls.date2int(end)
return int(ext.count_between(cls.month_frames, start, end))
@classmethod
def count_quarter_frames(cls, start: datetime.date, end: datetime.date) -> int:
"""calc trade quarters between start and end date in close-to-close way
Both start and end will be aligned to open trade day before calculation. After
that, if start == end, this will returns 1.
For examples, please refer to [count_day_frames][omicron.models.timeframe.TimeFrame.count_day_frames]
Args:
start (datetime.date): [description]
end (datetime.date): [description]
Returns:
quarters between start and end
"""
start = cls.date2int(start)
end = cls.date2int(end)
return int(ext.count_between(cls.quarter_frames, start, end))
@classmethod
def count_year_frames(cls, start: datetime.date, end: datetime.date) -> int:
"""calc trade years between start and end date in close-to-close way
Both start and end will be aligned to open trade day before calculation. After
that, if start == end, this will returns 1.
For examples, please refer to [count_day_frames][omicron.models.timeframe.TimeFrame.count_day_frames]
Args:
start (datetime.date): [description]
end (datetime.date): [description]
Returns:
years between start and end
"""
start = cls.date2int(start)
end = cls.date2int(end)
return int(ext.count_between(cls.year_frames, start, end))
@classmethod
def count_frames(
cls,
start: Union[datetime.date, datetime.datetime, Arrow],
end: Union[datetime.date, datetime.datetime, Arrow],
frame_type,
) -> int:
"""计算start与end之间有多少个周期为frame_type的frames
See also:
- [count_day_frames][omicron.models.timeframe.TimeFrame.count_day_frames]
- [count_week_frames][omicron.models.timeframe.TimeFrame.count_week_frames]
- [count_month_frames][omicron.models.timeframe.TimeFrame.count_month_frames]
Args:
start : start frame
end : end frame
frame_type : the type of frame
Raises:
ValueError: 如果frame_type不支持,则会抛出此异常。
Returns:
从start到end的帧数
"""
if frame_type == FrameType.DAY:
return cls.count_day_frames(start, end)
elif frame_type == FrameType.WEEK:
return cls.count_week_frames(start, end)
elif frame_type == FrameType.MONTH:
return cls.count_month_frames(start, end)
elif frame_type == FrameType.QUARTER:
return cls.count_quarter_frames(start, end)
elif frame_type == FrameType.YEAR:
return cls.count_year_frames(start, end)
elif frame_type in [
FrameType.MIN1,
FrameType.MIN5,
FrameType.MIN15,
FrameType.MIN30,
FrameType.MIN60,
]:
tm_start = start.hour * 60 + start.minute
tm_end = end.hour * 60 + end.minute
days = cls.count_day_frames(start.date(), end.date()) - 1
tm_start_pos = cls.ticks[frame_type].index(tm_start)
tm_end_pos = cls.ticks[frame_type].index(tm_end)
min_bars = tm_end_pos - tm_start_pos + 1
return days * len(cls.ticks[frame_type]) + min_bars
else: # pragma: no cover
raise ValueError(f"{frame_type} is not supported yet")
@classmethod
def is_trade_day(cls, dt: Union[datetime.date, datetime.datetime, Arrow]) -> bool:
"""判断`dt`是否为交易日
Examples:
>>> TimeFrame.is_trade_day(arrow.get('2020-1-1'))
False
Args:
dt :
Returns:
bool
"""
return cls.date2int(dt) in cls.day_frames
@classmethod
def is_open_time(cls, tm: Union[datetime.datetime, Arrow] = None) -> bool:
"""判断`tm`指定的时间是否处在交易时间段。
交易时间段是指集合竞价时间段之外的开盘时间
Examples:
>>> TimeFrame.day_frames = np.array([20200102, 20200103, 20200106, 20200107, 20200108])
>>> TimeFrame.is_open_time(arrow.get('2020-1-1 14:59').naive)
False
>>> TimeFrame.is_open_time(arrow.get('2020-1-3 14:59').naive)
True
Args:
tm : [description]. Defaults to None.
Returns:
bool
"""
tm = tm or arrow.now()
if not cls.is_trade_day(tm):
return False
tick = tm.hour * 60 + tm.minute
return tick in cls.ticks[FrameType.MIN1]
@classmethod
def is_opening_call_auction_time(
cls, tm: Union[Arrow, datetime.datetime] = None
) -> bool:
"""判断`tm`指定的时间是否为开盘集合竞价时间
Args:
tm : [description]. Defaults to None.
Returns:
bool
"""
if tm is None:
tm = cls.now()
if not cls.is_trade_day(tm):
return False
minutes = tm.hour * 60 + tm.minute
return 9 * 60 + 15 < minutes <= 9 * 60 + 25
@classmethod
def is_closing_call_auction_time(
cls, tm: Union[datetime.datetime, Arrow] = None
) -> bool:
"""判断`tm`指定的时间是否为收盘集合竞价时间
Fixme:
此处实现有误,收盘集合竞价时间应该还包含上午收盘时间
Args:
tm : [description]. Defaults to None.
Returns:
bool
"""
tm = tm or cls.now()
if not cls.is_trade_day(tm):
return False
minutes = tm.hour * 60 + tm.minute
return 15 * 60 - 3 <= minutes < 15 * 60
@classmethod
def floor(cls, moment: Frame, frame_type: FrameType) -> Frame:
"""求`moment`在指定的`frame_type`中的下界
比如,如果`moment`为10:37,则当`frame_type`为30分钟时,对应的上界为10:00
Examples:
>>> # 如果moment为日期,则当成已收盘处理
>>> TimeFrame.day_frames = np.array([20050104, 20050105, 20050106, 20050107, 20050110, 20050111])
>>> TimeFrame.floor(datetime.date(2005, 1, 7), FrameType.DAY)
datetime.date(2005, 1, 7)
>>> # moment指定的时间还未收盘,floor到上一个交易日
>>> TimeFrame.floor(datetime.datetime(2005, 1, 7, 14, 59), FrameType.DAY)
datetime.date(2005, 1, 6)
>>> TimeFrame.floor(datetime.date(2005, 1, 13), FrameType.WEEK)
datetime.date(2005, 1, 7)
>>> TimeFrame.floor(datetime.date(2005,2, 27), FrameType.MONTH)
datetime.date(2005, 1, 31)
>>> TimeFrame.floor(datetime.datetime(2005,1,5,14,59), FrameType.MIN30)
datetime.datetime(2005, 1, 5, 14, 30)
>>> TimeFrame.floor(datetime.datetime(2005, 1, 5, 14, 59), FrameType.MIN1)
datetime.datetime(2005, 1, 5, 14, 59)
>>> TimeFrame.floor(arrow.get('2005-1-5 14:59').naive, FrameType.MIN1)
datetime.datetime(2005, 1, 5, 14, 59)
Args:
moment:
frame_type:
Returns:
`moment`在指定的`frame_type`中的下界
"""
if frame_type in cls.minute_level_frames:
tm, day_offset = cls.minute_frames_floor(
cls.ticks[frame_type], moment.hour * 60 + moment.minute
)
h, m = tm // 60, tm % 60
if cls.day_shift(moment, 0) < moment.date() or day_offset == -1:
h = 15
m = 0
new_day = cls.day_shift(moment, day_offset)
else:
new_day = moment.date()
return datetime.datetime(new_day.year, new_day.month, new_day.day, h, m)
if type(moment) == datetime.date:
moment = datetime.datetime(moment.year, moment.month, moment.day, 15)
# 如果是交易日,但还未收盘
if (
cls.date2int(moment) in cls.day_frames
and moment.hour * 60 + moment.minute < 900
):
moment = cls.day_shift(moment, -1)
day = cls.date2int(moment)
if frame_type == FrameType.DAY:
arr = cls.day_frames
elif frame_type == FrameType.WEEK:
arr = cls.week_frames
elif frame_type == FrameType.MONTH:
arr = cls.month_frames
else: # pragma: no cover
raise ValueError(f"frame type {frame_type} not supported.")
floored = ext.floor(arr, day)
return cls.int2date(floored)
@classmethod
def last_min_frame(
cls, day: Union[str, Arrow, datetime.date], frame_type: FrameType
) -> Union[datetime.date, datetime.datetime]:
"""获取`day`日周期为`frame_type`的结束frame。
Example:
>>> TimeFrame.last_min_frame(arrow.get('2020-1-5').date(), FrameType.MIN30)
datetime.datetime(2020, 1, 3, 15, 0)
Args:
day:
frame_type:
Returns:
`day`日周期为`frame_type`的结束frame
"""
if isinstance(day, str):
day = cls.date2int(arrow.get(day).date())
elif isinstance(day, arrow.Arrow) or isinstance(day, datetime.datetime):
day = cls.date2int(day.date())
elif isinstance(day, datetime.date):
day = cls.date2int(day)
else:
raise TypeError(f"{type(day)} is not supported.")
if frame_type in cls.minute_level_frames:
last_close_day = cls.day_frames[cls.day_frames <= day][-1]
day = cls.int2date(last_close_day)
return datetime.datetime(day.year, day.month, day.day, hour=15, minute=0)
else: # pragma: no cover
raise ValueError(f"{frame_type} not supported")
@classmethod
def frame_len(cls, frame_type: FrameType) -> int:
"""返回以分钟为单位的frame长度。
对日线以上级别没有意义,但会返回240
Examples:
>>> TimeFrame.frame_len(FrameType.MIN5)
5
Args:
frame_type:
Returns:
返回以分钟为单位的frame长度。
"""
if frame_type == FrameType.MIN1:
return 1
elif frame_type == FrameType.MIN5:
return 5
elif frame_type == FrameType.MIN15:
return 15
elif frame_type == FrameType.MIN30:
return 30
elif frame_type == FrameType.MIN60:
return 60
else:
return 240
@classmethod
def first_min_frame(
cls, day: Union[str, Arrow, Frame], frame_type: FrameType
) -> Union[datetime.date, datetime.datetime]:
"""获取指定日期类型为`frame_type`的`frame`。
Examples:
>>> TimeFrame.day_frames = np.array([20191227, 20191230, 20191231, 20200102, 20200103])
>>> TimeFrame.first_min_frame('2019-12-31', FrameType.MIN1)
datetime.datetime(2019, 12, 31, 9, 31)
Args:
day: which day?
frame_type: which frame_type?
Returns:
`day`当日的第一帧
"""
day = cls.date2int(arrow.get(day).date())
if frame_type == FrameType.MIN1:
floor_day = cls.day_frames[cls.day_frames <= day][-1]
day = cls.int2date(floor_day)
return datetime.datetime(day.year, day.month, day.day, hour=9, minute=31)
elif frame_type == FrameType.MIN5:
floor_day = cls.day_frames[cls.day_frames <= day][-1]
day = cls.int2date(floor_day)
return datetime.datetime(day.year, day.month, day.day, hour=9, minute=35)
elif frame_type == FrameType.MIN15:
floor_day = cls.day_frames[cls.day_frames <= day][-1]
day = cls.int2date(floor_day)
return datetime.datetime(day.year, day.month, day.day, hour=9, minute=45)
elif frame_type == FrameType.MIN30:
floor_day = cls.day_frames[cls.day_frames <= day][-1]
day = cls.int2date(floor_day)
return datetime.datetime(day.year, day.month, day.day, hour=10)
elif frame_type == FrameType.MIN60:
floor_day = cls.day_frames[cls.day_frames <= day][-1]
day = cls.int2date(floor_day)
return datetime.datetime(day.year, day.month, day.day, hour=10, minute=30)
else: # pragma: no cover
raise ValueError(f"{frame_type} not supported")
@classmethod
def get_frames(cls, start: Frame, end: Frame, frame_type: FrameType) -> List[int]:
"""取[start, end]间所有类型为frame_type的frames
调用本函数前,请先通过`floor`或者`ceiling`将时间帧对齐到`frame_type`的边界值
Example:
>>> start = arrow.get('2020-1-13 10:00').naive
>>> end = arrow.get('2020-1-13 13:30').naive
>>> TimeFrame.day_frames = np.array([20200109, 20200110, 20200113,20200114, 20200115, 20200116])
>>> TimeFrame.get_frames(start, end, FrameType.MIN30)
[202001131000, 202001131030, 202001131100, 202001131130, 202001131330]
Args:
start:
end:
frame_type:
Returns:
frame list
"""
n = cls.count_frames(start, end, frame_type)
return cls.get_frames_by_count(end, n, frame_type)
@classmethod
def get_frames_by_count(
cls, end: Arrow, n: int, frame_type: FrameType
) -> List[int]:
"""取以end为结束点,周期为frame_type的n个frame
调用前请将`end`对齐到`frame_type`的边界
Examples:
>>> end = arrow.get('2020-1-6 14:30').naive
>>> TimeFrame.day_frames = np.array([20200102, 20200103,20200106, 20200107, 20200108, 20200109])
>>> TimeFrame.get_frames_by_count(end, 2, FrameType.MIN30)
[202001061400, 202001061430]
Args:
end:
n:
frame_type:
Returns:
frame list
"""
if frame_type == FrameType.DAY:
end = cls.date2int(end)
pos = np.searchsorted(cls.day_frames, end, side="right")
return cls.day_frames[max(0, pos - n) : pos].tolist()
elif frame_type == FrameType.WEEK:
end = cls.date2int(end)
pos = np.searchsorted(cls.week_frames, end, side="right")
return cls.week_frames[max(0, pos - n) : pos].tolist()
elif frame_type == FrameType.MONTH:
end = cls.date2int(end)
pos = np.searchsorted(cls.month_frames, end, side="right")
return cls.month_frames[max(0, pos - n) : pos].tolist()
elif frame_type in {
FrameType.MIN1,
FrameType.MIN5,
FrameType.MIN15,
FrameType.MIN30,
FrameType.MIN60,
}:
n_days = n // len(cls.ticks[frame_type]) + 2
ticks = cls.ticks[frame_type] * n_days
days = cls.get_frames_by_count(end, n_days, FrameType.DAY)
days = np.repeat(days, len(cls.ticks[frame_type]))
ticks = [
day.item() * 10000 + int(tm / 60) * 100 + tm % 60
for day, tm in zip(days, ticks)
]
# list index is much faster than ext.index_sorted when the arr is small
pos = ticks.index(cls.time2int(end)) + 1
return ticks[max(0, pos - n) : pos]
else: # pragma: no cover
raise ValueError(f"{frame_type} not support yet")
@classmethod
def ceiling(cls, moment: Frame, frame_type: FrameType) -> Frame:
"""求`moment`所在类型为`frame_type`周期的上界
比如`moment`为14:59分,如果`frame_type`为30分钟,则它的上界应该为15:00
Example:
>>> TimeFrame.day_frames = [20050104, 20050105, 20050106, 20050107]
>>> TimeFrame.ceiling(datetime.date(2005, 1, 7), FrameType.DAY)
datetime.date(2005, 1, 7)
>>> TimeFrame.week_frames = [20050107, 20050114, 20050121, 20050128]
>>> TimeFrame.ceiling(datetime.date(2005, 1, 4), FrameType.WEEK)
datetime.date(2005, 1, 7)
>>> TimeFrame.ceiling(datetime.date(2005,1,7), FrameType.WEEK)
datetime.date(2005, 1, 7)
>>> TimeFrame.month_frames = [20050131, 20050228]
>>> TimeFrame.ceiling(datetime.date(2005,1 ,1), FrameType.MONTH)
datetime.date(2005, 1, 31)
>>> TimeFrame.ceiling(datetime.datetime(2005,1,5,14,59), FrameType.MIN30)
datetime.datetime(2005, 1, 5, 15, 0)
>>> TimeFrame.ceiling(datetime.datetime(2005, 1, 5, 14, 59), FrameType.MIN1)
datetime.datetime(2005, 1, 5, 14, 59)
>>> TimeFrame.ceiling(arrow.get('2005-1-5 14:59').naive, FrameType.MIN1)
datetime.datetime(2005, 1, 5, 14, 59)
Args:
moment (datetime.datetime): [description]
frame_type (FrameType): [description]
Returns:
`moment`所在类型为`frame_type`周期的上界
"""
if frame_type in cls.day_level_frames and type(moment) == datetime.datetime:
moment = moment.date()
floor = cls.floor(moment, frame_type)
if floor == moment:
return moment
elif floor > moment:
return floor
else:
return cls.shift(floor, 1, frame_type)
@classmethod
def combine_time(
cls,
date: datetime.date,
hour: int,
minute: int = 0,
second: int = 0,
microsecond: int = 0,
) -> datetime.datetime:
"""用`date`指定的日期与`hour`, `minute`, `second`等参数一起合成新的时间
Examples:
>>> TimeFrame.combine_time(datetime.date(2020, 1, 1), 14, 30)
datetime.datetime(2020, 1, 1, 14, 30)
Args:
date : [description]
hour : [description]
minute : [description]. Defaults to 0.
second : [description]. Defaults to 0.
microsecond : [description]. Defaults to 0.
Returns:
合成后的时间
"""
return datetime.datetime(
date.year, date.month, date.day, hour, minute, second, microsecond
)
@classmethod
def replace_date(
cls, dtm: datetime.datetime, dt: datetime.date
) -> datetime.datetime:
"""将`dtm`变量的日期更换为`dt`指定的日期
Example:
>>> TimeFrame.replace_date(arrow.get('2020-1-1 13:49').datetime, datetime.date(2019, 1,1))
datetime.datetime(2019, 1, 1, 13, 49)
Args:
dtm (datetime.datetime): [description]
dt (datetime.date): [description]
Returns:
变换后的时间
"""
return datetime.datetime(
dt.year, dt.month, dt.day, dtm.hour, dtm.minute, dtm.second, dtm.microsecond
)
@classmethod
def resample_frames(
cls, trade_days: Iterable[datetime.date], frame_type: FrameType
) -> List[int]:
"""将从行情服务器获取的交易日历重采样,生成周帧和月线帧
Args:
trade_days (Iterable): [description]
frame_type (FrameType): [description]
Returns:
List[int]: 重采样后的日期列表,日期用整数表示
"""
if frame_type == FrameType.WEEK:
weeks = []
last = trade_days[0]
for cur in trade_days:
if cur.weekday() < last.weekday() or (cur - last).days >= 7:
weeks.append(last)
last = cur
if weeks[-1] < last:
weeks.append(last)
return weeks
elif frame_type == FrameType.MONTH:
months = []
last = trade_days[0]
for cur in trade_days:
if cur.day < last.day:
months.append(last)
last = cur
months.append(last)
return months
elif frame_type == FrameType.QUARTER:
quarters = []
last = trade_days[0]
for cur in trade_days:
if last.month % 3 == 0:
if cur.month > last.month or cur.year > last.year:
quarters.append(last)
last = cur
quarters.append(last)
return quarters
elif frame_type == FrameType.YEAR:
years = []
last = trade_days[0]
for cur in trade_days:
if cur.year > last.year:
years.append(last)
last = cur
years.append(last)
return years
else: # pragma: no cover
raise ValueError(f"Unsupported FrameType: {frame_type}")
@classmethod
def minute_frames_floor(cls, ticks, moment) -> Tuple[int, int]:
"""
对于分钟级的frame,返回它们与frame刻度向下对齐后的frame及日期进位。如果需要对齐到上一个交易
日,则进位为-1,否则为0.
Examples:
>>> ticks = [600, 630, 660, 690, 810, 840, 870, 900]
>>> TimeFrame.minute_frames_floor(ticks, 545)
(900, -1)
>>> TimeFrame.minute_frames_floor(ticks, 600)
(600, 0)
>>> TimeFrame.minute_frames_floor(ticks, 605)
(600, 0)
>>> TimeFrame.minute_frames_floor(ticks, 899)
(870, 0)
>>> TimeFrame.minute_frames_floor(ticks, 900)
(900, 0)
>>> TimeFrame.minute_frames_floor(ticks, 905)
(900, 0)
Args:
ticks (np.array or list): frames刻度
moment (int): 整数表示的分钟数,比如900表示15:00
Returns:
tuple, the first is the new moment, the second is carry-on
"""
if moment < ticks[0]:
return ticks[-1], -1
# ’right' 相当于 ticks <= m
index = np.searchsorted(ticks, moment, side="right")
return ticks[index - 1], 0
@classmethod
async def save_calendar(cls, trade_days):
# avoid circular import
from omicron import cache
for ft in [FrameType.WEEK, FrameType.MONTH, FrameType.QUARTER, FrameType.YEAR]:
days = cls.resample_frames(trade_days, ft)
frames = [cls.date2int(x) for x in days]
key = f"calendar:{ft.value}"
pl = cache.security.pipeline()
pl.delete(key)
pl.rpush(key, *frames)
await pl.execute()
frames = [cls.date2int(x) for x in trade_days]
key = f"calendar:{FrameType.DAY.value}"
pl = cache.security.pipeline()
pl.delete(key)
pl.rpush(key, *frames)
await pl.execute()
@classmethod
async def remove_calendar(cls):
# avoid circular import
from omicron import cache
for ft in cls.day_level_frames:
key = f"calendar:{ft.value}"
await cache.security.delete(key)
@classmethod
def is_bar_closed(cls, frame: Frame, ft: FrameType) -> bool:
"""判断`frame`所代表的bar是否已经收盘(结束)
如果是日线,frame不为当天,则认为已收盘;或者当前时间在收盘时间之后,也认为已收盘。
如果是其它周期,则只有当frame正好在边界上,才认为是已收盘。这里有一个假设:我们不会在其它周期上,判断未来的某个frame是否已经收盘。
Args:
frame : bar所处的时间,必须小于当前时间
ft: bar所代表的帧类型
Returns:
bool: 是否已经收盘
"""
floor = cls.floor(frame, ft)
now = arrow.now()
if ft == FrameType.DAY:
return floor < now.date() or now.hour >= 15
else:
return floor == frame
@classmethod
def get_frame_scope(cls, frame: Frame, ft: FrameType) -> Tuple[Frame, Frame]:
# todo: 函数的通用性不足,似乎应该放在具体的业务类中。如果是通用型的函数,参数不应该局限于周和月。
"""对于给定的时间,取所在周的第一天和最后一天,所在月的第一天和最后一天
Args:
frame : 指定的日期,date对象
ft: 帧类型,支持WEEK和MONTH
Returns:
Tuple[Frame, Frame]: 周或者月的首末日期(date对象)
"""
if frame is None:
raise ValueError("frame cannot be None")
if ft not in (FrameType.WEEK, FrameType.MONTH):
raise ValueError(f"FrameType only supports WEEK and MONTH: {ft}")
if isinstance(frame, datetime.datetime):
frame = frame.date()
if frame < CALENDAR_START:
raise ValueError(f"cannot be earlier than {CALENDAR_START}: {frame}")
# datetime.date(2021, 10, 8),这是个特殊的日期
if ft == FrameType.WEEK:
if frame < datetime.date(2005, 1, 10):
return datetime.date(2005, 1, 4), datetime.date(2005, 1, 7)
if not cls.is_trade_day(frame): # 非交易日的情况,直接回退一天
week_day = cls.day_shift(frame, 0)
else:
week_day = frame
w1 = TimeFrame.floor(week_day, FrameType.WEEK)
if w1 == week_day: # 本周的最后一个交易日
week_end = w1
else:
week_end = TimeFrame.week_shift(week_day, 1)
w0 = TimeFrame.week_shift(week_end, -1)
week_start = TimeFrame.day_shift(w0, 1)
return week_start, week_end
if ft == FrameType.MONTH:
if frame <= datetime.date(2005, 1, 31):
return datetime.date(2005, 1, 4), datetime.date(2005, 1, 31)
month_start = frame.replace(day=1)
if not cls.is_trade_day(month_start): # 非交易日的情况,直接加1
month_start = cls.day_shift(month_start, 1)
month_end = TimeFrame.month_shift(month_start, 1)
return month_start, month_end
@classmethod
def get_previous_trade_day(cls, now: datetime.date):
"""获取上一个交易日
如果当天是周六或者周日,返回周五(交易日),如果当天是周一,返回周五,如果当天是周五,返回周四
Args:
now : 指定的日期,date对象
Returns:
datetime.date: 上一个交易日
"""
if now == datetime.date(2005, 1, 4):
return now
if TimeFrame.is_trade_day(now):
pre_trade_day = TimeFrame.day_shift(now, -1)
else:
pre_trade_day = TimeFrame.day_shift(now, 0)
return pre_trade_day | zillionare-omicron | /zillionare_omicron-2.0.0a59-py3-none-any.whl/omicron/models/timeframe.py | timeframe.py |
import datetime
import itertools
import logging
import re
from typing import Dict, Generator, Iterable, List, Tuple, Union
import arrow
import cfg4py
import ciso8601
import numpy as np
import pandas as pd
from coretypes import (
BarsArray,
BarsPanel,
Frame,
FrameType,
LimitPriceOnlyBarsArray,
SecurityType,
bars_cols,
bars_dtype,
bars_dtype_with_code,
)
from deprecation import deprecated
from omicron import tf
from omicron.core.constants import (
TRADE_LATEST_PRICE,
TRADE_PRICE_LIMITS,
TRADE_PRICE_LIMITS_DATE,
)
from omicron.core.errors import BadParameterError
from omicron.dal import cache
from omicron.dal.influx.flux import Flux
from omicron.dal.influx.serialize import DataframeDeserializer, NumpyDeserializer
from omicron.extensions import array_price_equal, numpy_append_fields, price_equal
from omicron.models import get_influx_client
from omicron.models.security import Security, convert_nptime_to_datetime
logger = logging.getLogger(__name__)
cfg = cfg4py.get_instance()
INFLUXDB_MAX_QUERY_SIZE = 250 * 200
def ciso8601_parse_date(x):
return ciso8601.parse_datetime(x).date()
def ciso8601_parse_naive(x):
return ciso8601.parse_datetime_as_naive(x)
class Stock(Security):
""" "
Stock对象用于归集某支证券(股票和指数,不包括其它投资品种)的相关信息,比如行情数据(OHLC等)、市值数据、所属概念分类等。
"""
_is_cache_empty = True
def __init__(self, code: str):
self._code = code
self._stock = self.get_stock(code)
assert self._stock, "系统中不存在该code"
(_, self._display_name, self._name, ipo, end, _type) = self._stock
self._start_date = convert_nptime_to_datetime(ipo).date()
self._end_date = convert_nptime_to_datetime(end).date()
self._type = SecurityType(_type)
@classmethod
def choose_listed(cls, dt: datetime.date, types: List[str] = ["stock", "index"]):
cond = np.array([False] * len(cls._stocks))
dt = datetime.datetime.combine(dt, datetime.time())
for type_ in types:
cond |= cls._stocks["type"] == type_
result = cls._stocks[cond]
result = result[result["end"] > dt]
result = result[result["ipo"] <= dt]
# result = np.array(result, dtype=cls.stock_info_dtype)
return result["code"].tolist()
@classmethod
def fuzzy_match(cls, query: str) -> Dict[str, Tuple]:
"""对股票/指数进行模糊匹配查找
query可以是股票/指数代码,也可以是字母(按name查找),也可以是汉字(按显示名查找)
Args:
query (str): 查询字符串
Returns:
Dict[str, Tuple]: 查询结果,其中Tuple为(code, display_name, name, start, end, type)
"""
query = query.upper()
if re.match(r"\d+", query):
return {
sec["code"]: sec.tolist()
for sec in cls._stocks
if sec["code"].startswith(query)
}
elif re.match(r"[A-Z]+", query):
return {
sec["code"]: sec.tolist()
for sec in cls._stocks
if sec["name"].startswith(query)
}
else:
return {
sec["code"]: sec.tolist()
for sec in cls._stocks
if sec["alias"].find(query) != -1
}
def __str__(self):
return f"{self.display_name}[{self.code}]"
@property
def ipo_date(self) -> datetime.date:
return self._start_date
@property
def display_name(self) -> str:
return self._display_name
@property
def name(self) -> str:
return self._name
@property
def end_date(self) -> datetime.date:
return self._end_date
@property
def code(self) -> str:
return self._code
@property
def sim_code(self) -> str:
return re.sub(r"\.XSH[EG]", "", self.code)
@property
def security_type(self) -> SecurityType:
"""返回证券类型
Returns:
SecurityType: [description]
"""
return self._type
@staticmethod
def simplify_code(code) -> str:
return re.sub(r"\.XSH[EG]", "", code)
def days_since_ipo(self) -> int:
"""获取上市以来经过了多少个交易日
由于受交易日历限制(2005年1月4日之前的交易日历没有),对于在之前上市的品种,都返回从2005年1月4日起的日期。
Returns:
int: [description]
"""
epoch_start = arrow.get("2005-01-04").date()
ipo_day = self.ipo_date if self.ipo_date > epoch_start else epoch_start
return tf.count_day_frames(ipo_day, arrow.now().date())
@staticmethod
def qfq(bars: BarsArray) -> BarsArray:
"""对行情数据执行前复权操作"""
# todo: 这里可以优化
if bars.size == 0:
return bars
last = bars[-1]["factor"]
for field in ["open", "high", "low", "close", "volume"]:
bars[field] = bars[field] * (bars["factor"] / last)
return bars
@classmethod
async def batch_get_min_level_bars_in_range(
cls,
codes: List[str],
frame_type: FrameType,
start: Frame,
end: Frame,
fq: bool = True,
) -> Generator[Dict[str, BarsArray], None, None]:
"""获取多支股票(指数)在[start, end)时间段内的行情数据
如果要获取的行情数据是分钟级别(即1m, 5m, 15m, 30m和60m),使用本接口。
停牌数据处理请见[get_bars][omicron.models.stock.Stock.get_bars]。
本函数返回一个迭代器,使用方法示例:
```
async for code, bars in Stock.batch_get_min_level_bars_in_range(...):
print(code, bars)
```
如果`end`不在`frame_type`所属的边界点上,那么,如果`end`大于等于当前缓存未收盘数据时间,则将包含未收盘数据;否则,返回的记录将截止到`tf.floor(end, frame_type)`。
Args:
codes: 股票/指数代码列表
frame_type: 帧类型
start: 起始时间
end: 结束时间。如果未指明,则取当前时间。
fq: 是否进行复权,如果是,则进行前复权。Defaults to True.
Returns:
Generator[Dict[str, BarsArray], None, None]: 迭代器,每次返回一个字典,其中key为代码,value为行情数据
"""
closed_end = tf.floor(end, frame_type)
n = tf.count_frames(start, closed_end, frame_type)
max_query_size = min(cfg.influxdb.max_query_size, INFLUXDB_MAX_QUERY_SIZE)
batch_size = max(1, max_query_size // n)
ff = tf.first_min_frame(datetime.datetime.now(), frame_type)
for i in range(0, len(codes), batch_size):
batch_codes = codes[i : i + batch_size]
if end < ff:
part1 = await cls._batch_get_persisted_bars_in_range(
batch_codes, frame_type, start, end
)
part2 = pd.DataFrame([], columns=bars_dtype_with_code.names)
elif start >= ff:
part1 = pd.DataFrame([], columns=bars_dtype_with_code.names)
n = tf.count_frames(start, closed_end, frame_type) + 1
cached = await cls._batch_get_cached_bars_n(
frame_type, n, end, batch_codes
)
cached = cached[cached["frame"] >= start]
part2 = pd.DataFrame(cached, columns=bars_dtype_with_code.names)
else:
part1 = await cls._batch_get_persisted_bars_in_range(
batch_codes, frame_type, start, ff
)
n = tf.count_frames(start, closed_end, frame_type) + 1
cached = await cls._batch_get_cached_bars_n(
frame_type, n, end, batch_codes
)
part2 = pd.DataFrame(cached, columns=bars_dtype_with_code.names)
df = pd.concat([part1, part2])
for code in batch_codes:
filtered = df[df["code"] == code][bars_cols]
bars = filtered.to_records(index=False).astype(bars_dtype)
if fq:
bars = cls.qfq(bars)
yield code, bars
@classmethod
async def batch_get_day_level_bars_in_range(
cls,
codes: List[str],
frame_type: FrameType,
start: Frame,
end: Frame,
fq: bool = True,
) -> Generator[Dict[str, BarsArray], None, None]:
"""获取多支股票(指数)在[start, end)时间段内的行情数据
如果要获取的行情数据是日线级别(即1d, 1w, 1M),使用本接口。
停牌数据处理请见[get_bars][omicron.models.stock.Stock.get_bars]。
本函数返回一个迭代器,使用方法示例:
```
async for code, bars in Stock.batch_get_day_level_bars_in_range(...):
print(code, bars)
```
如果`end`不在`frame_type`所属的边界点上,那么,如果`end`大于等于当前缓存未收盘数据时间,则将包含未收盘数据;否则,返回的记录将截止到`tf.floor(end, frame_type)`。
Args:
codes: 代码列表
frame_type: 帧类型
start: 起始时间
end: 结束时间
fq: 是否进行复权,如果是,则进行前复权。Defaults to True.
Returns:
Generator[Dict[str, BarsArray], None, None]: 迭代器,每次返回一个字典,其中key为代码,value为行情数据
"""
today = datetime.datetime.now().date()
# 日线,end不等于最后交易日,此时已无缓存
if frame_type == FrameType.DAY and end == tf.floor(today, frame_type):
from_cache = True
elif frame_type != FrameType.DAY and start > tf.floor(today, frame_type):
from_cache = True
else:
from_cache = False
n = tf.count_frames(start, end, frame_type)
max_query_size = min(cfg.influxdb.max_query_size, INFLUXDB_MAX_QUERY_SIZE)
batch_size = max(max_query_size // n, 1)
for i in range(0, len(codes), batch_size):
batch_codes = codes[i : i + batch_size]
persisted = await cls._batch_get_persisted_bars_in_range(
batch_codes, frame_type, start, end
)
if from_cache:
cached = await cls._batch_get_cached_bars_n(
frame_type, 1, end, batch_codes
)
cached = pd.DataFrame(cached, columns=bars_dtype_with_code.names)
df = pd.concat([persisted, cached])
else:
df = persisted
for code in batch_codes:
filtered = df[df["code"] == code][bars_cols]
bars = filtered.to_records(index=False).astype(bars_dtype)
if fq:
bars = cls.qfq(bars)
yield code, bars
@classmethod
async def get_bars_in_range(
cls,
code: str,
frame_type: FrameType,
start: Frame,
end: Frame = None,
fq=True,
unclosed=True,
) -> BarsArray:
"""获取指定证券(`code`)在[`start`, `end`]期间帧类型为`frame_type`的行情数据。
Args:
code : 证券代码
frame_type : 行情数据的帧类型
start : 起始时间
end : 结束时间,如果为None,则表明取到当前时间。
fq : 是否对行情数据执行前复权操作
unclosed : 是否包含未收盘的数据
"""
now = datetime.datetime.now()
if frame_type in tf.day_level_frames:
end = end or now.date()
if unclosed and tf.day_shift(end, 0) == now.date():
part2 = await cls._get_cached_bars_n(code, 1, frame_type)
else:
part2 = np.array([], dtype=bars_dtype)
# get rest from persisted
part1 = await cls._get_persisted_bars_in_range(code, frame_type, start, end)
bars = np.concatenate((part1, part2))
else:
end = end or now
closed_end = tf.floor(end, frame_type)
ff = tf.first_min_frame(now, frame_type)
if end < ff:
part1 = await cls._get_persisted_bars_in_range(
code, frame_type, start, end
)
part2 = np.array([], dtype=bars_dtype)
elif start >= ff: # all in cache
part1 = np.array([], dtype=bars_dtype)
n = tf.count_frames(start, closed_end, frame_type) + 1
part2 = await cls._get_cached_bars_n(code, n, frame_type, end)
part2 = part2[part2["frame"] >= start]
else: # in both cache and persisted
part1 = await cls._get_persisted_bars_in_range(
code, frame_type, start, ff
)
n = tf.count_frames(ff, closed_end, frame_type) + 1
part2 = await cls._get_cached_bars_n(code, n, frame_type, end)
if not unclosed:
part2 = part2[part2["frame"] <= closed_end]
bars = np.concatenate((part1, part2))
if fq:
return cls.qfq(bars)
else:
return bars
@classmethod
async def get_bars(
cls,
code: str,
n: int,
frame_type: FrameType,
end: Frame = None,
fq=True,
unclosed=True,
) -> BarsArray:
"""获取到`end`为止的`n`个行情数据。
返回的数据是按照时间顺序递增排序的。在遇到停牌的情况时,该时段数据将被跳过,因此返回的记录可能不是交易日连续的,并且可能不足`n`个。
如果系统当前没有到指定时间`end`的数据,将尽最大努力返回数据。调用者可以通过判断最后一条数据的时间是否等于`end`来判断是否获取到了全部数据。
Args:
code: 证券代码
n: 记录数
frame_type: 帧类型
end: 截止时间,如果未指明,则取当前时间
fq: 是否对返回记录进行复权。如果为`True`的话,则进行前复权。Defaults to True.
unclosed: 是否包含最新未收盘的数据? Defaults to True.
