
code
stringlengths 501
5.19M
| package
stringlengths 2
81
| path
stringlengths 9
304
| filename
stringlengths 4
145
|
|---|---|---|---|
import logging
import multiprocessing
from datetime import datetime as dt
import networkx as nx
from concurrent.futures import wait, ALL_COMPLETED
from concurrent.futures.thread import ThreadPoolExecutor
from agora.fountain.index import core as index, seeds
__author__ = 'Fernando Serena'
log = logging.getLogger('agora.fountain.paths')
pgraph = nx.DiGraph()
match_elm_cycles = {}
th_pool = ThreadPoolExecutor(multiprocessing.cpu_count())
def chunks(l, n):
"""
Yield successive n-sized chunks from l.
:param l:
:param n:
:return:
"""
if n:
for i in xrange(0, len(l), n):
yield l[i:i + n]
def __build_directed_graph(generic=False, graph=None):
"""
:return:
"""
if graph is None:
graph = nx.DiGraph()
else:
graph.clear()
graph.add_nodes_from(index.get_types(), ty='type')
for node in index.get_properties():
p_dict = index.get_property(node)
dom = set(p_dict.get('domain'))
if generic:
dom = filter(lambda x: not set.intersection(set(index.get_type(x)['super']), dom), dom)
ran = set(p_dict.get('range'))
if generic:
try:
ran = filter(lambda x: not set.intersection(set(index.get_type(x)['super']), ran), ran)
except TypeError:
pass
edges = [(d, node) for d in dom]
if p_dict.get('type') == 'object':
edges.extend([(node, r) for r in ran])
graph.add_edges_from(edges)
graph.add_node(node, ty='prop', object=p_dict.get('type') == 'object', range=ran)
log.info('Known graph: {}'.format(list(graph.edges())))
return graph
def __build_paths(node, root, steps=None, level=0, path_graph=None, cache=None):
"""
:param node:
:param root:
:param steps:
:return:
"""
def contains_cycle(graph):
return bool(list(nx.simple_cycles(graph)))
paths = []
if steps is None:
steps = []
if path_graph is None:
path_graph = nx.DiGraph()
if cache is None:
cache = {}
log.debug(
'[{}][{}] building paths to {}, with root {} and {} previous steps'.format(root, level, node, root,
len(steps)))
pred = set(pgraph.predecessors(node))
for t in [x for x in pred]:
new_path_graph = path_graph.copy()
new_path_graph.add_nodes_from([t, node])
new_path_graph.add_edges_from([(t, node)])
step = {'property': node, 'type': t}
path = [step]
new_steps = steps[:]
new_steps.append(step)
log.debug('[{}][{}] added a new step {} in the path to {}'.format(root, level, (t, node), node))
any_subpath = False
next_steps = [x for x in pgraph.predecessors(t)]
for p in next_steps:
log.debug('[{}][{}] following {} as a pred property of {}'.format(root, level, p, t))
extended_new_path_graph = new_path_graph.copy()
extended_new_path_graph.add_node(p)
extended_new_path_graph.add_edges_from([(p, t)])
if contains_cycle(extended_new_path_graph):
continue
sub_paths = __build_paths(p, root, new_steps[:], level=level + 1, path_graph=extended_new_path_graph,
cache=cache)
any_subpath = any_subpath or len(sub_paths)
for sp in sub_paths:
paths.append(path + sp)
if (len(next_steps) and not any_subpath) or not len(next_steps):
paths.append(path)
log.debug(
'[{}][{}] returning {} paths to {}, with root {} and {} previous steps'.format(root, level, len(paths),
node,
root,
len(steps)))
return paths
def calculate_paths():
"""
:return:
"""
def __find_matching_cycles(_elm):
for j, c in enumerate(g_cycles):
extended_elm = [_elm]
if index.is_type(_elm):
extended_elm.extend(index.get_type(_elm)["super"])
if len([c for e in extended_elm if e in c]):
yield j
def __store_path(_i, _path):
pipe.zadd('paths:{}'.format(elm), _i, _path)
def __calculate_node_paths(n, d):
log.debug('[START] Calculating paths to {} with data {}'.format(n, d))
_paths = []
if d.get('ty') == 'type':
for p in pgraph.predecessors(n):
log.debug('Following root [{}] predecessor property {}'.format(n, p))
_paths.extend(__build_paths(p, n))
else:
_paths.extend(__build_paths(n, n))
log.debug('[END] {} paths for {}'.format(len(_paths), n))
if len(_paths):
node_paths[n] = _paths
log.info('Calculating paths...')
match_elm_cycles.clear()
start_time = dt.now()
__build_directed_graph(graph=pgraph)
g_graph = __build_directed_graph(generic=True)
cycle_keys = index.r.keys('*cycles*')
for ck in cycle_keys:
index.r.delete(ck)
g_cycles = list(nx.simple_cycles(g_graph))
with index.r.pipeline() as pipe:
pipe.multi()
for i, cy in enumerate(g_cycles):
print cy
cycle = []
t_cycle = None
for elm in cy:
if index.is_type(elm):
t_cycle = elm
elif t_cycle is not None:
cycle.append({'property': elm, 'type': t_cycle})
t_cycle = None
if t_cycle is not None:
cycle.append({'property': cy[0], 'type': t_cycle})
pipe.zadd('cycles', i, cycle)
pipe.execute()
locks = __lock_key_pattern('paths:*')
keys = [k for (k, _) in locks]
if len(keys):
index.r.delete(*keys)
node_paths = {}
futures = []
for node, data in pgraph.nodes(data=True):
futures.append(th_pool.submit(__calculate_node_paths, node, data))
wait(futures, timeout=None, return_when=ALL_COMPLETED)
# th_pool.shutdown()
for ty in [_ for _ in index.get_types() if _ in node_paths]:
for sty in [_ for _ in index.get_type(ty)['sub'] if _ in node_paths]:
node_paths[ty].extend(node_paths[sty])
node_paths = node_paths.items()
log.debug('preparing to persist the calculated paths...{}'.format(len(node_paths)))
with index.r.pipeline() as pipe:
pipe.multi()
# with ThreadPoolExecutor(multiprocessing.cpu_count()) as th_pool:
for (elm, paths) in node_paths:
futures = []
for (i, path) in enumerate(paths):
futures.append(th_pool.submit(__store_path, i, path))
for step in path:
step_ty = step.get('type')
if step_ty not in match_elm_cycles:
match_elm_cycles[step_ty] = __find_matching_cycles(step_ty)
step_pr = step.get('property')
if step_pr not in match_elm_cycles:
match_elm_cycles[step_pr] = __find_matching_cycles(step_pr)
wait(futures, timeout=None, return_when=ALL_COMPLETED)
pipe.execute()
# th_pool.shutdown()
# Store type and property cycles
for elm in match_elm_cycles.keys():
for c in match_elm_cycles[elm]:
pipe.sadd('cycles:{}'.format(elm), c)
pipe.execute()
for t in [_ for _ in index.get_types() if _ not in match_elm_cycles]:
for c in __find_matching_cycles(t):
pipe.sadd('cycles:{}'.format(t), c)
pipe.execute()
for _, l in locks:
l.release()
log.info('Found {} paths in {}ms'.format(len(index.r.keys('paths:*')),
(dt.now() - start_time).total_seconds() * 1000))
def __lock_key_pattern(pattern):
"""
:param pattern:
:return:
"""
pattern_keys = index.r.keys(pattern)
for k in pattern_keys:
yield k, index.r.lock(k)
def __detect_redundancies(source, steps):
"""
:param cycle:
:param steps:
:return:
"""
if source and source[0] in steps:
steps_copy = steps[:]
start_index = steps_copy.index(source[0])
end_index = start_index + len(source)
try:
cand_cycle = steps_copy[start_index:end_index]
if end_index >= len(steps_copy):
cand_cycle.extend(steps_copy[:end_index - len(steps_copy)])
if cand_cycle == source:
steps_copy = steps[0:start_index - end_index + len(steps_copy)]
if len(steps) > end_index:
steps_copy += steps[end_index:]
except IndexError:
pass
return steps_copy
return steps
def find_path(elm):
"""
:param elm:
:return:
"""
seed_av = {}
def check_seed_availability(ty):
if ty not in seed_av:
seed_av[ty] = seeds.get_type_seeds(ty)
return seed_av[ty]
def build_seed_path_and_identify_cycles(_seeds):
"""
:param _seeds:
:return:
"""
sub_steps = list(reversed(path[:step_index + 1]))
for _step in sub_steps:
cycle_ids.update([int(c) for c in index.r.smembers('cycles:{}'.format(_step.get('type')))])
sub_path = {'cycles': list(cycle_ids), 'seeds': _seeds, 'steps': sub_steps}
if sub_path not in seed_paths:
seed_paths.append(sub_path)
return cycle_ids
seed_paths = []
paths = [(int(score), eval(path)) for path, score in index.r.zrange('paths:{}'.format(elm), 0, -1, withscores=True)]
applying_cycles = set([])
cycle_ids = set([int(c) for c in index.r.smembers('cycles:{}'.format(elm))])
step_index = 0
for score, path in paths:
for step_index, step in enumerate(path):
ty = step.get('type')
type_seeds = check_seed_availability(ty)
if len(type_seeds):
seed_cycles = build_seed_path_and_identify_cycles(type_seeds)
applying_cycles = applying_cycles.union(set(seed_cycles))
# It only returns seeds if elm is a type and there are seeds of it
req_type_seeds = check_seed_availability(elm)
if len(req_type_seeds):
path = []
seed_cycles = build_seed_path_and_identify_cycles(req_type_seeds)
applying_cycles = applying_cycles.union(set(seed_cycles))
filtered_seed_paths = []
for seed_path in seed_paths:
for sp in [_ for _ in seed_paths if _ != seed_path and _['seeds'] == seed_path['seeds']]:
if __detect_redundancies(sp["steps"], seed_path["steps"]) != seed_path['steps']:
filtered_seed_paths.append(seed_path)
break
applying_cycles = [{'cycle': int(cid), 'steps': eval(index.r.zrange('cycles', cid, cid).pop())} for cid in
applying_cycles]
return [_ for _ in seed_paths if _ not in filtered_seed_paths], applying_cycles
# Build the current graph on import
log.info('Reconstructing path graph...')
__build_directed_graph(graph=pgraph)
|
Agora-Fountain
|
/Agora-Fountain-0.5.6.tar.gz/Agora-Fountain-0.5.6/agora/fountain/index/paths.py
|
paths.py
|
import base64
from agora.fountain.exceptions import FountainError
from agora.fountain.index import core as index
from agora.fountain.index.core import r
__author__ = 'Fernando Serena'
class TypeNotAvailableError(FountainError):
pass
class DuplicateSeedError(FountainError):
pass
class InvalidSeedError(FountainError):
pass
def add_seed(uri, ty):
"""
:param uri:
:param ty:
:return:
"""
from rfc3987 import parse
parse(uri, rule='URI')
type_found = False
type_keys = r.keys('*:types')
for tk in type_keys:
if r.sismember(tk, ty):
type_found = True
encoded_uri = base64.b64encode(uri)
if r.sismember('seeds:{}'.format(ty), encoded_uri):
raise DuplicateSeedError('{} is already registered as a seed of type {}'.format(uri, ty))
r.sadd('seeds:{}'.format(ty), base64.b64encode(uri))
break
if not type_found:
raise TypeNotAvailableError("{} is not a valid type".format(ty))
return base64.b64encode('{}|{}'.format(ty, uri))
def get_seed(sid):
"""
:param sid:
:return:
"""
try:
ty, uri = base64.b64decode(sid).split('|')
if r.sismember('seeds:{}'.format(ty), base64.b64encode(uri)):
return {'type': ty, 'uri': uri}
except TypeError as e:
raise InvalidSeedError(e.message)
raise InvalidSeedError(sid)
def delete_seed(sid):
"""
:param sid:
:return:
"""
try:
ty, uri = base64.b64decode(sid).split('|')
set_key = 'seeds:{}'.format(ty)
encoded_uri = base64.b64encode(uri)
if not r.srem(set_key, encoded_uri):
raise InvalidSeedError(sid)
except TypeError as e:
raise InvalidSeedError(e.message)
def delete_type_seeds(ty):
"""
:param ty:
:return:
"""
r.delete('seeds:{}'.format(ty))
def get_seeds():
"""
:return:
"""
def iterator():
seed_types = r.keys('seeds:*')
for st in seed_types:
ty = st.replace('seeds:', '')
for seed in list(r.smembers(st)):
yield ty, base64.b64decode(seed)
import collections
result_dict = collections.defaultdict(list)
for t, uri in iterator():
result_dict[t].append({"uri": uri, "id": base64.b64encode('{}|{}'.format(t, uri))})
return result_dict
def get_type_seeds(ty):
"""
:param ty:
:return:
"""
try:
t_dict = index.get_type(ty)
all_seeds = set([])
for t in t_dict['sub'] + [ty]:
all_seeds.update([base64.b64decode(seed) for seed in list(r.smembers('seeds:{}'.format(t)))])
return list(all_seeds)
except TypeError:
# Check if it is a property...and return an empty list
try:
index.get_property(ty)
return []
except TypeError:
raise TypeNotAvailableError(ty)
|
Agora-Fountain
|
/Agora-Fountain-0.5.6.tar.gz/Agora-Fountain-0.5.6/agora/fountain/index/seeds.py
|
seeds.py
|
import json
from agora.stoa.client import get_fragment_generator, get_query_generator
from agora.fragments.server import app
from flask import request, jsonify, Response, stream_with_context
from rdflib import Graph
__author__ = 'Fernando Serena'
STOA = app.config['STOA']
class APIError(Exception):
status_code = 400
def __init__(self, message, status_code=None, payload=None):
Exception.__init__(self)
self.message = message
if status_code is not None:
self.status_code = status_code
self.payload = payload
def to_dict(self):
rv = dict(self.payload or ())
rv['message'] = self.message
return rv
class NotFound(APIError):
def __init__(self, message, payload=None):
super(NotFound, self).__init__(message, 404, payload)
class Conflict(APIError):
def __init__(self, message, payload=None):
super(Conflict, self).__init__(message, 409, payload)
@app.errorhandler(APIError)
def handle_invalid_usage(error):
response = jsonify(error.to_dict())
response.status_code = error.status_code
return response
@app.route('/fragment')
def get_fragment():
def get_quads():
for prefix in prefixes:
yield '@prefix {}: <{}> .\n'.format(prefix, prefixes[prefix])
yield '\n'
for chunk in fragment_gen:
if chunk is None:
yield ''
else:
headers, (c, s, p, o) = chunk
triple = u'{} {} {} .\n'.format(s.n3(graph.namespace_manager), p.n3(graph.namespace_manager),
o.n3(graph.namespace_manager))
print headers, triple
yield triple
gp_str = request.args.get('gp', '{}')
import re
try:
gp_match = re.search(r'\{(.*)\}', gp_str).groups(0)
if len(gp_match) != 1:
raise APIError('Invalid graph pattern')
tps = re.split('\. ', gp_match[0])
extra_params = {k: request.args.get(k) for k in request.args.keys() if k in ['gen', 'updating', 'events']}
extra_params['STOA'] = STOA
prefixes, fragment_gen = get_fragment_generator(*tps, monitoring=30, **extra_params)
graph = Graph()
for prefix in prefixes:
graph.bind(prefix, prefixes[prefix])
return Response(stream_with_context(get_quads()), mimetype='text/n3')
except Exception as e:
raise APIError('There was a problem with the request: {}'.format(e.message), status_code=500)
@app.route('/query')
def query():
def get_results():
yield '['
first_row = True
for row in result_gen:
if row is None:
yield ''
else:
row_str = ',\n {}'.format(json.dumps(row[1]))
if first_row:
row_str = row_str.lstrip(',')
first_row = False
yield row_str
yield '\n]'
gp_str = request.args.get('gp', '{}')
import re
try:
gp_match = re.search(r'\{(.*)\}', gp_str).groups(0)
if len(gp_match) != 1:
raise APIError('Invalid graph pattern')
tps = re.split('\. ', gp_match[0])
extra_params = {k: request.args.get(k) for k in request.args.keys() if k in ['gen', 'updating', 'events']}
extra_params['STOA'] = STOA
prefixes, result_gen = get_query_generator(*tps, monitoring=10, **extra_params)
return Response(stream_with_context(get_results()), mimetype='application/json')
except Exception as e:
raise APIError('There was a problem with the request: {}'.format(e.message), status_code=500)
|
Agora-Fragments
|
/Agora-Fragments-0.1.1.tar.gz/Agora-Fragments-0.1.1/agora/fragments/api.py
|
api.py
|
import base64
import json
import os
from flask import request, make_response, jsonify, render_template
from flask_negotiate import produces
from rdflib import RDF
import agora.planner
from agora.planner.plan import Plan
from agora.planner.plan.graph import AGORA
from agora.planner.server import app
__author__ = 'Fernando Serena'
with open(os.path.join(agora.planner.__path__[0], 'metadata.json'), 'r') as stream:
metadata = json.load(stream)
class APIError(Exception):
status_code = 400
def __init__(self, message, status_code=None, payload=None):
Exception.__init__(self)
self.message = message
if status_code is not None:
self.status_code = status_code
self.payload = payload
def to_dict(self):
rv = dict(self.payload or ())
rv['message'] = self.message
return rv
class NotFound(APIError):
def __init__(self, message, payload=None):
super(NotFound, self).__init__(message, 404, payload)
class Conflict(APIError):
def __init__(self, message, payload=None):
super(Conflict, self).__init__(message, 409, payload)
@app.errorhandler(APIError)
def handle_invalid_usage(error):
response = jsonify(error.to_dict())
response.status_code = error.status_code
return response
@app.route('/api')
def get_api():
return jsonify({'meta': metadata})
@app.route('/plan')
@app.route('/plan/view')
@produces('application/json', 'text/turtle', 'text/html')
def get_plan():
def __graph_plan(g):
def __add_node(nid, end=False, shape='roundrectangle', label=None, seed=False):
node_data = {'data': {'id': base64.b16encode(nid), 'label': nid, 'shape': shape,
'width': max(100, len(nid) * 12)}}
if label is not None:
node_data['data']['label'] = str(label)
if end:
node_data['classes'] = 'end'
if seed:
node_data['classes'] = 'seed'
if nid in nodes:
prev_data = nodes[nid]
if 'classes' in prev_data:
node_data['classes'] = prev_data['classes']
nodes[nid] = node_data
def __add_edge(source, label, target, end=False):
eid = base64.b64encode(source + label + target)
edge_data = {'data': {'id': eid, 'source': nodes[source]['data']['id'], 'label': label + '\n\n',
'target': nodes[target]['data']['id']}}
if end:
edge_data['classes'] = 'end'
if eid in edges:
prev_data = edges[eid]
if 'classes' in prev_data:
edge_data['classes'] = prev_data['classes']
edges[eid] = edge_data
def __check_pattern(parent, link, sources):
patterns = g.objects(parent, AGORA.byPattern)
for tp in patterns:
t_pred = list(g.objects(tp, AGORA.predicate)).pop()
if t_pred == RDF.type:
p_type = g.qname(list(g.objects(tp, AGORA.object)).pop())
__add_node(p_type, end=True)
if sources is not None:
for st in sources:
__add_edge(st, link, p_type)
else:
t_pred = g.qname(t_pred)
t_obj = list(g.objects(tp, AGORA.object)).pop()
if (t_obj, RDF.type, AGORA.Literal) in g:
filter_value = list(g.objects(t_obj, AGORA.value)).pop()
filter_id = 'n{}'.format(len(nodes))
__add_node(filter_id, end=True, shape='ellipse', label='"{}"'.format(filter_value))
for st in sources:
__add_edge(st, t_pred, filter_id, end=True)
else:
pred_range = plan.fountain.get_property(t_pred)['range']
pred_range = [d for d in pred_range if
not set.intersection(set(plan.fountain.get_type(d).get('super')),
set(pred_range))]
for st in sources:
for rt in pred_range:
__add_node(rt)
__add_edge(st, t_pred, rt, end=True)
def __follow_next(parent, link=None, sources=None):
child = list(g.objects(parent, AGORA.next))
__check_pattern(parent, link, sources)
for ch in child:
expected_types = [g.qname(x) for x in g.objects(ch, AGORA.expectedType)]
for et in expected_types:
__add_node(et)
try:
for et in expected_types:
if link is not None:
for st in sources:
__add_edge(st, link, et)
on_property = g.qname(list(g.objects(ch, AGORA.onProperty)).pop())
last_property = on_property
source_types = expected_types
__follow_next(ch, last_property, source_types)
except IndexError:
__check_pattern(ch, None, expected_types)
nodes = {}
edges = {}
roots = set([])
trees = g.subjects(RDF.type, AGORA.SearchTree)
for tree in trees:
seed_type = g.qname(list(g.objects(tree, AGORA.fromType)).pop())
__add_node(seed_type, seed=True)
roots.add(nodes[seed_type]['data']['id'])
__follow_next(tree)
return nodes.values(), edges.values(), list(roots)
gp_str = request.args.get('gp', '{}')
try:
plan = Plan(gp_str)
except EnvironmentError as e:
raise NotFound(e.message)
except (AttributeError, NameError, TypeError) as e:
raise APIError(e.message)
mimetypes = str(request.accept_mimetypes).split(',')
if 'application/json' in mimetypes:
return jsonify(plan.json)
if 'view' in request.url_rule.rule:
tps = [tp.strip() for tp in gp_str.replace('"', "'").lstrip('{').rstrip('}').split('.') if tp != '']
nodes, edges, roots = __graph_plan(plan.graph)
return render_template('graph.html',
nodes=json.dumps(nodes),
edges=json.dumps(edges), roots=json.dumps(roots), tps=json.dumps(tps))
response = make_response(plan.graph.serialize(format='turtle'))
response.headers['Content-Type'] = 'text/turtle'
return response
|
Agora-Planner
|
/Agora-Planner-0.3.9.tar.gz/Agora-Planner-0.3.9/agora/planner/api.py
|
api.py
|
$(function () { // on dom ready
var cy = cytoscape({
container: document.getElementById('cy'),
style: cytoscape.stylesheet()
.selector('node')
.css({
'content': 'data(label)',
'color': '#484849',
'shape': 'data(shape)',
'width': 'mapData(width, 1, 200, 1, 200)',
'height': '40',
'text-valign': 'center',
'background-color': 'white',
'background-opacity': 0.2,
'font-weight': 'regular',
'visibility': 'hidden',
'font-family': 'EagerNaturalist',
'font-size': '22px'
})
.selector('edge')
.css({
'target-arrow-shape': 'triangle',
//'width': 3,
'line-color': '#484849',
'target-arrow-color': '#484849',
'content': 'data(label)',
'color': '#484849',
'edge-text-rotation': 'autorotate',
'text-valign': 'top',
'text-wrap': 'wrap',
'curve-style': 'bezier',
'visibility': 'hidden',
'font-family': 'EagerNaturalist',
'font-size': '18px'
}).selector('node.highlighted')
.css({
'transition-property': 'background-color, line-color, target-arrow-color, color, border-width, shadow-color, visibility',
'transition-duration': '0.8s',
'color': '#484849',
'border-width': 2,
'border-opacity': 0.7,
'font-weight': 'regular',
'shadow-color': '#484849',
'shadow-opacity': 0.5,
'shadow-offset-x': 0,
'shadow-offset-y': 0,
'shadow-blur': 2,
'visibility': 'visible'
}).selector('edge.highlighted')
.css({
'transition-property': 'line-color, target-arrow-color, color, border-width, shadow-color, visibility',
'transition-duration': '0.8s',
'visibility': 'visible'
}).selector('node.seed')
.css({
'border-color': '#0078B6',
'shadow-color': '#0078B6',
'visibility': 'visible',
'color': '#0078B6'
}).selector('edge.end')
.css({
'line-color': '#1F8A1F',
'color': '#1F8A1F',
'target-arrow-color': '#1F8A1F',
'text-shadow-color': '#1F8A1F',
'text-shadow-opacity': 0.5,
'text-shadow-offset-x': 0,
'text-shadow-offset-y': 0,
'text-shadow-blur': 2
}).selector('node.end')
.css({
'border-color': '#1F8A1F',
'shadow-color': '#1F8A1F',
'color': '#1F8A1F'
}),
elements: {
nodes: vGraph.nodes,
edges: vGraph.edges
}
});
var options = {
name: 'arbor',
animate: true, // whether to show the layout as it's running
maxSimulationTime: 4000, // max length in ms to run the layout
fit: false, // on every layout reposition of nodes, fit the viewport
padding: 30, // padding around the simulation
boundingBox: undefined, //{x1: 0, y1: 0, w: 1000, h: 1000}, // constrain layout bounds; { x1, y1, x2, y2 } or { x1, y1, w, h }
ungrabifyWhileSimulating: false, // so you can't drag nodes during layout
// callbacks on layout events
ready: undefined, // callback on layoutready
stop: undefined, // callback on layoutstop
// forces used by arbor (use arbor default on undefined)
repulsion: 50,
stiffness: 100,
friction: 0.9,
gravity: true,
fps: undefined,
precision: 0.9,
// static numbers or functions that dynamically return what these
// values should be for each element
// e.g. nodeMass: function(n){ return n.data('weight') }
nodeMass: undefined,
edgeLength: undefined,
stepSize: 0.2, // smoothing of arbor bounding box
// function that returns true if the system is stable to indicate
// that the layout can be stopped
stableEnergy: function (energy) {
var e = energy;
return (e.max <= 0.5) || (e.mean <= 0.3);
},
// infinite layout options
infinite: true // overrides all other options for a forces-all-the-time mode
};
cy.layout(options);
cy.outgoers = [];
vGraph.roots.forEach(function (r, index) {
var rootElement = cy.$('#' + vGraph.roots[index]);
rootElement.addClass('highlighted');
cy.outgoers.push(rootElement.outgoers());
});
var highlightNextEle = function (b) {
b.addClass('highlighted');
next = b.outgoers();
if (next.length > 0) {
var delay = 0;
next.forEach(function (n) {
if (!n.hasClass('highlighted')) {
setTimeout(function () {
highlightNextEle(n);
}, 500 + delay);
delay += 200;
}
});
}
};
// kick off first highlights
cy.outgoers.forEach(function (b) {
highlightNextEle(b);
});
}); // on dom ready
$(document).ready(function () {
tps.forEach(function (tp) {
$("#tps").append('<p>' + tp + ' .</p>')
});
});
|
Agora-Planner
|
/Agora-Planner-0.3.9.tar.gz/Agora-Planner-0.3.9/agora/planner/server/static/graph.js
|
graph.js
|
(function($){
/* etc.js */ var trace=function(msg){if(typeof(window)=="undefined"||!window.console){return}var len=arguments.length;var args=[];for(var i=0;i<len;i++){args.push("arguments["+i+"]")}eval("console.log("+args.join(",")+")")};var dirname=function(a){var b=a.replace(/^\/?(.*?)\/?$/,"$1").split("/");b.pop();return"/"+b.join("/")};var basename=function(b){var c=b.replace(/^\/?(.*?)\/?$/,"$1").split("/");var a=c.pop();if(a==""){return null}else{return a}};var _ordinalize_re=/(\d)(?=(\d\d\d)+(?!\d))/g;var ordinalize=function(a){var b=""+a;if(a<11000){b=(""+a).replace(_ordinalize_re,"$1,")}else{if(a<1000000){b=Math.floor(a/1000)+"k"}else{if(a<1000000000){b=(""+Math.floor(a/1000)).replace(_ordinalize_re,"$1,")+"m"}}}return b};var nano=function(a,b){return a.replace(/\{([\w\-\.]*)}/g,function(f,c){var d=c.split("."),e=b[d.shift()];$.each(d,function(){if(e.hasOwnProperty(this)){e=e[this]}else{e=f}});return e})};var objcopy=function(a){if(a===undefined){return undefined}if(a===null){return null}if(a.parentNode){return a}switch(typeof a){case"string":return a.substring(0);break;case"number":return a+0;break;case"boolean":return a===true;break}var b=($.isArray(a))?[]:{};$.each(a,function(d,c){b[d]=objcopy(c)});return b};var objmerge=function(d,b){d=d||{};b=b||{};var c=objcopy(d);for(var a in b){c[a]=b[a]}return c};var objcmp=function(e,c,d){if(!e||!c){return e===c}if(typeof e!=typeof c){return false}if(typeof e!="object"){return e===c}else{if($.isArray(e)){if(!($.isArray(c))){return false}if(e.length!=c.length){return false}}else{var h=[];for(var f in e){if(e.hasOwnProperty(f)){h.push(f)}}var g=[];for(var f in c){if(c.hasOwnProperty(f)){g.push(f)}}if(!d){h.sort();g.sort()}if(h.join(",")!==g.join(",")){return false}}var i=true;$.each(e,function(a){var b=objcmp(e[a],c[a]);i=i&&b;if(!i){return false}});return i}};var objkeys=function(b){var a=[];$.each(b,function(d,c){if(b.hasOwnProperty(d)){a.push(d)}});return a};var objcontains=function(c){if(!c||typeof c!="object"){return false}for(var b=1,a=arguments.length;b<a;b++){if(c.hasOwnProperty(arguments[b])){return true}}return false};var uniq=function(b){var a=b.length;var d={};for(var c=0;c<a;c++){d[b[c]]=true}return objkeys(d)};var arbor_path=function(){var a=$("script").map(function(b){var c=$(this).attr("src");if(!c){return}if(c.match(/arbor[^\/\.]*.js|dev.js/)){return c.match(/.*\//)||"/"}});if(a.length>0){return a[0]}else{return null}};
/* kernel.js */ var Kernel=function(b){var k=window.location.protocol=="file:"&&navigator.userAgent.toLowerCase().indexOf("chrome")>-1;var a=(window.Worker!==undefined&&!k);var i=null;var c=null;var f=[];f.last=new Date();var l=null;var e=null;var d=null;var h=null;var g=false;var j={system:b,tween:null,nodes:{},init:function(){if(typeof(Tween)!="undefined"){c=Tween()}else{if(typeof(arbor.Tween)!="undefined"){c=arbor.Tween()}else{c={busy:function(){return false},tick:function(){return true},to:function(){trace("Please include arbor-tween.js to enable tweens");c.to=function(){};return}}}}j.tween=c;var m=b.parameters();if(a){trace("arbor.js/web-workers",m);l=setInterval(j.screenUpdate,m.timeout);i=new Worker(arbor_path()+"arbor.js");i.onmessage=j.workerMsg;i.onerror=function(n){trace("physics:",n)};i.postMessage({type:"physics",physics:objmerge(m,{timeout:Math.ceil(m.timeout)})})}else{trace("arbor.js/single-threaded",m);i=Physics(m.dt,m.stiffness,m.repulsion,m.friction,j.system._updateGeometry,m.integrator);j.start()}return j},graphChanged:function(m){if(a){i.postMessage({type:"changes",changes:m})}else{i._update(m)}j.start()},particleModified:function(n,m){if(a){i.postMessage({type:"modify",id:n,mods:m})}else{i.modifyNode(n,m)}j.start()},physicsModified:function(m){if(!isNaN(m.timeout)){if(a){clearInterval(l);l=setInterval(j.screenUpdate,m.timeout)}else{clearInterval(d);d=null}}if(a){i.postMessage({type:"sys",param:m})}else{i.modifyPhysics(m)}j.start()},workerMsg:function(n){var m=n.data.type;if(m=="geometry"){j.workerUpdate(n.data)}else{trace("physics:",n.data)}},_lastPositions:null,workerUpdate:function(m){j._lastPositions=m;j._lastBounds=m.bounds},_lastFrametime:new Date().valueOf(),_lastBounds:null,_currentRenderer:null,screenUpdate:function(){var n=new Date().valueOf();var m=false;if(j._lastPositions!==null){j.system._updateGeometry(j._lastPositions);j._lastPositions=null;m=true}if(c&&c.busy()){m=true}if(j.system._updateBounds(j._lastBounds)){m=true}if(m){var o=j.system.renderer;if(o!==undefined){if(o!==e){o.init(j.system);e=o}if(c){c.tick()}o.redraw();var p=f.last;f.last=new Date();f.push(f.last-p);if(f.length>50){f.shift()}}}},physicsUpdate:function(){if(c){c.tick()}i.tick();var n=j.system._updateBounds();if(c&&c.busy()){n=true}var o=j.system.renderer;var m=new Date();var o=j.system.renderer;if(o!==undefined){if(o!==e){o.init(j.system);e=o}o.redraw({timestamp:m})}var q=f.last;f.last=m;f.push(f.last-q);if(f.length>50){f.shift()}var p=i.systemEnergy();if((p.mean+p.max)/2<0.05){if(h===null){h=new Date().valueOf()}if(new Date().valueOf()-h>1000){clearInterval(d);d=null}else{}}else{h=null}},fps:function(n){if(n!==undefined){var q=1000/Math.max(1,targetFps);j.physicsModified({timeout:q})}var r=0;for(var p=0,o=f.length;p<o;p++){r+=f[p]}var m=r/Math.max(1,f.length);if(!isNaN(m)){return Math.round(1000/m)}else{return 0}},start:function(m){if(d!==null){return}if(g&&!m){return}g=false;if(a){i.postMessage({type:"start"})}else{h=null;d=setInterval(j.physicsUpdate,j.system.parameters().timeout)}},stop:function(){g=true;if(a){i.postMessage({type:"stop"})}else{if(d!==null){clearInterval(d);d=null}}}};return j.init()};
/* atoms.js */ var Node=function(a){this._id=_nextNodeId++;this.data=a||{};this._mass=(a.mass!==undefined)?a.mass:1;this._fixed=(a.fixed===true)?true:false;this._p=new Point((typeof(a.x)=="number")?a.x:null,(typeof(a.y)=="number")?a.y:null);delete this.data.x;delete this.data.y;delete this.data.mass;delete this.data.fixed};var _nextNodeId=1;var Edge=function(b,c,a){this._id=_nextEdgeId--;this.source=b;this.target=c;this.length=(a.length!==undefined)?a.length:1;this.data=(a!==undefined)?a:{};delete this.data.length};var _nextEdgeId=-1;var Particle=function(a,b){this.p=a;this.m=b;this.v=new Point(0,0);this.f=new Point(0,0)};Particle.prototype.applyForce=function(a){this.f=this.f.add(a.divide(this.m))};var Spring=function(c,b,d,a){this.point1=c;this.point2=b;this.length=d;this.k=a};Spring.prototype.distanceToParticle=function(a){var c=that.point2.p.subtract(that.point1.p).normalize().normal();var b=a.p.subtract(that.point1.p);return Math.abs(b.x*c.x+b.y*c.y)};var Point=function(a,b){if(a&&a.hasOwnProperty("y")){b=a.y;a=a.x}this.x=a;this.y=b};Point.random=function(a){a=(a!==undefined)?a:5;return new Point(2*a*(Math.random()-0.5),2*a*(Math.random()-0.5))};Point.prototype={exploded:function(){return(isNaN(this.x)||isNaN(this.y))},add:function(a){return new Point(this.x+a.x,this.y+a.y)},subtract:function(a){return new Point(this.x-a.x,this.y-a.y)},multiply:function(a){return new Point(this.x*a,this.y*a)},divide:function(a){return new Point(this.x/a,this.y/a)},magnitude:function(){return Math.sqrt(this.x*this.x+this.y*this.y)},normal:function(){return new Point(-this.y,this.x)},normalize:function(){return this.divide(this.magnitude())}};
/* system.js */ var ParticleSystem=function(e,r,f,g,u,m,s,a){var k=[];var i=null;var l=0;var v=null;var n=0.04;var j=[20,20,20,20];var o=null;var p=null;if(typeof e=="object"){var t=e;f=t.friction;e=t.repulsion;u=t.fps;m=t.dt;r=t.stiffness;g=t.gravity;s=t.precision;a=t.integrator}if(a!="verlet"&&a!="euler"){a="verlet"}f=isNaN(f)?0.5:f;e=isNaN(e)?1000:e;u=isNaN(u)?55:u;r=isNaN(r)?600:r;m=isNaN(m)?0.02:m;s=isNaN(s)?0.6:s;g=(g===true);var q=(u!==undefined)?1000/u:1000/50;var c={integrator:a,repulsion:e,stiffness:r,friction:f,dt:m,gravity:g,precision:s,timeout:q};var b;var d={renderer:null,tween:null,nodes:{},edges:{},adjacency:{},names:{},kernel:null};var h={parameters:function(w){if(w!==undefined){if(!isNaN(w.precision)){w.precision=Math.max(0,Math.min(1,w.precision))}$.each(c,function(y,x){if(w[y]!==undefined){c[y]=w[y]}});d.kernel.physicsModified(w)}return c},fps:function(w){if(w===undefined){return d.kernel.fps()}else{h.parameters({timeout:1000/(w||50)})}},start:function(){d.kernel.start()},stop:function(){d.kernel.stop()},addNode:function(z,C){C=C||{};var D=d.names[z];if(D){D.data=C;return D}else{if(z!=undefined){var w=(C.x!=undefined)?C.x:null;var E=(C.y!=undefined)?C.y:null;var B=(C.fixed)?1:0;var A=new Node(C);A.name=z;d.names[z]=A;d.nodes[A._id]=A;k.push({t:"addNode",id:A._id,m:A.mass,x:w,y:E,f:B});h._notify();return A}}},pruneNode:function(x){var w=h.getNode(x);if(typeof(d.nodes[w._id])!=="undefined"){delete d.nodes[w._id];delete d.names[w.name]}$.each(d.edges,function(z,y){if(y.source._id===w._id||y.target._id===w._id){h.pruneEdge(y)}});k.push({t:"dropNode",id:w._id});h._notify()},getNode:function(w){if(w._id!==undefined){return w}else{if(typeof w=="string"||typeof w=="number"){return d.names[w]}}},eachNode:function(w){$.each(d.nodes,function(z,y){if(y._p.x==null||y._p.y==null){return}var x=(v!==null)?h.toScreen(y._p):y._p;w.call(h,y,x)})},addEdge:function(A,B,z){A=h.getNode(A)||h.addNode(A);B=h.getNode(B)||h.addNode(B);z=z||{};var y=new Edge(A,B,z);var C=A._id;var D=B._id;d.adjacency[C]=d.adjacency[C]||{};d.adjacency[C][D]=d.adjacency[C][D]||[];var x=(d.adjacency[C][D].length>0);if(x){$.extend(d.adjacency[C][D].data,y.data);return}else{d.edges[y._id]=y;d.adjacency[C][D].push(y);var w=(y.length!==undefined)?y.length:1;k.push({t:"addSpring",id:y._id,fm:C,to:D,l:w});h._notify()}return y},pruneEdge:function(B){k.push({t:"dropSpring",id:B._id});delete d.edges[B._id];for(var w in d.adjacency){for(var C in d.adjacency[w]){var z=d.adjacency[w][C];for(var A=z.length-1;A>=0;A--){if(d.adjacency[w][C][A]._id===B._id){d.adjacency[w][C].splice(A,1)}}}}h._notify()},getEdges:function(x,w){x=h.getNode(x);w=h.getNode(w);if(!x||!w){return[]}if(typeof(d.adjacency[x._id])!=="undefined"&&typeof(d.adjacency[x._id][w._id])!=="undefined"){return d.adjacency[x._id][w._id]}return[]},getEdgesFrom:function(w){w=h.getNode(w);if(!w){return[]}if(typeof(d.adjacency[w._id])!=="undefined"){var x=[];$.each(d.adjacency[w._id],function(z,y){x=x.concat(y)});return x}return[]},getEdgesTo:function(w){w=h.getNode(w);if(!w){return[]}var x=[];$.each(d.edges,function(z,y){if(y.target==w){x.push(y)}});return x},eachEdge:function(w){$.each(d.edges,function(A,y){var z=d.nodes[y.source._id]._p;var x=d.nodes[y.target._id]._p;if(z.x==null||x.x==null){return}z=(v!==null)?h.toScreen(z):z;x=(v!==null)?h.toScreen(x):x;if(z&&x){w.call(h,y,z,x)}})},prune:function(x){var w={dropped:{nodes:[],edges:[]}};if(x===undefined){$.each(d.nodes,function(z,y){w.dropped.nodes.push(y);h.pruneNode(y)})}else{h.eachNode(function(z){var y=x.call(h,z,{from:h.getEdgesFrom(z),to:h.getEdgesTo(z)});if(y){w.dropped.nodes.push(z);h.pruneNode(z)}})}return w},graft:function(x){var w={added:{nodes:[],edges:[]}};if(x.nodes){$.each(x.nodes,function(z,y){var A=h.getNode(z);if(A){A.data=y}else{w.added.nodes.push(h.addNode(z,y))}d.kernel.start()})}if(x.edges){$.each(x.edges,function(A,y){var z=h.getNode(A);if(!z){w.added.nodes.push(h.addNode(A,{}))}$.each(y,function(E,B){var D=h.getNode(E);if(!D){w.added.nodes.push(h.addNode(E,{}))}var C=h.getEdges(A,E);if(C.length>0){C[0].data=B}else{w.added.edges.push(h.addEdge(A,E,B))}})})}return w},merge:function(x){var w={added:{nodes:[],edges:[]},dropped:{nodes:[],edges:[]}};$.each(d.edges,function(B,A){if((x.edges[A.source.name]===undefined||x.edges[A.source.name][A.target.name]===undefined)){h.pruneEdge(A);w.dropped.edges.push(A)}});var z=h.prune(function(B,A){if(x.nodes[B.name]===undefined){w.dropped.nodes.push(B);return true}});var y=h.graft(x);w.added.nodes=w.added.nodes.concat(y.added.nodes);w.added.edges=w.added.edges.concat(y.added.edges);w.dropped.nodes=w.dropped.nodes.concat(z.dropped.nodes);w.dropped.edges=w.dropped.edges.concat(z.dropped.edges);return w},tweenNode:function(z,w,y){var x=h.getNode(z);if(x){d.tween.to(x,w,y)}},tweenEdge:function(x,w,A,z){if(z===undefined){h._tweenEdge(x,w,A)}else{var y=h.getEdges(x,w);$.each(y,function(B,C){h._tweenEdge(C,A,z)})}},_tweenEdge:function(x,w,y){if(x&&x._id!==undefined){d.tween.to(x,w,y)}},_updateGeometry:function(z){if(z!=undefined){var w=(z.epoch<l);b=z.energy;var A=z.geometry;if(A!==undefined){for(var y=0,x=A.length/3;y<x;y++){var B=A[3*y];if(w&&d.nodes[B]==undefined){continue}d.nodes[B]._p.x=A[3*y+1];d.nodes[B]._p.y=A[3*y+2]}}}},screen:function(w){if(w==undefined){return{size:(v)?objcopy(v):undefined,padding:j.concat(),step:n}}if(w.size!==undefined){h.screenSize(w.size.width,w.size.height)}if(!isNaN(w.step)){h.screenStep(w.step)}if(w.padding!==undefined){h.screenPadding(w.padding)}},screenSize:function(w,x){v={width:w,height:x};h._updateBounds()},screenPadding:function(z,A,w,x){if($.isArray(z)){trbl=z}else{trbl=[z,A,w,x]}var B=trbl[0];var y=trbl[1];var C=trbl[2];if(y===undefined){trbl=[B,B,B,B]}else{if(C==undefined){trbl=[B,y,B,y]}}j=trbl},screenStep:function(w){n=w},toScreen:function(y){if(!o||!v){return}var x=j||[0,0,0,0];var w=o.bottomright.subtract(o.topleft);var A=x[3]+y.subtract(o.topleft).divide(w.x).x*(v.width-(x[1]+x[3]));var z=x[0]+y.subtract(o.topleft).divide(w.y).y*(v.height-(x[0]+x[2]));return arbor.Point(A,z)},fromScreen:function(A){if(!o||!v){return}var z=j||[0,0,0,0];var y=o.bottomright.subtract(o.topleft);var x=(A.x-z[3])/(v.width-(z[1]+z[3]))*y.x+o.topleft.x;var w=(A.y-z[0])/(v.height-(z[0]+z[2]))*y.y+o.topleft.y;return arbor.Point(x,w)},_updateBounds:function(x){if(v===null){return}if(x){p=x}else{p=h.bounds()}var A=new Point(p.bottomright.x,p.bottomright.y);var z=new Point(p.topleft.x,p.topleft.y);var C=A.subtract(z);var w=z.add(C.divide(2));var y=4;var E=new Point(Math.max(C.x,y),Math.max(C.y,y));p.topleft=w.subtract(E.divide(2));p.bottomright=w.add(E.divide(2));if(!o){if($.isEmptyObject(d.nodes)){return false}o=p;return true}var D=n;_newBounds={bottomright:o.bottomright.add(p.bottomright.subtract(o.bottomright).multiply(D)),topleft:o.topleft.add(p.topleft.subtract(o.topleft).multiply(D))};var B=new Point(o.topleft.subtract(_newBounds.topleft).magnitude(),o.bottomright.subtract(_newBounds.bottomright).magnitude());if(B.x*v.width>1||B.y*v.height>1){o=_newBounds;return true}else{return false}},energy:function(){return b},bounds:function(){var x=null;var w=null;$.each(d.nodes,function(A,z){if(!x){x=new Point(z._p);w=new Point(z._p);return}var y=z._p;if(y.x===null||y.y===null){return}if(y.x>x.x){x.x=y.x}if(y.y>x.y){x.y=y.y}if(y.x<w.x){w.x=y.x}if(y.y<w.y){w.y=y.y}});if(x&&w){return{bottomright:x,topleft:w}}else{return{topleft:new Point(-1,-1),bottomright:new Point(1,1)}}},nearest:function(y){if(v!==null){y=h.fromScreen(y)}var x={node:null,point:null,distance:null};var w=h;$.each(d.nodes,function(C,z){var A=z._p;if(A.x===null||A.y===null){return}var B=A.subtract(y).magnitude();if(x.distance===null||B<x.distance){x={node:z,point:A,distance:B};if(v!==null){x.screenPoint=h.toScreen(A)}}});if(x.node){if(v!==null){x.distance=h.toScreen(x.node.p).subtract(h.toScreen(y)).magnitude()}return x}else{return null}},_notify:function(){if(i===null){l++}else{clearTimeout(i)}i=setTimeout(h._synchronize,20)},_synchronize:function(){if(k.length>0){d.kernel.graphChanged(k);k=[];i=null}},};d.kernel=Kernel(h);d.tween=d.kernel.tween||null;Node.prototype.__defineGetter__("p",function(){var x=this;var w={};w.__defineGetter__("x",function(){return x._p.x});w.__defineSetter__("x",function(y){d.kernel.particleModified(x._id,{x:y})});w.__defineGetter__("y",function(){return x._p.y});w.__defineSetter__("y",function(y){d.kernel.particleModified(x._id,{y:y})});w.__proto__=Point.prototype;return w});Node.prototype.__defineSetter__("p",function(w){this._p.x=w.x;this._p.y=w.y;d.kernel.particleModified(this._id,{x:w.x,y:w.y})});Node.prototype.__defineGetter__("mass",function(){return this._mass});Node.prototype.__defineSetter__("mass",function(w){this._mass=w;d.kernel.particleModified(this._id,{m:w})});Node.prototype.__defineSetter__("tempMass",function(w){d.kernel.particleModified(this._id,{_m:w})});Node.prototype.__defineGetter__("fixed",function(){return this._fixed});Node.prototype.__defineSetter__("fixed",function(w){this._fixed=w;d.kernel.particleModified(this._id,{f:w?1:0})});return h};
/* barnes-hut.js */ var BarnesHutTree=function(){var b=[];var a=0;var e=null;var d=0.5;var c={init:function(g,h,f){d=f;a=0;e=c._newBranch();e.origin=g;e.size=h.subtract(g)},insert:function(j){var f=e;var g=[j];while(g.length){var h=g.shift();var m=h._m||h.m;var p=c._whichQuad(h,f);if(f[p]===undefined){f[p]=h;f.mass+=m;if(f.p){f.p=f.p.add(h.p.multiply(m))}else{f.p=h.p.multiply(m)}}else{if("origin" in f[p]){f.mass+=(m);if(f.p){f.p=f.p.add(h.p.multiply(m))}else{f.p=h.p.multiply(m)}f=f[p];g.unshift(h)}else{var l=f.size.divide(2);var n=new Point(f.origin);if(p[0]=="s"){n.y+=l.y}if(p[1]=="e"){n.x+=l.x}var o=f[p];f[p]=c._newBranch();f[p].origin=n;f[p].size=l;f.mass=m;f.p=h.p.multiply(m);f=f[p];if(o.p.x===h.p.x&&o.p.y===h.p.y){var k=l.x*0.08;var i=l.y*0.08;o.p.x=Math.min(n.x+l.x,Math.max(n.x,o.p.x-k/2+Math.random()*k));o.p.y=Math.min(n.y+l.y,Math.max(n.y,o.p.y-i/2+Math.random()*i))}g.push(o);g.unshift(h)}}}},applyForces:function(m,g){var f=[e];while(f.length){node=f.shift();if(node===undefined){continue}if(m===node){continue}if("f" in node){var k=m.p.subtract(node.p);var l=Math.max(1,k.magnitude());var i=((k.magnitude()>0)?k:Point.random(1)).normalize();m.applyForce(i.multiply(g*(node._m||node.m)).divide(l*l))}else{var j=m.p.subtract(node.p.divide(node.mass)).magnitude();var h=Math.sqrt(node.size.x*node.size.y);if(h/j>d){f.push(node.ne);f.push(node.nw);f.push(node.se);f.push(node.sw)}else{var k=m.p.subtract(node.p.divide(node.mass));var l=Math.max(1,k.magnitude());var i=((k.magnitude()>0)?k:Point.random(1)).normalize();m.applyForce(i.multiply(g*(node.mass)).divide(l*l))}}}},_whichQuad:function(i,f){if(i.p.exploded()){return null}var h=i.p.subtract(f.origin);var g=f.size.divide(2);if(h.y<g.y){if(h.x<g.x){return"nw"}else{return"ne"}}else{if(h.x<g.x){return"sw"}else{return"se"}}},_newBranch:function(){if(b[a]){var f=b[a];f.ne=f.nw=f.se=f.sw=undefined;f.mass=0;delete f.p}else{f={origin:null,size:null,nw:undefined,ne:undefined,sw:undefined,se:undefined,mass:0};b[a]=f}a++;return f}};return c};
/* physics.js */ var Physics=function(a,m,n,e,h,o){var f=BarnesHutTree();var c={particles:{},springs:{}};var l={particles:{}};var p=[];var k=[];var d=0;var b={sum:0,max:0,mean:0};var g={topleft:new Point(-1,-1),bottomright:new Point(1,1)};var j=1000;var i={integrator:["verlet","euler"].indexOf(o)>=0?o:"verlet",stiffness:(m!==undefined)?m:1000,repulsion:(n!==undefined)?n:600,friction:(e!==undefined)?e:0.3,gravity:false,dt:(a!==undefined)?a:0.02,theta:0.4,init:function(){return i},modifyPhysics:function(q){$.each(["stiffness","repulsion","friction","gravity","dt","precision","integrator"],function(s,t){if(q[t]!==undefined){if(t=="precision"){i.theta=1-q[t];return}i[t]=q[t];if(t=="stiffness"){var r=q[t];$.each(c.springs,function(v,u){u.k=r})}}})},addNode:function(v){var u=v.id;var r=v.m;var q=g.bottomright.x-g.topleft.x;var t=g.bottomright.y-g.topleft.y;var s=new Point((v.x!=null)?v.x:g.topleft.x+q*Math.random(),(v.y!=null)?v.y:g.topleft.y+t*Math.random());c.particles[u]=new Particle(s,r);c.particles[u].connections=0;c.particles[u].fixed=(v.f===1);l.particles[u]=c.particles[u];p.push(c.particles[u])},dropNode:function(t){var s=t.id;var r=c.particles[s];var q=$.inArray(r,p);if(q>-1){p.splice(q,1)}delete c.particles[s];delete l.particles[s]},modifyNode:function(s,q){if(s in c.particles){var r=c.particles[s];if("x" in q){r.p.x=q.x}if("y" in q){r.p.y=q.y}if("m" in q){r.m=q.m}if("f" in q){r.fixed=(q.f===1)}if("_m" in q){if(r._m===undefined){r._m=r.m}r.m=q._m}}},addSpring:function(u){var t=u.id;var q=u.l;var s=c.particles[u.fm];var r=c.particles[u.to];if(s!==undefined&&r!==undefined){c.springs[t]=new Spring(s,r,q,i.stiffness);k.push(c.springs[t]);s.connections++;r.connections++;delete l.particles[u.fm];delete l.particles[u.to]}},dropSpring:function(t){var s=t.id;var r=c.springs[s];r.point1.connections--;r.point2.connections--;var q=$.inArray(r,k);if(q>-1){k.splice(q,1)}delete c.springs[s]},_update:function(q){d++;$.each(q,function(r,s){if(s.t in i){i[s.t](s)}});return d},tick:function(){i.tendParticles();if(i.integrator=="euler"){i.updateForces();i.updateVelocity(i.dt);i.updatePosition(i.dt)}else{i.updateForces();i.cacheForces();i.updatePosition(i.dt);i.updateForces();i.updateVelocity(i.dt)}i.tock()},tock:function(){var q=[];$.each(c.particles,function(s,r){q.push(s);q.push(r.p.x);q.push(r.p.y)});if(h){h({geometry:q,epoch:d,energy:b,bounds:g})}},tendParticles:function(){$.each(c.particles,function(r,q){if(q._m!==undefined){if(Math.abs(q.m-q._m)<1){q.m=q._m;delete q._m}else{q.m*=0.98}}q.v.x=q.v.y=0})},updateForces:function(){if(i.repulsion>0){if(i.theta>0){i.applyBarnesHutRepulsion()}else{i.applyBruteForceRepulsion()}}if(i.stiffness>0){i.applySprings()}i.applyCenterDrift();if(i.gravity){i.applyCenterGravity()}},cacheForces:function(){$.each(c.particles,function(r,q){q._F=q.f})},applyBruteForceRepulsion:function(){$.each(c.particles,function(r,q){$.each(c.particles,function(t,s){if(q!==s){var v=q.p.subtract(s.p);var w=Math.max(1,v.magnitude());var u=((v.magnitude()>0)?v:Point.random(1)).normalize();q.applyForce(u.multiply(i.repulsion*(s._m||s.m)*0.5).divide(w*w*0.5));s.applyForce(u.multiply(i.repulsion*(q._m||q.m)*0.5).divide(w*w*-0.5))}})})},applyBarnesHutRepulsion:function(){if(!g.topleft||!g.bottomright){return}var r=new Point(g.bottomright);var q=new Point(g.topleft);f.init(q,r,i.theta);$.each(c.particles,function(t,s){f.insert(s)});$.each(c.particles,function(t,s){f.applyForces(s,i.repulsion)})},applySprings:function(){$.each(c.springs,function(u,q){var t=q.point2.p.subtract(q.point1.p);var r=q.length-t.magnitude();var s=((t.magnitude()>0)?t:Point.random(1)).normalize();q.point1.applyForce(s.multiply(q.k*r*-0.5));q.point2.applyForce(s.multiply(q.k*r*0.5))})},applyCenterDrift:function(){var r=0;var s=new Point(0,0);$.each(c.particles,function(u,t){s.add(t.p);r++});if(r==0){return}var q=s.divide(-r);$.each(c.particles,function(u,t){t.applyForce(q)})},applyCenterGravity:function(){$.each(c.particles,function(s,q){var r=q.p.multiply(-1);q.applyForce(r.multiply(i.repulsion/100))})},updateVelocity:function(r){var s=0,q=0,t=0;$.each(c.particles,function(x,u){if(u.fixed){u.v=new Point(0,0);u.f=new Point(0,0);return}if(i.integrator=="euler"){u.v=u.v.add(u.f.multiply(r)).multiply(1-i.friction)}else{u.v=u.v.add(u.f.add(u._F.divide(u._m)).multiply(r*0.5)).multiply(1-i.friction)}u.f.x=u.f.y=0;var v=u.v.magnitude();if(v>j){u.v=u.v.divide(v*v)}var v=u.v.magnitude();var w=v*v;s+=w;q=Math.max(w,q);t++});b={sum:s,max:q,mean:s/t,n:t}},updatePosition:function(q){var s=null;var r=null;$.each(c.particles,function(v,u){if(i.integrator=="euler"){u.p=u.p.add(u.v.multiply(q))}else{var t=u.f.multiply(0.5*q*q).divide(u.m);u.p=u.p.add(u.v.multiply(q)).add(t)}if(!s){s=new Point(u.p.x,u.p.y);r=new Point(u.p.x,u.p.y);return}var w=u.p;if(w.x===null||w.y===null){return}if(w.x>s.x){s.x=w.x}if(w.y>s.y){s.y=w.y}if(w.x<r.x){r.x=w.x}if(w.y<r.y){r.y=w.y}});g={topleft:r||new Point(-1,-1),bottomright:s||new Point(1,1)}},systemEnergy:function(q){return b}};return i.init()};var _nearParticle=function(b,c){var c=c||0;var a=b.x;var f=b.y;var e=c*2;return new Point(a-c+Math.random()*e,f-c+Math.random()*e)};
// if called as a worker thread, set up a run loop for the Physics object and bail out
if (typeof(window)=='undefined') return (function(){
/* hermetic.js */ $={each:function(d,e){if($.isArray(d)){for(var c=0,b=d.length;c<b;c++){e(c,d[c])}}else{for(var a in d){e(a,d[a])}}},map:function(a,c){var b=[];$.each(a,function(f,e){var d=c(e);if(d!==undefined){b.push(d)}});return b},extend:function(c,b){if(typeof b!="object"){return c}for(var a in b){if(b.hasOwnProperty(a)){c[a]=b[a]}}return c},isArray:function(a){if(!a){return false}return(a.constructor.toString().indexOf("Array")!=-1)},inArray:function(c,a){for(var d=0,b=a.length;d<b;d++){if(a[d]===c){return d}}return -1},isEmptyObject:function(a){if(typeof a!=="object"){return false}var b=true;$.each(a,function(c,d){b=false});return b},};
/* worker.js */ var PhysicsWorker=function(){var b=20;var a=null;var d=null;var c=null;var g=[];var f=new Date().valueOf();var e={init:function(h){e.timeout(h.timeout);a=Physics(h.dt,h.stiffness,h.repulsion,h.friction,e.tock);return e},timeout:function(h){if(h!=b){b=h;if(d!==null){e.stop();e.go()}}},go:function(){if(d!==null){return}c=null;d=setInterval(e.tick,b)},stop:function(){if(d===null){return}clearInterval(d);d=null},tick:function(){a.tick();var h=a.systemEnergy();if((h.mean+h.max)/2<0.05){if(c===null){c=new Date().valueOf()}if(new Date().valueOf()-c>1000){e.stop()}else{}}else{c=null}},tock:function(h){h.type="geometry";postMessage(h)},modifyNode:function(i,h){a.modifyNode(i,h);e.go()},modifyPhysics:function(h){a.modifyPhysics(h)},update:function(h){var i=a._update(h)}};return e};var physics=PhysicsWorker();onmessage=function(a){if(!a.data.type){postMessage("¿kérnèl?");return}if(a.data.type=="physics"){var b=a.data.physics;physics.init(a.data.physics);return}switch(a.data.type){case"modify":physics.modifyNode(a.data.id,a.data.mods);break;case"changes":physics.update(a.data.changes);physics.go();break;case"start":physics.go();break;case"stop":physics.stop();break;case"sys":var b=a.data.param||{};if(!isNaN(b.timeout)){physics.timeout(b.timeout)}physics.modifyPhysics(b);physics.go();break}};
})()
arbor = (typeof(arbor)!=='undefined') ? arbor : {}
$.extend(arbor, {
// object constructors (don't use ‘new’, just call them)
ParticleSystem:ParticleSystem,
Point:function(x, y){ return new Point(x, y) },
// immutable object with useful methods
etc:{
trace:trace, // ƒ(msg) -> safe console logging
dirname:dirname, // ƒ(path) -> leading part of path
basename:basename, // ƒ(path) -> trailing part of path
ordinalize:ordinalize, // ƒ(num) -> abbrev integers (and add commas)
objcopy:objcopy, // ƒ(old) -> clone an object
objcmp:objcmp, // ƒ(a, b, strict_ordering) -> t/f comparison
objkeys:objkeys, // ƒ(obj) -> array of all keys in obj
objmerge:objmerge, // ƒ(dst, src) -> like $.extend but non-destructive
uniq:uniq, // ƒ(arr) -> array of unique items in arr
arbor_path:arbor_path, // ƒ() -> guess the directory of the lib code
}
})
})(this.jQuery)
|
Agora-Planner
|
/Agora-Planner-0.3.9.tar.gz/Agora-Planner-0.3.9/agora/planner/server/static/arbor.js
|
arbor.js
|
import logging
import re
from collections import namedtuple
from urlparse import urlparse
import networkx as nx
from rdflib import ConjunctiveGraph, URIRef, BNode, RDF, Literal
__author__ = 'Fernando Serena'
log = logging.getLogger('agora.planner.plan')
def extend_uri(uri, prefixes):
if ':' in uri:
prefix_parts = uri.split(':')
if len(prefix_parts) == 2 and prefix_parts[0] in prefixes:
return prefixes[prefix_parts[0]] + prefix_parts[1]
return uri
def is_variable(arg):
return arg.startswith('?')
def is_uri(uri, prefixes):
if uri.startswith('<') and uri.endswith('>'):
uri = uri.lstrip('<').rstrip('>')
parse = urlparse(uri, allow_fragments=True)
return bool(len(parse.scheme))
if ':' in uri:
prefix_parts = uri.split(':')
return len(prefix_parts) == 2 and prefix_parts[0] in prefixes
return False
class TP(namedtuple('TP', "s p o")):
@classmethod
def _make(cls, iterable, new=tuple.__new__, len=len, prefixes=None):
def transform_elm(elm):
if is_variable(elm):
return elm
elif is_uri(elm, prefixes):
elm = extend_uri(elm, prefixes)
return URIRef(elm.lstrip('<').rstrip('>'))
elif elm == 'a':
return RDF.type
else:
return Literal(elm)
if prefixes is None:
prefixes = []
res = filter(lambda x: x, map(transform_elm, iterable))
if len(res) == 3:
if not (isinstance(res[0], Literal) or isinstance(res[1], Literal)):
return new(cls, res)
raise TypeError('Bad TP arguments: {}'.format(iterable))
def __repr__(self):
def elm_to_string(elm):
if isinstance(elm, URIRef):
if elm == RDF.type:
return 'a'
return '<%s>' % elm
return str(elm)
strings = map(elm_to_string, [self.s, self.p, self.o])
return '{} {} {}'.format(*strings)
@staticmethod
def from_string(st, prefixes):
if st.endswith('"'):
parts = [st[st.find('"'):]]
st = st.replace(parts[0], '').rstrip()
parts = st.split(" ") + parts
else:
parts = st.split(' ')
return TP._make(parts, prefixes=prefixes)
class AgoraGP(object):
def __init__(self, prefixes):
self._tps = []
self.__prefixes = prefixes
@property
def triple_patterns(self):
return self._tps
@property
def prefixes(self):
return self.__prefixes
@property
def graph(self):
g = ConjunctiveGraph()
for prefix in self.__prefixes:
g.bind(prefix, self.__prefixes[prefix])
variables = {}
def nodify(elm):
if is_variable(elm):
if not (elm in variables):
elm_node = BNode(elm)
variables[elm] = elm_node
return variables[elm]
else:
if elm == 'a':
return RDF.type
elif elm.startswith('"'):
return Literal(elm.lstrip('"').rstrip('"'))
else:
try:
return float(elm)
except ValueError:
return URIRef(elm)
nxg = nx.Graph()
for (s, p, o) in self._tps:
nxg.add_nodes_from([s, o])
nxg.add_edge(s, o)
contexts = dict([(str(index), c) for (index, c) in enumerate(nx.connected_components(nxg))])
for (s, p, o) in self._tps:
s_node = nodify(s)
o_node = nodify(o)
p_node = nodify(p)
context = None
for uid in contexts:
if s in contexts[uid]:
context = str(uid)
g.get_context(context).add((s_node, p_node, o_node))
return g
@staticmethod
def from_string(st, prefixes):
gp = None
if st.startswith('{') and st.endswith('}'):
st = st.replace('{', '').replace('}', '').strip()
tps = re.split('\. ', st)
tps = map(lambda x: x.strip().strip('.'), filter(lambda y: y != '', tps))
gp = AgoraGP(prefixes)
for tp in tps:
gp.triple_patterns.append(TP.from_string(tp, gp.prefixes))
return gp
def __repr__(self):
tp_strings = map(lambda x: str(x), self._tps)
return '{ %s}' % reduce(lambda x, y: (x + '%s . ' % str(y)), tp_strings, '')
|
Agora-Planner
|
/Agora-Planner-0.3.9.tar.gz/Agora-Planner-0.3.9/agora/planner/plan/agp.py
|
agp.py
|
from rdflib import ConjunctiveGraph, URIRef, BNode, RDF, Literal
from rdflib.namespace import Namespace, XSD, RDFS
__author__ = 'Fernando Serena'
AGORA = Namespace('http://agora.org#')
def __extend_uri(prefixes, short):
(prefix, u) = short.split(':')
try:
return URIRef(prefixes[prefix] + u)
except KeyError:
return short
def graph_plan(plan, fountain):
plan_graph = ConjunctiveGraph()
plan_graph.bind('agora', AGORA)
prefixes = plan.get('prefixes')
ef_plan = plan.get('plan')
tree_lengths = {}
s_trees = set([])
patterns = {}
for (prefix, u) in prefixes.items():
plan_graph.bind(prefix, u)
def __get_pattern_node(p):
if p not in patterns:
patterns[p] = BNode('tp_{}'.format(len(patterns)))
return patterns[p]
def __inc_tree_length(tree, l):
if tree not in tree_lengths:
tree_lengths[tree] = 0
tree_lengths[tree] += l
def __add_variable(p_node, vid, subject=True):
sub_node = BNode(str(vid).replace('?', 'var_'))
if subject:
plan_graph.add((p_node, AGORA.subject, sub_node))
else:
plan_graph.add((p_node, AGORA.object, sub_node))
plan_graph.set((sub_node, RDF.type, AGORA.Variable))
plan_graph.set((sub_node, RDFS.label, Literal(str(vid), datatype=XSD.string)))
def include_path(elm, p_seeds, p_steps):
elm_uri = __extend_uri(prefixes, elm)
path_g = plan_graph.get_context(elm_uri)
b_tree = BNode(elm_uri)
s_trees.add(b_tree)
path_g.set((b_tree, RDF.type, AGORA.SearchTree))
path_g.set((b_tree, AGORA.fromType, elm_uri))
for seed in p_seeds:
path_g.add((b_tree, AGORA.hasSeed, URIRef(seed)))
previous_node = b_tree
__inc_tree_length(b_tree, len(p_steps))
for j, step in enumerate(p_steps):
prop = step.get('property')
b_node = BNode(previous_node.n3() + prop)
if j < len(p_steps) - 1 or pattern[1] == RDF.type:
path_g.add((b_node, AGORA.onProperty, __extend_uri(prefixes, prop)))
path_g.add((b_node, AGORA.expectedType, __extend_uri(prefixes, step.get('type'))))
path_g.add((previous_node, AGORA.next, b_node))
previous_node = b_node
p_node = __get_pattern_node(pattern)
path_g.add((previous_node, AGORA.byPattern, p_node))
for i, tp_plan in enumerate(ef_plan):
paths = tp_plan.get('paths')
pattern = tp_plan.get('pattern')
hints = tp_plan.get('hints')
context = BNode('space_{}'.format(tp_plan.get('context')))
for path in paths:
steps = path.get('steps')
seeds = path.get('seeds')
if not len(steps) and len(seeds):
include_path(pattern[2], seeds, steps)
elif len(steps):
ty = steps[0].get('type')
include_path(ty, seeds, steps)
for t in s_trees:
plan_graph.set((t, AGORA.length, Literal(tree_lengths.get(t, 0), datatype=XSD.integer)))
pattern_node = __get_pattern_node(pattern)
plan_graph.add((context, AGORA.definedBy, pattern_node))
plan_graph.set((context, RDF.type, AGORA.SearchSpace))
plan_graph.add((pattern_node, RDF.type, AGORA.TriplePattern))
(sub, pred, obj) = pattern
if isinstance(sub, BNode):
__add_variable(pattern_node, str(sub))
elif isinstance(sub, URIRef):
plan_graph.add((pattern_node, AGORA.subject, sub))
if isinstance(obj, BNode):
__add_variable(pattern_node, str(obj), subject=False)
elif isinstance(obj, Literal):
node = BNode(str(obj).replace(' ', ''))
plan_graph.add((pattern_node, AGORA.object, node))
plan_graph.set((node, RDF.type, AGORA.Literal))
plan_graph.set((node, AGORA.value, Literal(str(obj), datatype=XSD.string)))
else:
plan_graph.add((pattern_node, AGORA.object, obj))
plan_graph.add((pattern_node, AGORA.predicate, pred))
if pred == RDF.type:
if 'check' in hints:
plan_graph.add((pattern_node, AGORA.checkType, Literal(hints['check'], datatype=XSD.boolean)))
sub_expected = plan_graph.subjects(predicate=AGORA.expectedType)
for s in sub_expected:
expected_types = list(plan_graph.objects(s, AGORA.expectedType))
for et in expected_types:
plan_graph.remove((s, AGORA.expectedType, et))
q_expected_types = [plan_graph.qname(t) for t in expected_types]
expected_types = [d for d in expected_types if
not set.intersection(set(fountain.get_type(plan_graph.qname(d)).get('super')),
set(q_expected_types))]
for et in expected_types:
plan_graph.add((s, AGORA.expectedType, et))
return plan_graph
|
Agora-Planner
|
/Agora-Planner-0.3.9.tar.gz/Agora-Planner-0.3.9/agora/planner/plan/graph.py
|
graph.py
|
import logging
from rdflib import RDF, BNode, Literal
from agora.planner.plan.agp import AgoraGP
from agora.planner.plan.fountain import Fountain
from agora.planner.plan.graph import graph_plan
from agora.planner.server import app
__author__ = 'Fernando Serena'
log = logging.getLogger('agora.planner.plan')
def make_fountain():
return Fountain(**app.config['FOUNTAIN'])
def _stringify_tp(context, (s, p, o)):
def stringify_elm(elm):
if isinstance(elm, BNode):
return elm.n3(context.namespace_manager)
elif isinstance(elm, Literal):
return elm.toPython()
return context.qname(elm)
return '{} {} {} .'.format(stringify_elm(s), stringify_elm(p), stringify_elm(o))
class Plan(object):
def __subject_join(self, tp_paths, context, tp1, tp2, **kwargs):
subject, pr1, o1 = tp1
_, pr2, o2 = tp2
log.debug('trying to s-join {} and {}'.format(_stringify_tp(context, tp1), _stringify_tp(context, tp2)))
if pr2 == RDF.type:
o2 = context.qname(o2)
tp2_domain = [o2]
tp2_domain.extend(self.__fountain.get_type(o2).get('sub'))
else:
tp2_domain = self.__fountain.get_property(context.qname(pr2)).get('domain')
join_paths = tp_paths[tp1][:]
if pr1 == RDF.type:
for path in tp_paths[tp1]:
steps = path.get('steps')
if len(steps):
last_prop = path.get('steps')[-1].get('property')
dom_r = self.__fountain.get_property(last_prop).get('range')
if len(filter(lambda x: x in tp2_domain, dom_r)):
join_paths.remove(path)
else:
join_paths.remove(path)
elif pr2 == RDF.type:
for path in tp_paths[tp1]:
last_type = path.get('steps')[-1].get('type')
if last_type in tp2_domain:
join_paths.remove(path)
else:
for path in tp_paths[tp1]:
if path.get('steps')[-1].get('type') in tp2_domain:
join_paths.remove(path)
return join_paths
def __subject_object_join(self, tp_paths, context, tp1, tp2, hints=None):
subject, pr1, o1 = tp1
_, pr2, o2 = tp2
log.debug('trying to so-join {} and {}'.format(_stringify_tp(context, tp1), _stringify_tp(context, tp2)))
pr2 = context.qname(pr2)
join_paths = tp_paths[tp1][:]
if pr1 == RDF.type or subject == o2:
for path in tp_paths[tp1]:
steps = path.get('steps', [])
if len(steps):
if pr1 == RDF.type:
matching_steps = steps[:]
else:
matching_steps = steps[:-1]
for o_path in tp_paths[tp2]:
if o_path.get('steps') == matching_steps:
join_paths.remove(path)
elif pr2 == context.qname(RDF.type):
tp1_range = self.__fountain.get_property(context.qname(pr1)).get('range')
o2 = context.qname(o2)
for r_type in tp1_range:
check_types = self.__fountain.get_type(r_type).get('super')
check_types.append(r_type)
if o2 in check_types:
join_paths = []
break
if not join_paths and hints is not None:
hints[tp2]['check'] = hints[tp2].get('check', False) or len(tp1_range) > 1
else:
if not subject == o2:
for path in tp_paths[tp1]:
steps = path.get('steps', [])
if len(steps):
subject_prop = steps[-1].get('property')
subject_range = self.__fountain.get_property(subject_prop).get('range')
for join_subject in subject_range:
if pr2 in self.__fountain.get_type(join_subject).get('properties') and path in join_paths:
join_paths.remove(path)
return join_paths
def __object_join(self, tp_paths, context, tp1, tp2, **kwargs):
_, pr1, obj = tp1
_, pr2, _ = tp2
log.debug('trying to o-join {} and {}'.format(_stringify_tp(context, tp1), _stringify_tp(context, tp2)))
tp2_range = self.__fountain.get_property(context.qname(pr2)).get('range')
tp1_range = self.__fountain.get_property(context.qname(pr1)).get('range')
if len(filter(lambda x: x in tp1_range, tp2_range)):
return []
return tp_paths[tp1]
def __get_tp_paths(self):
def __join(f, joins):
invalid_paths = []
for (sj, pj, oj) in joins:
invalid_paths.extend(f(tp_paths, c, (s, pr, o), (sj, pj, oj), hints=tp_hints))
if len(joins):
tp_paths[(s, pr, o)] = filter(lambda z: z not in invalid_paths, tp_paths[(s, pr, o)])
join_paths.extend(invalid_paths)
tp_paths = {}
tp_hints = {}
for c in self.__agp.contexts():
for (s, pr, o) in c.triples((None, None, None)):
tp_hints[(s, pr, o)] = {}
try:
if pr == RDF.type:
tp_paths[(s, pr, o)] = self.__fountain.get_property_paths(self.__agp.qname(o))
else:
tp_paths[(s, pr, o)] = self.__fountain.get_property_paths(self.__agp.qname(pr))
except IOError as e:
raise NameError('Cannot get a path to an unknown subject: {}'.format(e.message))
while True:
join_paths = []
for (s, pr, o) in c.triples((None, None, None)):
if len(tp_paths[(s, pr, o)]):
s_join = [(x, pj, y) for (x, pj, y) in c.triples((s, None, None)) if pj != pr]
__join(self.__subject_join, s_join)
o_join = [(x, pj, y) for (x, pj, y) in c.triples((None, None, o)) if pj != pr]
__join(self.__object_join, o_join)
so_join = [(x, pj, y) for (x, pj, y) in c.triples((None, None, s))]
so_join.extend([(x, pj, y) for (x, pj, y) in c.triples((o, None, None))])
__join(self.__subject_object_join, so_join)
if not join_paths:
break
for (s, pr, o) in tp_hints:
if pr == RDF.type and 'check' not in tp_hints[(s, pr, o)]:
tp_hints[(s, pr, o)]['check'] = len(self.__fountain.get_type(self.__agp.qname(o)).get('super')) > 0
return tp_paths, tp_hints
def __get_context(self, (s, p, o)):
return str(list(self.__agp.contexts((s, p, o))).pop().identifier)
def __init__(self, gp):
self.__fountain = make_fountain()
agora_gp = AgoraGP.from_string(gp, self.fountain.prefixes)
if agora_gp is None:
raise AttributeError('{} is not a valid graph pattern'.format(gp))
self.__agp = agora_gp.graph
log.debug('Agora Graph Pattern:\n{}'.format(self.__agp.serialize(format='turtle')))
try:
paths, hints = self.__get_tp_paths()
self.__plan = {
"plan": [{"context": self.__get_context(tp), "pattern": tp, "paths": path, "hints": hints[tp]}
for (tp, path) in paths.items()], "prefixes": agora_gp.prefixes}
self.__g_plan = graph_plan(self.__plan, self.__fountain)
except TypeError:
raise NameError
@property
def json(self):
return self.__plan
@property
def graph(self):
return self.__g_plan
@property
def fountain(self):
return self.__fountain
|
Agora-Planner
|
/Agora-Planner-0.3.9.tar.gz/Agora-Planner-0.3.9/agora/planner/plan/__init__.py
|
__init__.py
|
import calendar
import logging
import time
import traceback
from datetime import datetime as dt, datetime
from datetime import timedelta
from threading import Thread
from time import sleep
import networkx as nx
from abc import abstractmethod, abstractproperty
from agora.client.namespaces import AGORA
from agora.client.wrapper import Agora
from agora.stoa.actions.core import STOA, AGENT_ID
from agora.stoa.actions.core.fragment import fragments_key, fragment_lock
from agora.stoa.actions.core.utils import tp_parts, GraphPattern
from agora.stoa.daemons.delivery import build_response
from agora.stoa.server import app
from agora.stoa.store import r
from agora.stoa.store.triples import fragments_cache, add_stream_triple, clear_fragment_stream, load_stream_triples, \
GraphProvider, event_resource_callbacks
from concurrent.futures.thread import ThreadPoolExecutor
from rdflib import RDF, RDFS
from rdflib.term import URIRef
__author__ = 'Fernando Serena'
log = logging.getLogger('agora.scholar.daemons.fragment')
# Load environment variables
agora_client = Agora(**app.config['AGORA'])
ON_DEMAND_TH = float(app.config.get('PARAMS', {}).get('on_demand_threshold', 2.0))
MIN_SYNC = int(app.config.get('PARAMS', {}).get('min_sync_time', 10))
N_COLLECTORS = int(app.config.get('PARAMS', {}).get('fragment_collectors', 1))
MAX_CONCURRENT_FRAGMENTS = int(app.config.get('PARAMS', {}).get('max_concurrent_fragments', 8))
COLLECT_THROTTLING = max(1, int(app.config.get('PARAMS', {}).get('collect_throttling', 30)))
THROTTLING_TIME = (1.0 / (COLLECT_THROTTLING * 1000))
log.info("""Fragment daemon setup:
- On-demand threshold: {}
- Minimum sync time: {}
- Maximum concurrent collectors: {}
- Maximum concurrent fragments: {}""".format(ON_DEMAND_TH, MIN_SYNC, N_COLLECTORS,
MAX_CONCURRENT_FRAGMENTS))
# Fragment collection threadpool
thp = ThreadPoolExecutor(max_workers=min(8, MAX_CONCURRENT_FRAGMENTS))
# Create a graph provider
graph_provider = GraphProvider()
log.info('Cleaning fragment locks...')
fragment_locks = r.keys('{}:*lock*'.format(fragments_key))
for flk in fragment_locks:
r.delete(flk)
log.info('Cleaning fragment pulling flags...')
fragment_pullings = r.keys('{}:*:pulling'.format(fragments_key))
for fpk in fragment_pullings:
r.delete(fpk)
resource_in_fragment = {}
fragment_resources = {}
resource_events = {}
class FragmentPlugin(object):
"""
Abstract class to be implemented for each action that requires to be notified after each fragment
collection event, e.g. new triple found
"""
# Plugins list, all of them will be notified in order
__plugins = []
@classmethod
def register(cls, p):
"""
Register a fragment plugin (they all should be subclasses of FragmentPlugin)
:param p: Plugin
"""
if issubclass(p, cls):
cls.__plugins.append(p())
else:
raise ValueError('{} is not a valid fragment plugin'.format(p))
@classmethod
def plugins(cls):
"""
:return: The list of registered plugins
"""
return cls.__plugins[:]
@abstractmethod
def consume(self, fid, quad, graph, *args):
"""
This method will be invoked just after a new fragment triple is found
:param fid: Fragment id
:param quad: (context, subject, predicate, object)
:param graph: The search plan graph that
:param args: Context arguments, e.g. sink
:return:
"""
pass
@abstractmethod
def complete(self, fid, *args):
"""
This method will be invoked just after a fragment is fully collected
:param fid: Fragment id
:param args: Context arguments, e.g. sink
"""
pass
@abstractproperty
def sink_class(self):
"""
The specific Sink class to work with
"""
pass
def sink_aware(self):
return True
def __bind_prefixes(source_graph):
"""
Binds all source graph prefixes to the cache graph
"""
map(lambda (prefix, uri): fragments_cache.bind(prefix, uri), source_graph.namespaces())
def match_filter(elm, f):
"""
Check if a given term is equal to a filter string
:param elm: The term
:param f: Filter string
:return: Boolean value
"""
if f.startswith('"'):
return unicode(elm) == f.lstrip('"').rstrip('"')
elif f.startswith('<'):
return unicode(elm) == f.lstrip('<').rstrip('>')
return False
def map_variables(tp, mapping=None, fmap=None):
"""
Find a mapping for a given triple pattern tuple
:param tp: (subject, predicate, object) string-based tuple
:param mapping: Concrete variables' mapping dictionary
:param fmap: Concrete filter-variable mapping dictionary
:return: A mapped triple pattern
"""
def apply_filter_map(x):
return x if fmap is None else fmap.get(x, x)
return tp if mapping is None else tuple(map(lambda x: apply_filter_map(mapping.get(x, x)), tp))
def __consume_quad(fid, (c, s, p, o), graph, sinks=None):
"""
Proxy all new-triple-found fragment events to the registered plugins
:param fid: Fragment id
:param graph: Search plan graph
:param sinks: Fragment requests' sinks
"""
def __process_filters(sink):
"""
It's very important to take into account the filter mapping of each request to not
notify about triples that do not fit with the actual graph pattern of each of them
:return: Boolean value that determines whether the triple must be sent to a specific sink-aware plugin
"""
filter_mapping = sink.filter_mapping
real_context = map_variables(c, sink.mapping, filter_mapping)
consume = True
if sink.map(c[2]) in filter_mapping:
consume = match_filter(o, real_context[2])
if consume and sink.map(c[0]) in filter_mapping:
consume = match_filter(s, real_context[0])
return consume, real_context
def __sink_consume():
"""
Function for notifying sink-aware plugins
"""
for rid in filter(lambda _: isinstance(sinks[_], plugin.sink_class), sinks):
sink = sinks[rid]
try:
consume, real_context = __process_filters(sink)
if consume:
plugin.consume(fid, (real_context, s, p, o), graph, sink)
except Exception as e:
log.warning(e.message)
plugin.complete(fid, sink)
sink.remove()
yield rid
def __generic_consume():
try:
plugin.consume(fid, (c, s, p, o), graph)
except Exception as e:
log.warning(e.message)
# In case the plugin is not sink-aware, proceed with a generic notification
for plugin in FragmentPlugin.plugins():
if plugin.sink_class is not None:
invalid_sinks = list(__sink_consume())
for _ in invalid_sinks:
del sinks[_]
else:
__generic_consume()
def __notify_completion(fid, sinks):
"""
Notify the ending of a fragment collection to all registered plugins
:param fid: Fragment id
:param sinks: Set of dependent sinks
:return:
"""
for sink in sinks.values():
if sink.delivery == 'accepted':
sink.delivery = 'ready'
if FragmentPlugin.plugins:
fragment_gp = GraphPattern(r.smembers('{}:fragments:{}:gp'.format(AGENT_ID, fid)))
for plugin in FragmentPlugin.plugins():
try:
filtered_sinks = filter(lambda _: isinstance(sinks[_], plugin.sink_class), sinks)
for rid in filtered_sinks:
sink = sinks[rid]
if plugin.sink_aware:
plugin.complete(fid, sink)
if not plugin.sink_aware:
plugin.complete(fid, fragment_gp)
except Exception as e:
log.warning(e.message)
def __extract_tp_from_plan(graph, c):
"""
:param graph: Search Plan graph
:param c: Triple pattern node in the search plan
:return: A string triple representing the pattern for a given search plan triple pattern node
"""
def extract_node_id(node):
nid = node
if (node, RDF.type, AGORA.Variable) in graph:
nid = list(graph.objects(node, RDFS.label)).pop()
elif (node, RDF.type, AGORA.Literal) in graph:
nid = list(graph.objects(node, AGORA.value)).pop()
return nid
predicate = list(graph.objects(c, AGORA.predicate)).pop()
subject_node = list(graph.objects(c, AGORA.subject)).pop()
object_node = list(graph.objects(c, AGORA.object)).pop()
subject = extract_node_id(subject_node)
obj = extract_node_id(object_node)
return str(subject), predicate.n3(graph.namespace_manager), str(obj)
# Cache is used as the triple store for fragments.
# Each fragment is assigned three different main contexts:
# - fid: Where all its triple patterns are persisted
# - /fid: Fragment data
# - (fid, c): Triple pattern based fragment data (1 context per triple pattern, c)
def graph_from_gp(gp):
gp_graph = nx.DiGraph()
gp_parts = [tp_parts(tp) for tp in gp]
for gp_part in gp_parts:
gp_graph.add_edge(gp_part[0], gp_part[2], predicate=gp_part[1])
return gp_graph
def __update_fragment_cache(fid, gp):
"""
Recreate fragment <fid> cached data and all its data-contexts from the corresponding stream (Redis)
:param fid:
:return:
"""
fragments_cache.remove_context(fragments_cache.get_context('/' + fid))
gp_graph = graph_from_gp(gp)
roots = filter(lambda x: gp_graph.in_degree(x) == 0, gp_graph.nodes())
fragment_triples = load_stream_triples(fid, calendar.timegm(dt.utcnow().timetuple()))
visited_contexts = set([])
for c, s, p, o in fragment_triples:
if c not in visited_contexts:
fragments_cache.remove_context(fragments_cache.get_context(str((fid, c))))
visited_contexts.add(c)
fragments_cache.get_context(str((fid, c))).add((s, p, o))
fragments_cache.get_context('/' + fid).add((s, p, o))
if c[0] in roots:
fragments_cache.get_context('/' + fid).add((s, RDF.type, STOA.Root))
visited_contexts.clear()
with r.pipeline() as pipe:
pipe.delete('{}:{}:stream'.format(fragments_key, fid))
pipe.execute()
def __cache_plan_context(fid, graph):
"""
Use <graph> to extract the triple patterns of the current fragment <fid> and replace them as the expected context
(triple patterns context) in the cache graph
"""
try:
fid_context = fragments_cache.get_context(fid)
fragments_cache.remove_context(fid_context)
tps = graph.subjects(RDF.type, AGORA.TriplePattern)
for tp in tps:
for (s, p, o) in graph.triples((tp, None, None)):
fid_context.add((s, p, o))
for t in graph.triples((o, None, None)):
fid_context.add(t)
except Exception as e:
log.error(e.message)
def __remove_fragment(fid):
"""
Completely remove a fragment from the system after notifying its known consumers
:param fid: Fragment identifier
"""
log.debug('Waiting to remove fragment {}...'.format(fid))
lock = fragment_lock(fid)
lock.acquire()
r_sinks = __load_fragment_requests(fid)
__notify_completion(fid, r_sinks)
fragment_keys = r.keys('{}:{}*'.format(fragments_key, fid))
with r.pipeline(transaction=True) as p:
p.multi()
map(lambda k: p.delete(k), fragment_keys)
p.srem(fragments_key, fid)
p.execute()
# Fragment lock key was just implicitly removed, so it's not necessary to release the lock
# lock.release()
log.info('Fragment {} has been removed'.format(fid))
def __load_fragment_requests(fid):
"""
Load all requests and their sinks that are related to a given fragment id
:param fid: Fragment id
:return: A dictionary of sinks of all fragment requests
"""
sinks_ = {}
fragment_requests_key = '{}:{}:requests'.format(fragments_key, fid)
for rid in r.smembers(fragment_requests_key):
try:
sinks_[rid] = build_response(rid).sink
except Exception as e:
log.warning(e.message)
with r.pipeline(transaction=True) as p:
p.multi()
p.srem(fragment_requests_key, rid)
p.execute()
return sinks_
def init_fragment_resources(fid):
if fid in fragment_resources:
for s in fragment_resources[fid]:
if s in resource_in_fragment:
resource_in_fragment[s].remove(fid)
del fragment_resources[fid]
fragment_resources[fid] = set([])
def resource_callback(resource):
resource_events[resource] = datetime.utcnow()
event_resource_callbacks.add(resource_callback)
def change_in_fragment_resource(fid, lapse):
if lapse is None:
return True
last = datetime.utcnow() - timedelta(seconds=lapse * 3)
if fid in fragment_resources:
if fragment_resources[fid]:
return any([str(s) in resource_events and resource_events[str(s)] >= last for s in fragment_resources[fid]])
return True
def __pull_fragment(fid):
"""
Pull and replace (if needed) a given fragment
:param fid: Fragment id
"""
fragment_key = '{}:{}'.format(fragments_key, fid)
on_events = r.get('{}:events'.format(fragment_key))
if on_events == 'True' and not change_in_fragment_resource(fid, int(r.get('{}:ud'.format(fragment_key)))):
with r.pipeline(transaction=True) as p:
p.multi()
sync_key = '{}:sync'.format(fragment_key)
p.set(sync_key, True)
durability = int(r.get('{}:ud'.format(fragment_key)))
p.expire(sync_key, durability)
p.set('{}:updated'.format(fragment_key), calendar.timegm(dt.utcnow().timetuple()))
p.delete('{}:pulling'.format(fragment_key))
p.execute()
return
# Load fragment graph pattern
tps = r.smembers('{}:gp'.format(fragment_key))
# Load fragment requests (including their sinks)
r_sinks = __load_fragment_requests(fid)
log.info("""Starting collection of fragment {}:
- GP: {}
- Supporting: ({}) {}""".format(fid, list(tps), len(r_sinks), list(r_sinks)))
init_fragment_resources(fid)
# Prepare the corresponding fragment generator and fetch the search plan
start_time = datetime.utcnow()
try:
fgm_gen, _, graph = agora_client.get_fragment_generator('{ %s }' % ' . '.join(tps), workers=N_COLLECTORS,
provider=graph_provider, queue_size=N_COLLECTORS*100)
except Exception:
traceback.print_exc()
log.error('Agora is not available')
return
# In case there is not SearchTree in the plan: notify, remove and abort collection
if not list(graph.subjects(RDF.type, AGORA.SearchTree)):
log.info('There is no search plan for fragment {}. Removing...'.format(fid))
# TODO: Send additional headers notifying the reason to end
__notify_completion(fid, r_sinks)
__remove_fragment(fid)
return
# Update cache graph prefixes
__bind_prefixes(graph)
# Extract triple patterns' dictionary from the search plan
context_tp = {tpn: __extract_tp_from_plan(graph, tpn) for tpn in
graph.subjects(RDF.type, AGORA.TriplePattern)}
frag_contexts = {tpn: (fid, context_tp[tpn]) for tpn in context_tp}
lock = fragment_lock(fid)
lock.acquire()
# Update fragment contexts
with r.pipeline(transaction=True) as p:
p.multi()
p.set('{}:pulling'.format(fragment_key), True)
contexts_key = '{}:contexts'.format(fragment_key)
p.delete(contexts_key)
clear_fragment_stream(fid)
for tpn in context_tp.keys():
p.sadd(contexts_key, frag_contexts[tpn])
p.execute()
lock.release()
# Init fragment collection counters
n_triples = 0
fragment_weight = 0
fragment_delta = 0
log.info('Collecting fragment {}...'.format(fid))
try:
# Iterate all fragment triples and their contexts
pre_ts = datetime.utcnow()
for (c, s, p, o) in fgm_gen:
# Update weights and counters
triple_weight = len(u'{}{}{}'.format(s, p, o))
fragment_weight += triple_weight
fragment_delta += triple_weight
# Store the triple if it was not obtained before and notify related requests
try:
lock.acquire()
new_triple = add_stream_triple(fid, context_tp[c], (s, p, o))
lock.release()
if new_triple:
if isinstance(s, URIRef):
if s not in resource_in_fragment:
resource_in_fragment[s] = set([])
resource_in_fragment[s].add(fid)
fragment_resources[fid].add(s)
__consume_quad(fid, (context_tp[c], s, p, o), graph, sinks=r_sinks)
n_triples += 1
except Exception as e:
log.warning(e.message)
traceback.print_exc()
if fragment_delta > 10000:
fragment_delta = 0
log.info('Pulling fragment {} [{} kB]'.format(fid, fragment_weight / 1000.0))
if n_triples % 100 == 0:
# Update fragment requests
if r.scard('{}:requests'.format(fragment_key)) != len(r_sinks):
r_sinks = __load_fragment_requests(fid)
post_ts = datetime.utcnow()
elapsed = (post_ts - pre_ts).total_seconds()
throttling = THROTTLING_TIME - elapsed
if throttling > 0:
sleep(throttling)
pre_ts = datetime.utcnow()
except Exception as e:
log.warning(e.message)
traceback.print_exc()
elapsed = (datetime.utcnow() - start_time).total_seconds()
log.info(
'{} triples retrieved for fragment {} in {} s [{} kB]'.format(n_triples, fid, elapsed,
fragment_weight / 1000.0))
# Update fragment cache and its contexts
lock.acquire()
try:
__update_fragment_cache(fid, tps)
log.info('Fragment {} data has been replaced with the recently collected'.format(fid))
__cache_plan_context(fid, graph)
log.info('BGP context of fragment {} has been cached'.format(fid))
log.info('Updating result set for fragment {}...'.format(fid))
# Calculate sync times and update fragment flags
with r.pipeline(transaction=True) as p:
p.multi()
sync_key = '{}:sync'.format(fragment_key)
demand_key = '{}:on_demand'.format(fragment_key)
# Fragment is now synced
p.set(sync_key, True)
# If the fragment collection time has not exceeded the threshold, switch to on-demand mode
# if elapsed < ON_DEMAND_TH and elapsed * random.random() < ON_DEMAND_TH / 4:
# p.set(demand_key, True)
# log.info('Fragment {} has been switched to on-demand mode'.format(fid))
# else:
p.delete(demand_key)
updated_delay = int(r.get('{}:ud'.format(fragment_key)))
last_requests_ts = map(lambda x: int(x), r.lrange('{}:hist'.format(fragment_key), 0, -1))
print last_requests_ts
current_ts = calendar.timegm(datetime.utcnow().timetuple())
first_collection = r.get('{}:updated'.format(fragment_key)) is None
base_ts = last_requests_ts[:]
if not first_collection:
if current_ts - base_ts[0] <= updated_delay:
current_ts += updated_delay # Force
base_ts = [current_ts] + base_ts
request_intervals = [i - j for i, j in zip(base_ts[:-1], base_ts[1:])]
if request_intervals:
avg_gap = reduce(lambda x, y: x + y, request_intervals) / len(request_intervals)
print avg_gap,
durability = avg_gap - elapsed if avg_gap > updated_delay else updated_delay - elapsed
else:
durability = updated_delay - elapsed
durability = int(max(durability, 1))
print durability
if durability <= updated_delay - elapsed:
p.expire(sync_key, durability)
log.info('Fragment {} is considered synced for {} s'.format(fid, durability))
else:
clear_fragment_stream(fid)
p.delete('{}:updated'.format(fragment_key))
p.delete('{}:hist'.format(fragment_key))
log.info('Fragment {} will no longer be automatically updated'.format(fid))
p.set('{}:updated'.format(fragment_key), calendar.timegm(dt.utcnow().timetuple()))
p.delete('{}:pulling'.format(fragment_key))
p.execute()
__notify_completion(fid, r_sinks)
finally:
lock.release()
log.info('Fragment {} collection is complete!'.format(fid))
def __collect_fragments():
registered_fragments = r.scard(fragments_key)
synced_fragments = len(r.keys('{}:*:sync'.format(fragments_key)))
log.info("""Collector daemon started:
- Fragments: {}
- Synced: {}""".format(registered_fragments, synced_fragments))
futures = {}
while True:
try:
for fid in filter(
lambda x: r.get('{}:{}:sync'.format(fragments_key, x)) is None and r.get(
'{}:{}:pulling'.format(fragments_key, x)) is None,
r.smembers(fragments_key)):
if fid in futures:
if futures[fid].done():
del futures[fid]
if fid not in futures:
futures[fid] = thp.submit(__pull_fragment, fid)
except Exception as e:
log.error(e.message)
finally:
time.sleep(0.1)
def fragment_updated_on(fid):
return r.get('{}:{}:updated'.format(fragments_key, fid))
def fragment_on_demand(fid):
return r.get('{}:{}:on_demand'.format(fragments_key, fid))
def is_pulling(fid):
return r.get('{}:{}:pulling'.format(fragments_key, fid)) is not None
def fragment_contexts(fid):
return r.smembers('{}:{}:contexts'.format(fragments_key, fid))
def is_fragment_synced(fid):
return fragment_updated_on(fid) is not None
def fragment_graph(fid):
return fragments_cache.get_context('/' + fid)
# Create and start collector daemon
th = Thread(target=__collect_fragments)
th.daemon = True
th.start()
|
Agora-Scholar
|
/Agora-Scholar-0.2.0.tar.gz/Agora-Scholar-0.2.0/agora/scholar/daemons/fragment.py
|
fragment.py
|
import calendar
import logging
from datetime import datetime as dt, datetime
from redis.lock import Lock
from agora.scholar.actions import FragmentConsumerResponse
from agora.scholar.daemons.fragment import FragmentPlugin, map_variables, match_filter, is_fragment_synced, \
fragment_contexts
from agora.scholar.daemons.fragment import fragment_lock
from agora.stoa.actions.core import AGENT_ID
from agora.stoa.actions.core import STOA
from agora.stoa.actions.core.fragment import FragmentRequest, FragmentAction, FragmentSink
from agora.stoa.actions.core.utils import parse_bool, chunks
from agora.stoa.messaging.reply import reply
from agora.stoa.store import r
from agora.stoa.store.triples import load_stream_triples, fragments_cache
__author__ = 'Fernando Serena'
log = logging.getLogger('agora.scholar.actions.stream')
log.info("'Cleaning stream requests' locks...")
request_locks = r.keys('{}:requests:*:lock'.format(AGENT_ID))
for rlk in request_locks:
r.delete(rlk)
class StreamPlugin(FragmentPlugin):
@property
def sink_class(self):
return StreamSink
def consume(self, fid, (c, s, p, o), graph, *args):
sink = args[0]
sink.lock.acquire()
try:
# Prevent from consuming a triple when the delivery state says it was completely sent
# Anyway, this HAS TO BE REMOVED from here, because the stream flag should be enough
if sink.delivery == 'sent':
return
# Proceed only if the stream flag is enabled
if sink.stream:
# log.info('[{}] Streaming fragment triple...'.format(sink.request_id))
reply((c, s.n3(), p.n3(), o.n3()), headers={'source': 'stream', 'format': 'tuple', 'state': 'streaming',
'response_to': sink.message_id,
'submitted_on': calendar.timegm(datetime.utcnow().timetuple()),
'submitted_by': sink.submitted_by},
**sink.recipient)
finally:
sink.lock.release()
def complete(self, fid, *args):
sink = args[0]
sink.lock.acquire()
try:
# At this point, the stream flag is disabled, and the delivery state might need to be updated
sink.stream = False
if sink.delivery == 'streaming':
log.debug('Sending end stream signal after {}'.format(sink.delivery))
sink.delivery = 'sent'
reply((), headers={'state': 'end', 'format': 'tuple'}, **sink.recipient)
log.info('Stream of fragment {} for request {} is done'.format(fid, sink.request_id))
finally:
sink.lock.release()
FragmentPlugin.register(StreamPlugin)
class StreamRequest(FragmentRequest):
def __init__(self):
super(StreamRequest, self).__init__()
def _extract_content(self, request_type=STOA.StreamRequest):
"""
Parse streaming request data. For this operation, there is no additional data to extract.
