license: apache-2.0
task_categories:
- multiple-choice
- question-answering
- visual-question-answering
language:
- en
size_categories:
- 100B<n<1T
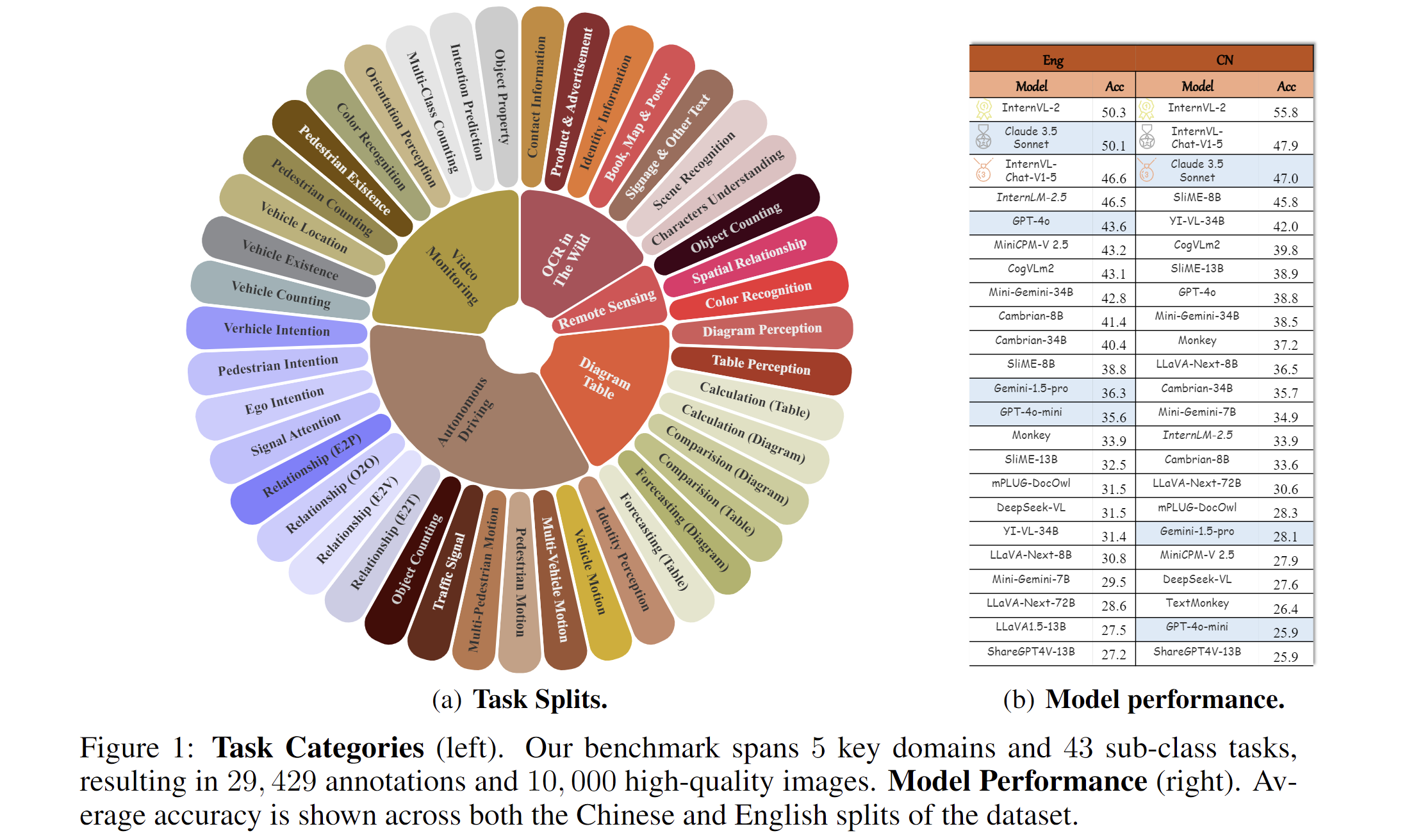
2024.11.14🌟 MME-RealWorld now has a lite version (50 samples per task) for inference acceleration, which is also supported by VLMEvalKit and Lmms-eval.2024.10.27🌟 LLaVA-OV currently ranks first on our leaderboard, but its overall accuracy remains below 55%, see our leaderboard for the detail.2024.09.03🌟 MME-RealWorld is now supported in the VLMEvalKit and Lmms-eval repository, enabling one-click evaluation—give it a try!"2024.08.20🌟 We are very proud to launch MME-RealWorld, which contains 13K high-quality images, annotated by 32 volunteers, resulting in 29K question-answer pairs that cover 43 subtasks across 5 real-world scenarios. As far as we know, MME-RealWorld is the largest manually annotated benchmark to date, featuring the highest resolution and a targeted focus on real-world applications.
