MME-RealWorld
Collection
Could Your Multimodal LLM Challenge High-Resolution Real-World Scenarios that are Difficult for Humans?
•
7 items
•
Updated
Error code: DatasetGenerationError
Exception: TypeError
Message: Mask must be a pyarrow.Array of type boolean
Traceback: Traceback (most recent call last):
File "/src/services/worker/.venv/lib/python3.9/site-packages/datasets/builder.py", line 1625, in _prepare_split_single
writer.write(example, key)
File "/src/services/worker/.venv/lib/python3.9/site-packages/datasets/arrow_writer.py", line 537, in write
self.write_examples_on_file()
File "/src/services/worker/.venv/lib/python3.9/site-packages/datasets/arrow_writer.py", line 495, in write_examples_on_file
self.write_batch(batch_examples=batch_examples)
File "/src/services/worker/.venv/lib/python3.9/site-packages/datasets/arrow_writer.py", line 609, in write_batch
self.write_table(pa_table, writer_batch_size)
File "/src/services/worker/.venv/lib/python3.9/site-packages/datasets/arrow_writer.py", line 624, in write_table
pa_table = embed_table_storage(pa_table)
File "/src/services/worker/.venv/lib/python3.9/site-packages/datasets/table.py", line 2270, in embed_table_storage
arrays = [
File "/src/services/worker/.venv/lib/python3.9/site-packages/datasets/table.py", line 2271, in <listcomp>
embed_array_storage(table[name], feature) if require_storage_embed(feature) else table[name]
File "/src/services/worker/.venv/lib/python3.9/site-packages/datasets/table.py", line 1795, in wrapper
return pa.chunked_array([func(chunk, *args, **kwargs) for chunk in array.chunks])
File "/src/services/worker/.venv/lib/python3.9/site-packages/datasets/table.py", line 1795, in <listcomp>
return pa.chunked_array([func(chunk, *args, **kwargs) for chunk in array.chunks])
File "/src/services/worker/.venv/lib/python3.9/site-packages/datasets/table.py", line 2140, in embed_array_storage
return feature.embed_storage(array)
File "/src/services/worker/.venv/lib/python3.9/site-packages/datasets/features/image.py", line 283, in embed_storage
storage = pa.StructArray.from_arrays([bytes_array, path_array], ["bytes", "path"], mask=bytes_array.is_null())
File "pyarrow/array.pxi", line 3257, in pyarrow.lib.StructArray.from_arrays
File "pyarrow/array.pxi", line 3697, in pyarrow.lib.c_mask_inverted_from_obj
TypeError: Mask must be a pyarrow.Array of type boolean
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/src/services/worker/.venv/lib/python3.9/site-packages/datasets/builder.py", line 1634, in _prepare_split_single
num_examples, num_bytes = writer.finalize()
File "/src/services/worker/.venv/lib/python3.9/site-packages/datasets/arrow_writer.py", line 636, in finalize
self.write_examples_on_file()
File "/src/services/worker/.venv/lib/python3.9/site-packages/datasets/arrow_writer.py", line 495, in write_examples_on_file
self.write_batch(batch_examples=batch_examples)
File "/src/services/worker/.venv/lib/python3.9/site-packages/datasets/arrow_writer.py", line 609, in write_batch