"""
super(StreamRequest, self)._extract_content(request_type=request_type)
class StreamAction(FragmentAction):
def __init__(self, message):
"""
Prepare request and sink objects before starting initialization
"""
self.__request = StreamRequest()
self.__sink = StreamSink()
super(StreamAction, self).__init__(message)
@property
def sink(self):
return self.__sink
@classmethod
def response_class(cls):
return StreamResponse
@property
def request(self):
return self.__request
def submit(self):
super(StreamAction, self).submit()
# A stream request is ready just after its submission
self.sink.delivery = 'ready'
class StreamSink(FragmentSink):
"""
Extends FragmentSink by adding a new property that helps to manage the stream state
"""
def _remove(self, pipe):
try:
self.lock.acquire()
super(StreamSink, self)._remove(pipe)
pipe.delete('{}lock'.format(self._request_key))
except Exception as e:
log.warning(e.message)
def __init__(self):
super(StreamSink, self).__init__()
self.__lock = None
def _save(self, action, general=True):
super(StreamSink, self)._save(action, general)
def _load(self):
super(StreamSink, self)._load()
# Create the request lock
lock_key = '{}lock'.format(self._request_key)
self.__lock = r.lock(lock_key, lock_class=Lock)
@property
def stream(self):
return parse_bool(r.hget('{}'.format(self._request_key), '__stream'))
@stream.setter
def stream(self, value):
with r.pipeline(transaction=True) as p:
p.multi()
p.hset('{}'.format(self._request_key), '__stream', value)
p.execute()
log.info('Request {} stream state is now "{}"'.format(self._request_id, value))
@property
def lock(self):
"""
Helps to manage request stream and delivery status from both plugin events and build response times
:return: A redis-based lock object for a given request
"""
return self.__lock
class StreamResponse(FragmentConsumerResponse):
def __init__(self, rid):
self.__sink = StreamSink()
self.__sink.load(rid)
self.__fragment_lock = fragment_lock(self.__sink.fragment_id)
super(StreamResponse, self).__init__(rid)
@property
def sink(self):
return self.__sink
def _build(self):
"""
This function yields nothing only when the new state is 'streaming'
:return: Quads like (context, subject, predicate, object)
"""
timestamp = calendar.timegm(dt.utcnow().timetuple())
fragment = None
self.sink.lock.acquire()
try:
fragment, streaming = self.fragment(timestamp=timestamp)
if streaming:
self.sink.stream = True
if fragment:
self.sink.delivery = 'mixing'
else:
self.sink.delivery = 'streaming'
else:
self.sink.stream = False
if fragment:
self.sink.delivery = 'pushing'
log.debug('Fragment retrieved from cache for request number {}'.format(self._request_id))
else:
self.sink.delivery = 'sent'
log.debug('Sending end stream signal since there is no fragment and stream is disabled')
yield (), {'state': 'end', 'format': 'tuple'}
except Exception as e:
log.warning(e.message)
self.sink.stream = True
self.sink.delivery = 'streaming'
finally:
self.sink.lock.release()
if fragment:
log.info('Building a stream result from cache for request number {}...'.format(self._request_id))
filter_mapping = self.sink.filter_mapping
self.__fragment_lock.acquire()
try:
for ch in chunks(fragment, 1000):
if ch:
rows = []
for (c, s, p, o) in ch:
real_context = map_variables(c, self.sink.mapping, filter_mapping)
consume = True
if self.sink.map(c[2]) in filter_mapping:
consume = match_filter(o, real_context[2])
if consume and self.sink.map(c[0]) in filter_mapping:
consume = match_filter(s, real_context[0])
if consume:
rows.append((real_context, s.n3(), p.n3(), o.n3()))
yield rows, {'source': 'store', 'format': 'tuple',
'state': 'streaming',
'response_to': self.sink.message_id,
'submitted_on': calendar.timegm(
datetime.utcnow().timetuple()),
'submitted_by': self.sink.submitted_by}
finally:
self.__fragment_lock.release()
self.sink.lock.acquire()
try:
if self.sink.delivery == 'pushing' or (self.sink.delivery == 'mixing' and not self.sink.stream):
self.sink.delivery = 'sent'
log.info(
'The response stream of request {} is completed. Notifying...'.format(self.sink.request_id))
yield (), {'state': 'end', 'format': 'tuple'}
elif self.sink.delivery == 'mixing' and self.sink.stream:
self.sink.delivery = 'streaming'
finally:
self.sink.lock.release()
def fragment(self, timestamp):
def __load_contexts():
contexts = fragment_contexts(self.sink.fragment_id)
triple_patterns = {context: eval(context)[1] for context in contexts}
# Yield triples for each known triple pattern context
for context in contexts:
for (s, p, o) in fragments_cache.get_context(context):
yield triple_patterns[context], s, p, o
if timestamp is None:
timestamp = calendar.timegm(dt.utcnow().timetuple())
self.__fragment_lock.acquire()
try:
from_streaming = not is_fragment_synced(self.sink.fragment_id)
return (load_stream_triples(self.sink.fragment_id, timestamp), True) if from_streaming else (
__load_contexts(), False)
finally:
self.__fragment_lock.release()
|
Agora-Scholar
|
/Agora-Scholar-0.2.0.tar.gz/Agora-Scholar-0.2.0/agora/scholar/actions/stream.py
|
stream.py
|
import calendar
import json
import logging
import traceback
from datetime import datetime
import networkx as nx
from agora.scholar.actions import FragmentConsumerResponse
from agora.scholar.daemons.fragment import fragment_lock, fragment_graph, fragments_key, fragment_updated_on, \
FragmentPlugin
from agora.stoa.actions.core import STOA
from agora.stoa.actions.core.fragment import FragmentRequest, FragmentAction, FragmentSink
from agora.stoa.actions.core.utils import chunks, tp_parts
from agora.stoa.store import r
from agora.stoa.store.tables import db
__author__ = 'Fernando Serena'
log = logging.getLogger('agora.scholar.actions.query')
def fragment_has_result_set(fid):
return r.get('{}:{}:rs'.format(fragments_key, fid)) is not None
def _update_result_set(fid, gp):
try:
result_gen = _query(fid, gp)
# solutions = _build_solutions(fid, gp)
# for s in solutions:
# print s
removed = db[fid].delete_many({}).deleted_count
log.info('{} rows removed from fragment {} result set'.format(removed, fid))
table = db[fid]
rows = set(result_gen)
if rows:
table.insert_many([{label: row[row.labels[label]] for label in row.labels} for row in rows])
log.info('{} rows inserted into fragment {} result set'.format(len(rows), fid))
with r.pipeline(transaction=True) as p:
p.multi()
p.set('{}:{}:rs'.format(fragments_key, fid), True)
p.execute()
except Exception as e:
traceback.print_exc()
log.error(e.message)
# def _build_solutions(fid, gp):
# gp_parts = [tp_parts(tp) for tp in gp]
# gp_graph = nx.DiGraph()
# for gp_part in gp_parts:
# gp_graph.add_edge(gp_part[0], gp_part[2], predicate=gp_part[1])
#
# roots = filter(lambda x: gp_graph.in_degree(x) == 0, gp_graph.nodes())
#
# sorted_pairs = []
# gp_graph.edges()
# for root in roots:
# succs = gp_graph.successors(root)
# sort
# yield fid
def _query(fid, gp):
"""
Query the fragment using the original request graph pattern
:param gp:
:param fid:
:return: The query result
"""
def __build_query_from(x, depth=0):
def build_pattern_query((u, v, data)):
return '\nOPTIONAL { %s %s %s %s }' % (u, data['predicate'], v, __build_query_from(v, depth + 1))
out_edges = list(gp_graph.out_edges_iter(x, data=True))
out_edges = reversed(sorted(out_edges, key=lambda x: gp_graph.out_degree))
if out_edges:
return ' '.join([build_pattern_query(x) for x in out_edges])
return ''
gp_parts = [tp_parts(tp) for tp in gp]
blocks = []
gp_graph = nx.DiGraph()
for gp_part in gp_parts:
gp_graph.add_edge(gp_part[0], gp_part[2], predicate=gp_part[1])
roots = filter(lambda x: gp_graph.in_degree(x) == 0, gp_graph.nodes())
blocks += ['%s a stoa:Root\nOPTIONAL { %s }' % (root, __build_query_from(root)) for root in roots]
where_gp = ' .\n'.join(blocks)
q = """SELECT DISTINCT * WHERE { %s }""" % where_gp
result = []
try:
log.info('Querying fragment {}:\n{}'.format(fid, q))
result = fragment_graph(fid).query(q)
except Exception as e: # ParseException from query
traceback.print_exc()
log.warning(e.message)
return result
class QueryPlugin(FragmentPlugin):
@property
def sink_class(self):
return QuerySink
def consume(self, fid, quad, graph, *args):
pass
# (subj, _, obj) = quad[0]
# collection_name = '{}:{}:{}:{}'.format(fragments_key, fid, subj, obj)
# db[collection_name].insert({subj: str(quad[1]), obj: str(quad[3])})
@property
def sink_aware(self):
return False
def complete(self, fid, *args):
fragment_gp = args[0]
try:
if fragment_has_result_set(fid):
_update_result_set(fid, fragment_gp)
except Exception, e:
traceback.print_exc()
log.error(e.message)
# collection_prefix = '{}:{}'.format(fragments_key, fid)
# for c in filter(lambda x: x.startswith(collection_prefix),
# db.collection_names(include_system_collections=False)):
# db.drop_collection(c)
# collection_name = '{}:{}:{}:{}'.format(fragments_key, fid, subj, obj)
# # intermediate_fid_keys = r.keys('{}:{}:int*'.format(fragments_key, fid))
# with r.pipeline() as p:
# for ifk in intermediate_fid_keys:
# p.delete(ifk)
# p.execute()
FragmentPlugin.register(QueryPlugin)
class QueryRequest(FragmentRequest):
def __init__(self):
super(QueryRequest, self).__init__()
def _extract_content(self, request_type=STOA.QueryRequest):
"""
Parse query request data. For this operation, there is no additional data to extract.
"""
super(QueryRequest, self)._extract_content(request_type=request_type)
class QueryAction(FragmentAction):
def __init__(self, message):
"""
Prepare request and sink objects before starting initialization
"""
self.__request = QueryRequest()
self.__sink = QuerySink()
super(QueryAction, self).__init__(message)
@property
def sink(self):
return self.__sink
@classmethod
def response_class(cls):
return QueryResponse
@property
def request(self):
return self.__request
def submit(self):
"""
If the fragment is already synced at submission time, the delivery becomes ready
"""
super(QueryAction, self).submit()
if fragment_updated_on(self.sink.fragment_id) is not None:
self.sink.delivery = 'ready'
class QuerySink(FragmentSink):
"""
Query sink does not need any extra behaviour
"""
def _remove(self, pipe):
super(QuerySink, self)._remove(pipe)
def __init__(self):
super(QuerySink, self).__init__()
def _save(self, action, general=True):
super(QuerySink, self)._save(action, general)
def _load(self):
super(QuerySink, self)._load()
class QueryResponse(FragmentConsumerResponse):
def __init__(self, rid):
# The creation of a response always require to load its corresponding sink
self.__sink = QuerySink()
self.__sink.load(rid)
super(QueryResponse, self).__init__(rid)
self.__fragment_lock = fragment_lock(self.__sink.fragment_id)
@property
def sink(self):
return self.__sink
def _build(self):
self.__fragment_lock.acquire()
result = self.result_set()
log.debug('Building a query result for request number {}'.format(self._request_id))
try:
# Query result chunking, yields JSON
for ch in chunks(result, 1000):
result_rows = []
for t in ch:
if any(t):
result_row = {self.sink.map('?' + v).lstrip('?'): t[v] for v in t}
result_rows.append(result_row)
if result_rows:
yield json.dumps(result_rows), {'state': 'streaming', 'source': 'store',
'response_to': self.sink.message_id,
'submitted_on': calendar.timegm(datetime.utcnow().timetuple()),
'submitted_by': self.sink.submitted_by,
'format': 'json'}
except Exception, e:
log.error(e.message)
raise
finally:
self.__fragment_lock.release()
yield [], {'state': 'end', 'format': 'json'}
# Just after sending the state:end message, the request delivery state switches to sent
self.sink.delivery = 'sent'
def result_set(self):
def extract_fields(result):
for r in result:
yield r['_id']
if not r.exists('{}:{}:rs'.format(fragments_key, self.sink.fragment_id)):
_update_result_set(self.sink.fragment_id, self.sink.fragment_gp)
pattern = {}
projection = {}
mapping = filter(lambda x: x.startswith('?'), self.sink.mapping)
for v in mapping:
value = self.sink.map(v, fmap=True)
if not value.startswith('?'):
if value.startswith('"'):
value = value.strip('"')
else:
value = value.lstrip('<').rstrip('>')
pattern[v.lstrip('?')] = value
elif not value.startswith('?_'):
# All those variables that start with '_' won't be projected
projection[v.lstrip('?')] = True
table = db[self.sink.fragment_id]
pipeline = [{"$match": {v: pattern[v] for v in pattern}},
{"$group": {'_id': {v: '$' + v for v in projection}}}]
return extract_fields(table.aggregate(pipeline))
|
Agora-Scholar
|
/Agora-Scholar-0.2.0.tar.gz/Agora-Scholar-0.2.0/agora/scholar/actions/query.py
|
query.py
|
__author__ = 'Fernando Serena'
from flask import Flask, jsonify, request, make_response
from functools import wraps
from agora.provider.jobs.collect import collect_fragment
from threading import Thread, Event
import time
from datetime import datetime, date
import pytz
from concurrent.futures import wait, ALL_COMPLETED
from concurrent.futures.thread import ThreadPoolExecutor
_batch_tasks = []
def get_accept():
return str(request.accept_mimetypes).split(',')
class APIError(Exception):
"""
Exception class to raise when an API request is not valid
"""
status_code = 400
def __init__(self, message, status_code=None, payload=None):
Exception.__init__(self)
self.message = message
if status_code is not None:
self.status_code = status_code
self.payload = payload
def to_dict(self):
rv = dict(self.payload or ())
rv['message'] = self.message
return rv
class NotFound(APIError):
"""
404 response class
"""
def __init__(self, message, payload=None):
super(NotFound, self).__init__(message, 404, payload)
class Conflict(APIError):
"""
409 response class
"""
def __init__(self, message, payload=None):
super(Conflict, self).__init__(message, 409, payload)
class AgoraApp(Flask):
"""
Provider base class for the Agora services
"""
def __init__(self, name, config_class):
"""
:param name: App name
:param config_class: String that represents the config class to be used
:return:
"""
super(AgoraApp, self).__init__(name)
self.__handlers = {}
self.__rdfizers = {}
self.errorhandler(self.__handle_invalid_usage)
self.config.from_object(config_class)
self._stop_event = Event()
@staticmethod
def __handle_invalid_usage(error):
response = jsonify(error.to_dict())
response.status_code = error.status_code
return response
def batch_work(self):
"""
Method to be executed in batch mode for collecting the required fragment (composite)
and then other custom tasks.
:return:
"""
while True:
gen = collect_fragment(self._stop_event, self.config['AGORA'])
for collector, (t, s, p, o) in gen:
for task in _batch_tasks:
task(collector, (t, s, p, o), self._stop_event)
if self._stop_event.isSet():
return
for task in _batch_tasks:
task(None, None, self._stop_event)
time.sleep(10)
def run(self, host=None, port=None, debug=None, **options):
"""
Start the AgoraApp expecting the provided config to have at least REDIS and PORT fields.
"""
tasks = options.get('tasks', [])
for task in tasks:
if task is not None and hasattr(task, '__call__'):
_batch_tasks.append(task)
thread = Thread(target=self.batch_work)
thread.start()
try:
super(AgoraApp, self).run(host='0.0.0.0', port=self.config['PORT'], debug=True, use_reloader=False)
except Exception, e:
print e.message
self._stop_event.set()
if thread.isAlive():
thread.join()
def __execute(self, f):
@wraps(f)
def wrapper():
mimes = get_accept()
if 'application/json' in mimes:
args, kwargs = self.__handlers[f.func_name](request)
context, data = f(*args, **kwargs)
response_dict = {'context': context, 'result': data}
return jsonify(response_dict)
else:
response = make_response(self.__rdfizers[f.func_name](f.func_name).serialize(format='turtle'))
response.headers['Content-Type'] = 'text-turtle'
return response
return wrapper
def __register(self, handler, rdfizer):
def decorator(f):
self.__handlers[f.func_name] = handler
self.__rdfizers[f.func_name] = rdfizer
return f
return decorator
def register(self, path, handler, rdfizer):
def decorator(f):
for dec in [self.__execute, self.__register(handler, rdfizer), self.route(path)]:
f = dec(f)
return f
return decorator
|
Agora-Service-Provider
|
/Agora-Service-Provider-0.0.17.tar.gz/Agora-Service-Provider-0.0.17/agora/provider/server/base.py
|
base.py
|
__author__ = 'Fernando Serena'
from agora.client.agora import Agora, AGORA
from rdflib import RDF, RDFS
import logging
from rdflib import Literal
import time
__triple_patterns = {}
__plan_patterns = {}
log = logging.getLogger('agora.provider')
def collect(tp, *args):
"""
Decorator to attach a collector function to a triple pattern
:param tp:
:param args:
:return:
"""
def decorator(f):
add_triple_pattern(tp, f, args)
return decorator
def add_triple_pattern(tp, collector, args):
"""0
Manage the relations between triple patterns and collector functions
:param tp:
:param collector:
:param args:
:return:
"""
tp_parts = [part.strip() for part in tp.strip().split(' ')]
tp = ' '.join(tp_parts)
if tp not in __triple_patterns.keys():
__triple_patterns[tp] = set([])
if collector is not None:
__triple_patterns[tp].add((collector, args))
def __extract_pattern_nodes(graph):
"""
Extract and bind the triple patterns contained in the search plan, so as to be able to identify
to which pattern is associated each triple of the fragment.
:return:
"""
tp_nodes = graph.subjects(RDF.type, AGORA.TriplePattern)
for tpn in tp_nodes:
subject = list(graph.objects(tpn, AGORA.subject)).pop()
predicate = list(graph.objects(tpn, AGORA.predicate)).pop()
obj = list(graph.objects(tpn, AGORA.object)).pop()
subject_str = list(graph.objects(subject, RDFS.label)).pop().toPython()
predicate_str = graph.qname(predicate)
if (obj, RDF.type, AGORA.Variable) in graph:
object_str = list(graph.objects(obj, RDFS.label)).pop().toPython()
else:
object_str = list(graph.objects(obj, AGORA.value)).pop().toPython()
__plan_patterns[tpn] = '{} {} {}'.format(subject_str, predicate_str, object_str)
def collect_fragment(event, agora_host):
"""
Execute a search plan for the declared graph pattern and sends all obtained triples to the corresponding
collector functions (config
"""
agora = Agora(agora_host)
graph_pattern = ""
for tp in __triple_patterns:
graph_pattern += '{} . '.format(tp)
fragment, _, graph = agora.get_fragment_generator('{%s}' % graph_pattern, stop_event=event, workers=4)
__extract_pattern_nodes(graph)
log.info('querying { %s}' % graph_pattern)
for (t, s, p, o) in fragment:
collectors = __triple_patterns[str(__plan_patterns[t])]
for c, args in collectors:
log.debug('Sending triple {} {} {} to {}'.format(s.n3(graph.namespace_manager), graph.qname(p),
o.n3(graph.namespace_manager), c))
c((s, p, o))
if event.isSet():
raise Exception('Abort collecting fragment')
yield (c.func_name, (t, s, p, o))
time.sleep(0.01)
|
Agora-Service-Provider
|
/Agora-Service-Provider-0.0.17.tar.gz/Agora-Service-Provider-0.0.17/agora/provider/jobs/collect.py
|
collect.py
|
import StringIO
import json
import logging
import time
import uuid
import re
from abc import abstractproperty, ABCMeta
from datetime import datetime
from threading import Thread
from urlparse import urlparse
import pika
from pika.exceptions import ChannelClosed
from rdflib import Graph, RDF, Literal, BNode, URIRef
from rdflib.namespace import Namespace, FOAF, XSD
from agora.client.wrapper import Agora
__author__ = 'Fernando Serena'
log = logging.getLogger('agora.stoa.client')
STOA = Namespace('http://www.smartdeveloperhub.org/vocabulary/stoa#')
TYPES = Namespace('http://www.smartdeveloperhub.org/vocabulary/types#')
AMQP = Namespace('http://www.smartdeveloperhub.org/vocabulary/amqp#')
class RequestGraph(Graph):
__metaclass__ = ABCMeta
def __init__(self):
super(RequestGraph, self).__init__()
self._request_node = BNode()
self._agent_node = BNode()
self._broker_node = BNode()
self._channel_node = BNode()
self._message_id = self._agent_id = self._submitted_on = self._exchange_name = None
self._routing_key = self._broker_host = self._broker_port = self._broker_vh = None
# Node binding
self.add((self.request_node, STOA.replyTo, self.channel_node))
self.add((self.request_node, STOA.submittedBy, self.agent_node))
self.add((self.channel_node, RDF.type, STOA.DeliveryChannel))
self.add((self.broker_node, RDF.type, AMQP.Broker))
self.add((self.channel_node, AMQP.broker, self.broker_node))
self.add((self.agent_node, RDF.type, FOAF.Agent))
# Default graph
self.message_id = uuid.uuid4()
self.submitted_on = datetime.now()
self.agent_id = uuid.uuid4()
self.exchange_name = ""
self.routing_key = ""
self.broker_host = "localhost"
self.broker_port = 5672
self.broker_vh = "/"
self.bind('stoa', STOA)
self.bind('amqp', AMQP)
self.bind('foaf', FOAF)
self.bind('types', TYPES)
@property
def request_node(self):
return self._request_node
@property
def broker_node(self):
return self._broker_node
@property
def channel_node(self):
return self._channel_node
@property
def agent_node(self):
return self._agent_node
@property
def message_id(self):
return self._message_id
@abstractproperty
def type(self):
pass
@message_id.setter
def message_id(self, value):
self._message_id = Literal(str(value), datatype=TYPES.UUID)
self.set((self._request_node, STOA.messageId, self._message_id))
@property
def agent_id(self):
return self._agent_id
@agent_id.setter
def agent_id(self, value):
self._agent_id = Literal(str(value), datatype=TYPES.UUID)
self.set((self._agent_node, STOA.agentId, self._agent_id))
@property
def submitted_on(self):
return self._submitted_on
@submitted_on.setter
def submitted_on(self, value):
self._submitted_on = Literal(value)
self.set((self._request_node, STOA.submittedOn, self._submitted_on))
@property
def exchange_name(self):
return self._exchange_name
@exchange_name.setter
def exchange_name(self, value):
self._exchange_name = Literal(value, datatype=TYPES.Name)
self.set((self.channel_node, AMQP.exchangeName, self._exchange_name))
@property
def routing_key(self):
return self._routing_key
@routing_key.setter
def routing_key(self, value):
self._routing_key = Literal(value, datatype=TYPES.Name)
self.set((self.channel_node, AMQP.routingKey, self._routing_key))
@property
def broker_host(self):
return self._broker_host
@broker_host.setter
def broker_host(self, value):
self._broker_host = Literal(value, datatype=TYPES.Hostname)
self.set((self.broker_node, AMQP.host, self._broker_host))
@property
def broker_port(self):
return self._broker_port
@broker_port.setter
def broker_port(self, value):
self._broker_port = Literal(value, datatype=TYPES.Port)
self.set((self.broker_node, AMQP.port, self._broker_port))
@property
def broker_vh(self):
return self._broker_vh
@broker_vh.setter
def broker_vh(self, value):
self._broker_vh = Literal(value, datatype=TYPES.Path)
self.set((self.broker_node, AMQP.virtualHost, self._broker_vh))
def transform(self, elem):
return elem
class FragmentRequestGraph(RequestGraph):
__metaclass__ = ABCMeta
@staticmethod
def __is_variable(elm):
return elm.startswith('?')
def __extend_uri(self, short):
"""
Extend a prefixed uri with the help of a specific dictionary of prefixes
:param short: Prefixed uri to be extended
:return:
"""
if short == 'a':
return RDF.type
for prefix in sorted(self.__prefixes, key=lambda x: len(x), reverse=True):
if short.startswith(prefix):
return URIRef(short.replace(prefix + ':', self.__prefixes[prefix]))
return short
def is_uri(self, uri):
if uri.startswith('<') and uri.endswith('>'):
uri = uri.lstrip('<').rstrip('>')
parse = urlparse(uri, allow_fragments=True)
return bool(len(parse.scheme))
elif ':' in uri:
prefix_parts = uri.split(':')
return len(prefix_parts) == 2 and prefix_parts[0] in self.__prefixes
return uri == 'a'
@staticmethod
def tp_parts(tp):
if tp.endswith('"'):
parts = [tp[tp.find('"'):]]
st = tp.replace(parts[0], '').rstrip()
parts = st.split(" ") + parts
else:
parts = tp.split(' ')
return tuple(parts)
def __init__(self, *args, **kwargs):
super(FragmentRequestGraph, self).__init__()
if not args:
raise AttributeError('A graph pattern must be provided')
self.__prefixes = kwargs.get('prefixes', None)
if self.__prefixes is None:
raise AttributeError('A prefixes list must be provided')
elements = {}
for tp in args:
s, p, o = self.tp_parts(tp.strip())
if s not in elements:
if self.__is_variable(s):
elements[s] = BNode(s.lstrip('?'))
self.set((elements[s], RDF.type, STOA.Variable))
self.set((elements[s], STOA.label, Literal(s, datatype=XSD.string)))
elif self.is_uri(s):
extended = self.__extend_uri(s)
if extended == s:
elements[s] = URIRef(s.lstrip('<').rstrip('>'))
else:
elements[s] = self.__extend_uri(s)
if p not in elements:
if self.is_uri(p):
elements[p] = self.__extend_uri(p)
if o not in elements:
if self.__is_variable(o):
elements[o] = BNode(o.lstrip('?'))
self.set((elements[o], RDF.type, STOA.Variable))
self.set((elements[o], STOA.label, Literal(o, datatype=XSD.string)))
elif self.is_uri(o):
extended = self.__extend_uri(o)
if extended == o:
elements[o] = URIRef(o.lstrip('<').rstrip('>'))
else:
elements[o] = self.__extend_uri(o)
else:
elements[o] = Literal(o.lstrip('"').rstrip('"'))
self.add((elements[s], elements[p], elements[o]))
class StreamRequestGraph(FragmentRequestGraph):
def __init__(self, *args, **kwargs):
super(StreamRequestGraph, self).__init__(*args, **kwargs)
self.add((self.request_node, RDF.type, STOA.StreamRequest))
@property
def type(self):
return 'stream'
def transform(self, quad):
def __extract_lang(v):
def __lang_tag_match(strg, search=re.compile(r'[^a-z]').search):
return not bool(search(strg))
if '@' in v:
(v_aux, lang) = tuple(v.split('@'))
(v, lang) = (v_aux, lang) if __lang_tag_match(lang) else (v, None)
else:
lang = None
return v, lang
def __transform(x):
if type(x) == str or type(x) == unicode:
if self.is_uri(x):
return URIRef(x.lstrip('<').rstrip('>'))
elif '^^' in x:
(value, ty) = tuple(x.split('^^'))
return Literal(value.replace('"', ''), datatype=URIRef(ty.lstrip('<').rstrip('>')))
elif x.startswith('_:'):
return BNode(x.replace('_:', ''))
else:
(elm, lang) = __extract_lang(x)
elm = elm.replace('"', '')
if lang is not None:
return Literal(elm, lang=lang)
else:
return Literal(elm, datatype=XSD.string)
return x
triple = quad[1:]
return tuple([quad[0]] + map(__transform, triple))
class QueryRequestGraph(FragmentRequestGraph):
def __init__(self, *args, **kwargs):
super(QueryRequestGraph, self).__init__(*args, **kwargs)
self.add((self.request_node, RDF.type, STOA.QueryRequest))
@property
def type(self):
return 'query'
class EnrichmentRequestGraph(FragmentRequestGraph):
def __init__(self, *args, **kwargs):
self._target_resource = ""
super(EnrichmentRequestGraph, self).__init__(*args, **kwargs)
self.add((self.request_node, RDF.type, STOA.EnrichmentRequest))
@property
def type(self):
return 'enrichment'
@property
def target_resource(self):
return self._target_resource
@target_resource.setter
def target_resource(self, value):
self._target_resource = URIRef(value)
self.set((self.request_node, STOA.targetResource, self._target_resource))
class StoaClient(object):
def __init__(self, broker_host='localhost', broker_port=5672, wait=False, monitoring=None, agora_host='localhost',
agora_port=5002, stop_event=None, exchange='stoa', topic_pattern='stoa.request',
response_prefix='stoa.response'):
self.agora = Agora(host=agora_host, port=agora_port)
self.__connection = pika.BlockingConnection(pika.ConnectionParameters(host=broker_host, port=broker_port))
self.__channel = self.__connection.channel()
self.__listening = False
self.__accept_queue = self.__response_queue = None
self.__monitor = Thread(target=self.__monitor_consume, args=[monitoring]) if monitoring else None
self.__last_consume = datetime.now()
self.__keep_monitoring = True
self.__accepted = False
self.__message = None
self.__wait = wait
self.__stop_event = stop_event
self.__exchange = exchange
self.__topic_pattern = topic_pattern
self.__response_prefix = response_prefix
def __monitor_consume(self, t):
log.debug('Stoa client monitor started...')
while self.__keep_monitoring:
if (datetime.now() - self.__last_consume).seconds > t:
self.stop()
break
else:
time.sleep(0.1)
def request(self, message):
self.__response_queue = self.__channel.queue_declare(auto_delete=True).method.queue
message.routing_key = self.__response_queue
self.__message = message
self.__accept_queue = self.__channel.queue_declare(auto_delete=True).method.queue
self.__channel.queue_bind(exchange=self.__exchange, queue=self.__accept_queue,
routing_key='{}.{}'.format(self.__response_prefix, str(message.agent_id)))
body = message.serialize(format='turtle')
self.__channel.basic_publish(exchange=self.__exchange,
routing_key='{}.{}'.format(self.__topic_pattern, self.__message.type),
body=body)
log.debug(body)
log.info('sent {} request!'.format(self.__message.type))
self.__listening = True
return self.agora.prefixes, self.__consume()
def __consume(self):
def __response_callback(properties, body):
stop_flag = False
if properties.headers.get('state', None) == 'end':
log.info('End of stream received!')
stop_flag = True
format = properties.headers.get('format', 'json')
if format == 'turtle':
graph = Graph()
graph.parse(StringIO.StringIO(body), format=format)
yield properties.headers, graph
else:
items = json.loads(body) if format == 'json' else eval(body)
if items and not isinstance(items, list):
items = [items]
for item in items:
yield properties.headers, item
if stop_flag:
self.stop()
log.debug('Waiting for acceptance...')
for message in self.__channel.consume(self.__accept_queue, no_ack=True, inactivity_timeout=1):
if message is not None:
method, properties, body = message
g = Graph()
g.parse(StringIO.StringIO(body), format='turtle')
if len(list(g.subjects(RDF.type, STOA.Accepted))) == 1:
log.info('Request accepted!')
self.__accepted = True
else:
log.error('Bad request!')
self.__channel.queue_delete(self.__accept_queue)
self.__channel.cancel()
break
elif self.__stop_event is not None:
if self.__stop_event.isSet():
self.stop()
if not self.__accepted:
log.debug('Request not accepted. Aborting...')
raise StopIteration()
if self.__monitor is not None:
self.__monitor.start()
log.debug('Listening...')
for message in self.__channel.consume(self.__response_queue, no_ack=True, inactivity_timeout=1):
if message is not None:
method, properties, body = message
for headers, item in __response_callback(properties, body):
yield headers, self.__message.transform(item)
elif not self.__wait:
yield None
elif self.__stop_event is not None:
if self.__stop_event.isSet():
self.stop()
raise StopIteration()
else:
log.debug('Inactivity timeout...')
self.__last_consume = datetime.now()
if self.__monitor is not None:
self.__keep_monitoring = False
log.debug('Waiting for client monitor to stop...')
self.__monitor.join()
def stop(self):
try:
self.__channel.queue_delete(self.__accept_queue)
self.__channel.queue_delete(self.__response_queue)
self.__channel.cancel()
self.__channel.close()
self.__listening = False
except ChannelClosed:
pass
log.debug('Stopped stoa client!')
@property
def listening(self):
return self.__listening
def get_fragment_generator(*args, **kwargs):
stoa_kwargs = kwargs['STOA']
stoa_kwargs.update({k: kwargs[k] for k in kwargs if k == 'wait' or k == 'monitoring'})
client = StoaClient(**stoa_kwargs)
request = StreamRequestGraph(prefixes=client.agora.prefixes, *args)
if 'updating' in kwargs:
request.add(
(request.request_node, STOA.expectedUpdatingDelay, Literal(kwargs['updating'], datatype=XSD.integer)))
if 'gen' in kwargs:
request.add((request.request_node, STOA.allowGeneralisation, Literal(True, datatype=XSD.boolean)))
if 'events' in kwargs:
request.add((request.request_node, STOA.updateOnEvents, Literal(True, datatype=XSD.boolean)))
request.broker_host = stoa_kwargs['broker_host']
return client.request(request)
def get_query_generator(*args, **kwargs):
stoa_kwargs = kwargs['STOA']
stoa_kwargs.update({k: kwargs[k] for k in kwargs if k == 'wait' or k == 'monitoring'})
client = StoaClient(**stoa_kwargs)
request = QueryRequestGraph(prefixes=client.agora.prefixes, *args)
if 'updating' in kwargs:
request.add(
(request.request_node, STOA.expectedUpdatingDelay, Literal(kwargs['updating'], datatype=XSD.integer)))
if 'gen' in kwargs:
request.add((request.request_node, STOA.allowGeneralisation, Literal(True, datatype=XSD.boolean)))
if 'events' in kwargs:
request.add((request.request_node, STOA.updateOnEvents, Literal(True, datatype=XSD.boolean)))
request.broker_host = stoa_kwargs['broker_host']
return client.request(request)
def get_enrichment_generator(*args, **kwargs):
def apply_target(x):
if x.startswith('*'):
return x.replace('*', '<{}>'.format(target))
return x
target = kwargs['target']
del kwargs['target']
args = map(lambda x: apply_target(x), args)
client = StoaClient(**kwargs)
request = EnrichmentRequestGraph(prefixes=client.agora.prefixes, *args)
request.broker_host = kwargs['broker_host']
request.target_resource = target
return client.request(request)
|
Agora-Stoa-Client
|
/Agora-Stoa-Client-0.2.2.tar.gz/Agora-Stoa-Client-0.2.2/agora/stoa/client/__init__.py
|
__init__.py
|
import json
import click
import re
from rdflib import Graph
from agora.stoa.client import get_fragment_generator,get_query_generator
@click.group()
def cli():
pass
@click.command()
@click.argument('gp', type=click.STRING)
@click.option('--broker', '-b', default=('localhost', 5672), type=(click.STRING, click.INT))
@click.option('--agora', '-a', default=('localhost', 9002), type=(click.STRING, click.INT))
@click.option('--channel', '-c', default=('stoa', 'stoa.request', 'stoa.response'),
type=(click.STRING, click.STRING, click.STRING))
@click.option('--updating', '-u', default=10, type=click.INT)
@click.option('--gen', '-g', default=False, type=click.BOOL)
def fragment(gp, broker, agora, channel, updating, gen):
try:
gp_match = re.search(r'\{(.*)\}', gp).groups(0)
if len(gp_match) != 1:
raise click.ClickException('Invalid graph pattern')
STOA = {
"broker_host": broker[0],
"broker_port": broker[1],
"agora_host": agora[0],
"agora_port": agora[1],
"exchange": channel[0],
"topic_pattern": channel[1],
"response_prefix": channel[2]
}
tps = re.split('\. ', gp_match[0])
prefixes, fragment_gen = get_fragment_generator(*tps, monitoring=30, STOA=STOA, updating=updating, gen=gen)
graph = Graph()
for prefix in prefixes:
graph.bind(prefix, prefixes[prefix])
click.echo('@prefix {}: <{}> .'.format(prefix, prefixes[prefix]))
click.echo('')
for chunk in fragment_gen:
if chunk is not None:
headers, (c, s, p, o) = chunk
triple = u'{} {} {} .'.format(s.n3(graph.namespace_manager), p.n3(graph.namespace_manager),
o.n3(graph.namespace_manager))
click.echo(triple)
except Exception as e:
raise click.ClickException('There was a problem with the request: {}'.format(e.message))
@click.command()
@click.argument('gp', type=click.STRING)
@click.option('--broker', '-b', default=('localhost', 5672), type=(click.STRING, click.INT))
@click.option('--agora', '-a', default=('localhost', 9002), type=(click.STRING, click.INT))
@click.option('--channel', '-c', default=('stoa', 'stoa.request', 'stoa.response'),
type=(click.STRING, click.STRING, click.STRING))
@click.option('--updating', '-u', default=10, type=click.INT)
@click.option('--gen', '-g', default=False, type=click.BOOL)
def query(gp, broker, agora, channel, updating, gen):
try:
gp_match = re.search(r'\{(.*)\}', gp).groups(0)
if len(gp_match) != 1:
raise click.ClickException('Invalid graph pattern')
STOA = {
"broker_host": broker[0],
"broker_port": broker[1],
"agora_host": agora[0],
"agora_port": agora[1],
"exchange": channel[0],
"topic_pattern": channel[1],
"response_prefix": channel[2]
}
tps = re.split('\. ', gp_match[0])
_, query_gen = get_query_generator(*tps, monitoring=30, STOA=STOA, updating=updating, gen=gen)
click.secho('[', nl=False, bold=True)
first_row = True
for chunk in query_gen:
if chunk is not None:
_, row = chunk
row_json = json.dumps(row)
row_str = ',\n {}'.format(row_json)
if first_row:
row_str = row_str.lstrip(',')
first_row = False
click.secho(row_str, nl=False)
click.secho('\n]', bold=True)
except Exception as e:
raise click.ClickException('There was a problem with the request: {}'.format(e.message))
cli.add_command(query)
cli.add_command(fragment)
if __name__ == '__main__':
cli()
|
Agora-Stoa-Client
|
/Agora-Stoa-Client-0.2.2.tar.gz/Agora-Stoa-Client-0.2.2/agora/stoa/client/cli.py
|
cli.py
|
from agora.stoa.server import app, NotFound
from agora.stoa.store import r
from flask import jsonify
from flask.views import View
__author__ = 'Fernando Serena'
AGENT_ID = app.config['ID']
def filter_hash_attrs(key, predicate):
hash_map = r.hgetall(key)
visible_attrs = filter(predicate, hash_map)
return {attr: hash_map[attr] for attr in filter(lambda x: x in visible_attrs, hash_map)}
@app.route('/requests')
def get_requests():
requests = [rk.split(':')[1] for rk in r.keys('{}:requests:*:'.format(AGENT_ID))]
return jsonify(requests=requests)
@app.route('/requests/<rid>')
def get_request(rid):
if not r.exists('{}:requests:{}:'.format(AGENT_ID, rid)):
raise NotFound('The request {} does not exist'.format(rid))
r_dict = filter_hash_attrs('{}:requests:{}:'.format(AGENT_ID, rid), lambda x: not x.startswith('__'))
channel = r_dict['channel']
ch_dict = r.hgetall('{}:channels:{}'.format(AGENT_ID, channel))
broker = r_dict['broker']
br_dict = r.hgetall('{}:brokers:{}'.format(AGENT_ID, broker))
r_dict['channel'] = ch_dict
r_dict['broker'] = br_dict
if 'mapping' in r_dict:
r_dict['mapping'] = eval(r_dict['mapping'])
return jsonify(r_dict)
@app.route('/fragments')
def get_fragments():
fragment_ids = list(r.smembers('{}:fragments'.format(AGENT_ID)))
f_list = [{'id': fid, 'gp': list(r.smembers('{}:fragments:{}:gp'.format(AGENT_ID, fid)))} for fid in fragment_ids]
return jsonify(fragments=f_list)
class FragmentView(View):
decorators = []
@staticmethod
def __get_fragment(fid):
if not r.sismember('{}:fragments'.format(AGENT_ID), fid):
raise NotFound('The fragment {} does not exist'.format(fid))
f_dict = {
'id': fid,
'gp': list(r.smembers('{}:fragments:{}:gp'.format(AGENT_ID, fid))),
'synced': r.exists('{}:fragments:{}:sync'.format(AGENT_ID, fid)),
'requests': list(r.smembers('{}:fragments:{}:requests'.format(AGENT_ID, fid)))
}
return f_dict
def dispatch_request(self, **kwargs):
result = self.__get_fragment(kwargs['fid'])
for decorator in FragmentView.decorators:
result = decorator(**result)
return jsonify(result)
app.add_url_rule('/fragments/<fid>', view_func=FragmentView.as_view('fragment'))
|
Agora-Stoa
|
/Agora-Stoa-0.2.0.tar.gz/Agora-Stoa-0.2.0/agora/stoa/api.py
|
api.py
|
import logging
from threading import Thread
import pika
import time
from agora.stoa.actions import execute
from agora.stoa.actions.core import PassRequest
from agora.stoa.server import app
__author__ = 'Fernando Serena'
log = logging.getLogger('agora.stoa.messaging')
# Load environment variables
BROKER_CONFIG = app.config['BROKER']
EXCHANGE_CONFIG = app.config['EXCHANGE']
exchange = EXCHANGE_CONFIG['exchange']
queue = EXCHANGE_CONFIG['queue']
topic_pattern = EXCHANGE_CONFIG['topic_pattern']
response_prefix = EXCHANGE_CONFIG['response_rk']
log.info("""Broker setup:
- host: {}
- port: {}
- exchange: {}
- queue: {}
- topic pattern: {}
- response prefix: {}""".format(BROKER_CONFIG['host'],
BROKER_CONFIG['port'],
exchange, queue, topic_pattern, response_prefix))
def callback(ch, method, properties, body):
action_args = method.routing_key.split('.')[2:]
log.info('--> Incoming {} request!'.format(action_args[0]))
try:
execute(*action_args, data=body)
except (NameError, SystemError) as e:
log.error(e.message)
ch.basic_reject(delivery_tag=method.delivery_tag, requeue=True)
log.debug('Sent REJECT')
except PassRequest:
log.info('Skipping request...')
ch.basic_reject(delivery_tag=method.delivery_tag, requeue=True)
log.debug('Sent REJECT')
except IOError as e:
ch.basic_ack(delivery_tag=method.delivery_tag)
log.error('There was a messaging problem with a request: {}'.format(e.message))
except Exception as e:
# EnvironmentError, such as 'Agora is not available' will be caught here...
ch.basic_ack(delivery_tag=method.delivery_tag)
log.error(e.message)
else:
ch.basic_ack(delivery_tag=method.delivery_tag)
log.debug('Sent ACK')
def __setup_queues():
"""
Establish the Stoa messaging system
"""
while True:
try:
connection = pika.BlockingConnection(pika.ConnectionParameters(
host=BROKER_CONFIG['host']))
except Exception, e:
log.error('AMQP broker is not available: {}'.format(e.message))
else:
channel = connection.channel()
log.info('Connected to the AMQP broker: {}'.format(BROKER_CONFIG))
log.info('Declaring exchange "{}"...'.format(exchange))
channel.exchange_declare(exchange=exchange,
type='topic', durable=True)
# Create the requests queue and binding
channel.queue_declare(queue, durable=True)
log.info('Declaring queue "{}"...'.format(queue))
channel.queue_bind(exchange=exchange, queue=queue, routing_key=topic_pattern)
log.info('Binding to topic "{}"...'.format(topic_pattern))
channel.basic_qos(prefetch_count=1)
channel.basic_consume(callback, queue=queue)
log.info('Ready to accept requests')
try:
channel.start_consuming()
except Exception, e:
log.error('Messaging system failed due to: {}'.format(e.message))
time.sleep(1)
# Create and start delivery daemon
th = Thread(target=__setup_queues)
th.daemon = True
th.start()
|
Agora-Stoa
|
/Agora-Stoa-0.2.0.tar.gz/Agora-Stoa-0.2.0/agora/stoa/messaging/__init__.py
|
__init__.py
|
import logging
import traceback
from threading import Thread
from agora.stoa.actions.core import AGENT_ID
from agora.stoa.messaging.reply import reply
from agora.stoa.server import app
from agora.stoa.store import r
from concurrent.futures.thread import ThreadPoolExecutor
__author__ = 'Fernando Serena'
__log = logging.getLogger('agora.stoa.daemons.delivery')
# Load environment variables
MAX_CONCURRENT_DELIVERIES = int(app.config.get('PARAMS', {}).get('max_concurrent_deliveries', 8))
# Delivery thread pool
__thp = ThreadPoolExecutor(max_workers=min(8, MAX_CONCURRENT_DELIVERIES))
__log.info("""Delivery daemon setup:
- Maximum concurrent deliveries: {}""".format(MAX_CONCURRENT_DELIVERIES))
__deliveries_key = '{}:deliveries'.format(AGENT_ID)
__ready_key = '{}:ready'.format(__deliveries_key)
__sent_key = '{}:sent'.format(__deliveries_key)
def build_response(rid):
"""
Creates a response instance for a given request id
:param rid: Request identifier
:return: The response object
"""
from agora.stoa.actions import get_instance
response_class = r.hget('{}:requests:{}:'.format(AGENT_ID, rid), '__response_class')
if response_class is None:
raise AttributeError('Cannot create a response for {}'.format(rid))
(module_name, class_name) = tuple(response_class.split('.'))
return get_instance(module_name, class_name, rid)
def __deliver_response(rid):
"""
The delivery task for a given request id
:param rid: Request id
"""
def deliver_message():
reply(message, headers=headers, **response.sink.recipient)
return len(str(message))
response = None
try:
response = build_response(rid)
delivery_state = response.sink.delivery
if delivery_state == 'ready':
messages = response.build()
# The creation of a response object may change the corresponding request delivery state
# (mixing, streaming, etc). The thing is that it was 'ready' before,
# so it should has something prepared to deliver.
n_messages = 0
deliver_weight = 0
message, headers = messages.next() # Actually, this is the trigger
deliver_weight += deliver_message()
n_messages += 1
deliver_delta = 0
for (message, headers) in messages:
message_weight = deliver_message()
deliver_weight += message_weight
deliver_delta += message_weight
n_messages += 1
if deliver_delta > 1000:
deliver_delta = 0
__log.info('Delivering response of request {} [{} kB]'.format(rid, deliver_weight / 1000.0))
deliver_weight /= 1000.0
__log.info('{} messages delivered for request {} [{} kB]'.format(n_messages, rid, deliver_weight))
elif delivery_state == 'accepted':
__log.error('Request {} should not be marked as deliver-ready, its state is inconsistent'.format(rid))
else:
__log.info('Response of request {} is being delivered by other means...'.format(rid))
r.srem(__ready_key, rid)
except StopIteration: # There was nothing prepared to deliver (Its state may have changed to
# 'streaming')
r.srem(__ready_key, rid)
except (EnvironmentError, AttributeError, Exception), e:
r.srem(__ready_key, rid)
# traceback.print_exc()
__log.warning(e.message)
if response is not None:
__log.error('Force remove of request {} due to a delivery error'.format(rid))
response.sink.remove()
else:
__log.error("Couldn't remove request {}".format(rid))
def __deliver_responses():
import time
__log.info('Delivery daemon started')
# Declare in-progress deliveries dictionary
futures = {}
while True:
try:
# Get all ready deliveries
ready = r.smembers(__ready_key)
for rid in ready:
# If the delivery is not in the thread pool, just submit it
if rid not in futures:
__log.info('Response delivery of request {} is ready. Putting it in queue...'.format(rid))
futures[rid] = __thp.submit(__deliver_response, rid)
# Clear futures that have already ceased to be ready
for obsolete_rid in set.difference(set(futures.keys()), ready):
if obsolete_rid in futures and futures[obsolete_rid].done():
del futures[obsolete_rid]
# All those deliveries that are marked as 'sent' are being cleared here along its request data
sent = r.smembers(__sent_key)
for rid in sent:
r.srem(__ready_key, rid)
r.srem(__deliveries_key, rid)
try:
response = build_response(rid)
response.sink.remove() # Its lock is removed too
__log.info('Request {} was sent and cleared'.format(rid))
except AttributeError:
traceback.print_exc()
__log.warning('Request number {} was deleted by other means'.format(rid))
pass
r.srem(__sent_key, rid)
except Exception as e:
__log.error(e.message)
traceback.print_exc()
finally:
time.sleep(0.1)
# Log delivery counters at startup
__registered_deliveries = r.scard(__deliveries_key)
__deliveries_ready = r.scard(__ready_key)
__log.info("""Delivery daemon started:
- Deliveries: {}
- Ready: {}""".format(__registered_deliveries, __deliveries_ready))
# Create and start delivery daemon
__thread = Thread(target=__deliver_responses)
__thread.daemon = True
__thread.start()
|
Agora-Stoa
|
/Agora-Stoa-0.2.0.tar.gz/Agora-Stoa-0.2.0/agora/stoa/daemons/delivery.py
|
delivery.py
|
import logging
import uuid
import os
__author__ = 'Fernando Serena'
def _api_port():
return int(os.environ.get('API_PORT', 5007))
def _agent_id():
aid = os.environ.get('AGENT_ID')
if not aid:
try:
with file('.AGENT_ID', mode='r') as f:
aid = f.readline()
except IOError:
pass
if not aid:
aid = str(uuid.uuid4())
with file('.AGENT_ID', mode='w') as f:
f.write(aid)
return aid
def _redis_conf(def_host, def_port, def_db):
return {'host': os.environ.get('DB_HOST', def_host),
'db': int(os.environ.get('DB_DB', def_db)),
'port': int(os.environ.get('DB_PORT', def_port))}
def _mongo_conf(def_host, def_port, def_db):
return {'host': os.environ.get('MONGO_HOST', def_host),
'db': os.environ.get('MONGO_DB', def_db),
'port': int(os.environ.get('MONGO_PORT', def_port))}
def _agora_conf(def_host, def_port):
return {'host': os.environ.get('AGORA_HOST', def_host),
'port': int(os.environ.get('AGORA_PORT', def_port))}
def _broker_conf(def_host, def_port):
return {'host': os.environ.get('AMQP_HOST', def_host),
'port': int(os.environ.get('AMQP_PORT', def_port))}
def _exchange_conf(def_exchange, def_queue, def_tp, def_response_rk):
return {
'exchange': os.environ.get('EXCHANGE_NAME', def_exchange),
'queue': os.environ.get('QUEUE_NAME', def_queue),
'topic_pattern': os.environ.get('TOPIC_PATTERN', def_tp),
'response_rk': os.environ.get('RESPONSE_RK_PREFIX', def_response_rk)
}
def _behaviour_conf(def_pass_threshold):
return {
'pass_threshold': float(os.environ.get('PASS_THRESHOLD', def_pass_threshold))
}
def _cache_conf(def_graph_throttling, def_min_cache_time):
return {
'graph_throttling': float(os.environ.get('GRAPH_THROTTLING', def_graph_throttling)),
'min_cache_time': float(os.environ.get('MIN_CACHE_TIME', def_min_cache_time))
}
def _logging_conf(def_level):
return int(os.environ.get('LOG_LEVEL', def_level))
class Config(object):
PORT = _api_port()
REDIS = _redis_conf('localhost', 6379, 4)
MONGO = _mongo_conf('localhost', 27017, 'scholar')
AGORA = _agora_conf('localhost', 9002)
BROKER = _broker_conf('localhost', 5672)
EXCHANGE = _exchange_conf('stoa', 'stoa_requests', 'stoa.request.*', 'stoa.response')
BEHAVIOUR = _behaviour_conf(0.1)
CACHE = _cache_conf(20, 60)
ID = _agent_id()
class DevelopmentConfig(Config):
DEBUG = True
LOG = logging.DEBUG
class TestingConfig(Config):
DEBUG = False
LOG = logging.DEBUG
TESTING = True
class ProductionConfig(Config):
DEBUG = False
LOG = _logging_conf(logging.INFO)
|
Agora-Stoa
|
/Agora-Stoa-0.2.0.tar.gz/Agora-Stoa-0.2.0/agora/stoa/server/config.py
|
config.py
|
import os
import logging
import agora.stoa as root
import json
from agora.stoa.server import app
from importlib import import_module
__author__ = 'Fernando Serena'
__log_level = int(os.environ.get('LOG_LEVEL', logging.INFO))
if __log_level is None:
__log_level = int(app.config['LOG'])
__ch = logging.StreamHandler()
__formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')
__ch.setFormatter(__formatter)
__ch.setLevel(__log_level)
__logger = logging.getLogger('agora')
__logger.addHandler(__ch)
__logger.setLevel(__log_level)
def bootstrap(config=None, modules=None, metadata_pkg=None, logger_name=None, api_ext=None):
if metadata_pkg is None:
metadata_pkg = root
metadata_path = os.path.join(metadata_pkg.__path__[0], 'metadata.json')
with open(metadata_path, 'r') as stream:
metadata = json.load(stream)
if config is not None:
current_config = app.config.items()
app.config.from_object(config)
app.config.update(current_config)
logger_name = logger_name or 'agora.stoa.bootstrap'
logger = logging.getLogger(logger_name)
logger.info('--- Starting {} v{} ---'.format(metadata.get('name'), metadata.get('version')))
logger.info('Loading stores...')
import agora.stoa.store
import agora.stoa.store.triples
import agora.stoa.store.tables
logger.info('Loading API description...')
if api_ext is not None and isinstance(modules, list):
for ext in api_ext:
import_module(ext)
from agora.stoa import api
if modules is not None and isinstance(modules, list):
from agora.stoa.actions import register_module
for name, module in modules:
register_module(name, import_module(module))
logger.info('Loading messaging system...')
import agora.stoa.messaging
import agora.stoa.daemons.delivery
logger.info('Starting REST API...')
app.run(host='0.0.0.0', port=app.config['PORT'], debug=False, use_reloader=False)
|
Agora-Stoa
|
/Agora-Stoa-0.2.0.tar.gz/Agora-Stoa-0.2.0/agora/stoa/server/bootstrap.py
|
bootstrap.py
|
import StringIO
import uuid
__author__ = 'Fernando Serena'
import pika
import sys
from rdflib import Graph, URIRef, RDF, Literal
from rdflib.namespace import Namespace, FOAF
import os
from datetime import datetime
CURATOR = Namespace('http://www.smartdeveloperhub.org/vocabulary/curator#')
TYPES = Namespace('http://www.smartdeveloperhub.org/vocabulary/types#')
AMQP = Namespace('http://www.smartdeveloperhub.org/vocabulary/amqp#')
accepted = False
def callback(ch, method, properties, body):
if properties.headers.get('state', None) == 'end':
print 'End of stream received!'
channel.stop_consuming()
else:
source = properties.headers.get('source', None)
print source,
print body
def accept_callback(ch, method, properties, body):
global accepted
if not accepted:
g = Graph()
g.parse(StringIO.StringIO(body), format='turtle')
if len(list(g.subjects(RDF.type, CURATOR.Accepted))) == 1:
print 'Request accepted!'
accepted = True
connection = pika.BlockingConnection(pika.ConnectionParameters(
host='localhost'))
channel = connection.channel()
routing_key = ''
exchange = ''
graph = Graph()
script_dir = os.path.dirname(__file__)
with open(os.path.join(script_dir, 'stream.ttl')) as f:
graph.parse(file=f, format='turtle')
req_node = list(graph.subjects(RDF.type, CURATOR.StreamRequest)).pop()
message_id = Literal(str(uuid.uuid4()), datatype=TYPES.UUID)
agent_id = Literal(str(uuid.uuid4()), datatype=TYPES.UUID)
graph.set((req_node, CURATOR.messageId, message_id))
graph.set((req_node, CURATOR.submittedOn, Literal(datetime.now())))
agent_node = list(graph.subjects(RDF.type, FOAF.Agent)).pop()
graph.set((agent_node, CURATOR.agentId, agent_id))
ch_node = list(graph.subjects(RDF.type, CURATOR.DeliveryChannel)).pop()
result = channel.queue_declare(exclusive=True)
queue_name = result.method.queue
# channel.queue_bind(exchange=exchange, queue=queue_name, routing_key=routing_key)
channel.basic_consume(callback, queue=queue_name, no_ack=True)
result = channel.queue_declare(exclusive=True)
accept_queue = result.method.queue
channel.queue_bind(exchange='sdh', queue=accept_queue, routing_key='curator.response.{}'.format(str(agent_id)))
channel.basic_consume(accept_callback, queue=accept_queue, no_ack=True)
# graph.set((ch_node, AMQP.queueName, Literal(queue_name)))
graph.set((ch_node, AMQP.routingKey, Literal(queue_name)))
graph.set((ch_node, AMQP.exchangeName, Literal(exchange)))
message = graph.serialize(format='turtle')
channel.basic_publish(exchange='sdh',
routing_key='curator.request.stream',
body=message)
channel.start_consuming()
|
Agora-Stoa
|
/Agora-Stoa-0.2.0.tar.gz/Agora-Stoa-0.2.0/agora/stoa/test/stream.py
|
stream.py
|
import StringIO
import uuid
__author__ = 'Fernando Serena'
import pika
import sys
from rdflib import Graph, URIRef, RDF, Literal
from rdflib.namespace import Namespace, FOAF
import os
from datetime import datetime
CURATOR = Namespace('http://www.smartdeveloperhub.org/vocabulary/curator#')
TYPES = Namespace('http://www.smartdeveloperhub.org/vocabulary/types#')
AMQP = Namespace('http://www.smartdeveloperhub.org/vocabulary/amqp#')
accepted = False
def callback(ch, method, properties, body):
if 'state' in properties.headers:
if properties.headers['state'] == 'end':
channel.stop_consuming()
return
print 'chunk headers: ', properties.headers
for _ in eval(body):
print _
def accept_callback(ch, method, properties, body):
global accepted
if not accepted:
g = Graph()
g.parse(StringIO.StringIO(body), format='turtle')
if len(list(g.subjects(RDF.type, CURATOR.Accepted))) == 1:
print 'Request accepted!'
accepted = True
connection = pika.BlockingConnection(pika.ConnectionParameters(
host='localhost'))
channel = connection.channel()
routing_key = ''
exchange = ''
graph = Graph()
script_dir = os.path.dirname(__file__)
with open(os.path.join(script_dir, 'query_usernames.ttl')) as f:
graph.parse(file=f, format='turtle')
req_node = list(graph.subjects(RDF.type, CURATOR.QueryRequest)).pop()
message_id = Literal(str(uuid.uuid4()), datatype=TYPES.UUID)
agent_id = Literal(str(uuid.uuid4()), datatype=TYPES.UUID)
graph.set((req_node, CURATOR.messageId, message_id))
graph.set((req_node, CURATOR.submittedOn, Literal(datetime.now())))
agent_node = list(graph.subjects(RDF.type, FOAF.Agent)).pop()
graph.set((agent_node, CURATOR.agentId, agent_id))
ch_node = list(graph.subjects(RDF.type, CURATOR.DeliveryChannel)).pop()
result = channel.queue_declare(exclusive=True)
queue_name = result.method.queue
# channel.queue_bind(exchange=exchange, queue=queue_name, routing_key=routing_key)
channel.basic_consume(callback, queue=queue_name, no_ack=True)
result = channel.queue_declare(exclusive=True)
accept_queue = result.method.queue
channel.queue_bind(exchange='sdh', queue=accept_queue, routing_key='curator.response.{}'.format(str(agent_id)))
channel.basic_consume(accept_callback, queue=accept_queue, no_ack=True)
# graph.set((ch_node, AMQP.queueName, Literal(queue_name)))
graph.set((ch_node, AMQP.routingKey, Literal(queue_name)))
graph.set((ch_node, AMQP.exchangeName, Literal(exchange)))
message = graph.serialize(format='turtle')
channel.basic_publish(exchange='sdh',
routing_key='curator.request.query',
body=message)
channel.start_consuming()
|
Agora-Stoa
|
/Agora-Stoa-0.2.0.tar.gz/Agora-Stoa-0.2.0/agora/stoa/test/query.py
|
query.py
|
import StringIO
import calendar
import logging
import shutil
import traceback
from random import random
from threading import Lock
import datetime
from datetime import datetime as dt
from rdflib.graph import Graph
from redis.lock import Lock as RedisLock
from time import sleep
import os
import shortuuid
from agora.stoa.actions.core import STOA, AGENT_ID
from agora.stoa.server import app
from agora.stoa.store import r
from concurrent.futures import ThreadPoolExecutor
from rdflib import ConjunctiveGraph, URIRef, Literal, XSD, BNode
import re
from agora.stoa.store.events import start_channel
from werkzeug.http import parse_dict_header
__author__ = 'Fernando Serena'
_log = logging.getLogger('agora.stoa.store.triples')
_pool = ThreadPoolExecutor(max_workers=4)
GRAPH_THROTTLING = max(1, int(app.config.get('CACHE', {}).get('graph_throttling', 30)))
MIN_CACHE_TIME = max(0, int(app.config.get('CACHE', {}).get('min_cache_time', 10)))
EVENTS_EXCHANGE = app.config.get('EVENTS_EXCHANGE', None)
EVENTS_TOPIC = app.config.get('EVENTS_TOPIC', None)
_log.info("""Triple store setup:
- Graph throttling: {}
- Minimum cache time: {}""".format(GRAPH_THROTTLING, MIN_CACHE_TIME))
_log.info('Cleaning cache...')
__uuid_locks = r.keys('{}:cache*'.format(AGENT_ID))
for ulk in __uuid_locks:
r.delete(ulk)
event_resource_callbacks = set([])
def load_stream_triples(fid, until):
def __triplify(x):
def __extract_lang(v):
def __lang_tag_match(strg, search=re.compile(r'[^a-z]').search):
return not bool(search(strg))
if '@' in v:
try:
(v_aux, lang) = tuple(v.split('@'))
(v, lang) = (v_aux, lang) if __lang_tag_match(lang) else (v, None)
except ValueError:
lang = None
else:
lang = None
return v, lang
def __term(elm):
if elm.startswith('<'):
return URIRef(elm.lstrip('<').rstrip('>'))
elif '^^' in elm:
(value, ty) = tuple(elm.split('^^'))
return Literal(value.replace('"', ''), datatype=URIRef(ty.lstrip('<').rstrip('>')))
elif elm.startswith('_:'):
return BNode(elm.replace('_:', ''))
else:
(elm, lang) = __extract_lang(elm)
elm = elm.replace('"', '')
if lang is not None:
return Literal(elm, lang=lang)
else:
return Literal(elm, datatype=XSD.string)
c, s, p, o = eval(x)
return c, __term(s), __term(p), __term(o)
for x in r.zrangebyscore('{}:fragments:{}:stream'.format(AGENT_ID, fid), '-inf', '{}'.format(float(until))):
yield __triplify(x)
def clear_fragment_stream(fid):
stream_key = '{}:fragments:{}:stream'.format(AGENT_ID, fid)
with r.pipeline() as pipe:
pipe.delete(stream_key)
pipe.execute()
def add_stream_triple(fid, tp, (s, p, o), timestamp=None):
try:
if timestamp is None:
timestamp = calendar.timegm(dt.utcnow().timetuple())
quad = (tp, s.n3(), p.n3(), o.n3())
stream_key = '{}:fragments:{}:stream'.format(AGENT_ID, fid)
not_found = not bool(r.zscore(stream_key, quad))
if not_found:
with r.pipeline() as pipe:
pipe.zadd(stream_key, timestamp, quad)
pipe.execute()
return not_found
except Exception as e:
traceback.print_exc()
_log.error(e.message)
class GraphProvider(object):
def __init__(self):
self.__last_creation_ts = dt.utcnow()
self.__graph_dict = {}
self.__uuid_dict = {}
self.__gid_uuid_dict = {}
self.__lock = Lock()
self.__cache_key = '{}:cache'.format(AGENT_ID)
self.__gids_key = '{}:gids'.format(self.__cache_key)
self.__resources_ts = {}
_pool.submit(self.__purge)
if EVENTS_EXCHANGE is not None and EVENTS_TOPIC is not None:
# Create channel with an auto-delete queue (None parameter)
start_channel(EVENTS_EXCHANGE, EVENTS_TOPIC, None, self.resource_callback)
@staticmethod
def __clean(name):
shutil.rmtree('store/resources/{}'.format(name))
@staticmethod
def uuid_lock(uuid):
lock_key = '{}:cache:{}:lock'.format(AGENT_ID, uuid)
return r.lock(lock_key, lock_class=RedisLock)
def __purge(self):
while True:
self.__lock.acquire()
try:
obsolete = filter(lambda x: not r.exists('{}:cache:{}'.format(AGENT_ID, x)),
r.smembers(self.__cache_key))
if obsolete:
with r.pipeline(transaction=True) as p:
p.multi()
_log.info('Removing {} resouces from cache...'.format(len(obsolete)))
for uuid in obsolete:
uuid_lock = self.uuid_lock(uuid)
uuid_lock.acquire()
try:
gid = r.hget(self.__gids_key, uuid)
counter_key = '{}:cache:{}:cnt'.format(AGENT_ID, uuid)
usage_counter = r.get(counter_key)
if usage_counter is None or int(usage_counter) <= 0:
try:
resources_cache.remove_context(resources_cache.get_context(uuid))
p.srem(self.__cache_key, uuid)
p.hdel(self.__gids_key, uuid)
p.hdel(self.__gids_key, gid)
p.delete(counter_key)
g = self.__uuid_dict[uuid]
del self.__uuid_dict[uuid]
del self.__graph_dict[g]
except Exception, e:
traceback.print_exc()
_log.error('Purging resource {} with uuid {}'.format(gid, uuid))
p.execute()
finally:
uuid_lock.release()
except Exception, e:
traceback.print_exc()
_log.error(e.message)
finally:
self.__lock.release()
sleep(1)
def create(self, conjunctive=False, gid=None, loader=None, format=None):
lock = None
cached = False
temp_key = None
p = r.pipeline(transaction=True)
p.multi()
uuid = shortuuid.uuid()
if conjunctive:
if 'persist' in app.config['STORE']:
g = ConjunctiveGraph('Sleepycat')
g.open('store/resources/{}'.format(uuid), create=True)
else:
g = ConjunctiveGraph()
g.store.graph_aware = False
self.__graph_dict[g] = uuid
self.__uuid_dict[uuid] = g
return g
else:
g = None
try:
st_uuid = r.hget(self.__gids_key, gid)
if st_uuid is not None:
cached = True
uuid = st_uuid
lock = self.uuid_lock(uuid)
lock.acquire()
g = self.__uuid_dict.get(uuid, None)
lock.release()
if st_uuid is None or g is None:
st_uuid = None
cached = False
uuid = shortuuid.uuid()
g = resources_cache.get_context(uuid)
temp_key = '{}:cache:{}'.format(AGENT_ID, uuid)
counter_key = '{}:cnt'.format(temp_key)
if st_uuid is None:
p.delete(counter_key)
p.sadd(self.__cache_key, uuid)
p.hset(self.__gids_key, uuid, gid)
p.hset(self.__gids_key, gid, uuid)
p.execute()
self.__last_creation_ts = dt.utcnow()
p.incr(counter_key)
lock = self.uuid_lock(uuid)
lock.acquire()
except Exception, e:
_log.error(e.message)
traceback.print_exc()
if g is not None:
self.__graph_dict[g] = uuid
self.__uuid_dict[uuid] = g
try:
if cached:
return g
source, headers = loader(gid, format)
if not isinstance(source, bool):
g.parse(source=source, format=format)
if not r.exists(temp_key):
cache_control = headers.get('Cache-Control', None)
ttl = MIN_CACHE_TIME + int(2 * random())
if cache_control is not None:
cache_dict = parse_dict_header(cache_control)
ttl = int(cache_dict.get('max-age', ttl))
ttl_ts = calendar.timegm((dt.utcnow() + datetime.timedelta(ttl)).timetuple())
p.set(temp_key, ttl_ts)
p.expire(temp_key, ttl)
p.execute()
return g
else:
p.hdel(self.__gids_key, gid)
p.hdel(self.__gids_key, uuid)
p.srem(self.__cache_key, uuid)
counter_key = '{}:cache:{}:cnt'.format(AGENT_ID, uuid)
p.delete(counter_key)
p.execute()
del self.__graph_dict[g]
del self.__uuid_dict[uuid]
return source
finally:
p.execute()
if lock is not None:
lock.release()
def release(self, g):
lock = None
try:
if g in self.__graph_dict:
if isinstance(g, ConjunctiveGraph):
if 'persist' in app.config['STORE']:
g.close()
_pool.submit(self.__clean, self.__graph_dict[g])
else:
g.remove((None, None, None))
g.close()
else:
uuid = self.__graph_dict[g]
if uuid is not None:
lock = GraphProvider.uuid_lock(uuid)
lock.acquire()
if r.sismember(self.__cache_key, uuid):
r.decr('{}:cache:{}:cnt'.format(AGENT_ID, uuid))
finally:
if lock is not None:
lock.release()
def __delete_linked_resource(self, g, subject):
for (s, p, o) in g.triples((subject, None, None)):
self.__delete_linked_resource(g, o)
g.remove((s, p, o))
def resource_callback(self, method, properties, body):
subject = properties.headers.get('resource', None)
print body
ts = properties.headers.get('ts', None)
if ts is not None:
ts = long(ts)
if subject:
self.__lock.acquire()
lock = None
uuid = None
try:
uuid = r.hget(self.__gids_key, subject)
if uuid is not None:
lock = GraphProvider.uuid_lock(uuid)
self.__lock.release()
lock.acquire()
if subject in self.__resources_ts and ts <= self.__resources_ts[subject]:
print 'ignoring {} event!'.format(subject)
temp_key = '{}:cache:{}'.format(AGENT_ID, uuid)
counter_key = '{}:cnt'.format(temp_key)
with r.pipeline() as p:
p.expire(temp_key, 2)
p.decr(counter_key)
p.execute()
else:
self.__resources_ts[subject] = ts
g = Graph()
g.parse(StringIO.StringIO(body), format='turtle')
cached_g = self.__uuid_dict[uuid]
for (s, p, o) in g:
if (s, p, o) not in cached_g:
for (s, p, ro) in cached_g.triples((s, p, None)):
self.__delete_linked_resource(cached_g, ro)
cached_g.remove((s, p, ro))
cached_g.add((s, p, o))
finally:
if lock is not None:
lock.release()
if uuid is None:
self.__lock.release()
[cb(subject) for cb in event_resource_callbacks]
__store_mode = app.config['STORE']
if 'persist' in __store_mode:
_log.info('Creating store folders...')
if not os.path.exists('store'):
os.makedirs('store')
if os.path.exists('store/resources'):
shutil.rmtree('store/resources/')
os.makedirs('store/resources')
cache_keys = r.keys('{}:cache*'.format(AGENT_ID))
for ck in cache_keys:
r.delete(ck)
_log.info('Loading known triples...')
fragments_cache = ConjunctiveGraph('Sleepycat')
_log.info('Building fragments graph...')
fragments_cache.open('store/fragments', create=True)
resources_cache = ConjunctiveGraph()
# fragments_cache = ConjunctiveGraph()
# resources_cache = ConjunctiveGraph('Sleepycat')
_log.info('Building resources graph...')
# resources_cache.open('store/resources', create=True)
else:
fragments_cache = ConjunctiveGraph()
resources_cache = ConjunctiveGraph()
fragments_cache.store.graph_aware = False
resources_cache.store.graph_aware = False
fragments_cache.bind('stoa', STOA)
resources_cache.bind('stoa', STOA)
|
Agora-Stoa
|
/Agora-Stoa-0.2.0.tar.gz/Agora-Stoa-0.2.0/agora/stoa/store/triples.py
|
triples.py
|
import inspect
import logging
from agora.stoa.actions.core.base import Action
from types import ModuleType
__author__ = 'Fernando Serena'
log = logging.getLogger('agora.stoa.actions')
action_modules = {}
def register_module(name, module):
"""
Registers a Stoa module
:param name: The unique module name
:param module: Module instance
"""
if name in action_modules:
raise NameError('The module {} already exists'.format(name))
if not isinstance(module, ModuleType):
raise AttributeError('{} is not a valid module instance'.format(module))
action_modules[name] = module
def search_module(module, predicate, limit=1):
"""
Searches in a module for elements that satisfy a given predicate
:param module: A module name
:param predicate: A predicate to check module elements
:param limit: Default 1
:return:
"""
py_mod = action_modules.get(module, None)
if py_mod is not None:
cand_elms = filter(predicate,
inspect.getmembers(py_mod, lambda x: inspect.isclass(x) and not inspect.isabstract(x)))
if len(cand_elms) > limit:
raise EnvironmentError('Too many elements in module {}'.format(module))
return cand_elms
return None
def get_instance(module, clz, *args):
"""
Creates an instance of a given class and module
:param module: Module name
:param clz: Instance class
:param args: Creation arguments
:return: The instance
"""
module = action_modules[module]
class_ = getattr(module, clz)
instance = class_(*args)
return instance
def execute(*args, **kwargs):
"""
Prepares and submits a Stoa-action
:param args: Action context arguments
:param kwargs: Action data dictionary
"""
# The action name (that must match one of the registered modules in order to be submitted)
name = args[0]
log.debug('Searching for a compliant "{}" action handler...'.format(name))
try:
_, clz = search_module(name,
lambda (_, cl): issubclass(cl, Action) and cl != Action).pop()
except EnvironmentError:
raise SystemError('Cannot handle {} requests'.format(name))
except IndexError:
raise ("Couldn't find an Action class inside {} module".format(name))
try:
# Extract the request message from kwargs,
data = kwargs.get('data', None)
log.debug(
'Found! Requesting an instance of {} to perform a/n {} action described as:\n{}'.format(clz, name,
data))
# Create the proper action instance...
action = clz(data)
except IndexError:
raise NameError('Action module found but class is missing: "{}"'.format(name))
else:
# and submit!
rid = action.submit()
if rid is not None:
log.info('A {} request was successfully submitted with id {}'.format(name, rid))
|
Agora-Stoa
|
/Agora-Stoa-0.2.0.tar.gz/Agora-Stoa-0.2.0/agora/stoa/actions/__init__.py
|
__init__.py
|
import StringIO
import calendar
import logging
from redis.lock import Lock
from abc import abstractproperty, abstractmethod, ABCMeta
from agora.stoa.actions.core import PassRequest, AGENT_ID
from agora.stoa.actions.core.utils import CGraph
from agora.stoa.store import r
from rdflib import RDF
from shortuuid import uuid
__author__ = 'Fernando Serena'
_log = logging.getLogger('agora.stoa.actions.base')
_log.info('Cleaning agent lock...')
r.delete('{}:lock'.format(AGENT_ID))
def agent_lock():
lock_key = '{}:lock'.format(AGENT_ID)
return r.lock(lock_key, lock_class=Lock)
class Action(object):
"""
Generic action class that supports requests to Stoas
"""
__metaclass__ = ABCMeta
def __init__(self, message):
"""
Base constructor
:param message: the incoming request (RDF)
:return:
"""
self.__message = message
self.__action_id = None
self.__request_id = None
@abstractproperty
def request(self):
pass
@classmethod
def response_class(cls):
"""
This method should be implemented on each final Action class
:return: The response class
"""
pass
@abstractproperty
def sink(self):
"""
:return: The sink instance
"""
pass
@property
def request_id(self):
"""
Every action is assigned a unique request id.
"""
return self.__request_id
@property
def id(self):
"""
In order to uniquely identify action requests, each incoming one produces an action id based on
the message id and the submitter id.
"""
return self.__action_id
@abstractmethod
def submit(self):
"""
Base method that parses and saves the request message
:return: The new request id
"""
if not issubclass(self.response_class(), Response):
raise SystemError(
'The response class for this action is invalid: {}'.format(self.response_class()))
_log.info('Parsing request message...')
self.request.parse(self.__message)
self.__action_id = u'{}@{}'.format(self.request.message_id, self.request.submitted_by)
self.__request_id = self.sink.save(self)
return self.__request_id
class Sink(object):
"""
Every action should have a sink that deals with Action persistency.
"""
__metaclass__ = ABCMeta
passed_requests = set([])
def __init__(self):
self._pipe = r.pipeline(transaction=True)
self._request_id = None
self._request_key = None
self._dict_fields = {}
self._requests_key = '{}:requests'.format(AGENT_ID)
def load(self, rid):
"""
Checks the given request id and loads its associated data
"""
lock = agent_lock()
lock.acquire()
try:
if not r.keys('{}:requests:{}:'.format(AGENT_ID, rid)):
raise ValueError('Cannot load request: Unknown request id {}'.format(rid))
self._request_id = rid
self._request_key = '{}:requests:{}:'.format(AGENT_ID, self._request_id)
self._load()
finally:
lock.release()
@staticmethod
def __response_fullname(f):
"""
The response class name has to to be stored so as to be instanced on load
:return: A string like <module>.<Response> based on the given response class function provider (f)
"""
def wrapper():
clz = f()
parts = clz.__module__.split('.')
if parts:
module_name = parts[-1]
return '{}.{}'.format(module_name, clz.__name__)
raise NameError('Invalid response class: {}'.format(clz))
return wrapper
@abstractmethod
def _load(self):
"""
Sink-specific load statements (to be extended)
:return:
"""
self._dict_fields = r.hgetall(self._request_key)
def __getattr__(self, item):
if item in self._dict_fields:
value = self._dict_fields[item]
if value == 'True' or value == 'False':
value = eval(value)
return value
return super(Sink, self).__getattribute__(item)
def save(self, action):
"""
Generates a new request id and stores all action data
:return: The new request id
"""
lock = agent_lock()
lock.acquire()
try:
self._request_id = str(uuid())
self._pipe.multi()
self._save(action)
# It is not until this point when the pipe is executed!
# If it fails, nothing is stored
self._pipe.execute()
_log.info("""Request {} was saved:
-message id: {}
-submitted on: {}
-submitted by: {}""".format(self._request_id, action.request.message_id,
action.request.submitted_on, action.request.submitted_by))
return self._request_id
finally:
lock.release()
def remove(self):
"""
Creates a pipe to remove all stored data of the current request
"""
# All dict_fields are being removed automatically here (hashmap request attributes)
lock = agent_lock()
lock.acquire()
try:
with r.pipeline(transaction=True) as p:
p.multi()
action_id = r.hget(self._request_key, 'id')
p.zrem(self._requests_key, action_id)
r_keys = r.keys('{}*'.format(self._request_key))
for key in r_keys:
p.delete(key)
self._remove(p)
p.execute()
_log.info('Request {} was removed'.format(self._request_id))
finally:
lock.release()
@abstractmethod
def _remove(self, pipe):
"""
Sink-specific remove statements (to be extended)
:param pipe: The pipe to be used on remove statements
"""
pass
@abstractmethod
def _save(self, action):
"""
Sink-specific save statements (to be extended)
:param action: The action that contains the data to be stored
"""
# Firstly, we have to check if the action was previously stored...
if r.zscore('{}:requests'.format(AGENT_ID), action.id):
raise ValueError('Duplicated request: {}'.format(action.id))
submitted_by_ts = calendar.timegm(action.request.submitted_on.timetuple())
# The action id is stored in a sorted set using its timestamp as score
self._pipe.zadd(self._requests_key, submitted_by_ts, action.id)
self._request_key = '{}:requests:{}:'.format(AGENT_ID, self._request_id)
# Basic request data is stored on a dictionary (hashmap)
self._pipe.hmset(self._request_key, {'submitted_by': action.request.submitted_by,
'submitted_on': action.request.submitted_on,
'message_id': action.request.message_id,
'id': self._request_id,
'__response_class': self.__response_fullname(action.response_class)(),
'type': action.__class__.__module__,
'__hash': action.id})
@staticmethod
def do_pass(action):
Sink.passed_requests.add(action.id)
raise PassRequest()
@property
def request_id(self):
return self._request_id
class Request(object):
"""
The generic class that knows how to parse action messages and supports specific action requests
"""
def __init__(self):
from agora.stoa.actions.core import STOA, AMQP
# Since the message is RDF, we create a graph to store and query its triples
self._graph = CGraph()
self._graph.bind('stoa', STOA)
self._graph.bind('amqp', AMQP)
self._request_node = None
# Base fields dictionary
self._fields = {}
def parse(self, message):
"""
Parses the message and extracts all useful content
:param message: The request message (RDF)
"""
_log.debug('Parsing message...')
try:
self._graph.parse(StringIO.StringIO(message), format='turtle')
except Exception, e:
raise SyntaxError(e.message)
self._extract_content()
@abstractmethod
def _extract_content(self, request_type=None):
"""
Request-specific method to query the message graph and extract key content
"""
q_res = self._graph.query("""SELECT ?node ?m ?d ?a WHERE {
?node stoa:messageId ?m;
stoa:submittedOn ?d;
stoa:submittedBy [
stoa:agentId ?a
]
}""")
q_res = list(q_res)
if len(q_res) != 1:
raise SyntaxError('Invalid request')
request_fields = q_res.pop()
if not all(request_fields):
raise SyntaxError('Missing fields for generic request')
(self._request_node, self._fields['message_id'],
self._fields['submitted_on'],
self._fields['submitted_by']) = request_fields
if request_type is not None:
request_types = set(self._graph.objects(self._request_node, RDF.type))
if len(request_types) != 1 or request_type not in request_types:
raise SyntaxError('Invalid request type declaration')
_log.debug(
"""Parsed attributes of generic action request:
-message id: {}
-submitted on: {}
-submitted by: {}""".format(
self._fields['message_id'], self._fields['submitted_on'], self._fields['submitted_by']))
@property
def message_id(self):
return self._fields['message_id'].toPython()
@property
def submitted_by(self):
return self._fields['submitted_by'].toPython()
@property
def submitted_on(self):
return self._fields['submitted_on'].toPython()
class Response(object):
"""
Every request should have a response.
"""
__metaclass__ = ABCMeta
def __init__(self, rid):
self._request_id = rid
@abstractmethod
def build(self):
"""
:return: A generator that provides the response
"""
pass
@abstractproperty
def sink(self):
"""
:return: The associated request sink
"""
pass
|
Agora-Stoa
|
/Agora-Stoa-0.2.0.tar.gz/Agora-Stoa-0.2.0/agora/stoa/actions/core/base.py
|
base.py
|
import itertools
import networkx as nx
from networkx.algorithms.isomorphism import DiGraphMatcher
from rdflib import Graph
__author__ = 'Fernando Serena'
def parse_bool(s):
"""
:param s: String to be parsed
:return: True iff s is equal to 'True', otherwise False
"""
if type(s) == str:
if s == 'True':
return True
return False
class CGraph(Graph):
def objects(self, subject=None, predicate=None, card=None):
objs_gen = super(CGraph, self).objects(subject, predicate)
if card is None:
return objs_gen
objs_gen, gen_bak = itertools.tee(objs_gen)
objs = list(objs_gen)
if card == 1:
if not (0 < len(objs) < 2):
raise ValueError(len(objs))
return objs.pop()
return gen_bak
def subjects(self, predicate=None, object=None, card=None):
subs_gen = super(CGraph, self).subjects(predicate, object)
if card is None:
return subs_gen
subs_gen, gen_bak = itertools.tee(subs_gen)
subs = list(subs_gen)
if card == 1:
if not (0 < len(subs) < 2):
raise ValueError(len(subs))
return subs.pop()
return gen_bak
def chunks(l, n):
"""
Yield successive n-sized chunks from l.
:param l:
:param n:
:return: Generated chunks
"""
if n:
if getattr(l, '__iter__') is not None:
l = l.__iter__()
finished = False
while not finished:
chunk = []
try:
for _ in range(n):
chunk.append(l.next())
except StopIteration:
finished = True
yield chunk
class GraphPattern(set):
"""
An extension of the set class that represents a graph pattern, which is a set of triple patterns
"""
def __init__(self, s=()):
super(GraphPattern, self).__init__(s)
# @property
# def gp(self):
# return self
@property
def wire(self):
"""
Creates a graph from the graph pattern
:return: The graph (networkx)
"""
g = nx.DiGraph()
for tp in self:
(s, p, o) = tuple(tp_parts(tp.strip()))
edge_data = {'link': p}
g.add_node(s)
if o.startswith('?'):
g.add_node(o)
else:
g.add_node(o, literal=o)
edge_data['to'] = o
g.add_edge(s, o, **edge_data)
return g
def __eq__(self, other):
"""
Two graph patterns are equal if they are isomorphic**
"""
if not isinstance(other, GraphPattern):
return super(GraphPattern, self).__eq__(other)
mapping = self.mapping(other)
return mapping is not None
def __repr__(self):
return str(list(self))
def mapping(self, other):
"""
:return: If there is any, the mapping with another graph pattern
"""
if not isinstance(other, GraphPattern):
return None
my_wire = self.wire
others_wire = other.wire
def __node_match(n1, n2):
return n1 == n2
def __edge_match(e1, e2):
return e1 == e2
matcher = DiGraphMatcher(my_wire, others_wire, node_match=__node_match, edge_match=__edge_match)
mapping = list(matcher.isomorphisms_iter())
if len(mapping) == 1:
return mapping.pop()
else:
return None
def tp_parts(tp):
"""
:param tp: A triple pattern string
:return: A string-based 3-tuple like (subject, predicate, object)
"""
if tp.endswith('"'):
parts = [tp[tp.find('"'):]]
st = tp.replace(parts[0], '').rstrip()
parts = st.split(" ") + parts
else:
parts = tp.split(' ')
return tuple(parts)
|
Agora-Stoa
|
/Agora-Stoa-0.2.0.tar.gz/Agora-Stoa-0.2.0/agora/stoa/actions/core/utils.py
|
utils.py
|
from __future__ import print_function
import calendar
"""
#-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=#
This file is part of the Smart Developer Hub Project:
http://www.smartdeveloperhub.org
Center for Open Middleware
http://www.centeropenmiddleware.com/
#-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=#
Copyright (C) 2015 Center for Open Middleware.