Returns:
返回dtype为`coretypes.bars_dtype`的一维numpy数组。
"""
now = datetime.datetime.now()
try:
cached = np.array([], dtype=bars_dtype)
if frame_type in tf.day_level_frames:
if end is None:
end = now.date()
elif type(end) == datetime.datetime:
end = end.date()
n0 = n
if unclosed:
cached = await cls._get_cached_bars_n(code, 1, frame_type)
if cached.size > 0:
# 如果缓存的未收盘日期 > end,则该缓存不是需要的
if cached[0]["frame"].item().date() > end:
cached = np.array([], dtype=bars_dtype)
else:
n0 = n - 1
else:
end = end or now
closed_frame = tf.floor(end, frame_type)
# fetch one more bar, in case we should discard unclosed bar
cached = await cls._get_cached_bars_n(code, n + 1, frame_type, end)
if not unclosed:
cached = cached[cached["frame"] <= closed_frame]
# n bars we need fetch from persisted db
n0 = n - cached.size
if n0 > 0:
if cached.size > 0:
end0 = cached[0]["frame"].item()
else:
end0 = end
bars = await cls._get_persisted_bars_n(code, frame_type, n0, end0)
merged = np.concatenate((bars, cached))
bars = merged[-n:]
else:
bars = cached[-n:]
if fq:
bars = cls.qfq(bars)
return bars
except Exception as e:
logger.exception(e)
logger.warning(
"failed to get bars for %s, %s, %s, %s", code, n, frame_type, end
)
raise
@classmethod
async def _get_persisted_bars_in_range(
cls, code: str, frame_type: FrameType, start: Frame, end: Frame = None
) -> BarsArray:
"""从持久化数据库中获取介于[`start`, `end`]间的行情记录
如果`start`到`end`区间某支股票停牌,则会返回空数组。
Args:
code: 证券代码
frame_type: 帧类型
start: 起始时间
end: 结束时间,如果未指明,则取当前时间
Returns:
返回dtype为`coretypes.bars_dtype`的一维numpy数组。
"""
end = end or datetime.datetime.now()
keep_cols = ["_time"] + list(bars_cols[1:])
measurement = cls._measurement_name(frame_type)
flux = (
Flux()
.bucket(cfg.influxdb.bucket_name)
.range(start, end)
.measurement(measurement)
.fields(keep_cols)
.tags({"code": code})
)
serializer = DataframeDeserializer(
encoding="utf-8",
names=[
"_",
"table",
"result",
"frame",
"code",
"amount",
"close",
"factor",
"high",
"low",
"open",
"volume",
],
engine="c",
skiprows=0,
header=0,
usecols=bars_cols,
parse_dates=["frame"],
)
client = get_influx_client()
result = await client.query(flux, serializer)
return result.to_records(index=False).astype(bars_dtype)
@classmethod
async def _get_persisted_bars_n(
cls, code: str, frame_type: FrameType, n: int, end: Frame = None
) -> BarsArray:
"""从持久化数据库中获取截止到`end`的`n`条行情记录
如果`end`未指定,则取当前时间。
基于influxdb查询的特性,在查询前,必须先根据`end`和`n`计算出起始时间,但如果在此期间某些股票有停牌,则无法返回的数据将小于`n`。而如果起始时间设置得足够早,虽然能满足返回数据条数的要求,但会带来性能上的损失。因此,我们在计算起始时间时,不是使用`n`来计算,而是使用了`min(n * 2, n + 20)`来计算起始时间,这样多数情况下,能够保证返回数据的条数为`n`条。
返回的数据按`frame`进行升序排列。
Args:
code: 证券代码
frame_type: 帧类型
n: 返回结果数量
end: 结束时间,如果未指明,则取当前时间
Returns:
返回dtype为`bars_dtype`的numpy数组
"""
# check is needed since tags accept List as well
assert isinstance(code, str), "`code` must be a string"
end = end or datetime.datetime.now()
closed_end = tf.floor(end, frame_type)
start = tf.shift(closed_end, -min(2 * n, n + 20), frame_type)
keep_cols = ["_time"] + list(bars_cols[1:])
measurement = cls._measurement_name(frame_type)
flux = (
Flux()
.bucket(cfg.influxdb.bucket_name)
.range(start, end)
.measurement(measurement)
.fields(keep_cols)
.tags({"code": code})
.latest(n)
)
serializer = DataframeDeserializer(
encoding="utf-8",
names=[
"_",
"table",
"result",
"frame",
"code",
"amount",
"close",
"factor",
"high",
"low",
"open",
"volume",
],
engine="c",
skiprows=0,
header=0,
usecols=bars_cols,
parse_dates=["frame"],
)
client = get_influx_client()
result = await client.query(flux, serializer)
return result.to_records(index=False).astype(bars_dtype)
@classmethod
async def _batch_get_persisted_bars_n(
cls, codes: List[str], frame_type: FrameType, n: int, end: Frame = None
) -> pd.DataFrame:
"""从持久化存储中获取`codes`指定的一批股票截止`end`时的`n`条记录。
返回的数据按`frame`进行升序排列。如果不存在满足指定条件的查询结果,将返回空的DataFrame。
基于influxdb查询的特性,在查询前,必须先根据`end`和`n`计算出起始时间,但如果在此期间某些股票有停牌,则无法返回的数据将小于`n`。如果起始时间设置的足够早,虽然能满足返回数据条数的要求,但会带来性能上的损失。因此,我们在计算起始时间时,不是使用`n`来计算,而是使用了`min(n * 2, n + 20)`来计算起始时间,这样多数情况下,能够保证返回数据的条数为`n`条。
Args:
codes: 证券代码列表。
frame_type: 帧类型
n: 返回结果数量
end: 结束时间,如果未指定,则使用当前时间
Returns:
DataFrame, columns为`code`, `frame`, `open`, `high`, `low`, `close`, `volume`, `amount`, `factor`
"""
max_query_size = min(cfg.influxdb.max_query_size, INFLUXDB_MAX_QUERY_SIZE)
if len(codes) * min(n + 20, 2 * n) > max_query_size:
raise BadParameterError(
f"codes的数量和n的乘积超过了influxdb的最大查询数量限制{max_query_size}"
)
end = end or datetime.datetime.now()
close_end = tf.floor(end, frame_type)
begin = tf.shift(close_end, -1 * min(n + 20, n * 2), frame_type)
# influxdb的查询结果格式类似于CSV,其列顺序为_, result_alias, table_seq, _time, tags, fields,其中tags和fields都是升序排列
keep_cols = ["code"] + list(bars_cols)
names = ["_", "result", "table", "frame", "code"]
# influxdb will return fields in the order of name ascending parallel
names.extend(sorted(bars_cols[1:]))
measurement = cls._measurement_name(frame_type)
flux = (
Flux()
.bucket(cfg.influxdb.bucket_name)
.range(begin, end)
.measurement(measurement)
.fields(keep_cols)
.latest(n)
)
if codes is not None:
assert isinstance(codes, list), "`codes` must be a list or None"
flux.tags({"code": codes})
deserializer = DataframeDeserializer(
names=names,
usecols=keep_cols,
encoding="utf-8",
time_col="frame",
engine="c",
)
client = get_influx_client()
return await client.query(flux, deserializer)
@classmethod
async def _batch_get_persisted_bars_in_range(
cls, codes: List[str], frame_type: FrameType, begin: Frame, end: Frame = None
) -> pd.DataFrame:
"""从持久化存储中获取`codes`指定的一批股票在`begin`和`end`之间的记录。
返回的数据将按`frame`进行升序排列。
注意,返回的数据有可能不是等长的,因为有的股票可能停牌。
Args:
codes: 证券代码列表。
frame_type: 帧类型
begin: 开始时间
end: 结束时间
Returns:
DataFrame, columns为`code`, `frame`, `open`, `high`, `low`, `close`, `volume`, `amount`, `factor`
"""
end = end or datetime.datetime.now()
n = tf.count_frames(begin, end, frame_type)
max_query_size = min(cfg.influxdb.max_query_size, INFLUXDB_MAX_QUERY_SIZE)
if len(codes) * n > max_query_size:
raise BadParameterError(
f"asked records is {len(codes) * n}, which is too large than {max_query_size}"
)
# influxdb的查询结果格式类似于CSV,其列顺序为_, result_alias, table_seq, _time, tags, fields,其中tags和fields都是升序排列
keep_cols = ["code"] + list(bars_cols)
names = ["_", "result", "table", "frame", "code"]
# influxdb will return fields in the order of name ascending parallel
names.extend(sorted(bars_cols[1:]))
measurement = cls._measurement_name(frame_type)
flux = (
Flux()
.bucket(cfg.influxdb.bucket_name)
.range(begin, end)
.measurement(measurement)
.fields(keep_cols)
)
flux.tags({"code": codes})
deserializer = DataframeDeserializer(
names=names,
usecols=keep_cols,
encoding="utf-8",
time_col="frame",
engine="c",
)
client = get_influx_client()
df = await client.query(flux, deserializer)
return df
@classmethod
async def batch_cache_bars(cls, frame_type: FrameType, bars: Dict[str, BarsArray]):
"""缓存已收盘的分钟线和日线
当缓存日线时,仅限于当日收盘后的第一次同步时调用。
Args:
frame_type: 帧类型
bars: 行情数据,其key为股票代码,其value为dtype为`bars_dtype`的一维numpy数组。
Raises:
RedisError: 如果在执行过程中发生错误,则抛出以此异常为基类的各种异常,具体参考aioredis相关文档。
"""
if frame_type == FrameType.DAY:
await cls.batch_cache_unclosed_bars(frame_type, bars)
return
pl = cache.security.pipeline()
for code, bars in bars.items():
key = f"bars:{frame_type.value}:{code}"
for bar in bars:
frame = tf.time2int(bar["frame"].item())
val = [*bar]
val[0] = frame
pl.hset(key, frame, ",".join(map(str, val)))
await pl.execute()
@classmethod
async def batch_cache_unclosed_bars(
cls, frame_type: FrameType, bars: Dict[str, BarsArray]
): # pragma: no cover
"""缓存未收盘的5、15、30、60分钟线及日线、周线、月线
Args:
frame_type: 帧类型
bars: 行情数据,其key为股票代码,其value为dtype为`bars_dtype`的一维numpy数组。bars不能为None,或者empty。
Raise:
RedisError: 如果在执行过程中发生错误,则抛出以此异常为基类的各种异常,具体参考aioredis相关文档。
"""
pl = cache.security.pipeline()
key = f"bars:{frame_type.value}:unclosed"
convert = tf.time2int if frame_type in tf.minute_level_frames else tf.date2int
for code, bar in bars.items():
val = [*bar[0]]
val[0] = convert(bar["frame"][0].item()) # 时间转换
pl.hset(key, code, ",".join(map(str, val)))
await pl.execute()
@classmethod
async def reset_cache(cls):
"""清除缓存的行情数据"""
try:
for ft in itertools.chain(tf.minute_level_frames, tf.day_level_frames):
keys = await cache.security.keys(f"bars:{ft.value}:*")
if keys:
await cache.security.delete(*keys)
finally:
cls._is_cache_empty = True
@classmethod
def _deserialize_cached_bars(cls, raw: List[str], ft: FrameType) -> BarsArray:
"""从redis中反序列化缓存的数据
如果`raw`空数组或者元素为`None`,则返回空数组。
Args:
raw: redis中的缓存数据
ft: 帧类型
sort: 是否需要重新排序,缺省为False
Returns:
BarsArray: 行情数据
"""
fix_date = False
if ft in tf.minute_level_frames:
convert = tf.int2time
else:
convert = tf.int2date
fix_date = True
recs = []
# it's possible to treat raw as csv and use pandas to parse, however, the performance is 10 times worse than this method
for raw_rec in raw:
if raw_rec is None:
continue
f, o, h, l, c, v, m, fac = raw_rec.split(",")
if fix_date:
f = f[:8]
recs.append(
(
convert(f),
float(o),
float(h),
float(l),
float(c),
float(v),
float(m),
float(fac),
)
)
return np.array(recs, dtype=bars_dtype)
@classmethod
async def _batch_get_cached_bars_n(
cls, frame_type: FrameType, n: int, end: Frame = None, codes: List[str] = None
) -> BarsPanel:
"""批量获取在cache中截止`end`的`n`个bars。
如果`end`不在`frame_type`所属的边界点上,那么,如果`end`大于等于当前缓存未收盘数据时间,则将包含未收盘数据;否则,返回的记录将截止到`tf.floor(end, frame_type)`。
Args:
frame_type: 时间帧类型
n: 返回记录条数
codes: 证券代码列表
end: 截止时间, 如果为None
Returns:
BarsPanel: 行情数据
"""
# 调用者自己保证end在缓存中
cols = list(bars_dtype_with_code.names)
if frame_type in tf.day_level_frames:
key = f"bars:{frame_type.value}:unclosed"
if codes is None:
recs = await cache.security.hgetall(key)
codes = list(recs.keys())
recs = recs.values()
else:
recs = await cache.security.hmget(key, *codes)
barss = cls._deserialize_cached_bars(recs, frame_type)
if barss.size > 0:
if len(barss) != len(codes):
# issue 39, 如果某支票当天停牌,则缓存中将不会有它的记录,此时需要移除其代码
codes = [
codes[i] for i, item in enumerate(recs) if item is not None
]
barss = numpy_append_fields(barss, "code", codes, [("code", "O")])
return barss[cols].astype(bars_dtype_with_code)
else:
return np.array([], dtype=bars_dtype_with_code)
else:
end = end or datetime.datetime.now()
close_end = tf.floor(end, frame_type)
all_bars = []
if codes is None:
keys = await cache.security.keys(
f"bars:{frame_type.value}:*[^unclosed]"
)
codes = [key.split(":")[-1] for key in keys]
else:
keys = [f"bars:{frame_type.value}:{code}" for code in codes]
if frame_type != FrameType.MIN1:
unclosed = await cache.security.hgetall(
f"bars:{frame_type.value}:unclosed"
)
else:
unclosed = {}
pl = cache.security.pipeline()
frames = tf.get_frames_by_count(close_end, n, frame_type)
for key in keys:
pl.hmget(key, *frames)
all_closed = await pl.execute()
for code, raw in zip(codes, all_closed):
raw.append(unclosed.get(code))
barss = cls._deserialize_cached_bars(raw, frame_type)
barss = numpy_append_fields(
barss, "code", [code] * len(barss), [("code", "O")]
)
barss = barss[cols].astype(bars_dtype_with_code)
all_bars.append(barss[barss["frame"] <= end][-n:])
try:
return np.concatenate(all_bars)
except ValueError as e:
logger.exception(e)
return np.array([], dtype=bars_dtype_with_code)
@classmethod
async def _get_cached_bars_n(
cls, code: str, n: int, frame_type: FrameType, end: Frame = None
) -> BarsArray:
"""从缓存中获取指定代码的行情数据
存取逻辑是,从`end`指定的时间向前取`n`条记录。`end`不应该大于当前系统时间,并且根据`end`和`n`计算出来的起始时间应该在缓存中存在。否则,两种情况下,返回记录数都将小于`n`。
如果`end`不处于`frame_type`所属的边界结束位置,且小于当前已缓存的未收盘bar时间,则会返回前一个已收盘的数据,否则,返回的记录中还将包含未收盘的数据。
args:
code: 证券代码,比如000001.XSHE
n: 返回记录条数
frame_type: 帧类型
end: 结束帧,如果为None,则取当前时间
returns:
元素类型为`coretypes.bars_dtype`的一维numpy数组。如果没有数据,则返回空ndarray。
"""
# 50 times faster than arrow.now().floor('second')
end = end or datetime.datetime.now().replace(second=0, microsecond=0)
if frame_type in tf.minute_level_frames:
cache_start = tf.first_min_frame(end.date(), frame_type)
closed = tf.floor(end, frame_type)
frames = (tf.get_frames(cache_start, closed, frame_type))[-n:]
if len(frames) == 0:
return np.empty(shape=(0,), dtype=bars_dtype)
key = f"bars:{frame_type.value}:{code}"
recs = await cache.security.hmget(key, *frames)
recs = cls._deserialize_cached_bars(recs, frame_type)
if closed < end:
# for unclosed
key = f"bars:{frame_type.value}:unclosed"
unclosed = await cache.security.hget(key, code)
unclosed = cls._deserialize_cached_bars([unclosed], frame_type)
if end < unclosed[0]["frame"].item():
# 如果unclosed为9:36, 调用者要求取9:29的5m数据,则取到的unclosed不合要求,抛弃。似乎没有更好的方法检测end与unclosed的关系
return recs[-n:]
else:
bars = np.concatenate((recs, unclosed))
return bars[-n:]
else:
return recs[-n:]
else: # 日线及以上级别,仅在缓存中存在未收盘数据
key = f"bars:{frame_type.value}:unclosed"
rec = await cache.security.hget(key, code)
return cls._deserialize_cached_bars([rec], frame_type)
@classmethod
async def cache_bars(cls, code: str, frame_type: FrameType, bars: BarsArray):
"""将当期已收盘的行情数据缓存
Note:
当前只缓存1分钟数据。其它分钟数据,都在调用时,通过resample临时合成。
行情数据缓存在以`bars:{frame_type.value}:{code}`为key, {frame}为field的hashmap中。
Args:
code: the full qualified code of a security or index
frame_type: frame type of the bars
bars: the bars to cache, which is a numpy array of dtype `coretypes.bars_dtype`
Raises:
RedisError: if redis operation failed, see documentation of aioredis
"""
# 转换时间为int
convert = tf.time2int if frame_type in tf.minute_level_frames else tf.date2int
key = f"bars:{frame_type.value}:{code}"
pl = cache.security.pipeline()
for bar in bars:
val = [*bar]
val[0] = convert(bar["frame"].item())
pl.hset(key, val[0], ",".join(map(str, val)))
await pl.execute()
@classmethod
async def cache_unclosed_bars(
cls, code: str, frame_type: FrameType, bars: BarsArray
): # pragma: no cover
"""将未结束的行情数据缓存
未结束的行情数据缓存在以`bars:{frame_type.value}:unclosed`为key, {code}为field的hashmap中。
尽管`bars`被声明为BarsArray,但实际上应该只包含一个元素。
Args:
code: the full qualified code of a security or index
frame_type: frame type of the bars
bars: the bars to cache, which is a numpy array of dtype `coretypes.bars_dtype`
Raises:
RedisError: if redis operation failed, see documentation of aioredis
"""
converter = tf.time2int if frame_type in tf.minute_level_frames else tf.date2int
assert len(bars) == 1, "unclosed bars should only have one record"
key = f"bars:{frame_type.value}:unclosed"
bar = bars[0]
val = [*bar]
val[0] = converter(bar["frame"].item())
await cache.security.hset(key, code, ",".join(map(str, val)))
@classmethod
async def persist_bars(
cls,
frame_type: FrameType,
bars: Union[Dict[str, BarsArray], BarsArray, pd.DataFrame],
):
"""将行情数据持久化
如果`bars`类型为Dict,则key为`code`,value为`bars`。如果其类型为BarsArray或者pd.DataFrame,则`bars`各列字段应该为`coretypes.bars_dtype` + ("code", "O")构成。
Args:
frame_type: the frame type of the bars
bars: the bars to be persisted
Raises:
InfluxDBWriteError: if influxdb write failed
"""
client = get_influx_client()
measurement = cls._measurement_name(frame_type)
logger.info("persisting bars to influxdb: %s, %d secs", measurement, len(bars))
if isinstance(bars, dict):
for code, value in bars.items():
await client.save(
value, measurement, global_tags={"code": code}, time_key="frame"
)
else:
await client.save(bars, measurement, tag_keys=["code"], time_key="frame")
@classmethod
def resample(
cls, bars: BarsArray, from_frame: FrameType, to_frame: FrameType
) -> BarsArray:
"""将原来为`from_frame`的行情数据转换为`to_frame`的行情数据
如果`to_frame`为日线或者分钟级别线,则`from_frame`必须为分钟线;如果`to_frame`为周以上级别线,则`from_frame`必须为日线。其它级别之间的转换不支持。
如果`from_frame`为1分钟线,则必须从9:31起。
Args:
bars (BarsArray): 行情数据
from_frame (FrameType): 转换前的FrameType
to_frame (FrameType): 转换后的FrameType
Returns:
BarsArray: 转换后的行情数据
"""
if from_frame == FrameType.MIN1:
return cls._resample_from_min1(bars, to_frame)
elif from_frame == FrameType.DAY: # pragma: no cover
return cls._resample_from_day(bars, to_frame)
else: # pragma: no cover
raise TypeError(f"unsupported from_frame: {from_frame}")
@classmethod
def _measurement_name(cls, frame_type):
return f"stock_bars_{frame_type.value}"
@classmethod
def _resample_from_min1(cls, bars: BarsArray, to_frame: FrameType) -> BarsArray:
"""将`bars`从1分钟线转换为`to_frame`的行情数据
重采样后的数据只包含frame, open, high, low, close, volume, amount, factor,无论传入数据是否还有别的字段,它们都将被丢弃。
resampling 240根分钟线到5分钟大约需要100微秒。
TODO: 如果`bars`中包含nan怎么处理?
"""
if bars[0]["frame"].item().minute != 31:
raise ValueError("resampling from 1min must start from 9:31")
if to_frame not in (
FrameType.MIN5,
FrameType.MIN15,
FrameType.MIN30,
FrameType.MIN60,
FrameType.DAY,
):
raise ValueError(f"unsupported to_frame: {to_frame}")
bins_len = {
FrameType.MIN5: 5,
FrameType.MIN15: 15,
FrameType.MIN30: 30,
FrameType.MIN60: 60,
FrameType.DAY: 240,
}[to_frame]
bins = len(bars) // bins_len
npart1 = bins * bins_len
part1 = bars[:npart1].reshape((-1, bins_len))
part2 = bars[npart1:]
open_pos = np.arange(bins) * bins_len
close_pos = np.arange(1, bins + 1) * bins_len - 1
if len(bars) > bins_len * bins:
close_pos = np.append(close_pos, len(bars) - 1)
resampled = np.empty((bins + 1,), dtype=bars_dtype)
else:
resampled = np.empty((bins,), dtype=bars_dtype)
resampled[:bins]["open"] = bars[open_pos]["open"]
resampled[:bins]["high"] = np.max(part1["high"], axis=1)
resampled[:bins]["low"] = np.min(part1["low"], axis=1)
resampled[:bins]["volume"] = np.sum(part1["volume"], axis=1)
resampled[:bins]["amount"] = np.sum(part1["amount"], axis=1)
if len(part2):
resampled[-1]["open"] = part2["open"][0]
resampled[-1]["high"] = np.max(part2["high"])
resampled[-1]["low"] = np.min(part2["low"])
resampled[-1]["volume"] = np.sum(part2["volume"])
resampled[-1]["amount"] = np.sum(part2["amount"])
cols = ["frame", "close", "factor"]
resampled[cols] = bars[close_pos][cols]
if to_frame == FrameType.DAY:
resampled["frame"] = bars[-1]["frame"].item().date()
return resampled
@classmethod
def _resample_from_day(cls, bars: BarsArray, to_frame: FrameType) -> BarsArray:
"""将`bars`从日线转换成`to_frame`的行情数据
Args:
bars (BarsArray): [description]
to_frame (FrameType): [description]
Returns:
转换后的行情数据
"""
rules = {
"frame": "last",
"open": "first",
"high": "max",
"low": "min",
"close": "last",
"volume": "sum",
"amount": "sum",
"factor": "last",
}
if to_frame == FrameType.WEEK:
freq = "W-Fri"
elif to_frame == FrameType.MONTH:
freq = "M"
elif to_frame == FrameType.QUARTER:
freq = "Q"
elif to_frame == FrameType.YEAR:
freq = "A"
else:
raise ValueError(f"unsupported to_frame: {to_frame}")
df = pd.DataFrame(bars)
df.index = pd.to_datetime(bars["frame"])
df = df.resample(freq).agg(rules)
bars = np.array(df.to_records(index=False), dtype=bars_dtype)
# filter out data like (None, nan, ...)
return bars[np.isfinite(bars["close"])]
@classmethod
async def _get_price_limit_in_cache(
cls, code: str, begin: datetime.date, end: datetime.date
):
date_str = await cache._security_.get(TRADE_PRICE_LIMITS_DATE)
if date_str:
date_in_cache = arrow.get(date_str).date()
if date_in_cache < begin or date_in_cache > end:
return None
else:
return None
dtype = [("frame", "O"), ("high_limit", "f4"), ("low_limit", "f4")]
hp = await cache._security_.hget(TRADE_PRICE_LIMITS, f"{code}.high_limit")
lp = await cache._security_.hget(TRADE_PRICE_LIMITS, f"{code}.low_limit")
if hp is None or lp is None:
return None
else:
return np.array([(date_in_cache, hp, lp)], dtype=dtype)
@classmethod
async def get_trade_price_limits(
cls, code: str, begin: Frame, end: Frame
) -> BarsArray:
"""从influxdb和cache中获取个股在[begin, end]之间的涨跌停价。
涨跌停价只有日线数据才有,因此,FrameType固定为FrameType.DAY,
当天的数据存放于redis,如果查询日期包含当天(交易日),从cache中读取并追加到结果中
Args:
code : 个股代码
begin : 开始日期
end : 结束日期
Returns:
dtype为[('frame', 'O'), ('high_limit', 'f4'), ('low_limit', 'f4')]的numpy数组
"""
cols = ["_time", "high_limit", "low_limit"]
dtype = [("frame", "O"), ("high_limit", "f4"), ("low_limit", "f4")]
if isinstance(begin, datetime.datetime):
begin = begin.date() # 强制转换为date
if isinstance(end, datetime.datetime):
end = end.date() # 强制转换为date
data_in_cache = await cls._get_price_limit_in_cache(code, begin, end)
client = get_influx_client()
measurement = cls._measurement_name(FrameType.DAY)
flux = (
Flux()
.bucket(client._bucket)
.measurement(measurement)
.range(begin, end)
.tags({"code": code})
.fields(cols)
.sort("_time")
)
ds = NumpyDeserializer(
dtype,
use_cols=cols,
converters={"_time": lambda x: ciso8601.parse_datetime(x).date()},
# since we ask parse date in convertors, so we have to disable parse_date
parse_date=None,
)
result = await client.query(flux, ds)
if data_in_cache:
result = np.concatenate([result, data_in_cache])
return result
@classmethod
async def reset_price_limits_cache(cls, cache_only: bool, dt: datetime.date = None):
if cache_only is False:
date_str = await cache._security_.get(TRADE_PRICE_LIMITS_DATE)
if not date_str:
return # skip clear action if date not found in cache
date_in_cache = arrow.get(date_str).date()
if dt is None or date_in_cache != dt: # 更新的时间和cache的时间相同,则清除cache
return # skip clear action
await cache._security_.delete(TRADE_PRICE_LIMITS)
await cache._security_.delete(TRADE_PRICE_LIMITS_DATE)
@classmethod
async def save_trade_price_limits(
cls, price_limits: LimitPriceOnlyBarsArray, to_cache: bool
):
"""保存涨跌停价
Args:
price_limits: 要保存的涨跌停价格数据。
to_cache: 是保存到缓存中,还是保存到持久化存储中
"""
if len(price_limits) == 0:
return
if to_cache: # 每个交易日上午9点更新两次
pl = cache._security_.pipeline()
for row in price_limits:
# .item convert np.float64 to python float
pl.hset(
TRADE_PRICE_LIMITS,
f"{row['code']}.high_limit",
row["high_limit"].item(),
)
pl.hset(
TRADE_PRICE_LIMITS,
f"{row['code']}.low_limit",
row["low_limit"].item(),
)
dt = price_limits[-1]["frame"]
pl.set(TRADE_PRICE_LIMITS_DATE, dt.strftime("%Y-%m-%d"))
await pl.execute()
else:
# to influxdb, 每个交易日的第二天早上2点保存
client = get_influx_client()
await client.save(
price_limits,
cls._measurement_name(FrameType.DAY),
tag_keys="code",
time_key="frame",
)
@classmethod
async def trade_price_limit_flags(
cls, code: str, start: datetime.date, end: datetime.date
) -> Tuple[List[bool]]:
"""获取个股在[start, end]之间的涨跌停标志
!!!Note
本函数返回的序列在股票有停牌的情况下,将不能与[start, end]一一对应。
Args:
code: 个股代码
start: 开始日期
end: 结束日期
Returns:
涨跌停标志列表(buy, sell)
"""
cols = ["_time", "close", "high_limit", "low_limit"]
client = get_influx_client()
measurement = cls._measurement_name(FrameType.DAY)
flux = (
Flux()
.bucket(client._bucket)
.measurement(measurement)
.range(start, end)
.tags({"code": code})
.fields(cols)
.sort("_time")
)
dtype = [
("frame", "O"),
("close", "f4"),
("high_limit", "f4"),
("low_limit", "f4"),
]
ds = NumpyDeserializer(
dtype,
use_cols=["_time", "close", "high_limit", "low_limit"],
converters={"_time": lambda x: ciso8601.parse_datetime(x).date()},
# since we ask parse date in convertors, so we have to disable parse_date
parse_date=None,
)
result = await client.query(flux, ds)
if result.size == 0:
return np.array([], dtype=dtype)
return (
array_price_equal(result["close"], result["high_limit"]),
array_price_equal(result["close"], result["low_limit"]),
)
@classmethod
async def trade_price_limit_flags_ex(
cls, code: str, start: datetime.date, end: datetime.date
) -> Dict[datetime.date, Tuple[bool, bool]]:
"""获取股票`code`在`[start, end]`区间的涨跌停标志
!!!Note:
如果end为当天,注意在未收盘之前,这个涨跌停标志都是不稳定的
Args:
code: 股票代码
start: 起始日期
end: 结束日期
Returns:
以日期为key,(涨停,跌停)为值的dict
"""
limit_prices = await cls.get_trade_price_limits(code, start, end)
bars = await Stock.get_bars_in_range(
code, FrameType.DAY, start=start, end=end, fq=False
)
close = bars["close"]
results = {}
# aligned = True
for i in range(len(bars)):
if bars[i]["frame"].item().date() != limit_prices[i]["frame"]:
# aligned = False
logger.warning("数据同步错误,涨跌停价格与收盘价时间不一致: %s, %s", code, bars[i]["frame"])
break
results[limit_prices[i]["frame"]] = (
price_equal(limit_prices[i]["high_limit"], close[i]),
price_equal(limit_prices[i]["low_limit"], close[i]),
)
# if not aligned:
# bars = bars[i:]
# limit_prices = limit_prices[i:]
# for frame in bars["frame"]:
# frame = frame.item().date()
# close = bars[bars["frame"].item().date() == frame]["close"].item()
# high = limit_prices[limit_prices["frame"] == frame]["high_limit"].item()
# low = limit_prices[limit_prices["frame"] == frame]["low_limit"].item()
# results[frame] = (
# price_equal(high, close),
# price_equal(low, close)
# )
return results
@classmethod
async def get_latest_price(cls, codes: Iterable[str]) -> List[str]:
"""获取多支股票的最新价格(交易日当天),暂不包括指数
价格数据每5秒更新一次,接受多只股票查询,返回最后缓存的价格
Args:
codes: 代码列表
Returns:
返回一个List,价格是字符形式的浮点数。
"""
if not codes:
return []
_raw_code_list = []
for code_str in codes:
code, _ = code_str.split(".")
_raw_code_list.append(code)
_converted_data = []
raw_data = await cache.feature.hmget(TRADE_LATEST_PRICE, *_raw_code_list)
for _data in raw_data:
if _data is None:
_converted_data.append(_data)
else:
_converted_data.append(float(_data))
return _converted_data | zillionare-omicron | /zillionare_omicron-2.0.0a59-py3-none-any.whl/omicron/models/stock.py | stock.py |
import datetime
import logging
import re
from typing import Optional, Union
import pytz
import tzlocal
from apscheduler.triggers.base import BaseTrigger
from coretypes import FrameType
from omicron.models.timeframe import TimeFrame
logger = logging.getLogger(__name__)
class FrameTrigger(BaseTrigger):
"""
A cron like trigger fires on each valid Frame
"""
def __init__(self, frame_type: Union[str, FrameType], jitter: str = None):
"""构造函数
jitter的格式用正则式表达为`r"([-]?)(\\d+)([mshd])"`,其中第一组为符号,'-'表示提前;
第二组为数字,第三组为单位,可以为`m`(分钟), `s`(秒), `h`(小时),`d`(天)。
下面的示例构造了一个只在交易日,每30分钟触发一次,每次提前15秒触的trigger。即它的触发时
间是每个交易日的09:29:45, 09:59:45, ...
Examples:
>>> FrameTrigger(FrameType.MIN30, '-15s') # doctest: +ELLIPSIS
<omicron.core.triggers.FrameTrigger object at 0x...>
Args:
frame_type:
jitter: 单位秒。其中offset必须在一个FrameType的长度以内
"""
self.frame_type = FrameType(frame_type)
if jitter is None:
_jitter = 0
else:
matched = re.match(r"([-]?)(\d+)([mshd])", jitter)
if matched is None: # pragma: no cover
raise ValueError(
"malformed. jitter should be [-](number)(unit), "
"for example, -30m, or 30s"
)
sign, num, unit = matched.groups()
num = int(num)
if unit.lower() == "m":
_jitter = 60 * num
elif unit.lower() == "s":
_jitter = num
elif unit.lower() == "h":
_jitter = 3600 * num
elif unit.lower() == "d":
_jitter = 3600 * 24 * num
else: # pragma: no cover
raise ValueError("bad time unit. only s,h,m,d is acceptable")
if sign == "-":
_jitter = -_jitter
self.jitter = datetime.timedelta(seconds=_jitter)
if (
frame_type == FrameType.MIN1
and abs(_jitter) >= 60
or frame_type == FrameType.MIN5
and abs(_jitter) >= 300
or frame_type == FrameType.MIN15
and abs(_jitter) >= 900
or frame_type == FrameType.MIN30
and abs(_jitter) >= 1800
or frame_type == FrameType.MIN60
and abs(_jitter) >= 3600
or frame_type == FrameType.DAY
and abs(_jitter) >= 24 * 3600
# it's still not allowed if offset > week, month, etc. Would anybody
# really specify an offset longer than that?
):
raise ValueError("offset must be less than frame length")
def __str__(self):
return f"{self.__class__.__name__}:{self.frame_type.value}:{self.jitter}"
def get_next_fire_time(
self,
previous_fire_time: Union[datetime.date, datetime.datetime],
now: Union[datetime.date, datetime.datetime],
):
""""""
ft = self.frame_type
# `now` is timezone aware, while ceiling isn't
now = now.replace(tzinfo=None)
next_tick = now
next_frame = TimeFrame.ceiling(now, ft)
while next_tick <= now:
if ft in TimeFrame.day_level_frames:
next_tick = TimeFrame.combine_time(next_frame, 15) + self.jitter
else:
next_tick = next_frame + self.jitter
if next_tick > now:
tz = tzlocal.get_localzone()
return next_tick.astimezone(tz)
else:
next_frame = TimeFrame.shift(next_frame, 1, ft)
class TradeTimeIntervalTrigger(BaseTrigger):
"""只在交易时间触发的固定间隔的trigger"""
def __init__(self, interval: str):
"""构造函数
interval的格式用正则表达式表示为 `r"(\\d+)([mshd])"` 。其中第一组为数字,第二组为单位。有效的
`interval`如 1 ,表示每1小时触发一次,则该触发器将在交易日的10:30, 11:30, 14:00和
15:00各触发一次
Args:
interval : [description]
Raises:
ValueError: [description]
"""
matched = re.match(r"(\d+)([mshd])", interval)
if matched is None:
raise ValueError(f"malform interval {interval}")
interval, unit = matched.groups()
interval = int(interval)
unit = unit.lower()
if unit == "s":
self.interval = datetime.timedelta(seconds=interval)
elif unit == "m":
self.interval = datetime.timedelta(minutes=interval)
elif unit == "h":
self.interval = datetime.timedelta(hours=interval)
elif unit == "d":
self.interval = datetime.timedelta(days=interval)
else:
self.interval = datetime.timedelta(seconds=interval)
def __str__(self):
return f"{self.__class__.__name__}:{self.interval.seconds}"
def get_next_fire_time(
self,
previous_fire_time: Optional[datetime.datetime],
now: Optional[datetime.datetime],
):
""""""
if previous_fire_time is not None:
fire_time = previous_fire_time + self.interval
else:
fire_time = now
if TimeFrame.date2int(fire_time.date()) not in TimeFrame.day_frames:
ft = TimeFrame.day_shift(now, 1)
fire_time = datetime.datetime(
ft.year, ft.month, ft.day, 9, 30, tzinfo=fire_time.tzinfo
)
return fire_time
minutes = fire_time.hour * 60 + fire_time.minute
if minutes < 570:
fire_time = fire_time.replace(hour=9, minute=30, second=0, microsecond=0)
elif 690 < minutes < 780:
fire_time = fire_time.replace(hour=13, minute=0, second=0, microsecond=0)
elif minutes > 900:
ft = TimeFrame.day_shift(fire_time, 1)
fire_time = datetime.datetime(
ft.year, ft.month, ft.day, 9, 30, tzinfo=fire_time.tzinfo
)
return fire_time | zillionare-omicron | /zillionare_omicron-2.0.0a59-py3-none-any.whl/omicron/core/triggers.py | triggers.py |
import logging
from asyncio import Lock
import aioredis
import cfg4py
from aioredis.client import Redis
logger = logging.getLogger(__file__)
_cache_lock = Lock()
class RedisCache:
databases = ["_sys_", "_security_", "_temp_", "_feature_"]
_security_: Redis
_sys_: Redis
_temp_: Redis
_feature_: Redis
_app_: Redis
_initialized = False
@property
def security(self) -> Redis:
if self._initialized is False:
return None
else:
return self._security_
@property
def sys(self) -> Redis:
if self._initialized is False:
return None
else:
return self._sys_
@property
def temp(self) -> Redis:
if self._initialized is False:
return None
else:
return self._temp_
@property
def feature(self) -> Redis:
if self._initialized is False:
return None
else:
return self._feature_
@property
def app(self) -> Redis:
if self._initialized is False:
return None
else:
return self._app_
def __init__(self):
self._initialized = False
async def close(self):
global _cache_lock
async with _cache_lock:
if self._initialized is False:
return True
logger.info("closing redis cache...")
for redis in [self.sys, self.security, self.temp, self.feature]:
await redis.close()
await self.app.close()
self._initialized = False
logger.info("redis caches are all closed")
async def init(self, app: int = 5):
global _cache_lock
async with _cache_lock:
if self._initialized:
return True
logger.info("init redis cache...")
cfg = cfg4py.get_instance()
for i, name in enumerate(self.databases):
auto_decode = True
if name == "_temp_":
auto_decode = False
db = aioredis.from_url(
cfg.redis.dsn,
encoding="utf-8",
decode_responses=auto_decode,
max_connections=10,
db=i,
)
await db.set("__meta__.database", name)
setattr(self, name, db)
# init app pool
if app < 5 or app > 15:
app = 5
db = aioredis.from_url(
cfg.redis.dsn,
encoding="utf-8",
decode_responses=True,
max_connections=10,
db=app,
)
await db.set("__meta__.database", "__app__")
setattr(self, "_app_", db)
self._initialized = True
logger.info("redis cache is inited")
return True
cache = RedisCache()
__all__ = ["cache"] | zillionare-omicron | /zillionare_omicron-2.0.0a59-py3-none-any.whl/omicron/dal/cache.py | cache.py |
import datetime
from collections import defaultdict
from typing import DefaultDict, List, Tuple
import arrow
import numpy as np
from coretypes import Frame
from omicron.core.errors import DuplicateOperationError
class Flux(object):
"""Helper functions for building flux query expression"""
EPOCH_START = datetime.datetime(1970, 1, 1, 0, 0, 0)
def __init__(self, auto_pivot=True, no_sys_cols=True):
"""初始化Flux对象
Args:
auto_pivot : 是否自动将查询列字段组装成行. Defaults to True.
no_sys_cols: 是否自动将系统字段删除. Defaults to True.请参考[drop_sys_cols][omicron.dal.influx.flux.Flux.drop_sys_cols]
"""
self._cols = None
self.expressions = defaultdict(list)
self._auto_pivot = auto_pivot
self._last_n = None
self.no_sys_cols = no_sys_cols
def __str__(self):
return self._compose()
def __repr__(self) -> str:
return f"<{self.__class__.__name__}>:\n{self._compose()}"
def _compose(self):
"""将所有表达式合并为一个表达式"""
if not all(
[
"bucket" in self.expressions,
"measurement" in self.expressions,
"range" in self.expressions,
]
):
raise AssertionError("bucket, measurement and range must be set")
expr = [self.expressions[k] for k in ("bucket", "range", "measurement")]
if self.expressions.get("tags"):
expr.append(self.expressions["tags"])
if self.expressions.get("fields"):
expr.append(self.expressions["fields"])
if "drop" not in self.expressions and self.no_sys_cols:
self.drop_sys_cols()
if self.expressions.get("drop"):
expr.append(self.expressions["drop"])
if self._auto_pivot and "pivot" not in self.expressions:
self.pivot()
if self.expressions.get("pivot"):
expr.append(self.expressions["pivot"])
if self.expressions.get("group"):
expr.append(self.expressions["group"])
if self.expressions.get("sort"):
expr.append(self.expressions["sort"])
if self.expressions.get("limit"):
expr.append(self.expressions["limit"])
# influxdb默认按升序排列,但last_n查询的结果则必然是降序的,所以还需要再次排序
if self._last_n:
expr.append(
"\n".join(
[
f' |> top(n: {self._last_n}, columns: ["_time"])',
' |> sort(columns: ["_time"], desc: false)',
]
)
)
return "\n".join(expr)
def bucket(self, bucket: str) -> "Flux":
"""add bucket to query expression
Raises:
DuplicateOperationError: 一个查询中只允许指定一个source,如果表达式中已经指定了bucket,则抛出异常
Returns:
Flux对象
"""
if "bucket" in self.expressions:
raise DuplicateOperationError("bucket has been set")
self.expressions["bucket"] = f'from(bucket: "{bucket}")'
return self
def measurement(self, measurement: str) -> "Flux":
"""add measurement filter to query
Raises:
DuplicateOperationError: 一次查询中只允许指定一个measurement, 如果表达式中已经存在measurement, 则抛出异常
Returns:
Flux对象自身,以便进行管道操作
"""
if "measurement" in self.expressions:
raise DuplicateOperationError("measurement has been set")
self.expressions[
"measurement"
] = f' |> filter(fn: (r) => r["_measurement"] == "{measurement}")'
return self
def range(
self, start: Frame, end: Frame, right_close=True, precision="s"
) -> "Flux":
"""添加时间范围过滤
必须指定的查询条件,否则influxdb会报unbound查询错,因为这种情况下,返回的数据量将非常大。
在格式化时间时,需要根据`precision`生成时间字符串。在向Influxdb发送请求时,应该注意查询参数中指定的时间精度与这里使用的保持一致。
Influxdb的查询结果默认不包含结束时间,当`right_close`指定为True时,我们将根据指定的精度修改`end`时间,使之仅比`end`多一个时间单位,从而保证查询结果会包含`end`。
Raises:
DuplicateOperationError: 一个查询中只允许指定一次时间范围,如果range表达式已经存在,则抛出异常
Args:
start: 开始时间
end: 结束时间
right_close: 查询结果是否包含结束时间。
precision: 时间精度,默认为秒。
Returns:
Flux对象,以支持管道操作
"""
if "range" in self.expressions:
raise DuplicateOperationError("range has been set")
if precision not in ["s", "ms", "us"]:
raise AssertionError("precision must be 's', 'ms' or 'us'")
end = self.format_time(end, precision, right_close)
start = self.format_time(start, precision)
self.expressions["range"] = f" |> range(start: {start}, stop: {end})"
return self
def limit(self, limit: int) -> "Flux":
"""添加返回记录数限制
Raises:
DuplicateOperationError: 一个查询中只允许指定一次limit,如果limit表达式已经存在,则抛出异常
Args:
limit: 返回记录数限制
Returns:
Flux对象,以便进行管道操作
"""
if "limit" in self.expressions:
raise DuplicateOperationError("limit has been set")
self.expressions["limit"] = " |> limit(n: %d)" % limit
return self
@classmethod
def to_timestamp(cls, tm: Frame, precision: str = "s") -> int:
"""将时间根据精度转换为unix时间戳
在往influxdb写入数据时,line-protocol要求的时间戳为unix timestamp,并且与其精度对应。
influxdb始终使用UTC时间,因此,`tm`也必须已经转换成UTC时间。
Args:
tm: 时间
precision: 时间精度,默认为秒。
Returns:
时间戳
"""
if precision not in ["s", "ms", "us"]:
raise AssertionError("precision must be 's', 'ms' or 'us'")
# get int repr of tm, in seconds unit
if isinstance(tm, np.datetime64):
tm = tm.astype("datetime64[s]").astype("int")
elif isinstance(tm, datetime.datetime):
tm = tm.timestamp()
else:
tm = arrow.get(tm).timestamp()
return int(tm * 10 ** ({"s": 0, "ms": 3, "us": 6}[precision]))
@classmethod
def format_time(cls, tm: Frame, precision: str = "s", shift_forward=False) -> str:
"""将时间转换成客户端对应的精度,并以 RFC3339 timestamps格式串(即influxdb要求的格式)返回。
如果这个时间是作为查询的range中的结束时间使用时,由于influx查询的时间范围是左闭右开的,因此如果你需要查询的是一个闭区间,则需要将`end`的时间向前偏移一个精度。通过传入`shift_forward = True`可以完成这种转换。
Examples:
>>> # by default, the precision is seconds, and convert a date
>>> Flux.format_time(datetime.date(2019, 1, 1))
'2019-01-01T00:00:00Z'
>>> # set precision to ms, convert a time
>>> Flux.format_time(datetime.datetime(1978, 7, 8, 12, 34, 56, 123456), precision="ms")
'1978-07-08T12:34:56.123Z'
>>> # convert and forward shift
>>> Flux.format_time(datetime.date(1978, 7, 8), shift_forward = True)
'1978-07-08T00:00:01Z'
Args:
tm : 待格式化的时间
precision: 时间精度,可选值为:'s', 'ms', 'us'
shift_forward: 如果为True,则将end向前偏移一个精度
Returns:
调整后符合influx时间规范的时间(字符串表示)
"""
timespec = {"s": "seconds", "ms": "milliseconds", "us": "microseconds"}.get(
precision
)
if timespec is None:
raise ValueError(
f"precision must be one of 's', 'ms', 'us', but got {precision}"
)
tm = arrow.get(tm).naive
if shift_forward:
tm = tm + datetime.timedelta(**{timespec: 1})
return tm.isoformat(sep="T", timespec=timespec) + "Z"
def tags(self, tags: DefaultDict[str, List[str]]) -> "Flux":
"""给查询添加tags过滤条件
此查询条件为过滤条件,并非必须。如果查询中没有指定tags,则会返回所有记录。
在实现上,既可以使用`contains`语法,也可以使用`or`语法(由于一条记录只能属于一个tag,所以,当指定多个tag进行查询时,它们之间的关系应该为`or`)。经验证,contains语法会始终先将所有符合条件的记录检索出来,再进行过滤。这样的效率比较低,特别是当tags的数量较少时,会远远比使用or语法慢。
Raises:
DuplicateOperationError: 一个查询中只允许执行一次,如果tag filter表达式已经存在,则抛出异常
Args:
tags : tags是一个{tagname: Union[str,[tag_values]]}对象。
Examples:
>>> flux = Flux()
>>> flux.tags({"code": ["000001", "000002"], "name": ["浦发银行"]}).expressions["tags"]
' |> filter(fn: (r) => r["code"] == "000001" or r["code"] == "000002" or r["name"] == "浦发银行")'
Returns:
Flux对象,以便进行管道操作
"""
if "tags" in self.expressions:
raise DuplicateOperationError("tags has been set")
filters = []
for tag, values in tags.items():
assert (
isinstance(values, str) or len(values) > 0
), f"tag {tag} should not be empty or None"
if isinstance(values, str):
values = [values]
for v in values:
filters.append(f'r["{tag}"] == "{v}"')
op_expression = " or ".join(filters)
self.expressions["tags"] = f" |> filter(fn: (r) => {op_expression})"
return self
def fields(self, fields: List, reserve_time_stamp: bool = True) -> "Flux":
"""给查询添加field过滤条件
此查询条件为过滤条件,用以指定哪些field会出现在查询结果中,并非必须。如果查询中没有指定tags,则会返回所有记录。
由于一条记录只能属于一个_field,所以,当指定多个_field进行查询时,它们之间的关系应该为`or`。
Raises:
DuplicateOperationError: 一个查询中只允许执行一次,如果filed filter表达式已经存在,则抛出异常
Args:
fields: 待查询的field列表
reserve_time_stamp: 是否保留时间戳`_time`,默认为True
Returns:
Flux对象,以便进行管道操作
"""
if "fields" in self.expressions:
raise DuplicateOperationError("fields has been set")
self._cols = fields.copy()
if reserve_time_stamp and "_time" not in self._cols:
self._cols.append("_time")
self._cols = sorted(self._cols)
filters = [f'r["_field"] == "{name}"' for name in self._cols]
self.expressions["fields"] = f" |> filter(fn: (r) => {' or '.join(filters)})"
return self
def pivot(
self,
row_keys: List[str] = ["_time"],
column_keys=["_field"],
value_column: str = "_value",
) -> "Flux":
"""pivot用来将以列为单位的数据转换为以行为单位的数据
Flux查询返回的结果通常都是以列为单位的数据,增加本pivot条件后,结果将被转换成为以行为单位的数据再返回。
这里实现的是measurement内的转换,请参考 [pivot](https://docs.influxdata.com/flux/v0.x/stdlib/universe/pivot/#align-fields-within-each-measurement-that-have-the-same-timestamp)
Args:
row_keys: 惟一确定输出中一行数据的列名字, 默认为["_time"]
column_keys: 列名称列表,默认为["_field"]
value_column: 值列名,默认为"_value"
Returns:
Flux对象,以便进行管道操作
"""
if "pivot" in self.expressions:
raise DuplicateOperationError("pivot has been set")
columns = ",".join([f'"{name}"' for name in column_keys])
rowkeys = ",".join([f'"{name}"' for name in row_keys])
self.expressions[
"pivot"
] = f' |> pivot(columnKey: [{columns}], rowKey: [{rowkeys}], valueColumn: "{value_column}")'
return self
def sort(self, by: List[str] = None, desc: bool = False) -> "Flux":
"""按照指定的列进行排序
根据[influxdb doc](https://docs.influxdata.com/influxdb/v2.0/query-data/flux/first-last/), 查询返回值默认地按时间排序。因此,如果仅仅是要求查询结果按时间排序,无须调用此API,但是,此API提供了按其它字段排序的能力。
另外,在一个有5000多个tag,共返回1M条记录的测试中,测试验证返回记录确实按_time升序排列。
Args:
by: 指定排序的列名称列表
Returns:
Flux对象,以便进行管道操作
"""
if "sort" in self.expressions:
raise DuplicateOperationError("sort has been set")
if by is None:
by = ["_value"]
if isinstance(by, str):
by = [by]
columns_ = ",".join([f'"{name}"' for name in by])
desc = "true" if desc else "false"
self.expressions["sort"] = f" |> sort(columns: [{columns_}], desc: {desc})"
return self
def group(self, by: Tuple[str]) -> "Flux":
"""[summary]
Returns:
[description]
"""
if "group" in self.expressions:
raise DuplicateOperationError("group has been set")
if isinstance(by, str):
by = [by]
cols = ",".join([f'"{col}"' for col in by])
self.expressions["group"] = f" |> group(columns: [{cols}])"
return self
def latest(self, n: int) -> "Flux":
"""获取最后n条数据,按时间增序返回
Flux查询的增强功能,相当于top + sort + limit
Args:
n: 最后n条数据
Returns:
Flux对象,以便进行管道操作
"""
assert "top" not in self.expressions, "top and last_n can not be used together"
assert (
"sort" not in self.expressions
), "sort and last_n can not be used together"
assert (
"limit" not in self.expressions
), "limit and last_n can not be used together"
self._last_n = n
return self
@property
def cols(self) -> List[str]:
"""the columns or the return records
the implementation is buggy. Influx doesn't tell us in which order these columns are.
Returns:
the columns name of the return records
"""
# fixme: if keep in expression, then return group key + tag key + value key
# if keep not in expression, then stream, table, _time, ...
return sorted(self._cols)
def delete(
self,
measurement: str,
stop: datetime.datetime,
tags: dict = {},
start: datetime.datetime = None,
precision: str = "s",
) -> dict:
"""构建删除语句。
according to [delete-predicate](https://docs.influxdata.com/influxdb/v2.1/reference/syntax/delete-predicate/), delete只支持AND逻辑操作,只支持“=”操作,不支持“!=”操作,可以使用任何字段或者tag,但不包括_time和_value字段。
由于influxdb这一段文档不是很清楚,根据试验结果,目前仅支持按时间范围和tags进行删除较好。如果某个column的值类型是字符串,则也可以通过`tags`参数传入,匹配后删除。但如果传入了非字符串类型的column,则将得到无法预料的结果。
Args:
measurement : [description]
stop : [description]
tags : 按tags和匹配的值进行删除。传入的tags中,key为tag名称,value为tag要匹配的取值,可以为str或者List[str]。
start : 起始时间。如果省略,则使用EPOCH_START.
precision : 时间精度。可以为“s”,“ms”,“us”
Returns:
删除语句
"""
timespec = {"s": "seconds", "ms": "milliseconds", "us": "microseconds"}.get(
precision
)
if start is None:
start = self.EPOCH_START.isoformat(timespec=timespec) + "Z"
predicate = [f'_measurement="{measurement}"']
for key, value in tags.items():
if isinstance(value, list):
predicate.extend([f'{key} = "{v}"' for v in value])
else:
predicate.append(f'{key} = "{value}"')
command = {
"start": start,
"stop": f"{stop.isoformat(timespec=timespec)}Z",
"predicate": " AND ".join(predicate),
}
return command
def drop(self, cols: List[str]) -> "Flux":
"""use this to drop columns before return result
Args:
cols : the name of columns to be dropped
Returns:
Flux object, to support pipe operation
"""
if "drop" in self.expressions:
raise DuplicateOperationError("drop operation has been set already")
# add surrounding quotes
_cols = [f'"{c}"' for c in cols]
self.expressions["drop"] = f" |> drop(columns: [{','.join(_cols)}])"
return self
def drop_sys_cols(self, cols: List[str] = None) -> "Flux":
"""use this to drop ["_start", "_stop", "_measurement"], plus columns specified in `cols`, before return query result
please be noticed, after drop sys columns, there's still two sys columns left, which is "_time" and "table", and "_time" should usually be kept, "table" is one we're not able to removed. If you don't like _time in return result, you can specify it in `cols` parameter.