self.write_table(pa_table, writer_batch_size)
File "/src/services/worker/.venv/lib/python3.9/site-packages/datasets/arrow_writer.py", line 624, in write_table
pa_table = embed_table_storage(pa_table)
File "/src/services/worker/.venv/lib/python3.9/site-packages/datasets/table.py", line 2270, in embed_table_storage
arrays = [
File "/src/services/worker/.venv/lib/python3.9/site-packages/datasets/table.py", line 2271, in <listcomp>
embed_array_storage(table[name], feature) if require_storage_embed(feature) else table[name]
File "/src/services/worker/.venv/lib/python3.9/site-packages/datasets/table.py", line 1795, in wrapper
return pa.chunked_array([func(chunk, *args, **kwargs) for chunk in array.chunks])
File "/src/services/worker/.venv/lib/python3.9/site-packages/datasets/table.py", line 1795, in <listcomp>
return pa.chunked_array([func(chunk, *args, **kwargs) for chunk in array.chunks])
File "/src/services/worker/.venv/lib/python3.9/site-packages/datasets/table.py", line 2140, in embed_array_storage
return feature.embed_storage(array)
File "/src/services/worker/.venv/lib/python3.9/site-packages/datasets/features/image.py", line 283, in embed_storage
storage = pa.StructArray.from_arrays([bytes_array, path_array], ["bytes", "path"], mask=bytes_array.is_null())
File "pyarrow/array.pxi", line 3257, in pyarrow.lib.StructArray.from_arrays
File "pyarrow/array.pxi", line 3697, in pyarrow.lib.c_mask_inverted_from_obj
TypeError: Mask must be a pyarrow.Array of type boolean
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "/src/services/worker/src/worker/job_runners/config/parquet_and_info.py", line 1412, in compute_config_parquet_and_info_response
parquet_operations, partial, estimated_dataset_info = stream_convert_to_parquet(
File "/src/services/worker/src/worker/job_runners/config/parquet_and_info.py", line 988, in stream_convert_to_parquet
builder._prepare_split(
File "/src/services/worker/.venv/lib/python3.9/site-packages/datasets/builder.py", line 1486, in _prepare_split
for job_id, done, content in self._prepare_split_single(
File "/src/services/worker/.venv/lib/python3.9/site-packages/datasets/builder.py", line 1643, in _prepare_split_single
raise DatasetGenerationError("An error occurred while generating the dataset") from e
datasets.exceptions.DatasetGenerationError: An error occurred while generating the datasetNeed help to make the dataset viewer work? Make sure to review how to configure the dataset viewer, and open a discussion for direct support.
image
image |
|---|
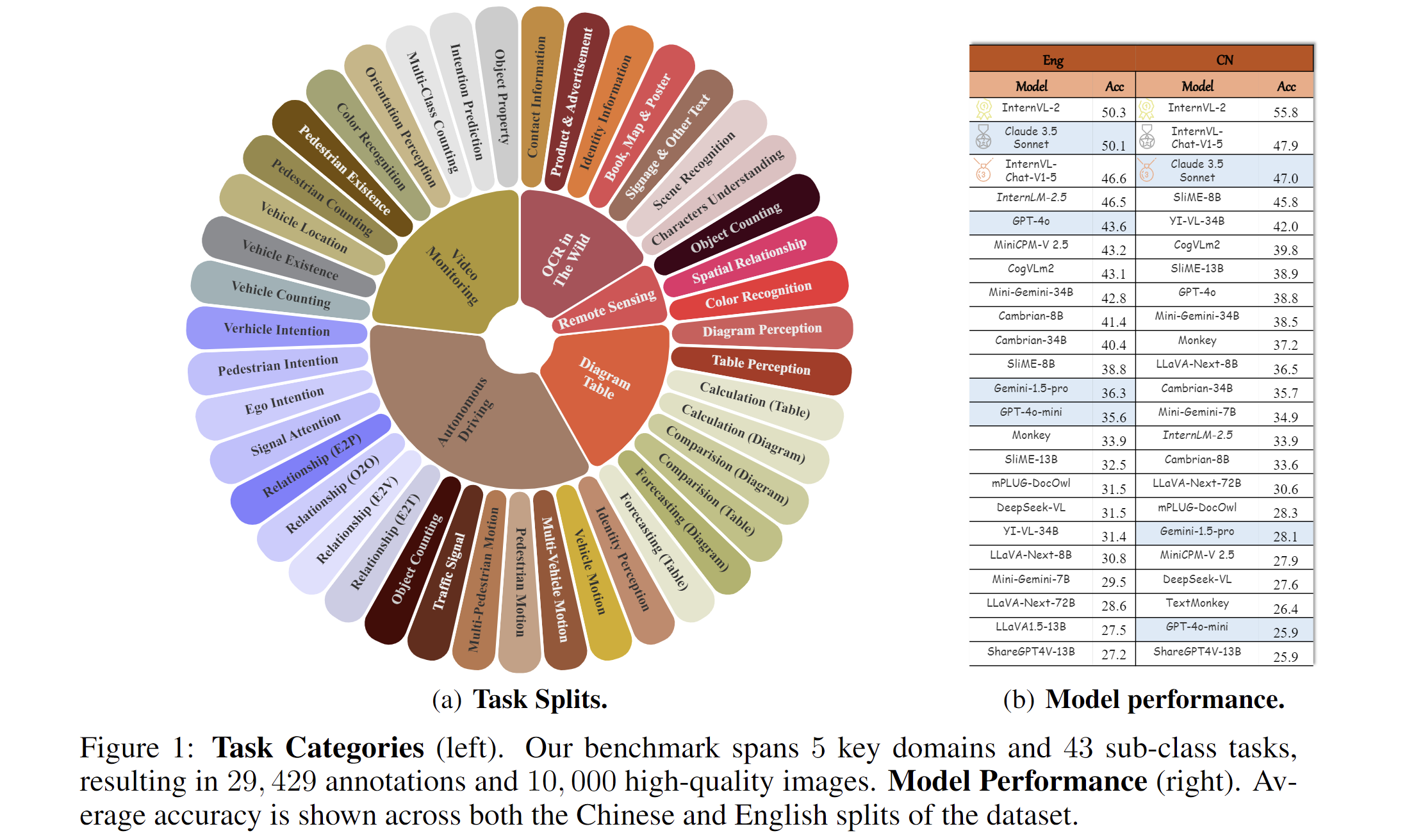