#-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=#
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
#-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=#
"""
import logging
from random import random
from abc import ABCMeta, abstractmethod
from agora.client.wrapper import Agora
from agora.stoa.actions.core import STOA, RDF, AGENT_ID
from agora.stoa.actions.core.delivery import DeliveryRequest, DeliveryAction, DeliveryResponse, DeliverySink
from agora.stoa.actions.core.utils import CGraph, GraphPattern
from agora.stoa.actions.core.utils import tp_parts
from agora.stoa.server import app
from agora.stoa.store import r
from rdflib import Literal, URIRef
from shortuuid import uuid
from datetime import datetime as dt, timedelta as delta, datetime
import sys
from redis.lock import Lock
__author__ = 'Fernando Serena'
_log = logging.getLogger('agora.stoa.actions.fragment')
_agora_conf = app.config['AGORA']
PASS_THRESHOLD = app.config['BEHAVIOUR']['pass_threshold']
MIN_SYNC_TIME = app.config['PARAMS']['min_sync_time']
_agora_client = Agora(**_agora_conf)
# Ping Agora
try:
_ = _agora_client.prefixes
except Exception:
_log.warning('Agora is not currently available at {}'.format(_agora_conf))
else:
_log.info('Connected to Agora: {}'.format(_agora_conf))
_log.info("""Behaviour parameters:
- Pass threshold: {}""".format(PASS_THRESHOLD))
fragments_key = '{}:fragments'.format(AGENT_ID)
def fragment_lock(fid):
"""
:param fid: Fragment id
:return: A redis-based lock object for a given fragment
"""
lock_key = '{}:{}:lock'.format(fragments_key, fid)
return r.lock(lock_key, lock_class=Lock)
class FragmentRequest(DeliveryRequest):
def __init__(self):
"""
Prepares the pattern graph object which will store the one that is contained in the
request
"""
super(FragmentRequest, self).__init__()
self.__request_graph = CGraph()
self.__request_graph.bind('stoa', STOA)
self.__preferred_labels = set([])
self.__variable_labels = {}
self._graph_pattern = GraphPattern()
# Copy Agora prefixes to the pattern graph
try:
prefixes = _agora_client.prefixes
for p in prefixes:
self.__request_graph.bind(p, prefixes[p])
except Exception as e:
raise EnvironmentError(e.message)
def _extract_content(self, request_type=None):
super(FragmentRequest, self)._extract_content(request_type)
# Firstly, it looks for all Variables that are inside the request
variables = set(self._graph.subjects(RDF.type, STOA.Variable))
if not variables:
raise SyntaxError('There are no variables specified for this request')
_log.debug(
'Found {} variables in the the fragment pattern'.format(len(variables)))
# Secondly, try to identify all links between variables (avoiding cycles)
visited = set([])
for v in variables:
self.__request_graph.add((v, RDF.type, STOA.Variable))
self.__follow_variable(v, visited=visited)
# Thirdly, the request graph is filtered and the request pattern only contains
# the relevant nodes and their relations
# Finally, an Agora-compliant Graph Pattern is created and offered as a property
self.__build_graph_pattern()
_log.debug('Extracted (fragment) pattern graph:\n{}'.format(self.__request_graph.serialize(format='turtle')))
q_res = self._graph.query("""SELECT ?r ?ud ?ag ?ue WHERE {
OPTIONAL { ?r stoa:expectedUpdatingDelay ?ud }
OPTIONAL { ?r stoa:allowGeneralisation ?ag }
OPTIONAL { ?r stoa:updateOnEvents ?ue }
}""")
q_res = list(q_res)
if len(q_res) > 1:
raise SyntaxError('Wrong number of parameters were defined')
fragment_params = q_res.pop()
if any(fragment_params):
try:
parent_node, updating_delay, allow_gen, update_events = fragment_params
if parent_node != self._request_node:
raise SyntaxError('Invalid parent node for stoa:expectedUpdatingDelay')
if updating_delay is not None:
self._fields['updating_delay'] = updating_delay.toPython()
if allow_gen is not None:
self._fields['allow_gen'] = allow_gen.toPython()
if update_events is not None:
self._fields['update_events'] = update_events.toPython()
except IndexError:
pass
def __n3(self, elm):
"""
:param elm: The element to be n3-formatted
:return: The n3 representation of elm
"""
return elm.n3(self.__request_graph.namespace_manager)
def __follow_variable(self, variable_node, visited=None):
"""
Recursively follows one variable node of the request graph
:param variable_node: Starting node
:param visited: Track of visited variable nodes
:return:
"""
def add_pattern_link(node, triple):
type_triple = (node, RDF.type, STOA.Variable)
condition = type_triple in self._graph
if condition:
self.__request_graph.add(type_triple)
elif isinstance(node, URIRef):
condition = True
if condition:
if triple not in self.__request_graph:
self.__request_graph.add(triple)
_log.debug('New pattern link: {}'.format(triple))
return condition
if visited is None:
visited = set([])
visited.add(variable_node)
subject_pattern = self._graph.subject_predicates(variable_node)
for (n, pr) in subject_pattern:
if add_pattern_link(n, (n, pr, variable_node)) and n not in visited:
self.__follow_variable(n, visited)
object_pattern = self._graph.predicate_objects(variable_node)
for (pr, n) in object_pattern:
if add_pattern_link(n, (variable_node, pr, n)):
if n not in visited:
self.__follow_variable(n, visited)
elif n != STOA.Variable:
self.__request_graph.add((variable_node, pr, n))
def __build_graph_pattern(self):
"""
Creates a GraphPattern with all the identified (Agora compliant) triple patterns
in the request graph
"""
def preferred_label():
# Each variable may have a property STOA.label that specifies its desired label
labels = list(self.__request_graph.objects(v, STOA.label))
p_label = labels.pop() if len(labels) == 1 else ''
if p_label:
self.__preferred_labels.add(str(p_label))
return p_label if p_label.startswith('?') else '?v{}'.format(i)
# Populates a dictionary with all variables and their labels
variables = self.__request_graph.subjects(RDF.type, STOA.Variable)
for i, v in enumerate(variables):
self.__variable_labels[v] = preferred_label()
# For each variable, generates one triple pattern per relation with other nodes as either subject or object
for v in self.__variable_labels.keys():
v_in = self.__request_graph.subject_predicates(v)
for (s, pr) in v_in:
s_part = self.__variable_labels[s] if s in self.__variable_labels else self.__n3(s)
self._graph_pattern.add(u'{} {} {}'.format(s_part, self.__n3(pr), self.__variable_labels[v]))
v_out = self.__request_graph.predicate_objects(v)
for (pr, o) in [_ for _ in v_out if _[1] != STOA.Variable and not _[0].startswith(STOA)]:
o_part = self.__variable_labels[o] if o in self.__variable_labels else (
'"{}"'.format(o) if isinstance(o, Literal) else self.__n3(o))
p_part = self.__n3(pr) if pr != RDF.type else 'a'
self._graph_pattern.add(u'{} {} {}'.format(self.__variable_labels[v], p_part, o_part))
@property
def pattern(self):
"""
:return: The request graph pattern
"""
return self._graph_pattern
@property
def preferred_labels(self):
"""
:return: The variable preferred labels
"""
return self.__preferred_labels
@property
def variable_labels(self):
"""
:return: All variable labels
"""
return self.__variable_labels.values()
def variable_label(self, n):
label = self.__variable_labels.get(n, None)
if isinstance(label, Literal):
label = label.toPython()
return label
@property
def updating_delay(self):
return self._fields.get('updating_delay', None)
@property
def allow_generalisation(self):
return self._fields.get('allow_gen', False)
@property
def update_on_events(self):
return self._fields.get('update_events', False)
class FragmentAction(DeliveryAction):
__metaclass__ = ABCMeta
def __init__(self, message):
super(FragmentAction, self).__init__(message)
class FragmentSink(DeliverySink):
__metaclass__ = ABCMeta
def __init__(self):
super(FragmentSink, self).__init__()
self._graph_pattern = GraphPattern()
self._fragment_pattern = GraphPattern()
self._filter_mapping = {}
self._fragments_key = '{}:fragments'.format(AGENT_ID)
self.__f_key_pattern = '{}:'.format(self._fragments_key) + '{}'
self._fragment_key = None
self._preferred_labels = set([])
def __check_gp_mappings(self, gp=None):
"""
Used in _save method. Seeks matches with some fragment already registered
:param gp: By default, _graph_pattern attribute is used when gp is None
:return: The matching fragment id and the mapping dictionary or None if there is no matching
"""
if gp is None:
gp = self._graph_pattern
gp_keys = r.keys('{}:*:gp'.format(self._fragments_key))
for gpk in gp_keys:
stored_gp = GraphPattern(r.smembers(gpk))
mapping = stored_gp.mapping(gp)
if mapping:
return gpk.split(':')[-2], mapping
return None
def _remove_tp_filters(self, tp):
"""
Transforms a triple pattern that may contain filters to a new one with both subject and object bounded
to variables
:param tp: The triple pattern to be filtered
:return: Filtered triple pattern
"""
def __create_var(elm, predicate):
if elm in self._filter_mapping.values():
elm = list(filter(lambda x: self._filter_mapping[x] == elm, self._filter_mapping)).pop()
elif predicate(elm):
v = '?{}'.format(uuid())
self._filter_mapping[v] = elm
elm = v
return elm
s, p, o = tp_parts(tp)
s = __create_var(s, lambda x: '<' in x and '>' in x)
o = __create_var(o, lambda x: '"' in x or ('<' in x and '>' in x))
return '{} {} {}'.format(s, p, o)
def _generalize_gp(self):
# Create a filtered graph pattern from the request one (general_gp)
general_gp = GraphPattern()
for new_tp in map(lambda x: self._remove_tp_filters(x), self._graph_pattern):
general_gp.add(new_tp)
if self._filter_mapping:
# Store the filter mapping
self._pipe.hmset('{}filters'.format(self._request_key), self._filter_mapping)
return general_gp
@abstractmethod
def _save(self, action, general=True):
"""
Stores data relating to the recovery of a fragment for this request
"""
super(FragmentSink, self)._save(action)
# Override general parameter
general = general and action.request.allow_generalisation
# Fragment collection parameters
requested_updating_delay = action.request.updating_delay
if action.request.updating_delay is None:
requested_updating_delay = MIN_SYNC_TIME
self._pipe.hset(self._request_key, 'updating_delay', requested_updating_delay)
self._pipe.hset(self._request_key, 'allow_generalisation', action.request.allow_generalisation)
# Recover pattern from the request object
self._graph_pattern = action.request.pattern
effective_gp = self._generalize_gp() if general else self._graph_pattern
# fragment_mapping is a tuple like (fragment_id, mapping)
fragment_mapping = self.__check_gp_mappings(gp=effective_gp)
exists = fragment_mapping is not None
# Decide to proceed depending on whether it's the first time this request is received and the fragment
# is already known
proceed = action.id in self.passed_requests or (
random() > 1.0 - PASS_THRESHOLD if not exists else random() > PASS_THRESHOLD)
if not proceed:
self.do_pass(action)
if action.id in self.passed_requests:
self.passed_requests.remove(action.id)
lock = None
try:
if not exists:
# If there is no mapping, register a new fragment collection for the general graph pattern
fragment_id = str(uuid())
self._fragment_key = self.__f_key_pattern.format(fragment_id)
self._pipe.sadd(self._fragments_key, fragment_id)
self._pipe.sadd('{}:gp'.format(self._fragment_key), *effective_gp)
mapping = {str(k): str(k) for k in action.request.variable_labels}
mapping.update({str(k): str(k) for k in self._filter_mapping})
else:
fragment_id, mapping = fragment_mapping
self._fragment_key = self.__f_key_pattern.format(fragment_id)
lock = fragment_lock(fragment_id)
lock.acquire()
# Remove the sync state if the fragment is on-demand mode
if r.get('{}:on_demand'.format(self._fragment_key)) is not None:
self._pipe.delete('{}:sync'.format(self._fragment_key))
# Here the following is persisted: mapping, pref_labels, fragment-request links and the original
# graph_pattern
self._pipe.hmset('{}map'.format(self._request_key), mapping)
if action.request.preferred_labels:
self._pipe.sadd('{}pl'.format(self._request_key), *action.request.preferred_labels)
self._pipe.sadd('{}:requests'.format(self._fragment_key), self._request_id)
self._pipe.hset(self._request_key, 'fragment_id', fragment_id)
self._pipe.sadd('{}gp'.format(self._request_key), *self._graph_pattern)
self._pipe.hset(self._request_key, 'pattern', ' . '.join(self._graph_pattern))
# Update collection parameters
fragment_synced = True
current_updated = r.get('{}:updated'.format(self._fragment_key))
if current_updated is not None:
current_updated = dt.utcfromtimestamp(float(current_updated))
utcnow = dt.utcnow()
limit = utcnow - delta(seconds=requested_updating_delay)
if limit > current_updated:
diff = (limit - current_updated).total_seconds()
self._pipe.delete('{}:sync'.format(self._fragment_key))
fragment_synced = False
# if diff > requested_updating_delay / 2.0:
# self._pipe.delete('{}:updated'.format(self._fragment_key))
current_updating_delay = int(
r.get('{}:ud'.format(self._fragment_key))) if exists and fragment_synced else sys.maxint
if current_updating_delay > requested_updating_delay:
self._pipe.set('{}:ud'.format(self._fragment_key), requested_updating_delay)
current_on_events = r.get('{}:events'.format(self._fragment_key))
requested_on_events = action.request.update_on_events
if current_on_events is None or (current_on_events is not None and current_on_events == 'True'):
self._pipe.set('{}:events'.format(self._fragment_key), requested_on_events)
# Update fragment request history
# if not fragment_synced:
# self._pipe.delete('{}:hist'.format(self._fragment_key))
self._pipe.lpush('{}:hist'.format(self._fragment_key), calendar.timegm(datetime.utcnow().timetuple()))
self._pipe.ltrim('{}:hist'.format(self._fragment_key), 0, 3)
# Populate attributes that may be required during the rest of the submission process
self._dict_fields['mapping'] = mapping
self._dict_fields['preferred_labels'] = action.request.preferred_labels
self._dict_fields['fragment_id'] = fragment_id
if not exists:
_log.info('Request {} has started a new fragment collection: {}'.format(self._request_id, fragment_id))
else:
_log.info('Request {} is going to re-use fragment {}'.format(self._request_id, fragment_id))
n_fragment_reqs = r.scard('{}:requests'.format(self._fragment_key))
_log.info('Fragment {} is supporting {} more requests'.format(fragment_id, n_fragment_reqs))
finally:
if lock is not None:
lock.release()
@abstractmethod
def _remove(self, pipe):
"""
Removes data relating to the recovery of a fragment for this request
"""
fragment_id = r.hget('{}'.format(self._request_key), 'fragment_id')
self._fragment_key = self.__f_key_pattern.format(fragment_id)
pipe.srem('{}:requests'.format(self._fragment_key), self._request_id)
pipe.delete('{}gp'.format(self._request_key))
pipe.delete('{}map'.format(self._request_key))
pipe.delete('{}pl'.format(self._request_key))
pipe.delete('{}filters'.format(self._request_key))
super(FragmentSink, self)._remove(pipe)
@abstractmethod
def _load(self):
"""
Loads data relating to the recovery of a fragment for this request
"""
super(FragmentSink, self)._load()
self._fragment_key = self.__f_key_pattern.format(self.fragment_id)
self._graph_pattern = GraphPattern(r.smembers('{}gp'.format(self._request_key)))
self._fragment_pattern = GraphPattern(r.smembers('{}:gp'.format(self._fragment_key)))
self._filter_mapping = r.hgetall('{}filters'.format(self._request_key))
self._dict_fields['mapping'] = r.hgetall('{}map'.format(self._request_key))
self._dict_fields['preferred_labels'] = set(r.smembers('{}pl'.format(self._request_key)))
if 'updating_delay' in self._dict_fields:
self._dict_fields['updating_delay'] = float(self.updating_delay)
def map(self, v, fmap=False):
"""
Maps a fragment variable to the corresponding variable or filter of the request
:param v: Fragment variable
:param fmap: Map to filter or not
:return: The mapped variable (or filter)
"""
if self.mapping is not None:
v = self.mapping.get(v, v)
if fmap:
v = self._filter_mapping.get(v, v)
return v
@property
def gp(self):
"""
:return: The request Graph Pattern
"""
return self._graph_pattern
@property
def fragment_gp(self):
"""
:return: The Graph Pattern of the supporting fragment
"""
return self._fragment_pattern
@property
def filter_mapping(self):
"""
:return: The mapping dictionary between original filters and on-the-fly created variables
"""
return self._filter_mapping
class FragmentResponse(DeliveryResponse):
__metaclass__ = ABCMeta
def __init__(self, rid):
super(FragmentResponse, self).__init__(rid)
@abstractmethod
def build(self):
super(FragmentResponse, self).build()
|
Agora-Stoa
|
/Agora-Stoa-0.2.0.tar.gz/Agora-Stoa-0.2.0/agora/stoa/actions/core/fragment.py
|
fragment.py
|
import base64
import logging
import traceback
import uuid
from datetime import datetime
from abc import ABCMeta, abstractmethod
from agora.stoa.actions.core import RDF, STOA, FOAF, TYPES, XSD, AGENT_ID
from agora.stoa.actions.core.base import Request, Action, Response, Sink
from agora.stoa.actions.core.utils import CGraph
from agora.stoa.messaging.reply import reply
from agora.stoa.server import app
from agora.stoa.store import r
from rdflib import BNode, Literal, RDFS
__author__ = 'Fernando Serena'
EXCHANGE_CONFIG = app.config['EXCHANGE']
_exchange = EXCHANGE_CONFIG['exchange']
response_rk = EXCHANGE_CONFIG['response_rk']
_log = logging.getLogger('agora.stoa.actions.delivery')
LIT_AGENT_ID = Literal(AGENT_ID, datatype=TYPES.UUID)
def _build_reply_templates():
"""
:return: Accept and Failure message templates
"""
accepted = CGraph()
failure = CGraph()
response_node = BNode()
agent_node = BNode()
accepted.add((response_node, RDF.type, STOA.Root))
accepted.add((response_node, RDF.type, STOA.Accepted))
accepted.add((agent_node, RDF.type, FOAF.Agent))
accepted.add((response_node, STOA.responseNumber, Literal("0", datatype=XSD.unsignedLong)))
accepted.add((response_node, STOA.submittedBy, agent_node))
accepted.add(
(agent_node, STOA.agentId, LIT_AGENT_ID))
accepted.bind('types', TYPES)
accepted.bind('stoa', STOA)
accepted.bind('foaf', FOAF)
for triple in accepted:
failure.add(triple)
failure.set((response_node, RDF.type, STOA.Failure))
for (prefix, ns) in accepted.namespaces():
failure.bind(prefix, ns)
return accepted, failure
def build_reply(template, reply_to, comment=None):
"""
:param template: A specific message template graph
:param reply_to: Recipient Agent UUID
:param comment: Optional comment
:return: The reply graph
"""
reply_graph = CGraph()
root_node = None
for (s, p, o) in template:
if o == STOA.Root:
root_node = s
else:
reply_graph.add((s, p, o))
reply_graph.add((root_node, STOA.responseTo, Literal(reply_to, datatype=TYPES.UUID)))
reply_graph.set((root_node, STOA.submittedOn, Literal(datetime.utcnow())))
reply_graph.set((root_node, STOA.messageId, Literal(str(uuid.uuid4()), datatype=TYPES.UUID)))
if comment is not None:
reply_graph.set((root_node, RDFS.comment, Literal(comment, datatype=XSD.string)))
for (prefix, ns) in template.namespaces():
reply_graph.bind(prefix, ns)
return reply_graph
# Create both accept and failure templates
accepted_template, failure_template = _build_reply_templates()
_log.info('Basic delivery templates created')
class DeliveryRequest(Request):
def __init__(self):
super(DeliveryRequest, self).__init__()
def _extract_content(self, request_type=None):
"""
Extracts delivery related data from message (delivery channel to reply to)
"""
super(DeliveryRequest, self)._extract_content(request_type)
q_res = self._graph.query("""SELECT ?node ?ex ?rk ?h ?p ?v WHERE {
?node stoa:replyTo [
a stoa:DeliveryChannel;
amqp:exchangeName ?ex;
amqp:routingKey ?rk;
amqp:broker [
a amqp:Broker;
amqp:host ?h;
amqp:port ?p;
amqp:virtualHost ?v
]
]
} """)
q_res = list(q_res)
if len(q_res) != 1:
raise SyntaxError('Invalid delivery request')
request_fields = q_res.pop()
if not any(request_fields):
raise SyntaxError('Missing fields for delivery request')
if request_fields[0] != self._request_node:
raise SyntaxError('Request node does not match')
delivery_data = {}
(delivery_data['exchange'],
delivery_data['routing_key'],
delivery_data['host'],
delivery_data['port'],
delivery_data['vhost']) = request_fields[1:]
_log.debug("""Parsed attributes of a delivery action request:
-exchange name: {}
-routing key: {}
-host: {}
-port: {}
-virtual host: {}""".format(
delivery_data['exchange'],
delivery_data['routing_key'],
delivery_data['host'], delivery_data['port'], delivery_data['vhost']))
# Copy delivery data dictionary to the base request fields attribute
self._fields['delivery'] = delivery_data.copy()
@property
def broker(self):
"""
:return: Broker to which response must be addressed
"""
broker_dict = {k: self._fields['delivery'][k].toPython() for k in ('host', 'port', 'vhost') if
k in self._fields['delivery']}
broker_dict['port'] = int(broker_dict['port'])
return broker_dict
@property
def channel(self):
"""
:return: Delivery channel attributes
"""
return {k: self._fields['delivery'][k].toPython() for k in ('exchange', 'routing_key') if
k in self._fields['delivery']}
@property
def recipient(self):
"""
:return: Broker and delivery channel data
"""
recipient = self.broker.copy()
recipient.update(self.channel)
return recipient
class DeliveryAction(Action):
__metaclass__ = ABCMeta
def __init__(self, message):
super(DeliveryAction, self).__init__(message)
def __reply(self, template, reason=None):
"""
Sends a protocol reply message to the submitter
"""
graph = build_reply(template, self.request.message_id, reason)
reply(graph.serialize(format='turtle'), exchange=_exchange,
routing_key='{}.{}'.format(response_rk, self.request.submitted_by),
**self.request.broker)
def __reply_accepted(self):
"""
Sends an Accept message to the submitter
"""
try:
self.__reply(accepted_template)
except Exception:
# KeyError: Delivery channel data may be invalid
# IOError: If the acceptance couldn't be sent, propagate the exception
raise
def _reply_failure(self, reason=None):
"""
Sends a Failure message to the submitter
"""
try:
self.__reply(failure_template, reason)
_log.info('Notified failure of request {} due to: {}'.format(self.request_id, reason))
except Exception, e:
# KeyError: Delivery channel data may be invalid
# IOError: In this case, if even the failure message couldn't be sent, we cannot do anymore :)
_log.warning('Sending failure message for request {}: {}'.format(self.request_id, e.message))
def submit(self):
"""
Submit and try to send an acceptance message to the submitter if everything is ok
"""
try:
super(DeliveryAction, self).submit()
except SyntaxError, e:
# If the message is of bad format, reply notifying the issue
self._reply_failure(e.message)
raise
else:
try:
self.__reply_accepted()
except Exception, e:
_log.warning('Acceptance of request {} failed due to: {}'.format(self.request_id, e.message))
# If the acceptance message couldn't be sent, remove the request and propagate the error
self.sink.remove()
raise
# If everything was ok, update the request delivery state
if self.sink.delivery is None:
self.sink.delivery = 'accepted'
def used_channels():
"""
Selects all channels that were declared by current requests
"""
req_channel_keys = r.keys('{}:requests:*:'.format(AGENT_ID))
for rck in req_channel_keys:
try:
channel = r.hget(rck, 'channel')
yield channel
except Exception as e:
traceback.print_exc()
_log.warning(e.message)
def channel_sharing(channel_b64):
"""
Calculates how many channel identifiers match the given one (channel_b64)
:param channel_b64:
"""
return len(list(filter(lambda x: x == channel_b64, used_channels()))) - 1 # Don't count itself
class DeliverySink(Sink):
__metaclass__ = ABCMeta
def __init__(self):
super(DeliverySink, self).__init__()
self.__deliveries_key = '{}:deliveries'.format(AGENT_ID)
self.__ready_key = '{}:ready'.format(self.__deliveries_key)
self.__sent_key = '{}:sent'.format(self.__deliveries_key)
@abstractmethod
def _save(self, action):
"""
Stores delivery channel data
"""
super(DeliverySink, self)._save(action)
self._pipe.sadd(self.__deliveries_key, self._request_id)
broker_b64 = base64.b64encode('|'.join(map(lambda x: str(x), action.request.broker.values())))
channel_b64 = base64.b64encode('|'.join(action.request.channel.values()))
self._pipe.hmset('{}:channels:{}'.format(AGENT_ID, channel_b64), action.request.channel)
self._pipe.hmset('{}:brokers:{}'.format(AGENT_ID, broker_b64), action.request.broker)
self._pipe.hset('{}'.format(self._request_key), 'channel', channel_b64)
self._pipe.hset('{}'.format(self._request_key), 'broker', broker_b64)
@abstractmethod
def _load(self):
"""
Loads all delivery data
"""
super(DeliverySink, self)._load()
self._dict_fields['channel'] = r.hgetall('{}:channels:{}'.format(AGENT_ID, self._dict_fields['channel']))
self._dict_fields['broker'] = r.hgetall('{}:brokers:{}'.format(AGENT_ID, self._dict_fields['broker']))
self._dict_fields['broker']['port'] = int(self._dict_fields['broker']['port'])
recipient = self._dict_fields['channel'].copy()
recipient.update(self._dict_fields['broker'])
self._dict_fields['recipient'] = recipient
# If present, remove previously stored delivery state so it can be retrieved each time the delivery getter
# is invoked
try:
del self._dict_fields['delivery']
except KeyError:
pass
@abstractmethod
def _remove(self, pipe):
"""
Remove all delivery data
"""
# If this request is the only one that's using such channel, it is removed
channel_b64 = r.hget(self._request_key, 'channel')
sharing = channel_sharing(channel_b64)
if not sharing:
_log.info('Removing delivery channel ({}) for request {}'.format(channel_b64, self._request_id))
pipe.delete('{}:channels:{}'.format(AGENT_ID, channel_b64))
else:
_log.info('Cannot remove delivery channel of request {}. It is being shared with {} another requests'.format(
self.request_id, sharing))
super(DeliverySink, self)._remove(pipe)
pipe.srem(self.__deliveries_key, self._request_id)
pipe.srem(self.__ready_key, self._request_id)
@property
def delivery(self):
return r.hget('{}'.format(self._request_key), 'delivery')
@delivery.setter
def delivery(self, value):
"""
Changes the delivery state of the request
:param value: 'ready', 'sent', 'accepted', ...
"""
with r.pipeline(transaction=True) as p:
p.multi()
if value == 'ready':
p.sadd(self.__ready_key, self._request_id)
elif value == 'sent':
p.sadd(self.__sent_key, self._request_id)
if value != 'ready':
p.srem(self.__ready_key, self._request_id)
p.hset('{}'.format(self._request_key), 'delivery', value)
p.execute()
_log.info('Request {} delivery state is now "{}"'.format(self._request_id, value))
class DeliveryResponse(Response):
__metaclass__ = ABCMeta
def __init__(self, rid):
super(DeliveryResponse, self).__init__(rid)
@abstractmethod
def build(self):
super(DeliveryResponse, self).build()
|
Agora-Stoa
|
/Agora-Stoa-0.2.0.tar.gz/Agora-Stoa-0.2.0/agora/stoa/actions/core/delivery.py
|
delivery.py
|
import inspect, argparse, new
def parser(description):
def new_fn(fn):
parser = register_parser(name=default_parser_name, description=description)
def parse_commands(fn, group):
commands = {}
class_functions = { x : fn.__dict__[x] for x in fn.__dict__ if inspect.isfunction(fn.__dict__[x]) }
for cfn_name, cfn in class_functions.iteritems():
if hasattr(cfn, "is_command") and cfn.is_command:
commands[cfn_name] = cfn
parser.add_command(cfn_name, cfn, group)
return commands
def parse_command_group(fn, group):
class_classes = { x : fn.__dict__[x] for x in fn.__dict__ if inspect.isclass(fn.__dict__[x]) }
for class_name, clazz in class_classes.iteritems():
if hasattr(clazz, "is_command_group") and clazz.is_command_group:
parser.add_command_group(class_name, group=group )
parse_command_group(clazz, class_name)
commands = parse_commands(fn, group)
parse_command_group(fn, None)
parser.parse()
return fn
return new_fn
def command_group(fn, name=None):
fn.is_command_group = True
return fn
def command(fn, name=None):
fn.is_command = True
return fn
def help(key, help=None):
def decorator(fn):
if help is None:
fn.help = key
else:
if not hasattr(fn, "helps"):
fn.helps = {}
fn.helps[key] = help
return fn
return decorator
class AgreeParser(object):
def __init__(self, description):
self.arg_parse = argparse.ArgumentParser(description=description)
self.sub_groups = {}
self.sub_groups[None] = self.arg_parse.add_subparsers(help=None)
self.groups = {}
def add_command(self, name, fn, group=None):
fnhelp = fn.help if hasattr(fn, "help") else None
self.groups[name] = self.sub_groups[group].add_parser(name.lower(), help=fnhelp)
argspec = inspect.getargspec(fn)
def generate_shorts(spec):
shorts = {}
for arg in spec.args:
letters = arg[0:1]
for x in range(0, len(spec.args)):
other_arg = spec.args[x]
default_index = x - (len(argspec.args) - len(argspec.defaults))
if default_index >= 0:
if other_arg != arg:
for i in range(0, len(other_arg)):
if letters == other_arg[0:i+1]:
letters = arg[0:i+2]
else:
break
shorts[arg] = '-' + letters
return shorts
shorts = generate_shorts(argspec)
for x in range(0, len(argspec.args)):
arg = argspec.args[x]
default = None
default_index = x - (len(argspec.args) - len(argspec.defaults))
if default_index < len(argspec.defaults) and default_index >= 0:
default = argspec.defaults[default_index]
help = None
if hasattr(fn, "helps") and arg in fn.helps:
help = fn.helps[arg]
# print str(x) + ": " + str(default) + ": " + arg
#if default is not None:
# print default.__dict__
short = shorts[arg] if default is not None else None
arg_name = ('--' + arg if default is not None else arg)
if isinstance(default, ArgWrapper):
wrapper = default
help = default.help if help is None else help
dest = arg if default.dest is None else default.dest
# There's got to be a better way to do this...too many if statements!
if wrapper.action == "store_true" or wrapper.action == "store_false":
if short is not None:
self.groups[name].add_argument(arg_name, short, action=wrapper.action,
default=wrapper.default, required=wrapper.required,
help=help, dest=dest)
else:
self.groups[name].add_argument(arg_name, action=wrapper.action,
default=wrapper.default, required=wrapper.required,
help=help, dest=dest)
elif wrapper.action == "store_const":
if short is not None:
self.groups[name].add_argument(arg_name, short,action=wrapper.action,
default=wrapper.default, required=wrapper.required, const=wrapper.const,
help=help, dest=dest)
else:
self.groups[name].add_argument(arg_name,action=wrapper.action,
default=wrapper.default, required=wrapper.required, const=wrapper.const,
help=help, dest=dest)
elif wrapper.action == "count":
if short is not None:
self.groups[name].add_argument(arg_name, short,action=wrapper.action,
default=wrapper.default, required=wrapper.required,
help=help, dest=dest)
else:
self.groups[name].add_argument(arg_name,action=wrapper.action,
default=wrapper.default, required=wrapper.required,
help=help, dest=dest)
else:
if short is not None:
self.groups[name].add_argument(arg_name,short, action=wrapper.action, nargs=wrapper.nargs, const=wrapper.const,
default=wrapper.default, type=wrapper.type, choices=wrapper.choices, required=wrapper.required,
help=help, metavar=wrapper.metavar, dest=dest)
else:
self.groups[name].add_argument(arg_name, action=wrapper.action, nargs=wrapper.nargs, const=wrapper.const,
default=wrapper.default, type=wrapper.type, choices=wrapper.choices, required=wrapper.required,
help=help, metavar=wrapper.metavar, dest=dest)
else:
if short is not None:
self.groups[name].add_argument(arg_name, short, default=default,
help=help)
else:
self.groups[name].add_argument(arg_name, default=default,
help=help)
self.groups[name].set_defaults(command=fn)
def add_command_group(self, name, help=None, group=None):
self.groups[name] = self.sub_groups[group].add_parser(name.lower(), help=None)
self.sub_groups[name] = self.groups[name].add_subparsers(help=None)
def parse(self):
parsed = self.arg_parse.parse_args()
arg_info = inspect.getargspec(parsed.command)
keywords = {}
for x in arg_info.args:
keywords[x] = parsed.__dict__[x]
parsed.command(**keywords)
class ArgWrapper(object):
def __init__(self, name, action="store", nargs=1, const=None, default=None, type=str, choices=None, required=False, help="", metavar=None, dest=None):
self.name = name
self.action = action
self.nargs = nargs
self.const = const
self.default = default
self.type = type
self.choices = choices
self.required = required
self.help = help
self.metavar = metavar
self.dest = dest
def __str__(self):
return self.action
def __repr__(self):
return self.__str__()
#ArgWrapper Convenience Methods
def store_const(default=None, const=None, dest=None):
return ArgWrapper(None, action="store_const", dest=dest, default=default, const=const)
def store(default=None, const=None, dest=None, nargs=1):
return ArgWrapper(None, action="store", dest=dest, default=default, const=const, nargs=nargs)
def store_true(default=True, dest=None):
return ArgWrapper(None, action="store_true", dest=dest, default=default)
def store_false(default=False, dest=None):
return ArgWrapper(None, action="store_false", dest=dest, default=default)
def append(default=0, dest=None):
return ArgWrapper(None, action="append", dest=dest, default=default)
def append_const(default=0, dest=None, const=None):
return ArgWrapper(None, action="append_const", dest=dest, const=const, default=default)
def count(default=0, dest=None):
return ArgWrapper(None, action="count", dest=dest, default=default)
parsers = {}
default_parser_name = "agree_default"
def register_parser(name, description=None):
parsers[name] = AgreeParser(description)
return parsers[name]
|
Agree
|
/Agree-0.2.2.tar.gz/Agree-0.2.2/agree/__init__.py
|
__init__.py
|
# Datafetch
> A Python package for retrieving 3DEP's geospatial data and enable users to easily manipulate, transform, subsample and visualize the data.
<hr>
> **LiDAR** (light detection and ranging) is a popular remote sensing mechanism used for measuring the exact distance of an object on the earth's surface. Since the introduction of GPS technology, it has become a widely used method for calculating accurate geospatial measurements. These geospatial data are used for different analysis purposes.
>
>The Purpose of this project is to **help users retrieve these data and enable them to use it easily**
>
>The Project will make it **easier** for users to access the AWS public dataset.
<hr>
## Data Source Used:
- https://registry.opendata.aws/usgs-lidar/
## License
[MIT](https://github.com/nebasam/AgriTech---USGS-LIDAR-package)
|
AgriTech
|
/AgriTech-0.1.tar.gz/AgriTech-0.1/README.md
|
README.md
|
import pdal
import json
import geopandas as gpd
from shapely.geometry import Polygon, Point
import sys
from logger import Logger
from file_read import FileHandler
import numpy as np
import matplotlib.pyplot as plt
class FetchData():
"""A Data Fetching Class which handles fetching, loading,
transforming, and visualization from AWS dataset
Parameters
----------
polygon : Polygon
Polygon of the area which is being searched for
epsg : str
CRS system which the polygon is constructed based on
region: str, optional
Region where the specified polygon is located in from the file name folder located in the AWS dataset. If
not provided the program will search and provide the region if it is in the AWS dataset
Returns
-------
None
"""
def __init__(self, polygon: Polygon, region: str, epsg: str) -> None:
try:
self.logger = Logger().get_logger(__name__)
self.json_path = "../usgs/get_data.json"
self.file_handler = FileHandler()
self.pipeline_json = self.file_handler.read_json(self.json_path)
self.get_polygon_margin(polygon, epsg)
self.public_data_url = "https://s3-us-west-2.amazonaws.com/usgs-lidar-public/"
self.region = region
self.epsg = epsg
self.logger.info('Successfully Instantiated DataFetcher Class Object')
except Exception as e:
self.logger.exception('Failed to Instantiate DataFetcher Class Object')
sys.exit(1)
def get_polygon_margin(self, polygon: Polygon, epsg: str) -> tuple:
"""To extract polygon margin and assign polygon input.
Parameters
----------
polygon : Polygon
Polygon object describing the boundary of the location required
epsg : str
CRS system on which the polygon is constructed on
Returns
-------
tuple
Returns bounds of the polygon provided(minx, miny, maxx, maxy) and polygon input
"""
try:
gd_df = gpd.GeoDataFrame([polygon], columns=['geometry'])
gd_df.set_crs(epsg=epsg, inplace=True)
gd_df['geometry'] = gd_df['geometry'].to_crs(epsg=3857)
minx, miny, maxx, maxy = gd_df['geometry'][0].bounds
polygon_input = 'POLYGON(('
xcords, ycords = gd_df['geometry'][0].exterior.coords.xy
for x, y in zip(list(xcords), list(ycords)):
polygon_input += f'{x} {y}, '
polygon_input = polygon_input[:-2]
polygon_input += '))'
extraction_boundaries = f"({[minx, maxx]},{[miny,maxy]})"
print(polygon_input)
print(extraction_boundaries)
self.logger.info( 'Successfully Extracted Polygon margin and Polygon Input')
return extraction_boundaries, polygon_input
except Exception as e:
self.logger.exception(
'Failed to Extract Polygon margin and Polygon Input')
def get_pipeline(self, polygon: Polygon, epsg: str, output_filename: str = "farm_land_IA_FullState"):
"""Generates a Pdal Pipeline .
Parameters
----------
file_name : str
File name used when saving the tiff and LAZ file
polygon
epsg
Returns
-------
pipeline
"""
try:
with open(self.json_path) as json_file:
self.pipeline_json = json.load(json_file)
extraction_boundaries, polygon_input = self.get_polygon_margin(polygon, epsg)
full_dataset_path = f"{self.public_data_url}{self.region}/ept.json"
self.pipeline_json['pipeline'][0]['filename'] = full_dataset_path
self.pipeline_json['pipeline'][0]['bounds'] = extraction_boundaries
self.pipeline_json['pipeline'][1]['polygon'] = polygon_input
self.pipeline_json['pipeline'][3]['out_srs'] = f'EPSG:{self.epsg}'
self.pipeline_json['pipeline'][4]['filename'] = "../data/laz/" + output_filename + ".laz"
self.pipeline_json['pipeline'][5]['filename'] = "../data/tif/" + output_filename + ".tif"
pipeline = pdal.Pipeline(json.dumps(self.pipeline_json))
self.logger.info(f'extracting pipeline successfull.')
print(pipeline)
return pipeline
except RuntimeError as e:
self.logger.exception('Pipeline extraction failed')
print(e)
def execute_pipeline(self):
"""executes a pdal pipeline
Parameters
----------
None
Returns
-------
executed pipeline
"""
pipeline = self.get_pipeline()
try:
pipeline.execute()
self.logger.info(f'Pipeline executed successfully.')
return pipeline
except RuntimeError as e:
self.logger.exception('Pipeline execution failed')
print(e)
def make_geo_df(self):
"""Calculates and returns a geopandas elevation dataframe from the cloud points generated before.
Parameters
----------
None
Returns
-------
gpd.GeoDataFrame with Elevation and coordinate points referenced as Geometry points
"""
try:
cloud_points = []
elevations =[]
geometry_points=[]
for row in self.get_pipeline_arrays()[0]:
lst = row.tolist()[-3:]
cloud_points.append(lst)
cloud_points = np.array(cloud_points)
self.cloud_points = cloud_points
elevations.append(lst[2])
point = Point(lst[0], lst[1])
geometry_points.append(point)
geodf = gpd.GeoDataFrame(columns=["elevation", "geometry"])
geodf['elevation'] = elevations
geodf['geometry'] = geometry_points
geodf = geodf.set_geometry("geometry")
geodf.set_crs(epsg = self.epsg, inplace=True)
self.logger.info(f'extracts geo dataframe')
return geodf
except RuntimeError as e:
self.logger.exception('fails to extract geo data frame')
print(e)
def scatter_plot(self, factor_value: int = 1, view_angle: tuple[int, int] = (0, 0)) -> plt:
"""Constructs a scatter plot graph of the cloud points.
Parameters
----------
factor_value : int, optional
Factoring value if the data points are huge
view_angle : tuple(int, int), optional
Values to change the view angle of the 3D projection
Returns
-------
plt
Returns a scatter plot grpah of the cloud points
"""
values = self.cloud_points[::factor_value]
fig = plt.figure(figsize=(10, 15))
ax = plt.axes(projection='3d')
ax.scatter3D(values[:, 0], values[:, 1],
values[:, 2], c=values[:, 2], s=0.1, cmap='terrain')
ax.set_xlabel('Longitude')
ax.set_ylabel('Latitude')
ax.set_zlabel('Elevation')
ax.set_title('Scatter Plot of elevation')
ax.view_init(view_angle[0], view_angle[1])
return plt
def terrain_map(self, markersize: int = 10, fig_size: tuple[int, int] = (15, 20)) -> plt:
"""Constructs a Terrain Map from the cloud points.
Parameters
----------
markersize : int, optional
Marker size used when ploting the figure
fig_size : Tuple[int, int], optional
Size of the figure to be returned
Returns
-------
plt
Returns a Terrain Map constructed from the cloud points
"""
self.make_geo_df()
self.make_geo_df.plot(c='elevation', scheme="quantiles", cmap='terrain', legend=True,
markersize=markersize,
figsize=(fig_size[0], fig_size[1]),
missing_kwds={
"color": "lightgrey",
"edgecolor": "red",
"hatch": "///",
"label": "Missing values"}
)
plt.title('Terrain Elevation Map')
plt.xlabel('Longitude')
plt.ylabel('Latitude')
return plt
def get_pipeline_arrays(self):
"""Returns the Pdal pipelines retrieved data arrays after the pipeline is run.
Parameters
----------
None
Returns
-------
None
"""
return self.pipeline.arrays
def get_pipeline_metadata(self):
"""Returns the metadata of Pdal pipelines.
Parameters
----------
None
Returns
-------
None
"""
return self.pipeline.metadata
def get_data(self):
"""Retrieves Data from the Dataset,
Parameters
----------
None
Returns
-------
geo dataframe with elevation and geometry point
"""
self.pipeline = self.execute_pipeline()
return self.make_geo_df()
if(__name__ == '__main__'):
MINX, MINY, MAXX, MAXY = [-93.756155, 41.918015, -93.756055, 41.918115]
polygon = Polygon(((MINX, MINY), (MINX, MAXY), (MAXX, MAXY), (MAXX, MINY), (MINX, MINY)))
Fetch_data = FetchData(polygon=polygon, region="IA_FullState", epsg="4326")
print(Fetch_data.get_data())
|
AgriTech
|
/AgriTech-0.1.tar.gz/AgriTech-0.1/package/fetch_data.py
|
fetch_data.py
|
from gpiozero import MotionSensor, OutputDevice
from cv2 import VideoCapture, imencode
from .request_helper import *
import io
import os
import logging
import sys
from serial import Serial
from agrothon_client import (
USB_PORT,
USB_BAUD_RATE,
RELAY_GPIO,
PIR1_GPIO,
PIR2_GPIO,
PIR3_GPIO,
PIR4_GPIO
)
serial_in = Serial(USB_PORT, USB_BAUD_RATE)
pump = OutputDevice(RELAY_GPIO, active_high=True, initial_value=True)
pir1 = MotionSensor(PIR1_GPIO)
pir2 = MotionSensor(PIR2_GPIO)
pir3 = MotionSensor(PIR3_GPIO)
pir4 = MotionSensor(PIR4_GPIO)
LOGGER = logging.getLogger(__name__)
def motion_intruder_detect():
LOGGER.info("Starting Intruder Module")
while True:
try:
if pir1.motion_detected or pir2.motion_detected or pir3.motion_detected or pir4.motion_detected:
LOGGER.info(f"PIR1 : {pir1.value}, PIR2 : {pir2.value}, PIR3 : {pir3.value}. PIR4 : {pir4.value}")
LOGGER.info("Launching camera")
img_cap = VideoCapture(0)
check, frame = img_cap.read()
is_success, cv2_img = imencode(".jpg", frame)
img_cap.release()
if is_success:
data = io.BytesIO(cv2_img)
resp = image_poster(data)
if resp:
LOGGER.info(f"Intruder Detected:{str(resp)}")
else:
LOGGER.error("maybe nothing found")
except KeyboardInterrupt:
LOGGER.info("Exiting, Intruder Module")
os._exit(0)
def serial_sensor_in():
"""
This Function just get the Serial lines from Arduino NANO and decode them
"""
LOGGER.info("Starting Sensor module")
while True:
try:
if serial_in.in_waiting:
serial_line = serial_in.readline().decode('utf-8').strip()
list_of_values = serial_line.split(",")
try:
no_of_moist_sens = len(list_of_values)-2
moist_list = [] * no_of_moist_sens
for i in range(no_of_moist_sens):
moist_list.append(float(list_of_values[i]))
sensor_dict = {"no_of_sensors": no_of_moist_sens, "moisture": moist_list, "humidity": float(list_of_values[len(list_of_values)-1]), "temperature":float(list_of_values[len(list_of_values)-2])}
sensor_data_post(json=sensor_dict)
except ValueError:
LOGGER.error(serial_line)
LOGGER.error("DHT Data read failed")
pass
except KeyboardInterrupt:
LOGGER.info("Exiting Sensor module...")
os._exit(0)
def pump_status():
LOGGER.info("Starting Pump status Check")
while True:
try:
resp = pump_status_check()
if resp:
pump.off()
LOGGER.info(f"Pump is ON")
elif not resp:
pump.on()
LOGGER.info(f"Pump is OFF")
else:
LOGGER.error("Error Updating PUMP Status")
pass
except KeyboardInterrupt:
pump.on() # Switching off the pump as program is exiting
LOGGER.info("Exiting Pump Status check module...")
os._exit(0)
|
AgroClient
|
/AgroClient-1.1.3.tar.gz/AgroClient-1.1.3/agrothon_client/utils.py
|
utils.py
|
<div align="center">
<h1>Agrothon</h1>
<h3>A Farm Monitoring Bot</h3>
<a href="https://pypi.org/project/Agrothon"><img alt="PyPI" src="https://img.shields.io/pypi/v/Agrothon?style=for-the-badge"></a>
<img alt="PyPI - Python Version" src="https://img.shields.io/pypi/pyversions/Agrothon?style=for-the-badge">
<img alt="PyPI - Wheel" src="https://img.shields.io/pypi/wheel/Agrothon?style=for-the-badge">
<img alt="PyPI - Implementation" src="https://img.shields.io/pypi/implementation/Agrothon?style=for-the-badge">
<img alt="PyPI - Downloads" src="https://img.shields.io/pypi/dm/Agrothon?style=for-the-badge">
<a href="https://github.com/viswanathbalusu/Agrothon/blob/main/LICENSE"><img alt="GitHub license" src="https://img.shields.io/github/license/ViswanathBalusu/agrothon?style=for-the-badge"></a>
<a href="https://github.com/ViswanathBalusu/agrothon/issues"><img alt="GitHub issues" src="https://img.shields.io/github/issues/ViswanathBalusu/agrothon?style=for-the-badge"></a>
<a href="https://github.com/ViswanathBalusu/agrothon/network"><img alt="GitHub forks" src="https://img.shields.io/github/forks/ViswanathBalusu/agrothon?style=for-the-badge"></a>
<a href="https://github.com/ViswanathBalusu/agrothon/stargazers"><img alt="GitHub stars" src="https://img.shields.io/github/stars/ViswanathBalusu/agrothon?style=for-the-badge"></a>
</div>
## Introduction
- This project has three parts
- The [Agrothon-Client](https://github.com/viswanathbalusu/Agrothon-Client) Module which will be running in Raspberry Pi
- API Server
- Telegram Bot
- API Server handles Everything, All the routes are shown below
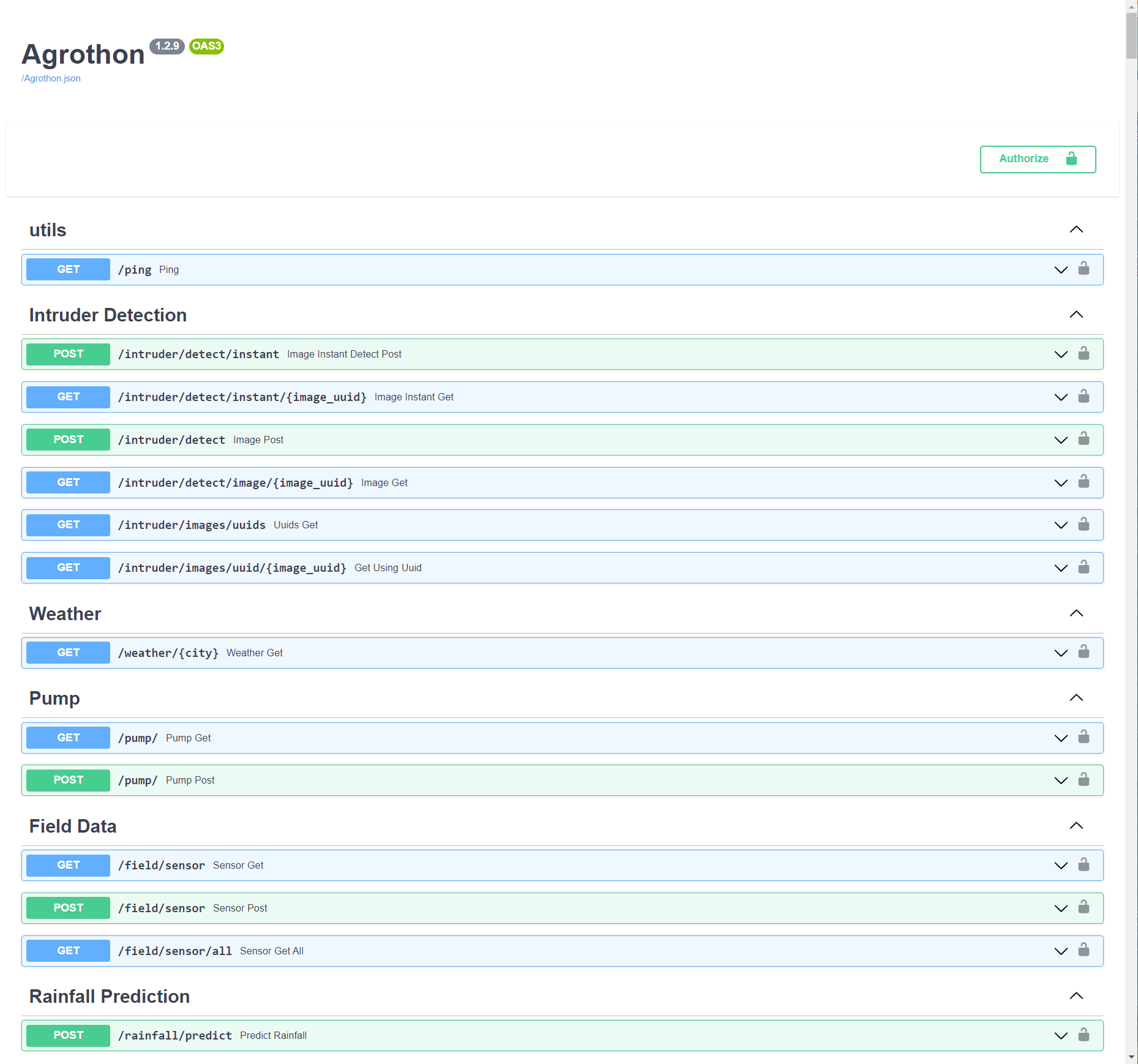
- Telegram bot is just a frontend for the whole Project
- [Agrothon-Client](https://github.com/viswanathbalusu/Agrothon-Client) Sends Sensor data, Intruder images to the API Server which will be analysed there and Stored in the Database
## Installation
- Via **pip**
- Install Dependencies
```
mkdir agrothon && cd agrothon
sudo add-apt-repository ppa:deadsnakes/ppa
sudo apt-get install python3.8 wget
wget -q https://github.com/caddyserver/caddy/releases/download/v2.4.1/caddy_2.4.1_linux_amd64.tar.gz
tar xzf caddy_2.4.1_linux_amd64.tar.gz
rm -rf caddy_2.4.1_linux_amd64.tar.gz
chmod a+x caddy
mv caddy /usr/local/bin/caddy
wget -q https://github.com/viswanathbalusu/Agrothon/raw/main/Caddyfile -O Caddyfile
```
- First fill the variables in `agrothon-sample.env` and rename it to `agrothon.env`
```
wget -q https://github.com/viswanathbalusu/Agrothon/raw/main/agrothon-sample.env -O agrothon.env
```
- you can extend all tha variables from [Base Config](agrothon/BaseConfig.py)
- Get the latest [Release](https://github.com/viswanathbalusu/Agrothon/releases/latest/download/Agrothon-Data.tar.gz) of data directory and untar in it the same directory where you placed `agrothon.env`
```
wget -q https://github.com/viswanathbalusu/Agrothon/releases/latest/download/Agrothon-Data.tar.gz
tar -xzf Agrothon-Data.tar.gz && rm -rf Agrothon-Data.tar.gz
```
- Edit the `$API_PORT` in `Caddyfile` or Just Set `$API_PORT` in your Shell Environment.
- Then Create a Virtual Environment (Optional but Recommended) and then install Agrothon with
```
python3.8 -m virtualenv venv
source venv/bin/activate
pip install Agrothon
```
- There are two commands in Agrothon
- `agroserver` - Which actually starts the Uvicorn Server on a Unix Domain Socket at `/usr/agrothon.sock`, So you should use a Reverse proxy (Preferably Caddy)
- `agrobot` - Which starts the telegram bot
- `agrothon` - Starts Both `agroserver` and `agrobot` with caddy reverse proxy
- Via **Docker**
- Download [Docker compose](./docker-compose.yml) and Map the ports according to your use
- ```wget -q https://viswanathbalusu.github.io/Agrothon/docker-compose.yml```
- Download [agrothon.env](./agrothon-sample.env) and Fill the Variables (can be extended from [Base Config](agrothon/BaseConfig.py))
- ```wget -q https://viswanathbalusu.github.io/Agrothon/agrothon-sample.env -O agrothon.env```
- Finally do `docker-compose up` it will pull the image from container registry and run the services
## Variables in `agrothon.env`
| Variable | Value | Example | Required | Description |
| :---: | :---: | :---: | :---: | :---: |
| - | - | Bot Configuration | - | - |
| TELEGRAM_APP_ID | Telegram API APP ID | 1234567 | True | Can be obtained from [Telegram](https://my.telegram.org/auth) |
| TELEGRAM_API_HASH | Telegram API Hash | 022d29afxxxxxxxxf825980a7974ec42 | True | Can be obtained from [Telegram](https://my.telegram.org/auth) |
| BOT_TOKEN | Telegram Bot Token | 123456:abcdefghij | True | Can be obtained from [Bot Father](https://t.me/botfather)
| API_BASE_URL | Api base Host URL | https://mysite.com/ | True | Must be host Without port (i.e Port 80/443* only) |
| ALERT_CHANNEL_ID | Alert channel ID | -100123456789 | True | Intruder Alerts will be posted to this channel |
| STATE | name of the state | Andhra Pradesh | True | Must be a state in India 🤔|
| DISTRICT | name of the district | East Godavari | True | name of your district |
| DEF_LANG | Default Language | english | False | Can be choosen from `english`, `telugu`, `tamil`, `hindi` (Default is `english`)|
| DEF_CITY | Default City | Vijayawada | True | City from which weather should be fetched |
| - | - | Server Configuration | - | - |
| OPEN_WEATHER_API | Open weather API Key| d6778a1acdd67c4xxxxxxe500e81987d | True | API to get the weather data of a particular region, Get this from [OpenWeather](https://openweathermap.org/api)|
| API_KEY | An API Key for your Server | Agrothon | True | This is like a Password for your API Server, So choose Wisely (Alphanumeric only) |
| DB_URL | MongoDB URL | mongodb+srv://xxx:[email protected] | True | Database to Store All the data, get this from [MongoDB](https://mongodb.com) |
| SENSOR_PRIORITY_INDEX | Moisture sensor priority | 2 | True | Which moisture sensor to use for predicting on/off the pump |
| AUTH_ID | Telegram user ID | 12345678 | False | If this is not provided, Bot access is given to all the telegram users ⚠️ |
`* if there are Other ports too the Bot will Work but it may not be able to post images`
## Note
- We are using heavy modules like tensorflow and Yolov3, so make sure you have atleast 2.5GB RAM free to get this running
- Only Works in UNIX environments
- `caddy`,`xz-utils`, all OpenCV Dependencies must be installed if you are choosing non Docker method.
- `Python3.8` is compulsory
<div align="center">
<h1>Agrothon Telegram bot</h1>
<h1>Screenshots</h1>
</div>
- Telegram Bot Start
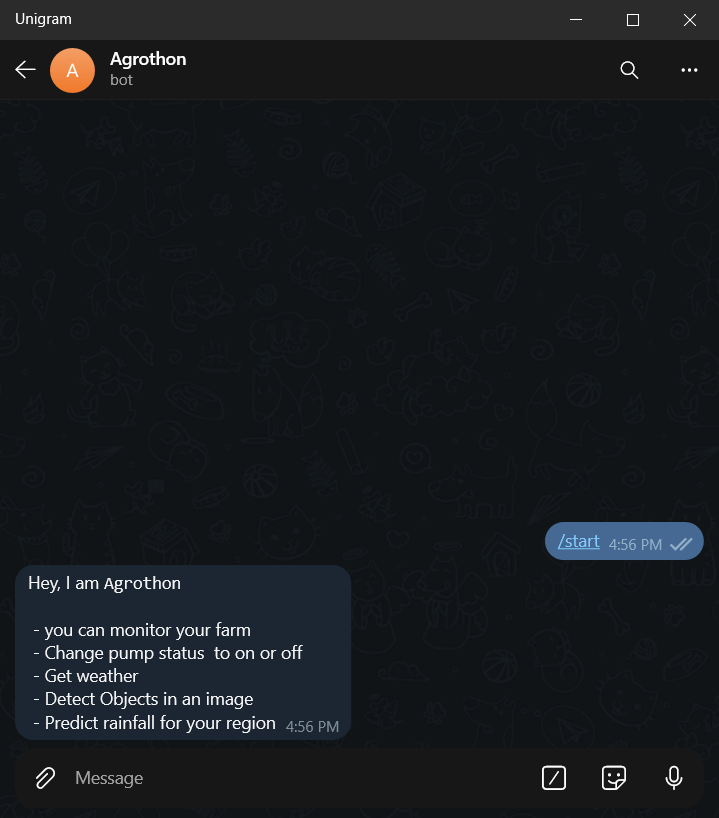
- Bot Commands
```
start - start command
field - get field status
weather - get weather status
rainfall - get predictions of rainfall for your region
settings - change settings of the bot
restart - restart the bot
log - get the log files
stats - get the server stats
ping - check ping of server
help - to get help message
```
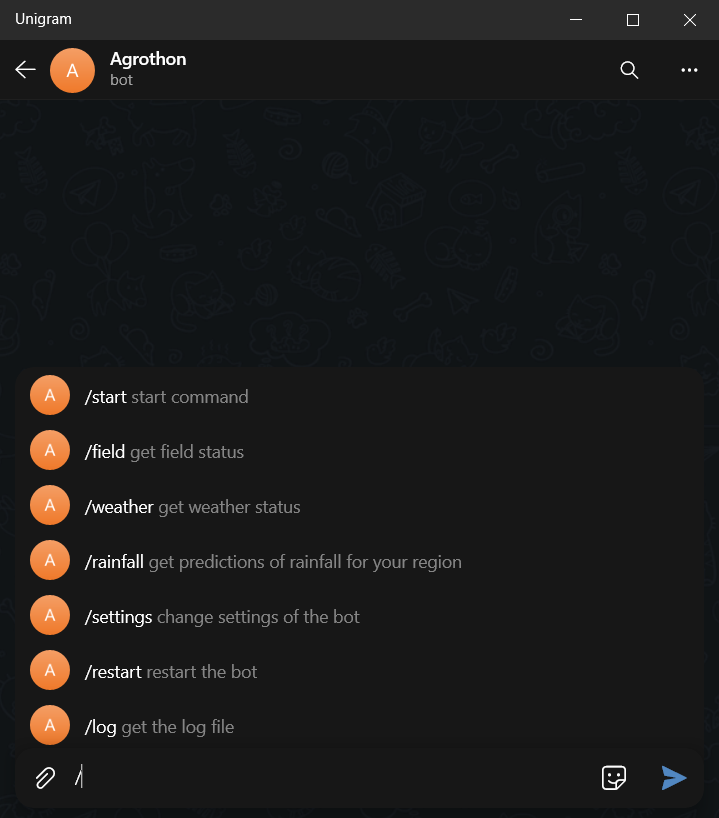
- Object Detection
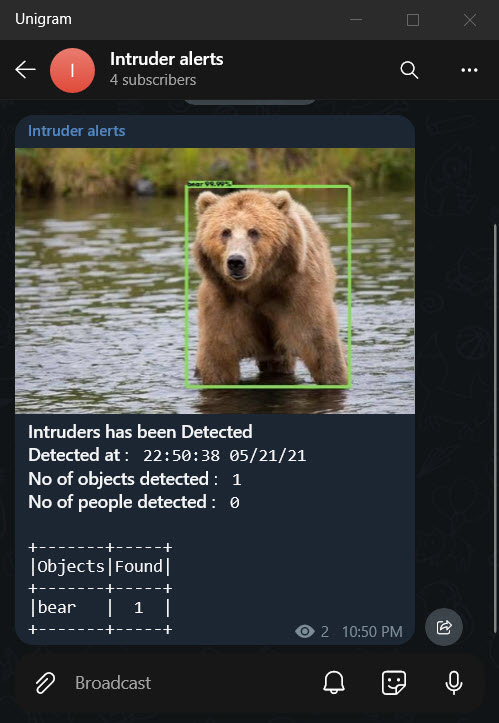
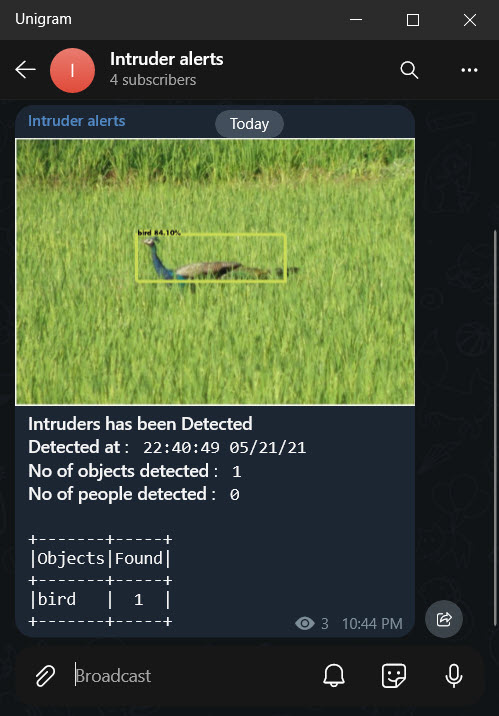
- Bot Commands Usage
- Pump Prediction
- Language Change
- Complete info
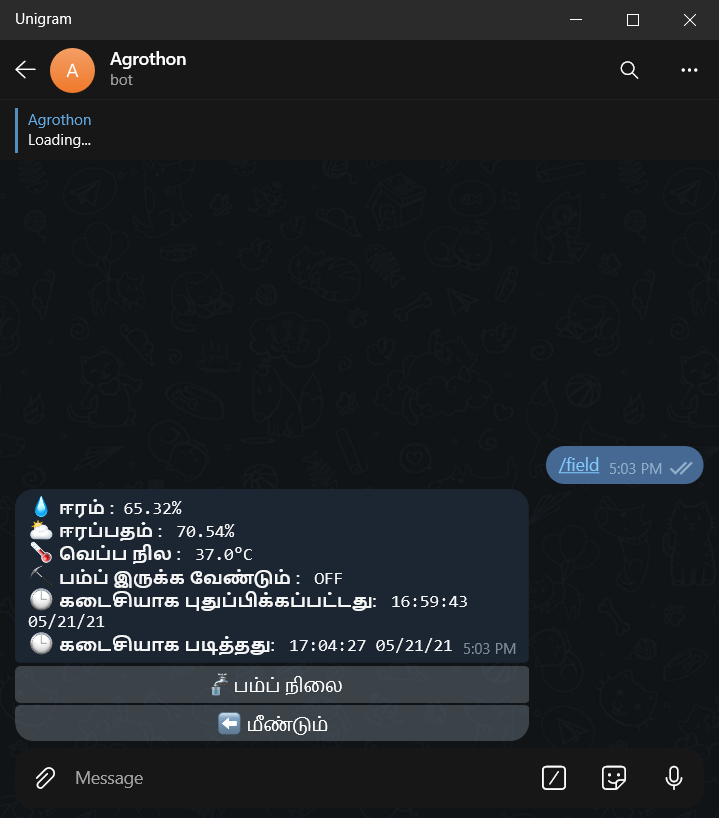
- Field Command
- Help Command
- Object Detection by sending an Image to Bot
- Language Menu
- Pump Keyboard
- Pump on/off
- Rainfall Prediction
- Settings Keyboard
- Server Stats
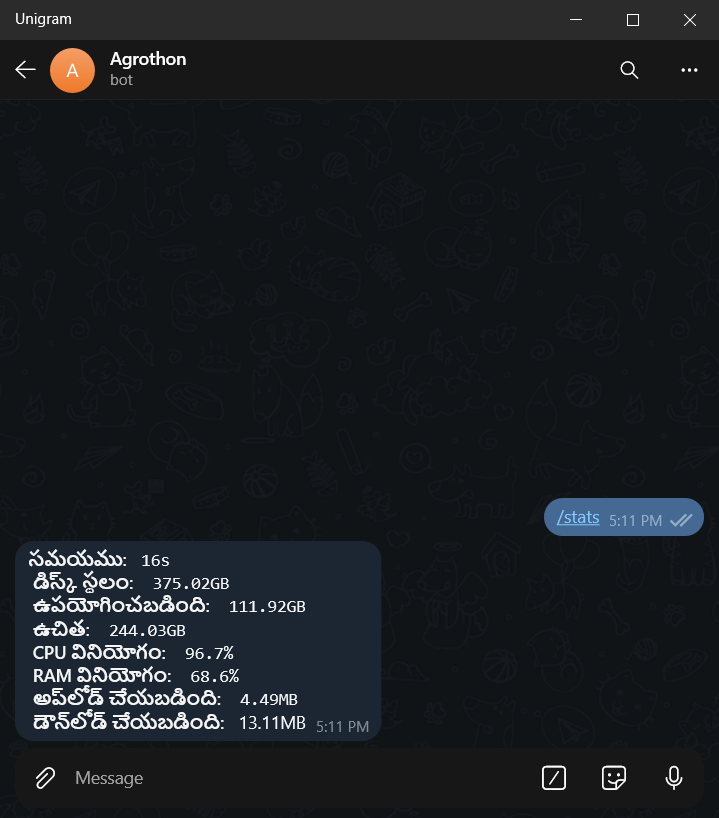
- Weather Data
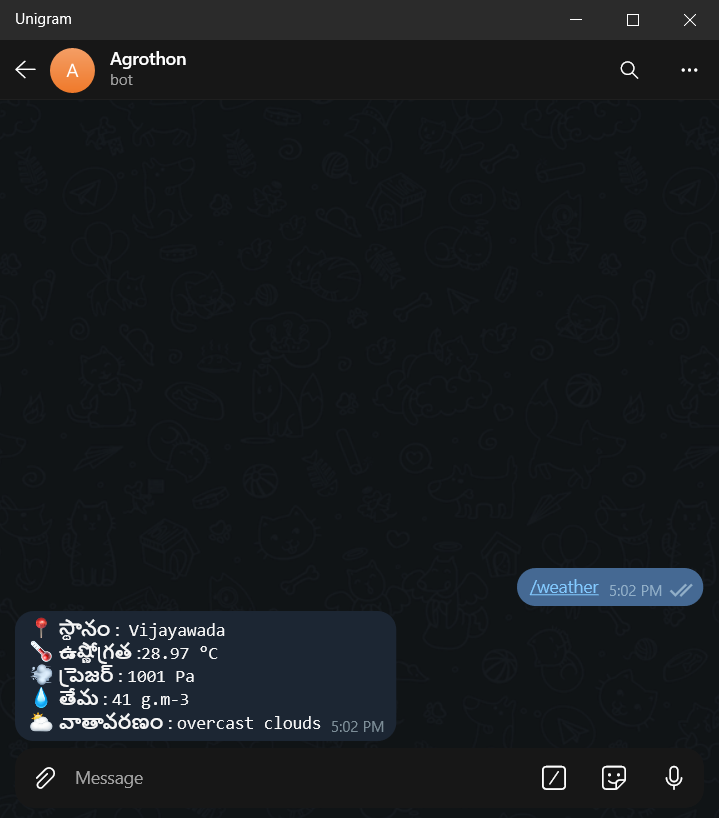
|
Agrothon
|
/Agrothon-1.3.2.tar.gz/Agrothon-1.3.2/README.md
|
README.md
|
import logging
from threading import Thread
from pyrogram import Client, filters
from pyrogram.handlers import CallbackQueryHandler, MessageHandler
from agrothon import (
AUTH_ID,
BOT_TOKEN,
FIELD_COMMAND,
HELP_COMMAND,
LOG_COMMAND,
LOGGER,
PING_COMMAND,
RAIN_COMMAND,
RESTART_COMMAND,
SETTINGS_COMMAND,
STATS_COMMAND,
TELEGRAM_API_HASH,
TELEGRAM_APP_ID,
WEATHER_COMMAND,
)
from .AlertBot import alerts_handler, language_change_check, restart_check
from .tgbot.modules.callbacks import (
backcbq,
callback_sensors,
lang_change,
languages,
pumpque,
restart_callback,
)
from .tgbot.modules.fieldstatus import field
from .tgbot.modules.photo_handler import photo_detect
from .tgbot.modules.rainfall import rainfall_predict
from .tgbot.modules.settings import help_command, ping_command, restart, settings, start
from .tgbot.modules.utils import send_log, stats
from .tgbot.modules.weather import weather
logging.getLogger("pyrogram").setLevel(logging.WARNING)
logging.getLogger("urllib3").setLevel(logging.WARNING)
logging.getLogger("telegram").setLevel(logging.INFO)
AgroBot = Client(
"Agrothon",
bot_token=BOT_TOKEN,
api_id=TELEGRAM_APP_ID,
api_hash=TELEGRAM_API_HASH,
workers=20,
device_model="Agrothon",
)
AUTH_FILTER = None
if AUTH_ID is not None:
AUTH_FILTER = filters.user(users=AUTH_ID)
else:
AUTH_FILTER = filters.all
# Callback Query handlers
cb_sensors = CallbackQueryHandler(
callback_sensors,
filters=filters.regex(pattern="^moisture|humidity|temperature|complete$"),
)
AgroBot.add_handler(cb_sensors)
back_cbq = CallbackQueryHandler(backcbq, filters=filters.regex(pattern="^back|exit$"))
AgroBot.add_handler(back_cbq)
pump_que = CallbackQueryHandler(
pumpque, filters=filters.regex(pattern="^pumpstat|pumpon|pumpoff|refresh|bot$")
)
AgroBot.add_handler(pump_que)
languages_ = CallbackQueryHandler(
languages, filters=filters.regex(pattern="^eng|tel|tam|hin$")
)
AgroBot.add_handler(languages_)
lang_hand = CallbackQueryHandler(lang_change, filters=filters.regex(pattern="^lang$"))
AgroBot.add_handler(lang_hand)
rsrt_hand = CallbackQueryHandler(
restart_callback, filters=filters.regex(pattern="^restart$")
)
AgroBot.add_handler(rsrt_hand)
# Command handlers
field_hand = MessageHandler(
field, filters=filters.command([FIELD_COMMAND]) & filters.private & AUTH_FILTER
)
AgroBot.add_handler(field_hand)
phot_detect = MessageHandler(
photo_detect, filters=filters.photo & filters.private & AUTH_FILTER
)
AgroBot.add_handler(phot_detect)
rain_hand = MessageHandler(
rainfall_predict,
filters=filters.command([RAIN_COMMAND]) & filters.private & AUTH_FILTER,
)
AgroBot.add_handler(rain_hand)
set_hand = MessageHandler(
settings,
filters=filters.command([SETTINGS_COMMAND]) & filters.private & AUTH_FILTER,
)
AgroBot.add_handler(set_hand)
rest_hand = MessageHandler(
restart, filters=filters.command([RESTART_COMMAND]) & filters.private & AUTH_FILTER
)
AgroBot.add_handler(rest_hand)
start_hand = MessageHandler(
start, filters=filters.command(["start"]) & filters.private & AUTH_FILTER
)
AgroBot.add_handler(start_hand)
help_hand = MessageHandler(
help_command,
filters=filters.command([HELP_COMMAND]) & filters.private & AUTH_FILTER,
)
AgroBot.add_handler(help_hand)
ping_hand = MessageHandler(
ping_command,
filters=filters.command([PING_COMMAND]) & filters.private & AUTH_FILTER,
)
AgroBot.add_handler(ping_hand)
stats_hand = MessageHandler(
stats, filters=filters.command([STATS_COMMAND]) & filters.private & AUTH_FILTER
)
AgroBot.add_handler(stats_hand)
log_hand = MessageHandler(
send_log, filters=filters.command([LOG_COMMAND]) & filters.private & AUTH_FILTER
)
AgroBot.add_handler(log_hand)
weather_hand = MessageHandler(
weather, filters=filters.command([WEATHER_COMMAND]) & filters.private & AUTH_FILTER
)
AgroBot.add_handler(weather_hand)
def main():
restart_check()
language_change_check()
LOGGER.info("Starting Bot")
Thread(target=alerts_handler, daemon=True).start()
AgroBot.run()
if __name__ == "__main__":
main()
|
Agrothon
|
/Agrothon-1.3.2.tar.gz/Agrothon-1.3.2/agrothon/__main__.py
|
__main__.py
|
import os
import time
from logging import getLogger
from prettytable import PrettyTable
from telegram.ext import Updater
from agrothon import ALERT_CHANNEL_ID, BOT_TOKEN, LANG
from .tgbot.helpers.apiserverhelper import get_image_url, get_image_uuids
LOGGER = getLogger(__name__)
tg = Updater(token=BOT_TOKEN)
AlertBot = tg.bot
def alerts_handler():
while True:
response = get_image_uuids()
if response is not None:
for image in response["image_data"]:
pt = PrettyTable([LANG.OBJECTS, LANG.DET_NO])
pt.align[LANG.OBJECTS] = "l"
pt.align[LANG.DET_NO] = "c"
pt.padding_width = 0
only_h = image["only_humans"]
image_url = get_image_url(image["uuid"])
detections = image["detections"]
hums = image["humans"]
tot_dets = image["no_of_detections"]
for obj in detections:
pt.add_row([obj["type"], obj["count"]])
at = image["at"]
try:
if not only_h:
AlertBot.sendPhoto(
chat_id=ALERT_CHANNEL_ID,
photo=image_url,
caption=LANG.ALERT_MESSAGE.format(at, tot_dets, hums, pt),
parse_mode="HTML",
)
else:
AlertBot.sendPhoto(
chat_id=ALERT_CHANNEL_ID,
photo=image_url,
caption=LANG.ALERT_MESSAGE.format(at, tot_dets, hums, pt),
parse_mode="HTML",
disable_notification=True,
)
except Exception as e:
LOGGER.error(
f"Error Occurred While Getting or Posting Alerts : {e}"
)
time.sleep(1)
def restart_check():
if os.path.isfile(".restartfile"):
with open(".restartfile") as f:
chat_id, msg_id = map(int, f)
AlertBot.edit_message_text(LANG.RESTART_DONE, chat_id, msg_id)
os.remove(".restartfile")
def language_change_check():
if os.path.isfile(".setlangfile"):
with open(".setlangfile") as f:
chat_id, msg_id = map(int, f)
AlertBot.edit_message_text(LANG.LANG_SET, chat_id, msg_id)
os.remove(".setlangfile")
|
Agrothon
|
/Agrothon-1.3.2.tar.gz/Agrothon-1.3.2/agrothon/AlertBot.py
|
AlertBot.py
|
import logging
import os
from pathlib import Path
from typing import List, Optional, Tuple
import cv2
import numpy as np
import tensorflow as tf
from PIL import Image, ImageDraw, ImageFont
from seaborn import color_palette
from tensorflow.keras import Model
from tensorflow.keras.layers import (
Add,
BatchNormalization,
Concatenate,
Conv2D,
Input,
Lambda,
LeakyReLU,
UpSampling2D,
ZeroPadding2D,
)
from tensorflow.keras.regularizers import l2
tf.get_logger().setLevel("ERROR")
tf.autograph.set_verbosity(3)
LOGGER = logging.getLogger(__name__)
yolo_max_boxes = 100 # maximum number of boxes per image
yolo_iou_threshold = 0.5 # iou threshold
yolo_score_threshold = 0.5 # score threshold
yolo_anchors = (
np.array(
[
(10, 13),
(16, 30),
(33, 23),
(30, 61),
(62, 45),
(59, 119),
(116, 90),
(156, 198),
(373, 326),
],
np.float32,
)
/ 416
)
yolo_anchor_masks = np.array([[6, 7, 8], [3, 4, 5], [0, 1, 2]])
YOLOV3_LAYER_LIST = [
"yolo_darknet",
"yolo_conv_0",
"yolo_output_0",
"yolo_conv_1",
"yolo_output_1",
"yolo_conv_2",
"yolo_output_2",
]
""" --------------------------------Models------------------------------ """
def DarknetConv(x, filters, size, strides=1, batch_norm=True):
if strides == 1:
padding = "same"
else:
x = ZeroPadding2D(((1, 0), (1, 0)))(x)
padding = "valid"
x = Conv2D(
filters=filters,
kernel_size=size,
strides=strides,
padding=padding,
use_bias=not batch_norm,
kernel_regularizer=l2(0.0005),
)(x)
if batch_norm:
x = BatchNormalization()(x)
x = LeakyReLU(alpha=0.1)(x)
return x
def DarknetResidual(x, filters):
prev = x
x = DarknetConv(x, filters // 2, 1)
x = DarknetConv(x, filters, 3)
x = Add()([prev, x])
return x
def DarknetBlock(x, filters, blocks):
x = DarknetConv(x, filters, 3, strides=2)
for _ in range(blocks):
x = DarknetResidual(x, filters)
return x
def Darknet(name=None):
x = inputs = Input([None, None, 3])
x = DarknetConv(x, 32, 3)
x = DarknetBlock(x, 64, 1)
x = DarknetBlock(x, 128, 2)
x = x_36 = DarknetBlock(x, 256, 8)
x = x_61 = DarknetBlock(x, 512, 8)
x = DarknetBlock(x, 1024, 4)
return tf.keras.Model(inputs, (x_36, x_61, x), name=name)
def YoloConv(filters, name=None):
def yolo_conv(x_in):
if isinstance(x_in, tuple):
inputs = Input(x_in[0].shape[1:]), Input(x_in[1].shape[1:])
x, x_skip = inputs
x = DarknetConv(x, filters, 1)
x = UpSampling2D(2)(x)
x = Concatenate()([x, x_skip])
else:
x = inputs = Input(x_in.shape[1:])
x = DarknetConv(x, filters, 1)
x = DarknetConv(x, filters * 2, 3)
x = DarknetConv(x, filters, 1)
x = DarknetConv(x, filters * 2, 3)
x = DarknetConv(x, filters, 1)
return Model(inputs, x, name=name)(x_in)
return yolo_conv
def YoloOutput(filters, anchors, classes, name=None):
def yolo_output(x_in):
x = inputs = Input(x_in.shape[1:])
x = DarknetConv(x, filters * 2, 3)
x = DarknetConv(x, anchors * (classes + 5), 1, batch_norm=False)
x = Lambda(
lambda x: tf.reshape(
x, (-1, tf.shape(x)[1], tf.shape(x)[2], anchors, classes + 5)
)
)(x)
return tf.keras.Model(inputs, x, name=name)(x_in)
return yolo_output
def _meshgrid(n_a, n_b):
return [
tf.reshape(tf.tile(tf.range(n_a), [n_b]), (n_b, n_a)),
tf.reshape(tf.repeat(tf.range(n_b), n_a), (n_b, n_a)),
]
def yolo_boxes(pred, anchors, classes):
grid_size = tf.shape(pred)[1:3]
box_xy, box_wh, objectness, class_probs = tf.split(
pred, (2, 2, 1, classes), axis=-1
)
box_xy = tf.sigmoid(box_xy)
objectness = tf.sigmoid(objectness)
class_probs = tf.sigmoid(class_probs)
pred_box = tf.concat((box_xy, box_wh), axis=-1)
grid = _meshgrid(grid_size[1], grid_size[0])
grid = tf.expand_dims(tf.stack(grid, axis=-1), axis=2)
box_xy = (box_xy + tf.cast(grid, tf.float32)) / tf.cast(grid_size, tf.float32)
box_wh = tf.exp(box_wh) * anchors
box_x1y1 = box_xy - box_wh / 2
box_x2y2 = box_xy + box_wh / 2
bbox = tf.concat([box_x1y1, box_x2y2], axis=-1)
return bbox, objectness, class_probs, pred_box
def yolo_nms(outputs, anchors, masks, classes):
b, c, t = [], [], []
for o in outputs:
b.append(tf.reshape(o[0], (tf.shape(o[0])[0], -1, tf.shape(o[0])[-1])))
c.append(tf.reshape(o[1], (tf.shape(o[1])[0], -1, tf.shape(o[1])[-1])))
t.append(tf.reshape(o[2], (tf.shape(o[2])[0], -1, tf.shape(o[2])[-1])))
bbox = tf.concat(b, axis=1)
confidence = tf.concat(c, axis=1)
class_probs = tf.concat(t, axis=1)
scores = confidence * class_probs
dscores = tf.squeeze(scores, axis=0)
scores = tf.reduce_max(dscores, [1])
bbox = tf.reshape(bbox, (-1, 4))
classes = tf.argmax(dscores, 1)
selected_indices, selected_scores = tf.image.non_max_suppression_with_scores(
boxes=bbox,
scores=scores,
max_output_size=yolo_max_boxes,
iou_threshold=yolo_iou_threshold,
score_threshold=yolo_score_threshold,
soft_nms_sigma=0.5,
)
num_valid_nms_boxes = tf.shape(selected_indices)[0]
selected_indices = tf.concat(
[selected_indices, tf.zeros(yolo_max_boxes - num_valid_nms_boxes, tf.int32)], 0
)
selected_scores = tf.concat(
[selected_scores, tf.zeros(yolo_max_boxes - num_valid_nms_boxes, tf.float32)],
-1,
)
boxes = tf.gather(bbox, selected_indices)
boxes = tf.expand_dims(boxes, axis=0)
scores = selected_scores
scores = tf.expand_dims(scores, axis=0)
classes = tf.gather(classes, selected_indices)
classes = tf.expand_dims(classes, axis=0)
valid_detections = num_valid_nms_boxes
valid_detections = tf.expand_dims(valid_detections, axis=0)
return boxes, scores, classes, valid_detections
def YoloV3(
size=None,
channels=3,
anchors=yolo_anchors,
masks=yolo_anchor_masks,
classes=80,
):
x = inputs = Input([size, size, channels], name="input")
x_36, x_61, x = Darknet(name="yolo_darknet")(x)
x = YoloConv(512, name="yolo_conv_0")(x)
output_0 = YoloOutput(512, len(masks[0]), classes, name="yolo_output_0")(x)
x = YoloConv(256, name="yolo_conv_1")((x, x_61))
output_1 = YoloOutput(256, len(masks[1]), classes, name="yolo_output_1")(x)
x = YoloConv(128, name="yolo_conv_2")((x, x_36))
output_2 = YoloOutput(128, len(masks[2]), classes, name="yolo_output_2")(x)
boxes_0 = Lambda(
lambda x: yolo_boxes(x, anchors[masks[0]], classes), name="yolo_boxes_0"
)(output_0)
boxes_1 = Lambda(
lambda x: yolo_boxes(x, anchors[masks[1]], classes), name="yolo_boxes_1"
)(output_1)
boxes_2 = Lambda(
lambda x: yolo_boxes(x, anchors[masks[2]], classes), name="yolo_boxes_2"
)(output_2)
outputs = Lambda(lambda x: yolo_nms(x, anchors, masks, classes), name="yolo_nms")(
(boxes_0[:3], boxes_1[:3], boxes_2[:3])
)
return Model(inputs, outputs, name="yolov3")
""" --------------------------------Utils------------------------------ """
def transform_images(x_train, size):
x_train = tf.image.resize(x_train, (size, size))
x_train = x_train / 255
return x_train
def load_darknet_weights(model, weights_file):
wf = open(weights_file, "rb")
major, minor, revision, seen, _ = np.fromfile(wf, dtype=np.int32, count=5)
layers = YOLOV3_LAYER_LIST
for layer_name in layers:
sub_model = model.get_layer(layer_name)
for i, layer in enumerate(sub_model.layers):
if not layer.name.startswith("conv2d"):
continue
batch_norm = None
if i + 1 < len(sub_model.layers) and sub_model.layers[
i + 1
].name.startswith("batch_norm"):
batch_norm = sub_model.layers[i + 1]
filters = layer.filters
size = layer.kernel_size[0]
in_dim = layer.get_input_shape_at(0)[-1]
if batch_norm is None:
conv_bias = np.fromfile(wf, dtype=np.float32, count=filters)
else:
bn_weights = np.fromfile(wf, dtype=np.float32, count=4 * filters)
bn_weights = bn_weights.reshape((4, filters))[[1, 0, 2, 3]]
conv_shape = (filters, in_dim, size, size)
conv_weights = np.fromfile(
wf, dtype=np.float32, count=np.product(conv_shape)
)
conv_weights = conv_weights.reshape(conv_shape).transpose([2, 3, 1, 0])
if batch_norm is None:
layer.set_weights([conv_weights, conv_bias])
else:
layer.set_weights([conv_weights])
batch_norm.set_weights(bn_weights)
assert len(wf.read()) == 0, "failed to read all data"
wf.close()
def draw_outputs(img, outputs, class_names):
colors = (np.array(color_palette("hls", 80)) * 255).astype(np.uint8)
boxes, objectness, classes, nums = outputs
wh = np.flip(img.shape[0:2])
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
img = Image.fromarray(img)
draw = ImageDraw.Draw(img)
font = ImageFont.truetype(
font="./data/fonts/futur.ttf", size=(img.size[0] + img.size[1]) // 100
)
for i in range(nums):
color = colors[int(classes[i])]
x1y1 = (np.array(boxes[i][0:2]) * wh).astype(np.int32)
x2y2 = (np.array(boxes[i][2:4]) * wh).astype(np.int32)
thickness = (img.size[0] + img.size[1]) // 200
x0, y0 = x1y1[0], x1y1[1]
for t in np.linspace(0, 1, thickness):
x1y1[0], x1y1[1] = x1y1[0] - t, x1y1[1] - t
x2y2[0], x2y2[1] = x2y2[0] - t, x2y2[1] - t
draw.rectangle([x1y1[0], x1y1[1], x2y2[0], x2y2[1]], outline=tuple(color))
confidence = "{:.2f}%".format(objectness[i] * 100)
text = "{} {}".format(class_names[int(classes[i])], confidence)
text_size = draw.textsize(text, font=font)
draw.rectangle(
[x0, y0 - text_size[1], x0 + text_size[0], y0], fill=tuple(color)
)
draw.text((x0, y0 - text_size[1]), text, fill="black", font=font)
rgb_img = img.convert("RGB")
img_np = np.asarray(rgb_img)
img = cv2.cvtColor(img_np, cv2.COLOR_BGR2RGB)
return img
""" --------------------------------Methods to Detect image goes here------------------------------ """
_yolo = YoloV3(classes=80)
gen_exist = False
try:
paths = []
for path in Path("data/models/yolo/weights/").glob("yolov3.tf*"):
paths.append(path)
if len(paths) == 2:
gen_exist = True
raise FileExistsError
except FileExistsError:
_yolo.load_weights("data/models/yolo/weights/yolov3.tf").expect_partial()
LOGGER.info("Loaded Generated Weights")
try:
if not gen_exist:
if os.path.exists("data/models/yolo/yolov3.weights"):
load_darknet_weights(_yolo, "data/models/yolo/yolov3.weights")
LOGGER.info("Loaded Yolov3 Weights")
_yolo.save_weights("data/models/yolo/weights/yolov3.tf")
LOGGER.info("Saved Yolov3 Weights")
_yolo.load_weights("data/models/yolo/weights/yolov3.tf").expect_partial()
LOGGER.info("Loaded Generated Weights")
else:
raise FileNotFoundError
except FileNotFoundError:
LOGGER.error("Neither Generated weights or yolov3.weights not found")
exit(1)
try:
if os.path.exists("data/models/yolo/coco.names"):
_class_names = [
c.strip() for c in open("data/models/yolo/coco.names").readlines()
]
LOGGER.info("Loaded classes from coco.names")
else:
raise FileNotFoundError
except FileNotFoundError:
LOGGER.error(f"Coco.names not found :(")
exit(1)
# INCLUDED_CLASSES = ["person", "bird", "cat", "dog", "horse", "sheep", "cow", "elephant", "bear", "zebra", "giraffe"]
INC_CLASS_NUMBERS = [0, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23]
def yolo_detect(
_image: bytes,
filter: bool = True,
) -> Tuple[
Optional[bool],
Optional[int],
Optional[List],
Optional[int],
Optional[bool],
Optional[bytes],
]:
try:
LOGGER.info("Started detection of Objects in the image")
img_raw = tf.image.decode_image(_image, channels=3)
_img_ = tf.expand_dims(img_raw, 0)
img__ = transform_images(_img_, 416)
_boxes, _scores, _classes, _nums = _yolo(img__)
filtered_boxes, filtered_scores, filtered_classes, new_nums = [], [], [], 0
if filter:
for i in range(_nums[0]):
if int(_classes[0][i]) in INC_CLASS_NUMBERS:
filtered_classes.append(int(_classes[0][i]))
filtered_boxes.append(_boxes[0][i])
filtered_scores.append(_scores[0][i])
new_nums += 1
else:
filtered_classes = _classes[0]
filtered_boxes = _boxes[0]
filtered_scores = _scores[0]
new_nums = _nums[0]
if new_nums > 0:
detections_list = []
humans = 0
only_humans = False
_objects = {}
_confidences = {}
for i in range(new_nums):
if str(_class_names[filtered_classes[i]]) in _objects:
_objects[str(_class_names[filtered_classes[i]])] += 1
_confidences[str(_class_names[filtered_classes[i]])].append(
round(float(np.array(filtered_scores[i])) * 100, 2)
)
else:
_objects[str(_class_names[filtered_classes[i]])] = 1
_confidences[str(_class_names[filtered_classes[i]])] = [
round(float(np.array(filtered_scores[i])) * 100, 2)
]
if (_class_names[int(filtered_classes[i])]) == "person":
humans += 1
for i in _objects:
detection_dict = {
"type": i,
"confidences": _confidences[i],
"count": _objects[i],
}
detections_list.append(detection_dict)
if _nums[0] == humans:
only_humans = True