Args:
cols : the extra columns to be dropped
Returns:
Flux query object
"""
_cols = ["_start", "_stop", "_measurement"]
if cols is not None:
_cols.extend(cols)
return self.drop(_cols) | zillionare-omicron | /zillionare_omicron-2.0.0a59-py3-none-any.whl/omicron/dal/influx/flux.py | flux.py |
import datetime
import gzip
import json
import logging
from typing import Any, Callable, Dict, List, Optional, Union
import arrow
import numpy as np
from aiohttp import ClientSession
from pandas import DataFrame
from omicron.core.errors import BadParameterError
from omicron.dal.influx.errors import (
InfluxDBQueryError,
InfluxDBWriteError,
InfluxDeleteError,
InfluxSchemaError,
)
from omicron.dal.influx.flux import Flux
from omicron.dal.influx.serialize import DataframeSerializer, NumpySerializer
logger = logging.getLogger(__name__)
class InfluxClient:
def __init__(
self,
url: str,
token: str,
bucket: str,
org: str = None,
enable_compress=False,
chunk_size: int = 5000,
precision: str = "s",
):
"""[summary]
Args:
url ([type]): [description]
token ([type]): [description]
bucket ([type]): [description]
org ([type], optional): [description]. Defaults to None.
enable_compress ([type], optional): [description]. Defaults to False.
chunk_size: number of lines to be saved in one request
precision: 支持的时间精度
"""
self._url = url
self._bucket = bucket
self._enable_compress = enable_compress
self._org = org
self._org_id = None # 需要时通过查询获取,此后不再更新
self._token = token
# influxdb 2.0起支持的时间精度有:ns, us, ms, s。本客户端只支持s, ms和us
self._precision = precision.lower()
if self._precision not in ["s", "ms", "us"]: # pragma: no cover
raise ValueError("precision must be one of ['s', 'ms', 'us']")
self._chunk_size = chunk_size
# write
self._write_url = f"{self._url}/api/v2/write?org={self._org}&bucket={self._bucket}&precision={self._precision}"
self._write_headers = {
"Content-Type": "text/plain; charset=utf-8",
"Authorization": f"Token {token}",
"Accept": "application/json",
}
if self._enable_compress:
self._write_headers["Content-Encoding"] = "gzip"
self._query_url = f"{self._url}/api/v2/query?org={self._org}"
self._query_headers = {
"Authorization": f"Token {token}",
"Content-Type": "application/vnd.flux",
# influx查询结果格式,无论如何指定(或者不指定),在2.1中始终是csv格式
"Accept": "text/csv",
}
if self._enable_compress:
self._query_headers["Accept-Encoding"] = "gzip"
self._delete_url = (
f"{self._url}/api/v2/delete?org={self._org}&bucket={self._bucket}"
)
self._delete_headers = {
"Authorization": f"Token {token}",
"Content-Type": "application/json",
}
async def save(
self,
data: Union[np.ndarray, DataFrame],
measurement: str = None,
tag_keys: List[str] = [],
time_key: str = None,
global_tags: Dict = {},
chunk_size: int = None,
) -> None:
"""save `data` into influxdb
if `data` is a pandas.DataFrame or numy structured array, it will be converted to line protocol and saved. If `data` is str, use `write` method instead.
Args:
data: data to be saved
measurement: the name of measurement
tag_keys: which columns name will be used as tags
chunk_size: number of lines to be saved in one request. if it's -1, then all data will be written in one request. If it's None, then it will be set to `self._chunk_size`
Raises:
InfluxDBWriteError: if write failed
"""
# todo: add more errors raise
if isinstance(data, DataFrame):
assert (
measurement is not None
), "measurement must be specified when data is a DataFrame"
if tag_keys:
assert set(tag_keys) in set(
data.columns.tolist()
), "tag_keys must be in data.columns"
serializer = DataframeSerializer(
data,
measurement,
time_key,
tag_keys,
global_tags,
precision=self._precision,
)
if chunk_size == -1:
chunk_size = len(data)
for lines in serializer.serialize(chunk_size or self._chunk_size):
await self.write(lines)
elif isinstance(data, np.ndarray):
assert (
measurement is not None
), "measurement must be specified when data is a numpy array"
assert (
time_key is not None
), "time_key must be specified when data is a numpy array"
serializer = NumpySerializer(
data,
measurement,
time_key,
tag_keys,
global_tags,
time_precision=self._precision,
)
if chunk_size == -1:
chunk_size = len(data)
for lines in serializer.serialize(chunk_size or self._chunk_size):
await self.write(lines)
else:
raise TypeError(
f"data must be pandas.DataFrame, numpy array, got {type(data)}"
)
async def write(self, line_protocol: str):
"""将line-protocol数组写入influxdb
Args:
line_protocol: 待写入的数据,以line-protocol数组形式存在
"""
# todo: add raise error declaration
if self._enable_compress:
line_protocol_ = gzip.compress(line_protocol.encode("utf-8"))
else:
line_protocol_ = line_protocol
async with ClientSession() as session:
async with session.post(
self._write_url, data=line_protocol_, headers=self._write_headers
) as resp:
if resp.status != 204:
err = await resp.json()
logger.warning(
"influxdb write error when processing: %s, err code: %s, message: %s",
{line_protocol[:100]},
err["code"],
err["message"],
)
logger.debug("data caused error:%s", line_protocol)
raise InfluxDBWriteError(
f"influxdb write failed, err: {err['message']}"
)
async def query(self, flux: Union[Flux, str], deserializer: Callable = None) -> Any:
"""flux查询
flux查询结果是一个以annotated csv格式存储的数据,例如:
```
,result,table,_time,code,amount,close,factor,high,low,open,volume
,_result,0,2019-01-01T00:00:00Z,000001.XSHE,100000000,5.15,1.23,5.2,5,5.1,1000000
```
上述`result`中,事先通过Flux.keep()限制了返回的字段为_time,code,amount,close,factor,high,low,open,volume。influxdb查询返回结果时,总是按照字段名称升序排列。此外,总是会额外地返回_result, table两个字段。
如果传入了deserializer,则会调用deserializer将其解析成为python对象。否则,返回bytes数据。
Args:
flux: flux查询语句
deserializer: 反序列化函数
Returns:
如果未提供反序列化函数,则返回结果为bytes array(如果指定了compress=True,返回结果为gzip解压缩后的bytes array),否则返回反序列化后的python对象
"""
if isinstance(flux, Flux):
flux = str(flux)
async with ClientSession() as session:
async with session.post(
self._query_url, data=flux, headers=self._query_headers
) as resp:
if resp.status != 200:
err = await resp.json()
logger.warning(
f"influxdb query error: {err} when processing {flux[:500]}"
)
logger.debug("data caused error:%s", flux)
raise InfluxDBQueryError(
f"influxdb query failed, status code: {err['message']}"
)
else:
# auto-unzip
body = await resp.read()
if deserializer:
try:
return deserializer(body)
except Exception as e:
logger.exception(e)
logger.warning(
"failed to deserialize data: %s, the query is:%s",
body,
flux[:500],
)
raise
else:
return body
async def drop_measurement(self, measurement: str):
"""从influxdb中删除一个measurement
调用此方法后,实际上该measurement仍然存在,只是没有数据。
"""
# todo: add raise error declaration
await self.delete(measurement, arrow.now().naive)
async def delete(
self,
measurement: str,
stop: datetime.datetime,
tags: Optional[Dict[str, str]] = {},
start: datetime.datetime = None,
precision: str = "s",
):
"""删除influxdb中指定时间段内的数据
关于参数,请参见[Flux.delete][omicron.dal.influx.flux.Flux.delete]。
Args:
measurement: 指定measurement名字
stop: 待删除记录的结束时间
start: 待删除记录的开始时间,如果未指定,则使用EPOCH_START
tags: 按tag进行过滤的条件
precision: 用以格式化起始和结束时间。
Raises:
InfluxDeleteError: 如果删除失败,则抛出此异常
"""
# todo: add raise error declaration
command = Flux().delete(
measurement, stop, tags, start=start, precision=precision
)
async with ClientSession() as session:
async with session.post(
self._delete_url, data=json.dumps(command), headers=self._delete_headers
) as resp:
if resp.status != 204:
err = await resp.json()
logger.warning(
"influxdb delete error: %s when processin command %s",
err["message"],
command,
)
raise InfluxDeleteError(
f"influxdb delete failed, status code: {err['message']}"
)
async def list_buckets(self) -> List[Dict]:
"""列出influxdb中对应token能看到的所有的bucket
Returns:
list of buckets, each bucket is a dict with keys:
```
id
orgID, a 16 bytes hex string
type, system or user
description
name
retentionRules
createdAt
updatedAt
links
labels
```
"""
url = f"{self._url}/api/v2/buckets"
headers = {"Authorization": f"Token {self._token}"}
async with ClientSession() as session:
async with session.get(url, headers=headers) as resp:
if resp.status != 200:
err = await resp.json()
raise InfluxSchemaError(
f"influxdb list bucket failed, status code: {err['message']}"
)
else:
return (await resp.json())["buckets"]
async def delete_bucket(self, bucket_id: str = None):
"""删除influxdb中指定bucket
Args:
bucket_id: 指定bucket的id。如果为None,则会删除本client对应的bucket。
"""
if bucket_id is None:
buckets = await self.list_buckets()
for bucket in buckets:
if bucket["type"] == "user" and bucket["name"] == self._bucket:
bucket_id = bucket["id"]
break
else:
raise BadParameterError(
"bucket_id is None, and we can't find bucket with name: %s"
% self._bucket
)
url = f"{self._url}/api/v2/buckets/{bucket_id}"
headers = {"Authorization": f"Token {self._token}"}
async with ClientSession() as session:
async with session.delete(url, headers=headers) as resp:
if resp.status != 204:
err = await resp.json()
logger.warning(
"influxdb delete bucket error: %s when processin command %s",
err["message"],
bucket_id,
)
raise InfluxSchemaError(
f"influxdb delete bucket failed, status code: {err['message']}"
)
async def create_bucket(
self, description=None, retention_rules: List[Dict] = None, org_id: str = None
) -> str:
"""创建influxdb中指定bucket
Args:
description: 指定bucket的描述
org_id: 指定bucket所属的组织id,如果未指定,则使用本client对应的组织id。
Raises:
InfluxSchemaError: 当influxdb返回错误时,比如重复创建bucket等,会抛出此异常
Returns:
新创建的bucket的id
"""
if org_id is None:
org_id = await self.query_org_id()
url = f"{self._url}/api/v2/buckets"
headers = {"Authorization": f"Token {self._token}"}
data = {
"name": self._bucket,
"orgID": org_id,
"description": description,
"retentionRules": retention_rules,
}
async with ClientSession() as session:
async with session.post(
url, data=json.dumps(data), headers=headers
) as resp:
if resp.status != 201:
err = await resp.json()
logger.warning(
"influxdb create bucket error: %s when processin command %s",
err["message"],
data,
)
raise InfluxSchemaError(
f"influxdb create bucket failed, status code: {err['message']}"
)
else:
result = await resp.json()
return result["id"]
async def list_organizations(self, offset: int = 0, limit: int = 100) -> List[Dict]:
"""列出本客户端允许查询的所组织
Args:
offset : 分页起点
limit : 每页size
Raises:
InfluxSchemaError: influxdb返回的错误
Returns:
list of organizations, each organization is a dict with keys:
```
id : the id of the org
links
name : the name of the org
description
createdAt
updatedAt
```
"""
url = f"{self._url}/api/v2/orgs?offset={offset}&limit={limit}"
headers = {"Authorization": f"Token {self._token}"}
async with ClientSession() as session:
async with session.get(url, headers=headers) as resp:
if resp.status != 200:
err = await resp.json()
logger.warning("influxdb query orgs err: %s", err["message"])
raise InfluxSchemaError(
f"influxdb query orgs failed, status code: {err['message']}"
)
else:
return (await resp.json())["orgs"]
async def query_org_id(self, name: str = None) -> str:
"""通过组织名查找组织id
只能查的本客户端允许查询的组织。如果name未提供,则使用本客户端创建时传入的组织名。
Args:
name: 指定组织名
Returns:
组织id
"""
if name is None:
name = self._org
orgs = await self.list_organizations()
for org in orgs:
if org["name"] == name:
return org["id"]
raise BadParameterError(f"can't find org with name: {name}") | zillionare-omicron | /zillionare_omicron-2.0.0a59-py3-none-any.whl/omicron/dal/influx/influxclient.py | influxclient.py |
import datetime
import io
import itertools
import logging
import math
import re
from email.generator import Generator
from typing import Any, Callable, Dict, List, Mapping, Union
import arrow
import ciso8601
import numpy as np
import pandas as pd
from pandas import DataFrame
from omicron.core.errors import BadParameterError, EmptyResult, SerializationError
from omicron.dal.influx.escape import KEY_ESCAPE, MEASUREMENT_ESCAPE, STR_ESCAPE
from omicron.models.timeframe import date_to_utc_timestamp, datetime_to_utc_timestamp
logger = logging.getLogger(__name__)
def _itertuples(data_frame):
cols = [data_frame.iloc[:, k] for k in range(len(data_frame.columns))]
return zip(data_frame.index, *cols)
def _not_nan(x):
return x == x
def _any_not_nan(p, indexes):
return any(map(lambda x: _not_nan(p[x]), indexes))
EPOCH = datetime.datetime(1970, 1, 1)
class Serializer(object):
"""base class of all serializer/deserializer"""
pass
class DataframeSerializer:
"""Serialize DataFrame into LineProtocols.
Most code is copied from [influxdb-python-client](https://github.com/influxdata/influxdb-client-python/blob/master/influxdb_client/client/write/dataframe_serializer.py), but modified interfaces.
"""
def __init__(
self,
data_frame: DataFrame,
measurement: str,
time_key: str = None,
tag_keys: Union[str, List[str]] = [],
global_tags: Dict = {},
precision="s",
) -> None:
"""Initialize DataframeSerializer.
field keys are column names minus tag keys.
Performance benchmark
- to serialize 10000 points
DataframeSerializer: 0.0893 seconds
NumpySerializer: 0.0698 seconds
- to serialize 1M points
DataframeSerializer: 8.06 seconds
NumpySerializer: 7.16 seconds
Args:
data_frame: DataFrame to be serialized.
measurement: measurement name.
time_key: the name of time column, which will be used as timestamp. If it's None, then the index will be used as timestamp.
tag_keys: List of tag keys.
global_tags: global tags to be added to every row.
precision: precision for write.
"""
# This function is hard to understand but for good reason:
# the approach used here is considerably more efficient
# than the alternatives.
#
# We build up a Python expression that efficiently converts a data point
# tuple into line-protocol entry, and then evaluate the expression
# as a lambda so that we can call it. This avoids the overhead of
# invoking a function on every data value - we only have one function
# call per row instead. The expression consists of exactly
# one f-string, so we build up the parts of it as segments
# that are concatenated together to make the full f-string inside
# the lambda.
#
# Things are made a little more complex because fields and tags with NaN
# values and empty tags are omitted from the generated line-protocol
# output.
#
# As an example, say we have a data frame with two value columns:
# a float
# b int
#
# This will generate a lambda expression to be evaluated that looks like
# this:
#
# lambda p: f"""{measurement_name} {keys[0]}={p[1]},{keys[1]}={p[2]}i {p[0].value}"""
#
# This lambda is then executed for each row p.
#
# When NaNs are present, the expression looks like this (split
# across two lines to satisfy the code-style checker)
#
# lambda p: f"""{measurement_name} {"" if math.isnan(p[1])
# else f"{keys[0]}={p[1]}"},{keys[1]}={p[2]}i {p[0].value}"""
#
# When there's a NaN value in column a, we'll end up with a comma at the start of the
# fields, so we run a regexp substitution after generating the line-protocol entries
# to remove this.
#
# We're careful to run these potentially costly extra steps only when NaN values actually
# exist in the data.
if not isinstance(data_frame, pd.DataFrame):
raise TypeError(
"Must be DataFrame, but type was: {0}.".format(type(data_frame))
)
data_frame = data_frame.copy(deep=False)
if time_key is not None:
assert (
time_key in data_frame.columns
), f"time_key {time_key} not in data_frame"
data_frame.set_index(time_key, inplace=True)
if isinstance(data_frame.index, pd.PeriodIndex):
data_frame.index = data_frame.index.to_timestamp()
if data_frame.index.dtype == "O":
data_frame.index = pd.to_datetime(data_frame.index)
if not isinstance(data_frame.index, pd.DatetimeIndex):
raise TypeError(
"Must be DatetimeIndex, but type was: {0}.".format(
type(data_frame.index)
)
)
if data_frame.index.tzinfo is None:
data_frame.index = data_frame.index.tz_localize("UTC")
if isinstance(tag_keys, str):
tag_keys = [tag_keys]
tag_keys = set(tag_keys or [])
# keys holds a list of string keys.
keys = []
# tags holds a list of tag f-string segments ordered alphabetically by tag key.
tags = []
# fields holds a list of field f-string segments ordered alphebetically by field key
fields = []
# field_indexes holds the index into each row of all the fields.
field_indexes = []
for key, value in global_tags.items():
data_frame[key] = value
tag_keys.add(key)
# Get a list of all the columns sorted by field/tag key.
# We want to iterate through the columns in sorted order
# so that we know when we're on the first field so we
# can know whether a comma is needed for that
# field.
columns = sorted(
enumerate(data_frame.dtypes.items()), key=lambda col: col[1][0]
)
# null_columns has a bool value for each column holding
# whether that column contains any null (NaN or None) values.
null_columns = data_frame.isnull().any()
# Iterate through the columns building up the expression for each column.
for index, (key, value) in columns:
key = str(key)
key_format = f"{{keys[{len(keys)}]}}"
keys.append(key.translate(KEY_ESCAPE))
# The field index is one more than the column index because the
# time index is at column zero in the finally zipped-together
# result columns.
field_index = index + 1
val_format = f"p[{field_index}]"
if key in tag_keys:
# This column is a tag column.
if null_columns[index]:
key_value = f"""{{
'' if {val_format} == '' or type({val_format}) == float and math.isnan({val_format}) else
f',{key_format}={{str({val_format}).translate(_ESCAPE_STRING)}}'
}}"""
else:
key_value = (
f",{key_format}={{str({val_format}).translate(_ESCAPE_KEY)}}"
)
tags.append(key_value)
continue
# This column is a field column.
# Note: no comma separator is needed for the first field.
# It's important to omit it because when the first
# field column has no nulls, we don't run the comma-removal
# regexp substitution step.
sep = "" if len(field_indexes) == 0 else ","
if issubclass(value.type, np.integer):
field_value = f"{sep}{key_format}={{{val_format}}}i"
elif issubclass(value.type, np.bool_):
field_value = f"{sep}{key_format}={{{val_format}}}"
elif issubclass(value.type, np.floating):
if null_columns[index]:
field_value = f"""{{"" if math.isnan({val_format}) else f"{sep}{key_format}={{{val_format}}}"}}"""
else:
field_value = f"{sep}{key_format}={{{val_format}}}"
else:
if null_columns[index]:
field_value = f"""{{
'' if type({val_format}) == float and math.isnan({val_format}) else
f'{sep}{key_format}="{{str({val_format}).translate(_ESCAPE_STRING)}}"'
}}"""
else:
field_value = f'''{sep}{key_format}="{{str({val_format}).translate(_ESCAPE_STRING)}}"'''
field_indexes.append(field_index)
fields.append(field_value)
measurement_name = str(measurement).translate(MEASUREMENT_ESCAPE)
tags = "".join(tags)
fields = "".join(fields)
timestamp = "{p[0].value}"
if precision.lower() == "us":
timestamp = "{int(p[0].value / 1e3)}"
elif precision.lower() == "ms":
timestamp = "{int(p[0].value / 1e6)}"
elif precision.lower() == "s":
timestamp = "{int(p[0].value / 1e9)}"
f = eval(
f'lambda p: f"""{{measurement_name}}{tags} {fields} {timestamp}"""',
{
"measurement_name": measurement_name,
"_ESCAPE_KEY": KEY_ESCAPE,
"_ESCAPE_STRING": STR_ESCAPE,
"keys": keys,
"math": math,
},
)
for k, v in dict(data_frame.dtypes).items():
if k in tag_keys:
data_frame[k].replace("", np.nan, inplace=True)
self.data_frame = data_frame
self.f = f
self.field_indexes = field_indexes
self.first_field_maybe_null = null_columns[field_indexes[0] - 1]
def serialize(self, chunk_size: int) -> Generator:
"""Serialize chunk into LineProtocols."""
for i in range(math.ceil(len(self.data_frame) / chunk_size)):
chunk = self.data_frame[i * chunk_size : (i + 1) * chunk_size]
if self.first_field_maybe_null:
# When the first field is null (None/NaN), we'll have
# a spurious leading comma which needs to be removed.
lp = (
re.sub("^(( |[^ ])* ),([a-zA-Z])(.*)", "\\1\\3\\4", self.f(p))
for p in filter(
lambda x: _any_not_nan(x, self.field_indexes),
_itertuples(chunk),
)
)
yield "\n".join(lp)
else:
yield "\n".join(map(self.f, _itertuples(chunk)))
class DataframeDeserializer(Serializer):
def __init__(
self,
sort_values: Union[str, List[str]] = None,
encoding: str = "utf-8",
names: List[str] = None,
usecols: Union[List[int], List[str]] = None,
dtype: dict = None,
time_col: Union[int, str] = None,
sep: str = ",",
header: Union[int, List[int], str] = "infer",
engine: str = None,
infer_datetime_format=True,
lineterminator: str = None,
converters: dict = None,
skipfooter=0,
index_col: Union[int, str, List[int], List[str], bool] = None,
skiprows: Union[int, List[int], Callable] = None,
**kwargs,
):
"""constructor a deserializer which convert a csv-like bytes array to pandas.DataFrame
the args are the same as pandas.read_csv. for details, please refer to the official doc: [pandas.read_csv](https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.read_csv.html)
for performance consideration, please specify the following args:
- engine = 'c' or 'pyarrow' when possible. Be noticed that 'pyarrow' is the fastest (multi-threaded supported) but may be error-prone. Only use it when you have thoroughly tested.
- specify dtype when possible
use `usecols` to specify the columns to read, and `names` to specify the column names (i.e., rename the columns), otherwise, the column names will be inferred from the first line.
when `names` is specified, it has to be as same length as actual columns of the data. If this causes column renaming, then you should always use column name specified in `names` to access the data (instead of which in `usecols`).
Examples:
>>> data = ",result,table,_time,code,name\\r\\n,_result,0,2019-01-01T09:31:00Z,000002.XSHE,国联证券"
>>> des = DataframeDeserializer(names=["_", "result", "table", "frame", "code", "name"], usecols=["frame", "code", "name"])
>>> des(data)
frame code name
0 2019-01-01T09:31:00Z 000002.XSHE 国联证券
Args:
sort_values: sort the dataframe by the specified columns
encoding: if the data is bytes, then encoding is required, due to pandas.read_csv only handle string array
sep: the separator/delimiter of each fields
header: the row number of the header, default is 'infer'
names: the column names of the dataframe
index_col: the column number or name of the index column
usecols: the column name of the columns to use
dtype: the dtype of the columns
engine: the engine of the csv file, default is None
converters: specify converter for columns.
skiprows: the row number to skip
skipfooter: the row number to skip at the end of the file
time_col: the columns to parse as dates
infer_datetime_format: whether to infer the datetime format
lineterminator: the line terminator of the csv file, only valid when engine is 'c'
kwargs: other arguments
"""
self.sort_values = sort_values
self.encoding = encoding
self.sep = sep
self.header = header
self.names = names
self.index_col = index_col
self.usecols = usecols
self.dtype = dtype
self.engine = engine
self.converters = converters or {}
self.skiprows = skiprows
self.skipfooter = skipfooter
self.infer_datetime_format = infer_datetime_format
self.lineterminator = lineterminator
self.kwargs = kwargs
if names is not None:
self.header = 0
if time_col is not None:
self.converters[time_col] = lambda x: ciso8601.parse_datetime_as_naive(x)
def __call__(self, data: Union[str, bytes]) -> pd.DataFrame:
if isinstance(data, str):
# treat data as string
stream = io.StringIO(data)
else:
stream = io.StringIO(data.decode(self.encoding))
df = pd.read_csv(
stream,
sep=self.sep,
header=self.header,
names=self.names,
index_col=self.index_col,
usecols=self.usecols,
dtype=self.dtype,
engine=self.engine,
converters=self.converters,
skiprows=self.skiprows,
skipfooter=self.skipfooter,
infer_datetime_format=self.infer_datetime_format,
lineterminator=self.lineterminator,
**self.kwargs,
)
if self.usecols:
df = df[list(self.usecols)]
if self.sort_values is not None:
return df.sort_values(self.sort_values)
else:
return df
class NumpySerializer(Serializer):
def __init__(
self,
data: np.ndarray,
measurement: str,
time_key: str = None,
tag_keys: List[str] = [],
global_tags: Dict[str, Any] = {},
time_precision: str = "s",
precisions: Dict[str, int] = {},
):
"""
serialize numpy structured array to influxdb line protocol.
field keys are column names minus tag keys.
compares to DataframeSerialize(influxdbClient), this one can NOT perform escape, but can set precisions per each column.
Performance benchmark
- to serialize 10000 points
DataframeSerializer: 0.0893 seconds
NumpySerializer: 0.0698 seconds
- to serialize 1M points
DataframeSerializer: 8.06 seconds
NumpySerializer: 7.16 seconds
Args:
data: the numpy structured array to be serialized.
measurement : name of the measurement
time_key: from which column to get the timestamp. if None, then server decides the timestamp of the record
tag_keys : columns in dataframe which should be considered as tag columns
global_tags : static tags, which will be added to every row.
time_precision : precision for time field.
escape: whether to escape special chars. If the data don't need to be escaped, then it's better to set it to False to improve performance.
precisions: precisions for floating fields. If not specified, then we'll stringify the column according to the type of the column, and default precision is assumed if it's floating type.
"""
if isinstance(tag_keys, str):
tag_keys = [tag_keys]
field_keys = sorted(set(data.dtype.names) - set(tag_keys) - set([time_key]))
assert len(field_keys) > 0, "field_columns must not be empty"
precision_factor = {"ns": 1, "us": 1e3, "ms": 1e6, "s": 1e9}.get(
time_precision, 1
)
# construct format string
# test,code=000001.XSHE a=1.1,b=2.024 631152000
fields = []
for field in field_keys:
if field in precisions:
fields.append(f"{field}={{:.{precisions[field]}}}")
else:
if np.issubdtype(data[field].dtype, np.floating):
fields.append(f"{field}={{}}")
elif np.issubdtype(data.dtype[field], np.unsignedinteger):
fields.append(f"{field}={{}}u")
elif np.issubdtype(data.dtype[field], np.signedinteger):
fields.append(f"{field}={{}}i")
elif np.issubdtype(data.dtype[field], np.bool_):
fields.append(f"{field}={{}}")
else:
fields.append(f'{field}="{{}}"')
global_tags = ",".join(f"{tag}={value}" for tag, value in global_tags.items())
tags = [f"{tag}={{}}" for tag in tag_keys]
tags = ",".join(tags)
# part1: measurement and tags part
part1 = ",".join(filter(lambda x: len(x) > 0, [measurement, global_tags, tags]))
# part2: fields
part2 = ",".join(fields)
# part3: timestamp part
part3 = "" if time_key is None else "{}"
self.format_string = " ".join(
filter(lambda x: len(x) > 0, [part1, part2, part3])
)
# transform data array so it can be serialized
output_dtype = [(name, "O") for name in itertools.chain(tag_keys, field_keys)]
cols = tag_keys + field_keys
if time_key is not None:
if np.issubdtype(data[time_key].dtype, np.datetime64):
frames = data[time_key].astype("M8[ns]").astype(int) / precision_factor
elif isinstance(data[0][time_key], datetime.datetime):
factor = 1e9 / precision_factor
frames = [datetime_to_utc_timestamp(x) * factor for x in data[time_key]]
elif isinstance(data[time_key][0], datetime.date):
factor = 1e9 / precision_factor
frames = [date_to_utc_timestamp(x) * factor for x in data[time_key]]
else:
raise TypeError(
f"unsupported data type: expected datetime64 or date, got {type(data[time_key][0])}"
)
output_dtype.append(("frame", "int64"))
self.data = np.empty((len(data),), dtype=output_dtype)
self.data["frame"] = frames
self.data[cols] = data[cols]
else:
self.data = data[cols].astype(output_dtype)
def _get_lines(self, data):
return "\n".join([self.format_string.format(*row) for row in data])
def serialize(self, batch: int) -> Generator:
for i in range(math.ceil(len(self.data) / batch)):
yield self._get_lines(self.data[i * batch : (i + 1) * batch])
class NumpyDeserializer(Serializer):
def __init__(
self,
dtype: List[tuple] = "float",
sort_values: Union[str, List[str]] = None,
use_cols: Union[List[str], List[int]] = None,
parse_date: Union[int, str] = "_time",
sep: str = ",",
encoding: str = "utf-8",
skip_rows: Union[int, List[int]] = 1,
header_line: int = 1,
comments: str = "#",
converters: Mapping[int, Callable] = None,
):
"""construct a deserializer, which will convert a csv like multiline string/bytes array to a numpy array
the data to be deserialized will be first split into array of fields, then use use_cols to select which fields to use, and re-order them by the order of use_cols. After that, the fields will be converted to numpy array and converted into dtype.
by default dtype is float, which means the data will be converted to float. If you need to convert to a numpy structured array, then you can specify the dtype as a list of tuples, e.g.
```
dtype = [('col_1', 'datetime64[s]'), ('col_2', '<U12'), ('col_3', '<U4')]
```
by default, the deserializer will try to convert every line from the very first line, if the very first lines contains comments and headers, these lines should be skipped by deserializer, you should set skip_rows to number of lines to skip.
for more information, please refer to [numpy.loadtxt](https://numpy.org/doc/stable/reference/generated/numpy.loadtxt.html)
Args:
dtype: dtype of the output numpy array.
sort_values: sort the output numpy array by the specified columns. If it's a string, then it's the name of the column, if it's a list of strings, then it's the names of the columns.
use_cols: use only the specified columns. If it's a list of strings, then it's the names of the columns (presented in raw data header line), if it's a list of integers, then it's the column index.
parse_date: by default we'll convert "_time" column into python datetime.datetime. Set it to None to turn off the conversion. ciso8601 is default parser. If you need to parse date but just don't like ciso8601, then you can turn off default parser (by set parse_date to None), and specify your own parser in converters.
sep: separator of each field
encoding: if the input is bytes, then encoding is used to decode the bytes to string.
skip_rows: required by np.loadtxt, skip the first n lines
header_line: which line contains header, started from 1. If you specify use_cols by list of string, then header line must be specified.
comments: required by np.loadtxt, skip the lines starting with this string
converters: required by np.loadtxt, a dict of column name to converter function.
"""
self.dtype = dtype
self.use_cols = use_cols
self.sep = sep
self.encoding = encoding
self.skip_rows = skip_rows
self.comments = comments
self.converters = converters or {}
self.sort_values = sort_values
self.parse_date = parse_date
self.header_line = header_line
if header_line is None:
assert parse_date is None or isinstance(
parse_date, int
), "parse_date must be an integer if data contains no header"
assert use_cols is None or isinstance(
use_cols[0], int
), "use_cols must be a list of integers if data contains no header"
if len(self.converters) > 1:
assert all(
[isinstance(x, int) for x in self.converters.keys()]
), "converters must be a dict of column index to converter function, if there's no header"
self._parsed_headers = None
def _parse_header_once(self, stream):
"""parse header and convert use_cols, if columns is specified in string. And if parse_date is required, add it into converters
Args:
stream : [description]
Raises:
SerializationError: [description]
"""
if self.header_line is None or self._parsed_headers is not None:
return
try:
line = stream.readlines(self.header_line)[-1]
cols = line.strip().split(self.sep)
self._parsed_headers = cols
use_cols = self.use_cols
if use_cols is not None and isinstance(use_cols[0], str):
self.use_cols = [cols.index(col) for col in self.use_cols]
# convert keys of converters to int
converters = {cols.index(k): v for k, v in self.converters.items()}
self.converters = converters
if isinstance(self.parse_date, str):
parse_date = cols.index(self.parse_date)
if parse_date in self.converters.keys():
logger.debug(
"specify duplicated converter in both parse_date and converters for col %s, use converters.",
self.parse_date,
)
else: # 增加parse_date到converters
self.converters[
parse_date
] = lambda x: ciso8601.parse_datetime_as_naive(x)
stream.seek(0)
except (IndexError, ValueError):
if line.strip() == "":
content = "".join(stream.readlines()).strip()
if len(content) > 0:
raise SerializationError(
f"specified heder line {self.header_line} is empty"
)
else:
raise EmptyResult()
else:
raise SerializationError(f"bad header[{self.header_line}]: {line}")
def __call__(self, data: bytes) -> np.ndarray:
if self.encoding and isinstance(data, bytes):
stream = io.StringIO(data.decode(self.encoding))
else:
stream = io.StringIO(data)
try:
self._parse_header_once(stream)
except EmptyResult:
return np.empty((0,), dtype=self.dtype)
arr = np.loadtxt(
stream.readlines(),
delimiter=self.sep,
skiprows=self.skip_rows,
dtype=self.dtype,
usecols=self.use_cols,
converters=self.converters,
encoding=self.encoding,
)
# 如果返回仅一条记录,有时会出现 shape == ()
if arr.shape == tuple():
arr = arr.reshape((-1,))
if self.sort_values is not None and arr.size > 1:
return np.sort(arr, order=self.sort_values)
else:
return arr
class PyarrowDeserializer(Serializer):
"""PyArrow can provide best performance for large data."""
def __init__(self) -> None:
raise NotImplementedError | zillionare-omicron | /zillionare_omicron-2.0.0a59-py3-none-any.whl/omicron/dal/influx/serialize.py | serialize.py |
import logging
from enum import IntEnum
from typing import Callable, List, Optional, Tuple
import numpy as np
import pandas as pd
import talib as ta
from coretypes import bars_dtype
from zigzag import peak_valley_pivots
from omicron.talib.core import clustering, moving_average
logger = logging.getLogger(__name__)
class CrossFlag(IntEnum):
UPCROSS = 1
DOWNCROSS = -1
NONE = 0
def cross(f: np.ndarray, g: np.ndarray) -> CrossFlag:
"""判断序列f是否与g相交。如果两个序列有且仅有一个交点,则返回1表明f上交g;-1表明f下交g
本方法可用以判断两条均线是否相交。
returns:
(flag, index), 其中flag取值为:
0 无效
-1 f向下交叉g
1 f向上交叉g
"""
indices = np.argwhere(np.diff(np.sign(f - g))).flatten()
if len(indices) == 0:
return CrossFlag.NONE, 0
# 如果存在一个或者多个交点,取最后一个
idx = indices[-1]
if f[idx] < g[idx]:
return CrossFlag.UPCROSS, idx
elif f[idx] > g[idx]:
return CrossFlag.DOWNCROSS, idx
else:
return CrossFlag(np.sign(g[idx - 1] - f[idx - 1])), idx
def vcross(f: np.array, g: np.array) -> Tuple:
"""判断序列f是否与g存在类型v型的相交。即存在两个交点,第一个交点为向下相交,第二个交点为向上
相交。一般反映为洗盘拉升的特征。
Examples:
>>> f = np.array([ 3 * i ** 2 - 20 * i + 2 for i in range(10)])
>>> g = np.array([ i - 5 for i in range(10)])
>>> flag, indices = vcross(f, g)
>>> assert flag is True
>>> assert indices[0] == 0
>>> assert indices[1] == 6
Args:
f: first sequence
g: the second sequence
Returns:
(flag, indices), 其中flag取值为True时,存在vcross,indices为交点的索引。
"""
indices = np.argwhere(np.diff(np.sign(f - g))).flatten()
if len(indices) == 2:
idx0, idx1 = indices
if f[idx0] > g[idx0] and f[idx1] < g[idx1]:
return True, (idx0, idx1)
return False, (None, None)
def inverse_vcross(f: np.array, g: np.array) -> Tuple:
"""判断序列f是否与序列g存在^型相交。即存在两个交点,第一个交点为向上相交,第二个交点为向下
相交。可用于判断见顶特征等场合。
Args:
f (np.array): [description]
g (np.array): [description]
Returns:
Tuple: [description]
"""
indices = np.argwhere(np.diff(np.sign(f - g))).flatten()
if len(indices) == 2:
idx0, idx1 = indices
if f[idx0] < g[idx0] and f[idx1] > g[idx1]:
return True, (idx0, idx1)
return False, (None, None)
class BreakoutFlag(IntEnum):
UP = 1
DOWN = -1
NONE = 0
def peaks_and_valleys(
ts: np.ndarray, up_thresh: float = None, down_thresh: float = None
) -> np.ndarray:
"""寻找ts中的波峰和波谷,返回数组指示在该位置上是否为波峰或波谷。如果为1,则为波峰;如果为-1,则为波谷。
本函数直接使用了zigzag中的peak_valley_pivots. 有很多方法可以实现本功能,比如scipy.signals.find_peaks_cwt, peak_valley_pivots等。本函数更适合金融时间序列,并且使用了cython加速。
Args:
ts (np.ndarray): 时间序列
up_thresh (float): 波峰的阈值,如果为None,则使用ts变化率的二倍标准差
down_thresh (float): 波谷的阈值,如果为None,则使用ts变化率的二倍标准差乘以-1
Returns:
np.ndarray: 返回数组指示在该位置上是否为波峰或波谷。
"""
if ts.dtype != np.float64:
ts = ts.astype(np.float64)
if any([up_thresh is None, down_thresh is None]):
change_rate = ts[1:] / ts[:-1] - 1
std = np.std(change_rate)
up_thresh = up_thresh or 2 * std
down_thresh = down_thresh or -2 * std
return peak_valley_pivots(ts, up_thresh, down_thresh)
def support_resist_lines(
ts: np.ndarray, upthres: float = None, downthres: float = None
) -> Tuple[Callable, Callable, np.ndarray]:
"""计算时间序列的支撑线和阻力线
使用最近的两个高点连接成阴力线,两个低点连接成支撑线。
Examples:
```python
def show_support_resist_lines(ts):
import plotly.graph_objects as go
fig = go.Figure()
support, resist, x_start = support_resist_lines(ts, 0.03, -0.03)
fig.add_trace(go.Scatter(x=np.arange(len(ts)), y=ts))
x = np.arange(len(ts))[x_start:]
fig.add_trace(go.Line(x=x, y = support(x)))
fig.add_trace(go.Line(x=x, y = resist(x)))
fig.show()
np.random.seed(1978)
X = np.cumprod(1 + np.random.randn(100) * 0.01)
show_support_resist_lines(X)
```
the above code will show this 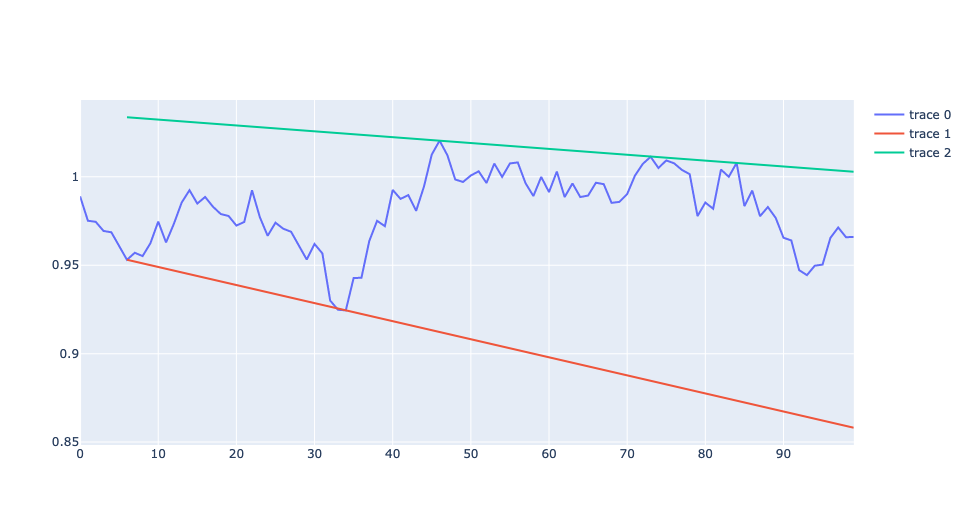
Args:
ts (np.ndarray): 时间序列
upthres (float, optional): 请参考[peaks_and_valleys][omicron.talib.patterns.peaks_and_valleys]
downthres (float, optional): 请参考[peaks_and_valleys][omicron.talib.patterns.peaks_and_valleys]
Returns:
返回支撑线和阻力线的计算函数及起始点坐标,如果没有支撑线或阻力线,则返回None
"""
if ts.dtype != np.float64:
ts = ts.astype(np.float64)
pivots = peaks_and_valleys(ts, upthres, downthres)
pivots[0] = 0
pivots[-1] = 0
arg_max = np.argwhere(pivots == 1).flatten()
arg_min = np.argwhere(pivots == -1).flatten()
resist = None
support = None
if len(arg_max) >= 2:
arg_max = arg_max[-2:]
y = ts[arg_max]
coeff = np.polyfit(arg_max, y, deg=1)
resist = np.poly1d(coeff)
if len(arg_min) >= 2:
arg_min = arg_min[-2:]
y = ts[arg_min]
coeff = np.polyfit(arg_min, y, deg=1)
support = np.poly1d(coeff)
return support, resist, np.min([*arg_min, *arg_max])
def breakout(
ts: np.ndarray, upthres: float = 0.01, downthres: float = -0.01, confirm: int = 1
) -> BreakoutFlag:
"""检测时间序列是否突破了压力线(整理线)
Args:
ts (np.ndarray): 时间序列
upthres (float, optional): 请参考[peaks_and_valleys][omicron.talib.patterns.peaks_and_valleys]
downthres (float, optional): 请参考[peaks_and_valleys][omicron.talib.patterns.peaks_and_valleys]
confirm (int, optional): 经过多少个bars后,才确认突破。默认为1
Returns:
如果上向突破压力线,返回1,如果向下突破压力线,返回-1,否则返回0
"""
support, resist, _ = support_resist_lines(ts[:-confirm], upthres, downthres)
x0 = len(ts) - confirm - 1
x = list(range(len(ts) - confirm, len(ts)))
if resist is not None:
if np.all(ts[x] > resist(x)) and ts[x0] <= resist(x0):
return BreakoutFlag.UP
if support is not None:
if np.all(ts[x] < support(x)) and ts[x0] >= support(x0):
return BreakoutFlag.DOWN
return BreakoutFlag.NONE
def plateaus(
numbers: np.ndarray, min_size: int, fall_in_range_ratio: float = 0.97
) -> List[Tuple]:
"""统计数组`numbers`中的可能存在的平台整理。
如果一个数组中存在着子数组,使得其元素与均值的距离落在三个标准差以内的比例超过`fall_in_range_ratio`的,则认为该子数组满足平台整理。
Args:
numbers: 输入数组
min_size: 平台的最小长度
fall_in_range_ratio: 超过`fall_in_range_ratio`比例的元素落在均值的三个标准差以内,就认为该子数组构成一个平台
Returns:
平台的起始位置和长度的数组
"""
if numbers.size <= min_size:
n = 1
else:
n = numbers.size // min_size
clusters = clustering(numbers, n)
plats = []
for (start, length) in clusters:
if length < min_size:
continue
y = numbers[start : start + length]
mean = np.mean(y)
std = np.std(y)
inrange = len(y[np.abs(y - mean) < 3 * std])
ratio = inrange / length
if ratio >= fall_in_range_ratio:
plats.append((start, length))
return plats
def rsi_bottom_divergent(
close: np.array, thresh: Tuple[float, float] = None, rsi_limit: float = 30
) -> int:
"""寻找最近满足条件的rsi底背离。
返回最后一个数据到最近底背离发生点的距离;没有满足条件的底背离,返回None。
Args:
close (np.array): 时间序列收盘价
thresh (Tuple[float, float]): 请参考[peaks_and_valleys][omicron.talib.morph.peaks_and_valleys]
rsi_limit (float, optional): RSI发生底背离时的阈值, 默认值30(20效果更佳,但是检测出来数量太少),
即只过滤RSI6<30的局部最低收盘价。
Returns:
返回int类型的整数,表示最后一个数据到最近底背离发生点的距离;没有满足条件的底背离,返回None。
"""
assert len(close) >= 60, "must provide an array with at least 60 length!"
if close.dtype != np.float64:
close = close.astype(np.float64)
rsi = ta.RSI(close, 6)
if thresh is None:
std = np.std(close[-59:] / close[-60:-1] - 1)
thresh = (2 * std, -2 * std)
pivots = peak_valley_pivots(close, thresh[0], thresh[1])
pivots[0], pivots[-1] = 0, 0
length = len(close)
valley_index = np.where((pivots == -1) & (rsi <= rsi_limit))[0]
if len(valley_index) >= 2:
if (close[valley_index[-1]] < close[valley_index[-2]]) and (
rsi[valley_index[-1]] > rsi[valley_index[-2]]
):
bottom_dev_distance = length - 1 - valley_index[-1]
return bottom_dev_distance
def rsi_top_divergent(
close: np.array, thresh: Tuple[float, float] = None, rsi_limit: float = 70
) -> Tuple[int, int]:
"""寻找最近满足条件的rsi顶背离。
返回最后一个数据到最近顶背离发生点的距离;没有满足条件的顶背离,返回None。
Args:
close (np.array): 时间序列收盘价
thresh (Tuple[float, float]): 请参考[peaks_and_valleys][omicron.talib.morph.peaks_and_valleys]
rsi_limit (float, optional): RSI发生顶背离时的阈值, 默认值70(80效果更佳,但是检测出来数量太少),
即只过滤RSI6>70的局部最高收盘价。
Returns:
返回int类型的整数,表示最后一个数据到最近顶背离发生点的距离;没有满足条件的顶背离,返回None。
"""
assert len(close) >= 60, "must provide an array with at least 60 length!"
if close.dtype != np.float64:
close = close.astype(np.float64)
rsi = ta.RSI(close, 6)
if thresh is None:
std = np.std(close[-59:] / close[-60:-1] - 1)
thresh = (2 * std, -2 * std)
pivots = peak_valley_pivots(close, thresh[0], thresh[1])
pivots[0], pivots[-1] = 0, 0
length = len(close)
peak_index = np.where((pivots == 1) & (rsi >= rsi_limit))[0]
if len(peak_index) >= 2:
if (close[peak_index[-1]] > close[peak_index[-2]]) and (
rsi[peak_index[-1]] < rsi[peak_index[-2]]
):
top_dev_distance = length - 1 - peak_index[-1]
return top_dev_distance
def valley_detect(
close: np.ndarray, thresh: Tuple[float, float] = (0.05, -0.02)
) -> int:
"""给定一段行情数据和用以检测近期已发生反转的最低点,返回该段行情中,最低点到最后一个数据的距离和收益率数组,
如果给定行情中未找到满足参数的最低点,则返回两个空值数组。
其中bars的长度一般不小于60,不大于120。此函数采用了zigzag中的谷峰检测方法,其中参数默认(0.05,-0.02),
此参数对所有股票数据都适用。若满足参数,返回值中,距离为大于0的整数,收益率是0~1的小数。
Args:
close (np.ndarray): 具有时间序列的收盘价
thresh (Tuple[float, float]) : 请参考[peaks_and_valleys][omicron.talib.morph.peaks_and_valleys]
Returns:
返回该段行情中,最低点到最后一个数据的距离和收益率数组,
如果给定行情中未找到满足参数的最低点,则返回两个空值数组。
"""
assert len(close) >= 60, "must provide an array with at least 60 length!"