Paper: arxiv.org/abs/2408.13257
Code: https://github.com/yfzhang114/MME-RealWorld
Project page: https://mme-realworld.github.io/

How to use?
Since the image files are large and have been split into multiple compressed parts, please first merge the compressed files with the same name and then extract them together.
#!/bin/bash
# Function to process each set of split files
process_files() {
local part="$1"
# Extract the base name of the file
local base_name=$(basename "$part" .tar.gz.part_aa)
# Merge the split files into a single archive
cat "${base_name}".tar.gz.part_* > "${base_name}.tar.gz"
# Extract the merged archive
tar -xzf "${base_name}.tar.gz"
# Remove the individual split files
rm -rf "${base_name}".tar.gz.part_*
rm -rf "${base_name}.tar.gz"
}
export -f process_files
# Find all .tar.gz.part_aa files and process them in parallel
find . -name '*.tar.gz.part_aa' | parallel process_files
# Wait for all background jobs to finish
wait
# nohup bash unzip_file.sh >> unfold.log 2>&1 &
MME-RealWorld Data Card
Dataset details
Existing Multimodal Large Language Model benchmarks present several common barriers that make it difficult to measure the significant challenges that models face in the real world, including:
- small data scale leads to a large performance variance;
- reliance on model-based annotations results in restricted data quality;
- insufficient task difficulty, especially caused by the limited image resolution.
We present MME-RealWord, a benchmark meticulously designed to address real-world applications with practical relevance. Featuring 13,366 high-resolution images averaging 2,000 × 1,500 pixels, MME-RealWord poses substantial recognition challenges. Our dataset encompasses 29,429 annotations across 43 tasks, all expertly curated by a team of 25 crowdsource workers and 7 MLLM experts. The main advantages of MME-RealWorld compared to existing MLLM benchmarks as follows:
Data Scale: with the efforts of a total of 32 volunteers, we have manually annotated 29,429 QA pairs focused on real-world scenarios, making this the largest fully human-annotated benchmark known to date.
Data Quality: 1) Resolution: Many image details, such as a scoreboard in a sports event, carry critical information. These details can only be properly interpreted with high- resolution images, which are essential for providing meaningful assistance to humans. To the best of our knowledge, MME-RealWorld features the highest average image resolution among existing competitors. 2) Annotation: All annotations are manually completed, with a professional team cross-checking the results to ensure data quality.
Task Difficulty and Real-World Utility.: We can see that even the most advanced models have not surpassed 60% accuracy. Additionally, many real-world tasks are significantly more difficult than those in traditional benchmarks. For example, in video monitoring, a model needs to count the presence of 133 vehicles, or in remote sensing, it must identify and count small objects on a map with an average resolution exceeding 5000×5000.
MME-RealWord-CN.: Existing Chinese benchmark is usually translated from its English version. This has two limitations: 1) Question-image mismatch. The image may relate to an English scenario, which is not intuitively connected to a Chinese question. 2) Translation mismatch [58]. The machine translation is not always precise and perfect enough. We collect additional images that focus on Chinese scenarios, asking Chinese volunteers for annotation. This results in 5,917 QA pairs.