cv2_img = cv2.cvtColor(img_raw.numpy(), cv2.COLOR_RGB2BGR)
cv2_img = draw_outputs(
cv2_img,
(filtered_boxes, filtered_scores, filtered_classes, new_nums),
_class_names,
)
is_success, cv2_img = cv2.imencode(".jpg", cv2_img)
LOGGER.debug(f"Finished Detecting, Objects found : {str(detections_list)}")
return True, int(new_nums), detections_list, humans, only_humans, cv2_img
else:
LOGGER.debug(f"Finished Detecting, Nothing Found in the image")
return False, None, None, None, None, None
except Exception as e:
LOGGER.error(f"Error occurred while predicting : {str(e)}")
return None, None, None, None, None, None
|
Agrothon
|
/Agrothon-1.3.2.tar.gz/Agrothon-1.3.2/agrothon/server/helpers/yolov3_helper.py
|
yolov3_helper.py
|
from typing import List, Optional
from uuid import UUID
from pydantic import BaseModel
class SuccessResponseSensor(BaseModel):
Success: bool
pump_status_updated: bool
class SuccessResponse(BaseModel):
Success: bool
class PumpGetResponse(BaseModel):
status: bool
by: str
time: str
last_read: Optional[str] = None
class PumpPostIN(BaseModel):
status: bool
by: str
class Config:
schema_extra = {
"example": {
"status": True,
"by": "A Person",
}
}
class ImageSuccessResponse(BaseModel):
Detected_Intruders: bool
uuid: UUID
class Weather(BaseModel):
city: str
temperature: int
pressure: int
humidity: int
weather: str
class Sensor(BaseModel):
no_of_sensors: int
moisture: List[float]
humidity: float
temperature: float
updated_at: str
pump_prediction: bool
sensor_priority: int
last_read: Optional[str] = None
class SensorData(BaseModel):
no_of_sensors: int
moisture: List[float]
humidity: float
temperature: float
class Config:
schema_extra = {
"example": {
"no_of_sensors": 2,
"moisture": [19.25, 56.25],
"humidity": 20.95,
"temperature": 35,
}
}
class SensorBase(BaseModel):
no_of_sensors: int
moisture: List[float]
humidity: int
temperature: int
pump_prediction: bool
sensor_priority: int
updated_at: str
class Config:
schema_extra = {
"example": {
"no_of_sensors": 2,
"moisture": [19.25, 56.25],
"humidity": 20.95,
"temperature": 35,
"pump_prediction": True,
"sensor_priority": 1,
"updated_at": "15:35:53 05/02/21",
}
}
class SensorAll(BaseModel):
no_of_entries: int
sensor_data: List[SensorBase]
class IntruderDetections(BaseModel):
type: str
confidences: List[float]
count: int
class IntruderInstantResponse(BaseModel):
uuid: UUID
detections: List[IntruderDetections]
no_of_detections: int
humans: int
only_humans: bool
at: str
class ImageUUID(BaseModel):
pending_alerts: int
image_data: List[IntruderInstantResponse]
class Region(BaseModel):
state: str
district: str
class Config:
schema_extra = {
"example": {
"state": "Andhra Pradesh",
"district": "East Godavari",
}
}
class MonthWisePrediction(BaseModel):
april: float
may: float
june: float
july: float
august: float
september: float
october: float
november: float
december: float
class RainPredictionOut(BaseModel):
state: str
district: str
units: str
predictions: MonthWisePrediction
|
Agrothon
|
/Agrothon-1.3.2.tar.gz/Agrothon-1.3.2/agrothon/server/helpers/response_models.py
|
response_models.py
|
import logging
from typing import Dict, Optional
import numpy as np
import pandas as pd
import tensorflow as tf
from keras.models import model_from_json
tf.get_logger().setLevel("ERROR")
tf.autograph.set_verbosity(3)
LOGGER = logging.getLogger(__name__)
with open("data/models/rainfall/rainfall_model.json") as json_file:
loaded_model = model_from_json(json_file.read())
csv_data = pd.read_csv("data/models/rainfall/india_rainfall.csv")
loaded_model.load_weights("data/models/rainfall/rainfall_model.h5")
_MONTHS = [
"DISTRICT",
"JAN",
"FEB",
"MAR",
"APR",
"MAY",
"JUN",
"JUL",
"AUG",
"SEP",
"OCT",
"NOV",
"DEC",
]
MONTHS = [
"JAN",
"FEB",
"MAR",
"APR",
"MAY",
"JUN",
"JUL",
"AUG",
"SEP",
"OCT",
"NOV",
"DEC",
]
MONTHS_ = [
"april",
"may",
"june",
"july",
"august",
"september",
"october",
"november",
"december",
]
def rainfall_predict(state: str, district: str) -> Optional[Dict]:
try:
LOGGER.info(f"Getting predictions for {district} in {state}")
filter_state = csv_data[_MONTHS].loc[csv_data["STATE/UT"] == state]
filter_district = np.asarray(
filter_state[MONTHS].loc[filter_state["DISTRICT"] == district]
)
x_year = None
for i in range(filter_district.shape[1] - 3):
if x_year is None:
x_year = filter_district[:, i : i + 3]
else:
x_year = np.concatenate((x_year, filter_district[:, i : i + 3]), axis=0)
y_year_pred = loaded_model.predict(np.expand_dims(x_year, axis=2))
predictions_dict = {}
if y_year_pred is not None:
for i in range(len(y_year_pred)):
predictions_dict[MONTHS_[i]] = round(float(y_year_pred[i]), 2)
LOGGER.debug(f"Predicted Rainfall Successfully : {str(predictions_dict)}")
return predictions_dict
else:
LOGGER.error(f"Prediction of rainfall returned None")
return None
except Exception as e:
LOGGER.error(f"Error in predicting Rainfall : {e}")
return None
|
Agrothon
|
/Agrothon-1.3.2.tar.gz/Agrothon-1.3.2/agrothon/server/helpers/rainpredict.py
|
rainpredict.py
|
import logging
from datetime import datetime
from fastapi import APIRouter, HTTPException
from fastapi.encoders import jsonable_encoder
from fastapi.responses import ORJSONResponse
from agrothon import MDBClient
from ..helpers.response_models import PumpGetResponse, PumpPostIN, SuccessResponse
LOGGER = logging.getLogger(__name__)
PumpRouter = APIRouter(
prefix="/pump",
tags=["Pump"],
responses={404: {"error": "Not found"}},
)
@PumpRouter.get("/", response_class=ORJSONResponse, response_model=PumpGetResponse)
async def pump_get():
"""
**Pump Status**
- Will return the present status of the pump in the field
"""
LOGGER.info(f"Getting Pump status")
_db = await MDBClient.get_db()
_pump = _db["pump"]
now = datetime.now()
time_date = now.strftime("%X %x")
try:
data = await _pump.find_one({"_id": "pump"}, {"_id": False})
if data is not None:
await _pump.update_one(
{"_id": "pump"}, {"$set": {"last_read": time_date}}, upsert=True
)
j_resp = jsonable_encoder(data)
LOGGER.debug(f"Pump status : {str(j_resp)}")
return ORJSONResponse(content=j_resp)
else:
raise HTTPException(
status_code=404, detail={"error": "Nothing found to Query"}
)
except AttributeError as e:
LOGGER.error(f"Error Occurred while getting Pump Status : {e}")
raise HTTPException(
status_code=404, detail={"error": "Something wrong with the database"}
)
@PumpRouter.post("/", response_class=ORJSONResponse, response_model=SuccessResponse)
async def pump_post(status: PumpPostIN):
"""
**Update Pump Status in the field**
"""
LOGGER.info(f"Updating Pump Status")
_db = await MDBClient.get_db()
_pump = _db["pump"]
now = datetime.now()
time_date = now.strftime("%X %x")
try:
await _pump.update_one(
{"_id": "pump"},
{
"$set": {
"status": status.status,
"time": time_date,
"by": status.by,
"last_read": time_date,
}
},
upsert=True,
)
j_resp = jsonable_encoder({"Success": True})
return ORJSONResponse(content=j_resp)
except Exception as e:
LOGGER.error(f"Error Occurred while Updating Pump Status : {e}")
raise HTTPException(status_code=404, detail={"error": "Cant Post"})
|
Agrothon
|
/Agrothon-1.3.2.tar.gz/Agrothon-1.3.2/agrothon/server/routers/pump.py
|
pump.py
|
import logging
from datetime import datetime
import orjson
from fastapi import APIRouter, HTTPException, status
from fastapi.encoders import jsonable_encoder
from fastapi.responses import ORJSONResponse
from agrothon import SENSOR_PRIORITY_INDEX, MDBClient
from ..helpers.pump_prediction import predict_pump
from ..helpers.response_models import (
Sensor,
SensorAll,
SensorData,
SuccessResponseSensor,
)
LOGGER = logging.getLogger(__name__)
SensorRouter = APIRouter(
prefix="/field",
tags=["Field Data"],
responses={404: {"error": "Not found"}},
)
@SensorRouter.get("/sensor", response_class=ORJSONResponse, response_model=Sensor)
async def sensor_get():
"""
Get the Last Update of the sensor data
"""
LOGGER.info(f"Getting Sensor data from the database")
_db = await MDBClient.get_db()
_sensor = _db["sensor"]
now = datetime.now()
time_date = now.strftime("%X %x")
try:
n_docs = await _sensor.estimated_document_count()
latest_doc_id = int(n_docs) - 1
data = await _sensor.find_one({"_id": latest_doc_id}, {"_id": False})
await _sensor.update_one(
{"_id": latest_doc_id}, {"$set": {"last_read": time_date}}
)
j_resp = jsonable_encoder(data)
LOGGER.debug(f"Fetched sensor data : {j_resp}")
return ORJSONResponse(content=j_resp)
except Exception as e:
LOGGER.error(f"Error Occurred While getting data from database, Error: {e}")
raise HTTPException(status_code=404, detail={"error": "Nothing Found"})
@SensorRouter.get(
"/sensor/all", response_class=ORJSONResponse, response_model=SensorAll
)
async def sensor_get_all():
"""
**Get all the Sensor data from the database**
"""
LOGGER.info("Getting all the available sensor data from database")
_db = await MDBClient.get_db()
_sensor = _db["sensor"]
n_docs = await _sensor.estimated_document_count()
sensor_data = []
if n_docs != 0:
async for doc in _sensor.find({}, {"_id": False, "last_read": False}).sort(
"_id"
).limit(n_docs):
sensor_data.append(jsonable_encoder(doc))
LOGGER.info(f"Fetched {n_docs} entries of sensor data")
return ORJSONResponse(
content={"no_of_entries": n_docs, "sensor_data": sensor_data}
)
else:
raise HTTPException(status_code=404, detail={"error": "Nothing Found"})
@SensorRouter.post(
"/sensor", response_class=ORJSONResponse, response_model=SuccessResponseSensor
)
async def sensor_post(data: SensorData):
"""
**post sensor data from the field to DB**
- Accepts Temperature, Humidity, Temperature as JSON
"""
LOGGER.info(f"Parsing Sensor data that was posted")
_db = await MDBClient.get_db()
_sensor = _db["sensor"]
_pump = _db["pump"]
now = datetime.now()
time_date: str = now.strftime("%X %x")
pump_data = await _pump.find_one({"_id": "pump"}, {"_id": False})
pump_set = False
pump_stat = await predict_pump(
data.moisture[SENSOR_PRIORITY_INDEX - 1], data.temperature, data.humidity
)
try:
try:
if pump_data["by"] == "AI Bot":
if pump_data["status"]:
if pump_stat:
pump_set = False
else:
pump_set = True
else:
if pump_stat:
pump_set = True
else:
pump_set = False
else:
pump_set = False
except TypeError:
pump_set = True
n_docs = await _sensor.estimated_document_count()
new_doc_id = int(n_docs)
data_dict = {
"no_of_sensors": data.no_of_sensors,
"moisture": data.moisture,
"humidity": data.humidity,
"temperature": data.temperature,
"pump_prediction": pump_stat,
"sensor_priority": SENSOR_PRIORITY_INDEX,
"updated_at": time_date,
"last_read": time_date,
}
await _sensor.update_one(
{"_id": new_doc_id},
{"$set": data_dict},
upsert=True,
)
if pump_set:
pump_dict = {
"status": pump_stat,
"time": time_date,
"by": "AI Bot",
"last_read": time_date,
}
await _pump.update_one(
{"_id": "pump"},
{"$set": pump_dict},
upsert=True,
)
LOGGER.debug(
f"Pump Status has been updated : {str(orjson.dumps(pump_dict))}"
)
j_resp = {"Success": True, "pump_status_updated": pump_set}
LOGGER.debug(f"Sensor Post response : {str(j_resp)}")
return ORJSONResponse(content=j_resp)
except Exception as e:
LOGGER.error(f"Error Occurred while Updating :{e}")
j_resp = jsonable_encoder({"Success": False})
return ORJSONResponse(
status_code=status.HTTP_422_UNPROCESSABLE_ENTITY, content=j_resp
)
|
Agrothon
|
/Agrothon-1.3.2.tar.gz/Agrothon-1.3.2/agrothon/server/routers/sensors.py
|
sensors.py
|
import base64
import io
import logging
import uuid
from datetime import datetime
from uuid import UUID
import orjson
from fastapi import APIRouter, File, HTTPException, UploadFile
from fastapi.encoders import jsonable_encoder
from fastapi.responses import ORJSONResponse
from starlette.responses import StreamingResponse
from agrothon import MDBClient
from ..helpers.response_models import (
ImageSuccessResponse,
ImageUUID,
IntruderInstantResponse,
)
from ..helpers.yolov3_helper import yolo_detect
LOGGER = logging.getLogger(__name__)
IntruderRouter = APIRouter(
prefix="/intruder",
tags=["Intruder Detection"],
responses={404: {"error": "Not found"}},
)
@IntruderRouter.post(
"/detect/instant",
response_class=ORJSONResponse,
response_model=IntruderInstantResponse,
)
async def image_instant_detect_post(image: UploadFile = File(...)):
image_cont = await image.read()
_db = await MDBClient.get_db()
_intruder_instant = _db["instant_detect"]
n_docs = await _intruder_instant.estimated_document_count()
status, nos, det_list, _hum, _only_hum, _img = yolo_detect(image_cont, filter=False)
if status is not None:
if status:
_uuid = str(uuid.uuid4())
b64_image_string = base64.b64encode(_img)
await _intruder_instant.update_one(
{"_id": n_docs},
{"$set": {"uuid": _uuid, "image": b64_image_string}},
upsert=True,
)
LOGGER.info(f"Saved an image in database with UUID {_uuid}")
detections_dict = {
"uuid": _uuid,
"detections": det_list,
"no_of_detections": nos,
"humans": _hum,
"only_humans": _only_hum,
}
LOGGER.debug(
f"Instant Image Detection Response : {orjson.dumps(detections_dict)}"
)
return ORJSONResponse(content=detections_dict)
else:
LOGGER.warning("Nothing found in the image")
raise HTTPException(
status_code=420, detail={"Error": "Nothing found in image"}
)
else:
LOGGER.error(f"Something wrong happened with Yolov3")
raise HTTPException(
status_code=404, detail={"Error": "Error occoured, try again"}
)
@IntruderRouter.get("/detect/instant/{image_uuid}", response_class=StreamingResponse)
async def image_instant_get(image_uuid: UUID):
"""
- **image_uuid** : Unique UUID to Search image in Database
* Response will be the Image
* Once the image is fetched it will be deleted from the database
"""
_db = await MDBClient.get_db()
_intruder_instant = _db["instant_detect"]
try:
LOGGER.info(f"Searching in Database for the IMage with UUID {image_uuid}")
data = await _intruder_instant.find_one_and_delete({"uuid": str(image_uuid)})
image = base64.b64decode(data["image"])
return StreamingResponse(io.BytesIO(image), media_type="image/jpeg")
except TypeError as e:
LOGGER.warning(f"Image not found in the database : Error: {e}")
raise HTTPException(
status_code=404,
detail={"status": f"Image UUID {image_uuid} not found in the DB"},
)
@IntruderRouter.post(
"/detect", response_class=ORJSONResponse, response_model=ImageSuccessResponse
)
async def image_post(image: UploadFile = File(...)):
"""
- **Post an image*
- **image** : Image
- This image will be analyzed for intruders and returns uuid of image
- if Nothing is found error 420 is returned
"""
_db = await MDBClient.get_db()
_intruder = _db["intruder"]
_intruder_images = _db["images"]
now = datetime.now()
time_date = now.strftime("%X %x")
image_cont = await image.read()
status, nos, det_list, _hum, _only_hum, _img = yolo_detect(image_cont)
n_docs = await _intruder.estimated_document_count()
if status is not None:
if status:
_uuid = str(uuid.uuid4())
b64_image_string = base64.b64encode(_img)
detections_dict = {
"uuid": _uuid,
"detections": det_list,
"no_of_detections": nos,
"humans": _hum,
"only_humans": _only_hum,
"at": time_date,
}
image_dict = {"uuid": _uuid, "image": b64_image_string}
await _intruder.update_one(
{"_id": n_docs}, {"$set": detections_dict}, upsert=True
)
await _intruder_images.update_one(
{"_id": n_docs}, {"$set": image_dict}, upsert=True
)
LOGGER.info(f"Saved an image in database with UUID {_uuid}")
j_resp = {"Detected_Intruders": True, "image_uuid": _uuid}
LOGGER.debug(f"no of intruders detected: {str(nos)}")
return ORJSONResponse(content=j_resp)
else:
LOGGER.warning("Nothing found in the image")
raise HTTPException(
status_code=420, detail={"Error": "Nothing found in image"}
)
else:
LOGGER.error(f"Something wrong happened with Yolov3")
raise HTTPException(
status_code=404, detail={"Error": "Error occoured, try again"}
)
@IntruderRouter.get("/detect/image/{image_uuid}", response_class=StreamingResponse)
async def image_get(image_uuid: UUID):
"""
- **image_uuid** : Unique UUID to Search image in Database
* Response will be the Image
* Once the image is fetched it will be deleted from the database
"""
_db = await MDBClient.get_db()
_intruder = _db["intruder"]
_intruder_images = _db["images"]
try:
data = await _intruder_images.find_one_and_delete({"uuid": str(image_uuid)})
await _intruder.delete_one({"uuid": str(image_uuid)})
image = base64.b64decode(data["image"])
return StreamingResponse(io.BytesIO(image), media_type="image/jpeg")
except KeyError as e:
LOGGER.warning(f"Image not found in the database, Error : {e}")
raise HTTPException(
status_code=404,
detail={"status": f"Image UUID {image_uuid} not found in the DB"},
)
@IntruderRouter.get(
"/images/uuids", response_class=ORJSONResponse, response_model=ImageUUID
)
async def uuids_get():
"""
get all the available image UUID's in the Database according to the Priority
"""
LOGGER.debug(f"Getting all the UUID's in the database")
_db = await MDBClient.get_db()
_intruder = _db["intruder"]
n_docs = await _intruder.estimated_document_count()
image_data = []
if n_docs != 0:
LOGGER.info(f"No of Pending Alerts found : {n_docs}")
async for doc in _intruder.find({}, {"_id": False}).sort("_id").limit(n_docs):
j_resp = jsonable_encoder(doc)
image_data.append(j_resp)
resp_dict = {"pending_alerts": n_docs, "image_data": image_data}
return ORJSONResponse(content=resp_dict)
else:
LOGGER.warning(f"Nothing Found in the Database")
raise HTTPException(
status_code=404, detail={"status": "LMAO Nothing found dude"}
)
@IntruderRouter.get(
"/images/uuid/{image_uuid}",
response_class=ORJSONResponse,
response_model=IntruderInstantResponse,
)
async def get_using_uuid(image_uuid: UUID):
"""
get all the available image UUID's in the Database according to the Priority
"""
LOGGER.debug(f"Getting all the UUID's in the database")
_db = await MDBClient.get_db()
_intruder = _db["intruder"]
data = await _intruder.find_one({"uuid": str(image_uuid)}, {"_id": False})
if data is not None:
j_resp = jsonable_encoder(data)
LOGGER.debug(f"Data fetched using UUID {str(image_uuid)}: {j_resp}")
return ORJSONResponse(content=j_resp)
else:
LOGGER.warning(f"Nothing Found in the Database")
raise HTTPException(
status_code=404, detail={"status": "LMAO Nothing found dude"}
)
|
Agrothon
|
/Agrothon-1.3.2.tar.gz/Agrothon-1.3.2/agrothon/server/routers/intruder.py
|
intruder.py
|
import os
from sys import executable
import dotenv
from agrothon import LANG
from ..helpers.apiserverhelper import *
from ..helpers.keyboards import *
async def callback_sensors(client, message):
response = await sensor_get_latest()
if response is not None:
last_read = response["last_read"]
up_at = response["updated_at"]
if message.data == "moisture":
msg = """"""
for i in range(response["no_of_sensors"]):
msg += LANG.MOISTURE_SENSOR.format(str(i + 1), response["moisture"][i])
msg += LANG.MOISTURE_RESP.format(up_at, last_read)
await message.message.edit_text(
text=msg,
reply_markup=sepkeyboard,
)
elif message.data == "humidity":
await message.message.edit_text(
text=LANG.HUMID_RESP.format(response["humidity"], up_at, last_read),
reply_markup=sepkeyboard,
)
elif message.data == "temperature":
await message.message.edit_text(
text=LANG.TEMPE_RESP.format(response["temperature"], up_at, last_read),
reply_markup=sepkeyboard,
)
elif message.data == "complete":
pump_ = (
LANG.PUMP_STATUS_ON
if response["pump_prediction"]
else LANG.PUMP_STATUS_OFF
)
msg = """"""
for i in range(response["no_of_sensors"]):
msg += LANG.COMPLETE_MOISTURE.format(
str(i + 1), response["moisture"][i]
)
msg += LANG.COMPLETE_RESP.format(
response["humidity"],
response["temperature"],
response["sensor_priority"],
pump_,
up_at,
last_read,
)
await message.message.edit_text(
text=msg,
reply_markup=sepkeyboard,
)
async def backcbq(client, message):
if message.data == "back":
await message.message.edit_text(text=LANG.MAIN_MENU, reply_markup=fieldkey)
elif message.data == "exit":
await message.message.delete()
async def pumpque(client, message):
if message.data == "pumpstat" or message.data == "refresh":
response = await pump_get()
if response is not None:
if response["status"]:
await message.message.edit_text(
text=LANG.PUMP_SWITCHED_ON.format(
response["by"], response["last_read"]
),
reply_markup=pumponmenu,
)
else:
await message.message.edit_text(
text=LANG.PUMP_SWITCHED_OFF.format(
response["by"], response["last_read"]
),
reply_markup=pumpoffmenu,
)
elif message.data == "pumpon":
response = await pump_post(True)
if response is not None:
await message.message.edit_text(
text=LANG.PUMP_BTN_ON, reply_markup=pumpoffkey
)
elif message.data == "pumpoff":
response = await pump_post(False)
if response is not None:
await message.message.edit_text(
text=LANG.PUMP_BTN_OFF, reply_markup=pumponkey
)
elif message.data == "bot":
response = await pump_post(True, by="AI Bot")
if response is not None:
await message.message.edit_text(
text=LANG.BOT_ACTIVATED, reply_markup=backkey("pumpstat")
)
def language_handler(mid, cid):
with open(".setlangfile", "w") as r_file:
r_file.truncate(0)
r_file.write(f"{cid}\n{mid}")
os.execl(executable, executable, "-m", "agrothon")
async def languages(client, message):
if message.data == "eng":
_lang = "english"
os.environ["DEF_LANG"] = _lang
dotenv.set_key("agrothon.env", "DEF_LANG", _lang)
langmsg = await message.message.edit_text(
text=LANG.LANG_CHANGED, reply_markup=backkey("lang")
)
language_handler(langmsg.message_id, langmsg.chat.id)
elif message.data == "tel":
_lang = "telugu"
os.environ["DEF_LANG"] = _lang
dotenv.set_key("agrothon.env", "DEF_LANG", _lang)
langmsg = await message.message.edit_text(
text=LANG.LANG_CHANGED, reply_markup=backkey("lang")
)
language_handler(langmsg.message_id, langmsg.chat.id)
elif message.data == "tam":
_lang = "tamil"
os.environ["DEF_LANG"] = _lang
dotenv.set_key("agrothon.env", "DEF_LANG", _lang)
langmsg = await message.message.edit_text(
text=LANG.LANG_CHANGED, reply_markup=backkey("lang")
)
language_handler(langmsg.message_id, langmsg.chat.id)
elif message.data == "hin":
_lang = "hindi"
os.environ["DEF_LANG"] = _lang
dotenv.set_key("agrothon.env", "DEF_LANG", _lang)
langmsg = await message.message.edit_text(
text=LANG.LANG_CHANGED, reply_markup=backkey("lang")
)
language_handler(langmsg.message_id, langmsg.chat.id)
async def lang_change(client, message):
await message.message.edit_text(text=LANG.SELECT_LANG, reply_markup=languageskey)
async def restart_callback(client, message):
restart_msg = await message.message.edit_text(text=LANG.RESTART)
with open(".restartfile", "w") as r_file:
r_file.truncate(0)
r_file.write(f"{restart_msg.chat.id}\n{restart_msg.message_id}")
os.execl(executable, executable, "-m", "agrothon")
|
Agrothon
|
/Agrothon-1.3.2.tar.gz/Agrothon-1.3.2/agrothon/tgbot/modules/callbacks.py
|
callbacks.py
|
from json.decoder import JSONDecodeError
from logging import getLogger
from typing import Optional
import aiohttp
import requests
from agrothon import API_BASE_URL, API_KEY
LOGGER = getLogger(__name__)
async def aiohttp_helper(
url: str, headers: dict, data: Optional[dict] = None, method: Optional[str] = "get"
):
async with aiohttp.ClientSession() as session:
if method == "get":
async with session.get(url=url, headers=headers) as response:
if response.status == 200:
try:
data = await response.json()
LOGGER.debug(data)
return True, data
except AttributeError as e:
LOGGER.error(e)
return False, None
else:
return False, None
elif method == "post":
async with session.post(url=url, json=data, headers=headers) as response:
if response.status == 200:
try:
data = await response.json()
LOGGER.debug(data)
return True, data
except AttributeError as e:
LOGGER.error(e)
return False, None
else:
return False, None
else:
return False, None
async def pump_get():
url = f"{API_BASE_URL}pump/?api_key={API_KEY}"
headers = {"accept": "application/json"}
status, response = await aiohttp_helper(url=url, headers=headers)
if status:
return response
else:
return None
async def pump_post(status: bool, by: Optional[str] = "User"):
url = f"{API_BASE_URL}pump/?api_key={API_KEY}"
headers = {"accept": "application/json", "Content-Type": "application/json"}
data = {"status": status, "by": by}
status, response = await aiohttp_helper(
url=url, headers=headers, data=data, method="post"
)
if status:
return response
else:
return None
async def sensor_get_latest():
url = f"{API_BASE_URL}field/sensor?api_key={API_KEY}"
headers = {"accept": "application/json"}
status, response = await aiohttp_helper(url=url, headers=headers)
if status:
return response
else:
return None
async def sensor_get_all():
url = f"{API_BASE_URL}field/sensor/all/?api_key={API_KEY}"
headers = {"accept": "application/json"}
status, response = await aiohttp_helper(url=url, headers=headers)
if status:
return response
else:
return None
async def open_weather(city: str):
url = f"{API_BASE_URL}weather/{city}?api_key={API_KEY}"
headers = {"accept": "application/json"}
status, response = await aiohttp_helper(url=url, headers=headers)
if status:
return response
else:
return None
def get_image_uuids():
url = f"{API_BASE_URL}intruder/images/uuids?api_key={API_KEY}"
headers = {"accept": "application/json"}
try:
response = requests.get(url, headers=headers)
if response.status_code == 200:
resp = response.json()
LOGGER.info(f"Getting UUIDS, Response : {str(resp)}")
return resp
else:
return None
except Exception as e:
LOGGER.error(e)
return None
except JSONDecodeError:
LOGGER.error(f"Json Decode Error")
return None
def get_image_url(uuid: str):
url = f"{API_BASE_URL}intruder/detect/image/{uuid}?api_key={API_KEY}"
return url
async def get_rainfall_prediction(state: str, district: str):
url = f"{API_BASE_URL}rainfall/predict?api_key={API_KEY}"
headers = {"accept": "application/json"}
data = {"state": state, "district": district}
status, response = await aiohttp_helper(
url=url, headers=headers, data=data, method="post"
)
if status:
return response
else:
return None
async def get_instant_image_url(uuid: str):
url = f"{API_BASE_URL}intruder/detect/instant/{uuid}?api_key={API_KEY}"
return url
async def upload_file_to_api(path):
url = f"{API_BASE_URL}intruder/detect/instant?api_key={API_KEY}"
with open(path, "rb") as file:
files = {"image": file}
async with aiohttp.ClientSession() as session:
async with session.post(url=url, data=files) as response:
if response.status == 200:
try:
data = await response.json()
image_url = await get_instant_image_url(data["uuid"])
del data["uuid"]
data["image_url"] = image_url
return True, data
except AttributeError:
return False, None
else:
return False, None
|
Agrothon
|
/Agrothon-1.3.2.tar.gz/Agrothon-1.3.2/agrothon/tgbot/helpers/apiserverhelper.py
|
apiserverhelper.py
|
from pyrogram.types import InlineKeyboardButton, InlineKeyboardMarkup
from agrothon import LANG
fieldkey = InlineKeyboardMarkup(
[
[
InlineKeyboardButton("💧 " + LANG.MOISTURE, callback_data="moisture"),
InlineKeyboardButton("⛅ " + LANG.HUMIDITY, callback_data="humidity"),
],
[
InlineKeyboardButton("🌡️ " + LANG.TEMPERATURE, callback_data="temperature"),
InlineKeyboardButton("✅ " + LANG.COMPLETE_INFO, callback_data="complete"),
],
[InlineKeyboardButton("🚰 " + LANG.PUMP_STATUS, callback_data="pumpstat")],
[InlineKeyboardButton("🛑 " + LANG.QUIT, callback_data="exit")],
]
)
sepkeyboard = InlineKeyboardMarkup(
[
[InlineKeyboardButton("🚰 " + LANG.PUMP_STATUS, callback_data="pumpstat")],
[InlineKeyboardButton("⬅️ " + LANG.BACK, callback_data="back")],
]
)
pumpoffkey = InlineKeyboardMarkup(
[
[
InlineKeyboardButton("🛑 " + LANG.PUMP_OFF, callback_data="pumpoff"),
],
[InlineKeyboardButton("⬅️ " + LANG.BACK, callback_data="pumpstat")],
]
)
pumponkey = InlineKeyboardMarkup(
[
[
InlineKeyboardButton("✅ " + LANG.PUMP_ON, callback_data="pumpon"),
],
[InlineKeyboardButton("⬅️ " + LANG.BACK, callback_data="pumpstat")],
]
)
pumponmenu = InlineKeyboardMarkup(
[
[
InlineKeyboardButton("🛑 " + LANG.PUMP_OFF, callback_data="pumpoff"),
InlineKeyboardButton("🔄 " + LANG.REFRESH, callback_data="refresh"),
],
[
InlineKeyboardButton("🤖 " + LANG.BOT_PRED, callback_data="bot"),
],
[InlineKeyboardButton("⬅️ " + LANG.BACK, callback_data="back")],
]
)
pumpoffmenu = InlineKeyboardMarkup(
[
[
InlineKeyboardButton("✅ " + LANG.PUMP_ON, callback_data="pumpon"),
InlineKeyboardButton("🔄 " + LANG.REFRESH, callback_data="refresh"),
],
[
InlineKeyboardButton("🤖 " + LANG.BOT_PRED, callback_data="bot"),
],
[InlineKeyboardButton("⬅️ " + LANG.BACK, callback_data="back")],
]
)
def backkey(callback):
return InlineKeyboardMarkup(
[[InlineKeyboardButton("⬅️ " + LANG.BACK, callback_data=callback)]]
)
settingskey = InlineKeyboardMarkup(
[
[InlineKeyboardButton(LANG.LANG, callback_data="lang")],
[InlineKeyboardButton("🔄 " + LANG.RESTART_CALLBACK, callback_data="restart")],
[InlineKeyboardButton("🛑 " + LANG.QUIT, callback_data="exit")],
]
)
languageskey = InlineKeyboardMarkup(
[
[
InlineKeyboardButton("English ", callback_data="eng"),
InlineKeyboardButton("తెలుగు", callback_data="tel"),
],
[
InlineKeyboardButton("தமிழ்", callback_data="tam"),
InlineKeyboardButton("हिन्दी", callback_data="hin"),
],
[InlineKeyboardButton("🛑 " + LANG.QUIT, callback_data="exit")],
]
)
|
Agrothon
|
/Agrothon-1.3.2.tar.gz/Agrothon-1.3.2/agrothon/tgbot/helpers/keyboards.py
|
keyboards.py
|
class Language(object):
# Main Menu
MAIN_MENU = "<b>முதன்மை பட்டியல்</b>"
# Open Weather
WEATHER_FETCH = "விவரங்களைப் பெறுதல் தயவுசெய்து காத்திருங்கள்"
WEATHER = """
<b>📍 இடம் :</b><code> {}</code>
<b>🌡️ வெப்ப நிலை : </b><code>{} °C</code>
<b>💨 அழுத்தம் : </b><code>{} Pa</code>
<b>💧 ஈரப்பதம் : </b><code>{} g.m-3</code>
<b>⛅ வானிலை : </b><code>{}</code>
"""
WEATHER_ERR = "<b>பிழை ஏற்பட்டது, பதில் : <code>{}</code> </b>"
# Button Callbacks
MOISTURE = "ஈரம்"
HUMIDITY = "ஈரப்பதம்"
TEMPERATURE = "வெப்ப நிலை"
RAIN = "மழைக்கால நிலை"
PUMP_STATUS = "பம்ப் நிலை"
COMPLETE_INFO = "முழுமையான தகவல்"
QUIT = "விட்டுவிட"
PUMP_OFF = "அனைத்து விடு"
PUMP_ON = "மாறவும்"
BACK = "மீண்டும்"
BOT_PRED = "பாட் ப்ரிடிக்டனை இயக்கவும்"
REFRESH = "நிலையை புதுப்பிக்கவும்"
MOISTURE_SENSOR = """<b>💧 மண்ணில் ஈரப்பதம் (சென்சார் {}): </b><code> {}%</code>\n"""
MOISTURE_RESP = """<b>🕒 கடைசியாக புதுப்பிக்கப்பட்டது: </b><code> {}</code>
<b>🕒 கடைசியாக படித்தது: </b><code> {}</code>
"""
HUMID_RESP = """
<b>⛅ புலத்தில் ஈரப்பதம் : </b><code> {}%</code>
<b>🕒 கடைசியாக புதுப்பிக்கப்பட்டது: </b><code> {}</code>
<b>🕒 கடைசியாக படித்தது: </b><code> {}</code>
"""
TEMPE_RESP = """
<b>🌡️ புலத்தில் தற்காலிகம் : </b><code> {}°C</code>
<b>🕒 கடைசியாக புதுப்பிக்கப்பட்டது: </b><code> {}</code>
<b>🕒 கடைசியாக படித்தத: </b><code> {}</code>
"""
RAIN_YES_RESP = """
<b>பண்ணையில் மழை பெய்கிறது 🌧️ </b>
"""
RAIN_NO_RESP = """
<b>பண்ணையில் மழை பெய்யவில்லை 🌞</b>
"""
COMPLETE_MOISTURE = """<b>💧 ஈரம் (சென்சார் {}): </b><code> {}%</code>\n"""
COMPLETE_RESP = """<b>⛅ ஈரப்பதம் : </b><code> {}%</code>
<b>🌡️ வெப்ப நில : </b><code> {}°C</code>
<b>⛏️ பம்ப் இருக்க வேண்டும் (சென்சார் {}): </b><code> {}</code>
<b>🕒 கடைசியாக புதுப்பிக்கப்பட்டது: </b><code> {}</code>
<b>🕒 கடைசியாக படித்தது: </b><code> {}</code>
"""
# Pump
PUMP_SWITCHED_ON = """
<b>பம்ப் இயங்குகிறது</b>
இயக்கப்பட்டது <code> {}</code>
கடைசி சோதனை : <code> {}</code>
"""
PUMP_SWITCHED_OFF = """
<b>பம்ப் முடக்கப்பட்டுள்ளது</b>
ஆல் மாற்றப்பட்டது <code> {}</code>
கடைசி சோதனை : <code> {}</code>
"""
BOT_ACTIVATED = """<b>🤖 போட் பயன்முறை செயல்படுத்தப்பட்டது</b>
இப்போது நீங்கள் உட்கார்ந்து ஓய்வெடுக்கலாம் மற்றும் உங்கள் 🤖 பண்ணையை நிர்வகிக்க போட் அனுமதிக்கலாம் 🚜
"""
PUMP_BTN_ON = """
<b> ✅ இயங்கும் நிலை மாற்றப்பட்டது </b>
இயக்கப்பட்டது<code> User</code>
"""
PUMP_BTN_OFF = """
<b> ✅ இயங்கும் நிலை மாற்றப்பட்டது </b>
ஆல் மாற்றப்பட்டது<code> User</code>
"""
SETTINGS = "⚙️ அமைப்புகள் ⚙️"
LANG = "🌐 மொழியை மாற்றுங்கள் 🌐"
SELECT_LANG = "விருப்பமான மொழியைத் தேர்ந்தெடுக்கவும்"
LANG_CHANGED = "மொழி ஆங்கிலத்திற்கு மாற்றப்பட்டுள்ளது"
OBJECTS = "பொருள்கள்"
DET_NO = "கண்டறியப்பட்டது"
ALERT_MESSAGE = """
<b>ஊடுருவும் நபர்கள் கண்டறியப்பட்டுள்ளனர் </b>
<b>இல் கண்டறியப்பட்டது</b> : <code> {}</code>
<b>பொருள்கள் எதுவும் கண்டறியப்படவில்லை</b> : <code> {}</code>
<b>மக்கள் யாரும் கண்டறியப்படவில்லை</b> : <code> {}</code>
<pre>{}</pre>
"""
MONTHS = [
"ஏப்ரல்",
"மே",
"ஜூன்",
"ஜூலை",
"ஆகஸ்ட்",
"செப்டம்பர்",
"அக்டோபர்",
"நவம்பர்",
"டிசம்பர்",
]
MONTH = "மாதம்"
RAINFALL = "மழைப்பொழிவு(இல் {})"
RAIN_PREDICT = """
<b>இந்த ஆண்டிற்கான மழைப்பொழிவு கணிப்புகள்</b>
<b>நிலை</b>: <code> {}</code>
<b>மாவட்டம் </b>: <code> {}</code>
<pre>{}</pre>
"""
RAIN_PREDICT_ERR = """
கணிக்கும் போது பிழை
"""
IMAGE_MESSAGE = """
<b>பொருள்கள் கண்டறியப்பட்டுள்ளன </b>
<b>பொருள்கள் எதுவும் கண்டறியப்படவில்லை</b> : <code> {}</code>
<b>மக்கள் யாரும் கண்டறியப்படவில்லை</b> : <code> {}</code>
<pre>{}</pre>
"""
ERR_IMAGE_RESPONSE = """
<b>படத்தில் எதுவும் காணப்படவில்லை</b>
"""
PRED_PUMP_OFF = "மஆஃப்ு"
PRED_PUMP_ON = "ஆன்"
STATS = """
<b>முடிந்தநேரம் :</b><code> {}</code>
<b>வட்டு அளவு :</b><code> {}</code>
<b>பயன்படுத்தப்பட்டது :</b><code> {}</code>
<b>இலவசம் :</b><code> {}</code>
<b>CPU பயன்பாடு :</b><code> {}%</code>
<b>RAM பயன்பாடு :</b><code> {}%</code>
<b>பதிவேற்றப்பட்டது :</b><code> {}</code>
<b>பதிவிறக்கம் செய்யப்பட்டது :</b><code> {}</code>
"""
DL_TG = "டெலிகிராமிலிருந்து பதிவிறக்குகிறது"
PROC_IMAGE = (
"Dசொந்தமாக ஏற்றப்பட்டது, பொருள்களைக் கண்டறிதல் தயவுசெய்து காத்திருங்கள் ..."
)
RESTART = "மறுதொடக்கம், தயவுசெய்து காத்திருங்கள் ...."
RESTART_DONE = "மீண்டும் தொடங்கப்பட்டது வெற்றிகரமாக!"
RESTART_CALLBACK = "மறுதொடக்கம்"
WEATHER_FETCHING = "வானிலை பெறுகிறது, தயவுசெய்து காத்திருங்கள்"
HELP_MESSAGE = """
<code>/{}</code> : உங்கள் நகரத்தின் வானிலை நிலை
<code>/{}</code> : உங்கள் பிராந்தியத்தின் மழையை கணிக்கவும்
<code>/{}</code> : உங்கள் புல நிலையைப் பெற்று உங்கள் பம்பை நிர்வகிக்கவும்
<code>/{}</code> : உங்கள் போட் அமைப்புகளை மாற்றவும்
<code>/{}</code> : சேவையக புள்ளிவிவரங்களைப் பெறுங்கள்
<code>/{}</code> : பிங் சரிபார்க்கவும்
<code>/{}</code> : சேவையகத்தின் பதிவைப் பெறுங்கள்
<code>/{}</code> : சேவையகத்தை மறுதொடக்கம் செய்யுங்கள்
<code>/{}</code> : இந்த செய்தியைப் பெற
<code>ஒரு படத்தில் உள்ள பொருட்களைக் கண்டறிய படத்தை அனுப்பவும்</code>
"""
START = """
ஏய், நான் <code>அக்ரோத்தான்</code>
- உங்கள் பண்ணையை கண்காணிக்கலாம்
- பம்ப் நிலையை ஆன் அல்லது ஆஃப் என மாற்றவும்
- வானிலை கிடைக்கும்
- ஒரு படத்தில் பொருள்களைக் கண்டறியவும்
- உங்கள் பிராந்தியத்திற்கு மழையை கணிக்கவும்
"""
PING_START = "பிங் தொடங்குகிறது"
PING_FINAL = "அளவிடப்பட்ட பிங் : {}"
LANG_SET = "விருப்பமான மொழி தொகுப்பு வெற்றிகரமாக"
PUMP_STATUS_ON = "மீது"
PUMP_STATUS_OFF = "ஆஃப்"
|
Agrothon
|
/Agrothon-1.3.2.tar.gz/Agrothon-1.3.2/agrothon/tgbot/translations/tamil.py
|
tamil.py
|
class Language(object):
# Main Menu
MAIN_MENU = "<b>ప్రధాన మెనూ</b>"
# Open Weather
WEATHER_FETCH = "వివరాలు శోధిస్తోంది దయచేసి వేచి ఉండండి"
WEATHER = """
<b>📍 స్థానం :</b><code> {}</code>
<b>🌡️ ఉష్ణోగ్రత : </b><code>{} °C</code>
<b>💨 ప్రెజర్ : </b><code>{} Pa</code>
<b>💧 తేమ : </b><code>{} g.m-3</code>
<b>⛅ వాతావరణం : </b><code>{}</code>
"""
WEATHER_ERR = "<b>లోపం సంభవించింది, ప్రతిస్పందన: <code>{}</code> </b>"
# Button Callbacks
MOISTURE = "తేమ"
HUMIDITY = "తడి"
TEMPERATURE = "ఉష్ణోగ్రత"
RAIN = "వర్షపాతం స్థితి"
PUMP_STATUS = "పంప్ స్థితి"
COMPLETE_INFO = "పూర్తి సమాచారం"
QUIT = "క్విట్"
PUMP_OFF = "ఆపి వేయి"
PUMP_ON = "స్విచ్ ఆన్"
BACK = "వెనుక మెను"
BOT_PRED = "బొట్ ప్రిడిక్షన్ ఆన్ చేయండి"
REFRESH = "స్థితిని రిఫ్రెష్"
# Thing Speak Data
MOISTURE_SENSOR = """<b>💧 మట్టిలో తేమ (సెన్సార్ {}): </b><code> {}%</code>\n"""
MOISTURE_RESP = """<b>🕒 చివరిసారి నవీకరించబడింది : </b><code> {}</code>
<b>🕒 చివరి తనిఖీ : </b><code> {}</code>
"""
HUMID_RESP = """
<b>⛅ పొలంలో తేమ : </b><code> {}%</code>
<b>🕒 చివరిసారి నవీకరించబడింది : </b><code> {}</code>
<b>🕒 చివరి తనిఖీ : </b><code> {}</code>
"""
TEMPE_RESP = """
<b>🌡️ పొలంలో ఉష్ణోగ్రత : </b><code> {}°C</code>
<b>🕒 చివరిసారి నవీకరించబడింది: </b><code> {}</code>
<b>🕒 చివరి తనిఖీ: </b><code> {}</code>
"""
RAIN_YES_RESP = """
<b>పొలంలో వర్షం పడుతోంది 🌧️</b>
"""
RAIN_NO_RESP = """
<b>పొలంలో వర్షం పడటం లేదు 🌞</b>
"""
COMPLETE_MOISTURE = """<b>💧 తేమ (సెన్సార్ {}): </b><code> {}%</code>\n"""
COMPLETE_RESP = """<b>⛅ తడి: </b><code> {}%</code>
<b>🌡️ ఉష్ణోగ్రత : </b><code> {}°C</code>
<b>⛏️ పంప్ స్థితి ఎలా ఉండాలి (సెన్సార్ {}): </b><code> {}</code>
<b>🕒 చివరిసారి నవీకరించబడింది : </b><code> {}</code>
<b>🕒 చివరి తనిఖీ : </b><code> {}</code>
"""
# Pump
PUMP_SWITCHED_ON = """
<b>పంప్ ఆన్లో ఉంది</b>
<code>{} </code> ద్వారా మార్చబడింది
చివరి తనిఖీ : <code> {}</code>
"""
PUMP_SWITCHED_OFF = """
<b>పంప్ ఆఫ్లో ఉంది</b>
<code>{} </code> ద్వారా స్విచ్ ఆఫ్ చేయబడింది
చివరి తనిఖీ : <code> {}</code>
"""
BOT_ACTIVATED = """<b>🤖 బాట్ మోడ్ సక్రియం చేయబడింది </b>
ఇప్పుడు మీరు తిరిగి కూర్చుని విశ్రాంతి తీసుకోవచ్చు 🛏️ మరియు మీ 🤖 బొట్ మీ పొలాన్ని నిర్వహించడానికి అనుమతించండి 🚜
"""
PUMP_BTN_ON = """
<b> ✅ రన్నింగ్ స్థితి మార్చబడింది</b>
<code>User </code> ద్వారా మార్చబడింది
"""
PUMP_BTN_OFF = """
<b> ✅ రన్నింగ్ స్థితి మార్చబడింది </b>
<code>User </code> ద్వారా మార్చబడింది
"""
LANG = "🌐 భాష మార్చు 🌐"
SETTINGS = "⚙️ సెట్టింగులు ⚙️"
SELECT_LANG = "ప్రాధాన్య భాష"
LANG_CHANGED = "భాష మారుతోంది, దయచేసి వేచి ఉండండి"
OBJECTS = "వస్తువులు"
DET_NO = "కనుగొన్నారు"
ALERT_MESSAGE = """
<b>చొరబాటుదారులు కనుగొనబడ్డారు </b>
<b>కనుగొనబడిన సమయం</b> : <code> {}</code>
<b>వస్తువుల సంఖ్య</b> : <code> {}</code>
<b>వ్యక్తుల సంఖ్య</b> : <code> {}</code>
<pre>{}</pre>
"""
MONTHS = [
"ఏప్రిల్",
"మే",
"జూన్",
"జూలై",
"ఆగస్టు",
"సెప్టెంబర్",
"అక్టోబర్",
"నవంబర్",
"డిసెంబర్",
]
MONTH = "నెల"
RAINFALL = "వర్షపాతం ({} లో)"
RAIN_PREDICT = """
<b> ఈ సంవత్సరానికి వర్షపాతం అంచనాలు </b>
<b> రాష్ట్రం </b>: <code> {} </code>
<b> జిల్లా </b>: <code> {} </code>
<pre>{}</pre>
"""
RAIN_PREDICT_ERR = """
ప్రిడిక్షన్ చేస్తున్నప్పుడు లోపం
"""
IMAGE_MESSAGE = """
<b>వస్తువులు కనుగొనబడ్డాయి</b>
<b>వస్తువుల సంఖ్య</b> : <code> {}</code>
<b>వ్యక్తుల సంఖ్య</b> : <code> {}</code>
<pre>{}</pre>
"""
ERR_IMAGE_RESPONSE = """
<b>చిత్రంలో ఏమీ కనుగొనబడలేదు</b>
"""
PRED_PUMP_OFF = "ఆఫ్"
PRED_PUMP_ON = "ఆన్"
STATS = """
<b> సమయము: </b> <code> {} </code>
<b> డిస్క్ స్థలం: </b> <code> {} </code>
<b> ఉపయోగించబడింది: </b> <code> {} </code>
<b> ఉచిత: </b> <code> {} </code>
<b> CPU వినియోగం: </b> <code> {}% </code>
<b> RAM వినియోగం: </b> <code> {}% </code>
<b> అప్లోడ్ చేయబడింది: </b> <code> {} </code>
<b> డౌన్లోడ్ చేయబడింది: </b> <code> {} </code>
"""
DL_TG = "టెలిగ్రామ్ నుండి డౌన్లోడ్ అవుతోంది"
PROC_IMAGE = "డౌన్లోడ్ చేయబడింది, వస్తువులను గుర్తించడం దయచేసి వేచి ఉండండి ..."
RESTART = "పునఃప్రారంభించి, దయచేసి వేచి ...."
RESTART_DONE = "విజయవంతంగా పునఃప్రారంభం!"
RESTART_CALLBACK = "పునఃప్రారంభించండి"
WEATHER_FETCHING = "వాతావరణం పొందడం, దయచేసి వేచి ఉండండి"
HELP_MESSAGE = """
<code>/{} </code>: మీ నగరం యొక్క వాతావరణ స్థితి
<code>/{} </code>: మీ ప్రాంతం యొక్క వర్షపాతాన్ని అంచనా వేయండి
<code>/{} </code>: మీ ఫీల్డ్ స్థితిని పొందండి మరియు మీ పంపుని నిర్వహించండి
<code>/{} </code>: మీ బొట్ యొక్క సెట్టింగులను మార్చండి
<code>/{} </code>: సర్వర్ గణాంకాలను పొందండి
<code>/{} </code>: పింగ్ను తనిఖీ చేయండి
<code>/{} </code>: సర్వర్ యొక్క లాగ్ పొందండి
<code>/{} </code>: సర్వర్ను పున ప్రారంభించండి
<code>/{} </code>: ఈ సందేశాన్ని పొందడానికి
<code> చిత్రంలోని వస్తువులను గుర్తించడానికి చిత్రాన్ని పంపండి </code>
"""
START = """
హే, నేను <code> అగ్రోథాన్ </code>
- మీరు మీ పొలాన్ని పర్యవేక్షించవచ్చు
- పంప్ స్థితిని ఆన్ లేదా ఆఫ్కు మార్చండి
- వాతావరణం పొందండి
- చిత్రంలోని వస్తువులను గుర్తించండి
- మీ ప్రాంతానికి వర్షపాతాన్ని అంచనా వేయండి
"""
PING_START = "పింగ్ ప్రారంభమవుతుంది"
PING_FINAL = "కొలిచిన పింగ్ : {}"
LANG_SET = "విజయవంతంగా భాషను తెలుగుగా మార్చారు"
PUMP_STATUS_ON = "ఆన్"
PUMP_STATUS_OFF = "ఆఫ్"
|
Agrothon
|
/Agrothon-1.3.2.tar.gz/Agrothon-1.3.2/agrothon/tgbot/translations/telugu.py
|
telugu.py
|
class Language(object):
# Main Menu
MAIN_MENU = "<b>मुख्य मेन्यू</b>"
# Open Weather
WEATHER_FETCH = "कृपया प्रतीक्षा करें जानकारी के लिये...."
WEATHER = """
<b>📍 स्थान :</b><code> {}</code>
<b>🌡️ तापमान : </b><code>{} °C</code>
<b>💨 दबाव/प्रिशर : </b><code>{} Pa</code>
<b>💧 आर्द्रता : </b><code>{} g.m-3</code>
<b>⛅ मौसम : </b><code>{}</code>
"""
WEATHER_ERR = "<b>गड़बड़ी हुइ हे, प्रतिक्रिया : <code>{}</code> </b>"
# Button Callbacks
MOISTURE = "नमी"
HUMIDITY = "आर्द्रता"
TEMPERATURE = "तापमान"
RAIN = "वर्षा स्थिति"
PUMP_STATUS = "पंप स्थिति"
COMPLETE_INFO = "पूर्ण जानकारी"
QUIT = "बंद करे"
PUMP_OFF = "स्विच ऑफ"
PUMP_ON = "स्विच वन"
BACK = "पीछे"
BOT_PRED = "बौट पूर्वानुमान को चालू करें"
REFRESH = "रिफ्रेश स्थिति"
MOISTURE_SENSOR = """<b>💧 मिट्टी में नमी (सेंसर {}): </b><code> {}%</code>\n"""
MOISTURE_RESP = """<b>🕒 अंतिम बार अपडेट किया गया: </b><code> {}</code>
<b>🕒 अंतिम बार देखा गया था: </b><code> {}</code>
"""
HUMID_RESP = """
<b>⛅ मैदान में आर्द्रता : </b><code> {}%</code>
<b>🕒 अंतिम बार अपडेट किया गया: </b><code> {}</code>
<b>🕒 अंतिम बार देखा गया था: </b><code> {}</code>
"""
TEMPE_RESP = """
<b>मैदान में तापमान🌡️ : </b><code> {}°C</code>
<b>🕒 अंतिम बार अपडेट किया गया: </b><code> {}</code>
<b>🕒 अंतिम बार देखा गया था: </b><code> {}</code>
"""
RAIN_YES_RESP = """
<b>वहां बारिश🌧️ हो रही है</b>
"""
RAIN_NO_RESP = """
<b>बारिश नहीं हो रही है 🌞</b>
"""
COMPLETE_MOISTURE = """<b>💧 नमी (सेंसर {}): </b><code> {}%</code>\n"""
COMPLETE_RESP = """<b>⛅ आर्द्रता : </b><code> {}%</code>
<b>🌡️ तापमान : </b><code> {}°C</code>
<b>⛏️ पंप होना चाहिए (सेंसर {}): </b><code> {}</code>
<b>🕒 अंतिम बार अपडेट किया गया: </b><code> {}</code>
<b>🕒 अंतिम बार देखा गया था: : </b><code> {}</code>
"""
# Pump
PUMP_SWITCHED_ON = """
<b>पंप चल रहा है</b>
स्विच वन किया <code> {}</code>
अंतिम जांच : <code> {}</code>
"""
PUMP_SWITCHED_OFF = """
<b>पंप बंद है</b>
स्विच ऑफ किया <code> {}</code>
अंतिम जांच : <code> {}</code>
"""
BOT_ACTIVATED = """<b>🤖 बॉट मोड सक्रिय है </b>
अब आप आराम से बैठ सकते हैं 🛏️ और 🤖 बॉट को अपने खेत को संभालने दें 🚜
"""
PUMP_BTN_ON = """
<b> ✅ चलने का स्थिति बदल दिया </b>
स्विच वन किया <code> User</code>
"""
PUMP_BTN_OFF = """
<b> ✅ चलने का स्थिति बदल दिया </b>
स्विच ऑफ किया <code> User</code>
"""
SETTINGS = "⚙️ सेटिंग ⚙️"
LANG = "🌐 भाषा बदलें 🌐"
SELECT_LANG = "पसंदीदा भाषा का चयन करें"
LANG_CHANGED = "भाषा बदलने की प्रतीक्षा करें"
OBJECTS = "वस्तुओं"
DET_NO = "मिल गया"
ALERT_MESSAGE = """
<b>घुसपैठियों का पता चला है </b>
<b>येहा पता चला हे</b> : <code> {}</code>
<b>वस्तुओं की संख्या पता लगाना</b> : <code> {}</code>
<b>लोगों की संख्या पता लगाना</b> : <code> {}</code>
<pre>{}</pre>
"""
MONTHS = [
"अप्रैल",
"मई",
"जून",
"जुलाई",
"अगस्त",
"सितम्बर",
"अक्टूबर",
"नवम्बर",
"दिसम्बर",
]
MONTH = "महीना"
RAINFALL = "वर्षा(in {})"
RAIN_PREDICT = """
<b>वर्षा पूर्वानुमान इस साल के लिए</b>
<b>राज्य </b>: <code> {}</code>
<b>जिला </b>: <code> {}</code>
<pre>{}</pre>
"""
RAIN_PREDICT_ERR = """
गड़बड़ी जबकि
"""
IMAGE_MESSAGE = """
<b>वस्तुओं या लोगों का पता चला है </b>
<b>वस्तुओं की संख्या पता लगाना</b> : <code> {}</code>
<b>लोगों की संख्या पता लगाना</b> : <code> {}</code>
<pre>{}</pre>
"""
ERR_IMAGE_RESPONSE = """
<b>छवि में कुछ भी नहीं मिला</b>
"""
PRED_PUMP_OFF = "ऑफ"
PRED_PUMP_ON = "वन"
STATS = """
<b>अपटाइम:</b><code> {}</code>
<b>डिस्क स्थान :</b><code> {}</code>
<b>प्रयुक्त :</b><code> {}</code>
<b>निःशुल्क :</b><code> {}</code>
<b>CPU उपयोग:</b><code> {}%</code>
<b>RAM :</b><code> {}%</code>
<b>अपलोड किया गया:</b><code> {}</code>
<b>डाउनलोड किया गया:</b><code> {}</code>
"""
DL_TG = "टेलीग्राम से डाउनलोड करना"
PROC_IMAGE = "डाउनलोड किया गया, वस्तुओं का पता लगाना कृपया प्रतीक्षा करें..."
RESTART = "पुनः प्रारंभ हो रहा है, कृपया प्रतीक्षा करें...."
RESTART_DONE = "सफलतापूर्वक पुनरारंभ किया गया!"
RESTART_CALLBACK = "पुनः आरंभ करें"
WEATHER_FETCHING = "मौसम आ रहा है, कृपया प्रतीक्षा करें"
HELP_MESSAGE = """
<code>/{}</code> : आपके शहर की मौसम स्थिति
<code>/{}</code> : अपने क्षेत्र की वर्षा की भविष्यवाणी करें
<code>/{}</code> : अपने क्षेत्र की स्थिति प्राप्त करें और अपने पंप का प्रबंधन करें
<code>/{}</code> : अपने बॉट की सेटिंग बदलें
<code>/{}</code> : सर्वर आँकड़े प्राप्त करें
<code>/{}</code> : पिंग चेक करें
<code>/{}</code> : सर्वर का लॉग प्राप्त करें
<code>/{}</code> : सर्वर को पुनरारंभ करें
<code>/{}</code> : यह संदेश पाने के लिए
<code>किसी इमेज में ऑब्जेक्ट का पता लगाने के लिए बस इमेज भेजें</code>
"""
START = """
अरे, मैं हूं <code>एग्रोथॉन</code>
- आप अपने खेत की निगरानी कर सकते हैं
- पंप की स्थिति को चालू या बंद में बदलें
- मौसम प्राप्त करें
- एक छवि में वस्तुओं का पता लगाएं
- अपने क्षेत्र के लिए वर्षा की भविष्यवाणी करें
"""
PING_START = "पिंग शुरू करना"
PING_FINAL = "मापा पिंग : {}"
LANG_SET = "हिंदी को पसंदीदा भाषा के रूप में सेट करना सफल रहा"
PUMP_STATUS_ON = "चालू"
PUMP_STATUS_OFF = "बंद"
|
Agrothon
|
/Agrothon-1.3.2.tar.gz/Agrothon-1.3.2/agrothon/tgbot/translations/hindi.py
|
hindi.py
|
class Language(object):
# Main Menu
MAIN_MENU = "<b>Main Menu</b>"
# Open Weather
WEATHER_FETCH = "Fetching Details Please Wait"
WEATHER = """
<b>📍 Location :</b><code> {}</code>
<b>🌡️ Temperature : </b><code>{} °C</code>
<b>💨 Pressure : </b><code>{} Pa</code>
<b>💧 Humidity : </b><code>{} g.m-3</code>
<b>⛅ Weather : </b><code>{}</code>
"""
WEATHER_ERR = "<b>Error Occoured</b>"
# Button Callbacks
MOISTURE = "Moisture"
HUMIDITY = "Humidity"
TEMPERATURE = "Temperature"
RAIN = "Rainfall Status"
PUMP_STATUS = "Pump Status"
COMPLETE_INFO = "Complete info"
QUIT = "Quit"
PUMP_OFF = "Switch OFF"
PUMP_ON = "Switch On"
BACK = "Back"
BOT_PRED = "Turn on Bot Prediction"
REFRESH = "Refresh Status"
MOISTURE_SENSOR = (
"""<b>💧 Moisture in the Soil (Sensor {}): </b><code> {}%</code>\n"""
)
MOISTURE_RESP = """<b>🕒 Last Updated at: </b><code> {}</code>
<b>🕒 Last Read at: </b><code> {}</code>
"""
HUMID_RESP = """
<b>⛅ Humidity in the Field : </b><code> {}%</code>
<b>🕒 Last Updated at: </b><code> {}</code>
<b>🕒 Last Read at: </b><code> {}</code>
"""
TEMPE_RESP = """
<b>🌡️ Temparature in the Field : </b><code> {}°C</code>
<b>🕒 Last Updated at: </b><code> {}</code>
<b>🕒 Last Read at: </b><code> {}</code>
"""
RAIN_YES_RESP = """
<b>It's raining 🌧️ out there</b>
"""
RAIN_NO_RESP = """
<b>It's not raining 🌞</b>
"""
COMPLETE_MOISTURE = """<b>💧 Moisture (Sensor {}): </b><code> {}%</code>\n"""
COMPLETE_RESP = """<b>⛅ Humidity : </b><code> {}%</code>
<b>🌡️ Temperature : </b><code> {}°C</code>
<b>⛏️ Pump Should be (by Sensor {}): </b><code> {}</code>
<b>🕒 Last Updated at: </b><code> {}</code>
<b>🕒 Last Read at: </b><code> {}</code>
"""
# Pump
PUMP_SWITCHED_ON = """
<b>The Pump is Running</b>
Switched ON by <code> {}</code>
Last Check : <code> {}</code>
"""
PUMP_SWITCHED_OFF = """
<b>The Pump is OFF</b>
Switched OFF by <code> {}</code>
Last Check : <code> {}</code>
"""
BOT_ACTIVATED = """<b>🤖 Bot mode is Activated </b>
Now you can sit back and relax 🛏️ and let 🤖 Bot manage your farm 🚜
"""
PUMP_BTN_ON = """
<b> ✅ Running Status Changed </b>
Switched ON by<code> User</code>
"""
PUMP_BTN_OFF = """
<b> ✅ Running Status Changed </b>
Switched OFF by<code> User</code>
"""
SETTINGS = "⚙️ Settings ⚙️"
LANG = "🌐 Change Language 🌐"
SELECT_LANG = "Select Preferred Language"
LANG_CHANGED = "Changing Language, Please wait..."
OBJECTS = "Objects"
DET_NO = "Found"
ALERT_MESSAGE = """
<b>Intruders has been Detected </b>
<b>Detected at</b> : <code> {}</code>
<b>No of objects detected</b> : <code> {}</code>
<b>No of people detected</b> : <code> {}</code>
<pre>{}</pre>
"""
MONTHS = [
"april",
"may",
"june",
"july",
"august",
"september",
"october",
"november",
"december",
]
MONTH = "Month"
RAINFALL = "Rainfall(in {})"
RAIN_PREDICT = """
<b>Rainfall predictions for this year</b>
<b>State </b>: <code> {}</code>
<b>District </b>: <code> {}</code>
<pre>{}</pre>
"""
RAIN_PREDICT_ERR = """
Error while
"""
IMAGE_MESSAGE = """
<b>Objects has been Detected </b>
<b>No of objects detected</b> : <code> {}</code>
<b>No of people detected</b> : <code> {}</code>
<pre>{}</pre>
"""
ERR_IMAGE_RESPONSE = """
<b>Nothing Found in the image</b>
"""
PRED_PUMP_OFF = "Off"
PRED_PUMP_ON = "On"
STATS = """
<b>Uptime :</b><code> {}</code>
<b>Disk Space :</b><code> {}</code>
<b>Used :</b><code> {}</code>
<b>Free :</b><code> {}</code>
<b>CPU Usage :</b><code> {}%</code>
<b>RAM :</b><code> {}%</code>
<b>Uploaded :</b><code> {}</code>
<b>Downloaded :</b><code> {}</code>
"""
DL_TG = "Downloading from Telegram"
PROC_IMAGE = "Downloaded, Detecting Objects please wait..."
RESTART = "Restarting, please wait...."
RESTART_DONE = "Restarted Successfully!"
RESTART_CALLBACK = "Restart"
WEATHER_FETCHING = "Fetching Weather, Please Wait"
HELP_MESSAGE = """
<code>/{}</code> : Weather Status of your City
<code>/{}</code> : Predict rainfall of your region
<code>/{}</code> : Get your field status and manage your pump
<code>/{}</code> : Change settings of your Bot
<code>/{}</code> : Get the server stats
<code>/{}</code> : Check ping
<code>/{}</code> : Get the log of the server
<code>/{}</code> : Restart the server
<code>/{}</code> : To get this message
<code>To detect objects in an image just send the image</code>
"""
START = """
Hey, I am <code>Agrothon</code>
- you can monitor your farm
- Change pump status to on or off
- Get weather
- Detect Objects in an image
- Predict rainfall for your region
"""
PING_START = "Starting Ping"
PING_FINAL = "Measured Ping : {}"
LANG_SET = "English is successfully set as preferred language"
PUMP_STATUS_ON = "ON"
PUMP_STATUS_OFF = "OFF"
|
Agrothon
|
/Agrothon-1.3.2.tar.gz/Agrothon-1.3.2/agrothon/tgbot/translations/english.py
|
english.py
|
Ahem
====
Ahem is a notifications framework for Django projects, it uses
declarative style just like Django models.
Instalation
===========
::
pip install Ahem
Add it to the list of installed apps in your settings file:
.. code:: python
# settings.py
INSTALLED_APPS = (
'ahem',
)
If you are using ``Celery``, configure the celery beat schedule variable
so periodic tasks can run:
.. code:: python
# settings.py
from ahem.loader import get_celery_beat_schedule
CELERYBEAT_SCHEDULE = get_celery_beat_schedule()
# you may add more periodic tasks after this:
CELERYBEAT_SCHEDULE.update({
'other-task': {
'task': 'mytasks.the_taks',
'schedule': crontab(...),
}
})
Documentation
=============
| Ahem can be runned both with or without
`celery <http://celery.readthedocs.org/>`__. If the celery lib can be
imported, it will try sending notifications asynchronously, else it will
send then in the same thread it was called.
| Periodic notifications will not work without celery.
| **Attention**
| Sending notifications without celery may slow down your system, please
be careful.
Notifications
-------------
To define notifications, create a ``notifications.py`` file in any of
the installed apps of your project and create a class that extends ahem
``Notification`` class.
.. code:: python
# my_django_app/notifications.py
from datetime import timedelta
from ahem.notification import Notification
from ahem.scopes import QuerySetScope
from ahem.triggers import DelayedTrigger
class MyProjectNotification(Notification):
name = 'my_project'
scope = QuerySetScope()
trigger = DelayedTrigger(timedelta(days=1))
backends = ['email']
templates = {
'default': 'path/to/template.html'}
- ``name`` will be used as the id of your notification, it should be
unique in your project.
- ``scope`` defines which users will receive the notification.
- ``trigger`` defines how and when the notification will be triggered.
- ``backends`` is a list of available backend names for the
notification.
- ``templates`` dictionary with templates to be used for each backend.
Context
-------
get\_context\_data(self, user, backend\_name, \*\*kwargs):
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
You can override ``get_context_data`` to add more variables to the
context. ``User`` is added to context by default, remember to call
``super`` if overriding.
.. code:: python
class TheNotification(Notification):
...
def get_context_data(self, user, backend_name, **kwargs):
kwargs = super(TheNotification, self).get_context_data(
user, backend_name, **kwargs)
kwargs['extra_context'] = 'This will be shown in the notification'
return kwargs
Backends
--------
Currently, ``EmailBackend`` is the only backend available. Developers
are encouraged to build new ones and merge then to this repository via
Pull Request.
Registering users in a backend
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
Before sending a notification to a user using a specific backend, you
need to register it.
.. code:: python
from ahem.utils import register_user
register_user('backend_name', user,
setting1='username', setting2='secure_key')
EmailBackend
~~~~~~~~~~~~
- name: ``email``
- settings: no settings required. The ``User`` email will be used.
Context data
''''''''''''
- ``subject`` will be used as the email subject.
- ``from_email`` the email the message will be sent from, default is
DEFAULT\_FROM\_EMAIL.
- ``use_html`` if true, the email will be sent with html content type.
Scheduling a notification
-------------------------
Use the ``schedule`` method to trigger a notification. Use the
``context`` kwarg to pass a context dictionary to the notification.
.. code:: python
# this will trigger the notification according to it's `trigger`
# for the MyProjectNotification, it will wait 1 day before sending
# the notification.
MyProjectNotification.schedule(context={'some_param': 'value'})
Overriding backends
~~~~~~~~~~~~~~~~~~~
You can also limit the backends that will be used by passing a list to
the ``backends`` kwarg.
**Since the EmailBackend is currently the only one available, this
feature is currently useless**
.. code:: python
MyProjectNotification.schedule(backends=['email'])
Overriding trigger
~~~~~~~~~~~~~~~~~~
You can also explicitly tell when the notification should be sent by
passing ``delay_timedelta`` or ``eta``.
.. code:: python
# Notification will be sent at 23:45
from celery.schedules import crontab
MyProjectNotification.schedule(eta=crontab(crontab(hour=23, minute=45)))
# Notification will be send 20 minutes after it was scheduled
from datetime import timedelta
MyProjectNotification.schedule(delay_timedelta=timedelta(minutes=20))
Scopes
------
Scopes are a declarative way to select which users will receive the
notification when it's executed. Ahem comes with 2 scopes by default,
but if you are feeling adventurous you can build your onw one.
QuerySetScope
~~~~~~~~~~~~~
``QuerySetScope`` will return all users if no argument is passed but you
can pass a queryset to filter only the ones you desire.
.. code:: python
from ahem.scopes import QuerySetScope
class TheNotification(Notification):
...
scope = QuerySetScope(User.objects.filter(is_staff=True))
...
This will scope the notification only to staff users.
ContextFilterScope
~~~~~~~~~~~~~~~~~~
``ContextFilterScope`` filters the ``User`` model according to a param
specified in the context passed to the notification when it's scheduled.
.. code:: python
from ahem.scopes import ContextFilterScope
class TheNotification(Notification):
...
scope = ContextFilterScope(
context_key='user_is_admin', lookup_field='is_admin')
...
# This will send the notification only to non admin users
TheNotification.schedule(context={'user_is_admin': False})
filter\_scope(self, queryset, context)
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
Extra filters can be performed in the ``Notification`` ``scope`` by
adding a ``filter_scope`` method to your notification. This method
should return a list of ``User``\ s
.. code:: python
# This will restrict the notification to users with `first_name` "Camila"
class TheNotification(Notification):
...
scope = QuerySetScope(User.objects.filter(is_staff=True))
def filter_scope(self, queryset, context):
return queryset.filter(first_name='Camila').all()
Triggers
--------
Triggers define when notifications will be send. Currently the two types
of triggers available are: ``DelayedTrigger`` and ``CalendarTrigger``,
but you can also write custom ones by extending ``NotificationTrigger``.
DelayedTrigger
~~~~~~~~~~~~~~
``DelayedTrigger``\ s should receive a timedelta as their first param.
This will specify how long should be waited before sending the
notification. If a timedelta is not specified, the notification will be
imediately sent. You can optitionaly pass ``at_hour`` and/or
``at_minute`` kwargs. By doing this, after timedelta is added to the
current time, the hour and minute will be overwriten to the ones you
specified.
.. code:: python
from datetime import timedelta
from ahem.triggers import DelayedTrigger
# Will send 2 days after scheduled at 18:00.
class TheNotification(Notification):
...
trigger = DelayedTrigger(timedelta(days=2), at_hour=18, at_minute=0)
...
CalendarTrigger
~~~~~~~~~~~~~~~
``CalendarTrigger`` are periodic notifications, use ``Celery``
``crontab`` to define it's periodicity. See ``Celery`` documentation for
more info:
http://celery.readthedocs.org/en/latest/userguide/periodic-tasks.html#crontab-schedules
.. code:: python
from celery.schedules import crontab
from ahem.triggers import CalendarTrigger
# Will send notifications everyday at midnight
class TheNotification(Notification):
...
trigger = CalendarTrigger(crontab(hour=0, minute=0))
...
Templates
---------
``templates`` specify which template should be used to render
notification content. There should be at least a ``default`` template,
but you can specify a different one for each backend. When rendering the
template, all context variables will be available.
.. code:: python
class TheNotification(Notification):
...
templates = {
'default': 'path/to/your/template.html',
'email': 'path/to/email/template.html'}
Tests
-----
Use ``tox`` to run tests.
|
Ahem
|
/Ahem-0.2.1.tar.gz/Ahem-0.2.1/README.rst
|
README.rst
|
from __future__ import unicode_literals
from django.utils import timezone
from django.template.loader import get_template
from django.template import Context, Template
from django.db.models.query import EmptyQuerySet
from django.contrib.auth.models import AnonymousUser
from ahem.tasks import dispatch_to_users
from ahem.utils import celery_is_available
class Notification(object):
"""
Base notification class. Notifications extend this class.
VARIABLES
name - A unique string that identifies the notification
across the project
backends - A list of supported backends for this notification
templates - A dictionary with a backend name as the key and
a path for a template as value. Must have a 'default'.
scope - the scope of the notification.
trigger - A trigger class that specifies when the
notification will be sent.
METHODS
get_context_data - returns a dictionary containing context variables
schedule - schedules tasks according to notification configuration
and passed arguments
filter_scope - can be used to perform context based filters. Returns
a list of users.
"""
def get_scope(self, backend):
return self.scope
def get_users(self, backend, context):
scope = self.get_scope(backend)
queryset = scope.get_users_queryset(context)
if queryset == EmptyQuerySet:
users = [AnonymousUser()]
elif hasattr(self, 'filter_scope'):
users = self.filter_scope(queryset, context)
else:
users = queryset.all()
return users
def get_next_run_eta(self, last_run_at=None):
return self.trigger.next_run_eta(last_run_at)
@classmethod
def is_periodic(cls):
return cls.trigger.is_periodic
def render_template(self, user, backend_name, context={}, **kwargs):
template_path = self.templates.get(backend_name)
if not template_path:
template_path = self.templates.get('default')
if not template_path:
raise Exception("""A template for the specified backend could not be found.
Please define a 'default' template for the notification""")
template = get_template(template_path)
return template.render(Context(context))
def get_context_data(self, user, backend_name, **kwargs):
kwargs['user'] = user
return kwargs
def get_task_eta(self, delay_timedelta, eta):
run_eta = None
if delay_timedelta is None and eta is None:
run_eta = self.get_next_run_eta()
elif delay_timedelta:
run_eta = timezone.now() + delay_timedelta
elif eta:
run_eta = eta
return run_eta
def get_task_backends(self, restrict_backends):
if restrict_backends:
return list(set(self.backends).intersection(set(restrict_backends)))
return self.backends
def schedule(self, context={}, delay_timedelta=None, eta=None, backends=None):
run_eta = self.get_task_eta(delay_timedelta, eta)
backends = self.get_task_backends(backends)
if celery_is_available():
dispatch_to_users.delay(
self.name,
eta=run_eta,
context=context,
backends=backends)
else:
dispatch_to_users(
self.name,
eta=run_eta,
context=context,
backends=backends)
|
Ahem
|
/Ahem-0.2.1.tar.gz/Ahem-0.2.1/ahem/notification.py
|
notification.py
|
from __future__ import unicode_literals
import logging
from django.core.exceptions import ObjectDoesNotExist
from django.core.mail import send_mail
from django.conf import settings as django_settings
from ahem.models import UserBackendRegistry
class BaseBackend(object):
"""
VARIABLES
name - A unique string that identifies the backend
across the project
required_settings - A list of setings required to register
a user in the backend
METHODS
send_notification - Custom method for each backend that
sends the desired notification
"""
required_settings = []
@classmethod
def register_user(cls, user, **settings):
required_settings = []
if hasattr(cls, 'required_settings'):
required_settings = cls.required_settings
if not set(required_settings).issubset(set(settings.keys())):
raise Exception("Missing backend settings.") # TODO: change to custom exception
try:
registry = UserBackendRegistry.objects.get(
user=user, backend=cls.name)
except ObjectDoesNotExist:
registry = UserBackendRegistry(
user=user, backend=cls.name)
registry.settings = settings
registry.save()
return registry
def send_notification(self, user, notification, context={}, settings={}):
raise NotImplementedError
class EmailBackend(BaseBackend):
"""
CONTEXT PARAMS
subject - An subject for the email.
from_email - The email the message will be sent from,
default is DEFAULT_FROM_EMAIL.
use_html - If true, the email will be sent with html content type.
"""
name = 'email'
def send_notification(self, user, notification, context={}, settings={}):
body = notification.render_template(user, self.name, context=context)
subject = context.get('subject', '')
from_email = context.get('from_email', django_settings.DEFAULT_FROM_EMAIL)
recipient_list = [user.email]
use_html = context.get('use_html', False)
email_params = {}
if use_html:
email_params['html_message'] = body
send_mail(subject, body, from_email, recipient_list, **email_params)
class LoggingBackend(BaseBackend):
"""
CONTEXT PARAMS
logger - logger name
logging_level - the level of the logger
"""
name = 'logging'
def get_logger(self, logger_name):
if logger_name:
logger = logging.getLogger(logger_name)
else:
logger = logging
return logger
def send_notification(self, user, notification, context={}, settings={}):
text = notification.render_template(user, self.name, context=context)
logging_level = context.get('logging_level', 'info')
logger = self.get_logger(context.get('logger', None))
getattr(logger, logging_level)(text)
|
Ahem
|
/Ahem-0.2.1.tar.gz/Ahem-0.2.1/ahem/backends.py
|
backends.py
|
from __future__ import unicode_literals
from django.utils import timezone
from django.contrib.auth.models import AnonymousUser
from ahem.utils import get_notification, get_backend, celery_is_available
from ahem.models import DeferredNotification, UserBackendRegistry
if celery_is_available():
from celery import shared_task
else:
def shared_task(func):
return func
@shared_task
def dispatch_to_users(notification_name, eta=None, context={}, backends=None, **kwargs):
notification = get_notification(notification_name)
task_backends = notification.get_task_backends(backends)
for backend in task_backends:
users = notification.get_users(backend, context)
for user in users:
if isinstance(user, AnonymousUser):
send_anonymous_notification.apply_async(
(notification_name, backend, context),
eta=eta)
else:
user_backend = UserBackendRegistry.objects.filter(
user=user, backend=backend).first()
if user_backend:
deferred = DeferredNotification.objects.create(
notification=notification_name,
user_backend=user_backend,
context=context)
if celery_is_available():
task_id = send_notification.apply_async(
(deferred.id,),
eta=eta)
deferred.task_id = task_id
deferred.save()
else:
send_notification(deferred.id)
@shared_task
def send_anonymous_notification(notification_name, backend_name, context):
notification = get_notification(notification_name)
backend = get_backend(backend_name)
backend.send_notification(
AnonymousUser(), notification, context=context)
@shared_task
def send_notification(deferred_id):
deferred = ((DeferredNotification.objects
.select_related('user_backend', 'user_backend__user'))
.get(id=deferred_id))
user = deferred.user_backend.user
backend_settings = deferred.user_backend.settings
backend = get_backend(deferred.user_backend.backend)
notification = get_notification(deferred.notification)
context = notification.get_context_data(user, backend.name, **deferred.context)
backend.send_notification(
user, notification, context=context, settings=backend_settings)
deferred.ran_at = timezone.now()
deferred.save()
|
Ahem
|
/Ahem-0.2.1.tar.gz/Ahem-0.2.1/ahem/tasks.py
|
tasks.py
|
import math
import matplotlib.pyplot as plt
from .Generaldistribution import Distribution
class Gaussian(Distribution):
""" Gaussian distribution class for calculating and
visualizing a Gaussian distribution.
Attributes:
mean (float) representing the mean value of the distribution
stdev (float) representing the standard deviation of the distribution
data_list (list of floats) a list of floats extracted from the data file
"""
def __init__(self, mu=0, sigma=1):
Distribution.__init__(self, mu, sigma)
def calculate_mean(self):
"""Function to calculate the mean of the data set.
Args:
None
Returns:
float: mean of the data set
"""
avg = 1.0 * sum(self.data) / len(self.data)
self.mean = avg
return self.mean
def calculate_stdev(self, sample=True):
"""Function to calculate the standard deviation of the data set.
Args:
sample (bool): whether the data represents a sample or population
Returns:
float: standard deviation of the data set
"""
if sample:
n = len(self.data) - 1
else:
n = len(self.data)
mean = self.calculate_mean()
sigma = 0
for d in self.data:
sigma += (d - mean) ** 2
sigma = math.sqrt(sigma / n)
self.stdev = sigma
return self.stdev
def plot_histogram(self):
"""Function to output a histogram of the instance variable data using
matplotlib pyplot library.
Args:
None
Returns:
None
"""
plt.hist(self.data)
plt.title('Histogram of Data')
plt.xlabel('data')
plt.ylabel('count')
def pdf(self, x):
"""Probability density function calculator for the gaussian distribution.
Args:
x (float): point for calculating the probability density function
Returns:
float: probability density function output
"""
return (1.0 / (self.stdev * math.sqrt(2*math.pi))) * math.exp(-0.5*((x - self.mean) / self.stdev) ** 2)
def plot_histogram_pdf(self, n_spaces = 50):
"""Function to plot the normalized histogram of the data and a plot of the
probability density function along the same range
Args:
n_spaces (int): number of data points
Returns:
list: x values for the pdf plot
list: y values for the pdf plot
"""
mu = self.mean
sigma = self.stdev
min_range = min(self.data)
max_range = max(self.data)
# calculates the interval between x values
interval = 1.0 * (max_range - min_range) / n_spaces
x = []
y = []
# calculate the x values to visualize
for i in range(n_spaces):
tmp = min_range + interval*i
x.append(tmp)
y.append(self.pdf(tmp))
# make the plots
fig, axes = plt.subplots(2,sharex=True)
fig.subplots_adjust(hspace=.5)
axes[0].hist(self.data, density=True)
axes[0].set_title('Normed Histogram of Data')
axes[0].set_ylabel('Density')
axes[1].plot(x, y)
axes[1].set_title('Normal Distribution for \n Sample Mean and Sample Standard Deviation')
axes[0].set_ylabel('Density')
plt.show()
return x, y
def __add__(self, other):
"""Function to add together two Gaussian distributions
Args:
other (Gaussian): Gaussian instance
Returns:
Gaussian: Gaussian distribution
"""
result = Gaussian()
result.mean = self.mean + other.mean
result.stdev = math.sqrt(self.stdev ** 2 + other.stdev ** 2)
return result
def __repr__(self):
"""Function to output the characteristics of the Gaussian instance
Args:
None
Returns:
string: characteristics of the Gaussian
"""
return "mean {}, standard deviation {}".format(self.mean, self.stdev)
|
Ahmed-M.-Gamaleldin
|
/Ahmed%20M.%20Gamaleldin-0.0.1.tar.gz/Ahmed M. Gamaleldin-0.0.1/distributions/Gaussiandistribution.py
|
Gaussiandistribution.py
|
import math
import matplotlib.pyplot as plt
from .Generaldistribution import Distribution
class Binomial(Distribution):
""" Binomial distribution class for calculating and
visualizing a Binomial distribution.
Attributes:
mean (float) representing the mean value of the distribution
stdev (float) representing the standard deviation of the distribution
data_list (list of floats) a list of floats to be extracted from the data file
p (float) representing the probability of an event occurring
n (int) number of trials
TODO: Fill out all functions below
"""
def __init__(self, prob=.5, size=20):
self.n = size
self.p = prob
Distribution.__init__(self, self.calculate_mean(), self.calculate_stdev())
def calculate_mean(self):
"""Function to calculate the mean from p and n
Args:
None
Returns:
float: mean of the data set
"""
self.mean = self.p * self.n
return self.mean
def calculate_stdev(self):
"""Function to calculate the standard deviation from p and n.
Args:
None
Returns:
float: standard deviation of the data set
"""
self.stdev = math.sqrt(self.n * self.p * (1 - self.p))
return self.stdev
def replace_stats_with_data(self):
"""Function to calculate p and n from the data set
Args:
None
Returns:
float: the p value
float: the n value
"""
self.n = len(self.data)
self.p = 1.0 * sum(self.data) / len(self.data)
self.mean = self.calculate_mean()
self.stdev = self.calculate_stdev()
def plot_bar(self):
"""Function to output a histogram of the instance variable data using
matplotlib pyplot library.
Args:
None
Returns:
None
"""
plt.bar(x = ['0', '1'], height = [(1 - self.p) * self.n, self.p * self.n])
plt.title('Bar Chart of Data')
plt.xlabel('outcome')
plt.ylabel('count')
def pdf(self, k):
"""Probability density function calculator for the gaussian distribution.