if close.dtype != np.float64:
close = close.astype(np.float64)
if thresh is None:
std = np.std(close[-59:] / close[-60:-1] - 1)
thresh = (2 * std, -2 * std)
pivots = peak_valley_pivots(close, thresh[0], thresh[1])
flags = pivots[pivots != 0]
increased = None
lowest_distance = None
if (flags[-2] == -1) and (flags[-1] == 1):
length = len(pivots)
valley_index = np.where(pivots == -1)[0]
increased = (close[-1] - close[valley_index[-1]]) / close[valley_index[-1]]
lowest_distance = int(length - 1 - valley_index[-1])
return lowest_distance, increased
def rsi_watermarks(
close: np.array, thresh: Tuple[float, float] = None
) -> Tuple[float, float, float]:
"""给定一段行情数据和用以检测顶和底的阈值,返回该段行情中,谷和峰处RSI均值,最后一个RSI6值。
其中close的长度一般不小于60,不大于120。返回值中,一个为low_wartermark(谷底处RSI值),
一个为high_wartermark(高峰处RSI值),一个为RSI6的最后一个值,用以对比前两个警戒值。
Args:
close (np.array): 具有时间序列的收盘价
thresh (Tuple[float, float]) : None适用所有股票,不必更改,也可自行设置。
Returns:
返回数组[low_watermark, high_watermark, rsi[-1]], 第一个为最近两个最低收盘价的RSI均值, 第二个为最近两个最高收盘价的RSI均值。
若传入收盘价只有一个最值,只返回一个。没有最值,则返回None, 第三个为实际的最后RSI6的值。
"""
assert len(close) >= 60, "must provide an array with at least 60 length!"
if thresh is None:
std = np.std(close[-59:] / close[-60:-1] - 1)
thresh = (2 * std, -2 * std)
if close.dtype != np.float64:
close = close.astype(np.float64)
rsi = ta.RSI(close, 6)
pivots = peak_valley_pivots(close, thresh[0], thresh[1])
pivots[0], pivots[-1] = 0, 0 # 掐头去尾
# 峰值RSI>70; 谷处的RSI<30;
peaks_rsi_index = np.where((rsi > 70) & (pivots == 1))[0]
valleys_rsi_index = np.where((rsi < 30) & (pivots == -1))[0]
if len(peaks_rsi_index) == 0:
high_watermark = None
elif len(peaks_rsi_index) == 1:
high_watermark = rsi[peaks_rsi_index[0]]
else: # 有两个以上的峰,通过最近的两个峰均值来确定走势
high_watermark = np.nanmean(rsi[peaks_rsi_index[-2:]])
if len(valleys_rsi_index) == 0:
low_watermark = None
elif len(valleys_rsi_index) == 1:
low_watermark = rsi[valleys_rsi_index[0]]
else: # 有两个以上的峰,通过最近的两个峰来确定走势
low_watermark = np.nanmean(rsi[valleys_rsi_index[-2:]])
return low_watermark, high_watermark, rsi[-1]
def rsi_bottom_distance(close: np.array, thresh: Tuple[float, float] = None) -> int:
"""根据给定的收盘价,计算最后一个数据到上一个发出rsi低水平的距离,
如果从上一个最低点rsi到最后一个数据并未发出低水平信号,
返回最后一个数据到上一个发出最低点rsi的距离。
其中close的长度一般不小于60。
返回值为距离整数,不满足条件则返回None。
Args:
close (np.array): 具有时间序列的收盘价
thresh (Tuple[float, float]) : None适用所有股票,不必更改,也可自行设置。
Returns:
返回最后一个数据到上一个发出rsi低水平的距离。
如果从上一个最低点rsi到最后一个数据并未发出低水平信号,
返回最后一个数据到上一个发出最低点rsi的距离。
除此之外,返回None。"""
assert len(close) >= 60, "must provide an array with at least 60 length!"
if close.dtype != np.float64:
close = close.astype(np.float64)
if thresh is None:
std = np.std(close[-59:] / close[-60:-1] - 1)
thresh = (2 * std, -2 * std)
rsi = ta.RSI(close, 6)
watermarks = rsi_watermarks(close, thresh)
if watermarks is not None:
low_watermark, _, _ = watermarks
pivots = peak_valley_pivots(close, thresh[0], thresh[1])
pivots[0], pivots[-1] = 0, 0
# 谷值RSI<30
valley_rsi_index = np.where((rsi < 30) & (pivots == -1))[0]
# RSI低水平的最大值:低水平*1.01
low_rsi_index = np.where(rsi <= low_watermark * 1.01)[0]
if len(valley_rsi_index) > 0:
distance = len(rsi) - 1 - valley_rsi_index[-1]
if len(low_rsi_index) > 0:
if low_rsi_index[-1] >= valley_rsi_index[-1]:
distance = len(rsi) - 1 - low_rsi_index[-1]
return distance
def rsi_top_distance(close: np.array, thresh: Tuple[float, float] = None) -> int:
"""根据给定的收盘价,计算最后一个数据到上一个发出rsi高水平的距离,
如果从上一个最高点rsi到最后一个数据并未发出高水平信号,
返回最后一个数据到上一个发出最高点rsi的距离。
其中close的长度一般不小于60。
返回值为距离整数,不满足条件则返回None。
Args:
close (np.array): 具有时间序列的收盘价
thresh (Tuple[float, float]) : None适用所有股票,不必更改,也可自行设置。
Returns:
返回最后一个数据到上一个发出rsi高水平的距离。
如果从上一个最高点rsi到最后一个数据并未发出高水平信号,
返回最后一个数据到上一个发出最高点rsi的距离。
除此之外,返回None。"""
assert len(close) >= 60, "must provide an array with at least 60 length!"
if close.dtype != np.float64:
close = close.astype(np.float64)
if thresh is None:
std = np.std(close[-59:] / close[-60:-1] - 1)
thresh = (2 * std, -2 * std)
rsi = ta.RSI(close, 6)
watermarks = rsi_watermarks(close, thresh)
if watermarks is not None:
_, high_watermark, _ = watermarks
pivots = peak_valley_pivots(close, thresh[0], thresh[1])
pivots[0], pivots[-1] = 0, 0
# 峰值RSI>70
peak_rsi_index = np.where((rsi > 70) & (pivots == 1))[0]
# RSI高水平的最小值:高水平*0.99
high_rsi_index = np.where(rsi >= high_watermark * 0.99)[0]
if len(peak_rsi_index) > 0:
distance = len(rsi) - 1 - peak_rsi_index[-1]
if len(high_rsi_index) > 0:
if high_rsi_index[-1] >= peak_rsi_index[-1]:
distance = len(rsi) - 1 - high_rsi_index[-1]
return distance
def rsi_predict_price(
close: np.ndarray, thresh: Tuple[float, float] = None
) -> Tuple[float, float]:
"""给定一段行情,根据最近的两个RSI的极小值和极大值预测下一个周期可能达到的最低价格和最高价格。
其原理是,以预测最近的两个最高价和最低价,求出其相对应的RSI值,求出最高价和最低价RSI的均值,
若只有一个则取最近的一个。再由RSI公式,反推价格。此时返回值为(None, float),即只有最高价,没有最低价。反之亦然。
Args:
close (np.ndarray): 具有时间序列的收盘价
thresh (Tuple[float, float]) : 请参考[peaks_and_valleys][omicron.talib.morph.peaks_and_valleys]
Returns:
返回数组[predicted_low_price, predicted_high_price], 数组第一个值为利用达到之前最低收盘价的RSI预测的最低价。
第二个值为利用达到之前最高收盘价的RSI预测的最高价。
"""
assert len(close) >= 60, "must provide an array with at least 60 length!"
if thresh is None:
std = np.std(close[-59:] / close[-60:-1] - 1)
thresh = (2 * std, -2 * std)
if close.dtype != np.float64:
close = close.astype(np.float64)
valley_rsi, peak_rsi, _ = rsi_watermarks(close, thresh=thresh)
pivot = peak_valley_pivots(close, thresh[0], thresh[1])
pivot[0], pivot[-1] = 0, 0 # 掐头去尾
price_change = pd.Series(close).diff(1).values
ave_price_change = (abs(price_change)[-6:].mean()) * 5
ave_price_raise = (np.maximum(price_change, 0)[-6:].mean()) * 5
if valley_rsi is not None:
predicted_low_change = (ave_price_change) - ave_price_raise / (
0.01 * valley_rsi
)
if predicted_low_change > 0:
predicted_low_change = 0
predicted_low_price = close[-1] + predicted_low_change
else:
predicted_low_price = None
if peak_rsi is not None:
predicted_high_change = (ave_price_raise - ave_price_change) / (
0.01 * peak_rsi - 1
) - ave_price_change
if predicted_high_change < 0:
predicted_high_change = 0
predicted_high_price = close[-1] + predicted_high_change
else:
predicted_high_price = None
return predicted_low_price, predicted_high_price
def energy_hump(bars: bars_dtype, thresh=2) -> Optional[Tuple[int, int]]:
"""检测`bars`中是否存在两波以上量能剧烈增加的情形(能量驼峰),返回最后一波距现在的位置及区间长度。
注意如果最后一个能量驼峰距现在过远(比如超过10个bar),可能意味着资金已经逃离,能量已经耗尽。
Args:
bars: 行情数据
thresh: 最后一波量必须大于20天均量的倍数。
Returns:
如果不存在能量驼峰的情形,则返回None,否则返回最后一个驼峰离现在的距离及区间长度。
"""
vol = bars["volume"]
std = np.std(vol[1:] / vol[:-1])
pvs = peak_valley_pivots(vol, std, 0)
frames = bars["frame"]
pvs[0] = 0
pvs[-1] = -1
peaks = np.argwhere(pvs == 1)
mn = np.mean(vol[peaks])
# 顶点不能缩量到尖峰均值以下
real_peaks = np.intersect1d(np.argwhere(vol > mn), peaks)
if len(real_peaks) < 2:
return None
logger.debug("found %s peaks at %s", len(real_peaks), frames[real_peaks])
lp = real_peaks[-1]
ma = moving_average(vol, 20)[lp]
if vol[lp] < ma * thresh:
logger.debug(
"vol of last peak[%s] is less than mean_vol(20) * thresh[%s]",
vol[lp],
ma * thresh,
)
return None
return len(bars) - real_peaks[-1], real_peaks[-1] - real_peaks[0] | zillionare-omicron | /zillionare_omicron-2.0.0a59-py3-none-any.whl/omicron/talib/morph.py | morph.py |
from math import copysign
from typing import List, Sequence, Tuple
import ckwrap
import numpy as np
import sklearn
from bottleneck import move_mean, nanmean
from scipy.linalg import norm
from scipy.signal import savgol_filter
from sklearn.preprocessing import MaxAbsScaler, StandardScaler, minmax_scale
def moving_average(ts: Sequence, win: int, padding=True) -> np.ndarray:
"""生成ts序列的移动平均值
Examples:
>>> ts = np.arange(7)
>>> moving_average(ts, 5)
array([nan, nan, nan, nan, 2., 3., 4.])
Args:
ts (Sequence): the input array
win (int): the window size
padding: if True, then the return will be equal length as input, padding with np.NaN at the beginning
Returns:
The moving mean of the input array along the specified axis. The output has the same shape as the input.
"""
ma = move_mean(ts, win)
if padding:
return ma
else:
return ma[win - 1 :]
def weighted_moving_average(ts: np.array, win: int) -> np.array:
"""计算加权移动平均
Args:
ts (np.array): [description]
win (int): [description]
Returns:
np.array: [description]
"""
w = [2 * (i + 1) / (win * (win + 1)) for i in range(win)]
return np.convolve(ts, w, "valid")
def exp_moving_average(values, window):
"""Numpy implementation of EMA"""
weights = np.exp(np.linspace(-1.0, 0.0, window))
weights /= weights.sum()
a = np.convolve(values, weights, mode="full")[: len(values)]
a[:window] = a[window]
return a
def polyfit(ts: Sequence, deg: int = 2, loss_func="re") -> Tuple:
"""对给定的时间序列进行直线/二次曲线拟合。
二次曲线可以拟合到反生反转的行情,如圆弧底、圆弧顶;也可以拟合到上述趋势中的单边走势,即其中一段曲线。对于如长期均线,在一段时间内走势可能呈现为一条直线,故也可用此函数进行直线拟合。
为便于在不同品种、不同的时间之间对误差、系数进行比较,请事先对ts进行归一化。
如果遇到无法拟合的情况(异常),将返回一个非常大的误差,并将其它项置为np.nan
Examples:
>>> ts = [i for i in range(5)]
>>> err, (a, b) = polyfit(ts, deg=1)
>>> print(round(err, 3), round(a, 1))
0.0 1.0
Args:
ts (Sequence): 待拟合的时间序列
deg (int): 如果要进行直线拟合,取1;二次曲线拟合取2. Defaults to 2
loss_func (str): 误差计算方法,取值为`mae`, `rmse`,`mse` 或`re`。Defaults to `re` (relative_error)
Returns:
[Tuple]: 如果为直线拟合,返回误差,(a,b)(一次项系数和常数)。如果为二次曲线拟合,返回
误差, (a,b,c)(二次项、一次项和常量), (vert_x, vert_y)(顶点处的index,顶点值)
"""
if deg not in (1, 2):
raise ValueError("deg must be 1 or 2")
try:
if any(np.isnan(ts)):
raise ValueError("ts contains nan")
x = np.array(list(range(len(ts))))
z = np.polyfit(x, ts, deg=deg)
p = np.poly1d(z)
ts_hat = np.array([p(xi) for xi in x])
if loss_func == "mse":
error = np.mean(np.square(ts - ts_hat))
elif loss_func == "rmse":
error = np.sqrt(np.mean(np.square(ts - ts_hat)))
elif loss_func == "mae":
error = mean_absolute_error(ts, ts_hat)
else: # defaults to relative error
error = pct_error(ts, ts_hat)
if deg == 2:
a, b, c = z[0], z[1], z[2]
axis_x = -b / (2 * a)
if a != 0:
axis_y = (4 * a * c - b * b) / (4 * a)
else:
axis_y = None
return error, z, (axis_x, axis_y)
elif deg == 1:
return error, z
except Exception:
error = 1e9
if deg == 1:
return error, (np.nan, np.nan)
else:
return error, (np.nan, np.nan, np.nan), (np.nan, np.nan)
def slope(ts: np.array, loss_func="re"):
"""求ts表示的直线(如果能拟合成直线的话)的斜率
Args:
ts (np.array): [description]
loss_func (str, optional): [description]. Defaults to 're'.
"""
err, (a, b) = polyfit(ts, deg=1, loss_func=loss_func)
return err, a
# pragma: no cover
def smooth(ts: np.array, win: int, poly_order=1, mode="interp"):
"""平滑序列ts,使用窗口大小为win的平滑模型,默认使用线性模型
提供本函数主要基于这样的考虑: omicron的使用者可能并不熟悉信号处理的概念,这里相当于提供了相关功能的一个入口。
Args:
ts (np.array): [description]
win (int): [description]
poly_order (int, optional): [description]. Defaults to 1.
"""
return savgol_filter(ts, win, poly_order, mode=mode)
def angle(ts, threshold=0.01, loss_func="re") -> Tuple[float, float]:
"""求时间序列`ts`拟合直线相对于`x`轴的夹角的余弦值
本函数可以用来判断时间序列的增长趋势。当`angle`处于[-1, 0]时,越靠近0,下降越快;当`angle`
处于[0, 1]时,越接近0,上升越快。
如果`ts`无法很好地拟合为直线,则返回[float, None]
Examples:
>>> ts = np.array([ i for i in range(5)])
>>> round(angle(ts)[1], 3) # degree: 45, rad: pi/2
0.707
>>> ts = np.array([ np.sqrt(3) / 3 * i for i in range(10)])
>>> round(angle(ts)[1],3) # degree: 30, rad: pi/6
0.866
>>> ts = np.array([ -np.sqrt(3) / 3 * i for i in range(7)])
>>> round(angle(ts)[1], 3) # degree: 150, rad: 5*pi/6
-0.866
Args:
ts:
Returns:
返回 (error, consine(theta)),即拟合误差和夹角余弦值。
"""
err, (a, b) = polyfit(ts, deg=1, loss_func=loss_func)
if err > threshold:
return (err, None)
v = np.array([1, a + b])
vx = np.array([1, 0])
return err, copysign(np.dot(v, vx) / (norm(v) * norm(vx)), a)
def mean_absolute_error(y: np.array, y_hat: np.array) -> float:
"""返回预测序列相对于真值序列的平均绝对值差
两个序列应该具有相同的长度。如果存在nan,则nan的值不计入平均值。
Examples:
>>> y = np.arange(5)
>>> y_hat = np.arange(5)
>>> y_hat[4] = 0
>>> mean_absolute_error(y, y)
0.0
>>> mean_absolute_error(y, y_hat)
0.8
Args:
y (np.array): 真值序列
y_hat: 比较序列
Returns:
float: 平均绝对值差
"""
return nanmean(np.abs(y - y_hat))
def pct_error(y: np.array, y_hat: np.array) -> float:
"""相对于序列算术均值的误差值
Examples:
>>> y = np.arange(5)
>>> y_hat = np.arange(5)
>>> y_hat[4] = 0
>>> pct_error(y, y_hat)
0.4
Args:
y (np.array): [description]
y_hat (np.array): [description]
Returns:
float: [description]
"""
mae = mean_absolute_error(y, y_hat)
return mae / nanmean(np.abs(y))
def normalize(X, scaler="maxabs"):
"""对数据进行规范化处理。
如果scaler为maxabs,则X的各元素被压缩到[-1,1]之间
如果scaler为unit_vector,则将X的各元素压缩到单位范数
如果scaler为minmax,则X的各元素被压缩到[0,1]之间
如果scaler为standard,则X的各元素被压缩到单位方差之间,且均值为零。
参考 [sklearn]
[sklearn]: https://scikit-learn.org/stable/auto_examples/preprocessing/plot_all_scaling.html#results
Examples:
>>> X = [[ 1., -1., 2.],
... [ 2., 0., 0.],
... [ 0., 1., -1.]]
>>> expected = [[ 0.4082, -0.4082, 0.8165],
... [ 1., 0., 0.],
... [ 0., 0.7071, -0.7071]]
>>> X_hat = normalize(X, scaler='unit_vector')
>>> np.testing.assert_array_almost_equal(expected, X_hat, decimal=4)
>>> expected = [[0.5, -1., 1.],
... [1., 0., 0.],
... [0., 1., -0.5]]
>>> X_hat = normalize(X, scaler='maxabs')
>>> np.testing.assert_array_almost_equal(expected, X_hat, decimal = 2)
>>> expected = [[0.5 , 0. , 1. ],
... [1. , 0.5 , 0.33333333],
... [0. , 1. , 0. ]]
>>> X_hat = normalize(X, scaler='minmax')
>>> np.testing.assert_array_almost_equal(expected, X_hat, decimal= 3)
>>> X = [[0, 0],
... [0, 0],
... [1, 1],
... [1, 1]]
>>> expected = [[-1., -1.],
... [-1., -1.],
... [ 1., 1.],
... [ 1., 1.]]
>>> X_hat = normalize(X, scaler='standard')
>>> np.testing.assert_array_almost_equal(expected, X_hat, decimal = 3)
Args:
X (2D array):
scaler (str, optional): [description]. Defaults to 'maxabs_scale'.
"""
if scaler == "maxabs":
return MaxAbsScaler().fit_transform(X)
elif scaler == "unit_vector":
return sklearn.preprocessing.normalize(X, norm="l2")
elif scaler == "minmax":
return minmax_scale(X)
elif scaler == "standard":
return StandardScaler().fit_transform(X)
def clustering(numbers: np.ndarray, n: int) -> List[Tuple[int, int]]:
"""将数组`numbers`划分为`n`个簇
返回值为一个List, 每一个元素为一个列表,分别为簇的起始点和长度。
Examples:
>>> numbers = np.array([1,1,1,2,4,6,8,7,4,5,6])
>>> clustering(numbers, 2)
[(0, 4), (4, 7)]
Returns:
划分后的簇列表。
"""
result = ckwrap.cksegs(numbers, n)
clusters = []
for pos, size in zip(result.centers, result.sizes):
clusters.append((int(pos - size // 2 - 1), int(size)))
return clusters | zillionare-omicron | /zillionare_omicron-2.0.0a59-py3-none-any.whl/omicron/talib/core.py | core.py |
from collections import defaultdict
from tkinter.messagebox import showwarning
from typing import List, Tuple
import arrow
import numpy as np
import plotly.graph_objects as go
import talib
from plotly.subplots import make_subplots
from omicron.talib import (
moving_average,
peaks_and_valleys,
plateaus,
support_resist_lines,
)
class Candlestick:
RED = "#FF4136"
GREEN = "#3DAA70"
TRANSPARENT = "rgba(0,0,0,0)"
LIGHT_GRAY = "rgba(0, 0, 0, 0.1)"
MA_COLORS = {
5: "#1432F5",
10: "#EB52F7",
20: "#C0C0C0",
30: "#882111",
60: "#5E8E28",
120: "#4294F7",
250: "#F09937",
}
def __init__(
self,
bars: np.ndarray,
ma_groups: List[int] = None,
win_size: int = 120,
title: str = None,
show_volume=True,
show_rsi=True,
show_peaks=False,
**kwargs,
):
"""构造函数
Args:
bars: 行情数据
ma_groups: 均线组参数。比如[5, 10, 20]表明向k线图中添加5, 10, 20日均线。如果不提供,将从数组[5, 10, 20, 30, 60, 120, 250]中取直到与`len(bars) - 5`匹配的参数为止。比如bars长度为30,则将取[5, 10, 20]来绘制均线。
win_size: 缺省绘制多少个bar,超出部分将不显示。
title: k线图的标题
show_volume: 是否显示成交量图
show_rsi: 是否显示RSI图。缺省显示参数为6的RSI图。
show_peaks: 是否标记检测出来的峰跟谷。
"""
self.title = title
self.bars = bars
self.win_size = win_size
# traces for main area
self.main_traces = {}
# traces for indicator area
self.ind_traces = {}
self.ticks = self._format_tick(bars["frame"])
# for every candlestick, it must contain a candlestick plot
cs = go.Candlestick(
x=self.ticks,
open=bars["open"],
high=bars["high"],
low=bars["low"],
close=bars["close"],
line=dict({"width": 1}),
name="K线",
**kwargs,
)
# Set line and fill colors
cs.increasing.fillcolor = "rgba(255,255,255,0.9)"
cs.increasing.line.color = self.RED
cs.decreasing.fillcolor = self.GREEN
cs.decreasing.line.color = self.GREEN
self.main_traces["ohlc"] = cs
if show_volume:
self.add_indicator("volume")
if show_peaks:
self.add_main_trace("peaks")
if show_rsi:
self.add_indicator("rsi")
# 增加均线
if ma_groups is None:
nbars = len(bars)
if nbars < 9:
ma_groups = []
else:
groups = np.array([5, 10, 20, 30, 60, 120, 250])
idx = max(np.argwhere(groups < (nbars - 5))).item() + 1
ma_groups = groups[:idx]
for win in ma_groups:
name = f"ma{win}"
if win > len(bars):
continue
ma = moving_average(bars["close"], win)
line = go.Scatter(
y=ma,
x=self.ticks,
name=name,
line=dict(width=1, color=self.MA_COLORS.get(win)),
)
self.main_traces[name] = line
@property
def figure(self):
"""返回一个figure对象"""
rows = len(self.ind_traces) + 1
specs = [[{"secondary_y": False}]] * rows
specs[0][0]["secondary_y"] = True
row_heights = [0.7, *([0.2] * (rows - 1))]
cols = 1
fig = make_subplots(
rows=rows,
cols=cols,
shared_xaxes=True,
vertical_spacing=0.05,
subplot_titles=(self.title, *self.ind_traces.keys()),
row_heights=row_heights,
specs=specs,
)
for _, trace in self.main_traces.items():
fig.add_trace(trace, row=1, col=1)
for i, (_, trace) in enumerate(self.ind_traces.items()):
fig.add_trace(trace, row=i + 2, col=1)
fig.update(layout_xaxis_rangeslider_visible=False)
fig.update_yaxes(showgrid=True, gridcolor=self.LIGHT_GRAY)
fig.update_layout(plot_bgcolor=self.TRANSPARENT)
fig.update_xaxes(type="category", tickangle=45, nticks=len(self.ticks) // 5)
end = len(self.ticks)
start = end - self.win_size
fig.update_xaxes(range=[start, end])
return fig
def _format_tick(self, tm: np.array) -> str:
if tm.item(0).hour == 0: # assume it's date
return np.array(
[
f"{x.item().year:02}-{x.item().month:02}-{x.item().day:02}"
for x in tm
]
)
else:
return np.array(
[
f"{x.item().month:02}-{x.item().day:02} {x.item().hour:02}:{x.item().minute:02}"
for x in tm
]
)
def add_main_trace(self, trace_name: str, **kwargs):
"""add trace to main plot
支持的图例类别有peaks, bbox(bounding-box), bt(回测), support_line, resist_line
Args:
trace_name : 图例名称
**kwargs : 其他参数
"""
if trace_name == "peaks":
self.mark_peaks_and_valleys(
kwargs.get("up_thres", 0.03), kwargs.get("down_thres", -0.03)
)
# 标注矩形框
elif trace_name == "bbox":
self.add_bounding_box(kwargs.get("boxes"))
# 回测结果
elif trace_name == "bt":
self.add_backtest_result(kwargs.get("bt"))
# 增加直线
elif trace_name == "support_line":
self.add_line("支撑线", kwargs.get("x"), kwargs.get("y"))
elif trace_name == "resist_line":
self.add_line("压力线", kwargs.get("x"), kwargs.get("y"))
def add_line(self, trace_name: str, x: List[int], y: List[float]):
"""在k线图上增加以`x`,`y`表示的一条直线
Args:
trace_name : 图例名称
x : x轴坐标,所有的x值都必须属于[0, len(self.bars)]
y : y值
"""
line = go.Scatter(x=self.ticks[x], y=y, mode="lines", name=trace_name)
self.main_traces[trace_name] = line
def mark_support_resist_lines(
self, upthres: float = None, downthres: float = None, use_close=True, win=60
):
"""在K线图上标注支撑线和压力线
在`win`个k线内,找出所有的局部峰谷点,并以最高的两个峰连线生成压力线,以最低的两个谷连线生成支撑线。
Args:
upthres : 用来检测峰谷时使用的阈值,参见`omicron.talib.patterns.peaks_and_valleys`
downthres : 用来检测峰谷时使用的阈值,参见`omicron.talib.patterns.peaks_and_valleys`.
use_close : 是否使用收盘价来进行检测。如果为False,则使用high来检测压力线,使用low来检测支撑线.
win : 检测局部高低点的窗口.
"""
bars = self.bars[-win:]
clipped = len(self.bars) - win
if use_close:
support, resist, x_start = support_resist_lines(
bars["close"], upthres, downthres
)
x = np.arange(len(bars))[x_start:]
self.add_main_trace("support_line", x=x + clipped, y=support(x))
self.add_main_trace("resist_line", x=x + clipped, y=resist(x))
else: # 使用"high"和"low"
bars = self.bars[-win:]
support, _, x_start = support_resist_lines(bars["low"], upthres, downthres)
x = np.arange(len(bars))[x_start:]
self.add_main_trace("support_line", x=x + clipped, y=support(x))
_, resist, x_start = support_resist_lines(bars["high"], upthres, downthres)
x = np.arange(len(bars))[x_start:]
self.add_main_trace("resist_line", x=x + clipped, y=resist(x))
def mark_bbox(self, min_size: int = 20):
"""在k线图上检测并标注矩形框
Args:
min_size : 矩形框的最小长度
"""
boxes = plateaus(self.bars["close"], min_size)
self.add_main_trace("bbox", boxes=boxes)
def mark_backtest_result(self, result: dict):
"""标记买卖点和回测数据
Args:
points : 买卖点的坐标。
"""
trades = result.get("trades")
assets = result.get("assets")
x, y, labels = [], [], []
hover = []
labels_color = defaultdict(list)
for trade in trades:
trade_date = arrow.get(trade["time"]).date()
asset = assets.get(trade_date)
security = trade["security"]
price = trade["price"]
volume = trade["volume"]
side = trade["order_side"]
x.append(self._format_tick(trade_date))
bar = self.bars[self.bars["frame"] == trade_date]
if side == "买入":
hover.append(
f"总资产:{asset}<br><br>{side}:{security}<br>买入价:{price}<br>股数:{volume}"
)
y.append(bar["high"][0] * 1.1)
labels.append("B")
labels_color["color"].append(self.RED)
else:
y.append(bar["low"][0] * 0.99)
hover.append(
f"总资产:{asset}<hr><br>{side}:{security}<br>卖出价:{price}<br>股数:{volume}"
)
labels.append("S")
labels_color["color"].append(self.GREEN)
labels_color.append(self.GREEN)
# txt.append(f'{side}:{security}<br>卖出价:{price}<br>股数:{volume}')
trace = go.Scatter(
x=x,
y=y,
mode="text",
text=labels,
name="backtest",
hovertext=hover,
textfont=labels_color,
)
self.main_traces["bs"] = trace
def mark_peaks_and_valleys(self, up_thres: float = None, down_thres: float = None):
"""在K线图上标注峰谷点
Args:
up_thres : 用来检测峰谷时使用的阈值,参见[omicron.talib.morph.peaks_and_valleys][]
down_thres : 用来检测峰谷时使用的阈值,参见[omicron.talib.morph.peaks_and_valleys][]
"""
bars = self.bars
flags = peaks_and_valleys(
bars["close"].astype(np.float64), up_thres, down_thres
)
# 移除首尾的顶底标记,一般情况下它们都不是真正的顶和底。
flags[0] = 0
flags[-1] = 0
marker_margin = (max(bars["high"]) - min(bars["low"])) * 0.05
ticks_up = self.ticks[flags == 1]
y_up = bars["high"][flags == 1] + marker_margin
ticks_down = self.ticks[flags == -1]
y_down = bars["low"][flags == -1] - marker_margin
trace = go.Scatter(
mode="markers", x=ticks_up, y=y_up, marker_symbol="triangle-down", name="峰"
)
self.main_traces["peaks"] = trace
trace = go.Scatter(
mode="markers",
x=ticks_down,
y=y_down,
marker_symbol="triangle-up",
name="谷",
)
self.main_traces["valleys"] = trace
def add_bounding_box(self, boxes: List[Tuple]):
"""bbox是标记在k线图上某个区间内的矩形框,它以该区间最高价和最低价为上下边。
Args:
boxes: 每个元素(start, width)表示各个bbox的起点和宽度。
"""
for j, box in enumerate(boxes):
x, y = [], []
i, width = box
if len(x):
x.append(None)
y.append(None)
group = self.bars[i : i + width]
mean = np.mean(group["close"])
std = 2 * np.std(group["close"])
# 落在两个标准差以内的实体最上方和最下方值
hc = np.max(group[group["close"] < mean + std]["close"])
lc = np.min(group[group["close"] > mean - std]["close"])
ho = np.max(group[group["open"] < mean + std]["open"])
lo = np.min(group[group["open"] > mean - std]["open"])
h = max(hc, ho)
low = min(lo, lc)
x.extend(self.ticks[[i, i + width - 1, i + width - 1, i, i]])
y.extend((h, h, low, low, h))
hover = f"宽度: {width}<br>振幅: {h/low - 1:.2%}"
trace = go.Scatter(x=x, y=y, fill="toself", name=f"平台整理{j}", text=hover)
self.main_traces[f"bbox-{j}"] = trace
def add_indicator(self, indicator: str):
""" "向k线图中增加技术指标"""
if indicator == "volume":
colors = np.repeat(self.RED, len(self.bars))
colors[self.bars["close"] <= self.bars["open"]] = self.GREEN
trace = go.Bar(
x=self.ticks,
y=self.bars["volume"],
showlegend=False,
marker={"color": colors},
)
elif indicator == "rsi":
rsi = talib.RSI(self.bars["close"].astype(np.float64))
trace = go.Scatter(x=self.ticks, y=rsi, showlegend=False)
else:
raise ValueError(f"{indicator} not supported")
self.ind_traces[indicator] = trace
def add_marks(self, x: List[int]):
"""向k线图中增加标记点"""
trace = go.Scatter(
x=x, y=self.bars["high"][x], mode="markers", marker_symbol="cross"
)
self.main_traces["marks"] = trace
def plot(self):
"""绘制图表"""
fig = self.figure
fig.show()
def plot_candlestick(
bars: np.ndarray, ma_groups: List[int], title: str = None, **kwargs
):
cs = Candlestick(bars, ma_groups, title=title)
cs.plot() | zillionare-omicron | /zillionare_omicron-2.0.0a59-py3-none-any.whl/omicron/plotting/candlestick.py | candlestick.py |
import asyncio
import base64
import hashlib
import hmac
import json
import logging
import time
import urllib.parse
from typing import Awaitable, Union
import cfg4py
import httpx
from deprecation import deprecated
from omicron.core.errors import ConfigError
logger = logging.getLogger(__name__)
cfg = cfg4py.get_instance()
class DingTalkMessage:
"""
钉钉的机器人消息推送类,封装了常用的消息类型以及加密算法
需要在配置文件中配置钉钉的机器人的access_token
如果配置了加签,需要在配置文件中配置钉钉的机器人的secret
如果配置了自定义关键词,需要在配置文件中配置钉钉的机器人的keyword,多个关键词用英文逗号分隔
全部的配置文件示例如下, 其中secret和keyword可以不配置, access_token必须配置
notify:
dingtalk_access_token: xxxx
dingtalk_secret: xxxx
"""
url = "https://oapi.dingtalk.com/robot/send"
@classmethod
def _get_access_token(cls):
"""获取钉钉机器人的access_token"""
if hasattr(cfg.notify, "dingtalk_access_token"):
return cfg.notify.dingtalk_access_token
else:
logger.error(
"Dingtalk not configured, please add the following items:\n"
"notify:\n"
" dingtalk_access_token: xxxx\n"
" dingtalk_secret: xxxx\n"
)
raise ConfigError("dingtalk_access_token not found")
@classmethod
def _get_secret(cls):
"""获取钉钉机器人的secret"""
if hasattr(cfg.notify, "dingtalk_secret"):
return cfg.notify.dingtalk_secret
else:
return None
@classmethod
def _get_url(cls):
"""获取钉钉机器人的消息推送地址,将签名和时间戳拼接在url后面"""
access_token = cls._get_access_token()
url = f"{cls.url}?access_token={access_token}"
secret = cls._get_secret()
if secret:
timestamp, sign = cls._get_sign(secret)
url = f"{url}×tamp={timestamp}&sign={sign}"
return url
@classmethod
def _get_sign(cls, secret: str):
"""获取签名发送给钉钉机器人"""
timestamp = str(round(time.time() * 1000))
secret_enc = secret.encode("utf-8")
string_to_sign = "{}\n{}".format(timestamp, secret)
string_to_sign_enc = string_to_sign.encode("utf-8")
hmac_code = hmac.new(
secret_enc, string_to_sign_enc, digestmod=hashlib.sha256
).digest()
sign = urllib.parse.quote_plus(base64.b64encode(hmac_code))
return timestamp, sign
@classmethod
def _send(cls, msg):
"""发送消息到钉钉机器人"""
url = cls._get_url()
response = httpx.post(url, json=msg, timeout=30)
if response.status_code != 200:
logger.error(
f"failed to send message, content: {msg}, response from Dingtalk: {response.content.decode()}"
)
return
rsp = json.loads(response.content)
if rsp.get("errcode") != 0:
logger.error(
f"failed to send message, content: {msg}, response from Dingtalk: {rsp}"
)
return response.content.decode()
@classmethod
async def _send_async(cls, msg):
"""发送消息到钉钉机器人"""
url = cls._get_url()
async with httpx.AsyncClient() as client:
r = await client.post(url, json=msg, timeout=30)
if r.status_code != 200:
logger.error(
f"failed to send message, content: {msg}, response from Dingtalk: {r.content.decode()}"
)
return
rsp = json.loads(r.content)
if rsp.get("errcode") != 0:
logger.error(
f"failed to send message, content: {msg}, response from Dingtalk: {rsp}"
)
return r.content.decode()
@classmethod
@deprecated("2.0.0", details="use function `ding` instead")
def text(cls, content):
msg = {"text": {"content": content}, "msgtype": "text"}
return cls._send(msg)
def ding(msg: Union[str, dict]) -> Awaitable:
"""发送消息到钉钉机器人
支持发送纯文本消息和markdown格式的文本消息。如果要发送markdown格式的消息,请通过字典传入,必须包含包含"title"和"text"两个字段。更详细信息,请见[钉钉开放平台文档](https://open.dingtalk.com/document/orgapp-server/message-type)
???+ Important
必须在异步线程(即运行asyncio loop的线程)中调用此方法,否则会抛出异常。
此方法返回一个Awaitable,您可以等待它完成,也可以忽略返回值,此时它将作为一个后台任务执行,但完成的时间不确定。
Args:
msg: 待发送消息。
Returns:
发送消息的后台任务。您可以使用此返回句柄来取消任务。
"""
if isinstance(msg, str):
msg_ = {"text": {"content": msg}, "msgtype": "text"}
elif isinstance(msg, dict):
msg_ = {
"msgtype": "markdown",
"markdown": {"title": msg["title"], "text": msg["text"]},
}
else:
raise TypeError
task = asyncio.create_task(DingTalkMessage._send_async(msg_))
return task | zillionare-omicron | /zillionare_omicron-2.0.0a59-py3-none-any.whl/omicron/notify/dingtalk.py | dingtalk.py |
import asyncio
import logging
import mimetypes
import os
from email.message import EmailMessage
from typing import Awaitable, List, Union
import aiosmtplib
import cfg4py
logger = logging.getLogger(__name__)
def mail_notify(
subject: str = None,
body: str = None,
msg: EmailMessage = None,
html=False,
receivers=None,
) -> Awaitable:
"""发送邮件通知。
发送者、接收者及邮件服务器等配置请通过cfg4py配置:
```
notify:
mail_from: [email protected]
mail_to:
- [email protected]
mail_server: smtp.ym.163.com
```
验证密码请通过环境变量`MAIL_PASSWORD`来配置。
subject/body与msg必须提供其一。
???+ Important
必须在异步线程(即运行asyncio loop的线程)中调用此方法,否则会抛出异常。
此方法返回一个Awaitable,您可以等待它完成,也可以忽略返回值,此时它将作为一个后台任务执行,但完成的时间不确定。
Args:
msg (EmailMessage, optional): [description]. Defaults to None.
subject (str, optional): [description]. Defaults to None.
body (str, optional): [description]. Defaults to None.
html (bool, optional): body是否按html格式处理? Defaults to False.
receivers (List[str], Optional): 接收者信息。如果不提供,将使用预先配置的接收者信息。
Returns:
发送消息的后台任务。您可以使用此返回句柄来取消任务。
"""
if all([msg is not None, subject or body]):
raise TypeError("msg参数与subject/body只能提供其中之一")
elif all([msg is None, subject is None, body is None]):
raise TypeError("必须提供msg参数或者subjecdt/body参数")
if msg is None:
if html:
msg = compose(subject, html=body)
else:
msg = compose(subject, plain_txt=body)
cfg = cfg4py.get_instance()
if not receivers:
receivers = cfg.notify.mail_to
password = os.environ.get("MAIL_PASSWORD")
return send_mail(
cfg.notify.mail_from, receivers, password, msg, host=cfg.notify.mail_server
)
def send_mail(
sender: str,
receivers: List[str],
password: str,
msg: EmailMessage = None,
host: str = None,
port: int = 25,
cc: List[str] = None,
bcc: List[str] = None,
subject: str = None,
body: str = None,
username: str = None,
) -> Awaitable:
"""发送邮件通知。
如果只发送简单的文本邮件,请使用 send_mail(sender, receivers, subject=subject, plain=plain)。如果要发送较复杂的带html和附件的邮件,请先调用compose()生成一个EmailMessage,然后再调用send_mail(sender, receivers, msg)来发送邮件。
???+ Important
必须在异步线程(即运行asyncio loop的线程)中调用此方法,否则会抛出异常。
此方法返回一个Awaitable,您可以等待它完成,也可以忽略返回值,此时它将作为一个后台任务执行,但完成的时间不确定。
Args:
sender (str): [description]
receivers (List[str]): [description]
msg (EmailMessage, optional): [description]. Defaults to None.
host (str, optional): [description]. Defaults to None.
port (int, optional): [description]. Defaults to 25.
cc (List[str], optional): [description]. Defaults to None.
bcc (List[str], optional): [description]. Defaults to None.
subject (str, optional): [description]. Defaults to None.
plain (str, optional): [description]. Defaults to None.
username (str, optional): the username used to logon to mail server. if not provided, then `sender` is used.
Returns:
发送消息的后台任务。您可以使用此返回句柄来取消任务。
"""
if all([msg is not None, subject is not None or body is not None]):
raise TypeError("msg参数与subject/body只能提供其中之一")
elif all([msg is None, subject is None, body is None]):
raise TypeError("必须提供msg参数或者subjecdt/body参数")
msg = msg or EmailMessage()
if isinstance(receivers, str):
receivers = [receivers]
msg["From"] = sender
msg["To"] = ", ".join(receivers)
if subject:
msg["subject"] = subject
if body:
msg.set_content(body)
if cc:
msg["Cc"] = ", ".join(cc)
if bcc:
msg["Bcc"] = ", ".join(bcc)
username = username or sender
if host is None:
host = sender.split("@")[-1]
task = asyncio.create_task(
aiosmtplib.send(
msg, hostname=host, port=port, username=sender, password=password
)
)
return task
def compose(
subject: str, plain_txt: str = None, html: str = None, attachment: str = None
) -> EmailMessage:
"""编写MIME邮件。
Args:
subject (str): 邮件主题
plain_txt (str): 纯文本格式的邮件内容
html (str, optional): html格式的邮件内容. Defaults to None.
attachment (str, optional): 附件文件名
Returns:
MIME mail
"""
msg = EmailMessage()
msg["Subject"] = subject
if html:
msg.preamble = plain_txt or ""
msg.set_content(html, subtype="html")
else:
assert plain_txt, "Either plain_txt or html is required."
msg.set_content(plain_txt)
if attachment:
ctype, encoding = mimetypes.guess_type(attachment)
if ctype is None or encoding is not None:
ctype = "application/octet-stream"
maintype, subtype = ctype.split("/", 1)
with open(attachment, "rb") as f:
msg.add_attachment(
f.read(), maintype=maintype, subtype=subtype, filename=attachment
)
return msg | zillionare-omicron | /zillionare_omicron-2.0.0a59-py3-none-any.whl/omicron/notify/mail.py | mail.py |
## Omicron的开发流程
Omicron遵循[ppw](https://zillionare.github.io/python-project-wizard)定义的开发流程和代码规范。您可以阅读[tutorial](https://zillionare.github.io/python-project-wizard/tutorial/)来了解更多。
简单来说,通过ppw构建的工程,具有以下能力:
### 基于poetry进行依赖管理
1. 通过poetry add给项目增加新的依赖。如果依赖项仅在开发环境下使用,请增加为Extra项,并正确归类为dev, doc和test中的一类。
2. 使用poetry lock来锁定依赖的版本。
3. 使用poetry update更新依赖项。
### flake8, isort, black
omicron使用flake8, isort和black进行语法检查和代码格式化
### pre-commit
使用pre-commit来确保提交的代码都符合规范。如果是刚下载代码,请运行pre-commit install安装钩子。
## TODO: 将通用部分转换到大富翁的开发者指南中
## 如何进行单元测试?
### 设置环境变量
Omicron在notify包中提供了发送邮件和钉钉消息的功能。在进行单元测试前,需要设置相关的环境变量:
```bash
DINGTALK_ACCESS_TOKEN=?
DINGTALK_SECRET=?
export MAIL_FROM=?
export MAIL_SERVER=?
export MAIL_TO=?
export MAIL_PASSWORD=?