2024.11.14 🌟 MME-RealWorld now has a lite version (50 samples per task, or all if fewer than 50) for inference acceleration, which is also supported by VLMEvalKit and Lmms-eval.2024.09.03 🌟 MME-RealWorld is now supported in the VLMEvalKit and Lmms-eval repository, enabling one-click evaluation—give it a try!" 2024.08.20 🌟 We are very proud to launch MME-RealWorld, which contains 13K high-quality images, annotated by 32 volunteers, resulting in 29K question-answer pairs that cover 43 subtasks across 5 real-world scenarios. As far as we know, MME-RealWorld is the largest manually annotated benchmark to date, featuring the highest resolution and a targeted focus on real-world applications.Paper: arxiv.org/abs/2408.13257
Code: https://github.com/yfzhang114/MME-RealWorld
Project page: https://mme-realworld.github.io/
The data.zip file contains all images and question JSON files, with the question format identical to the full split.
Results of representative models on the MME-RealWorld-lite subset:

Existing Multimodal Large Language Model benchmarks present several common barriers that make it difficult to measure the significant challenges that models face in the real world, including:
We present MME-RealWord, a benchmark meticulously designed to address real-world applications with practical relevance. Featuring 13,366 high-resolution images averaging 2,000 × 1,500 pixels, MME-RealWord poses substantial recognition challenges. Our dataset encompasses 29,429 annotations across 43 tasks, all expertly curated by a team of 25 crowdsource workers and 7 MLLM experts. The main advantages of MME-RealWorld compared to existing MLLM benchmarks as follows:
Data Scale: with the efforts of a total of 32 volunteers, we have manually annotated 29,429 QA pairs focused on real-world scenarios, making this the largest fully human-annotated benchmark known to date.
Data Quality: 1) Resolution: Many image details, such as a scoreboard in a sports event, carry critical information. These details can only be properly interpreted with high- resolution images, which are essential for providing meaningful assistance to humans. To the best of our knowledge, MME-RealWorld features the highest average image resolution among existing competitors. 2) Annotation: All annotations are manually completed, with a professional team cross-checking the results to ensure data quality.
Task Difficulty and Real-World Utility.: We can see that even the most advanced models have not surpassed 60% accuracy. Additionally, many real-world tasks are significantly more difficult than those in traditional benchmarks. For example, in video monitoring, a model needs to count the presence of 133 vehicles, or in remote sensing, it must identify and count small objects on a map with an average resolution exceeding 5000×5000.
MME-RealWord-CN.: Existing Chinese benchmark is usually translated from its English version. This has two limitations: 1) Question-image mismatch. The image may relate to an English scenario, which is not intuitively connected to a Chinese question. 2) Translation mismatch [58]. The machine translation is not always precise and perfect enough. We collect additional images that focus on Chinese scenarios, asking Chinese volunteers for annotation. This results in 5,917 QA pairs.