Args:
x (float): point for calculating the probability density function
Returns:
float: probability density function output
"""
a = math.factorial(self.n) / (math.factorial(k) * (math.factorial(self.n - k)))
b = (self.p ** k) * (1 - self.p) ** (self.n - k)
return a * b
def plot_bar_pdf(self):
"""Function to plot the pdf of the binomial distribution
Args:
None
Returns:
list: x values for the pdf plot
list: y values for the pdf plot
"""
x = []
y = []
# calculate the x values to visualize
for i in range(self.n + 1):
x.append(i)
y.append(self.pdf(i))
# make the plots
plt.bar(x, y)
plt.title('Distribution of Outcomes')
plt.ylabel('Probability')
plt.xlabel('Outcome')
plt.show()
return x, y
def __add__(self, other):
"""Function to add together two Binomial distributions with equal p
Args:
other (Binomial): Binomial instance
Returns:
Binomial: Binomial distribution
"""
try:
assert self.p == other.p, 'p values are not equal'
except AssertionError as error:
raise
result = Binomial()
result.n = self.n + other.n
result.p = self.p
result.calculate_mean()
result.calculate_stdev()
return result
def __repr__(self):
"""Function to output the characteristics of the Binomial instance
Args:
None
Returns:
string: characteristics of the Gaussian
"""
return "mean {}, standard deviation {}, p {}, n {}".\
format(self.mean, self.stdev, self.p, self.n)
|
Ahmed-M.-Gamaleldin
|
/Ahmed%20M.%20Gamaleldin-0.0.1.tar.gz/Ahmed M. Gamaleldin-0.0.1/distributions/Binomialdistribution.py
|
Binomialdistribution.py
|
import pickle
from random import random
from Cardspck.Carta import Carta
class Baraja:
Numerodecartas = 40
carta=[]
cartasdisponible = 40
def __init__(self):
self.carta = [self.Numerodecartas]
self.posAleatoria = 0
self.Crearbaraja()
self.barajar()
def Crearbaraja(self):
self.c = Carta.palo
for i in range(4):
for j in range(10):
if j != 7 or j != 8:
if j >= 9:
# ahmer = ((i * (12 - 2)) + j-2)
a = Carta(j + 1, self.c[i])
self.carta.append(a)
else:
a = Carta(j + 1, self.c[i])
self.carta.append(a)
print("Se han barajado las cartas")
def barajar(self):
self.posAleatoria = 0
self.c = Carta.palo
for i in range(40):
num = (int)(random() * (0 - (self.Numerodecartas - 1 + 1)) + (self.Numerodecartas - 1 + 1))
self.posAleatoria = num
self.c = self.carta[i]
self.carta[i] = self.carta[self.posAleatoria]
self.carta[self.posAleatoria] = self.c
self.posSiguienteCarta = 0
def siguienteCarta(self):
c = Carta
if self.posSiguienteCarta == self.Numerodecartas:
print("Ya no hay mas cartas, barajea de nuevo")
else:
self.posSiguienteCarta += 1
c = self.carta[self.posSiguienteCarta]
print("Numero= " + str(c.numero), "Palo= " + c.palo)
return c
def darCartas(self, numCartas):
if numCartas > self.Numerodecartas:
print("No se puede dar mas cartas de las que hay")
elif self.cartasdisponible < numCartas:
print("No hay suficientes cartas que mostrar")
else:
cartasDar = [numCartas]
for i in range(5):
cartasDar.append(self.siguienteCarta())
def cartasDisponible(self):
self.cartasdisponible = self.Numerodecartas - self.posSiguienteCarta
print(self.cartasdisponible)
def cartasMonton(self):
if self.cartasdisponible == self.Numerodecartas:
print("No se ha sacado ninguna carta")
else:
for i in range(self.posSiguienteCarta):
a = self.carta[i]
b = a.numero
c = a.palo
print("numero= " + str(b), "palo= " + c)
def Guardar(self):
fichero = ("cartas", "wb")
pickle.dump(self.carta, fichero)
fichero.close()
for p in self.carta:
print(p.numero)
def mostrarBaraja(self):
if self.cartasDisponible() == 0:
print("No hay cartas que mostrar")
else:
for i in range(self.posSiguienteCarta):
print("Numero= " + str(self.carta[i].numero) + "Palo= " + self.carta[i].palo)
|
AhmerCard
|
/AhmerCard-0.0.1-py3-none-any.whl/Cardspck/Baraja.py
|
Baraja.py
|
import pickle
from random import random
from Cardspck.Carta import Carta
class Baraja:
Numerodecartas = 40
carta=[]
cartasdisponible = 40
def __init__(self):
self.carta = [self.Numerodecartas]
self.posAleatoria = 0
self.Crearbaraja()
self.barajar()
def Crearbaraja(self):
self.c = Carta.palo
for i in range(4):
for j in range(10):
if j != 7 or j != 8:
if j >= 9:
# ahmer = ((i * (12 - 2)) + j-2)
a = Carta(j + 1, self.c[i])
self.carta.append(a)
else:
a = Carta(j + 1, self.c[i])
self.carta.append(a)
print("Se han barajado las cartas")
def barajar(self):
self.posAleatoria = 0
self.c = Carta.palo
for i in range(40):
num = (int)(random() * (0 - (self.Numerodecartas - 1 + 1)) + (self.Numerodecartas - 1 + 1))
self.posAleatoria = num
self.c = self.carta[i]
self.carta[i] = self.carta[self.posAleatoria]
self.carta[self.posAleatoria] = self.c
self.posSiguienteCarta = 0
def siguienteCarta(self):
c = Carta
if self.posSiguienteCarta == self.Numerodecartas:
print("Ya no hay mas cartas, barajea de nuevo")
else:
self.posSiguienteCarta += 1
c = self.carta[self.posSiguienteCarta]
print("Numero= " + str(c.numero), "Palo= " + c.palo)
return c
def darCartas(self, numCartas):
if numCartas > self.Numerodecartas:
print("No se puede dar mas cartas de las que hay")
elif self.cartasdisponible < numCartas:
print("No hay suficientes cartas que mostrar")
else:
cartasDar = [numCartas]
for i in range(5):
cartasDar.append(self.siguienteCarta())
def cartasDisponible(self):
self.cartasdisponible = self.Numerodecartas - self.posSiguienteCarta
print(self.cartasdisponible)
def cartasMonton(self):
if self.cartasdisponible == self.Numerodecartas:
print("No se ha sacado ninguna carta")
else:
for i in range(self.posSiguienteCarta):
a = self.carta[i]
b = a.numero
c = a.palo
print("numero= " + str(b), "palo= " + c)
def Guardar(self):
fichero = ("cartas", "wb")
pickle.dump(self.carta, fichero)
fichero.close()
for p in self.carta:
print(p.numero)
def mostrarBaraja(self):
if self.cartasDisponible() == 0:
print("No hay cartas que mostrar")
else:
for i in range(self.posSiguienteCarta):
print("Numero= " + str(self.carta[i].numero) + "Palo= " + self.carta[i].palo)
|
AhmerCards
|
/AhmerCards-0.0.1-py3-none-any.whl/Cardspck/Baraja.py
|
Baraja.py
|
from ahwaz.Copyright import copyright
from ahwaz.PostData import method_Rubika,httpregister,_download,_download_with_server
from ahwaz.Error import AuthError,TypeMethodError
from ahwaz.Device import DeviceTelephone
from re import findall
from ahwaz.Clien import clien
from random import randint,choice
import datetime
import io, PIL.Image
from ahwaz.Getheader import Upload
from ahwaz.Encoder import encoderjson
from tinytag import TinyTag
from ahwaz.TypeText import TypeText
import asyncio
from threading import Thread
class Messenger:
def __init__(self,Sh_account: str):
self.Auth = str("".join(findall(r"\w",Sh_account)))
self.prinet = copyright.CopyRight
self.methods = method_Rubika(Sh_account)
self.Upload = Upload(Sh_account)
if self.Auth.__len__() < 32:
raise AuthError("The Auth entered is incorrect")
elif self.Auth.__len__() > 32:
raise AuthError("The Auth entered is incorrect")
def sendMessage(self, guid,text,Type = None,Guid_mention = None,message_id=None):
if Type == "MentionText":
if Guid_mention != None:
return self.methods.methodsRubika("json",methode ="sendMessage",indata = {"object_guid":guid,"rnd":f"{randint(100000,999999999)}","text":text,"metadata":{"meta_data_parts":TypeText("MentionText",text,Guid_mention)},"reply_to_message_id":message_id},wn = clien.web)
elif Type == "Mono":
return self.methods.methodsRubika("json",methode ="sendMessage",indata = {"object_guid":guid,"rnd":f"{randint(100000,999999999)}","text":text,"metadata":{"meta_data_parts":TypeText("Mono",text = text)},"reply_to_message_id":message_id},wn = clien.web)
elif Type == "Bold":
return self.methods.methodsRubika("json",methode ="sendMessage",indata = {"object_guid":guid,"rnd":f"{randint(100000,999999999)}","text":text,"metadata":{"meta_data_parts":TypeText("Bold",text = text)},"reply_to_message_id":message_id},wn = clien.web)
elif Type == "Italic":
return self.methods.methodsRubika("json",methode ="sendMessage",indata = {"object_guid":guid,"rnd":f"{randint(100000,999999999)}","text":text,"metadata":{"meta_data_parts":TypeText("Italic",text = text)},"reply_to_message_id":message_id},wn = clien.web)
elif Type == None:
return self.methods.methodsRubika("json",methode ="sendMessage",indata = {"object_guid":guid,"rnd":f"{randint(100000,999999999)}","text":text,"reply_to_message_id":message_id},wn = clien.android)
def editMessage(self, guid, new, message_id):
return self.methods.methodsRubika("json",methode ="editMessage",indata = {"message_id":message_id,"object_guid":guid,"text":new},wn = clien.web)
def deleteMessages(self, guid, message_ids):
return self.methods.methodsRubika("json",methode ="deleteMessages",indata = {"object_guid":guid,"message_ids":message_ids,"type":"Global"},wn = clien.android)
def getMessagefilter(self, guid, filter_whith):
return self.methods.methodsRubika("json",methode ="getMessages",indata = {"filter_type":filter_whith,"max_id":"NaN","object_guid":guid,"sort":"FromMax"},wn = clien.web).get("data").get("messages")
def getMessages(self, guid, min_id):
return self.methods.methodsRubika("json",methode ="getMessagesInterval",indata = {"object_guid":guid,"middle_message_id":min_id},wn = clien.web).get("data").get("messages")
def getChats(self, start_id=None):
return self.methods.methodsRubika("json",methode ="getChats",indata = {"start_id":start_id},wn = clien.web).get("data").get("chats")
@property
def getChatsUpdate(self):
state = str(round(datetime.datetime.today().timestamp()) - 200)
return self.methods.methodsRubika("json",methode ="getChatsUpdates",indata = {"state":state},wn = clien.web).get("data").get("chats")
def deleteUserChat(self, user_guid, last_message):
return self.methods.methodsRubika("json",methode ="deleteUserChat",indata = {"last_deleted_message_id":last_message,"user_guid":user_guid},wn = clien.web)
def getInfoByUsername(self, username):
return self.methods.methodsRubika("json",methode ="getObjectByUsername",indata = {"username":username},wn = clien.web)
def banGroupMember(self, guid_gap, user_id):
return self.methods.methodsRubika("json",methode ="banGroupMember",indata = {"group_guid": guid_gap,"member_guid": user_id,"action":"Set"},wn = clien.android)
def unbanGroupMember(self, guid_gap, user_id):
return self.methods.methodsRubika("json",methode ="banGroupMember",indata = {"group_guid": guid_gap,"member_guid": user_id,"action":"Unset"},wn = clien.android)
def banChannelMember(self, guid_channel, user_id):
return self.methods.methodsRubika("json",methode ="banChannelMember",indata = {"channel_guid": guid_channel,"member_guid": user_id,"action":"Set"},wn = clien.android)
def unbanChannelMember(self, guid_channel, user_id):
return self.methods.methodsRubika("json",methode ="banChannelMember",indata = {"channel_guid": guid_channel,"member_guid": user_id,"action":"Unset"},wn = clien.android)
def getbanGroupUsers(self, guid_group, start_id = None):
return self.methods.methodsRubika("json",methode ="getBannedGroupMembers",indata = {"group_guid": guid_group,"start_id":start_id},wn = clien.android)
def getbanChannelUsers(self, guid_channel, start_id = None):
return self.methods.methodsRubika("json",methode ="getBannedChannelMembers",indata = {"channel_guid": guid_channel,"start_id":start_id},wn = clien.android)
def getGroupInfo(self, guid_gap):
return self.methods.methodsRubika("json",methode ="getGroupInfo",indata = {"group_guid": guid_gap},wn = clien.web)
def getChannelInfo(self, guid_channel):
return self.methods.methodsRubika("json",methode ="getChannelInfo",indata = {"channel_guid": guid_channel},wn = clien.web)
def addMemberGroup(self, guid_gap, user_ids):
return self.methods.methodsRubika("json",methode ="addGroupMembers",indata = {"group_guid": guid_gap,"member_guids": user_ids},wn = clien.web)
def addMemberChannel(self, guid_channel, user_ids):
return self.methods.methodsRubika("json",methode ="addChannelMembers",indata = {"channel_guid": guid_channel,"member_guids": user_ids},wn = clien.web)
def getGroupAdmins(self, guid_gap):
return self.methods.methodsRubika("json",methode ="getGroupAdminMembers",indata = {"group_guid":guid_gap},wn = clien.web)
def getChannelAdmins(self, guid_channel):
return self.methods.methodsRubika("json",methode ="getChannelAdminMembers",indata = {"channel_guid":guid_channel},wn = clien.web)
def AddNumberPhone(self, first_num, last_num, numberPhone):
return self.methods.methodsRubika("json",methode ="addAddressBook",indata = {"phone":numberPhone,"first_name":first_num,"last_name":last_num},wn = clien.web)
def getMessagesInfo(self, guid, message_ids):
return self.methods.methodsRubika("json",methode ="getMessagesByID",indata = {"object_guid":guid,"message_ids": message_ids},wn = clien.web)
def getGroupMembers(self, guid_gap, start_id=None):
return self.methods.methodsRubika("json",methode ="getGroupAllMembers",indata = {"group_guid": guid_gap,"start_id": start_id},wn = clien.web)
def getChannelMembers(self, channel_guid, text=None, start_id=None):
return self.methods.methodsRubika("json",methode ="getChannelAllMembers",indata = {"channel_guid":channel_guid,"search_text":text,"start_id":start_id},wn = clien.android)
def lockGroup(self, guid_gap):
return self.methods.methodsRubika("json",methode ="setGroupDefaultAccess",indata = {"access_list": ["AddMember"],"group_guid": guid_gap},wn = clien.android)
def unlockGroup(self, guid_gap):
return self.methods.methodsRubika("json",methode ="setGroupDefaultAccess",indata = {"access_list": ["SendMessages", "AddMember"],"group_guid": guid_gap},wn = clien.android)
def getGroupLink(self, guid_gap):
return self.methods.methodsRubika("json",methode ="getGroupLink",indata = {"group_guid": guid_gap},wn = clien.web).get("data").get("join_link")
def getChannelLink(self, guid_channel):
return self.methods.methodsRubika("json",methode ="getChannelLink",indata = {"channel_guid": guid_channel},wn = clien.web).get("data").get("join_link")
def changeGroupLink(self, guid_gap):
return self.methods.methodsRubika("json",methode ="setGroupLink",indata = {"group_guid": guid_gap},wn = clien.web).get("data").get("join_link")
def changeChannelLink(self, guid_channel):
return self.methods.methodsRubika("json",methode ="setChannelLink",indata = {"channel_guid": guid_channel},wn = clien.web).get("data").get("join_link")
def setGroupTimer(self, guid_gap, time):
return self.methods.methodsRubika("json",methode ="editGroupInfo",indata = {"group_guid": guid_gap,"slow_mode": time,"updated_parameters":["slow_mode"]},wn = clien.android)
def setGroupAdmin(self, guid_gap, guid_member,access_admin = None):
if access_admin == None: access_admin = ["ChangeInfo","SetJoinLink","SetAdmin","BanMember","DeleteGlobalAllMessages","PinMessages","SetMemberAccess"] if access_admin == None else access_admin
return self.methods.methodsRubika("json",methode ="setGroupAdmin",indata = {"group_guid": guid_gap,"access_list":access_admin,"action": "SetAdmin","member_guid": guid_member},wn = clien.android)
def deleteGroupAdmin(self,guid_gap,guid_admin):
return self.methods.methodsRubika("json",methode ="setGroupAdmin",indata = {"group_guid": guid_gap,"action": "UnsetAdmin","member_guid": guid_admin},wn = clien.android)
def setChannelAdmin(self, guid_channel, guid_member,access_admin = None):
if access_admin == None: access_admin = ["SetAdmin","SetJoinLink","AddMember","DeleteGlobalAllMessages","EditAllMessages","SendMessages","PinMessages","ViewAdmins","ViewMembers","ChangeInfo"] if access_admin == None else access_admin
return self.methods.methodsRubika("json",methode ="setChannelAdmin",indata = {"channel_guid": guid_channel,"access_list":access_admin,"action": "SetAdmin","member_guid": guid_member},wn = clien.android)
def deleteChannelAdmin(self,guid_channel,guid_admin):
return self.methods.methodsRubika("json",methode ="setChannelAdmin",indata = {"channel_guid": guid_channel,"action": "UnsetAdmin","member_guid": guid_admin},wn = clien.android)
def getStickersByEmoji(self,emojee):
return self.methods.methodsRubika("json",methode ="getStickersByEmoji",indata = {"emoji_character": emojee,"suggest_by": "All"},wn = clien.web).get("data").get("stickers")
def activenotification(self,guid):
return self.methods.methodsRubika("json",methode ="setActionChat",indata = {"action": "Unmute","object_guid": guid},wn = clien.web)
def offnotification(self,guid):
return self.methods.methodsRubika("json",methode ="setActionChat",indata = {"action": "Mute","object_guid": guid},wn = clien.web)
def sendPoll(self,guid,soal,lists):
return self.methods.methodsRubika("json",methode ="createPoll",indata = {"allows_multiple_answers": "false","is_anonymous": "true","object_guid": guid,"options":lists,"question":soal,"rnd":f"{randint(100000,999999999)}","type":"Regular"},wn = clien.web)
def forwardMessages(self, From, message_ids, to):
return self.methods.methodsRubika("json",methode ="forwardMessages",indata = {"from_object_guid": From,"message_ids": message_ids,"rnd": f"{randint(100000,999999999)}","to_object_guid": to},wn = clien.web)
def VisitChatGroup(self,guid_gap,visiblemsg):
return self.methods.methodsRubika("json",methode ="editGroupInfo",indata = {"chat_history_for_new_members": "Visible","group_guid": guid_gap,"updated_parameters": visiblemsg},wn = clien.web)
def HideChatGroup(self,guid,hiddenmsg):
return self.methods.methodsRubika("json",methode ="editGroupInfo",indata = {"chat_history_for_new_members": "Hidden","group_guid": guid_gap,"updated_parameters": hiddenmsg},wn = clien.web)
def pin(self, guid, message_id):
return self.methods.methodsRubika("json",methode ="setPinMessage",indata = {"action":"Pin","message_id": message_id,"object_guid": guid},wn = clien.web)
def unpin(self,guid,message_id):
return self.methods.methodsRubika("json",methode ="setPinMessage",indata = {"action":"Unpin","message_id": message_id,"object_guid": guid},wn = clien.web)
@property
def logout(self):
return self.methods.methodsRubika("json",methode ="logout",indata = {},wn = clien.web)
def joinGroup(self,link):
hashLink = link.split("/")[-1]
return self.methods.methodsRubika("json",methode ="joinGroup",indata = {"hash_link": hashLink},wn = clien.web)
def joinChannelAll(self,guid):
if ("https://" or "http://") in guid:
link = guid.split("/")[-1]
return self.methods.methodsRubika("json",methode ="joinChannelByLink",indata = {"hash_link": link},wn = clien.android)
elif "@" in guid:
IDE = ide.split("@")[-1]
guid = self.getInfoByUsername(IDE)["data"]["channel"]["channel_guid"]
return self.methods.methodsRubika("json",methode ="joinChannelAction",indata = {"action": "Join","channel_guid": guid},wn = clien.web)
else:
guid = guid
return self.methods.methodsRubika("json",methode ="joinChannelAction",indata = {"action": "Join","channel_guid": guid},wn = clien.web)
def leaveGroup(self,guid_gap):
if "https://" in guid_gap:
guid_gap = self.joinGroup(guid_gap)["data"]["group"]["group_guid"]
else:
guid_gap = guid_gap
return self.methods.methodsRubika("json",methode ="leaveGroup",indata = {"group_guid": guid_gap},wn = clien.web)
def leaveChannel(self,guid_channel):
if "https://" in guid_channel:
guid_channel = self.joinChannelByLink(guid_channel)["data"]["chat_update"]["object_guid"]
elif "@" in guid_channel:
guid_channel = self.joinChannelByID(guid_channel)["data"]["chat_update"]["object_guid"]
else:
guid_channel = guid_channel
return self.methods.methodsRubika("json",methode ="joinChannelAction",indata = {"action": "Leave","channel_guid": guid_channel},wn = clien.web)
def EditNameGroup(self,groupgu,namegp,biogp=None):
return self.methods.methodsRubika("json",methode ="editGroupInfo",indata = {"description": biogp,"group_guid": groupgu,"title":namegp,"updated_parameters":["title","description"]},wn = clien.web)
def EditBioGroup(self,groupgu,biogp,namegp=None):
return self.methods.methodsRubika("json",methode ="editGroupInfo",indata = {"description": biogp,"group_guid": groupgu,"title":namegp,"updated_parameters":["title","description"]},wn = clien.web)
def block(self, guid_user):
return self.methods.methodsRubika("json",methode ="setBlockUser",indata = {"action": "Block","user_guid": guid_user},wn = clien.web)
def unblock(self, guid_user):
return self.methods.methodsRubika("json",methode ="setBlockUser",indata = {"action": "Unblock","user_guid": guid_user},wn = clien.web)
def startVoiceChat(self, guid):
return self.methods.methodsRubika("json",methode ="createGroupVoiceChat",indata = {"chat_guid":guid},wn = clien.web)
def editVoiceChat(self,guid,voice_chat_id, title):
return self.methods.methodsRubika("json",methode ="setGroupVoiceChatSetting",indata = {"chat_guid":guid,"voice_chat_id" : voice_chat_id,"title" : title ,"updated_parameters": ["title"]},wn = clien.web)
def finishVoiceChat(self, guid):
voice_chat_id = self.getGroupInfo(guid)["data"]["chat"]["group_voice_chat_id"]
return self.methods.methodsRubika("json",methode ="discardGroupVoiceChat",indata = {"chat_guid":guid,"voice_chat_id" : voice_chat_id},wn = clien.web)
def getUserInfo(self, guid_user):
return self.methods.methodsRubika("json",methode ="getUserInfo",indata = {"user_guid":guid_user},wn = clien.web)
def getUserInfoByIDE(self, IDE_user):
guiduser = self.getInfoByUsername(IDE_user.replace("@",""))["data"]["user"]["user_guid"]
return self.methods.methodsRubika("json",methode ="getUserInfo",indata = {"user_guid":guiduser},wn = clien.web)
def seeGroupbyLink(self,link_gap):
link = link_gap.split("https://rubika.ir/joing/")[-1]
return self.methods.methodsRubika("json",methode ="groupPreviewByJoinLink",indata = {"hash_link": link},wn = clien.web).get("data")
def seeChannelbyLink(self,link_channel):
link = link_channel.split("https://rubika.ir/joinc/")[-1]
return self.methods.methodsRubika("json",methode ="channelPreviewByJoinLink",indata = {"hash_link": link},wn = clien.web).get("data")
def __getImageSize(self,image_bytes:bytes):
bytimg = PIL.Image.open(io.BytesIO(image_bytes))
width, height = bytimg.size
return [width , height]
def getAvatars(self,guid):
return self.methods.methodsRubika("json",methode ="getAvatars",indata = {"object_guid":guid},wn = clien.web)
def uploadAvatar_replay(self,guid,files_ide):
return self.methods.methodsRubika("json",methode ="uploadAvatar",indata = {"object_guid":guid,"thumbnail_file_id":files_ide,"main_file_id":files_ide},wn = clien.web)
def uploadAvatar(self,guid,main,thumbnail=None):
mainID = str(self.Upload.uploadFile(main)[0]["id"])
thumbnailID = str(self.Upload.uploadFile(thumbnail or main)[0]["id"])
return self.methods.methodsRubika("json",methode ="uploadAvatar",indata = {"object_guid":guid,"thumbnail_file_id":thumbnailID,"main_file_id":mainID},wn = clien.web)
def removeAvatar(self,guid):
avatar_id = self.getAvatars(guid)['data']['avatars'][0]['avatar_id']
return self.methods.methodsRubika("json",methode ="deleteAvatar",indata = {"object_guid":guid,"avatar_id":avatar_id},wn = clien.web)
def removeAllAvatars(self,guid):
while 1:
try:
avatar = self.getAvatars(guid)['data']['avatars']
if avatar != []:
avatar_id = self.getAvatars(guid)['data']['avatars'][0]['avatar_id']
self.methods.methodsRubika("json",methode ="deleteAvatar",indata = {"object_guid":guid,"avatar_id":avatar_id},wn = clien.web)
else:
return 'Ok remove Avatars'
break
except:
continue
@property
def Devicesrubika(self):
return self.methods.methodsRubika("json",methode ="getMySessions",indata = {},wn = clien.web)
def deleteChatHistory(self,guid,last_message_id):
return self.methods.methodsRubika("json",methode ="deleteChatHistory",indata = {"last_message_id": last_message_id,"object_guid": guid},wn = clien.web)
def addFolder(self, Name = "ahwaz", include_chat = None,include_object = None ,exclude_chat = None,exclude_object = None):
return self.methods.methodsRubika("json",methode ="addFolder",indata = {"exclude_chat_types": exclude_chat,"exclude_object_guids": exclude_object,"include_chat_types": include_chat,"include_object_guids": include_object,"is_add_to_top":True,"name": Name},wn = clien.web)
def deleteFolder(self,folder_id):
return self.methods.methodsRubika("json",methode ="deleteFolder",indata = {"folder_id": folder_id},wn = clien.web)
def addGroup(self,title,guidsUser = None):
return self.methods.methodsRubika("json",methode ="addGroup",indata = {"member_guids": guidsUser,"title": title},wn = clien.web)
def addChannel(self,title,typeChannell,bio,guidsUser = None):
return self.methods.methodsRubika("json",methode ="addChannel",indata = {"addChannel": typeChannell,"description": bio,"member_guids": guidsUser,"title": title},wn = clien.web)
def breturn(self,start_id = None):
return self.methods.methodsRubika("json",methode ="getBreturnUsers",indata = {"start_id": start_id},wn = clien.web)
def editUser(self,first_name = None,last_name = None,bio = None):
return self.methods.methodsRubika("json",methode ="updateProfile",indata = {"bio": bio,"first_name": first_name,"last_name": last_name,"updated_parameters":["first_name","last_name","bio"]},wn = clien.web)
def editusername(self,username):
ide = username.split("@")[-1]
return self.methods.methodsRubika("json",methode ="updateUsername",indata = {"username": ide},wn = clien.web)
def Postion(self,guid,guiduser):
return self.methods.methodsRubika("json",methode ="requestChangeObjectOwner",indata = {"object_guid": guid,"new_owner_user_guid": guiduser},wn = clien.android)
def getPostion(self,guid):
return self.methods.methodsRubika("json",methode ="getPendingObjectOwner",indata = {"object_guid": guid},wn = clien.android)
@property
def ClearAccounts(self):
return self.methods.methodsRubika("json",methode ="terminateOtherSessions",indata = {},wn = clien.web)
def HidePhone(self,**kwargs):
return self.methods.methodsRubika("json",methode ="setSetting",indata = {"settings": kwargs,"update_parameters":["show_my_phone_number"]},wn = clien.web)
def HideOnline(self,**kwargs):
return self.methods.methodsRubika("json",methode ="setSetting",indata = {"settings": kwargs,"update_parameters":["show_my_last_online"]},wn = clien.web)
def search_inaccount(self,text):
return self.methods.methodsRubika("json",methode ="searchGlobalMessages",indata = {"search_text": text,"start_id":None,"type": "Text"},wn = clien.web).get("data").get("messages")
def search_inrubika(self,text):
return self.methods.methodsRubika("json",methode ="searchGlobalObjects",indata = {"search_text": text},wn = clien.web).get("data").get('objects')
def getAbsObjects(self,guid):
return self.methods.methodsRubika("json",methode ="getAbsObjects",indata = {"objects_guids": guid},wn = clien.web)
def Infolinkpost(self,linkpost):
return self.methods.methodsRubika("json",methode ="getLinkFromAppUrl",indata = {"app_url": linkpost},wn = clien.web)
def getContactsLastOnline(self,user_guids:list):
return self.methods.methodsRubika("json",methode ="getContactsLastOnline",indata = {"user_guids": user_guids},wn = clien.web)
def SignMessageChannel(self,guid_channel,sign:bool):
return self.methods.methodsRubika("json",methode ="editChannelInfo",indata = { "channel_guid": guid_channel,"sign_messages": sign,"updated_parameters": ["sign_messages"]},wn = clien.web)
@property
def ActiveContectJoin(self):
return self.methods.methodsRubika("json",methode ="setSetting",indata = {"settings":{"can_join_chat_by":"MyContacts"},"update_parameters":["can_join_chat_by"]},wn = clien.web)
@property
def ActiveEverybodyJoin(self):
return self.methods.methodsRubika("json",methode ="setSetting",indata = {"settings":{"can_join_chat_by":"Everybody"},"update_parameters":["can_join_chat_by"]},wn = clien.web)
def CalledBy(self,typeCall:str):
return self.methods.methodsRubika("json",methode ="setSetting",indata = {"settings": {"can_called_by": typeCall}, "update_parameters": ["can_called_by"]},wn = clien.android)
def changeChannelID(self,guid_channel,username):
return self.methods.methodsRubika("json",methode ="updateChannelUsername",indata = {"channel_guid": guid_channel,"username": username},wn = clien.web)
@property
def getBlockedUsers(self):
return self.methods.methodsRubika("json",methode ="getBlockedUsers",indata = {},wn = clien.web)
def deleteContact(self,guid_user):
return self.methods.methodsRubika("json",methode ="deleteContact",indata = {"user_guid":guid_user},wn = clien.web)
@property
def getContacts(self):
return self.methods.methodsRubika("json",methode ="getContacts",indata = {},wn = clien.web).get("data").get("users")
def getLiveStatus(self,live_id,token_live):
return self.methods.methodsRubika("json",methode ="getLiveStatus",indata = {"live_id":live_id,"access_token":token_live},wn = clien.web)
def commonGroup(self,guid_user):
IDE = guid_user.split("@")[-1]
GUID = self.getInfoByUsername(IDE)["data"]["user"]["user_guid"]
return self.methods.methodsRubika("json",methode ="getCommonGroups",indata = {"user_guid": GUID},wn = clien.android)
def setTypeChannel(self,guid_channel,type_Channel):
if type_Channel == "Private":
return self.methods.methodsRubika("json",methode ="editChannelInfo",indata = {"channel_guid":guid_channel,"channel_type":"Private","updated_parameters":["channel_type"]},wn = clien.web)
else:
if type_Channel == "Public":
return self.methods.methodsRubika("json",methode ="editChannelInfo",indata = {"settings":{"channel_guid":guid_channel,"channel_type":"Public","updated_parameters":["channel_type"]}},wn = clien.web)
def getChatAds(self,user_guids:list):
state = str(round(datetime.datetime.today().timestamp()) - 200)
return self.methods.methodsRubika("json",methode ="getChatAds",indata = {"state": state},wn = clien.web)
@property
def getContactsUpdates(self):
state = str(round(datetime.datetime.today().timestamp()) - 200)
return self.methods.methodsRubika("json",methode ="getContactsUpdates",indata = {"state": state},wn = clien.web)
# methods Download
def Download(self,guid = None,type_file = None,file_name = None,frmt = None,ms = None):
if type_file == "file" and "http://" or "https://" in ms and guid == None and file_name != None and frmt != None:
loop = asyncio.get_event_loop()
getdownload = loop.run_until_complete(_download_with_server(server = ms))
with open(f"{file_name}.{frmt}","wb") as files:
files.write(getdownload)
return "Ok Download"
print("Ok Download")
elif type_file == "rubika" and frmt == None and file_name == None and guid != None and ms != None:
result:bytes = ""
get_info_File = self.getMessagesInfo(guid, [ms.get("message_id")])["data"]["messages"]
for m in get_info_File:
access_hash_rec = m["file_inline"]["access_hash_rec"]
file_id = m["file_inline"]["file_id"]
size = m["file_inline"]["size"]
dc_id = m["file_inline"]["dc_id"]
file_name = m["file_inline"]["file_name"]
header_Download = {'auth': self.Auth, 'file-id':file_id, "start-index": "0", "last-index": str(size), 'access-hash-rec':access_hash_rec}
GetFile = f"https://messenger{dc_id}.iranlms.ir/GetFile.ashx"
while 1:
try:
if size <= 131072:
loop = asyncio.get_event_loop()
result += loop.run_until_complete(_download(server = GetFile,header = header_Download))
break
else:
for i in range(0,size,131072):
header_Download["start-index"], header_Download["last-index"] = str(i), str(i+131072 if i+131072 <= size else size)
loop = asyncio.get_event_loop()
result += loop.run_until_complete(_download(server = GetFile,header = header_Download))
break
except:continue
with open(first_name,"wb") as f:
f.write(result)
return "Ok Download"
print("Ok Download")
# methods sendfiles
def sendSticker(self,guid,emoji,w_h_rati,sticker_id,file_id,access_hash,set_id):
return self.methods.methodsRubika("json",methode ="sendMessage",indata = {"object_guid": guid,"rnd": f"{randint(100000,999999999)}","sticker": {"emoji_character": emoji,"w_h_ratio": w_h_rati,"sticker_id": sticker_id,"file": {"file_id": file_id,"mime": "png","dc_id": 32,"access_hash_rec": access_hash,"file_name": "sticker.png"},"sticker_set_id": set_id}},wn = clien.web)
def sendFile(self, guid, file, caption=None, message_id=None):
uresponse = self.Upload.uploadFile(file)
file_id = str(uresponse[0]["id"])
mime = file.split(".")[-1]
dc_id = uresponse[0]["dc_id"]
access_hash_rec = uresponse[1]
file_name = file.split("/")[-1]
loop = asyncio.get_event_loop()
return self.methods.methodsRubika("json",methode ="sendMessage",indata = {"object_guid":guid,"reply_to_message_id":message_id,"rnd":f"{randint(100000,999999999)}","file_inline":{"dc_id":str(dc_id),"file_id":str(file_id),"type":"File","file_name":file_name,"size":str(len(loop.run_until_complete(_download_with_server(server = file)) if ("http" or "https") in file else open(file,"rb").read())),"mime":mime,"access_hash_rec":access_hash_rec},"text":caption},wn = clien.android)
def sendVoice(self, guid, file, time = None, caption=None, message_id=None):
uresponse = self.Upload.uploadFile(file)
file_id = str(uresponse[0]["id"])
mime = file.split(".")[-1]
dc_id = uresponse[0]["dc_id"]
access_hash_rec = uresponse[1]
file_name = file.split("/")[-1]
loop = asyncio.get_event_loop()
time = TinyTag.get(file).duration if time == None else time
print(TinyTag.get(file).duration)
return self.methods.methodsRubika("json",methode ="sendMessage",indata = {"object_guid":guid,"reply_to_message_id":message_id,"rnd":f"{randint(100000,999999999)}","file_inline":{"dc_id":str(dc_id),"file_id":str(file_id),"type":"Voice","file_name":file_name,"size":str(len(loop.run_until_complete(_download_with_server(server = file)) if ("http" or "https") in file else open(file,"rb").read())),"time":time,"mime":mime,"access_hash_rec":access_hash_rec},"text":caption},wn = clien.android)
def sendMusic(self, guid, file, time = None, caption=None, message_id=None):
uresponse = self.Upload.uploadFile(file)
file_id = str(uresponse[0]["id"])
mime = file.split(".")[-1]
dc_id = uresponse[0]["dc_id"]
access_hash_rec = uresponse[1]
file_name = file.split("/")[-1]
loop = asyncio.get_event_loop()
if time == None: time = round(TinyTag.get(file).duration * 1000)
return self.methods.methodsRubika("json",methode ="sendMessage",indata = {"object_guid":guid,"reply_to_message_id":message_id,"rnd":f"{randint(100000,999999999)}","file_inline":{"dc_id":str(dc_id),"file_id":str(file_id),"type":"Music","music_performer":"","file_name":file_name,"size":str(len(loop.run_until_complete(_download_with_server(server = file)) if ("http" or "https") in file else open(file,"rb").read())),"time": time,"mime":mime,"access_hash_rec":access_hash_rec},"text":caption},wn = clien.web)
def sendGif(self, guid, file, breadth:list= None, caption=None, message_id=None, thumbnail=None):
uresponse = self.Upload.uploadFile(file)
file_id = str(uresponse[0]["id"])
mime = file.split(".")[-1]
dc_id = uresponse[0]["dc_id"]
access_hash_rec = uresponse[1]
file_name = file.split("/")[-1]
loop = asyncio.get_event_loop()
if breadth == None: breadth = [640,640] if not ("http" or "https") in file else [640,640]
time = round(int(TinyTag.get(file).duration) * 1000)
size = str(len(loop.run_until_complete(_download_with_server(server = file)) if ("http" or "https") in file else open(file,"rb").read()))
if thumbnail == None: thumbnail = r"iVBORw0KGgoAAAANSUhEUgAAACQAAAAoCAYAAACWwljjAAAAAXNSR0IArs4c6QAACnRJREFUWEelmFtsXMUZx/9zOWd3vd61vWt7Wd9iOxcULqHhokBaKkQBgSJMSQpVIQkUVQL1qaqE6Eulqu1L1UpVX/vQAkmAQCCKQilNCYHSkOBEuTm2iUlix8nG97V3vbdzmZlqznrNsrGxk460Wq32nDn/8/u+b77/DMH1DwKAARAAFAD9OwIgAOBK2XQcgJz7LPsperLlDjr3cC1ED84539DS0v5svOHmx2fGbX9ivPdAOn/1dQCHANhz15Xu0+L0C3zrWEqQ/l9PWJpM/26sq6vb3N62dmtT/a0bORqQSws4tgupXKSzI2I8NdA7OXNhl+3OvgNg8HqoLSZIi9Aft0TDMIy7m5pat7W33PFkpKozbuVNzKbycBzLpQyMUAICIik1CCGMFuyUSqaH0mNTff9I56++BuCTMmo65HpcQ61cUImGxqov1L+jNTU1P1zRtnZrS8Ot9xukkWZTArl8TkgpwDllhBCoskAoHRWlJKVcMmpwIR3MZkbEWPpcT3Lmwi7Lze4BMFRBrZSP3kP1KCWplxuGYdwZj7dsbW9e92SkurPFKQQ8GrataSjGGCPlIhZLCqWkIqSMmqWpXUyNJc/tT+cTOtc+BeCU5ZrUgkqiwn7D2Lym7ZZtKzo3fp+RKJudtpHL5YSSAoxTSglZlpBKgZXUXGEhnR91J1MXz0zPnN+Zd9JvAhjVWrQYf7Qx/lTz/Q/+eqR1zeqqvguoGUgjIKpdX7iOwjSoFI6Ogs6RpYrkW//Xc4BQxakpIQXJ5ifocH5YTsMadkbPvgKRf4fU3fVQjawP7wn88rc/mE7P2k4hy8lgPw12nyD1X46i3q5GoDoG+HzQ+aBpXY8wj46uEGqAKQLHSiNZGMU48siE6yWJrHSNqijyp3btd0dO/ohgw2NhUhN4lf/s5SdYLiUJMzh8fuhgumOXYRw/hrqTA2hMAmF/DKwqDEEUpLDneC1MTSkFQikYNQDhIpefxKQ1iSmTwoq0gIZbwLkPcG2hKHWsvr1vOYkTP/UE8bB/h/nSK10yk3ZBGYdGqwBi+qBME24mCXL2NELdp9BwKY0oojCrI5AGhxAO9PVFakUelDAwyiHsHFL5MUyINFLBMERkBXiwAVRfK2wvDUCoADOE1fvubidxYvu8IOOlV7pUSVApE3Qp6YcxA/AHIIQFOTgAf/cxRHuvoCHnRzAYA0y/EsoBpZxQRWAVpjFVGMMkdZGtjYHUtYGbIRApoPQL6OGlrzeuQ1B5ikoJvebA9ENyCnfiKtiJblV7akDEUgavMWPIF5LuhDVKp/1+akfawEJNYMws0pDunIhrQnyDgubfx9ULn6DBMFS4hjlTIxBv/01Vf3zYcVvWmzJ+OwxfSBLXUUpYxT5G9Nei4wYE6dBJqcC5gD/A9TNkYkiKo58k1JGD78nE0C44JINw9Bmjfu3TvGHtGhaOg1AGJXSTE1QnS1mYytVdhyAtQrcRnx8wfUxl0pC9Jx353w8/EaeO7kI2ux9AsuLdq8HMR0lk5XNGfN3DRv0aHzVDgHCkEo5+Mwrd+L4eSwgilJdoEH8V13UjLw9K8cWnw+LwgT24PKhX1RNlE+q2U+pm5Q2ZAeYtNFj3DGm49SkzfttKFrrJy8MKaosIevHlx1UmbcMf5B6N9AxE73FbfHbgoDr9xU7k8/8EMD0npNKklUNaqEmHwAKbSKRzuxlf9yCvX21Ss0pTE0o4WhCsvr1flz2LVO8I/OI3XTI1DXd4SIojBwdF96G3cXnoLQBnFqCh3cByRqWNYYBxGw1GnyGxW542b1rXzkMxgPmswuk3djuJ488RrNoQ5nX+He7GRx/Bofffw7njO2BZhwHMltEoN2nLEVJ5zSLUfA+QUNt2s3n9JjnRs8cZ799GHluFMPf7dj7SZj284xje6J7AXwEcK/PCJTNVsq43IshrZ5Wmry7kvy/aFH+xqjW++UL/+XezifGioIZatuPPW4yukbRCzxUh9vWK0wfOqdeTWWgzlShToI37vJlahrJKMjQQCMSDodCPYx3t23k8ekcSAhO5jFU4c243Rqee8wTVhsmO3z/GH09bsMM+GIyCXkoq9e8BObHvrNzbMwJtpj6/jly6hkbAMO6ub21+Ptq5YrMdDjaMWVlMz6aldF2XGybkwNBuOTK13RMU0YI28a5UHi4h4EpB+gzIgAGeKQBfXJLO3jPy8KHz6rWsg31l1Va5oygPr6ZTXRcOdzV2rHgh0Bp/IG0QOpZJI5vLCgJCDMb0/UIxKsSXgwsLYhQ6LJ5PlgqKMcgqAxQK5KtJJT/ok5ff75O7L05hJ4CeMmrFdq9rxudbWVdX92z96vafkPrI6klhYTI9A8e2XUa1A2aeES8uXkqAsaUFfaOv6jsVpN+A8nOwySzwnwvS2tsjDxy7ol7N2/hAv6kvGHwg3tz0Qm1Hy6Zc0B8az2eQyswKJSQ0DUIp0T7pm+MGBJUm0I3ElVB+k4poUHE7Z+NfPUT86UjV+UK4JRO5rfOuKR8wMZNEPptztQKuw+LtTBbbI96AIK+jgcBnEBjExWxa4OyooY7arbK/dRWudNSyxLlhZE6OK6SFZKEwZSE/AVFQrjZ72u0t5seXKcjrqgrglMJnKsCykZgkOJasxZHASvR1tGOiPYDZqgIcJy8pZYpmHaYGkpBnk8CoA8L8oKEAYDLtFoqfazYKSwjyqmyOhqkdX1qgb8zAEasFx2OrMLwqhumYgkUykJYNIigoocWQ6KLxMUBIqEQasmcK+GoWKDDQ6iBIlQlNTcd9/phioaSurSGv/e5R/kTGJiLoA4djY0TTmKrF5/5O9He0Y6yjCrnqAmwrD9gCFMwz8aVamU/UYnyLVAwKpAuQ/Umo3mlgzAExAqDV2s7MURNCb/ocr+xHp54nD3WipjlK3vnLk/yhSxOuPZCg/EihmR1rXI1LN8c9GgWShbSseRqa+pLHGF5lejEvUtPVcDkF2TMJnM8WqQUDklT7XHAG0Xtxn7w68TRpakJVSOJXW27nP7/gb4+eufMuTHQEkTUzrl3IMtiS6F3EgjSW0Tu8SzQ1ndMG15t2hVRBqqEUkf0zFFdsBUck5fDYH5HN/6G0ldbfMdTXdJH1ka1qfcP32KpGsKAPsF2hbK+vMnzD6C1XTWmVhQQnEj7Odb6pkVkhPxvqVQcH30Be7p47gJivxZK90E/h4HwD2oLbyIbWJ+g9TTfRWLVe4AHLdfVCD0qWt3mVereoLTAnMCiV03mlTo/OysNXPkDvhO6PHwOwymyOWug4pvxwKoZw1Rasb9hK7225l94cBfEZWpiAswg1r+dAwiASfoPrdUgNTQt5NNGvuq++ianc2wDOVziI+aO/bzuw0v+VPJABzjeiPbyN3tfcRe6MN9BGj5ryxElVbKoeDV1djKnpAuTZsaz87PKH6B//OwQOAijMCVn0mG+p44xK76wniqM2sIV8J7aV3NdyD10TKVKb68bykkfjK9WdeBPjOZ0b5xajsVAWLiWo/J7KQ09N7btoD2+l9zZvQtDwyaOJj3B2cieE+AhAbika/6+g0v0LUWuYOxauPKq77mPh/wFf1bF3tCYEwQAAAABJRU5ErkJggg=="
return self.methods.methodsRubika("json",methode ="sendMessage",indata = {'file_inline':{"access_hash_rec":access_hash_rec,"auto_play":False,"dc_id":dc_id,"file_id":file_id,"file_name":file_name,"height":360,"mime":mime,"size":size,"thumb_inline":thumbnail,"time":time,"type":"Gif","width":360},"is_mute":False,"object_guid":guid,"rnd":f"{randint(100000,999999999)}","reply_to_message_id":message_id},wn = clien.android)
def sendVideo(self, guid, file,breadth:list = None, caption=None, message_id=None, thumbnail=None):
uresponse = self.Upload.uploadFile(file)
print(uresponse)
file_id = str(uresponse[0]["id"])
mime = file.split(".")[-1]
dc_id = uresponse[0]["dc_id"]
access_hash_rec = uresponse[1]
file_name = file.split("/")[-1]
loop = asyncio.get_event_loop()
if breadth == None: breadth = [360,360]
size = str(len(loop.run_until_complete(_download_with_server(server = file)) if ("http" or "https") in file else open(file,"rb").read()))
time = round(TinyTag.get(file).duration * 1000)
if thumbnail == None: thumbnail = r"iVBORw0KGgoAAAANSUhEUgAAACQAAAAoCAYAAACWwljjAAAAAXNSR0IArs4c6QAACnRJREFUWEelmFtsXMUZx/9zOWd3vd61vWt7Wd9iOxcULqHhokBaKkQBgSJMSQpVIQkUVQL1qaqE6Eulqu1L1UpVX/vQAkmAQCCKQilNCYHSkOBEuTm2iUlix8nG97V3vbdzmZlqznrNsrGxk460Wq32nDn/8/u+b77/DMH1DwKAARAAFAD9OwIgAOBK2XQcgJz7LPsperLlDjr3cC1ED84539DS0v5svOHmx2fGbX9ivPdAOn/1dQCHANhz15Xu0+L0C3zrWEqQ/l9PWJpM/26sq6vb3N62dmtT/a0bORqQSws4tgupXKSzI2I8NdA7OXNhl+3OvgNg8HqoLSZIi9Aft0TDMIy7m5pat7W33PFkpKozbuVNzKbycBzLpQyMUAICIik1CCGMFuyUSqaH0mNTff9I56++BuCTMmo65HpcQ61cUImGxqov1L+jNTU1P1zRtnZrS8Ot9xukkWZTArl8TkgpwDllhBCoskAoHRWlJKVcMmpwIR3MZkbEWPpcT3Lmwi7Lze4BMFRBrZSP3kP1KCWplxuGYdwZj7dsbW9e92SkurPFKQQ8GrataSjGGCPlIhZLCqWkIqSMmqWpXUyNJc/tT+cTOtc+BeCU5ZrUgkqiwn7D2Lym7ZZtKzo3fp+RKJudtpHL5YSSAoxTSglZlpBKgZXUXGEhnR91J1MXz0zPnN+Zd9JvAhjVWrQYf7Qx/lTz/Q/+eqR1zeqqvguoGUgjIKpdX7iOwjSoFI6Ogs6RpYrkW//Xc4BQxakpIQXJ5ifocH5YTsMadkbPvgKRf4fU3fVQjawP7wn88rc/mE7P2k4hy8lgPw12nyD1X46i3q5GoDoG+HzQ+aBpXY8wj46uEGqAKQLHSiNZGMU48siE6yWJrHSNqijyp3btd0dO/ohgw2NhUhN4lf/s5SdYLiUJMzh8fuhgumOXYRw/hrqTA2hMAmF/DKwqDEEUpLDneC1MTSkFQikYNQDhIpefxKQ1iSmTwoq0gIZbwLkPcG2hKHWsvr1vOYkTP/UE8bB/h/nSK10yk3ZBGYdGqwBi+qBME24mCXL2NELdp9BwKY0oojCrI5AGhxAO9PVFakUelDAwyiHsHFL5MUyINFLBMERkBXiwAVRfK2wvDUCoADOE1fvubidxYvu8IOOlV7pUSVApE3Qp6YcxA/AHIIQFOTgAf/cxRHuvoCHnRzAYA0y/EsoBpZxQRWAVpjFVGMMkdZGtjYHUtYGbIRApoPQL6OGlrzeuQ1B5ikoJvebA9ENyCnfiKtiJblV7akDEUgavMWPIF5LuhDVKp/1+akfawEJNYMws0pDunIhrQnyDgubfx9ULn6DBMFS4hjlTIxBv/01Vf3zYcVvWmzJ+OwxfSBLXUUpYxT5G9Nei4wYE6dBJqcC5gD/A9TNkYkiKo58k1JGD78nE0C44JINw9Bmjfu3TvGHtGhaOg1AGJXSTE1QnS1mYytVdhyAtQrcRnx8wfUxl0pC9Jx353w8/EaeO7kI2ux9AsuLdq8HMR0lk5XNGfN3DRv0aHzVDgHCkEo5+Mwrd+L4eSwgilJdoEH8V13UjLw9K8cWnw+LwgT24PKhX1RNlE+q2U+pm5Q2ZAeYtNFj3DGm49SkzfttKFrrJy8MKaosIevHlx1UmbcMf5B6N9AxE73FbfHbgoDr9xU7k8/8EMD0npNKklUNaqEmHwAKbSKRzuxlf9yCvX21Ss0pTE0o4WhCsvr1flz2LVO8I/OI3XTI1DXd4SIojBwdF96G3cXnoLQBnFqCh3cByRqWNYYBxGw1GnyGxW542b1rXzkMxgPmswuk3djuJ488RrNoQ5nX+He7GRx/Bofffw7njO2BZhwHMltEoN2nLEVJ5zSLUfA+QUNt2s3n9JjnRs8cZ799GHluFMPf7dj7SZj284xje6J7AXwEcK/PCJTNVsq43IshrZ5Wmry7kvy/aFH+xqjW++UL/+XezifGioIZatuPPW4yukbRCzxUh9vWK0wfOqdeTWWgzlShToI37vJlahrJKMjQQCMSDodCPYx3t23k8ekcSAhO5jFU4c243Rqee8wTVhsmO3z/GH09bsMM+GIyCXkoq9e8BObHvrNzbMwJtpj6/jly6hkbAMO6ub21+Ptq5YrMdDjaMWVlMz6aldF2XGybkwNBuOTK13RMU0YI28a5UHi4h4EpB+gzIgAGeKQBfXJLO3jPy8KHz6rWsg31l1Va5oygPr6ZTXRcOdzV2rHgh0Bp/IG0QOpZJI5vLCgJCDMb0/UIxKsSXgwsLYhQ6LJ5PlgqKMcgqAxQK5KtJJT/ok5ff75O7L05hJ4CeMmrFdq9rxudbWVdX92z96vafkPrI6klhYTI9A8e2XUa1A2aeES8uXkqAsaUFfaOv6jsVpN+A8nOwySzwnwvS2tsjDxy7ol7N2/hAv6kvGHwg3tz0Qm1Hy6Zc0B8az2eQyswKJSQ0DUIp0T7pm+MGBJUm0I3ElVB+k4poUHE7Z+NfPUT86UjV+UK4JRO5rfOuKR8wMZNEPptztQKuw+LtTBbbI96AIK+jgcBnEBjExWxa4OyooY7arbK/dRWudNSyxLlhZE6OK6SFZKEwZSE/AVFQrjZ72u0t5seXKcjrqgrglMJnKsCykZgkOJasxZHASvR1tGOiPYDZqgIcJy8pZYpmHaYGkpBnk8CoA8L8oKEAYDLtFoqfazYKSwjyqmyOhqkdX1qgb8zAEasFx2OrMLwqhumYgkUykJYNIigoocWQ6KLxMUBIqEQasmcK+GoWKDDQ6iBIlQlNTcd9/phioaSurSGv/e5R/kTGJiLoA4djY0TTmKrF5/5O9He0Y6yjCrnqAmwrD9gCFMwz8aVamU/UYnyLVAwKpAuQ/Umo3mlgzAExAqDV2s7MURNCb/ocr+xHp54nD3WipjlK3vnLk/yhSxOuPZCg/EihmR1rXI1LN8c9GgWShbSseRqa+pLHGF5lejEvUtPVcDkF2TMJnM8WqQUDklT7XHAG0Xtxn7w68TRpakJVSOJXW27nP7/gb4+eufMuTHQEkTUzrl3IMtiS6F3EgjSW0Tu8SzQ1ndMG15t2hVRBqqEUkf0zFFdsBUck5fDYH5HN/6G0ldbfMdTXdJH1ka1qfcP32KpGsKAPsF2hbK+vMnzD6C1XTWmVhQQnEj7Odb6pkVkhPxvqVQcH30Be7p47gJivxZK90E/h4HwD2oLbyIbWJ+g9TTfRWLVe4AHLdfVCD0qWt3mVereoLTAnMCiV03mlTo/OysNXPkDvhO6PHwOwymyOWug4pvxwKoZw1Rasb9hK7225l94cBfEZWpiAswg1r+dAwiASfoPrdUgNTQt5NNGvuq++ianc2wDOVziI+aO/bzuw0v+VPJABzjeiPbyN3tfcRe6MN9BGj5ryxElVbKoeDV1djKnpAuTZsaz87PKH6B//OwQOAijMCVn0mG+p44xK76wniqM2sIV8J7aV3NdyD10TKVKb68bykkfjK9WdeBPjOZ0b5xajsVAWLiWo/J7KQ09N7btoD2+l9zZvQtDwyaOJj3B2cieE+AhAbika/6+g0v0LUWuYOxauPKq77mPh/wFf1bF3tCYEwQAAAABJRU5ErkJggg=="
return self.methods.methodsRubika("json",methode ="sendMessage",indata = {'file_inline':{"access_hash_rec":access_hash_rec,"auto_play":False,"dc_id":dc_id,"file_id":file_id,"file_name":file_name,"height":360,"mime":mime,"size":size,"thumb_inline":thumbnail,"time":time,"type":"Video","width":360},"is_mute":False,"object_guid":guid,"rnd":f"{randint(100000,999999999)}","reply_to_message_id":message_id},wn = clien.android)
def sendPhoto(self, guid, file, breadth:list= None, thumbnail=None, caption=None, message_id=None):
import PIL.Image
uresponse = self.Upload.uploadFile(file)
file_id = str(uresponse[0]["id"])
mime = file.split(".")[-1]
dc_id = uresponse[0]["dc_id"]
access_hash_rec = uresponse[1]
file_name = file.split("/")[-1]
loop = asyncio.get_event_loop()
if breadth == None: breadth = PIL.Image.open(file).size if not ("http" or "https") in file else [640,640]
if thumbnail == None: thumbnail = r"iVBORw0KGgoAAAANSUhEUgAAACQAAAAoCAYAAACWwljjAAAAAXNSR0IArs4c6QAACnRJREFUWEelmFtsXMUZx/9zOWd3vd61vWt7Wd9iOxcULqHhokBaKkQBgSJMSQpVIQkUVQL1qaqE6Eulqu1L1UpVX/vQAkmAQCCKQilNCYHSkOBEuTm2iUlix8nG97V3vbdzmZlqznrNsrGxk460Wq32nDn/8/u+b77/DMH1DwKAARAAFAD9OwIgAOBK2XQcgJz7LPsperLlDjr3cC1ED84539DS0v5svOHmx2fGbX9ivPdAOn/1dQCHANhz15Xu0+L0C3zrWEqQ/l9PWJpM/26sq6vb3N62dmtT/a0bORqQSws4tgupXKSzI2I8NdA7OXNhl+3OvgNg8HqoLSZIi9Aft0TDMIy7m5pat7W33PFkpKozbuVNzKbycBzLpQyMUAICIik1CCGMFuyUSqaH0mNTff9I56++BuCTMmo65HpcQ61cUImGxqov1L+jNTU1P1zRtnZrS8Ot9xukkWZTArl8TkgpwDllhBCoskAoHRWlJKVcMmpwIR3MZkbEWPpcT3Lmwi7Lze4BMFRBrZSP3kP1KCWplxuGYdwZj7dsbW9e92SkurPFKQQ8GrataSjGGCPlIhZLCqWkIqSMmqWpXUyNJc/tT+cTOtc+BeCU5ZrUgkqiwn7D2Lym7ZZtKzo3fp+RKJudtpHL5YSSAoxTSglZlpBKgZXUXGEhnR91J1MXz0zPnN+Zd9JvAhjVWrQYf7Qx/lTz/Q/+eqR1zeqqvguoGUgjIKpdX7iOwjSoFI6Ogs6RpYrkW//Xc4BQxakpIQXJ5ifocH5YTsMadkbPvgKRf4fU3fVQjawP7wn88rc/mE7P2k4hy8lgPw12nyD1X46i3q5GoDoG+HzQ+aBpXY8wj46uEGqAKQLHSiNZGMU48siE6yWJrHSNqijyp3btd0dO/ohgw2NhUhN4lf/s5SdYLiUJMzh8fuhgumOXYRw/hrqTA2hMAmF/DKwqDEEUpLDneC1MTSkFQikYNQDhIpefxKQ1iSmTwoq0gIZbwLkPcG2hKHWsvr1vOYkTP/UE8bB/h/nSK10yk3ZBGYdGqwBi+qBME24mCXL2NELdp9BwKY0oojCrI5AGhxAO9PVFakUelDAwyiHsHFL5MUyINFLBMERkBXiwAVRfK2wvDUCoADOE1fvubidxYvu8IOOlV7pUSVApE3Qp6YcxA/AHIIQFOTgAf/cxRHuvoCHnRzAYA0y/EsoBpZxQRWAVpjFVGMMkdZGtjYHUtYGbIRApoPQL6OGlrzeuQ1B5ikoJvebA9ENyCnfiKtiJblV7akDEUgavMWPIF5LuhDVKp/1+akfawEJNYMws0pDunIhrQnyDgubfx9ULn6DBMFS4hjlTIxBv/01Vf3zYcVvWmzJ+OwxfSBLXUUpYxT5G9Nei4wYE6dBJqcC5gD/A9TNkYkiKo58k1JGD78nE0C44JINw9Bmjfu3TvGHtGhaOg1AGJXSTE1QnS1mYytVdhyAtQrcRnx8wfUxl0pC9Jx353w8/EaeO7kI2ux9AsuLdq8HMR0lk5XNGfN3DRv0aHzVDgHCkEo5+Mwrd+L4eSwgilJdoEH8V13UjLw9K8cWnw+LwgT24PKhX1RNlE+q2U+pm5Q2ZAeYtNFj3DGm49SkzfttKFrrJy8MKaosIevHlx1UmbcMf5B6N9AxE73FbfHbgoDr9xU7k8/8EMD0npNKklUNaqEmHwAKbSKRzuxlf9yCvX21Ss0pTE0o4WhCsvr1flz2LVO8I/OI3XTI1DXd4SIojBwdF96G3cXnoLQBnFqCh3cByRqWNYYBxGw1GnyGxW542b1rXzkMxgPmswuk3djuJ488RrNoQ5nX+He7GRx/Bofffw7njO2BZhwHMltEoN2nLEVJ5zSLUfA+QUNt2s3n9JjnRs8cZ799GHluFMPf7dj7SZj284xje6J7AXwEcK/PCJTNVsq43IshrZ5Wmry7kvy/aFH+xqjW++UL/+XezifGioIZatuPPW4yukbRCzxUh9vWK0wfOqdeTWWgzlShToI37vJlahrJKMjQQCMSDodCPYx3t23k8ekcSAhO5jFU4c243Rqee8wTVhsmO3z/GH09bsMM+GIyCXkoq9e8BObHvrNzbMwJtpj6/jly6hkbAMO6ub21+Ptq5YrMdDjaMWVlMz6aldF2XGybkwNBuOTK13RMU0YI28a5UHi4h4EpB+gzIgAGeKQBfXJLO3jPy8KHz6rWsg31l1Va5oygPr6ZTXRcOdzV2rHgh0Bp/IG0QOpZJI5vLCgJCDMb0/UIxKsSXgwsLYhQ6LJ5PlgqKMcgqAxQK5KtJJT/ok5ff75O7L05hJ4CeMmrFdq9rxudbWVdX92z96vafkPrI6klhYTI9A8e2XUa1A2aeES8uXkqAsaUFfaOv6jsVpN+A8nOwySzwnwvS2tsjDxy7ol7N2/hAv6kvGHwg3tz0Qm1Hy6Zc0B8az2eQyswKJSQ0DUIp0T7pm+MGBJUm0I3ElVB+k4poUHE7Z+NfPUT86UjV+UK4JRO5rfOuKR8wMZNEPptztQKuw+LtTBbbI96AIK+jgcBnEBjExWxa4OyooY7arbK/dRWudNSyxLlhZE6OK6SFZKEwZSE/AVFQrjZ72u0t5seXKcjrqgrglMJnKsCykZgkOJasxZHASvR1tGOiPYDZqgIcJy8pZYpmHaYGkpBnk8CoA8L8oKEAYDLtFoqfazYKSwjyqmyOhqkdX1qgb8zAEasFx2OrMLwqhumYgkUykJYNIigoocWQ6KLxMUBIqEQasmcK+GoWKDDQ6iBIlQlNTcd9/phioaSurSGv/e5R/kTGJiLoA4djY0TTmKrF5/5O9He0Y6yjCrnqAmwrD9gCFMwz8aVamU/UYnyLVAwKpAuQ/Umo3mlgzAExAqDV2s7MURNCb/ocr+xHp54nD3WipjlK3vnLk/yhSxOuPZCg/EihmR1rXI1LN8c9GgWShbSseRqa+pLHGF5lejEvUtPVcDkF2TMJnM8WqQUDklT7XHAG0Xtxn7w68TRpakJVSOJXW27nP7/gb4+eufMuTHQEkTUzrl3IMtiS6F3EgjSW0Tu8SzQ1ndMG15t2hVRBqqEUkf0zFFdsBUck5fDYH5HN/6G0ldbfMdTXdJH1ka1qfcP32KpGsKAPsF2hbK+vMnzD6C1XTWmVhQQnEj7Odb6pkVkhPxvqVQcH30Be7p47gJivxZK90E/h4HwD2oLbyIbWJ+g9TTfRWLVe4AHLdfVCD0qWt3mVereoLTAnMCiV03mlTo/OysNXPkDvhO6PHwOwymyOWug4pvxwKoZw1Rasb9hK7225l94cBfEZWpiAswg1r+dAwiASfoPrdUgNTQt5NNGvuq++ianc2wDOVziI+aO/bzuw0v+VPJABzjeiPbyN3tfcRe6MN9BGj5ryxElVbKoeDV1djKnpAuTZsaz87PKH6B//OwQOAijMCVn0mG+p44xK76wniqM2sIV8J7aV3NdyD10TKVKb68bykkfjK9WdeBPjOZ0b5xajsVAWLiWo/J7KQ09N7btoD2+l9zZvQtDwyaOJj3B2cieE+AhAbika/6+g0v0LUWuYOxauPKq77mPh/wFf1bF3tCYEwQAAAABJRU5ErkJggg=="
return self.methods.methodsRubika("json",methode ="sendMessage",indata = {"is_mute":False,"object_guid":guid,"reply_to_message_id":message_id,"rnd":f"{randint(100000,999999999)}","file_inline":{"dc_id": dc_id,"file_id": file_id,"type":"Image","file_name": file_name,"size": str(len(loop.run_until_complete(_download_with_server(server = file)) if ("http" or "https") in file else open(file,"rb").read())),"mime": mime,"access_hash_rec": access_hash_rec,"width": breadth[0],"height": breadth[1],"thumb_inline": thumbnail},"text":caption},wn = clien.android)
def twolocks(self,ramz,hide):
locked = self.methods.methodsRubika("json",methode ="setupTwoStepVerification",indata = {"hint": hide,"password": ramz},wn = clien.web)
if locked["status"] == 'ERROR_GENERIC':
return locked["client_show_message"]["link"]["alert_data"]["message"]
else:return locked
def ProfileEdit(self,first_name = None,last_name = None,bio = None,username = None):
while 1:
try:
self.editUser(first_name = first_name,last_name = last_name,bio = bio)
self.editusername(username)
return "Profile edited"
break
except:continue
def getChatGroup(self,guid_gap):
while 1:
try:
lastmessages = self.getGroupInfo(guid_gap)["data"]["chat"]["last_message_id"]
messages = self.getMessages(guid_gap, lastmessages)
return messages
break
except:continue
def getChatChannel(self,guid_channel):
while 1:
try:
lastmessages = self.getChannelInfo(guid_channel)["data"]["chat"]["last_message_id"]
messages = self.getMessages(guid_channel, lastmessages)
return messages
break
except:continue
def getChatUser(self,guid_User):
while 1:
try:
lastmessages = self.getUserInfo(guid_User)["data"]["chat"]["last_message_id"]
messages = self.getMessages(guid_User, lastmessages)
return messages
break
except:continue
@property
def Authrandom(self):
auth = ""
meghdar = "qwertyuiopasdfghjklzxcvbnm0123456789"
for string in range(32):
auth += choice(meghdar)
return auth
def SendCodeSMS(self,phonenumber):
tmp = self.Authrandom()
enc = encoderjson(tmp)
return self.methods.methodsRubika("json",methode ="sendCode",indata = {"phone_number":f"98{phonenumber[1:]}","send_type":"SMS"},wn = clien.web)
def SendCodeWhithPassword(self,phone_number:str,pass_you):
tmp = self.Authrandom()
enc = encoderjson(tmp)
return self.methods.methodsRubika("json",methode ="sendCode",indata = {"pass_key":pass_you,"phone_number":f"98{phonenumber[1:]}","send_type":"SMS"},wn = clien.web)
def signIn(self,phone_number,phone_code_hash,phone_code):
tmp = self.Authrandom()
enc = encoderjson(tmp)
return self.methods.methodsRubika("json",methode ="signIn",indata = {"phone_number":f"98{phone_number[1:]}","phone_code_hash":phone_code_hash,"phone_code":phone_code},wn = clien.web)
def registerDevice(self,auth):
enc = encoderjson(auth)
while 1:
try:
loop = asyncio.get_event_loop()
ersal = loads(enc.decrypt(loads(loop.run_until_complete(httpregister(auth)))))
return ersal
break
except:
continue
def Auth(self,readfile):
while 1:
try:
with open(f"{readfile}", "r") as file:
jget = json.load(file)
s = jget["data"]["auth"]
regs = self.registerDevice(s)
return regs
except:continue
class Robot_Rubika(Messenger):
...
|
Ahwaz
|
/Ahwaz-2.2.3-py3-none-any.whl/ahwaz/Arsein.py
|
Arsein.py
|
import aiohttp
import asyncio
from ahwaz.Encoder import encoderjson
from ahwaz.PostData import method_Rubika,httpfiles,_download_with_server
from json import loads
from pathlib import Path
from ahwaz.Clien import clien
class Upload:
def __init__(self, Sh_account:str):
self.Auth = Sh_account
self.enc = encoderjson(Sh_account)
self.methodUpload = method_Rubika(Sh_account)
def requestSendFile(self,file):
return self.methodUpload.methodsRubika("json",methode ="requestSendFile",indata = {"file_name": str(file.split("/")[-1]),"mime": file.split(".")[-1],"size": Path(file).stat().st_size},wn = clien.web).get("data")
def uploadFile(self, file):
if not "http" in file:
REQUES = self.requestSendFile(file)
bytef = open(file,"rb").read()
hash_send = REQUES["access_hash_send"]
file_id = REQUES["id"]
url = REQUES["upload_url"]
header = {
'auth':self.Auth,
'Host':url.replace("https://","").replace("/UploadFile.ashx",""),
'chunk-size':str(Path(file).stat().st_size),
'file-id':str(file_id),
'access-hash-send':hash_send,
"content-type": "application/octet-stream",
"content-length": str(Path(file).stat().st_size),
"accept-encoding": "gzip",
"user-agent": "okhttp/3.12.1"
}
if len(bytef) <= 131072:
header["part-number"], header["total-part"] = "1","1"
while True:
try:
#loop = asyncio.get_event_loop()
j = self.methodUpload.methodsRubika(types = "file",server = url,podata = bytef,header = header)
j = loads(j)['data']['access_hash_rec']
break
except Exception as e:
continue
return [REQUES, j]
else:
t = round(len(bytef) / 131072 + 1)
for i in range(1,t+1):
if i != t:
k = i - 1
k = k * 131072
while True:
try:
header["chunk-size"], header["part-number"], header["total-part"] = "131072", str(i),str(t)
#loop = asyncio.get_event_loop()
o = self.methodUpload.methodsRubika(types = "file",server = url,podata = bytef[k:k + 131072],header = header)
o = loads(o)['data']
break
except Exception as e:
continue
else:
k = i - 1
k = k * 131072
while True:
try:
header["chunk-size"], header["part-number"], header["total-part"] = str(len(bytef[k:])), str(i),str(t)
#loop = asyncio.get_event_loop()
p = self.methodUpload.methodsRubika(types = "file",server = url,podata = bytef[k:],header = header)
p = loads(p)['data']['access_hash_rec']
break
except Exception as e:
continue
return [REQUES, p]
else:
loop = asyncio.get_event_loop()
REQUES = self.methodUpload.methodsRubika("json",methode ="requestSendFile",indata = {"file_name": str(file.split("/")[-1]),"mime": file.split(".")[-1],"size": len(loop.run_until_complete(_download_with_server(server = file)))},wn = clien.web).get("data")
hash_send = REQUES["access_hash_send"]
file_id = REQUES["id"]
url = REQUES["upload_url"]
loop = asyncio.get_event_loop()
bytef = loop.run_until_complete(_download_with_server(server = file))
header = {
'auth':self.Auth,
'Host':url.replace("https://","").replace("/UploadFile.ashx",""),
'chunk-size':str(len(loop.run_until_complete(_download_with_server(server = file)))),
'file-id':str(file_id),
'access-hash-send':hash_send,
"content-type": "application/octet-stream",
"content-length": str(len(loop.run_until_complete(_download_with_server(server = file)))),
"accept-encoding": "gzip",
"user-agent": "okhttp/3.12.1"
}
if len(bytef) <= 131072:
header["part-number"], header["total-part"] = "1","1"
while True:
try:
#loop = asyncio.get_event_loop()
j = self.methodUpload.methodsRubika(types = "file",server = url,podata = bytef,header = header)
j = loads(j)['data']['access_hash_rec']
break
except Exception as e:
continue
return [REQUES, j]
else:
t = round(len(bytef) / 131072 + 1)
for i in range(1,t+1):
if i != t:
k = i - 1
k = k * 131072
while True:
try:
header["chunk-size"], header["part-number"], header["total-part"] = "131072", str(i),str(t)
#loop = asyncio.get_event_loop()
o = self.methodUpload.methodsRubika(types = "file",server = url,podata = bytef[k:k + 131072],header = header)
o = loads(o)['data']
break
except Exception as e:
continue
else:
k = i - 1
k = k * 131072
while True:
try:
header["chunk-size"], header["part-number"], header["total-part"] = str(len(bytef[k:])), str(i),str(t)
#loop = asyncio.get_event_loop()
p = self.methodUpload.methodsRubika(types = "file",server = url,podata = bytef[k:],header = header)
p = loads(p)['data']['access_hash_rec']
break
except Exception as e:
continue
return [REQUES, p]
|
Ahwaz
|
/Ahwaz-2.2.3-py3-none-any.whl/ahwaz/Getheader.py
|
Getheader.py
|
import aiohttp
import asyncio
from ahwaz.Encoder import encoderjson
from ahwaz.GtM import default_api
from json import dumps, loads
from random import choice,randint
from ahwaz.Clien import clien
from ahwaz.Device import DeviceTelephone
async def http(js,auth):
Full = default_api()
s = Full.defaultapi()
enc = encoderjson(auth)
async with aiohttp.ClientSession() as session:
async with session.post(s, data = dumps({"api_version":"5","auth": auth,"data_enc":enc.encrypt(dumps(js))}) , headers = {'Content-Type': 'application/json'}) as response:
Post = await response.text()
return Post
async def httpregister(auth):
Full = default_api()
s = Full.defaultapi()
enc = encoderjson(auth)
async with aiohttp.ClientSession() as session:
async with session.post(s, data = dumps({"api_version":"4","auth":auth,"client": clien.android,"data_enc":enc.encrypt(dumps(DeviceTelephone.defaultDevice)),"method":"registerDevice"})) as response:
Post = await response.json()
return Post
async def _download_with_server(server):
async with aiohttp.ClientSession() as session:
async with session.get(server) as response:
Post = await response.read()
return Post
async def _download(server,header):
async with aiohttp.ClientSession() as session:
async with session.get(server,header) as response:
Post = await response.read()
return Post
async def httpfiles(s,dade,head):
async with aiohttp.ClientSession() as session:
async with session.post(s, data = dade , headers = head) as response:
Post = await response.text()
return Post
class method_Rubika:
def __init__(self,auth:str):
self.Auth = auth
self.enc = encoderjson(auth)
def methodsRubika(self,types:str = None,methode:str = None,indata:dict = None,wn:dict = None,server:str = None,podata = None,header:dict = None):
self.Type = types
self.inData = {"method":methode,"input":indata,"client":wn}
self.serverfile = server
self.datafile = podata
self.headerfile = header
while 1:
try:
loop = asyncio.get_event_loop()
if self.Type == "json":
return loads(self.enc.decrypt(loads(loop.run_until_complete(http(self.inData,self.Auth))).get("data_enc")))
break
elif self.Type == "file":
return loop.run_until_complete(httpfiles(self.serverfile,self.datafile,self.headerfile))
break
except Exception as w:
print(w)
|
Ahwaz
|
/Ahwaz-2.2.3-py3-none-any.whl/ahwaz/PostData.py
|
PostData.py
|
from ahwaz.Arsein import Messenger
from re import findall
from ahwaz.Error import AuthError,TypeAnti
from ahwaz.Copyright import copyright
from ahwaz.PostData import method_Rubika
class Antiadvertisement:
def __init__(self,Sh_account: str):
self.Auth = str("".join(findall(r"\w",Sh_account)))
self.prinet = copyright.CopyRight
self.methods = method_Rubika(Sh_account)
self.bot = Messenger(Sh_account)
if self.Auth.__len__() < 32:
raise AuthError("The Auth entered is incorrect")
elif self.Auth.__len__() > 32:
raise AuthError("The Auth entered is incorrect")
def Anti(self,Type:str = None,admins:list = None,guid_gap:str = None,msg:str = None):
if Type == "Gif":
while 1:
try:
if admins == None:
if msg["file_inline"]["type"] == "Gif":
self.bot.deleteMessages(guid_gap, [msg.get("message_id")])
return "delete Gif"
break
else:break
elif type(admins) == list and admins != []:
if msg["file_inline"]["type"] == "Gif" and not msg["author_object_guid"] in admins:
self.bot.deleteMessages(guid_gap, [msg.get("message_id")])
return "delete Gif"
break
else:break
except:
continue
elif Type == "Sticker":
while 1:
try:
if admins == None:
if msg["file_inline"]["type"] == "Sticker":
self.bot.deleteMessages(guid_gap, [msg.get("message_id")])
return "delete Sticker"
break
else:break
elif type(admins) == list and admins != []:
if msg["file_inline"]["type"] == "Sticker" and not msg["author_object_guid"] in admins:
self.bot.deleteMessages(guid_gap, [msg.get("message_id")])
return "delete Sticker"
break
else:break
except:
continue
elif Type == "Image":
while 1:
try:
if admins == None:
if msg["file_inline"]["type"] == "Image":
self.bot.deleteMessages(guid_gap, [msg.get("message_id")])
return "delete Image"
break
else:break
elif type(admins) == list and admins != []:
if msg["file_inline"]["type"] == "Image" and not msg["author_object_guid"] in admins:
self.bot.deleteMessages(guid_gap, [msg.get("message_id")])
return "delete Image"
break
else:break
except:
continue
elif Type == "Music":
while 1:
try:
if admins == None:
if msg["file_inline"]["type"] == "Music":
self.bot.deleteMessages(guid_gap, [msg.get("message_id")])
return "delete Music"
break
else:break
elif type(admins) == list and admins != []:
if msg["file_inline"]["type"] == "Music" and not msg["author_object_guid"] in admins:
self.bot.deleteMessages(guid_gap, [msg.get("message_id")])
return "delete Music"
break
else:break
except:
continue
elif Type == "Video":
while 1:
try:
if admins == None:
if msg["file_inline"]["type"] == "Video":
self.bot.deleteMessages(guid_gap, [msg.get("message_id")])
return "delete Video"
break
else:break
elif type(admins) == list and admins != []:
if msg["file_inline"]["type"] == "Video" and not msg["author_object_guid"] in admins:
self.bot.deleteMessages(guid_gap, [msg.get("message_id")])
return "delete Video"
break
else:break
except:
continue
elif Type == "Voice":
while 1:
try:
if admins == None:
if msg["file_inline"]["type"] == "Voice":
self.bot.deleteMessages(guid_gap, [msg.get("message_id")])
return "delete Voice"
break
else:break
elif type(admins) == list and admins != []:
if msg["file_inline"]["type"] == "Voice" and not msg["author_object_guid"] in admins:
self.bot.deleteMessages(guid_gap, [msg.get("message_id")])
return "delete Voice"
break
else:break
except:
continue
elif Type == "File":
while 1:
try:
if admins == None:
if msg["file_inline"]["type"] == "File":
self.bot.deleteMessages(guid_gap, [msg.get("message_id")])
return "delete File"
break
else:break
elif type(admins) == list and admins != []:
if msg["file_inline"]["type"] == "File" and not msg["author_object_guid"] in admins:
self.bot.deleteMessages(guid_gap, [msg.get("message_id")])
return "delete File"
break
else:break
except:
continue
elif Type == "forward":
while 1:
try:
if admins == None:
if "forwarded_from" in msg.keys():
msge = self.bot.getMessagesInfo(guid_gap, [msg.get("message_id")])
messag = msge["data"]["messages"]
for ms in messag:
msgID = ms["message_id"]
getjsfor = ms["forwarded_from"]["type_from"]
if getjsfor == "Channel" or "User":
self.bot.deleteMessages(guid_gap, [msgID])
return "delete forward"
break
else:break
else:break
elif type(admins) == list and admins != []:
if "forwarded_from" in msg.keys():
msge = self.bot.getMessagesInfo(guid_gap, [msg.get("message_id")])
messag = msge["data"]["messages"]
for ms in messag:
msgID = ms["message_id"]
getjsfor = ms["forwarded_from"]["type_from"]
if getjsfor == "Channel" or "User" and not msg["author_object_guid"] in admins:
self.bot.deleteMessages(guid_gap, [msgID])
return "delete forward"
break
else:break
else:break
except:
continue
elif Type == "link":
while 1:
try:
if admins == None:
msgID = msg.get("message_id")
if msg["type"] == 'Text' and not "forwarded_from" in msg.keys():
if findall(r"https://rubika.ir/joing/\w{32}", msg['text']) or findall(r"https://rubika.ir/joinc/\w{32}", msg['text']) or findall(r"https://rubika.ir/\w{32}", msg['text']) or findall(r"https://\w", msg['text']) or findall(r"http://\w", msg['text']) or findall(r"@\w", msg['text']) != []:
self.bot.deleteMessages(guid_gap, [msgID])
return "delete link"
break
else:break
else:break
elif type(admins) == list and admins != []:
msgID = msg.get("message_id")
if msg["type"] == 'Text' and not "forwarded_from" in msg.keys() and not msg["author_object_guid"] in admins:
if findall(r"https://rubika.ir/joing/\w{32}", msg['text']) or findall(r"https://rubika.ir/joinc/\w{32}", msg['text']) or findall(r"https://rubika.ir/\w{32}", msg['text']) or findall(r"https://\w", msg['text']) or findall(r"http://\w", msg['text']) or findall(r"@\w", msg['text']) != []:
self.bot.deleteMessages(guid_gap, [msgID])
return "delete link"
break
else:break
else:break
except:
continue
else: raise TypeAnti("The TypeAnti entered is incorrect")
|
Ahwaz
|
/Ahwaz-2.2.3-py3-none-any.whl/ahwaz/Zedcontent.py
|
Zedcontent.py
|
import abc
import json
import multiprocessing
import os
import socket
import socketserver
import threading
import time
from ast import literal_eval
from datetime import datetime
from typing import Optional, Dict, List, Tuple, Union
from loguru import logger
# from ._multiprocess import multiprocess
from ._utils import _protect, _Region, _Algorithm, _SubColors
spawn = multiprocessing.get_context("spawn")
# _LOG_PATH = Path(__file__).parent.resolve() / "logs"
# # rotation 文件分割,可按时间或者大小分割
# # retention 日志保留时间
# # compression="zip" 压缩方式
#
# # logger.add(LOG_PATH / 'runtime.log', rotation='100 MB', retention='15 days') 按大小分割,日志保留 15 天
# # logger.add(LOG_PATH / 'runtime.log', rotation='1 week') # rotation 按时间分割,每周分割一次
#
# # 按时间分割,每日 12:00 分割一次,保留 15 天
# logger.add(_LOG_PATH / "runtime_{time}.log", rotation="12:00", retention="15 days")
# 高级方法
# debug_fo = logger.add("debug.log", filter=lambda record: record["level"].name == "DEBUG")
# debug_logger = logger.bind(name=debug_fo)
# logger.add("a.log", filter=lambda record: record["extra"].get("name") == "a")
# logger.add("b.log", filter=lambda record: record["extra"].get("name") == "b")
# logger_a = logger.bind(name="a")
# logger_b = logger.bind(name="b")
Log_Format = "<green>{time:YYYY-MM-DD HH:mm:ss.SSS}</green> | " \
"<level>{level: <8}</level> | " \
"{process.id} - {thread.id: <8} | " \
"<cyan>{module}:{line}</cyan> | " \
"<level>{message}</level>" # 日志内容
class Point:
def __init__(self, x: float, y: float, driver: "AndroidBotMain"):
self.x = x
self.y = y
self.__driver = driver
def click(self, offset_x: float = 0, offset_y: float = 0):
"""
点击坐标
:param offset_x: 坐标 x 轴偏移量
:param offset_y: 坐标 y 轴偏移量
:return:
"""
return self.__driver.click(self, offset_x=offset_x, offset_y=offset_y)
def get_points_center(self, other_point: "Point") -> "Point":
"""
获取两个坐标点的中间坐标
:param other_point: 其他的坐标点
:return: Point
"""
return self.__class__(x=self.x + (other_point.x - self.x) / 2, y=self.y + (other_point.y - self.y) / 2,
driver=self.__driver)
def __getitem__(self, item):
if item == 0:
return self.x
elif item == 1:
return self.y
else:
raise IndexError("list index out of range")
def __repr__(self):
return f"Point(x={self.x}, y={self.y})"
class Point2s:
"""
代替 Point 元组
"""
def __init__(self, p1: Point, p2: Point):
self.p1 = p1
self.p2 = p2
def click(self, offset_x: float = 0, offset_y: float = 0) -> bool:
"""
点击元素的中心坐标
:param offset_x:
:param offset_y:
:return:
"""
return self.central_point().click(offset_x=offset_x, offset_y=offset_y)
def central_point(self) -> Point:
"""
获取元素的中心坐标
:return:
"""
return self.p1.get_points_center(self.p2)
def __getitem__(self, item):
if item == 0:
return self.p1
elif item == 1:
return self.p2
else:
raise IndexError("list index out of range")
def __repr__(self):
return f"({self.p1}, {self.p2})"
_Point_Tuple = Union[Point, Tuple[float, float]]
class _ThreadingTCPServer(socketserver.ThreadingTCPServer):
daemon_threads = True
allow_reuse_address = True
def server_bind(self) -> None:
"""Called by constructor to bind the socket.
May be overridden.
"""
if os.name != "nt":
self.socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEPORT, 1)
else: # In windows, SO_REUSEPORT is not available
self.socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
self.socket.bind(self.server_address)
self.server_address = self.socket.getsockname()
class AndroidBotMain(socketserver.BaseRequestHandler, metaclass=_protect("handle", "execute")):
raise_err = False
wait_timeout = 3 # seconds
interval_timeout = 0.5 # seconds
log_storage = False
log_level = "INFO"
log_size = 10 # MB
# 基础存储路径
_base_path = "/storage/emulated/0/Android/data/com.aibot.client/files/"
def __init__(self, request, client_address, server):
self._lock = threading.Lock()
self.log = logger
if self.log_storage:
log_file_name = f"{multiprocessing.current_process().ident}_{threading.current_thread().ident}"
log_path = "./logs/runtime_{time}_" + f"{log_file_name}" + ".log"
logger.add(log_path, level=self.log_level.upper(), format=Log_Format,
filter=lambda record: f"{record['process'].id}_{record['thread'].id}" == log_file_name,
rotation=f'{self.log_size} MB',
retention='0 days')
super().__init__(request, client_address, server)
def __send_data_return_bytes(self, *args) -> bytes:
args_len = ""
args_text = ""
for argv in args:
argv = str(argv)
args_text += argv
args_len += str(len(bytes(argv, 'utf8'))) + "/"
data = (args_len.strip("/") + "\n" + args_text).encode("utf8")
try:
with self._lock:
self.log.debug(rf"---> {data}")
self.request.sendall(data)
response = self.request.recv(65535)
if response == b"":
raise ConnectionAbortedError(f"{self.client_address[0]}:{self.client_address[1]} 客户端断开链接")
data_length, data = response.split(b"/", 1)
while int(data_length) > len(data):
data += self.request.recv(65535)
self.log.debug(rf"<--- {data}")
except Exception as e:
self.log.error("send/read tcp data error: " + str(e))
raise e
return data
def __send_data(self, *args) -> str:
data = self.__send_data_return_bytes(*args)
return data.decode("utf8").strip()
def __push_file(self, func_name: str, to_path: str, file: bytes):
func_name = bytes(func_name, "utf8")
to_path = bytes(to_path, "utf8")
str_data = ""
str_data += str(len(func_name)) + "/" # func_name 字节长度
str_data += str(len(to_path)) + "/" # to_path 字节长度
str_data += str(len(file)) + "\n" # file 字节长度
bytes_data = bytes(str_data, "utf8")
bytes_data += func_name
bytes_data += to_path
bytes_data += file
with self._lock:
self.log.debug(rf"---> {bytes_data}")
self.request.sendall(bytes_data)
response = self.request.recv(65535)
if response == b"":
raise ConnectionAbortedError(f"{self.client_address[0]}:{self.client_address[1]} 客户端断开链接")
data_length, data = response.split(b"/", 1)
while int(data_length) > len(data):
data += self.request.recv(65535)
self.log.debug(rf"<--- {data}")
return data.decode("utf8").strip()
def __pull_file(self, *args) -> bytes:
args_len = ""
args_text = ""
for argv in args:
argv = str(argv)
args_text += argv
args_len += str(len(bytes(argv, 'utf8'))) + "/"
data = (args_len.strip("/") + "\n" + args_text).encode("utf8")
with self._lock:
self.log.debug(rf"---> {data}")
self.request.sendall(data)
response = self.request.recv(65535)
if response == b"":
raise ConnectionAbortedError(f"{self.client_address[0]}:{self.client_address[1]} 客户端断开链接")
data_length, data = response.split(b"/", 1)
while int(data_length) > len(data):
data += self.request.recv(65535)
self.log.debug(rf"<--- {data}")
return data
def save_screenshot(self, image_name: str, region: _Region = None, algorithm: _Algorithm = None) -> Optional[str]:
"""
保存截图,返回图片地址(手机中)或者 None
:param image_name: 图片名称,保存在手机 /storage/emulated/0/Android/data/com.aibot.client/files/ 路径下;
:param region: 截图区域,默认全屏,``region = (起点x、起点y、终点x、终点y)``,得到一个矩形
:param algorithm:
处理截图所用算法和参数,默认保存原图,
``algorithm = (algorithm_type, threshold, max_val)``
按元素顺序分别代表:
0. ``algorithm_type`` 算法类型
1. ``threshold`` 阈值
2. ``max_val`` 最大值
``threshold`` 和 ``max_val`` 同为 255 时灰度处理.
``algorithm_type`` 算法类型说明:
0. ``THRESH_BINARY`` 算法,当前点值大于阈值 `threshold` 时,取最大值 ``max_val``,否则设置为 0;
1. ``THRESH_BINARY_INV`` 算法,当前点值大于阈值 `threshold` 时,设置为 0,否则设置为最大值 max_val;
2. ``THRESH_TOZERO`` 算法,当前点值大于阈值 `threshold` 时,不改变,否则设置为 0;
3. ``THRESH_TOZERO_INV`` 算法,当前点值大于阈值 ``threshold`` 时,设置为 0,否则不改变;
4. ``THRESH_TRUNC`` 算法,当前点值大于阈值 ``threshold`` 时,设置为阈值 ``threshold``,否则不改变;
5. ``ADAPTIVE_THRESH_MEAN_C`` 算法,自适应阈值;
6. ``ADAPTIVE_THRESH_GAUSSIAN_C`` 算法,自适应阈值;
:return: 图片地址(手机中)或者 None
"""
if image_name.find("/") != -1:
raise ValueError("`image_name` cannot contain `/`.")
if not region:
region = [0, 0, 0, 0]
if not algorithm:
algorithm_type, threshold, max_val = [0, 0, 0]
else:
algorithm_type, threshold, max_val = algorithm
if algorithm_type in (5, 6):
threshold = 127
max_val = 255
response = self.__send_data("saveScreenshot", self._base_path + image_name, *region,
algorithm_type, threshold, max_val)
if response == "true":
return self._base_path + image_name
return None
def save_element_screenshot(self, image_name: str, xpath: str) -> Optional[str]:
"""
保存元素截图
:param image_name: 图片名称,保存在手机 /storage/emulated/0/Android/data/com.aibot.client/files/ 路径下
:param xpath: xpath路径
:return: 图片地址(手机中)或者 None
"""
rect = self.get_element_rect(xpath)
if rect is None:
return None
return self.save_screenshot(image_name, region=(rect[0].x, rect[0].y, rect[1].x, rect[1].y))
def take_screenshot(self, region: _Region = None, algorithm: _Algorithm = None) -> Optional[bytes]:
"""
保存截图,返回图像字节格式或者"null"的字节格式
:param region: 截图区域,默认全屏,``region = (起点x、起点y、终点x、终点y)``,得到一个矩形
:param algorithm:
处理截图所用算法和参数,默认保存原图,
``algorithm = (algorithm_type, threshold, max_val)``
按元素顺序分别代表:
0. ``algorithm_type`` 算法类型
1. ``threshold`` 阈值
2. ``max_val`` 最大值
``threshold`` 和 ``max_val`` 同为 255 时灰度处理.
``algorithm_type`` 算法类型说明:
0. ``THRESH_BINARY`` 算法,当前点值大于阈值 `threshold` 时,取最大值 ``max_val``,否则设置为 0;
1. ``THRESH_BINARY_INV`` 算法,当前点值大于阈值 `threshold` 时,设置为 0,否则设置为最大值 max_val;
2. ``THRESH_TOZERO`` 算法,当前点值大于阈值 `threshold` 时,不改变,否则设置为 0;
3. ``THRESH_TOZERO_INV`` 算法,当前点值大于阈值 ``threshold`` 时,设置为 0,否则不改变;
4. ``THRESH_TRUNC`` 算法,当前点值大于阈值 ``threshold`` 时,设置为阈值 ``threshold``,否则不改变;
5. ``ADAPTIVE_THRESH_MEAN_C`` 算法,自适应阈值;
6. ``ADAPTIVE_THRESH_GAUSSIAN_C`` 算法,自适应阈值;
:return: 图像字节格式或者"null"的字节格式
"""
if not region:
region = [0, 0, 0, 0]
if not algorithm:
algorithm_type, threshold, max_val = [0, 0, 0]
else:
algorithm_type, threshold, max_val = algorithm
if algorithm_type in (5, 6):
threshold = 127
max_val = 255
response = self.__send_data_return_bytes("takeScreenshot", *region, algorithm_type, threshold, max_val)
if response == b'null':
return None
return response
# #############
# 色值相关 #
# #############
def get_color(self, point: _Point_Tuple) -> Optional[str]:
"""
获取指定坐标点的色值
:param point: 坐标点
:return: 色值字符串(例如: #008577)或者 None
"""
response = self.__send_data("getColor", point[0], point[1])
if response == "null":
return None
return response
def find_color(self,
color: str,
sub_colors: _SubColors = None,
region: _Region = None,
similarity: float = 0.9,
wait_time: float = None,
interval_time: float = None,
raise_err: bool = None) -> Optional[Point]:
"""
获取指定色值的坐标点,返回坐标或者 None
:param color: 颜色字符串,必须以 # 开头,例如:#008577;
:param sub_colors: 辅助定位的其他颜色;
:param region: 截图区域,默认全屏,``region = (起点x、起点y、终点x、终点y)``,得到一个矩形
:param similarity: 相似度,0-1 的浮点数,默认 0.9;
:param wait_time: 等待时间,默认取 self.wait_timeout;
:param interval_time: 轮询间隔时间,默认取 self.interval_timeout;
:param raise_err: 超时是否抛出异常;
:return: 坐标或者 None
"""
if wait_time is None:
wait_time = self.wait_timeout
if interval_time is None:
interval_time = self.interval_timeout
if raise_err is None:
raise_err = self.raise_err
if not region:
region = [0, 0, 0, 0]
if sub_colors:
sub_colors_str = ""
for sub_color in sub_colors:
offset_x, offset_y, color_str = sub_color
sub_colors_str += f"{offset_x}/{offset_y}/{color_str}\n"
# 去除最后一个 \n
sub_colors_str = sub_colors_str.strip()
else:
sub_colors_str = "null"
end_time = time.time() + wait_time
while time.time() < end_time:
response = self.__send_data("findColor", color, sub_colors_str, *region, similarity)
# 找色失败
if response == "-1.0|-1.0":
time.sleep(interval_time)
else:
# 找色成功
x, y = response.split("|")
return Point(x=float(x), y=float(y), driver=self)
# 超时
if raise_err:
raise TimeoutError("`find_color` 操作超时")
return None
# #############
# 找图相关 #
# #############
def find_image(self,
image_name, region: _Region = None,
algorithm: _Algorithm = None,
similarity: float = 0.9,
wait_time: float = None,
interval_time: float = None,
raise_err: bool = None) -> Optional[Point]:
"""
寻找图片坐标,在当前屏幕中寻找给定图片中心点的坐标,返回图片坐标或者 None
:param image_name: 图片名称(手机中);
:param region: 截图区域,默认全屏,``region = (起点x、起点y、终点x、终点y)``,得到一个矩形
:param algorithm:
处理屏幕截图所用的算法,默认原图,注意:给定图片处理时所用的算法,应该和此方法的算法一致;
``algorithm = (algorithm_type, threshold, max_val)``
按元素顺序分别代表:
0. ``algorithm_type`` 算法类型
1. ``threshold`` 阈值
2. ``max_val`` 最大值
``threshold`` 和 ``max_val`` 同为 255 时灰度处理.
``algorithm_type`` 算法类型说明:
0. ``THRESH_BINARY`` 算法,当前点值大于阈值 `threshold` 时,取最大值 ``max_val``,否则设置为 0;
1. ``THRESH_BINARY_INV`` 算法,当前点值大于阈值 `threshold` 时,设置为 0,否则设置为最大值 max_val;
2. ``THRESH_TOZERO`` 算法,当前点值大于阈值 `threshold` 时,不改变,否则设置为 0;
3. ``THRESH_TOZERO_INV`` 算法,当前点值大于阈值 ``threshold`` 时,设置为 0,否则不改变;
4. ``THRESH_TRUNC`` 算法,当前点值大于阈值 ``threshold`` 时,设置为阈值 ``threshold``,否则不改变;
5. ``ADAPTIVE_THRESH_MEAN_C`` 算法,自适应阈值;
6. ``ADAPTIVE_THRESH_GAUSSIAN_C`` 算法,自适应阈值;
:param similarity: 相似度,0-1 的浮点数,默认 0.9
:param wait_time: 等待时间,默认取 self.wait_timeout
:param interval_time: 轮询间隔时间,默认取 self.interval_timeout
:param raise_err: 超时是否抛出异常
:return: 图片坐标或者 None
"""
result = self.find_images(image_name, region, algorithm, similarity, 1, wait_time, interval_time, raise_err)
if not result:
return None
return result[0]
def find_images(self,
image_name,
region: _Region = None,
algorithm: _Algorithm = None,
similarity: float = 0.9,
multi: int = 1,
wait_time: float = None,
interval_time: float = None,
raise_err: bool = None) -> List[Point]:
"""
寻找图片坐标,在当前屏幕中寻找给定图片中心点的坐标,返回坐标列表
:param image_name: 图片名称(手机中);
:param region: 截图区域,默认全屏,``region = (起点x、起点y、终点x、终点y)``,得到一个矩形
:param algorithm:
处理屏幕截图所用的算法,默认原图,注意:给定图片处理时所用的算法,应该和此方法的算法一致;
``algorithm = (algorithm_type, threshold, max_val)``
按元素顺序分别代表:
0. ``algorithm_type`` 算法类型
1. ``threshold`` 阈值
2. ``max_val`` 最大值
``threshold`` 和 ``max_val`` 同为 255 时灰度处理.