```
上述环境变量已在gh://zillionare/omicron中设置。如果您fork了omicron并且想通过github actions进行测试,请在您的repo中设置相应的secrets。
### 启动测试
通过tox来运行测试。tox将启动必要的测试环境(通过`stop_service.sh`和`start_service.sh`)。
### 文档
文档由两部分组成。一部分是项目文档,存放在docs目录下。另一部分是API文档,它们从源代码的注释中提取。生成文档的工具是mkdocs。API文档的提取则由mkdocs的插件mkdocstrings提取。
| zillionare-omicron | /zillionare_omicron-2.0.0a59-py3-none-any.whl/docs/developer.md | developer.md |
# 配置和初始化omicron
Omicron 使用 [cfg4py](https://pypi.org/project/cfg4py/) 来管理配置。
cfg4py 使用 yaml 文件来保存配置项。在使用 cfg4py 之前,您需要在某处初始化 cfg4py,然后再初始化omicron:
???+ tip
为了简洁起见,我们在顶层代码中直接使用了async/await。通常,这些代码能够直接在notebook中运行,但如果需要在普通的python脚本中运行这些代码,您通常需要将其封装到一个异步函数中,再通过`asyncio.run`来运行它。
```python
import asyncio
import cfg4py
import omicron
async def main():
cfg4py.init('path/to/your/config/dir')
await omicron.init()
# do your great job with omicron
asyncio.run(main())
```
```python
import cfg4py
import omicron
cfg4py.init('path/to/your/config/dir')
await omicron.init()
```
注意初始化 cfg4py 时,需要提供包含配置文件的**文件夹**的路径,而**不是配置文件**的路径。配置文件名必须为 defaults.yml。
您至少应该为omicron配置Redis 连接串和influxdb连接串。下面是常用配置示例:
```yaml
# defaults.yaml
redis:
dsn: redis://${REDIS_HOST}:${REDIS_PORT}
influxdb:
url: http://${INFLUXDB_HOST}:${INFLUXDB_PORT}
token: ${INFLUXDB_TOKEN}
org: ${INFLUXDB_ORG}
bucket_name: ${INFLUXDB_BUCKET_NAME}
enable_compress: true
max_query_size: 150000
notify:
mail_from: ${MAIL_FROM}
mail_to:
- ${MAIL_TO}
mail_server: ${MAIL_SERVER}
dingtalk_access_token: ${DINGTALK_ACCESS_TOKEN}
dingtalk_secret: ${DINGTALK_SECRET}
```
请根据您实际环境配置来更改上述文件。上述配置中,${{REDIS_HOST}}意味着环境变量。如果是windows,您需要在系统 > 环境变量中进行设置。如果是Linux或者Mac,您需要修改.bashrc,例如:
```
export REDIS_HOST=localhost
```
Omicron提供了证券列表、交易日历、行情数据及其它功能。
# 2. 关闭omicron
在您的进程即将退出之前,请记得关闭omicron。如果您是在notebook中使用omicron,则可以忽略此步聚。
```python
await omicron.close()
```
# 3. 证券列表
您可以通过以下方法来获取某一天的证券列表
```python
# 4. assume you have omicron init
dt = datetime.date(2022, 5, 20)
query = Security.select(dt)
codes = await query.eval()
print(codes)
# the outputs is like ["000001.XSHE", "000004.XSHE", ...]
```
这里的`dt`如果没有提供的话,将使用最新的证券列表。但在回测中,您通常不同时间的证券列表,因此,`dt`在这种情况下是必须的,否则,您将会使用最新的证券列表来回测过去。
这里的`Security.select()`方法返回一个`Query`对象,用以按查询条件进行过滤。该对象支持链式操作。它的方法中,除了`eval`,基本都是用来指定过滤条件,构建查询用的。如果要得到最终结果,请使用`Query.eval`方法。
## 返回所有股票或者指数
```python
query = Security.select(dt)
codes = await query.types(["stock"]).eval()
print(codes)
```
## 排除某种股票(证券)
```python
query = Security.select(dt)
codes = await query.exclude_st().exclude_kcb().exclude_cyb().eval()
print(codes)
```
## 如果只要求某种股票(证券)
```python
query = Security.select(dt)
codes = await query.only_kcb().only_st().only_cyb().eval()
print(codes)
#得到空列表
```
## 按别名进行模糊查询
A股的证券在标识上,一般有代码(code或者symbol)、拼音简写(name)和汉字表示名(display_name)三种标识。比如中国平安,其代码为601318.XSHG;其拼音简写为ZGPA;而中国平安被称为它的别名(`alias`)。
如果要查询所有中字头的股票:
```python
query = Security.select(dt)
codes = await query.alias_like("中").eval()
print(codes)
```
## 通过代码查询其它信息
通过前面的查询我们可以得到一个证券列表,如果要得到具体的信息,可以通过`info`接口来查询:
```python
dt = datetime.date(2022, 5, 20)
info = await Security.info("688001.XSHG", dt)
print(info)
```
输出为:
```json
{
'type': 'stock',
'display_name': '华兴源创',
'alias': '华兴源创',
'end': datetime.date(2200, 1, 1),
'start': datetime.date(2019, 7, 22),
'name': 'HXYC'
}
```
# TimeFrame时间计算
Omicron不仅提供了交易日历,与其它量化框架相比,我们还提供了丰富的时间相关的运算操作。这些操作都有详细的文档和示例,您可以通过[TimeFrame](/api/timeframe)来进一步阅读。
omicron中,常常会遇到时间帧(Time Frame)这个概念。因为行情数据都是按一定的时间长度组织的,比如5分钟,1天,等等。因此,在omicron中,我们经常使用某个时间片结束的时间,来标识这个时间片,并将其称之为帧(Time Frame)。
omicron中,我们支持的时间帧是有限的,主要是日内的分钟帧(FrameType.MIN1), 5分钟帧(FrameType.MIN5), 15分钟帧、30分钟帧和00分钟帧,以及日线级别的FrameType.DAY, FrameType.WEEK等。关于详细的类型说明,请参见[coretypes](https://zillionare.github.io/core-types/)
omicron提供的交易日历起始于2005年1月4日。提供的行情数据,最早从这一天起。
大致上,omicron提供了以下操作:
## 交易时间的偏移
如果今天是2022年5月20日,您想得到100天前的交易日,则可以使用day_shift:
```python
from omicron import tf
dt = datetime.date(2022, 5, 20)
tf.day_shift(dt, -100)
```
输出是datetime.date(2021, 12, 16)。在这里,day_shift的第二个参数`n`是偏移量,当它小于零时,是找`dt`前`n`个交易日;当它大于零时,是找`dt`之后的`n`个交易日。
比如有意思的是`n` == 0的时候。对上述`dt`,day_shift(dt, 0)得到的仍然是同一天,但如果`dt`是2022年5月21日是周六,则day_shift(datetime.date(2022, 5, 21))将返回2022年5月20日。因为5月21日这一天是周六,不是交易日,day_shift将返回其对应的交易日,这在多数情况下会非常方便。
除了`day_shift`外,timeframe还提供了类似函数比如`week_shift`等。一般地,您可以用shift(dt, n, frame_type)来对任意支持的时间进行偏移。
## 边界操作 ceiling和floor
很多时候我们需要知道具体的某个时间点(moment)所属的帧。如果要取其上一帧,则可以用floor操作,反之,使用ceiling。
```python
tf.ceiling(datetime.date(2005, 1, 4), FrameType.WEEK)
# output is datetime.date(2005, 1, 7)
```
## 时间转换
为了加快速度,以及方便持久化存储,在timeframe内部,有时候使用整数来表示时间。比如20220502表示的是2022年5月20日,而202205220931则表示2022年5月20日9时31分钟。
这种表示法,有时候要求我们进行一些转换:
```python
# 将整数表示的日期转换为日期
tf.int2date(20220522) # datetime.date(2022, 5, 22)
# 将整数表示的时间转换为时间
tf.int2time(202205220931) # datetime.datetime(2022, 5, 22, 9, 31)
# 将日期转换成为整数
tf.date2int(datetime.date(2022, 5, 22)) # 20220520
# 将时间转换成为时间
tf.date2time(datetime.datetime(2022, 5, 22, 9, 21)) # 202205220921
```
## 列时间帧
有时候我们需要得到`start`和`end`之间某个时间帧类型的所有时间帧:
```python
start = arrow.get('2020-1-13 10:00').naive
end = arrow.get('2020-1-13 13:30').naive
tf.get_frames(start, end, FrameType.MIN30)
[202001131000, 202001131030, 202001131100, 202001131130, 202001131330]
```
???+ Important
上面的示例中,出现了可能您不太熟悉的`naive`属性。它指的是取不带时区的时间。在python中,时间可以带时区(timezone-aware)和不带时区(naive)。
如果您使用datetime.datetime(2022, 5, 20),它就是不带时区的,除非您专门指定时区。
在omicron中,我们在绝大多数情况下,仅使用naive表示的时间,即不带时区,并且假定时区为东八区(即北京时间)。
如果您只知道结束时间,需要向前取`n`个时间帧,则可以使用`get_frames_by_count`。
如果您只是需要知道在`start`和`end`之间,总共有多少个帧,请使用 `count_frames`:
```python
start = datetime.date(2019, 12, 21)
end = datetime.date(2019, 12, 21)
tf.count_frames(start, end, FrameType.DAY)
```
输出将是1。上述方法还有一个快捷方法,即`count_day_frames`,并且,对week, month, quaters也是一样。
# 取行情数据
现在,让我们来获取一段行情数据:
```python
code = "000001.XSHE"
end = datetime.date(2022, 5, 20)
bars = await Stock.get_bars(code, 10, FrameType.DAY, end)
```
返回的`bars`将是一个numpy structured array, 其类型为[bars_dtype](https://zillionare.github.io/core-types/)。一般地,它包括了以下字段:
* frame(帧)
* open(开盘价)
* high(最高价)
* low(最低价)
* close(收盘价)
* volume(成交量,股数)
* amount(成交额)
* factor(复权因子)
# 评估指标
omicron提供了mean_absolute_error函数和pct_error函数。它们在scipy或者其它库中也能找到,为了方便不熟悉这些第三方库的使用者,我们内置了这个常指标。
对一些常见的策略评估函数,我们引用了empyrical中的相关函数,比如alpha, beta, shapre_ratio, calmar_ratio等。
# talib库
您应该把这里提供的函数当成实验性的。这些API也可能在某天被废弃、重命名、修改,或者这些API并没有多大作用,或者它们的实现存在错误。
但是,如果我们将来会抛弃这些API的话,我们一定会通过depracted方法提前进行警告。
| zillionare-omicron | /zillionare_omicron-2.0.0a59-py3-none-any.whl/docs/usage.md | usage.md |
# 1. 安装
要使用Omicron来获取行情数据,请先安装[Omega](https://pypi.org/project/zillionare-omega/),并按说明文档要求完成初始化配置。
然后在开发机上,运行下面的命令安装Omicron:
``` bash
pip install zillionare-omicron
```
omicron依赖numpy, pandas, scipy, sklearn。这些库的体积比较大,因此在安装omicron时,请保持网络连接畅通,必要时,请添加阿里或者清华的PyPI镜像。
omicron还依赖于talib, zigzag, ciso8601等高性能的C/C++库。安装这些库往往需要在您本机执行一个编译过程。请遵循以下步骤完成:
!!! 安装原生库
=== "Windows"
**注意我们不支持32位windows**
请跟随[windows下安装omicron](_static/Omicron_Windows10.docx)来完成安装。
=== "Linux"
1. 请执行下面的脚本以完成ta-lib的安装
```bash
sudo apt update && sudo apt upgrade -y && sudo apt autoremove -y
sudo apt-get install build-essential -y
curl -L http://prdownloads.sourceforge.net/ta-lib/ta-lib-0.4.0-src.tar.gz | tar -xzv -C /tmp/
cd /tmp/ta-lib
./configure --prefix=/usr
make
sudo make install
```
1. 现在安装omicron,所有其它依赖的安装将自动完成。
=== "MacOS"
1. 请通过`brew install ta-lib`来完成ta-lib的安装
2. 现在安装omicron,所有其它依赖的安装都将自动完成。
# 2. 常见问题
## 无法访问aka.ms
如果遇到aka.ms无法访问的问题,有可能是IP地址解析的问题。请以管理员权限,打开并编辑位于c:\windows\system32\drivers\etc\下的hosts文件,将此行加入到文件中:
```
23.41.86.106 aka.ms
```
| zillionare-omicron | /zillionare_omicron-2.0.0a59-py3-none-any.whl/docs/installation.md | installation.md |
import logging
import os
import cfg4py
import omicron
import pkg_resources
from apscheduler.schedulers.asyncio import AsyncIOScheduler
from sanic import Sanic
from pluto.store.buy_limit_pool import pooling_latest
from pluto.store.long_parallel_pool import LongParallelPool
from pluto.store.steep_slopes_pool import SteepSlopesPool
from pluto.store.touch_buy_limit_pool import TouchBuyLimitPoolStore
from pluto.web.blueprints import bp
application = Sanic("pluto")
logger = logging.getLogger(__name__)
ver = pkg_resources.get_distribution("zillionare-pluto").parsed_version
# @application.route('/')
# async def index(request):
# return response.json({
# "greetings": "welcome to zillionare-pluto",
# "version": str(ver)
# })
def serve_static_files(app):
# set static path
app_dir = os.path.dirname(__file__)
app.static("/", os.path.join(app_dir, "web/static/index.html"))
app.static("dist", os.path.join(app_dir, "web/static/dist"))
app.static("pages", os.path.join(app_dir, "web/static/pages"))
app.static("data", os.path.join(app_dir, "web/static/data"))
async def init(app, loop):
await omicron.init()
lpp = LongParallelPool()
tblp = TouchBuyLimitPoolStore()
lpp = LongParallelPool()
tblp = TouchBuyLimitPoolStore()
ssp = SteepSlopesPool()
scheduler = AsyncIOScheduler(event_loop=loop)
scheduler.add_job(lpp.pooling, "cron", hour=15, minute=2)
scheduler.add_job(pooling_latest, "cron", hour=15, minute=5)
scheduler.add_job(tblp.pooling, "cron", hour=15, minute=8)
scheduler.add_job(ssp.pooling, "cron", hour=15, minute=8)
scheduler.start()
def start(port: int = 2712):
cfg4py.init(os.path.expanduser("~/zillionare/pluto"))
application.register_listener(init, "before_server_start")
application.blueprint(bp)
serve_static_files(application)
application.run(
host="0.0.0.0",
port=port,
register_sys_signals=True,
workers=1,
single_process=True,
)
logger.info("pluto serve stopped")
if __name__ == "__main__":
start() | zillionare-pluto | /zillionare_pluto-0.2.0-py3-none-any.whl/pluto/app.py | app.py |
import datetime
import json
import logging
import os
import re
import signal
import subprocess
import sys
import time
from typing import Any
import arrow
import fire
import httpx
from omicron import tf
from prettytable import PrettyTable
from pluto.store.buy_limit_pool import BuyLimitPoolStore
from pluto.store.long_parallel_pool import LongParallelPool
from pluto.store.steep_slopes_pool import SteepSlopesPool
from pluto.store.touch_buy_limit_pool import TouchBuyLimitPoolStore
logger = logging.getLogger(__name__)
pools = {
"涨停": BuyLimitPoolStore(),
"触及涨停": TouchBuyLimitPoolStore(),
"上升均线": SteepSlopesPool(),
"多头排列": LongParallelPool(),
}
def _day_closed(timestamp):
now = datetime.datetime.now()
if (
tf.is_trade_day(timestamp)
and timestamp == now.date()
and datetime.datetime.now().hour < 15
):
return tf.day_shift(timestamp, -1)
else:
return tf.day_shift(timestamp, 0)
def _parse_as_str_array(args: Any):
if args is None:
return None
elif isinstance(args, str):
arr = re.split(r"[,,]", args)
elif hasattr(args, "__iter__"):
arr = args
elif isinstance(args, int):
arr = [args]
return [str(item) for item in arr]
def _save_proc_info(port, proc):
path = os.path.dirname(__file__)
file = os.path.join(path, "config")
with open(file, "w") as f:
f.writelines(json.dumps({"port": port, "proc": proc}))
def _read_proc_info():
path = os.path.dirname(__file__)
file = os.path.join(path, "config")
try:
with open(file, "r") as f:
info = json.load(f)
return info
except FileNotFoundError:
pass
except Exception as e:
print(e)
return None
def _port():
info = _read_proc_info()
return info.get("port")
def is_service_alive(port: int = None) -> bool:
if port is None:
info = _read_proc_info()
if info is None:
raise ValueError("请指定端口")
port = info["port"]
try:
resp = httpx.get(f"http://localhost:{port}/", trust_env=False)
except httpx.NetworkError:
return False
return resp.status_code == 200
def status(port: int = None) -> bool:
if not is_service_alive(port):
print("------ pluto服务未运行 ------")
return
print("------ pluto服务正在运行 ------")
x = PrettyTable()
x.field_names = ["pool", "total", "latest"]
for name, pool in pools.items():
try:
latest = sorted(pool.pooled)[-1]
except Exception:
x.add_row([name, "NA", "NA"])
continue
x.add_row([name, len(pool.pooled), latest])
print(x)
def stop():
info = _read_proc_info()
if info is None:
print("未发现正在运行的pluto服务")
return
proc = info["proc"]
try:
os.kill(proc, signal.SIGKILL)
except ProcessLookupError:
sys.exit()
if not is_service_alive():
print("pluto")
else:
print("停止pluto服务失败,请手工停止。")
def serve(port: int = 2712):
if is_service_alive(port):
print("pluto正在运行中,忽略此命令。")
return
proc = subprocess.Popen([sys.executable, "-m", "pluto", "serve", f"{port}"])
for _ in range(30):
if is_service_alive(port):
_save_proc_info(port=port, proc=proc.pid)
break
else:
time.sleep(1)
def stop():
info = _read_proc_info()
if info is None:
print("未发现正在运行的pluto服务")
return
proc = info["proc"]
try:
os.kill(proc, signal.SIGKILL)
except ProcessLookupError:
sys.exit()
if not is_service_alive():
print("pluto已停止运行")
else:
print("停止pluto服务失败,请手工停止。")
def pooling(pool: str, date: str = None):
"""启动`pool`(比如涨停池)的统计"""
cmd = {"涨停": "blp", "触及涨停": "tblp", "上升均线": "ssp", "多头排列": "lpp"}.get(pool)
if cmd is None:
print("参数必须为(涨停,触及涨停,上升均线,多头排列)中的任一个。")
return
if not is_service_alive():
print("服务未运行,或者配置端口错误")
return
port = _port()
url = f"http://localhost:{port}/pluto/pools/pooling"
rsp = httpx.post(url, json={"cmd": cmd, "end": date})
if rsp.status_code == 200:
print(f"统计{pool}的任务已创建!")
def show(pool_name: str, date: str = None):
if pool_name not in pools:
print(f"{pool_name}错误。支持的类型有{','.join(pools.keys())}")
return
pool = pools.get(pool_name)
x = PrettyTable()
x.field_names = []
dt = arrow.get(date or arrow.now()).date()
x.add_rows(pool.get(dt))
print(x)
def strategy(name: str, **kwargs):
if not is_service_alive():
print("服务未运行,或者配置端口错误")
return
port = _port()
url = f"http://localhost:{port}/pluto/strategies/{name}"
rsp = httpx.post(url, json=kwargs, timeout=120)
print(rsp.json())
def restart(port: int = 2712):
stop()
serve(port)
def main():
fire.Fire(
{
"serve": serve,
"status": status,
"stop": stop,
"restart": restart,
"pooling": pooling,
"show": show,
"strategy": strategy,
}
)
if __name__ == "__main__":
main() | zillionare-pluto | /zillionare_pluto-0.2.0-py3-none-any.whl/pluto/cli.py | cli.py |
import datetime
from typing import List, Tuple
import arrow
from boards.board import ConceptBoard, IndustryBoard
from coretypes import BarsArray, FrameType
from omicron.models.security import Security
from omicron.models.stock import Stock
from omicron.plotting.candlestick import Candlestick
from omicron.talib import moving_average, valley_detect
from pluto.core.volume import describe_volume_morph, morph_pattern, net_buy_volume
from pluto.strategies.base import BaseStrategy
class StrategyCrossYear(BaseStrategy):
name = "cross-year-strategy"
desc = "个股在由下上攻年线时,更容易出现涨停"
def extract_features(self, code: str, bars: BarsArray) -> Tuple:
if len(bars) < 260:
return None
close = bars["close"]
# opn = bars["open"]
# 底部距离、上涨幅度
dist, adv = valley_detect(close)
ma250 = moving_average(close, 250, padding=False)
c0 = close[-1]
# 距年线距离
gap = ma250[-1] / c0 - 1
# morph pattern
morph = morph_pattern(bars[-5:])
# 净买入量
nbv = net_buy_volume(bars[-5:])
return (dist, adv, gap, morph, nbv)
def evaluate_long(self, code: str, bars: BarsArray):
if bars[-1]["close"] < bars[-1]["open"]:
return False, None
features = self.extract_features(code, bars)
if features is None:
return False, None
dist, adv, gap, morph, nbv = features
if dist is None or gap > 0.11 or gap < 0:
return False, None
return True, (dist, adv, gap, morph, nbv)
def _belong_to_boards(
self,
code: str,
ib,
cb,
with_industry: List[str] = None,
with_concepts: List[str] = None,
):
symbol = code.split(".")[0]
if ib:
industries = ib.get_boards(symbol)
if set(industries).intersection(set(with_industry)):
return True
if cb:
concepts = cb.get_boards(symbol)
if set(concepts).intersection(with_concepts):
return True
return False
async def backtest(self, start: datetime.date, end: datetime.date):
return await super().backtest(start, end)
async def scan(
self,
end: datetime.date = None,
industry: List[str] = None,
concepts: List[str] = None,
):
end = end or arrow.now().date()
codes = (
await Security.select(end)
.types(["stock"])
.exclude_cyb()
.exclude_kcb()
.exclude_st()
.eval()
)
if industry is not None:
ib = IndustryBoard()
ib.init()
industry = ib.normalize_board_name(industry)
else:
ib = None
if concepts is not None:
cb = ConceptBoard()
cb.init()
concepts = cb.normalize_board_name(concepts)
else:
cb = None
for code in codes:
bars = await Stock.get_bars(code, 260, FrameType.DAY)
fired, features = self.evaluate_long(code, bars)
if not fired or (
not self._belong_to_boards(code, ib, cb, industry, concepts)
):
continue
name = await Security.alias(code)
dist, adv, gap, morph, nbv = features
morph = describe_volume_morph(morph)
cs = Candlestick(
bars,
title=f"{name} 底部跨度:{dist} 底部涨幅:{adv:.1%} 年线距离:{gap:.1%} 净买入量{nbv:.1f} {morph}",
)
cs.plot() | zillionare-pluto | /zillionare_pluto-0.2.0-py3-none-any.whl/pluto/strategies/crossyear.py | crossyear.py |
import datetime
import logging
from typing import List
import numpy as np
import pandas as pd
import talib as ta
from coretypes import BarsArray, FrameType
from empyrical import sharpe_ratio
from numpy.typing import NDArray
from omicron import tf
from omicron.extensions import price_equal, smallest_n_argpos, top_n_argpos
from omicron.models.stock import Stock
from omicron.talib import moving_average, polyfit
from talib import RSI
from pluto.core.metrics import adjust_close_at_pv, parallel_score
from pluto.core.volume import top_volume_direction
from pluto.store.base import ZarrStore
from pluto.store.buy_limit_pool import BuyLimitPoolStore
from pluto.store.touch_buy_limit_pool import TouchBuyLimitPoolStore
logger = logging.getLogger(__name__)
def pct_change_by_m30(bars: BarsArray):
"""根据30分钟行情计算出当天涨跌幅"""
today = bars[-1]["frame"].item().date()
prev_day = tf.day_shift(today, -1)
c1 = bars[bars["frame"] == tf.combine_time(prev_day, 15)][0]["close"]
return bars["close"][-1] / c1 - 1
class MomemtumStrategy:
def __init__(self, path: str = None):
self.store = ZarrStore(path)
def describe_short_features(self, features: List):
""""""
fmt = [
"RSI高水位差: {:.1f}", # 正值表明已超出高水位
"距离RSI前高: {} bars",
"近期RSI摸高次数: {}", # 3周期内RSI摸高次数
"前高: {:.2%}", # 当前股份距前高百分位。0表明正在创新高
"3日内最大跌幅: {:.2%}",
"3日收阴率: {:.1%}",
"3日sharpe: {:.1f}",
"最后bar涨幅: {:.2%}",
"frame序号: {}",
"最大成交量比(负数为卖出): {:.1f}",
"异向成交量比: {:.1f}",
"是否涨停: {}",
"下方均线数: {}",
"5_10_20多头指数: {:.1%}",
"10_20_30多头指数: {:.1%}",
"10_20_60多头指数: {:.1%}",
"5日均线走势: {:.2%} {:.2%} {:.2%} {:.0f}",
"10日均线走势: {:.2%} {:.2%} {:.2%} {:.0f}",
"20日均线走势: {:.2%} {:.2%} {:.2%} {:.0f}",
"30日均线走势: {:.2%} {:.2%} {:.2%} {:.0f}",
"60日均线走势: {:.2%} {:.2%} {:.2%} {:.0f}",
]
if len(features) != 36:
raise ValueError(
f"length of features {len(features)} should math to formatters"
)
msg = []
for i in range(0, 16):
msg.append(fmt[i].format(features[i]))
for i in range(0, 5):
msg.append(fmt[16 + i].format(*features[16 + i * 4 : 16 + (i + 1) * 4]))
return msg
def extract_short_features(self, bars: BarsArray):
"""从30分钟bars中提取看空相关特征"""
assert len(bars) >= 70, "size of bars must be at least 70."
features = []
close = bars["close"]
returns = close[-24:] / close[-25:-1] - 1
# 当前rsi与rsi高水位差值
_, hclose, pvs = adjust_close_at_pv(bars[-60:], 1)
rsi = ta.RSI(hclose.astype("f8"), 6)
hrsi = top_n_argpos(rsi, 3)
hrsi_mean = np.mean(rsi[hrsi])
rsi_gap = rsi[-1] - hrsi_mean
features.append(rsi_gap)
# 当前距离rsi前高位置,以及3个bar以内有多少次高点:如果当前为最高,则距离为零
dist = len(hclose) - hrsi - 1
count = np.count_nonzero(dist < 2)
features.extend((np.min(dist), count))
# 最近的峰顶压力位
peaks = np.argwhere(pvs == 1).flatten()
if len(peaks) > 0 and peaks[-1] == 59:
peaks = peaks[:-1]
price_at_peaks = hclose[peaks]
if len(price_at_peaks) > 0:
gaps = price_at_peaks / close[-1] - 1
gaps = gaps[gaps > 0]
if len(gaps) > 0:
peak_pressure = gaps[-1]
else:
peak_pressure = 0 # 创新高
else:
peak_pressure = -1 # 找不到顶,但也没创新高
features.append(peak_pressure)
# 3日内(24bars) 最大跌幅
features.append(np.min(returns))
# 3日内(24bars)阴线比率
bulls = np.count_nonzero((bars["close"] > bars["open"])[-24:])
features.append(bulls / 24)
# 3日内(24 bars)的sharpe (不用sortino是因为sortino有可能为np.inf)
# rf 必须为0,因为我们使用的是30分钟bar
features.append(sharpe_ratio(returns))
# 当前bar的序号 10:00 -> 0, 15:00 -> 8
# 如果尾盘拉涨,一般要卖
features.append(returns[-1])
last_frame = bars[-1]["frame"].item()
i = 0 if last_frame.minute == 0 else 1
ilf = {600: 0, 630: 1, 660: 2, 690: 3, 810: 4, 840: 5, 870: 6, 900: 7}.get(
last_frame.hour * 60 + i * 30
)
features.append(ilf)
# 最大成交方向及力度
vmax, vreverse = top_volume_direction(bars, 24)
features.extend((vmax, vreverse))
# 当前是否已涨停?涨停的情况下总是不卖
# 如果close == high并且涨幅超9.5%,则认为已涨停
df = pd.DataFrame(bars)
day_bars = df.resample("1D", on="frame").agg({"close": "last", "high": "max"})
c0 = day_bars["close"][-1]
c1 = day_bars["close"][-2]
h0 = day_bars["high"][-1]
zt = price_equal(c0, h0) and c1 / c0 - 1 >= 0.095
features.append(zt)
# 均线走势
mas = []
maline_features = []
for win in (5, 10, 20, 30, 60):
ma = moving_average(close, win)[-10:]
mas.append(ma[-1])
err, (a, b, _), (vx, _) = polyfit(ma / ma[0], deg=2)
maline_features.extend((err, a, b, np.clip(vx, -1, 10)))
# 当前股价与均线关系, 0表示位于所有均线之下
flag = np.count_nonzero(close[-1] >= np.array(mas))
features.append(flag)
# 5, 10, 20多头指数
features.append(parallel_score(mas[:3]))
# 10, 20, 30多头指数
features.append(parallel_score(mas[1:4]))
# 10, 20, 60多头指数
features.append(parallel_score((mas[1], mas[2], mas[4])))
# 加入均线走势特征
features.extend(maline_features)
return features
async def add_short_sample(
self, code: str, frame: datetime.datetime, label: int = 1
) -> int:
"""向`short`训练集中增加样本
Args:
code: 股票代码
frame: 行情所属时间
label: 样本标签,取值分别为-1(无操作),0(减半仓),1(清仓)
Returns:
datastore中的记录条数
"""
bars = await Stock.get_bars(code, 70, FrameType.MIN30, end=frame)
if len(bars) < 70:
raise ValueError(f"size of bars {len(bars)} is less than 70")
feature = self.extract_short_features(bars)
logger.debug(
"%s@%s\n:%s", code, frame, "\n".join(self.describe_short_features(feature))
)
key = "train/short/data"
feature.append(label)
self.store.append(np.array([feature]), key)
data_size = len(self.store.get(key))
meta_key = f"train/short/meta"
self.store.append([f"{code}:{tf.time2int(frame)}"], meta_key)
meta_size = len(self.store.get(meta_key))
if data_size != meta_size:
raise ValueError("存储出错,元记录个数不等于数据个数。")
return data_size
def get_train_data(self, is_long):
if not is_long:
return self.store.get("train/short/data") | zillionare-pluto | /zillionare_pluto-0.2.0-py3-none-any.whl/pluto/strategies/momentum.py | momentum.py |
import datetime
from typing import Tuple
import numpy as np
import pandas as pd
from coretypes import BarsArray, FrameType
from omicron.models.security import Security
from omicron.models.stock import Stock
from sklearn.metrics.pairwise import cosine_similarity
from pluto.core.metrics import vanilla_score
from pluto.strategies.base import BaseStrategy
class TheForceStrategy(BaseStrategy):
# we mimic a neural network here, which eigens are `trained` weights, cosine_similarity is the function learned from training
# todo: to mimic a full connected layer, let the result of function `predict` will fall into categories, instead of the raw similarity
# by doing this (the mimic), we avoid building huge training dataset
force_eigens = [
[1, 1.4, 2]
# negative eigen goes here
]
returns_eigens = [
[0, 0.02, 0.03]
# negative eigen goes here
]
index_eigens = [[]]
amplitude_eigens = [[]]
def __init__(self, thresh: float = 0.95):
"""
Args:
thresh: 进行特征断言时需要满足的最小相似度阈值。
"""
self.thresh = thresh
def extract_features(self, bars: BarsArray) -> Tuple[np.array, np.array]:
"""从k线数据中提取本策略需要的特征"""
if len(bars) < 4:
raise ValueError("size of bars must be at least 4")
bars = bars[-4:]
vol = bars["volume"]
close = bars["close"]
vol = vol[1:] / vol[:-1]
returns = close[1:] / close[:-1] - 1
return np.vstack((vol, returns))
def predict(self, bars: BarsArray) -> int:
"""
Args:
bars: 行情数据,不得小于4个bar。
Returns:
如果大于零,表明符合买入模式中的某一个。如果小于零,表明符合卖出中的某一个。等于零表明未响应特征。
"""
vol_features, returns_features = self.extract_features(bars)
# want row-wise sim result only
sim_vol = cosine_similarity(self.force_eigens, vol_features)
sim_returns = cosine_similarity(self.returns_eigens, returns_features)
sim = np.hstack((sim_vol, sim_returns))
# 判断是否某一行全部大于thresh
mask = (sim >= self.thresh).all(axis=1)
return np.any(mask)
async def backtest(self, start: datetime.date, end: datetime.date):
"""回测"""
codes = (
await Security.select()
.types(["stock"])
.exclude_st()
.exclude_cyb()
.exclude_kcb()
.eval()
)
results = []
for code in codes:
bars = await Stock.get_bars_in_range(code, FrameType.DAY, start, end)
name = await Security.alias(code)
for i in range(4, len(bars) - 3):
xbars = bars[:i]
fired = self.predict(xbars)
if fired:
ybars = bars[i - 1 : i + 3]
# close = ybars["close"]
# t0 = ybars["frame"][0].item().date()
# c0 = round(ybars["close"][0].item(), 2)
_, max_returns, mdds = await vanilla_score(ybars, code)
if len(max_returns):
if len(mdds):
results.append(
(
name,
ybars[0]["frame"].item().date(),
max_returns[0],
mdds[0],
)
)
else:
results.append(
(
name,
ybars[0]["frame"].item().date(),
max_returns[0],
None,
)
)
return pd.DataFrame(results, columns=["name", "frame", "max_return", "mdd"])
async def scan(self):
"""以最新行情扫描市场,以期发现投资机会"""
codes = (
await Security.select()
.types(["stock"])
.exclude_st()
.exclude_cyb()
.exclude_kcb()
.eval()
)
results = []
for code in codes:
bars = await Stock.get_bars(code, 4, FrameType.DAY)
if len(bars) < 4:
continue
signal = self.predict(bars)
if signal > 0:
name = await Security.alias(code)
results.append((name, code, signal))
return results | zillionare-pluto | /zillionare_pluto-0.2.0-py3-none-any.whl/pluto/strategies/theforce.py | theforce.py |
import datetime
import logging as log
from collections import defaultdict
from typing import List, Tuple
import numpy as np
import pandas as pd
from boards.board import IndustryBoard
from coretypes import BarsArray, FrameType
from omicron import tf
from omicron.models.security import Security
from omicron.models.stock import Stock
from zigzag import peak_valley_pivots
IndustryBoard.init()
ib = IndustryBoard()
class TurnaroundStrategy(object):
"""检测除科创板,除创业板股票中包含发生底部反转股票最多的板块"""
def evaluate_long(
self,
bars: BarsArray,
period_limit: float,
distance_limit: int,
thresh: Tuple[float, float] = None,
) -> int:
"""底部反转条件设置
条件与方法:
1. 使用peaks_and_valleys,检出最末一段标志为-1,1(默认使用自适应算法)
2. 上述最末段的涨幅大于period_limit%,最低点距今不超过distance_limit天
上述数字部分可以通过参数设置。
Args:
bars: 包含最后底部信号发出日的行情数据
period_limit: 底部信号发出日到最后一天的涨幅限制,即不大于period_limit%
distance_limit: 底部信号发出日到最后一天的距离限制,即不大于distance_limit个单位距离
thresh: 反转参数,默认为两个涨跌幅标准差。
Returns:
返回满足条件的底部信号发出日到最后一天的实际距离,如果不满足所设条件,返回None。
"""
assert len(bars) > 59, "must provide an array with at least 60 length!"
close = bars["close"].astype(np.float64)
if thresh is None:
std = np.std(close[-59:] / close[-60:-1] - 1)
thresh = (2 * std, -2 * std)
pivots = peak_valley_pivots(close, thresh[0], thresh[1])
flags = pivots[pivots != 0]
period_increase = None
lowest_distance = None
distance = None
if (flags[-2] == -1) and (flags[-1] == 1):
length = len(pivots)
last_valley_index = np.where(pivots == -1)[0][-1]
period_increase = (close[-1] - close[last_valley_index]) / close[
last_valley_index
]
lowest_distance = length - 1 - last_valley_index
if (
(period_increase >= period_limit * 0.01)
and (lowest_distance <= distance_limit)
and (lowest_distance > 0)
):
distance = lowest_distance
return distance
async def scan(
self,
codes: List[str],
dt: datetime.date,
period_limit: float,
distance_limit: int,
thresh: Tuple,
) -> List[str]:
"""遍历`dt`日codes中指定的股票,并调用evaluate_long找出发出买入信号的股票代码
Args:
codes: 股票代码列表
dt: 指定日期
period_limit: 底部信号发出日到最后一天的涨幅限制,即不大于period_limit%
distance_limit: 底部信号发出日到最后一天的距离限制,即不大于distance_limit个单位距离
thresh: 反转参数,默认为两个涨跌幅标准差。
Returns:
返回发出底部反转信号的股票列表
"""
signal_codes = []
num = 0
for code in codes:
if num % 100 == 0:
log.info(f"遍历第{num}只股票")
num += 1
bar = await Stock.get_bars_in_range(
code, FrameType.DAY, start=tf.day_shift(dt, -59), end=dt
)
if len(bar) < 60:
continue
distance = self.evaluate_long(bar, period_limit, distance_limit, thresh)
if distance is not None:
signal_codes.append(code[:6])
log.info(f"满足条件的股票:{code}: {await Security.alias(code)}")
return signal_codes
async def score(
self,
codes: List[str],
signal_date: datetime.date,
period_limit: float,
distance_limit: int,
thresh: Tuple,
) -> List[list]:
"""以signal_date当日收盘价买入,次日收盘价卖出的收益。
如果买入当天股票涨停,则无法买入。
Args:
codes: 发出底部反转信号的股票列表
signal_date: 买入日期
period_limit: 底部信号发出日到最后一天的涨幅限制,即不大于period_limit%
distance_limit: 底部信号发出日到最后一天的距离限制,即不大于distance_limit个单位距离
thresh: 反转参数,默认为两个涨跌幅标准差。
Returns:
returns: 返回包含每个发出信号股票买入日期,股票名称,代码,收益率%,距离,所属板块的列
"""
returns = []
for code in codes:
code = tuple(Stock.fuzzy_match(code).keys())
if len(code) < 1:
continue
code = code[0]
bar = await Stock.get_bars_in_range(
code,
FrameType.DAY,
start=tf.day_shift(signal_date, -59),
end=tf.day_shift(signal_date, 1),
)
if len(bar) < 61:
continue
# 判断当日是否涨停,涨停则无法买入
limit_flag = (
await Stock.trade_price_limit_flags(code, signal_date, signal_date)
)[0][0]
if not limit_flag:
return_ = (bar["close"][-1] - bar["close"][-2]) / bar["close"][-2]
distance = self.evaluate_long(
bar[:-1], period_limit, distance_limit, thresh
)
board_names = []
for board_code in ib.get_boards(code[:6]):
board_names.append((board_code, ib.get_name(board_code)))
name = await Security.alias(code)
returns.append(
[signal_date, name, code, return_ * 100, distance, board_names]
)
return returns
async def backtest(
self,
start: datetime.date,
end: datetime.date,
period_limit: float,
distance_limit: int,
thresh: Tuple,
) -> pd.DataFrame:
"""在[start, end]区间对除科创板,除创业板有底部反转的所有股票筛选,
选出出现频率最高的行业板块,买入此板块下筛选出来的股票,并计算次日收益
Args:
start: 筛选底部反转板块起始时间
end: 筛选底部反转终止时间
period_limit: 底部信号发出日到最后一天的涨幅限制,即不大于period_limit%
distance_limit: 底部信号发出日到最后一天的距离限制,即不大于distance_limit个单位距离
thresh: 反转参数,默认为两个涨跌幅标准差。
Returns:
返回包含每个发出信号股票买入日期,股票名称,代码,未涨停的此日收益率%,到反转的距离,所属板块的表格
"""
results = []
for frame in tf.get_frames(start, end, FrameType.DAY):
frame = tf.int2date(frame)
log.info(f"遍历时间:{frame}")
codes = (
await Security.select(frame)
.types(["stock"])
.exclude_st()
.exclude_kcb()
.exclude_cyb()
.eval()
)
fired = await self.scan(codes, frame, period_limit, distance_limit, thresh)
belong_boards = defaultdict(int)
for scaned_code in fired:
for board in ib.get_boards(scaned_code):
belong_boards[board] += 1
if len(belong_boards) < 1:
continue
sort_pd = pd.DataFrame(belong_boards.items()).sort_values(
by=1, ascending=False, ignore_index=True
)
most_boards = sort_pd[sort_pd[1] == sort_pd[1][0]][0].values
selected_codes = np.array([])
for most_board in most_boards:
log.info(f"出现最多的板块:{most_board}: {ib.get_name(most_board)}")
board_members = ib.get_members(most_board)
# 买入选出出现最多板块的成分股
selected_code = np.intersect1d(board_members, fired)
selected_codes = np.append(selected_codes, selected_code)
# 去除不同板块的重复股票
selected_codes = np.unique(selected_codes)
log.info(
f"板块中符合条件的股票:{tuple(list((Stock.fuzzy_match(x)).items())[0][1][:2] for x in selected_codes)}"
)
# 计算次日收益率
result = await self.score(
selected_codes, frame, period_limit, distance_limit, thresh
)
results += result
results = pd.DataFrame(results, columns="日期,名称,代码,收益率%,距离,板块".split(","))
return results | zillionare-pluto | /zillionare_pluto-0.2.0-py3-none-any.whl/pluto/strategies/u_turn_board.py | u_turn_board.py |
import datetime
import logging
from abc import ABCMeta, abstractmethod
from typing import Final, Optional, Union
from coretypes import Frame
from omicron import tf
from pyemit import emit
from traderclient import TraderClient
# 归类与回测相关的事件,比如回测开始、结束等
E_BACKTEST: Final = "BACKTEST"
# 归类与策略相关的事件,比如买入,卖出等。
E_STRATEGY: Final = "STRATEGY"
logger = logging.getLogger(__name__)
class BaseStrategy(object, metaclass=ABCMeta):
"""所有Strategy的基类。
本基类实现了以下功能:
1. 所有继承本基类的子类策略,都可以通过[alpha.strategies.get_all_strategies][] 获取到所有策略的列表,包括name和description。这些信息可用于在控制台上显示策略的列表。
2. 策略实现`buy`, `sell`功能,调用结果会通过事件通知发送出来,以便回测框架、控制台来刷新和更新进度。
3. 在实盘和回测之间无缝切换。
本模块依赖于zillionare-backtest和zillionare-trader-client库。
Args:
Raises:
TaskIsRunningError:
NotImplementedError:
"""
name = "base-strategy"
alias = "base for all strategies"
desc = "Base Strategy Class"
version = "NA"
def __init__(
self, broker: Optional[TraderClient] = None, mdd: float = 0.1, sl: float = 0.05
):
"""
Args:
broker : 交易代理
mdd : 止损前允许的最大回撤
sl : 止损前允许的最大亏损
"""
# 当前持仓 code -> {security: , shares: , sellable: sl: }
self._positions = {}
self._principal = 0
self._broker = None
# 用于策略止损的参数
self.thresholds = {"mdd": mdd, "sl": sl}
if broker:
self.broker = broker
cash = self.broker.available_money
if cash is None:
raise ValueError("Failed to get available money from server")
self._bt = None
@property
def broker(self) -> TraderClient:
"""交易代理"""
if self._bt is None:
return self._broker
else:
return self._bt._broker
@property
def cash(self) -> float:
"""可用资金"""
return self.broker.available_money
@property
def principal(self) -> float:
"""本金"""
return self._principal if self._bt is None else self._bt._principal
@property
def positions(self):
return self.broker.positions
async def notify(self, event: str, msg: dict):
"""通知事件。
在发送消息之前,总是添加账号信息,以便区分。
Args:
msg: dict
"""
assert event in (
"started",
"progress",
"failed",
"finished",
), f"Unknown event: {event}, event must be one of ('started', 'progress', 'failed', 'finished')"
msg.update(
{
"event": event,
"account": self.broker._account,
"token": self.broker._token,
}
)
channel = E_BACKTEST if self._bt is not None else E_STRATEGY
await emit.emit(channel, msg)
async def update_progress(self, current_frame: Frame):
"""更新回测进度
此函数只在日线级别上触发进度更新。
Args:
current_frame : 最新的回测时间
"""
if self._bt is None:
logger.warning("Backtest is not running, can't update progress")
return
last_frame = tf.day_shift(current_frame, -1)
if self._bt._last_frame is None:
self._bt._last_frame = last_frame
else:
msg = f"frame rewinded: {self._bt._last_frame} -> {last_frame}"
assert last_frame >= self._bt._last_frame, msg
self._bt._last_frame = last_frame
info = self.broker.info()
await self.notify(
"progress",
{
"frame": last_frame,
"info": info,
},
)
async def buy(
self,
code: str,
shares: int,
order_time: Optional[Frame] = None,
price: Optional[float] = None,
):
"""买入股票
Args:
code: 股票代码
shares: 买入数量。应该为100的倍数。如果不为100的倍数,会被取整到100的倍数。
price: 买入价格,如果为None,则以市价买入
order_time: 下单时间,仅在回测时需要,实盘时,即使传入也会被忽略
"""
logger.info("buy: %s %s %s", code, shares, order_time)
if price is None:
self.broker.market_buy(code, shares, order_time=order_time)
else:
self.broker.buy(code, price, shares, order_time=order_time)
async def sell(
self,
code: str,
shares: float,
order_time: Optional[Frame] = None,
price: Optional[float] = None,
):
"""卖出持仓股票
Args:
code : 卖出的证券代码
shares : 如果在(0, 1]之间,则为卖出持仓的比例,或者股数。
order_time : 委卖时间,在实盘时不必要传入
price : 卖出价。如果为None,则为市价卖出
"""
assert (
shares >= 100 or 0 < shares <= 1
), f"shares should be in (0, 1] or multiple of 100, get {shares}"
if self._bt is not None:
broker = self._bt._broker
if type(order_time) == datetime.date:
order_time = tf.combine_time(order_time, 14, 56)
else:
broker = self.broker
sellable = broker.available_shares(code)
if sellable == 0:
logger.warning("%s has no sellable shares", code)
return
if 0 < shares <= 1:
volume = sellable * shares
else:
volume = min(sellable, shares)
logger.info("sell: %s %s %s", code, volume, order_time)
if price is None:
broker.market_sell(code, volume, order_time=order_time)
else:
broker.sell(code, price, volume, order_time=order_time)
@abstractmethod
async def backtest(self, start: datetime.date, end: datetime.date):
"""调用子类的回测函数以启动回测
Args:
start: 回测起始时间
end: 回测结束时间
"""
raise NotImplementedError
def check_required_params(self, params: Union[None, dict]):
"""检查策略参数是否完整
一些策略在回测时往往需要传入特别的参数。派生类应该实现这个方法,以确保在回测启动前,参数都已经传入。
Args:
params: 策略参数
"""
raise NotImplementedError | zillionare-pluto | /zillionare_pluto-0.2.0-py3-none-any.whl/pluto/strategies/base.py | base.py |
import datetime
import cfg4py
from coretypes import BarsArray
from omicron.talib import moving_average
from pluto.store import BuyLimitPoolStore
from pluto.strategies.base import BaseStrategy
class StrategyZBJT(BaseStrategy):
name = "zbjt-strategy"
desc = "2022年9月7日,中百集团在经过4个月横盘,下打、涨跌试盘、缩量回踩之后,连拉4个板。"
def __init__(self, **kwargs):
super().__init__()
cfg = cfg4py.get_instance()
self._buylimit_store = BuyLimitPoolStore(cfg.pluto.store_path)
async def backtest(self, start: datetime.date, end: datetime.date, params: dict):
pass
async def extract_features(self, code: str, bars: BarsArray):
if len(bars) < 60:
return None
end = bars["frame"][-1]
c0 = bars["close"][-1]
low0 = bars["low"][-1]
buy_limit_rec = await self._buylimit_store.query(end, code)
# 近期必须有涨停
if buy_limit_rec is None:
return
*_, total, continuous, _, till_now = buy_limit_rec
# 不做连板高位股
if continuous > 1:
return None
# 均线多头
ma5 = moving_average(bars["close"], 5)
ma10 = moving_average(bars["close"], 5)
ma20 = moving_average(bars["close"], 5)
if not (
ma5[-1].item() >= ma10[-1].item() and ma20[-1].item() >= ma20[-1].item()
):
return None
# 上方无长均线压制
for win in (60, 120, 250):
ma = moving_average(bars["close"], win)[-1].item()
if ma > c0:
return None
# 区间统计
i_last_date = len(bars) - till_now
bars_ = bars[:i_last_date][-60:]
high = bars_["high"]
low = bars_["low"]
close = bars_["close"][-1].item()
opn = bars_["open"][-1].item()
amp = max(high) / min(low) - 1
adv = close / opn - 1
# 20日线支撑?如果touch_20在[0, 1.5%]之间,说明支撑较强;3%以上表明未考验支撑。-0.5%以下说明没有支撑。其它情况表明是否存在支撑不显著。
touch_20 = low0 / ma20 - 1
return total, till_now, amp, adv, touch_20
async def evaluate_long(self, code: str, bars: BarsArray):
features = self.extract_features(code, bars)
if features is None:
return False
else:
_, till_now, amp, adv, touch_20 = features
if till_now > 5 or adv > 0.1 or amp > 0.25 or touch_20 < -0.005:
return False
return True | zillionare-pluto | /zillionare_pluto-0.2.0-py3-none-any.whl/pluto/strategies/zbjt.py | zbjt.py |
import datetime
import logging
from typing import Optional, Tuple
import arrow
import numpy as np
from coretypes import FrameType
from numpy.typing import NDArray
from omicron import tf
from omicron.extensions import math_round, price_equal
from omicron.models.security import Security
from omicron.models.stock import Stock
from pluto.store.base import ZarrStore
logger = logging.getLogger(__name__)
"""touch_buy_limit_pool的存储结构,包括name, code, date, upper_line, max_adv, hit等字段
"""
touch_pool_dtype = np.dtype(
[
("name", "<U16"), # 股票名
("code", "<U16"), # 股票代码
("date", "datetime64[s]"), # 触及涨停日期
("upper_line", "f4"), # 上影线
("max_adv", "f4"), # 最大涨幅
("hit", "i4"), # 是否完全触及
]
)
class TouchBuyLimitPoolStore(ZarrStore):
def __init__(self, path: str = None, thresh=0.985):
"""
Args:
thresh: 当股份超过high_limit * thresh时即计入统计
path: 存储位置
"""
self.thresh = thresh
super().__init__(path)
def save(self, date: datetime.date, records):
if len(records) == 0:
return
try:
if tf.date2int(date) in self.pooled:
return
except KeyError:
pass
logger.info("save pool for day %s", date)
super().append(records)
pooled = self.data.attrs.get("pooled", [])
pooled.append(tf.date2int(date))
self.data.attrs["pooled"] = pooled
def get(self, timestamp: datetime.date):
if tf.date2int(timestamp) not in self.pooled:
return None
start = tf.combine_time(timestamp, 0)
end = tf.combine_time(timestamp, 15)
idx = np.argwhere(
(self.data["date"] >= start) & (self.data["date"] < end)
).flatten()
return self.data[idx]
async def extract_touch_buy_limit_features(
self, code: str, end: datetime.date
) -> Optional[Tuple]:
"""提取个股在[end]期间冲涨停特征, 只记录当天第一次涨停时间
Args:
code: 股票代码
end: 截止时间
Returns:
如果存在涨停,则返回(name, code, 涨停时间(30MIN为单位), 上引线百分比, 最大涨幅, 是否触板)
"""
try:
prices = await Stock.get_trade_price_limits(code, end, end)
if len(prices) == 0:
return None
high_limit = math_round(prices["high_limit"][0].item(), 2)
start = tf.combine_time(tf.day_shift(end, -1), 15)
end_time = tf.combine_time(end, 15)
bars = await Stock.get_bars_in_range(
code, FrameType.MIN30, start=start, end=end_time
)
frames = bars["frame"]
if frames[0].item().date() != tf.day_shift(end, -1):
return None
c1 = math_round(bars["close"][0], 2)
bars = bars[1:]
close = math_round(bars["close"][-1], 2)
opn = math_round(bars["open"][0], 2)
idx = np.argmax(bars["high"])
high = math_round(bars["high"][idx], 2)
if high >= high_limit * self.thresh and not price_equal(close, high_limit):
name = await Security.alias(code)
upper_line = high / max(close, opn) - 1
max_adv = high / c1 - 1
if price_equal(high, high_limit):
hit_flag = True
else:
hit_flag = False
return (
name,
code,
bars["frame"][idx].item(),
upper_line,
max_adv,
hit_flag,
)
except Exception as e:
logger.exception(e)
return None
async def pooling(self, end: datetime.date = None):
end = end or datetime.datetime.now().date()
if tf.date2int(end) in self.pooled:
logger.info("%s already pooled.", end)
return self.get(end)
logger.info(
"building touch buy limit pool on %s, currently pooled: %s",
end,
len(self.pooled),
)
secs = (
await Security.select()
.types(["stock"])
.exclude_kcb()
.exclude_cyb()
.exclude_st()
.eval()
)
result = []
for i, sec in enumerate(secs):
if (i + 1) % 500 == 0:
logger.info("progress update: %s/%s", i + 1, len(secs))
r = await self.extract_touch_buy_limit_features(sec, end)
if r is not None:
result.append(r)
records = np.array(result, dtype=touch_pool_dtype)
if end == self._day_closed(end):
self.save(end, records)
return records
async def query(
self, start: datetime.date, code: str = None, hit_flag=True, end=None
) -> NDArray[touch_pool_dtype]:
"""查询某日触板股票情况
Args:
start: 起始日期
code: 如果未传入,则返回当天所有触板股票
hit_flag: 如果为None,则返回当天完全触板及尝试触板的股票.
end: 结束日期,如果不传入,则为最后一个交易日。
Returns:
类型为_dtype的numpy structured array
"""
end = end or arrow.now().date()
results = np.array([], dtype=touch_pool_dtype)
for date in tf.get_frames(start, end, FrameType.DAY):
date = tf.int2date(date)
pool = self.get(date)
if pool is None:
continue
if code is not None:
pool = pool[pool["code"] == code]
if hit_flag is not None:
results = np.append(results, pool[(pool["hit"] == hit_flag)])
else:
results = np.append(results, pool)
return results | zillionare-pluto | /zillionare_pluto-0.2.0-py3-none-any.whl/pluto/store/touch_buy_limit_pool.py | touch_buy_limit_pool.py |
import datetime
import logging
from collections import defaultdict
import numpy as np
from coretypes import FrameType
from numpy.typing import NDArray
from omicron import tf
from omicron.models.security import Security
from omicron.models.stock import Stock
from omicron.talib import moving_average, polyfit
from pluto.core.metrics import parallel_score
from pluto.store.base import ZarrStore
logger = logging.getLogger(__name__)
ssp_dtype = np.dtype([("code", "U16"), ("slp", "f4"), ("win", "i4")])
class SteepSlopesPool(ZarrStore):
def __init__(self, path: str = None):
super().__init__(path)
def save(self, date: datetime.date, records):
if len(records) == 0:
return
logger.info("saving %s records for %s", len(records), date)
date = tf.date2int(date)
super().save(records, key=f"{date}")
pooled = self.data.attrs.get(f"pooled", [])
pooled.append(date)
self.data.attrs["pooled"] = pooled
def get(self, dt: datetime.date = None, win: int = None) -> NDArray[ssp_dtype]:
if dt is not None:
result = super().get(f"{tf.date2int(dt)}")
else:
try:
dt = self.pooled[-1]
result = super().get(f"{dt}")
except IndexError:
return None
if result is None:
return None
# convert zarr to numpy array
result = result[:]
if win is None:
return result
return result[result["win"] == win]
async def pooling(self, dt: datetime.date = None, n: int = 30):
"""采集`dt`期间(10, 20, 60)日均线最陡的记录
Args:
dt: 日期
n: 取排列在前面的`n`条记录
"""
if dt is None:
dt = self._day_closed(datetime.datetime.now().date())
if tf.date2int(dt) in self.pooled:
logger.info("%s already pooled", dt)
return self.get(dt)
logger.info(
"building steep slopes pool on %s, currently pooled: %s",
dt,
len(self.pooled),
)
secs = (
await Security.select()
.types(["stock"])
.exclude_st()
.exclude_cyb()
.exclude_kcb()
.eval()
)
results = defaultdict(list)
for i, code in enumerate(secs):
if (i + 1) % 500 == 0:
logger.info("progress update: %s/%s", i + 1, len(secs))
bars = await Stock.get_bars(code, 70, FrameType.DAY, end=dt)
if len(bars) < 10:
continue
close = bars["close"]
# 尽管可以后期过滤,但当天涨幅过大的仍没有必要选取,它们在后面应该仍有机会被重新发现
if close[-1] / close[-2] - 1 > 0.07:
continue
last_mas = []
mas = {}
for win in (10, 20, 30, 60):
if len(bars) < win + 10:
break
ma = moving_average(close, win)[-10:]
last_mas.append(ma[-1])
mas[win] = ma
# 如果均线不为多头,则仍然不选取
try:
if parallel_score(last_mas) < 5 / 6:
continue
except ZeroDivisionError:
pass
for win in (10, 20, 60):
ma = mas.get(win)
if ma is not None:
err, (slp, _) = polyfit(ma / ma[0], deg=1)
if err > 3e-3 or slp <= 0:
continue
results[win].append((code, slp))
# 对10, 20, 60均线,每种取前30支
records = []
for win in (10, 20, 60):
recs = results.get(win)
if recs is None or len(recs) == 0:
continue
recs = sorted(recs, key=lambda x: x[1], reverse=True)
for rec in recs[:n]:
records.append((*rec, win))
records = np.array(records, dtype=ssp_dtype)
self.save(dt, records) | zillionare-pluto | /zillionare_pluto-0.2.0-py3-none-any.whl/pluto/store/steep_slopes_pool.py | steep_slopes_pool.py |
import datetime
import os
from typing import Any, List
import zarr
from omicron import tf
class ZarrStore(object):
def __init__(self, path=None):
cur_dir = os.path.dirname(__file__)
self._store_path = (
path
or os.environ.get("pluto_store_path")
or os.path.join(cur_dir, "pluto.zarr")
)
self._store = zarr.open(self._store_path, mode="a")
def save(self, records: Any, key: str = None):
"""将`records` 存到`key`下面(替换式)
Args:
records: 要存储的数据
key: 如果为None,则存到根下面。
"""
if key is not None:
key = f"{self.__class__.__name__.lower()}/{key}"
else:
key = f"{self.__class__.__name__.lower()}/"
self._store[key] = records
def append(self, records: Any, key: str = None):
"""向key所引用的数组增加数据"""
if key is not None:
key = f"{self.__class__.__name__.lower()}/{key}"
else:
key = f"{self.__class__.__name__.lower()}"
if self._store.get(key):
self._store[key].append(records)
else:
self._store[key] = records
def get(self, key: str):
key = f"{self.__class__.__name__.lower()}/{key}"
return self._store[key]
@property
def data(self):
key = f"{self.__class__.__name__.lower()}/"
return self._store[key]
@property
def pooled(self) -> List[int]:
"""返回已进行涨停特征提取的交易日列表。
注意这里返回的交易日为整数类型,即类似20221011。
"""
try:
pooled = self.data.attrs.get("pooled", [])
except KeyError:
pooled = []
return pooled
def _day_closed(self, timestamp: datetime.date) -> datetime.date:
"""给定`timestamp`,返回已结束的交易日"""
now = datetime.datetime.now()
if (
tf.is_trade_day(timestamp)
and timestamp == now.date()
and datetime.datetime.now().hour < 15
):
return tf.day_shift(timestamp, -1)
else:
return tf.day_shift(timestamp, 0) | zillionare-pluto | /zillionare_pluto-0.2.0-py3-none-any.whl/pluto/store/base.py | base.py |
import datetime
import logging
from typing import List, Tuple
import numpy as np
import talib as ta
from coretypes import FrameType
from numpy.typing import NDArray
from omicron import tf
from omicron.models.security import Security
from omicron.models.stock import Stock
from omicron.notify.dingtalk import ding
from omicron.talib import moving_average
from pluto.core.ma import predict_next_price
from pluto.core.metrics import last_wave, parallel_score
from pluto.store.base import ZarrStore
logger = logging.getLogger(__name__)
momentum_feature_dtype = np.dtype(
[
("code", "U16"), # 股票代码
("pred5", "f4"), # 用5日线预测的股价涨跌幅
("pred10", "f4"), # 用10日线预测的股价涨跌幅
("rsi", "f4"), # 当前RSI值
("dist", "i4"), # 距离RSI高点位置
("gap2year", "f4"), # 到年线距离
("ps", "f4"), # 均线排列分数
("wave_len", "i4"), # 最后一个波段涨幅
("wave_amp", "f4"), # 最后一个波段涨跌幅
("max_adv", "f4"), # 近5日日线最大涨幅
]
)
class LongParallelPool(ZarrStore):
def __init__(self, path: str = None):
super().__init__(path)
def save(self, date: datetime.date, records):
if len(records) == 0:
return
logger.info("saving %s records for %s", len(records), date)
date = tf.date2int(date)
super().save(records, key=str(date))
pooled = self.data.attrs.get("pooled", [])
pooled.append(date)
self.data.attrs["pooled"] = pooled
async def pooling(self, end: datetime.date = None):
"""采集`end`日线多头数据并存盘
Args:
end: 结束日期
"""
end = self._day_closed(end or datetime.datetime.now().date())
if tf.date2int(end) in self.pooled:
logger.info("%s already pooled", end)
return await self.get(end)
logger.info(
"building long parallel pool on %s, currently pooled: %s",
end,
len(self.pooled),
)
secs = (
await Security.select()
.types(["stock"])
.exclude_st()
.exclude_kcb()
.exclude_cyb()
.eval()
)
result = []
for i, code in enumerate(secs):
if (i + 1) % 500 == 0:
logger.info("progress update: %s/%s", i + 1, len(secs))
bars = await Stock.get_bars(code, 260, FrameType.DAY, end=end)
if len(bars) < 60:
continue
close = bars["close"]
returns = close[-10:] / close[-11:-1] - 1
# 最近10天上涨都小于3.5%,暂不关注
if np.max(returns) < 0.035:
continue
mas = []
for win in (5, 10, 20, 60, 120, 250):
if len(close) < win:
break
ma = moving_average(close, win)[-1]
mas.append(ma)
if len(mas) == 6:
gap2year = close[-1] / mas[-1] - 1
else:
gap2year = None
mas = np.array(mas)
# 短均线(5,10,20)必须多头
ps = parallel_score(mas[:3])
if ps != 1:
continue
ps = parallel_score(mas)
# 去掉正处于40日内RSI高位的
rsi = ta.RSI(close[-60:].astype("f8"), 6)
dist = 40 - np.nanargmax(rsi[-40:])
if dist == 1 and rsi[-1] >= 85:
continue
# 预测下一个收盘价
pred5, _ = predict_next_price(bars, win=5)
pred10, _ = predict_next_price(bars, win=10)
# 波段涨幅和长度
wave_len, wave_amp = last_wave(close)
result.append(
(
code,
pred5,
pred10,
rsi[-1],
dist,
gap2year,
ps,
wave_len,
wave_amp,
np.max(returns),
)
)
records = np.array(result, dtype=momentum_feature_dtype)
self.save(end, records)
def get(self, date: datetime.date = None) -> NDArray[momentum_feature_dtype]:
try:
if date is None:
date = self.pooled[-1]
except Exception as e:
logger.exception(e)
return None
return super().get(tf.date2int(date))
async def filter_long_parallel(
self,
max_gap2year: float = None,
wave_amp_rng: Tuple = None,
date: datetime.date = None,
):
date = self._day_closed(date or datetime.datetime.now().date())
results = self.get(date)
if max_gap2year is not None:
idx = np.argwhere(results["gap2year"] <= max_gap2year).flatten()
if len(idx) > 0:
results = results[idx]
else:
return []
if wave_amp_rng is not None:
idx = np.argwhere(
(results["wave_amp"] <= wave_amp_rng[1])
& (results["wave_amp"] >= wave_amp_rng[0])
).flatten()
if len(idx) > 0:
results = results[idx]
else:
return []
return results
async def scan_30m_frames(self) -> List[Tuple]:
"""在日线多头个股中,寻找30分钟也多头的股票。
Returns:
返回一个数组,其中每一行由以下各列构成:code, name, change, pred5, pred10, rsi, dist, gap2year, ps, wave_len, wave_amp, max_adv
"""
end = tf.floor(datetime.datetime.now(), FrameType.MIN30)
data = []
filtered = await self.filter_long_parallel(0.2, [0.05, 0.25])
for (
code,
pred5,
pred10,
rsi,
dist,
gap2year,
ps,
wave_len,
wave_amp,
max_adv,
) in filtered:
bars = await Stock.get_bars(code, 60, FrameType.MIN30, end=end)
if len(bars) < 60:
continue
close = bars["close"]
today = bars[-1]["frame"].item().date()
prev_day = tf.day_shift(today, -1)
c1 = bars[bars["frame"] == tf.combine_time(prev_day, 15)][0]["close"]
# 今日涨幅
change = close[-1] / c1 - 1
name = await Security.alias(code)
mas = []
for win in (5, 10, 20, 60):
ma = moving_average(close, win)[-1]
mas.append(ma)
mas = np.array(mas)
# 上方有均线压制则不考虑
if not (np.all(close[-1] > mas) and parallel_score(mas) == 1):
continue
# 从现在起,还可以上涨多少?
pred5 = pred5 / close[-1] - 1
pred10 = pred10 / close[-1] - 1
data.append(
(
code,
name,
change,
pred5,
pred10,
rsi,
dist,
gap2year,
ps,
wave_len,
wave_amp,
max_adv,
)
)
msg = [
"30分钟多头选股选出以下股票:",
"-----------------------",
" ".join([item[1] for item in data]),
]
await ding("\n".join(msg))
return data | zillionare-pluto | /zillionare_pluto-0.2.0-py3-none-any.whl/pluto/store/long_parallel_pool.py | long_parallel_pool.py |
import datetime
import logging
from typing import List, Tuple
import arrow
import numpy as np
from coretypes import FrameType
from numpy.typing import NDArray
from omicron import tf
from omicron.extensions import find_runs
from omicron.models.security import Security
from omicron.models.stock import Stock
from pluto.store.base import ZarrStore
logger = logging.getLogger(__name__)
buylimitquery_dtype = np.dtype(
[("code", "<U16"), ("total", "i4"), ("continuous", "i4"), ("last", "O")]
)
class BuyLimitPoolStore(ZarrStore):
dtype = np.dtype([("code", "<U16"), ("date", "i8")])
def __init__(self, path: str = None):
super().__init__(path)
def save(self, records, dates: List[int]):
if len(records) == 0:
return
logger.info("save pool from %s~%s", dates[0], dates[-1])
super().append(records)
pooled = self.data.attrs.get("pooled", [])
pooled.extend(dates)
self.data.attrs["pooled"] = pooled
async def pooling(self, start: datetime.date, end: datetime.date = None):
"""采集`[start, end]`期间涨跌停数据并存盘。
Args:
start: 起始日期
end: 结束日期。如果结束日期为交易日且未收盘,只统计到前一个交易日
"""
end = self._day_closed(end or arrow.now().date())
logger.info("building buy limit pool from %s - %s...", start, end)
secs = (
await Security.select()
.types(["stock"])
.exclude_cyb()
.exclude_kcb()
.exclude_st()
.eval()
)
to_persisted = []
frames = tf.get_frames(start, end, FrameType.DAY)
missed = set(frames) - set(self.pooled)
if len(missed) == 0:
return
start = tf.int2date(min(missed))
end = tf.int2date(max(missed))
for i, sec in enumerate(secs):
if i + 1 % 500 == 0:
logger.info("progress: %s of %s", i + 1, len(secs))
flags = await Stock.trade_price_limit_flags_ex(sec, start, end)
if len(flags) == 0:
continue
for frame, (flag, _) in flags.items():
if not flag:
continue
# 有可能该frame已经存储过,此处避免存入重复的数据
frame = tf.date2int(frame)
if frame not in self.pooled:
to_persisted.append((sec, frame))
records = np.array(to_persisted, dtype=self.dtype)
frames = tf.get_frames(start, end, FrameType.DAY)
self.save(records, frames)
def count_continous(self, records, frames: List[int]) -> int:
"""找出最长的连续板个数"""
flags = np.isin(frames, records["date"])
v, _, length = find_runs(flags)
return max(length[v])
def _calc_stats(self, records, frames):
total = len(records)
last = np.max(records["date"])
continuous = self.count_continous(records, frames)
return total, continuous, tf.int2date(last)
def find_all(
self, start: datetime.date, end: datetime.date = None
) -> NDArray[buylimitquery_dtype]:
"""找出`[start, end]`区间所有涨停的个股,返回代码、涨停次数、最长连续板数和最后涨停时间
Args:
start: 起始时间
end: 结束时间
Raises:
ValueError: 如果指定区间存在一些交易日未进行过pooling操作,则抛出此错误
Returns:
返回代码、涨停次数、最长连续板数和最后涨停时间
"""
frames = tf.get_frames(start, end, FrameType.DAY)
missed = set(frames) - set(self.pooled)
if len(missed) > 0:
raise ValueError(f"data not ready for frames, run pooling first: {missed}")
start = tf.date2int(start)
end = tf.date2int(end)
idx = np.argwhere((self.data["date"] >= start) & (self.data["date"] <= end))
records = self.data[idx.flatten()]
results = []
for code in set(records["code"]):
sub = records[records["code"] == code]
results.append((code, *self._calc_stats(sub, frames)))
return np.array(results, buylimitquery_dtype)
def find_by_code(
self, code: str, start: datetime.date, end: datetime.date = None
) -> Tuple[int, int, datetime.date]:
"""查找个股`code`在区间[`start`, `end`]里的涨停数据
Args:
code: 股票代码
start: 起始日期
end: 结束日期
Raises:
ValueError: 如果指定区间存在一些交易日未进行过pooling操作,则抛出此错误
Returns:
返回涨停次数、最长连续板数和最后涨停时间
"""
end = end or arrow.now().date()
frames = tf.get_frames(start, end, FrameType.DAY)
missed = set(frames) - set(self.pooled)
if len(missed) > 0:
raise ValueError(f"data not ready for frames, run pooling first: {missed}")
start = tf.date2int(start)
end = tf.date2int(end)
idx = np.argwhere((self.data["date"] >= start) & (self.data["date"] <= end))
records = self.data[idx.flatten()]
return self._calc_stats(records[records["code"] == code], frames)
def find_raw_recs_by_code(
self, code: str, start: datetime.date, end: datetime.date = None
) -> NDArray:
"""查找`code`在`[start, end]`区间的涨停原始记录"""
idx = np.argwhere(self.data["code"] == code).flatten()
recs = self.data[idx]
recs = recs[
(recs["date"] >= tf.date2int(start)) & (recs["date"] <= tf.date2int(end))
]
recs = [(item[0], tf.int2date(item[1])) for item in recs]
return np.array(recs, dtype=np.dtype([("code", "U16"), ("date", "O")]))
async def pooling_latest():
blp = BuyLimitPoolStore()
end = blp._day_closed(datetime.datetime.now().date())
await blp.pooling(end, end) | zillionare-pluto | /zillionare_pluto-0.2.0-py3-none-any.whl/pluto/store/buy_limit_pool.py | buy_limit_pool.py |
import logging
from itertools import combinations
from typing import Iterable, List, Optional, Tuple
import numpy as np
import talib as ta
from coretypes import BarsArray, FrameType, bars_dtype
from numpy.typing import NDArray
from omicron import tf
from omicron.extensions import find_runs, price_equal, top_n_argpos
from omicron.models.stock import Stock
from omicron.talib import moving_average, peaks_and_valleys
from pluto.strategies.dompressure import dom_pressure
logger = logging.getLogger(__name__)
async def vanilla_score(
bars: bars_dtype, code: str = None, frametype: FrameType = FrameType.DAY
) -> Tuple:
"""对买入信号发出之后一段时间的表现进行评价。
规则:
1. bars中的第一根bar为信号发出时间。如果此时未涨停,则以收盘价作为买入价,
以信号发出日为T0日,分别计算T1, T2, ..., T(len(bars)-1)日的累计涨跌幅。
2. 如果第一根bar已涨停(此处默认10%为涨停限制),则使用第二天的开盘价作为买入价,
以信号发出日为T0日,分别计算T2, T3, ..., T(len(bars)-2)日的累计涨跌幅
3. 计算累计最大涨幅。
4. 计算出现累计最大跌幅(上涨之前)
5. 计算中除情况2之外,都使用收盘价计算。
Args:
bars: 包含信号发出日的行情数据
code: 股票代码
frametype: 传入带有时间序列数据的时间类型,
只有两种时间类型可被接受:FrameType.DAY or FrameType.MIN30
Returns:
包含每日累计涨跌幅,最大涨幅和最大跌幅的元组。
"""
returns = []
max_returns = []
mdds = []
assert frametype in (
FrameType.DAY,
FrameType.MIN30,
), "'frametype' must be either FrameType.DAY or FrameType.MIN30!"
if frametype == FrameType.DAY:
assert (
len(bars) >= 3
), "must provide a day frametype array with at least 3 length!"
limit_flag = (
await Stock.trade_price_limit_flags(
code, bars["frame"][0].item(), bars["frame"][0].item()
)
)[0][0]
# 如果检测当天涨停,第二天开盘价未涨停买入,第二天开始收盘价作为收益。
if limit_flag & (
(bars["open"][1] - bars["close"][0]) / bars["close"][0] < 0.099
):
price_np = np.append(bars["open"][1], bars["close"][2:])
returns = (price_np[1:] - price_np[0]) / price_np[0]
max_return = np.nanmax(returns)
max_returns.append(max_return)
max_index = np.argmax(returns)
# 防止涨停之前的最大跌幅为空值,取到最大值
to_max = returns[: max_index + 1]
mdd = np.nanmin(to_max)
if mdd < 0:
mdds.append(mdd)
# 如果检测当天可以买进,则直接买入,后五天的收盘价作为收益,开盘涨停则不考虑
elif not limit_flag:
returns = (bars["close"][1:] - bars["close"][0]) / bars["close"][0]
max_return = np.nanmax(returns)
max_returns.append(max_return)
max_index = np.argmax(returns)
# 防止涨停之前的最大跌幅为空值,取到最大值
to_max = returns[: max_index + 1]
mdd = np.nanmin(to_max)
if mdd < 0:
mdds.append(mdd)
elif frametype == FrameType.MIN30:
assert (
len(bars) >= 24
), "must prrovide a min30 framtype array with at least 24 length!"
first_frame = bars["frame"][0].item()
first_day = tf.day_shift(first_frame, 0)
second_day = tf.day_shift(first_frame, 1)
second_open_time = tf.combine_time(second_day, 10)
second_day_end_index = np.where(
bars["frame"] == tf.combine_time(second_day, 15)
)[0].item()
# 检测第二天开始日收盘价
day_bars = bars[second_day_end_index:][::8]
# 获取当天涨停价
first_limit_price = (
await Stock.get_trade_price_limits(code, first_day, first_day)
)[0][1]
# 获取第二天涨停价
second_limit_price = (
await Stock.get_trade_price_limits(code, second_day, second_day)
)[0][1]
# 检测点已涨停,第二天开盘未涨停,开盘价买入,从第三天收盘价开始计算收益率:
if price_equal(bars["close"][0], first_limit_price) and (
bars["open"][bars["frame"] == second_open_time].item() != second_limit_price
):
price = np.append(
bars["open"][bars["frame"] == second_open_time], day_bars["close"][1:]
)
returns = (price[1:] - price[0]) / price[0]
max_return = np.nanmax(returns)
max_returns.append(max_return)
max_index = np.argmax(returns)
# 防止涨停之前的最大跌幅为空值,取到最大值
to_max = returns[: max_index + 1]
mdd = np.nanmin(to_max)
if mdd < 0:
mdds.append(mdd)
# 检测点未涨停,直接买入,第二天收盘价开始计算收益率:
elif bars["close"][0] != first_limit_price:
price = np.append(bars["close"][0], day_bars["close"])
returns = (price[1:] - price[0]) / price[0]
max_return = np.nanmax(returns)
max_returns.append(max_return)
max_index = np.argmax(returns)
# 防止涨停之前的最大跌幅为空值,取到最大值
to_max = returns[: max_index + 1]
mdd = np.nanmin(to_max)
if mdd < 0:
mdds.append(mdd)
return returns, max_returns, mdds
def parallel_score(mas: Iterable[float]) -> float:
"""求均线排列分数。
返回值介于[0, 1]之间。如果为1,则最后一期均线值为全多头排列,即所有的短期均线都位于所有的长期均线之上;如果为0,则是全空头排列,即所有的短期均线都位于所有的长期均线之下。值越大,越偏向于多头排列;值越小,越偏向于空头排列。
Args:
mas: 移动平均线数组
Returns:
排列分数,取值在[0,1]区间内。
"""
count = 0
total = 0
for a, b in combinations(mas, 2):
total += 1
if a >= b:
count += 1
return count / total
def last_wave(ts: np.array, max_win: int = 60):
"""返回顶点距离,以及波段涨跌幅
Args:
ts: 浮点数的时间序列
max_win: 在最大为`max_win`的窗口中检测波段。设置这个值是出于性能考虑,但也可能存在最后一个波段长度大于60的情况。
"""
ts = ts[-max_win:]
pv = peaks_and_valleys(ts)
prev = np.argwhere(pv != 0).flatten()[-2]
return len(ts) - prev, ts[-1] / ts[prev] - 1
def adjust_close_at_pv(
bars: BarsArray, flag: int
) -> Tuple[np.array, np.array, np.array]:
"""将close序列中的峰谷值替换成为对应的high/low。
通过指定flag为(-1, 0, 1)中的任一个,以决定进行何种替换。如果flag为-1,则将close中对应谷处的数据替换为low;如果flag为1,则将close中对应峰处的数据替换为high。如果为0,则返回两组数据。
最后,返回替换后的峰谷标志序列(1为峰,-1为谷)
Args:
bars: 输入的行情数据
flag: 如果为-1,表明只替换low; 如果为1,表明只替换high;如果为0,表明全换
Returns:
返回替换后的序列: 最低点替换为low之后的序列,最高点替换为high之后的序列,以及峰谷标记
"""
close = bars["close"]
high = bars["high"]
low = bars["low"]
pvs = peaks_and_valleys(close)
last = pvs[-1]
# 如果最后的bar是从高往下杀,低于昨收,peaks_and_valleys会判为-1,此时可能要用high代替close
if high[-1] > close[-2] and last == -1:
pvs[-1] = 1
# 如果最后的bar是底部反转,高于昨收,peaks_and_valleys会判定为1,但此时仍然可能要用low代替close
if low[-1] < close[-2] and last == 1:
pvs[-1] = -1
for p in np.argwhere(pvs == 1).flatten(): # 对p前后各2元素检查谁最大
if p < 2:
pvs[p] = 0
i = np.argmax(high[:2])
pvs[i] = 1
elif p >= len(pvs) - 2:
pvs[p] = 0
i = np.argmax(high[-2:])
pvs[i - 2] = 1
else:
i = np.argmax(high[p - 2 : p + 3])
if i != 2:
pvs[p] = 0
pvs[p + i - 2] = 1
for v in np.argwhere(pvs == -1).flatten():
if v < 2:
pvs[v] = 0
i = np.argmin(low[:2])
pvs[i] = -1
elif v >= len(pvs) - 2:
pvs[v] = 0
i = np.argmin(low[-2:])
pvs[i - 2] = -1
else:
i = np.argmin(low[v - 2 : v + 3])
if i != 2:
pvs[v] = 0
pvs[v + i - 2] = -1
if flag == -1:
return np.where(pvs == -1, low, close), None, pvs
elif flag == 0:
return np.where(pvs == -1, low, close), np.where(pvs == 1, high, close), pvs
else:
return None, np.where(pvs == 1, high, close), pvs
def convex_signal(
bars: BarsArray = None,
wins=(5, 10, 20),
mas: List[NDArray] = None,
ex_info=False,
thresh: float = 3e-3,
) -> Tuple[int, List[float]]:
"""根据均线的升降性,判断是否发出买入或者卖出信号
调用者需要保证参与计算的均线,至少有10个以上的有效值(即非np.NaN).
Args:
bars: 行情数据。
wins: 均线生成参数
ex_info: 是否返回均线的详细评分信息
thresh: 决定均线是按直线拟合还是按曲线拟合的阈值
Returns:
如果出现空头信号,则返回-1,多头信号则返回1,否则返回0;如果ex_info为True,还将返回详细评估分数。
"""
if mas is None:
assert bars is not None, "either 'bars' or 'mas' should be presented"
mas = []
close = bars["close"]
for win in wins:
ma = moving_average(close, win)
mas.append(ma)
scores = []
for ma in mas:
assert len(ma) >= 10, "length of moving average array should be at least 10."
scores.append(convex_score(ma[-10:], thresh=thresh))
scores = np.array(scores)
# 如果均线为0,则表明未表态
non_zero = np.count_nonzero(scores)
if np.count_nonzero(scores > 0) == non_zero:
flag = 1
elif np.count_nonzero(scores < 0) == non_zero:
flag = -1
else:
flag = 0
if ex_info:
return flag, scores
else:
return flag
def convex_score(ts: NDArray, n: int = 0, thresh: float = 1.5e-3) -> float:
"""评估时间序列`ts`的升降性
如果时间序列中间的点都落在端点连线上方,则该函数为凸函数;反之,则为凹函数。使用点到连线的差值的
平均值来表明曲线的凹凸性。进一步地,我们将凹凸性引申为升降性,并且对单调上升/下降(即直线),我们
使用平均涨跌幅来表明其升降性,从而使得在凹函数、凸函数和直线三种情况下,函数的返回值都能表明
均线的未来升降趋势。
Args:
ts: 时间序列
n: 用来检测升降性的元素个数。
thresh: 当点到端点连线之间的平均相对差值小于此值时,认为该序列的几何图形为直线
Returns:
返回评估分数,如果大于0,表明为上升曲线,如果小于0,表明为下降曲线。0表明无法评估或者为横盘整理。
"""
if n == 0:
n = len(ts)
elif n == 2:
return (ts[1] / ts[0] - 1) / n
elif n == 1:
raise ValueError(f"'n' must be great than 1")
ts = ts[-n:]
ts_hat = np.arange(n) * (ts[-1] - ts[0]) / (n - 1) + ts[0]
# 如果点在连线下方,则曲线向上,分数为正
interleave = ts_hat - ts
score = np.mean(ts_hat[1:-1] / ts[1:-1] - 1)
slp = (ts[-1] / ts[0] - 1) / n
if abs(score) < thresh and abs(slp) > 1.5e-3:
# 如果convex_score小于阈值,且按直线算斜率又大于1.5e-3,认为直线是趋势
score = slp
if np.all(interleave >= 0) or np.all(interleave <= 0):
return score * 100
# 存在交织的情况,取最后一段
else:
_, start, length = find_runs(interleave >= 0)
if length[-1] == 1: # 前一段均为负,最后一个为零时,会被单独分为一段,需要合并
n = length[-2] + 1
begin = start[-2]
else:
n = length[-1]
begin = start[-1]
return convex_score(ts[begin:], n)
async def short_signal(
bars: BarsArray, ex_info=True
) -> Tuple[int, Optional[dict]]:
"""通过穹顶压力、rsi高位和均线拐头来判断是否出现看空信号。
Args:
bars: 行情数据
ex_info: 是否返回附加信息。这些信息可用以诊断
"""
info = {}
mas = []
close = bars["close"]
wins = (5, 10, 20)
for win in wins:
mas.append(moving_average(close, win)[-10:])
# 检测多均线拐头或者下降压力
flag, scores = convex_signal(mas=mas, ex_info=True)
info.update({
"convex_scores": scores
})
if flag == -1:
return flag, info
# 检测穹顶压力
for win, score in zip(wins, scores):
if score < -0.3: # todo: need to tune this parameter
dp = dom_pressure(bars, win)
info.update({
"dom_pressure": dp,
"win": win
})
if dp >= 1/7:
return -1, info
# 检测8周期内是否出现RSI高位,并且已经触发回调
if len(bars) >= 60:
_, hclose, pvs = adjust_close_at_pv(bars, 1)
rsi = ta.RSI(hclose.astype("f8"), 6)
top_rsis = top_n_argpos(rsi[-60:], 2)
dist = np.min(60 - top_rsis)
# 触发回调逻辑
# t0 触发RSI,从高点算起,到现在,合并成一个bar,其上影大于实体
info.update({
"top_rsi_dist": dist
})
if dist <= 8:
return -1, info
# 其它情况
return 0, info | zillionare-pluto | /zillionare_pluto-0.2.0-py3-none-any.whl/pluto/core/metrics.py | metrics.py |
import datetime
from typing import Dict, Iterable, List, Optional, Tuple
import numpy as np
import pandas as pd
import talib as ta
from coretypes import BarsArray, FrameType
from omicron.extensions import array_math_round, math_round
from omicron.models.stock import Stock
from omicron.talib import moving_average, polyfit
def magic_numbers(close: float, opn: float, low: float) -> List[float]:
"""根据当前的收盘价、开盘价和最低价,猜测整数支撑、最低位支撑及开盘价支撑价格
当前并未针对开盘价和最低价作特殊运算,将其返回仅仅为了使用方便考虑(比如,一次性打印出所有的支撑价)
猜测支撑价主要使用整数位和均线位。
Example:
>>> magic_numbers(9.3, 9.3, 9.1)
[8.4, 8.5, 8.6, 8.7, 8.8, 8.9, 9.0, 9.3, 9.1]
Args:
close: 当前收盘价
opn: 当前开盘价
low: 当前最低价
Returns:
可能的支撑价格列表
"""
numbers = []
order = len(str(int(close))) - 1
step = 10 ** (order - 1)
half_step = step // 2 or 0.5
lower = int((close * 0.9 // step) * step)
upper = int((close // step) * step)
if close >= 10:
for i in np.arange(lower, upper, step):
numbers.append(round(i, 1))
numbers.append(round(i + half_step, 1))
else:
for i in range(int(close * 9), int(close * 10)):
if i / (10 * close) < 0.97 and i / (10 * close) > 0.9:
numbers.append(i / 10)
numbers.extend((opn, low))
return numbers
def predict_next_ma(
ma: Iterable[float], win: int, err_thresh: float = 3e-3
) -> Tuple[float, Tuple]:
"""预测下一个均线值。
对于短均线如(5, 10, 20, 30),我们使用二阶拟合,如果不能拟合,则返回None, None
对于长均线,使用一阶拟合。
Args:
ma: 均线数据
win: 均线窗口。
err_thresh: 进行均线拟合时允许的误差。
Returns:
预测的均线值,及其它信息,比如对短均线(<=30)进行预测时,还可能返回顶点坐标。
"""
if win <= 30 and len(ma) >= 7:
ma = ma[-7:]
err, (a, b, c), (vx, _) = polyfit(ma / ma[0], deg=2)
if err < err_thresh:
f = np.poly1d((a, b, c))
ma_hat = f(np.arange(8))
pred_ma = math_round(ma_hat[-1] * ma[0], 2)
return pred_ma, (a, vx)
else:
return None, ()
if win > 30 and len(ma) >= 3:
ma = ma[-3:]
_, (a, b) = polyfit(ma, deg=1)
f = np.poly1d((a, b))
ma_hat = f([0, 1, 2, 3])
pred_ma = math_round(ma_hat[-1], 2)
return pred_ma, (a,)
return None, ()
def ma_support_prices(mas: Dict[int, np.array], c0: float) -> Dict[int, float]:
"""计算下一周期的均线支撑价
返回值中,如果某一均线对应值为负数,则表明该均线处于下降状态,不具有支撑力;如果为None, 则表明无法进行计算或者不适用(比如距离超过一个涨跌停);否则返回正的支撑价。
Args:
mas: 移动均线序列,可包含np.NAN.键值必须为[5, 10, 20, 30, 60, 120, 250]中的一个。
c0: 当前收盘价
Returns:
均线支撑价格.
"""
# 判断短均线(5, 10, 20, 30)中有无向下拐头
pred_prices = {}
c0 = math_round(c0, 2)
for win in (5, 10, 20, 30):
ma = mas.get(win)
if ma is None or c0 < math_round(ma[-1], 2):
pred_prices[win] = None
continue
ma = ma[-7:]
if np.count_nonzero(np.isnan(ma)) >= 1:
pred_prices[win] = None
continue
pred_ma, extra = predict_next_ma(ma, win)
if pred_ma is not None:
vx, _ = extra
vx = min(max(round(vx), 0), 6)
if pred_ma < ma[vx] or pred_ma > c0:
pred_prices[win] = -1
else:
gap = pred_ma / c0 - 1
if abs(gap) < 0.099:
pred_prices[win] = pred_ma
else:
pred_prices[win] = None
elif ma[-1] < ma[-3]:
pred_prices[win] = -1
else:
pred_prices[win] = None
# 判断长均线走势及预期
for win in (60, 120, 250):
ma = mas.get(win)
if ma is None or c0 < ma[-1]:
pred_prices[win] = None
continue
pred_ma, (*_,) = predict_next_ma(ma, win)
gap = pred_ma / c0 - 1
if pred_ma > ma[-2]:
pred_prices[win] = pred_ma
elif pred_ma < ma[-2]:
pred_prices[win] = -1
else:
pred_prices[win] = pred_ma
return pred_prices
def name2code(name):
"""临时性用以计划的函数,需要添加到omicron"""
result = Stock.fuzzy_match(name)
if len(result) == 1:
return list(result.keys())[0]
else:
return None
async def weekend_score(
name: str, start: datetime.date
) -> Tuple[str, float, float, float, float]:
"""用以每周末给当周所选股进行评价的函数
Args:
name: 股票名
start: 买入日期
"""
code = name2code(name)
if code is None:
raise ValueError(f"股票名({name})错误")
bars = await Stock.get_bars_in_range(code, FrameType.DAY, start)
opn = bars["open"][0]
close = bars["close"][-1]
high = np.max(bars["high"])
returns = close / opn - 1
return name, opn, close, high, returns
async def group_weekend_score(names: str, start: datetime.date):
"""对一组同一时间买入的股票,计算到评估日(调用时)的表现"""
results = []
for name in names:
results.append(await weekend_score(name, start))
df = pd.DataFrame(results, columns=["股票", "开盘价", "周五收盘", "最高", "收盘收益"])
return df.style.format(
{
"开盘价": lambda x: f"{x:.2f}",
"周五收盘": lambda x: f"{x:.2f}",
"最高": lambda x: f"{x:.2f}",
"收盘收益": lambda x: f"{x:.1%}",
}
)
async def round_numbers(
price: float, limit_prices: Tuple[float, float]
) -> Tuple[list, list]:
"""该函数列出当前传入行情数据下的整数支撑,整数压力。
传入行情价格可以是日线级别,也可以是30分钟级别。
整数的含义不仅是以元为单位的整数,还有以角为单位的整数。
原理:
支撑位整数是跌停价到传入价格之间的五档整数。
压力位整数是传入价格价到涨停价之间的五档整数。
除此之外,0.5,5和50的倍数也是常用支撑压力位。
Example:
>>> round_numbers(10.23, 10.2, 10.56, 10.11)
([9.9, 10.0, 10.1, 10.2], [10.6, 10.7, 10.8])
Args:
price: 传入的价格
limit_prices: 传入需要计算整数支撑和压力的当天[跌停价,涨停价]
Returns:
返回有两个元素的Tuple, 第一个为支撑数列, 第二个为压力数列。
"""
low_limit = limit_prices[0]
high_limit = limit_prices[1]
mean_limit = (low_limit + high_limit) / 2
step = int(mean_limit) / 50 # 上下涨跌20%,再分10档,即2%左右为一档
# 根据传入的价格,100以内保留一位小数,大于100只保留整数位
if price < 10:
step_ints = np.around(np.arange(low_limit, high_limit + step, step), 1)
# 涨跌停价格之间0.5为倍数的所有数+十档
int_low = low_limit - low_limit % 0.5 + 0.5
five_times = np.around(np.arange(int_low, high_limit, 0.5), 1)
total_int = np.append(step_ints, five_times)
elif 10 <= price < 100:
# 涨跌停价格之间0.5为倍数的所有数
int_low = low_limit - low_limit % 0.5 + 0.5
total_int = np.around(np.arange(int_low, high_limit, 0.5), 1)
elif 100 <= price < 500:
step_ints = np.around(np.arange(low_limit, high_limit + step, step), 0)
# 涨跌停价格之间5为倍数的所有数
int_low = low_limit - low_limit % 5 + 5
five_times = np.around(np.arange(int_low, high_limit, 5), 1)
total_int = np.append(step_ints, five_times)
elif 500 <= price < 1000:
# 涨跌停价格之间50为倍数的所有数
int_low = low_limit - low_limit % 5 + 5
total_int = np.around(np.arange(int_low, high_limit, 5), 1)
else:
# 涨跌停价格之间50为倍数的所有数
int_low = low_limit - low_limit % 50 + 50
total_int = np.around(np.arange(int_low, high_limit, 50), 1)
total_int = total_int[(total_int <= high_limit) & (total_int >= low_limit)]
total_int = np.append(low_limit, total_int)
total_int = np.append(total_int, high_limit)
total_int = np.unique(np.around(total_int, 2))
support_list = total_int[total_int < price]
resist_list = total_int[total_int > price]
return support_list, resist_list
async def ma_sup_resist(code: str, bars: BarsArray) -> Tuple[dict, dict]:
"""均线支撑、压力位与当前k线周期同步,即当k线为日线时,
使用日线均线计算;如果为30分钟,则使用30分钟均线;
对超过涨跌停的支撑、压力位不显示;当有多个支撑位时,
支撑位从上到下只显示3档;对压力位也是如此。
包含wins = [5, 10, 20, 30, 60, 90, 120, 250]的均线;
均线只有趋势向上才可做为支撑;
只返回传输行情数据的最后一天的支撑均线, 压力均线。
Args:
code: 股票代码
bars: 具有时间序列的行情数据,长度必须大于250。
Returns:
返回包含两个Dictionary类型的Tuple。
第一个为均线支撑的Dictionary:keys是均线的win, values是(对应win的最后一个均线值, 均线值/最低价-1);
第二个为均线压力的Dictionary:keys是均线的win, values是(对应win的最后一个均线值, 均线值/最高价-1)。
"""
assert len(bars) > 260, "Length of data must more than 260!"