``algorithm_type`` 算法类型说明:
0. ``THRESH_BINARY`` 算法,当前点值大于阈值 `threshold` 时,取最大值 ``max_val``,否则设置为 0;
1. ``THRESH_BINARY_INV`` 算法,当前点值大于阈值 `threshold` 时,设置为 0,否则设置为最大值 max_val;
2. ``THRESH_TOZERO`` 算法,当前点值大于阈值 `threshold` 时,不改变,否则设置为 0;
3. ``THRESH_TOZERO_INV`` 算法,当前点值大于阈值 ``threshold`` 时,设置为 0,否则不改变;
4. ``THRESH_TRUNC`` 算法,当前点值大于阈值 ``threshold`` 时,设置为阈值 ``threshold``,否则不改变;
5. ``ADAPTIVE_THRESH_MEAN_C`` 算法,自适应阈值;
6. ``ADAPTIVE_THRESH_GAUSSIAN_C`` 算法,自适应阈值;
:param similarity: 相似度,0-1 的浮点数,默认 0.9;
:param multi: 目标数量,默认为 1,找到 1 个目标后立即结束;
:param wait_time: 等待时间,默认取 self.wait_timeout
:param interval_time: 轮询间隔时间,默认取 self.interval_timeout
:param raise_err: 超时是否抛出异常;
:return:
"""
if wait_time is None:
wait_time = self.wait_timeout
if interval_time is None:
interval_time = self.interval_timeout
if raise_err is None:
raise_err = self.raise_err
if not region:
region = [0, 0, 0, 0]
if not algorithm:
algorithm_type, threshold, max_val = [0, 0, 0]
else:
algorithm_type, threshold, max_val = algorithm
if algorithm_type in (5, 6):
threshold = 127
max_val = 255
end_time = time.time() + wait_time
while time.time() < end_time:
response = self.__send_data("findImage", self._base_path + image_name, *region, similarity,
algorithm_type, threshold, max_val, multi)
# 找图失败
if response == "-1.0|-1.0":
time.sleep(interval_time)
else:
# 找图成功,返回图片左上角坐标
# 分割出多个图片的坐标
image_points = response.split("/")
point_list = []
for point_str in image_points:
x, y = point_str.split("|")
point_list.append(Point(x=float(x), y=float(y), driver=self))
return point_list
# 超时
if raise_err:
raise TimeoutError("`find_images` 操作超时")
return []
def find_dynamic_image(self,
interval_ti: int,
region: _Region = None,
wait_time: float = None,
interval_time: float = None,
raise_err: bool = None) -> List[Point]:
"""
找动态图,对比同一张图在不同时刻是否发生变化,返回坐标列表
:param interval_ti: 前后时刻的间隔时间,单位毫秒;
:param region: 截图区域,默认全屏,``region = (起点x、起点y、终点x、终点y)``,得到一个矩形
:param wait_time: 等待时间,默认取 self.wait_timeout
:param interval_time: 轮询间隔时间,默认取 self.interval_timeout
:param raise_err: 超时是否抛出异常;
:return: 坐标列表
"""
if wait_time is None:
wait_time = self.wait_timeout
if interval_time is None:
interval_time = self.interval_timeout
if raise_err is None:
raise_err = self.raise_err
if not region:
region = [0, 0, 0, 0]
end_time = time.time() + wait_time
while time.time() < end_time:
response = self.__send_data("findAnimation", interval_ti, *region)
# 找图失败
if response == "-1.0|-1.0":
time.sleep(interval_time)
else:
# 找图成功,返回图片左上角坐标
# 分割出多个图片的坐标
image_points = response.split("/")
point_list = []
for point_str in image_points:
x, y = point_str.split("|")
point_list.append(Point(x=float(x), y=float(y), driver=self))
return point_list
# 超时
if raise_err:
raise TimeoutError("`find_dynamic_image` 操作超时")
return []
# ################
# 坐标操作相关 #
# ################
def click(self, point: _Point_Tuple, offset_x: float = 0, offset_y: float = 0) -> bool:
"""
点击坐标
:param point: 坐标
:param offset_x: 坐标 x 轴偏移量
:param offset_y: 坐标 y 轴偏移量
:return:
"""
return self.__send_data("click", point[0] + offset_x, point[1] + offset_y) == "true"
def double_click(self, point: _Point_Tuple, offset_x: float = 0, offset_y: float = 0) -> bool:
"""
双击坐标
:param point: 坐标
:param offset_x: 坐标 x 轴偏移量
:param offset_y: 坐标 y 轴偏移量
:return:
"""
return self.__send_data("doubleClick", point[0] + offset_x, point[1] + offset_y) == "true"
def long_click(self, point: _Point_Tuple, duration: float, offset_x: float = 0, offset_y: float = 0) -> bool:
"""
长按坐标
:param point: 坐标
:param duration: 按住时长,单位秒
:param offset_x: 坐标 x 轴偏移量
:param offset_y: 坐标 y 轴偏移量
:return:
"""
return self.__send_data("longClick", point[0] + offset_x, point[1] + offset_y, duration * 1000) == "true"
def swipe(self, start_point: _Point_Tuple, end_point: _Point_Tuple, duration: float) -> bool:
"""
滑动坐标
:param start_point: 起始坐标
:param end_point: 结束坐标
:param duration: 滑动时长,单位秒
:return:
"""
return self.__send_data("swipe", start_point[0], start_point[1], end_point[0], end_point[1],
duration * 1000) == "true"
def gesture(self, gesture_path: List[_Point_Tuple], duration: float) -> bool:
"""
执行手势
:param gesture_path: 手势路径,由一系列坐标点组成
:param duration: 手势执行时长, 单位秒
:return:
"""
gesture_path_str = ""
for point in gesture_path:
gesture_path_str += f"{point[0]}/{point[1]}/\n"
gesture_path_str = gesture_path_str.strip()
return self.__send_data("dispatchGesture", gesture_path_str, duration * 1000) == "true"
def press(self, point: _Point_Tuple, duration: float) -> bool:
"""
手指按下
:param point: 坐标
:param duration: 持续时间,单位秒
:return:
"""
return self.__send_data("press", point[0], point[1], duration * 1000) == "true"
def move(self, point: _Point_Tuple, duration: float) -> bool:
"""
手指移动
:param point: 坐标
:param duration: 持续时间
:return:
"""
return self.__send_data("move", point[0], point[1], duration * 1000) == "true"
def release(self) -> bool:
"""手指抬起"""
return self.__send_data("release") == "true"
def press_release(self, point: _Point_Tuple, duration: float) -> bool:
"""
按下屏幕坐标点并释放
:param point: 按压坐标
:param duration: 按压时长,单位秒
:return:
"""
result = self.press(point, duration)
if not result:
return False
time.sleep(duration)
result2 = self.release()
if not result2:
return False
return True
def press_release_by_ele(self, xpath, duration: float, wait_time: float = None,
interval_time: float = None, ) -> bool:
"""
按压元素并释放
:param xpath: 要按压的元素
:param duration: 按压时长,单位秒
:param wait_time: 查找元素的最长等待时间
:param interval_time: 查找元素的轮询间隔时间
:return:
"""
point2s = self.get_element_rect(xpath, wait_time=wait_time, interval_time=interval_time, raise_err=False)
if point2s is None:
return False
return self.press_release(point2s.central_point(), duration)
# ##############
# OCR 相关 #
################
@staticmethod
def __parse_ocr(text: str) -> list:
"""
解析 OCR 识别出出来的信息
:param text:
:return:
"""
# pattern = re.compile(r'(\[\[\[).+?(\)])')
# matches = pattern.finditer(text)
#
# text_info_list = []
# for match in matches:
# result_str = match.group()
# text_info = literal_eval(result_str)
# text_info_list.append(text_info)
#
# return text_info_list
return literal_eval(text)
def __ocr_server(self, region: _Region = None, algorithm: _Algorithm = None, scale: float = 1.0) -> list:
"""
OCR 服务,通过 OCR 识别屏幕中文字
:param region:
:param algorithm:
:param scale:
:return:
"""
if not region:
region = [0, 0, 0, 0]
if not algorithm:
algorithm_type, threshold, max_val = [0, 0, 0]
else:
algorithm_type, threshold, max_val = algorithm
if algorithm_type in (5, 6):
threshold = 127
max_val = 255
# scale 仅支持区域识别
if region[2] == 0:
scale = 1.0
response = self.__send_data("ocr", *region, algorithm_type, threshold, max_val, scale)
if response == "null" or response == "":
return []
return self.__parse_ocr(response)
def init_ocr_server(self, ip: str, port: int = 9752) -> bool:
"""
初始化 OCR 服务
:param ip:
:param port:
:return:
"""
return self.__send_data("initOcr", ip, port) == "true"
def get_text(self, region: _Region = None, algorithm: _Algorithm = None, scale: float = 1.0) -> List[str]:
"""
通过 OCR 识别屏幕中的文字,返回文字列表
:param region: 识别区域,默认全屏;
:param algorithm: 处理图片/屏幕所用算法和参数,默认保存原图;
:param scale: 图片缩放率,默认为 1.0,1.0 以下为缩小,1.0 以上为放大;
:return: 文字列表
.. seealso::
:meth:`find_image`: ``region`` 和 ``algorithm`` 的参数说明
"""
text_info_list = self.__ocr_server(region, algorithm, scale)
text_list = []
for text_info in text_info_list:
text = text_info[-1][0]
text_list.append(text)
return text_list
def find_text(self, text: str, region: _Region = None, algorithm: _Algorithm = None, scale: float = 1.0) -> \
List[Point]:
"""
查找文字所在的坐标,返回坐标列表(坐标是文本区域中心位置)
:param text: 要查找的文字;
:param region: 识别区域,默认全屏;
:param algorithm: 处理图片/屏幕所用算法和参数,默认保存原图;
:param scale: 图片缩放率,默认为 1.0,1.0 以下为缩小,1.0 以上为放大;
:return: 坐标列表(坐标是文本区域中心位置)
.. seealso::
:meth:`find_image`: ``region`` 和 ``algorithm`` 的参数说明
"""
if not region:
region = [0, 0, 0, 0]
text_info_list = self.__ocr_server(region, algorithm, scale)
text_points = []
for text_info in text_info_list:
if text in text_info[-1][0]:
points, words_tuple = text_info
left, top, right, bottom = points
# 文本区域起点坐标
start_x = left[0]
start_y = left[1]
# 文本区域终点坐标
end_x = right[0]
end_y = right[1]
# 文本区域中心点据左上角的偏移量
# 可能指定文本只是部分文本,要计算出实际位置(x轴)
words: str = words_tuple[0]
width = end_x - start_x
# 单字符宽度
single_word_width = width / len(words)
# 文本在整体文本的起始位置
pos = words.find(text)
offset_x = pos * single_word_width + len(text) * single_word_width / 2
offset_y = (end_y - start_y) / 2
# [ { x: 108, y: 1153 } ]
# 计算文本区域中心坐标
if region[2] != 0: # 缩放
text_point = Point(
x=float(region[0] + (start_x + offset_x) / scale),
y=float(region[1] + (start_y + offset_y) / scale),
driver=self
)
else:
text_point = Point(
x=float(region[0] + (start_x + offset_x) * 2),
y=float(region[1] + (start_y + offset_y) * 2),
driver=self
)
text_points.append(text_point)
return text_points
# #############
# 元素操作 #
###############
def get_element_rect(self, xpath: str, wait_time: float = None, interval_time: float = None,
raise_err: bool = None) -> Optional[Point2s]:
"""
获取元素位置,返回元素区域左上角和右下角坐标
:param xpath: xpath 路径
:param wait_time: 等待时间,默认取 self.wait_timeout
:param interval_time: 轮询间隔时间,默认取 self.interval_timeout
:param raise_err: 超时是否抛出异常;
:return: 元素区域左上角和右下角坐标
"""
if wait_time is None:
wait_time = self.wait_timeout
if interval_time is None:
interval_time = self.interval_timeout
if raise_err is None:
raise_err = self.raise_err
end_time = time.time() + wait_time
while time.time() < end_time:
data = self.__send_data("getElementRect", xpath)
# 失败
if data == "-1|-1|-1|-1":
time.sleep(interval_time)
# 成功
else:
start_x, start_y, end_x, end_y = data.split("|")
return Point2s(p1=Point(x=float(start_x), y=float(start_y), driver=self),
p2=Point(x=float(end_x), y=float(end_y), driver=self))
# 超时
if raise_err:
raise TimeoutError("`get_element_rect` 操作超时")
return None
def get_element_desc(self, xpath: str, wait_time: float = None, interval_time: float = None,
raise_err: bool = None) -> Optional[str]:
"""
获取元素描述
:param xpath: xpath 路径
:param wait_time: 等待时间,默认取 self.wait_timeout
:param interval_time: 轮询间隔时间,默认取 self.interval_timeout
:param raise_err: 超时是否抛出异常;
:return: 元素描述字符串
"""
if wait_time is None:
wait_time = self.wait_timeout
if interval_time is None:
interval_time = self.interval_timeout
if raise_err is None:
raise_err = self.raise_err
end_time = time.time() + wait_time
while time.time() < end_time:
data = self.__send_data("getElementDescription", xpath)
# 失败
if data == "null":
time.sleep(interval_time)
# 成功
else:
return data
# 超时
if raise_err:
raise TimeoutError("`get_element_desc` 操作超时")
return None
def get_element_text(self, xpath: str, wait_time: float = None, interval_time: float = None,
raise_err: bool = None) -> Optional[str]:
"""
获取元素文本
:param xpath: xpath 路径
:param wait_time: 等待时间,默认取 self.wait_timeout
:param interval_time: 轮询间隔时间,默认取 self.interval_timeout
:param raise_err: 超时是否抛出异常;
:return: 元素文本
"""
if wait_time is None:
wait_time = self.wait_timeout
if interval_time is None:
interval_time = self.interval_timeout
if raise_err is None:
raise_err = self.raise_err
end_time = time.time() + wait_time
while time.time() < end_time:
data = self.__send_data("getElementText", xpath)
# 失败
if data == "null":
time.sleep(interval_time)
# 成功
else:
return data
# 超时
if raise_err:
raise TimeoutError("`get_element_text` 操作超时")
return None
def set_element_text(self, xpath: str, text: str, wait_time: float = None, interval_time: float = None,
raise_err: bool = None) -> bool:
"""
设置元素文本
:param xpath:
:param text:
:param wait_time: 等待时间,默认取 self.wait_timeout
:param interval_time: 轮询间隔时间,默认取 self.interval_timeout
:param raise_err: 超时是否抛出异常;
:return:
"""
if wait_time is None:
wait_time = self.wait_timeout
if interval_time is None:
interval_time = self.interval_timeout
if raise_err is None:
raise_err = self.raise_err
end_time = time.time() + wait_time
while time.time() < end_time:
# 失败
if self.__send_data("setElementText", xpath, text) != "true":
time.sleep(interval_time)
# 成功
else:
return True
# 超时
if raise_err:
raise TimeoutError("`set_element_text` 操作超时")
return False
def click_element(self, xpath: str, wait_time: float = None, interval_time: float = None,
raise_err: bool = None) -> bool:
"""
点击元素
:param xpath:
:param wait_time: 等待时间,默认取 self.wait_timeout
:param interval_time: 轮询间隔时间,默认取 self.interval_timeout
:param raise_err: 超时是否抛出异常;
:return:
"""
if wait_time is None:
wait_time = self.wait_timeout
if interval_time is None:
interval_time = self.interval_timeout
if raise_err is None:
raise_err = self.raise_err
end_time = time.time() + wait_time
while time.time() < end_time:
# 失败
if self.__send_data("clickElement", xpath) != "true":
time.sleep(interval_time)
# 成功
else:
return True
# 超时
if raise_err:
raise TimeoutError("`click_element` 操作超时")
return False
def click_any_elements(self, xpath_list: List[str], wait_time: float = None, interval_time: float = None,
raise_err: bool = None) -> bool:
"""
遍历点击列表中的元素,直到任意一个元素返回 True
:param xpath_list: xpath 列表
:param wait_time: 等待时间,默认取 self.wait_timeout
:param interval_time: 轮询间隔时间,默认取 self.interval_timeout
:param raise_err: 超时是否抛出异常;
:return:
"""
if wait_time is None:
wait_time = self.wait_timeout
if interval_time is None:
interval_time = self.interval_timeout
if raise_err is None:
raise_err = self.raise_err
end_time = time.time() + wait_time
while time.time() < end_time:
for xpath in xpath_list:
result = self.click_element(xpath, wait_time=0.05, interval_time=0.01, raise_err=False)
if result:
return True
time.sleep(interval_time)
if raise_err:
raise TimeoutError("`click_any_elements` 操作超时")
return False
def scroll_element(self, xpath: str, direction: int = 0) -> bool:
"""
滚动元素,0 向上滑动,1 向下滑动
:param xpath: xpath 路径
:param direction: 滚动方向,0 向上滑动,1 向下滑动
:return:
"""
return self.__send_data("scrollElement", xpath, direction) == "true"
def element_not_exists(self, xpath: str, wait_time: float = None, interval_time: float = None) -> bool:
"""
元素是否不存在
:param xpath: xpath 路径
:param wait_time: 等待时间,默认取 self.wait_timeout
:param interval_time: 轮询间隔时间,默认取 self.interval_timeout
:return:
"""
if wait_time is None:
wait_time = self.wait_timeout
if interval_time is None:
interval_time = self.interval_timeout
end_time = time.time() + wait_time
while time.time() < end_time:
# 存在
if self.__send_data("existsElement", xpath) == "true":
time.sleep(interval_time)
# 不存在
else:
return True
return False
def element_exists(self, xpath: str, wait_time: float = None, interval_time: float = None) -> bool:
"""
元素是否存在
:param xpath: xpath 路径
:param wait_time: 等待时间,默认取 self.wait_timeout
:param interval_time: 轮询间隔时间,默认取 self.interval_timeout
:return:
"""
if wait_time is None:
wait_time = self.wait_timeout
if interval_time is None:
interval_time = self.interval_timeout
end_time = time.time() + wait_time
while time.time() < end_time:
# 失败
if self.__send_data("existsElement", xpath) != "true":
time.sleep(interval_time)
# 成功
else:
return True
return False
def any_elements_exists(self, xpath_list: List[str], wait_time: float = None, interval_time: float = None) -> \
Optional[str]:
"""
遍历列表中的元素,只要任意一个元素存在就返回 True
:param xpath_list: xpath 列表
:param wait_time: 等待时间,默认取 self.wait_timeout
:param interval_time: 轮询间隔时间,默认取 self.interval_timeout
:return: 任意一个元素存在就返回 True
"""
if wait_time is None:
wait_time = self.wait_timeout
if interval_time is None:
interval_time = self.interval_timeout
end_time = time.time() + wait_time
while time.time() < end_time:
for xpath in xpath_list:
result = self.element_exists(xpath, wait_time=0.05, interval_time=0.01)
if result:
return xpath
time.sleep(interval_time)
return None
def element_is_selected(self, xpath: str) -> bool:
"""
元素是否存在
:param xpath: xpath 路径
:return:
"""
return self.__send_data("isSelectedElement", xpath) == "true"
def click_element_by_slide(self, xpath, distance: int = 1000, duration: float = 0.5, direction: int = 1,
count: int = 999, end_flag_xpath: str = None, wait_time: float = 600,
interval_time: float = 0.5, raise_err: bool = None) -> bool:
"""
滑动列表,查找并点击指定元素
:param xpath: xpath路径
:param distance: 滑动距离,默认 1000
:param duration: 滑动时间,默认 0.5 秒
:param direction: 滑动方向,默认为 1; 1=上滑,2=下滑
:param count: 滑动次数
:param end_flag_xpath: 结束标志 xpath,无标志不检测此标志
:param wait_time: 等待时间,默认 10 分钟
:param interval_time: 轮询间隔时间,默认 0.5 秒
:param raise_err: 超时是否抛出异常;
:return:
"""
if raise_err is None:
raise_err = self.raise_err
if direction == 1:
_end_point = (500, 300)
_start_point = (500, _end_point[1] + distance)
elif direction == 2:
_start_point = (500, 300)
_end_point = (500, _start_point[1] + distance)
else:
raise RuntimeError(f"未知方向:{direction}")
end_time = time.time() + wait_time
current_count = 0
while time.time() < end_time and current_count < count:
current_count += 1
if self.click_element(xpath, wait_time=1, interval_time=0.5, raise_err=False):
return True
if end_flag_xpath and self.element_exists(end_flag_xpath, wait_time=1, interval_time=0.5):
return False
self.swipe(_start_point, _end_point, duration)
time.sleep(interval_time)
if raise_err:
raise TimeoutError("`click_element_by_slide` 操作超时")
return False
# #############
# 文件传输 #
# #############
def push_file(self, origin_path: str, to_path: str) -> bool:
"""
将电脑文件传输到手机端
:param origin_path: 源文件路径
:param to_path: 目标存储路径
:return:
ex:
origin_path: /
to_path: /storage/emulated/0/Android/data/com.aibot.client/files/code479259.png
"""
if not to_path.startswith("/storage/emulated/0/"):
to_path = "/storage/emulated/0/" + to_path
with open(origin_path, "rb") as file:
data = file.read()
return self.__push_file("pushFile", to_path, data) == "true"
def pull_file(self, remote_path: str, local_path: str) -> bool:
"""
将手机文件传输到电脑端
:param remote_path: 手机端文件路径
:param local_path: 电脑本地文件存储路径
:return:
ex:
remote_path: /storage/emulated/0/Android/data/com.aibot.client/files/code479259.png
local_path: /
"""
if not remote_path.startswith("/storage/emulated/0/"):
remote_path = "/storage/emulated/0/" + remote_path
data = self.__pull_file("pullFile", remote_path)
if data == b"null":
return False
with open(local_path, "wb") as file:
file.write(data)
return True
# #############
# 设备操作 #
# #############
def start_app(self, name: str, wait_time: float = None, interval_time: float = None) -> bool:
"""
启动 APP
:param name: APP名字或者包名
:param wait_time: 等待时间,默认取 self.wait_timeout
:param interval_time: 轮询间隔时间,默认取 self.interval_timeout
:return:
"""
if wait_time is None:
wait_time = self.wait_timeout
if interval_time is None:
interval_time = self.interval_timeout
end_time = time.time() + wait_time
while time.time() < end_time:
# 失败
if self.__send_data("startApp", name) != "true":
time.sleep(interval_time)
# 成功
else:
return True
# 超时
return False
def get_device_ip(self) -> str:
"""
获取设备IP地址
:return: 设备IP地址字符串
"""
return self.client_address[0]
def get_android_id(self) -> str:
"""
获取 Android 设备 ID
:return: Android 设备 ID 字符串
"""
return self.__send_data("getAndroidId")
def get_window_size(self) -> Dict[str, float]:
"""
获取屏幕大小
:return: 屏幕大小, 字典格式
"""
width, height = self.__send_data("getWindowSize").split("|")
return {"width": float(width), "height": float(height)}
def get_image_size(self, image_path) -> Dict[str, float]:
"""
获取图片大小
:param image_path: 图片路径
:return: 图片大小, 字典格式
"""
width, height = self.__send_data("getImageSize", image_path).split("|")
return {"width": float(width), "height": float(height)}
def show_toast(self, text: str, duration: float = 3) -> bool:
"""
Toast 弹窗
:param text: 弹窗内容
:param duration: 弹窗持续时间,单位:秒
:return:
"""
return self.__send_data("showToast", text, duration * 1000) == "true"
def sleep(self, wait_time: float, interval_time: float = 1.5):
"""
强制等待
:param wait_time: 等待时长
:param interval_time: 等待时轮询间隔时间
:return:
"""
end_time = datetime.now().timestamp() + wait_time
while datetime.now().timestamp() < end_time:
self.show_toast("等待中...", 1)
time.sleep(interval_time)
def send_keys(self, text: str) -> bool:
"""
发送文本,需要打开 AiBot 输入法
:param text: 文本内容
:return:
"""
return self.__send_data("sendKeys", text) == "true"
def send_vk(self, vk: int) -> bool:
"""
发送 vk
:param vk: 虚拟键值
:return:
虚拟键值按键对照表 https://blog.csdn.net/yaoyaozaiye/article/details/122826340
"""
return self.__send_data("sendVk", vk) == "true"
def write_android_file(self, remote_path: str, text: str, append: bool) -> bool:
"""
写入安卓文件
:param remote_path: 安卓文件路径
:param text: 要写入的文本内容
:param append: 是否追加模式
:return:
"""
if not remote_path.endswith(".txt"):
raise TypeError("文件必须是.txt后缀结尾")
if not remote_path.startswith("/storage/emulated/0/"):
remote_path = "/storage/emulated/0/" + remote_path
return self.__send_data("writeAndroidFile", remote_path, text, append) == "true"
def read_android_file(self, remote_path: str) -> Optional[str]:
"""
读取安卓文件
:param remote_path: 安卓文件路径
:return:
"""
if not remote_path.startswith("/storage/emulated/0/"):
remote_path = "/storage/emulated/0/" + remote_path
response = self.__send_data("readAndroidFile", remote_path)
if response == "null":
return None
return response
def delete_android_file(self, remote_path: str) -> bool:
"""
删除安卓文件
:param remote_path: 安卓文件路径
:return:
"""
if not remote_path.startswith("/storage/emulated/0/"):
remote_path = "/storage/emulated/0/" + remote_path
return self.__send_data("deleteAndroidFile", remote_path) == "true"
def exists_android_file(self, remote_path: str) -> bool:
"""
安卓文件是否存在
:param remote_path: 安卓文件路径
:return:
"""
if not remote_path.startswith("/storage/emulated/0/"):
remote_path = "/storage/emulated/0/" + remote_path
return self.__send_data("existsAndroidFile", remote_path) == "true"
def back(self) -> bool:
"""
返回
:return:
"""
return self.__send_data("back") == "true"
def home(self) -> bool:
"""
返回桌面
:return:
"""
return self.__send_data("home") == "true"
def recent_tasks(self) -> bool:
"""
显示最近任务
:return:
"""
return self.__send_data("recents") == "true"
def open_uri(self, uri: str) -> bool:
"""
唤起 app
:param uri: app 唤醒协议
:return:
open_uri("alipayqr://platformapi/startapp?saId=10000007")
"""
return self.__send_data("openUri", uri) == "true"
def start_activity(self, action: str, uri: str = '', package_name: str = '', class_name: str = '',
typ: str = '') -> bool:
"""
Intent 跳转
:param action: 动作,例如 "android.intent.action.VIEW"
:param uri: 跳转链接,例如:打开支付宝扫一扫界面,"alipayqr://platformapi/startapp?saId=10000007"
:param package_name: 包名,"com.xxx.xxxxx"
:param class_name: 类名
:param typ: 类型
:return: True或者 False
"""
return self.__send_data("startActivity", action, uri, package_name, class_name, typ) == "true"
def call_phone(self, mobile: str) -> bool:
"""
拨打电话
:param mobile: 手机号码
:return:
"""
return self.__send_data("callPhone", mobile) == "true"
def send_msg(self, mobile, text) -> bool:
"""
发送短信
:param mobile: 手机号码
:param text: 短信内容
:return:
"""
return self.__send_data("sendMsg", mobile, text) == "true"
def get_activity(self) -> str:
"""
获取活动页
:return:
"""
return self.__send_data("getActivity")
def get_package(self) -> str:
"""
获取包名
:return:
"""
return self.__send_data("getPackage")
def set_clipboard_text(self, text: str) -> bool:
"""
设置剪切板文本
:param text:
:return:
"""
return self.__send_data("setClipboardText", text) == "true"
def get_clipboard_text(self) -> str:
"""
获取剪切板内容
:return:
"""
return self.__send_data("getClipboardText")
# ##############
# 控件与参数 #
# ##############
def create_text_view(self, _id: int, text: str, x: int, y: int, width: int = 400, height: int = 60):
"""
创建文本框控件
:param _id: 控件ID,不可与其他控件重复
:param text: 控件文本
:param x: 控件在屏幕上x坐标
:param y: 控件在屏幕上y坐标
:param width: 控件宽度,默认 400
:param height: 控件高度,默认 60
:return:
"""
return self.__send_data("createTextView", _id, text, x, y, width, height)
def create_edit_view(self, _id: int, text: str, x: int, y: int, width: int = 400, height: int = 150):
"""
创建编辑框控件
:param _id: 控件ID,不可与其他控件重复
:param text: 控件文本
:param x: 控件在屏幕上x坐标
:param y: 控件在屏幕上y坐标
:param width: 控件宽度,默认 400
:param height: 控件高度,默认 150
:return:
"""
return self.__send_data("createEditText", _id, text, x, y, width, height)
def create_check_box(self, _id: int, text: str, x: int, y: int, width: int = 400, height: int = 60):
"""
创建复选框控件
:param _id: 控件ID,不可与其他控件重复
:param text: 控件文本
:param x: 控件在屏幕上x坐标
:param y: 控件在屏幕上y坐标
:param width: 控件宽度,默认 400
:param height: 控件高度,默认 60
:return:
"""
return self.__send_data("createCheckBox", _id, text, x, y, width, height)
def create_web_view(self, _id: int, url: str, x: int = -1, y: int = -1, width: int = -1, height: int = -1) -> bool:
"""
创建WebView控件
:param _id: 控件ID,不可与其他控件重复
:param url: 加载的链接
:param x: 控件在屏幕上 x 坐标,值为 -1 时自动填充宽高
:param y: 控件在屏幕上 y 坐标,值为 -1 时自动填充宽高
:param width: 控件宽度,值为 -1 时自动填充宽高
:param height: 控件高度,值为 -1 时自动填充宽高
:return:
"""
return self.__send_data("createWebView", _id, url, x, y, width, height) == "true"
def clear_script_widget(self) -> bool:
"""
清除脚本控件
:return:
"""
return self.__send_data("clearScriptControl") == "true"
def get_script_params(self) -> Optional[dict]:
"""
获取脚本参数
:return:
"""
response = self.__send_data("getScriptParam")
if response == "null":
return None
try:
params = json.loads(response)
except Exception as e:
self.show_toast(f"获取脚本参数异常: {e}")
self.log.error(f"获取脚本参数异常: {e}")
raise e
return params
# ##########
# 验证码 #
############
def get_captcha(self, file_path: str, username: str, password: str, soft_id: str, code_type: str,
len_min: str = '0') -> Optional[dict]:
"""
识别验证码
:param file_path: 图片文件路径
:param username: 用户名
:param password: 密码
:param soft_id: 软件ID
:param code_type: 图片类型 参考 https://www.chaojiying.com/price.html
:param len_min: 最小位数 默认0为不启用,图片类型为可变位长时可启用这个参数
:return: JSON
err_no,(数值) 返回代码 为0 表示正常,错误代码 参考 https://www.chaojiying.com/api-23.html
err_str,(字符串) 中文描述的返回信息
pic_id,(字符串) 图片标识号,或图片id号
pic_str,(字符串) 识别出的结果
md5,(字符串) md5校验值,用来校验此条数据返回是否真实有效
"""
if not file_path.startswith("/storage/emulated/0/"):
file_path = "/storage/emulated/0/" + file_path
response = self.__send_data("getCaptcha", file_path, username, password, soft_id, code_type, len_min)
return json.loads(response)
def error_captcha(self, username: str, password: str, soft_id: str, pic_id: str) -> Optional[dict]:
"""
识别报错返分
:param username: 用户名
:param password: 密码
:param soft_id: 软件ID
:param pic_id: 图片ID 对应 getCaptcha返回值的pic_id 字段
:return: JSON
err_no,(数值) 返回代码
err_str,(字符串) 中文描述的返回信息
"""
response = self.__send_data("errorCaptcha", username, password, soft_id, pic_id)
return json.loads(response)
def score_captcha(self, username: str, password: str) -> Optional[dict]:
"""
查询验证码剩余题分
:param username: 用户名
:param password: 密码
:return: JSON
err_no,(数值) 返回代码
err_str,(字符串) 中文描述的返回信息
tifen,(数值) 题分
tifen_lock,(数值) 锁定题分
"""
response = self.__send_data("scoreCaptcha", username, password)
return json.loads(response)
# ##########
# 其他 #
############
def handle(self) -> None:
# 设置阻塞模式
# self.request.setblocking(False)
# 设置缓冲区
# self.request.setsockopt(socket.SOL_SOCKET, socket.SO_RCVBUF, 65535)
self.request.setsockopt(socket.SOL_SOCKET, socket.SO_SNDBUF, 1024 * 1024) # 发送缓冲区 10M
# 执行脚本
self.script_main()
@abc.abstractmethod
def script_main(self):
"""脚本入口,由子类重写
"""
@classmethod
def execute(cls, listen_port: int, multi: int = 1):
"""
多线程启动 Socket 服务,执行脚本
:return:
"""
if listen_port < 0 or listen_port > 65535:
raise OSError("`listen_port` must be in 0-65535.")
if multi < 1:
raise ValueError("`multi` must be >= 1.")
# 获取 IPv4 可用地址
address_info = \
socket.getaddrinfo(None, listen_port, socket.AF_INET, socket.SOCK_STREAM, 0, socket.AI_PASSIVE)[0]
*_, socket_address = address_info
# 启动 Socket 服务
sock = _ThreadingTCPServer(socket_address, cls, bind_and_activate=True)
sock.request_queue_size = int(getattr(cls, "request_queue_size", 5))
print("启动服务...")
print("等待设备连接...")
sock.serve_forever()
|
AiBot.py
|
/AiBot.py-1.3.0-py3-none-any.whl/AiBot/_AndroidBot.py
|
_AndroidBot.py
|
import abc
import json
import random
import socket
import socketserver
import subprocess
import sys
import threading
from typing import Optional, Tuple, Any, Literal
from loguru import logger
from ._utils import _protect, Point, _Point_Tuple
class _ThreadingTCPServer(socketserver.ThreadingTCPServer):
daemon_threads = True
allow_reuse_address = True
class WebBotMain(socketserver.BaseRequestHandler, metaclass=_protect("handle", "execute")):
raise_err = False
wait_timeout = 3 # seconds
interval_timeout = 0.5 # seconds
log_path = ""
log_level = "INFO"
log_format = "<green>{time:YYYY-MM-DD HH:mm:ss.SSS}</green> | " \
"<level>{level: <8}</level> | " \
"{thread.name: <8} | " \
"<cyan>{module}.{function}:{line}</cyan> | " \
"<level>{message}</level>" # 日志内容
def __init__(self, request, client_address, server):
self._lock = threading.Lock()
self.log = logger
self.log.remove()
self.log.add(sys.stdout, level=self.log_level.upper(), format=self.log_format)
if self.log_path:
self.log.add(self.log_path, level=self.log_level.upper(), format=self.log_format,
rotation='5 MB', retention='2 days')
super().__init__(request, client_address, server)
def __send_data(self, *args) -> str:
args_len = ""
args_text = ""
for argv in args:
if argv is None:
argv = ""
elif isinstance(argv, bool) and argv:
argv = "true"
elif isinstance(argv, bool) and not argv:
argv = "false"
argv = str(argv)
args_text += argv
args_len += str(len(bytes(argv, 'utf8'))) + "/"
data = (args_len.strip("/") + "\n" + args_text).encode("utf8")
try:
with self._lock:
self.log.debug(rf"->>> {data}")
self.request.sendall(data)
response = self.request.recv(65535)
if response == b"":
raise ConnectionAbortedError(f"{self.client_address[0]}:{self.client_address[1]} 客户端断开链接。")
data_length, data = response.split(b"/", 1)
while int(data_length) > len(data):
data += self.request.recv(65535)
self.log.debug(rf"<<<- {data}")
return data.decode("utf8").strip()
except Exception as e:
self.log.error("send/read tcp data error: " + str(e))
raise e
#############
# 页面和导航 #
#############
def goto(self, url: str) -> bool:
"""
跳转页面
:param url: url 地址
:return:
"""
return self.__send_data("goto", url) == "true"
def new_page(self, url: str) -> bool:
"""
新建 Tab 并跳转页面
:param url: url 地址
:return:
"""
return self.__send_data("newPage", url) == "true"
def back(self) -> bool:
"""
后退
:return:
"""
return self.__send_data("back") == "true"
def forward(self) -> bool:
"""
前进
:return:
"""
return self.__send_data("forward") == "true"
def refresh(self) -> bool:
"""
刷新
:return:
"""
return self.__send_data("refresh") == "true"
def save_screenshot(self, xpath: str = None) -> Optional[str]:
"""
截图,返回 PNG 格式的 base64
:param xpath: 元素路径,如果指定该参数则截取元素图片;
:return: PNG 格式的 base64 的字符串或 None
"""
if xpath is None:
response = self.__send_data("takeScreenshot")
else:
response = self.__send_data("takeScreenshot", xpath)
if response == "null":
return None
return response
def get_current_page_id(self) -> Optional[str]:
"""
获取当前页面 ID
:return:
"""
response = self.__send_data("getCurPageId")
if response == "null":
return None
return response
def get_all_page_id(self) -> list:
"""
获取所有页面 ID
:return:
"""
response = self.__send_data("getAllPageId")
if response == "null":
return []
return response.split("|")
def switch_to_page(self, page_id: str) -> bool:
"""
切换到指定页面
:param page_id: page id
:return:
"""
return self.__send_data("switchPage", page_id) == "true"
def close_current_page(self) -> bool:
"""
关闭当前页面
:return:
"""
return self.__send_data("closePage") == "true"
def get_current_url(self) -> Optional[str]:
"""
获取当前页面 URL
:return: 当前页面 URL 字符串或 None
"""
response = self.__send_data("getCurrentUrl")
if response == "webdriver error":
return None
return response
def get_current_title(self) -> Optional[str]:
"""
获取当前页面标题
:return:
"""
response = self.__send_data("getTitle")
if response == "webdriver error":
return None
return response
###############
# iframe 操作 #
###############
def switch_to_frame(self, xpath) -> bool:
"""
切换到指定 frame
:param xpath: xpath 路径
:return:
"""
return self.__send_data("switchFrame", xpath) == "true"
def switch_to_main_frame(self) -> bool:
"""
切回主 frame
:return:
"""
return self.__send_data("switchMainFrame") == "true"
###########
# 元素操作 #
###########
def click_element(self, xpath: str) -> bool:
"""
点击元素
:param xpath: xpath 路径
:return:
"""
return self.__send_data("clickElement", xpath) == "true"
def get_element_text(self, xpath: str) -> Optional[str]:
"""
获取元素文本
:param xpath: xpath 路径
:return: 元素文本字符串或 None
"""
response = self.__send_data("getElementText", xpath)
if response == "null":
return None
return response
def get_element_rect(self, xpath: str) -> Optional[Tuple[Point, Point]]:
"""
获取元素矩形坐标
:param xpath: xpath 路径
:return: 元素矩形坐标或None
"""
response = self.__send_data("getElementRect", xpath)
if response == "null":
return None
rect: dict = json.loads(response)
return (Point(x=float(rect.get("left")), y=float(rect.get("top"))),
Point(x=float(rect.get("right")), y=float(rect.get("bottom"))))
def get_element_attr(self, xpath: str, attr_name: str) -> Optional[str]:
"""
获取元素的属性
:param xpath: xpath 路径
:param attr_name: 属性名称字符串
:return:
"""
response = self.__send_data("getElementAttribute", xpath, attr_name)
if response == "null":
return None
return response
def get_element_outer_html(self, xpath: str) -> Optional[str]:
"""
获取元素的 outerHtml
:param xpath: xpath 路径
:return:
"""
response = self.__send_data("getElementOuterHTML", xpath)
if response == "null":
return None
return response
def get_element_inner_html(self, xpath: str) -> Optional[str]:
"""
获取元素的 innerHtml
:param xpath: xpath 路径
:return:
"""
response = self.__send_data("getElementInnerHTML", xpath)
if response == "null":
return None
return response
def is_selected(self, xpath: str) -> bool:
"""
元素是否已选中
:param xpath: xpath 路径
:return:
"""
return self.__send_data("isSelected", xpath) == "true"
def is_displayed(self, xpath: str) -> bool:
"""
元素是否可见
:param xpath: xpath 路径
:return:
"""
return self.__send_data("isDisplayed", xpath) == "true"
def is_available(self, xpath: str) -> bool:
"""
元素是否可用
:param xpath: xpath 路径
:return:
"""
return self.__send_data("isEnabled", xpath) == "true"
def clear_element(self, xpath: str) -> bool:
"""
清除元素值
:param xpath: xpath 路径
:return:
"""
return self.__send_data("clearElement", xpath) == "true"
def set_element_focus(self, xpath: str) -> bool:
"""
设置元素焦点
:param xpath: xpath 路径
:return:
"""
return self.__send_data("setElementFocus", xpath) == "true"
def upload_file_by_element(self, xpath: str, file_path: str) -> bool:
"""
通过元素上传文件
:param xpath: 元素 xpath 路径
:param file_path: 文件路径
:return:
"""
return self.__send_data("uploadFile", xpath, file_path) == "true"
def send_keys(self, xpath: str, value: str) -> bool:
"""
输入值;如果元素不能设置焦点,应先 click_mouse 点击元素获得焦点后再输入
:param xpath: 元素 xpath 路径
:param value: 输入的内容
:return:
"""
return self.__send_data("sendKeys", xpath, value) == "true"
def set_element_value(self, xpath: str, value: str) -> bool:
"""
设置元素值
:param xpath: 元素 xpath 路径
:param value: 设置的内容
:return:
"""
return self.__send_data("setElementValue", xpath, value) == "true"
def set_element_attr(self, xpath: str, attr_name: str, attr_value: str) -> bool:
"""
设置元素属性
:param xpath: 元素 xpath 路径
:param attr_name: 属性名称
:param attr_value: 属性值
:return:
"""
return self.__send_data("setElementAttribute", xpath, attr_name, attr_value) == "true"
def send_vk(self, vk: str) -> bool:
"""
输入值
:param vk: 输入内容
:return:
"""
return self.__send_data("sendKeys", vk) == "true"
###########
# 键鼠操作 #
###########
def click_mouse(self, point: _Point_Tuple, typ: int) -> bool:
"""
点击鼠标
:param point: 坐标点
:param typ: 点击类型,单击左键:1 单击右键:2 按下左键:3 弹起左键:4 按下右键:5 弹起右键:6 双击左键:7
:return:
"""
return self.__send_data("clickMouse", point[0], point[1], typ) == "true"
def move_mouse(self, point: _Point_Tuple) -> bool:
"""
移动鼠标
:param point: 坐标点
:return:
"""
return self.__send_data("moveMouse", point[0], point[1]) == "true"
def scroll_mouse(self, offset_x: float, offset_y: float, x: float = 0, y: float = 0) -> bool:
"""
滚动鼠标
:param offset_x: 水平滚动条移动的距离
:param offset_y: 垂直滚动条移动的距离
:param x: 鼠标横坐标位置, 默认为0
:param y: 鼠标纵坐标位置, 默认为0
:return:
"""
return self.__send_data("wheelMouse", offset_x, offset_y, x, y) == "true"
def click_mouse_by_element(self, xpath: str, typ: int) -> bool:
"""
根据元素位置点击鼠标(元素中心点)
:param xpath: 元素 xpath 路径
:param typ: 点击类型,单击左键:1 单击右键:2 按下左键:3 弹起左键:4 按下右键:5 弹起右键:6 双击左键:7
:return:
"""
return self.__send_data("clickMouseByXpath", xpath, typ) == "true"
def move_to_element(self, xpath: str) -> bool:
"""
移动鼠标到元素位置(元素中心点)
:param xpath: 元素 xpath 路径
:return:
"""
return self.__send_data("moveMouseByXpath", xpath) == "true"
def scroll_mouse_by_element(self, xpath: str, offset_x: float, offset_y: float) -> bool:
"""
根据元素位置滚动鼠标
:param xpath: 元素路径
:param offset_x: 水平滚动条移动的距离
:param offset_y: 垂直滚动条移动的距离
:return:
"""
return self.__send_data("wheelMouseByXpath", xpath, offset_x, offset_y) == "true"
#############
# Alert #
#############
def click_alert(self, accept: bool, prompt_text: str = "") -> bool:
"""
点击警告框
:param accept: 确认或取消
:param prompt_text: 可选参数,输入的警告框文本
:return:
"""
return self.__send_data("clickAlert", accept, prompt_text) == "true"
def get_alert_text(self) -> Optional[str]:
"""
获取警告框文本
:return: 警告框文本字符串
"""
response = self.__send_data("getAlertText")
if response == "null":
return None
return response
###############
# 窗口操作 #
###############
def get_window_pos(self) -> Optional[dict]:
"""
获取窗口位置和状态
:return: 返回窗口左上角坐标点,宽度和高度,状态
"""
response = self.__send_data("getWindowPos")
if response == "null":
return None
resp: dict = json.loads(response)
return {
"pos": Point(x=float(resp.get("left")), y=float(resp.get("top"))),
"size": {"width": float(resp.get("width")), "height": float(resp.get("height"))},
"status": resp.get("windowState")
}
def set_window_pos(self, left: float, top: float, width: float, height: float, status) -> bool:
"""
设置窗口位置和状态
:param left: 窗口 x 坐标
:param top: 窗口 y 坐标
:param width: 宽度
:param height: 高度
:param status: 状态
:return:
"""
return self.__send_data("setWindowPos", status, left, top, width, height) == "true"
def mobile_emulation(self, width: int, height: int, ua: str, _sys: Literal["Android", "iOS"], sys_version: str,
lang: str = "", tz: str = "", latitude: float = 0, longitude: float = 0,
accuracy: float = 0) -> bool:
"""
模拟移动端浏览器
:param width: 宽度
:param height: 高度
:param ua: 用户代理
:param _sys: 系统
:param sys_version: 系统版本
:param lang: 语言
:param tz: 时区
:param latitude: 纬度
:param longitude: 经度
:param accuracy: 准确度
:return:
"""
return self.__send_data("mobileEmulation", width, height, ua, _sys, sys_version, lang, tz, latitude, longitude,
accuracy) == "true"
###############
# Cookies #
###############
def get_cookies(self, url: str) -> Optional[list]:
"""
获取指定 url 的 Cookies
:param url: url 字符串
:return:
"""
response = self.__send_data("getCookies", url)
if response == "null":
return None
return json.loads(response)
def get_all_cookies(self) -> Optional[list]:
"""
获取所有的 Cookies
:return: 列表格式的 cookies
"""
response = self.__send_data("getAllCookies")
if response == "null":
return None
return json.loads(response)
def set_cookies(self, url: str, name: str, value: str, options: dict = None) -> bool:
"""
设置指定 url 的 Cookies
:param url: 要设置 Cookie 的域
:param name: Cookie 名
:param value: Cookie 值
:param options: 其他属性
:return:
"""
default_options = {
"domain": "",
"path": "",
"secure": False,
"httpOnly": False,
"sameSite": "",
"expires": 0,
"priority": "",
"sameParty": False,
"sourceScheme": "",
"sourcePort": 0,
"partitionKey": "",
}
if options:
default_options.update(options)
return self.__send_data("setCookie", name, value, url, *default_options.values()) == "true"
def delete_cookies(self, name: str, url: str = "", domain: str = "", path: str = "") -> bool:
"""
删除指定 Cookie
:param name: 要删除的 Cookie 的名称
:param url: 删除所有匹配 url 和 name 的 Cookie
:param domain: 删除所有匹配 domain 和 name 的 Cookie
:param path: 删除所有匹配 path 和 name 的 Cookie
:return:
"""
return self.__send_data("deleteCookies", name, url, domain, path) == "true"
def delete_all_cookies(self) -> bool:
"""
删除所有 Cookie
:return:
"""
return self.__send_data("deleteAllCookies") == "true"
def clear_cache(self) -> bool:
"""
清除缓存
:return:
"""
return self.__send_data("clearCache") == "true"
##############
# JS 注入 #
##############
def execute_script(self, script: str) -> Optional[Any]:
"""
注入执行 JS
:param script: 要执行的 JS 代码
:return: 假如注入代码有返回值,则返回此值,否则返回 None;
Examples:
>>> result = execute_script('(()=>"aibote rpa")()')
>>> print(result)
"aibote rpa"
"""
response = self.__send_data("executeScript", script)
if response == "null":
return None
return response
#################
# 浏览器操作 #
#################
def quit(self) -> bool:
"""
退出浏览器
:return:
"""
return self.__send_data("closeBrowser") == "true"
#################
# 驱动程序相关 #
#################
def get_extend_param(self) -> Optional[str]:
"""
获取WebDriver.exe 命令扩展参数
:return: WebDriver 驱动程序的命令行["extendParam"] 字段的参数
"""
return self.__send_data("getExtendParam")
def close_driver(self) -> bool:
"""
关闭WebDriver.exe驱动程序
:return:
"""
self.__send_data("closeDriver")
return
############
# 其他 #
############
def handle(self) -> None:
# 设置阻塞模式
# self.request.setblocking(False)
# 设置缓冲区
# self.request.setsockopt(socket.SOL_SOCKET, socket.SO_RCVBUF, 65535)
self.request.setsockopt(socket.SOL_SOCKET, socket.SO_SNDBUF, 1024 * 1024) # 发送缓冲区 10M
# 执行脚本
self.script_main()
@abc.abstractmethod
def script_main(self):
"""脚本入口,由子类重写
"""
@classmethod
def execute(cls, listen_port: int, local: bool = True, driver_params: dict = None):
"""
多线程启动 Socket 服务
:param listen_port: 脚本监听的端口
:param local: 脚本是否部署在本地
:param driver_params: Web 驱动启动参数
:return:
"""
if listen_port < 0 or listen_port > 65535:
raise OSError("`listen_port` must be in 0-65535.")
print("启动服务...")
# 获取 IPv4 可用地址
address_info = socket.getaddrinfo(None, listen_port, socket.AF_INET, socket.SOCK_STREAM, 0, socket.AI_PASSIVE)[
0]
*_, socket_address = address_info
# 如果是本地部署,则自动启动 WebDriver.exe
if local:
default_params = {
"serverIp": "127.0.0.1",
"serverPort": listen_port,
"browserName": "chrome",
"debugPort": 0,
"userDataDir": f"./UserData{random.randint(100000, 999999)}",
"browserPath": None,
"argument": None,
}
if driver_params:
default_params.update(driver_params)
default_params = json.dumps(default_params)
try:
print("尝试本地启动 WebDriver ...")
subprocess.Popen(["WebDriver.exe", default_params])
print("本地启动 WebDriver 成功,开始执行脚本")
except FileNotFoundError as e:
err_msg = "\n异常排除步骤:\n1. 检查 Aibote.exe 路径是否存在中文;\n2. 是否启动 Aibote.exe 初始化环境变量;\n3. 检查电脑环境变量是否初始化成功,环境变量中是否存在 %Aibote% 开头的;\n4. 首次初始化环境变量后,是否重启开发工具;\n5. 是否以管理员权限启动开发工具;\n"
print("\033[92m", err_msg, "\033[0m")
raise e
else:
print("等待驱动连接...")
# 启动 Socket 服务
sock = _ThreadingTCPServer(socket_address, cls, bind_and_activate=True)
sock.serve_forever()
|
AiBot.py
|
/AiBot.py-1.3.0-py3-none-any.whl/AiBot/_WebBot.py
|
_WebBot.py
|
import os
import signal
import threading
from multiprocessing.context import SpawnProcess
from typing import Callable
import click
from loguru import logger
def multiprocess(workers_num: int, create_process: Callable[[], SpawnProcess]) -> None:
should_exit = threading.Event()
logger.info(
"Started parent process [{}]".format(
click.style(str(os.getpid()), fg="cyan", bold=True)
)
)
for sig in (
signal.SIGINT, # Sent by Ctrl+C.
signal.SIGTERM # Sent by `kill <pid>`. Not sent on Windows.
if os.name != "nt"
else signal.SIGBREAK, # Sent by `Ctrl+Break` on Windows.
):
signal.signal(sig, lambda sig, frame: should_exit.set())
processes: list[SpawnProcess] = []
def create_child() -> SpawnProcess:
process = create_process()
processes.append(process)
process.start()
logger.info(
"Started child process [{}]".format(
click.style(str(process.pid), fg="cyan", bold=True)
)
)
return process
for _ in range(workers_num):
create_child()
while not should_exit.wait(0.5):
for idx, process in enumerate(tuple(processes)):
if process.is_alive():
continue
logger.info(
"Child process [{}] died unexpectedly".format(
click.style(str(process.pid), fg="cyan", bold=True)
)
)
del processes[idx]
create_child()
for process in processes:
if process.pid is None:
continue
if os.name == "nt":
# Windows doesn't support SIGTERM.
os.kill(process.pid, signal.CTRL_BREAK_EVENT)
else:
os.kill(process.pid, signal.SIGTERM)
for process in processes:
logger.info(
"Waiting for child process [{}] to terminate".format(
click.style(str(process.pid), fg="cyan", bold=True)
)
)
process.join()
logger.info(
"Stopped parent process [{}]".format(
click.style(str(os.getpid()), fg="cyan", bold=True)
)
)
|
AiBot.py
|
/AiBot.py-1.3.0-py3-none-any.whl/AiBot/_multiprocess.py
|
_multiprocess.py
|
import abc
import socket
import socketserver
import subprocess
import sys
import threading
import time
import re
from ast import literal_eval
from typing import Optional, List, Tuple
from loguru import logger
from ._utils import _protect, Point, _Region, _Algorithm, _SubColors
from urllib import request, parse
import json
import base64
class _ThreadingTCPServer(socketserver.ThreadingTCPServer):
daemon_threads = True
allow_reuse_address = True
class WinBotMain(socketserver.BaseRequestHandler, metaclass=_protect("handle", "execute")):
raise_err = False
wait_timeout = 3 # seconds
interval_timeout = 0.5 # seconds
log_path = ""
log_level = "INFO"
log_format = "<green>{time:YYYY-MM-DD HH:mm:ss.SSS}</green> | " \
"<level>{level: <8}</level> | " \
"{thread.name: <8} | " \
"<cyan>{module}.{function}:{line}</cyan> | " \
"<level>{message}</level>" # 日志内容
def __init__(self, request, client_address, server):
self._lock = threading.Lock()
self.log = logger
self.log.remove()
self.log.add(sys.stdout, level=self.log_level.upper(), format=self.log_format)
if self.log_path:
self.log.add(self.log_path, level=self.log_level.upper(), format=self.log_format,
rotation='5 MB', retention='2 days')
super().__init__(request, client_address, server)
def __send_data(self, *args) -> str:
args_len = ""
args_text = ""
for argv in args:
if argv is None:
argv = ""
elif isinstance(argv, bool) and argv:
argv = "true"
elif isinstance(argv, bool) and not argv:
argv = "false"
argv = str(argv)
args_text += argv
args_len += str(len(bytes(argv, 'utf8'))) + "/"
data = (args_len.strip("/") + "\n" + args_text).encode("utf8")
try:
with self._lock:
self.log.debug(rf"->-> {data}")
self.request.sendall(data)
response = self.request.recv(65535)
if response == b"":
raise ConnectionAbortedError(f"{self.client_address[0]}:{self.client_address[1]} 客户端断开链接。")
data_length, data = response.split(b"/", 1)
while int(data_length) > len(data):
data += self.request.recv(65535)
self.log.debug(rf"<-<- {data}")
return data.decode("utf8").strip()
except Exception as e:
self.log.error("send/read tcp data error: " + str(e))
raise e
# #############
# 窗口操作 #
# #############
def find_window(self, class_name: str = None, window_name: str = None) -> Optional[str]:
"""
查找窗口句柄,仅查找顶级窗口,不包含子窗口
:param class_name: 窗口类名
:param window_name: 窗口名
:return:
"""
response = self.__send_data("findWindow", class_name, window_name)
if response == "null":
return None
return response
def find_windows(self, class_name: str = None, window_name: str = None) -> List[str]:
"""
查找窗口句柄数组,仅查找顶级窗口,不包含子窗口
class_name 和 window_name 都为 None,则返回所有窗口句柄
:param class_name: 窗口类名
:param window_name: 窗口名
:return: 窗口句柄的列表
"""
response = self.__send_data("findWindows", class_name, window_name)
if response == "null":
return []
return response.split("|")
def find_sub_window(self, hwnd: str, class_name: str = None, window_name: str = None) -> Optional[str]:
"""
查找子窗口句柄
:param hwnd: 当前窗口句柄
:param class_name: 窗口类名
:param window_name: 窗口名
:return: 子窗口句柄或 None
"""
response = self.__send_data("findSubWindow", hwnd, class_name, window_name)
if response == "null":
return None
return response
def find_parent_window(self, hwnd: str) -> Optional[str]:
"""
查找父窗口句柄
:param hwnd: 当前窗口句柄
:return: 父窗口句柄或 None
"""
response = self.__send_data("findParentWindow", hwnd)
if response == "null":
return None
return response
def find_desktop_window(self) -> Optional[str]:
"""
查找桌面窗口句柄
:return: 桌面窗口句柄或 None
"""
response = self.__send_data("findDesktopWindow")
if response == "null":
return None
return response
def get_window_name(self, hwnd: str) -> Optional[str]:
"""
获取窗口名称
:param hwnd: 当前窗口句柄
:return: 窗口名称或 None
"""
response = self.__send_data("getWindowName", hwnd)
if response == "null":
return None
return response
def show_window(self, hwnd: str, show: bool) -> bool:
"""
显示/隐藏窗口
:param hwnd: 当前窗口句柄
:param show: 是否显示窗口
:return:
"""
return self.__send_data("showWindow", hwnd, show) == "true"
def set_window_top(self, hwnd: str, top: bool) -> bool:
"""
设置窗口到最顶层
:param hwnd: 当前窗口句柄
:param top: 是否置顶,True 置顶, False 取消置顶
:return:
"""
return self.__send_data("setWindowTop", hwnd, top) == "true"
def get_window_pos(self, hwnd: str, wait_time: float = None, interval_time: float = None) -> Optional[
Tuple[Point, Point]]:
"""
获取窗口位置
:param hwnd: 窗口句柄
:return:
"""
if wait_time is None:
wait_time = self.wait_timeout
if interval_time is None:
interval_time = self.interval_timeout
end_time = time.time() + wait_time
while time.time() < end_time:
response = self.__send_data("getWindowPos", hwnd)
if response == "-1|-1|-1|-1":
time.sleep(interval_time)
continue
else:
x1, y1, x2, y2 = response.split("|")
return Point(x=float(x1), y=float(y1)), Point(x=float(x2), y=float(y2))
# 超时
return None
def set_window_pos(self, hwnd: str, left: float, top: float, width: float, height: float) -> bool:
"""
设置窗口位置
:param hwnd: 当前窗口句柄
:param left: 左上角横坐标
:param top: 左上角纵坐标
:param width: 窗口宽度
:param height: 窗口高度
:return:
"""
return self.__send_data("setWindowPos", hwnd, left, top, width, height) == "true"
# #############
# 键鼠操作 #
# #############
def move_mouse(self, hwnd: str, x: float, y: float, mode: bool = False, ele_hwnd: str = "0") -> bool:
"""
移动鼠标
:param hwnd: 当前窗口句柄
:param x: 横坐标
:param y: 纵坐标
:param mode: 操作模式,后台 true,前台 false, 默认前台操作
:param ele_hwnd: 元素句柄,如果 mode=True 且目标控件有单独的句柄,则需要通过 get_element_window 获得元素句柄,指定 ele_hwnd 的值(极少应用窗口由父窗口响应消息,则无需指定);
:return:
"""
return self.__send_data("moveMouse", hwnd, x, y, mode, ele_hwnd) == "true"
def move_mouse_relative(self, hwnd: str, x: float, y: float, mode: bool = False) -> bool:
"""
移动鼠标(相对坐标)
:param hwnd: 当前窗口句柄
:param x: 相对横坐标
:param y: 相对纵坐标
:param mode: 操作模式,后台 true,前台 false, 默认前台操作
:return:
"""
return self.__send_data("moveMouseRelative", hwnd, x, y, mode) == "true"
def scroll_mouse(self, hwnd: str, x: float, y: float, count: int, mode: bool = False) -> bool:
"""
滚动鼠标
:param hwnd: 当前窗口句柄
:param x: 横坐标
:param y: 纵坐标
:param count: 鼠标滚动次数, 负数下滚鼠标, 正数上滚鼠标
:param mode: 操作模式,后台 true,前台 false, 默认前台操作
:return:
"""
return self.__send_data("rollMouse", hwnd, x, y, count, mode) == "true"
def click_mouse(self, hwnd: str, x: float, y: float, typ: int, mode: bool = False, ele_hwnd: str = "0") -> bool:
"""
鼠标点击
:param hwnd: 当前窗口句柄
:param x: 横坐标
:param y: 纵坐标
:param typ: 点击类型,单击左键:1 单击右键:2 按下左键:3 弹起左键:4 按下右键:5 弹起右键:6 双击左键:7 双击右键:8
:param mode: 操作模式,后台 true,前台 false, 默认前台操作
:param ele_hwnd: 元素句柄,如果 mode=True 且目标控件有单独的句柄,则需要通过 get_element_window 获得元素句柄,指定 ele_hwnd 的值(极少应用窗口由父窗口响应消息,则无需指定);
:return:
"""
return self.__send_data("clickMouse", hwnd, x, y, typ, mode, ele_hwnd) == "true"
def send_keys(self, text: str) -> bool:
"""
输入文本
:param text: 输入的文本
:return:
"""
return self.__send_data("sendKeys", text) == "true"
def send_keys_by_hwnd(self, hwnd: str, text: str) -> bool:
"""
后台输入文本(杀毒软件可能会拦截)
:param hwnd: 窗口句柄
:param text: 输入的文本
:return:
"""
return self.__send_data("sendKeysByHwnd", hwnd, text) == "true"
def send_vk(self, vk: int, typ: int) -> bool:
"""
输入虚拟键值(VK)
:param vk: VK键值
:param typ: 输入类型,按下弹起:1 按下:2 弹起:3
:return:
"""
return self.__send_data("sendVk", vk, typ) == "true"
def send_vk_by_hwnd(self, hwnd: str, vk: int, typ: int) -> bool:
"""
后台输入虚拟键值(VK)
:param hwnd: 窗口句柄
:param vk: VK键值
:param typ: 输入类型,按下弹起:1 按下:2 弹起:3
:return:
"""
return self.__send_data("sendVkByHwnd", hwnd, vk, typ) == "true"
# #############
# 图色操作 #
# #############
def save_screenshot(self, hwnd: str, save_path: str, region: _Region = None, algorithm: _Algorithm = None,
mode: bool = False) -> bool:
"""
截图
:param hwnd: 窗口句柄
:param save_path: 图片存储路径
:param region: 截图区域,默认全屏,``region = (起点x、起点y、终点x、终点y)``,得到一个矩形
:param algorithm:
处理截图所用算法和参数,默认保存原图,
``algorithm = (algorithm_type, threshold, max_val)``
按元素顺序分别代表:
0. ``algorithm_type`` 算法类型
1. ``threshold`` 阈值
2. ``max_val`` 最大值
``threshold`` 和 ``max_val`` 同为 255 时灰度处理.
``algorithm_type`` 算法类型说明:
0. ``THRESH_BINARY`` 算法,当前点值大于阈值 `threshold` 时,取最大值 ``max_val``,否则设置为 0;
1. ``THRESH_BINARY_INV`` 算法,当前点值大于阈值 `threshold` 时,设置为 0,否则设置为最大值 max_val;
2. ``THRESH_TOZERO`` 算法,当前点值大于阈值 `threshold` 时,不改变,否则设置为 0;
3. ``THRESH_TOZERO_INV`` 算法,当前点值大于阈值 ``threshold`` 时,设置为 0,否则不改变;
4. ``THRESH_TRUNC`` 算法,当前点值大于阈值 ``threshold`` 时,设置为阈值 ``threshold``,否则不改变;
5. ``ADAPTIVE_THRESH_MEAN_C`` 算法,自适应阈值;
6. ``ADAPTIVE_THRESH_GAUSSIAN_C`` 算法,自适应阈值;
:param mode: 操作模式,后台 true,前台 false, 默认前台操作
:return:
"""
if not region:
region = [0, 0, 0, 0]
if not algorithm:
algorithm_type, threshold, max_val = [0, 0, 0]
else:
algorithm_type, threshold, max_val = algorithm
if algorithm_type in (5, 6):
threshold = 127
max_val = 255
return self.__send_data("saveScreenshot", hwnd, save_path, *region, algorithm_type, threshold, max_val,
mode) == "true"
def get_color(self, hwnd: str, x: float, y: float, mode: bool = False) -> Optional[str]:
"""
获取指定坐标点的色值,返回色值字符串(#008577)或者 None
:param hwnd: 窗口句柄;
:param x: x 坐标;
:param y: y 坐标;
:param mode: 操作模式,后台 true,前台 false, 默认前台操作;
:return:
"""
response = self.__send_data("getColor", hwnd, x, y, mode)
if response == "null":
return None
return response
def find_color(self, hwnd: str, color: str, sub_colors: _SubColors = None, region: _Region = None,
similarity: float = 0.9, mode: bool = False, wait_time: float = None,
interval_time: float = None):
"""
获取指定色值的坐标点,返回坐标或者 None
:param hwnd: 窗口句柄;
:param color: 颜色字符串,必须以 # 开头,例如:#008577;
:param sub_colors: 辅助定位的其他颜色;
:param region: 在指定区域内找色,默认全屏;
:param similarity: 相似度,0-1 的浮点数,默认 0.9;
:param mode: 操作模式,后台 true,前台 false, 默认前台操作;
:param wait_time: 等待时间,默认取 self.wait_timeout;
:param interval_time: 轮询间隔时间,默认取 self.interval_timeout;
:return:
.. seealso::
:meth:`save_screenshot`: ``region`` 和 ``algorithm`` 的参数说明
"""
if wait_time is None:
wait_time = self.wait_timeout
if interval_time is None:
interval_time = self.interval_timeout
if not region:
region = [0, 0, 0, 0]
if sub_colors:
sub_colors_str = ""
for sub_color in sub_colors:
offset_x, offset_y, color_str = sub_color
sub_colors_str += f"{offset_x}/{offset_y}/{color_str}\n"
# 去除最后一个 \n
sub_colors_str = sub_colors_str.strip()
else:
sub_colors_str = "null"
end_time = time.time() + wait_time
while time.time() < end_time:
response = self.__send_data("findColor", hwnd, color, sub_colors_str, *region, similarity, mode)
# 找色失败
if response == "-1.0|-1.0":
time.sleep(interval_time)
else:
# 找色成功
x, y = response.split("|")
return Point(x=float(x), y=float(y))
# 超时
return None
def compare_color(self,
hwnd: str,
main_x: float,
main_y: float,
color: str,
sub_colors: _SubColors = None,
region: _Region = None,
similarity: float = 0.9,
mode: bool = False,
wait_time: float = None,
interval_time: float = None,
raise_err: bool = None) -> Optional[Point]:
"""
比较指定坐标点的颜色值
:param hwnd: 窗口句柄;
:param main_x: 主颜色所在的X坐标;
:param main_y: 主颜色所在的Y坐标;
:param color: 颜色字符串,必须以 # 开头,例如:#008577;
:param sub_colors: 辅助定位的其他颜色;
:param region: 截图区域,默认全屏,``region = (起点x、起点y、终点x、终点y)``,得到一个矩形
:param similarity: 相似度,0-1 的浮点数,默认 0.9;
:param mode: 操作模式,后台 true,前台 false, 默认前台操作;
:param wait_time: 等待时间,默认取 self.wait_timeout;
:param interval_time: 轮询间隔时间,默认取 self.interval_timeout;
:param raise_err: 超时是否抛出异常;
:return: True或者 False
"""
if wait_time is None:
wait_time = self.wait_timeout
if interval_time is None:
interval_time = self.interval_timeout
if raise_err is None:
raise_err = self.raise_err
if not region:
region = [0, 0, 0, 0]
if sub_colors:
sub_colors_str = ""
for sub_color in sub_colors:
offset_x, offset_y, color_str = sub_color
sub_colors_str += f"{offset_x}/{offset_y}/{color_str}\n"
# 去除最后一个 \n
sub_colors_str = sub_colors_str.strip()
else:
sub_colors_str = "null"
end_time = time.time() + wait_time
while time.time() < end_time:
return self.__send_data("compareColor", hwnd, main_x, main_y, color, sub_colors_str, *region, similarity,
mode) == "true"
# 超时
if raise_err:
raise TimeoutError("`compare_color` 操作超时")
return None
def extract_image_by_video(self, video_path: str, save_folder: str, jump_frame: int = 1) -> bool:
"""
提取视频帧
:param video_path: 视频路径
:param save_folder: 提取的图片保存的文件夹目录
:param jump_frame: 跳帧,默认为1 不跳帧
:return: True或者False
"""
return self.__send_data("extractImageByVideo", video_path, save_folder, jump_frame) == "true"
def crop_image(self, image_path, save_path, left, top, rigth, bottom) -> bool:
"""
裁剪图片
:param image_path: 图片路径
:param save_path: 裁剪后保存的图片路径
:param left: 裁剪的左上角横坐标
:param top: 裁剪的左上角纵坐标
:param rigth: 裁剪的右下角横坐标
:param bottom: 裁剪的右下角纵坐标
:return: True或者False
"""
return self.__send_data("cropImage", image_path, save_path, left, top, rigth, bottom) == "true"
def find_images(self, hwnd: str, image_path: str, region: _Region = None, algorithm: _Algorithm = None,
similarity: float = 0.9, mode: bool = False, multi: int = 1, wait_time: float = None,
interval_time: float = None) -> List[Point]:
"""
寻找图片坐标,在当前屏幕中寻找给定图片中心点的坐标,返回坐标列表
:param hwnd: 窗口句柄;
:param image_path: 图片的绝对路径;
:param region: 从指定区域中找图,默认全屏;
:param algorithm: 处理屏幕截图所用的算法,默认原图,注意:给定图片处理时所用的算法,应该和此方法的算法一致;
:param similarity: 相似度,0-1 的浮点数,默认 0.9;
:param mode: 操作模式,后台 true,前台 false, 默认前台操作;
:param multi: 返回图片数量,默认1张;
:param wait_time: 等待时间,默认取 self.wait_timeout;
:param interval_time: 轮询间隔时间,默认取 self.interval_timeout;
:return:
.. seealso::
:meth:`save_screenshot`: ``region`` 和 ``algorithm`` 的参数说明
"""
if wait_time is None:
wait_time = self.wait_timeout
if interval_time is None:
interval_time = self.interval_timeout
if not region:
region = [0, 0, 0, 0]
if not algorithm:
algorithm_type, threshold, max_val = [0, 0, 0]
else:
algorithm_type, threshold, max_val = algorithm
if algorithm_type in (5, 6):
threshold = 127
max_val = 255
end_time = time.time() + wait_time
while time.time() < end_time:
response = self.__send_data("findImage", hwnd, image_path, *region, similarity, algorithm_type,
threshold, max_val, multi, mode)
# 找图失败
if response in ["-1.0|-1.0", "-1|-1"]:
time.sleep(interval_time)
continue
else:
# 找图成功,返回图片左上角坐标
# 分割出多个图片的坐标
image_points = response.split("/")
point_list = []
for point_str in image_points:
x, y = point_str.split("|")
point_list.append(Point(x=float(x), y=float(y)))
return point_list
# 超时
return []
def find_dynamic_image(self, hwnd: str, interval_ti: int, region: _Region = None, mode: bool = False,
wait_time: float = None, interval_time: float = None) -> List[Point]:
"""
找动态图,对比同一张图在不同时刻是否发生变化,返回坐标列表
:param hwnd: 窗口句柄;
:param interval_ti: 前后时刻的间隔时间,单位毫秒;
:param region: 在指定区域找图,默认全屏;
:param mode: 操作模式,后台 true,前台 false, 默认前台操作;
:param wait_time: 等待时间,默认取 self.wait_timeout;
:param interval_time: 轮询间隔时间,默认取 self.interval_timeout;
:return:
.. seealso::
:meth:`save_screenshot`: ``region`` 的参数说明
"""
if wait_time is None:
wait_time = self.wait_timeout
if interval_time is None:
interval_time = self.interval_timeout
if not region:
region = [0, 0, 0, 0]
end_time = time.time() + wait_time
while time.time() < end_time:
response = self.__send_data("findAnimation", hwnd, interval_ti, *region, mode)
# 找图失败
if response == "-1.0|-1.0":
time.sleep(interval_time)
continue
else:
# 找图成功,返回图片左上角坐标
# 分割出多个图片的坐标
image_points = response.split("/")
point_list = []
for point_str in image_points:
x, y = point_str.split("|")
point_list.append(Point(x=float(x), y=float(y)))
return point_list
# 超时
return []
# ##############
# OCR 相关 #
# ##############
@staticmethod
def __parse_ocr(text: str) -> list:
"""
解析 OCR 识别出出来的信息
:param text:
:return:
"""
# pattern = re.compile(r'(\[\[\[).+?(\)])')
# matches = pattern.finditer(text)
#
# text_info_list = []
# for match in matches:
# result_str = match.group()
# text_info = literal_eval(result_str)
# text_info_list.append(text_info)
return literal_eval(text)
def __ocr_server(self, hwnd: str, region: _Region = None, algorithm: _Algorithm = None, mode: bool = False) -> list:
"""
OCR 服务,通过 OCR 识别屏幕中文字
:param hwnd:
:param region:
:param algorithm:
:param mode:
:return:
"""
if not region:
region = [0, 0, 0, 0]
if not algorithm:
algorithm_type, threshold, max_val = [0, 0, 0]
else:
algorithm_type, threshold, max_val = algorithm
if algorithm_type in (5, 6):
threshold = 127
max_val = 255
response = self.__send_data("ocr", hwnd, *region, algorithm_type, threshold, max_val, mode)
if response == "null" or response == "":
return []
return self.__parse_ocr(response)
def __ocr_server_by_file(self, image_path: str, region: _Region = None, algorithm: _Algorithm = None) -> list:
"""
OCR 服务,通过 OCR 识别屏幕中文字
:param image_path:
:param region:
:param algorithm:
:return:
"""
if not region:
region = [0, 0, 0, 0]
if not algorithm:
algorithm_type, threshold, max_val = [0, 0, 0]
else:
algorithm_type, threshold, max_val = algorithm
if algorithm_type in (5, 6):
threshold = 127
max_val = 255
response = self.__send_data("ocrByFile", image_path, *region, algorithm_type, threshold, max_val)
if response == "null" or response == "":
return []
return self.__parse_ocr(response)
def init_ocr_server(self, ip: str, port: int = 9752) -> bool:
"""
初始化 OCR 服务
:param ip:
:param port:
:return:
"""
return self.__send_data("initOcr", ip, port) == "true"
def get_text(self, hwnd_or_image_path: str, region: _Region = None, algorithm: _Algorithm = None,
mode: bool = False) -> List[str]:
"""
通过 OCR 识别窗口/图片中的文字,返回文字列表
:param hwnd_or_image_path: 窗口句柄或者图片路径;
:param region: 识别区域,默认全屏;
:param algorithm: 处理图片/屏幕所用算法和参数,默认保存原图;
:param mode: 操作模式,后台 true,前台 false, 默认前台操作;
:return:
.. seealso::
:meth:`save_screenshot`: ``region`` 和 ``algorithm`` 的参数说明
"""
if hwnd_or_image_path.isdigit():
# 句柄
text_info_list = self.__ocr_server(hwnd_or_image_path, region, algorithm, mode)
else:
# 图片
text_info_list = self.__ocr_server_by_file(hwnd_or_image_path, region, algorithm)
text_list = []
for text_info in text_info_list:
text = text_info[-1][0]
text_list.append(text)
return text_list
def find_text(self, hwnd_or_image_path: str, text: str, region: _Region = None, algorithm: _Algorithm = None,
mode: bool = False) -> List[Point]:
"""
通过 OCR 识别窗口/图片中的文字,返回文字列表
:param hwnd_or_image_path: 句柄或者图片路径
:param text: 要查找的文字
:param region: 识别区域,默认全屏
:param algorithm: 处理图片/屏幕所用算法和参数,默认保存原图
:param mode: 操作模式,后台 true,前台 false, 默认前台操作
:return: 文字列表
.. seealso::
:meth:`save_screenshot`: ``region`` 和 ``algorithm`` 的参数说明
"""
if not region:
region = [0, 0, 0, 0]
if hwnd_or_image_path.isdigit():
# 句柄
text_info_list = self.__ocr_server(hwnd_or_image_path, region, algorithm, mode)
else:
# 图片
text_info_list = self.__ocr_server_by_file(hwnd_or_image_path, region, algorithm)
text_points = []
for text_info in text_info_list:
if text in text_info[-1][0]:
points, words_tuple = text_info
left, _, right, _ = points
# 文本区域起点坐标
start_x = left[0]
start_y = left[1]
# 文本区域终点坐标
end_x = right[0]
end_y = right[1]
# 文本区域中心点据左上角的偏移量
# 可能指定文本只是部分文本,要计算出实际位置(x轴)
width = end_x - start_x
height = end_y - start_y
words: str = words_tuple[0]
# 单字符宽度
single_word_width = width / len(words)
# 文本在整体文本的起始位置
pos = words.find(text)
offset_x = single_word_width * (pos + len(text) / 2)
offset_y = height / 2
# 计算文本区域中心坐标
text_point = Point(
x=float(region[0] + start_x + offset_x),
y=float(region[1] + start_y + offset_y),
)
text_points.append(text_point)
return text_points
# ##############
# 元素操作 #
# ##############
def get_element_name(self, hwnd: str, xpath: str, wait_time: float = None, interval_time: float = None) \
-> Optional[str]:
"""
获取元素名称
:param hwnd: 窗口句柄
:param xpath: 元素路径
:param wait_time: 等待时间,默认取 self.wait_timeout;
:param interval_time: 轮询间隔时间,默认取 self.interval_timeout;
:return: 元素名称字符串或 None
"""
if wait_time is None:
wait_time = self.wait_timeout
if interval_time is None:
interval_time = self.interval_timeout
end_time = time.time() + wait_time
while time.time() < end_time:
response = self.__send_data("getElementName", hwnd, xpath)
if response == "null":
time.sleep(interval_time)
continue
else:
return response
# 超时
return None
def get_element_value(self, hwnd: str, xpath: str, wait_time: float = None, interval_time: float = None) \
-> Optional[str]:
"""
获取元素文本
:param hwnd: 窗口句柄
:param xpath: 元素路径
:param wait_time: 等待时间,默认取 self.wait_timeout;
:param interval_time: 轮询间隔时间,默认取 self.interval_timeout;
:return: 元素文本字符串或 None
"""
if wait_time is None:
wait_time = self.wait_timeout
if interval_time is None:
interval_time = self.interval_timeout
end_time = time.time() + wait_time
while time.time() < end_time:
response = self.__send_data("getElementValue", hwnd, xpath)
if response == "null":
time.sleep(interval_time)
continue
else:
return response
# 超时
return None
def get_element_rect(self, hwnd: str, xpath: str, wait_time: float = None, interval_time: float = None) \
-> Optional[Tuple[Point, Point]]:
"""
获取元素矩形,返回左上和右下坐标
:param hwnd: 窗口句柄
:param xpath: 元素路径
:param wait_time: 等待时间,默认取 self.wait_timeout;
:param interval_time: 轮询间隔时间,默认取 self.interval_timeout;
:return: 左上和右下坐标
:rtype: Optional[Tuple[Point, Point]]
"""
if wait_time is None:
wait_time = self.wait_timeout
if interval_time is None:
interval_time = self.interval_timeout
end_time = time.time() + wait_time
while time.time() < end_time:
response = self.__send_data("getElementRect", hwnd, xpath)
if response == "-1|-1|-1|-1":
time.sleep(interval_time)
continue
else:
x1, y1, x2, y2 = response.split("|")
return Point(x=float(x1), y=float(y1)), Point(x=float(x2), y=float(y2))
# 超时
return None
def get_element_window(self, hwnd: str, xpath: str, wait_time: float = None, interval_time: float = None) \
-> Optional[str]:
"""
获取元素窗口句柄
:param hwnd: 窗口句柄
:param xpath: 元素路径
:param wait_time: 等待时间,默认取 self.wait_timeout;
:param interval_time: 轮询间隔时间,默认取 self.interval_timeout;
:return: 元素窗口句柄字符串或 None
"""
if wait_time is None:
wait_time = self.wait_timeout
if interval_time is None:
interval_time = self.interval_timeout
end_time = time.time() + wait_time
while time.time() < end_time:
response = self.__send_data("getElementWindow", hwnd, xpath)
if response == "null":
time.sleep(interval_time)
continue
else:
return response
# 超时
return None
def click_element(self, hwnd: str, xpath: str, typ: int, wait_time: float = None,
interval_time: float = None) -> bool:
"""
点击元素
:param hwnd: 窗口句柄
:param xpath: 元素路径
:param typ: 操作类型,单击左键:1 单击右键:2 按下左键:3 弹起左键:4 按下右键:5 弹起右键:6 双击左键:7 双击右键:8
:param wait_time: 等待时间,默认取 self.wait_timeout;
:param interval_time: 轮询间隔时间,默认取 self.interval_timeout;
:return:
"""
if wait_time is None:
wait_time = self.wait_timeout
if interval_time is None:
interval_time = self.interval_timeout
end_time = time.time() + wait_time
while time.time() < end_time:
response = self.__send_data('clickElement', hwnd, xpath, typ)
if response == "false":
time.sleep(interval_time)
continue
else:
return True
# 超时
return False
def invoke_element(self, hwnd: str, xpath: str, wait_time: float = None,
interval_time: float = None) -> bool:
"""
执行元素默认操作(一般是点击操作)
:param hwnd: 窗口句柄
:param xpath: 元素路径
:param wait_time: 等待时间,默认取 self.wait_timeout;
:param interval_time: 轮询间隔时间,默认取 self.interval_timeout;
:return:
"""
if wait_time is None:
wait_time = self.wait_timeout
if interval_time is None:
interval_time = self.interval_timeout
end_time = time.time() + wait_time
while time.time() < end_time:
response = self.__send_data('invokeElement', hwnd, xpath)
if response == "false":
time.sleep(interval_time)
continue
else:
return True
# 超时
return False
def set_element_focus(self, hwnd: str, xpath: str, wait_time: float = None,
interval_time: float = None) -> bool:
"""
设置元素作为焦点
:param hwnd: 窗口句柄
:param xpath: 元素路径
:param wait_time: 等待时间,默认取 self.wait_timeout;
:param interval_time: 轮询间隔时间,默认取 self.interval_timeout;
:return:
"""
if wait_time is None:
wait_time = self.wait_timeout
if interval_time is None:
interval_time = self.interval_timeout
end_time = time.time() + wait_time
while time.time() < end_time:
response = self.__send_data('setElementFocus', hwnd, xpath)
if response == "false":
time.sleep(interval_time)
continue
else:
return True
# 超时
return False
def set_element_value(self, hwnd: str, xpath: str, value: str,
wait_time: float = None, interval_time: float = None) -> bool:
"""
设置元素文本
:param hwnd: 窗口句柄
:param xpath: 元素路径
:param value: 要设置的内容
:param wait_time: 等待时间,默认取 self.wait_timeout;
:param interval_time: 轮询间隔时间,默认取 self.interval_timeout;
:return:
"""
if wait_time is None:
wait_time = self.wait_timeout
if interval_time is None:
interval_time = self.interval_timeout
end_time = time.time() + wait_time
while time.time() < end_time:
response = self.__send_data('setElementValue', hwnd, xpath, value)
if response == "false":
time.sleep(interval_time)
continue
else:
return True
# 超时
return False
def scroll_element(self, hwnd: str, xpath: str, horizontal: int, vertical: int,
wait_time: float = None, interval_time: float = None) -> bool:
"""
滚动元素
:param hwnd: 窗口句柄
:param xpath: 元素路径
:param horizontal: 水平百分比 -1不滚动
:param vertical: 垂直百分比 -1不滚动
:param wait_time: 等待时间,默认取 self.wait_timeout;
:param interval_time: 轮询间隔时间,默认取 self.interval_timeout;
:return:
"""
if wait_time is None:
wait_time = self.wait_timeout
if interval_time is None:
interval_time = self.interval_timeout
end_time = time.time() + wait_time
while time.time() < end_time:
response = self.__send_data('setElementScroll', hwnd, xpath, horizontal, vertical)
if response == "false":
time.sleep(interval_time)
continue
else:
return True
# 超时
return False
def is_selected(self, hwnd: str, xpath: str,
wait_time: float = None, interval_time: float = None) -> bool:
"""
单/复选框是否选中
:param hwnd: 窗口句柄
:param xpath: 元素路径
:param wait_time: 等待时间,默认取 self.wait_timeout;
:param interval_time: 轮询间隔时间,默认取 self.interval_timeout;
:return:
"""
if wait_time is None:
wait_time = self.wait_timeout
if interval_time is None:
interval_time = self.interval_timeout
end_time = time.time() + wait_time
while time.time() < end_time:
response = self.__send_data('isSelected', hwnd, xpath)
if response == "false":
time.sleep(interval_time)
continue
else:
return True
# 超时
return False
def close_window(self, hwnd: str, xpath: str) -> bool:
"""
关闭窗口
:param hwnd: 窗口句柄
:param xpath: 元素路径
:return:
"""
return self.__send_data('closeWindow', hwnd, xpath) == 'true'
def set_element_state(self, hwnd: str, xpath: str, state: str) -> bool:
"""
设置窗口状态
:param hwnd: 窗口句柄
:param xpath: 元素路径
:param state: 0正常 1最大化 2 最小化
:return:
"""
return self.__send_data('setWindowState', hwnd, xpath, state) == 'true'
# ###############
# 系统剪切板 #
# ###############
def set_clipboard_text(self, text: str) -> bool:
"""
设置剪切板内容
:param text: 要设置的内容
:return:
"""
return self.__send_data("setClipboardText", text) == 'true'
def get_clipboard_text(self) -> str:
"""
设置剪切板内容
:return:
"""
return self.__send_data("getClipboardText")
# #############
# 启动进程 #
# #############
def start_process(self, cmd: str, show_window=True, is_wait=False) -> bool:
"""
执行cmd命令
:param cmd: 命令
:param show_window: 是否显示窗口,默认显示
:param is_wait: 是否等待程序结束, 默认不等待
:return:
"""
return self.__send_data("startProcess", cmd, show_window, is_wait) == "true"
def execute_command(self, command: str, waitTimeout: int = 300) -> str:
"""
执行cmd命令
:param command: cmd命令,不能含 "cmd"字串
:param waitTimeout: 可选参数,等待结果返回超时,单位毫秒,默认300毫秒
:return: cmd执行结果
"""
return self.__send_data("executeCommand", command, waitTimeout)
def download_file(self, url: str, file_path: str, is_wait: bool) -> bool:
"""
下载文件
:param url: 文件地址
:param file_path: 文件保存的路径
:param is_wait: 是否等待下载完成
:return:
"""
return self.__send_data("downloadFile", url, file_path, is_wait) == "true"
# #############
# EXCEL操作 #
# #############
def open_excel(self, excel_path: str) -> Optional[dict]:
"""
打开excel文档
:param excel_path: excle路径
:return: excel对象或者None
"""
response = self.__send_data("openExcel", excel_path)
if response == "null":
return None
return json.loads(response)
def open_excel_sheet(self, excel_object: dict, sheet_name: str) -> Optional[dict]:
"""
打开excel表格
:param excel_object: excel对象
:param sheet_name: 表名
:return: sheet对象或者None
"""
response = self.__send_data("openExcelSheet", excel_object['book'], excel_object['path'], sheet_name)
if response == "null":
return None
return response
def save_excel(self, excel_object: dict) -> bool:
"""
保存excel文档
:param excel_object: excel对象
:return: True或者False
"""
return self.__send_data("saveExcel", excel_object['book'], excel_object['path']) == "true"
def write_excel_num(self, excel_object: dict, row: int, col: int, value: int) -> bool:
"""
写入数字到excel表格
:param excel_object: excel对象
:param row: 行
:param col: 列
:param value: 写入的值
:return: True或者False
"""
return self.__send_data("writeExcelNum", excel_object, row, col, value) == "true"
def write_excel_str(self, excel_object: dict, row: int, col: int, str_value: str) -> bool:
"""
写入字符串到excel表格
:param excel_object: excel对象
:param row: 行
:param col: 列
:param str_value: 写入的值
:return: True或者False
"""
return self.__send_data("writeExcelStr", excel_object, row, col, str_value) == "true"
def read_excel_num(self, excel_object: dict, row: int, col: int) -> int:
"""
读取excel表格数字
:param excel_object: excel对象
:param row: 行
:param col: 列
:return: 读取到的数字
"""
response = self.__send_data("readExcelNum", excel_object, row, col)
return float(response)
def read_excel_str(self, excel_object: dict, row: int, col: int) -> str:
"""
读取excel表格字符串
:param excel_object: excel对象
:param row: 行
:param col: 列
:return: 读取到的字符
"""
return self.__send_data("readExcelStr", excel_object, row, col)
def remove_excel_row(self, excel_object: dict, row_first: int, row_last: int) -> bool:
"""
删除excel表格行
:param excel_object: excel对象
:param row_first: 起始行
:param row_last: 结束行
:return: True或者False
"""
return self.__send_data("removeExcelRow", excel_object, row_first, row_last) == "true"
def remove_excel_col(self, excel_object: dict, col_first: int, col_last: int) -> bool:
"""
删除excel表格列
:param excel_object: excel对象
:param col_first: 起始列
:param col_last: 结束列
:return: True或者False
"""
return self.__send_data("removeExcelCol", excel_object, col_first, col_last) == "true"
# ##########
# 验证码 #
############
def get_captcha(self, file_path: str, username: str, password: str, soft_id: str, code_type: str,
len_min: str = '0') -> Optional[dict]:
"""
识别验证码
:param file_path: 图片文件路径
:param username: 用户名
:param password: 密码
:param soft_id: 软件ID
:param code_type: 图片类型 参考https://www.chaojiying.com/price.html
:param len_min: 最小位数 默认0为不启用,图片类型为可变位长时可启用这个参数
:return: JSON
err_no,(数值) 返回代码 为0 表示正常,错误代码 参考https://www.chaojiying.com/api-23.html
err_str,(字符串) 中文描述的返回信息
pic_id,(字符串) 图片标识号,或图片id号
pic_str,(字符串) 识别出的结果
md5,(字符串) md5校验值,用来校验此条数据返回是否真实有效
"""
file = open(file_path, mode="rb")
file_data = file.read()
file_base64 = base64.b64encode(file_data)
file.close()
url = "http://upload.chaojiying.net/Upload/Processing.php"
data = {
'user': username,
'pass': password,
'softid': soft_id,
'codetype': code_type,
'len_min': len_min,
'file_base64': file_base64
}
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.8; rv:24.0) Gecko/20100101 Firefox/24.0',
'Content-Type': 'application/x-www-form-urlencoded'
}
parseData = parse.urlencode(data).encode('utf8')
req = request.Request(url, parseData, headers)
response = request.urlopen(req)
result = response.read().decode()
return json.loads(result)
def error_captcha(self, username: str, password: str, soft_id: str, pic_id: str) -> Optional[dict]:
"""
识别报错返分
:param username: 用户名
:param password: 密码
:param soft_id: 软件ID
:param pic_id: 图片ID 对应 getCaptcha返回值的pic_id 字段
:return: JSON
err_no,(数值) 返回代码
err_str,(字符串) 中文描述的返回信息
"""
url = "http://upload.chaojiying.net/Upload/ReportError.php"
data = {
'user': username,
'pass': password,
'softid': soft_id,
'id': pic_id,
}
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.8; rv:24.0) Gecko/20100101 Firefox/24.0',
'Content-Type': 'application/x-www-form-urlencoded'
}
parseData = parse.urlencode(data).encode('utf8')
req = request.Request(url, parseData, headers)
response = request.urlopen(req)
result = response.read().decode()
return json.loads(result)
def score_captcha(self, username: str, password: str) -> Optional[dict]:
"""
查询验证码剩余题分
:param username: 用户名
:param password: 密码
:return: JSON
err_no,(数值) 返回代码
err_str,(字符串) 中文描述的返回信息
tifen,(数值) 题分
tifen_lock,(数值) 锁定题分
"""
url = "http://upload.chaojiying.net/Upload/GetScore.php"
data = {
'user': username,
'pass': password,
}
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.8; rv:24.0) Gecko/20100101 Firefox/24.0',
'Content-Type': 'application/x-www-form-urlencoded'
}
parseData = parse.urlencode(data).encode('utf8')
req = request.Request(url, parseData, headers)
response = request.urlopen(req)
result = response.read().decode()
return json.loads(result)
# #############
# 语音服务 #
# #############
def activate_speech_service(self, activate_key: str) -> bool:
"""
激活 initSpeechService (不支持win7)
:param activate_key: 激活密钥,联系管理员
:return: True或者False
"""
return self.__send_data("activateSpeechService", activate_key) == "true"
def init_speech_service(self, speech_key: str, speech_region: str) -> bool:
"""
初始化语音服务(不支持win7),需要调用 activateSpeechService 激活
:param speech_key: 密钥
:param speech_region: 区域
:return: True或者False
"""
return self.__send_data("initSpeechService", speech_key, speech_region) == "true"
def audio_file_to_text(self, file_path, language: str) -> Optional[str]:
"""
音频文件转文本
:param file_path: 音频文件路径
:param language: 语言,参考开发文档 语言和发音人
:return: 转换后的音频文本或者None
"""
response = self.__send_data("audioFileToText", file_path, language)
if response == "null":
return None
return response
def microphone_to_text(self, language: str) -> Optional[str]:
"""
麦克风输入流转换文本
:param language: 语言,参考开发文档 语言和发音人
:return: 转换后的音频文本或者None
"""
response = self.__send_data("microphoneToText", language)
if response == "null":
return None
return response
def text_to_bullhorn(self, ssmlPath_or_text: str, language: str, voice_name: str) -> bool:
"""
文本合成音频到扬声器
:param ssmlPath_or_text: 要转换语音的文本或者".xml"格式文件路径
:param language: 语言,参考开发文档 语言和发音人
:param voice_name: 发音人,参考开发文档 语言和发音人
:return: True或者False
"""
return self.__send_data("textToBullhorn", ssmlPath_or_text, language, voice_name) == "true"
def text_to_audio_file(self, ssmlPath_or_text: str, language: str, voice_name: str, audio_path: str) -> bool:
"""
文本合成音频并保存到文件
:param ssmlPath_or_text: 要转换语音的文本或者".xml"格式文件路径
:param language: 语言,参考开发文档 语言和发音人
:param voice_name: 发音人,参考开发文档 语言和发音人
:param audio_path: 保存音频文件路径
:return: True或者False
"""
return self.__send_data("textToAudioFile", ssmlPath_or_text, language, voice_name, audio_path) == "true"
def microphone_translation_text(self, source_language: str, target_language: str) -> Optional[str]:
"""
麦克风输入流转换文本
:param source_language: 要翻译的语言,参考开发文档 语言和发音人
:param target_language: 翻译后的语言,参考开发文档 语言和发音人
:return: 转换后的音频文本或者None
"""
response = self.__send_data("microphoneTranslationText", source_language, target_language)
if response == "null":
return None
return response
def audio_file_translation_text(self, audio_path: str, source_language: str, target_language: str) -> Optional[str]:
"""
麦克风输入流转换文本
:param audio_path: 要翻译的音频文件路径
:param source_language: 要翻译的语言,参考开发文档 语言和发音人
:param target_language: 翻译后的语言,参考开发文档 语言和发音人
:return: 转换后的音频文本或者None
"""
response = self.__send_data("audioFileTranslationText", audio_path, source_language, target_language)
if response == "null":
return None
return response
# #############
# 数字人 #
# #############
def init_metahuman(self, metahuman_mde_path: str, metahuman_scale_value: str,
is_update_metahuman: bool = False) -> bool:
"""
初始化数字人,第一次初始化需要一些时间
:param metahuman_mde_path: 数字人模型路径
:param metahuman_scale_value: 数字人缩放倍数,1为原始大小。为0.5时放大一倍,2则缩小一半
:param is_update_metahuman: 是否强制更新,默认fasle。为true时强制更新会拖慢初始化速度
:return: True或者False
"""
return self.__send_data("initMetahuman", metahuman_mde_path, metahuman_scale_value,
is_update_metahuman) == "true"
def metahuman_speech(self, save_voice_folder: str, text: str, language: str, voice_name: str,
quality: int = 0, wait_play_sound: bool = True, speech_rate: int = 0,
voice_style: str = "General") -> bool:
"""
数字人说话,此函数需要调用 initSpeechService 初始化语音服务
:param save_voice_folder: 保存的发音文件目录,文件名以0开始依次增加,扩展为.wav格式
:param text: 要转换语音的文本
:param language: 语言,参考开发文档 语言和发音人
:param voice_name: 发音人,参考开发文档 语言和发音人
:param quality: 音质,0低品质 1中品质 2高品质, 默认为0低品质
:param wait_play_sound: 等待音频播报完毕,默认为 true等待
:param speech_rate: 语速,默认为0,取值范围 -100 至 200
:param voice_style: 语音风格,默认General常规风格,其他风格参考开发文档 语言和发音人
:return: True或者False
"""
return self.__send_data("metahumanSpeech", save_voice_folder, text, language, voice_name, quality,
wait_play_sound, speech_rate, voice_style) == "true"
def metahuman_speech_cache(self, save_voice_folder: str, text: str, language: str, voice_name: str,
quality: int = 0, wait_play_sound: bool = True, speech_rate: int = 0,
voice_style: str = "General") -> bool:
"""
*数字人说话缓存模式,需要调用 initSpeechService 初始化语音服务。函数一般用于常用的话术播报,非常用话术切勿使用,否则内存泄漏
:param save_voice_folder: 保存的发音文件目录,文件名以0开始依次增加,扩展为.wav格式
:param text: 要转换语音的文本
:param language: 语言,参考开发文档 语言和发音人
:param voice_name: 发音人,参考开发文档 语言和发音人
:param quality: 音质,0低品质 1中品质 2高品质, 默认为0低品质
:param wait_play_sound: 等待音频播报完毕,默认为 true等待
:param speech_rate: 语速,默认为0,取值范围 -100 至 200
:param voice_style: 语音风格,默认General常规风格,其他风格参考开发文档 语言和发音人
:return: True或者False
"""
return self.__send_data("metahumanSpeechCache", save_voice_folder, text, language, voice_name, quality,
wait_play_sound, speech_rate, voice_style) == "true"
def metahuman_insert_video(self, video_file_path: str, audio_file_path: str, wait_play_video: bool = True) -> bool:
"""
数字人插入视频
:param video_file_path: 插入的视频文件路径
:param audio_file_path: 插入的音频文件路径
:param wait_play_video: 等待视频播放完毕,默认为 true等待
:return: True或者False
"""
return self.__send_data("metahumanInsertVideo", video_file_path, audio_file_path, wait_play_video) == "true"
def replace_background(self, bg_file_path: str, replace_red: int = -1, replace_green: int = -1,
replace_blue: int = -1, sim_value: int = 0) -> bool:
"""
替换数字人背景
:param bg_file_path: 数字人背景 图片/视频 路径,默认不替换背景。仅替换绿幕背景的数字人模型
:param replace_red: 数字人背景的三通道之一的 R通道色值。默认-1 自动提取
:param replace_green: 数字人背景的三通道之一的 G通道色值。默认-1 自动提取
:param replace_blue: 数字人背景的三通道之一的 B通道色值。默认-1 自动提取
:param sim_value: 相似度。 默认为0,取值应当大于等于0
:return: True或者False
"""
return self.__send_data("replaceBackground", bg_file_path, replace_red, replace_green, replace_blue,
sim_value) == "true"
def show_speech_text(self, origin_y: int = 0, font_type: str = "Arial", font_size: int = 30, font_red: int = 128,
font_green: int = 255, font_blue: int = 0, italic: bool = False,
underline: bool = False) -> bool:
"""
显示数字人说话的文本
:param origin_y, 第一个字显示的起始Y坐标点。 默认0 自适应高度
:param font_type, 字体样式,支持操作系统已安装的字体。例如"Arial"、"微软雅黑"、"楷体"
:param font_size, 字体的大小。默认30
:param font_red, 字体颜色三通道之一的 R通道色值。默认128
:param font_green, 字体颜色三通道之一的 G通道色值。默认255
:param font_blue, 字体颜色三通道之一的 B通道色值。默认0
:param italic, 是否斜体,默认false
:param underline, 是否有下划线,默认false
:return: True或者False
"""
return self.__send_data("showSpeechText", origin_y, font_type, font_size, font_red, font_green, font_blue,
italic, underline) == "true"
#################
# 驱动程序相关 #
#################
def get_extend_param(self) -> Optional[str]:
"""
获取WindowsDriver.exe 命令扩展参数
:return: WindowsDriver 驱动程序的命令行["extendParam"] 字段的参数
"""
return self.__send_data("getExtendParam")
def close_driver(self) -> bool:
"""
关闭WindowsDriver.exe驱动程序
:return:
"""
self.__send_data("closeDriver")
return
# ##########
# 其他 #
############
def handle(self) -> None:
# 设置阻塞模式
# self.request.setblocking(False)
# 设置缓冲区
# self.request.setsockopt(socket.SOL_SOCKET, socket.SO_RCVBUF, 65535)
self.request.setsockopt(socket.SOL_SOCKET, socket.SO_SNDBUF, 1024 * 1024) # 发送缓冲区 10M
# 执行脚本
self.script_main()
@abc.abstractmethod
def script_main(self):
"""脚本入口,由子类重写
"""
@classmethod
def execute(cls, listen_port: int, local: bool = True):
"""
多线程启动 Socket 服务
:param listen_port: 脚本监听的端口
:param local: 脚本是否部署在本地
:return:
"""
if listen_port < 0 or listen_port > 65535:
raise OSError("`listen_port` must be in 0-65535.")
print("启动服务...")
# 获取 IPv4 可用地址
address_info = socket.getaddrinfo(None, listen_port, socket.AF_INET, socket.SOCK_STREAM, 0, socket.AI_PASSIVE)[
0]
*_, socket_address = address_info
# 如果是本地部署,则自动启动 WindowsDriver.exe
if local:
try:
print("尝试本地启动 WindowsDriver ...")
subprocess.Popen(["WindowsDriver.exe", "127.0.0.1", str(listen_port)])
print("本地启动 WindowsDriver 成功,开始执行脚本")
except FileNotFoundError as e:
err_msg = "\n异常排除步骤:\n1. 检查 Aibote.exe 路径是否存在中文;\n2. 是否启动 Aibote.exe 初始化环境变量;\n3. 检查电脑环境变量是否初始化成功,环境变量中是否存在 %Aibote% 开头的;\n4. 首次初始化环境变量后,是否重启开发工具;\n5. 是否以管理员权限启动开发工具;\n"
print("\033[92m", err_msg, "\033[0m")
raise e
else:
print("等待驱动连接...")
# 启动 Socket 服务
sock = _ThreadingTCPServer(socket_address, cls, bind_and_activate=True)
sock.serve_forever()
|
AiBot.py
|
/AiBot.py-1.3.0-py3-none-any.whl/AiBot/_WinBot.py
|
_WinBot.py
|
# Project1
## Outline
This project aims to predict stock prices through the following methods
Sentiment analysis:
- Sentiment on news headlines
- Sentiment on tweets from twitter
- Sentiment on Reddit feeds
Stock prices:
- Use stock historic data to evaluate current stock prices
- Calculate the risk of a stock (how volatile a stock is)
Machine learning:
- Use machine learning techniques to further predict stock prices
## TO USE
Please add the required parameters of your pgAdmin 4 data base to the config.py file before runnning
|
AiCoreSentimentStock-scraper2021Eta
|
/AiCoreSentimentStock_scraper2021Eta-0.0.4.tar.gz/AiCoreSentimentStock_scraper2021Eta-0.0.4/README.md
|
README.md
|
from .config import settingUp
import configparser
import os.path
import getpass
def sqlCreds(DATABASE_TYPE,DBAPI,HOST,USER,PASSWORD,DATABASE,PORT):
'''
This function uses the parameters set by user to connect to PGadmin database
The purpose of this function is to get the correct parameters and credentials
from the user to connect to PGAdmin 4 sql data base via sqlalchamy engine. The
function uses the data provided by the user and creates a .ini file named sqlconfig.ini
The values for the parameters can be found on pgAdmin 4. Most of them are under properties.
Hints:
DATABASE_TYPE: Server type on pgAdmin 4 (all lower case)
DBAPI: psycopg2
HOST: Host name / address on pgAdmin 4
USER: Username on pgAdmin 4
PASSWORD: Password created by user when setting up pgAdmin 4
DATABASE: The name of the database under Databases in pgAdmin 4
PORT: Port in pgAdmin 4
Output:
.ini file contained the paremeters and credentials
'''
config = configparser.ConfigParser()
config['DEFAULT'] = {'DATABASE_TYPE': DATABASE_TYPE,
'DBAPI': DBAPI,
'HOST': HOST,
'USER': USER,
'PASSWORD': PASSWORD,
'DATABASE': DATABASE,
'PORT': PORT}
with open('sqlconfig.ini', 'w') as configfile:
config.write(configfile)
print('Welcome to stock scraper')
print('Lets begin...')
print('Checking if config file is populated')
requiredFields = []
config_parser = configparser.ConfigParser()
settingUp()
config_parser.read('sqlconfig.ini')
DATABASE_TYPE = config_parser['DEFAULT']['DATABASE_TYPE']
DBAPI = config_parser['DEFAULT']['DBAPI']
HOST = config_parser['DEFAULT']['HOST']
USER = config_parser['DEFAULT']['USER']
PASSWORD = config_parser['DEFAULT']['PASSWORD']
DATABASE = config_parser['DEFAULT']['DATABASE']
PORT = config_parser['DEFAULT']['PORT']
configValues = ['DATABASE_TYPE','DBAPI','HOST','USER','PASSWORD','DATABASE','PORT']
configParameters = [DATABASE_TYPE,DBAPI,HOST,USER,PASSWORD,DATABASE,PORT]
counter = 0
for parameters in configParameters:
if parameters=='Replace':
requiredFields.append(configValues[counter])
counter = +1
if not requiredFields:
print('Config file has been populated')
print('Starting scraper')
from .process import stockData,stockHeadlineData,sentimentData
# Declaring datatable names
dt_stockContent = "stock_content"
dt_headlines = "stock_headlines"
dt_sentiment = "stock_sentiment"
stockData(stockContent_name=dt_stockContent, updateFlag=True)
stockHeadlineData(headlineDatatable_name = dt_headlines, stockInfoDatatable_name = dt_stockContent, updateFlag = True)
sentimentData(sentimentDatatable_name=dt_sentiment, updateFlag=True, headlineDatatable_name=dt_headlines)
print('Scraping complete')
else:
print('Config file has NOT been populated')
print('PGAdmin credentials required to proceed')
credsQuestion = input('Would you like to Enter credentials now?(y/n)')
if credsQuestion == 'y':
print('Please enter the value for the following parameters')
DATABASE_TYPE = input('DATABASE_TYPE: ')
DBAPI = input('DBAPI: ')
HOST = input('HOST: ')
USER = input('USER: ')
PASSWORD = getpass.getpass('PASSWORD: ')
DATABASE = input('DATABASE: ')
PORT = input('PORT: ')
sqlCreds(DATABASE_TYPE=DATABASE_TYPE.strip(), DBAPI=DBAPI.strip(),HOST=HOST.strip(),USER=USER.strip(),PASSWORD=PASSWORD.strip(),DATABASE=DATABASE.strip(),PORT=PORT.strip())
from .process import stockData,stockHeadlineData,sentimentData
# Declaring datatable names
dt_stockContent = "stock_content"
dt_headlines = "stock_headlines"
dt_sentiment = "stock_sentiment"
stockData(stockContent_name=dt_stockContent, updateFlag=True)
stockHeadlineData(headlineDatatable_name = dt_headlines, stockInfoDatatable_name = dt_stockContent, updateFlag = True)
sentimentData(sentimentDatatable_name=dt_sentiment, updateFlag=True, headlineDatatable_name=dt_headlines)
print('Scraping complete')
else:
print('You did not select y')
print('Please populate congig.py file and re-run the code')
print('The code is now exiting...')
print('Scraping complete')
|
AiCoreSentimentStock-scraper2021Eta
|
/AiCoreSentimentStock_scraper2021Eta-0.0.4.tar.gz/AiCoreSentimentStock_scraper2021Eta-0.0.4/stock_scraper_AiCore/__main__.py
|
__main__.py
|
import pandas as pd
from bs4 import BeautifulSoup
from urllib.request import urlopen
from urllib.request import Request
import pandas as pd
from collections import defaultdict
from tqdm import tqdm
from typing import Optional
from vaderSentiment.vaderSentiment import SentimentIntensityAnalyzer
analyzer = SentimentIntensityAnalyzer()
obj = SentimentIntensityAnalyzer()
def getSnpCompanies() -> Optional[list]:
'''
This method scrapes the snp500 stocks from wikidpedia.
The purpose of this method is to retrieve data from
wikipedia as its constantly being updated.
Returns:
list: A list of ticker symbols
'''
tickers = []
table=pd.read_html('https://en.wikipedia.org/wiki/List_of_S%26P_500_companies')
snp_df = table[0]
symbol = snp_df['Symbol']
for ticker in symbol:
tickers.append(ticker)
return tickers
def getStockContent(tickers:list) -> Optional[pd.DataFrame]:
'''
This method scrapes stock info on each stock
The purpose of this method is to use the list of
snp500 stocks and scrape stock name, stock sector,
stock type, stock region ,stock info
Args:
tickers: Stock tickers of the snp500 stocks
Returns:
Pandas dataframe: A datatable of stock info in pandas format
'''
dict_name = ['ticker','stock_name','stock_sector','stock_type','stock_region','stock_info']
stock_data = {}
for i in range(len(dict_name)):
stock_data[dict_name[i]] = []
for ticker in tqdm(tickers):
if "." in ticker:
ticker = ticker.replace(".","-")
finviz_url = 'https://finviz.com/quote.ashx?t='
news_tables = {}
url = finviz_url + ticker
try:
req = Request(url=url,headers={'user-agent': 'my-app/0.0.1'})
resp = urlopen(req)
html = BeautifulSoup(resp, features="lxml")
stock_name = html.find_all('a', {'class':'tab-link'})[12].text
stock_sector= html.find_all('a', {'class':'tab-link'})[13].text
stock_type= html.find_all('a', {'class':'tab-link'})[14].text
stock_region= html.find_all('a', {'class':'tab-link'})[15].text
stock_info= html.find('td', {'class':'fullview-profile'}).text
except Exception as e:
stock_name='Unknown'
stock_sector='Unknown'
stock_type='Unknown'
stock_region='Unknown'
stock_info='Unknown'
print(e, url)
finally:
stock_value = [ticker,stock_name,stock_sector,stock_type,stock_region,stock_info]
for i in range(len(stock_value)):
stock_data[dict_name[i]].append(stock_value[i])
df = pd.DataFrame.from_dict(stock_data)
return df
def getNewsHeadlines(tickers:list) -> Optional[pd.DataFrame]:
'''
This method scrapes news headlines of the stocks in the snp500
The purpose of this method is to use the stock tickers and scrapes
the top 100 news headlines related to the stock
Args:
tickers: Stock tickers of the snp500 stocks
Returns:
Pandas dataframe: A datatable of stock info in pandas format
'''
dict_name = ['ticker','headline','date']
headline_data = {}
for i in range(len(dict_name)):
headline_data[dict_name[i]] = []
for ticker in tqdm(tickers):
if "." in ticker:
ticker = ticker.replace(".","-")
try:
finviz_url = 'https://finviz.com/quote.ashx?t='
news_tables = {}
url = finviz_url + ticker
req = Request(url=url,headers={'user-agent': 'my-app/0.0.1'})
resp = urlopen(req)
html = BeautifulSoup(resp, features="lxml")
n=100
news_tables = html.find(id='news-table')
news_tables[ticker] = news_tables
df = news_tables[ticker]
df_tr = df.findAll('tr')
for i, table_row in enumerate(df_tr):
article_headline = table_row.a.text
td_text = table_row.td.text
article_date = td_text.strip()
headline_value = [ticker,article_headline,article_date]
for i in range(len(headline_value)):
headline_data[dict_name[i]].append(headline_value[i])
if i == n-1:
break
except Exception as e:
print(e, ticker)
headline_value = [ticker,article_headline,article_date]
for i in range(len(headline_value)):
headline_data[dict_name[i]].append("unknown")
df = pd.DataFrame.from_dict(headline_data)
return df
def getTwiterData():
try:
pass
except Exception as e:
print(e)
|
AiCoreSentimentStock-scraper2021Eta
|
/AiCoreSentimentStock_scraper2021Eta-0.0.4.tar.gz/AiCoreSentimentStock_scraper2021Eta-0.0.4/stock_scraper_AiCore/stock_scraper.py
|
stock_scraper.py
|
from .stock_scraper import getSnpCompanies,getStockContent,getNewsHeadlines
from .data_base import SqlDB
import pandas as pd
from .Sentiment_analysis import sentimentAnalysis
#configuing stockscraper because it is a class
#config_stock = StockScraper()
config_sql = SqlDB()
def tableExitsCheck(table_exists:bool, table_name:str):
if table_exists == False:
raise ValueError('Data table doesnt exist... Creating one')
else:
print("Database exists")
retrieve_table = config_sql.retriveTableInfo(table_name=table_name)
return retrieve_table
def createDataTable(table_name:str, dt_contents):
create_table = config_sql.createTable(table_name=table_name, dt_contents=dt_contents)
retrieve_table = config_sql.retriveTableInfo(table_name=table_name)
print("Data table:",table_name, "Has been created")
def updateStockInfo(updateFlag:bool, retrieve_table):
if updateFlag == True:
stock_list = getSnpCompanies()
content = getStockContent(tickers=stock_list)
else:
stock_list = retrieve_table['ticker']
content = getStockContent(tickers=stock_list)
return content
def pushData(source_dt,new_dt,table_name):
fresh_dt = config_sql.getNewRows(source_dt=source_dt, new_dt=new_dt)
config_sql.appendData(table_name=table_name, dt_contents=fresh_dt)
def stockData(stockContent_name:str ,updateFlag:bool):
'''
This function is used to perform stock data activities
The purpose of this function is to create a stock info database,
retrieve the snp 500 companies from wikipedia, get
the stock name, stock industry stock sector,stock type
stock region, stock_info for each stock, and populate
the database with that data
Args:
stockContent_name: The name of the database for the stock contents
updateFlag: A flag to be used if updating stock content is required or not
'''
print("Starting stock details extraction")
stock_col = ['ticker','stock_name','stock_sector','stock_type','stock_region','stock_info']
df = pd.DataFrame(columns=stock_col)
content = df
table_exists = config_sql.tableExists(table_name=stockContent_name)
try:
tableExitsCheck(table_exists=table_exists, table_name=stockContent_name)
retrieve_table = config_sql.retriveTableInfo(table_name=stockContent_name)
except ValueError as e:
print(e)
createDataTable(table_name=stockContent_name, dt_contents=content)
retrieve_table = config_sql.retriveTableInfo(table_name=stockContent_name)
finally:
content = updateStockInfo(updateFlag=updateFlag, retrieve_table=retrieve_table)
pushData(source_dt=retrieve_table, new_dt=content, table_name=stockContent_name)
# new_dt = config_sql.getNewRows(source_dt=retrieve_table, new_dt=content)
# config_sql.appendData(table_name=stockContent_name, dt_contents=new_dt)
print("Stock details extraction complete")
def stockHeadlineData(stockInfoDatatable_name:str,updateFlag:bool,headlineDatatable_name:str):
'''
This function is used to retrieve headlines about the stock
The purpose of this function is create a database for headlines,
use the stock info database to retrieve headlines about the stock,
and populate the headlines database
Args:
stockInfoDatatable_name: The stock info database name. This gets used to retrieve headlines
updateFlag: A flag to be used if updating stock content is required or not
headlineDatatable_name: The stock headline database name
'''
print("Starting headlines extraction")
config_sql = SqlDB()
headline_col = ['ticker', 'headline', 'date']
headline_tableExists = config_sql.tableExists(table_name=headlineDatatable_name)
try:
tableExitsCheck(table_exists=headline_tableExists, table_name=headlineDatatable_name)
retrieve_table = config_sql.retriveTableInfo(table_name=headlineDatatable_name)
except ValueError as e:
print(e)
df = pd.DataFrame(columns=headline_col)
createDataTable(table_name=headlineDatatable_name, dt_contents=df)
retrieve_table = config_sql.retriveTableInfo(table_name=headlineDatatable_name)
finally:
if updateFlag == True:
retrieve_headline_table = config_sql.retriveTableInfo(table_name=headlineDatatable_name)
retrieve_stock_info = config_sql.retriveTableInfo(table_name=stockInfoDatatable_name)
dt_tickers = retrieve_stock_info['ticker'].tolist()
new_dt= getNewsHeadlines(dt_tickers)
original_dt = retrieve_headline_table
else:
retrieve_headline_table = config_sql.retriveTableInfo(table_name=headlineDatatable_name)
new_dt = retrieve_headline_table
original_dt = retrieve_headline_table
append_dt = config_sql.getNewRows(source_dt=original_dt, new_dt=new_dt)
config_sql.appendData(table_name=headlineDatatable_name, dt_contents=append_dt)
print("Headlines extraction complete")
#stockHeadlineData(stockInfoDatatable_name = 'stock_content', updateFlag=True, headlineDatatable_name='stock_headlines')
def sentimentData(sentimentDatatable_name:str ,updateFlag:bool, headlineDatatable_name:str):
'''
This function is used to perform sentiment analysis activities
The purpose of this function is to create a sentiment datatbale,
use the headlines from the headline datatable to perform sentiment
analysis and populate the sentiment datatable
Args:
sentimentDatatable_name: The name of the sentiment datatable
updateFlag: A flag to be used if updating stock content is required or not
headlineData_name: The name of the headline datatable
'''
print("Starting sentiment analysis")
sentiment_col = ['date','ticker','headline','sentiment']
content = pd.DataFrame(columns=sentiment_col)
sentiment_tableExists = config_sql.tableExists(table_name=sentimentDatatable_name)
try:
if sentiment_tableExists == False:
raise ValueError('Data table doesnt exist... Creating one')
else:
retrieve_sentiment_table = config_sql.retriveTableInfo(table_name=sentimentDatatable_name)
print("Datatable already exists")
except ValueError as e:
create_table = config_sql.createTable(table_name=sentimentDatatable_name, dt_contents=content)
retrieve_sentiment_table = config_sql.retriveTableInfo(table_name=sentimentDatatable_name)
print("Data table:",sentimentDatatable_name, "Created")
finally:
if updateFlag == True:
retrieve_headline_table = config_sql.retriveTableInfo(table_name=headlineDatatable_name)
tickersList = retrieve_headline_table['ticker'].tolist()
dt_headlines = retrieve_headline_table['headline'].tolist()
dt_date = retrieve_headline_table['date'].tolist()
new_dt=sentimentAnalysis(ticker=tickersList, headlines=dt_headlines, date=dt_date)
append_dt = config_sql.getNewRows(source_dt=retrieve_sentiment_table, new_dt=new_dt)
config_sql.appendData(table_name=sentimentDatatable_name, dt_contents=append_dt)
print("Sentiment analysis complete")
|
AiCoreSentimentStock-scraper2021Eta
|
/AiCoreSentimentStock_scraper2021Eta-0.0.4.tar.gz/AiCoreSentimentStock_scraper2021Eta-0.0.4/stock_scraper_AiCore/process.py
|
process.py
|
import psycopg2
from sqlalchemy import create_engine, engine
import pandas as pd
import os
import sqlalchemy
import configparser
from typing import Optional
from sqlalchemy import MetaData
from sqlalchemy.ext.declarative import declarative_base
class SqlDB:
'''
This class is used to perform SQL datbase activities
'''
def __init__(self):
'''
This method is used to establish the database connection
The purpose of this method is to use the sqlconfig.ini
file to create a connection with the database using the
sqlalchmy engine.
'''
config_parser = configparser.ConfigParser()
config_parser.read('sqlconfig.ini')
DATABASE_TYPE = config_parser['DEFAULT']['DATABASE_TYPE']
DBAPI = config_parser['DEFAULT']['DBAPI']
HOST = config_parser['DEFAULT']['HOST']
USER = config_parser['DEFAULT']['USER']
PASSWORD = config_parser['DEFAULT']['PASSWORD']
DATABASE = config_parser['DEFAULT']['DATABASE']
PORT = config_parser['DEFAULT']['PORT']
engine = create_engine(f"{DATABASE_TYPE}+{DBAPI}://{USER}:{PASSWORD}@{HOST}:{PORT}/{DATABASE}")
self.engine = engine
def deleteTable(self,table_name: str):
Base = declarative_base()
metadata = MetaData()
metadata.reflect(bind=self.engine)
table = metadata.tables[table_name]
if table is not None:
Base.metadata.drop_all(self.engine, [table], checkfirst=True)
def tableExists(self,table_name: str) -> Optional[bool]:
'''
This method checks if a table exists in a database.
Args:
table_name: The name of the table to check if it exits
in database
Returns:
bool: True if the table exists. False if it doesnt exist
'''
table_exists = sqlalchemy.inspect(self.engine).has_table(table_name)
return table_exists
def retriveTableInfo(self,table_name: str) -> Optional[pd.DataFrame]:
'''
This method returns the data from a table
Args:
table_name: The name of the table to check if it exits
in database
Returns:
Pandas dataframe: The data of the table in pandas format
'''
stock_db = pd.read_sql_table(table_name, self.engine)
return stock_db
def createTable(self,table_name: str,dt_contents:pd.DataFrame):
'''
This method creates a table in the database
Args:
table_name: The name of the table to check if it exits
in database
dt_contents: The data to be inserted into the table
'''
creatededDt = dt_contents.to_sql(table_name, self.engine, index=False)
def appendData(self,table_name: str,dt_contents:pd.DataFrame):
'''
This method appends data to a table in the database
Args:
table_name: The name of the table to check if it exits
in database
dt_contents: The data to be inserted into the table
'''
dt_contents.to_sql(table_name, self.engine, if_exists='append',index=False)
def getNewRows(self,source_dt: pd.DataFrame, new_dt: pd.DataFrame):
'''
This method checks if data from one datable exists in another
Args:
source_dt: The source datatable that to be checks against
new_dt: The new datatable to check
Returns:
Pandas dataframe: Datatable with data that does not exist in source_dt
'''
merged_df = source_dt.merge(new_dt, indicator=True, how='outer')
changed_rows_df = merged_df[merged_df['_merge'] == 'right_only']
return changed_rows_df.drop('_merge', axis=1)
# db = SqlDB()
# db.deleteTable(table_name='a')
|
AiCoreSentimentStock-scraper2021Eta
|
/AiCoreSentimentStock_scraper2021Eta-0.0.4.tar.gz/AiCoreSentimentStock_scraper2021Eta-0.0.4/stock_scraper_AiCore/data_base.py
|
data_base.py
|
# Project1
## Outline
This project aims to predict stock prices through the following methods
Sentiment analysis:
- Sentiment on news headlines
- Sentiment on tweets from twitter
- Sentiment on Reddit feeds
Stock prices:
- Use stock historic data to evaluate current stock prices
- Calculate the risk of a stock (how volatile a stock is)
Machine learning:
- Use machine learning techniques to further predict stock prices
## TO USE
Please add the required parameters of your pgAdmin 4 data base to the config.py file before runnning
|
AiCoreSentimentStock-scraper2021EtaCohort
|
/AiCoreSentimentStock_scraper2021EtaCohort-0.0.4.tar.gz/AiCoreSentimentStock_scraper2021EtaCohort-0.0.4/README.md
|
README.md
|
from .config import settingUp
import configparser
import os.path
import getpass
def sqlCreds(DATABASE_TYPE,DBAPI,HOST,USER,PASSWORD,DATABASE,PORT):
'''
This function uses the parameters set by user to connect to PGadmin database
The purpose of this function is to get the correct parameters and credentials
from the user to connect to PGAdmin 4 sql data base via sqlalchamy engine. The
function uses the data provided by the user and creates a .ini file named sqlconfig.ini
The values for the parameters can be found on pgAdmin 4. Most of them are under properties.
Hints:
DATABASE_TYPE: Server type on pgAdmin 4 (all lower case)
DBAPI: psycopg2
HOST: Host name / address on pgAdmin 4
USER: Username on pgAdmin 4
PASSWORD: Password created by user when setting up pgAdmin 4
DATABASE: The name of the database under Databases in pgAdmin 4
PORT: Port in pgAdmin 4
Output:
.ini file contained the paremeters and credentials
'''
config = configparser.ConfigParser()
config['DEFAULT'] = {'DATABASE_TYPE': DATABASE_TYPE,
'DBAPI': DBAPI,
'HOST': HOST,
'USER': USER,
'PASSWORD': PASSWORD,
'DATABASE': DATABASE,
'PORT': PORT}
with open('sqlconfig.ini', 'w') as configfile:
config.write(configfile)
print('Welcome to stock scraper')
print('Lets begin...')
print('Checking if config file is populated')
requiredFields = []
config_parser = configparser.ConfigParser()
settingUp()
config_parser.read('sqlconfig.ini')
DATABASE_TYPE = config_parser['DEFAULT']['DATABASE_TYPE']
DBAPI = config_parser['DEFAULT']['DBAPI']
HOST = config_parser['DEFAULT']['HOST']
USER = config_parser['DEFAULT']['USER']
PASSWORD = config_parser['DEFAULT']['PASSWORD']
DATABASE = config_parser['DEFAULT']['DATABASE']
PORT = config_parser['DEFAULT']['PORT']
configValues = ['DATABASE_TYPE','DBAPI','HOST','USER','PASSWORD','DATABASE','PORT']
configParameters = [DATABASE_TYPE,DBAPI,HOST,USER,PASSWORD,DATABASE,PORT]
counter = 0
for parameters in configParameters:
if parameters=='Replace':
requiredFields.append(configValues[counter])
counter = +1
if not requiredFields:
print('Config file has been populated')
print('Starting scraper')
from .process import stockData,stockHeadlineData,sentimentData
# Declaring datatable names
dt_stockContent = "stock_content"
dt_headlines = "stock_headlines"
dt_sentiment = "stock_sentiment"
stockData(stockContent_name=dt_stockContent, updateFlag=True)
stockHeadlineData(headlineDatatable_name = dt_headlines, stockInfoDatatable_name = dt_stockContent, updateFlag = True)
sentimentData(sentimentDatatable_name=dt_sentiment, updateFlag=True, headlineDatatable_name=dt_headlines)
print('Scraping complete')
else:
print('Config file has NOT been populated')
print('PGAdmin credentials required to proceed')
credsQuestion = input('Would you like to Enter credentials now?(y/n)')
if credsQuestion == 'y':
print('Please enter the value for the following parameters')
DATABASE_TYPE = input('DATABASE_TYPE: ')
DBAPI = input('DBAPI: ')
HOST = input('HOST: ')
USER = input('USER: ')
PASSWORD = getpass.getpass('PASSWORD: ')
DATABASE = input('DATABASE: ')
PORT = input('PORT: ')
sqlCreds(DATABASE_TYPE=DATABASE_TYPE.strip(), DBAPI=DBAPI.strip(),HOST=HOST.strip(),USER=USER.strip(),PASSWORD=PASSWORD.strip(),DATABASE=DATABASE.strip(),PORT=PORT.strip())
from .process import stockData,stockHeadlineData,sentimentData
# Declaring datatable names
dt_stockContent = "stock_content"
dt_headlines = "stock_headlines"
dt_sentiment = "stock_sentiment"
stockData(stockContent_name=dt_stockContent, updateFlag=True)
stockHeadlineData(headlineDatatable_name = dt_headlines, stockInfoDatatable_name = dt_stockContent, updateFlag = True)
sentimentData(sentimentDatatable_name=dt_sentiment, updateFlag=True, headlineDatatable_name=dt_headlines)
print('Scraping complete')
else:
print('You did not select y')
print('Please populate congig.py file and re-run the code')
print('The code is now exiting...')
print('Scraping complete')
|
AiCoreSentimentStock-scraper2021EtaCohort
|
/AiCoreSentimentStock_scraper2021EtaCohort-0.0.4.tar.gz/AiCoreSentimentStock_scraper2021EtaCohort-0.0.4/stock_scraper_AiCore/__main__.py
|
__main__.py
|
import pandas as pd
from bs4 import BeautifulSoup
from urllib.request import urlopen
from urllib.request import Request
import pandas as pd
from collections import defaultdict
from tqdm import tqdm
from typing import Optional
from vaderSentiment.vaderSentiment import SentimentIntensityAnalyzer
analyzer = SentimentIntensityAnalyzer()
obj = SentimentIntensityAnalyzer()
def getSnpCompanies() -> Optional[list]:
'''
This method scrapes the snp500 stocks from wikidpedia.
The purpose of this method is to retrieve data from
wikipedia as its constantly being updated.
Returns:
list: A list of ticker symbols
'''
tickers = []
table=pd.read_html('https://en.wikipedia.org/wiki/List_of_S%26P_500_companies')
snp_df = table[0]
symbol = snp_df['Symbol']
for ticker in symbol:
tickers.append(ticker)
return tickers
def getStockContent(tickers:list) -> Optional[pd.DataFrame]:
'''
This method scrapes stock info on each stock
The purpose of this method is to use the list of
snp500 stocks and scrape stock name, stock sector,
stock type, stock region ,stock info
Args:
tickers: Stock tickers of the snp500 stocks
Returns:
Pandas dataframe: A datatable of stock info in pandas format
'''
dict_name = ['ticker','stock_name','stock_sector','stock_type','stock_region','stock_info']
stock_data = {}
for i in range(len(dict_name)):
stock_data[dict_name[i]] = []
for ticker in tqdm(tickers):
if "." in ticker:
ticker = ticker.replace(".","-")
finviz_url = 'https://finviz.com/quote.ashx?t='
news_tables = {}
url = finviz_url + ticker
try:
req = Request(url=url,headers={'user-agent': 'my-app/0.0.1'})
resp = urlopen(req)
html = BeautifulSoup(resp, features="lxml")
stock_name = html.find_all('a', {'class':'tab-link'})[12].text
stock_sector= html.find_all('a', {'class':'tab-link'})[13].text
stock_type= html.find_all('a', {'class':'tab-link'})[14].text
stock_region= html.find_all('a', {'class':'tab-link'})[15].text
stock_info= html.find('td', {'class':'fullview-profile'}).text
except Exception as e:
stock_name='Unknown'
stock_sector='Unknown'
stock_type='Unknown'
stock_region='Unknown'
stock_info='Unknown'
print(e, url)
finally:
stock_value = [ticker,stock_name,stock_sector,stock_type,stock_region,stock_info]
for i in range(len(stock_value)):
stock_data[dict_name[i]].append(stock_value[i])
df = pd.DataFrame.from_dict(stock_data)
return df
def getNewsHeadlines(tickers:list) -> Optional[pd.DataFrame]:
'''
This method scrapes news headlines of the stocks in the snp500
The purpose of this method is to use the stock tickers and scrapes
the top 100 news headlines related to the stock
Args:
tickers: Stock tickers of the snp500 stocks
Returns:
Pandas dataframe: A datatable of stock info in pandas format
'''
dict_name = ['ticker','headline','date']
headline_data = {}
for i in range(len(dict_name)):
headline_data[dict_name[i]] = []
for ticker in tqdm(tickers):
if "." in ticker:
ticker = ticker.replace(".","-")
try:
finviz_url = 'https://finviz.com/quote.ashx?t='
news_tables = {}
url = finviz_url + ticker
req = Request(url=url,headers={'user-agent': 'my-app/0.0.1'})
resp = urlopen(req)
html = BeautifulSoup(resp, features="lxml")
n=100
news_tables = html.find(id='news-table')
news_tables[ticker] = news_tables
df = news_tables[ticker]
df_tr = df.findAll('tr')
for i, table_row in enumerate(df_tr):
article_headline = table_row.a.text
td_text = table_row.td.text
article_date = td_text.strip()
headline_value = [ticker,article_headline,article_date]
for i in range(len(headline_value)):
headline_data[dict_name[i]].append(headline_value[i])
if i == n-1:
break
except Exception as e:
print(e, ticker)
headline_value = [ticker,article_headline,article_date]
for i in range(len(headline_value)):
headline_data[dict_name[i]].append("unknown")
df = pd.DataFrame.from_dict(headline_data)
return df
def getTwiterData():
try:
pass
except Exception as e:
print(e)
|
AiCoreSentimentStock-scraper2021EtaCohort
|
/AiCoreSentimentStock_scraper2021EtaCohort-0.0.4.tar.gz/AiCoreSentimentStock_scraper2021EtaCohort-0.0.4/stock_scraper_AiCore/stock_scraper.py
|
stock_scraper.py
|
from .stock_scraper import getSnpCompanies,getStockContent,getNewsHeadlines
from .data_base import SqlDB
import pandas as pd
from .Sentiment_analysis import sentimentAnalysis
#configuing stockscraper because it is a class
#config_stock = StockScraper()
config_sql = SqlDB()
def tableExitsCheck(table_exists:bool, table_name:str):
if table_exists == False:
raise ValueError('Data table doesnt exist... Creating one')
else:
print("Database exists")
retrieve_table = config_sql.retriveTableInfo(table_name=table_name)
return retrieve_table
def createDataTable(table_name:str, dt_contents):
create_table = config_sql.createTable(table_name=table_name, dt_contents=dt_contents)
retrieve_table = config_sql.retriveTableInfo(table_name=table_name)
print("Data table:",table_name, "Has been created")
def updateStockInfo(updateFlag:bool, retrieve_table):
if updateFlag == True:
stock_list = getSnpCompanies()
content = getStockContent(tickers=stock_list)
else:
stock_list = retrieve_table['ticker']
content = getStockContent(tickers=stock_list)
return content
def pushData(source_dt,new_dt,table_name):
fresh_dt = config_sql.getNewRows(source_dt=source_dt, new_dt=new_dt)
config_sql.appendData(table_name=table_name, dt_contents=fresh_dt)
def stockData(stockContent_name:str ,updateFlag:bool):
'''
This function is used to perform stock data activities
The purpose of this function is to create a stock info database,
retrieve the snp 500 companies from wikipedia, get
the stock name, stock industry stock sector,stock type
stock region, stock_info for each stock, and populate
the database with that data
Args:
stockContent_name: The name of the database for the stock contents
updateFlag: A flag to be used if updating stock content is required or not
'''
print("Starting stock details extraction")
stock_col = ['ticker','stock_name','stock_sector','stock_type','stock_region','stock_info']
df = pd.DataFrame(columns=stock_col)
content = df
table_exists = config_sql.tableExists(table_name=stockContent_name)
try:
tableExitsCheck(table_exists=table_exists, table_name=stockContent_name)
retrieve_table = config_sql.retriveTableInfo(table_name=stockContent_name)
except ValueError as e:
print(e)
createDataTable(table_name=stockContent_name, dt_contents=content)
retrieve_table = config_sql.retriveTableInfo(table_name=stockContent_name)
finally:
content = updateStockInfo(updateFlag=updateFlag, retrieve_table=retrieve_table)
pushData(source_dt=retrieve_table, new_dt=content, table_name=stockContent_name)
# new_dt = config_sql.getNewRows(source_dt=retrieve_table, new_dt=content)
# config_sql.appendData(table_name=stockContent_name, dt_contents=new_dt)
print("Stock details extraction complete")
def stockHeadlineData(stockInfoDatatable_name:str,updateFlag:bool,headlineDatatable_name:str):
'''
This function is used to retrieve headlines about the stock
The purpose of this function is create a database for headlines,
use the stock info database to retrieve headlines about the stock,
and populate the headlines database
Args:
stockInfoDatatable_name: The stock info database name. This gets used to retrieve headlines
updateFlag: A flag to be used if updating stock content is required or not
headlineDatatable_name: The stock headline database name
'''
print("Starting headlines extraction")
config_sql = SqlDB()
headline_col = ['ticker', 'headline', 'date']
headline_tableExists = config_sql.tableExists(table_name=headlineDatatable_name)
try:
tableExitsCheck(table_exists=headline_tableExists, table_name=headlineDatatable_name)
retrieve_table = config_sql.retriveTableInfo(table_name=headlineDatatable_name)
except ValueError as e:
print(e)
df = pd.DataFrame(columns=headline_col)
createDataTable(table_name=headlineDatatable_name, dt_contents=df)
retrieve_table = config_sql.retriveTableInfo(table_name=headlineDatatable_name)
finally:
if updateFlag == True:
retrieve_headline_table = config_sql.retriveTableInfo(table_name=headlineDatatable_name)
retrieve_stock_info = config_sql.retriveTableInfo(table_name=stockInfoDatatable_name)
dt_tickers = retrieve_stock_info['ticker'].tolist()
new_dt= getNewsHeadlines(dt_tickers)
original_dt = retrieve_headline_table
else:
retrieve_headline_table = config_sql.retriveTableInfo(table_name=headlineDatatable_name)
new_dt = retrieve_headline_table
original_dt = retrieve_headline_table
append_dt = config_sql.getNewRows(source_dt=original_dt, new_dt=new_dt)
config_sql.appendData(table_name=headlineDatatable_name, dt_contents=append_dt)
print("Headlines extraction complete")
#stockHeadlineData(stockInfoDatatable_name = 'stock_content', updateFlag=True, headlineDatatable_name='stock_headlines')
def sentimentData(sentimentDatatable_name:str ,updateFlag:bool, headlineDatatable_name:str):
'''
This function is used to perform sentiment analysis activities
The purpose of this function is to create a sentiment datatbale,
use the headlines from the headline datatable to perform sentiment
analysis and populate the sentiment datatable
Args:
sentimentDatatable_name: The name of the sentiment datatable
updateFlag: A flag to be used if updating stock content is required or not
headlineData_name: The name of the headline datatable
'''
print("Starting sentiment analysis")
sentiment_col = ['date','ticker','headline','sentiment']
content = pd.DataFrame(columns=sentiment_col)
sentiment_tableExists = config_sql.tableExists(table_name=sentimentDatatable_name)
try:
if sentiment_tableExists == False:
raise ValueError('Data table doesnt exist... Creating one')
else:
retrieve_sentiment_table = config_sql.retriveTableInfo(table_name=sentimentDatatable_name)
print("Datatable already exists")
except ValueError as e:
create_table = config_sql.createTable(table_name=sentimentDatatable_name, dt_contents=content)
retrieve_sentiment_table = config_sql.retriveTableInfo(table_name=sentimentDatatable_name)
print("Data table:",sentimentDatatable_name, "Created")
finally:
if updateFlag == True:
retrieve_headline_table = config_sql.retriveTableInfo(table_name=headlineDatatable_name)
tickersList = retrieve_headline_table['ticker'].tolist()
dt_headlines = retrieve_headline_table['headline'].tolist()
dt_date = retrieve_headline_table['date'].tolist()
new_dt=sentimentAnalysis(ticker=tickersList, headlines=dt_headlines, date=dt_date)
append_dt = config_sql.getNewRows(source_dt=retrieve_sentiment_table, new_dt=new_dt)
config_sql.appendData(table_name=sentimentDatatable_name, dt_contents=append_dt)
print("Sentiment analysis complete")
|
AiCoreSentimentStock-scraper2021EtaCohort
|
/AiCoreSentimentStock_scraper2021EtaCohort-0.0.4.tar.gz/AiCoreSentimentStock_scraper2021EtaCohort-0.0.4/stock_scraper_AiCore/process.py
|
process.py
|
import psycopg2
from sqlalchemy import create_engine, engine
import pandas as pd
import os
import sqlalchemy
import configparser
from typing import Optional
from sqlalchemy import MetaData
from sqlalchemy.ext.declarative import declarative_base
class SqlDB:
'''
This class is used to perform SQL datbase activities
'''
def __init__(self):
'''
This method is used to establish the database connection
The purpose of this method is to use the sqlconfig.ini
file to create a connection with the database using the
sqlalchmy engine.
'''
config_parser = configparser.ConfigParser()
config_parser.read('sqlconfig.ini')
DATABASE_TYPE = config_parser['DEFAULT']['DATABASE_TYPE']
DBAPI = config_parser['DEFAULT']['DBAPI']
HOST = config_parser['DEFAULT']['HOST']
USER = config_parser['DEFAULT']['USER']
PASSWORD = config_parser['DEFAULT']['PASSWORD']
DATABASE = config_parser['DEFAULT']['DATABASE']
PORT = config_parser['DEFAULT']['PORT']
engine = create_engine(f"{DATABASE_TYPE}+{DBAPI}://{USER}:{PASSWORD}@{HOST}:{PORT}/{DATABASE}")
self.engine = engine
def deleteTable(self,table_name: str):
Base = declarative_base()
metadata = MetaData()
metadata.reflect(bind=self.engine)
table = metadata.tables[table_name]
if table is not None:
Base.metadata.drop_all(self.engine, [table], checkfirst=True)
def tableExists(self,table_name: str) -> Optional[bool]:
'''
This method checks if a table exists in a database.
Args:
table_name: The name of the table to check if it exits
in database
Returns:
bool: True if the table exists. False if it doesnt exist
'''
table_exists = sqlalchemy.inspect(self.engine).has_table(table_name)
return table_exists
def retriveTableInfo(self,table_name: str) -> Optional[pd.DataFrame]:
'''
This method returns the data from a table
Args:
table_name: The name of the table to check if it exits
in database
Returns:
Pandas dataframe: The data of the table in pandas format
'''
stock_db = pd.read_sql_table(table_name, self.engine)
return stock_db
def createTable(self,table_name: str,dt_contents:pd.DataFrame):
'''
This method creates a table in the database
Args:
table_name: The name of the table to check if it exits
in database
dt_contents: The data to be inserted into the table
'''
creatededDt = dt_contents.to_sql(table_name, self.engine, index=False)
def appendData(self,table_name: str,dt_contents:pd.DataFrame):
'''
This method appends data to a table in the database
Args:
table_name: The name of the table to check if it exits
in database
dt_contents: The data to be inserted into the table
'''
dt_contents.to_sql(table_name, self.engine, if_exists='append',index=False)
def getNewRows(self,source_dt: pd.DataFrame, new_dt: pd.DataFrame):
'''
This method checks if data from one datable exists in another
Args:
source_dt: The source datatable that to be checks against
new_dt: The new datatable to check
Returns:
Pandas dataframe: Datatable with data that does not exist in source_dt
'''
merged_df = source_dt.merge(new_dt, indicator=True, how='outer')
changed_rows_df = merged_df[merged_df['_merge'] == 'right_only']
return changed_rows_df.drop('_merge', axis=1)
# db = SqlDB()
# db.deleteTable(table_name='a')
|
AiCoreSentimentStock-scraper2021EtaCohort
|
/AiCoreSentimentStock_scraper2021EtaCohort-0.0.4.tar.gz/AiCoreSentimentStock_scraper2021EtaCohort-0.0.4/stock_scraper_AiCore/data_base.py
|
data_base.py
|
# Project1
## Outline
This project aims to predict stock prices through the following methods
Sentiment analysis:
- Sentiment on news headlines
- Sentiment on tweets from twitter
- Sentiment on Reddit feeds
Stock prices:
- Use stock historic data to evaluate current stock prices
- Calculate the risk of a stock (how volatile a stock is)
Machine learning:
- Use machine learning techniques to further predict stock prices
## TO USE
Please add the required parameters of your pgAdmin 4 data base to the config.py file before runnning
|
AiCoreSentimentStockScraper
|
/AiCoreSentimentStockScraper-0.0.4.tar.gz/AiCoreSentimentStockScraper-0.0.4/README.md
|
README.md
|
from .config import settingUp
import configparser
import os.path
import getpass
def sqlCreds(DATABASE_TYPE,DBAPI,HOST,USER,PASSWORD,DATABASE,PORT):
'''
This function uses the parameters set by user to connect to PGadmin database
The purpose of this function is to get the correct parameters and credentials
from the user to connect to PGAdmin 4 sql data base via sqlalchamy engine. The
function uses the data provided by the user and creates a .ini file named sqlconfig.ini
The values for the parameters can be found on pgAdmin 4. Most of them are under properties.
Hints:
DATABASE_TYPE: Server type on pgAdmin 4 (all lower case)
DBAPI: psycopg2
HOST: Host name / address on pgAdmin 4
USER: Username on pgAdmin 4
PASSWORD: Password created by user when setting up pgAdmin 4
DATABASE: The name of the database under Databases in pgAdmin 4
PORT: Port in pgAdmin 4
Output:
.ini file contained the paremeters and credentials
'''
config = configparser.ConfigParser()
config['DEFAULT'] = {'DATABASE_TYPE': DATABASE_TYPE,
'DBAPI': DBAPI,
'HOST': HOST,
'USER': USER,
'PASSWORD': PASSWORD,
'DATABASE': DATABASE,
'PORT': PORT}
with open('sqlconfig.ini', 'w') as configfile:
config.write(configfile)
print('Welcome to stock scraper')
print('Lets begin...')
print('Checking if config file is populated')
requiredFields = []
config_parser = configparser.ConfigParser()
settingUp()
config_parser.read('sqlconfig.ini')
DATABASE_TYPE = config_parser['DEFAULT']['DATABASE_TYPE']
DBAPI = config_parser['DEFAULT']['DBAPI']
HOST = config_parser['DEFAULT']['HOST']
USER = config_parser['DEFAULT']['USER']
PASSWORD = config_parser['DEFAULT']['PASSWORD']
DATABASE = config_parser['DEFAULT']['DATABASE']
PORT = config_parser['DEFAULT']['PORT']
configValues = ['DATABASE_TYPE','DBAPI','HOST','USER','PASSWORD','DATABASE','PORT']
configParameters = [DATABASE_TYPE,DBAPI,HOST,USER,PASSWORD,DATABASE,PORT]
counter = 0
for parameters in configParameters:
if parameters=='Replace':
requiredFields.append(configValues[counter])
counter = +1
if not requiredFields:
print('Config file has been populated')
print('Starting scraper')
from .process import stockData,stockHeadlineData,sentimentData
# Declaring datatable names
dt_stockContent = "stock_content"
dt_headlines = "stock_headlines"
dt_sentiment = "stock_sentiment"
stockData(stockContent_name=dt_stockContent, updateFlag=True)
stockHeadlineData(headlineDatatable_name = dt_headlines, stockInfoDatatable_name = dt_stockContent, updateFlag = True)
sentimentData(sentimentDatatable_name=dt_sentiment, updateFlag=True, headlineDatatable_name=dt_headlines)
print('Scraping complete')
else:
print('Config file has NOT been populated')
print('PGAdmin credentials required to proceed')
credsQuestion = input('Would you like to Enter credentials now?(y/n)')
if credsQuestion == 'y':
print('Please enter the value for the following parameters')
DATABASE_TYPE = input('DATABASE_TYPE: ')
DBAPI = input('DBAPI: ')
HOST = input('HOST: ')
USER = input('USER: ')
PASSWORD = getpass.getpass('PASSWORD: ')
DATABASE = input('DATABASE: ')
PORT = input('PORT: ')
sqlCreds(DATABASE_TYPE=DATABASE_TYPE.strip(), DBAPI=DBAPI.strip(),HOST=HOST.strip(),USER=USER.strip(),PASSWORD=PASSWORD.strip(),DATABASE=DATABASE.strip(),PORT=PORT.strip())
from .process import stockData,stockHeadlineData,sentimentData
# Declaring datatable names
dt_stockContent = "stock_content"
dt_headlines = "stock_headlines"
dt_sentiment = "stock_sentiment"
stockData(stockContent_name=dt_stockContent, updateFlag=True)
stockHeadlineData(headlineDatatable_name = dt_headlines, stockInfoDatatable_name = dt_stockContent, updateFlag = True)
sentimentData(sentimentDatatable_name=dt_sentiment, updateFlag=True, headlineDatatable_name=dt_headlines)
print('Scraping complete')
else:
print('You did not select y')
print('Please populate congig.py file and re-run the code')
print('The code is now exiting...')
print('Scraping complete')
|
AiCoreSentimentStockScraper
|
/AiCoreSentimentStockScraper-0.0.4.tar.gz/AiCoreSentimentStockScraper-0.0.4/stock_scraper_AiCore/__main__.py
|
__main__.py
|
import pandas as pd
from bs4 import BeautifulSoup
from urllib.request import urlopen
from urllib.request import Request
import pandas as pd
from collections import defaultdict
from tqdm import tqdm
from typing import Optional
from vaderSentiment.vaderSentiment import SentimentIntensityAnalyzer
analyzer = SentimentIntensityAnalyzer()
obj = SentimentIntensityAnalyzer()
def getSnpCompanies() -> Optional[list]:
'''
This method scrapes the snp500 stocks from wikidpedia.
The purpose of this method is to retrieve data from
wikipedia as its constantly being updated.
Returns:
list: A list of ticker symbols
'''
tickers = []
table=pd.read_html('https://en.wikipedia.org/wiki/List_of_S%26P_500_companies')
snp_df = table[0]
symbol = snp_df['Symbol']
for ticker in symbol:
tickers.append(ticker)
return tickers
def getStockContent(tickers:list) -> Optional[pd.DataFrame]:
'''
This method scrapes stock info on each stock
The purpose of this method is to use the list of
snp500 stocks and scrape stock name, stock sector,
stock type, stock region ,stock info
Args:
tickers: Stock tickers of the snp500 stocks
Returns:
Pandas dataframe: A datatable of stock info in pandas format
'''
dict_name = ['ticker','stock_name','stock_sector','stock_type','stock_region','stock_info']
stock_data = {}
for i in range(len(dict_name)):
stock_data[dict_name[i]] = []
for ticker in tqdm(tickers):
if "." in ticker:
ticker = ticker.replace(".","-")
finviz_url = 'https://finviz.com/quote.ashx?t='
news_tables = {}
url = finviz_url + ticker
try:
req = Request(url=url,headers={'user-agent': 'my-app/0.0.1'})
resp = urlopen(req)
html = BeautifulSoup(resp, features="lxml")
stock_name = html.find_all('a', {'class':'tab-link'})[12].text
stock_sector= html.find_all('a', {'class':'tab-link'})[13].text
stock_type= html.find_all('a', {'class':'tab-link'})[14].text
stock_region= html.find_all('a', {'class':'tab-link'})[15].text
stock_info= html.find('td', {'class':'fullview-profile'}).text
except Exception as e:
stock_name='Unknown'
stock_sector='Unknown'
stock_type='Unknown'
stock_region='Unknown'
stock_info='Unknown'
print(e, url)
finally:
stock_value = [ticker,stock_name,stock_sector,stock_type,stock_region,stock_info]
for i in range(len(stock_value)):
stock_data[dict_name[i]].append(stock_value[i])
df = pd.DataFrame.from_dict(stock_data)
return df
def getNewsHeadlines(tickers:list) -> Optional[pd.DataFrame]:
'''
This method scrapes news headlines of the stocks in the snp500
The purpose of this method is to use the stock tickers and scrapes
the top 100 news headlines related to the stock
Args:
tickers: Stock tickers of the snp500 stocks
Returns:
Pandas dataframe: A datatable of stock info in pandas format
'''
dict_name = ['ticker','headline','date']
headline_data = {}
for i in range(len(dict_name)):
headline_data[dict_name[i]] = []
for ticker in tqdm(tickers):
if "." in ticker:
ticker = ticker.replace(".","-")
try:
finviz_url = 'https://finviz.com/quote.ashx?t='
news_tables = {}
url = finviz_url + ticker
req = Request(url=url,headers={'user-agent': 'my-app/0.0.1'})
resp = urlopen(req)
html = BeautifulSoup(resp, features="lxml")
n=100
news_tables = html.find(id='news-table')
news_tables[ticker] = news_tables
df = news_tables[ticker]
df_tr = df.findAll('tr')
for i, table_row in enumerate(df_tr):
article_headline = table_row.a.text
td_text = table_row.td.text
article_date = td_text.strip()
headline_value = [ticker,article_headline,article_date]
for i in range(len(headline_value)):
headline_data[dict_name[i]].append(headline_value[i])
if i == n-1:
break
except Exception as e:
print(e, ticker)
headline_value = [ticker,article_headline,article_date]
for i in range(len(headline_value)):
headline_data[dict_name[i]].append("unknown")
df = pd.DataFrame.from_dict(headline_data)
return df
def getTwiterData():
try:
pass
except Exception as e:
print(e)
|
AiCoreSentimentStockScraper
|
/AiCoreSentimentStockScraper-0.0.4.tar.gz/AiCoreSentimentStockScraper-0.0.4/stock_scraper_AiCore/stock_scraper.py
|
stock_scraper.py
|
from .stock_scraper import getSnpCompanies,getStockContent,getNewsHeadlines
from .data_base import SqlDB
import pandas as pd
from .Sentiment_analysis import sentimentAnalysis
#configuing stockscraper because it is a class
#config_stock = StockScraper()
config_sql = SqlDB()
def tableExitsCheck(table_exists:bool, table_name:str):
if table_exists == False:
raise ValueError('Data table doesnt exist... Creating one')
else:
print("Database exists")
retrieve_table = config_sql.retriveTableInfo(table_name=table_name)
return retrieve_table
def createDataTable(table_name:str, dt_contents):
create_table = config_sql.createTable(table_name=table_name, dt_contents=dt_contents)
retrieve_table = config_sql.retriveTableInfo(table_name=table_name)
print("Data table:",table_name, "Has been created")
def updateStockInfo(updateFlag:bool, retrieve_table):
if updateFlag == True:
stock_list = getSnpCompanies()
content = getStockContent(tickers=stock_list)
else:
stock_list = retrieve_table['ticker']
content = getStockContent(tickers=stock_list)
return content
def pushData(source_dt,new_dt,table_name):
fresh_dt = config_sql.getNewRows(source_dt=source_dt, new_dt=new_dt)
config_sql.appendData(table_name=table_name, dt_contents=fresh_dt)
def stockData(stockContent_name:str ,updateFlag:bool):
'''
This function is used to perform stock data activities
The purpose of this function is to create a stock info database,
retrieve the snp 500 companies from wikipedia, get
the stock name, stock industry stock sector,stock type
stock region, stock_info for each stock, and populate
the database with that data
Args:
stockContent_name: The name of the database for the stock contents
updateFlag: A flag to be used if updating stock content is required or not
'''
print("Starting stock details extraction")
stock_col = ['ticker','stock_name','stock_sector','stock_type','stock_region','stock_info']
df = pd.DataFrame(columns=stock_col)
content = df
table_exists = config_sql.tableExists(table_name=stockContent_name)
try:
tableExitsCheck(table_exists=table_exists, table_name=stockContent_name)
retrieve_table = config_sql.retriveTableInfo(table_name=stockContent_name)
except ValueError as e:
print(e)
createDataTable(table_name=stockContent_name, dt_contents=content)
retrieve_table = config_sql.retriveTableInfo(table_name=stockContent_name)
finally:
content = updateStockInfo(updateFlag=updateFlag, retrieve_table=retrieve_table)
pushData(source_dt=retrieve_table, new_dt=content, table_name=stockContent_name)
# new_dt = config_sql.getNewRows(source_dt=retrieve_table, new_dt=content)
# config_sql.appendData(table_name=stockContent_name, dt_contents=new_dt)
print("Stock details extraction complete")
def stockHeadlineData(stockInfoDatatable_name:str,updateFlag:bool,headlineDatatable_name:str):
'''
This function is used to retrieve headlines about the stock
The purpose of this function is create a database for headlines,
use the stock info database to retrieve headlines about the stock,
and populate the headlines database
Args:
stockInfoDatatable_name: The stock info database name. This gets used to retrieve headlines
updateFlag: A flag to be used if updating stock content is required or not
headlineDatatable_name: The stock headline database name
'''
print("Starting headlines extraction")
config_sql = SqlDB()
headline_col = ['ticker', 'headline', 'date']
headline_tableExists = config_sql.tableExists(table_name=headlineDatatable_name)
try:
tableExitsCheck(table_exists=headline_tableExists, table_name=headlineDatatable_name)
retrieve_table = config_sql.retriveTableInfo(table_name=headlineDatatable_name)
except ValueError as e:
print(e)
df = pd.DataFrame(columns=headline_col)
createDataTable(table_name=headlineDatatable_name, dt_contents=df)
retrieve_table = config_sql.retriveTableInfo(table_name=headlineDatatable_name)
finally:
if updateFlag == True:
retrieve_headline_table = config_sql.retriveTableInfo(table_name=headlineDatatable_name)
retrieve_stock_info = config_sql.retriveTableInfo(table_name=stockInfoDatatable_name)
dt_tickers = retrieve_stock_info['ticker'].tolist()
new_dt= getNewsHeadlines(dt_tickers)
original_dt = retrieve_headline_table
else:
retrieve_headline_table = config_sql.retriveTableInfo(table_name=headlineDatatable_name)
new_dt = retrieve_headline_table
original_dt = retrieve_headline_table
append_dt = config_sql.getNewRows(source_dt=original_dt, new_dt=new_dt)
config_sql.appendData(table_name=headlineDatatable_name, dt_contents=append_dt)
print("Headlines extraction complete")
#stockHeadlineData(stockInfoDatatable_name = 'stock_content', updateFlag=True, headlineDatatable_name='stock_headlines')
def sentimentData(sentimentDatatable_name:str ,updateFlag:bool, headlineDatatable_name:str):
'''
This function is used to perform sentiment analysis activities
The purpose of this function is to create a sentiment datatbale,
use the headlines from the headline datatable to perform sentiment
analysis and populate the sentiment datatable
Args:
sentimentDatatable_name: The name of the sentiment datatable
updateFlag: A flag to be used if updating stock content is required or not
headlineData_name: The name of the headline datatable
'''
print("Starting sentiment analysis")
sentiment_col = ['date','ticker','headline','sentiment']
content = pd.DataFrame(columns=sentiment_col)
sentiment_tableExists = config_sql.tableExists(table_name=sentimentDatatable_name)
try:
if sentiment_tableExists == False:
raise ValueError('Data table doesnt exist... Creating one')
else:
retrieve_sentiment_table = config_sql.retriveTableInfo(table_name=sentimentDatatable_name)
print("Datatable already exists")
except ValueError as e:
create_table = config_sql.createTable(table_name=sentimentDatatable_name, dt_contents=content)
retrieve_sentiment_table = config_sql.retriveTableInfo(table_name=sentimentDatatable_name)
print("Data table:",sentimentDatatable_name, "Created")
finally:
if updateFlag == True:
retrieve_headline_table = config_sql.retriveTableInfo(table_name=headlineDatatable_name)
tickersList = retrieve_headline_table['ticker'].tolist()
dt_headlines = retrieve_headline_table['headline'].tolist()
dt_date = retrieve_headline_table['date'].tolist()
new_dt=sentimentAnalysis(ticker=tickersList, headlines=dt_headlines, date=dt_date)
append_dt = config_sql.getNewRows(source_dt=retrieve_sentiment_table, new_dt=new_dt)
config_sql.appendData(table_name=sentimentDatatable_name, dt_contents=append_dt)
print("Sentiment analysis complete")
|
AiCoreSentimentStockScraper
|
/AiCoreSentimentStockScraper-0.0.4.tar.gz/AiCoreSentimentStockScraper-0.0.4/stock_scraper_AiCore/process.py
|
process.py
|
import psycopg2
from sqlalchemy import create_engine, engine
import pandas as pd
import os
import sqlalchemy
import configparser
from typing import Optional
from sqlalchemy import MetaData
from sqlalchemy.ext.declarative import declarative_base
class SqlDB:
'''
This class is used to perform SQL datbase activities
'''
def __init__(self):
'''
This method is used to establish the database connection
The purpose of this method is to use the sqlconfig.ini
file to create a connection with the database using the
sqlalchmy engine.
'''
config_parser = configparser.ConfigParser()
config_parser.read('sqlconfig.ini')
DATABASE_TYPE = config_parser['DEFAULT']['DATABASE_TYPE']
DBAPI = config_parser['DEFAULT']['DBAPI']
HOST = config_parser['DEFAULT']['HOST']
USER = config_parser['DEFAULT']['USER']
PASSWORD = config_parser['DEFAULT']['PASSWORD']
DATABASE = config_parser['DEFAULT']['DATABASE']
PORT = config_parser['DEFAULT']['PORT']
engine = create_engine(f"{DATABASE_TYPE}+{DBAPI}://{USER}:{PASSWORD}@{HOST}:{PORT}/{DATABASE}")
self.engine = engine
def deleteTable(self,table_name: str):
Base = declarative_base()
metadata = MetaData()
metadata.reflect(bind=self.engine)
table = metadata.tables[table_name]
if table is not None:
Base.metadata.drop_all(self.engine, [table], checkfirst=True)
def tableExists(self,table_name: str) -> Optional[bool]:
'''
This method checks if a table exists in a database.
Args:
table_name: The name of the table to check if it exits
in database
Returns:
bool: True if the table exists. False if it doesnt exist
'''
table_exists = sqlalchemy.inspect(self.engine).has_table(table_name)
return table_exists
def retriveTableInfo(self,table_name: str) -> Optional[pd.DataFrame]:
'''
This method returns the data from a table
Args:
table_name: The name of the table to check if it exits
in database
Returns:
Pandas dataframe: The data of the table in pandas format
'''
stock_db = pd.read_sql_table(table_name, self.engine)
return stock_db
def createTable(self,table_name: str,dt_contents:pd.DataFrame):
'''
This method creates a table in the database
Args:
table_name: The name of the table to check if it exits
in database
dt_contents: The data to be inserted into the table
'''
creatededDt = dt_contents.to_sql(table_name, self.engine, index=False)
def appendData(self,table_name: str,dt_contents:pd.DataFrame):
'''
This method appends data to a table in the database
Args:
table_name: The name of the table to check if it exits
in database
dt_contents: The data to be inserted into the table
'''
dt_contents.to_sql(table_name, self.engine, if_exists='append',index=False)
def getNewRows(self,source_dt: pd.DataFrame, new_dt: pd.DataFrame):
'''
This method checks if data from one datable exists in another
Args:
source_dt: The source datatable that to be checks against
new_dt: The new datatable to check
Returns:
Pandas dataframe: Datatable with data that does not exist in source_dt
'''
merged_df = source_dt.merge(new_dt, indicator=True, how='outer')
changed_rows_df = merged_df[merged_df['_merge'] == 'right_only']
return changed_rows_df.drop('_merge', axis=1)
# db = SqlDB()
# db.deleteTable(table_name='a')
|
AiCoreSentimentStockScraper
|
/AiCoreSentimentStockScraper-0.0.4.tar.gz/AiCoreSentimentStockScraper-0.0.4/stock_scraper_AiCore/data_base.py
|
data_base.py
|
# Project1
## Outline
This project aims to predict stock prices through the following methods
Sentiment analysis:
- Sentiment on news headlines
- Sentiment on tweets from twitter
- Sentiment on Reddit feeds
Stock prices:
- Use stock historic data to evaluate current stock prices
- Calculate the risk of a stock (how volatile a stock is)
Machine learning:
- Use machine learning techniques to further predict stock prices
## TO USE
Please add the required parameters of your pgAdmin 4 data base to the config.py file before runnning
|
AiCoreSentimentStockScraper2021EtaCohort
|
/AiCoreSentimentStockScraper2021EtaCohort-0.0.2.tar.gz/AiCoreSentimentStockScraper2021EtaCohort-0.0.2/README.md
|
README.md
|
from .config import settingUp
import configparser
import os.path
import getpass
def sqlCreds(DATABASE_TYPE,DBAPI,HOST,USER,PASSWORD,DATABASE,PORT):
'''
This function uses the parameters set by user to connect to PGadmin database
The purpose of this function is to get the correct parameters and credentials
from the user to connect to PGAdmin 4 sql data base via sqlalchamy engine. The
function uses the data provided by the user and creates a .ini file named sqlconfig.ini
The values for the parameters can be found on pgAdmin 4. Most of them are under properties.
Hints:
DATABASE_TYPE: Server type on pgAdmin 4 (all lower case)
DBAPI: psycopg2
HOST: Host name / address on pgAdmin 4
USER: Username on pgAdmin 4
PASSWORD: Password created by user when setting up pgAdmin 4
DATABASE: The name of the database under Databases in pgAdmin 4
PORT: Port in pgAdmin 4
Output:
.ini file contained the paremeters and credentials
'''
config = configparser.ConfigParser()
config['DEFAULT'] = {'DATABASE_TYPE': DATABASE_TYPE,
'DBAPI': DBAPI,
'HOST': HOST,
'USER': USER,
'PASSWORD': PASSWORD,
'DATABASE': DATABASE,
'PORT': PORT}
with open('sqlconfig.ini', 'w') as configfile:
config.write(configfile)
print('Welcome to stock scraper')
print('Lets begin...')
print('Checking if config file is populated')
requiredFields = []
config_parser = configparser.ConfigParser()
settingUp()
config_parser.read('sqlconfig.ini')
DATABASE_TYPE = config_parser['DEFAULT']['DATABASE_TYPE']
DBAPI = config_parser['DEFAULT']['DBAPI']
HOST = config_parser['DEFAULT']['HOST']
USER = config_parser['DEFAULT']['USER']
PASSWORD = config_parser['DEFAULT']['PASSWORD']
DATABASE = config_parser['DEFAULT']['DATABASE']
PORT = config_parser['DEFAULT']['PORT']
configValues = ['DATABASE_TYPE','DBAPI','HOST','USER','PASSWORD','DATABASE','PORT']
configParameters = [DATABASE_TYPE,DBAPI,HOST,USER,PASSWORD,DATABASE,PORT]
counter = 0
for parameters in configParameters:
if parameters=='Replace':
requiredFields.append(configValues[counter])
counter = +1
if not requiredFields:
print('Config file has been populated')
print('Starting scraper')
from .process import stockData,stockHeadlineData,sentimentData
# Declaring datatable names
dt_stockContent = "stock_content"
dt_headlines = "stock_headlines"
dt_sentiment = "stock_sentiment"
stockData(stockContent_name=dt_stockContent, updateFlag=True)
stockHeadlineData(headlineDatatable_name = dt_headlines, stockInfoDatatable_name = dt_stockContent, updateFlag = True)
sentimentData(sentimentDatatable_name=dt_sentiment, updateFlag=True, headlineDatatable_name=dt_headlines)
print('Scraping complete')
else:
print('Config file has NOT been populated')
print('PGAdmin credentials required to proceed')
credsQuestion = input('Would you like to Enter credentials now?(y/n)')
if credsQuestion == 'y':
print('Please enter the value for the following parameters')
DATABASE_TYPE = input('DATABASE_TYPE: ')
DBAPI = input('DBAPI: ')
HOST = input('HOST: ')
USER = input('USER: ')
PASSWORD = getpass.getpass('PASSWORD: ')
DATABASE = input('DATABASE: ')
PORT = input('PORT: ')
sqlCreds(DATABASE_TYPE=DATABASE_TYPE.strip(), DBAPI=DBAPI.strip(),HOST=HOST.strip(),USER=USER.strip(),PASSWORD=PASSWORD.strip(),DATABASE=DATABASE.strip(),PORT=PORT.strip())
from .process import stockData,stockHeadlineData,sentimentData
# Declaring datatable names
dt_stockContent = "stock_content"
dt_headlines = "stock_headlines"
dt_sentiment = "stock_sentiment"
stockData(stockContent_name=dt_stockContent, updateFlag=True)
stockHeadlineData(headlineDatatable_name = dt_headlines, stockInfoDatatable_name = dt_stockContent, updateFlag = True)
sentimentData(sentimentDatatable_name=dt_sentiment, updateFlag=True, headlineDatatable_name=dt_headlines)
print('Scraping complete')
else:
print('You did not select y')
print('Please populate congig.py file and re-run the code')
print('The code is now exiting...')
print('Scraping complete')
|
AiCoreSentimentStockScraper2021EtaCohort
|
/AiCoreSentimentStockScraper2021EtaCohort-0.0.2.tar.gz/AiCoreSentimentStockScraper2021EtaCohort-0.0.2/stock_scraper_AiCore/__main__.py
|
__main__.py
|
import pandas as pd
from bs4 import BeautifulSoup
from urllib.request import urlopen
from urllib.request import Request
import pandas as pd
from collections import defaultdict
from tqdm import tqdm
from typing import Optional
from vaderSentiment.vaderSentiment import SentimentIntensityAnalyzer
analyzer = SentimentIntensityAnalyzer()
obj = SentimentIntensityAnalyzer()
def getSnpCompanies() -> Optional[list]:
'''
This method scrapes the snp500 stocks from wikidpedia.
The purpose of this method is to retrieve data from
wikipedia as its constantly being updated.
Returns:
list: A list of ticker symbols
'''
tickers = []
table=pd.read_html('https://en.wikipedia.org/wiki/List_of_S%26P_500_companies')
snp_df = table[0]
symbol = snp_df['Symbol']
for ticker in symbol:
tickers.append(ticker)
return tickers
def getStockContent(tickers:list) -> Optional[pd.DataFrame]:
'''
This method scrapes stock info on each stock
The purpose of this method is to use the list of
snp500 stocks and scrape stock name, stock sector,
stock type, stock region ,stock info
Args:
tickers: Stock tickers of the snp500 stocks
Returns:
Pandas dataframe: A datatable of stock info in pandas format
'''
dict_name = ['ticker','stock_name','stock_sector','stock_type','stock_region','stock_info']
stock_data = {}
for i in range(len(dict_name)):
stock_data[dict_name[i]] = []
for ticker in tqdm(tickers):
if "." in ticker:
ticker = ticker.replace(".","-")
finviz_url = 'https://finviz.com/quote.ashx?t='
news_tables = {}
url = finviz_url + ticker
try:
req = Request(url=url,headers={'user-agent': 'my-app/0.0.1'})
resp = urlopen(req)
html = BeautifulSoup(resp, features="lxml")
stock_name = html.find_all('a', {'class':'tab-link'})[12].text
stock_sector= html.find_all('a', {'class':'tab-link'})[13].text
stock_type= html.find_all('a', {'class':'tab-link'})[14].text
stock_region= html.find_all('a', {'class':'tab-link'})[15].text
stock_info= html.find('td', {'class':'fullview-profile'}).text
except Exception as e:
stock_name='Unknown'
stock_sector='Unknown'
stock_type='Unknown'
stock_region='Unknown'
stock_info='Unknown'
print(e, url)
finally:
stock_value = [ticker,stock_name,stock_sector,stock_type,stock_region,stock_info]
for i in range(len(stock_value)):
stock_data[dict_name[i]].append(stock_value[i])
df = pd.DataFrame.from_dict(stock_data)
return df
def getNewsHeadlines(tickers:list) -> Optional[pd.DataFrame]:
'''
This method scrapes news headlines of the stocks in the snp500
The purpose of this method is to use the stock tickers and scrapes
the top 100 news headlines related to the stock
Args:
tickers: Stock tickers of the snp500 stocks
Returns:
Pandas dataframe: A datatable of stock info in pandas format
'''
dict_name = ['ticker','headline','date']
headline_data = {}
for i in range(len(dict_name)):
headline_data[dict_name[i]] = []
for ticker in tqdm(tickers):
if "." in ticker:
ticker = ticker.replace(".","-")
try:
finviz_url = 'https://finviz.com/quote.ashx?t='
news_tables = {}
url = finviz_url + ticker
req = Request(url=url,headers={'user-agent': 'my-app/0.0.1'})
resp = urlopen(req)
html = BeautifulSoup(resp, features="lxml")
n=100
news_tables = html.find(id='news-table')
news_tables[ticker] = news_tables
df = news_tables[ticker]
df_tr = df.findAll('tr')
for i, table_row in enumerate(df_tr):
article_headline = table_row.a.text
td_text = table_row.td.text
article_date = td_text.strip()
headline_value = [ticker,article_headline,article_date]
for i in range(len(headline_value)):
headline_data[dict_name[i]].append(headline_value[i])
if i == n-1:
break
except Exception as e:
print(e, ticker)
headline_value = [ticker,article_headline,article_date]
for i in range(len(headline_value)):
headline_data[dict_name[i]].append("unknown")
df = pd.DataFrame.from_dict(headline_data)
return df
def getTwiterData():
try:
pass
except Exception as e:
print(e)
|
AiCoreSentimentStockScraper2021EtaCohort
|
/AiCoreSentimentStockScraper2021EtaCohort-0.0.2.tar.gz/AiCoreSentimentStockScraper2021EtaCohort-0.0.2/stock_scraper_AiCore/stock_scraper.py
|
stock_scraper.py
|
from .stock_scraper import getSnpCompanies,getStockContent,getNewsHeadlines
from .data_base import SqlDB
import pandas as pd
from .Sentiment_analysis import sentimentAnalysis
#configuing stockscraper because it is a class
#config_stock = StockScraper()
config_sql = SqlDB()
def tableExitsCheck(table_exists:bool, table_name:str):
if table_exists == False:
raise ValueError('Data table doesnt exist... Creating one')
else:
print("Database exists")
retrieve_table = config_sql.retriveTableInfo(table_name=table_name)
return retrieve_table
def createDataTable(table_name:str, dt_contents):
create_table = config_sql.createTable(table_name=table_name, dt_contents=dt_contents)
retrieve_table = config_sql.retriveTableInfo(table_name=table_name)
print("Data table:",table_name, "Has been created")
def updateStockInfo(updateFlag:bool, retrieve_table):
if updateFlag == True:
stock_list = getSnpCompanies()
content = getStockContent(tickers=stock_list)
else:
stock_list = retrieve_table['ticker']
content = getStockContent(tickers=stock_list)
return content
def pushData(source_dt,new_dt,table_name):
fresh_dt = config_sql.getNewRows(source_dt=source_dt, new_dt=new_dt)
config_sql.appendData(table_name=table_name, dt_contents=fresh_dt)
def stockData(stockContent_name:str ,updateFlag:bool):
'''
This function is used to perform stock data activities
The purpose of this function is to create a stock info database,
retrieve the snp 500 companies from wikipedia, get
the stock name, stock industry stock sector,stock type
stock region, stock_info for each stock, and populate
the database with that data
Args:
stockContent_name: The name of the database for the stock contents
updateFlag: A flag to be used if updating stock content is required or not
'''
print("Starting stock details extraction")
stock_col = ['ticker','stock_name','stock_sector','stock_type','stock_region','stock_info']
df = pd.DataFrame(columns=stock_col)
content = df
table_exists = config_sql.tableExists(table_name=stockContent_name)
try:
tableExitsCheck(table_exists=table_exists, table_name=stockContent_name)
retrieve_table = config_sql.retriveTableInfo(table_name=stockContent_name)
except ValueError as e:
print(e)
createDataTable(table_name=stockContent_name, dt_contents=content)
retrieve_table = config_sql.retriveTableInfo(table_name=stockContent_name)
finally:
content = updateStockInfo(updateFlag=updateFlag, retrieve_table=retrieve_table)
pushData(source_dt=retrieve_table, new_dt=content, table_name=stockContent_name)
# new_dt = config_sql.getNewRows(source_dt=retrieve_table, new_dt=content)
# config_sql.appendData(table_name=stockContent_name, dt_contents=new_dt)
print("Stock details extraction complete")
def stockHeadlineData(stockInfoDatatable_name:str,updateFlag:bool,headlineDatatable_name:str):
'''
This function is used to retrieve headlines about the stock
The purpose of this function is create a database for headlines,
use the stock info database to retrieve headlines about the stock,
and populate the headlines database
Args:
stockInfoDatatable_name: The stock info database name. This gets used to retrieve headlines
updateFlag: A flag to be used if updating stock content is required or not
headlineDatatable_name: The stock headline database name
'''
print("Starting headlines extraction")
config_sql = SqlDB()
headline_col = ['ticker', 'headline', 'date']
headline_tableExists = config_sql.tableExists(table_name=headlineDatatable_name)
try:
tableExitsCheck(table_exists=headline_tableExists, table_name=headlineDatatable_name)
retrieve_table = config_sql.retriveTableInfo(table_name=headlineDatatable_name)
except ValueError as e:
print(e)
df = pd.DataFrame(columns=headline_col)
createDataTable(table_name=headlineDatatable_name, dt_contents=df)
retrieve_table = config_sql.retriveTableInfo(table_name=headlineDatatable_name)
finally:
if updateFlag == True:
retrieve_headline_table = config_sql.retriveTableInfo(table_name=headlineDatatable_name)
retrieve_stock_info = config_sql.retriveTableInfo(table_name=stockInfoDatatable_name)
dt_tickers = retrieve_stock_info['ticker'].tolist()
new_dt= getNewsHeadlines(dt_tickers)
original_dt = retrieve_headline_table
else:
retrieve_headline_table = config_sql.retriveTableInfo(table_name=headlineDatatable_name)
new_dt = retrieve_headline_table
original_dt = retrieve_headline_table
append_dt = config_sql.getNewRows(source_dt=original_dt, new_dt=new_dt)
config_sql.appendData(table_name=headlineDatatable_name, dt_contents=append_dt)
print("Headlines extraction complete")
#stockHeadlineData(stockInfoDatatable_name = 'stock_content', updateFlag=True, headlineDatatable_name='stock_headlines')
def sentimentData(sentimentDatatable_name:str ,updateFlag:bool, headlineDatatable_name:str):
'''
This function is used to perform sentiment analysis activities
The purpose of this function is to create a sentiment datatbale,
use the headlines from the headline datatable to perform sentiment
analysis and populate the sentiment datatable
Args:
sentimentDatatable_name: The name of the sentiment datatable
updateFlag: A flag to be used if updating stock content is required or not
headlineData_name: The name of the headline datatable
'''
print("Starting sentiment analysis")
sentiment_col = ['date','ticker','headline','sentiment']
content = pd.DataFrame(columns=sentiment_col)
sentiment_tableExists = config_sql.tableExists(table_name=sentimentDatatable_name)
try:
if sentiment_tableExists == False:
raise ValueError('Data table doesnt exist... Creating one')
else:
retrieve_sentiment_table = config_sql.retriveTableInfo(table_name=sentimentDatatable_name)
print("Datatable already exists")
except ValueError as e:
create_table = config_sql.createTable(table_name=sentimentDatatable_name, dt_contents=content)
retrieve_sentiment_table = config_sql.retriveTableInfo(table_name=sentimentDatatable_name)
print("Data table:",sentimentDatatable_name, "Created")
finally:
if updateFlag == True:
retrieve_headline_table = config_sql.retriveTableInfo(table_name=headlineDatatable_name)
tickersList = retrieve_headline_table['ticker'].tolist()
dt_headlines = retrieve_headline_table['headline'].tolist()
dt_date = retrieve_headline_table['date'].tolist()
new_dt=sentimentAnalysis(ticker=tickersList, headlines=dt_headlines, date=dt_date)
append_dt = config_sql.getNewRows(source_dt=retrieve_sentiment_table, new_dt=new_dt)
config_sql.appendData(table_name=sentimentDatatable_name, dt_contents=append_dt)
print("Sentiment analysis complete")
|
AiCoreSentimentStockScraper2021EtaCohort
|
/AiCoreSentimentStockScraper2021EtaCohort-0.0.2.tar.gz/AiCoreSentimentStockScraper2021EtaCohort-0.0.2/stock_scraper_AiCore/process.py
|
process.py
|
import psycopg2
from sqlalchemy import create_engine, engine
import pandas as pd
import os
import sqlalchemy
import configparser
from typing import Optional
from sqlalchemy import MetaData
from sqlalchemy.ext.declarative import declarative_base
class SqlDB:
'''
This class is used to perform SQL datbase activities
'''
def __init__(self):
'''
This method is used to establish the database connection
The purpose of this method is to use the sqlconfig.ini
file to create a connection with the database using the
sqlalchmy engine.
'''
config_parser = configparser.ConfigParser()
config_parser.read('sqlconfig.ini')
DATABASE_TYPE = config_parser['DEFAULT']['DATABASE_TYPE']
DBAPI = config_parser['DEFAULT']['DBAPI']
HOST = config_parser['DEFAULT']['HOST']
USER = config_parser['DEFAULT']['USER']
PASSWORD = config_parser['DEFAULT']['PASSWORD']
DATABASE = config_parser['DEFAULT']['DATABASE']
PORT = config_parser['DEFAULT']['PORT']
engine = create_engine(f"{DATABASE_TYPE}+{DBAPI}://{USER}:{PASSWORD}@{HOST}:{PORT}/{DATABASE}")
self.engine = engine
def deleteTable(self,table_name: str):
Base = declarative_base()
metadata = MetaData()
metadata.reflect(bind=self.engine)
table = metadata.tables[table_name]
if table is not None:
Base.metadata.drop_all(self.engine, [table], checkfirst=True)
def tableExists(self,table_name: str) -> Optional[bool]:
'''
This method checks if a table exists in a database.
Args:
table_name: The name of the table to check if it exits
in database
Returns:
bool: True if the table exists. False if it doesnt exist
'''
table_exists = sqlalchemy.inspect(self.engine).has_table(table_name)
return table_exists
def retriveTableInfo(self,table_name: str) -> Optional[pd.DataFrame]:
'''
This method returns the data from a table
Args:
table_name: The name of the table to check if it exits
in database
Returns:
Pandas dataframe: The data of the table in pandas format
'''
stock_db = pd.read_sql_table(table_name, self.engine)
return stock_db
def createTable(self,table_name: str,dt_contents:pd.DataFrame):
'''
This method creates a table in the database
Args:
table_name: The name of the table to check if it exits
in database
dt_contents: The data to be inserted into the table
'''
creatededDt = dt_contents.to_sql(table_name, self.engine, index=False)
def appendData(self,table_name: str,dt_contents:pd.DataFrame):
'''
This method appends data to a table in the database
Args:
table_name: The name of the table to check if it exits
in database
dt_contents: The data to be inserted into the table
'''
dt_contents.to_sql(table_name, self.engine, if_exists='append',index=False)
def getNewRows(self,source_dt: pd.DataFrame, new_dt: pd.DataFrame):
'''
This method checks if data from one datable exists in another
Args:
source_dt: The source datatable that to be checks against
new_dt: The new datatable to check
Returns:
Pandas dataframe: Datatable with data that does not exist in source_dt
'''
merged_df = source_dt.merge(new_dt, indicator=True, how='outer')
changed_rows_df = merged_df[merged_df['_merge'] == 'right_only']
return changed_rows_df.drop('_merge', axis=1)
# db = SqlDB()
# db.deleteTable(table_name='a')
|
AiCoreSentimentStockScraper2021EtaCohort
|
/AiCoreSentimentStockScraper2021EtaCohort-0.0.2.tar.gz/AiCoreSentimentStockScraper2021EtaCohort-0.0.2/stock_scraper_AiCore/data_base.py
|
data_base.py
|
# Aidantic
Aidantic is a tiny library inspired by Pydantic,
made to be more suitable for:
- Data parsing.
- Subclasses lookup (like `OneOf` in JSON-Schema).
- Input data validation:
- Exceptions store precise path.
- Plain types values validation, see `PlainWrapper`.
- Custom complex objects validation, see `ModelVisitorBase`.
The library isn't aimed to become a full replacement of Pydantic
(e.g, there is no planned support of JSON Schema, OpenAPI),
but in some cases it's worth using `:)`
ToDo List:
- 1: optional strict value type check
- 2: field name aliases
- 3: OneOf typing: pass inner class methods
- 4: probably some default types are missed and not supported
License: GPL 3
# Usage
Install with pip: `pip install Aidantic`
Or simply obtain a single source file from the repo.
## 1. Basics
```py
from typing import List
from aidantic import BaseModel
class Model(BaseModel):
name: str
data: List[int]
obj = Model(name="Foo", data=[61, 80, 33, 98])
assert obj.data[2] == 33
```
Simple yet boring, let's dive deeper!
## 2. OneOf
Sometimes an object may contain instance(s)
of plenty subclasses, and you, or your auxiliary lib,
have to decide which class to use during parsing process.
For this aim, Aidantic provides built-in support of
One-Of logic: all you need is to specify a key,
which should be used to subclass picking,
and declare its values for the subclasses.
No `Union` with boring enumeration is needed!
```py
from typing import List, Literal
from aidantic import BaseModel, OneOf
class RandomModel(BaseModel):
_discriminator = "key"
key: int
class EuropeModel(RandomModel):
key: Literal[271]
value: str
class PieModel(RandomModel):
key: Literal[314]
value: int
class PackageModel(BaseModel):
title: str
content: List[OneOf[RandomModel]]
data = dict(title="Bar42", content=[
dict(key=314, value=15926535),
dict(key=271, value="lol"),
])
package = PackageModel(**data)
package.validate()
assert package.content[1].value == "lol"
print(package)
```
Result:
```py
PackageModel(
title='Bar42',
content=[
PieModel(key=314, value=15926535),
EuropeModel(key=271, value='lol')
])
```
BTW, `_discriminator` may be a tuple of field names.
## 3. PlainWrapper
If you need to validate a set of values of plain types
(like str, int), you can utilise `PlainWrapper` class,
which can be used as a simple replacement of any plain type.
However, you should note that a wrapped value has
some limitations: typical `isinstance` usage won't work.
But comparison to plain values works well,
and you can easily access wrapper's `value` property.
There are a couple of use-cases:
### 3.1. Creation time validation
```py
from aidantic import PlainWrapper, BaseModel, CreationError, PathType
class StatusCode(PlainWrapper["str"]):
_allowed = {"foo", "bar", "lol"}
def __init__(self, code, path: PathType):
if code not in self._allowed:
raise CreationError(f"Unknown code '{code}'", path)
super().__init__(code, path)
class SomeModel(BaseModel):
code: StatusCode
obj = SomeModel(code="bar")
assert obj.code == "bar"
```
The same could be also written as a Union of Literals,
but this would be too verbose.
### 3.2. Validator class
If you have to perform more complex logic,
e.g load allowed values later, or compare values
from different objects, you can use a separate validator
that will traverse your data models:
```py
from typing import List
from aidantic import PlainWrapper, BaseModel, ModelVisitorBase, ValidationError
class StatusCode(PlainWrapper["str"]):
pass
class SomeModel(BaseModel):
codes: List[StatusCode]
class CrossValidator(ModelVisitorBase):
_label = "Cross"
_allowed = {"foo", "bar", "lol"}
def __init__(self,):
super().__init__()
self.collected_codes = set()
def visit(self, obj):
super().visit(obj)
unknown_codes = self.collected_codes - self._allowed
if unknown_codes:
raise ValidationError(f"Got {len(unknown_codes)} unknown codes", ())
def visit_wrapper(self, obj, _type, path):
if issubclass(_type, StatusCode):
self.collected_codes.add(str(obj))
obj = SomeModel(codes=["foo", "bar", "lol"])
CrossValidator().visit(obj)
```
## 4. Plain values parsing
Thanks to `from_plain` method,
it's pretty simple to write a parser that will translate
plain values like strings into objects:
```py
from aidantic import BaseModel
from expr import AnyExpr
class Message(BaseModel):
title: str
formula: AnyExpr
msg = Message(
title="Please calculate the attached expression",
formula="log(pi, 2.7182)",
)
print(msg)
```
```py
Message(
title="Please calculate the attached expression",
formula=ExprFunction(operator='FUNCTION', name='log', arguments=[
ExprField(operator='FIELD', name='pi'), ExprLiteral(operator='LITERAL', value=2.7182)
])
)
```
See `tests/test_expr.py` for implementation details!
# Historical intro
While I was developing CI and scenario scripts for
my GameDev pet-project [Destiny Garden](https://www.aivanf.com/destiny-garden-1),
I've met a need to parse and validate large scripts
written in custom YAML-based format.
I tried to use my beloved Pydantic for this problem,
but found it too focused on networking, ORM logic and too
rigid for game scenario scripting, so quickly I've
developed this library which is small yet powerful
for dealing with such specialised problems.
|
Aidantic
|
/Aidantic-1.0.1.tar.gz/Aidantic-1.0.1/README.md
|
README.md
|
__author__ = "AivanF"
__copyright__ = "AivanF"
__email__ = "[email protected]"
__license__ = "GPL3"
__version__ = "2022.04.12"
__status__ = "Dev"
from typing import (
Generic, TypeVar, _GenericAlias, Any,
Type, Optional, Union, Iterable, Tuple, Dict,
)
from typing_extensions import Literal
__all__ = [
"ValidationError", "CreationError", "PathType",
"BaseModel", "PlainWrapper", "OneOf",
"ModelVisitorBase", "ModelValidator",
]
PathType = Tuple[str, ...]
JsonType = Union[dict, list, str, int, float, type(None)]
def join_path(path: PathType):
return " -> ".join(map(str, path))
class ValidationError(BaseException):
def __init__(self, msg, path: PathType):
self.msg = msg
self.path = path
def __repr__(self):
if self.path:
return f"{join_path(self.path)}: {self.msg}"
else:
return self.msg
def __str__(self):
return self.__repr__()
class CreationError(ValidationError):
pass
T = TypeVar("T")
class OneOf(Generic[T]):
"""
Usage: OneOf[SomeClass]
But SomeClass must have a field _discriminator: Union[str, Iterable[str]],
which specifies fields used to determine specific subclass.
"""
pass
PT = TypeVar("PT")
class PlainWrapper(Generic[PT]):
"""
Wrapper for plain types like str, int.
It's really useful for complex data validation,
especially for sets of literal values known at run-time only.
To validate values, you can overload __init__/validate methods,
or use a custom ModelValidator visitor.
"""
def __init__(self, value: PT, path: PathType = ()):
self.value = value
def validate(self):
pass
def __eq__(self, other):
return self.value == other
def __ne__(self, other):
return self.value != other
def __lt__(self, other):
return self.value < other
def __le__(self, other):
return self.value <= other
def __gt__(self, other):
return self.value > other
def __ge__(self, other):
return self.value >= other
def __hash__(self):
return hash(self.value)
def __bool__(self):
return bool(self.value)
def __getattr__(self, key):
return getattr(self.value, key)
def __str__(self):
return str(self.value)
def __repr__(self):
return f"{repr(self.value)}:{self.__class__.__name__}(PlainWrapper)"
# Parent model into key fields
TRACKED_MODEL_KEYS: Dict[Type["BaseModel"], Tuple[str, ...]] = {}
# Parent model into map of key values into child models
TRACKED_MODELS: Dict[Type["BaseModel"], Dict[Tuple, Type["BaseModel"]]] = {}
class BaseModelMeta(type):
def __new__(mcs, name, bases, namespace):
# Inherit annotations
ann = namespace.get("__annotations__", {})
for parent in bases:
pan = parent.__dict__.get("__annotations__", {})
for key in pan:
if key not in ann:
ann[key] = pan[key]
namespace["__annotations__"] = ann
cls: Type["BaseModel"]
cls = super().__new__(mcs, name, bases, namespace)
# Hanle OneOf logic
if "_discriminator" in namespace:
if isinstance(cls._discriminator, str):
cls._discriminator = (cls._discriminator,)
TRACKED_MODEL_KEYS[cls] = cls._discriminator
TRACKED_MODELS[cls] = {}
elif not name.endswith("Base"):
# Register child model
for parent in TRACKED_MODEL_KEYS:
if issubclass(cls, parent):
# Annotation key fields must be Literals
keys = tuple(
cls.__annotations__[name].__args__[0]
for name in TRACKED_MODEL_KEYS[parent]
)
TRACKED_MODELS[parent][keys] = cls
return cls
class ModelVisitorBase:
"""
Visitor pattern is used to traverse nested models,
to create and validate the data objects.
"""
_visible = False
_label = "?"
def __init__(self):
self.root = None
def visit(self, obj):
self.root = obj
return self.visit_model(obj, obj.__class__, ())
def visit_field(self, obj, _type, path) -> Any:
if isinstance(_type, _GenericAlias):
return self.visit_generic(obj, _type, path)
elif issubclass(_type, BaseModel):
return self.visit_model(obj, _type, path)
elif issubclass(_type, PlainWrapper):
return self.visit_wrapper(obj, _type, path)
else:
return self.visit_plain(obj, _type, path)
def visit_generic(self, obj, _type, path) -> Any:
self.show("Generic", path, _type)
origin = _type.__origin__
if origin == list:
return self.visit_list(obj, _type, path)
elif origin == Iterable:
return self.visit_iterable(obj, _type, path)
elif origin == Union:
return self.visit_union(obj, _type, path)
elif origin == Literal:
return self.visit_literal(obj, _type, path)
elif origin == OneOf:
parent = _type.__args__[0]
return self.visit_one_of(obj, parent, path)
else:
return self.visit_generic_other(obj, _type, path)
def show(self, method, path, _type, value=None):
if self._visible:
if value is not None:
print(f"{self._label} {path}: {method} {_type} {value}")
else:
print(f"{self._label} {path}: {method} {_type}")
def visit_generic_other(self, obj, _type, path):
pass
def visit_list(self, obj, _type, path) -> Any:
return self.visit_iterable(obj, _type, path)
def visit_iterable(self, obj, _type, path) -> Any:
self.show("Iterable", path, _type)
if len(_type.__args__) == 0:
return
subtype = _type.__args__[0]
if len(_type.__args__) > 0:
subtype = _type.__args__[0]
for i, value in enumerate(obj):
next_path = path + (i,)
self.visit_field(value, subtype, next_path)
def visit_union(self, obj, _type, path) -> Any:
# Special handle for Optional
if len(_type.__args__) == 2 and \
isinstance(None, _type.__args__[1]):
if obj is not None:
self.visit_field(obj, _type.__args__[0], path)
else:
self.visit_field(obj, obj.__class__, path)
def visit_literal(self, obj, _type, path) -> Any:
pass
def visit_wrapper(self, obj, _type, path) -> Any:
pass
def visit_plain(self, obj, _type, path) -> Any:
pass
def visit_one_of(self, obj, parent, path) -> Any:
return self.visit_model(obj, obj.__class__, path)
def visit_model(self, obj, _type, path) -> Any:
self.show("BaseModel", path, _type)
for key, subtype in _type.__annotations__.items():
value = getattr(obj, key, None)
next_path = path + (key,)
self.visit_field(value, subtype, next_path)
class ModelValidator(ModelVisitorBase):
# _visible = True
_label = "Vali"
def visit_generic_other(self, obj, _type, path):
raise ValidationError(
f"type {_type} is not supported for validation", path
)
def visit_list(self, obj, _type, path):
origin = _type.__origin__
if not isinstance(obj, origin):
raise ValidationError(f"is not {origin}", path)
super().visit_list(obj, _type, path)
def visit_union(self, obj, _type, path):
self.show("Union", path, _type)
appropriate = None
first_ex = None
for subtype in _type.__args__:
try:
self.visit_field(obj, subtype, path)
appropriate = subtype
break
except ValidationError as ex:
if first_ex is None:
first_ex = ex
continue
if appropriate is None:
# Handle Optional specially
if len(_type.__args__) == 2 and \
isinstance(None, _type.__args__[1]):
raise first_ex
raise ValidationError(f"{obj} is not {_type}", path)
def visit_literal(self, obj, _type, path):
self.show("Literal", path, _type)
literal_value = _type.__args__[0]
if obj != literal_value:
raise ValidationError(
f"expected literal {literal_value} but got {obj}", path
)
def visit_wrapper(self, obj, _type, path):
self.show("Wrapper", path, _type, obj)
if not isinstance(obj, _type):
raise ValidationError(
f"expected plain {_type} but got {obj}", path
)
obj.validate()
def visit_plain(self, obj, _type, path):
self.show("Plain", path, _type, obj)
if not isinstance(obj, _type):
raise ValidationError(
f"expected plain {_type} but got {obj}", path
)
def visit_one_of(self, obj, parent, path):
self.show("OneOf", path, parent)
if obj.__class__ not in TRACKED_MODELS[parent].values():
raise ValidationError(
f"expected a child of {parent} but got {obj.__class__}",
path
)
super().visit_one_of(obj, parent, path)
def visit_model(self, obj, _type, path):
if not isinstance(obj, _type):
raise ValidationError(f"{obj} is not {_type}", path)
super().visit_model(obj, _type, path)
obj._validate(path, self)
class ModelCreator(ModelVisitorBase):
# _visible = True
_label = "Crea"
def visit_generic_other(self, obj, _type, path):
raise CreationError(
f"type {_type} is not supported for creation", path
)
def visit_iterable(self, obj, _type, path) -> object:
if len(_type.__args__) > 0:
subtype = _type.__args__[0]
result = []
for i, value in enumerate(obj):
next_path = path + (i,)
result.append(self.visit_field(value, subtype, next_path))
return result
else:
return obj
def visit_union(self, value, _type, path) -> object:
result = None
appropriate = None
# Special handle for Optional
if len(_type.__args__) == 2 and \
type(None) == _type.__args__[1]:
if value is None:
return None
else:
subtype = _type.__args__[0]
result = self.visit_field(value, subtype, path)
VALIDATOR.visit_field(result, subtype, path)
return result
for subtype in _type.__args__:
try:
result = self.visit_field(value, subtype, path)
VALIDATOR.visit_field(result, subtype, path)
appropriate = subtype
break
except (TypeError, ValidationError):
continue
if appropriate is None:
raise CreationError(f"{value} is not {_type}", path)
return result
def visit_literal(self, value, _type, path) -> object:
literal_value = _type.__args__[0]
if value != literal_value:
raise CreationError(
f"expected literal {literal_value}"
f" but got {value}", path
)
return literal_value
def visit_wrapper(self, value, _type, path) -> object:
return _type(value, path=path)
def visit_plain(self, value, _type, path) -> object:
# TODO: consider strict value type checking
return _type(value)
def visit_one_of(self, value, parent, path) -> object:
# Pass appropriate object
if isinstance(value, parent):
return value
# Try create from keys
key_names = TRACKED_MODEL_KEYS[parent]
keys = None
kwargs = value
if isinstance(value, dict):
keys = tuple(value.get(key) for key in key_names)
elif len(key_names) == 1 and isinstance(value, (str, int)):
# Consider single value as a key
keys = (value,)
kwargs = {key_names[0]: value}
if keys is not None:
_type = TRACKED_MODELS[parent].get(keys)
if _type is not None:
return _type(__start__path__=path, **kwargs)
result = parent.from_plain(value, path)
if result is not None:
return result
raise CreationError(
f"OneOf of {parent.__name__} cannot resolve {value}", path)
def visit_model(self, value, _type, path) -> object:
if isinstance(value, _type):
return value
else:
if not isinstance(value, dict):
result = _type.from_plain(value, path)
if result is None:
raise CreationError(
f"expected {dict}, got {value}", path
)
else:
result = _type(__start__path__=path, **value)
return result
CREATOR = ModelCreator()
VALIDATOR = ModelValidator()
class BaseModel(metaclass=BaseModelMeta):
def __init__(self, __start__path__: PathType = (), **kwargs):
for key, value in kwargs.items():
_type = self.__annotations__.get(key)
if _type is None:
raise CreationError(
f"got unexpected {key}={value}"
f" for {self.__class__.__name__}",
__start__path__
)
value = CREATOR.visit_field(value, _type, __start__path__ + (key,))
setattr(self, key, value)
# Add missing literal values
for key, _type in self.__annotations__.items():
if isinstance(_type, _GenericAlias):
origin = _type.__origin__
if origin == Literal:
literal_value = _type.__args__[0]
if key in kwargs:
if literal_value != kwargs[key]:
raise CreationError(
f"got bad literal {key}={kwargs[key]}"
f" expected {literal_value}"
f" for {self.__class__.__name__}",
__start__path__
)
else:
setattr(self, key, literal_value)
# Handle NoneType similar to a literal
elif isinstance(None, _type):
setattr(self, key, None)
@classmethod
def from_plain(cls, value, path) -> object:
"""
This allows to parse some value, usually string, into an object.
To be overridden.
"""
return None
@classmethod
def get_children(cls) -> Dict[Tuple, Type["BaseModel"]]:
return TRACKED_MODELS[cls]
@classmethod
def child_by_keys(cls, keys) -> Optional[Type["BaseModel"]]:
return TRACKED_MODELS[cls].get(keys)
def validate(self, validator=VALIDATOR):
validator.visit(self)
def _validate(self, path, validator: ModelValidator):
"""
To be overridden.
"""
pass
@classmethod
def _serialize_value(cls, value) -> JsonType:
if isinstance(value, list) or isinstance(value, tuple):
return cls._serialize_iterable(value)
elif isinstance(value, dict):
return {
key: cls._serialize_value(val)
for key, val in value.items()
}
elif isinstance(value, BaseModel):
return value.serialize()
elif isinstance(value, PlainWrapper):
return value.value
# TODO: raise error?
return value
@classmethod
def _serialize_iterable(cls, obj) -> JsonType:
result = []
for value in obj:
result.append(cls._serialize_value(value))
return result
def serialize(self) -> JsonType:
result = {}
for key, _type in self.__annotations__.items():
value = getattr(self, key, None)
result[key] = self._serialize_value(value)
return result
def __repr__(self):
result = self.__class__.__name__ + "("
result += ", ".join(
f"{key}={repr(getattr(self, key, None))}"
for key in self.__annotations__
)
return result + ")"
|
Aidantic
|
/Aidantic-1.0.1.tar.gz/Aidantic-1.0.1/aidantic/aidantic.py
|
aidantic.py
|
from typing import List
from Aidlab.AidlabSDK import AidlabSDK
from Aidlab.AidlabPeripheral import AidlabPeripheral
from Aidlab.IAidlab import IAidlab
from Aidlab.Signal import Signal
class Aidlab:
def __init__(self):
# Container for AidlabSDK libs
self.aidlab_sdk = {}
self.aidlab_peripheral = AidlabPeripheral(self)
def create_aidlabSDK(self, aidlab_address):
self.aidlab_sdk[aidlab_address] = AidlabSDK(self, aidlab_address)
self.aidlab_sdk[aidlab_address].setup_user_callback()
self.aidlab_sdk[aidlab_address].setup_synchronization_callback()
def destroy(self, aidlab_address: str):
self.aidlab_sdk[aidlab_address].destroy()
def connect(self, real_time_signal: List[Signal], sync_signal: List[Signal] =[], aidlabsMAC: List[str]=None):
self.aidlab_peripheral.run(real_time_signal, sync_signal, aidlabsMAC)
def disconnect(self, aidlab_address: str):
self.aidlab_peripheral.disconnect(aidlab_address)
def did_connect_aidlab(self, aidlab_address: str):
self.aidlab_sdk[aidlab_address].did_connect_aidlab()
def did_disconnect_aidlab(self, aidlab_address: str):
self.aidlab_sdk[aidlab_address].did_disconnect_aidlab()
def did_receive_raw_temperature(self, data: List[int], aidlab_address: str):
self.aidlab_sdk[aidlab_address].calculate_temperature(data)
def did_receive_raw_ecg(self, data: List[int], aidlab_address: str):
self.aidlab_sdk[aidlab_address].calculate_ecg(data)
def did_receive_raw_respiration(self, data: List[int], aidlab_address: str):
self.aidlab_sdk[aidlab_address].calculate_respiration(data)
def did_receive_raw_battery_level(self, data: List[int], aidlab_address: str):
self.aidlab_sdk[aidlab_address].calculate_battery(data)
def did_receive_raw_imu_values(self, data: List[int], aidlab_address: str):
self.aidlab_sdk[aidlab_address].calculate_motion(data)
def did_receive_raw_orientation(self, data: List[int], aidlab_address: str):
self.aidlab_sdk[aidlab_address].calculate_orientation(data)
def did_receive_raw_steps(self, data: List[int], aidlab_address: str):
self.aidlab_sdk[aidlab_address].calculate_steps(data)
def did_receive_raw_activity(self, data: List[int], aidlab_address: str):
self.aidlab_sdk[aidlab_address].calculate_activity(data)
def did_receive_raw_heart_rate(self, data: List[int], aidlab_address: str):
self.aidlab_sdk[aidlab_address].calculate_heart_rate(data)
def did_receive_raw_sound_volume(self, data: List[int], aidlab_address: str):
self.aidlab_sdk[aidlab_address].calculate_sound_volume(data)
def did_receive_raw_cmd_value(self, data: List[int], aidlab_address: str):
self.aidlab_sdk[aidlab_address].did_receive_raw_cmd_value(data)
def did_receive_raw_firmware_revision(self, data: str, aidlab_address: str):
self.aidlab_sdk[aidlab_address].did_receive_firmware_revision(data)
def did_receive_raw_hardware_revision(self, data: str, aidlab_address: str):
self.aidlab_sdk[aidlab_address].did_receive_hardware_revision(data)
def did_receive_raw_manufacture_name(self, data: str, aidlab_address: str):
self.aidlab_sdk[aidlab_address].did_receive_manufacture_name(data)
def did_receive_raw_serial_number(self, data: str, aidlab_address: str):
self.aidlab_sdk[aidlab_address].did_receive_serial_number(data)
def get_command(self, aidlab_address: str, message: str):
return self.aidlab_sdk[aidlab_address].get_command(message)
def get_collect_command(self, aidlab_address: str, realTime, sync):
return self.aidlab_sdk[aidlab_address].get_collect_command(realTime, sync)
def start_synchronization(self, address: str):
self.aidlab_peripheral.start_synchronization(address)
def stop_synchronization(self, address: str):
self.aidlab_peripheral.stop_synchronization(address)
def send(self, address: str, command: str):
self.aidlab_peripheral.send(address, command)
# -- Aidlab callbacks ----------------------------------------------------------------------------
def did_connect(self, aidlab: IAidlab):
pass
def did_disconnect(self, aidlab: IAidlab):
pass
def did_receive_ecg(self, aidlab: IAidlab, timestamp: int, values: List[float]):
"""Called when a new ECG samples was received.