close = bars["close"]
close = close.astype(np.float64)
frame = bars["frame"][-1]
low = bars["low"][-1]
high = bars["high"][-1]
open_ = bars["open"][-1]
high_body = max(close[-1], open_)
low_body = min(close[-1], open_)
date = frame.item()
limit_flag = await Stock.get_trade_price_limits(code, date, date)
high_limit = limit_flag["high_limit"].item()
low_limit = limit_flag["low_limit"].item()
wins = [5, 10, 20, 30, 60, 90, 120, 250]
ma_sups = {}
ma_resist = {}
for win in wins:
all_ma = ta.MA(close, win)
ma_trade = all_ma[-1] - all_ma[-5]
ma = all_ma[-1]
if (ma >= low_limit) and (ma <= low_body) and (ma_trade > 0):
ma_sups[win] = ma, ma / low - 1
elif (ma >= high_body) and (ma <= high_limit):
ma_resist[win] = ma, ma / high - 1
sorted_ma_sups = sorted(ma_sups.items(), key=lambda x: (x[1], x[0]), reverse=True)
selected_ma_sups = dict(sorted_ma_sups[:3])
sorted_ma_resist = sorted(ma_resist.items(), key=lambda x: (x[1], x[0]))
selected_ma_resists = dict(sorted_ma_resist[:3])
return selected_ma_sups, selected_ma_resists | zillionare-pluto | /zillionare_pluto-0.2.0-py3-none-any.whl/pluto/core/plan.py | plan.py |
from typing import Tuple
import numpy as np
from bottleneck import move_mean, move_sum
from coretypes import BarsArray
from omicron.extensions import top_n_argpos
def volume_feature(volume: np.array) -> Tuple:
"""提取成交量特征
返回值:
0: 最后4列的形态特征
"""
pass
def describe_volume_morph(pattern: int) -> str:
return {
0: "未知成交量形态",
1: "持续放量阳线",
2: "持续缩量阳线",
3: "间歇放量阳线",
-1: "持续放量阴线",
-2: "持续缩量阴线",
-3: "间歇放量阴线",
}.get(pattern, "未知成交量形态")
def morph_pattern(bars: BarsArray) -> int:
"""成交量的形态特征
bars的长度必须大于5,当bars大于5时,只取最后5个周期进行计算。
算法:
1. 根据阳线、阴线,赋予成交量符号
2. 计算形态特征
返回类型:
0: 未检测到模式
1: 单调递增, 比如 0.9 1.2 1.3 1.4 (收阳)
2: 单调递减, 比如 1.4 1.3 1.2 1 (收阳)
3: 放量阳,缩量阴
-1: 单调递增,都收阴
-2: 单调递减,都收阴
-3: 放量阴,缩量阳
Args:
bars: 行情数据
Returns:
形态特征
"""
if len(bars) < 5:
raise ValueError("bars must be at least 5 length")
bars = bars[-5:]
close = bars["close"]
opn = bars["open"]
vol = bars["volume"]
yinyang = np.select((close > opn, close < opn), [1, -1], 0)[1:]
vol = vol[1:] / vol[:-1]
inc_dec = np.select((vol >= 1.1, vol <= 0.9), [1, 3], 2)
flags = yinyang * inc_dec
if np.all(flags == 1):
return 1
elif np.all(flags == 3):
return 2
elif np.all(flags == -1):
return -1
elif np.all(flags == -3):
return -2
elif np.all(flags == np.array([1, -3, 1, -3])) or np.all(
flags == np.array([-3, 1, -3, 1])
):
return 3
elif np.all(flags == np.array([-1, 3, -1, 3])) or np.all(
flags == np.array((3, -1, 3, -1))
):
return -3
else:
return 0
def top_volume_direction(bars: BarsArray, n: int = 10) -> Tuple[float, float]:
"""计算`n`周期内,最大成交量的量比(带方向)及该笔成交量与之后的最大异向成交量的比值(带方向)。
成交量方向:如果当前股价收阳则成交量方向为1,下跌则为-1。本函数用以发现某个时间点出现大笔买入(或者卖出),并且在随后的几个周期里,缩量下跌(或者上涨)的情形。主力往往会根据这个特征来判断跟风资金的意图,从而制定操作计划。
计算方法:
1. 找出最大成交量的位置
2. 找出其后一个最大异向成交量的位置
3. 计算最大成交量与之前`n`个成交量均值的量比及方向
4. 计算最大成交量与之后的所有成交量中,最大反向成交量的量比
args:
bars: 行情数据
n: 参与计算的周期。太长则影响到最大成交量的影响力。
return:
前一个元素表明最大成交量与之前`n`个成交量均值的量比,其符号表明是阳线还是阴线;后一个元素表明最大成交量与之后所有成交量中,最大异向成交量的量比。如果不存在异向成交量,则值为0。
"""
bars = bars[-n:]
volume = bars["volume"]
flags = np.select(
(bars["close"] > bars["open"], bars["close"] < bars["open"]), [1, -1], 0
)
pmax = np.argmax(volume)
# 移除3个最大成交量后的成交量均值
top_volume = np.sum(volume[top_n_argpos(volume, 3)])
vmean = (np.sum(volume[-n:]) - top_volume) / n
# 最大成交量及之后的成交量
vol = (volume * flags)[pmax:]
vmax = vol[0]
if flags[pmax] == 1 and np.any(vol[1:] < 0):
vr = [vmax / vmean, np.min(vol) / vmax]
elif flags[pmax] == -1 and np.any(vol[1:] > 0):
vr = [vmax / vmean, abs(np.max(vol) / vmax)]
else:
vr = [vmax / vmean, 0]
return vr
def moving_net_volume(bars: BarsArray, win=5) -> np.array:
"""移动净余成交量
args:
bars: 行情数据
win: 滑动窗口
return:
np.array: `win`周期内归一化(除以周期内成交量均值)的移动和
"""
vol = bars["volume"]
close = bars["close"]
open_ = bars["open"]
flags = np.select((close > open_, close < open_), [1, -1], 0)
signed_vol = vol * flags
return move_sum(signed_vol, win) / move_mean(vol, win)
def net_buy_volume(bars) -> float:
"""bars全部区间内的净买入量
如果k线为阳线,则为买入量;如果为阴线,则为卖出量
"""
volume = bars["volume"]
close = bars["close"]
open_ = bars["open"]
flags = np.select((close > open_, close < open_), [1, -1], 0)
signed_vol = volume * flags
return np.sum(signed_vol) / np.mean(volume) | zillionare-pluto | /zillionare_pluto-0.2.0-py3-none-any.whl/pluto/core/volume.py | volume.py |
import asyncio
import arrow
import numpy as np
from omicron.models.security import Security
from sanic import Blueprint, response
from sanic.exceptions import SanicException
from pluto.store.buy_limit_pool import BuyLimitPoolStore
from pluto.store.long_parallel_pool import LongParallelPool
from pluto.store.steep_slopes_pool import SteepSlopesPool
from pluto.store.touch_buy_limit_pool import TouchBuyLimitPoolStore
pools = Blueprint("pools", url_prefix="/pools")
@pools.route("/pooling", methods=["POST"])
async def pooling(request):
params = request.json
cmd = params.get("cmd")
end = params.get("end")
if cmd is None or cmd not in ("blp", "tblp", "ssp", "lpp"):
msg = "必须提供命令参数: blp, tblp, ssp, lpp"
raise SanicException(msg, status_code=401)
if end is not None:
end = arrow.get(end).date()
if cmd == "blp":
pool = BuyLimitPoolStore()
elif cmd == "tblp":
pool = TouchBuyLimitPoolStore()
elif cmd == "ssp":
pool = SteepSlopesPool()
elif cmd == "lpp":
pool = LongParallelPool()
asyncio.create_task(pool.pooling(end))
return response.text(f"task 'pooling {cmd}' is scheduled and running")
@pools.route("/buylimit/find_all")
async def buylimit_find_all(request):
params = request.json
start = arrow.get(params.get("start")).date()
end = arrow.get(params.get("end")).date()
total_min = params.get("total_min", 1)
total_max = params.get("total_max", 10)
continuous_min = params.get("continuous_min", 1)
continuous_max = params.get("continuous_max", 3)
till_now = params.get("till_now", 10)
@pools.route("/steep_slopes_pool")
async def steep_slopes(request):
params = request.args
win = params.get("win")
if win is None:
raise SanicException("必须指定均线'win'")
dt = params.get("dt")
if dt is not None:
dt = arrow.get(dt).date()
pool = SteepSlopesPool()
records = pool.get(dt=dt, win=int(win))
if records is None:
return response.json([])
names = [await Security.alias(code) for code in records[:]["code"]]
results = np.empty(
shape=(len(records[:]),),
dtype=[("name", "U16"), ("code", "U16"), ("slp", "U16")],
)
results["name"] = names
results["code"] = records[:]["code"]
results["slp"] = [f"{slp:.2%}" for slp in records[:]["slp"]]
# serialized = orjson.dumps(results[:].tolist(),option=orjson.OPT_SERIALIZE_NUMPY)
return response.json(results[:].tolist()) | zillionare-pluto | /zillionare_pluto-0.2.0-py3-none-any.whl/pluto/web/handlers/pool_handler.py | pool_handler.py |
# Security Policy
## Supported Versions
Use this section to tell people about which versions of your project are
currently being supported with security updates.
| Version | Supported |
| ------- | ------------------ |
| 5.1.x | :white_check_mark: |
| 5.0.x | :x: |
| 4.0.x | :white_check_mark: |
| < 4.0 | :x: |
## Reporting a Vulnerability
Use this section to tell people how to report a vulnerability.
Tell them where to go, how often they can expect to get an update on a
reported vulnerability, what to expect if the vulnerability is accepted or
declined, etc.
| zillionare-pluto | /zillionare_pluto-0.2.0-py3-none-any.whl/pluto/web/static/SECURITY.md | SECURITY.md |
* Demo : https://blackx-732.github.io/AwesomeMenu/
* Under open source license
* No ©copyright issues
* Anyone can be modify this code as well
* Specifically we will be happy whenever you use our code in your website(^_^)
* Designed by @BlackX-Lolipop
* Content available by @BlackX-732
* Content available @ https://github.com/BlackX-732/AwesomeMenu
* Version 21.2.7
* @https://facebook.com/BlackX-732
Module/Library/function/icons used in this project:
------------------------------------------------------
* cdjns of font-awesome https://cdnjs.cloudflare.com/ajax/libs/font-awesome/5.15.2/css/all.min.css
* jQuery v3.3.1 | (c) JS Foundation and other contributors | jquery.org/license
* HTML-5
* Custom css
* Custom javascript
* & some icon.I don't know if someone have enough time to claim that's ownership [XD] .
Important information of this project:
-------------------------------------------
* Custom css file path -> /dist/css/menu-style.css
* Custom js file path -> /dist/js/menu.js
* Path of jquery -> /dist/js/jquery.min.js
* Path of font-awesome -> /dist/font-awesome/ [We remove it for huge size.You can download it by below's instruction]
* Path of icon and image -> /dist/img/
Dowload font-awesome:
---------------------
* Download font-awesome's latest librabry https://fontawesome.com/
* Replace it into /dist as /dist/font-awesome
* Remove the comment of font-awesome link from index.html
* Also you can delete the cdnjs linkup from index.html
Why .collapse:
--------------------
* we used .collapse in -> /dist/css/menu-style.css if though it doesn't exist in -> /index.html
* .collapse is exist in -> /dist/js/menu.js
* We created this class by this script/selector -> $(".wrapper").toggleClass("collapse");
Change the Header Text:
------------------------
* Find out class="title" in /index.html
* Then change the text of class="title-hide" && class="sec-span"
Change the Sidebar icon and username:
--------------------------------------
* Find out class="profile" in /index.html
* Then change <img src="dist/img/avatar.png" alt=""><p>BlackX-732</p>
How to classify different background source before collapse and after collapse:
--------------------------------------------------------------------------------
If you want to change background source of .main-container after collapse then ad below's code into .collapse .main-container
background: url(new-image.jpg) no-repeat center center;
background-size: cover;
height: 100vh;
* no-repeat -> for miss-match size of image
* center -> vertically center
* center -> horizontally center
* 100vh -> 100% vertical & 100% horizontal
For little more smoothness add this to previous class
transition: 0.3s;
That's all.Enjoy Our code by your own way.(^_^)
| zillionare-pluto | /zillionare_pluto-0.2.0-py3-none-any.whl/pluto/web/static/README.md | README.md |
# boards
<p align="center">
<a href="https://pypi.org/pypi/zillionare-ths-boards">
<img src="https://img.shields.io/pypi/v/zillionare-ths-boards.svg"
alt = "Release Status">
</a>
<a href="https://github.com/zillionare/boards/actions">
<img src="https://github.com/zillionare/boards/actions/workflows/release.yml/badge.svg?branch=release" alt="CI Status">
</a>
<a href="https://zillionare.github.io/boards/">
<img src="https://img.shields.io/website/https/zillionare.github.io/boards/index.html.svg?label=docs&down_message=unavailable&up_message=available" alt="Documentation Status">
</a>
</p>
同花顺概念板块与行业板块数据本地化项目
* Free software: MIT
* Documentation: <https://zillionare.github.io/boards/>
## Features
### 自动同步
通过boards serve启动服务器之后,每日凌晨5时自动同步板块数据,并将其按当天日期保存。
注意我们使用了akshare来从同花顺获取板块数据。akshare的相应接口并没有时间参数,也即,所有同步的板块数据都只能是最新的板块数据。但如果在当天5时之后,同花顺更新的板块数据,则更新的数据将不会反映在当天日期为索引的数据当中。
### 板块操作
提供了根据板块代码获取板块名字(get_name)、根据名字查代码(get_code)、根据名字进行板块名的模糊查找(fuzzy_match_board_name增)等功能。
此外,我们还提供了filter方法,允许查找同时属于于多个板块的个股。
### 获取新增加的概念板块
新概念板块往往是近期炒作的热点。您可以通过ConceptBoard.find_new_concept_boards来查询哪些板块是新增加的。
此功能对行业板块无效。
### 获取新加入概念板块的个股
对某个概念而言,新加入的个股可能是有资金将要运作的标志。通过ConceptBoard.new_members_in_board可以查询新加入某个概念板块的个股列表。
### 命令行接口
提供了命令行接口以启动和停止服务,以及进行一些查询,详情请见[][#]
#### 查询同时处于某几个概念板块中的个股
```
boards filter --industry 计算机应用 --with-concpets 医药 医疗器械 --without 跨境支付
```
## 其他
boards使用akshare来下载数据。下载速度较慢,且可能遇到服务器拒绝应答的情况。这种情况下,boards将会以退火算法,自动延迟下载速度重试5次,以保证最终能完全下载数据,且不被封IP。在此过程中,您可能看到诸如下面的信息输出,这是正常现象。
```text
Document is empty, retrying in 30 seconds...
Document is empty, retrying in 30 seconds...
Document is empty, retrying in 30 seconds...
Document is empty, retrying in 60 seconds...
Document is empty, retrying in 120 seconds...
```
## Credits
This package was created with the [ppw](https://zillionare.github.io/python-project-wizard) tool. For more information, please visit the [project page](https://zillionare.github.io/python-project-wizard/).
| zillionare-ths-boards | /zillionare-ths-boards-0.2.2.tar.gz/zillionare-ths-boards-0.2.2/README.md | README.md |
import contextlib
import datetime
import io
import logging
import os
import re
from typing import Any, Dict, List, Optional, Set
import akshare as ak
import arrow
import numpy as np
import pandas as pd
import zarr
from numpy.core import defchararray
from retry import retry
logger = logging.getLogger(__name__)
def to_float_or_none(v: Any):
try:
return float(v)
except Exception:
return None
@retry(Exception, tries=5, backoff=2, delay=30, logger=logger)
def stock_board_industry_cons_ths(symbol):
logger.info("fetching industry board members for %s", symbol)
with contextlib.redirect_stderr(io.StringIO()):
return ak.stock_board_industry_cons_ths(symbol)
@retry(Exception, tries=5, backoff=2, delay=30, logger=logger)
def stock_board_concept_cons_ths(symbol):
logger.info("fetching concept board members for %s", symbol)
with contextlib.redirect_stderr(io.StringIO()):
return ak.stock_board_concept_cons_ths(symbol)
@retry(Exception, tries=5, backoff=2, delay=30, logger=logger)
def stock_board_industry_name_ths():
logger.info("fetching industry board list")
with contextlib.redirect_stderr(io.StringIO()):
return ak.stock_board_industry_name_ths()
@retry(Exception, tries=5, backoff=2, delay=30, logger=logger)
def stock_board_concept_name_ths():
logger.info("fetching concept board list")
with contextlib.redirect_stderr(io.StringIO()):
return ak.stock_board_concept_name_ths()
class Board:
"""行业板块及概念板块基类
数据组织:
/
├── concept
│ ├── boards [date, name, code, members] #members is count of all members
│ ├── members
│ │ ├── 20220925 [('board', '<U6'), ('code', '<U6')]
│ │ └── 20221001 [('board', '<U6'), ('code', '<U6')]
│ └── valuation
│ ├── 20220925 [code, turnover, vr, amount, circulation_stock, circulation_market_value]
/{category}/members.attrs.get("latest")表明当前数据更新到哪一天。
"""
_store = None
_store_path = None
category = "NA"
syncing = False
@classmethod
def init(cls, store_path: str = None):
"""初始化存储。如果本地数据为空,还将启动数据同步。
Args:
store_path: 存储路径。如果未指定,则将读取`boards_store_path`环境变量。如果未指定环境变量,则使用安装目录下的boards.zarr目录。
"""
if cls._store is not None:
return
cur_dir = os.path.dirname(__file__)
cls._store_path = (
store_path
or os.environ.get("boards_store_path")
or os.path.join(cur_dir, "boards.zarr")
)
logger.info("the store is %s", cls._store_path)
try:
cls._store = zarr.open(cls._store_path, mode="a")
if f"/{cls.category}/boards" in cls._store: # already contains data
return
except FileNotFoundError:
pass
except Exception as e:
logger.exception(e)
os.rename(cls._store_path, f"{store_path}.corrupt")
if cls.syncing:
return
try:
cls.syncing = True
# we need fetch boards list and its members for at least last day
cls.fetch_board_list()
cls.fetch_board_members()
finally:
cls.syncing = False
@classmethod
def close(cls):
"""关闭存储"""
cls._store = None
logger.info("store closed")
@classmethod
def fetch_board_list(cls):
if cls.category == "industry":
df = stock_board_industry_name_ths()
df["members"] = 0
dtype = [("name", "<U16"), ("code", "<U6"), ("members", "i4")]
boards = (
df[["name", "code", "members"]].to_records(index=False).astype(dtype)
)
else:
df = stock_board_concept_name_ths()
df = df.rename(
columns={
"日期": "date",
"概念名称": "name",
"成分股数量": "members",
"网址": "url",
"代码": "code",
}
)
df.members.fillna(0, inplace=True)
dtype = [
("date", "datetime64[D]"),
("name", "<U16"),
("code", "<U6"),
("members", "i4"),
]
boards = (
df[["date", "name", "code", "members"]]
.to_records(index=False)
.astype(dtype)
)
key = f"{cls.category}/boards"
cls._store[key] = boards
@classmethod
def fetch_board_members(cls):
members = []
counts = []
valuation = []
seen_valuation = set()
boards = cls._store[f"{cls.category}/boards"]
total_boars = len(boards)
for i, name in enumerate(boards["name"]):
code = cls.get_code(name)
if i in range(1, total_boars // 10):
logger.info(f"progress for fetching {cls.category} board: {i/10:.0%}")
if cls.category == "industry":
df = stock_board_industry_cons_ths(symbol=name)
df["board"] = code
counts.append(len(df))
members.append(df)
# 记录市值
for (
_,
_,
code,
*_,
turnover,
vr,
amount,
circulation_stock,
circulation_market_value,
pe,
_,
) in df.itertuples():
if code in seen_valuation:
continue
else:
if "亿" in amount:
amount = float(amount.replace("亿", "")) * 1_0000_0000
if "亿" in circulation_stock:
circulation_stock = (
float(circulation_stock.replace("亿", "")) * 1_0000_0000
)
if "亿" in circulation_market_value:
circulation_market_value = (
float(circulation_market_value.replace("亿", ""))
* 1_0000_0000
)
turnover = to_float_or_none(turnover)
vr = to_float_or_none(vr)
amount = to_float_or_none(amount)
circulation_stock = to_float_or_none(circulation_stock)
circulation_market_value = to_float_or_none(
circulation_market_value
)
pe = to_float_or_none(pe)
valuation.append(
(
code,
turnover,
vr,
amount,
circulation_stock,
circulation_market_value,
pe,
)
)
else:
df = stock_board_concept_cons_ths(symbol=name)
df["board"] = code
members.append(df)
# for industry board, ak won't return count of the board, had to do by ourself
if cls.category == "industry":
cls._store[f"{cls.category}/boards"]["members"] = counts
# Notice: without calendar, we'll duplicate valuation/members in case of today is holiday
today = arrow.now().format("YYYYMMDD")
members_path = f"{cls.category}/members/{today}"
members = (pd.concat(members))[["board", "代码", "名称"]].to_records(index=False)
members_dtype = [("board", "<U6"), ("code", "<U6"), ("name", "<U8")]
cls._store[members_path] = np.array(members, dtype=members_dtype)
cls._store[f"{cls.category}/members"].attrs["latest"] = today
valuation_path = f"{cls.category}/valuation/{today}"
valuation_dtype = [
("code", "<U6"),
("turnover", "f4"),
("vr", "f4"),
("amount", "f8"),
("circulation_stock", "f8"),
("circulation_market_value", "f8"),
("pe", "f4"),
]
cls._store[valuation_path] = np.array(valuation, dtype=valuation_dtype)
@property
def members_group(self):
return self.__class__._store[f"{self.category}/members"]
@property
def valuation_group(self):
return self.__class__._store[f"{self.category}/valuation"]
@property
def boards(self):
return self.__class__._store[f"{self.category}/boards"]
@boards.setter
def boards(self, value):
self.__class__._store[f"{self.category}/boards"] = value
@property
def latest_members(self):
last_sync_date = self.store[f"{self.category}/members"].attrs.get("latest")
date = arrow.get(last_sync_date).format("YYYYMMDD")
return self.members_group[date]
@property
def store(self):
return self.__class__._store
def info(self) -> Dict[str, Any]:
last_sync_date = self.store[f"{self.category}/members"].attrs.get("latest")
history = list(self.members_group.keys())
return {
"last_sync_date": last_sync_date,
"history": history,
}
def get_boards(self, code_or_name: str, date: datetime.date = None) -> List[str]:
"""给定股票,返回其所属的板块
Args:
code_or_name: 股票代码或者名字
Returns:
股票所属板块列表
"""
if not re.match(r"\d+$", code_or_name):
indice = np.argwhere(self.latest_members["name"] == code_or_name).flatten()
return self.latest_members[indice]["board"]
else:
indice = np.argwhere(self.latest_members["code"] == code_or_name).flatten()
return self.latest_members[indice]["board"]
def get_members(self, code: str, date: datetime.date = None) -> List[str]:
"""给定板块代码,返回该板块内所有的股票代码
Args:
code: 板块代码
date: 指定日期。如果为None,则使用最后下载的数据
Returns:
属于该板块的所有股票代码的列表
"""
latest = self.store[f"{self.category}/members"].attrs.get("latest")
if latest is None:
raise ValueError("data not ready, please call `sync` first!")
date = arrow.get(date or latest).format("YYYYMMDD")
members = self.members_group[date]
idx = np.argwhere(members["board"] == code).flatten()
if len(idx):
return members[idx]["code"].tolist()
else:
return None
def get_name(self, code: str) -> str:
"""translate code to board name"""
idx = np.argwhere(self.boards["code"] == code).flatten()
if len(idx):
return self.boards[idx]["name"][0]
else:
return None
def get_stock_alias(self, code: str) -> str:
"""给定股票代码,返回其名字"""
latest = self.store[f"{self.category}/members"].attrs.get("latest")
members = self.members_group[latest]
idx = np.argwhere(members["code"] == code).flatten()
if len(idx) > 0:
return members[idx[0]]["name"].item()
return code
def fuzzy_match_board_name(self, name: str) -> List[str]:
"""给定板块名称,查找名字近似的板块,返回其代码
# todo: 返回
Args:
name: 用以搜索的板块名字
Returns:
板块代码列表
"""
idx = np.flatnonzero(defchararray.find(self.boards["name"], name) != -1)
if len(idx):
return self.boards[idx]["code"].tolist()
else:
return None
@classmethod
def get_code(cls, name: str) -> str:
"""给定板块名字,转换成代码
Args:
name: 板块名字
Returns:
对应板块代码
"""
boards = cls._store[f"{cls.category}/boards"]
idx = np.argwhere(boards["name"] == name).flatten()
if len(idx):
return boards[idx][0]["code"]
return None
def get_bars(
self, code_or_name: str, start: datetime.date, end: datetime.date = None
):
"""获取板块的日线指数数据
Args:
code_or_name: 板块代码或者名字。
Returns:
"""
if code_or_name.startswith("8"):
name = self.get_name(code_or_name)
if name is None:
raise ValueError(f"invalid {code_or_name}")
else:
name = code_or_name
start = f"{start.year}{start.month:02}{start.day:02}"
if end is None:
end = arrow.now().format("YYYYMMDD")
else:
end = f"{end.year}{end.month:02}{end.day:02}"
return ak.stock_board_industry_index_ths(name, start, end)
def normalize_board_name(self, in_boards: List[str]) -> List[str]:
"""将名称与代码混装的`boards`转换为全部由板块代码表示的列表。
`in_boards`传入的值,除板块代码外,还可以是板块名全称或者名称的一部分。在后者这种情况下,将通过模糊匹配进行补全。
Args:
in_boards: 板块代码或者名称
Returns:
板块代码列表
"""
normalized = []
for board in in_boards:
if not re.match(r"\d+$", board):
found = self.fuzzy_match_board_name(board) or []
if not found:
logger.warning("%s is not in our board list", board)
else:
# 通过模糊查找到的一组板块,它们之间是union关系,放在最前面
normalized.extend(found)
else:
normalized.append(board)
return normalized
def filter(self, in_boards: List[str], without: List[str] = []) -> List[str]:
"""查找同时存在于`in_boards`板块,但不在`without`板块的股票
in_boards中的元素,既可以是代码、也可以是板块名称,还可以是模糊查询条件
Args:
in_boards: 查询条件,股票必须在这些板块中同时存在
without: 板块列表,股票必须不出现在这些板块中。
Returns:
满足条件的股票代码列表
"""
normalized = []
for board in in_boards:
if not re.match(r"\d+$", board):
found = self.fuzzy_match_board_name(board) or []
if not found:
logger.warning("%s is not in our board list", board)
else:
# 通过模糊查找到的一组板块,它们之间是union关系,放在最前面
normalized.insert(0, found)
else:
normalized.append(board)
results = None
for item in normalized:
if isinstance(item, list): # union all stocks
new_set = []
for board in item:
if board not in self.boards["code"]:
continue
new_set.extend(self.get_members(board))
new_set = set(new_set)
else:
if item not in self.boards["code"]:
logger.warning("wrong board code %, skipped", item)
continue
new_set = set(self.get_members(item))
if results is None:
results = new_set
else:
results = results.intersection(new_set)
normalized_without = []
for item in without:
if not re.match(r"\d+$", item):
codes = self.fuzzy_match_board_name(item)
if not codes:
logger.warning("%s is not in our board list", item)
normalized_without.extend(codes)
else:
normalized_without.append(item)
if not results:
return []
final_result = []
for stock in results:
if set(self.get_boards(stock)).intersection(set(normalized_without)):
continue
final_result.append(stock)
return final_result
class IndustryBoard(Board):
category = "industry"
class ConceptBoard(Board):
category = "concept"
def find_new_concept_boards(self, days=10) -> pd.DataFrame:
"""查找`days`以内新出的概念板块
Args:
days:
Returns:
在`days`天以内出现的新概念板块代码列表,包含date, name, code, members诸列
"""
df = pd.DataFrame(self.boards[:])
today = arrow.now()
start = today.shift(days=-days).date()
return df[df.date.dt.date >= start]
def find_latest_n_concept_boards(self, n: int = 3) -> pd.DataFrame:
"""查找最近新增的`n`个板块
Args:
n: 返回板块个数
Returns:
最近新增的`n`个板块信息
"""
df = pd.DataFrame(self.boards[:])
return df.nlargest(n, "date")
def new_members_in_board(self, days: int = 10) -> Dict[str, Set]:
"""查找在`days`天内新增加到某个概念板块的个股列表
如果某个板块都是新加入,则所有成员都会被返回
Args:
days: 查找范围
Raises:
ValueError: 如果板块数据没有更新到最新,则抛出此异常。
Returns:
以板块为key,个股集合为键值的字典。
"""
start = arrow.now().shift(days=-days)
start_key = int(start.format("YYYYMMDD"))
for x in self.members_group.keys():
if int(x) >= start_key:
start = x
break
else:
logger.info("board data is old than %s, call sync before this op", start)
raise ValueError("data is out of dayte")
old = self.members_group[start]
latest_day = self.members_group.attrs.get("latest")
if (arrow.get(latest_day, "YYYYMMDD") - arrow.now()).days > 1:
logger.info("concept board is out of date, latest is %s", latest_day)
raise ValueError("concept board is out-of-date. Please do sync first")
latest = self.members_group[latest_day]
results = {}
for board in set(latest["board"]):
idx = np.argwhere([latest["board"] == board]).flatten()
latest_stocks = set(latest[idx]["code"])
idx_old = np.argwhere([old["board"] == board]).flatten()
if len(idx_old) == 0:
results[board] = latest_stocks
else:
old_stocks = set(old[idx_old]["code"])
diff = latest_stocks - old_stocks
if len(diff):
results[board] = diff
return results
def sync_board():
try:
logger.info("start sync...")
IndustryBoard.syncing = True
IndustryBoard.init()
IndustryBoard.fetch_board_list()
IndustryBoard.fetch_board_members()
ConceptBoard.syncing = True
ConceptBoard.init()
ConceptBoard.fetch_board_list()
ConceptBoard.fetch_board_members()
except Exception as e:
logger.exception(e)
finally:
IndustryBoard.syncing = False
ConceptBoard.syncing = False
def combined_filter(
industry: str = None, with_concepts: Optional[List[str]] = None, without=[]
) -> List[str]:
"""针对行业板块与概念板块的联合筛选
Args:
industry: 返回代码必须包含在这些行业板块内
with_concepts: 返回代码必须包含在这些概念内
without: 返回代码必须不在这些概念内
Returns:
股票代码列表
"""
if with_concepts is not None:
cb = ConceptBoard()
cb.init()
if isinstance(with_concepts, str):
with_concepts = [with_concepts]
if isinstance(without, str):
without = [without]
concepts_codes = set(cb.filter(with_concepts, without=without))
else:
concepts_codes = None
codes = None
if industry is not None:
ib = IndustryBoard()
ib.init()
codes = ib.filter([industry])
if codes is not None:
codes = set(codes)
else:
codes = None
final_results = []
if codes is None or concepts_codes is None:
final_results = codes or concepts_codes
else:
final_results = codes.intersection(concepts_codes)
return final_results | zillionare-ths-boards | /zillionare-ths-boards-0.2.2.tar.gz/zillionare-ths-boards-0.2.2/boards/board.py | board.py |
import json
import logging
import os
import re
import signal
import subprocess
import sys
import time
from typing import Any, List, Optional
import fire
import httpx
from boards.board import ConceptBoard, IndustryBoard, combined_filter, sync_board
logger = logging.getLogger(__name__)
def _parse_as_str_array(args: Any):
if args is None:
return None
elif isinstance(args, str):
arr = re.split(r"[,,]", args)
elif hasattr(args, "__iter__"):
arr = args
elif isinstance(args, int):
arr = [args]
return [str(item) for item in arr]
def _save_proc_info(port, proc):
path = os.path.dirname(__file__)
file = os.path.join(path, "config")
with open(file, "w") as f:
f.writelines(json.dumps({"port": port, "proc": proc}))
def _read_proc_info():
path = os.path.dirname(__file__)
file = os.path.join(path, "config")
try:
with open(file, "r") as f:
info = json.load(f)
return info
except FileNotFoundError:
pass
except Exception as e:
print(e)
return None
def is_service_alive(port: int = None) -> bool:
if port is None:
info = _read_proc_info()
if info is None:
raise ValueError("请指定端口")
port = info["port"]
try:
resp = httpx.get(f"http://localhost:{port}/", trust_env=False)
except httpx.NetworkError:
return False
return resp.status_code == 200
def status(port: int = None) -> bool:
if is_service_alive(port):
print("------ board服务正在运行 ------")
else:
print("------ board服务未运行 ------")
ib = IndustryBoard()
cb = ConceptBoard()
ib.init()
cb.init()
try:
info = ib.info()
print(f"行业板块已更新至: {info['last_sync_date']},共{len(info['history'])}天数据。")
except KeyError:
print("行业板块数据还从未同步过。")
try:
info = cb.info()
print(f"概念板块已更新至: {info['last_sync_date']},共{len(info['history'])}天数据。")
except KeyError:
print("概念板块数据还从未同步过。")
def stop():
info = _read_proc_info()
if info is None:
print("未发现正在运行的boards服务")
return
proc = info["proc"]
try:
os.kill(proc, signal.SIGKILL)
except ProcessLookupError:
sys.exit()
if not is_service_alive():
print("boards已停止运行")
else:
print("停止boards服务失败,请手工停止。")
def serve(port: int = 2308):
if is_service_alive(port):
print("boards正在运行中,忽略此命令。")
return
proc = subprocess.Popen([sys.executable, "-m", "boards", "serve", f"{port}"])
for _ in range(30):
if is_service_alive(port):
_save_proc_info(port=port, proc=proc.pid)
break
else:
time.sleep(1)
def new_boards(days: int = 10):
cb = ConceptBoard()
cb.init()
result = cb.find_new_concept_boards(days)
if result is None or len(result) == 0:
print(f"近{days}天内没有新的概念板块")
else:
print(result)
def latest_boards(n: int = 3):
cb = ConceptBoard()
cb.init()
df = cb.find_latest_n_concept_boards(n)
print(df)
def new_members(days: int = 10, prot: int = None):
cb = ConceptBoard()
cb.init()
try:
results = cb.new_members_in_board(days)
if len(results) == 0:
print(f"近{days}天内没有板块有新增成员")
else:
for board, stocks in results.items():
print(cb.get_name(board) + ":")
aliases = [cb.get_stock_alias(stock) for stock in stocks]
print(" ".join(aliases))
except Exception as e:
print(e)
def sync():
sync_board()
def filter(industry=None, with_concepts: Optional[List[str]] = None, without=[]):
if industry is not None and isinstance(industry, int):
industry = str(industry)
if with_concepts is not None and isinstance(with_concepts, list):
with_concepts = [str(item) for item in with_concepts]
elif isinstance(with_concepts, str):
with_concepts = re.split(r"[,,]", with_concepts)
if without is not None and isinstance(without, list):
without = [str(item) for item in without]
elif isinstance(without, str):
without = re.split(r"[,,]", without)
results = combined_filter(industry, with_concepts, without)
if industry is None:
board = IndustryBoard()
board.init()
else:
board = ConceptBoard()
board.init()
for code in results:
name = board.get_stock_alias(code)
print(code, name)
def concepts(code: str):
cb = ConceptBoard()
cb.init()
for board in cb.get_boards(code):
print(board, cb.get_name(board))
def industry(code: str):
ib = IndustryBoard()
ib.init()
for board in ib.get_boards(code):
print(board, ib.get_name(board))
def list_boards(sub: str):
if sub == "concepts":
cb = ConceptBoard()
cb.init()
for i, (date, code, name, *_) in enumerate(cb.boards):
print(date, code, name)
elif sub == "industry":
ib = IndustryBoard()
ib.init()
for i, (date, code, name, *_) in enumerate(ib.boards):
print(date, code, name)
def main():
fire.Fire(
{
"new_members": new_members,
"new_boards": new_boards,
"latest_boards": latest_boards,
"serve": serve,
"status": status,
"sync": sync,
"stop": stop,
"filter": filter,
"concepts": concepts,
"industry": industry,
"list": list_boards,
}
)
if __name__ == "__main__":
main() | zillionare-ths-boards | /zillionare-ths-boards-0.2.2.tar.gz/zillionare-ths-boards-0.2.2/boards/cli.py | cli.py |
import datetime
import logging
from typing import Dict, List, Optional, Union
import arrow
import numpy as np
from traderclient.datatypes import OrderSide, OrderStatus, OrderType
from traderclient.transport import delete, get, post_json
logger = logging.getLogger(__name__)
class TraderClient:
"""大富翁实盘和回测的客户端。
在使用客户端时,需要先构建客户端实例,再调用其他方法,并处理[traderclient.errors.TradeError][]的异常,可以通过`status_code`和`message`来获取错误信息。如果是回测模式,一般会在回测结束时调用`metrics`方法来查看策略评估结果。如果要进一步查看信息,可以调用`bills`方法来获取历史持仓、交易记录和每日资产数据。
!!! Warn
此类实例既非线程安全,也非异步事件安全。即你不能在多个线程中,或者多个异步队列中使用它。
"""
def __init__(
self, url: str, acct: str, token: str, is_backtest: bool = False, **kwargs
):
"""构建一个交易客户端
当`is_backtest`为True时,会自动在服务端创建新账户。
Info:
如果`url`指向了回测服务器,但`is_backtest`设置为False,且如果提供的账户acct,token在服务器端存在,则将重用该账户,该账户之前的一些数据仍将保留,这可能导致某些错误,特别是继续进行测试时,时间发生rewind的情况。一般情况下,这种情况只用于获取之前的测试数据。
Args:
url : 服务器地址及路径,比如 http://localhost:port/trade/api/v1
acct : 子账号
token : 子账号对应的服务器访问令牌
is_backtest : 是否为回测模式,默认为False。
Keyword Args:
principal: float 初始资金,默认为1_000_000
commission: float 手续费率,默认为1e-4
start: datetime.date 回测开始日期,必选
end: datetime.date 回测结束日期,必选
"""
self._url = url.rstrip("/")
self._token = token
self._account = acct
self.headers = {"Authorization": self._token}
self.headers["Account"] = self._account
self._is_backtest = is_backtest
if is_backtest:
self._principal = kwargs.get("principal", 1_000_000)
commission = kwargs.get("commission", 1e-4)
start = kwargs.get("start")
end = kwargs.get("end")
if start is None or end is None:
raise ValueError("start and end must be specified in backtest mode")
self._start_backtest(acct, token, self._principal, commission, start, end)
self._is_dirty = False
self._cash = None
def _cmd_url(self, cmd: str) -> str:
return f"{self._url}/{cmd}"
def _start_backtest(
self,
acct: str,
token: str,
principal: float,
commission: float,
start: datetime.date,
end: datetime.date,
):
"""在回测模式下,创建一个新账户
Args:
acct : 账号名
token : 账号对应的服务器访问令牌
principal : 初始资金
commission : 手续费率
start : 回测开始日期
end : 回测结束日期
"""
url = self._cmd_url("start_backtest")
data = {
"name": acct,
"token": token,
"principal": principal,
"commission": commission,
"start": start.isoformat(),
"end": end.isoformat(),
}
post_json(url, data)
def info(self) -> Dict:
"""账户的当前基本信息,比如账户名、资金、持仓和资产等
!!! info
在回测模式下,info总是返回`last_trade`对应的那天的信息,因为这就是回测时的当前日期。
Returns:
dict: 账户信息
- name: str, 账户名
- principal: float, 初始资金
- assets: float, 当前资产
- start: datetime.date, 账户创建时间
- last_trade: datetime.datetime, 最后一笔交易时间
- available: float, 可用资金
- market_value: 股票市值
- pnl: 盈亏(绝对值)
- ppnl: 盈亏(百分比),即pnl/principal
- positions: 当前持仓,dtype为[position_dtype](https://zillionare.github.io/backtesting/0.3.2/api/trade/#backtest.trade.datatypes.position_dtype)的numpy structured array
"""
url = self._cmd_url("info")
r = get(url, headers=self.headers)
self._is_dirty = False
return r
def balance(self) -> Dict:
"""取该账号对应的账户余额信息
Returns:
Dict: 账户余额信息
- available: 现金
- market_value: 股票市值
- assets: 账户总资产
- pnl: 盈亏(绝对值)
- ppnl: 盈亏(百分比),即pnl/principal
"""
url = self._cmd_url("info")
r = get(url, headers=self.headers)
return {
"available": r["available"],
"market_value": r["market_value"],
"assets": r["assets"],
"pnl": r["pnl"],
"ppnl": r["ppnl"],
}
@property
def account(self) -> str:
return self._account
@property
def available_money(self) -> float:
"""取当前账户的可用金额。策略函数可能需要这个数据进行仓位计算
Returns:
float: 账户可用资金
"""
if self._is_dirty or self._cash is None:
info = self.info()
self._cash = info.get("available")
return self._cash
@property
def principal(self) -> float:
"""账户本金
Returns:
本金
"""
if self._is_backtest:
return self._principal
url = self._cmd_url("info")
r = get(url, headers=self.headers)
return r.get("principal")
def positions(self, dt: Optional[datetime.date] = None) -> np.ndarray:
"""取该子账户当前持仓信息
Warning:
在回测模式下,持仓信息不包含alias字段
Args:
dt: 指定日期,默认为None,表示取当前日期(最新)的持仓信息,trade server暂不支持此参数
Returns:
np.ndarray: dtype为[position_dtype](https://zillionare.github.io/backtesting/0.3.2/api/trade/#backtest.trade.datatypes.position_dtype)的numpy structured array
"""
if self._is_backtest and dt is None:
raise ValueError("`dt` is required under backtest mode")
url = self._cmd_url("positions")
return get(
url,
params={"date": dt.isoformat() if dt is not None else None},
headers=self.headers,
)
def available_shares(
self, security: str, dt: Optional[datetime.date] = None
) -> float:
"""返回某支股票在`dt`日的可售数量
Args:
security: 股票代码
dt: 持仓查询日期。在实盘下可为None,表明取最新持仓。
Returns:
float: 指定股票在`dt`日可卖数量,无可卖即为0
"""
if self._is_backtest and dt is None:
raise ValueError("`dt` is required under backtest!")
positions = self.positions(dt)
found = positions[positions["security"] == security]
if found.size == 1:
return found["sellable"][0].item()
elif found.size == 0:
return 0
else:
logger.warning("found more than one position entry in response: %s", found)
raise ValueError(f"found more than one position entry in response: {found}")
def today_entrusts(self) -> List:
"""查询账户当日所有委托,包括失败的委托
此API在回测模式下不可用。
Returns:
List: 委托信息数组,各元素字段参考buy
"""
url = self._cmd_url("today_entrusts")
return get(url, headers=self.headers)
def cancel_entrust(self, cid: str) -> Dict:
"""撤销委托
此API在回测模式下不可用。
Args:
cid (str): 交易服务器返回的委托合同号
Returns:
Dict: 被取消的委托的信息,参考`buy`的结果
"""
url = self._cmd_url("cancel_entrust")
data = {"cid": cid}
self._is_dirty = True
return post_json(url, params=data, headers=self.headers)
def cancel_all_entrusts(self) -> List:
"""撤销当前所有未完成的委托,包括部分成交,不同交易系统实现不同
此API在回测模式下不可用。
Returns:
List: 所有被撤的委托单信息,每个委托单的信息同buy
"""
url = self._cmd_url("cancel_all_entrusts")
self._is_dirty = True
return post_json(url, headers=self.headers)
async def buy_by_money(
self,
security: str,
money: float,
price: Optional[float] = None,
timeout: float = 0.5,
order_time: Optional[datetime.datetime] = None,
**kwargs,
) -> Dict:
"""按金额买入股票。
Returns:
参考[buy][traderclient.client.TraderClient.buy]
"""
order_time = order_time or datetime.datetime.now()
if price is None:
price = await self._get_market_buy_price(security, order_time)
volume = int(money / price / 100) * 100
return self.market_buy(
security, volume, timeout=timeout, order_time=order_time
)
else:
volume = int(money / price / 100) * 100
return self.buy(security, price, volume, timeout, order_time)
def buy(
self,
security: str,
price: float,
volume: int,
timeout: float = 0.5,
order_time: Optional[datetime.datetime] = None,
**kwargs,
) -> Dict:
"""证券买入
Notes:
注意如果是回测模式,还需要传入order_time,因为回测模式下,服务器是不可能知道下单这一刻的时间的。注意在回测模式下,返回字段少于实盘。
使用回测服务器时,无论成交实际上是在哪些时间点发生的,都使用order_time。在实盘模式下,则会分别返回create_at, recv_at两个字段
Args:
security (str): 证券代码
price (float): 买入价格(限价)。在回测时,如果price指定为None,将转换为市价买入
volume (int): 买入股票数(非手数)
timeout (float, optional): 默认等待交易反馈的超时为0.5秒
order_time: 下单时间。在回测模式下使用。
Returns:
Dict: 成交返回
实盘返回以下字段:
{
"cid" : "xxx-xxxx-xxx", # 券商给出的合同编号,内部名为entrust_no
"security": "000001.XSHE",
"name": "平安银行",
"price": 5.10, # 委托价格
"volume": 1000, # 委托量
"order_side": 1, # 成交方向,1买,-1卖
"order_type": 1, # 成交方向,1限价,2市价
"status": 3, # 执行状态,1已报,2部分成交,3成交,4已撤
"filled": 500, # 已成交量
"filled_vwap": 5.12, # 已成交均价,不包括税费
"filled_value": 2560, # 成交额,不包括税费
"trade_fees": 12.4, # 交易税费,包括佣金、印花税、杂费等
"reason": "", # 如果委托失败,原因?