"""
pass
def did_receive_respiration(self, aidlab: IAidlab, timestamp: int, values: List[float]):
"""Called when a new respiration samples was received.
"""
pass
def did_receive_respiration_rate(self, aidlab: IAidlab, timestamp: int, value: int):
"""
Called when respiration rate is available.
"""
pass
def did_receive_battery_level(self, aidlab: IAidlab, state_of_charge: int):
"""If battery monitoring is enabled, this event will notify about Aidlab's
state of charge. You never want Aidlab to run low on battery, as it can
lead to it's sudden turn off. Use this event to inform your users about
Aidlab's low energy.
"""
pass
def did_receive_skin_temperature(self, aidlab: IAidlab, timestamp: int, value: float):
"""Called when a skin temperature was received.
"""
pass
def did_receive_accelerometer(self, aidlab: IAidlab, timestamp: int, ax: float, ay: float, az: float):
"""Called when new accelerometer data were received.
"""
pass
def did_receive_gyroscope(self, aidlab: IAidlab, timestamp: int, gx: float, gy: float, gz: float):
"""Called when new gyroscope data were received.
"""
pass
def did_receive_magnetometer(self, aidlab: IAidlab, timestamp: int, mx: float, my: float, mz: float):
"""Called when new magnetometer data were received.
"""
pass
def did_receive_orientation(self, aidlab: IAidlab, timestamp: int, roll: float, pitch: float, yaw: float):
"""Called when received orientation, represented in RPY angles.
"""
pass
def did_receive_body_position(self, aidlab: IAidlab, timestamp: int, body_position: str):
"""Called when received body position.
"""
pass
def did_receive_quaternion(self, aidlab: IAidlab, timestamp: int, qw: float, qx: float, qy: float, qz: float):
"""Called when new quaternion data were received.
"""
pass
def did_receive_activity(self, aidlab: IAidlab, timestamp: int, activity: str):
"""Called when activity data were received.
"""
pass
def did_receive_steps(self, aidlab: IAidlab, timestamp: int, steps: int):
"""Called when total steps did change.
"""
pass
def did_receive_heart_rate(self, aidlab: IAidlab, timestamp: int, heart_rate: int):
"""Called when a heart rate did change.
"""
pass
def did_receive_rr(self, aidlab: IAidlab, timestamp: int, rr: int):
pass
def wear_state_did_change(self, aidlab: IAidlab, state: str):
"""Called when a significant change of wear state did occur. You can use
that information to make decisions when to start processing data, or
display short user guide on how to wear Aidlab in your app.
"""
pass
def did_receive_pressure(self, aidlab: IAidlab, timestamp: int, values: List[int]):
pass
def pressure_wear_state_did_change(self, aidlab: IAidlab, wear_state: str):
pass
def did_receive_sound_volume(self, aidlab: IAidlab, timestamp: int, sound_volume: int):
pass
def did_receive_signal_quality(self, aidlab: IAidlab, timestamp: int, value: int):
pass
def did_detect_exercise(self, aidlab: IAidlab, exercise: str):
pass
def did_receive_command(self, aidlab: IAidlab):
pass
def did_detect_user_event(self, aidlab: IAidlab, timestamp: int):
pass
# -- Aidlab Synchronization ---------------------------------------------------------------------
def sync_state_did_change(self, aidlab: IAidlab, sync_state: str):
pass
def did_receive_unsynchronized_size(self, aidlab: IAidlab, unsynchronized_size: int, sync_bytes_per_second: float):
pass
def did_receive_past_ecg(self, aidlab: IAidlab, timestamp: int, values: List[float]):
pass
def did_receive_past_respiration(self, aidlab: IAidlab, timestamp: int, values: List[float]):
pass
def did_receive_past_respiration_rate(self, aidlab: IAidlab, timestamp: int, value: int):
pass
def did_receive_past_skin_temperature(self, aidlab: IAidlab, timestamp: int, value: float):
pass
def did_receive_past_accelerometer(self, aidlab: IAidlab, timestamp: int, ax: float, ay: float, az: float):
pass
def did_receive_past_gyroscope(self, aidlab: IAidlab, timestamp: int, gx: float, gy: float, gz: float):
pass
def did_receive_past_magnetometer(self, aidlab: IAidlab, timestamp: int, mx: float, my: float, mz: float):
pass
def did_receive_past_orientation(self, aidlab: IAidlab, timestamp: int, roll: float, pitch: float, yaw: float):
pass
def did_receive_past_body_position(self, aidlab: IAidlab, timestamp: int, body_position: str):
pass
def did_receive_past_quaternion(self, aidlab: IAidlab, timestamp: int, qw: float, qx: float, qy: float, qz: float):
pass
def did_receive_past_activity(self, aidlab: IAidlab, timestamp: int, activity: str):
pass
def did_receive_past_steps(self, aidlab: IAidlab, timestamp: int, steps: int):
pass
def did_receive_past_heart_rate(self, aidlab: IAidlab, timestamp: int, heart_rate: int):
pass
def did_receive_past_rr(self, aidlab: IAidlab, timestamp: int, rr: int):
pass
def did_receive_past_pressure(self, aidlab: IAidlab, timestamp: int, values: List[int]):
pass
def did_receive_past_sound_volume(self, aidlab: IAidlab, timestamp: int, sound_volume: int):
pass
def did_receive_past_user_event(self, aidlab: IAidlab, timestamp: int):
pass
def did_receive_past_signal_quality(self, aidlab: IAidlab, timestamp: int, value: int):
pass
|
AidlabSDK
|
/AidlabSDK-1.3.28.tar.gz/AidlabSDK-1.3.28/Aidlab/Aidlab.py
|
Aidlab.py
|
from Aidlab.AidlabCharacteristicsUUID import AidlabCharacteristicsUUID
from Aidlab.AidlabNotificationHandler import AidlabNotificationHandler
from Aidlab.Signal import Signal
from bleak import BleakClient, discover, BleakError
import asyncio
from multiprocessing import Process
import sys
import logging
from packaging import version
from time import time
logging.getLogger("bleak").setLevel(logging.ERROR)
logger = logging.getLogger(__name__)
class AidlabPeripheral():
connected_aidlab = []
def __init__(self, aidlab_delegate):
self.aidlab_delegate = aidlab_delegate
self.queue_to_send = []
self.max_cmd_length = 20
self.should_disconnect = dict()
async def scan_for_aidlab(self):
devices = await discover()
# Container for Aidlab's MAC addresses (these were found during the scan process)
aidlabMACs = []
for dev in devices:
# Device found with dev.name
if dev.name == "Aidlab" and dev.address not in self.connected_aidlab:
aidlabMACs.append(dev.address)
return aidlabMACs
def run(self, real_time_signal, sync_signal, aidlabs_address=None):
try:
loop = asyncio.get_event_loop()
except RuntimeError:
asyncio.set_event_loop(asyncio.new_event_loop())
loop = asyncio.get_event_loop()
self.connect(real_time_signal, sync_signal, loop, aidlabs_address)
def connect(self, real_time_signal, sync_signal, loop, aidlabs_address=None):
# Connect to all Aidlabs from `aidlabsMAC` list
if aidlabs_address:
logging.info("Connecting to %s", aidlabs_address)
self.create_task(real_time_signal, sync_signal, aidlabs_address, loop, False)
# All Aidlabs connected, end the loop
return
# Connect to every discoverable Aidlab
else:
logging.info("Scanning ...")
while True:
aidlabs_address = loop.run_until_complete(self.scan_for_aidlab())
if aidlabs_address != []:
logging.info("Connecting to %s",aidlabs_address)
self.create_task(real_time_signal, sync_signal, aidlabs_address, loop, True)
def create_task(self, real_time_signal, sync_signal, aidlabs_address, loop, should_scan):
if 'linux' in sys.platform:
# during my testing, this method seemed to work relatively stable, but can connect to one aidlab at the time
# it requires more testing though - leaving the previous approach below (and creating task on trello)
loop.run_until_complete(self.connect_to_aidlab(real_time_signal, sync_signal, aidlabs_address[0], loop, 0.5))
else:
for aidlab_address in aidlabs_address:
try:
loop.create_task(self.connect_to_aidlab(real_time_signal, sync_signal, aidlab_address, loop))
except:
pass
finally:
self.connected_aidlab.append(aidlab_address)
if should_scan:
# task to look for more aidlabs
loop.create_task(self.connect(real_time_signal, sync_signal, loop))
loop.run_forever()
async def connect_to_aidlab(self, real_time_signal, sync_signal, aidlab_address, loop, command_send_delay_sec = 0):
client = BleakClient(aidlab_address, loop=loop)
try:
await client.connect(timeout=10)
self.aidlab_delegate.create_aidlabSDK(aidlab_address)
# Harvest Device Information
firmware_revision = (await client.read_gatt_char("00002a26-0000-1000-8000-00805f9b34fb")).decode('ascii')
self.aidlab_delegate.did_receive_raw_firmware_revision(firmware_revision, aidlab_address)
self.aidlab_delegate.did_receive_raw_hardware_revision(
(await client.read_gatt_char("00002a27-0000-1000-8000-00805f9b34fb")).decode('ascii'), aidlab_address)
self.aidlab_delegate.did_receive_raw_manufacture_name(
(await client.read_gatt_char("00002a29-0000-1000-8000-00805f9b34fb")).decode('ascii'), aidlab_address)
self.aidlab_delegate.did_receive_raw_serial_number(
(await client.read_gatt_char("00002a25-0000-1000-8000-00805f9b34fb")).decode('ascii'), aidlab_address)
self.aidlab_delegate.did_connect_aidlab(aidlab_address)
self.aidlabCharacteristicsUUID = AidlabCharacteristicsUUID(firmware_revision)
aidlabNotificationHandler = AidlabNotificationHandler(aidlab_address, self.aidlab_delegate, self.aidlabCharacteristicsUUID)
for characteristic in self.converter_to_uuids(real_time_signal, aidlab_address):
try:
await client.start_notify(characteristic, aidlabNotificationHandler.handle_notification)
except BleakError as e:
logger.debug(str(e) + " (this might be due to compatibility with older aidlabs)")
pass
await self.set_aidlab_time(client, time())
if version.parse("3.6.0") < version.parse(firmware_revision):
logger.debug("Version later than 3.6 start collect data")
await self.start_collect_data(client, aidlab_address, real_time_signal, sync_signal)
else:
logger.debug("Version older than 3.6")
while True:
await asyncio.sleep(command_send_delay_sec)
await self.send_command_if_needed(client)
if self.should_disconnect.get(aidlab_address, False):
self.should_disconnect.pop(aidlab_address, None)
await client.disconnect()
if not client.is_connected:
self.aidlab_delegate.did_disconnect_aidlab(aidlab_address)
self.aidlab_delegate.destroy(aidlab_address)
self.connected_aidlab.remove(aidlab_address)
break
except Exception as e:
logger.debug("Exception " + str(e))
if aidlab_address in self.connected_aidlab: self.connected_aidlab.remove(aidlab_address)
def disconnect(self, aidlab_address):
self.should_disconnect[aidlab_address] = True
def start_synchronization(self, address):
self.queue_to_send.append({"address": address, "command": "sync start"})
def stop_synchronization(self, address):
self.queue_to_send.append({"address": address, "command": "sync stop"})
def send(self, address, command):
self.queue_to_send.append({"address": address, "command": command})
async def send_command_if_needed(self, client):
while self.queue_to_send:
command = self.queue_to_send.pop(0)
await self.send_command(client, command["address"], command["command"])
await asyncio.sleep(1)
async def send_command(self, client, aidlab_address, command):
write_value = self.aidlab_delegate.get_command(aidlab_address, command)
size = write_value[3] | (write_value[4] << 8)
message = [write_value[i] for i in range(size)]
await self.send_to_aidlab(client, message, size)
async def send_to_aidlab(self, client, message, size):
logger.debug("will send msg" + str(message) + " len " + str(size))
for i in range(round(int(size/self.max_cmd_length) + (size%self.max_cmd_length > 0))):
message_byte = bytearray(message[i*self.max_cmd_length:(i+1)*self.max_cmd_length])
logger.debug("sending bytes\n" + str(message_byte))
await client.write_gatt_char(self.aidlabCharacteristicsUUID.cmdUUID["uuid"], message_byte, True)
async def set_aidlab_time(self, client, timestamp):
timestamp = int(timestamp)
message = [b for b in timestamp.to_bytes(4, "little")]
await client.write_gatt_char(self.aidlabCharacteristicsUUID.currentTimeUUID["uuid"], bytearray(message), True)
def signal_list_to_int_list(self, signals):
int_list = []
for signal in signals:
int_list.append(signal.value)
return int_list
async def start_collect_data(self, client, aidlab_address, real_time_signal, sync_signal):
write_value = self.aidlab_delegate.get_collect_command(
aidlab_address,
self.signal_list_to_int_list(real_time_signal),
self.signal_list_to_int_list(sync_signal)
)
size = write_value[3] | (write_value[4] << 8)
message = [write_value[i] for i in range(size)]
await self.send_to_aidlab(client, message, size)
def converter_to_uuids(self, signals, aidlab_address):
# We always want to notify the command line
out = [self.aidlabCharacteristicsUUID.cmdUUID["uuid"]]
for signal in signals:
if signal == Signal.skin_temperature:
out.append(self.aidlabCharacteristicsUUID.temperatureUUID["uuid"])
elif signal == Signal.ecg:
out.append(self.aidlabCharacteristicsUUID.ecgUUID["uuid"])
elif signal == Signal.battery:
out.append(self.aidlabCharacteristicsUUID.batteryUUID["uuid"])
out.append(self.aidlabCharacteristicsUUID.batteryLevelUUID["uuid"])
elif signal == Signal.respiration:
out.append(self.aidlabCharacteristicsUUID.respirationUUID["uuid"])
elif signal == Signal.motion:
out.append(self.aidlabCharacteristicsUUID.motionUUID["uuid"])
elif signal == Signal.activity:
out.append(self.aidlabCharacteristicsUUID.activityUUID["uuid"])
elif signal == Signal.steps:
out.append(self.aidlabCharacteristicsUUID.stepsUUID["uuid"])
elif signal == Signal.orientation:
out.append(self.aidlabCharacteristicsUUID.orientationUUID["uuid"])
elif signal == Signal.sound_volume:
out.append(self.aidlabCharacteristicsUUID.soundVolumeUUID["uuid"])
elif signal == Signal.heart_rate:
out.append(self.aidlabCharacteristicsUUID.heartRateUUID["uuid"])
elif signal == Signal.rr:
out.append(self.aidlabCharacteristicsUUID.heartRateUUID["uuid"])
elif signal == Signal.pressure:
pass
elif signal == Signal.respiration_rate:
pass
elif signal == Signal.body_position:
pass
else:
logging.error(f"Signal {signal} not supported")
self.aidlab_delegate.did_disconnect_aidlab(aidlab_address)
exit()
return out
|
AidlabSDK
|
/AidlabSDK-1.3.28.tar.gz/AidlabSDK-1.3.28/Aidlab/AidlabPeripheral.py
|
AidlabPeripheral.py
|
class AidlabNotificationHandler(object):
def __init__(self, aidlab_address, delegate, aidlab_characteristics_uuid):
self.aidlab_address = aidlab_address
self.delegate = delegate
self.aidlab_characteristics_uuid = aidlab_characteristics_uuid
def handle_notification(self, sender, data):
try:
sender = sender.upper()
except AttributeError:
pass
if sender == self.aidlab_characteristics_uuid.temperatureUUID["handle"] or sender == self.aidlab_characteristics_uuid.temperatureUUID["uuid"].upper():
self.delegate.did_receive_raw_temperature(data, self.aidlab_address)
elif sender == self.aidlab_characteristics_uuid.ecgUUID["handle"] or sender == self.aidlab_characteristics_uuid.ecgUUID["uuid"].upper():
self.delegate.did_receive_raw_ecg(data, self.aidlab_address)
elif sender == self.aidlab_characteristics_uuid.batteryUUID["handle"] or sender == self.aidlab_characteristics_uuid.batteryUUID["uuid"].upper():
self.delegate.did_receive_raw_battery_level(data, self.aidlab_address)
elif sender == self.aidlab_characteristics_uuid.respirationUUID["handle"] or sender == self.aidlab_characteristics_uuid.respirationUUID["uuid"].upper():
self.delegate.did_receive_raw_respiration(data, self.aidlab_address)
elif sender == self.aidlab_characteristics_uuid.activityUUID["handle"] or sender == self.aidlab_characteristics_uuid.activityUUID["uuid"].upper():
self.delegate.did_receive_raw_activity(data, self.aidlab_address)
elif sender == self.aidlab_characteristics_uuid.stepsUUID["handle"] or sender == self.aidlab_characteristics_uuid.stepsUUID["uuid"].upper():
self.delegate.did_receive_raw_steps(data, self.aidlab_address)
elif sender == self.aidlab_characteristics_uuid.heartRateUUID["handle"] or sender == self.aidlab_characteristics_uuid.heartRateUUID["uuid"].upper() or sender == "2A37":
self.delegate.did_receive_raw_heart_rate(data, self.aidlab_address)
elif sender == self.aidlab_characteristics_uuid.soundVolumeUUID["handle"] or sender == self.aidlab_characteristics_uuid.soundVolumeUUID["uuid"].upper():
self.delegate.did_receive_raw_sound_volume(data, self.aidlab_address)
elif sender == self.aidlab_characteristics_uuid.cmdUUID["handle"] or sender == self.aidlab_characteristics_uuid.cmdUUID["uuid"].upper():
self.delegate.did_receive_raw_cmd_value(data, self.aidlab_address)
elif sender == self.aidlab_characteristics_uuid.orientationUUID["handle"] or sender == self.aidlab_characteristics_uuid.orientationUUID["uuid"].upper():
self.delegate.did_receive_raw_orientation(data, self.aidlab_address)
elif sender == self.aidlab_characteristics_uuid.motionUUID["handle"] or sender == self.aidlab_characteristics_uuid.motionUUID["uuid"].upper():
self.delegate.did_receive_raw_imu_values(data, self.aidlab_address)
|
AidlabSDK
|
/AidlabSDK-1.3.28.tar.gz/AidlabSDK-1.3.28/Aidlab/AidlabNotificationHandler.py
|
AidlabNotificationHandler.py
|
import sys
import os
import logging
from ctypes import c_uint8, CFUNCTYPE, c_void_p, c_uint64, c_float, POINTER, c_int, Structure, c_uint16, c_uint32, c_bool, cdll, c_char, c_char_p
from Aidlab.IAidlab import IAidlab
logger = logging.getLogger(__name__)
class AidlabSDK_ptr(Structure):
pass
class AidlabSDK:
sample_time_callback_type = CFUNCTYPE(None, c_void_p, c_uint64, c_float)
samples_time_callback_type = CFUNCTYPE(None, c_void_p, c_uint64, POINTER(c_float), c_int)
activity_callback_type = CFUNCTYPE(None, c_void_p, c_uint64, c_uint8)
respiration_rate_callback_type = CFUNCTYPE(None, c_void_p, c_uint64, c_uint32)
accelerometer_callback_type = CFUNCTYPE(None, c_void_p, c_uint64, c_float, c_float, c_float)
gyroscope_callback_type = CFUNCTYPE(None, c_void_p, c_uint64, c_float, c_float, c_float)
magnetometer_callback_type = CFUNCTYPE(None, c_void_p, c_uint64, c_float, c_float, c_float)
battery_callback_type = CFUNCTYPE(None, c_void_p, c_uint8)
steps_callback_type = CFUNCTYPE(None, c_void_p, c_uint64, c_uint64)
orientation_callback_type = CFUNCTYPE(None, c_void_p, c_uint64, c_float, c_float, c_float)
body_position_callback_type = CFUNCTYPE(None, c_void_p, c_uint64, c_uint8)
quaternion_callback_type = CFUNCTYPE(None, c_void_p, c_uint64, c_float, c_float, c_float, c_float)
wear_state_callback_type = CFUNCTYPE(None, c_void_p, c_uint8)
heart_rate_callback_type = CFUNCTYPE(None, c_void_p, c_uint64, c_int)
rr_callback_type = CFUNCTYPE(None, c_void_p, c_uint64, c_int)
pressure_callback_type = CFUNCTYPE(None, c_void_p, c_uint64, POINTER(c_int), c_int)
pressure_wear_state_callback_type = CFUNCTYPE(None, c_void_p, c_uint8)
sound_volume_callback_type = CFUNCTYPE(None, c_void_p, c_uint64, c_uint16)
exercise_callback_type = CFUNCTYPE(None, c_void_p, c_uint8)
received_command_callback_type = CFUNCTYPE(None, c_void_p)
sync_state_callback_type = CFUNCTYPE(None, c_void_p, c_uint8)
unsynchronized_size_callback_type = CFUNCTYPE(None, c_void_p, c_uint16, c_float)
received_message_type = CFUNCTYPE(None, c_void_p, POINTER(c_char), POINTER(c_char))
user_event_callback_type = CFUNCTYPE(None, c_void_p, c_uint64)
did_receive_error_callback_type = CFUNCTYPE(None, c_void_p, c_char_p)
signal_quality_callback_type = CFUNCTYPE(None, c_void_p, c_uint64, c_int)
Activity_type = {
1: "automotive",
2: "walking",
4: "running",
8: "cycling",
16: "still",
32: "still"
}
Wear_state_type = {
0: "placed properly",
1: "loose",
2: "placed upside down",
3: "detached"
}
Exercise = {
0: "pushUp",
1: "jump",
2: "sitUp",
3: "burpee",
4: "pullUp",
5: "squat",
6: "plankStart",
7: "plankEnd"
}
Sync_state = {
0: "start",
1: "end",
2: "stop",
3: "empty"
}
Body_position = {
0: "unknown",
1: "front",
2: "back",
3: "left side",
4: "right side"
}
ecgFiltrationMethod = {"normal": False, "aggressive": True}
def __init__(self, delegate, aidlab_address):
self.delegate = delegate
self.aidlab = IAidlab(self)
self.aidlab.address = aidlab_address
# loading aidlabsdk lib
full_path = os.path.realpath(__file__)
cwd, filename = os.path.split(full_path)
if 'linux' in sys.platform:
if os.uname()[4][:3] == 'arm':
self.lib = cdll.LoadLibrary(cwd+"/aidlabsdk_raspberry.so") # arm(raspberry pi) version
else:
self.lib = cdll.LoadLibrary(cwd+"/aidlabsdk.so")
elif 'win32' in sys.platform:
self.lib = cdll.LoadLibrary(cwd+"/aidlabsdk.dll")
elif 'darwin' in sys.platform:
self.lib = cdll.LoadLibrary(cwd+"/aidlabsdk.dylib")
else:
raise RuntimeError("Unsupported operating system: {}".format(sys.platform))
self.lib.initial.restype = POINTER(AidlabSDK_ptr)
self.aidlab_sdk_ptr = self.lib.initial()
# setting up type of variables and return values
self.setup_process_types()
def calculate_temperature(self, data):
self.lib.processTemperaturePackage((c_uint8 * len(data))(*data), len(data), self.aidlab_sdk_ptr)
def calculate_respiration(self, data):
self.lib.processRespirationPackage((c_uint8 * len(data))(*data), len(data), self.aidlab_sdk_ptr)
def calculate_ecg(self, data):
self.lib.processECGPackage((c_uint8 * len(data))(*data), len(data), self.aidlab_sdk_ptr)
def calculate_battery(self, data):
self.lib.processBatteryPackage((c_uint8 * len(data))(*data), len(data), self.aidlab_sdk_ptr)
def calculate_motion(self, data):
self.lib.processMotionPackage((c_uint8 * len(data))(*data), len(data), self.aidlab_sdk_ptr)
def calculate_activity(self, data):
self.lib.processActivityPackage((c_uint8 * len(data))(*data), len(data), self.aidlab_sdk_ptr)
def calculate_orientation(self, data):
self.lib.processOrientationPackage((c_uint8 * len(data))(*data), len(data), self.aidlab_sdk_ptr)
def calculate_steps(self, data):
self.lib.processStepsPackage((c_uint8 * len(data))(*data), len(data), self.aidlab_sdk_ptr)
def calculate_heart_rate(self, data):
self.lib.processHeartRatePackage((c_uint8 * len(data))(*data), len(data), self.aidlab_sdk_ptr)
def calculate_sound_volume(self, data):
self.lib.processSoundVolumePackage((c_uint8 * len(data))(*data), len(data), self.aidlab_sdk_ptr)
def did_receive_raw_cmd_value(self, data):
logger.debug("receive cmd\n" + str(data))
self.lib.processCMD((c_uint8 * len(data))(*data), len(data), self.aidlab_sdk_ptr)
def get_command(self, message):
data_array =(c_uint8 * (len(message)+1))(*message.encode('utf-8'))
return self.lib.get_command(data_array, self.aidlab_sdk_ptr)
def get_collect_command(self, realTime, sync):
return self.lib.get_collect_command((c_uint8 * len(realTime))(*realTime), len(realTime), (c_uint8 * len(sync))(*sync), len(sync), self.aidlab_sdk_ptr)
def did_receive_firmware_revision(self, firmware_revision):
self.lib.setFirmwareRevision((c_uint8 * len(firmware_revision))(*firmware_revision.encode('utf-8')), len(firmware_revision), self.aidlab_sdk_ptr)
self.aidlab.firmware_revision = firmware_revision
def did_receive_hardware_revision(self, hardware_revision):
self.lib.setHardwareRevision((c_uint8 * len(hardware_revision))(*hardware_revision.encode('utf-8')), len(hardware_revision), self.aidlab_sdk_ptr)
self.aidlab.hardware_revision = hardware_revision
def did_receive_manufacture_name(self, manufacture_name):
self.aidlab.manufacture_name = manufacture_name
def did_receive_serial_number(self, serial_number):
self.aidlab.serial_number = serial_number
def set_ecg_filtration_method(self, method):
self.lib.setAggressiveECGFiltration(self.ecgFiltrationMethod.get(method,False), self.aidlab_sdk_ptr)
def start_synchronization(self, address):
self.delegate.start_synchronization(address)
def stop_synchronization(self, address):
self.delegate.stop_synchronization(address)
def send(self, address, command):
self.delegate.send(address, command)
def disconnect(self, address):
self.delegate.disconnect(address)
def destroy(self):
self.lib.destroy(self.aidlab_sdk_ptr)
def did_connect_aidlab(self):
self.delegate.did_connect(self.aidlab)
def did_disconnect_aidlab(self):
self.delegate.did_disconnect(self.aidlab)
def setup_user_callback(self):
self.ecg_c_callback = self.samples_time_callback_type(self.ecg_callback)
self.respiration_c_callback = self.samples_time_callback_type(self.respiration_callback)
self.temperature_c_callback = self.sample_time_callback_type(self.temperature_callback)
self.activity_c_callback = self.activity_callback_type(self.activity_callback)
self.steps_c_callback = self.steps_callback_type(self.steps_callback)
self.accelerometer_c_callback = self.accelerometer_callback_type(self.accelerometer_callback)
self.gyroscope_c_callback = self.gyroscope_callback_type(self.gyroscope_callback)
self.magnetometer_c_callback = self.magnetometer_callback_type(self.magnetometer_callback)
self.quaternion_c_callback = self.quaternion_callback_type(self.quaternion_callback)
self.orientation_c_callback = self.orientation_callback_type(self.orientation_callback)
self.body_position_c_callback = self.body_position_callback_type(self.body_position_callback)
self.heart_rate_c_callback = self.heart_rate_callback_type(self.heart_rate_callback)
self.rr_c_callback = self.rr_callback_type(self.rr_callback)
self.respiration_rate_c_callback = self.respiration_rate_callback_type(self.respiration_rate_callback)
self.wear_state_c_callback = self.wear_state_callback_type(self.wear_state_did_change)
self.sound_volume_c_callback = self.sound_volume_callback_type(self.sound_volume_callback)
self.exercise_c_callback = self.exercise_callback_type(self.exercise_callback)
self.receive_command_c_callback = self.received_command_callback_type(self.receive_command_callback)
self.pressure_c_callback = self.pressure_callback_type(self.pressure_callback)
self.pressure_wear_state_c_callback = self.pressure_wear_state_callback_type(self.pressure_wear_state_did_change)
self.received_message_c_callback = self.received_message_type(self.received_message_callback)
self.user_event_c_callback = self.user_event_callback_type(self.user_event_callback)
self.did_receive_error_c_callback = self.did_receive_error_callback_type(self.did_receive_error_callback)
self.battery_c_callback = self.battery_callback_type(self.battery_callback)
self.signal_quality_c_callback = self.signal_quality_callback_type(self.signal_quality_callback)
self.lib.initUserServiceCallback(
self.ecg_c_callback, self.respiration_c_callback, self.temperature_c_callback,
self.accelerometer_c_callback, self.gyroscope_c_callback, self.magnetometer_c_callback,
self.battery_c_callback, self.activity_c_callback, self.steps_c_callback,
self.orientation_c_callback, self.quaternion_c_callback, self.respiration_rate_c_callback,
self.wear_state_c_callback, self.heart_rate_c_callback, self.rr_c_callback,
self.sound_volume_c_callback, self.exercise_c_callback, self.receive_command_c_callback,
self.received_message_c_callback, self.user_event_c_callback, self.pressure_c_callback,
self.pressure_wear_state_c_callback, self.body_position_c_callback,
self.did_receive_error_c_callback, self.signal_quality_c_callback, self.aidlab_sdk_ptr)
def setup_synchronization_callback(self):
self.sync_state_c_callback = self.sync_state_callback_type(self.sync_state_did_change)
self.unsynchronized_size_c_callback = self.unsynchronized_size_callback_type(self.did_receive_unsynchronized_size)
self.past_ecg_c_callback = self.samples_time_callback_type(self.past_ecg_callback)
self.past_respiration_c_callback = self.samples_time_callback_type(self.past_respiration_callback)
self.past_temperature_c_callback = self.sample_time_callback_type(self.past_temperature_callback)
self.past_activity_c_callback = self.activity_callback_type(self.past_activity_callback)
self.past_steps_c_callback = self.steps_callback_type(self.past_steps_callback)
self.past_accelerometer_c_callback = self.accelerometer_callback_type(self.past_accelerometer_callback)
self.past_gyroscope_c_callback = self.gyroscope_callback_type(self.past_gyroscope_callback)
self.past_magnetometer_c_callback = self.magnetometer_callback_type(self.past_magnetometer_callback)
self.past_quaternion_c_callback = self.quaternion_callback_type(self.past_quaternion_callback)
self.past_orientation_c_callback = self.orientation_callback_type(self.past_orientation_callback)
self.past_body_position_c_callback = self.body_position_callback_type(self.past_body_position_callback)
self.past_heart_rate_c_callback = self.heart_rate_callback_type(self.past_heart_rate_callback)
self.past_rr_c_callback = self.rr_callback_type(self.past_rr_callback)
self.past_respiration_rate_c_callback = self.respiration_rate_callback_type(self.past_respiration_rate_callback)
self.past_sound_volume_c_callback = self.sound_volume_callback_type(self.past_sound_volume_callback)
self.past_pressure_c_callback = self.pressure_callback_type(self.past_pressure_callback)
self.past_user_event_c_callback = self.user_event_callback_type(self.past_user_event_callback)
self.past_signal_quality_c_callback = self.signal_quality_callback_type(self.past_signal_quality_callback)
self.lib.initSynchronizationCallback(
self.sync_state_c_callback, self.unsynchronized_size_c_callback, self.past_ecg_c_callback,
self.past_respiration_c_callback, self.past_temperature_c_callback, self.past_heart_rate_c_callback,
self.past_rr_c_callback, self.past_activity_c_callback, self.past_respiration_rate_c_callback,
self.past_steps_c_callback, self.past_user_event_c_callback, self.past_sound_volume_c_callback,
self.past_pressure_c_callback, self.past_accelerometer_c_callback, self.past_gyroscope_c_callback,
self.past_quaternion_c_callback, self.past_orientation_c_callback, self.past_magnetometer_c_callback,
self.past_body_position_c_callback, self.past_rr_c_callback, self.past_accelerometer_c_callback,
self.aidlab_sdk_ptr)
def setup_process_types(self):
self.lib.processECGPackage.argtypes = [POINTER(c_uint8), c_int, c_void_p]
self.lib.processECGPackage.restype = None
self.lib.processTemperaturePackage.argtypes = [POINTER(c_uint8), c_int, c_void_p]
self.lib.processTemperaturePackage.restype = None
self.lib.processMotionPackage.argtypes = [POINTER(c_uint8), c_int, c_void_p]
self.lib.processMotionPackage.restype = None
self.lib.processRespirationPackage.argtypes = [POINTER(c_uint8), c_int, c_void_p]
self.lib.processRespirationPackage.restype = None
self.lib.processBatteryPackage.argtypes = [ POINTER(c_uint8), c_int, c_void_p]
self.lib.processBatteryPackage.restype = None
self.lib.processActivityPackage.argtypes = [POINTER(c_uint8), c_int, c_void_p]
self.lib.processActivityPackage.restype = None
self.lib.processStepsPackage.argtypes = [POINTER(c_uint8), c_int, c_void_p]
self.lib.processStepsPackage.restype = None
self.lib.processOrientationPackage.argtypes = [POINTER(c_uint8), c_int, c_void_p]
self.lib.processOrientationPackage.restype = None
self.lib.processHeartRatePackage.argtypes = [POINTER(c_uint8), c_int, c_void_p]
self.lib.processHeartRatePackage.restype = None
self.lib.processCMD.argtypes = [POINTER(c_uint8), c_int, c_void_p]
self.lib.processCMD.restype = None
self.lib.setHardwareRevision.argtypes = [POINTER(c_uint8), c_void_p]
self.lib.setHardwareRevision.restype = None
self.lib.setFirmwareRevision.argtypes = [POINTER(c_uint8), c_void_p]
self.lib.setFirmwareRevision.restype = None
self.lib.setAggressiveECGFiltration.argtypes = [c_bool, c_void_p]
self.lib.setAggressiveECGFiltration.restype = None
self.lib.destroy.argtypes = [c_void_p]
self.lib.destroy.restype = None
self.lib.get_command.argtypes = [POINTER(c_uint8), c_void_p]
self.lib.get_command.restype = POINTER(c_uint8)
self.lib.get_collect_command.argtypes = [POINTER(c_uint8), c_int, POINTER(c_uint8), c_int, c_void_p]
self.lib.get_collect_command.restype = POINTER(c_uint8)
def user_event_callback(self, context, timestamp):
self.delegate.did_detect_user_event(self.aidlab, timestamp)
def did_receive_error_callback(self, context, log_text):
try:
logger.debug(" [DLL] " + log_text.decode("utf-8"))
except UnicodeDecodeError:
logger.debug(" [DLL] " + str(log_text))
def exercise_callback(self, context, exercise):
exercise = self.Exercise.get(exercise, "None")
self.delegate.did_detect_exercise(self.aidlab, exercise)
def ecg_callback(self, context, timestamp, values, size):
values = [values[i] for i in range(size)]
self.delegate.did_receive_ecg(self.aidlab, timestamp, values)
def respiration_callback(self, context, timestamp, values, size):
values = [values[i] for i in range(size)]
self.delegate.did_receive_respiration(self.aidlab, timestamp, values)
def battery_callback(self, context, state_of_charge):
self.delegate.did_receive_battery_level(self.aidlab, state_of_charge)
def temperature_callback(self, context, timestamp, value):
self.delegate.did_receive_skin_temperature(self.aidlab, timestamp, value)
def accelerometer_callback(self, context, timestamp, ax, ay, az):
self.delegate.did_receive_accelerometer(self.aidlab, timestamp, ax, ay, az)
def gyroscope_callback(self, context, timestamp, gx, gy, gz):
self.delegate.did_receive_gyroscope(self.aidlab, timestamp, gx, gy, gz)
def magnetometer_callback(self, context, timestamp, mx, my, mz):
self.delegate.did_receive_magnetometer(self.aidlab, timestamp, mx, my, mz)
def orientation_callback(self, context, timestamp, roll, pitch, yaw):
self.delegate.did_receive_orientation(self.aidlab, timestamp, roll, pitch, yaw)
def quaternion_callback(self, context, timestamp, qw, qx, qy, qz):
self.delegate.did_receive_quaternion(self.aidlab, timestamp, qw, qx, qy, qz)
def body_position_callback(self, context, timestamp, body_position):
body_position = self.Body_position.get(body_position, "unknown")
self.delegate.did_receive_body_position(self.aidlab, timestamp, body_position)
def activity_callback(self, context, timestamp, activity):
activity = self.Activity_type.get(activity, "still")
self.delegate.did_receive_activity(self.aidlab, timestamp, activity)
def steps_callback(self, context, timestamp, value):
self.delegate.did_receive_steps(self.aidlab, timestamp, value)
def heart_rate_callback(self, context, timestamp, heart_rate):
self.delegate.did_receive_heart_rate(self.aidlab, timestamp, heart_rate)
def rr_callback(self, context, timestamp, rr):
self.delegate.did_receive_rr(self.aidlab, timestamp, rr)
def respiration_rate_callback(self, context, timestamp, value):
self.delegate.did_receive_respiration_rate(self.aidlab, timestamp, value)
def pressure_callback(self, context, timestamp, values, size):
values = [values[i] for i in range(size)]
self.delegate.did_receive_pressure(self.aidlab, timestamp, values)
def pressure_wear_state_did_change(self, context, wear_state):
wear_state = self.Wear_state_type.get(wear_state, "detached")
self.delegate.pressure_wear_state_did_change(self.aidlab, wear_state)
def wear_state_did_change(self, context, wear_state):
wear_state = self.Wear_state_type.get(wear_state, "detached")
self.delegate.wear_state_did_change(self.aidlab, wear_state)
def sound_volume_callback(self, context, timestamp, sound_volume):
self.delegate.did_receive_sound_volume(self.aidlab, timestamp, sound_volume)
def receive_command_callback(self, context):
self.delegate.did_receive_command(self.aidlab)
def received_message_callback(self, context, process, message):
pass
def signal_quality_callback(self, context, timestamp, value):
self.delegate.did_receive_signal_quality(self.aidlab, timestamp, value)
# Synchronization
def past_user_event_callback(self, context, timestamp):
self.delegate.did_receive_past_user_event(self.aidlab, timestamp)
def past_ecg_callback(self, context, timestamp, values, size):
values = [values[i] for i in range(size)]
self.delegate.did_receive_past_ecg(self.aidlab, timestamp, values)
def past_respiration_callback(self, context, timestamp, values, size):
values = [values[i] for i in range(size)]
self.delegate.did_receive_past_respiration(self.aidlab, timestamp, values)
def past_temperature_callback(self, context, timestamp, value):
self.delegate.did_receive_past_skin_temperature(self.aidlab, timestamp, value)
def past_accelerometer_callback(self, context, timestamp, ax, ay, az):
self.delegate.did_receive_past_accelerometer(self.aidlab, timestamp, ax, ay, az)
def past_gyroscope_callback(self, context, timestamp, gx, gy, gz):
self.delegate.did_receive_past_gyroscope(self.aidlab, timestamp, gx, gy, gz)
def past_magnetometer_callback(self, context, timestamp, mx, my, mz):
self.delegate.did_receive_past_magnetometer(self.aidlab, timestamp, mx, my, mz)
def past_orientation_callback(self, context, timestamp, roll, pitch, yaw):
self.delegate.did_receive_past_orientation(self.aidlab, timestamp, roll, pitch, yaw)
def past_quaternion_callback(self, context, timestamp, qw, qx, qy, qz):
self.delegate.did_receive_past_quaternion(self.aidlab, timestamp, qw, qx, qy, qz)
def past_activity_callback(self, context, timestamp, activity):
activity = self.Activity_type.get(activity, "still")
self.delegate.did_receive_past_activity(self.aidlab, timestamp, activity)
def past_body_position_callback(self, context, timestamp, body_position):
body_position = self.Body_position.get(body_position, "unknown")
self.delegate.did_receive_past_body_position(self.aidlab, timestamp, body_position)
def past_pressure_callback(self, context, timestamp, values, size):
values = [values[i] for i in range(size)]
self.delegate.did_receive_past_pressure(self.aidlab, timestamp, values)
def past_steps_callback(self, context, timestamp, value):
self.delegate.did_receive_past_steps(self.aidlab, timestamp, value)
def past_heart_rate_callback(self, context, timestamp, heart_rate):
self.delegate.did_receive_past_heart_rate(self.aidlab, timestamp, heart_rate)
def past_rr_callback(self, context, timestamp, rr):
self.delegate.did_receive_past_rr(self.aidlab, timestamp, rr)
def past_respiration_rate_callback(self, context, timestamp, value):
self.delegate.did_receive_past_respiration_rate(self.aidlab, timestamp, value)
def past_sound_volume_callback(self, context, timestamp, sound_volume):
self.delegate.did_receive_past_sound_volume(self.aidlab, timestamp, sound_volume)
def past_signal_quality_callback(self, context, timestamp, value):
self.delegate.did_receive_past_signal_quality(self.aidlab, timestamp, value)
def sync_state_did_change(self, context, sync_state):
sync_state = self.Sync_state.get(sync_state, "empty")
self.delegate.sync_state_did_change(self.aidlab, sync_state)
def did_receive_unsynchronized_size(self, context, unsynchronized_size, sync_bytes_per_second):
self.delegate.did_receive_unsynchronized_size(self.aidlab, unsynchronized_size, sync_bytes_per_second)
|
AidlabSDK
|
/AidlabSDK-1.3.28.tar.gz/AidlabSDK-1.3.28/Aidlab/AidlabSDK.py
|
AidlabSDK.py
|
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
from keras.models import Sequential
from keras.layers import Conv2D
from keras.layers import MaxPooling2D
from keras.layers import Flatten
from keras.layers import Dense
from keras.layers.core import Flatten, Dense, Dropout
from keras.layers.convolutional import Convolution2D, MaxPooling2D, ZeroPadding2D
from keras.optimizers import SGD
from keras.preprocessing.image import ImageDataGenerator
from keras.models import Sequential
from keras.layers import Dropout, Flatten, Dense, BatchNormalization
from keras import applications
from datetime import datetime as dt
from keras import regularizers as reg
from keras.optimizers import RMSprop
from keras.utils import to_categorical
import warnings
warnings.filterwarnings("ignore")
from keras.callbacks import ModelCheckpoint
def graph(x,y,xlabel,ylabel):
plt.plot(x,y)
plt.xlabel(xlabel)
plt.ylabel(ylabel)
plt.show()
def neural_network(input_shape,layer_activation,dense_unit,dense_activation,optim,loss_comp):
classifier = Sequential()
classifier.add(Conv2D(32, (3, 3), input_shape = (64, 64, 3), activation = layer_activation))
classifier.add(MaxPooling2D(pool_size = (2, 2)))
classifier.add(Conv2D(32, (3, 3), activation = layer_activation))
classifier.add(MaxPooling2D(pool_size = (2, 2)))
classifier.add(Conv2D(32, (3, 3), activation = layer_activation))
classifier.add(MaxPooling2D(pool_size = (2, 2)))
classifier.add(Flatten())
# Step 4 - Full connection
classifier.add(Dense(units = 128, activation = layer_activation))
classifier.add(Dense(units = dense_unit, activation = dense_activation))
# Compiling the CNN
classifier.compile(optimizer = optim, loss = loss_comp, metrics = ['accuracy'])
classifier.summary()
def data_zone_csv(x):
'''
CSV = data_zone_csv
'''
self=pd.read_csv(x)
return self
def vgg16(input_shap,dense_unit,dense_activation,optim,loss_comp):
model = Sequential()
model.add(ZeroPadding2D((1, 1), input_shape=input_shap))
model.add(Convolution2D(64, 3, 3, activation='relu'))
model.add(ZeroPadding2D((1, 1)))
model.add(Convolution2D(64, 3, 3, activation='relu'))
model.add(MaxPooling2D((2, 2), strides=(2, 2)))
model.add(ZeroPadding2D((1, 1)))
model.add(Convolution2D(128, 3, 3, activation='relu'))
model.add(ZeroPadding2D((1, 1)))
model.add(Convolution2D(128, 3, 3, activation='relu'))
model.add(MaxPooling2D((2, 2), strides=(2, 2)))
model.add(ZeroPadding2D((1, 1)))
model.add(Convolution2D(256, 3, 3, activation='relu'))
model.add(ZeroPadding2D((1, 1)))
model.add(Convolution2D(256, 3, 3, activation='relu'))
model.add(ZeroPadding2D((1, 1)))
model.add(Convolution2D(256, 3, 3, activation='relu'))
model.add(MaxPooling2D((2, 2), strides=(2, 2)))
model.add(ZeroPadding2D((1, 1)))
model.add(Convolution2D(512, 3, 3, activation='relu'))
model.add(ZeroPadding2D((1, 1)))
model.add(Convolution2D(512, 3, 3, activation='relu'))
model.add(ZeroPadding2D((1, 1)))
model.add(Convolution2D(512, 3, 3, activation='relu'))
model.add(MaxPooling2D((2, 2), strides=(2, 2)))
model.add(ZeroPadding2D((1, 1)))
model.add(Convolution2D(512, 3, 3, activation='relu'))
model.add(ZeroPadding2D((1, 1)))
model.add(Convolution2D(512, 3, 3, activation='relu'))
model.add(ZeroPadding2D((1, 1)))
model.add(Convolution2D(512, 3, 3, activation='relu'))
model.add(MaxPooling2D((2, 2), strides=(2, 2)))
model.add(Flatten())
model.add(Dense(4096, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(4096, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(dense_unit, activation=dense_activation))
model.summary()
model.compile(optimizer = optim, loss = loss_comp, metrics = ['accuracy'])
def Transfer_learning(train_data,val_data,epochs,batch_size):
'''
Keywords :
train_data = training dataset
val_data = Validation dataset
epochs = number of epochs
batch_size = batch size
'''
global_start=dt.now()
#Dimensions of our flicker images is 256 X 256
img_width, img_height = 256, 256
#Declaration of parameters needed for training and validation
epochs = epochs
batch_size = batch_size
#Get the bottleneck features by Weights.T * Xi
def save_bottlebeck_features():
datagen = ImageDataGenerator(rescale=1./255)
#Load the pre trained VGG16 model from Keras, we will initialize only the convolution layers and ignore the top layers.
model = applications.VGG16(include_top=False, weights='imagenet')
generator_tr = datagen.flow_from_directory(train_data,
target_size=(img_width, img_height),
batch_size=batch_size,
class_mode=None, #class_mode=None means the generator won't load the class labels.
shuffle=False) #We won't shuffle the data, because we want the class labels to stay in order.
nb_train_samples = len(generator_tr.filenames) #3600. 1200 training samples for each class
bottleneck_features_train = model.predict_generator(generator_tr, nb_train_samples // batch_size)
np.save('weights/bottleneck_features_train.npy',bottleneck_features_train) #bottleneck_features_train is a numpy array
generator_ts = datagen.flow_from_directory(val_data,
target_size=(img_width, img_height),
batch_size=batch_size,
class_mode=None,
shuffle=False)
nb_validation_samples = len(generator_ts.filenames) #1200. 400 training samples for each class
bottleneck_features_validation = model.predict_generator(generator_ts, nb_validation_samples // batch_size)
np.save('weights/bottleneck_features_validation.npy',bottleneck_features_validation)
print("Got the bottleneck features in time: ",dt.now()-global_start)
num_classes = len(generator_tr.class_indices)
return nb_train_samples,nb_validation_samples,num_classes,generator_tr,generator_ts
nb_train_samples,nb_validation_samples,num_classes,generator_tr,generator_ts=save_bottlebeck_features()
def train_top_model():
global_start=dt.now()
train_data = np.load('weights/bottleneck_features_train.npy')
validation_data = np.load('weights/bottleneck_features_validation.npy')
train_labels=generator_tr.classes
validation_labels=generator_ts.classes
model = Sequential()
model.add(Flatten(input_shape=train_data.shape[1:])) #Ignore the first index. It contains ID
model.add(Dense(256, activation='relu',kernel_initializer='he_normal',kernel_regularizer=reg.l1_l2(l1=0.001, l2=0.001))) #Best weight initializer for relu is he_normal
model.add(BatchNormalization()) #Add a BatchNormalization layer to control internel covariance shift
model.add(Dropout(rate=0.5)) #Using droput for regularization
model.add(Dense(256, activation='relu',kernel_initializer='he_normal',kernel_regularizer=reg.l1_l2(l1=0.001, l2=0.001)))
model.add(BatchNormalization()) #Add a BatchNormalization layer to control internel covariance shift
model.add(Dropout(rate=0.5))
model.add(Dense(1, activation='sigmoid',kernel_initializer='glorot_uniform')) #Because we have 3 classes. Remember, softmax is to multi-class, what sigmoid (log reg) is to binary
optim=RMSprop(lr=0.0001, epsilon=1e-8, decay=1e-6)
model.compile(loss='binary_crossentropy',optimizer=optim,metrics=['accuracy'])
model.summary()
#Save the weights for the best epoch accuracy
checkpointer = ModelCheckpoint(filepath="weights/bottleneck_features_model_weights.hdf5", monitor = 'val_acc',verbose=1, save_best_only=True)
model.fit(x=train_data,
y=train_labels,
epochs=epochs,
validation_data=(validation_data, validation_labels),
callbacks=[checkpointer])
#Refit our model with the best weights saved before
model.load_weights('weights/bottleneck_features_model_weights.hdf5')
model.save('weights/bottleneck_feature_model.h5')
print("The top layer trained in time: ",dt.now()-global_start)
return model
model=train_top_model()
|
Aihub-demo
|
/Aihub-demo-1.0.1.tar.gz/Aihub-demo-1.0.1/aihub/utils.py
|
utils.py
|
AioCrypto
==================
.. image:: https://img.shields.io/badge/telegram-ErVinTract-blue.svg?style=flat
:target: https://t.me/ErVinTract
:alt: [Telegram] ErVinTract
.. image:: https://img.shields.io/pypi/v/AioCrypto.svg?style=flat
:target: https://pypi.python.org/pypi/AioCrypto
:alt: PyPi Package Version
.. image:: https://img.shields.io/pypi/dm/AioCrypto.svg?style=flat
:target: https://pypi.python.org/pypi/AioCrypto
:alt: PyPi downloads
.. image:: https://img.shields.io/pypi/pyversions/AioCrypto.svg?style=flat
:target: https://pypi.python.org/pypi/AioCrypto
:alt: Supported python versions
.. image:: https://img.shields.io/badge/AioCrypto-1.1.1-blue.svg?style=flat
:target: https://help.crypt.bot/crypto-pay-api
:alt: Crypto API
.. image:: https://img.shields.io/github/issues/ErVinTract/aiocrypto.svg?style=flat-square
:target: https://github.com/ErVinTract/AioCrypto/issues
:alt: Github issues
.. image:: https://img.shields.io/pypi/l/AioCrypto.svg?style=flat-square
:target: https://opensource.org/licenses/Apache-2.0
:alt: Apache-2.0 license
**AioCrypto** is a fairly simple and convenient library for working with the `Crypto API <https://help.crypt.bot/crypto-pay-api>`_, written in Python 3.8+ with `asyncio <https://docs.python.org/3/library/asyncio.html>`_ and `aiohttp <https://github.com/aio-libs/aiohttp>`_.
**Official aiocrypto resources**
- News: `@CryptoBotRu <https://t.me/CryptoBotRU>`_
- Community: `@CryptoBotRussian <https://t.me/CryptoBotRussian>`_
- Pip: `AioCrypto <https://pypi.python.org/pypi/aiocrypto>`_
- Source: `Github repo <https://github.com/ErVinTract/AioCrypto>`_
- Issues/Bug tracker: `Github issues tracker <https://github.com/ErVinTract/AioCrypto/issues>`_
|
AioCrypto
|
/AioCrypto-1.0.6.tar.gz/AioCrypto-1.0.6/README.rst
|
README.rst
|
from dataclasses import dataclass
from typing import Optional
@dataclass
class Assets:
BTC: str = 'BTC'
TON: str = 'TON'
ETH: str = 'ETH'
USDT: str = 'USDT'
USDC: str = 'USDC'
BUSD: str = 'BUSD'
@dataclass
class Balance:
currency_code: str
available: float
def __post_init__(self) -> None:
self.available = float(self.available)
@dataclass
class Invoice:
"""
## Invoice
Parameters
----------
* invoice_id - Unique ID for this invoice.
* status - Status of the invoice, can be either “active”, “paid” or “expired”.
* hash - Hash of the invoice.
* asset - Currency code. Currently, can be “BTC”, “TON”, “ETH” (testnet only), “USDT”, “USDC” or “BUSD”.
* amount - Amount of the invoice.
* pay_url - URL should be presented to the user to pay the invoice.
* description - Optional. Description for this invoice.
* created_at - Date the invoice was created in ISO 8601 format.
* allow_comments - True, if the user can add comment to the payment.
* allow_anonymous - True, if the user can pay the invoice anonymously.
* expiration_date - Optional. Date the invoice expires in Unix time.
* paid_at - Optional. Date the invoice was paid in Unix time.
* paid_anonymously - True, if the invoice was paid anonymously.
* comment - Optional. Comment to the payment from the user.
* hidden_message - Optional. Text of the hidden message for this invoice.
* payload - Optional. Previously provided data for this invoice.
* paid_btn_name - Optional. Name of the button, can be “viewItem”, “openChannel”, “openChannel” or “callback”.
* paid_btn_url - Optional. URL of the button.
"""
invoice_id: int
status: int
hash: str
asset: str
amount: str
pay_url: str
created_at: str
allow_comments: Optional[bool] = None
allow_anonymous: Optional[bool] = None
paid_anonymously: Optional[bool] = None
description: Optional[str] = None
expiration_date: Optional[str] = None
paid_at: Optional[str] = None
comment: Optional[str] = None
hidden_message: Optional[str] = None
payload: Optional[str] = None
paid_btn_name: Optional[str] = None
paid_btn_url: Optional[str] = None
@dataclass
class Transfer:
"""
## Transfer
Parameters
----------
* transfer_id - Unique ID for this transfer.
* user_id: - Telegram user ID the transfer was sent to.
* asset - Currency code. Currently, can be “BTC”, “TON”, “ETH” (testnet only), “USDT”, “USDC” or “BUSD”.
* amount - Amount of the transfer.
* status - Status of the transfer, can be “completed”.
* completed_at - Date the transfer was completed in ISO 8601 format.
* comment - Optional. Comment for this transfer.
"""
transfer_id: int
user_id: int
asset: str
amount: str
status: str
completed_at: str
comment: Optional[str] = None
@dataclass
class ExchangeRate:
is_valid: bool
source: str
target: str
rate: float
def __post_init__(self) -> None:
self.rate = float(self.rate)
@dataclass
class Currency:
is_blockchain: bool
is_stablecoin: bool
is_fiat: bool
name: str
code: str
decimals: int
url: Optional[str] = None
@dataclass
class PaidButtonNames:
VIEW_ITEM: str = 'viewItem',
OPEN_CHANNEL: str = 'openChannel',
OPEN_BOT: str = 'openBot',
CALLBACK: str = 'callback'
@dataclass
class Hostnames:
MAIN_NET: str = 'https://pay.crypt.bot'
TEST_NET: str = 'https://testnet-pay.crypt.bot'
@dataclass
class App:
app_id: int
name: str
payment_processing_bot_username: str
@dataclass
class Status:
active: str = "active"
paid: str = "paid"
|
AioCrypto
|
/AioCrypto-1.0.6.tar.gz/AioCrypto-1.0.6/aiocrypto/types.py
|
types.py
|
from aiocrypto import App, Invoice, Balance, Currency, Transfer, ExchangeRate, Unauthorized, __version__
from aiocrypto.types import Hostnames, Assets
from aiohttp import ClientSession
from typing import List, Union, Optional
class CryptoApi:
def __init__(self, token, hostname: str = Hostnames.MAIN_NET) -> None:
"""
### Init CryptoPay api
* async class CryptoApi
### Args:
token (str): CryptoPay api token from @CryptoBot or @CryptoTestnetBot
hostname (str, optional): Api endpoint hostname. Defaults to Hostnames.MAIN_NET.
delay (int, optional): Not implemented, wait for version 1.2, zero by default
"""
self._token = token
self._hostname = hostname
self._client: ClientSession = ClientSession(
base_url=self._hostname, headers={
'Crypto-Pay-API-Token': self._token, 'user-agent': f'AioCrypto Stable {__version__}', }
)
def _raise(self, response: dict) -> Exception:
"""
### Raise api errors
#### Args:
response (dict): [response dict data]
#### Returns:
Exception: [Exception models]
"""
if response['ok'] == False:
if response['error']['code'] == 401:
raise Unauthorized(
response['error']['code'], response['error']['name'])
else:
raise response
@classmethod
def _validate_asset(cls, asset):
assert asset in Assets.__annotations__.keys()
@classmethod
def _clear_dict(cls, dict_: dict):
return {key: value for key, value in dict_.items() if value is not None}
async def get_me(self) -> App:
"""
### About
Use this method to test your app's authentication token. Requires no parameters.
On success, returns basic information about an app.
Returns
--------
- App: object[App]
"""
async with self._client.get(url='/api/getMe') as response:
resp = await response.json()
self._raise(response=resp)
return App(**resp['result'])
async def create_invoice(self,
asset: str,
amount: float,
**kwargs: Union[str, bool, int]):
"""
### About
Use this method to test your app's authentication token. Requires no parameters.
On success, returns basic information about an app.
Params
-------
- asset (String): Supported assets: “BTC”, “TON”, “ETH”, “USDT”, “USDC” and “BUSD”.
- amount (Float)
- description (String): Optional. Description for the invoice. User will see this description when they pay the invoice. Up to 1024 characters.
- hidden_message (String): Optional. Text of the message that will be shown to a user after the invoice is paid. Up to 2048 characters.
- paid_btn_name (String): Optional. Name of the button that will be shown to a user after the invoice is paid.
- Supported names:
1. viewItem – “View Item”
2. openChannel – “View Channel”
3. openBot – “Open Bot”
4. callback – “Return”
- paid_btn_url (String): Optional. Required if paid_btn_name is used.URL to be opened when the button is pressed. You can set any success link (for example, a link to your bot). Starts with https or http.
- payload (String): Optional. Any data you want to attach to the invoice (for example, user ID, payment ID, ect). Up to 4kb.
- allow_comments (Boolean): Optional. Allow a user to add a comment to the payment. Default is true.
- allow_anonymous (Boolean): Optional. Allow a user to pay the invoice anonymously. Default is true.
- expires_in (Number): Optional. You can set a payment time limit for the invoice in seconds. Values between 1-2678400 are accepted.
Returns
--------
- Invoice: dict
"""
data = {
k: v for k, v in kwargs.items()
}
data['asset'] = asset
data['amount'] = amount
async with self._client.get(url="/api/createInvoice", data=data) as response:
resp = await response.json()
self._raise(response=resp)
return resp['result']
async def transfer(self, user_id: int, asset: str, amount: Union[float, str], spend_id: str, **kwargs) -> Transfer:
"""
### About
Use this method to send your coins to other users.
If successful, returns information about the given translation.
Params
-------
- user_id (Number): Telegram user ID. User must have previously used @CryptoBot (@CryptoTestnetBot for testnet).
- asset (String): Currency code. Supported assets: “BTC”, “TON”, “ETH”, “USDT”, “USDC” and “BUSD”.
- amount (String): Amount of the transfer in float. The minimum and maximum amounts for each of the support asset roughly correspond to the limit of 1-25000 USD. Use getExchangeRates to convert amounts. For example: 125.50
- spend_id (String): Unique ID to make your request idempotent and ensure that only one of the transfers with the same spend_id is accepted from your app. This parameter is useful when the transfer should be retried (i.e. request timeout, connection reset, 500 HTTP status, etc). Up to 64 symbols.
- comment (String): Optional. Comment for the transfer. Users will see this comment when they receive a notification about the transfer. Up to 1024 symbols.
- disable_send_notification (Boolean): Optional. Pass true if the user should not receive a notification about the transfer.Default is false.
Returns
--------
- Transfer: object[Transfer]
"""
data = {
k: v for k, v in kwargs.items()
}
data['user_id'] = user_id
data['asset'] = asset
data['amount'] = amount
data['spend_id'] = spend_id
async with self._client.get(url='/api/transfer', data=data) as response:
resp = await response.json()
self._raise(response=resp)
return Transfer(**resp['result'])
async def get_balance(self) -> List[Balance]:
"""
### About
Use this method to check your balance. Requires no parameters.
If successful, returns information about the balance of the connected application.
- Supported assets: “BTC”, “TON”, “ETH”, “USDT”, “USDC” and “BUSD”.
Returns
--------
- list[Balance]: Balance list object
"""
async with self._client.get(url='/api/getBalance') as response:
resp = await response.json()
self._raise(response=resp)
return [Balance(**balance) for balance in resp['result']]
async def get_invoices(
self,
asset: Optional[str] = None,
invoice_ids: Optional[List[Union[str, int]]] = None,
status: Optional[str] = None,
offset: Optional[int] = None,
count: Optional[int] = None
) -> List[Invoice]:
"""
### About
Use this method to view active invoices.
If successful, returns a sheet with information about all specified invoices.
Returns
--------
- list[Invoice]: Invoice list object
"""
if asset is not None:
self._validate_asset(asset)
if invoice_ids is not None:
invoice_ids = ",".join(map(str, invoice_ids))
params = {"asset": asset, "invoice_ids": invoice_ids, "status": status, "offset": offset, "count": count}
async with self._client.get(url='/api/getInvoices', params=self._clear_dict(params)) as response:
resp = await response.json()
self._raise(response=resp)
return [Invoice(**invoice) for invoice in resp['result']['items']]
async def get_exchange_rates(self) -> List[ExchangeRate]:
"""
### About
Use this method to get exchange rates of supported currencies. Returns array of currencies.
Returns:
--------
- List[ExchangeRate]: ExchangeRate list object
"""
async with self._client.get(url='/api/getExchangeRates') as response:
resp = await response.json()
self._raise(response=resp)
return [ExchangeRate(**rate) for rate in resp['result']]
async def get_currencies(self) -> List[Currency]:
"""
### About
Use this method to get a list of supported currencies. Returns array of currencies.
Returns:
--------
- List[Currency]: Currency list object
"""
async with self._client.get(url='/api/getCurrencies') as response:
resp = await response.json()
self._raise(response=resp)
return [Currency(**currency) for currency in resp['result']]
async def close(self) -> str:
"""
### Close client session
"""
await self._client.close()
return "Success!"
|
AioCrypto
|
/AioCrypto-1.0.6.tar.gz/AioCrypto-1.0.6/aiocrypto/app.py
|
app.py
|
CHANGES
=======
0.8.3 (2022-01-13)
------------------
- No real change, just release
0.8.2 (2020-10-28)
------------------
- Catch more exception
0.8.1 (2020-10-20)
------------------
- Check value length, default max 1 megabyte
0.8.0 (2020-09-08)
------------------
- Rewrite almost code
- Redesigned API
- Support unicode string for key
- Support flags
- Support URI
- More test coverage
0.7.0 (2020-08-28)
------------------
- Change pypi packages name to aiomemcached
- Drop python 3.4-3.6 support
- Add python 3.7+ support
0.6.0 (2017-12-03)
------------------
- Drop python 3.3 support
0.5.2 (2017-05-27)
------------------
- Fix issue with pool concurrency and task cancellation
0.5.1 (2017-03-08)
------------------
- Added MANIFEST.in
0.5.0 (2017-02-08)
------------------
- Added gets and cas commands
0.4.0 (2016-09-26)
------------------
- Make max_size strict #14
0.3.0 (2016-03-11)
------------------
- Dockerize tests
- Reuse memcached connections in Client Pool #4
- Fix stats parse to compatible more mc class software #5
0.2 (2015-12-15)
----------------
- Make the library Python 3.5 compatible
0.1 (2014-06-18)
----------------
- Initial release
|
AioMemcached
|
/AioMemcached-0.8.4.tar.gz/AioMemcached-0.8.4/CHANGES.rst
|
CHANGES.rst
|
# AioMemcached


[](https://codecov.io/gh/rexzhang/aiomemcached)
[](https://github.com/psf/black)
[](https://pypi.org/project/aiomemcached/)
[](https://pypi.org/project/aiomemcached/)
[](https://pypi.org/project/aiomemcached/)
A pure-Python(3.7+) zero-depend asyncio memcached client, fork from [aiomcache](https://pypi.org/project/aiomcache/).
| | people |
|---------------|------------------------------------------------|
| Author | Nikolay Kim <[email protected]> |
| Maintainer | Rex Zhang <[email protected]> |
| Contributions | Nikolay Novik <[email protected]> |
| | Andrew Svetlov <[email protected]> |
| | Rex Zhang <[email protected]> |
| | Manuel Miranda <[email protected]> |
| | Jeong YunWon <https://github.com/youknowone> |
| | Thanos Lefteris <https://github.com/alefteris> |
| | Maarten Draijer <[email protected]> |
| | Michael Gorven <[email protected]> |
## Install
```shell
pip install -U AioMemcached
```
## Usage
### Base command examples
Code
```python
import asyncio
import aiomemcached
async def base_command():
client = aiomemcached.Client()
print('client.version() =>', await client.version())
print('\ninit key and value:')
k1, k2, v1, v2 = b'k1', b'k2', b'1', b'v2'
print("k1, k2, v1, v2 = b'k1', b'k2', b'1', b'2'")
keys = [k1, k2]
print("keys = [k1, k2]")
print('\nget and set key:')
print('client.set(k1, v1) =>', await client.set(k1, v1))
print('client.get(k1) =>', await client.get(k1))
print('client.set(k2, v2) =>', await client.set(k2, v2))
print('client.get(k2) =>', await client.get(k2))
print('\nincr and decr value:')
print('client.incr(k1) =>', await client.incr(k1))
print('client.decr(k1) =>', await client.decr(k1))
print('\nget multi key:')
print('client.get_many(keys) =>', await client.get_many(keys))
print('client.gets_many(keys) =>', await client.gets_many(keys))
print('client.set(k2, v2) =>', await client.set(k2, v2))
print('client.gets_many(keys) =>', await client.gets_many(keys))
print('\ndelete key:')
print('client.delete(k1) =>', await client.delete(k1))
print('client.gets_many(keys) =>', await client.gets_many(keys))
print('\nappend value to key:')
print("client.append(k2, b'append') =>",
await client.append(k2, b'append'))
print('client.get(k2) =>', await client.get(k2))
print('flush memcached:')
print('client.flush_all() =>', await client.flush_all())
print('client.get_many(keys) =>', await client.get_many(keys))
return
if __name__ == '__main__':
asyncio.run(base_command())
```
Output
```
client.version() => b'1.6.9'
init key and value:
k1, k2, v1, v2 = b'k1', b'k2', b'1', b'2'
keys = [k1, k2]
get and set key:
client.set(k1, v1) => True
client.get(k1) => (b'1', {'flags': 0, 'cas': None})
client.set(k2, v2) => True
client.get(k2) => (b'v2', {'flags': 0, 'cas': None})
incr and decr value:
client.incr(k1) => 2
client.decr(k1) => 1
get multi key:
client.get_many(keys) => ({b'k1': b'1', b'k2': b'v2'}, {b'k1': {'flags': 0, 'cas': None}, b'k2': {'flags': 0, 'cas': None}})
client.gets_many(keys) => ({b'k1': b'1', b'k2': b'v2'}, {b'k1': {'flags': 0, 'cas': 168}, b'k2': {'flags': 0, 'cas': 166}})
client.set(k2, v2) => True
client.gets_many(keys) => ({b'k1': b'1', b'k2': b'v2'}, {b'k1': {'flags': 0, 'cas': 168}, b'k2': {'flags': 0, 'cas': 169}})
delete key:
client.delete(k1) => True
client.gets_many(keys) => ({b'k2': b'v2'}, {b'k2': {'flags': 0, 'cas': 169}})
append value to key:
client.append(k2, b'append') => True
client.get(k2) => (b'v2append', {'flags': 0, 'cas': None})
flush memcached:
client.flush_all() => True
client.get_many(keys) => ({}, {})
```
## Development
Unit test and coverage report
```shell
python -m pytest
```
|
AioMemcached
|
/AioMemcached-0.8.4.tar.gz/AioMemcached-0.8.4/README.md
|
README.md
|
import asyncio
from asyncio.streams import StreamReader, StreamWriter
from collections import deque
from .constants import DEFAULT_POOL_MAXSIZE, DEFAULT_POOL_MINSIZE, DEFAULT_TIMEOUT
from .exceptions import ConnectException
__all__ = ["MemcachedPool", "MemcachedConnection"]
class MemcachedConnection:
def __init__(self, reader: StreamReader, writer: StreamWriter):
self.in_use = False
self.reader = reader
self.writer = writer
async def close(self):
self.reader.feed_eof()
self.writer.close()
class MemcachedPool:
def __init__(
self,
host: str,
port: int,
minsize: int = DEFAULT_POOL_MINSIZE,
maxsize: int = DEFAULT_POOL_MAXSIZE,
connect_timeout: int = DEFAULT_TIMEOUT,
):
self._host = host
self._port = port
self._connect_timeout = connect_timeout
self._pool = deque()
self._pool_minsize = minsize
self._pool_maxsize = maxsize
self._pool_lock = asyncio.Lock()
def size(self) -> int:
return len(self._pool)
async def _create_new_connection(self) -> MemcachedConnection:
while self.size() >= self._pool_maxsize:
await asyncio.sleep(1)
try:
reader, writer = await asyncio.wait_for(
asyncio.open_connection(self._host, self._port),
timeout=self._connect_timeout,
)
except (ConnectionError, TimeoutError, OSError) as e:
raise ConnectException(e)
return MemcachedConnection(reader, writer)
async def acquire(self) -> MemcachedConnection:
"""Acquires a not in used connection from pool.
Creates new connection if needed.
"""
try:
conn = self._pool[0]
if conn.in_use:
raise IndexError
conn.in_use = True
self._pool.rotate(-1)
return conn
except IndexError:
pass
conn = await self._create_new_connection()
conn.in_use = True
self._pool.append(conn)
return conn
async def release(self, conn: MemcachedConnection) -> None:
"""Returns used connection back into pool.
When pool size > minsize the connection will be dropped.
"""
await self._pool_lock.acquire()
try:
if conn not in self._pool:
return
if self.size() > self._pool_minsize:
await conn.close()
self._pool.remove(conn)
else:
conn.in_use = False
finally:
self._pool_lock.release()
async def dispose(self, conn: MemcachedConnection) -> None:
"""Closes and disposes of the connection."""
if conn in self._pool:
self._pool.remove(conn)
try:
await conn.close()
except ConnectionError:
pass
async def clear(self) -> None:
"""Clear pool connections.
Close and remove all free connections.
"""
while self._pool:
conn = self._pool.pop()
await conn.close()
|
AioMemcached
|
/AioMemcached-0.8.4.tar.gz/AioMemcached-0.8.4/aiomemcached/pool.py
|
pool.py
|
import asyncio
import functools
import re
import warnings
from io import BytesIO
from typing import Dict, List, Optional
from .constants import (
DEFAULT_MAX_KEY_LENGTH,
DEFAULT_MAX_VALUE_LENGTH,
DEFAULT_POOL_MAXSIZE,
DEFAULT_POOL_MINSIZE,
DEFAULT_SERVER_HOST,
DEFAULT_SERVER_PORT,
DEFAULT_TIMEOUT,
DELETED,
END,
EXISTS,
NOT_FOUND,
NOT_STORED,
OK,
STORED,
TOUCHED,
VERSION,
)
from .exceptions import (
ConnectException,
ResponseException,
TimeoutException,
ValidationException,
)
from .pool import MemcachedConnection, MemcachedPool
"""
Ref:
- https://github.com/memcached/memcached/blob/master/doc/protocol.txt
- https://dzone.com/refcardz/getting-started-with-memcached
"""
__all__ = ["Client"]
# key supports ascii sans space and control chars
# \x21 is !, right after space, and \x7e is -, right before DEL
# also 1 <= len <= 250 as per the spec
_VALIDATE_KEY_RE = re.compile(b"^[^\x00-\x20\x7f]{1,%d}$" % DEFAULT_MAX_KEY_LENGTH)
# URI: memcached://localhost:11211
_URI_RE = re.compile(
r"^memcached://(?P<host>[.a-z0-9_-]+|[0-9]+.[0-9]+.[0-9]+.[0-9]+)"
r"(:(?P<port>[0-9]+))?"
)
def acquire(func):
@functools.wraps(func)
async def wrapper(self, *args, **kwargs):
conn = await self._pool.acquire()
try:
return await func(self, conn, *args, **kwargs)
except (ConnectionError, ConnectException):
await self._pool.dispose(conn)
raise
finally:
await self._pool.release(conn)
return wrapper
class Client(object):
def __init__(
self,
uri: str = None,
host: str = DEFAULT_SERVER_HOST,
port: int = DEFAULT_SERVER_PORT,
pool_minsize: int = DEFAULT_POOL_MINSIZE,
pool_maxsize: int = DEFAULT_POOL_MAXSIZE,
timeout: int = DEFAULT_TIMEOUT,
connect_timeout: int = DEFAULT_TIMEOUT,
value_length: int = DEFAULT_MAX_VALUE_LENGTH,
):
if uri is None:
self._host = host
self._port = port
else:
self._host, self._port = self.uri_parser(uri)
self._timeout = timeout
self._value_length = value_length
self._pool = MemcachedPool(
host=self._host,
port=self._port,
minsize=pool_minsize,
maxsize=pool_maxsize,
connect_timeout=connect_timeout,
)
@staticmethod
def uri_parser(uri: str) -> (str, int):
m = re.match(_URI_RE, uri.lower())
try:
host = m.group("host")
port = m.group("port")
if port is None:
port = DEFAULT_SERVER_PORT
else:
port = int(port)
except AttributeError:
raise ValidationException("URI:{} parser failed!".format(uri))
return host, port
@staticmethod
def validate_key(key: bytes) -> None:
"""A key (arbitrary string up to 250 bytes in length.
No space or newlines for ASCII mode)
"""
if not isinstance(key, bytes): # TODO maybe remove in next version?
raise ValidationException("key must be bytes:{}".format(key))
m = _VALIDATE_KEY_RE.match(key)
if not m or len(m.group(0)) != len(key):
raise ValidationException(
"A key (arbitrary string up to 250 bytes in length. "
"No space or newlines for ASCII mode):{}".format(key)
)
return
def validate_value(self, value: bytes):
if len(value) > self._value_length:
raise ValidationException(
"A value up to {} bytes in length.".format(len(value))
)
async def close(self):
"""Closes the sockets if its open."""
await self._pool.clear()
@acquire
async def _execute_raw_cmd(
self,
conn: MemcachedConnection,
cmd: bytes,
one_line_response: bool = False,
end_symbols: List[bytes] = None,
) -> BytesIO:
"""
skip end_symbols if one_line_response is True
"""
if end_symbols is None:
end_symbols = list()
conn.writer.write(cmd)
response_stream = BytesIO()
while True:
try:
line = await asyncio.wait_for(
conn.reader.readline(), timeout=self._timeout
)
except ConnectionError as e:
raise ConnectException(e)
except asyncio.TimeoutError as e:
raise TimeoutException(e) # TODO test
response_stream.write(line)
if one_line_response:
break
if line in end_symbols:
break
response_stream.seek(0)
return response_stream
async def _storage_command(
self,
cmd: bytes,
key: bytes,
value: bytes,
flags: int = 0,
exptime: int = 0,
cas: int = None,
) -> bool:
"""
Storage commands
----------------
First, the client sends a command line which looks like this:
<command name> <key> <flags> <exptime> <bytes> [noreply]\r\n
cas <key> <flags> <exptime> <bytes> <cas unique> [noreply]\r\n
- <command name> is "set", "add", "replace", "append" or "prepend"
"set" means "store this data".
"add" means "store this data, but only if the server *doesn't* already
hold data for this key".
"replace" means "store this data, but only if the server *does*
already hold data for this key".
"append" means "add this data to an existing key after existing data".
"prepend" means "add this data to an existing key before existing data".
The append and prepend commands do not accept flags or exptime.
They update existing data portions, and ignore new flag and exptime
settings.
"cas" is a check and set operation which means "store this data but
only if no one else has updated since I last fetched it."
- <key> is the key under which the client asks to store the data
- <flags> is an arbitrary 16-bit unsigned integer (written out in
decimal) that the server stores along with the data and sends back
when the item is retrieved. Clients may use this as a bit field to
store data-specific information; this field is opaque to the server.
Note that in memcached 1.2.1 and higher, flags may be 32-bits, instead
of 16, but you might want to restrict yourself to 16 bits for
compatibility with older versions.
- <exptime> is expiration time. If it's 0, the item never expires
(although it may be deleted from the cache to make place for other
items). If it's non-zero (either Unix time or offset in seconds from
current time), it is guaranteed that clients will not be able to
retrieve this item after the expiration time arrives (measured by
server time). If a negative value is given the item is immediately
expired.
- <bytes> is the number of bytes in the data block to follow, *not*
including the delimiting \r\n. <bytes> may be zero (in which case
it's followed by an empty data block).
- <cas unique> is a unique 64-bit value of an existing entry.
Clients should use the value returned from the "gets" command
when issuing "cas" updates.
- "noreply" optional parameter instructs the server to not send the
reply. NOTE: if the request line is malformed, the server can't
parse "noreply" option reliably. In this case it may send the error
to the client, and not reading it on the client side will break
things. Client should construct only valid requests.
After this line, the client sends the data block:
<data block>\r\n
- <data block> is a chunk of arbitrary 8-bit data of length <bytes>
from the previous line.
After sending the command line and the data block the client awaits
the reply, which may be:
- "STORED\r\n", to indicate success.
- "NOT_STORED\r\n" to indicate the data was not stored, but not
because of an error. This normally means that the
condition for an "add" or a "replace" command wasn't met.
- "EXISTS\r\n" to indicate that the item you are trying to store with
a "cas" command has been modified since you last fetched it.
- "NOT_FOUND\r\n" to indicate that the item you are trying to store
with a "cas" command did not exist.
"""
# validate key, value
self.validate_key(key)
self.validate_value(value)
if flags < 0 or exptime < 0:
raise ValidationException(
"flags:[{}] and exptime:[{}] must be unsigned integer"
"".format(flags, exptime)
)
if cas:
raw_cmd = b"cas %b %d %d %d %d\r\n%b\r\n" % (
key,
flags,
exptime,
len(value),
cas,
value,
)
else:
raw_cmd = b"%b %b %d %d %d\r\n%b\r\n" % (
cmd,
key,
flags,
exptime,
len(value),
value,
)
response_stream = await self._execute_raw_cmd(
cmd=raw_cmd, one_line_response=True
)
response = response_stream.readline()
if response == STORED:
return True
elif response in (NOT_STORED, EXISTS, NOT_FOUND):
# TODO raise with status , depend option raise_exp?
return False
raise ResponseException(raw_cmd, response_stream.getvalue())
async def set(
self, key: bytes, value: bytes, flags: int = 0, exptime: int = 0
) -> bool:
""" "set" means "store this data"."""
return await self._storage_command(
cmd=b"set", key=key, value=value, flags=flags, exptime=exptime
)
async def add(
self, key: bytes, value: bytes, flags: int = 0, exptime: int = 0
) -> bool:
"""
"add" means "store this data, but only if the server *doesn't* already
hold data for this key".
"""
return await self._storage_command(
cmd=b"add", key=key, value=value, flags=flags, exptime=exptime
)
async def replace(
self, key: bytes, value: bytes, flags: int = 0, exptime: int = 0
) -> bool:
"""
"replace" means "store this data, but only if the server *does*
already hold data for this key".
"""
return await self._storage_command(
cmd=b"replace", key=key, value=value, flags=flags, exptime=exptime
)
async def append(
self, key: bytes, value: bytes, flags: int = 0, exptime: int = 0
) -> bool:
"""
"append" means "add this data to an existing key after existing data".
"""
return await self._storage_command(
cmd=b"append", key=key, value=value, flags=flags, exptime=exptime
)
async def prepend(
self, key: bytes, value: bytes, flags: int = 0, exptime: int = 0
) -> bool:
""" "prepend" means
"add this data to an existing key before existing data".
"""
return await self._storage_command(
cmd=b"prepend", key=key, value=value, flags=flags, exptime=exptime
)
async def cas(
self, key: bytes, value: bytes, cas: int, flags: int = 0, exptime: int = 0
) -> bool:
"""
"cas" is a check and set operation which means "store this data but
only if no one else has updated since I last fetched it."
"""
return await self._storage_command(
cmd=b"cas", key=key, value=value, flags=flags, exptime=exptime, cas=cas
)
async def _retrieval_command(
self, keys: List[bytes], with_cas: bool = False
) -> (Dict[bytes, bytes], Dict[bytes, Dict[bytes, Optional[int]]]):
"""
Retrieval command:
------------------
The retrieval commands "get" and "gets" operate like this:
get <key>*\r\n
gets <key>*\r\n
- <key>* means one or more key strings separated by whitespace.
After this command, the client expects zero or more items, each of
which is received as a text line followed by a data block. After all
the items have been transmitted, the server sends the string
"END\r\n"
to indicate the end of response.
Each item sent by the server looks like this:
VALUE <key> <flags> <bytes> [<cas unique>]\r\n
<data block>\r\n
- <key> is the key for the item being sent
- <flags> is the flags value set by the storage command
- <bytes> is the length of the data block to follow, *not* including
its delimiting \r\n
- <cas unique> is a unique 64-bit integer that uniquely identifies
this specific item.
- <data block> is the data for this item.
If some of the keys appearing in a retrieval request are not sent back
by the server in the item list this means that the server does not
hold items with such keys (because they were never stored, or stored
but deleted to make space for more items, or expired, or explicitly
deleted by a client).
"""
# validate keys
[self.validate_key(key) for key in keys]
cmd_format = b"gets %b\r\n" if with_cas else b"get %b\r\n"
raw_cmd = cmd_format % b" ".join(keys)
response_stream = await self._execute_raw_cmd(
cmd=raw_cmd,
end_symbols=[
END,
],
)
values = {}
info = {}
# values = {
# key: data,
# ...
# }
# info = {
# key: {
# 'flags': flags,
# 'cas': cas,
# },
# ...
# }
line = response_stream.readline()
while line != b"" and line != END:
terms = line.split()
try:
if terms[0] != b"VALUE":
raise ResponseException(raw_cmd, response_stream.getvalue())
key = terms[1]
if key in values:
raise ResponseException(
raw_cmd,
response_stream.getvalue(),
ext_message="Duplicate results from server",
)
flags = int(terms[2])
cas = int(terms[4]) if with_cas else None
data_len = int(terms[3])
data = response_stream.read(data_len + 2).rstrip(b"\r\n")
if len(data) != data_len:
raise ValueError
except ValueError:
raise ResponseException(raw_cmd, response_stream.getvalue())
values[key] = data
info[key] = {
"flags": flags,
"cas": cas,
}
line = response_stream.readline()
if len(values) > len(keys):
raise ResponseException(
raw_cmd,
response_stream.readline(),
ext_message="received too many responses",
)
return values, info
async def get(
self, key: bytes, default: bytes = None
) -> (bytes, Dict[bytes, Optional[int]]):
"""Gets a single value from the server."""
keys = [
key,
]
values, info = await self._retrieval_command(keys)
return values.get(key, default), info.get(key, dict())
async def gets(
self, key: bytes, default: bytes = None
) -> (bytes, Dict[bytes, Optional[int]]):
"""Gets a single value from the server together with the cas token."""
keys = [
key,
]
values, info = await self._retrieval_command(keys, with_cas=True)
return values.get(key, default), info.get(key, dict())
async def get_many(
self, keys: List[bytes]
) -> ( # TODO default?!
Dict[bytes, bytes],
Dict[bytes, Dict[bytes, Optional[int]]],
):
"""Takes a list of keys and returns a list of values."""
# check keys
if len(keys) == 0:
return dict(), dict()
keys = list(set(keys)) # ignore duplicate keys error
values, info = await self._retrieval_command(keys)
return values, info
async def gets_many(
self, keys: List[bytes]
) -> (Dict[bytes, bytes], Dict[bytes, Dict[bytes, Optional[int]]]):
"""Takes a list of keys and returns a list of values
together with the cas token.
"""
# check keys
if len(keys) == 0:
return dict(), dict()
keys = list(set(keys)) # ignore duplicate keys error
values, info = await self._retrieval_command(keys, with_cas=True)
return values, info
async def multi_get(self, *args):
"""shadow for get_multi, DeprecationWarning"""
warnings.warn(
"multi_get is deprecated since AioMemcached 0.8, "
"and scheduled for removal in AioMemcached 0.9 .)",
DeprecationWarning,
)
keys = [arg for arg in args]
values, _ = await self.get_many(keys)
return tuple(values.get(key) for key in keys)
async def delete(self, key: bytes) -> bool:
"""
Deletion
--------
The command "delete" allows for explicit deletion of items:
delete <key> [noreply]\r\n
- <key> is the key of the item the client wishes the server to delete
- "noreply" optional parameter instructs the server to not send the
reply. See the note in Storage commands regarding malformed
requests.
The response line to this command can be one of:
- "DELETED\r\n" to indicate success
- "NOT_FOUND\r\n" to indicate that the item with this key was not
found.
See the "flush_all" command below for immediate invalidation
of all existing items.
"""
# validate key
self.validate_key(key)
raw_cmd = b"delete %b\r\n" % key
response_stream = await self._execute_raw_cmd(
cmd=raw_cmd, one_line_response=True
)
response = response_stream.readline()
if response == DELETED:
return True
elif response == NOT_FOUND:
# TODO raise with status , depend option raise_exp?
return False
raise ResponseException(raw_cmd, response_stream.getvalue())
async def _incr_decr(self, cmd: bytes, key: bytes, value: int) -> Optional[int]:
"""
Increment/Decrement
-------------------
Commands "incr" and "decr" are used to change data for some item
in-place, incrementing or decrementing it. The data for the item is
treated as decimal representation of a 64-bit unsigned integer. If
the current data value does not conform to such a representation, the
incr/decr commands return an error (memcached <= 1.2.6 treated the
bogus value as if it were 0, leading to confusion). Also, the item
must already exist for incr/decr to work; these commands won't pretend
that a non-existent key exists with value 0; instead, they will fail.
The client sends the command line:
incr <key> <value> [noreply]\r\n
or
decr <key> <value> [noreply]\r\n
- <key> is the key of the item the client wishes to change
- <value> is the amount by which the client wants to increase/decrease
the item. It is a decimal representation of a 64-bit unsigned integer.
- "noreply" optional parameter instructs the server to not send the
reply. See the note in Storage commands regarding malformed
requests.
The response will be one of:
- "NOT_FOUND\r\n" to indicate the item with this value was not found
- <value>\r\n , where <value> is the new value of the item's data,
after the increment/decrement operation was carried out.
Note that underflow in the "decr" command is caught: if a client tries
to decrease the value below 0, the new value will be 0. Overflow in
the "incr" command will wrap around the 64 bit mark.
Note also that decrementing a number such that it loses length isn't
guaranteed to decrement its returned length. The number MAY be
space-padded at the end, but this is purely an implementation
optimization, so you also shouldn't rely on that.
"""
# validate key
self.validate_key(key)
if value < 0 or not isinstance(value, int):
raise ValidationException(
"value:[{}] must be unsigned integer".format(value)
)
raw_cmd = b"%b %b %d\r\n" % (cmd, key, value)
response_stream = await self._execute_raw_cmd(
cmd=raw_cmd, one_line_response=True
)
response = response_stream.readline()
try:
if response == NOT_FOUND:
# TODO raise with status , depend option raise_exp?
return None
new_value = int(response)
except ValueError:
raise ResponseException(raw_cmd, response_stream.getvalue())
return new_value
async def incr(
self, key: bytes, value: int = 1, increment: int = None
) -> Optional[int]:
if increment:
warnings.warn(
"incr() param increment is deprecated since AioMemcached 0.8, "
"and scheduled for removal in AioMemcached 0.9 .)",
DeprecationWarning,
)
value = increment
return await self._incr_decr(cmd=b"incr", key=key, value=value)
async def decr(
self, key: bytes, value: int = 1, decrement: int = None
) -> Optional[int]:
if decrement:
warnings.warn(
"incr() param increment is deprecated since AioMemcached 0.8, "
"and scheduled for removal in AioMemcached 0.9 .)",
DeprecationWarning,
)
value = decrement
return await self._incr_decr(cmd=b"decr", key=key, value=value)
async def touch(self, key: bytes, exptime: int) -> bool:
"""
Touch
-----
The "touch" command is used to update the expiration time of an existing item
without fetching it.
touch <key> <exptime> [noreply]\r\n
- <key> is the key of the item the client wishes the server to touch
- <exptime> is expiration time. Works the same as with the update commands
(set/add/etc). This replaces the existing expiration time. If an existing
item were to expire in 10 seconds, but then was touched with an
expiration time of "20", the item would then expire in 20 seconds.
- "noreply" optional parameter instructs the server to not send the
reply. See the note in Storage commands regarding malformed
requests.
The response line to this command can be one of:
- "TOUCHED\r\n" to indicate success
- "NOT_FOUND\r\n" to indicate that the item with this key was not
found.
"""
# validate key
self.validate_key(key)
raw_cmd = b"touch %b %d\r\n" % (key, exptime)
response_stream = await self._execute_raw_cmd(
cmd=raw_cmd, one_line_response=True
)
response = response_stream.readline()
if response == TOUCHED:
return True
elif response == NOT_FOUND:
# TODO raise with status , depend option raise_exp?
return False
raise ResponseException(raw_cmd, response_stream.getvalue())
async def stats(self, args: bytes = None) -> dict:
"""
Statistics
----------
The command "stats" is used to query the server about statistics it
maintains and other internal data. It has two forms. Without
arguments:
stats\r\n
it causes the server to output general-purpose statistics and
settings, documented below. In the other form it has some arguments:
stats <args>\r\n
Depending on <args>, various internal data is sent by the server. The
kinds of arguments and the data sent are not documented in this version
of the protocol, and are subject to change for the convenience of
memcache developers.
"""
if args is None:
args = b""
raw_cmd = b"stats %b\r\n" % args
response_stream = await self._execute_raw_cmd(
cmd=raw_cmd,
end_symbols=[
END,
],
)
result = {}
line = response_stream.readline()
while line != END:
terms = line.split()
if len(terms) == 2 and terms[0] == b"STAT":
result[terms[1]] = None
elif len(terms) == 3 and terms[0] == b"STAT":
result[terms[1]] = terms[2]
elif len(terms) >= 3 and terms[0] == b"STAT":
result[terms[1]] = b" ".join(terms[2:])
else:
raise ResponseException(raw_cmd, response_stream.getvalue())
line = response_stream.readline()
return result
async def version(self) -> bytes:
"""
"version" is a command with no arguments:
version\r\n
In response, the server sends
"VERSION <version>\r\n", where <version> is the version string for the
server.
"verbosity" is a command with a numeric argument. It always succeeds,
and the server sends "OK\r\n" in response (unless "noreply" is given
as the last parameter). Its effect is to set the verbosity level of
the logging output.
"""
raw_cmd = b"version\r\n"
response_stream = await self._execute_raw_cmd(
cmd=raw_cmd, one_line_response=True
)
response = response_stream.readline()
if not response.startswith(VERSION):
raise ResponseException(raw_cmd, response_stream.getvalue())
versions = response.rstrip(b"\r\n").split(maxsplit=1)
return versions[1]
async def flush_all(self) -> bool:
"""Its effect is to invalidate all existing items immediately
"flush_all" is a command with an optional numeric argument. It always
succeeds, and the server sends "OK\r\n" in response (unless "noreply"
is given as the last parameter). Its effect is to invalidate all
existing items immediately (by default) or after the expiration
specified. After invalidation none of the items will be returned in
response to a retrieval command (unless it's stored again under the
same key *after* flush_all has invalidated the items). flush_all
doesn't actually free all the memory taken up by existing items; that
will happen gradually as new items are stored. The most precise
definition of what flush_all does is the following: it causes all
items whose update time is earlier than the time at which flush_all
was set to be executed to be ignored for retrieval purposes.
"""
raw_cmd = b"flush_all\r\n"
response_stream = await self._execute_raw_cmd(
cmd=raw_cmd, one_line_response=True
)
response = response_stream.readline()
if not response.startswith(OK):
raise ResponseException(raw_cmd, response_stream.getvalue())
return True
|
AioMemcached
|
/AioMemcached-0.8.4.tar.gz/AioMemcached-0.8.4/aiomemcached/client.py
|
client.py
|
# AioPTTCrawler (PTT 網路版爬蟲)
This is Python Package use to crawl PTT's article data by using asyncio.
## Documentation
### [PyPi Page][]
[PyPi Page]:<https://pypi.org/project/AioPTTCrawler/>
```bash
pip install AioPTTCrawler
```
```python
from AioPTTCrawler import AioPTTCrawler
ptt_crawler = AioPTTCrawler()
```
## Usage
### get data from PTT
```python
ptt_crawler = AioPTTCrawler()
BOARD = "Gossiping"
ptt_data = ptt_crawler.get_board_latest_articles(board=BOARD, page_count=10)
```
```python
ptt_crawler = AioPTTCrawler()
BOARD = "Gossiping"
ptt_data = ptt_crawler.get_board_articles(board=BOARD, start_index=100, end_index=200)
```
#### ptt_data is a PTTData object. To extract data you need to use get_article_dict(), get_article_dataframe(), get_article_list() etc
---
### get dict from PTTData
```python
article_dict = ptt_data.get_article_dict()
comment_dict = ptt_data.get_comment_dict()
```
article's dict format
```json
[
{
"article" : "Article's ID. ex:M.1663144920.A.A6E",
"article_title" : "Article's title. ex:[公告] 批踢踢27週年活動宣導公告更新",
"user_id" : "Author's ID. ex: ubcs",
"user_name" : "Author's name. ex:(覺★青年超冒險蓋)",
"board" : "BBS Board ex: Gossiping",
"datetime" : "Post time. ex: Wed Sep 14 16:41:58 2022.",
"context" : "Context of article. ex: PTT 27 周年活動開始囉,本篇為置底宣導,詳情參閱下面資料...",
"ip_address" : "IP address. ex: 59.120.192.119",
"comment_list" : [
{"comment_dict"},
{"comment_dict"},
]
}, {"..."}
]
```
comment's dict format
```json
[
{
"article_id" : "Article's ID. ex:M.1663144920.A.A6E",
"tag" : "comment's reaction. ex: 推 噓 →",
"user_id" : "User's ID. ex: bill403777",
"comment_order" : "order of comment. ex: 1",
"context" : "Context of comment. ex: 錢",
"datetime" : "Post time. ex: 09/14 16:42",
"ip_address" : "27.53.96.42",
}, {"..."}
]
```
#### use this [article][] for example
[article]: https://www.ptt.cc/bbs/Gossiping/M.1663144920.A.A6E.html
## Comparison
### Used time difference between normal method and async method

#### (unit: second)
## Support
You may report bugs, ask for help and discuss various other issues on the [issuse][]
[issuse]: https://github.com/DOUIF/aio-ptt-crawler/issues
|
AioPTTCrawler
|
/AioPTTCrawler-0.0.12.tar.gz/AioPTTCrawler-0.0.12/README.md
|
README.md
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.