"created_at": "2022-03-23 14:55:00.1000", # 委托时间,带毫秒值
"recv_at": "2022-03-23 14:55:00.1000", # 交易执行时间,带毫秒值
}
回测时将只返回以下字段:
{
"tid": 成交号
"eid": 委托号
"security": 证券代码
"order_side": 成交方向,1买,-1卖
"price": 成交价格
"filled": 已成交量
"time": 成交时间
"trade_fees": 交易费用
}
"""
if volume != volume // 100 * 100:
volume = volume // 100 * 100
logger.warning("买入数量必须是100的倍数, 已取整到%d", volume)
url = self._cmd_url("buy")
parameters = {
"security": security,
"price": price,
"volume": volume,
"timeout": timeout,
**kwargs,
}
if self._is_backtest:
if order_time is None:
raise ValueError("order_time is required in backtest mode")
_order_time = order_time.strftime("%Y-%m-%d %H:%M:%S")
parameters["order_time"] = _order_time
self._is_dirty = True
r = post_json(url, params=parameters, headers=self.headers)
for key in ("time", "created_at", "recv_at"):
if key in r:
r[key] = arrow.get(r[key]).naive
return r
def market_buy(
self,
security: str,
volume: int,
order_type: OrderType = OrderType.MARKET,
limit_price: Optional[float] = None,
timeout: float = 0.5,
order_time: Optional[datetime.datetime] = None,
**kwargs,
) -> Dict:
"""市价买入股票
Notes:
同花顺终端需要改为涨跌停限价,掘金客户端支持市价交易,掘金系统默认五档成交剩撤消。
在回测模式下,市价买入相当于持涨停价进行撮合。
在回测模式下,必须提供order_time参数。
Args:
security (str): 证券代码
volume (int): 买入数量
order_type (OrderType, optional): 市价买入类型,缺省为五档成交剩撤.
limit_price (float, optional): 剩余转限价的模式下,设置的限价
timeout (float, optional): 默认等待交易反馈的超时为0.5秒
order_time: 下单时间。在回测模式下使用。
Returns:
Dict: 成交返回,详见`buy`方法
"""
if volume != volume // 100 * 100:
volume = volume // 100 * 100
logger.warning("买入数量必须是100的倍数, 已取整到%d", volume)
url = self._cmd_url("market_buy")
parameters = {
"security": security,
"price": 0,
"volume": volume,
"order_type": order_type,
"timeout": timeout,
"limit_price": limit_price,
**kwargs,
}
if self._is_backtest:
if order_time is None:
raise ValueError("order_time is required in backtest mode")
_order_time = order_time.strftime("%Y-%m-%d %H:%M:%S")
parameters["order_time"] = _order_time
self._is_dirty = True
r = post_json(url, params=parameters, headers=self.headers)
for key in ("time", "created_at", "recv_at"):
if key in r:
r[key] = arrow.get(r[key]).naive
return r
def sell(
self,
security: str,
price: float,
volume: int,
timeout: float = 0.5,
order_time: Optional[datetime.datetime] = None,
**kwargs,
) -> Union[List, Dict]:
"""以限价方式卖出股票
Notes:
如果是回测模式,还需要传入order_time,因为回测模式下,服务器是不可能知道下单这一刻的时间的。如果服务器是回测服务器,则返回的数据为多个成交记录的列表(即使只包含一个数据)
Args:
security (str): 证券代码
price (float): 买入价格(限价)。在回测中如果指定为None,将转换为市价卖出
volume (int): 买入股票数
timeout (float, optional): 默认等待交易反馈的超时为0.5秒
order_time: 下单时间。在回测模式下使用。
Returns:
Union[List, Dict]: 成交返回,详见`buy`方法,trade server只返回一个委托单信息
"""
# todo: check return type?
url = self._cmd_url("sell")
parameters = {
"security": security,
"price": price,
"volume": volume,
"timeout": timeout,
**kwargs,
}
if self._is_backtest:
if order_time is None:
raise ValueError("order_time is required in backtest mode")
_order_time = order_time.strftime("%Y-%m-%d %H:%M:%S")
parameters["order_time"] = _order_time
self._is_dirty = True
r = post_json(url, params=parameters, headers=self.headers)
for key in ("created_at", "recv_at"):
if key in r:
r[key] = arrow.get(r[key]).naive
if self._is_backtest:
for rec in r:
rec["time"] = arrow.get(rec["time"]).naive
return r
def market_sell(
self,
security: str,
volume: int,
order_type: OrderType = OrderType.MARKET,
limit_price: Optional[float] = None,
timeout: float = 0.5,
order_time: Optional[datetime.datetime] = None,
**kwargs,
) -> Union[List, Dict]:
"""市价卖出股票
Notes:
同花顺终端需要改为涨跌停限价,掘金客户端支持市价交易,掘金系统默认五档成交剩撤
如果是回测模式,则市价卖出意味着以跌停价挂单进行撮合。
目前模拟盘和实盘模式下没有实现限价。
Args:
security (str): 证券代码
volume (int): 卖出数量
order_type (OrderType, optional): 市价卖出类型,缺省为五档成交剩撤.
limit_price (float, optional): 剩余转限价的模式下,设置的限价
timeout (float, optional): 默认等待交易反馈的超时为0.5秒
order_time: 下单时间。在回测模式下使用。
Returns:
Union[List, Dict]: 成交返回,详见`buy`方法,trade server只返回一个委托单信息
"""
url = self._cmd_url("market_sell")
parameters = {
"security": security,
"price": 0,
"volume": volume,
"order_type": order_type,
"timeout": timeout,
"limit_price": limit_price,
**kwargs,
}
if self._is_backtest:
if order_time is None:
raise ValueError("order_time is required in backtest mode")
_order_time = order_time.strftime("%Y-%m-%d %H:%M:%S")
parameters["order_time"] = _order_time
self._is_dirty = True
r = post_json(url, params=parameters, headers=self.headers)
for key in ("time", "created_at", "recv_at"):
if key in r:
r[key] = arrow.get(r[key]).naive
return r
async def _get_market_sell_price(
self, sec: str, order_time: Optional[datetime.datetime] = None
) -> float:
"""获取当前股票的市价卖出价格
如果无法取得跌停价,则以当前价卖出。
"""
from coretypes import FrameType
from omicron.models.stock import Stock
order_time = order_time or datetime.datetime.now()
frame = order_time.date()
limit_prices = await Stock.get_trade_price_limits(sec, frame, frame)
if len(limit_prices) >= 0:
price = limit_prices["low_limit"][0]
else:
price = (await Stock.get_bars(sec, 1, FrameType.MIN1, end=order_time))[
"close"
][0]
return price.item()
async def _get_market_buy_price(
self, sec: str, order_time: Optional[datetime.datetime] = None
) -> float:
"""获取当前股票的市价买入价格
如果无法取得涨停价,则以当前价买入。
"""
from coretypes import FrameType
from omicron.models.stock import Stock
order_time = order_time or datetime.datetime.now()
frame = order_time.date()
limit_prices = await Stock.get_trade_price_limits(sec, frame, frame)
if len(limit_prices) >= 0:
price = limit_prices["high_limit"][0]
else:
price = (await Stock.get_bars(sec, 1, FrameType.MIN1, end=order_time))[
"close"
][0]
return price.item()
def sell_percent(
self,
security: str,
price: float,
percent: float,
timeout: float = 0.5,
order_time: Optional[datetime.datetime] = None,
**kwargs,
) -> Union[List, Dict]:
"""按比例卖出特定的股票(基于可卖股票数),比例的数字由调用者提供
Notes:
注意实现中存在取整问题。比如某支股票当前有500股可卖,如果percent=0.3,则要求卖出150股。实际上卖出的将是100股。
Args:
security (str): 特定的股票代码
price (float): 市价卖出,价格参数可为0
percent (float): 调用者给出的百分比,(0, 1]
time_out (int, optional): 缺省超时为0.5秒
order_time: 下单时间。在回测模式下使用。
Returns:
Union[List, Dict]: 股票卖出委托单的详细信息,于sell指令相同
"""
if percent <= 0 or percent > 1:
raise ValueError("percent should between [0, 1]")
if len(security) < 6:
raise ValueError(f"wrong security format {security}")
url = self._cmd_url("sell_percent")
parameters = {
"security": security,
"price": price,
"timeout": timeout,
"percent": percent,
}
if self._is_backtest:
if order_time is None:
raise ValueError("order_time is required in backtest mode")
_order_time = order_time.strftime("%Y-%m-%d %H:%M:%S")
parameters["order_time"] = _order_time
self._is_dirty = True
r = post_json(url, params=parameters, headers=self.headers)
for key in ("time", "created_at", "recv_at"):
if key in r:
r[key] = arrow.get(r[key]).naive
return r
def sell_all(self, percent: float, timeout: float = 0.5) -> List:
"""将所有持仓按percent比例进行减仓,用于特殊情况下的快速减仓(基于可买股票数)
此API在回测模式下不可用。
Args:
percent (float): 调用者给出的百分比,(0, 1]
time_out (int, optional): 缺省超时为0.5秒
Returns:
List: 所有卖出股票的委托单信息,于sell指令相同
"""
if percent <= 0 or percent > 1:
raise ValueError("percent should between [0, 1]")
url = self._cmd_url("sell_all")
parameters = {"percent": percent, "timeout": timeout}
self._is_dirty = True
return post_json(url, params=parameters, headers=self.headers)
def metrics(
self,
start: Optional[datetime.date] = None,
end: Optional[datetime.date] = None,
baseline: Optional[str] = None,
) -> Dict:
"""获取指定时间段[start, end]间的账户指标评估数据
Args:
start: 起始日期
end: 结束日期
baseline: the security code for baseline
Returns:
Dict: 账户指标评估数据
- start 回测起始时间
- end 回测结束时间
- window 资产暴露时间
- total_tx 发生的配对交易次数
- total_profit 总盈亏
- total_profit_rate 总盈亏率
- win_rate 胜率
- mean_return 每笔配对交易平均回报率
- sharpe 夏普比率
- max_drawdown 最大回撤
- sortino
- calmar
- annual_return 年化收益率
- volatility 波动率
- baseline: dict
- win_rate
- sharpe
- max_drawdown
- sortino
- annual_return
- total_profit_rate
- volatility
"""
url = self._cmd_url("metrics")
params = {
"start": start.strftime("%Y-%m-%d") if start else None,
"end": end.strftime("%Y-%m-%d") if end else None,
"baseline": baseline,
}
return get(url, headers=self.headers, params=params)
def bills(self) -> Dict:
"""获取账户的交易、持仓、市值流水信息。
Returns:
Dict: 账户的交易、持仓、市值流水信息
- trades
- positions
- assets
- tx
"""
url = self._cmd_url("bills")
return get(url, headers=self.headers)
def get_assets(
self,
start: Optional[datetime.date] = None,
end: Optional[datetime.date] = None,
) -> np.ndarray:
"""获取账户在[start, end]时间段内的资产信息。
此数据可用以资产曲线的绘制。
Args:
start: 起始日期
end: 结束日期
Returns:
np.ndarray: 账户在[start, end]时间段内的资产信息,是一个dtype为[rich_assets_dtype](https://zillionare.github.io/backtesting/0.4.0/api/trade/#backtest.trade.datatypes.rich_assets_dtype)的numpy structured array
"""
url = self._cmd_url("assets")
_start = start.strftime("%Y-%m-%d") if start else None
_end = end.strftime("%Y-%m-%d") if end else None
return get(url, headers=self.headers, params={"start": _start, "end": _end})
def stop_backtest(self):
"""停止回测。
此API仅在回测模式下可用。其作用是冻结回测账户,并计算回测的各项指标。在未调用本API前,调用`metrics`也能同样获取到回测的各项指标,但如果需要多次调用`metrics`,则账户在冻结之后,由于指标不再需要更新,因而速度会更快。
另外,在[zillionare-backtest](https://zillionare.github.io/backtesting/)的未来版本中,将可能使用本方法来实现回测数据的持久化保存,因此,建议您从现在起就确保在回测后调用本方法。
"""
url = self._cmd_url("stop_backtest")
return post_json(url, headers=self.headers)
@staticmethod
def list_accounts(url_prefix: str, admin_token: str) -> List:
"""列举服务器上所有账户(不包含管理员账户)
此命令需要管理员权限。
Args:
url_prefix : 服务器地址及前缀
admin_token : 管理员token
Returns:
账户列表,每个元素信息即`info`返回的信息
"""
url_prefix = url_prefix.rstrip("/")
url = f"{url_prefix}/accounts"
headers = {"Authorization": admin_token}
return get(url, headers=headers)
@staticmethod
def delete_account(url_prefix: str, account_name: str, token: str) -> int:
"""删除账户
仅回测模式下实现。
此API不需要管理员权限。只要知道账户名和token即可删除账户。对管理员要删除账户的,可以先通过管理员账户列举所有账户,得到账户和token后再删除。
Args:
url_prefix (str): 服务器地址及前缀
account_name (str): 待删除的账户名
token (str): 账户token
Returns:
服务器上剩余账户个数
"""
url_prefix = url_prefix.rstrip("/")
url = f"{url_prefix}/accounts"
headers = {"Authorization": token}
return delete(url, headers=headers, params={"name": account_name}) | zillionare-trader-client | /zillionare_trader_client-0.4.3-py3-none-any.whl/traderclient/client.py | client.py |
import datetime
import logging
import pickle
from traderclient import TraderClient
logger = logging.getLogger(__name__)
def init_logging(level=logging.INFO):
logger = logging.getLogger()
handler = logging.StreamHandler()
formatter = logging.Formatter(fmt="---%(message)s")
handler.setFormatter(formatter)
logger.addHandler(handler)
logger.setLevel(level)
def test_info():
url = "http://192.168.100.133:8000/api/trade/v0.1"
acct = "henry"
token = "29b7cce7-e9bb-4510-9231-6d492750b4db"
client = TraderClient(url, acct, token)
print("\n------------- info --------------")
try:
result = client.info()
if result is None:
logger.error("failed to get information")
return None
print(result)
except Exception as e:
print(e)
return False
print("\n------------- balance --------------")
result = client.balance()
print(result)
tmp = client.principal
print("principal: ", tmp)
tmp = client.available_money
print("available money: ", tmp)
def test_info_with_error():
url = "http://192.168.100.133:8000/api/trade/v0.1"
acct = "henry111111"
token = "41e84e9a-c281-4ed3-86f3-01ef412f3970"
client = TraderClient(url, acct, token)
print("\n------------- info --------------")
try:
result = client.info()
if result is None:
logger.error("failed to get information")
return None
print(result)
except Exception as e:
print(e)
return False
def test_position():
url = "http://192.168.100.133:8000/api/trade/v0.1"
acct = "henry"
token = "29b7cce7-e9bb-4510-9231-6d492750b4db"
client = TraderClient(url, acct, token)
print("\n------------- positions --------------")
try:
result = client.positions()
print(result)
print("\n------------- available_shares --------------")
result = client.available_shares("601118.XSHG")
print(result)
except Exception as e:
print(e)
return False
def test_entrusts():
url = "http://192.168.100.133:8000/api/trade/v0.1"
acct = "henry"
token = "29b7cce7-e9bb-4510-9231-6d492750b4db"
# initialize client instance
client = TraderClient(url, acct, token)
print("\n------------- today_entrusts --------------")
result = client.today_entrusts()
if result is None:
return None
print(result)
def test_trade_cancel():
url = "http://192.168.100.133:8000/api/trade/v0.1"
acct = "henry"
token = "29b7cce7-e9bb-4510-9231-6d492750b4db"
# initialize client instance
client = TraderClient(url, acct, token)
print("\n------------- cancel_entrust --------------")
result = client.cancel_entrust("50f5aaee-6fa8-470c-a630-39b43bc9dda7")
if result is None:
return None
print(result)
def test_trade_cancel_all():
url = "http://192.168.100.133:8000/api/trade/v0.1"
acct = "henry"
token = "29b7cce7-e9bb-4510-9231-6d492750b4db"
# initialize client instance
client = TraderClient(url, acct, token)
print("\n------------- cancel_all_entrust --------------")
result = client.cancel_all_entrusts()
print(result)
def test_trade_buy():
url = "http://192.168.100.133:8000/api/trade/v0.1"
acct = "henry"
token = "29b7cce7-e9bb-4510-9231-6d492750b4db"
# initialize client instance
client = TraderClient(url, acct, token)
# test buy
print("\n------------- buy --------------")
result = client.buy(security="002537.XSHE", price=8.45, volume=200)
if result is None:
return None
print(result)
# buy for cancel
result = client.buy(security="002537.XSHE", price=6.97, volume=600)
if result is None:
return None
print(result)
def test_trade_market_buy():
url = "http://192.168.100.133:8000/api/trade/v0.1"
acct = "henry"
token = "29b7cce7-e9bb-4510-9231-6d492750b4db"
# initialize client instance
client = TraderClient(url, acct, token)
print("\n------------- market_buy --------------")
rsp = client.market_buy(security="002537.XSHE", price=7.8, volume=500)
print(rsp)
def test_for_nginx():
url = "http://203.189.206.225:9100/api/trade/v0.1"
acct = "guobotest"
token = "b1733675-f525-49e9-82c4-a91360ec36e6"
# initialize client instance
client = TraderClient(url, acct, token)
try:
result = client.info()
if result is None:
logger.error("failed to get information")
print(result)
except Exception as e:
print(e)
def test_trade_sell():
url = "http://192.168.100.133:8000/api/trade/v0.1"
acct = "henry"
token = "29b7cce7-e9bb-4510-9231-6d492750b4db"
# initialize client instance
client = TraderClient(url, acct, token)
print("\n------------- sell --------------")
rsp = client.sell(security="002537.XSHE", price=9.9, volume=200)
print(rsp)
print("\n------------- market_sell ---------------")
rsp = client.market_sell(security="002537.XSHE", price=9.7, volume=400)
print(rsp)
def test_sell_percent():
url = "http://192.168.100.19:9000/backtest/api/trade/v0.1"
acct = "henry"
token = "29b7cce7-e9bb-4510-9231-6d492750b4db"
# initialize client instance
client = TraderClient(url, acct, token)
# test buy
print("\n------------- sell_percent --------------")
result = client.sell_percent("002537.XSHE", 0.2, 0.6)
if result is None:
return None
print(result)
def test_sell_all():
url = "http://192.168.100.19:9000/backtest/api/trade/v0.1"
acct = "henry"
token = "29b7cce7-e9bb-4510-9231-6d492750b4db"
# initialize client instance
client = TraderClient(url, acct, token)
# test buy
print("\n------------- sell_all --------------")
result = client.sell_all(0.2, 0.6)
if result is None:
return None
print(result)
def test_get_data_in_range():
url = "http://192.168.100.19:9000/backtest/api/trade/v0.1"
acct = "henry"
token = "29b7cce7-e9bb-4510-9231-6d492750b4db"
# initialize client instance
client = TraderClient(url, acct, token)
print("\n------------- get_trade_in_range --------------")
start = datetime.datetime(2022, 3, 1, 9, 35)
end = datetime.datetime(2022, 3, 10, 9, 35)
result = client.get_trades_in_range(start=start, end=end)
if result is None:
return None
print(result)
print("\n------------- get_enturst_in_range --------------")
start = datetime.datetime(2022, 3, 1, 9, 35)
end = datetime.datetime(2022, 3, 10, 9, 35)
result = client.get_entrusts_in_range(start=start, end=end)
if result is None:
return None
print(result)
def trade_test_entry():
test_trade_market_buy()
if __name__ == "__main__":
test_for_nginx() | zillionare-trader-client | /zillionare_trader_client-0.4.3-py3-none-any.whl/traderclient/demo.py | demo.py |
import logging
import os
import pickle
import uuid
from typing import Any, Dict, Optional
import httpx
from traderclient.utils import get_cmd, status_ok
from .errors import TradeError
logger = logging.getLogger(__name__)
def timeout(params: Optional[dict] = None) -> int:
"""determine timeout value for httpx request
if there's envar "TRADER_CLIENT_TIMEOUT", it will precedes, then the max of user timeout and default 30
Args:
params : user specified in request
Returns:
timeout
"""
if os.environ.get("TRADER_CLIENT_TIMEOUT"):
return int(os.environ.get("TRADER_CLIENT_TIMEOUT", "5"))
if params is None or params.get("timeout") is None:
return 30
return max(params.get("timeout", 5), 30)
def process_response_result(rsp: httpx.Response, cmd: Optional[str] = None) -> Any:
"""获取响应中的数据,并检查结果合法性
Args:
rsp (response): HTTP response object
cmd (str, optional): trade instuction
Raises:
traderclient.errors.Error: 如果服务器返回状态码不为2xx,则抛出错误
"""
if cmd is None:
cmd = get_cmd(str(rsp.url))
content_type = rsp.headers.get("Content-Type")
# process 20x response, check response code first
if status_ok(rsp.status_code):
if content_type == "application/json":
return rsp.json()
elif content_type.startswith("text"):
return rsp.text
else:
return pickle.loads(rsp.content)
# http 1.1 allow us to extend http status code, so we choose 499 as our error code. The upstream server is currently built on top of sanic, it doesn't support customer reason phrase (always return "Unknown Error" if the status code is extened. So we have to use body to carry on reason phrase.
if rsp.status_code == 499:
logger.warning("%s failed: %s, %s", cmd, rsp.status_code, rsp.text)
raise TradeError(rsp.status_code, rsp.text)
else:
rsp.raise_for_status()
def get(url, params: Optional[dict] = None, headers=None) -> Any:
"""发送GET请求到上游服务接口
Args:
url : 目标URL,带服务器信息
params : JSON格式的参数清单
headers : 额外的header选项
"""
if headers is None:
headers = {"Request-ID": uuid.uuid4().hex}
else:
headers.update({"Request-ID": uuid.uuid4().hex})
rsp = httpx.get(url, params=params, headers=headers, timeout=timeout(params))
action = get_cmd(url)
result = process_response_result(rsp, action)
return result
def post_json(url, params=None, headers=None) -> Any:
"""以POST发送JSON数据请求
Args:
url : 目标URL,带服务器信息
params : JSON格式的参数清单
headers : 额外的header选项
"""
if headers is None:
headers = {"Request-ID": uuid.uuid4().hex}
else:
headers.update({"Request-ID": uuid.uuid4().hex})
rsp = httpx.post(url, json=params, headers=headers, timeout=timeout(params))
action = get_cmd(url)
result = process_response_result(rsp, action)
return result
def delete(url, params: Optional[Dict] = None, headers=None) -> Any:
"""从服务器上删除资源
Args:
url : 目标URL,带服务器信息
params : 查询参数
headers : 额外的header选项
Returns:
"""
if headers is None:
headers = {"Request-ID": uuid.uuid4().hex}
else:
headers.update({"Request-ID": uuid.uuid4().hex})
rsp = httpx.delete(url, params=params, headers=headers, timeout=timeout(params))
action = get_cmd(url)
result = process_response_result(rsp, action)
return result | zillionare-trader-client | /zillionare_trader_client-0.4.3-py3-none-any.whl/traderclient/transport.py | transport.py |
==========
zillionare
==========
.. image:: https://img.shields.io/pypi/v/zillionare.svg
:target: https://pypi.python.org/pypi/zillionare
.. image:: https://img.shields.io/travis/zillionare/zillionare.svg
:target: https://travis-ci.com/zillionare/zillionare
.. image:: https://readthedocs.org/projects/zillionare/badge/?version=latest
:target: https://zillionare.readthedocs.io/en/latest/?badge=latest
:alt: Documentation Status
AI量化交易
* Free software: MIT license
* Documentation: https://zillionare.readthedocs.io.
Features
--------
* TODO
Credits
-------
This package was created with Cookiecutter_ and the `audreyr/cookiecutter-pypackage`_ project template.
.. _Cookiecutter: https://github.com/audreyr/cookiecutter
.. _`audreyr/cookiecutter-pypackage`: https://github.com/audreyr/cookiecutter-pypackage
| zillionare | /zillionare-0.1.0.tar.gz/zillionare-0.1.0/README.rst | README.rst |
.. highlight:: shell
============
Contributing
============
Contributions are welcome, and they are greatly appreciated! Every little bit
helps, and credit will always be given.
You can contribute in many ways:
Types of Contributions
----------------------
Report Bugs
~~~~~~~~~~~
Report bugs at https://github.com/zillionare/zillionare/issues.
If you are reporting a bug, please include:
* Your operating system name and version.
* Any details about your local setup that might be helpful in troubleshooting.
* Detailed steps to reproduce the bug.
Fix Bugs
~~~~~~~~
Look through the GitHub issues for bugs. Anything tagged with "bug" and "help
wanted" is open to whoever wants to implement it.
Implement Features
~~~~~~~~~~~~~~~~~~
Look through the GitHub issues for features. Anything tagged with "enhancement"
and "help wanted" is open to whoever wants to implement it.
Write Documentation
~~~~~~~~~~~~~~~~~~~
zillionare could always use more documentation, whether as part of the
official zillionare docs, in docstrings, or even on the web in blog posts,
articles, and such.
Submit Feedback
~~~~~~~~~~~~~~~
The best way to send feedback is to file an issue at https://github.com/zillionare/zillionare/issues.
If you are proposing a feature:
* Explain in detail how it would work.
* Keep the scope as narrow as possible, to make it easier to implement.
* Remember that this is a volunteer-driven project, and that contributions
are welcome :)
Get Started!
------------
Ready to contribute? Here's how to set up `zillionare` for local development.
1. Fork the `zillionare` repo on GitHub.
2. Clone your fork locally::
$ git clone [email protected]:your_name_here/zillionare.git
3. Install your local copy into a virtualenv. Assuming you have virtualenvwrapper installed, this is how you set up your fork for local development::
$ mkvirtualenv zillionare
$ cd zillionare/
$ python setup.py develop
4. Create a branch for local development::
$ git checkout -b name-of-your-bugfix-or-feature
Now you can make your changes locally.
5. When you're done making changes, check that your changes pass flake8 and the
tests, including testing other Python versions with tox::
$ flake8 zillionare tests
$ python setup.py test or pytest
$ tox
To get flake8 and tox, just pip install them into your virtualenv.
6. Commit your changes and push your branch to GitHub::
$ git add .
$ git commit -m "Your detailed description of your changes."
$ git push origin name-of-your-bugfix-or-feature
7. Submit a pull request through the GitHub website.
Pull Request Guidelines
-----------------------
Before you submit a pull request, check that it meets these guidelines:
1. The pull request should include tests.
2. If the pull request adds functionality, the docs should be updated. Put
your new functionality into a function with a docstring, and add the
feature to the list in README.rst.
3. The pull request should work for Python 3.5, 3.6, 3.7 and 3.8, and for PyPy. Check
https://travis-ci.com/zillionare/zillionare/pull_requests
and make sure that the tests pass for all supported Python versions.
Tips
----
To run a subset of tests::
$ python -m unittest tests.test_zillionare
Deploying
---------
A reminder for the maintainers on how to deploy.
Make sure all your changes are committed (including an entry in HISTORY.rst).
Then run::
$ bump2version patch # possible: major / minor / patch
$ git push
$ git push --tags
Travis will then deploy to PyPI if tests pass.
| zillionare | /zillionare-0.1.0.tar.gz/zillionare-0.1.0/CONTRIBUTING.rst | CONTRIBUTING.rst |
.. highlight:: shell
============
Installation
============
Stable release
--------------
To install zillionare, run this command in your terminal:
.. code-block:: console
$ pip install zillionare
This is the preferred method to install zillionare, as it will always install the most recent stable release.
If you don't have `pip`_ installed, this `Python installation guide`_ can guide
you through the process.
.. _pip: https://pip.pypa.io
.. _Python installation guide: http://docs.python-guide.org/en/latest/starting/installation/
From sources
------------
The sources for zillionare can be downloaded from the `Github repo`_.
You can either clone the public repository:
.. code-block:: console
$ git clone git://github.com/zillionare/zillionare
Or download the `tarball`_:
.. code-block:: console
$ curl -OJL https://github.com/zillionare/zillionare/tarball/master
Once you have a copy of the source, you can install it with:
.. code-block:: console
$ python setup.py install
.. _Github repo: https://github.com/zillionare/zillionare
.. _tarball: https://github.com/zillionare/zillionare/tarball/master
| zillionare | /zillionare-0.1.0.tar.gz/zillionare-0.1.0/docs/installation.rst | installation.rst |
# Zilliqa ETL CLI
[](https://travis-ci.org/blockchain-etl/zilliqa-etl)
Zilliqa ETL CLI lets you convert Zilliqa data into JSON newline-delimited format.
[Full documentation available here](http://zilliqa-etl.readthedocs.io/).
## Quickstart
Install Zilliqa ETL CLI:
```bash
pip3 install zilliqa-etl
```
Export directory service blocks ([Schema](../docs/schema.md), [Reference](../docs/commands.md)):
```bash
> zilliqaetl export_ds_blocks --start-block 1 --end-block 500000 \
--output-dir output --provider-uri https://api.zilliqa.com
```
Find other commands [here](https://zilliqa-etl.readthedocs.io/en/latest/commands/).
For the latest version, check out the repo and call
```bash
> pip3 install -e .
> python3 zilliqaetl.py
```
## Useful Links
- [Schema](https://zilliqa-etl.readthedocs.io/en/latest/schema/)
- [Command Reference](https://zilliqa-etl.readthedocs.io/en/latest/commands/)
- [Documentation](https://zilliqa-etl.readthedocs.io/)
## Running Tests
```bash
> pip3 install -e .[dev]
> export ZILLIQAETL_PROVIDER_URI=https://api.zilliqa.com
> pytest -vv
```
### Running Tox Tests
```bash
> pip3 install tox
> tox
```
## Running in Docker
1. Install Docker https://docs.docker.com/install/
2. Build a docker image
> docker build -t zilliqa-etl:latest .
> docker image ls
3. Run a container out of the image
> docker run -v $HOME/output:/zilliqa-etl/output zilliqa-etl:latest export_ds_blocks -s 1 -e 500000 -o output
| zilliqa-etl | /zilliqa-etl-1.0.9.tar.gz/zilliqa-etl-1.0.9/README.md | README.md |
from blockchainetl_common.executors.batch_work_executor import BatchWorkExecutor
from blockchainetl_common.jobs.base_job import BaseJob
from blockchainetl_common.utils import validate_range
from zilliqaetl.jobs.retriable_exceptions import RETRY_EXCEPTIONS
from zilliqaetl.mappers.event_log_mapper import map_event_logs
from zilliqaetl.mappers.exception_mapper import map_exceptions
from zilliqaetl.mappers.transaction_mapper import map_transaction
from zilliqaetl.mappers.transition_mapper import map_transitions
from zilliqaetl.mappers.tx_block_mapper import map_tx_block
from zilliqaetl.service.zilliqa_service import ZilliqaService
# Exports tx blocks
class ExportTxBlocksJob(BaseJob):
def __init__(
self,
start_block,
end_block,
zilliqa_api,
max_workers,
item_exporter,
export_transactions=True,
export_event_logs=True,
export_exceptions=True,
export_transitions=True):
validate_range(start_block, end_block)
self.start_block = start_block
self.end_block = end_block
self.batch_work_executor = BatchWorkExecutor(1, max_workers, retry_exceptions=RETRY_EXCEPTIONS)
self.item_exporter = item_exporter
self.zilliqa_service = ZilliqaService(zilliqa_api)
self.export_transactions = export_transactions
self.export_event_logs = export_event_logs
self.export_exceptions = export_exceptions
self.export_transitions = export_transitions
def _start(self):
self.item_exporter.open()
def _export(self):
self.batch_work_executor.execute(
range(self.start_block, self.end_block + 1),
self._export_batch,
total_items=self.end_block - self.start_block + 1
)
def _export_batch(self, block_number_batch):
items = []
for number in block_number_batch:
tx_block = map_tx_block(self.zilliqa_service.get_tx_block(number))
txns = list(self.zilliqa_service.get_transactions(number)) if tx_block.get('num_transactions') > 0 else []
if self._should_export_transactions():
for txn in txns:
items.append(map_transaction(tx_block, txn))
if self._should_export_event_logs(txn):
items.extend(map_event_logs(tx_block, txn))
if self._should_export_exceptions(txn):
items.extend(map_exceptions(tx_block, txn))
if self._should_export_transitions(txn):
items.extend(map_transitions(tx_block, txn))
tx_block['num_present_transactions'] = len(txns)
items.append(tx_block)
for item in items:
self.item_exporter.export_item(item)
def _should_export_transactions(self):
return self.export_transactions
def _should_export_event_logs(self, txn):
return self.export_event_logs and txn.get('receipt')
def _should_export_exceptions(self, txn):
return self.export_exceptions and txn.get('receipt')
def _should_export_transitions(self, txn):
return self.export_transitions and txn.get('receipt')
def _end(self):
self.batch_work_executor.shutdown()
self.item_exporter.close() | zilliqa-etl | /zilliqa-etl-1.0.9.tar.gz/zilliqa-etl-1.0.9/zilliqaetl/jobs/export_tx_blocks_job.py | export_tx_blocks_job.py |
import logging
import os
import threading
from blockchainetl_common.atomic_counter import AtomicCounter
from blockchainetl_common.exporters import JsonLinesItemExporter, CsvItemExporter
from blockchainetl_common.file_utils import get_file_handle, close_silently
class ZilliqaItemExporter:
def __init__(self, output_dir, item_type_to_filename=None, output_format='json'):
self.output_dir = output_dir
self.item_type_to_filename = item_type_to_filename
if self.item_type_to_filename is None:
self.item_type_to_filename = lambda item_type: f'{item_type}s.{output_format}'
self.output_format = output_format
self.exporter_mapping = {}
self.file_mapping = {}
self.counter_mapping = {}
self.init_lock = threading.Lock()
self.logger = logging.getLogger('ZilliqaItemExporter')
def open(self):
pass
def export_items(self, items):
for item in items:
self.export_item(item)
def export_item(self, item):
item_type = item.get('type')
if item_type is None:
raise ValueError('"type" key is not found in item {}'.format(repr(item)))
exporter = self._get_exporter_for_item_type(item_type)
exporter.export_item(item)
counter = self._get_counter_for_item_type(item_type)
counter.increment()
def _get_exporter_for_item_type(self, item_type):
if self.exporter_mapping.get(item_type) is None:
with self.init_lock:
if self.exporter_mapping.get(item_type) is None:
filename = os.path.join(self.output_dir, self.item_type_to_filename(item_type))
file = get_file_handle(filename, binary=True)
self.file_mapping[item_type] = file
self.exporter_mapping[item_type] = get_item_exporter(self.output_format, file)
return self.exporter_mapping[item_type]
def _get_counter_for_item_type(self, item_type):
if self.counter_mapping.get(item_type) is None:
with self.init_lock:
if self.counter_mapping.get(item_type) is None:
self.counter_mapping[item_type] = AtomicCounter()
return self.counter_mapping[item_type]
def close(self):
for item_type, file in self.file_mapping.items():
close_silently(file)
counter = self.counter_mapping[item_type]
if counter is not None:
self.logger.info('{} items exported: {}'.format(item_type, counter.increment() - 1))
def get_item_exporter(output_format, file):
if output_format == 'json':
return JsonLinesItemExporter(file)
elif output_format == 'csv':
return CsvItemExporter(file)
else:
ValueError(f'output format {output_format} is not recognized') | zilliqa-etl | /zilliqa-etl-1.0.9.tar.gz/zilliqa-etl-1.0.9/zilliqaetl/exporters/zilliqa_item_exporter.py | zilliqa_item_exporter.py |
import requests
from urllib.parse import urlencode
ZILLOW_LISTING_API = 'https://api.scrape-it.cloud/zillow/listing'
ZILLOW_PROPERTY_API = 'https://api.scrape-it.cloud/zillow/property'
class ZillowAPI:
def __init__(self, apiKey=None):
if apiKey is None:
raise ValueError('API Key is not provided')
self.apiKey = apiKey
def handleErrors(self, result, statusCode):
if "status" in result and result['status'] and result['status'] == 'error' and 'message' in result:
raise ValueError(result['message'])
if statusCode == 403:
raise ValueError("You don't have enough API credits to perform this request")
if statusCode == 401:
raise ValueError('Invalid API Key')
if statusCode == 429:
raise ValueError('You reached concurrency limit')
if 'errors' in result and len(result['errors']) > 0:
error = ValueError('Validation error')
error.validation_errors = result['errors']
raise error
if 'requestMetadata' not in result:
raise ValueError('Invalid response')
if "status" in result['requestMetadata'] and result['requestMetadata']['status'] == 'error':
raise ValueError('Invalid response')
def search(self, params):
url = f"{ZILLOW_LISTING_API}?{urlencode(params, doseq=True)}"
headers = {
'x-api-key': self.apiKey,
}
requestParams = {
'source': 'python_sdk'
}
response = requests.get(url, headers=headers, params=requestParams)
result = response.json()
self.handleErrors(result, response.status_code)
if result['requestMetadata']['status'] == 'ok':
return result
return result
def property(self, params):
url = f"{ZILLOW_PROPERTY_API}?{urlencode(params)}"
headers = {
'x-api-key': self.apiKey,
}
requestParams = {
'source': 'python_sdk'
}
response = requests.get(url, headers=headers, params=requestParams)
result = response.json()
self.handleErrors(result, response.status_code)
if result['requestMetadata']['status'] == 'ok':
return result
return result | zillow-api-s | /zillow_api_s-1.0.1-py3-none-any.whl/zillow_api/client.py | client.py |
============
Zim-Places
============
.. image:: https://img.shields.io/pypi/v/country_list.svg
:target: https://pypi.org/project/zim-places
.. image:: https://img.shields.io/badge/code%20style-black-000000.svg
:target: https://github.com/RONALD55/ZimPlaces-Python-Library
Features
--------
- This is a python package that allows you to search for cities, provinces, and districts in Zimbabwe.Zimbabwe is split into eight provinces and two cities that are designated as provincial capitals.
Districts are organized into 59 provinces.Wards are organized into 1,200 districts.Visit the project homepage for further information on how to use the package.
Installation
------------
To can install the zim_places open shell or terminal and run::
pip install zim-places
Usage
-----
Get all wards:
.. code-block:: python
from zim_places import wards
print(wards.get_wards())
Get all districts:
.. code-block:: python
from zim_places import districts
print(districts.get_districts())
Get all cities:
.. code-block:: python
from zim_places import cities
print(cities.get_cities())
Get all provinces:
.. code-block:: python
from zim_places import provinces
print(provinces.get_provinces())
.. code-block:: python
from zim_places import *
import json
# Get the data as json
print(get_cities())
print(get_wards())
print(get_provinces())
print(get_districts())
# Get the data as a list of dictionaries, remember you can customize the list to suit your need
data = json.loads(get_wards())
list_of_wards = [{i['Ward'] + ' ' + i['Province_OR_District']} for i in data.values()]
print(list_of_wards)
data = json.loads(get_districts())
list_of_districts = [{i['District'] + ' ' + i['Province']} for i in data.values()]
print(list_of_districts)
data = json.loads(get_provinces())
list_of_provinces = [{i['Province'] + ' ' + i['Capital'] + i['Area(km2)'] + i['Population(2012 census)']} for i in data.values()]
print(list_of_provinces)
data = json.loads(get_cities())
list_of_cities = [{i['City'] + ' ' + i['Province']} for i in data.values()]
print(list_of_cities)
License
-------
The project is licensed under the MIT license.
| zim-places | /zim_places-2.0.0.tar.gz/zim_places-2.0.0/README.rst | README.rst |
============
zim-validate
============
.. image:: https://img.shields.io/pypi/v/country_list.svg
:target: https://pypi.org/project/zim-validate
.. image:: https://img.shields.io/badge/code%20style-black-000000.svg
:target: https://github.com/RONALD55/Zim-Validate
Features
--------
- This is package to assist developers to validate zimbabwean driver's license numbers, vehicle registration numbers, mobile numbers for Telecel,Econet,Netone and any other valid zim number registered under the major MNOs,Zim passports, national IDs among other things. Visit the project homepage for further information on how to use the package.
Installation
------------
To can install the zim_validate package open shell or terminal and run::
pip install zim_validate
Usage
-----
Validate National ID:
If dashes are mandatory the ID will be in the format `12-3456789-X-01`
If the `dashes` are not mandatory the format will be `123456789X01`
Note parameter `dashes`: (Optional) If you want to make dashes compulsory on the input string
.. code-block:: python
from zim_validate import national_id
print(national_id("12-3456789-X-01",dashes=True))
Validate Passport:
All Zimbabwean passports are in the format AB123456
.. code-block:: python
from zim_validate import passport
print(passport("AB123456"))
Validate ID or passport:
All Zimbabwean passports are in the format `AB123456`
If dashes are mandatory the ID will be in the format `12-3456789-X-01`
If the `dashes` are not mandatory the format will be `123456789X01`
.. code-block:: python
from zim_validate import id_or_passport
print(id_or_passport("12-3456789-X-01",dashes=True))
Validate Telecel Numbers:
This can be used to check if the given mobile number is a valid Telecel number.
Pass the optional parameter `prefix` you want to make the prefix 263 mandatory
.. code-block:: python
from zim_validate import telecel_number
print(telecel_number("263735111111",prefix=True))
Validate Econet Numbers:
This can be used to check if the given mobile number is a valid Econet number.
Pass the optional parameter `prefix` you want to make the prefix 263 mandatory
.. code-block:: python
from zim_validate import econet_number
print(econet_number("263775111111",prefix=True))
Validate Netone Numbers:
This can be used to check if the given mobile number is a valid Netone number.
Pass the optional parameter `prefix` you want to make the prefix 263 mandatory
.. code-block:: python
from zim_validate import netone_number
print(netone_number("263715111111",prefix=True))
Validate Any Number from Telecel,Econet,Netone among other MNOs:
This can be used to check if the given mobile number is a valid Telecel,Econet or Netone number.
Pass the optional parameter `prefix` you want to make the prefix 263 mandatory
.. code-block:: python
from zim_validate import mobile_number
print(mobile_number("263782123345",prefix=True))
Validate Drivers License:
All Zimbabwean drivers licenses are in the format `111111AB`
Pass the optional parameter `space` if you want a space between the first 6 numbers and the last two letters
.. code-block:: python
from zim_validate import license_number
print(license_number("111111AB",space=False))
Validate Zim Vehicle Registration Number:
All Zimbabwean number plates are in the format `ABC1234`
Pass the optional parameter `space` if you want a space between the first three letters and the preceding letters numbers
.. code-block:: python
from zim_validate import number_plate
print(number_plate("ABF4495",space=False))
Bonus :Password:
Validate password to contain at at least one upper case,at least one lower case,at least one digit, at least one special character, minimum length 8
.. code-block:: python
from zim_validate import password
print(password("Password@1"))
License
-------
The project is licensed under the MIT license.
| zim-validate | /zim_validate-0.0.4.tar.gz/zim_validate-0.0.4/README.rst | README.rst |
import re
def national_id(value, dashes=True):
"""You can validate zimbabwean national ID using this method.
If dashes are mandatory the ID will be in the format 12-3456789-X-01
If the dashes are not mandatory the format will be 123456789X01
:param value: The string to be tested
:param dashes: (Optional) If you want to make dashes compulsory
:return: boolean
"""
is_valid = False
if dashes:
pattern = re.compile(r"^([0-9]{2}-[0-9]{6,7}-[a-z,A-Z]-[0-9]{2})$")
else:
pattern = re.compile(r"^([0-9]{2}[0-9]{6,7}[a-z,A-Z][0-9]{2})$")
try:
if re.fullmatch(pattern, value):
is_valid = True
except re.error:
is_valid = False
return is_valid
def passport(value):
"""
This method is used to validate zim passport.
All Zimbabwean passports are in the format AB123456
:param value: The string to be tested
:return: boolean
"""
is_valid = False
pattern = re.compile(r"^[A-Z]{2}[0-9]{6}$")
try:
if re.fullmatch(pattern, value):
is_valid = True
except re.error:
is_valid = False
return is_valid
def number_plate(value, space=True):
"""
This method is used to validate zim vehicle number plates.
All Zimbabwean number plates are in the format ABC1234
:param value: The string to be tested
:param space: If you want a space between the first three letters and the preceding letters numbers
:return: boolean
"""
is_valid = False
if space:
pattern = re.compile(r"^[a-zA-Z]{3}\s[0-9]{4}$")
else:
pattern = re.compile(r"^[a-zA-Z]{3}[0-9]{4}")
try:
if re.fullmatch(pattern, value):
is_valid = True
except re.error:
is_valid = False
return is_valid
def id_or_passport(value, id_dashes=True):
"""You can validate Zimbabwean national ID and passport using this single method.
All Zimbabwean passports are in the format AB123456
If dashes are mandatory the ID will be in the format 12-3456789-X-01
If the dashed are not mandatory the format will be 123456789X01
:param value: The string to be tested
:param id_dashes: (Optional) If you want to make dashes compulsory
:return: boolean
"""
is_valid = False
if id_dashes:
pattern = re.compile(r"^([0-9]{2}-[0-9]{6,7}-[a-z,A-Z]-[0-9]{2})$|^[A-Z]{2}[0-9]{6}$")
else:
pattern = re.compile(r"^([0-9]{2}[0-9]{6,7}[a-z,A-Z][0-9]{2})$|^[A-Z]{2}[0-9]{6}$")
try:
if re.fullmatch(pattern, value):
is_valid = True
except re.error:
is_valid = False
return is_valid
def telecel_number(value, prefix=True):
"""
This can be used to check if the given mobile number is a valid Telecel number.
All numbers
:param value: The string to be tested
:param prefix: (Optional) If you want to make the prefix 263 mandatory
:return: boolean
"""
is_valid = False
if prefix:
pattern = re.compile(r"^26373[0-9]{7}$")
else:
pattern = re.compile(r"^073[0-9]{7}$")
try:
if re.fullmatch(pattern, value):
is_valid = True
except re.error:
is_valid = False
return is_valid
def netone_number(value, prefix=True):
"""
This can be used to check if the given mobile number is a valid Netone number.
All numbers
:param value: The string to be tested
:param prefix: (Optional) If you want to make the prefix 263 mandatory
:return: boolean
"""
is_valid = False
if prefix:
pattern = re.compile(r"^26371[0-9]{7}$")
else:
pattern = re.compile(r"^071[0-9]{7}$")
try:
if re.fullmatch(pattern, value):
is_valid = True
except re.error:
is_valid = False
return is_valid
def econet_number(value, prefix=True):
"""
This can be used to check if the given mobile number is a valid Econet number.
All numbers
:param value: The string to be tested
:param prefix: (Optional) If you want to make the prefix 263 mandatory
:return: boolean
"""
is_valid = False
if prefix:
pattern = re.compile(r"^2637[7-8][0-9]{7}$")
else:
pattern = re.compile(r"^07[7-8][0-9]{7}$")
try:
if re.fullmatch(pattern, value):
is_valid = True
except re.error:
is_valid = False
return is_valid
def mobile_number(value, prefix=True):
"""
This can be used to check if the given mobile number is a valid number for Econet
,Netone and Telecel
All numbers
:param value: The string to be tested
:param prefix: (Optional) If you want to make the prefix 263 mandatory
:return: boolean
"""
is_valid = False
if prefix:
pattern = re.compile(r"^2637[13478][0-9]{7}$")
else:
pattern = re.compile(r"^07[13478][0-9]{7}$")
try:
if re.fullmatch(pattern, value):
is_valid = True
except re.error:
is_valid = False
return is_valid
def password(value):
"""
Regex to validate is the password has at least one upper case, one lowercase,
one special character at least one number
and a minimum length of 8
:param value:
:return: boolean
"""
is_valid = False
pattern = re.compile(r"^(?=.*[a-z])(?=.*[A-Z])(?=.*\d)(?=.*[@$!%*?&])[A-Za-z\d@$!%*?&]{8,}$")
try:
if re.fullmatch(pattern, value):
is_valid = True
except re.error:
is_valid = False
return is_valid
def license_number(value, space=True):
"""
Regex to validate is the string passed is a valid Zimbabwean driver's license
:param value: The string passed
:param space: (Optional) if you want a space between the first 6 numbers and the last two letters
:return: boolean
"""
is_valid = False
if space:
pattern = re.compile(r"^[0-9]{6}\s[a-zA-Z]{2}$")
else:
pattern = re.compile(r"^[0-9]{6}[a-zA-Z]{2}$")
try:
if re.fullmatch(pattern, value):
is_valid = True
except re.error:
is_valid = False
return is_valid | zim-validate | /zim_validate-0.0.4.tar.gz/zim_validate-0.0.4/zim_validate/validate.py | validate.py |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.